HTML
现行标准 — 最后更新 2026年7月20日
现行标准 — 最后更新 2026年7月20日
a
元素em
元素strong
元素small
元素s
元素cite
元素q
元素dfn
元素abbr
元素ruby
元素rt
元素rp
元素data
元素time
元素code
元素var
元素samp
元素kbd
元素sub 和
sup 元素i
元素b
元素u
元素mark
元素bdi
元素bdo
元素span
元素br
元素wbr
元素a 和
area 元素创建的链接a 和
area 元素的 APIalternate”
author”
bookmark”
canonical”
dns-prefetch”expect”
external”
help”icon”license”manifest”
modulepreload”nofollow”
noopener”
noreferrer”opener”
pingback”
preconnect”prefetch”
preload”privacy-policy”search”
stylesheet”tag”terms-of-service”picture 元素
source
元素img
元素source、
img
和 link
元素共有的属性
iframe 元素embed
元素object
元素video 元素audio 元素track
元素TrackEvent
接口map
元素area
元素form
元素label
元素input
元素
type 属性的状态
type=hidden)type=text)状态和搜索状态(type=search)type=tel)type=url)type=email)type=password)type=date)type=month)type=week)type=time)type=datetime-local)type=number)type=range)type=color)type=checkbox)type=radio)type=file)type=submit)type=image)type=reset)type=button)input
元素的通用
属性
input 元素的通用
APIbutton
元素select
元素datalist 元素
optgroup 元素
option
元素
textarea 元素
output
元素
progress 元素
meter
元素fieldset 元素
legend
元素
selectedcontent 元素script 元素
noscript 元素
template 元素
slot
元素canvas 元素
Path2D 对象
ImageBitmap 渲染
上下文
OffscreenCanvas
接口
canvas 元素的安全性Window、
WindowProxy 和 Location 对象的安全基础设施
Window 对象
WindowProxy
奇异对象
Location 接口
History 接口
NotRestoredReasons
接口X-Frame-Options` 标头
Refresh` 标头WindowOrWorkerGlobalScope
混入接口button 元素
details 和
summary
元素input
元素input
元素input 元素input 元素input
元素input
元素input
元素marquee 元素
meter 元素
progress 元素select 元素
textarea 元素本规范非常详细地定义了 Web 平台的很大一部分。就本规范在 Web 平台规范体系中相对于其他规范的 位置而言,可以将其概括如下:
本节是非规范性的。
简而言之:是的。
详细而言:“HTML5”一词被广泛用作一个流行术语,指代现代 Web 技术,其中许多技术(但绝非全部)由 WHATWG 开发。本文档就是其中之一;其他规范可参见 WHATWG 标准 概览。
本节是非规范性的。
HTML 是万维网的核心标记语言。最初,HTML 主要被设计为一种 用于从语义上描述科学文档的语言。不过,其通用设计使其能够在随后的多年中 适应于描述多种其他类型的文档,甚至应用程序。
本节是非规范性的。
本规范面向使用本规范所定义特性的文档和脚本作者、实现用于处理 使用本规范所定义特性的页面之工具的实现者,以及希望根据本规范的要求 确认文档或实现是否正确的个人。
本文档可能不适合那些对 Web 技术连基本了解都没有的读者,因为在某些地方, 它为了精确性而牺牲了清晰性,并为了完整性而牺牲了简洁性。更易于理解的教程和编写指南 可以更平缓地介绍这一主题。
特别是,要完整理解本规范中一些更具技术性的部分,必须熟悉 DOM 的基础知识。 在某些地方,了解 Web IDL、HTTP、XML、Unicode、字符编码、JavaScript 和 CSS 也会有所帮助,但并非必需。
本节是非规范性的。
本规范仅限于提供一种语义层级的标记语言及相关的 语义层级脚本 API,用于编写 Web 上从静态文档到动态应用程序的无障碍页面。
本规范的范围不包括提供针对特定媒体自定义呈现形式的机制 (不过,本规范末尾确实包含 Web 浏览器的默认渲染规则,并且该语言还提供了若干 与 CSS 对接的机制)。
本规范的范围并不是描述一个完整的操作系统。尤其是, 硬件配置软件、图像处理工具,以及通常预期用户会在高端工作站上每天使用的应用程序, 均不在本规范范围内。就应用程序而言,本规范特别面向那些预期用户偶尔使用, 或者经常使用但会从不同位置访问,并且 CPU 要求较低的应用程序。这类应用程序的示例包括 在线购物系统、搜索系统、游戏(尤其是多人在线游戏)、公共电话簿或地址簿、 通信软件(电子邮件客户端、即时消息客户端、讨论软件)、文档 编辑软件等。
本节是非规范性的。
在最初五年(1990—1995 年)中,HTML 经历了多次修订并获得了 多项扩展,这些工作最初主要在 CERN 进行,之后转移到 IETF。
随着 W3C 的成立,HTML 的开发场所再次发生变化。1995 年首次尝试扩展 HTML 的 HTML 3.0 最终未能成功,随后让位于一种更务实的方法,即 HTML 3.2,该版本于 1997 年完成。同年稍晚,HTML4 很快随之发布。
第二年,W3C 成员决定停止继续发展 HTML,转而开始开发 一种基于 XML 的等效语言,称为 XHTML。这项 工作首先将 HTML4 重新表述为 XML,即 XHTML 1.0;除新的 序列化形式外,它没有增加任何新特性,并于 2000 年完成。在 XHTML 1.0 之后,W3C 将重点转向使其他工作组更容易扩展 XHTML,这项工作以 XHTML 模块化为名。与此同时,W3C 还开发了一种与早期 HTML 和 XHTML 语言不兼容的新语言,并将其称为 XHTML2。
大约在 1998 年 HTML 停止继续发展的同时,由浏览器供应商开发的部分 HTML API 以 DOM Level 1(1998 年)以及 DOM Level 2 Core 和 DOM Level 2 HTML(始于 2000 年并于 2003 年完成)的名称完成规范化并发布。 此后,这些工作逐渐停滞;虽然部分 DOM Level 3 规范于 2004 年发布, 但工作组在所有 Level 3 草案完成之前便已关闭。
2003 年,作为下一代 Web 表单技术推出的 XForms 发布, 这重新激发了人们继续发展 HTML 本身,而不是寻找其替代品的兴趣。这种兴趣源于这样一种认识: XML 作为 Web 技术的部署仅限于全新的技术(例如 RSS 和后来的 Atom), 而不是替代已经部署的现有技术(例如 HTML)。
这一新兴趣首先产生了一个概念验证:证明可以扩展 HTML4 的表单, 使其提供 XForms 1.0 所引入的许多特性,而不要求浏览器实现 与现有 HTML 网页不兼容的渲染引擎。在这一早期阶段,尽管该草案已经公开, 并且已经开始向各方征求意见,但该规范仅受 Opera Software 的版权保护。
2004 年,人们在一次 W3C 研讨会上检验了重新启动 HTML 发展的想法;Mozilla 和 Opera 联合向 W3C 提交了构成 HTML5 工作基础的一些原则(如下所述),以及前述 仅涵盖表单相关特性的早期草案提案。该提案因与此前选择的 Web 发展方向冲突而被否决;W3C 工作人员和成员投票决定继续开发基于 XML 的替代方案。
不久之后,Apple、Mozilla 和 Opera 联合宣布,他们打算在一个名为 WHATWG 的新组织框架下继续这项工作。随后创建了一个公开邮件列表, 并将草案移至 WHATWG 网站。之后,版权被修改为由这三家供应商共同拥有, 并允许重复使用该规范。
WHATWG 建立在若干核心原则之上,尤其包括:技术需要向后兼容; 规范和实现必须相互匹配,即使这意味着修改规范而不是实现;以及规范需要足够 详细,使实现无需相互逆向工程即可实现完全互操作。
尤其是最后一项要求,使 HTML5 规范的范围必须包含此前分别在 三份文档中规定的内容:HTML4、XHTML1 和 DOM2 HTML。这也意味着规范必须包含 远超此前通常标准的详细程度。
2006 年,W3C 最终表示有意参与 HTML5 的开发, 并于 2007 年成立了一个工作组,其章程规定该工作组应与 WHATWG 合作开发 HTML5 规范。Apple、Mozilla 和 Opera 允许 W3C 以 W3C 版权发布该规范, 同时在 WHATWG 网站上保留使用限制较少许可证的版本。
随后数年中,两个组织一直共同合作。不过在 2011 年,双方得出结论, 认为各自的目标不同:W3C 希望发布一个“完成”的“HTML5”版本, 而 WHATWG 则希望继续维护 HTML 的现行标准,持续 维护规范,而不是将其冻结在包含已知问题的状态,并根据平台发展需要添加 新特性。
2019 年,WHATWG 和 W3C 签署了一项 协议,决定今后合作维护单一版本的 HTML,即本文档。
本节是非规范性的。
必须承认,HTML 的许多方面乍看之下似乎毫无道理且互不一致。
HTML、其配套的 DOM API 以及许多支持技术,都是在数十年的时间里, 由大量优先事项各不相同的人共同开发的;在许多情况下,他们甚至不知道彼此的存在。
因此,各种特性来自许多不同来源,其设计并不总是特别一致。此外,由于 Web 的独特特征,实现中的错误往往会先成为事实标准,随后成为法律意义上的标准; 这是因为在这些错误得到修复之前,内容常常已经在无意中以依赖这些错误的方式编写。
尽管如此,人们仍努力遵循若干设计目标。接下来的几个小节将介绍这些目标。
本节是非规范性的。
为避免让 Web 作者面对多线程的复杂性,HTML 和 DOM API 的设计保证, 任何脚本都无法检测到其他脚本正在同时执行。即使使用 worker,其设计意图也是使实现的行为 可以被视为将所有全局环境中的所有脚本执行完全序列化。
这一通用设计原则的例外是 JavaScript 的 SharedArrayBuffer
类。通过使用 SharedArrayBuffer
对象,实际上可以观察到其他 代理
中的脚本正在同时执行。此外,由于 JavaScript 内存模型的存在,有些情况不仅无法通过
序列化的脚本执行来表示,也无法通过这些脚本之间序列化的
语句执行来表示。
本节是非规范性的。
HTML 提供了多种可扩展性机制,可用于以安全的方式添加语义:
作者可以使用 class 属性扩展
元素,实际上相当于创建自己的元素,同时使用最适用的现有“真正”HTML
元素,使不了解该扩展的浏览器和其他工具仍能在一定程度上良好地支持它。
例如,微格式采用的就是这种方法。
作者可以使用 data-*=""
属性包含供内联客户端脚本或服务器端全站脚本处理的数据。这些属性保证
永远不会被浏览器触碰,并允许脚本在 HTML 元素中包含数据,随后再由脚本
查找和处理这些数据。
作者可以使用 <meta name="" content="">
机制包含页面范围的元数据。
作者可以使用 rel=""
机制,通过注册预定义链接类型集合的扩展,
为链接标注特定含义。微格式也会使用这种机制。
作者可以使用带有自定义类型的 <script type="">
机制嵌入原始数据,以供内联脚本或服务器端脚本进一步处理。
作者可以使用 JavaScript 原型机制扩展 API。例如,脚本库广泛使用这一机制。
作者可以使用微数据特性(即 itemscope="" 和 itemprop=""
属性)嵌入嵌套的名称-值数据对,以便与其他应用程序和网站共享。
作者可以定义、共享和使用自定义元素, 以扩展 HTML 的词汇表。对有效自定义元素名称的要求可确保向前兼容 (因为未来不会向 HTML、SVG 或 MathML 添加局部名称中包含连字符的元素)。
本节是非规范性的。
本规范定义了一种用于描述文档和应用程序的抽象语言,以及一些用于与使用该语言的 资源在内存中的表示进行交互的 API。
这种内存表示称为“DOM HTML”,简称“DOM”。
可以使用多种具体语法来传输使用这种抽象语言的资源,其中两种由本规范定义。
第一种具体语法是 HTML 语法。这是建议大多数作者使用的格式。
它与大多数旧式 Web 浏览器兼容。如果文档以
text/html MIME 类型传输,那么 Web 浏览器会将其作为 HTML
文档
处理。本规范定义了最新的 HTML 语法,简称“HTML”。
第二种具体语法是 XML。当文档以 XML MIME
类型传输时,例如 application/xhtml+xml,Web 浏览器会将其视为 XML
文档,并由 XML 处理器进行解析。特此提醒作者,XML 和 HTML 的处理方式不同;
尤其是,即使是轻微的语法错误,也会导致标记为 XML 的文档无法完整渲染,
而在 HTML 语法中这些错误会被忽略。
HTML 的 XML 语法以前被称为“XHTML”,但本规范 不使用该术语(原因之一是 MathML 和 SVG 的 HTML 语法也没有使用这样的术语)。
DOM、HTML 语法和 XML 语法并不能表示完全相同的内容。例如,
命名空间无法使用 HTML 语法表示,但 DOM 和 XML 语法支持命名空间。
同样,使用 noscript 特性的文档可以使用 HTML 语法表示,
但不能使用 DOM 或 XML 语法表示。包含字符串“-->”的注释只能在
DOM 中表示,不能在 HTML 和 XML 语法中表示。
本节是非规范性的。
本规范分为以下主要章节:
EventSource 的服务器推送事件流机制,以及一种供脚本使用的、
称为 WebSocket 的双向全双工套接字协议。
此外还有一些附录,列出废弃特性和 IANA 注意事项,以及若干索引。
阅读本规范的方式应与阅读所有其他规范相同。首先,应从头到尾阅读多次。 然后,应至少倒着阅读一次。之后,应从目录中随机选择章节并跟随其中所有交叉引用进行阅读。
如下文符合性要求一节所述,本规范描述了适用于多种符合性类别的 符合性标准。特别是,有些符合性要求适用于生产者,例如作者及其创建的文档; 还有些符合性要求适用于消费者,例如 Web 浏览器。 可以根据要求的对象来区分它们:针对生产者的要求规定允许什么, 而针对消费者的要求规定软件应如何行动。
针对生产者的要求与消费者完全无关。
继续上面的示例,规定某个特定属性的值必须是有效 整数的要求,绝不意味着消费者必须遵循任何相应要求。消费者实际上可能被要求 将该属性视为不透明字符串,完全不受其值是否符合要求的影响。也可能(如前一个示例) 要求消费者使用特定规则解析该值,这些规则定义了如何处理无效值 (在这种情况下即非数字值)。
这是一个定义、要求或说明。
这是一条注释。
这是一个示例。
这是一个未解决的问题。
这是一条警告。
[Exposed =Window ]
interface Example {
// 这是一个 IDL 定义
};variable = object.method([optionalArgument])
这是向作者说明接口用法的注释。
/* 这是一个 CSS 片段 */ 术语的定义实例使用类似 这样的标记。该术语的使用实例使用类似 这样或类似 这样的标记。
元素、属性或 API 的定义实例使用类似 这样的标记。
对该元素、属性或 API 的引用使用类似
这样的标记。
其他代码片段使用类似这样的标记。
变量使用类似 这样的标记。
在算法中,同步 节中的步骤使用 ⌛ 标记。
在某些情况下,要求以包含条件及其对应要求的列表形式给出。在这种情况下, 适用于某个条件的要求始终是该条件之后出现的第一组要求,即使这些要求对应多组 条件也是如此。这类情况按如下方式呈现:
本节是非规范性的。
一个基本的 HTML 文档如下所示:
<!DOCTYPE html>
< html lang = "zh-CN" >
< head >
< title > 示例页面</ title >
</ head >
< body >
< h1 > 示例页面</ h1 >
< p > 这是一个< a href = "demo.html" > 简单的</ a > 示例。</ p >
<!-- 这是一条注释 -->
</ body >
</ html > HTML 文档由元素和文本组成的树构成。每个元素在源代码中由一个
开始标签表示,例如
“<body>”,并由一个
结束标签表示,例如
“</body>”。
(在某些情况下,某些开始标签和结束标签可以被省略,并由其他标签隐含。)
标签必须以元素彼此完全包含且不重叠的方式嵌套:
< p > 这< em > 非常< strong > 错误</ em > !</ strong ></ p > < p > 这< em > 是< strong > 正确的</ strong > 。</ em ></ p > 本规范定义了一组可在 HTML 中使用的元素,以及这些元素可以如何嵌套的规则。
元素可以具有属性,用于控制元素的工作方式。在下面的示例中,
使用 a 元素及其 href 属性构成了一个超链接:
< a href = "demo.html" > 简单的</ a > 属性位于
开始标签内,由一个名称和一个值组成,两者由
“=”字符分隔。
如果属性值不包含 ASCII
空白或 "、'、`、=、< 或
> 中的任何字符,则可以保持不加引号。否则,
必须使用单引号或双引号将其括起来。如果值为空字符串,则该值连同
“=”字符可以一并省略。
<!-- 空属性 -->
< input name = address disabled >
< input name = address disabled = "" >
<!-- 带值的属性 -->
< input name = address maxlength = 200 >
< input name = address maxlength = '200' >
< input name = address maxlength = "200" > HTML 用户代理(例如 Web 浏览器)随后会解析这些标记,将其转换为 DOM(文档对象模型)树。DOM 树是文档在内存中的表示。
DOM 树包含多种节点,尤其包括 DocumentType
节点、Element
节点、Text
节点、Comment
节点,以及在某些情况下的
ProcessingInstruction
节点。
本节开头的标记片段会转换为以下 DOM 树:
这棵树的文档元素是 html 元素,
在 HTML 文档中,该位置始终是这个元素。它包含两个元素:
head 和
body,以及位于两者之间的一个
Text
节点。
DOM 树中的 Text
节点比最初预期的多得多,因为源代码中包含许多空格(此处以“␣”表示)和换行符
(以“⏎”表示),它们最终都会成为 DOM 中的 Text
节点。不过,由于历史原因,原始标记中的空格和换行符并非全部都会出现在 DOM 中。
尤其是,head 开始标签之前的所有空白都会被静默丢弃,
而 body 结束标签之后的所有空白最终都会被放置在
body 的末尾。
head 元素包含一个 title 元素,该元素本身包含一个文本为“示例页面”的
Text
节点。同样,body 元素包含一个 h1
元素、一个 p 元素和一条注释。
可以通过页面中的脚本操作这棵 DOM 树。脚本(通常使用 JavaScript)是一些小程序,
可以使用 script 元素或事件处理程序内容属性
嵌入。例如,下面是一个带脚本的表单,该脚本将表单的 output 元素的值设置为“你好,世界”:
< form name = "main" >
结果:< output name = "result" ></ output >
< script >
document. forms. main. elements. result. value = '你好,世界' ;
</ script >
</ form > DOM 树中的每个元素都由一个对象表示,这些对象提供可用于操作它们的 API。
例如,可以通过多种方式更改一个链接(例如上面树中的 a 元素)的
“href”属性:
var a = document. links[ 0 ]; // 获取文档中的第一个链接
a. href = 'sample.html' ; // 更改链接的目标 URL
a. protocol = 'https' ; // 仅更改 URL 的方案部分
a. setAttribute( 'href' , 'https://example.com/' ); // 直接更改内容属性 由于实现(尤其是 Web 浏览器等交互式实现)在处理和呈现 HTML 文档时使用 DOM 树来表示文档,因此本规范大多以 DOM 树来表述,而不是以上述标记来表述。
HTML 文档表示对交互式内容的一种与媒体无关的描述。HTML 文档可以渲染到屏幕上, 也可以通过语音合成器输出,或者显示在盲文显示器上。为精确影响这种渲染的方式, 作者可以使用 CSS 等样式语言。
在下面的示例中,使用 CSS 将页面设置为蓝底黄字。
<!DOCTYPE html>
< html lang = "zh-CN" >
< head >
< title > 带样式的示例页面</ title >
< style >
body { background : navy ; color : yellow ; }
</ style >
</ head >
< body >
< h1 > 带样式的示例页面</ h1 >
< p > 此页面仅用于演示。</ p >
</ body >
</ html > 有关如何使用 HTML 的更多详细信息,建议作者查阅教程和指南。 本规范中包含的一些示例也可能有所帮助,但需要提醒初学者: 本规范出于必要性,以一种起初可能难以理解的详细程度定义该语言。
本节是非规范性的。
使用 HTML 创建交互式网站时,需要谨慎避免引入漏洞,使攻击者能够破坏 网站本身或网站用户的完整性。
全面研究这一问题超出了本文档的范围,因此强烈建议作者更深入地研究该问题。 不过,本节尝试简要介绍 HTML 应用程序开发中的一些常见陷阱。
Web 的安全模型基于“源”的概念,因此 Web 上许多潜在攻击都涉及跨源操作。 [ORIGIN]
接收不可信输入时,例如文本评论等用户生成内容、URL 参数中的值、 来自第三方网站的消息等,必须在使用数据之前对其进行验证,并在显示数据时 正确转义。未能做到这一点,可能使恶意用户实施多种攻击: 从危害可能较小的攻击,例如提供负数年龄等虚假用户信息; 到严重攻击,例如每次用户查看包含该信息的页面时运行脚本,并可能在此过程中传播攻击; 再到灾难性攻击,例如删除服务器中的所有数据。
编写用于验证用户输入的过滤器时,必须始终采用安全列表方式: 只允许已知安全的构造,并禁止所有其他输入。采用阻止列表方式的过滤器 会禁止已知恶意输入并允许其他所有内容,这种方式并不安全,因为并非所有恶意内容 都已经被发现(例如,新的恶意方式可能会在未来被发明)。
例如,假设某个页面查看其 URL 的查询字符串以确定要显示的内容, 随后网站将用户重定向到该页面以显示消息,如下所示:
< ul >
< li >< a href = "message.cgi?say=Hello" > 显示“你好”</ a >
< li >< a href = "message.cgi?say=Welcome" > 显示“欢迎”</ a >
< li >< a href = "message.cgi?say=Kittens" > 显示“小猫”</ a >
</ ul > 如果消息未经转义就直接显示给用户,恶意攻击者便可以构造一个包含 script 元素的 URL:
https://example.com/message.cgi?say=%3Cscript%3Ealert%28%27Oh%20no%21%27%29%3C/script%3E
如果攻击者随后诱使受害用户访问该页面,攻击者选择的脚本就会在页面上运行。 这种脚本可以执行任意数量的恶意操作,其能力仅受网站所提供功能的限制: 例如,如果该网站是电子商务商店,该脚本可能会导致用户在不知情的情况下 进行任意多次不需要的购买。
这称为跨站脚本攻击。
有许多构造可以用于诱骗网站执行代码。下面列出了一些建议作者在编写 安全列表过滤器时考虑的情况:
img,也必须将其提供的属性纳入安全列表。
如果允许所有属性,攻击者便可以使用 onload 属性运行任意脚本。javascript:”,
但用户代理还可以实现(事实上历史上也确实实现过)其他方案。base 元素,意味着页面中任何使用相对链接的
script 元素都可能被劫持,
同样,任何表单提交也可能被重定向到恶意网站。
如果网站允许用户提交会产生用户特定副作用的表单,例如以用户的名义 在论坛上发布消息、进行购买或申请护照,那么必须验证该请求是用户有意发出的, 而不是其他网站诱骗用户在不知情的情况下发出请求。
出现这一问题是因为 HTML 表单可以提交到其他源。
网站可以通过在表单中填充用户特定的隐藏令牌,或者检查所有请求中的
`Origin` 标头来防止此类攻击。
为用户提供执行其可能并不希望执行之操作的界面时,页面的设计需要避免 用户被诱骗激活该界面的可能性。
一种诱骗用户的方式是:恶意网站将受害网站放入一个很小的 iframe 中,然后诱使用户点击,
例如让用户玩反应游戏。一旦用户开始游戏,恶意网站就可以在用户即将点击时,
快速将 iframe 移动到鼠标光标下方,从而诱骗用户点击受害网站的界面。
为避免这种情况,不预期在框架中使用的网站应只在检测到自身不在框架中时
启用其界面(例如,将 window 对象与 top
属性的值进行比较)。
本节是非规范性的。
HTML 中的脚本具有“运行至完成”语义,这意味着浏览器通常会不间断地运行脚本, 然后才执行其他操作,例如触发后续事件或继续解析文档。
另一方面,HTML 文件是以增量方式解析的,这意味着解析器可以在任何时候暂停, 以便让脚本运行。这通常是一件好事,但也意味着作者需要小心, 避免在事件可能已经触发之后才挂接事件处理程序。
有两种方法可以可靠地做到这一点:使用事件处理程序内容 属性,或者在同一个脚本中创建元素并添加事件处理程序。后一种方式是安全的, 因为如前所述,脚本会先运行至完成,之后才可能触发后续事件。
这一问题的一种表现形式涉及 img 元素和 load 事件。该事件可能会在元素完成解析后立即触发,
尤其是在图像已经被缓存的情况下(这种情况很常见)。
在这里,作者在 img 元素上使用 onload 处理程序来捕获 load 事件:
< img src = "games.png" alt = "游戏" onload = "gamesLogoHasLoaded(event)" > 如果元素由脚本添加,那么只要事件处理程序是在同一个脚本中添加的, 仍然不会错过该事件:
< script >
var img = new Image();
img. src = 'games.png' ;
img. alt = '游戏' ;
img. onload = gamesLogoHasLoaded;
// img.addEventListener('load', gamesLogoHasLoaded, false); // 这样也可以
</ script > 不过,如果作者先创建 img 元素,然后在另一个单独的脚本中添加事件监听器,
那么 load 事件可能会在两者之间触发,导致该事件被错过:
<!-- 不要使用这种方式,它存在竞态条件! -->
< img id = "games" src = "games.png" alt = "游戏" >
<!-- 当解析器暂停时,'load' 事件可能在此处触发,
在这种情况下你将无法捕获它! -->
< script >
var img = document. getElementById( 'games' );
img. onload = gamesLogoHasLoaded; // 可能永远不会触发!
</ script > 本节是非规范性的。
建议作者使用一致性检查器(也称为验证器)来发现常见错误。 WHATWG 在以下地址维护了一份此类工具的列表:https://whatwg.org/validator/
本节是非规范性的。
与此前版本的 HTML 规范不同,本规范不仅定义了有效文档的必要处理方式, 还相当详细地定义了无效文档的必要处理方式。
不过,即使在大多数情况下无效内容的处理方式都有明确定义, 文档的符合性要求仍然很重要:在实践中,互操作性(即所有实现都以可靠且相同或 等效的方式处理特定内容的情形)并不是文档符合性要求的唯一目标。 本节详细介绍了仍需区分符合规范的文档和包含错误的文档的一些较常见原因。
本节是非规范性的。
此前 HTML 版本中的大多数表现性特性已不再允许使用。 人们发现,表现性标记通常存在若干问题:
虽然可以通过某种方式使用表现性标记,为辅助技术(AT)用户提供可接受的体验 (例如使用 ARIA),但与使用语义适当的标记相比,这样做要困难得多。此外, 即使使用这些技术,也无法帮助非辅助技术的非图形界面用户,例如文本模式浏览器的用户, 获得无障碍页面。
另一方面,使用与媒体无关的标记,可以轻松地以适用于更多用户 (例如文本浏览器用户)的方式编写文档。
以标记与样式相互独立的方式编写网站,会显著更容易维护。例如,
更改一个在整个网站中使用 <font color=""> 的网站颜色,
需要修改整个网站;而对基于 CSS 的网站进行类似更改,只需修改一个文件。
表现性标记往往具有更多冗余,因此会导致文档体积更大。
基于这些原因,本版本的 HTML 已移除表现性标记。这一变化并不令人意外; HTML4 早在许多年前就已弃用表现性标记,并提供了一种模式(HTML4 Transitional), 帮助作者逐步停止使用表现性标记;之后,XHTML 1.1 更进一步,彻底废弃了这些特性。
HTML 中仅存的表现性标记特性是 style 属性和 style 元素。
在生产环境中不太建议使用 style 属性,但它可用于快速原型设计
(之后可以直接将其中的规则移动到单独的样式表中),也可用于在单独样式表不方便的
特殊情况下提供特定样式。同样,style
元素可用于内容聚合或页面特定样式,但如果样式适用于多个页面,
通常使用外部样式表会更加方便。
还值得注意的是,一些此前属于表现性的元素已在本规范中被重新定义为与媒体无关:
b、i、
hr、s、small 和 u。
本节是非规范性的。
HTML 的语法受到约束,以避免多种问题。
某些无效语法构造在解析后,会产生极其不直观的 DOM 树。
为使用户代理能够在受控环境中使用,而无需实现更为古怪和复杂的错误处理规则, 允许用户代理在遇到解析错误时直接失败。
某些错误处理行为,例如上述 <table><hr>... 示例的行为,
与流式用户代理(即一次性处理 HTML 文件且不存储状态的用户代理)不兼容。
为避免与这类用户代理产生互操作性问题,任何导致此类行为的语法都被视为无效。
当基于 XML 的用户代理连接到 HTML 解析器时,HTML 文件可能会违反 XML 强制执行的某些不变量,例如元素名称或属性名称绝不能包含多个冒号。 处理这类情况可能需要解析器将 HTML DOM 强制转换为兼容 XML 的信息集。 大多数需要此类处理的语法构造都被视为无效。 (包含两个连续连字符或以连字符结尾的注释是例外,在 HTML 语法中允许使用。)
某些语法构造可能导致性能不成比例地下降。为阻止使用这类构造, 通常会将它们规定为不符合规范。
由于历史原因,某些语法构造相对脆弱。为帮助减少用户意外遇到此类问题的情况, 这些构造被规定为不符合规范。
例如,即使省略结尾分号,属性中的某些命名字符引用仍会被解析。 可以安全地包含一个与号,后跟不构成命名字符引用的字母; 但如果将这些字母更改为确实构成命名字符引用的字符串, 它们就会被解释为相应字符。
在该片段中,属性值为“?bill&ted”:
< a href = "?bill&ted" > 比尔和泰德</ a > 然而,在下面的片段中,属性值实际上是“?art©”,而不是
预期的“?art©”,因为即使没有结尾分号,
“©”也会与“©”采用相同的处理方式,
因而被解释为“©”:
< a href = "?art©" > 艺术与复制</ a > 为避免这一问题,所有命名字符引用都必须以分号结尾, 未使用分号的命名字符引用会被标记为错误。
因此,正确表达上述情况的方式如下:
< a href = "?bill&ted" > 比尔和泰德</ a > <!-- &ted 没有问题,因为它不是命名字符引用 --> < a href = "?art&copy" > 艺术与复制</ a > <!-- 必须转义 &,因为 © 确实 是命名字符引用 --> 已知某些语法构造会在旧式用户代理中引发特别隐蔽或严重的问题, 因而将其标记为不符合规范,以帮助作者避免这些问题。
例如,这就是为什么不允许在不加引号的属性中使用 U+0060 GRAVE ACCENT 字符(`)。某些旧式用户代理有时会将其视为引号字符。
某些限制纯粹是为了避免已知的安全问题。
例如,禁止使用 UTF-7 的限制纯粹是为了避免作者遭受一种已知的、使用 UTF-7 的跨站脚本攻击。[UTF7]
当标记中作者的意图非常不明确时,通常会将其规定为不符合规范。 尽早纠正这些错误可使后续维护更加容易。
当用户犯了一个简单的拼写错误时,如果能够尽早发现该错误,将会很有帮助, 因为这可以节省作者大量调试时间。因此,本规范通常将使用与本规范中定义的名称 不匹配的元素名称、属性名称等视为错误。
例如,如果作者输入了 <capton> 而不是
<caption>,这将被标记为错误,作者便可以立即纠正该拼写错误。
为使语言语法在未来能够扩展,禁止使用某些原本无害的特性。
例如,结束标签中的“属性”目前会被忽略,但它们仍然无效, 以便未来修改语言并使用该语法特性时,不会与已经部署的(且有效的)内容发生冲突。
一些作者认为,养成始终为所有属性加引号、始终包含所有可选标签的习惯很有帮助; 与利用 HTML 语法的灵活性所获得的轻微简洁优势相比,他们更喜欢这种习惯所带来的一致性。 为帮助这些作者,一致性检查器可以提供强制执行这些约定的操作模式。
本节是非规范性的。
除语言语法外,本规范还限制元素和属性的指定方式。存在这些限制的原因类似:
为避免误用具有已定义含义的元素,本规范定义了内容模型, 当元素的某种嵌套方式价值可疑时,会限制这种嵌套。
同样,为了让作者注意元素使用中的错误,所表达语义中明显的矛盾也会被视为 符合性错误。
例如,在下面的片段中,语义毫无意义:分隔符不能同时是单元格, 单选按钮也不能同时是进度条。
< hr role = "cell" > < input type = radio role = progressbar > 另一个示例是对 ul 元素内容模型的限制,该元素只允许将 li 元素作为子元素。根据定义,列表仅由零个或多个列表项组成,
因此如果 ul 元素包含 li 元素之外的内容,就不清楚作者的意图是什么。
某些元素具有默认样式或行为,使某些组合很可能造成混淆。 如果存在没有这一问题的等效替代方案,则禁止使用这些令人困惑的组合。
例如,div 元素渲染为块级框,而
span 元素渲染为行内框。在行内框中放置块级框会造成不必要的混淆;仅嵌套
div 元素、仅嵌套 span 元素,或者在 div 元素中嵌套 span 元素,都能达到与在 span 元素中嵌套 div 元素相同的目的,但只有最后一种方式涉及在
行内框中放置块级框,因此禁止使用最后一种组合。
另一个示例是交互式内容
不能相互嵌套。例如,button 元素不能包含 textarea 元素。这是因为嵌套这类交互式元素时的默认行为
会令用户极其困惑。应将这些元素并排放置,而不是相互嵌套。
有时,禁止某些内容是因为允许它很可能会造成作者混淆。
例如,禁止将 disabled 属性设置为值“false”,
因为尽管从表面上看,这似乎表示元素已启用,但实际上它表示元素
已禁用(对实现而言,重要的是该属性是否存在,而不是其值)。
某些符合性错误可以简化作者需要学习的语言。
例如,area 元素的 shape 属性在实践中同时接受 circ 和 circle 作为同义值,
但仍禁止使用 circ 值,以简化教程和其他学习资料。
允许同时使用两者没有任何好处,反而会在教授该语言时造成额外混淆。
某些元素的解析方式有些特殊(通常出于历史原因), 对其内容模型的限制旨在避免让作者遇到这些问题。
某些错误旨在帮助防止出现难以调试的脚本问题。
例如,这就是为什么两个 id 属性具有相同值是不符合规范的。
重复 ID 会导致选择错误的元素,有时会产生灾难性影响,而其原因又很难确定。
某些构造被禁止,是因为从历史上看,它们曾导致大量编写时间被浪费; 通过鼓励作者避免这些构造,可以为作者今后的工作节省时间。
例如,script 元素的 src 属性会导致元素内容被忽略。
不过,这一点并不明显,尤其是当元素内容看起来像可执行脚本时;
这可能导致作者花费大量时间尝试调试内联脚本,却没有意识到它根本没有执行。
为减少这一问题,本规范规定,当 script 元素存在 src 属性时,其中包含可执行脚本是不符合规范的。
这意味着验证文档的作者不太可能在这类错误上浪费时间。
一些作者希望编写可同时被解释为 XML 和 HTML,并产生相似结果的文件。 尽管由于其中涉及大量细微复杂性,通常不建议采用这种做法 (尤其是在涉及脚本、样式或任何类型的自动序列化时),但本规范仍规定了若干限制, 旨在至少在一定程度上缓解这些困难。这使作者在 HTML 和 XML 语法之间迁移时, 更容易将这种方式作为过渡步骤。
例如,围绕 lang 和 xml:lang 属性存在一些较复杂的规则,
旨在使两者保持同步。
另一个示例是 HTML 序列化中对 xmlns 属性值的限制,
这些限制旨在确保符合规范的文档中的元素,无论按 HTML 还是 XML 处理,
最终都会进入相同的命名空间。
正如针对语法的限制旨在允许未来版本的语言引入新语法一样, 对元素内容模型和属性值的某些限制旨在允许 HTML 词汇表在未来扩展。
例如,将 target 属性中以 U+005F LOW LINE
字符(_)开头的值限制为仅允许特定预定义值,可以在未来引入新的预定义值,
而不会与作者定义的值发生冲突。
某些限制旨在支持其他规范所规定的限制。
例如,要求接受媒体查询列表的属性只能使用有效的 媒体查询列表,可以强化遵循该规范符合性规则的重要性。
本节是非规范性的。
以下文档可能会引起本规范读者的兴趣。
本架构规范为规范作者、软件 开发者和内容开发者提供了在万维网上进行可互操作文本处理的共同参考,其基础是由 Unicode 标准和 ISO/IEC 10646 共同定义的通用字符集。涉及的主题包括“字符”“编码”和 “字符串”等术语的使用、参考处理模型、字符编码的选择和标识、 字符转义以及字符串索引。
由于 Unicode 包含大量字符,并涵盖 世界各地多种不同的书写系统,不正确的使用方式可能使程序或系统面临 潜在的安全攻击。随着越来越多的产品实现国际化,这一点尤其重要。 本文档介绍了程序员、系统分析师、标准开发者和用户应当考虑的一些安全注意事项, 并提供了降低问题风险的具体建议。
Web 内容无障碍指南(WCAG)涵盖了广泛的 建议,用于使 Web 内容更具无障碍性。遵循这些指南可使内容惠及更广泛的残障人士, 包括盲人和低视力人士、失聪和听力受损人士、学习障碍人士、认知能力受限人士、 行动受限人士、言语障碍人士、光敏感人士,以及同时具有上述多种障碍的人士。遵循这些 指南通常还会使 Web 内容对一般用户来说更加易用。
本规范提供了有关设计 Web 内容 创作工具的指南,以提高其对残障人士的无障碍性。符合这些指南的创作工具 将通过为残障作者提供无障碍用户界面,以及使所有作者能够创建、支持并促进 无障碍 Web 内容的制作,从而推动无障碍性。
本文档提供了有关设计用户代理的指南, 以降低残障人士访问 Web 时所面临的障碍。用户代理包括浏览器和其他用于获取并渲染 Web 内容的软件。符合这些指南的用户代理将通过其自身的用户界面以及其他 内部功能来促进无障碍性,其中包括与其他技术(尤其是辅助技术)进行通信的能力。 此外,不仅是残障用户,所有用户都应当会发现符合规范的用户代理更加易用。
本规范依赖于 Infra。[INFRA]
本规范同时引用 HTML 和 XML 属性以及 IDL 属性,并且经常在相同的 上下文中引用。当无法明确所指的是哪一种属性时,HTML 和 XML 属性称为 内容属性, 而在 IDL 接口上定义的属性称为 IDL 属性。同样,术语 “属性”同时用于 JavaScript 对象属性和 CSS 属性。当存在歧义时,会分别将其限定为 对象属性和 CSS 属性。
通常,当本规范规定某项特性适用于 HTML 语法 或 XML 语法时,也包括另一种语法。 当某项特性明确仅 适用于这两种语言中的一种时,会明确指出其不适用于 另一种格式,例如“对于 HTML,……(这不适用于 XML)”。
本规范使用术语 文档指代 HTML 的任何使用形式,
从简短的静态文档到具有丰富多媒体内容的长篇文章或报告,也包括
功能完备的交互式应用程序。根据上下文,该术语既用于指代 Document
对象及其后代 DOM 树,也用于指代使用 HTML 语法或 XML 语法的序列化字节流。
在 DOM 结构的上下文中,术语 HTML
文档和 XML 文档按照
DOM 中的定义使用,专门指代 Document 对象
可能处于的两种不同模式。[DOM](此类用法始终以超链接指向其
定义。)
在字节流的上下文中,术语 HTML 文档指被标记为
text/html 的资源,而术语 XML 文档指
被标记为 XML
MIME 类型的资源。
为简便起见,在指代文档向用户渲染的方式时,有时可能会使用 显示、呈现和 可见等术语。这些术语并不意味着必须使用视觉媒体;必须将它们视为 以等效方式适用于其他媒体。
并行运行步骤,意味着这些步骤会一个接一个地运行, 同时与标准中的其他逻辑并行执行(例如,与 事件 循环同时执行)。本标准不定义实现这一点的确切机制,无论是 分时协作式多任务、纤程、线程、进程,还是使用不同的超线程、 核心、CPU、计算机等。相比之下,要立即运行的操作必须 中断当前正在运行的任务,运行自身,然后恢复先前正在运行的任务。
有关编写利用并行机制的规范的指导,请参阅从其他规范处理事件循环。
为了避免操作相同数据的不同并行 算法之间出现 竞态条件,可以使用并行队列。
并行队列表示必须 串行运行的算法步骤队列。
要启动新的并行队列,请运行以下步骤:
并行运行的步骤本身也可以 并行运行 其他步骤。例如,在并行队列内部, 让一系列步骤与该队列 并行运行可能很有用。
假设某个标准定义了 nameList(一个列表),以及一个用于 将 name 添加到 nameList 的方法;除非 nameList 已经包含 name,在这种情况下该方法会拒绝。
以下解决方案存在竞态条件:
上述过程的两次调用可能会同时运行,这意味着在步骤 3.1 中 name 不在 nameList 中,但它在步骤 3.3 运行之前可能已被添加, 这意味着 name 最终会在 nameList 中出现两次。
并行队列解决了这一问题。该标准会令 nameListQueue 为 启动新的并行 队列的结果,并按如下方式定义添加名称的步骤:
这些步骤现在会排队运行,从而避免竞态。
当提及用户代理是否具有能够解码外部资源语义的实现时,本规范使用术语 受支持。如果实现能够处理某种 格式或类型的外部资源,而不会忽略该资源的关键部分,则称该格式或 类型是受支持的。某个特定资源是否 受支持,可能取决于正在使用该资源格式的哪些特性。
例如,如果 PNG 图像的像素数据能够被解码和渲染,那么即使实现并不知道该图像 还包含动画数据,也会认为该图像采用受支持的格式。
如果 MPEG-4 视频文件所使用的压缩格式不受支持,那么即使实现能够根据文件的元数据确定 影片的尺寸,也不会认为该文件采用受支持的格式。
某些规范,尤其是 HTTP 规范中所称的 表示,在本规范中称为资源。 [HTTP]
资源的关键子资源是该资源为了得到正确处理而需要 可用的资源。哪些资源被视为关键资源,由定义该资源格式的 规范确定。
对于 CSS 样式表,我们在此暂时将其
关键子资源定义为通过 @import
规则导入的其他样式表,包括由其他已导入样式表间接导入的样式表。
此定义尚未实现完全互操作;此外,一些用户代理似乎会将 背景图像或 Web 字体等资源视为关键子资源。理想情况下,应由 CSS 工作组定义这一点;有关这方面的 进展,请参阅 w3c/csswg-drafts 问题 #1088。
为了便于从 HTML 迁移到 XML,符合本
规范的用户代理会将 HTML 中的元素放入 http://www.w3.org/1999/xhtml
命名空间中,至少在 DOM 和
CSS 中如此。术语“HTML 元素”指该命名空间中的任何元素,
即使该元素位于
XML 文档中也是如此。
除非另有说明,本规范定义或提及的所有元素都位于
HTML 命名空间(“http://www.w3.org/1999/xhtml”)中,而本规范
定义或提及的所有属性均没有命名空间。
术语元素类型用于指具有给定
局部名称和命名空间的元素集合。例如,button 元素是元素
类型为 button 的元素,这意味着它们具有
局部名称“button”,并且
(根据上述定义隐式地)位于 HTML 命名空间中。
当规定某个元素或属性被忽略, 或被视为其他某个值,或被当作其他事物处理时,这仅指 节点进入 DOM 后对该节点进行的处理。在这种情况下,用户代理不得更改 DOM。
仅当内容属性的新值与其先前值 不同时,才称其值发生更改;将属性设置为其已有的值并不会更改 它。
术语空用于属性值、Text
节点
或字符串时,表示文本的长度为零(即其中甚至不包含控制字符或
U+0020 SPACE)。
可以针对 HTML 元素的局部 名称定义特定的HTML 元素插入步骤、HTML 元素 连接后步骤、HTML 元素移除步骤和HTML 元素移动 步骤。
给定 insertedNode,HTML 标准的插入步骤定义如下:
给定 insertedNode,HTML 标准的连接后步骤定义如下:
如果 insertedNode 是一个元素,其命名空间是 HTML 命名空间, 并且本 标准为 insertedNode 的局部 名称定义了HTML 元素连接后 步骤,则以 insertedNode 为参数运行相应的HTML 元素连接后步骤。
给定 removedNode、isSubtreeRoot 和 oldAncestor,HTML 标准的移除步骤定义如下:
令 document 为 removedNode 的节点文档。
如果 document 的聚焦区域是 removedNode,则将 document 的聚焦区域设置为 document 的视口,并将 document 的相关 全局对象的导航 API的正在进行的 导航期间焦点已更改设置为 false。
如果 removedNode 是一个元素,其命名空间是 HTML 命名空间, 并且本 标准为 removedNode 的局部名称 定义了HTML 元素移除步骤, 则以 removedNode、 isSubtreeRoot 和 oldAncestor 为参数运行相应的HTML 元素移除步骤。
如果 removedNode 是一个具有非空 表单所有者的表单相关元素,并且 removedNode 及其表单所有者已不再 位于同一棵树中,则重置 removedNode 的表单所有者。
如果 removedNode 的 popover
属性不处于
无弹出框状态,则以
removedNode、false、false、false 和 null 为参数运行隐藏
弹出框算法。
给定 movedNode、isSubtreeRoot 和 oldAncestor,HTML 标准的移动步骤定义如下:
如果 movedNode 是一个元素,其命名空间是 HTML 命名空间,并且本 标准为 movedNode 的局部名称定义了HTML 元素 移动步骤,则以 movedNode、isSubtreeRoot 和 oldAncestor 为参数运行相应的HTML 元素移动步骤。
如果 movedNode 是一个具有非空 表单所有者的表单相关元素,并且 movedNode 及其表单所有者已不再位于 同一棵树中,则重置 movedNode 的表单所有者。
当节点已连接,并且其影子包含根的浏览上下文非空时,该节点为浏览上下文已连接。当以某个节点为参数调用插入步骤,并且该节点现在浏览上下文 已连接时,该节点变为浏览上下文已连接。当以某个节点为参数调用移除步骤,并且该节点现在已不再浏览上下文已连接时,或者当其影子包含 根的浏览上下文变为 null 时,该节点变为浏览上下文已断开连接。
有时会使用“一个 Foo 对象”这一表述,其中 Foo
实际上是一个接口,而不是使用更准确的“一个实现
Foo 接口的对象”。
当正在检索 IDL 属性的值时(例如由作者脚本检索),称该属性正在 获取;当为其分配新值时,称该属性正在 设置。
如果某个 DOM 对象被称为实时对象,则该对象上的属性和方法 必须对实际的底层数据进行操作,而不是对该 数据的快照进行操作。
术语插件指用户代理使用的一组由实现定义的内容
处理程序。这些处理程序可以参与用户代理对
Document 对象的渲染,但既不充当该 Document 的子
可导航对象,也不会向该
Document 的 DOM 中引入任何
Node
对象。
通常,此类内容处理程序由第三方提供,不过用户代理也可以 将内置内容处理程序指定为插件。
用户代理不得认为类型 text/plain
和
application/octet-stream
具有已注册的插件。
插件的一个示例是:当用户导航到 PDF 文件时,在 可导航对象中实例化的 PDF 查看器。无论 实现该 PDF 查看器组件的一方是否与 实现用户代理本身的一方相同,它都会被视为插件。不过,与用户代理分开启动的 PDF 查看器应用程序(而不是使用相同的界面)根据本 定义并不是插件。
本规范没有定义与插件进行交互的机制,因为预期该机制 取决于具体的用户代理和平台。一些用户代理可能选择支持 Netscape Plugin API 等插件机制;另一些可能使用远程内容转换器,或 内置对某些类型的支持。事实上,本规范根本不要求用户代理 支持插件。[NPAPI]
浏览器在与供插件使用的外部内容交互时 应当极其谨慎。当第三方软件以与用户代理本身相同的 权限运行时,第三方软件中的漏洞会变得与 用户代理中的漏洞一样危险。
![]() 由于不同用户拥有不同的插件集合会形成一种
跟踪向量,从而增加用户被唯一识别的可能性,因此建议用户代理
为每个用户支持完全相同的插件集合。
由于不同用户拥有不同的插件集合会形成一种
跟踪向量,从而增加用户被唯一识别的可能性,因此建议用户代理
为每个用户支持完全相同的插件集合。
字符 编码,或者在不存在歧义时简称为编码,是 Encoding 中定义的,在字节流和 Unicode 字符串之间进行转换的既定方式。一个 编码具有一个编码 名称和一个或多个编码标签,在 Encoding 标准中分别称为 该编码的名称和标签。[ENCODING]
本规范描述用户代理 (与实现者相关)和文档(与作者及 创作工具实现者相关)的符合性标准。
符合规范的文档是遵守所有文档符合性标准 的 文档。为了便于阅读,其中一些符合性要求被表述为对作者的符合性 要求;此类要求隐含地也是对文档的要求:根据 定义,假定所有文档都曾有一名作者。(在某些情况下,该作者 本身可能是用户代理——如下所述,此类用户代理还须遵守额外规则。)
例如,如果某项要求规定“作者不得
使用 foobar 元素”,则意味着文档不允许
包含名为 foobar 的元素。
文档符合性要求与实现符合性要求之间不存在隐含关系。 用户代理不能随意处理不符合规范的 文档;无论输入文档是否符合规范,本规范所述的处理模型都适用于 实现。
用户代理分为多个具有不同符合性 要求的类别,这些类别之间可能重叠。
支持XML 语法的 Web 浏览器必须按照本规范的说明,处理 XML 文档中 来自 HTML 命名空间的元素和属性, 以便用户能够与其交互,除非这些元素的语义已被 其他规范覆盖。
符合规范的 Web 浏览器在 XML 文档中发现 script 元素时,
会执行该元素中包含的脚本。不过,如果该元素位于
以 XSLT 表示的转换中(假定用户代理也支持 XSLT),则
处理器会将该 script 元素视为
构成该转换一部分的
不透明元素。
支持HTML 语法的 Web 浏览器必须按照本规范的说明, 处理被标记为 HTML MIME 类型的文档,以便用户能够 与其交互。
支持脚本的用户代理还必须按照 Web IDL 中的说明,成为本规范中 IDL 片段的符合规范的实现。[WEBIDL]
除非明确说明,否则覆盖 HTML
元素语义的规范不会覆盖对表示这些元素的 DOM 对象的要求。例如,
上述示例中的 script
元素仍会实现
HTMLScriptElement
接口。
仅为了渲染 HTML 和 XML 文档的非交互式版本而处理这些文档的用户代理, 必须遵守与 Web 浏览器相同的符合性标准,但可以不遵守 与用户交互有关的要求。
非交互式呈现用户代理的典型示例包括打印机 (静态用户代理)和投影显示器(动态用户代理)。预期大多数静态 非交互式呈现用户代理还会选择不支持 脚本。
非交互但动态的呈现用户代理仍会执行脚本, 从而允许动态提交表单等。不过,由于用户无法与文档交互时,“焦点” 概念无关紧要,因此该用户代理无需支持 任何与焦点相关的 DOM API。
无论是否具有交互性,用户代理都可以被指定为(可能作为用户选项) 支持本规范定义的建议默认渲染。
这不是强制要求。尤其是,即使用户代理确实实现了建议默认 渲染,也建议其提供可覆盖该默认设置的选项,以改善 用户体验,例如更改颜色对比度、使用不同的焦点样式,或以其他方式 使体验对用户更具无障碍性和易用性。
被指定为支持建议默认渲染的用户代理,在保持该 指定期间,必须实现渲染一节定义为 用户代理应当实现之行为的规则。
不支持脚本(或完全禁用了脚本特性)的实现,可以不支持本 规范中提及的事件和 DOM 接口。对于本规范中以事件模型 或 DOM 为依据定义的部分,此类用户代理仍必须表现得如同支持事件和 DOM 一样。
脚本可能构成应用程序不可分割的一部分。不支持脚本或 已禁用脚本的 Web 浏览器可能无法完整表达作者的 意图。
符合性检查器必须验证文档是否符合本规范所述的适用符合性
标准。自动符合性检查器可以不
检测那些需要解释作者意图的错误(例如,如果
blockquote
元素的内容不是引文,则该文档不符合规范,
但在没有人工判断输入的情况下运行的符合性检查器无需检查
blockquote
元素是否只包含引用材料)。
符合性检查器必须检查输入文档在没有 浏览上下文的情况下解析时是否符合规范(这意味着 不运行任何脚本,并且 解析器的脚本模式为已禁用),还应当 检查输入文档 在具有执行脚本之浏览上下文的情况下解析时是否符合规范, 并检查这些脚本是否从不导致出现不符合规范的状态,脚本执行本身期间 短暂出现的状态除外。(这只是一项“应当”而非“必须”的 要求,因为已证明这不可能做到。[COMPUTABLE])
术语“HTML 验证器”可以用于指代自身符合 本规范适用要求的符合性检查器。
XML DTD 无法表达本规范的所有符合性要求。因此,一个 验证型 XML 处理器和一个 DTD 不能构成符合性检查器。此外,由于 本规范定义的两种创作格式都不是 SGML 的应用,因此 验证型 SGML 系统也不能构成符合性检查器。
换言之,符合性标准分为三种类型:
符合性检查器必须检查前两种标准。简单的基于 DTD 的验证器只检查 第一类错误,因此根据 本规范,它不是符合规范的符合性检查器。
出于渲染文档或检查文档符合性以外的原因而处理 HTML 和 XML 文档的 应用程序和工具,应当按照其所处理文档的语义 行事。
创作工具和标记生成器必须生成符合规范的文档。 适用于作者的符合性标准,在适当情况下也适用于创作工具。
创作工具可以不严格遵守元素只能用于其 指定用途的要求,但仅限于创作工具尚无法确定 作者意图的范围。不过,创作工具不得自动误用元素,也不得鼓励 用户这样做。
例如,将 address 元素用于
任意联系信息不符合规范;该元素只能用于标记
其最近的 article 或
body 元素祖先的联系信息。
不过,由于
创作工具可能无法判断两者之间的差异,因此创作工具可以不遵守
该要求。但这并不意味着创作工具可以将 address
元素用于任何斜体文本块(例如);这只意味着创作工具
不必验证当用户使用工具为
article
元素插入联系信息时,
用户确实是在这样做,而不是插入
其他内容。
就符合性检查而言,编辑器必须输出符合规范的文档, 其符合程度应与符合性检查器所验证的程度相同。
当使用创作工具编辑不符合规范的文档时,该工具可以保留 编辑会话期间未被编辑之文档部分中的符合性错误 (即允许编辑工具往返处理错误内容)。不过,如果保留了此类错误, 创作工具不得声称输出符合规范。
创作工具预期大致分为两类:基于结构 或语义数据工作的工具,以及采用所见即所得、特定媒体编辑 方式工作的工具(WYSIWYG)。
对于用于创作 HTML 的工具,前一种机制是首选,因为可以利用 源信息中的结构,对哪些 HTML 元素和 属性最合适作出有根据的选择。
不过,WYSIWYG 工具也是合理的。WYSIWYG 工具应当使用其已知
合适的元素,而不应使用其不知道是否合适的元素。在
某些极端情况下,这可能意味着将流式元素的使用限制为少数几个元素,例如
div、b、i 和 span,并大量使用
style 属性。
无论是否为 WYSIWYG,所有创作工具都应当尽最大努力,使 用户能够创建结构良好、语义丰富且与媒体无关的内容。
为了与现有内容和先前规范兼容,本规范描述了 两种创作格式:一种基于 XML, 另一种使用受 SGML 启发的自定义格式(称为HTML 语法)。 实现必须至少支持这两种格式中的一种,不过建议 同时支持两种格式。
某些符合性要求被表述为对元素、属性、方法或 对象的要求。此类要求分为两类:描述内容模型限制的要求, 以及描述实现行为的要求。前一类是对 文档和创作工具的要求。后一类是对用户代理的要求。 同样,某些符合性要求被表述为对作者的要求;此类要求 应解释为对作者所生成文档的符合性要求。(换言之, 本规范不区分对作者的符合性标准和 对文档的符合性标准。)
本规范依赖于其他若干底层规范。
以下术语在 Infra 中定义:[INFRA]
Unicode 字符集用于表示文本数据,而 Encoding 定义了有关字符编码的要求。 [UNICODE]
如前所述,本规范根据这些规范中定义的术语 引入术语。
以下术语按照 Encoding 中的定义使用:[ENCODING]
支持 HTML 的XML 语法的实现必须支持某个版本 的 XML 及其对应的命名空间规范,因为该语法使用带有命名空间的 XML 序列化。[XML] [XMLNS]
在不运行脚本、不求值 CSS 或 XPath 表达式,也不以其他方式将生成的 DOM 暴露给任意内容的情况下,对内容执行操作的数据挖掘工具和其他用户代理, 可以仅通过断言其 DOM 节点对应物位于 某些命名空间中来“支持命名空间”,而无需实际公开命名空间字符串。
在HTML 语法中,命名空间前缀和 命名空间声明 与在 XML 中的作用不同。例如,冒号在 HTML 元素名称中没有特殊含义。
space 这一名称的属性位于XML 命名空间中,由
可扩展标记语言(XML)定义。[XML]
本规范还引用了<?xml-stylesheet?>
处理指令,该指令在将样式表与 XML 文档关联中定义。
[XMLSSPI]
本规范还以非规范性方式提及 XSLTProcessor
接口及其 transformToFragment() 和
transformToDocument() 方法。
[XSLTP]
以下术语在 URL 中定义:[URL]
application/x-www-form-urlencoded
格式application/x-www-form-urlencoded
序列化器本规范还引用了若干方案和协议:
about: 方案
[ABOUT]
blob: 方案
[FILEAPI]
data: 方案
[RFC2397]
http: 方案
[HTTP]
https: 方案
[HTTP]
mailto:
方案 [MAILTO]sms: 方案
[SMS]
urn: 方案
[URN]
媒体 片段 语法在媒体片段 URI中定义。[MEDIAFRAG]
以下术语在 URL Pattern 中定义:[URLPATTERN]
以下术语在 HTTP 规范中定义:[HTTP]
Accept` 标头Accept-Language`
标头Cache-Control`
标头Content-Disposition` 标头Content-Language`
标头Content-Range`
标头Last-Modified`
标头Range` 标头Referer` 标头以下术语在HTTP 状态管理机制中定义: [COOKIES]
以下术语在Web 链接中定义:[WEBLINK]
Link`
标头Link` 字段值以下术语在HTTP 结构化字段值中定义: [STRUCTURED-FIELDS]
以下术语在 MIME 嗅探中定义:[MIMESNIFF]
以下术语在 Fetch 中定义:[FETCH]
about:blankSec-Purpose`User-Agent` 值Origin`
标头Cross-Origin-Resource-Policy`
标头RequestCredentials
枚举RequestDestination
枚举fetch()
方法以下术语在引用来源策略中定义: [REFERRERPOLICY]
Referrer-Policy`
HTTP 标头Referrer-Policy` 标头解析引用来源策略算法no-referrer”、
“no-referrer-when-downgrade”、
“origin-when-cross-origin”
和
“unsafe-url”
以下术语在混合内容中定义:[MIX]
以下术语在子资源完整性中定义:[SRI]
以下术语在No-Vary-Search HTTP 响应标头字段中定义: [NOVARYSEARCH]
以下术语在绘制计时中定义:[PAINTTIMING]
以下术语在导航计时中定义: [NAVIGATIONTIMING]
NavigationTimingType
及其
“navigate”、
“reload”
和
“back_forward”
值。以下术语在资源计时中定义: [RESOURCETIMING]
以下术语在性能时间线中定义: [PERFORMANCETIMELINE]
PerformanceEntry
及其
name、
entryType、
startTime
和
duration
属性。
以下术语在长动画帧中定义:[LONGANIMATIONFRAMES]
以下术语在长任务中定义:[LONGTASKS]
本规范中的 IDL 片段必须按照 Web IDL 中对符合规范的 IDL 片段所述的要求进行解释。[WEBIDL]
以下术语在 Web IDL 中定义:
[Global][LegacyFactoryFunction]
[LegacyLenientThis][LegacyNullToEmptyString]
[LegacyOverrideBuiltIns]
[LegacyTreatNonObjectAsNull]
[LegacyUnenumerableNamedProperties]
[LegacyUnforgeable]Web IDL 还定义了本规范中使用的以下类型:
ArrayBufferArrayBufferView
boolean
DOMStringdouble
Float16ArrayFunctionlongobject
Promise
Uint8ClampedArray
unrestricted double
unsigned longUSVStringVoidFunctionQuotaExceededError本规范中的术语抛出
按照 Web IDL 中的定义使用。DOMException
类型和以下异常名称由 Web IDL 定义,并由本
规范使用:
IndexSizeError”HierarchyRequestError”
InvalidCharacterError”
NoModificationAllowedError”
NotFoundError”NotSupportedError”InvalidStateError”SyntaxError”InvalidAccessError”
SecurityError”NetworkError”AbortError”DataCloneError”EncodingError”NotAllowedError”当本规范要求用户代理创建表示特定时间的 Date
对象
时(该时间可能是特殊值 Not-a-Number),该时间的毫秒
分量(如果存在)必须截断为整数,并且新创建的 Date
对象的时间值必须表示截断后所得的时间。
例如,给定 2000 年 1 月 1 日 UTC 时间 01:00 之后
23045 微秒的时间,即时间 2000-01-01T00:00:00.023045Z,则为表示该时间而创建的 Date
对象
所表示的时间,将与为表示时间
2000-01-01T00:00:00.023Z 而创建的对象所表示的时间相同,即提前 45 微秒。如果给定时间为 NaN,则结果
是一个表示时间值 NaN 的 Date
对象(表示该对象并不
表示某个特定时刻)。
本规范所述语言的某些部分仅支持以 JavaScript 作为 底层脚本语言。[JAVASCRIPT]
术语“JavaScript”用于指代 ECMA-262,而不是正式 术语 ECMAScript,因为 JavaScript 这一术语更为人熟知。
以下术语在 JavaScript 规范中定义,并在本 规范中使用:
Atomics
对象Atomics.waitAsync 对象
Date 类
FinalizationRegistry
类RegExp
类SharedArrayBuffer
类SyntaxError
类TypeError
类RangeError
类WeakRef 类
eval() 函数
WeakRef.prototype.deref()
函数import()
import.metatypeof
运算符delete
运算符支持 JavaScript 的用户代理还必须实现动态代码品牌 检查提案。以下术语在其中定义,并在本规范中使用: [JSDYNAMICCODEBRANDCHECKS]
支持 JavaScript 的用户代理还必须实现导入文本提案。 以下术语在其中定义,并在本规范中使用:[JSIMPORTTEXT]
支持 JavaScript 的用户代理还必须实现 ECMAScript 国际化 API。[JSINTL]
支持 JavaScript 的用户代理还必须实现 Temporal 提案。 以下术语在其中定义,并在本规范中使用:[JSTEMPORAL]
以下术语在 WebAssembly JavaScript 接口中定义: [WASMJS]
文档对象模型(DOM)是文档及其内容的一种表示——一种模型。 DOM 不仅仅是一个 API;本规范根据对 DOM 的操作 定义 HTML 实现的符合性标准。[DOM]
实现必须支持 DOM 和 UI Events 中定义的事件,因为本 规范是根据 DOM 定义的,并且某些特性被定义为 DOM 接口的扩展。[DOM] [UIEVENTS]
特别是,以下特性在 DOM 中定义:[DOM]
Attr 接口
CharacterData
接口Comment 接口DOMImplementation
接口Document 接口及其
doctype 属性
DocumentOrShadowRoot
接口DocumentFragment
接口DocumentType 接口
ChildNode 接口Element
接口attachShadow()
方法。Node 接口
NodeList 接口ProcessingInstruction
接口及其
目标
概念
ShadowRoot 接口
Text 接口
Range
接口HTMLCollection
接口、其
length 属性,
以及其
item() 和
namedItem()
方法
DOMTokenList
接口及其
value 属性和
supports 操作
createDocument()
方法createHTMLDocument()
方法createElement()
方法createElementNS()
方法getElementById()
方法getElementsByClassName()
方法append() 方法appendChild() 方法
cloneNode() 方法moveBefore() 方法
importNode() 方法
preventDefault()
方法id
属性setAttribute()
方法textContent 属性
children 属性
slotchange
事件CharacterData
节点的数据及其
替换数据
算法
Event
接口Event 及派生接口的
构造函数行为EventTarget 接口
EventInit 字典类型
type
属性currentTarget
属性bubbles 属性cancelable 属性
composed 属性isTrusted 属性initEvent() 方法addEventListener()
方法EventListener
回调接口Document 的
编码(在本文中称为
字符编码)、
模式、
自定义元素注册表、
允许声明式
影子根和
内容类型
is 值
MutationObserver 接口
以及一般意义上的变动
观察器AbortController及其
信号
AbortSignal以下特性在 UI Events 中定义:[UIEVENTS]
FocusEvent 接口FocusEvent
接口的relatedTarget
属性UIEvent
接口UIEvent
接口的view 属性beforeinput 事件
contextmenu 事件
input 事件keydown 事件keypress 事件keyup 事件以下特性在触摸事件中定义:[TOUCH]
以下特性在指针事件中定义: [POINTEREVENTS]
MouseEvent 接口
MouseEvent
接口的relatedTarget
属性MouseEvent
接口的button
属性MouseEventInit
字典类型PointerEvent
接口PointerEvent
接口的pointerType
属性auxclick 事件click
事件dblclick 事件mousedown 事件mouseenter 事件mouseleave 事件mousemove 事件mouseout 事件mouseover 事件mouseup 事件pointerdown
事件pointerup 事件
pointercancel
事件wheel
事件以下事件在剪贴板 API 和事件中定义: [CLIPBOARD-APIS]
本规范有时使用术语名称指代事件的
类型,例如“名为 click 的事件”或“如果事件
名称为 keypress”。对于事件而言,术语
“名称”和“类型”是同义词。
以下特性在DOM 解析和序列化中定义: [DOMPARSING]
以下特性在选择 API中定义:[SELECTION]
建议用户代理实现 execCommand 中描述的特性。[EXECCOMMAND]
以下特性在全屏 API中定义:[FULLSCREEN]
高精度时间提供以下特性:[HRT]
本规范使用文件 API中定义的以下特性: [FILEAPI]
Blob 接口
及其
type
属性
File 接口
及其
name 和
lastModified 属性
FileList 接口Blob
的快照状态
概念
以下术语在索引数据库 API中定义: [INDEXEDDB]
以下术语在媒体源扩展中定义: [MEDIASOURCE]
以下术语在媒体捕获和流中定义: [MEDIASTREAM]
以下术语在报告中定义:[REPORTING]
以下特性和术语在 XMLHttpRequest 中定义: [XHR]
XMLHttpRequest 接口及其
responseXML
属性
ProgressEvent
接口及其
lengthComputable、
loaded和
total 属性
FormData
接口及其关联的
条目
列表
以下特性在电池状态 API中定义:[BATTERY]
getBattery()
方法实现必须支持媒体查询。其中定义了 <media-condition> 特性。[MQ]
尽管本规范的实现不必支持完整的 CSS (不过建议至少 Web 浏览器支持),但某些特性是根据 特定 CSS 要求定义的。
当本规范要求按照特定 CSS 语法进行解析时,必须遵循 CSS 语法中的相关算法, 包括错误处理规则。[CSSSYNTAX]
例如,当意外遇到样式表末尾时,用户代理必须关闭所有打开的结构。
因此,当将字符串“rgb(0,0,0”(缺少
右括号)解析为颜色值时,该错误处理规则会隐含补上右
括号,并得到一个值(颜色“black”)。
但是,类似的结构“rgb(0,0,”(同时缺少
括号和“blue”值)无法解析,因为关闭打开的结构并不会
得到可用的值。
以下术语和特性在层叠样式表 (CSS)中定义:[CSS]
'display' 属性的基本版本 在 CSS 中定义,其他 CSS 模块对该属性进行了扩展。 [CSS] [CSSRUBY] [CSSTABLE]
以下术语和特性在 CSS 盒模型中定义: [CSSBOX]
以下特性在 CSS 逻辑属性中定义: [CSSLOGICAL]
以下术语和特性在 CSS 颜色中定义: [CSSCOLOR]
以下术语在 CSS 图像中定义:[CSSIMAGES]
术语绘制 源按照 CSS 图像第 4 级中的定义使用, 以定义某些 HTML 元素与 CSS 'element()' 函数之间的交互。 [CSSIMAGES4]
以下特性在 CSS 背景和边框中定义: [CSSBG]
CSS 背景和边框还定义了以下边框属性: [CSSBG]
以下特性在 CSS 盒对齐中定义:[CSSALIGN]
以下术语和特性在 CSS 显示中定义: [CSSDISPLAY]
以下特性在 CSS 弹性盒布局中定义: [CSSFLEXBOX]
以下术语和特性在 CSS 字体中定义: [CSSFONTS]
以下特性在 CSS 表单中定义: [CSSFORMS]
以下特性在 CSS 间隙中定义: [CSSGAPS]
以下特性在 CSS 网格布局中定义:[CSSGRID]
以下术语在 CSS 行内布局中定义:[CSSINLINE]
以下术语和特性在 CSS 盒尺寸中定义: [CSSSIZING]
以下特性在 CSS 列表和计数器中定义。 [CSSLISTS]
以下特性在 CSS 溢出中定义。[CSSOVERFLOW]
以下术语和特性在 CSS 定位布局中定义: [CSSPOSITION]
以下特性在 CSS 多列布局中定义。 [CSSMULTICOL]
'display' 属性的 'ruby-base' 值在 CSS 注音布局中定义。 [CSSRUBY]
以下特性在 CSS 表格中定义:[CSSTABLE]
以下特性在 CSS 文本中定义:[CSSTEXT]
以下特性在 CSS 书写模式中定义:[CSSWM]
以下特性在 CSS 基本用户界面中定义: [CSSUI]
更新 动画并发送事件算法在 Web 动画中定义。 [WEBANIMATIONS]
支持脚本的实现必须支持 CSS 对象模型。以下 特性和术语在 CSSOM 规范中定义:[CSSOM] [CSSOMVIEW]
Screen 接口
LinkStyle
接口CSSStyleDeclaration
接口style IDL
属性CSSStyleDeclaration
的cssText
属性
StyleSheet
接口CSSStyleSheet
接口CSSStyleSheetCSSStyleSheet 的规则resize 事件
scroll 事件
scrollend
事件以下特性和术语在 CSS 语法中定义: [CSSSYNTAX]
以下术语在选择器中定义:[SELECTORS]
以下特性在 CSS 值和单位中定义: [CSSVALUES]
以下特性在 CSS 视图过渡中定义: [CSSVIEWTRANSITIONS]
ViewTransition
术语style 属性 在 CSS 样式属性中定义。[CSSATTR]
以下术语在 CSS 层叠和继承中定义: [CSSCASCADE]
CanvasRenderingContext2D
对象对字体的使用依赖于 CSS 字体和字体加载规范中
描述的特性,尤其包括 FontFace 对象和字体源概念。
[CSSFONTS] [CSSFONTLOAD]
以下接口和术语在几何接口中定义: [GEOMETRY]
DOMMatrix 接口及其关联的
m11 元素、
m12 元素、
m21 元素、
m22 元素、
m41 元素和
m42 元素
DOMMatrix2DInit
和
DOMMatrixInit
字典
DOMMatrix2DInit
或 DOMMatrixInit
的从字典创建
DOMMatrix
和从二维字典创建
DOMMatrix
算法
DOMPointInit
字典及其关联的
x 和
y 成员
以下术语在 CSS 作用域中定义:[CSSSCOPING]
以下术语和特性在 CSS 颜色调整中定义: [CSSCOLORADJUST]
以下术语在 CSS 伪元素中定义:[CSSPSEUDO]
以下术语在 CSS 包含中定义:[CSSCONTAIN]
以下术语在 CSS 锚点定位中定义:[CSSANCHOR]
以下术语在交叉观察器中定义: [INTERSECTIONOBSERVER]
以下术语在调整大小观察器中定义: [RESIZEOBSERVER]
以下接口在 WebGL 规范中定义:[WEBGL]
以下接口在 WebGPU 中定义:[WEBGPU]
实现可以支持将 WebVTT 用作媒体资源的字幕、说明文字、元数据等文本轨道格式。 [WEBVTT]
本规范中使用的以下术语在 WebVTT 中定义:
role 属性在
无障碍富互联网应用(ARIA)中定义,以下
角色也在其中定义:[ARIA]
此外,以下 aria-* 内容
属性在 ARIA 中定义:[ARIA]
最后,以下术语在 ARIA 中定义:[ARIA]
ARIAMixin
接口及其关联的
ARIAMixin getter
步骤和
ARIAMixin setter
步骤钩子,以及其
role和
aria*
属性
以下术语在内容安全策略中定义:[CSP]
report-uri 指令frame-ancestors
指令sandbox
指令SecurityPolicyViolationEvent
接口securitypolicyviolation
事件以下术语在 Service Worker 中定义:[SW]
以下算法在安全上下文中定义: [SECURE-CONTEXTS]
以下术语在权限策略中定义: [PERMISSIONSPOLICY]
以下特性在支付请求 API中定义: [PAYMENTREQUEST]
尽管本规范不要求支持完整的 MathML(不过建议至少 Web 浏览器支持), 但某些特性依赖于实现 MathML 的一小部分。 [MATHML]
以下特性在数学标记语言 (MathML)中定义:
a
元素annotation-xml 元素math 元素merror 元素mfrac 元素mi 元素mmultiscripts 元素mn 元素mo 元素mover 元素mpadded 元素mphantom 元素mprescripts 元素mroot 元素mrow 元素ms 元素mspace 元素msqrt 元素mstyle 元素msub 元素msubsup 元素msup 元素mtable 元素mtd 元素mtext 元素mtr 元素munder 元素munderover 元素semantics 元素accent 属性accentunder 属性columnspan 属性depth 属性fence 属性form 属性height 属性largeop 属性lspace 属性maxsize 属性minsize 属性movablelimits 属性rowspan 属性rspace 属性separator 属性stretchy 属性symmetric 属性voffset 属性width 属性displaystyle 属性mathbackground 属性mathcolor 属性mathsize 属性scriptlevel 属性尽管本规范不要求支持完整的 SVG(不过建议至少 Web 浏览器支持), 但某些特性依赖于实现 SVG 的部分内容。
实现 SVG 的用户代理必须实现 SVG 2 规范,而不得实现 任何较早版本。
以下特性在 SVG 2 规范中定义: [SVG]
SVGElement
接口SVGImageElement
接口SVGScriptElement
接口SVGSVGElement
接口a 元素animate 元素animateTransform 元素circle 元素defs 元素desc 元素ellipse 元素foreignObject 元素g 元素image 元素line 元素marker 元素metadata 元素path 元素polygon 元素polyline 元素rect 元素script 元素set 元素svg 元素text 元素textPath 元素title 元素tspan 元素use 元素action 属性attributeName 属性cx 属性cy 属性d 属性dx 属性dy 属性formaction 属性height 属性href 属性hreflang 属性lengthAdjust 属性markerHeight 属性markerUnits 属性markerWidth 属性method 属性orient 属性path 属性pathLength 属性points 属性preserveAspectRatio 属性r 属性refX 属性refY 属性rotate 属性rx 属性ry 属性side 属性spacing 属性startOffset 属性textLength 属性type 属性viewBox 属性width 属性x 属性x1 属性x2 属性y 属性y1 属性y2 属性text-rendering 属性alignment-baseline 属性baseline-shift 属性clip-path 属性clip-rule 属性color 属性color-interpolation 属性cursor 属性direction 属性display 属性dominant-baseline 属性fill 属性fill-opacity 属性fill-rule 属性font-family 属性font-size 属性font-size-adjust 属性font-stretch 属性font-style 属性font-variant 属性font-weight 属性letter-spacing 属性marker-end 属性marker-mid 属性marker-start 属性opacity 属性paint-order 属性pointer-events 属性shape-rendering 属性stop-color 属性stop-opacity 属性stroke 属性stroke-dasharray 属性stroke-dashoffset 属性stroke-linecap 属性stroke-linejoin 属性stroke-miterlimit 属性stroke-opacity 属性stroke-width 属性text-anchor 属性text-decoration 属性text-overflow 属性transform 属性transform-origin 属性unicode-bidi 属性vector-effect 属性visibility 属性white-space 属性word-spacing 属性writing-mode 属性以下特性在滤镜效果中定义:[FILTERS]
以下特性在合成和混合中定义: [COMPOSITE]
以下特性在后台任务的协作式 调度中定义:[REQUESTIDLECALLBACK]
以下术语在屏幕方向中定义: [SCREENORIENTATION]
以下术语在存储中定义:[STORAGE]
以下特性在Web 应用清单中定义:[MANIFEST]
以下术语在 WebAssembly JavaScript 接口:ESM 集成中定义:[WASMESM]
以下特性在 WebCodecs 中定义:[WEBCODECS]
以下术语在 WebDriver 中定义:[WEBDRIVER]
以下术语在 WebDriver BiDi 中定义:[WEBDRIVERBIDI]
以下术语在 Web 加密 API中定义: [WEBCRYPTO]
以下术语在 WebSocket 中定义:[WEBSOCKETS]
以下术语在 WebTransport 中定义:[WEBTRANSPORT]
以下术语在Web 认证:用于访问公钥 凭据的 API中定义:[WEBAUTHN]
以下术语在凭据管理中定义:[CREDMAN]
以下术语在控制台中定义:[CONSOLE]
以下术语在 Web 锁 API中定义:[WEBLOCKS]
本规范使用可信类型中定义的以下特性: [TRUSTED-TYPES]
以下术语在 WebRTC API 中定义:[WEBRTC]
以下术语在画中画 API中定义:[PICTUREINPICTURE]
以下术语在空闲检测 API中定义:
以下术语在 Web 语音 API中定义:
以下术语在 WebOTP API 中定义:
以下术语在 Web 共享 API中定义:
以下术语在 Web 智能卡 API中定义:
以下术语在Web 后台同步中定义:
以下术语在Web 周期性后台同步中定义:
以下术语在后台获取中定义:
以下术语在键盘锁定中定义:
以下术语在 Web MIDI API 中定义:
以下术语在通用传感器 API中定义:
以下术语在 WebHID API 中定义:
以下术语在 WebXR 设备 API中定义:
本规范不要求支持任何特定的网络协议、样式 表语言、脚本语言,或上述列表所要求内容之外的任何 DOM 规范。然而,本规范所描述的语言 偏向于使用 CSS 作为样式语言、JavaScript 作为脚本语言,并使用 HTTP 作为网络协议,而且 若干特性假定正在使用这些语言和协议。
实现 HTTP 协议的用户代理还必须实现 HTTP 状态管理 机制(Cookie)。[HTTP] [COOKIES]
本规范可能在相应章节中对字符 编码、图像格式、音频格式和视频格式提出某些附加要求。
强烈不建议用户代理供应商为本规范添加供应商专有扩展。 文档不得使用此类扩展,因为这样做会降低互操作性并 分割用户群,使得只有特定用户代理的用户才能访问相关 内容。
所有扩展都必须以这样的方式定义:使用扩展既不会与规范中定义的功能 相矛盾,也不会导致这些功能不符合规范。
例如,尽管强烈不建议这样做,实现可以向控件添加新的 IDL
属性“typeTime”,该属性返回用户
选择控件当前值所花费的时间(例如)。另一方面,定义一个会出现在表单的 elements
数组中的新控件将违反
上述要求,因为它会违反本规范中给出的 elements
定义。
当需要对本规范进行供应商中立的扩展时,可以相应地更新本规范, 或者编写一个覆盖本规范要求的扩展规范。当将本规范应用于其活动的人员 决定承认此类扩展规范的要求时,就本规范中的符合性要求而言,该扩展规范将成为 一个适用规范。
有人可以编写一个规范,将任意字节流定义为 符合规范,然后声称其随机垃圾数据符合规范。然而,这并不意味着 其随机垃圾数据实际上对所有人的用途而言都符合规范:如果其他人决定 该规范不适用于其工作,那么他们完全可以合理地指出, 上述随机垃圾数据就只是垃圾数据,根本不符合规范。就符合性 而言,在特定群体中重要的是该群体一致同意哪些规范 适用。
用户代理必须将其无法理解的元素和属性视为在语义上 中立;将它们保留在 DOM 中(对于 DOM 处理器),并按照 CSS 对其设置样式(对于 CSS 处理器),但不得从中推断任何含义。
当某项特性的支持被禁用时(例如,作为缓解安全 问题的紧急措施、辅助开发,或出于性能原因),用户代理必须表现得如同其 完全不支持该特性,并且如同本规范中未提及该特性一样。 例如,如果某项特性通过 Web IDL 接口中的属性访问, 则实现该接口的对象中应省略该属性本身 ——将该属性保留在对象上,但使其返回 null 或抛出异常是 不够的。
对按照本规范所述方式解析或创建的 HTML
文档进行操作的 XPath 1.0 实现(例如,作为
document.evaluate() API 的一部分)必须表现得如同对
XPath 1.0 规范应用了以下编辑。
首先,移除以下段落:
节点测试中的 QName 使用表达式上下文中的命名空间声明 扩展为一个扩展名称。 这与起始标签和结束标签中的元素类型名称的扩展方式相同,但使用
xmlns声明的默认命名空间不会被使用:如果 QName 没有 前缀,则命名空间 URI 为 null(这与属性名称的扩展方式相同)。如果 QName 具有前缀,但表达式上下文中不存在 对应的命名空间声明,则会发生错误。
然后,在其位置插入以下内容:
节点测试中的 QName 使用表达式上下文中的命名空间声明扩展为扩展名称。 如果 QName 具有前缀,则表达式上下文中必须存在该前缀的命名空间声明, 与该前缀关联的相应命名空间 URI 就会被使用。 如果 QName 具有前缀,但表达式上下文中不存在对应的命名空间声明,则会发生错误。
如果 QName 没有前缀,并且轴的主要节点类型为元素,则使用 默认元素命名空间。否则,如果 QName 没有前缀,则命名空间 URI 为 null。默认元素命名空间是 XPath 表达式上下文的成员。通过 DOM3 XPath API 执行 XPath 表达式时,默认元素命名空间的值按以下方式确定:
- 如果上下文节点来自 HTML DOM,则默认元素命名空间为 “http://www.w3.org/1999/xhtml”。
- 否则,默认元素命名空间 URI 为 null。
这等同于将 XPath 2.0 的默认元素命名空间特性添加到 XPath 1.0,并将 HTML 命名空间用作 HTML 文档的默认元素命名空间。 其动机是希望实现既能与旧式 HTML 内容兼容, 又能支持本规范针对 HTML 元素所使用命名空间而引入的 HTML 更改,同时希望使用 XPath 1.0 而不是 XPath 2.0。
此更改是对 XPath 1.0 规范的有意违反, 其动机是希望实现既能与旧式内容兼容,又能 支持本规范针对 HTML 元素所使用的命名空间而引入的 HTML 更改。[XPATH10]
当输出方法为“html”(无论是明确指定,还是通过 XSLT 1.0 中的默认规则确定)时, 向 DOM 输出的 XSLT 1.0 处理器会受到如下 影响:
如果转换程序输出一个不属于任何命名空间的元素,则处理器必须在 构造相应的 DOM 元素节点之前,将该元素的命名空间更改为 HTML 命名空间,将元素的局部名称转换为 ASCII 小写形式,并将元素上所有不属于命名空间的属性的 名称转换为 ASCII 小写形式。
此要求是对 XSLT 1.0 规范的有意违反, 之所以需要这样做,是因为本规范更改了 HTML 的命名空间和区分大小写 规则,否则这些规则将与基于 DOM 的 XSLT 转换不兼容。(序列化输出的处理器不受影响。)[XSLT10]
本规范并未精确规定 XSLT 处理如何与 HTML
解析器基础设施交互(例如,XSLT 处理器是否表现得如同将某些
元素放入开放
元素栈中)。但是,如果 XSLT 处理器成功完成处理,则必须停止
解析;如果处理被中止,则必须先将当前文档就绪状态更新为
“interactive”,然后再更新为“complete”。
本规范未规定 XSLT 如何与导航算法交互、如何融入事件循环,也未规定 如何处理错误页面(例如,XSLT 错误是替换增量 XSLT 输出,还是以内联方式渲染等)。
关于 XSLT 与 HTML 的交互,在script 元素章节中,
以及关于 XSLT、XPath 与 HTML 的交互,在template 元素
章节中,还有其他非规范性说明。
Headers/Permissions-Policy/document-domain
仅一个引擎支持。
本文档定义了以下策略控制的特性:
Headers/Feature-Policy/autoplay
Headers/Permissions-Policy/autoplay
仅一个引擎支持。
autoplay”,其默认
允许列表为 'self'。cross-origin-isolated”,其默认
允许列表为 'self'。focus-without-user-activation”,其
默认
允许列表为 'self'。
HTML 中有许多位置接受特定的数据类型,例如日期或数字。 本节描述这些格式中内容的符合性标准,以及如何 解析它们。
强烈建议实现者仔细检查其可能考虑用于实现下述语法解析的任何第三方库。 例如,日期 库很可能会实现与本规范所要求行为不同的错误处理行为,因为在描述与本规范所用日期语法类似的 规范中,错误处理行为通常没有定义,因此不同实现 处理错误的方式往往差异很大。
下述某些微型解析器遵循这样一种模式:使用一个保存待解析字符串的 input 变量,并使用一个指向 input 中下一个待解析字符的 position 变量。
许多属性是布尔属性。 元素上存在布尔属性表示 true 值,不存在该 属性表示 false 值。
如果该属性存在,则其值必须为空字符串,或者是与该属性规范名称 ASCII 不区分大小写匹配的值,并且不得包含前导或 尾随空白。
布尔属性不允许使用值“true”和“false”。要表示 false 值,必须完全省略该属性。
以下示例展示了一个已选中且已禁用的复选框。checked 和 disabled
属性是布尔属性。
< label >< input type = checkbox checked name = cheese disabled > Cheese</ label > 也可以等价地写成这样:
< label >< input type = checkbox checked = checked name = cheese disabled = disabled > Cheese</ label > 也可以混合使用不同风格;以下写法仍然等价:
< label >< input type = 'checkbox' checked name = cheese disabled = "" > Cheese</ label > 某些属性称为枚举 属性,它们具有有限的一组状态。此类 属性的状态通过组合属性值、一组关键字/状态映射,以及 该属性规范中还可以给出的三种特殊状态来确定。这些 特殊状态是无效值默认状态、缺失值 默认状态和空值默认状态。
多个关键字可以映射到同一状态。
要确定属性的状态,请使用以下步骤:
出于创作符合性目的,如果指定了枚举属性,则该属性的 值必须是以下之一:
与该属性的某个符合规范的关键字 ASCII 不区分大小写匹配,并且没有前导或尾随空白。
空字符串,并且该属性必须定义一个空 值默认状态。
出于反射目的,任何具有关键字映射 到其上的状态都称为具有一个规范关键字。其确定方式如下:
如果只有一个关键字映射到给定状态,则该关键字就是规范关键字。
如果只有一个符合规范的关键字映射到给定状态,则该符合规范的关键字就是 规范关键字。
如果有两个符合规范的关键字映射到给定状态,并且其中一个是空 字符串,则规范关键字是那个不是空 字符串的符合规范关键字。
否则,该状态的规范关键字将在该属性的 规范中明确给出。
如果一个字符串由一个或多个ASCII 数字组成,并且可以选择以 U+002D HYPHEN-MINUS 字符 (-) 为前缀,则该字符串是一个有效整数。
不带 U+002D HYPHEN-MINUS (-) 前缀的有效整数表示 该数字字符串以十进制表示的数。带有 U+002D HYPHEN-MINUS (-) 前缀的有效整数 表示从零中减去 U+002D HYPHEN-MINUS 之后的数字字符串以十进制表示的数。
解析整数的规则由以下 算法给出。调用时, 必须按照给定顺序执行这些步骤,并在第一个返回 值的步骤处中止。此算法将返回整数或错误。
令 input 为正在解析的字符串。
令 position 为指向 input 内部的指针,最初指向 字符串的开头。
令 sign 的值为“positive”。
给定 position,在 input 中 跳过 ASCII 空白。
如果 position 已超过 input 的末尾,则返回错误。
如果 position 所指示的字符(第一个字符)是 U+002D HYPHEN-MINUS 字符 (-):
否则,如果 position 所指示的字符(第一个字符)是 U+002B PLUS SIGN 字符 (+):
+”会被
忽略,但其不符合规范。)如果 position 所指示的字符不是ASCII 数字,则返回错误。
给定 position,从 input 中 收集一个码位序列,该序列由ASCII 数字组成,并将所得序列解释为十进制 整数。令 value 为该整数。
如果 sign 为“positive”,则返回 value;否则返回 从零中减去 value 的结果。
如果一个字符串由一个或多个 ASCII 数字组成,则该字符串是一个有效非负整数。
一个有效非负 整数表示该数字字符串以十进制 表示的数。
解析非负整数的规则由以下 算法给出。 调用时,必须按照给定顺序执行这些步骤,并在第一个 返回值的步骤处中止。此算法将返回零、正整数或错误。
令 input 为正在解析的字符串。
令 value 为使用 解析 整数的规则解析 input 的结果。
如果 value 是错误,则返回错误。
如果 value 小于零,则返回错误。
返回 value。
如果一个字符串由以下内容组成,则它是一个有效浮点数:
一个有效 浮点数表示通过将有效数字乘以十的指数次幂所得的数,其中有效数字是第一个数, 按十进制解释(包括小数点和小数点后的数,如果 存在;并且如果整个字符串以 U+002D HYPHEN-MINUS 字符 (-) 开头且该数不为零,则将有效数字解释为负数),指数是 E 之后的数(如果存在;如果 E 和该数之间有 U+002D HYPHEN-MINUS 字符 (-) 且该数不为零,则将其解释为负数;否则,如果 E 与该数之间有 U+002B PLUS SIGN 字符 (+),则忽略该字符)。如果没有 E,则 指数视为零。
Infinity 和 Not-a-Number (NaN) 值不是有效浮点数。
有效浮点数概念通常
只用于限制作者可以使用的内容,而用户代理要求使用下述解析
浮点数值的规则(例如,max
属性属于 progress 元素)。
但是,在
某些情况下,用户代理要求包括检查字符串是否为有效
浮点数(例如,input 元素的Number 状态的值清理算法,或解析 srcset
属性算法)。
数字 n 作为浮点数的最佳 表示是运行 ToString(n) 所得到的字符串。抽象操作 ToString 并非唯一确定。当特定值通过 ToString 可能得到多个字符串时,用户代理必须始终 为该值返回相同的字符串(尽管它可以与其他用户 代理使用的值不同)。
解析浮点 数值的规则由以下 算法给出。此算法必须在第一个返回某项内容的步骤处中止。 此算法将返回一个数或错误。
令 input 为正在解析的字符串。
令 position 为指向 input 内部的指针,最初指向 字符串的开头。
令 value 的值为 1。
令 divisor 的值为 1。
令 exponent 的值为 1。
给定 position,在 input 中 跳过 ASCII 空白。
如果 position 已超过 input 的末尾,则返回错误。
如果 position 所指示的字符是 U+002D HYPHEN-MINUS 字符 (-):
否则,如果 position 所指示的字符(第一个字符)是 U+002B PLUS SIGN 字符 (+):
+”
会被忽略,但其不符合规范。)如果 position 所指示的字符是 U+002E FULL STOP (.),并且它 不是 input 中的最后一个字符,而且 position 所指示字符之后的字符 是ASCII 数字,则将 value 设置为零,并跳转到标记为小数部分的步骤。
如果 position 所指示的字符不是ASCII 数字,则返回错误。
给定 position,从 input 中 收集一个码位序列,该序列由ASCII 数字组成,并将所得序列解释为十进制 整数。将 value 乘以该整数。
小数部分:如果 position 所指示的字符是 U+002E FULL STOP (.),则运行以下子步骤:
将 position 前进到下一个字符。
如果 position 已超过 input 的末尾,或者 position 所指示的字符不是ASCII 数字、 U+0065 LATIN SMALL LETTER E (e) 或 U+0045 LATIN CAPITAL LETTER E (E),则跳转到标记为 转换的步骤。
如果 position 所指示的字符是 U+0065 LATIN SMALL LETTER E 字符 (e) 或 U+0045 LATIN CAPITAL LETTER E 字符 (E),则跳过其余 子步骤。
小数循环:将 divisor 乘以十。
将 position 前进到下一个字符。
如果 position 已超过 input 的末尾,则跳转到标记为 转换的步骤。
如果 position 所指示的字符是ASCII 数字,则跳回这些 子步骤中标记为小数循环的步骤。
如果 position 所指示的字符是 U+0065 (e) 或 U+0045 (E):
将 position 前进到下一个字符。
如果 position 已超过 input 的末尾,则跳转到标记为 转换的步骤。
如果 position 所指示的字符是 U+002D HYPHEN-MINUS 字符 (-):
如果 position 已超过 input 的末尾,则跳转到标记为 转换的步骤。
否则,如果 position 所指示的字符是 U+002B PLUS SIGN 字符 (+):
如果 position 已超过 input 的末尾,则跳转到标记为 转换的步骤。
如果 position 所指示的字符不是ASCII 数字,则跳转到标记为转换的步骤。
给定 position,从 input 中 收集一个码位序列,该序列由ASCII 数字组成,并将所得序列解释为十进制 整数。将 exponent 乘以该整数。
将 value 乘以十的 exponent 次幂。
转换:令 S 为除 −0 以外的有限 IEEE 754 双精度 浮点值集合,并额外加入两个特殊值:21024 和 −21024。
令 rounded-value 为 S 中最接近 value 的数;如果有两个同样接近的 值,则选择有效数字为偶数的那个。(为此目的,两个特殊值 21024 和 −21024 被视为具有偶数有效数字。)
如果 rounded-value 为 21024 或 −21024,则返回错误。
返回 rounded-value。
解析尺寸值的规则由以下 算法给出。调用时, 必须按照给定顺序执行这些步骤,并在第一个返回 值的步骤处中止。此算法将返回大于或等于 0.0 的数或失败;如果返回 一个数,则还会进一步将其归类为百分比或长度。
令 input 为正在解析的字符串。
令 position 为 input 的一个位置 变量, 最初指向 input 的开头。
给定 position,在 input 中 跳过 ASCII 空白。
如果 position 已超过 input 的末尾,或者 input 中 position 处的码位不是ASCII 数字,则返回失败。
给定 position,从 input 中 收集一个码位序列,该序列由ASCII 数字组成,并将所得序列解释为十进制 整数。令 value 为该数。
如果 position 已超过 input 的末尾,则将 value 作为长度返回。
如果 input 中 position 处的码位是 U+002E (.):
使用 value、 input 和 position 返回当前尺寸值。
给定 value、input 和 position,当前尺寸值按以下方式确定:
如果 position 已超过 input 的末尾,则将 value 作为长度返回。
如果 input 中 position 处的码位是 U+0025 (%),则将 value 作为百分比返回。
将 value 作为长度返回。
解析非零尺寸 值的规则由以下算法给出。调用时,必须按照给定顺序执行这些步骤, 并在第一个返回值的步骤处中止。此算法将返回 大于 0.0 的数或错误;如果返回一个数,则还会进一步 将其归类为百分比或长度。
令 input 为正在解析的字符串。
令 value 为使用解析 尺寸值的规则解析 input 的结果。
如果 value 是错误,则返回错误。
如果 value 为零,则返回错误。
如果 value 是百分比,则将 value 作为百分比返回。
将 value 作为长度返回。
一个有效浮点数列表由若干个有效 浮点数组成,这些数由 U+002C COMMA 字符分隔, 并且不包含任何其他字符(例如,不包含ASCII 空白)。 此外,还可能 对可给出的浮点数数量或允许的值范围 施加限制。
解析浮点 数列表的规则如下:
令 input 为正在解析的字符串。
令 position 为指向 input 内部的指针,最初指向 字符串的开头。
令 numbers 为最初为空的浮点数列表。该列表 将作为此算法的结果。
给定 position,从 input 中 收集一个码位序列,该序列由ASCII 空白、 U+002C COMMA 或 U+003B SEMICOLON 字符组成。 这会跳过所有前导分隔符。
当 position 未超过 input 的末尾时:
给定 position,从 input 中 收集一个码位序列,该序列中的码位不是 ASCII 空白、U+002C COMMA、U+003B SEMICOLON、ASCII 数字、 U+002E FULL STOP 或 U+002D HYPHEN-MINUS 字符。这会跳过 前导垃圾内容。
给定 position,从 input 中 收集一个码位序列,该序列中的码位不是 ASCII 空白、U+002C COMMA 或 U+003B SEMICOLON 字符,并令 unparsed number 为所得结果。
令 number 为使用 解析 浮点数值的规则解析 unparsed number 的结果。
如果 number 是错误,则将 number 设置为零。
将 number 追加到 numbers。
给定 position,从 input 中 收集一个码位序列,该序列由ASCII 空白、 U+002C COMMA 或 U+003B SEMICOLON 字符组成。 这会跳过分隔符。
返回 numbers。
解析尺寸列表的规则如下。 这些规则返回一个由零个或多个数值/单位对组成的列表, 其中单位为百分比、相对或绝对之一。
令 raw input 为正在解析的字符串。
如果 raw input 中的最后一个字符是 U+002C COMMA 字符 (,), 则从 raw input 中移除该字符。
在逗号处分割字符串 raw input。 令 raw tokens 为所得标记列表。
令 result 为空的数值/单位对列表。
对于 raw tokens 中的每个标记,运行以下子步骤:
令 input 为该标记。
令 position 为指向 input 内部的指针, 最初指向字符串的开头。
令 value 为数字 0。
令 unit 为绝对。
如果 position 已超过 input 的末尾,则将 unit 设置为相对并 跳转到最后一个子步骤。
如果 position 处的字符是ASCII 数字,则给定 position,从 input 中收集一个码位序列,该序列由ASCII 数字组成,将所得序列解释为十进制整数,并将 value 增加该整数。
如果 position 处的字符是 U+002E (.):
给定 position,在 input 中 跳过 ASCII 空白。
如果 position 处的字符是 U+0025 PERCENT SIGN 字符 (%), 则将 unit 设置为百分比。
否则,如果 position 处的字符是 U+002A ASTERISK 字符 (*),则将 unit 设置为相对。
向 result 添加一个条目,该条目由 value 给出的数和 unit 给出的单位组成。
返回列表 result。
在下述算法中,year 年 month 月的天数为:如果 month 是 1、3、5、7、8、 10 或 12,则为 31;如果 month 是 4、6、9 或 11,则为 30;如果 month 是 2 且 year 是能被 400 整除的数,或者 year 是能被 4 整除但不能被 100 整除的数,则为 29;否则为 28。这考虑了公历中的 闰年。[GREGORIAN]
本节所定义的日期和时间语法中使用的 ASCII 数字表示十进制数。
虽然此处描述的格式旨在作为相应 ISO8601 格式的子集,但本规范所定义的解析规则比 ISO8601 详细得多。 因此,建议实现者在使用任何日期解析库实现 下述解析规则之前仔细检查这些库;ISO8601 库解析日期和 时间的方式可能并不完全相同。[ISO8601]
本规范所称的外推公历,是指 向前追溯至公元 1 年的现代公历。外推 公历中的日期,有时明确称为外推公历 日期,是指使用该历法描述的日期,即使该历法在相关 时间(或地点)尚未使用。[GREGORIAN]
在本规范中使用公历作为传输格式,是由参与该决定者的文化偏向造成的
任意选择。另请参阅表单中讨论日期、时间和数字格式的章节
(面向作者)、有关表单控件
本地化的实现说明,以及 time 元素。
一个月份由一个特定的外推公历 日期组成,不包含时区信息,也不包含年份和月份之外的日期信息。 [GREGORIAN]
如果一个字符串按给定顺序由以下组成部分构成,则它是表示年份 year 和 月份 month 的有效月份字符串:
解析月份字符串的规则如下。该算法将返回年份和 月份,或者不返回任何内容。如果算法在任何时候指出“失败”,则表示算法在该处 中止,并且不返回任何内容。
令 input 为正在解析的字符串。
令 position 为指向 input 内部的指针,最初 指向字符串的开头。
解析月份组成部分以获得 year 和 month。如果这不返回任何内容,则失败。
如果 position 未超过 input 的末尾,则失败。
返回 year 和 month。
给定一个 input 字符串和 一个 position,解析月份组成部分的规则如下。该算法将返回年份和月份,或者 不返回任何内容。如果算法在任何时候指出“失败”,则表示算法在该 处中止,并且不返回任何内容。
给定 position,从 input 中收集一个码位序列,该序列由ASCII 数字组成。如果收集到的序列长度不足四个 字符,则失败。否则,将所得序列解释为十进制整数。 令 year 为该数。
如果 year 不是大于零的数,则失败。
如果 position 已超过 input 的末尾,或者 position 处的字符不是 U+002D HYPHEN-MINUS 字符,则失败。 否则,将 position 向前移动一个字符。
给定 position,从 input 中收集一个码位序列,该序列由ASCII 数字组成。如果收集到的序列长度不恰好为两个 字符,则失败。否则,将所得序列解释为十进制整数。 令 month 为该数。
如果 month 不是范围 1 ≤ month ≤ 12 内的数,则失败。
返回 year 和 month。
一个日期由一个特定的外推公历 日期组成,不包含时区信息,由年份、月份和日期构成。 [GREGORIAN]
如果一个字符串按给定顺序由以下组成部分构成,则它是表示年份 year、月份 month 和日期 day 的有效日期字符串:
解析日期字符串的规则如下。该算法将返回一个 日期,或者不返回任何内容。如果算法在任何时候指出“失败”,则表示算法在该 处中止,并且不返回任何内容。
令 input 为正在解析的字符串。
令 position 为指向 input 内部的指针,最初 指向字符串的开头。
解析日期组成部分以获得 year、month 和 day。如果这不返回任何内容,则失败。
如果 position 未超过 input 的末尾,则失败。
令 date 为年份是 year、月份是 month、日期是 day 的日期。
返回 date。
给定一个 input 字符串和一个 position,解析日期组成部分的规则如下。该算法将返回年份、月份和日期, 或者不返回任何内容。如果算法在任何时候指出“失败”,则表示算法在 该处中止,并且不返回任何内容。
解析月份组成部分以获得 year 和 month。如果这不返回任何内容,则失败。
令 maxday 为 year 年 month 月的天数。
如果 position 已超过 input 的末尾,或者 position 处的字符不是 U+002D HYPHEN-MINUS 字符,则失败。 否则,将 position 向前移动一个字符。
给定 position,从 input 中收集一个码位序列,该序列由ASCII 数字组成。如果收集到的序列长度不恰好为两个 字符,则失败。否则,将所得序列解释为十进制整数。 令 day 为该数。
如果 day 不是范围 1 ≤ day ≤ maxday 内的数, 则失败。
返回 year、month 和 day。
一个无年份日期由公历月份和该月份中的 某一天组成,但不关联任何年份。[GREGORIAN]
如果一个字符串按给定顺序由以下组成部分构成,则它是表示月份 month 和日期 day 的有效无年份日期字符串:
换言之,如果 month 是“02”,
表示二月,那么日期可以是 29,就如同年份是闰年一样。
解析无年份日期字符串的规则如下。该算法将 返回月份和日期,或者不返回任何内容。如果算法在任何时候指出“失败”,则表示 算法在该处中止,并且不返回任何内容。
令 input 为正在解析的字符串。
令 position 为指向 input 内部的指针,最初 指向字符串的开头。
解析 无年份日期组成部分以获得 month 和 day。如果这不返回任何内容,则 失败。
如果 position 未超过 input 的末尾,则失败。
返回 month 和 day。
给定一个 input 字符串和一个 position,解析无年份日期组成部分的规则如下。该算法将返回月份和 日期,或者不返回任何内容。如果算法在任何时候指出“失败”,则表示算法在该处 中止,并且不返回任何内容。
给定 position,从 input 中收集一个码位序列,该序列由 U+002D HYPHEN-MINUS 字符 (-) 组成。如果收集到的序列长度既不恰好为零 也不恰好为两个字符,则失败。
给定 position,从 input 中收集一个码位序列,该序列由ASCII 数字组成。如果收集到的序列长度不恰好为两个 字符,则失败。否则,将所得序列解释为十进制整数。 令 month 为该数。
如果 month 不是范围 1 ≤ month ≤ 12 内的数,则失败。
令 maxday 为任意闰年(例如 4 或 2000)中月份 month 的天数。
如果 position 已超过 input 的末尾,或者 position 处的字符不是 U+002D HYPHEN-MINUS 字符,则失败。 否则,将 position 向前移动一个字符。
给定 position,从 input 中收集一个码位序列,该序列由ASCII 数字组成。如果收集到的序列长度不恰好为两个 字符,则失败。否则,将所得序列解释为十进制整数。 令 day 为该数。
如果 day 不是范围 1 ≤ day ≤ maxday 内的数, 则失败。
返回 month 和 day。
一个时间由一个不包含时区 信息的特定时间组成,包括小时、分钟、秒和秒的小数部分。
如果一个字符串按给定顺序由以下组成部分构成,则它是表示小时 hour、 分钟 minute 和秒 second 的有效时间字符串:
second 组成部分不能是 60 或 61;无法 表示闰秒。
解析时间字符串的规则如下。该算法将返回一个 时间,或者不返回任何内容。如果算法在任何时候指出“失败”,则表示算法在该 处中止,并且不返回任何内容。
令 input 为正在解析的字符串。
令 position 为指向 input 内部的指针,最初 指向字符串的开头。
解析时间组成部分以获得 hour、minute 和 second。如果这不返回任何内容,则失败。
如果 position 未超过 input 的末尾,则失败。
令 time 为小时是 hour、分钟是 minute、秒是 second 的时间。
返回 time。
给定一个 input 字符串和一个 position,解析时间组成部分的规则如下。该算法将返回小时、分钟和 秒,或者不返回任何内容。如果算法在任何时候指出“失败”,则表示算法在该处 中止,并且不返回任何内容。
给定 position,从 input 中收集一个码位序列,该序列由ASCII 数字组成。如果收集到的序列长度不恰好为两个 字符,则失败。否则,将所得序列解释为十进制整数。 令 hour 为该数。
如果 position 已超过 input 的末尾,或者 position 处的字符不是 U+003A COLON 字符,则失败。否则, 将 position 向前移动一个字符。
给定 position,从 input 中收集一个码位序列,该序列由ASCII 数字组成。如果收集到的序列长度不恰好为两个 字符,则失败。否则,将所得序列解释为十进制整数。 令 minute 为该数。
令 second 为 0。
如果 position 未超过 input 的末尾,并且 position 处的字符是 U+003A (:):
将 position 前进到 input 中的下一个字符。
如果 position 已超过 input 的末尾,或位于 input 中的最后一个字符处,或者从 position 开始的 input 中接下来的两个字符 不都是ASCII 数字,则失败。
给定 position,从 input 中收集一个码位序列,该序列由ASCII 数字 或 U+002E FULL STOP 字符组成。如果收集到的 序列长度为三个字符,或者长度大于三个字符且第三个字符不是 U+002E FULL STOP 字符, 或者包含多个 U+002E FULL STOP 字符,则失败。否则,将所得序列解释为十进制数 (可能带有小数部分)。将 second 设置为该数。
如果 second 不是范围 0 ≤ second < 60 内的数,则失败。
返回 hour、minute 和 second。
一个本地日期和时间由一个特定的 外推公历 日期(包括年份、月份和日期)以及一个时间 (包括小时、分钟、秒和秒的小数部分)组成,但不使用 时区表示。[GREGORIAN]
如果一个字符串按给定顺序由以下组成部分构成,则它是表示 日期和时间的有效本地日期和时间字符串:
如果一个字符串按给定顺序由以下组成部分构成,则它是表示日期和时间的有效 规范化本地日期和时间字符串:
解析本地日期和时间字符串的规则 如下。该算法将返回 日期和时间,或者不返回任何内容。如果算法在任何时候指出“失败”,则表示 算法在该处中止,并且不返回任何内容。
令 input 为正在解析的字符串。
令 position 为指向 input 内部的指针,最初 指向字符串的开头。
解析日期 组成部分以获得 year、month 和 day。如果这不返回任何内容,则 失败。
如果 position 已超过 input 的末尾,或者 position 处的字符既不是 U+0054 LATIN CAPITAL LETTER T 字符 (T),也不是 U+0020 SPACE 字符,则失败。否则,将 position 向前移动一个字符。
解析时间 组成部分以获得 hour、minute 和 second。如果这不返回任何内容, 则失败。
如果 position 未超过 input 的末尾,则失败。
令 date 为年份是 year、月份是 month、日期是 day 的日期。
令 time 为小时是 hour、分钟是 minute、秒是 second 的时间。
返回 date 和 time。
时区偏移由带符号的小时数和 分钟数组成。
如果一个字符串由以下任一形式组成,则它是表示 时区偏移的有效时区偏移字符串:
此格式允许的时区偏移范围为 -23:59 至 +23:59。目前在 实际使用中,真实时区的偏移范围为 -12:00 至 +14:00,并且真实时区偏移的分钟组成部分 始终为 00、30 或 45。不过,无法保证这种情况会永远 保持不变,因为时区常被当作政治角力工具,因此 容易受到非常反复无常的政策决定影响。
另请参阅下文全局 日期和时间章节中的使用说明和示例,以了解如何将时区偏移用于 早于正式时区形成时期的历史时间。
解析时区偏移字符串的规则如下。该算法将返回 时区偏移,或者不返回任何内容。如果算法在任何时候指出“失败”,则表示 算法在该处中止,并且不返回任何内容。
令 input 为正在解析的字符串。
令 position 为指向 input 内部的指针,最初 指向字符串的开头。
解析 时区偏移组成部分以获得 timezonehours 和 timezoneminutes。如果这 不返回任何内容,则失败。
如果 position 未超过 input 的末尾,则失败。
返回一个相对于 UTC 偏移 timezonehours 小时和 timezoneminutes 分钟的时区偏移。
给定一个 input 字符串和一个 position,解析时区偏移组成部分的规则如下。该算法将返回时区小时数 和时区分钟数,或者不返回任何内容。如果算法在任何时候指出“失败”,则表示 算法在该处中止,并且不返回任何内容。
如果 position 处的字符是 U+005A LATIN CAPITAL LETTER Z 字符 (Z):
令 timezonehours 为 0。
令 timezoneminutes 为 0。
将 position 前进到 input 中的下一个字符。
否则,如果 position 处的字符是 U+002B PLUS SIGN (+) 或 U+002D HYPHEN-MINUS (-):
如果 position 处的字符是 U+002B PLUS SIGN (+),令 sign 为“positive”。 否则,它是 U+002D HYPHEN-MINUS (-);令 sign 为“negative”。
将 position 前进到 input 中的下一个字符。
如果 s 的长度恰好为两个字符:
将 s 解释为十进制整数。令 timezonehours 为该数。
如果 position 已超过 input 的末尾,或者 position 处的字符不是 U+003A COLON 字符,则失败。 否则,将 position 向前移动一个字符。
给定 position,从 input 中收集一个码位序列,该序列由 ASCII 数字组成。如果收集到的序列长度不恰好为两个 字符,则失败。否则,将所得序列解释为十进制 整数。令 timezoneminutes 为该数。
如果 s 的长度恰好为四个字符:
将 s 的前两个字符解释为十进制整数。令 timezonehours 为该数。
将 s 的后两个字符解释为十进制整数。令 timezoneminutes 为该数。
否则,失败。
否则,失败。
返回 timezonehours 和 timezoneminutes。
一个全局日期和时间由一个特定的 外推公历 日期(包括年份、月份和日期)以及一个时间 (包括小时、分钟、秒和秒的小数部分)组成,并使用由带符号的小时数和分钟数 构成的时区偏移来表示。[GREGORIAN]
如果一个字符串按给定顺序由以下组成部分构成,则它是表示 日期、时间和时区偏移的有效全局日期和时间字符串:
在二十世纪中期 UTC 形成之前的日期中的时间,必须以 UT1 (0° 经度处同时代的地球太阳时)来表示和解释,而不是 UTC (以 SI 秒计时的 UT1 近似值)。在时区形成之前的时间,必须 表示和解释为带有显式时区的 UT1 时间,该时区近似表示同时代的 相应本地时间与英国伦敦格林尼治所在地所观测时间之间的差异。
以下是一些写成有效全局日期和时间字符串的日期示例。
0037-12-13 00:00Z”1979-10-14T12:00:00.001-04:00”8592-01-01T02:09+02:09”这些日期有几点值得注意:
T”替换为空格,则必须是单个空格
字符。字符串“2001-12-21 12:00Z”(组成部分之间有两个空格)
无法成功解析。解析全局日期和时间字符串的规则 如下。该算法将返回 UTC 时间,并附带用于往返转换或显示 的关联时区偏移信息,或者不返回任何内容。如果算法在任何时候指出“失败”,则表示 算法在该处中止,并且不返回任何内容。
令 input 为正在解析的字符串。
令 position 为指向 input 内部的指针,最初 指向字符串的开头。
解析日期 组成部分以获得 year、month 和 day。如果这不返回任何内容,则 失败。
如果 position 已超过 input 的末尾,或者 position 处的字符既不是 U+0054 LATIN CAPITAL LETTER T 字符 (T),也不是 U+0020 SPACE 字符,则失败。否则,将 position 向前移动一个字符。
解析时间 组成部分以获得 hour、minute 和 second。如果这不返回任何内容, 则失败。
如果 position 已超过 input 的末尾,则 失败。
解析时区偏移组成部分以 获得 timezonehours 和 timezoneminutes。如果这 不返回任何内容,则失败。
如果 position 未超过 input 的末尾,则失败。
令 time 为年份 year、月份 month、日期 day、小时 hour、分钟 minute、秒 second 所表示的时刻,再减去 timezonehours 小时和 timezoneminutes 分钟。该时刻是 UTC 时区中的一个时刻。
令 timezone 为相对于 UTC 偏移 timezonehours 小时和 timezoneminutes 分钟的时区。
返回 time 和 timezone。
一个周由周年份编号和周编号组成, 表示从星期一开始的七天期间。此日历系统中的每个周年份 都有 52 或 53 个这样的七天期间,定义如下。始于 公历 1969 年 12 月 29 日星期一(1969-12-29)的七天期间,被定义为周年份 1970 的第 1 周。连续的周按顺序编号。某个 周年份中第 1 周之前的一周,是前一个周年份的最后一周,反之亦然。[GREGORIAN]
编号为 year 的周年份在以下任一情况下有 53 周: 它对应外推公历中以星期四 为第一天(1 月 1 日)的年份 year;或者对应外推 公历中以星期三为第一天(1 月 1 日)的年份 year,并且 year 是 能被 400 整除的数,或者是能被 4 整除但不能被 100 整除的数。所有 其他周年份均有 52 周。
有 53 周的周年份,其最后一天的周编号为 53; 有 52 周的周年份,其最后一天的周编号为 52。
某一天的周年份编号可能不同于 外推公历中包含该日的年份编号。 周年份 y 中的第一周,是包含公历年份 y 第一个星期四的那一周。
就现代用途而言,此处定义的周 等同于 ISO 8601 中定义的 ISO 周。[ISO8601]
如果一个字符串按给定顺序由以下组成部分构成,则它是表示周年份 year 和周 week 的有效周字符串:
解析周字符串的规则如下。该算法将返回 周年份编号和周编号,或者不返回任何内容。如果算法在任何时候指出“失败”,则表示 算法在该处中止,并且不返回任何内容。
令 input 为正在解析的字符串。
令 position 为指向 input 内部的指针,最初 指向字符串的开头。
给定 position,从 input 中收集一个码位序列,该序列由ASCII 数字组成。如果收集到的序列长度不足四个 字符,则失败。否则,将所得序列解释为十进制整数。 令 year 为该数。
如果 year 不是大于零的数,则失败。
如果 position 已超过 input 的末尾,或者 position 处的字符不是 U+002D HYPHEN-MINUS 字符,则失败。 否则,将 position 向前移动一个字符。
如果 position 已超过 input 的末尾,或者 position 处的字符不是 U+0057 LATIN CAPITAL LETTER W 字符 (W), 则失败。否则,将 position 向前移动一个字符。
给定 position,从 input 中收集一个码位序列,该序列由ASCII 数字组成。如果收集到的序列长度不恰好为两个 字符,则失败。否则,将所得序列解释为十进制整数。 令 week 为该数。
令 maxweek 为年份 year 的最后一天的周编号。
如果 week 不是范围 1 ≤ week ≤ maxweek 内的数, 则失败。
如果 position 未超过 input 的末尾,则失败。
返回周年份编号 year 和周编号 week。
持续时间由秒数组成。
由于月份和秒无法比较(一个月并不是精确的 秒数,而是一个精确长度取决于从哪一天开始 测量的期间),因此本规范中定义的持续时间不能 包含月份(也不能包含等同于 十二个月的年份)。只能描述表示特定秒数的持续时间。
如果一个字符串由以下任一形式组成,则它是表示持续时间 t 的 有效持续时间字符串:
一个字面量 U+0050 LATIN CAPITAL LETTER P 字符,后跟下列一个或多个 子组成部分,并按给定顺序排列,其中天数、小时数、分钟数和 秒数对应于与 t 相同的秒数:
一个或多个ASCII 数字,后跟一个 U+0044 LATIN CAPITAL LETTER D 字符,表示天数。
一个 U+0054 LATIN CAPITAL LETTER T 字符,后跟下列一个或多个 子组成部分,并按给定顺序排列:
与本规范中定义的许多其他日期和时间相关微语法一样, 这种格式基于 ISO 8601 中定义的一种格式。[ISO8601]
一个或多个持续时间 组成部分,每个组成部分具有 不同的持续时间组成部分 比例,顺序任意;所表示秒数的总和等于 t 中的秒数。
持续时间组成部分是由以下 组成部分构成的字符串:
零个或多个ASCII 空白。
一个或多个ASCII 数字,表示若干时间单位,并按指定的 持续时间组成部分比例(见下文)进行换算,以表示 秒数。
如果指定的持续时间 组成部分比例为 1(即单位为 秒),则可选地包含一个 U+002E FULL STOP 字符 (.),后跟一个、两个或三个 ASCII 数字,表示秒的小数部分。
零个或多个ASCII 空白。
以下字符之一,表示持续时间组成部分的数值部分所用时间单位的 持续时间 组成部分比例:
零个或多个ASCII 空白。
这并非基于 ISO 8601 中的任何格式。其目的是作为 ISO 8601 持续时间格式的一种更便于人类阅读的替代形式。
解析持续时间字符串的规则如下。该算法将返回 持续时间,或者不返回任何内容。如果算法在任何时候 指出“失败”,则表示算法在该处中止,并且不返回任何内容。
令 input 为正在解析的字符串。
令 position 为指向 input 内部的指针,最初 指向字符串的开头。
令 months、seconds 和 component count 均为零。
令 M-disambiguator 为minutes。
此标志的另一个值是months。它用于消除 ISO8601 持续时间中“M”单位的歧义,因为月份和分钟使用同一单位。月份不被 允许,但仍会被解析,以便将来兼容,并避免错误解释在其他上下文中 本来有效的 ISO8601 持续时间。
给定 position,在 input 中 跳过 ASCII 空白。
如果 position 已超过 input 的末尾,则 失败。
如果 input 中 position 所指向的字符是 U+0050 LATIN CAPITAL LETTER P 字符,则将 position 前进到下一个字符,将 M-disambiguator 设置为months,并且给定 position,在 input 中跳过 ASCII 空白。
当 true 时:
令 units 为未定义。随后将为其指定以下值之一: years、months、weeks、days、hours、minutes 和 seconds。
令 next character 为未定义。它用于处理 input 中的字符。
如果 position 已超过 input 的末尾,则中断。
如果 input 中 position 所指向的字符是 U+0054 LATIN CAPITAL LETTER T 字符,则将 position 前进到下一个字符,将 M-disambiguator 设置为minutes,给定 position,在 input 中跳过 ASCII 空白,然后继续。
将 next character 设置为 input 中 position 所指向的字符。
如果 next character 是 U+002E FULL STOP 字符 (.),则令 N 为 0。(不要 前进 position。这会在 下文处理。)
否则,如果 next character 是ASCII 数字,则给定 position,从 input 中收集一个码位序列,该序列由ASCII 数字组成,将所得 序列解释为十进制整数,并令 N 为该数。
否则,next character 不是数值的一部分;失败。
如果 position 已超过 input 的末尾,则 失败。
将 next character 设置为 input 中 position 所指向的字符,并在这次将 position 前进到下一个字符。(如果 next character 之前是 U+002E FULL STOP 字符 (.),这次它仍然是该字符。)
如果 next character 是 U+002E (.):
如果 s 是空字符串,则失败。
令 length 为 s 中的字符数。
令 fraction 为将 s 解释为十进制整数后,再将该数除以 10length 的结果。
将 N 增加 fraction。
给定 position,在 input 中 跳过 ASCII 空白。
如果 position 已超过 input 的末尾,则 失败。
将 next character 设置为 input 中 position 所指向的字符,并将 position 前进到 下一个字符。
如果 next character 既不是 U+0053 LATIN CAPITAL LETTER S 字符,也不是 U+0073 LATIN SMALL LETTER S 字符,则失败。
将 units 设置为seconds。
否则:
如果 next character 是ASCII 空白,则给定 position,在 input 中跳过 ASCII 空白,将 next character 设置为 input 中 position 所指向的字符,并 将 position 前进到下一个字符。
如果 next character 是 U+0059 LATIN CAPITAL LETTER Y 字符,或 U+0079 LATIN SMALL LETTER Y 字符,则将 units 设置为years,并将 M-disambiguator 设置为months。
如果 next character 是 U+004D LATIN CAPITAL LETTER M 字符或 U+006D LATIN SMALL LETTER M 字符,并且 M-disambiguator 为 months,则将 units 设置为months。
如果 next character 是 U+0057 LATIN CAPITAL LETTER W 字符或 U+0077 LATIN SMALL LETTER W 字符,则将 units 设置为weeks,并将 M-disambiguator 设置为minutes。
如果 next character 是 U+0044 LATIN CAPITAL LETTER D 字符或 U+0064 LATIN SMALL LETTER D 字符,则将 units 设置为days,并将 M-disambiguator 设置为minutes。
如果 next character 是 U+0048 LATIN CAPITAL LETTER H 字符或 U+0068 LATIN SMALL LETTER H 字符,则将 units 设置为hours,并将 M-disambiguator 设置为minutes。
如果 next character 是 U+004D LATIN CAPITAL LETTER M 字符或 U+006D LATIN SMALL LETTER M 字符,并且 M-disambiguator 为 minutes,则将 units 设置为minutes。
如果 next character 是 U+0053 LATIN CAPITAL LETTER S 字符或 U+0073 LATIN SMALL LETTER S 字符,则将 units 设置为seconds,并 将 M-disambiguator 设置为minutes。
否则,如果 next character 不是上述任何字符,则 失败。
将 component count 增加 1。
令 multiplier 为 1。
如果 units 为years,则将 multiplier 乘以 12,并将 units 设置为months。
如果 units 为months,则将 N 与 multiplier 的乘积加到 months。
否则:
如果 units 为weeks,则将 multiplier 乘以 7,并将 units 设置为days。
如果 units 为days,则将 multiplier 乘以 24,并将 units 设置为hours。
如果 units 为hours,则将 multiplier 乘以 60,并将 units 设置为minutes。
如果 units 为minutes,则将 multiplier 乘以 60,并将 units 设置为seconds。
此时,units 必然为seconds。将 N 与 multiplier 的乘积加到 seconds。
给定 position,在 input 中 跳过 ASCII 空白。
如果 component count 为零, 则失败。
如果 months 不为零,则失败。
返回由 seconds 秒组成的持续时间。
如果一个字符串也是以下任一项,则它是带可选时间的有效日期字符串:
解析日期或时间字符串的规则如下。该 算法将返回一个日期、一个时间、一个全局日期和时间,或者不返回任何内容。如果算法在任何时候 指出“失败”,则表示算法在该处中止,并且不返回任何内容。
令 input 为正在解析的字符串。
令 position 为指向 input 内部的指针,最初 指向字符串的开头。
将 start position 设置为与 position 相同的位置。
将 date present 和 time present 标志设置为 true。
解析日期 组成部分以获得 year、month 和 day。如果失败,则将 date present 标志设置为 false。
如果 date present 为 true,且 position 未超过 input 的末尾,并且 position 处的字符 是 U+0054 LATIN CAPITAL LETTER T 字符 (T) 或 U+0020 SPACE 字符之一,则将 position 前进到 input 中的下一个字符。
否则,如果 date present 为 true,并且 position 已超过 input 的末尾,或者 position 处的字符既不是 U+0054 LATIN CAPITAL LETTER T 字符 (T),也不是 U+0020 SPACE 字符,则将 time present 设置为 false。
否则,如果 date present 为 false,则将 position 恢复到与 start position 相同的位置。
如果 time present 标志为 true,则解析时间 组成部分以获得 hour、minute 和 second。如果这不返回任何内容, 则失败。
如果 date present 和 time present 标志 均为 true,但 position 已超过 input 的末尾,则 失败。
如果 date present 和 time present 标志 均为 true,则解析时区偏移组成部分以 获得 timezonehours 和 timezoneminutes。如果这 不返回任何内容,则失败。
如果 position 未超过 input 的末尾,则失败。
如果 date present 标志为 true 且 time present 标志为 false,则令 date 为年份是 year、 月份是 month、日期是 day 的日期,并返回 date。
否则,如果 time present 标志为 true 且 date present 标志为 false,则令 time 为小时是 hour、分钟是 minute、秒是 second 的时间, 并返回 time。
否则,令 time 为年份 year、月份 month、日期 day、小时 hour、分钟 minute、秒 second 所表示的时刻,再减去 timezonehours 小时和 timezoneminutes 分钟,该时刻是 UTC 时区中的时刻;令 timezone 为相对于 UTC 偏移 timezonehours 小时和 timezoneminutes 分钟的时区;并返回 time 和 timezone。
某些已过时的旧式属性使用 解析旧式颜色 值的规则来解析颜色,并给定一个字符串 input。这些规则将返回 CSS 颜色或失败。
如果 input 是空字符串,则返回失败。
从 input 中去除前导和尾随 ASCII 空白。
如果 input 与“transparent”ASCII
不区分大小写匹配,则返回失败。
如果 input 与某个命名颜色ASCII 不区分大小写匹配,则返回与该 关键字对应的 CSS 颜色。[CSSCOLOR]
不识别 CSS2 系统 颜色。
如果 input 的码 位长度为四,第一个字符是 U+0023 (#),并且 input 的最后三个字符均为 ASCII 十六进制数字:
令 result 为一个 CSS 颜色。
将 input 的第二个字符解释为十六进制数字;令 result 的红色分量为所得数字乘以 17。
将 input 的第三个字符解释为十六进制数字;令 result 的绿色分量为所得数字乘以 17。
将 input 的第四个字符解释为十六进制数字;令 result 的蓝色分量为所得数字乘以 17。
返回 result。
将 input 中所有大于 U+FFFF 的码位(即不在基本多文种平面中的任何字符)替换为“00”。
如果 input 的码 位长度大于 128,则截断 input,仅保留前 128 个字符。
如果 input 中的第一个字符是 U+0023 (#),则将其移除。
将 input 中不是ASCII 十六进制数字的任何字符替换为 U+0030 (0)。
当 input 的码 位长度为零或不是 三的倍数时,将 U+0030 (0) 追加到 input。
将 input 分割为三个码 位长度相等的字符串,以 获得三个分量。令 length 为这些分量共同具有的码 位长度(即 input 的码 位长度的三分之一)。
如果 length 大于 8,则移除每个分量中前面的 length-8 个字符,并令 length 为 8。
当 length 大于二且每个 分量的第一个字符均为 U+0030 (0) 时,移除该字符并将 length 减一。
如果 length 仍然大于二,则截断每个分量, 每个分量仅保留前两个字符。
令 result 为一个 CSS 颜色。
将第一个分量解释为十六进制数;令 result 的红色分量为 所得数字。
将第二个分量解释为十六进制数;令 result 的绿色分量为 所得数字。
将第三个分量解释为十六进制数;令 result 的蓝色分量为 所得数字。
返回 result。
唯一空格分隔标记的无序集合是一个空格分隔的 标记集合,其中没有重复的标记。
唯一空格分隔标记的有序集合是一个 空格分隔的 标记集合,其中没有重复的标记,但标记的顺序 具有意义。
空格分隔的 标记集合有时 会定义一组允许值。定义允许值集合后,所有标记都必须 来自该允许值列表;其他值不符合规范。如果未提供此类允许值 集合,则所有值均符合规范。
空格分隔的标记集合中的标记应如何比较 (例如是否区分大小写),由每个集合分别定义。
逗号分隔的标记集合是一个包含零个或多个 标记的字符串,每个标记与下一个标记之间由单个 U+002C COMMA 字符 (,) 分隔,其中标记由任意 零个或多个字符组成,不以ASCII 空白开头或结尾,也不 包含任何 U+002C COMMA 字符 (,),并且可以选择由ASCII 空白包围。
例如,字符串“ a ,b,,d d ”由四个标记组成:
“a”、“b”、空
字符串和“d d”。每个标记周围的前导和尾随空白不算作
标记的一部分,并且空字符串可以作为标记。
逗号分隔的 标记集合有时 会进一步限制有效标记的构成方式。定义此类限制后,所有 标记都必须符合这些限制;其他值不符合规范。如果未指定此类 限制,则所有值均符合规范。
对类型为 type 的元素的有效散列名称引用是一个
由 U+0023 NUMBER SIGN 字符 (#) 后跟一个字符串构成的字符串,该字符串与
同一树中类型为
type 的元素的 name 属性值完全匹配。
给定上下文节点 scope,对类型为 type 的元素 解析散列名称引用的规则如下:
如果正在解析的字符串不包含 U+0023 NUMBER SIGN 字符,或者 字符串中第一个此类字符是字符串中的最后一个字符,则返回 null。
令 s 为正在解析的字符串中第一个 U+0023 NUMBER SIGN 字符之后紧邻的字符至该字符串末尾的字符串。
返回 scope 的树中按
树顺序排列的第一个类型为 type 的元素,该元素具有值为
s 的 id 或
name
属性;如果不存在此类
元素,则返回 null。
虽然解析时会考虑 id 属性,
但在确定一个值是否为有效散列名称
引用时不会使用它们。也就是说,基于 id 引用元素的散列名称引用属于符合性错误
(除非该元素还具有值相同的 name 属性)。
如果一个字符串匹配媒体查询的
<media-query-list> 产生式,则它是有效媒体查询列表。
[MQ]
唯一内部值是一个可序列化、可按值比较, 且 从不暴露给脚本的值。
要创建一个新的唯一内部值,返回一个 此算法以前从未返回过的唯一内部值。
如果一个字符串是有效 URL 字符串,但不是 空字符串,则它是有效非空 URL。
如果从一个字符串中去除前导和尾随 ASCII 空白后,该字符串是有效 URL 字符串, 则它是可能由空白包围的有效 URL。
如果从一个字符串中去除前导和尾随 ASCII 空白后,该字符串是有效 非空 URL,则它是可能由空白包围的有效非空 URL。
本规范将 URL about:legacy-compat 定义为一个保留但无法解析的
about:
URL,用于在需要与 XML 工具
兼容时,在HTML 文档中的DOCTYPE 中使用。[ABOUT]
本规范将 URL about:html-kind 定义为一个保留但无法解析的
about:
URL,用作
媒体轨道种类的标识符。[ABOUT]
本规范将 URL about:srcdoc 定义为一个保留但
无法解析的 about:
URL,用作iframe
srcdoc 文档的URL。
[ABOUT]
此类 URL 的查询和片段可以不为 null。例如,通过解析“about:blank?foo#bar”创建的URL
记录匹配 about:blank。
匹配
about:srcdoc要求
URL 的查询为 null,是因为无法
创建其URL具有非 null 查询的iframe
srcdoc 文档,这不同于其
URL匹配 about:blank的 Document。换
言之,所有URL 中匹配
about:srcdoc的 URL 仅在其片段上有所不同。
解析 URL 是获取一个字符串并取得它所表示的URL 记录的过程。 虽然此过程在 URL 中定义,但 HTML 标准定义了 若干包装算法,以抽象基准 URL 和编码。[URL]
大多数新 API 应使用解析 URL。较旧的 API 和 HTML 元素 可能有理由使用使用编码解析 URL。当需要 自定义基准 URL 或不需要基准 URL 时,当然也可以直接使用URL 解析器。
给定字符串 url,相对于一个 Document 对象或环境设置
对象 environment,要解析 URL,请运行以下步骤。它们返回失败或一个URL。
如果 environment 是一个 Document
对象,则令
baseURL 为 environment 的基准
URL;否则为
environment 的API 基准 URL。
返回使用 baseURL 将URL 解析器应用于 url 的结果。
给定字符串 url,相对于一个 Document 对象或环境
设置对象 environment,要使用编码解析 URL,
请运行以下步骤。它们返回失败或一个
URL。
令 encoding 为 UTF-8。
如果 environment 是一个 Document
对象,则将 encoding
设置为 environment 的字符
编码。
否则,如果 environment 的相关全局对象是一个
Window 对象,则将 encoding 设置为
environment 的相关
全局对象的关联的
Document的字符
编码。
如果 environment 是一个 Document
对象,则令
baseURL 为 environment 的基准
URL;否则为
environment 的API 基准 URL。
返回使用 baseURL 和 encoding 将URL 解析器应用于 url 的结果。
给定字符串 url,相对于一个 Document 对象或
环境设置
对象 environment,要使用编码解析并序列化
URL,请运行以下步骤。它们返回
失败或字符串。
令 url 为给定 url,相对于 environment 使用编码解析 URL的结果。
如果 url 为失败,则返回失败。
返回将URL 序列化器应用于 url 的结果。
Document 对象 document 的后备基准 URL是通过运行以下步骤获得的
URL 记录:
如果 document 是iframe
srcdoc 文档:
断言:document 的about 基准 URL不为 null。
返回 document 的about 基准 URL。
如果 document 的URL匹配
about:blank,并且 document 的about 基准 URL不为 null,则返回
document 的about 基准
URL。
返回 document 的URL。
要将 Document document 的
URL 设置为一个URL
记录 url:
将 document 的URL设置为 url。
给定 document,响应基准 URL 更改。
要为
Document document
响应基准 URL 更改:
这意味着更改基准
URL 不会影响例如由 img 元素显示的图像。因此,
脚本随后访问 src IDL
属性时,将
返回一个新的绝对 URL,该 URL 可能不再对应正在
显示的图像。
给定 url、destination、 corsAttributeState 和可选的同源后备标志,要创建一个潜在 CORS 请求,请运行以下 步骤:
资源的Content-Type 元数据必须以符合MIME 嗅探 要求的方式获取和解释。 [MIMESNIFF]
资源的计算所得 MIME 类型必须以符合MIME 嗅探中所给要求的方式确定。[MIMESNIFF]
专门嗅探图像的 规则、区分资源是文本还是 二进制数据的规则以及专门 嗅探音频和视频的规则也在MIME 嗅探中定义。 这些规则返回一个MIME 类型作为结果。[MIMESNIFF]
必须严格遵循MIME 嗅探中的规则。 当用户代理使用与服务器预期不同的启发式方法检测内容类型时, 可能会出现安全问题。有关更多详细信息,请参阅MIME 嗅探。 [MIMESNIFF]
meta
元素中提取字符编码给定一个字符串 s,从
meta 元素中提取
字符编码的算法如下。它返回字符编码或
不返回任何内容。
令 position 为指向 s 内部的指针,最初 指向字符串的开头。
循环:在 s 中查找 position 之后最先出现的七个字符,
这些字符与单词“charset”ASCII
不区分大小写匹配。如果未找到此类匹配,则不返回任何内容。
跳过紧随单词“charset”之后的所有ASCII
空白(可能不存在)。
如果下一个字符不是 U+003D EQUALS SIGN (=),则移动 position,使其指向 该下一个字符之前的位置,然后跳回标记为循环的步骤。
跳过紧随等号之后的所有ASCII 空白(可能不存在)。
按以下方式处理下一个字符:
此算法与 HTTP 规范中的算法不同(例如, HTTP 不允许使用单引号,并要求支持一种 本算法不支持的反斜杠转义机制)。虽然该 算法用于历史上与 HTTP 相关的上下文,但实现所支持的语法 很久以前就已产生分歧。[HTTP]
所有当前引擎均支持。
CORS 设置属性是一个枚举属性,具有以下 关键字和状态:
| 关键字 | 状态 | 简要描述 |
|---|---|---|
anonymous
|
匿名 | 对该元素发出的请求,其
模式将设置为
“cors”,其
凭据模式将设置为“same-origin”。
|
use-credentials
|
使用凭据 | 对该元素发出的请求,其模式将设置为
“cors”,其凭据模式将设置为“include”。
|
由CORS 设置 属性控制的大多数获取操作,将通过创建潜在 CORS 请求算法执行。
对于更现代的特性,其请求的模式始终为“cors”,某些CORS 设置
属性已被重新用于表达略有不同的含义,即它们只影响请求的凭据模式。为了执行这种转换,我们将给定CORS
设置属性的CORS 设置属性凭据
模式定义为根据属性状态进行分支确定:
引用来源策略属性是一个枚举属性。每个 引用来源 策略(包括空字符串)都是该属性的关键字,并映射 到同名状态。
这些状态对各种获取处理模型的影响,在本规范的各处、 Fetch 和引用来源策略中有更详细的定义。[FETCH] [REFERRERPOLICY]
多种信号都可能影响为给定获取使用哪种处理模型;引用来源策略属性只是其中 之一。通常,这些信号的处理顺序如下:
首先,是否存在 noreferrer
链接
类型;
然后,引用来源策略属性的值;
最后,`Referrer-Policy`
HTTP
标头。
所有当前引擎均支持。
nonce 内容
属性表示一个加密 nonce(“仅使用一次的数字”),内容
安全策略可以使用它来确定是否允许继续执行给定的获取操作。其
值为文本。[CSP]
具有 nonce 内容
属性的元素,通过从内容属性中取得值,将其移动到名为
[[CryptographicNonce]] 的内部槽中,通过
HTMLOrSVGOrMathMLElement
接口混入将其暴露给脚本,并将内容属性
设置为空字符串,以确保加密 nonce 只暴露给脚本,而不暴露给 CSS 属性
选择器等侧信道。除非另有规定,该槽的值为空字符串。
element.nonce
返回为 element 的加密 nonce 设置的值。如果未使用
设置器,则该值是最初在 nonce
内容属性中找到的值。
element.nonce = value
更新 element 的加密 nonce 值。
nonce IDL 属性在获取时必须
返回此元素的[[CryptographicNonce]]值;在设置时,将此
元素的[[CryptographicNonce]]设置为
给定值。
请注意,
nonce IDL 属性的
设置器不会更新
相应的内容属性。这一点以及下文在元素
变为与浏览上下文连接时,将 nonce 内容属性设置为空字符串,
旨在防止通过选择器等可轻松读取内容属性的机制泄露 nonce
值。请参阅引入此行为的
议题 #2369了解更多信息。
如果 element 不包含 HTMLOrSVGOrMathMLElement,
则返回。
如果 localName 不是 nonce,或者
namespace 不为 null,则返回。
如果 value 为 null,则将 element 的 [[CryptographicNonce]]设置为空字符串。
否则,将 element 的[[CryptographicNonce]]设置为 value。
每当一个包含
HTMLOrSVGOrMathMLElement 的元素变为
与浏览上下文连接时,用户
代理必须对 element 执行以下步骤:
如果 CSP list包含通过标头传递的内容
安全策略,并且
element 具有一个值不为空字符串的 nonce
内容属性:
令 nonce 为 element 的 [[CryptographicNonce]]。
将 element 的[[CryptographicNonce]]设置为 nonce。
如果未恢复 element 的[[CryptographicNonce]],则此时它 将为空字符串。
给定 node、copy 和 subtree,对包含 HTMLOrSVGOrMathMLElement 的元素执行的克隆步骤,是将 copy 的[[CryptographicNonce]]设置为
node 的[[CryptographicNonce]]。
所有当前引擎均支持。
延迟加载属性是一个枚举属性,具有以下 关键字和状态:
| 关键字 | 状态 | 简要描述 |
|---|---|---|
lazy
|
延迟 | 用于将资源获取推迟到满足某些条件之后。 |
eager
|
立即 | 用于立即获取资源;这是默认状态。 |
该属性根据其当前状态,指示用户代理立即获取资源,或者将获取推迟到 与该元素相关的某些条件得到满足时。
给定元素 element,元素将延迟加载步骤如下:
每个 img、audio、video 和 iframe 元素都有关联的
延迟加载恢复步骤,初始值为 null。
每个 video 元素
还具有相关联的海报延迟加载恢复步骤,
初始值为 null。
对于将延迟
加载的 img、
audio、video 和 iframe 元素,
这些步骤会从延迟加载
交叉观察器的回调中运行,或者在其延迟加载
属性被设置为立即状态时运行。这会
使元素继续加载。对于 video
元素,海报延迟加载
恢复步骤也会同时运行。
每个 Document 都具有一个
延迟加载交叉观察器,初始设置为
null,但可以设置为一个 IntersectionObserver
实例。
要开始交叉观察延迟加载 元素 element,请运行以下 步骤:
令 doc 为 element 的节点文档。
如果 doc 的延迟加载交叉观察器为 null,
则将其设置为新的
IntersectionObserver
实例,并按以下方式初始化:
其意图是使用
IntersectionObserver
构造函数的原始值。但是,在交叉观察器为规范公开可用的底层钩子之前,
本规范不得不使用暴露给 JavaScript 的构造函数。请参阅跟踪此问题的
w3c/IntersectionObserver#464。
[INTERSECTIONOBSERVER]
callback 为以下步骤,参数为 entries 和 observer:
对于 entries 中的每个 entry,使用不会触发开发者可修改的数组访问器或 迭代钩子的迭代方法:
令 resumptionSteps 为 null。
如果 entry.isIntersecting
为 true,则
将 resumptionSteps 设置为 entry.target
的
延迟
加载恢复步骤。
令 posterResumptionSteps 为 null。
如果 entry.isIntersecting
为 true,并且 entry.target
是一个
video
元素,则将 posterResumptionSteps 设置为该 video
元素的海报延迟加载恢复
步骤。
如果 resumptionSteps 为 null 且 posterResumptionSteps 为 null, 则返回。
为 entry.target
停止
交叉观察延迟加载元素。
如果 resumptionSteps 不为 null:
如果 posterResumptionSteps 不为 null:
将 video
元素的海报延迟加载恢复
步骤
设置为 null。
调用 posterResumptionSteps。
其意图是使用
isIntersecting
和
target
获取器的原始值。请参阅w3c/IntersectionObserver#464。
[INTERSECTIONOBSERVER]
options 是一个 IntersectionObserverInit
字典,具有以下字典成员:«[ “scrollMargin” → 延迟加载滚动
边距 ]»
这允许在滚动期间获取图像,此时图像尚未与视口相交, 但即将与之相交。
延迟加载滚动边距的建议意味着需要
动态更改该
值,但 IntersectionObserver
API 不支持更改滚动
边距。请参阅议题w3c/IntersectionObserver#428。
以 element 作为参数,调用 doc 的延迟加载交叉观察器的 observe
方法。
其意图是使用 observe
方法的原始值。请参阅w3c/IntersectionObserver#464。
[INTERSECTIONOBSERVER]
要停止交叉观察延迟加载 元素 element,请运行以下 步骤:
令 doc 为 element 的节点文档。
以 element 作为
参数,调用 doc 的延迟加载交叉观察器的 unobserve
方法。
其意图是使用 unobserve
方法的原始值。请参阅w3c/IntersectionObserver#464。
[INTERSECTIONOBSERVER]
![]() 延迟加载滚动边距是一个
由实现定义的值,但应考虑以下建议:
延迟加载滚动边距是一个
由实现定义的值,但应考虑以下建议:
设置一个最小值,使资源在给定设备的正常使用模式下,大多数情况下能在 与视口相交之前完成加载。
典型滚动速度:对于典型滚动速度更快的设备,增大该值。
当前滚动速度或惯性:用户代理可以尝试预测滚动 可能停止的位置,并相应调整该值。
网络质量:对于速度较慢或高延迟的连接,增大该值。
用户偏好可以影响该值。
为保护隐私,重要的是 延迟加载滚动边距 不得泄露额外信息。例如,当前设备上的典型 滚动速度可以保持不精确,以免引入新的 指纹识别向量。
阻塞属性明确表示,在获取外部资源时应 阻塞某些操作。可被阻塞的操作由 可能的阻塞标记表示,这些标记是下表列出的 字符串:
| 可能的阻塞标记 | 描述 |
|---|---|
“render”
|
该元素可能阻塞渲染。 |
将来, 可能会有更多可能的 阻塞标记。
阻塞属性的 值必须是唯一空格分隔 标记的无序集合,其中每个标记都是可能的 阻塞标记。阻塞属性的受支持标记是这些可能的阻塞 标记。任何元素最多只能具有一个阻塞属性。
元素 el 的阻塞标记集合是以下 步骤的结果:
令 value 为 el 的阻塞属性的值;如果不存在 此类属性,则为空字符串。
将 value 设置为转换为 ASCII 小写形式后的 value。
令 rawTokens 为在 ASCII 空白处分割 value的结果。
返回一个集合,其中包含 rawTokens 中属于可能的阻塞标记的元素。
获取优先级属性是一个枚举属性,具有 以下关键字和状态:
| 关键字 | 状态 | 简要描述 |
|---|---|---|
high
|
高 | 表示相对于具有相同目标的其他 资源,这是一次高优先级获取。 |
low
|
低 | 表示相对于具有相同目标的其他 资源,这是一次低优先级获取。 |
auto
|
自动 | 表示相对于具有相同目标的其他资源,自动确定 获取优先级。 |
反映的构成要素如下:
反映目标是一个元素或 ElementInternals
对象。通常可从上下文中明确得知,并且通常与
反映的 IDL 属性的接口相同。当它是
ElementInternals
对象时,它始终与该接口相同。
反映的 IDL 属性是一个属性接口成员。
反映的内容属性名称是一个字符串。当反映
目标是元素时,它表示命名空间为 null 的内容属性的本地名称。当反映目标是一个 ElementInternals
对象时,它
表示反映目标的目标
元素的内部内容属性
映射中的一个键。
可以将反映的 IDL 属性定义为 反映某个反映目标的 反映的内容属性 名称。一般而言,这 意味着 IDL 属性获取器返回内容属性的当前值,而 设置器会将内容属性的值更改为给定值。
反映 目标具有以下关联算法:
对于作为元素 element 的反映目标,这些算法定义 如下:
返回 element。
令 attribute 为给定 null、反映的 内容属性名称和 element,按命名空间和 本地名称获取属性的结果。
如果 attribute 为 null,则返回 null。
返回 attribute 的值。
给定 element、反映的 内容属性名称和 value,设置属性值。
给定 null、反映的 内容属性名称和 element,按命名空间和本地名称 移除属性。
对于作为 ElementInternals
对象
elementInternals 的反映目标,这些算法定义如下:
如果 elementInternals 的目标元素的 内部内容 属性映射[反映的 内容属性名称] 不 存在,则返回 null。
返回 elementInternals 的目标 元素的内部内容 属性映射[反映的 内容 属性名称]。
将 elementInternals 的目标元素的内部内容 属性映射[反映的 内容属性名称]设置为 value。
从 elementInternals 的目标元素的内部内容 属性映射[反映的 内容属性名称]中移除相应条目。
这会使
ElementInternals
对象具有某种程度上冗余的数据结构,因为其目标
元素的内部内容属性
映射无法被直接操作,因此
反映只会沿单一方向发生。尽管如此,仍选择了这种方法,以便在定义由多个反映目标共享并受益于
通用 API 语义的 IDL 属性时更不容易出错。
类型为 DOMString
或
DOMString?
并反映枚举内容属性的
IDL 属性,可以被
限制为仅使用已知值。
根据下述处理模型,这会使此类 IDL 属性的获取器仅
返回这些枚举属性的关键字、空字符串或 null。
如果一个反映的 IDL 属性的
类型为 DOMString:
获取器步骤如下:
令 attributeDefinition 为 element 的内容属性的属性定义,该内容属性的 命名空间为 null,且本地名称为反映的 内容 属性名称。
如果 attributeDefinition 表明它是一个枚举属性,并且 反映的 IDL 属性被定义为限制为仅使用已知 值:
如果 contentAttributeValue 为 null,则返回空字符串。
返回 contentAttributeValue。
如果一个反映的 IDL 属性的
类型为
DOMString?:
获取器步骤如下:
令 attributeDefinition 为 element 的内容属性的属性定义,该内容属性的 命名空间为 null,且本地名称为反映的 内容 属性名称。
如果 attributeDefinition 表明它是一个枚举属性:
返回 contentAttributeValue。
如果一个反映的 IDL 属性的
类型为 USVString,
并且可以选择作为 URL 处理:
获取器步骤如下:
如果 contentAttributeValue 为 null,则返回空字符串。
令 urlString 为给定 contentAttributeValue,相对于 element 的节点 文档,使用编码解析并序列化 URL的结果。
如果 urlString 不是失败,则返回 urlString。
返回转换为标量值字符串后的 contentAttributeValue。
如果一个反映的 IDL 属性的
类型为 boolean:
这对应于布尔内容 属性的规则。
如果一个反映的 IDL 属性的
类型为 long,
并且可以选择限制为仅使用非负数,还可以选择具有一个
默认
值 defaultValue:
获取器步骤如下:
如果 contentAttributeValue 不为 null:
如果反映的 IDL 属性未被限制 为仅使用非负数,则令 parsedValue 为对 contentAttributeValue 进行整数 解析的结果;否则为对 contentAttributeValue 进行非负 整数 解析的结果。
如果 parsedValue 不是错误,并且位于 long
范围内,则返回 parsedValue。
如果反映的 IDL 属性具有默认值,则 返回 defaultValue。
如果反映的 IDL 属性被限制为 仅使用非负 数,则返回 −1。
返回 0。
设置器步骤如下:
如果反映的 IDL
属性被限制为
仅使用非负
数,并且给定值为负数,则抛出
“IndexSizeError” DOMException。
如果一个反映的 IDL 属性的
类型为 unsigned long,
并且可以选择限制为仅使用正
数、限制为仅
使用带后备值的正
数,或者限制在范围
[clampedMin,
clampedMax] 内,还可以选择具有一个默认值 defaultValue:
获取器步骤如下:
令 minimum 为 0。
如果反映的 IDL 属性被限制 为仅使用正 数,或者被限制 为仅使用带后备值的正数,则将 minimum 设置为 1。
如果反映的 IDL 属性被限制在范围内,则 将 minimum 设置为 clampedMin。
如果反映的 IDL 属性未被 限制在范围内,则令 maximum 为 2147483647;否则为 clampedMax。
如果 contentAttributeValue 不为 null:
令 parsedValue 为对 contentAttributeValue 进行非负 整数解析的结果。
如果 parsedValue 不是错误,并且位于从 minimum 到 maximum 的闭区间内,则返回 parsedValue。
如果 parsedValue 不是错误,并且反映的 IDL 属性被 限制在 范围内:
如果 parsedValue 小于 minimum,则返回 minimum。
返回 maximum。
如果反映的 IDL 属性具有默认值,则 返回 defaultValue。
返回 minimum。
设置器步骤如下:
如果反映的 IDL
属性被限制
为仅使用正
数,并且给定值为 0,则抛出
“IndexSizeError” DOMException。
令 minimum 为 0。
如果反映的 IDL 属性被限制 为仅使用正 数,或者被限制 为仅使用带后备值的正数,则将 minimum 设置为 1。
令 newValue 为 minimum。
如果反映的 IDL 属性具有默认值,则将 newValue 设置为 defaultValue。
如果给定值位于从 minimum 到 2147483647 的闭区间内, 则将 newValue 设置为该值。
限制在范围内对 设置器步骤没有影响。
如果一个反映的 IDL 属性的
类型为 double,
并且可以选择被限制为仅使用正数,
还可以选择具有一个默认值
defaultValue:
获取器步骤如下:
如果 contentAttributeValue 不为 null:
令 parsedValue 为对 contentAttributeValue 进行浮点 数解析的结果。
如果 parsedValue 不是错误,并且大于 0,则返回 parsedValue。
如果 parsedValue 不是错误,并且反映的 IDL 属性 未被限制 为仅使用正数,则返回 parsedValue。
如果反映的 IDL 属性具有默认值,则 返回 defaultValue。
返回 0。
设置器步骤如下:
如果反映的 IDL 属性被限制 为仅使用正 数,并且给定值不大于 0,则返回。
使用转换为数字作为浮点 数的最佳表示的给定值,运行 this 的设置内容 属性。
如 Web IDL 中所定义,设置 Infinity 和 Not-a-Number (NaN) 值时会抛出异常。 [WEBIDL]
如果一个反映的 IDL 属性的
类型为 DOMTokenList,则其
获取器步骤是返回一个 DOMTokenList
对象,其关联元素为
this,关联属性的本地名称为反映的内容
属性名称。规范作者不能在
ElementInternals
上反映此类型的 IDL 属性。
如果一个反映的 IDL 属性的
类型为 T?,
其中 T 是 Element
或继承自
Element
的接口,并且 attr 是反映的内容
属性
名称:
其反映目标具有一个显式设置的 attr 元素,它是对某个元素的弱引用或 null。其初始值为 null。
其反映目标 reflectedTarget 具有一个获取 attr 关联元素算法,该算法运行以下步骤:
令 element 为运行 reflectedTarget 的获取 元素所得的结果。
令 contentAttributeValue 为运行 reflectedTarget 的获取内容 属性所得的结果。
如果 reflectedTarget 的显式设置的 attr 元素不为 null:
如果 reflectedTarget 的显式设置的 attr 元素是 element 的任意影子包含祖先的后代,则返回 reflectedTarget 的显式设置的 attr 元素。
返回 null。
否则,如果 contentAttributeValue 不为 null,则返回按树顺序排列的 第一个满足以下条件的元素 candidate:
如果不存在此类元素,则返回 null。
返回 null。
获取器步骤是返回运行 this 的获取 attr 关联元素所得的结果。
设置器步骤如下:
如果给定值为 null:
将 this 的显式设置的 attr 元素设置为 null。
返回。
将 this 的显式设置的 attr 元素设置为对 给定值的弱引用。
仅对于元素反映目标:给定 element、localName、oldValue、value 和 namespace,以下属性更改步骤用于在内容属性与 IDL 属性之间同步:
如果 localName 不是 attr,或者 namespace 不为 null,则 返回。
将 element 的显式设置的 attr 元素设置为 null。
强烈建议使此类型的反映的 IDL 属性的
标识符以“Element”结尾,以保持
一致性。
如果一个反映的 IDL 属性的
类型为 FrozenArray<T>?,其中 T 是
Element
或继承自 Element
的接口,并且
attr 是反映的内容
属性名称:
其反映目标具有缓存的 attr 关联
元素对象,它是一个 FrozenArray<T>?。其
初始值为 null。
其反映目标 reflectedTarget 具有一个获取 attr 关联元素算法,该算法运行以下步骤:
令 elements 为空列表。
令 element 为运行 reflectedTarget 的获取 元素所得的结果。
如果 reflectedTarget 的显式设置的 attr 元素不为 null:
否则:
令 contentAttributeValue 为运行 reflectedTarget 的获取内容 属性所得的结果。
如果 contentAttributeValue 为 null,则返回 null。
令 tokens 为在 ASCII 空白处分割后的 contentAttributeValue。
对于 tokens 中的每个 id:
返回 elements。
获取器步骤如下:
令 elements 为运行 this 的获取 attr 关联元素所得的结果。
如果 elements 的内容等于 this 的 缓存的 attr 关联元素的内容,则返回 this 的 缓存的 attr 关联元素对象。
令 elementsAsFrozenArray 为转换为
FrozenArray<T>? 的 elements。
将 this 的缓存的 attr 关联元素设置为 elements。
将 this 的缓存的 attr 关联元素对象 设置为 elementsAsFrozenArray。
返回 elementsAsFrozenArray。
此额外缓存层对于保持
element.reflectedElements === element.reflectedElements 这一不变量是必要的。
仅对于元素反映目标:给定 element、localName、oldValue、value 和 namespace,以下属性更改步骤用于在内容属性与 IDL 属性之间同步:
如果 localName 不是 attr,或者 namespace 不为 null,则 返回。
将 element 的显式设置的 attr 元素设置为 null。
强烈建议使此类型的反映的 IDL 属性的
标识符以“Elements”结尾,以保持
一致性。
可以通过扩展
属性从 IDL 使用反映。[Reflect]、[ReflectSetter]、[ReflectURL]、
[ReflectNonNegative]、[ReflectPositive] 和
[ReflectPositiveWithFallback] 都会
触发反映。它们必须
不接受参数或接受一个
字符串;不得出现在接口成员属性以外的任何位置;并且一次只能使用其中一个。
对于这些主要反映扩展 属性之一,如果提供了字符串值,则其反映的内容属性 名称为该字符串值; 否则为转换为 ASCII 小写形式后的 IDL 属性名称。
具有 [Reflect]
扩展
属性的 IDL 属性必须反映 [Reflect] 的
反映的内容属性
名称。
具有 [ReflectSetter]
扩展
属性的 IDL 属性,在设置时必须反映 [ReflectSetter]
的
反映的内容属性
名称。
[ReflectURL]
扩展
属性必须
仅出现在类型为 USVString
的属性上。
具有 [ReflectURL]
扩展
属性的 IDL 属性,必须作为
URL反映 [ReflectURL]
的
反映的内容属性
名称。
[ReflectNonNegative]
扩展
属性必须仅出现在类型为 long
的属性上。
具有 [ReflectNonNegative]
扩展
属性的 IDL 属性,必须在限制为仅使用非负
数的情况下反映 [ReflectNonNegative]
的
反映的内容属性
名称。
[ReflectPositive]
和 [ReflectPositiveWithFallback]
扩展
属性必须仅出现在类型
为 double
或 unsigned
long 的属性上。
具有 [ReflectPositive]
扩展
属性的 IDL 属性,必须在限制为
仅使用正
数的情况下反映 [ReflectPositive]
的
反映的
内容属性名称。
具有 [ReflectPositiveWithFallback]
扩展
属性的 IDL 属性,必须在限制
为仅使用带
后备值的正数的情况下反映 [ReflectPositiveWithFallback]
的
反映的
内容属性名称。
为了补充上述扩展
属性,我们还
引入了 [ReflectRange] 和 [ReflectDefault]。它们
扩展了反映的工作方式,并且
也必须仅出现在接口
成员属性上。
[ReflectRange]
扩展
属性
必须接受一个仅限两个值的整数列表。它必须仅用于类型为
unsigned long
的属性。此外,它还必须仅与 [Reflect]
同时出现。
具有 [ReflectRange]
扩展
属性的 IDL 属性会被限制在范围
[clampedMin,
clampedMax] 内,其中 clampedMin 是提供给 [ReflectRange]
的列表的第一个参数,clampedMax 是第二个参数。
[ReflectDefault]
扩展
属性
必须仅用于类型为 double、
long
或 unsigned long
的属性上。当用于
类型为 double
的属性时,它必须接受十进制数;否则
必须接受整数。此外,它还必须仅与 [Reflect]、
[ReflectNonNegative]、
[ReflectPositive]
或 [ReflectPositiveWithFallback]
同时出现。
具有 [ReflectDefault]
扩展
属性的 IDL 属性具有一个由提供给 [ReflectDefault]
的参数所提供的默认
值。
反映主要用于改善 Web 开发者的人机工程学体验, 使其能够通过反映的 IDL 属性以类型化方式访问内容属性。Web 平台 构建所依据的最终事实来源是内容属性本身。也就是说,规范作者不得使用 反映的 IDL 属性的获取器或设置器步骤,而必须使用内容 属性是否存在及其值。(或者使用建立在其上的抽象,例如枚举 属性的状态。)
两个重要的例外是类型为以下任一类型的反映的 IDL 属性:
对于这些属性,规范作者必须分别使用反映目标的 获取 attr 关联元素和获取 attr 关联元素。不得使用内容属性是否存在及其值, 因为它们无法与反映的 IDL 属性完全同步。
反映 目标的显式设置的 attr 元素、 显式 设置的 attr 元素、缓存的 attr 关联 元素以及缓存的 attr 关联 元素对象应被 视为内部实现细节,不应依赖它们进行构建。
HTMLFormControlsCollection
和 HTMLOptionsCollection
接口是派生自
HTMLCollection
接口的集合。HTMLAllCollection
接口是一个集合,但并非如此派生。
HTMLAllCollection
接口HTMLAllCollection
接口用于旧式 document.all
属性。它的操作方式与
HTMLCollection
类似;主要区别在于,它允许以数量惊人的各种不同方式(滥)用其方法,
而最终都能返回某些内容,并且它可以作为函数调用,
以替代属性访问。
所有 HTMLAllCollection
对象都以一个 Document
为根,并具有匹配所有元素的过滤器,因此一个 HTMLAllCollection
对象的集合所表示的
元素由根 Document
的所有后代元素组成。
实现 HTMLAllCollection
接口的对象是旧式
平台对象,并具有下文章节所述的额外 [[Call]] 内部
方法。它们还具有一个
[[IsHTMLDDA]] 内部槽。
实现 HTMLAllCollection
接口的对象具有几种异常
行为,这是因为它们具有一个[[IsHTMLDDA]]
内部槽:
当向 JavaScript 中的 ToBoolean 抽象操作传入实现
HTMLAllCollection
接口的对象时,该操作返回
false。
当向 IsLooselyEqual 抽象操作
传入实现 HTMLAllCollection
接口的对象时,将其与 undefined 和 null 值
比较会返回 true。
(使用 IsStrictlyEqual 抽象
操作进行的比较,以及 IsLooselyEqual 与字符串或对象等其他值的比较,
不受影响。)
当 JavaScript 中的 typeof
运算符应用于实现
HTMLAllCollection
接口的对象时,会返回字符串
"undefined"。
这些特殊行为是出于与两类旧式
内容兼容的需要:一类使用 document.all
是否存在来
检测旧式用户代理;另一类仅支持这些旧式用户代理,并且在未先检测
document.all
对象是否存在的情况下使用该对象。[JAVASCRIPT]
[Exposed =Window ,
LegacyUnenumerableNamedProperties ]
interface HTMLAllCollection {
readonly attribute unsigned long length ;
getter Element (unsigned long index );
getter (HTMLCollection or Element )? namedItem (DOMString name );
(HTMLCollection or Element )? item (optional DOMString nameOrIndex );
// Note: HTMLAllCollection objects have a custom [[Call]] internal method and an [[IsHTMLDDA]] internal slot.
};该对象的受支持属性索引按照
HTMLCollection
对象的定义。
受支持属性名称由所有元素的所有 id
属性的非空值,以及所有由集合表示的
元素中,所有“all”命名
元素的所有 name 属性的非空值组成;这些元素均由集合表示,并按
树顺序排列,忽略后续重复项;如果一个元素同时提供 id 和
name,二者彼此不同,且均不是先前条目的重复项,则该元素的 id
位于其 name 之前。
length 获取器步骤是返回集合所表示的节点数量。
索引属性获取器必须返回给定传入索引,从 获取“all”索引元素的结果,该元素来自 this。
namedItem(name) 方法步骤是
返回给定 name,从 获取“all”命名
元素所得的结果,该元素来自 this。
item(nameOrIndex) 方法步骤
如下:
如果未提供 nameOrIndex,则返回 null。
返回给定 nameOrIndex,从 获取 “all”索引或命名元素所得的结果,该元素来自 this。
以下元素是“all”命名元素:
a、
button、
embed、
form、
frame、
frameset、
iframe、
img、
input、
map、
meta、
object、
select 和
textarea
给定索引 index,要从
HTMLAllCollection
collection 中获取“all”索引元素,返回
collection 中第 index个元素;如果不存在这样的第
index个元素,则返回 null。
给定名称 name,要从
HTMLAllCollection
collection 中获取“all”命名元素,执行
以下步骤:
如果 name 为空字符串,则返回 null。
令 subCollection 为一个 HTMLCollection
对象,其根与
collection 相同,均为
Document,其过滤器仅匹配
符合以下任一条件的元素:
具有等于
name 的 name 属性的“all”命名
元素,或者
具有等于 name 的ID 的元素。
如果 subCollection 中恰好有一个元素,则返回该 元素。
否则,如果 subCollection 为空,则返回 null。
否则,返回 subCollection。
给定
nameOrIndex,要从 HTMLAllCollection
collection 中获取“all”索引或命名
元素:
如果 nameOrIndex转换 为 JavaScript String 值后,是一个数组索引属性名称,则返回给定 nameOrIndex 所表示的数,从 collection 中获取 “all”索引元素所得的结果。
返回给定 nameOrIndex,从 collection 中获取“all”命名 元素所得的结果。
如果 argumentsList 的大小为零,或者 argumentsList[0] 为 undefined,则返回 null。
令 result 为给定 nameOrIndex,从此 HTMLAllCollection
中获取“all”索引或命名
元素所得的结果。
返回将 result转换 为 ECMAScript 值的结果。
thisArgument 会被忽略,因此诸如
Function.prototype.call.call(document.all, null, "x") 这样的代码仍会搜索
元素。(document.all.call 不存在,因为 document.all 不继承自
Function.prototype。)
HTMLFormControlsCollection
接口HTMLFormControlsCollection
接口用于 form
元素中列出的
元素的集合。
所有当前引擎均支持。
所有当前引擎均支持。
[Exposed =Window ]
interface HTMLFormControlsCollection : HTMLCollection {
// inherits length and item()
getter (RadioNodeList or Element )? namedItem (DOMString name ); // shadows inherited namedItem()
};
[Exposed =Window ]
interface RadioNodeList : NodeList {
attribute DOMString value ;
};collection.length
返回 collection 中的元素数量。
element = collection.item(index)
element = collection[index]返回 collection 中索引 index 处的项目。项目按 树顺序排序。
element = collection.namedItem(name)
HTMLFormControlsCollection/namedItem
所有当前引擎均支持。
radioNodeList = collection.namedItem(name)
element = collection[name]radioNodeList = collection[name]从 collection 中返回 ID 或 name
为 name 的项目。
如果存在多个匹配项目,则返回一个包含所有
这些元素的 RadioNodeList
对象。
radioNodeList.value
返回由 radioNodeList 表示的第一个已选中单选按钮的值。
radioNodeList.value = value
选中由 radioNodeList 表示的、值为 value 的第一个单选按钮。
该对象的受支持属性索引按照
HTMLCollection
对象的定义。
受支持属性名称由该集合所表示的所有
元素的所有 id
和 name
属性的非空值组成;这些
元素由集合表示,并按树顺序排列,忽略
后续
重复项;如果一个元素同时提供 id 和
name,二者
彼此不同,且均不是先前条目的
重复项,则该元素的 id 位于其 name 之前。
namedItem(name) 方法
必须按照以下算法运行:
id
属性或 name
属性,则返回该节点并停止算法。
id
属性或 name
属性,
则返回 null 并停止算法。
RadioNodeList
对象,该对象表示 HTMLFormControlsCollection
对象的实时
视图,并进一步进行过滤,使 RadioNodeList
对象中仅包含具有等于
name 的 id
属性或 name
属性的
节点。RadioNodeList
对象中的节点必须按
树顺序排序。
RadioNodeList
对象。RadioNodeList
接口中继承自 NodeList
接口的成员,必须像在 NodeList
对象上一样运行。
所有当前引擎均支持。
RadioNodeList
对象上的 value IDL 属性在获取时,必须返回运行
以下步骤所返回的值:
在设置时,value
IDL 属性必须运行
以下步骤:
如果新值是字符串“on”:令 element 为 RadioNodeList
对象所表示的、按树顺序排列的
第一个满足以下条件的元素:它是一个 input
元素,其
type
属性处于单选按钮状态,并且
其 value
内容属性不存在,或者存在且等于新值(如有)。如果不存在此类元素,
则改为令 element 为 null。
否则:令 element 为 RadioNodeList
对象所表示的、按树顺序排列的
第一个满足以下条件的元素:它是一个 input
元素,其
type
属性处于单选按钮状态,并且
其 value
内容属性存在且等于新值(如有)。如果不存在此类元素,
则改为令 element 为 null。
如果 element 不为 null,则将其选中性设置为 true。
HTMLOptionsCollection
接口所有当前引擎均支持。
HTMLOptionsCollection
接口用于 option
元素的集合。
它始终以一个
select
元素为根,并具有用于操作该
元素后代的属性和方法。
[Exposed =Window ]
interface HTMLOptionsCollection : HTMLCollection {
// inherits item(), namedItem()
[CEReactions ] attribute unsigned long length ; // shadows inherited length
[CEReactions ] setter undefined (unsigned long index , HTMLOptionElement ? option );
[CEReactions ] undefined add ((HTMLOptionElement or HTMLOptGroupElement ) element , optional (HTMLElement or long )? before = null );
[CEReactions ] undefined remove (long index );
attribute long selectedIndex ;
};collection.length
返回 collection 中的元素数量。
collection.length = value
当设置为小于现有长度的数时,截短与
collection 对应的容器中的 option
元素数量。
当设置为大于现有长度的数时,如果该数小于或等于
100000,则向与
collection 对应的容器添加新的空白 option
元素。
element = collection.item(index)
element = collection[index]返回 collection 中索引 index 处的项目。项目按 树顺序排序。
collection[index] = element当 index 大于 collection 中的项目数量时,
向相应容器添加新的空白 option
元素。
当设置为 null 时,从 collection 中移除索引 index 处的项目。
当设置为一个 option
元素时,在 collection 中的索引 index 处添加或替换该元素。
element = collection.namedItem(name)
element = collection[name]从 collection 中返回 ID 或 name
为 name 的项目。
如果有多个匹配项目,则返回第一个。
collection.add(element[, before])
将 element 插入到由 before 指定的节点之前。
before 参数可以是一个数字,此时 element 会插入到 具有该编号的项目之前;也可以是 collection 中的一个元素,此时 element 会插入到该元素之前。
如果省略 before、其为 null 或者是超出范围的数字,则会将 element 添加到列表末尾。
如果
element 是要将其插入的元素的祖先,则抛出 “HierarchyRequestError” DOMException。
collection.remove(index)
从 collection 中移除索引为 index 的项目。
collection.selectedIndex
如果存在选中项目,则返回第一个选中项目的索引;如果没有选中 项目,则返回 −1。
collection.selectedIndex = index
将选择更改为 collection 中索引 index 处的 option
元素。
该对象的受支持属性索引按照
HTMLCollection
对象的定义。
length 获取器步骤是返回该集合所表示的节点数量。
length
设置器步骤如下:
令 current 为该集合所表示的 节点数量。
如果给定值大于 current:
如果给定值大于 100,000,则返回。
令 n 为 value − current。
给定 n,向 this 所以之为根的 select
元素追加新的 option 元素。
如果给定值小于 current:
令 n 为 current − value。
从各自的父节点中移除集合中的最后 n 个节点。
设置 length
从不会移除
或添加任何 optgroup
元素,也从不会向现有
optgroup
元素添加新的子节点(但可以从中移除子节点)。
受支持属性名称由所有
元素的所有 id 和
name
属性的非空值组成;这些
元素由集合表示,并按树顺序排列,忽略后续
重复项;如果一个元素同时提供 id 和
name,二者
彼此不同,且均不是
先前条目的重复项,则该元素的 id 位于其 name 之前。
给定非负整数 count,要向 select
元素
select 追加新的 option 元素:
给定属性索引 index
和新值 value,要为
HTMLOptionsCollection
collection设置新索引属性的值
或设置现有索引
属性的值:
add(element, before)
方法步骤如下:
如果 element 是 this 所以之为根的 select
元素的祖先,则抛出 “HierarchyRequestError”
DOMException。
如果 before 是一个元素,但该元素不是
this 所以之为根的
select
元素的后代,则抛出
“NotFoundError” DOMException。
如果 element 和 before 是同一个元素,则返回。
令 reference 为 null。
如果 before 是一个节点,则将 reference 设置为 before。 否则,如果 before 是一个整数,并且 this 中存在第 before 个节点,则将 reference 设置为该节点。
如果 reference 不为 null,则令 parent 为
reference 的父节点;否则为 this 所以之为根的 select
元素。
在 reference 之前,将 element预插入到 parent 节点。
给定整数 index,要从
HTMLOptionsCollection
collection 中移除一个选项:
selectedIndex
设置器步骤
是将 this 所以之为根的 select
元素的选中
索引设置为给定值。
DOMStringList 接口所有当前引擎均支持。
DOMStringList
接口是一种不再流行的复古字符串列表表示方式。
[Exposed =(Window ,Worker )]
interface DOMStringList {
readonly attribute unsigned long length ;
getter DOMString ? item (unsigned long index );
boolean contains (DOMString string );
};新 API 必须使用 sequence<DOMString> 或
等效形式,而不是 DOMStringList。
strings.length
返回 strings 中的字符串数量。
strings[index]strings.item(index)
从 strings 中返回索引为 index 的字符串。
strings.contains(string)
如果 strings 包含 string,则返回 true;否则 返回 false。
每个 DOMStringList
对象都有关联的列表。
DOMStringList
接口支持索引属性。其
受支持属性索引是 this 的
关联列表的索引。
所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
为了支持跨领域
边界传递 JavaScript 对象,包括平台对象,
本规范定义了以下用于序列化和反序列化对象的基础设施,其中在某些情况下会传输底层数据,
而不是复制它。这个序列化和反序列化过程统称为
“结构化克隆”,尽管大多数 API 会执行单独的序列化和反序列化步骤。
(一个显著的例外是 structuredClone()
方法。)
本节使用 JavaScript 规范中的术语和排版约定。[JAVASCRIPT]
/developer.mozilla.org/en-US/docs/Glossary/Serializable_object
/developer.mozilla.org/en-US/docs/Glossary/Serializable_object
/developer.mozilla.org/en-US/docs/Glossary/Serializable_object
/developer.mozilla.org/en-US/docs/Glossary/Serializable_object
/developer.mozilla.org/en-US/docs/Glossary/Serializable_object
/developer.mozilla.org/en-US/docs/Glossary/Serializable_object
/developer.mozilla.org/en-US/docs/Glossary/Serializable_object
可序列化对象支持 以独立于任何给定领域的方式进行序列化,并在以后进行反序列化。这允许将它们存储在磁盘上并 在以后恢复,或者跨代理乃至代理集群 边界进行克隆。
并非所有对象都是可序列化 对象,而且作为 可序列化对象的对象的所有方面, 也不一定会在序列化时得到保留。
如果平台对象的主接口带有 [Serializable] IDL
扩展
属性,则该平台对象可以是可序列化对象。此类接口还必须定义以下算法:
一组将 value 中的数据序列化到 serialized 的字段中的步骤。序列化到 serialized 中的结果数据必须 独立于任何领域。
如果无法进行序列化,这些步骤可以抛出异常。
这些步骤可以执行子序列化来序列化嵌套数据 结构。它们不应直接调用 StructuredSerialize,因为这样做会 省略重要的 memory 参数。
如果 forStorage 参数与算法无关,则这些步骤的引言应 省略对该参数的提及。
由各个平台对象的定义来决定这些步骤会序列化和反序列化哪些数据。 通常,这些步骤是高度对称的。
[Serializable] 扩展
属性不得接受任何
参数,并且只能出现在接口上。它不得在一个
接口上出现多次。
对于给定的平台对象,
在序列化和反序列化过程中,只考虑该对象的主
接口。因此,如果接口定义涉及继承,则继承链中每个带有 [Serializable] 注解的接口
都需要定义独立的序列化步骤和
反序列化步骤,
包括考虑可能来自继承接口的任何重要数据。
假设我们正在定义一个平台对象 Person,该对象具有
两项关联数据:
名称值,它是一个字符串;以及
好友值,它是另一个 Person 实例
或 null。
然后,我们可以通过使用 [Serializable] 扩展属性注解 Person 接口,并定义
以下配套算法,将 Person 实例定义为可序列化
对象:
JavaScript 规范中定义的对象由 StructuredSerialize 抽象 操作直接处理。
最初,本 规范定义了“可克隆对象”的概念,此类对象可以从一个领域克隆到另一个领域。但是,为了 更准确地规定某些更复杂情况下的行为,该模型后来被更新,以显式区分 序列化和反序列化。
可转移对象支持 跨代理转移。转移实际上是重新创建对象,同时共享对 底层数据的引用,然后分离正在转移的对象。这对于 转移昂贵资源的所有权非常有用。并非所有对象都是可转移 对象,而且作为可转移对象的对象的所有方面, 也不一定会在转移时得到保留。
转移是一项不可逆且非幂等的操作。对象一旦 被转移,就不能再次转移,事实上也不能再次使用。
如果平台对象的主接口带有 [Transferable] IDL
扩展
属性,则该平台对象可以是可转移对象。此类接口还必须定义以下算法:
由各个平台对象的定义来决定这些步骤会转移哪些数据。 通常,这些步骤是高度对称的。
[Transferable] 扩展
属性不得接受任何
参数,并且只能出现在接口上。它不得在一个
接口上出现多次。
对于给定的平台对象,
在转移过程中,只考虑该对象的主
接口。因此,如果接口定义涉及继承,则继承链中每个带有 [Transferable] 注解的接口
都需要定义独立的转移步骤和
转移接收步骤,
包括考虑可能来自继承接口的任何重要数据。
作为可转移 对象的平台对象具有一个 [[Detached]] 内部槽。该槽用于确保平台对象一旦被转移,就不能 再次转移。
JavaScript 规范中定义的对象由 StructuredSerializeWithTransfer 抽象操作 直接处理。
StructuredSerializeInternal 抽象操作 接受一个 JavaScript 值 value 作为输入,并将其序列化为独立于领域的形式,此处表示为一个记录。此 序列化形式包含以后在不同领域中 反序列化为新 JavaScript 值所需的全部信息。
此过程可能抛出异常,例如尝试序列化不可序列化的 对象时。
如果未提供 memory,则令 memory 为一个空映射。
memory 映射的目的是避免对对象进行两次序列化。 最终这会保留图中的循环以及重复对象的同一性。
如果 memory[value]存在,则 返回 memory[value]。
令 deep 为 false。
如果 value 是 undefined、null、布尔值、数值、BigInt 值或字符串,则返回 { [[Type]]: "primitive", [[Value]]: value }。
如果 value是 Symbol,则抛出
“DataCloneError” DOMException。
令 serialized 为一个未初始化的值。
如果 value 具有 [[BooleanData]] 内部槽,则将 serialized 设置为 { [[Type]]: "Boolean", [[BooleanData]]: value.[[BooleanData]] }。
否则,如果 value 具有 [[NumberData]] 内部槽,则将 serialized 设置为 { [[Type]]: "Number", [[NumberData]]: value.[[NumberData]] }。
否则,如果 value 具有 [[BigIntData]] 内部槽,则将 serialized 设置为 { [[Type]]: "BigInt", [[BigIntData]]: value.[[BigIntData]] }。
否则,如果 value 具有 [[StringData]] 内部槽,则将 serialized 设置为 { [[Type]]: "String", [[StringData]]: value.[[StringData]] }。
否则,如果 value 具有 [[DateValue]] 内部槽,则将 serialized 设置为 { [[Type]]: "Date", [[DateValue]]: value.[[DateValue]] }。
否则,如果 value 具有 [[RegExpMatcher]] 内部槽,则将 serialized 设置为 { [[Type]]: "RegExp", [[RegExpMatcher]]: value.[[RegExpMatcher]], [[OriginalSource]]: value.[[OriginalSource]], [[OriginalFlags]]: value.[[OriginalFlags]] }。
否则,如果 value 具有 [[ArrayBufferData]] 内部槽:
如果 IsSharedArrayBuffer(value) 为 true:
如果当前设置对象的跨源
隔离
能力为 false,则抛出 “DataCloneError”
DOMException。
仅在序列化时(而不是反序列化时)需要执行此检查,因为
跨源
隔离能力不会随时间发生变化,并且 SharedArrayBuffer
无法离开一个代理
集群。
如果 forStorage 为 true,则抛出
“DataCloneError” DOMException。
如果 value 具有 [[ArrayBufferMaxByteLength]] 内部槽,则将 serialized 设置为 { [[Type]]: "GrowableSharedArrayBuffer", [[ArrayBufferData]]: value.[[ArrayBufferData]], [[ArrayBufferByteLengthData]]: value.[[ArrayBufferByteLengthData]], [[ArrayBufferMaxByteLength]]: value.[[ArrayBufferMaxByteLength]], [[AgentCluster]]: 周围 代理的代理集群 }。
否则,将 serialized 设置为 { [[Type]]: "SharedArrayBuffer", [[ArrayBufferData]]: value.[[ArrayBufferData]], [[ArrayBufferByteLength]]: value.[[ArrayBufferByteLength]], [[AgentCluster]]: 周围 代理的代理集群 }。
否则:
如果 IsDetachedBuffer(value) 为 true,则抛出
“DataCloneError” DOMException。
令 size 为 value.[[ArrayBufferByteLength]]。
令 dataCopy 为 ? CreateByteDataBlock(size)。
如果分配失败,这可能抛出 RangeError
异常。
执行 CopyDataBlockBytes(dataCopy, 0, value.[[ArrayBufferData]], 0, size)。
如果 value 具有 [[ArrayBufferMaxByteLength]] 内部槽,则将 serialized 设置为 { [[Type]]: "ResizableArrayBuffer", [[ArrayBufferData]]: dataCopy, [[ArrayBufferByteLength]]: size, [[ArrayBufferMaxByteLength]]: value.[[ArrayBufferMaxByteLength]] }。
否则,将 serialized 设置为 { [[Type]]: "ArrayBuffer", [[ArrayBufferData]]: dataCopy, [[ArrayBufferByteLength]]: size }。
否则,如果 value 具有 [[ViewedArrayBuffer]] 内部槽:
如果 IsArrayBufferViewOutOfBounds(value) 为
true,则抛出
“DataCloneError” DOMException。
令 buffer 为 value 的 [[ViewedArrayBuffer]] 内部 槽的值。
令 bufferSerialized 为 ? StructuredSerializeInternal(buffer, forStorage, memory)。
断言:bufferSerialized.[[Type]] 是 "ArrayBuffer"、 "ResizableArrayBuffer"、"SharedArrayBuffer" 或 "GrowableSharedArrayBuffer"。
如果 value 具有 [[DataView]] 内部槽,则将 serialized 设置为 { [[Type]]: "ArrayBufferView", [[Constructor]]: "DataView", [[ArrayBufferSerialized]]: bufferSerialized, [[ByteLength]]: value.[[ByteLength]], [[ByteOffset]]: value.[[ByteOffset]] }。
否则:
断言:value 具有 [[TypedArrayName]] 内部槽。
将 serialized 设置为 { [[Type]]: "ArrayBufferView", [[Constructor]]: value.[[TypedArrayName]], [[ArrayBufferSerialized]]: bufferSerialized, [[ByteLength]]: value.[[ByteLength]], [[ByteOffset]]: value.[[ByteOffset]], [[ArrayLength]]: value.[[ArrayLength]] }。
否则,如果 value 具有 [[MapData]] 内部槽:
将 serialized 设置为 { [[Type]]: "Map", [[MapData]]: 一个新的空列表 }。
将 deep 设置为 true。
否则,如果 value 具有 [[SetData]] 内部槽:
将 serialized 设置为 { [[Type]]: "Set", [[SetData]]: 一个新的空列表 }。
将 deep 设置为 true。
否则,如果 value 具有 [[ErrorData]] 内部槽,并且 value 不是 平台 对象:
令 name 为 ? Get(value, "name")。
如果 name 不是 "Error"、"EvalError"、"RangeError"、"ReferenceError"、 "SyntaxError"、"TypeError" 或 "URIError" 之一,则将 name 设置为 "Error"。
令 valueMessageDesc 为 ? value.[[GetOwnProperty]]("message")。
如果 IsDataDescriptor(valueMessageDesc) 为 false,则令 message 为 undefined;否则为 ? ToString(valueMessageDesc.[[Value]])。
令 stack 为一个表示 value.[[Stack]] 的由实现定义的字符串。[JSERRORSTACKACCESSOR] [JSERRORSTACKS]
将 serialized 设置为 { [[Type]]: "Error", [[Name]]: name, [[Message]]: message, [[Stack]]: stack }。
用户代理应将尚未规定的任何值得关注的伴随数据的序列化表示 附加到 serialized。
否则,如果 value 是一个 Array 异常对象:
令 valueLenDescriptor 为 ?
OrdinaryGetOwnProperty(value,
"length")。
令 valueLen 为 valueLenDescriptor.[[Value]]。
将 serialized 设置为 { [[Type]]: "Array", [[Length]]: valueLen, [[Properties]]: 一个新的空列表 }。
将 deep 设置为 true。
否则,如果 value 是一个作为可序列化对象的平台 对象:
如果 value 具有值为 true 的 [[Detached]]
内部槽,则抛出 “DataCloneError” DOMException。
令 typeString 为 value 的主 接口的标识符。
将 serialized 设置为 { [[Type]]: typeString }。
将 deep 设置为 true。
否则,如果 value 是一个平台
对象,则抛出
“DataCloneError” DOMException。
否则,如果 IsCallable(value) 为 true,则抛出
“DataCloneError” DOMException。
否则,如果 value 具有 [[Prototype]]、[[Extensible]] 或 [[PrivateElements]]
以外的任何内部槽,则抛出 “DataCloneError”
DOMException。
例如,[[PromiseState]] 或 [[WeakMapData]] 内部槽。
否则,如果 value 是一个异常对象,并且 value 不是
与任何领域关联的
%Object.prototype% 内建对象,则
抛出 “DataCloneError” DOMException。
例如,代理对象。
否则:
将 serialized 设置为 { [[Type]]: "Object", [[Properties]]: 一个新的空列表 }。
将 deep 设置为 true。
%Object.prototype% 最终将通过此步骤及 后续步骤处理。最终结果是忽略其异常性,并且反序列化后 得到一个空对象(而不是不可变原型异常对象)。
将 memory[value]设置为 serialized。
如果 deep 为 true:
如果 value 具有 [[MapData]] 内部槽:
令 copiedList 为一个新的空列表。
对于 copiedList 中的每个记录 { [[Key]], [[Value]] } entry:
令 serializedKey 为 ? StructuredSerializeInternal(entry.[[Key]], forStorage, memory)。
令 serializedValue 为 ? StructuredSerializeInternal(entry.[[Value]], forStorage, memory)。
将 { [[Key]]: serializedKey, [[Value]]: serializedValue }追加到 serialized.[[MapData]]。
否则,如果 value 具有 [[SetData]] 内部槽:
否则,如果 value 是一个作为可序列化对象的平台 对象,则给定 value、 serialized 和 forStorage,执行 value 的主 接口的序列化 步骤。
序列化 步骤可能需要执行子序列化。该 操作接受一个值 subValue 作为输入,并返回 StructuredSerializeInternal(subValue, forStorage, memory)。(换言之,子序列化 是 StructuredSerializeInternal 的一种专门化, 以在本次调用中保持一致。)
否则,对于 ! EnumerableOwnProperties(value, key) 中的每个 key:
如果 ! HasOwnProperty(value, key) 为 true:
令 inputValue 为 ? value.[[Get]](key, value)。
令 outputValue 为 ? StructuredSerializeInternal(inputValue, forStorage, memory)。
将 { [[Key]]: key, [[Value]]: outputValue }追加到 serialized.[[Properties]]。
返回 serialized。
需要认识到,由 StructuredSerializeInternal 生成的记录 可能包含指向其他记录的“指针”,从而形成循环引用。例如,当我们将以下 JavaScript 对象传入 StructuredSerializeInternal 时:
const o = {};
o. myself = o; 它会生成以下结果:
{
[[Type]]: "Object",
[[Properties]]: «
{
[[Key]]: "myself",
[[Value]]: <指向整个结构的指针>
}
»
}
返回 ? StructuredSerializeInternal(value, false)。
返回 ? StructuredSerializeInternal(value, true)。
StructuredDeserialize 抽象操作接受一个先前由 StructuredSerialize 或 StructuredSerializeForStorage 生成的记录 serialized 作为输入,并将其反序列化为 在 targetRealm 中创建的新 JavaScript 值。
此过程可能抛出异常,例如尝试为新对象
分配内存时(尤其是 ArrayBuffer 对象)。
如果未提供 memory,则令 memory 为一个空映射。
memory 映射的目的是避免对对象进行 两次反序列化。最终这会保留图中的循环以及重复对象的同一性。
如果 memory[serialized]存在,则 返回 memory[serialized]。
令 deep 为 false。
令 value 为一个未初始化的值。
如果 serialized.[[Type]] 是 "primitive",则将 value 设置为 serialized.[[Value]]。
否则,如果 serialized.[[Type]] 是 "Boolean",则将 value 设置为 targetRealm 中一个新的 Boolean 对象,其 [[BooleanData]] 内部槽的值为 serialized.[[BooleanData]]。
否则,如果 serialized.[[Type]] 是 "Number",则将 value 设置为 targetRealm 中一个新的 Number 对象,其 [[NumberData]] 内部槽的值为 serialized.[[NumberData]]。
否则,如果 serialized.[[Type]] 是 "BigInt",则将 value 设置为 targetRealm 中一个新的 BigInt 对象,其 [[BigIntData]] 内部槽的值为 serialized.[[BigIntData]]。
否则,如果 serialized.[[Type]] 是 "String",则将 value 设置为 targetRealm 中一个新的 String 对象,其 [[StringData]] 内部槽的值为 serialized.[[StringData]]。
否则,如果 serialized.[[Type]] 是 "Date",则将 value 设置为 targetRealm 中一个新的 Date 对象,其 [[DateValue]] 内部槽的值为 serialized.[[DateValue]]。
否则,如果 serialized.[[Type]] 是 "RegExp",则将 value 设置为 targetRealm 中一个新的 RegExp 对象,其 [[RegExpMatcher]] 内部槽的值为 serialized.[[RegExpMatcher]],其 [[OriginalSource]] 内部槽的值为 serialized.[[OriginalSource]],其 [[OriginalFlags]] 内部槽的值为 serialized.[[OriginalFlags]]。
否则,如果 serialized.[[Type]] 是 "SharedArrayBuffer":
如果 targetRealm 对应的代理集群
不是
serialized.[[AgentCluster]],则抛出
“DataCloneError” DOMException。
否则,将 value 设置为 targetRealm 中一个新的 SharedArrayBuffer 对象,其 [[ArrayBufferData]] 内部槽的值为 serialized.[[ArrayBufferData]],其 [[ArrayBufferByteLength]] 内部槽的 值为 serialized.[[ArrayBufferByteLength]]。
否则,如果 serialized.[[Type]] 是 "GrowableSharedArrayBuffer":
如果 targetRealm 对应的代理集群
不是
serialized.[[AgentCluster]],则抛出
“DataCloneError” DOMException。
否则,将 value 设置为 targetRealm 中一个新的 SharedArrayBuffer 对象,其 [[ArrayBufferData]] 内部槽的值为 serialized.[[ArrayBufferData]],其 [[ArrayBufferByteLengthData]] 内部槽的 值为 serialized.[[ArrayBufferByteLengthData]],其 [[ArrayBufferMaxByteLength]] 内部槽的值为 serialized.[[ArrayBufferMaxByteLength]]。
否则,如果 serialized.[[Type]] 是 "ArrayBuffer",则将 value 设置为 targetRealm 中一个新的 ArrayBuffer 对象,其 [[ArrayBufferData]] 内部槽的值 为 serialized.[[ArrayBufferData]],其 [[ArrayBufferByteLength]] 内部槽的 值为 serialized.[[ArrayBufferByteLength]]。
如果这抛出异常,则捕获该异常,然后抛出
“DataCloneError” DOMException。
如果没有足够的可用内存来 创建此类 ArrayBuffer 对象,此步骤可能抛出异常。
否则,如果 serialized.[[Type]] 是 "ResizableArrayBuffer",则将 value 设置为 targetRealm 中一个新的 ArrayBuffer 对象,其 [[ArrayBufferData]] 内部槽的值为 serialized.[[ArrayBufferData]],其 [[ArrayBufferByteLength]] 内部槽的值为 serialized.[[ArrayBufferByteLength]],其 [[ArrayBufferMaxByteLength]] 内部 槽的值为 serialized.[[ArrayBufferMaxByteLength]]。
如果这抛出异常,则捕获该异常,然后抛出
“DataCloneError” DOMException。
如果没有足够的可用内存来 创建此类 ArrayBuffer 对象,此步骤可能抛出异常。
否则,如果 serialized.[[Type]] 是 "ArrayBufferView":
令 deserializedArrayBuffer 为 ? StructuredDeserialize(serialized.[[ArrayBufferSerialized]], targetRealm, memory)。
如果 serialized.[[Constructor]] 是 "DataView",则将 value 设置为 targetRealm 中一个新的 DataView 对象,其 [[ViewedArrayBuffer]] 内部槽的值 为 deserializedArrayBuffer,其 [[ByteLength]] 内部槽的值为 serialized.[[ByteLength]],其 [[ByteOffset]] 内部槽的值为 serialized.[[ByteOffset]]。
否则,使用 serialized.[[Constructor]] 给出的构造函数,在 targetRealm 中将 value 设置为一个新的类型化数组对象, 其 [[ViewedArrayBuffer]] 内部槽的值为 deserializedArrayBuffer,其 [[TypedArrayName]] 内部槽的值为 serialized.[[Constructor]],其 [[ByteLength]] 内部槽的值为 serialized.[[ByteLength]],其 [[ByteOffset]] 内部槽的值为 serialized.[[ByteOffset]],其 [[ArrayLength]] 内部槽的值为 serialized.[[ArrayLength]]。
否则,如果 serialized.[[Type]] 是 "Map":
将 value 设置为 targetRealm 中一个新的 Map 对象,其 [[MapData]] 内部槽的值为一个新的空列表。
将 deep 设置为 true。
否则,如果 serialized.[[Type]] 是 "Set":
将 value 设置为 targetRealm 中一个新的 Set 对象,其 [[SetData]] 内部槽的值为一个新的空列表。
将 deep 设置为 true。
否则,如果 serialized.[[Type]] 是 "Array":
令 outputProto 为 targetRealm.[[Intrinsics]].[[%Array.prototype%]]。
将 value 设置为 ! ArrayCreate(serialized.[[Length]], outputProto)。
将 deep 设置为 true。
否则,如果 serialized.[[Type]] 是 "Object":
将 value 设置为 targetRealm 中一个新的 Object。
将 deep 设置为 true。
否则,如果 serialized.[[Type]] 是 "Error":
令 prototype 为 %Error.prototype%。
如果 serialized.[[Name]] 是 "EvalError",则将 prototype 设置为 %EvalError.prototype%。
如果 serialized.[[Name]] 是 "RangeError",则将 prototype 设置为 %RangeError.prototype%。
如果 serialized.[[Name]] 是 "ReferenceError",则将 prototype 设置为 %ReferenceError.prototype%。
如果 serialized.[[Name]] 是 "SyntaxError",则将 prototype 设置为 %SyntaxError.prototype%。
如果 serialized.[[Name]] 是 "TypeError",则将 prototype 设置为 %TypeError.prototype%。
如果 serialized.[[Name]] 是 "URIError",则将 prototype 设置为 %URIError.prototype%。
令 message 为 serialized.[[Message]]。
将 value 设置为 OrdinaryObjectCreate(prototype, « [[ErrorData]], [[Stack]] »)。
令 messageDesc 为 属性描述符 { [[Value]]: message, [[Writable]]: true, [[Enumerable]]: false, [[Configurable]]: true }。
如果 message 不是 undefined,则执行 !
OrdinaryDefineOwnProperty(value,
"message",
messageDesc)。
将 value.[[Stack]] 设置为 serialized.[[Stack]]。
应反序列化附加到 serialized 的任何值得关注的伴随数据,并将其 附加到 value。
否则:
令 interfaceName 为 serialized.[[Type]]。
如果由 interfaceName 标识的接口未在 targetRealm 中
暴露,则抛出
“DataCloneError” DOMException。
将在 targetRealm 中创建的、由 interfaceName 标识的接口的新实例设置为 value。
将 deep 设置为 true。
将 memory[serialized]设置为 value。
如果 deep 为 true:
如果 serialized.[[Type]] 是 "Map":
对于 serialized.[[MapData]] 中的每个记录 { [[Key]], [[Value]] } entry:
令 deserializedKey 为 ? StructuredDeserialize(entry.[[Key]], targetRealm, memory)。
令 deserializedValue 为 ? StructuredDeserialize(entry.[[Value]], targetRealm, memory)。
将 { [[Key]]: deserializedKey, [[Value]]: deserializedValue }追加到 value.[[MapData]]。
否则,如果 serialized.[[Type]] 是 "Set":
对于 serialized.[[SetData]] 中的每个 entry:
令 deserializedEntry 为 ? StructuredDeserialize(entry, targetRealm, memory)。
将 deserializedEntry追加到 value.[[SetData]]。
否则,如果 serialized.[[Type]] 是 "Array" 或 "Object":
对于 serialized.[[Properties]] 中的每个记录 { [[Key]], [[Value]] } entry:
令 deserializedValue 为 ? StructuredDeserialize(entry.[[Value]], targetRealm, memory)。
令 result 为 ! CreateDataProperty(value, entry.[[Key]], deserializedValue)。
断言:result 为 true。
否则:
给定 serialized、value 和 targetRealm,执行由 serialized.[[Type]] 标识的接口相应的反序列化步骤。
反序列化步骤可能需要执行 子反序列化。该操作接受一个 先前序列化的记录 subSerialized 作为输入,并返回 StructuredDeserialize(subSerialized, targetRealm, memory)。(换言之,子反序列化是 StructuredDeserialize 的一种专门化, 以在本次调用中保持一致。)
返回 value。
令 memory 为一个空映射。
除了 StructuredSerializeInternal 通常对其的使用方式之外,在此 算法中,memory 还用于 确保 StructuredSerializeInternal 忽略 transferList 中的项目, 并让我们改为自行处理。
对于每个 transferList 中的 transferable:
如果 transferable 既没有 [[ArrayBufferData]] 内部槽,也没有
[[Detached]] 内部槽,则
抛出一个
"DataCloneError" DOMException。
如果 transferable 具有 [[ArrayBufferData]] 内部槽,并且
IsSharedArrayBuffer(transferable) 为 true,则
抛出一个
"DataCloneError" DOMException。
如果 memory[transferable] 存在,
则抛出一个 "DataCloneError" DOMException。
将 memory[transferable] 设置为 { [[Type]]: 一个未初始化的值 }。
transferable 尚未被转移,因为转移具有副 作用,而 StructuredSerializeInternal 需要 能够先抛出异常。
令 serialized 为 ? StructuredSerializeInternal(value, false, memory)。
令 transferDataHolders 为一个新的空列表。
对于每个 transferList 中的 transferable:
如果 transferable 具有 [[ArrayBufferData]] 内部槽,并且
IsDetachedBuffer(transferable) 为 true,则抛出一个
"DataCloneError" DOMException。
如果 transferable 具有 [[Detached]] 内部槽,并且
transferable.[[Detached]] 为 true,则抛出一个
"DataCloneError" DOMException。
令 dataHolder 为 memory[transferable]。
如果 transferable 具有 [[ArrayBufferData]] 内部槽:
如果 transferable 具有 [[ArrayBufferMaxByteLength]] 内部槽:
将 dataHolder.[[Type]] 设置为 "ResizableArrayBuffer"。
将 dataHolder.[[ArrayBufferData]] 设置为 transferable.[[ArrayBufferData]]。
将 dataHolder.[[ArrayBufferByteLength]] 设置为 transferable.[[ArrayBufferByteLength]]。
将 dataHolder.[[ArrayBufferMaxByteLength]] 设置为 transferable.[[ArrayBufferMaxByteLength]]。
否则:
将 dataHolder.[[Type]] 设置为 "ArrayBuffer"。
将 dataHolder.[[ArrayBufferData]] 设置为 transferable.[[ArrayBufferData]]。
将 dataHolder.[[ArrayBufferByteLength]] 设置为 transferable.[[ArrayBufferByteLength]]。
执行 ? DetachArrayBuffer(transferable)。
规范可以使用 [[ArrayBufferDetachKey]] 内部槽来防止
ArrayBuffer
被分离。例如,
WebAssembly JavaScript 接口便使用了这种方式。[WASMJS]
否则:
将 dataHolder 追加到 transferDataHolders。
返回 { [[Serialized]]: serialized, [[TransferDataHolders]]: transferDataHolders }。
令 memory 为一个空映射。
与 StructuredSerializeWithTransfer 类似,除了 StructuredDeserialize 通常使用它的方式之外,在此算法中, memory 还 用于确保 StructuredDeserialize 忽略 serializeWithTransferResult.[[TransferDataHolders]] 中的项目,并让我们改为自行处理 它们。
令 transferredValues 为一个新的空列表。
对于每个 serializeWithTransferResult.[[TransferDataHolders]] 中的 transferDataHolder:
令 value 为一个未初始化的值。
如果 transferDataHolder.[[Type]] 是 "ArrayBuffer",则将 value 设置为 targetRealm 中一个新的 ArrayBuffer 对象,其 [[ArrayBufferData]] 内部槽的值 为 transferDataHolder.[[ArrayBufferData]],其 [[ArrayBufferByteLength]] 内部槽的值为 transferDataHolder.[[ArrayBufferByteLength]]。
在反序列化期间可以访问 [[ArrayBufferData]] 原本占用的内存的 情况下,此步骤不太可能抛出异常,因为不需要分配新的 内存:而只是将 [[ArrayBufferData]] 占用的内存 转移到新的 ArrayBuffer 中。例如,当源 Realm 和目标 Realm 位于同一进程中时,便可能如此。
否则,如果 transferDataHolder.[[Type]] 是 "ResizableArrayBuffer",则将 value 设置为 targetRealm 中一个新的 ArrayBuffer 对象,其 [[ArrayBufferData]] 内部槽的值为 transferDataHolder.[[ArrayBufferData]], 其 [[ArrayBufferByteLength]] 内部槽的值为 transferDataHolder.[[ArrayBufferByteLength]],其 [[ArrayBufferMaxByteLength]] 内部槽的值为 transferDataHolder.[[ArrayBufferMaxByteLength]]。
出于与上一步相同的原因,此步骤也不太可能抛出 异常。
否则:
令 interfaceName 为 transferDataHolder.[[Type]]。
如果由 interfaceName 标识的接口未在
targetRealm 中暴露,则抛出一个 "DataCloneError"
DOMException。
将 value 设置为由 interfaceName 标识的接口在 targetRealm 中创建的新实例。
给定 transferDataHolder 和 value,执行由 interfaceName 标识的 接口相应的转移接收步骤。
将 memory[transferDataHolder] 设置为 value。
将 value 追加到 transferredValues。
令 deserialized 为 ? StructuredDeserialize(serializeWithTransferResult.[[Serialized]], targetRealm, memory)。
返回 { [[Deserialized]]: deserialized, [[TransferredValues]]: transferredValues }。
其他规范可以使用此处定义的抽象操作。以下内容通过示例提供了一些 有关每个抽象操作通常适用于何种情况的指导。
使用转移列表将值克隆到另一个 Realm,但无法预先知道目标 Realm。在这种情况下,可以立即执行序列化步骤, 并将反序列化步骤延迟到目标 Realm 已知时执行。
messagePort.postMessage()
使用这对抽象操作,因为在
MessagePort
被
传送之前,目标 Realm 是未知的。
为给定值创建一个独立于 Realm 的快照,该快照可以保存 任意长的时间,之后再将其具体化为 JavaScript 值,并且可能 多次执行此操作。
StructuredSerializeForStorage
可用于预计要以持久方式存储序列化结果,
而不是在 Realm 之间传递的情况。尝试序列化 SharedArrayBuffer
对象时,它会抛出异常,因为存储共享内存
没有意义。同样,当向其提供一个具有自定义平台
对象的序列化步骤,并且
forStorage 参数为 true 时,它可能抛出异常,也可能具有不同的行为。
history.pushState()
和 history.replaceState()
对作者提供的状态对象使用
StructuredSerializeForStorage,并将其作为
序列化状态存储在相应的
会话历史记录条目中。
然后,使用
StructuredDeserialize,
以便 history.state
属性可以返回最初提供的状态对象的克隆。
broadcastChannel.postMessage()
对其输入使用
StructuredSerialize,
然后对结果多次使用 StructuredDeserialize,
为广播所发送到的每个目标生成一个全新的克隆。请注意,在具有多个目标的情况下,
转移没有意义。
任何用于将 JavaScript 值持久保存到文件系统的 API,也会对其输入使用 StructuredSerializeForStorage, 并对其输出使用 StructuredDeserialize。
通常,调用点可以传入 Web IDL 值而不是 JavaScript 值;应将此理解为 在调用这些算法之前,先隐式转换为 JavaScript 值。
如果调用点不是由作者代码同步调用用户代理方法而触发的,并且要对任意对象执行 StructuredSerialize、 StructuredSerializeForStorage 或 StructuredSerializeWithTransfer 抽象操作,则在调用这些操作之前,必须注意正确地准备运行脚本并准备 运行回调。这是必要的,因为序列化过程可以在其最后的 深度序列化步骤中调用作者定义的访问器,而这些访问器可能调用依赖于入口和现任概念 已正确设置的操作。
window.postMessage()
对其参数执行
StructuredSerializeWithTransfer,
但会谨慎地在其算法的同步部分中立即执行该操作。因此,它能够使用这些
算法,而无需准备运行脚本和
准备运行
回调。
相比之下,假设某个 API 使用 StructuredSerialize 定期序列化某个作者提供的对象,并直接从事件循环中的一个任务执行,则需要确保它 事先执行适当的准备工作。目前,我们尚不知道平台上存在任何此类 API; 通常,更简单的做法是提前执行序列化,作为作者代码同步产生的结果。
result = self.structuredClone(value[, { transfer }])
接受输入值,并通过执行结构化克隆算法返回一个深度副本。
可转移对象列在
transfer
数组中的对象会被转移,而不只是
被克隆,这意味着它们在输入值中将不再可用。
如果输入值的任何部分都不是可序列化的,则抛出一个
"DataCloneError" DOMException。
所有当前引擎均支持。
structuredClone(value,
options) 方法的步骤如下:
令 serialized 为 ?
StructuredSerializeWithTransfer(value,
options["transfer"])。
令 deserializeRecord 为 ? StructuredDeserializeWithTransfer(serialized, this 的 相关 Realm)。
返回 deserializeRecord.[[Deserialized]]。
HTML 用户代理中的每个 XML 和 HTML 文档都由一个 Document 对象表示。
[DOM]
Document 对象的 URL 定义
于
DOM 中。它最初在创建 Document 对象时设置,但可以
在 Document 对象的生命周期内发生变化;
例如,当用户
导航到页面上的一个片段
时,以及使用新的 URL 调用
pushState() 方法时,它都会改变。[DOM]
交互式用户代理通常会在其用户界面中公开 Document 对象的
URL。这是用户判断某个网站是否试图冒充另一个网站的主要
机制。
Document 对象的 源 定义
于
DOM 中。它最初在创建 Document 对象时设置,并且在 Document 的生命周期内,仅会在设置
document.domain 时发生变化。一个 Document 的源可能与其 URL 的源不同;
例如,当一个子可导航对象被创建时,其活动文档的源继承自其父级的活动文档的
源,即使其活动文档的
URL 是
about:blank。[DOM]
当一个 Document 由脚本使用
createDocument()
或 createHTMLDocument()
方法创建时,该
Document 会立即准备好执行加载后任务。
文档的来源网址是一个字符串(表示一个 URL),它
可以在创建 Document 时设置。如果未
显式设置,则其值
为空字符串。
Document 对象所有当前引擎均支持。
DOM 定义了一个 Document
接口,本规范对其进行了
大幅扩展。
enum DocumentReadyState { "loading" , "interactive" , "complete" };
enum DocumentVisibilityState { "visible" , "hidden" };
typedef (HTMLScriptElement or SVGScriptElement ) HTMLOrSVGScriptElement ;
[LegacyOverrideBuiltIns ]
partial interface Document {
static Document parseHTMLUnsafe ((TrustedHTML or DOMString ) html , optional ParseHTMLUnsafeOptions options = {});
static Document parseHTML (DOMString html , optional SetHTMLOptions options = {});
// resource metadata management
[PutForwards =href , LegacyUnforgeable ] readonly attribute Location ? location ;
attribute USVString domain ;
readonly attribute USVString referrer ;
attribute USVString cookie ;
readonly attribute DOMString lastModified ;
readonly attribute DocumentReadyState readyState ;
// DOM tree accessors
getter object (DOMString name );
[CEReactions ] attribute DOMString title ;
[CEReactions ] attribute DOMString dir ;
[CEReactions ] attribute HTMLElement ? body ;
readonly attribute HTMLHeadElement ? head ;
[SameObject ] readonly attribute HTMLCollection images ;
[SameObject ] readonly attribute HTMLCollection embeds ;
[SameObject ] readonly attribute HTMLCollection plugins ;
[SameObject ] readonly attribute HTMLCollection links ;
[SameObject ] readonly attribute HTMLCollection forms ;
[SameObject ] readonly attribute HTMLCollection scripts ;
NodeList getElementsByName (DOMString elementName );
readonly attribute HTMLOrSVGScriptElement ? currentScript ; // classic scripts in a document tree only
// dynamic markup insertion
[CEReactions ] Document open (optional DOMString unused1 , optional DOMString unused2 ); // both arguments are ignored
WindowProxy ? open (USVString url , DOMString name , DOMString features );
[CEReactions ] undefined close ();
[CEReactions ] undefined write ((TrustedHTML or DOMString )... text );
[CEReactions ] undefined writeln ((TrustedHTML or DOMString )... text );
// user interaction
readonly attribute WindowProxy ? defaultView ;
boolean hasFocus ();
[CEReactions ] attribute DOMString designMode ;
[CEReactions ] boolean execCommand (DOMString commandId , optional boolean showUI = false , optional DOMString value = "");
boolean queryCommandEnabled (DOMString commandId );
boolean queryCommandIndeterm (DOMString commandId );
boolean queryCommandState (DOMString commandId );
boolean queryCommandSupported (DOMString commandId );
DOMString queryCommandValue (DOMString commandId );
readonly attribute boolean hidden ;
readonly attribute DocumentVisibilityState visibilityState ;
// special event handler IDL attributes that only apply to Document objects
[LegacyLenientThis ] attribute EventHandler onreadystatechange ;
attribute EventHandler onvisibilitychange ;
// also has obsolete members
};
Document includes GlobalEventHandlers ;每个 Document 都有一个策略容器(一个策略容器),最初是一个新的策略
容器,其中包含适用于该 Document 的策略。
每个 Document 都有一个权限策略,它
是一个权限
策略,最初
为空。
每个 Document 都有一个模块映射,
它是一个模块映射,最初为空。
每个 Document 都有一个打开者策略,
它是一个打开者
策略,最初是一个新的打开者策略。
每个 Document 都有一个是否为初始 about:blank,它是一个
布尔值,最初为 false。
每个 Document 都有一个用于 WebDriver BiDi 的加载期间
导航 ID,它是一个导航 ID 或 null,最初为
null。
顾名思义,它用于与 WebDriver
BiDi 规范交互;该规范需要获知 Document
生命周期早期阶段发生的某些事件,并以
将这些事件与创建该 Document 的导航作为
正在进行的导航时使用的原始
导航 ID关联起来的方式进行通知。最终,
在 WebDriver
BiDi 认为加载过程已完成后,它会被重新设置为 null。[BIDI]
每个 Document 都有一个about 基准
URL,它是一个 URL 或 null,最初为 null。
仅为使用 "about:" 方案的
Document 填充此项。
每个 Document 都有一个bfcache 阻止详情,它是一个由
未恢复原因详情组成的
集合,最初为空。
每个 Document 都有一个打开的对话框列表,它是一个由
dialog 元素组成的列表,最初为空。
DocumentOrShadowRoot
接口DOM 定义了 DocumentOrShadowRoot
混入,本规范对其
进行了扩展。
partial interface mixin DocumentOrShadowRoot {
readonly attribute Element ? activeElement ;
};一个 Document 对象具有一个关联的内部
祖先源对象
列表,最初为 null。
给定一个
Document 对象 document 和一个来源网址策略
referrerPolicy,内部祖先源对象列表创建
步骤如下:
令 output 为 « »。
令 parentDoc 为 document 的容器文档。
如果 parentDoc 为 null,则返回 output。
令 ancestorOrigins 为 parentDoc 的内部祖先源 对象 列表。
令 masked 为 false。
如果 referrerPolicy 是 "no-referrer",则将
masked 设置为 true。
否则,如果 referrerPolicy 是 "same-origin",并且
parentDoc 的源与
document 的源不是同
源,则将 masked 设置为 true。
由于混合
内容检查会阻止安全上下文环境中的非安全
上下文环境,因此对于
"strict-origin"、"strict-origin-when-cross-origin" 和
"no-referrer-when-downgrade",无需检查安全上下文。"origin" 和
"origin-when-cross-origin" 值也无需特殊处理,因为此处
最多只会公开一个源。
对于每个 ancestorOrigins 中的 ancestorOrigin:
返回 output。
一个 Document 对象具有一个关联的祖先源列表,
最初为 null。
给定一个 Document 对象
document,祖先源列表创建步骤如下:
令 ancestorOrigins 为 document 的内部祖先源 对象 列表。
断言:ancestorOrigins 不为 null。
令 output 为 « »。
对于每个 ancestorOrigins 中的 origin:
返回一个新的 DOMStringList
对象,其关联列表为
output。
考虑一个 URL 为 https://a.example/top 的顶级
浏览上下文文档:
<!doctype html>
< title > top</ title >
< iframe referrerpolicy = "no-referrer" src = "https://a.example/child" ></ iframe > 子文档:
<!doctype html>
< title > child</ title >
< iframe src = "https://b.example/grandchild" ></ iframe >
< script >
console. log([... location. ancestorOrigins]);
</ script > 孙文档:
<!doctype html>
< title > grandchild</ title >
< script >
console. log([... location. ancestorOrigins]);
</ script > 创建子文档的 Document 对象时,
其父级的源会被遮蔽,
因为 iframe
元素的 referrerpolicy
属性值为 "no-referrer",即使这些文档是同源的。记录的值
为 « "null" »。
创建孙文档的 Document 对象时,
会使用子文档的
Document 对象的内部祖先源对象
列表(其中包含一个不透明源)
作为起点,并将子文档的源
添加到该列表中。因此记录的值为 « "https://a.example",
"null" »。
考虑上一个示例,但顶级
文档中的 iframe 元素
没有 referrerpolicy
属性,而子文档中的
iframe 元素具有
referrerpolicy="no-referrer"。
在这种情况下,顶级文档的源会被添加
到子文档的 Document 对象的内部祖先源对象
列表中。记录的值为 « "https://a.example" »。
对于孙文档,子文档的源会被遮蔽
为一个不透明源。由于
顶级文档的源与子
文档的源同源,它也会
被遮蔽。因此记录的值为 « "null", "null" »。
在此示例中,我们说明顶级文档的源不会被遮蔽,即使存在一个源被遮蔽的 同源后代文档,因为它们之间存在一个 跨源文档。
URL 为 https://a.example/top 的顶级文档
< iframe src = "https://b.example/child" ></ iframe > 祖先源列表的 关联列表为 « »。
URL 为 https://b.example/child 的子文档
< iframe src = "https://a.example/grandchild" ></ iframe > 祖先源列表的
关联列表为 « "https://a.example" »。
URL 为 https://a.example/grandchild 的孙文档
< iframe src = "https://c.example/great-grandchild"
referrerpolicy = "no-referrer" ></ iframe > 祖先源列表的
关联列表为 « "https://b.example", "https://a.example" »。
URL 为 https://c.example/great-grandchild 的曾孙文档
祖先源列表的
关联列表为 « "null", "https://b.example",
"https://a.example" »。顶级源未被遮蔽。
考虑上一个示例,但顶级文档的 iframe
也具有
referrerpolicy="no-referrer",则每个文档所得的祖先源列表关联列表
将如下所示:
顶级文档:« »
子文档:« "null" »
孙文档:« "https://b.example", "null"
»
曾孙文档:« "null", "https://b.example", "null" »。顶级
源会被
遮蔽,因为子文档运行内部祖先源
对象列表创建步骤时,它已被遮蔽,并且该结果会传递给孙文档的
内部祖先源
对象列表创建步骤,依此类推。
document.referrer
所有当前引擎均支持。
返回用户导航到此文档之前所在的 Document 的
URL,
除非该信息被阻止或不存在这样的文档,在这种情况下返回空字符串。
可以使用 noreferrer
链接类型阻止发送来源网址。
referrer
属性必须返回文档的来源网址。
document.cookie [ = value ]
返回适用于该 Document 的 HTTP
Cookie。如果没有
Cookie,或者 Cookie 无法应用于此资源,则返回空字符串。
可以设置该属性,以向元素的 HTTP Cookie 集合中添加新的 Cookie。
如果内容被沙盒化为不透明源(例如,位于具有
sandbox
属性的 iframe
中),
则在获取和设置时都会抛出
"SecurityError" DOMException。
所有当前引擎均支持。
cookie
属性表示由文档的 URL
标识的资源的 Cookie。
使用同步的 document.cookie
API 可能导致性能问题。可以改用 Cookie Store API,
因为它提供了一种异步处理 Cookie 的方式,以避免性能问题。有关更多
信息,请参阅 Cookie Store API 简介。[COOKIESTORE]
满足以下任一条件的 Document
对象是一个
拒绝 Cookie 的 Document 对象:
![]() 获取时,如果文档是拒绝 Cookie 的
获取时,如果文档是拒绝 Cookie 的 Document 对象,
则用户代理必须返回空字符串。否则,如果 Document 的源
是一个不透明
源,则用户代理必须抛出
"SecurityError"
DOMException。
否则,用户代理必须返回用于文档
URL
的“非 HTTP”API 的Cookie
字符串,并使用不带
BOM 的 UTF-8 解码进行解码。[COOKIES]
设置时,如果文档是拒绝 Cookie 的 Document
对象,则
用户代理必须不执行任何操作。否则,如果 Document 的源
是一个不透明
源,则用户代理必须抛出
"SecurityError"
DOMException。
否则,用户代理必须像通过“非 HTTP”API
接收设置 Cookie 字符串一样处理文档的
URL,
该字符串由新值
编码为 UTF-8组成。[COOKIES] [ENCODING]
由于 cookie 属性
可以跨框架访问,因此 Cookie 的路径限制只是一种帮助管理应将哪些 Cookie
发送到网站哪些部分的工具,绝不是安全功能。
cookie
属性的获取器和
设置器会同步访问共享状态。由于不存在锁定机制,多进程用户代理中的其他浏览
上下文可以在脚本运行时修改 Cookie。例如,网站可能尝试读取一个 Cookie,
增加其值,然后将其写回,并将 Cookie 的新值用作会话的唯一标识符;如果网站
同时在两个不同的浏览器窗口中执行两次此操作,最终可能会对两个会话使用相同的
“唯一”标识符,并可能产生灾难性后果。
document.lastModified
所有当前引擎均支持。
以用户的本地时区,按 "MM/DD/YYYY hh:mm:ss" 形式返回服务器所报告的
文档最后修改日期。
如果最后修改日期未知,则改为返回当前时间。
lastModified 属性在获取时,必须以用户的
本地时区,按以下格式返回 Document 源文件最后
修改的日期和时间:
日期的月份部分。
一个 U+002F SOLIDUS 字符(/)。
日期的日部分。
一个 U+002F SOLIDUS 字符(/)。
日期的年份部分。
一个 U+0020 SPACE 字符。
时间的小时部分。
一个 U+003A COLON 字符(:)。
时间的分钟部分。
一个 U+003A COLON 字符(:)。
时间的秒部分。
除年份外,上述所有数字组成部分必须使用两个ASCII 数字表示十进制数字,必要时用零填充。年份必须 使用由四个或更多ASCII 数字组成的尽可能短的字符串 表示十进制数字,必要时用零填充。
Document 源文件最后
修改的日期和时间必须从所使用网络协议的
相关功能中派生,例如从文档的 HTTP `Last-Modified`
标头的值,或本地文件的文件系统
元数据中派生。如果最后修改日期和时间未知,该属性
必须以上述格式返回当前日期和时间。
document.readyState
当 Document 正在加载时返回
"loading",完成解析但仍在加载子资源时返回
"interactive",加载完成后返回 "complete"。
当此值发生变化时,会在
Document 对象上触发
readystatechange
事件。
DOMContentLoaded
事件会在转换为
"interactive" 之后、转换为 "complete" 之前,即除 async script
元素以外的所有子资源均已加载时触发。
所有当前引擎均支持。
每个 Document 都有一个
当前文档就绪状态,它是一个字符串,最初为
"complete"。
对于通过创建并初始化
Document 对象算法创建的
Document
对象,在任何脚本能够观察 document.readyState
的值之前,该值会立即重置为 "loading"。此
默认值适用于其他情况,例如初始
about:blank Document,或没有
浏览上下文的
Document。
要将 Document
document 的当前文档就绪状态更新为
readinessValue:
如果 document 的当前文档就绪状态等于 readinessValue,则返回。
将 document 的当前文档就绪状态设置为 readinessValue。
如果 document 与一个HTML 解析器关联:
在 document 上触发一个
事件,其名称为 readystatechange。
一个 Document 具有一个
文档加载
计时信息加载计时信息。
一个 Document 具有一个
文档
卸载计时信息上一个
文档卸载计时。
一个 Document 具有一个布尔值
是否通过跨源重定向创建,
最初为 false。
DOMHighResTimeStamp
值DOMHighResTimeStamp
值每个 Document 都有一个
渲染阻塞元素集合,它是一个元素的集合,最初为空集合。
如果以下两项都为 true,则一个 Document
document 是渲染受阻的:
document 的渲染阻塞元素集合非空,或者 document允许添加渲染阻塞 元素。
要在元素 el 上阻塞渲染:
令 document 为 el 的节点文档。
如果 document允许添加渲染阻塞 元素,则将 el追加到 document 的 渲染阻塞元素集合。
每当一个渲染阻塞元素 el 变为与浏览上下文断开连接, 或者 el 的blocking 属性的值 发生更改,使 el 不再是可能 阻塞渲染的元素时,则在 el 上解除 渲染阻塞。
document.head
所有当前引擎均支持。
返回head
元素。
document.title [ = value ]
返回文档的标题;对于 HTML,该标题由title 元素给出;
对于 SVG,则由 SVG
title 元素给出。
可以设置该属性以更新文档标题。如果没有可供更新的适当元素,则忽略 新值。
所有当前引擎均支持。
title 属性
在获取时必须运行以下
算法:
document.body [ = value ]
所有当前引擎均支持。
返回body 元素。
可以设置该属性,以替换body 元素。
如果新值不是 body 或 frameset 元素,则会抛出
"HierarchyRequestError" DOMException。
body
属性
在获取时必须返回文档的body
元素(一个 body
元素、一个 frameset 元素或 null)。
设置时,必须运行以下算法:
body 或 frameset 元素,则抛出
"HierarchyRequestError" DOMException。
HierarchyRequestError" DOMException。
body 获取器返回的值
并不总是传递给设置器的值。
在此示例中,设置器成功插入了一个 body
元素(尽管这是
不符合规范的,因为 SVG 不允许将 body 作为
SVG
svg 的子元素)。但是,获取器会返回 null,因为文档元素不是
html。
< svg xmlns = "http://www.w3.org/2000/svg" >
< script >
document. body = document. createElementNS( "http://www.w3.org/1999/xhtml" , "body" );
console. assert( document. body === null );
</ script >
</ svg > document.images
所有当前引擎均支持。
返回一个 HTMLCollection,
其中包含 Document 中的
img 元素。
document.embeds
所有当前引擎均支持。
document.plugins
所有当前引擎均支持。
返回一个 HTMLCollection,
其中包含
Document 中的 embed 元素。
document.links
所有当前引擎均支持。
返回一个 HTMLCollection,
其中包含 Document 中具有
href
属性的 a 和 area 元素。
document.forms
所有当前引擎均支持。
返回一个 HTMLCollection,
其中包含
Document 中的 form 元素。
document.scripts
所有当前引擎均支持。
返回一个 HTMLCollection,
其中包含
Document 中的 script 元素。
images
属性必须返回一个以 Document
节点为根的 HTMLCollection,
其过滤器仅匹配 img 元素。
embeds
属性必须返回一个以 Document
节点为根的 HTMLCollection,
其过滤器仅匹配 embed 元素。
plugins
属性必须返回与 embeds
属性所返回对象相同的对象。
forms
属性必须返回一个以 Document
节点为根的 HTMLCollection,
其过滤器仅匹配 form 元素。
scripts
属性必须返回一个以 Document
节点为根的 HTMLCollection,
其过滤器仅匹配 script 元素。
collection = document.getElementsByName(name)
所有当前引擎均支持。
getElementsByName(elementName) 方法
的步骤是返回一个实时 NodeList,
其中包含该文档中所有 name 属性值与
elementName 参数完全相同的HTML
元素,并按树顺序排列。当再次使用相同参数在一个
Document 对象上调用该
方法时,用户代理可以返回与先前调用返回的对象相同的对象。在其他情况下,必须返回一个新的
NodeList
对象。
document.currentScript
所有当前引擎均支持。
返回当前正在执行的 script
元素或 SVG
script 元素,
前提是该元素表示一个经典脚本。在可重入脚本执行的情况下,
返回尚未执行完毕的脚本中最近开始执行的那个。
如果 Document 当前未
执行 script 或
SVG
script 元素(例如,因为正在运行的脚本是事件
处理器或超时回调),或者当前正在执行的 script 或 SVG
script 元素表示一个模块脚本,则返回
null。
currentScript 属性在获取时,必须返回
最近一次为其设置的值。创建 Document 时,必须将 currentScript
初始化为 null。
此 API 在实现者和标准社区中已不再受青睐,因为它会全局公开
script 或 SVG script 元素。因此,
它在较新的上下文中不可用,例如运行模块
脚本时,或在影子树中运行脚本时。
我们正在研究一种用于在这些上下文中识别正在运行的脚本的新解决方案,该解决方案不会使其
全局可用:参见 议题 #1013。
Document 接口支持命名
属性。一个
Document 对象
document 在任何时刻的受支持属性名称由以下内容组成,并根据提供这些名称的元素按
树顺序排列,忽略后续重复项;
当同一元素同时提供二者时,来自 id
属性的值位于来自 name 属性的值之前:
要为一个 Document确定命名属性
name 的值,用户
代理必须返回使用以下步骤获得的值:
令 elements 为名称为 name,并且位于以
Document 为根的文档
树中的命名
元素列表。
至少会有一个这样的元素,否则该算法不会被 Web IDL 调用。
如果 elements 仅有一个元素,并且该元素是一个 iframe
元素,并且该 iframe
元素的内容可导航对象不为 null,则
返回该元素的内容可导航对象的活动 WindowProxy。
否则,如果 elements 仅有一个元素,则返回该元素。
否则,返回一个以 Document 节点为根的
HTMLCollection,
其过滤器仅匹配名称为 name 的命名元素。
就上述算法而言,名称为 name 的命名元素是以下任一种元素:
如果一个 embed 或 object 元素
没有已公开的 object 祖先,
并且对于 object 元素,
它还满足未显示其后备
内容,或者没有 object 或
embed 后代,
则称该元素是已公开的。
Document 接口上的 dir
属性与 dir
内容属性一同定义。
HTML 中的元素、属性和属性值由本规范定义为具有
特定含义(语义)。例如,ol 元素表示一个有序列表,
而 lang 属性表示内容的语言。
这些定义使 HTML 处理器(例如 Web 浏览器或搜索引擎)能够在作者可能没有 考虑过的各种上下文中呈现和使用文档与应用程序。
作为一个简单示例,考虑一个仅考虑桌面 计算机 Web 浏览器的作者编写的网页:
<!DOCTYPE HTML>
< html lang = "en" >
< head >
< title > My Page</ title >
</ head >
< body >
< h1 > Welcome to my page</ h1 >
< p > I like cars and lorries and have a big Jeep!</ p >
< h2 > Where I live</ h2 >
< p > I live in a small hut on a mountain!</ p >
</ body >
</ html > 由于 HTML 传达的是含义而不是表现形式,同一 页面也可以在手机上的小型浏览器中使用,而无需对页面进行任何更改。 例如,桌面浏览器可能使用大号文字显示标题,而手机上的 浏览器则可能对整个页面使用相同大小的文字,但将标题显示为粗体。
但差异不仅限于屏幕大小:同一页面也完全可以供盲人用户 使用基于语音合成的浏览器访问;该浏览器不会在屏幕上显示 页面,而是向用户朗读页面,例如通过耳机。语音浏览器可能不会使用 大号文字表示标题,而会使用不同的音量或更慢的语速。
这还不是全部。由于浏览器知道页面的哪些部分是标题,它们 可以创建文档大纲,用户可使用该大纲快速在文档中导航, 例如使用“跳转到下一个标题”或“跳转到上一个标题”的按键。这类功能在 语音浏览器中尤为常见,否则用户会发现很难快速浏览页面。
即使在浏览器之外,软件也可以利用这些信息。搜索引擎可以使用 标题更有效地为页面建立索引,或在搜索结果中提供指向页面 子章节的快速链接。工具可以使用标题创建目录(事实上, 本规范的目录正是以这种方式生成的)。
此示例重点讨论了标题,但相同原则适用于 HTML 中的所有语义。
作者不得将元素、属性或属性值用于其适当预期语义用途以外的 目的,因为这样做会阻止软件正确处理 页面。
例如,以下片段旨在表示 公司网站的标题,但它不符合规范,因为第二行并非旨在 作为子章节的标题,而只是一个副标题或次标题(同一章节的 从属标题)。
< body >
< h1 > ACME Corporation</ h1 >
< h2 > The leaders in arbitrary fast delivery since 1920</ h2 >
...hgroup 元素可用于
此类情况:
< body >
< hgroup >
< h1 > ACME Corporation</ h1 >
< p > The leaders in arbitrary fast delivery since 1920</ p >
</ hgroup >
...下一个示例中的文档虽然
语法正确,但同样不符合规范,因为放置在单元格中的数据显然
不是表格数据,并且 cite
元素被误用:
<!DOCTYPE HTML>
< html lang = "en-GB" >
< head > < title > Demonstration </ title > </ head >
< body >
< table >
< tr > < td > My favourite animal is the cat. </ td > </ tr >
< tr >
< td >
—< a href = "https://example.org/~ernest/" >< cite > Ernest</ cite ></ a > ,
in an essay from 1992
</ td >
</ tr >
</ table >
</ body >
</ html > 这会导致依赖这些语义的软件失效:例如, 允许盲人用户浏览文档中表格的语音浏览器 会将上述引文报告为一个表格,从而使用户感到困惑;同样, 从页面提取作品标题的工具会将“Ernest”提取为 作品标题,尽管它实际上是人名而不是标题。
此文档的修正版可以是:
<!DOCTYPE HTML>
< html lang = "en-GB" >
< head > < title > Demonstration </ title > </ head >
< body >
< blockquote >
< p > My favourite animal is the cat. </ p >
</ blockquote >
< p >
—< a href = "https://example.org/~ernest/" > Ernest</ a > ,
in an essay from 1992
</ p >
</ body >
</ html > 作者不得使用本规范或其他 适用规范不允许的元素、属性或属性值,因为这样做会显著 增加未来扩展该语言的难度。
在下一个示例中,存在一个不符合规范的属性值("carpet")以及一个本规范不允许的 不符合规范的属性("texture"):
< label > Carpet: < input type = "carpet" name = "c" texture = "deep pile" ></ label > 以下是一种替代且正确的标记方式:
< label > Carpet: < input type = "text" class = "carpet" name = "c" data-texture = "deep pile" ></ label > 其节点文档的浏览上下文为 null 的 DOM 节点, 除HTML 语法要求和XML 语法要求外,不受所有 文档一致性要求约束。
特别是,template 元素的模板内容的节点
文档的浏览上下文为
null。例如,内容
模型要求和
属性值微语法要求不适用于 template 元素的
模板内容。在此示例中,一个 img 元素具有
在 template 元素之外会无效的占位属性值。
< template >
< article >
< img src = "{{src}}" alt = "{{alt}}" >
< h1 ></ h1 >
</ article >
</ template > 但是,如果上述标记省略 </h1> 结束标签,
则会违反 HTML 语法,因此一致性检查器会将其标记为
错误。
通过脚本和其他机制,当用户代理处理文档时,属性值、文本乃至 文档的整个结构都可能动态变化。某个时刻文档的 语义由该时刻文档的状态表示,因此文档的语义可以随时间变化。用户 代理必须在发生这种 情况时更新文档的呈现。
HTML 具有一个描述进度条的 progress 元素。如果脚本动态更新其
"value" 属性,用户代理会更新渲染以显示
进度的变化。
DOM 中表示HTML 元素的节点必须 实现并向脚本公开本规范相关章节中为其列出的接口。这包括 HTML 元素位于 XML 文档中的情况,即使 这些文档处于其他上下文中(例如位于 XSLT 转换中)。
DOM 中的元素表示事物;也就是说,它们具有 内在的含义,也称为语义。
例如,ol 元素表示一个有序
列表。
可以通过某种方式显式或隐式地引用元素。
显式引用 DOM 中元素的一种方式是为
元素提供一个 id 属性,然后创建一个
超链接,并将该 id 属性的值用作该
超链接的 href 属性值中的片段。
但是,引用并不一定需要超链接;任何能够指代相关元素的方式都可以。
考虑以下 figure 元素,该元素具有
一个 id 属性:
< figure id = "module-script-graph" >
< img src = "module-script-graph.svg"
alt = "Module A depends on module B, which depends
on modules C and D." >
< figcaption > Figure 27: a simple module graph</ figcaption >
</ figure > As we can see in < a href = "#module-script-graph" > figure 27</ a > , ...不过,还可以通过许多其他方式引用
figure 元素,例如:
“如模块 A、B、C 和 D 的图中所示……”
“在图 27 中……”(不带超链接)
“根据‘简单模块图’中的内容……”
“在下图中……”(但不建议这样做)
所有HTML 元素接口都继承自一个基础接口,
并且没有额外要求的元素必须使用该接口,即
HTMLElement 接口。
所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
[Exposed =Window ]
interface HTMLElement : Element {
[HTMLConstructor ] constructor ();
// metadata attributes
[CEReactions , Reflect ] attribute DOMString title ;
[CEReactions , Reflect ] attribute DOMString lang ;
[CEReactions ] attribute boolean translate ;
[CEReactions ] attribute DOMString dir ;
// user interaction
[CEReactions ] attribute (boolean or unrestricted double or DOMString )? hidden ;
[CEReactions , Reflect ] attribute boolean inert ;
undefined click ();
[CEReactions , Reflect ] attribute DOMString accessKey ;
readonly attribute DOMString accessKeyLabel ;
[CEReactions ] attribute boolean draggable ;
[CEReactions ] attribute boolean spellcheck ;
[CEReactions , ReflectSetter ] attribute DOMString writingSuggestions ;
[CEReactions , ReflectSetter ] attribute DOMString autocapitalize ;
[CEReactions ] attribute boolean autocorrect ;
[CEReactions ] attribute [LegacyNullToEmptyString ] DOMString innerText ;
[CEReactions ] attribute [LegacyNullToEmptyString ] DOMString outerText ;
ElementInternals attachInternals ();
// The popover API
undefined showPopover (optional ShowPopoverOptions options = {});
undefined hidePopover ();
boolean togglePopover (optional (TogglePopoverOptions or boolean ) options = {});
[CEReactions ] attribute DOMString ? popover ;
[CEReactions , Reflect , ReflectRange=(0, 8)] attribute unsigned long headingOffset ;
[CEReactions , Reflect ] attribute boolean headingReset ;
};
dictionary ShowPopoverOptions {
HTMLElement source ;
};
dictionary TogglePopoverOptions : ShowPopoverOptions {
boolean force ;
};
HTMLElement includes GlobalEventHandlers ;
HTMLElement includes ElementContentEditable ;
HTMLElement includes HTMLOrSVGOrMathMLElement ;
[Exposed =Window ]
interface HTMLUnknownElement : HTMLElement {
// Note: intentionally no [HTMLConstructor]
};HTMLElement 接口包含
与许多不同功能相关的方法和属性,因此该接口的成员在本规范的
各个不同章节中进行说明。
对于 HTML 命名空间中名称为 name 的元素,其元素接口按以下方式确定:
如果 name 是 applet、bgsound、blink、
isindex、keygen、multicol、nextid 或
spacer,则返回 HTMLUnknownElement。
如果 name 是 acronym、basefont、big、
center、nobr、noembed、noframes、
plaintext、rb、rtc、strike 或
tt,则返回 HTMLElement。
如果 name 是 listing 或 xmp,则返回
HTMLPreElement。
否则,如果本规范为与本地名称 name 对应的元素 类型定义了适当接口,则返回该接口。
如果其他 适用规范为 name 定义了适当接口, 则返回它们所定义的接口。
如果 name 是一个有效自定义元素名称,则返回
HTMLElement。
对于有效自定义
元素名称,使用 HTMLElement
而不是 HTMLUnknownElement,
是为了确保未来任何可能的升级只会导致元素的原型链发生
线性转换,即从 HTMLElement 转换为其子类,
而不是发生横向转换,即从 HTMLUnknownElement 转换为
不相关的子类。
HTML、SVG 和 MathML 元素之间共享的功能使用
HTMLOrSVGOrMathMLElement
接口混入:[SVG] [MATHML]
仅一个引擎支持。
interface mixin HTMLOrSVGOrMathMLElement {
[SameObject ] readonly attribute DOMStringMap dataset ;
attribute DOMString nonce ; // intentionally no [CEReactions]
[CEReactions , Reflect ] attribute boolean autofocus ;
[CEReactions , ReflectSetter ] attribute long tabIndex ;
undefined focus (optional FocusOptions options = {});
undefined blur ();
};既不是 HTML 元素、也不是 SVG 元素或 MathML 元素的一个元素示例,可以按 以下方式创建:
const el = document.createElementNS("some namespace", "example");
console.assert(el.constructor === Element);为了支持自定义元素功能,所有 HTML 元素都具有
特殊的构造函数行为。这通过 [HTMLConstructor] IDL
扩展属性表示。它表示给定接口的接口对象
在被调用时将具有特定行为,具体定义如下。
[HTMLConstructor]
扩展属性不得接受任何
参数,并且只能出现在构造函数
操作上。它在一个构造函数操作上只能出现一次,并且接口必须
仅包含这个带注解的构造函数操作,而不能包含其他构造函数操作。带注解的
构造函数操作必须声明为不接受任何参数。
声明了带有 [HTMLConstructor]
扩展属性注解的构造函数操作的接口,具有以下
重写构造函数步骤:
如果 NewTarget 等于活动函数
对象,则抛出一个 TypeError。
当使用一个元素 接口作为自定义元素的构造函数来定义该元素时,可能会出现这种情况:
customElements. define( "bad-1" , HTMLButtonElement);
new HTMLButtonElement(); // (1)
document. createElement( "bad-1" ); // (2) 在这种情况下,在执行 HTMLButtonElement
时(无论是如 (1) 中那样
显式执行,还是如 (2) 中那样隐式执行),活动
函数对象和
NewTarget 都是 HTMLButtonElement。
如果不存在此项检查,
就可以创建一个局部名称为
bad-1 的 HTMLButtonElement
实例。
令 registry 为 null。
如果周围代理的活动自定义元素构造函数 映射[NewTarget] 存在,则将 registry 设置为周围 代理的活动自定义元素 构造函数映射[NewTarget]。
否则,将 registry 设置为当前全局对象的关联的
Document的自定义元素注册表。
令 definition 为 registry 的自定义元素
定义集中构造函数等于
NewTarget 的项。如果不存在这样的项,则抛出一个 TypeError。
由于 registry 的自定义元素 定义集中不可能存在构造函数为 undefined 的项,因此 此 步骤还会阻止将 HTML 元素构造函数作为函数调用(因为在这种情况下 NewTarget 将为 undefined)。
令 isValue 为 null。
如果 definition 的局部 名称等于 definition 的名称(即 definition 用于 一个自主 自定义元素):
如果活动
函数对象不是 HTMLElement,则抛出一个
TypeError。
当自定义元素被定义为不扩展任何局部名称,但却
继承自一个非 HTMLElement
类时,可能会出现这种情况:
customElements. define( "bad-2" , class Bad2 extends HTMLParagraphElement {}); 在这种情况下,在构造 Bad2 实例时发生的
(隐式)super() 调用期间,活动
函数
对象是 HTMLParagraphElement,
而不是 HTMLElement。
否则(即 definition 用于一个自定义内置 元素):
令 valid local names 为本规范或其他适用规范中定义的元素的局部名称列表, 这些元素使用活动 函数对象作为其元素接口。
如果 valid local names 不包含 definition 的局部名称,则抛出
一个
TypeError。
当自定义元素被定义为扩展给定局部名称,但却继承自 错误的类时,可能会出现这种情况:
customElements. define( "bad-3" , class Bad3 extends HTMLQuoteElement {}, { extends : "p" }); 在这种情况下,在构造 Bad3 实例时发生的
(隐式)super() 调用期间,valid local names 是
包含 q
和 blockquote
的列表,但 definition 的局部名称是 p,
而该名称不在列表中。
将 isValue 设置为 definition 的名称。
如果 definition 的构造栈 为空:
令 element 为在内部创建一个实现该接口的新 对象的结果, 该接口是活动 函数对象所对应的接口,并给定当前 realm和NewTarget。
将 element 的节点
文档设置为当前全局
对象的关联的
Document。
将 element 的命名空间 前缀设置为 null。
将 element 的自定义元素 注册表设置为 registry。
将 element 的自定义元素状态设置为“custom”。
将 element 的自定义 元素定义设置为 definition。
将 element 的is 值设置为 isValue。
返回 element。
当作者脚本直接构造一个新的自定义元素时会出现这种情况,例如
通过 new MyCustomElement()。
如果 prototype 不是对象:
令 realm 为 ? GetFunctionRealm(NewTarget)。
活动 函数对象的 realm 可能不是 realm,因此这里使用跨 realm 的更一般概念“相同接口”; 我们并非在查找接口 对象是否相等。这种回退行为,包括使用 NewTarget 的 realm 并 在其中查找适当的原型,旨在匹配 JavaScript 内置对象和 Web IDL 的在内部创建一个实现 接口的新对象算法的类似行为。
令 element 为 definition 的构造 栈中的最后一个条目。
如果 element 是一个已
构造标记,则抛出一个 TypeError。
当自定义元素
构造函数内的作者代码在调用 super() 之前,不符合规范地创建正在构造的类的另一个
实例时,可能会出现这种情况:
let doSillyThing = true ;
class DontDoThis extends HTMLElement {
constructor() {
if ( doSillyThing) {
doSillyThing = false ;
new DontDoThis();
// Now the construction stack will contain an already constructed marker.
}
// This will then fail with a TypeError:
super ();
}
} 执行 ? element.[[SetPrototypeOf]](prototype)。
返回 element。
通常在升级自定义元素时会到达此步骤;现有元素会被
返回,以便自定义元素
构造函数内部的 super() 调用将该现有元素赋值给 this。
除了 [HTMLConstructor]
所隐含的构造函数行为之外,一些
元素还具有具名构造函数(它们
实际上是具有修改后的 prototype 属性的工厂函数)。
在定义自定义
元素构造函数时,HTML 元素的具名构造函数也可以用于 extends
子句:
class AutoEmbiggenedImage extends Image {
constructor( width, height) {
super ( width * 10 , height * 10 );
}
}
customElements. define( "auto-embiggened" , AutoEmbiggenedImage, { extends : "img" });
const image = new AutoEmbiggenedImage( 15 , 20 );
console. assert( image. width === 150 );
console. assert( image. height === 200 ); 本规范中的每个元素都有一个定义,其中包括以下 信息:
对可以在何处使用该元素的非规范性描述。此信息 与允许将该元素作为子元素的元素的内容模型重复,仅为方便而提供。
对必须作为该元素的子级和后代包含哪些内容的规范性描述。
对在 text/html 语法中,
开始和结束标签是否可以
省略的非规范性描述。此信息与可选标签一节中给出的规范性要求重复,
仅为方便而在元素
定义中提供。
可以在元素上指定的属性的规范性列表(除非在其他地方 禁止),以及这些属性的非规范性描述。(破折号左侧的内容是规范性的, 右侧的内容不是规范性的。)
对于作者:使用 ARIA role 和 aria-* 属性的一致性要求
在 HTML 中的 ARIA 中定义。[ARIA] [ARIAHTML]
对于实现者:实现无障碍 API 语义的用户代理要求 在 HTML 无障碍 API 映射 中定义。[HTMLAAM]
每个元素的净化信息定义了其净化 类别,该类别会影响元素在净化期间的处理方式。它还可以将元素的一个或多个属性定义为 导航 URL 属性。
此类元素必须实现的 DOM 接口的规范性定义。
随后是对该元素所表示内容的描述,以及 可能适用于作者和实现的任何其他规范性一致性标准。有时还会包含示例。
属性值是一个字符串。除非另有规定, HTML 元素上的属性值可以是任何字符串 值,包括空字符串,并且对此类属性值中可以指定的文本没有任何限制。
本规范中定义的每个元素都有一个内容模型:对该元素预期 内容的描述。一个HTML 元素必须具有符合该元素内容模型中所述要求的内容。 元素的内容是其在 DOM 中的子级。
元素之间始终允许存在ASCII 空白。用户代理将源标记中元素之间的这些
字符表示为 DOM 中的 Text
节点。空的 Text
节点以及
仅由这些字符序列组成的 Text
节点被视为
元素间空白。
在确定元素的内容是否符合该元素的内容模型时,必须忽略元素间空白、 注释节点和处理指令节点;在遵循定义文档和元素语义的算法时,也必须 忽略它们。
因此,如果元素 A 和 B
具有相同的父节点,并且它们之间不存在其他元素节点或 Text
节点(
元素间空白除外),
则称元素 A 位于第二个元素 B 的之前或之后。
类似地,如果一个元素除元素间
空白、注释节点和处理指令节点之外不包含其他节点,
则某个节点是该元素的唯一子级。
除非每个元素的定义明确允许,或其他规范明确要求,否则作者不得在任何地方使用 HTML 元素。对于 XML 复合文档,如果其他命名空间中的元素被定义为提供相关上下文,则这些上下文 可以位于这些元素内部。
Atom 联合格式定义了一个 content 元素。当其
type 属性的值为
xhtml 时,Atom 联合格式要求它包含单个
HTML div 元素。因此,在该上下文中允许使用
div 元素,
即使本规范没有明确地规范性说明这一点。[ATOM]
此外,HTML 元素可以是孤立节点 (即没有父节点)。
例如,创建一个 td 元素
并将其存储在脚本的全局变量中是符合规范的,即使 td
元素在其他情况下只应
在 tr 元素内部使用。
var data = {
name: "Banana" ,
cell: document. createElement( 'td' ),
}; 当元素的内容模型为无时,
该元素不得包含任何 Text
节点(元素间空白除外)
或元素节点。
为方便起见,大多数内容模型为“无”的 HTML 元素也是 空元素(在 HTML 语法中没有结束标签的元素)。但是,这些是完全独立的概念。
HTML 中的每个元素都属于零个或多个类别, 这些类别将具有相似特征的元素归为一组。本规范使用以下广义类别:
一些元素还属于其他类别,这些类别在本规范的其他部分中定义。
这些类别之间的关系如下:
分节内容、标题内容、短语内容、嵌入内容和交互式 内容都属于流式内容。元数据有时属于流式内容。元数据和 交互式内容有时属于短语内容。嵌入内容也属于短语 内容,有时还属于交互式内容。
其他类别也用于特定目的,例如,表单控件使用多个 类别来定义共同要求。一些元素具有独特的要求,不 属于任何特定类别。
元数据内容是用于设置其余内容的呈现方式或 行为,设置文档与其他文档之间的关系,或 传达其他“带外”信息的内容。
来自其他命名空间且其语义主要与元数据有关的元素(例如 RDF)也属于 元数据内容。
因此,在 XML 序列化中,可以像这样使用 RDF:
< html xmlns = "http://www.w3.org/1999/xhtml"
xmlns:r = "http://www.w3.org/1999/02/22-rdf-syntax-ns#" xml:lang = "en" >
< head >
< title > Hedral's Home Page</ title >
< r:RDF >
< Person xmlns = "http://www.w3.org/2000/10/swap/pim/contact#"
r:about = "https://hedral.example.com/#" >
< fullName > Cat Hedral</ fullName >
< mailbox r:resource = "mailto:hedral@damowmow.com" />
< personalTitle > Sir</ personalTitle >
</ Person >
</ r:RDF >
</ head >
< body >
< h1 > My home page</ h1 >
< p > I like playing with string, I guess. Sister says squirrels are fun
too so sometimes I follow her to play with them.</ p >
</ body >
</ html > 不过,在 HTML 序列化中无法这样做。
文档和应用程序主体中使用的大多数元素都被归类为 流式内容。
aabbraddressarea(如果它是
map 元素的后代)
articleasideaudiobbdibdoblockquotebrbuttoncanvascitecodedatadatalistdeldetailsdfndialogdivdlemembedfieldsetfigurefooterformh1
h2
h3
h4
h5
h6
headerhgrouphriiframeimginputinskbdlabellink(如果它允许出现在主体中)main(如果它是一个层次结构正确的
main 元素)mapmarkmathmenumeta(如果存在 itemprop
属性)meternavnoscriptobjectoloutputppicturepreprogressqrubyssampscriptsearchsectionselectslotsmallspanstrongsubsupsvgtabletemplatetextareatimeuulvarvideowbr分节内容是定义 header
和 footer 元素作用域的内容。
标题内容定义节的标题(无论是 使用分节内容元素显式 标记,还是由标题内容本身隐式形成)。
短语内容是文档中的文本,以及在 段落内部级别标记该文本的元素。连续的短语内容形成段落。
aabbrarea(如果它是
map 元素的后代)
audiobbdibdobrbuttoncanvascitecodedatadatalistdeldfnemembediiframeimginputinskbdlabellink(如果它允许出现在主体中)mapmarkmathmeta(如果存在 itemprop
属性)meternoscriptobjectoutputpictureprogressqrubyssampscriptselectselectedcontent
(如果它是 select 中的
button 的后代)
slotsmallspanstrongsubsupsvgtemplatetextareatimeuvarvideowbr大多数被归类为短语内容的元素只能包含 本身也被归类为短语内容的元素,而不能包含任意流式内容。
在内容模型的上下文中,文本表示无内容,
或者 Text
节点。文本有时单独用作内容
模型,但它也属于短语
内容,并且可以是元素间
空白(如果 Text
节点为空或仅包含ASCII
空白)。
Text
节点和属性值必须由标量
值组成,但不包括非字符,以及除ASCII 空白之外的控制字符。
本规范根据 Text
节点和属性值所处的精确上下文,对其确切值施加了额外约束。
嵌入内容是将 另一资源导入文档的内容,或将另一词汇表中的内容 插入文档的内容。
来自 HTML 命名空间以外的命名空间, 并且传达内容而非元数据的元素,就本规范中定义的内容模型而言,属于 嵌入内容。(例如 MathML 或 SVG。)
一些嵌入内容元素可以具有回退内容:当外部资源 无法使用时(例如因为其格式不受支持)所使用的内容。 元素定义会说明回退内容是什么(如果有)。
交互式内容是专门用于 用户交互的内容。
a(如果存在 href 属性)audio(如果存在 controls 属性)buttondetailsembediframeimg(如果存在 usemap 或 controls 属性)input(如果 type 属性不处于
状态)
labelselecttextareavideo(如果存在 controls 属性)一般来说,内容模型允许任何流式内容或 短语内容的元素,应在其内容中至少具有一个属于可感知内容且 未指定 属性的节点。
可感知内容通过提供
非空的后代文本,或用户可以
听到的内容(audio 元素)、可以查看的内容
(video、img 或
canvas 元素),或
可以通过其他方式交互的内容(例如交互式表单
控件),使元素成为非空元素。
但是,此要求并非硬性要求,因为在许多情况下元素 可以合法地为空,例如,当它被用作稍后将由脚本填充的占位符时, 或当该元素是模板的一部分,并且在大多数页面上会被填充,但 在某些页面上并不相关时。
鼓励一致性检查器提供一种机制,帮助作者查找 未能满足此要求的元素,作为创作辅助。
以下元素属于可感知内容:
aabbraddressarticleasideaudio(如果存在 controls 属性)bbdibdoblockquotebuttoncanvascitecodedatadeldetailsdfndivdl(如果该元素的子级
包含至少一个名称-值组)emembedfieldsetfigurefooterformh1
h2
h3
h4
h5
h6
headerhgroupiiframeimginput(如果 type 属性不处于
状态)
inskbdlabelmainmapmarkmathmenu(如果该元素的
子级包含至少一个 li
元素)meternavobjectol(如果该元素的子级
包含至少一个 li 元素)
outputppicturepreprogressqrubyssampsearchsectionselectsmallspanstrongsubsupsvgtabletextareatimeuul(如果该元素的子级
包含至少一个 li 元素)
varvideo脚本支持元素是自身不表示任何内容(即不会被渲染),但用于 支持脚本的元素,例如为用户提供功能。
以下元素是脚本支持元素:
一些元素被描述为透明的;其内容模型的描述中包含“透明”。 透明元素的内容模型 派生自其父元素的内容模型:内容模型中“透明”部分所要求的元素,与透明元素所在位置对应的 父元素内容模型部分所要求的元素相同。
在某些情况下,当透明元素彼此嵌套时,必须 迭代应用此过程。
考虑以下标记片段:
< p >< object >< ins >< map >< a href = "/" > Apples</ a ></ map ></ ins ></ object ></ p > 要检查是否允许在 a
元素内放置“Apples”,需要检查
内容模型。a
元素的内容模型是透明的,map
元素也是如此,ins 元素也是如此,
object
元素也是如此。
object 元素
位于 p 元素中,
后者的内容模型是
短语内容。因此,
允许使用“Apples”,因为文本属于短语内容。
当透明元素没有父元素时,其内容模型中“透明”的部分 必须改为视为接受任何流式内容。
本节定义的段落一词不仅仅
用于定义 p 元素。这里定义的段落概念
用于描述如何解释文档。p 元素仅仅是
标记段落的多种方式之一。
段落通常是一段短语内容,它构成一个 文本块,其中包含讨论特定主题的一个或多个句子,这与排版中的段落类似,但也可以 用于更一般的主题分组。例如,地址也是一个段落,表单的一部分、署名行或诗歌的一节 也都是段落。
在以下示例中,一个节内有两个段落。还有一个标题, 其中包含不属于段落的短语内容。请注意,注释和 元素间空白不会 形成段落。
< section >
< h2 > Example of paragraphs</ h2 >
This is the < em > first</ em > paragraph in this example.
< p > This is the second.</ p >
<!-- This is not a paragraph. -->
</ section > 流式内容中的段落,是相对于
去除 a、ins、del 和 map 元素所造成的复杂性之后的文档外观来定义的,
因为这些具有混合内容模型的元素可以跨越段落边界,如下面前两个示例所示。
一般而言,最好避免让元素跨越段落边界。 维护这种标记可能很困难。
以下示例采用前一个示例中的标记,并在其中一些标记周围放置 ins 和
del 元素,
以表示文本已发生更改(尽管在本例中,这些更改确实没有太大意义)。
请注意,尽管存在 ins 和 del 元素,
此示例仍与前一个示例具有完全相同的段落——ins
元素跨越标题和第一个段落,而
del 元素跨越
两个段落之间的边界。
< section >
< ins >< h2 > Example of paragraphs</ h2 >
This is the < em > first</ em > paragraph in</ ins > this example< del > .
< p > This is the second.</ p ></ del >
<!-- This is not a paragraph. -->
</ section > 令 view 为 DOM 的一个视图,该视图将文档中的所有 a、
ins、del 和 map 元素替换为其
内容。然后,在 view 中,
对于每一段未被其他类型内容中断的相邻短语内容节点,
如果它们位于一个既接受短语内容也接受其他内容的元素中,
则令 first 为该段的第一个节点,令 last 为该段的最后一个节点。
对于每一段至少包含一个既不是嵌入内容也不是元素间
空白的节点的此类连续内容,
原始 DOM 中从紧邻 first 之前到紧邻 last 之后存在一个段落。
(因此,段落可以跨越 a、
ins、del 和 map 元素。)
一致性检查器可以就段落彼此重叠的情况向作者发出警告
(这种情况可能发生在 object、video、audio 和
canvas 元素中,也可能通过
其他命名空间中允许进一步嵌入 HTML 的元素间接发生,例如 SVG
svg 或 MathML
math)。
当不存在短语内容以外的其他内容可用于将各段落
相互分隔时,可以使用 p 元素
包裹各个段落。
在以下示例中,链接跨越第一个段落的一半、分隔两个段落的整个标题, 以及第二个段落的一半。它横跨两个段落和标题。
< header >
Welcome!
< a href = "about.html" >
This is home of...
< h1 > The Falcons!</ h1 >
The Lockheed Martin multirole jet fighter aircraft!
</ a >
This page discusses the F-16 Fighting Falcon's innermost secrets.
</ header > 下面是另一种标记方式,这次显式显示这些段落,并将 一个链接元素拆分为三个:
< header >
< p > Welcome! < a href = "about.html" > This is home of...</ a ></ p >
< h1 >< a href = "about.html" > The Falcons!</ a ></ h1 >
< p >< a href = "about.html" > The Lockheed Martin multirole jet
fighter aircraft!</ a > This page discusses the F-16 Fighting
Falcon's innermost secrets.</ p >
</ header > 使用某些定义回退内容的元素时,段落可能发生重叠。 例如,在以下节中:
< section >
< h2 > My Cats</ h2 >
You can play with my cat simulator.
< object data = "cats.sim" >
To see the cat simulator, use one of the following links:
< ul >
< li >< a href = "cats.sim" > Download simulator file</ a >
< li >< a href = "https://sims.example.com/watch?v=LYds5xY4INU" > Use online simulator</ a >
</ ul >
Alternatively, upgrade to the Mellblom Browser.
</ object >
I'm quite proud of it.
</ section > 其中有五个段落:
object 元素。第一个段落被其他四个段落重叠。支持“cats.sim” 资源的用户代理只会显示第一个段落,但显示回退内容的用户代理会令人困惑地 将第一个段落的第一句话显示为与第二个段落处于同一段落中, 并将最后一个段落显示为仿佛位于第一个段落第二句话的开头。
为避免这种混淆,可以使用显式的 p
元素。例如:
< section >
< h2 > My Cats</ h2 >
< p > You can play with my cat simulator.</ p >
< object data = "cats.sim" >
< p > To see the cat simulator, use one of the following links:</ p >
< ul >
< li >< a href = "cats.sim" > Download simulator file</ a >
< li >< a href = "https://sims.example.com/watch?v=LYds5xY4INU" > Use online simulator</ a >
</ ul >
< p > Alternatively, upgrade to the Mellblom Browser.</ p >
</ object >
< p > I'm quite proud of it.</ p >
</ section > 以下属性为所有HTML 元素所共有,并且可以在所有这些元素上指定(即使这些元素未在本规范中定义):
accesskey
autocapitalizeautocorrectautofocuscontenteditable
dirdraggableenterkeyhintheadingoffsetheadingresetinertinputmodeisitemiditemprop
itemrefitemscopeitemtypelangnoncepopoverspellcheckstyletabindextitletranslatewritingsuggestions
本规范仅将这些属性定义为HTML 元素的属性。当本规范提到具有这些属性的元素时,不得将 未被定义为具有这些属性的其他命名空间中的元素视为 具有这些属性的元素。
例如,在以下 XML 片段中,尽管“bogus”元素
具有字面名称为“dir”的属性,但它并不具有本规范所定义的
dir 属性。因此,最内层
span 元素的方向性为“rtl”,它通过
“bogus”元素间接继承自 div
元素。
< div xmlns = "http://www.w3.org/1999/xhtml" dir = "rtl" >
< bogus xmlns = "https://example.net/ns" dir = "ltr" >
< span xmlns = "http://www.w3.org/1999/xhtml" >
</ span >
</ bogus >
</ div > 所有当前引擎均支持。
DOM 定义了用户代理对任何命名空间中任何元素的 class、id 和 slot 属性的要求。
[DOM]
class、id 和 slot 属性可以在所有HTML 元素上指定。
在HTML 元素上指定时,class
属性的值必须是一个以空格分隔的词元集合,用于表示
该元素所属的各种类。
为元素分配类会影响 CSS 选择器中的类匹配、DOM 中的 getElementsByClassName()
方法,以及其他类似功能。
作者可以在 class 属性中使用的词元没有其他限制,
但鼓励作者使用描述内容
性质的值,而不是描述内容所需呈现方式的值。
在HTML 元素上指定时,id 属性
值必须在该元素树中的所有ID中唯一,
并且必须至少包含一个字符。该值不得包含任何
ASCII 空白。
ID 的形式没有其他限制;尤其是,ID 可以仅由数字组成、 以数字开头、以下划线开头、仅由标点符号组成,等等。
元素的唯一标识符可用于多种 用途,最值得注意的是,可作为一种通过片段链接到文档特定部分的方式、 在脚本编程时定位元素的方式,以及从 CSS 中为特定元素设置样式的方式。
标识符是不透明字符串。不应从 id 属性的值中
推导出特定含义。
对于 slot 属性,
没有专门针对HTML 元素的一致性要求。
slot 属性用于为元素
分配
插槽:具有 slot 属性的元素会被
分配到由 slot 元素创建的插槽,
前提是该元素的 name
属性值与该 slot
属性值匹配——但只有当该 slot 元素位于一个影子树中,并且该影子树
根的宿主
具有相应的
slot 属性值时才是如此。
为了使辅助技术产品能够公开比仅使用 HTML 元素和属性时
更细粒度的接口,可以指定一组用于辅助技术产品的
注解(即 ARIA role 和 aria-* 属性)。
[ARIA]
onauxclickonbeforeinput
onbeforematch
onbeforetoggle
onblur*oncanceloncanplayoncanplaythrough
onchangeonclickoncloseoncommandoncontextlost
oncontextmenu
oncontextrestored
oncopyoncuechangeoncutondblclickondragondragendondragenterondragleaveondragoverondragstartondropondurationchange
onemptiedonendedonerror*onfocus*onformdataoninputoninvalidonkeydownonkeypressonkeyuponload*onloadeddataonloadedmetadata
onloadstartonmousedownonmouseenteronmouseleaveonmousemoveonmouseoutonmouseoveronmouseuponpasteonpauseonplayonplayingonprogressonratechangeonresetonresize*onscroll*onscrollend*onsecuritypolicyviolation
onseekedonseekingonselectonslotchangeonstalledonsubmitonsuspendontimeupdateontoggleonvolumechange
onwaitingonwheel标有星号的属性在 body
元素上指定时具有不同含义,
因为这些元素公开了 Window 对象中同名的事件处理器。
尽管这些属性适用于所有元素,但它们并非对所有元素都有用。
例如,只有媒体元素才会接收到
用户代理触发的 volumechange
事件。
自定义数据属性(例如
data-foldername 或 data-msgid)可以在任何
HTML 元素上指定,
以存储页面特有的自定义数据、状态、注解及类似信息。
在HTML 文档中,HTML 命名空间中的元素
可以指定一个 xmlns 属性,当且仅当其值恰好为
“http://www.w3.org/1999/xhtml”。这不适用于XML
文档。
在 HTML 中,xmlns 属性完全不起作用。
它基本上只是一个护身符。允许使用它,仅仅是为了让往返 XML 的迁移稍微容易一些。
当由HTML 解析器解析时,该属性最终
不属于任何命名空间。在 XML 中,该属性是命名空间声明机制的一部分,并且始终属于
“http://www.w3.org/2000/xmlns/”命名空间。
XML 还允许在XML
文档中的任何元素上,使用位于XML 命名空间中的 xml:space
属性。该属性对HTML
元素没有影响,因为 HTML 的默认
行为是保留空白。[XML]
无法在 text/html 语法中,
对HTML 元素上的 xml:space
属性进行序列化。
title 属性所有当前引擎均支持。
title 属性
表示元素的提示信息,例如适合在
工具提示中显示的信息。对于链接,这可以是目标资源的标题或描述;对于图像,
可以是图像署名或图像描述;对于段落,可以是脚注
或对文本的评论;对于引文,可以是有关来源的更多信息;对于
交互式内容,可以是
元素的标签或使用说明;等等。其值为文本。
目前不鼓励依赖 title
属性,因为许多用户代理没有按照本规范的要求,以无障碍方式公开该属性
(例如,需要使用鼠标之类的指向设备才能显示工具提示,
这会排除仅使用键盘的用户和仅使用触摸的用户,例如使用现代
手机或平板电脑的任何人)。
如果元素省略此属性,则意味着设置了 title 属性的最近祖先HTML 元素的 title 属性也与
此元素相关。设置该属性会覆盖这一点,明确表明任何祖先的
提示信息均与此元素无关。将该属性设置为空字符串
表示该元素没有提示信息。
如果 title 属性的值
包含 U+000A 换行符(LF)
字符,则内容会被拆分为多行。每个 U+000A 换行符(LF)
字符表示一个换行。
在 title 属性中使用换行符时应谨慎。
例如,以下片段实际上定义了一个缩写的展开形式,其中包含 换行:
< p > My logs show that there was some interest in < abbr title = "Hypertext
Transport Protocol" > HTTP</ abbr > today.</ p > 某些元素,例如 link、
abbr 和 input,为 title
属性定义了上述语义之外的
其他语义。
元素的提示信息是以下算法 返回的值;一旦返回一个值,算法即中止。当算法返回 空字符串时,表示不存在提示信息。
当元素具有提示信息时,用户代理应告知用户, 否则这些信息将无法被发现。
lang 和 xml:lang
属性所有当前引擎均支持。
lang 属性
(不在任何命名空间中)指定元素内容以及该元素包含文本的任何
属性的主要语言。其值必须是有效的 BCP 47 语言标签,或
空字符串。将该属性设置为空字符串表示主要语言
未知。[BCP47]
XML 命名空间中的 lang 属性在 XML 中定义。
[XML]
如果元素省略这些属性,则此元素的语言与其父元素的
语言相同(如果存在父元素),但影子树中的 slot 元素除外。
不在任何命名空间中的 lang 属性可以用于任何HTML
元素。
XML 命名空间中的lang
属性可以用于XML 文档中的HTML 元素,
如果相关规范允许,也可以用于其他命名空间中的元素(特别是,
MathML 和 SVG 允许在其元素上指定XML 命名空间中的lang 属性)。
如果不在任何命名空间中的 lang 属性
和XML 命名空间中的lang
属性同时指定在同一
元素上,则在以ASCII
不区分大小写的方式进行比较时,它们必须具有完全相同的值。
作者不得在HTML
文档的HTML 元素上使用XML
命名空间中的lang 属性。
为了方便往返 XML 的迁移,作者可以在HTML 文档中的HTML 元素上指定一个不在任何
命名空间中、没有前缀且字面局部名称为“xml:lang”的属性,
但仅当同时指定了不在任何命名空间中的 lang
属性时,才可以指定此类属性,并且在以ASCII
不区分大小写的方式进行比较时,两个属性必须具有相同的值。
不在任何命名空间中、没有前缀且字面局部名称为“xml:lang”的属性
对语言处理没有影响。
为了确定节点的语言,用户代理必须 使用以下列表中第一个适用的步骤:
lang
属性的元素使用该属性的值。
lang
属性
使用该属性的值。
如果设置了由 pragma 设置的默认语言,则 该语言就是节点的语言。如果未设置由 pragma 设置的默认语言, 则必须改用更高级别协议(例如 HTTP)提供的语言信息(如果有)作为最终回退 语言。在不存在任何此类语言信息以及更高级别协议 报告多种语言的情况下,节点的语言未知,相应的 语言标签为空字符串。
如果所得值不是可识别的语言标签,则必须将其视为一种具有给定语言标签的 未知语言,并且与所有其他语言不同。为了与其他需要语言标签的服务 进行往返传输或通信,用户代理应原样传递未知语言标签,并将其标记为 BCP 47 语言标签,以便后续服务不会将该数据解释为另一种语言描述。 [BCP47]
因此,例如,具有 lang="xyzzy" 的元素会被
选择器 :lang(xyzzy)(例如在 CSS 中)匹配,但不会被
:lang(abcde) 匹配,即使二者同样无效。类似地,如果
Web 浏览器和屏幕阅读器协同工作,并就元素的语言进行通信,
即使浏览器知道“xyzzy”无效,也会告知屏幕阅读器该语言是“xyzzy”,
以防屏幕阅读器实际上支持具有该标签的语言。
即使屏幕阅读器同时支持 BCP 47 和另一种对语言名称进行编码的语法,
并且在另一种语法中字符串“xyzzy”是表示白俄罗斯语的一种方式,
屏幕阅读器随后开始将文本视为白俄罗斯语也是不正确的,因为
BCP 47 代码并不使用“xyzzy”表示白俄罗斯语(BCP 47 使用代码“be”
表示白俄罗斯语)。
如果所得值为空字符串,则必须将其解释为节点的 语言明确未知。
用户代理可以使用元素的语言来确定适当的处理或渲染方式(例如, 选择适当的字体或发音、选择词典,或确定日期选择器等表单控件的 用户界面)。
translate 属性所有当前引擎均支持。
translate
属性用于指定在页面本地化时,是否应翻译元素的属性值及其
Text
节点子级的值,或者是否应
保持它们不变。它是一个枚举属性,具有
以下关键字和状态:
| 关键字 | 状态 | 简要描述 |
|---|---|---|
yes
|
是 | 将翻译模式设置为启用翻译。 |
no
|
否 | 将翻译模式设置为不翻译。 |
每个元素(甚至非 HTML 元素)都有一个翻译模式,它处于
启用翻译状态或
不翻译状态。如果一个HTML 元素的 translate
属性处于是状态,则该元素的
翻译模式处于启用翻译状态;
否则,如果该元素的 translate
属性处于否
状态,则该元素的翻译
模式
处于不翻译状态。否则,
该元素的 translate 属性处于
继承
状态,或者该元素不是HTML
元素,因而没有 translate
属性;在
这两种情况下,如果该元素有父元素,则该元素的
翻译模式与父元素处于相同
状态;如果该元素的父元素为
null,则处于启用翻译
状态。
当元素处于启用翻译状态时,在
页面本地化时,应翻译元素的可翻译
属性及其 Text
节点子级的值。
当元素处于不翻译状态时,在页面本地化时,应保持元素的属性值及其
Text
节点子级的值不变,例如因为该元素包含某人的姓名或计算机程序的名称。
以下属性是可翻译属性:
abbr,用于 th 元素alt,用于 area、
img 和
input 元素
content,用于
meta 元素,前提是
name 属性指定了
一个已知其值可翻译的元数据名称
download,用于
a 和
area 元素
label,用于 optgroup、
option 和
track 元素
lang,用于HTML 元素;必须“翻译”为
与译文所使用的语言相匹配placeholder,用于 input 和
textarea
元素
srcdoc,用于
iframe 元素;
必须进行解析并递归处理
style,用于HTML 元素;必须进行解析并
递归处理(例如,处理 'content' 属性的值)
title,用于所有HTML 元素value,用于其
type 属性处于
按钮状态
或重置按钮状态的 input 元素
其他规范可以定义同样属于可翻译
属性的其他属性。例如,ARIA 会将 aria-label
属性定义为可翻译的。
translate IDL
属性在获取时,如果元素的翻译模式为
启用翻译,则必须返回 true,
否则返回 false。在设置时,如果新值为 true,则必须将内容
属性的值设置为“yes”;否则将内容
属性的值设置为“no”。
在此示例中,当页面进行本地化时,文档中的所有内容都应翻译, 但示例键盘输入和示例程序输出除外:
<!DOCTYPE HTML>
< html lang = en > <!-- default on the document element is translate=yes -->
< head >
< title > The Bee Game</ title > <!-- implied translate=yes inherited from ancestors -->
</ head >
< body >
< p > The Bee Game is a text adventure game in English.</ p >
< p > When the game launches, the first thing you should do is type
< kbd translate = no > eat honey</ kbd > . The game will respond with:</ p >
< pre >< samp translate = no > Yum yum! That was some good honey!</ samp ></ pre >
</ body >
</ html > dir 属性所有当前引擎均支持。
dir 属性
是一个枚举属性,具有
以下关键字和状态:
| 关键字 | 状态 | 简要描述 |
|---|---|---|
ltr
|
LTR | 元素的内容是显式进行方向隔离的从左到右文本。 |
rtl
|
RTL | 元素的内容是显式进行方向隔离的从右到左文本。 |
auto
|
自动 | 元素的内容是显式进行方向隔离的文本,但其方向 将以编程方式使用元素的内容来确定(如下文 所述)。 |
自动 状态所使用的启发式方法非常粗略 (它只是查找第一个具有强方向性的字符,其方式类似于 双向算法中的段落级别确定)。强烈建议作者仅在文本方向确实未知, 并且无法应用更好的服务器端启发式方法时,才将此值作为最后的手段。 [BIDI]
由于 dir 属性仅为
HTML 元素定义,因此它不能出现在
其他命名空间中的元素上。因此,其他命名空间中的元素最终始终使用父级方向性。
给定元素 element,要计算其自动方向性:
如果 element 是一个自动方向性表单关联 元素:
返回 element 的所含文本自动方向性,并将 canExcludeRoot 设置为 false。
给定元素 element 和一个布尔值 canExcludeRoot,要计算该元素的所含文本自动方向性:
给定一个 Text
节点
text,要计算其文本节点方向性:
给定元素 element,要计算其父级方向性:
此属性具有涉及双向算法的 渲染要求。
当一个HTML 元素的属性文本将以某种方式包含在 渲染中时,该属性的方向性按照以下列表中 第一个适用的步骤集合确定:
以下属性是支持方向性的属性:
所有当前引擎均支持。
所有当前引擎均支持。
强烈建议作者使用 dir
属性而不是 CSS 来指示文本方向,因为这样即使缺少 CSS,其文档仍将
正确渲染(例如由搜索
引擎解释时)。
此标记片段表示一段即时消息对话。
< p dir = auto class = "u1" >< b >< bdi > Student</ bdi > :</ b > How do you write "What's your name?" in Arabic?</ p >
< p dir = auto class = "u2" >< b >< bdi > Teacher</ bdi > :</ b > ما اسمك؟</ p >
< p dir = auto class = "u1" >< b >< bdi > Student</ bdi > :</ b > Thanks.</ p >
< p dir = auto class = "u2" >< b >< bdi > Teacher</ bdi > :</ b > That's written "شكرًا".</ p >
< p dir = auto class = "u2" >< b >< bdi > Teacher</ bdi > :</ b > Do you know how to write "Please"?</ p >
< p dir = auto class = "u1" >< b >< bdi > Student</ bdi > :</ b > "من فضلك", right?</ p > 给定适当的样式表,以及 p 元素的默认对齐样式,
即将文本与段落的起始边缘对齐,所得渲染结果可能
如下:

如前所述,auto 值
并非万能解决方案。本例中的
最后一个段落被错误地解释为从右到左的文本,因为它以
阿拉伯字符开头,这导致“right?”出现在阿拉伯文本的左侧。
style 属性所有当前引擎均支持。
所有HTML 元素都可以设置 style 内容属性。
这是一个由CSS 样式
属性定义的样式属性。
[CSSATTR]
在支持 CSS 的用户代理中,当添加该属性或更改其值时,必须根据为样式属性规定的规则, 解析该属性的值。 [CSSATTR]
但是,如果对该属性的元素、“style attribute”和该属性的值执行元素的内联行为是否应被内容安全策略
阻止?算法时返回“Blocked”,则不得将该属性值中定义的样式规则应用于
该元素。[CSP]
在其任何元素上使用 style 属性的
文档,即使移除这些属性,也仍必须可以理解和使用。
尤其是,使用 style 属性隐藏和显示
内容,或者传达文档中未以其他方式包含的含义,是不符合规范的。(要隐藏和显示内容,请使用
属性。)
element.style
返回一个表示元素的 style 属性的 CSSStyleDeclaration
对象。
style
IDL 属性在 CSS 对象
模型中定义。[CSSOM]
在以下示例中,使用 span 元素和 style 属性标记表示颜色的词语,
使这些词语在视觉媒体中以相应颜色显示。
< p > My sweat suit is < span style = "color: green; background:
transparent" > green</ span > and my eyes are < span style = "color: blue;
background: transparent" > blue</ span > .</ p > data-*
属性嵌入自定义不可见数据
所有当前引擎均支持。
自定义数据属性是一个不在任何命名空间中的属性,其名称以字符串
“data-”开头,连字符之后至少有一个字符,
是一个有效属性局部名称,并且不包含任何ASCII 大写字母。
HTML 文档中的HTML 元素上的所有属性名称 都会自动转换为 ASCII 小写形式,因此,对 ASCII 大写字母的限制不会影响 此类文档。
自定义数据属性 旨在存储页面或应用程序专用的自定义 数据、状态、注解及类似信息,并且不存在更合适的属性或元素可用于这些信息。
这些属性并非旨在供使用这些属性的网站管理员所不知晓的软件使用。 对于将由多个独立工具使用的通用扩展,应扩展本规范以明确提供该功能, 或者应使用微数据之类的技术(配合 标准化词汇表)。
例如,一个音乐网站可以使用包含每首曲目时长的自定义数据属性, 对表示专辑中曲目的列表项进行注解。随后,网站本身可以使用这些信息, 允许用户按曲目时长对列表进行排序,或者筛选出具有特定时长的曲目。
< ol >
< li data-length = "2m11s" > Beyond The Sea</ li >
...
</ ol > 但是,用户使用与该音乐网站无关的通用软件,通过查看这些数据来搜索 特定时长的曲目是不合适的。
这是因为这些属性旨在由网站自己的脚本使用,而不是作为一种 可公开使用的元数据通用扩展机制。
类似地,页面作者可以编写为其计划使用的翻译工具 提供信息的标记:
< p > The third < span data-mytrans-de = "Anspruch" > claim</ span > covers the case of < span
translate = "no" > HTML</ span > markup.</ p > 在此示例中,“data-mytrans-de”属性提供了
MyTrans 产品在将短语“claim”翻译为德语时使用的特定文本。但是,
标准的 translate
属性用于告知该工具,在所有
语言中,“HTML”均应保持不变。如果已有标准属性可用,就无需使用自定义数据
属性。
在此示例中,自定义数据属性用于存储对 PaymentRequest
进行特性检测的结果,该结果可以在 CSS 中用于以不同方式设置结账页面的样式。
< script >
if ( 'PaymentRequest' in window) {
document. documentElement. dataset. hasPaymentRequest = '' ;
}
</ script > 这里,data-has-payment-request 属性实际上被用作
布尔属性;
只需检查该属性是否存在即可。
不过,如果作者愿意,稍后也可以为其填入某个值,例如用于表明
该特性的功能受限。
每个HTML 元素都可以指定任意 数量、具有任意值的自定义数据 属性。
作者应谨慎设计此类扩展,以确保当这些属性被忽略并且任何 相关 CSS 被移除时,页面仍然可用。
用户代理不得从这些属性或值推导出任何实现行为。 面向用户代理的规范不得将这些属性定义为具有任何有意义的值。
JavaScript 库可以使用自定义数据 属性,因为它们被视为其所在页面的一部分。鼓励 被许多作者重复使用的库的作者在属性名称中加入库名, 以降低冲突风险。在合理的情况下,还鼓励库作者使属性名称中使用的 确切名称可自定义,以便作者在不知情的情况下选择了相同名称的库 可以在同一页面中使用,并且即使某个库的多个版本彼此不兼容, 也可以在同一页面中使用。
例如,名为“DoQuery”的库可以使用 data-doquery-range 之类的属性名称,而
名为“jJo”的库可以使用
data-jjo-range 之类的属性名称。jJo 库还可以提供一个 API,用于设置要使用的
前缀(例如 J.setDataPrefix('j2'),使属性采用
data-j2-range 之类的名称)。
element.dataset
所有当前引擎均支持。
所有当前引擎均支持。
返回一个表示元素的 data-*
属性的 DOMStringMap
对象。
带连字符的名称会转换为驼峰式。例如,data-foo-bar=""
会变成 element.dataset.fooBar。
dataset IDL
属性为访问元素上的所有 data-*
属性提供了便捷的访问器。在获取时,dataset
IDL 属性
必须返回一个其关联元素为此元素的 DOMStringMap。
DOMStringMap
接口用于 dataset
属性。每个 DOMStringMap
都有一个关联元素。
[Exposed =Window ,
LegacyOverrideBuiltIns ]
interface DOMStringMap {
getter DOMString (DOMString name );
[CEReactions ] setter undefined (DOMString name , DOMString value );
[CEReactions ] deleter undefined (DOMString name );
};要获取 DOMStringMap 的名称-值
对,请运行以下算法:
令 list 为一个空的名称-值对列表。
按照属性在元素的属性
列表中列出的顺序,对 DOMStringMap
的关联
元素上的每个内容属性,如果其前五个字符是字符串“data-”,并且其余字符
(如果有)不包含任何ASCII 大写字母,则向
list 添加一个名称-值对,其名称是移除该属性名称的前五个字符后的结果,
其值为该属性的值。
对于 list 中的每个名称,对于该名称中后跟ASCII 小写字母的每个 U+002D 连字符-减号字符(-),移除该 U+002D 连字符-减号字符 (-),并将其后的字符替换为转换为 ASCII 大写形式的相同字符。
返回 list。
任意时刻,DOMStringMap
对象上的支持的属性名称,是该时刻通过获取
DOMStringMap 的名称-值对所返回的每个名称-值对的名称,并按返回顺序排列。
要为一个 DOMStringMap
确定具名属性的值
name,返回由获取
DOMStringMap 的名称-值
对所返回的列表中,名称分量为 name 的名称-值对的值分量。
给定属性名称 name 和新值 value,要为一个 DOMStringMap
设置新具名属性的值,或
设置现有具名属性的值,
请运行以下步骤:
如果 name 包含一个后跟ASCII
小写字母的 U+002D 连字符-减号字符(-),则抛出一个“SyntaxError”
DOMException。
对于 name 中的每个ASCII 大写字母,在该字符之前插入一个 U+002D 连字符-减号字符(-),并将该字符替换为转换为 ASCII 小写形式的相同字符。
在 name 的开头插入字符串 data-。
如果 name 不是一个有效属性局部名称,则抛出一个
“InvalidCharacterError” DOMException。
使用 name 和 value,为 DOMStringMap
的关联
元素设置属性值。
要为一个 DOMStringMap
删除现有具名属性
name,请运行以下步骤:
对于 name 中的每个ASCII 大写字母,在该字符之前插入一个 U+002D 连字符-减号字符(-),并将该字符替换为转换为 ASCII 小写形式的相同字符。
在 name 的开头插入字符串 data-。
给定 name 和 DOMStringMap
的关联
元素,按名称移除属性。
对于此前用于获取
DOMStringMap 的名称-值对的算法所给出的名称,Web IDL 才会调用此算法。
[WEBIDL]
如果网页希望一个元素表示一艘太空飞船,例如作为游戏的一部分,则必须将 class
属性与 data-*
属性结合使用:
< div class = "spaceship" data-ship-id = "92432"
data-weapons = "laser 2" data-shields = "50%"
data- x = "30" data-y = "10" data-z = "90" >
< button class = "fire"
onclick = "spaceships[this.parentNode.dataset.shipId].fire()" >
Fire
</ button >
</ div > 请注意,带连字符的属性名称在 API 中会变为驼峰式。
给定以下片段和具有类似结构的元素:
< img class = "tower" id = "tower5" data- x = "12" data-y = "5"
data-ai = "robotarget" data-hp = "46" data-ability = "flames"
src = "towers/rocket.png" alt = "Rocket Tower" > ……可以设想有一个接受若干参数的函数 splashDamage(),其中第一个
参数是要处理的元素:
function splashDamage( node, x, y, damage) {
if ( node. classList. contains( 'tower' ) && // checking the 'class' attribute
node. dataset. x == x && // reading the 'data-x' attribute
node. dataset. y == y) { // reading the 'data-y' attribute
var hp = parseInt( node. dataset. hp); // reading the 'data-hp' attribute
hp = hp - damage;
if ( hp < 0 ) {
hp = 0 ;
node. dataset. ai = 'dead' ; // setting the 'data-ai' attribute
delete node. dataset. ability; // removing the 'data-ability' attribute
}
node. dataset. hp = hp; // setting the 'data-hp' attribute
}
} innerText 和 outerText 属性所有当前引擎均支持。
element.innerText [ = value ]
返回元素“按渲染结果”的文本内容。
可以设置,以给定值替换元素的子级,但会将换行符
转换为 br
元素。
element.outerText [ = value ]
返回元素“按渲染结果”的文本内容。
可以设置,以给定值替换该元素,但会将换行符转换为
br 元素。
给定一个 HTMLElement element,获取文本步骤为:
如果 element 未正在渲染,或者用户代理是非 CSS 用户代理,则返回 element 的后代文本内容。
此步骤可能产生令人意外的结果,因为在未正在
渲染的元素上调用 innerText 获取器时,
会返回其文本内容;但在正在渲染的元素上访问时,
其所有未正在
渲染的子级的文本内容都会被忽略。
令 results 为一个新的空列表。
对于 element 的每个子节点 node:
令 current 为使用 node 运行已渲染 文本收集步骤所得的列表。results 中的每一项 都是一个字符串或一个正整数(所需换行数)。
直观而言,所需换行数项意味着在该位置会出现一定数量的 换行符,但它们可以与相邻所需换行数项所引入的换行符 折叠,这类似于 CSS 外边距折叠。
对于 current 中的每一项 item,将 item 追加到 results。
从 results 中移除所有为空字符串的项。
移除 results 开头或结尾的任何连续所需换行 数项序列。
将每个剩余的连续所需换行 数项序列替换为一个字符串,其中包含的 U+000A LF 码位数量 等于这些所需换行数项中值的最大值。
返回 results 中各字符串项的串联结果。
所有当前引擎均支持。
给定一个节点 node,已渲染文本收集步骤如下:
令 items 为以下结果:按照树顺序, 对 node 的每个子节点运行已渲染文本收集 步骤,然后将各结果串联成单个列表。
如果 node 的 'visibility' 的计算 值不是 'visible',则返回 items。
如果 node 未正在 渲染,则返回 items。就此步骤而言,如果 'display' 属性的计算 值不是 'none',则以下元素必须按所述方式运行:
由于 'display:contents',items 可以为非空。
如果 node 是一个 Text
节点,则对于 node 产生的每个 CSS 文本盒,按照内容顺序,
计算应用 CSS 'white-space' 处理规则和 'text-transform' 规则后的盒文本,将
items 设置为所得字符串组成的列表,然后返回 items。
CSS 'white-space' 处理规则略有修改:行末的可折叠空格
始终会被折叠,但只有当该行是块中的最后一行,或者该行以 br 元素结尾时,
才会移除这些空格。应保留软连字符。
[CSSTEXT]
如果 node 的 'display' 的计算 值为 'table-cell',并且 node 的CSS 盒不是其所包含的 'table-row' 盒中的最后一个 'table-cell' 盒,则向 items 追加一个包含 单个 U+0009 TAB 码位的字符串。
如果 node 的 'display' 的计算 值为 'table-row',并且 node 的CSS 盒不是最近祖先 'table' 盒中的最后一个 'table-row' 盒,则向 items 追加一个包含 单个 U+000A LF 码位的字符串。
如果 node 的 'display' 的使用值为 块级或 'table-caption',则在 items 的开头和结尾追加 1(一个所需换行数)。 [CSSDISPLAY]
浮动元素和绝对定位元素属于此类别。
返回 items。
请注意,严格来说,大多数替换元素(例如 textarea、
input 和 video——但不包括
button)的后代节点
不由 CSS 渲染,因此就此算法而言,它们没有CSS 盒。
此算法适合推广为作用于范围。这样,我们就可以将其用作 Selection
字符串转换器的基础,并且可能直接在范围上公开它。请参阅
Bugzilla 错误 10583。
给定一个 HTMLElement element 和一个字符串 value,设置内部文本步骤为:
outerText 设置器
步骤为:
如果 this 的父级为 null,则抛出一个
“NoModificationAllowedError” DOMException。
如果 fragment 没有子级,则向
fragment 追加一个新的
Text
节点,其数据为空
字符串,其节点文档
为
this 的节点文档。
如果 next 不为 null,并且 next 的上一个同胞是一个
Text
节点,则给定 next 的上一个同胞,执行与下一个文本节点合并。
如果 previous 是一个 Text
节点,则给定 previous,执行与下一个文本
节点合并。
给定一个 Document
document,字符串 input 的已渲染文本片段是运行以下步骤的结果:
令 fragment 为在给定 document 的情况下,创建 文档片段的结果。
令 position 为 input 的一个位置 变量, 最初指向 input 的开头。
令 text 为空字符串。
当 position 尚未越过 input 的末尾时:
在给定 position 的情况下,从 input 中收集一系列不是 U+000A LF 或 U+000D CR 的码点,并将 text 设置为结果。
如果 text 不是空字符串,则将一个新的 Text
节点追加
到 fragment,该节点的数据为
text,且其节点
文档为
document。
当 position 尚未越过 input 的末尾,并且 position 处的码点是 U+000A LF 或 U+000D CR 时:
返回 fragment。
给定一个 Text
节点 node,要与下一个文本节点合并:
文本
内容,即其内容中具有
Text
节点的HTML
元素中的文本,以及允许自由格式文本的HTML
元素属性中的文本,可以包含 U+202A 至 U+202E
和 U+2066 至 U+2069 范围内的字符(双向算法格式化字符)。[BIDI]
鼓励作者使用 dir
属性、
bdo
元素和 bdi
元素,而不是手动维护
双向算法格式化字符。双向算法格式化
字符与 CSS 的交互效果不佳。
用户代理必须实现 Unicode 双向算法,以便在渲染文档及文档的各个部分时确定字符的正确顺序。 [BIDI]
必须以三种方式之一完成 HTML 到 Unicode 双向算法的映射。 用户代理必须实现 CSS,尤其包括 CSS 'unicode-bidi'、'direction' 和 'content' 属性,并且 必须在其用户代理样式表中包含本规范渲染一节中给出的、使用这些属性的规则;或者, 用户代理必须表现得如同仅实现了上述属性,并具有一个包含所有上述规则的用户代理样式表, 但不允许文档中指定的样式表覆盖这些规则;或者,用户代理必须实现另一种具有 等效语义的样式语言。[CSSGC]
以下元素和属性具有由渲染一节定义的要求;根据本节中的要求, 这些要求适用于所有用户代理(而不仅仅是那些支持建议的 默认渲染的用户代理):
在HTML 元素上实现无障碍 API 语义的用户代理要求在 HTML 无障碍 API 映射中定义。除其中的 规则外,对于一个自定义元素 element, 默认 ARIA 角色语义 按如下方式确定:[HTMLAAM]
类似地,对于一个自定义元素 element, 名为 stateOrProperty 的状态或属性的默认 ARIA 状态和 属性语义按如下方式确定:
如果 element 的已附加内部对象 不为 null:
如果 element 的已附加 内部对象的获取 stateOrProperty 关联元素存在, 则返回运行它的结果。
如果 element 的已附加 内部对象的获取 stateOrProperty 关联元素列表存在, 则返回运行它的结果。
返回 stateOrProperty 的默认值。
此处所指的“默认语义”在 ARIA 中有时也称为“原生”、 “隐式”或“宿主语言”语义。[ARIA]
这些定义的一个含义是,默认语义可以随时间而变化。
这使自定义元素具有与内置元素相同的表达能力;例如,可以比较
a
元素的默认 ARIA 角色语义如何随着 href
属性的添加或移除而变化。
有关其实际运作的示例,请参阅自定义元素 一节。
用于检查HTML 元素上 ARIA role 和 aria-* 属性用法的一致性检查器要求,在 HTML 中的 ARIA 中定义。
[ARIAHTML]
html
元素所有当前引擎均支持。
所有当前引擎均支持。
head 元素,后跟一个
body 元素。
html 元素内的第一项不是注释,则可以省略
html 元素的开始标签。
html 元素后面没有
紧跟注释,则可以省略
html 元素的结束标签。
[Exposed =Window ]
interface HTMLHtmlElement : HTMLElement {
[HTMLConstructor ] constructor ();
// also has obsolete members
};鼓励作者在根
html 元素上指定 lang
属性,以给出文档的语言。这有助于语音合成工具
确定应使用何种发音,帮助翻译工具确定应使用何种规则,等等。
以下示例中的 html 元素
声明文档的语言
为英语。
<!DOCTYPE html>
< html lang = "en" >
< head >
< title > Swapping Songs</ title >
</ head >
< body >
< h1 > Swapping Songs</ h1 >
< p > Tonight I swapped some of the songs I wrote with some friends, who
gave me some of the songs they wrote. I love sharing my music.</ p >
</ body >
</ html > head
元素所有当前引擎均支持。
所有当前引擎均支持。
html 元素中的第一个元素。iframe srcdoc 文档,或者可以从更高级别协议获得标题信息:
零个或多个元数据
内容元素,其中至多一个是 title
元素,至多一个是
base 元素。
title 元素,至多一个是
base 元素。
head 元素内的第一项是一个
元素,则可以省略 head
元素的开始标签。head 元素后面没有
紧跟ASCII 空白
或
注释,则可以省略 head 元素的结束标签。
[Exposed =Window ]
interface HTMLHeadElement : HTMLElement {
[HTMLConstructor ] constructor ();
};head 元素中的元数据集合可以很大,
也可以很小。以下是一个
非常简短的示例:
<!doctype html>
< html lang = en >
< head >
< title > A document with a short head</ title >
</ head >
< body >
...以下是一个较长的示例:
<!DOCTYPE HTML>
< HTML LANG = "EN" >
< HEAD >
< META CHARSET = "UTF-8" >
< BASE HREF = "https://www.example.com/" >
< TITLE > An application with a long head</ TITLE >
< LINK REL = "STYLESHEET" HREF = "default.css" >
< LINK REL = "STYLESHEET ALTERNATE" HREF = "big.css" TITLE = "Big Text" >
< SCRIPT SRC = "support.js" ></ SCRIPT >
< META NAME = "APPLICATION-NAME" CONTENT = "Long headed application" >
</ HEAD >
< BODY >
...title
元素在大多数情况下是必需的子级,但当
更高级别协议提供标题信息时,例如当 HTML 用作电子邮件创作格式时由电子邮件主题行
提供标题信息,则可以省略 title 元素。
title
元素所有当前引擎均支持。
所有当前引擎均支持。
title
元素的 head 元素中。[Exposed =Window ]
interface HTMLTitleElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions ] attribute DOMString text ;
};title 元素表示文档的标题或名称。作者
应使用即使在脱离上下文时也能识别其文档的标题,例如在用户的历史记录或书签中,
或在搜索结果中。文档标题通常
不同于其第一个标题,因为第一个标题在脱离上下文时不必能够独立表达含义。
每个文档中不得有超过一个 title 元素。
如果 Document 没有标题是合理的,则
可能不需要 title
元素。有关何时需要该元素的说明,
请参阅 head
元素的内容
模型。
title.text [ = value ]
返回元素的子级文本 内容。
可以设置,以给定值替换元素的子级。
以下是一些合适标题的示例,并与同一页面中可能使用的顶级标题进行对比。
< title > Introduction to The Mating Rituals of Bees</ title >
...
< h1 > Introduction</ h1 >
< p > This companion guide to the highly successful
< cite > Introduction to Medieval Bee-Keeping</ cite > book is...下一个页面可能是同一网站的一部分。请注意,标题如何明确无歧义地描述主题, 而第一个标题则假定读者知道上下文,因此 不会疑惑其中的舞蹈是萨尔萨舞还是华尔兹:
< title > Dances used during bee mating rituals</ title >
...
< h1 > The Dances</ h1 > 用作文档标题的字符串由 document.title IDL
属性给出。
用户代理在其用户界面中引用文档时应使用文档标题。当 title 元素的内容以这种
方式使用时,应使用该 title 元素的方向性来设置用户界面中
文档标题的方向性。
base
元素所有当前引擎均支持。
所有当前引擎均支持。
base 元素的 head 元素中。href — 文档基准 URL
target — 用于超链接导航和表单提交的默认可导航对象
[Exposed =Window ]
interface HTMLBaseElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , ReflectSetter ] attribute USVString href ;
[CEReactions , Reflect ] attribute DOMString target ;
};base 元素允许
作者指定用于解析 URL
的文档基准 URL,以及用于跟随超链接的默认
可导航对象的名称。该元素不
表示这些信息之外的任何内容。
每个文档中不得有超过一个 base 元素。
base 元素必须具有
href
属性、target 属性,
或同时具有二者。
如果指定了 href 内容
属性,则其必须包含一个可能被空格包围的有效 URL。
如果 base 元素具有
href 属性,
则它必须位于树中所有具有被定义为接受 URL 的属性的其他元素之前。
如果存在多个具有 href 属性的
base 元素,则除第一个之外
其余均会被忽略。
如果指定了 target
属性,
则其必须包含一个有效的可导航对象目标名称或关键字,该名称或关键字指定
当 Document 中的超链接和表单导致导航时,应默认使用哪个可导航对象。
如果 base 元素具有
target
属性,则它必须位于树中所有表示超链接的元素之前。
如果存在多个具有 target
属性的 base 元素,则除第一个之外
其余均会被忽略。
在文档树中,第一个具有 href 内容属性的 base 元素,也就是第一个 base 元素,具有一个
冻结的基准 URL。每当发生以下任一
情况时,都必须为元素立即设置冻结的基准 URL:
要为元素 element 设置冻结的基准 URL:
令 document 为 element 的节点文档。
令 urlRecord 为以下结果:使用
document 的回退基准
URL和 document 的字符编码,对
element 的 href
内容属性值进行解析。(因此,base
元素不会受到自身影响。)
如果以下任一项为 true:
urlRecord 为失败;
urlRecord 的方案为
“data”或“javascript”;或者
对 urlRecord 和
document 运行Document 是否允许该基准?返回“Blocked”,
将 element 的冻结的基准 URL设置为 urlRecord。
给定 document,响应基准 URL 更改。
href IDL
属性在获取时必须返回运行以下算法的结果:
<!DOCTYPE html>
< html lang = "en" >
< head >
< title > This is an example for the < base> element</ title >
< base href = "https://www.example.com/news/index.html" >
</ head >
< body >
< p > Visit the < a href = "archives.html" > archives</ a > .</ p >
</ body >
</ html > 上述示例中的链接将指向“https://www.example.com/news/archives.html”。
link
元素所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
head 元素子级的
noscript
元素中。
href — 超链接的地址
crossorigin —
元素处理跨源请求的方式
rel — 包含超链接的文档与目标资源之间的关系
media — 适用的媒体
integrity —
子资源完整性检查中使用的完整性元数据 [SRI]
hreflang —
所链接资源的语言
type — 所引用资源类型的提示
referrerpolicy —
元素发起的获取所使用的来源策略
sizes — 图标的尺寸
(用于 rel="icon")
imagesrcset —
在不同情况下使用的图像,例如高分辨率显示器、小型显示器等(用于 rel="preload")
imagesizes —
不同页面布局下的图像尺寸(用于 rel="preload")
as — 预加载请求的目标
(用于 rel="preload" 和 rel="modulepreload")
blocking — 元素是否可能阻塞渲染
color —
自定义网站图标时使用的颜色(用于 rel="mask-icon")
disabled —
链接是否被禁用
fetchpriority
— 设置元素发起的获取的优先级
title 属性在此元素上具有特殊语义:链接的标题;CSS
样式表集名称
[Exposed =Window ]
interface HTMLLinkElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , ReflectURL ] attribute USVString href ;
[CEReactions ] attribute DOMString ? crossOrigin ;
[CEReactions , Reflect ] attribute DOMString rel ;
[CEReactions ] attribute DOMString as ;
[SameObject , PutForwards =value , Reflect="rel"] readonly attribute DOMTokenList relList ;
[CEReactions , Reflect ] attribute DOMString media ;
[CEReactions , Reflect ] attribute DOMString integrity ;
[CEReactions , Reflect ] attribute DOMString hreflang ;
[CEReactions , Reflect ] attribute DOMString type ;
[SameObject , PutForwards =value , Reflect ] readonly attribute DOMTokenList sizes ;
[CEReactions , Reflect ] attribute USVString imageSrcset ;
[CEReactions , Reflect ] attribute DOMString imageSizes ;
[CEReactions ] attribute DOMString referrerPolicy ;
[SameObject , PutForwards =value , Reflect ] readonly attribute DOMTokenList blocking ;
[CEReactions , Reflect ] attribute boolean disabled ;
[CEReactions ] attribute DOMString fetchPriority ;
// also has obsolete members
};
HTMLLinkElement includes LinkStyle ;link 元素允许作者
将其文档链接到其他资源。
链接的地址由 href 属性给出。如果存在
href 属性,则其
值必须是一个可能被空格包围的有效
非空 URL。href 或 imagesrcset
属性中必须至少存在一个,也可以二者均存在。
如果 href 和 imagesrcset 属性
均不存在,则该元素不
定义链接。
所指示的链接类型(关系)由 rel
属性的值给出;如果存在,
其值必须是一个由唯一且以空格分隔的词元组成的无序集合。
允许的关键字及其含义在后文一节中定义。如果
rel 属性不存在、不包含
关键字,或者所使用的关键字均不符合本规范定义的允许条件,则该
元素不会创建任何链接。
rel 的支持的词元是在
HTML 链接类型中定义、允许用于 link 元素、
会影响处理模型并受用户代理支持的关键字。可能的支持的词元为
alternate、
dns-prefetch、
expect、
icon、
manifest、
modulepreload、
next、
pingback、
preconnect、
prefetch、
preload、
search 和
stylesheet。
rel 的支持的
词元必须仅包括此列表中用户代理已实现其处理模型的词元。
理论上,如果用户代理是会执行 JavaScript 的搜索引擎,它可以支持 canonical 关键字的
处理模型。但在实践中,这种情况极不可能。因此在大多数情况下,不应将 canonical 包含在
rel 的支持的
词元中。
link 元素必须具有
rel
属性或 itemprop
属性之一,但不能同时具有二者。
如果使用 rel 属性,
该元素只有在某些情况下
才能用于页面的 body 中。与
itemprop
属性一起使用时,在遵守
微数据模型约束的前提下,该元素既可以用于
head 元素,也可以用于页面的
body 中。
可以使用 link 元素创建两类链接:外部资源链接和超链接。链接类型
一节定义了特定链接类型是外部资源链接还是超链接。一个 link
元素可以创建多个链接(其中一些可能是外部资源链接,另一些可能是超链接);具体创建哪些链接以及创建多少链接,取决于 rel
属性中给出的关键字。用户代理必须逐个链接进行处理,而不是逐个元素进行处理。
为 link
元素创建的每个链接都会被
分别处理。例如,如果有两个
link 元素具有
rel="stylesheet",
则它们各自算作一个单独的外部资源,并且分别独立地受到自身属性的影响。类似地,如果单个 link 元素具有值为
next stylesheet 的 rel
属性,
则它会同时创建一个超链接(针对 next 关键字)和
一个外部资源链接(针对
stylesheet
关键字),并且它们会以不同方式受到其他属性(例如 media 或
title)的影响。
< link rel = "author license" href = "/about" > 此元素创建的两个链接中,一个的语义是目标页面包含有关当前页面作者的信息, 另一个的语义是目标页面包含有关当前页面所采用许可证的信息。
使用 link 元素及其
rel 属性创建的超链接适用于整个
文档。这与 a 和 area
元素的 rel 属性形成对比;后者所指示的
链接类型,其上下文由链接在文档中的位置给出。
与 a 和 area 元素创建的链接不同,
在支持建议的默认渲染的用户代理中,由 link 元素创建的超链接默认不会作为
文档的一部分显示。即使使用 CSS 强制显示它们,它们也没有激活行为。相反,它们主要提供语义
信息,页面或使用页面内容的其他软件可能会使用这些信息。此外,用户
代理可以提供
自身的用户界面以跟随此类超链接。
外部资源链接的确切行为 取决于确切的关系,如相关链接类型中所定义。
crossorigin
属性是一个CORS 设置
属性。它旨在与外部资源链接一起使用。
media 属性
指明资源适用于哪些媒体。其值必须是一个有效媒体查询
列表。
所有当前引擎均支持。
integrity
属性表示此元素所负责请求的完整性
元数据。其值为文本。该属性只能指定在具有一个包含 stylesheet、preload 或 modulepreload
关键字的 rel 属性的 link 元素上。[SRI]
link 元素上的
hreflang
属性,与 a 元素上的
hreflang 属性具有相同语义。
type 属性
给出所链接资源的 MIME 类型。它仅作为提示。其值必须是
一个有效的 MIME 类型字符串。
对于外部资源链接,
type 属性用作
给用户代理的提示,使其可以避免获取不支持的资源。
referrerpolicy 属性是一个来源策略
属性。它旨在与外部
资源链接一起使用,在获取并处理所链接资源时,有助于设置所使用的来源
策略。
[REFERRERPOLICY]
title 属性
给出链接的标题。除一种例外情况外,它仅作为提示。其值为文本。该例外适用于位于文档
树中的样式表链接;对于这类链接,title
属性定义 CSS
样式表集。
link
元素上的 title
属性与大多数其他
元素的全局 title
属性不同:没有标题的链接不会继承父元素的标题;它仅仅没有标题。
可以存在 imagesrcset
属性,它是一个 srcset
属性。
imagesrcset 和
href 属性(如果未使用宽度
描述符)共同为源集贡献图像
源。
如果存在 imagesrcset
属性,并且其中有任何使用宽度
描述符的图像候选字符串,则还必须存在 imagesizes 属性,并且它是一个
sizes 属性。imagesizes 属性
为源集贡献源尺寸。
imagesrcset 和
imagesizes 属性
只能指定在同时具有一个指定 preload
关键字的 rel 属性,以及
一个处于“image”状态的 as 属性的
link 元素上。
这些属性允许预加载适当的资源,该资源随后会由一个其 srcset 和 sizes
属性具有相应值的 img 元素使用:
< link rel = "preload" as = "image"
imagesrcset = "wolf_400px.jpg 400w, wolf_800px.jpg 800w, wolf_1600px.jpg 1600w"
imagesizes = "50vw" >
<!-- ... later, or perhaps inserted dynamically ... -->
< img src = "wolf.jpg" alt = "A rad wolf"
srcset = "wolf_400px.jpg 400w, wolf_800px.jpg 800w, wolf_1600px.jpg 1600w"
sizes = "50vw" > 请注意,我们省略了 href
属性,因为它仅与不支持 imagesrcset 的浏览器
有关,并且在这些情况下,它很可能会导致预加载错误的图像。
imagesrcset
属性可以与
media 属性结合使用,以便为艺术指导预加载从 picture
元素的源中选择的适当资源:
< link rel = "preload" as = "image"
imagesrcset = "dog-cropped-1x.jpg, dog-cropped-2x.jpg 2x"
media = "(max-width: 800px)" >
< link rel = "preload" as = "image"
imagesrcset = "dog-wide-1x.jpg, dog-wide-2x.jpg 2x"
media = "(min-width: 801px)" >
<!-- ... later, or perhaps inserted dynamically ... -->
< picture >
< source srcset = "dog-cropped-1x.jpg, dog-cropped-2x.jpg 2x"
media = "(max-width: 800px)" >
< img src = "dog-wide-1x.jpg" srcset = "dog-wide-2x.jpg 2x"
alt = "An awesome dog" >
</ picture > sizes 属性
给出视觉媒体中图标的尺寸。其值(如果存在)仅作为提示。如果有多个图标
可用,用户代理可以使用该值决定使用哪些图标。如果指定了该属性,其值必须是一个由
唯一且以空格分隔的词元组成的无序集合,并且这些词元采用ASCII
不区分大小写的方式。每个值
必须是与字符串“any”以ASCII
不区分大小写方式匹配的值,或者由两个有效非负
整数组成的值;这两个整数不得具有前导 U+0030 数字
零(0)字符,并且必须由单个 U+0078 拉丁小写字母 X 或 U+0058 拉丁
大写字母 X 字符分隔。该属性只能指定在具有一个指定 icon 关键字或
apple-touch-icon 关键字的 rel 属性的 link 元素上。
apple-touch-icon 关键字是预定义链接类型集合的一个已注册扩展,但不要求用户
代理以任何方式支持它。
as 属性
为由 href
属性给出的资源的预加载请求,指定预加载目标或模块预加载
目标。
它是一个枚举
属性。预加载目标与模块预加载目标并集中的每一项都是此
属性的关键字,并映射到同名状态。该属性必须指定在具有一个包含
preload
关键字的 rel 属性的
link 元素上;
在这种情况下,其值必须是一个预加载目标。该属性可以指定在具有一个包含
modulepreload
关键字的 rel 属性的 link
元素上;在这种情况下,其值必须是一个模块预加载
目标。对于其他 link 元素,不得
指定该属性。
as
属性的使用方式处理模型,在各链接类型的获取并处理所链接资源
算法中给出。
该属性没有缺失值
默认值或无效值
默认值,这意味着该属性的无效值
或缺失值不会映射到任何状态。处理模型已对此作出规定。对于 preload 链接,
这两种情况都是错误;对于
modulepreload
链接,缺失值会被视为
“script”。
blocking
属性是一个阻塞属性。链接类型
stylesheet 和 expect 会使用该属性,并且
该属性只能指定在具有一个包含这些关键字的 rel 属性的 link
元素上。
color 属性
与
mask-icon 链接类型一起使用。该属性只能指定在具有一个包含
mask-icon 关键字的 rel 属性的
link 元素上。
其值必须是一个与 CSS <color> 产生式匹配的字符串,用于定义一种建议颜色,用户代理可以使用该颜色
自定义用户固定你的网站时所看到的图标显示。
本规范没有为 color
属性规定任何用户代理要求。
mask-icon 关键字是预定义链接类型集合的一个已注册扩展,但不要求用户
代理以任何方式支持它。
link 元素有一个关联的
显式启用布尔值。其
初始值为 false。
disabled
属性是一个与 stylesheet
链接类型一起
使用的布尔属性。该
属性只能指定在具有一个包含 stylesheet 关键字的
rel 属性的
link 元素上。
动态移除 disabled
属性,例如使用
document.querySelector("link").removeAttribute("disabled"),将
获取并应用该样式表:
< link disabled rel = "alternate stylesheet" href = "css/pooh" > fetchpriority
属性是一个获取
优先级属性,旨在与外部资源链接一起使用;在获取并处理所链接
资源时,它用于设置所使用的优先级。
color 属性没有反映它的 IDL
属性,
但以后可能会添加。
所有当前引擎均支持。
crossOrigin IDL 属性必须反映
crossorigin
内容属性,并仅限于
已知值。
HTMLLinkElement/referrerPolicy
所有当前引擎均支持。
referrerPolicy IDL 属性必须
反映 referrerpolicy
内容
属性,并仅限于
已知值。
fetchPriority IDL 属性必须
反映 fetchpriority
内容
属性,并仅限于
已知值。
relList
属性可用于
特性检测,方法是调用其 supports()
方法,检查支持哪些链接类型。
media 属性如果链接是一个超链接,则 media
属性仅作为提示,用于描述相关文档是为哪些媒体设计的。
但是,如果链接是一个外部资源链接,则
media 属性
具有规定性。当 media 属性的
值
与环境
匹配,并且其他相关条件适用时,用户代理必须应用该
外部资源;否则不得应用。
如果省略 media 属性,
则默认值为“all”,这意味着链接默认适用于所有媒体。
外部资源内部可能定义了进一步限制,以限制其
适用范围。例如,CSS 样式表可能包含一些 @media
块。本规范不会覆盖此类进一步限制或要求。
type 属性如果存在 type
属性,则用户代理必须
假定资源属于给定类型(即使该值不是有效的 MIME 类型
字符串,例如空字符串)。如果省略该属性,但该外部
资源链接类型定义了默认类型,则用户代理必须假定
资源属于该类型。如果用户代理不支持给定链接关系所指定的MIME 类型,则用户代理不应获取并处理所链接
资源;如果用户代理支持给定链接关系所指定的MIME 类型,则用户代理应按照该外部资源链接的特定类型所规定的方式,在
适当时间获取并处理所链接
资源。
如果省略该属性,并且该外部资源链接类型没有定义
默认类型,但如果类型已知且受支持,用户代理原本会获取并处理所链接
资源,则用户代理应在假定该资源将受支持的情况下获取并处理所链接
资源。
用户代理不得将 type 属性
视为权威信息——获取资源后,用户代理不得使用 type 属性
确定资源的实际类型。只有实际类型
(如下一段所定义)用于确定是否应用资源,
而不是上述假定类型。
如果外部资源链接类型定义了 处理资源的Content-Type 元数据的规则,则应用这些 规则。否则,如果预期资源是图像,用户代理可以应用 图像嗅探规则,其中 official type 为根据资源的Content-Type 元数据确定的类型,并将所得的资源的计算 类型视为实际类型。否则,如果这些条件均不适用,或者 用户代理选择不应用图像嗅探规则,则用户代理必须使用 资源的Content-Type 元数据来 确定资源的类型。如果没有类型元数据,但该外部资源链接类型定义了 默认类型,则用户代理必须假定资源属于该类型。
stylesheet 链接
类型定义了处理资源的Content-Type
元数据的规则。
用户代理确定资源类型后,如果该资源属于受支持的类型且其他相关条件适用, 则必须应用该资源;否则必须忽略该资源。
如果文档包含如下标记的样式表链接:
< link rel = "stylesheet" href = "A" type = "text/plain" >
< link rel = "stylesheet" href = "B" type = "text/css" >
< link rel = "stylesheet" href = "C" > ……那么,仅支持 CSS 样式表的符合规范的用户代理会获取 B 和 C 文件,并
跳过 A 文件(因为 text/plain
不是 CSS 样式表的 MIME 类型)。
对于 B 和 C 文件,用户代理随后会检查服务器返回的实际类型。对于以
text/css 发送的文件,它会
应用样式;但对于标记为
text/plain
或任何其他类型的文件,则不会应用。
如果这两个文件之一在返回时没有 Content-Type
元数据,或者具有
类似 Content-Type: "null" 这样的语法错误类型,则会使用
stylesheet
链接的默认类型。由于该
默认类型是 text/css,
因此该样式表仍然会被应用。
link
元素获取并处理资源所有外部资源
链接都有一个获取并处理所链接资源
算法,该算法接受一个
link
元素 el。它们还有所链接资源获取设置
步骤,这些步骤接受一个 link
元素 el 和一个请求 request。各个链接类型可以提供
自身的获取并
处理所链接资源算法,但除非明确
说明,否则它们使用默认
获取并处理所链接资源算法。
类似地,各个链接类型可以提供自身的所链接资源
获取设置
步骤,但除非明确说明,否则这些步骤仅返回 true。
给定一个 link
元素
el,默认获取并处理所链接资源的步骤如下:
令 options 为从 el 创建链接 选项的结果。
令 request 为给定 options 创建 链接请求的结果。
如果 request 为 null,则返回。
设置 request 的同步 标志。
给定 el 和 request,运行所链接 资源获取设置步骤。如果结果为 false,则返回。
如果 el 的 rel
属性包含关键字 stylesheet,
则将 request 的发起者
类型设置为“css”;否则设置为“link”。
获取 request,并将 processResponseConsumeBody 设置 为以下步骤;这些步骤接受一个响应 response,以及 null、失败或 一个字节序列 bodyBytes:
给定一个链接处理选项 options,要创建链接请求:
令 url 为以下结果:给定 options 的href,相对于 options 的基准 URL编码解析 URL。
传递基准 URL 而不是文档或环境的问题由 议题 #9715跟踪。
如果 url 为失败,则返回 null。
令 request 为以下结果:给定 url、options 的 目标和 options 的crossorigin,创建 潜在 CORS 请求。
将 request 的加密 nonce 元数据设置为 options 的加密 nonce 元数据。
返回 request。
用户代理可以选择仅在需要此类资源时才尝试获取 并处理它们,而不是主动获取所有未被应用的 外部资源。
与获取并
处理所链接资源算法类似,所有外部资源链接
都有一个处理所链接
资源算法,该算法接受一个 link
元素 el、一个布尔值
success、一个响应 response,以及一个
字节序列
bodyBytes。各个链接类型可以提供自身的
处理所链接
资源算法,但除非明确说明,否则该算法
不执行任何操作。
除非为给定的 rel
关键字另有规定,否则该
元素必须延迟加载事件,直到该
元素的节点文档中
所有获取并
处理所链接资源及其关键
子资源的尝试完成为止。(用户代理尚未尝试获取
和处理的资源,例如因为它正在等待需要该资源时才获取,不会延迟
加载事件。)
Link`
标头所有可以作为外部资源
链接的链接类型都定义了一个处理链接标头算法,该算法接受一个链接
处理选项。该算法定义了这些链接类型在 HTTP `Link`
响应标头中出现时,是否以及如何作出反应。
对于大多数链接类型,此算法不执行任何操作。汇总 表是快速了解某个链接 类型是否定义了处理链接 标头步骤的良好参考。
link”)DocumentDocument 的算法自动)
一个链接 处理选项具有基准 URL和href, 而不是已解析的 URL,因为该 URL 可能是选项的源集所得的结果。
给定一个 link 元素
el,要从元素创建链接选项:
令 document 为 el 的节点文档。
令 options 为一个新的链接处理选项,其各项如下:
crossorigin
内容属性的状态referrerpolicy
内容属性的状态fetchpriority
内容属性的状态如果 el 具有 integrity
属性,
则将 options 的integrity 设置为
el 的 integrity
内容
属性的值。
断言:options 的 href不是 空字符串,或者 options 的源 集不为 null。
既没有 href 也没有
imagesrcset
的 link 元素
不表示链接。
返回 options。
给定一个标头 列表 headers,要从标头中提取链接:
给定一个 Document doc、
一个响应 response,以及一个
“pre-media”或“media”phase,要处理链接标头:
对于 links 中的每个 linkObject:
令 rel 为 linkObject["relation_type"]。
令 attribs 为 linkObject["target_attributes"]。
如果 attribs 中存在“srcset”、
“imagesrcset”
或“media”中的任一项,则令
expectedPhase 为“media”;否则为“pre-media”。
如果 expectedPhase 不等于 phase,则 继续。
令 options 为一个新的链接处理选项,其各项如下:
给定 attribs 和 rel,对 options 应用来自 已解析标头属性的链接选项。如果该操作返回 false,则返回。
如果 attribs["imagesrcset"]
存在,并且 attribs["imagesizes"]
存在,
则将 options 的源集设置为以下结果:给定
linkObject["target_uri"]、attribs["imagesrcset"]、
attribs["imagesizes"]
和 null,创建
源集。
给定 options,运行 rel 的处理 链接标头步骤。
给定 attribs 和一个字符串 rel,要对一个链接处理 选项 options 应用来自已解析标头 属性的链接选项:
如果 rel 是“preload”:
如果 attribs["crossorigin"]
存在,并且以ASCII
不区分大小写的方式匹配某个
CORS 设置
属性的关键字,
则将 options 的crossorigin设置为与该关键字对应的
CORS 设置
属性状态。
如果 attribs["integrity"] 存在,则将 options 的integrity设置为 attribs["integrity"]。
如果 attribs["referrerpolicy"]
存在,并且以ASCII
不区分大小写的方式匹配某个来源策略,则将 options 的来源
策略设置为该来源策略。
如果 attribs["nonce"]
存在,则将 options 的nonce设置为 attribs["nonce"]。
如果 attribs["fetchpriority"]
存在,并且以ASCII
不区分大小写的方式匹配某个
获取优先级
属性关键字,则将 options 的获取优先级设置为该获取优先级
属性关键字。
返回 true。
早期提示允许用户代理在导航请求被服务器完全 处理并返回响应代码之前,执行某些操作,例如推测性地 加载文档可能会使用的资源。服务器可以在提供最终 响应之前,提供一个状态代码为 103 的响应,以指示早期提示。[RFC8297]
出于兼容性原因,早期提示通常通过 HTTP/2 或更高版本传递,但为了便于阅读,下文使用 HTTP/1.1 风格的表示法。
例如,给定以下响应序列:
103 Early Hint Link: </image.png>; rel=preload; as=image
200 OK Content-Type: text/html <!DOCTYPE html> ... <img src="/image.png">
图像将在 HTML 内容到达之前开始加载。
只会处理导航期间提供的第一个早期提示响应;如果随后发生 跨源重定向,则会将其丢弃。
除了 `Link`
标头之外,103
响应还可能包含一个内容安全策略标头,处理
早期提示时会执行该策略。
例如,给定以下响应序列:
103 Early Hint Content-Security-Policy: style-src: self; Link: </style.css>; rel=preload; as=style
103 Early Hint Link: </image.png>; rel=preload; as=image
302 Redirect Location: /alternate.html
200 OK Content-Security-Policy: style-src: none; Link: </font.ttf>; rel=preload; as=font
字体和样式会被加载,而图像将被丢弃,因为只会采用最终重定向链中的第一个 早期提示响应。后出现的内容安全 策略标头是在获取样式的请求已经执行之后才出现的,但 文档将无法访问该样式。
给定一个响应 response 和一个环境 reservedEnvironment,要处理早期提示标头:
早期提示的 `Link`
标头始终在最终响应中的
`Link`
标头之前处理,之后再处理 link 元素。这等效于
按相应顺序将早期响应和最终响应中的 `Link`
标头内容添加到 Document 的 head 元素开头。
令 earlyPolicyContainer 为以下结果:给定 response 和 reservedEnvironment,从获取响应创建策略容器。
令 earlyHints 为一个空列表。
对于 links 中的每个 linkObject:
收到早期提示链接标头时,我们立即开始获取 earlyRequest。如果获取结果在
Document 创建之前返回,则将
earlyResponse 设置为该次获取的响应,并在
Document 创建后提交它(方法是使其可用于预加载资源
映射,如同它是一个 link 元素)。如果
Document 先创建,则响应会在可用后立即
提交。
令 rel 为 linkObject["relation_type"]。
令 options 为一个新的链接处理选项,其各项如下:
令 attribs 为 linkObject["target_attributes"]。
早期提示处理只处理 as、crossorigin、integrity 和 type
属性。其他属性,特别是 blocking、imagesrcset、imagesizes 和 media,只有在
Document 创建后才适用。
给定 attribs 和 rel,对 options 应用来自已解析标头 属性的链接选项。如果该操作返回 false,则返回。
给定 options,运行 rel 的处理链接标头 步骤。
将 options 追加到 earlyHints。
link
元素创建的超链接的方法交互式用户代理可以在其用户界面的某处,为用户提供一种方法来跟随
超链接,这些超链接是使用 link
元素创建的。此类对跟随
超链接算法的调用,必须将 userInvolvement 参数设置为“浏览器 UI”。
本规范没有定义确切的界面,但对于文档中每个 link
元素创建的每个超链接,
该界面可以以某种形式(可能经过简化)包含以下信息
(这些信息从元素的属性中获得,具体同样按下文定义):
rel
属性给出)title
属性给出)。href
属性给出)。hreflang
属性给出)。media
属性给出)。用户代理还可以包含其他信息,例如资源的类型(由
type
属性给出)。
meta
元素所有当前引擎均支持。
所有当前引擎均支持。
itemprop
属性:流式内容。itemprop
属性:短语内容。
charset 属性,
或者元素的 http-equiv 属性处于
编码
声明状态:位于 head 元素中。
http-equiv
属性,但其不处于编码声明状态:位于 head 元素中。http-equiv
属性,但其不处于编码声明状态:位于作为
head 元素子级的
noscript 元素中。
name 属性:
位于预期元数据内容的位置。itemprop
属性:位于预期元数据
内容的位置。itemprop
属性:位于预期短语
内容的位置。name — 元数据名称
http-equiv —
Pragma 指令
content — 元素的值
charset — 字符编码
声明
media — 适用的媒体
[Exposed =Window ]
interface HTMLMetaElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect ] attribute DOMString name ;
[CEReactions , Reflect="http-equiv"] attribute DOMString httpEquiv ;
[CEReactions , Reflect ] attribute DOMString content ;
[CEReactions , Reflect ] attribute DOMString media ;
// also has obsolete members
};meta 元素表示无法使用 title、base、link、style
和 script 元素表达的
各种元数据。
meta 元素可以使用
name 属性表示文档级元数据,
使用 http-equiv
属性表示 Pragma 指令,并在 HTML 文档被序列化为字符串形式(例如通过
网络传输或存储在磁盘上)时,使用 charset
属性表示文件的字符编码
声明。
name、http-equiv、charset
和 itemprop
属性中必须恰好指定一个。
如果指定了 name、http-equiv 或 itemprop
中的任一个,则还必须指定 content
属性。否则,必须省略该属性。
charset
属性指定文档使用的字符编码。
这是一个字符
编码声明。如果存在该属性,则其值必须以ASCII
不区分大小写的方式匹配字符串“utf-8”。
meta 元素上的
charset
属性在 XML 文档中不起作用,但为了便于与 XML 之间进行迁移,允许在 XML 文档中使用。
每个文档中不得有超过一个具有 charset 属性的
meta 元素。
content
属性在元素用于这些目的时,给出文档元数据或 Pragma 指令的值。
允许的值取决于确切上下文,如本规范后续各节所述。
如果 meta 元素具有
name 属性,
则它会设置文档元数据。文档元数据以名称-值对的形式表达,meta 元素上的 name 属性
给出名称,而同一元素上的 content
属性给出值。名称指定要设置元数据的哪个方面;有效名称及其值的含义
在以下各节中描述。如果 meta 元素没有 content 属性,则元数据
名称-值对的值部分为空字符串。
media 属性
指明元数据适用于哪些媒体。其值必须是一个有效媒体查询列表。
除非 name 为 theme-color,否则 media
属性不会影响处理模型,并且作者不得使用它。
所有当前引擎均支持。
名称不区分大小写,并且必须以ASCII 不区分大小写的方式进行比较。
application-name其值必须是一个简短的自由格式字符串,用于给出页面所表示的 Web 应用程序的名称。
如果该页面不是 Web 应用程序,则不得使用 application-name
元数据名称。
可以提供 Web 应用程序名称的翻译,并使用 lang
属性指定每个名称的语言。
每个文档中,对于给定的语言,不得有超过一个 meta 元素,
且该元素的 name
属性值以ASCII
不区分大小写的方式匹配
application-name。
用户代理可以在 UI 中优先使用应用程序名称,而不是页面的
title,
因为标题可能包含与页面在特定时刻的状态相关的状态消息等内容,
而不仅仅是应用程序的名称。
给定一个有序语言列表(例如英式英语、美式英语和英语),要查找应使用的应用程序名称, 用户代理必须运行以下步骤:
令 languages 为该语言列表。
如果存在 default language,并且它与 languages 中的任何语言 都不相同,则将其追加到 languages。
令 winning language 为 languages 中满足以下条件的第一个语言:
Document 中存在一个
meta 元素,
其 name
属性值以ASCII 不区分大小写的方式匹配
application-name,
并且该元素的语言是相关语言。
如果这些语言中没有任何语言具有这样的 meta 元素,
则返回;没有给定应用程序名称。
返回 Document 中,
按树顺序排列的第一个满足以下条件的 meta
元素的 content
属性值:
其 name
属性值以ASCII 不区分大小写的方式匹配 application-name,
并且其语言为 winning
language。
浏览器在需要页面名称时会使用此算法,例如为书签添加标签。 浏览器提供给该算法的语言将是用户的首选语言。
author其值必须是一个自由格式字符串,用于给出页面某位作者的名称。
description
其值必须是一个描述页面的自由格式字符串。该值必须适合在页面目录中使用,
例如用于搜索引擎。每个文档中不得有超过一个 meta 元素,
其 name
属性值以ASCII
不区分大小写的方式匹配
description。
generator其值必须是一个自由格式字符串,用于标识生成文档时使用的某个软件包。 该值不得用于标记不是由软件生成的页面,例如其标记由用户在文本编辑器中编写的页面。
以下内容是名为“Frontweaver”的工具可以包含在其输出页面的
head 元素中的内容,
用于将自身标识为生成该页面的工具:
< meta name = generator content = "Frontweaver 8.2" > keywords其值必须是一个逗号分隔词元集合,其中每个词元都是 与页面相关的关键字。
这个有关英国高速公路字体的页面使用 meta 元素指定
用户在查找该页面时可能使用的一些关键字:
<!DOCTYPE HTML>
< html lang = "en-GB" >
< head >
< title > Typefaces on UK motorways</ title >
< meta name = "keywords" content = "british,type face,font,fonts,highway,highways" >
</ head >
< body >
...许多搜索引擎不会考虑此类关键字,因为此功能过去经常以不可靠甚至 具有误导性的方式被用于向搜索引擎结果中塞入垃圾信息,而这对用户没有帮助。
要获取作者指定为适用于页面的关键字列表,用户代理必须运行以下步骤:
当对值的可靠性没有足够信心时,用户代理不应使用此信息。
例如,内容管理系统使用系统内页面的关键字信息来填充 站点专用搜索引擎的索引是合理的;但大规模内容聚合器如果使用此信息, 很可能会发现某些用户试图通过使用不适当的关键字来操纵其排名机制。
referrer其值必须是一个来源策略,用于定义 Document 的默认来源
策略。[REFERRERPOLICY]
如果任何 meta
元素 element 被插入文档,或者其
name 或 content
属性发生更改,则用户代理必须运行以下算法:
如果 element 不位于文档树中,则返回。
如果 element 没有一个值以ASCII 不区分大小写的方式匹配“referrer”的
name
属性,则返回。
如果 element 没有 content
属性,或者该属性的值为空字符串,则返回。
令 value 为 element 的 content
属性值,并将其转换为
ASCII
小写形式。
如果 value 是下表第一列给出的值之一,则将 value 设置为第二列给出的值:
| 旧值 | 来源策略 |
|---|---|
never
|
no-referrer
|
default
|
默认来源策略 |
always
|
unsafe-url
|
origin-when-crossorigin
|
origin-when-cross-origin
|
由于历史原因,与其他标准元数据名称不同,referrer 的处理
模型不会响应元素的移除,也不使用树顺序。只有最近插入或
最近修改且处于此状态的 meta
元素才会产生作用。
theme-color
其值必须是一个匹配 CSS <color> 产生式的 字符串,用于定义一种建议颜色,用户代理应使用该颜色来自定义页面或周围用户界面的显示。 例如,浏览器可以使用指定值为页面的标题栏着色,或者将其用作标签栏或任务切换器中的 高亮颜色。
在 HTML 文档中,所有将其 name
属性值设置为
以ASCII
不区分大小写的方式匹配 theme-color 的
meta 元素之间,
media 属性值
必须是唯一的。
本标准本身使用“WHATWG 绿色”作为其主题颜色:
<!DOCTYPE HTML>
< title > HTML Standard</ title >
< meta name = "theme-color" content = "#3c790a" >
...media 属性
可用于描述应使用所提供颜色的上下文。
如果我们只想在深色模式下使用“WHATWG 绿色”作为本标准的主题颜色,
则可以使用 prefers-color-scheme 媒体特性:
<!DOCTYPE HTML>
< title > HTML Standard</ title >
< meta name = "theme-color" content = "#3c790a" media = "(prefers-color-scheme: dark)" >
...要获取页面的主题颜色,用户代理必须运行以下步骤:
令 candidate elements 为按树顺序排列的所有满足以下条件的
meta 元素的列表:
该元素位于文档树中;
该元素具有 name
属性,
且其值以ASCII 不区分大小写的方式匹配 theme-color;
并且
该元素具有 content
属性。
对于 candidate elements 中的每个 element:
不返回任何内容(页面没有主题颜色)。
如果任何 meta
元素被插入文档或被从文档中移除,或者现有
meta 元素的
name、content 或
media 属性
发生更改,或者环境发生更改,使得任何 meta
元素的 media
属性值现在可能或可能不再与环境
匹配,则用户代理必须重新运行上述算法,并将结果应用于任何
受影响的 UI。
在 UI 中使用主题颜色时,用户代理可以采用实现特定的方式对其进行调整, 使其更适合相关 UI。例如,如果用户代理打算将主题颜色用作背景并在其上显示白色文本, 则可以在 UI 的该部分使用主题颜色的较深变体,以确保足够的对比度。
color-scheme
为了帮助用户代理立即使用所需的颜色方案渲染页面背景
(而不是等待页面中的所有 CSS 加载完毕),可以在 meta 元素中提供
一个 'color-scheme' 值。
其值必须是一个与 CSS 'color-scheme' 属性值语法匹配的字符串。它确定页面支持的颜色方案。
每个文档中不得有超过一个 meta
元素,
其 name 属性值
被设置为以ASCII
不区分大小写的方式匹配 color-scheme。
以下声明表明页面能够识别并处理一种使用深色背景和浅色前景的颜色方案:
< meta name = "color-scheme" content = "dark" > 要获取页面支持的颜色方案,用户代理必须运行 以下步骤:
令 candidate elements 为按树顺序排列的所有满足以下条件的
meta 元素的列表:
该元素位于文档树中;
该元素具有 name
属性,
且其值以ASCII 不区分大小写的方式匹配 color-scheme;
并且
该元素具有 content
属性。
对于 candidate elements 中的每个 element:
content
属性值,解析组件值列表。
返回 null。
如果任何 meta
元素被插入文档或被从文档中移除,或者现有
meta 元素的
name 或 content
属性发生更改,则用户代理必须重新运行上述算法。
由于这些规则会依次检查元素,直到找到匹配项,因此作者可以提供多个此类值, 以便为旧版用户代理提供回退。与 CSS 属性的回退方式相反,多个 meta 元素需要将 旧版值排列在较新值之后。
任何人都可以创建并使用自己对预定义元数据名称集合的 扩展。无需注册此类扩展。
但是,在以下任何情况下都不应创建新的元数据名称:
如果名称本身是一个 URL,或者其配套的 content 属性值是一个
URL;在这些情况下,鼓励将其注册为预定义链接类型集合的扩展
(而不是创建新的元数据名称)。
如果该名称用于预期在用户代理中具有处理要求的内容;在这种情况下,应对其进行标准化。
此外,在创建并使用新的元数据名称之前,鼓励查阅 WHATWG Wiki MetaExtensions 页面—— 以避免选择已被使用的元数据名称,避免与任何已被使用的元数据名称的用途重复, 并避免新的标准化名称与所选名称发生冲突。[WHATWGWIKI]
任何人都可以随时编辑 WHATWG Wiki MetaExtensions 页面以添加元数据名称。 新元数据名称可以使用以下信息进行说明:
实际定义的名称。该名称不应与任何其他已定义名称相似到容易混淆 (例如仅大小写不同)。
对元数据名称含义的简短非规范性描述,包括要求其值采用的格式。
具有完全相同处理要求的其他名称列表。作者不应使用被定义为同义词的名称 (它们仅用于允许用户代理支持旧版内容)。任何人都可以移除实践中未使用的同义词; 只有为了兼容旧版内容而需要作为同义词处理的名称,才应以这种方式注册。
以下状态之一:
如果发现某个元数据名称与现有值重复,则应将其移除,并将其列为现有值的同义词。
如果一个元数据名称以“提议”状态添加后持续一个月或更长时间, 但未被使用或说明,则可以将其从 WHATWG Wiki MetaExtensions 页面中移除。
如果一个元数据名称以“提议”状态添加后被发现与现有值重复,则应将其移除, 并将其列为现有值的同义词。如果一个元数据名称以“提议”状态添加后被发现有害, 则应将其状态更改为“停用”。
任何人都可以随时更改状态,但只能按照上述定义进行更改。
当在 meta 元素上指定
http-equiv
属性时,该元素是一个
Pragma 指令。
http-equiv
属性是一个具有以下关键字和状态的枚举属性:
| 关键字 | 符合规范 | 状态 | 简要描述 |
|---|---|---|---|
content-language
|
否 | 内容语言 | 设置由 Pragma 设置的默认语言。 |
content-type
|
编码声明 | 设置 charset 的另一种形式。
|
|
default-style
|
默认样式 | 设置默认 CSS 样式表集的名称。 | |
refresh
|
刷新 | 充当定时重定向。 | |
set-cookie
|
否 | Set-Cookie | 没有作用。 |
x-ua-compatible
|
X-UA-Compatible | 在实践中,促使 Internet Explorer 更严格地遵循规范。 | |
content-security-policy
|
内容安全策略 | 对 Document
执行一个内容安全
策略。
|
当一个 meta 元素被插入
文档时,如果存在其 http-equiv 属性,
并且该属性表示上述状态之一,则用户代理必须运行适用于该状态的算法,
如以下列表所述:
http-equiv="content-language")
此功能不符合规范。鼓励作者改用 lang 属性。
此 Pragma 设置由 Pragma 设置的默认语言。在成功处理 此类 Pragma 之前,不存在由 Pragma 设置的默认语言。
如果元素的 content
属性包含
U+002C 逗号字符(,),则返回。
令 input 为元素的 content 属性值。
令 position 指向 input 的第一个字符。
给定 position,在 input 中跳过 ASCII 空白。
令 candidate 为上一步所得的字符串。
如果 candidate 为空字符串,则返回。
将由 Pragma 设置的默认语言设置为 candidate。
如果该值由多个以空格分隔的词元组成,则会忽略第一个词元之后的词元。
此 Pragma 与同名 HTTP `Content-Language`
标头几乎相同,但并非完全相同。
[HTTP]
http-equiv="content-type")
编码声明状态只是设置 charset
属性的另一种形式:它是一个字符编码声明。此状态的所有用户代理要求
均由本规范的解析一节处理。
对于其 http-equiv
属性处于编码声明
状态的 meta 元素,content 属性必须具有
一个以ASCII
不区分大小写的方式匹配由以下部分组成的字符串的值:
“text/html;”,其后可以跟任意数量的ASCII
空白,再跟“charset=utf-8”。
文档不得同时包含一个其 http-equiv
属性处于编码声明状态的 meta 元素,以及一个具有
charset 属性的
meta 元素。
编码声明状态可以在HTML 文档中使用,但其 http-equiv
属性处于该状态的元素不得用于
XML 文档。
http-equiv="default-style")
仅一个引擎支持。
以元素的 content
属性值作为
名称,更改首选 CSS 样式表集名称。
[CSSOM]
http-equiv="refresh")
此 Pragma 充当定时重定向。
一个 Document 对象具有一个关联的
将进行声明式
刷新(一个布尔值)。其初始值为 false。
令 input 为元素的 content 属性值。
给定一个 Document 对象
document、字符串 input,以及可选的 meta 元素
meta,共享声明式刷新步骤如下:
如果 document 的将进行声明式刷新为 true,则返回。
令 position 指向 input 的第一个码点。
给定 position,在 input 中跳过 ASCII 空白。
令 time 为 0。
如果 timeString 为空字符串:
如果 input 中 position 所指向的码点不是 U+002E(.),则返回。
否则,使用解析非负整数的规则解析 timeString,并将 time 设置为所得结果。
给定 position,从 input 中收集一系列ASCII 数字和 U+002E 句点字符(.)码点。忽略所有收集到的字符。
令 urlRecord 为 document 的 URL。
如果 position 尚未超过 input 的末尾:
如果 input 中 position 所指向的码点不是 U+003B(;)、U+002C(,)或ASCII 空白,则返回。
给定 position,在 input 中跳过 ASCII 空白。
如果 input 中 position 所指向的码点是 U+003B(;)或 U+002C(,),则将 position 前移到下一个码点。
给定 position,在 input 中跳过 ASCII 空白。
如果 position 尚未超过 input 的末尾:
令 urlString 为 input 中从 position 所在码点到字符串末尾的子字符串。
如果 input 中 position 所指向的码点是 U+0055(U)或 U+0075(u),则将 position 前移到下一个码点。否则,跳转到标记为跳过引号的步骤。
如果 input 中 position 所指向的码点是 U+0052(R)或 U+0072(r),则将 position 前移到下一个码点。否则,跳转到标记为解析的步骤。
如果 input 中 position 所指向的码点是 U+004C(L)或 U+006C(l),则将 position 前移到下一个码点。否则,跳转到标记为解析的步骤。
给定 position,在 input 中跳过 ASCII 空白。
如果 input 中 position 所指向的码点是 U+003D(=),则将 position 前移到下一个码点。 否则,跳转到标记为解析的步骤。
给定 position,在 input 中跳过 ASCII 空白。
跳过引号:如果 input 中 position 所指向的码点是 U+0027(')或 U+0022("),则令 quote 为该码点,并将 position 前移到下一个码点。 否则,令 quote 为空字符串。
将 urlString 设置为 input 中从 position 所在码点到字符串末尾的子字符串。
如果 quote 不是空字符串,并且 urlString 中存在一个等于 quote 的码点, 则在该码点处截断 urlString,以移除该码点及其后的所有码点。
解析:给定 urlString,相对于 document 编码解析 URL,并将 urlRecord 设置为所得结果。
如果 urlRecord 为失败,则返回。
如果 urlRecord 的方案为“javascript”,
则返回。
将 document 的将进行声明式刷新设置为 true。
执行以下一个或多个步骤:
刷新到期后(定义见下文),如果用户未取消重定向,并且如果给定了
meta,document 的活动沙盒标志集未设置沙盒化自动功能浏览上下文
标志,则使用 document 将 document 的节点
可导航对象导航到
urlRecord,并将 historyHandling 设置为“replace”。
就上一段而言,一旦以下两个条件中较晚发生的条件成立,就称刷新已到期:
此处使用 document 而不是 meta 的节点文档非常重要,因为从初始步骤集到刷新到期之间,
后者可能已经发生更改,并且并不总是会给出 meta(例如使用 HTTP
`Refresh` 标头时)。
向用户提供一个界面,当该界面被选中时,使用 document 将 document 的节点 可导航对象导航到 urlRecord。
不执行任何操作。
此外,与其他任何情况一样,用户代理可以向用户告知其操作的任何和所有方面, 包括任何计时器的状态、任何定时重定向的目标等。
对于其
http-equiv
属性处于刷新状态的
meta 元素,content 属性必须具有
由以下任一形式组成的值:
URL”的子字符串,
后跟 U+003D 等号字符(=),再跟一个有效 URL
字符串,且该字符串不得以字面 U+0027 撇号(')或 U+0022 引号(")字符开头。在前一种情况下,该整数表示页面重新加载前的秒数;在后一种情况下,该整数表示 页面被给定 URL 处的页面替换前的秒数。
新闻机构的首页可以在页面的 head
元素中包含以下标记,
以确保页面每五分钟自动从服务器重新加载:
< meta http-equiv = "Refresh" content = "300" > 可以通过让序列中的每个页面刷新到下一个页面,将一系列页面用作自动幻灯片放映, 所用标记如下:
< meta http-equiv = "Refresh" content = "20; URL=page4.html" > http-equiv="set-cookie")
此 Pragma 不符合规范,并且没有作用。
要求用户代理忽略此 Pragma。
http-equiv="x-ua-compatible")
在实践中,此 Pragma 促使 Internet Explorer 更严格地遵循规范。
对于其 http-equiv
属性处于X-UA-Compatible 状态的 meta 元素,content 属性必须具有
一个以ASCII
不区分大小写的方式匹配字符串“IE=edge”的值。
要求用户代理忽略此 Pragma。
http-equiv="content-security-policy")
此 Pragma 对 Document
执行一个内容安全
策略。[CSP]
令 policy 为以下结果:对 meta 元素的
content
属性值执行内容安全策略的解析序列化内容安全策略算法,
其中源为“meta”,处置为“enforce”。
从 policy 中移除所有出现的 report-uri、
frame-ancestors
和 sandbox
指令。
执行策略 policy。
对于其 http-equiv
属性处于内容安全
策略状态的 meta
元素,content 属性必须具有
由一个有效内容安全
策略组成的值,但不得包含任何 report-uri、
frame-ancestors
或 sandbox
指令。
content 属性中
给出的内容安全策略将对当前文档执行。[CSP]
将 meta
元素插入文档时,
某些资源可能已经被获取。例如,在动态插入一个其 http-equiv
属性处于内容安全策略状态的 meta
元素之前,图像可能已经存储在可用图像列表中。对于较晚才执行的内容安全策略,不能保证已获取的资源会被阻止。
页面可以选择通过阻止执行内联 JavaScript 以及阻止所有插件内容, 使用如下策略来降低跨站脚本攻击的风险:
< meta http-equiv = "Content-Security-Policy" content = "script-src 'self'; object-src 'none'" > 文档中同一时刻不得有超过一个具有任何特定状态的 meta 元素。
字符编码声明是一种用于指定存储或传输文档时所使用的字符编码的机制。
编码标准要求使用 UTF-8 字符
编码,并要求使用“utf-8”编码标签
标识它。这些要求使得文档的字符编码
声明(如果存在)必须指定一个以ASCII
不区分大小写的方式匹配“utf-8”的编码标签。无论是否存在字符编码
声明,用于编码文档的实际字符编码
都必须是
UTF-8。[ENCODING]
为了执行上述规则,创作工具必须默认对新建文档使用 UTF-8。
此外还适用以下限制:
此外,由于对 meta 元素存在多项限制,每个文档只能有
一个基于 meta 的字符编码声明。
如果一个HTML 文档不是以 BOM 开头,并且其编码未由Content-Type
元数据明确给出,并且该文档不是一个
iframe srcdoc 文档,
则必须使用一个具有 charset 属性的 meta 元素,或者一个其 http-equiv
属性处于编码声明
状态的 meta 元素来指定编码。
即使所有字符都位于 ASCII 范围内,也需要字符编码声明(位于Content-Type 元数据中或在文件中明确给出),因为处理用户在表单中 输入的非 ASCII 字符、脚本生成的 URL 等内容时需要字符编码。
使用非 UTF-8 编码可能会在表单提交和 URL 编码中产生意外结果, 因为它们默认使用文档的字符编码。
如果文档是一个
iframe srcdoc
文档,则该文档不得具有字符编码声明。(在这种情况下,源已经被解码,
因为它是包含 iframe 的文档的一部分。)
在 XML 中,如有必要,应使用 XML 声明提供内联字符编码信息。
在 HTML 中,要声明字符编码为 UTF-8,作者可以在文档顶部附近
(在 head 元素中)
包含以下标记:
< meta charset = "utf-8" > 在 XML 中,则会改为在标记的最顶部使用 XML 声明:
<?xml version="1.0" encoding="utf-8"?> style
元素所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
head 元素子级的 noscript
元素中。media — 适用的媒体
blocking — 元素是否
可能阻塞渲染
title 属性
在此元素上具有特殊语义:
CSS 样式表集名称
[Exposed =Window ]
interface HTMLStyleElement : HTMLElement {
[HTMLConstructor ] constructor ();
attribute boolean disabled ;
[CEReactions , Reflect ] attribute DOMString media ;
[SameObject , PutForwards =value , Reflect ] readonly attribute DOMTokenList blocking ;
// also has obsolete members
};
HTMLStyleElement includes LinkStyle ;style 元素允许
作者在其文档中嵌入 CSS 样式表。
style 元素是样式处理
模型的若干输入之一。该元素不表示面向用户的内容。
所有当前引擎均支持。
disabled 的获取器步骤如下:
如果 this 没有关联的 CSS 样式表,则返回 false。
如果 this 的关联的 CSS 样式表的禁用标志已设置,则返回 true。
返回 false。
disabled 的设置器
步骤如下:
如果 this 没有关联的 CSS 样式表, 则返回。
如果给定值为 true,则设置 this 的关联的 CSS 样式 表的禁用标志。 否则,取消设置 this 的关联的 CSS 样式表的禁用标志。
需要特别注意的是,只有当 style
元素具有关联的 CSS 样式表时,对 disabled
属性的赋值才会生效:
const style = document. createElement( 'style' );
style. disabled = true ;
style. textContent = 'body { background-color: red; }' ;
document. body. append( style);
console. log( style. disabled); // false media 属性
指明样式适用于哪些媒体。其值必须是一个有效媒体查询列表。
当 media 属性值与环境匹配,
并且其他相关条件适用时,用户代理必须应用这些样式;否则不得应用。
这些样式的作用范围可能受到进一步限制,例如在 CSS 中使用 @media 块。
本规范不会覆盖此类进一步限制或要求。
如果省略 media
属性,则默认值为“all”,这意味着样式默认适用于所有媒体。
blocking
属性是一个阻塞属性。
仅一个引擎支持。
style
元素上的
title 属性定义
CSS 样式表集。如果 style 元素
没有 title 属性,
则它没有标题;祖先元素的 title 属性不适用于 style
元素。如果 style
元素不位于文档树中,则会忽略 title 属性。[CSSOM]
style 元素上的
title
属性与 link
元素上的 title 属性一样,与全局
title 属性的不同之处在于,
没有标题的 style 块不会继承父元素的标题:
它只是没有标题。
style 元素的子级文本内容必须是一个
符合规范的样式表的内容。
每当发生以下任何条件时,用户代理都必须运行更新
style 块算法:
更新 style 块算法如下:
令 element 为 style 元素。
如果 element 具有关联的 CSS 样式表,则移除相关 CSS 样式表。
如果 element 未连接,则返回。
如果存在 element 的 type 属性,并且其值
既不是空字符串,也不以ASCII
不区分大小写的方式匹配
“text/css”,则返回。
特别是,带有参数的 type 值,
例如“text/css; charset=utf-8”,将导致此算法提前返回。
如果对 style 元素、
“style”和 style 元素的子级文本内容执行元素的内联行为是否应被内容安全策略
阻止?算法时返回“Blocked”,则返回。[CSP]
使用以下属性创建 CSS 样式表:
如果 element 提供阻塞脚本的样式表,则将 element 追加到其节点文档的阻塞脚本的样式表集。
如果 element 的 media 属性值与环境
匹配,并且 element 可能阻塞渲染,则在
element 上阻塞渲染。
一旦获取样式表的关键子资源(如果有)的尝试完成,或者如果样式表没有关键子资源,则在样式表解析并处理完成后, 用户代理必须运行以下步骤:
获取关键
子资源的过程没有得到明确定义;议题
#968可能是解决该问题的最佳方案。
在此期间,任何关键
子资源的请求都应根据 style 元素当前是否阻塞渲染,设置其阻塞渲染。
该元素必须延迟该元素的 加载事件,直到该元素的节点文档中 所有获取样式表的关键子资源(如果有)的 尝试完成为止。
本规范没有指定样式系统,但预计大多数 Web 浏览器都会支持 CSS。 [CSS]
以下文档将强调重音设置为亮红色文本而不是斜体文本,同时保留作品标题和拉丁语词汇的默认斜体。 它展示了使用适当的元素如何使文档更容易重新设置样式。
<!DOCTYPE html>
< html lang = "en-US" >
< head >
< title > My favorite book</ title >
< style >
body { color : black ; background : white ; }
em { font-style : normal ; color : red ; }
</ style >
</ head >
< body >
< p > My < em > favorite</ em > book of all time has < em > got</ em > to be
< cite > A Cat's Life</ cite > . It is a book by P. Rahmel that talks
about the < i lang = "la" > Felis catus</ i > in modern human society.</ p >
</ body >
</ html > 如果样式表未引用任何其他资源(例如,它是由一个不含 @import 规则的
style
元素给出的内部样式表),则样式规则必须立即对脚本可用;否则,只有当事件
循环到达其更新
渲染步骤时,样式规则才必须对脚本可用。
在 HTML 解析器或 XML 解析器的
Document 上下文中,如果
以下所有条件均为真,则元素 el 提供阻塞脚本的
样式表:
el 是由该 Document 的解析器创建的。
el 是一个 style
元素,或者是一个在解析器创建 el 时属于参与样式
处理模型的外部资源链接的 link
元素。
el 的 media 属性值
与
环境匹配。
当解析器创建该元素时,el 的样式表处于启用状态。
用户代理尚未放弃加载该特定样式表。用户代理可以随时放弃加载样式表。
如果在样式表加载之前放弃该样式表,而样式表最终仍然加载成功, 则脚本最终可能会使用不正确的信息进行操作。例如,如果样式表将某元素的颜色设置为绿色, 但检查最终样式的脚本在样式表加载之前执行,则脚本会发现该元素是黑色的 (或任何默认颜色),因而可能做出不佳的选择 (例如,决定在页面其他位置使用黑色而不是绿色)。实现者必须在脚本使用错误信息的可能性, 与等待缓慢网络请求完成期间不执行任何操作所造成的性能影响之间取得平衡。
预计上述规则的对应规则也适用于
<?xml-stylesheet?>
处理指令。但是,这一点尚未得到彻底
调查。
一个 Document 具有一个
阻塞脚本的样式表集,它是一个有序集合,初始为空。
如果以下步骤返回 true,则 Document
document 具有阻塞
脚本的样式表:
如果 document 的阻塞脚本的样式表 集不为空,则 返回 true。
如果 document 的节点可导航对象为 null,则返回 false。
如果 containerDocument 不为 null,并且 containerDocument 的 阻塞脚本的样式表 集不为空, 则返回 true。
返回 false。
如果一个 Document 不
具有阻塞
脚本的样式表,则它没有阻塞脚本的样式表。
Introduction_to_HTML/Document_and_website_structure#HTML_for_structuring_content
所有当前引擎均支持。
body
元素所有当前引擎均支持。
所有当前引擎均支持。
html 元素中的第二个元素。body 元素为空,
或者 body 元素内的第一项不是
ASCII 空白或注释,则可以省略该元素的开始标签;但如果
body
元素内的第一项是 meta、noscript、
link、script、style 或 template 元素,则除外。
body 元素后面
没有紧跟注释,则可以省略
body 元素的结束标签。
onafterprint
onbeforeprint
onbeforeunload
onhashchange
onlanguagechange
onmessage
onmessageerror
onoffline
ononlineonpageswap
onpagehide
onpagereveal
onpageshow
onpopstate
onrejectionhandled
onstorage
onunhandledrejection
onunload[Exposed =Window ]
interface HTMLBodyElement : HTMLElement {
[HTMLConstructor ] constructor ();
// also has obsolete members
};
HTMLBodyElement includes WindowEventHandlers ;在符合规范的文档中,只存在一个 body 元素。document.body IDL 属性
使脚本可以轻松访问
文档的 body 元素。
某些 DOM 操作(例如拖放模型的部分内容)
是根据“body
元素”定义的。这是指按照该术语定义的 DOM 中特定元素,
而不是任意 body 元素。
body 元素将 Window 对象的若干事件处理器公开为事件处理器
内容属性。它还镜像这些处理器的事件处理器 IDL
属性。
由Window 反映 body 元素的
事件处理器集合命名、并在
body 元素上公开的
Window 对象事件处理器,会替换HTML 元素通常支持的同名通用事件处理器。
因此,例如,在一个 Document 的body
元素的子级上分派的冒泡 error 事件,会首先
触发该元素的 onerror 事件处理器
内容
属性,然后触发根 html 元素上的该属性,只有
随后才会触发 body 元素上的
onerror 事件处理器
内容属性。这是因为
事件会从目标冒泡到
body,再到 html,再到 Document,再到
Window,并且 body 上的事件处理器监听的是 Window 而不是 body。但是,使用
addEventListener() 附加到 body 的常规事件监听器,
会在事件冒泡通过 body 时运行,而不是在事件到达
Window 对象时运行。
此页面更新一个指示器,以显示用户是否在线:
<!DOCTYPE HTML>
< html lang = "en" >
< head >
< title > Online or offline?</ title >
< script >
function update( online) {
document. getElementById( 'status' ). textContent =
online ? 'Online' : 'Offline' ;
}
</ script >
</ head >
< body ononline = "update(true)"
onoffline = "update(false)"
onload = "update(navigator.onLine)" >
< p > You are: < span id = "status" > (Unknown)</ span ></ p >
</ body >
</ html > article
元素
所有当前引擎均支持。
HTMLElement。article 元素表示文档、页面、应用程序或站点中的一个完整或独立的
组成部分,并且原则上可以独立分发或复用,例如用于联合发布。这可以是论坛帖子、杂志或
报纸文章、博客条目、用户提交的评论、交互式挂件或小工具,或者任何
其他独立的内容项。
当 article
元素嵌套时,内部的 article 元素
表示原则上与外部文章内容相关的文章。例如,接受用户评论的网站上的博客条目,
可以将评论表示为嵌套在该博客条目的 article 元素中的
article 元素。
与一个 article
元素关联的作者信息
(参见 address 元素)
不适用于嵌套的 article 元素。
当专门用于要通过联合发布重新分发的内容时,
article 元素
在用途上与 Atom 中的 entry 元素相似。[ATOM]
schema.org 微数据词汇表可用于使用 CreativeWork 的某个子类型,
为 article
元素提供发布日期。
当页面的主要内容(即不包括页脚、页眉、导航块和侧栏)全部是一个独立完整的组成部分时,
可以使用 article 标记该内容,
但从技术上讲,在这种情况下它是多余的(因为该页面作为单个文档,
显然就是一个单独的组成部分)。
此示例展示了使用 article
元素的博客帖子,
其中包含一些 schema.org
注解:
< article itemscope itemtype = "http://schema.org/BlogPosting" >
< header >
< h2 itemprop = "headline" > The Very First Rule of Life</ h2 >
< p >< time itemprop = "datePublished" datetime = "2009-10-09" > 3 days ago</ time ></ p >
< link itemprop = "url" href = "?comments=0" >
</ header >
< p > If there's a microphone anywhere near you, assume it's hot and
sending whatever you're saying to the world. Seriously.</ p >
< p > ...</ p >
< footer >
< a itemprop = "discussionUrl" href = "?comments=1" > Show comments...</ a >
</ footer >
</ article > 以下是同一个博客帖子,但显示了其中一些评论:
< article itemscope itemtype = "http://schema.org/BlogPosting" >
< header >
< h2 itemprop = "headline" > The Very First Rule of Life</ h2 >
< p >< time itemprop = "datePublished" datetime = "2009-10-09" > 3 days ago</ time ></ p >
< link itemprop = "url" href = "?comments=0" >
</ header >
< p > If there's a microphone anywhere near you, assume it's hot and
sending whatever you're saying to the world. Seriously.</ p >
< p > ...</ p >
< section >
< h1 > Comments</ h1 >
< article itemprop = "comment" itemscope itemtype = "http://schema.org/Comment" id = "c1" >
< link itemprop = "url" href = "#c1" >
< footer >
< p > Posted by: < span itemprop = "creator" itemscope itemtype = "http://schema.org/Person" >
< span itemprop = "name" > George Washington</ span >
</ span ></ p >
< p >< time itemprop = "dateCreated" datetime = "2009-10-10" > 15 minutes ago</ time ></ p >
</ footer >
< p > Yeah! Especially when talking about your lobbyist friends!</ p >
</ article >
< article itemprop = "comment" itemscope itemtype = "http://schema.org/Comment" id = "c2" >
< link itemprop = "url" href = "#c2" >
< footer >
< p > Posted by: < span itemprop = "creator" itemscope itemtype = "http://schema.org/Person" >
< span itemprop = "name" > George Hammond</ span >
</ span ></ p >
< p >< time itemprop = "dateCreated" datetime = "2009-10-10" > 5 minutes ago</ time ></ p >
</ footer >
< p > Hey, you have the same first name as me.</ p >
</ article >
</ section >
</ article > 请注意使用 footer 为每条评论提供
信息(例如评论者是谁以及评论时间):在适当情况下,例如本例中,footer 元素
可以出现在其
章节的开头。(在本例中使用 header
也并非错误;
这主要取决于作者的偏好。)
在此示例中,article 元素
用于在门户页面上承载挂件。这些
挂件被实现为定制内置
元素,以获得特定的样式和脚本行为。
<!DOCTYPE HTML>
< html lang = en >
< title > eHome Portal</ title >
< script src = "/scripts/widgets.js" ></ script >
< link rel = stylesheet href = "/styles/main.css" >
< article is = "stock-widget" >
< h2 > Stocks</ h2 >
< table >
< thead > < tr > < th > Stock < th > Value < th > Delta
< tbody > < template > < tr > < td > < td > < td > </ template >
</ table >
< p > < input type = button value = "Refresh" onclick = "this.parentElement.refresh()" >
</ article >
< article is = "news-widget" >
< h2 > News</ h2 >
< ul >
< template >
< li >
< p >< img > < strong ></ strong >
< p >
</ template >
</ ul >
< p > < input type = button value = "Refresh" onclick = "this.parentElement.refresh()" >
</ article > section
元素
所有当前引擎均支持。
HTMLElement。section 元素表示文档或应用程序中的一个通用章节。
在此上下文中,章节是内容的主题分组,通常带有
标题。
章节的示例包括章、选项卡式对话框中的各个选项卡页面, 或论文中编号的各节。网站的主页可以拆分为介绍、新闻条目和联系信息等 章节。
当对元素内容进行联合发布具有合理意义时,鼓励作者使用 article 元素,而不是
section 元素。
section 元素不是一个通用
容器元素。当仅出于样式目的或为了方便脚本而需要某个元素时,鼓励作者改用 div 元素。一般规则是,
只有当元素的内容会在文档的大纲中明确列出时,
section
元素才是合适的。
在以下示例中,我们看到一篇关于苹果的文章(更大网页的一部分), 其中包含两个简短章节。
< article >
< hgroup >
< h2 > Apples</ h2 >
< p > Tasty, delicious fruit!</ p >
</ hgroup >
< p > The apple is the pomaceous fruit of the apple tree.</ p >
< section >
< h3 > Red Delicious</ h3 >
< p > These bright red apples are the most common found in many
supermarkets.</ p >
</ section >
< section >
< h3 > Granny Smith</ h3 >
< p > These juicy, green apples make a great filling for
apple pies.</ p >
</ section >
</ article > 以下是一份包含两个章节的毕业典礼节目单,一个章节列出毕业人员, 另一个章节描述典礼。(此示例中的标记采用一种不常见的样式, 有时用于尽量减少元素间空白的数量。)
<!DOCTYPE Html>
< Html Lang = En
>< Head
>< Title
> Graduation Ceremony Summer 2022</ Title
></ Head
>< Body
>< H1
> Graduation</ H1
>< Section
>< H2
> Ceremony</ H2
>< P
> Opening Procession</ P
>< P
> Speech by Valedictorian</ P
>< P
> Speech by Class President</ P
>< P
> Presentation of Diplomas</ P
>< P
> Closing Speech by Headmaster</ P
></ Section
>< Section
>< H2
> Graduates</ H2
>< Ul
>< Li
> Molly Carpenter</ Li
>< Li
> Anastasia Luccio</ Li
>< Li
> Ebenezar McCoy</ Li
>< Li
> Karrin Murphy</ Li
>< Li
> Thomas Raith</ Li
>< Li
> Susan Rodriguez</ Li
></ Ul
></ Section
></ Body
></ Html > 在此示例中,一位图书作者将一些章节标记为正文各章,将另一些标记为附录, 并使用 CSS 对这两类章节中的标题应用不同样式。
< style >
section { border : double medium ; margin : 2 em ; }
section . chapter h2 { font : 2 em Roboto , Helvetica Neue , sans-serif ; }
section . appendix h2 { font : small-caps 2 em Roboto , Helvetica Neue , sans-serif ; }
</ style >
< header >
< hgroup >
< h1 > My Book</ h1 >
< p > A sample with not much content</ p >
</ hgroup >
< p >< small > Published by Dummy Publicorp Ltd.</ small ></ p >
</ header >
< section class = "chapter" >
< h2 > My First Chapter</ h2 >
< p > This is the first of my chapters. It doesn't say much.</ p >
< p > But it has two paragraphs!</ p >
</ section >
< section class = "chapter" >
< h2 > It Continues: The Second Chapter</ h2 >
< p > Bla dee bla, dee bla dee bla. Boom.</ p >
</ section >
< section class = "chapter" >
< h2 > Chapter Three: A Further Example</ h2 >
< p > It's not like a battle between brightness and earthtones would go
unnoticed.</ p >
< p > But it might ruin my story.</ p >
</ section >
< section class = "appendix" >
< h2 > Appendix A: Overview of Examples</ h2 >
< p > These are demonstrations.</ p >
</ section >
< section class = "appendix" >
< h2 > Appendix B: Some Closing Remarks</ h2 >
< p > Hopefully this long example shows that you < em > can</ em > style
sections, so long as they are used to indicate actual sections.</ p >
</ section > nav
元素所有当前引擎均支持。
HTMLElement。nav 元素表示页面中链接到其他
页面或页面内部各部分的章节:一个包含导航链接的章节。
页面上的链接组并非都需要放在 nav
元素中——
该元素主要用于由主要导航块组成的章节。特别是,页脚通常包含一个指向站点各个页面的简短链接列表,
例如服务条款、主页和版权页面。仅使用 footer 元素
就足以应对此类情况;尽管在这些情况下也可以使用 nav
元素,但通常
没有必要。
面向以下用户的用户代理(例如屏幕阅读器)可以使用此元素来确定 页面上的哪些内容应在初始阶段跳过、应按需提供,或两者兼有: 这些用户可以从初始渲染中省略导航信息中受益,或者可以从立即获得导航信息中受益。
在以下示例中,有两个 nav 元素,一个用于站点的主要
导航,
另一个用于页面自身的次要导航。
< body >
< h1 > The Wiki Center Of Exampland</ h1 >
< nav >
< ul >
< li >< a href = "/" > Home</ a ></ li >
< li >< a href = "/events" > Current Events</ a ></ li >
...more...
</ ul >
</ nav >
< article >
< header >
< h2 > Demos in Exampland</ h2 >
< p > Written by A. N. Other.</ p >
</ header >
< nav >
< ul >
< li >< a href = "#public" > Public demonstrations</ a ></ li >
< li >< a href = "#destroy" > Demolitions</ a ></ li >
...more...
</ ul >
</ nav >
< div >
< section id = "public" >
< h2 > Public demonstrations</ h2 >
< p > ...more...</ p >
</ section >
< section id = "destroy" >
< h2 > Demolitions</ h2 >
< p > ...more...</ p >
</ section >
...more...
</ div >
< footer >
< p >< a href = "?edit" > Edit</ a > | < a href = "?delete" > Delete</ a > | < a href = "?Rename" > Rename</ a ></ p >
</ footer >
</ article >
< footer >
< p >< small > © copyright 1998 Exampland Emperor</ small ></ p >
</ footer >
</ body > 在以下示例中,页面上有多个包含链接的位置,但只有其中一个 被视为导航章节。
< body itemscope itemtype = "http://schema.org/Blog" >
< header >
< h1 > Wake up sheeple!</ h1 >
< p >< a href = "news.html" > News</ a > -
< a href = "blog.html" > Blog</ a > -
< a href = "forums.html" > Forums</ a ></ p >
< p > Last Modified: < span itemprop = "dateModified" > 2009-04-01</ span ></ p >
< nav >
< h2 > Navigation</ h2 >
< ul >
< li >< a href = "articles.html" > Index of all articles</ a ></ li >
< li >< a href = "today.html" > Things sheeple need to wake up for today</ a ></ li >
< li >< a href = "successes.html" > Sheeple we have managed to wake</ a ></ li >
</ ul >
</ nav >
</ header >
< main >
< article itemprop = "blogPosts" itemscope itemtype = "http://schema.org/BlogPosting" >
< header >
< h2 itemprop = "headline" > My Day at the Beach</ h2 >
</ header >
< div itemprop = "articleBody" >
< p > Today I went to the beach and had a lot of fun.</ p >
...more content...
</ div >
< footer >
< p > Posted < time itemprop = "datePublished" datetime = "2009-10-10" > Thursday</ time > .</ p >
</ footer >
</ article >
...more blog posts...
</ main >
< footer >
< p > Copyright ©
< span itemprop = "copyrightYear" > 2010</ span >
< span itemprop = "copyrightHolder" > The Example Company</ span >
</ p >
< p >< a href = "about.html" > About</ a > -
< a href = "policy.html" > Privacy Policy</ a > -
< a href = "contact.html" > Contact Us</ a ></ p >
</ footer >
</ body > 在上述示例中还可以看到使用 schema.org 词汇表的微数据注解, 用于提供博客帖子的发布日期和其他元数据。
nav 元素不一定
必须包含列表,它也可以包含其他类型的
内容。在此导航块中,链接以散文形式提供:
< nav >
< h1 > Navigation</ h1 >
< p > You are on my home page. To the north lies < a href = "/blog" > my
blog</ a > , from whence the sounds of battle can be heard. To the east
you can see a large mountain, upon which many < a
href = "/school" > school papers</ a > are littered. Far up thus mountain
you can spy a little figure who appears to be me, desperately
scribbling a < a href = "/school/thesis" > thesis</ a > .</ p >
< p > To the west are several exits. One fun-looking exit is labeled < a
href = "https://games.example.com/" > "games"</ a > . Another more
boring-looking exit is labeled < a
href = "https://isp.example.net/" > ISP™</ a > .</ p >
< p > To the south lies a dark and dank < a href = "/about" > contacts
page</ a > . Cobwebs cover its disused entrance, and at one point you
see a rat run quickly out of the page.</ p >
</ nav > 在此示例中,nav 用于
电子邮件应用程序,以允许用户切换
文件夹:
< p >< input type = button value = "Compose" onclick = "compose()" ></ p >
< nav >
< h1 > Folders</ h1 >
< ul >
< li > < a href = "/inbox" onclick = "return openFolder(this.href)" > Inbox</ a > < span class = count ></ span >
< li > < a href = "/sent" onclick = "return openFolder(this.href)" > Sent</ a >
< li > < a href = "/drafts" onclick = "return openFolder(this.href)" > Drafts</ a >
< li > < a href = "/trash" onclick = "return openFolder(this.href)" > Trash</ a >
< li > < a href = "/customers" onclick = "return openFolder(this.href)" > Customers</ a >
</ ul >
</ nav > aside
元素所有当前引擎均支持。
HTMLElement。aside 元素表示页面中由与 aside 元素周围内容
仅有间接关系的内容构成的章节,并且
可以将该章节视为与周围内容相分离。此类章节在印刷排版中通常表示为
侧栏。
该元素可用于题引或侧栏等排版效果、广告、nav 元素组,
以及被视为与页面主要内容相分离的其他内容。
仅为括号内补充内容使用 aside 元素是不合适的,
因为这些内容属于文档的主要内容流。
以下示例展示了如何在一篇篇幅更长的欧洲新闻报道中,使用 aside 标记关于瑞士的 背景材料。
< aside >
< h2 > Switzerland</ h2 >
< p > Switzerland, a land-locked country in the middle of geographic
Europe, has not joined the geopolitical European Union, though it is
a signatory to a number of European treaties.</ p >
</ aside > 以下示例展示了如何在一篇较长的文章中使用 aside 标记一段 题引。
...
< p > He later joined a large company, continuing on the same work.
< q > I love my job. People ask me what I do for fun when I'm not at
work. But I'm paid to do my hobby, so I never know what to
answer. Some people wonder what they would do if they didn't have to
work... but I know what I would do, because I was unemployed for a
year, and I filled that time doing exactly what I do now.</ q ></ p >
< aside >
< q > People ask me what I do for fun when I'm not at work. But I'm
paid to do my hobby, so I never know what to answer.</ q >
</ aside >
< p > Of course his work — or should that be hobby? —
isn't his only passion. He also enjoys other pleasures.</ p >
...以下摘录展示了如何使用 aside 表示
博客链接列表和博客中的其他侧边
内容:
< body >
< header >
< h1 > My wonderful blog</ h1 >
< p > My tagline</ p >
</ header >
< aside >
<!-- this aside contains two sections that are tangentially related
to the page, namely, links to other blogs, and links to blog posts
from this blog -->
< nav >
< h2 > My blogroll</ h2 >
< ul >
< li >< a href = "https://blog.example.com/" > Example Blog</ a >
</ ul >
</ nav >
< nav >
< h2 > Archives</ h2 >
< ol reversed >
< li >< a href = "/last-post" > My last post</ a >
< li >< a href = "/first-post" > My first post</ a >
</ ol >
</ nav >
</ aside >
< aside >
<!-- this aside is tangentially related to the page also, it
contains twitter messages from the blog author -->
< h1 > Twitter Feed</ h1 >
< blockquote cite = "https://twitter.example.net/t31351234" >
I'm on vacation, writing my blog.
</ blockquote >
< blockquote cite = "https://twitter.example.net/t31219752" >
I'm going to go on vacation soon.
</ blockquote >
</ aside >
< article >
<!-- this is a blog post -->
< h2 > My last post</ h2 >
< p > This is my last post.</ p >
< footer >
< p >< a href = "/last-post" rel = bookmark > Permalink</ a >
</ footer >
</ article >
< article >
<!-- this is also a blog post -->
< h2 > My first post</ h2 >
< p > This is my first post.</ p >
< aside >
<!-- this aside is about the blog post, since it's inside the
<article> element; it would be wrong, for instance, to put the
blogroll here, since the blogroll isn't really related to this post
specifically, only to the page as a whole -->
< h2 > Posting</ h2 >
< p > While I'm thinking about it, I wanted to say something about
posting. Posting is fun!</ p >
</ aside >
< footer >
< p >< a href = "/first-post" rel = bookmark > Permalink</ a >
</ footer >
</ article >
< footer >
< p >< a href = "/archives" > Archives</ a > -
< a href = "/about" > About me</ a > -
< a href = "/copyright" > Copyright</ a ></ p >
</ footer >
</ body > h1、h2、h3、h4、h5 和 h6
元素所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
hgroup
元素的子级。[Exposed =Window ]
interface HTMLHeadingElement : HTMLElement {
[HTMLConstructor ] constructor ();
// also has obsolete members
};这些元素表示其 章节的标题。
这些元素的语义和含义在标题 和大纲一节中定义。
这些元素具有由其名称中的数字给出的标题
级别。标题级别对应
嵌套章节的级别。h1
元素用于顶级章节,h2
用于子章节,h3
用于
子子章节,依此类推。
就各自的文档大纲(标题和章节结构)而言, 以下两个片段在语义上等价:
< body >
< h1 > Let's call it a draw(ing surface)</ h1 >
< h2 > Diving in</ h2 >
< h2 > Simple shapes</ h2 >
< h2 > Canvas coordinates</ h2 >
< h3 > Canvas coordinates diagram</ h3 >
< h2 > Paths</ h2 >
</ body > < body >
< h1 > Let's call it a draw(ing surface)</ h1 >
< section >
< h2 > Diving in</ h2 >
</ section >
< section >
< h2 > Simple shapes</ h2 >
</ section >
< section >
< h2 > Canvas coordinates</ h2 >
< section >
< h3 > Canvas coordinates diagram</ h3 >
</ section >
</ section >
< section >
< h2 > Paths</ h2 >
</ section >
</ body > 作者可能因前一种样式更简洁而偏好它,也可能因后一种样式提供额外的样式挂钩而偏好它。 哪一种最好纯粹取决于首选的创作风格。
hgroup
元素所有当前引擎均支持。
p 元素,
后跟一个 h1、
h2、
h3、
h4、
h5
或 h6
元素,再后跟零个
或多个 p 元素,并且可以选择
与脚本支持
元素混合。
HTMLElement。hgroup 元素表示标题及相关内容。该
元素可用于将一个 h1–h6
元素与一个或多个
p 元素分为一组,这些元素包含
表示副标题、替代标题或
标语的内容。
以下是包含在 hgroup
元素中的一些有效标题示例。
< hgroup >
< h1 > The reality dysfunction</ h1 >
< p > Space is not the only void</ p >
</ hgroup > < hgroup >
< h1 > Dr. Strangelove</ h1 >
< p > Or: How I Learned to Stop Worrying and Love the Bomb</ p >
</ hgroup > header
元素所有当前引擎均支持。
header 或 footer 元素
后代。HTMLElement。header
元素通常旨在包含标题
(一个 h1–h6
元素或一个 hgroup
元素),但这
并非必需。header
元素还可用于包裹章节的
目录、搜索表单或任何相关徽标。
以下是一些页眉示例。第一个示例用于游戏:
< header >
< p > Welcome to...</ p >
< h1 > Voidwars!</ h1 >
</ header > 以下片段展示了如何使用该元素标记 规范的页眉:
< header >
< hgroup >
< h1 > Fullscreen API</ h1 >
< p > Living Standard — Last Updated 19 October 2015< p >
</ hgroup >
< dl >
< dt > Participate:</ dt >
< dd >< a href = "https://github.com/whatwg/fullscreen" > GitHub whatwg/fullscreen</ a ></ dd >
< dt > Commits:</ dt >
< dd >< a href = "https://github.com/whatwg/fullscreen/commits" > GitHub whatwg/fullscreen/commits</ a ></ dd >
</ dl >
</ header > 在此示例中,页面具有由 h1
元素给出的页面标题,以及两个
标题由 h2
元素给出的子章节。位于
header 元素之后的内容
仍然属于在
header 元素中开始的最后一个子章节,
因为 header
元素不参与
大纲算法。
< body >
< header >
< h1 > Little Green Guys With Guns</ h1 >
< nav >
< ul >
< li >< a href = "/games" > Games</ a >
< li >< a href = "/forum" > Forum</ a >
< li >< a href = "/download" > Download</ a >
</ ul >
</ nav >
< h2 > Important News</ h2 > <!-- this starts a second subsection -->
<!-- this is part of the subsection entitled "Important News" -->
< p > To play today's games you will need to update your client.</ p >
< h2 > Games</ h2 > <!-- this starts a third subsection -->
</ header >
< p > You have three active games:</ p >
<!-- this is still part of the subsection entitled "Games" -->
...footer
元素所有当前引擎均支持。
header 或 footer 元素
后代。HTMLElement。footer 元素表示其最近祖先
分节内容元素的页脚,或者
如果不存在此类
祖先,则表示body 元素的页脚。
页脚通常包含有关其章节的信息,例如作者、相关文档的链接、
版权数据等。
当 footer 元素
包含完整章节时,这些章节表示附录、
索引、较长的出版说明、冗长的许可
协议及其他此类内容。
章节作者或编辑者的联系信息应放在
address 元素中,
该元素本身也可能位于 footer
内。署名及其他
同时适合放在 header 或 footer 中的信息,可以
放在任意一个元素中(也可以都不放)。这些元素的主要目的仅仅是帮助作者
编写易于维护和设置样式、语义清晰的标记;它们并非旨在向作者强制规定
特定结构。
页脚不一定必须出现在章节的末尾,尽管它们通常 位于末尾。
当不存在祖先分节 内容元素时,它适用于整个 页面。
以下页面具有两个内容相同的页脚,一个位于顶部,一个位于底部:
< body >
< footer >< a href = "../" > Back to index...</ a ></ footer >
< hgroup >
< h1 > Lorem ipsum</ h1 >
< p > The ipsum of all lorems</ p >
</ hgroup >
< p > A dolor sit amet, consectetur adipisicing elit, sed do eiusmod
tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim
veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex
ea commodo consequat. Duis aute irure dolor in reprehenderit in
voluptate velit esse cillum dolore eu fugiat nulla
pariatur. Excepteur sint occaecat cupidatat non proident, sunt in
culpa qui officia deserunt mollit anim id est laborum.</ p >
< footer >< a href = "../" > Back to index...</ a ></ footer >
</ body > 以下示例展示了 footer 元素同时用于
全站
页脚和章节页脚。
<!DOCTYPE HTML>
< HTML LANG = "en" >< HEAD >
< TITLE > The Ramblings of a Scientist</ TITLE >
< BODY >
< H1 > The Ramblings of a Scientist</ H1 >
< ARTICLE >
< H1 > Episode 15</ H1 >
< VIDEO SRC = "/fm/015.ogv" CONTROLS PRELOAD >
< P >< A HREF = "/fm/015.ogv" > Download video</ A > .</ P >
</ VIDEO >
< FOOTER > <!-- footer for article -->
< P > Published < TIME DATETIME = "2009-10-21T18:26-07:00" > on 2009/10/21 at 6:26pm</ TIME ></ P >
</ FOOTER >
</ ARTICLE >
< ARTICLE >
< H1 > My Favorite Trains</ H1 >
< P > I love my trains. My favorite train of all time is a Köf.</ P >
< P > It is fun to see them pull some coal cars because they look so
dwarfed in comparison.</ P >
< FOOTER > <!-- footer for article -->
< P > Published < TIME DATETIME = "2009-09-15T14:54-07:00" > on 2009/09/15 at 2:54pm</ TIME ></ P >
</ FOOTER >
</ ARTICLE >
< FOOTER > <!-- site wide footer -->
< NAV >
< P >< A HREF = "/credits.html" > Credits</ A > —
< A HREF = "/tos.html" > Terms of Service</ A > —
< A HREF = "/index.html" > Blog Index</ A ></ P >
</ NAV >
< P > Copyright © 2009 Gordon Freeman</ P >
</ FOOTER >
</ BODY >
</ HTML > 某些站点设计具有有时被称为“胖页脚”的内容——即 包含大量材料的页脚,其中包括图像、指向其他文章的链接、指向用于发送 反馈的页面的链接、特别优惠……在某些方面,它相当于页脚中的完整“首页”。
此片段展示了一个具有“胖页脚”的站点中某页面的底部:
...
< footer >
< nav >
< section >
< h1 > Articles</ h1 >
< p >< img src = "images/somersaults.jpeg" alt = "" > Go to the gym with
our somersaults class! Our teacher Jim takes you through the paces
in this two-part article. < a href = "articles/somersaults/1" > Part
1</ a > · < a href = "articles/somersaults/2" > Part 2</ a ></ p >
< p >< img src = "images/kindplus.jpeg" > Tired of walking on the edge of
a clif<!-- sic --> ? Our guest writer Lara shows you how to bumble
your way through the bars. < a href = "articles/kindplus/1" > Read
more...</ a ></ p >
< p >< img src = "images/crisps.jpeg" > The chips are down, now all
that's left is a potato. What can you do with it? < a
href = "articles/crisps/1" > Read more...</ a ></ p >
</ section >
< ul >
< li > < a href = "/about" > About us...</ a >
< li > < a href = "/feedback" > Send feedback!</ a >
< li > < a href = "/sitemap" > Sitemap</ a >
</ ul >
</ nav >
< p >< small > Copyright © 2015 The Snacker —
< a href = "/tos" > Terms of Service</ a ></ small ></ p >
</ footer >
</ body > address
元素
所有当前引擎均支持。
header、footer 或
address 元素
后代。
HTMLElement。address 元素
表示其最近的 article 或
body 元素祖先的联系信息。如果
该祖先是body
元素,则联系信息适用于整个文档。
例如,W3C 网站中与 HTML 相关的页面可能 包含以下联系信息:
< ADDRESS >
< A href = "../People/Raggett/" > Dave Raggett</ A > ,
< A href = "../People/Arnaud/" > Arnaud Le Hors</ A > ,
contact persons for the < A href = "Activity" > W3C HTML Activity</ A >
</ ADDRESS > address 元素
不得用于表示任意地址(例如邮政
地址),除非这些地址实际上是相关联系信息。(通常应使用
p 元素
标记邮政地址。)
address 元素
除联系信息之外不得包含其他
信息。
例如,以下是对
address
元素的不符合规范的使用:
< ADDRESS > Last Modified: 1999/12/24 23:37:50</ ADDRESS > 通常,address 元素会与
其他信息一起包含在
footer 元素中。
节点 node 的联系信息是一个
address 元素集合,
由以下列表中第一个适用的条目定义:
用户代理可以向用户公开节点的联系信息,或将其用于其他 目的,例如根据章节的联系信息为章节编制索引。
在此示例中,页脚包含联系信息和版权声明。
< footer >
< address >
For more details, contact
< a href = "mailto:js@example.com" > John Smith</ a > .
</ address >
< p >< small > © copyright 2038 Example Corp.</ small ></ p >
</ footer > h1–h6
元素具有一个标题级别,该级别通过获取元素的计算
标题级别给出。
这些元素表示标题。一个标题的标题级别越低,该标题拥有的祖先 章节就越少。
大纲应当用于生成文档 大纲,例如生成目录时。创建交互式目录时,条目应当 将用户跳转到相关标题。
如果文档具有一个或多个标题,则大纲中至少一个 标题的标题级别应当为 1。
以下示例不符合规范:
< body >
< h1 > Apples</ h1 >
< p > Apples are fruit.</ p >
< section >
< h3 > Taste</ h3 >
< p > They taste lovely.</ p >
</ section >
</ body > 可以将其写成以下形式,这样它就符合规范:
< body >
< h1 > Apples</ h1 >
< p > Apples are fruit.</ p >
< section >
< h2 > Taste</ h2 >
< p > They taste lovely.</ p >
</ section >
</ body > headingoffset
内容属性允许作者偏移后代的标题级别。
如果指定了 headingoffset
属性,则它必须
具有一个介于 0 和 8 之间(含两端)的有效非负整数值。
headingreset
内容属性是一个布尔
属性。它允许作者阻止标题
偏移量计算遍历到具有该属性的元素之外。
要获取元素的计算标题级别,给定一个 元素 element:
令 level 为 0。
如果 element 的局部名称是 h1,
则将
level 设置为 1。
如果 element 的局部名称是 h2,
则将
level 设置为 2。
如果 element 的局部名称是 h3,
则将
level 设置为 3。
如果 element 的局部名称是 h4,
则将
level 设置为 4。
如果 element 的局部名称是 h5,
则将
level 设置为 5。
如果 element 的局部名称是 h6,
则将
level 设置为 6。
断言:level 不为 0。
将 level 增加以下结果:给定 element,获取元素的计算 标题 偏移量。
如果 level 大于 9,则返回 9。
返回 level。
要获取元素的计算标题偏移量,给定一个 元素 element, 执行以下步骤。这些步骤返回一个非负整数。
令 offset 为 0。
令 inclusiveAncestor 为 element。
当 inclusiveAncestor 不为 null 时:
令 nextOffset 为 0。
如果 inclusiveAncestor 是一个HTML 元素并且
具有 headingoffset
属性,则使用解析非负
整数的规则解析其值。
如果解析该值的结果不是错误,则将 nextOffset 设置为该 值。
将 offset 增加 nextOffset。
如果 inclusiveAncestor 是一个HTML 元素
并且具有 headingreset
属性,则返回
offset。
如果 inclusiveAncestor 的父级是一个影子根, 则将 inclusiveAncestor 设置为该影子根的 宿主并继续。
将 inclusiveAncestor 设置为 inclusiveAncestor 的父 元素。
返回 offset。
此示例展示了 headingoffset、
headingreset
和 aria-level
属性的组合,并通过注释演示各自的
标题级别。此示例说明各种组合,而不是最佳实践
示例。
< body >
< main >
< h1 > This is a heading level 1</ h1 >
< article headingoffset = "1" >
< h1 > This is a heading level 2</ h1 >
< section headingoffset = "1" >
< h1 > This is a heading level 3</ h1 >
< dialog headingreset >
< h1 > This is a heading level 1</ h1 >
</ dialog >
</ section >
</ article >
< h1 aria-level = "2" > This is a heading level 2</ h1 >
</ main >
</ body > 以下标记片段:
< body >
< hgroup id = "document-title" >
< h1 > HTML: Living Standard</ h1 >
< p > Last Updated 12 August 2016</ p >
</ hgroup >
< p > Some intro to the document.</ p >
< h2 > Table of contents</ h2 >
< ol id = toc > ...</ ol >
< h2 > First section</ h2 >
< p > Some intro to the first section.</ p >
</ body > ……会产生 3 个文档标题:
<h1>HTML: Living Standard</h1>
<h2>Table of contents</h2>。
<h2>First section</h2>。
大纲的渲染视图可能如下所示:

首先,以下是一个文档,它是一本章节和子章节都很短的书:
<!DOCTYPE HTML>
< html lang = en >
< title > The Tax Book (all in one page)</ title >
< h1 > The Tax Book</ h1 >
< h2 > Earning money</ h2 >
< p > Earning money is good.</ p >
< h3 > Getting a job</ h3 >
< p > To earn money you typically need a job.</ p >
< h2 > Spending money</ h2 >
< p > Spending is what money is mainly used for.</ p >
< h3 > Cheap things</ h3 >
< p > Buying cheap things often not cost-effective.</ p >
< h3 > Expensive things</ h3 >
< p > The most expensive thing is often not the most cost-effective either.</ p >
< h2 > Investing money</ h2 >
< p > You can lend your money to other people.</ p >
< h2 > Losing money</ h2 >
< p > If you spend money or invest money, sooner or later you will lose money.
< h3 > Poor judgement</ h3 >
< p > Usually if you lose money it's because you made a mistake.</ p > 其大纲可以如下呈现:
一个文档可以包含多个顶级标题:
<!DOCTYPE HTML>
< html lang = en >
< title > Alphabetic Fruit</ title >
< h1 > Apples</ h1 >
< p > Pomaceous.</ p >
< h1 > Bananas</ h1 >
< p > Edible.</ p >
< h1 > Carambola</ h1 >
< p > Star.</ p > 该文档的大纲可以如下呈现:
<!DOCTYPE HTML>
< html lang = "en" >
< title > We're adopting a child! — Ray's blog</ title >
< h1 > Ray's blog</ h1 >
< article >
< header >
< nav >
< a href = "?t=-1d" > Yesterday</ a > ;
< a href = "?t=-7d" > Last week</ a > ;
< a href = "?t=-1m" > Last month</ a >
</ nav >
< h2 > We're adopting a child!</ h2 >
</ header >
< p > As of today, Janine and I have signed the papers to become
the proud parents of baby Diane! We've been looking forward to
this day for weeks.</ p >
</ article >
</ html > 该文档的大纲可以如下呈现:
以下示例符合规范,但不鼓励使用,因为它没有标题的标题级别为 1:
<!DOCTYPE HTML>
< html lang = en >
< title > Alphabetic Fruit</ title >
< section >
< h2 > Apples</ h2 >
< p > Pomaceous.</ p >
</ section >
< section >
< h2 > Bananas</ h2 >
< p > Edible.</ p >
</ section >
< section >
< h2 > Carambola</ h2 >
< p > Star.</ p >
</ section > 该文档的大纲可以如下呈现:
以下示例符合规范,但不鼓励使用,因为第一个标题的标题级别不是 1:
<!DOCTYPE HTML>
< html lang = en >
< title > Feathers on The Site of Encyclopedic Knowledge</ title >
< h2 > A plea from our caretakers</ h2 >
< p > Please, we beg of you, send help! We're stuck in the server room!</ p >
< h1 > Feathers</ h1 >
< p > Epidermal growths.</ p > 该文档的大纲可以如下呈现:
鼓励用户代理向用户公开页面大纲, 以帮助导航。这对于非视觉媒体尤其如此,例如屏幕阅读器。
例如,用户代理可以按如下方式映射方向键:
本节为非规范性内容。
| 元素 | 用途 |
|---|---|
| 示例 | |
body
|
文档的内容。 |
|
|
article
|
文档、页面、应用程序或站点中的一个完整或独立的 组成部分,并且原则上可以独立 分发或复用,例如用于联合发布。这可以是论坛帖子、杂志或 报纸文章、博客条目、用户提交的评论、交互式挂件或小工具,或者任何 其他独立的内容项。 |
|
|
section
|
文档或应用程序中的通用章节。 在此上下文中,章节是内容的主题分组,通常带有 标题。 |
|
|
nav
|
页面中链接到其他 页面或页面内部各部分的章节:一个包含导航链接的章节。 |
|
|
aside
|
页面中由与 aside 元素周围内容
仅有间接关系的内容构成的章节,并且
可以将该章节视为与周围内容相分离。此类章节在印刷排版中通常表示为
侧栏。
|
|
|
h1–h6
|
标题 |
|
|
hgroup
|
标题及相关内容。该
元素可用于将一个 h1–h6
元素与一个或多个
p 元素分为一组,这些元素包含
表示副标题、替代标题或
标语的内容。
|
|
|
header
|
一组介绍性或导航 辅助内容。 |
|
|
footer
|
其最近祖先 分节内容元素的页脚,或者 如果不存在此类 祖先,则为body 元素的页脚。 页脚通常包含有关其章节的信息,例如作者、相关文档的链接、 版权数据等。 |
|
本节为非规范性内容。
section 构成其他
事物的一部分。article
本身是一个独立事物。
但如何知道哪个是哪个?多数情况下,真正的答案是“这取决于作者的意图”。
例如,可以设想一本书具有一个“Granny Smith”章节,其中只写着“These
juicy, green apples make a great filling for apple pies.”;这将是一个 section,
因为其中还会有许多关于(也许)其他苹果种类的章节。
另一方面,可以设想一条推文、reddit 评论、tumblr 帖子或报纸
分类广告,其中只写着“Granny Smith. These juicy, green apples make a great filling for
apple pies.”;那么它们将是 article,
因为那就是全部内容。
对文章的评论不属于它所评论的 article,
因此它本身就是一个 article。
p
元素所有当前引擎均支持。
所有当前引擎均支持。
hgroup
元素的子级。p 元素后面紧跟
一个 p 元素,并且该元素后面紧跟
一个 address、article、
aside、blockquote、details、dialog、
div、dl、fieldset、figcaption、
figure、footer、form、h1、
h2、
h3、
h4、
h5、
h6、
header、
hgroup、hr、main、menu、nav、
ol、p、pre、search、section、
table 或 ul 元素,则可以省略其结束标签;或者,如果父
元素中没有更多内容,并且父元素是一个HTML 元素,
且不是
一个 a、audio、del、ins、map、
noscript 或 video 元素,也不是一个自主自定义
元素。
[Exposed =Window ]
interface HTMLParagraphElement : HTMLElement {
[HTMLConstructor ] constructor ();
// also has obsolete members
};尽管在视觉媒体中,段落通常表示为通过空行与相邻文本块 物理分隔的文本块,但样式表或用户代理同样可以合理地 以不同方式呈现段落分隔,例如使用行内段落标记(¶)。
以下示例是符合规范的 HTML 片段:
< p > The little kitten gently seated herself on a piece of
carpet. Later in her life, this would be referred to as the time the
cat sat on the mat.</ p > < fieldset >
< legend > Personal information</ legend >
< p >
< label > Name: < input name = "n" ></ label >
< label >< input name = "anon" type = "checkbox" > Hide from other users</ label >
</ p >
< p >< label > Address: < textarea name = "a" ></ textarea ></ label ></ p >
</ fieldset > < p > There was once an example from Femley,< br >
Whose markup was of dubious quality.< br >
The validator complained,< br >
So the author was pained,< br >
To move the error from the markup to the rhyming.</ p > 当存在更适合的具体元素时,不应使用 p 元素。
以下示例在技术上是正确的:
< section >
<!-- ... -->
< p > Last modified: 2001-04-23</ p >
< p > Author: fred@example.com</ p >
</ section > 但是,最好按如下方式标记:
< section >
<!-- ... -->
< footer > Last modified: 2001-04-23</ footer >
< address > Author: fred@example.com</ address >
</ section > 或者:
< section >
<!-- ... -->
< footer >
< p > Last modified: 2001-04-23</ p >
< address > Author: fred@example.com</ address >
</ footer >
</ section > 列表元素(特别是 ol
和 ul 元素)不能作为
p 元素的子级。因此,当一个句子
包含项目符号列表时,人们可能会想知道
应当如何标记它。
例如,这个奇妙的句子包含与以下内容有关的项目符号:
并将在下文进一步讨论。
解决办法是认识到,在 HTML 术语中,段落不是一个 逻辑概念,而是一个结构性概念。在上述奇妙示例中,按照本规范的定义,实际上存在 五个段落: 列表之前一个,每个项目符号各一个,列表之后一个。
因此,上述示例的标记可以是:
< p > For instance, this fantastic sentence has bullets relating to</ p >
< ul >
< li > wizards,
< li > faster-than-light travel, and
< li > telepathy,
</ ul >
< p > and is further discussed below.</ p > 希望方便地为由多个“结构性”段落组成的此类“逻辑”段落设置样式的作者,可以使用 div 元素代替 p
元素。
因此,例如,上述示例可以变为以下形式:
< div > For instance, this fantastic sentence has bullets relating to
< ul >
< li > wizards,
< li > faster-than-light travel, and
< li > telepathy,
</ ul >
and is further discussed below.</ div > 此示例仍然具有五个结构性段落,但现在作者只需为
div 设置样式,而不必
分别考虑示例的每个部分。
hr
元素所有当前引擎均支持。
所有当前引擎均支持。
select 元素的后代。[Exposed =Window ]
interface HTMLHRElement : HTMLElement {
[HTMLConstructor ] constructor ();
// 还具有已废弃成员
};hr 元素表示一个段落级主题
分隔,例如故事中的场景变化,或参考书某一节内向另一个主题的过渡;或者,它表示
select 元素的一组选项之间的分隔符。
以下虚构的项目手册摘录展示了两个使用
hr 元素分隔节内主题的章节。
< section >
< h1 > 通信</ h1 >
< p > 通信方式多种多样。本节介绍项目所使用的若干
重要通信方式。</ p >
< hr >
< p > 通信石似乎总是成对出现,并具有神秘的
特性:</ p >
< ul >
< li > 单独使用时,一旦激活,它们可以双向传递
思想。</ li >
< li > 与另一台设备配合使用时,它们可以将一个人的
意识转移到另一个身体中。</ li >
< li > 如果两块石头都与另一台设备配合使用,
两人的意识将交换身体。</ li >
</ ul >
< hr >
< p > 无线电使用米级以及更长波长范围内的
电磁频谱。</ p >
< hr >
< p > 信号弹使用纳米级范围内的
电磁频谱。</ p >
</ section >
< section >
< h1 > 食物</ h1 >
< p > 项目中的所有食物均实行配给:</ p >
< dl >
< dt > 土豆</ dt >
< dd > 每天两个</ dd >
< dt > 汤</ dt >
< dd > 每天一碗</ dd >
</ dl >
< hr >
< p > 烹饪工作由厨师按照固定轮班表完成。</ p >
</ section > 以下摘自彼得·F·汉密尔顿所著的《潘多拉之星》,展示了场景转换之前的两个
段落以及其后的段落。在印刷书籍中,场景转换表现为第二个
与第三个段落之间的一块空白区域,其中有一颗孤立居中的星;此处使用 hr 元素表示。
< p > 达德利九十二岁,正处于他的第二次生命中,并且很快就要
再次接受返老还童。尽管他的身体拥有标准五十岁者的生理
年龄,但在学术界进行一场漫长而令人屈辱的
斗争,仍是他恐惧面对的事情。对于一个
号称先进的文明而言,星际联邦有时却
落后得骇人,更不用说残酷了。</ p >
< p >< i > 也许事情不会那么糟</ i > ,他对自己说。这个谎言
带来的安慰足以让他熬过当晚余下的
值班时间。</ p >
< hr >
< p > 黎明刚过,卡尔顿全地形车便载着达德利回家。和这位
天文学家一样,这辆车又旧又破,但仍完全能够
完成自己的工作。它装有廉价的柴油发动机,在
格拉蒙德这样的半边疆世界十分常见,不过它的驱动阵列却是
完全现代化的光神经处理器。凭借高悬架和
深纹轮胎,它能在各种天气和季节中沿着通往
天文台的土路前行,包括格拉蒙德冬季深达一米的
积雪。</ p > pre
元素所有当前引擎均支持。
所有当前引擎均支持。
[Exposed =Window ]
interface HTMLPreElement : HTMLElement {
[HTMLConstructor ] constructor ();
// 还具有已废弃成员
};pre 元素表示一个预格式化文本块,其中的
结构通过排版约定而不是元素来表示。
在HTML 语法中,紧跟在
pre 元素开始标签之后的
起始换行符会被移除。
可以使用 pre 元素的一些情况示例:
建议作者考虑当格式丢失时用户会如何体验预格式化文本, 语音合成器、盲文显示器等设备的用户便会遇到这种情况。对于 ASCII 艺术之类的情况, 替代呈现形式(例如文本描述)可能更便于文档的 所有读者访问。
若要表示计算机代码块,可以将 pre 元素与
code 元素结合使用;若要表示
计算机输出块,可以将 pre
元素
与 samp 元素结合使用。
类似地,可以在 pre 元素
内使用 kbd 元素,以指示
用户需要输入的文本。
此元素具有涉及双向文本算法的 渲染要求。
以下代码片段展示了一个计算机代码示例。
< p > 这是 < code > Panel</ code > 构造函数:</ p >
< pre >< code > function Panel(element, canClose, closeHandler) {
this.element = element;
this.canClose = canClose;
this.closeHandler = function () { if (closeHandler) closeHandler() };
}</ code ></ pre > 在以下代码片段中,samp 和 kbd 元素混合用于
pre 元素的内容中,以
展示一次《魔域 I》游戏过程。
< pre >< samp > 你身处一片开阔的田野,西边是一座前门被木板封住的
白色大房子。
这里有一个小邮箱。
></ samp > < kbd > 打开邮箱</ kbd >
< samp > 打开邮箱后发现:
一张传单。
></ samp ></ pre > 以下展示了一首当代诗歌,它使用 pre 元素保留其
不寻常的格式,而这种格式本身就是该诗不可分割的一部分。
< pre > maxling
我怀着一颗 沉重的
心
承认失去了一只猫
如此 深爱
一位朋友消失在
未知之中
(夜)
~cdr 11dec07</ pre > blockquote 元素
所有当前引擎均支持。
所有当前引擎均支持。
cite — 指向
引用来源或有关编辑的更多信息的链接
cite 属性。
[Exposed =Window ]
interface HTMLQuoteElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , ReflectURL ] attribute USVString cite ;
};HTMLQuoteElement 接口
也由 q
元素使用。
blockquote 元素
表示一个引用自
其他来源的章节。
blockquote
内的内容必须
引用自其他来源;如果该来源有地址,则可以在 cite 属性中引用该地址。
如果存在 cite
属性,则其必须是
可能由空格包围的有效
URL。要获得
对应的引用链接,必须相对于元素的节点文档解析该属性的值。用户代理可以
允许用户访问此类引用链接,但它们主要用于私有用途(例如,
由服务器端脚本收集站点使用引用情况的统计信息),而不是供
读者使用。
blockquote
的内容可以
按照该文本语言的惯例进行缩写或添加
上下文。
例如,在英语中,这通常使用方括号完成。假设某个页面包含 “Jane ate the cracker. She then said she liked apples and fish.”这句话;可以按 如下方式引用:
< blockquote >
< p > [简]随后说她喜欢……鱼。</ p >
</ blockquote > 引用的署名信息(如有)必须放在 blockquote
元素之外。
例如,此处的署名信息位于引用之后的一个段落中:
< blockquote >
< p > 我认为我们都是无神论者。只不过我比你少相信
一个神。当你理解自己为何否定所有其他
可能存在的神时,你也会理解我为何否定你所信的神。</ p >
</ blockquote >
< p > — 斯蒂芬·罗伯茨</ p > 下面的其他示例展示了其他署名方式。
此处将 blockquote
元素与 figure
元素及其 figcaption
结合使用,以
明确关联引用及其署名信息(署名信息
不属于引用内容,因此不应放在 blockquote
本身内部):
< figure >
< blockquote >
< p > 真相可能令人困惑。理解它可能需要付出一些努力。
它可能违反直觉,可能与根深蒂固的
偏见相冲突,也可能与我们迫切希望
成真的事物并不一致。但我们的偏好并不能决定何为真相。我们有一种
方法,而这种方法帮助我们抵达的并非绝对真理,而只是
渐近地接近真理——永远无法真正抵达,只会越来越
接近,同时不断发现大片尚未探索的
可能性海洋。精心设计的实验是关键。</ p >
</ blockquote >
< figcaption > 卡尔·萨根,摘自《< cite > 惊奇与怀疑主义</ cite > 》,刊载于
《< cite > 怀疑论调查者</ cite > 》第 19 卷第 1 期(1995 年
1—2 月)</ figcaption >
</ figure > 下一个示例展示了将 cite 与 blockquote
配合使用:
< p > 他的下一首作品有一个恰如其分的名称——< cite > 十四行诗第 130 首</ cite > :</ p >
< blockquote cite = "https://quotes.example.org/s/sonnet130.html" >
< p > 我情人的眼睛一点也不像太阳,< br >
珊瑚远比她双唇的红色更红,< br >
……此示例展示了论坛帖子如何使用 blockquote
来显示用户
正在回复的帖子。每个帖子都使用 article 元素,
以标记帖子之间的
线程关系。
< article >
< h1 >< a href = "https://bacon.example.com/?blog=109431" > 撬棍上的培根</ a ></ h1 >
< article >
< header >< strong > t3yw</ strong > 12 分,1 小时前</ header >
< p > 我敢说独角鲸肯定会喜欢那个。</ p >
< footer >< a href = "?pid=29578" > 永久链接</ a ></ footer >
< article >
< header >< strong > greg</ strong > 8 分,1 小时前</ header >
< blockquote >< p > 我敢说独角鲸肯定会喜欢那个。</ p ></ blockquote >
< p > 老兄,独角鲸不吃培根。</ p >
< footer >< a href = "?pid=29579" > 永久链接</ a ></ footer >
< article >
< header >< strong > t3yw</ strong > 15 分,1 小时前</ header >
< blockquote >
< blockquote >< p > 我敢说独角鲸肯定会喜欢那个。</ p ></ blockquote >
< p > 老兄,独角鲸不吃培根。</ p >
</ blockquote >
< p > 接下来你是不是还要说它们也没有斗篷和巫师
帽!</ p >
< footer >< a href = "?pid=29580" > 永久链接</ a ></ footer >
< article >
< article >
< header >< strong > boing</ strong > -5 分,1 小时前</ header >
< p > 独角鲸比天花板猫还糟糕</ p >
< footer >< a href = "?pid=29581" > 永久链接</ a ></ footer >
</ article >
</ article >
</ article >
</ article >
< article >
< header >< strong > fred</ strong > 1 分,23 分钟前</ header >
< blockquote >< p > 我敢说独角鲸肯定会喜欢那个。</ p ></ blockquote >
< p > 我敢说它们也会喜欢剥香蕉。</ p >
< footer >< a href = "?pid=29582" > 永久链接</ a ></ footer >
</ article >
</ article >
</ article > 此示例展示了将 blockquote 用于
短片段,说明
不一定要在 blockquote
元素内使用 p
元素:
< p > 他的“经验教训”列表以下列内容开头:</ p >
< blockquote > 绝不能想当然地认为自己对
问题的看法会得到认可,更不能认为其
优点会得到承认。</ blockquote >
< p > 他继续列举了一些类似的观点,最后写道:</ p >
< blockquote > 最后,应当随时做好谈判
破裂的准备,而不能因这种可能性
而退缩。</ blockquote >
< p > 下面我们将讨论这些观点……后面的章节展示了如何表示对话的示例;
不应为此目的使用 cite 和 blockquote
元素。
ol
元素所有当前引擎均支持。
所有当前引擎均支持。
li 元素:可感知内容。li 元素和脚本支持
元素。reversed — 反向为列表
编号
start — 列表的起始值
type — 列表标记的类型
reversed、start、type 属性。
[Exposed =Window ]
interface HTMLOListElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect ] attribute boolean reversed ;
[CEReactions , Reflect , ReflectDefault=1] attribute long start ;
[CEReactions , Reflect ] attribute DOMString type ;
// 还具有已废弃成员
};ol 元素表示一个项目列表,其中的项目经过
有意排序,以致更改其顺序将改变文档的含义。
列表的项目是 li
元素的子节点,这些子节点属于 ol
元素,并按树顺序排列。
所有当前引擎均支持。
reversed 属性
是一个布尔属性。如果存在,则
表示该列表是降序列表
(……、3、2、1)。如果省略该属性,则列表为升序列表(1、2、3、……)。
如果存在 start 属性,
则其必须是一个有效整数。它用于
确定列表的起始值。
ol 元素具有一个起始值,它是
按如下方式确定的整数:
type 属性可用于
在标记类型有意义的情况下,指定列表中使用的标记类型(例如,
因为项目将通过其编号或字母被引用)。
如果指定了该属性,
则其值必须与下表某一行
第一个单元格中给出的字符之一相同。type 属性表示其属性值与第一列
单元格匹配的那一行第二
列单元格中给出的状态;如果没有任何单元格匹配,或者
省略了该属性,则该属性表示十进制状态。
| 关键字 | 状态 | 描述 | 值为 1—3 和 3999—4001 时的示例 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
1
(U+0031)
|
decimal | 十进制数字 | 1. | 2. | 3. | …… | 3999. | 4000. | 4001. | …… |
a (U+0061)
|
lower-alpha | 小写拉丁字母 | a. | b. | c. | …… | ewu. | ewv. | eww. | …… |
A (U+0041)
|
upper-alpha | 大写拉丁字母 | A. | B. | C. | …… | EWU. | EWV. | EWW. | …… |
i (U+0069)
|
lower-roman | 小写罗马数字 | i. | ii. | iii. | …… | mmmcmxcix. | i̅v̅. | i̅v̅i. | …… |
I (U+0049)
|
upper-roman | 大写罗马数字 | I. | II. | III. | …… | MMMCMXCIX. | I̅V̅. | I̅V̅I. | …… |
用户代理应以与 ol 元素的 type 属性状态一致的方式渲染列表项目。小于
或等于零的数字应始终使用十进制系统,而不考虑 type 属性。
对于 CSS 用户代理,本属性到 'list-style-type' CSS 属性的映射在渲染 章节中给出(该映射很直接:上述状态与其 对应的 CSS 值具有相同的名称)。
可以重新定义 CSS 用户代理用于实现本属性的默认 CSS 列表样式; 这样做将影响列表项目的渲染方式。
由于 [ReflectDefault],
在省略 start 内容
属性并指定 reversed 内容属性的情况下,
start IDL 属性不一定
与列表的起始值一致。
以下标记展示了一个顺序很重要的列表,因此使用 ol
元素是合适的。将此列表与 ul
章节中的等效列表进行比较,可查看使用 ul 元素表示相同项目的示例。
< p > 我曾在以下国家生活过(按照我
首次在那里生活的时间排序):</ p >
< ol >
< li > 瑞士
< li > 英国
< li > 美国
< li > 挪威
</ ol > 请注意,更改列表顺序会改变文档的含义。在以下 示例中,更改前两个项目的相对顺序改变了 作者的出生地:
< p > 我曾在以下国家生活过(按照我
首次在那里生活的时间排序):</ p >
< ol >
< li > 英国
< li > 瑞士
< li > 美国
< li > 挪威
</ ol > ul
元素所有当前引擎均支持。
所有当前引擎均支持。
li 元素:可感知内容。li 元素和脚本支持
元素。[Exposed =Window ]
interface HTMLUListElement : HTMLElement {
[HTMLConstructor ] constructor ();
// 还具有已废弃成员
};ul 元素表示一个项目列表,其中项目的
顺序并不重要——也就是说,更改顺序不会实质性地改变
文档的含义。
列表的项目是 li
元素的子节点,这些子节点属于 ul
元素。
以下标记展示了一个顺序无关紧要的列表,因此
使用 ul 元素是
合适的。将此列表与
ol 章节中的等效列表比较,可查看
使用 ol
元素表示相同项目的示例。
< p > 我曾在以下国家生活过:</ p >
< ul >
< li > 挪威
< li > 瑞士
< li > 英国
< li > 美国
</ ul > 请注意,更改列表顺序不会改变文档的含义。上面 代码片段中的项目按字母顺序给出,而下面的代码片段则 按照它们在 2007 年的当前账户余额大小排列,但这完全没有改变 文档的含义:
< p > 我曾在以下国家生活过:</ p >
< ul >
< li > 瑞士
< li > 挪威
< li > 英国
< li > 美国
</ ul > menu 元素所有当前引擎均支持。
所有当前引擎均支持。
li 元素:可感知内容。li 元素和脚本支持
元素。[Exposed =Window ]
interface HTMLMenuElement : HTMLElement {
[HTMLConstructor ] constructor ();
// 还具有已废弃成员
};menu 元素表示一个由其内容组成的工具栏,其形式为
项目的无序列表(由 li 元素表示),其中每个项目
表示用户可以执行或激活的命令。
menu 元素
只是 ul
的语义替代方案,用于表示命令的无序列表(“工具栏”)。
在此示例中,文本编辑应用程序使用 menu 元素提供一
系列编辑命令:
< menu >
< li >< button onclick = "copy()" >< img src = "copy.svg" alt = "复制" ></ button ></ li >
< li >< button onclick = "cut()" >< img src = "cut.svg" alt = "剪切" ></ button ></ li >
< li >< button onclick = "paste()" >< img src = "paste.svg" alt = "粘贴" ></ button ></ li >
</ menu > 请注意,要使其看起来像传统的工具栏菜单,具体样式由 应用程序决定。
li
元素所有当前引擎均支持。
所有当前引擎均支持。
ol 元素内。ul 元素内。menu 元素内。li 元素后紧跟着
另一个 li 元素,或者
父元素中已无更多内容,则可以省略该
li 元素的结束标签。
ul 或 menu 元素的子项:value — 列表项目的序数值
value 属性。
[Exposed =Window ]
interface HTMLLIElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect ] attribute long value ;
// 还具有已废弃成员
};li 元素表示一个列表项目。如果其父元素是
ol、ul 或 menu 元素,则按照这些元素的
定义,该元素是父元素列表中的一个
项目。否则,该列表项目与任何其他 li 元素之间没有已定义的
列表相关关系。
如果存在 value 属性,
则其必须是一个有效整数。当 li 的列表所有者是
ol 元素时,它用于
确定列表项目的序数
值。
要确定给定列表 所有者 owner 所拥有的每个元素的序数值,请执行以下步骤:
令 i 为 1。
如果 owner 是 ol
元素,则令 numbering 为
owner 的起始值。
否则,令
numbering 为 1。
循环:如果 i 大于owner 所拥有的列表项目数量,则返回;owner 所拥有的所有列表项目都已被 分配序数值。
令 parsed 为将 属性值解析为整数的结果。
如果 parsed 不是错误,则将 numbering 设置为 parsed。
item 的序数值为 numbering。
如果 owner 是 ol
元素,并且 owner 具有 reversed 属性,则将
numbering 减 1;
否则,将 numbering 加 1。
将 i 加 1。
转到标记为循环的步骤。
以下示例按倒序列出了排名前十的电影。请注意如何通过使用 figure 元素及其 figcaption
元素为列表添加标题。
< figure >
< figcaption > 史上十大电影</ figcaption >
< ol >
< li value = "10" >< cite > 《乔茜与小猫乐队》</ cite > ,2001</ li >
< li value = "9" >< cite lang = "sh" > Црна мачка, бели мачор</ cite > ,1998</ li >
< li value = "8" >< cite > 《虫虫危机》</ cite > ,1998</ li >
< li value = "7" >< cite > 《玩具总动员》</ cite > ,1995</ li >
< li value = "6" >< cite > 《怪兽电力公司》</ cite > ,2001</ li >
< li value = "5" >< cite > 《赛车总动员》</ cite > ,2006</ li >
< li value = "4" >< cite > 《玩具总动员 2》</ cite > ,1999</ li >
< li value = "3" >< cite > 《海底总动员》</ cite > ,2003</ li >
< li value = "2" >< cite > 《超人总动员》</ cite > ,2004</ li >
< li value = "1" >< cite > 《料理鼠王》</ cite > ,2007</ li >
</ ol >
</ figure > 也可以按如下方式编写标记,在 ol 元素上使用 reversed 属性:
< figure >
< figcaption > 史上十大电影</ figcaption >
< ol reversed >
< li >< cite > 《乔茜与小猫乐队》</ cite > ,2001</ li >
< li >< cite lang = "sh" > Црна мачка, бели мачор</ cite > ,1998</ li >
< li >< cite > 《虫虫危机》</ cite > ,1998</ li >
< li >< cite > 《玩具总动员》</ cite > ,1995</ li >
< li >< cite > 《怪兽电力公司》</ cite > ,2001</ li >
< li >< cite > 《赛车总动员》</ cite > ,2006</ li >
< li >< cite > 《玩具总动员 2》</ cite > ,1999</ li >
< li >< cite > 《海底总动员》</ cite > ,2003</ li >
< li >< cite > 《超人总动员》</ cite > ,2004</ li >
< li >< cite > 《料理鼠王》</ cite > ,2007</ li >
</ ol >
</ figure > 虽然在
li 元素内包含标题元素(例如 h1)
是符合要求的,但这很可能无法
传达作者所意图的语义。标题会开始一个新章节,因此列表中的标题会隐式地将列表拆分为
横跨多个章节的内容。
dl
元素所有当前引擎均支持。
所有当前引擎均支持。
dt
元素后跟一个或多个
dd 元素组成,并可选择与脚本支持
元素混合。
div 元素,
并可选择与脚本支持元素混合。[Exposed =Window ]
interface HTMLDListElement : HTMLElement {
[HTMLConstructor ] constructor ();
// 还具有已废弃成员
};dl 元素表示一个由零个或
多个名称-值组组成的关联列表(描述列表)。名称-值组由一个或多个名称
(dt 元素,可能作为 div 元素子项的子项)后跟
一个或多个值(dd 元素,
可能作为 div
元素子项的子项)组成;确定时忽略除 dt 和 dd 元素子项,以及作为 div 元素
子项之子项的 dt 和 dd 元素之外的任何节点。在单个
dl
元素内,每个名称不应有多个
dt 元素。
名称-值组可以是术语与定义、元数据主题与值、问题与 答案,或任何其他名称-值数据组。
组内的值是可选方案;构成同一个值的多个段落
必须全部放在同一个 dd
元素内。
组列表的顺序,以及每个组中名称和值的顺序,都可能 具有重要意义。
为了使用微数据属性为组添加注释,或者应用
适用于整个组的其他全局
属性,又或者仅出于样式目的,可以将
dl 元素中的每个组包装在 div 元素中。这不会改变
dl 元素的语义。
dl
元素 dl 的名称-值组使用
以下算法确定。名称-值组具有一个名称(dt 元素列表,初始
为空)和一个值(dd
元素列表,初始为空)。
令 groups 为空的名称-值组列表。
令 current 为一个新的名称-值组。
令 seenDd 为 false。
令 child 为 dl 的第一个 子节点。
令 grandchild 为 null。
当 child 不为 null 时:
如果 child 是 div 元素:
令 grandchild 为 child 的第一个 子节点。
当 grandchild 不为 null 时:
为 grandchild
处理 dt 或
dd。
将 grandchild 设置为 grandchild 的下一个 兄弟节点。
否则,为 child
处理 dt
或 dd。
将 child 设置为 child 的下一个 兄弟节点。
如果 current 不为空,则将 current 追加到 groups。
返回 groups。
当名称-值组的名称或值为空列表时,通常是由于
错误地用 dd 元素代替
dt 元素,或反之。
一致性检查器可以发现此类错误,并且可能能够建议作者如何
正确使用标记。
在以下示例中,一个条目(“作者”)关联到两个值(“John”和 “Luke”)。
< dl >
< dt > 作者
< dd > John
< dd > Luke
< dt > 编辑
< dd > Frank
</ dl > 在以下示例中,一个定义关联到两个术语。
< dl >
< dt lang = "en-US" > < dfn > color</ dfn > </ dt >
< dt lang = "en-GB" > < dfn > colour</ dfn > </ dt >
< dd > 一种感觉,它(在人类中)源自
眼睛的精细结构区分同一视图的三种不同
滤波分析结果的能力。</ dd >
</ dl > 以下示例说明如何使用 dl 元素标记某种
元数据。在示例末尾,一个组具有两个元数据标签(“作者”和“编辑”)
以及两个值(“Robert Rothman”和“Daniel Jackson”)。此示例还在
dt 和 dd 元素的组外使用
div 元素,以便
设置样式。
< dl >
< div >
< dt > 最后修改时间 </ dt >
< dd > 2004-12-23T23:33Z </ dd >
</ div >
< div >
< dt > 建议更新间隔 </ dt >
< dd > 60s </ dd >
</ div >
< div >
< dt > 作者 </ dt >
< dt > 编辑 </ dt >
< dd > Robert Rothman </ dd >
< dd > Daniel Jackson </ dd >
</ div >
</ dl > 以下示例展示了使用 dl 元素给出一组
指令。
此处指令的顺序很重要(在其他示例中,各块的顺序
并不重要)。
< p > 按如下方式确定胜利点数(使用
第一个匹配的情况):</ p >
< dl >
< dt > 如果你恰好有五枚金币 </ dt >
< dd > 你获得五个胜利点 </ dd >
< dt > 如果你有一枚或多枚金币,并且有一枚或多枚银币 </ dt >
< dd > 你获得两个胜利点 </ dd >
< dt > 如果你有一枚或多枚银币 </ dt >
< dd > 你获得一个胜利点 </ dd >
< dt > 否则 </ dt >
< dd > 你不会获得胜利点 </ dd >
</ dl > 以下代码片段展示了将 dl
元素用作术语表。请注意使用
dfn 来指示正在
定义的词。
< dl >
< dt >< dfn > Apartment</ dfn > ,名词</ dt >
< dd > 将一个或多个线程与一个或
多个 COM 对象分组的执行上下文。</ dd >
< dt >< dfn > Flat</ dfn > ,名词</ dt >
< dd > 漏气的轮胎。</ dd >
< dt >< dfn > Home</ dfn > ,名词</ dt >
< dd > 用户的登录目录。</ dd >
</ dl > 此示例在 dl 元素中结合
div 元素使用微数据属性,以
注释一家法国餐厅的冰淇淋甜点。
< dl >
< div itemscope itemtype = "http://schema.org/Product" >
< dt itemprop = "name" > Café ou Chocolat Liégeois
< dd itemprop = "offers" itemscope itemtype = "http://schema.org/Offer" >
< span itemprop = "price" > 3.50</ span >
< data itemprop = "priceCurrency" value = "EUR" > €</ data >
< dd itemprop = "description" >
2 boules Café ou Chocolat, 1 boule Vanille, sauce café ou chocolat, chantilly
</ div >
< div itemscope itemtype = "http://schema.org/Product" >
< dt itemprop = "name" > Américaine
< dd itemprop = "offers" itemscope itemtype = "http://schema.org/Offer" >
< span itemprop = "price" > 3.50</ span >
< data itemprop = "priceCurrency" value = "EUR" > €</ data >
< dd itemprop = "description" >
1 boule Crème brûlée, 1 boule Vanille, 1 boule Caramel, chantilly
</ div >
</ dl > 如果没有 div 元素,
标记将需要使用 itemref
属性,将 dd 元素中的数据
与项目关联起来,如下所示。
< dl >
< dt itemscope itemtype = "http://schema.org/Product" itemref = "1-offer 1-description" >
< span itemprop = "name" > Café ou Chocolat Liégeois</ span >
< dd id = "1-offer" itemprop = "offers" itemscope itemtype = "http://schema.org/Offer" >
< span itemprop = "price" > 3.50</ span >
< data itemprop = "priceCurrency" value = "EUR" > €</ data >
< dd id = "1-description" itemprop = "description" >
2 boules Café ou Chocolat, 1 boule Vanille, sauce café ou chocolat, chantilly
< dt itemscope itemtype = "http://schema.org/Product" itemref = "2-offer 2-description" >
< span itemprop = "name" > Américaine</ span >
< dd id = "2-offer" itemprop = "offers" itemscope itemtype = "http://schema.org/Offer" >
< span itemprop = "price" > 3.50</ span >
< data itemprop = "priceCurrency" value = "EUR" > €</ data >
< dd id = "2-description" itemprop = "description" >
1 boule Crème brûlée, 1 boule Vanille, 1 boule Caramel, chantilly
</ dl > dl 元素
不适合用于标记对话。请参阅一些如何标记对话的示例。
dt
元素所有当前引擎均支持。
dl 元素内的 dd 或 dt 元素之前。dl 元素子项的 div 元素内的 dd 或 dt 元素之前。
header、footer、分节内容或标题内容后代。dt 元素后紧跟着
另一个 dt 元素或一个
dd 元素,则可以省略该
dt 元素的结束标签。
HTMLElement。dt 元素表示描述列表(dl 元素)中
术语-描述组的术语或名称部分。
dt 元素本身
在 dl 元素中使用时,
并不表示其内容是正在定义的术语,但可以使用
dfn 元素表明这一点。
此示例展示了使用
dt 元素标记问题,并使用
dd 元素标记答案的
常见问题列表(FAQ)。
< article >
< h1 > 常见问题</ h1 >
< dl >
< dt > 我们想要什么?</ dt >
< dd > 我们的数据。</ dd >
< dt > 我们什么时候要?</ dt >
< dd > 现在。</ dd >
< dt > 数据在哪里?</ dt >
< dd > 我们不确定。</ dd >
</ dl >
</ article > dd
元素所有当前引擎均支持。
dl 元素内的 dt 或 dd 元素之后。dl 元素子项的 div 元素内的 dt 或 dd 元素之后。
dd 元素后紧跟着
另一个 dd 元素或一个
dt 元素,或者父元素中
已无更多内容,则可以省略该 dd 元素的结束标签。
HTMLElement。dd 元素表示描述列表(dl 元素)中
术语-描述组的描述、定义或值部分。
dl 可用于定义类似字典的
词汇表。在以下示例中,每个由包含 dfn 的 dt 给出的条目都有多个
dd,用于展示定义的
各个部分。
< dl >
< dt >< dfn > 幸福</ dfn ></ dt >
< dd class = "pronunciation" > /ˈhæpinəs/</ dd >
< dd class = "part-of-speech" >< i >< abbr > 名词</ abbr ></ i ></ dd >
< dd > 感到幸福的状态。</ dd >
< dd > 好运;成功。< q > 啊,真< b > 幸福</ b > !成功了!</ q ></ dd >
< dt >< dfn > 欣喜</ dfn ></ dt >
< dd class = "pronunciation" > /rɪˈdʒɔɪs/</ dd >
< dd >< i class = "part-of-speech" >< abbr > 不及物动词</ abbr ></ i > 自己感到高兴。</ dd >
< dd >< i class = "part-of-speech" >< abbr > 及物动词</ abbr ></ i > 使某人感到高兴。</ dd >
</ dl > figure
元素所有当前引擎均支持。
figcaption 元素,
后跟流式内容。figcaption
元素。HTMLElement。figure 元素表示某些流式内容,
可以带有说明文字,并且这些内容是独立的(如一个完整的句子),通常会从文档的主流中
作为一个整体被引用。
此处的“独立”不一定意味着不依赖其他内容。例如,
段落中的每个句子都是独立的;作为句子一部分的图像不适合使用 figure,但完全由
图像组成的整个句子则适合。
因此,该元素可用于标记插图、图表、照片、代码清单等。
当文档的主要内容通过 figure
的说明文字
(例如图号)识别并引用它时,便可以轻松地将该内容从主要内容旁移开,例如移到页面一侧、
专用页面或附录中,而不会影响文档的流。
如果通过相对位置引用一个 figure 元素,例如
“在上面的照片中”或“如下一个图所示”,那么移动该图将破坏页面的含义。建议作者考虑使用标签
引用图,而不要使用此类相对引用,以便可以轻松地重新设置页面样式而不影响页面含义。
元素的第一个 figcaption 子元素
(如有)表示 figure 元素内容的说明文字。
如果没有 figcaption
子元素,则没有说明文字。
figure 元素的
内容是周围流的一部分。如果页面的目的就是显示该图,例如图像共享网站上的照片,则可以使用
figure 和 figcaption 元素
明确为该图提供说明文字。对于仅与周围流间接相关或具有不同用途的内容,应使用 aside 元素(其本身也可以
包装一个 figure)。
例如,重复 article 内容的突出引文
更适合放在 aside
中,而不是 figure 中,因为它不是
内容本身的一部分,而是为了吸引读者或突出关键主题而对内容进行的重复。
此示例展示了使用 figure 元素标记
代码清单。
< p > 在 < a href = "#l4" > 清单 4</ a > 中,我们可以看到主要核心接口的
API 声明。</ p >
< figure id = "l4" >
< figcaption > 清单 4。主要核心接口的 API 声明。</ figcaption >
< pre >< code > interface PrimaryCore {
boolean verifyDataLine();
undefined sendData(sequence< byte> data);
undefined initSelfDestruct();
}</ code ></ pre >
</ figure >
< p > 该 API 被设计为使用 UTF-8。</ p > 这里我们看到使用 figure
元素标记作为页面主要内容的照片(如画廊中所示)。
<!DOCTYPE HTML>
< html lang = "en" >
< title > 工作中的 Bubbles — 我的画廊™</ title >
< figure >
< img src = "bubbles-work.jpeg"
alt = "Bubbles 坐在办公室椅子上,专注地处理他的
最新项目。" >
< figcaption > 工作中的 Bubbles</ figcaption >
</ figure >
< nav >< a href = "19414.html" > 上一张</ a > — < a href = "19416.html" > 下一张</ a ></ nav > 在此示例中,我们可以看到一个不是图的图像,以及另一个图像和一个
视频,它们都是图。第一个图像实际上是示例第二句话的一部分,因此它不是
独立单元,所以不适合使用 figure。
< h2 > Malinko 的漫画</ h2 >
< p > 此案围绕某种与漫画有关的“知识产权”
侵权展开(见证物 A)。诉讼是在一则以以下文字结尾的
预告片播出后开始的:
< blockquote >
< img src = "promblem-packed-action.png" alt = "粗糙副本!充满问题的动作场面!" >
</ blockquote >
< p > ……播出了。一名带着更大笔记本的律师使用雪球
发动了先发制人的攻击。预告片的完整副本
随证物 B 一并提供。
< figure >
< img src = "ex-a.png" alt = "一张脏纸上的两条曲线。" >
< figcaption > 证物 A。被指控的《< cite > 粗糙副本</ cite > 》漫画。</ figcaption >
</ figure >
< figure >
< video src = "ex-b.mov" ></ video >
< figcaption > 证物 B。《< cite > 粗糙副本</ cite > 》预告片。</ figcaption >
</ figure >
< p > 该案件在庭外和解。此处使用 figure
标记诗歌的一部分。
< figure >
< p > 正值暮色,滑溜的托夫兽< br >
在草地上旋转穿梭;< br >
波罗哥夫鸟全都虚弱不堪,< br >
而莫姆拉斯兽发出哀嚎。</ p >
< figcaption >< cite > 《炸脖龙》</ cite > (第一节)。刘易斯·卡罗尔,1832—1898</ figcaption >
</ figure > 在此示例中,它可以是讨论一座城堡的更大型作品的一部分,嵌套的
figure 元素
用于为组提供整体说明文字,并为组中的每个图提供单独的说明文字:
< figure >
< figcaption > 不同年代的城堡:依次为 1423 年、1858 年和 1999 年。</ figcaption >
< figure >
< figcaption > 蚀刻画。作者不详,约 1423 年。</ figcaption >
< img src = "castle1423.jpeg" alt = "城堡有一座塔楼,周围环绕着一堵高墙。" >
</ figure >
< figure >
< figcaption > 布面油画。Maria Towle,1858 年。</ figcaption >
< img src = "castle1858.jpeg" alt = "城堡现在有两座塔楼和两堵墙。" >
</ figure >
< figure >
< figcaption > 胶片照片。Peter Jankle,1999 年。</ figcaption >
< img src = "castle1999.jpeg" alt = "城堡已成废墟,只有原来的塔楼仍完整保留。" >
</ figure >
</ figure > 前一个示例也可以更简洁地写成如下形式(使用 title 属性代替嵌套的
figure/figcaption 对):
< figure >
< img src = "castle1423.jpeg" title = "蚀刻画。作者不详,约 1423 年。"
alt = "城堡有一座塔楼,周围环绕着一堵高墙。" >
< img src = "castle1858.jpeg" title = "布面油画。Maria Towle,1858 年。"
alt = "城堡现在有两座塔楼和两堵墙。" >
< img src = "castle1999.jpeg" title = "胶片照片。Peter Jankle,1999 年。"
alt = "城堡已成废墟,只有原来的塔楼仍完整保留。" >
< figcaption > 不同年代的城堡:依次为 1423 年、1858 年和 1999 年。</ figcaption >
</ figure > 有时内容只会隐式地引用图:
< article >
< h1 > 期限临近,国会财政谈判陷入僵局</ h1 >
< figure >
< img src = "obama-reid.jpeg" alt = "奥巴马和里德面带微笑,一同坐在椭圆形办公室中。" >
< figcaption > 巴拉克·奥巴马和哈里·里德。白宫新闻照片。</ figcaption >
</ figure >
< p > 周二,国会为结束财政僵局而进行的谈判断断续续,使参众两院都在寻找
重新开放政府并提高国家举债权限的方法,而周四的最后期限正在临近。</ p >
...
</ article > figcaption 元素
所有当前引擎均支持。
figure 元素的
第一个或最后一个子项。HTMLElement。figcaption 元素
表示其父 figure 元素
(如有)中除该 figcaption
元素以外其余内容的说明文字或图例。
该元素可以包含有关来源的附加信息:
< figcaption >
< p > 一只鸭子。</ p >
< p >< small > 照片由 🌟 新闻提供。</ small ></ p >
</ figcaption > < figcaption >
< p > 三居室公寓的平均租金,不包括非营利公寓</ p >
< p > 苏黎世统计局 — < time datetime = 2017-11-14 > 2017 年 11 月 14 日</ time ></ p >
</ figcaption > main
元素所有当前引擎均支持。
main 元素时。HTMLElement。文档中不得有多个未指定 属性的 main 元素。
层次结构正确的 main 元素是指其祖先元素
仅限于 html、body、div、不具有
无障碍名称的 form,以及自主自定义元素的元素。每个 main 元素都必须是
层次结构正确的
main
元素。
在此示例中,作者使用了一种将页面的每个组成部分渲染在盒中的呈现方式。为了包装页面的
主要内容(而不是页眉、页脚、导航栏和侧边栏),使用了 main 元素。
<!DOCTYPE html>
< html lang = "en" >
< title > RPG 系统 17</ title >
< style >
header , nav , aside , main , footer {
margin : 0.5 em ; border : thin solid ; padding : 0.5 em ;
background : #EFF ; color : black ; box-shadow : 0 0 0.25 em #033 ;
}
h1 , h2 , p { margin : 0 ; }
nav , main { float : left ; }
aside { float : right ; }
footer { clear : both ; }
</ style >
< header >
< h1 > 系统十八</ h1 >
</ header >
< nav >
< a href = "../16/" > ← 系统 17</ a >
< a href = "../18/" > RPXIX →</ a >
</ nav >
< aside >
< p > 这个系统没有生命值机制,因此也没有治疗。
</ aside >
< main >
< h2 > 创建角色</ h2 >
< p > 属性(魔法、力量、敏捷)按每级一点的成本购买。</ p >
< h2 > 掷骰</ h2 >
< p > 每次遭遇时,为你的所有技能掷骰。如果你的点数高于对手,你便获胜。</ p >
</ main >
< footer >
< p > 版权所有 © 2013
</ footer >
</ html > 在以下示例中,使用了多个 main 元素,并使用脚本
使导航无需与服务器往返即可工作,同时在非当前元素上设置 属性:
<!doctype html>
< html lang = en-CA >
< meta charset = utf-8 >
< title > … </ title >
< link rel = stylesheet href = spa.css >
< script src = spa.js async ></ script >
< nav >
< a href = / > 首页</ a >
< a href = /about > 关于</ a >
< a href = /contact > 联系</ a >
</ nav >
< main >
< h1 > 首页</ h1 >
…
</ main >
< main hidden >
< h1 > 关于</ h1 >
…
</ main >
< main hidden >
< h1 > 联系</ h1 >
…
</ main >
< footer > 由 < a href = https://example.com/ > Example 👻</ a > 用 ❤️ 制作。</ footer > search
元素当前引擎均不支持。
HTMLElement。search 元素表示文档或应用程序中包含一组表单控件或其他
与执行搜索或筛选操作有关的内容的部分。这可以是搜索网站或应用程序;在当前网页上搜索或筛选
搜索结果的方式;或者全局或互联网范围的搜索功能。
不宜仅使用 search 元素来呈现
搜索结果,不过作为“快速搜索”结果一部分的建议和链接可以包含在搜索功能中。相反,返回的
搜索结果网页通常应作为该网页主要内容的一部分呈现。
在以下示例中,作者在网页的
header 中包含
一个搜索表单:
< header >
< h1 >< a href = "/" > 我的精美博客</ a ></ h1 >
...
< search >
< form action = "search.php" >
< label for = "query" > 查找文章</ label >
< input id = "query" name = "q" type = "search" >
< button type = "submit" > 搜索!</ button >
</ form >
</ search >
</ header > 在此示例中,作者完全使用 JavaScript 实现了其 Web 应用程序的搜索功能。没有使用 form 元素执行服务器端提交,
但包含它的 search 元素在语义上
将后代内容的用途标识为表示搜索功能。
< search >
< label >
查找并筛选你的查询
< input type = "search" id = "query" >
</ label >
< label >
< input type = "checkbox" id = "exact-only" >
仅精确匹配
</ label >
< section >
< h3 > 找到的结果:</ h3 >
< ul id = "results" >
< li >
< p >< a href = "services/consulting" > 咨询服务</ a ></ p >
< p >
了解我们的综合顾问 Bob 和 Bob 如何帮助你改善业务。
</ p >
</ li >
...
</ ul >
<!--
当查询未返回任何结果或筛选掉所有结果时
在此处渲染无结果消息
-->
< output id = "no-results" ></ output >
</ section >
</ search > 在以下示例中,页面具有两个搜索功能。第一个位于网页的
header 中,作为
搜索网站内容的全局机制。其用途由指定的 title
属性表明。第二个
作为页面主要内容的一部分,因为它表示搜索和筛选当前页面内容的机制。它包含
一个用于表明其用途的标题。
< body >
< header >
...
< search title = "网站" >
...
</ search >
</ header >
< main >
< h1 > 你所在位置附近的酒店</ h1 >
< search >
< h2 > 筛选结果</ h2 >
...
</ search >
< article >
<!-- 搜索结果内容 -->
</ article >
</ main >
</ body > div
元素所有当前引擎均支持。
所有当前引擎均支持。
dl 元素的子项。option 元素、optgroup 元素或
select 元素的后代。
dl 元素的子项:一个或多个 dt 元素,后跟一个或多个
dd 元素,并可选择与脚本支持
元素混合。
option
元素、optgroup 元素或
select 元素的后代:
透明。
[Exposed =Window ]
interface HTMLDivElement : HTMLElement {
[HTMLConstructor ] constructor ();
// 还具有已废弃成员
};div 元素完全没有特殊含义。
它表示其子项。它可以与 class、lang 和 title 属性配合使用,以标记
一组连续元素所共有的语义。它也可以在 dl 元素中使用,用于包装
dt 和
dd 元素组。
强烈建议作者将 div 元素视为
没有其他合适元素时才使用的最后手段。使用更合适的元素代替
div 元素,可以为
读者提供更好的无障碍体验,也使作者更容易维护内容。
例如,博客文章应使用 article
标记,章节使用
section,页面的
导航辅助内容使用 nav,而
一组表单控件使用 fieldset。
另一方面,div
元素可用于样式目的,或用于包装章节中需要以相同方式添加注释的多个段落。在以下
示例中,我们可以看到使用 div
元素一次性设置两个段落的语言,而不是分别在两个段落元素上设置语言:
< article lang = "en-US" >
< h1 > 我的语言用法和我的猫</ h1 >
< p > 自从她离开后,我的猫的行为并没有太大变化,只不过
她经常在邻居面前展示自己的新体形,试图让人
抚摸她。</ p >
< div lang = "en-GB" >
< p > 我的另一只猫是黑白相间的,非常可爱。他今天跟着
我们去了游泳池,和我们一起沿着人行道走。昨天
他似乎拜访了我们的邻居。我想知道他是否意识到
他们的公寓是我们公寓的镜像。</ p >
< p > 嗯,我刚刚注意到,我在上一段中使用了英式
英语。但我本应使用美式英语。因此我
不该说“pavement”“flat”或“colour”……</ p >
</ div >
< p > 我应该说“sidewalk”“apartment”和“color”!</ p >
</ article > a
元素所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
href 属性:交互式内容。a 元素后代,或指定了
tabindex 属性的后代。
href — 超链接的地址
target — 用于
超链接导航的可导航对象
download —
是否下载资源而不是导航到该资源,以及在下载时使用的文件名
ping — 要 ping 的
URL
rel — 文档中包含
超链接的位置与目标资源之间的关系
hreflang —
链接资源的语言
type — 被引用资源
类型的提示
referrerpolicy
— 由该元素发起的获取所使用的来源策略
href 属性:面向作者;面向实现者。
href、hreflang
和 type 属性,以及
导航 URL 属性
href。
[Exposed =Window ]
interface HTMLAnchorElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect ] attribute DOMString download ;
[CEReactions , Reflect ] attribute USVString ping ;
[CEReactions , Reflect ] attribute DOMString rel ;
[SameObject , PutForwards =value , Reflect="rel"] readonly attribute DOMTokenList relList ;
[CEReactions ] attribute DOMString text ;
[CEReactions ] attribute DOMString referrerPolicy ;
// 还具有已废弃成员
};
HTMLAnchorElement includes HyperlinkElementUtils ;
HTMLAnchorElement includes HTMLHyperlinkElementUtils ;如果 a 元素具有 href 属性,
则它表示一个由其内容标记的超链接(超文本锚点)。
如果 a 元素没有 href 属性,
则该元素表示一个占位符,用于表示在相关情况下
原本可能放置链接的位置,并且仅由该元素的内容组成。
如果不存在 href
属性,则必须省略 target、download、ping、rel、hreflang、type 和 referrerpolicy
属性。
如果在 a 元素上指定了
itemprop
属性,则还必须指定 href 属性。
如果某个站点在每个页面上使用一致的导航工具栏,那么通常会链接到页面自身的链接可以
使用不带链接地址的 a 元素进行标记:
< nav >
< ul >
< li > < a href = "/" > 首页</ a > </ li >
< li > < a href = "/news" > 新闻</ a > </ li >
< li > < a > 示例</ a > </ li >
< li > < a href = "/legal" > 法律信息</ a > </ li >
</ ul >
</ nav > href、target、download、ping 和 referrerpolicy
属性会影响用户跟随超链接或
下载超链接时发生的情况,
这些超链接由 a
元素创建。rel、hreflang 和 type
属性可用于在用户跟随链接之前,向用户表明目标资源可能具有的性质。
a.text与 textContent
相同。
HTMLAnchorElement/referrerPolicy
所有当前引擎均支持。
IDL 属性 referrerPolicy 必须反映 referrerpolicy
内容属性,并仅限于
已知值。
text
属性的获取器必须返回此元素的后代文本内容。
a 元素可以包装整个段落、
列表、表格等,甚至整个章节,只要其中没有交互式内容(例如按钮或其他链接)。此示例展示了
如何利用这一点将整个广告块变成链接:
< aside class = "advertising" >
< h1 > 广告</ h1 >
< a href = "https://ad.example.com/?adid=1929&pubid=1422" >
< section >
< h1 > Mellblomatic 9000!</ h1 >
< p > 将你的所有小部件变成 mellblom!</ p >
< p > 仅售 9.99 美元,另加运费和手续费。</ p >
</ section >
</ a >
< a href = "https://ad.example.com/?adid=375&pubid=1422" >
< section >
< h1 > Mellblom 浏览器</ h1 >
< p > 以光速浏览 Web。</ p >
< p > 没有其他浏览器速度更快!</ p >
</ section >
</ a >
</ aside > 以下示例展示了如何使用少量脚本,有效地将职位列表表格中的整行变成超链接:
< table >
< tr >
< th > 职位
< th > 团队
< th > 地点
< tr >
< td >< a href = "/jobs/manager" > 经理</ a >
< td > 远程团队
< td > 远程
< tr >
< td >< a href = "/jobs/director" > 总监</ a >
< td > 远程团队
< td > 远程
< tr >
< td >< a href = "/jobs/astronaut" > 宇航员</ a >
< td > 架构团队
< td > 远程
</ table >
< script >
document. querySelector( "table" ). onclick = ({ target }) => {
if ( target. parentElement. localName === "tr" ) {
const link = target. parentElement. querySelector( "a" );
if ( link) {
link. click();
}
}
}
</ script > em
元素所有当前引擎均支持。
HTMLElement。特定内容的强调程度由其祖先
em 元素的数量决定。
着重强调的位置会改变句子的含义。因此,该元素构成内容不可分割的一部分。 以这种方式使用强调的确切方法取决于语言。
以下示例展示了改变着重强调如何改变含义。首先是一项没有强调的一般事实陈述:
< p > 猫是可爱的动物。</ p > 强调第一个词后,该陈述暗示正在讨论的动物种类存在争议 (也许有人声称狗才是可爱的):
< p >< em > 猫</ em > 是可爱的动物。</ p > 将强调移到动词上,则突出整个句子的真实性存在争议 (也许有人说猫并不可爱):
< p > 猫< em > 是</ em > 可爱的动物。</ p > 将强调移到形容词上,则再次断言猫的确切性质 (也许有人认为猫是凶恶的动物):
< p > 猫是< em > 可爱的</ em > 动物。</ p > 同样,如果有人声称猫是蔬菜,纠正这一说法的人可能会强调最后一个词:
< p > 猫是可爱的< em > 动物</ em > 。</ p > 通过强调整个句子,可以明确说话者正在竭力表达这一观点。这种着重强调通常也会 影响标点,因此此处使用感叹号。
< p >< em > 猫是可爱的动物!</ em ></ p > 愤怒情绪与对“可爱”的强调相结合时,可能产生如下标记:
< p >< em > 猫是< em > 可爱的</ em > 动物!</ em ></ p > strong
元素所有当前引擎均支持。
HTMLElement。strong 元素表示其内容具有高度重要性、严肃性或
紧迫性。
重要性:strong 元素可用于
标题、说明文字或段落中,以区分真正重要的部分与其他可能更详细、更轻松或仅为样板文字的部分。
(这不同于标记副标题,副标题适合使用 hgroup
元素。)
例如,上一段的第一个词使用
strong 标记,
以将其与段落其余部分中更详细的文本区分开来。
严肃性:strong 元素可用于
标记警告或注意事项。
紧迫性:strong 元素可用于
表示用户需要比文档其他部分更早看到的内容。
某段内容的相对重要程度由其祖先
strong 元素的
数量决定;每个 strong 元素都会提高
其内容的重要性。
使用 strong 元素改变一段
文本的重要性不会改变句子的含义。
此处,“章”一词和实际章节编号只是样板文字,而章节的实际名称使用 strong 标记:
< h1 > 第 1 章:< strong > 实践</ strong ></ h1 > 在以下示例中,说明文字中的图表名称使用
strong 标记,
以将其与前面的样板文字和后面的描述区分开来:
< figcaption > 图 1。< strong > 蚁群动态</ strong > 。该蚁群中的蚂蚁
受到热源(左上)和食物源(右下)的影响。</ figcaption > 在此示例中,标题实际为“花、蜜蜂和蜂蜜”,但作者为标题添加了一段轻松诙谐的内容。
因此使用 strong 元素标记
第一部分,以将其与后一部分区分开来。
< h1 >< strong > 花、蜜蜂和蜂蜜</ strong > ,以及其他我不理解的事物</ h1 > 以下是游戏中警告通知的示例,其中各部分按照其重要程度进行标记:
< p >< strong > 警告。</ strong > 这个地牢很危险。
< strong > 避开鸭子。</ strong > 拿走你发现的所有金币。
< strong >< strong > 不要拿走任何钻石</ strong > ,
它们具有爆炸性,并且< strong > 会摧毁十米范围内的
一切。</ strong ></ strong > 你已经收到警告。</ p > 在此示例中,strong 元素用于
表示希望用户首先阅读的文本部分。
< p > 欢迎使用提醒系统 Remy。</ p >
< p > 你今天的任务:</ p >
< ul >
< li >< p >< strong > 关闭烤箱。</ strong ></ p ></ li >
< li >< p > 倒垃圾。</ p ></ li >
< li >< p > 洗衣服。</ p ></ li >
</ ul > small
元素所有当前引擎均支持。
HTMLElement。小字通常包括免责声明、附加条件、法律限制或版权信息。小字有时也用于 署名,或满足许可要求。
small
元素不会“减弱强调”,也不会降低由 em 元素强调或由 strong 元素标记为重要的
文本的重要性。若要将文本标记为不强调或不重要,只需分别不使用
em 或 strong 元素标记即可。
small 元素不应
用于较长的文本范围,例如多个段落、列表或文本章节。它仅适用于短文本。例如,列出使用条款的
页面文本不适合使用 small 元素:在这种
情况下,该文本不是旁注,而是页面的主要内容。
small 元素不得
用于副标题;为此,应使用
hgroup 元素。
在此示例中,small 元素用于
表明酒店房间的价格中不包括增值税:
< dl >
< dt > 单人间
< dd > 199 欧元 < small > 含早餐,不含增值税</ small >
< dt > 双人间
< dd > 239 欧元 < small > 含早餐,不含增值税</ small >
</ dl > 在第二个示例中,small 元素用于文章中的
旁注。
< p > Example Corp 今日宣布第二季度利润创下纪录
< small > (完整披露:Foo News 是
Example Corp 的子公司)</ small > ,由此引发了有关第三季度
与 Demo Group 合并的猜测。</ p > 这不同于侧边栏,后者可能包含多个段落,并从文本的主要流中移出。在以下示例中, 我们可以看到同一篇文章中的侧边栏。该侧边栏也包含小字,用于表明侧边栏中信息的来源。
< aside >
< h1 > Example Corp</ h1 >
< p > 该公司主要创建小型软件和 Web
站点。</ p >
< p > Example Corp 的公司使命是“以示例方式提供娱乐
和新闻”。</ p >
< p >< small > 信息获取自 < a
href = "https://example.com/about.html" > example.com</ a > 首页。</ small ></ p >
</ aside > 在最后一个示例中,small 元素被标记为
重要小字。
< p >< strong >< small > 继续使用此服务将会得到一个吻。</ small ></ strong ></ p > s
元素所有当前引擎均支持。
HTMLElement。s 元素不适合
用于表示文档编辑;若要标记已从文档中删除的一段文本,请使用 del 元素。
在此示例中,由于相关产品有了新的促销价,建议零售价被标记为不再相关。
< p > 购买我们的冰茶和柠檬水!</ p >
< p >< s > 建议零售价:每瓶 3.99 美元</ s ></ p >
< p >< strong > 现仅售每瓶 2.99 美元!</ strong ></ p > cite
元素所有当前引擎均支持。
HTMLElement。cite 元素表示作品的标题(例如
书籍、
论文、
文章、
诗歌、
乐谱、
歌曲、
剧本、
电影、
电视节目、
游戏、
雕塑、
绘画、
戏剧制作、
戏剧、
歌剧、
音乐剧、
展览、
法律案例报告、
计算机程序
等)。这可以是正在被引用或详细提及的作品(即引用来源),也可以只是顺带提到的作品。
人的姓名不是作品的标题——即使有人称某个人是个“作品”——因此不得使用该元素标记人名。
(在某些情况下,b 元素
可能适合用于姓名;例如,在八卦文章中,名人的姓名是使用不同样式呈现以吸引注意力的关键字。
在其他情况下,如果确实需要元素,则可以使用 span 元素。)
下一个示例展示了 cite 元素的典型用法:
< p > My favorite book is < cite > The Reality Dysfunction</ cite > by
Peter F. Hamilton. My favorite comic is < cite > Pearls Before
Swine</ cite > by Stephan Pastis. My favorite track is < cite > Jive
Samba</ cite > by the Cannonball Adderley Sextet.</ p > 这是正确用法:
< p > According to the Wikipedia article < cite > HTML</ cite > , as it
stood in mid-February 2008, leaving attribute values unquoted is
unsafe. This is obviously an over-simplification.</ p > 然而,以下用法是不正确的,因为这里的 cite 元素
包含的内容远不止作品标题:
<!-- do not copy this example, it is an example of bad usage! -->
< p > According to < cite > the Wikipedia article on HTML</ cite > , as it
stood in mid-February 2008, leaving attribute values unquoted is
unsafe. This is obviously an over-simplification.</ p > cite 元素是参考文献中任何引用的关键
部分,但它仅
用于标记标题:
< p >< cite > Universal Declaration of Human Rights</ cite > , United Nations,
December 1948. Adopted by General Assembly resolution 217 A (III).</ p > 引用并不是
引语(对于引语,使用 q
元素
更合适)。
这是不正确的用法,因为 cite 不用于引语:
< p >< cite > This is wrong!</ cite > , said Ian.</ p > 这也是不正确的用法,因为人并不是作品:
< p >< q > This is still wrong!</ q > , said < cite > Ian</ cite > .</ p > 正确用法不使用 cite 元素:
< p >< q > This is correct</ q > , said Ian.</ p > 如上所述,b 元素
可能适合用于在某些类型的文档中将名称标记为
关键字:
< p > And then < b > Ian</ b > said < q > this might be right, in a
gossip column, maybe!</ q > .</ p > 当作品标题按惯例用
标点符号括起来时——例如,英语文章标题周围使用的引号,或日语书名周围使用的方头括号(『』)——这些标点符号并不是标题的一部分,应放在
cite 元素之外。
这是正确用法:
< p > My review of 『< cite lang = "ja" > 阪急電車</ cite > 』 was titled “< cite > A cute series of short stories</ cite > ”.</ p > q
元素所有当前引擎均支持。
cite — 指向引文来源或有关编辑的更多信息的链接
HTMLQuoteElement。用于引用该元素内容的引文标点(例如引号)不得紧接在 q
元素之前、之后或其内部出现;
用户代理会在渲染时插入这些标点。
q 元素内的内容必须引自另一个
来源;如果该来源有地址,则可以在 cite
属性中引用该地址。来源可以是虚构的,
例如引用小说或剧本中的人物时。
如果存在 cite 属性,则它必须是一个
可能被空格包围的有效
URL。为了获取相应的引用链接,必须相对于该元素的节点文档解析该属性的值。用户代理可以允许
用户跟随此类引用链接,但这些链接主要用于私有用途(例如由服务器端脚本收集站点使用引文的统计信息),
而不是供读者使用。
q 元素不得用于代替并不表示
引文的引号;例如,使用 q 元素标记讽刺性陈述是不合适的。
使用 q 元素标记引文完全是
可选的;不使用 q 元素,而直接
使用明确的引文标点同样正确。
以下是使用 q 元素的简单示例:
< p > 那个人说:< q > 不可能的事情只是需要
更长时间</ q > 。我不同意他的看法。</ p > 以下示例既在 q 元素中包含明确的引用链接,
也在其外部包含明确的引用来源:
< p > W3C 页面< cite > 《关于 W3C》</ cite > 称,W3C 的
使命是< q cite = "https://www.w3.org/Consortium/" > 通过制定确保 Web
长期发展的协议和指南,充分发挥万维网的潜力</ q > 。我
不同意这一使命。</ p > 在以下示例中,引文本身包含另一个引文:
< p > 在< cite > 《示例一》</ cite > 中,他写道:< q > 那个人
说:< q > 不可能的事情只是需要更长时间</ q > 。我
不同意他的看法</ q > 。嗯,我更不同意!</ p > 在以下示例中,使用引号代替 q 元素:
< p > 他最有力的论点是❝我不同意❞,而我
认为这很可笑。</ p > 在以下示例中,没有引文——引号用于指称一个词。在这种情况下使用 q
元素是不合适的。
< p > “难以言喻”一词本可以用来描述因竞选活动管理不善
而造成的灾难。</ p > dfn
元素所有当前引擎均支持。
dfn 元素后代。
title 属性在此元素上
具有特殊语义:完整术语或缩写的展开形式
HTMLElement。dfn 元素表示术语的定义实例。作为 dfn 元素最近祖先的段落、描述列表组或章节,还必须包含由 dfn 元素给出的术语的定义。
正在定义的术语:如果 dfn 元素具有 title 属性,则该属性的
确切值就是正在定义的术语。否则,如果它恰好包含一个元素子节点且不包含子 Text
节点,并且该子元素是具有 title 属性的 abbr 元素,则该属性的
确切值就是正在定义的术语。否则,由 dfn 元素的后代文本内容给出正在定义的术语。
如果存在 dfn 元素的
title 属性,则它必须仅包含
正在定义的术语。
链接到 dfn 元素的 a 元素,表示由该 dfn 元素定义的术语的一个实例。
在以下片段中,术语“Garage Door Opener”首先在第一个段落中定义,然后在第二个段落中使用。 在这两种情况下,实际显示的都是其缩写。
< p > < dfn >< abbr title = "Garage Door Opener" > GDO</ abbr ></ dfn >
是一种允许外星任务小组开启虹膜装置的设备。</ p >
<!-- ……稍后在文档中: -->
< p > Teal'c 启动了他的 < abbr title = "Garage Door Opener" > GDO</ abbr > ,
于是 Hammond 下令开启虹膜装置。</ p > < p > < dfn id = gdo >< abbr title = "Garage Door Opener" > GDO</ abbr ></ dfn >
是一种允许外星任务小组开启虹膜装置的设备。</ p >
<!-- ……稍后在文档中: -->
< p > Teal'c 启动了他的 < a href = #gdo > < abbr title = "Garage Door Opener" > GDO</ abbr > </ a > ,
于是 Hammond 下令开启虹膜装置。</ p > abbr
元素所有当前引擎均支持。
title 属性在此元素上
具有特殊语义:完整术语或缩写的展开形式
HTMLElement。abbr 元素表示缩写或首字母缩略词,并可选择包含其展开形式。
title
属性可用于提供缩写的展开形式。如果指定该属性,
则它必须仅包含该缩写的展开形式,不得包含其他内容。
以下段落包含一个使用 abbr 元素标记的缩写。
此段落定义术语“Web Hypertext Application
Technology Working Group”。
< p > < dfn id = whatwg >< abbr
title = "Web Hypertext Application Technology Working Group" > WHATWG</ abbr ></ dfn >
是由 Web 浏览器制造商和相关各方组成的松散、非正式协作组织,
这些参与者希望开发新技术,使作者能够在万维网上编写和部署
应用程序。</ p > 另一种写法如下:
< p > < dfn id = whatwg > Web Hypertext Application Technology
Working Group</ dfn > (< abbr
title = "Web Hypertext Application Technology Working Group" > WHATWG</ abbr > )
是由 Web 浏览器制造商和相关各方组成的松散、非正式协作组织,
这些参与者希望开发新技术,使作者能够在万维网上编写和部署
应用程序。</ p > 此段落包含两个缩写。请注意,只有一个缩写得到定义;另一个缩写没有关联的展开形式,
因此未使用 abbr 元素。
< p >
< abbr title = "Web Hypertext Application Technology Working Group" > WHATWG</ abbr >
于 2004 年开始研究 HTML5。</ p > 此段落将一个缩写链接到其定义。
< p > < a href = "#whatwg" >< abbr
title = "Web Hypertext Application Technology Working Group" > WHATWG</ abbr ></ a >
社区在亚洲的代表性不高。</ p > 此段落标记了一个没有给出展开形式的缩写,可能是为了提供一个应用缩写样式 (例如小型大写字母)的挂钩。
< p > Philip` 和 Dashiva 都否认他们打算从规范的旧修订版中
获取议题数量,以回填 < abbr > WHATWG</ abbr > 议题图表。</ p > 如果缩写采用复数形式,则展开形式的语法数(复数或单数)必须与元素内容的语法数相匹配。
此处复数形式位于元素外部,因此展开形式使用单数:
< p > 两个 < abbr title = "Working Group" > WG</ abbr > s 参与了
此规范的制定:< abbr > WHATWG</ abbr > 和
< abbr > HTMLWG</ abbr > 。</ p > 此处复数形式位于元素内部,因此展开形式使用复数:
< p > 两个 < abbr title = "Working Groups" > WGs</ abbr > 参与了
此规范的制定:< abbr > WHATWG</ abbr > 和
< abbr > HTMLWG</ abbr > 。</ p > 缩写不一定必须使用此元素进行标记。预计它在以下情况下会很有用:
title 属性的
abbr 元素,是在行内包含
展开形式(例如放在括号中)的替代方案。
title 属性的
abbr 元素标记缩写,
或在第一次使用该缩写时在文本中行内包含其展开形式。
title 属性的
abbr 元素。
在某个 title 属性中提供一次展开形式,
并不一定会使同一文档中内容相同但没有 title 属性的其他 abbr 元素表现得像具有
相同展开形式一样。每个 abbr 元素都是独立的。
ruby
元素所有当前引擎均支持。
HTMLElement。ruby 元素允许使用
ruby 注释来标记一个或多个短语内容范围。Ruby 注释是与基准文本并列呈现的短文本,主要用于
东亚排版中作为读音指南,或包含其他注释。在日语中,这种排版形式也称为 furigana(振假名)。
ruby 元素的内容模型
由一个或多个以下序列组成:
以下二者之一:
以下二者之一:
ruby 和 rt 元素可用于多种类型的注释,
尤其包括(但绝不限于)下述类型。有关日语 Ruby 的更多详细信息,以及如何渲染日语 Ruby,请参阅
日文排版需求。[JLREQ]
在撰写本文时,CSS 尚未提供完全控制 HTML ruby 元素渲染的方式。
希望 CSS 以后能够扩展,以支持下述样式。
在每个表意字符(基准文本)旁放置一个或多个平假名或片假名字符(ruby 注释)。 这用于提供汉字的读音。
< ruby > B< rt > 注释</ ruby > 在此示例中,请注意每个注释如何对应单个基准字符。
< ruby > 君< rt > くん</ ruby >< ruby > 子< rt > し</ ruby > は< ruby > 和< rt > わ</ ruby > して< ruby > 同< rt > どう</ ruby > ぜず。君子は和して同 ぜず。
此示例也可以按如下方式编写:使用一个 ruby
元素,其中包含
两个基准文本片段和两个注释(每个片段一个),而不是使用两个首尾相连的 ruby 元素,
每个元素各有一个基准文本片段和一个注释(如上面的标记所示):
< ruby > 君< rt > くん</ rt > 子< rt > し</ ruby > は< ruby > 和< rt > わ</ ruby > して< ruby > 同< rt > どう</ ruby > ぜず。这与前一种情况类似:复合词中的每个表意字符(基准文本)都通过平假名或片假名字符 (ruby 注释)给出读音。不同之处在于,这些基准文本片段构成一个复合词,而不是彼此分离。
< ruby > B< rt > 注释</ rt > B< rt > 注释</ ruby > 在此示例中,请再次注意每个注释如何对应单个基准字符。在此示例中,
每个复合词(熟语)对应一个 ruby 元素。
预期的渲染方式是:每个注释放置在相应基准字符的上方(或在竖排文本中放置在其旁边), 并且注释不会延伸到任何相邻字符之上。
< ruby > 鬼< rt > き</ rt > 門< rt > もん</ rt ></ ruby > の< ruby > 方< rt > ほう</ rt > 角< rt > がく</ rt ></ ruby > を< ruby > 凝< rt > ぎょう</ rt > 視< rt > し</ rt ></ ruby > する鬼門の方角を凝視する
在语义上,这与前一种情况完全相同(基准复合词中的每个单独表意字符,都通过平假名或片假名 字符组成的注释给出其读音),但渲染采用更复杂的熟语 Ruby 渲染方式。
这与上面的复合词单字符 Ruby 示例相同。预期通过不同样式(例如 CSS)实现不同的渲染, 此处未予展示。
< ruby > 鬼< rt > き</ rt > 門< rt > もん</ rt ></ ruby > の< ruby > 方< rt > ほう</ rt > 角< rt > がく</ rt ></ ruby > を< ruby > 凝< rt > ぎょう</ rt > 視< rt > し</ rt ></ ruby > する有关熟语 Ruby 渲染的更多详细信息,请参阅日文排版需求附录 F。[JLREQ]
注释描述的是基准文本的含义,而不是(或不仅是)读音。因此,基准文本和注释都可以由多个字符组成。
< ruby > 基准文本< rt > 注释</ ruby > 此处,一个复合表意词具有作为注释给出的相应片假名。
< ruby > 境界面< rt > インターフェース</ ruby > 境界面
此处,一个复合表意词具有作为注释提供的英文翻译。
< ruby lang = "ja" > 編集者< rt lang = "en" > editor</ ruby > 編集者
一种对应多个基准字符的语音读法,因为一一对应会很困难。(在英语中,“Colonel”和 “Lieutenant”是这类词的示例;在某些方言中,其发音与各个字母之间的直接对应关系相当不明确。)
在此示例中,某种花卉名称使用组 Ruby 提供语音读法:
< ruby > 紫陽花< rt > あじさい</ ruby > 紫陽花
有时会组合使用上述 Ruby 样式。
如果这会导致两个注释覆盖同一个基准片段,则只需将这些注释首尾相连地放置。
< ruby > 基准文本< rt > 注释 1< rt > 注释 2</ ruby > < ruby > B< rt > a< rt > a</ ruby >< ruby > A< rt > a< rt > a</ ruby >< ruby > S< rt > a< rt > a</ ruby >< ruby > E< rt > a< rt > a</ ruby > 在这个刻意构造的示例中,一些符号被赋予了英文和法文名称。
< ruby >
♥ < rt > Heart < rt lang = fr > Cœur </ rt >
☘ < rt > Shamrock < rt lang = fr > Trèfle </ rt >
✶ < rt > Star < rt lang = fr > Étoile </ rt >
</ ruby > 在如下示例所示的更复杂情形中,使用嵌套的 ruby 元素提供内部注释,
然后再在“外部”层级为整个 ruby 提供注释。
< ruby >< ruby > B< rt > a</ rt > A< rt > n</ rt > S< rt > t</ rt > E< rt > n</ rt ></ ruby >< rt > 注释</ ruby > 此处,语音读法和含义都通过 Ruby 注释给出。嵌套 ruby 元素上的注释,
为每个基准字符提供单字符 Ruby 语音注释;而作为外层 ruby 元素子项的
rt 元素中的注释,
使用平假名给出含义。
< ruby >< ruby > 東< rt > とう</ rt > 南< rt > なん</ rt ></ ruby >< rt > たつみ</ rt ></ ruby > の方角東南 の方角
这是同一个示例,但含义使用英文而不是日文给出:
< ruby >< ruby > 東< rt > とう</ rt > 南< rt > なん</ rt ></ ruby >< rt lang = en > Southeast</ rt ></ ruby > の方角東南 の方角
在没有 ruby 元素祖先的
ruby 元素内,
内容被划分为若干片段,这些片段分为三类:基准文本片段、注释片段和忽略片段。忽略片段不构成
文档语义的一部分(它们由一些元素间空白和 rp 元素组成;后者用于完全不支持
Ruby 的旧式用户代理)。基准文本片段可以重叠(在 DOM 中任一位置最多可有两个片段重叠;任何开始点早于
与其重叠片段的片段,也必须具有等于或晚于该重叠片段的结束点;任何结束点晚于与其重叠片段的片段,
也必须具有等于或早于该重叠片段的开始点)。注释片段对应于 rt
元素。每个注释片段可以与
一个基准文本片段关联,每个基准文本片段也可以有与其关联的注释片段。(在符合规范的文档中,
每个基准文本片段至少与一个注释片段关联,每个注释片段与一个基准文本片段关联。)ruby 元素表示其包含的基准文本片段的并集,以及这些
基准文本片段到注释片段的映射。片段使用 DOM 范围描述;注释片段范围始终恰好由一个元素组成。
[DOM]
在任意给定时刻,ruby 元素内容的
分段和分类,是运行以下算法所得到的结果:
令 base text segments 为基准文本片段的空列表,每个片段都可能带有一个 基准文本子片段列表。
令 annotation segments 为注释片段的空列表,每个片段都可能与一个基准文本 片段或子片段关联。
令 root 为正在对其运行该算法的 ruby 元素。
如果 root 具有 ruby 元素祖先,
则跳转到标记为end的步骤。
令 current parent 为 root。
令 index 为 0。
令 start index 为 null。
令 saved start index 为 null。
令 current base text 为 null。
Start mode:如果 index 大于或等于 current parent 中子节点的数量, 则跳转到标记为end mode的步骤。
如果 current parent 中第 index 个节点是
rt 或 rp 元素,则跳转到标记为
annotation mode 的步骤。
将 start index 设置为 index 的值。
Base mode:如果 current parent 中第 index 个节点是 ruby 元素,并且
current parent 与 root 是同一个元素,则压入一个 Ruby 层级,然后跳转到标记为
start mode 的步骤。
如果 current parent 中第 index 个节点是
rt 或 rp 元素,则设置当前基准
文本,然后跳转到标记为annotation mode的步骤。
将 index 增加一。
Base mode post-increment:如果 index 大于或等于 current parent 中子节点的数量,则跳转到标记为end mode的步骤。
跳回标记为base mode的步骤。
Annotation mode:如果 current parent 中第 index 个节点是 rt 元素,则压入一个 Ruby
注释,并跳转到标记为annotation mode increment的步骤。
如果 current parent 中第 index 个节点是 rp 元素,则跳转到标记为
annotation mode increment 的步骤。
如果 current parent 中第 index 个节点不是 Text
节点,或者是一个并非元素间空白的
Text
节点,则跳转到标记为base mode的步骤。
Annotation mode increment:令 lookahead index 为 index 加一。
Annotation mode white-space skipper:如果 lookahead index 等于 current parent 中子节点的数量,则跳转到标记为end mode的步骤。
如果 current parent 中第 lookahead index 个节点是 rt 元素或 rp 元素,则将
index 设置为 lookahead index,并跳转到标记为
annotation mode 的步骤。
如果 current parent 中第 lookahead index 个节点不是 Text
节点,或者是一个并非元素间空白的
Text
节点,则跳转到标记为base mode的步骤(不再进一步增加 index,这样目前所见的
元素间空白就会成为下一个基准文本片段的一部分)。
将 lookahead index 增加一。
跳转到标记为annotation mode white-space skipper的步骤。
End mode:如果 current parent 与 root 不是同一个元素,则弹出一个 Ruby 层级, 并跳转到标记为base mode post-increment的步骤。
End:返回 base text segments 和 annotation
segments。ruby
元素中未由
这两个列表中的片段描述的任何内容,都隐式地位于一个忽略片段中。
当上述步骤要求设置当前基准文本时,表示在算法中的该处运行 以下步骤:
当上述步骤要求压入一个 Ruby 层级时,表示在算法中的该处运行 以下步骤:
令 current parent 为 current parent 中第 index 个节点。
令 index 为 0。
将 saved start index 设置为 start index 的值。
令 start index 为 null。
当上述步骤要求弹出一个 Ruby 层级时,表示在算法中的该处运行 以下步骤:
令 index 为 current parent 在 root 中的位置。
令 current parent 为 root。
将 index 增加一。
将 start index 设置为 saved start index 的值。
令 saved start index 为 null。
当上述步骤要求压入一个 Ruby 注释时,表示在算法中的该处运行 以下步骤:
令 rt 为 current parent 中第 index 个节点所对应的 rt 元素。
令 annotation range 为一个 DOM 范围,其起点是边界点(current parent,index),其终点是边界点 (current parent,index 加一)(即该范围仅包含 rt)。
令 new annotation segment 为由范围 annotation range 描述的注释片段。
如果 current base text 不为 null,则将 new annotation segment 与 current base text 关联。
将 new annotation segment 添加到 annotation segments。
在此示例中,日文文本 漢字 中的每个表意字符都使用其平假名读音进行注释。
...
< ruby > 漢< rt > かん</ rt > 字< rt > じ</ rt ></ ruby >
...其渲染效果可能如下:

在此示例中,繁体中文文本 漢字 中的每个表意字符都使用其注音符号读音进行注释。
< ruby > 漢< rt > ㄏㄢˋ</ rt > 字< rt > ㄗˋ</ rt ></ ruby > 其渲染效果可能如下:

在此示例中,简体中文文本 汉字 中的每个表意字符都使用其拼音读音进行注释。
...< ruby > 汉< rt > hàn</ rt > 字< rt > zì</ rt ></ ruby > ...其渲染效果可能如下:

在这个较为刻意构造的示例中,首字母缩略词“HTML”具有四个注释:一个针对整个缩略词, 简要说明它是什么;一个针对字母“HT”,将其展开为“Hypertext”;一个针对字母“M”, 将其展开为“Markup”;另一个针对字母“L”,将其展开为“Language”。
< ruby >
< ruby > HT< rt > Hypertext</ rt > M< rt > Markup</ rt > L< rt > Language</ rt ></ ruby >
< rt > 一种用于描述文档和应用程序的抽象语言
</ ruby > rt
元素所有当前引擎均支持。
ruby 元素的子项。
rt 元素后紧跟着
一个 rt 或 rp 元素,
或者父元素中已无更多内容,则可以省略该
rt 元素的结束标签。
HTMLElement。rt 元素标记 Ruby 注释的
Ruby 文本组件。当它是 ruby 元素的子项时,
它本身不表示任何内容,但 ruby 元素会将其作为
确定自身表示内容的一部分。
不是 ruby 元素子项的
rt 元素,
表示与其子项相同的内容。
rp
元素所有当前引擎均支持。
ruby 元素的子项,
紧接在 rt 元素之前或之后。rp 元素后紧跟着
一个 rt 或 rp 元素,
或者父元素中已无更多内容,则可以省略该
rp 元素的结束标签。
HTMLElement。rp 元素可用于在 Ruby 注释的
Ruby 文本组件周围提供括号或其他内容,以供不支持 Ruby 注释的用户代理显示。
作为 ruby
元素子项的 rp 元素
不表示任何内容。父元素不是 ruby 元素的 rp 元素表示其子项。
上面的示例中,文本 漢字 中的每个表意字符都使用其语音读法进行注释;
可以扩展该示例以使用 rp,使旧式用户代理将读音
显示在括号中:
...
< ruby > 漢< rp > (</ rp >< rt > かん</ rt >< rp > )</ rp > 字< rp > (</ rp >< rt > じ</ rt >< rp > )</ rp ></ ruby >
...在符合规范的用户代理中,其渲染效果将与上面相同;但在不支持 Ruby 的用户代理中, 渲染效果将为:
... 漢(かん)字(じ)...
当一个片段具有多个注释时,也可以在注释之间放置 rp
元素。下面再次给出
前面那个刻意构造的示例,其中一些符号具有英文和法文名称,但这次还包含 rp 元素:
< ruby >
♥< rp > : </ rp >< rt > Heart</ rt >< rp > , </ rp >< rt lang = fr > Cœur</ rt >< rp > .</ rp >
☘< rp > : </ rp >< rt > Shamrock</ rt >< rp > , </ rp >< rt lang = fr > Trèfle</ rt >< rp > .</ rp >
✶< rp > : </ rp >< rt > Star</ rt >< rp > , </ rp >< rt lang = fr > Étoile</ rt >< rp > .</ rp >
</ ruby > 这会使该示例在不支持 Ruby 的用户代理中渲染如下:
♥: Heart, Cœur. ☘: Shamrock, Trèfle. ✶: Star, Étoile.
data
元素所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
value — 机器可读值
value 属性。
[Exposed =Window ]
interface HTMLDataElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect ] attribute DOMString value ;
};data 元素表示其内容,以及在 value 属性中给出的
该内容的机器可读形式。
必须存在 value
属性。其值必须以机器可读格式表示该元素的内容。
当值与日期或时间有关时,可以改用更具体的 time 元素。
该元素可用于多种用途。
与微格式或本规范中定义的微数据属性结合使用时,该元素既可为数据处理器
提供机器可读值,也可为 Web 浏览器中的渲染提供人类可读值。在这种情况下,value 属性所使用的格式
由正在使用的微格式或微数据词汇表确定。
不过,该元素也可以与页面中的脚本结合使用,以便脚本在一个人类可读值旁存储一个字面值。
在这种情况下,使用何种格式只取决于脚本的需要。(data-*
属性在此类情况下也可能有用。)
此处,一个小型表格使用 data 元素编码其数值,
因此即使一列中的数字以文本形式呈现,而另一列中的数字以分解形式呈现,表格排序 JavaScript
库仍可为每一列提供排序机制。
< script src = "sortable.js" ></ script >
< table class = "sortable" >
< thead > < tr > < th > 游戏 < th > 公司 < th > 地图大小
< tbody >
< tr > < td > 1830 < td > < data value = "8" > 八</ data > < td > < data value = "93" > 19+74 个六边形格(共 93 个)</ data >
< tr > < td > 1856 < td > < data value = "11" > 十一</ data > < td > < data value = "99" > 12+87 个六边形格(共 99 个)</ data >
< tr > < td > 1870 < td > < data value = "10" > 十</ data > < td > < data value = "149" > 4+145 个六边形格(共 149 个)</ data >
</ table > time
元素所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
datetime 属性:短语内容。datetime —
机器可读值
datetime 属性。
[Exposed =Window ]
interface HTMLTimeElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect ] attribute DOMString dateTime ;
};time 元素表示其内容,以及在 datetime 属性中给出的
该内容的机器可读形式。内容类型仅限于下文所述的各种日期、时间、时区偏移量和持续时间。
可以存在 datetime
属性。如果存在,其值必须以机器可读格式
表示该元素的内容。
没有 datetime
内容属性的 time 元素
不得有任何元素后代。
< time > 2011-11</ time > < time > 2011-11-18</ time > < time > 11-18</ time > < time > 14:54</ time > < time > 14:54:39</ time > < time > 14:54:39.929</ time > < time > 2011-11-18T14:54</ time > < time > 2011-11-18T14:54:39</ time > < time > 2011-11-18T14:54:39.929</ time > < time > 2011-11-18 14:54</ time > < time > 2011-11-18 14:54:39</ time > < time > 2011-11-18 14:54:39.929</ time > 带有日期但没有时区偏移量的时间,适用于指定在一整天中各时区都于相同特定 本地时间庆祝或举行的事件。例如,2020 年新年是在每个时区的 2020-01-01 00:00 庆祝, 而不是在所有时区的同一精确时刻庆祝。对于在所有时区同一时刻发生的事件,例如视频会议, 有效全局日期和时间字符串可能更有用。
< time > Z</ time > < time > +0000</ time > < time > +00:00</ time > < time > -0800</ time > < time > -08:00</ time > 对于没有日期的时间(或指代在多个日期重复发生的事件的时间),指定控制该时间的 地理位置通常比指定时区偏移量更有用,因为地理位置会随着夏令时改变时区偏移量。在某些情况下, 地理位置甚至会改变时区,例如时区边界被重新划定时,2011 年底的萨摩亚便发生过这种情况。 有一个时区数据库描述时区边界以及各时区内适用的规则,称为时区数据库。 [TZDATABASE]
< time > 2011-11-18T14:54Z</ time > < time > 2011-11-18T14:54:39Z</ time > < time > 2011-11-18T14:54:39.929Z</ time > < time > 2011-11-18T14:54+0000</ time > < time > 2011-11-18T14:54:39+0000</ time > < time > 2011-11-18T14:54:39.929+0000</ time > < time > 2011-11-18T14:54+00:00</ time > < time > 2011-11-18T14:54:39+00:00</ time > < time > 2011-11-18T14:54:39.929+00:00</ time > < time > 2011-11-18T06:54-0800</ time > < time > 2011-11-18T06:54:39-0800</ time > < time > 2011-11-18T06:54:39.929-0800</ time > < time > 2011-11-18T06:54-08:00</ time > < time > 2011-11-18T06:54:39-08:00</ time > < time > 2011-11-18T06:54:39.929-08:00</ time > < time > 2011-11-18 14:54Z</ time > < time > 2011-11-18 14:54:39Z</ time > < time > 2011-11-18 14:54:39.929Z</ time > < time > 2011-11-18 14:54+0000</ time > < time > 2011-11-18 14:54:39+0000</ time > < time > 2011-11-18 14:54:39.929+0000</ time > < time > 2011-11-18 14:54+00:00</ time > < time > 2011-11-18 14:54:39+00:00</ time > < time > 2011-11-18 14:54:39.929+00:00</ time > < time > 2011-11-18 06:54-0800</ time > < time > 2011-11-18 06:54:39-0800</ time > < time > 2011-11-18 06:54:39.929-0800</ time > < time > 2011-11-18 06:54-08:00</ time > < time > 2011-11-18 06:54:39-08:00</ time > < time > 2011-11-18 06:54:39.929-08:00</ time > 带有日期和时区偏移量的时间,适用于指定特定事件,或者时间不锚定到特定 地理位置的重复虚拟事件。例如,小行星撞击的精确时刻,或无论世界上任何特定地区是否采用 夏令时,每天都在 UTC 14:00 举行的一系列会议中的某次会议。对于精确时间会随特定地理位置的 本地时区偏移量而变化的事件,结合该地理位置使用有效本地日期和时间 字符串可能更有用。
< time > 2011-W47</ time > < time > 2011</ time > < time > 0001</ time > < time > PT4H18M3S</ time > < time > 4h 18m 3s</ time > 必须使用以下算法,从该元素的日期时间值中获取元素内容的机器可读等价值:
如果从元素的日期时间值中解析无年份日期 字符串返回一个无年份日期,则该日期就是机器可读等价值;返回。
如果从元素的日期时间值中解析本地日期和时间 字符串返回一个本地日期和时间,则它就是机器可读等价值;返回。
如果从元素的日期时间值中解析时区偏移量字符串返回一个时区偏移量,则该偏移量就是 机器可读等价值;返回。
如果从元素的日期时间值中解析全局日期和时间 字符串返回一个全局日期和 时间,则它就是机器可读等价值;返回。
如果元素的日期时间值仅由ASCII 数字组成,并且其中至少一个不是 U+0030 DIGIT ZERO (0), 则机器可读等价值是这些数字的十进制解释,表示一个年份;返回。
如果从元素的日期时间值中解析持续时间 字符串返回一个持续时间, 则该持续时间就是机器可读等价值;返回。
不存在机器可读等价值。
上述算法的设计意图是:对于任意字符串 s,只有一个算法会返回 值。更高效的方法可能是创建一个算法,在一次遍历中解析所有这些数据类型;此算法的开发留作 读者练习。
time 元素可用于
编码日期,例如在微格式中。下面展示了一种假想方式,使用采用 time 元素的
hCalendar 变体来编码事件:
< div class = "vevent" >
< a class = "url" href = "http://www.web2con.com/" > http://www.web2con.com/</ a >
< span class = "summary" > Web 2.0 大会</ span > :
< time class = "dtstart" datetime = "2005-10-05" > 10 月 5 日</ time > 至
< time class = "dtend" datetime = "2005-10-07" > 7 日</ time > ,
地点:< span class = "location" > 加利福尼亚州旧金山 Argent 酒店</ span >
</ div > 此处,一个基于 Atom 词汇表的虚构微数据词汇表与 time 元素一起使用,
以标记博客文章的发布日期。
< article itemscope itemtype = "https://n.example.org/rfc4287" >
< h1 itemprop = "title" > 大型任务</ h1 >
< footer > 发布于 < time itemprop = "published" datetime = "2009-08-29" > 两天前</ time > 。</ footer >
< p itemprop = "content" > 今天,我出门给孩子买了一辆自行车。</ p >
</ article > 在此示例中,另一篇文章的发布日期使用 time 标记,
这次使用 schema.org 微数据词汇表:
< article itemscope itemtype = "http://schema.org/BlogPosting" >
< h1 itemprop = "headline" > 小型任务</ h1 >
< footer > 发布于 < time itemprop = "datePublished" datetime = "2009-08-30" > 昨天</ time > 。</ footer >
< p itemprop = "articleBody" > 我在她的自行车上装了一个车铃。</ p >
</ article > 在以下片段中,time 元素用于以
ISO8601 格式编码日期,以供脚本稍后处理:
< p > 我们的第一次约会是在 < time datetime = "2006-09-23" > 一个星期六</ time > 。</ p > 在第二个片段中,该值还包含时间:
< p > 我们一直聊到< time datetime = "2006-09-24T05:00-07:00" > 第二天早上 5 点</ time > 才停下来。</ p > 页面加载的脚本(因此了解页面使用 time
元素标记日期和
时间的内部约定)可以扫描整个页面,并查看其中所有 time 元素,
以创建日期和时间索引。
例如,此元素传达字符串“星期五”,并附加“2011 年 11 月 18 日是与‘星期五’对应的含义”这一语义:
今天是 < time datetime = "2011-11-18" > 星期五</ time > 。在此示例中,指定了太平洋标准时区中的一个特定时间:
你的下一次会议是在 < time datetime = "2011-11-18T15:00-08:00" > 下午 3 点</ time > 。code
元素所有当前引擎均支持。
HTMLElement。code 元素表示一段计算机代码。它可以是 XML 元素名称、
文件名、计算机程序,或计算机能够识别的任何其他字符串。
没有正式方式可表明所标记计算机代码的语言。希望使用所用语言标记 code 元素的作者,
例如为了让语法高亮脚本使用正确的规则,可以使用 class 属性,例如向该元素添加一个以
“language-”为前缀的类。
以下示例展示了如何在段落中使用该元素标记元素名称和计算机代码,包括标点符号。
< p > < code > code</ code > 元素表示一段计算机
代码。</ p >
< p > 当你在 < code > robotSnowman</ code > 对象上调用
< code > activate()</ code > 方法时,它的眼睛会发光。</ p >
< p > 下面的示例使用 < code > begin</ code > 关键字表示
语句块的开始。它与 < code > end</ code >
关键字配对,后者之后跟着 < code > .</ code > 标点符号
(句点),表示程序结束。</ p > 以下示例展示了如何使用 pre 和 code 元素标记代码块。
< pre >< code class = "language-pascal" > var i: Integer;
begin
i := 1;
end.</ code ></ pre > 该示例使用类来表示所用的语言。
更多详细信息,请参阅 pre 元素。
var
元素所有当前引擎均支持。
HTMLElement。var 元素表示变量。它可以是数学表达式或编程上下文中的实际
变量、表示常量的标识符、标识物理量的符号、函数参数,或只是散文中用作占位符的术语。
在下面的段落中,字母“n”在散文中用作 变量:
< p > 如果有 < var > n</ var > 根管道通往冰淇淋
工厂,那么我预计至少会有 < var > n</ var > 种冰淇淋口味
< em > 至少</ em > 可供购买!</ p > 对于数学内容,尤其是比最简单表达式更复杂的内容,MathML 更为合适。不过,var
元素仍可用于指代随后在 MathML 表达式中提到的特定变量。
在此示例中,显示了一个方程,并附有引用方程中变量的图例。表达式本身使用 MathML 标记,
但图形图例中提到的变量使用 var 标记。
< figure >
< math >
< mi > a</ mi >
< mo > =</ mo >
< msqrt >
< msup >< mi > b</ mi >< mn > 2</ mn ></ msup >
< mi > +</ mi >
< msup >< mi > c</ mi >< mn > 2</ mn ></ msup >
</ msqrt >
</ math >
< figcaption >
使用勾股定理求具有边长 < var > b</ var > 和 < var > c</ var > 的三角形的
斜边 < var > a</ var >
</ figcaption >
</ figure > 此处,在句子中使用了描述质能等价关系的方程,并使用
var 元素标记该方程中的
变量和常量:
< p > 随后她转向黑板,拿起粉笔。思考片刻后,
她写下了 < var > E</ var > = < var > m</ var > < var > c</ var >< sup > 2</ sup > 。老师
看起来很满意。</ p > samp
元素所有当前引擎均支持。
HTMLElement。samp 元素表示来自另一个程序或计算系统的示例输出或
引用输出。
此元素可与 output
元素形成对比,
后者可用于在 Web 应用程序中提供即时输出。
此示例展示了 samp
元素的行内用法:
< p > 计算机显示< samp > 第二个托盘中的奶酪
太多</ samp > ,但我不知道这是什么意思。</ p > 第二个示例展示了控制台程序的一块示例输出。嵌套的
samp 和 kbd 元素允许使用样式表
对示例输出的特定元素进行样式化。samp 中还有一些部分
使用了更详细的标记进行注释,以便实现非常精确的样式化。为此使用了
span 元素。
< pre >< samp >< span class = "prompt" > jdoe@mowmow:~$</ span > < kbd > ssh demo.example.com</ kbd >
上次登录:2005 年 4 月 12 日星期二 09:10:17,来自 mowmow.example.com,终端为 pts/1
Linux demo 2.6.10-grsec+gg3+e+fhs6b+nfs+gr0501+++p3+c4a+gr2b-reslog-v6.189 #1 SMP Tue Feb 1 11:22:36 PST 2005 i686 unknown
< span class = "prompt" > jdoe@demo:~$</ span > < span class = "cursor" > _</ span ></ samp ></ pre > 第三个示例展示了一块输入及其相应输出。该示例同时使用
code 和 samp 元素。
< pre >
< code class = "language-javascript" > console.log(2.3 + 2.4)</ code >
< samp > 4.699999999999999</ samp >
</ pre > kbd
元素所有当前引擎均支持。
HTMLElement。kbd 元素表示用户输入(通常是键盘输入,
但也可用于表示其他输入,例如语音命令)。
当 kbd 元素嵌套在
samp 元素内时,它表示
系统回显的输入。
当 kbd 元素
包含 samp
元素时,它表示基于系统输出的输入,例如调用菜单项。
当 kbd 元素嵌套在
另一个 kbd 元素内时,
它表示适用于该输入机制的实际按键或其他单个输入单位。
此处使用 kbd 元素
表示需要按下的按键:
< p > 要让 George 吃苹果,请按 < kbd >< kbd > Shift</ kbd > + < kbd > F3</ kbd ></ kbd ></ p > 在第二个示例中,用户被告知选择一个特定菜单项。外层
kbd 元素标记一块输入,
内层 kbd
元素表示输入的各个单独步骤,而其中的 samp 元素
表明这些步骤是基于系统显示内容的输入,在此例中即菜单标签:
< p > 要让 George 吃苹果,请选择
< kbd >< kbd >< samp > 文件</ samp ></ kbd > |< kbd >< samp > 吃苹果……</ samp ></ kbd ></ kbd >
</ p > 无需如此精确;以下写法同样正确:
< p > 要让 George 吃苹果,请选择 < kbd > 文件 | 吃苹果……</ kbd ></ p > sub 和 sup 元素
所有当前引擎均支持。
所有当前引擎均支持。
sub
元素:面向作者;面向实现者。sup
元素:面向作者;面向实现者。HTMLElement。这些元素必须仅用于标记具有特定含义的排版惯例,而不能仅仅为了排版呈现而使用。例如,
在 LaTeX 文档准备系统的名称中使用 sub 和
sup
元素是不合适的。一般而言,只有在缺少这些元素会改变内容含义时,作者才应使用它们。
在某些语言中,上标是部分缩写的排版惯例之一。
< p > 她们的名字是
< span lang = "fr" >< abbr > M< sup > lle</ sup ></ abbr > Gwendoline</ span > 和
< span lang = "fr" >< abbr > M< sup > me</ sup ></ abbr > Denise</ span > 。</ p > sub
元素可在 var 元素内使用,
以表示具有下标的变量。
此处,sub
元素用于表示标识一系列变量中某个变量的下标:
< p > 第 < var > i</ var > 个点的坐标为
(< var > x< sub >< var > i</ var ></ sub ></ var > , < var > y< sub >< var > i</ var ></ sub ></ var > )。
例如,第 10 个点的坐标为
(< var > x< sub > 10</ sub ></ var > , < var > y< sub > 10</ sub ></ var > )。</ p > 数学表达式经常使用下标和上标。建议作者使用 MathML 标记数学内容,但如果不需要详细的数学标记,
作者可以选择使用 sub 和
sup。
[MATHML]
< var > E</ var > =< var > m</ var >< var > c</ var >< sup > 2</ sup > f(< var > x</ var > , < var > n</ var > ) = log< sub > 4</ sub >< var > x</ var >< sup >< var > n</ var ></ sup > i
元素所有当前引擎均支持。
HTMLElement。i 元素表示以不同语气或情绪呈现的一段文本,或以表示不同文本性质的方式
与普通散文区分开来的文本,例如分类学名称、技术术语、来自另一种语言的惯用短语、
音译、思想,或西方文本中的船名。
与主要文本语言不同的术语应使用 lang 属性进行注释(或者在 XML 中使用
XML 命名空间中的 lang 属性)。
以下示例展示了 i 元素的用法:
< p > < i class = "taxonomy" > Felis silvestris catus</ i > 很可爱。</ p >
< p > 术语 < i > 散文内容</ i > 已在上文定义。</ p >
< p > 空气中有一种难以言喻的 < i lang = "fr" > je ne sais quoi</ i > 。</ p > 在以下示例中,使用
i 元素标记梦境片段。
< p > Raymond 试图入睡。</ p >
< p >< i > 船在星期四驶离了</ i > ,他
梦见。< i > 船上有许多人,其中包括一位名叫 Carey 的美丽
公主。他日复一日地注视着她,希望她能注意到自己,但她从未如此。</ i ></ p >
< p >< i > 终于有一天晚上,他鼓起勇气与
她交谈——</ i ></ p >
< p > 火警响起时,Raymond 猛然惊醒。</ p > 作者可以在 i
元素上使用 class 属性来标识使用该元素的
原因,这样,如果以后需要更改某种特定用法的样式(例如梦境片段,而不是分类学术语),作者就不必
遍历整个文档(或一系列相关文档)并为每处用法添加注释。
建议作者考虑是否有其他元素比
i 元素更适用,例如使用 em 元素标记着重强调,
或使用 dfn 元素标记术语的
定义实例。
样式表可用于格式化 i
元素,就像可以重新设置任何其他
元素的样式一样。因此,i 元素中的内容不一定会以斜体显示。
b
元素所有当前引擎均支持。
HTMLElement。b 元素表示出于实用目的而吸引注意力的一段文本,但不传达任何额外重要性,
也不暗示不同的语气或情绪,例如文档摘要中的关键字、评论中的产品名称、
文本驱动型交互式软件中的可操作词语,或文章导语。
以下示例展示了如何使用 b 元素突出显示关键字,
但不将其标记为重要内容:
< p > < b > frobonitor</ b > 和 < b > barbinator</ b > 组件烧坏了。</ p > 在以下示例中,文本冒险游戏中的对象使用
b 元素突出显示为特殊对象。
< p > 你进入一个小房间。你的< b > 剑</ b > 发出的光
变得更亮。一只< b > 老鼠</ b > 从墙角飞快跑过。</ p > b 元素的另一个适用场景是
标记导语句或导语段落。以下示例展示了如何标记一篇有关小猫被宠物兔子
当作自己孩子收养的 BBC 文章:
< article >
< h2 > 小猫被宠物兔子“收养”</ h2 >
< p >< b class = "lede" > 六只被遗弃的小猫找到了一个
意想不到的新母亲形象——一只宠物兔子。</ b ></ p >
< p > 兽医护士 Melanie Humble 将这些三周大的
小猫带回了她位于阿伯丁的家中。</ p >
[...]与 i 元素一样,作者可以在
b 元素上使用
class 属性来标识使用该元素的原因,
这样,如果以后要更改某种特定用法的样式,作者就不必遍历并为每处用法添加注释。
只有在没有其他更合适元素时,才应将 b 元素作为最后手段使用。
特别是,标题应使用 h1
至 h6
元素,着重强调应使用 em 元素,重要性应使用
strong 元素表示,
而标记或突出显示的文本应使用 mark 元素。
样式表可用于格式化 b
元素,就像可以重新设置任何其他
元素的样式一样。因此,b 元素中的内容不一定会加粗。
u
元素所有当前引擎均支持。
HTMLElement。u 元素表示一段带有未明确表达但显式呈现的非文本注释的文本,例如在中文文本中
将文本标记为专有名称(中文专名号),或将文本标记为拼写错误。
在大多数情况下,其他元素可能更合适:标记着重强调时,应使用
em 元素;标记关键字或短语时,
应根据上下文使用 b 元素或 mark 元素;
标记书名时,应使用 cite 元素;使用明确的文本注释
标记文本时,应使用 ruby 元素;对于技术术语、
分类学名称、音译、思想,或西方文本中的船名,应使用 i 元素。
u 元素在视觉呈现中的默认渲染方式
与超链接的惯常渲染方式(下划线)冲突。建议作者避免在可能被误认为超链接的地方使用
u 元素。
在此示例中,使用 u 元素
将一个单词标记为拼写错误:
< p > < u > see</ u > 里有很多鱼。</ p > mark
元素所有当前引擎均支持。
HTMLElement。mark 元素表示由于与另一上下文相关,而在某个文档中出于
引用目的被标记或突出显示的一段文本。
当用于引文或散文中所提及的其他文本块时,它表示原文中并不存在的突出显示,该突出显示是为了将读者
的注意力引向文本中的某一部分;原作者在最初撰写该文本块时可能并未认为该部分重要,但该部分现在正受到
先前未曾预料的审视。当用于文档的主要散文中时,它表示文档中由于可能与用户当前活动相关而被突出显示
的部分。
此示例展示了如何使用 mark 元素将注意力引向
引文的特定部分:
< p lang = "en-US" > 请考虑以下引文:</ p >
< blockquote lang = "en-GB" >
< p > 环顾四周,你会发现,没有人真正是
< mark > colour</ mark > blind。</ p >
</ blockquote >
< p lang = "en-US" > 从该词的< em > 拼写</ em > 可以看出,
撰写这段引文的人显然不是美国人。</ p > (但是,如果目的是将该元素标记为拼写错误,那么使用 u
元素,并可能添加一个类,
会更合适。)
mark 元素的另一个
示例是突出显示文档中与某个搜索字符串匹配的部分。如果有人查看某个文档,而服务器知道用户正在
搜索单词“kitten”,则服务器可能返回该文档,并将其中一个段落修改如下:
< p > 这些天还有一些< mark > 小猫</ mark > 来拜访我。
它们真的很可爱。我想它们喜欢我的花园!也许我应该收养一只
< mark > 小猫</ mark > 。</ p > 在以下片段中,一段文本引用了代码片段的特定部分。
< p > 下面突出显示的部分就是错误所在:</ p >
< pre >< code > var i: Integer;
begin
i := < mark > 1.1</ mark > ;
end.</ code ></ pre > 这与语法高亮不同,后者更适合使用 span。
将二者结合,会得到:
< p > 下面突出显示的部分就是错误所在:</ p >
< pre >< code >< span class = keyword > var</ span > < span class = ident > i</ span > : < span class = type > Integer</ span > ;
< span class = keyword > begin</ span >
< span class = ident > i</ span > := < span class = literal >< mark > 1.1</ mark ></ span > ;
< span class = keyword > end</ span > .</ code ></ pre > 这是另一个示例,展示了如何使用 mark
突出显示引文中
原本未受强调的一部分。在此示例中,常见的排版惯例促使作者显式设置引文中
mark 元素的样式,
使其以斜体呈现。
< style >
blockquote mark , q mark {
font : inherit ; font-style : italic ;
text-decoration : none ;
background : transparent ; color : inherit ;
}
. bubble em {
font : inherit ; font-size : larger ;
text-decoration : underline ;
}
</ style >
< article >
< h1 > 她知道</ h1 >
< p > 你注意到第 4 格笑话中的那个微妙笑点了吗?</ p >
< blockquote >
< p class = "bubble" > 我并不< em > 想要</ em > 相信。< mark > 当然,
在某种程度上,我意识到这是一种已知明文攻击。</ mark > 但在我
亲眼看到之前,我无法承认这一点。</ p >
</ blockquote >
< p > (强调为我所加。)我觉得这很棒。它非常拘泥细节,却又
把一切解释得清清楚楚。</ p >
</ article > 以下示例展示了表示一段文本的重要性(strong)
与表示一段文本的相关性(mark)之间的区别。
这是教科书中的一段摘录,其中与考试相关的部分已被突出显示。安全警告尽管可能很重要,
但显然与考试无关。
< h3 > 虫洞物理学简介</ h3 >
< p >< mark > 在正常条件下,虫洞最多只能保持开启
略少于 39 分钟。</ mark > 可延长该时间的条件包括:
将强大能源连接到与虫洞相连的一个或两个星门,以及一个大型引力井
(例如黑洞)。</ p >
< p >< mark > 动量在穿过虫洞时保持不变。电磁
辐射可以双向穿过虫洞,
但物质不能。</ mark ></ p >
< p > 创建虫洞时,通常会形成一个涡流。
< strong > 警告:虫洞开启所产生的涡流会
湮灭路径上的一切。</ strong > 使用足够先进的拨号技术时,
可以避免涡流。</ p >
< p >< mark > 星门中的障碍物会阻止其接受
虫洞连接。</ mark ></ p > bdi
元素所有当前引擎均支持。
dir 全局属性在此元素上具有
特殊语义。HTMLElement。bdi 元素表示为了双向文本格式化而需要与周围内容隔离的一段
文本。[BIDI]
dir 全局属性在此元素上
默认为 auto(它绝不会像
其他元素那样从父元素继承)。
此元素具有涉及双向文本算法的渲染要求。
此元素在嵌入方向未知的用户生成内容时尤其有用。
在此示例中,用户名与用户提交的帖子数量一起显示。如果不使用
bdi 元素,
阿拉伯语用户的用户名最终会扰乱文本(双向文本算法会将冒号和数字“3”放到单词“用户”旁边,
而不是放到单词“帖子”旁边)。
< ul >
< li > 用户 < bdi > jcranmer</ bdi > :12 篇帖子。
< li > 用户 < bdi > hober</ bdi > :5 篇帖子。
< li > 用户 < bdi > إيان</ bdi > :3 篇帖子。
</ ul > 
bdi
元素时,用户名会按预期工作。
bdi 元素
替换为 b 元素,
用户名会扰乱双向文本算法,第三个列表项最终会显示“用户 3:”,
后跟阿拉伯语姓名(从右到左),再后跟“帖子”和句号。bdo
元素所有当前引擎均支持。
dir 全局属性在此元素上具有
特殊语义。HTMLElement。bdo 元素表示对子项进行显式文本方向格式化控制。
它允许作者通过显式指定方向覆盖来覆盖 Unicode 双向文本算法。[BIDI]
作者必须在此元素上指定 dir 属性:值为
ltr 时指定从左到右覆盖,
值为 rtl 时指定从右到左覆盖。
不得指定 auto 值。
此元素具有涉及双向文本算法的渲染要求。
span
元素所有当前引擎均支持。
所有当前引擎均支持。
[Exposed =Window ]
interface HTMLSpanElement : HTMLElement {
[HTMLConstructor ] constructor ();
};span 元素本身没有任何
含义,但与全局属性一起使用时
可能很有用,例如 class、
lang 或 dir。它
表示其子项。
在此示例中,代码片段使用 span 元素和 class 属性进行标记,以便使用 CSS
为其关键字和标识符设置不同颜色:
< pre >< code class = "lang-c" >< span class = "keyword" > for</ span > (< span class = "ident" > j</ span > = 0; < span class = "ident" > j</ span > < 256; < span class = "ident" > j</ span > ++) {
< span class = "ident" > i_t3</ span > = (< span class = "ident" > i_t3</ span > & 0x1ffff) | (< span class = "ident" > j</ span > << 17);
< span class = "ident" > i_t6</ span > = (((((((< span class = "ident" > i_t3</ span > >> 3) ^ < span class = "ident" > i_t3</ span > ) >> 1) ^ < span class = "ident" > i_t3</ span > ) >> 8) ^ < span class = "ident" > i_t3</ span > ) >> 5) & 0xff;
< span class = "keyword" > if</ span > (< span class = "ident" > i_t6</ span > == < span class = "ident" > i_t1</ span > )
< span class = "keyword" > break</ span > ;
}</ code ></ pre > br
元素所有当前引擎均支持。
所有当前引擎均支持。
[Exposed =Window ]
interface HTMLBRElement : HTMLElement {
[HTMLConstructor ] constructor ();
// 还有废弃成员
};虽然在视觉媒体中,换行通常通过将后续文本实际移至新行来表示,但样式表或用户代理 同样可以合理地使换行以不同方式渲染,例如呈现为绿色圆点或额外间距。
br 元素必须仅用于
确实属于内容一部分的换行,例如诗歌或地址中的换行。
以下示例是 br 元素的正确用法:
< p > P. Sherman< br >
42 Wallaby Way< br >
悉尼</ p > br 元素不得用于
分隔段落中的主题组。
以下示例滥用了 br 元素,因此不符合规范:
< p >< a ...> 34 条评论。</ a >< br >
< a ...> 添加评论。</ a ></ p > < p >< label > 姓名:< input name = "name" ></ label >< br >
< label > 地址:< input name = "address" ></ label ></ p > 以下是上述内容的正确替代方案:
< p >< a ...> 34 条评论。</ a ></ p >
< p >< a ...> 添加评论。</ a ></ p > < p >< label > 姓名:< input name = "name" ></ label ></ p >
< p >< label > 地址:< input name = "address" ></ label ></ p > 如果一个段落仅由单个 br 元素组成,则它
表示占位空行(例如模板中的空行)。不得将此类空行用于呈现目的。
br 元素内的任何内容
均不得被视为周围文本的一部分。
此元素具有涉及双向文本算法的渲染要求。
wbr
元素所有当前引擎均支持。
HTMLElement。在以下示例中,引用了某人所说的一句话;为了达到某种效果,该句话被写成一个很长的单词。
但是,为确保文本能够以可读方式换行,引文中的各个单词使用 wbr 元素分隔。
< p > 于是她指着老虎尖叫道:
“你< wbr > 绝< wbr > 对< wbr > 不< wbr > 可< wbr > 能< wbr > 抓< wbr > 到< wbr > 我”!</ p > wbr 元素内的任何内容
均不得被视为周围文本的一部分。
var wbr = document. createElement( "wbr" );
wbr. textContent = "This is wrong" ;
document. body. appendChild( wbr); 此元素具有涉及双向文本算法的渲染要求。
本节为非规范性内容。
| 元素 | 用途 | 示例 |
|---|---|---|
a
|
超链接 |
|
em
|
着重强调 |
|
strong
|
重要性 |
|
small
|
附注 |
|
s
|
不准确的文本 |
|
cite
|
作品标题 |
|
q
|
引文 |
|
dfn
|
定义实例 |
|
abbr
|
缩写 |
|
ruby、rt、rp
|
Ruby 注释 |
|
data
|
机器可读等价值 |
|
time
|
日期或时间相关数据的机器可读等价值 |
|
code
|
计算机代码 |
|
var
|
变量 |
|
samp
|
计算机输出 |
|
kbd
|
用户输入 |
|
sub
|
下标 |
|
sup
|
上标 |
|
i
|
不同语气 |
|
b
|
关键字 |
|
u
|
注释 |
|
mark
|
突出显示 |
|
bdi
|
文本方向隔离 |
|
bdo
|
文本方向格式化 |
|
span
|
其他 |
|
br
|
换行 |
|
wbr
|
换行机会 |
|
链接是一种概念性构造,由 a、area、
form 和 link 元素创建,用于表示
两个资源之间的连接,其中一个资源是当前 Document。HTML 中有三种链接:
这些链接指向用于增强当前文档的资源,通常由用户代理自动处理。所有外部资源链接都有一个获取 并处理所链接资源的算法,用于描述如何获取该资源。
这些链接指向其他资源,用户代理通常会将其呈现给用户,使用户能够让用户代理导航到这些资源,例如在浏览器中访问或下载它们。
这些链接指向当前文档中的资源,用于赋予这些资源特殊含义或行为。
对于同时具有 href 属性和
rel 属性的 link 元素,必须按照
链接类型一节中对这些关键字的定义,为
rel 属性中的关键字创建链接。
类似地,对于同时具有 href 属性和 rel 属性的 a 和 area 元素,必须按照
链接类型一节中对这些关键字的定义,为
rel 属性中的关键字
创建链接。不过,与 link 元素不同,具有 href
属性的 a 和 area 元素,如果没有 rel 属性,或者其
rel 属性中没有
被定义为指定超链接的关键字,也必须创建一个超链接。
除了将该元素的节点文档
链接到该元素的 href 属性所给出的资源
之外,此隐式超链接没有特殊含义(它没有链接类型)。
类似地,对于具有 rel
属性的 form 元素,
必须按照链接类型一节中对这些关键字的定义,为 rel
属性中的关键字创建链接。没有 rel 属性,或者其 rel 属性中没有被定义为指定
超链接的关键字的 form 元素,也必须创建一个超链接。
一个超链接可以具有一个或多个超链接 注释,用于修改该超链接的处理语义。
a 和 area 元素创建的链接a
和 area
元素上的 href
属性的值必须是一个可能被空格包围的有效
URL。
a
和
area
元素上的 href
属性不是必需的;当这些元素没有 href
属性时,它们不会创建超链接。
如果存在 target
属性,则其值必须是一个有效的可导航目标名称或
关键字。它给出将要使用的可导航对象的名称。用户代理在跟随超链接时使用此名称。
如果存在 download
属性,则表示作者希望将该超链接用于下载资源。
该属性可以具有值;如果有值,则该值指定作者建议用于在本地文件系统中标记该资源的默认文件名。
允许的值不受限制,但作者应注意,大多数文件系统对文件名所支持的标点符号有所限制,
用户代理可能会据此调整文件名。
所有当前引擎均支持。
如果存在 ping 属性,
则它给出一些资源的 URL,这些资源希望在用户跟随该超链接时收到通知。其值必须是一个以空格分隔的令牌集合,
其中每个令牌都必须是一个有效的非空
URL,且其方案
必须是 HTTP(S)
方案。用户代理将该值用于超链接
审计。
a
和 area
元素上的 rel
属性控制这些元素创建何种链接。该属性的值必须是一个无序且唯一的
以空格分隔的令牌集合。下文定义了允许的关键字及其含义。
rel 的
受支持令牌,是在 HTML 链接类型中定义的关键字;这些关键字允许用于 a 和 area
元素,会影响处理模型,并受用户代理支持。可能的受支持令牌包括 noreferrer、
noopener
和 opener。
rel 的
受支持令牌只能包含此列表中用户代理已实现其处理模型的令牌。
rel
属性没有默认值。如果省略该属性,或者用户代理无法识别该属性中的任何值,
则除了两者之间存在超链接之外,文档与目标资源之间没有特定关系。
referrerpolicy 属性是一个来源网址政策属性。
其用途是设置来源网址政策,以供跟随
超链接时使用。[REFERRERPOLICY]
当调用 a 或
area
元素的激活行为时,用户代理可以允许用户表明偏好:
是将该超链接用于导航,还是下载其指定的资源。
如果用户没有表明偏好,则当元素没有
download
属性时,默认行为应为导航;如果具有该属性,则默认行为应为下载指定资源。
给定事件 event 时,a 或 area 元素
element 的激活行为如下:
如果 element 没有 href
属性,则返回。
令 hyperlinkSuffix 为 null。
令 userInvolvement 为 event 的用户 导航参与程度。
如果用户已表明希望下载该超链接,则将
userInvolvement 设置为“浏览器 UI”。
也就是说,如果用户明确表明了下载偏好,则这不再仅仅算作“激活”。
如果 element 具有 download
属性,或者用户已表明希望下载该超链接,则下载
由 element 创建的超链接,并将
hyperlinkSuffix 设置为 hyperlinkSuffix,
将 userInvolvement 设置为
userInvolvement。
否则,跟随由 element 创建的超链接,并将 hyperlinkSuffix 设置为 hyperlinkSuffix,将 userInvolvement 设置为 userInvolvement。
interface mixin HyperlinkElementUtils {
readonly attribute USVString origin ;
[CEReactions ] attribute USVString protocol ;
[CEReactions ] attribute USVString username ;
[CEReactions ] attribute USVString password ;
[CEReactions ] attribute USVString host ;
[CEReactions ] attribute USVString hostname ;
[CEReactions ] attribute USVString port ;
[CEReactions ] attribute USVString pathname ;
[CEReactions ] attribute USVString search ;
[CEReactions ] attribute USVString hash ;
[CEReactions , Reflect ] attribute DOMString hreflang ;
[CEReactions , Reflect ] attribute DOMString type ;
};hyperlink.origin
所有当前引擎均支持。
所有当前引擎均支持。
返回超链接 URL 的源。
hyperlink.protocol
所有当前引擎均支持。
所有当前引擎均支持。
返回超链接 URL 的方案。
可以设置,以更改 URL 的方案。
hyperlink.username
所有当前引擎均支持。
所有当前引擎均支持。
返回超链接 URL 的用户名。
可以设置,以更改 URL 的用户名。
hyperlink.password
所有当前引擎均支持。
所有当前引擎均支持。
返回超链接 URL 的密码。
可以设置,以更改 URL 的密码。
hyperlink.host
所有当前引擎均支持。
所有当前引擎均支持。
返回超链接 URL 的主机和端口(如果端口不同于该方案的默认端口)。
可以设置,以更改 URL 的主机和端口。
hyperlink.hostname
所有当前引擎均支持。
所有当前引擎均支持。
返回超链接 URL 的主机。
可以设置,以更改 URL 的主机。
hyperlink.port
所有当前引擎均支持。
所有当前引擎均支持。
返回超链接 URL 的端口。
可以设置,以更改 URL 的端口。
hyperlink.pathname
所有当前引擎均支持。
所有当前引擎均支持。
返回超链接 URL 的路径。
可以设置,以更改 URL 的路径。
hyperlink.search
所有当前引擎均支持。
所有当前引擎均支持。
返回超链接 URL 的查询(非空时包括开头的“?”)。
可以设置,以更改 URL 的查询(忽略开头的“?”)。
hyperlink.hash
所有当前引擎均支持。
所有当前引擎均支持。
返回超链接 URL 的片段(非空时包括开头的“#”)。
可以设置,以更改 URL 的片段(忽略开头的“#”)。
实现 HyperlinkElementUtils
混入的元素是超链接
元素。
一个超链接元素具有一个 关联的 URL(null 或一个 URL)。其初始值为 null。
一个超链接元素必须具有 一个关联的设置 URL算法。
一个超链接元素必须具有
一个关联的更新 href
算法。
创建超链接的超链接元素上的
hreflang
属性(如果存在)给出所链接资源的语言。它纯粹是建议性的。其值必须是有效的 BCP 47 语言标签。
[BCP47] 用户代理不得将此属性视为权威信息——获取资源后,用户代理必须仅使用
与资源关联的语言信息来确定其语言,而不能使用资源链接中包含的元数据。
超链接
元素上的 type
属性(如果存在)给出所链接资源的
MIME 类型。它纯粹是建议性的。其值必须是一个
有效的 MIME 类型字符串。用户代理不得将 type 属性
视为权威信息——获取资源后,用户代理不得使用资源链接中包含的元数据来确定其
类型。
protocol
设置器步骤如下:
username
设置器步骤如下:
password
设置器步骤如下:
host 获取器步骤如下:
host
设置器步骤如下:
hostname
设置器步骤如下:
port
设置器步骤如下:
pathname 获取器步骤如下:
如果 url 为 null,则返回空字符串。
返回序列化 URL 路径 url 的结果。
pathname
设置器步骤如下:
search 获取器步骤如下:
search
设置器
步骤如下:
hash 获取器步骤如下:
hash
设置器步骤如下:
a 和 area 元素的 APIinterface mixin HTMLHyperlinkElementUtils {
[CEReactions , ReflectSetter ] stringifier attribute USVString href ;
[CEReactions , Reflect ] attribute DOMString target ;
};hyperlink.toString()hyperlink.href
所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
返回超链接的 URL。
可以设置,以更改 URL。
href 获取器步骤如下:
给定 insertedNode,a 和 area
元素的 HTML
元素插入步骤如下:
给定 removedNode、isSubtreeRoot 和 oldAncestor,a 和 area 元素的
HTML
元素移除步骤如下:
给定 movedNode,a 和 area 元素的
HTML 元素
移动步骤如下:
给定 element、localName、oldValue、
value 和 namespace,以下属性更改
步骤用于所有 a 和 area
元素:
如果 namespace 不为 null,则返回。
如果 oldValue 等于 value,则返回。
如果 localName 为 href,则
给定 element,设置
URL。
这仅对 blob:
URL 可观察,因为对它们进行解析涉及一次 Blob URL 存储
查找。
如果 localName 为 href、referrerpolicy
或 rel,
则给定 element 的节点文档,考虑推测性加载。
要为 HTMLAnchorElement 或
HTMLAreaElement
元素更新 href,请将该元素的
href
内容属性的值设置为该元素的 URL
的序列化。
HTMLAnchorElement
和 HTMLAreaElement
元素的设置
URL算法如下:
这也由 form 元素的表单
提交使用。对 a 元素的例外是为了
与 Web 内容兼容。
要获取元素的 noopener,给定 a、area 或
form 元素
element、一个 URL 记录 url 和一个
字符串 target,执行以下步骤。它们返回一个布尔值。
如果 element 的链接类型包含 noopener 或 noreferrer
关键字,则返回 true。
如果 element 的链接类型
不包含 opener 关键字,且
target 与“_blank”ASCII
不区分大小写匹配,则返回
true。
如果 url 的 blob URL 条目 不为 null:
返回 false。
要跟随由元素
subject 创建的超链接,给定一个可选的 hyperlinkSuffix
(默认为 null)和一个可选的 userInvolvement(默认为“none”):
如果 subject 无法 导航,则返回。
令 targetAttributeValue 为空字符串。
如果 subject 是 a
或 area 元素,则将
targetAttributeValue 设置为给定 subject,获取
元素的目标所得的结果。
令 urlRecord 为给定 subject 的 href 属性
值,并相对于 subject 的节点文档,执行
编码解析 URL所得的结果。
如果 urlRecord 为失败,则返回。
令 noopener 为使用 subject、urlRecord 和 targetAttributeValue,获取 元素的 noopener所得的结果。
令 targetNavigable 为给定 targetAttributeValue、subject 的 节点可导航对象和 noopener,应用选择 可导航对象的规则所得的第一个返回值。
如果 targetNavigable 为 null,则返回。
令 urlString 为将 URL 序列化器应用于 urlRecord 所得的结果。
如果 hyperlinkSuffix 非 null,则将其附加到 urlString。
使用 subject 的节点文档,将 targetNavigable 导航到 urlString,并将 referrerPolicy 设置为 subject 的 超链接来源 策略,将 userInvolvement 设置为 userInvolvement,并将 sourceElement 设置为 subject。
与许多其他类型的导航不同,当文档尚未完全
加载时,跟随超链接没有特殊的“replace”
行为。这既适用于用户发起的跟随超链接,也适用于例如通过
aElement.click() 由脚本触发的跟随超链接。
元素 subject 的超链接来源策略是由以下步骤 返回的值:
如果 subject 的链接
类型包含 noreferrer
关键字,则返回
“no-referrer”。
返回 subject 的 referrerpolicy
内容属性的当前状态。
所有当前引擎均支持。
在某些情况下,资源旨在供以后使用,而不是立即查看。为了表明某个资源旨在下载以供以后使用,
而不是立即使用,可以在创建指向该资源超链接的
a 或 area 元素上指定
download
属性。
此外,还可以为该属性提供一个值,以指定用户代理将资源存储到文件系统时要使用的文件名。
此值可由 `Content-Disposition`
HTTP 标头的文件名参数覆盖。
[RFC6266]
在跨源情况下,download
属性必须与 `Content-Disposition`
HTTP 标头结合使用,具体而言,应与
attachment 处置类型结合使用,以避免警告用户可能存在恶意活动。
(这是为了保护用户,避免他们在未充分理解的情况下被迫下载敏感的个人或机密信息。)
要下载由元素
subject 创建的超链接,给定一个可选的 hyperlinkSuffix(默认为 null)和一个
可选的 userInvolvement(默认为
“none”):
如果 subject 无法 导航,则返回。
如果 subject 的节点 文档的活动 沙盒标志集合设置了沙盒化下载浏览上下文 标志,则返回。
令 urlString 为给定 subject 的 href 属性
值,并相对于 subject 的节点文档,执行
编码解析并序列化
URL所得的结果。
如果 urlString 为失败,则返回。
如果 hyperlinkSuffix 非 null,则将其附加到 urlString。
如果 userInvolvement 不是“浏览器 UI”:
令 filename 为 subject 的 download
属性的值。
令 continue 为在
navigation 上触发下载请求
navigate 事件所得的结果,并将 destinationURL
设置为 urlString,将 userInvolvement 设置为
userInvolvement,将 sourceElement
设置为 subject,并将 filename 设置为
filename。
如果 continue 为 false,则返回。
给定 subject 的节点可导航对象,通知导航 API 导航中止。
并行运行以下步骤:
要使用一个可导航对象 navigable 和一个导航 ID或 null navigationId,将一个响应 response 作为下载处理:
令 suggestedFilename 为针对 response 获取建议 文件名所得的结果。
令 download behavior 为使用 navigable 和一个新的 WebDriver BiDi 导航状态执行WebDriver BiDi 下载即将
开始所得的结果,其中该状态的 id 为
navigationId,status
为“pending”,
url 为
response 的 URL,且 suggestedFilename 为
suggestedFilename。
如果 download behavior 不为 null,且 download behavior 的 allowed 为 false:
使用 navigable 和一个新的
WebDriver BiDi 导航状态调用WebDriver BiDi 下载结束,其中该状态的 id 为
navigationId,status 为“canceled”,
url 为
response 的 URL。
返回。
如果 download behavior 不为 null,则令 destinationFolder 为 download behavior 的destinationFolder。
并行运行以下步骤:
运行由实现定义的步骤,以保存 response 供以后使用。 如果 destinationFolder 不为 null,则用户代理应将文件保存到该路径。 如果用户代理需要文件名,则用户代理应使用 suggestedFilename。
如果以下任一条件为真:
用户取消下载;
用户代理取消下载;
发生错误(例如网络错误、存储空间不足、目标文件夹不可用);
则:
使用 navigable 和一个新的
WebDriver BiDi 导航状态调用WebDriver BiDi 下载结束,其中该状态的 id 为
navigationId,status 为“canceled”,
url
为 response 的 URL。
返回。
下载成功完成时,使用 navigable 和一个新的 WebDriver BiDi 导航状态调用WebDriver BiDi 下载
结束,其中该状态的 id 为
navigationId,status 为“complete”,
downloadedFilepath 在可用时为已下载文件的
绝对路径,否则为 null,url 为
response 的 URL。
要为响应 response 获取建议文件名:
此算法旨在减轻从不受信任的网站下载文件所涉及的安全风险,强烈建议用户代理遵循该算法。
令 filename 为 undefined 值。
如果 response 具有 `Content-Disposition`
标头,该标头指定
attachment 处置类型,并且该标头包含文件名信息,
则令 filename 具有该标头指定的值,并跳转到下面标记为
清理的步骤。[RFC6266]
令 response origin 为
response 的 URL 的源,除非该 URL
的方案组件
为 data;在这种情况下,如果存在 interface origin,则令
response origin 与 interface origin 相同。
如果不存在 interface origin,则令 trusted operation 为 true。 否则,如果 response origin 与 interface origin 同源,则令 trusted operation 为 true,否则为 false。
如果 trusted operation 为 true,且 response 具有 `Content-Disposition`
标头,并且该标头包含文件名信息,则令 filename 具有该标头指定的值,并
跳转到下面标记为 清理 的步骤。[RFC6266]
如果下载不是从由 a 或 area 元素创建的超链接发起的,或者发起下载的超链接元素在发起下载时没有 download
属性,或者存在该属性但其在发起下载时的值为空字符串,则跳转到标记为无建议
文件名的步骤。
如果 trusted operation 为 true,则令 filename 具有 proposed filename 的值,并跳转到下面标记为 清理 的步骤。
如果 response 具有 `Content-Disposition`
标头,且该标头指定
attachment 处置类型,则令 filename 具有
proposed filename 的值,并跳转到下面标记为 清理 的步骤。
[RFC6266]
无建议文件名:如果 trusted operation 为 true,或者用户 表明了希望下载相关响应的偏好,则令 filename 以由实现定义的方式具有一个从 response 的 URL 派生的值,并跳转到下面标记为 清理 的步骤。
将 filename 设置为用户偏好的文件名或用户代理选择的文件名,并跳转到下面标记为 清理 的步骤。
如果算法到达此步骤,则下载是从与 response 不同的源开始的,
而该源没有将文件标记为适合下载,并且下载也不是由用户发起的。这可能是因为使用了 download
属性触发下载,或者
因为 response 的类型不受用户代理支持。
这可能很危险,因为例如恶意服务器可能试图诱使用户在不知情的情况下下载私人信息, 然后再将其上传回恶意服务器,方法是欺骗用户,使其认为数据来自恶意服务器。
因此,为了用户的利益,应以某种方式通知用户 response 来自完全不同的来源;为防止混淆,应忽略潜在恶意 interface origin 建议的任何文件名。
清理:可选地,允许用户影响 filename。例如, 用户代理可以提示用户输入文件名,并可能将上面确定的 filename 值作为默认值。
调整 filename,使其适合本地文件系统。
例如,这可能包括移除文件名中不合法的字符,或者修剪开头和结尾的空白。
如果平台惯例完全不使用扩展名来确定文件系统中文件的类型, 则将 filename 作为文件名返回。
如果已知,则令 claimed type 为 response 的 Content-Type 元数据给出的类型。如果已知,则令 named type 为 filename 的扩展名给出的类型。 就此步骤而言,类型是从一个MIME 类型 到一个扩展名的映射。
如果 named type 与用户的偏好一致(例如因为 filename 的值是通过提示用户确定的),则将 filename 作为文件名返回。
如果 claimed type 和 named type 是相同类型(即 response 的 Content-Type 元数据给出的类型与 filename 的扩展名给出的类型一致),则将 filename 作为文件名返回。
如果 claimed type 已知,则修改 filename,为其添加与 claimed type 对应的扩展名。
否则,如果已知 named type 可能存在危险(例如平台惯例会将其视为本机可执行文件、
shell 脚本、HTML 应用程序或支持可执行宏的文档),则可以选择修改
filename,添加一个已知安全的扩展名
(例如“.txt”)。
最后这一步会使下载可执行文件变得不可能,而这可能并不理想。 与往常一样,实现者不得不在此问题上平衡安全性和可用性。
将 filename 作为文件名返回。
就此算法而言,文件的扩展名
由平台惯例规定将用于识别文件类型的文件名任何部分组成。例如,许多操作系统使用文件名中
最后一个点号(“.”)之后的部分来确定文件类型,并据此确定打开或执行该文件的
方式。
用户代理在决定将生成的文件存储到用户文件系统中的何处时,应忽略响应本身、
其 URL
以及任何 download
属性提供的任何目录或路径信息。
如果由 a 或 area 元素创建的超链接具有
ping 属性,并且用户跟随该超链接,
且相对于元素的节点
文档,元素的 href
属性值可以被解析而不失败,则用户代理必须取得
ping 属性的值,在 ASCII 空白处分割该字符串,相对于元素的节点文档解析每个所得令牌,然后对每个所得的
URL
ping URL 运行以下步骤,
忽略解析返回失败的情况:
如果 ping URL 的方案不是 HTTP(S) 方案,则返回。
可选地,返回。(例如,用户代理可能希望根据用户表达的偏好忽略任意或 所有 ping URL。)
令 request 为一个新的请求,其URL 为 ping URL,方法为 `POST`,标头
列表为 « (`Content-Type`,
`text/ping`) »,主体为 `PING`,客户端为
settingsObject,目标为空
字符串,凭据模式为“include”,来源网址为
“no-referrer”,并设置其使用 URL 凭据标志,且其
发起者类型为“ping”。
令 target URL 为给定元素的 href 属性的值,
并相对于元素的节点文档,执行编码解析并序列化
URL所得的结果,然后:
获取 request。
这可以与主要获取并行完成, 并且独立于该获取的结果。
用户代理应允许用户调整此行为,例如与禁用发送 HTTP `Referer`
(原文如此)
标头的设置结合使用。根据用户的偏好,用户代理可以完全忽略
ping 属性,或者选择性地忽略列表中的
URL(例如忽略任何第三方 URL);上述步骤已明确考虑到这一点。
用户代理必须忽略响应中返回的任何实体主体。用户代理开始接收响应主体后,可以提前关闭 连接。
![]() 如果存在一个创建超链接并具有
如果存在一个创建超链接并具有
ping 属性的 a 或 area 元素,用户代理可以向用户表明,
跟随该超链接还会导致在后台发送辅助请求,并且可能包括列出实际的目标 URL。
例如,视觉用户代理可以在状态栏或工具提示中,将目标 ping URL 的主机名与超链接的实际 URL 一起显示。
ping 属性与 HTTP 重定向和 JavaScript
等既有技术功能重复,因为这些技术也允许网页跟踪哪些站外链接最受欢迎,或允许广告商跟踪点击率。
不过,与这些替代方案相比,ping 属性为用户提供了
以下优势:
Ping-From` 和 `Ping-To` 标头`Ping-From` 和 `Ping-To` HTTP 请求标头包含在超链接
审计请求中。它们的值是一个经过序列化的URL。
所有当前引擎均支持。
下表按相应关键字汇总了本规范定义的链接类型。此表为非规范性内容; 链接类型的实际定义见接下来的几个小节。
在本节中,术语被引用文档是指由表示链接的元素所标识的资源, 术语当前文档是指表示链接的元素所在的资源。
要确定哪些链接类型适用于 link、a、area
或 form 元素,必须对该元素的
rel 属性按 ASCII 空白分割。
所得令牌就是适用于该元素的链接类型关键字。
除非另有规定,否则每个 rel 属性中的同一关键字不得指定多次。
下表之后的某些小节列出了特定关键字的同义词。用户代理应按照规定处理所指明的同义词,
但不得在文档中使用它们(例如关键字“copyright”)。
关键字始终ASCII 不区分大小写,并且必须如此进行比较。
因此,rel="next" 与 rel="NEXT" 相同。
body-ok 关键字会影响 link 元素是否允许出现在 body 中。body-ok 关键字为
dns-prefetch、
modulepreload、
pingback、
preconnect、
prefetch、
preload 和
stylesheet。
要由 Web 浏览器实现的新链接类型应添加到本标准中。其余链接类型可注册为扩展。
| 链接类型 | 对以下内容的影响... | body-ok | 具有 `Link`
处理 |
简要说明 | ||
|---|---|---|---|---|---|---|
link |
a 和 area |
form |
||||
alternate |
超链接 | 不允许 | · | · | 给出当前文档的替代表示。 | |
canonical |
超链接 | 不允许 | · | · | 给出当前文档的首选 URL。 | |
author |
超链接 | 不允许 | · | · | 给出指向当前文档或文章作者的链接。 | |
bookmark |
不允许 | 超链接 | 不允许 | · | · | 给出最近祖先章节的永久链接。 |
dns-prefetch |
外部资源 | 不允许 | 是 | · | 指定用户代理应抢先对目标资源的源执行 DNS 解析。 | |
expect |
内部资源 | 不允许 | · | · | 预期具有目标 ID 的元素出现在当前文档中。 | |
external |
不允许 | 注释 | · | · | 表示被引用文档与当前文档不属于同一站点。 | |
help |
超链接 | · | · | 提供指向上下文相关帮助的链接。 | ||
icon |
外部资源 | 不允许 | · | · | 导入一个表示当前文档的图标。 | |
manifest |
外部资源 | 不允许 | · | · | 导入或链接到一个应用程序 清单。[MANIFEST] | |
modulepreload
|
外部资源 | 不允许 | 是 | · | 指定用户代理必须抢先获取模块 脚本,并将其存储到文档的模块映射中,以供稍后 求值。可选地,也可以获取模块的依赖项。 | |
license |
超链接 | · | · | 表示当前文档的主要内容受被引用文档所描述的著作权许可证约束。 | ||
next |
超链接 | · | · | 表示当前文档是某个系列的一部分,并且该系列中的下一个文档是被引用文档。 | ||
nofollow |
不允许 | 注释 | · | · | 表示当前文档的原作者或发布者不认可被引用文档。 | |
noopener |
不允许 | 注释 | · | · | 如果超链接原本会创建一个辅助的顶层可遍历对象,则创建一个具有非辅助浏览
上下文的顶层可遍历对象(即具有适当的 target
属性值)。 |
|
noreferrer |
不允许 | 注释 | · | · | 不会包含 `Referer`
(原文如此)标头。
此外,其效果与 noopener 相同。 |
|
opener |
不允许 | 注释 | · | · | 如果超链接原本会创建一个具有非辅助浏览
上下文的顶层可遍历对象,
则创建一个辅助浏览上下文(即
target
属性值为“_blank”)。
|
|
pingback |
外部资源 | 不允许 | 是 | · | 给出处理当前文档 pingback 的 pingback 服务器地址。 | |
preconnect |
外部资源 | 不允许 | 是 | 是 | 指定用户代理应抢先连接到目标资源的源。 | |
prefetch |
外部资源 | 不允许 | 是 | · | 指定用户代理应抢先获取并缓存目标资源,因为后续导航很可能需要它。 | |
preload |
外部资源 | 不允许 | 是 | 是 | 指定用户代理必须根据 as 属性给出的预加载目标(以及与相应目标关联的优先级),为当前导航抢先获取并缓存目标资源。 |
|
prev |
超链接 | · | · | 表示当前文档是某个系列的一部分,并且该系列中的上一个文档是被引用文档。 | ||
privacy-policy
|
超链接 | 不允许 | · | · | 给出指向适用于当前文档的数据收集和使用惯例信息的链接。 | |
search |
超链接 | · | · | 给出指向可用于搜索当前文档及其相关页面的资源的链接。 | ||
stylesheet |
外部资源 | 不允许 | 是 | · | 导入样式表。 | |
tag |
不允许 | 超链接 | 不允许 | · | · | 给出适用于当前文档的标签(由给定地址标识)。 |
terms-of-service
|
超链接 | 不允许 | · | · | 给出指向当前文档的提供者与希望使用当前文档的用户之间协议相关信息的链接。 | |
alternate”仅一个引擎支持。
alternate 关键字可以与
link、
a 和 area 元素一起使用。
此关键字的含义取决于其他属性的值。
link
元素,并且 rel
属性还包含关键字 stylesheetalternate 关键字按照
stylesheet
关键字所述的方式修改该关键字的
含义。alternate 关键字本身不创建
链接。
此处,一组 link
元素提供了一些样式表:
<!-- 持久样式表 -->
< link rel = "stylesheet" href = "default.css" >
<!-- 首选替代样式表 -->
< link rel = "stylesheet" href = "green.css" title = "绿色样式" >
<!-- 一些替代样式表 -->
< link rel = "alternate stylesheet" href = "contrast.css" title = "高对比度" >
< link rel = "alternate stylesheet" href = "big.css" title = "大字体" >
< link rel = "alternate stylesheet" href = "wide.css" title = "宽屏" > alternate 关键字与
type 属性一起使用,并且该属性设置为
application/rss+xml 或 application/atom+xml
该关键字创建一个引用聚合 源的超链接(尽管该源不一定聚合与当前页面完全相同的内容)。
出于源自动发现的目的,用户代理应考虑文档中所有使用了 alternate 关键字,并且其
type
属性设置为 application/rss+xml 或 application/atom+xml 的 link
元素。如果用户代理具有默认聚合源的概念,则应使用第一个此类元素(按树顺序)作为
默认源。
以下 link
元素为一个博客提供聚合源:
< link rel = "alternate" type = "application/atom+xml" href = "posts.xml" title = "Cool Stuff 博客" >
< link rel = "alternate" type = "application/atom+xml" href = "posts.xml?category=robots" title = "Cool Stuff 博客:robots 类别" >
< link rel = "alternate" type = "application/atom+xml" href = "comments.xml" title = "Cool Stuff 博客:评论" > 此类 link 元素会被
参与源自动发现的用户代理使用,并将第一个元素作为默认值(如适用)。
以下示例使用 a 元素,
向用户提供多个不同的聚合源:
< p > 你可以使用 Atom 源访问行星数据库:</ p >
< ul >
< li >< a href = "recently-visited-planets.xml" rel = "alternate" type = "application/atom+xml" > 最近访问的行星</ a ></ li >
< li >< a href = "known-bad-planets.xml" rel = "alternate" type = "application/atom+xml" > 已知的危险行星</ a ></ li >
< li >< a href = "unexplored-planets.xml" rel = "alternate" type = "application/atom+xml" > 未探索的行星</ a ></ li >
</ ul > 这些链接不会用于源自动发现。
该关键字创建一个引用当前文档替代表示的超链接。
被引用文档的性质由 hreflang 和 type 属性给出。
如果 alternate 关键字与
hreflang
属性一起使用,
且该属性的值与文档元素的语言不同,则表示被引用文档是一个翻译版本。
如果 alternate 关键字与
type
属性一起使用,则表示被引用文档是当前文档按指定格式重新表述的版本。
hreflang
和 type 属性可以在与
alternate 关键字一起指定时组合使用。
以下示例展示了如何指定使用替代格式、面向其他语言以及适用于其他媒体的页面版本:
< link rel = alternate href = "/en/html" hreflang = en type = text/html title = "英语 HTML" >
< link rel = alternate href = "/fr/html" hreflang = fr type = text/html title = "法语 HTML" >
< link rel = alternate href = "/en/html/print" hreflang = en type = text/html media = print title = "英语 HTML(用于打印)" >
< link rel = alternate href = "/fr/html/print" hreflang = fr type = text/html media = print title = "法语 HTML(用于打印)" >
< link rel = alternate href = "/en/pdf" hreflang = en type = application/pdf title = "英语 PDF" >
< link rel = alternate href = "/fr/pdf" hreflang = fr type = application/pdf title = "法语 PDF" > 此关系具有传递性——也就是说,如果一个文档使用链接类型“alternate”链接到另外两个文档,
那么除了表示这两个文档是第一个文档的替代表示之外,还表示
这两个文档彼此也是替代表示。
author”author 关键字可以与
link、
a 和 area 元素一起使用。此关键字创建
一个超链接。
对于 a 和 area 元素,author
关键字表示被引用文档提供有关定义该超链接的元素最近的 article
元素祖先的作者的更多信息(如果存在),否则提供有关整个页面作者的更多信息。
对于 link 元素,author 关键字表示
被引用文档提供有关整个页面作者的更多信息。
“被引用文档”可以是,而且通常是一个给出作者电子邮件地址的 mailto:
URL。[MAILTO]
同义词:由于历史原因,用户代理还必须将具有值为“made”的
rev 属性的 link、a 和 area 元素视为将 author 关键字指定为链接关系。
bookmark”bookmark 关键字可以
与 a 和
area 元素一起使用。此关键字
创建一个超链接。
bookmark 关键字
为相关链接元素最近的祖先 article
元素提供永久链接;如果
没有祖先 article 元素,则为
与该链接元素关联最密切的章节提供永久链接。
以下代码片段具有三个永久链接。用户代理可以通过查看永久链接所在的位置, 确定每个永久链接适用于规范的哪个部分。
...
< body >
< h1 > 永久链接示例</ h1 >
< div id = "a" >
< h2 > 第一个示例</ h2 >
< p >< a href = "a.html" rel = "bookmark" > 此永久链接仅适用于
从第一个 H2 到第二个 H2 的内容</ a > 。DIV 并不
精确对应于该章节,但大致与其相符。</ p >
</ div >
< h2 > 第二个示例</ h2 >
< article id = "b" >
< p >< a href = "b.html" rel = "bookmark" > 此永久链接适用于
外层 ARTICLE 元素</ a > (例如,它可以是一篇博客文章)。</ p >
< article id = "c" >
< p >< a href = "c.html" rel = "bookmark" > 此永久链接适用于
内层 ARTICLE 元素</ a > (例如,它可以是一条博客评论)。</ p >
</ article >
</ article >
</ body >
...canonical”canonical 关键字
可以与 link
元素一起使用。此关键字创建一个超链接。
canonical
关键字表示 href 属性给出的 URL 是当前文档的首选
URL。
这有助于搜索引擎减少重复内容,详见 The Canonical
Link Relation。[RFC6596]
dns-prefetch”dns-prefetch
关键字可以与
link 元素一起使用。此
关键字创建一个外部
资源链接。此关键字是 body-ok。
dns-prefetch
关键字表示,抢先对指定资源的源执行 DNS 解析可能有益,因为用户很可能需要位于该
源的资源,并且抢先消除
与 DNS 解析相关的延迟成本会改善用户体验。
由 dns-prefetch
关键字给出的资源没有默认类型。
获取并 处理此类链接的适当时机为:
给定一个 link 元素
el,此类所链接资源的获取并处理所链接资源步骤如下:
expect”expect 关键字可以与
link
元素一起使用。此关键字创建一个内部资源
链接。
由 expect
关键字创建的内部资源链接可用于阻塞渲染,直到其指示的元素连接到文档并被完全解析。
由 expect
关键字给出的资源没有默认类型。
每当 link 元素
el 发生以下任一情况时:
已经在 el 上创建了一个 expect 内部资源链接,el 已经与浏览上下文连接,并且
el 的 href 属性被
设置、更改或移除;
或者
已经在 el 上创建了一个 expect 内部资源链接,el 已经与浏览上下文连接,并且
el 的 media
属性被设置、更改或
移除,
则处理 el。
要给定一个 link 元素 el
处理内部资源链接,运行以下步骤:
令 doc 为 el 的节点文档。
如果此操作失败,或者在将 排除片段设置为 true 时, url 不与 doc 的 URL 相等,则对 el 解除渲染阻塞并返回。
令 indicatedElement 为给定 doc 和 url,选择指示部分所得的结果。
如果以下所有条件均为真:
doc 的当前文档就绪状态为
“loading”;
el 创建一个内部资源链接;
el 与浏览上下文连接;
el 可能阻塞渲染;
indicatedElement 不是元素,或者位于某个 HTML
解析器的
开放元素栈中,
且该解析器关联的 Document 为 doc,
则对 el 阻塞渲染。
否则,对 el 解除渲染阻塞。
external”external 关键字可以
与 a、
area 和 form 元素一起使用。此关键字不会
创建超链接,但会注释该元素创建的任何其他
超链接(如果没有其他关键字创建超链接,则为隐含超链接)。
external 关键字
表示该链接指向一个不属于当前文档所在站点的文档。
help”help 关键字可以与
link、
a、area 和 form 元素一起使用。此关键字创建一个
超链接。
对于 a、area 和 form 元素,help 关键字表示被引用文档为
定义该超链接的元素的父元素及其子元素提供更多帮助信息。
在以下示例中,表单控件关联了上下文相关帮助。例如,如果用户按下“Help”或“F1”键, 用户代理可以使用此信息显示被引用文档。
< p >< label > 主题:< input name = topic > < a href = "help/topic.html" rel = "help" > (帮助)</ a ></ label ></ p > 对于 link 元素,help 关键字表示
被引用文档为整个页面提供帮助。
对于 a 和 area 元素,在某些浏览器中,
help 关键字会使链接使用
不同的光标。
icon”所有当前引擎均支持。
icon 关键字可以与 link 元素一起使用。
此关键字创建一个外部资源
链接。
指定的资源是表示页面或站点的图标,用户代理在用户界面中表示页面时应使用该图标。
图标可以是听觉图标、视觉图标或其他类型的图标。如果
提供了多个图标,用户代理必须根据 type、media 和 sizes 属性选择最合适的图标。如果有多个
同样合适的图标,用户代理必须使用其收集图标列表时按树顺序最后声明的图标。
如果用户代理尝试使用某个图标,但在进一步检查后发现该图标实际上不合适
(例如因为其使用不受支持的格式),则用户代理必须按照属性所确定的顺序尝试
下一个最合适的图标。
图标列表发生变化时,不要求用户代理更新图标,但鼓励这样做。
由 icon 关键字给出的资源没有默认类型。
不过,出于确定资源类型的目的,用户代理必须预期该资源为图像。
sizes 关键字以原始像素表示图标尺寸
(而不是 CSS
像素)。
一个宽度为 50 CSS 像素、用于设备像素密度为每个 CSS 像素两个设备像素 (2x,192dpi)的显示器的图标,宽度将为 100 个原始像素。此功能不支持指明小型高分辨率图标与 大型低分辨率图标应使用不同资源 (例如 50×50 2x 与 100×100 1x)。
要解析和处理该属性的值,用户代理必须首先在 ASCII 空白处分割属性值,然后必须解析每个所得关键字, 以确定其表示的内容。
any 关键字表示该资源包含可缩放图标,
例如 SVG 图像提供的图标。
其他关键字必须按如下方式进一步解析,以确定它们表示的内容:
如果关键字不恰好包含一个 U+0078 LATIN SMALL LETTER X 或 U+0058 LATIN CAPITAL LETTER X 字符,则此关键字不表示任何内容。对该关键字返回。
令 width string 为“x”或
“X”之前的字符串。
令 height string 为“x”或
“X”之后的字符串。
如果 width string 或 height string 中任一个以 U+0030 DIGIT ZERO (0) 字符开头,或者包含ASCII 数字以外的任何字符, 则此关键字不表示任何内容。对该关键字返回。
对 width string 应用解析非负整数的规则,以获得 width。
对 height string 应用解析非负整数的规则,以获得 height。
该关键字表示资源包含一个宽度为 width 设备像素、高度为 height 设备 像素的位图图标。
在 sizes
属性上指定的关键字不得表示所链接资源中实际上不可用的图标尺寸。
给定一个 link 元素
el 和请求
request,此类所链接资源的所链接资源获取设置步骤如下:
将 request 的目标设置为
“image”。
返回 true。
此类所链接资源的处理 Link 标头步骤是什么也不做。
以下代码片段展示了一个具有多个图标的应用程序顶部部分。
<!DOCTYPE HTML>
< html lang = "en" >
< head >
< title > lsForums — 收件箱</ title >
< link rel = icon href = favicon.png sizes = "16x16" type = "image/png" >
< link rel = icon href = windows.ico sizes = "32x32 48x48" type = "image/vnd.microsoft.icon" >
< link rel = icon href = mac.icns sizes = "128x128 512x512 8192x8192 32768x32768" >
< link rel = icon href = iphone.png sizes = "57x57" type = "image/png" >
< link rel = icon href = gnome.svg sizes = "any" type = "image/svg+xml" >
< link rel = stylesheet href = lsforums.css >
< script src = lsforums.js ></ script >
< meta name = application-name content = "lsForums" >
</ head >
< body >
...由于历史原因,icon 关键字前可以有
关键字“shortcut”。如果存在“shortcut”关键字,
则 rel 属性的整个值必须与字符串
“shortcut icon”ASCII
不区分大小写匹配(令牌之间恰好有一个
U+0020 SPACE 字符,且没有其他ASCII 空白)。
license”license 关键字可以与
link、
a、area 和 form 元素一起使用。此关键字创建
一个
超链接。
license 关键字
表示被引用文档提供当前文档主要内容所依据的著作权许可条款。
本规范未指定如何区分文档的主要内容与不被视为主要内容一部分的内容。 应向用户明确说明这种区分。
考虑一个照片共享站点。该站点上的一个页面可能描述并显示一张照片,并且 该页面可能按如下方式标记:
<!DOCTYPE HTML>
< html lang = "en" >
< head >
< title > Exampl Pictures:Kissat</ title >
< link rel = "stylesheet" href = "/style/default" >
</ head >
< body >
< h1 > Kissat</ h1 >
< nav >
< a href = "../" > 返回照片索引</ a >
</ nav >
< figure >
< img src = "/pix/39627052_fd8dcd98b5.jpg" >
< figcaption > Kissat</ figcaption >
</ figure >
< p > 其中一只长了六个脚趾!</ p >
< p >< small >< a rel = "license" href = "http://www.opensource.org/licenses/mit-license.php" > 采用 MIT 许可证</ a ></ small ></ p >
< footer >
< a href = "/" > 首页</ a > | < a href = "../" > 照片索引</ a >
< p >< small > © 版权所有 2009 Exampl Pictures。保留所有权利。</ small ></ p >
</ footer >
</ body >
</ html > 在这种情况下,license
仅适用于照片(文档的主要
内容),而不是整个文档。尤其不适用于页面本身的设计,该设计受文档底部给出的著作权声明约束。
可以通过样式更清楚地表达这一点(例如,将许可证链接显著地放置在照片附近,
同时将页面著作权声明以浅色小字显示在页面底部)。
同义词:由于历史原因,用户代理还必须将关键字
“copyright”视同 license 关键字。
manifest”仅一个引擎支持。
manifest 关键字可以
与 link 元素一起使用。
此关键字创建一个外部
资源链接。
manifest 关键字
表示提供与当前文档关联的元数据的清单文件。
由 manifest
关键字给出的资源没有默认类型。
当 Web 应用尚未安装时, 用户代理认为必要时,就是此链接类型获取并处理所链接资源的适当时机。例如, 当用户选择安装 Web 应用时。
对于一个已安装的 Web 应用,此链接类型获取并处理所链接资源的适当时机 为:
无论如何,只有按树顺序第一个其 rel 属性包含令牌 manifest 的 link 元素可以使用。
用户代理不得为此链接类型延迟 load 事件。
给定一个 link 元素
el 和请求
request,此类所链接资源的所链接
资源获取设置步骤如下:
如果 navigable 为 null,则返回 false。
如果 navigable 不是顶层可遍历对象,则返回 false。
将 request 的发起者设置为
“manifest”。
将 request 的目标设置为
“manifest”。
将 request 的模式设置为
“cors”。
将 request 的凭据
模式设置为 el 的
crossorigin
内容属性的CORS 设置属性凭据
模式。
返回 true。
给定一个 link 元素
el、布尔值 success、响应
response 和字节序列
bodyBytes,要处理此类
所链接资源:
如果 response 的 Content-Type 元数据不是 JSON MIME 类型,则将 success 设置为 false。
如果 success 为 true:
此类所链接资源的处理 Link 标头 步骤是什么也不做。
modulepreload”modulepreload
关键字可以与
link 元素一起使用。此
关键字创建一个外部
资源链接。此
关键字是 body-ok。
modulepreload
关键字是 preload
关键字的一种专用替代方案,其处理模型面向
预加载模块脚本。具体而言,它
使用模块脚本特定的
获取行为(包括例如对 crossorigin
属性的不同解释),并将结果放入
适当的模块
映射中以供稍后求值。相比之下,使用 preload 关键字的类似外部
资源链接会将结果放入预加载缓存,而不会
影响文档的模块映射。
此外,实现可以利用模块脚本声明其依赖项这一事实,同时获取指定模块的
依赖项。这旨在提供优化机会,因为用户代理知道
这些依赖项很可能稍后也会需要。若不使用服务工作线程等技术,或不在服务器端进行监控,
通常无法观察到这一点。
值得注意的是,适当的 load 或
error 事件会在
指定模块获取后发生,并且
不会等待任何依赖项。
用户代理不得为此链接类型延迟 load 事件。
模块预加载目标是“json”、
“style”、“text”或类脚本目标。
此类链接获取并处理所链接资源的适当时机 为:
与某些其他链接关系不同,更改此类 link
的相关属性(例如 as、crossorigin 和
referrerpolicy)
不会触发新的获取。这是因为文档的模块映射已经由先前的
获取填充,因此重新获取毫无意义。
给定一个 link
元素
el,modulepreload
链接的获取并处理所链接资源
算法如下:
如果 el 的 href 属性值为
空字符串,则返回。
令 destination 为 el 的 as 属性的当前状态(一个目标),如果
它不处于任何状态,则为“script”。
如果 destination 不是模块预加载目标,则
给定 el,在网络任务
源上排入元素任务,以在
el 上触发名为 error 的事件,然后
返回。
如果 url 为失败,则返回。
令 credentials mode 为 el 的 crossorigin
属性的CORS 设置属性凭据
模式。
令 cryptographic nonce 为 el.[[CryptographicNonce]]。
如果指定了 el 的 integrity
属性,则令 integrity metadata 为该属性的值,否则为
空字符串。
如果 el 没有 integrity
属性,则将 integrity metadata 设置为使用 url 和
settings object 解析模块
完整性元数据所得的结果。
令 referrer policy 为 el 的 referrerpolicy
属性的当前状态。
令 fetch priority 为 el 的 fetchpriority
属性的当前状态。
令 options 为一个脚本获取选项,其加密 nonce 为
cryptographic
nonce,完整性元数据为
integrity metadata,解析器
元数据为“not-parser-inserted”,凭据模式为
credentials
mode,来源策略为
referrer policy,并且获取优先级为
fetch priority。
给定 url、 destination、settings object 和 options,并给定 result 运行以下步骤,获取 modulepreload 模块脚本 图:
此类所链接资源的处理 Link 标头 步骤是什么也不做。
以下代码片段展示了一个预加载了多个模块的应用程序顶部部分:
<!DOCTYPE html>
< html lang = "en" >
< title > IRCFog</ title >
< link rel = "modulepreload" href = "app.mjs" >
< link rel = "modulepreload" href = "helpers.mjs" >
< link rel = "modulepreload" href = "irc.mjs" >
< link rel = "modulepreload" href = "fog-machine.mjs" >
< script type = "module" src = "app.mjs" >
... 假设该应用程序的模块图如下:

此处可以看到,应用程序开发者使用了 modulepreload
来声明其模块图中的所有模块,
从而确保用户代理为它们全部发起获取。如果没有这种预加载,并且
HTTP/2 Server Push 等技术未参与其中,则用户
代理可能需要经过多次网络往返才能发现 helpers.mjs。通过
这种方式,modulepreload
link 元素可以
用作应用程序模块的一种“清单”。
以下代码展示了如何将 modulepreload
链接与 import()
结合使用,以确保网络获取提前
完成,从而在调用 import()
时,模块已经在模块映射中准备就绪(但尚未
求值):
< link rel = "modulepreload" href = "awesome-viewer.mjs" >
< button onclick = "import('./awesome-viewer.mjs').then(m => m.view())" >
查看精彩内容
</ button > nofollow”nofollow 关键字可以
与 a、
area 和 form 元素一起使用。此关键字
不会创建
超链接,但会注释该元素创建的任何其他
超链接(如果没有其他关键字创建超链接,则为隐含超链接)。
nofollow 关键字
表示该链接未得到页面原作者或发布者的认可,或者指向被引用文档的链接
主要是由于与两个页面关联的人员之间存在商业关系而包含的。
noopener”所有当前引擎均支持。
所有当前引擎均支持。
noopener 关键字可以
与 a、
area 和 form 元素一起使用。此关键字
不会创建
超链接,但会注释该元素创建的任何其他
超链接(如果没有其他关键字创建超链接,则为隐含超链接)。
该关键字表示,跟随超链接所产生的任何新创建的顶层可遍历对象都不会包含辅助浏览
上下文。例如,所得 Window 的 opener
获取器将返回 null。
另请参阅处理模型。
这通常会创建一个具有辅助浏览
上下文的顶层可遍历对象(假设不存在目标名称为“example”的现有可导航对象):
< a href = help.html target = example > 帮助!</ a > 这会创建一个具有非辅助浏览 上下文的顶层 可遍历对象(假设情况相同):
< a href = help.html target = example rel = noopener > 帮助!</ a > 以下两者等效,并且只导航父 可导航对象:
< a href = index.html target = _parent > 首页</ a > < a href = index.html target = _parent rel = noopener > 首页</ a > noreferrer”
所有当前引擎均支持。
所有当前引擎均支持。
noreferrer
关键字可以与 a、
area 和 form 元素一起使用。此关键字
不会创建
超链接,但会注释该元素创建的任何其他
超链接(如果没有其他关键字创建超链接,则为隐含超链接)。
它表示跟随链接时不得泄露任何来源信息,并且在相同
条件下还隐含 noopener
关键字的行为。
另请参阅直接操纵来源网址的处理 模型。
<a href="..." rel="noreferrer" target="_blank">
与 <a href="..." rel="noreferrer noopener" target="_blank"> 具有相同的行为。
opener”opener 关键字可以与
a、
area 和 form 元素一起使用。此关键字不会
创建
超链接,但会注释该元素创建的任何其他
超链接(如果没有其他关键字创建超链接,则为隐含超链接)。
该关键字表示,跟随超链接所产生的任何新创建的顶层可遍历对象都将包含辅助浏览 上下文。
另请参阅处理模型。
在以下示例中,使用 opener 允许帮助
页面弹出窗口导航其开启者,例如,当用户寻找的内容可能在其他位置找到时。另一种方法可能是使用命名目标,
而不是 _blank,但这可能会与现有名称发生冲突。
< a href = "..." rel = opener target = _blank > 帮助!</ a > pingback”pingback 关键字可以
与 link
元素一起使用。此关键字创建一个外部资源
链接。此关键字是 body-ok。
有关 pingback 关键字的语义,请参阅
Pingback 1.0。[PINGBACK]
preconnect”
所有当前引擎均支持。
preconnect
关键字可以与 link
元素一起使用。此关键字创建一个外部资源
链接。此关键字是 body-ok。
preconnect
关键字表示,抢先发起与指定资源的源的连接可能
有益,因为用户很可能需要位于该
源的资源,并且抢先消除
与建立连接相关的延迟成本会改善用户体验。
由 preconnect
关键字给出的资源没有默认类型。
用户代理不得为此链接类型延迟 load 事件。
获取并 处理此类链接的适当时机为:
给定一个 link 元素
el,此类所链接资源的获取并处理所链接资源
步骤是从 el 创建链接选项,并给定其结果进行预连接。
给定一个链接处理选项 options,此类所链接资源的处理 Link 标头 步骤是给定 options 进行预连接。
要给定一个链接处理选项 options 进行预连接:
如果 options 的 href 是空字符串,则返回。
令 url 为给定 options 的 href,并相对于 options 的 基准 URL,执行编码解析 URL所得的结果。
传递基准 URL 而不是文档或环境的问题由 issue #9715 跟踪。
如果 url 为失败,则返回。
如果 url 的方案不是 HTTP(S) 方案,则返回。
令 useCredentials 为 true。
如果 options 的 crossorigin 为 Anonymous,并且 options 的 源与 url 的 源不同源,则将 useCredentials 设置为 false。
用户代理应给定 partitionKey、 url 的源和 useCredentials,获取 连接。
此连接会被获取,但不会直接使用。它将保留在 连接池中以供后续使用。
用户代理应尽可能尝试发起预连接并执行完整的连接 握手(对于 HTTP 为 DNS+TCP,对于 HTTPS 源为 DNS+TCP+TLS),但由于资源限制或其他原因, 允许选择执行部分握手(对于 HTTP 仅 DNS,对于 HTTPS 源为 DNS 或 DNS+TCP),或者完全跳过握手。
每个源的最佳连接数量取决于协商的协议、用户 当前的连接配置文件、可用设备资源、全局连接限制以及其他 上下文特定变量。因此,应打开多少连接的决定 由用户代理作出。
prefetch”prefetch 关键字可以
与 link
元素一起使用。此关键字创建一个外部资源
链接。此关键字是 body-ok。
prefetch 关键字
表示,抢先获取并缓存指定
资源或同站点文档可能
有益,因为用户很可能在将来的导航中需要此资源。
由 prefetch
关键字给出的资源没有默认类型。
获取并 处理此类链接的适当时机为:
给定一个 link
元素
el,prefetch
链接的获取并处理所链接资源
算法如下:
如果 el 的 href
属性值为
空字符串,则返回。
令 options 为从 el 创建链接选项所得的结果。
令 request 为给定 options 创建 链接请求所得的结果。
如果 request 为 null,则返回。
将 request 的发起者
设置为
“prefetch”。
令 processPrefetchResponse 为给定一个响应 response 以及 null、失败或一个字节序列 bytesOrNull 时的以下步骤:
用户代理应获取 request,并将 processResponseConsumeBody 设置为 processPrefetchResponse。用户代理可以延迟获取 request,以 优先处理当前文档所必需的其他请求。
此类所链接资源的处理 Link 标头 步骤是什么也不做。
preload”仅一个引擎支持。
preload 关键字可以
与 link
元素一起使用。此关键字创建一个外部资源
链接。此关键字是 body-ok。
preload 关键字
表示用户代理将根据
as
属性给出的预加载目标,以及
fetchpriority
属性给出的优先级,
抢先获取并缓存指定资源,因为用户很可能在
当前导航中需要此资源。
用户代理在加载资源时可能会执行额外操作,例如 抢先解码图像或创建样式表。但是,这些额外 操作不能产生可观察的效果。
由 preload
关键字给出的资源没有默认类型。
用户代理不得为此链接类型延迟 load 事件。
此类链接获取并处理所链接资源的适当时机 为:
Document 具有一个预加载资源映射,它是一个
有序映射,初始为空。
same-origin”、“cors”或
“no-cors”
要为 Window window
消费预加载资源,给定一个URL url、一个字符串
destination、一个字符串
mode、一个字符串 credentialsMode、一个字符串 integrityMetadata 和
onResponseAvailable,后者是一个接受响应的算法:
令 key 为一个预加载键,其URL 为 url,destination 为 destination,mode 为 mode,并且 credentials mode 为 credentialsMode。
令 preloads 为 window 的关联的 Document 的预加载
资源映射。
如果 key 不存在于 preloads 中, 则返回 false。
令 entry 为 preloads[key]。
令 consumerIntegrityMetadata 为 解析 integrityMetadata 所得的结果。
令 preloadIntegrityMetadata 为 解析 entry 的 integrity metadata所得的结果。
如果以下条件均不适用:
consumerIntegrityMetadata 为 no metadata;
consumerIntegrityMetadata 等于 preloadIntegrityMetadata; 或者
此比较会忽略未知的完整性选项。请参阅 issue #116。
则返回 false。
预加载与消费者之间的完整性元数据不匹配,即使 两者都与数据匹配,也会导致从网络进行额外获取。
将网络错误 添加到预加载缓存中很重要,这样,如果预加载请求导致错误,错误的 响应以后就不会再次从网络请求。这也具有安全影响; 考虑这样一种情况:开发者在预加载请求上指定了子资源完整性元数据, 但没有在后续资源请求上指定。如果预加载请求未通过子资源 完整性验证并被丢弃,则资源请求会从网络获取并消费一个 可能恶意的响应,而不验证其完整性。 [SRI]
移除 preloads[key]。
如果 entry 的 response 为 null,则将 entry 的 on response available 设置为 onResponseAvailable。
否则,使用 entry 的 response 调用 onResponseAvailable。
返回 true。
就本节而言,如果以下算法返回 true,则字符串 type 匹配一个预加载目标 destination:
如果 type 是空字符串,则返回 true。
如果 destination 为“fetch”,则返回 true。
令 mimeTypeRecord 为 解析 type 所得的结果。
如果 mimeTypeRecord 为失败,则返回 false。
如果 mimeTypeRecord 不受用户代理支持,则 返回 false。
如果以下任一条件为真:
destination 为“script”,并且
mimeTypeRecord 是JavaScript MIME 类型;
destination 为“image”,并且
mimeTypeRecord 是图像 MIME
类型;
destination 为“font”,并且
mimeTypeRecord 是字体 MIME
类型;
则返回 true。
返回 false。
要为一个请求 request 创建预加载键,返回一个新的预加载键,其 URL 为 request 的URL,destination 为 request 的目标,mode 为 request 的模式,并且 credentials mode 为 request 的凭据模式。
预加载目标是“fetch”、“font”、
“image”、“script”、“style”或“track”。
要给定一个链接处理选项 options 和 一个可选的 processResponse(它是一个接受响应的算法)进行预加载:
如果 options 的 type 不匹配 options 的 destination,则 返回。
如果 options 的 destination 为
“image”,并且 options 的 源集不为 null,则将 options 的href 设置为从
options 的源集中选择图像源所得的结果。
令 request 为给定 options 创建 链接请求所得的结果。
如果 request 为 null,则返回。
令 unsafeEndTime 为 0。
令 entry 为一个新的预加载条目,其 integrity metadata 为 options 的 integrity。
令 key 为给定 request 创建 预加载键所得的结果。
如果 options 的 document 为 null,则
将 request 的发起者类型设置为
“early hint”。
令 controller 为 null。
令给定一个 Document document 时的
reportTiming 为:给定 document 的相关
全局对象,为 controller 报告计时。
将 controller 设置为获取 request 所得的结果,并将 processResponseConsumeBody 设置为给定一个响应 response 以及 null、失败 或一个字节序列 bodyBytes 时的以下步骤:
如果 bodyBytes 是字节序列, 则将 response 的 主体设置为 bodyBytes 作为 主体。
通过使用 processResponseConsumeBody, 我们已经提取了完整的 主体。这是 确保预加载器从网络加载整个主体所必需的,无论该预加载是否会被消费(此时尚不确定)。 然后,此步骤将请求的主体重置为包含相同字节的新主体, 以便其他规范可以在实际消费时读取它,尽管我们已经这样做过一次。
否则,将 response 设置为网络 错误。
将 unsafeEndTime 设置为不安全的共享当前时间。
如果 options 的 document 不为 null,则给定 options 的 document 调用 reportTiming。
如果 entry 的 on response available 为 null,则将 entry 的 response 设置为 response;否则给定 response 调用 entry 的 on response available。
如果给出了 processResponse,则使用 response 调用 processResponse。
令 commit 为给定一个 Document
document 时的以下步骤:
如果 options 的 document 为 null,则将 options 的on document ready 设置为 commit。 否则,使用 options 的 document 调用 commit。
给定一个 link 元素
el,此类所链接资源的获取并处理所链接资源步骤
如下:
为 el 更新源集。
令 options 为从 el 创建链接选项所得的结果。
如果 destination 为 null,则返回。
将 options 的 destination 设置为 destination。
给定一个链接处理 选项 options,此类链接的处理 Link 标头步骤 是预加载 options。
privacy-policy”privacy-policy
关键字可以与
link、a 和 area 元素一起使用。此关键字
创建一个
超链接。
privacy-policy
关键字表示
被引用文档包含有关适用于当前文档的数据收集和使用惯例的信息,详见
Additional Link Relation
Types。被引用文档可以是独立的隐私政策,也可以是
某个更通用文档的特定章节。[RFC6903]
search”search 关键字可以与
link、
a、area 和 form 元素一起使用。此关键字创建
一个
超链接。
search 关键字表示
被引用文档
提供专门用于搜索该文档及其相关资源的接口。
OpenSearch 描述文档可以与 link 元素和
search 链接类型一起使用,以使
用户代理能够自动发现搜索
接口。[OPENSEARCH]
stylesheet”
stylesheet
关键字可以与 link
元素一起使用。此关键字创建一个参与样式处理模型的外部资源
链接。此关键字是
body-ok。
指定的资源是一个CSS 样式表,用于 描述如何呈现 文档。
仅一个引擎支持。
如果还在
link 元素上指定了
alternate 关键字,则该链接是
替代样式表;在这种情况下,必须在 link 元素上指定 title 属性,且其值
不得为空。
由 stylesheet
关键字给出的资源的默认类型是 text/css。
当具有 stylesheet
关键字的
link
元素的 disabled
属性被设置时,禁用其
关联的 CSS 样式表。
获取并 处理此类链接的适当时机为:
怪异行为:如果文档已被设置为怪异模式,与外部资源的
URL 同源,
并且外部资源的Content-Type 元数据不是
受支持的样式表类型,则用户代理必须改为假定其为 text/css。
给定一个
link 元素
el 和请求
request,此类所链接资源的所链接资源获取设置步骤
如下:
有关使用 CSSOM 的获取 CSS
样式表算法替代默认获取并处理所链接
资源算法的计划,请参阅 issue #968。在此期间,任何关键
子资源请求的渲染阻塞应设置为
link 元素当前是否
阻塞渲染。
给定一个 link 元素
el、布尔值 success、响应 response
和字节序列
bodyBytes,要处理此类
所链接资源:
如果资源的Content-Type 元数据不是
text/css,则将
success 设置为 false。
如果 el 具有关联的 CSS 样式表,则移除该 CSS 样式表。
如果 success 为 true:
使用以下属性创建 CSS 样式表:
response 的URL 列表[0]
我们在此提供一个 URL,前提是假定 w3c/csswg-drafts issue #9316 将 得到修复。
el
el 的 media
属性。
这是对该属性(此时可能不存在)的引用,而不是 该属性当前值的副本。CSSOM 定义了 动态设置、更改或移除该属性时会发生什么。
如果
el 位于
文档树中,则为 el 的 title
属性,否则为空字符串。
同样,这是对该属性的引用,而不是 该属性当前值的副本。
如果该链接是替代样式 表,并且 el 的 显式启用为 false,则设置;否则不设置。
如果资源CORS 同源,则设置;否则不设置。
null
保留其默认值。
保持未初始化。
这似乎不正确。大概我们应该使用 bodyBytes? 由 issue #2997 跟踪。
CSS 环境编码是运行以下步骤所得的结果: [CSSSYNTAX]
如果 el 具有 charset
属性,则从该属性的值获取
编码。如果
成功,则返回所得编码。[ENCODING]
如果 el 贡献脚本阻塞样式 表:
在 el 上解除渲染阻塞。
此类所链接资源的处理 Link 标头 步骤是什么也不做。
tag”tag 关键字可以与 a 和
area 元素一起使用。此关键字创建
一个超链接。
tag 关键字表示
被引用文档所表示的标签适用于当前文档。
由于它表示该标签适用于当前文档,因此在标签云的标记中使用此关键字是不合适的,因为标签云 列出一组页面中流行的标签。
此文档介绍一些宝石,因此使用
“https://en.wikipedia.org/wiki/Gemstone”为其添加标签,从而明确将其归类为
与“珠宝”意义上的宝石相关,而不是例如美国的城镇、Ruby 包格式或
瑞士机车类别:
<!DOCTYPE HTML>
< html lang = "en" >
< head >
< title > 我的宝贝</ title >
</ head >
< body >
< header >< h1 > 我的宝贝</ h1 > < p > 2012 年夏季</ p ></ header >
< p > 最近,我设法处理掉了一颗一直
困扰我的红色宝石。现在我有一颗漂亮得多的蓝宝石。</ p >
< p > 那颗红色宝石是在我挖掘
办公层时从一块铝土矿石中发现的,但没人愿意把它运走。同一颗
红色宝石就这样在那里待了很多年。</ p >
< footer >
标签:< a rel = tag href = "https://en.wikipedia.org/wiki/Gemstone" > 宝石</ a >
</ footer >
</ body >
</ html > 在此文档中,有两篇文章。不过,“tag”
链接适用于整个页面(无论将其放置在何处都是如此,包括放在
article
元素内部)。
<!DOCTYPE HTML>
< html lang = "en" >
< head >
< title > Gem 4/4</ title >
</ head >
< body >
< article >
< h1 > 801:Steinbock</ h1 >
< p > 编号 801 的 Gem 4/4 电力-柴油机车带有一只野山羊图案,并于 2002 年进行了重建。</ p >
</ article >
< article >
< h1 > 802:Murmeltier</ h1 >
< figure >
< img src = "https://upload.wikimedia.org/wikipedia/commons/b/b0/Trains_de_la_Bernina_en_hiver_2.jpg"
alt = "802 号机车为红色,带有受电弓,侧面有高大的通风口。" >
< figcaption > 20 世纪 80 年代位于 Lago Bianco 上方的 802 号机车。</ figcaption >
</ figure >
< p > 编号 802 的 Gem 4/4 电力-柴油机车带有一只旱獭图案,并于 2003 年进行了重建。</ p >
</ article >
< p class = "topic" >< a rel = tag href = "https://en.wikipedia.org/wiki/Rhaetian_Railway_Gem_4/4" > Gem 4/4</ a ></ p >
</ body >
</ html > terms-of-service”terms-of-service
关键字可以与
link、a 和 area 元素一起使用。此
关键字创建一个
超链接。
terms-of-service
关键字表示
被引用文档包含有关当前文档提供者与希望使用当前文档的用户之间协议的信息,详见
Additional Link Relation Types。[RFC6903]
某些文档构成文档序列的一部分。
文档序列是指其中每个文档都可以具有一个上一个兄弟文档和一个 下一个兄弟文档。没有上一个兄弟文档的文档是其序列的起点, 没有下一个兄弟文档的文档是其序列的终点。
一个文档可以属于多个序列。
next”next 关键字可以与
link、
a、area 和 form 元素一起使用。此关键字创建一个
超链接。
next 关键字表示
当前文档是某个
序列的一部分,并且该链接指向该序列中逻辑上的下一个文档。
当 next 关键字与
link
元素一起使用时,用户代理应处理此类链接,就像它们使用了 dns-prefetch、preconnect 或
prefetch 关键字之一。
用户代理希望使用哪个
关键字取决于实现;例如,用户代理在尝试节省数据、电池
电量或处理能力时,可能希望使用成本较低的 preconnect 处理模型,
或者可能希望根据对类似场景中过往
用户行为的启发式分析来选择关键字。
prev”prev 关键字可以与
link、
a、area 和 form 元素一起使用。此关键字创建一个
超链接。
prev 关键字表示
当前文档是某个
序列的一部分,并且该链接指向该序列中逻辑上的上一个文档。
同义词:由于历史原因,用户代理还必须将关键字
“previous”视同 prev 关键字。
预定义链接类型集合的扩展可以 注册在现有 rel 值的 microformats 页面上。[MFREL]
任何人都可以随时编辑现有 rel 值的 microformats 页面以 添加一种类型。扩展类型必须使用以下信息进行说明:
正在定义的实际值。该值不应与任何其他 已定义值混淆性地相似(例如仅大小写不同)。
如果该值包含 U+003A COLON 字符(:),则它还必须是一个绝对 URL。
link以下之一:
link 元素上指定该关键字。
link
元素上指定该关键字;它创建一个
超链接。
link
元素上指定该关键字;它创建一个
外部
资源链接。
a 和 area以下之一:
a 和 area 元素上指定该关键字。a 和 area 元素上指定该关键字;它创建一个
超链接。
a 和 area 元素上指定该关键字;它创建
一个外部资源
链接。a 和 area 元素上指定该关键字;它会注释该元素创建的其他超链接。
form以下之一:
form 元素上指定该关键字。
form
元素上指定该关键字;它创建一个
超链接。
form
元素上指定该关键字;它创建一个
外部
资源链接。
form
元素上指定该关键字;它会注释该元素创建的其他超链接。对该关键字含义的简短非规范性说明。
指向该关键字语义和要求的更详细说明的链接。它 可以是 wiki 上的另一个页面,也可以是指向外部页面的链接。
具有完全相同处理要求的其他关键字值列表。作者 不应使用定义为同义词的值,它们仅用于允许用户代理 支持旧版内容。任何人都可以移除实际中未使用的同义词;只有 为与旧版内容兼容而需要作为同义词处理的名称才应以 这种方式注册。
以下之一:
如果发现某个关键字与现有值重复,则应将其移除,并列为 现有值的同义词。
如果某个关键字以“提议”状态注册一个月或更长时间,而 未被使用或规范化,则可以将其从注册表中移除。
如果某个关键字以“提议”状态添加后被发现与现有 值重复,则应将其移除,并列为现有值的同义词。如果某个关键字以 “提议”状态添加后被发现有害,则应将其更改为 “停用”状态。
任何人都可以随时更改状态,但只能按照上述 定义进行更改。
一致性检查器必须使用现有 rel 值的 microformats 页面上提供的信息来 确定某个值是否允许:本规范中定义的值或标记为“提议”或“批准”的值,在用于 “对以下内容的影响...”字段所述适用元素时必须被接受,而标记为“停用”的值 或既未列于本规范也未列于上述页面中的值必须被视为 无效而拒绝。一致性检查器可以缓存此信息(例如出于性能原因或避免 使用不可靠的网络连接)。
当作者使用既未由本规范也未由 wiki 页面定义的新类型时, 一致性检查器应建议将该值添加到 wiki,并附上上述详细信息, 状态设为“提议”。
在现有 rel 值的 microformats
页面中定义为扩展且状态为“提议”或“批准”的类型,可以按照
“对以下内容的影响...”字段,在 link、a 和 area
元素的 rel 属性中使用。[MFREL]
ins
元素所有当前引擎均支持。
cite — 指向引文来源或
关于编辑的更多信息的链接
datetime — 更改的日期和
(可选)时间
cite、datetime 属性。
HTMLModElement。以下表示添加一个段落:
< aside >
< ins >
< p > 我喜欢水果。 </ p >
</ ins >
</ aside > 以下示例也是如此,因为此处 aside
元素中的所有内容都算作
短语内容,因此
只有一个段落:
< aside >
< ins >
苹果很< em > 美味</ em > 。
</ ins >
< ins >
梨也一样。
</ ins >
</ aside > 以下示例表示添加两个段落,其中第二个段落分成两部分
插入。因此,此示例中的第一个 ins 元素跨越了
段落边界,这被视为不良形式。
< aside >
<!-- 不要这样做 -->
< ins datetime = "2005-03-16 00:00Z" >
< p > 我喜欢水果。 </ p >
苹果很< em > 美味</ em > 。
</ ins >
< ins datetime = "2007-12-19 00:00Z" >
梨也一样。
</ ins >
</ aside > 以下是更好的标记方式。它使用了更多元素,但没有任何元素跨越 隐含段落边界。
< aside >
< ins datetime = "2005-03-16 00:00Z" >
< p > 我喜欢水果。 </ p >
</ ins >
< ins datetime = "2005-03-16 00:00Z" >
苹果很< em > 美味</ em > 。
</ ins >
< ins datetime = "2007-12-19 00:00Z" >
梨也一样。
</ ins >
</ aside > del
元素所有当前引擎均支持。
cite — 指向引文来源或
关于编辑的更多信息的链接
datetime — 更改的日期和
(可选)时间
cite、datetime 属性。
HTMLModElement。以下展示一个“待办事项”列表,其中已完成的项目会被划掉,并附有 完成日期和时间。
< h1 > 待办事项</ h1 >
< ul >
< li > 清空洗碗机</ li >
< li >< del datetime = "2009-10-11T01:25-07:00" > 观看 Walter Lewin 的讲座</ del ></ li >
< li >< del datetime = "2009-10-10T23:38-07:00" > 下载更多曲目</ del ></ li >
< li > 购买打印机</ li >
</ ul > ins 和 del
元素共有的属性cite 属性
可用于指定解释该更改的文档的URL。当该文档很长时,例如会议记录,鼓励作者
包含一个指向该文档中讨论该更改的
特定部分的片段。
如果存在 cite
属性,则它必须是一个解释该更改的可能由空格包围的有效
URL。要获得
相应的引用链接,必须相对于元素的节点文档解析该属性的值。用户
代理可以
允许用户跟随此类引用链接,但它们主要供私下使用(例如,
由收集站点编辑统计信息的服务器端脚本使用),而不是供读者使用。
datetime
属性可用于指定更改的时间和日期。
如果存在,datetime
属性的值必须是
带有可选时间的有效日期字符串。
用户代理必须按照解析日期或时间字符串
算法解析 datetime
属性。如果该算法未返回日期或全局日期和时间,
则该修改没有关联的时间戳(该值不符合要求;它不是
带有可选时间的有效日期字符串)。否则,该修改被标记为
在给定日期或全局日期和时间进行。如果给定值
是全局日期和
时间,则用户代理应使用关联的
时区偏移信息来确定以哪个时区呈现给定日期时间。
可以向用户显示此值,但它主要供 私下使用。
ins 和
del
元素必须实现
HTMLModElement
接口:
所有当前引擎均支持。
[Exposed =Window ]
interface HTMLModElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , ReflectURL ] attribute USVString cite ;
[CEReactions , Reflect ] attribute DOMString dateTime ;
};本节为非规范性内容。
由于 ins 和 del 元素不会影响段落划分,因此在某些段落为隐含的情况(没有显式的 p 元素)下,
ins 或 del 元素可以同时跨越
整个段落或其他
非短语内容元素,以及
另一个段落的一部分。例如:
< section >
< ins >
< p >
这是一个被插入的段落。
</ p >
这是另一个段落,其第一句话与上面的段落
同时被插入。
</ ins >
这是第二句话,它一直都在那里。
</ section > 通过仅用 p 元素包裹某些段落,甚至可以使一个
段落的结尾、完整的第二个段落和第三个段落的开头由同一个
ins 或 del 元素覆盖(尽管这非常
令人困惑,也不被视为
良好做法):
< section >
这是第一个段落。< ins > 这句话是
插入的。
< p > 第二个段落是插入的。</ p >
这句话也是插入的。</ ins > 这是本示例中的
第三个段落。
<!-- (不要这样做) -->
</ section > 不过,由于隐含段落的定义方式,
无法使用同一个
ins 或 del 元素标记一个段落的结尾和
紧接着的下一个段落的开头。相反,必须使用一个(或两个)p
元素和两个 ins 或
del 元素,例如:
< section >
< p > 这是第一个段落。< del > 这句话被
删除了。</ del ></ p >
< p >< del > 这句话也被删除了。</ del > 那
句话需要一个单独的 < del> 元素。</ p >
</ section > 部分由于上述混乱,强烈建议作者始终使用 p
元素标记所有段落,而不是让 ins 或
del 元素跨越隐含段落
边界。
本节为非规范性内容。
ol 和
ul 元素的内容模型不允许
ins 和 del 元素作为子元素。列表始终
表示其所有
项目,包括原本会标记为已删除的项目。
要表示某个项目已插入或删除,可以在 li 元素的内容外包裹一个
ins 或 del
元素。要表示某个
项目已被另一个项目替换,一个 li 元素可以包含一个或多个
del 元素,后跟一个或
多个 ins 元素。
在以下示例中,一个最初为空的列表随着时间推移添加和移除了项目。 示例中被强调的部分显示列表的“当前” 状态。不过,列表项编号并未考虑这些编辑。
< h1 > 阻止发布的缺陷</ h1 >
< ol >
< li >< ins datetime = "2008-02-12T15:20Z" > 缺陷 225:
雨水探测器在雪中无法工作</ ins ></ li >
< li >< del datetime = "2008-03-01T20:22Z" >< ins datetime = "2008-02-14T12:02Z" > 缺陷 228:
水缓冲区在四月溢出</ ins ></ del ></ li >
< li >< ins datetime = "2008-02-16T13:50Z" > 缺陷 230:
热水器未使用可再生燃料</ ins ></ li >
< li >< del datetime = "2008-02-20T21:15Z" >< ins datetime = "2008-02-16T14:25Z" > 缺陷 232:
启动后检测到二氧化碳排放</ ins ></ del ></ li >
</ ol > 在以下示例中,一个最初只包含水果的列表被替换为一个只包含 颜色的列表。
< h1 > < del > 水果</ del >< ins > 颜色</ ins > 列表</ h1 >
< ul >
< li >< del > 青柠</ del >< ins > 绿色</ ins ></ li >
< li >< del > 苹果</ del ></ li >
< li > 橙色</ li >
< li >< del > 梨</ del ></ li >
< li >< ins > 蓝绿色</ ins ></ li >
< li >< del > 柠檬</ del >< ins > 黄色</ ins ></ li >
< li > 橄榄色</ li >
< li >< ins > 紫色</ ins ></ li >
</ ul > 本节为非规范性内容。
构成表格模型一部分的元素具有复杂的内容模型要求,
不允许使用 ins 和 del 元素,因此表示对
表格的编辑可能很困难。
要表示添加或移除了整行或整列,可以将该行或列中
每个单元格的全部内容分别包裹在 ins 或 del
元素中。
此处向表格添加了一行:
< table >
< thead >
< tr > < th > 游戏名称 < th > 游戏发行商 < th > 评价
< tbody >
< tr > < td > Diablo 2 < td > Blizzard < td > 8/10
< tr > < td > Portal < td > Valve < td > 10/10
< tr > < td > < ins > Portal 2</ ins > < td > < ins > Valve</ ins > < td > < ins > 10/10</ ins >
</ table > 此处移除了一列(同时给出了移除时间以及指向 解释原因的页面的链接):
< table >
< thead >
< tr > < th > 游戏名称 < th > 游戏发行商 < th > < del cite = "/edits/r192" datetime = "2011-05-02 14:23Z" > 评价</ del >
< tbody >
< tr > < td > Diablo 2 < td > Blizzard < td > < del cite = "/edits/r192" datetime = "2011-05-02 14:23Z" > 8/10</ del >
< tr > < td > Portal < td > Valve < td > < del cite = "/edits/r192" datetime = "2011-05-02 14:23Z" > 10/10</ del >
< tr > < td > Portal 2 < td > Valve < td > < del cite = "/edits/r192" datetime = "2011-05-02 14:23Z" > 10/10</ del >
</ table > 一般而言,没有很好的方法来表示更复杂的编辑(例如移除一个单元格, 从而使后续所有单元格向上或向左移动)。
picture 元素
所有当前引擎均支持。
所有当前引擎均支持。
source
元素,后跟一个 img
元素,
其间可以选择性地混入脚本支持元素。[Exposed =Window ]
interface HTMLPictureElement : HTMLElement {
[HTMLConstructor ] constructor ();
};picture 元素是
一个容器,
它为所包含的 img 元素提供多个来源,
使作者能够根据屏幕像素密度、视口大小、图像格式及
其他因素,以声明方式控制或向用户代理提示应使用哪个图像资源。
它表示其子节点。
picture
元素
与外观相似的
video 和 audio 元素有所不同。尽管它们
都包含 source
元素,但当 source
元素嵌套在 picture 元素中时,其
src 属性
没有意义,并且资源
选择算法也不同。此外,picture
元素本身
不显示
任何内容;它只是为所包含的 img 元素提供上下文,使其
能够从多个 URL
中进行选择。
source
元素所有当前引擎均支持。
所有当前引擎均支持。
picture 元素的子节点,位于
img 元素之前。
track 元素之前。
type — 嵌入
资源的类型
media — 适用的媒体
src(在 audio 或 video 中)—
资源地址
srcset(在 picture 中)— 在
不同情形下使用的图像,例如高分辨率显示器、小型显示器等
sizes(在 picture 中)— 用于不同页面布局的
图像尺寸
width(在 picture 中)— 水平
尺寸
height(在 picture 中)— 垂直
尺寸
[Exposed =Window ]
interface HTMLSourceElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , ReflectURL ] attribute USVString src ;
[CEReactions , Reflect ] attribute DOMString type ;
[CEReactions , Reflect ] attribute USVString srcset ;
[CEReactions , Reflect ] attribute DOMString sizes ;
[CEReactions , Reflect ] attribute DOMString media ;
[CEReactions , Reflect ] attribute unsigned long width ;
[CEReactions , Reflect ] attribute unsigned long height ;
};source 元素允许
作者为 img 元素指定多个替代
来源集,或为媒体
元素指定多个替代
媒体资源。它自身不表示任何内容。
可以存在 type
属性。如果存在,其值必须是有效的 MIME 类型
字符串。
也可以存在 media
属性。如果存在,其值必须包含有效的媒体查询
列表。如果该值
不与环境匹配,
用户代理将跳到下一个 source 元素。
media
属性仅在媒体元素的资源选择算法
期间求值一次。相比之下,使用
picture 元素时,
用户代理将响应
环境变化。
source 元素的
父节点是 picture
元素必须存在 srcset
属性,并且它是一个 srcset
属性。
如果
source 元素被
选中,则 srcset
属性会将图像来源贡献给
来源集。
如果 srcset
属性具有任何使用宽度
描述符的图像
候选字符串,则也可以存在
sizes 属性。如果此外,
后续兄弟 img
元素不允许
自动尺寸,则必须存在 sizes
属性。
sizes
属性是一个 sizes 属性;如果 source 元素被
选中,它会将来源尺寸贡献给
来源集。
如果 img
元素允许自动尺寸,则可以在前面的兄弟
source 元素上省略
sizes 属性。在
这种情况下,它等同于指定 auto。
source 元素
支持尺寸属性。
img 元素可以使用某个
source 元素的
width 和 height 属性,而不是使用
img 元素自身的
属性,以确定其渲染尺寸和
宽高比,如“渲染”章节中所定义。
type 属性
给出来源集中图像的类型,以便在用户代理
不支持给定类型时跳到下一个 source
元素。
如果未
指定 type 属性,则用户代理在
获取图像后发现不支持该图像格式时,不会选择另一个 source 元素。
当 source
元素具有后续兄弟 source
元素或指定了
srcset 属性的
img 元素时,
它必须至少具有以下一项:
指定了 media 属性,
且其值在去除前导和尾随
ASCII 空白后,不是空字符串,也不与字符串
“all”进行ASCII
不区分大小写匹配。
指定了 type 属性。
不得存在 src 属性。
source
元素的父节点是媒体元素src
属性
给出媒体
资源的 URL。其值必须是可能由空格包围的有效
非空 URL。必须存在此属性。
type 属性
给出媒体
资源的类型,以帮助用户代理在获取该媒体
资源之前确定是否能够播放它。某些
MIME 类型定义的 codecs 参数可能是准确指定资源编码方式所必需的。
[RFC6381]
当 source 元素已经插入
video 或 audio 元素中时,动态修改其
src 或 type 属性
不会产生任何效果。要更改正在播放的内容,只需直接使用媒体元素上的 src
属性,并且可能使用 canPlayType()
方法从可用
资源中进行选择。通常,在文档
解析完成后手动操作 source 元素
是一种不必要地复杂的方法。
以下列表展示了如何在 type
属性中使用 codecs= MIME
参数的一些示例。
< source src = 'video.mp4' type = 'video/mp4; codecs="avc1.42E01E, mp4a.40.2"' > < source src = 'video.mp4' type = 'video/mp4; codecs="avc1.58A01E, mp4a.40.2"' > < source src = 'video.mp4' type = 'video/mp4; codecs="avc1.4D401E, mp4a.40.2"' > < source src = 'video.mp4' type = 'video/mp4; codecs="avc1.64001E, mp4a.40.2"' > < source src = 'video.mp4' type = 'video/mp4; codecs="mp4v.20.8, mp4a.40.2"' > < source src = 'video.mp4' type = 'video/mp4; codecs="mp4v.20.240, mp4a.40.2"' > < source src = 'video.3gp' type = 'video/3gpp; codecs="mp4v.20.8, samr"' > < source src = 'video.ogv' type = 'video/ogg; codecs="theora, vorbis"' > < source src = 'video.ogv' type = 'video/ogg; codecs="theora, speex"' > < source src = 'audio.ogg' type = 'audio/ogg; codecs=vorbis' > < source src = 'audio.spx' type = 'audio/ogg; codecs=speex' > < source src = 'audio.oga' type = 'audio/ogg; codecs=flac' > < source src = 'video.ogv' type = 'video/ogg; codecs="dirac, vorbis"' > 给定
insertedNode,source 的HTML 元素插入
步骤为:
给定 movedNode、
isSubtreeRoot 和 oldAncestor,source 的HTML 元素移动
步骤为:
给定
removedNode、isSubtreeRoot 和 oldAncestor,source 的HTML 元素移除
步骤为:
如果作者不确定所有用户代理是否都能够渲染所提供的媒体资源,
则作者可以监听最后一个
source 元素上的
error 事件,并
触发回退行为:
< script >
function fallback( video) {
// replace <video> with its contents
while ( video. hasChildNodes()) {
if ( video. firstChild instanceof HTMLSourceElement)
video. removeChild( video. firstChild);
else
video. parentNode. insertBefore( video. firstChild, video);
}
video. parentNode. removeChild( video);
}
</ script >
< video controls autoplay >
< source src = 'video.mp4' type = 'video/mp4; codecs="avc1.42E01E, mp4a.40.2"' >
< source src = 'video.ogv' type = 'video/ogg; codecs="theora, vorbis"'
onerror = "fallback(parentNode)" >
...
</ video > img
元素所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
usemap 或
controls 属性:交互式内容。
picture
元素的子节点,位于所有 source
元素之后。alt — 图像不可用时使用的
替代文本
src — 资源地址
srcset — 在
不同情形下使用的图像,例如高分辨率显示器、小型显示器等
sizes — 用于不同
页面布局的图像尺寸
crossorigin —
元素如何处理跨源请求
usemap — 要使用的
图像映射名称
ismap — 图像是否为
服务器端图像映射
controls — 显示用户
代理控件
width — 水平尺寸
height — 垂直尺寸
referrerpolicy
— 元素发起的获取所使用的来源策略
decoding — 处理此图像以进行呈现时
使用的解码提示
loading — 用于
确定是否延迟加载
fetchpriority —
设置元素发起的获取的优先级
alt
属性:面向作者;面向实现者。[Exposed =Window ,
LegacyFactoryFunction =Image (optional unsigned long width , optional unsigned long height )]
interface HTMLImageElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect ] attribute DOMString alt ;
[CEReactions , ReflectURL ] attribute USVString src ;
[CEReactions , Reflect ] attribute USVString srcset ;
[CEReactions , Reflect ] attribute DOMString sizes ;
[CEReactions ] attribute DOMString ? crossOrigin ;
[CEReactions , Reflect ] attribute DOMString useMap ;
[CEReactions , Reflect ] attribute boolean isMap ;
[CEReactions , Reflect ] attribute boolean controls ;
[CEReactions , ReflectSetter ] attribute unsigned long width ;
[CEReactions , ReflectSetter ] attribute unsigned long height ;
readonly attribute unsigned long naturalWidth ;
readonly attribute unsigned long naturalHeight ;
readonly attribute boolean complete ;
readonly attribute USVString currentSrc ;
[CEReactions ] attribute DOMString referrerPolicy ;
[CEReactions ] attribute DOMString decoding ;
[CEReactions ] attribute DOMString loading ;
[CEReactions ] attribute DOMString fetchPriority ;
Promise <undefined > decode ();
// also has obsolete members
};img 元素表示一幅
图像。
img 元素具有一个尺寸
属性来源,其初始设置为元素自身。
所有当前引擎均支持。
所有当前引擎均支持。
由 src
和 srcset 属性给出的图像,
以及当父节点是 picture
元素时,任何前面的兄弟
source
元素的 srcset
属性所给出的图像,是
嵌入内容;alt 属性的值为
无法处理图像或已禁用图像加载的人提供等效内容(即,
它是 img 元素的回退内容)。
如果存在 src 属性,则它
必须包含一个引用非交互式、可以选择性地带有动画、既非分页也非脚本化图像资源的
可能由空格
包围的有效非空 URL。
上述要求意味着图像可以是静态位图(例如 PNG、GIF、 JPEG)、单页矢量文档(单页 PDF、具有 SVG 文档元素的 XML 文件)、 动画位图(APNG、动画 GIF)、动画矢量图形(使用声明式 SMIL 动画且具有 SVG 文档元素的 XML 文件)等等。 不过,这些 定义排除了带有脚本的 SVG 文件、多页 PDF 文件、交互式 MNG 文件、HTML 文档、纯文本文档等。[PNG] [GIF] [JPEG] [PDF] [XML] [APNG] [SVG] [MNG]
srcset 属性和
src 属性(如果未使用宽度
描述符)会将图像
来源
贡献给来源集(如果未选择任何 source 元素)。
如果存在 srcset 属性,
并且它具有任何使用宽度
描述符的图像候选
字符串,则还必须存在 sizes
属性。
如果未指定
srcset 属性,并且
loading 属性处于
延迟状态,则可以为
sizes 属性指定值
“auto”(ASCII
不区分大小写)。sizes
属性是一个 sizes 属性,
它会将来源尺寸贡献给来源集(如果未
选择任何 source 元素)。
如果满足以下条件,则 img 元素允许自动尺寸:
loading 属性处于
延迟状态,并且
sizes 属性的值
是“auto”(ASCII
不区分大小写),或以“auto,”开头(ASCII
不区分大小写)。所有当前引擎均支持。
crossorigin
属性是一个CORS 设置
属性。其目的是允许来自
允许跨源访问的第三方站点的图像与 canvas 一起使用。
referrerpolicy
属性是一个来源
策略属性。其目的是设置获取图像时使用的来源
策略。[REFERRERPOLICY]
decoding
属性指示解码此
图像的首选方法。如果存在,该属性必须是一个图像解码提示。此属性的缺失值默认值和无效值默认值均为
自动状态。
HTMLImageElement/fetchPriority
fetchpriority
属性是一个获取
优先级属性。其目的是设置获取图像时使用的优先级。
loading 属性
是一个延迟
加载属性。其目的是指示加载视口
之外图像的策略。
< img src = "1.jpeg" alt = "1" >
< img src = "2.jpeg" loading = eager alt = "2" >
< img src = "3.jpeg" loading = lazy alt = "3" >
< div id = very-large ></ div > <!-- 此 div 之后的所有内容都位于视口下方 -->
< img src = "4.jpeg" alt = "4" >
< img src = "5.jpeg" loading = lazy alt = "5" > 在以上示例中,图像按如下方式加载:
1.jpeg、2.jpeg、
4.jpeg
这些图像立即加载,并延迟窗口的 load 事件。
3.jpeg由于图像位于视口中,因此它会在布局已知时加载,但不会 延迟窗口的 load 事件。
5.jpeg该图像仅在滚动进入视口后才加载,并且不会延迟窗口的 load 事件。
鼓励开发者在延迟加载的图像上通过 width 和 height 属性
指定首选宽高比,即使 CSS 设置了图像的宽度和高度属性也是如此,以防止
图像加载后页面布局发生偏移。
给定 insertedNode,
img 的HTML 元素插入
步骤为:
给定 movedNode、
isSubtreeRoot 和 oldAncestor,img 的HTML 元素移动步骤
为:
给定 removedNode、
oldAncestor 和 isSubtreeRoot,img 的HTML 元素移除
步骤为:
img 元素不得
用作布局工具。特别是,不应使用 img
元素显示透明图像,因为此类图像很少传达含义,也
很少为文档添加任何有用内容。
img 元素
表示什么,取决于 src
属性和 alt
属性。
src 属性,并且
alt 属性设置为空
字符串
图像要么是装饰性的,要么是对其余内容的补充,并与 文档中的某些其他信息重复。
如果图像可用,并且用户代理配置为 显示该图像,则元素表示 元素的图像数据。
否则,元素不表示任何内容,并且 可以从渲染中完全省略。用户代理可以向用户提供通知,说明存在图像,但 已从渲染中省略。
src 属性,并且
alt 属性设置为
非空值
图像是内容的关键部分;alt 属性
给出图像的文本等效内容或替代内容。
src 属性,但
未设置 alt 属性图像可能是内容的关键部分,但没有可用的图像文本等效内容。
在符合要求的文档中,缺少 alt
属性表示该
图像是内容的关键部分,
但在生成图像时无法获得图像的文本替代内容。
如果图像可用,并且用户 代理配置为 显示该图像,则元素表示 元素的图像数据。
如果图像具有 src 属性,
且其值为
空字符串,则元素不表示任何内容。
否则,用户代理应显示某种指示,表明存在一幅 未被渲染的图像;并且在用户请求、进行了相应配置,或者在响应导航时需要 提供上下文信息的情况下,可以提供图像的说明文字信息, 其派生方式如下:
如果图像具有 title 属性,
且其值不是
空字符串,则返回该属性的值。
如果图像是 figure
元素的后代,
该元素具有一个子
figcaption
元素,并且忽略 figcaption
元素及其
后代后,figure 元素除
元素间
空白和 img 元素外,没有其他
流式内容后代,则返回第一个此类
figcaption
元素的内容。
不返回任何内容。(没有说明文字信息。)
src 属性,
并且 alt 属性
设置为空字符串,或者根本未设置 alt
属性元素不表示任何内容。
alt 属性不表示
建议性信息。
用户代理不得以与 title
属性内容相同的方式呈现 alt 属性的内容。
用户代理始终可以为用户提供显示任何图像或阻止任何 图像显示的选项。当用户无法看到图像时,例如由于视觉障碍,或因为正在使用 不具备图形功能的文本终端,用户代理还可以应用启发式方法来帮助用户利用 图像。例如,此类启发式方法可以包括 对图像中发现的文本进行光学字符识别(OCR)。
虽然鼓励用户代理修复缺少 alt
属性的情况,但作者不得依赖
此类行为。提供用作图像替代内容的文本的要求将在
下文详细说明。
img
元素的内容(如果有)在
渲染时会被忽略。
如果存在 usemap
属性,
它可以指示图像具有关联的
图像映射。
当 ismap 属性
用于某个元素上,而该元素是具有 href 属性的
a 元素的后代时,该属性的
存在表示该元素
提供对服务器端图像映射的访问。这会影响相应 a 元素上事件的处理方式。
ismap 属性是一个
布尔属性。不得在
没有具有 href 属性的祖先 a 元素的元素上指定
该属性。
当与 picture
元素中指定了
media
属性的 source
元素一起使用时,usemap 和
ismap 属性可能导致
令人困惑的行为。
controls
属性是一个布尔属性。如果
存在,它表示用户代理可以
向用户公开用户界面。不得在没有 alt 属性,或其
alt 属性值为空
字符串的元素上指定该属性。
如果存在 controls 属性,
用户代理
可以公开图像控件(例如全屏查看控件)。所提供的具体
控件由实现定义,并且可以特定于平台或基于
用户的偏好。
如果用户代理通过在 img
元素上显示控件来公开用户界面,则用户代理在用户
与该界面交互时应抑制任何用户交互事件。
Issue #12318 跟踪 图像控件与动画图像之间的交互。在该问题解决之前,用户代理不应公开 图像的动画控件。
所有当前引擎均支持。
crossOrigin IDL 属性必须
反映 crossorigin 内容
属性,并仅限于已知
值。
HTMLImageElement/referrerPolicy
所有当前引擎均支持。
referrerPolicy IDL 属性必须
反映 referrerpolicy
内容
属性,并仅限于
已知值。
所有当前引擎均支持。
所有当前引擎均支持。
fetchPriority IDL 属性
必须反映 fetchpriority 内容
属性,并仅限于
已知值。
image.width [ = value ]
所有当前引擎均支持。
image.height [ = value ]
所有当前引擎均支持。
这些属性返回图像实际渲染的尺寸;如果尺寸 未知,则返回 0。
可以设置这些属性,以更改相应的内容属性。
image.naturalWidth
所有当前引擎均支持。
image.naturalHeight
HTMLImageElement/naturalHeight
所有当前引擎均支持。
这些属性返回图像经过密度校正的自然宽度和 高度;如果图像不可用,则返回 0。
image.complete
所有当前引擎均支持。
如果图像已完全下载,或者未指定图像,则返回 true; 否则返回 false。
image.currentSrc
所有当前引擎均支持。
返回图像的绝对 URL。
image.decode()
所有当前引擎均支持。
此方法会使用户代理并行解码 图像,并返回一个在解码完成时兑现的 promise。
如果无法解码图像,该 promise 将以 “EncodingError”
DOMException
拒绝。
image = new Image([ width [, height ] ])
所有当前引擎均支持。
要确定 img 元素
image 的尺寸:
如果 image 可用,并且具有 经过密度校正的自然宽度和 高度,则以 CSS 像素为单位返回其 经过密度校正的自然宽度和 高度。
返回宽度 0 和高度 0。
naturalWidth 和 naturalHeight 的获取器
步骤如下:
如果图像不可用,则 返回 0。
以 CSS 像素为单位,返回图像经过密度校正的自然宽度和 高度中的相应分量。[CSS]
由于图像的经过密度校正的自然宽度和高度
会考虑其元数据中指定的任何方向,因此 naturalWidth 和 naturalHeight 所反映的是
应用正确确定图像方向所需的任何
旋转后的尺寸,而不考虑
'image-orientation' 属性的值。
complete
的获取器步骤如下:
调用 decode()
方法时,必须执行以下步骤:
令 promise 为一个新的 promise。
排入一个微任务以执行 以下步骤:
这样做是因为更新 图像数据 也发生在微任务中。因此,为了使如下代码
img. src = "stars.jpg" ;
img. decode(); 正确解码 stars.jpg,需要将任何处理延迟一个
微任务。
如果以下任一项为 true:
则以 “EncodingError”
DOMException
拒绝 promise。
否则,并行地等待以下 情况之一发生,并 执行相应操作:
img 元素的
节点文档不再是完全
活动的
img 元素的
当前请求发生更改或
突变
img 元素的
当前请求的状态变为损坏
使用
global,在DOM
操作任务源上排入一个全局任务,以
“EncodingError” DOMException
拒绝 promise。
img 元素的
当前请求的状态变为完全
可用
解码图像。
如果此图像不需要执行解码(例如,因为它是 矢量图形),或者解码过程成功完成,则使用 global,在DOM 操作任务源上排入一个全局 任务,以使用 undefined 兑现 promise。
如果解码失败(例如由于图像数据无效),则使用
global,在DOM 操作任务源上排入一个全局
任务,以 “EncodingError”
DOMException
拒绝 promise。
用户代理应确保已解码的媒体数据至少在事件循环中下一次成功的更新渲染步骤结束前保持随时可用。 这是 API 合约的重要组成部分,如果可能,不应 破坏它。(通常,只有在内存不足而需要驱逐已解码图像数据, 或者图像太大而无法在这段时间内保持解码形式时,才会违反这一点。)
动画图像只有在所有帧都加载后才会变为完全 可用。 因此,尽管实现可以在此之前解码 第一帧,但上述步骤不会这样做,而是等待所有 帧都可用。
返回 promise。
如果没有 decode() 方法,
加载
img 元素然后
显示它的过程可能如下所示:
const img = new Image();
img. src = "nebula.jpg" ;
img. onload = () => {
document. body. appendChild( img);
};
img. onerror = () => {
document. body. appendChild( new Text( "Could not load the nebula :(" ));
}; 不过,这可能导致明显的丢帧,因为在将 图像插入 DOM 后发生的绘制会在主线程上引发同步解码。
可以改为使用 decode()
方法重写:
const img = new Image();
img. src = "nebula.jpg" ;
img. decode(). then(() => {
document. body. appendChild( img);
}). catch (() => {
document. body. appendChild( new Text( "Could not load the nebula :(" ));
}); 后一种形式允许用户代理并行解码图像,并且仅在 解码过程完成后才将其插入 DOM(从而 使其被绘制),因而避免了原始形式中的丢帧。
由于 decode() 方法
会尝试确保
已解码图像数据至少可用于一帧,因此它可以与 requestAnimationFrame()
API 结合使用。
这意味着,它可以与确保所有 DOM 修改都作为动画帧
回调批量执行的编码风格或框架一起使用:
const container = document. querySelector( "#container" );
const { containerWidth, containerHeight } = computeDesiredSize();
requestAnimationFrame(() => {
container. style. width = containerWidth;
container. style. height = containerHeight;
});
// ...
const img = new Image();
img. src = "supernova.jpg" ;
img. decode(). then(() => {
requestAnimationFrame(() => container. appendChild( img));
}); 除了 DOM 中的工厂方法(例如 createElement())外,
还提供了一个用于创建 HTMLImageElement
对象的旧版工厂函数:
Image(width, height)。调用时,
旧版工厂函数必须执行以下步骤:
同一幅图像可以根据上下文具有不同的适当替代文本。
在以下每种情况中,都使用了同一幅图像,但每次的 alt 文本都不同。该
图像是瑞士日内瓦州
Carouge 市镇的徽章。
这里将其用作补充图标:
< p > 我曾住在 < img src = "carouge.svg" alt = "" > Carouge。</ p > 这里将其用作表示该城镇的图标:
< p > 家乡:< img src = "carouge.svg" alt = "Carouge" ></ p > 这里将其用作关于该城镇的文本的一部分:
< p > Carouge 有一个徽章。</ p >
< p >< img src = "carouge.svg" alt = "徽章描绘了一只坐在树前的狮子。" ></ p >
< p > 它被用作城镇各处的装饰。</ p > 这里将其用于支持类似的文本,其中描述与图像一同给出, 而不是作为图像的替代内容:
< p > Carouge 有一个徽章。</ p >
< p >< img src = "carouge.svg" alt = "" ></ p >
< p > 徽章描绘了一只坐在树前的狮子。
它被用作城镇各处的装饰。</ p > 这里将其用作故事的一部分:
< p > 她拿起文件夹,一张纸掉了出来。</ p >
< p >< img src = "carouge.svg" alt = "这张纸形似盾牌,具有
红色背景、一棵绿树和一只伸着舌头的黄色狮子,
其尾巴呈 S 形。" ></ p >
< p > 她盯着文件夹。S!她一直寻找的答案
原来只是字母 S!她以前怎么没有发现?现在一切都串联起来了。
Hector 在电话中提到狮子尾巴的那次,
Maria 吐舌头的那次……</ p > 这里在发布时并不知道图像会是什么,只知道它将是某种
徽章,因此无法提供替代文本,而只能在 title 属性中提供图像的简短
说明文字:
< p > 最后一位上传徽章的用户上传了这个:</ p >
< p >< img src = "last-uploaded-coat-of-arms.cgi" title = "用户上传的徽章。" ></ p > 理想情况下,即使在这种情况下,作者也应设法提供真正的替代文本,例如 询问上一位用户。不提供替代文本会使文档更难被 无法查看图像的人使用,例如盲人用户、使用极低带宽 连接或按字节付费的用户,或者被迫使用纯文本 Web 浏览器的用户。
下面还有一些示例,展示同一幅图像在不同上下文中使用, 并且每次具有不同的适当替代文本。
< article >
< h1 > 我的猫</ h1 >
< h2 > Fluffy</ h2 >
< p > Fluffy 是我最喜欢的。</ p >
< img src = "fluffy.jpg" alt = "她喜欢玩毛线球。" >
< p > 她实在太可爱了。</ p >
< h2 > Miles</ h2 >
< p > 我的另一只猫 Miles 只会吃饭和睡觉。</ p >
</ article > < article >
< h1 > 摄影</ h1 >
< h2 > 在室内拍摄移动目标</ h2 >
< p > 这里的诀窍是懂得预判;要知道拍摄对象会以什么速度、
从多远的距离经过。</ p >
< img src = "fluffy.jpg" alt = "使用这种技术,可以很好地拍摄一只
追逐毛线球、飞奔而过的猫。" >
< h2 > 夜间自然摄影</ h2 >
< p > 要做到这一点,需要极其敏感的胶片,
或极强的闪光灯。</ p >
</ article > < article >
< h1 > 关于我</ h1 >
< h2 > 我的宠物</ h2 >
< p > 我有一只名叫 Fluffy 的猫和一只名叫 Miles 的狗。</ p >
< img src = "fluffy.jpg" alt = "我的猫 Fluffy 总能让自己忙起来。" >
< p > 我和我的狗 Miles 喜欢一起长距离散步。</ p >
< h2 > 音乐</ h2 >
< p > 散步后头脑放空时,我喜欢听 Bach。</ p >
</ article > < article >
< h1 > Fluffy 和毛线</ h1 >
< p > Fluffy 是一只喜欢玩毛线的猫。她也喜欢跳跃。</ p >
< aside >< img src = "fluffy.jpg" alt = "" title = "Fluffy" ></ aside >
< p > 她早上会玩,晚上也会玩。</ p >
</ article > 本节为非规范性内容。
要在 HTML 中嵌入图像,当只有一个图像资源时,请使用 img
元素及其 src 属性。
< h2 > 来自今日特色文章</ h2 >
< img src = "/uploads/100-marie-lloyd.jpg" alt = "" width = "100" height = "150" >
< p >< b >< a href = "/wiki/Marie_Lloyd" > Marie Lloyd</ a ></ b > (1870–1922)
是一位英国< a href = "/wiki/Music_hall" > 音乐厅</ a > 歌手,……但是,在许多情况下,作者可能希望使用多个图像资源,并让用户代理从中选择:
不同用户可能具有不同的环境特征:
用户的物理屏幕尺寸可能彼此不同。
手机屏幕的对角线尺寸可能为 4 英寸,而笔记本电脑屏幕的对角线尺寸可能为 14 英寸。
这仅在图像的渲染尺寸取决于 视口尺寸时才相关。
用户屏幕的像素密度可能彼此不同。
无论物理屏幕尺寸如何,一部手机的屏幕每英寸所包含的物理像素数量 可能是另一部手机屏幕的三倍。
用户的缩放级别可能彼此不同,或者同一用户的缩放级别可能随时间变化。
用户可能会放大某幅特定图像,以便查看更详细的内容。
缩放级别和屏幕像素密度(上一点)都可能影响每个 CSS 像素所对应的物理屏幕像素数量。此比率通常 称为设备像素比。
用户屏幕的方向可能彼此不同,或者同一用户的屏幕方向可能随时间变化。
平板电脑可以竖直拿握,也可以旋转 90 度,使屏幕处于 "纵向"或"横向"。
用户的网络速度、网络延迟和带宽成本可能彼此不同,或者同一用户的这些条件 可能随时间变化。
用户在工作时可能使用快速、低延迟且成本固定的连接, 在家时使用缓慢、低延迟且成本固定的连接,而在其他任何地方则使用 速度可变、高延迟且成本可变的连接。
作者可能希望显示相同的图像内容,但根据通常是视口的宽度采用不同的渲染尺寸。这通常称为 基于视口的选择。
网页顶部可能有一个始终横跨整个 视口 宽度的横幅。在这种情况下,图像的渲染尺寸取决于屏幕的物理尺寸 (假设浏览器窗口已最大化)。
另一个网页可能以分栏方式显示图像:物理尺寸较小的屏幕使用单栏, 物理尺寸中等的屏幕使用两栏,物理尺寸较大的屏幕使用三栏,并且在每种情况下 图像的渲染尺寸都会变化以填满 视口。在这种情况下,尽管屏幕更小, 单栏布局中的图像渲染尺寸可能比两栏布局中的图像 更大。
作者可能希望根据图像的渲染尺寸显示不同的图像内容。 这通常称为艺术指导。
当网页在物理尺寸较大的屏幕上查看时(假设浏览器窗口已最大化), 作者可能希望包含围绕图像关键部分的一些相关性较低的部分。当同一网页 在物理尺寸较小的屏幕上查看时,作者可能希望仅显示图像的关键部分。
作者可能希望显示相同的图像内容,但根据用户代理支持的图像格式, 使用不同的图像格式。这通常称为 基于图像格式的选择。
网页可能具有 JPEG、WebP 和 JPEG XR 图像格式的图像, 后两者相较于 JPEG 具有更好的压缩能力。由于不同用户代理可能支持不同的图像格式, 并且某些格式可提供更好的压缩率,因此作者希望向支持这些格式的用户代理提供 更好的格式,同时为不支持这些格式的用户代理提供 JPEG 回退。
上述情况并不相互排斥。例如,将用于不同设备像素比的不同资源与用于 艺术指导的不同资源结合使用是合理的。
虽然可以使用脚本解决这些问题,但这样做会引入一些其他问题:
某些用户代理会在脚本有机会运行之前,积极下载 HTML 标记中指定的图像, 以便网页更快完成加载。如果脚本更改要下载的图像,用户代理可能会启动 两次独立的下载,反而可能导致更差的页面加载性能。
如果作者避免在 HTML 标记中指定任何图像,而是通过脚本实例化一次 下载,则可以避免上述重复下载问题,但禁用脚本的用户将完全无法下载图像, 并且积极下载图像的优化也会被禁用。
鉴于此,本规范引入了许多功能,以声明方式解决上述问题。
img 元素上的
src 和 srcset
属性可以使用 x
描述符提供多个仅尺寸不同的图像(较小图像是较大图像的缩小版本)。
当图像的渲染尺寸取决于视口宽度
(基于视口的选择)时,x
描述符并不合适,
但可以与
艺术指导一起使用。
< h2 > 来自今日特色文章</ h2 >
< img src = "/uploads/100-marie-lloyd.jpg"
srcset = "/uploads/150-marie-lloyd.jpg 1.5x, /uploads/200-marie-lloyd.jpg 2x"
alt = "" width = "100" height = "150" >
< p >< b >< a href = "/wiki/Marie_Lloyd" > Marie Lloyd</ a ></ b > (1870–1922)
是一位英国< a href = "/wiki/Music_hall" > 音乐厅</ a > 歌手,……用户代理可以根据用户屏幕的像素密度、缩放级别,以及可能存在的其他因素 (例如用户的网络状况),选择任何给定资源。
为了与尚不理解 srcset 属性的旧版用户代理
保持向后兼容,其中一个 URL 会在
img 元素的 src 属性中指定。这样即使在旧版用户代理中,
也会显示一些有用的内容(尽管分辨率可能低于用户期望)。对于新版用户代理,src
属性会参与资源选择,就如同它在 srcset 中使用
1x
描述符指定一样。
srcset 和 sizes 属性可以使用
w
描述符提供多个仅尺寸不同的图像(较小图像是较大图像的缩小版本)。
在此示例中,横幅图像占据整个视口宽度 (使用适当的 CSS)。
< h1 >< img sizes = "100vw" srcset = "wolf-400.jpg 400w, wolf-800.jpg 800w, wolf-1600.jpg 1600w"
src = "wolf-400.jpg" alt = "这只帅气的狼" ></ h1 > 用户代理将根据指定的 w 描述符和 sizes 属性中指定的渲染尺寸,
计算每幅图像的有效像素密度。然后,它可以根据用户屏幕的像素密度、缩放级别,
以及可能存在的其他因素(例如用户的网络状况),选择任何给定资源。
如果用户屏幕宽 320 CSS 像素,则这等同于指定
wolf-400.jpg 1.25x, wolf-800.jpg 2.5x, wolf-1600.jpg 5x。
另一方面,如果用户屏幕宽 1200 CSS 像素,
则这等同于指定 wolf-400.jpg 0.33x, wolf-800.jpg 0.67x, wolf-1600.jpg 1.33x。通过使用
w 描述符和 sizes
属性,无论用户设备有多大,用户代理都可以选择要下载的正确图像来源。
为了向后兼容,其中一个 URL 会在 img 元素的
src 属性中指定。在新版用户代理中,
当 srcset 属性使用
w 描述符时,src 属性会被忽略。
在此示例中,网页根据视口宽度具有三种布局。窄布局使用单栏图像
(每幅图像的宽度约为 100%),中等布局使用两栏图像
(每幅图像的宽度约为 50%),最宽布局使用三栏图像并带有一些页面边距
(每幅图像的宽度约为 33%)。当视口宽度分别为
30em 和 50em 时,会在这些布局之间切换。
< img sizes = "(max-width: 30em) 100vw, (max-width: 50em) 50vw, calc(33vw - 100px)"
srcset = "swing-200.jpg 200w, swing-400.jpg 400w, swing-800.jpg 800w, swing-1600.jpg 1600w"
src = "swing-400.jpg" alt = "壶铃摆动" > sizes 属性在
30em 和 50em 处设置布局断点,并声明这些断点之间的图像尺寸为
100vw、50vw 或
calc(33vw - 100px)。这些尺寸不一定必须与 CSS 中指定的实际图像宽度
完全匹配。
用户代理将从 sizes
属性中选择一个宽度:使用第一个包含求值为 true 的<media-condition>(括号中的部分)的项目,
如果所有项目均求值为 false,则使用最后一个项目(calc(33vw -
100px))。
例如,如果视口宽度为 29em,则
(max-width: 30em) 求值为 true,并使用 100vw,
因此就资源选择而言,图像尺寸为 29em。如果
视口宽度改为 32em,则
(max-width: 30em) 求值为 false,但
(max-width: 50em) 求值为 true,
并使用 50vw,因此就资源选择而言,图像尺寸为
16em(视口宽度的一半)。请注意,由于布局不同,
略宽的视口反而会产生更小的图像。
然后,用户代理可以计算有效像素密度,并以与前一个示例类似的方式选择适当的资源。
此示例与前一个示例相同,但图像是延迟加载的。在这种情况下,sizes 属性可以使用 auto 关键字,并且用户
代理将使用 width
属性(或 CSS 中指定的宽度)作为
来源尺寸。
< img loading = "lazy" width = "200" height = "200" sizes = "auto"
srcset = "swing-200.jpg 200w, swing-400.jpg 400w, swing-800.jpg 800w, swing-1600.jpg 1600w"
src = "swing-400.jpg" alt = "壶铃摆动" > 为了与不支持 auto 关键字的旧版用户代理
实现更好的向后兼容,可以根据需要指定回退尺寸。
< img loading = "lazy" width = "200" height = "200"
sizes = "auto, (max-width: 30em) 100vw, (max-width: 50em) 50vw, calc(33vw - 100px)"
srcset = "swing-200.jpg 200w, swing-400.jpg 400w, swing-800.jpg 800w, swing-1600.jpg 1600w"
src = "swing-400.jpg" alt = "壶铃摆动" > picture 元素和
source 元素,
连同 media
属性,可以用于提供图像内容不同的多个图像(例如,较小图像可能是较大图像的裁剪版本)。
< picture >
< source media = "(min-width: 45em)" srcset = "large.jpg" >
< source media = "(min-width: 32em)" srcset = "med.jpg" >
< img src = "small.jpg" alt = "狼在雪中奔跑。" >
</ picture > 用户代理将选择第一个其 media
属性中的媒体查询
匹配的 source 元素,
然后从其 srcset 属性中选择适当的
URL。
图像的渲染尺寸会根据所选资源而变化。为了指定用户代理可在图像下载前使用的 尺寸,可以使用 CSS。
img { width : 300 px ; height : 300 px }
@media ( min-width: 32em) { img { width: 500px; height:300px } }
@media (min-width: 45em) { img { width: 700px; height:400px } }source 元素上的
type 属性
可以用于提供不同格式的多个图像。
< h2 > 来自今日特色文章</ h2 >
< picture >
< source srcset = "/uploads/100-marie-lloyd.webp" type = "image/webp" >
< source srcset = "/uploads/100-marie-lloyd.jxr" type = "image/vnd.ms-photo" >
< img src = "/uploads/100-marie-lloyd.jpg" alt = "" width = "100" height = "150" >
</ picture >
< p >< b >< a href = "/wiki/Marie_Lloyd" > Marie Lloyd</ a ></ b > (1870–1922)
是一位英国< a href = "/wiki/Music_hall" > 音乐厅</ a > 歌手,……在此示例中,用户代理将选择第一个其 type
属性包含受支持
MIME 类型的来源。如果用户代理支持 WebP 图像,则会选择第一个 source 元素。
否则,如果用户代理支持 JPEG XR 图像,则会选择第二个 source 元素。
如果这两种格式都不受支持,则会选择 img 元素。
本节为非规范性内容。
CSS 和媒体查询可以用于构建可动态适应用户环境的图形页面布局,
尤其是适应不同的视口尺寸和像素密度。
不过,对于内容,CSS 无法提供帮助;相反,我们可以使用 img
元素的
srcset 属性和 picture 元素。
本节通过一个示例说明如何使用这些功能。
考虑这样一种情况:在宽屏(宽于 600 CSS
像素)上,要使用一幅名为 a-rectangle.png 的 300×150 图像,
而在较小的屏幕(600 CSS
像素及以下)上,则要使用一幅名为
a-square.png 的较小 100×100 图像。其标记如下:
< figure >
< picture >
< source srcset = "a-square.png" media = "(max-width: 600px)" >
< img src = "a-rectangle.png" alt = "Barney Frank 穿着西装并戴着眼镜。" >
</ picture >
< figcaption > Barney Frank,2011 年</ figcaption >
</ figure > 有关应在 alt
属性中放置什么的详细信息,请参阅提供用作图像替代内容的文本的要求一节。
这种做法的问题在于,用户代理在图像加载时不一定知道应使用什么尺寸。 为避免页面加载期间布局不得不多次重排,可以使用 CSS 和 CSS 媒体查询来提供尺寸:
< style >
# a { width : 300 px ; height : 150 px ; }
@ media ( max-width : 600px ) { # a { width : 100 px ; height : 100 px ; } }
</ style >
< figure >
< picture >
< source srcset = "a-square.png" media = "(max-width: 600px)" >
< img src = "a-rectangle.png" alt = "Barney Frank 穿着西装并戴着眼镜。" id = "a" >
</ picture >
< figcaption > Barney Frank,2011 年</ figcaption >
</ figure > 或者,可以在 source 和
img 元素上使用
width 和 height 属性来提供宽度和高度:
< figure >
< picture >
< source srcset = "a-square.png" media = "(max-width: 600px)" width = "100" height = "100" >
< img src = "a-rectangle.png" width = "300" height = "150"
alt = "Barney Frank 穿着西装并戴着眼镜。" >
</ picture >
< figcaption > Barney Frank,2011 年</ figcaption >
</ figure >
img 元素与
src 属性一起使用,
后者给出供不支持 picture
元素的旧版用户代理
使用的图像 URL。这就产生了一个问题:应在 src 属性中提供哪幅图像。
如果作者希望旧版用户代理使用最大的图像,则标记可以如下所示:
< picture >
< source srcset = "pear-mobile.jpeg" media = "(max-width: 720px)" >
< source srcset = "pear-tablet.jpeg" media = "(max-width: 1280px)" >
< img src = "pear-desktop.jpeg" alt = "这个梨汁水丰富。" >
</ picture > 但是,如果旧版移动用户代理更为重要,则可以在
source 元素中列出全部三幅图像,
从而完全覆盖 src 属性。
< picture >
< source srcset = "pear-mobile.jpeg" media = "(max-width: 720px)" >
< source srcset = "pear-tablet.jpeg" media = "(max-width: 1280px)" >
< source srcset = "pear-desktop.jpeg" >
< img src = "pear-mobile.jpeg" alt = "这个梨汁水丰富。" >
</ picture > 由于此时支持 picture
的用户代理实际上会完全
忽略 src 属性,因此
src 属性可以默认为任何图像,
包括既不是最小也不是最大的图像:
< picture >
< source srcset = "pear-mobile.jpeg" media = "(max-width: 720px)" >
< source srcset = "pear-tablet.jpeg" media = "(max-width: 1280px)" >
< source srcset = "pear-desktop.jpeg" >
< img src = "pear-tablet.jpeg" alt = "这个梨汁水丰富。" >
</ picture > 上面使用了 max-width 媒体特性,用于给出图像所面向的最大
(视口)尺寸。也可以改用
min-width。
< picture >
< source srcset = "pear-desktop.jpeg" media = "(min-width: 1281px)" >
< source srcset = "pear-tablet.jpeg" media = "(min-width: 721px)" >
< img src = "pear-mobile.jpeg" alt = "这个梨汁水丰富。" >
</ picture > source、
img
和 link
元素共有的属性
srcset 属性是具有本节所定义要求的属性。
如果存在,其值必须由一个或多个图像 候选字符串组成,每个字符串之间由 U+002C COMMA 字符(,)分隔。如果某个 图像候选字符串 不包含描述符,并且 URL 后没有ASCII 空白, 则后续的图像候选字符串(如果存在)必须以 一个或多个ASCII 空白开头。
图像候选字符串由以下组件按顺序组成, 并受此列表下方所述进一步限制:
同一元素的某个图像候选字符串不得具有与该元素的另一个 图像候选 字符串的宽度描述符值相同的 宽度描述符值。
同一元素的某个图像候选字符串不得具有与该元素的另一个
图像候选字符串的
像素密度描述符值相同的
像素密度描述符值。
就此要求而言,不含描述符的图像候选字符串等同于具有
1x 描述符的图像候选字符串。
如果元素的某个图像候选字符串指定了宽度描述符, 则该元素的所有其他图像候选字符串也必须指定宽度描述符。
如果资源具有自然宽度,则图像候选字符串的宽度描述符中指定的宽度, 必须与该图像候选字符串的 URL 所给资源中的 自然宽度匹配。
如果元素存在sizes 属性, 则该元素的所有图像候选字符串都必须指定宽度描述符。
sizes 属性是具有本节所定义要求的属性。
如果存在,其值必须是有效来源尺寸列表。
有效来源尺寸列表是与以下语法匹配的字符串: [CSSVALUES] [MQ]
< source-size-list > = < source-size > #? , < source-size-value >
< source-size > = < media-condition > < source-size-value > | auto
< source-size-value > = < length > | auto属于<length> 的<source-size-value>不得为负数, 并且不得使用数学函数以外的 CSS 函数。
关键字 auto 是在解析 sizes 属性中计算的宽度。
如果存在,它必须是第一个条目,并且整个<source-size-list>
值必须是字符串
"auto"(ASCII
不区分大小写),或以字符串
"auto,"(ASCII
不区分大小写)开头。
如果发起图像加载(通过更新图像数据或响应环境变化算法)的
img 元素允许自动尺寸并且正在渲染,
则 auto 为具体对象尺寸的宽度。
否则,auto 值会被忽略,
并改用下一个来源尺寸(如果存在)。
如果满足以下条件,可以在 source 元素的
sizes
属性和 img 元素的
sizes 属性中指定
auto 关键字。
否则,不得指定 auto。
此外,强烈建议使用 width 和
height 属性
或 CSS 来指定尺寸。如果未指定尺寸,图像可能会以 300x150 的尺寸渲染,
因为 sizes="auto" 会在“渲染”章节中隐含
contain-intrinsic-size: 300px
150px。
<source-size-value> 给出图像预期的布局宽度。 作者可以使用 <media-condition> 为不同环境指定不同宽度。
<source-size-value> 中不允许使用百分比, 以避免对其相对对象产生混淆。 可以使用 'vw' 单位来指定相对于视口宽度的尺寸。
一个 img 元素具有一个
当前请求和一个待处理请求。
当前请求最初设置为一个新的图像请求。
待处理请求最初设置为 null。
一个图像请求具有一个状态、一个当前 URL和图像数据。
当一个 img 元素的当前请求为可用时,该 img 元素提供一个绘制
来源,其宽度为图像经过密度校正的自然宽度(如果有),
其高度为图像经过密度校正的自然高度(如果有),
其外观为图像的自然外观。
每个 img 元素都有一个
最后选择的来源,其初始值必须为 null。
每个图像请求都有一个当前像素密度,其初始值必须为 1。
每个图像请求都有首选的经过密度校正的尺寸, 该值要么是由宽度和高度组成的结构体,要么为 null。其初始值必须为 null。
要确定 img 元素
img 的经过密度校正的
自然宽度和高度:
令 dimensions 为 img 的当前请求的首选的经过密度校正的 尺寸。
首选的经过密度校正的 尺寸会在准备图像以供呈现算法中, 根据图像中的元信息设置。
如果 dimensions 不为 null,则将 dimensions 的宽度设置为其宽度除以 density,将 dimensions 的高度设置为其高度除以 density,然后返回 dimensions。
令 intrinsicWidth、intrinsicHeight 和 intrinsicRatio 分别为 img 的固有宽度、固有高度和固有宽高比(如果有)。
如果 intrinsicWidth 不缺失,则将 intrinsicWidth 设置为 intrinsicWidth 除以 density。
如果 intrinsicHeight 不缺失,则将 intrinsicHeight 设置为 intrinsicHeight 除以 density。
返回使用 intrinsicWidth、intrinsicHeight 和 intrinsicRatio 应用默认尺寸算法的结果, 其中使用 300×150 的默认对象尺寸。
例如,如果当前像素密度为 3.125, 这意味着每 CSS 英寸有 300 个设备像素, 因此如果图像数据为 300x600,则其经过密度校正的自然宽度和 高度分别为 96 CSS 像素和 192 CSS 像素。
图像来源是一个URL, 并且可以选择性地带有像素密度描述符或宽度描述符。
来源尺寸是一个<source-size-value>。
当来源尺寸具有相对于视口的单位时,必须相对于 img 元素的节点文档的
视口解释该单位。其他单位必须与媒体查询中的解释方式相同。
[MQ]
本节算法中的解析错误 表示输入与要求之间存在非致命的不匹配。鼓励用户代理以某种方式公开解析错误。
在确定图像类型以及图像是否有效时,必须忽略图像是否成功获取 (例如响应状态是否为成功状态)。
这允许服务器在错误响应中返回图像,并使其仍然能够显示。
用户代理应应用图像嗅探规则来确定图像类型, 并将图像的关联 Content-Type 标头作为 official type。如果不应用这些规则,则图像类型必须为图像的关联 Content-Type 标头给出的类型。
用户代理不得通过 img 元素支持非图像资源
(例如其文档元素为 HTML 元素的 XML 文件)。
用户代理不得运行嵌入图像资源中的可执行代码(例如脚本)。
用户代理必须只显示多页资源(例如 PDF 文件)的第一页。
用户代理不得允许资源以交互方式运行,但应遵循资源中的任何动画。
本规范未规定必须支持哪些图像类型。
默认情况下,会立即获取图像。用户代理可以向用户提供改为按需获取图像的选项。 (例如,带宽受限的用户可能会使用按需选项。)
立即获取图像时,只要 img
元素被创建或经历了相关突变,用户代理就必须同步更新该元素的图像
数据;如果有相应说明,则设置重新启动动画标志。
按需获取图像时,用户代理每当需要图像数据(即按需)时,都必须更新
img 元素的图像数据,但仅当该
img 元素的当前请求的状态为不可用时才如此。当一个
img 元素经历了
相关变更时,如果用户代理仅
按需获取图像,则该 img 元素的当前请求的状态必须恢复为不可用。
img 元素的相关突变如下:
元素的 crossorigin
属性的状态发生更改。
元素的 referrerpolicy
属性的状态发生更改。
img 或 source 的HTML
元素插入步骤、HTML 元素
移除步骤和HTML
元素移动步骤将该
突变计为一次相关突变。
元素的父节点是 picture 元素,
并且作为前一个兄弟节点的 source 元素的
srcset、sizes、media、type、width 或 height 属性被设置、
更改或移除。
运行元素的收养 步骤。
如果元素允许自动尺寸:元素开始或停止渲染,或者其具体对象尺寸的宽度发生更改。这必须为更新图像数据算法设置 可能省略事件标志。
每个 Document 对象都必须具有一个
可用图像列表。此列表中的每幅图像
由一个元组标识,该元组由一个绝对 URL、一个CORS
设置属性模式,以及当该模式不是无
CORS时的一个源组成。
此外,每幅图像都有一个忽略高层缓存标志。
用户代理可以随时将一个 Document
对象的可用图像列表中的条目复制到另一个对象中
(例如,当创建 Document 时,用户代理
可以向其中添加已在其他 Document 中加载的所有图像),
但这样做时不得更改以这种方式复制的条目的键,并且必须取消设置所复制条目的忽略高层缓存标志。
用户代理还可以随时从此类列表中移除图像(例如,为了节省
内存)。
当忽略
高层缓存标志未设置时,用户代理必须根据资源的高层缓存语义
(例如 HTTP `Cache-Control`
响应标头),酌情移除可用图像列表中的条目。
可用图像列表旨在实现以下功能:当将
src 属性更改为先前已经
加载过的 URL 时进行同步切换;即使图像根据 HTTP 不允许缓存,也能避免在同一文档中
重新下载图像。它不用于在先前图像仍在加载时避免重新下载同一图像。
用户代理还可以将图像数据与可用图像列表分开存储。
例如,如果某个资源具有 HTTP 响应标头
`Cache-Control: must-revalidate`,并且其忽略高层
缓存标志未设置,则用户代理会将其从可用图像
列表中移除,但可以单独保留图像数据,并在服务器以
304 Not Modified 状态响应时使用该数据。
图像数据通常会进行编码以减小文件大小。这意味着,为了让 用户代理将图像呈现在屏幕上,需要对数据进行解码。 解码是将图像的媒体 数据转换为适合呈现在屏幕上的位图形式的过程。请注意,相对于呈现内容所涉及的 其他过程,此过程可能较慢。因此,为了创造最佳用户体验,用户代理可以选择 何时执行解码。
如果图像解码会在完成之前阻止呈现其他内容,则称该解码为同步解码。 通常,这会使图像与任何其他内容同时以原子方式呈现。但是,这种呈现会因 执行解码所需的时间而延迟。
如果图像解码不会阻止呈现其他内容,则称该解码为异步解码。 这样可以更快地呈现非图像内容。但是,在解码完成之前,屏幕上不会显示 图像内容。解码完成后,屏幕会使用该图像进行更新。
在同步和异步解码模式下,最终内容都会在经过相同的时间后呈现在屏幕上。 主要区别在于,用户代理是否会在呈现最终内容之前先呈现非图像内容。
为了帮助用户代理决定执行同步解码还是异步解码,可以在
img 元素上设置
decoding 属性。
decoding 属性的
可能值是以下图像解码
提示关键字:
| 关键字 | 状态 | 描述 |
|---|---|---|
sync
|
同步 | 表示倾向于同步解码此图像, 以便与其他内容一起进行原子呈现。 |
async
|
异步 | 表示倾向于异步解码此图像, 以避免延迟其他内容的呈现。 |
auto
|
自动 | 表示对解码模式没有偏好(默认)。 |
在解码图像时,用户代理应
遵循 decoding
属性状态所表示的偏好。如果所表示的状态为自动,则用户代理可以自由选择任何
解码行为。
还可以使用 decode()
方法控制解码行为。由于
decode() 方法执行的解码独立于负责
将内容呈现在屏幕上的过程,因此不受 decoding
属性影响。
不能从并行运行的步骤中调用此算法。如果 用户代理需要从并行运行的步骤中调用此算法,则需要 排入一个任务来执行。
当用户代理要更新一个 img 元素的图像数据时,
可以选择设置重新开始动画标志,也可以选择设置可能省略
事件标志;它必须运行以下步骤:
如果用户代理不支持图像,或者其图像支持已被禁用,则 为当前 请求和待处理 请求中止图像 请求,将当前 请求的状态设置为 不可用,将待处理请求设置为 null,然后 返回。
令 selected source 为 null,令 selected pixel density 为 undefined。
如果元素不使用
srcset 或
picture,并且指定了值不是空字符串的 src 属性,
则将 selected source 设置为元素的 src 属性值,并将
selected pixel density 设置为
1.0。
将元素的最后 选择的来源设置为 selected source。
如果 selected source 不为 null:
令 urlString 为以元素的节点 文档为基准,对 selected source 执行编码解析并序列化 URL的结果。
如果 urlString 为失败,则中止此内部步骤集。
令 key 为一个元组,该元组由 urlString、img
元素的 crossorigin
属性的模式,以及当该
模式不是无
CORS时,节点
文档的源组成。
如果可用 图像列表包含 key 的条目:
为该条目设置忽略高层缓存标志。
将待处理请求设置为 null。
给定 img
元素,准备当前
请求以供呈现。
中止更新 图像数据算法。
如果在此实例之后启动了针对此 img
元素的另一个
此算法实例(即使该实例已经中止且不再运行),则返回。
只有最后一个实例会生效,以避免在例如依次设置
src、srcset
和 crossorigin
属性时发出多个请求。
令 selected source 和 selected pixel density 分别为选择图像来源所得的 URL 和像素 密度。
如果 selected source 为 null:
令 urlString 为以元素的节点 文档为基准,对 selected source 执行编码解析并序列化 URL的结果。
如果 urlString 为失败:
如果当前请求的状态为不可用或损坏,则将 当前请求设置为 image request。否则,将待处理 请求设置为 image request。
令 request 为给定
urlString、"image" 和元素的 crossorigin
内容属性的当前状态时,创建潜在 CORS 请求的结果。
如果元素使用
srcset 或
picture,则将 request 的发起者设置为 "imageset"。
将 request 的来源
策略设置为元素的 referrerpolicy
属性的当前状态。
将 request 的优先级设置为
元素的 fetchpriority
属性的当前状态。
如果 img 的延迟加载
属性处于立即状态,或者对于
img
脚本已禁用,则令
delay load event 为 true;否则为 false。
为 img 元素开始
对延迟加载元素进行交叉观察。
返回。
获取图像:获取 request。 从此算法 返回,并将其余步骤作为获取操作针对响应 response 的 processResponse 的一部分运行。
以这种方式获得的资源(如果有)是 image request 的图像数据。它可以是 CORS 同源或
CORS 跨源;这
会影响图像与其他 API 的交互(例如,
在 canvas 上使用时)。
当 delay load event 为 true 时,获取图像必须延迟加载 事件,即元素的节点文档的加载事件, 直到资源获取完成后由 网络任务 源排入队列的任务(定义如下)运行完毕。
遗憾的是,这可以用于对用户的 本地网络执行初步的端口扫描(尤其是与脚本结合使用时,尽管实施这种攻击实际上 并不需要脚本)。用户代理可以实施比上述策略更严格的跨源访问控制策略,以缓解 这种 攻击,但遗憾的是,此类策略通常与现有 Web 内容 不兼容。
尽快跳转至以下列表中第一个适用的条目:
multipart/x-mixed-replace
在获取图像期间,由网络任务 源排入队列的下一个任务 必须运行以下步骤:
如果 image request 是待处理请求 且至少有一个主体部分已完全解码, 则中止 图像请求,即针对当前请求的图像请求, 并将待处理 请求升级为当前请求。
否则,如果 image request 是待处理请求,并且 用户代理能够确定 image request 的图像以某种 致命方式损坏,以致无法获得图像尺寸,则中止图像 请求,即针对当前请求的图像请求;将 待处理请求升级为 当前请求,并将当前请求的状态设置为损坏。
否则,如果 image request 是当前请求,其状态为不可用,并且 用户代理能够确定 image request 的图像宽度和高度,则将 当前请求的状态设置为部分可用。
否则,如果 image request 是当前请求,其状态为不可用,并且 用户代理能够确定 image request 的图像以某种 致命方式损坏,以致无法获得图像尺寸,则将当前 请求的状态设置为损坏。
在获取图像期间,由网络任务
源排入队列的每个任务
都必须更新图像的呈现;但每当新的主体部分到达时,如果
用户代理能够确定图像的宽度和高度,则必须根据 img 元素,准备 img 元素的
当前请求
用于呈现,并
替换先前的图像。
一旦某个主体部分已完全解码,执行以下步骤:
在获取图像期间,由网络任务 源排入队列的下一个任务 必须运行以下步骤:
如果用户代理能够确定 image request 的图像宽度和 高度,并且 image request 是待处理请求,则将 image request 的状态设置为 部分 可用。
否则,如果用户代理能够确定 image request 的图像
宽度和高度,并且 image request 是当前请求,则根据 img 元素准备 image request
用于
呈现,
并将 image request 的
状态设置为部分
可用。
否则,如果用户代理能够确定 image request 的图像 以某种致命方式损坏,以致无法获得图像尺寸,并且 image request 是待处理请求:
否则,如果用户代理能够确定 image request 的图像 以某种致命方式损坏,以致无法获得图像尺寸,并且 image request 是当前请求:
如果 image request 是当前 请求,则该任务以及 在获取图像期间由 网络任务 源排入队列的每个后续任务都必须适当地更新图像的呈现 (例如,如果图像是渐进式 JPEG,则每个数据包都可以提高图像的 分辨率)。
图像数据不是受支持的文件格式;用户代理必须将 image
request 的状态设置为损坏,中止图像
请求,即针对当前
请求和待处理
请求的图像请求;如果 image request 是待处理请求,则将待处理
请求升级为
当前请求;并且
随后,如果未设置 maybe omit events,或者 previousURL 不等于
urlString,则在DOM
操作任务
源上,根据 img 元素将元素任务排入队列,以在该
img
元素上触发
事件,该事件名为 error。
为一个图像请求或为 null 的 image request 中止图像请求,意味着运行以下步骤:
给定图像元素 img,要为图像请求 req 准备图像以供呈现,其中 req 是一个图像请求:
令 physicalWidth 和 physicalHeight 为根据相关编解码器的定义, 从 req 的图像数据中获得的宽度和高度。
令 dimX 为 exifTagMap 的标签 0xA002
(PixelXDimension)的值。
令 dimY 为 exifTagMap 的标签 0xA003
(PixelYDimension)的值。
令 resX 为 exifTagMap 的标签 0x011A
(XResolution)的值。
令 resY 为 exifTagMap 的标签 0x011B
(YResolution)的值。
令 resUnit 为 exifTagMap 的标签 0x0128
(ResolutionUnit)的值。
如果以下所有条件均为 true:
dimX 是正整数;
dimY 是正整数;
resX 是正浮点数;
resY 是正浮点数;
physicalWidth × 72 / resX 等于 dimX;
physicalHeight × 72 / resY 等于 dimY;
resUnit 为 2(Inch),
则:
如果 req 的图像 数据是 CORS 跨源的,则将 img 的自然尺寸设置为 dimX 和 dimY,并相应缩放 img 的像素数据。
否则,将 req 的首选的 经过密度校正的尺寸设置为一个结构体, 其宽度设置为 dimX,高度设置为 dimY。
适当地更新 req 的 img 元素的
呈现。
EXIF 中的分辨率等同于每英寸的 CSS 点数,因此 72 是根据分辨率计算尺寸时所使用的基数。
目前尚未规定在图像已经呈现之后 EXIF 才到达时应如何处理。请参阅议题 #4929。
给定一个 img 元素
el,要
选择图像来源:
给定一个来源集 sourceSet,要 从来源集中选择图像来源:
当要求在给定字符串 default source、字符串 srcset、字符串 sizes,以及元素或 null img 的情况下 创建来源集时:
当要求为给定的 img 或
link 元素
el 更新来源集时,用户代理必须执行以下操作:
令 elements 为 « el »。
如果 el 是一个 img 元素,且其
父节点是一个
picture
元素,则以 el 父节点的子元素替换
elements 的内容,并保留相对顺序。
如果 el 是一个 img 元素,则令
img 为 el,否则为 null。
对于 elements 中的每个 child:
如果 child 是 el:
令 default source 为空字符串。
令 srcset 为空字符串。
令 sizes 为空字符串。
否则,如果 el 是一个具有 imagesrcset
属性的 link
元素,
则将 srcset 设置为该属性的值。
否则,如果 el 是一个具有 imagesizes
属性的 link
元素,
则将 sizes 设置为该属性的值。
将 el 的来源集设置为在给定 default source、srcset、 sizes 和 img 的情况下创建 来源集的结果。
返回。
如果 el 是一个 link 元素,
则 elements 仅包含 el,因此会立即到达此步骤,而算法的其余部分不会运行。
解析 child 的 srcset 属性,并令 source set 为返回的来源集。
使用 img 解析 child 的 sizes 属性,并令 source set 的来源尺寸为返回的值。
如果 child 具有 width 或 height 属性,
则将 el 的尺寸属性来源设置为
child。否则,将 el 的尺寸属性来源设置为
el。
规范化来源密度 source set。
将 el 的来源集设置为 source set。
返回。
每个 img
元素都会独立考虑其之前的兄弟
source 元素
以及该 img 元素本身,以选择一个图像
来源,并忽略任何其他(无效的)元素,包括同一
picture
元素中的其他 img 元素,或者作为相关
img
元素后续兄弟节点的 source
元素。
当要求从元素中解析 srcset 属性时,按如下方式解析 元素的srcset 属性的值:
令 input 为传递给此算法的值。
令 position 为指向 input 内部的指针, 最初指向字符串的开头。
令 candidates 为一个最初为空的来源集。
分割循环:给定 position,从 input 中收集由ASCII 空白或 U+002C COMMA 字符组成的代码点序列。如果收集到了任何 U+002C COMMA 字符,则这是一个解析错误。
如果 position 已超过 input 的末尾, 则返回 candidates。
令 descriptors 为一个新的空列表。
如果 url 以 U+002C (,) 结尾:
从 url 中移除所有尾随的 U+002C COMMA 字符。 如果这移除了不止一个字符, 则这是一个解析错误。
否则:
描述符分词器:给定 position,在 input 中跳过 ASCII 空白。
令 current descriptor 为空字符串。
令 state 为描述符中。
令 c 为 position 处的字符。 根据 state 的值执行以下操作。 就此步骤而言,"EOF" 是一个特殊字符,表示 position 已超过 input 的末尾。
根据 c 的值执行以下操作:
如果 current descriptor 不为空, 则将 current descriptor 追加到 descriptors, 并令 current descriptor 为空字符串。 将 state 设置为描述符之后。
将 position 前进到 input 中的下一个字符。 如果 current descriptor 不为空, 则将 current descriptor 追加到 descriptors。 跳转到标记为描述符解析器的步骤。
将 c 追加到 current descriptor。 将 state 设置为括号中。
如果 current descriptor 不为空, 则将 current descriptor 追加到 descriptors。 跳转到标记为描述符解析器的步骤。
将 c 追加到 current descriptor。
根据 c 的值执行以下操作:
将 c 追加到 current descriptor。 将 state 设置为描述符中。
将 current descriptor 追加到 descriptors。 跳转到标记为描述符解析器的步骤。
将 c 追加到 current descriptor。
根据 c 的值执行以下操作:
保持在此状态。
跳转到标记为描述符解析器的步骤。
将 state 设置为描述符中。 将 position 设置为 input 中的前一个字符。
将 position 前进到 input 中的下一个字符。重复此 步骤。
为了与未来的扩展兼容, 此算法支持多个描述符和带括号的描述符。
描述符解析器:令 error 为否。
令 width 为缺失。
令 density 为缺失。
令 future-compat-h 为缺失。
对于 descriptors 中的每个描述符, 从以下列表中运行适当的步骤集:
如果用户代理不支持 sizes 属性,
则令 error 为是。
符合要求的用户代理将支持 sizes
属性。
然而,在实践中,用户代理通常以渐进方式实现并发布功能。
如果 width 和 density 并非均为缺失, 则令 error 为是。
对描述符应用解析 非负整数的规则。如果结果为 0,则令 error 为是。 否则,令 width 为结果。
如果 width、density 和 future-compat-h 并非均为缺失, 则令 error 为是。
对描述符应用解析 浮点数值的规则。 如果结果小于 0,则令 error 为是。否则,令 density 为结果。
这是一个解析错误。
如果 future-compat-h 和 density 并非均为缺失, 则令 error 为是。
对描述符应用解析 非负整数的规则。如果结果为 0,则令 error 为是。否则,令 future-compat-h 为结果。
令 error 为是。
如果 future-compat-h 不是缺失,且 width 是缺失, 则令 error 为是。
如果 error 仍为否, 则向 candidates 追加一个新的图像来源, 其 URL 为 url, 如果 width 不是缺失,则关联宽度 width, 如果 density 不是缺失,则关联像素密度 density。 否则,存在一个解析错误。
返回标记为分割循环的步骤。
当要求从元素 element 中解析 sizes 属性时,并给定一个
img 元素或 null
img:
令 unparsed sizes list 为从 element 的sizes 属性的值(如果该属性缺失,则为空字符串)中解析以逗号分隔的 组件值列表的结果。[CSSSYNTAX]
令 size 为 null。
对于 unparsed sizes list 中的每个 unparsed size:
从 unparsed size 的末尾移除所有连续的<whitespace-token>。 如果 unparsed size 现在为空, 则这是一个解析错误; 继续。
如果 unparsed size 中的最后一个组件 值是有效的非负<source-size-value>, 则将 size 设置为其值, 并从 unparsed size 中移除该组件 值。 除数学 函数之外的任何 CSS 函数均无效。 否则,存在一个解析错误; 继续。
如果 size 是 auto,且
img
不为 null,且 img 正在渲染,且 img
允许自动尺寸,则将
size 设置为 img 的具体对象
尺寸的宽度,以CSS 像素为单位。
如果 size 仍然是 auto,
则会忽略它。
从 unparsed size 的末尾移除所有连续的<whitespace-token>。如果 unparsed size 现在为空:
将 unparsed size 中剩余的组件值 解析为<media-condition>。 如果未能正确解析, 或者正确解析但该<media-condition>求值为 false, 则继续。[MQ]
如果 size 不是 auto,
则返回
size。否则,继续。
返回 100vw。
在<source-size-list> 中,将一个裸露的、
属于<length> 的<source-size-value>
(不带相应的<media-condition>)
用作非最后一个条目是无效的。
不过,解析算法允许它出现在<source-size-list> 中的任何位置,
并且如果列表中的前置条目均未被使用,则会立即接受它作为尺寸。
这是为了支持未来的扩展,
并防止简单的作者错误,例如末尾多余的逗号。
允许裸露的 auto 关键字
后面还有其他条目,以便为旧版用户代理提供回退。
一个图像来源的 URL 可以伴随一个像素密度 描述符、一个宽度 描述符,或者完全不带描述符。规范化一个来源 集会为每个图像来源提供一个像素密度 描述符。
当要求对源集 source set 的源 密度进行规范化时,用户代理必须执行 以下操作:
用户代理可以随时运行以下算法,以更新 img
元素的图像,从而响应环境
变化。(用户代理不需要在任何时候运行此算法;例如,
如果用户不再查看该页面,用户代理可能希望等到用户返回页面后再确定要使用哪幅图像,
以防环境在此期间再次发生变化。)
特别鼓励用户代理在用户更改视口尺寸时(例如调整窗口大小或更改页面缩放),以及当
img 元素被插入
文档时运行此算法,以使经过密度校正的自然
宽度和高度与新的视口匹配,并在涉及艺术指导时选择正确的图像。
⌛ 如果 img
元素
不使用
srcset 或
picture,其节点文档
不是完全活动的,它具有资源类型为
multipart/x-mixed-replace 的图像数据,
或者其待处理
请求不为 null,则返回。
⌛ 令 selected source 和 selected pixel density 分别为选择图像来源所得的 URL 和像素密度。
⌛ 如果 selected source 为 null,则返回。
⌛ 如果 selected source 和 selected pixel density 与元素的最后选择的来源和当前 像素密度相同,则返回。
⌛ 令 urlString 为以元素的节点 文档为基准,对 selected source 执行编码解析并序列化 URL的结果。
⌛ 如果 urlString 为失败,则返回。
⌛ 令 corsAttributeState 为元素的 crossorigin
内容属性的状态。
⌛ 令 key 为一个元组,该元组由 urlString、 corsAttributeState,以及当 corsAttributeState 不是无 CORS时的 origin 组成。
⌛ 将元素的待处理 请求设置为 image request。
如果可用 图像列表包含 key 的条目, 则将 image request 的图像数据设置为该条目的图像数据。 继续执行下一步骤。
否则:
令 request 为在给定
urlString、"image" 和
corsAttributeState 时创建潜在 CORS
请求的结果。
将 request 的客户端设置为
client,将 request 的发起者设置为 "imageset",并设置
request 的同步
标志。
将 request 的
来源策略设置为
元素的 referrerpolicy
属性的当前状态。
将 request 的优先级设置为元素的 fetchpriority
属性的当前状态。
令 response 为获取 request 的结果。
如果 response 的不安全响应是一个网络
错误,或者图像格式不受支持(通过应用前文所述的图像嗅探规则来确定),
或者用户代理能够确定 image request 的图像以某种致命方式损坏,
导致无法获得图像尺寸,或者资源类型为
multipart/x-mixed-replace,
则将待处理
请求设置为 null,并中止这些步骤。
否则,response 的不安全响应是
image request 的图像
数据。它可以是
CORS 同源或
CORS 跨源;
这会影响图像与其他 API 的交互(例如,在 canvas
上使用时)。
除非另有规定,否则必须指定 alt 属性,
且其值不得为空;该值必须是图像的适当替代内容。alt
属性的具体要求取决于
图像所要表示的内容,如以下各节所述。
编写替代文本时需要考虑的最通用规则如下:其意图是,将每幅图像替换为其
alt
属性的文本后,不会改变页面的含义。
因此,一般而言,可以通过考虑在无法包含图像时原本会写些什么来编写替代文本。
由此可以推论,alt
属性的值绝不应包含可被视为图像说明文字、标题或
图例的文本。它应包含供用户代替图像使用的替代文本;
它并非用于补充图像。title 属性可用于补充信息。
另一个推论是,alt
属性的值不应重复图像旁边的正文中已经提供的信息。
理解替代文本的一种方式是,设想如何通过电话向某人朗读包含该图像的页面, 同时不提及页面中存在图像。你用来代替图像所说的内容,通常是编写替代文本的良好起点。
当创建超链接的
a 元素,或者
button
元素没有文本内容但包含一幅或多幅图像时,alt
属性必须包含合在一起能够传达链接或按钮用途的文本。
在此示例中,要求用户从三种颜色的列表中选择其偏好的颜色。每种颜色都由一幅图像表示, 但对于已将用户代理配置为不显示图像的用户,则改用颜色名称:
< h1 > Pick your color</ h1 >
< ul >
< li >< a href = "green.html" > < img src = "green.jpeg" alt = "Green" > </ a ></ li >
< li >< a href = "blue.html" > < img src = "blue.jpeg" alt = "Blue" > </ a ></ li >
< li >< a href = "red.html" > < img src = "red.jpeg" alt = "Red" > </ a ></ li >
</ ul > 在此示例中,每个按钮都有一组图像,用来表示用户希望获得的颜色输出类型。 每种情况下都会使用第一幅图像提供替代文本。
< button name = "rgb" > < img src = "red" alt = "RGB" >< img src = "green" alt = "" >< img src = "blue" alt = "" > </ button >
< button name = "cmyk" > < img src = "cyan" alt = "CMYK" >< img src = "magenta" alt = "" >< img src = "yellow" alt = "" >< img src = "black" alt = "" > </ button > 由于每幅图像都表示文本的一部分,也可以这样编写:
< button name = "rgb" > < img src = "red" alt = "R" >< img src = "green" alt = "G" >< img src = "blue" alt = "B" > </ button >
< button name = "cmyk" > < img src = "cyan" alt = "C" >< img src = "magenta" alt = "M" >< img src = "yellow" alt = "Y" >< img src = "black" alt = "K" > </ button > 不过,对于其他替代文本,这种方式可能不可行,而在每种情况下将所有替代文本放入一幅图像中 可能更合理:
< button name = "rgb" > < img src = "red" alt = "sRGB profile" >< img src = "green" alt = "" >< img src = "blue" alt = "" > </ button >
< button name = "cmyk" > < img src = "cyan" alt = "CMYK profile" >< img src = "magenta" alt = "" >< img src = "yellow" alt = "" >< img src = "black" alt = "" > </ button > 有时,某些内容以图形形式表达会更加清晰,例如流程图、示意图、曲线图或显示路线的简单地图。
在这种情况下,可以使用 img
元素提供图像,但仍然必须提供较为简略的文本版本,以便无法查看图像的用户
(例如连接速度非常慢、使用纯文本浏览器、通过免提车载语音 Web 浏览器收听页面,
或仅仅因为失明)仍然能够理解所传达的信息。
该文本必须在 alt
属性中给出,并且必须传达与 src
属性中指定的图像相同的信息。
必须认识到,替代文本是图像的替代内容,而不是对图像的描述。
在以下示例中,有一幅以图像形式呈现的流程图,
alt
属性中的文本将该流程图改写为正文形式:
< p > In the common case, the data handled by the tokenization stage
comes from the network, but it can also come from script.</ p >
< p > < img src = "images/parsing-model-overview.svg" alt = "The Network
passes data to the Input Stream Preprocessor, which passes it to the
Tokenizer, which passes it to the Tree Construction stage. From there,
data goes to both the DOM and to Script Execution. Script Execution is
linked to the DOM, and, using document.write(), passes data to the
Tokenizer." > </ p > 下面是另一个示例,展示了在描述中包含图像这一问题的正确解决方案和错误解决方案。
首先是正确的解决方案。此示例展示了替代文本应当只是当图像从未存在时, 原本会放入正文中的内容。
<!-- This is the correct way to do things. -->
< p >
You are standing in an open field west of a house.
< img src = "house.jpeg" alt = "The house is white, with a boarded front door." >
There is a small mailbox here.
</ p > 其次是错误的解决方案。在这种错误做法中,替代文本只是对图像的描述, 而不是图像的文本替代内容。这种做法不好,因为当图像未显示时, 文本的衔接不如第一个示例自然。
<!-- This is the wrong way to do things. -->
< p >
You are standing in an open field west of a house.
< img src = "house.jpeg" alt = "A white house, with a boarded front door." >
There is a small mailbox here.
</ p > 诸如 "Photo of white house with boarded door" 这样的文本同样是糟糕的替代文本
(不过它可能适合用于 title
属性,或者用于包含此图像的 figure
中的
figcaption
元素)。
文档可以包含图标形式的信息。图标旨在帮助视觉浏览器的用户一眼识别功能。
在某些情况下,图标是对表达相同含义的文本标签的补充。在这些情况下,
alt
属性必须存在,但必须为空。
这里的图标位于表达相同含义的文本旁边,因此其 alt
属性为空:
< nav >
< p >< a href = "/help/" > < img src = "/icons/help.png" alt = "" > Help</ a ></ p >
< p >< a href = "/configure/" > < img src = "/icons/configuration.png" alt = "" >
Configuration Tools</ a ></ p >
</ nav > 在其他情况下,图标旁边没有说明其含义的文本;图标本应不言自明。
在这些情况下,必须在 alt
属性中提供等效的文本标签。
这里,新闻网站上的帖子使用图标标明其主题。
< body >
< article >
< header >
< h1 > Ratatouille wins < i > Best Movie of the Year</ i > award</ h1 >
< p > < img src = "movies.png" alt = "Movies" > </ p >
</ header >
< p > Pixar has won yet another < i > Best Movie of the Year</ i > award,
making this its 8th win in the last 12 years.</ p >
</ article >
< article >
< header >
< h1 > Latest TWiT episode is online</ h1 >
< p > < img src = "podcasts.png" alt = "Podcasts" > </ p >
</ header >
< p > The latest TWiT episode has been posted, in which we hear
several tech news stories as well as learning much more about the
iPhone. This week, the panelists compare how reflective their
iPhones' Apple logos are.</ p >
</ article >
</ body > 许多页面包含徽标、徽章、旗帜或标志,用来代表特定实体,例如公司、组织、项目、 乐队、软件包、国家或类似事物。
如果徽标用于代表该实体,例如作为页面标题,则 alt
属性必须包含徽标所代表实体的名称。alt
属性不得包含诸如 "logo" 一词之类的文本,因为要传达的不是它是徽标这一事实,
而是实体本身。
如果徽标位于其所代表实体的名称旁边,则该徽标属于补充内容,其 alt
属性必须改为空。
如果徽标仅用作装饰材料(例如品牌标识,或在提及该徽标所属实体的文章中作为侧边图像), 则适用下文关于纯装饰性图像的条目。如果实际讨论的是该徽标,则它被用作具有替代图形表示 (徽标本身)的短语或段落(对徽标的描述),因此适用上面的第一个条目。
在以下片段中,上述四种情况全部出现。首先,可以看到一个用于代表公司的徽标:
< h1 > < img src = "XYZ.gif" alt = "The XYZ company" > </ h1 > 接下来,可以看到一个在公司名称旁边使用徽标的段落,因此该徽标没有 任何替代文本:
< article >
< h2 > News</ h2 >
< p > We have recently been looking at buying the < img src = "alpha.gif"
alt = "" > ΑΒΓ company, a small Greek company
specializing in our type of product.</ p > 在第三个片段中,一个徽标被用于旁注中,作为讨论收购事宜的较大文章的一部分:
< aside >< p >< img src = "alpha-large.gif" alt = "" ></ p ></ aside >
< p > The ΑΒΓ company has had a good quarter, and our
pie chart studies of their accounts suggest a much bigger blue slice
than its green and orange slices, which is always a good sign.</ p >
</ article > 最后,有一篇讨论某个徽标的评论文章,因此在替代文本中详细描述了该徽标。
< p > Consider for a moment their logo:</ p >
< p >< img src = "/images/logo" alt = "It consists of a green circle with a
green question mark centered inside it." ></ p >
< p > How unoriginal can you get? I mean, oooooh, a question mark, how
< em > revolutionary</ em > , how utterly < em > ground-breaking</ em > , I'm
sure everyone will rush to adopt those specifications now! They could
at least have tried for some sort of, I don't know, sequence of
rounded squares with varying shades of green and bold white outlines,
at least that would look good on the cover of a blue book.</ p > 此示例展示了替代文本的编写方式:当图像不是可用的,并且改用文本时,该文本能够无缝融入周围文本, 就像图像从未存在过一样。
有时,图像仅由文本组成,而图像的目的不是突出用于渲染文本的实际排版效果, 而只是传达文本本身。
在这种情况下,alt
属性必须存在,并且必须包含与图像本身所写文本相同的文本。
设想一幅包含文本 "Earth Day" 的图形,其中所有字母都用花朵和植物装饰。 如果该文本仅被用作标题,以使页面对图形用户更具吸引力,那么正确的替代文本就是相同的文本 "Earth Day",无需提及这些装饰:
< h1 > < img src = "earthdayheading.png" alt = "Earth Day" > </ h1 > 彩饰手抄本可能会对其中一些字符使用图形。在这种情况下,替代文本就是该图像所代表的字符。
< p >< img src = "initials/o.svg" alt = "O" > nce upon a time and a long long time ago, late at
night, when it was dark, over the hills, through the woods, across a great ocean, in a land far
away, in a small house, on a hill, under a full moon...当图像用于表示无法以其他方式在 Unicode 中表示的字符时,例如外字、异体字, 或新的字符(如新颖的货币符号),替代文本应采用更常规的方式书写相同内容, 例如使用表音平假名或片假名给出字符的读音。
在这个 1997 年的示例中,一个看起来像卷曲的 E、但中间有两条横线而不是一条横线的新式货币符号 使用图像表示。替代文本给出了该字符的读音。
< p > Only < img src = "euro.png" alt = "euro " > 5.99!如果字符能够达到相同目的,则不应使用图像。只有当文本无法直接使用字符表示时, 例如由于装饰效果或没有适当的字符(如外字),才适合使用图像。
如果作者因为其默认系统字体不支持某个给定字符而想使用图像, 那么 Web 字体是比图像更好的解决方案。
在许多情况下,图像实际上只是补充内容,其存在仅仅加强周围文本的表达。
在这些情况下,alt
属性必须存在,但其值必须为空字符串。
一般而言,如果移除图像不会降低页面的实用性,但包含图像会使视觉浏览器用户 更容易理解概念,则该图像属于此类别。
以图形形式重复前一个段落的流程图:
< p > The Network passes data to the Input Stream Preprocessor, which
passes it to the Tokenizer, which passes it to the Tree Construction
stage. From there, data goes to both the DOM and to Script Execution.
Script Execution is linked to the DOM, and, using document.write(),
passes data to the Tokenizer.</ p >
< p >< img src = "images/parsing-model-overview.svg" alt = "" ></ p > 在这些情况下,仅包含说明文字的替代文本是错误的。如果要包含说明文字,
则可以使用 title
属性,或者使用 figure
和 figcaption
元素。在后一种情况下,图像实际上是具有替代图形表示的短语或段落,
因此需要替代文本。
<!-- Using the title="" attribute -->
< p > The Network passes data to the Input Stream Preprocessor, which
passes it to the Tokenizer, which passes it to the Tree Construction
stage. From there, data goes to both the DOM and to Script Execution.
Script Execution is linked to the DOM, and, using document.write(),
passes data to the Tokenizer.</ p >
< p > < img src = "images/parsing-model-overview.svg" alt = ""
title = "Flowchart representation of the parsing model." > </ p > <!-- Using <figure> and <figcaption> -->
< p > The Network passes data to the Input Stream Preprocessor, which
passes it to the Tokenizer, which passes it to the Tree Construction
stage. From there, data goes to both the DOM and to Script Execution.
Script Execution is linked to the DOM, and, using document.write(),
passes data to the Tokenizer.</ p >
< figure >
< img src = "images/parsing-model-overview.svg" alt = "The Network leads to
the Input Stream Preprocessor, which leads to the Tokenizer, which
leads to the Tree Construction stage. The Tree Construction stage
leads to two items. The first is Script Execution, which leads via
document.write() back to the Tokenizer. The second item from which
Tree Construction leads is the DOM. The DOM is related to the Script
Execution." >
< figcaption > Flowchart representation of the parsing model.</ figcaption >
</ figure > <!-- This is WRONG. Do not do this. Instead, do what the above examples do. -->
< p > The Network passes data to the Input Stream Preprocessor, which
passes it to the Tokenizer, which passes it to the Tree Construction
stage. From there, data goes to both the DOM and to Script Execution.
Script Execution is linked to the DOM, and, using document.write(),
passes data to the Tokenizer.</ p >
< p >< img src = "images/parsing-model-overview.svg"
alt = "Flowchart representation of the parsing model." ></ p >
<!-- Never put the image's caption in the alt="" attribute! --> 以图形形式重复前一个段落的曲线图:
< p > According to a study covering several billion pages,
about 62% of documents on the web in 2007 triggered the Quirks
rendering mode of web browsers, about 30% triggered the Almost
Standards mode, and about 9% triggered the Standards mode.</ p >
< p >< img src = "rendering-mode-pie-chart.png" alt = "" ></ p > 有时,图像对内容并不关键,但既不是纯装饰性的,也不与文本完全重复。
在这些情况下,alt 属性必须存在,其值
应为空字符串,或为图像所传达信息的文本表示。如果图像具有给出其标题的说明文字,
则 alt
属性的值不得为空(因为这会使非视觉读者感到非常困惑)。
设想一篇有关某位政治人物的新闻文章,其中以图像显示了该人物的面孔。 该图像并非纯装饰性的,因为它与报道相关。该图像也不完全与报道重复, 因为它展示了政治人物的外貌。是否需要提供任何替代文本属于作者决定, 取决于该图像是否会影响对正文的理解。
在第一个变体中,图像在没有上下文的情况下显示,并且未提供替代文本:
< p > < img src = "president.jpeg" alt = "" > Ahead of today's referendum,
the President wrote an open letter to all registered voters. In it, she admitted that the country was
divided.</ p > 如果图片只是一张脸,描述它可能没有任何价值。读者不会关心该人物是红发还是金发, 是白皮肤还是黑皮肤,是一只眼睛还是两只眼睛。
不过,如果图片更具动态性,例如展示政治人物生气、格外高兴或悲痛欲绝, 那么一些替代文本有助于确立文章的基调,否则这种基调可能会被忽略:
< p > < img src = "president.jpeg" alt = "The President is sad." >
Ahead of today's referendum, the President wrote an open letter to all
registered voters. In it, she admitted that the country was divided.
</ p > < p > < img src = "president.jpeg" alt = "The President is happy!" >
Ahead of today's referendum, the President wrote an open letter to all
registered voters. In it, she admitted that the country was divided.
</ p > 该人物是 "sad" 还是 "happy" 会影响对段落其余部分的理解:她是在表示 对国家分裂感到不满,还是在表示国家分裂的前景有利于她的政治生涯? 解释会因图像而异。
如果图像有说明文字,那么包含替代文本可以避免非视觉用户困惑于该说明文字所指的对象。
< p > Ahead of today's referendum, the President wrote an open letter to
all registered voters. In it, she admitted that the country was divided.</ p >
< figure >
< img src = "president.jpeg"
alt = "A high forehead, cheerful disposition, and dark hair round out the President's face." >
< figcaption > The President of Ruritania. Photo © 2014 PolitiPhoto. </ figcaption >
</ figure > 如果图像是装饰性的,但并非特别针对某个页面——例如构成全站设计方案一部分的图像—— 则该图像应在网站的 CSS 中指定,而不是在文档的标记中指定。
不过,可以使用 img
元素在页面中包含一幅未被周围文本讨论、但仍具有一定相关性的装饰性图像。
此类图像是装饰性的,但仍构成内容的一部分。在这些情况下,alt
属性必须存在,但其值必须为空字符串。
尽管与内容相关,但图像仍然是纯装饰性的示例包括:在一篇介绍火人节某场活动的博客文章中, 使用一张黑石城景观照片;或者在朗诵某首诗的页面上,使用一幅受该诗启发创作的画作。 以下片段展示了后一种情况的示例(此片段仅包含第一节诗):
< h1 > The Lady of Shalott</ h1 >
< p >< img src = "shalott.jpeg" alt = "" ></ p >
< p > On either side the river lie< br >
Long fields of barley and of rye,< br >
That clothe the wold and meet the sky;< br >
And through the field the road run by< br >
To many-tower'd Camelot;< br >
And up and down the people go,< br >
Gazing where the lilies blow< br >
Round an island there below,< br >
The island of Shalott.</ p > 当一幅图片被切分为多个较小的图像文件,然后将它们一起显示以重新形成完整图片时,
其中一幅图像的 alt
属性必须按照适用于整幅图片的相关规则进行设置,
然后所有剩余图像的 alt
属性都必须设置为空字符串。
在以下示例中,表示 XYZ Corp 公司徽标的图片被分为两部分,第一部分包含字母 "XYZ",第二部分 包含单词 "Corp"。替代文本("XYZ Corp")全部位于第一幅图像中。
< h1 > < img src = "logo1.png" alt = "XYZ Corp" >< img src = "logo2.png" alt = "" > </ h1 > 在以下示例中,评分显示为三颗实心星和两颗空心星。虽然 替代文本可以是 "★★★☆☆",但作者 决定以更有帮助的 "3 out of 5" 形式给出评分。这是 第一幅图像的替代文本,其余图像的替代文本为空。
< p > Rating: < meter max = 5 value = 3 > < img src = "1" alt = "3 out of 5"
>< img src = "1" alt = "" >< img src = "1" alt = "" >< img src = "0" alt = ""
>< img src = "0" alt = "" > </ meter ></ p > 通常,应使用图像 映射,而不是为了链接而切分图像。
但是,如果确实切分了图像,并且切分后图片的任何组成部分是链接的
唯一内容,则每个链接中的一幅图像必须在其 alt
属性中包含表示该链接用途的替代文本。
在以下示例中,一幅图片表示飞天意面神教的徽标,其中 左侧的面条状附肢和右侧的面条状附肢分别位于不同图像中,以便 用户在冒险中选择左侧或右侧。
< h1 > The Church</ h1 >
< p > You come across a flying spaghetti monster. Which side of His
Noodliness do you wish to reach out for?</ p >
< p >< a href = "?go=left" >< img src = "fsm-left.png" alt = "Left side. " ></ a
>< img src = "fsm-middle.png" alt = ""
>< a href = "?go=right" >< img src = "fsm-right.png" alt = "Right side." ></ a ></ p > 在某些情况下,图像是内容的关键部分。例如, 在照片库中的某个页面上可能就是如此。图像就是包含它的 页面存在的全部意义。
如何为作为内容关键部分的图像提供替代文本,取决于该 图像的来源。
当可以提供详细的替代文本时,例如图像是
杂志评测中一系列屏幕截图的一部分、连环漫画的一部分,或者是
关于该照片的博客文章中的照片时,必须在 alt
属性的内容中提供可以替代
该图像的文本。
新操作系统屏幕截图库中的一幅屏幕截图,带有一些替代文本:
< figure >
< img src = "KDE%20Light%20desktop.png"
alt = "The desktop is blue, with icons along the left hand side in
two columns, reading System, Home, K-Mail, etc. A window is
open showing that menus wrap to a second line if they
cannot fit in the window. The window has a list of icons
along the top, with an address bar below it, a list of
icons for tabs along the left edge, a status bar on the
bottom, and two panes in the middle. The desktop has a bar
at the bottom of the screen with a few buttons, a pager, a
list of open applications, and a clock." >
< figcaption > Screenshot of a KDE desktop.</ figcaption >
</ figure > 财务报告中的曲线图:
< img src = "sales.gif"
title = "Sales graph"
alt = "From 1998 to 2005, sales increased by the following percentages
with each year: 624%, 75%, 138%, 40%, 35%, 9%, 21%" > 请注意,"sales graph" 对销售曲线图而言是不充分的替代文本。适合作为 说明文字的文本通常不适合作为替代文本。
在某些情况下,图像的性质可能使得提供全面的替代 文本并不切实际。例如,图像可能模糊不清,可能是复杂的分形, 也可能是详细的地形图。
在这些情况下,alt
属性必须包含一些合适的替代文本,但可以较为简短。
有时根本不存在能够充分表现图像的文本。例如, 很难用有用的方式描述罗夏墨迹测验。不过,即使描述很简短, 也仍然好过什么都没有:
< figure >
< img src = "/commons/a/a7/Rorschach1.jpg" alt = "A shape with left-right
symmetry with indistinct edges, with a small gap in the center, two
larger gaps offset slightly from the center, with two similar gaps
under them. The outline is wider in the top half than the bottom
half, with the sides extending upwards higher than the center, and
the center extending below the sides." >
< figcaption > A black outline of the first of the ten cards
in the Rorschach inkblot test.</ figcaption >
</ figure > 请注意,以下做法是对替代文本非常糟糕的使用方式:
<!-- This example is wrong. Do not copy it. -->
< figure >
< img src = "/commons/a/a7/Rorschach1.jpg" alt = "A black outline
of the first of the ten cards in the Rorschach inkblot test." >
< figcaption > A black outline of the first of the ten cards
in the Rorschach inkblot test.</ figcaption >
</ figure > 像这样在替代文本中包含说明文字并没有用,因为对于无法看到图像的用户, 这实际上会重复说明文字,连续两次戏弄他们,却没有比只阅读或听到一次说明文字 提供更多帮助。
另一个无法完整描述的图像示例是分形,按照定义, 它具有无限的细节。
以下示例展示了为曼德博集合图像的完整视图提供替代文本的一种可能方式。
< img src = "ms1.jpeg" alt = "The Mandelbrot set appears as a cardioid with
its cusp on the real axis in the positive direction, with a smaller
bulb aligned along the same center line, touching it in the negative
direction, and with these two shapes being surrounded by smaller bulbs
of various sizes." > 类似地,例如传记中的人物面部照片,可以被视为 与内容非常相关且十分关键,但很难用文本完全替代:
< section class = "bio" >
< h1 > A Biography of Isaac Asimov</ h1 >
< p > Born < b > Isaak Yudovich Ozimov</ b > in 1920, Isaac was a prolific author.</ p >
< p >< img src = "headpics/asimov.jpeg" alt = "Isaac Asimov had dark hair, a tall forehead, and wore glasses.
Later in life, he wore long white sideburns." ></ p >
< p > Asimov was born in Russia, and moved to the US when he was three years old.</ p >
< p > ...</ p >
</ section > 在这种情况下,没有必要(实际上也不鼓励)在替代文本中提及 图像本身的存在,因为这种文本会与浏览器本身报告图像存在的内容重复。 例如,如果替代文本是 "A photo of Isaac Asimov",则符合要求的用户代理可能会将其 朗读为 "(Image) A photo of Isaac Asimov",而不是更有用的 "(Image) Isaac Asimov had dark hair, a tall forehead, and wore glasses..."。
在某些不幸的情况下,可能完全没有可用的替代文本,原因可能是 图像通过某种自动化方式获得,并且没有任何相关的替代文本 (例如网络摄像头);或者页面由脚本使用用户提供的图像生成, 而用户没有提供合适或可用的替代文本(例如照片分享 网站);或者作者本人不知道图像表示什么(例如盲人 摄影师在博客上分享图像)。
在这种情况下,可以省略 alt
属性,但还必须满足以下条件之一:
img 元素
位于一个
figure
元素中,该元素包含一个 figcaption
元素,且该元素包含
除元素间空白以外的内容;并且在忽略
figcaption
元素及其后代的情况下,figure
元素中没有
除元素间空白和
img 元素以外的
流式内容后代。
title 属性
存在且具有非空值。
目前不鼓励依赖 title 属性,
因为许多用户代理没有按照本规范的要求以无障碍方式公开该属性
(例如,要求使用鼠标等指针设备才能显示工具提示,这会排除
仅使用键盘的用户和仅使用触摸的用户,例如使用现代手机或平板电脑的任何人)。
此类情况必须保持在绝对最低限度。如果作者哪怕只有极小的
可能性能够提供真正的替代文本,那么省略 alt
属性也是不可接受的。
照片分享网站上的照片,如果网站收到的图像除 说明文字以外没有任何元数据,则可以按如下方式标记:
< figure >
< img src = "1100670787_6a7c664aef.jpg" >
< figcaption > Bubbles traveled everywhere with us.</ figcaption >
</ figure > 不过,更好的做法是从用户处获得图像重要部分的详细描述, 并将其包含在页面中。
一个盲人用户的博客,其中显示了该用户拍摄的照片。起初,用户可能 完全不知道自己拍摄的照片显示了什么:
< article >
< h1 > I took a photo</ h1 >
< p > I went out today and took a photo!</ p >
< figure >
< img src = "photo2.jpeg" >
< figcaption > A photograph taken blindly from my front porch.</ figcaption >
</ figure >
</ article > 不过最终,用户可能会从朋友那里获得对图像的描述, 然后便可以包含替代文本:
< article >
< h1 > I took a photo</ h1 >
< p > I went out today and took a photo!</ p >
< figure >
< img src = "photo2.jpeg" alt = "The photograph shows my squirrel
feeder hanging from the edge of my roof. It is half full, but there
are no squirrels around. In the background, out-of-focus trees fill the
shot. The feeder is made of wood with a metal grate, and it contains
peanuts. The edge of the roof is wooden too, and is painted white
with light blue streaks." >
< figcaption > A photograph taken blindly from my front porch.</ figcaption >
</ figure >
</ article > 有时,图像的全部意义就在于没有可用的文本描述,
而用户需要提供该描述。例如,CAPTCHA 图像的目的就是查看
用户能否真正读出图形。下面是标记 CAPTCHA 的一种方式(请注意 title 属性):
< p >< label > What does this image say?
< img src = "captcha.cgi?id=8934" title = "CAPTCHA" >
< input type = text name = captcha ></ label >
(If you cannot see the image, you can use an < a
href = "?audio" > audio</ a > test instead.)</ p > 另一个示例是显示图像并要求提供替代文本的软件, 其目的正是随后编写带有正确替代文本的页面。这样的页面 可以包含一个图像表格,如下所示:
< table >
< thead >
< tr > < th > Image < th > Description
< tbody >
< tr >
< td > < img src = "2421.png" title = "Image 640 by 100, filename 'banner.gif'" >
< td > < input name = "alt2421" >
< tr >
< td > < img src = "2422.png" title = "Image 200 by 480, filename 'ad3.gif'" >
< td > < input name = "alt2422" >
</ table > 请注意,即使在此示例中,title
属性中仍然包含了尽可能多的有用信息。
由于某些用户完全无法使用图像(例如,因为连接速度非常慢,
或使用纯文本浏览器,或通过免提车载语音 Web 浏览器收听
页面内容,或者仅仅因为失明),因此只有在没有替代文本可用且无法
提供任何替代文本时,才允许省略 alt
属性,而不是
提供替代文本,如以上示例所示。作者没有付出努力并不是
省略 alt 属性的可接受理由。
一般而言,作者应避免将 img
元素用于
显示图像以外的目的。
如果 img
元素被用于显示图像以外的目的,例如作为
统计页面浏览次数的服务的一部分,则 alt
属性
必须为空字符串。
在这种情况下,width 和
height 属性
都应设置为零。
本节不适用于可公开访问的文档,也不适用于目标 受众不一定为作者本人所知的文档,例如网站上的文档、 发送到公共邮件列表的电子邮件或软件文档。
当图像包含在面向某个已知能够查看图像的
特定人员的私密通信(例如 HTML 电子邮件)中时,可以省略 alt
属性。不过,即使在这种情况下,也强烈建议作者包含
替代文本(根据所涉及图像的类型,按照上述条目中的说明适当编写),
这样,即使用户使用不支持图像的邮件客户端,或者该文档被转发给
其他可能无法轻松看到图像的用户,电子邮件仍然可用。
标记生成器(例如所见即所得创作工具)应尽可能从用户处获取 替代文本。不过,可以理解的是,在许多情况下,这并不可行。
对于作为链接唯一内容的图像,标记生成器应检查链接 目标,以确定目标的标题或目标的 URL,并将以这种方式 获得的信息用作替代文本。
对于具有说明文字的图像,标记生成器应使用 figure 和
figcaption
元素,或者使用 title
属性来提供图像的说明文字。
作为最后的手段,实现者应将 alt
属性设置为空字符串,并假定该图像是不会添加任何信息、
但仍与周围内容相关的纯装饰性图像;或者完全省略
alt 属性,
并假定该图像是内容的关键部分。
标记生成器可以在无法获得替代文本、
因而省略了 alt 属性的 img
元素上指定 generator-unable-to-provide-required-alt
属性。该属性的值必须为空字符串。包含此类属性的文档不
符合要求,但一致性检查器将静默
忽略此错误。
这样做是为了避免标记生成器受到压力,将
省略 alt 属性的错误替换为更加
严重的提供虚假替代文本的错误,因为最先进的自动化
一致性检查器无法区分虚假替代文本和正确的替代文本。
标记生成器通常应避免使用图像自身的文件名作为替代 文本。同样,标记生成器应避免从任何同样可供呈现用户代理 (例如 Web 浏览器)使用的内容中生成替代文本。
这是因为页面生成后通常不会更新, 而以后读取该页面的浏览器可以由用户更新,因此浏览器 很可能具有比标记生成器生成页面时更为最新且经过精细调整的启发式规则。
除非满足下列条件之一,否则一致性检查器必须将缺少 alt
属性报告为错误:
一致性检查器已被配置为假定该文档是面向已知能够查看图像的 特定人员的电子邮件或文档。
img
元素具有一个值为空字符串的(不符合要求的)generator-unable-to-provide-required-alt
属性。未将缺少
alt
属性报告为错误的一致性检查器,也不得将存在空的 generator-unable-to-provide-required-alt
属性报告为错误。(这种情况并不表示文档符合要求,
只表示生成器无法确定适当的替代文本——验证器在这种情况下
不需要显示错误,因为这样的错误可能会鼓励标记
生成器纯粹为了消除验证器的错误而包含虚假的替代文本。
当然,即使存在 generator-unable-to-provide-required-alt
属性,一致性检查器也可以将缺少 alt 属性报告为
错误;例如,可以提供一个用户选项,以报告所有一致性错误,
甚至包括那些可能是使用标记
生成器时或多或少不可避免的错误。)
iframe 元素
所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
src — 资源的
地址
srcdoc — 要在
iframe 中渲染的文档
name — 内容可导航对象的名称
sandbox — 嵌套内容的安全
规则
allow — 应用于 iframe 内容的权限
策略
allowfullscreen
— 是否允许 iframe 的内容使用
requestFullscreen()
width — 水平尺寸
height — 垂直尺寸
referrerpolicy
— 由元素发起的获取所使用的来源策略
loading — 用于
确定是否推迟加载
[Exposed =Window ]
interface HTMLIFrameElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , ReflectURL ] attribute USVString src ;
[CEReactions ] attribute (TrustedHTML or DOMString ) srcdoc ;
[CEReactions , Reflect ] attribute DOMString name ;
[SameObject , PutForwards =value , Reflect ] readonly attribute DOMTokenList sandbox ;
[CEReactions , Reflect ] attribute DOMString allow ;
[CEReactions , Reflect ] attribute boolean allowFullscreen ;
[CEReactions , Reflect ] attribute DOMString width ;
[CEReactions , Reflect ] attribute DOMString height ;
[CEReactions ] attribute DOMString referrerPolicy ;
[CEReactions ] attribute DOMString loading ;
readonly attribute Document ? contentDocument ;
readonly attribute WindowProxy ? contentWindow ;
Document ? getSVGDocument ();
// also has obsolete members
};src 属性给出元素的内容可导航对象所要包含页面的URL。如果存在,该属性必须是一个可能被空格
包围的有效非空 URL。如果在
iframe 元素上指定了
itemprop
属性,则还必须指定
src 属性。
所有当前引擎均支持。
srcdoc
属性给出元素的内容可导航对象所要包含的页面内容。
该属性的值用于构造一个 iframe srcdoc 文档,它是一个
Document,其
URL 匹配 about:srcdoc。
上述要求同样适用于XML 文档。
这里,一个博客将 srcdoc 属性与
下文所述的 sandbox
属性结合使用,为支持此功能的用户代理的用户提供额外一层保护,
防止博客文章评论中的脚本注入:
< article >
< h1 > I got my own magazine!</ h1 >
< p > After much effort, I've finally found a publisher, and so now I
have my own magazine! Isn't that awesome?! The first issue will come
out in September, and we have articles about getting food, and about
getting in boxes, it's going to be great!</ p >
< footer >
< p > Written by < a href = "/users/cap" > cap</ a > , 1 hour ago.
</ footer >
< article >
< footer > Thirteen minutes ago, < a href = "/users/ch" > ch</ a > wrote: </ footer >
< iframe sandbox srcdoc = "<p>did you get a cover picture yet?" ></ iframe >
</ article >
< article >
< footer > Nine minutes ago, < a href = "/users/cap" > cap</ a > wrote: </ footer >
< iframe sandbox srcdoc = "<p>Yeah, you can see it <a href="/gallery?mode=cover&amp;page=1">in my gallery</a>." ></ iframe >
</ article >
< article >
< footer > Five minutes ago, < a href = "/users/ch" > ch</ a > wrote: </ footer >
< iframe sandbox srcdoc = "<p>hey that's earl's table.
<p>you should get earl&amp;me on the next cover." ></ iframe >
</ article > 请注意,引号必须进行转义(否则 srcdoc 属性会过早
结束),而沙盒化内容中提及的原始
与号(例如 URL 或正文中的与号)必须进行双重转义——第一次是为了
在最初解析 srcdoc 属性时保留与号,
第二次是为了防止在解析沙盒化内容时
错误解释该与号。
此外,请注意,由于在iframe
srcdoc 文档中,DOCTYPE
是可选的,并且 html、
head 和 body 元素具有可选的
开始标签和结束标签,而且 title
元素在iframe
srcdoc
文档中也是可选的,所以即使 srcdoc 属性中的标记
表示整个文档,也可以相对简洁,因为语法中只需逐字出现
body 元素的内容。
其他元素仍然存在,但仅通过隐含方式存在。
在HTML 语法中,作者只需记住
使用 U+0022 QUOTATION MARK 字符 (") 包围属性内容,然后转义所有 U+0026
AMPERSAND (&) 和 U+0022 QUOTATION MARK (") 字符,并指定 sandbox 属性,
即可确保安全地嵌入内容。(并且
请记住先转义与号,再转义引号,以确保引号变为 "
而不是 &quot;。)
在 XML 中,U+003C LESS-THAN SIGN 字符 (<) 也需要转义。为了 防止属性值 规范化,XML 的某些空白字符——具体而言是 U+0009 CHARACTER TABULATION(制表符)、U+000A LINE FEED(LF)和 U+000D CARRIAGE RETURN(CR)——也需要 转义。[XML]
如果同时指定了 src
属性和 srcdoc
属性,则 srcdoc 属性优先。
这允许作者为不支持 srcdoc
属性的旧版用户代理
提供回退 URL。
给定
insertedNode,iframe 的HTML
元素连接后步骤如下:
如果 insertedNode 具有 sandbox
属性,则给定该属性的值和 insertedNode 的
iframe
沙盒标志集,解析沙盒
指令。
为 insertedNode 创建新的 子可导航对象。
为 insertedNode 处理
iframe 属性,并将
initialInsertion 设置为 true。
给定
removedNode,iframe 的HTML 元素移除
步骤是给定
removedNode 销毁子可导航对象。
此过程不会触发任何 unload 事件
(元素的内容
文档被销毁,而不是被卸载)。
虽然根据上述规定,iframe 会在
影子树中进行处理,
但其行为的其他若干方面与影子树之间的关系尚未得到明确定义。有关更多
详细信息,请参阅议题 #763。
只要具有非 null 内容
可导航对象的 iframe
元素的
srcdoc 属性被设置、
更改或移除,用户
代理就必须处理
iframe 属性。
类似地,只要具有非 null 内容
可导航对象、但未指定 srcdoc 属性的
iframe 元素的
src 属性被设置、
更改或移除,用户
代理就必须处理
iframe 属性。
要为元素
element 处理 iframe 属性,
并带有可选的布尔值 initialInsertion(默认为
false):
如果指定了 element 的 srcdoc 属性:
将 element 的当前导航已延迟加载 布尔值设置为 false。
如果给定 element 的将 延迟加载元素步骤返回 true:
将 element 的延迟加载恢复步骤设置为此 算法从标记为导航到 srcdoc 资源的步骤开始的其余部分。
将 element 的当前导航已延迟加载 布尔值设置为 true。
为 element 开始 对延迟加载元素进行交叉观察。
返回。
导航到 srcdoc 资源:给定 element、about:srcdoc、空
字符串和 element 的 srcdoc
属性值,导航
iframe 或
frame。
生成的 Document 必须被视为一个
iframe srcdoc 文档。
否则:
令 url 为给定 element 和
initialInsertion,运行iframe
和 frame 元素的共享属性
处理步骤所得的结果。
如果 url 为 null,则返回。
如果 url 匹配
about:blank,且
initialInsertion 为 true:
给定 element,运行iframe load 事件步骤。
返回。
令 referrerPolicy 为 element 的 referrerpolicy
内容属性的当前状态。
将 element 的当前导航已延迟加载 布尔值设置为 false。
如果给定 element 的将延迟加载元素步骤返回 true:
将 element 的延迟加载恢复步骤设置为此 算法从标记为导航的步骤开始的其余部分。
将 element 的当前导航已延迟加载 布尔值设置为 true。
为 element 开始 对延迟加载元素进行交叉观察。
返回。
导航:给定 element、url 和
referrerPolicy,导航 iframe 或
frame。
给定元素
element 和布尔值 initialInsertion,iframe 和
frame 元素的共享属性处理步骤如下:
令 url 为 URL 记录 about:blank。
如果 element 指定了 src 属性,
且其值不是空字符串:
如果 element 的节点 可导航对象的包含自身的祖先可导航对象中,包含一个 可导航对象,其活动 文档的URL在将排除片段设置为 true 时 等于 url, 则返回 null。
如果 url 匹配
about:blank,且
initialInsertion 为 true,则给定 element 的内容
可导航对象的活动
文档和 url,执行URL 和历史记录更新步骤。
这是必要的,因为 url 可能是类似
about:blank?foo 的内容。如果
url 只是普通的 about:blank,则此操作不会产生任何效果。
返回 url。
给定元素
element、URL url、来源策略
referrerPolicy、可选的字符串或 null srcdocString(默认为
null),以及可选的布尔值 initialInsertion(默认为 false),要
导航 iframe 或 frame:
令 historyHandling 为 "auto"。
如果 element 的内容
可导航对象的活动文档尚未完全加载,则将
historyHandling 设置为 "replace"。
如果 element 是一个 iframe:
将 element 的待处理资源计时开始时间 设置为给定 element 的 节点文档的相关全局对象时的当前高分辨率时间。
将 element 的待处理资源计时 URL设置为 url。
使用 element 的节点文档,将 element 的内容 可导航对象导航到 url,并将 historyHandling 设置为 historyHandling,将referrerPolicy 设置为 referrerPolicy,将documentResource 设置为 srcdocString,并将initialInsertion 设置为 initialInsertion。
每个 Document 都有一个iframe load 正在进行标志和一个抑制
iframe load标志。当创建 Document 时,必须为该
Document 取消设置这些标志。
给定 iframe 元素
element,要运行iframe load 事件步骤:
如果设置了 childDocument 的抑制 iframe load标志,则 返回。
如果 element 的待处理资源计时开始时间 不是 null:
断言:element 的待处理资源计时 URL不是 null。
令 fallbackTimingInfo 为一个新的获取计时信息,其开始时间是 element 的待处理资源计时开始 时间,其响应 结束时间是给定 global 时的 当前高分辨率时间。
给定 fallbackTimingInfo、解析
element 的待处理资源计时 URL所得的结果、
"iframe"、
global、空字符串、一个新的响应主体信息和 0,标记资源计时。
将 element 的待处理资源计时开始 时间 设置为 null。
将 element 的待处理资源计时 URL 设置为 null。
设置 childDocument 的iframe load 正在进行标志。
取消设置 childDocument 的iframe load 正在进行标志。
结合脚本使用时,这可以用于探测 本地网络 HTTP 服务器的 URL 空间。用户代理可以实施比上述策略更严格的跨源 访问控制策略来缓解此攻击,但遗憾的是,此类策略通常与现有 Web 内容不兼容。
如果某种元素类型可能延迟加载事件,则对于该类型的每个元素 element,如果 element 的内容 可导航对象非空,并且以下任一条件为 true,则用户代理必须延迟加载事件,即 element 的节点文档的加载事件:
element 的内容 可导航对象的活动 文档尚未为加载后任务做好准备;
element 的内容
可导航对象的正在
延迟 load 事件为 true;或者
如果在处理 load 事件期间,
element 的内容
可导航对象再次被导航,则会进一步
延迟 load 事件。
每个 iframe 元素
都有一个相关联的当前导航已延迟
加载布尔值,初始为 false。该值在处理
iframe 属性算法中设置和取消设置。
其当前导航已延迟加载布尔值为
false 的 iframe 元素
可能延迟 load
事件。
每个 iframe 元素
都有一个相关联的 null 或
DOMHighResTimeStamp 待处理资源计时开始时间,
初始设置为 null。
每个 iframe 元素
都有一个相关联的 null 或
URL 待处理资源计时 URL,初始设置为
null。
如果在创建元素时未设置 srcdoc 属性,
并且 src 属性
也未设置,或者已设置但其值无法被解析,则元素的内容
可导航对象将停留在初始
about:blank Document。
如果用户从此页面导航离开,
iframe 的内容可导航对象的活动
WindowProxy 对象会为新的
Document 对象代理新的 Window 对象,但 src 属性
不会改变。
如果存在,name
属性必须是一个有效的可导航对象目标名称。如果在元素的内容
可导航对象被创建时该值存在,则给定值
用于命名该内容可导航对象。
所有当前引擎均支持。
指定 sandbox
属性时,会对由
iframe
承载的任何内容启用一组额外限制。其值必须
是一个无序的唯一空格分隔
令牌集,并且这些令牌按 ASCII
不区分大小写。允许的值如下:
allow-downloads
allow-forms
allow-modals
allow-orientation-lock
allow-pointer-lock
allow-popups
allow-popups-to-escape-sandbox
allow-presentation
allow-same-origin
allow-scripts
allow-top-navigation
allow-top-navigation-by-user-activation
allow-top-navigation-to-custom-protocols
设置该属性后,内容将被视为来自唯一的不透明源,表单、脚本和各种可能
令人烦恼的 API 会被禁用,链接也无法以其他可导航对象为目标。allow-same-origin
关键字使内容
被视为来自其真实源,而不是强制将其置于不透明源中;allow-top-navigation
关键字允许内容
导航其可遍历可导航对象;
allow-top-navigation-by-user-activation
关键字的行为类似,但仅当浏览上下文的活动窗口具有瞬态
激活时,才允许此类导航;allow-top-navigation-to-custom-protocols
会重新允许将面向非获取方案的导航移交给外部
软件;而 allow-forms、
allow-modals、
allow-orientation-lock、
allow-pointer-lock、
allow-popups、
allow-presentation、
allow-scripts
和 allow-popups-to-escape-sandbox
关键字分别重新启用表单、模态对话框、屏幕方向锁定、指针锁定 API、弹出窗口、
演示 API、脚本以及创建未沙盒化的辅助浏览上下文。allow-downloads
关键字允许内容
执行下载。[POINTERLOCK] [SCREENORIENTATION] [PRESENTATION]
allow-top-navigation
和 allow-top-navigation-by-user-activation
关键字不得同时指定,因为这样做是多余的;在此类不符合要求的标记中,只有 allow-top-navigation
会产生作用。
类似地,如果指定了 allow-top-navigation
或 allow-popups,
则不得指定 allow-top-navigation-to-custom-protocols
关键字,因为这样做是
多余的。
要在沙盒化内容中允许 alert()、confirm() 和 prompt(),需要同时
指定 allow-modals
和 allow-same-origin
关键字,并且加载的 URL 需要与顶层
源同源。如果没有 allow-same-origin
关键字,内容始终
被视为跨源,而跨源内容无法显示简单
对话框。
当嵌入页面与包含 iframe 的页面同源时,同时设置 allow-scripts
和 allow-same-origin
关键字,会允许嵌入页面直接移除 sandbox
属性,然后重新加载自身,从而实际上完全逃离沙盒。
这些标志仅在 iframe 元素的内容可导航对象被导航时生效。移除这些标志,或者
移除整个 sandbox 属性,对
已加载的页面没有任何影响。
不应从与包含 iframe
元素的文件相同的服务器提供可能具有敌意的文件。如果攻击者能够
诱使用户直接访问敌意内容,而不是在
iframe 中访问,
则对敌意内容进行沙盒化几乎没有帮助。为了限制敌意 HTML 内容
可能造成的损害,应从一个独立的专用域提供该内容。使用不同的域可以确保
文件中的脚本无法攻击网站,即使用户被骗直接访问这些页面,
而没有受到 sandbox
属性的保护。
当具有非 null 内容可导航对象的 iframe
元素的 sandbox
属性被移除时,用户代理必须
清空 iframe
元素的iframe
沙盒标志集。
在此示例中,一些完全未知、可能具有敌意、由用户提供的 HTML 内容 被嵌入页面中。由于它由另一个域提供,因此会受到所有常规 跨站限制。此外,嵌入页面禁用了脚本、插件和 表单,并且无法导航自身以外的任何框架或窗口(或者它自身嵌入的任何框架或 窗口)。
< p > We're not scared of you! Here is your content, unedited:</ p >
< iframe sandbox src = "https://usercontent.example.net/getusercontent.cgi?id=12193" ></ iframe > 使用独立域非常重要,这样即使攻击者诱使 用户直接访问该页面,该页面也不会在网站源的上下文中运行,否则 用户将容易受到页面中任何攻击的影响。
在此示例中,嵌入了来自另一个网站的小工具。该小工具启用了脚本和表单, 并且取消了源沙盒限制,允许小工具与 其来源服务器通信。不过,沙盒仍然有用,因为它禁用了插件和弹出窗口, 从而降低用户接触恶意软件和其他烦扰的风险。
< iframe sandbox = "allow-same-origin allow-forms allow-scripts"
src = "https://maps.example.com/embedded.html" ></ iframe > 假设文件 A 包含以下片段:
< iframe sandbox = "allow-same-origin allow-forms" src = B ></ iframe > 假设文件 B 也包含一个 iframe:
< iframe sandbox = "allow-scripts" src = C ></ iframe > 进一步假设文件 C 包含一个链接:
< a href = D > Link</ a > 对于此示例,假设所有文件都以 text/html 提供。
此情景中的页面 C 设置了所有沙盒标志。脚本被禁用,因为
A 中的 iframe 禁用了
脚本,并且这会覆盖 B 中
iframe 上设置的
allow-scripts
关键字。表单也被禁用,因为内部的 iframe(位于 B 中)
没有设置 allow-forms
关键字。
现在假设 A 中的脚本移除了 A 和 B 中的所有 sandbox 属性。
这不会立即改变任何内容。如果用户单击 C 中的链接,将页面 D 加载到
B 中的 iframe 中,则页面
D 现在的行为就像 B 中的 iframe
设置了
allow-same-origin
和 allow-forms
关键字一样,因为这就是页面 B 加载时,A 中
iframe 的内容可导航对象的状态。
一般而言,不建议动态移除或更改 sandbox 属性,
因为这会使判断允许什么以及不允许什么变得非常
困难。
指定 allow
属性时,该属性确定在初始化 iframe
的内容可导航对象中的
Document 的权限策略时使用的容器
策略。
其值必须是一个序列化的权限
策略。[PERMISSIONSPOLICY]
在此示例中,使用 iframe
嵌入来自在线导航
服务的地图。使用 allow
属性在嵌套上下文中启用
Geolocation API。
< iframe src = "https://maps.example.com/" allow = "geolocation" ></ iframe > allowfullscreen 属性是一个布尔
属性。指定时,它表示 iframe
元素的内容可导航对象中的 Document 对象将使用一个允许从任何源使用
"fullscreen" 功能的权限策略进行初始化。这由
处理权限策略
属性算法强制执行。[PERMISSIONSPOLICY]
这里,使用 iframe
嵌入来自视频网站的播放器。需要使用 allowfullscreen
属性,才能允许
播放器以全屏方式显示视频。
< article >
< header >
< p >< img src = "/usericons/1627591962735" > < b > Fred Flintstone</ b ></ p >
< p >< a href = "/posts/3095182851" rel = bookmark > 12:44</ a > — < a href = "#acl-3095182851" > Private Post</ a ></ p >
</ header >
< p > Check out my new ride!</ p >
< iframe src = "https://video.example.com/embed?id=92469812" allowfullscreen ></ iframe >
</ article > 如果元素的节点
文档尚未被允许使用某项功能,则 allow 和 allowfullscreen
都无法向
iframe 元素的内容可导航对象授予对该功能的访问权限。
要确定 Document 对象
document 是否被允许使用策略控制功能 feature,运行以下
步骤:
如果 document 的浏览 上下文为 null,则返回 false。
如果 document 不是完全活动的, 则返回 false。
如果对 feature、document 和
document 的源运行文档中是否为源启用了
功能所得的结果是 "Enabled",则返回
true。
返回 false。
由于 allow
和 allowfullscreen
属性只影响内容
可导航对象的活动文档的权限策略,因此这些属性仅在
iframe 的内容可导航对象被导航时生效。添加或移除这些属性对
已加载的文档没有任何影响。
对于嵌入内容具有特定尺寸的情况(例如广告单元具有明确定义的尺寸),
iframe 元素
支持尺寸属性。
iframe 元素
永远没有回退内容,因为无论指定的初始
内容是否成功使用,它始终都会创建新的子
可导航对象。
referrerpolicy 属性是一个
来源策略
属性。其目的是设置在处理
iframe
属性时使用的来源
策略,并允许在内部祖先源对象列表
创建步骤中屏蔽某些源。[REFERRERPOLICY]
loading
属性是一个延迟
加载属性。其目的是指示加载位于视口之外的 iframe
元素时所使用的策略。
iframe
元素的后代不表示任何内容。(在不
支持 iframe
元素的旧版用户代理中,其内容会被解析为可作为
回退内容的标记。)
HTML 解析器会将
iframe 元素内部的标记视为
文本。
所有当前引擎均支持。
srcdoc
的获取器步骤如下:
令 attribute 为给定 null、srcdoc 的本地
名称和this,执行按命名空间和本地
名称获取属性所得的结果。
如果 attribute 为 null,则返回空字符串。
返回 attribute 的值。
srcdoc 的设置器步骤
如下:
令 compliantString 为使用 TrustedHTML、
this
的相关全局
对象、给定值、"HTMLIFrameElement srcdoc" 和 "script" 调用获取符合可信类型要求的
字符串算法所得的结果。
sandbox 的 DOMTokenList
的受支持令牌,
是 sandbox 属性中定义并且
用户代理支持的允许值。
HTMLIFrameElement/referrerPolicy
所有当前引擎均支持。
referrerPolicy IDL 属性必须
反映 referrerpolicy
内容
属性,并仅限于
已知值。
HTMLIFrameElement/contentDocument
所有当前引擎均支持。
HTMLIFrameElement/contentWindow
所有当前引擎均支持。
以下是页面使用 iframe 包含来自
广告经纪商的广告的示例:
< iframe src = "https://ads.example.com/?customerid=923513721&format=banner"
width = "468" height = "60" ></ iframe > embed
元素所有当前引擎均支持。
所有当前引擎均支持。
src — 资源的地址
type — 嵌入
资源的类型
width — 水平尺寸
height — 垂直尺寸
[Exposed =Window ]
interface HTMLEmbedElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , ReflectURL ] attribute USVString src ;
[CEReactions , Reflect ] attribute DOMString type ;
[CEReactions , Reflect ] attribute DOMString width ;
[CEReactions , Reflect ] attribute DOMString height ;
Document ? getSVGDocument ();
// also has obsolete members
};embed 元素为
外部应用程序或交互式内容提供集成点。
src 属性
给出被嵌入资源的 URL。如果存在,该属性必须包含
一个可能被空格包围的有效非空
URL。
如果在
embed 元素上指定了
itemprop
属性,则还必须指定
src 属性。
如果存在,type 属性
给出用于选择要实例化的插件的 MIME 类型。该值必须是一个有效 MIME 类型
字符串。如果 type
属性和 src
属性都存在,则 type 属性必须指定
与由 src
属性给出的资源的显式 Content-Type 元数据相同的类型。
当同时满足以下所有条件时,称 embed 元素
可能
处于活动状态:
只要一个原先并非可能
处于活动状态的 embed
元素变为可能
处于活动状态,或者只要一个保持可能处于活动状态的可能处于活动状态的 embed 元素的
src 属性被设置、
更改或移除,或者其 type 属性被设置、更改或
移除,用户代理就必须给定该元素,在
embed 任务源上排入一个元素任务,
以为该元素运行embed
元素设置步骤。
给定 embed 元素
element,embed 元素设置步骤如下:
如果此后已经排入另一个任务,以为 element 运行embed
元素设置步骤,则返回。
如果 element 设置了 src 属性:
令 url 为给定
element 的 src 属性值,并以
element 的节点
文档为基准,执行编码解析
URL所得的结果。
如果 url 为失败,则返回。
令 request 为一个新的请求,其
URL 为 url,客户端为
element 的节点
文档的相关设置对象,目标为
"embed",
凭据模式为 "include",模式为 "navigate",发起者
类型为 "embed",并设置其使用 URL 凭据标志。
获取 request,并将processResponse 设置为给定响应 response 时执行以下步骤:
如果此后已经排入另一个任务,以为
element 运行embed
元素设置步骤,则返回。
令 type 为给定 element 和 response,确定内容类型所得的结果。
根据 type 切换:
否则,为 element 显示无插件。
给定
embed 元素
element 和响应 response,要确定内容的类型,运行以下步骤:
如果 response 的 url 的路径组成部分匹配插件支持的模式, 则返回该插件能够处理的类型。
例如,某个插件可能声明它可以处理路径组成部分以四字符字符串
".swf" 结尾的 URL。
如果 response 具有显式 Content-Type 元数据,且该值是插件支持的类型,则返回该 值。
返回 null。
上述算法有意允许 response 具有非正常状态。这允许服务器即使通过错误 响应也为插件返回数据(例如,HTTP 500 Internal Server Error 代码仍然可以包含插件数据)。
要为 embed 元素
element 显示无插件:
object
元素所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
data — 资源的
地址
type — 嵌入
资源的类型
name — 内容可导航对象的名称
form — 将该元素
与 form 元素关联
width — 水平尺寸
height — 垂直尺寸
[Exposed =Window ]
interface HTMLObjectElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , ReflectURL ] attribute USVString data ;
[CEReactions , Reflect ] attribute DOMString type ;
[CEReactions , Reflect ] attribute DOMString name ;
readonly attribute HTMLFormElement ? form ;
[CEReactions , Reflect ] attribute DOMString width ;
[CEReactions , Reflect ] attribute DOMString height ;
readonly attribute Document ? contentDocument ;
readonly attribute WindowProxy ? contentWindow ;
Document ? getSVGDocument ();
readonly attribute boolean willValidate ;
readonly attribute ValidityState validity ;
readonly attribute DOMString validationMessage ;
boolean checkValidity ();
boolean reportValidity ();
undefined setCustomValidity (DOMString error );
// also has obsolete members
};根据
object 元素实例化的内容类型,该
节点还支持其他
接口。
object 元素可以
表示外部资源;根据
资源的类型,该资源会被视为图像或子
可导航对象。
data 属性
指定资源的 URL。该属性必须存在,并且必须包含一个
可能被空格包围的有效非空
URL。
如果存在,type
属性
指定资源的类型。如果存在,该属性必须是一个有效的
MIME 类型字符串。
如果存在,name
属性必须是一个有效的可导航对象目标名称。如果适用,并且在元素的内容可导航对象被创建时该值存在,则给定值用于命名元素的内容
可导航对象。
只要出现以下任一条件:
object 元素
开始或停止显示其
回退内容,
classid 属性被
设置、更改或
移除,
classid 属性
不存在,并且
其 data 属性被
设置、更改或移除,
classid 属性和
data 属性
都不存在,并且其 type
属性被设置、更改或移除,
……用户代理必须根据 object
元素,在DOM 操作任务
源上将元素
任务排入队列,以运行以下步骤,从而(重新)确定
object
元素表示什么。此任务
被排入队列或正在主动运行时,必须延迟加载
事件,即元素的节点文档的加载事件。
如果用户已表示更希望显示此 object 元素的回退
内容,而不是采用该元素的通常行为,则跳转到下方标记为
回退的步骤。
例如,用户可能会要求显示该元素的回退内容, 因为该内容使用了用户认为更易于访问的格式。
如果该元素具有媒体
元素祖先,或者具有一个未显示其回退内容的祖先
object 元素,
或者该元素不位于一个浏览
上下文非 null 的文档中,或者该元素的节点文档
并非完全
活动,或者该元素仍位于 HTML 解析器或XML 解析器的开放元素栈中,或者该元素并非正在
渲染,则跳转到下方标记为回退的步骤。
如果 data 属性
存在且其值不是
空字符串:
如果 type
属性存在,并且其值
不是用户代理支持的类型,则用户代理可以不获取内容来检查其实际类型,
而直接跳转到下方标记为
回退的步骤。
令 request 为一个新的请求,其
URL 为 url,客户端为
该元素的节点
文档的
相关设置
对象,目标为 "object",
凭据模式为 "include",模式为 "navigate",发起者
类型为 "object",并设置其使用 URL 凭据
标志。
获取 request。
获取资源必须延迟加载事件,即元素的节点 文档的加载事件,直到资源获取完成后由网络任务源 排入队列的任务 (接下来定义)运行完毕。
如果资源尚不可用(例如,因为缓存中没有该资源, 因而加载该资源需要通过网络发出请求),则跳转到 下方标记为回退的步骤。资源可用后 由网络任务 源排入的任务 必须从此步骤重新启动该算法。资源可以 增量加载;只要已获得足以开始处理资源的数据,用户代理就可以选择将资源视为 "可用"。
如果加载失败(例如出现 HTTP 404 错误或 DNS 错误),则在该元素上触发一个名为 error
的事件,然后跳转到下方标记为回退的步骤。
按如下方式确定 resource type:
令 resource type 为未知。
如果用户代理被配置为严格遵守此资源的 Content-Type 标头, 并且该资源具有关联的 Content-Type 元数据, 则令 resource type 为该资源的 Content-Type 元数据中指定的类型, 然后跳转到下方标记为 处理程序的步骤。
这可能引入漏洞:某个网站试图嵌入 使用特定类型的资源,但远程网站覆盖该类型,转而 向用户代理提供会触发具有不同安全特征的另一种内容类型的资源。
从以下列表中运行适当的一组 步骤:
令 binary 为 false。
如果该资源的 Content-Type
元数据中指定的类型为 "text/plain",
并且对该资源应用区分资源是
文本还是二进制内容的规则所得的结果表明该资源并非
text/plain,
则将 binary 设置为 true。
如果该资源的 Content-Type
元数据中指定的类型为 "application/octet-stream",
则将 binary 设置为 true。
如果 binary 为 false,则令 resource type 为该资源的 Content-Type 元数据中指定的类型,然后跳转到下方标记为 处理程序的步骤。
如果
object
元素上存在 type
属性,并且其值不是 application/octet-stream,
则运行以下步骤:
如果该属性的值是以 "image/" 开头的类型,并且
不是 XML MIME 类型,则令
resource type 为该 type
属性中指定的
类型。
跳转到下方标记为处理程序的步骤。
如果
object
元素上存在 type
属性,则令 tentative type 为该 type
属性中指定的类型。
否则,令 tentative type 为计算得出的资源类型。
如果 tentative type 不是
application/octet-stream,
则令 resource type 为
tentative type,并跳转到下方标记为
处理程序的步骤。
如果对指定资源在任何重定向后的 URL应用URL 解析器 算法,产生的URL 记录的路径组成部分匹配插件 支持的模式,则令 resource type 为该插件能够 处理的类型。
例如,某个插件可能声明它可以处理路径组成部分以四字符字符串
".swf" 结尾的资源。
此步骤可能在 resource type 仍为未知的情况下结束, 或者上述某个子步骤可能在 resource type 仍为未知时直接跳转到下一步骤。 在这两种情况下,下一步骤都会触发回退。
处理程序:按照以下第一个匹配的情况处理内容:
image/" 开头如果 object
元素的内容
可导航对象为 null,则为该元素
创建
新的子可导航对象。
如果 response 的URL不
匹配
about:blank,则使用该元素的
节点文档,将该元素的内容可导航对象导航到
response 的URL,并将historyHandling 设置为
"replace"。
image/" 开头,并且未禁用
图像支持应用图像嗅探规则, 以确定图像的类型。
如果无法渲染该图像,例如因为图像格式错误或采用不受支持的 格式,则跳转到下方标记为回退的步骤。
给定的 resource type 不受支持。跳转到下方 标记为回退的步骤。
如果前一步骤结束时 resource type 为未知,则会触发这种情况。
该元素的内容不属于 object 元素
所表示的内容。
如果 object 元素
不表示其内容
可导航对象,
则在资源完全加载后,给定该 object 元素,
在DOM
操作任务源上排入一个元素任务,以在该元素上触发一个名为 load
的事件。
返回。
由于上述算法,object
元素的内容充当回退
内容,仅在无法显示所引用的资源时使用(例如,因为该资源返回了 404
错误)。这允许多个 object 元素相互
嵌套,面向能力不同的多个用户代理,并由用户代理选择其支持的第一个
元素。
form 属性用于
将
object 元素与其
表单所有者显式关联。
HTMLObjectElement/contentDocument
所有当前引擎均支持。
HTMLObjectElement/contentWindow
所有当前引擎均支持。
willValidate、
validity 和 validationMessage
属性,以及 checkValidity()、reportValidity()
和 setCustomValidity()
方法,是
约束验证
API的一部分。form IDL 属性
是该元素表单 API 的一部分。
在此示例中,使用 object
元素将一个 HTML 页面嵌入另一个页面。
< figure >
< object data = "clock.html" ></ object >
< figcaption > My HTML Clock</ figcaption >
</ figure > video 元素所有当前引擎均支持。
所有当前引擎均支持。
controls
属性:交互式内容。src
属性:
零个或多个 track
元素,然后是
透明内容,但不得有媒体元素后代。
src 属性:零个或多个 source 元素,然后是
零个或多个 track
元素,然后是
透明内容,但不得有媒体元素后代。
src — 资源的地址
crossorigin —
元素如何处理跨源请求
poster — 视频播放前
显示的海报帧
preload — 提示
媒体资源可能需要
缓冲多少内容
autoplay — 提示
页面加载时可以自动启动
媒体资源
playsinline —
鼓励用户代理在元素的播放区域内显示视频内容
loop — 是否循环播放媒体资源
muted — 是否默认将
媒体资源静音
controls — 显示
用户代理控件
loading — 用于
确定是否延迟加载
width — 水平尺寸
height — 垂直尺寸
[Exposed =Window ]
interface HTMLVideoElement : HTMLMediaElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect ] attribute unsigned long width ;
[CEReactions , Reflect ] attribute unsigned long height ;
readonly attribute unsigned long videoWidth ;
readonly attribute unsigned long videoHeight ;
[CEReactions , ReflectURL ] attribute USVString poster ;
[CEReactions , Reflect ] attribute boolean playsInline ;
};video 元素用于
播放视频或影片,以及带
字幕的音频文件。
可以在 video 元素内提供内容。用户代理
不应向用户显示此内容;此内容面向不
支持 video 的旧版
Web 浏览器,以便向这些旧版浏览器的用户显示文本,
告知他们如何访问视频内容。
尤其需要注意的是,此内容并非用于解决无障碍问题。为了
使弱视者、盲人、听力障碍者、聋人
以及其他身体或认知障碍者能够访问视频内容,可以使用多种功能。
可以提供字幕,它们既可以嵌入视频流,也可以使用
track 元素作为外部文件提供。
可以在视频流中嵌入手语轨道。音频
描述可以嵌入视频流,也可以使用由 track
元素引用的 WebVTT 文件
以文本形式提供,并由用户代理合成为语音。
WebVTT 还可以用于提供章节标题。对于完全不愿使用媒体
元素的用户,可以直接在 video
元素附近的正文中链接
文本记录或其他文本替代内容。[WEBVTT]
video 元素是一个媒体元素,其媒体数据表面上是
视频数据,并且可能带有关联的音频数据。
video 元素具有一个
不含 slot 元素的内部影子树。
src、crossorigin、
preload、autoplay、
loop、muted 和 controls 属性是所有
媒体元素共有的属性。
poster
属性给出一个图像文件的 URL,当没有可用视频
数据时,用户代理可以显示该图像。如果存在,该属性必须包含一个可能被空格包围的有效非空
URL。
如果要使用指定资源,则在创建元素时,或者当 poster 属性被设置、
更改或移除时,用户代理必须
运行以下步骤来确定元素的海报帧(无论元素的显示海报标志为何值):
如果 poster
属性的值为空字符串,
或者该属性不存在:
将 video
元素的海报延迟加载恢复步骤设置为
null。
不存在海报帧;返回。
如果 url 为失败,则返回。不存在海报 帧。
令 request 为一个新的请求,其URL 为 url,客户端为元素的节点文档的
相关设置
对象,目标为
"image",发起者类型为 "video",
凭据模式为 "include",并设置其
使用 URL 凭据标志。
如果给定 video 后,元素是否将延迟
加载步骤返回
true:
令 posterResumptionSteps 为从标记为获取的步骤开始的此算法其余部分。
将 video
元素的海报延迟加载恢复步骤设置为
posterResumptionSteps。
返回。
由 poster
属性给出的图像,
即海报帧,旨在作为
视频的代表性帧(通常是最早的非空白帧之一),让用户了解视频
的大致内容。
playsinline
属性是一个布尔
属性。如果存在,它会向用户代理提示,默认应将视频
"内联"显示在文档中,限制在元素的播放区域内,而不是
全屏显示或显示在独立的可调整大小窗口中。
缺少 playsinline
属性并不意味着视频默认会全屏显示。事实上,大多数用户
代理都选择默认内联播放所有视频,在此类用户代理中,playsinline 属性
不起作用。
如果 poster 属性
存在,并且 loading
属性处于延迟
状态,则用户代理必须推迟加载海报
图像源数据,直到调用元素的延迟加载恢复步骤。
< video src = "1.mp4" poster = "1.jpg" type = "video/mp4" >
< video src = "2.mp4" type = "video/mp4" loading = "eager" >
< video src = "3.mp4" type = "video/mp4" loading = "lazy" >
< video src = "4.mp4" type = "video/mp4" loading = "lazy" autoplay >
< div id = "very-large" ></ div > <!-- Everything after this div is below the viewport -->
< video src = "5.mp4" type = "video/mp4" >
< video src = "6.mp4" type = "video/mp4" loading = "lazy" >
< video src = "7.mp4" type = "video/mp4" autoplay loading = "lazy" >
< video src = "8.mp4" type = "video/mp4" poster = "8.jpg" loading = "lazy" >
< video src = "9.mp4" type = "video/mp4" preload = "none" poster = "9.jpg" loading = "lazy" >
< video src = "10.mp4" type = "video/mp4" preload = "metadata" loading = "lazy" >
< video src = "11.mp4" type = "video/mp4" poster = "11.jpg" preload = "none" loading = "eager" > 在上述示例中,视频按如下方式加载:
1.mp4视频和海报图像立即加载,并延迟窗口的 load 事件。
2.mp4, 5.mp4视频立即加载,并延迟窗口的 load 事件。
3.mp4由于视频位于视口中,因此在布局已知时加载,但它 不会延迟窗口的 load 事件。
4.mp4由于视频位于视口中,因此在布局已知时加载视频并开始自动播放, 但它不会延迟窗口的 load 事件。
6.mp4只有滚动到视口中时才会加载视频,并且不会延迟窗口的 load 事件。
7.mp4只有滚动到视口中时才会加载视频并开始自动播放, 并且不会延迟窗口的 load 事件。
8.mp4只有滚动到视口中时才会加载视频和海报图像,并且不会 延迟窗口的 load 事件。
9.mp4视频在播放前不会加载。只有滚动到 视口中时才会加载海报图像,并且不会延迟窗口的 load 事件。
10.mp4只有滚动到视口中时才会加载视频的元数据,并且不会延迟 窗口的 load 事件。
11.mp4视频在播放前不会加载。海报图像立即加载,并延迟窗口的 load 事件。
video 元素
表示下列列表中第一个匹配条件给出的内容:
readyState 属性
为 HAVE_NOTHING,或者为
HAVE_METADATA
但尚未获得任何
视频数据,或者元素的 readyState 属性
为任何后续值,但媒体资源
没有视频通道)
video 元素表示其海报帧(如果有),
否则表示没有自然尺寸的透明黑色。
video
元素已暂停,当前播放
位置是视频的第一帧,
并且设置了元素的显示海报标志时video 元素表示其海报帧(如果有),
否则表示视频的第一帧。video
元素已暂停,并且
与当前播放
位置对应的视频帧不可用时(例如,因为视频正在跳转或缓冲)video
元素既非可能正在
播放,也非暂停时(例如正在跳转或停滞时)video 元素表示最后一个已
渲染的视频帧。video
元素已暂停时video 元素表示与
当前播放
位置对应的视频帧。
video
元素具有视频通道,并且可能正在
播放)video 元素表示处于持续
增加的"当前"
位置的视频帧。当
当前播放
位置发生变化,使最后渲染的帧不再是
视频中与当前播放位置对应的帧时,必须渲染新帧。
必须从事件循环上一次到达 步骤 1时选定的视频轨道获取视频帧。
视频流中的哪个帧对应特定的播放位置, 由视频流的格式定义。
video 元素还表示在当前播放
位置处,所有已设置文本轨道提示活动标志,且其
文本轨道处于显示模式的文本轨道提示,以及
媒体资源中的任何音频。
与媒体资源关联的任何音频, 如果播放,必须与当前播放位置同步播放,并采用元素的有效 媒体音量。用户代理必须播放事件循环上一次到达步骤 1 时启用的音频轨道中的音频。
除上述内容外,用户代理还可以通过在视频 或元素播放区域的其他区域上叠加文本或图标,或以其他适当方式, 向用户提供消息(例如 "正在缓冲"、 "未加载视频"、"错误" 或更详细的信息)。
无法渲染视频的用户代理可以改为使该元素表示指向外部视频播放实用程序或视频 数据本身的链接。
当 video 元素的媒体资源具有视频通道时,该
元素提供一个绘制源,其宽度为媒体资源的
自然宽度,
其高度为
媒体资源的自然
高度,其外观为与当前播放位置对应的视频帧(如果可用),否则
(例如视频正在跳转或缓冲时)为其先前的外观(如果有),否则(例如
因为视频仍在加载第一帧)为黑色。
video.videoWidth
所有当前引擎均支持。
video.videoHeight
所有当前引擎均支持。
这些属性返回视频的自然尺寸,如果尺寸 未知,则返回 0。
媒体资源的自然 宽度和自然高度是 在考虑资源的尺寸、宽高比、有效孔径、分辨率等因素后, 按资源所用格式的定义得出的资源尺寸,以CSS 像素表示。如果变形格式未定义如何将宽高 比应用于视频数据的尺寸以获得 "正确" 尺寸,则用户代理必须 通过增大一个尺寸并保持另一个尺寸不变来应用该比例。
videoWidth 的获取器步骤为:
如果 this
的 readyState
属性为
HAVE_NOTHING,
则返回 0。
videoHeight 的获取器步骤为:
如果 this 的 readyState
属性为
HAVE_NOTHING,
则返回 0。
只要视频的自然宽度
或自然
高度发生变化
(例如,包括因为选定的视频
轨道发生变化),并且元素的 readyState
属性不是 HAVE_NOTHING,
用户代理就必须给定该媒体元素,排入一个媒体元素
任务,以在该媒体元素上触发一个名为 resize 的事件。
在没有相反样式规则的情况下,视频内容应在 元素的播放区域内渲染,使视频内容以能够完全容纳在播放区域内的 最大尺寸居中显示,并保持视频内容的宽高比。 因此,如果播放区域的宽高比与 视频的宽高比不匹配,视频将以信箱模式或邮筒模式显示。元素播放区域内 不包含视频的区域不表示任何内容。
在实现 CSS 的用户代理中,可以通过 使用“渲染”章节中建议的样式规则实现上述要求。
默认对象尺寸为宽 300 CSS 像素 、高 150 CSS 像素。[CSSIMAGES]
用户代理应提供控件,用于启用或禁用闭路字幕、音频 描述轨道以及与视频流关联的其他附加数据的显示,不过这些 功能同样不应干扰页面的正常渲染。
用户代理可以允许用户以更适合用户的方式查看视频内容,
例如全屏显示或在独立的可调整大小窗口中显示。用户代理甚至可以在播放视频时默认触发此类
查看模式,不过在指定 playsinline 属性
时不应这样做。与其他用户
界面功能一样,用于启用此功能的控件不应干扰页面的正常渲染,
除非用户代理正在向用户公开用户
界面。不过,在此类独立查看模式中,即使
缺少 controls 属性,
用户代理也可以显示完整的用户界面。
用户代理可以允许视频播放影响可能干扰 用户体验的系统功能;例如,用户代理可以在视频播放 过程中禁用屏幕保护程序。
此示例展示如何检测视频未能正确播放:
< script >
function failed( e) {
// video playback failed - show a message saying why
switch ( e. target. error. code) {
case e. target. error. MEDIA_ERR_ABORTED:
alert( 'You aborted the video playback.' );
break ;
case e. target. error. MEDIA_ERR_NETWORK:
alert( 'A network error caused the video download to fail part-way.' );
break ;
case e. target. error. MEDIA_ERR_DECODE:
alert( 'The video playback was aborted due to a corruption problem or because the video used features your browser did not support.' );
break ;
case e. target. error. MEDIA_ERR_SRC_NOT_SUPPORTED:
alert( 'The video could not be loaded, either because the server or network failed or because the format is not supported.' );
break ;
default :
alert( 'An unknown error occurred.' );
break ;
}
}
</ script >
< p >< video src = "tgif.vid" autoplay controls onerror = "failed(event)" ></ video ></ p >
< p >< a href = "tgif.vid" > Download the video file</ a > .</ p > audio 元素所有当前引擎均支持。
所有当前引擎均支持。
controls
属性:交互式内容。controls
属性:可感知内容。src
属性:
零个或多个 track
元素,然后是
透明内容,但不得有媒体元素后代。
src 属性:零个或多个 source 元素,然后是
零个或多个 track
元素,然后是
透明内容,但不得有媒体元素后代。
src — 资源的地址
crossorigin —
元素如何处理跨源请求
preload — 提示
媒体资源可能需要
缓冲多少内容
autoplay — 提示
页面加载时可以自动启动
媒体资源
loop — 是否循环播放媒体资源
muted — 是否默认将
媒体资源静音
controls — 显示
用户代理控件
loading — 用于
确定是否延迟加载
[Exposed =Window ,
LegacyFactoryFunction =Audio (optional DOMString src )]
interface HTMLAudioElement : HTMLMediaElement {
[HTMLConstructor ] constructor ();
};可以在 audio 元素内提供内容。用户代理
不应向用户显示此内容;此内容面向不
支持 audio 的旧版
Web 浏览器,以便向这些旧版浏览器的用户显示文本,
告知他们如何访问音频内容。
尤其需要注意的是,此内容并非用于解决无障碍问题。为了
使聋人或其他身体或认知
障碍者能够访问音频内容,可以使用多种功能。如果有字幕或手语视频
可用,可以使用 video 元素代替 audio 元素来
播放音频,从而允许用户启用视觉替代内容。可以使用 track 元素和 WebVTT 文件提供
章节标题,以帮助导航。当然,也可以直接在 audio
元素附近的正文中链接文本记录或其他文本替代内容。[WEBVTT]
audio 元素是一个媒体元素,其媒体数据表面上是
音频数据。
audio 元素具有一个
不含 slot 元素的内部影子树。
src、crossorigin、
preload、autoplay、
loop、muted、controls 和 loading 属性是所有
媒体元素共有的属性。
没有 controls 属性的 audio
元素不会由用户代理显示,从而阻止它们延迟加载。
< audio src = "1.mp3" type = "audio/mpeg" controls >
< audio src = "2.mp3" type = "audio/mpeg" controls loading = "eager" >
< audio src = "3.mp3" type = "audio/mpeg" controls loading = "lazy" >
< audio src = "4.mp3" type = "audio/mpeg" controls loading = "lazy" autoplay >
< div id = "very-large" ></ div > <!-- Everything after this div is below the viewport -->
< audio src = "5.mp3" type = "audio/mpeg" controls >
< audio src = "6.mp3" type = "audio/mpeg" controls loading = "lazy" >
< audio src = "7.mp3" type = "audio/mpeg" controls autoplay loading = "lazy" >
< audio src = "8.mp3" type = "audio/mpeg" controls preload = "metadata" loading = "lazy" > 在上述示例中,音频文件按如下方式加载:
1.mp3, 2.mp3, 5.mp3音频文件立即加载,并延迟窗口的 load 事件。
3.mp3由于音频位于视口中,因此在布局已知时加载,但它 不会延迟窗口的 load 事件。
4.mp3由于音频位于视口中,因此在布局已知时加载音频并开始自动播放, 但它不会延迟窗口的 load 事件。
6.mp3只有滚动到视口中时才会加载音频,并且不会延迟窗口的 load 事件。
7.mp3只有滚动到视口中时才会加载音频并开始自动播放, 并且不会延迟窗口的 load 事件。
8.mp3只有滚动到视口中时才会加载音频的元数据,并且不会延迟 窗口的 load 事件。
audio = new Audio([ url ])
所有当前引擎均支持。
除 DOM 中的工厂方法(例如 createElement())外,
还提供了一个用于创建 HTMLAudioElement
对象的旧式工厂函数:
Audio(src)。调用时,该旧式工厂函数
必须执行以下步骤:
track
元素所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
kind — 文本轨道的类型
src — 资源的地址
srclang —
文本轨道的语言
label — 用户可见标签
default — 如果没有
其他文本轨道更合适,则启用该
轨道
[Exposed =Window ]
interface HTMLTrackElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions ] attribute DOMString kind ;
[CEReactions , ReflectURL ] attribute USVString src ;
[CEReactions , Reflect ] attribute DOMString srclang ;
[CEReactions , Reflect ] attribute DOMString label ;
[CEReactions , Reflect ] attribute boolean default ;
const unsigned short NONE = 0;
const unsigned short LOADING = 1;
const unsigned short LOADED = 2;
const unsigned short ERROR = 3;
readonly attribute unsigned short readyState ;
readonly attribute TextTrack track ;
};track 元素允许
作者为媒体元素指定显式的外部定时文本轨道。它
本身不表示任何内容。
kind 属性
是一个枚举属性,
具有以下关键字和状态:
| 关键字 | 状态 | 简要说明 |
|---|---|---|
subtitles
|
字幕 | 对对话的转录或翻译,适用于声音可用但无法理解的情况 (例如,因为用户不理解媒体资源音频轨道的语言)。 叠加在视频上。 |
captions
|
闭路字幕 | 对对话、音效、相关音乐提示以及其他相关音频 信息的转录或翻译,适用于声音不可用或无法清晰听见的情况(例如因为声音已静音、 被环境噪声淹没,或因为用户失聪)。 叠加在视频上;标记为适合听力障碍者。 |
descriptions
|
描述 | 对媒体资源视频组成部分的文本描述,当视觉 组成部分被遮挡、不可用或无法使用时,用于音频合成(例如用户在驾驶时 不使用屏幕与应用程序交互,或因为用户失明)。 合成为音频。 |
chapters
|
章节元数据 | 供脚本使用的轨道。 用户代理不显示这些轨道。 |
metadata
|
元数据 |
src 属性
给出文本轨道数据的 URL。该值必须是一个可能被空格包围的有效非空
URL。该属性必须存在。
该元素具有关联的轨道 URL(字符串),初始为空字符串。
设置元素的 src
属性时,运行以下步骤:
令 trackURL 为失败。
令 value 为元素的 src 属性
值。
如果 value 不是空字符串,则将 trackURL 设置为 给定 value,并以 元素的节点文档为基准,执行编码解析并序列化 URL所得的结果。
如果 trackURL 不是失败,则将元素的轨道 URL设置为 trackURL; 否则设置为空字符串。
如果元素的轨道 URL标识 WebVTT
资源,并且元素的 kind 属性不处于章节元数据或元数据状态,则
WebVTT 文件必须是
使用提示文本的 WebVTT 文件。[WEBVTT]
srclang
属性给出文本轨道数据的语言。该值必须是有效的 BCP 47 语言
标签。如果元素的 kind
属性处于字幕状态,则该属性必须存在。
[BCP47]
label 属性
给出轨道的用户可读标题。用户代理在其用户界面中列出字幕、闭路字幕和音频描述
轨道时会使用该标题。
如果存在 label
属性,其值
不得为空字符串。此外,同一个媒体元素不能有两个
track
元素子节点满足以下全部条件:其 kind 属性处于相同
状态;其 srclang
属性均缺失,或其值
表示相同的语言;并且其 label 属性
同样均缺失,或均具有相同的值。
default
属性是一个布尔属性,如果指定,
则表示在用户偏好未表明其他轨道更
合适时,应启用该轨道。
每个媒体元素至多只能有一个
track 元素子节点,
其 kind 属性处于
字幕或闭路字幕状态,并且指定了其
default 属性。
每个媒体元素至多只能有一个
track 元素子节点,
其 kind 属性处于
描述状态,
并且指定了其 default
属性。
每个媒体元素至多只能有一个
track 元素子节点,
其 kind 属性处于
章节元数据状态,
并且指定了其 default
属性。
对于 kind 属性处于元数据状态,并且指定了其
default 属性的 track 元素,
其数量没有限制。
track.readyState返回文本轨道 就绪状态,该状态由以下 列表中的数字表示:
track.track此视频具有多种语言的字幕:
< video src = "brave.webm" >
< track kind = subtitles src = brave.en.vtt srclang = en label = "English" >
< track kind = captions src = brave.en.hoh.vtt srclang = en label = "English for the Hard of Hearing" >
< track kind = subtitles src = brave.fr.vtt srclang = fr lang = fr label = "Français" >
< track kind = subtitles src = brave.de.vtt srclang = de lang = de label = "Deutsch" >
</ video > (最后两个元素上的 lang 属性描述
label 属性的语言,而不是
字幕本身的语言。字幕的语言由 srclang
属性给出。)
HTMLMediaElement 对象(在本
规范中为 audio 和 video)简称为媒体
元素。
所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
enum CanPlayTypeResult { "" /* empty string */, " maybe " , " probably " };
typedef (MediaStream or MediaSource or Blob ) MediaProvider ;
[Exposed =Window ]
interface HTMLMediaElement : HTMLElement {
// error state
readonly attribute MediaError ? error ;
// network state
[CEReactions , ReflectURL ] attribute USVString src ;
attribute MediaProvider ? srcObject ;
readonly attribute USVString currentSrc ;
[CEReactions ] attribute DOMString ? crossOrigin ;
const unsigned short NETWORK_EMPTY = 0;
const unsigned short NETWORK_IDLE = 1;
const unsigned short NETWORK_LOADING = 2;
const unsigned short NETWORK_NO_SOURCE = 3;
readonly attribute unsigned short networkState ;
[CEReactions ] attribute DOMString preload ;
readonly attribute TimeRanges buffered ;
undefined load ();
CanPlayTypeResult canPlayType (DOMString type );
// ready state
const unsigned short HAVE_NOTHING = 0;
const unsigned short HAVE_METADATA = 1;
const unsigned short HAVE_CURRENT_DATA = 2;
const unsigned short HAVE_FUTURE_DATA = 3;
const unsigned short HAVE_ENOUGH_DATA = 4;
readonly attribute unsigned short readyState ;
readonly attribute boolean seeking ;
// playback state
attribute double currentTime ;
undefined fastSeek (double time );
readonly attribute unrestricted double duration ;
object getStartDate ();
readonly attribute boolean paused ;
attribute double defaultPlaybackRate ;
attribute double playbackRate ;
attribute boolean preservesPitch ;
readonly attribute TimeRanges played ;
readonly attribute TimeRanges seekable ;
readonly attribute boolean ended ;
[CEReactions , Reflect ] attribute boolean autoplay ;
[CEReactions , Reflect ] attribute boolean loop ;
Promise <undefined > play ();
undefined pause ();
// controls
[CEReactions , Reflect ] attribute boolean controls ;
attribute double volume ;
attribute boolean muted ;
[CEReactions , Reflect="muted"] attribute boolean defaultMuted ;
[CEReactions ] attribute DOMString loading ;
// tracks
[SameObject ] readonly attribute AudioTrackList audioTracks ;
[SameObject ] readonly attribute VideoTrackList videoTracks ;
[SameObject ] readonly attribute TextTrackList textTracks ;
TextTrack addTextTrack (TextTrackKind kind , optional DOMString label = "", optional DOMString language = "");
};媒体元素属性,即 src、crossorigin、preload、autoplay、
loop、muted、controls 和 loading,适用于所有媒体元素。它们在本节中定义。
loading
属性是一个延迟加载
属性。其用途是指示
加载视口外媒体资源的策略。
当 loading
属性的状态变为
立即状态时,用户代理
必须运行以下
步骤:
令 posterResumptionSteps 为 null。
如果媒体元素是 video 元素,则将
posterResumptionSteps 设置为该 video 元素的海报延迟
加载
恢复步骤。
如果 resumptionSteps 为 null 且 posterResumptionSteps 为 null,则 返回。
如果 resumptionSteps 不为 null:
如果 posterResumptionSteps 不为 null:
将 video
元素的海报延迟加载恢复步骤设置为
null。
调用 posterResumptionSteps。
当 loading 属性
处于延迟状态时,它通过推迟数据获取
优先于 preload
属性。
如果 autoplay 属性
存在,并且 loading
属性处于延迟状态,
用户代理还必须推迟开始
播放(以及自动播放可能引入的任何关联网络请求),直到调用元素的
延迟加载恢复
步骤。
媒体元素用于向用户呈现音频数据,或者 视频和 音频数据。在本节中,这称为媒体数据, 因为本节同等适用于音频或视频的媒体 元素。 术语媒体资源用于指代完整的媒体数据集合,例如 完整的视频文件或完整的音频文件。
媒体资源具有关联的
源,其值为
"none"、"multiple"、
"rewritten" 或一个源。其初始值为
"none"。
媒体资源可以具有多个音频和
视频轨道。对于
媒体元素而言,媒体资源的视频数据仅为
事件循环上一次
到达步骤 1时,由元素的 videoTracks 属性给出的
当前选定轨道(如果有)的数据;而媒体资源的音频数据,是
事件循环上一次
到达步骤 1时,由元素的 audioTracks 属性给出的
所有当前启用轨道(如果有)混合所得的结果。
audio 和
video 元素都可以用于
音频
和视频。两者之间的主要区别只是 audio 元素
没有用于视觉内容(例如视频或字幕)的播放区域,而 video
元素有。
每个媒体元素都有一个唯一的媒体元素事件任务源。
要使用一个媒体元素 element 和一系列步骤 steps 排入一个媒体元素任务,则给定 element 和 steps,在该媒体元素的媒体元素事件 任务源上排入一个元素任务。
所有当前引擎均支持。
media.error
所有当前引擎均支持。
返回一个表示元素当前错误状态的 MediaError
对象。
如果没有错误,则返回 null。
所有媒体元素都有一个关联的错误状态,该状态记录自上次调用元素的资源选择算法以来元素遇到的最后一个错误。获取
error
属性时,必须返回为该最后一个错误创建的 MediaError
对象;如果尚未发生错误,则返回 null。
[Exposed =Window ]
interface MediaError {
const unsigned short MEDIA_ERR_ABORTED = 1;
const unsigned short MEDIA_ERR_NETWORK = 2;
const unsigned short MEDIA_ERR_DECODE = 3;
const unsigned short MEDIA_ERR_SRC_NOT_SUPPORTED = 4;
readonly attribute unsigned short code ;
readonly attribute DOMString message ;
};media.error.code
所有当前引擎均支持。
从下方列表中返回当前错误的错误代码。
media.error.message
所有当前引擎均支持。
返回关于所遇到错误条件的特定诊断信息。不同用户代理之间的消息内容和消息格式通常并不统一。如果没有此类 消息可用,则返回空字符串。
每个 MediaError 对象都有一个作为字符串的
消息,以及一个属于下列值之一的 代码:
MEDIA_ERR_ABORTED(数值 1)MEDIA_ERR_NETWORK(数值 2)MEDIA_ERR_DECODE(数值 3)MEDIA_ERR_SRC_NOT_SUPPORTED(数值 4)src
属性或已分配的媒体提供者对象所指示的媒体资源不适用。要在给定一个属于上述值之一的错误代码时创建一个
MediaError,返回一个新的 MediaError 对象,其
代码为给定的错误代码,其
消息为一个字符串,
其中包含用户代理能够提供的有关错误条件原因的任何详细信息;如果用户代理无法提供此类详细信息,则为空字符串。
此消息字符串不得仅包含已通过所提供错误代码获得的信息;例如,它不得只是将代码翻译成字符串格式。
如果除错误代码所提供的信息之外没有其他信息可用,则必须将消息设置为空字符串。
媒体元素上的
src 内容属性给出了
要显示的媒体资源(视频、音频)的 URL。如果存在,该属性必须包含一个可能由空格包围的有效非空
URL。
如果在媒体元素上指定了 itemprop
属性,则也必须指定 src 属性。
媒体元素上的 crossorigin
内容属性是一个CORS 设置属性。
所有当前引擎均支持。
crossOrigin IDL 属性必须反映
crossorigin
内容属性,并仅限于已知值。
媒体提供者对象是一个可以表示媒体资源的对象,
并独立于 URL。MediaStream
对象、MediaSource
对象和 Blob
对象都是媒体提供者对象。
每个媒体元素都有一个 已分配的媒体提供者对象,它是一个 媒体提供者对象或 null, 初始值为 null。
media.srcObject [ = source ]
仅一个引擎支持。
media.currentSrc
所有当前引擎均支持。
currentSrc IDL 属性最初必须设置为空字符串。
其值由下文定义的资源选择算法更改。
srcObject 获取器步骤为返回
this 的已分配的媒体提供者对象。
srcObject
设置器步骤为:
将 this 的已分配的媒体提供者对象设置为给定值。
有三种方式可以指定媒体资源:srcObject IDL
属性、src
内容属性,以及 source 元素。
IDL 属性的优先级最高,其次是内容属性,最后是元素。
可以根据媒体资源的类型来描述它,具体而言是
MIME
类型,在某些情况下还带有一个 codecs 参数。(是否允许
codecs 参数取决于 MIME 类型。)
[RFC6381]
类型通常是不完整的描述;例如,"video/mpeg" 除了说明容器类型之外不包含任何信息,
即使是像 "video/mp4; codecs="avc1.42E01E, mp4a.40.2"" 这样的类型,也不包含实际比特率之类的信息
(只包含最大比特率)。因此,给定一个类型时,用户代理通常只能知道它是否可能能够播放该类型的媒体
(置信程度各不相同),或者它是否确定无法播放该类型的媒体。
用户代理已知无法渲染的类型 是描述用户代理明确不支持的资源的类型,例如,因为用户代理无法识别容器类型,或者不支持所列出的编解码器。
不带参数的 MIME 类型 "application/octet-stream"
绝不会是用户代理已知无法渲染的类型。
当该类型用于标记潜在的媒体资源时,
用户代理必须将其视为等同于缺少任何明确的Content-Type
元数据。
此处只有不带参数的 MIME 类型 "application/octet-stream"
会得到特殊处理;如果它带有任何参数,则会像其他任何
MIME
类型一样处理。这偏离了应忽略未知
MIME
类型参数的规则。
media.canPlayType(type)
所有当前引擎均支持。
根据用户代理对其能否播放给定类型的媒体资源的确信程度,返回空字符串(否定响应)、"maybe" 或 "probably"。
如果 type 是用户代理已知无法渲染的类型,或者是
"application/octet-stream"
类型,则 canPlayType(type) 方法必须返回
空字符串;如果用户代理确信该类型表示一个在与此
audio 或
video 元素一起使用时能够渲染的
媒体资源,则必须返回
"probably";否则必须返回
"maybe"。除非能够确信确定该类型受支持或不受支持,
否则鼓励实现者返回 "maybe"。
通常,对于允许使用 codecs 参数但未提供该参数的类型,用户代理绝不应返回
"probably"。
此脚本测试用户代理是否支持一种(虚构的)新格式,以动态决定是否使用
video 元素:
< section id = "video" >
< p >< a href = "playing-cats.nfv" > Download video</ a ></ p >
</ section >
< script >
const videoSection = document. getElementById( 'video' );
const videoElement = document. createElement( 'video' );
const support = videoElement. canPlayType( 'video/x-new-fictional-format;codecs="kittens,bunnies"' );
if ( support === "probably" ) {
videoElement. setAttribute( "src" , "playing-cats.nfv" );
videoSection. replaceChildren( videoElement);
}
</ script > source 元素的
type 属性允许用户代理避免下载
使用其无法渲染的格式的资源。
media.networkState
所有当前引擎均支持。
从下方列表中的代码返回元素当前的网络活动状态。
当媒体元素与网络交互时,其当前网络活动由
networkState 属性表示。获取该属性时,它必须返回元素当前的
网络状态,该状态必须是以下值之一:
NETWORK_EMPTY(数值 0)NETWORK_IDLE(数值 1)NETWORK_LOADING(数值 2)NETWORK_NO_SOURCE(数值 3)下文定义的资源选择算法
准确描述了 networkState
属性何时更改值,以及会触发哪些事件来指示此状态的变化。
media.load()
所有当前引擎均支持。
使元素重置,并从头开始选择和加载新的媒体资源。
所有媒体元素都有一个 可自动播放标志,其初始状态必须为 true;以及一个 延迟加载事件标志,其初始状态必须为 false。 当延迟加载事件标志为 true 时,元素必须延迟其文档的加载事件。
当调用媒体元素上的
load()
方法时,用户代理必须运行以下步骤:
一个媒体元素有关联的布尔值 当前已停滞,其初始值为 false。
媒体元素加载算法由以下步骤组成:
将此元素的当前已停滞 设置为 false。
中止此元素任何已在运行的资源选择算法实例。
对于 pending tasks 中每个将会兑现待处理播放 promise或拒绝待处理播放 promise的任务, 按相应任务入队的顺序立即兑现或拒绝这些 promise。
从各自的任务队列中移除 pending tasks 中的每个任务。
基本上,当媒体元素开始加载新资源时,待处理事件和回调会被丢弃,而正在等待兑现或拒绝的 promise 会被立即兑现或拒绝。
如果该媒体元素的
networkState
设置为 NETWORK_LOADING
或 NETWORK_IDLE,
则以该媒体元素为参数将媒体元素任务入队,
以在该媒体元素处触发一个名为 abort 的事件。
如果该媒体元素的
networkState
未设置为 NETWORK_EMPTY:
如果该媒体元素正在进行获取过程,用户代理应停止该过程。
如果该媒体元素的已分配的媒体提供者对象是一个
MediaSource
对象,则将其分离。
如果 readyState
未设置为 HAVE_NOTHING,
则将其设置为该状态。
如果 paused
属性为
false:
将 paused
属性设置为 true。
取出待处理播放 promise,
并使用该结果和一个 "AbortError"
DOMException
来拒绝待处理播放 promise。
如果 seeking 为
true,则将其设置为 false。
将当前播放位置设置为 0。
将正式播放位置设置为 0。
如果这更改了正式播放位置,则以该媒体元素为参数将媒体元素任务入队,
以在该媒体元素处触发一个事件,
其名称为 timeupdate。
将时间线偏移设置为非数值 (NaN)。
将 duration
属性更新为非数值 (NaN)。
对于 duration 的这一特定更改,用户代理不会触发
durationchange
事件。
将 playbackRate
属性设置为 defaultPlaybackRate
属性的值。
此元素之前正在播放的任何媒体资源都会停止播放。
媒体元素的 资源选择算法如下。此算法始终作为一个任务的一部分被调用, 但该算法最初的几个步骤之一会返回,并继续并行运行其余步骤。此外,此算法与事件循环机制紧密交互; 特别是,它包含同步段(这些同步段作为事件循环算法的一部分触发)。 此类段中的步骤以 ⌛ 标记。
将元素的 networkState
属性设置为 NETWORK_NO_SOURCE
值。
将元素的显示海报标志 设置为 true。
如果该媒体元素的延迟加载属性处于 立即状态,或者脚本已禁用, 则将该媒体元素的延迟加载事件标志设置为 true (这会延迟加载事件)。
等待稳定状态, 允许调用此算法的任务继续运行。 同步段由此算法剩余的所有步骤组成, 直到算法说明同步段已经结束。 (同步段中的步骤以 ⌛ 标记。)
⌛ 如果该媒体元素的被解析器阻塞标志为 false, 则填充待处理文本轨道列表。
⌛ 令 mode 为 null。
⌛ 令 candidate 为 null。
⌛ 如果该媒体元素的已分配的媒体提供者对象 不为 null,则将 mode 设置为 object。
⌛ 否则,如果该媒体元素具有
source 元素子级,
则将 mode 设置为 children,并将 candidate 设置为树顺序中的第一个
source
元素子级。
⌛ 否则:
⌛ 将 networkState
设置为 NETWORK_EMPTY。
结束同步段并返回。
⌛ 将该媒体元素的
networkState
设置为 NETWORK_LOADING。
运行下列列表中的适当步骤:
⌛ 将 currentSrc
属性设置为空字符串。
使用已分配的媒体提供者对象运行资源获取算法。 如果该算法在未中止此算法的情况下返回,则加载失败。
使用媒体提供者失败:到达此步骤表示媒体资源加载失败。取出待处理播放 promise, 并以该媒体元素为参数将媒体元素任务入队, 以使用该结果运行专用媒体源失败步骤。
等待上一步入队的任务执行完毕。
返回。在再次触发此算法之前,元素不会尝试加载其他资源。
⌛ 令 urlRecord 为以下操作的结果:以
src
属性的值为参数,并以该 src 属性
最后更改时该媒体元素的节点文档
为相对基准,进行编码解析
URL。
⌛ 如果 urlRecord 不是失败,则将 currentSrc
属性设置为对 urlRecord 应用 URL
序列化器的结果。
如果 urlRecord 不是失败,则使用 urlRecord 运行资源获取算法。 如果该算法在未中止此算法的情况下返回,则加载失败。
使用属性失败:到达此步骤表示媒体资源加载失败,或者 urlRecord 为失败。 取出待处理播放 promise, 并以该媒体元素为参数将媒体元素任务入队, 以使用该结果运行专用媒体源失败步骤。
等待上一步入队的任务执行完毕。
返回。在再次触发此算法之前,元素不会尝试加载其他资源。
⌛ 令 pointer 为该媒体元素子级列表中由两个相邻节点定义的位置, 并将列表开头(列表中第一个子级之前,如果有)和列表结尾(列表中最后一个子级之后,如果有) 也视为各自独立的节点。一个节点是 pointer 之前的节点,另一个节点是 pointer 之后的节点。最初,如果 candidate 节点之后存在节点, 则令 pointer 为 candidate 节点与下一个节点之间的位置; 如果它是最后一个节点,则令其为列表末尾。
当节点被插入、移除或移动到该媒体元素中时, 必须按以下方式更新 pointer:
其他更改不会影响 pointer。
⌛ 处理候选项:如果 candidate 没有
src
属性,或者其 src
属性的值为空字符串,则结束同步段,并跳转到下方的
使用元素失败步骤。
⌛ 如果 candidate 具有 media
属性,并且其值与环境不匹配,
则结束同步段,并跳转到下方的
使用元素失败步骤。
⌛ 令 urlRecord 为以下操作的结果:以 candidate 的
src
属性的值为参数,并以该 src 属性
最后更改时 candidate 的节点文档
为相对基准,进行编码解析 URL。
⌛ 如果 urlRecord 为失败,则结束同步段,并跳转到下方的 使用元素失败步骤。
⌛ 如果 candidate 具有 type
属性,并且其值在解析为 MIME
类型时(对于定义了 codecs 参数的类型,包括该参数所描述的所有编解码器),
表示用户代理已知无法渲染的类型,
则结束同步段,并跳转到下方的
使用元素失败步骤。
⌛ 将 currentSrc
属性设置为对 urlRecord 应用URL 序列化器的结果。
使用 urlRecord 运行资源获取算法。 如果该算法在未中止此算法的情况下返回,则加载失败。
使用元素失败:以该媒体元素为参数将媒体元素任务入队,
以在 candidate 处触发一个事件,
其名称为 error。
⌛ 查找下一个候选项:令 candidate 为 null。
⌛ 搜索循环:如果 pointer 之后的节点是列表末尾, 则跳转到下方的等待步骤。
⌛ 如果 pointer 之后的节点是一个 source
元素,则令 candidate 为该元素。
⌛ 推进 pointer,使得 pointer 之前的节点现在是原先位于 pointer 之后的节点,并且如果存在,则 pointer 之后的节点现在是 原先位于 pointer 之后的节点的下一个节点。
⌛ 如果 candidate 为 null,则跳回搜索循环步骤。 否则,跳回处理候选项步骤。
⌛ 等待:将元素的 networkState
属性设置为 NETWORK_NO_SOURCE
值。
⌛ 将元素的显示海报标志设置为 true。
等待,直到 pointer 之后的节点是列表末尾之外的某个节点。 (此步骤可能永远等待。)
⌛ 将 networkState
重新设置为 NETWORK_LOADING。
⌛ 跳回上方的查找下一个候选项步骤。
使用 promise 列表 promises 的 专用媒体源失败步骤如下:
将 error 属性
设置为以下操作的结果:使用 MEDIA_ERR_SRC_NOT_SUPPORTED
创建一个
MediaError。
将元素的 networkState
属性设置为 NETWORK_NO_SOURCE
值。
将元素的显示海报标志 设置为 true。
使用 promises 和一个 "NotSupportedError" DOMException
来拒绝待处理播放 promise。
要在给定一个响应 response、一个媒体资源 resource,
以及 "entire resource" 或一个
(数字、数字或 "until end")元组 byteRange 时
验证媒体响应:
如果 response 是一个网络错误, 则返回 false。
如果 byteRange 为 "entire resource",则返回 true。
令 internalResponse 为 response 的不安全响应。
如果 internalResponse 的状态 为 200,则返回 true。
如果 internalResponse 的状态不是 206,则返回 false。
如果从 internalResponse 中提取 content-range 值的结果为失败,则返回 false。
请注意,提取出的值不会被使用,尤其不会与 byteRange 进行比较。
因此,此步骤用于对 `Content-Range`
标头进行语法验证;但如果响应上的 `Content-Range`
值与请求上的 `Range`
值不匹配,则不会将其视为失败。
如果 internalResponse 的 URL 为
null,则令 origin 为 "rewritten";否则令其为
internalResponse 的 URL 的
源。
令 previousOrigin 为 resource 的源。
如果以下任一项为 true:
previousOrigin 为 "none";
origin 和 previousOrigin 都是 "rewritten";或者
则将 resource 的源设置为 origin。
否则,如果 response 是CORS 跨源的,则返回 false。
否则,将 resource 的源设置为 "multiple"。
这可确保带有范围标头的不透明响应不会因与来自不同源的其他响应拼接在一起而泄露信息。
返回 true。
用于媒体元素以及给定 URL 记录或媒体提供者对象的 资源获取算法如下:
如果以该媒体元素为参数的 将延迟加载元素步骤返回 true:
令 resumptionSteps 为从标有令 mode 为 remote的步骤开始的本算法其余部分。
返回。
令 mode 为 remote。
如果调用该算法时传入的是媒体提供者对象,则将 mode 设置为 local。
否则:
令 isTopLevelSelfFetch 为 false。
如果以下所有条件均为 true:
则将 isTopLevelSelfFetch 设置为 true。
如果 isTopLevelSelfFetch 为 true,则令 stringOrEnvironment 为
"top-level-self-fetch";否则令其为 settingsObject。
令 object 为以下操作的结果:使用该URL 记录的blob URL 条目和 stringOrEnvironment,获取 blob 对象。
如果 object 是一个媒体提供者对象,则将 mode 设置为 local。
如果 mode 为 remote,则令当前媒体资源为传递给此算法的 URL 记录所给出的资源; 否则,令当前媒体资源为媒体提供者对象所给出的资源。 无论哪种情况,当前媒体资源现在都是元素的媒体资源。
从该媒体元素的待处理文本轨道列表中移除所有媒体资源专用文本轨道(如果有)。
运行下列列表中的适当步骤:
可以选择运行以下子步骤。如果用户代理打算在用户明确请求资源之前不尝试获取该资源
(例如,作为实现 preload
属性的 none
关键字的一种方式),则这是预期行为。
将 networkState
设置为 NETWORK_IDLE。
等待该任务运行。
等待一个由实现定义的事件 (例如,用户请求媒体元素开始播放)。
将 networkState
设置为 NETWORK_LOADING。
令 request 为以下操作的结果:以当前媒体资源的URL 记录、
destination 以及该媒体元素的
crossorigin
内容属性的当前状态为参数,创建潜在 CORS 请求。
将 request 的发起者类型设置为 destination。
令 byteRange 为满足媒体数据中缺失数据所需的字节范围,
它是 "entire resource" 或一个
(数字、数字或 "until end")元组。此值是由实现定义的,
并且可能依赖编解码器、网络条件或其他启发式规则。用户代理可以决定完整获取该资源,
在这种情况下 byteRange 为 "entire resource";
可以决定从某个字节偏移处获取到末尾,在这种情况下 byteRange 为
(数字、"until end");或者可以决定获取两个字节偏移之间的范围,
在这种情况下 byteRange 为表示这两个偏移量的(数字、数字)元组。
如果 byteRange 不是 "entire resource":
获取 request,并将 processResponse 设置为以下步骤,给定一个响应 response:
令 updateMedia 为以下操作:以该媒体元素为参数将媒体元素任务入队, 以运行下方媒体数据处理步骤列表中的 第一个适当步骤。(此处使用新任务,以便下文描述的工作相对于适当的媒体元素事件任务源发生, 而不是使用网络任务源。)
令 processEndOfMedia 为以下步骤:如果获取过程已完成且没有错误, 包括媒体数据的解码,并且所有数据无需网络访问即可供用户代理使用, 则用户代理必须继续执行下方的最终步骤。这可能永远不会发生, 例如在流式传输网络广播等无限资源时,或者资源长度超过用户代理缓存数据的能力时。
如果在给定当前媒体资源和 byteRange 时验证 response 的结果为 false,则中止这些步骤。
否则,给定 updateMedia、processEndOfMedia、一个空算法和 global,增量读取 response 的主体。
使用以这种方式获得的 response 的不安全响应内容更新媒体数据。
response 可以是CORS 同源或CORS 跨源的;
这会影响媒体数据中引用的字幕是否在 API 中暴露,
并且对于 video
元素,还会影响在将视频绘制到 canvas
上时该 canvas 是否被污染。
媒体元素停滞超时是一个由实现定义的时长,应约为三秒。 当一个正在主动尝试获取媒体数据的媒体元素在等同于媒体元素停滞超时的时长内未能接收到任何数据时, 用户代理必须以该媒体元素为参数将媒体元素任务入队,以执行:
用户代理可以允许用户选择性地阻止或减慢媒体数据下载。 当媒体元素的下载被完全阻止时, 用户代理必须表现得像下载已停滞,而不是表现得像连接已关闭。用户代理还可以自动限制下载速率, 例如,为了在共享相同带宽的其他连接之间平衡下载。
用户代理可以随时决定不再下载更多内容,例如,在一个一小时的媒体资源已缓冲
五分钟之后,在等待用户决定是否播放该资源时,在交互式资源中等待用户输入时,
或者在用户导航离开页面时。当媒体元素的下载已暂停时,
用户代理必须以该媒体元素为参数将媒体元素任务入队,
以将 networkState
设置为 NETWORK_IDLE,
并在该元素处触发一个事件,
其名称为 suspend。
如果资源的下载恢复,用户代理必须以该媒体元素为参数将媒体元素任务入队,
以将 networkState
设置为 NETWORK_LOADING。
在这些任务入队期间,加载处于暂停状态(因此,如上所述,不会触发 progress
事件)。
preload
属性提供了有关作者认为适宜进行多少缓冲的提示,即使不存在 autoplay
属性也是如此。
当用户代理决定完全暂停下载时,例如,如果它在用户开始播放之前等待而不下载更多内容, 用户代理必须以该媒体元素为参数将媒体元素任务入队, 以将元素的延迟加载事件标志设置为 false。 这会停止延迟加载事件。
虽然上述步骤给出了发出请求的算法,但用户代理可以使用这些确切方式之外的其他方式, 尤其是在遇到错误条件时。例如,用户代理可以重新连接到服务器,或者切换到流式传输协议。 只有在用户代理已经放弃尝试获取资源时,才必须将该资源视为错误资源,并进入上述步骤的错误分支。
为了确定媒体资源的格式,用户代理必须使用专门嗅探音频和视频的规则。
当加载未暂停时(见下文),每 350ms(±200ms)或每接收一个字节,以频率较低者为准, 以该媒体元素为参数将媒体元素任务入队,以执行:
只要用户代理仍可能需要网络访问才能获取媒体资源的某些部分, 用户代理就必须停留在此步骤。
例如,如果用户代理已丢弃视频的前半部分,那么即使播放已经结束,
用户代理仍会停留在此步骤,因为用户始终有可能回退到开头。实际上,在这种情况下,
一旦播放结束,
用户代理最终会触发一个 suspend
事件,如前文所述。
由当前媒体资源描述的资源(如果有)包含媒体数据。它是CORS 同源的。
如果当前媒体资源是原始数据流(例如来自
File
对象),则为了确定媒体资源的格式,
用户代理必须使用专门嗅探音频和视频的规则。
否则,如果数据流已预先解码,则格式为相关规范所给出的格式。
每当当前媒体资源的新数据可用时,以该媒体元素为参数将媒体元素任务入队, 以运行下方媒体数据处理步骤列表中的第一个适当步骤。
当当前媒体资源被永久耗尽时(例如,一个
Blob
的所有字节都已处理),如果没有解码错误,则用户代理必须继续执行下方的最终步骤。
这可能永远不会发生,例如,如果当前媒体资源是一个
MediaStream。
媒体数据处理步骤列表如下:
DNS 错误、HTTP 4xx 和 5xx 错误(以及其他协议中的等效错误),以及用户代理在确定 当前媒体资源是否可用之前发生的其他致命网络错误,还有文件使用不受支持的 容器格式,或者其所有数据都使用不受支持的编解码器,都必须使用户代理执行以下步骤:
用户代理应取消获取过程。
中止此子算法,并返回资源选择算法。
创建一个 AudioTrack 对象
来表示该音频轨道。
使用新的 AudioTrack
对象
更新该媒体元素的
audioTracks
属性的 AudioTrackList
对象。
令 enable 为 unknown。
如果媒体资源或 当前媒体资源的 URL 指示了要启用的特定音频轨道集合,或者用户代理拥有可帮助选择特定音频轨道以改善用户体验的信息: 如果此音频轨道是要启用的轨道之一,则将 enable 设置为 true, 否则将 enable 设置为 false。
这可以由媒体片段语法触发, 也可以由其他情况触发,例如,用户代理选择 5.1 环绕声音频轨道而非立体声音频轨道。
如果 enable 仍为 unknown,那么,如果该媒体元素还没有已启用的音频轨道, 则将 enable 设置为 true;否则,将 enable 设置为 false。
如果 enable 为 true,则启用此音频轨道; 否则,不启用此音频轨道。
在此 AudioTrackList
对象处触发一个事件,
其名称为 addtrack;
使用 TrackEvent,
并将 track
属性初始化为新的 AudioTrack 对象。
创建一个 VideoTrack
对象来表示该视频轨道。
使用新的 VideoTrack
对象
更新该媒体元素的
videoTracks
属性的 VideoTrackList
对象。
令 enable 为 unknown。
如果媒体资源或 当前媒体资源的 URL 指示了要启用的特定视频轨道集合,或者用户代理拥有可帮助选择特定视频轨道以改善用户体验的信息: 如果此视频轨道是这类视频轨道中的第一条,则将 enable 设置为 true; 否则,将 enable 设置为 false。
这同样可以由媒体片段语法触发。
如果 enable 仍为 unknown,那么,如果该媒体元素还没有已选中的视频轨道, 则将 enable 设置为 true;否则,将 enable 设置为 false。
如果 enable 为 true,则选中此轨道,并取消选中任何之前已选中的视频轨道;
否则,不选中此视频轨道。如果取消选中了其他轨道,则会触发一个
change 事件。
在此 VideoTrackList
对象处触发一个事件,
其名称为 addtrack;
使用 TrackEvent,
并将 track
属性初始化为新的 VideoTrack 对象。
这表示该资源可用。用户代理必须遵循以下子步骤:
如果存在,则将时间线偏移更新为与上一步建立的媒体时间线中的零时刻 相对应的日期和时间。如果媒体资源未给出明确的时间和日期, 则必须将时间线偏移设置为非数值 (NaN)。
如果已知,则使用上文建立的媒体时间线中资源最后一帧的时间更新
duration
属性。如果未知(例如,原则上无限的流),则将 duration
属性更新为正无穷大。
此时,用户代理将以该媒体元素为参数将媒体元素任务入队,
以在该元素处触发一个事件,
其名称为 durationchange。
对于 video
元素,设置 videoWidth
和 videoHeight
属性,并以该媒体元素为参数将媒体元素任务入队,
以在该媒体元素处触发一个事件,
其名称为 resize。
如果之后尺寸发生变化,还会触发更多 resize
事件。
将 readyState
属性设置为 HAVE_METADATA。
将 readyState
属性设置为新值时,作为该过程的一部分,将触发一个
loadedmetadata
DOM 事件。
令 jumped 为 false。
令初始播放位置为 0。
如果媒体资源或 当前媒体资源的 URL 指示了特定的开始时间,则将初始播放位置设置为该时间; 如果 jumped 仍为 false,则定位到该时间。
如果不存在已启用的音频轨道,
则启用一个音频轨道。这将导致触发一个 change 事件。
如果不存在已选中的视频轨道,
则选中一个视频轨道。这将导致触发一个 change 事件。
一旦 readyState
属性达到 HAVE_CURRENT_DATA,
就在loadeddata 事件触发之后,
将元素的延迟加载事件标志设置为 false。
这会停止延迟加载事件。
试图在仍获取每个媒体资源的元数据时减少网络使用量的用户代理,
也会在此时停止缓冲,并遵循前述规则;
这些规则涉及将 networkState
属性切换为 NETWORK_IDLE
值,并触发一个 suspend
事件。
用户代理必须确定媒体资源的时长,并在播放之前完成此步骤。
将 networkState
设置为 NETWORK_IDLE,
并在该媒体元素处触发一个事件,
其名称为 suspend。
如果用户代理曾丢弃任何媒体数据,之后又需要恢复网络活动以重新获取这些数据,
则必须以该媒体元素为参数将媒体元素任务入队,
以将 networkState
设置为 NETWORK_LOADING。
如果用户代理可以使媒体资源保持已加载状态, 则算法将继续执行下方的最终步骤,该步骤会中止算法。
在用户代理确定当前媒体资源是否可用之后(即一旦该媒体元素的
readyState
属性不再是 HAVE_NOTHING)
发生的致命网络错误,必须使用户代理执行以下步骤:
用户代理应取消获取过程。
将 error
属性设置为以下操作的结果:使用 MEDIA_ERR_NETWORK
创建一个
MediaError。
将元素的 networkState
属性设置为 NETWORK_IDLE
值。
中止整个资源选择算法。
在用户代理确定当前媒体资源是否可用之后(即一旦该媒体元素的
readyState
属性不再是 HAVE_NOTHING)
发生的媒体数据解码致命错误,
必须使用户代理执行以下步骤:
用户代理应取消获取过程。
将 error
属性设置为以下操作的结果:使用 MEDIA_ERR_DECODE
创建一个
MediaError。
将元素的 networkState
属性设置为 NETWORK_IDLE
值。
中止整个资源选择算法。
如果获取过程被用户中止,例如因为用户按下了“停止”按钮,
用户代理必须执行以下步骤。如果在这些步骤运行期间调用了
load() 方法本身,
则不遵循这些步骤,因为上述步骤会处理这种特定类型的中止。
用户代理应取消获取过程。
将 error
属性设置为以下操作的结果:使用 MEDIA_ERR_ABORTED
创建一个
MediaError。
如果该媒体元素的
readyState
属性的值等于 HAVE_NOTHING,
则将元素的 networkState
属性设置为 NETWORK_EMPTY
值,将元素的显示海报标志设置为
true,
并在该元素处触发一个事件,
其名称为 emptied。
否则,将元素的 networkState
属性设置为 NETWORK_IDLE
值。
中止整个资源选择算法。
服务器返回的数据部分可用但无法以最佳方式渲染时,必须使用户代理仅渲染其能够处理的部分, 并忽略其余部分。
如果媒体数据是CORS 同源的, 则使用相关数据运行暴露媒体资源专用文本轨道的步骤。
跨源视频不会暴露其字幕,因为这样做会允许恶意网站读取用户内联网中机密视频的字幕等攻击。
最终步骤:如果用户代理曾到达此步骤(这只有在整个资源都已加载并保持可用时才可能发生): 中止整个资源选择算法。
当媒体元素要
忘记媒体元素的媒体资源专用轨道时,
用户代理必须从该媒体元素的文本轨道列表中移除所有媒体资源专用文本轨道,
然后清空该媒体元素的
audioTracks
属性的 AudioTrackList 对象,
然后清空该媒体元素的
videoTracks
属性的 VideoTrackList 对象。
作为此过程的一部分不会触发任何事件(尤其不会触发 removetrack
事件);可以改用调用此算法的算法所触发的 error 和
emptied
事件。
preload
属性是一个枚举属性,具有以下关键字和状态:
| 关键字 | 状态 | 简要说明 |
|---|---|---|
auto
|
自动 | 向用户代理提示,用户代理可以在不会给服务器带来风险的情况下优先考虑用户需求, 甚至可以乐观地下载整个资源。 |
none
|
无 | 向用户代理提示,作者预计用户不需要该媒体资源,或者服务器希望尽量减少不必要的流量。 此状态不会提示在缓冲无论如何都已开始时(例如,一旦用户点击“播放”)应以多激进的方式实际下载媒体资源。 |
metadata
|
元数据 | 向用户代理提示,作者预计用户不需要该媒体资源,但获取资源的元数据(尺寸、轨道列表、时长等),
甚至可能获取前几帧,是合理的。如果用户代理精确地只获取元数据,则媒体元素最终会将其
readyState
属性设置为 HAVE_METADATA;
但通常也会获取一些帧,因此它很可能为 HAVE_CURRENT_DATA
或 HAVE_FUTURE_DATA。
当媒体资源正在播放时,向用户代理提示应将带宽视为稀缺资源,例如,建议限制下载速度,
使媒体数据以仍能维持连续播放的最低速率获取。
|
即使媒体资源已经在缓冲或播放, 仍可以更改该属性;应据此理解上表中的说明。
作者可以在用户开始播放后,动态地将属性从 "none"
或 "metadata"
切换为 "auto"。
例如,在包含许多视频的页面上,可以使用这种方式指示除非用户请求,否则不下载这些视频;
但一旦请求其中一个视频,就应积极下载它。
preload
属性旨在向用户代理提供有关作者认为怎样做会带来最佳用户体验的提示。
该属性可以被完全忽略,例如,基于明确的用户偏好或可用的连接条件。
autoplay 属性
可以覆盖 preload 属性
(因为如果媒体要播放,无论 preload 属性
给出了什么提示,它自然都必须先缓冲)。但是,同时包含这两个属性并不是错误。
在 audio 和
video 元素中,
如果脚本已启用,则
loading 属性
可以推迟 preload 属性
所提示的行为,直到运行元素的延迟加载恢复步骤。
media.buffered
所有当前引擎均支持。
返回一个 TimeRanges 对象,
该对象表示用户代理已经缓冲的媒体资源范围。
buffered 获取器步骤为返回一个新的规范化的
TimeRanges 对象,该对象表示用户代理已经缓冲的
this 的媒体资源范围(如果有)。
即使对于只能通过繁琐检查才能确定可用范围的媒体流,用户代理也必须准确确定这些范围。
通常,这将是一个锚定在零点的单一范围;但例如,如果用户代理为了响应定位而使用 HTTP 范围请求,则可能存在多个范围。
用户代理可以丢弃先前已缓冲的数据。
因此,在某一时刻包含于 buffered 属性
所返回对象范围内的时间位置,之后可能不再包含于同一属性所返回对象的范围中。
每次都返回新对象对于属性获取器而言是一种不良模式, 这里只是因为更改这一行为的成本很高而将其保留下来。新的 API 不应复制这种模式。
media.duration
所有当前引擎均支持。
返回媒体资源的时长, 以秒为单位,并假定媒体资源的起点位于时间零点。
如果时长不可用,则返回 NaN。
对于无界流,返回 Infinity。
media.currentTime [ = value ]
所有当前引擎均支持。
返回正式播放位置,以秒为单位。
可以设置该值,以定位到给定时间。
媒体资源具有一个 媒体时间线,它将时间(以秒为单位)映射到媒体资源中的位置。 时间线的原点是其最早定义的位置。时间线的时长是其最后定义的位置。
建立媒体时间线:如果媒体资源以某种方式指定了一条原点不为负数的明确时间线
(即,为每一帧提供特定的时间偏移量,并为第一帧提供零或正偏移量),那么媒体时间线应当就是该时间线。
(媒体资源是否能够指定时间线,
取决于该媒体资源的格式。)
如果媒体资源指定了明确的
开始时间和日期,则该时间和日期应被视为媒体时间线中的零点;时间线偏移将是该时间和日期,
并通过 getStartDate()
方法公开。
如果媒体资源具有 不连续的时间线,用户代理必须将资源开头所使用的时间线扩展到整个资源,从而使媒体资源的媒体时间线从最早可能位置 (定义见下文)开始线性增加,即使底层媒体数据具有顺序错乱甚至相互重叠的时间码。
例如,如果两个剪辑被串接到一个视频文件中,但视频格式公开了这两个剪辑的原始时间, 则视频数据可能公开一条类似 00:15..00:29,随后为 00:05..00:38 的时间线。然而,用户代理不会公开这些时间; 它会将时间公开为 00:15..00:29 和 00:29..01:02,就像单个视频一样。
![]() 在媒体资源没有明确时间线的
罕见情况下,媒体时间线上的
零时间应对应于媒体资源的第一帧。在更罕见的情况下,如果媒体资源完全没有任何明确的
时间信息,甚至没有帧时长,则用户代理必须以由实现定义的方式自行确定每一帧的时间。
在媒体资源没有明确时间线的
罕见情况下,媒体时间线上的
零时间应对应于媒体资源的第一帧。在更罕见的情况下,如果媒体资源完全没有任何明确的
时间信息,甚至没有帧时长,则用户代理必须以由实现定义的方式自行确定每一帧的时间。
没有明确时间线但具有明确帧时长的文件格式示例是动画 GIF 格式。完全没有明确时间信息的
文件格式示例是 JPEG 推送格式(包含 JPEG 帧的 multipart/x-mixed-replace,
通常用作 MJPEG 流的格式)。
对于没有时间信息的资源,如果用户代理仍然能够定位到服务器最初提供的第一帧之前的某个位置, 则零时间应对应于媒体资源中最早的可定位时间; 否则,它应对应于从服务器接收到的第一帧(即用户代理开始接收流时在媒体资源中的位置)。
在编写本规范时,尚不存在已知的格式既缺少明确的帧时间偏移量, 又仍支持定位到服务器发送的第一帧之前的某一帧。
考虑来自电视广播机构的一个流,它在十月某个阳光明媚的星期五下午开始流式传输,
并始终在同一条媒体时间线上向连接的用户代理发送媒体数据,其零时间设置为该流开始的时刻。
数月之后,连接到此流的用户代理将发现,它们接收到的第一帧具有数百万秒的时间值。getStartDate()
方法将始终返回广播开始的日期;这将允许控制器在其进度条中显示实际时间(例如“下午 2:30”),
而不是相对于广播开始时间的时长(“8 个月、4 小时、12 分钟和 23 秒”)。
考虑一个流,其中包含由多个串接片段组成的视频,并由不允许用户代理请求特定时间的服务器广播,
而只是按照预定顺序传输视频数据,且传送的第一帧始终被标识为时间为零的帧。
如果用户代理连接到此流,并接收到时间戳范围分别为 2010-03-20 23:15:00 UTC 至
2010-03-21 00:05:00 UTC,以及 2010-02-12 14:25:00 UTC 至 2010-02-12 14:35:00 UTC 的片段,
则它将通过一条从 0 秒开始并延伸至 3,600 秒(一小时)的媒体时间线公开该内容。
假设流式传输服务器在第二个剪辑结束时断开连接,则 duration
属性随后将返回 3,600。getStartDate()
方法将返回一个时间对应于 2010-03-20 23:15:00 UTC 的 Date
对象。但是,如果另一个用户代理在五分钟后连接,它将(大概)接收到时间戳范围分别为
2010-03-20 23:20:00 UTC 至 2010-03-21 00:05:00 UTC,以及 2010-02-12 14:25:00 UTC 至
2010-02-12 14:35:00 UTC 的片段,并通过一条从 0 秒开始、延伸至 3,300 秒(五十五分钟)的媒体时间线公开该内容。
在这种情况下,getStartDate()
方法将返回一个时间对应于 2010-03-20 23:20:00 UTC 的 Date
对象。
在这两个示例中,seekable
属性都会提供控制器实际希望在其 UI 中显示的范围;通常,如果服务器不支持定位到任意时间,
这将是从用户代理连接到流的时刻起,到用户代理已获取的最新帧为止的时间范围;
但是,如果用户代理开始丢弃较早的信息,则实际范围可能更短。
无论如何,用户代理必须确保使用所建立的媒体时间线计算出的最早可能位置(定义见下文) 大于或等于零。
媒体时间线还具有一个 关联时钟。使用哪个时钟由用户代理定义,并且可能取决于媒体资源,但该时钟应近似于用户的挂钟时间。
媒体元素具有一个 当前播放位置,其初始值(即没有媒体数据时)必须为零秒。当前播放位置 是媒体时间线上的一个时间。
媒体元素还具有一个 正式播放位置,其初始值必须设置为零秒。正式播放位置是当前播放位置的近似值, 并在脚本运行期间保持稳定。
媒体元素还具有一个 默认播放起始位置,其初始值必须设置为零秒。 此时间用于允许在媒体加载之前定位元素。
每个媒体元素都有一个
显示海报标志。创建媒体元素时,必须将此标志设置为 true。
此标志用于控制用户代理何时应为 video 元素
显示海报帧,而不是显示视频内容。
currentTime 属性在获取时,必须返回媒体元素的默认播放起始位置,
除非该值为零,在这种情况下必须返回元素的正式播放位置。
返回值必须以秒表示。设置时,如果媒体元素的 readyState
为 HAVE_NOTHING,
则必须将媒体元素的默认播放起始位置设置为新值;
否则,必须将正式播放位置设置为新值,
然后定位到新值。
新值必须解释为以秒为单位。
如果媒体资源是流式资源, 则某些资源部分从用户代理的缓冲区过期之后,用户代理可能无法再次获取这些部分。类似地,某些媒体资源可能具有一条 不从零开始的媒体时间线。最早可能位置是流或资源中用户代理能够再次获取的最早位置。 它也是媒体时间线上的一个时间。
最早可能位置不会在 API 中显式公开;
如果 seekable
属性的 TimeRanges
对象具有范围,则它对应于第一个范围的开始时间;否则对应于当前播放位置。
当最早可能位置发生变化时:
如果当前播放位置位于最早可能位置之前,
则用户代理必须定位到最早可能位置;
否则,如果用户代理在过去 15 至 250ms 内尚未在该元素处触发 timeupdate
事件,并且当前也未在运行此类事件的事件处理程序,则用户代理必须以该媒体元素为参数将媒体元素任务入队,
以在该元素处触发一个事件,
其名称为 timeupdate。
由于上述要求,以及资源获取算法中在剪辑的元数据变为已知时生效的要求,当前播放位置绝不可能小于最早可能位置。
如果用户代理在任何时候获知某条音频或视频轨道已经结束,并且与该轨道相关的所有媒体数据都对应于媒体时间线中位于最早可能位置之前的部分, 则用户代理可以以该媒体元素为参数将媒体元素任务入队, 以运行以下步骤:
根据需要,从 audioTracks
属性的 AudioTrackList
对象,或 videoTracks
属性的 VideoTrackList
对象中移除该轨道。
在该媒体元素的
上述 AudioTrackList
或 VideoTrackList
对象处触发一个事件,
其名称为 removetrack;
使用 TrackEvent,
并将 track
属性初始化为表示该轨道的 AudioTrack
或 VideoTrack 对象。
duration 属性必须返回媒体时间线上媒体资源结束时的时间,
以秒为单位。如果没有可用的媒体数据,则该属性必须返回非数值 (NaN)。
如果尚不确定媒体资源是否有界
(例如流式广播或没有公布结束时间的直播事件),则该属性必须返回正无穷大。
用户代理必须在播放媒体数据的任何部分之前,以及将 readyState
设置为大于或等于 HAVE_METADATA
的值之前,确定媒体资源的时长,
即使这样做需要获取资源的多个部分。
当媒体资源的长度变为某个已知值时
(例如从未知变为已知,或从先前确定的长度变为新的长度),用户代理必须以该媒体元素为参数将媒体元素任务入队,
以在该媒体元素处触发一个事件,
其名称为 durationchange。
(当时长在加载新媒体资源的过程中重置时,不会触发该事件。)如果时长发生变化,导致当前播放位置最终大于媒体资源结束时的时间,
则用户代理还必须定位到媒体资源结束时的时间。
如果一个“无限”流由于某种原因结束,则时长将从正无穷大变为流中最后一帧或样本的时间,
并将触发 durationchange
事件。类似地,如果用户代理最初估算了媒体资源的时长,而不是精确确定它,
并在之后根据新信息修正该估算,则时长将发生变化,并将触发 durationchange
事件。
某些视频文件还具有与媒体时间线中的零时间相对应的明确日期和时间, 称为时间线偏移。最初,时间线偏移必须设置为非数值 (NaN)。
getStartDate() 方法必须返回一个新的
Date 对象,表示当前的时间线偏移。
loop
属性是一个布尔属性;如果指定了该属性,
则表示媒体元素在到达媒体资源末尾时,
应定位回资源开头。
media.readyState
所有当前引擎均支持。
从下方列表中的代码返回一个值,表示元素相对于渲染当前播放位置的当前状态。
媒体元素具有一个就绪状态, 它描述元素在当前播放位置处准备好进行渲染的程度。 可能的值如下;媒体元素在任何特定时刻的就绪状态,是能够描述该元素状态的最大值:
HAVE_NOTHING(数值 0)没有任何关于媒体资源的信息可用。
没有可用于当前播放位置的数据。networkState
属性设置为 NETWORK_EMPTY 的媒体元素始终处于 HAVE_NOTHING 状态。
HAVE_METADATA(数值 1)已获取足够的资源数据,因此资源的时长可用。对于 video
元素,
视频的尺寸也可用。没有可用于紧接着的当前播放位置的媒体数据。
HAVE_CURRENT_DATA(数值 2)紧接着的当前播放位置的数据可用,
但要么没有足够的数据供用户代理沿播放方向哪怕稍微推进当前播放位置而不立即恢复到 HAVE_METADATA 状态,
要么沿播放方向已没有更多数据可获取。
例如,在视频中,这对应于当前播放位置位于当前帧末尾时,用户代理具有当前帧的数据但没有下一帧的数据;
也对应于播放已经结束的情况。
HAVE_FUTURE_DATA(数值 3)紧接着的当前播放位置的数据可用,
并且具有足够的数据供用户代理沿播放方向至少稍微推进当前播放位置,而不会立即恢复到 HAVE_METADATA 状态,
并且文本轨道已就绪。
例如,在视频中,这对应于当前播放位置处于两帧之间的瞬间时,用户代理至少拥有当前帧和下一帧的数据;
或者当前播放位置位于一帧中间时,用户代理拥有当前帧的视频数据,以及足以继续播放一小段时间的音频数据。
如果播放已经结束,
用户代理不能处于此状态,因为在这种情况下当前播放位置绝不可能继续推进。
HAVE_ENOUGH_DATA(数值 4)满足针对 HAVE_FUTURE_DATA
状态描述的所有条件,并且还满足以下任一条件:
playbackRate 推进,
则在播放到达媒体资源末尾之前,它不会超过可用数据。实际上,HAVE_METADATA 与
HAVE_CURRENT_DATA
之间的区别可以忽略不计。真正相关的唯一情况是在将 video
元素绘制到
canvas 上时;
它用于区分会绘制某些内容的情况(HAVE_CURRENT_DATA
或更高)和不会绘制任何内容的情况(HAVE_METADATA
或更低)。类似地,HAVE_CURRENT_DATA
(仅当前帧)与 HAVE_FUTURE_DATA
(至少当前帧和下一帧)之间的区别也可以忽略不计(在极端情况下,仅相差一帧)。
这种区别真正重要的唯一情况,是页面提供“逐帧”导航界面时。
当 networkState
不为 NETWORK_EMPTY
的媒体元素的就绪状态发生变化时,
用户代理必须遵循以下步骤:
应用以下列表中第一个适用的子步骤集:
HAVE_NOTHING,
而新的就绪状态为 HAVE_METADATA
以该媒体元素为参数将媒体元素任务入队,
以在该元素处触发一个事件,
其名称为 loadedmetadata。
HAVE_METADATA,
而新的就绪状态为 HAVE_CURRENT_DATA
或更高如果这是自上次调用 load() 算法以来,
此媒体元素首次发生这种情况,
则用户代理必须以该媒体元素为参数将媒体元素任务入队,
以在该元素处触发一个事件,
其名称为 loadeddata。
如果新的就绪状态为 HAVE_FUTURE_DATA
或 HAVE_ENOUGH_DATA,
则随后还必须运行下方的相关步骤。
HAVE_FUTURE_DATA
或更高,而新的就绪状态为
HAVE_CURRENT_DATA
或更低
如果媒体元素在其
readyState
属性变为低于 HAVE_FUTURE_DATA
的值之前可能正在播放,
且该元素尚未结束播放,
播放也尚未因错误而停止、因用户交互而暂停,或因带内内容而暂停,
则用户代理必须以该媒体元素为参数将媒体元素任务入队,
以在该元素处触发一个事件,
其名称为 timeupdate;
并以该媒体元素为参数将媒体元素任务入队,
以在该元素处触发一个事件,
其名称为 waiting。
HAVE_CURRENT_DATA
或更低,而新的就绪状态为
HAVE_FUTURE_DATA
HAVE_ENOUGH_DATA
如果先前的就绪状态为 HAVE_CURRENT_DATA
或更低,则用户代理必须以该媒体元素为参数将媒体元素任务入队,
以在该元素处触发一个事件,
其名称为 canplay;
并且,如果元素的 paused 属性为
false,
则为该元素通知正在播放。
用户代理必须以该媒体元素为参数将媒体元素任务入队,
以在该元素处触发一个事件,
其名称为 canplaythrough。
如果元素不符合自动播放条件,则用户代理必须中止这些子步骤。
用户代理可以运行以下子步骤:
paused
属性设置为 false。play。
或者,如果元素是一个 video 元素,
用户代理可以开始观察该元素是否与视口相交。
当该元素开始与视口相交时,
如果该元素仍然符合自动播放条件,则运行上述子步骤。
可选地,当该元素停止与视口相交时,
如果可自动播放标志仍为 true,
并且仍指定了 autoplay 属性,
则运行以下子步骤:
只要可自动播放标志为 true, 播放和暂停子步骤就可以随着元素开始或停止与视口相交而运行多次。
用户代理不需要支持自动播放,并建议用户代理尊重用户在此方面的偏好。
建议作者使用 autoplay
属性,
而不是使用脚本强制播放视频,以便用户可以根据需要覆盖该行为。
媒体元素的就绪状态可能在这些状态之间不连续地跳转。
例如,媒体元素的状态可以直接从 HAVE_METADATA
跳转到 HAVE_ENOUGH_DATA,
而不经过 HAVE_CURRENT_DATA
和 HAVE_FUTURE_DATA
状态。
readyState IDL 属性在获取时,
必须返回上述用于描述媒体元素当前就绪状态的值。
autoplay
属性是一个布尔属性。
如果存在该属性,用户代理(按照此处描述的算法)将在无需停止即可播放时,
自动开始播放媒体资源。
建议作者使用 autoplay
属性,而不是使用脚本触发自动播放,因为这样可以允许用户在不希望自动播放时覆盖该行为,
例如在使用屏幕阅读器时。还鼓励作者考虑完全不使用自动播放行为,
而是让用户代理等待用户明确开始播放。
media.paused
所有当前引擎均支持。
如果播放已暂停,则返回 true;否则返回 false。
media.ended
所有当前引擎均支持。
如果播放已到达媒体资源的末尾,则返回 true。
media.defaultPlaybackRate [ = value ]
HTMLMediaElement/defaultPlaybackRate
所有当前引擎均支持。
返回用户未快进或倒放媒体资源时的默认播放速率。
可以设置该值,以更改默认播放速率。
默认速率不会直接影响播放,但如果用户切换到快进模式, 则在其返回正常播放模式时,预计播放速率将恢复为默认播放速率。
media.playbackRate [ = value ]
所有当前引擎均支持。
返回当前播放速率,其中 1.0 表示正常速度。
可以设置该值,以更改播放速率。
media.preservesPitch
HTMLMediaElement/preservesPitch
如果在 playbackRate
不为 1.0 时使用了保持音高的算法,则返回 true。默认值为 true。
可以将其设置为 false,使媒体资源的音频音高根据 playbackRate
升高或降低。这在美学和性能方面都很有用。
media.played返回一个 TimeRanges 对象,
表示用户代理已经播放过的媒体资源范围。
media.play()
所有当前引擎均支持。
media.pause()
所有当前引擎均支持。
paused
属性表示媒体元素是否已暂停。
该属性最初必须为 true。
如果一个媒体元素的 readyState
属性处于 HAVE_NOTHING
状态、HAVE_METADATA
状态或 HAVE_CURRENT_DATA
状态,或者该元素已经
因用户
交互而暂停或因带内内容而暂停,则该元素是被阻塞的媒体元素。
当一个可能正在播放的元素因其
readyState
属性变为低于 HAVE_FUTURE_DATA
的值而停止播放时,可能会触发一个 waiting DOM 事件。
当以下所有条件均为 true 时,称媒体元素 符合自动播放条件:
如果用户代理和系统允许在当前上下文中播放媒体,则称媒体元素 被允许播放。
例如,用户代理可以仅在媒体元素的 Window 对象具有瞬态激活时才允许播放,
但可以为静音播放设立例外。
当以下条件成立时,称媒体元素已经 结束播放:
元素的 readyState
属性为 HAVE_METADATA
或更高,并且
满足以下任一情况:
或者:
当媒体元素的 readyState
属性为 HAVE_METADATA
或更高,并且用户代理在处理媒体数据时遇到非致命错误,
且由于该错误无法播放当前播放位置处的内容时,
称该元素已经因错误而停止。
当媒体元素的 paused
属性为 false,readyState
属性为 HAVE_FUTURE_DATA
或 HAVE_ENOUGH_DATA,
并且用户代理已到达媒体资源中的某个位置,
用户必须在此作出选择才能使资源继续播放时,称该元素已
因用户交互而暂停。
当媒体元素的 paused
属性为 false,readyState
属性为 HAVE_FUTURE_DATA
或 HAVE_ENOUGH_DATA,
并且用户代理已暂停播放媒体资源,
以播放在时间上锚定到该媒体资源且长度不为零的内容,
或播放在时间上锚定到媒体资源某个片段、但长度长于该片段的内容时,
称该元素已因带内内容而暂停。
例如,当用户代理正在播放外部 WebVTT 文件中的音频描述, 并且为某个提示生成的合成语音长于文本轨道提示开始时间与文本轨道提示结束时间之间的时长时, 媒体元素就会因带内内容而暂停。
当播放方向为向前, 且当前播放位置到达媒体资源末尾时, 用户代理必须遵循以下步骤:
在该媒体元素处触发一个事件,
其名称为 timeupdate。
如果媒体元素已结束播放,播放方向为向前, 并且 paused 为 false:
将 paused
属性设置为 true。
取出待处理播放 promise,
并使用该结果和一个 "AbortError"
DOMException
来拒绝待处理播放 promise。
此处的“到达”一词并不意味着当前播放位置必须在正常播放期间发生变化; 例如,它也可能通过定位而到达。
defaultPlaybackRate 属性给出媒体资源所需的播放速度,
表示为其固有速度的倍数。该属性是可变的:获取时,必须返回上次设置的值;
如果尚未设置,则返回 1.0;设置时,必须将该属性设置为新值。
用户代理在向用户公开用户界面时,
会使用 defaultPlaybackRate。
playbackRate 属性给出有效播放速率,
即媒体资源的播放速度,
表示为其固有速度的倍数。如果该值不等于 defaultPlaybackRate,
则意味着用户正在使用快进或慢动作播放等功能。该属性是可变的:
获取时,必须返回上次设置的值;如果尚未设置,则返回 1.0;
设置时,用户代理必须遵循以下步骤:
如果用户代理不支持给定值,则抛出一个
"NotSupportedError" DOMException。
将 playbackRate
设置为新值;如果元素可能正在播放,则更改播放速度。
当 defaultPlaybackRate
或 playbackRate
属性的值发生变化时(无论是由脚本设置,还是由用户代理直接更改,例如响应用户控件),
用户代理必须以该媒体元素为参数将媒体元素任务入队,
以在该媒体元素处触发一个事件,
其名称为 ratechange。
用户代理必须平滑地处理属性变化,并且不得因此引入任何可感知的播放间隙或静音。
preservesPitch 获取器步骤为:
如果播放期间正在使用保持音高的算法,则返回 true。设置器步骤为相应地启用或禁用保持音高的算法,
且不得引入任何可感知的播放间隙或静音。默认情况下,必须使用这种保持音高的算法
(即获取器最初将返回 true)。
played
获取器步骤为返回一个新的规范化的
TimeRanges 对象,该对象表示在正常播放期间,通过 this 的当前播放位置通常的单调递增,
到达的 this 的媒体资源的媒体时间线上的位置范围(如果有)。
每次都返回新对象对于属性获取器而言是一种不良模式, 这里只是因为更改这一行为的成本很高而将其保留下来。新的 API 不应复制这种模式。
每个媒体元素都有一个 待处理播放 promise 列表,其初始值必须为空。
要为一个媒体元素 取出待处理播放 promise, 用户代理必须运行以下步骤:
令 promises 为一个空的 promise 列表。
将该媒体元素的待处理播放 promise 列表 复制到 promises。
清空该媒体元素的待处理播放 promise 列表。
要使用 promise 列表 promises 为一个媒体元素 兑现待处理播放 promise, 用户代理必须使用 undefined 兑现 promises 中的每个 promise。
要使用 promise 列表 promises 和异常名称 error 为一个媒体元素 拒绝待处理播放 promise, 用户代理必须使用 error 拒绝 promises 中的每个 promise。
要为一个媒体元素 通知正在播放,用户代理必须运行以下步骤:
取出待处理播放 promise, 并令 promises 为结果。
以该元素和以下步骤为参数将媒体元素任务入队:
使用 promises兑现待处理播放 promise。
当调用媒体元素上的
play()
方法时,用户代理必须运行以下步骤:
如果该媒体元素未被允许播放,
则返回一个使用 "NotAllowedError"
DOMException
拒绝的 promise。
如果该媒体元素的 error 属性
不为 null,并且其代码为
MEDIA_ERR_SRC_NOT_SUPPORTED,
则返回一个使用 "NotSupportedError"
DOMException
拒绝的 promise。
如果 resumptionSteps 不为 null:
令 promise 为一个新的 promise,并将 promise 追加到待处理播放 promise 列表。
返回 promise。
一个媒体元素的 内部播放步骤如下:
如果该媒体元素的 networkState
属性值为 NETWORK_EMPTY,
则调用该媒体元素的资源选择算法。
如果播放已经结束,并且播放方向为向前, 则定位到媒体资源的最早可能位置。
这将导致用户代理以该媒体元素为参数将媒体元素任务入队,
以在该媒体元素处触发一个事件,
其名称为 timeupdate。
将 paused
的值更改为 false。
如果该媒体元素的 readyState
属性值为 HAVE_NOTHING、
HAVE_METADATA
或 HAVE_CURRENT_DATA,
则以该媒体元素为参数将媒体元素任务入队,
以在该元素处触发一个事件,
其名称为 waiting。
否则,该媒体元素的 readyState
属性值为 HAVE_FUTURE_DATA
或 HAVE_ENOUGH_DATA:
为该元素通知正在播放。
否则,如果该媒体元素的 readyState
属性值为 HAVE_FUTURE_DATA
或 HAVE_ENOUGH_DATA,
则取出待处理播放
promise,
并以该媒体元素为参数将媒体元素任务入队,
以使用结果兑现待处理播放 promise。
媒体元素已经在播放。但是,promise 仍可能在入队任务运行之前被拒绝。
当调用 pause()
方法时,以及当要求用户代理暂停媒体元素时,
用户代理必须运行以下步骤:
如果该媒体元素的 networkState
属性值为 NETWORK_EMPTY,
则调用该媒体元素的资源选择算法。
一个媒体元素的 内部暂停步骤如下:
如果该媒体元素的 paused 属性
为 false,则运行以下步骤:
将 paused
的值更改为 true。
取出待处理播放 promise, 并令 promises 为结果。
在该元素处触发一个事件,
其名称为 timeupdate。
使用 promises 和一个
"AbortError" DOMException
来拒绝待处理播放 promise。
如果元素的 playbackRate
为正数或零,则播放方向为向前。否则为向后。
当一个媒体元素可能正在播放,
且其 Document 是一个完全活动的 Document 时,
其当前播放位置必须按照元素的 playbackRate
个媒体时间单位每媒体时间线时钟单位时间的速率单调增加。
(本规范始终将此称为增加,但如果元素的 playbackRate
为负数,这种增加实际上可能是减少。)
元素的 playbackRate
可以为 0.0;在这种情况下,尽管播放并未暂停,当前播放位置也不会移动
(paused
不会变为 true,并且不会触发 pause 事件)。
本规范不定义用户代理如何实现适当的播放速率——根据可用的协议和媒体, 用户代理可能会与服务器协商,让服务器以适当的速率提供媒体数据, 从而使客户端实际上不需要丢弃或插值任何帧 (速率发生变化到服务器更新流的播放速率之间的时间段除外)。
如果元素的 playbackRate
不为 1.0,并且 preservesPitch
为 true,则用户代理必须应用音高调整,以保持音频的原始音高。
否则,用户代理必须在不进行任何音高调整的情况下加快或减慢音频。
不在文档中但可能正在播放的媒体元素不得播放任何视频, 但应播放任何音频组件。媒体元素不得仅仅因为所有对它的引用都已被移除而停止播放; 只有当媒体元素处于一种再也不可能播放任何音频的状态时,才可以对其进行垃圾回收。
不存在任何显式引用的元素仍可能播放音频,即使该元素当前不再主动播放:
例如,它可能未暂停但由于等待内容缓冲而停滞,或者它可能仍在缓冲,
但具有一个会开始播放的 suspend
事件监听器。即使一个媒体元素的媒体资源不包含任何音频轨道,
如果它具有会更改媒体资源的事件监听器,
它最终仍可能再次播放音频。
每个媒体元素都有一个 新引入提示列表,其初始值必须为空。 每当一个文本轨道提示被添加到某个文本轨道的提示列表中, 并且该文本轨道位于某个媒体元素的文本轨道列表中时, 必须将该提示添加到该媒体元素的新引入提示列表中。 每当一个文本轨道被添加到某个媒体元素的文本轨道列表中时, 必须将该文本轨道的提示列表中的所有提示添加到该媒体元素的新引入提示列表中。 当一个媒体元素的新引入提示列表中添加了新提示, 且该媒体元素的显示海报标志未设置时, 用户代理必须运行时间继续推进步骤。
当一个文本轨道提示从某个文本轨道的提示列表中移除, 并且该文本轨道位于某个媒体元素的文本轨道列表中时, 以及每当一个文本轨道从某个媒体元素的文本轨道列表中移除时, 如果该媒体元素的显示海报标志未设置, 则用户代理必须运行时间继续推进步骤。
当媒体元素的当前播放位置发生变化时 (例如由于播放或定位),用户代理必须运行时间继续推进步骤。 为支持依赖提示事件触发时间准确性的使用场景,例如将字幕与视频中的镜头切换同步, 用户代理应尽可能接近提示在媒体时间线上的位置触发提示事件,理想情况下应在 20 毫秒以内。 如果当前播放位置在这些步骤运行期间发生变化, 则用户代理必须等待这些步骤完成,然后立即重新运行这些步骤。 因此,这些步骤应尽可能频繁地运行,或按需要运行。
如果某次迭代耗时很长,则用户代理为了“赶上”进度而向前推进时,
可能会跳过持续时间很短的提示,
因此这些提示不会出现在 activeCues
列表中。
时间继续推进步骤如下:
令 current cues 为一个提示列表, 初始化为包含该媒体元素所有或显示的文本轨道 (不包括禁用的文本轨道)中的所有提示; 这些提示的开始时间小于或等于当前播放位置, 并且其结束时间大于当前播放位置。
令 other cues 为一个提示列表, 初始化为包含该媒体元素所有和显示的文本轨道中, 不存在于 current cues 中的所有提示。
如果自该算法上一次运行以来,当前播放位置仅通过正常播放期间 通常的单调递增而发生变化,则令 missed cues 为 other cues 中这样的提示列表: 其开始时间大于或等于 last time,并且其结束时间小于或等于当前播放位置。 否则,令 missed cues 为空列表。
如果该时间是通过正常播放期间当前播放位置通常的单调递增而到达的,
并且用户代理在过去 15 至 250ms 内尚未在该元素处触发 timeupdate
事件,并且当前也未在运行此类事件的事件处理程序,
则用户代理必须以该媒体元素为参数将媒体元素任务入队,
以在该元素处触发一个事件,
其名称为 timeupdate。
(在其他情况下,例如显式定位,相关事件会作为更改当前播放位置的整个过程的一部分触发。)
因此,该事件的触发频率不应快于约 66Hz,也不应慢于 4Hz (假设事件处理程序的运行时间不超过 250ms)。鼓励用户代理根据系统负载和每次处理事件的平均成本 调整事件频率,使 UI 更新频率不会超过用户代理在解码视频时能够轻松处理的程度。
如果 current cues 中的所有提示均已设置其文本轨道提示活动标志, other cues 中没有任何提示设置其文本轨道提示活动标志, 并且 missed cues 为空,则返回。
如果该时间是通过正常播放期间当前播放位置通常的单调递增而到达的, 并且 other cues 中存在这样的提示: 其文本轨道提示退出时暂停标志已设置, 并且其文本轨道提示活动标志已设置, 或者它也存在于 missed cues 中,则立即暂停该媒体元素。
在其他情况下,例如显式定位,即使某个提示设置了文本轨道提示退出时暂停标志, 播放也不会因为越过该提示的结束时间而暂停。
令 events 为一个初始为空的任务列表。 此列表中的每个任务都将与一个文本轨道、 一个文本轨道提示和一个时间相关联, 在这些任务入队之前, 将使用这些信息对列表进行排序。
令 affected tracks 为一个初始为空的文本轨道列表。
当下方步骤要求为一个文本轨道提示 target 和时间 time 准备一个事件 event 时, 用户代理必须运行以下步骤:
对于 missed cues 中的每个文本轨道提示,
使用文本轨道提示开始时间,
为该 TextTrackCue 对象准备一个事件,
其名称为 enter。
对于 other cues 中每个已设置其文本轨道提示活动标志,
或存在于 missed cues 中的文本轨道提示,
使用文本轨道提示结束时间与文本轨道提示开始时间中较晚的时间,
为该 TextTrackCue 对象准备一个事件,
其名称为 exit。
对于 current cues 中每个尚未设置其文本轨道提示活动标志的文本轨道提示,
使用文本轨道提示开始时间,
为该 TextTrackCue
对象准备一个事件,
其名称为 enter。
按照时间升序排列 events 中的任务 (时间较早的任务在前)。
对于 events 中时间相同的任务, 再按照与这些任务相关联的文本轨道提示的相对文本轨道提示顺序进行排序。
最后,对于 events 中时间和文本轨道提示顺序均相同的任务,
将触发 enter
事件的任务排在触发 exit
事件的任务之前。
按照列表顺序,对于 affected tracks 中的每个文本轨道,
以该媒体元素为参数将媒体元素任务入队,
以在该 TextTrack 对象处触发一个事件,
其名称为 cuechange;
如果该文本轨道具有对应的 track 元素,
则随后还要在该 track 元素处触发一个事件,
其名称同样为 cuechange。
设置 current cues 中所有提示的文本轨道提示活动标志, 并取消设置 other cues 中所有提示的文本轨道提示活动标志。
对于 affected tracks 中每个处于显示状态的文本轨道, 运行其更新文本轨道渲染的规则; 如果该文本轨道的文本轨道语言不是空字符串, 则将其作为后备语言。例如,对于基于 WebVTT 的文本轨道, 使用更新 WebVTT 文本轨道显示的规则。 [WEBVTT]
如果媒体元素的节点文档不再是一个完全活动的文档, 则播放将停止,直到该文档再次变为活动状态。
当一个媒体元素从
Document 中移除时,用户代理必须运行以下步骤:
media.seeking如果用户代理当前正在定位,则返回 true。
media.seekable
所有当前引擎均支持。
返回一个 TimeRanges 对象,表示用户代理
能够定位到的媒体资源范围。
media.fastSeek(time)
通过牺牲精度来尽快定位到给定 time 附近。(要定位到精确时间,请使用 currentTime
属性。)
如果媒体资源尚未加载,则此操作不会执行任何操作。
seeking
属性的初始值必须为 false。
fastSeek(time) 方法必须在设置
为速度近似标志的情况下,定位到 time 给出的时间。
当要求用户代理在媒体资源中 定位到特定的新播放位置时, 可以选择设置为速度近似标志,这意味着用户代理必须运行以下步骤。 此算法与事件循环机制密切交互; 特别是,它包含一个同步段(作为事件循环算法的一部分触发)。该段中的步骤以 ⌛ 标记。
如果媒体元素的 readyState
为 HAVE_NOTHING,
则返回。
如果元素的 seeking IDL
属性为 true,则此算法的另一个实例已经在运行。中止该算法的另一个实例,
无需等待其当前正在运行的步骤完成。
将 seeking IDL 属性
设置为 true。
如果定位是为了响应 DOM 方法调用或 IDL 属性设置,则继续执行脚本。 这些步骤的其余部分必须并行运行。除标有 ⌛ 的步骤外, 它们随时可能因调用此算法的另一个实例而中止。
如果新播放位置小于最早可能位置,则改为令其等于该位置。
如果(现在可能已更改的)新播放位置不在 seekable 属性给出的任一范围中,
则令其等于 seekable 属性给出的范围中
最接近新播放位置的位置。如果有两个位置都满足此约束
(即新播放位置恰好处于 seekable 属性中的两个范围
之间的正中位置),则使用最接近当前播放位置的位置。如果
seekable 属性未给出任何范围,
则将 seeking IDL 属性
设置为 false,然后返回。
如果设置了为速度近似标志,则将新播放位置调整为能够让播放及时恢复的值。 如果此步骤之前的新播放位置位于当前播放位置之前, 则调整后的新播放位置也必须位于当前播放位置之前。类似地, 如果此步骤之前的新播放位置位于当前播放位置之后, 则调整后的新播放位置也必须位于当前播放位置之后。
例如,用户代理可以对齐到附近的关键帧, 从而无需在恢复播放之前花费时间解码并丢弃中间帧。
将当前播放位置设置为新播放位置。
如果媒体元素在开始定位之前
可能正在播放,
但定位导致其 readyState 属性
变为低于 HAVE_FUTURE_DATA
的值,则会在该元素处触发一个 waiting 事件。
此步骤设置当前播放位置,因此可以立即触发其他条件, 例如关于播放何时“到达媒体资源末尾”的规则 (处理循环逻辑的一部分),甚至在用户代理实际能够渲染该位置的媒体数据之前 (这将在下一步中确定)。
currentTime 属性返回
正式播放位置,
而不是当前播放位置,
因此它会在脚本执行之前更新,并且与此算法分开。
等待用户代理确定新播放位置处的媒体数据是否可用;如果可用, 则继续等待,直到其解码了足够的数据以播放该位置。
⌛ 将 seeking IDL
属性设置为 false。
⌛ 运行时间继续推进步骤。
⌛ 以该媒体元素为参数将媒体元素任务入队,
以在该元素处触发一个事件,
其名称为 timeupdate。
seekable 获取器步骤为返回一个新的规范化的
TimeRanges 对象,该对象表示用户代理能够定位到的
this 的媒体资源范围(如果有)。
如果用户代理能够定位到媒体资源中的任何位置,例如因为它是一个简单的电影文件,
并且用户代理和服务器支持 HTTP Range 请求,则该属性将返回一个具有单个范围的对象;
其起点是第一帧的时间(最早可能位置,通常为零),
其终点等于第一帧的时间加上 duration 属性的值
(该值将等于最后一帧的时间,并且可能为正无穷大)。
该范围可能持续变化,例如用户代理正在缓冲无限流上的滑动窗口。 例如,这是使用 DVR 观看直播电视时所见的行为。
每次都返回新对象对于属性获取器而言是一种不良模式, 这里只是因为更改这一行为的成本很高而将其保留下来。新的 API 不应复制这种模式。
用户代理应对哪些内容可以定位采取非常宽松和乐观的看法。 用户代理还应在可能的情况下缓冲最近的内容,以便快速定位。
例如,考虑一个由不支持 HTTP Range 请求的 HTTP 服务器提供的大型视频文件。 浏览器可以通过仅缓冲当前帧及为后续帧获取的数据来实现这一点, 并且从不允许定位,唯一的例外是通过重新开始播放来定位到最开头。 但是,这将是一种糟糕的实现。高质量的实现会缓冲最近几分钟的内容 (如果有足够的存储空间,则缓冲更多内容),使用户能够无延迟地跳回并重看令人意外的内容; 此外,还会在必要时通过从头重新加载文件来允许任意定位, 虽然这样会更慢,但仍比为了到达较早且未缓冲的位置而不得不真正重新开始视频并从头看到尾更加方便。
媒体资源内部可能包含脚本或交互功能。 因此,媒体元素可以采用非线性方式播放。 如果发生这种情况,则每当当前播放位置以不连续方式发生变化时, 用户代理必须表现得如同使用了定位算法一样(以便触发相关事件)。
媒体资源可以具有多个嵌入式音频和视频轨道。 例如,除主要视频和音频轨道外,媒体资源还可以包含外语配音对白、 导演评论、音频描述、替代视角或手语叠加层。
media.audioTracks
所有当前引擎均支持。
返回一个 AudioTrackList
对象,表示媒体资源中可用的音频轨道。
media.videoTracks
所有当前引擎均支持。
返回一个 VideoTrackList
对象,表示媒体资源中可用的视频轨道。
媒体元素的
audioTracks 属性必须返回一个实时 AudioTrackList
对象,表示该媒体元素的媒体资源中可用的音频轨道。
媒体元素的
videoTracks 属性必须返回一个实时 VideoTrackList
对象,表示该媒体元素的媒体资源中可用的视频轨道。
每个媒体元素始终只有一个 AudioTrackList
对象和一个 VideoTrackList
对象,即使将另一个媒体资源加载到该元素中也是如此:
这些对象会被重用。(但是 AudioTrack
和 VideoTrack
对象不会被重用。)
AudioTrackList
和 VideoTrackList
对象所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
AudioTrackList
和 VideoTrackList
接口由上一节定义的属性使用。
所有当前引擎均支持。
所有当前引擎均支持。
[Exposed =Window ]
interface AudioTrackList : EventTarget {
readonly attribute unsigned long length ;
getter AudioTrack (unsigned long index );
AudioTrack ? getTrackById (DOMString id );
attribute EventHandler onchange ;
attribute EventHandler onaddtrack ;
attribute EventHandler onremovetrack ;
};
[Exposed =Window ]
interface AudioTrack {
readonly attribute DOMString id ;
readonly attribute DOMString kind ;
readonly attribute DOMString label ;
readonly attribute DOMString language ;
attribute boolean enabled ;
};
[Exposed =Window ]
interface VideoTrackList : EventTarget {
readonly attribute unsigned long length ;
getter VideoTrack (unsigned long index );
VideoTrack ? getTrackById (DOMString id );
readonly attribute long selectedIndex ;
attribute EventHandler onchange ;
attribute EventHandler onaddtrack ;
attribute EventHandler onremovetrack ;
};
[Exposed =Window ]
interface VideoTrack {
readonly attribute DOMString id ;
readonly attribute DOMString kind ;
readonly attribute DOMString label ;
readonly attribute DOMString language ;
attribute boolean selected ;
};media.audioTracks.length
所有当前引擎均支持。
media.videoTracks.length
所有当前引擎均支持。
返回列表中的轨道数。
audioTrack = media.audioTracks[index]
videoTrack = media.videoTracks[index]
返回指定的 AudioTrack 或
VideoTrack
对象。
audioTrack = media.audioTracks.getTrackById(id)
所有当前引擎均支持。
videoTrack = media.videoTracks.getTrackById(id)
所有当前引擎均支持。
返回具有给定标识符的 AudioTrack 或
VideoTrack
对象;如果没有轨道具有该标识符,则返回 null。
audioTrack.id
所有当前引擎均支持。
videoTrack.id
所有当前引擎均支持。
返回给定轨道的 ID。如果格式支持媒体片段语法,
则这是可以与片段一起使用的 ID,
也可以与 getTrackById() 方法一起使用。
audioTrack.kind
所有当前引擎均支持。
videoTrack.kind
所有当前引擎均支持。
返回给定轨道所属的类别。下方给出了可能的轨道类别。
audioTrack.label
所有当前引擎均支持。
videoTrack.label
所有当前引擎均支持。
如果已知,则返回给定轨道的标签;否则返回空字符串。
audioTrack.language
所有当前引擎均支持。
videoTrack.language
所有当前引擎均支持。
如果已知,则返回给定轨道的语言;否则返回空字符串。
audioTrack.enabled [ = value ]
所有当前引擎均支持。
如果给定轨道处于活动状态,则返回 true;否则返回 false。
可以设置该值,以更改轨道是否启用。如果同时启用多个音频轨道,则会将它们混合。
media.videoTracks.selectedIndex
所有当前引擎均支持。
如果存在当前选中的轨道,则返回其索引;否则返回 −1。
videoTrack.selected [ = value ]
所有当前引擎均支持。
如果给定轨道处于活动状态,则返回 true;否则返回 false。
可以设置该值,以更改轨道是否被选中。可以不选中任何视频轨道,也可以选中一条视频轨道; 在已选中一条轨道时选择新轨道,会取消选择先前的轨道。
AudioTrackList
对象表示包含零条或多条音频轨道的动态列表,其中可以同时启用零条或多条轨道。
每条音频轨道均由一个 AudioTrack
对象表示。
VideoTrackList
对象表示包含零条或多条视频轨道的动态列表,其中一次可以不选择任何轨道或选择一条轨道。
每条视频轨道均由一个 VideoTrack
对象表示。
AudioTrackList
和 VideoTrackList
对象中的轨道必须以一致的顺序排列。如果媒体资源采用定义了顺序的格式,
则必须使用该顺序;否则,顺序必须是轨道在媒体资源中声明的相对顺序。
所使用的顺序称为列表的自然顺序。
因此,这些对象中的每条轨道都有一个索引;第一条轨道的索引为 0, 后续每条轨道的编号都比前一条大一。如果媒体资源动态添加或移除音频或视频轨道, 则轨道的索引会动态变化。如果媒体资源完全发生变化, 则所有先前的轨道都会被移除,并替换为新轨道。
AudioTrackList
的 length 属性获取器,以及 VideoTrackList
的 length 属性获取器,
必须返回获取时其对象所表示的轨道数。
在任何时刻,AudioTrackList
和 VideoTrackList
对象的支持的属性索引,
如果其表示了轨道,则为从零到相应对象所表示的轨道数减一之间的数字。
如果一个 AudioTrackList
或 VideoTrackList
对象不表示任何轨道,则它没有支持的属性索引。
要为 AudioTrackList
或 VideoTrackList
对象 list 中的给定索引 index确定索引属性的值,
用户代理必须返回表示 list 中第 index 条轨道的 AudioTrack 或
VideoTrack
对象。
AudioTrackList
的 getTrackById(id) 方法和
VideoTrackList
的 getTrackById(id) 方法,
必须分别返回相应 AudioTrackList
或 VideoTrackList
对象中标识符等于 id 参数值的第一个 AudioTrack 或
VideoTrack
对象(按照上文定义的列表自然顺序)。如果没有轨道与给定参数匹配,则方法必须返回 null。
AudioTrack
和 VideoTrack
对象表示媒体资源的特定轨道。
每条轨道都可以具有标识符、类别、标签和语言。在轨道的整个生命周期内,
轨道的这些方面都是永久不变的;即使从媒体资源的 AudioTrackList
或 VideoTrackList
对象中移除某条轨道,这些方面也不会改变。
此外,每个 AudioTrack
对象
都可以被启用或禁用;这称为音频轨道的启用状态。创建 AudioTrack 时,
必须将其启用状态设置为 false(已禁用)。资源获取算法可以覆盖此设置。
类似地,每个 VideoTrackList
对象中可以选中一个 VideoTrack 对象;
这称为视频轨道的选择状态。创建 VideoTrack 时,
必须将其选择状态设置为 false(未选中)。资源获取算法可以覆盖此设置。
AudioTrack 的
id 属性和 VideoTrack 的
id 属性,
如果轨道具有标识符,则必须返回该标识符;否则返回空字符串。如果媒体资源采用支持媒体片段语法的格式,
则为特定轨道返回的标识符必须与以下标识符相同:
当该标识符用作这种片段的轨道维度中的轨道名称时,
能够启用该轨道的标识符。[INBAND]
例如,在 Ogg 文件中,这将是轨道的 Name 标头字段。 [OGGSKELETONHEADERS]
AudioTrack 的
kind 属性和
VideoTrack 的
kind 属性,
如果轨道具有类别,则必须返回该类别;否则返回空字符串。
轨道的类别是下表第一列中,根据表格第二列和第三列中的定义,
由媒体资源内轨道所包含的元数据确定的、
最适合该轨道的字符串。某一行第三列的单元格说明该行第一列单元格中给出的类别适用于什么;
只有当类别适用于音频轨道时,它才适合音频轨道;
只有当类别适用于视频轨道时,它才适合视频轨道。仅当类别适用于音频时,
才能为 AudioTrack
对象返回该类别;仅当类别适用于视频时,才能为 VideoTrack
对象返回该类别。
对于 Ogg 文件,轨道的 Role 标头字段提供相关元数据。对于 DASH 媒体资源,
Role 元素传达该信息。对于 WebM,目前只有 FlagDefault 元素映射到一个值。
将媒体容器中的带内媒体资源轨道引入 HTML提供了更多详细信息。
[OGGSKELETONHEADERS] [DASH] [WEBMCG] [INBAND]
| 类别 | 定义 | 适用于…… | 示例 |
|---|---|---|---|
"alternative"
|
主要轨道的一种可能替代方案,例如歌曲的不同录音版本(音频),或不同的拍摄角度(视频)。 | 音频和视频。 | Ogg:"audio/alternate" 或 "video/alternate";DASH:具有 "alternate", 但不具有 "main" 和 "commentary" 角色,并且对于音频,不具有 "dub" 角色 (忽略其他角色)。 |
"captions"
|
将字幕烧录到主要视频轨道中的版本。(用于旧版内容;新内容应使用文本轨道。) | 仅视频。 | DASH:同时具有 "caption" 和 "main" 角色(忽略其他角色)。 |
"descriptions"
|
视频轨道的音频描述。 | 仅音频。 | Ogg:"audio/audiodesc"。 |
"main"
|
主要音频或视频轨道。 | 音频和视频。 | Ogg:"audio/main" 或 "video/main";WebM:设置了 "FlagDefault" 元素; DASH:具有 "main" 角色,但不具有 "caption"、"subtitle" 和 "dub" 角色 (忽略其他角色)。 |
"main-desc"
|
与音频描述混合的主要音频轨道。 | 仅音频。 | MPEG-2 TS 中的 AC3 音频:bsmod=2 且 full_svc=1。 |
"sign"
|
音频轨道的手语解说。 | 仅视频。 | Ogg:"video/sign"。 |
"subtitles"
|
将字幕烧录到主要视频轨道中的版本。(用于旧版内容;新内容应使用文本轨道。) | 仅视频。 | DASH:同时具有 "subtitle" 和 "main" 角色(忽略其他角色)。 |
"translation"
|
主要音频轨道的翻译版本。 | 仅音频。 | Ogg:"audio/dub"。DASH:同时具有 "dub" 和 "main" 角色(忽略其他角色)。 |
"commentary"
|
对主要音频或视频轨道的评论,例如导演评论。 | 音频和视频。 | DASH:具有 "commentary" 角色但不具有 "main" 角色(忽略其他角色)。 |
" |
没有明确的种类,或者用户代理无法识别轨道元数据给出的种类。 | 音频和视频。 |
AudioTrack 的
label 属性和
VideoTrack 的
label 属性,
如果轨道具有标签,则必须返回该标签;否则返回空字符串。[INBAND]
AudioTrack 的
language
属性和
VideoTrack
的 language 属性,
如果轨道具有语言,则必须返回该语言的 BCP 47 语言标签;否则返回空字符串。
如果用户代理无法将该语言表示为 BCP 47 语言标签
(例如,因为媒体资源格式中的语言信息是
没有定义解释方式的自由格式字符串),则该方法必须返回空字符串,
就如同轨道没有语言一样。[INBAND]
AudioTrack 的
enabled
属性在获取时,
如果轨道当前已启用,则必须返回 true;否则返回 false。设置时,如果新值为 true,
则必须启用轨道;否则禁用轨道。(如果轨道已不再位于 AudioTrackList
对象中,则启用或禁用轨道除了更改 AudioTrack
对象上该属性的值之外,不会产生任何影响。)
每当 AudioTrackList
中一条先前已禁用的音频轨道被启用时,以及一条先前已启用的音频轨道被禁用时,
用户代理必须以该媒体元素为参数将媒体元素任务入队,
以在该 AudioTrackList
对象处触发一个事件,
其名称为 change。
对于媒体时间线上的特定位置, 如果音频轨道没有数据,或者在该位置不存在,则必须将其解释为在时间线上的该位置静音。
VideoTrackList
的 selectedIndex 属性必须返回当前选中轨道的索引(如果有)。
如果 VideoTrackList
对象当前不表示任何轨道,或者没有选中任何轨道,则必须改为返回 −1。
VideoTrack 的
selected
属性在获取时,
如果轨道当前已选中,则必须返回 true;否则返回 false。设置时,如果新值为 true,
则必须选中轨道;否则取消选中。如果轨道位于一个 VideoTrackList
中,则必须取消选中该列表中的所有其他 VideoTrack
对象。(如果轨道已不再位于 VideoTrackList
对象中,则选中或取消选中轨道除了更改 VideoTrack
对象上该属性的值之外,不会产生任何影响。)
每当 VideoTrackList
中一条先前未选中的轨道被选中时,以及 VideoTrackList
中已选中的轨道被取消选中、且没有新轨道取代它被选中时,
用户代理必须以该媒体元素为参数将媒体元素任务入队,
以在该 VideoTrackList
对象处触发一个事件,
其名称为 change。
如果存在触发 resize
事件的任务,
则此任务必须在该任务之前入队。
对于媒体时间线上的特定位置, 如果视频轨道没有数据,则必须将其解释为在时间线上的该位置呈透明黑色, 其尺寸与该位置之前的最后一帧相同;如果该位置位于该轨道的所有数据之前, 则其尺寸与该轨道的第一帧相同。当前播放位置完全不存在的轨道必须被视为存在但没有数据。
例如,如果视频具有一条在播放一小时之后才引入的轨道, 用户选择该轨道后又返回开头,则用户代理将表现得如同该轨道从媒体资源的开头开始, 但在第一小时内仅呈透明状态。
以下是所有实现 AudioTrackList
和 VideoTrackList
接口的对象都必须作为事件处理程序 IDL 属性
支持的事件处理程序
(以及其对应的事件处理程序事件类型):
| 事件处理程序 | 事件处理程序事件类型 |
|---|---|
onchange
所有当前引擎均支持。 Firefox🔰
33+Safari7+Chrome🔰 37+
Opera?Edge🔰 79+ Edge(旧版)否Internet Explorer10+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? 所有当前引擎均支持。 Firefox31+Safari7+Chrome33+
Opera?Edge79+ Edge(旧版)18Internet Explorer否 Firefox Android?Safari iOS?Chrome Android?WebView Android4.4+Samsung Internet?Opera Android? 所有当前引擎均支持。 Firefox🔰
33+Safari7+Chrome🔰 37+
Opera?Edge🔰 79+ Edge(旧版)否Internet Explorer10+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? |
change
|
onaddtrack
所有当前引擎均支持。 Firefox🔰
33+Safari7+Chrome🔰 37+
Opera?Edge🔰 79+ Edge(旧版)否Internet Explorer10+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? 所有当前引擎均支持。 Firefox31+Safari6+Chrome23+
Opera12.1+Edge79+ Edge(旧版)12+Internet Explorer11 Firefox Android?Safari iOS7+Chrome Android?WebView Android?Samsung Internet?Opera Android12.1+ 所有当前引擎均支持。 Firefox🔰
33+Safari7+Chrome🔰 37+
Opera?Edge🔰 79+ Edge(旧版)否Internet Explorer10+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? |
addtrack
|
onremovetrack
AudioTrackList/removetrack_event 所有当前引擎均支持。 Firefox🔰
33+Safari7+Chrome🔰 37+
Opera?Edge🔰 79+ Edge(旧版)否Internet Explorer10+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? TextTrackList/removetrack_event 所有当前引擎均支持。 Firefox31+Safari7+Chrome33+
Opera20+Edge79+ Edge(旧版)18Internet Explorer否 Firefox Android?Safari iOS?Chrome Android?WebView Android4.4+Samsung Internet?Opera Android20+ VideoTrackList/removetrack_event 所有当前引擎均支持。 Firefox🔰
33+Safari7+Chrome🔰 37+
Opera?Edge🔰 79+ Edge(旧版)否Internet Explorer10+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? |
removetrack
|
audioTracks
和 videoTracks
属性允许脚本选择应播放的轨道,但也可以通过在媒体资源的
URL 的片段中指定特定轨道,以声明方式选择特定轨道。该
片段的格式取决于MIME 类型以及
媒体
资源。[RFC2046] [URL]
在此示例中,以一种支持媒体 片段语法的格式制作的视频,以启用标记为“Alternative”的替代视角而非默认视频轨道的方式嵌入。
< video src = "myvideo#track=Alternative" ></ video > 一个媒体元素可以具有一组关联的 文本轨道,称为该媒体元素的文本轨道列表。这些文本轨道按以下方式排序:
使用 addTextTrack()
方法添加的所有文本轨道,
按添加顺序排列,最早添加的在前。
所有媒体资源专用文本轨道 (与媒体资源中的数据相对应的 文本轨道), 按媒体资源格式规范所定义的顺序排列。
一个文本轨道是一个 TextTrack 对象,并由以下部分组成:
这决定用户代理如何处理该轨道。种类由字符串表示。可能的字符串为:
subtitles
captions
descriptions
chapters
metadata
这是一个用于向用户标识轨道的人类可读字符串。
对于与 track 元素相对应的
文本轨道,
其轨道标签可以动态变化。
当文本轨道标签为空字符串时, 用户代理应根据文本轨道的其他属性(例如文本轨道种类和文本轨道语言), 自动生成适合在其用户界面中使用的标签。这个自动生成的标签不会在 API 中公开。
这是一个专门为带内元数据轨道从媒体资源中提取的字符串, 用于使这类轨道能够分派给文档中的不同脚本。
例如,通过 Web 串流并增加了 Web 专用交互功能的传统电视台广播, 可以包含带有广告定向元数据、游戏节目期间的知识问答游戏数据、体育比赛期间的选手状态、 美食节目期间的食谱信息等内容的文本轨道。随着各个节目开始和结束, 可能会向流中添加新轨道或从中移除轨道;每当添加一条轨道时, 用户代理可以使用此属性的值将其绑定到专用脚本模块。
除带内元数据文本轨道外,带内元数据轨道分派类型 为空字符串。对于不同的媒体格式,如何填充此值在公开媒体资源专用文本轨道的步骤 中进行了说明。
这是一个表示文本轨道提示语言的字符串(BCP 47 语言标签)。 [BCP47]
一个字符串。
以下状态之一:
以下模式之一:
表示文本轨道未处于活动状态。除了在 DOM 中公开该轨道之外, 用户代理会忽略该文本轨道。没有任何提示处于活动状态,不会触发任何事件, 并且用户代理不会尝试获取该轨道的提示。
表示文本轨道处于活动状态,但用户代理没有主动显示提示。 如果尚未尝试获取该轨道的提示,用户代理会立即进行此类尝试。 用户代理会维护哪些提示处于活动状态的列表,并相应地触发事件。
表示文本轨道处于活动状态。如果尚未尝试获取该轨道的提示,
用户代理会立即进行此类尝试。用户代理会维护哪些提示处于活动状态的列表,
并相应地触发事件。此外,对于种类为 subtitles
或 captions
的文本轨道,会按适当方式将提示叠加在视频上;对于种类为 descriptions
的文本轨道,用户代理会以非视觉方式向用户提供提示;对于种类为 chapters
的文本轨道,用户代理会向用户提供一种机制,使用户能够通过选择提示导航到媒体资源中的任意位置。
一个文本轨道提示列表, 以及更新文本轨道渲染的规则。 例如,对于 WebVTT,是更新 WebVTT 文本轨道显示的规则。 [WEBVTT]
每个媒体元素都有一个 待处理文本轨道列表,其初始值必须为空; 一个被解析器阻塞标志,其初始值必须为 false; 以及一个已执行自动轨道选择标志, 其初始值也必须为 false。
当要求用户代理填充待处理文本轨道列表时, 用户代理必须将该媒体元素的 文本轨道列表中, 所有文本轨道模式不是已禁用,并且其 文本轨道就绪状态为正在加载的 文本轨道,添加到该元素的 待处理文本轨道列表中。
当媒体元素由 HTML 解析器或XML 解析器创建时,用户代理必须将该元素的被解析器阻塞标志设置为 true。 当媒体元素从 HTML 解析器或XML 解析器的开放元素栈中弹出时,用户代理必须遵循用户的自动文本轨道选择偏好、 填充待处理文本轨道列表, 并将该元素的被解析器阻塞标志设置为 false。
每个媒体元素都有一个 待处理文本轨道更改通知标志, 其初始状态必须为未设置。
每当位于媒体元素的 文本轨道列表中的 文本轨道的 文本轨道模式值发生变化时, 用户代理必须为该媒体元素运行以下步骤:
如果该媒体元素的 待处理文本轨道更改通知标志 已设置,则返回。
设置该媒体元素的 待处理文本轨道更改通知标志。
取消设置该媒体元素的 待处理文本轨道更改通知标志。
在该媒体元素的
textTracks
属性的 TextTrackList
对象处触发一个事件,
其名称为 change。
文本轨道提示是文本轨道中时间敏感数据的单位, 例如对于字幕和说明字幕,它对应于在某一时刻出现并在另一时刻消失的文本。
每个文本轨道提示由以下部分组成:
任意字符串。
以秒和秒的小数表示的时间,用于描述该提示所适用的媒体数据范围的开始位置。
一个布尔值,表示当到达该提示所适用范围的末尾时,是否暂停媒体资源的播放。
该格式所需的其他字段,包括提示的实际数据。例如,WebVTT 具有文本轨道提示书写方向等。 [WEBVTT]
无界文本轨道提示是 文本轨道提示结束时间设置为正无穷大的文本轨道提示。 在正常播放期间,活动的无界文本轨道提示不能仅通过 当前播放位置通常的单调递增而变为非活动状态 (例如,直播活动中没有公布结束时间的章节元数据提示)。
文本轨道提示开始时间和文本轨道提示结束时间可以为负数。 (不过,当前播放位置永远不能为负数, 因此完全位于时间零之前的提示不能处于活动状态。)
每个文本轨道提示都有一个对应的
TextTrackCue 对象
(更准确地说,是一个继承自 TextTrackCue 的对象——
例如,WebVTT 提示使用 VTTCue 接口)。
可以通过此 TextTrackCue API
动态更改文本轨道提示的内存表示。
[WEBVTT]
文本轨道提示与
更新文本轨道渲染的规则相关联,
这些规则由特定类型的文本轨道提示的规范定义。
当使用 addCue()
方法将表示该提示的对象添加到 TextTrack 对象时,
会专门使用这些规则。
此外,每个文本轨道提示 都具有两项动态信息:
此标志的初始状态必须为未设置。该标志用于确保在提示变为活动或非活动状态时 适当地触发事件,并确保渲染正确的提示。
每当文本轨道提示从其
文本轨道的
文本轨道提示列表中移除时;
每当该文本轨道本身从其
媒体元素的
文本轨道列表中移除,
或者其文本轨道模式
变为已禁用时;
以及每当媒体元素的
readyState
变回 HAVE_NOTHING 时,
用户代理都必须同步取消设置此标志。当通过这种方式为相关事件发生之前处于显示状态的
文本轨道中的一个或多个提示
取消设置该标志时,用户代理必须在为所有受影响提示取消设置该标志之后,
应用这些文本轨道的
更新文本轨道渲染的规则。
例如,对于基于 WebVTT 的文本轨道,应用更新 WebVTT 文本轨道显示的规则。
[WEBVTT]
它作为渲染模型的一部分使用,以使提示保持在一致的位置。其初始值必须为空。 每当文本轨道提示活动标志被取消设置时, 用户代理必须清空文本轨道提示显示状态。
媒体元素的 文本轨道中的 文本轨道提示, 按照文本轨道提示顺序相互排序,确定方式如下: 首先按提示所属的文本轨道对 提示进行分组, 各组的排序顺序与其文本轨道在 媒体元素的 文本轨道列表中出现的顺序相同; 然后,在每组内,必须按开始时间对 提示排序,最早的在前; 然后,开始时间相同的所有提示必须按其结束时间排序,最晚的在前; 最后,结束时间相同的所有提示,必须按它们最后被添加到各自 文本轨道提示列表中的顺序排序, 最早添加的在前(例如,对于来自 WebVTT 文件的提示,其初始顺序就是提示在文件中列出的顺序)。 [WEBVTT]
媒体资源专用文本轨道是与 媒体资源中发现的数据 相对应的文本轨道。
处理和渲染这类数据的规则由相关规范定义,例如,如果媒体资源是视频, 则由视频格式规范定义。一些旧格式的详细信息可在 将媒体容器中的带内媒体资源轨道引入 HTML中找到。 [INBAND]
当媒体资源包含 用户代理识别并支持为等同于文本轨道的数据时, 用户代理使用相关数据运行 公开媒体资源专用文本轨道的步骤, 如下所示。
将相关数据与一个新的文本轨道关联。 该文本轨道是 媒体资源专用文本轨道。
根据相关规范所定义的相关数据语义,设置新文本轨道的种类、 标签、 语言和 标识符。 如果该数据中没有标签,则必须将标签设置为空字符串。
如果媒体资源采用支持媒体片段语法的格式, 则该标识符必须与以下标识符相同: 当该标识符用作这种片段的轨道维度中的轨道名称时, 能够启用该轨道的标识符。
将文本轨道提示列表与适用于相关格式的 更新文本轨道渲染的规则 关联。
如果新文本轨道的
种类为 chapters
或 metadata,
则根据媒体资源的类型,
按以下方式设置文本轨道带内元数据轨道分派类型:
CodecID 元素的值。[WEBMCG]moov box 中,
该文本轨道的
trak box 的第一个 mdia box 的第一个 minf box 的
第一个 stbl box 的第一个 stsd box;
如果不存在这样的 stsd box,则为 null。
如果stsd box为 null,或者stsd box既没有 mett box,
也没有 metx box,则必须将文本轨道
带内元数据轨道分派类型设置为空字符串。
否则,如果stsd box具有 mett box,则必须将文本轨道
带内元数据轨道分派类型设置为字符串 "mett"、一个 U+0020 SPACE 字符和
stsd box 的第一个 mett box 的第一个 mime_format
字段值的串联;如果该 box 中不存在该字段,则设置为空字符串。
否则,如果stsd box没有 mett box,但具有 metx box,
则必须将文本轨道带内元数据轨道分派类型
设置为字符串 "metx"、一个 U+0020 SPACE 字符和stsd box 的
第一个 metx box 的第一个 namespace 字段值的串联;
如果该 box 中不存在该字段,则设置为空字符串。
[MPEG4]
将新文本轨道的 模式 设置为与用户偏好和相关数据规范要求相符的模式。
例如,如果没有其他活动字幕,并且这是强制字幕轨道 (一种使用音频轨道主要语言提供字幕,但仅为实际采用另一种语言的音频提供字幕的轨道), 则可以在此处启用这些字幕。
使用 TrackEvent,
在媒体元素的
textTracks
属性的 TextTrackList
对象处触发一个事件,
其名称为 addtrack,
并将 track
属性初始化为该文本轨道。
文本轨道种类根据元素的 kind
属性的状态,按照下表确定;对于第一列单元格中给出的状态,
种类是第二列中给出的字符串:
| 状态 | 字符串 |
|---|---|
| 字幕 | subtitles
|
| 说明字幕 | captions
|
| 描述 | descriptions
|
| 章节元数据 | chapters
|
| 元数据 | metadata
|
随着 kind、label、
srclang 和 id
属性被设置、更改或移除,文本轨道必须按照上述定义相应更新。
对轨道 URL的更改由下方算法处理。
文本轨道就绪状态的初始值为未加载, 文本轨道模式的初始值为已禁用。
文本轨道提示列表的初始值为空。 解析所引用的文件时,会动态修改该列表。与该列表关联的是适用于相关格式的 更新文本轨道渲染的规则; 对于 WebVTT,这是更新 WebVTT 文本轨道显示的规则。 [WEBVTT]
当 track
元素的父元素发生变化,并且新的父元素是媒体元素时,
用户代理必须将该 track
元素对应的文本轨道添加到该
媒体元素的
文本轨道列表中,
然后以该媒体元素为参数将媒体元素任务入队,
以使用 TrackEvent,
在该媒体元素的 textTracks
属性的 TextTrackList
对象处触发一个事件,
其名称为 addtrack,
并将 track
属性初始化为该文本轨道。
当 track
元素的父元素发生变化,并且旧的父元素是媒体元素时,
用户代理必须从该媒体元素的
文本轨道列表中移除该 track
元素对应的文本轨道,
然后以该媒体元素为参数将媒体元素任务入队,
以使用 TrackEvent,
在该媒体元素的 textTracks
属性的 TextTrackList
对象处触发一个事件,
其名称为 removetrack,
并将 track
属性初始化为该文本轨道。
当与 track
元素相对应的文本轨道被添加到
媒体元素的
文本轨道列表中时,
用户代理必须以该媒体元素为参数将媒体元素任务入队,
以为该媒体元素运行以下步骤:
如果该元素的被解析器阻塞标志为 true,则返回。
如果该元素的已执行自动轨道选择 标志为 true,则返回。
为此元素遵循用户的 自动文本轨道选择偏好。
当要求用户代理为一个媒体元素遵循用户的自动文本轨道选择偏好时, 用户代理必须运行以下步骤:
当上述步骤要求为一个或多个文本轨道种类 执行自动文本轨道选择时, 意味着运行以下步骤:
令candidates为一个列表,其中包含媒体元素的 文本轨道列表中, 文本轨道种类为传递给算法的种类之一的 文本轨道(如果有), 并按照文本轨道列表中给出的顺序排列。
如果candidates为空,则返回。
如果用户根据candidates中某条轨道的文本轨道种类、 文本轨道语言和 文本轨道标签, 表达了启用该轨道的意愿,则将其文本轨道模式设置为显示。
例如,用户可以设置如下浏览器偏好:“尽可能使用法语说明字幕”, 或“如果存在标题中包含‘Commentary’的字幕轨道,则启用它”, 或“如果存在音频描述轨道,则启用一条,最好使用瑞士德语, 如果没有,则使用标准瑞士德语或标准德语”。
否则,如果candidates中存在文本轨道,
其对应于设置了 default
属性的 track
元素,并且其文本轨道模式被设置为已禁用,
则将第一条此类轨道的文本轨道模式设置为显示。
当与 track
元素相对应的文本轨道遇到以下任一情况时,
用户代理必须为该文本轨道及其 track
元素启动 track 处理模型:
当用户代理要为一个文本轨道及其 track
元素启动 track 处理模型时,
必须运行以下算法。此算法与事件循环机制密切交互;
特别是,它包含一个同步段
(作为事件循环算法的一部分触发)。
该段中的步骤以 ⌛ 标记。
并行运行这些步骤的其余部分, 允许导致这些步骤运行的操作继续执行。
⌛ 如果 track
元素的父元素是媒体元素,
则令corsAttributeState为父媒体元素的 crossorigin
内容属性的状态。否则,令corsAttributeState为无 CORS。
如果URL不是空字符串:
令request为使用URL、"track" 和
corsAttributeState,并设置同源回退标志后创建潜在 CORS 请求的结果。
将request的发起者类型设置为 "track"。
获取request。
获取算法在网络任务源上入队, 用于在获取数据时处理数据的任务,必须确定资源类型。 如果资源类型不是受支持的文本轨道格式,则加载将按下文所述失败。 否则,资源数据在接收时必须传递给适当的解析器 (例如,WebVTT 解析器),并使用文本轨道提示列表 作为该解析器的输出。[WEBVTT]
当这些网络任务源的 任务逐个使用 从网络接收到的数据运行时,适当的解析器会递增更新文本轨道提示列表。
本规范目前没有说明是否或如何检查文本轨道的 MIME 类型, 也没有说明是否或如何使用实际文件数据执行文件类型嗅探。 实现者对此问题的意图存在差异,因此尚不清楚正确的解决方案是什么。 在此处没有任何要求的情况下,HTTP 规范关于遵循 Content-Type 标头的严格要求优先 (“Content-Type 指定底层数据的媒体类型。”……“当且仅当 Content-Type 字段没有给出媒体类型时, 接收方可以尝试通过检查其内容和/或用于标识资源的 URI 的名称扩展名来猜测媒体类型。”)。
如果获取由于任何原因失败(网络错误、服务器返回错误代码、CORS 失败等),
或者URL为空字符串,则在DOM 操作任务源上,
以该媒体元素为参数将元素任务入队,
首先将文本轨道就绪状态更改为加载失败,
然后在 track
元素处触发一个事件,
其名称为 error。
如果获取没有失败,但资源类型不是受支持的文本轨道格式,
或者文件未被成功处理(例如,相关格式是 XML 格式,而文件包含
XML 要求检测并向应用程序报告的良构性错误),
则发现上述问题的、在网络任务源上入队的
任务,
必须将文本轨道就绪状态更改为加载失败,
并在 track
元素处触发一个事件,
其名称为 error。
如果获取没有失败,并且文件已成功处理,则在完成数据解析后,
由网络任务源入队的最后一个
任务,
必须将文本轨道就绪状态更改为已加载,
并在 track
元素处触发一个事件,
其名称为 load。
如果在获取进行期间发生以下任一情况:
……则用户代理必须中止获取,
丢弃该算法生成的所有待处理任务
(特别是,在 URL 发生变化之后,不再向文本轨道提示列表添加任何提示),
然后在DOM 操作任务源上,
以该 track
元素为参数将元素任务入队,
首先将文本轨道就绪状态更改为加载失败,
然后在 track
元素处触发一个事件,
其名称为 error。
跳转到标记为顶部的步骤。
每当 track
元素的 src
属性被设置、更改或移除时,用户代理必须立即清空该元素的文本轨道的
文本轨道提示列表。
(如果存在使用先前给定 URL 获取的资源,这也会导致上述算法停止从该资源添加提示。)
如何为 HTML 用户代理处理的目的解释特定格式的文本轨道提示,由该格式定义。 如果不存在这样的规范,本节提供一些约束,实现可以在这些约束内尝试以一致方式公开此类格式。
为了支持 HTML 的文本轨道模型, 每个定时数据单位都会转换为一个文本轨道提示。 如果没有定义该格式的功能如何映射到本规范所定义的文本轨道提示的各个方面, 实现必须确保该映射与上文定义的文本轨道提示 各方面的定义以及以下约束保持一致:
如果该格式没有明显类似于每个提示标识符的概念,则应将其设置为空字符串。
应将其设置为 false。
所有当前引擎均支持。
[Exposed =Window ]
interface TextTrackList : EventTarget {
readonly attribute unsigned long length ;
getter TextTrack (unsigned long index );
TextTrack ? getTrackById (DOMString id );
attribute EventHandler onchange ;
attribute EventHandler onaddtrack ;
attribute EventHandler onremovetrack ;
};media.textTracks.length
所有当前引擎均支持。
media.textTracks[ n ]
textTrack = media.textTracks.getTrackById(id)
所有当前引擎均支持。
返回具有给定标识符的 TextTrack
对象;如果没有轨道具有该标识符,则返回 null。
TextTrackList 对象表示按给定顺序
动态更新的文本轨道列表。
所有当前引擎均支持。
TextTrackList
对象的 length 属性必须返回该
TextTrackList
对象所表示的列表中的文本轨道数量。
在任何时刻,TextTrackList 对象的
支持的属性索引,
如果存在,则为从零到该 TextTrackList 对象所表示的列表中的
文本轨道数量减一之间的数字。
如果列表中没有文本轨道,则没有
支持的属性索引。
要为 TextTrackList 对象的给定索引
index确定索引属性的值,
用户代理必须返回该 TextTrackList
对象所表示列表中的第 index 条文本轨道。
getTrackById(id) 方法必须返回
TextTrackList 对象中,
其 id IDL 属性将返回
与 id 参数值相等的值的第一个 TextTrack。
当没有轨道与给定参数匹配时,该方法必须返回 null。
所有当前引擎均支持。
enum TextTrackMode { " disabled " , " hidden " , " showing " };
enum TextTrackKind { " subtitles " , " captions " , " descriptions " , " chapters " , " metadata " };
[Exposed =Window ]
interface TextTrack : EventTarget {
readonly attribute TextTrackKind kind ;
readonly attribute DOMString label ;
readonly attribute DOMString language ;
readonly attribute DOMString id ;
readonly attribute DOMString inBandMetadataTrackDispatchType ;
attribute TextTrackMode mode ;
readonly attribute TextTrackCueList ? cues ;
readonly attribute TextTrackCueList ? activeCues ;
undefined addCue (TextTrackCue cue );
undefined removeCue (TextTrackCue cue );
attribute EventHandler oncuechange ;
};textTrack = media.addTextTrack(kind [, label [, language ] ])
textTrack.kind
所有当前引擎均支持。
返回文本轨道种类字符串。
textTrack.label
所有当前引擎均支持。
如果存在文本轨道标签, 则返回该标签;否则返回空字符串 (表示如果将该对象公开给用户,可能需要根据该对象的其他属性生成自定义标签)。
textTrack.language
所有当前引擎均支持。
返回文本轨道语言字符串。
textTrack.id
所有当前引擎均支持。
返回给定轨道的 ID。
对于带内轨道,如果该格式支持媒体片段语法,这是可与片段一起使用的 ID,并且也可以与 getTrackById()
方法一起使用。
textTrack.inBandMetadataTrackDispatchType
TextTrack/inBandMetadataTrackDispatchType
返回文本轨道带内元数据轨道分派类型字符串。
textTrack.mode [ = value ]
所有当前引擎均支持。
返回文本轨道模式, 由以下列表中的字符串表示:
可以设置,以更改模式。
textTrack.cues
所有当前引擎均支持。
以 TextTrackCueList
对象的形式返回文本轨道提示列表。
textTrack.activeCues
所有当前引擎均支持。
以 TextTrackCueList 对象的形式,
返回文本轨道提示列表中当前处于活动状态的
文本轨道提示
(即在当前播放位置之前开始并在其之后结束的提示)。
textTrack.addCue(cue)
所有当前引擎均支持。
将给定提示添加到 textTrack 的文本轨道提示列表中。
textTrack.removeCue(cue)
所有当前引擎均支持。
从 textTrack 的文本轨道提示列表中移除给定提示。
媒体元素的
addTextTrack(kind, label,
language) 方法在调用时必须运行以下步骤:
创建一个新的文本轨道, 并将其文本轨道种类设置为 kind,将其文本轨道标签设置为 label, 将其文本轨道语言设置为 language, 将其文本轨道就绪状态设置为 文本轨道已加载状态, 将其文本轨道模式设置为 模式, 并将其文本轨道提示列表设置为空列表。
最初,文本轨道提示列表不与任何 更新文本轨道渲染的规则相关联。 当向其中添加文本轨道提示时, 该文本轨道提示列表的规则会相应地永久设置。
以该媒体元素为参数将媒体元素任务入队,
以使用 TrackEvent,
在该媒体元素的
textTracks 属性的
TextTrackList 对象处触发一个事件,其名称为 addtrack,
并将 track
属性初始化为新的文本轨道。
返回新的文本轨道。
inBandMetadataTrackDispatchType
获取器步骤为返回 this
的带内元数据轨道分派类型。
cues 获取器步骤为:
返回一个实时 TextTrackCueList 对象,
该对象表示 this 的文本轨道提示列表中,
其结束时间位于脚本开始时的最早可能位置
或其后的子集,并按文本轨道提示顺序排列。
对于每个 TextTrack 对象,
当返回对象时,每次都必须返回同一个 TextTrackCueList 对象。
activeCues 获取器步骤为:
返回一个实时 TextTrackCueList 对象,
该对象表示 this 的文本轨道提示列表中,
脚本开始时活动标志已设置的子集,
并按文本轨道提示顺序排列。
对于每个 TextTrack 对象,
当返回对象时,每次都必须返回同一个 TextTrackCueList 对象。
如果事件循环上一次到达 步骤 1时,某个文本轨道提示的文本轨道提示活动标志已设置, 则该文本轨道提示的脚本开始时活动标志已设置。
addCue(cue) 方法步骤为:
如果list尚未与任何更新文本轨道渲染的规则相关联, 则将list与适用于cue的更新文本轨道渲染的规则相关联。
如果与list关联的更新文本轨道渲染的规则
与适用于cue的更新文本轨道渲染的规则不同,
则抛出一个 "InvalidStateError"
DOMException。
将cue添加到list。
removeCue(cue) 方法步骤为:
如果给定的cue不在 this 的
文本轨道提示列表中,
则抛出一个 "NotFoundError"
DOMException。
在此示例中,使用一个 audio
元素播放包含许多音效的声音文件中的特定音效。使用一个提示暂停音频,
使其恰好在片段末尾结束,即使浏览器正忙于运行某些脚本也是如此。
如果页面依赖脚本暂停音频,那么当浏览器无法在指定的精确时间运行脚本时,
可能会听到下一个片段的开头。
var sfx = new Audio( 'sfx.wav' );
var sounds = sfx. addTextTrack( 'metadata' );
// add sounds we care about
function addFX( start, end, name) {
var cue = new VTTCue( start, end, '' );
cue. id = name;
cue. pauseOnExit = true ;
sounds. addCue( cue);
}
addFX( 12.783 , 13.612 , 'dog bark' );
addFX( 13.612 , 15.091 , 'kitten mew' );
function playSound( id) {
sfx. currentTime = sounds. getCueById( id). startTime;
sfx. play();
}
// play a bark as soon as we can
sfx. oncanplaythrough = function () {
playSound( 'dog bark' );
}
// meow when the user tries to leave,
// and have the browser ask them to stay
window. onbeforeunload = function ( e) {
playSound( 'kitten mew' );
e. preventDefault();
} 所有当前引擎均支持。
[Exposed =Window ]
interface TextTrackCueList {
readonly attribute unsigned long length ;
getter TextTrackCue (unsigned long index );
TextTrackCue ? getCueById (DOMString id );
};cuelist.length
返回列表中的提示数量。
cuelist[index]cuelist.getCueById(id)
返回文本轨道提示顺序中, 文本轨道提示标识符为 id 的 第一个文本轨道提示。
如果没有提示具有给定标识符,或者参数为空字符串,则返回 null。
TextTrackCueList
对象表示按给定顺序动态更新的文本轨道提示列表。
所有当前引擎均支持。
length 属性必须返回
TextTrackCueList
对象所表示列表中的提示数量。
在任何时刻,TextTrackCueList 对象的
支持的属性索引,
如果存在,则为从零到该 TextTrackCueList
对象所表示列表中的提示数量减一之间的数字。
如果列表中没有提示,则没有
支持的属性索引。
要为给定索引 index确定索引属性的值,
用户代理必须返回 TextTrackCueList
对象所表示列表中的第 index 个文本轨道提示。
所有当前引擎均支持。
getCueById(id) 方法,
使用非空字符串参数调用时,必须返回 TextTrackCueList
对象所表示列表中,文本轨道提示标识符为
id 的
第一个文本轨道提示(如果有);
否则返回 null。如果参数为空字符串,则该方法必须返回 null。
所有当前引擎均支持。
[Exposed =Window ]
interface TextTrackCue : EventTarget {
readonly attribute TextTrack ? track ;
attribute DOMString id ;
attribute double startTime ;
attribute unrestricted double endTime ;
attribute boolean pauseOnExit ;
attribute EventHandler onenter ;
attribute EventHandler onexit ;
};cue.trackcue.id [ = value ]
返回文本轨道提示标识符。
可以设置。
cue.startTime [ = value ]
以秒为单位返回文本轨道提示开始时间。
可以设置。
cue.endTime [ = value ]
以秒为单位返回文本轨道提示结束时间。
对于无界文本轨道提示,返回正无穷大。
可以设置。
cue.pauseOnExit [ = value ]
如果文本轨道提示退出时暂停标志已设置, 则返回 true;否则返回 false。
可以设置。
所有当前引擎均支持。
所有当前引擎均支持。
id 属性在获取时,
必须返回该 TextTrackCue 对象所表示的
文本轨道提示的
文本轨道提示标识符。
设置时,必须将文本轨道提示标识符设置为新值。
所有当前引擎均支持。
startTime 属性在获取时,
必须以秒为单位返回该 TextTrackCue 对象所表示的
文本轨道提示的
文本轨道提示开始时间。
设置时,必须将文本轨道提示开始时间
设置为以秒解释的新值;然后,如果该 TextTrackCue 对象的
文本轨道提示位于某个
文本轨道的
提示列表中,
并且该文本轨道位于某个
媒体元素的
文本轨道列表中,
且该媒体元素的
显示海报标志未设置,
则为该媒体元素运行
时间继续推进步骤。
所有当前引擎均支持。
endTime 属性在获取时,
必须以秒或正无穷大为单位返回该 TextTrackCue 对象所表示的
文本轨道提示的
文本轨道提示结束时间。
设置时,如果新值为负无穷大或非数字(NaN)值,则抛出一个
TypeError
异常。否则,必须将文本轨道提示结束时间设置为新值。
然后,如果该 TextTrackCue 对象的
文本轨道提示位于某个
文本轨道的
提示列表中,
并且该文本轨道位于某个
媒体元素的
文本轨道列表中,
且该媒体元素的
显示海报标志未设置,
则为该媒体元素运行
时间继续推进步骤。
所有当前引擎均支持。
pauseOnExit 属性在获取时,
如果该 TextTrackCue 对象所表示的
文本轨道提示的
文本轨道提示退出时暂停标志已设置,
则必须返回 true;否则返回 false。设置时,如果新值为 true,
则必须设置文本轨道提示退出时暂停标志;
否则必须取消设置该标志。
以下是所有实现 TextTrackList 接口的对象,
都必须作为事件处理程序 IDL 属性支持的
事件处理程序
(以及其对应的事件处理程序事件类型):
| 事件处理程序 | 事件处理程序事件类型 |
|---|---|
onchange |
change
|
onaddtrack |
addtrack
|
onremovetrack |
removetrack
|
以下是所有实现 TextTrack 接口的对象,
都必须作为事件处理程序 IDL 属性支持的
事件处理程序
(以及其对应的事件处理程序事件类型):
| 事件处理程序 | 事件处理程序事件类型 |
|---|---|
oncuechange
所有当前引擎均支持。 Firefox31+Safari6+Chrome23+
Opera12.1+Edge79+ Edge(旧版)12+Internet Explorer10+ Firefox Android?Safari iOS7+Chrome Android?WebView Android?Samsung Internet?Opera Android12.1+ |
cuechange
|
以下是所有实现 TextTrackCue 接口的对象,
都必须作为事件处理程序 IDL 属性支持的
事件处理程序
(以及其对应的事件处理程序事件类型):
| 事件处理程序 | 事件处理程序事件类型 |
|---|---|
onenter
所有当前引擎均支持。 Firefox31+Safari6+Chrome23+
Opera12.1+Edge79+ Edge(旧版)12+Internet Explorer10+ Firefox Android?Safari iOS7+Chrome Android?WebView Android?Samsung Internet?Opera Android12.1+ |
enter
|
onexit
所有当前引擎均支持。 Firefox31+Safari6+Chrome23+
Opera12.1+Edge79+ Edge(旧版)12+Internet Explorer10+ Firefox Android?Safari iOS7+Chrome Android?WebView Android?Samsung Internet?Opera Android12.1+ |
exit
|
本节为非规范性内容。
文本轨道可用于存储与媒体数据相关的数据,以实现交互式或增强视图。
例如,显示体育赛事转播的页面可以包含当前比分信息。 假设某项机器人竞赛正在直播。可以将比分叠加到图像上,如下所示:
为了使用户定位到视频中的任意位置时比分显示都能正确渲染, 元数据文本轨道提示需要持续与该比分相适应的时间长度。 例如,在上面的画面中,可能有一个持续整场比赛、给出比赛编号的提示, 一个持续到蓝方联盟比分发生变化的提示,以及一个持续到红方联盟比分发生变化的提示。 如果视频只是直播事件的流,则右下角的时间大概会根据当前视频时间自动推导, 而不是基于提示。但是,如果视频只是精彩片段,那么该时间也可以通过提示给出。
以下展示了这些内容在 WebVTT 文件中的片段可能是什么样子:
WEBVTT ... 05:10:00.000 --> 05:12:15.000 matchtype:qual matchnumber:37 ... 05:11:02.251 --> 05:11:17.198 red:78 05:11:03.672 --> 05:11:54.198 blue:66 05:11:17.198 --> 05:11:25.912 red:80 05:11:25.912 --> 05:11:26.522 red:83 05:11:26.522 --> 05:11:26.982 red:86 05:11:26.982 --> 05:11:27.499 red:89 ...
这里的关键在于,信息通过持续覆盖相关事件适用时间长度的提示给出。 相反,如果只在比分变化时使用零长度(或非常短、接近零长度)的提示给出比分, 例如在 05:11:17.198 给出“red+2”、在 05:11:25.912 给出“red+3”等, 就会出现问题:最主要的是,定位会更难实现,因为脚本必须遍历整个提示列表, 以确保没有遗漏任何通知;此外,如果提示很短,除非脚本专门监听这些提示, 否则脚本可能永远看不到它们处于活动状态。
以这种方式使用提示时,鼓励作者使用 cuechange
事件更新当前注释。(特别是,使用 timeupdate
事件不太合适,因为即使提示没有发生变化,也需要执行工作;更重要的是,
由于 timeupdate
事件受到频率限制,它会在元数据提示变为活动状态与显示更新之间引入更高延迟。)
需要使用 URL
标识 AudioTrack
的 kind
或 VideoTrack
的 kind
IDL 属性返回值,或者标识文本轨道种类的其他规范或格式,
必须使用 about:html-kind
URL。
controls
属性是一个布尔属性。
如果存在,则表示作者没有提供脚本化控制器,并希望用户代理提供自己的一组控件。
如果该属性存在,或者对于该媒体元素禁用了脚本,则用户代理应向用户公开用户界面。 此用户界面应包含开始播放、暂停播放、定位到内容中的任意位置 (如果内容支持任意定位)、更改音量、更改隐藏式字幕或嵌入式手语轨道的显示、 选择不同的音频轨道或启用音频描述,以及以更适合用户的方式显示媒体内容 (例如全屏视频或在独立的可调整大小窗口中显示)等功能。还可以提供其他控件。
不过,即使该属性不存在,用户代理也可以提供影响媒体资源播放的控件
(例如播放、暂停、定位、轨道选择和音量控件),但这些功能不应干扰页面的正常渲染。
例如,可以在媒体元素的上下文菜单、平台媒体键或遥控器中公开这些功能。
用户代理可以简单地按照上述方式向用户公开用户界面
(就像存在 controls 属性一样)来实现。
如果用户代理通过在媒体元素上方显示控件来向用户公开用户界面,
则当用户代理与此界面交互时,应抑制所有用户交互事件。
(例如,如果用户点击视频的播放控件,则不会同时在页面元素处触发 mousedown 事件等。)
在可能的情况下(具体而言,包括开始、停止、暂停和恢复播放;定位; 更改播放速率;快进或倒退;列出、启用和禁用文本轨道;以及静音或更改音量), 用户代理公开的用户界面功能必须通过上述 DOM API 实现,从而例如触发所有相同的事件。
快进或倒退等功能必须仅通过更改 playbackRate
属性来实现(不得更改 defaultPlaybackRate 属性)。
定位必须通过定位到 媒体元素的 媒体时间线中的请求位置来实现。 对于定位到任意位置会很慢的媒体资源,鼓励用户代理在响应用户操作定位条等近似位置界面进行定位时, 使用为速度近似标志。
media.volume [ = value ]
所有当前引擎均支持。
返回当前播放音量,其值是 0.0 到 1.0 范围内的数字,其中 0.0 最安静,1.0 最响亮。
可以设置,以更改音量。
如果新值不在 0.0 到 1.0 的范围内,则抛出一个
"IndexSizeError" DOMException。
media.muted [ = value ]
所有当前引擎均支持。
如果音频已静音,从而覆盖 volume
属性,则返回 true;如果正在采用 volume
属性,则返回 false。
可以设置,以更改音频是否静音。
媒体元素具有一个 播放音量,它是 0.0(静音)到 1.0(最响亮)范围内的数值。 音量初始值应为 1.0,但用户代理可以按站点或以其他方式跨会话记住最后设置的值, 因此音量可能以其他值开始。
要将媒体元素 element 的 播放音量设置为数字 value:
volume 设置器步骤为:
如果给定值不在包含端点的 0.0 到 1.0 范围内,则抛出一个
"IndexSizeError" DOMException。
如果以下任一条件为 true,则媒体元素处于静音状态:
其静音状态为 true。
播放方向为向后。
其 playbackRate
过低或过高,以至于用户代理无法有效播放音频。
每个媒体元素都有一个
静音状态,其值为 true、false 或
"default";其初始值为 "default"。
用户代理可以将媒体元素的静音状态设置为 true 或 false
(例如,按站点或以其他方式跨会话记住最后设置的值)。
要将媒体元素 element 的 静音状态设置为布尔值 value:
用户代理具有一个关联的音量锁定状态(布尔值)。 其值由实现定义,并决定播放音量是否生效。
元素的有效媒体音量按以下方式确定:
媒体元素上的
muted 内容属性是一个
布尔属性,用于给出静音的默认值。
一旦调用了 muted 设置器,
或者用户表明了偏好,此属性就不再产生任何其他影响。
此视频(一个广告)会自动播放,但为了避免打扰用户,它会无声播放,并允许用户打开声音。 如果视频在没有用户交互的情况下取消静音,用户代理可以暂停该视频。
< video src = "adverts.cgi?kind=video" controls autoplay loop muted ></ video > 所有当前引擎均支持。
实现 TimeRanges 接口的对象表示一个时间
范围(时间段)列表。
[Exposed =Window ]
interface TimeRanges {
readonly attribute unsigned long length ;
double start (unsigned long index );
double end (unsigned long index );
};media.length
所有当前引擎均支持。
返回对象中的范围数量。
time = media.start(index)
所有当前引擎均支持。
返回具有给定索引的范围的开始时间。
如果索引超出范围,则抛出一个 "IndexSizeError" DOMException。
time = media.end(index)
所有当前引擎均支持。
返回具有给定索引的范围的结束时间。
如果索引超出范围,则抛出一个 "IndexSizeError" DOMException。
TimeRanges 对象具有
范围,即由零个或多个时间范围组成的
列表。
一个开始,以秒为单位的数字。
一个结束,以秒为单位的数字。
start(index) 方法步骤为:
如果 index 大于或等于 this 的
范围的
大小,则抛出一个
"IndexSizeError" DOMException。
end(index) 方法步骤为:
如果 index 大于或等于 this 的
范围的
大小,则抛出一个
"IndexSizeError" DOMException。
如果对于 TimeRanges 对象的
范围中的每个
时间范围,以下条件均为 true,
则该对象是一个规范化的
TimeRanges 对象:
换句话说,这种对象中的时间范围是有序的、互不重叠且互不接触的 (相邻的范围会合并为一个更大的时间范围)。一个时间范围可以为空(仅引用某个时间点), 例如,当媒体元素暂停时, 如果用户代理除当前帧外已丢弃整个媒体资源,则可以用它表示当前仅缓冲了一帧。
因此,一个时间范围的结束,将等于其后相邻 (接触但不重叠)的时间范围的开始。类似地,一个覆盖以零为起点的整个时间线的 时间范围, 其开始将等于零,而其 结束 将等于时间线的持续时间。
媒体元素的
buffered、
seekable 和
played IDL 属性所返回对象
使用的时间线,必须是该元素的媒体时间线。
TrackEvent 接口所有当前引擎均支持。
[Exposed =Window ]
interface TrackEvent : Event {
constructor (DOMString type , optional TrackEventInit eventInitDict = {});
readonly attribute (VideoTrack or AudioTrack or TextTrack )? track ;
};
dictionary TrackEventInit : EventInit {
(VideoTrack or AudioTrack or TextTrack )? track = null ;
};event.track
所有当前引擎均支持。
返回事件所涉及的轨道对象(TextTrack、AudioTrack 或
VideoTrack)。
track
属性必须返回其初始化时所使用的值。它表示该事件的上下文信息。
本节为非规范性内容。
作为上述处理模型的一部分,以下事件会在媒体元素上触发:
| 事件名称 | 接口 | 触发时机…… | 前置条件 |
|---|---|---|---|
loadstart
HTMLMediaElement/loadstart_event 所有当前引擎均支持。 Firefox6+Safari4+Chrome3+
Opera12.1+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android?Samsung Internet?Opera Android12.1+ |
Event
|
作为资源选择算法的一部分,用户代理开始查找 媒体数据。 | networkState
等于 NETWORK_LOADING
|
progress
HTMLMediaElement/progress_event 所有当前引擎均支持。 Firefox6+Safari3.1+Chrome3+
Opera12.1+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android?Samsung Internet?Opera Android12.1+ |
Event
|
用户代理正在获取媒体数据。 | networkState
等于 NETWORK_LOADING
|
suspend
HTMLMediaElement/suspend_event 所有当前引擎均支持。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
Event
|
用户代理当前有意不获取媒体数据。 | networkState
等于 NETWORK_IDLE
|
abort
所有当前引擎均支持。 Firefox9+Safari3.1+Chrome3+
Opera12.1+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android?Samsung Internet?Opera Android12.1+ |
Event
|
用户代理在媒体数据完全下载之前停止获取, 但不是由于错误。 | error 是一个代码为
MEDIA_ERR_ABORTED
的对象。networkState
等于 NETWORK_EMPTY
或
NETWORK_IDLE,
具体取决于下载何时中止。
|
error
所有当前引擎均支持。 Firefox6+Safari3.1+Chrome3+
Opera11.6+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android?Samsung Internet?Opera Android12+ |
Event
|
获取媒体数据时发生错误, 或者资源类型不是受支持的媒体格式。 | error 是一个代码为
MEDIA_ERR_NETWORK
或更高值的对象。networkState 等于
NETWORK_EMPTY 或
NETWORK_IDLE,
具体取决于下载何时中止。
|
emptied
HTMLMediaElement/emptied_event 所有当前引擎均支持。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
Event
|
一个此前其 networkState
不处于 NETWORK_EMPTY
状态的媒体元素,刚刚切换到该状态
(原因可能是加载期间发生即将报告的致命错误,也可能是在
资源选择算法已运行时调用了
load() 方法)。
|
networkState
为 NETWORK_EMPTY;
所有 IDL 属性均处于其初始状态。
|
stalled
HTMLMediaElement/stalled_event 所有当前引擎均支持。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
Event
|
用户代理正在尝试获取媒体数据,但数据意外地未能到达。 | networkState
为 NETWORK_LOADING。
|
loadedmetadata
HTMLMediaElement/loadedmetadata_event 所有当前引擎均支持。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
Event
|
用户代理刚刚确定了媒体资源的持续时间和尺寸,并且 文本轨道已就绪。 | readyState
首次新变为等于或大于 HAVE_METADATA。
|
loadeddata
HTMLMediaElement/loadeddata_event 所有当前引擎均支持。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
Event
|
用户代理首次能够渲染当前播放位置处的 媒体数据。 | readyState
首次新增加到等于或大于 HAVE_CURRENT_DATA。
|
canplay
HTMLMediaElement/canplay_event 所有当前引擎均支持。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
Event
|
用户代理可以恢复播放媒体数据, 但估计如果现在开始播放,则媒体资源无法以当前播放速率一直渲染到结尾, 而无需停止以进一步缓冲内容。 | readyState
新增加到等于或大于 HAVE_FUTURE_DATA。
|
canplaythrough
HTMLMediaElement/canplaythrough_event 所有当前引擎均支持。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
Event
|
用户代理估计,如果现在开始播放,则媒体资源可以按当前播放速率一直渲染到结尾, 而无需停止以进一步缓冲。 | readyState
新变为等于 HAVE_ENOUGH_DATA。
|
playing
HTMLMediaElement/playing_event 所有当前引擎均支持。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
Event
|
在因缺少媒体数据而暂停或延迟之后, 播放已准备好开始。 | readyState
新变为大于或等于
HAVE_FUTURE_DATA
且 paused 为 false,
或者 paused
新变为 false 且 readyState
大于或等于 HAVE_FUTURE_DATA。
即使此事件触发,该元素仍可能并非可能正在播放,例如该元素因
用户交互而暂停,或因
带内内容而暂停。
|
waiting
HTMLMediaElement/waiting_event 所有当前引擎均支持。 Firefox6+Safari3.1+Chrome3+
Opera12.1+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android12.1+ |
Event
|
由于下一帧不可用,播放已停止,但用户代理预期该帧最终会变为可用。 | readyState
小于或等于 HAVE_CURRENT_DATA,
且 paused 为 false。
要么 seeking 为 true,
要么当前播放位置不包含在
buffered
中的任何范围内。播放也可能因其他原因停止,而 paused
仍为 false,
但这些原因不会触发此事件(当这些情况解除时,也不会另外触发
playing 事件):
例如,播放已结束、
播放因错误而停止,或者元素已
因用户交互而暂停或
因带内内容而暂停。
|
seeking
HTMLMediaElement/seeking_event 所有当前引擎均支持。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
Event
|
seeking IDL 属性
变为 true,并且用户代理已开始定位到新位置。
|
|
seeked
所有当前引擎均支持。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
Event
|
在当前播放位置发生变化后,
seeking IDL 属性
变为 false。
|
|
ended
所有当前引擎均支持。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
Event
|
由于到达媒体资源的结尾,播放已停止。 | currentTime
等于媒体资源的结尾;
ended 为 true。
|
durationchange
HTMLMediaElement/durationchange_event 所有当前引擎均支持。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
Event
|
duration 属性
刚刚更新。
|
|
timeupdate
HTMLMediaElement/timeupdate_event 所有当前引擎均支持。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
Event
|
当前播放位置作为正常播放的一部分发生变化, 或以特别值得关注的方式发生变化,例如不连续地变化。 | |
play
所有当前引擎均支持。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
Event
|
元素不再暂停。在 play()
方法返回后,或者在 autoplay
属性导致播放开始时触发。
|
paused
新变为 false。
|
pause
所有当前引擎均支持。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
Event
|
元素已暂停。在 pause()
方法返回后触发。
|
paused
新变为 true。
|
ratechange
HTMLMediaElement/ratechange_event 所有当前引擎均支持。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
Event
|
defaultPlaybackRate
或 playbackRate
属性刚刚更新。
|
|
resize
|
Event
|
videoWidth 和
videoHeight
属性中的一个或两个刚刚更新。
|
媒体元素是一个
video 元素;
readyState
不是 HAVE_NOTHING
|
volumechange
HTMLMediaElement/volumechange_event 所有当前引擎均支持。 Firefox6+Safari3.1+Chrome3+
Opera12.1+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android12.1+ |
Event
|
volume 属性或
muted 属性已更改。
在相关属性的设置器返回后触发。
|
以下事件会在 source 元素上触发:
| 事件名称 | 接口 | 触发时机…… |
|---|---|---|
error
|
Event
|
获取媒体数据时发生错误, 或者资源类型不是受支持的媒体格式。 |
以下事件会在 AudioTrackList、VideoTrackList 和
TextTrackList 对象上触发:
| 事件名称 | 接口 | 触发时机…… |
|---|---|---|
change
所有当前引擎均支持。 Firefox🔰 33+Safari7+Chrome🔰 37+
Opera?Edge🔰 79+ Edge(旧版)否Internet Explorer10+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? 所有当前引擎均支持。 Firefox31+Safari7+Chrome33+
Opera?Edge79+ Edge(旧版)18Internet Explorer否 Firefox Android?Safari iOS?Chrome Android?WebView Android4.4+Samsung Internet?Opera Android? 所有当前引擎均支持。 Firefox🔰 33+Safari7+Chrome🔰 37+
Opera?Edge🔰 79+ Edge(旧版)否Internet Explorer10+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? |
Event
|
轨道列表中的一个或多个轨道已启用或禁用。 |
addtrack
所有当前引擎均支持。 Firefox🔰 33+Safari7+Chrome🔰 37+
Opera?Edge🔰 79+ Edge(旧版)否Internet Explorer10+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? 所有当前引擎均支持。 Firefox31+Safari6+Chrome23+
Opera12.1+Edge79+ Edge(旧版)12+Internet Explorer11 Firefox Android?Safari iOS7+Chrome Android?WebView Android?Samsung Internet?Opera Android12.1+ 所有当前引擎均支持。 Firefox🔰 33+Safari7+Chrome🔰 37+
Opera?Edge🔰 79+ Edge(旧版)否Internet Explorer10+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? |
TrackEvent
|
一个轨道已添加到轨道列表中。 |
removetrack
AudioTrackList/removetrack_event 所有当前引擎均支持。 Firefox🔰 33+Safari7+Chrome🔰 37+
Opera?Edge🔰 79+ Edge(旧版)否Internet Explorer10+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? TextTrackList/removetrack_event 所有当前引擎均支持。 Firefox31+Safari7+Chrome33+
Opera20+Edge79+ Edge(旧版)18Internet Explorer否 Firefox Android?Safari iOS?Chrome Android?WebView Android4.4+Samsung Internet?Opera Android20+ VideoTrackList/removetrack_event 所有当前引擎均支持。 Firefox🔰 33+Safari7+Chrome🔰 37+
Opera?Edge🔰 79+ Edge(旧版)否Internet Explorer10+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? |
TrackEvent
|
一个轨道已从轨道列表中移除。 |
以下事件会在 TextTrack 对象和
track 元素上触发:
| 事件名称 | 接口 | 触发时机…… |
|---|---|---|
cuechange
HTMLTrackElement/cuechange_event 所有当前引擎均支持。 Firefox68+Safari10+Chrome32+
Opera19+Edge79+ Edge(旧版)14+Internet Explorer否 Firefox Android?Safari iOS?Chrome Android?WebView Android4.4.3+Samsung Internet?Opera Android19+ 所有当前引擎均支持。 Firefox31+Safari6+Chrome23+
Opera12.1+Edge79+ Edge(旧版)12+Internet Explorer10+ Firefox Android?Safari iOS7+Chrome Android?WebView Android?Samsung Internet?Opera Android12.1+ |
Event
|
轨道中的一个或多个提示变为活动状态,或者不再处于活动状态。 |
以下事件会在 track 元素上触发:
| 事件名称 | 接口 | 触发时机…… |
|---|---|---|
error
|
Event
|
获取轨道数据时发生错误,或者资源类型不是受支持的文本轨道格式。 |
load
|
Event
|
轨道数据已获取并成功处理。 |
以下事件会在 TextTrackCue
对象上触发:
| 事件名称 | 接口 | 触发时机…… |
|---|---|---|
enter
所有当前引擎均支持。 Firefox31+Safari6+Chrome23+
Opera12.1+Edge79+ Edge(旧版)12+Internet Explorer10+ Firefox Android?Safari iOS7+Chrome Android?WebView Android?Samsung Internet?Opera Android12.1+ |
Event
|
提示已变为活动状态。 |
exit
所有当前引擎均支持。 Firefox31+Safari6+Chrome23+
Opera12.1+Edge79+ Edge(旧版)12+Internet Explorer10+ Firefox Android?Safari iOS7+Chrome Android?WebView Android?Samsung Internet?Opera Android12.1+ |
Event
|
提示已不再处于活动状态。 |
video 和
audio
元素的主要安全和隐私影响源于跨源嵌入媒体的能力。威胁可以沿两个方向传播:
从恶意内容传播到受害页面,以及从恶意页面传播到受害内容。
如果受害页面嵌入恶意内容,威胁在于该内容可能包含试图与嵌入该内容的
Document
交互的脚本代码。为避免这种情况,用户代理必须确保内容无法访问嵌入页面。
对于使用 DOM 概念的媒体内容,必须将嵌入内容视为位于其自身无关的
顶级可遍历对象中。
例如,如果在 video
元素中嵌入 SVG 动画,用户代理不会允许它访问外部页面的 DOM。从 SVG 资源中的脚本来看,
该 SVG 文件将表现为位于一个没有父级的独立顶级可遍历对象中。
如果恶意页面嵌入受害内容,威胁在于嵌入页面可能从该内容中获得其原本无权访问的信息。
API 确实公开了一些信息:媒体是否存在、其类型、持续时间、尺寸以及其主机的性能特征。
此类信息本身可能已经存在问题,但实际上,或多或少可以使用 img
元素获得相同信息,因此这被认为是可以接受的。
但是,如果用户代理进一步公开内容中的元数据(例如字幕),则可能获得明显更加敏感的信息。
因此,只有当视频资源使用 CORS 时,才会公开这些信息。crossorigin
属性允许作者启用 CORS。[FETCH]
如果没有此限制,攻击者可以诱骗位于企业网络中的用户访问某个站点, 该站点会尝试从企业内部网中先前泄露的位置加载视频。如果此类视频包含新产品的机密计划, 那么能够读取字幕将造成严重的机密性泄露。
本节是非规范性的。
在机顶盒或移动电话等小型设备上播放音频和视频资源时,
通常会受到设备中有限硬件资源的制约。例如,一台设备可能只
支持同时播放三个视频。因此,在播放完毕后释放
媒体
元素所占用的资源是一种良好实践,具体做法可以是
非常谨慎地移除对该元素的所有引用并允许对其进行垃圾
回收,或者更好的做法是将该元素的 src
属性设置为空字符串。如果设置了 srcObject,
则应改为将 srcObject
设置为 null。
同样,当播放速率不恰好为 1.0 时,硬件、软件或格式限制 可能会导致视频丢帧,以及音频断续或静音。
本节是非规范性的。
媒体元素 API 各方面的实现精确程度 被视为实现质量问题。
例如,在实现 buffered
属性时,
实现报告已缓冲范围的精确程度取决于
用户代理检查数据的细致程度。由于 API 以时间形式报告范围,而数据是
以字节流形式获得的,接收可变比特率流的用户代理可能只有实际解码
全部数据才能确定精确时间。不过,并不要求用户代理
这样做;它们可以返回估算值(例如基于目前观察到的平均比特率),并在
获得更多信息时对其进行修订。
一般而言,建议用户代理采取保守而非乐观的方式。例如, 在并非所有内容都已缓冲时报告所有内容均已缓冲会很糟糕。
另一个实现质量问题是在编解码器 仅为正向播放而设计时反向播放视频(例如关键帧很少且彼此相距很远, 中间帧仅包含相对于上一帧的差异)。用户代理可能实现得很差, 例如只显示关键帧;不过,更好的实现会完成更多工作,从而获得 更好的效果,例如实际正向解码部分视频、存储完整帧,然后 反向播放这些帧。
同样,尽管允许实现在任何时候丢弃已缓冲的数据(并不 要求用户代理在媒体 元素的整个生命周期内保留所获得的全部媒体数据),这仍然是实现质量问题:建议拥有足够资源 保留所有数据的用户代理这样做,因为这可以提供更好的用户体验。例如, 如果用户正在观看直播流,用户代理可以只允许用户查看 实时视频;不过,更好的用户代理会缓冲所有内容,并允许用户在 较早的内容中跳转、暂停以及正向和反向播放等。
当一个已暂停的媒体 元素被从 文档中移除,并且在事件 循环下一次到达步骤 1之前未重新插入时,建议资源受限的实现利用 该机会释放媒体元素使用的所有硬件资源(例如视频平面、网络资源和 数据缓冲区)。(不过,用户代理仍然必须记录 播放位置等信息,以防稍后重新开始播放。)
map
元素所有当前引擎均支持。
所有当前引擎均支持。
name — 要通过 usemap 属性引用的图像映射名称
[Exposed =Window ]
interface HTMLMapElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect ] attribute DOMString name ;
[SameObject ] readonly attribute HTMLCollection areas ;
};map 元素与 img 元素以及作为其后代的任意 area 元素结合使用时,定义一个图像映射。该元素
表示其子级。
name 属性为
映射提供一个名称,以便可以引用它。该
属性必须存在,并且必须
具有不包含任何 ASCII 空白的非空值。
name 属性的值不得
等于同一
树中另一个 map 元素的 name
属性值。如果还指定了
id 属性,则两个
属性必须具有相同的值。
map.areas返回一个 HTMLCollection,
其中包含 map 中的
area 元素。
areas
属性必须返回一个以 map 元素为根的 HTMLCollection,
其
过滤器仅匹配 area
元素。
图像映射可以与页面上的其他内容结合定义,以便于维护。 此示例展示了一个页面,其顶部具有图像映射,底部具有一组对应的 文本链接。
<!DOCTYPE HTML>
< HTML LANG = "EN" >
< TITLE > Babies™: Toys</ TITLE >
< HEADER >
< H1 > Toys</ H1 >
< IMG SRC = "/images/menu.gif"
ALT = "Babies™ navigation menu. Select a department to go to its page."
USEMAP = "#NAV" >
</ HEADER >
...
< FOOTER >
< MAP NAME = "NAV" >
< P >
< A HREF = "/clothes/" > Clothes</ A >
< AREA ALT = "Clothes" COORDS = "0,0,100,50" HREF = "/clothes/" > |
< A HREF = "/toys/" > Toys</ A >
< AREA ALT = "Toys" COORDS = "100,0,200,50" HREF = "/toys/" > |
< A HREF = "/food/" > Food</ A >
< AREA ALT = "Food" COORDS = "200,0,300,50" HREF = "/food/" > |
< A HREF = "/books/" > Books</ A >
< AREA ALT = "Books" COORDS = "300,0,400,50" HREF = "/books/" >
</ P >
</ MAP >
</ FOOTER > area
元素所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
map
元素时。alt — 图像不可用时使用的
替代文本
coords — 要在图像映射中创建的形状的坐标
shape — 要在图像映射中创建的形状类型
href — 超链接的地址
target — 用于超链接导航的可导航对象
download —
是否下载资源而不是导航到该资源,以及在下载时使用的文件名
ping — 要 ping 的 URL
rel — 文档中包含超链接的位置与目标资源之间的关系
referrerpolicy
— 元素发起的获取所使用的引用来源策略
hreflang —
链接资源的语言
type — 被引用资源
类型的提示
href 属性:对于作者;对于实现者。href。
[Exposed =Window ]
interface HTMLAreaElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect ] attribute DOMString alt ;
[CEReactions , Reflect ] attribute DOMString coords ;
[CEReactions , Reflect ] attribute DOMString shape ;
[CEReactions , Reflect ] attribute DOMString download ;
[CEReactions , Reflect ] attribute USVString ping ;
[CEReactions , Reflect ] attribute DOMString rel ;
[SameObject , PutForwards =value , Reflect="rel"] readonly attribute DOMTokenList relList ;
[CEReactions ] attribute DOMString referrerPolicy ;
// also has obsolete members
};
HTMLAreaElement includes HyperlinkElementUtils ;
HTMLAreaElement includes HTMLHyperlinkElementUtils ;area 元素表示带有一些文本并在图像映射上具有对应区域的超链接,或者图像映射上的无效区域。
具有父节点的 area 元素
必须具有一个祖先 map
元素。
如果 area 元素具有
href
属性,则 area
元素表示一个超链接。在这种情况下,
alt 属性必须
存在。它指定超链接的文本。其值必须是这样一段文本:当它与图像
映射中其他超链接所指定的文本以及
图像的替代文本一起呈现,但不呈现图像本身时,能够向用户提供与该超链接
在不使用其文本但将其形状应用于图像时所提供的相同类型的选择。如果同一图像映射中存在另一个
area 元素指向相同资源,并且
具有非空白的 alt 属性,则 alt 属性可以留空。
如果 area 元素没有
href
属性,则无法选择该元素所表示的区域,并且必须省略 alt 属性。
在这两种情况下,shape 和
coords 属性指定该
区域。
shape 属性
是一个具有以下关键字和状态的枚举属性:
| 关键字 | 符合要求 | 状态 | 简要说明 |
|---|---|---|---|
circle
|
圆形状态 | 指定一个圆,在 coords 属性中恰好使用三个整数。
|
|
circ
|
否 | ||
default
|
默认状态 | 该区域是整个图像。(不使用 coords
属性。)
|
|
poly
|
多边形状态 | 指定一个多边形,在 coords 属性中使用至少六个整数。
|
|
polygon
|
否 | ||
rect
|
矩形状态 | 指定一个矩形,在 coords 属性中恰好使用四个整数。
|
|
rectangle
|
否 |
如果指定了 coords
属性,则它必须包含一个有效浮点数列表。该
属性
为 shape
属性描述的形状提供坐标。此属性的处理作为图像
映射处理模型的一部分进行描述。
在圆形状态下,
area 元素必须具有
包含三个整数的 coords 属性,
最后一个整数必须为非负数。第一个整数必须是从图像左边缘到
圆心的距离,以 CSS
像素为单位;第二个整数必须是从图像上边缘到圆心的距离,以 CSS
像素为单位;第三个整数
必须是圆的半径,同样以 CSS 像素为单位。
在默认状态下,
area 元素不得具有
coords
属性。(该区域是整个图像。)
在多边形状态下,
area 元素必须具有
至少包含六个整数的 coords 属性,
并且整数数量必须为偶数。每对整数必须
分别表示一个坐标,即以 CSS 像素
为单位、相对于图像左边缘和上边缘的距离,并且所有坐标必须按顺序表示
多边形的各个点。
在矩形状态下,
area 元素必须具有
恰好包含四个整数的 coords 属性,
其中第一个整数必须小于第三个整数,第二个
整数必须小于第四个整数。这四个点必须分别表示
从图像左边缘到矩形左侧的距离、从图像上边缘
到矩形上侧的距离、从图像左边缘到矩形右侧的距离,以及从图像上
边缘到矩形下侧的距离,均以 CSS 像素为单位。
当用户代理允许用户跟随超链接或
下载超链接,而这些超链接是使用
该
area 元素创建的时,href、target、download 和 ping 属性决定如何跟随该链接。rel 属性可用于
在用户跟随链接之前向用户指示目标资源可能的
性质。
如果不存在 href 属性,则必须省略 target、download、ping、
rel、referrerpolicy、
hreflang 和
type 属性。
如果在
area 元素上指定了 itemprop
属性,则还必须指定 href 属性。
HTMLAreaElement/referrerPolicy
所有当前引擎均支持。
IDL 属性 referrerPolicy 必须反映 referrerpolicy
内容属性,并仅限于
已知值。
图像映射允许将图像上的几何区域与超链接关联。
可以通过在 img 元素上指定
usemap
属性,将以 img 元素形式存在的图像
与以 map 元素形式存在的图像映射关联。
如果指定了 usemap 属性,
则它必须是指向 map 元素的有效
哈希名称引用。
考虑一个如下所示的图像:
如果我们只希望彩色区域可点击,可以按如下方式实现:
< p >
Please select a shape:
< img src = "shapes.png" usemap = "#shapes"
alt = "Four shapes are available: a red hollow box, a green circle, a blue triangle, and a yellow four-pointed star." >
< map name = "shapes" >
< area shape = rect coords = "50,50,100,100" > <!-- the hole in the red box -->
< area shape = rect coords = "25,25,125,125" href = "red.html" alt = "Red box." >
< area shape = circle coords = "200,75,50" href = "green.html" alt = "Green circle." >
< area shape = poly coords = "325,25,262,125,388,125" href = "blue.html" alt = "Blue triangle." >
< area shape = poly coords = "450,25,435,60,400,75,435,90,450,125,465,90,500,75,465,60"
href = "yellow.html" alt = "Yellow star." >
</ map >
</ p > 如果 img 元素
指定了 usemap
属性,则用户代理必须按如下方式处理它:
以该元素作为上下文节点,使用解析哈希名称
引用的规则,将属性值解析为对 map 元素的引用。
这将返回一个
元素(map)或 null。
如果返回 null,则返回。该图像最终并未与图像 映射关联。
否则,用户代理必须收集作为 map 后代的所有 area 元素。
令 areas 为该列表。
获得构成图像映射的 area
元素列表
(areas)后,交互式用户代理必须以两种方式之一处理该列表。
如果用户代理打算显示 img
元素所表示的文本,
则
必须使用以下步骤:
如果 areas 中存在另一个 area 元素,
其 href
属性具有相同的值,并且具有非空的 alt
属性,则从
areas 中移除所有没有 alt 属性,或者其
alt
属性值为空字符串的 area
元素。
areas 中剩余的每个 area 元素表示一个
超链接。应以与 img 的文本
相关联的方式向用户提供所有这些超链接。
在此上下文中,对于未指定 alt 属性,或者其 alt
属性为空字符串或其他不可见文本的 area 和 img 元素,
用户代理可以采用一种旨在表明缺少合适的
作者提供文本的由实现定义的方式来表示。
如果用户代理打算显示图像,并允许通过与图像交互来选择
超链接,则图像必须与一组分层形状关联,这些形状取自
areas 中的 area 元素,并按照树顺序的逆序排列
(因此,map 中最后指定的 area
元素是最底层形状,而 map 中按树顺序排列的
第一个元素是最顶层形状)。
必须按如下方式处理 areas 中的每个 area
元素,以获得要分层放置在图像上的形状:
查找该元素的 shape 属性
所表示的状态。
如果元素的 coords 属性存在,则使用解析浮点数列表的
规则解析该属性,并令
coords 列表为结果。如果该属性不存在,则令 coords 列表
为空列表。
如果 coords 列表中的项目数少于下表中针对 area 元素
当前状态给出的最小数量,则
该形状为空;返回。
| 状态 | 最小项目数 |
|---|---|
| 圆形 状态 | 3 |
| 默认 状态 | 0 |
| 多边形状态 | 6 |
| 矩形 状态 | 4 |
根据以下列表中与 shape
属性
状态对应的条目,检查 coords 列表中是否存在多余项目:
现在,元素所表示的形状是以下列表中与 shape 属性
状态对应的条目所描述的形状:
令 x 为 coords 中的第一个数,y 为第二个数,并令 r 为第三个数。
该形状是一个恰好覆盖整个图像的矩形。
令 xi 为 coords 中的第 (2i) 项,并令 yi 为 coords 中的第 (2i+1) 项 (coords 中第一项的索引为 0)。
令 the coordinates 为 (xi, yi), 将其解释为从图像左上角测量的 CSS 像素,其中 i 取从 0 到 (N/2)-1 的所有整数值, N 是 coords 中的项目数。
该形状是一个顶点由 the coordinates 给出的多边形,其 内部使用奇偶规则确定。[GRAPHICS]
令 x1 为 coords 中的第一个数,y1 为 第二个数,x2 为第三个数,并令 y2 为第四个 数。
该形状是一个矩形,其左上角由坐标 (x1, y1) 给出,其 右下角由坐标 (x2, y2) 给出,这些坐标被解释为距图像左上角的 CSS 像素。
由于历史原因,坐标必须相对于由 CSS 'width' 和
'height' 属性造成任何拉伸后的
已显示图像进行解释(对于非 CSS 浏览器,则使用图像元素的
width 和 height 属性——CSS 浏览器会将
这些属性映射到上述 CSS 属性)。
浏览器缩放功能以及使用 CSS 或 SVG 应用的变换不会影响 坐标。
按照上述算法,与一组分层形状关联的图像之间的指针设备交互
必须导致相关用户交互事件首先在覆盖指针设备所指示点的最顶层
形状上触发(如果存在),如果没有形状覆盖该点,则在图像元素
本身上触发。用户代理还可以允许选择并激活表示超链接的各个
area 元素
(例如使用键盘)。
由于一个 map
元素(及其 area 元素)可以与
多个 img 元素关联,因此一个
area
元素可能对应文档的多个可聚焦区域。
图像映射是实时的;如果 DOM 发生变化,则用户 代理必须表现得如同其已重新运行图像映射算法。
HTML/HTML5/HTML5_Parser#Inline_SVG_and_MathML_support
所有当前引擎均支持。
MathML math 元素属于嵌入内容、
短语内容、流式内容和可感知内容
类别,以用于本规范中的内容模型。
当 MathML annotation-xml 元素包含来自
HTML 命名空间的元素时,这些元素必须全部是流式内容。
当 MathML 标记元素(mi、
mo、
mn、
ms
和 mtext)
是 HTML 元素的后代时,它们可以包含
来自 HTML 命名空间的短语内容元素。
对于在内容模型不允许直接文本的 MathML
元素中发现的、除元素间空白之外的文本,用户代理必须进行处理:
就 MathML 内容模型、布局和渲染而言,假装该文本实际上被包装在一个 MathML
mtext 元素中。(不过,此类文本并不符合要求。)
对于内容不匹配元素内容模型的任何 MathML 元素,用户代理必须表现得如同:
为了 MathML 布局和渲染,该元素已被一个包含适当错误消息的 MathML
merror 元素替换。
MathML 元素的语义由 MathML 和其他适用 规范定义。[MATHML]
以下是在 HTML 文档中使用 MathML 的示例:
<!DOCTYPE html>
< html lang = "en" >
< head >
< title > The quadratic formula</ title >
</ head >
< body >
< h1 > The quadratic formula</ h1 >
< p >
< math >
< mi > x</ mi >
< mo > =</ mo >
< mfrac >
< mrow >
< mo form = "prefix" > −</ mo > < mi > b</ mi >
< mo > ±</ mo >
< msqrt >
< msup > < mi > b</ mi > < mn > 2</ mn > </ msup >
< mo > −</ mo >
< mn > 4</ mn > < mo > </ mo > < mi > a</ mi > < mo > </ mo > < mi > c</ mi >
</ msqrt >
</ mrow >
< mrow >
< mn > 2</ mn > < mo > </ mo > < mi > a</ mi >
</ mrow >
</ mfrac >
</ math >
</ p >
</ body >
</ html > HTML/HTML5/HTML5_Parser#Inline_SVG_and_MathML_support
所有当前引擎均支持。
SVG svg 元素属于嵌入内容、
短语内容、流式内容和可感知内容
类别,以用于本规范中的内容模型。
当 SVG foreignObject 元素包含来自
HTML 命名空间的元素时,这些元素必须全部是流式内容。
HTML
文档内的 SVG
title 元素的内容模型是短语内容。(这进一步
限制了 SVG 2 中给出的
要求。)
SVG 元素的语义由 SVG 2 和其他适用 规范定义。[SVG]
doc = iframe.getSVGDocument()
doc = embed.getSVGDocument()
doc = object.getSVGDocument()
getSVGDocument() 方法步骤为:
如果 document 非空,并且它由XML 文件的
页面加载处理模型一节创建,因为在导航算法中,资源的计算类型为
image/svg+xml,则返回
document。
返回 null。
作者要求:可以在 img、iframe、
embed、object、video、父元素为 picture 元素时的 source 元素,以及当其 type
属性处于图像按钮状态时的
input 元素上指定 width 和
height 属性,以 CSS 像素为单位给出元素视觉内容的尺寸
(分别为相对于输出介质标称方向的宽度和高度)。如果指定了这些属性,则其值
必须是有效
非负整数。
给出的指定尺寸可能与资源本身指定的尺寸不同, 因为资源的分辨率可能与 CSS 像素分辨率不同。(在屏幕上, CSS 像素的分辨率为 96ppi,但通常 CSS 像素 分辨率取决于观看距离。)如果两个属性都已指定,则以下 语句之一必须为 true:
target ratio 是资源中自然宽度与
自然高度之比。specified width 和
specified
height 分别是 width 和
height 属性的值。
如果相关资源不同时具有自然宽度和自然高度, 则必须省略这两个属性。
如果两个属性均为 0,则表示该元素并非面向用户 (例如,它可能是页面浏览量统计服务的一部分)。
尺寸属性并非用于拉伸图像。
用户代理要求:用户代理应使用这些属性作为渲染提示。
对于 iframe、embed 和 object,IDL
属性为 DOMString;
对于 video 和
source,IDL
属性为 unsigned
long。
img 和
input 元素的对应 IDL 属性
在各自元素的
章节中定义,因为它们相对于这些元素的其他行为稍微更具体。
table
元素所有当前引擎均支持。
所有当前引擎均支持。
caption
元素,后跟
零个或多个
colgroup 元素,
再后跟可选的一个 thead 元素,之后是
零个或多个 tbody
元素,或者一个或多个 tr
元素,最后
可选地后跟一个 tfoot
元素,并且可以选择性地与一个或多个
脚本支持
元素混合出现。
[Exposed =Window ]
interface HTMLTableElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions ] attribute HTMLTableCaptionElement ? caption ;
HTMLTableCaptionElement createCaption ();
[CEReactions ] undefined deleteCaption ();
[CEReactions ] attribute HTMLTableSectionElement ? tHead ;
HTMLTableSectionElement createTHead ();
[CEReactions ] undefined deleteTHead ();
[CEReactions ] attribute HTMLTableSectionElement ? tFoot ;
HTMLTableSectionElement createTFoot ();
[CEReactions ] undefined deleteTFoot ();
[SameObject ] readonly attribute HTMLCollection tBodies ;
HTMLTableSectionElement createTBody ();
[SameObject ] readonly attribute HTMLCollection rows ;
HTMLTableRowElement insertRow (optional long index = -1);
[CEReactions ] undefined deleteRow (long index );
// also has obsolete members
};table 元素参与
表格
模型。表格具有由其后代给出的行、列和单元格。行和
列形成网格;表格的单元格必须完整覆盖该网格,且不得重叠。
用于确定是否满足此一致性要求的精确规则 在表格模型的说明中描述。
建议作者提供描述如何解读复杂表格的信息。 有关如何提供此类信息的指导见 下文。
不得将表格用作布局辅助工具。过去,一些 Web 作者曾在 HTML 中滥用表格来控制页面布局。这种用法不符合要求,因为尝试 从此类文档中提取表格数据的工具会得到非常令人困惑的结果。尤其是, 屏幕阅读器等无障碍工具的用户可能会发现很难浏览 使用表格进行布局的页面。
除使用 HTML 表格进行布局外,还有多种替代方案,例如 CSS 网格布局、CSS 弹性盒布局(“flexbox”)、CSS 多列布局、CSS 定位以及 CSS 表格模型。[CSS]
表格可能很难理解和浏览。为了帮助用户,除非用户代理已将 表格归类为(不符合要求的)布局表格,否则用户代理 应清晰地区分表格中的各个单元格。
建议作者和实现者考虑 使用下文所述的一些表格设计技术, 以使用户更容易浏览表格。
建议用户代理,尤其是对任意内容执行表格分析的用户代理, 寻找启发式方法,以确定哪些表格实际包含数据,哪些表格仅用于 布局。本规范未定义精确的启发式方法,但建议将以下内容 作为可能的指示因素:
| 特征 | 指示 |
|---|---|
使用值为 presentation
的 role
属性
|
可能是布局表格 |
使用值为不符合要求的 0 的不符合要求的 border 属性
|
可能是布局表格 |
使用值为 0 的不符合要求的 cellspacing 和
cellpadding
属性
|
可能是布局表格 |
使用 caption、thead 或 th 元素
|
可能不是布局表格 |
使用 headers 和 scope 属性
|
可能不是布局表格 |
使用值不为 0 的不符合要求的 border 属性
|
可能不是布局表格 |
| 使用 CSS 设置显式可见边框 | 可能不是布局表格 |
使用 summary 属性
|
不是良好的指示因素(过去布局表格和非布局表格都曾使用此属性) |
上述建议很可能是错误的。强烈建议实现者 提供反馈,详细说明其尝试创建布局表格 检测启发式方法时的经验。
如果一个 table 元素具有
一个(不符合要求的)summary
属性,并且用户代理尚未将该
表格归类为布局表格,则用户代理可以向用户报告该属性的内容。
table.caption [ = value ]
所有当前引擎均支持。
返回表格的 caption 元素。
可以对其进行设置,以替换 caption 元素。
caption = table.createCaption()
HTMLTableElement/createCaption
所有当前引擎均支持。
确保表格具有一个 caption
元素,并
返回该元素。
table.deleteCaption()
HTMLTableElement/deleteCaption
所有当前引擎均支持。
确保表格不具有 caption
元素。
table.tHead [ = value ]
所有当前引擎均支持。
返回表格的 thead 元素。
可以对其进行设置,以替换 thead
元素。如果新
值不是
thead 元素,则抛出
"HierarchyRequestError"
DOMException。
thead = table.createTHead()
所有当前引擎均支持。
确保表格具有一个 thead 元素,并返回
该元素。
table.deleteTHead()
所有当前引擎均支持。
确保表格不具有 thead 元素。
table.tFoot [ = value ]
所有当前引擎均支持。
返回表格的 tfoot 元素。
可以对其进行设置,以替换 tfoot
元素。如果新
值不是
tfoot 元素,则抛出
"HierarchyRequestError"
DOMException。
tfoot = table.createTFoot()
所有当前引擎均支持。
确保表格具有一个 tfoot 元素,并返回
该元素。
table.deleteTFoot()
所有当前引擎均支持。
确保表格不具有 tfoot 元素。
table.tBodies
所有当前引擎均支持。
返回一个由表格的 tbody 元素组成的
HTMLCollection。
tbody = table.createTBody()
所有当前引擎均支持。
创建一个 tbody
元素,将其插入表格,并返回该元素。
table.rows
所有当前引擎均支持。
返回一个由表格的 tr 元素组成的
HTMLCollection。
tr = table.insertRow([ index ])
所有当前引擎均支持。
创建一个 tr 元素,并在
需要时同时创建一个 tbody,
将它们插入
表格中由参数给出的位置,并返回该 tr。
该位置相对于表格中的行。索引 −1 是默认值, 如果省略参数,则等同于在表格末尾插入。
如果给定位置小于 −1 或大于行数,则抛出
"IndexSizeError" DOMException。
table.deleteRow(index)
所有当前引擎均支持。
移除表格中给定位置的 tr
元素。
该位置相对于表格中的行。索引 −1 等同于 删除表格的最后一行。
如果给定位置小于 −1 或大于最后一行的索引,或者
不存在任何行,则抛出 "IndexSizeError"
DOMException。
给定一个 table 元素
tableElement 和一个字符串 localName,要创建表格元素,返回在给定
tableElement 的节点
文档、localName 和 HTML 命名空间的情况下创建元素的结果。
createCaption() 方法步骤为:
tHead 设置器步骤为:
如果给定值既不是 null,也不是 thead 元素,则抛出
一个
"HierarchyRequestError" DOMException。
如果给定值不为 null,则将其紧接在 this 的第一个既不是 caption 元素,也不是
colgroup
元素的元素子级之前插入(如果存在);否则将其插入到 this 的末尾。
createTHead() 方法步骤为:
tFoot 设置器步骤为:
如果给定值既不是 null,也不是 tfoot 元素,则抛出
一个
"HierarchyRequestError" DOMException。
如果给定值不为 null,则将其插入到 this 的末尾。
createTFoot() 方法步骤为:
tBodies
获取器步骤是返回一个以 this 为根的 HTMLCollection,
其
过滤器仅匹配作为 this 子级的 tbody
元素。
createTBody() 方法步骤为:
rows
获取器步骤是返回一个以 this 为根的 HTMLCollection,
其
过滤器仅匹配如下 tr 元素:
它们要么是 this 的子级,要么是本身作为
this 子级的
thead、tbody 或 tfoot 元素的子级。
集合中的元素必须按如下方式排序:
首先包含父级为 thead 的元素,并按
树
顺序排列;随后是父级为 this 或
tbody 元素的元素,同样按
树顺序排列;最后是父级为 tfoot
元素的元素,仍按 树顺序排列。
insertRow(index) 方法步骤为:
如果 index 小于 −1,或大于
rows 集合中的元素数,
则抛出一个
"IndexSizeError" DOMException。
否则,如果 index 为 −1,或等于 rows 集合中的项目数,
则将 tr 追加到
rows
集合中最后一个 tr 元素的父级。
返回 tr。
deleteRow(index) 方法步骤为:
如果 index 小于 −1,或大于或等于
rows
集合中的元素数,则抛出一个
"IndexSizeError" DOMException。
如果 index 为 −1,则从其
父级中移除
rows 集合中的最后一个元素;如果
rows
集合为空,则不执行任何操作。
以下是使用表格标记数独谜题的示例。请注意其中没有 表头,因为此类表格不需要表头。
< style >
# sudoku { border-collapse : collapse ; border : solid thick ; }
# sudoku colgroup , table # sudoku tbody { border : solid medium ; }
# sudoku td { border : solid thin ; height : 1.4 em ; width : 1.4 em ; text-align : center ; padding : 0 ; }
</ style >
< h1 > Today's Sudoku</ h1 >
< table id = "sudoku" >
< colgroup >< col >< col >< col >
< colgroup >< col >< col >< col >
< colgroup >< col >< col >< col >
< tbody >
< tr > < td > 1 < td > < td > 3 < td > 6 < td > < td > 4 < td > 7 < td > < td > 9
< tr > < td > < td > 2 < td > < td > < td > 9 < td > < td > < td > 1 < td >
< tr > < td > 7 < td > < td > < td > < td > < td > < td > < td > < td > 6
< tbody >
< tr > < td > 2 < td > < td > 4 < td > < td > 3 < td > < td > 9 < td > < td > 8
< tr > < td > < td > < td > < td > < td > < td > < td > < td > < td >
< tr > < td > 5 < td > < td > < td > 9 < td > < td > 7 < td > < td > < td > 1
< tbody >
< tr > < td > 6 < td > < td > < td > < td > 5 < td > < td > < td > < td > 2
< tr > < td > < td > < td > < td > < td > 7 < td > < td > < td > < td >
< tr > < td > 9 < td > < td > < td > 8 < td > < td > 2 < td > < td > < td > 5
</ table > 对于不仅仅由第一行中的表头和第一列中的表头组成的单元格网格的表格, 以及通常任何读者可能难以理解其内容的表格,作者都应包含用于介绍该表格的说明信息。 此信息对所有用户都有用,但对于无法看到表格的用户(例如屏幕阅读器用户)尤其有用。
此类说明信息应介绍表格的用途,概述其基本单元格 结构,突出显示任何趋势或模式,并总体上教会用户如何使用该 表格。
例如,以下表格:
| 负面 | 特征 | 正面 |
|---|---|---|
| 悲伤 | 心情 | 快乐 |
| 不及格 | 成绩 | 及格 |
……可能会受益于一段说明表格布局方式的描述,例如 “特征列于第二列,负面一面位于左列, 正面一面位于右列”。
可以通过多种方式包含此信息,例如:
< p > In the following table, characteristics are given in the second
column, with the negative side in the left column and the positive
side in the right column.</ p >
< table >
< caption > Characteristics with positive and negative sides</ caption >
< thead >
< tr >
< th id = "n" > Negative
< th > Characteristic
< th > Positive
< tbody >
< tr >
< td headers = "n r1" > Sad
< th id = "r1" > Mood
< td > Happy
< tr >
< td headers = "n r2" > Failing
< th id = "r2" > Grade
< td > Passing
</ table > caption 中< table >
< caption >
< strong > Characteristics with positive and negative sides.</ strong >
< p > Characteristics are given in the second column, with the
negative side in the left column and the positive side in the right
column.</ p >
</ caption >
< thead >
< tr >
< th id = "n" > Negative
< th > Characteristic
< th > Positive
< tbody >
< tr >
< td headers = "n r1" > Sad
< th id = "r1" > Mood
< td > Happy
< tr >
< td headers = "n r2" > Failing
< th id = "r2" > Grade
< td > Passing
</ table > caption 中的
details
元素内
< table >
< caption >
< strong > Characteristics with positive and negative sides.</ strong >
< details >
< summary > Help</ summary >
< p > Characteristics are given in the second column, with the
negative side in the left column and the positive side in the right
column.</ p >
</ details >
</ caption >
< thead >
< tr >
< th id = "n" > Negative
< th > Characteristic
< th > Positive
< tbody >
< tr >
< td headers = "n r1" > Sad
< th id = "r1" > Mood
< td > Happy
< tr >
< td headers = "n r2" > Failing
< th id = "r2" > Grade
< td > Passing
</ table > figure 中< figure >
< figcaption > Characteristics with positive and negative sides</ figcaption >
< p > Characteristics are given in the second column, with the
negative side in the left column and the positive side in the right
column.</ p >
< table >
< thead >
< tr >
< th id = "n" > Negative
< th > Characteristic
< th > Positive
< tbody >
< tr >
< td headers = "n r1" > Sad
< th id = "r1" > Mood
< td > Happy
< tr >
< td headers = "n r2" > Failing
< th id = "r2" > Grade
< td > Passing
</ table >
</ figure > figure 的 figcaption
中
< figure >
< figcaption >
< strong > Characteristics with positive and negative sides</ strong >
< p > Characteristics are given in the second column, with the
negative side in the left column and the positive side in the right
column.</ p >
</ figcaption >
< table >
< thead >
< tr >
< th id = "n" > Negative
< th > Characteristic
< th > Positive
< tbody >
< tr >
< td headers = "n r1" > Sad
< th id = "r1" > Mood
< td > Happy
< tr >
< td headers = "n r2" > Failing
< th id = "r2" > Grade
< td > Passing
</ table >
</ figure > 作者还可以酌情使用其他技术或上述技术的组合。
当然,与其编写说明表格布局方式的描述,最佳选择是调整表格, 使其无需任何说明。
对于上述示例中使用的表格,只需简单地重新排列该表格,
使表头位于顶部和左侧,即可消除说明的必要性,同时也
无需使用 headers
属性:
< table >
< caption > Characteristics with positive and negative sides</ caption >
< thead >
< tr >
< th > Characteristic
< th > Negative
< th > Positive
< tbody >
< tr >
< th > Mood
< td > Sad
< td > Happy
< tr >
< th > Grade
< td > Failing
< td > Passing
</ table > 良好的表格设计是提高表格可读性和可用性的关键。
在视觉媒体中,提供列边框和行边框,并交替使用不同的行背景, 可以非常有效地提高复杂表格的可读性。
对于包含大量数值内容的表格,使用等宽字体可以帮助用户发现 模式,尤其是在用户代理不渲染边框的情况下。(遗憾的是, 由于历史原因,默认不渲染表格边框很常见。)
在语音媒体中,可以通过在读取单元格内容之前报告相应的表头, 并允许用户以网格方式浏览表格,而不是按照源顺序将表格的全部内容 串行化,来区分各个表格单元格。
建议作者使用 CSS 实现这些效果。
当页面不使用 CSS,并且表格未被归类为布局表格时,建议用户代理 使用这些技术渲染表格。
caption
元素
所有当前引擎均支持。
所有当前引擎均支持。
table 元素的第一个元素子级。
table 元素。caption 元素
后面没有紧跟 ASCII 空白
或
注释,则可以省略该 caption 元素的
结束标签。
[Exposed =Window ]
interface HTMLTableCaptionElement : HTMLElement {
[HTMLConstructor ] constructor ();
// also has obsolete members
};如果 caption 元素
具有父元素,并且该父元素是 table 元素,则它
表示作为其父元素的 table
的标题。
当一个 table 元素
是 figure 元素中除
figcaption
之外的唯一内容时,应省略 caption
元素,而改用
figcaption。
标题可以为表格引入上下文,从而显著提高表格的可理解性。
例如,考虑以下表格:
| 1 | 2 | 3 | 4 | 5 | 6 | |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
抽象地看,此表格并不清楚。不过,如果用标题给出表格编号 (以便在正文中引用)并说明其 用途,它就更容易理解:
< caption >
< p > Table 1.
< p > This table shows the total score obtained from rolling two
six-sided dice. The first row represents the value of the first die,
the first column the value of the second die. The total is given in
the cell that corresponds to the values of the two dice.
</ caption > 这为用户提供了更多上下文:
| 1 | 2 | 3 | 4 | 5 | 6 | |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
colgroup 元素
所有当前引擎均支持。
所有当前引擎均支持。
table
元素的子级,位于所有
caption 元素之后,
并位于所有 thead、
tbody、tfoot 和 tr
元素之前。
span
属性:无。span
属性:零个或多个 col 和 template 元素。
colgroup
元素内的第一个内容是
col 元素,
并且该元素前面没有紧邻另一个省略了
结束标签的 colgroup 元素,
则可以省略该 colgroup
元素的开始标签。(如果元素
为空,则不可省略。)
colgroup
元素后面没有紧跟 ASCII 空白
或注释,则可以省略该 colgroup
元素的结束标签。span — 元素跨越的
列数
span。
[Exposed =Window ]
interface HTMLTableColElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect , ReflectDefault=1, ReflectRange=(1, 1000)] attribute unsigned long span ;
// also has obsolete members
};如果 colgroup
元素具有父元素,并且该父元素是 table
元素,则它
表示作为其父元素的 table 中一个或多个列的组。
如果 colgroup
元素不包含任何 col
元素,则可以为该元素指定一个 span
内容属性,其值必须是大于零且小于或等于 1000 的有效非负整数。
col
元素所有当前引擎均支持。
span 属性的 colgroup 元素的子级。
span — 元素跨越的列数
span。colgroup
元素定义的 HTMLTableColElement。如果一个 col 元素具有父元素,
且该父元素是一个 colgroup
元素,而该元素本身的父元素又是一个 table 元素,则该
col 元素
表示由该 colgroup 表示的列组中的一个或多个列。
可以为该元素指定一个 span
内容属性,其值必须是
大于零且小于或等于 1000 的有效非负整数。
tbody
元素所有当前引擎均支持。
所有当前引擎均支持。
table
元素的子级,位于所有
caption、colgroup 和
thead 元素之后,但仅当
不存在作为该
table 元素子级的
tr 元素时。
tr 元素和脚本支持
元素。tbody 元素内的第一个内容是
tr 元素,并且该
元素前面没有紧邻一个省略了结束标签的 tbody、thead 或
tfoot 元素,则可以省略该 tbody 元素的开始标签。(如果元素为空,
则不可省略。)
tbody 元素
后面紧跟一个 tbody 或
tfoot 元素,或者
父元素中不再有其他内容,则可以省略该 tbody
元素的结束标签。
[Exposed =Window ]
interface HTMLTableSectionElement : HTMLElement {
[HTMLConstructor ] constructor ();
[SameObject ] readonly attribute HTMLCollection rows ;
HTMLTableRowElement insertRow (optional long index = -1);
[CEReactions ] undefined deleteRow (long index );
// also has obsolete members
};HTMLTableSectionElement
接口还用于 thead 和
tfoot 元素。
如果 tbody 元素
具有父元素,并且该父元素是一个 table,则该
tbody 元素表示由构成父 table 元素数据主体的行组成的块。
tbody.rows返回一个由表格节中的 tr 元素组成的 HTMLCollection。
tr = tbody.insertRow([ index ])
创建一个 tr 元素,
将其插入表格节中由
参数给出的位置,并返回该 tr。
该位置相对于表格节中的行。索引 −1 是 省略参数时的默认值,等同于在表格 节的末尾插入。
如果给定位置小于 −1 或大于行数,则抛出
"IndexSizeError" DOMException。
tbody.deleteRow(index)
移除表格节中给定位置的 tr 元素。
该位置相对于表格节中的行。索引 −1 等同于 删除表格节的最后一行。
如果给定位置小于 −1 或大于最后一行的索引,或者
不存在任何行,则抛出 "IndexSizeError"
DOMException。
rows
属性必须返回一个以此元素为根的 HTMLCollection,
其过滤器仅匹配作为
此元素子级的 tr 元素。
insertRow(index) 方法必须按
如下方式执行:
调用 deleteRow(index) 方法时,必须
按如下方式执行:
如果 index 小于 −1,或大于或等于
rows
集合中的元素数,则抛出
"IndexSizeError" DOMException。
如果 index 为 −1,则从此元素中移除
rows 集合中的最后一个元素;
如果 rows 集合
为空,则不执行任何操作。
thead
元素所有当前引擎均支持。
table
元素的子级,位于所有
caption 和 colgroup
元素之后,并位于所有 tbody、tfoot 和
tr 元素之前,但仅当
不存在其他作为该
table 元素子级的
thead 元素时。
tr 元素和脚本支持
元素。thead 元素
后面紧跟一个 tbody 或
tfoot 元素,则可以省略该 thead 元素的结束标签。
tbody
元素定义的 HTMLTableSectionElement。
如果 thead
元素具有父元素,并且该父元素是一个 table,则该
thead 元素表示由父 table
元素的列标签(表头)以及任何辅助性非表头单元格组成的行块。
此示例展示了 thead 元素的用法。
请注意 thead 元素中同时使用了
th 和 td 元素:第一行是
表头,第二行说明如何填写该表格。
< table >
< caption > School auction sign-up sheet </ caption >
< thead >
< tr >
< th >< label for = e1 > Name</ label >
< th >< label for = e2 > Product</ label >
< th >< label for = e3 > Picture</ label >
< th >< label for = e4 > Price</ label >
< tr >
< td > Your name here
< td > What are you selling?
< td > Link to a picture
< td > Your reserve price
< tbody >
< tr >
< td > Ms Danus
< td > Doughnuts
< td >< img src = "https://example.com/mydoughnuts.png" title = "Doughnuts from Ms Danus" >
< td > $45
< tr >
< td >< input id = e1 type = text name = who required form = f >
< td >< input id = e2 type = text name = what required form = f >
< td >< input id = e3 type = url name = pic form = f >
< td >< input id = e4 type = number step = 0.01 min = 0 value = 0 required form = f >
</ table >
< form id = f action = "/auction.cgi" >
< input type = button name = add value = "Submit" >
</ form > tfoot
元素所有当前引擎均支持。
table
元素的子级,位于所有
caption、colgroup、thead、
tbody 和 tr 元素之后,但仅当不存在
其他作为该
table 元素子级的
tfoot 元素时。
tr 元素和脚本支持
元素。tfoot 元素的结束标签。tbody
元素定义的 HTMLTableSectionElement。
如果 tfoot 元素具有父元素,
并且该父元素是一个 table,
则该 tfoot 元素表示由父 table 元素的列汇总
(表尾)组成的行块。
tr
元素所有当前引擎均支持。
所有当前引擎均支持。
thead
元素的子级。tbody
元素的子级。tfoot
元素的子级。table
元素的子级,位于所有
caption、colgroup 和 thead
元素之后,但仅当不存在作为该 table 元素子级的
tbody 元素时。
td、th 和脚本支持
元素。tr 元素后面紧跟
另一个 tr 元素,或者
父元素中不再有其他内容,则可以省略该 tr 元素的结束标签。
[Exposed =Window ]
interface HTMLTableRowElement : HTMLElement {
[HTMLConstructor ] constructor ();
readonly attribute long rowIndex ;
readonly attribute long sectionRowIndex ;
[SameObject ] readonly attribute HTMLCollection cells ;
HTMLTableCellElement insertCell (optional long index = -1);
[CEReactions ] undefined deleteCell (long index );
// also has obsolete members
};tr.rowIndex
所有当前引擎均支持。
返回该行在表格的 rows
列表中的位置。
如果该元素不在表格中,则返回 −1。
tr.sectionRowIndex
返回该行在表格节的 rows 列表中的位置。
如果该元素不在表格节中,则返回 −1。
tr.cells返回一个由该行的 td 和 th 元素组成的
HTMLCollection。
cell = tr.insertCell([ index ])
HTMLTableRowElement/insertCell
所有当前引擎均支持。
创建一个 td 元素,将
其插入表格行中由
参数给出的位置,并返回该 td。
该位置相对于行中的单元格。索引 −1 是 省略参数时的默认值,等同于在行末尾插入。
如果给定位置小于 −1 或大于单元格数,则抛出
"IndexSizeError" DOMException。
tr.deleteCell(index)
该位置相对于行中的单元格。索引 −1 等同于 删除该行的最后一个单元格。
如果给定位置小于 −1 或大于最后一个单元格的索引,或者
不存在任何单元格,则抛出 "IndexSizeError"
DOMException。
如果此元素的父元素是
table 元素,或者
此元素的父元素是 tbody、thead 或
tfoot 元素,并且其
祖父元素是 table
元素,则 rowIndex 属性必须返回此 tr 元素在该 table 元素的 rows 集合中的索引。如果不存在这样的
table 元素,
则该属性必须返回 −1。
如果此元素的父元素是 table、tbody、thead 或 tfoot 元素,则
sectionRowIndex 属性必须返回该 tr 元素在父元素的
rows 集合中的索引(对于表格,它是 HTMLTableElement 的 rows 集合;对于表格节,它是
HTMLTableSectionElement
的
rows
集合)。如果不存在这样的父元素,则该属性必须返回 −1。
cells
属性必须返回一个以此 tr 元素为根的 HTMLCollection,
其过滤器仅匹配作为该 tr 元素子级的 td 和 th 元素。
insertCell(index) 方法必须按
如下方式执行:
deleteCell(index) 方法必须按
如下方式执行:
如果 index 小于 −1,或大于或等于
cells 集合中的元素数,
则抛出
"IndexSizeError" DOMException。
如果 index 为 −1,则从其
父级中移除
cells
集合中的最后一个元素;如果 cells
集合为空,则不执行任何操作。
td
元素所有当前引擎均支持。
所有当前引擎均支持。
tr 元素的子元素。td 元素后面紧接着
td 或 th 元素,或者父元素中不再有任何内容,
则可以省略该 td 元素的
结束标签。
colspan — 单元格要跨越的列数
rowspan — 单元格要跨越的行数
headers — 此单元格的标题单元格
colspan、headers、rowspan 的
默认类别。
[Exposed =Window ]
interface HTMLTableCellElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect , ReflectDefault=1, ReflectRange=(1, 1000)] attribute unsigned long colSpan ;
[CEReactions , Reflect , ReflectDefault=1, ReflectRange=(0, 65534)] attribute unsigned long rowSpan ;
[CEReactions , Reflect ] attribute DOMString headers ;
readonly attribute long cellIndex ;
[CEReactions ] attribute DOMString scope ; // only conforming for th elements
[CEReactions , Reflect ] attribute DOMString abbr ; // only conforming for th elements
// also has obsolete members
};HTMLTableCellElement
接口也用于 th
元素。
td 元素及其 colspan、rowspan 和 headers
属性参与表格模型。
用户代理,尤其是在非可视环境中或无法切实将表格显示为二维网格时,可以在渲染单元格的内容时向用户提供该单元格的上下文;
例如,给出它在表格模型中的位置,或者列出该单元格的标题单元格
(由分配标题单元格的算法确定)。当列出一个单元格的标题
单元格时,用户代理可以使用这些标题单元格上 abbr
属性的值(如果存在),而不是标题单元格自身的内容。
在此示例中,我们看到一个由可编辑单元格网格组成的 Web 应用程序片段
(本质上是一个简单的电子表格)。其中一个单元格已配置为显示其上方各单元格的总和。
三个单元格被标记为标题,它们使用 th 元素而不是
td 元素。脚本会为这些元素附加
事件处理器以维护总计。
< table >
< tr >
< th >< input value = "Name" >
< th >< input value = "Paid ($)" >
< tr >
< td >< input value = "Jeff" >
< td >< input value = "14" >
< tr >
< td >< input value = "Britta" >
< td >< input value = "9" >
< tr >
< td >< input value = "Abed" >
< td >< input value = "25" >
< tr >
< td >< input value = "Shirley" >
< td >< input value = "2" >
< tr >
< td >< input value = "Annie" >
< td >< input value = "5" >
< tr >
< td >< input value = "Troy" >
< td >< input value = "5" >
< tr >
< td >< input value = "Pierce" >
< td >< input value = "1000" >
< tr >
< th >< input value = "Total" >
< td >< output value = "1060" >
</ table > th
元素所有当前引擎均支持。
tr 元素的子元素。header、footer、
分节内容或标题内容后代。
th 元素后面紧接着
th 元素或 td 元素,或者父元素中不再有任何内容,
则可以省略该 th 元素的
结束标签。
colspan — 单元格要跨越的列数
rowspan — 单元格要跨越的行数
headers — 此单元格的标题单元格
scope — 指定标题单元格适用于哪些单元格
abbr — 在其他上下文中引用该单元格时,
用于标题单元格的替代标签
abbr、colspan、headers、rowspan、scope 的
默认类别。
td 元素定义的 HTMLTableCellElement。th 元素可以指定 scope 内容属性。
| 关键字 | 状态 | 简要说明 |
|---|---|---|
row
|
行 | 标题单元格适用于同一行中的部分后续单元格。 |
col
|
列 | 标题单元格适用于同一列中的部分后续单元格。 |
rowgroup
|
行组 | 标题单元格适用于该行组中所有剩余的单元格。 |
colgroup
|
列组 | 标题单元格适用于该列组中所有剩余的单元格。 |
如果 th 元素没有锚定在
行组中,则其 scope 属性不得处于
行组状态;如果该元素没有锚定在
列组中,则该属性也不得处于列组状态。
th 元素可以指定 abbr 内容属性。
其值必须是标题单元格的替代标签,用于在其他上下文中引用该单元格
(例如,在描述适用于某个数据单元格的标题单元格时)。它通常是完整标题单元格内容的缩写形式,
但也可以是扩展形式,或者仅仅是不同的措辞。
th 元素及其 colspan、rowspan、headers 和
scope 属性参与表格模型。
以下示例展示 scope 属性的 rowgroup 值如何影响
标题单元格适用于哪些数据单元格。
以下是一个展示表格的标记片段:
< table >
< thead >
< tr > < th > ID < th > Measurement < th > Average < th > Maximum
< tbody >
< tr > < td > < th scope = rowgroup > Cats < td > < td >
< tr > < td > 93 < th > Legs < td > 3.5 < td > 4
< tr > < td > 10 < th > Tails < td > 1 < td > 1
< tbody >
< tr > < td > < th scope = rowgroup > English speakers < td > < td >
< tr > < td > 32 < th > Legs < td > 2.67 < td > 4
< tr > < td > 35 < th > Tails < td > 0.33 < td > 1
</ table > 这将生成以下表格:
| ID | 测量项 | 平均值 | 最大值 |
|---|---|---|---|
| 猫 | |||
| 93 | 腿 | 3.5 | 4 |
| 10 | 尾巴 | 1 | 1 |
| 英语使用者 | |||
| 32 | 腿 | 2.67 | 4 |
| 35 | 尾巴 | 0.33 | 1 |
第一行中的所有标题均直接向下适用于其所在列中的各行。
具有处于行组状态的 scope 属性的标题,
适用于其行组中除第一列单元格之外的所有单元格。
其余标题仅适用于它们右侧的单元格。

td
和 th
元素的通用属性td 和
th 元素
可以指定 colspan
内容属性,其值必须是大于零且小于或等于 1000 的
有效
非负整数。
td 和
th 元素
还可以指定 rowspan 内容属性,
其值必须是小于或等于 65534 的有效非负整数。对于
此属性,值为零意味着单元格要跨越行组中所有剩余的行。
这些属性分别给出单元格要跨越的列数和行数。 不得使用这些属性使单元格重叠,如表格模型的说明中所述。
td 和
th 元素
可以指定 headers
内容属性。如果指定,headers
属性必须包含一个由无序的唯一空格分隔
令牌集组成的字符串,其中任何令牌都不得与另一个令牌相同,并且每个令牌的值都必须是与该 td 或 th 元素处于
同一表格中的某个 th 元素的
ID(由表格模型定义)。
对于 ID 为 id
的 th
元素,如果同一表格中的某个 td 或 th 元素的
headers
属性值包含值为 id 的 ID 令牌,则称前者被后者
直接指向。如果 th 元素
A 被 th 或 td 元素
B 直接指向,或者存在一个元素
C,该元素自身被元素 B 指向,且 A 被 C
直接指向,则称 A 被 B 指向。
th
元素不得被自身指向。
colspan、
rowspan
和 headers
属性参与表格
模型。
cell.cellIndex返回该单元格在行的 cells 列表中的位置。
这不一定与该单元格在表格中的 x 位置相对应,
因为前面的单元格可能跨越多行或多列。
如果该元素不在任何行中,则返回 −1。
各种表格元素及其内容属性共同定义表格模型。
一个表格由对齐在二维槽位网格上的单元格组成,
槽位坐标为(x, y)。该网格是有限的,并且要么为空,要么具有一个或多个槽位。如果网格
具有一个或多个槽位,则 x 坐标始终处于
0 ≤ x < xwidth 范围内,而 y
坐标始终处于
0 ≤ y < yheight 范围内。如果
xwidth 和 yheight 中的一个或两者为零,则
表格为空(没有槽位)。表格对应于 table
元素。
一个单元格是锚定在槽位(cellx,
celly)上的一组槽位,并具有特定的 width 和 height,使该单元格覆盖
坐标为(x, y)且满足
cellx ≤ x < cellx+width
和
celly ≤ y < celly+height
的所有槽位。单元格可以是数据单元格或标题单元格。数据单元格对应于 td 元素,标题单元格
对应于 th 元素。
两种类型的单元格都可以有零个或多个关联的标题单元格。
在某些错误情况下,两个单元格可能占据同一个槽位。
一行是对于某个特定的 y 值,从 x=0 到
x=xwidth-1 的一整套槽位。行通常
对应于 tr 元素,
但在某些涉及跨越多行的单元格的情况下,
一个行组
的末尾可能具有一些隐含的行。
一列是对于某个特定的 x 值,从 y=0 到
y=yheight-1 的一整套槽位。列可以
对应于 col
元素。在没有 col 元素时,列是隐含的。
一个行组是一组行,锚定在槽位(0, groupy)上,
并具有特定的 height,使行组覆盖坐标为(x, y)且满足
0 ≤ x < xwidth 和
groupy ≤ y < groupy+height
的所有槽位。行组对应于
tbody、thead 和 tfoot 元素。并非每一行都
必然处于某个行组中。
一个列组是一组列,锚定在槽位(groupx, 0)上,
并具有特定的 width,使列组覆盖坐标为(x, y)且满足
groupx ≤ x < groupx+width
和 0 ≤ y < yheight 的所有槽位。列组
对应于 colgroup 元素。
并非每一列都必然处于某个列组中。
一个单元格不能覆盖来自两个或更多 行组的槽位。但是,一个单元格 可以处于多个列组中。构成一个单元格的所有槽位 属于零个或一个行组 以及零个或多个列 组。
除单元格、列、行、行组和列组之外,表格还可以关联一个 caption 元素。
它为表格提供标题或图例。
表格模型错误是由 table
元素及其后代所表示的数据中的错误。文档不得存在表格模型错误。
为了确定与 table 元素关联的表格中哪些元素对应于哪些槽位,
确定表格的尺寸(xwidth 和 yheight),并确定是否存在任何
表格模型错误,用户代理必须使用以下算法:
令 xwidth 为 0。
令 yheight 为 0。
令该表格为由 table 元素表示的表格。
变量 xwidth 和 yheight 给出该表格的尺寸。
该表格初始为空。
如果 table 元素
没有子元素,则返回该表格(它将为空)。
将 table 元素的
第一个 caption
子元素与该表格关联。如果不存在这样的子元素,则该表格没有关联的
caption 元素。
令当前元素为 table 元素的第一个元素子元素。
如果此算法中的某个步骤要求在没有下一个子元素时,将当前元素前进到 table
的下一个子元素,则用户代理必须跳转到此算法接近
末尾、标记为结束的步骤。
如果当前元素是 colgroup,则执行以下
子步骤:
列组:根据以下适当情况处理当前元素:
col 元素子元素执行以下步骤:
令 xstart 具有 xwidth 的值。
列:如果当前列的 col 元素具有
span 属性,
则使用解析非负整数的规则解析其值。
如果解析该值的结果既不是错误也不是零,则令 span 为该值。
否则,如果 col
元素没有
span
属性,或者尝试解析该属性的值时产生错误或得到零,则令 span 为 1。
如果 span 大于 1000,则改令其为 1000。
将 xwidth 增加 span。
如果当前列不是 colgroup
元素的最后一个 col
元素子元素,
则令当前列为该 colgroup
元素的下一个 col
元素子元素,并返回标记为列的步骤。
令该表格中从 x=xstart 到
x=xwidth-1 的所有最后的列构成一个新的列组,锚定在槽位
(xstart, 0),宽度为
xwidth-xstart,并对应于 colgroup
元素。
col 元素子元素
如果当前元素是 colgroup
元素,则跳转到上面标记为列组的步骤。
令 ycurrent 为 0。
令向下增长的单元格列表为空列表。
运行结束行组的算法。
如果当前元素是 tfoot,则将该元素添加到
待处理的 tfoot
元素列表中,
将当前元素前进到 table 的下一个子元素,
然后返回标记为行的步骤。
运行处理行组的算法。
返回标记为行的步骤。
返回该表格。
结束行组的算法由上面的步骤集在开始和结束一块行时调用, 如下:
当 ycurrent 小于 yheight 时,执行以下步骤:
运行增长向下增长单元格的算法。
将 ycurrent 增加 1。
清空向下增长的单元格列表。
处理行的算法由上面用于处理 tr 元素的步骤集调用,如下:
如果 yheight 等于 ycurrent,则将 yheight 增加 1。(ycurrent 永远不会大于 yheight。)
令 xcurrent 为 0。
运行增长向下增长单元格的算法。
如果正在处理的 tr 元素没有 td 或 th
元素子元素,则将 ycurrent 增加 1,中止此步骤集,并返回上面的算法。
单元格:当 xcurrent 小于 xwidth,且坐标为 (xcurrent, ycurrent)的槽位已经分配有一个单元格时, 将 xcurrent 增加 1。
如果 xcurrent 等于 xwidth,则将 xwidth 增加 1。(xcurrent 永远不会大于 xwidth。)
如果当前单元格具有 colspan
属性,则解析该属性的值,并令
colspan 为结果。
如果解析该值失败、返回零或该属性不存在,则改令 colspan 为 1。
如果 colspan 大于 1000,则改令其为 1000。
如果当前单元格具有 rowspan
属性,则解析该属性的值,并令
rowspan 为结果。
如果解析该值失败或该属性不存在,则改令 rowspan 为 1。
如果 rowspan 大于 65534,则改令其为 65534。
令单元格向下增长为 false。
如果 rowspan 为零,则将单元格向下增长设置为 true,并将 rowspan 设置为 1。
如果 xwidth < xcurrent+colspan,则令 xwidth 为 xcurrent+colspan。
如果 yheight < ycurrent+rowspan,则令 yheight 为 ycurrent+rowspan。
令坐标为(x, y)且满足 xcurrent ≤ x < xcurrent+colspan 和 ycurrent ≤ y < ycurrent+rowspan 的槽位由一个新的单元格 c 覆盖, 该单元格锚定在(xcurrent, ycurrent), 宽度为 colspan,高度为 rowspan,并对应于当前单元格元素。
如果当前单元格元素是 th
元素,则令这个新
单元格 c 为标题单元格;否则,令其为数据单元格。
为了确定哪些标题单元格适用于当前单元格元素,请使用下一节中所述的分配标题单元格的算法。
如果单元格向下增长为 true,则将元组 {c, xcurrent, colspan} 添加到向下增长的单元格列表中。
将 xcurrent 增加 colspan。
如果当前单元格是正在处理的 tr 元素中的最后一个 td 或 th 元素子元素,
则将 ycurrent 增加 1,中止此步骤集,并返回上面的算法。
返回标记为单元格的步骤。
当上述算法要求用户代理运行增长向下增长单元格的算法时,用户代理必须针对 向下增长的单元格列表中的每个 {cell, cellx, width} 元组(如果有),扩展单元格 cell,使其也覆盖坐标为 (x, ycurrent)且满足 cellx ≤ x < cellx+width 的槽位。
每个单元格可以分配零个或多个标题单元格。将标题单元格分配给单元格 principal cell 的 标题单元格 分配算法如下。
令 header list 为一个空的单元格列表。
令(principalx、principaly)为 principal cell 所锚定到的槽位的坐标。
headers
属性获取 principal cell 的 headers
属性值,并按 ASCII 空白拆分该值,令 id
list 为由此获得的记号列表。
对于 id list 中的每个记号,如果 Document 中ID 等于该记号的第一个元素,是同一表格中的单元格,并且该单元格不是
principal cell,则将该单元格添加到 header list。
headers
属性令 principalwidth 为 principal cell 的宽度。
令 principalheight 为 principal cell 的高度。
对于从 principaly 到 principaly+principalheight-1 的每个 y 值,运行扫描并 分配标题单元格的内部算法,并传入 principal cell、header list、初始坐标 (principalx、y),以及增量 Δx=−1 和 Δy=0。
对于从 principalx 到 principalx+principalwidth-1 的每个 x 值,运行扫描并 分配标题单元格的内部算法,并传入 principal cell、header list、初始坐标 (x、principaly),以及增量 Δx=0 和 Δy=−1。
如果 principal cell 锚定在一个行组中,则将所有属于行组标题、锚定在同一 行组中,并且 x 坐标小于或等于 principalx+principalwidth-1、y 坐标小于或 等于 principaly+principalheight-1 的标题单元格添加到 header list。
如果 principal cell 锚定在一个列组中,则将所有属于列组 标题、锚定在同一列组中,并且 x 坐标小于或等于 principalx+principalwidth-1、y 坐标小于或 等于 principaly+principalheight-1 的标题单元格添加到 header list。
从 header list 中移除所有空单元格。
从 header list 中移除所有重复项。
如果 principal cell 位于 header list 中,则将其移除。
将 header list 中的标题分配给 principal cell。
给定一个 principal cell、一个 header list、初始坐标 (initialx、initialy),以及 Δx 和 Δy 增量,扫描并 分配标题单元格的内部算法如下:
令 x 等于 initialx。
令 y 等于 initialy。
令 opaque headers 为一个空的单元格列表。
令 in header block 为 true,并令 headers from current header block 为仅包含 principal cell 的单元格列表。
令 in header block 为 false,并令 headers from current header block 为一个空的单元格列表。
循环:将 x 增加 Δx;将 y 增加 Δy。
每次调用此算法时,Δx 和 Δy 中的一个为 −1,另一个为 0。
如果 x 或 y 中任意一个小于 0,则中止此内部算法。
如果没有单元格覆盖槽位(x、y),或者有多个单元格覆盖槽位 (x、y),则返回标记为循环的子步骤。
令 current cell 为覆盖槽位(x、y)的单元格。
将 in header block 设置为 true。
将 current cell 添加到 headers from current header block。
令 blocked 为 false。
如果 blocked 为 false,则将 current cell 添加到 header list。
将 in header block 设置为 false。将 headers from current header block 中的所有单元格添加到 opaque headers 列表,并清空 headers from current header block 列表。
返回标记为循环的步骤。
如果一个宽度为 width、高度为 height,并锚定于坐标为 (x、y)的槽位的标题单元格满足以下任一条件,则称其为列标题:
如果一个宽度为 width、高度为 height,并锚定于坐标为 (x、y)的槽位的标题单元格满足以下任一条件,则称其为行标题:
本节是非规范性的。
以下展示了如何标记《史密森尼物理表,第 71 卷》中表 45 的底部部分:
< table >
< caption > 规格值:< b > 钢材</ b > ,< b > 铸件</ b > ,
Ann. A.S.T.M. A27-16,B 级;* P 最大值 0.06;S 最大值 0.05。</ caption >
< thead >
< tr >
< th rowspan = 2 > 等级。</ th >
< th rowspan = 2 > 屈服点。</ th >
< th colspan = 2 > 极限抗拉强度</ th >
< th rowspan = 2 > 伸长率百分比,50.8 mm 或 2 in。</ th >
< th rowspan = 2 > 断面收缩率百分比。</ th >
</ tr >
< tr >
< th > kg/mm< sup > 2</ sup ></ th >
< th > lb/in< sup > 2</ sup ></ th >
</ tr >
</ thead >
< tbody >
< tr >
< td > 硬</ td >
< td > 极限值的 0.45</ td >
< td > 56.2</ td >
< td > 80,000</ td >
< td > 15</ td >
< td > 20</ td >
</ tr >
< tr >
< td > 中等</ td >
< td > 极限值的 0.45</ td >
< td > 49.2</ td >
< td > 70,000</ td >
< td > 18</ td >
< td > 25</ td >
</ tr >
< tr >
< td > 软</ td >
< td > 极限值的 0.45</ td >
< td > 42.2</ td >
< td > 60,000</ td >
< td > 22</ td >
< td > 30</ td >
</ tr >
</ tbody >
</ table > 此表格可能如下所示:
| 等级。 | 屈服点。 | 极限抗拉强度 | 伸长率百分比,50.8 mm 或 2 in。 | 断面收缩率百分比。 | |
|---|---|---|---|---|---|
| kg/mm2 | lb/in2 | ||||
| 硬 | 极限值的 0.45 | 56.2 | 80,000 | 15 | 20 |
| 中等 | 极限值的 0.45 | 49.2 | 70,000 | 18 | 25 |
| 软 | 极限值的 0.45 | 42.2 | 60,000 | 22 | 30 |
以下展示了如何标记苹果公司 2008 财年 10-K 申报文件第 46 页上的毛利表:
< table >
< thead >
< tr >
< th >
< th > 2008
< th > 2007
< th > 2006
< tbody >
< tr >
< th > 净销售额
< td > $ 32,479
< td > $ 24,006
< td > $ 19,315
< tr >
< th > 销售成本
< td > 21,334
< td > 15,852
< td > 13,717
< tbody >
< tr >
< th > 毛利
< td > $ 11,145
< td > $ 8,154
< td > $ 5,598
< tfoot >
< tr >
< th > 毛利率
< td > 34.3%
< td > 34.0%
< td > 29.0%
</ table > 此表格可能如下所示:
| 2008 | 2007 | 2006 | |
|---|---|---|---|
| 净销售额 | $ 32,479 | $ 24,006 | $ 19,315 |
| 销售成本 | 21,334 | 15,852 | 13,717 |
| 毛利 | $ 11,145 | $ 8,154 | $ 5,598 |
| 毛利率 | 34.3% | 34.0% | 29.0% |
以下展示了如何标记该文档同一页下方的营业费用表:
< table >
< colgroup > < col >
< colgroup > < col > < col > < col >
< thead >
< tr > < th > < th > 2008 < th > 2007 < th > 2006
< tbody >
< tr > < th scope = rowgroup > 研发
< td > $ 1,109 < td > $ 782 < td > $ 712
< tr > < th scope = row > 占净销售额的百分比
< td > 3.4% < td > 3.3% < td > 3.7%
< tbody >
< tr > < th scope = rowgroup > 销售、一般及行政费用
< td > $ 3,761 < td > $ 2,963 < td > $ 2,433
< tr > < th scope = row > 占净销售额的百分比
< td > 11.6% < td > 12.3% < td > 12.6%
</ table > 此表格可能如下所示:
| 2008 | 2007 | 2006 | |
|---|---|---|---|
| 研发 | $ 1,109 | $ 782 | $ 712 |
| 占净销售额的百分比 | 3.4% | 3.3% | 3.7% |
| 销售、一般及行政费用 | $ 3,761 | $ 2,963 | $ 2,433 |
| 占净销售额的百分比 | 11.6% | 12.3% | 12.6% |
所有当前引擎均支持。
本节是非规范性的。
表单是网页中包含表单控件的组件,例如文本、按钮、复选框、范围或颜色选择器控件。用户可以与这种表单 交互,提供随后可发送到服务器进行进一步处理的数据(例如返回搜索或计算的结果)。在许多情况下不需要 客户端脚本,不过也提供了 API,使脚本能够增强用户体验,或将表单用于向服务器提交数据以外的用途。
编写表单包括若干步骤,这些步骤可以按任意顺序执行:编写用户界面、实现服务器端处理,以及配置用户 界面与服务器通信。
本节是非规范性的。
为了进行此简短介绍,我们将创建一个披萨订购表单。
任何表单都以一个 form
元素开始,
控件放置在该元素内部。大多数控件由 input 元素表示,
默认情况下,该元素提供文本控件。要为控件添加标签,应使用 label 元素;
标签文本和控件本身都放在 label 元素中。
表单的每个部分都被视为一个段落,通常使用 p 元素与其他部分分隔。
将这些内容组合起来,可以按如下方式询问顾客的姓名:
< form >
< p >< label > 顾客姓名:< input ></ label ></ p >
</ form > 为了让用户选择披萨的尺寸,可以使用一组单选按钮。单选按钮也使用 input 元素,
但这次使用值为 radio 的 type 属性。
为了使这些单选按钮作为一个组工作,需要使用 name 属性为它们提供共同的名称。
要将一批控件组合在一起,例如本例中的单选按钮,可以使用 fieldset
元素。这种控件组的标题由 fieldset
中的第一个元素给出,该元素必须是 legend 元素。
< form >
< p >< label > 顾客姓名:< input ></ label ></ p >
< fieldset >
< legend > 披萨尺寸 </ legend >
< p >< label > < input type = radio name = size > 小 </ label ></ p >
< p >< label > < input type = radio name = size > 中 </ label ></ p >
< p >< label > < input type = radio name = size > 大 </ label ></ p >
</ fieldset >
</ form > 相对于上一步的更改已突出显示。
为了选择配料,可以使用复选框。这些复选框使用 input 元素,
并带有值为 checkbox 的 type 属性:
< form >
< p >< label > 顾客姓名:< input ></ label ></ p >
< fieldset >
< legend > 披萨尺寸 </ legend >
< p >< label > < input type = radio name = size > 小 </ label ></ p >
< p >< label > < input type = radio name = size > 中 </ label ></ p >
< p >< label > < input type = radio name = size > 大 </ label ></ p >
</ fieldset >
< fieldset >
< legend > 披萨配料 </ legend >
< p >< label > < input type = checkbox > 培根 </ label ></ p >
< p >< label > < input type = checkbox > 额外奶酪 </ label ></ p >
< p >< label > < input type = checkbox > 洋葱 </ label ></ p >
< p >< label > < input type = checkbox > 蘑菇 </ label ></ p >
</ fieldset >
</ form > 编写此表单的披萨店总是出错,因此需要一种联系顾客的方式。为此,可以使用专门用于电话号码的表单控件
(input 元素,其 type 属性设置为
tel)和电子邮件地址控件
(input 元素,其 type 属性设置为
email):
< form >
< p >< label > 顾客姓名:< input ></ label ></ p >
< p >< label > 电话:< input type = tel ></ label ></ p >
< p >< label > 电子邮件地址:< input type = email ></ label ></ p >
< fieldset >
< legend > 披萨尺寸 </ legend >
< p >< label > < input type = radio name = size > 小 </ label ></ p >
< p >< label > < input type = radio name = size > 中 </ label ></ p >
< p >< label > < input type = radio name = size > 大 </ label ></ p >
</ fieldset >
< fieldset >
< legend > 披萨配料 </ legend >
< p >< label > < input type = checkbox > 培根 </ label ></ p >
< p >< label > < input type = checkbox > 额外奶酪 </ label ></ p >
< p >< label > < input type = checkbox > 洋葱 </ label ></ p >
< p >< label > < input type = checkbox > 蘑菇 </ label ></ p >
</ fieldset >
</ form > 可以使用一个 input
元素,
并将其 type 属性设置为 time,以询问送达时间。许多此类表单控件都有用于精确控制可指定值的
属性;在本例中,三个特别值得关注的属性是 min、max 和 step。它们分别设置
最早时间、最晚时间以及允许值之间的间隔(以秒为单位)。这家披萨店只在上午 11 点至晚上 9 点之间送货,
并且不承诺精确到小于 15 分钟的增量,可以按如下方式进行标记:
< form >
< p >< label > 顾客姓名:< input ></ label ></ p >
< p >< label > 电话:< input type = tel ></ label ></ p >
< p >< label > 电子邮件地址:< input type = email ></ label ></ p >
< fieldset >
< legend > 披萨尺寸 </ legend >
< p >< label > < input type = radio name = size > 小 </ label ></ p >
< p >< label > < input type = radio name = size > 中 </ label ></ p >
< p >< label > < input type = radio name = size > 大 </ label ></ p >
</ fieldset >
< fieldset >
< legend > 披萨配料 </ legend >
< p >< label > < input type = checkbox > 培根 </ label ></ p >
< p >< label > < input type = checkbox > 额外奶酪 </ label ></ p >
< p >< label > < input type = checkbox > 洋葱 </ label ></ p >
< p >< label > < input type = checkbox > 蘑菇 </ label ></ p >
</ fieldset >
< p >< label > 首选送达时间:< input type = time min = "11:00" max = "21:00" step = "900" ></ label ></ p >
</ form > textarea 元素可用于提供多行文本控件。在本例中,我们将使用它为
顾客提供填写送货说明的空间:
< form >
< p >< label > 顾客姓名:< input ></ label ></ p >
< p >< label > 电话:< input type = tel ></ label ></ p >
< p >< label > 电子邮件地址:< input type = email ></ label ></ p >
< fieldset >
< legend > 披萨尺寸 </ legend >
< p >< label > < input type = radio name = size > 小 </ label ></ p >
< p >< label > < input type = radio name = size > 中 </ label ></ p >
< p >< label > < input type = radio name = size > 大 </ label ></ p >
</ fieldset >
< fieldset >
< legend > 披萨配料 </ legend >
< p >< label > < input type = checkbox > 培根 </ label ></ p >
< p >< label > < input type = checkbox > 额外奶酪 </ label ></ p >
< p >< label > < input type = checkbox > 洋葱 </ label ></ p >
< p >< label > < input type = checkbox > 蘑菇 </ label ></ p >
</ fieldset >
< p >< label > 首选送达时间:< input type = time min = "11:00" max = "21:00" step = "900" ></ label ></ p >
< p >< label > 送货说明:< textarea ></ textarea ></ label ></ p >
</ form > 最后,为了使表单可以提交,应使用 button 元素:
< form >
< p >< label > 顾客姓名:< input ></ label ></ p >
< p >< label > 电话:< input type = tel ></ label ></ p >
< p >< label > 电子邮件地址:< input type = email ></ label ></ p >
< fieldset >
< legend > 披萨尺寸 </ legend >
< p >< label > < input type = radio name = size > 小 </ label ></ p >
< p >< label > < input type = radio name = size > 中 </ label ></ p >
< p >< label > < input type = radio name = size > 大 </ label ></ p >
</ fieldset >
< fieldset >
< legend > 披萨配料 </ legend >
< p >< label > < input type = checkbox > 培根 </ label ></ p >
< p >< label > < input type = checkbox > 额外奶酪 </ label ></ p >
< p >< label > < input type = checkbox > 洋葱 </ label ></ p >
< p >< label > < input type = checkbox > 蘑菇 </ label ></ p >
</ fieldset >
< p >< label > 首选送达时间:< input type = time min = "11:00" max = "21:00" step = "900" ></ label ></ p >
< p >< label > 送货说明:< textarea ></ textarea ></ label ></ p >
< p >< button > 提交订单</ button ></ p >
</ form > 本节是非规范性的。
编写服务器端处理程序的确切细节不在本规范的范围内。为了进行此介绍,我们假设位于
https://pizza.example.com/order.cgi 的脚本已配置为接受使用 application/x-www-form-urlencoded
格式提交的数据,并预期在 HTTP POST 正文中发送以下参数:
custnamecusttelcustemailsizesmall、medium 或 largetoppingbacon、cheese、
onion 和 mushroom
deliverycomments本节是非规范性的。
表单提交以多种方式呈现给服务器,最常见的是 HTTP GET 或 POST 请求。要指定所使用的确切方法,应在
form 元素上指定 method 属性。不过,这并不指定表单数据的编码方式;要指定编码方式,
应使用 enctype 属性。还必须使用 action 属性,指定处理所提交数据的服务的 URL。
随后,对于希望提交的每个表单控件,必须提供一个名称,该名称将在提交中用于引用相应数据。我们已经为
单选按钮组指定了名称;同一个属性(name)也指定提交名称。通过使用 value 属性为单选按钮提供不同的值,可以在提交中区分它们。
多个控件可以具有相同的名称;例如,此处为所有复选框提供相同的名称,服务器通过查看使用该名称提交了
哪些值,来区分选中了哪个复选框——与单选按钮一样,也使用 value 属性为它们提供唯一值。
采用上一节中的设置后,所有内容将变为:
< form method = "post"
enctype = "application/x-www-form-urlencoded"
action = "https://pizza.example.com/order.cgi" >
< p >< label > 顾客姓名:< input name = "custname" ></ label ></ p >
< p >< label > 电话:< input type = tel name = "custtel" ></ label ></ p >
< p >< label > 电子邮件地址:< input type = email name = "custemail" ></ label ></ p >
< fieldset >
< legend > 披萨尺寸 </ legend >
< p >< label > < input type = radio name = size value = "small" > 小 </ label ></ p >
< p >< label > < input type = radio name = size value = "medium" > 中 </ label ></ p >
< p >< label > < input type = radio name = size value = "large" > 大 </ label ></ p >
</ fieldset >
< fieldset >
< legend > 披萨配料 </ legend >
< p >< label > < input type = checkbox name = "topping" value = "bacon" > 培根 </ label ></ p >
< p >< label > < input type = checkbox name = "topping" value = "cheese" > 额外奶酪 </ label ></ p >
< p >< label > < input type = checkbox name = "topping" value = "onion" > 洋葱 </ label ></ p >
< p >< label > < input type = checkbox name = "topping" value = "mushroom" > 蘑菇 </ label ></ p >
</ fieldset >
< p >< label > 首选送达时间:< input type = time min = "11:00" max = "21:00" step = "900" name = "delivery" ></ label ></ p >
< p >< label > 送货说明:< textarea name = "comments" ></ textarea ></ label ></ p >
< p >< button > 提交订单</ button ></ p >
</ form > 某些属性的值使用引号括起,而另一些没有,这种差异并无特殊意义。HTML 语法允许使用多种 同样有效的方式指定属性,相关内容在语法一节中进行了讨论。
例如,如果顾客输入“Denise Lawrence”作为姓名,输入“555-321-8642”作为电话号码,未指定电子邮件 地址,订购中号披萨,选择额外奶酪和蘑菇配料,输入晚上 7 点作为送达时间,并将送货说明文本控件留空, 则用户代理将向在线 Web 服务提交以下内容:
custname=Denise+Lawrence&custtel=555-321-8642&custemail=&size=medium&topping=cheese&topping=mushroom&delivery=19%3A00&comments=所有当前引擎均支持。
本节是非规范性的。
可以通过为表单添加注解,使用户代理在提交表单之前检查用户输入。服务器仍然必须验证输入是否有效 (因为恶意用户可以轻易绕过表单验证),但这可以避免让用户等待服务器作为唯一的输入检查方完成检查。
最简单的注解是 required 属性,
可以在 input 元素上指定该属性,以表明在提供值之前不得提交表单。通过将此
属性添加到顾客姓名、披萨尺寸和送达时间字段,可以让用户代理在用户未填写这些字段便提交表单时通知用户:
< form method = "post"
enctype = "application/x-www-form-urlencoded"
action = "https://pizza.example.com/order.cgi" >
< p >< label > 顾客姓名:< input name = "custname" required ></ label ></ p >
< p >< label > 电话:< input type = tel name = "custtel" ></ label ></ p >
< p >< label > 电子邮件地址:< input type = email name = "custemail" ></ label ></ p >
< fieldset >
< legend > 披萨尺寸 </ legend >
< p >< label > < input type = radio name = size required value = "small" > 小 </ label ></ p >
< p >< label > < input type = radio name = size required value = "medium" > 中 </ label ></ p >
< p >< label > < input type = radio name = size required value = "large" > 大 </ label ></ p >
</ fieldset >
< fieldset >
< legend > 披萨配料 </ legend >
< p >< label > < input type = checkbox name = "topping" value = "bacon" > 培根 </ label ></ p >
< p >< label > < input type = checkbox name = "topping" value = "cheese" > 额外奶酪 </ label ></ p >
< p >< label > < input type = checkbox name = "topping" value = "onion" > 洋葱 </ label ></ p >
< p >< label > < input type = checkbox name = "topping" value = "mushroom" > 蘑菇 </ label ></ p >
</ fieldset >
< p >< label > 首选送达时间:< input type = time min = "11:00" max = "21:00" step = "900" name = "delivery" required ></ label ></ p >
< p >< label > 送货说明:< textarea name = "comments" ></ textarea ></ label ></ p >
< p >< button > 提交订单</ button ></ p >
</ form > 还可以使用 maxlength 属性限制输入长度。通过将此属性添加到 textarea 元素,可以将用户限制为输入 1000 个字符,防止他们不保持
内容集中简明,反而给忙碌的送货司机撰写冗长文章:
< form method = "post"
enctype = "application/x-www-form-urlencoded"
action = "https://pizza.example.com/order.cgi" >
< p >< label > 顾客姓名:< input name = "custname" required ></ label ></ p >
< p >< label > 电话:< input type = tel name = "custtel" ></ label ></ p >
< p >< label > 电子邮件地址:< input type = email name = "custemail" ></ label ></ p >
< fieldset >
< legend > 披萨尺寸 </ legend >
< p >< label > < input type = radio name = size required value = "small" > 小 </ label ></ p >
< p >< label > < input type = radio name = size required value = "medium" > 中 </ label ></ p >
< p >< label > < input type = radio name = size required value = "large" > 大 </ label ></ p >
</ fieldset >
< fieldset >
< legend > 披萨配料 </ legend >
< p >< label > < input type = checkbox name = "topping" value = "bacon" > 培根 </ label ></ p >
< p >< label > < input type = checkbox name = "topping" value = "cheese" > 额外奶酪 </ label ></ p >
< p >< label > < input type = checkbox name = "topping" value = "onion" > 洋葱 </ label ></ p >
< p >< label > < input type = checkbox name = "topping" value = "mushroom" > 蘑菇 </ label ></ p >
</ fieldset >
< p >< label > 首选送达时间:< input type = time min = "11:00" max = "21:00" step = "900" name = "delivery" required ></ label ></ p >
< p >< label > 送货说明:< textarea name = "comments" maxlength = 1000 ></ textarea ></ label ></ p >
< p >< button > 提交订单</ button ></ p >
</ form > 提交表单时,会在每个无效的表单控件上触发 invalid 事件。由于浏览器
本身通常一次只报告一个问题,因此这对于显示表单问题的摘要很有用。
本节是非规范性的。
某些浏览器会尝试通过自动填充表单控件来帮助用户,而不要求用户每次都重新输入其信息。例如,要求输入 用户电话号码的字段可以自动填入用户的电话号码。
为了帮助用户代理完成此操作,可以使用 autocomplete 属性描述字段的用途。对于此表单,可以通过这种
方式有效注解三个字段:有关披萨送达对象的信息。添加这些信息后如下所示:
< form method = "post"
enctype = "application/x-www-form-urlencoded"
action = "https://pizza.example.com/order.cgi" >
< p >< label > 顾客姓名:< input name = "custname" required autocomplete = "shipping name" ></ label ></ p >
< p >< label > 电话:< input type = tel name = "custtel" autocomplete = "shipping tel" ></ label ></ p >
< p >< label > 电子邮件地址:< input type = email name = "custemail" autocomplete = "shipping email" ></ label ></ p >
< fieldset >
< legend > 披萨尺寸 </ legend >
< p >< label > < input type = radio name = size required value = "small" > 小 </ label ></ p >
< p >< label > < input type = radio name = size required value = "medium" > 中 </ label ></ p >
< p >< label > < input type = radio name = size required value = "large" > 大 </ label ></ p >
</ fieldset >
< fieldset >
< legend > 披萨配料 </ legend >
< p >< label > < input type = checkbox name = "topping" value = "bacon" > 培根 </ label ></ p >
< p >< label > < input type = checkbox name = "topping" value = "cheese" > 额外奶酪 </ label ></ p >
< p >< label > < input type = checkbox name = "topping" value = "onion" > 洋葱 </ label ></ p >
< p >< label > < input type = checkbox name = "topping" value = "mushroom" > 蘑菇 </ label ></ p >
</ fieldset >
< p >< label > 首选送达时间:< input type = time min = "11:00" max = "21:00" step = "900" name = "delivery" required ></ label ></ p >
< p >< label > 送货说明:< textarea name = "comments" maxlength = 1000 ></ textarea ></ label ></ p >
< p >< button > 提交订单</ button ></ p >
</ form > 本节是非规范性的。
某些设备,特别是带有虚拟键盘的设备,可以为用户提供多种输入模态。例如,在输入信用卡号时,用户可能 只希望看到数字 0-9 的按键,而在输入姓名时,他们可能希望看到默认将每个单词首字母大写的表单字段。
使用 inputmode 属性,可以选择适当的输入模态:
< form method = "post"
enctype = "application/x-www-form-urlencoded"
action = "https://pizza.example.com/order.cgi" >
< p >< label > 顾客姓名:< input name = "custname" required autocomplete = "shipping name" ></ label ></ p >
< p >< label > 电话:< input type = tel name = "custtel" autocomplete = "shipping tel" ></ label ></ p >
< p >< label > 门铃代码:< input name = "custbuzz" inputmode = "numeric" ></ label ></ p >
< p >< label > 电子邮件地址:< input type = email name = "custemail" autocomplete = "shipping email" ></ label ></ p >
< fieldset >
< legend > 披萨尺寸 </ legend >
< p >< label > < input type = radio name = size required value = "small" > 小 </ label ></ p >
< p >< label > < input type = radio name = size required value = "medium" > 中 </ label ></ p >
< p >< label > < input type = radio name = size required value = "large" > 大 </ label ></ p >
</ fieldset >
< fieldset >
< legend > 披萨配料 </ legend >
< p >< label > < input type = checkbox name = "topping" value = "bacon" > 培根 </ label ></ p >
< p >< label > < input type = checkbox name = "topping" value = "cheese" > 额外奶酪 </ label ></ p >
< p >< label > < input type = checkbox name = "topping" value = "onion" > 洋葱 </ label ></ p >
< p >< label > < input type = checkbox name = "topping" value = "mushroom" > 蘑菇 </ label ></ p >
</ fieldset >
< p >< label > 首选送达时间:< input type = time min = "11:00" max = "21:00" step = "900" name = "delivery" required ></ label ></ p >
< p >< label > 送货说明:< textarea name = "comments" maxlength = 1000 ></ textarea ></ label ></ p >
< p >< button > 提交订单</ button ></ p >
</ form > 本节是非规范性的。
type、autocomplete 和 inputmode 属性看起来可能十分相似,容易令人困惑。例如,在这三种情况下,
字符串“email”都是有效值。本节尝试说明这三个属性之间的区别,并提供关于如何使用它们的建议。
type 属性决定用户代理使用何种控件向用户呈现 input 元素的字段。在该属性的不同值之间进行选择,与选择使用 input 元素、textarea 元素、select 元素等是相同的选择。
相比之下,autocomplete 属性描述用户将输入的值实际表示什么。在该属性的不同
值之间进行选择,与选择该元素的标签内容是相同的选择。
首先考虑电话号码。如果页面要求用户提供电话号码,正确的表单控件是 <input type=tel>。但是,应使用哪个 autocomplete 值,取决于页面要求的是哪个电话号码、预期电话号码采用
国际格式还是仅采用本地格式,等等。
例如,电子商务网站结账流程中的页面,可能需要为购买礼物并将其寄给朋友的顾客收集买家的电话号码 (以便在付款出现问题时联系)以及朋友的电话号码(以便在送货出现问题时联系)。如果网站预期使用带有 国家代码前缀的国际电话号码,则可以如下所示:
< p >< label > 您的电话号码:< input type = tel name = custtel autocomplete = "billing tel" ></ label >
< p >< label > 收件人的电话号码:< input type = tel name = shiptel autocomplete = "shipping tel" ></ label >
< p > 请输入包含国家代码前缀的完整电话号码,例如“+1 555 123 4567”。但是,如果网站仅支持英国顾客和收件人,则可能改为如下所示(请注意使用了 tel-national,而不是
tel):
< p >< label > 您的电话号码:< input type = tel name = custtel autocomplete = "billing tel-national" ></ label >
< p >< label > 收件人的电话号码:< input type = tel name = shiptel autocomplete = "shipping tel-national" ></ label >
< p > 请输入完整的英国电话号码,例如“(01632) 960 123”。现在,考虑一个人的首选语言。正确的 autocomplete 值是 language。但是,可用于此目的的表单控件有很多种:
文本控件(<input type=text>)、下拉列表
(<select>)、单选按钮(<input
type=radio>)等。这仅取决于所需的界面类型。
最后,考虑姓名。如果页面只需要用户提供一个姓名,则相关控件是 <input type=text>。如果页面要求
用户提供全名,则相关的 autocomplete 值是 name。
< p >< label > 日文姓名:< input name = "j" type = "text" autocomplete = "section-jp name" ></ label >
< label > 罗马字姓名:< input name = "e" type = "text" autocomplete = "section-en name" ></ label > 在此示例中,autocomplete 属性值中的“section-*”关键字告诉用户代理,这两个字段预期使用
不同的姓名。如果没有这些关键字,当用户为第一个字段提供值时,用户代理可能会使用第一个字段中
提供的值自动填充第二个字段。
关键字的“-jp”和“-en”部分对用户代理而言是不透明的;用户代理
无法根据这些部分推断出两个姓名分别应使用日文和英文。
与关于 type 和 autocomplete 的选择不同,当控件是文本控件时,inputmode 属性决定使用何种输入模态(例如虚拟键盘)。
考虑信用卡号。适当的输入类型不是 <input type=number>,原因如下文所述;而应当使用 <input type=text>。为了仍然
鼓励用户代理使用数字输入模态(例如只显示数字的虚拟键盘),页面应使用
< p >< label > 信用卡号:
< input name = "cc" type = "text" inputmode = "numeric" pattern = "[0-9]{8,19}" autocomplete = "cc-number" >
</ label ></ p > 本节是非规范性的。
在此披萨配送示例中,时间以“HH:MM”格式指定:小时使用 24 小时制的两位数字表示,分钟也使用两位数字 表示。(也可以指定秒,但本例中并不需要。)
然而,在某些语言环境中,向用户显示时间时通常采用不同的表示方式。例如,在美国,仍然普遍使用带有 am/pm 指示符的 12 小时制,例如“2pm”。在法国,通常使用“h”字符分隔小时和分钟,例如“14h00”。
日期也存在类似的问题,而且各组成部分的顺序也并不总是一致,这使情况更加复杂——例如,在塞浦路斯, 2003 年 2 月 1 日通常写作“1/2/03”,而在日本,同一日期通常写作“2003年02月01日”——数字也存在类似 问题,例如不同语言环境使用的十进制分隔符和千位分隔符标点不同。
因此,务必将 HTML 和表单提交中使用的时间、日期和数字格式,与浏览器向用户显示并接受用户输入时使用 的时间、日期和数字格式区分开来。前者始终采用本规范定义的格式(并以广泛确立的、用于计算机可读日期和 时间格式的 ISO 8601 标准为基础)。
“在线路上”使用的格式,即 HTML 标记和表单提交中使用的格式,旨在实现计算机可读,并且不受用户语言 环境影响,始终保持一致。例如,日期始终以“YYYY-MM-DD”格式书写,如“2003-02-01”。某些用户可能看到 此格式,而其他用户可能看到“01.02.2003”或“February 1, 2003”。
页面以线路格式给出的时间、日期或数字,在显示给用户之前,会转换为用户首选的表现形式(基于用户偏好 或页面本身的语言环境)。类似地,在用户使用其首选格式输入时间、日期或数字后,用户代理会在将其放入 DOM 或提交之前,将其转换回线路格式。
这样,页面和服务器上的脚本便可以用一致的方式处理时间、日期和数字,而无需支持数十种不同格式,同时 仍能满足用户的需求。
另请参阅有关表单控件本地化的实现说明。
主要出于历史原因,本节中的元素除了属于流式内容、短语内容和交互式内容等通常类别之外,还属于若干相互重叠 (但存在细微差别)的类别。
其中一些元素是表单关联元素,这意味着它们可以拥有一个表单所有者。
表单关联元素分为若干 子类别:
表示会列在 form.elements
和
fieldset.elements API 中的元素。这些元素还具有
form 内容属性,以及与之匹配的
form IDL 属性,允许作者指定一个
显式的表单所有者。
某些可提交元素可以根据其属性成为按钮。下文定义元素何时是按钮。某些按钮特别属于提交按钮。
表示从其表单
所有者继承 autocapitalize
和 autocorrect 属性的元素。
某些元素(并非全部都是表单关联元素)被归类为可标注元素。这些元素可以与 label 元素相关联。
form
元素所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
form 元素后代。accept-charset —
用于表单
提交的字符编码
action — 用于
表单提交的 URL
autocomplete —
表单中控件的自动填充功能的默认设置
enctype — 表单提交所使用的条目列表编码类型
method — 用于表单提交的变体
name — 在
document.forms API
中使用的表单名称
novalidate — 在表单提交时绕过表单控件验证
target — 用于表单提交的可导航对象
relaction。[Exposed =Window ,
LegacyOverrideBuiltIns ,
LegacyUnenumerableNamedProperties ]
interface HTMLFormElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect="accept-charset"] attribute DOMString acceptCharset ;
[CEReactions , ReflectSetter ] attribute USVString action ;
[CEReactions ] attribute DOMString autocomplete ;
[CEReactions ] attribute DOMString enctype ;
[CEReactions ] attribute DOMString encoding ;
[CEReactions ] attribute DOMString method ;
[CEReactions , Reflect ] attribute DOMString name ;
[CEReactions , Reflect ] attribute boolean noValidate ;
[CEReactions , Reflect ] attribute DOMString target ;
[CEReactions , Reflect ] attribute DOMString rel ;
[SameObject , PutForwards =value , Reflect="rel"] readonly attribute DOMTokenList relList ;
[SameObject ] readonly attribute HTMLFormControlsCollection elements ;
readonly attribute unsigned long length ;
getter Element (unsigned long index );
getter (RadioNodeList or Element ) (DOMString name );
undefined submit ();
undefined requestSubmit (optional HTMLElement ? submitter = null );
[CEReactions ] undefined reset ();
boolean checkValidity ();
boolean reportValidity ();
};form 元素表示一个可通过一组表单关联
元素进行操作的超链接,其中一些元素可以表示可编辑的值,这些值可以提交到服务器进行
处理。
accept-charset 属性给出提交时要使用的字符
编码。如果指定,其值必须与“UTF-8”进行ASCII
不区分大小写匹配。[ENCODING]
name 属性
表示 form 在 forms
集合中的名称。该值不得为空字符串,并且在其所在的 forms 集合中(如有),该值在各
form 元素之间必须唯一。
autocomplete
属性是一个枚举
属性,具有以下关键字和状态:
| 关键字 | 状态 | 简要说明 |
|---|---|---|
on
|
开启 | 默认情况下,表单控件的自动填充字段名称将设置为“on”。
|
off
|
关闭 | 默认情况下,表单控件的自动填充字段名称将设置为“off”。
|
action、enctype、
method、novalidate
和 target 属性是表单提交
属性。
form 元素上的
rel 属性控制这些元素创建何种
链接。该属性的值必须是一个无序且唯一的空格分隔
标记集合。允许的关键字及其含义在前面的章节中定义。
rel 的受支持
标记是在HTML 链接类型中定义、允许用于 form 元素、会影响处理模型并且受用户
代理支持的关键字。可能的受支持标记
为 noreferrer、noopener 和 opener。rel 的受支持标记必须只包含此
列表中用户代理实现了相应处理模型的标记。
form.elements
所有当前引擎均支持。
返回表单中各表单控件的 HTMLFormControlsCollection
(出于历史原因,不包括图像按钮)。
form.length
所有当前引擎均支持。
返回表单中表单控件的数量(出于历史原因,不包括图像按钮)。
form[index]返回表单中的第 index 个元素(出于历史原因,不包括图像按钮)。
form[name]返回表单中具有给定 ID 或 name 的表单控件(或者,如果有多个,则返回这些表单
控件组成的 RadioNodeList)(出于历史原因,不包括图像按钮);
如果没有,则返回具有给定 ID 的 img
元素。
一旦使用特定名称引用了某个元素,只要该元素仍位于树中,即使该元素实际的 ID 或 name 发生更改,该名称仍将继续可用于通过此方法引用该元素。
如果存在多个匹配项,则返回一个包含所有这些元素的 RadioNodeList 对象。
form.submit()
所有当前引擎均支持。
form.requestSubmit([ submitter ])
所有当前引擎均支持。
请求提交表单。与 submit() 不同,此
方法包括交互式约束
验证和触发 submit 事件,其中任一操作
都可以取消提交。
submitter 参数可用于指向特定的提交按钮,其 formaction、formenctype、formmethod、formnovalidate 和
formtarget 属性
可以影响提交。此外,在为提交构造条目列表时,将包括提交者;
通常情况下,按钮会被排除。
form.reset()
所有当前引擎均支持。
重置表单。
form.checkValidity()
如果表单的所有控件均有效,则返回 true;否则返回 false。
form.reportValidity()
如果表单的所有控件均有效,则返回 true;否则返回 false 并通知 用户。
elements
IDL 属性必须返回一个 HTMLFormControlsCollection,
其根位于 form 元素的根,其过滤器匹配列出元素中表单所有者为该
form 元素的元素,但 input 元素中,其 type 属性处于图像按钮
状态的元素除外;出于历史原因,必须从此特定集合中
排除这些元素。
每个 form 元素都有一个
从名称到元素的映射,称为过去名称
映射。它用于在控件更改名称后仍保留这些名称。
受支持属性名称由以下 算法按该算法获得的顺序所获得的名称组成:
令 sourced names 为一个初始为空的有序元组列表, 每个元组由一个字符串、一个元素和一个来源组成,其中来源为 id、name 或 past 之一;如果来源为 past,则还包含一个时长。
对于每个列出元素
candidate,其表单所有者为 form 元素,但任何
input 元素中,其
type 属性处于
图像
按钮状态的元素除外:
对于过去名称映射中的每个条目 past entry,向 sourced names 添加一个条目,以 past entry 的名称作为 字符串,以 past entry 的元素作为元素,以 past 作为来源,并以 past entry 位于过去名称映射中的时长作为 时长。
按每个元组中元素条目的树顺序对 sourced names 进行排序;对于具有相同元素的条目,先放置来源为 id 的条目,然后放置来源为 name 的条目,最后放置来源为 past 的条目; 对于具有相同元素和来源的条目,则按时长排序,最早的在前。
从 sourced names 中移除名称为空字符串的所有 条目。
从 sourced names 中移除名称与映射中较早条目相同的所有 条目。
返回 sourced names 中的名称列表,并保持其 相对顺序。
要为 form 元素确定命名属性的值
name,用户代理必须运行以下步骤:
令 candidates 为一个实时 RadioNodeList 对象,
其中包含所有列出元素:
这些元素的表单
所有者为该 form
元素,并且具有等于 name 的 id 属性或 name 属性;
但 input 元素中,其
type 属性处于图像
按钮状态的元素除外;这些元素按树顺序排列。
如果 candidates 为空,则令 candidates 为一个实时
RadioNodeList 对象,
其中包含所有 img
元素:这些元素的表单
所有者为该 form
元素,并且具有等于 name 的 id 属性或 name 属性;
这些元素按树顺序排列。
如果 candidates 为空,并且 name 是 form 元素的过去名称映射中某个条目的名称,则返回该映射中
与 name 关联的对象。
如果 candidates 包含多个节点,则返回 candidates。
否则,candidates 恰好包含一个节点。在 form
元素的过去名称映射中,添加从
name 到 candidates 中该节点的映射,并替换具有相同名称的先前条目(如果
存在)。
返回 candidates 中的节点。
如果 form 元素的过去名称映射中列出的元素更改了
表单所有者,则必须从该映射中移除其条目。
submit()
方法步骤是:从 this
使用 this 来提交,并将从
submit() 方法提交设置为 true。
requestSubmit(submitter) 方法在
调用时,必须运行以下步骤:
如果 submitter 不为 null:
如果 submitter 的表单所有者不是此 form 元素,
则抛出 “NotFoundError” DOMException。
否则,将 submitter 设置为此 form 元素。
reset()
方法在调用时,必须运行以下步骤:
此示例展示了两个搜索表单:
< form action = "https://www.google.com/search" method = "get" >
< label > Google:< input type = "search" name = "q" ></ label > < input type = "submit" value = "搜索……" >
</ form >
< form action = "https://www.bing.com/search" method = "get" >
< label > Bing:< input type = "search" name = "q" ></ label > < input type = "submit" value = "搜索……" >
</ form > label
元素所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
label 元素后代。
for — 将标签与
表单控件关联
[Exposed =Window ]
interface HTMLLabelElement : HTMLElement {
[HTMLConstructor ] constructor ();
readonly attribute HTMLFormElement ? form ;
[CEReactions , Reflect="for"] attribute DOMString htmlFor ;
readonly attribute HTMLElement ? control ;
};label 元素表示用户界面中的标题。该
标题可以与特定表单控件关联,该控件称为 label
元素的被标注控件;可以使用 for 属性进行关联,也可以将表单
控件放置在 label 元素本身内部。
除非以下规则另有规定,否则 label 元素没有
被标注控件。
所有当前引擎均支持。
可以指定 for 属性,以
指明标题要与之关联的表单控件。如果指定该属性,则其值必须是与 label 元素位于同一树中的可标签元素的 ID。如果指定了该属性,并且树中存在一个元素,其 ID 等于 for 属性的值,并且按树
顺序排列的第一个此类元素是可标签元素,则该元素是 label 元素的被标注控件。
label 元素的
确切默认呈现和行为,特别是其可能具有的激活行为(如果有),应与平台的标签
行为相匹配。对于以 label 元素的交互式内容后代,以及这些交互式
内容后代的任何后代为目标的事件,label 元素的激活行为必须是什么也不做。
表单关联自定义
元素是可标签元素,因此对于
label 元素的激活行为会影响被标注
控件的用户代理,内置元素和自定义元素都会受到影响。
例如,在单击标签会激活表单控件的平台上,单击以下代码片段中的
label,可能会使用户代理
在 input 元素上触发 click 事件,就像该
元素本身由用户触发一样:
< label >< input type = checkbox name = lost > 丢失</ label > 类似地,假设 my-checkbox 被声明为一个
表单关联
自定义元素(如此
示例所示),则代码
< label >< my-checkbox name = lost ></ my-checkbox > 丢失</ label > 将具有相同的行为,在 my-checkbox
元素上触发
click 事件。
在其他平台上,这两种情况下的行为可能只是聚焦控件,或者什么也不做。
以下示例展示了三个各自带有标签的表单控件,其中两个还包含向用户展示正确格式的 小号文本。
< p >< label > 全名:< input name = fn > < small > 格式:名字 姓氏</ small ></ label ></ p >
< p >< label > 年龄:< input name = age type = number min = 0 ></ label ></ p >
< p >< label > 邮政编码:< input name = pc > < small > 格式:AB12 3CD</ small ></ label ></ p > label.control
所有当前引擎均支持。
返回与此元素关联的表单控件。
label.form
所有当前引擎均支持。
返回与此元素关联的表单控件的表单所有者。
如果不存在,则返回 null。
form
IDL
属性必须运行以下步骤:
label
元素上的 form IDL
属性不同于列出的表单关联元素上的 form IDL
属性,并且 label 元素没有
form 内容属性。
control.labels
所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
可标签元素以及所有 input 元素
都有一个与之关联的实时 NodeList
对象,该对象表示按树顺序排列的 label 元素列表,
这些元素的被标注
控件是所讨论的元素。不是表单关联
自定义元素的可标签元素的 labels IDL 属性,以及 input 元素的 labels IDL 属性,在获取时,
必须返回该 NodeList
对象,并且必须始终返回同一个值;除非该元素是 input
元素,且其 type
属性处于状态,在这种情况下必须改为返回
null。
所有当前引擎均支持。
表单关联
自定义元素没有
labels IDL 属性。
相反,其
ElementInternals 对象具有
labels IDL 属性。在获取时,如果目标元素不是表单关联
自定义
元素,则必须抛出 “NotSupportedError” DOMException。
否则,必须返回该 NodeList
对象,并且必须始终返回同一个值。
此(不符合要求的)示例展示了当 input
元素的
type 属性发生更改时,
NodeList
会发生什么,以及 labels 会返回什么。
<!doctype html>
< p >< label >< input ></ label ></ p >
< script >
const input = document. querySelector( 'input' );
const labels = input. labels;
console. assert( labels. length === 1 );
input. type = 'hidden' ;
console. assert( labels. length === 0 ); // input 不再是 label 的 >被标注控件
console. assert( input. labels === null );
input. type = 'checkbox' ;
console. assert( labels. length === 1 ); // input 再次成为 label 的 >被标注控件
console. assert( input. labels === labels); // 与最初返回的值相同
</ script > input
元素所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
type 属性
不处于隐藏状态:交互式内容。
type 属性
不处于隐藏状态:列出、可标签、可提交、可重置且继承自动大写和自动更正的表单关联元素。
type 属性处于
隐藏状态:列出、可提交、可重置且继承自动大写和自动更正的表单关联元素。
type 属性
不处于隐藏状态:可感知内容。
accept — 文件上传控件中预期文件类型的提示
alpha — 允许设置颜色的
alpha 分量
alt — 图像不可用时使用的
替代文本
autocomplete —
表单自动填充功能的提示
checked — 控件是否
被选中
colorspace —
序列化颜色的色彩空间
dirname — 在表单提交中发送元素方向性时使用的表单控件名称
disabled — 表单
控件是否被禁用
form — 将元素与
form 元素关联
formaction — 用于
表单提交的 URL
formenctype — 表单提交所使用的条目列表编码类型
formmethod — 用于
表单提交的变体
formnovalidate
— 在表单
提交时绕过表单控件验证
formtarget — 用于表单提交的可导航对象
height — 垂直尺寸
list — 自动完成
选项列表
max — 最大值
maxlength — 值的最大
长度
min — 最小值
minlength — 值的最小
长度
multiple — 是否
允许多个值
name — 在表单提交以及 form.elements API
中使用的元素名称
pattern — 表单控件的值
要匹配的模式
placeholder —
放置在表单控件内、用户可见的标签
popovertarget — 以
要切换、显示或隐藏的弹出框元素为目标
popovertargetaction
— 指示是切换、显示还是隐藏目标弹出框元素
readonly — 是否
允许用户编辑该值
required — 控件是否
是表单
提交所必需的
size — 控件的大小
src — 资源的地址
step — 表单控件的值
要匹配的粒度
type — 表单控件的类型
value — 表单控件的值
width — 水平尺寸
title 属性
在此元素上具有特殊语义:
模式的说明(与 pattern
属性一起使用时)
type 属性处于隐藏状态:面向作者;面向实现者。type 属性处于文本状态:面向作者;面向实现者。type 属性处于搜索状态:面向作者;面向实现者。type 属性处于电话状态:面向作者;面向实现者。type 属性处于URL 状态:面向作者;面向实现者。type 属性处于电子邮件状态:面向作者;面向实现者。type 属性处于密码状态:
面向作者;面向实现者。
type 属性处于日期状态:面向作者;面向实现者。type 属性处于月状态:面向作者;面向实现者。type 属性处于周状态:面向作者;面向实现者。type 属性处于时间状态:面向作者;面向实现者。type 属性处于本地日期和时间状态:面向作者;面向实现者。type 属性处于数字状态:面向作者;面向实现者。type 属性处于范围状态:面向作者;面向实现者。type 属性处于颜色状态:面向作者;面向实现者。type 属性处于复选框状态:
面向作者;面向实现者。
type 属性处于单选按钮
状态:面向作者;面向实现者。type 属性处于文件上传
状态:面向作者;面向实现者。type 属性处于提交
按钮状态:面向作者;面向实现者。type 属性处于图像按钮
状态:面向作者;面向实现者。type 属性处于重置按钮
状态:面向作者;面向实现者。type 属性处于按钮状态:面向作者;面向实现者。formaction。
[Exposed =Window ]
interface HTMLInputElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect ] attribute DOMString accept ;
[CEReactions , Reflect ] attribute boolean alpha ;
[CEReactions , Reflect ] attribute DOMString alt ;
[CEReactions , ReflectSetter ] attribute DOMString autocomplete ;
[CEReactions , Reflect="checked"] attribute boolean defaultChecked ;
attribute boolean checked ;
[CEReactions ] attribute DOMString colorSpace ;
[CEReactions , Reflect ] attribute DOMString dirName ;
[CEReactions , Reflect ] attribute boolean disabled ;
readonly attribute HTMLFormElement ? form ;
attribute FileList ? files ;
[CEReactions , ReflectSetter ] attribute USVString formAction ;
[CEReactions ] attribute DOMString formEnctype ;
[CEReactions ] attribute DOMString formMethod ;
[CEReactions , Reflect ] attribute boolean formNoValidate ;
[CEReactions , Reflect ] attribute DOMString formTarget ;
[CEReactions , ReflectSetter ] attribute unsigned long height ;
attribute boolean indeterminate ;
readonly attribute HTMLDataListElement ? list ;
[CEReactions , Reflect ] attribute DOMString max ;
[CEReactions , ReflectNonNegative ] attribute long maxLength ;
[CEReactions , Reflect ] attribute DOMString min ;
[CEReactions , ReflectNonNegative ] attribute long minLength ;
[CEReactions , Reflect ] attribute boolean multiple ;
[CEReactions , Reflect ] attribute DOMString name ;
[CEReactions , Reflect ] attribute DOMString pattern ;
[CEReactions , Reflect ] attribute DOMString placeholder ;
[CEReactions , Reflect ] attribute boolean readOnly ;
[CEReactions , Reflect ] attribute boolean required ;
[CEReactions , Reflect ] attribute unsigned long size ;
[CEReactions , ReflectURL ] attribute USVString src ;
[CEReactions , Reflect ] attribute DOMString step ;
[CEReactions ] attribute DOMString type ;
[CEReactions , Reflect="value"] attribute DOMString defaultValue ;
[CEReactions ] attribute [LegacyNullToEmptyString ] DOMString value ;
attribute object ? valueAsDate ;
attribute unrestricted double valueAsNumber ;
[CEReactions , ReflectSetter ] attribute unsigned long width ;
undefined stepUp (optional long n = 1);
undefined stepDown (optional long n = 1);
readonly attribute boolean willValidate ;
readonly attribute ValidityState validity ;
readonly attribute DOMString validationMessage ;
boolean checkValidity ();
boolean reportValidity ();
undefined setCustomValidity (DOMString error );
readonly attribute NodeList ? labels ;
undefined select ();
attribute unsigned long ? selectionStart ;
attribute unsigned long ? selectionEnd ;
attribute DOMString ? selectionDirection ;
undefined setRangeText (DOMString replacement );
undefined setRangeText (DOMString replacement , unsigned long start , unsigned long end , optional SelectionMode selectionMode = "preserve");
undefined setSelectionRange (unsigned long start , unsigned long end , optional DOMString direction );
undefined showPicker ();
// 还具有已废弃的成员
};
HTMLInputElement includes PopoverTargetAttributes ;input 元素表示一个有类型的数据字段,通常带有允许用户编辑数据的表单
控件。
type 属性
控制元素的数据类型(以及关联控件)。它是一个枚举
属性,具有以下关键字和状态:
| 关键字 | 状态 | 数据类型 | 控件类型 |
|---|---|---|---|
hidden
|
任意字符串 | 不适用 | |
text
|
文本 | 不含换行符的文本 | 文本控件 |
search
|
搜索 | 不含换行符的文本 | 搜索控件 |
tel
|
电话 | 不含换行符的文本 | 文本控件 |
url
|
URL | 绝对 URL | 文本控件 |
email
|
电子邮件 | 电子邮件地址或电子邮件地址列表 | 文本控件 |
password
|
密码 | 不含换行符的文本(敏感信息) | 遮蔽数据输入的文本控件 |
date
|
日期 | 不含时区的日期(年、月、日) | 日期控件 |
month
|
月 | 由年和月组成且不含时区的日期 | 月控件 |
week
|
周 | 由周年份编号和周编号组成且不含时区的日期 | 周控件 |
time
|
时间 | 不含时区的时间(小时、分钟、秒、小数秒) | 时间控件 |
datetime-local
|
本地日期和时间 | 不含时区的日期和时间(年、月、日、小时、分钟、秒、小数秒) | 日期和时间控件 |
number
|
数字 | 数值 | 文本控件或微调控件 |
range
|
范围 | 数值,并具有确切值并不重要这一额外语义 | 滑块控件或类似控件 |
color
|
颜色 | 具有 8 位红、绿、蓝分量的 sRGB 颜色 | 颜色选择器 |
checkbox
|
复选框 | 预定义列表中的零个或多个值组成的集合 | 复选框 |
radio
|
单选 按钮 | 枚举值 | 单选按钮 |
file
|
文件 上传 | 零个或多个文件,每个文件都有一个 MIME 类型以及可选的 文件名 | 标签和按钮 |
submit
|
提交按钮 | 枚举值,并具有必须是最后选择的值且会启动表单提交这一额外语义 | 按钮 |
image
|
图像 按钮 | 相对于特定图像尺寸的坐标,并具有必须是最后选择的值且会启动表单提交这一额外语义 | 可单击的图像或按钮 |
reset
|
重置 按钮 | 不适用 | 按钮 |
button
|
按钮 | 不适用 | 按钮 |
accept、
alpha、
alt、
autocomplete、
checked、
colorspace、
dirname、
formaction、
formenctype、
formmethod、
formnovalidate、
formtarget、
height、
list、
max、
maxlength、
min、
minlength、
multiple、
pattern、
placeholder、
readonly、
required、
size、
src、
step 和
width 内容属性,
checked、
files、
valueAsDate、
valueAsNumber
和
list IDL 属性,
select()
方法,
selectionStart、
selectionEnd
和
selectionDirection
IDL 属性,
setRangeText()
和
setSelectionRange()
方法,
stepUp() 和
stepDown() 方法,以及
input
和
change 事件是否适用于 input 元素,取决于其
type 属性的状态。
定义各类型的小节还会在规范性的“簿记”章节中明确规定哪些功能适用,以及哪些功能不适用于各类型。这些功能的行为取决于它们是否适用,具体定义见其各自章节(参见
内容属性、API 和事件)。
下表是非规范性的,概述了这些内容属性、IDL 属性、方法和事件中的哪些 适用于各状态:
| 文本, 搜索 | 电话, URL | 电子邮件 | 密码 | 日期, 月, 周, 时间 | 本地日期和时间 | 数字 | 范围 | 颜色 | 复选框, 单选按钮 | 文件 上传 | 提交按钮 | 图像按钮 | 重置按钮, 按钮 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 内容属性 | |||||||||||||||
accept
|
· | · | · | · | · | · | · | · | · | · | · | 是 | · | · | · |
alpha
|
· | · | · | · | · | · | · | · | · | 是 | · | · | · | · | · |
alt
|
· | · | · | · | · | · | · | · | · | · | · | · | · | 是 | · |
autocomplete
|
是 | 是 | 是 | 是 | 是 | 是 | 是 | 是 | 是 | 是 | · | · | · | · | · |
checked
|
· | · | · | · | · | · | · | · | · | · | 是 | · | · | · | · |
colorspace
|
· | · | · | · | · | · | · | · | · | 是 | · | · | · | · | · |
dirname
|
是 | 是 | 是 | 是 | 是 | · | · | · | · | · | · | · | 是 | · | · |
formaction
|
· | · | · | · | · | · | · | · | · | · | · | · | 是 | 是 | · |
formenctype
|
· | · | · | · | · | · | · | · | · | · | · | · | 是 | 是 | · |
formmethod
|
· | · | · | · | · | · | · | · | · | · | · | · | 是 | 是 | · |
formnovalidate
|
· | · | · | · | · | · | · | · | · | · | · | · | 是 | 是 | · |
formtarget
|
· | · | · | · | · | · | · | · | · | · | · | · | 是 | 是 | · |
height
|
· | · | · | · | · | · | · | · | · | · | · | · | · | 是 | · |
list
|
· | 是 | 是 | 是 | · | 是 | 是 | 是 | 是 | 是 | · | · | · | · | · |
max
|
· | · | · | · | · | 是 | 是 | 是 | 是 | · | · | · | · | · | · |
maxlength
|
· | 是 | 是 | 是 | 是 | · | · | · | · | · | · | · | · | · | · |
min
|
· | · | · | · | · | 是 | 是 | 是 | 是 | · | · | · | · | · | · |
minlength
|
· | 是 | 是 | 是 | 是 | · | · | · | · | · | · | · | · | · | · |
multiple
|
· | · | · | 是 | · | · | · | · | · | · | · | 是 | · | · | · |
pattern
|
· | 是 | 是 | 是 | 是 | · | · | · | · | · | · | · | · | · | · |
placeholder
|
· | 是 | 是 | 是 | 是 | · | · | 是 | · | · | · | · | · | · | · |
popovertarget
|
· | · | · | · | · | · | · | · | · | · | · | · | 是 | 是 | 是 |
popovertargetaction
|
· | · | · | · | · | · | · | · | · | · | · | · | 是 | 是 | 是 |
readonly
|
· | 是 | 是 | 是 | 是 | 是 | 是 | 是 | · | · | · | · | · | · | · |
required
|
· | 是 | 是 | 是 | 是 | 是 | 是 | 是 | · | · | 是 | 是 | · | · | · |
size
|
· | 是 | 是 | 是 | 是 | · | · | · | · | · | · | · | · | · | · |
src
|
· | · | · | · | · | · | · | · | · | · | · | · | · | 是 | · |
step
|
· | · | · | · | · | 是 | 是 | 是 | 是 | · | · | · | · | · | · |
width
|
· | · | · | · | · | · | · | · | · | · | · | · | · | 是 | · |
| IDL 属性和方法 | |||||||||||||||
checked
|
· | · | · | · | · | · | · | · | · | · | 是 | · | · | · | · |
files
|
· | · | · | · | · | · | · | · | · | · | · | 是 | · | · | · |
value
|
默认 | 值 | 值 | 值 | 值 | 值 | 值 | 值 | 值 | 值 | 默认/on | 文件名 | 默认 | 默认 | 默认 |
valueAsDate
|
· | · | · | · | · | 是 | · | · | · | · | · | · | · | · | · |
valueAsNumber
|
· | · | · | · | · | 是 | 是 | 是 | 是 | · | · | · | · | · | · |
list
|
· | 是 | 是 | 是 | · | 是 | 是 | 是 | 是 | 是 | · | · | · | · | · |
select()
|
· | 是 | 是 | 是† | 是 | 是† | 是† | 是† | · | 是† | · | 是† | · | · | · |
selectionStart
|
· | 是 | 是 | · | 是 | · | · | · | · | · | · | · | · | · | · |
selectionEnd
|
· | 是 | 是 | · | 是 | · | · | · | · | · | · | · | · | · | · |
selectionDirection
|
· | 是 | 是 | · | 是 | · | · | · | · | · | · | · | · | · | · |
setRangeText()
|
· | 是 | 是 | · | 是 | · | · | · | · | · | · | · | · | · | · |
setSelectionRange()
|
· | 是 | 是 | · | 是 | · | · | · | · | · | · | · | · | · | · |
stepDown()
|
· | · | · | · | · | 是 | 是 | 是 | 是 | · | · | · | · | · | · |
stepUp()
|
· | · | · | · | · | 是 | 是 | 是 | 是 | · | · | · | · | · | · |
| 事件 | |||||||||||||||
input
事件
|
· | 是 | 是 | 是 | 是 | 是 | 是 | 是 | 是 | 是 | 是 | 是 | · | · | · |
change 事件
|
· | 是 | 是 | 是 | 是 | 是 | 是 | 是 | 是 | 是 | 是 | 是 | · | · | · |
† 如果控件没有可选择的文本,则 select()
方法不会执行任何操作,也不会抛出
“InvalidStateError” DOMException。
type
属性的某些状态定义了一个值
净化算法。
每个 input 元素都有一个
值,该值通过 value IDL
属性公开。某些状态定义了
将字符串转换为数字的算法、
将数字转换为
字符串的算法、将字符串转换为
Date 对象的算法,以及将
Date 对象转换为字符串的算法,这些算法由 max、min、step、valueAsDate、
valueAsNumber
和 stepUp() 使用。
value 内容
属性给出 input
元素的默认值。添加、设置或移除
value
内容属性时,如果控件的脏值标志
为 false,则用户代理必须将元素的值设置为 value
内容属性的值(如果存在),否则设置为空字符串,然后运行当前的值净化
算法(如果定义了该算法)。
每个 input 元素都有一个
选中状态,
该状态通过 checked IDL 属性公开。
每个 input 元素都有一个
布尔型的脏选中状态标志。当该标志为 true 时,
称该元素具有脏选中状态。
创建元素时,脏
选中状态标志最初必须
设置为 false;每当用户以更改选中状态的方式与控件交互时,该标志都必须设置为 true。
所有当前引擎均支持。
checked
内容属性是一个布尔属性,它给出 input 元素的默认选中状态。
添加 checked
内容属性时,如果控件不具有脏选中状态,用户
代理必须将元素的选中状态设置为 true;
移除 checked
内容属性时,如果
控件不具有脏选中状态,用户
代理必须将元素的选中状态设置为
false。
input
元素的重置算法是:将其用户有效性、脏值标志和脏
选中状态标志
重新设置为 false;将元素的值设置为 value 内容
属性的值(如果存在),否则设置为空字符串;如果元素具有 checked 内容
属性,则将元素的选中状态设置为 true,否则设置为
false;清空所选文件列表;然后,如果 type 属性的
当前状态定义了值
净化算法,则调用该算法。
每个 input 元素都可以是
可变的。除非
另有规定,否则 input 元素始终是可变的。同样,除非
另有规定,否则用户
代理不应允许用户修改元素的值或选中状态。
readonly
属性在
某些情况下(例如对于日期
状态,但不包括复选框状态)也可以阻止 input 元素
成为可变的。
input 元素可以
支持选择器。选择器是一种允许最终用户选择值的用户界面元素。
input 元素是否支持
选择器,取决于 type
属性的状态和由实现定义的
行为。当 input 元素的
type 属性处于文件
上传状态时,该元素必须支持选择器。
截至本文撰写时,典型的浏览器实现会为以下内容显示这种选择器 UI:
请记住,元素的激活行为既会针对
用户发起的激活运行,也会针对合成激活(例如通过 el.click())运行。用户代理还可能
针对给定控件具有仅由真正的用户发起激活所触发的行为——这些行为未在
此处规定。一种常见选择是为控件显示选择器(如
适用)。相比之下,输入
激活行为仅在文件上传和
颜色状态这些特殊的历史情况中显示选择器。
当 input
元素的 type 属性
更改状态时,用户代理必须运行以下步骤:
如果元素的 type 属性的先前状态
使 value IDL
属性处于值模式,元素的值不是空字符串,并且元素的
type 属性的新状态使
value IDL 属性
处于默认模式或默认/on模式,则将元素的 value 内容属性
设置为元素的值。
否则,如果元素的 type
属性的先前状态使
value
IDL 属性处于值模式以外的任何模式,并且元素的 type 属性的新状态使
value IDL 属性
处于值模式,
则将元素的值设置为 value 内容属性的值
(如果存在),否则设置为空字符串,然后将控件的脏值标志设置为
false。
否则,如果元素的 type
属性的先前状态使
value IDL 属性
处于文件名模式以外的任何模式,并且元素的 type 属性的新状态使
value IDL 属性
处于文件名模式,则将元素的值设置为空字符串。
将元素的呈现和行为更新为新状态的呈现和行为。
为元素发出类型更改信号。(特别是单选 按钮状态会使用此信号。)
如果 setRangeText()
先前适用于该元素,则令
previouslySelectable 为 true,否则为 false。
如果 setRangeText()
现在适用于该元素,则令
nowSelectable 为 true,否则为 false。
如果 previouslySelectable 为 false 且 nowSelectable 为 true,则将
元素的文本
输入光标位置设置为
文本控件的开头,并将其选择
方向设置为“none”。
name 属性表示
元素的名称。
dirname 属性控制
如何提交元素的方向性。
disabled 属性
用于使控件不可交互,并阻止提交其值。
form 属性用于
将 input 元素与其表单所有者显式关联。
autocomplete
属性控制用户代理如何提供自动填充行为。
每个 input 元素都有一个
不确定状态,它是一个初始值为 false 的布尔值。
它仅对复选框控件产生影响,
包括其呈现和无障碍语义。input 元素的
不确定状态独立于其选中状态。
HTMLInputElement#indeterminate
所有当前引擎均支持。
indeterminate
的设置器步骤是将
this 的不确定状态
设置为给定值。
colorSpace IDL 属性必须反映
colorspace
内容属性,并仅限于
已知值。type IDL 属性必须反映相应的
同名内容属性,并仅限于已知值。
如果图像正在渲染,则 IDL 属性 width 和 height 必须以CSS
像素为单位返回图像的渲染宽度和
高度;否则,如果图像可用但未正在渲染,则以
CSS
像素为单位返回图像的固有宽度和高度;否则,如果没有图像可用,则返回 0。
当 input
元素的 type 属性
不处于图像按钮状态时,没有图像是可用的。[CSS]
willValidate、
validity 和 validationMessage
IDL 属性,以及 checkValidity()、reportValidity() 和
setCustomValidity()
方法,是约束验证
API的一部分。labels IDL
属性提供元素的 label 元素列表。select()、selectionStart、
selectionEnd、
selectionDirection、
setRangeText()
和 setSelectionRange()
方法和 IDL 属性
公开元素的文本选择。disabled、
form 和 name IDL 属性
是元素的表单 API 的一部分。
type 属性的状态type=hidden)所有当前引擎均支持。
当 元素的 属性处于 状态时,适用本节中的规则。
元素 一个不打算由用户 检查或操作的值。
约束验证:如果 元素的 属性处于 状态,则该元素。
如果存在 属性,并且其值与 “”进行 的匹配,则必须省略 元素的 属性。
和 内容属性于 此元素。
IDL 属性于 此元素,并且处于模式。
不得指定以下内容属性,并且这些属性于该元素: 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、 、 ,以及 。
以下 IDL 属性和方法于该 元素: 、 、 、 、 、 、 , 以及 IDL 属性; 、 、 、 ,以及 方法。
和 事件。
type=text)状态和搜索状态(type=search)所有当前引擎均支持。
所有当前引擎均支持。
当 input
元素的 type
属性处于
文本
状态或搜索
状态时,适用本节中的规则。
文本 状态 与搜索 状态之间的区别主要体现在样式上:在 搜索控件与普通文本控件有所区别的平台上,搜索 状态可能会产生与平台搜索控件一致的外观, 而不是显示为普通文本控件。
如果元素是可变的,则用户应该能够编辑其值。 用户代理不得允许 用户将 U+000A LINE FEED (LF) 或 U+000D CARRIAGE RETURN (CR) 字符插入元素的 值中。
如果元素是可变的,用户代理 应该允许 用户更改元素的书写方向,将其设置为从左到右或从右到左的书写 方向。如果用户这样做,用户代理随后必须运行 以下步骤:
如果指定了 value
属性,则其值不得
包含 U+000A LINE FEED (LF) 或 U+000D CARRIAGE RETURN (CR) 字符。
以下常见的 input
元素内容
属性、IDL 属性和方法适用于该元素:
autocomplete、
dirname、
list、
maxlength、
minlength、
pattern、
placeholder、
readonly、
required,
以及
size
内容属性;
list、
selectionStart、
selectionEnd、
selectionDirection,
以及
value
IDL 属性;
select()、
setRangeText(),
以及
setSelectionRange()
方法。
不得指定以下内容属性,并且这些属性不
适用于该元素:
accept、
alpha、
alt、
checked、
colorspace、
formaction、
formenctype、
formmethod、
formnovalidate、
formtarget、
height、
max、
min、
multiple、
popovertarget、
popovertargetaction、
src、
step,
以及
width。
以下 IDL 属性和方法不适用于该
元素:
checked、
files、
valueAsDate,
以及
valueAsNumber
IDL 属性;
stepDown()
和
stepUp()
方法。
type=tel)所有当前引擎均支持。
当 input
元素的 type 属性处于
电话
状态时,适用本节中的规则。
input 元素
表示一个用于编辑元素值中给出的电话号码的
控件。
如果元素是可变的,则用户应该能够编辑其 值。用户代理可以更改用户输入的 值的间距,并且在谨慎处理的情况下,可以更改其标点符号。 用户代理不得允许用户将 U+000A LINE FEED (LF) 或 U+000D CARRIAGE RETURN (CR) 字符插入元素的值中。
如果指定了 value 属性,
则其值不得
包含 U+000A LINE FEED (LF) 或 U+000D CARRIAGE RETURN (CR) 字符。
与 URL 和电子邮件类型不同,电话类型
不强制采用特定语法。这是
有意如此的;在实践中,电话号码字段往往是自由格式字段,因为存在
各种各样的有效电话号码。需要强制执行特定格式的系统
应使用 pattern 属性或
setCustomValidity()
方法接入客户端
验证机制。
以下常见的 input 元素
内容
属性、IDL 属性和方法适用于该元素:
autocomplete、
dirname、
list、
maxlength、
minlength、
pattern、
placeholder、
readonly、
required,以及
size 内容
属性;
list、
selectionStart、
selectionEnd、
selectionDirection,
以及
value IDL 属性;
select()、
setRangeText(),
以及
setSelectionRange()
方法。
不得指定以下内容属性,并且这些属性不
适用于该元素:
accept、
alpha、
alt、
checked、
colorspace、
formaction、
formenctype、
formmethod、
formnovalidate、
formtarget、
height、
max、
min、
multiple、
popovertarget、
popovertargetaction、
src、
step,以及
width。
以下 IDL 属性和方法不适用于该
元素:
checked、
files、
valueAsDate,
以及
valueAsNumber
IDL 属性;
stepDown() 和
stepUp() 方法。
type=url)所有当前引擎均支持。
当 input 元素的
type 属性处于
URL 状态时,适用本
节中的规则。
input 元素表示一个用于编辑元素值中给出的单个
绝对 URL的控件。
如果元素是可变的,用户 代理应该允许 用户更改其值所表示的 URL。用户代理 可以允许用户将值设置为 不是有效绝对 URL的字符串,但也可以 或者改为 自动转义用户输入的字符,使值始终是有效的 绝对 URL(即使这不是用户在 界面中实际看到和编辑的值)。用户代理应该允许用户将值设置为空字符串。用户代理不得允许用户 将 U+000A LINE FEED (LF) 或 U+000D CARRIAGE RETURN (CR) 字符插入值中。
如果指定了 value 属性且其
不为空,则其值必须是
可能被空格包围的有效
URL,并且还必须是
绝对 URL。
值 净化算法如下:从值中移除 换行符,然后从值中移除开头 和结尾的 ASCII 空白。
以下常见的 input 元素内容
属性、IDL 属性和方法适用于该元素:
autocomplete、
dirname、
list、
maxlength、
minlength、
pattern、
placeholder、
readonly、
required,以及
size 内容属性;
list、
selectionStart、
selectionEnd、
selectionDirection,
以及
value IDL 属性;
select()、
setRangeText(),
以及
setSelectionRange()
方法。
不得指定以下内容属性,并且这些属性不
适用于该元素:
accept、
alpha、
alt、
checked、
colorspace、
formaction、
formenctype、
formmethod、
formnovalidate、
formtarget、
height、
max、
min、
multiple、
popovertarget、
popovertargetaction、
src、
step,以及
width。
以下 IDL 属性和方法不
适用于该
元素:
checked、
files、
valueAsDate,以及
valueAsNumber
IDL 属性;
stepDown() 和
stepUp() 方法。
如果文档包含以下标记:
< input type = "url" name = "location" list = "urls" >
< datalist id = "urls" >
< option label = "MIME: Format of Internet Message Bodies" value = "https://www.rfc-editor.org/rfc/rfc2045" >
< option label = "HTML" value = "https://html.spec.whatwg.org/" >
< option label = "DOM" value = "https://dom.spec.whatwg.org/" >
< option label = "Fullscreen" value = "https://fullscreen.spec.whatwg.org/" >
< option label = "Media Session" value = "https://mediasession.spec.whatwg.org/" >
< option label = "The Single UNIX Specification, Version 3" value = "http://www.unix.org/version3/" >
</ datalist > ……并且用户输入了“spec.w”,而用户代理还发现用户
最近访问过 https://url.spec.whatwg.org/#url-parsing 和
https://streams.spec.whatwg.org/,则渲染结果可能如下所示:

此示例中的前四个 URL 由作者指定列表中与用户输入的文本 匹配的四个 URL 组成,并以某种由实现定义的方式排序 (可能依据用户引用这些 URL 的频率)。请注意,UA 如何利用 这些值是 URL 这一信息,允许用户省略方案部分,并对域名执行智能 匹配。
最后两个 URL(考虑到滚动条表明还有更多值 可用,可能还有更多 URL)是来自用户代理会话历史记录数据的匹配项。这些数据不会 提供给页面 DOM。在这个特定示例中,UA 没有可为 这些值提供的标题。
type=email)所有当前引擎均支持。
当 input
元素的 type 属性处于
电子邮件状态时,
适用本节中的规则。
电子邮件
状态的工作方式取决于是否
指定了 multiple 属性。
multiple 属性时input
元素表示一个用于编辑元素值中给出的电子邮件
地址的控件。
如果元素是可变的, 用户代理应该允许 用户更改其值所表示的电子邮件地址。用户代理可以允许用户将值设置为不是 有效电子邮件 地址的字符串。用户代理的行为应该与期望用户 提供单个电子邮件地址的情况一致。用户代理应该允许用户将值设置为空字符串。用户代理不得允许 用户将 U+000A LINE FEED (LF) 或 U+000D CARRIAGE RETURN (CR) 字符插入值中。用户代理可以转换值以用于显示和编辑; 特别是,用户代理应该 在显示时将值的域标签中的 punycode 转换为 IDN,并 反向转换。
约束验证:当用户界面表示的输入 无法由用户代理转换为 punycode 时,控件存在错误 输入。
如果指定了 value
属性且其不为空,则其值必须
是单个有效电子邮件地址。
值净化算法如下: 从值中移除 换行符,然后从值中移除开头 和结尾的 ASCII 空白。
multiple 属性时
input
元素表示一个用于添加、移除和
编辑元素多个值中给出的电子邮件地址的控件。
如果元素是可变的, 用户代理应该允许 用户添加、移除和编辑其多个值所表示的电子邮件地址。用户代理可以允许用户将 多个值列表中的任何单个值设置为 不是有效 电子邮件地址的字符串,但不得允许用户将任何 单个值设置为包含 U+002C COMMA (,)、U+000A LINE FEED (LF) 或 U+000D CARRIAGE RETURN (CR) 字符的字符串。用户代理应该允许用户移除 元素多个值中的所有地址。用户 代理可以 转换多个值以用于 显示和编辑;特别是,用户代理应该在显示时将值的域标签中的 punycode 转换为 IDN,并反向转换。
约束验证:当用户界面描述的情况中, 某个单独的值包含 U+002C COMMA (,) 或表示的输入无法由用户代理 转换为 punycode 时,控件存在错误输入。
每当用户更改元素的多个值时,用户代理必须运行以下 步骤:
令 latest values 为元素多个值的副本。
从 latest values 中的每个值移除开头和结尾的 ASCII 空白。
将元素的值 设置为连接 latest values 中所有值所得的结果, 在每个值与下一个值之间插入一个 U+002C COMMA 字符 (,),并保持列表 顺序。
如果指定了 value
属性,则其值
必须是有效
电子邮件地址列表。
值净化算法如下:
约束验证:当元素的值 不是有效电子邮件地址列表时,该元素存在 类型不匹配。
有效电子邮件地址是与以下 ABNF 的 email
产生式匹配的字符串,其字符集为 Unicode。
此 ABNF 实现了 RFC 1123 中描述的扩展。[ABNF] [RFC5322]
[RFC1034] [RFC1123]
email = 1* ( atext / "." ) "@" label * ( "." label )
label = let-dig [ [ ldh-str ] let-dig ] ; limited to a length of 63 characters by RFC 1034 section 3.5
atext = < as defined in RFC 5322 section 3 .2 .3 >
let-dig = < as defined in RFC 1034 section 3 .5 >
ldh-str = < as defined in RFC 1034 section 3 .5 >此要求是对 RFC 5322 的有意违反。 RFC 5322 定义了一种 电子邮件地址语法,但该语法同时过于严格(在“@”字符之前)、过于 模糊(在“@”字符之后),并且过于宽松(允许以大多数用户不熟悉的方式 使用注释、空白字符和带引号的字符串),因此在此处没有实际用途。
以下与 JavaScript 和 Perl 兼容的正则表达式实现了 上述定义。
/^[a-zA-Z0-9.!#$%&'*+\/=?^_`{|}~-]+@[a-zA-Z0-9](?:[a-zA-Z0-9-]{0,61}[a-zA-Z0-9])?(?:\.[a-zA-Z0-9](?:[a-zA-Z0-9-]{0,61}[a-zA-Z0-9])?)*$/
有效电子邮件地址列表是一个以 逗号分隔的令牌集合,其中每个令牌本身都是一个有效电子邮件地址。 要从有效电子邮件地址列表中获取令牌列表, 实现必须按 逗号拆分 字符串。
以下常见的 input 元素内容
属性、IDL 属性和方法适用于该元素:
autocomplete、
dirname、
list、
maxlength、
minlength、
multiple、
pattern、
placeholder、
readonly、
required,以及
size 内容属性;
list 和
value IDL 属性;
select()
方法。
不得指定以下内容属性,并且这些属性不
适用于该元素:
accept、
alpha、
alt、
checked、
colorspace、
formaction、
formenctype、
formmethod、
formnovalidate、
formtarget、
height、
max、
min、
popovertarget、
popovertargetaction、
src、
step,以及
width。
以下 IDL 属性和方法不
适用于该
元素:
checked、
files、
selectionStart、
selectionEnd、
selectionDirection、
valueAsDate,
以及
valueAsNumber
IDL 属性;
setRangeText()、
setSelectionRange()、
stepDown() 和
stepUp() 方法。
type=password)所有当前引擎均支持。
当 input
元素的 type
属性处于
密码状态时,适用本节中的
规则。
input
元素表示一个用于编辑
元素值的单行纯文本控件。用户
代理应该遮蔽该值,
使用户以外的人无法看到它。
如果元素是可变的, 则用户应该能够编辑其值。用户代理不得允许 用户将 U+000A LINE FEED (LF) 或 U+000D CARRIAGE RETURN (CR) 字符插入值中。
如果指定了 value
属性,则其值不得
包含 U+000A LINE FEED (LF) 或 U+000D CARRIAGE RETURN (CR) 字符。
以下常见的 input
元素
内容
属性、IDL 属性和方法适用于该元素:
autocomplete、
dirname、
maxlength、
minlength、
pattern、
placeholder、
readonly、
required,
以及
size 内容
属性;
selectionStart、
selectionEnd、
selectionDirection,
以及
value IDL
属性;
select()、
setRangeText(),
以及
setSelectionRange()
方法。
不得指定以下内容属性,并且这些属性不
适用于该元素:
accept、
alpha、
alt、
checked、
colorspace、
formaction、
formenctype、
formmethod、
formnovalidate、
formtarget、
height、
list、
max、
min、
multiple、
popovertarget、
popovertargetaction、
src、
step,以及
width。
以下 IDL 属性和方法不适用于该
元素:
checked、
files、
list、
valueAsDate,
以及
valueAsNumber
IDL 属性;
stepDown()
和
stepUp()
方法。
type=date)所有当前引擎均支持。
当 input 元素的
type 属性处于
日期状态时,适用
本节中的规则。
input 元素表示一个用于将元素的
值设置为表示特定日期的字符串的控件。
如果元素是可变的,用户 代理应该允许 用户更改通过从其值中解析 日期而得到的日期。用户代理不得允许用户将值设置为不是有效日期 字符串的非空字符串。如果用户代理提供用于选择日期的用户界面,则必须将值设置 为表示用户所选内容的有效日期字符串。用户代理应该允许 用户将值设置为 空字符串。
有关日期、时间和数字表单 控件的输入格式与提交格式之间差异的讨论,请参阅介绍部分;有关表单控件本地化的说明,请参阅 实现说明。
如果指定了 value 属性且其
不为空,则其值必须
是有效日期
字符串。
如果指定了 min 属性,
则其值必须是
有效日期字符串。如果
指定了 max 属性,
则其值必须是有效日期字符串。
step 属性
以天为单位表示。步长
比例因子为 86,400,000
(它会将天转换为毫秒,供其他算法使用)。默认步长为 1
天。
当元素存在步长不匹配时,用户代理可以将 元素的值舍入为最近的、使元素不会存在 步长不匹配的日期。
给定字符串 input,将字符串转换为
数字的算法如下:如果从 input 中解析日期的结果是
错误,则返回错误;否则,返回从 1970-01-01 早晨 UTC
午夜(由值“1970-01-01T00:00:00.0Z”表示的时间)到解析所得日期早晨 UTC 午夜所经过的毫秒数,
忽略闰秒。
给定数字 input,将数字转换为
字符串的算法如下:返回一个有效日期字符串,该字符串表示
在 UTC 中,1970-01-01 早晨 UTC 午夜
(由值“1970-01-01T00:00:00.0Z”表示的时间)之后 input 毫秒时的日期。
给定字符串 input,将字符串转换为
Date 对象的算法如下:
如果从 input 中解析日期的结果
是错误,则返回错误;否则,返回一个新的
Date 对象,该对象表示解析所得日期早晨的
UTC 午夜。
给定 Date
对象 input,将
Date 对象转换为字符串的算法
如下:返回一个有效
日期字符串,该字符串表示 UTC
时区中由 input 所表示时间对应的日期。
日期状态(以及 后续章节中描述的其他与日期和时间相关的 状态)不适合用于输入无法相对于现代历法 确定精确日期和时间的值。例如, 它不适合输入“宇宙大爆炸后一毫秒”、“侏罗纪 早期”或“公元前 250 年左右的一个冬天”之类的时间。
对于公历采用之前日期的输入,建议作者
不要使用日期状态(以及后续章节中描述的其他
与日期和时间相关的状态),因为不要求用户代理
支持将更早时期的日期和时间转换为公历,并且要求
用户手动完成这种转换会给用户带来不合理的负担。(由于
公历的逐步采用方式,这一问题更为复杂;不同
国家采用公历的时间不同,从 16 世纪中期一直延续到 20 世纪初。)
相反,建议作者使用
select 元素和
处于数字状态的
input 元素,
提供细粒度的输入控件。
以下常见的 input 元素内容
属性、IDL 属性和方法适用于该元素:
autocomplete、
list、
max、
min、
readonly、
required,以及
step 内容属性;
list、
value、
valueAsDate,
以及
valueAsNumber
IDL 属性;
select()、
stepDown(),以及
stepUp() 方法。
不得指定以下内容属性,并且这些属性不
适用于该元素:
accept、
alpha、
alt、
checked、
colorspace、
dirname、
formaction、
formenctype、
formmethod、
formnovalidate、
formtarget、
height、
maxlength、
minlength、
multiple、
pattern、
placeholder、
popovertarget、
popovertargetaction、
size、
src,以及
width。
以下 IDL 属性和方法不
适用于该
元素:
checked、
selectionStart、
selectionEnd,
以及
selectionDirection
IDL 属性;
setRangeText(),
以及
setSelectionRange()
方法。
type=month)所有当前引擎均支持。
当 input
元素的 type 属性处于
月状态时,
适用本节中的规则。
input 元素
表示一个用于将元素的
值设置为表示特定月份的字符串的控件。
如果元素是可变的,用户 代理应该允许 用户更改通过从其值中解析 月份而得到的月份。用户代理不得允许用户将值设置为不是有效月份 字符串的非空字符串。如果用户代理提供用于选择月份的用户界面,则必须将值 设置为表示用户所选内容的有效月份字符串。用户代理应该 允许用户将值设置为 空字符串。
有关日期、时间和数字表单 控件的输入格式与提交格式之间差异的讨论,请参阅介绍部分;有关表单控件本地化的说明,请参阅 实现说明。
如果指定了 value 属性且其
不为空,则其值必须
是有效月份
字符串。
如果指定了 min 属性,
则其值必须是
有效月份字符串。如果
指定了 max 属性,
则其值必须是有效月份字符串。
step 属性
以月为单位表示。步长比例因子为
1(因为算法使用月,
所以无需转换)。默认步长为 1
个月。
当元素存在步长不匹配时,用户代理 可以将 元素的值舍入为最近的、使元素不会存在 步长不匹配的月份。
给定字符串 input,将字符串转换为 数字的算法如下:如果从 input 中解析月份的结果是 错误,则返回错误;否则,返回 1970 年 1 月与解析所得月份之间相隔的月数。
给定数字 input,将数字转换为 字符串的算法如下:返回一个 有效月份字符串,该字符串 表示与 1970 年 1 月相隔 input 个月的月份。
给定字符串 input,将字符串转换为
Date 对象的算法如下:
如果从 input 中解析月份的
结果是错误,则返回错误;否则,返回一个
新的 Date 对象,该对象表示解析所得月份第一天早晨的 UTC 午夜。
给定 Date
对象 input,将
Date 对象转换为字符串的算法
如下:返回一个有效月份字符串,该字符串表示
UTC 时区中由 input 所表示时间对应的月份。
以下常见的 input 元素内容
属性、IDL 属性和方法适用于该元素:
autocomplete、
list、
max、
min、
readonly、
required,以及
step 内容
属性;
list、
value、
valueAsDate,
以及
valueAsNumber
IDL 属性;
select()、
stepDown(),以及
stepUp() 方法。
不得指定以下内容属性,并且这些属性不
适用于该元素:
accept、
alpha、
alt、
checked、
colorspace、
dirname、
formaction、
formenctype、
formmethod、
formnovalidate、
formtarget、
height、
maxlength、
minlength、
multiple、
pattern、
placeholder、
popovertarget、
popovertargetaction、
size、
src,以及
width。
以下 IDL 属性和方法不
适用于该
元素:
checked、
files、
selectionStart、
selectionEnd,
以及
selectionDirection
IDL 属性;
setRangeText(),
以及
setSelectionRange()
方法。
type=week)当 input 元素的
type 属性处于
周状态时,适用
本节中的规则。
input 元素表示一个用于将元素的
值设置为表示特定周的字符串的控件。
如果元素是可变的,用户 代理应该允许 用户更改通过从其值中解析 周而得到的周。用户代理不得允许用户将值设置为不是有效周 字符串的非空字符串。如果用户代理提供用于选择周的用户界面,则必须将值设置 为表示用户所选内容的有效周字符串。用户代理应该允许 用户将值设置为 空字符串。
有关日期、时间和数字表单 控件的输入格式与提交格式之间差异的讨论,请参阅介绍部分;有关表单控件本地化的说明,请参阅 实现说明。
如果指定了 value 属性且其
不为空,则其值必须
是有效周
字符串。
如果指定了 min 属性,
则其值必须是
有效周字符串。如果
指定了 max 属性,
则其值必须是有效周字符串。
step 属性
以周为单位表示。步长比例因子为
604,800,000
(它会将周转换为毫秒,供其他算法使用)。默认步长为 1
周。默认步长基数为
−259,200,000(即
1970-W01 周的起始时间)。
当元素存在步长不匹配时,用户代理可以将 元素的值舍入为最近的、使元素不会存在 步长不匹配的周。
给定字符串 input,将字符串转换为
数字的算法如下:如果从 input 中解析周字符串的结果是
错误,则返回错误;否则,返回从 1970-01-01 早晨 UTC
午夜(由值“1970-01-01T00:00:00.0Z”表示的时间)到解析所得
周的星期一早晨 UTC 午夜所经过的毫秒数,
忽略闰秒。
给定数字 input,将数字转换为
字符串的算法如下:返回一个
有效周字符串,该字符串表示
在 UTC 中,1970-01-01 早晨 UTC 午夜
(由值“1970-01-01T00:00:00.0Z”表示的时间)之后 input 毫秒时的周。
给定字符串 input,将字符串转换为
Date 对象的算法如下:如果从
input 中解析周的结果是错误,则
返回错误;否则,返回一个新的 Date
对象,该对象表示解析所得周的星期一早晨 UTC 午夜。
给定 Date
对象 input,将
Date 对象转换为字符串的算法
如下:返回一个有效
周字符串,该字符串表示 UTC
时区中由 input 所表示时间对应的周。
以下常见的 input 元素内容
属性、IDL 属性和
方法适用于该元素:
autocomplete、
list、
max、
min、
readonly、
required,以及
step 内容属性;
list、
value、
valueAsDate,
以及
valueAsNumber
IDL 属性;
select()、
stepDown(),以及
stepUp() 方法。
不得指定以下内容属性,并且这些属性不适用于该
元素:
accept、
alpha、
alt、
checked、
colorspace、
dirname、
formaction、
formenctype、
formmethod、
formnovalidate、
formtarget、
height、
maxlength、
minlength、
multiple、
pattern、
placeholder、
popovertarget、
popovertargetaction、
size、
src,以及
width。
以下 IDL 属性和方法不
适用于该
元素:
checked、
files、
selectionStart、
selectionEnd,
以及
selectionDirection
IDL 属性;
setRangeText(),
以及
setSelectionRange()
方法。
type=time)所有当前引擎均支持。
当 input 元素的
type 属性处于
时间状态时,适用
本节中的规则。
input 元素表示一个用于将元素的
值设置为表示特定
时间的字符串的控件。
如果元素是可变的,用户 代理应该允许 用户更改通过从其值中解析 时间而得到的时间。用户代理不得允许用户将值设置为不是有效时间 字符串的非空字符串。如果用户代理提供用于选择时间的用户界面,则必须将值设置 为表示用户所选内容的有效时间字符串。用户代理应该允许 用户将值设置为 空字符串。
有关日期、时间和数字表单 控件的输入格式与提交格式之间差异的讨论,请参阅介绍部分;有关表单控件本地化的说明,请参阅 实现说明。
如果指定了 value 属性且其
不为空,则其值必须
是有效时间
字符串。
该表单控件具有周期性 域。
如果指定了 min 属性,
则其值必须是
有效时间字符串。如果
指定了 max 属性,
则其值必须是有效时间字符串。
step 属性
以秒为单位表示。步长比例因子为 1000(它会
将秒转换为毫秒,供其他算法使用)。默认步长为 60 秒。
当元素存在步长不匹配时,用户代理可以将 元素的值舍入为最近的、使元素不会存在 步长不匹配的时间。
给定字符串 input,将字符串转换为 数字的算法如下:如果从 input 中解析时间的结果是 错误,则返回错误;否则,返回在没有时间变化的一天中,从午夜到 解析所得时间所经过的毫秒数。
给定数字 input,将数字转换为 字符串的算法如下:返回一个 有效时间字符串,该字符串表示 在没有时间变化的一天中,午夜之后 input 毫秒时的 时间。
给定字符串 input,将字符串转换为
Date 对象的算法
如下:如果从
input 中解析
时间的结果
是错误,则返回错误;否则,返回一个新的
Date 对象,该对象表示 1970-01-01 UTC 中解析所得的时间。
给定 Date
对象 input,将
Date 对象转换为字符串的算法
如下:返回一个有效
时间字符串,该字符串表示由 input 所表示的 UTC 时间分量。
以下常见的 input 元素内容
属性、IDL 属性和
方法适用于该元素:
autocomplete、
list、
max、
min、
readonly、
required,以及
step 内容属性;
list、
value、
valueAsDate,
以及
valueAsNumber
IDL 属性;
select()、
stepDown(),以及
stepUp() 方法。
不得指定以下内容属性,并且这些属性不适用于该
元素:
accept、
alpha、
alt、
checked、
colorspace、
dirname、
formaction、
formenctype、
formmethod、
formnovalidate、
formtarget、
height、
maxlength、
minlength、
multiple、
pattern、
placeholder、
popovertarget、
popovertargetaction、
size、
src,以及
width。
以下 IDL 属性和方法不
适用于该元素:
checked、
files、
selectionStart、
selectionEnd,
以及
selectionDirection
IDL 属性;
setRangeText(),
以及
setSelectionRange()
方法。
type=datetime-local)
所有当前引擎均支持。
当 input
元素的 type
属性处于
本地日期
和时间状态时,适用
本节中的规则。
input
元素表示一个
用于将元素的
值设置为
表示本地日期和时间且不含
时区偏移
信息的字符串的控件。
如果元素是可变的,用户代理应该允许 用户 更改通过从其值中解析日期和 时间而得到的日期和时间。用户代理不得允许用户将 值设置为 不是有效 标准化本地日期和时间字符串的非空字符串。如果用户代理提供用于 选择本地日期和时间的用户界面,则必须将值 设置为表示用户所选内容的有效 标准化本地日期和时间 字符串。用户代理应该允许用户将 值设置为 空字符串。
约束验证:当用户界面描述的输入无法由用户 代理转换为有效 标准化本地日期和时间字符串时,控件 存在错误输入。
有关日期、时间和数字表单 控件的输入格式与提交格式之间差异的讨论,请参阅介绍部分;有关表单控件本地化的说明,请参阅 实现说明。
如果指定了 value
属性且其不为空,则其值必须
是有效本地日期和时间
字符串。
值净化 算法如下:如果元素的值是有效本地日期和 时间 字符串,则将其设置为表示相同日期和时间的有效 标准化本地日期和时间字符串; 否则,将其设置为空字符串。
如果指定了 min
属性,则其值必须是
有效本地日期和时间
字符串。如果指定了 max
属性,则其值必须是有效本地日期和时间
字符串。
step
属性以秒为单位表示。步长比例因子为 1000(它会
将秒转换为毫秒,供其他算法使用)。默认步长为 60 秒。
当元素存在步长 不匹配时,用户代理可以将 元素的值舍入为最近的、使元素不会存在步长 不匹配的本地 日期和时间。
给定字符串 input,将
字符串转换为
数字的算法如下:如果从 input 中解析日期和
时间的结果是错误,则返回错误;否则,返回从 1970-01-01 早晨午夜(由值
“1970-01-01T00:00:00.0”表示的时间)到解析所得本地日期和时间所经过的
毫秒数,忽略
闰秒。
给定数字 input,将
数字转换为
字符串的算法如下:返回一个
有效
标准化本地日期和时间字符串,该字符串表示 1970-01-01 早晨午夜之后
input 毫秒时的日期和时间(由值“1970-01-01T00:00:00.0”
表示该时间)。
以下常见的 input
元素内容
属性、IDL 属性和方法适用于该元素:
autocomplete、
list、
max、
min、
readonly、
required,
以及
step
内容属性;
list、
value,
以及
valueAsNumber
IDL 属性;
select()、
stepDown(),
以及
stepUp()
方法。
不得指定以下内容属性,并且这些属性不
适用于该元素:
accept、
alpha、
alt、
checked、
colorspace、
dirname、
formaction、
formenctype、
formmethod、
formnovalidate、
formtarget、
height、
maxlength、
minlength、
multiple、
pattern、
placeholder、
popovertarget、
popovertargetaction、
size、
src,
以及
width。
以下 IDL 属性和方法不适用于该
元素:
checked、
files、
selectionStart、
selectionEnd、
selectionDirection,
以及
valueAsDate
IDL 属性;
setRangeText(),
以及
setSelectionRange()
方法。
以下示例展示了航班预订应用程序的一部分。该应用程序使用
一个 input
元素,并将其 type
属性设置为
datetime-local,
然后在所选机场的时区中解释
给定的日期和时间。
< fieldset >
< legend > Destination</ legend >
< p >< label > Airport: < input type = text name = to list = airports ></ label ></ p >
< p >< label > Departure time: < input type = datetime-local name = totime step = 3600 ></ label ></ p >
</ fieldset >
< datalist id = airports >
< option value = ATL label = "Atlanta" >
< option value = MEM label = "Memphis" >
< option value = LHR label = "London Heathrow" >
< option value = LAX label = "Los Angeles" >
< option value = FRA label = "Frankfurt" >
</ datalist > type=number)所有当前引擎均支持。
当 input
元素的 type 属性处于
数字
状态时,适用本节中的规则。
input 元素
表示一个用于将元素的
值设置为表示
数字的字符串的控件。
如果元素是可变的,用户 代理应该允许 用户更改通过对其值应用解析浮点 数值的规则而得到的数字。用户 代理不得允许用户将值设置为 不是有效浮点数的非空字符串。如果用户代理 提供用于选择数字的用户界面,则必须将值设置为将表示用户 所选数字表示为浮点数的最佳表示形式。用户代理应该允许用户将值设置为空字符串。
本规范未定义用户代理应使用何种用户界面; 建议用户代理供应商考虑什么最能满足其用户的需求。例如, 面向波斯语或阿拉伯语市场的用户代理可以支持波斯语和阿拉伯语数字输入 (并将其转换为上述提交所需的格式)。同样,专为 罗马人设计的用户代理可以用罗马数字而不是十进制数字显示该值;或者(更 现实地说),面向法国市场的用户代理可以在千位之间使用 撇号、在小数之前使用逗号来显示该值,并允许用户以这种方式输入值, 然后在内部将其转换为上述提交格式。
如果指定了 value 属性且其
不为空,则其值必须
是有效浮点数。
如果指定了 min 属性,
则其值必须是
有效
浮点数。如果指定了 max 属性,
则其值必须是有效浮点数。
步长比例 因子为 1。默认 步长为 1(仅允许 用户选择整数,除非步长 基数具有非整数值)。
当元素存在步长不匹配时,用户代理 可以将 元素的值舍入为最近的、 使元素不会存在步长不匹配的数字。如果 存在两个这样的数字,建议用户代理选择最接近正 无穷大的那个。
给定字符串 input,将字符串转换为 数字的算法如下:如果对 input 应用 解析 浮点数值的规则得到 错误,则返回错误;否则,返回所得数字。
给定数字 input,将数字转换为 字符串的算法如下:返回一个表示 input 的 有效 浮点数。
以下常见的 input 元素
内容属性、IDL 属性和
方法适用于该
元素:
autocomplete、
list、
max、
min、
placeholder、
readonly、
required,以及
step 内容
属性;
list、
value,以及
valueAsNumber
IDL 属性;
select()、
stepDown(),以及
stepUp() 方法。
不得指定以下内容属性,并且这些属性不适用于该
元素:
accept、
alpha、
alt、
checked、
colorspace、
dirname、
formaction、
formenctype、
formmethod、
formnovalidate、
formtarget、
height、
maxlength、
minlength、
multiple、
pattern、
popovertarget、
popovertargetaction、
size、
src,以及
width。
以下 IDL 属性和方法不适用于该元素:
checked、
files、
selectionStart、
selectionEnd、
selectionDirection,
以及
valueAsDate
IDL 属性;
setRangeText(),
以及
setSelectionRange()
方法。
以下是使用数字输入控件的示例:
< label > How much do you want to charge? $< input type = number min = 0 step = 0.01 name = price ></ label > 如上所述,用户代理可以支持采用用户本地格式的数字输入, 并将其转换为上述提交所需的格式。这可能包括 处理分组分隔符(如“872,000,000,000”)和各种小数分隔符(如 “3,99”与“3.99”),或使用本地数字(例如阿拉伯文、天城文、波斯文和 泰文数字)。
type=number 状态
不适用于恰好仅由数字组成,但严格来说并不是
数字的输入。例如,它不适用于信用卡号码或美国邮政编码。
判断是否应使用 type=number 的简单方法是考虑
输入控件具有数字微调框界面(例如带有“向上”和“向下”
箭头)是否合理。信用卡号码最后一位错 1 并不是小错误,而是与
每一位都错误同样严重。因此,让用户使用“向上”和“向下”按钮选择
信用卡号码并不合理。当数字微调框界面不合适时,type=text
可能是正确的选择(也许还应使用 inputmode
或 pattern
属性)。
type=range)所有当前引擎均支持。
当 input
元素的 type 属性处于
范围状态时,
适用本节中的规则。
input 元素
表示一个用于将元素的
值设置为表示
数字的字符串的控件,但附带
精确值并不重要这一条件,从而允许 UA 提供比
数字
状态更简单的界面。
如果元素是可变的,用户 代理应该允许 用户更改通过对其值应用解析浮点 数值的规则而得到的数字。 用户代理不得允许用户将值设置为 不是有效浮点数的字符串。如果用户代理 提供用于选择数字的用户 界面,则必须将值 设置为将表示用户所选数字 表示为浮点数的最佳 表示形式。用户代理不得允许用户将值设置为空字符串。
如果指定了 value 属性,
则其值
必须是有效
浮点数。
值净化算法如下: 如果元素的值 不是有效浮点 数,则将其设置为默认值的浮点数 最佳表示形式。
当元素存在下溢时,用户代理必须将 元素的值设置为最小值的浮点数 最佳表示形式。
当元素存在步长不匹配时,用户代理 必须将 元素的值舍入为 最近的、使 元素不会存在步长 不匹配,并且大于或等于最小值的数字;如果最大值不小于最小值,该数字还必须小于或等于最大值,前提是存在 满足这些约束的数字。 如果有两个数字满足这些约束,则用户代理必须使用最接近正 无穷大的那个。
例如,标记
<input type="range" min=0 max=100 step=20 value=50>
会生成一个初始值为 60 的范围控件。
以下是使用 list
属性和自动完成列表的范围控件示例。如果
控件的整个范围中存在特别重要的值,
例如预配置的照明级别,或用作速度控件的范围控件中的典型速度限制,
这可能很有用。以下标记
片段:
< input type = "range" min = "-100" max = "100" value = "0" step = "10" name = "power" list = "powers" >
< datalist id = "powers" >
< option value = "0" >
< option value = "-30" >
< option value = "30" >
< option value = "++50" >
</ datalist > ……并应用以下样式表:
input { writing-mode : vertical-lr; height : 75 px ; width : 49 px ; background : #D5CCBB; color : black; } ……可能渲染为:
![]()
请注意,UA 如何根据样式表中指定的高度和宽度属性之比确定
控件的方向。颜色同样源自
样式表。不过,刻度标记源自标记。特别是,step
属性并未
影响刻度标记的位置,
UA 决定只使用作者指定的完成值,然后在两端添加较长的
刻度标记。
还请注意,无效值 ++50 被忽略了。
再举一个例子,请考虑以下标记片段:
< input name = x type = range min = 100 max = 700 step = 9.09090909 value = 509.090909 > 用户代理可以采用多种方式显示,例如:
或者,例如:

用户代理可以根据样式 表中给出的尺寸选择显示哪一种。这使它能够在 宽度不同的情况下,保持刻度标记具有相同的分辨率。
最后,以下是带有两个已标注值的范围控件示例:
< input type = "range" name = "a" list = "a-values" >
< datalist id = "a-values" >
< option value = "10" label = "Low" >
< option value = "90" label = "High" >
</ datalist > 使用使控件垂直绘制的样式时,它可能如下所示:
在此状态下,即使在用户输入期间也会强制执行范围和步长约束, 并且无法将值设置为空字符串。
如果指定了 min 属性,
则其值必须是
有效
浮点数。默认
最小值为 0。如果指定了 max
属性,则其值必须
是有效浮点数。默认最大值为
100。
步长比例
因子为
1。默认
步长为 1(仅允许
整数,除非 min
属性具有非整数
值)。
给定字符串 input,将字符串转换为 数字的算法如下:如果对 input 应用 解析浮点 数值的规则得到 错误,则返回错误;否则,返回所得数字。
给定数字 input,将数字转换为 字符串的算法如下:返回 input 的浮点数 最佳 表示形式。
以下常见的 input 元素内容
属性、IDL 属性和
方法适用于该元素:
autocomplete、
list、
max、
min,以及
step 内容
属性;
list、
value,以及
valueAsNumber
IDL 属性;
stepDown() 和
stepUp() 方法。
不得指定以下内容属性,并且这些属性不适用于该
元素:
accept、
alpha、
alt、
checked、
colorspace、
dirname、
formaction、
formenctype、
formmethod、
formnovalidate、
formtarget、
height、
maxlength、
minlength、
multiple、
pattern、
placeholder、
popovertarget、
popovertargetaction、
readonly、
required、
size、
src,以及
width。
以下 IDL 属性和方法不
适用于该元素:
checked、
files、
selectionStart、
selectionEnd、
selectionDirection,
以及
valueAsDate
IDL 属性;
select()、
setRangeText(),
以及
setSelectionRange()
方法。
type=color)所有当前引擎均支持。
当 input
元素的 type 属性处于
颜色状态时,
适用本节中的规则。
input 元素
表示一个颜色井控件,用于将
元素的值设置为表示
CSS 颜色序列化结果的字符串。
在此状态下,始终会选择一种 CSS 颜色,并且最终 用户无法将该值设置为空字符串。
alpha 属性
是一个布尔属性。如果存在,
则表示最终用户可以操作 CSS 颜色的 alpha 分量,
并且该分量不必完全不透明。
colorspace
属性指示序列化 CSS 颜色的色彩空间。它还提示用于选择 CSS 颜色的期望
用户界面。它是一个枚举属性,具有以下
关键字和状态:
| 关键字 | 状态 | 简要说明 |
|---|---|---|
limited-srgb
|
受限 sRGB | CSS 颜色会转换为'srgb' 色彩空间,
并限制为每个
分量 8 位,例如“#123456”或“color(srgb 0 1 0 / 0.5)”。
|
display-p3
|
Display P3 | CSS 颜色会转换为'display-p3' 色彩空间,例如
“color(display-p3 1.84 -0.19 0.72 / 0.6)”。
|
每当元素的 alpha 或 colorspace
属性发生更改时,用户代理必须给定该元素运行
更新
颜色井控件颜色。
如果元素是可变的,用户 代理应该允许 用户更改通过解析其值而得到的颜色。用户代理不得 允许用户将值设置为 对元素运行更新颜色井控件颜色时不会将其设置为的 字符串。如果用户 代理提供用于选择 CSS 颜色的用户界面,则必须将值设置为给定元素和 最终用户所选内容序列化颜色井控件颜色的结果。
此类元素 element 的input 激活 行为是为 element 显示 选择器(如适用)。
如果指定了 value 属性且其
不是空
字符串,则其值必须是 CSS 颜色。
值净化算法如下: 为该元素运行更新 颜色井控件颜色。
给定元素 element,要更新颜色井控件颜色:
给定元素 element 和 CSS 颜色 color,要序列化颜色井控件颜色:
令 htmlCompatible 为 false。
如果未指定 element 的 alpha 属性,
则将 color 的 alpha 分量设置为完全不透明。
如果 element 的 colorspace
属性处于受限 sRGB 状态:
否则:
断言:element 的 colorspace
属性处于Display P3 状态。
将 color 设置为转换到 'display-p3' 色彩空间后的 color。
返回序列化 color 的结果。如果 htmlCompatible 为 true,则在请求 HTML 兼容序列化的情况下执行。
以下常见的 input 元素内容
属性和 IDL 属性适用于该元素:
alpha、
autocomplete、
colorspace,
以及
list 内容属性;
list 和
value IDL 属性;
select()
方法。
不得指定以下内容属性,并且这些属性不适用于该
元素:
accept、
alt、
checked、
dirname、
formaction、
formenctype、
formmethod、
formnovalidate、
formtarget、
height、
max、
maxlength、
min、
minlength、
multiple、
pattern、
placeholder、
popovertarget、
popovertargetaction、
readonly、
required、
size、
src、
step,以及
width。
以下 IDL 属性和方法不
适用于该元素:
checked、
files、
selectionStart、
selectionEnd、
selectionDirection、
valueAsDate
以及
valueAsNumber
IDL 属性;
setRangeText()、
setSelectionRange()、
stepDown(),以及
stepUp() 方法。
type=checkbox)所有当前引擎均支持。
当 input
元素的 type
属性处于
复选框状态时,适用本节中的
规则。
input
元素表示一个表示
元素选中状态的二态控件。
如果元素的选中状态为 true,则控件表示肯定
选择;如果为 false,则表示否定选择。如果元素的不确定状态为 true,则应该遮蔽
控件的选择状态。
input 激活行为是运行以下步骤:
input.indeterminate [ = value ]
设置后,会覆盖复选框 控件的渲染,使当前值不可见。
以下常见的 input
元素
内容属性和 IDL 属性适用于该元素:
checked 和
required
内容属性;
checked 和
value IDL
属性。
不得指定以下内容属性,并且这些属性不适用于该
元素:
accept、
alpha、
alt、
autocomplete、
colorspace、
dirname、
formaction、
formenctype、
formmethod、
formnovalidate、
formtarget、
height、
list、
max、
maxlength、
min、
minlength、
multiple、
pattern、
placeholder、
popovertarget、
popovertargetaction、
readonly、
size、
src、
step,以及
width。
以下 IDL 属性和方法不适用于该元素:
files、
list、
selectionStart、
selectionEnd、
selectionDirection、
valueAsDate,
以及
valueAsNumber
IDL 属性;
select()、
setRangeText()、
setSelectionRange()、
stepDown(),
以及
stepUp()
方法。
type=radio)所有当前引擎均支持。
当 input
元素的 type
属性处于
单选按钮状态时,适用本
节中的
规则。
input
元素表示一个控件,该控件与
其他 input 元素
结合使用时,会形成一个单选按钮
组,其中只有一个
控件的选中状态可以设置为 true。如果
元素的选中状态为 true,则该控件
表示组中已选择的控件;如果为 false,则表示组中
未选择的控件。
一棵树不得包含一个 input 元素,
其单选按钮
组仅包含该元素。
input 激活行为是运行以下步骤:
以下示例出于某种原因,将 puppers 同时指定为必需的和禁用的:
< form >
< p >< label >< input type = "radio" name = "dog-type" value = "pupper" required disabled > Pupper</ label >
< p >< label >< input type = "radio" name = "dog-type" value = "doggo" > Doggo</ label >
< p >< button > Make your choice</ button >
</ form > 如果用户在未先选择“Doggo”的情况下尝试提交此表单,则两个
input
元素都将缺少必需值,因为
单选按钮
组中的一个元素是必需的
(即第一个元素),并且单选按钮组中的两个元素都具有 false 的选中状态。
另一方面,如果用户选择“Doggo”然后提交表单,则两个
input
元素都不会缺少必需值,因为
尽管其中一个
是必需的,但并非所有元素都具有 false 的选中状态。
如果单选按钮组中没有任何单选按钮被选中, 则它们最初在界面中都将处于未选中状态,直到其中一个 被选中(由用户或脚本选中)。
以下常见的 input 元素
内容属性和 IDL 属性适用于该元素:
checked 和
required
内容属性;
checked 和
value IDL
属性。
不得指定以下内容属性,并且这些属性不适用于该
元素:
accept、
alpha、
alt、
autocomplete、
colorspace、
dirname、
formaction、
formenctype、
formmethod、
formnovalidate、
formtarget、
height、
list、
max、
maxlength、
min、
minlength、
multiple、
pattern、
placeholder、
popovertarget、
popovertargetaction、
readonly、
size、
src、
step,以及
width。
以下 IDL 属性和方法不适用于该元素:
files、
list、
selectionStart、
selectionEnd、
selectionDirection、
valueAsDate,
以及
valueAsNumber
IDL 属性;
select()、
setRangeText()、
setSelectionRange()、
stepDown(),
以及
stepUp()
方法。
type=file)所有当前引擎均支持。
当 input
元素的 type
属性处于
文件
上传状态时,适用本节中的
规则。
input
元素表示一个已选择文件列表,每个文件均由
文件名、文件类型和文件主体(文件的内容)组成。
文件名不得包含路径组成部分,即使 用户选择了整个目录层次结构,或选择了不同目录中具有相同 名称的多个文件。就文件上传状态而言,路径组成部分是文件名中由 U+005C REVERSE SOLIDUS 字符(\) 分隔的部分。
除非设置了 multiple
属性,否则
已选择
文件列表中不得有一个以上的文件。
此类元素 element 的input 激活行为是为 element 显示 选择器(如适用)。
如果元素是可变的, 用户代理还应该允许 用户以其他方式更改列表中的文件,例如通过 拖放添加或移除文件。当用户这样做时,用户代理必须为该元素更新文件选择。
如果元素不是可变的,用户代理不得允许 用户更改元素的选择。
要为元素 element 更新文件选择:
所有当前引擎均支持。
所有当前引擎均支持。
可以指定 accept
属性,以向用户代理提示将
接受哪些文件类型。
如果指定,该属性必须由一组逗号分隔的令牌组成,其中每个 令牌都必须与以下项目之一进行ASCII 不区分大小写匹配:
audio/*”video/*”image/*”这些令牌不得与任何其他令牌进行ASCII 不区分大小写匹配 (即不允许重复)。为了从该属性中获取令牌列表, 用户代理必须按 逗号拆分 属性值。
用户代理可以使用此属性的值,显示比通用文件选择器更合适的用户界面。
例如,给定值 image/* 时,用户
代理可以向用户提供使用本地相机或从其
照片集合中选择照片的选项;给定值 audio/* 时,用户代理可以向用户
提供使用耳麦录制音频片段的选项。
用户代理应该阻止用户选择不被这些令牌中的一个(或多个) 接受的文件。
当查找特定格式的数据时,建议作者同时指定任何 MIME 类型和任何相应的 扩展名。
例如,考虑一个将 Microsoft Word 文档转换为开放文档 格式文件的应用程序。由于 Microsoft Word 文档使用多种 MIME 类型和 扩展名进行描述,因此站点可以列出多个,如下所示:
< input type = "file" accept = ".doc,.docx,.xml,application/msword,application/vnd.openxmlformats-officedocument.wordprocessingml.document" > 在仅使用文件扩展名描述文件类型的平台上,此处列出的扩展名 可用于筛选允许的文档,而 MIME 类型可以与系统的 类型注册表(将 MIME 类型映射到系统使用的扩展名)一起使用(如果存在),以 确定要允许的其他扩展名。同样,在没有文件名或 扩展名,但在内部使用 MIME 类型标记文档的系统上,可以使用 MIME 类型选择 允许的文件;如果系统具有将已知扩展名映射到系统所使用 MIME 类型的扩展名注册 表,也可以使用这些扩展名。
扩展名往往具有歧义(例如,使用“.dat”扩展名的格式
数量难以计数,并且用户通常可以相当轻松地重命名
文件,使其具有“.doc”扩展名,即使它们并非 Microsoft Word
文档),而 MIME 类型往往不可靠(例如,许多格式没有正式注册的
类型,并且许多格式实际上使用多个不同的 MIME 类型进行标记)。提醒作者,
与通常情况一样,应该谨慎处理从客户端接收的数据,因为即使用户没有
恶意,并且用户代理完全遵守了
accept
属性的要求,数据也可能不符合预期格式。
由于历史原因,value IDL
属性会在
文件名前加上字符串“C:\fakepath\”。某些旧式用户代理
实际上会包含完整路径(这是一个安全漏洞)。因此,
以向后兼容的方式从 value
IDL 属性中
获取文件名并非易事。以下函数以
适当兼容的方式提取文件名:
function extractFilename( path) {
if ( path. substr( 0 , 12 ) == "C:\\fakepath\\" )
return path. substr( 12 ); // modern browser
var x;
x = path. lastIndexOf( '/' );
if ( x >= 0 ) // Unix-based path
return path. substr( x+ 1 );
x = path. lastIndexOf( '\\' );
if ( x >= 0 ) // Windows-based path
return path. substr( x+ 1 );
return path; // just the filename
} 可以按如下方式使用:
< p >< input type = file name = image onchange = "updateFilename(this.value)" ></ p >
< p > The name of the file you picked is: < span id = "filename" > (none)</ span ></ p >
< script >
function updateFilename( path) {
var name = extractFilename( path);
document. getElementById( 'filename' ). textContent = name;
}
</ script > 以下常见的 input
元素
内容属性和 IDL 属性适用于该元素:
accept、
multiple,
以及
required
内容属性;
files 和
value IDL
属性;
select()
方法。
不得指定以下内容属性,并且这些属性不适用于该
元素:
alpha、
alt、
autocomplete、
checked、
colorspace、
dirname、
formaction、
formenctype、
formmethod、
formnovalidate、
formtarget、
height、
list、
max、
maxlength、
min、
minlength、
pattern、
popovertarget、
popovertargetaction、
placeholder、
readonly、
size、
src、
step,以及
width。
必须省略元素的 value
属性。
以下 IDL 属性和方法不适用于该元素:
checked、
list、
selectionStart、
selectionEnd、
selectionDirection、
valueAsDate,
以及
valueAsNumber
IDL 属性;
setRangeText()、
setSelectionRange()、
stepDown(),
以及
stepUp() 方法。
type=submit)所有当前引擎均支持。
当 input 元素的
type 属性
处于
提交按钮状态时,适用
本节中的规则。
![]()
input
元素表示一个按钮,该按钮被
激活时会提交
表单。如果元素具有 value
属性,
则按钮的标签必须是该属性的值;否则,它必须是一个
表示“提交”或类似含义的由实现定义的字符串。该
元素是一个按钮,具体而言是一个提交按钮。
由于默认标签是由实现定义的,并且 按钮的宽度通常取决于按钮的标签,因此按钮的宽度可能泄露少量 可用于指纹识别的信息。这些信息很可能与 用户代理的身份和用户的区域设置高度相关。
给定 event,元素的input 激活行为如下:
formaction、
formenctype、
formmethod、
formnovalidate
和 formtarget
属性是用于表单
提交的属性。
formnovalidate
属性可用于
创建不会触发约束验证的提交按钮。
以下常见的 input 元素
内容属性和 IDL 属性适用于该元素:
dirname、
formaction、
formenctype、
formmethod、
formnovalidate、
formtarget、
popovertarget,
以及
popovertargetaction
内容
属性;value IDL
属性。
不得指定以下内容属性,并且这些属性不适用于该
元素:
accept、
alpha、
alt、
autocomplete、
checked、
colorspace、
height、
list、
max、
maxlength、
min、
minlength、
multiple、
pattern、
placeholder、
readonly、
required、
size、
src、
step,以及
width。
以下 IDL 属性和方法不适用于该元素:
checked、
files、
list、
selectionStart、
selectionEnd、
selectionDirection、
valueAsDate,
以及
valueAsNumber
IDL 属性;
select()、
setRangeText()、
setSelectionRange()、
stepDown(),
以及
stepUp()
方法。
type=image)所有当前引擎均支持。
当 input
元素的 type
属性处于
图像按钮状态时,适用本
节中的
规则。
input
元素表示一幅图像,用户可以从中
选择坐标并提交表单;或者表示一个用户可通过其提交
表单的按钮。该元素是一个按钮,具体而言是一个提交
按钮。
该坐标会在表单提交期间发送到服务器,方式是为
该元素发送两个条目,这两个条目派生自控件的名称,
但会分别将“.x”和“.y”附加到
名称后,并分别使用坐标的 x 和 y 分量。
所有当前引擎均支持。
图像由 src 属性给出。src
属性必须存在,并且必须包含一个可能被空格包围的有效非空
URL,该 URL 引用一个非交互式、可选动画、既不
分页也不含脚本的图像资源。
当发生以下任一事件时:
input
元素的 type 属性
首次设置为图像按钮状态(可能在
首次创建元素时),并且存在 src 属性input
元素的 type 属性
被改回图像按钮状态,并且存在 src 属性,
且其值自上次
type
属性处于图像按钮状态以来已发生更改
input
元素的 type 属性
处于
图像按钮状态,并且 src 属性被
设置或更改
则除非用户代理无法支持图像、其图像支持已被禁用、
用户代理仅按需获取图像,或者 src
属性的值为空字符串,否则运行以下步骤:
令 url 为给定 src 属性的
值,并相对于元素的节点
文档对 URL
进行编码解析的结果。
如果 url 为失败,则返回。
令 request 为一个新的请求,其URL为
url,客户端为元素的节点
文档的
相关设置对象,目标为“image”,发起者类型为“input”,
凭据模式为“include”,并且其
使用 URL 凭据标志已设置。
获取 request,并将 processResponseEndOfBody 设置为给定响应 response 的以下步骤:
如果图像已成功获取、没有网络错误、图像类型是 受支持的图像类型,并且图像是该类型的有效图像,则称该图像 可用。如果在图像 完全下载之前即满足此条件,则在获取图像期间由网络任务 源排入的每个任务 都必须适当地更新图像的呈现。
用户代理应该应用图像嗅探 规则来确定图像类型,并将图像的关联 Content-Type 标头作为 official type。如果未应用这些规则,则图像类型必须是由 图像的关联 Content-Type 标头给出的类型。
用户代理不得通过 input 元素
支持非图像资源。用户
代理不得运行嵌入图像资源中的可执行代码。用户代理必须仅显示
多页资源的第一页。用户代理不得允许资源以
交互方式运行,但应该遵循资源中的任何动画。
所有当前引擎均支持。
alt 属性
为无法使用图像的用户和用户代理提供按钮的文本标签。alt 属性必须
存在,并且必须包含一个非空
字符串,该字符串给出当图像不可用时适合等效按钮的标签。
如果设置了 src
属性,图像可用,并且用户代理已配置为显示该图像,
则元素表示一个用于从
src 属性指定的图像中
选择坐标的控件。在
这种情况下,如果元素是可变的,用户代理应该允许用户
选择此坐标。
给定 event,元素的input 激活行为如下:
元素的已选择坐标 由一个 x 分量和一个 y 分量组成。其初始值为 (0, 0)。 这些坐标表示相对于元素图像边缘的位置,坐标空间中的 x 正方向向右,y 正方向向下。
x 分量必须是一个有效整数,表示范围 −(borderleft+paddingleft) ≤ x ≤ width+borderright+paddingright 内的数字 x,其中 width 是图像的渲染宽度, borderleft 是图像左侧边框的宽度,paddingleft 是图像左侧内边距的宽度, borderright 是图像右侧边框的宽度, paddingright 是图像右侧内边距的宽度, 所有尺寸均以CSS 像素给出。
y 分量必须是一个有效整数,表示范围 −(bordertop+paddingtop) ≤ y ≤ height+borderbottom+paddingbottom 内的数字 y,其中 height 是图像的渲染高度,bordertop 是图像上方边框的宽度, paddingtop 是图像上方内边距的宽度, borderbottom 是图像下方边框的宽度, paddingbottom 是图像下方内边距的宽度, 所有尺寸均以CSS 像素给出。
如果边框或内边距不存在,则其宽度为零CSS 像素。
formaction、formenctype、
formmethod、
formnovalidate
和 formtarget
属性是用于表单
提交的属性。
image.width [ = value ]
image.height [ = value ]
这些属性返回图像实际渲染的尺寸,如果尺寸 未知,则返回 0。
可以设置这些属性,以更改相应的内容属性。
以下常见的 input 元素
内容属性和 IDL 属性适用于该元素:
alt、
formaction、
formenctype、
formmethod、
formnovalidate、
formtarget、
height、
popovertarget、
popovertargetaction、
src,以及
width 内容
属性;
value IDL
属性。
不得指定以下内容属性,并且这些属性不适用于该
元素:
accept、
alpha、
autocomplete、
checked、
colorspace、
dirname、
list、
max、
maxlength、
min、
minlength、
multiple、
pattern、
placeholder、
readonly、
required、
size,以及
step。
必须省略元素的 value
属性。
以下 IDL 属性和方法不适用于该元素:
checked、
files、
list、
selectionStart、
selectionEnd、
selectionDirection、
valueAsDate,
以及
valueAsNumber
IDL 属性;
select()、
setRangeText()、
setSelectionRange()、
stepDown(),
以及
stepUp()
方法。
此状态行为的许多方面都与
img 元素的行为类似。
建议读者阅读该节,其中对许多相同的
要求进行了更详细的说明。
考虑以下表单:
< form action = "process.cgi" >
< input type = image src = map.png name = where alt = "Show location list" >
</ form > 如果用户单击了图像中的坐标 (127,40),则用于提交表单的 URL
将是“process.cgi?where.x=127&where.y=40”。
(在此示例中,假定对于看不到地图,而只看到 标有“Show location list”的按钮的用户,单击该按钮将使服务器显示一个 可供选择的位置列表,而不是地图。)
type=reset)所有当前引擎均支持。
当 input
元素的 type
属性处于
重置按钮状态时,适用本
节中的
规则。
![]()
input
元素表示一个按钮,该按钮被
激活时会重置
表单。如果元素具有 value
属性,
则按钮的标签必须是该属性的值;否则,它必须是一个
表示“重置”或类似含义的由实现定义的字符串。该
元素是一个按钮。
由于默认标签是由实现定义的,并且 按钮的宽度通常取决于按钮的标签,因此按钮的宽度可能泄露少量 可用于指纹识别的信息。这些信息很可能与 用户代理的身份和用户的区域设置高度相关。
约束验证:该元素被禁止进行约束 验证。
以下常见的 input 元素
内容属性适用于该元素:
popovertarget
和
popovertargetaction。
不得指定以下内容属性,并且这些属性不适用于该
元素:
accept、
alpha、
alt、
autocomplete、
checked、
colorspace、
dirname、
formaction、
formenctype、
formmethod、
formnovalidate、
formtarget、
height、
list、
max、
maxlength、
min、
minlength、
multiple、
pattern、
placeholder、
readonly、
required、
size、
src、
step,以及
width。
以下 IDL 属性和方法不适用于该元素:
checked、
files、
list、
selectionStart、
selectionEnd、
selectionDirection、
valueAsDate,
以及
valueAsNumber
IDL 属性;
select()、
setRangeText()、
setSelectionRange()、
stepDown(),
以及
stepUp()
方法。
type=button)所有当前引擎均支持。
当 input
元素的 type 属性
处于
按钮
状态时,适用本节中的规则。
input 元素
表示一个没有默认行为的按钮。按钮的
标签必须在 value
属性中提供,不过该属性可以是空字符串。如果元素具有 value 属性,则
按钮的标签必须是该
属性的值;否则,它必须是空字符串。该元素是一个按钮。
该元素没有input 激活行为。
约束验证:该元素被禁止进行约束 验证。
以下常见的 input 元素
内容属性适用
于该元素:
popovertarget
和
popovertargetaction。
不得指定以下内容属性,并且这些属性不适用于该
元素:
accept、
alpha、
alt、
autocomplete、
checked、
colorspace、
dirname、
formaction、
formenctype、
formmethod、
formnovalidate、
formtarget、
height、
list、
max、
maxlength、
min、
minlength、
multiple、
pattern、
placeholder、
readonly、
required、
size、
src、
step,以及
width。
以下 IDL 属性和方法不适用于该元素:
checked、
files、
list、
selectionStart、
selectionEnd、
selectionDirection、
valueAsDate,
以及
valueAsNumber
IDL 属性;
select()、
setRangeText()、
setSelectionRange()、
stepDown(),以及
stepUp() 方法。
本节为非规范性内容。
日期、时间和数字控件中向用户显示的格式与 用于表单提交的格式无关。
建议浏览器使用按照 input 元素的
语言所隐含的区域设置,或用户首选区域设置的惯例来呈现
日期、时间和数字的用户界面。使用页面的
区域设置将确保与页面提供的数据保持一致。
例如,如果一个美国英语页面声称 某场 Cirque De Soleil 演出将在 02/03 举行,而用户的 浏览器配置为使用英国英语区域设置,却仅在购票日期 选择器中显示日期 03/02,这会使用户感到困惑。使用页面的区域设置至少可以确保 日期在所有位置都以相同的格式呈现。(当然,用户仍有可能 晚到一个月,但对于这种文化 差异,能做的也只有这么多……)
input 元素的通用
属性仅当 input
元素的 type
属性所处状态的定义
声明该属性适用时,这些属性才适用于该元素。当某个属性
不适用于 input 元素时,
无论下文的要求和定义如何,用户代理都必须
忽略该属性。
maxlength
和 minlength
属性所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
当 maxlength
属性适用时,它是
一个表单控件
maxlength
属性。
所有当前引擎均支持。
当 minlength
属性适用时,它是
一个表单控件
minlength
属性。
如果 input
元素具有允许的最大值长度,则
元素的 value
属性值的长度必须小于或等于元素的允许的最大值
长度。
以下摘录展示了如何将消息客户端的文本输入任意 限制为固定数量的字符,从而迫使通过此媒介进行的任何对话 都必须简短,并阻碍有深度的讨论。
< label > What are you doing? < input name = status maxlength = 140 ></ label > 此处为密码指定了最小长度:
< p >< label > Username: < input name = u required ></ label >
< p >< label > Password: < input name = p required minlength = 12 ></ label > size 属性size 属性
给出在视觉渲染中,用户代理应允许用户在编辑元素的值时
看到的字符数。
如果指定了 size 属性,
则其值必须是一个大于零的
有效非负
整数。
如果存在该属性,则必须使用解析 非负整数的规则解析其值;如果结果是大于零的数字,则用户代理 应该确保至少有这么多个字符可见。
readonly 属性所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
readonly
属性是一个布尔属性,用于
控制用户是否可以编辑
表单控件。指定该属性时,元素不是可变的。
disabled 和 readonly 之间的区别在于,
只读控件仍然可以发挥作用,
而已禁用控件在启用之前通常不能作为控件发挥作用。本规范的其他部分
通过引用已禁用概念的规范性要求
对此进行了更详细的说明(例如,元素的
激活行为、它是否是可聚焦区域,或何时
构造
条目列表)。与用户同已禁用控件交互有关的任何其他行为,
例如文本是否可以被选择或复制,本
标准未予定义。
只有文本控件可以设为只读,因为对于其他控件(例如复选框和
按钮),只读与已禁用之间不存在有用的区别,因此
readonly
属性不
适用。
在以下示例中,现有的产品标识符不能修改,但它们 仍作为表单的一部分显示,以便与表示新产品的行保持一致 (该行中的标识符尚未填写)。
< form action = "products.cgi" method = "post" enctype = "multipart/form-data" >
< table >
< tr > < th > Product ID < th > Product name < th > Price < th > Action
< tr >
< td > < input readonly = "readonly" name = "1.pid" value = "H412" >
< td > < input required = "required" name = "1.pname" value = "Floor lamp Ulke" >
< td > $< input required = "required" type = "number" min = "0" step = "0.01" name = "1.pprice" value = "49.99" >
< td > < button formnovalidate = "formnovalidate" name = "action" value = "delete:1" > Delete</ button >
< tr >
< td > < input readonly = "readonly" name = "2.pid" value = "FG28" >
< td > < input required = "required" name = "2.pname" value = "Table lamp Ulke" >
< td > $< input required = "required" type = "number" min = "0" step = "0.01" name = "2.pprice" value = "24.99" >
< td > < button formnovalidate = "formnovalidate" name = "action" value = "delete:2" > Delete</ button >
< tr >
< td > < input required = "required" name = "3.pid" value = "" pattern = "[A-Z0-9]+" >
< td > < input required = "required" name = "3.pname" value = "" >
< td > $< input required = "required" type = "number" min = "0" step = "0.01" name = "3.pprice" value = "" >
< td > < button formnovalidate = "formnovalidate" name = "action" value = "delete:3" > Delete</ button >
</ table >
< p > < button formnovalidate = "formnovalidate" name = "action" value = "add" > Add</ button > </ p >
< p > < button name = "action" value = "update" > Save</ button > </ p >
</ form > required 属性required
属性是一个布尔属性。
指定该属性时,元素是必需的。
以下表单有两个必填字段,一个用于电子邮件地址,另一个用于密码。 它还有第三个字段,仅当用户在 密码字段和该第三个字段中输入相同密码时,才被视为有效。
< h1 > Create new account</ h1 >
< form action = "/newaccount" method = post
oninput = "up2.setCustomValidity(up2.value != up.value ? 'Passwords do not match.' : '')" >
< p >
< label for = "username" > Email address:</ label >
< input id = "username" type = email required name = un >
< p >
< label for = "password1" > Password:</ label >
< input id = "password1" type = password required name = up >
< p >
< label for = "password2" > Confirm password:</ label >
< input id = "password2" type = password name = up2 >
< p >
< input type = submit value = "Create account" >
</ form > 对于单选按钮,如果组中的任何一个单选按钮
被选中,则满足 required
属性。
因此,在以下示例中,可以选中任何一个单选按钮,而不仅仅是
标记为必需的那个:
< fieldset >
< legend > Did the movie pass the Bechdel test?</ legend >
< p >< label >< input type = "radio" name = "bechdel" value = "no-characters" > No, there are not even two female characters in the movie. </ label >
< p >< label >< input type = "radio" name = "bechdel" value = "no-names" > No, the female characters never talk to each other. </ label >
< p >< label >< input type = "radio" name = "bechdel" value = "no-topic" > No, when female characters talk to each other it's always about a male character. </ label >
< p >< label >< input type = "radio" name = "bechdel" value = "yes" required > Yes. </ label >
< p >< label >< input type = "radio" name = "bechdel" value = "unknown" > I don't know. </ label >
</ fieldset > 为了避免在单选按钮组是否为必需的问题上产生混淆,建议作者 在组中的所有单选按钮上都指定该属性。事实上,一般而言, 建议作者首先避免创建没有任何初始选中 控件的单选按钮组,因为用户无法返回到这种状态,因此 通常认为这是一种糟糕的用户界面。
multiple 属性所有当前引擎均支持。
所有当前引擎均支持。
multiple
属性是一个布尔属性,用于
指示是否允许用户
指定多个值。
以下摘录展示了电子邮件客户端的“收件人”字段如何接受多个电子邮件 地址。
< label > To: < input type = email multiple name = to ></ label > 假设用户的联系人数据库中有许多朋友,其中有两位朋友 “Spider-Man”(地址为“spider@parker.example.net”)和“Scarlet Witch”(地址为 “scarlet@avengers.example.net”),那么在用户输入“s”之后,用户代理 可能会向用户建议这两个电子邮件地址。

页面还可以从站点中关联用户的联系人数据库:
< label > To: < input type = email multiple name = to list = contacts ></ label >
...
< datalist id = "contacts" >
< option value = "hedral@damowmow.com" >
< option value = "pillar@example.com" >
< option value = "astrophy@cute.example" >
< option value = "astronomy@science.example.org" >
</ datalist > 假设用户已在此文本控件中输入“bob@example.net”,然后
开始输入以“s”开头的第二个电子邮件地址。用户代理可能会显示
之前提到的两位朋友,以及
datalist
元素中给出的“astrophy”和“astronomy”值。

以下摘录展示了电子邮件客户端的“附件”字段如何接受多个 要上传的文件。
< label > Attachments: < input type = file multiple name = att ></ label > pattern 属性所有当前引擎均支持。
所有当前引擎均支持。
pattern
属性指定一个正则表达式,用于检查控件的值;或者,当 multiple 属性适用并已设置时,用于检查控件的
多个值。
如果指定,该属性的值必须匹配 JavaScript Pattern[+UnicodeSetsMode, +N]
产生式。
input 元素的已编译模式正则表达式(如果存在)是一个 JavaScript RegExp
对象。按如下方式确定:
如果元素未指定 pattern 属性,
则不返回任何内容。该元素没有已编译模式正则
表达式。
令 pattern 为元素的 pattern 属性的
值。
令 regexpCompletion 为 RegExpCreate(pattern,
"v")。
如果 regexpCompletion 是一个突然 完成,则不返回任何内容。该元素没有已编译模式正则 表达式。
建议用户代理将此错误记录到开发者控制台中,以帮助 调试。
令 anchoredPattern 为字符串“^(?:”,后跟
pattern,再后跟“)$”。
返回 ! RegExpCreate(anchoredPattern, "v")。
采用这些步骤而不是直接使用 pattern 属性值的原因
有两个。首先,我们希望
确保与字符串匹配时,正则表达式的起点锚定到字符串的起点,
终点锚定到字符串的终点。其次,我们希望确保正则
表达式以独立形式就是有效的,而不是只有在被
“^(?:”和“)$”锚点包围后才变为有效。
如果 ! RegExpBuiltinExec(regexp, input) 不为 null,
则 RegExp
对象 regexp 匹配字符串 input。
约束验证:如果元素的值不是空字符串,并且元素的 multiple 属性
未指定,或者根据 input
元素的 type 属性的
当前状态,该属性不适用于该元素,并且元素具有
已编译模式正则表达式,但
该正则表达式不匹配元素的值,则该元素存在
模式
不匹配。
约束验证:如果元素的值不是空字符串,并且元素的 multiple 属性
已指定且适用于
input 元素,并且
元素具有
一个已编译模式正则表达式,但
该正则表达式不匹配元素的每个值,则该元素存在模式
不匹配。
当 input 元素
指定了 pattern
属性时,作者应该包含一个 title
属性,以给出对模式的描述。如果存在此属性,
用户代理可以在告知用户模式不匹配时,或在其他任何适当的时机,
例如在工具提示中,或者当控件获得焦点时由
辅助技术读出时,使用该属性的内容。
例如,以下代码片段:
< label > Part number:
< input pattern = "[0-9][A-Z]{3}" name = "part"
title = "A part number is a digit followed by three uppercase letters." />
</ label > ……可能导致用户代理显示如下警告:
部件编号由一个数字后跟三个大写字母组成。 字段内容不正确时,无法提交此表单。
当控件具有 pattern
属性时,如果使用
title 属性,
则该属性必须描述模式。也可以包含其他
信息,只要它有助于用户填写控件即可。
否则,辅助技术的使用会受到影响。
例如,如果 title 属性包含控件的标题, 辅助技术最终可能会说出类似以下内容:您输入的文本不 匹配所需模式。生日,这并无帮助。
用户代理仍然可以在非错误情况下显示 title(例如,
将鼠标悬停在控件上时作为工具提示),因此作者应该注意,不要将
title 的措辞写得像是
错误必然已经发生。
min 和 max 属性所有当前引擎均支持。
所有当前引擎均支持。
某些表单控件可以应用显式约束,以限制用户可提供值的 允许范围。通常,这种范围是线性且连续的。不过,表单控件 可以具有周期域,在这种情况下, 表单控件可能的最宽范围是有限的,而作者可以在其中指定 跨越边界的显式范围。
具体而言,type=time
控件的最宽范围是从午夜到午夜(24 小时),并且
作者既可以设置连续线性范围(例如晚上 9 点到晚上 11 点),也可以设置
跨越午夜的不连续范围(例如晚上 11 点到凌晨 1 点)。
min 和 max 属性指示
元素允许的
值范围。
它们的语法由定义 type 属性当前
状态的章节定义。
如果元素具有 min 属性,并且
将将字符串转换为
数字的算法应用于 min
属性的值所得的
结果是一个数字,则该数字是元素的最小值;否则,如果
type 属性的
当前状态定义了默认最小值,则该值是最小值;否则,元素
没有最小值。
如果元素具有 max 属性,并且
将将字符串转换为
数字的算法应用于 max
属性的值所得的
结果是一个数字,则该数字是元素的最大值;否则,如果
type 属性的
当前状态定义了默认最大值,则该值是最大值;否则,元素
没有最大值。
如果元素不具有
周期域,则
max 属性的值
(即最大值)不得小于
min 属性的
值(即其最小值)。
如果一个不具有周期 域的元素的最大值小于其最小值,那么 只要该元素具有值, 它就会存在下溢 或存在 上溢。
以下日期控件将输入限制为 1980 年代之前的日期:
< input name = bday type = date max = "1979-12-31" > 以下数字控件将输入限制为大于零的整数:
< input name = quantity required = "" type = "number" min = "1" value = "1" > 以下时间控件将输入限制为晚上 9 点到早上 6 点之间的分钟, 默认值为午夜:
< input name = "sleepStart" type = time min = "21:00" max = "06:00" step = "60" value = "00:00" > step 属性所有当前引擎均支持。
step 属性
通过限制允许的值,指示值或多个值所预期(且要求)的
粒度。定义 type 属性当前状态的章节还
定义了默认步长、步长
比例因子,并且在某些情况下还定义了默认步长基数,
它们用于按照下文所述处理该
属性。
如果指定了 step 属性,
则其值必须是一个有效
浮点数,且经解析后得到大于
零的数字;或者其
值必须与字符串“any”进行ASCII
不区分大小写匹配。
该属性按照如下方式为元素提供允许值步长:
否则,如果该属性的值与字符串“any”
进行ASCII
不区分大小写匹配,则不存在允许
值步长。
否则,如果将解析浮点 数值的规则 应用于该属性的值时,返回错误、零或小于零的数字,则 允许值步长为默认步长 乘以步长 比例因子。
否则,允许值 步长为将解析浮点 数值的规则应用于 该属性的值时所返回的数字,乘以步长 比例因子。
步长基数是以下 算法返回的值:
如果元素具有 min
内容属性,并且
将将
字符串转换为数字的算法应用于 min
内容
属性的值所得的结果不是错误,则返回该结果。
如果元素具有 value 内容属性,并且
将将
字符串转换为数字的算法应用于 value
内容属性的值所得的结果不是错误,则返回该结果。
返回零。
约束验证:当元素具有允许值步长,并且将将 字符串转换为数字的算法应用于 元素的值所给出的字符串所得的结果 是一个数字,并且 步长基数减去该数字所得的值不是 允许值 步长的整数倍时, 元素存在步长不匹配。
以下范围控件仅接受 0..1 范围内的值,并允许在 该范围内使用 256 个步长:
< input name = opacity type = range min = 0 max = 1 step = 0.00392156863 > 以下控件允许以任意精度选择一天中的任何时间(例如 千分之一秒或更高的精度):
< input name = favtime type = time step = any > 通常,时间控件的精度限制为一分钟。
list 属性所有当前引擎均支持。
list 属性
用于
标识一个列出向用户建议的预定义选项的元素。
如果存在,其值必须是同一树中 datalist
元素的ID。
建议源元素是
树中按树顺序排列的第一个元素,
该元素的ID
等于 list 属性的值,并且该元素
是 datalist
元素。如果不存在 list
属性,或者不存在具有该ID的元素,或者具有该ID的
第一个元素不是 datalist
元素,则不存在建议
源
元素。
如果存在建议源
元素,则当
用户代理允许用户编辑 input 元素的值时,用户代理应该以
适合所用控件类型的方式,向用户提供由
建议源元素表示的建议。
如果适当,用户代理应该使用建议的
标签和值向用户标识该建议。
当建议数量很大时,建议用户代理筛选由建议源元素表示的建议, 只包含最相关的建议(例如,根据用户目前的输入)。没有定义精确 阈值,但将列表限制在四到七个值是合理的。如果根据用户的输入进行筛选, 用户代理应该在建议的标签和值 中搜索匹配项。用户代理应该考虑输入变体如何影响 匹配过程。应该应用 Unicode 规范化,使由不同键盘或输入专用机制导致的 不同底层 Unicode 代码点序列不会 干扰匹配过程。应该忽略大小写差异,这可能需要 特定语言的大小写映射。有关这些内容的示例,请参阅万维网字符模型: 字符串匹配。用户代理还可以提供其他匹配功能,例如: 一些示例包括将不同形式的假名彼此匹配(或与汉字匹配)、 忽略重音符号或应用拼写纠正。[CHARMODNORM]
此文本字段允许选择一种 JavaScript 函数类型。
< input type = "text" list = "function-types" >
< datalist id = "function-types" >
< option value = "function" > function</ option >
< option value = "async function" > async function</ option >
< option value = "function*" > generator function</ option >
< option value = "=>" > arrow function</ option >
< option value = "async =>" > async arrow function</ option >
< option value = "async function*" > async generator function</ option >
</ datalist > 
然后,输入“arrow”或“=>”会将列表筛选为标签为 “arrow function”和“async arrow function”的条目。输入“generator”或 “*”会将列表筛选为标签为“generator function”和“async generator function”的条目。
与往常一样,用户代理可以自由作出适合其特定要求和 用户特定情况的用户界面决定。不过, 从历史上看,这一直是实现者、Web 开发者和用户都会感到困惑的领域, 因此我们在上文给出了一些“应该”建议。
如何处理用户对建议的选择,取决于元素是仅接受 单个值的控件,还是接受多个值:
此 URL 字段提供了一些建议。
< label > Homepage: < input name = hp type = url list = hpurls ></ label >
< datalist id = hpurls >
< option value = "https://www.google.com/" label = "Google" >
< option value = "https://www.reddit.com/" label = "Reddit" >
</ datalist > 用户历史记录中的其他 URL 也可能显示;这由用户代理决定。
此示例演示如何设计一个使用自动补全列表功能,同时 在旧式用户代理中仍能有效降级的表单。
如果自动补全列表仅是一种辅助功能,对内容并不重要,那么只需
使用一个包含 option 子元素的
datalist
元素即可。为了
防止这些值在旧式用户代理中被渲染,需要将它们放在
value 属性中,而不是
直接内联。
< p >
< label >
Enter a breed:
< input type = "text" name = "breed" list = "breeds" >
< datalist id = "breeds" >
< option value = "Abyssinian" >
< option value = "Alpaca" >
<!-- ... -->
</ datalist >
</ label >
</ p > 不过,如果需要在旧式用户代理中显示这些值,则可以将回退内容放在
datalist 元素
内部,如下所示:
< p >
< label >
Enter a breed:
< input type = "text" name = "breed" list = "breeds" >
</ label >
< datalist id = "breeds" >
< label >
or select one from the list:
< select name = "breed" >
< option value = "" > (none selected)
< option > Abyssinian
< option > Alpaca
<!-- ... -->
</ select >
</ label >
</ datalist >
</ p > 回退内容只会显示在不支持 datalist 的用户代理中。
另一方面,所有用户代理都会检测到这些选项,即使它们并不是
datalist 元素的子元素。
请注意,如果 datalist
中使用的
option 元素是 selected,
则旧式用户代理会默认选中它
(因为它会影响 select 元素),但它不会
对支持 datalist
的用户代理中的
input 元素产生任何影响。
placeholder
属性所有当前引擎均支持。
Element/input#attr-placeholder
所有当前引擎均支持。
placeholder
属性表示一个简短的
提示(一个词或短语),用于在控件没有
值时帮助用户输入数据。提示可以是示例值或对预期格式的简短描述。如果
指定该属性,则其值不得包含 U+000A LINE FEED(LF)或 U+000D
CARRIAGE RETURN(CR)字符。
placeholder
属性不应该用作
label 的替代项。对于较长的提示
或其他建议性文本,title
属性更为合适。
这些机制非常相似,但存在细微差别:由
控件的 label
给出的提示始终显示;placeholder
属性中给出的简短提示在用户输入
值之前显示;而 title
属性中的提示在用户
请求进一步帮助时显示。
当元素的值为空字符串时,用户代理应该在对提示移除换行符后将其呈现给用户,尤其是在控件未 获得焦点时。
如果用户代理通常在控件
获得焦点时不向用户显示此提示,
但如果控件因 autofocus 属性而
获得焦点,则用户代理仍应该为该控件显示提示,因为
在这种情况下,用户在控件获得焦点之前没有机会查看
它。
以下是一个使用 placeholder
属性的邮件配置用户界面示例:
< fieldset >
< legend > Mail Account</ legend >
< p >< label > Name: < input type = "text" name = "fullname" placeholder = "John Ratzenberger" ></ label ></ p >
< p >< label > Address: < input type = "email" name = "address" placeholder = "john@example.net" ></ label ></ p >
< p >< label > Password: < input type = "password" name = "password" ></ label ></ p >
< p >< label > Description: < input type = "text" name = "desc" placeholder = "My Email Account" ></ label ></ p >
</ fieldset > 在控件内容具有一种方向性,但占位符需要 具有不同方向性的情况下,可以在属性值中使用 Unicode 双向算法格式化字符:
< input name = t1 type = tel placeholder = " ‫ رقم الهاتف 1 ‮ " >
< input name = t2 type = tel placeholder = " ‫ رقم الهاتف 2 ‮ " > 为了稍微更清晰一些,以下是使用数字字符引用而不是内联阿拉伯语的同一示例:
< input name = t1 type = tel placeholder = " ‫ رقم الهاتف 1 ‮ " >
< input name = t2 type = tel placeholder = " ‫ رقم الهاتف 2 ‮ " > input 元素的通用 APIinput.value [ = value ]
返回表单控件当前的值。
可以设置,以更改该值。
当控件是文件上传控件,并且将其
设置为空字符串以外的任何值时,抛出“InvalidStateError” DOMException。
input.checked [ = value ]
返回表单 控件当前的选中状态。
可以设置,以更改选中状态。
input.files [ = files ]
所有当前引擎均支持。
所有当前引擎均支持。
返回一个 FileList
对象,其中列出表单控件的已选择文件。
如果控件不是文件控件,则返回 null。
input.valueAsDate [ = value ]
如果适用,则返回一个表示表单控件值的 Date
对象;否则返回 null。
可以设置,以更改该值。
如果控件
不基于日期或时间,则抛出“InvalidStateError” DOMException。
input.valueAsNumber [ = value ]
如果适用,则返回一个表示表单控件值的数字;否则返回 NaN。
可以设置,以更改该值。将其设置为 NaN 会将底层值设置为 空字符串。
如果控件既不基于日期或时间,也不是数值控件,则抛出“InvalidStateError” DOMException。
input.stepUp([ n ])
input.stepDown([ n ])
按照 step 属性
给出的值乘以 n,更改表单控件的值。n 的
默认值为 1。
如果控件
既不基于日期或时间,也不是数值控件,或者 step
属性的值为“any”,则抛出“InvalidStateError” DOMException。
input.listinput.showPicker()
显示适用于 input 的任何选择器 UI,以便用户可以选择一个值。
如果 input 不支持选择器, 则此方法不执行任何操作。
如果
input 不是可变的,则抛出“InvalidStateError” DOMException。
如果在没有瞬态用户
激活的情况下调用,则抛出“NotAllowedError” DOMException。
如果
input 位于跨源 iframe 内,则抛出“SecurityError” DOMException,除非
input 处于
文件
上传或颜色状态。
value
IDL
属性允许脚本操作
input 元素的值。该
属性处于以下模式之一,这些模式定义其
行为:
获取时,返回元素当前的值。
获取时,如果元素具有 value
内容
属性,则返回该属性的值;否则返回空字符串。
设置时,将元素的 value
内容属性的值设置为新值。
获取时,如果元素具有 value 内容
属性,则返回该属性的值;否则返回字符串“on”。
设置时,将元素的 value
内容属性的值设置为新值。
获取时,如果已选择
文件列表中存在文件,则返回字符串“C:\fakepath\”后跟
第一个文件的名称;如果列表为空,则返回空字符串。
设置时,如果新值为空字符串,则清空已选择文件列表;否则抛出
“InvalidStateError” DOMException。
此“fakepath”要求是一个令人遗憾的历史意外。有关更多 信息,请参阅文件上传状态章节中的 示例。
checked
IDL 属性允许脚本操作 input 元素的选中状态。获取时,它
必须返回元素当前的选中状态;而
设置时,它必须将元素的选中状态设置为
新值,并将元素的脏选中状态
标志设置为 true。
files
IDL
属性允许脚本访问元素的已选择文件。
获取时,如果该 IDL 属性适用,则必须
返回一个表示当前已选择文件的 FileList
对象。在已选择文件列表发生更改之前,
必须返回同一对象。
如果该 IDL 属性不适用,则必须改为
返回 null。[FILEAPI]
valueAsDate IDL 属性表示元素的值,并将其解释为日期。
获取时,如果根据 input
元素的 type
属性的当前状态所作的定义,valueAsDate
属性不适用,则返回 null。否则,对元素的值运行该状态定义的将字符串转换为
Date 对象的算法;如果该算法返回了一个 Date
对象,则
返回该对象,否则返回 null。
设置时,如果根据 input
元素的 type
属性的当前状态所作的定义,valueAsDate
属性不适用,则抛出
“InvalidStateError” DOMException;
否则,如果新
值不为 null 且不是 Date
对象,则抛出 TypeError
异常;
否则,如果新值为 null,或为表示 NaN 时间值的 Date
对象,
则将元素的值设置为空字符串;
否则,对新值运行该状态定义的将
Date 对象转换为字符串的算法,并将元素的值设置为
所得字符串。
valueAsNumber IDL 属性表示元素的值,并将其解释
为数字。
获取时,如果根据 input
元素的 type
属性的当前状态所作的定义,valueAsNumber
属性不适用,则返回非数字(NaN)
值。否则,对元素的值运行该状态定义的将
字符串转换为数字的算法;如果该算法返回一个数字,则返回
该数字,
否则返回非数字(NaN)值。
设置时,如果新值为无穷大,则抛出 TypeError
异常。
否则,如果根据 input
元素的 type
属性的当前状态所作的定义,valueAsNumber
属性不适用,则抛出
“InvalidStateError” DOMException。
否则,如果新
值是非数字(NaN)值,则将
元素的值设置为空字符串。否则,对新值运行
该状态定义的将数字转换为字符串的算法,并
将元素的值
设置为所得字符串。
stepDown(n) 和 stepUp(n) 方法
被调用时,必须运行以下算法:
如果根据 input
元素的 type
属性的当前状态所作的定义,stepDown() 和
stepUp() 方法
不适用,
则抛出“InvalidStateError” DOMException。
如果元素没有允许
值步长,则
抛出“InvalidStateError” DOMException。
如果元素具有最小值和最大值,并且不存在一个大于或等于 元素的最小值且小于或等于元素的 最大值的值,使该值减去步长基数后为允许值步长的整数倍, 则返回。
如果将将 字符串转换为数字的算法应用于元素的值所给出的字符串时未产生错误,则令 value 为该算法的结果。否则,令 value 为零。
令 valueBeforeStepping 为 value。
如果 value 减去步长
基数后不是允许值
步长的整数倍,则将 value 设置为最接近的值,使该值减去
步长基数后
是允许值步长的整数倍;如果
调用的方法是 stepDown()
方法,则该值小于 value,否则
大于 value。
令 n 为参数。
令 delta 为允许值 步长乘以 n。
如果调用的方法是 stepDown()
方法,
则对 delta 取负。
令 value 为 value 加上 delta 的结果。
如果元素具有最小值,并且 value 小于该最小值,则将 value 设置为满足以下条件的最小值:该值减去步长基数后是允许值步长的整数倍,并且 该值大于或等于该最小值。
如果元素具有最大值,并且 value 大于该最大值,则 将 value 设置为满足以下条件的最大值:该值减去步长基数后是允许值步长的整数倍,并且 该值小于或等于该最大值。
如果调用的方法是 stepDown()
方法且 value 大于 valueBeforeStepping,或者调用的方法
是 stepUp() 方法且
value
小于 valueBeforeStepping,则返回。
令 value as string 为对 value 运行
input 元素的
type
属性当前状态所定义的将数字转换为
字符串的算法所得的结果。
将元素的值设置为 value as string。
list
IDL
属性必须返回当前的建议源
元素(如果存在),否则返回 null。
所有当前引擎均支持。
HTMLInputElement
的 showPicker() 和 HTMLSelectElement 的
showPicker()
方法步骤如下:
如果 this 不是可变的,则抛出
“InvalidStateError” DOMException。
如果 this 的相关设置对象的源与
this 的相关设置对象的顶级源不是同源,并且
this 是一个 select 元素,
或者
this 的 type 属性不
处于文件上传状态或颜色状态,
则抛出
“SecurityError” DOMException。
文件和颜色输入因历史 原因免除此检查:它们的input 激活行为也会显示其 选择器,并且从未 受到源检查的保护。
如果 this 的相关全局对象不具有瞬态
激活,则抛出“NotAllowedError”
DOMException。
如果 this 是一个 select 元素,
并且 this 未
正在渲染,则抛出“NotSupportedError”
DOMException。
要为 input 或
select
元素 element 显示选择器(如适用):
如果 element 不是可变的,则 返回。
如果 element 不支持 选择器,则返回。
如果 element 是一个 input 元素,
并且 element 的 type 属性处于
文件上传状态,则并行运行以下步骤:
可选地,等待此算法之前的任何执行终止。
令 dismissed 为使用 element 调用WebDriver BiDi 文件对话框已打开 所得的结果。
如果 dismissed 为 false:
向用户显示提示,请求用户指定一些文件。如果未在 element 上设置 multiple
属性,则
最多只能选择一个文件;否则可以选择任意数量的文件。文件可以
来自文件系统,也可以即时创建,例如使用连接到
用户设备的相机拍摄的照片。
等待用户完成选择。
如果 dismissed 为 true,或者用户在未更改
选择的情况下关闭了提示,则给定 element,在用户
交互任务
源上排入一个元素任务,以在
element 上触发一个
名为 cancel
的事件,并将
bubbles
属性初始化为 true。
否则,为 element 更新文件选择。
与所有用户界面规范一样,用户代理在如何解释这些要求方面拥有很大的
自由度。上述文本意味着用户要么
关闭提示,要么更改其选择;两者中恰好有一个为真。但是,
本标准并未规定这些可能性如何映射到特定用户界面元素。
例如,当之前已选择文件时,用户代理可能会将单击“取消”按钮解释为
将选择更改为零个文件,从而触发 input
和 change。或者,它也可能
将此类单击解释为关闭提示并保持选择不变,从而触发 cancel。同样,重新选择
之前已选择的相同文件是算作关闭提示,还是算作更改
选择,由用户代理决定。
否则,用户代理应该以用户与控件交互时通常采用的方式, 显示用于为 element 选择值的相关用户界面。
显示此类用户界面时,必须遵守规范相关部分中
针对 element 在其 type 属性
状态下应如何表现而规定的要求。(例如,各章节描述了
对所得值字符串的各种限制。)
此步骤可能产生副作用,例如关闭之前由此
算法显示的其他选择器。(如果这关闭了文件选择器,则根据上文,
将导致触发 input
和 change 事件,或者
cancel
事件。)
当 input
和 change 事件适用时
(除按钮以及 type 属性处于状态的控件外,
所有 input 控件都是如此),
会触发这些事件,以表示用户已与控件进行交互。每当用户修改了控件的数据时,都会触发 input
事件。如果对该控件而言存在合理的值提交时机,则会在值被提交时触发 change 事件;
否则会在控件失去焦点时触发。
在所有情况下,input
事件都先于相应的
change 事件(如果有)。
当 input
元素定义了 input
激活行为时,如果这些事件适用,则其分派规则在上文定义 type 属性状态的
章节中给出。(对于 type 属性处于复选框状态、单选
按钮状态或文件上传状态的所有 input 控件,
都是如此。)
对于未定义 input
激活行为,但这些事件对其适用,并且其用户界面同时涉及交互式操作和
显式提交操作的 input
元素,当用户更改元素的值时,用户代理必须给定该
input 元素,
在用户
交互任务源上排入一个元素任务,以在该 input 元素上触发一个名为 input
的事件,并将 bubbles
和 composed
属性初始化为 true;每当用户提交更改时,用户代理必须给定该
input 元素,
在用户交互任务源上排入一个元素
任务,将其用户有效性设置为 true,
并在该 input
元素上触发一个名为 change
的事件,并将 bubbles
属性初始化为 true。
同时涉及交互式操作和提交操作的用户界面示例,是使用滑块的范围控件,并通过指针设备操作该控件。
当用户拖动控件的滑块时,每当位置发生变化都会触发 input
事件,而只有当用户松开滑块、提交到某个特定值时,才会触发 change 事件。
对于未定义 input
激活行为,但这些事件对其适用,并且其用户界面涉及显式提交操作、
但不涉及中间操作的 input
元素,每当用户提交对元素值的更改时,用户代理必须给定该
input 元素,
在用户交互任务源上排入一个元素任务,
首先在该 input
元素上触发一个
名为 input
的事件,并将 bubbles
和 composed
属性初始化为 true,然后在该 input 元素上触发一个名为
change
的事件,并将 bubbles
属性初始化为 true。
具有提交操作的用户界面示例,是一个由单个按钮组成的颜色控件,该按钮会打开一个色轮: 如果值仅在对话框关闭时 更改,那么关闭对话框就是显式提交操作。另一方面,如果操作控件会以交互方式更改颜色, 那么可能不存在提交操作。
另一个具有提交操作的用户界面示例,是一个日期控件, 它既允许基于文本的用户输入,也允许用户从下拉日历中进行选择:文本输入可能没有显式提交步骤, 而从下拉日历中选择日期后再关闭下拉日历,则属于提交操作。
对于未定义 input
激活行为,但这些事件对其适用的
input
元素,每当用户在没有显式提交操作的情况下使元素的值发生变化时,用户代理必须给定该 input 元素,
在用户交互任务
源上排入一个元素任务,以在该
input
元素上触发一个名为 input
的事件,并将 bubbles
和 composed
属性初始化为 true。相应的 change
事件(如果有)
将在控件失去焦点时触发。
用户更改元素值的示例包括:用户在文本控件中键入内容、 将新值粘贴到控件中,或者撤销在该控件中的编辑。某些用户交互不会导致值发生变化, 例如在空文本控件中按下“delete”键,或者使用剪贴板中恰好完全相同的文本 替换控件中的某段文本。
用户已经聚焦并使用键盘进行交互的滑块形式范围控件,是用户在没有提交步骤的情况下 更改元素值的另一个示例。
对于仅触发 input
事件的任务,用户代理可以等待
用户交互中的适当间歇,然后再排入任务;例如,用户代理可以等待用户
100 毫秒未按下任何键,从而仅在用户暂停时触发事件,而不是为每次按键持续触发事件。
当用户代理要代表用户更改 input 元素的值时
(例如,作为表单预填充功能的一部分),用户代理必须给定该 input 元素,
在用户交互
任务源上排入一个元素任务,首先相应地更新值,然后在该 input
元素上触发一个名为
input
的事件,并将 bubbles
和 composed
属性初始化为 true,然后在该 input
元素上触发一个名为
change
的事件,并将 bubbles
属性初始化为 true。
脚本更改表单控件的值时,不会触发这些事件。(这样可以更容易地 响应用户对控件的操作来更新表单控件的值,而不必随后过滤掉脚本自身所作的更改, 以避免无限循环。)
当浏览器在导航期间恢复状态的过程中更改 表单控件的值时,也不会触发这些事件。
button
元素所有当前引擎均支持。
所有当前引擎均支持。
select 元素的第一个子元素。
tabindex 属性的后代。
如果该元素是 select
元素的第一个子元素,
则它还可以有一个 selectedcontent
后代元素。command —
指示目标元素要执行的操作。
commandfor —
将另一个元素作为要调用的目标。
disabled —
表单控件是否已禁用
form —
将该元素与一个 form 元素关联
formaction —
用于表单提交的 URL
formenctype —
用于表单提交的条目列表编码类型
formmethod —
用于表单提交的变体
formnovalidate
— 为表单
提交绕过表单控件验证
formtarget —
用于表单提交的可导航对象
name —
用于表单提交以及 form.elements API 中的元素名称
popovertarget —
将要切换、显示或隐藏的弹出框元素作为目标
popovertargetaction
— 指示目标弹出框元素是要切换、显示还是隐藏
type — 按钮类型
value —
用于表单提交的值
formaction。
[Exposed =Window ]
interface HTMLButtonElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , ReflectSetter ] attribute DOMString command ;
[CEReactions , Reflect ] attribute Element ? commandForElement ;
[CEReactions , Reflect ] attribute boolean disabled ;
readonly attribute HTMLFormElement ? form ;
[CEReactions , ReflectSetter ] attribute USVString formAction ;
[CEReactions ] attribute DOMString formEnctype ;
[CEReactions ] attribute DOMString formMethod ;
[CEReactions , Reflect ] attribute boolean formNoValidate ;
[CEReactions , Reflect ] attribute DOMString formTarget ;
[CEReactions , Reflect ] attribute DOMString name ;
[CEReactions , ReflectSetter ] attribute DOMString type ;
[CEReactions , Reflect ] attribute DOMString value ;
readonly attribute boolean willValidate ;
readonly attribute ValidityState validity ;
readonly attribute DOMString validationMessage ;
boolean checkValidity ();
boolean reportValidity ();
undefined setCustomValidity (DOMString error );
readonly attribute NodeList labels ;
};
HTMLButtonElement includes PopoverTargetAttributes ;该元素是一个按钮。
type 属性
控制按钮被激活时的行为。它是一个枚举
属性,具有以下关键字和状态:
| 关键字 | 状态 | 简要说明 |
|---|---|---|
submit
|
提交按钮 | 提交表单。 |
reset
|
重置按钮 | 重置表单。 |
button
|
按钮 | 不执行任何操作。 |
约束验证:如果该元素不是提交按钮,则该元素被阻止参与 约束 验证。
如果 button 元素
是 select 元素中
第一个属于元素的子节点,则它是惰性的。
如果指定了 commandfor 属性,则其值必须是与具有 commandfor
属性的按钮位于同一树中的某个元素的ID。
command
属性是一个枚举
属性,具有以下关键字和状态:
| 关键字 | 状态 | 简要说明 |
|---|---|---|
toggle-popover
|
切换弹出框 | 显示或隐藏目标 popover 元素。
|
show-popover
|
显示弹出框 | 显示目标 popover
元素。
|
hide-popover
|
隐藏弹出框 | 隐藏目标 popover
元素。
|
close
|
关闭 | 关闭目标 dialog 元素。
|
request-close
|
请求关闭 | 请求关闭目标 dialog
元素。
|
show-modal
|
显示模态框 | 将目标 dialog 元素
作为模态框打开。
|
| 一个自定义命令 关键字 | 自定义 | 仅在目标元素上分派 command
事件。
|
自定义命令关键字是一个以“--”开头的字符串。
给定一个 command 属性
command 和一个元素 target,要确定命令对目标是否有效:
如果 command 处于未知状态,则返回 false。
如果 command 处于自定义状态,则返回 true。
如果 target 不是 HTML 元素,则返回 false。
如果 command 处于以下任一状态:
则返回 true。
如果本标准未针对 target 的本地 名称定义是否为有效命令的步骤,则返回 false。
否则,返回给定 command 运行 target 相应的是否为有效 命令的步骤所得的结果。
给定 event,button 元素
element 的激活行为为:
如果 element 已禁用,则返回。
如果 element 具有表单所有者:
令 target 为运行 element 的获取与 commandfor 关联的
元素所得的结果。
如果 target 不为 null:
令 command 为 element 的 command
属性。
如果给定 command 和 target,确定命令对目标是否 有效所得的结果为 false,则返回。
令 continue 为在 target 上使用
CommandEvent触发一个
名为 command
的事件所得的结果,
将其 command
属性初始化为 command,将其 source
属性初始化为 element,并将其 cancelable
属性初始化为 true。
DOM 标准议题 #1328跟踪如何以对事件合理的方式更好地标准化关联事件数据。目前, 初始化为某个值的事件属性不能同时具有获取器,因此需要一个内部槽 (或附加字段映射)才能正确规定这一点。
如果 continue 为 false,则返回。
如果 target 未连接,则返回。
如果 command 处于自定义状态,则返回。
如果 command 处于隐藏弹出框状态:
否则,如果 command 处于切换弹出框状态:
否则,如果 command 处于显示弹出框状态:
否则,如果本标准针对 target 的本地 名称定义了命令步骤,则给定 target、element 和 command,运行相应的命令步骤。
否则,给定 element 和 event 的目标, 运行弹出框目标属性激活 行为。
可以针对一个 HTML 元素的本地名称定义特定的 是否为有效命令的步骤和 命令步骤。
form 属性用于将
button 元素
与其表单所有者显式关联。name 属性表示元素的名称。
disabled 属性
用于使控件不可交互,并防止提交其值。formaction、
formenctype、formmethod、formnovalidate 和
formtarget 属性
是用于表单
提交的属性。
formnovalidate
属性可用于创建不触发约束验证的提交按钮。
如果该元素不是提交按钮,则不得指定 formaction、formenctype、formmethod、formnovalidate 和
formtarget。
command 的获取器步骤为:
只有当按钮本身用于发起表单提交时,按钮(及其值)才会包含在表单提交中。
type
的获取器步骤为:
willValidate、
validity 和 validationMessage
IDL 属性,以及 checkValidity()、reportValidity()
和 setCustomValidity()
方法,均属于约束验证
API。labels IDL
属性提供元素的 label 列表。disabled、form 和 name IDL 属性属于
该元素的表单 API。
以下按钮的标签为“Show hint”,激活时会弹出一个对话框:
< button type = button
onclick = "alert('This 15-20 minute piece was composed by George Gershwin.')" >
Show hint
</ button > 以下示例展示了按钮如何使用 commandfor,
在激活时显示和隐藏具有 popover 属性的元素:
< button type = button
commandfor = "the-popover"
command = "show-popover" >
Show menu
</ button >
< div popover
id = "the-popover" >
< button commandfor = "the-popover"
command = "hide-popover" >
Hide menu
</ button >
</ div >
以下示例展示了按钮如何在元素上将 commandfor
与自定义命令
关键字结合使用,演示如何使用自定义命令实现未规定的行为:
< button type = button
commandfor = "the-image"
command = "--rotate-landscape" >
Rotate Left
</ button >
< button type = button
commandfor = "the-image"
command = "--rotate-portrait" >
Rotate Right
</ button >
< img id = "the-image"
src = "photo.jpg" >
< script >
const image = document. getElementById( "the-image" );
image. addEventListener( "command" , ( event) => {
if ( event. command == "--rotate-landscape" ) {
event. target. style. rotate = "-90deg"
} else if ( event. command == "--rotate-portrait" ) {
event. target. style. rotate = "0deg"
}
});
</ script >
select
元素所有当前引擎均支持。
所有当前引擎均支持。
select
是下拉
框,则为零个或一个 button
元素,
后跟零个或多个 option 元素、optgroup
元素、hr 元素、脚本支持
元素、noscript
元素或 div 元素。
autocomplete —
表单自动填充功能的提示
disabled —
表单控件是否已禁用
form —
将该元素与一个 form 元素关联
multiple —
是否允许多个值
name —
用于表单提交以及 form.elements API 中的元素名称
required —
控件对于表单
提交是否为必需
size — 控件的大小
multiple
属性,
或具有值 > 1 的 size 属性:
对于作者;对于实现者。
[Exposed =Window ]
interface HTMLSelectElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , ReflectSetter ] attribute DOMString autocomplete ;
[CEReactions , Reflect ] attribute boolean disabled ;
readonly attribute HTMLFormElement ? form ;
[CEReactions , Reflect ] attribute boolean multiple ;
[CEReactions , Reflect ] attribute DOMString name ;
[CEReactions , Reflect ] attribute boolean required ;
[CEReactions , Reflect , ReflectDefault=0] attribute unsigned long size ;
readonly attribute DOMString type ;
[SameObject ] readonly attribute HTMLOptionsCollection options ;
[CEReactions ] attribute unsigned long length ;
getter HTMLOptionElement ? item (unsigned long index );
HTMLOptionElement ? namedItem (DOMString name );
[CEReactions ] undefined add ((HTMLOptionElement or HTMLOptGroupElement ) element , optional (HTMLElement or long )? before = null );
[CEReactions ] undefined remove (); // ChildNode overload
[CEReactions ] undefined remove (long index );
[CEReactions ] setter undefined (unsigned long index , HTMLOptionElement ? option );
[SameObject ] readonly attribute HTMLCollection selectedOptions ;
attribute long selectedIndex ;
attribute DOMString value ;
readonly attribute boolean willValidate ;
readonly attribute ValidityState validity ;
readonly attribute DOMString validationMessage ;
boolean checkValidity ();
boolean reportValidity ();
undefined setCustomValidity (DOMString error );
undefined showPicker ();
readonly attribute NodeList labels ;
};select 元素
表示一个用于从一组选项中进行选择的控件。
所有当前引擎均支持。
multiple
属性是一个布尔属性。如果存在该属性,则
select 元素表示一个用于从选项
列表中选择零个或多个选项的控件。如果不存在该属性,则 select
元素表示一个用于从选项列表中选择单个选项的控件。
所有当前引擎均支持。
size 属性
给出要向用户显示的选项数量。如果指定了 size
属性,则其值必须是大于零的有效非负整数。
所有当前引擎均支持。
required
属性是一个布尔属性。指定该属性时,
用户必须在提交表单之前选择一个值。
form 属性用于将
select 元素
与其表单所有者显式关联。name 属性表示元素的名称。
disabled 属性
用于使控件不可交互,并防止提交其值。autocomplete 属性
控制用户代理如何提供自动填充行为。
如果 select 元素
指定了 required
属性,并且显示
大小为 1;并且该 select
元素的选项列表中第一个 option 元素
(如果有)的值为空字符串,并且该 option 元素的父节点
是该 select 元素
(而不是 optgroup 元素),
则该 option
是该 select 元素的
占位符标签选项。
实际上,仅当 select 元素
没有值大于 1 的 size 属性时,
上一段所述的要求才可能适用。
约束验证:如果元素指定了 required 属性,
并且该 select 元素的选项列表中没有任何 option 元素的选中性设置为 true,或者该
select 元素的选项列表中唯一将选中性设置为 true 的
option 元素
是占位符标签
选项,则该元素存在缺失。
用户代理应该允许用户通过给定 select 元素、
option 元素,
以及在select 的
内容正使用基础外观渲染时相应的 keydown
或 mouseup
事件(否则为 null),运行选取
选项算法,使用户从 select 元素的选项
列表中选取一个 option
元素
(可以通过单击、更改元素值后使其失去焦点、通过菜单命令或任何其他机制)。
给定一个 select 元素
select、一个 option 元素
option,以及一个 Event
或 null event,要选取一个选项:
如果 event 不为 null,并且设置了 event 的已取消标志,则返回。
如果 event 是 MouseEvent,
并且 event 的 button
属性不为 1,则返回。
将 option 的选中性设置为 true。
将 option 的脏状态设置为 true。
给定 select,发送
select 更新通知。
如果 select 正以具有基础 外观的下拉框形式渲染,则给定 select 的select 弹出框,运行隐藏弹出框算法。
如果不存在 multiple
属性,则每当该 select 元素的选项列表中的一个 option 元素的选中性设置为
true,以及每当一个将选中性设置为 true 的 option 元素
被添加到该 select 元素的选项列表中时,用户代理都必须将其选项
列表中所有其他 option
元素的选中性设置为 false。
如果不存在 multiple
属性,
并且元素的显示大小大于 1,则用户代理还应该允许用户请求
取消选中将选中性设置为 true
的 option
(如果有)。当用户代理收到该请求时,在排入相关用户交互事件之前(例如,在 click
事件之前),用户代理必须将该 option
元素的选中性设置为
false,将其脏状态设置为
true,然后发送
select 更新通知。
如果 select
正以具有基础
外观的下拉框形式渲染,则用户代理应该允许用户在给定相应的
select
元素 select 和相应的 mousedown
或 keydown
事件 event 时打开选择器:
如果设置了 event 的已取消标志,则返回。
如果 event 的 button
属性不为 1,则返回。
给定 select 的select 弹出框、false 和 select,运行显示弹出框算法。
实现通常允许用户使用向上和向下箭头键聚焦下一个或上一个选项, 使用 Home 或 End 键聚焦第一个或最后一个选项,或者使用 PageUp 或 PageDown 键 聚焦选择器视口中的第一个或最后一个选项。
具体哪些键盘按键会导致这些操作,可能因实现和平台而异。 ARIA 创作实践指南对此行为提供了很好的建议。
如果存在 multiple
属性,并且该
元素未被禁用,则
用户代理应
允许用户切换其选项列表中本身未被禁用的 option 元素的选中状态。当这样的元素被切换时(无论是通过点击、
通过菜单命令,还是通过任何其他机制),
并且在相关用户
交互事件排入队列之前(例如,在相关的 click
事件之前),option 元素的选中状态必须
更改(从 true 更改为 false,或从 false 更改为 true),该元素的脏度必须设置为 true,并且
用户代理必须发送
select 更新通知。
select 元素的
显示大小,是在元素具有 size 属性并且
成功解析时,将解析非负整数的规则应用于
该属性值所得的结果。如果将这些规则应用于该属性值未成功,或者不存在 size 属性,
则当元素存在 multiple
内容属性时,元素的显示大小为 4,否则为 1。
给定一个 select 元素
select,要获取选项列表:
给定一个 select 元素
element,选中性设置算法是运行以下步骤:
要为 select 元素
element 发送 select 更新通知,给定
element,在用户交互任务
源上排入一个元素任务,以运行以下步骤:
给定 element,运行更新 select 的
selectedcontent。
给定 element,运行将选中的 option 克隆到
select 按钮中。
在 element 上触发一个名为 input
的事件,并将 bubbles
和 composed
属性初始化为 true。
select.type
所有当前引擎均支持。
如果元素具有 multiple 属性,
则返回“select-multiple”,否则返回“select-one”。
select.options
所有当前引擎均支持。
返回选项
列表的一个 HTMLOptionsCollection。
select.length [ = value ]
返回选项 列表中的元素数量。
element = select.item(index)
所有当前引擎均支持。
select[index]element = select.namedItem(name)
所有当前引擎均支持。
从选项列表中返回第一个 ID 或 name 为
name 的项。
如果找不到具有该 ID 的元素,则返回 null。
select.add(element [, before ])
所有当前引擎均支持。
在 before 给出的节点之前插入 element。
before 参数可以是一个数字,在这种情况下,会在具有该编号的项之前插入 element;也可以是选项列表中的一个元素, 在这种情况下,会在该元素之前插入 element。
如果省略 before、其为 null,或者其为超出范围的数字,则会将 element 添加到列表末尾。
如果 element 是要插入其中的元素的祖先,则此方法将抛出
“HierarchyRequestError”
DOMException。
select.selectedOptions
HTMLSelectElement/selectedOptions
所有当前引擎均支持。
返回一个 HTMLCollection,
其中包含选项
列表中已选中的选项。
select.selectedIndex [ = value ]
HTMLSelectElement/selectedIndex
所有当前引擎均支持。
返回第一个选中项的索引(如果有);如果没有选中项,则返回 −1。
可以设置,以更改选择。
select.value [ = value ]
返回第一个选中项的值(如果有); 如果没有选中项,则返回空字符串。
可以设置,以更改选择。
select.showPicker()
显示适用于 select 的任何选择器 UI,以便用户选择一个值。
如果 select 不是可变的,则抛出
“InvalidStateError” DOMException。
如果在没有瞬态用户
激活的情况下调用,则抛出
“NotAllowedError” DOMException。
如果 select 位于跨源 iframe 内,
则抛出 “SecurityError” DOMException。
如果 select 未正在渲染,则抛出
“NotSupportedError” DOMException。
type IDL
属性在获取时,
如果不存在 multiple
属性,
则必须返回字符串“select-one”;如果存在 multiple
属性,则必须返回字符串“select-multiple”。
options IDL 属性必须返回一个
以 select
节点为根的 HTMLOptionsCollection,
其筛选器匹配选项列表中的元素。
options
集合也镜像到 HTMLSelectElement
对象上。
任意时刻的受支持属性索引,是该时刻由 options 属性
返回的对象所支持的索引。
当用户代理要为 select 元素设置新索引
属性的值或设置现有索引
属性的值时,它必须改为在该 select 元素的 options 集合上运行相应的算法。
同样,add(element, before) 方法
必须与同一个 options
集合上的同名方法行为相同。
所有当前引擎均支持。
remove()
方法在有参数时,必须与同一个 options 集合上的
同名方法行为相同;在没有参数时,必须与 HTMLSelectElement
的祖先接口 Element
所实现的 ChildNode
接口上的同名方法行为相同。
selectedOptions IDL 属性必须返回一个
以 select
节点为根的 HTMLCollection,
其筛选器匹配选项
列表中选中性设置为
true 的元素。
select 元素的
选中索引,是其选项列表中按树顺序排列的第一个将选中性设置为 true 的 option 元素的索引。
如果不存在这样的元素,则为 −1。
要将 select 元素
select 的选中索引设置为值 value:
令 firstMatchingOption 为 null。
对于 select 的选项列表中的每个 option:
如果 firstMatchingOption 不为 null,则将 firstMatchingOption 的选中性设置为 true,并将 firstMatchingOption 的脏状态设置为 true。
给定 select,运行更新 select 的
selectedcontent。
这可能导致没有任何元素的选中性设置为 true,
即使 select
元素没有 multiple
属性,并且显示大小为 1。
selectedIndex
的设置器步骤是将 this 的选中索引设置为给定值。
value 的设置器步骤为:
这可能导致没有任何元素的选中性设置为 true,
即使 select
元素没有 multiple
属性,并且显示大小为 1。
由于历史原因,size IDL
属性的默认值
不会返回实际使用的大小;在不存在 size
内容属性时,该大小根据是否存在 multiple
属性而为 1 或 4。
willValidate、
validity 和 validationMessage
IDL 属性,以及 checkValidity()、reportValidity()
和 setCustomValidity()
方法,均属于约束验证
API。labels IDL
属性提供元素的 label 列表。disabled、form 和 name IDL 属性属于
该元素的表单 API。
以下示例展示了如何使用 select
元素
向用户提供一组选项,用户可以从中选择一个选项。默认选项已预先选中。
< p >
< label for = "unittype" > Select unit type:</ label >
< select id = "unittype" name = "unittype" >
< option value = "1" > Miner </ option >
< option value = "2" > Puffer </ option >
< option value = "3" selected > Snipey </ option >
< option value = "4" > Max </ option >
< option value = "5" > Firebot </ option >
</ select >
</ p > 没有默认选项时,可以改用占位符:
< select name = "unittype" required >
< option value = "" > Select unit type </ option >
< option value = "1" > Miner </ option >
< option value = "2" > Puffer </ option >
< option value = "3" > Snipey </ option >
< option value = "4" > Max </ option >
< option value = "5" > Firebot </ option >
</ select > 这里向用户提供一组选项,用户可以从中选择任意数量的选项。默认情况下, 所有五个选项都已选中。
< p >
< label for = "allowedunits" > Select unit types to enable on this map:</ label >
< select id = "allowedunits" name = "allowedunits" multiple >
< option value = "1" selected > Miner </ option >
< option value = "2" selected > Puffer </ option >
< option value = "3" selected > Snipey </ option >
< option value = "4" selected > Max </ option >
< option value = "5" selected > Firebot </ option >
</ select >
</ p > 有时,用户必须选择一个或多个项目。此示例展示了这样的界面。
< label >
Select the songs from that you would like on your Act II Mix Tape:
< select multiple required name = "act2" >
< option value = "s1" > It Sucks to Be Me (Reprise)
< option value = "s2" > There is Life Outside Your Apartment
< option value = "s3" > The More You Ruv Someone
< option value = "s4" > Schadenfreude
< option value = "s5" > I Wish I Could Go Back to College
< option value = "s6" > The Money Song
< option value = "s7" > School for Monsters
< option value = "s8" > The Money Song (Reprise)
< option value = "s9" > There's a Fine, Fine Line (Reprise)
< option value = "s10" > What Do You Do With a B.A. in English? (Reprise)
< option value = "s11" > For Now
</ select >
</ label > 有时,使用分隔符会很有用:
< label >
Select the song to play next:
< select required name = "next" >
< option value = "sr" > Random
< hr >
< option value = "s1" > It Sucks to Be Me (Reprise)
< option value = "s2" > There is Life Outside Your Apartment
…以下示例使用了 div、legend、
img、button 和 selectedcontent
元素:
< select >
< button >
< selectedcontent ></ selectedcontent >
</ button >
< div class = "border" >
< optgroup >
< legend > WHATWG Specifications</ legend >
< option >
< img src = "html.jpg" alt = "" >
HTML
</ option >
< option >
< img src = "dom.jpg" alt = "" >
DOM
</ option >
</ optgroup >
</ div >
< div class = "border" >
< optgroup >
< legend > W3C Specifications</ legend >
< option >
< img src = "forms.jpg" alt = "" >
CSS Form Control Styling
</ option >
< option >
< img src = "pseudo.jpg" alt = "" >
CSS Pseudo-Elements
</ option >
</ optgroup >
</ div >
</ select > datalist 元素
所有当前引擎均支持。
option
元素和脚本支持元素。[Exposed =Window ]
interface HTMLDataListElement : HTMLElement {
[HTMLConstructor ] constructor ();
[SameObject ] readonly attribute HTMLCollection options ;
};datalist
元素表示一组 option 元素,这些元素
表示其他控件的预定义选项。在渲染中,datalist
元素不表示任何内容,并且该元素及其
子元素都应该被隐藏。
datalist
元素可以通过两种方式使用。在最简单的情况下,
datalist 元素
只有 option
元素子节点。
< label >
Animal:
< input name = animal list = animals >
< datalist id = animals >
< option value = "Cat" >
< option value = "Dog" >
</ datalist >
</ label > 在更复杂的情况下,可以向 datalist 元素
提供要向不支持 datalist
的旧版
客户端显示的内容。在这种情况下,
option 元素
被放置在 select
元素内,而该元素又位于
datalist 元素内。
< label >
Animal:
< input name = animal list = animals >
</ label >
< datalist id = animals >
< label >
or select from the list:
< select name = animal >
< option value = "" >
< option > Cat
< option > Dog
</ select >
</ label >
</ datalist > datalist
元素通过 input 元素上的 list 属性与该 input 元素关联。
作为 datalist
元素后代、未被禁用,并且其值为非空字符串的每个 option 元素,
表示一个建议。每个建议都有一个值和一个标签。
datalist.options返回一个 HTMLCollection,
其中包含
datalist
元素的 option
元素。
options IDL 属性必须返回一个
以 datalist 节点
为根的 HTMLCollection,
其筛选器匹配
option 元素。
optgroup 元素
所有当前引擎均支持。
所有当前引擎均支持。
select 元素的后代。
legend
元素,后跟零个或多个 option
元素、脚本支持元素、noscript 元素或
div 元素。
optgroup
元素后紧跟另一个 optgroup
元素、后紧跟一个
hr 元素,或者父
元素中不再有其他内容,则可以省略该 optgroup
元素的结束标签。
disabled —
表单控件是否已禁用
label —
用户可见的标签
[Exposed =Window ]
interface HTMLOptGroupElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect ] attribute boolean disabled ;
[CEReactions , Reflect ] attribute DOMString label ;
};optgroup
元素表示一组具有共同标签的option 元素组。
在 select
元素中显示 option
元素时,用户代理应该将此类组中的 option
元素显示为彼此相关,并与其他 option
元素分隔开来。
所有当前引擎均支持。
disabled
属性是一个布尔
属性,可用于同时禁用一个option 元素组。
如果 optgroup 没有子
legend
元素,则必须指定 label
属性。
给定一个 optgroup
optgroup,要获取 optgroup 元素的标签:
如果 optgroup 具有子 legend 元素,则
返回以下结果:从 optgroup 的第一个子 legend
元素的所有 Text
节点后代按树顺序排列的数据拼接结果中,去除并折叠 ASCII
空白;但排除属于该 legend 后代
的后代,并且自身为 script
或 SVG
script 元素的节点。
否则,返回 optgroup 的 label 属性值。
optgroup 标签
算法的值给出用于用户界面的组名称。用户代理应该在 select 元素中标记
option 元素组时,
使用此属性的值。
无法选择 optgroup 元素。
只能选择 option 元素。optgroup 元素
仅为一组 option 元素提供
标签。
以下片段展示了如何在 select
下拉
控件中提供三个课程的一组课时:
< form action = "courseselector.dll" method = "get" >
< p > Which course would you like to watch today?
< p >< label > Course:
< select name = "c" >
< optgroup label = "8.01 Physics I: Classical Mechanics" >
< option value = "8.01.1" > Lecture 01: Powers of Ten
< option value = "8.01.2" > Lecture 02: 1D Kinematics
< option value = "8.01.3" > Lecture 03: Vectors
< optgroup label = "8.02 Electricity and Magnetism" >
< option value = "8.02.1" > Lecture 01: What holds our world together?
< option value = "8.02.2" > Lecture 02: Electric Field
< option value = "8.02.3" > Lecture 03: Electric Flux
< optgroup label = "8.03 Physics III: Vibrations and Waves" >
< option value = "8.03.1" > Lecture 01: Periodic Phenomenon
< option value = "8.03.2" > Lecture 02: Beats
< option value = "8.03.3" > Lecture 03: Forced Oscillations with Damping
</ select >
</ label >
< p >< input type = submit value = "▶ Play" >
</ form > option
元素所有当前引擎均支持。
所有当前引擎均支持。
select 元素的后代。datalist 元素的后代。
optgroup 元素的后代。
label 属性和 value 属性:无内容。label 属性,但没有
value 属性:文本。
label 属性,并且不是
datalist 元素的后代:
零个或多个 div 元素或
短语内容,但不得存在交互式内容后代、
datalist 元素
后代、object
元素后代,或指定了 tabindex 属性的后代
label 属性,并且是
datalist
元素的后代:文本。
option 元素后
紧跟另一个 option 元素、后紧跟一个
optgroup 元素、
后紧跟一个 hr 元素,或者父元素中不再有
其他内容,则可以省略该 option
元素的结束标签。
disabled —
表单控件是否已禁用
label —
用户可见的标签
selected —
选项默认是否被选中
value —
用于表单提交的值
[Exposed =Window ,
LegacyFactoryFunction =Option (optional DOMString text = "", optional DOMString value , optional boolean defaultSelected = false , optional boolean selected = false )]
interface HTMLOptionElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect ] attribute boolean disabled ;
readonly attribute HTMLFormElement ? form ;
[CEReactions , ReflectSetter ] attribute DOMString label ;
[CEReactions , Reflect="selected"] attribute boolean defaultSelected ;
attribute boolean selected ;
[CEReactions , ReflectSetter ] attribute DOMString value ;
[CEReactions ] attribute DOMString text ;
readonly attribute long index ;
};option 元素表示 select
元素中的一个选项,或 datalist
元素中的
建议列表的一部分。
在 select 元素定义中所述的
某些情况下,option 元素可以是
select 元素的占位符标签
选项。占位符
标签选项不表示实际选项,而是表示 select 控件的标签。
所有当前引擎均支持。
被禁用的 option 元素必须
阻止在用户交互任务源上排入的任何 click
事件在该元素上分派。
被禁用并不会阻止对 option 元素进行所有
修改。例如,可以通过 JavaScript 以编程方式修改其选中性。
或者,可以通过用户操作间接修改它,例如修改同一个 select 元素中的其他
未禁用 option 元素时。
如果指定了 label 内容属性,
则其不得为空。
selected
属性是一个布尔属性。它表示
元素的默认选中性。
option 元素的
脏状态是一个初始为 false 的布尔状态。它控制添加或移除 selected 内容
属性是否会产生效果。
option
元素的 选中性是一个初始为 false 的布尔状态。
除非另有规定,在创建元素时,如果该元素具有 selected 属性,
则必须将其选中性设置为 true。
每当添加 option 元素的
selected 属性
时,如果其脏状态为 false,则必须将其选中性设置为
true。每当移除
option 元素的
selected 属性
时,如果其脏状态为 false,则必须将其
选中性设置为 false。
使用三个或更少参数调用 Option()
构造函数时,即使第三个
参数为 true(这意味着将设置 selected 属性),
它也会覆盖选中性状态的初始状态,使其始终为 false。
使用该构造函数时,可以使用第四个参数显式设置初始选中性状态。
未指定 multiple
属性的 select 元素,
不得有多个设置了 selected
属性的后代 option 元素。
每个 option 元素
都有一个缓存的最近祖先 select
元素,其值为 select
元素或 null,
初始设置为 null。
给定一个 option
option,要更新 option 的
最近祖先 select:
令 oldSelect 为 option 的缓存的最近祖先
select 元素。
令 newSelect 为 option 的option 元素的
最近祖先 select。
如果 oldSelect 不是 newSelect:
将 option 的缓存的最近祖先 select
元素设置为 newSelect。
给定 insertedOption,option 的HTML 元素插入
步骤,是给定 insertedOption 运行更新 option 的最近祖先
select。
给定 removedNode、isSubtreeRoot 和 oldAncestor,option 的HTML 元素移除
步骤,是给定 removedNode 运行
更新 option 的最近祖先
select。
给定 movedNode、isSubtreeRoot 和 oldAncestor,option 的HTML 元素移动
步骤,是给定 movedNode 运行更新
option 的最近祖先 select。
给定一个 option
option,要可能将 option 克隆到
selectedcontent 中:
令 select 为 option 的option 元素的最近
祖先 select。
如果以下所有条件均为 true:
select 不为 null;
option 的选中性为 true;并且
select 的已启用
selectedcontent不为 null,
则给定 option 和 select 的已启用
selectedcontent,运行将 option 克隆到
selectedcontent 中。
给定一个 select 元素
select,要将选中的 option 克隆到
select 按钮中:
令 text 为空字符串。
如果 option 不为 null,则将 text 设置为 option 的标签。
将 select 的select 后备按钮文本设置为 text。
option.selected如果元素已选中,则返回 true;否则返回 false。
可以设置,以覆盖元素的当前状态。
option.indexoption.form返回元素的 form 元素(如果有);
否则返回 null。
option.text与 textContent
相同,但空格会被折叠,并且会跳过 script
元素。
option = new Option([ text [, value [, defaultSelected [, selected ] ] ] ])
所有当前引擎均支持。
返回一个新的 option 元素。
text 参数设置元素的内容。
value 参数设置 value
属性。
defaultSelected 参数设置 selected 属性。
selected 参数设置元素是否被选中。如果省略该参数,则即使 defaultSelected 参数为 true,元素也不会被选中。
selected IDL 属性在获取时,如果
元素的选中性为
true,则必须返回 true;
否则返回 false。设置时,它必须将元素的选中性设置为新值,将其脏状态设置为 true,然后使元素请求重置。
index
IDL 属性必须返回元素的索引。
form
的获取器步骤为:
令 select 为 this 的option 元素的最近
祖先 select。
如果 select 为 null,则返回 null。
返回 select 的表单所有者。
提供了一个用于创建 HTMLOptionElement 对象的
旧式工厂函数(除 DOM 中诸如 createElement()
之类的工厂方法外):
Option(text, value,
defaultSelected, selected)。调用时,该旧式工厂
函数必须执行以下步骤:
给定一个 option 元素
option 和布尔值 includeAltText,要收集选项文本:
令 text 为空字符串。
返回给定 text,去除并折叠 ASCII 空白所得的结果。
当 option 元素上未设置
value
属性时,会使用其文本内容生成可提交的值。如果 option 元素具有子
元素,则可能产生意外结果,例如不同渲染方式的 option 元素具有
相同的值。为解决此问题,建议在 option
元素上设置
value 属性。
textarea 元素
所有当前引擎均支持。
所有当前引擎均支持。
autocomplete —
表单自动填充功能的提示
cols —
每行的最大字符数
dirname —
用于在表单提交中发送元素方向性的表单控件名称
disabled —
表单控件是否已禁用
form —
将该元素与一个 form
元素关联
maxlength
— 值的最大长度
minlength
— 值的最小长度
name —
用于表单提交以及
form.elements API
中的元素名称
placeholder
— 要放置在表单控件内的用户可见标签
readonly —
是否允许用户编辑值
required —
控件对于表单提交是否为必需
rows —
要显示的行数
wrap —
如何为表单提交换行表单控件的值
[Exposed =Window ]
interface HTMLTextAreaElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , ReflectSetter ] attribute DOMString autocomplete ;
[CEReactions , ReflectPositiveWithFallback , ReflectDefault=20] attribute unsigned long cols ;
[CEReactions , Reflect ] attribute DOMString dirName ;
[CEReactions , Reflect ] attribute boolean disabled ;
readonly attribute HTMLFormElement ? form ;
[CEReactions , ReflectNonNegative ] attribute long maxLength ;
[CEReactions , ReflectNonNegative ] attribute long minLength ;
[CEReactions , Reflect ] attribute DOMString name ;
[CEReactions , Reflect ] attribute DOMString placeholder ;
[CEReactions , Reflect ] attribute boolean readOnly ;
[CEReactions , Reflect ] attribute boolean required ;
[CEReactions , ReflectPositiveWithFallback , ReflectDefault=2] attribute unsigned long rows ;
[CEReactions , Reflect ] attribute DOMString wrap ;
readonly attribute DOMString type ;
[CEReactions ] attribute DOMString defaultValue ;
attribute [LegacyNullToEmptyString ] DOMString value ;
readonly attribute unsigned long textLength ;
readonly attribute boolean willValidate ;
readonly attribute ValidityState validity ;
readonly attribute DOMString validationMessage ;
boolean checkValidity ();
boolean reportValidity ();
undefined setCustomValidity (DOMString error );
readonly attribute NodeList labels ;
undefined select ();
attribute unsigned long selectionStart ;
attribute unsigned long selectionEnd ;
attribute DOMString selectionDirection ;
undefined setRangeText (DOMString replacement );
undefined setRangeText (DOMString replacement , unsigned long start , unsigned long end , optional SelectionMode selectionMode = "preserve");
undefined setSelectionRange (unsigned long start , unsigned long end , optional DOMString direction );
};textarea
元素表示一个用于编辑元素原始值的多行纯文本控件。控件的内容表示该控件的默认值。
此元素具有涉及双向算法的渲染要求。
readonly
属性是一个布尔
属性,用于控制用户是否可以编辑文本。
在此示例中,文本控件被标记为只读,因为它表示一个只读文件:
Filename: < code > /etc/bash.bashrc</ code >
< textarea name = "buffer" readonly >
# System-wide .bashrc file for interactive bash(1) shells.
# To enable the settings / commands in this file for login shells as well,
# this file has to be sourced in /etc/profile.
# If not running interactively, don't do anything
[ -z "$PS1" ] && return
...</ textarea > 当 textarea
是可变的时,其原始值应该可由用户编辑:用户
代理应该允许用户编辑、插入和移除文本,并以 U+000A LINE FEED (LF) 字符的形式插入和移除换行符。
每当用户使元素的原始值发生更改时,用户代理必须给定
textarea 元素,
在用户交互任务源上排入一个
元素任务,以在 textarea
元素上触发一个名为
input
的事件,并将 bubbles
和 composed
属性初始化为 true。用户代理可以等待用户交互中的适当间歇,然后再排入任务;例如,用户代理可以等待
用户 100 毫秒未按下任何键,从而仅在用户暂停时触发事件,而不是为每次按键持续触发事件。
如果元素是可变的,则用户代理应该允许 用户更改元素的书写方向,将其设置为从左到右的书写方向或从右到左的书写方向。如果用户这样做, 用户代理随后必须运行以下步骤:
cols
属性指定每行预期的最大字符数。如果指定了 cols 属性,
则其值必须是大于零的有效
非负整数。如果将解析
非负整数的规则应用于该属性值所得的结果是大于零的数字,则元素的字符宽度为该值;否则为 20。
用户代理可以使用 textarea 元素的
字符宽度,向用户提示服务器偏好的每行
字符数(例如,视觉用户代理可以使控件宽度为相应的字符数)。在视觉渲染中,用户代理应该对用户
输入进行换行,使每行不超过此字符数。
rows
属性指定要显示的行数。如果指定了 rows 属性,
则其值必须是大于零的有效
非负整数。如果将解析
非负整数的规则应用于该属性值所得的结果是大于零的数字,则元素的字符高度为该值;否则为 2。
视觉用户代理应该将控件的高度设置为字符高度给出的行数。
wrap
属性是一个枚举
属性,具有以下关键字和状态:
| 关键字 | 状态 | 简要说明 |
|---|---|---|
soft
|
软 | 提交文本时不进行换行(但渲染时仍可换行)。 |
hard
|
硬 | 用户代理要向文本添加换行符,使文本在提交时换行。 |
如果元素的 wrap
属性处于硬状态,则必须指定
cols 属性。
由于历史原因,元素的值会为三种不同的用途以三种不同的方式进行规范化。原始值是最初设置的值。它不会被规范化。
API
值是 value IDL
属性、textLength IDL
属性以及 maxlength 和 minlength 内容属性中使用的值。
它会被规范化,使换行符使用 U+000A LINE FEED (LF) 字符。最后,还有本标准中的表单提交和其他处理模型
所使用的值。它会按照API
值的方式进行规范化,并且此外,如元素的 wrap 属性有此要求,
还会插入额外的换行符,以按给定宽度对文本进行换行。
元素的值定义为应用了textarea 换行 转换的元素API 值。textarea 换行 转换是应用于字符串的以下算法:
maxlength
属性是一个表单控件 maxlength 属性。
如果 textarea
元素具有允许的
最大值长度,则元素的子节点必须满足以下条件:元素的后代文本内容在规范化
换行符后的值的长度,小于或等于元素的允许的最大值
长度。
minlength
属性是一个表单控件 minlength 属性。
required
属性是一个布尔
属性。指定该属性时,用户必须在提交表单之前输入一个值。
placeholder 属性表示一个简短的
提示(一个词或短语),用于在控件没有值时帮助用户输入数据。提示可以是示例值或对预期格式的简要说明。
placeholder
属性不应该用作 label 的替代项。
对于较长的提示或其他建议性文本,title 属性更合适。
这些机制非常相似,但存在细微差别:控件的 label 给出的提示
始终显示;placeholder
属性中给出的简短提示会在用户输入值之前显示;而 title
属性中的提示会在用户请求进一步帮助时显示。
当元素的值为空字符串,并且控件未聚焦时,用户代理应该向用户呈现此提示 (例如,将其显示在空白且未聚焦的控件内)。渲染提示时,提示中的所有 U+000D CARRIAGE RETURN U+000A LINE FEED 字符对 (CRLF),以及提示中的所有其他 U+000D CARRIAGE RETURN (CR) 和 U+000A LINE FEED (LF) 字符,都必须被视为换行符。
如果用户代理通常不会在控件聚焦时向用户显示此提示,那么当控件因 autofocus 属性而获得
焦点时,用户代理仍然应该显示该控件的提示,因为在这种情况下,用户在控件获得焦点之前没有机会
查看该控件。
name 属性表示元素的名称。
dirname 属性
控制如何提交元素的方向性。
disabled 属性
用于使控件不可交互,并防止提交其值。
form 属性用于将
textarea
元素与其表单所有者显式关联。
autocomplete
属性控制用户代理如何提供自动填充行为。
textarea.type返回字符串“textarea”。
textarea.value返回元素的当前值。
可以设置,以更改该值。
type
IDL 属性必须返回值“textarea”。
defaultValue 属性的获取器必须返回元素的子文本
内容。
defaultValue
属性的设置器必须使用给定值在此元素内字符串全部替换。
value IDL 属性在获取时必须返回元素的API 值。设置时,它必须执行以下步骤:
willValidate、
validity 和 validationMessage
IDL 属性,以及 checkValidity()、
reportValidity()
和 setCustomValidity()
方法,均属于约束
验证 API。labels IDL
属性提供元素的 label 列表。select()、
selectionStart、
selectionEnd、
selectionDirection、
setRangeText()
和 setSelectionRange()
方法与 IDL 属性公开元素的文本选择。disabled、form 和 name IDL 属性属于
该元素的表单 API。
以下示例展示了如何在表单中使用 textarea
进行不受限制的自由格式文本输入:
< p > If you have any comments, please let us know: < textarea cols = 80 name = comments ></ textarea ></ p > 要为意见指定最大长度,可以使用 maxlength
属性:
< p > If you have any short comments, please let us know: < textarea cols = 80 name = comments maxlength = 200 ></ textarea ></ p > 要提供默认值,可以在元素内包含文本:
< p > If you have any comments, please let us know: < textarea cols = 80 name = comments > You rock!</ textarea ></ p > 还可以提供最小长度。这里,需要由用户填写一封信;提供了一个模板(其长度短于最小长度), 但该模板不足以提交表单:
< textarea required minlength = "500" > Dear Madam Speaker,
Regarding your letter dated ...
...
Yours Sincerely,
...</ textarea > 也可以提供占位符,向用户提示基本格式,而不提供显式模板:
< textarea placeholder = "Dear Francine,
They closed the parks this week, so we won't be able to
meet your there. Should we just have dinner?
Love,
Daddy" ></ textarea > 要让浏览器在提交值的同时提交元素的方向性,可以指定 dirname 属性:
< p > If you have any comments, please let us know (you may use either English or Hebrew for your comments):
< textarea cols = 80 name = comments dirname = comments.dir ></ textarea ></ p > output
元素所有当前引擎均支持。
所有当前引擎均支持。
for — 指定用于计算输出的控件
form — 将该元素
与一个 form 元素关联
name — 在
form.elements API
中使用的元素名称。
[Exposed =Window ]
interface HTMLOutputElement : HTMLElement {
[HTMLConstructor ] constructor ();
[SameObject , PutForwards =value , Reflect="for"] readonly attribute DOMTokenList htmlFor ;
readonly attribute HTMLFormElement ? form ;
[CEReactions , Reflect ] attribute DOMString name ;
readonly attribute DOMString type ;
[CEReactions ] attribute DOMString defaultValue ;
[CEReactions ] attribute DOMString value ;
readonly attribute boolean willValidate ;
readonly attribute ValidityState validity ;
readonly attribute DOMString validationMessage ;
boolean checkValidity ();
boolean reportValidity ();
undefined setCustomValidity (DOMString error );
readonly attribute NodeList labels ;
};output 元素表示应用程序所执行计算的结果,或用户操作的结果。
此元素可以与 samp
元素进行对比,后者适合用于引用此前运行的其他程序的输出。
所有当前引擎均支持。
for 内容
属性允许在计算结果与表示参与该计算或以其他方式影响该计算的值的元素之间建立显式关系。for
属性如有指定,必须包含一个字符串,该字符串由无序的唯一空格分隔标记集合组成,其中没有任何标记与另一标记相同,并且每个标记都必须是同一树中某个元素的 ID 值。
form 属性用于将
output 元素与其
表单所有者显式关联。name 属性表示元素的名称。output
元素与表单关联,以便能够从表单控件的事件处理器中轻松引用它;提交表单时,不会提交该元素本身的值。
该元素具有一个默认值 覆盖(null 或字符串)。其初始值必须为 null。
output.value [ = value ]
返回元素的当前值。
可以设置,以更改该值。
output.defaultValue [ = value ]
返回元素的当前默认值。
可以设置,以更改默认值。
output.type返回字符串“output”。
type
的获取器步骤是返回“output”。
willValidate、
validity 和 validationMessage
IDL 属性,以及 checkValidity()、reportValidity()
和 setCustomValidity()
方法,是约束验证 API
的一部分。labels IDL
属性提供该元素的 label 列表。form 和 name IDL 属性
是该元素表单 API 的一部分。
一个简单计算器可以使用 output
显示其计算结果:
< form onsubmit = "return false" oninput = "o.value = a.valueAsNumber + b.valueAsNumber" >
< input id = a type = number step = any > +
< input id = b type = number step = any > =
< output id = o for = "a b" ></ output >
</ form > 在此示例中,使用一个 output 元素,
随着远程服务器所执行计算的结果陆续到达,对其进行报告:
< output id = "result" ></ output >
< script >
var primeSource = new WebSocket( 'ws://primes.example.net/' );
primeSource. onmessage = function ( event) {
document. getElementById( 'result' ). value = event. data;
}
</ script > progress 元素
所有当前引擎均支持。
所有当前引擎均支持。
progress
元素后代。
value — 元素的当前值
max — 范围的上限
[Exposed =Window ]
interface HTMLProgressElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , ReflectSetter ] attribute double value ;
[CEReactions , ReflectPositive , ReflectDefault=1.0] attribute double max ;
readonly attribute double position ;
readonly attribute NodeList labels ;
};progress
元素表示任务的完成进度。
该进度可以是不确定的,表示任务正在取得进展,但尚不清楚任务完成前还有多少工作要做
(例如,因为任务正在等待远程主机响应);或者,该进度是一个介于零与最大值之间的数字,
表示迄今为止已完成工作的比例。
所有当前引擎均支持。
有两个属性决定该元素所表示的当前任务完成情况。
value
属性指定任务已完成的工作量,而 max 属性指定任务总共需要的工作量。
单位是任意的,未作指定。
要创建确定进度条,请添加一个 value 属性,并将其设为当前进度
(可以是从 0.0 到 1.0 的数字;如果指定了 max 属性,
则可以是从 0 到 max 属性值之间的数字)。
要创建不确定进度条,请移除 value
属性。
建议作者还在元素内部以内联文本形式包含当前值和最大值, 以便使用旧版用户代理的用户也能获得进度信息。
以下是一个显示某项自动化任务进度的 Web 应用程序片段:
< section >
< h2 > 任务进度</ h2 >
< p > 进度:< progress id = p max = 100 >< span > 0</ span > %</ progress ></ p >
< script >
var progressBar = document. getElementById( 'p' );
function updateProgress( newValue) {
progressBar. value = newValue;
progressBar. getElementsByTagName( 'span' )[ 0 ]. textContent = newValue;
}
</ script >
</ section > (此示例中的 updateProgress() 方法会由页面上的其他代码调用,
随着任务推进来更新实际的进度条。)
value 和 max 属性如存在,
其值必须是有效浮点数。value 属性如存在,
其值必须大于或等于零,并且小于或等于 max
属性的值(如果存在),
否则小于或等于 1.0。max 属性如存在,
其值必须大于零。
progress 元素
不适合用于仅仅表示仪表值而非任务进度的事物。例如,使用
progress
表示磁盘空间使用量是不合适的。对于此类用例,应改用 meter 元素。
用户代理要求:如果省略了 value
属性,则该进度条是不确定进度条。否则,它是确定进度条。
如果进度条是确定进度条并且元素具有 max
属性,
用户代理必须按照浮点数值解析规则解析 max 属性的值。
如果解析未产生错误,并且解析所得值大于零,则进度条的最大值为该值。否则,如果元素没有 max 属性,
或者虽有该属性但解析产生错误,或者解析所得值小于或等于零,则进度条的最大值为 1.0。
如果进度条是确定进度条,用户代理必须按照浮点数值解析规则解析 value 属性的值。
如果解析未产生错误并且解析所得值大于零,则进度条的值为该解析值。否则,如果解析 value 属性的值
产生错误或得到小于或等于零的数字,则进度条的值为零。
显示进度条的 UA 要求:向用户表示
progress 元素时,
UA 应指示它是确定进度条还是不确定进度条;在前一种情况下,还应指示当前值
相对于最大值的位置。
progress.position
对于确定进度条(当前值和最大值均已知),返回当前值除以最大值的结果。
对于不确定进度条,返回 −1。
当对应的内容属性不存在时,将 value IDL 属性设置为其自身,
会将进度条从不确定进度条更改为没有任何进度的确定进度条。
labels IDL 属性
提供该元素的
label 列表。
meter
元素所有当前引擎均支持。
所有当前引擎均支持。
meter 元素后代。
value — 元素的当前值
min — 范围的下限
max — 范围的上限
low — 低值范围的上限
high — 高值范围的下限
optimum — 仪表中的最佳值
[Exposed =Window ]
interface HTMLMeterElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , ReflectSetter ] attribute double value ;
[CEReactions , ReflectSetter ] attribute double min ;
[CEReactions , ReflectSetter ] attribute double max ;
[CEReactions , ReflectSetter ] attribute double low ;
[CEReactions , ReflectSetter ] attribute double high ;
[CEReactions , ReflectSetter ] attribute double optimum ;
readonly attribute NodeList labels ;
};meter 元素表示已知范围内的标量测量值或分数值;
例如磁盘使用量、查询结果的相关性,或选择某位候选人的投票人口比例。
这也称为仪表。
meter 元素不应
用于表示进度(如进度条)。
对于该用途,HTML 提供了单独的 progress 元素。
meter
元素也不表示任意范围的标量值——例如,除非存在已知的最大值,否则用它报告重量或高度是错误的。
有六个属性决定该元素所表示仪表的语义。
所有当前引擎均支持。
所有当前引擎均支持。
min 属性
指定范围的下限,而 max
属性指定上限。value 属性
指定仪表要指示为“测量”值的值。
其他三个属性可用于将仪表的范围划分为“低”“中”和“高”部分,
并指示仪表的哪个部分是“最佳”部分。low
属性指定被视为“低”部分的范围,
而 high
属性指定被视为“高”部分的范围。
optimum
属性给出“最佳”位置;
如果该位置高于“高”值,则表示值越高越好;
如果它低于“低”标记,则表示值越低越好;自然地,如果它位于两者之间,
则表示过高或过低的值都不好。
创作要求:必须指定 value 属性。value、min、low、high、max 和 optimum 属性
如存在,其值必须是有效浮点数。
此外,这些属性的值还受到进一步约束:
令 value 为 value
属性的数字。
如果指定了 min 属性,
则令 minimum 为该属性的值;否则,令其为 0。
如果指定了 max 属性,
则令 maximum 为该属性的值;否则,令其为 1.0。
以下不等式必须在适用时成立:
如果未指定最小值或最大值,则假定范围为 0..1, 因而该值必须位于此范围内。
建议作者在元素内容中包含仪表状态的文本表示,
以供所用用户代理不支持 meter
元素的用户使用。
与微数据结合使用时,meter 元素的 value 属性提供该元素的机器可读值。
以下示例展示了三个均会显示为四分之三满的仪表:
存储空间使用量:< meter value = 6 max = 8 > 已使用 6 个区块(共 8 个)</ meter > 投票率:< meter value = 0.75 >< img alt = "75%" src = "graph75.png" ></ meter > 已售门票:< meter min = "0" max = "100" value = "75" ></ meter > 以下示例错误地使用了该元素,因为它没有给出范围 (并且由于默认最大值为 1,两个仪表最终都会看起来已达到最大值):
< p > 葡萄柚派的半径为 < meter value = 12 > 12cm</ meter >
高度为 < meter value = 2 > 2cm</ meter > 。</ p > <!-- 错误! --> 相反,可以不包含 meter 元素,或者使用具有已定义范围的 meter 元素, 以便在与其他派进行比较的上下文中给出尺寸:
< p > 葡萄柚派的半径为 12cm,高度为
2cm。</ p >
< dl >
< dt > 半径:< dd > < meter min = 0 max = 20 value = 12 > 12cm</ meter >
< dt > 高度:< dd > < meter min = 0 max = 10 value = 2 > 2cm</ meter >
</ dl > meter 元素
没有显式指定单位的方法,但可以在 title 属性中以自由格式文本指定单位。
可以扩展上面的示例来说明单位:
< dl >
< dt > 半径:< dd > < meter min = 0 max = 20 value = 12 title = "厘米" > 12cm</ meter >
< dt > 高度:< dd > < meter min = 0 max = 10 value = 2 title = "厘米" > 2cm</ meter >
</ dl > 用户代理要求:用户代理必须使用浮点数值解析规则解析 min、max、value、low、high 和 optimum
属性。
然后,用户代理必须使用所有这些数字,按如下方式获得仪表上六个点的值。 (这些值的求值顺序很重要,因为某些值引用了先前的值。)
如果指定了 min 属性
并且能够从中解析出值,则最小值为该值。否则,最小值为零。
如果指定了 max 属性
并且能够从中解析出值,则候选最大值为该值。否则,候选最大值为 1.0。
如果候选最大值大于或等于最小值,则最大值为候选最大值。 否则,最大值与最小值相同。
如果指定了 value 属性
并且能够从中解析出值,则该值为候选实际值。否则,候选实际值为零。
如果候选实际值小于最小值,则实际值为最小值。
否则,如果候选实际值大于最大值,则实际值为最大值。
否则,实际值为候选实际值。
如果指定了 low 属性
并且能够从中解析出值,则候选低值边界为该值。否则,候选低值边界与最小值相同。
如果候选低值边界小于最小值,则低值边界为最小值。
否则,如果候选低值边界大于最大值,则低值边界为最大值。
否则,低值边界为候选低值边界。
如果指定了 high 属性
并且能够从中解析出值,则候选高值边界为该值。否则,候选高值边界与最大值相同。
如果候选高值边界小于低值边界,则高值边界为低值边界。
否则,如果候选高值边界大于最大值,则高值边界为最大值。
否则,高值边界为候选高值边界。
如果指定了 optimum
属性并且能够从中解析出值,则候选最佳点为该值。否则,
候选最佳点为最小值与最大值之间的中点。
如果候选最佳点小于最小值,则最佳点为最小值。
否则,如果候选最佳点大于最大值,则最佳点为最大值。
否则,最佳点为候选最佳点。
所有这些将使以下不等式全部成立:
最小值 ≤ 实际值 ≤ 最大值
最小值 ≤ 低值边界 ≤ 高值边界 ≤ 最大值
最小值 ≤ 最佳点 ≤ 最大值
仪表区域的 UA 要求:如果最佳点等于低值边界或高值边界, 或位于两者之间的任意位置,则必须将仪表低值边界与高值边界之间的区域视为最佳区域, 并且必须将低值部分和高值部分(如有)视为次优区域。否则,如果最佳点低于低值边界, 则必须将最小值与低值边界之间的区域视为最佳区域,将从低值边界到高值边界的区域 视为次优区域,并将剩余区域视为更差的区域。最后,如果最佳点高于高值边界, 情况则相反;必须将高值边界与最大值之间的区域视为最佳区域, 将从高值边界向下到低值边界的区域视为次优区域, 并将剩余区域视为更差的区域。
显示仪表的 UA 要求:向用户表示 meter
元素时,UA 应指示实际值相对于最小值和最大值的位置,
以及实际值与仪表三个区域之间的关系。
以下标记:
< h3 > 建议的群组</ h3 >
< menu >
< li >< a href = "?cmd=hsg" onclick = "hideSuggestedGroups()" > 隐藏建议的群组</ a ></ li >
</ menu >
< ul >
< li >
< p >< a href = "/group/comp.infosystems.www.authoring.stylesheets/view" > comp.infosystems.www.authoring.stylesheets</ a > -
< a href = "/group/comp.infosystems.www.authoring.stylesheets/subscribe" > 加入</ a ></ p >
< p > 群组描述:< strong > 万维网上的布局/呈现。</ strong ></ p >
< p > < meter value = "0.5" > 活动度中等,</ meter > Usenet,618 名订阅者</ p >
</ li >
< li >
< p >< a href = "/group/netscape.public.mozilla.xpinstall/view" > netscape.public.mozilla.xpinstall</ a > -
< a href = "/group/netscape.public.mozilla.xpinstall/subscribe" > 加入</ a ></ p >
< p > 群组描述:< strong > Mozilla XPInstall 讨论。</ strong ></ p >
< p > < meter value = "0.25" > 活动度低,</ meter > Usenet,22 名订阅者</ p >
</ li >
< li >
< p >< a href = "/group/mozilla.dev.general/view" > mozilla.dev.general</ a > -
< a href = "/group/mozilla.dev.general/subscribe" > 加入</ a ></ p >
< p > < meter value = "0.25" > 活动度低,</ meter > Usenet,66 名订阅者</ p >
</ li >
</ ul > 可能呈现如下:
用户代理可以结合 title 属性与其他属性的值,
提供上下文相关的帮助或详细说明实际值的内联文本。
例如,以下代码片段:
< meter min = 0 max = 60 value = 23.2 title = 秒 ></ meter > ……可能会使用户代理显示一个带工具提示的仪表, 第一行显示“值:60 中的 23.2。”,第二行显示“秒”。
labels IDL 属性
提供该元素的
label 列表。
以下示例展示仪表如何回退到本地化或美化格式的文本。
< p > 磁盘使用量:< meter min = 0 value = 170261928 max = 233257824 > 已使用 170 261 928 字节,
可用总量为 233 257 824 字节</ meter ></ p > fieldset 元素
所有当前引擎均支持。
所有当前引擎均支持。
legend
元素,后跟流式内容。disabled —
除位于 legend 内的控件外,
后代表单控件是否禁用
form — 将该元素
与一个 form 元素关联
name — 在
form.elements
API 中使用的元素名称。
[Exposed =Window ]
interface HTMLFieldSetElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect ] attribute boolean disabled ;
readonly attribute HTMLFormElement ? form ;
[CEReactions , Reflect ] attribute DOMString name ;
readonly attribute DOMString type ;
[SameObject ] readonly attribute HTMLCollection elements ;
readonly attribute boolean willValidate ;
[SameObject ] readonly attribute ValidityState validity ;
readonly attribute DOMString validationMessage ;
boolean checkValidity ();
boolean reportValidity ();
undefined setCustomValidity (DOMString error );
};fieldset
元素表示一组分在一起的表单控件
(或其他内容),并且可以带有标题。如果存在作为 fieldset 元素子元素的
legend 元素,
则第一个这样的元素提供标题。其余后代构成该组。
Element/fieldset#attr-disabled
所有当前引擎均支持。
如果 fieldset
元素符合以下任一条件,则它是一个禁用的
fieldset:
form 属性用于将
fieldset 元素
与其表单所有者显式关联。name 属性表示该元素的名称。
fieldset.type返回字符串“fieldset”。
fieldset.elements
返回元素中表单控件组成的 HTMLCollection。
type
IDL 属性必须返回字符串“fieldset”。
elements IDL 属性必须返回一个
以 fieldset 元素为根、
其过滤器匹配可列出元素的 HTMLCollection。
willValidate、
validity 和 validationMessage
属性,以及 checkValidity()、
reportValidity()
和 setCustomValidity()
方法,是约束验证
API的一部分。form 和
name IDL 属性
是该元素表单 API 的一部分。
此示例展示使用 fieldset 元素
对一组相关控件进行分组:
< fieldset >
< legend > 显示</ legend >
< p >< label >< input type = radio name = c value = 0 checked > 白底黑字</ label >
< p >< label >< input type = radio name = c value = 1 > 黑底白字</ label >
< p >< label >< input type = checkbox name = g > 使用灰度</ label >
< p >< label > 增强对比度 < input type = range name = e list = contrast min = 0 max = 100 value = 0 step = 1 ></ label >
< datalist id = contrast >
< option label = 正常 value = 0 >
< option label = 最大 value = 100 >
</ datalist >
</ fieldset > 以下代码片段展示一个 fieldset,其 legend 中的复选框控制该 fieldset 是否启用。 fieldset 的内容由两个必填文本控件以及一个可选的年/月控件组成。
< fieldset name = "clubfields" disabled >
< legend > < label >
< input type = checkbox name = club onchange = "form.clubfields.disabled = !checked" >
使用会员卡
</ label > </ legend >
< p >< label > 卡片上的姓名:< input name = clubname required ></ label ></ p >
< p >< label > 卡号:< input name = clubnum required pattern = "[-0-9]+" ></ label ></ p >
< p >< label > 到期日期:< input name = clubexp type = month ></ label ></ p >
</ fieldset > 还可以嵌套 fieldset
元素。
以下示例在前一个示例的基础上进行了扩展,并使用了嵌套:
< fieldset name = "clubfields" disabled >
< legend > < label >
< input type = checkbox name = club onchange = "form.clubfields.disabled = !checked" >
使用会员卡
</ label > </ legend >
< p >< label > 卡片上的姓名:< input name = clubname required ></ label ></ p >
< fieldset name = "numfields" >
< legend > < label >
< input type = radio checked name = clubtype onchange = "form.numfields.disabled = !checked" >
我的卡片上有数字
</ label > </ legend >
< p >< label > 卡号:< input name = clubnum required pattern = "[-0-9]+" ></ label ></ p >
</ fieldset >
< fieldset name = "letfields" disabled >
< legend > < label >
< input type = radio name = clubtype onchange = "form.letfields.disabled = !checked" >
我的卡片上有字母
</ label > </ legend >
< p >< label > 卡片代码:< input name = clublet required pattern = "[A-Za-z]+" ></ label ></ p >
</ fieldset >
</ fieldset > 在此示例中,如果外层的“使用会员卡”复选框未选中,则外层
fieldset
内的所有内容都会被禁用,包括两个嵌套
fieldset
的 legend 中的两个单选按钮。但是,如果选中了该复选框,则两个单选按钮都会启用,
并允许选择启用两个内部 fieldset
中的哪一个。
此示例展示了一组控件,其中 legend 元素既为
该分组提供标签,嵌套的标题元素又使该分组显示在文档大纲中:
< fieldset >
< legend > < h2 >
我们怎样联系您最合适?
</ h2 > </ legend >
< p > < label >
< input type = radio checked name = contact_pref >
电话
</ label > </ p >
< p > < label >
< input type = radio name = contact_pref >
短信
</ label > </ p >
< p > < label >
< input type = radio name = contact_pref >
电子邮件
</ label > </ p >
</ fieldset > legend
元素所有当前引擎均支持。
所有当前引擎均支持。
fieldset 元素的第一个子元素。optgroup 元素的第一个子元素。optgroup
元素的子元素:
短语内容,
但不得有交互式内容,
也不得有带 tabindex 属性的后代。
[Exposed =Window ]
interface HTMLLegendElement : HTMLElement {
[HTMLConstructor ] constructor ();
readonly attribute HTMLFormElement ? form ;
// 还具有已废弃的成员
};如果 legend 元素
的父元素是 fieldset 元素,则
legend 元素表示该父元素其余内容的标题。否则,如果
legend 的父元素是
optgroup 元素,
则 legend 表示
optgroup 的标签。
legend.form如果存在,则返回该元素的 form 元素;否则返回
null。
form
IDL 属性的行为取决于 legend
元素是否位于
fieldset 元素中。
如果 legend
的父元素是 fieldset 元素,
则 form IDL 属性必须返回
与该 fieldset 元素上的
form IDL 属性相同的值。
否则,它必须返回 null。
selectedcontent 元素button
元素
的后代,该元素是一个 select
元素的子元素。[Exposed =Window ]
interface HTMLSelectedContentElement : HTMLElement {
[HTMLConstructor ] constructor ();
};selectedcontent
元素反映 select
元素当前选中的 option
元素的内容。
selectedcontent
元素可用于以声明方式,在 select
元素的第一个子 button
元素中,
显示所选 option
元素的内容。
option 元素的
label
属性可用于为选项呈现可见标签,但
selectedcontent
元素不会反映 label
属性的内容。
每个 selectedcontent
元素都有一个布尔值 disabled,其初始值为 false。
给定一个 select
元素 select,要更新 select 的
selectedcontent:
令 selectedcontent 为给定 select,获取 select 的已启用
selectedcontent所得的结果。
如果 selectedcontent 为 null,则返回。
如果 select 的选项列表中存在选中性为
true 的 option,
则令 option 为其中第一个 option;
否则为 null。
如果 option 为 null,则给定 selectedcontent,运行清除 selectedcontent。
否则,给定 option 和 selectedcontent,运行将 option 克隆到
selectedcontent 中。
给定一个 select
元素
select,要获取 select 的已启用
selectedcontent:
如果 select 具有 multiple
属性,则返回 null。
如果存在,则令 selectedcontent 为按树顺序排列的、作为
select 的后代的第一个 selectedcontent
元素;否则返回 null。
如果 selectedcontent 的 disabled 为 true,则返回 null。
返回 selectedcontent。
要将一个 option 克隆到一个
selectedcontent 中,给定一个
option
元素 option 和一个 selectedcontent
元素
selectedcontent:
要清除一个 selectedcontent,给定一个 selectedcontent
元素
selectedcontent:
在 selectedcontent 中,用 null 替换全部。
要清除一个 select 的非主要
selectedcontent 元素,
给定一个 select
元素
select:
令 passedFirstSelectedcontent 为 false。
对于 select 的后代中,按树顺序排列且为
selectedcontent
元素的每个 descendant:
如果 passedFirstSelectedcontent 为 false,则将 passedFirstSelectedcontent 设置为 true。
否则,给定
descendant,运行清除一个 selectedcontent。
selectedcontent
的HTML 元素连接后步骤,
给定
selectedcontent,如下:
令 nearestSelectAncestor 为 null。
将 selectedcontent 的disabled 设置为 false。
如果 selectedcontent 的disabled 为
true,nearestSelectAncestor 为 null,或者 nearestSelectAncestor 具有
multiple
属性,则返回。
给定
nearestSelectAncestor,运行更新一个 select 的
selectedcontent。
给定 nearestSelectAncestor,运行清除一个
select 的非主要 selectedcontent
元素。
给定 removedNode、isSubtreeRoot 和 oldAncestor,selectedcontent
的HTML
元素移除步骤是:
大多数表单控件都有一个值和一个选中性。(后者仅由 input
元素使用。)它们用于描述用户如何与控件交互。
控件的值是其内部状态。因此,它 可能与用户当前的输入不匹配。
例如,如果用户在一个需要数字的数值字段中输入单词“three”,
则用户的输入将是字符串“three”,但控件的值将保持不变。或者,如果用户在电子邮件字段中输入电子邮件地址“ awesome@example.com”
(带有前导空白),则用户的输入将是字符串“ awesome@example.com”,但浏览器的电子邮件字段 UI
可能会将其转换为值“awesome@example.com”(不带前导空白)。
input
和 textarea
元素具有脏值标志。
此标志用于跟踪值与默认值之间的交互。如果它为 false,值将反映默认值。
如果它为 true,则忽略默认值。
某些表单控件还具有一个可选值。 它在很大程度上反映值,但不会规范化为空字符串。 应谨慎使用它;通常应使用值。
input、textarea 和 select 元素具有一个
用户有效性布尔值。其初始设置为 false。
为了定义面对 input
元素的 multiple
属性时的约束验证行为,input
元素还可以具有单独定义的多个值。
为了定义 maxlength 和 minlength 属性的行为,
以及其他特定于 textarea
元素的 API,所有具有值的表单控件还具有一个用于获取API 值的算法。
默认情况下,此算法仅返回控件的值。
select 元素
没有值;
实际使用的是其 option
元素的选中性。
表单控件可以被指定为可变的。
这将决定用户能否修改表单控件的值或选中性,以及控件能否被自动预填充 (通过本规范中依赖元素是否被如此指定的定义和要求来决定)。
表单关联
元素可以与 form
元素建立关系,该 form 元素称为该元素的表单
所有者。如果表单关联元素未与 form
元素关联,则称其表单所有者为 null。
表单关联元素具有一个关联的 解析器插入标志。
所有当前引擎均支持。
所有当前引擎均支持。
默认情况下,表单关联元素与其最近的祖先 form 元素关联
(如下所述);但如果它是可列出的,则可以指定一个 form 属性来覆盖此行为。
此功能允许作者规避不支持嵌套
form
元素的问题。
本节的规则较为复杂,因为尽管符合规范的文档或树绝不会包含嵌套的 form
元素,但完全有可能(例如,使用执行 DOM 操作的脚本)生成具有此类嵌套元素的树。HTML 解析器中的规则也使其更加复杂:由于历史原因,
这些规则可能导致表单关联
元素与一个并非其祖先的 form 元素关联。
当一个可列出的表单关联
元素的
form 属性
被设置、更改或移除时,用户代理必须重置该元素的表单所有者。
当一个已列出的表单关联元素具有
form 属性,
并且一个具有 ID 的元素被插入
到或从
Document 中移除,或者运行了其HTML 元素
移动步骤时,用户代理
必须重置该
表单所有者,该所有者属于该表单关联元素。
HTML 元素插入步骤、 HTML 元素移除步骤和HTML 元素移动步骤 也会重置表单所有者。
在以下不符合规范的代码片段中
...
< form id = "a" >
< div id = "b" ></ div >
</ form >
< script >
document. getElementById( 'b' ). innerHTML =
'<table><tr><td></form><form id="c"><input id="d"></table>' +
'<input id="e">' ;
</ script >
...“d”的表单所有者将是内部嵌套表单“c”, 而“e”的表单 所有者将是外部表单“a”。
具体过程如下:首先,“e”节点在 HTML
解析器中与“c”关联。然后,innerHTML
算法将这些节点从临时文档移动到“b”元素。此时,这些节点发现其祖先链发生变化,
因此解析器建立的所有“特殊”关联都会被重置为普通的祖先关联。
element.form
所有当前引擎均支持。
所有当前引擎均支持。
返回该元素的表单所有者。
如果没有,则返回 null。
所有当前引擎均支持。
表单关联自定义元素
没有 form IDL 属性。
相反,其 ElementInternals
对象具有一个 form IDL 属性。获取该属性时,如果目标元素不是表单关联自定义
元素,则必须抛出一个
“NotSupportedError” DOMException。
否则,它必须返回该元素的表单所有者,如果没有,则返回 null。
name 属性所有当前引擎均支持。
name 内容属性提供表单控件的名称,该名称用于表单
提交和 form
元素的 elements
对象。如果指定了该属性,其值不得为空字符串或 isindex。
历史上,许多用户代理为表单中第一个名为 isindex 的文本控件
实现了特殊支持,本规范此前也为其定义了相关的用户代理要求。不过,一些用户代理随后取消了
此特殊支持,本规范也移除了相关要求。因此,为避免旧版用户代理进行有问题的重新解释,
不再允许使用名称 isindex。
除 isindex 外,name
可以使用任何非空值。名称 _charset_ 的ASCII
不区分大小写匹配具有特殊含义:如果将其用作没有 value
属性的控件的名称,
则在提交过程中,会自动为 value
属性提供一个由提交字符编码组成的值。
DOM 覆盖是安全问题的常见原因。避免在 name 内容
属性中使用内置表单属性的名称。
在此示例中,input
元素覆盖了内置的 method
属性:
let form = document. createElement( "form" );
let input = document. createElement( "input" );
form. appendChild( input);
form. method; // => "get"
input. name = "method" ; // 此处发生 DOM 覆盖
form. method === input; // => true 由于 input 的名称优先于内置表单属性,因此 JavaScript 引用
form.method 将指向名为“method”的 input
元素,而不是内置的 method
属性。
dirname
属性所有当前引擎均支持。
表单控件元素上的 dirname 属性允许提交元素的方向性,
并提供在表单
提交期间包含该值的控件名称。如果指定了此属性,其值不得为空字符串。
在此示例中,表单包含一个文本控件和一个提交按钮:
< form action = "addcomment.cgi" method = post >
< p >< label > 评论:< input type = text name = "comment" dirname = "comment.dir" required ></ label ></ p >
< p >< button name = "mode" type = submit value = "add" > 发布评论</ button ></ p >
</ form > 用户提交表单时,用户代理会包含三个字段:一个名为“comment”, 一个名为“comment.dir”,另一个名为“mode”;因此,如果用户输入“Hello”,提交 正文可能类似如下:
comment=Hello&comment.dir=ltr&mode=add
如果用户手动切换到从右到左的书写方向并输入“مرحبا”,提交正文可能 类似如下:
comment=%D9%85%D8%B1%D8%AD%D8%A8%D8%A7&comment.dir=rtl&mode=add
maxlength
属性由脏值标志控制的
表单控件
maxlength 属性声明用户可输入的字符数上限。
字符数使用长度来测量;
对于 textarea
元素,所有换行符均规范化为单个字符(而不是 CRLF 对)。
如果元素指定了其表单控件
maxlength 属性,则该属性的值必须是有效的
非负整数。如果指定了该属性,并且将非负整数
解析规则应用于其值后得到一个数字,则该数字是元素的允许的最大值长度。如果省略该属性或解析其值时产生错误,
则不存在允许的最大值
长度。
用户代理可以阻止用户使元素的API 值被设置为一个 长度大于元素允许的最大值 长度的值。
对于 textarea
元素,API 值和值
不同。具体而言,在检查允许的最大值
长度之前会应用换行符规范化
(但不会应用textarea
换行转换)。
minlength
属性由脏值标志控制的
表单控件
minlength 属性声明用户可输入字符数的下限。
“字符数”使用长度来测量;
对于 textarea
元素,所有换行符均规范化为单个字符(而不是 CRLF 对)。
minlength
属性并不意味着存在 required 属性。如果表单控件没有 required 属性,
则仍然可以省略该值;minlength
属性仅在用户实际输入了某个值后才生效。如果不允许空字符串,则还需要设置 required
属性。
如果元素指定了其表单控件
minlength 属性,则该属性的值必须是有效的
非负整数。如果指定了该属性,并且将非负整数
解析规则应用于其值后得到一个数字,则该数字是元素的允许的最小值长度。如果省略该属性或解析其值时产生错误,
则不存在允许的
最小值长度。
如果元素同时具有允许的 最大值长度和允许的 最小值长度,则允许的 最小值长度必须小于或等于允许的 最大值长度。
约束验证:如果元素具有允许的 最小值长度,其脏值标志 为 true,其值最后一次是由用户编辑更改的 (而不是由脚本更改),其值不是空字符串, 并且元素的API 值的 长度小于元素的允许的 最小值长度,则该元素 过短。
在此示例中,有四个文本控件。第一个是必填的,并且长度必须至少为 5 个字符。 其他三个是可选的,但如果用户填写了其中一个,则必须输入至少 10 个字符。
< form action = "/events/menu.cgi" method = "post" >
< p >< label > 活动名称:< input required minlength = 5 maxlength = 50 name = event ></ label ></ p >
< p >< label > 请描述您希望早餐吃什么(如有):
< textarea name = "breakfast" minlength = "10" ></ textarea ></ label ></ p >
< p >< label > 请描述您希望午餐吃什么(如有):
< textarea name = "lunch" minlength = "10" ></ textarea ></ label ></ p >
< p >< label > 请描述您希望晚餐吃什么(如有):
< textarea name = "dinner" minlength = "10" ></ textarea ></ label ></ p >
< p >< input type = submit value = "提交请求" ></ p >
</ form > disabled
属性所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
disabled 内容属性是一个布尔
属性。
option
元素的 disabled
属性和 optgroup
元素的 disabled
属性是单独定义的。
如果以下任一条件为 true,则表单控件为禁用的:
禁用的表单控件必须阻止
在用户交互
任务源上排队的任何
click
事件被派发到该元素。
禁用并不会阻止 对表单控件进行所有修改。例如,可以通过 JavaScript 以编程方式修改控件的值或选中性。 或者,也可以通过用户操作间接修改它们,例如修改控件的单选按钮组中的其他 未禁用元素。
Element/form#Attributes_for_form_submission
所有当前引擎均支持。
表单提交属性既可以在 form 元素上指定,
也可以在提交按钮
(表示提交表单的按钮的元素,例如 input 元素,其
type 属性处于
提交按钮状态)上指定。
可以在 form
元素上指定的表单提交属性是 action、enctype、method、novalidate 和 target。
可以在提交
按钮上指定的相应表单提交属性是 formaction、formenctype、formmethod、formnovalidate
和 formtarget。
省略这些属性时,它们默认为 form
元素上
相应属性给出的值。
所有当前引擎均支持。
action 和
formaction
内容属性一经指定,其值必须是一个可能被空格包围的有效非空
URL。
元素的操作是:如果该元素是提交按钮且具有 formaction
属性,则为该属性的值;否则,如果其表单所有者具有 action 属性,则为
该属性的值;否则为空字符串。
所有当前引擎均支持。
method 和
formmethod
内容属性是具有以下关键字和状态的枚举属性:
| 关键字 | 状态 | 简要说明 |
|---|---|---|
get
|
GET | 表示 form 将使用
HTTP GET 方法。
|
post
|
POST | 表示 form 将使用
HTTP POST 方法。
|
dialog
|
对话框 | 表示 form 旨在关闭
该表单所在的 dialog 框
(如果有),否则不进行提交。
|
method 属性的
缺失值
默认值和无效值默认值
都是 GET 状态。
formmethod
属性没有缺失
值默认值,其无效值
默认值是 GET 状态。
元素的方法是这些状态之一。如果该元素是提交
按钮且具有 formmethod
属性,则该元素的方法是该属性的状态;否则,它是表单
所有者的 method
属性的状态。
这里使用 method
属性显式指定默认值“get”,
从而在 URL 中提交搜索查询:
< form method = "get" action = "/search.cgi" >
< p >< label > 搜索词:< input type = search name = q ></ label ></ p >
< p >< input type = submit ></ p >
</ form > 另一方面,这里使用 method 属性
指定值“post”,
从而在 HTTP 请求正文中提交用户的消息:
< form method = "post" action = "/post-message.cgi" >
< p >< label > 消息:< input type = text name = m ></ label ></ p >
< p >< input type = submit value = "提交消息" ></ p >
</ form > 在此示例中,form 与
dialog
一起使用。使用 method 属性的
“dialog”
关键字,使对话框在提交表单时自动关闭。
< dialog id = "ship" >
< form method = dialog >
< p > 一艘船已抵达港口。</ p >
< button type = submit value = "board" > 登船</ button >
< button type = submit value = "call" > 呼叫船长</ button >
</ form >
</ dialog >
< script >
var ship = document. getElementById( 'ship' );
ship. showModal();
ship. onclose = function ( event) {
if ( ship. returnValue == 'board' ) {
// ...
} else {
// ...
}
};
</ script > 所有当前引擎均支持。
enctype
和
formenctype
内容属性是具有以下关键字和状态的枚举属性:
application/x-www-form-urlencoded”关键字及其对应状态。multipart/form-data”关键字及其对应状态。text/plain”关键字及其对应状态。该属性的缺失值默认值和无效值
默认值都是 application/x-www-form-urlencoded
状态。
formenctype
属性没有缺失
值默认值,其无效值
默认值是 application/x-www-form-urlencoded
状态。
元素的enctype是这三个状态之一。
如果该元素是提交按钮且具有 formenctype
属性,则该元素的 enctype
是该属性的状态;否则,它是
表单所有者的 enctype 属性的状态。
所有当前引擎均支持。
target 和
formtarget
内容属性一经指定,其值必须是有效的可导航目标名称或
关键字。
所有当前引擎均支持。
novalidate
和 formnovalidate 内容属性是
布尔属性。如果存在,
它们表示提交期间不验证表单。
如果该元素是提交按钮且该元素的
formnovalidate
属性存在,或者该元素的表单所有者的 novalidate
属性存在,则元素的不验证状态为 true;否则为 false。
此属性适合用于在具有验证约束的表单中加入“保存”按钮,使用户即使尚未完整输入表单数据, 也能保存其进度。以下示例展示了一个具有两个必填字段的简单表单。共有三个按钮: 一个用于提交表单,要求两个字段均已填写;一个用于保存表单,以便用户稍后返回继续填写; 另一个用于完全取消表单。
< form action = "editor.cgi" method = "post" >
< p >< label > 姓名:< input required name = fn ></ label ></ p >
< p >< label > 文章:< textarea required name = essay ></ textarea ></ label ></ p >
< p >< input type = submit name = submit value = "提交文章" ></ p >
< p >< input type = submit formnovalidate name = save value = "保存文章" ></ p >
< p >< input type = submit formnovalidate name = cancel value = "取消" ></ p >
</ form > 所有当前引擎均支持。
action
的获取器步骤是:
formAction 的获取器步骤是:
所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
method
和
enctype IDL
属性必须反映相应的同名内容属性,
并仅限于
已知值。encoding IDL 属性必须反映 enctype 内容
属性,并仅限于已知
值。formEnctype IDL 属性必须反映
formenctype
内容属性,并仅限于
已知值。formMethod IDL 属性必须反映
formmethod
内容属性,并仅限于已知
值。
autocomplete
属性所有当前引擎均支持。
用户代理有时具有帮助用户填写表单的功能,例如根据用户先前的输入预填充用户的地址。
autocomplete 内容属性可用于向用户代理提示
应如何提供此类功能,或者是否应提供此类功能。
此属性有两种使用方式。当披上自动填充预期
外衣时,autocomplete
属性描述预期用户输入的内容。当披上自动填充锚点外衣时,
autocomplete
属性描述给定值的含义。
在一个 input
元素上,如果其 type
属性处于状态,则 autocomplete
属性披上自动填充锚点
外衣。在所有其他情况下,它披上自动填充预期
外衣。
当披上自动填充预期
外衣时,autocomplete
属性一经指定,其值必须是有序的空格分隔
标记集,由以下三者之一组成:单个标记,且该标记与字符串“off”进行
ASCII
不区分大小写匹配;单个标记,且该标记与字符串“on”进行
ASCII
不区分大小写匹配;或者自动填充详细标记。
当披上自动填充锚点
外衣时,autocomplete
属性一经指定,其值必须是有序的空格分隔
标记集,且仅由自动填充详细标记
组成(即不允许使用“on”
和“off”
关键字)。
自动填充详细标记按以下顺序组成:
可以有一个标记,其前八个字符与字符串“section-”进行
ASCII
不区分大小写匹配,表示该字段属于
指定名称的组。
例如,如果表单中有两个收货地址,则可将其标记为:
< fieldset >
< legend > 将蓝色礼物寄送至……</ legend >
< p > < label > 地址: < textarea name = ba autocomplete = "section-blue shipping street-address" ></ textarea > </ label >
< p > < label > 城市: < input name = bc autocomplete = "section-blue shipping address-level2" > </ label >
< p > < label > 邮政编码:< input name = bp autocomplete = "section-blue shipping postal-code" > </ label >
</ fieldset >
< fieldset >
< legend > 将红色礼物寄送至……</ legend >
< p > < label > 地址: < textarea name = ra autocomplete = "section-red shipping street-address" ></ textarea > </ label >
< p > < label > 城市: < input name = rc autocomplete = "section-red shipping address-level2" > </ label >
< p > < label > 邮政编码:< input name = rp autocomplete = "section-red shipping postal-code" > </ label >
</ fieldset > 可以有一个标记,与以下字符串之一进行ASCII 不区分大小写匹配:
shipping”,表示该
字段是收货地址或联系信息的一部分
billing”,表示该
字段是账单地址或联系信息的一部分
以下两个选项之一:
一个标记,与以下自动填充字段名称之一 进行ASCII 不区分大小写匹配,但排除对控件不适用 的名称:
name”
honorific-prefix”
given-name”
additional-name”
family-name”
honorific-suffix”
nickname”
username”
new-password”
current-password”
one-time-code”
organization-title”
organization”
street-address”
address-line1”
address-line2”
address-line3”
address-level4”
address-level3”
address-level2”
address-level1”
country”
country-name”
postal-code”
cc-name”
cc-given-name”
cc-additional-name”
cc-family-name”
cc-number”
cc-exp”
cc-exp-month”
cc-exp-year”
cc-csc”
cc-type”
transaction-currency”
transaction-amount”
language”
bday”
bday-day”
bday-month”
bday-year”
sex”
url”
photo”
(有关这些值的说明,请参阅下表。)
按给定顺序包括以下内容:
可以有一个标记,与以下字符串之一进行ASCII 不区分大小写匹配:
home”,表示该
字段用于在某人的住所联系该人
work”,表示该
字段用于在某人的工作场所联系该人
mobile”,表示
该字段用于不受地点限制地联系某人
fax”,表示该
字段描述传真机的联系详细信息
pager”,表示该
字段描述寻呼机的联系详细信息
一个标记,与以下自动填充字段 名称之一进行ASCII 不区分大小写匹配,但排除对控件不适用 的名称:
tel”
tel-country-code”
tel-national”
tel-area-code”
tel-local”
tel-local-prefix”
tel-local-suffix”
tel-extension”
email”
impp”
(有关这些值的说明,请参阅下表。)
可以有一个标记,与字符串“webauthn”
进行ASCII
不区分大小写匹配,表示当用户与表单控件交互时,
用户代理应显示可通过 条件式
中介获得的公钥凭据。webauthn
仅对 input
和 textarea
元素有效。
如前所述,该属性及其关键字的含义取决于该属性所披的外衣。
“off”关键字表示以下情况之一:
控件的输入数据特别敏感(例如核武器的激活码);或者该值永远不会重复使用
(例如银行登录的一次性密钥),因此用户每次都必须显式输入数据,而不能依赖用户代理为其预填该值;
或者文档提供了自己的自动完成机制,并且不希望用户代理提供自动完成值。
“on”关键字表示允许用户代理
向用户提供自动完成值,但不提供有关用户预期输入何种数据的进一步信息。用户代理必须使用
启发式方法来决定建议哪些自动完成值。
上面列出的自动填充字段表示允许 用户代理向用户提供自动完成值,并指定预期的值类型。每个此类关键字的含义在下表中说明。
如果省略 autocomplete
属性,则改用与元素的表单所有者的
autocomplete
属性状态相对应的默认值(“on”
或“off”)。
如果没有表单所有者,则使用值“on”。
上面列出的自动填充字段表示: 对于此元素所提供的值,该值属于指定的特定值类型。每个此类关键字的含义在下表中说明。
在此示例中,页面显式指定了交易的货币和金额。表单请求信用卡及其他账单详细信息。 用户代理可以利用此信息建议一张其已知具有足够余额且支持相应货币的信用卡。
< form method = post action = "step2.cgi" >
< input type = hidden autocomplete = transaction-currency value = "CHF" >
< input type = hidden autocomplete = transaction-amount value = "15.00" >
< p >< label > 信用卡号:< input type = text inputmode = numeric autocomplete = cc-number ></ label >
< p >< label > 到期日期:< input type = month autocomplete = cc-exp ></ label >
< p >< input type = submit value = "继续……" >
</ form > 自动填充字段关键字之间的关系如下表所述。
此表中每一行列出的字段名称对应于该行“含义”列单元格中给出的含义。
某些字段对应于其他字段的子部分;例如,信用卡到期日期可以表示为一个同时给出到期月份和年份的字段
(“cc-exp”),
也可以表示为两个字段,一个给出月份
(“cc-exp-month”),
另一个给出年份
(“cc-exp-year”)。
在这种情况下,较宽泛字段的名称会跨越定义较具体字段的多行。
通常建议作者使用较宽泛的字段,而不是较具体的字段,因为较具体的字段往往带有 西方文化偏见。例如,在一些西方文化中,人们通常按名字在前、姓氏在后的顺序拥有名字和姓氏 (因此常称为名和姓),但许多文化将姓氏放在名字之前,另有许多人只有一个姓名 (单名)。因此,使用单个字段更加灵活。
| 字段名称 | 含义 | 规范格式 | 规范格式示例 | 控件组 | |||
|---|---|---|---|---|---|---|---|
“name”
|
全名 | 自由格式文本,不含换行符 | Sir Timothy John Berners-Lee, OM, KBE, FRS, FREng, FRSA | 文本 | |||
“honorific-prefix”
|
前缀或称谓(例如“Mr.”、“Ms.”、“Dr.”、“Mlle”) | 自由格式文本,不含换行符 | Sir | 文本 | |||
“given-name”
|
名字(在某些西方文化中,也称为名) | 自由格式文本,不含换行符 | Timothy | 文本 | |||
“additional-name”
|
附加名字(在某些西方文化中,也称为中间名,即除第一个名字之外的名字) | 自由格式文本,不含换行符 | John | 文本 | |||
“family-name”
|
姓氏(在某些西方文化中,也称为姓) | 自由格式文本,不含换行符 | Berners-Lee | 文本 | |||
“honorific-suffix”
|
后缀(例如“Jr.”、“B.Sc.”、“MBASW”、“II”) | 自由格式文本,不含换行符 | OM, KBE, FRS, FREng, FRSA | 文本 | |||
“nickname”
|
昵称、网名、代号:通常用于代替全名的短名称 | 自由格式文本,不含换行符 | Tim | 文本 | |||
“organization-title”
|
职务名称(例如“软件工程师”、“高级副总裁”、“副总经理”) | 自由格式文本,不含换行符 | Professor | 文本 | |||
“username”
|
用户名 | 自由格式文本,不含换行符 | timbl | 用户名 | |||
“new-password”
|
新密码(例如创建账户或更改密码时) | 自由格式文本,不含换行符 | GUMFXbadyrS3 | 密码 | |||
“current-password”
|
由 username
字段标识的账户的当前密码(例如登录时)
|
自由格式文本,不含换行符 | qwerty | 密码 | |||
“one-time-code”
|
用于验证用户身份的一次性代码 | 自由格式文本,不含换行符 | 123456 | 密码 | |||
“organization”
|
与关联于此字段的其他字段中的人员、地址或联系信息相对应的公司名称 | 自由格式文本,不含换行符 | World Wide Web Consortium | 文本 | |||
“street-address”
|
街道地址(多行,保留换行符) | 自由格式文本 | 32 Vassar Street MIT Room 32-G524 |
多行 | |||
“address-line1”
|
街道地址(每个字段一行) | 自由格式文本,不含换行符 | 32 Vassar Street | 文本 | |||
“address-line2”
|
自由格式文本,不含换行符 | MIT Room 32-G524 | 文本 | ||||
“address-line3”
|
自由格式文本,不含换行符 | 文本 | |||||
“address-level4”
|
在具有四级行政区划的地址中,粒度最细的行政级别 | 自由格式文本,不含换行符 | 文本 | ||||
“address-level3”
|
在具有三级或更多行政区划的地址中的第三级行政区划 | 自由格式文本,不含换行符 | 文本 | ||||
“address-level2”
|
在具有两级或更多行政区划的地址中的第二级行政区划; 在具有两级行政区划的国家中,这通常是相关街道地址所在的城市、城镇、村庄或其他地区 | 自由格式文本,不含换行符 | Cambridge | 文本 | |||
“address-level1”
|
地址中范围最广的行政级别,即地区所在的省级区域; 例如,在美国这将是州,在瑞士将是州,在英国则是邮政城镇 | 自由格式文本,不含换行符 | MA | 文本 | |||
“country”
|
国家代码 | 有效的 ISO 3166-1 alpha-2 国家代码 [ISO3166] | US | 文本 | |||
“country-name”
|
国家名称 | 自由格式文本,不含换行符;在某些情况下派生自 country
|
US | 文本 | |||
“postal-code”
|
邮政编码、邮编、ZIP 编码、CEDEX 编码(如果是 CEDEX,则将“CEDEX”和相关的法语行政区附加到 address-level2
字段)
|
自由格式文本,不含换行符 | 02139 | 文本 | |||
“cc-name”
|
支付工具上给出的全名 | 自由格式文本,不含换行符 | Tim Berners-Lee | 文本 | |||
“cc-given-name”
|
支付工具上给出的名字(在某些西方文化中,也称为名) | 自由格式文本,不含换行符 | Tim | 文本 | |||
“cc-additional-name”
|
支付工具上给出的附加名字(在某些西方文化中,也称为中间名,即除第一个名字之外的名字) | 自由格式文本,不含换行符 | 文本 | ||||
“cc-family-name”
|
支付工具上给出的姓氏(在某些西方文化中,也称为姓) | 自由格式文本,不含换行符 | Berners-Lee | 文本 | |||
“cc-number”
|
标识支付工具的代码(例如信用卡号) | ASCII 数字 | 4114360123456785 | 文本 | |||
“cc-exp”
|
支付工具的到期日期 | 有效月份字符串 | 2014-12 | 月份 | |||
“cc-exp-month”
|
支付工具到期日期的月份部分 | 范围为 1..12 的有效整数 | 12 | 数值 | |||
“cc-exp-year”
|
支付工具到期日期的年份部分 | 大于零的有效整数 | 2014 | 数值 | |||
“cc-csc”
|
支付工具的安全码(也称为卡片安全码(CSC)、卡片验证代码(CVC)、卡片验证值(CVV)、 签名栏代码(SPC)、信用卡标识码(CCID)等) | ASCII 数字 | 419 | 文本 | |||
“cc-type”
|
支付工具的类型 | 自由格式文本,不含换行符 | Visa | 文本 | |||
“transaction-currency”
|
用户希望交易使用的货币 | ISO 4217 货币代码 [ISO4217] | GBP | 文本 | |||
“transaction-amount”
|
用户希望用于交易的金额(例如输入出价或售价时) | 有效浮点 数 | 401.00 | 数值 | |||
“language”
|
首选语言 | 有效的 BCP 47 语言标记 [BCP47] | en | 文本 | |||
“bday”
|
生日 | 有效日期字符串 | 1955-06-08 | 日期 | |||
“bday-day”
|
生日的日部分 | 范围为 1..31 的有效整数 | 8 | 数值 | |||
“bday-month”
|
生日的月份部分 | 范围为 1..12 的有效整数 | 6 | 数值 | |||
“bday-year”
|
生日的年份部分 | 大于零的有效整数 | 1955 | 数值 | |||
“sex”
|
性别认同(例如女性、Fa'afafine) | 自由格式文本,不含换行符 | Male | 文本 | |||
“url”
|
与关联于此字段的其他字段中的公司、人员、地址或联系信息相对应的主页或其他网页 | 有效 URL 字符串 | https://www.w3.org/People/Berners-Lee/ | URL | |||
“photo”
|
与关联于此字段的其他字段中的公司、人员、地址或联系信息相对应的照片、图标或其他图像 | 有效 URL 字符串 | https://www.w3.org/Press/Stock/Berners-Lee/2001-europaeum-eighth.jpg | URL | |||
“tel”
|
完整电话号码,包括国家代码 | ASCII 数字和 U+0020 SPACE 字符,并以 U+002B PLUS SIGN 字符(+)为前缀 | +1 617 253 5702 | 电话 | |||
“tel-country-code”
|
电话号码的国家代码部分 | 以 U+002B PLUS SIGN 字符(+)为前缀的ASCII 数字 | +1 | 文本 | |||
“tel-national”
|
不含国家代码部分的电话号码,并在适用时应用国家内部前缀 | ASCII 数字和 U+0020 SPACE 字符 | 617 253 5702 | 文本 | |||
“tel-area-code”
|
电话号码的区号部分,并在适用时应用国家内部前缀 | ASCII 数字 | 617 | 文本 | |||
“tel-local”
|
不含国家代码和区号部分的电话号码 | ASCII 数字 | 2535702 | 文本 | |||
“tel-local-prefix”
|
当区号之后的电话号码部分被拆分成两个部分时,该部分的第一部分 | ASCII 数字 | 253 | 文本 | |||
“tel-local-suffix”
|
当区号之后的电话号码部分被拆分成两个部分时,该部分的第二部分 | ASCII 数字 | 5702 | 文本 | |||
“tel-extension”
|
电话号码的内部分机号 | ASCII 数字 | 1000 | 文本 | |||
“email”
|
电子邮件地址 | 有效电子邮件地址 | timbl@w3.org | 用户名 | |||
“impp”
|
表示即时消息协议端点的 URL(例如
“aim:goim?screenname=example”或“xmpp:fred@example.net”)
|
有效 URL 字符串 | irc://example.org/timbl,isuser | URL | |||
各组与控件的对应关系如下:
input
元素,其 type
属性处于隐藏状态
input
元素,其 type
属性处于文本
状态
input
元素,其 type
属性处于搜索
状态
textarea
元素
select
元素
input
元素,其 type
属性处于隐藏状态
textarea
元素
select
元素
input
元素,其 type
属性处于隐藏状态
input
元素,其 type
属性处于文本
状态
input
元素,其 type
属性处于搜索
状态
input
元素,其 type
属性处于密码状态
textarea
元素
select
元素
input
元素,其 type
属性处于隐藏状态
input
元素,其 type
属性处于文本
状态
input
元素,其 type
属性处于搜索
状态
input
元素,其 type
属性处于 URL 状态
textarea
元素
select
元素
input
元素,其 type
属性处于隐藏状态
input
元素,其 type
属性处于文本
状态
input
元素,其 type
属性处于搜索
状态
input
元素,其 type
属性处于电子邮件状态
textarea
元素
select
元素
input
元素,其 type
属性处于隐藏状态
input
元素,其 type
属性处于文本
状态
input
元素,其 type
属性处于搜索
状态
input
元素,其 type
属性处于电话状态
textarea
元素
select
元素
input
元素,其 type
属性处于隐藏状态
input
元素,其 type
属性处于文本
状态
input
元素,其 type
属性处于搜索
状态
input
元素,其 type
属性处于数字状态
textarea
元素
select
元素
input
元素,其 type
属性处于隐藏状态
input
元素,其 type
属性处于文本
状态
input
元素,其 type
属性处于搜索
状态
input
元素,其 type
属性处于月份状态
textarea
元素
select
元素
input
元素,其 type
属性处于隐藏状态
input
元素,其 type
属性处于文本
状态
input
元素,其 type
属性处于搜索
状态
input
元素,其 type
属性处于日期状态
textarea
元素
select
元素
地址级别:“address-level1”
至“address-level4”
字段用于描述街道地址所在的地区。不同区域具有不同数量的级别。例如,美国使用两级
(州和城镇);英国根据地址使用一级或两级(邮政城镇,在某些情况下还包括地区);
中国可以使用三级(省、市、区)。“address-level1”
字段表示范围最广的行政区划。不同区域以不同方式排列这些字段;例如,在美国,城镇
(第 2 级)位于州(第 1 级)之前;而在日本,都道府县(第 1 级)位于市(第 2 级)之前,
市又位于区(第 3 级)之前。建议作者提供符合相应国家惯例的表单
(随着用户更改国家,相应地隐藏、显示和重新排列字段)。
每个适用 autocomplete
属性的 input 元素、
每个 select 元素,以及
每个 textarea
元素,都具有一个自动填充提示集、一个自动填充作用域、一个自动填充字段名称、一个
非自动填充凭据类型和一个IDL 公开的自动填充值。
自动填充字段名称
指定字段中预期的特定数据类型,例如“street-address”
或“cc-exp”。
自动填充提示集标识
用户代理要查看的地址或联系信息类型,例如“shipping
fax”
或“billing”。
非自动填充凭据类型标识一种凭据类型,
当用户与字段交互时,用户代理可以将该类型与其他自动填充字段值一起提供。如果此值为“webauthn”
而不是 null,则选择该类型的凭据将解决一个待处理的 条件式
中介 navigator.credentials.get()
请求,而不是自动填充该字段。
例如,登录页面可以指示用户代理自动填充已保存的密码,或者显示一个公钥凭据,以解决一个待处理的
navigator.credentials.get()
请求。用户可以选择任一方式登录。
< input name = password type = password autocomplete = "current-password webauthn" > 自动填充作用域标识
信息涉及同一主体的字段组,并由自动填充提示集以及适用时的
“section-*”前缀组成,例如“billing”、
“section-parent shipping”或“section-child shipping
home”。
这些值定义为运行以下算法所得的结果:
如果元素没有 autocomplete
属性,则跳转到标记为默认的步骤。
令 tokens 为按 ASCII 空白拆分该属性值所得的结果。
如果 tokens 为空,则跳转到标记为默认的步骤。
令 index 为 tokens 中最后一个标记的索引。
令 field 为 tokens 中第 index 个标记。
将 category、maximum tokens 对设置为给定 field 时确定字段类别所得的结果。
如果 category 为 null,则跳转到标记为默认的步骤。
如果 tokens 中的标记数量大于 maximum tokens, 则跳转到标记为默认的步骤。
如果 category 是 Off 或 Automatic,但元素的 autocomplete
属性披上了自动填充锚点
外衣,则跳转到标记为默认的步骤。
如果 category 是 Off,则将元素的自动填充字段名称
设置为字符串“off”,将其自动填充提示集设置为空,并将其
IDL
公开的自动填充值设置为字符串
“off”。然后返回。
如果 category 是 Automatic,则将元素的自动填充字段
名称设置为字符串“on”,将其自动填充提示集设置为空,并将其
IDL
公开的自动填充值设置为字符串
“on”。然后返回。
令 scope tokens 为空列表。
令 hint tokens 为空集合。
令 credential type 为 null。
令 IDL value 与 field 具有相同的值。
如果 category 是 Credential,并且 tokens 中第
index 个标记与“webauthn”
进行ASCII
不区分大小写匹配,则运行以下子步骤:
将 credential type 设置为“webauthn”。
如果 tokens 中第 index 个标记是第一个条目, 则跳到标记为完成的步骤。
将 index 减一。
将 category、maximum tokens 对设置为给定 tokens 中第 index 个标记时确定字段类别所得的结果。
如果 category 既不是 Normal 也不是 Contact,则跳转到标记为默认的步骤。
如果 index 大于 maximum tokens 减一 (即剩余标记数大于 maximum tokens),则跳转到标记为默认的步骤。
将 IDL value 设置为以下内容的串联:tokens 中第 index 个标记、一个 U+0020 SPACE 字符和 IDL value 的先前值。
如果 tokens 中第 index 个标记是第一个条目, 则跳到标记为完成的步骤。
将 index 减一。
如果 category 是 Contact,并且 tokens 中第 index 个标记与以下列表中的某个字符串进行ASCII 不区分大小写匹配,则运行以下子步骤:
子步骤如下:
令 contact 为上面列表中匹配的字符串。
将 contact 插入 scope tokens 的开头。
将 contact 添加到 hint tokens。
令 IDL value 为以下内容的串联:contact、一个 U+0020 SPACE 字符和 IDL value 的先前值。
如果 tokens 中第 index 个条目是第一个 条目,则跳到标记为完成的步骤。
将 index 减一。
如果 tokens 中第 index 个标记与以下列表中的某个字符串进行ASCII 不区分大小写匹配,则运行以下子步骤:
子步骤如下:
令 mode 为上面列表中匹配的字符串。
将 mode 插入 scope tokens 的开头。
将 mode 添加到 hint tokens。
令 IDL value 为以下内容的串联:mode、一个 U+0020 SPACE 字符和 IDL value 的先前值。
如果 tokens 中第 index 个条目是第一个 条目,则跳到标记为完成的步骤。
将 index 减一。
如果 tokens 中第 index 个条目不是第一个条目,则跳转到 标记为默认的步骤。
如果 tokens 中第 index 个标记的前八个字符与字符串“section-”
不是ASCII
不区分大小写匹配,则跳转到标记为
默认的步骤。
令 section 为 tokens 中第 index 个标记,并将其 转换为 ASCII 小写形式。
将 section 插入 scope tokens 的开头。
令 IDL value 为以下内容的串联:section、一个 U+0020 SPACE 字符和 IDL value 的先前值。
完成:将元素的自动填充提示集设置为 hint tokens。
将元素的非自动填充凭据类型设置为 credential type。
将元素的自动填充 作用域设置为 scope tokens。
将元素的自动填充字段名称设置为 field。
将元素的IDL 公开的自动填充值设置为 IDL value。
返回。
默认:将元素的IDL 公开的自动填充值设置为空 字符串,并将其自动填充提示 集和自动填充作用域 设置为空。
如果元素的 autocomplete
属性披上了自动填充
锚点外衣,则将元素的自动填充字段
名称设置为空字符串并返回。
令 form 为元素的表单 所有者(如果有),否则为 null。
如果 form 不为 null,并且 form 的 autocomplete
属性处于 Off 状态,则将元素的
自动填充字段名称
设置为“off”。
要给定 field,确定字段类别:
如果 field 与下表第一列中给出的任一标记都不是ASCII 不区分大小写匹配,则返回对 (null, null)。
| 标记 | 标记最大数量 | 类别 |
|---|---|---|
“off”
|
1 | Off |
“on”
|
1 | Automatic |
“name”
|
3 | Normal |
“honorific-prefix”
|
3 | Normal |
“given-name”
|
3 | Normal |
“additional-name”
|
3 | Normal |
“family-name”
|
3 | Normal |
“honorific-suffix”
|
3 | Normal |
“nickname”
|
3 | Normal |
“organization-title”
|
3 | Normal |
“username”
|
3 | Normal |
“new-password”
|
3 | Normal |
“current-password”
|
3 | Normal |
“one-time-code”
|
3 | Normal |
“organization”
|
3 | Normal |
“street-address”
|
3 | Normal |
“address-line1”
|
3 | Normal |
“address-line2”
|
3 | Normal |
“address-line3”
|
3 | Normal |
“address-level4”
|
3 | Normal |
“address-level3”
|
3 | Normal |
“address-level2”
|
3 | Normal |
“address-level1”
|
3 | Normal |
“country”
|
3 | Normal |
“country-name”
|
3 | Normal |
“postal-code”
|
3 | Normal |
“cc-name”
|
3 | Normal |
“cc-given-name”
|
3 | Normal |
“cc-additional-name”
|
3 | Normal |
“cc-family-name”
|
3 | Normal |
“cc-number”
|
3 | Normal |
“cc-exp”
|
3 | Normal |
“cc-exp-month”
|
3 | Normal |
“cc-exp-year”
|
3 | Normal |
“cc-csc”
|
3 | Normal |
“cc-type”
|
3 | Normal |
“transaction-currency”
|
3 | Normal |
“transaction-amount”
|
3 | Normal |
“language”
|
3 | Normal |
“bday”
|
3 | Normal |
“bday-day”
|
3 | Normal |
“bday-month”
|
3 | Normal |
“bday-year”
|
3 | Normal |
“sex”
|
3 | Normal |
“url”
|
3 | Normal |
“photo”
|
3 | Normal |
“tel”
|
4 | Contact |
“tel-country-code”
|
4 | Contact |
“tel-national”
|
4 | Contact |
“tel-area-code”
|
4 | Contact |
“tel-local”
|
4 | Contact |
“tel-local-prefix”
|
4 | Contact |
“tel-local-suffix”
|
4 | Contact |
“tel-extension”
|
4 | Contact |
“email”
|
4 | Contact |
“impp”
|
4 | Contact |
“webauthn”
|
5 | Credential |
否则,令 maximum tokens 和 category 分别为该行第二列和第三列单元格中的值。
返回对(category,maximum tokens)。
出于自动填充的目的,控件的数据取决于控件的种类:
如何处理自动填充提示集、自动填充作用域和自动填充字段名称,取决于 autocomplete
属性所披的外衣。
当元素的自动填充字段名称为“off”
时,用户代理不应记住控件的数据,也不应向用户提供过去的值。
此外,当元素的自动填充字段名称为“off”
时,在重新激活文档时,值会被重置。
银行通常不希望用户代理预填充登录信息:
< p >< label > 账户:< input type = "text" name = "ac" autocomplete = "off" ></ label ></ p >
< p >< label > PIN:< input type = "password" name = "pin" autocomplete = "off" ></ label ></ p > 当元素的自动填充字段名称不是“off”
时,用户代理可以存储控件的数据,并可以向用户提供先前存储的值。
例如,假设用户访问了一个包含以下控件的页面:
< select name = "country" >
< option > 阿富汗
< option > 阿尔巴尼亚
< option > 阿尔及利亚
< option > 安道尔
< option > 安哥拉
< option > 安提瓜和巴布达
< option > 阿根廷
< option > 亚美尼亚
<!-- ... -->
< option > 也门
< option > 赞比亚
< option > 津巴布韦
</ select > 其呈现效果可能如下:
假设用户第一次访问此页面时选择了“赞比亚”。第二次访问时,用户代理可以在列表顶部 复制赞比亚条目,使界面改为如下形式:
当自动填充字段名称为“on”
时,用户代理应尝试使用启发式方法确定最适合提供给用户的值,例如基于元素的 name 值、元素在其树中的位置、表单中还存在哪些其他字段等。
当自动填充字段名称是上述自动填充字段名称之一时, 用户代理应提供与本节前面表格中给出的字段名称含义相匹配的建议。应使用自动填充提示集 在多个可能的建议之间进行选择。
例如,如果用户曾在使用“shipping”
关键字的字段中输入一个地址,并在使用“billing”
关键字的字段中输入另一个地址,那么在后续表单中,只有第一个地址会被建议给自动填充提示集包含关键字“shipping”
的表单控件。不过,对于自动填充提示集不包含任一关键字的地址相关
表单控件,则可能会建议这两个地址。
当自动填充字段名称不是空字符串时, 用户代理必须表现得如同用户已为给定的自动填充提示集、自动填充作用域和自动填充字段名称组合指定了控件的数据。
当用户代理自动填充表单控件时,具有相同表单所有者和相同自动填充作用域的元素必须使用与同一人员、地址、
支付工具和联系详细信息有关的数据。当用户代理自动填充具有相同表单
所有者和相同自动填充作用域的“country”
和“country-name”
字段,并且用户代理具有 country”
字段的值时,则必须使用同一国家的人类可读名称填充“country-name”
字段。当用户代理一次填充多个字段时,具有相同自动填充字段名称、相同表单所有者和相同自动填充作用域的所有字段必须填充相同的值。
假设用户代理知道两个电话号码:+1 555 123 1234 和 +1 555 666
7777。如果用户代理将一个 autocomplete="shipping tel-local-prefix" 字段填充为
“123”,而将同一表单中的另一个 autocomplete="shipping tel-local-suffix" 字段填充为
“7777”,则不符合规范。根据上述信息,唯一有效的预填充值应分别为“123”和“1234”,
或者“666”和“7777”。
同样,如果表单由于某种原因同时包含一个“cc-exp”
字段和一个“cc-exp-month”
字段,并且用户代理预填充了该表单,则前者的月份部分必须与后者匹配。
此要求也会与自动填充锚点外衣交互。考虑以下标记片段:
< form >
< input type = hidden autocomplete = "nickname" value = "TreePlate" >
< input type = text autocomplete = "nickname" >
</ form > 符合规范的用户代理在文本控件中唯一可以建议的值是“TreePlate”,即隐藏的 input
元素所给出的值。
自动填充作用域中的“section-*”标记
是不透明的;用户代理不得尝试从这些标记的具体值中推导含义。
例如,如果用户代理决定对“section-child”提供其所知的用户女儿的地址,
并对“section-spouse”提供其所知的用户配偶的地址,则不符合规范。
自动完成机制必须由用户代理实现,其行为如同用户修改了控件的数据,并且必须在元素可变时完成 (例如元素刚被插入文档后,或用户代理停止解析时)。用户代理只能使用用户本可以输入的值 来预填充控件。
例如,如果一个 select 元素只有
值为“Steve”、“Rebecca”、“Jay”和“Bob”的 option 元素,
并且其自动填充字段名称为“given-name”,
但用户代理唯一想到的预填充值是“Evan”,那么用户代理不能预填充该字段。以某种方式将 select 元素设置为
值“Evan”将不符合规范,因为用户自己无法做到这一点。
用户代理在预填充表单控件时,不得区别对待位于文档树中的表单控件和已连接的表单控件;也就是说,根据元素的根是影子根还是 Document 来决定是否自动填充,
不符合规范。
用户代理预填充表单控件的值时,不得导致该控件发生类型不匹配、过长、过短、下溢、上溢或步长不匹配。用户代理预填充表单控件的 值时,也不得导致该控件 发生模式不匹配。在控件约束允许的情况下, 用户代理必须使用上述表格中给出的规范格式。如果无法使用规范格式,则用户代理应使用启发式方法 尝试转换值,以使其可以使用。
例如,如果用户代理知道用户的中间名是“Ines”,并尝试预填充如下所示的表单控件:
< input name = middle-initial maxlength = 1 autocomplete = "additional-name" > ……那么用户代理可以将“Ines”转换为“I”,并以这种方式预填充。
一个更复杂的示例涉及月份值。如果用户代理知道用户的生日是 2012 年 7 月 27 日, 则可以尝试使用由此信息驱动的略有不同的值预填充以下所有控件:
|
2012-07 |
由于月份状态只接受月份/年份组合,
因此会舍弃日期部分。(请注意,此示例不符合规范,因为自动填充字段名称 bday
不允许与月份状态一起使用。)
|
|
七月 | 用户代理从列出的选项中选择月份,可以通过注意到共有十二个选项并选择第七个, 或者通过识别其中某个字符串(三个字符“Jul”,后跟一个换行符和一个空格)与用户代理 所支持语言之一中的月份名称(July)非常接近,或通过其他类似机制。 |
|
7 | 用户代理将“July”转换为与字段相同的 1..12 范围内的月份数字。 |
|
6 | 用户代理将“July”转换为与字段相同的 0..11 范围内的月份数字。 |
|
用户代理不填充该字段,因为它无法合理猜测表单预期的内容。 |
用户代理可以允许用户覆盖元素的自动填充字段名称,例如将其从“off”
更改为“on”,
以便无视页面作者的反对,允许记住并预填充值;或者始终设为“off”,
从不记住值。
更具体地说,当与下表第一列中给出的描述相匹配的表单控件,其自动填充字段名称为“on”
或“off”
时,用户代理尤其可以考虑将该控件的自动填充字段
名称替换为该行第二个单元格中给出的值。如果使用此表,则必须按树顺序进行替换,因为除第一行外,其他各行都引用较早元素的自动填充字段名称。当下面的描述提到表单控件
前面或后面有其他控件时,是指共享同一表单所有者的可列出元素列表中的顺序。
| 表单控件 | 新的自动填充字段名称 |
|---|---|
一个 input
元素,其 type 属性处于
文本状态,并且
后面跟着一个 input
元素,
后者的 type
属性处于密码状态
|
“username”
|
一个 input
元素,其 type 属性处于
密码状态,并且前面有一个
input 元素,
后者的自动填充字段名称为“username”
|
“current-password”
|
一个 input
元素,其 type 属性处于
密码状态,并且前面有一个
input
元素,后者的自动填充字段名称为“current-password”
|
“new-password”
|
一个 input
元素,其 type 属性处于
密码状态,并且前面有一个
input
元素,后者的自动填充字段名称为“new-password”
|
“new-password”
|
autocomplete IDL 属性在获取时,必须返回元素的IDL 公开的自动填充值。
input 和 textarea 元素定义了
若干用于处理其选区的属性和方法。它们的共用算法在此定义。
element.select()
选择文本控件中的全部内容。
element.selectionStart [ = value ]
返回选区起点的偏移量。
可以设置,以更改选区的起点。
element.selectionEnd [ = value ]
返回选区终点的偏移量。
可以设置,以更改选区的终点。
element.selectionDirection [ = value ]
返回选区的当前方向。
可以设置,以更改选区的方向。
可能的值为“forward”、“backward”
和“none”。
element.setSelectionRange(start, end [, direction])
HTMLInputElement/setSelectionRange
所有当前引擎均支持。
更改选区,使其按给定方向覆盖给定的子字符串。如果省略方向, 则会将其重置为平台默认值(none 或 forward)。
element.setRangeText(replacement [, start, end [, selectionMode ] ])
所有当前引擎均支持。
使用新文本替换一段文本。如果未提供 start 和 end 参数,则假定该范围为选区。
最后一个参数决定替换文本后如何设置选区。 可能的值为:
select”start”end”preserve”这些 API 所适用的所有
input 元素,以及所有
textarea 元素,
在任何时候都具有一个选区或一个文本输入光标位置(即使元素没有被渲染),其度量方式为控件相关值的代码单元偏移量。初始状态必须由位于控件开头的文本
输入光标组成。
对于 input 元素,
这些 API 必须对元素的值进行操作。
对于 textarea
元素,这些 API 必须对元素的 API
值进行操作。在下面的算法中,我们将被操作的值字符串
称为相关值。
对 textarea
元素使用 API 值而不是原始值,意味着 U+000D (CR)
字符会被规范化掉。
例如:
< textarea id = "demo" ></ textarea >
< script >
demo. value = "A\r\nB" ;
demo. setRangeText( "replaced" , 0 , 2 );
assert( demo. value === "replacedB" );
</ script > 如果我们对“A\r\nB”的原始值进行操作,那么我们会替换字符
“A\r”,最终得到“replaced\nB”。但由于我们使用的是
“A\nB”的 API
值,因此我们替换了字符
“A\n”,得到“replacedB”。
没有可见呈现的字符(例如 U+200D ZERO WIDTH JOINER)仍然计为字符。 因此,例如,选区可以只包含一个不可见字符,而文本插入光标可以放置在此类字符的任一侧。
每当这些 API 所适用的元素的相关值发生更改时, 运行以下步骤:
在相关值发生变化的某些情况下,
本规范的其他部分还会修改文本输入光标
位置,而不仅是执行上述限制步骤。例如,请参阅 textarea 的
value 设置器。
在可能的情况下,用于更改 input 和
textarea
元素中文本选区的用户界面功能,必须使用设置
选区范围算法来实现,以便例如触发所有相同的事件。
input 和
textarea
元素的选区具有一个选区方向,其值为“forward”、
“backward”或“none”。
选区方向的确切含义取决于平台。当用户操纵选区时,会设置此方向。如果平台支持
“none”方向,则初始选区方向必须为“none”,否则为
“forward”。
在 Windows 上,方向表示插入符相对于选区的位置:“forward”选区的插入符位于
选区末尾,而“backward”选区的插入符位于选区起点。
Windows 没有“none”方向。
在 Mac 上,方向表示当用户使用带 Shift 修饰键的方向键调整选区大小时,选区的哪一端会受到影响:
“forward”方向意味着修改选区的末端,而“backward”方向意味着修改
选区的起点。“none”方向是 Mac 上的默认值,表示尚未选择特定方向。
用户在首次调整选区时,根据所使用的方向键隐式设置方向。
所有当前引擎均支持。
select() 方法被调用时,必须运行以下步骤:
如果此元素是一个 input
元素,并且
select()
不适用于此元素,或者相应控件没有
可选择的文本,则返回。
例如,在将 <input type=color>
渲染为带有选取器的颜色井,而不是接受十六进制颜色代码的文本控件的用户代理中,
不存在可选择的文本,因此对该方法的调用会被忽略。
使用 0 和无穷大设置选区范围。
selectionStart 属性的获取器必须运行以下步骤:
selectionStart
属性的设置器必须运行以下步骤:
如果此元素是一个 input
元素,并且
selectionStart
不适用于此元素,则抛出一个
“InvalidStateError”
DOMException。
令 end 为此元素的 selectionEnd
属性的值。
如果 end 小于给定值,则将 end 设置为给定值。
使用给定值、end 和此元素的 selectionDirection
属性的值设置选区范围。
selectionEnd 属性的获取器必须运行以下步骤:
selectionEnd
属性的设置器必须运行以下步骤:
如果此元素是一个 input
元素,并且
selectionEnd
不适用于此元素,则抛出一个
“InvalidStateError”
DOMException。
使用此元素的 selectionStart
属性的值、给定值和此元素的 selectionDirection
属性的值设置选区范围。
selectionDirection 属性的获取器必须运行以下步骤:
如果此元素是一个 input
元素,并且
selectionDirection
不适用于此元素,则返回
null。
返回此元素的选区方向。
selectionDirection
属性的设置器必须运行以下步骤:
如果此元素是一个 input
元素,并且
selectionDirection
不适用于此元素,则抛出一个
“InvalidStateError” DOMException。
使用此元素的 selectionStart
属性的值、此元素的 selectionEnd
属性的值和给定值设置选区范围。
setSelectionRange(start, end,
direction) 方法被调用时,必须运行以下步骤:
如果此元素是一个 input
元素,并且
setSelectionRange()
不适用于此元素,则抛出一个
“InvalidStateError” DOMException。
使用 start、end 和 direction 设置选区范围。
要使用整数或 null 的 start、整数、null 或特殊值无穷大的 end, 以及可选的字符串 direction 来设置选区范围, 运行以下步骤:
如果 start 为 null,则令 start 为 0。
如果 end 为 null,则令 end 为 0。
将文本控件的选区设置为相关值中从第 start 个位置(按逻辑顺序)的代码单元开始,到第 (end-1) 个位置的代码单元结束的代码单元序列。 大于文本控件相关值的长度的参数(包括特殊值无穷大),必须被视为指向文本控件的末尾。 如果 end 小于或等于 start,则选区的起点和终点都必须放置在偏移量为 end 的字符之前。在没有空选区概念的用户代理中,这必须将光标设置在偏移量为 end 的字符之前。
如果 direction 与“backward”或“forward”
都不相同,或者未给出 direction
参数,则将 direction 设置为“none”。
将文本控件的选区方向设置为 direction。
如果前面的步骤导致文本控件的选区发生修改
(无论是范围还是方向),则在给定元素的用户交互任务源上排入一个
元素任务,以在该元素处触发一个名为
select 的事件,
并将 bubbles
属性初始化为 true。
setRangeText(replacement, start,
end, selectMode) 方法被调用时,必须运行以下步骤:
如果此元素是一个 input
元素,并且
setRangeText()
不适用于此元素,则抛出一个
“InvalidStateError”
DOMException。
将此元素的脏值标志设置为 true。
如果该方法只有一个参数,则令 start 和 end 分别为
selectionStart
属性和 selectionEnd
属性的值。
否则,令 start、end 分别为第二个和第三个参数的值。
如果 start 大于 end,则抛出一个
“IndexSizeError” DOMException。
令 selection start 为 selectionStart
属性的当前值。
令 selection end 为 selectionEnd
属性的当前值。
如果 start 小于 end,则删除元素相关值中从第 start 个位置的代码单元开始,到第 (end-1) 个位置的 代码单元结束的代码单元序列。
令 new length 为第一个参数值的长度。
令 new end 为 start 与 new length 之和。
运行以下列表中适当的一组子步骤:
select”令 selection start 为 start。
令 selection end 为 new end。
start”令 selection start 和 selection end 为 start。
end”令 selection start 和 selection end 为 new end。
preserve”令 old length 为 end 减去 start。
令 delta 为 new length 减去 old length。
如果 selection start 大于 end,则将其增加 delta。(如果 delta 为负数,即新文本比旧文本短, 则这会减小 selection start 的值。)
否则:如果 selection start 大于 start,则将其设置为 start。(如果选区起点位于被替换文本的中间,这会将选区起点吸附到 新文本的起点。)
如果 selection end 大于 end,则以相同方式将其增加 delta。
否则:如果 selection end 大于 start,则将其设置为 new end。(如果选区终点位于被替换文本的中间,这会将选区终点吸附到 新文本的终点。)
使用 selection start 和 selection end 设置选区范围。
setRangeText()
方法使用以下枚举:
enum SelectionMode {
" select " ,
" start " ,
" end " ,
" preserve " // 默认值
};要获取当前选中的文本,以下 JavaScript 即可:
var selectionText = control. value. substring( control. selectionStart, control. selectionEnd); 要在保持文本选区的同时,在文本控件的开头添加一些文本,必须保留这三个属性:
var oldStart = control. selectionStart;
var oldEnd = control. selectionEnd;
var oldDirection = control. selectionDirection;
var prefix = "http://" ;
control. value = prefix + control. value;
control. setSelectionRange( oldStart + prefix. length, oldEnd + prefix. length, oldDirection); 元素可以定义一个自定义有效性错误消息。
最初,元素的自定义有效性错误消息必须设置为空字符串。
当其值不是空字符串时,该元素存在自定义错误。除表单关联自定义
元素外,可以使用 setCustomValidity()
方法设置该消息。表单关联自定义元素可以通过其 ElementInternals 对象的
setValidity()
方法设置自定义有效性错误消息。当向用户提示控件的问题时,
用户代理应使用自定义有效性错误消息。
元素可以受到多种方式的约束。以下是表单控件可能处于的有效性状态列表, 这些状态会使控件在约束验证中无效。(以下定义是非规范性的;本规范的其他部分更精确地定义了 每种状态何时适用或不适用。)
当控件没有值,但具有
required 属性(input
required、textarea required)时;
或者,对于 select
元素和单选按钮组中的控件,
按其相应章节中规定的更复杂规则处理。
当 setValidity()
方法将表单关联自定义元素的
valueMissing 标志设置为 true 时。
当允许任意用户输入的控件具有不符合正确语法的值时(电子邮件、URL)。
当 setValidity()
方法将表单关联自定义元素的
typeMismatch 标志设置为 true 时。
当 setValidity()
方法将表单关联自定义元素的
patternMismatch 标志设置为 true 时。
当控件的值对于表单控件 maxlength
属性而言过长时(input maxlength、textarea
maxlength)。
当 setValidity()
方法将表单关联自定义元素的
tooLong 标志设置为 true 时。
当控件的值对于表单控件 minlength
属性而言过短时(input minlength、textarea
minlength)。
当 setValidity()
方法将表单关联自定义元素的
tooShort 标志设置为 true 时。
当控件具有一个不是空字符串,并且对于 min 属性而言过低的值时。
当 setValidity()
方法将表单关联自定义元素的
rangeUnderflow 标志设置为 true 时。
当控件具有一个不是空字符串,并且对于 max 属性而言过高的值时。
当 setValidity()
方法将表单关联自定义元素的
rangeOverflow 标志设置为 true 时。
当 setValidity()
方法将表单关联自定义元素的
stepMismatch 标志设置为 true 时。
当控件包含不完整输入,并且用户代理认为用户不应能够在当前状态下提交表单时。
当 setValidity()
方法将表单关联自定义元素的
badInput 标志设置为 true 时。
当控件的自定义有效性错误消息(由元素的
setCustomValidity()
方法或 ElementInternals 的
setValidity()
方法设置)不是空字符串时。
即使元素已禁用,元素仍可能处于这些状态;因此,即使在提交期间验证表单时 不会向用户指出问题,这些状态仍可在 DOM 中表示。
如果元素没有处于上述任何有效性状态,则该元素满足其约束。
当要求用户代理静态验证
form 元素
form 的约束时,它必须运行以下步骤,这些步骤返回肯定结果
(表单中的所有控件均有效)或否定结果(存在无效控件),并附带一个元素列表
(可能为空),这些元素无效且没有脚本声明对其负责:
令 invalid controls 为一个初始为空的元素列表。
对于 controls 中按树顺序排列的每个元素 field:
如果 invalid controls 为空,则返回肯定结果。
令 unhandled invalid controls 为一个初始为空的元素列表。
对于 invalid controls 中按树顺序排列的每个元素 field(如果有):
令 notCanceled 为在 field 处触发一个名为 invalid 的事件所得的
结果,并将 cancelable
属性初始化为 true。
如果 notCanceled 为 true,则将 field 添加到 unhandled invalid controls。
返回否定结果,并附带 unhandled invalid controls 列表中的元素列表。
如果用户代理要交互式验证 form
元素 form 的约束,则用户代理必须运行以下步骤:
静态验证 form 的约束,如果结果为否定,则令 unhandled invalid controls 为返回的元素列表。
如果结果为肯定,则返回该结果。
向用户报告 unhandled invalid controls 中给出的至少一个元素的约束问题。
返回否定结果。
element.willValidate
HTMLObjectElement/willValidate
所有当前引擎均支持。
如果提交表单时将验证该元素,则返回 true;否则返回 false。
element.setCustomValidity(message)
HTMLObjectElement/setCustomValidity
所有当前引擎均支持。
HTMLSelectElement/setCustomValidity
所有当前引擎均支持。
设置自定义错误,使元素无法通过验证。给定消息是在向用户报告问题时显示给用户的消息。
如果参数为空字符串,则清除自定义错误。
element.validity.valueMissing
所有当前引擎均支持。
如果元素没有值但属于必填字段,则返回 true;否则返回 false。
element.validity.typeMismatch
如果元素的值不符合正确语法,则返回 true;否则返回 false。
element.validity.patternMismatch
如果元素的值与所提供的模式不匹配,则返回 true;否则返回 false。
element.validity.tooLong
所有当前引擎均支持。
如果元素的值长于所提供的最大长度,则返回 true;否则返回 false。
element.validity.tooShort
所有当前引擎均支持。
如果元素的值不是空字符串,并且短于所提供的最小长度,则返回 true;否则返回 false。
element.validity.rangeUnderflow
如果元素的值低于所提供的最小值,则返回 true;否则返回 false。
element.validity.rangeOverflow
如果元素的值高于所提供的最大值,则返回 true;否则返回 false。
element.validity.stepMismatch
如果元素的值不符合 step
属性给出的
规则,则返回 true;否则返回 false。
element.validity.badInput
所有当前引擎均支持。
如果用户在用户界面中提供了用户代理无法转换为值的输入,则返回 true;否则返回 false。
element.validity.customError
如果元素存在自定义错误,则返回 true;否则返回 false。
element.validity.valid
如果元素的值不存在有效性问题,则返回 true;否则返回 false。
valid = element.checkValidity()
HTMLInputElement/checkValidity
所有当前引擎均支持。
HTMLObjectElement/checkValidity
所有当前引擎均支持。
HTMLSelectElement/checkValidity
所有当前引擎均支持。
如果元素的值不存在有效性问题,则返回 true;否则返回 false,并在后一种情况下在元素上触发
invalid 事件。
valid = element.reportValidity()
HTMLFormElement/reportValidity
所有当前引擎均支持。
HTMLInputElement/reportValidity
所有当前引擎均支持。
如果元素的值不存在有效性问题,则返回 true;否则返回 false,在元素上触发一个
invalid 事件,
并且如果该事件未被取消,则向用户报告问题。
element.validationMessage
HTMLObjectElement/validationMessage
所有当前引擎均支持。
返回在检查元素有效性时会显示给用户的错误消息。
willValidate 属性的获取器必须在
此元素是约束验证候选项时返回 true,
否则返回 false(即,如果有任何条件阻止其参与
约束验证,则返回 false)。
所有当前引擎均支持。
ElementInternals
接口的 willValidate 属性在获取时,如果目标元素不是表单关联自定义元素,则必须抛出一个
“NotSupportedError” DOMException。
否则,如果目标元素是约束验证候选项,
则必须返回 true,否则返回 false。
HTMLInputElement/setCustomValidity
所有当前引擎均支持。
setCustomValidity(error)
方法的步骤为:
将 error 设置为给定 error 时规范化换行符所得的结果。
将自定义有效性错误消息设置为 error。
在以下示例中,脚本会在每次编辑表单控件时检查其值,并在该值无效时使用 setCustomValidity()
方法设置适当的消息。
< label > 感受:< input name = f type = "text" oninput = "check(this)" ></ label >
< script >
function check( input) {
if ( input. value == "good" ||
input. value == "fine" ||
input. value == "tired" ) {
input. setCustomValidity( '"' + input. value + '" is not a feeling.' );
} else {
// 输入有效——重置错误消息
input. setCustomValidity( '' );
}
}
</ script > 所有当前引擎均支持。
validity 属性的获取器必须返回一个
ValidityState
对象,该对象表示此元素的有效性状态。此对象是实时的。
所有当前引擎均支持。
ElementInternals
接口的 validity 属性在获取时,如果目标元素不是表单关联自定义元素,则必须抛出一个
“NotSupportedError” DOMException。
否则,它必须返回一个 ValidityState 对象,
该对象表示目标元素的有效性状态。
此对象是实时的。
[Exposed =Window ]
interface ValidityState {
readonly attribute boolean valueMissing ;
readonly attribute boolean typeMismatch ;
readonly attribute boolean patternMismatch ;
readonly attribute boolean tooLong ;
readonly attribute boolean tooShort ;
readonly attribute boolean rangeUnderflow ;
readonly attribute boolean rangeOverflow ;
readonly attribute boolean stepMismatch ;
readonly attribute boolean badInput ;
readonly attribute boolean customError ;
readonly attribute boolean valid ;
};ValidityState
对象具有以下属性。在获取时,如果下列列表中给出的相应条件为 true,则它们必须返回 true,
否则返回 false。
valueMissing控件缺少值。
typeMismatch
所有当前引擎均支持。
控件存在类型不匹配。
patternMismatch
所有当前引擎均支持。
控件存在模式不匹配。
tooLong控件过长。
tooShort控件过短。
rangeUnderflow
所有当前引擎均支持。
控件存在下溢。
rangeOverflow
所有当前引擎均支持。
控件存在上溢。
stepMismatch
所有当前引擎均支持。
控件存在步长不匹配。
badInput控件存在错误输入。
customError控件存在自定义错误。
valid其他条件均不为 true。
元素 element 的检查有效性步骤为:
如果 element 是约束验证候选项, 并且不满足其约束:
在 element 处触发一个名为
invalid 的事件,
并将 cancelable
属性初始化为 true(尽管取消该事件没有效果)。
返回 false。
返回 true。
checkValidity() 方法被调用时,
必须对该元素运行检查有效性步骤。
ElementInternals/checkValidity
所有当前引擎均支持。
ElementInternals
接口的 checkValidity() 方法必须运行以下步骤:
令 element 为此 ElementInternals
的目标元素。
如果 element 不是表单关联自定义元素,则抛出一个
“NotSupportedError” DOMException。
对 element 运行检查有效性步骤。
元素 element 的报告有效性步骤为:
reportValidity() 方法被调用时,
必须对该元素运行报告有效性步骤。
ElementInternals/reportValidity
所有当前引擎均支持。
ElementInternals
接口的 reportValidity() 方法必须运行以下步骤:
令 element 为此 ElementInternals
的目标元素。
如果 element 不是表单关联自定义元素,则抛出一个
“NotSupportedError” DOMException。
对 element 运行报告有效性步骤。
validationMessage 属性的获取器
必须运行以下步骤:
返回一条适当本地化的消息,该消息是在此元素是唯一存在有效性约束问题的表单控件时, 用户代理会向用户显示的消息。如果用户代理在这种情况下实际上不会显示文本消息 (例如,改为显示图形提示),则返回一条适当本地化的消息,用于表达控件未满足的一个或多个 有效性约束。如果元素是约束验证候选项, 并且存在自定义错误, 则返回值中应包含自定义有效性错误消息。
服务器不应依赖客户端验证。恶意用户可以有意绕过客户端验证,而使用未实现这些功能的 较旧用户代理或自动化工具的用户也可能无意中绕过客户端验证。约束验证功能仅旨在改善用户体验, 而不是提供任何形式的安全机制。
本节为非规范性内容。
提交表单时,表单中的数据会被转换为由 enctype 指定的结构,然后使用给定的 method,发送到由 action 指定的目标。
例如,考虑以下表单:
< form action = "/find.cgi" method = get >
< input type = text name = t >
< input type = search name = q >
< input type = submit >
</ form > 如果用户在第一个字段中输入“cats”,在第二个字段中输入“fur”,然后点击提交按钮,
则用户代理将加载 /find.cgi?t=cats&q=fur。
另一方面,考虑以下表单:
< form action = "/find.cgi" method = post enctype = "multipart/form-data" >
< input type = text name = t >
< input type = search name = q >
< input type = submit >
</ form > 对于相同的用户输入,提交结果会非常不同:用户代理改为向给定 URL 发出 HTTP POST, 其实体主体类似于以下文本:
------kYFrd4jNJEgCervE Content-Disposition: form-data; name="t" cats ------kYFrd4jNJEgCervE Content-Disposition: form-data; name="q" fur ------kYFrd4jNJEgCervE--
如果用户代理支持让用户隐式提交表单(例如,在某些平台上,当文本控件获得焦点时按下“Enter”键会隐式提交表单),那么对于其默认按钮具有激活
行为且未禁用的表单,执行隐式提交时,必须使用户代理在该默认
按钮处触发一个
click 事件。
Web 上存在一些只有在可以隐式提交表单时才能使用的页面,因此强烈建议用户代理支持此功能。
如果表单没有提交按钮,则隐式提交机制必须执行以下步骤:
如果表单具有多个阻止隐式提交的字段, 则返回。
从 form 元素自身
提交 form 元素,并将
userInvolvement
设置为“activation”。
就上一段而言,如果一个元素是 input
元素,其表单所有者为该 form 元素,并且其 type 属性处于以下状态之一,
则该元素是 form 元素的阻止隐式
提交的字段:
文本、
搜索、
电话、
URL、
电子邮件、
密码、
日期、
月份、
周、
时间、
本地日期和时间、
数字
每个 form 元素都有
一个正在构造条目列表布尔值,其初始值为
false。
每个 form 元素
都有一个正在触发提交事件布尔值,其初始值为
false。
要从元素 submitter(通常为按钮)提交一个 form 元素
form,并给定一个可选布尔值 通过 submit()
方法提交(默认为 false)
和一个可选的用户导航
参与度 userInvolvement(默认为“none”):
如果 form 无法导航,则返回。
如果 form 的正在构造条目列表为 true,则返回。
令 form document 为 form 的节点文档。
如果 form document 的活动沙盒标志 集设置了沙盒化表单浏览上下文 标志,则返回。
如果 通过 submit() 方法提交
为 false:
如果 form 的正在触发提交事件为 true,则返回。
将 form 的正在触发提交事件设置为 true。
如果 submitter 元素的不验证 状态为 false,则交互式验证 form 的约束并检查结果。如果结果为否定(即约束验证断定存在无效字段, 并且可能已将此情况告知用户):
将 form 的正在触发提交事件设置为 false。
返回。
如果 submitter 是 form,则令 submitterButton 为 null。 否则,令 submitterButton 为 submitter。
令 shouldContinue 为在 form 处使用
SubmitEvent
触发一个
名为 submit 的事件所得的结果,
其中 submitter
属性初始化为 submitterButton,bubbles
属性初始化为 true,并且 cancelable
属性初始化为 true。
将 form 的正在触发提交事件设置为 false。
如果 shouldContinue 为 false,则返回。
如果 form 无法导航,则返回。
令 encoding 为为表单选择编码所得的结果。
令 entry list 为使用 form、submitter 和 encoding 构造条目列表所得的结果。
断言:entry list 不为 null。
如果 form 无法导航,则返回。
令 method 为 submitter 元素的method。
如果 method 为 dialog:
令 action 为 submitter 元素的action。
如果 action 为空字符串,则令 action 为 form document 的 URL。
令 parsed action 为以 submitter 的节点文档为基准,给定 action 时使用编码解析 URL所得的结果。
如果 parsed action 为失败,则返回。
令 scheme 为 parsed action 的方案。
令 enctype 为 submitter 元素的enctype。
令 formTarget 为 null。
如果 submitter 元素是一个提交
按钮,并且具有 formtarget
属性,则将 formTarget 设置为 formtarget
属性值。
令 noopener 为使用 form、parsed action 和 target 获取 元素的 noopener所得的结果。
令 targetNavigable 为给定 target、form 的节点 可导航对象和 noopener 时,应用选择可导航对象的规则所得的第一个返回值。
如果 targetNavigable 为 null,则返回。
令 historyHandling 为“auto”。
如果 form document 等于 targetNavigable 的活动文档,并且 form document 尚未完全加载,则将
historyHandling 设置为“replace”。
根据每行第一个单元格中给出的 scheme,在下表中选择适当的行。然后根据每列第一个 单元格中给出的 method,选择该行中的适当单元格。然后跳转到该单元格中命名且在表格下方 定义的步骤。
| GET | POST | |
|---|---|---|
http
|
修改 action URL | 作为实体主体提交 |
https
|
修改 action URL | 作为实体主体提交 |
ftp
|
获取 action URL | 获取 action URL |
javascript
|
获取 action URL | 获取 action URL |
data
|
修改 action URL | 获取 action URL |
mailto
|
使用标头 发送邮件 | 将内容作为正文发送邮件 |
如果 scheme 不是此表中列出的方案之一,则本规范未定义其行为。在没有其他规范对此 进行定义时,用户代理应以类似于本规范针对相似方案所定义的方式运行。
每个 form
元素都有一个计划导航,其值为 null 或一个任务;首次创建 form 时,其
计划导航必须设置为
null。在下面描述的行为中,当要求用户代理给定一个可选的POST
资源或 null 的
postResource(默认为 null),计划导航到一个URL url 时,必须运行以下步骤:
令 referrerPolicy 为空字符串。
如果 form
元素的
链接类型包含 noreferrer
关键字,则将 referrerPolicy 设置为“no-referrer”。
在给定 form 元素的DOM 操作任务源上排入一个元素
任务,以运行以下步骤:
使用 form
元素的节点文档,将
targetNavigable
导航到 url,
其中 historyHandling
设置为 historyHandling,userInvolvement 设置为 userInvolvement,
sourceElement 设置为 submitter,
referrerPolicy 设置为 referrerPolicy,
documentResource 设置为 postResource,并将 formDataEntryList 设置为 entry
list。
行为如下:
令 pairs 为使用 entry list 转换为名称-值对列表所得的结果。
令 query 为使用 pairs 和 encoding 运行
application/x-www-form-urlencoded
序列化器所得的结果。
将 parsed action 的查询组件设置为 query。
计划导航到 parsed action。
根据 enctype 切换:
application/x-www-form-urlencoded
令 pairs 为使用 entry list 转换为名称-值对 列表所得的结果。
令 body 为使用 pairs 和 encoding 运行
application/x-www-form-urlencoded
序列化器所得的结果。
将 body 设置为对 body 进行编码所得的结果。
令 mimeType 为 `application/x-www-form-urlencoded`。
multipart/form-data
令 body 为使用 entry list 和 encoding 运行multipart/form-data
编码算法所得的结果。
令 mimeType 为字符串“multipart/form-data; boundary=”与由multipart/form-data
编码算法生成的 multipart/form-data
边界字符串串联后所得字符串的同构编码。
text/plain
令 pairs 为使用 entry list 转换为名称-值对 列表所得的结果。
令 body 为使用 pairs 运行text/plain
编码算法所得的结果。
将 body 设置为使用 encoding 对 body 进行编码所得的结果。
令 mimeType 为 `text/plain`。
给定一个POST 资源,其中请求主体为 body,且请求 内容类型为 mimeType,计划导航到 parsed action。
计划导航到 parsed action。
entry list 会被丢弃。
令 pairs 为使用 entry list 转换为名称-值对 列表所得的结果。
令 headers 为使用 pairs 和 encoding 运行
application/x-www-form-urlencoded
序列化器所得的结果。
将 headers 中出现的 U+002B PLUS SIGN 字符(+)替换为字符串
“%20”。
将 parsed action 的查询设置为 headers。
计划导航到 parsed action。
令 pairs 为使用 entry list 转换为名称-值对 列表所得的结果。
根据 enctype 切换:
text/plain
令 body 为使用 pairs 运行text/plain
编码算法所得的结果。
将 body 设置为使用默认编码集对 body 运行UTF-8 百分号编码所得的结果。[URL]
令 body 为使用 pairs 和 encoding 运行
application/x-www-form-urlencoded
序列化器所得的结果。
如果 parsed action 的查询为 null,则将其设置为空字符串。
如果 parsed action 的查询不是空字符串,则向其追加一个 U+0026 AMPERSAND 字符(&)。
向 parsed action 的查询追加“body=”。
向 parsed action 的查询追加 body。
计划导航到 parsed action。
条目列表是一个由条目组成的列表,通常表示表单的内容。条目是一个元组,由一个名称(一个标量值字符串)和一个值(一个标量值
字符串或一个 File
对象)组成。
要给定一个字符串 name、一个字符串或 Blob
对象 value,以及可选的标量值字符串
filename,创建条目:
要给定一个 form、一个可选的 submitter(默认为 null),以及一个可选的 encoding(默认为 UTF-8),构造条目列表:
如果 form 的正在构造条目列表为 true,则返回 null。
将 form 的正在构造条目列表设置为 true。
令 entry list 为一个新的空条目列表。
对于 controls 中按树顺序排列的每个元素 field:
如果以下任一条件为 true:
则继续。
令 name 为 field 元素的 name 属性值。
如果 field 元素是一个 select
元素,则对于 select
元素的选项列表中,所有选中性为
true 且未禁用的
option
元素,使用 name 和该 option
元素的值创建一个条目,并将其追加到 entry
list。
否则,如果 field 元素是一个 input
元素,其 type
属性处于
状态,并且 name 与
“_charset_”进行ASCII
不区分大小写匹配:
如果元素具有 dirname 属性,
该属性值不是空字符串,并且该元素是一个自动方向性表单关联
元素:
令 form data 为一个与 entry list 关联的新 FormData
对象。
在 form 处使用 FormDataEvent
触发一个事件,其名称为
formdata,
并将 formData
属性初始化为 form data,将 bubbles
属性初始化为 true。
将 form 的正在构造条目列表设置为 false。
返回 entry list 的一个克隆。
如果用户代理要为表单选择编码,则必须运行以下步骤:
令 encoding 为文档的字符编码。
如果 form
元素具有 accept-charset
属性,则将 encoding 设置为
运行以下子步骤所得的返回值:
令 input 为 form
元素的 accept-charset
属性值。
令 candidate encoding labels 为在 ASCII 空白处拆分 input 所得的结果。
令 candidate encodings 为一个空的字符 编码列表。
依次处理 candidate encoding labels 中的每个标记(按照它们在 input 中出现的顺序),为该标记获取 编码,并且如果结果不是失败,则将该编码追加到 candidate encodings。
如果 candidate encodings 为空,则返回 UTF-8。
返回 candidate encodings 中的第一个编码。
返回从 encoding 获取输出 编码所得的结果。
application/x-www-form-urlencoded
和 text/plain
编码算法接受名称-值对列表,其中的值
必须是字符串,而不是值可以是 File
的条目列表。
以下算法执行此转换。
要将一个条目列表 entry list 转换为名称-值对列表,运行以下步骤:
令 list 为一个空的名称-值对列表。
对于 entry list 中的每个 entry:
令 name 为 entry 的名称, 其中每个后面没有 U+000A (LF) 的 U+000D (CR),以及每个前面没有 U+000D (CR) 的 U+000A (LF),都替换为由 U+000D (CR) 和 U+000A (LF) 组成的字符串。
如果 entry 的值是一个
File
对象,则令 value 为 entry 的值的 name。
否则,令
value 为 entry 的值。
将 value 中每个后面没有 U+000A (LF) 的 U+000D (CR),以及每个 前面没有 U+000D (CR) 的 U+000A (LF),替换为由 U+000D (CR) 和 U+000A (LF) 组成的字符串。
向 list 追加一个新的名称-值对,其 名称为 name,值为 value。
返回 list。
有关 application/x-www-form-urlencoded
的详细信息,请参阅 URL。
[URL]
给定一个条目
列表 entry list 和一个编码 encoding,
multipart/form-data 编码
算法如下:
对于 entry list 中的每个 entry:
返回使用 RFC 7578《从表单返回值:multipart/form-data》中
所述规则,在给定以下条件的情况下对 entry list 进行编码所得的字节序列:
[RFC7578]
各部分的顺序必须与 entry list 中字段的顺序相同。 名称相同的多个条目必须被视为不同的字段。
在生成的 multipart/form-data
资源中,字段名称、非文件字段的字段值以及文件字段的文件名,必须设置为使用
encoding 对相应条目的名称或值进行编码,并转换为字节序列所得的结果。
对于字段名称和文件字段的文件名,上一项中的编码结果必须通过以下方式转义:
将所有 0x0A (LF) 字节替换为字节序列
`%0A`,将 0x0D (CR) 替换为 `%0D`,并将 0x22 (") 替换为
`%22`。用户代理不得执行任何其他转义。
生成的 multipart/form-data
资源中对应于非文件字段的部分不得指定 `Content-Type` 标头。
用户代理在生成此算法的返回值时使用的边界是multipart/form-data 边界
字符串。(此值用于生成由此算法产生的表单提交载荷的 MIME 类型。)
有关如何解释 multipart/form-data
载荷的详细信息,请参阅 RFC 7578。
[RFC7578]
给定一个名称-值对列表 pairs,text/plain 编码算法如下:
令 result 为空字符串。
对于 pairs 中的每个 pair:
将 pair 的名称追加到 result。
将一个 U+003D EQUALS SIGN 字符(=)追加到 result。
将 pair 的值追加到 result。
将一对 U+000D CARRIAGE RETURN (CR) U+000A LINE FEED (LF) 字符追加到 result。
返回 result。
使用 text/plain
格式的载荷旨在供人类阅读。计算机无法可靠地解释它们,
因为该格式存在歧义(例如,无法区分值中的字面换行符与值末尾的换行符)。
SubmitEvent 接口所有当前引擎均支持。
所有当前引擎均支持。
[Exposed =Window ]
interface SubmitEvent : Event {
constructor (DOMString type , optional SubmitEventInit eventInitDict = {});
readonly attribute HTMLElement ? submitter ;
};
dictionary SubmitEventInit : EventInit {
HTMLElement ? submitter = null ;
};submitter 属性必须返回它被
初始化为的值。
FormDataEvent 接口所有当前引擎均支持。
所有当前引擎均支持。
[Exposed =Window ]
interface FormDataEvent : Event {
constructor (DOMString type , FormDataEventInit eventInitDict );
readonly attribute FormData formData ;
};
dictionary FormDataEventInit : EventInit {
required FormData formData ;
};当一个 form 元素
form 被重置时,运行以下步骤:
每个可重置元素都定义了自己的重置算法。作为这些算法的一部分对表单控件所做的更改
不算作由用户引起的更改(因此,例如,不会导致触发 input
事件)。
details
元素
所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
summary 元素,
后跟流式内容。name — 一组相互排斥的
details 元素的名称
open — 详细信息是否
可见
[Exposed =Window ]
interface HTMLDetailsElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect ] attribute DOMString name ;
[CEReactions , Reflect ] attribute boolean open ;
};details 元素
表示一个披露小部件,用户可以从中
获取附加信息或控件。
与所有 HTML 元素一样,在尝试表示另一种类型的控件时使用 details
元素是不符合要求的。例如,选项卡小部件和
菜单小部件不是披露小部件,因此滥用 details 元素来
实现这些模式是不正确的。
details
元素不适合
用于脚注。有关如何标记脚注的详细信息,请参阅关于脚注的章节。
元素的第一个 summary
子元素(如果有)
表示详细信息的摘要或图例。如果没有
子 summary
元素,则用户代理应提供自己的图例(例如
“详细信息”)。
元素其余的内容表示附加信息或 控件。
name 内容
属性给出该元素所属的相关 details
元素组的
名称。打开该组中的一个成员会导致该组的其他成员关闭。如果指定了该
属性,其值不得为空字符串。
在使用此功能之前,作者应考虑将相关
details 元素分组为
排他式手风琴组件对用户是有帮助还是有害。
虽然使用排他式手风琴组件可以减少一组内容可能占据的最大空间,
但它也可能使必须打开许多项目才能找到所需内容的用户,或
希望同时查看多个项目内容的用户感到沮丧。
文档不得在同一个details 名称组中包含多个具有 open
属性的 details 元素。
作者不得使用脚本以会导致某个details 名称
组具有多个带有 open 属性的
details 元素的方式,
向文档添加 details 元素。
由共同的 name
属性创建的元素组是排他的,
这意味着最多只能同时打开其中一个
details 元素。
虽然这种排他性由用户
代理强制执行,但由此产生的强制执行会立即更改标记中的 open 属性。对作者的此项
要求禁止这种误导性标记。
文档不得包含一个 details
元素,
该元素是同一details 名称组中另一个
details 元素的后代。
使用 name 属性对多个
相关 details
元素进行分组的文档,应将这些相关元素放在同一个容器
元素中(例如 section 元素或
article 元素)。
当使用标题引出该组是合理的时,作者应将该标题放在容器元素开头的标题元素中。
在视觉上和编程上将相关元素分组在一起,对于提供无障碍的用户体验可能很重要。 这可以帮助用户理解这些元素之间的关系。当相关元素散布在网页的不同部分而不是组合在一起时, 元素之间的关系可能更难被发现或理解。
open 内容
属性是一个布尔属性。如果
存在,则表示应向用户同时显示摘要和
附加信息。如果该属性不存在,则只显示
摘要。
创建元素时,如果该属性不存在,则应隐藏附加信息; 如果该属性存在,则应显示该信息。此后,如果移除该 属性,则应隐藏信息;如果添加该属性,则应显示 信息。
用户代理应允许用户请求显示或隐藏附加信息。
为满足显示详细信息的请求,用户代理必须将元素上的 open 属性设置为空字符串。为满足
隐藏信息的请求,用户代理必须从元素中移除 open 属性。
这种请求显示或隐藏附加信息的能力,
在存在适当的 summary 元素时,
可能只是该元素的激活行为。但是,如果不存在此类元素,
用户代理仍可以通过其他用户界面
可供性来提供此能力。
每个 details
元素都有一个details 切换任务跟踪器,它是一个
切换任务跟踪器或 null,
初始值为 null。
以下属性更改
步骤给定 element、localName、oldValue、
value 和 namespace,用于所有 details 元素:
如果 namespace 不为 null,则返回。
如果 localName 为 name,则给定
element,通过在需要时关闭给定元素来
确保 details 排他性。
如果 localName 为 open:
如果 oldValue 和 value 中的一个为 null,而另一个不为 null,
则为此 details
元素运行以下步骤,这些步骤称为details
通知任务步骤:
当连续多次切换 open 属性时,
产生的任务实际上会被合并,以便只触发一个
事件。
如果 oldValue 为 null,则给定
details
元素、“closed”和“open”,排入一个 details 切换事件任务。
否则,给定
details
元素、“open”和“closed”,排入一个 details 切换事件任务。
如果 oldValue 为 null 且 value 不为 null,则给定 element,通过在需要时关闭其他元素来 确保 details 排他性。
给定 insertedNode,details 的HTML 元素
插入
步骤为:
给定 insertedNode,通过在需要时关闭给定元素来确保 details 排他性。
需要明确的是,当通过解析器插入属性 或元素时,也会运行这些属性更改步骤和插入步骤。
要给定一个 details 元素
element、一个字符串 oldState 和一个字符串 newState,排入一个 details 切换事件任务:
如果 element 的details 切换任务跟踪器不为 null:
将 oldState 设置为 element 的details 切换任务 跟踪器的旧 状态。
从其任务队列中移除 element 的details 切换任务跟踪器的任务。
将 element 的details 切换任务跟踪器设置为 null。
给定DOM 操作任务源和 element,排入一个元素任务,以运行以下步骤:
在 element 处使用 ToggleEvent 触发一个事件,其名称为 toggle,并将
oldState
属性初始化为
oldState,将 newState
属性
初始化为 newState。
将 element 的details 切换任务跟踪器设置为 null。
将 element 的details 切换任务跟踪器设置为一个结构体, 其中任务设置为刚刚排入的任务,并且旧状态设置为 oldState。
要给定一个
details 元素
element,通过在需要时关闭
其他元素来确保 details 排他性:
要给定一个
details 元素
element,通过在需要时
关闭给定元素来确保 details 排他性:
以下示例展示了如何使用 details 元素
隐藏进度报告中的技术
细节。
< section class = "progress window" >
< h1 > 正在复制“真正实现你童年的梦想”</ h1 >
< details >
< summary > 正在复制…… < progress max = "375505392" value = "97543282" ></ progress > 25%</ summary >
< dl >
< dt > 传输速率:</ dt > < dd > 452KB/s</ dd >
< dt > 本地文件名:</ dt > < dd > /home/rpausch/raycd.m4v</ dd >
< dt > 远程文件名:</ dt > < dd > /var/www/lectures/raycd.m4v</ dd >
< dt > 持续时间:</ dt > < dd > 01:16:27</ dd >
< dt > 颜色配置文件:</ dt > < dd > SD (6-1-6)</ dd >
< dt > 尺寸:</ dt > < dd > 320×240</ dd >
</ dl >
</ details >
</ section > 以下展示了如何使用 details
元素
默认隐藏一些控件:
< details >
< summary >< label for = fn > 名称和扩展名:</ label ></ summary >
< p >< input type = text id = fn name = fn value = "Pillar Magazine.pdf" >
< p >< label >< input type = checkbox name = ext checked > 隐藏扩展名</ label >
</ details > 可以将此方法与列表中的其他 details 元素结合使用,
让用户将一组字段折叠成一小组标题,并能够逐个
打开它们。
在这些示例中,摘要实际上只是概括了控件可以更改的内容,而不是 实际值,这并不理想。
以下示例展示了如何使用 details 元素的
name 属性
创建排他式手风琴组件,即一组
details 元素,
当用户执行打开一个 details
元素的操作时,
会导致任何已打开的 details
元素关闭。
< section class = "characteristics" >
< details name = "frame-characteristics" >
< summary > 材料</ summary >
相框由实心橡木制成。
</ details >
< details name = "frame-characteristics" >
< summary > 尺寸</ summary >
相框适合高 40cm、宽 30cm 的照片。
相框高 45cm、宽 35cm、厚 2cm。
</ details >
< details name = "frame-characteristics" >
< summary > 颜色</ summary >
相框可采用天然木材
颜色,或染成黑色。
</ details >
</ section > 以下示例展示了当在一组使用
name 属性
创建排他式手风琴组件的元素中的一个 details 元素上设置
open
属性时会发生什么。
给定初始标记:
< section class = "characteristics" >
< details name = "frame-characteristics" id = "d1" open > ...</ details >
< details name = "frame-characteristics" id = "d2" > ...</ details >
< details name = "frame-characteristics" id = "d3" > ...</ details >
</ section > 以及脚本:
document. getElementById( "d2" ). setAttribute( "open" , "" ); 那么脚本执行后的结果树将等效于以下标记:
< section class = "characteristics" >
< details name = "frame-characteristics" id = "d1" > ...</ details >
< details name = "frame-characteristics" id = "d2" open > ...</ details >
< details name = "frame-characteristics" id = "d3" > ...</ details >
</ section > 因为在 d2 上设置 open 属性
会从 d1 上移除该属性。
当用户激活 d2 内部的 summary 元素时,
也会发生同样的情况。
由于当用户与控件交互时,会自动添加和移除 open
属性,因此可以在 CSS 中根据元素的状态
对其应用不同的样式。这里使用样式表,在元素打开或关闭时对摘要的颜色进行动画处理:
< style >
details > summary { transition : color 1 s ; color : black ; }
details [ open ] > summary { color : red ; }
</ style >
< details >
< summary > 自动化状态:运行正常</ summary >
< p > 速度:12m/s</ p >
< p > 方向:北</ p >
</ details > summary
元素
所有当前引擎均支持。
details 元素的第一个子元素。HTMLElement。summary 元素表示其父 details
元素(如果有)其余内容的摘要、标题或图例。
如果以下算法返回 true,则 summary 元素
是其父 details 的摘要:
如果此 summary 元素
不是其父
details 的摘要,则返回。
令 parent 为此 summary 元素的
父元素。
如果 parent 上存在 open
属性,则移除它。
否则,将 parent 的
open 属性设置为空字符串。
这随后会运行details 通知任务步骤。
命令是菜单项、按钮和 链接背后的抽象。定义命令后,界面的其他部分可以引用同一命令, 从而允许单个功能的多个访问点共享禁用状态等分面。
命令被定义为具有以下分面:
尤其是对于具有访问键的命令,建议用户代理这样做,作为向 用户宣传这些按键的一种方式。
例如,可以在用户代理的菜单栏中列出此类命令。
a
元素定义命令如果该元素具有 属性, 则命令的为 true (隐藏),否则为 false。
命令的操作
是在该元素处触发一个
click 事件。
button 元素定义命令
input 元素定义命令命令的标签按 以下方式确定:
如果该元素具有 属性, 则命令的为 true(隐藏),否则为 false。
命令的操作是在该元素处触发一个
click 事件。
option 元素定义命令
如果该元素具有 属性,则命令的为 true(隐藏),否则为 false。
legend 元素上的 accesskey 属性
定义命令
命令的、禁用
状态和操作
分面分别与legend
元素的 accesskey 被委托者的对应分面相同。
在此示例中,legend
元素指定了一个 accesskey,
激活时会将操作委托给 legend
元素内部的 input
元素。
< fieldset >
< legend accesskey = p >
< label > 我要 < input name = pizza type = number step = 1 value = 1 min = 0 >
个带有以下配料的披萨</ label >
</ legend >
< label >< input name = pizza-cheese type = checkbox checked > 奶酪</ label >
< label >< input name = pizza-ham type = checkbox checked > 火腿</ label >
< label >< input name = pizza-pineapple type = checkbox > 菠萝</ label >
</ fieldset > accesskey
属性在其他元素上定义命令
如果前面某个定义定义 命令的元素的章节规定此元素定义一个命令, 则该章节适用于此元素,而本节不适用。否则,本节 适用于该元素。
命令的标签取决于元素。如果
该元素是带标签控件,
则树顺序中第一个其带标签控件
为所讨论元素的 label
元素的后代文本内容是标签(用
JavaScript 表示,即 element.labels[0].textContent)。
否则,标签为
该元素的后代
文本内容。
如果该元素具有 属性,则命令的为 true(隐藏),否则为 false。
命令的操作是运行以下 步骤:
click 事件。dialog
元素所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
closedby — 哪些
用户操作会关闭对话框
open — 对话
框是否显示
[Exposed =Window ]
interface HTMLDialogElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect ] attribute boolean open ;
attribute DOMString returnValue ;
[CEReactions , ReflectSetter ] attribute DOMString closedBy ;
[CEReactions ] undefined show ();
[CEReactions ] undefined showModal ();
[CEReactions ] undefined close (optional DOMString returnValue );
[CEReactions ] undefined requestClose (optional DOMString returnValue );
};dialog 元素
表示应用程序的一个暂时性部分,形式为一个
小窗口(“对话框”),用户通过与其交互来执行任务或获取
信息。用户完成操作后,对话框可以由应用程序自动关闭,或
由用户手动关闭。
特别是对于模态对话框——它们是各种类型应用程序中都很常见的模式—— 作者应努力确保其 Web 应用程序中的对话框以 非 Web 应用程序用户所熟悉的方式运行。
与所有 HTML 元素一样,在尝试表示另一种类型的控件时使用 dialog
元素是不符合要求的。例如,上下文菜单、
工具提示和弹出列表框都不是对话框,因此滥用 dialog 元素来
实现这些模式是不正确的。
面向用户的对话框行为中的一个重要部分是初始焦点的位置。
对话框聚焦步骤会尝试在
显示对话框时选择一个良好的初始焦点候选项,但这可能无法替代作者认真思考
对特定对话框而言符合用户预期的正确选择。因此,作者应在
对话框打开后预计用户会立即与之交互的后代元素上使用 autofocus 属性。如果没有这样的
元素,则作者应在 dialog 元素
本身上使用 autofocus 属性。
在以下示例中,对话框用于编辑 库存管理 Web 应用程序中产品的详细信息。
< dialog >
< label > 产品编号 < input type = "text" readonly ></ label >
< label > 产品名称 < input type = "text" autofocus ></ label >
</ dialog > 如果不存在 autofocus
属性,对话框聚焦步骤会将焦点置于
产品编号字段。尽管这是合理的行为,但作者确定更相关的应聚焦字段是产品
名称字段,因为产品编号字段为只读,不需要用户输入。因此,作者
使用 autofocus 覆盖了默认行为。
即使作者希望默认聚焦产品编号字段,也最好
通过在该 input 元素上使用 autofocus
明确指定。这会使
意图对未来阅读代码的人显而易见,并确保代码在
未来更新时保持稳健。(例如,如果另一位开发者添加了关闭按钮,并将其放置在
节点树中产品编号字段之前。)
用户行为的另一个重要方面是对话框是否可滚动。在某些 情况下,溢出(从而产生可滚动性)无法避免,例如由用户 设置较高的文本缩放比例引起时。但通常,用户并不期望可滚动的对话框。直接向 对话框元素添加大型文本节点尤其糟糕,因为这很可能导致 对话框元素本身溢出。作者最好避免这样做。
以下服务条款对话框遵循了上述建议。
< dialog style = "height: 80vh;" >
< div style = "overflow: auto; height: 60vh;" autofocus >
< p > 在公元 2010 年第四个月的第一天通过本网站下单,即表示您同意授予我们一项不可转让的选择权,以便从现在起乃至永远
索取您不朽的灵魂。</ p >
< p > 如果我们希望行使此选择权,您同意在收到本网站或其正式授权仆从的书面
通知后 5(五)个工作日内交出您不朽的灵魂,
以及您可能对其拥有的任何权利主张。</ p >
<!-- ... 等等,还有许多其他 <p> 元素 ... -->
</ div >
< form method = "dialog" >
< button type = "submit" value = "agree" > 同意</ button >
< button type = "submit" value = "disagree" > 不同意</ button >
</ form >
</ dialog > 请注意,对话框聚焦
步骤默认会选择可滚动的
div 元素,但
与上一个示例类似,我们在 div 上放置了 autofocus,以便表达得更加明确,
并能稳健应对未来的更改。
相比之下,如果表示服务条款的 p 元素
没有这样的包装 div 元素,那么
dialog 本身
将变得可滚动,从而违反上述建议。此外,在没有任何 autofocus 属性的情况下,这样的
标记模式会违反上述建议,并干扰对话框聚焦步骤的默认行为,导致焦点跳转到“同意”
button,这会带来糟糕的用户
体验。
此对话框包含一些细则。使用 strong
元素是为了将
用户的注意力吸引到更重要的部分。
< dialog >
< h1 > 添加到钱包</ h1 >
< p >< strong >< label for = amt > 您想向钱包中添加多少枚金币?</ label ></ strong ></ p >
< p >< input id = amt name = amt type = number min = 0 step = 0.01 value = 100 ></ p >
< p >< small > 添加金币的风险由您自行承担。</ small ></ p >
< p >< label >< input name = round type = checkbox > 仅添加完美圆形的金币</ label ></ p >
< p >< input type = button onclick = "submit()" value = "Add Coins" ></ p >
</ dialog > open 属性
是一个布尔属性。指定时,
它表示 dialog
元素处于活动状态,并且用户可以与之交互。
closedby
内容属性是一个枚举
属性,具有以下关键字和
状态:
| 关键字 | 状态 | 简要说明 |
|---|---|---|
any
|
任意 | 关闭请求或在外部单击会关闭 对话框。 |
closerequest
|
关闭请求 | 关闭请求会关闭对话框。 |
none
|
无 | 没有任何用户操作会自动关闭对话框。 |
closedby
属性的无效值
默认值和缺失
值
默认值均为自动状态。
当 dialog 使用其 showModal()
方法显示时,自动状态的行为与
关闭请求状态相同;否则与无状态相同。
未指定 open 属性的
dialog 元素
不应向用户显示。此要求可以通过样式层间接实现。例如,支持建议默认渲染的用户代理使用渲染章节中描述的 CSS 规则实现此要求。
移除 open
属性通常会隐藏
对话框。但是,这样做会产生一些奇怪的额外后果:
由于这些原因,通常最好不要手动移除 open
属性。
相反,应使用 requestClose()
或 close() 方法
关闭对话框,或者使用
属性将其隐藏。
dialog.show()
所有当前引擎均支持。
显示 dialog 元素。
dialog.showModal()
所有当前引擎均支持。
显示 dialog 元素,并
使其成为最顶层的模态对话框。
此方法遵循 autofocus 属性。
dialog.close([ result ])
所有当前引擎均支持。
关闭 dialog
元素。
如果提供了参数,则该参数提供返回值。
dialog.requestClose([ result ])
其行为就像向 dialog 发送了一个以其为目标的关闭请求:首先触发 cancel 事件,如果
该事件未通过 preventDefault()
取消,则以与 close()
方法相同的方式继续关闭
dialog(包括触发 close 事件)。
这是一个辅助工具,可用于将取消和关闭逻辑统一到
cancel 和 close 事件
处理程序中,方法是让所有非关闭请求的关闭
可供性调用此方法。
请注意,此方法会忽略 closedby
属性:也就是说,即使 closedby 设置为
“none”,
仍会应用相同的行为。
如果提供了参数,则该参数提供返回值。
dialog.returnValue [ = result ]
所有当前引擎均支持。
返回 dialog 的返回值。
可以设置它以更新返回值。
show()
方法步骤如下:
如果 this 具有 open 属性,则
抛出一个 “InvalidStateError” DOMException。
如果在 this 处使用
ToggleEvent 触发一个事件所得的结果为
false,则返回;该事件名为
beforetoggle,
其中 cancelable
属性初始化为 true,oldState
属性初始化为“closed”,并且 newState
属性初始化为“open”。
给定 this、“closed”、
“open”和 null,排入一个
对话框切换事件任务。
给定 document、hideUntil、false 和 true,运行隐藏弹出框直至。
requestClose(returnValue) 方法步骤
如下:
对于 dialog 元素,我们使用
show/close 作为动词,而不是更常被视为反义词的
动词对,例如 show/hide 或 open/close,原因是存在以下
约束:
隐藏对话框不同于关闭对话框。关闭对话框会为其提供返回值、
触发事件、解除页面对其他对话框的阻止等。而隐藏对话框是一个
纯粹的视觉属性,并且可以通过 属性或移除
open 属性来实现。(另请
参阅上面的注释,其中讨论了移除 open 属性,以及为何
通常不希望以这种方式隐藏对话框。)
显示对话框不同于打开对话框。打开对话框包括创建
并显示该对话框(类似于 window.open() 同时
创建并显示新窗口)。而显示对话框则是将一个已经位于 DOM 中的
dialog 元素
变为可交互并对用户可见的过程。
尽管有上述情况,如果仍提供 dialog.open() 方法,
它会与 dialog.open 属性冲突。
此外,对与 dialog
元素最初设计同期的许多其他 UI 框架进行的调查
清楚表明,show/close 动词对相当常见。
总而言之,事实证明,某些动词的含义以及它们在 技术语境中的用法意味着,显示和关闭对话框等成对操作并不 总能用反义词表达。
returnValue IDL 属性在获取时必须返回
最后一次设置给它的值。在设置时,必须将其设置为新值。创建元素
时,必须将其设置为空字符串。
closedBy 的 getter 步骤是给定 this,返回与计算出的
closed-by 状态相对应的关键字。
每个 Document 都有一个对话框 pointerdown 目标,它是一个HTML 对话框元素或 null,初始值为 null。
每个HTML 元素都有一个先前聚焦的
元素,它为 null 或一个元素,初始值为 null。当调用 showModal() 和 show()
时,在运行对话框聚焦步骤之前,此元素会被设置为当前聚焦的元素。具有 popover
属性的元素在显示弹出框算法期间,会将此元素设置为当前聚焦的元素。
每个 dialog 元素
都有一个对话框切换任务跟踪器,它是一个
切换任务跟踪器或 null,
初始值为 null。
每个 dialog 元素
都有一个关闭监视器,
它是一个关闭监视器或 null,初始值为 null。
每个 dialog 元素
都有一个请求关闭返回值,它是
字符串或 null,初始值为 null。
每个 dialog 元素
都有一个请求关闭源元素,它是一个
Element
或 null,初始值为 null。
每个 dialog 元素
都有一个为 request close 启用关闭监视器布尔值,
初始值为 false。
dialog 的
为
request close 启用关闭监视器用于
在请求关闭对话框时强制启用其关闭
监视器。如果对话框的计算出的
closed-by 状态为无状态,
否则其关闭监视器会被禁用。
每个 dialog 元素
都有一个是否为模态布尔值,初始值为 false。
给定 insertedNode,dialog 的HTML 元素插入
步骤为:
给定 removedNode、isSubtreeRoot 和 oldAncestor,dialog 的HTML 元素移除
步骤为:
要给定一个 dialog 元素
subject 和一个
Element
或 null source,显示模态对话框:
如果 subject 具有 open 属性,则
抛出一个 “InvalidStateError” DOMException。
如果 subject 的节点文档不是完全活动的,则
抛出一个 “InvalidStateError” DOMException。
如果 subject 未连接,则抛出一个
“InvalidStateError” DOMException。
如果 subject 处于弹出框显示
状态,则抛出一个 “InvalidStateError”
DOMException。
如果在 subject 处使用 ToggleEvent 触发一个事件所得的结果为 false,则返回;该事件名为
beforetoggle,
其中 cancelable
属性初始化为 true,oldState
属性初始化为“closed”,newState
属性初始化为“open”,并且 source 属性
初始化为 source。
如果 subject 具有 open 属性,
则返回。
如果 subject 未连接,则返回。
如果 subject 处于弹出框显示 状态,则返回。
给定 subject、“closed”、“open”和
source,排入
一个对话框切换事件任务。
向 subject 添加一个 open
属性,其值为空字符串。
将 subject 的是否为模态设置为 true。
将 subject 的节点文档设置为被模态对话框 subject 阻止。
这将导致文档的聚焦区域变为惰性(除非当前聚焦区域是 subject 的包括影子树的后代)。在 这种情况下,文档的聚焦区域很快会被重置为 视口。几步之后,我们将尝试寻找更好的候选项来 聚焦。
令 document 为 subject 的节点文档。
令 hideUntil 为给定 subject、null 和 false 运行最顶层弹出框祖先所得的结果。
给定 document、hideUntil、false 和 true,运行隐藏弹出框直至。
给定 subject,运行对话框聚焦 步骤。
要给定一个 dialog
元素 dialog,设置对话框关闭监视器:
将 dialog 的关闭 监视器设置为给定 dialog 的相关全局对象建立关闭监视器所得的结果,并使用:
cancelAction 给定
canPreventClose,返回在 dialog 处触发一个事件所得的结果,该事件名为 cancel,其中 cancelable
属性初始化为
canPreventClose。
closeAction 是给定 dialog、dialog 的请求关闭返回 值和 dialog 的请求关闭源元素,关闭 对话框。
getEnabledState 是在 dialog 的为 request close 启用关闭监视器为 true,或者 dialog 的计算出的 closed-by 状态不是无时返回 true;否则返回 false。
以下按钮使用 commandfor,
在激活时以模态方式打开和
关闭一个“确认”dialog:
< button type = button
commandfor = "the-dialog"
command = "show-modal" >
删除
</ button >
< dialog id = "the-dialog" >
< form action = "/delete" method = "POST" >
< button type = "submit" >
删除
</ button >
< button commandfor = "the-dialog"
command = "close" >
取消
</ button >
</ form >
</ dialog >
当要使用 null 或字符串 result 以及一个 Element
或 null source 关闭 dialog
元素 subject 时,运行以下步骤:
如果 subject 不具有 open
属性,则返回。
在 subject 处使用 ToggleEvent 触发一个事件,其名称为 beforetoggle,
其中 oldState
属性初始化为“open”,newState
属性初始化为“closed”,并且 source
属性初始化为 source。
如果 subject 不具有 open
属性,则返回。
给定 subject、“open”、“closed”和
source,排入
一个对话框切换事件任务。
移除 subject 的 open
属性。
如果 subject 的是否为模态为 true,则给定 subject,请求从 顶层移除元素。
令 wasModal 为 subject 的是否为 模态标志的值。
将 subject 的是否为模态设置为 false。
如果 result 不为 null,则将 subject 的 returnValue
属性设置为 result。
将 subject 的请求关闭返回值设置为 null。
将 subject 的请求关闭源元素设置为 null。
如果 subject 的先前聚焦的元素不为 null:
在用户
交互任务源上,给定 subject 元素排入一个元素任务,以在
subject 处触发一个事件,其名称为
close。
要给定一个 dialog 元素
element、一个字符串 oldState、一个字符串 newState,以及一个
Element
或 null source,排入一个对话框切换事件任务:
如果 element 的对话框切换任务跟踪器不为 null:
将 oldState 设置为 element 的对话框切换任务 跟踪器的旧 状态。
从其任务队列中移除 element 的对话框切换任务跟踪器的任务。
将 element 的对话框切换任务跟踪器设置为 null。
给定DOM 操作任务源和 element,排入一个元素任务,以运行以下步骤:
在 element 处使用 ToggleEvent 触发一个事件,其名称为 toggle,
其中 oldState
属性初始化为
oldState,newState
属性初始化为 newState,并且 source
属性初始化为
source。
将 element 的对话框切换任务跟踪器设置为 null。
将 element 的对话框切换任务跟踪器设置为一个结构体, 其中任务设置为刚刚排入的任务,并且旧状态设置为 oldState。
要给定一个 dialog
dialog,检索对话框的计算出的 closed-by 状态:
给定一个 dialog 元素
subject,对话框聚焦步骤
如下:
令 control 为 null。
如果 subject 具有 autofocus
属性,则将 control 设置为 subject。
如果 control 为 null,则将 control 设置为 subject 的焦点 委托。
如果 control 为 null,则将 control 设置为 subject。
为 control 运行聚焦步骤。
如果 control 不可聚焦,则这不会执行任何操作。只有在
subject 没有焦点委托,并且用户代理决定
dialog 元素
通常不可聚焦时才会发生这种情况。在这种情况下,对文档聚焦
区域的任何先前修改都将适用。
将 topDocument 的自动聚焦已处理标志设置为 true。
给定一个 dialog 元素
subject,对话框设置步骤
如下:
给定一个 dialog 元素
subject,对话框清理步骤
如下:
“轻触关闭”是指,单击 dialog 元素外部时,如果其
closedby 属性处于任意状态,
则会关闭该 dialog
元素。这
是对此类 dialog 元素响应关闭请求方式的补充。
要给定一个 PointerEvent
event,轻触关闭已打开的对话框:
令 ancestor 为给定 event 运行最近被单击的对话框 所得的结果。
如果 event 的 type
为
“pointerdown”,
则将 document 的
对话框 pointerdown
目标设置为 ancestor。
如果 event 的 type
为
“pointerup”:
如果 ancestor 是 document 的 对话框 pointerdown 目标,则令 sameTarget 为 true。
将 document 的对话框 pointerdown 目标设置为 null。
如果 sameTarget 为 false,则返回。
令 topmostDialog 为 document 的已打开 对话框列表中的最后一个元素。
如果 ancestor 是 topmostDialog,则返回。
如果 topmostDialog 的计算出的 closed-by 状态不是任意,则返回。
要给定一个 PointerEvent
event,运行轻触关闭活动:
使用 event 运行轻触 关闭已打开的弹出框。
使用 event 运行轻触关闭 已打开的对话框。
当用户在页面任意位置单击 或触摸时,Pointer Events 规范将调用运行 轻触关闭活动。
要给定一个 PointerEvent
event,查找最近被单击的对话框:
脚本允许作者向其文档添加交互性。
建议作者尽可能使用声明式替代方案而不是脚本,因为 声明式机制通常更易于维护,并且许多用户会禁用脚本。
例如,可以使用
details 元素,
而不是使用脚本显示或隐藏某个章节以展示更多详细信息。
还建议作者确保其应用程序在不支持 脚本时能够优雅降级。
例如,如果作者在表格标题中提供一个链接以动态重新排序表格, 则也可以通过向 服务器请求已排序的表格,使该链接在没有脚本时仍可使用。
script 元素所有当前引擎均支持。
所有当前引擎均支持。
src
属性,则取决于 type 属性的值,但必须符合
脚本内容限制。
src
属性,则该元素必须为空,或者只包含同样符合脚本
内容限制的脚本文档。
type — 脚本类型
src — 资源的
地址
nomodule —
阻止在支持模块脚本的用户代理中执行
async — 在脚本
可用时执行,获取期间不阻塞
defer — 延迟脚本
执行
blocking —
元素是否可能阻塞渲染
crossorigin
— 元素如何处理跨源请求
referrerpolicy
— 元素发起的获取所使用的引用来源策略
integrity —
用于子资源完整性检查的完整性元数据 [SRI]
fetchpriority
— 设置元素发起的获取的优先级
[Exposed =Window ]
interface HTMLScriptElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect ] attribute DOMString type ;
[CEReactions , ReflectURL ] attribute USVString src ;
[CEReactions , Reflect ] attribute boolean noModule ;
[CEReactions ] attribute boolean async ;
[CEReactions , Reflect ] attribute boolean defer ;
[SameObject , PutForwards =value , Reflect ] readonly attribute DOMTokenList blocking ;
[CEReactions ] attribute DOMString ? crossOrigin ;
[CEReactions ] attribute DOMString referrerPolicy ;
[CEReactions , Reflect ] attribute DOMString integrity ;
[CEReactions ] attribute DOMString fetchPriority ;
[CEReactions ] attribute DOMString text ;
static boolean supports (DOMString type );
// also has obsolete members
};script 元素允许
作者在其文档中包含动态脚本、给用户代理的指令和
数据块。该元素不表示面向用户的内容。
所有当前引擎均支持。
script 元素有两个核心属性。type 属性允许自定义所表示的脚本类型:
省略该属性、将其设置为空字符串,或将其设置为
JavaScript MIME 类型本质匹配项,意味着该
脚本是一个经典
脚本,应根据 JavaScript Script 顶层
产生式进行解释。作者应省略 type
属性,而不是
冗余地设置它。
将该属性设置为与“module”ASCII
不区分大小写匹配,意味着该脚本是一个JavaScript 模块
脚本,应
根据 JavaScript Module 顶层
产生式进行解释。
将该属性设置为与“importmap”ASCII
不区分大小写匹配,意味着该脚本是一个导入映射,其中包含
用于控制模块说明符解析行为的
JSON。
将该属性设置为与“speculationrules”ASCII
不区分大小写匹配,意味着该脚本定义一个推测规则
集,其中包含用于描述推测加载的 JSON。
将该属性设置为任何其他值,意味着该脚本是一个数据块, 它不由用户代理处理,而是由作者脚本或其他工具处理。作者 必须使用一个不是JavaScript MIME 类型本质 匹配项的有效 MIME 类型字符串来表示数据块。
要求使用有效 MIME
类型字符串表示数据块,是为了
避免未来潜在的冲突。不是 MIME 类型的 type
属性值,例如“module”或“importmap”,由
标准用于表示在用户代理中具有
特殊行为的脚本类型。现在使用有效 MIME 类型字符串,可确保您的
数据块即使在未来的用户代理中,也永远不会被重新解释为其他脚本类型。
第二个核心属性是 src
属性。它只能为经典脚本和JavaScript 模块脚本
指定,并表示不使用元素的
子文本内容作为脚本内容,而是从
指定的 URL
获取脚本。如果指定了 src,则它必须是
一个可能被空格包围的有效非空 URL。
可以在给定 script
元素上指定哪些其他属性,由
下表确定:
nomodule
|
async
|
defer
|
blocking
|
crossorigin
|
referrerpolicy
|
integrity
|
fetchpriority
|
|
|---|---|---|---|---|---|---|---|---|
| 外部经典脚本 | 支持 | 支持 | 支持 | 支持 | 支持 | 支持 | 支持 | 支持 |
| 内联经典脚本 | 支持 | · | · | · | 支持* | 支持* | · | ·† |
| 外部模块脚本 | · | 支持 | · | 支持 | 支持 | 支持 | 支持 | 支持 |
| 内联模块脚本 | · | 支持 | · | · | 支持* | 支持* | · | ·† |
| 导入映射 | · | · | · | · | · | · | · | · |
| 推测规则 | · | · | · | · | · | · | · | · |
| 数据块 | · | · | · | · | · | · | · | · |
* 尽管内联脚本没有初始获取,但内联脚本上的 crossorigin 和
referrerpolicy
属性会影响模块导入(包括动态 import())所使用的
凭据模式和引用来源
策略。
† 与 crossorigin 和
referrerpolicy
不同,fetchpriority
不会影响模块导入。请参阅议题
#10276中的一些讨论。
对于经典脚本和JavaScript 模块脚本,内联 script 元素的内容或
外部脚本资源必须分别符合 JavaScript 规范的 Script 或 Module 产生式的要求。[JAVASCRIPT]
用于导入
映射的内联 script
元素内容必须符合导入映射创作要求。
用于推测规则集的内联 script 元素内容必须符合
推测规则集创作
要求。
当用于包含数据块时,数据必须
内联嵌入,必须使用 type
属性给出数据格式,并且 script
元素的内容必须符合
所用格式定义的要求。
nomodule
属性是一个布尔属性,用于
阻止脚本在支持模块脚本的用户代理中执行。这允许
在现代用户代理中选择性执行模块脚本,并在旧版用户代理中执行经典脚本,如下所示。
所有当前引擎均支持。
所有当前引擎均支持。
async 和
defer 属性
是
布尔属性,用于指示应如何
求值脚本。根据脚本类型,可以使用这些属性选择
多种可能的模式。
对于外部经典脚本,如果存在 async 属性,
则经典脚本将与解析并行获取,并在
可用后立即求值(可能
在解析完成之前)。如果不存在 async
属性,但存在
defer
属性,则经典脚本将被并行获取,并在页面完成
解析后求值。如果两个属性都不存在,则立即获取并求值脚本,
并阻塞解析,直到这两个操作都完成。
对于模块脚本,如果存在 async 属性,
则模块脚本及其所有
依赖项将与解析并行获取,并且模块脚本将在
可用后立即求值(可能在解析完成之前)。否则,
模块脚本及其依赖项将与解析并行获取,并在
页面完成解析后求值。(defer
属性对模块脚本无效。)
以下示意图总结了所有这些情况:

由于主要是历史原因,这些属性的确切处理细节
有些复杂,涉及 HTML 的多个方面。因此,
实现要求必然分散在整个规范中。下方的算法描述了此处理的核心,但
这些算法会引用并被以下内容引用:HTML 中 script 的开始和结束标签的解析规则、外来内容中的规则、XML 中的规则、
document.write() 方法的规则、
对脚本的处理等。
使用 document.write()
方法插入时,script 元素通常
会执行(通常会阻塞进一步的脚本执行或 HTML 解析)。使用
innerHTML 和 outerHTML 属性插入时,
它们完全不会执行。
即使指定了 async 属性,也可以指定
defer 属性,
从而使仅支持 defer(而
不支持 async)的旧版 Web 浏览器
回退到 defer 行为,而不是回退到
默认的阻塞行为。
blocking
属性是一个阻塞属性。
crossorigin
属性是一个CORS 设置
属性。对于外部经典
脚本,它控制
从其他源获取脚本时是否公开错误信息。对于外部模块脚本,
如果跨源,它控制模块源初始获取所使用的凭据模式。对于经典脚本和模块脚本,它都控制跨源
模块导入所使用的凭据模式。
referrerpolicy 属性是一个引用来源
策略属性。它设置外部脚本初始获取以及任何导入模块脚本获取所使用的引用来源
策略。
[REFERRERPOLICY]
以下示例展示了获取导入脚本时使用 script 元素的引用来源
策略,而获取其他子资源时不使用该策略:
< script referrerpolicy = "origin" >
fetch( '/api/data' ); // 不使用 <script> 的引用来源策略获取
import ( './utils.mjs' ); // 使用 <script> 的引用来源策略获取(此处为 "origin")
</ script > integrity
属性设置外部脚本初始获取所使用的完整性元数据。
该值必须符合integrity 属性的
要求。[SRI]
fetchpriority 属性是一个获取优先级
属性。它设置外部脚本初始获取所使用的优先级。
动态更改这些属性中的任何一个都不会产生直接影响;这些属性只会在 处理模型中所述的特定时刻使用。
crossOrigin IDL 属性必须反映
crossorigin
内容属性,并仅限于
已知值。
HTMLScriptElement/referrerPolicy
所有当前引擎均支持。
referrerPolicy IDL 属性必须
反映 referrerpolicy
内容
属性,并仅限
于已知值。
fetchPriority IDL 属性必须
反映 fetchpriority
内容属性,并仅限于已知值。
async 的 setter 步骤
如下:
script.text [ = value ]
返回元素的子文本 内容。
script.text = value
使用 value 给出的文本替换元素的子节点。
HTMLScriptElement.supports(type)如果给定 type 是用户代理支持的脚本类型,则返回 true。本规范中
可能的脚本类型为“classic”、“module”和
“importmap”,但将来可能添加其他类型。
HTMLScriptElement/supports_static
所有当前引擎均支持。
静态 supports(type) 方法步骤如下:
type 参数必须与这些值完全匹配;我们不会
执行ASCII
不区分大小写匹配。这与处理 type
内容属性值的方式
以及
DOMTokenList
的
supports()
方法
的工作方式不同,但与 Worker()
构造函数中使用的 WorkerType 枚举保持一致。
在此示例中,使用了两个 script
元素。
一个嵌入外部
经典脚本,另一个包含一些
作为数据块的数据。
< script src = "game-engine.js" ></ script >
< script type = "text/x-game-map" >
........ U......... e
o............ A.... e
..... A..... AAA.... e
. A.. AAA... AAAAA... e
</ script > 在此情况下,脚本可能会使用这些数据生成电子游戏地图。不过, 这些数据不一定要这样使用;也许地图数据实际上嵌入在页面标记的其他 部分,而此处的数据块仅由网站的搜索引擎使用,以 帮助寻找游戏地图中特定功能的用户。
以下示例展示了如何使用 script
元素
定义一个函数,然后由文档的其他部分使用,作为经典脚本的一部分。它
还展示了如何在文档
解析期间使用 script 元素调用脚本,
在本例中用于初始化表单输出。
< script >
function calculate( form) {
var price = 52000 ;
if ( form. elements. brakes. checked)
price += 1000 ;
if ( form. elements. radio. checked)
price += 2500 ;
if ( form. elements. turbo. checked)
price += 5000 ;
if ( form. elements. sticker. checked)
price += 250 ;
form. elements. result. value = price;
}
</ script >
< form name = "pricecalc" onsubmit = "return false" onchange = "calculate(this)" >
< fieldset >
< legend > 计算汽车价格</ legend >
< p > 基本价格:£52000。</ p >
< p > 选择附加选项:</ p >
< ul >
< li >< label >< input type = checkbox name = brakes > 陶瓷制动器(£1000)</ label ></ li >
< li >< label >< input type = checkbox name = radio > 卫星广播(£2500)</ label ></ li >
< li >< label >< input type = checkbox name = turbo > 涡轮增压器(£5000)</ label ></ li >
< li >< label >< input type = checkbox name = sticker > “XZ”贴纸(£250)</ label ></ li >
</ ul >
< p > 总计:£< output name = result ></ output ></ p >
</ fieldset >
< script >
calculate( document. forms. pricecalc);
</ script >
</ form > 以下示例展示了如何使用 script
元素
包含一个外部
JavaScript 模块
脚本。
< script type = "module" src = "app.mjs" ></ script > 将获取此模块及其所有依赖项(在源
文件中通过 JavaScript import 语句表示)。整个
生成的模块图导入完成且文档完成解析后,将对
app.mjs 的内容进行求值。
此外,如果同一 Window
中另一个 script 元素的代码
从 app.mjs 导入模块(例如通过 import
"./app.mjs";),则会导入由前一个 script 元素创建的同一个
JavaScript 模块脚本。
此示例展示了如何为现代用户代理包含一个JavaScript 模块脚本,并为旧版 用户代理包含一个经典脚本:
< script type = "module" src = "app.mjs" ></ script >
< script nomodule defer src = "classic-app-bundle.js" ></ script > 在支持JavaScript 模块
脚本的现代用户代理中,具有
nomodule 属性的
script 元素
将被忽略,而
type 为
“module”的 script 元素将被获取并求值
(作为JavaScript 模块
脚本)。相反,旧版用户代理会忽略 type 为
“module”的 script 元素,因为这对它们而言是
未知脚本类型——但它们可以毫无问题地获取并求值另一个
script 元素(作为
经典脚本),因为它们没有实现
nomodule
属性。
以下示例展示了如何使用 script
元素
编写一个内联
JavaScript 模块
脚本,该脚本对文档文本执行多项替换,以提供更有趣的阅读体验
(例如在新闻网站上):
[XKCD1288]
< script type = "module" >
import { walkAllTextNodeDescendants } from "./dom-utils.mjs" ;
const substitutions = new Map([
[ "witnesses" , "these dudes I know" ]
[ "allegedly" , "kinda probably" ]
[ "new study" , "Tumblr post" ]
[ "rebuild" , "avenge" ]
[ "space" , "spaaace" ]
[ "Google glass" , "Virtual Boy" ]
[ "smartphone" , "Pokédex" ]
[ "electric" , "atomic" ]
[ "Senator" , "Elf-Lord" ]
[ "car" , "cat" ]
[ "election" , "eating contest" ]
[ "Congressional leaders" , "river spirits" ]
[ "homeland security" , "Homestar Runner" ]
[ "could not be reached for comment" , "is guilty and everyone knows it" ]
]);
function substitute( textNode) {
for ( const [ before, after] of substitutions. entries()) {
textNode. data = textNode. data. replace( new RegExp( `\\b ${ before} \\b` , "ig" ), after);
}
}
walkAllTextNodeDescendants( document. body, substitute);
</ script > 使用 JavaScript 模块脚本所获得的一些显著功能包括:能够从其他
JavaScript 模块导入函数、默认启用严格模式,以及顶层声明
不会在全局
对象上引入新属性。还请注意,无论此 script
元素出现在文档中的哪个位置,在文档解析完成并且其依赖项
(dom-utils.mjs)已获取和求值之前,都不会对其求值。
以下示例展示了如何从 JavaScript 模块 脚本内部导入JSON 模块脚本:
< script type = "module" >
import peopleInSpace from "http://api.open-notify.org/astros.json" with { type: "json" };
const list = document. querySelector( "#people-in-space" );
for ( const { craft, name } of peopleInSpace. people) {
const li = document. createElement( "li" );
li. textContent = ` ${ name} / ${ craft} ` ;
list. append( li);
}
</ script > 模块脚本的 MIME 类型检查是严格的。为了成功获取JSON
模块脚本,HTTP 响应必须具有JSON MIME 类型,
例如 Content-Type: text/json。另一方面,如果省略语句中的
with { type: "json" } 部分,则假定意图是导入一个JavaScript 模块脚本,如果 HTTP
响应的 MIME 类型不是JavaScript
MIME 类型,则获取将失败。
script 元素具有
若干关联状态。
script 元素
具有一个解析器文档,它为 null 或
Document,初始值为 null。它由
HTML 解析器和
XML 解析器在它们插入的 script 元素上设置,
并影响这些元素的处理。具有非 null 解析器文档的 script 元素称为
由解析器插入的。
script 元素
具有一个准备时文档,它为 null
或 Document,初始值为 null。它
用于阻止在准备期间在文档之间移动的脚本执行。
script 元素具有一个
强制异步布尔值,初始值为 true。对于
HTML 解析器和
XML 解析器插入的 script 元素,
解析器会将其设置为 false;当元素添加
async 内容属性时,
也会将其设置为 false。
script 元素
具有一个来自外部
文件布尔值,初始值为 false。它在脚本被准备时,根据该时刻元素的 src
属性确定。
script 元素
具有一个已准备好由解析器执行布尔值,初始值为
false。它仅用于同样是由解析器插入的元素,以便让
解析器知道何时执行脚本。
script 元素
具有一个已开始布尔值,初始值为 false。
script 元素
具有一个延迟 load
事件布尔值,初始值为 false。
script 元素
具有一个类型,它为
null、“classic”、“module”、“importmap”或
“speculationrules”之一,初始值为 null。它在元素被准备时,根据
该时刻元素的 type
属性确定。
script 元素具有一个
结果,它为“uninitialized”、null(表示
错误)、一个脚本、一个导入映射解析结果或一个
推测规则解析结果。其初始值为
“uninitialized”。
script 元素具有
结果准备好时要运行的
步骤,它为一系列步骤或 null,初始值为 null。要给定 result,将
script 元素
el 标记为准备就绪:
将 el 的结果设置为 result。
如果 el 的结果准备好时要运行的步骤 不为 null,则运行它们。
将 el 的结果准备好时要运行的 步骤设置为 null。
将 el 的延迟 load 事件设置为 false。
每当 script 元素
el 的延迟
load 事件为 true 时,用户代理
必须延迟
el 的准备时文档的 load 事件。
给定 insertedNode,script 的HTML
元素连接后步骤为:
HTML 元素连接后步骤仅在所插入元素
仍然已连接时运行,这可以防止较早插入的
script 移除
较晚插入的 script
的情况。例如:
< script >
const script1 = document. createElement( 'script' );
script1. innerText = `
document.querySelector('#script2').remove();
` ;
const script2 = document. createElement( 'script' );
script2. id = 'script2' ;
script2. textContent = `console.log('script#2 running')` ;
document. body. append( script1, script2);
</ script > 在此示例中,不会向控制台输出任何内容。当由 append() 原子插入的第一个 script 的HTML 元素
连接后步骤运行时,它可以观察到第二个
script 已经
连接到 DOM,并将其从 DOM 中移除。
由于第二个 script 不再
连接,其HTML
元素连接后步骤不会运行,并且它不会被准备。
给定 removedNode,script 的HTML 元素
移除步骤为:
这对于 script 元素
与任何新插入的子 script
元素的执行顺序
有一个有趣的影响。请考虑以下代码片段:
< script id = outer-script ></ script >
< script >
const outerScript = document. querySelector( '#outer-script' );
const start = new Text( 'console.log(1);' );
const innerScript = document. createElement( 'script' );
innerScript. textContent = `console.log('inner script executing')` ;
const end = new Text( 'console.log(2);' );
outerScript. append( start, innerScript, end);
// Logs:
// 1
// 2
// inner script executing
</ script > 当第二个脚本块执行时,outer-script 已经被准备,但由于它为空,
所以未执行,因此也未被标记为已开始。原子
插入 Text
节点和嵌套的 script
元素会产生
以下影响:
以下属性更改
步骤给定 element、localName、oldValue、
value 和 namespace,用于所有 script 元素:
如果 namespace 不为 null,则返回。
如果 localName 为 src,value
不为 null,并且 element 已连接,则给定 element 运行
script
的HTML 元素连接后步骤。
要给定一个 script
元素 el,准备脚本元素:
如果 el 的已 开始为 true,则返回。
令 parser document 为 el 的解析器文档。
将 el 的解析器 文档设置为 null。
这样做是为了在由解析器插入的 script 元素
于解析器尝试运行它们时运行失败的情况下,例如由于它们为空或指定了不受支持的
脚本语言,另一个脚本稍后可以修改它们并使其再次运行。
如果 parser document 不为 null,并且 el 没有 async 属性,
则将 el 的强制
异步设置为 true。
这样做是为了在由解析器插入的 script 元素
于解析器尝试运行它时运行失败,但稍后在脚本动态
更新它后执行的情况下,即使未设置 async 属性,
它也会以异步方式执行。
令 source text 为 el 的子 文本内容。
如果 el 没有 src 属性,并且
source text 为空字符串,
则返回。
如果 el 未连接,则返回。
如果以下任一条件为 true:
el 具有一个 type 属性,
其值为空字符串;
则令此 script
元素的
the script block's type string 为
“text/javascript”。
否则,如果 el 具有 type 属性,则
令 the script block's type string 为该属性的值,并去除前导和尾随 ASCII 空白。
否则,el 具有一个非空的 language
属性;令 the script block's type string 为“text/”与
el 的 language
属性值的串联。
如果 the script block's type string 是一个JavaScript MIME 类型本质
匹配项,则将 el 的类型设置为“classic”。
否则,如果 the script block's type string 与字符串
“module”ASCII
不区分大小写匹配,则将
el 的类型设置为
“module”。
否则,如果 the script block's type string 与字符串
“importmap”ASCII
不区分大小写匹配,则将
el 的类型设置为
“importmap”。
否则,如果 the script block's type string 与字符串
“speculationrules”ASCII
不区分大小写匹配,则将
el 的类型设置为
“speculationrules”。
否则,返回。(不执行任何脚本,并且 el 的类型保持为 null。)
如果 parser document 不为 null,则将 el 的解析器 文档恢复为 parser document,并将 el 的强制异步设置为 false。
将 el 的已 开始设置为 true。
如果 parser document 不为 null,并且 parser document 不等于 el 的准备时文档,则返回。
如果 el 的脚本已禁用,则返回。
脚本已
禁用的定义意味着,除其他情况外,以下脚本不会执行:XMLHttpRequest 的
responseXML
文档中的脚本、由 DOMParser 创建的文档中的脚本、
由 XSLTProcessor 的 transformToDocument
功能创建的文档中的脚本,以及最初由脚本插入使用
createDocument()
API 创建的 Document 中的脚本。[XHR]
[DOMPARSING] [XSLTP] [DOM]
如果 el 的类型为
“speculationrules”,则令 cspType 为
“script speculationrules”;否则为“script”。
如果 el 没有 src 内容属性,
并且给定 el、cspType 和 source
text 时,元素的内联
行为是否应被内容安全策略阻止?算法返回“Blocked”,则返回。[CSP]
如果 el 具有 event 属性和
for 属性,并且
el 的类型为
“classic”:
令 for 为 el 的 for 属性值。
令 event 为 el 的 event
属性值。
从 event 和 for 中去除前导和尾随 ASCII 空白。
如果 for 不与字符串
“window”ASCII 不区分大小写匹配,则返回。
如果 event 不与字符串“onload”或字符串
“onload()”中的任一个ASCII 不区分大小写匹配,则
返回。
如果 el 具有 charset
属性,则令
encoding 为从 charset
属性值获取编码所得的结果。
如果 el 没有 charset
属性,或者获取编码失败,则令 encoding 为
el 的节点
文档的编码。
如果 el 的类型为“module”,则会忽略此编码。
令 classic script CORS setting 为 el 的 crossorigin
内容属性的当前状态。
令 module script credentials mode 为 el 的 crossorigin
内容属性的CORS 设置属性凭据模式。
令 cryptographic nonce 为 el 的[[CryptographicNonce]] 内部槽值。
如果 el 具有 integrity
属性,则令 integrity metadata 为该属性的值。
否则,令 integrity metadata 为空字符串。
令 referrer policy 为 el 的 referrerpolicy
内容属性的当前状态。
令 fetch priority 为 el 的 fetchpriority
内容属性的当前状态。
如果 el 是由解析器插入的,则令
parser metadata 为“parser-inserted”,否则为
“not-parser-inserted”。
令 options 为一个脚本获取选项,其加密 nonce为 cryptographic nonce,完整性元数据为 integrity metadata,解析器 元数据为 parser metadata,凭据模式为 module script credentials mode,引用来源 策略为 referrer policy,并且获取优先级为 fetch priority。
如果 el 具有 src 内容属性:
如果 el 的类型为“importmap”或
“speculationrules”,则给定 el,在DOM 操作任务源上排入一个
元素任务,以在 el 处触发一个事件,其名称为
error,然后返回。
目前不支持外部导入映射和推测规则。有关添加支持的讨论,请参阅 WICG/import-maps 议题 #235和 WICG/nav-speculation 议题 #348。
令 src 为 el 的 src 属性值。
如果 src 为空字符串,则给定 el,在
DOM
操作任务源上排入一个元素任务,以在
el 处触发一个事件,其名称为
error,然后返回。
将 el 的来自外部文件 设置为 true。
令 url 为给定 src,相对于 el 的节点 文档使用编码解析 URL所得的结果。
如果 url 为失败,则给定 el,在DOM
操作任务源上排入一个元素任务,以在
el 处触发
一个事件,其名称为 error,然后返回。
将 el 的延迟 load 事件设置为 true。
令给定 result 的 onComplete 为以下步骤:
给定 result,将 el 标记为准备就绪。
根据 el 的类型进行切换:
classic”给定 url、settings object、 options、classic script CORS setting、encoding 和 onComplete,获取经典 脚本。
module”如果 el 没有 integrity
属性,则将 options 的完整性元数据设置为
使用 url 和 settings
object解析模块完整性
元数据所得的结果。
给定 url、settings object、options 和 onComplete,获取外部模块脚本图。
出于性能原因,用户代理可以改为在设置 src 属性后立即
开始获取经典脚本或模块图(如上文定义),希望 el 将变为已连接
(并且 crossorigin
属性在此期间不会更改值)。无论哪种方式,一旦 el 变为已连接,加载必须已按照此步骤中的描述
开始。如果用户代理执行了此类预取,但 el
从未变为已连接,或者 src
属性被
动态更改,或者 crossorigin
属性被动态更改,则
用户代理不会执行以这种方式获得的脚本,并且获取过程实际上将被浪费。
如果 el 没有 src 内容
属性:
根据 el 的类型进行切换:
classic”module”将 el 的延迟 load 事件设置为 true。
如果 el 可能阻塞渲染:
给定 source text、 base URL、settings object、options,获取内联模块脚本 图,并使用给定 result 的以下步骤:
importmap”令 result 为给定 source text 和 base URL创建导入映射解析 结果所得的结果。
给定 result,将 el 标记为准备就绪。
speculationrules”令 result 为给定 source text 和 el 的节点 文档创建推测 规则解析结果所得的结果。
给定 result,将 el 标记为准备就绪。
如果 el 的类型为“classic”且
el 具有 src
属性,或者 el 的类型为“module”:
如果 el 具有 async 属性,
或 el 的强制
异步为 true:
令 scripts 为 el 的准备时文档的 将尽快执行的脚本 集合。
将 el 追加到 scripts。
将 el 的结果准备好时要运行的 步骤设置为以下步骤:
否则,如果 el 不是 由解析器插入的:
令 scripts 为 el 的准备时文档的 将尽快按顺序 执行的脚本列表。
将 el 追加到 scripts。
将 el 的结果准备好时要运行的 步骤设置为以下步骤:
否则,如果 el 具有
defer
属性,或者 el 的类型为“module”:
将 el 追加到其解析器 文档的将在文档完成 解析后执行的脚本列表。
将 el 的结果准备好时要运行的 步骤设置为以下步骤:将 el 的已准备好由解析器执行设置为 true。 (解析器将负责执行该脚本。)
否则:
将 el 的解析器 文档的待处理的解析阻塞 脚本设置为 el。
在 el 上阻塞渲染。
将 el 的结果准备好时要运行的 步骤设置为以下步骤:将 el 的已准备好由解析器执行设置为 true。 (解析器将负责执行该脚本。)
否则:
如果以下所有条件均为 true:
classic”;则:
将 el 的解析器 文档的待处理的解析阻塞 脚本设置为 el。
将 el 的已准备好由解析器执行设置为 true。 (解析器将负责执行该脚本。)
每个 Document 都有一个待处理的解析阻塞脚本,它为一个
script 元素或
null,初始值为 null。
每个 Document 都有一个将尽快执行的脚本集合,它是一个由 script 元素组成的
集合,初始为空。
每个 Document 都有一个将尽快按顺序
执行的脚本列表,它是一个由 script 元素组成的
列表,初始
为空。
每个 Document 都有一个将在文档完成
解析后执行的脚本列表,它是一个由 script 元素组成的
列表,初始
为空。
如果阻塞解析器的 script 元素在
通常停止阻塞该解析器之前被移动到另一个
Document,它仍会
继续阻塞该解析器,直到使其阻塞解析器的条件不再
适用(例如,如果脚本之所以是待处理的解析阻塞脚本,是因为原始
Document 在解析时具有阻塞
脚本的样式表,但随后在阻塞样式
表加载之前将脚本移动到另一个 Document,则该脚本仍会阻塞解析器,
直到所有样式表都加载完毕,此时脚本执行,解析器解除阻塞)。
要给定一个
script 元素
el,执行脚本元素:
令 document 为 el 的节点文档。
如果 el 的准备时文档不等于 document,则返回。
在 el 上解除渲染阻塞。
如果 el 的来自外部文件为
true,或者 el 的类型为“module”,则递增
document 的忽略破坏性写入
计数器。
根据 el 的类型进行切换:
classic”令 oldCurrentScript 为 document 的 currentScript
对象最近一次被
设置成的值。
如果 el 的根不是一个影子
根,则将
document 的 currentScript
属性设置为 el。否则,将其设置为 null。
这里不使用位于
文档树中检查,因为
el 可能在执行前已从文档中移除,而在这种
情况下,currentScript
仍需要
指向它。
将 document 的 currentScript
属性设置为
oldCurrentScript。
module”断言:document 的 currentScript
属性为 null。
importmap”speculationrules”如果在前面的步骤中递增了 document 的忽略破坏性写入计数器, 则将其递减。
不要求用户代理支持 JavaScript。如果出现 JavaScript 以外的语言,并且同样被 Web 浏览器
广泛采用,则需要更新本标准。在此之前,鉴于为 script 元素定义的
处理模型,实现其他语言与本标准相冲突。
根据
ECMAScript 媒体类型更新,服务器应对 JavaScript
资源使用 text/javascript。服务器不应对
JavaScript 资源使用其他
JavaScript MIME 类型,并且
不得使用非 JavaScript MIME 类型。
[RFC9239]
对于外部 JavaScript 资源,`Content-Type`
标头中的 MIME 类型参数
通常会被忽略。(在某些情况下,`charset` 参数会产生
影响。)但是,对于 script 元素的
type 属性,它们具有
重要意义;该属性使用 JavaScript
MIME 类型本质匹配概念。
例如,type
属性设置为“text/javascript; charset=utf-8”的脚本不会被
求值,即使在解析后它是一个有效的 JavaScript
MIME 类型。
此外,同样对于外部 JavaScript 资源,`Content-Type` 标头的处理还需要特别
考虑,具体见准备
脚本
元素算法和 Fetch。[FETCH]
script
元素内容的限制避免本节所述这些相当奇怪的限制,最简单且最安全的方法是:当
“<!--”的 ASCII 不区分大小写匹配项出现在脚本的字面量中
(例如字符串、正则表达式或注释中)时,始终将其转义为
“\x3C!--”,将“<script”转义为“\x3Cscript”,并将
“</script”转义为
“\x3C/script”,同时避免编写在表达式中使用此类构造的
代码。这样做可以避免本节限制容易触发的陷阱:即由于历史原因,HTML 中
script
块的解析是一种奇怪且特殊的做法,在面对这些序列时会表现得不符合直觉。
script
元素的后代文本内容必须与以下 ABNF 中的 script
产生式匹配,其字符集为 Unicode。
[ABNF]
script = outer * ( comment-open inner comment-close outer )
outer = < any string that doesn 't contain a substring that matches not-in-outer >
not-in-outer = comment-open
inner = < any string that doesn 't contain a substring that matches not-in-inner >
not-in-inner = comment-close / script-open
comment-open = "<!--"
comment-close = "-->"
script-open = "<" s c r i p t tag-end
s = %x0053 ; U+0053 LATIN CAPITAL LETTER S
s =/ %x0073 ; U+0073 LATIN SMALL LETTER S
c = %x0043 ; U+0043 LATIN CAPITAL LETTER C
c =/ %x0063 ; U+0063 LATIN SMALL LETTER C
r = %x0052 ; U+0052 LATIN CAPITAL LETTER R
r =/ %x0072 ; U+0072 LATIN SMALL LETTER R
i = %x0049 ; U+0049 LATIN CAPITAL LETTER I
i =/ %x0069 ; U+0069 LATIN SMALL LETTER I
p = %x0050 ; U+0050 LATIN CAPITAL LETTER P
p =/ %x0070 ; U+0070 LATIN SMALL LETTER P
t = %x0054 ; U+0054 LATIN CAPITAL LETTER T
t =/ %x0074 ; U+0074 LATIN SMALL LETTER T
tag-end = %x0009 ; U+0009 CHARACTER TABULATION (tab)
tag-end =/ %x000A ; U+000A LINE FEED (LF)
tag-end =/ %x000C ; U+000C FORM FEED (FF)
tag-end =/ %x0020 ; U+0020 SPACE
tag-end =/ %x002F ; U+002F SOLIDUS (/)
tag-end =/ %x003E ; U+003E GREATER-THAN SIGN (>) 当 script
元素包含脚本
文档时,该元素的内容还受到
进一步限制,如下节所述。
以下脚本说明了此问题。假设有一个脚本包含如下字符串:
const example = 'Consider this string: <!-- <script>' ;
console. log( example); 如果将此字符串直接放入 script
块中,则会违反
上述限制:
< script >
const example = 'Consider this string: <!-- <script>' ;
console. log( example);
</ script > 不过,更大的问题以及它会违反这些限制的原因,是
脚本实际上会以奇怪的方式被解析:上面的脚本块并未终止。
也就是说,此代码片段中看起来像“</script>”结束标签的内容
实际上仍然是 script
块的一部分。脚本不会执行(因为它没有
终止);如果它以某种方式执行了,例如标记如下所示,则它会
失败,因为脚本(此处高亮显示)不是有效的 JavaScript:
< script >
const example = 'Consider this string: <!-- <script>' ;
console. log( example);
</ script >
<!-- despite appearances, this is actually part of the script still! -->
< script >
... // this is the same script block still...
</ script > 这里发生的情况是,出于旧版兼容原因,HTML 中 script
元素内的“<!--”和“<script”字符串需要保持平衡,
解析器才会考虑关闭该块。
按照本节开头所述对有问题的字符串进行转义,即可完全 避免该问题:
< script >
// Note: `\x3C` is an escape sequence for `<`.
const example = 'Consider this string: \x3C!-- \x3Cscript>' ;
console. log( example);
</ script >
<!-- this is just a comment between script blocks -->
< script >
... // this is a new script block
</ script > 这些序列可能自然出现在脚本表达式中,如以下 示例所示:
if ( x<!-- y) { ... }
if ( player< script ) { ... } 在这种情况下,字符无法转义,但可以重写表达式,使这些 序列不再出现,例如:
if ( x < !-- y) { ... }
if ( !-- y > x) { ... }
if ( ! ( -- y) > x) { ... }
if ( player < script) { ... }
if ( script > player) { ... } 这样做还可以避免另一个陷阱:同样出于相关的历史原因,经典 脚本中的字符串 “<!--”实际上会被视为行 注释的开始,与“//”相同。
如果指定了 script
元素的 src
属性,
则 script
元素的内容(如果有)必须使得
从元素内容派生的 text IDL
属性值与以下
ABNF 中的 documentation 产生式匹配,其字符集为 Unicode。[ABNF]
documentation = * ( * ( space / tab / comment ) [ line-comment ] newline )
comment = slash star * ( not-star / star not-slash ) 1* star slash
line-comment = slash slash * not-newline
; characters
tab = %x0009 ; U+0009 CHARACTER TABULATION (tab)
newline = %x000A ; U+000A LINE FEED (LF)
space = %x0020 ; U+0020 SPACE
star = %x002A ; U+002A ASTERISK (*)
slash = %x002F ; U+002F SOLIDUS (/)
not-newline = %x0000-0009 / %x000B-10FFFF
; a scalar value other than U+000A LINE FEED (LF)
not-star = %x0000-0029 / %x002B-10FFFF
; a scalar value other than U+002A ASTERISK (*)
not-slash = %x0000-002E / %x0030-10FFFF
; a scalar value other than U+002F SOLIDUS (/) 这相当于将元素内容放入 JavaScript 注释中。
此要求是在前面对 script
元素内容语法限制的基础上附加的。
这允许作者在仍然引用外部脚本文件的同时,在其文档中包含许可证信息或 API 信息等
文档。语法受到限制,
以免作者在同时提供 src
属性时,意外包含看起来像有效脚本的内容。
< script src = "cool-effects.js" >
// create new instances using:
// var e = new Effect();
// start the effect using .play, stop using .stop:
// e.play();
// e.stop();
</ script > script 元素与 XSLT 的交互本节为非规范性内容。
本规范未定义 XSLT 如何与 script 元素交互。
但是,在没有其他规范实际定义此行为的情况下,以下是一些基于现有实现的
实现者指南:
当 XSLT 转换程序由 <?xml-stylesheet?> 处理
指令触发,并且浏览器实现直接到 DOM 的
转换时,由 XSLT 处理器创建的 script
元素需要
正确设置其解析器文档,并且
在转换进行时按文档顺序(标有 defer 或 async 的脚本除外)立即运行。
XSLTProcessor 的 transformToDocument()
方法会向浏览上下文为 null 的 Document 对象添加元素,因此,它们创建的任何
script 元素都需要在准备脚本
元素
算法中将其已开始设置为 true,并且永远不执行(脚本已
禁用)。不过,此类 script
元素仍然需要
设置其解析器
文档,以便在没有 async
内容属性时,其 async IDL
属性返回 false。
XSLTProcessor 的 transformToFragment()
方法需要
创建一个与使用 document.createElementNS()
创建元素后手动构建的片段等效的片段。例如,它需要
创建解析器文档为 null 且已开始设置为 false 的 script 元素,以便它们在
片段插入文档时执行。
前两种情况与最后一种情况的主要区别在于,前两种情况
操作 Document,而最后一种情况操作
片段。
noscript 元素
所有当前引擎均支持。
head 元素中,前提是没有祖先
noscript 元素。
noscript 元素。
select 元素或 optgroup 元素的后代,
前提是没有祖先 noscript
元素。
head 元素中:以任意
顺序包含零个或多个 link
元素、零个或多个 style 元素,以及零个或
多个 meta 元素。
head 元素中:透明,但不得有 noscript 元素
后代。
HTMLElement。如果脚本已启用,则
noscript
元素不表示任何内容;如果
脚本已禁用,则表示其子节点。通过影响
文档的解析方式,它用于向支持脚本和不支持脚本的用户代理呈现不同的
标记。
在HTML 文档中使用时,允许的内容模型如下:
head 元素中,如果
noscript 元素的
脚本已
禁用
head 元素中,如果
noscript
元素的脚本已启用
noscript
元素必须仅包含文本,但有一个例外:以
noscript
元素作为 上下文
元素、以文本内容作为 input 调用HTML
片段解析算法时,所得节点列表必须仅由 link、style 和 meta 元素组成;如果这些
元素是 noscript
元素的
子元素,则必须符合规范,并且不得有解析错误。
head
元素之外,如果 noscript 元素的脚本已
禁用
noscript
元素的内容模型是透明的,另有
一项附加限制:noscript 元素
不得以另一个 noscript
元素作为祖先(即 noscript 不能
嵌套)。
head
元素之外,如果 noscript 元素的脚本已
启用
noscript
元素必须仅包含文本,但文本必须满足以下条件:
运行下列算法后,得到一个符合规范的文档,其中没有
noscript
元素,也没有 script 元素,并且
算法中的任何步骤都不会抛出异常,也不会导致 HTML
解析器标记解析
错误:
所有这些曲折处理都是必需的,因为出于历史原因,
noscript 元素
会由 HTML 解析器根据
调用解析器时脚本模式是否为已禁用而以不同方式处理。
noscript 元素仅在HTML
语法中有效,在XML
语法中不起作用。这是因为它的工作方式
本质上是在启用脚本时“关闭”解析器,使元素内容被视为纯文本而不是实际元素。XML 没有定义
实现此行为的机制。
noscript
元素没有其他要求。特别是,
noscript 元素
的子节点并不会免除表单提交、脚本处理等,
即使该元素的脚本已启用。
在以下示例中,使用 noscript 元素
为脚本提供后备内容。
< form action = "calcSquare.php" >
< p >
< label for = x > Number</ label > :
< input id = "x" name = "x" type = "number" >
</ p >
< script >
var x = document. getElementById( 'x' );
var output = document. createElement( 'p' );
output. textContent = 'Type a number; it will be squared right then!' ;
x. form. appendChild( output);
x. form. onsubmit = function () { return false ; }
x. oninput = function () {
var v = x. valueAsNumber;
output. textContent = v + ' squared is ' + v * v;
};
</ script >
< noscript >
< input type = submit value = "Calculate Square" >
</ noscript >
</ form > 禁用脚本时,会出现一个按钮,用于在服务器端执行计算。启用 脚本时,则会即时计算该值。
noscript
元素是一种粗糙的手段。有时脚本可能已启用,
但页面脚本可能由于某种原因失败。因此,通常最好避免
使用 noscript,
而是将脚本设计为即时将页面从无脚本页面
转换为有脚本页面,如下一个示例所示:
< form action = "calcSquare.php" >
< p >
< label for = x > Number</ label > :
< input id = "x" name = "x" type = "number" >
</ p >
< input id = "submit" type = submit value = "Calculate Square" >
< script >
var x = document. getElementById( 'x' );
var output = document. createElement( 'p' );
output. textContent = 'Type a number; it will be squared right then!' ;
x. form. appendChild( output);
x. form. onsubmit = function () { return false ; }
x. oninput = function () {
var v = x. valueAsNumber;
output. textContent = v + ' squared is ' + v * v;
};
var submit = document. getElementById( 'submit' );
submit. parentNode. removeChild( submit);
</ script >
</ form > template 元素
所有当前引擎均支持。
所有当前引擎均支持。
span
属性的 colgroup
元素的子元素。shadowrootmode
— 启用流式声明式影子根
shadowrootdelegatesfocus
— 在声明式影子根上设置委托焦点
shadowrootslotassignment
— 在声明式影子根上设置槽位
分配
shadowrootclonable
— 在声明式影子根上设置可克隆
shadowrootserializable
— 在声明式影子根上设置可序列化
shadowrootcustomelementregistry
— 允许声明式影子根指示其将使用自定义元素注册表
[Exposed =Window ]
interface HTMLTemplateElement : HTMLElement {
[HTMLConstructor ] constructor ();
readonly attribute DocumentFragment content ;
[CEReactions ] attribute DOMString shadowRootMode ;
[CEReactions , Reflect ] attribute boolean shadowRootDelegatesFocus ;
[CEReactions ] attribute DOMString shadowRootSlotAssignment ;
[CEReactions , Reflect ] attribute boolean shadowRootClonable ;
[CEReactions , Reflect ] attribute boolean shadowRootSerializable ;
[CEReactions , Reflect ] attribute DOMString shadowRootCustomElementRegistry ;
};template
元素用于声明可由脚本克隆并
插入文档的 HTML 片段。
shadowrootmode 内容属性是一个
枚举属性,具有以下
关键字和状态:
| 关键字 | 状态 | 简要说明 |
|---|---|---|
open
|
开放 | template 元素表示一个开放的声明式影子根。 |
closed
|
关闭 | template 元素表示一个关闭的声明式影子根。 |
shadowrootmode
属性的无效值
默认值和缺失
值默认值均为无状态。
shadowrootdelegatesfocus 内容
属性是一个布尔属性。
shadowrootslotassignment 内容
属性是一个枚举
属性,具有以下关键字和状态:
| 关键字 | 状态 | 简要说明 |
|---|---|---|
named
|
命名 | 声明式影子根使用命名槽位分配。 |
manual
|
手动 | 声明式影子根使用手动槽位分配。 |
shadowrootslotassignment
属性的无效值
默认值和缺失值默认值均为命名状态。
shadowrootclonable 内容属性是一个
布尔属性。
shadowrootserializable 内容
属性是一个布尔属性。
shadowrootcustomelementregistry
内容属性是一个布尔
属性。
由于 DOM 操作,template
元素也可能包含 Text
节点和元素节点;但是,包含任何此类节点都违反
template
元素的内容模型,因为其内容模型被定义为无内容。
例如,请考虑以下文档:
<!doctype html>
< html lang = "en" >
< head >
< title > Homework</ title >
< body >
< template id = "template" >< p > Smile!</ p ></ template >
< script >
let num = 3 ;
const fragment = document. getElementById( 'template' ). content. cloneNode( true );
while ( num-- > 1 ) {
fragment. firstChild. before( fragment. firstChild. cloneNode( true ));
fragment. firstChild. textContent += fragment. lastChild. textContent;
}
document. body. appendChild( fragment);
</ script >
</ html > template 中的
p 元素
不是 DOM 中
template 的
子节点;它是由
template
元素的 content IDL
属性返回的 DocumentFragment
的子节点。
如果脚本在
template
元素上调用 appendChild(),
则会向 template
元素添加
子节点(与
任何其他元素一样);但是,这样做违反 template 元素的
内容模型。
template.content
所有当前引擎均支持。
返回模板内容(一个
DocumentFragment)。
每个 template
元素都有一个关联的 DocumentFragment
对象,该对象是其模板内容。模板内容没有
一致性要求。创建 template 元素时,
用户代理必须运行以下步骤,以建立模板
内容:
令 document 为 template
元素的节点
文档的适当的模板内容所有者
文档。
创建一个 DocumentFragment
对象,其节点文档
为
document,其宿主为
template
元素。
将 template
元素的模板内容设置为新
创建的 DocumentFragment
对象。
对于 template 元素,
以 node 和 oldDocument 为参数的收养步骤
如下:
令 document 为 node 的节点 文档的 适当的模板内容所有者 文档。
将 node 的
模板内容(一个 DocumentFragment
对象)收养到
document 中。
shadowRootMode IDL 属性必须
反映 shadowrootmode
内容
属性,并仅限
于已知值。
shadowRootSlotAssignment IDL 属性
必须反映 shadowrootslotassignment
内容属性,并
仅限于
已知值。
shadowRootCustomElementRegistry IDL 属性有意不使用布尔类型,以便可以扩展。
在此示例中,脚本使用数据结构中的数据填充一个四列表格,并使用
template
提供元素结构,而不是手动从标记生成该
结构。
<!DOCTYPE html>
< html lang = 'en' >
< title > Cat data</ title >
< script >
// Data is hard-coded here, but could come from the server
var data = [
{ name: 'Pillar' , color: 'Ticked Tabby' , sex: 'Female (neutered)' , legs: 3 },
{ name: 'Hedral' , color: 'Tuxedo' , sex: 'Male (neutered)' , legs: 4 },
];
</ script >
< table >
< thead >
< tr >
< th > Name < th > Color < th > Sex < th > Legs
< tbody >
< template id = "row" >
< tr >< td >< td >< td >< td >
</ template >
</ table >
< script >
var template = document. querySelector( '#row' );
for ( var i = 0 ; i < data. length; i += 1 ) {
var cat = data[ i];
var clone = template. content. cloneNode( true );
var cells = clone. querySelectorAll( 'td' );
cells[ 0 ]. textContent = cat. name;
cells[ 1 ]. textContent = cat. color;
cells[ 2 ]. textContent = cat. sex;
cells[ 3 ]. textContent = cat. legs;
template. parentNode. appendChild( clone);
}
</ script > 此示例在
template 的
内容上使用 cloneNode();
也可以等效地使用 document.importNode(),
它执行相同的操作。这两个 API
之间的唯一区别是节点文档更新的时机:使用
cloneNode()
时,它会在使用 appendChild()
追加节点时更新;使用 document.importNode()
时,它会在克隆节点时
更新。
template 元素与
XSLT 和 XPath 的交互本节为非规范性内容。
本规范未定义 XSLT 和 XPath 如何与 template
元素交互。但是,在没有其他规范实际定义此行为的情况下,以下是一些
面向实现者的指南,旨在与本规范中描述的其他处理保持一致:
基于按照本规范所述方式
工作的 XML 解析器的 XSLT 处理器,在进行转换时,需要将 template 元素
视为将其模板内容作为
后代包含在内。
使用 XPath DOM API 进行 XPath 求值时,如果应用于使用本规范所述的
HTML 解析器或XML 解析器解析的 Document,则需要忽略模板内容。
slot
元素所有当前引擎均支持。
所有当前引擎均支持。
name — 影子树槽位的名称
[Exposed =Window ]
interface HTMLSlotElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect ] attribute DOMString name ;
sequence <Node > assignedNodes (optional AssignedNodesOptions options = {});
sequence <Element > assignedElements (optional AssignedNodesOptions options = {});
undefined assign ((Element or Text )... nodes );
};
dictionary AssignedNodesOptions {
boolean flatten = false ;
};slot 元素定义一个槽位。它
通常用于影子树中。slot 元素表示
其已分配节点(如果有),否则表示其内容。
name 内容
属性可以包含任何字符串值。它表示槽位的
名称。
name 属性
用于向其他元素分配槽位:具有
name 属性的 slot 元素会创建一个命名槽位;如果任何元素具有 slot 属性,且其
值与该 name
属性值匹配,并且
slot 元素是
影子树的子节点,而该影子树的根的
宿主具有
对应的 slot 属性值,则该元素会被分配到该槽位。
slot.name
所有当前引擎均支持。
slot.assignedNodes()
所有当前引擎均支持。
slot.assignedNodes({ flatten: true })
slot 元素递归执行
相同操作,直到不再有 slot
元素。slot.assignedElements()
HTMLSlotElement/assignedElements
所有当前引擎均支持。
slot.assignedElements({ flatten: true })
assignedNodes({ flatten: true
}) 相同的结果,但仅限于元素。slot.assign(...nodes)
将 slot 的手动分配节点设置为给定的 nodes。
slot 元素具有手动分配
节点,它是由 assign() 设置的可分槽节点的有序集合。
此集合初始为空。
手动 分配节点集合可以使用对可分槽节点的弱引用来实现,因为脚本无法 直接访问此集合。
assignedNodes(options) 方法的步骤
如下:
返回使用 this查找扁平化可分槽节点所得的结果。
assignedElements(options) 方法
的步骤如下:
所有当前引擎均支持。
assign(...nodes) 方法的步骤如下:
canvas 元素所有当前引擎均支持。
所有当前引擎均支持。
a 元素、具有
usemap 属性的
img 元素、
button 元素、
其 type 属性处于
复选框
或单选
按钮状态的 input 元素、作为
按钮的 input 元素,以及具有
multiple 属性或
显示大小大于 1 的 select 元素。
width — 水平
尺寸
height — 垂直
尺寸
typedef (CanvasRenderingContext2D or ImageBitmapRenderingContext or WebGLRenderingContext or WebGL2RenderingContext or GPUCanvasContext ) RenderingContext ;
[Exposed =Window ]
interface HTMLCanvasElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions ] attribute unsigned long width ;
[CEReactions ] attribute unsigned long height ;
RenderingContext ? getContext (DOMString contextId , optional any options = null );
USVString toDataURL (optional DOMString type = "image/png", optional any quality );
undefined toBlob (BlobCallback _callback , optional DOMString type = "image/png", optional any quality );
OffscreenCanvas transferControlToOffscreen ();
};
callback BlobCallback = undefined (Blob ? blob );canvas 元素
向脚本提供一个依赖分辨率的位图画布,
可用于即时渲染图表、游戏图形、艺术作品或其他可视图像。
当存在更适合的元素时,作者不应在文档中使用 canvas 元素。
例如,使用 canvas 元素
渲染页面标题是不合适的:如果标题所需的呈现具有很强的图形效果,则
应使用适当的元素(通常是 h1)
进行标记,然后使用
CSS 以及影子树等支持技术设置样式。
作者使用 canvas 元素时,还必须
提供这样的内容:向用户呈现时,其传达的功能或目的与
canvas 的位图基本相同。
此内容可以放置为 canvas
元素的内容。canvas 元素的内容(如果有)
是该元素的后备
内容。
在交互式视觉媒体中,如果 canvas
元素的脚本已
启用,并且已启用对 canvas
元素的支持,则 canvas 元素
表示由动态创建的图像,即该元素的位图,
所组成的嵌入内容。
在非交互式、静态的视觉媒体中,如果 canvas 元素之前
已与渲染上下文关联(例如,页面曾在交互式
视觉媒体中查看,现在正在打印,或者页面布局过程中运行的某个脚本
在该元素上进行了绘制),则 canvas
元素表示
具有该元素当前位图和尺寸的嵌入内容。否则,该元素
改为表示其后备内容。
在非视觉媒体中,以及在视觉媒体中,如果 canvas 元素的脚本已
禁用,或者对 canvas
元素的支持已禁用,则 canvas 元素改为表示其后备
内容。
当 canvas 元素
表示嵌入内容时,
用户仍然可以聚焦 canvas 元素的后代
(位于后备
内容中)。当元素被聚焦时,它是键盘交互
事件的目标(即使该元素本身不可见)。这允许作者使交互式
画布可通过键盘访问:作者应将交互区域与后备内容中的可聚焦区域一一映射。(焦点不会
影响鼠标交互事件。)[UIEVENTS]
canvas 元素具有
两个用于控制元素位图尺寸的属性:
width 和 height。指定这些
属性时,其值必须是有效的
非负整数。必须使用解析非负
整数的规则来获得其数值。如果属性缺失,或者解析其值返回错误,则必须
改用默认值。width
属性的默认值为 300,height 属性
的默认值为 150。
设置 width 或 height 属性的值时,如果
canvas
元素的上下文模式设置为占位符,则
用户代理必须抛出一个 "InvalidStateError" DOMException
并保持该属性的值不变。
用户代理必须为 canvas 及其渲染
上下文的位图使用正方形像素密度,即每个
坐标空间单位对应一个图像数据像素。
canvas
元素可以通过样式表任意调整尺寸,其
位图随后受 'object-fit' CSS
属性约束。
canvas
元素的位图、ImageBitmap
对象的位图,
以及某些渲染上下文的位图,例如下文有关
CanvasRenderingContext2D、
OffscreenCanvasRenderingContext2D
和
ImageBitmapRenderingContext
对象的章节中所述的位图,都具有一个源干净标志,该标志可设置为 true 或
false。
最初,创建 canvas 元素或 ImageBitmap 对象时,其
位图的源干净标志必须设置为
true。
canvas 元素可以
绑定渲染上下文。最初,它没有
绑定的渲染上下文。为了跟踪它是否具有渲染上下文以及
该渲染上下文的类型,canvas
还具有一个canvas 上下文模式,初始为无,但可以由本规范定义的算法更改为占位符、2d、bitmaprenderer、webgl、webgl2 或 webgpu。
当其canvas
上下文模式为无时,canvas 元素没有
渲染上下文,
并且其位图必须为透明
黑色,其自然宽度等于该
元素的 width 属性的
数值,其自然高度等于
该元素的 height
属性的数值;这些值按CSS
像素解释,并在属性被设置、
更改或移除时更新。
当其canvas
上下文模式为占位符时,canvas 元素没有
渲染上下文。它作为 OffscreenCanvas
对象的占位符,
并且
canvas 元素的内容
由 OffscreenCanvas
对象的渲染上下文更新。
当 canvas 元素
表示嵌入
内容时,它提供一个绘制源,其宽度为该元素的自然宽度,其高度
为该元素的自然高度,
其外观为该元素的位图。
每当设置、移除、更改 width 和
height 内容
属性,或者将它们重复设置为已有值时,用户代理必须执行
下表中与 canvas 元素的上下文模式相对应的行中的操作。
|
操作 |
|
|---|---|
|
遵循 WebGL 规范中定义的行为。[WEBGL] |
|
|
遵循 WebGPU 中定义的行为。[WEBGPU] |
|
|
如果上下文的位图
模式设置为空白,
则运行设置
|
|
|
不执行任何操作。 |
|
|
不执行任何操作。 |
所有当前引擎均支持。
所有当前引擎均支持。
width
和 height
IDL 属性必须反映各自同名的内容
属性,并使用
相同的默认值。
context = canvas.getContext(contextId [, options ])
所有当前引擎均支持。
返回一个公开用于在画布上绘制的 API 的对象。contextId
指定所需的 API:“2d”、“bitmaprenderer”、
“webgl”、“webgl2”或“webgpu”。
options 由该 API 处理。
本规范在下文定义“2d”和“bitmaprenderer”
上下文。WebGL
规范定义“webgl”和“webgl2”上下文。
WebGPU 定义“webgpu”上下文。
[WEBGL] [WEBGPU]
如果不支持 contextId,或者画布已经使用另一种上下文类型
初始化,则返回 null(例如,在获取
“webgl”
上下文后尝试获取“2d”上下文)。
调用 canvas 元素的
getContext(contextId, options)
方法时,必须运行以下步骤:
如果 options 不是对象,则将 options 设置为 null。
将 options 设置为把 options转换为 JavaScript 值所得的结果。
运行下表中列标题与此 canvas 元素的
canvas 上下文
模式匹配、且行标题与 contextId 匹配的单元格中的步骤:
| 无 | 2d | bitmaprenderer | webgl 或 webgl2 | webgpu | 占位符 | |
|---|---|---|---|---|---|---|
"2d"
|
|
返回上次使用相同第一个参数调用该方法时返回的同一对象。 | 返回 null。 | 返回 null。 | 返回 null。 |
抛出一个 "InvalidStateError" DOMException。
|
"bitmaprenderer"
|
|
返回 null。 | 返回上次使用相同第一个参数调用该方法时返回的同一对象。 | 返回 null。 | 返回 null。 |
抛出一个 "InvalidStateError" DOMException。
|
如果用户代理在其当前配置中支持 WebGL 功能,则为
"webgl" 或 "webgl2"
|
返回 null。 | 返回 null。 | 返回上次使用相同第一个参数调用该方法时返回的同一对象。 | 返回 null。 |
抛出一个 "InvalidStateError" DOMException。
|
|
如果用户代理在其当前配置中支持 WebGPU 功能,则为
"webgpu"
|
返回 null。 | 返回 null。 | 返回 null。 | 返回上次使用相同第一个参数调用该方法时返回的同一对象。 |
抛出一个 "InvalidStateError" DOMException。
|
|
| 不受支持的值* | 返回 null。 | 返回 null。 | 返回 null。 | 返回 null。 | 返回 null。 |
抛出一个 "InvalidStateError" DOMException。
|
url = canvas.toDataURL([ type [, quality ] ])
所有当前引擎均支持。
返回画布中图像的一个 data: URL。
如果提供了第一个参数,它控制要返回的图像类型(例如 PNG 或
JPEG)。默认值为“image/png”;
如果不支持给定类型,也会使用该
类型。如果该类型是支持可变
质量的图像格式(例如“image/jpeg”),则第二个参数生效,
它是一个介于 0.0 到 1.0(含)之间的数字,
表示结果图像所需的质量级别。
尝试使用“image/png”以外的类型时,作者可以检查
返回的字符串是否以精确字符串“data:image/png,”或“data:image/png;”之一开头,
以确认图像是否确实以请求的格式返回。如果是,则
图像为 PNG,因此不支持请求的类型。
(唯一的例外是画布没有高度或没有宽度,此时结果可能只是
“data:,”。)
canvas.toBlob(callback [, type [, quality ] ])
所有当前引擎均支持。
创建一个 Blob
对象,表示包含画布中图像的文件,
并使用该对象的句柄调用回调。
如果提供了第二个参数,它控制要返回的图像类型(例如 PNG 或
JPEG)。默认值为“image/png”;
如果不支持给定类型,也会使用
该类型。如果该类型是支持可变
质量的图像格式(例如“image/jpeg”),则第三个参数生效,
它是一个介于 0.0 到 1.0(含)之间的数字,
表示结果图像所需的质量级别。
canvas.transferControlToOffscreen()
HTMLCanvasElement/transferControlToOffscreen
所有当前引擎均支持。
返回一个新创建的 OffscreenCanvas
对象,该对象
使用
canvas 元素作为
占位符。一旦 canvas 元素
成为
OffscreenCanvas 对象的
占位符,其
自然尺寸就不能再更改,并且它不能具有渲染上下文。占位符画布的内容
会在 OffscreenCanvas 的相关代理的事件循环的更新渲染
步骤中更新。
调用 toDataURL(type, quality) 方法时,
必须运行以下步骤:
如果此 canvas
元素位图的源干净标志设置为
false,则抛出一个
"SecurityError" DOMException。
如果此 canvas
元素的位图没有像素(即其水平
尺寸或垂直尺寸为零),则返回字符串“data:,”。(这是最短的
data: URL;它表示
text/plain 资源中的空字符串。)
令 file 为此
canvas 元素位图作为文件的序列化结果,并在给定时传入
type 和 quality。
如果 file 为 null,则返回“data:,”。
调用 toBlob(callback, type,
quality) 方法时,必须运行以下步骤:
如果此 canvas
元素位图的源干净标志设置为
false,则抛出一个
"SecurityError" DOMException。
令 result 为 null。
如果此 canvas
元素的位图具有像素(即其水平
尺寸和垂直尺寸均不为零),则将 result 设置为此
canvas 元素
位图的副本。
并行运行以下步骤:
调用 transferControlToOffscreen() 方法时,
必须运行以下步骤:
如果此 canvas
元素的上下文
模式未设置为无,则抛出一个
"InvalidStateError" DOMException。
令 offscreenCanvas 为一个新的 OffscreenCanvas 对象,
其
宽度和高度分别等于此
canvas 元素的
width
和 height 内容
属性的值。
将 offscreenCanvas 的占位符 canvas 元素
设置为对此 canvas
元素的弱引用。
返回 offscreenCanvas。
所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
typedef (HTMLImageElement or
SVGImageElement ) HTMLOrSVGImageElement ;
typedef (HTMLOrSVGImageElement or
HTMLVideoElement or
HTMLCanvasElement or
ImageBitmap or
OffscreenCanvas or
VideoFrame ) CanvasImageSource ;
enum CanvasColorType { " unorm8 " , " float16 " };
enum CanvasFillRule { " nonzero " , " evenodd " };
dictionary CanvasRenderingContext2DSettings {
boolean alpha = true ;
boolean desynchronized = false ;
PredefinedColorSpace colorSpace = "srgb";
CanvasColorType colorType = "unorm8";
boolean willReadFrequently = false ;
};
enum ImageSmoothingQuality { " low " , " medium " , " high " };
[Exposed =Window ]
interface CanvasRenderingContext2D {
// back-reference to the canvas
readonly attribute HTMLCanvasElement canvas ;
};
CanvasRenderingContext2D includes CanvasSettings ;
CanvasRenderingContext2D includes CanvasState ;
CanvasRenderingContext2D includes CanvasTransform ;
CanvasRenderingContext2D includes CanvasCompositing ;
CanvasRenderingContext2D includes CanvasImageSmoothing ;
CanvasRenderingContext2D includes CanvasFillStrokeStyles ;
CanvasRenderingContext2D includes CanvasShadowStyles ;
CanvasRenderingContext2D includes CanvasFilters ;
CanvasRenderingContext2D includes CanvasRect ;
CanvasRenderingContext2D includes CanvasDrawPath ;
CanvasRenderingContext2D includes CanvasUserInterface ;
CanvasRenderingContext2D includes CanvasText ;
CanvasRenderingContext2D includes CanvasDrawImage ;
CanvasRenderingContext2D includes CanvasImageData ;
CanvasRenderingContext2D includes CanvasPathDrawingStyles ;
CanvasRenderingContext2D includes CanvasTextDrawingStyles ;
CanvasRenderingContext2D includes CanvasPath ;
interface mixin CanvasSettings {
// settings
CanvasRenderingContext2DSettings getContextAttributes ();
};
interface mixin CanvasState {
// state
undefined save (); // push state on state stack
undefined restore (); // pop state stack and restore state
undefined reset (); // reset the rendering context to its default state
boolean isContextLost (); // return whether context is lost
};
interface mixin CanvasTransform {
// transformations (default transform is the identity matrix)
undefined scale (unrestricted double x , unrestricted double y );
undefined rotate (unrestricted double angle );
undefined translate (unrestricted double x , unrestricted double y );
undefined transform (unrestricted double a , unrestricted double b , unrestricted double c , unrestricted double d , unrestricted double e , unrestricted double f );
[NewObject ] DOMMatrix getTransform ();
undefined setTransform (unrestricted double a , unrestricted double b , unrestricted double c , unrestricted double d , unrestricted double e , unrestricted double f );
undefined setTransform (optional DOMMatrix2DInit transform = {});
undefined resetTransform ();
};
interface mixin CanvasCompositing {
// compositing
attribute unrestricted double globalAlpha ; // (default 1.0)
attribute DOMString globalCompositeOperation ; // (default "source-over")
};
interface mixin CanvasImageSmoothing {
// image smoothing
attribute boolean imageSmoothingEnabled ; // (default true)
attribute ImageSmoothingQuality imageSmoothingQuality ; // (default low)
};
interface mixin CanvasFillStrokeStyles {
// colors and styles (see also the CanvasPathDrawingStyles and CanvasTextDrawingStyles interfaces)
attribute (DOMString or CanvasGradient or CanvasPattern ) strokeStyle ; // (default black)
attribute (DOMString or CanvasGradient or CanvasPattern ) fillStyle ; // (default black)
CanvasGradient createLinearGradient (double x0 , double y0 , double x1 , double y1 );
CanvasGradient createRadialGradient (double x0 , double y0 , double r0 , double x1 , double y1 , double r1 );
CanvasGradient createConicGradient (double startAngle , double x , double y );
CanvasPattern ? createPattern (CanvasImageSource image , [LegacyNullToEmptyString ] DOMString repetition );
};
interface mixin CanvasShadowStyles {
// shadows
attribute unrestricted double shadowOffsetX ; // (default 0)
attribute unrestricted double shadowOffsetY ; // (default 0)
attribute unrestricted double shadowBlur ; // (default 0)
attribute DOMString shadowColor ; // (default transparent black)
};
interface mixin CanvasFilters {
// filters
attribute DOMString filter ; // (default "none")
};
interface mixin CanvasRect {
// rects
undefined clearRect (unrestricted double x , unrestricted double y , unrestricted double w , unrestricted double h );
undefined fillRect (unrestricted double x , unrestricted double y , unrestricted double w , unrestricted double h );
undefined strokeRect (unrestricted double x , unrestricted double y , unrestricted double w , unrestricted double h );
};
interface mixin CanvasDrawPath {
// path API (see also CanvasPath)
undefined beginPath ();
undefined fill (optional CanvasFillRule fillRule = "nonzero");
undefined fill (Path2D path , optional CanvasFillRule fillRule = "nonzero");
undefined stroke ();
undefined stroke (Path2D path );
undefined clip (optional CanvasFillRule fillRule = "nonzero");
undefined clip (Path2D path , optional CanvasFillRule fillRule = "nonzero");
boolean isPointInPath (unrestricted double x , unrestricted double y , optional CanvasFillRule fillRule = "nonzero");
boolean isPointInPath (Path2D path , unrestricted double x , unrestricted double y , optional CanvasFillRule fillRule = "nonzero");
boolean isPointInStroke (unrestricted double x , unrestricted double y );
boolean isPointInStroke (Path2D path , unrestricted double x , unrestricted double y );
};
interface mixin CanvasUserInterface {
undefined drawFocusIfNeeded (Element element );
undefined drawFocusIfNeeded (Path2D path , Element element );
};
interface mixin CanvasText {
// text (see also the CanvasPathDrawingStyles and CanvasTextDrawingStyles interfaces)
undefined fillText (DOMString text , unrestricted double x , unrestricted double y , optional unrestricted double maxWidth );
undefined strokeText (DOMString text , unrestricted double x , unrestricted double y , optional unrestricted double maxWidth );
TextMetrics measureText (DOMString text );
};
interface mixin CanvasDrawImage {
// drawing images
undefined drawImage (CanvasImageSource image , unrestricted double dx , unrestricted double dy );
undefined drawImage (CanvasImageSource image , unrestricted double dx , unrestricted double dy , unrestricted double dw , unrestricted double dh );
undefined drawImage (CanvasImageSource image , unrestricted double sx , unrestricted double sy , unrestricted double sw , unrestricted double sh , unrestricted double dx , unrestricted double dy , unrestricted double dw , unrestricted double dh );
};
interface mixin CanvasImageData {
// pixel manipulation
ImageData createImageData ([EnforceRange ] long sw , [EnforceRange ] long sh , optional ImageDataSettings settings = {});
ImageData createImageData (ImageData imageData );
ImageData getImageData ([EnforceRange ] long sx , [EnforceRange ] long sy , [EnforceRange ] long sw , [EnforceRange ] long sh , optional ImageDataSettings settings = {});
undefined putImageData (ImageData imageData , [EnforceRange ] long dx , [EnforceRange ] long dy );
undefined putImageData (ImageData imageData , [EnforceRange ] long dx , [EnforceRange ] long dy , [EnforceRange ] long dirtyX , [EnforceRange ] long dirtyY , [EnforceRange ] long dirtyWidth , [EnforceRange ] long dirtyHeight );
};
enum CanvasLineCap { "butt" , "round" , "square" };
enum CanvasLineJoin { "round" , "bevel" , "miter" };
enum CanvasTextAlign { " start " , " end " , " left " , " right " , " center " };
enum CanvasTextBaseline { " top " , " hanging " , " middle " , " alphabetic " , " ideographic " , " bottom " };
enum CanvasDirection { " ltr " , " rtl " , " inherit " };
enum CanvasFontKerning { " auto " , " normal " , " none " };
enum CanvasFontStretch { " ultra-condensed " , " extra-condensed " , " condensed " , " semi-condensed " , " normal " , " semi-expanded " , " expanded " , " extra-expanded " , " ultra-expanded " };
enum CanvasFontVariantCaps { " normal " , " small-caps " , " all-small-caps " , " petite-caps " , " all-petite-caps " , " unicase " , " titling-caps " };
enum CanvasTextRendering { " auto " , " optimizeSpeed " , " optimizeLegibility " , " geometricPrecision " };
interface mixin CanvasPathDrawingStyles {
// line caps/joins
attribute unrestricted double lineWidth ; // (default 1)
attribute CanvasLineCap lineCap ; // (default "butt")
attribute CanvasLineJoin lineJoin ; // (default "miter")
attribute unrestricted double miterLimit ; // (default 10)
// dashed lines
undefined setLineDash (sequence <unrestricted double > segments ); // default empty
sequence <unrestricted double > getLineDash ();
attribute unrestricted double lineDashOffset ;
};
interface mixin CanvasTextDrawingStyles {
// text
attribute DOMString lang ; // (default: "inherit")
attribute DOMString font ; // (default 10px sans-serif)
attribute CanvasTextAlign textAlign ; // (default: "start")
attribute CanvasTextBaseline textBaseline ; // (default: "alphabetic")
attribute CanvasDirection direction ; // (default: "inherit")
attribute DOMString letterSpacing ; // (default: "0px")
attribute CanvasFontKerning fontKerning ; // (default: "auto")
attribute CanvasFontStretch fontStretch ; // (default: "normal")
attribute CanvasFontVariantCaps fontVariantCaps ; // (default: "normal")
attribute CanvasTextRendering textRendering ; // (default: "auto")
attribute DOMString wordSpacing ; // (default: "0px")
};
interface mixin CanvasPath {
// shared path API methods
undefined closePath ();
undefined moveTo (unrestricted double x , unrestricted double y );
undefined lineTo (unrestricted double x , unrestricted double y );
undefined quadraticCurveTo (unrestricted double cpx , unrestricted double cpy , unrestricted double x , unrestricted double y );
undefined bezierCurveTo (unrestricted double cp1x , unrestricted double cp1y , unrestricted double cp2x , unrestricted double cp2y , unrestricted double x , unrestricted double y );
undefined arcTo (unrestricted double x1 , unrestricted double y1 , unrestricted double x2 , unrestricted double y2 , unrestricted double radius );
undefined rect (unrestricted double x , unrestricted double y , unrestricted double w , unrestricted double h );
undefined roundRect (unrestricted double x , unrestricted double y , unrestricted double w , unrestricted double h , optional (unrestricted double or DOMPointInit or sequence <(unrestricted double or DOMPointInit )>) radii = 0);
undefined arc (unrestricted double x , unrestricted double y , unrestricted double radius , unrestricted double startAngle , unrestricted double endAngle , optional boolean counterclockwise = false );
undefined ellipse (unrestricted double x , unrestricted double y , unrestricted double radiusX , unrestricted double radiusY , unrestricted double rotation , unrestricted double startAngle , unrestricted double endAngle , optional boolean counterclockwise = false );
};
[Exposed =(Window ,Worker )]
interface CanvasGradient {
// opaque object
undefined addColorStop (double offset , DOMString color );
};
[Exposed =(Window ,Worker )]
interface CanvasPattern {
// opaque object
undefined setTransform (optional DOMMatrix2DInit transform = {});
};
[Exposed =(Window ,Worker )]
interface TextMetrics {
// x-direction
readonly attribute double width ; // advance width
readonly attribute double actualBoundingBoxLeft ;
readonly attribute double actualBoundingBoxRight ;
// y-direction
readonly attribute double fontBoundingBoxAscent ;
readonly attribute double fontBoundingBoxDescent ;
readonly attribute double actualBoundingBoxAscent ;
readonly attribute double actualBoundingBoxDescent ;
readonly attribute double emHeightAscent ;
readonly attribute double emHeightDescent ;
readonly attribute double hangingBaseline ;
readonly attribute double alphabeticBaseline ;
readonly attribute double ideographicBaseline ;
};
[Exposed =(Window ,Worker )]
interface Path2D {
constructor (optional (Path2D or DOMString ) path );
undefined addPath (Path2D path , optional DOMMatrix2DInit transform = {});
};
Path2D includes CanvasPath ;为了保持与现有 Web 内容的兼容性,用户代理需要在
CanvasRenderingContext2D
对象上的 stroke() 方法之后,立即
枚举 CanvasUserInterface 中定义的
方法。
context = canvas.getContext('2d' [, { [ alpha: true ] [, desynchronized: false ] [, colorSpace: 'srgb'] [, willReadFrequently: false ]} ])
返回一个永久绑定到特定 canvas 元素的 CanvasRenderingContext2D
对象。
如果 alpha
成员为
false,则强制上下文始终不透明。
如果 desynchronized
成员为
true,则上下文可能是非同步的。
colorSpace
成员
指定渲染上下文的色彩空间。
如果 willReadFrequently
成员为 true,则将上下文标记为进行回读优化。
context.canvas
CanvasRenderingContext2D/canvas
所有当前引擎均支持。
返回 canvas 元素。
attributes = context.getContextAttributes()
返回一个具有以下成员的对象:
alpha
成员为 true;否则为 false。desynchronized
成员为 true。
colorSpace
成员是
一个指示上下文色彩
空间的字符串。colorType
成员是
一个指示上下文颜色
类型的字符串。willReadFrequently
成员为 true。CanvasRenderingContext2D
2D 渲染上下文表示一个平坦的线性
笛卡尔平面,其原点 (0,0) 位于左上角;在该坐标空间中,向右时
x 值增加,向下时 y 值增加。最右侧边缘的
x 坐标等于渲染上下文的输出位图以CSS 像素表示的宽度;类似地,
最底部边缘的 y 坐标等于渲染上下文的
输出位图以CSS 像素表示的高度。
坐标空间的大小不一定表示用户代理在内部或渲染期间实际使用的位图大小。 例如,在高清显示器上,用户代理可能在内部使用每个坐标空间单位对应四个设备像素的 位图,以使整个渲染过程始终保持高质量。抗锯齿也可以类似地使用 分辨率高于显示器最终图像的位图进行过采样来实现。
使用CSS 像素描述渲染上下文的 输出位图大小,并不意味着画布在渲染时会覆盖 等同数量的CSS 像素区域。为便于与文本布局等 CSS 功能集成,这里复用了CSS 像素。
换句话说,下面的 canvas
元素的渲染上下文具有一个 200x200 的
输出位图(为便于与 CSS 集成,其内部使用CSS 像素作为
单位),并渲染为 100x100 个CSS
像素:
< canvas width = 200 height = 200 style = width:100px;height:100px > 2D 上下文创建算法会接收
target(一个
canvas 元素)和
options,并运行以下步骤:
令 settings 为将 options转换为字典类型
CanvasRenderingContext2DSettings
所得的结果。
(这可能抛出异常。)
令 context 为一个新的 CanvasRenderingContext2D
对象。
初始化 context 的 canvas
属性,使其指向 target。
将 context 的输出位图设置为与 target 的位图相同的位图(从而共享它们)。
给定 context 和 settings,运行canvas 设置 输出位图 初始化算法。
返回 context。
当用户代理需要将位图 尺寸设置为 width 和 height 时,必须运行以下步骤:
在以下示例中,看起来只绘制了一个正方形:
// canvas is a reference to a <canvas> element
var context = canvas. getContext( '2d' );
context. fillRect( 0 , 0 , 50 , 50 );
canvas. setAttribute( 'width' , '300' ); // clears the canvas
context. fillRect( 0 , 100 , 50 , 50 );
canvas. width = canvas. width; // clears the canvas
context. fillRect( 100 , 0 , 50 , 50 ); // only this square remains canvas 属性必须返回创建对象时
初始化给它的值。
CanvasColorType 枚举用于
指定画布后备存储的颜色类型。
"unorm8" 值表示所有颜色分量的类型
是 8 位无符号归一化类型。
"float16" 值表示所有颜色分量的类型
是 16 位浮点类型。
CanvasFillRule 枚举用于
选择填充规则算法,以确定一个点位于路径内部还是外部。
"nonzero" 值表示非零环绕
规则,其中
如果从该点绘制的一条半无限直线沿一个方向穿过形状路径的次数,等于
沿另一个方向穿过路径的次数,则认为该点位于形状外部。
"evenodd" 值表示奇偶规则,
其中
如果从该点绘制的一条半无限直线穿过形状路径的次数为偶数,则认为
该点位于形状外部。
如果一个点不在形状外部,则它在形状内部。
ImageSmoothingQuality
枚举用于表示平滑图像时所使用的
插值质量偏好。
"low" 值表示偏好
较低级别的图像插值质量。低质量图像插值在计算上可能比更高设置
更高效。
"medium" 值表示
偏好中等级别的图像插值质量。
"high" 值表示偏好
较高级别的图像插值质量。高质量图像插值在计算上可能比较低设置
更昂贵。
双线性缩放是一种相对快速、质量较低的图像平滑 算法。双三次缩放或 Lanczos 缩放是能够产生 更高质量输出的图像平滑算法示例。本规范不要求使用特定的插值算法。
本节为非规范性内容。
当输出位图不由用户代理直接
显示时,实现可以不更新该位图,而仅记住已应用于它的绘制
操作序列,直到需要该位图的实际数据时为止
(例如,由于调用了 drawImage(),
或调用了 createImageBitmap()
工厂方法)。在许多
情况下,这样做的内存效率更高。
canvas
元素的位图实际上几乎总是
需要的唯一位图。渲染上下文的输出位图(如果有)
始终只是某个 canvas 元素位图的别名。
有时需要额外的位图,例如,当画布以不同于其自然尺寸的大小 进行绘制时实现快速绘制,或者启用双缓冲,以便在执行画布绘制命令的同时, 并发处理诸如页面滚动之类的图形更新。
CanvasSettings 对象具有一个
输出位图,该位图在
创建对象时初始化。
输出位图具有一个源干净标志, 该标志可设置为 true 或 false。 最初,创建这些位图之一时,其源干净标志必须设置为 true。
CanvasSettings 对象还
具有一个alpha 布尔值。当 CanvasSettings 对象的
alpha 为 false 时,其 alpha
分量必须固定
为 1.0(完全不透明),并且任何更改像素 alpha 分量的尝试都必须
被静默忽略。
因此,这种上下文的位图初始为不透明黑色,而不是透明黑色;clearRect()
总是产生不透明黑色像素,从 getImageData()
返回的每第四个字节始终为 255,putImageData()
方法实际上会忽略其输入中的每第四个
字节,依此类推。但是,绘制到
画布上的样式和图像的 alpha 分量仍会得到遵循,直到它们会影响输出位图的
alpha 分量为止;例如,在一个新创建且 alpha 设置为
false 的
输出位图上绘制一个 50% 透明的白色
正方形,将产生一个完全不透明的灰色正方形。
CanvasSettings 对象还
具有一个desynchronized 布尔值。当
CanvasSettings 对象的
desynchronized 为
true 时,用户代理可以通过使画布绘制周期与事件循环不同步、绕过
常规用户代理渲染算法,或同时采用这两种方式,来优化画布渲染,以减少从输入事件到
光栅化之间测得的延迟。只要这种模式涉及绕过
常规绘制机制、光栅化或两者,就可能引入可见的撕裂伪影。
用户代理通常会在一个未显示的缓冲区上进行渲染,然后快速地 将其与正在扫描输出以供呈现的缓冲区交换;前一个缓冲区称为后备 缓冲区,后一个称为前置缓冲区。一种常用的降低延迟技术称为 前置缓冲区渲染,也称为单缓冲区渲染,在这种情况下,渲染与 扫描输出过程并行且存在竞争地进行。该技术以可能引入撕裂伪影为代价 降低延迟,并可全部或部分用于实现 desynchronized 布尔值。 [MULTIPLEBUFFERING]
desynchronized 布尔值在 实现某些类型的应用程序时可能很有用,例如绘图应用程序,在这些应用中, 输入与光栅化之间的延迟至关重要。
CanvasSettings 对象还
具有一个将频繁读取布尔值。当
CanvasSettings 对象的将频繁
读取为 true 时,用户代理可以针对回读操作优化画布。
在大多数设备上,用户代理需要决定是将画布的
输出位图存储在 GPU 上(也称为
"硬件加速"),还是存储在 CPU
上(也称为"软件")。大多数渲染操作在加速画布上性能更好,
主要例外是使用 getImageData()、
toDataURL() 或
toBlob() 进行回读。CanvasSettings 对象的将
频繁读取等于 true,表示网页很可能执行许多回读操作,使用软件画布会更有利。
CanvasSettings 对象还
具有一个类型为
PredefinedColorSpace
的色彩空间设置。
CanvasSettings 对象的色彩空间表示
输出位图的色彩空间。
CanvasSettings 对象
还具有一个类型为
CanvasColorType
的颜色类型设置。CanvasSettings 对象的颜色类型表示
输出位图像素的
颜色和 alpha 分量的数据类型。
给定一个 CanvasSettings
context 和一个
CanvasRenderingContext2DSettings
settings,要初始化 CanvasSettings 输出
位图:
将 context 的alpha 设置为
settings["alpha"]。
将 context 的desynchronized 设置为
settings["desynchronized"]。
将 context 的色彩空间设置为
settings["colorSpace"]。
将 context 的颜色类型设置为
settings["colorType"]。
将 context 的将频繁
读取设置为 settings["willReadFrequently"]。
getContextAttributes() 方法
的步骤是返回 «[ "alpha"
→
this 的alpha,"desynchronized"
→
this 的
desynchronized,"colorSpace"
→ this 的
色彩空间,
"colorType"
→ this 的
颜色类型,"willReadFrequently"
→
this 的
将
频繁读取
]»。
实现 CanvasState
接口的对象维护一个绘制
状态栈。绘制状态由以下内容组成:
当前变换 矩阵。
当前裁剪区域。
以下属性的当前值:lineWidth、lineCap、lineJoin、miterLimit、
lineDashOffset、
shadowOffsetX、
shadowOffsetY、
shadowBlur、
lang、font、textAlign、textBaseline、
direction、
fontKerning、
fontStretch、
fontVariantCaps、
textRendering、
imageSmoothingEnabled、
imageSmoothingQuality。
当前虚线列表。
渲染上下文的位图不是绘制状态的一部分,因为它们
取决于渲染上下文是否以及如何绑定到 canvas 元素。
实现 CanvasState
mixin 的对象具有一个上下文丢失布尔值,该值在
创建对象时初始化为 false。上下文丢失
值在上下文丢失
步骤中更新。
context.save()
所有当前引擎均支持。
将当前状态压入栈中。
context.restore()
CanvasRenderingContext2D/restore
所有当前引擎均支持。
弹出栈顶状态,将上下文恢复到该状态。
context.reset()重置渲染上下文,包括后备缓冲区、绘制状态栈、 路径和样式。
context.isContextLost()
如果渲染上下文已丢失,则返回 true。上下文丢失可能由于驱动程序 崩溃、内存耗尽等原因而发生。在这些情况下,画布会丢失其后备存储,并 执行步骤以将渲染上下文重置为其 默认状态。
save()
方法
的步骤是将当前绘制状态的副本压入绘制状态栈。
restore()
方法的步骤是弹出绘制状态栈的顶部条目,并重置到其
描述的绘制状态。如果没有保存的状态,则该方法必须不执行任何操作。
CanvasRenderingContext2D/reset
OffscreenCanvasRenderingContext2D#canvasrenderingcontext2d.reset
reset()
方法的步骤是将渲染上下文重置为其
默认状态。
CanvasRenderingContext2D/isContextLost
仅一个引擎支持。
context.lineWidth [ = value ]
CanvasRenderingContext2D/lineWidth
所有当前引擎均支持。
styles.lineWidth [ = value ]
返回当前线宽。
可以设置,以更改线宽。不是大于零的有限值的值将被 忽略。
context.lineCap [ = value ]
CanvasRenderingContext2D/lineCap
所有当前引擎均支持。
styles.lineCap [ = value ]
返回当前线帽样式。
可以设置,以更改线帽样式。
可能的线帽样式为“butt”、“round”和“square”。其他
值将被忽略。
context.lineJoin [ = value ]
CanvasRenderingContext2D/lineJoin
所有当前引擎均支持。
styles.lineJoin [ = value ]
返回当前线条连接样式。
可以设置,以更改线条连接样式。
可能的线条连接样式为“bevel”、“round”和“miter”。其他
值将被忽略。
context.miterLimit [ = value ]
CanvasRenderingContext2D/miterLimit
所有当前引擎均支持。
styles.miterLimit [ = value ]
返回当前斜接限制比率。
可以设置,以更改斜接限制比率。不是大于 零的有限值的值将被忽略。
context.setLineDash(segments)
CanvasRenderingContext2D/setLineDash
所有当前引擎均支持。
styles.setLineDash(segments)
设置当前线条虚线模式(在描边时使用)。参数是一个距离列表,依次交替 表示线条绘制和线条不绘制的长度。
segments = context.getLineDash()
CanvasRenderingContext2D/getLineDash
所有当前引擎均支持。
segments = styles.getLineDash()
返回当前线条虚线模式的副本。返回的数组始终包含偶数 个条目(即该模式经过规范化)。
context.lineDashOffset
CanvasRenderingContext2D/lineDashOffset
所有当前引擎均支持。
styles.lineDashOffset
返回相位偏移量(使用与线条虚线模式相同的单位)。
可以设置,以更改相位偏移量。不是有限值的值将被忽略。
实现 CanvasPathDrawingStyles
接口的对象具有用于控制该对象如何处理线条的属性和
方法(在本节中定义)。
lineWidth 属性给出线条的宽度,单位为
坐标空间单位。获取时,它必须返回当前值。设置时,零、负值、
无穷大和 NaN 值必须被忽略,并保持值不变;其他值必须将
当前值更改为新值。
当实现 CanvasPathDrawingStyles
接口的对象被创建时,
lineWidth 属性
的初始值必须为
1.0。
lineCap 属性定义 UA 在线条末端放置的
端点类型。三个有效值为“butt”、
“round”和“square”。
获取时,它必须返回当前值。设置时,当前值必须更改 为新值。
当实现 CanvasPathDrawingStyles
接口的对象被创建时,
lineCap 属性的
初始值必须为
“butt”。
lineJoin 属性定义 UA 在两条线相交处放置的
拐角类型。三个有效值为“bevel”、
“round”和“miter”。
获取时,它必须返回当前值。设置时,当前值必须更改 为新值。
当实现 CanvasPathDrawingStyles
接口的对象被创建时,
lineJoin 属性
的初始值必须为
“miter”。
当 lineJoin
属性的值为“miter”时,描边使用斜接限制比率来决定如何渲染连接处。可以使用 miterLimit
属性显式设置斜接限制比率。获取时,它必须返回当前值。设置时,零、负值、无穷大和
NaN 值必须被忽略,并保持值不变;其他值必须将当前
值更改为新值。
当实现 CanvasPathDrawingStyles
接口的对象被创建时,
miterLimit
属性的初始值必须为
10.0。
每个 CanvasPathDrawingStyles
对象都有一个虚线列表,该列表要么为空,
要么由偶数个非负数构成。最初,虚线列表
必须为空。
调用 setLineDash(segments) 方法时,必须运行
以下步骤:
如果 segments 中的任何值不是有限值(例如 Infinity 或 NaN 值),或者 任何值为负数(小于零),则返回(不抛出异常; 不过,用户代理可以在开发者控制台中显示消息,因为这有助于 调试)。
如果 segments 中的元素数为奇数,则令 segments 为两个 segments 副本的串联。
将对象的虚线列表设置为 segments。
调用 getLineDash() 方法时,它必须返回一个
序列,其值按照相同
顺序对应于对象的虚线
列表中的值。
有时更改虚线模式的“相位”很有用,例如实现“行进蚂蚁”
效果。可以使用 lineDashOffset 属性设置相位。获取
时,它必须
返回当前值。设置时,无穷大和 NaN 值必须被忽略,并保持值
不变;其他值必须将当前值更改为新值。
当实现 CanvasPathDrawingStyles
接口的对象被创建时,
lineDashOffset
属性的初始
值必须为 0.0。
当用户代理要在给定实现 CanvasPathDrawingStyles
接口的对象 style 的情况下描摹路径时,它必须运行以下
算法。该算法返回一条新的路径。
令 path 为正在描摹的路径的副本。
从 path 中删除所有长度为零的线段。
从 path 中移除不包含任何线条的子路径(即仅包含 一个点的子路径)。
将 path 的每个子路径中除首点和 末点以外的每个点替换为一个连接处,该连接处将通向该点的线与 从该点引出的线连接起来,使所有子路径都由两个点(一个带有引出线的起 点和一个带有引入线的终点)、一条或 多条线(连接各点和连接处)以及零个或多个连接处(每个连接一条 线与另一条线)组成,并以如下方式连接:每个子路径都是由一条或多条线组成的序列, 每两条线之间具有一个连接处,并且两端各有一个点。
向 path 中的每个闭合子路径添加一条直的闭合线,用于连接 该子路径的末点和首点;将末点更改为一个连接处(从 先前的最后一条线连接到新添加的闭合线),并将首点更改为一个连接处(从 新添加的闭合线连接到第一条线)。
如果 style 的虚线列表为空,则跳转到 标记为转换的步骤。
令 pattern width 为 style 的虚线列表中所有条目的总和,单位为坐标空间单位。
对于 path 中的每个子路径 subpath,运行 以下子步骤。这些子步骤会原地修改 path 中的子路径。
令 subpath width 为 subpath 中所有线条的总长度,单位为坐标空间 单位。
令 offset 为 style 的 lineDashOffset
的值,单位为坐标空间
单位。
当 offset 大于 pattern width 时, 将其减去 pattern width。
当 offset 小于零时,将其加上 pattern width。
将 L 定义为沿着 subpath 中所有线条定义的线性坐标线,使子路径中第一条线的起点被定义 为坐标 0,子路径中最后一条线的终点被定义为坐标 subpath width。
令 position 为 0 减去 offset。
令 index 为 0。
令 current state 为关闭(其他状态为开启 和零长度开启)。
虚线开启:令 segment length 为 style 的虚线 列表中第 index 个条目的值。
将 position 增加 segment length。
如果 position 大于 subpath width, 则结束此子路径的这些子步骤,并为下一个子路径重新开始这些子步骤;如果 没有更多子路径,则改为跳转到标记为转换的步骤。
如果 segment length 不为零,则令 current state 为 开启。
将 index 增加一。
虚线关闭:令 segment length 为 style 的虚线 列表中第 index 个条目的值。
令 start 为 L 上偏移量为 position 的位置。
将 position 增加 segment length。
如果 position 小于零,则跳转到标记为 切割后的步骤。
如果 start 小于零,则令 start 为 零。
如果 position 大于 subpath width, 则令 end 为 L 上偏移量为 subpath width 的位置。否则,令 end 为 L 上偏移量为 position 的位置。
跳转到第一个适用的步骤:
不执行任何操作,直接继续下一步。
在 end 处截断 end 所在的线并在那里放置一个点, 将其所在的子路径切成两部分; 移除 start 与 end 之间的所有线段、连接处、点和子路径;最后在 start 处放置一个不连接任何线条的点。
该点具有用于绘制线帽的方向性(见下文)。 该方向性是在该点处原始线条的方向(即在上文定义 L 时的方向)。
在 start 处将 start 所在的线切成两部分并在那里放置一个点, 将其所在的子路径切成两部分;类似地,在 end 处截断 end 所在的线并在那里放置一个点, 将它所在的子路径切成两部分; 然后移除 start 与 end 之间的所有线段、连接处、点和子路径。
如果 start 和 end 是同一个点,那么这 只会导致线条被切成两部分,并在该处插入两个点,而不会 移除任何内容;但如果该点也恰好存在一个连接处,则必须 移除该连接处。
切割后:如果 position 大于 subpath width,则跳转到标记为 转换的步骤。
将 index 增加一。如果它等于 style 的虚线列表中的条目数,则令 index 为 0。
返回到标记为虚线开启的步骤。
转换:此步骤将路径转换为一条表示其 描边的新路径。
创建一条新的路径,该路径描述以下区域的边缘:
如果一条长度等于 style 的
lineWidth 的直线
沿着 path 中的每个子路径扫过,同时保持与所扫过路径正交的角度,
并按照前述及下文进一步说明的方式,将每个点替换为满足 style 的 lineCap 属性所需的线帽,
并将每个连接处替换为满足
style 的 lineJoin
类型所需的连接处,则会覆盖这些区域。
线帽:每个点都有一条垂直于从该点引出的线条方向的平直边缘。
随后根据 style 的 lineCap 的值扩展该边缘。
“butt”值表示不添加额外的线帽。“round”值表示
还必须在从每个点引出的线条上放置一个直径等于
style 的 lineWidth 宽度
的半圆。“square”值表示必须在每个
点处添加一个矩形,该矩形的长度为 style 的 lineWidth 宽度,
宽度为 style 的 lineWidth 宽度的一半,
并紧贴垂直于从该点引出的线条方向的边缘放置。
没有线条从中引出的点必须背靠背放置两个线帽,就好像它实际上是 由一条沿该点方向性(定义见上文)的无限短直线 相互连接的两个点。
连接处:除连接处所在的点外,每个连接处还涉及另外两个点, 每条线对应一个点:这两个拐角位于距离连接点半个线宽的位置, 分别垂直于各自的线,并且都位于离另一条 线最远的一侧。
必须在所有连接处添加一个三角形,该三角形用一条直线连接这两个相对的拐角,
第三个顶点为连接点。lineJoin 属性
控制是否还渲染其他内容。上述三个值具有以下含义:
“bevel”值表示连接处仅渲染上述内容。
“round”值表示必须在连接处添加一段圆弧,
该圆弧连接上述连接处的两个拐角,与上述三角形相接(但不重叠),
直径等于线宽,圆心位于连接点。
“miter”值表示必须(如果斜接长度允许)
在连接处添加第二个三角形,其中一条边是上述两个
拐角之间的线,并与第一个三角形相接,另外两条边是
两条相接线的外侧边缘的延长线,其延伸长度以能够相交且不超过
斜接长度为限。
斜接长度是从连接点到连接处外侧线条边缘交点的距离。
斜接限制比率是斜接长度与线宽一半之比所允许的最大值。如果斜接长度会导致
斜接限制比率(由 style 的 miterLimit
属性设置)被超过,则不得添加第二个
三角形。
新创建路径中的子路径必须按如下方式定向:对于任意点,从该点绘制的 一条半无限直线与子路径相交的次数为偶数,当且仅当 从同一点绘制的半无限直线沿一个方向穿过子路径的次数,等于其沿 另一方向穿过子路径的次数。
返回新创建的路径。
context.lang [ = value ]
styles.lang [ = value ]
返回当前语言设置。
可以设置为 BCP 47 语言标签、空字符串或“inherit”,以
更改解析字体时使用的语言。“inherit”
从 canvas 元素的
语言获取语言;如果没有 canvas
元素,则从关联的文档
元素获取语言。
默认值为“inherit”。
context.font [ = value ]
所有当前引擎均支持。
styles.font [ = value ]
返回当前字体设置。
可以设置,以更改字体。其语法与 CSS 'font' 属性相同;无法解析为 CSS 字体值的值将被忽略。默认值为“10px sans-serif”。
相对关键字和长度是相对于 canvas
元素的字体计算的。
context.textAlign [ = value ]
CanvasRenderingContext2D/textAlign
所有当前引擎均支持。
styles.textAlign [ = value ]
返回当前文本对齐设置。
可以设置,以更改对齐方式。可能的值及其含义在
下文给出。其他值将被忽略。默认值为“start”。
context.textBaseline [ = value ]
CanvasRenderingContext2D/textBaseline
所有当前引擎均支持。
styles.textBaseline [ = value ]
返回当前基线对齐设置。
可以设置,以更改基线对齐方式。可能的值及其含义在
下文给出。其他值将被忽略。默认值为“alphabetic”。
context.direction [ = value ]
CanvasRenderingContext2D/direction
所有当前引擎均支持。
styles.direction [ = value ]
返回当前方向性。
可以设置,以更改方向性。可能的值及其含义在
下文给出。其他值将被忽略。默认值为“inherit”。
context.letterSpacing [ = value ]
styles.letterSpacing [ = value ]
返回文本中字符之间的当前间距。
可以设置,以更改字符之间的间距。无法解析为 CSS
<length> 的值将被忽略。默认值为“0px”。
context.fontKerning [ = value ]
styles.fontKerning [ = value ]
返回当前字体字距调整设置。
可以设置,以更改字体字距调整。可能的值及其含义在
下文给出。其他值将被忽略。默认值为“auto”。
context.fontStretch [ = value ]
styles.fontStretch [ = value ]
返回当前字体拉伸设置。
可以设置,以更改字体拉伸。可能的值及其含义在
下文给出。其他值将被忽略。默认值为“normal”。
context.fontVariantCaps [ = value ]
styles.fontVariantCaps [ = value ]
返回当前字体变体大写设置。
可以设置,以更改字体变体大写。可能的值及其含义在
下文给出。其他值将被忽略。默认值为“normal”。
context.textRendering [ = value ]
styles.textRendering [ = value ]
返回当前文本渲染设置。
可以设置,以更改文本渲染。可能的值及其含义在
下文给出。其他值将被忽略。默认值为“auto”。
context.wordSpacing [ = value ]
styles.wordSpacing [ = value ]
返回文本中单词之间的当前间距。
可以设置,以更改单词之间的间距。无法解析为 CSS
<length> 的值将被忽略。默认值为“0px”。
实现 CanvasTextDrawingStyles
接口的对象具有用于控制对象如何布局文本(栅格化或轮廓化)的属性
(在本节中定义)。此类对象还可以具有一个字体样式源对象。对于
CanvasRenderingContext2D
对象,该对象是由上下文的 canvas 属性值给出的
canvas
元素。对于
OffscreenCanvasRenderingContext2D
对象,该对象是关联的
OffscreenCanvas 对象。
为字体样式
源对象解析字体需要一个字体
源。对于给定的实现
CanvasTextDrawingStyles
的 object,按照以下步骤确定字体源:[CSSFONTLOAD]
否则,object 的字体样式源对象是一个
OffscreenCanvas 对象:
令 global 为 object 的相关全局 对象。
如果 global 是一个 Window 对象,则
返回 global 的
关联的
Document。
断言:global 实现了
WorkerGlobalScope。
返回 global。
这是使用 ID 为
c1 的普通 canvas
元素进行字体解析的示例。
const font = new FontFace( "MyCanvasFont" , "url(mycanvasfont.ttf)" );
documents. fonts. add( font);
const context = document. getElementById( "c1" ). getContext( "2d" );
document. fonts. ready. then( function () {
context. font = "64px MyCanvasFont" ;
context. fillText( "hello" , 0 , 0 );
}); 在此示例中,画布将使用 mycanvasfont.ttf 作为
字体来显示文本。
这是如何使用 OffscreenCanvas 进行字体解析的示例。
假设一个 ID 为 c2 的 canvas 元素
按如下方式传输给
worker:
const offscreenCanvas = document. getElementById( "c2" ). transferControlToOffscreen();
worker. postMessage( offscreenCanvas, [ offscreenCanvas]); 然后,在 worker 中:
self. onmessage = function ( ev) {
const transferredCanvas = ev. data;
const context = transferredCanvas. getContext( "2d" );
const font = new FontFace( "MyFont" , "url(myfont.ttf)" );
self. fonts. add( font);
self. fonts. ready. then( function () {
context. font = "64px MyFont" ;
context. fillText( "hello" , 0 , 0 );
});
}; 在此示例中,画布将使用 myfont.ttf 显示文本。
请注意,该字体仅在 worker 内部加载,而不在文档上下文中加载。
font IDL 属性在设置时,必须被解析为 CSS <'font'> 值(但
不支持诸如“inherit”这样的与属性无关的样式表语法),并且必须将所得字体
分配给上下文,同时将 'line-height'
分量强制设为“normal”,
将 'font-size' 分量转换为 CSS 像素,
并将系统字体计算为显式值。如果新值在语法上
不正确(包括使用诸如“inherit”或“initial”这样的与属性无关的样式表语法),
则必须忽略该值,并且不分配新的字体值。[CSS]
字体系列名称在使用字体时,必须在字体样式源
对象的上下文中解释;因此,通过 @font-face 嵌入或使用 FontFace 对象加载,并且对
字体样式源对象可见的任何字体,
在加载后都必须可用。(每个字体样式源
对象都有一个字体源,它决定哪些字体可用。)如果字体
在完全加载之前被使用,或者字体样式源对象在要使用该字体时的作用域中
不包含该字体,则必须将其视为未知字体,并按照相关 CSS 规范所述
回退到另一个字体。
[CSSFONTS] [CSSFONTLOAD]
获取时,font
属性必须返回上下文当前字体的序列化形式(不包含
'line-height' 分量)。[CSSOM]
例如,在执行以下语句后:
context. font = 'italic 400 12px/2 Unknown Font, sans-serif' ; ……表达式 context.font 的求值结果将是字符串
“italic 12px "Unknown Font", sans-serif”。“400”
字体粗细不会出现,因为它是默认值。行高不会出现,
因为它被强制设为默认值“normal”。
当实现 CanvasTextDrawingStyles
接口的对象被创建时,上下文的
字体必须设置为 10px sans-serif。当 'font-size' 分量
使用百分比、'em' 或 'ex'
单位的长度,或者“larger”或
“smaller”关键字设置时,如果字体样式源对象是元素,则必须相对于设置属性时该对象的
'font-size' 属性的计算值
解释这些值。当 'font-weight'
分量设置为
相对值“bolder”和“lighter”时,如果字体样式
源对象是元素,则必须相对于设置属性时该对象的 'font-weight'
属性的计算值解释这些值。如果某种情况下计算值未定义(例如
因为字体样式源对象
不是元素或未正在
渲染),则必须相对于正常粗细的
10px sans-serif 默认值解释相对关键字。
textAlign IDL 属性在获取时必须返回
当前值。设置时,当前值必须更改为新值。当实现 CanvasTextDrawingStyles
接口的对象被创建时,textAlign 属性
的初始值必须为 start。
textBaseline IDL 属性在获取时必须
返回当前值。设置时,当前值必须更改为新值。当实现 CanvasTextDrawingStyles
接口的对象被创建时,textBaseline
属性的初始值必须为
alphabetic。
实现 CanvasTextDrawingStyles
接口的对象具有一个关联的
语言值,用于本地化字体
渲染。有效值为 BCP 47 语言标签、空字符串,或“inherit”;使用“inherit”时,语言来自
canvas 元素的语言;如果
没有 canvas 元素,则来自关联的文档元素。
最初,语言必须为“inherit”。
direction IDL 属性在获取时必须返回
当前值。设置时,当前值必须更改为新值。当实现 CanvasTextDrawingStyles
接口的对象被创建时,direction 属性
的初始值必须为“inherit”。
实现 CanvasTextDrawingStyles
接口的对象具有控制
字母与单词之间间距的属性。此类对象具有关联的字母间距和单词间距值,它们都是 CSS
<length> 值。最初,两者都必须是将“0px”作为 CSS
<length> 进行解析的结果。
CanvasRenderingContext2D/letterSpacing
仅一个引擎支持。
letterSpacing
的设置器步骤为:
CanvasRenderingContext2D/wordSpacing
仅一个引擎支持。
wordSpacing
的设置器步骤为:
CanvasRenderingContext2D/fontKerning
fontKerning IDL 属性在
获取时必须返回当前值。设置时,当前值必须更改为新
值。当实现 CanvasTextDrawingStyles
接口的对象被创建时,
fontKerning
属性的
初始值必须为“auto”。
CanvasRenderingContext2D/fontStretch
仅一个引擎支持。
fontStretch IDL 属性在
获取时必须返回当前值。设置时,当前值必须更改为新
值。当实现 CanvasTextDrawingStyles
接口的对象被创建时,
fontStretch
属性的
初始值必须为“normal”。
CanvasRenderingContext2D/fontVariantCaps
仅一个引擎支持。
fontVariantCaps IDL 属性在
获取时必须返回当前值。设置时,当前值必须更改为新
值。当实现 CanvasTextDrawingStyles
接口的对象被创建时,
fontVariantCaps
属性的
初始值必须为“normal”。
CanvasRenderingContext2D/textRendering
仅一个引擎支持。
textRendering IDL 属性在
获取时必须返回当前值。设置时,当前值必须更改为新
值。当实现 CanvasTextDrawingStyles
接口的对象被创建时,
textRendering
属性的
初始值必须为“auto”。
textAlign
属性允许的关键字
如下:
start
与文本的起始边缘对齐(从左到右文本的左侧,从右到左 文本的右侧)。
end
与文本的结束边缘对齐(从左到右文本的右侧,从右到左 文本的左侧)。
left
向左对齐。
right
向右对齐。
center
居中对齐。
textBaseline
属性允许的关键字对应于字体中的对齐点:

关键字与这些对齐点的映射如下:
top
hanging
middle
alphabetic
ideographic
bottom
direction
属性允许的关键字
如下:
ltr
将文本 准备算法的输入视为从左到右的文本。
rtl
将文本 准备算法的输入视为从右到左的文本。
inherit
使用文本
准备算法中的过程,从 canvas
元素、占位
canvas 元素或
文档元素获取文本
方向。
fontKerning
属性允许的关键字
如下:
auto
由用户代理自行决定是否应用字距调整。
normal
应用字距调整。
none
不应用字距调整。
fontStretch
属性允许的关键字
如下:
ultra-condensed
与 CSS 'font-stretch' 的 'ultra-condensed' 设置相同。
extra-condensed
与 CSS 'font-stretch' 的 'extra-condensed' 设置相同。
condensed
与 CSS 'font-stretch' 的 'condensed' 设置相同。
semi-condensed
与 CSS 'font-stretch' 的 'semi-condensed' 设置相同。
normal
默认设置,字形宽度为 100%。
semi-expanded
与 CSS 'font-stretch' 的 'semi-expanded' 设置相同。
expanded
与 CSS 'font-stretch' 的 'expanded' 设置相同。
extra-expanded
与 CSS 'font-stretch' 的 'extra-expanded' 设置相同。
ultra-expanded
与 CSS 'font-stretch' 的 'ultra-expanded' 设置相同。
fontVariantCaps
属性允许的
关键字如下:
normal
不启用下列任何特性。
small-caps
与 CSS 'font-variant-caps' 的 'small-caps' 设置相同。
all-small-caps
与 CSS 'font-variant-caps' 的 'all-small-caps' 设置相同。
petite-caps
与 CSS 'font-variant-caps' 的 'petite-caps' 设置相同。
all-petite-caps
与 CSS 'font-variant-caps' 的 'all-petite-caps' 设置相同。
unicase
与 CSS 'font-variant-caps' 的 'unicase' 设置相同。
titling-caps
与 CSS 'font-variant-caps' 的 'titling-caps' 设置相同。
textRendering
属性允许的
关键字如下:
auto
与 SVG text-rendering 属性中的“auto”相同。
optimizeSpeed
与 SVG text-rendering 属性中的“optimizeSpeed”相同。
optimizeLegibility
与 SVG text-rendering 属性中的“optimizeLegibility”相同。
geometricPrecision
与 SVG text-rendering 属性中的“geometricPrecision”相同。
文本准备算法如下。它接受一个字符串 text、
一个 CanvasTextDrawingStyles
对象 target 和一个可选长度
maxWidth 作为输入。它返回一个字形形状数组,每个字形形状都定位在共同的坐标
空间中;还返回一个值为左、右或
居中之一的 physical alignment,以及一个行内框。(该算法的大多数调用者会忽略
physical alignment 和行内框。)
如果提供了 maxWidth,但其小于或等于零或等于 NaN, 则返回空数组。
将 text 中的所有 ASCII 空白替换为 U+0020 SPACE 字符。
令 font 为 target 的当前字体,由
该对象的 font
属性给出。
令 language 为 target 的语言。
如果 language 为“inherit”:
如果 language 为空字符串,则将 language 设置为 明确未知。
应用以下列表中适当的步骤,以确定 direction 的值:
构造一个假想的无限宽 CSS 行框,其中包含单个 行内框,该行内框包含文本 text,CSS 内容语言设置为 language,并且其 CSS 属性设置如下:
| 属性 | 来源 |
|---|---|
| 'direction' | direction |
| 'font' | font |
| 'font-kerning' | target 的 fontKerning
|
| 'font-stretch' | target 的 fontStretch
|
| 'font-variant-caps' | target 的 fontVariantCaps
|
| 'letter-spacing' | target 的字母间距 |
| SVG text-rendering | target 的 textRendering
|
| 'white-space' | 'pre' |
| 'word-spacing' | target 的单词间距 |
并将所有其他属性设置为其初始值。
如果提供了 maxWidth,并且假想 行框中假想行内框的宽度大于 maxWidth CSS 像素,则将 font 更改为 更窄的字体(如果有可用字体,或者可以通过对字体应用水平缩放因子 合成一个具有合理可读性的字体)或更小的字体,然后返回上一步。
anchor point 是行内框上的一个点,而
physical
alignment 是左、右和居中之一。这些
变量根据 textAlign 和
textBaseline
的值按如下方式确定:
水平位置:
textAlign 为
left
textAlign 为
start
且 direction 为
'ltr'
textAlign 为
end
且 direction 为 'rtl'
textAlign 为
right
textAlign 为
end
且 direction 为 'ltr'
textAlign 为
start
且 direction 为
'rtl'
textAlign 为
center
垂直位置:
textBaseline
为 top
textBaseline
为 hanging
textBaseline
为 middle
textBaseline
为 alphabetic
textBaseline
为 ideographic
textBaseline
为 bottom
令 result 为通过从左到右迭代 行内框中的每个字形(如果有)而构造的数组;对于每个 字形,将该字形在行内框中的形状添加到数组中,并将其定位在一个以 anchor point 为原点、使用 CSS 像素的坐标空间中。
返回 result、physical alignment 和行内 框。
实现 CanvasPath
接口的对象具有一条路径。一条路径具有一个包含零条或
多条子路径的列表。每条子路径由一个包含一个或多个点的列表构成,这些点通过直线或
曲线线段连接,并具有一个指示该子路径是否闭合的标志。
闭合子路径是指该子路径的最后一个点通过直线连接到该
子路径的第一个点。绘制路径时,将忽略仅包含一个点的子路径。
路径具有一个需要新 子路径标志。设置此 标志后,某些 API 会创建新子路径,而不是扩展上一条子路径。创建 路径时,必须设置其需要新子路径标志。
创建实现 CanvasPath
接口的对象时,必须将其路径初始化为
零条子路径。
context.moveTo(x, y)
CanvasRenderingContext2D/moveTo
所有当前引擎均支持。
path.moveTo(x, y)
使用给定点创建一条新子路径。
context.closePath()
CanvasRenderingContext2D/closePath
所有当前引擎均支持。
path.closePath()
将当前子路径标记为闭合,并开始一条新子路径,其点与 新闭合子路径的起点和终点相同。
context.lineTo(x, y)
CanvasRenderingContext2D/lineTo
所有当前引擎均支持。
path.lineTo(x, y)
将给定点添加到当前子路径,并通过一条直线将其连接到 前一个点。
context.quadraticCurveTo(cpx, cpy, x, y)
CanvasRenderingContext2D/quadraticCurveTo
所有当前引擎均支持。
path.quadraticCurveTo(cpx, cpy, x, y)
将给定点添加到当前子路径,并使用具有给定控制点的二次 贝塞尔曲线将其连接到前一个点。
context.bezierCurveTo(cp1x, cp1y, cp2x, cp2y, x, y)
CanvasRenderingContext2D/bezierCurveTo
所有当前引擎均支持。
path.bezierCurveTo(cp1x, cp1y, cp2x, cp2y, x, y)
将给定点添加到当前子路径,并使用具有给定控制点的三次贝塞尔 曲线将其连接到前一个点。
context.arcTo(x1, y1, x2, y2, radius)
CanvasRenderingContext2D/arcTo
所有当前引擎均支持。
path.arcTo(x1, y1, x2, y2, radius)
使用给定的控制点和半径向当前子路径添加一条圆弧,并通过一条 直线将其连接到前一个点。
如果给定
半径为负数,则抛出一个 “IndexSizeError” DOMException。
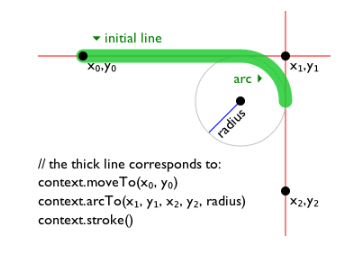
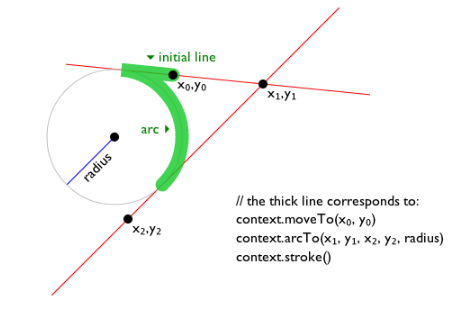
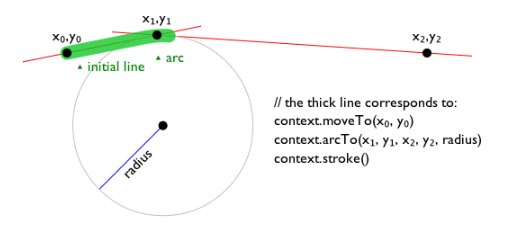
context.arc(x, y, radius, startAngle, endAngle [, counterclockwise ])
所有当前引擎均支持。
path.arc(x, y, radius, startAngle, endAngle [, counterclockwise ])
向子路径添加点,以便将由参数所描述的圆的圆周所描述的圆弧 添加到路径;该圆弧从给定起始角开始,到给定结束角结束, 沿给定方向延伸(默认为顺时针),并通过一条直线连接到 前一个点。
如果给定
半径为负数,则抛出一个 “IndexSizeError” DOMException。
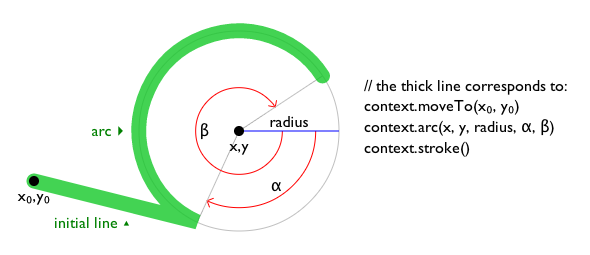
context.ellipse(x, y, radiusX, radiusY, rotation, startAngle, endAngle [, counterclockwise])
CanvasRenderingContext2D/ellipse
所有当前引擎均支持。
path.ellipse(x, y, radiusX, radiusY, rotation, startAngle, endAngle [, counterclockwise])
向子路径添加点,以便将由参数所描述的椭圆的圆周所描述的圆弧 添加到路径;该圆弧从给定起始角开始,到给定结束角结束, 沿给定方向延伸(默认为顺时针),并通过一条直线连接到 前一个点。
如果给定
半径为负数,则抛出一个 “IndexSizeError” DOMException。
context.rect(x, y, w, h)
所有当前引擎均支持。
path.rect(x, y, w, h)
向路径添加一条表示给定矩形的新闭合子路径。
context.roundRect(x, y, w, h, radii)
path.roundRect(x, y, w, h, radii)
向路径添加一条表示给定圆角矩形的新闭合子路径。 radii 是一个半径列表,或者是一个表示矩形各角的单个 像素半径。如果提供列表,则这些半径的数量和顺序与 CSS 'border-radius' 属性的工作方式 相同。单个半径的行为与只包含一个元素的列表相同。
如果 w 和 h 都大于或等于 0,或者两者都小于 0,则按顺时针方向绘制路径。否则,按逆时针方向绘制路径。
当 w 为负数时,圆角矩形会水平翻转,这意味着 通常应用于左侧各角的半径值会用于右侧,反之 亦然。类似地,当 h 为负数时,圆角矩形会垂直翻转。
当 radii 中的值 r 为数字时,相应的一个或多个角 会绘制为半径为 r 的圆弧。
当 radii 中的值 r 是具有 { x, y
} 属性的对象时,相应的一个或多个角会绘制为椭圆弧,其 x
半径和 y 半径分别等于 r.x 和 r.y。
当同一边上两个角的 radii 之和大于该 边的长度时,圆角矩形的所有 radii 都会按 length / (r1 + r2) 的系数缩放。如果多条边都具有此属性,则使用 缩放系数最小的边的缩放系数。这与 CSS 的行为一致。
如果 radii 是一个大小
不是一、二、三或四的列表,则抛出 RangeError。
如果 radii 中的值为
负数,或者是一个 { x, y } 对象,且其 x
或 y 属性为负数,则抛出 RangeError。
以下方法允许作者操作实现 CanvasPath
接口的对象的路径。
对于实现 CanvasDrawPath 和 CanvasTransform
接口的对象,传递给这些方法的点,以及这些方法添加到当前
默认路径的结果线条,在添加到
路径之前,必须根据当前变换矩阵进行变换。
调用 moveTo(x,
y) 方法时,必须运行以下步骤:
如果任一参数为无穷大或 NaN,则返回。
创建一条新子路径,并将指定点作为其第一个(也是唯一的)点。
当用户代理要为路径上的坐标
(x,
y) 确保存在一条子路径时,用户代理必须检查
路径是否设置了需要新子路径标志。如果
设置了,则用户代理必须创建一条新子路径,并将点 (x, y) 作为
其第一个(也是唯一的)点,就像调用了 moveTo() 方法
一样,然后必须清除路径的需要新
子路径标志。
调用 closePath() 方法时,如果对象的路径没有子路径,
则必须不执行任何操作。否则,它必须将最后一条子路径标记为闭合,创建一条
新子路径,使其第一个点与上一条子路径的第一个点相同,最后将
这条新子路径添加到路径。
如果最后一条子路径的点列表中包含多个点,则这 等同于添加一条直线,将最后一个点连接回最后一条 子路径的第一个点,从而“闭合”该子路径。
使用下述方法向子路径添加新点以及连接它们的线条。 在所有情况下,这些方法都只修改对象路径中的最后一条子路径。
调用 lineTo(x,
y) 方法时,必须运行以下步骤:
如果任一参数为无穷大或 NaN,则返回。
如果对象的路径没有子路径,则为 (x, y) 确保存在一条子路径。
否则,使用一条直线将子路径中的最后一个点连接到给定点 (x, y),然后将给定点 (x, y) 添加到 子路径。
调用 quadraticCurveTo(cpx, cpy,
x, y) 方法时,必须运行以下步骤:
如果任一参数为无穷大或 NaN,则返回。
为 (cpx, cpy) 确保存在一条 子路径。
使用一条控制点为 (cpx, cpy) 的二次贝塞尔曲线, 将子路径中的最后一个点连接到给定点 (x, y)。 [BEZIER]
将给定点 (x, y) 添加到子路径。
调用 bezierCurveTo(cp1x, cp1y,
cp2x, cp2y, x, y) 方法时,
必须运行以下步骤:
如果任一参数为无穷大或 NaN,则返回。
为 (cp1x, cp1y) 确保存在一条 子路径。
使用一条控制点为 (cp1x, cp1y) 和 (cp2x, cp2y) 的三次贝塞尔曲线,将子路径中的最后一个点连接到 给定点 (x, y)。[BEZIER]
将点 (x, y) 添加到子路径。
调用 arcTo(x1,
y1, x2, y2, radius) 方法时,
必须运行以下步骤:
如果任一参数为无穷大或 NaN,则返回。
为 (x1, y1) 确保存在一条 子路径。
如果 radius 为负数,则抛出一个 “IndexSizeError”
DOMException。
令点 (x0, y0) 为子路径中的最后一个点,并使用 当前变换 矩阵的逆矩阵对其进行变换(使其与传递给 方法的点处于同一坐标系)。
如果点 (x0, y0) 等于点 (x1, y1),或者点 (x1, y1) 等于点 (x2, y2),或者 radius 为零,则将点 (x1, y1) 添加到子路径,并通过一条直线将该点连接到前一个点 (x0, y0)。
否则,如果点 (x0, y0)、(x1, y1) 和 (x2, y2) 全部位于同一条直线上,则将点 (x1, y1) 添加到子路径,并通过一条直线将该点连接到前一个点 (x0, y0)。
否则,令 The Arc 为由圆周给出的最短圆弧,该圆 的半径为 radius,其一个点与穿过 点 (x0, y0) 并终止于点 (x1, y1) 的半无限直线相切,另一个不同的点与终止于 点 (x1, y1) 并穿过点 (x2, y2) 的半无限直线相切。该 圆与这两条直线相切的点分别称为起始切点和结束切点。 通过一条直线将点 (x0, y0) 连接到起始切点, 将起始切点添加到子路径,然后使用 The Arc 将起始切点 连接到结束切点,并将结束切点添加到 子路径。
调用 arc(x,
y, radius, startAngle, endAngle,
counterclockwise) 方法时,必须使用 this、x、y、radius、radius、0、
startAngle、endAngle 和 counterclockwise 运行椭圆方法
步骤。
这使其等同于 ellipse(),
区别在于两个半径相等,并且 rotation 为 0。
调用 ellipse(x,
y, radiusX, radiusY, rotation, startAngle,
endAngle, counterclockwise) 方法时,必须使用 this、
x、y、radiusX、
radiusY、rotation、startAngle、endAngle 和
counterclockwise 运行
椭圆方法步骤。
给定 ellipse 和 angle,确定椭圆上的点的步骤为:
令 eccentricCircle 为与 ellipse 共享原点,且半径等于 ellipse 半长轴的圆。
令 outerPoint 为 eccentricCircle 圆周上的点,其 angle 是从 ellipse 的半长轴开始顺时针测量的弧度值。
令 chord 为位于该轴与 outerPoint 之间,并垂直于 ellipse 长轴的线。
返回 chord 上穿过 ellipse 圆周的点。
给定 canvasPath、x、 y、 radiusX、radiusY、rotation、startAngle、 endAngle 和 counterclockwise,椭圆方法步骤为:
如果任一参数为无穷大或 NaN,则返回。
如果 radiusX 或 radiusY 中任一个为负数,则抛出一个
“IndexSizeError” DOMException。
如果 canvasPath 的路径包含任何子路径,则添加一条从子路径中最后一个 点到圆弧起点的直线。
将圆弧的起点和终点添加到子路径,并用圆弧连接它们。 圆弧及其起点和终点定义如下:
考虑一个原点位于 (x, y) 的椭圆,该椭圆具有 长轴半径 radiusX 和短轴半径 radiusY,并绕其原点 旋转,使其半长轴相对于 x 轴顺时针倾斜 rotation 弧度。
如果 counterclockwise 为 false,并且 endAngle − startAngle 大于或等于 2π,或者如果 counterclockwise 为true,并且 startAngle − endAngle 大于或等于 2π,则 圆弧为该椭圆的整个圆周,并且起点和终点均为在给定该 椭圆和 startAngle 的情况下运行确定椭圆上的点的步骤所得的结果。
否则,起点为在给定该椭圆和 startAngle 的情况下运行确定椭圆上的 点的步骤所得的结果,终点为在给定该椭圆和 endAngle 的情况下运行确定椭圆上的点的步骤所得的结果, 而圆弧则是沿着该椭圆圆周从 起点到终点的路径;如果 counterclockwise 为 true,则按逆时针方向, 否则按顺时针方向。由于这些点位于椭圆上,而不仅仅是相对于零点的 角度,因此圆弧覆盖的角度绝不会大于 2π 弧度。
即使圆弧覆盖椭圆的整个圆周,并且子路径中没有
其他点,除非适当地调用 closePath()
方法,否则路径也不会闭合。
调用 rect(x,
y, w, h) 方法时,必须运行以下
步骤:
如果任一参数为无穷大或 NaN,则返回。
创建一条新子路径,该子路径仅依次包含以下四个点: (x, y)、 (x+w, y)、(x+w, y+h)、(x, y+h),并用直线连接这 四个点。
将子路径标记为闭合。
创建一条新子路径,并将点 (x, y) 作为该 子路径中的唯一点。
CanvasRenderingContext2D/roundRect
所有当前引擎均支持。
roundRect(x, y, w,
h, radii) 方法的步骤为:
如果 x、y、w 或 h 中的任何一个为无穷大或 NaN, 则返回。
如果 radii 是 无限制
双精度浮点数或 DOMPointInit,
则将 radii 设置为 « radii
»。
如果 radii 不是一个大小为一、二、三或四的列表,则抛出 RangeError。
令 normalizedRadii 为空列表。
对于 radii 中的每个 radius:
如果 radius 是 DOMPointInit:
如果 radius["x"]
或
radius["y"]
为负数,则抛出 RangeError。
否则,将 radius 追加到 normalizedRadii。
如果 radius 是 无限制
双精度浮点数:
如果 radius 为无穷大或 NaN,则返回。
如果 radius 为负数,则抛出 RangeError。
令 upperLeft、upperRight、lowerRight 和 lowerLeft 为 null。
如果 normalizedRadii 的大小为 4,则将 upperLeft 设置为 normalizedRadii[0],将 upperRight 设置为 normalizedRadii[1],将 lowerRight 设置为 normalizedRadii[2],并将 lowerLeft 设置为 normalizedRadii[3]。
如果 normalizedRadii 的大小为 3,则将 upperLeft 设置为 normalizedRadii[0],将 upperRight 和 lowerLeft 设置为 normalizedRadii[1],并将 lowerRight 设置为 normalizedRadii[2]。
如果 normalizedRadii 的大小为 2,则将 upperLeft 和 lowerRight 设置为 normalizedRadii[0],并将 upperRight 和 lowerLeft 设置为 normalizedRadii[1]。
如果 normalizedRadii 的大小为 1,则将 upperLeft、 upperRight、lowerRight 和 lowerLeft 设置为 normalizedRadii[0]。
拐角曲线不得重叠。缩放所有半径以防止这种情况:
创建一条新子路径:
移动到点 (x + upperLeft["x"],
y)。
绘制一条直线到点 (x + w −
upperRight["x"],
y)。
绘制一条圆弧到点 (x + w, y +
upperRight["y"])。
绘制一条直线到点 (x + w, y +
h − lowerRight["y"])。
绘制一条圆弧到点 (x + w −
lowerRight["x"],
y +
h)。
绘制一条直线到点 (x + lowerLeft["x"],
y + h)。
绘制一条圆弧到点 (x, y + h −
lowerLeft["y"])。
绘制一条直线到点 (x, y +
upperLeft["y"])。
绘制一条圆弧到点 (x + upperLeft["x"],
y)。
将子路径标记为闭合。
创建一条新子路径,并将点 (x, y) 作为该 子路径中的唯一点。
其设计目的是使其行为类似于 CSS 'border-radius' 属性。
Path2D 对象
所有当前引擎均支持。
Path2D 对象可用于声明路径,随后在
实现 CanvasDrawPath 接口的对象上使用。
除前面章节所述的许多 API 外,Path2D 对象还具有
用于合并路径以及向路径添加文本的方法。
path = new Path2D()
所有当前引擎均支持。
创建一个新的空 Path2D 对象。
path = new Path2D(path)
当 path 是一个 Path2D 对象时,
返回其副本。
当 path 是字符串时,创建由该参数描述的路径,并将其解释为 SVG 路径数据。[SVG]
path.addPath(path [, transform ])
所有当前引擎均支持。
将参数给出的路径添加到该路径。
调用 Path2D(path) 构造函数时,必须运行以下
步骤:
令 output 为一个新的 Path2D 对象。
如果未给出 path,则返回 output。
如果 path 是一个 Path2D 对象,则
将 path 的所有子路径添加到 output,并返回 output。(换言之,它返回
参数的副本。)
令 svgPath 为按照 SVG 2 的路径数据规则解析并解释 path 所得的结果。[SVG]
所得路径可能为空。SVG 定义了解析和应用路径数据时的错误处理规则。
令 (x, y) 为 svgPath 中的最后一个点。
将 svgPath 中的所有子路径(如果有)添加到 output。
在 output 中创建一条新子路径,并将 (x, y) 作为该 子路径中的唯一点。
返回 output。
在 Path2D 对象
a 上调用 addPath(path,
transform) 方法时,必须运行以下步骤:
实现 CanvasTransform 接口的对象具有一个当前
变换矩阵,以及用于操作该矩阵的方法(在本节中介绍)。创建
实现 CanvasTransform 接口的对象时,
必须将其变换
矩阵初始化为单位矩阵。
在实现 CanvasTransform 接口的对象上创建
当前默认路径以及
绘制文本、形状和 Path2D
对象时,会将当前
变换矩阵应用于坐标。
变换必须按相反顺序执行。
例如,如果先对画布应用一个使宽度加倍的缩放变换, 随后应用一个使绘制操作旋转四分之一圈的旋转变换, 然后在画布上绘制一个宽度为高度两倍的矩形,则实际结果将是 一个正方形。
context.scale(x, y)
CanvasRenderingContext2D/scale
所有当前引擎均支持。
更改当前变换矩阵,以应用具有 给定特征的缩放变换。
context.rotate(angle)
CanvasRenderingContext2D/rotate
所有当前引擎均支持。
更改当前变换矩阵,以应用 具有给定特征的旋转变换。角度以弧度表示。
context.translate(x, y)
CanvasRenderingContext2D/translate
所有当前引擎均支持。
更改当前变换矩阵,以应用 具有给定特征的平移变换。
context.transform(a, b, c, d, e, f)
CanvasRenderingContext2D/transform
所有当前引擎均支持。
更改当前变换矩阵,以应用由 参数给出的、如下所述的矩阵。
matrix = context.getTransform()
CanvasRenderingContext2D/getTransform
所有当前引擎均支持。
context.setTransform(a, b, c, d, e, f)
CanvasRenderingContext2D/setTransform
所有当前引擎均支持。
将当前变换矩阵更改为由 参数给出的、如下所述的矩阵。
context.setTransform(transform)
将当前变换矩阵更改为所传入
DOMMatrix2DInit
字典表示的矩阵。
context.resetTransform()
CanvasRenderingContext2D/resetTransform
所有当前引擎均支持。
将当前变换矩阵更改为单位矩阵。
调用 scale(x,
y) 方法时,必须运行以下步骤:
如果任一参数为无穷大或 NaN,则返回。
将参数所描述的缩放变换添加到当前 变换矩阵。x 参数表示水平方向的缩放系数, y 参数表示垂直 方向的缩放系数。这些系数为倍数。
调用 rotate(angle) 方法时,必须
运行以下步骤:
如果 angle 为无穷大或 NaN,则返回。
将参数所描述的旋转变换添加到当前 变换矩阵。angle 参数表示以弧度表达的顺时针旋转角度。
调用 translate(x, y) 方法时,
必须运行以下步骤:
如果任一参数为无穷大或 NaN,则返回。
将参数所描述的平移变换添加到当前 变换矩阵。x 参数表示 水平方向的平移距离,y 参数表示 垂直方向的平移距离。参数使用坐标空间单位。
调用 transform(a, b, c,
d, e, f) 方法时,必须运行以下
步骤:
参数 a、b、c、d、 e 和 f 有时称为 m11、m12、 m21、m22、dx 和 dy,或者称为 m11、 m21、m12、m22、dx 和 dy。尤其应当 注意第二个和第三个参数(b 和 c)的顺序,因为它们的顺序在不同 API 之间会有所不同,并且 API 有时对这些位置使用 m12/m21 表示法,有时则使用 m21/m12 表示法。
返回的对象不是活动对象,因此更新它不会影响
当前
变换矩阵;更新当前变换
矩阵也不会影响已经返回的 DOMMatrix。
调用 setTransform(a, b, c,
d, e, f) 方法时,必须运行以下
步骤:
如果任一参数为无穷大或 NaN,则返回。
将当前变换矩阵重置为 下述矩阵:
| a | c | e |
| b | d | f |
| 0 | 0 | 1 |
调用 setTransform(transform)
方法时,必须运行以下步骤:
调用 resetTransform() 方法时,必须
将当前
变换矩阵重置为单位矩阵。
给定一个由 transform() 和
setTransform()
方法创建的如下形式的矩阵:
| a | c | e |
| b | d | f |
| 0 | 0 | 1 |
与变换矩阵相乘后所得的变换坐标为
xnew = a x + c y + e
ynew = b x + d y + f
CanvasDrawImage
和 CanvasFillStrokeStyles
接口上的某些方法接受联合类型 CanvasImageSource
作为参数。
此联合类型允许将实现以下任一接口的对象用作图像 源:
HTMLOrSVGImageElement
(img 或
SVG
image
元素)
HTMLVideoElement
(video
元素)HTMLCanvasElement
(canvas
元素)OffscreenCanvas
ImageBitmap
VideoFrame
尽管没有正式如此规定,但预期 SVG
image
元素的实现应与 img 元素几乎完全相同。
也就是说,
SVG
image 元素与
img
元素共享基本概念和特性。
ImageBitmap 接口
可以由许多其他表示图像的
类型创建,包括 ImageData。
要检查 image
参数的可用性,其中 image
是一个 CanvasImageSource
对象,请运行以下步骤:
根据 image 执行切换:
HTMLOrSVGImageElement
如果 image 的当前请求的状态为损坏,则
抛出一个 “InvalidStateError” DOMException。
如果 image 不能完全解码, 则返回不可用。
HTMLVideoElement
如果 image 的 readyState
属性为 HAVE_NOTHING
或 HAVE_METADATA,
则返回不可用。
HTMLCanvasElement
OffscreenCanvas
如果 image 的水平尺寸或垂直尺寸
等于零,则抛出一个 “InvalidStateError”
DOMException。
ImageBitmap
VideoFrame
如果 image 的 [[Detached]] 内部槽值
被设置为 true,则抛出一个 “InvalidStateError”
DOMException。
返回可用。
当 CanvasImageSource
对象表示一个 HTMLOrSVGImageElement
时,
必须将该元素的图像用作源图像。
具体而言,当 CanvasImageSource
对象表示 HTMLOrSVGImageElement
中的动画图像时,用户代理在为
CanvasRenderingContext2D
API 渲染图像时,必须使用动画的默认图像
(即格式定义为在不支持或禁用动画时使用的图像);
如果不存在此类图像,则使用动画的第一帧。
当 CanvasImageSource
对象表示一个 HTMLVideoElement
时,
在调用带有该参数的方法时,位于当前播放位置的帧
必须作为为
CanvasRenderingContext2D
API 渲染图像时的源图像,并且源图像的尺寸必须是媒体资源的自然宽度和自然高度
(即应用任何宽高比校正之后的尺寸)。
当 CanvasImageSource
对象表示一个 HTMLCanvasElement
时,
必须将该
元素的位图用作源图像。
当 CanvasImageSource
对象表示一个正在
渲染且已经调整大小的元素时,必须使用源图像的原始图像数据,
而不是使用其渲染后的图像(例如,源元素上的 width 和
height
属性不会影响为 CanvasRenderingContext2D
API 渲染图像时对该对象的解释方式)。
当 CanvasImageSource
对象表示一个 ImageBitmap 时,
必须将该对象的位图图像数据用作源图像。
当 CanvasImageSource
对象表示一个 OffscreenCanvas
时,
必须将该
对象的位图用作源图像。
当 CanvasImageSource
对象表示一个 VideoFrame
时,
必须将该对象的
像素数据用作源图像,并且源图像的尺寸必须是该
对象的 [[显示宽度]]和[[显示高度]]。
如果根据 image 的类型执行切换后满足以下条件,则对象 image 不是 源洁净的:
HTMLOrSVGImageElement
HTMLVideoElement
HTMLCanvasElement
ImageBitmap
OffscreenCanvas
image 的位图的源洁净 标志为 false。
context.fillStyle [ = value ]
CanvasRenderingContext2D/fillStyle
所有当前引擎均支持。
返回当前用于填充形状的样式。
可以设置该属性,以更改填充 样式。
该样式可以是包含 CSS 颜色的字符串,也可以是 CanvasGradient 或
CanvasPattern 对象。
无效值会被忽略。
context.strokeStyle [ = value ]
CanvasRenderingContext2D/strokeStyle
所有当前引擎均支持。
返回当前用于描边形状的样式。
可以设置该属性,以更改描边 样式。
该样式可以是包含 CSS 颜色的字符串,也可以是 CanvasGradient 或
CanvasPattern 对象。
无效值会被忽略。
实现 CanvasFillStrokeStyles
接口的对象具有控制对象如何处理形状的属性和
方法(在本节中定义)。
此类对象具有关联的填充
样式和描边样式
值,这些值可以是 CSS 颜色、CanvasPattern
或 CanvasGradient。
最初,两者都必须是对字符串“#000000”进行解析
所得的结果。
当值为 CSS 颜色时,在使用该值绘制到位图上时,它不得受到变换矩阵的影响。
当设置为 CanvasPattern 或 CanvasGradient 对象时,
赋值后对该对象所做的更改会影响随后对形状进行的描边或填充。
fillStyle
设置器步骤为:
strokeStyle
设置器步骤为:
渐变有三种类型:线性渐变、径向渐变和锥形渐变,
它们由实现不透明 CanvasGradient
接口的对象表示。
创建渐变后(见下文),会沿渐变放置色标,以 定义颜色沿渐变分布的方式。渐变在每个色标处的颜色是为该色标指定的颜色,并会转换到上下文的颜色空间。在每两个此类色标之间, 必须在上下文的颜色空间中对颜色和 alpha 分量进行线性插值, 且不得预乘 alpha 值,以确定在该偏移处使用的颜色。在第一个色标之前,颜色必须是 第一个色标的颜色。在最后一个色标之后,颜色必须是最后一个色标的颜色。当 没有色标时,渐变为透明 黑色。
gradient.addColorStop(offset, color)
所有当前引擎均支持。
在给定偏移处向渐变添加一个具有给定颜色的色标。0.0 是渐变 一端的偏移,1.0 是另一端的偏移。
如果偏移超出范围,则抛出一个 “IndexSizeError” DOMException。
如果
无法解析颜色,则抛出一个 “SyntaxError” DOMException。
gradient = context.createLinearGradient(x0, y0, x1, y1)
CanvasRenderingContext2D/createLinearGradient
所有当前引擎均支持。
返回一个 CanvasGradient
对象,该对象
表示沿参数所表示坐标给出的直线进行
绘制的线性渐变。
gradient = context.createRadialGradient(x0, y0, r0, x1, y1, r1)
CanvasRenderingContext2D/createRadialGradient
所有当前引擎均支持。
返回一个 CanvasGradient
对象,该对象
表示沿参数所表示圆给出的锥体进行
绘制的径向渐变。
如果任一半径为负数,则抛出一个 “IndexSizeError”
DOMException。
gradient = context.createConicGradient(startAngle, x, y)
CanvasRenderingContext2D/createConicGradient
所有当前引擎均支持。
返回一个 CanvasGradient
对象,该对象
表示围绕参数所表示的中心顺时针旋转
绘制的锥形渐变。
调用 CanvasGradient 上的 addColorStop(offset,
color) 方法时,必须运行
以下步骤:
如果 offset 小于 0 或大于 1,则抛出一个
“IndexSizeError” DOMException。
令 parsed color 为对 color 进行解析所得的结果。
不会向解析器传递任何元素,因为 CanvasGradient 对象
与 canvas 无关——由一个
canvas 创建的
CanvasGradient 对象
可以由另一个画布使用,因此在指定颜色时无法知道哪个是
“相关元素”。
如果 parsed color 为失败,则抛出一个 “SyntaxError”
DOMException。
在相对于整个渐变的偏移 offset 处放置一个新色标, 其颜色为 parsed color。
如果在渐变上的同一偏移处添加了多个色标,则必须按添加顺序放置, 第一个色标最接近渐变起点,随后每个色标都朝终点方向 无限小地更远一些(实际上会导致在每个位置添加的色标中,除第一个和 最后一个之外的所有色标都被忽略)。
createLinearGradient(x0, y0,
x1, y1) 方法接受四个参数,分别表示渐变的起
点 (x0, y0) 和终点 (x1, y1)。
调用该方法时,必须返回一个使用
指定直线初始化的线性 CanvasGradient。
渲染线性渐变时,必须使与穿过起点和终点的直线垂直的任一直线上的 所有点,都具有这两条直线交点处的颜色(颜色来自上文所述的插值和外推)。渲染时,线性渐变中的点必须按照当前变换矩阵所述进行变换。
如果 x0 = x1 且 y0 = y1,则线性 渐变不得绘制任何内容。
createRadialGradient(x0, y0,
r0, x1, y1, r1) 方法接受六个
参数,前三个表示原点为 (x0,
y0)、半径为 r0 的起始圆,后三个表示原点为
(x1, y1)、半径为 r1 的结束圆。这些值以坐标空间
单位表示。如果 r0 或 r1 中任一个为负数,则必须抛出一个
“IndexSizeError” DOMException。
否则,
调用该方法时,必须返回一个使用
两个指定圆初始化的径向 CanvasGradient。
必须按照以下步骤渲染径向渐变:
如果 x0 = x1 且 y0 = y1 且 r0 = r1,则径向渐变不得 绘制任何内容。返回。
令 x(ω) = (x1-x0)ω + x0。
令 y(ω) = (y1-y0)ω + y0。
令 r(ω) = (r1-r0)ω + r0。
令 ω 处的颜色为渐变上该位置的颜色 (颜色来自上文所述的插值和外推)。
对于所有满足 r(ω) > 0 的 ω 值,从最接近正无穷大的 ω 值开始,到最接近负无穷大的 ω 值结束,在位置 (x(ω), y(ω)) 绘制半径为 r(ω) 的圆周, 使用 ω 处的颜色,但只绘制到位图中尚未 被本步骤中较早的圆为此次渐变渲染所绘制的部分。
这实际上会创建一个与创建渐变时定义的两个圆相切的锥体, 起始圆(0.0)之前的锥体部分使用第一个偏移的颜色, 结束圆(1.0)之后的锥体部分使用最后一个偏移的颜色, 锥体之外的区域不受渐变影响(为透明 黑色)。
渲染时,所得径向渐变随后必须按照当前变换矩阵所述进行变换。
createConicGradient(startAngle,
x, y) 方法接受三个参数,第一个参数
startAngle 表示渐变开始处的弧度角,后两个参数
(x, y) 表示渐变中心,以 CSS
像素为单位。调用该方法时,必须返回一个使用指定中心和角度
初始化的锥形 CanvasGradient。
它遵循与 CSS 'conic-gradient' 相同的渲染规则,并且 等同于 CSS 'conic-gradient(from adjustedStartAnglerad at xpx ypx, angularColorStopList)'。其中:
adjustedStartAngle 由 startAngle + π/2 给出;
angularColorStopList 由使用
addColorStop()
添加到 CanvasGradient
的色标给出,
并将色标偏移
解释为百分比。
仅当相关描边或填充效果要求绘制渐变时,才必须绘制渐变。
图案由实现不透明 CanvasPattern
接口的对象表示。
pattern = context.createPattern(image, repetition)
CanvasRenderingContext2D/createPattern
所有当前引擎均支持。
返回一个 CanvasPattern
对象,该对象使用给定图像,并沿 repetition 参数给出的
一个或多个方向重复。
repetition 的允许值为 repeat(两个
方向)、repeat-x(仅水平方向)、repeat-y
(仅垂直方向)和 no-repeat(均不重复)。如果 repetition
参数为空,则使用值 repeat。
如果图像尚未完全解码,则不绘制任何内容。如果图像是没有
数据的画布,则抛出一个 “InvalidStateError” DOMException。
pattern.setTransform(transform)
所有当前引擎均支持。
设置在填充或描边绘制操作期间渲染图案时使用的变换矩阵。
调用 createPattern(image,
repetition) 方法时,必须运行以下步骤:
令 usability 为检查 image 可用性所得的结果。
如果 usability 为不可用,则返回 null。
断言:usability 为可用。
如果 repetition 是空字符串,则将其设置为“repeat”。
如果 repetition 与
“repeat”、“repeat-x”、“repeat-y”
或“no-repeat”中的任一个都不相同,则抛出一个
“SyntaxError” DOMException。
令 pattern 为一个新的 CanvasPattern 对象,其图像为
image,重复行为由 repetition 给出。
如果 image 不是源洁净的,则将 pattern 标记为非源洁净。
返回 pattern。
调用 createPattern()
方法后,修改创建 CanvasPattern
对象时使用的
image,不得影响该 CanvasPattern 对象所渲染的
图案。
图案具有变换矩阵,用于控制绘制图案时如何使用该图案。 最初,图案的变换矩阵必须是单位矩阵。
调用 setTransform(transform) 方法时,
必须运行以下步骤:
当要在某一区域内渲染图案时,用户代理必须运行以下步骤来 确定渲染内容:
创建一个无限大的透明 黑色位图。
在位图上放置图像的副本,锚定该副本,使其左上角位于
坐标空间的原点,并使图像的每个 CSS
像素对应一个坐标空间单位;然后,如果重复行为是“repeat-x”,则在
水平方向向左和向右放置该图像的重复副本;如果重复行为是“repeat-y”,则在
垂直方向向上和向下放置;如果重复行为是“repeat”,则在位图上的四个
方向放置。
如果原始图像数据是位图图像,则重复区域中某一点处绘制的值
通过对原始图像数据进行滤波来计算。放大时,如果
imageSmoothingEnabled
属性被
设置为 false,则必须使用最近邻插值渲染图像。否则,
用户代理可以使用任何滤波算法(例如双线性插值或
最近邻插值)。支持多种滤波算法的用户代理可以使用
imageSmoothingQuality
属性值
来指导滤波算法的选择。当此类滤波算法需要原始图像数据之外的像素
值时,必须改为使用将该像素坐标环绕到原始图像尺寸后所得的值。
(也就是说,无论图案的重复行为值为何,滤波器都使用“repeat”
行为。)
根据图案的变换矩阵变换所得位图。
再次变换所得位图,这次根据当前变换矩阵进行变换。
将图案要渲染到的区域之外的图像任何部分替换为 透明 黑色。
所得位图即为要渲染的内容,并具有相同的原点和相同的 比例。
如果在变换矩阵为奇异矩阵时使用径向渐变或重复图案, 则所得样式必须为透明 黑色(否则渐变或图案 会被折叠为一个点或一条线,使其他像素处于未定义状态)。即使使用奇异变换矩阵, 线性渐变和纯色也始终会定义所有点。
实现 CanvasRect 接口的对象提供以下
用于立即将矩形绘制到位图的方法。每个方法都接受四个参数;前两个
给出矩形左上角的 x 和 y 坐标,后两个分别
给出矩形的宽度 w 和高度 h。
必须将当前变换 矩阵应用于以下四个坐标,这些坐标构成随后必须闭合以获得 指定矩形的路径:(x, y)、(x+w, y)、(x+w, y+h)、(x, y+h)。
绘制形状不会影响当前默认路径,并且会受到
裁剪区域的约束;除 clearRect()
外,还会受到阴影
效果、全局
alpha 和
当前合成和混合
运算符的约束。
context.clearRect(x, y, w, h)
CanvasRenderingContext2D/clearRect
所有当前引擎均支持。
将位图中给定矩形内的所有像素清除为透明 黑色。
context.fillRect(x, y, w, h)
CanvasRenderingContext2D/fillRect
所有当前引擎均支持。
使用当前填充样式将给定矩形绘制到位图上。
context.strokeRect(x, y, w, h)
CanvasRenderingContext2D/strokeRect
所有当前引擎均支持。
使用当前描边 样式,将勾勒给定矩形轮廓的框绘制到位图上。
调用 clearRect(x, y, w,
h) 方法时,必须运行以下步骤:
如果高度或宽度中任一个为零,则此方法不起作用,因为像素 集合将为空。
调用 fillRect(x,
y, w, h) 方法时,必须运行以下
步骤:
调用 strokeRect(x, y, w,
h) 方法时,必须运行以下步骤:
如果任一参数为无穷大或 NaN,则返回。
使用 CanvasPathDrawingStyles
接口的线条样式,对下述路径进行描摹,并使用
this 的描边
样式填充所得结果。
如果 w 和 h 都为零,则路径具有一条仅包含 一个点 (x, y) 且不含线条的子路径,因此此方法 不起作用(在这种情况下,描摹 路径算法返回空路径)。
如果 w 或 h 中仅有一个为零,则路径具有 一条由两个点组成的子路径,这两个点的坐标依次为 (x, y) 和 (x+w, y+h),并由一条直线连接。
否则,路径具有一条由四个点组成的子路径,其坐标为 (x, y)、(x+w, y)、(x+w, y+h) 和 (x, y+h), 并按该顺序使用直线相互连接。
所有当前引擎均支持。
context.fillText(text, x, y [, maxWidth ])
CanvasRenderingContext2D/fillText
所有当前引擎均支持。
context.strokeText(text, x, y [, maxWidth ])
CanvasRenderingContext2D/strokeText
所有当前引擎均支持。
分别在给定位置填充或描边给定文本。如果提供了最大宽度, 必要时会缩放文本以适应该宽度。
metrics = context.measureText(text)
CanvasRenderingContext2D/measureText
所有当前引擎均支持。
返回一个 TextMetrics
对象,其中包含使用当前
字体时给定文本的度量值。
metrics.width
所有当前引擎均支持。
metrics.actualBoundingBoxLeft
TextMetrics/actualBoundingBoxLeft
所有当前引擎均支持。
metrics.actualBoundingBoxRight
TextMetrics/actualBoundingBoxRight
所有当前引擎均支持。
metrics.fontBoundingBoxAscent
TextMetrics/fontBoundingBoxAscent
所有当前引擎均支持。
metrics.fontBoundingBoxDescent
TextMetrics/fontBoundingBoxDescent
所有当前引擎均支持。
metrics.actualBoundingBoxAscent
TextMetrics/actualBoundingBoxAscent
所有当前引擎均支持。
metrics.actualBoundingBoxDescent
TextMetrics/actualBoundingBoxDescent
所有当前引擎均支持。
metrics.emHeightAscent
所有当前引擎均支持。
metrics.emHeightDescent
所有当前引擎均支持。
metrics.hangingBaseline
metrics.alphabeticBaseline
TextMetrics/alphabeticBaseline
metrics.ideographicBaseline
TextMetrics/ideographicBaseline
返回下述度量值。
实现 CanvasText 接口的对象提供以下
用于渲染文本的方法。
fillText(text, x, y,
maxWidth) 和 strokeText(text, x, y,
maxWidth) 方法使用当前 font、textAlign
和 textBaseline
值,在给定的 (x, y) 坐标处渲染给定
text,并在指定 maxWidth 时确保文本宽度不超过它。具体而言,调用这些方法
时,用户代理必须运行以下步骤:
如果任一参数为无穷大或 NaN,则返回。
运行文本
准备算法,向其传递 text、实现 CanvasText 接口的对象,
以及在提供 maxWidth 参数时传递该参数。令 glyphs 为结果。
绘制 glyphs 中给出的形状,并按照当前变换矩阵进行变换,将 glyphs 坐标空间中的每个 CSS 像素映射到一个坐标空间单位。
对于 fillText(),
必须将 this 的填充样式应用于
形状,并且必须忽略 this 的描边
样式。对于 strokeText(),
情况相反:必须将 this 的描边样式应用于
使用实现 CanvasText 接口的对象
作为线条样式,对形状进行描摹所得的
结果,并且必须忽略 this 的填充样式。
绘制这些形状不会影响当前路径,并且会受到阴影效果、全局 alpha、裁剪 区域和当前合成和混合 运算符的约束。
![]()
measureText(text) 方法的步骤是
运行文本
准备算法,向其传递 text 和实现 CanvasText
接口的对象,然后使用返回的行内
框返回一个新的 TextMetrics
对象,其成员
按以下列表所述方式运行:[CSS]
width
属性actualBoundingBoxLeft 属性从 textAlign
属性给出的对齐点沿基线到给定文本边界
矩形左侧的距离,以 CSS 像素为单位;正数
表示从给定对齐点向左的距离。
此值与下一个值(actualBoundingBoxRight)
之和可能大于
行内框的宽度(width),
特别是在斜体字体中,字符可能伸出其前进宽度。
actualBoundingBoxRight 属性从 textAlign
属性给出的对齐点沿基线到给定文本边界
矩形右侧的距离,以 CSS 像素为单位;正数
表示从给定对齐点向右的距离。
fontBoundingBoxAscent 属性从 textBaseline
属性指示的水平线到第一个
可用字体的上升
度量的距离,以 CSS
像素为单位;正数表示从给定基线向上的距离。
当要渲染高度必须保持一致的背景时,即使实际渲染的文本
发生变化,此值和下一个值也很有用。actualBoundingBoxAscent
属性(以及其对应的下降属性)在围绕
特定文本绘制边界框时很有用。
fontBoundingBoxDescent 属性从 textBaseline
属性指示的水平线到第一个
可用字体的下降
度量的距离,以 CSS 像素为单位;
正数表示从给定基线向下的距离。
actualBoundingBoxAscent 属性从 textBaseline
属性指示的水平线到给定文本边界
矩形顶部的距离,以 CSS 像素为单位;正数
表示从给定基线向上的距离。
即使指定的第一个字体覆盖输入中的所有字符,此数值也可能会根据
输入文本而产生很大变化。例如,从字母基线测得的小写
“o”的 actualBoundingBoxAscent
会小于大写“F”的相应值。该
值很容易为负数;例如,当给定文本只是单个逗号“,”时,从 em 框顶部(textBaseline
值“top”)
到边界矩形顶部的距离很可能为负数
(除非字体非常特殊)。
actualBoundingBoxDescent 属性从 textBaseline
属性指示的水平线到给定文本边界
矩形底部的距离,以 CSS 像素为单位;正数
表示从给定基线向下的距离。
emHeightAscent 属性从 textBaseline
属性指示的水平线到行内框中的em 上方
基线的距离,以 CSS 像素为单位;
正数表示给定基线位于em 上方
基线
之下(因此此值通常为正)。如果给定基线就是em 上方
基线,则为零;如果给定基线位于em 上方
基线与em 下方
基线之间的中点,则为字体大小的一半。
emHeightDescent 属性从 textBaseline
属性指示的水平线到行内框中的em 下方
基线的距离,以 CSS 像素为单位;
正数表示给定基线位于em 下方
基线之上。
(如果给定基线就是em 下方
基线,则为零。)
hangingBaseline 属性从 textBaseline
属性指示的水平线到行内框的悬挂
基线的距离,以 CSS 像素为单位;
正数表示给定基线位于悬挂
基线之下。
(如果给定基线就是悬挂
基线,则为零。)
alphabeticBaseline 属性从 textBaseline
属性指示的水平线到行内框的字母
基线的距离,以 CSS 像素为单位;
正数表示给定基线位于字母
基线之下。(如果给定基线就是字母基线,则为零。)
ideographicBaseline 属性从 textBaseline
属性指示的水平线到行内框的表意文字下方
基线的距离,以 CSS 像素为单位;
正数表示给定基线位于表意文字下方
基线之下。(如果给定基线就是表意文字下方
基线,则为零。)
使用 fillText()
和
strokeText()
渲染的字形可能会溢出由
字体大小和 measureText()
返回的宽度(文本宽度)所给出的框。如果这是一个问题,建议作者使用上述
边界框值。
2D 上下文 API 的未来版本可能会提供一种将使用 CSS 渲染的文档片段直接渲染到画布的方法。与提供专用的 多行布局方式相比,将优先提供这种方法。
实现 CanvasDrawPath
接口的对象具有
一个当前默认
路径。只有一个当前默认路径,它不是
绘制状态的一部分。当前默认路径是一个
如上所述的路径。
context.beginPath()
CanvasRenderingContext2D/beginPath
所有当前引擎均支持。
重置当前 默认路径。
context.fill([ fillRule ])
所有当前引擎均支持。
context.fill(path [, fillRule ])
使用当前填充样式填充当前默认路径或给定路径的子路径, 并遵循给定的填充规则。
context.stroke()
CanvasRenderingContext2D/stroke
所有当前引擎均支持。
context.stroke(path)
使用当前描边样式为当前默认路径或给定路径的子路径 描边。
context.clip([ fillRule ])
所有当前引擎均支持。
context.clip(path [, fillRule ])
进一步将裁剪区域约束到当前默认路径或给定 路径,并使用给定填充规则确定哪些点位于路径中。
context.isPointInPath(x, y [, fillRule ])
CanvasRenderingContext2D/isPointInPath
所有当前引擎均支持。
context.isPointInPath(path, x, y [, fillRule ])
如果给定点位于当前默认路径或给定 路径中,则返回 true,并使用给定填充规则确定哪些点位于路径中。
context.isPointInStroke(x, y)
CanvasRenderingContext2D/isPointInStroke
所有当前引擎均支持。
context.isPointInStroke(path, x, y)
如果给定点位于使用当前描边样式对 当前默认路径 或给定路径描边时所覆盖的区域中,则返回 true。
当预期路径是一个 Path2D 对象时,这些方法使用它时,
必须根据实现 CanvasTransform
接口的对象上的当前变换矩阵来变换其子路径的坐标和线条
(但不影响 Path2D 对象本身)。
当预期路径是当前
默认路径时,它不受变换影响。(这是因为在构建当前
默认路径时,变换已经对其产生影响,因此如果在绘制时再次应用变换,
将导致双重变换。)
给定一个 CanvasDrawPath
context、一个
Path2D-或-null path 和一个
填充规则 fillRule,
填充步骤是:使用
context 的填充样式,
并使用 fillRule 指示的填充规则,填充
path 的预期路径的所有子路径。填充时必须
隐式闭合开放子路径(但不影响实际子路径)。
给定一个 CanvasDrawPath
context 和一个
Path2D-或-null path,
描边步骤是:使用由
context 的 CanvasPathDrawingStyles
混入所设置的线条样式,对 path 的预期路径进行描摹,然后使用
context 的描边
样式,并使用非零环绕
规则填充所得路径。
由于描摹路径算法的定义方式, 一次描边操作中路径的重叠部分会被视为绘制了它们的并集。
即使使用当前默认 路径,描边样式在绘制期间仍会受到变换影响。
填充或描边路径时,不得影响当前默认
路径或任何 Path2D 对象,并且
必须受到阴影效果、全局
alpha、裁剪区域和当前合成和混合
运算符的约束。(变换的效果如上所述,并根据所使用的路径而有所不同。)
给定一个 CanvasDrawPath
context、一个
Path2D-或-null path 和一个
填充规则 fillRule,
裁剪步骤是:计算
context 的当前裁剪区域与 path 的预期
路径所描述区域的交集,并使用 fillRule 指示的填充
规则,以创建新的裁剪区域。计算裁剪区域时,必须隐式闭合
开放子路径,但不得影响实际子路径。新的裁剪区域将替换当前裁剪
区域。
初始化上下文时,其当前裁剪区域必须设置为最大的 无限表面(即默认情况下不进行裁剪)。
isPointInPath(x, y,
fillRule) 方法的步骤是返回点是否位于
路径中步骤的结果,并传入 this、null、x、y 和
fillRule。
isPointInPath(path, x,
y, fillRule) 方法的步骤是返回
点是否位于路径中
步骤的结果,并传入 this、path、x、y
和 fillRule。
给定一个 CanvasDrawPath
context、
一个 Path2D-或-null path、两个
数值 x 和 y,以及一个
填充规则 fillRule,
点是否位于路径中步骤为:
isPointInStroke(x, y)
方法的步骤是返回点是否位于描边中步骤的结果,并传入
this、null、x 和 y。
isPointInStroke(path, x,
y) 方法的步骤是返回点是否位于描边中
步骤的结果,并传入 this、path、x 和 y。
给定一个 CanvasDrawPath
context、一个 Path2D-或-null
path,以及两个数值 x
和 y,点是否位于描边中步骤为:
如果 x 或 y 为无穷大或 NaN,则返回 false。
如果由 x 和 y 坐标给出的点,在被视为画布坐标空间中
不受当前变换影响的坐标时,位于以下路径内部:使用非零环绕规则,并使用由
context 的 CanvasPathDrawingStyles
混入所设置的线条样式,对 path 的预期
路径进行描摹所得的路径,
则返回 true。所得路径上的点必须被视为位于路径内部。
返回 false。
此 canvas
元素具有一对复选框。与路径相关的命令已
突出显示:
< canvas height = 400 width = 750 >
< label >< input type = checkbox id = showA > Show As</ label >
< label >< input type = checkbox id = showB > Show Bs</ label >
<!-- ... -->
</ canvas >
< script >
function drawCheckbox( context, element, x, y, paint) {
context. save();
context. font = '10px sans-serif' ;
context. textAlign = 'left' ;
context. textBaseline = 'middle' ;
var metrics = context. measureText( element. labels[ 0 ]. textContent);
if ( paint) {
context. beginPath();
context. strokeStyle = 'black' ;
context. rect( x- 5 , y- 5 , 10 , 10 );
context. stroke();
if ( element. checked) {
context. fillStyle = 'black' ;
context. fill();
}
context. fillText( element. labels[ 0 ]. textContent, x+ 5 , y);
}
context. beginPath();
context. rect( x- 7 , y- 7 , 12 + metrics. width+ 2 , 14 );
context. drawFocusIfNeeded( element);
context. restore();
}
function drawBase() { /* ... */ }
function drawAs() { /* ... */ }
function drawBs() { /* ... */ }
function redraw() {
var canvas = document. getElementsByTagName( 'canvas' )[ 0 ];
var context = canvas. getContext( '2d' );
context. clearRect( 0 , 0 , canvas. width, canvas. height);
drawCheckbox( context, document. getElementById( 'showA' ), 20 , 40 , true );
drawCheckbox( context, document. getElementById( 'showB' ), 20 , 60 , true );
drawBase();
if ( document. getElementById( 'showA' ). checked)
drawAs();
if ( document. getElementById( 'showB' ). checked)
drawBs();
}
function processClick( event) {
var canvas = document. getElementsByTagName( 'canvas' )[ 0 ];
var context = canvas. getContext( '2d' );
var x = event. clientX;
var y = event. clientY;
var node = event. target;
while ( node) {
x -= node. offsetLeft - node. scrollLeft;
y -= node. offsetTop - node. scrollTop;
node = node. offsetParent;
}
drawCheckbox( context, document. getElementById( 'showA' ), 20 , 40 , false );
if ( context. isPointInPath( x, y) )
document. getElementById( 'showA' ). checked = ! ( document. getElementById( 'showA' ). checked);
drawCheckbox( context, document. getElementById( 'showB' ), 20 , 60 , false );
if ( context. isPointInPath( x, y) )
document. getElementById( 'showB' ). checked = ! ( document. getElementById( 'showB' ). checked);
redraw();
}
document. getElementsByTagName( 'canvas' )[ 0 ]. addEventListener( 'focus' , redraw, true );
document. getElementsByTagName( 'canvas' )[ 0 ]. addEventListener( 'blur' , redraw, true );
document. getElementsByTagName( 'canvas' )[ 0 ]. addEventListener( 'change' , redraw, true );
document. getElementsByTagName( 'canvas' )[ 0 ]. addEventListener( 'click' , processClick, false );
redraw();
</ script > context.drawFocusIfNeeded(element)
CanvasRenderingContext2D/drawFocusIfNeeded
所有当前引擎均支持。
context.drawFocusIfNeeded(path, element)
如果 element 获得焦点,则按照平台的焦点环约定, 围绕 path 绘制焦点环。
实现 CanvasUserInterface
接口的对象提供以下
用于绘制焦点环的方法。
给定一个实现
CanvasUserInterface
的对象 context、一个元素 element 和一个路径 path,要按需绘制焦点:
按照平台约定,沿 path 绘制适当样式的焦点环。
某些平台只会围绕通过键盘获得焦点的元素绘制焦点环,
而不会围绕通过鼠标获得焦点的元素绘制焦点环。其他平台则根本不会围绕某些元素绘制焦点
环,除非启用了相关无障碍功能。此 API
旨在遵循这些约定。实现了根据元素获得焦点方式进行区分的用户代理,建议根据触发
调用的用户交互事件类型(如果有),对由 focus()
方法驱动的焦点进行分类。
焦点环不应受到阴影效果、
全局 alpha、当前
合成和混合运算符、填充
样式、描边
样式,或者
CanvasPathDrawingStyles、
CanvasTextDrawingStyles
接口中任何成员的影响,
但应当受到裁剪区域的约束。(变换的效果
如上所述,并根据所使用的路径而有所不同。)
绘制焦点环时,用户代理不应隐式闭合预期路径中的开放子路径。
不过,这一点可能无关紧要。例如,如果焦点环被绘制为 围绕预期路径中各点的轴对齐边界矩形,那么子路径是否 闭合不会产生影响。本规范有意不精确规定 焦点环应如何绘制:预期用户代理遵循其平台的原生 约定。
本节中使用的“告知用户”并不意味着任何持久状态 更改。例如,它可以表示调用系统无障碍 API,通知放大工具等辅助 技术,使用户的放大镜移动到画布的给定区域。 但是,它不会将路径与元素关联,也不会提供用于 触觉反馈的区域等。
实现 CanvasDrawImage 接口的对象具有
用于绘制图像的 drawImage()
方法。
此方法可以使用三组不同的参数进行调用:
drawImage(image, dx, dy)
drawImage(image, dx, dy, dw, dh)
drawImage(image, sx, sy, sw, sh, dx, dy, dw, dh)
context.drawImage(image, dx, dy)
CanvasRenderingContext2D/drawImage
所有当前引擎均支持。
context.drawImage(image, dx, dy, dw, dh)
context.drawImage(image, sx, sy, sw, sh, dx, dy, dw, dh)
将给定图像绘制到画布上。参数解释如下:
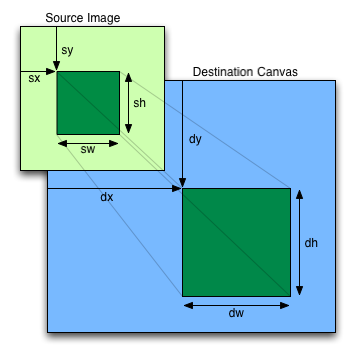
如果图像尚未完全解码,则不绘制任何内容。如果图像是没有
数据的画布,则抛出一个 “InvalidStateError” DOMException。
调用 drawImage() 方法
时,用户代理必须运行以下步骤:
如果任一参数为无穷大或 NaN,则返回。
令 usability 为检查 image 可用性所得的结果。
如果 usability 为不可用,则返回(不绘制任何内容)。
按如下方式确定源矩形和目标矩形:
如果未指定,则 dw 和 dh 参数必须默认为 sw 和 sh 的值,并按以下方式解释:图像中的一个 CSS 像素 被视为输出 位图坐标空间中的一个单位。如果省略 sx、sy、sw 和 sh 参数,则它们必须依次 默认为 0、0、图像以图像像素表示的自然宽度 和图像以图像像素表示的 自然高度。如果图像没有自然 尺寸,则必须改用具体对象大小,该大小使用 CSS“具体对象 大小解析”算法确定,其中指定大小既没有确定宽度 也没有确定高度,并且没有任何附加约束;对象的自然属性为 image 参数的自然属性;默认对象大小为 输出位图的大小。[CSSIMAGES]
源矩形是四个角分别为 (sx, sy)、 (sx+sw, sy)、(sx+sw, sy+sh)、 (sx, sy+sh) 的矩形。
目标矩形是四个角分别为 (dx, dy)、 (dx+dw, dy)、(dx+dw, dy+dh)、 (dx, dy+dh) 的矩形。
当源矩形位于源图像之外时,必须将源矩形裁剪到 源图像,并按相同比例裁剪目标矩形。
当目标矩形位于目标图像(即 输出位图)之外时,落在 输出位图之外的像素将被 丢弃,就像目标是一个无限画布,而其渲染被裁剪到 输出位图的尺寸一样。
如果 sw 或 sh 参数中有一个为零,则返回。不 绘制任何内容。
将 image 参数中由源矩形指定的区域 绘制到渲染上下文的输出 位图中由目标矩形指定的区域,并先将当前 变换矩阵应用于目标矩形。
即使给定的尺寸为负数,也必须按原始方向处理图像数据。
放大时,如果 imageSmoothingEnabled
属性被设置为
true,则用户代理应当在缩放图像数据时尝试对其应用平滑算法。
支持多种滤波算法的用户代理可以在 imageSmoothingEnabled
属性被设置为
true 时,使用 imageSmoothingQuality
属性值来指导滤波算法的选择。否则,必须使用最近邻插值渲染图像。
本规范未定义缩小图像时,或者在 imageSmoothingEnabled
属性被设置为
true 时放大图像所使用的精确算法。
当一个 canvas
元素被绘制到
自身时,绘制
模型要求在绘制图像之前复制源,因此可以将
canvas
元素的一部分复制到其自身的重叠部分。
如果原始图像数据是位图图像,则目标矩形中某一点处绘制的值 通过对原始图像数据进行滤波来计算。用户代理可以使用 任何滤波算法(例如双线性插值或最近邻插值)。当 滤波算法需要原始图像数据之外的像素值时,必须改为 使用最近边缘像素的值。(也就是说,滤波器使用“clamp-to-edge”行为。) 当滤波算法需要源矩形之外但仍位于 原始图像数据之内的像素值时,则必须使用原始图像数据中的值。
因此,分部分缩放图像或整体缩放图像将产生相同效果。不过,这确实
意味着,当要缩放来自单个精灵图的精灵时,
精灵图中的相邻图像可能会相互干扰。可以通过确保图中的每个精灵
周围都有透明
黑色边框,或者将要缩放的精灵复制到临时
canvas
元素中并从那里绘制缩放后的精灵,来避免这种情况。
绘制图像不会影响当前路径,并且会受到阴影效果、全局 alpha、裁剪区域和 当前合成和混合 运算符的约束。
如果 image 不是源洁净的,则将
CanvasRenderingContext2D
的
源洁净标志
设置为 false。
imageData = context.createImageData(imageData)
imageData = context.createImageData(sw, sh [, settings])
CanvasRenderingContext2D/createImageData
所有当前引擎均支持。
返回一个具有给定尺寸的 ImageData 对象。除非被
settings 覆盖,否则返回对象的颜色空间是
context 的颜色空间。返回
对象中的所有像素均为透明
黑色。
如果宽度或高度参数中任一个为零,则抛出一个 “IndexSizeError” DOMException。
imageData = context.getImageData(sx, sy, sw, sh [, settings])
CanvasRenderingContext2D/getImageData
所有当前引擎均支持。
返回一个 ImageData 对象,
其中包含位图给定矩形的图像数据。
除非被 settings 覆盖,否则返回对象的颜色空间是
context 的颜色空间。
如果宽度或高度参数中任一个为零,则抛出一个 “IndexSizeError” DOMException。
context.putImageData(imageData, dx, dy [, dirtyX, dirtyY, dirtyWidth, dirtyHeight ])
CanvasRenderingContext2D/putImageData
所有当前引擎均支持。
将给定 ImageData 对象中的数据绘制到位图上。如果提供了
脏
矩形,则只绘制该矩形中的像素。
对于此方法调用,会忽略 globalAlpha
和 globalCompositeOperation
属性以及阴影属性;
画布中的像素会被整体替换,不进行合成、alpha
混合、阴影处理等。
如果 imageData 对象的 data 属性值的
[[ViewedArrayBuffer]] 内部槽已分离,则抛出一个 “InvalidStateError” DOMException。
实现 CanvasImageData 接口的对象提供
以下用于
读取和写入位图像素数据的方法。
createImageData(sw, sh,
settings) 方法的步骤为:
如果 sw 和 sh 中一个或两个为零,则抛出一个
“IndexSizeError” DOMException。
使用 sw 的绝对值、sh 的绝对值、 settings,以及设置为 this 的 颜色空间的 defaultColorSpace,初始化 newImageData。
将 newImageData 的图像数据初始化为透明 黑色。
返回 newImageData。
createImageData(imageData)
方法的步骤为:
令 settings 为 ImageDataSettings 对象
«[
“colorSpace”
→
this
的 colorSpace,
“pixelFormat”
→
this
的 pixelFormat ]»。
使用 imageData 的 width
属性值、imageData 的 height
属性值以及 settings,初始化 newImageData。
将 newImageData 的图像数据初始化为透明 黑色。
返回 newImageData。
getImageData(sx, sy, sw,
sh, settings) 方法的步骤为:
如果 sw 或 sh 参数中任一个为零,则抛出一个
“IndexSizeError” DOMException。
如果 CanvasRenderingContext2D
的
源洁净
标志设置为 false,则抛出一个
“SecurityError” DOMException。
使用 sw、sh、settings,以及设置为 this 的颜色空间的 defaultColorSpace, 初始化 imageData。
令源矩形为四个角分别为 (sx, sy)、(sx+sw, sy)、(sx+sw, sy+sh)、 (sx, sy+sh) 的矩形。
将 imageData 的像素值设置为 this 的
输出位图中,在位图
坐标空间单位内由源矩形指定区域中的像素,并使用
'relative-colorimetric'
渲染意图,将其从 this 的颜色空间转换到
imageData 的 colorSpace。
返回 imageData。
putImageData(imageData,
dx, dy) 方法的步骤是
将
ImageData 中的像素放到位图上,并传入
imageData、this 的输出
位图、
dx、dy、0、0、
imageData 的 width 和
imageData 的 height。
putImageData(imageData,
dx, dy, dirtyX, dirtyY,
dirtyWidth, dirtyHeight) 方法的步骤是
将
ImageData 中的像素放到位图上,并传入
imageData、this 的输出
位图、
dx、dy、dirtyX、dirtyY、
dirtyWidth 和 dirtyHeight。
给定一个 ImageData imageData、
一个输出位图 bitmap,以及
数值 dx、dy、
dirtyX、dirtyY、dirtyWidth 和 dirtyHeight,要将 ImageData 中的像素
放到位图上:
令 buffer 为 imageData 的 data 属性值的
[[ViewedArrayBuffer]] 内部
槽。
如果 IsDetachedBuffer(buffer) 为 true,则抛出一个
“InvalidStateError” DOMException。
如果 dirtyWidth 为负数,则令 dirtyX 为 dirtyX+dirtyWidth,并令 dirtyWidth 等于 dirtyWidth 的绝对值。
如果 dirtyHeight 为负数,则令 dirtyY 为 dirtyY+dirtyHeight,并令 dirtyHeight 等于 dirtyHeight 的绝对值。
如果 dirtyX 为负数,则令 dirtyWidth 为 dirtyWidth+dirtyX,并令 dirtyX 为 0。
如果 dirtyY 为负数,则令 dirtyHeight 为 dirtyHeight+dirtyY,并令 dirtyY 为 0。
如果 dirtyX+dirtyWidth 大于 imageData 参数的 width 属性,
则令 dirtyWidth 为该 width
属性值减去 dirtyX 的值。
如果 dirtyY+dirtyHeight 大于 imageData 参数的 height 属性,
则令 dirtyHeight 为该 height 属性值
减去 dirtyY 的值。
如果经过这些更改后,dirtyWidth 或 dirtyHeight 中任一个为负数 或零,则返回,且不影响任何位图。
对于满足以下条件的所有整数 x 和 y:
dirtyX ≤ x < dirtyX+dirtyWidth
且
dirtyY ≤ y < dirtyY+dirtyHeight,
将 bitmap 中坐标为 (dx+x,
dy+y) 的像素设置为 imageData 数据结构的
位图中坐标为
(x, y) 的像素颜色,并使用
'relative-colorimetric' 渲染意图,
将其从 imageData 的 colorSpace
转换到 bitmap 的颜色
空间。
由于颜色空间之间的转换以及与预乘
alpha颜色值之间的转换具有有损性,刚刚使用 putImageData()
设置且并非完全不透明的像素,在通过对应的 getImageData()
返回时,其值可能会不同。
当前路径、变换矩阵、 阴影属性、全局 alpha、裁剪区域和当前合成和混合 运算符不得影响本节所述的方法。
在以下示例中,脚本生成一个 ImageData 对象,以便可以
在其上绘制。
// canvas is a reference to a <canvas> element
var context = canvas. getContext( '2d' );
// create a blank slate
var data = context. createImageData( canvas. width, canvas. height);
// create some plasma
FillPlasma( data, 'green' ); // green plasma
// add a cloud to the plasma
AddCloud( data, data. width/ 2 , data. height/ 2 ); // put a cloud in the middle
// paint the plasma+cloud on the canvas
context. putImageData( data, 0 , 0 );
// support methods
function FillPlasma( data, color) { ... }
function AddCloud( data, x, y) { ... } 下面是使用 getImageData()
和 putImageData()
实现边缘检测
滤镜的示例。
<!DOCTYPE HTML>
< html lang = "en" >
< head >
< title > Edge detection demo</ title >
< script >
var image = new Image();
function init() {
image. onload = demo;
image. src = "image.jpeg" ;
}
function demo() {
var canvas = document. getElementsByTagName( 'canvas' )[ 0 ];
var context = canvas. getContext( '2d' );
// draw the image onto the canvas
context. drawImage( image, 0 , 0 );
// get the image data to manipulate
var input = context. getImageData( 0 , 0 , canvas. width, canvas. height);
// get an empty slate to put the data into
var output = context. createImageData( canvas. width, canvas. height);
// alias some variables for convenience
// In this case input.width and input.height
// match canvas.width and canvas.height
// but we'll use the former to keep the code generic.
var w = input. width, h = input. height;
var inputData = input. data;
var outputData = output. data;
// edge detection
for ( var y = 1 ; y < h- 1 ; y += 1 ) {
for ( var x = 1 ; x < w- 1 ; x += 1 ) {
for ( var c = 0 ; c < 3 ; c += 1 ) {
var i = ( y* w + x) * 4 + c;
outputData[ i] = 127 + - inputData[ i - w* 4 - 4 ] - inputData[ i - w* 4 ] - inputData[ i - w* 4 + 4 ] +
- inputData[ i - 4 ] + 8 * inputData[ i] - inputData[ i + 4 ] +
- inputData[ i + w* 4 - 4 ] - inputData[ i + w* 4 ] - inputData[ i + w* 4 + 4 ];
}
outputData[( y* w + x) * 4 + 3 ] = 255 ; // alpha
}
}
// put the image data back after manipulation
context. putImageData( output, 0 , 0 );
}
</ script >
</ head >
< body onload = "init()" >
< canvas ></ canvas >
</ body >
</ html > 下面是绘制纯色并使用 getImageData()
读回结果时应用颜色空间转换的示例。
<!DOCTYPE HTML>
< html lang = "en" >
< title > Color space image data demo</ title >
< canvas ></ canvas >
< script >
const canvas = document. querySelector( 'canvas' );
const context = canvas. getContext( '2d' , { colorSpace: 'display-p3' });
// Draw a red rectangle. Note that the hex color notation
// specifies sRGB colors.
context. fillStyle = "#FF0000" ;
context. fillRect( 0 , 0 , 64 , 64 );
// Get the image data.
const pixels = context. getImageData( 0 , 0 , 1 , 1 );
// This will print 'display-p3', reflecting the default behavior
// of returning image data in the canvas's color space.
console. log( pixels. colorSpace);
// This will print the values 234, 51, and 35, reflecting the
// red fill color, converted to 'display-p3'.
console. log( pixels. data[ 0 ]);
console. log( pixels. data[ 1 ]);
console. log( pixels. data[ 2 ]);
</ script > context.globalAlpha [ = value ]
CanvasRenderingContext2D/globalAlpha
所有当前引擎均支持。
返回应用于渲染操作的当前全局 alpha值。
可以设置此属性,以更改全局 alpha 值。超出 0.0 .. 1.0 范围的值将被忽略。
context.globalCompositeOperation [ = value ]
CanvasRenderingContext2D/globalCompositeOperation
所有当前引擎均支持。
从合成与混合中定义的值返回当前合成和混合运算符。[COMPOSITE]
可以设置此属性,以更改当前合成和混合运算符。 未知 值将被忽略。
实现 CanvasCompositing 接口的对象具有一个全局 alpha值和一个当前合成
和混合运算符值,两者都会影响对此
对象执行的所有绘制操作。
全局 alpha值给出一个 alpha 值, 该值会在形状和图像合成到输出位图上之前应用于它们。 该值的范围为 0.0(完全透明)到 1.0(不增加额外透明度)。其 初始值必须为 1.0。
globalAlpha
设置器
步骤为:
当前合成和混合运算符值
控制在应用了全局 alpha和当前变换
矩阵后,形状和图像如何绘制到输出位图上。最初,它必须设置为“source-over”。
globalCompositeOperation 获取器
步骤是返回 this 的当前合成和混合
运算符。
globalCompositeOperation
设置器步骤
为:
如果给定值与 <blend-mode> 或 <composite-mode> 属性被定义为可接受的任何值都不相同,则返回。[COMPOSITE]
否则,将 this 的当前合成和混合运算符 设置为给定值。
context.imageSmoothingEnabled [ = value ]
CanvasRenderingContext2D/imageSmoothingEnabled
所有当前引擎均支持。
返回在放大图像时,如果图案填充和 drawImage()
方法所使用图像的像素未与显示器精确对齐,是否会尝试平滑
图像。
可以设置此属性,以更改是否平滑图像(true)或不平滑图像(false)。
context.imageSmoothingQuality [ = value ]
CanvasRenderingContext2D/imageSmoothingQuality
返回当前图像平滑质量首选项。
可以设置此属性,以更改首选的图像平滑质量。可能的值为
“low”、
“medium”
和“high”。
未知值将被忽略。
实现 CanvasImageSmoothing
接口的对象具有控制如何执行
图像平滑的属性。
imageSmoothingEnabled 属性在
获取时必须返回最后一次设置的值。设置时,必须将其设置为新值。
创建实现 CanvasImageSmoothing
接口的对象时,该
属性必须设置为 true。
imageSmoothingQuality 属性在
获取时必须返回最后一次设置的值。设置时,必须将其设置为新值。
创建实现 CanvasImageSmoothing
接口的对象时,该
属性必须设置为“low”。
对实现 CanvasShadowStyles
接口的对象执行的所有绘制操作都会受到四个全局阴影属性的影响。
context.shadowColor [ = value ]
CanvasRenderingContext2D/shadowColor
所有当前引擎均支持。
返回当前阴影颜色。
可以设置此属性,以更改阴影颜色。无法解析为 CSS 颜色的值将被 忽略。
context.shadowOffsetX [ = value ]
CanvasRenderingContext2D/shadowOffsetX
所有当前引擎均支持。
context.shadowOffsetY [ = value ]
CanvasRenderingContext2D/shadowOffsetY
所有当前引擎均支持。
返回当前阴影偏移量。
可以设置此属性,以更改阴影偏移量。不是有限数值的值将被忽略。
context.shadowBlur [ = value ]
CanvasRenderingContext2D/shadowBlur
所有当前引擎均支持。
返回当前应用于阴影的模糊程度。
可以设置此属性,以更改模糊程度。不是大于或 等于零的有限数值的值将被忽略。
实现 CanvasShadowStyles 接口的对象具有
一个关联的阴影颜色,它是一个 CSS 颜色。
最初,它必须是透明黑色。
shadowColor 获取器步骤是:在请求与 HTML 兼容的序列化时,返回
this 的阴影
颜色的序列化。
shadowColor
设置器步骤为:
shadowOffsetX 和 shadowOffsetY
属性分别指定阴影在水平正方向和
垂直正方向上的偏移距离。其值以坐标空间单位表示。它们不
受当前变换矩阵影响。
创建上下文时,阴影偏移属性的初始值必须为 0。
获取时,它们必须返回其当前值。设置时,正在设置的属性必须 设置为新值;但如果该值为无穷大或 NaN,则必须 忽略新值。
shadowBlur 属性指定
模糊效果的程度。(其单位不映射到坐标空间单位,并且不受
当前变换矩阵影响。)
创建上下文时,shadowBlur
属性的初始值必须为 0。
获取时,该属性必须返回其当前值。设置时,该属性必须设置 为新值;但如果该值为负数、无穷大或 NaN,则必须 忽略新值。
仅在以下情况下绘制阴影:阴影
颜色的 alpha 分量中的不透明度分量非零,并且 shadowBlur
非零,或者 shadowOffsetX
非零,或者
shadowOffsetY
非零。
绘制阴影时,必须按如下方式 渲染阴影:
令 A 为一个无限的透明 黑色位图,要为其创建阴影的源 图像已渲染在该位图上。
令 B 为一个无限的透明 黑色位图,其坐标 空间和原点与 A 相同。
将 A 的 alpha 分量复制到 B,在 x 正
方向上偏移 shadowOffsetX,
并在
y 正方向上偏移 shadowOffsetY。
如果 shadowBlur
大于 0:
令 σ 为 shadowBlur
值的一半。
对 B 执行二维高斯模糊,并使用 σ 作为标准差。
用户代理可以将 σ 的值限制为特定于实现的 最大值,以避免在高斯模糊操作期间超出硬件限制。
将 B 中每个像素的红色、绿色和蓝色分量分别设置为 阴影颜色的红色、绿色和蓝色分量。
将 B 中每个像素的 alpha 分量乘以阴影 颜色的 alpha 分量。
阴影位于位图 B 中,并作为下述绘制模型的一部分进行渲染。
如果当前合成和混合运算符是“copy”,
则实际上不会渲染阴影(因为形状会
覆盖阴影)。
对实现 CanvasFilters
接口的对象执行的所有绘制操作都会受到全局 filter 属性的影响。
context.filter [ = value ]
CanvasRenderingContext2D/filter
返回当前滤镜。
可以设置此属性,以更改滤镜。值可以是字符串“none”,也可以是可解析为
<filter-value-list> 的字符串。其他
值将被忽略。
此类对象具有一个关联的当前
滤镜,它是一个字符串。最初,当前滤镜被设置为字符串“none”。只要
当前
滤镜的值为字符串“none”,上下文的滤镜就会被禁用。
filter 设置器步骤
为:
虽然
context. 会禁用
上下文的滤镜,但
filter
= "none"context.、
filter
= ""context.
和
filter
= nullcontext. 都被视为无法解析的输入,并且当前滤镜的值保持不变。
filter
=
undefined
当前 滤镜值中使用的坐标按如下方式解释:一个像素等于一个 SVG 用户空间单位,也等于 一个画布坐标空间单位。滤镜坐标不受当前变换矩阵影响。当前 变换矩阵仅影响滤镜的输入。滤镜在 输出位图的坐标空间中应用。
当当前
滤镜的值是一个可解析为 <filter-value-list> 的字符串,并且该值使用
百分比或者 'em' 或 'ex' 单位定义长度时,必须相对于
设置该属性时字体样式源对象的
'font-size' 属性的计算值来解释这些长度。如果某个特定
情况下的计算值未定义(例如,
因为字体样式源对象不是
元素或者没有正在
渲染),则必须相对于 font
属性的默认值解释相对关键字。不支持
'larger' 和 'smaller' 关键字。
如果当前 滤镜的值是一个可解析为 <filter-value-list> 的字符串,并引用同一文档中的 SVG 滤镜,而该 SVG 滤镜发生更改,则下一次绘制 操作会使用更改后的滤镜。
如果当前 滤镜的值是一个可解析为 <filter-value-list> 的字符串,并引用外部资源文档中的 SVG 滤镜,而调用绘制操作时该文档尚未加载, 则绘制操作必须在不应用滤镜的情况下继续进行。
本节是非规范性的。
由于在外部定义的滤镜完成加载之前,绘制会使用滤镜值“none”,
因此作者可能希望在继续执行绘制操作之前确定此类
滤镜是否已完成加载。一种实现方式是
在同一页面内的其他位置,将外部定义的滤镜加载到某个会
发送 load 事件的元素中(例如一个 SVG
use
元素),然后等待分派 load 事件。
绘制形状或图像时,用户代理必须按给定顺序遵循以下步骤(或者 表现得如同遵循了这些步骤):
按照前述各节的说明,将形状或图像渲染到一个无限的透明 黑色位图上,创建 图像 A。对于形状,必须遵循当前填充、描边 和线条样式,并且描边本身也必须受到当前 变换矩阵的影响。
将图像 A 转换到上下文的 颜色空间。
不存在颜色空间未定义的二维上下文输入。 CSS 颜色的颜色空间在 CSS Color 中定义。未指定颜色配置文件信息的 图像的颜色空间是 'srgb',如 CSS Color 的未标记 颜色的颜色空间一节中所规定。[CSSCOLOR]
将 A 中每个像素的 alpha 分量乘以 全局 alpha。
当当前
滤镜被设置为“none”以外的值,并且其引用的所有外部定义滤镜(如果有)
都位于当前已加载的文档中时,使用图像 A 作为
当前滤镜的输入,创建
图像 B。如果当前滤镜
是一个可解析为 <filter-value-list> 的字符串,则使用当前滤镜,以与 SVG
相同的方式进行绘制。
否则,令 B 为 A 的别名。
绘制阴影时, 使用当前阴影样式,根据图像 B 渲染阴影, 创建图像 C。
绘制阴影时, 使用当前 合成和混合运算符,在裁剪区域内将 C 合成到当前输出位图上。
使用当前合成和混合 运算符,在裁剪 区域内将 B 合成到当前 输出位图上。
合成到输出位图上时, 会落在 输出位图之外的像素必须被丢弃。
当画布具有交互性时,作者应在元素的后备内容中,为画布的每个可聚焦 部分包含对应的可聚焦元素,如 上面的示例所示。
渲染焦点环时,为确保焦点环具有原生焦点
环的外观,作者应使用 drawFocusIfNeeded()
方法,并向其传入
正在为其绘制焦点环的元素。此方法仅在元素获得焦点时绘制焦点环,因此每次绘制
该元素时都可以直接调用此方法,而无需
先检查元素是否获得焦点。
作者应避免使用 canvas 元素
实现文本编辑控件。这样做有大量缺点:
这是一项极其庞大的工作,因此强烈建议作者不要执行任何
此类工作,而应改用 input
元素、textarea
元素或
contenteditable 属性。
本节是非规范性的。
下面是一个使用画布绘制漂亮的 发光线条的脚本示例。
< canvas width = "800" height = "450" ></ canvas >
< script >
var context = document. getElementsByTagName( 'canvas' )[ 0 ]. getContext( '2d' );
var lastX = context. canvas. width * Math. random();
var lastY = context. canvas. height * Math. random();
var hue = 0 ;
function line() {
context. save();
context. translate( context. canvas. width/ 2 , context. canvas. height/ 2 );
context. scale( 0.9 , 0.9 );
context. translate( - context. canvas. width/ 2 , - context. canvas. height/ 2 );
context. beginPath();
context. lineWidth = 5 + Math. random() * 10 ;
context. moveTo( lastX, lastY);
lastX = context. canvas. width * Math. random();
lastY = context. canvas. height * Math. random();
context. bezierCurveTo( context. canvas. width * Math. random(),
context. canvas. height * Math. random(),
context. canvas. width * Math. random(),
context. canvas. height * Math. random(),
lastX, lastY);
hue = hue + 10 * Math. random();
context. strokeStyle = 'hsl(' + hue + ', 50%, 50%)' ;
context. shadowColor = 'white' ;
context. shadowBlur = 10 ;
context. stroke();
context. restore();
}
setInterval( line, 50 );
function blank() {
context. fillStyle = 'rgba(0,0,0,0.1)' ;
context. fillRect( 0 , 0 , context. canvas. width, context. canvas. height);
}
setInterval( blank, 40 );
</ script > canvas 的二维渲染上下文常用于基于精灵的
游戏。以下
示例对此进行了演示:
以下是此示例的源代码:
<!DOCTYPE HTML>
< html lang = "en" >
< meta charset = "utf-8" >
< title > Blue Robot Demo</ title >
< style >
html { overflow : hidden ; min-height : 200 px ; min-width : 380 px ; }
body { height : 200 px ; position : relative ; margin : 8 px ; }
. buttons { position : absolute ; bottom : 0 px ; left : 0 px ; margin : 4 px ; }
</ style >
< canvas width = "380" height = "200" ></ canvas >
< script >
var Landscape = function ( context, width, height) {
this . offset = 0 ;
this . width = width;
this . advance = function ( dx) {
this . offset += dx;
};
this . horizon = height * 0.7 ;
// This creates the sky gradient (from a darker blue to white at the bottom)
this . sky = context. createLinearGradient( 0 , 0 , 0 , this . horizon);
this . sky. addColorStop( 0.0 , 'rgb(55,121,179)' );
this . sky. addColorStop( 0.7 , 'rgb(121,194,245)' );
this . sky. addColorStop( 1.0 , 'rgb(164,200,214)' );
// this creates the grass gradient (from a darker green to a lighter green)
this . earth = context. createLinearGradient( 0 , this . horizon, 0 , height);
this . earth. addColorStop( 0.0 , 'rgb(81,140,20)' );
this . earth. addColorStop( 1.0 , 'rgb(123,177,57)' );
this . paintBackground = function ( context, width, height) {
// first, paint the sky and grass rectangles
context. fillStyle = this . sky;
context. fillRect( 0 , 0 , width, this . horizon);
context. fillStyle = this . earth;
context. fillRect( 0 , this . horizon, width, height- this . horizon);
// then, draw the cloudy banner
// we make it cloudy by having the draw text off the top of the
// canvas, and just having the blurred shadow shown on the canvas
context. save();
context. translate( width- (( this . offset+ ( this . width* 3.2 )) % ( this . width* 4.0 )) + 0 , 0 );
context. shadowColor = 'white' ;
context. shadowOffsetY = 30 + this . horizon/ 3 ; // offset down on canvas
context. shadowBlur = '5' ;
context. fillStyle = 'white' ;
context. textAlign = 'left' ;
context. textBaseline = 'top' ;
context. font = '20px sans-serif' ;
context. fillText( 'WHATWG ROCKS' , 10 , - 30 ); // text up above canvas
context. restore();
// then, draw the background tree
context. save();
context. translate( width- (( this . offset+ ( this . width* 0.2 )) % ( this . width* 1.5 )) + 30 , 0 );
context. beginPath();
context. fillStyle = 'rgb(143,89,2)' ;
context. lineStyle = 'rgb(10,10,10)' ;
context. lineWidth = 2 ;
context. rect( 0 , this . horizon+ 5 , 10 , - 50 ); // trunk
context. fill();
context. stroke();
context. beginPath();
context. fillStyle = 'rgb(78,154,6)' ;
context. arc( 5 , this . horizon- 60 , 30 , 0 , Math. PI* 2 ); // leaves
context. fill();
context. stroke();
context. restore();
};
this . paintForeground = function ( context, width, height) {
// draw the box that goes in front
context. save();
context. translate( width- (( this . offset+ ( this . width* 0.7 )) % ( this . width* 1.1 )) + 0 , 0 );
context. beginPath();
context. rect( 0 , this . horizon - 5 , 25 , 25 );
context. fillStyle = 'rgb(220,154,94)' ;
context. lineStyle = 'rgb(10,10,10)' ;
context. lineWidth = 2 ;
context. fill();
context. stroke();
context. restore();
};
};
</ script >
< script >
var BlueRobot = function () {
this . sprites = new Image();
this . sprites. src = 'blue-robot.png' ; // this sprite sheet has 8 cells
this . targetMode = 'idle' ;
this . walk = function () {
this . targetMode = 'walk' ;
};
this . stop = function () {
this . targetMode = 'idle' ;
};
this . frameIndex = {
'idle' : [ 0 ], // first cell is the idle frame
'walk' : [ 1 , 2 , 3 , 4 , 5 , 6 ], // the walking animation is cells 1-6
'stop' : [ 7 ], // last cell is the stopping animation
};
this . mode = 'idle' ;
this . frame = 0 ; // index into frameIndex
this . tick = function () {
// this advances the frame and the robot
// the return value is how many pixels the robot has moved
this . frame += 1 ;
if ( this . frame >= this . frameIndex[ this . mode]. length) {
// we've reached the end of this animation cycle
this . frame = 0 ;
if ( this . mode != this . targetMode) {
// switch to next cycle
if ( this . mode == 'walk' ) {
// we need to stop walking before we decide what to do next
this . mode = 'stop' ;
} else if ( this . mode == 'stop' ) {
if ( this . targetMode == 'walk' )
this . mode = 'walk' ;
else
this . mode = 'idle' ;
} else if ( this . mode == 'idle' ) {
if ( this . targetMode == 'walk' )
this . mode = 'walk' ;
}
}
}
if ( this . mode == 'walk' )
return 8 ;
return 0 ;
},
this . paint = function ( context, x, y) {
if ( ! this . sprites. complete) return ;
// draw the right frame out of the sprite sheet onto the canvas
// we assume each frame is as high as the sprite sheet
// the x,y coordinates give the position of the bottom center of the sprite
context. drawImage( this . sprites,
this . frameIndex[ this . mode][ this . frame] * this . sprites. height, 0 , this . sprites. height, this . sprites. height,
x- this . sprites. height/ 2 , y- this . sprites. height, this . sprites. height, this . sprites. height);
};
};
</ script >
< script >
var canvas = document. getElementsByTagName( 'canvas' )[ 0 ];
var context = canvas. getContext( '2d' );
var landscape = new Landscape( context, canvas. width, canvas. height);
var blueRobot = new BlueRobot();
// paint when the browser wants us to, using requestAnimationFrame()
function paint() {
context. clearRect( 0 , 0 , canvas. width, canvas. height);
landscape. paintBackground( context, canvas. width, canvas. height);
blueRobot. paint( context, canvas. width/ 2 , landscape. horizon* 1.1 );
landscape. paintForeground( context, canvas. width, canvas. height);
requestAnimationFrame( paint);
}
paint();
// but tick every 100ms, so that we don't slow down when we don't paint
setInterval( function () {
var dx = blueRobot. tick();
landscape. advance( dx);
}, 100 );
</ script >
< p class = "buttons" >
< input type = button value = "Walk" onclick = "blueRobot.walk()" >
< input type = button value = "Stop" onclick = "blueRobot.stop()" >
< footer >
< small > Blue Robot Player Sprite by < a href = "https://johncolburn.deviantart.com/" > JohnColburn</ a > .
Licensed under the terms of the Creative Commons Attribution Share-Alike 3.0 Unported license.</ small >
< small > This work is itself licensed under a < a rel = "license" href = "https://creativecommons.org/licenses/by-sa/3.0/" > Creative
Commons Attribution-ShareAlike 3.0 Unported License</ a > .</ small >
</ footer >
ImageBitmap 渲染
上下文ImageBitmapRenderingContext
是一个面向性能的接口,它提供一种开销较低的方法来显示 ImageBitmap
对象的内容。它使用
传输语义来降低总体内存消耗。与
CanvasRenderingContext2D
的 drawImage()
方法不同,
它还通过避免中间合成来提高性能。
例如,使用 img 元素作为
将图像资源放入画布的中间媒介,会导致内存中同时存在
解码图像的两个副本:img 元素的副本,
以及画布后备存储中的副本。处理极大图像时,这种
内存成本可能高得无法接受。使用 ImageBitmapRenderingContext
可以避免这种情况。
使用 ImageBitmapRenderingContext,
可以按以下方式,以节省内存和 CPU 的方式将图像转码为 JPEG
格式:
createImageBitmap( inputImageBlob). then( image => {
const canvas = document. createElement( 'canvas' );
const context = canvas. getContext( 'bitmaprenderer' );
context. transferFromImageBitmap( image);
canvas. toBlob( outputJPEGBlob => {
// Do something with outputJPEGBlob.
}, 'image/jpeg' );
}); ImageBitmapRenderingContext
接口所有当前引擎均支持。
[Exposed =(Window ,Worker )]
interface ImageBitmapRenderingContext {
readonly attribute (HTMLCanvasElement or OffscreenCanvas ) canvas ;
undefined transferFromImageBitmap (ImageBitmap ? bitmap );
};
dictionary ImageBitmapRenderingContextSettings {
boolean alpha = true ;
};context = canvas.getContext('bitmaprenderer' [, { [ alpha: false ] } ])
返回一个永久绑定到特定 canvas
元素的 ImageBitmapRenderingContext
对象。
如果提供了 alpha
设置并将其设置为 false,则强制画布始终不透明。
context.canvas
返回上下文所绑定的 canvas
元素。
context.transferFromImageBitmap(imageBitmap)
ImageBitmapRenderingContext/transferFromImageBitmap
所有当前引擎均支持。
将底层位图数据
从 imageBitmap 传输到 context,并且该位图会成为
context 所绑定的 canvas
元素的内容。
context.transferFromImageBitmap(null)
将 context 所绑定的 canvas
元素的内容替换为一个透明
黑色位图,该位图的大小与 canvas
元素的 width
和 height
内容属性相对应。
canvas 属性必须返回创建对象时
将其初始化为的值。
一个 ImageBitmapRenderingContext
对象具有一个输出位图,它是对位图数据的引用。
一个 ImageBitmapRenderingContext
对象具有一个位图模式,该模式可以设置为
valid 或 blank。值 valid 表示
上下文的
输出位图
引用的是通过 transferFromImageBitmap()
获取的位图数据。
值 blank 表示
上下文的输出
位图是默认透明位图。
一个 ImageBitmapRenderingContext
对象还具有一个alpha 标志,该标志可以设置为 true
或
false。当一个 ImageBitmapRenderingContext
对象的alpha 标志被设置为
false 时,上下文所绑定的 canvas
元素的内容通过以下方式获得:使用 source-over 合成运算符,将上下文的输出
位图合成到一个同样大小的不透明黑色位图上。如果alpha 标志被设置为
true,则
输出
位图会用作上下文所绑定的 canvas
元素的内容。
[COMPOSITE]
只要能够通过其他方式更高效地获得等效结果,就应当省略 合成到不透明黑色位图上的步骤。
当用户代理需要设置
ImageBitmapRenderingContext 的输出
位图时,给定一个属于
ImageBitmapRenderingContext
对象的 context 参数,以及一个可选的、引用位图数据的
bitmap 参数,必须运行以下
步骤:
如果未提供 bitmap 参数:
如果提供了 bitmap 参数:
ImageBitmapRenderingContext 创建
算法接收
target 和 options,并由以下步骤组成:
令 settings 为将 options 转换为字典类型
ImageBitmapRenderingContextSettings
所得的结果。(这可能会抛出异常。)
令 context 为一个新的 ImageBitmapRenderingContext
对象。
将 context 的 canvas
属性初始化为指向 target。
将 context 的输出 位图设置为与 target 的位图相同的 位图(从而共享该位图)。
使用 context 运行设置
ImageBitmapRenderingContext 的输出
位图的步骤。
将 context 的alpha 标志初始化为 true。
按如下方式处理 settings 的每个成员:
alpha返回 context。
transferFromImageBitmap(bitmap)
方法在调用时必须运行以下步骤:
令 bitmapContext 为调用 transferFromImageBitmap()
方法的
ImageBitmapRenderingContext
对象。
如果 bitmap 为 null,则运行设置 ImageBitmapRenderingContext 的输出位图的步骤,并将 bitmapContext 作为 context 参数,不提供 bitmap 参数,然后返回。
如果 bitmap 的 [[Detached]] 内部槽值被设置为
true,则抛出一个 “InvalidStateError” DOMException。
运行设置
ImageBitmapRenderingContext 的输出
位图的步骤,其中 context 参数等于 bitmapContext,
bitmap 参数引用 bitmap 的底层位图数据。
将 bitmap 的 [[Detached]] 内部槽值设置为 true。
取消设置 bitmap 的位图 数据。
OffscreenCanvas
接口所有当前引擎均支持。
typedef (OffscreenCanvasRenderingContext2D or ImageBitmapRenderingContext or WebGLRenderingContext or WebGL2RenderingContext or GPUCanvasContext ) OffscreenRenderingContext ;
dictionary ImageEncodeOptions {
DOMString type = "image/png";
unrestricted double quality ;
};
enum OffscreenRenderingContextId { " 2d " , " bitmaprenderer " , " webgl " , " webgl2 " , " webgpu " };
[Exposed =(Window ,Worker ), Transferable ]
interface OffscreenCanvas : EventTarget {
constructor ([EnforceRange ] unsigned long long width , [EnforceRange ] unsigned long long height );
attribute [EnforceRange ] unsigned long long width ;
attribute [EnforceRange ] unsigned long long height ;
OffscreenRenderingContext ? getContext (OffscreenRenderingContextId contextId , optional any options = null );
ImageBitmap transferToImageBitmap ();
Promise <Blob > convertToBlob (optional ImageEncodeOptions options = {});
attribute EventHandler oncontextlost ;
attribute EventHandler oncontextrestored ;
};OffscreenCanvas 是一个
EventTarget,
因此
OffscreenCanvasRenderingContext2D
和 WebGL 都可以向其触发事件。
OffscreenCanvasRenderingContext2D
可以触发 contextlost
和 contextrestored,
而 WebGL 可以触发 webglcontextlost 和 webglcontextrestored。
[WEBGL]
OffscreenCanvas
对象与
HTMLCanvasElement
类似,用于创建渲染上下文,但与 DOM 没有连接。这使得在工作线程中使用画布渲染上下文成为可能。
一个 OffscreenCanvas
对象可以持有对一个占位符 canvas
元素的弱引用,该元素通常位于 DOM 中,其嵌入内容由 OffscreenCanvas
对象提供。OffscreenCanvas 对象的位图
会在 OffscreenCanvas
的相关代理的事件循环的更新渲染
步骤中,被推送到占位符
canvas 元素。
offscreenCanvas = new OffscreenCanvas(width,
height)
OffscreenCanvas/OffscreenCanvas
所有当前引擎均支持。
返回一个新的 OffscreenCanvas
对象,该对象未链接到占位符 canvas 元素,
并且其
位图大小由 width 和 height 参数确定。
context = offscreenCanvas.getContext(contextId [,
options ])
所有当前引擎均支持。
返回一个公开用于在 OffscreenCanvas
对象上进行绘制的 API 的对象。
contextId 指定所需的 API:“2d”、
“bitmaprenderer”、
“webgl”、
“webgl2”
或“webgpu”。
options 由该
API 处理。
本规范在下文定义“2d”上下文,
它与从 canvas
元素创建的
“2d”
上下文相似但有所不同。
WebGL 规范定义了
“webgl”
和“webgl2”
上下文。WebGPU 定义了
“webgpu”
上下文。[WEBGL]
[WEBGPU]
如果画布已经使用另一种上下文类型进行了初始化,则返回 null(例如,
在获得“webgl”
上下文后,尝试获得“2d”
上下文)。
一个 OffscreenCanvas 对象
具有一个在创建对象时初始化的内部位图。该位图的宽度和高度
等于 OffscreenCanvas
对象的 width
和 height
属性值。最初,位图的所有像素都是透明
黑色。
一个 OffscreenCanvas 对象
具有一个内部继承语言和一个内部继承方向,它们在创建
OffscreenCanvas 时
设置。
一个 OffscreenCanvas 对象
可以绑定一个渲染上下文。最初,
它没有绑定的渲染上下文。为了跟踪它是否具有渲染上下文
以及该渲染上下文的类型,一个 OffscreenCanvas 对象
还具有一个上下文模式,其初始值为 none,但本
规范中定义的算法可以将其更改为 2d、bitmaprenderer、
webgl、webgl2、webgpu 或 detached。
new OffscreenCanvas(width,
height) 构造函数步骤为:
如果 global 是一个 Window
对象:
OffscreenCanvas
对象是可传输的。给定
value 和
dataHolder,它们的传输步骤如下:
如果 value 的上下文模式
不等于 none,则抛出一个
“InvalidStateError” DOMException。
令 width 和 height 为 value 的位图的尺寸。
取消设置 value 的位图。
将 dataHolder.[[Width]] 设置为 width,并将 dataHolder.[[Height]] 设置为 height。
将 dataHolder.[[Language]] 设置为 language,并将 dataHolder.[[Direction]] 设置为 direction。
如果 value 具有占位符 canvas
元素,则将 dataHolder.[[PlaceholderCanvas]] 设置为对该元素的弱引用;
如果没有,则设置为 null。
给定 dataHolder 和 value,它们的传输接收步骤 为:
将 value 的位图初始化为一个 透明 黑色像素矩形数组,其宽度由 dataHolder.[[Width]] 给出,高度由 dataHolder.[[Height]] 给出。
将 value 的继承 语言设置为 dataHolder.[[Language]],并将其继承方向设置为 dataHolder.[[Direction]]。
如果 dataHolder.[[PlaceholderCanvas]] 不为 null,则将
value 的占位符 canvas 元素
设置为
dataHolder.[[PlaceholderCanvas]](同时维持弱引用
语义)。
一个 OffscreenCanvas
对象的 getContext(contextId,
options) 方法在调用时
必须运行以下步骤:
如果 options 不是一个对象,则将 options 设置为 null。
将 options 设置为把 options 转换为 JavaScript 值所得的结果。
运行下表中符合以下条件的单元格内的步骤:其列标题与此
OffscreenCanvas
对象的上下文
模式匹配,并且其行标题与 contextId 匹配:
| none | 2d | bitmaprenderer | webgl 或 webgl2 | webgpu | detached | |
|---|---|---|---|---|---|---|
“2d”
|
|
返回上次使用同一第一个参数调用该方法时返回的同一对象。 | 返回 null。 | 返回 null。 | 返回 null。 |
抛出一个 “InvalidStateError” DOMException。
|
“bitmaprenderer”
|
|
返回 null。 | 返回上次使用同一第一个参数调用该方法时返回的同一对象。 | 返回 null。 | 返回 null。 |
抛出一个 “InvalidStateError” DOMException。
|
“webgl”或“webgl2”
|
返回 null。 | 返回 null。 | 返回上次使用同一第一个参数调用该方法时返回的同一值。 | 返回 null。 |
抛出一个 “InvalidStateError” DOMException。
|
|
“webgpu”
|
返回 null。 | 返回 null。 | 返回 null。 | 返回上次使用同一第一个参数调用该方法时返回的同一值。 |
抛出一个 “InvalidStateError” DOMException。
|
offscreenCanvas.width [
= value ]
所有当前引擎均支持。
offscreenCanvas.height [
= value ]
所有当前引擎均支持。
这些属性返回 OffscreenCanvas
对象的位图的尺寸。
如果一个 OffscreenCanvas
对象的 width 或 height 属性被设置
(设置为新值或与先前相同的值),并且
OffscreenCanvas
对象的上下文
模式为 2d,则将渲染
上下文重置为默认状态,并将 OffscreenCanvas
对象的位图
调整为 width
和 height
属性的新值。
“webgl”
和“webgl2”
上下文的大小调整行为在 WebGL
规范中定义。[WEBGL]
“webgpu”
上下文的大小调整行为
在 WebGPU 中定义。[WEBGPU]
如果一个尺寸已更改的 OffscreenCanvas 对象
具有
占位符
canvas 元素,则
占位符
canvas 元素的
自然大小只会在
OffscreenCanvas 的
相关代理的事件循环的更新渲染
步骤期间更新。
promise = offscreenCanvas.convertToBlob([options])
所有当前引擎均支持。
返回一个 promise,该 promise 将以一个新的 Blob
对象兑现,该对象表示一个包含
OffscreenCanvas
对象中图像的文件。
如果提供了参数,则该参数是一个控制要创建的图像
文件编码选项的字典。type
字段指定
文件格式,其默认值为“image/png”;如果
不支持请求的类型,也会使用该类型。如果图像格式支持可变质量(例如
“image/jpeg”),则
quality
字段是一个介于 0.0 到 1.0(含)范围内的数值,用于指示
所得图像所需的质量等级。
canvas.transferToImageBitmap()
OffscreenCanvas/transferToImageBitmap
所有当前引擎均支持。
返回一个新创建的 ImageBitmap
对象,其中包含
OffscreenCanvas
对象中的图像。OffscreenCanvas
对象中的图像会被
一个新的空白图像替换。
convertToBlob(options) 方法
的步骤为:
如果 this 的 [[Detached]] 内部槽值为 true,则
返回一个以 “InvalidStateError”
DOMException
拒绝的 promise。
如果 this 的上下文模式为
2d,
并且渲染上下文的输出
位图的源洁净标志被设置为
false,则返回一个以
“SecurityError” DOMException
拒绝的 promise。
如果 this 的位图没有像素
(即其水平尺寸或垂直尺寸为零),则返回一个以 “IndexSizeError”
DOMException
拒绝的 promise。
令 result 为一个新的 promise 对象。
并行运行以下步骤:
令 file 为将
bitmap 序列化为文件所得的结果,并使用 options 中存在的
type 和 quality。
在画布 Blob 序列化任务 源上,针对 global 排入一个全局 任务,以运行以下步骤:
如果 file 为 null,则以一个
“EncodingError” DOMException
拒绝 result。
否则,以一个新的 Blob
对象兑现 result,该对象在
global 的相关领域中创建,并表示
file。[FILEAPI]
返回 result。
transferToImageBitmap() 方法
在调用时必须运行以下步骤:
如果此 OffscreenCanvas
对象的 [[Detached]]
内部槽被设置为 true,则抛出一个 “InvalidStateError”
DOMException。
如果此 OffscreenCanvas
对象的上下文模式被设置为 none,则抛出一个
“InvalidStateError” DOMException。
令 image 为一个新创建的 ImageBitmap 对象,
该对象引用
此 OffscreenCanvas
对象的位图所使用的相同底层位图数据。
将此 OffscreenCanvas
对象的位图设置为引用一个新创建的位图,
该位图与先前位图具有相同的
尺寸和颜色空间,并将其像素初始化为
透明
黑色;如果渲染上下文的alpha 为 false,则初始化为不透明黑色。
这意味着,如果此 OffscreenCanvas
的渲染上下文
是一个 WebGLRenderingContext,
则 preserveDrawingBuffer
的值不会产生任何影响。
[WEBGL]
返回 image。
以下是所有实现
OffscreenCanvas
接口的对象都必须支持的事件
处理程序(及其对应的事件处理程序事件类型),并将其作为事件
处理程序 IDL 属性:
| 事件处理程序 | 事件 处理程序事件类型 |
|---|---|
oncontextlost |
contextlost
|
oncontextrestored |
contextrestored
|
OffscreenCanvasRenderingContext2D
所有当前引擎均支持。
[Exposed =(Window ,Worker )]
interface OffscreenCanvasRenderingContext2D {
readonly attribute OffscreenCanvas canvas ;
};
OffscreenCanvasRenderingContext2D includes CanvasSettings ;
OffscreenCanvasRenderingContext2D includes CanvasState ;
OffscreenCanvasRenderingContext2D includes CanvasTransform ;
OffscreenCanvasRenderingContext2D includes CanvasCompositing ;
OffscreenCanvasRenderingContext2D includes CanvasImageSmoothing ;
OffscreenCanvasRenderingContext2D includes CanvasFillStrokeStyles ;
OffscreenCanvasRenderingContext2D includes CanvasShadowStyles ;
OffscreenCanvasRenderingContext2D includes CanvasFilters ;
OffscreenCanvasRenderingContext2D includes CanvasRect ;
OffscreenCanvasRenderingContext2D includes CanvasDrawPath ;
OffscreenCanvasRenderingContext2D includes CanvasText ;
OffscreenCanvasRenderingContext2D includes CanvasDrawImage ;
OffscreenCanvasRenderingContext2D includes CanvasImageData ;
OffscreenCanvasRenderingContext2D includes CanvasPathDrawingStyles ;
OffscreenCanvasRenderingContext2D includes CanvasTextDrawingStyles ;
OffscreenCanvasRenderingContext2D includes CanvasPath ;OffscreenCanvasRenderingContext2D
对象是一个渲染上下文,用于在
OffscreenCanvas
对象的位图上进行绘制。
它与 CanvasRenderingContext2D
对象类似,但存在以下
差异:
不支持用户界面 功能;
其 canvas
属性引用的是
OffscreenCanvas
对象,而不是 canvas
元素;
OffscreenCanvasRenderingContext2D
对象具有一个关联的
OffscreenCanvas 对象,它是创建该 OffscreenCanvasRenderingContext2D
对象时所源自的 OffscreenCanvas
对象。
offscreenCanvas = offscreenCanvasRenderingContext2D.canvas
离屏 2D 上下文创建算法会接收一个
target(一个 OffscreenCanvas
对象)以及可选的一些参数,
该算法包括运行以下步骤:
如果向算法传递了一些参数,则令 arg 为其中的第一个 参数。否则,令 arg 为 undefined。
令 settings 为将 arg 转换为字典类型
CanvasRenderingContext2DSettings
的结果。(这可能会抛出异常。)
令 context 为一个新的 OffscreenCanvasRenderingContext2D
对象。
将 context 的关联的
OffscreenCanvas 对象设置为
target。
以 context 和 settings 为参数,运行画布设置输出位图 初始化算法。
将 context 的输出位图设置为一个新创建的位图,其尺寸由
target 的 width
和 height
属性指定,并将
target 的位图设置为同一个位图(以使它们共享该位图)。
如果 context 的 alpha 标志被设置为 true,则将 context 的输出位图的所有像素初始化为 透明 黑色。否则,将这些像素初始化为不透明 黑色。
返回 context。
为了将占位符 canvas 元素的内容更新到
显示器,实现应尽量采用捷径来执行窗口事件循环的图形更新步骤。例如,这可能意味着将位图内容直接复制到映射至占位符
canvas 元素物理显示位置的图形
缓冲区。此类或
类似的捷径方式可以显著降低显示延迟,特别是在通过
工作线程事件循环更新 OffscreenCanvas,
而占位符
canvas 元素的窗口事件循环
正忙的情况下。
但是,此类捷径不得产生任何脚本可观察到的副作用。这意味着已提交的位图仍然需要发送到占位符 canvas 元素,
以防该
元素被用作 CanvasImageSource、
ImageBitmapSource,
或者在
该元素上调用了 toDataURL()
或 toBlob()。
获取 canvas 属性时,必须返回此
OffscreenCanvasRenderingContext2D
的关联的
OffscreenCanvas
对象。
enum PredefinedColorSpace { " srgb " , " srgb-linear " , " display-p3 " , " display-p3-linear " };PredefinedColorSpace
枚举用于指定画布后备存储的色彩空间。
“srgb”值表示 'srgb'
色彩空间。
“srgb-linear”值表示
'srgb-linear' 色彩空间。
“display-p3”值表示
'display-p3'
色彩空间。
“display-p3-linear”值表示
'display-p3-linear' 色彩空间。
将画布渲染到输出设备时,必须对画布的后备存储应用色彩空间转换。
色彩空间之间的转换算法可在 CSS Color 的
转换
色彩一节中找到。此色彩空间转换
与对具有色彩配置文件的 img
元素应用的
色彩空间转换相同,该色彩配置文件指定的色彩
空间与画布后备存储的色彩空间相同。[CSSCOLOR]
当用户代理要在给定 type 和可选的 quality 的情况下创建位图作为文件的 序列化结果时,它必须创建一个格式由 type 指定的图像文件。如果在 创建图像文件期间发生错误(例如内部编码器错误),则 序列化结果为 null。[PNG]
图像文件的像素数据必须是按每个坐标空间单位对应一个图像像素进行缩放的位图像素数据, 并且如果所使用的文件格式支持对分辨率元数据进行编码,则分辨率 必须指定为 96dpi(每个 CSS 像素对应一个图像像素)。
如果提供了 type,则必须将其解释为一个MIME 类型,用于指定要使用的格式。如果该类型具有任何参数,则必须将其视为 不受支持。
例如,值“image/png”表示生成
PNG
图像,值“image/jpeg”
表示生成 JPEG 图像,而值
“image/svg+xml”表示
生成 SVG 图像(这将要求
用户代理跟踪位图的生成方式;虽然不太可能实现,但可能会是一个很棒的
功能)。
用户代理必须支持 PNG(“image/png”)。用户代理可以
支持其他类型。
如果用户代理不支持请求的类型,则必须使用 PNG
格式创建文件。[PNG]
用户代理在确定是否支持所提供的类型之前,必须将所提供的类型转换为 ASCII 小写形式。
对于不支持 alpha 分量的图像类型,序列化后的图像必须是使用源覆盖 合成运算符将位图图像合成到不透明黑色 背景之上的结果。
对于支持色彩配置文件的图像类型,序列化后的图像必须包含一个色彩配置文件, 用于指示底层位图的色彩空间。对于不支持色彩 配置文件的图像类型,必须使用 'relative-colorimetric' 渲染意图,将序列化后的图像转换为 'srgb' 色彩空间。
因此,在 2D 上下文中,在给定适当尺寸的情况下,调用 drawImage()
方法将 toDataURL()
或 toBlob()
方法的输出渲染到画布上,
最多只会将画布的色彩裁剪到更窄的色域,不会产生其他可见效果。
对于支持多种位深度的图像类型,序列化后的图像必须使用最能保留 底层位图内容的位深度。
例如,将一个
色彩类型
为
float16
的 2D 上下文序列化为 type
“image/png”时,生成的
图像将具有每个样本 16 位的位深度。
此序列化仍会丢失大量细节(所有小于 0.5/65535
的值都将被钳制为 0,所有大于 1 的值都将被钳制为 1)。
如果 type 是支持可变质量的图像格式(例如
“image/jpeg”),
给出了 quality,并且 type 不是
“image/png”,那么,如果
quality 是 0.0 到 1.0(含)范围内的数值,
用户代理必须将 quality 视为所需的
质量等级。否则,用户代理必须使用其默认质量值,就像未给出
quality 参数一样。
这里使用类型测试,而不是简单地将 quality 声明为
Web IDL double,是一个历史遗留问题。
不同实现对“质量”的解释可能略有不同。 未指定质量时,将使用实现特定的默认值,该值代表 压缩率、图像质量和编码时间之间的合理折中。
canvas 元素的安全性本节为非规范性内容。
如果来自一个源的脚本能够 访问来自另一个源(与其不同源)的图像中的信息(例如读取像素),则可能发生信息泄露。
为缓解此问题,与 canvas 元素、
OffscreenCanvas
对象和 ImageBitmap
对象一起使用的位图被定义为具有一个标志,用于指示它们是否
源干净。所有位图的
源干净标志最初都设置为 true。使用跨源图像时,该标志会被设置为
false。
toDataURL()、
toBlob() 和
getImageData()
方法会检查该标志,并且将
抛出 “SecurityError” DOMException,而不是泄露
跨源数据。
源干净标志的值
会由 createImageBitmap()
从源的位图传播到新的 ImageBitmap
对象。
相反,如果源图像是一个
位图的源干净标志被设置为 false 的
ImageBitmap 对象,则
drawImage
会将目标 canvas
元素位图的
源干净标志设置为
false。
该标志可以在某些情况下重置;例如,更改 CanvasRenderingContext2D
所绑定的 canvas
元素的
width 或
height 内容
属性的值时,位图会被
清除,并且其源干净标志会被重置。
使用 ImageBitmapRenderingContext
时,通过 transferFromImageBitmap()
将 ImageBitmap 对象
传输到 canvas
时,源干净标志的值会从这些对象传播过去。
预乘 alpha是指在图像中 表示透明度的一种方式,另一种方式是非预乘 alpha。
在非预乘 alpha 下,像素的红色、绿色和蓝色分量表示该 像素的色彩,而其 alpha 分量表示该像素的不透明度。
但在预乘 alpha 下,像素的红色、绿色和蓝色分量表示 该像素添加到图像中的色彩量,而其 alpha 分量表示 该像素遮挡其后方内容的程度。
例如,假设色彩分量的范围为 0(关闭)到 255(全强度),以下 示例色彩将按下列方式表示:
| CSS 色彩表示形式 | 预乘表示形式 | 非预乘表示形式 | 色彩说明 | 色彩混合在其他内容上方的图像 |
|---|---|---|---|---|
| rgba(255, 127, 0, 1) | 255, 127, 0, 255 | 255, 127, 0, 255 | 完全不透明的橙色 | 
|
| rgba(255, 255, 0, 0.5) | 127, 127, 0, 127 | 255, 255, 0, 127 | 半不透明的黄色 | 
|
| 无法表示 | 255, 127, 0, 127 | 无法表示 | 加法式半不透明橙色 | 
|
| 无法表示 | 255, 127, 0, 0 | 无法表示 | 加法式完全透明橙色 | 
|
| rgba(255, 127, 0, 0) | 0, 0, 0, 0 | 255, 127, 0, 0 | 完全透明(“不可见”)的橙色 | 
|
| rgba(0, 127, 255, 0) | 0, 0, 0, 0 | 255, 127, 0, 0 | 完全透明(“不可见”)的青绿色 |
|
将色彩值从非预乘 表示形式转换为预乘表示形式,需要将色彩的红色、绿色和 蓝色分量乘以其 alpha 分量(重新映射 alpha 分量的范围,使 “完全透明”为 0,“完全不透明”为 1)。
将色彩值从预乘 表示形式转换为非预乘表示形式,需要执行相反操作:将色彩的红色、 绿色和蓝色分量除以其 alpha 分量。
由于某些色彩只能在预乘 alpha 下表示(例如加法色), 而另一些色彩只能在非预乘 alpha 下表示(例如,即使完全不透明度为零也保留特定 红色、绿色和蓝色值的“不可见”色彩);并且 使用有限精度进行除法和乘法会导致精度损失,因此,对于并非完全 不透明的色彩,在预乘 alpha 与非预乘 alpha 之间进行转换是一种有损操作。
CanvasRenderingContext2D
的输出位图和
OffscreenCanvasRenderingContext2D
的输出位图
必须使用预乘
alpha 表示透明色彩。
画布位图使用预乘 alpha 表示色彩非常重要,
因为这会影响可表示色彩的范围。虽然目前无法直接将加法色
绘制到画布上,因为 CSS 色彩是非预乘的,无法表示此类色彩,
但仍然可以将加法色绘制到 WebGL 画布上,然后通过 drawImage()
将该 WebGL 画布绘制到 2D 画布上。
所有当前引擎均支持。
本节为非规范性内容。
自定义元素为作者提供了一种构建 自己功能完备的 DOM 元素的方式。虽然作者一直可以在 文档中使用非标准元素,并在之后通过脚本或类似方式添加应用程序特定的行为,但 此类元素历来不符合规范,并且功能非常有限。通过定义自定义元素,作者可以告知解析器如何 正确构造元素,以及该类元素应如何响应变化。
自定义元素是“使平台合理化”这一更大工作的一部分,它通过 较低层级、向作者公开的扩展点(例如自定义元素定义)来解释 现有的平台功能(例如 HTML 元素)。尽管目前自定义元素的能力在 功能和语义方面都存在许多限制,使其无法 完整解释 HTML 现有元素的行为,但我们希望随着 时间的推移缩小这一差距。
本节为非规范性内容。
为了说明如何创建自主自定义元素,我们来 定义一个自定义元素,用于封装国家旗帜小图标的渲染。我们的目标是 能够像下面这样使用它:
< flag-icon country = "nl" ></ flag-icon > 为此,我们首先为自定义元素声明一个类,并扩展
HTMLElement:
class FlagIcon extends HTMLElement {
constructor() {
super ();
this . _countryCode = null ;
}
static observedAttributes = [ "country" ];
attributeChangedCallback( name, oldValue, newValue) {
// 由于 observedAttributes,name 始终为 "country"
this . _countryCode = newValue;
this . _updateRendering();
}
connectedCallback() {
this . _updateRendering();
}
get country() {
return this . _countryCode;
}
set country( v) {
this . setAttribute( "country" , v);
}
_updateRendering() {
// 留给读者作为练习。不过,你可能需要
// 检查 this.ownerDocument.defaultView,以确定我们是否已被
// 插入到具有浏览上下文的文档中,并在没有浏览上下文时
// 避免执行任何工作。
}
} 然后,我们需要使用此类来定义元素:
customElements. define( "flag-icon" , FlagIcon); 此时,上面的代码就可以正常工作了!每当解析器看到 flag-icon 标签时,它都会
构造一个新的 FlagIcon 类实例,并将其新的 country
属性通知我们的代码,然后我们使用该属性设置元素的内部状态并更新其渲染(在
适当的时候)。
还可以使用 DOM API 创建 flag-icon 元素:
const flagIcon = document. createElement( "flag-icon" )
flagIcon. country = "jp"
document. body. appendChild( flagIcon) 最后,我们还可以使用自定义元素构造函数本身。也就是说, 上面的 代码等价于:
const flagIcon = new FlagIcon()
flagIcon. country = "jp"
document. body. appendChild( flagIcon) 本节为非规范性内容。
添加一个值为 true 的静态 formAssociated 属性,会使
自主自定义
元素成为表单关联自定义元素。ElementInternals
接口可帮助你实现表单控件元素共有的
功能和属性。
class MyCheckbox extends HTMLElement {
static formAssociated = true ;
static observedAttributes = [ 'checked' ];
constructor() {
super ();
this . _internals = this . attachInternals();
this . addEventListener( 'click' , this . _onClick. bind( this ));
}
get form() { return this . _internals. form; }
get name() { return this . getAttribute( 'name' ); }
get type() { return this . localName; }
get checked() { return this . hasAttribute( 'checked' ); }
set checked( flag) { this . toggleAttribute( 'checked' , Boolean( flag)); }
attributeChangedCallback( name, oldValue, newValue) {
// 由于 observedAttributes,name 始终为 "checked"
this . _internals. setFormValue( this . checked ? 'on' : null );
}
_onClick( event) {
this . checked = ! this . checked;
}
}
customElements. define( 'my-checkbox' , MyCheckbox); 可以像使用内置的表单关联元素一样使用自定义元素 my-checkbox。
例如,将其放入 form 或
label
中会使 my-checkbox 元素与它们关联,而提交
form 时将发送
my-checkbox 实现提供的数据。
< form action = "..." method = "..." >
< label >< my-checkbox name = "agreed" ></ my-checkbox > 我已阅读协议。</ label >
< input type = "submit" >
</ form >
本节为非规范性内容。
通过使用 ElementInternals
的适当属性,自定义元素可以
具有默认无障碍语义。以下代码扩展了上一节中的表单关联复选框,
以便按照无障碍技术所看到的方式正确设置其默认角色和选中状态:
class MyCheckbox extends HTMLElement {
static formAssociated = true ;
static observedAttributes = [ 'checked' ];
constructor() {
super ();
this . _internals = this . attachInternals();
this . addEventListener( 'click' , this . _onClick. bind( this ));
this . _internals. role = 'checkbox' ;
this . _internals. ariaChecked = 'false' ;
}
get form() { return this . _internals. form; }
get name() { return this . getAttribute( 'name' ); }
get type() { return this . localName; }
get checked() { return this . hasAttribute( 'checked' ); }
set checked( flag) { this . toggleAttribute( 'checked' , Boolean( flag)); }
attributeChangedCallback( name, oldValue, newValue) {
// 由于 observedAttributes,name 始终为 "checked"
this . _internals. setFormValue( this . checked ? 'on' : null );
this . _internals. ariaChecked = this . checked;
}
_onClick( event) {
this . checked = ! this . checked;
}
}
customElements. define( 'my-checkbox' , MyCheckbox); 请注意,与内置元素一样,这些只是默认值,页面作者可以使用 role 和 aria-* 属性覆盖它们:
<!-- 此标记不符合规范 -->
< input type = "checkbox" checked role = "button" aria-checked = "false" > <!-- 此标记可能并非自定义元素作者的本意 -->
< my-checkbox role = "button" checked aria-checked = "false" > 建议自定义元素作者声明其无障碍语义的哪些方面
属于强原生语义,即不应被自定义元素的使用者覆盖。在本
示例中,my-checkbox 元素的作者会声明其
角色和 aria-checked
值属于强
原生语义,从而不鼓励使用上述代码。
本节为非规范性内容。
自定义内置元素是一种独特的 自定义元素, 与自主自定义 元素相比,其定义方式略有不同,使用方式也非常不同。它们的存在是为了 允许复用 HTML 现有元素的行为,方法是 使用新的自定义功能扩展这些元素。这一点很重要,因为遗憾的是,HTML 元素的许多 现有行为无法仅使用自主自定义元素来复制。 相反,自定义内置元素 允许在现有元素上安装 自定义构造行为、生命周期钩子和原型链, 实质上是在已有元素之上“混入”这些能力。
自定义内置元素需要使用 与自主自定义元素不同的语法, 因为用户代理和其他软件会根据元素的本地名称来识别 元素的语义和行为。也就是说,自定义内置元素 在现有行为之上进行构建这一概念,关键取决于 被扩展元素保留其原始本地名称。
在此示例中,我们将创建一个名为 plastic-button 的自定义内置元素,
它的行为与普通按钮类似,但每次单击时都会添加炫酷的动画
效果。我们像之前一样从定义一个类开始,不过
这次扩展的是 HTMLButtonElement,
而不是 HTMLElement:
class PlasticButton extends HTMLButtonElement {
constructor() {
super ();
this . addEventListener( "click" , () => {
// 绘制一些炫酷的动画效果!
});
}
} 定义自定义元素时,我们还必须指定 extends
选项:
customElements. define( "plastic-button" , PlasticButton, { extends : "button" }); 一般来说,不能仅通过查看元素所扩展的
元素接口来确定被扩展元素的名称,因为许多元素共享同一个接口(例如
q 和 blockquote
都共享 HTMLQuoteElement)。
要从解析后的 HTML 源文本构造我们的自定义内置元素,我们需要在
button
元素上使用 is 属性:
< button is = "plastic-button" > 单击我!</ button > 尝试将自定义内置元素用作
自主自定义
元素将无法正常工作;也就是说,<plastic-button>单击
我?</plastic-button>只会创建一个没有
特殊行为的 HTMLElement。
如果需要以编程方式创建自定义内置元素,可以使用以下形式的 createElement():
const plasticButton = document. createElement( "button" , { is: "plastic-button" });
plasticButton. textContent = "单击我!" ; 和之前一样,构造函数也同样有效:
const plasticButton2 = new PlasticButton();
console. log( plasticButton2. localName); // 将输出 "button"
console. assert( plasticButton2 instanceof PlasticButton);
console. assert( plasticButton2 instanceof HTMLButtonElement); 请注意,以编程方式创建自定义内置元素时,is 属性不会
出现在 DOM 中,因为并未显式
设置它。不过,序列化时,它将被添加到输出中:
console. assert( ! plasticButton. hasAttribute( "is" ));
console. log( plasticButton. outerHTML); // 将输出 '<button is="plastic-button"></button>' 无论以何种方式创建,button
所有特殊之处
也都适用于此类“塑料按钮”:其焦点行为、参与表单
提交的能力、disabled
属性等。
自定义内置元素旨在
允许扩展具有实用的用户代理所提供行为或 API 的现有 HTML
元素。因此,它们只能扩展
本规范中定义的现有 HTML 元素,不能扩展诸如
bgsound、blink、isindex、keygen、
multicol、nextid 或 spacer 等旧式元素,这些元素被定义为使用
HTMLUnknownElement
作为其元素
接口。
此要求的原因之一是未来兼容性:如果定义了一个扩展当前未知元素(例如
combobox)的自定义内置
元素,这将阻止本规范在未来定义 combobox 元素,因为派生的
自定义
内置元素的使用者将已经依赖于其基础元素不具有任何值得关注的
用户代理所提供行为。
本节为非规范性内容。
如下文所述,也如上文所提及的那样,仅仅定义并使用一个名为
taco-button 的元素,并不意味着此类元素表示按钮。也就是说,Web 浏览器、搜索引擎
或无障碍技术等工具不会仅仅
根据其定义的名称,就自动将所生成的元素视为按钮。
为了在仍然使用自主 自定义元素的同时,向各种用户传达所需的按钮语义,需要采用多种技术:
添加 tabindex
属性
会使
taco-button 可聚焦。
请注意,如果
taco-button 在逻辑上变为禁用状态,则需要移除 tabindex
属性。
添加 ARIA 角色以及各种 ARIA 状态和属性,有助于向无障碍技术传达语义。
例如,将角色设置为“button”
将传达这是一个按钮的语义,
使用户能够使用其无障碍技术中常见的按钮式交互成功操作该控件。
必须设置 aria-label
属性,才能为按钮提供一个无障碍
名称,而不是让无障碍技术遍历其子文本节点并
朗读它们。当按钮在逻辑上处于禁用状态时,将 aria-disabled
状态设置为
“true”,则会向无障碍
技术传达按钮的禁用状态。
添加事件处理程序来处理通常预期的按钮行为,有助于向
Web 浏览器用户传达按钮的语义。在这种情况下,最相关的事件处理程序
是将适当的 keydown
事件代理为
click
事件的处理程序,使你既可以
使用键盘,也可以通过单击来激活按钮。
除了为 taco-button
元素提供的任何默认视觉样式之外,还需要更新视觉样式以反映逻辑状态的变化,
例如变为禁用状态;也就是说,无论哪个样式表包含针对 taco-button 的规则,也需要
包含针对 taco-button[disabled] 的规则。
考虑到这些要点,一个承担传达按钮语义
责任(包括被禁用的能力)的功能完备的 taco-button,可能如下所示:
class TacoButton extends HTMLElement {
static observedAttributes = [ "disabled" ];
constructor() {
super ();
this . _internals = this . attachInternals();
this . _internals. role = "button" ;
this . addEventListener( "keydown" , e => {
if ( e. code === "Enter" || e. code === "Space" ) {
this . dispatchEvent( new PointerEvent( "click" , {
bubbles: true ,
cancelable: true
}));
}
});
this . addEventListener( "click" , e => {
if ( this . disabled) {
e. preventDefault();
e. stopImmediatePropagation();
}
});
this . _observer = new MutationObserver(() => {
this . _internals. ariaLabel = this . textContent;
});
}
connectedCallback() {
this . setAttribute( "tabindex" , "0" );
this . _observer. observe( this , {
childList: true ,
characterData: true ,
subtree: true
});
}
disconnectedCallback() {
this . _observer. disconnect();
}
get disabled() { return this . hasAttribute( "disabled" ); }
set disabled( flag) {
this . toggleAttribute( "disabled" , Boolean( flag));
}
attributeChangedCallback( name, oldValue, newValue) {
// 由于 observedAttributes,name 始终为 "disabled"
if ( this . disabled) {
this . removeAttribute( "tabindex" );
this . _internals. ariaDisabled = "true" ;
} else {
this . setAttribute( "tabindex" , "0" );
this . _internals. ariaDisabled = "false" ;
}
}
} 即使使用了这种相当复杂的元素定义,该元素对
使用者来说仍然并不好用:它会不断地自行“长出” tabindex
属性,而且它所选择的 tabindex="0" 可聚焦
行为可能与当前平台上的 button
行为不一致。这是因为
目前尚无法为自定义元素指定默认聚焦行为,因此只能被迫使用
tabindex
属性来实现这一点(尽管该属性通常
用于允许使用者覆盖默认行为)。
相比之下,如上一
节所示,一个简单的自定义内置元素会自动继承
button
元素的语义和行为,而无需手动实现这些行为。通常,对于任何
在现有 HTML 元素之上构建且具有复杂行为和语义的元素,自定义内置元素将更容易
开发、维护和使用。
本节为非规范性内容。
由于元素 定义可以在任何时候发生,因此一个非自定义元素可以先被 创建,然后 在注册适当的定义后,稍后变为自定义 元素。我们将元素从普通元素变为自定义 元素的这一过程称为“升级”。
升级支持这样的场景:与元素最初由
解析器等方式创建相比,稍后注册自定义元素定义可能更为合适。
升级允许对自定义元素中的内容进行
渐进增强。例如,在以下 HTML
文档中,img-viewer 的元素定义是异步加载的:
<!DOCTYPE html>
< html lang = "en" >
< title > 图像查看器示例</ title >
< img-viewer filter = "Kelvin" >
< img src = "images/tree.jpg" alt = "一棵美丽的大树高耸在空旷的稀树草原上" >
</ img-viewer >
< script src = "js/elements/img-viewer.js" async ></ script > 这里的 img-viewer 元素定义是使用一个带有 async
属性标记的 script
元素加载的,该元素在标记中位于 <img-viewer> 标签之后。在
脚本加载期间,img-viewer 元素将被视为未定义
元素,类似于 span。脚本
加载完成后,它将定义 img-viewer 元素,页面上现有的 img-viewer 元素
将被升级,并应用自定义元素的定义(该定义大概包括
应用由字符串“Kelvin”标识的图像滤镜,以增强图像的视觉
外观)。
请注意,升级仅适用于 文档树中的元素。(形式上来说,是已连接的元素。)未 插入文档中的元素将保持未升级状态。以下示例说明了这一点:
<!DOCTYPE html>
< html lang = "en" >
< title > 升级边界情况示例</ title >
< example-element ></ example-element >
< script >
"use strict" ;
const inDocument = document. querySelector( "example-element" );
const outOfDocument = document. createElement( "example-element" );
// 在定义元素之前,两者都是 HTMLElement:
console. assert( inDocument instanceof HTMLElement);
console. assert( outOfDocument instanceof HTMLElement);
class ExampleElement extends HTMLElement {}
customElements. define( "example-element" , ExampleElement);
// 定义元素后,文档内的元素已被升级:
console. assert( inDocument instanceof ExampleElement);
console. assert( ! ( outOfDocument instanceof ExampleElement));
document. body. appendChild( outOfDocument);
// 现在我们已将该元素移入文档,它也被升级了:
console. assert( outOfDocument instanceof ExampleElement);
</ script > 为了使多个库无需显式协调即可共存,
CustomElementRegistry
也可以以限定作用域的方式使用。
const scoped = new CustomElementRegistry();
scoped. define( "example-element" , ExampleElement);
const element = document. createElement( "example-element" , { customElementRegistry: scoped }); 具有关联的限定作用域 CustomElementRegistry
的节点会在
其所有操作中使用该注册表,例如调用 setHTMLUnsafe()
时。
用户代理提供的内置元素具有某些状态,这些状态可随时间
根据用户交互和其他因素发生变化,并通过伪类向 Web 作者公开。例如,一些表单控件具有“无效”
状态,该状态通过 :invalid
伪类公开。
与内置元素一样,自定义 元素也可以具有各种 状态,而自定义 元素作者希望以类似于内置元素的方式公开这些状态。
这是通过 :state()
伪类实现的。
自定义
元素作者可以使用
ElementInternals
的 states
属性来添加和移除此类自定义状态,然后这些状态会作为
:state()
伪类的参数公开。
以下示例展示了如何使用 :state()
设置自定义
复选框元素的样式。假设 LabeledCheckbox 不通过内容属性公开其
“选中”状态。
< script >
class LabeledCheckbox extends HTMLElement {
constructor() {
super ();
this . _internals = this . attachInternals();
this . addEventListener( 'click' , this . _onClick. bind( this ));
const shadowRoot = this . attachShadow({ mode: 'closed' });
shadowRoot. innerHTML =
`<style>
:host::before {
content: '[ ]';
white-space: pre;
font-family: monospace;
}
:host(:state(checked))::before { content: '[x]' }
</style>
<slot>标签</slot>` ;
}
get checked() { return this . _internals. states. has( 'checked' ); }
set checked( flag) {
if ( flag)
this . _internals. states. add( 'checked' );
else
this . _internals. states. delete ( 'checked' );
}
_onClick( event) {
this . checked = ! this . checked;
}
}
customElements. define( 'labeled-checkbox' , LabeledCheckbox);
</ script >
< style >
labeled-checkbox { border : dashed red ; }
labeled-checkbox : state ( checked ) { border : solid ; }
</ style >
< labeled-checkbox > 你需要勾选此项</ labeled-checkbox > 自定义伪类甚至可以以 shadow 部件为目标。上述示例的扩展展示了 这一点:
< script >
class QuestionBox extends HTMLElement {
constructor() {
super ();
const shadowRoot = this . attachShadow({ mode: 'closed' });
shadowRoot. innerHTML =
`<div><slot>问题</slot></div>
<labeled-checkbox part='checkbox'>是</labeled-checkbox>` ;
}
}
customElements. define( 'question-box' , QuestionBox);
</ script >
< style >
question-box :: part ( checkbox ) { color : red ; }
question-box :: part ( checkbox ) : state ( checked ) { color : green ; }
</ style >
< question-box > 继续吗?</ question-box > 编写自定义元素构造函数时, 作者必须遵守以下符合性要求:
不带参数的 super() 调用必须是
构造函数主体中的第一条语句,以便在运行任何
后续代码之前建立正确的原型链和 this 值。
return 语句不得出现在构造函数
主体中的任何位置,除非它是简单的提前返回(return 或 return
this)。
构造函数不得使用 document.write()
或 document.open()
方法。
不得检查元素的属性和子节点,因为在非升级情况下,这些内容均不存在,而且依赖 升级会降低元素的可用性。
元素不得获得任何属性或子节点,因为这会违背使用 createElement
或 createElementNS
方法的使用者的预期。
通常,应尽可能将工作推迟到 connectedCallback 中执行,尤其是
涉及获取资源或渲染的工作。但是,请注意,
connectedCallback 可能会被调用多次,因此任何真正只需执行一次的初始化工作
都需要设置防护,以防止其运行两次。
通常,构造函数应用于设置初始状态和默认值, 设置事件监听器,并且可能设置一个shadow 根。
这些要求中的若干项会在元素 创建期间被直接或间接检查,不遵守这些要求将导致自定义 元素无法由解析器或 DOM API 实例化。即使相关工作是在构造函数启动的 微任务中完成,也是如此,因为 微任务 检查点可能在构造后立即发生。
编写自定义元素反应时, 作者应避免操纵节点树,因为这可能导致意外结果。
元素的 connectedCallback 可以在元素
断开连接之前进入队列,但由于回调队列仍会被处理,结果会对一个
已不再连接的元素执行 connectedCallback:
class CParent extends HTMLElement {
connectedCallback() {
this . firstChild. remove();
}
}
customElements. define( "c-parent" , CParent);
class CChild extends HTMLElement {
connectedCallback() {
console. log( "CChild connectedCallback: isConnected =" , this . isConnected);
}
}
customElements. define( "c-child" , CChild);
const parent = new CParent(),
child = new CChild();
parent. append( child);
document. body. append( parent);
// 输出:
// CChild connectedCallback: isConnected = false 本节为非规范性内容。
操纵 DOM 树时,元素可以在保持连接的情况下在树中被移动。这同样适用于自定义
元素。默认情况下,会依次在该元素上调用
“disconnectedCallback”和“connectedCallback”。这样做是为了
保持与早于 moveBefore()
方法出现的现有自定义元素的兼容性。这意味着,默认情况下,自定义
元素会像被移除并重新插入一样重置其状态。在上面的示例中,其影响是
观察器会断开连接并重新连接,而且制表索引会被重置。
为了在移动时选择采用保留状态的行为,作者可以实现
“connectedMoveCallback”。只要存在此回调,即使其为空,也会
取代调用“disconnectedCallback”和“connectedCallback”的默认行为。
“connectedMoveCallback”也可以是
执行依赖于元素祖先的逻辑的适当位置。例如:
class TacoButton extends HTMLElement {
static observedAttributes = [ "disabled" ];
constructor() {
super ();
this . _internals = this . attachInternals();
this . _internals. role = "button" ;
this . _observer = new MutationObserver(() => {
this . _internals. ariaLabel = this . textContent;
});
}
_notifyMain() {
if ( this . parentElement. tagName === "MAIN" ) {
// 执行依赖于祖先的逻辑。
}
}
connectedCallback() {
this . setAttribute( "tabindex" , "0" );
this . _observer. observe( this , {
childList: true ,
characterData: true ,
subtree: true
});
this . _notifyMain();
}
disconnectedCallback() {
this . _observer. disconnect();
}
// 实现此函数可以避免在该元素未断开连接而在 DOM 内部移动时,
// 重置制表索引或重新注册变异观察器。
connectedMoveCallback() {
// 在保留状态的移动期间,父元素可能发生变化。
this . _notifyMain();
}
} 自定义元素是一个自定义的元素。 非正式地说,这意味着其构造函数和 原型由作者定义,而不是由用户代理定义。这个由作者提供的 构造函数称为自定义元素 构造函数。
可以定义两种不同类型的自定义 元素:
自定义内置元素,其定义中带有
extends
选项。这类自定义
元素的本地名称等于传递给其 extends
选项的值,而其定义名称用作
is 属性的值,因此
它必须是有效的自定义元素名称。
自定义元素被创建后,
更改 is
属性的值不会
改变元素的行为,因为该值会作为元素的 is 值保存在元素上。
自主自定义 元素具有以下 元素定义:
is 属性除外
form,用于表单关联自定义元素 —
将元素与 form 元素关联
disabled,用于
表单关联自定义元素 —
表单控件是否被禁用
readonly,
用于表单关联自定义元素 —
影响 willValidate,
以及自定义元素作者添加的任何行为
name,用于表单关联自定义元素 — 用于表单
提交以及 form.elements API
的元素名称
HTMLElement)
自主 自定义元素不具有任何特殊含义:它 表示其子节点。自定义 内置元素继承其所扩展元素的 语义。
由元素作者确定的、与元素功能有关的任何无命名空间属性,都可以指定在自主自定义元素上,只要
属性名称是有效的
属性本地名称,且不包含任何 ASCII 大写
字母。例外情况是 is 属性,该属性不得
指定在自主自定义
元素上(即使指定也不会产生任何效果)。
自定义
内置元素根据其所扩展的元素遵循
常规属性要求。要添加基于属性的自定义
行为,请使用 data-* 属性。
name 属性
表示表单关联
自定义元素的名称。disabled 属性
用于使表单关联自定义元素
不可交互,并防止提交其
提交值。form 属性用于
将表单关联自定义元素与其表单所有者显式关联。
表单关联自定义元素的 readonly 属性指定
该元素被禁止
进行约束验证。用户代理不会为该属性提供任何其他行为,
但自定义元素作者应尽可能利用该属性的存在,以某种适当方式使其控件
不可编辑,类似于内置表单控件上 readonly
属性的行为。
约束验证:如果在表单关联
自定义元素上指定了 readonly
属性,则该元素被禁止进行约束验证。
表单关联自定义元素的重置
算法是:使用该元素、回调名称“formResetCallback”和 «
» 来将
自定义元素回调反应加入队列。
如果以下所有条件均为 true,则字符串 name 是有效的自定义元素名称:
name 是有效的元素本地名称;
这可以确保使用 createElement()
创建自定义元素。
name 的第 0 个码点是一个 ASCII 小写字母;
这可以确保 HTML 解析器将该名称视为标签名称,而不是 文本。
name 不包含任何 ASCII 大写 字母;
这可以确保用户代理始终能够以 ASCII 不区分大小写的方式处理 HTML 元素。
name 包含一个 U+002D (-);并且
这用于命名空间划分并确保向前兼容性(因为今后 不会向 HTML、SVG 或 MathML 添加本地名称中包含连字符的 元素)。
name 不是以下任何一个:
annotation-xml”color-profile”font-face”font-face-src”font-face-uri”font-face-format”font-face-name”missing-glyph”上述名称列表汇总了所有来自适用规范(即 SVG 2 和 MathML)的、包含连字符的元素名称。[SVG] [MATHML]
除这些限制之外,还允许使用各种各样的名称,以便为
<math-α> 或 <emotion-😍> 等用例提供最大的灵活性。
自定义元素定义描述一个自定义元素,并 由以下内容组成:
CustomElementConstructor
回调函数类型值,它封装
自定义
元素构造函数
sequence<DOMString>connectedCallback”、“disconnectedCallback”、
“connectedMoveCallback”、“adoptedCallback”、“attributeChangedCallback”、
“formAssociatedCallback”、“formDisabledCallback”、“formResetCallback”和
“formStateRestoreCallback”。对应的值可以是 Web IDL Function
回调
函数类型值,也可以是 null。默认情况下,每个条目的值都是 null。attachInternals()。
attachShadow()。
要在给定 null 或 CustomElementRegistry
对象 registry、字符串或 null
namespace、字符串 localName 和字符串或 null is 的情况下,查找自定义元素定义,请执行
以下步骤。这些步骤将返回一个自定义元素定义或 null:
CustomElementRegistry
接口所有当前引擎均支持。
每个相似源
窗口代理都有一个关联的活动自定义元素构造函数映射,
它是一个从构造函数到 CustomElementRegistry
对象的映射。
所有当前引擎均支持。
Window 的 customElements 获取器步骤如下:
断言:this 的关联的
Document的自定义元素
注册表是一个 CustomElementRegistry
对象。
Window 的关联的
Document始终使用一个新的
CustomElementRegistry
对象创建。
返回 this 的关联的
Document的自定义元素
注册表。
[Exposed =Window ]
interface CustomElementRegistry {
constructor ();
[CEReactions ] undefined define (DOMString name , CustomElementConstructor constructor , optional ElementDefinitionOptions options = {});
(CustomElementConstructor or undefined ) get (DOMString name );
DOMString ? getName (CustomElementConstructor constructor );
Promise <CustomElementConstructor > whenDefined (DOMString name );
[CEReactions ] undefined upgrade (Node root );
[CEReactions ] undefined initialize (Node root );
};
callback CustomElementConstructor = HTMLElement ();
dictionary ElementDefinitionOptions {
DOMString extends ;
};每个 CustomElementRegistry
都有一个是否限定
作用域布尔值,其初始值为 false。
每个 CustomElementRegistry
都有一个限定作用域的
文档集,它是一个由 Document
对象组成的集合,初始为 « »。
每个 CustomElementRegistry
都有一个自定义元素定义集,它是一个由
自定义元素
定义组成的集合,
初始为 « »。在此集合中查找条目时,会使用其名称、本地名称或构造函数。
每个 CustomElementRegistry
还都有一个元素定义正在运行
布尔值,用于防止元素定义的可重入调用。其
初始值为 false。
每个 CustomElementRegistry
还都有一个定义时 promise 映射,它是一个从有效自定义
元素名称到 promise 的映射。它用于实现 whenDefined()
方法。
要在给定一个 Node
对象
node 的情况下,查找自定义元素注册表:
registry = window.customElements
Document 的 CustomElementRegistry
对象。registry = new CustomElementRegistry()
CustomElementRegistry
对象,以供限定作用域使用。registry.define(name,
constructor)
所有当前引擎均支持。
registry.define(name, constructor,
{ extends: baseLocalName })CustomElementRegistry
对象时,将抛出 “NotSupportedError”
DOMException。
registry.get(name)
所有当前引擎均支持。
registry.getName(constructor)
registry.whenDefined(name)
CustomElementRegistry/whenDefined
所有当前引擎均支持。
SyntaxError” DOMException
拒绝的 promise。registry.upgrade(root)
所有当前引擎均支持。
registry.initialize(root)
CustomElementRegistry
对象。如果此
CustomElementRegistry
对象不是用于限定作用域,且 root 是一个
Document 节点,或者
root 的节点文档的自定义元素注册表不是此
CustomElementRegistry
对象,则将抛出 “NotSupportedError” DOMException。
元素定义是将一个自定义元素定义
添加到 CustomElementRegistry
的过程。此过程通过 define()
方法完成。
define(name, constructor,
options) 方法的步骤如下:
如果 IsConstructor(constructor) 为 false,则抛出一个
TypeError。
如果 name 不是有效的自定义元素名称,则抛出一个
“SyntaxError” DOMException。
如果 this 的自定义元素定义集包含一个名称为 name 的条目,则抛出一个
“NotSupportedError” DOMException。
如果 this 的自定义元素定义集包含一个构造函数为
constructor 的条目,
则抛出一个 “NotSupportedError” DOMException。
令 localName 为 name。
如果 extends 不为 null:
如果 this 的是否
限定作用域为 true,则抛出一个
“NotSupportedError” DOMException。
如果 extends 是一个有效的自定义元素名称,则抛出一个
“NotSupportedError” DOMException。
如果 extends 和 HTML
命名空间对应的元素接口是 HTMLUnknownElement
(例如,如果 extends 未
指示本规范中的元素定义),则抛出一个
“NotSupportedError” DOMException。
将 localName 设置为 extends。
如果 this 的元素定义正在运行为 true,则抛出
一个 “NotSupportedError” DOMException。
令 formAssociated 为 false。
令 disableInternals 为 false。
令 disableShadow 为 false。
令 observedAttributes 为一个空的 sequence<DOMString>。
在捕获任何异常的同时运行以下步骤:
令 prototype 为 ? Get(constructor, "prototype")。
令 lifecycleCallbacks 为有序映射 «[
"connectedCallback" → null, "disconnectedCallback" →
null, "connectedMoveCallback" → null, "adoptedCallback" → null,
"attributeChangedCallback" →
null ]»。
对于 lifecycleCallbacks 的键中的每个 callbackName:
如果 lifecycleCallbacks["attributeChangedCallback"] 不为
null:
令 disabledFeatures 为一个空的 sequence<DOMString>。
令 disabledFeaturesIterable 为 ? Get(constructor, "disabledFeatures")。
如果 disabledFeaturesIterable 不是 undefined,则将
disabledFeatures 设置为把 disabledFeaturesIterable 转换为
sequence<DOMString> 的结果。重新抛出转换过程中产生的任何异常。
如果 disabledFeatures 包含
"internals",则将 disableInternals 设置为 true。
如果 disabledFeatures 包含
"shadow",则将 disableShadow 设置为 true。
令 formAssociatedValue 为 ? Get( constructor, "formAssociated")。
将 formAssociated 设置为把
formAssociatedValue 转换为
boolean 的结果。
如果 formAssociated 为 true,则对于 «
"formAssociatedCallback", "formResetCallback",
"formDisabledCallback", "formStateRestoreCallback"
» 中的每个 callbackName:
然后,无论上述步骤是否抛出异常:都将 this 的元素定义正在运行设置为 false。
最后,如果这些步骤抛出了异常,则重新抛出该异常。
令 definition 为一个新的自定义元素定义,其名称为 name,本地名称为 localName, 构造函数为 constructor,被观察属性为 observedAttributes,生命周期回调为 lifecycleCallbacks, 表单关联为 formAssociated,禁用内部结构为 disableInternals,且禁用 shadow为 disableShadow。
如果 this 的是否限定作用域为 true,则对于 this 的限定作用域的文档集中的每个 document:使用 this、document、definition 和 localName,升级文档中的特定元素。
否则,使用
this、this 的相关全局
对象的关联的
Document、
definition、
localName 和 name,升级文档中的特定元素。
如果 this 的定义时 promise 映射[name] 存在:
使用 constructor 兑现 this 的定义时 promise 映射[name]。
从 this 的定义时 promise 映射中移除[name]。
要在给定一个
CustomElementRegistry
对象 registry、一个 Document 对象
document、一个自定义元素定义 definition、一个字符串
localName 以及可选字符串 name(默认为 localName)的情况下,升级文档中的特定元素:
令 upgradeCandidates 为 document 的所有包含
shadow 的后代元素,这些元素的自定义元素注册表为 registry,
命名空间为 HTML 命名空间,
且本地名称为 localName,
并按包含 shadow 的树顺序排列。此外,如果
name 不是
localName,则只包含其is
值等于 name 的元素。
对于 upgradeCandidates 中的每个元素 element:使用 element 和 definition,将自定义元素升级反应加入队列。
whenDefined(name) 方法的
步骤如下:
如果 name 不是有效的自定义元素名称,则返回一个以 “SyntaxError”
DOMException
拒绝的 promise。
如果 this 的自定义元素定义集包含一个名称为 name 的条目,则返回一个以该条目的构造函数兑现的 promise。
如果 this 的定义时 promise 映射[name] 不存在,则将 this 的定义时 promise 映射[name] 设置为一个新的 promise。
返回 this 的定义时 promise 映射[name]。
whenDefined()
方法可用于
避免在所有适当的自定义
元素都被定义之前执行操作。在此
示例中,我们
将它与 :defined 伪类结合使用,以隐藏
动态加载文章的内容,直到确定该文章使用的所有自主自定义元素均已定义。
articleContainer. hidden = true ;
fetch( articleURL)
. then( response => response. text())
. then( text => {
articleContainer. innerHTML = text;
return Promise. all(
[... articleContainer. querySelectorAll( ":not(:defined)" )]
. map( el => customElements. whenDefined( el. localName))
);
})
. then(() => {
articleContainer. hidden = false ;
}); upgrade(root) 方法的步骤
如下:
对于 root 的每个包含 shadow 的含自身后代 candidate,按包含 shadow 的树顺序:
upgrade()
方法允许根据需要升级
元素。通常,元素在变为已连接时会自动升级,但如果需要在准备
连接元素之前进行升级,则可以使用此方法。
const el = document. createElement( "spider-man" );
class SpiderMan extends HTMLElement {}
customElements. define( "spider-man" , SpiderMan);
console. assert( ! ( el instanceof SpiderMan)); // 尚未升级
customElements. upgrade( el);
console. assert( el instanceof SpiderMan); // 已升级! initialize(root) 方法的
步骤如下:
一旦节点的自定义元素注册表被初始化为一个
CustomElementRegistry
对象,就会有意禁止进一步更改它。这样可以
简化对代码的推理,并允许实现进行优化。
要在给定一个自定义元素定义 definition 和一个元素 element 作为输入的情况下,升级元素,请运行以下步骤:
如果 element 的自定义元素状态不是“undefined”或
“uncustomized”,则返回。
可能发生这种情况的一种场景是此算法的可重入调用,如以下示例所示:
<!DOCTYPE html>
< x-foo id = "a" ></ x-foo >
< x-foo id = "b" ></ x-foo >
< script >
// 定义会为“a”和“b”都将升级反应加入队列
customElements. define( "x-foo" , class extends HTMLElement {
constructor() {
super ();
const b = document. querySelector( "#b" );
b. remove();
// 当此构造函数正在为“a”运行时,“b”仍然是
// 未定义的,因此将其插入文档会为“b”将第二个
// 升级反应加入队列,此外还有定义 x-foo 时加入
// 队列的那个升级反应。
document. body. appendChild( b);
}
})
</ script > 因此,当第二次使用“b”调用升级元素时,此步骤会提前退出该算法。
将 element 的自定义 元素定义设置为 definition。
将 element 的自定义元素状态设置为“failed”。
它将在升级成功后设置为
“custom”。目前,我们将其设置为“failed”,以便任何可重入调用都会进入上述提前退出步骤。
对于 element 的属性
列表中的每个 attribute,按顺序使用
element、回调名称“attributeChangedCallback”和 «
attribute 的本地名称、null、attribute 的值、attribute 的命名空间
»,将自定义元素回调反应加入队列。
如果 element 已连接,则使用 element、回调名称
“connectedCallback”和 « »,将自定义元素
回调反应加入队列。
将 element 添加到 definition 的构造栈末尾。
令 C 为 definition 的构造函数。
令 previousRegistry 为周围 代理的活动自定义 元素构造函数映射[C],默认值为 null。
将周围代理的活动自定义 元素构造函数映射[C] 设置为 element 的自定义 元素注册表。
运行以下步骤,同时捕获任何异常:
如果 definition 的禁用影子为 true,并且
element 的影子根
为
非 null,则抛出一个 "NotSupportedError"
DOMException。
这是必需的,因为 attachShadow()
不会使用查找自定义
元素定义,而 attachInternals()
会使用。
将 element 的自定义元素状态设置为 "precustomized"。
令 constructResult 为不带参数构造 C 的结果。
如果 C 不符合规范地
使用了以 [CEReactions] 扩展
属性修饰的 API,则在此算法开始时排入的反应将在
此步骤期间执行,即在 C 完成且控制权返回此算法之前执行。否则,它们
将在 C 和升级过程的其余部分完成后执行。
如果 SameValue(constructResult, element) 为 false,则
抛出一个 TypeError。
如果 C 在调用 super() 之前构造了同一自定义
元素的另一个实例,或者 C 使用 JavaScript 的
return 覆盖功能从构造函数返回任意 HTMLElement
对象,则可能发生这种情况。
然后,无论上述步骤是否抛出异常,都执行以下步骤:
如果 previousRegistry 为 null,则从 周围代理的活动自定义元素构造函数 映射[C] 中移除该项。
否则,将周围 代理的 活动自定义元素构造函数 映射[C] 设置为 previousRegistry。
从 definition 的构造堆栈末尾移除最后一个条目。
假设 C 调用了 super()(如果它符合规范,它就会这样做),并且调用成功,那么这将是
在此算法开始时替换我们所推入的 element 的已
构造标记。(HTML 元素构造函数
执行此替换。)
如果 C 未调用 super()(即它不符合规范),或者HTML 元素构造函数中的任何步骤抛出异常,那么此条目
仍将是 element。
最后,如果上述步骤抛出异常:
如果上述步骤抛出异常,则 element 的自定义
元素状态将保持为 "failed" 或 "precustomized"。
如果 element 是一个表单关联自定义元素:
重置
element 的表单所有者。如果 element
与一个 form
元素关联,则
使用 element、回调
名称 "formAssociatedCallback",以及 « 关联的 form
»,排入一个自定义元素回调
反应。
如果 element 已禁用,
则
使用 element、回调名称
"formDisabledCallback",以及 « true »,排入一个自定义元素回调
反应。
将 element 的自定义
元素状态设置为 "custom"。
要在给定元素 element 的情况下,尝试升级元素:
自定义元素能够通过 运行作者代码来响应某些事件:
当它变为已连接时,会不带参数调用其
connectedCallback。
当它变为
已断开连接时,会不带参数调用其 disconnectedCallback。
当它被移动时,会不带参数调用其
connectedMoveCallback。
当它被收养到新文档中时,会调用其
adoptedCallback,并将旧文档和新文档作为参数。
当其任何属性被更改、追加、移除或替换时,会调用其
attributeChangedCallback,并将属性的本地名称、旧值、
新值和命名空间作为参数。(当属性分别被添加或移除时,属性的旧值或新值被视为 null。)
当用户代理重置
表单所有者时,该表单所有者属于一个
表单关联自定义元素,并且这样做
更改了表单所有者,则会调用其 formAssociatedCallback,并将新的表单所有者(如果
没有所有者,则为 null)
作为参数传入。
当用户代理代表用户更新表单关联自定义元素的值,或者作为导航的一部分更新该值时,会调用其
formStateRestoreCallback,并将新状态和表示原因的字符串
“autocomplete”或“restore”作为参数。
我们将这些反应统称为自定义 元素反应。
调用自定义元素反应的方式经过特别谨慎的设计, 以避免在敏感操作的中途运行作者代码。实际上,它们会延迟到“即将返回用户脚本之前”。 这意味着在大多数情况下,它们看起来是同步执行的,但对于复杂的 复合操作(例如克隆或范围操作),它们会延迟到所有 相关的用户代理处理步骤完成之后,然后作为一个批次一起运行。
此外,这些反应的精确顺序通过下文所述的一套 较为复杂的队列栈系统进行管理。该系统旨在 保证自定义元素反应始终按照 触发它们的操作相同的顺序调用,至少在单个自定义 元素的局部上下文中如此。(由于自定义元素 反应代码可以执行其自身的变更,因此无法对多个元素提供全局顺序 保证。)
每个相似源窗口代理都有一个自定义元素反应栈, 其初始为空。一个相似源窗口代理的当前元素 队列是其自定义元素反应 栈顶部的元素队列。栈中的每个条目都是一个 元素队列,其初始也为空。元素队列中的每个条目都是一个元素。(这些元素不一定已经是 自定义的,因为此队列也用于升级。)
每个自定义元素反应栈都有一个关联的备用元素
队列,它是一个初始为空的元素队列。在执行会影响
DOM、但不经过带有
[CEReactions]
的 API,也不经过解析器的为令牌创建
元素算法的操作期间,元素会被推入备用元素队列。一个示例是用户发起的
编辑操作,该操作修改了可编辑
元素的后代或属性。为了在处理备用元素队列时防止可重入,每个
自定义
元素反应栈还有一个正在处理备用元素
队列标志,其初始未设置。
所有元素都有一个关联的自定义元素反应队列, 其初始为空。自定义元素反应队列中的每个 条目属于以下两种类型之一:
所有这些内容汇总在以下示意图中:

要在给定元素 element 的情况下,将元素加入适当的元素 队列,请运行以下步骤:
如果 reactionsStack 为空:
将 element 添加到 reactionsStack 的备用元素 队列。
如果 reactionsStack 的正在处理备用元素 队列标志已设置,则返回。
设置 reactionsStack 的正在处理备用元素 队列标志。
将一个微任务加入队列,以执行以下步骤:
取消设置 reactionsStack 的正在处理备用元素 队列标志。
要在给定一个自定义 元素 element、回调名称 callbackName 和参数列表 args 的情况下,将自定义元素回调 反应加入队列,请运行以下步骤:
令 definition 为 element 的自定义元素定义。
令 callback 为 definition 的生命周期回调中 键为 callbackName 的条目值。
如果 callbackName 为“connectedMoveCallback”且
callback 为 null:
令 disconnectedCallback 为 definition 的生命周期
回调中键为“disconnectedCallback”的条目值。
令 connectedCallback 为 definition 的生命周期
回调中键为“connectedCallback”的条目值。
如果 connectedCallback 和 disconnectedCallback 均为 null,则 返回。
将 callback 设置为以下步骤:
如果 disconnectedCallback 不为 null,则不带参数调用 disconnectedCallback。
如果 connectedCallback 不为 null,则不带参数调用 connectedCallback。
如果 callback 为 null,则返回。
如果 callbackName 为“attributeChangedCallback”:
令 attributeName 为 args 的第一个元素。
如果 definition 的被观察 属性不包含 attributeName,则返回。
向 element 的自定义元素 反应队列添加一个新的回调反应,其回调函数为 callback,参数为 args。
使用 element,将元素加入 适当的元素队列。
要在给定元素 element 和自定义元素定义 definition 的情况下,将自定义元素升级 反应加入队列,请运行以下步骤:
向 element 的自定义元素 反应队列添加一个新的升级反应,其自定义元素定义为 definition。
使用 element,将元素加入 适当的元素队列。
要在一个元素队列 queue 中调用自定义元素反应,请运行以下步骤:
当 queue 不为空时:
令 element 为从 queue 中出队的结果。
令 reactions 为 element 的自定义元素反应 队列。
重复执行,直到 reactions 为空:
为了确保自定义元素反应得到
适当触发,我们引入了 [CEReactions] IDL 扩展
属性。它表示需要为相关算法补充额外步骤,以便
正确跟踪并调用自定义元素
反应。
[CEReactions] 扩展
属性不得接受任何参数,并且不得出现在操作、属性、设置器或删除器以外的任何位置。
此外,它不得出现在只读属性上。
带有 [CEReactions] 扩展属性的
操作、属性、设置器或删除器,必须运行以下步骤,以替代
其描述中指定的步骤:
此扩展属性背后的意图相当微妙。实现其 目标的一种方式,是规定平台上的每个操作、属性、设置器和删除器 都必须插入这些步骤,并允许实现者优化掉 不必要的情况(即不可能发生可能导致自定义元素反应的 DOM 变更的情况)。
然而在实践中,这种不精确性可能会导致自定义 元素反应的实现无法互操作,因为某些实现 可能会忘记在某些情况下调用这些步骤。因此,我们最终采用了 显式标注所有相关 IDL 构造的方式,以确保可互操作的行为, 并帮助实现轻松准确定位所有需要这些步骤的情况。
用户代理引入的任何非标准 API,如果可能以会导致将自定义元素
回调反应加入队列或将
自定义元素升级反应加入队列的方式修改 DOM,例如修改任何属性或子元素,
也必须带有 [CEReactions] 属性。
截至本文撰写时,已知以下非标准或尚未标准化的 API 属于此类别:
HTMLInputElement
的
webkitdirectory 和 incremental IDL 属性
HTMLLinkElement 的
scope IDL 属性
某些能力旨在提供给自定义元素作者,而不是自定义
元素使用者。这些能力由 element.attachInternals()
方法提供,该方法返回一个
ElementInternals 实例。
ElementInternals 的属性和方法允许
控制用户代理向所有元素提供的内部功能。
element.attachInternals()
返回一个以自定义元素
element 为目标的 ElementInternals 对象。如果
element 不是自定义
元素,元素定义中禁用了“internals”功能,或者在同一元素上调用了两次,则抛出异常。
每个 HTMLElement 都有一个
已附加内部结构(null 或一个
ElementInternals 对象),
初始为 null。
所有当前引擎均支持。
attachInternals() 方法的步骤如下:
如果 this
的is
值不为 null,则抛出一个 “NotSupportedError”
DOMException。
令 definition 为在给定 this 的自定义元素注册表、this 的命名空间、this 的本地 名称和 null 的情况下,查找自定义元素定义的结果。
如果 definition 为 null,则抛出一个
“NotSupportedError” DOMException。
如果 definition 的禁用内部结构为 true,
则抛出一个 “NotSupportedError” DOMException。
如果 this 的已附加内部结构不为 null,则抛出一个
“NotSupportedError” DOMException。
如果 this 的自定义元素状态不是“precustomized”或
“custom”,则抛出一个
“NotSupportedError” DOMException。
将 this 的已附加内部结构设置为一个新的
ElementInternals
实例,其目标
元素为 this。
ElementInternals
接口所有当前引擎均支持。
ElementInternals
接口的 IDL 如下,其中各种操作和属性
在以下各节中定义:
[Exposed =Window ]
interface ElementInternals {
// Shadow 根访问
readonly attribute ShadowRoot shadowRoot ;
// 表单关联自定义元素
undefined setFormValue ((File or USVString or FormData )? value ,
optional (File or USVString or FormData )? state );
readonly attribute HTMLFormElement ? form ;
undefined setValidity (optional ValidityStateFlags flags = {},
optional DOMString message ,
optional HTMLElement anchor );
readonly attribute boolean willValidate ;
readonly attribute ValidityState validity ;
readonly attribute DOMString validationMessage ;
boolean checkValidity ();
boolean reportValidity ();
readonly attribute NodeList labels ;
// 自定义状态伪类
[SameObject ] readonly attribute CustomStateSet states ;
};
// 无障碍语义
ElementInternals includes ARIAMixin ;
dictionary ValidityStateFlags {
boolean valueMissing = false ;
boolean typeMismatch = false ;
boolean patternMismatch = false ;
boolean tooLong = false ;
boolean tooShort = false ;
boolean rangeUnderflow = false ;
boolean rangeOverflow = false ;
boolean stepMismatch = false ;
boolean badInput = false ;
boolean customError = false ;
};每个 ElementInternals
都有
一个目标元素,
它是一个自定义元素。
internals.shadowRoot
如果 internals 的目标
元素是一个shadow 宿主,则返回该目标
元素的 ShadowRoot;
否则返回 null。
所有当前引擎均支持。
shadowRoot 获取器步骤如下:
internals.setFormValue(value)
将 internals 的目标元素的状态和提交值都设置为 value。
如果 value 为 null,则该元素不会参与表单提交。
internals.setFormValue(value,
state)将 internals 的目标元素的提交值设置为 value,并将其状态设置为 state。
如果 value 为 null,则该元素不会参与表单提交。
internals.form
internals.setValidity(flags,
message [, anchor ])将 internals 的目标元素标记为
存在由 flags 参数指示的约束问题,并将元素的
验证消息设置为 message。如果指定了 anchor,则当以交互方式验证表单所有者,或者调用 reportValidity()
时,用户代理可以使用它来指出 internals 的目标元素的约束问题。
internals.setValidity({})
internals.willValidate
如果提交表单时会验证 internals 的目标 元素,则返回 true;否则返回 false。
internals.validity
返回 internals 的目标元素的 ValidityState 对象。
internals.validationMessage
返回在检查 internals 的目标元素的有效性时会向用户显示的错误消息。
valid = internals.checkValidity()
如果 internals 的目标
元素没有有效性问题,则返回 true;否则返回 false。在后一种情况下,会在该元素上触发一个
invalid 事件。
valid = internals.reportValidity()
如果 internals 的目标
元素没有有效性问题,则返回 true;否则返回 false,在该元素上触发一个
invalid 事件,
并且(如果该事件未被取消)
向用户报告问题。
internals.labels
每个表单关联自定义元素都有一个提交值。它用于在表单提交时提供一个或多个
条目。
提交值的初始值为 null,并且
提交值
可以是 null、字符串、一个
File,
或者一个由条目组成的列表。
每个表单关联自定义元素都有一个状态。
它是用户代理可用来恢复用户对该元素输入的信息。
状态的初始值为 null,并且
状态可以是 null、字符串、一个
File,
或者一个由条目组成的列表。
setFormValue()
方法由
自定义元素作者用于设置元素的提交
值和状态,从而将这些信息传达给用户
代理。
当用户代理认为恢复表单关联自定义
元素的状态是一个好主意时,例如导航之后或重新启动用户代理之后,它可以使用该元素、回调名称
“formStateRestoreCallback”和 « 要恢复的状态,“restore” »,将自定义元素回调反应加入队列。
如果用户代理具有表单填充辅助功能,那么在调用该功能时,它可以使用一个表单关联自定义
元素、回调名称“formStateRestoreCallback”和 « 根据状态值历史记录和某些启发式方法确定的状态
值,“autocomplete” »,将自定义元素
回调反应加入队列。
通常,状态是用户指定的信息,而 提交 值是经过规范化 或净化后的值,适合提交给服务器。以下示例对此进行了具体说明:
假设我们有一个要求
用户指定日期的表单关联自定义元素。用户指定
“3/15/2019”,但控件希望向服务器
提交 “2019-03-15”。“3/15/2019” 将是该元素的状态,而 “2019-03-15” 将是一个提交
值。
假设你开发了一个模拟现有
复选框 input 类型行为的自定义元素。
其提交值
将是其 value 内容属性的值,或者字符串 “on”。其状态将是
“checked”、“unchecked”、“checked/indeterminate” 或
“unchecked/indeterminate” 之一。
所有当前引擎均支持。
setFormValue(value,
state) 方法的步骤如下:
每个表单关联自定义元素都有名为
valueMissing、typeMismatch、
patternMismatch、tooLong、
tooShort、rangeUnderflow、
rangeOverflow、stepMismatch 和
customError 的有效性标志。它们的初始值为 false。
每个表单关联自定义元素都有一个 验证消息字符串。其初始为空字符串。
每个表单关联自定义元素都有一个 验证锚点元素。其初始为 null。
所有当前引擎均支持。
setValidity(flags, message,
anchor) 方法的步骤如下:
如果 element 不是表单关联自定义元素,
则抛出一个
“NotSupportedError” DOMException。
如果 flags 包含一个或多个 true 值,并且未给出
message 或者其为空字符串,则抛出一个 TypeError。
对于 flags 的每个条目 flag → value,将 element 中名称为 flag 的有效性标志设置为 value。
如果未给出 message,或者 element 的所有有效性 标志均为 false,则将 element 的验证消息 设置为空字符串;否则设置为 message。
如果 element 的 customError 有效性标志为 true,则将
element 的自定义有效性错误消息设置为
element 的
验证
消息。否则,将
element 的自定义有效性错误消息设置为
空字符串。
如果未给出 anchor,则将其设置为 element。
否则,如果 anchor 不是 element 的包含 shadow 的含自身
后代,则抛出一个 “NotFoundError”
DOMException。
将 element 的验证锚点设置为 anchor。
ElementInternals/validationMessage
所有当前引擎均支持。
validationMessage 获取器步骤
如下:
如果 element 不是表单关联自定义元素,
则抛出一个
“NotSupportedError” DOMException。
返回 element 的验证 消息。
internals.role [ = value ]
设置或检索 internals 的目标元素的默认 ARIA 角色,除非页面作者使用 role 属性覆盖该角色,否则将使用该角色。
internals.aria* [ = value ]
设置或检索
internals 的目标
元素的各种默认 ARIA 状态或属性值,除非页面作者使用 aria-*
属性覆盖它们,否则将使用这些值。
每个自定义元素都有一个内部内容属性映射,它是一个初始为空的 映射。有关这如何影响平台无障碍 API 的信息,请参阅与 ARIA 和平台无障碍 API 相关的要求一节。
internals.states.add(value)
将字符串 value 添加到元素的状态集中,以作为伪类公开。
internals.states.has(value)
如果 value 位于元素的状态集中,则返回 true;否则 返回 false。
internals.states.delete(value)
如果元素的状态集中包含 value,则将其移除并 返回 true。否则,返回 false。
internals.states.clear()
从元素的状态 集中移除所有值。
for (const stateName of internals.states)
for (const stateName of internals.states.entries())
for (const stateName of internals.states.keys())
for (const stateName of internals.states.values())
迭代元素的状态集中的所有值。
internals.states.forEach(callback)
通过对每个值调用一次 callback,迭代元素的状态集中的所有值。
internals.states.size
返回元素的状态集中的值的数量。
每个自定义元素都有一个状态集,它是一个初始为空的
CustomStateSet。
[Exposed =Window ]
interface CustomStateSet {
setlike <DOMString >;
};状态集可以公开由字符串值是否存在
表示的布尔状态。如果作者想公开一个可以有三个值的状态,则可以将其
转换为三个互斥的布尔状态。例如,一个名为 readyState、具有
"loading"、"interactive" 和 "complete" 值的状态可以映射为
三个互斥的布尔状态:"loading"、"interactive" 和 "complete":
// 将 readyState 从任意值更改为 "complete"。
this . _readyState = "complete" ;
this . _internals. states. delete ( "loading" );
this . _internals. states. delete ( "interactive" );
this . _internals. states. add( "complete" ); 本规范没有提供描述面包屑导航
菜单的机器可读方式。建议作者只在段落中使用一系列链接。可以使用 nav
元素将包含这些段落的节标记为导航
块。
在以下示例中,可以通过两条路径到达当前页面。
< nav >
< p >
< a href = "/" > 主页</ a > ▸
< a href = "/products/" > 产品</ a > ▸
< a href = "/products/dishwashers/" > 洗碗机</ a > ▸
< a > 二手</ a >
</ p >
< p >
< a href = "/" > 主页</ a > ▸
< a href = "/second-hand/" > 二手</ a > ▸
< a > 洗碗机</ a >
</ p >
</ nav > 本规范没有定义任何专门用于标记适用于一组页面的关键字列表
(也称为标签云)的标记。通常,建议作者使用 ul
元素标记此类列表,并添加明确的内联
计数,然后使用样式表将这些计数隐藏并转换为表现效果,或者使用
SVG。
这里,在一个简短的标签云中包含三个标签:
< style >
. tag-cloud > li > span { display : none ; }
. tag-cloud > li { display : inline ; }
. tag-cloud-1 { font-size : 0.7 em ; }
. tag-cloud-2 { font-size : 0.9 em ; }
. tag-cloud-3 { font-size : 1.1 em ; }
. tag-cloud-4 { font-size : 1.3 em ; }
. tag-cloud-5 { font-size : 1.5 em ; }
@ media speech {
. tag-cloud > li > span { display : inline }
}
</ style >
...
< ul class = "tag-cloud" >
< li class = "tag-cloud-4" >< a title = "28 个实例" href = "/t/apple" > 苹果</ a > < span > (热门)</ span >
< li class = "tag-cloud-2" >< a title = "6 个实例" href = "/t/kiwi" > 猕猴桃</ a > < span > (少见)</ span >
< li class = "tag-cloud-5" >< a title = "41 个实例" href = "/t/pear" > 梨</ a > < span > (非常热门)</ span >
</ ul > 每个标签的实际出现频率使用 title
属性给出。提供了 CSS 样式表,以将标记转换为由不同大小的
单词组成的云;但对于不支持 CSS 或非视觉的用户代理,标记中包含
“(热门)”或“(少见)”之类的注释,以按频率对各种标签进行分类,从而
使所有用户都能从这些信息中受益。
使用 ul 元素(而不是
ol)是因为顺序并非
特别重要:虽然该列表实际上按字母顺序排列,但如果按标签长度等方式排序,也会传达
相同的信息。
这些 a 元素上没有使用
tag rel 关键字,
因为它们不表示适用于页面本身的标签;它们只是列出标签本身的索引的一部分。
本规范没有定义用于标记对话、会议 记录、聊天记录、剧本中的对白、即时消息日志以及其他由不同参与者轮流发言的情形的 特定元素。
相反,建议作者使用 p 元素和
标点符号标记对话。需要为样式目的标记发言者的作者,建议使用
span 或 b。文本包含在
i
元素中的段落可用于标记舞台指示。
此示例使用阿博特和科斯特洛著名短剧 谁在一垒中的一段内容进行演示:
< p > 科斯特洛:听着,你们有一垒手吗?
< p > 阿博特:当然有。
< p > 科斯特洛:谁守一垒?
< p > 阿博特:没错。
< p > 科斯特洛变得恼火。
< p > 科斯特洛:你每个月给一垒手发薪水时,谁拿到钱?
< p > 阿博特:每一美元都给他。以下摘录展示了如何标记即时消息对话日志,其中使用
data 元素为每一行提供 Unix
时间戳。请注意,这些时间戳采用 time
元素不支持的格式,因此改用
data 元素
(即 Unix time_t 时间戳)。
如果作者希望使用 time
元素支持的某种日期和时间格式标记数据,则可以使用该元素
代替 data。这
可能更有利,因为它允许数据分析工具明确检测时间戳,
而无需与页面作者协调。
< p > < data value = "1319898155" > 14:22</ data > < b > egof</ b > 我没那么宅,《星际迷航》的剧集我只看了 30%
< p > < data value = "1319898192" > 14:23</ data > < b > kaj</ b > 如果你知道自己看过《星际迷航》剧集的百分比,那你毫无疑问就是个宅
< p > < data value = "1319898200" > 14:23</ data > < b > egof</ b > 是“毫无争议”
< p > < data value = "1319898228" > 14:23</ data > < i > * kaj 眨了眨眼</ i >
< p > < data value = "1319898260" > 14:24</ data > < b > kaj</ b > 你这样可没法证明自己HTML 没有很好地标记图的方式,因此游戏中交互式对话的描述
更难标记。此示例展示了一种可能的约定,即使用
dl 元素列出对话中每个节点的可能
回应。
另一个可考虑的选项是以 DOT 文件的形式描述对话,并
将结果输出为 SVG 图像放入文档中。[DOT]
< p > 接下来,你遇到一名渔妇。你可以说以下几种问候语之一:
< dl >
< dt > “你好!”
< dd >
< p > 她回答:“你好,我能帮你什么?”;你可以回答:
< dl >
< dt > “我想买一条鱼。”
< dd > < p > 她卖给你一条鱼,对话结束。
< dt > “我能借你的船吗?”
< dd >
< p > 她很惊讶,并问:“你拿什么作为回报?”
< dl >
< dt > “五枚金币。”(如果你有足够的金币)
< dt > “十枚金币。”(如果你有足够的金币)
< dt > “十五枚金币。”(如果你有足够的金币)
< dd > < p > 她把船借给你。对话结束。
< dt > “一条鱼。”(如果你有一条)
< dt > “一份报纸。”(如果你有一份)
< dt > “一块鹅卵石。”(如果你有一块)
< dd > < p > “不了,谢谢。”她回答。此时你的对话选项
与询问借她的船之后的选项相同,但不包括你之前
已经提议过的选项。
</ dl >
</ dd >
</ dl >
</ dd >
< dt > “下次选举请投我一票!”
< dd > < p > 她转过身去。对话结束。
< dt > “女士,你知道你的鱼正在逃跑吗?”
< dd >
< p > 她怀疑地看着你,说:“鱼不会跑,小姐。”
< dl >
< dt > “被你识破了!”
< dd > < p > 渔妇叹了口气,对话结束。
< dt > “只是开个玩笑。”
< dd > < p > “真有趣!”她反驳道。此时你的对话选项
与上面“你好!”之后的选项相同。
< dt > “哦,那它们在做什么?”
< dd > < p > 她看向自己的鱼,给了你偷走
她的船的机会,你也确实这样做了。对话结束。
</ dl >
</ dd >
</ dl > 在某些游戏中,对话更简单:每个角色只有一组固定的台词。 在此示例中,游戏常见问题解答或攻略列出了每个角色的一些已知可能回应:
< section >
< h1 > 对话</ h1 >
< p >< small > 有些角色每次互动时都会按顺序重复台词,
另一些则会从台词中随机选择。按顺序回应的角色
在下面的列表中使用编号条目。</ small >
< h2 > 店主</ h2 >
< ul >
< li > 我能帮您什么?
< li > 新鲜的苹果!
< li > 女士,要来一条面包吗?
</ ul >
< h2 > 飞行员</ h2 >
< p > 事故之前:
< ul >
< li > 我马上要起飞了,抱歉!
< li > 抱歉,我只是在等待飞行许可,然后就会出发!
</ ul >
< p > 事故之后:
< ol >
< li > 我马上要起飞了,抱歉!
< li > 好吧,我现在不会走,我的飞机正在清洁。
< li > 好吧,它不是在清洁,而是需要先进行小修。
< li > 好吧,好吧,别再烦我了!事实是,我坠机了。
</ ol >
< h2 > 氏族首领</ h2 >
< p > 第一次氏族会议期间:
< ul >
< li > 嘿,你见过我女儿吗?我敢打赌她又在策划什么坏事……
< li > 今天天气不错,对吧?
< li > 我叫贝利,杰夫·贝利。今天我能帮你什么?
< li > 要一杯水吗?刚从井里打上来的!
</ ul >
< p > 地震之后:
< ol >
< li > 所有人都在避难所里安然无恙,我们只需要把火扑灭!
< li > 我去通知消防队,你继续用水浇灭它!
</ ol >
</ section > HTML 没有用于标记脚注的专用机制。下面是建议的 替代方案。
对于简短的内联注释,可以使用 title 属性。
在此示例中,使用
title 属性为对话的两个部分添加类似脚注的内容。
< p > < b > 顾客</ b > :你好!我想投诉。你好。小姐?
< p > < b > 店主</ b > :< span title = "“What do you”的口语发音"
> 你说什么呢,小姐?</ span >
< p > < b > 顾客</ b > :呃,对不起,我感冒了。我想提出投诉。
< p > < b > 店主</ b > :抱歉,< span title = "当然,这是谎话。" > 我们
要关门吃午饭了</ span > 。遗憾的是,目前不建议依赖 title
属性,因为许多用户代理没有按照本规范的要求以无障碍方式公开该属性
(例如,需要使用鼠标等指向设备才能显示
工具提示,从而排除了仅使用键盘和仅使用触摸的用户,例如使用
现代手机或平板电脑的任何人)。
如果使用 title 属性,则可以使用 CSS
吸引读者注意具有该属性的元素。
例如,以下 CSS 会在具有 title 属性的元素下方绘制虚线。
[title] { border-bottom : thin dashed; } 对于较长的注释,应使用 a 元素,并指向文档中稍后的元素。
约定是链接内容为方括号中的数字。
在此示例中,对话中的脚注链接到对话下方的段落。该 段落随后反向链接回对话,使用户能够返回 脚注所在的位置。
< p > 报幕员:第 16 号:< i > 手</ i > 。
< p > 采访者:晚上好。今晚来到演播室的是
诺曼·圣约翰·撑杆先生,过去几年里他一直
反驳别人。撑杆先生,你为什么< em > 要</ em > 反驳别人?
< p > 诺曼:我没有。< sup >< a href = "#fn1" id = "r1" > [1]</ a ></ sup >
< p > 采访者:你告诉过我你有!
……
< section >
< p id = "fn1" >< a href = "#r1" > [1]</ a > 当然,这是谎话,
但矛盾的是,如果这是真的,他就无法在不
反驳采访者并因此使其变成假的情况下这样说。</ p >
</ section > 对于旁注,即适用于整个文本节而不仅仅是
特定单词或句子的较长注释,应使用 aside 元素。
在此示例中,对话之后给出了一个侧栏,为其提供一些上下文。
< p > < span class = "speaker" > 顾客</ span > :我不会买这张唱片,它有划痕。
< p > < span class = "speaker" > 店主</ span > :对不起?
< p > < span class = "speaker" > 顾客</ span > :我不会买这张唱片,它有划痕。
< p > < span class = "speaker" > 店主</ span > :不不不,这是一家烟草店。
< aside >
< p > 1970 年,大英帝国已成废墟,外国
民族主义者经常出没于街道——其中许多人是匈牙利人
(不是街道是匈牙利人,而是外国人)。遗憾的是,亚历山大·
亚尔特一直在出版写得很糟糕的短语手册。
</ aside > 对于图或表格,脚注可以包含在相关的 figcaption 或
caption 元素中,或者包含在
周围的正文中。
在此示例中,表格的单元格带有以正文形式给出的脚注。使用
figure 元素为表格和
其脚注的组合提供一个统一的说明。
< figure >
< figcaption > 表 1. 骑士的替代活动。</ figcaption >
< table >
< tr >
< th > 活动
< th > 地点
< th > 费用
< tr >
< td > 跳舞
< td > 任何可行的地方
< td > £0< sup >< a href = "#fn1" > 1</ a ></ sup >
< tr >
< td > 例行动作、合唱场景< sup >< a href = "#fn2" > 2</ a ></ sup >
< td > 未披露
< td > 未披露
< tr >
< td > 用餐< sup >< a href = "#fn3" > 3</ a ></ sup >
< td > 卡美洛
< td > 火腿、果酱和午餐肉的费用< sup >< a href = "#fn4" > 4</ a ></ sup >
</ table >
< p id = "fn1" > 1. 推定如此。</ p >
< p id = "fn2" > 2. 舞步无可挑剔。</ p >
< p id = "fn3" > 3. 品质被描述为“不错”。</ p >
< p id = "fn4" > 4. 很多。</ p >
</ figure > 如果一个元素属于以下情况之一,则称其实际上已禁用:
此定义用于确定哪些元素是可聚焦的,以及
哪些元素匹配 :enabled 和
:disabled 伪
类。
CSS 值和单位将为 'attr()' 函数确定属性名称大小写敏感性的工作交给宿主语言。 [CSSVALUES]
将 CSS 'attr()' 函数的属性名称部分与 HTML 文档中HTML 元素上无命名空间的属性名称进行比较时,必须先将 CSS 'attr()' 函数的名称 部分转换为 ASCII 小写形式。将同一函数与其他属性进行比较时,必须按照 其原始大小写进行比较。在这两种情况下,要匹配,这些值必须彼此相同 (因此比较区分大小写)。
这与比较下一节中指定的 CSS 属性 选择器的名称部分相同。
选择器将元素名称、属性名称和 属性值的大小写敏感性留给宿主语言定义。[SELECTORS]
将 CSS 元素类型选择器与 HTML 文档中HTML 元素的名称进行比较时,必须先将 CSS 元素类型选择器转换为 ASCII 小写形式。将同一选择器与其他 元素进行比较时,必须按照其原始大小写进行比较。在这两种情况下,要匹配,这些值必须 彼此相同(因此比较区分大小写)。
将 CSS 属性 选择器的名称部分与HTML 文档中HTML 元素上的属性名称进行比较时,必须先将 CSS 属性 选择器的名称部分转换为 ASCII 小写形式。将同一选择器与其他属性进行比较时,必须按照 其原始大小写进行比较。在这两种情况下,比较均区分大小写。
属性 选择器在HTML 文档中的HTML 元素上使用时,必须将具有以下名称的属性的值视为 ASCII 大小写不敏感:
accept
accept-charset
align
alink
axis
bgcolor
charset
checked
clear
codetype
color
compact
declare
defer
dir
direction
disabled
enctype
face
frame
hreflang
http-equiv
lang
language
link
media
method
multiple
nohref
noresize
noshade
nowrap
readonly
rel
rev
rules
scope
scrolling
selected
shape
target
text
type
valign
valuetype
vlink
例如,选择器 [bgcolor="#ffffff"] 将匹配任何
具有值包括 #ffffff、#FFFFFF 和
#fffFFF 的 bgcolor 属性的 HTML
元素。即使 bgcolor 对给定元素不起作用(例如
div),也会如此。
由于使用了 s 标志,选择器 [type=a s] 将匹配任何
type 属性值为 a 的 HTML 元素,但不会匹配其值为
A 的元素。
为了进行选择器匹配,所有其他属性值和其他所有内容都必须被视为彼此完全相同。这包括:
选择器规定,当 ID 和类选择器(例如 #foo 和
.bar)与处于怪异模式的文档中的元素匹配时,将以ASCII
大小写不敏感的
方式进行匹配。但是,这不适用于名称部分为“id”或
“class”的属性选择器。即使在
怪异模式中,选择器 [class="foobar"] 也会将其值视为
区分大小写。
有许多动态选择器可与 HTML 一起使用。本节定义 这些选择器何时匹配 HTML 元素。[SELECTORS] [CSSUI]
:defined
所有当前引擎均支持。
:link
所有当前引擎均支持。
:visited
所有当前引擎均支持。
所有具有 href
属性的 a 元素,以及所有具有
href 属性的 area
元素,都必须匹配 :link 和 :visited 之一。
其他规范可能会应用关于这些元素应如何 匹配这些伪类的更具体规则,以减轻 直接实现此要求所带来的一些隐私问题。
:active
所有当前引擎均支持。
:active 伪类被定义为匹配一个元素,当元素正被用户激活时
。
当用户使用处于“按下”状态的指向设备指示 元素时,称该元素正被主动指向(例如,对于 鼠标,是从按下鼠标按钮到释放鼠标按钮之间;对于 多点触控环境中的手指,是手指接触显示表面期间)。
根据选择器中的定义,:active 还会匹配正被激活的元素的扁平树祖先。
[SELECTORS]
此外,如果任何元素是当前匹配 :active 的
label
元素的被标记
控件,则它也匹配
:active。(但它不算作正被激活。)
:hover
所有当前引擎均支持。
:hover 伪类被定义为匹配一个元素,当用户使用指向
设备指示该元素时
。仅为了定义 :hover
伪类,如果用户使用指向设备指示一个元素,则 HTML 用户代理必须将该元素视为
用户指示的元素。
根据选择器中的定义,:hover 还会匹配被指示的元素的扁平树祖先。
[SELECTORS]
此外,如果任何元素是当前匹配 :hover 的 label
元素的被标记
控件,则它也匹配
:hover。(但它不算作正被指示。)
特别考虑以下片段:
< p > < label for = c > < input id = a > </ label > < span id = b > < input id = c > </ span > </ p > 如果用户使用指向
设备指示 ID 为“a”的元素,则 p
元素(以及
上述片段中未显示的所有祖先)、label
元素、ID 为“a”的元素以及
ID 为“c”的元素将匹配 :hover 伪类。ID 为“a”的元素通过被指示而匹配;label 和 p 元素由于
选择器中有关扁平树祖先的条件而匹配;ID 为“c”的元素则通过
上述有关被标记
控件的附加条件而匹配(即它的 label 元素匹配 :hover)。但是,ID 为
“b”的元素不匹配 :hover:其
扁平树后代并未被指示,即使该扁平树后代匹配 :hover。
:focus
所有当前引擎均支持。
:target
所有当前引擎均支持。
:popover-open
所有当前引擎均支持。
:popover-open
伪类被
定义为匹配任何满足以下条件的HTML 元素:其 popover 属性不处于无弹出框状态,且其弹出框可见性
状态为正在显示。
:enabled
所有当前引擎均支持。
:enabled 伪类必须匹配任何
未实际上已禁用的
button、input、select、textarea、
optgroup、option、fieldset 元素或
表单关联
自定义元素。
:disabled
所有当前引擎均支持。
:checked
所有当前引擎均支持。
:indeterminate
所有当前引擎均支持。
:indeterminate
伪类
必须匹配属于以下类别之一的任何元素:
:default
所有当前引擎均支持。
:placeholder-shown:placeholder-shown
伪类必须匹配属于以下类别之一的任何元素:
placeholder
属性,并且当前正在向用户显示该属性值的 input 元素placeholder
属性,并且当前正在向用户显示该属性值的 textarea
元素:valid
所有当前引擎均支持。
:invalid
所有当前引擎均支持。
:user-valid:user-valid 伪类必须
匹配这样的 input、textarea 和 select 元素:其
用户有效性为 true,属于
约束验证候选项,
并且满足其约束。
:user-invalid
:user-invalid
伪类必须
匹配这样的 input、textarea 和 select 元素:其
用户有效性为 true,属于
约束验证候选项,
但不满足其约束。
:in-range
所有当前引擎均支持。
:out-of-range
所有当前引擎均支持。
:required
所有当前引擎均支持。
:optional
所有当前引擎均支持。
:autofill
:-webkit-autofill:autofill 和 :-webkit-autofill
伪类必须匹配由用户代理
自动填充的 input 元素。如果用户编辑
自动填充的字段,这些伪类必须停止匹配。
发生此类自动填充的一种方式是通过 autocomplete 属性,
但即使
不涉及该属性,用户代理也可以自动填充。
:read-only
所有当前引擎均支持。
:read-write
所有当前引擎均支持。
:read-write 伪类必须
匹配属于以下类别之一的任何元素,因此为了选择器的目的,这些元素被视为可由用户更改:
[SELECTORS]
readonly
属性适用且可变的 input 元素(即没有
指定 readonly
属性,并且未禁用)
readonly
属性
且未禁用的 textarea
元素input
元素也不是 textarea
元素的元素:read-only 伪类必须匹配
所有其他HTML 元素。
:modal:dir(ltr)
:dir(rtl):state(identifier)
伪类必须
匹配所有这样的自定义元素:其状态集的集合条目
包含 identifier。
:heading:heading(integer#):heading(integer#)
伪类必须匹配所有
h1、
h2、
h3、
h4、
h5
和 h6
元素中,标题级别为
integer 的元素。[CSSSYNTAX] [CSSVALUES]
:playing:paused:seeking:buffering:buffering 伪类必须匹配
所有这样的媒体元素:其 paused 属性为 false,networkState 属性
为 NETWORK_LOADING,
且就绪状态为 HAVE_CURRENT_DATA
或更低。
:stalled:stalled 伪类必须匹配
所有匹配 :buffering 伪类,且其当前
已停滞为 true 的媒体元素。
此伪类旨在视频播放
缓冲时间过长时显示播放器状态 UI。它不同于 stalled 事件,后者
无论播放状态或就绪状态如何,只要网络下载
停滞就会触发。
:muted:volume-locked
当用户代理的音量锁定为 true 时,:volume-locked 伪类
必须匹配所有媒体元素。
:open本规范没有定义元素何时匹配 :lang() 动态伪类,因为选择器已经以与语言无关的方式对此进行了足够详细的定义。
[SELECTORS]
本节是非规范性的。
有时需要使用特定的机器可读标签为内容添加注释,例如,使 通用脚本能够提供针对页面定制的服务,或者使来自多个相互协作的作者的内容 能够由单个脚本以一致的 方式处理。
为此,作者可以使用本节所述的微数据功能。微数据 允许将嵌套的名称—值对组与现有 内容并行添加到文档中。
本节是非规范性的。
从较高层面来看,微数据由一组名称—值对组成。这些组称为项目,每个名称—值对都是一个属性。项目和属性 由普通元素表示。
要创建项目,可使用 itemscope
属性。
要向项目添加属性,可在该项目的某个后代上使用 itemprop
属性。
这里有两个项目,每个项目都具有“name”属性:
< div itemscope >
< p > 我的名字是 < span itemprop = "name" > 伊丽莎白</ span > 。</ p >
</ div >
< div itemscope >
< p > 我的名字是 < span itemprop = "name" > 丹尼尔</ span > 。</ p >
</ div > 不含微数据相关属性的标记不会对微数据 模型产生任何影响。
在微数据层面,以下两个示例分别与前面的两个示例 完全等效:
< div itemscope >
< p > 我的< em > 名字</ em > 是 < span itemprop = "name" > 伊< strong > 丽莎</ strong > 白</ span > 。</ p >
</ div >
< section >
< div itemscope >
< aside >
< p > 我的名字是 < span itemprop = "name" >< a href = "/?user=daniel" > 丹尼尔</ a ></ span > 。</ p >
</ aside >
</ div >
</ section > 属性的值通常是字符串。
这里的项目具有三个属性:
< div itemscope >
< p > 我的名字是 < span itemprop = "name" > 尼尔</ span > 。</ p >
< p > 我的乐队名为 < span itemprop = "band" > 四份水</ span > 。</ p >
< p > 我是< span itemprop = "nationality" > 英国人</ span > 。</ p >
</ div > 当字符串值是一个 URL
时,可使用 a 元素及其 href 属性、img 元素及其
src 属性,或者其他链接到或嵌入外部
资源的元素来表示。
在此示例中,项目具有一个“image”属性,其值是 URL:
< div itemscope >
< img itemprop = "image" src = "google-logo.png" alt = "Google" >
</ div > 当字符串值采用某种不适合人类阅读的机器可读格式时,可使用 data
元素的 value
属性表示,并在元素内容中提供人类可读的版本。
这里有一个项目,其中某个属性的值是产品 ID。该 ID 不便于 人类阅读,因此使用产品名称代替 ID 作为人类可见的文本。
< h1 itemscope >
< data itemprop = "product-id" value = "9678AOU879" > 煽动者 2000</ data >
</ h1 > 对于数值数据,可以改用 meter
元素及其 value 属性。
这里使用 meter 元素给出评分。
< div itemscope itemtype = "http://schema.org/Product" >
< span itemprop = "name" > 松下白色 60 升冰箱</ span >
< img src = "panasonic-fridge-60l-white.jpg" alt = "" >
< div itemprop = "aggregateRating"
itemscope itemtype = "http://schema.org/AggregateRating" >
< meter itemprop = "ratingValue" min = 0 value = 3.5 max = 5 > 评分 3.5/5</ meter >
(基于 < span itemprop = "reviewCount" > 11</ span > 条顾客评价)
</ div >
</ div > 同样,对于与日期和时间相关的数据,可以改用 time
元素及其 datetime 属性。
在此示例中,项目具有一个“birthday”属性,其值是日期:
< div itemscope >
我出生于 < time itemprop = "birthday" datetime = "2009-05-10" > 2009 年 5 月 10 日</ time > 。
</ div > 通过在声明属性的元素上放置 itemscope
属性,属性本身也可以是一组名称—值对。
不属于其他项目组成部分的项目称为顶级微数据项目。
在此示例中,外部项目表示一个人,内部项目表示一个乐队:
< div itemscope >
< p > 姓名:< span itemprop = "name" > 阿曼达</ span ></ p >
< p > 乐队:< span itemprop = "band" itemscope > < span itemprop = "name" > 爵士乐队</ span > (< span itemprop = "size" > 12</ span > 名演奏者)</ span ></ p >
</ div > 这里的外部项目具有“name”和“band”两个属性。“name”为“阿曼达”, “band”本身是一个项目,具有“name”和“size”两个属性。该 乐队的“name”为“爵士乐队”,“size”为“12”。
此示例中的外部项目是顶级微数据项目。
不属于具有 itemscope
属性的元素的后代的属性,可以使用 itemref 属性与
项目关联。
除遍历具有 itemscope
属性的元素的子元素之外,此属性还接受一个需要遍历的元素 ID 列表。
此示例与前一个示例相同,但所有属性都与其 项目分离:
< div itemscope id = "amanda" itemref = "a b" ></ div >
< p id = "a" > 姓名:< span itemprop = "name" > 阿曼达</ span ></ p >
< div id = "b" itemprop = "band" itemscope itemref = "c" ></ div >
< div id = "c" >
< p > 乐队:< span itemprop = "name" > 爵士乐队</ span ></ p >
< p > 人数:< span itemprop = "size" > 12</ span > 名演奏者</ p >
</ div > 这会产生与前一个示例相同的结果。第一个项目具有“name”和“band”两个属性, “name”设为“阿曼达”,“band”设为另一个项目。第二个项目还具有另外两个属性, “name”设为“爵士乐队”,“size”设为“12”。
一个项目可以具有多个名称相同但 值不同的属性。
此示例描述了一种具有两种口味的冰淇淋:
< div itemscope >
< p > 我最喜欢的冰淇淋口味:</ p >
< ul >
< li itemprop = "flavor" > 柠檬雪葩</ li >
< li itemprop = "flavor" > 杏子雪葩</ li >
</ ul >
</ div > 因此,这会产生一个具有两个属性的项目,这两个属性都名为“flavor”,其值分别为“柠檬 雪葩”和“杏子雪葩”。
引入属性的元素还可以一次引入多个属性,以避免 在某些属性具有相同值时出现重复。
这里有一个具有“favorite-color”和“favorite-fruit”两个属性的项目,这两个属性都设为 值“橙色”:
< div itemscope >
< span itemprop = "favorite-color favorite-fruit" > 橙色</ span >
</ div > 需要特别注意的是,微数据与标记这些微数据的文档 内容之间不存在任何关系。
例如,以下两个示例之间没有语义差异:
< figure >
< img src = "castle.jpeg" >
< figcaption >< span itemscope >< span itemprop = "name" > 城堡</ span ></ span > (1986)</ figcaption >
</ figure > < span itemscope >< meta itemprop = "name" content = "城堡" ></ span >
< figure >
< img src = "castle.jpeg" >
< figcaption > 城堡(1986)</ figcaption >
</ figure > 两者都有一个带有说明文字的图,并且两者都有一个与该图完全无关的项目, 该项目具有一个名称为“name”、值为“城堡”的名称—值对。唯一的区别是, 如果用户将说明文字拖出文档,在前一种情况下,该项目会被 包含在拖放数据中。在这两种情况下,图像都不会以任何方式与该 项目关联。
本节是非规范性的。
上一节中的示例展示了如何在不期望其微数据被重复使用的页面上 标记信息。不过,当微数据用于其他作者和读者能够相互协作, 以利用这些标记实现新用途的上下文中时,微数据最有用。
为此,有必要为每个项目指定一个 类型, 例如“https://example.com/person”、“https://example.org/cat”或 “https://band.example.net/”。类型由 URL 标识。
项目的类型由与
itemscope 属性位于同一元素上的 itemtype 属性值给出。
这里,项目的类型是“https://example.org/animals#cat”:
< section itemscope itemtype = "https://example.org/animals#cat" >
< h1 itemprop = "name" > 赫德拉尔</ h1 >
< p itemprop = "desc" > 赫德拉尔是一只雄性美国本土
短毛猫,长着蓬松的黑色毛发,爪子和腹部为白色。</ p >
< img itemprop = "img" src = "hedral.jpeg" alt = "" title = "赫德拉尔,18 个月大" >
</ section > 在此示例中,“https://example.org/animals#cat”项目具有三个属性:“name” (“赫德拉尔”)、“desc”(“赫德拉尔是……”)和“img”(“hedral.jpeg”)。
类型为属性提供上下文,从而选择一个词汇表:为类型为
“https://census.example/person”的项目提供名为“class”的属性时,它可能指个人的经济
阶层;而为类型为
“https://example.com/school/teacher”的项目提供名为“class”的属性时,它可能指分配给教师的教室。
多个类型可以共享一个词汇表。例如,可以将类型“https://example.org/people/teacher”和
“https://example.org/people/engineer”定义为使用相同的词汇表
(尽管某些属性在两种情况下可能并非都特别有用,例如
“https://example.org/people/engineer”类型通常可能不会与
“classroom”属性一起使用)。通过在属性值中将 URL 列为以空格分隔的列表,
可以为单个项目指定多个被定义为使用同一词汇表的类型。
但是,如果两个类型不使用同一词汇表,则不能将它们同时指定给一个项目。
本节是非规范性的。
有时,一个项目会提供 有关具有全局标识符的主题的 信息。例如,可以使用 ISBN 编号标识图书。
可以对词汇表(由 itemtype 属性标识)
进行设计,使项目通过将全局标识符表示为
itemid 属性中给出的 URL,以明确的方式与其全局
标识符关联。
itemid 属性中给出的 URL 的确切含义取决于所使用的
词汇表。
这里,一个项目描述的是一本特定的图书:
< dl itemscope
itemtype = "https://vocab.example.net/book"
itemid = "urn:isbn:0-330-34032-8" >
< dt > 书名
< dd itemprop = "title" > 现实失常
< dt > 作者
< dd itemprop = "author" > 彼得·F·汉密尔顿
< dt > 出版日期
< dd >< time itemprop = "pubdate" datetime = "1996-01-26" > 1996 年 1 月 26 日</ time >
</ dl > 此示例中的“https://vocab.example.net/book”词汇表会
定义 itemid
属性接受一个指向图书 ISBN 的 urn:
URL。
本节是非规范性的。
使用微数据意味着使用词汇表。对于某些用途,临时词汇表已经足够。 对于其他用途,则需要设计词汇表。在可能的情况下,建议作者 重复使用现有词汇表,因为这会使内容更易于重复使用。
设计新词汇表时,可以使用 URL 创建标识符;对于属性,也可以使用普通单词(不含句点或冒号)。对于 URL, 只使用与作者能够控制的页面相对应的标识符, 可以避免与其他词汇表发生冲突。
例如,如果乔恩和亚当都在 example.com 上编写内容,分别位于
https://example.com/~jon/... 和 https://example.com/~adam/...,那么
他们可以分别选择
“https://example.com/~jon/name”和“https://example.com/~adam/name”
形式的标识符。
名称只是普通单词的属性只能在其预期类型的上下文中使用; 使用 URL 命名的属性可以在任何类型的项目中重复使用。如果一个 项目没有类型,并且不属于另一个项目的一部分,那么如果其属性名称只是 普通单词,这些名称并非旨在全局唯一,而只是旨在 有限范围内使用。通常,建议作者使用具有全局 唯一名称(URL)的属性,或者确保其项目具有类型。
这里,一个项目是“https://example.org/animals#cat”,大多数属性的名称 都是在该类型的上下文中定义的单词。另有一些附加属性, 其名称来自其他词汇表。
< section itemscope itemtype = "https://example.org/animals#cat" >
< h1 itemprop = "name https://example.com/fn" > 赫德拉尔</ h1 >
< p itemprop = "desc" > 赫德拉尔是一只雄性美国本土
短毛猫,长着蓬松的< span
itemprop = "https://example.com/color" > 黑色</ span > 毛发,爪子和腹部为< span
itemprop = "https://example.com/color" > 白色</ span > 。</ p >
< img itemprop = "img" src = "hedral.jpeg" alt = "" title = "赫德拉尔,18 个月大" >
</ section > 此示例有一个类型为“https://example.org/animals#cat”的项目,并具有以下 属性:
| 属性 | 值 |
| name | 赫德拉尔 |
| https://example.com/fn | 赫德拉尔 |
| desc | 赫德拉尔是一只雄性美国本土短毛猫,长着蓬松的黑色毛发,爪子和腹部为白色。 |
| https://example.com/color | 黑色 |
| https://example.com/color | 白色 |
| img | .../hedral.jpeg |
微数据模型由称为项目的名称—值对组组成。
每个组称为一个项目。每个项目可以具有项目类型、一个全局 标识符(如果项目类型所指定的词汇表支持项目的全局 标识符),以及一个名称—值对列表。名称—值对中的每个名称称为一个属性,每个属性具有一个 或多个值。每个值要么是字符串,要么 本身是一组名称—值 对(一个项目)。各名称相互之间没有顺序, 但如果特定名称具有多个值,这些值则具有相对顺序。
所有当前引擎均支持。
每个HTML 元素都可以指定一个 itemscope 属性。
itemscope 属性是一个布尔属性。
指定了 itemscope 属性的元素会创建一个
新的项目,即一组名称—值对。
所有当前引擎均支持。
具有 itemscope 属性的元素可以
指定一个 itemtype
属性,
以给出项目的项目类型。
如果指定了 itemtype 属性,则其值必须
是一个由唯一且以空格分隔的令牌组成的无序集合,其中没有任何令牌与
另一个令牌相同,每个令牌都是一个属于绝对 URL的有效 URL 字符串,
并且所有令牌都被定义为使用同一词汇表。该属性值必须至少包含一个令牌。
项目的项目类型是通过
在 ASCII 空白处拆分元素的 itemtype 属性值而获得的
令牌。如果缺少 itemtype
属性,或者以这种方式解析该属性时找不到
令牌,则称该项目没有项目类型。
所有项目类型都必须是在适用规范中定义的类型, 并且都必须被定义为使用同一 词汇表。
除非该规范另有规定,否则不应自动解引用作为项目类型给出的 URL。
例如,某个规范可以定义其项目类型 可以被解引用,以向用户提供帮助信息。事实上,建议词汇表 作者在给定的 URL 中提供有用的信息。
项目类型是不透明的标识符,用户代理不得 解引用未知的项目类型,也不得以其他方式分解它们,以确定 如何处理使用这些类型的项目。
不得在未指定 itemscope 属性的
元素上指定 itemtype 属性。
如果一个项目具有项目类型,或者它是某个带类型的 项目的属性的值,则称该项目为带类型的 项目。对于一个 带类型的项目,其相关类型是该项目的项目类型(如果存在); 否则,是将该项目作为某个属性的值的那个项目的相关类型。
所有当前引擎均支持。
具有 itemscope 属性和
itemtype 属性,并且后者引用了被定义为
支持项目全局标识符的词汇表的元素,还可以指定一个 itemid 属性,
以给出该项目的
全局标识符,使其可以与 Web 上其他页面中的
其他项目关联。
如果指定了 itemid 属性,则其
值必须是一个可能被空格包围的有效
URL。
不得在没有同时指定 itemscope 属性和
itemtype 属性的元素上指定
itemid 属性;也不得在这样的元素上指定该属性:
该元素具有 itemscope 属性,而其 itemtype 属性指定的词汇表,根据该词汇表的规范定义,
不支持
项目的全局标识符。
全局标识符的确切含义由词汇表的 规范确定。此类规范负责定义是否允许存在多个具有相同 全局标识符的项目(无论是在同一页面还是不同页面上),以及 对于处理多个项目具有同一 ID 的情况,该词汇表应采用哪些处理规则。
所有当前引擎均支持。
具有 itemscope 属性的元素可以
指定一个 itemref
属性,
以给出为查找该项目的名称—值对而需要遍历的附加元素列表。
如果指定了 itemref 属性,则其
值必须是一个由唯一且以空格分隔的令牌组成的无序集合,
其中没有任何令牌与另一个令牌相同,并且这些令牌由同一树中元素的 ID 组成。
不得在未指定 itemscope 属性的
元素上指定 itemref 属性。
itemref 属性不属于
微数据数据模型。它只是一种语法构造,用于帮助作者在
待注释数据未遵循便利树结构的页面中添加注释。例如,它
允许作者标记表格中的数据,使每一列定义一个单独的项目,同时将属性保留在单元格中。
此示例展示了一个用于描述铁路模型 制造商产品的简单词汇表。该词汇表只有五个属性名称:
此词汇表定义了四种项目类型:
使用此词汇表的每个项目都可以根据产品的种类, 被指定一种或多种 此类类型。
因此,可以按如下方式标记一台机车:
< dl itemscope itemtype = "https://md.example.com/loco
https://md.example.com/lighting" >
< dt > 名称:
< dd itemprop = "name" > 水柜式蒸汽机车(DB 80)
< dt > 产品代码:
< dd itemprop = "product-code" > 33041
< dt > 比例:
< dd itemprop = "scale" > HO
< dt > 数字系统:
< dd itemprop = "digital" > Delta
</ dl > 可以按如下方式标记一个道岔信号灯改装套件:
< dl itemscope itemtype = "https://md.example.com/track
https://md.example.com/lighting" >
< dt > 名称:
< dd itemprop = "name" > 道岔信号灯套件
< dt > 产品代码:
< dd itemprop = "product-code" > 74470
< dt > 用途:
< dd > 用于改装 2 个 < span itemprop = "track-type" > C</ span > 型轨道
道岔。< meta itemprop = "scale" content = "HO" >
</ dl > 可以按如下方式标记一节没有照明设备的客车:
< dl itemscope itemtype = "https://md.example.com/passengers" >
< dt > 名称:
< dd itemprop = "name" > 特快列车客车(DB Am 203)
< dt > 产品代码:
< dd itemprop = "product-code" > 8710
< dt > 比例:
< dd itemprop = "scale" > Z
</ dl > 创建新词汇表时必须格外谨慎。通常,可以对 类型采用分层方法,从而使词汇表中的每个项目始终只有一种类型, 这通常更容易管理。
itemprop 属性所有当前引擎均支持。
每个HTML 元素都可以指定一个 itemprop
属性,前提是这样做会向一个或多个项目添加一个或多个属性(定义见下文)。
如果指定了 itemprop
属性,则其值必须是一个由唯一且
以空格分隔的令牌组成的无序集合,其中没有任何令牌与另一个令牌相同;这些令牌表示该元素所
添加的名称—值对的名称。该属性值必须至少包含一个令牌。
每个令牌必须属于以下情况之一:
引入已定义属性名称的规范 必须确保所有此类属性名称不包含 U+002E FULL STOP 字符(.)、U+003A COLON 字符(:)以及ASCII 空白。
上述规则禁止在非 URL 值中使用 U+003A COLON 字符(:),因为 否则无法将它们与 URL 区分开。包含 U+002E FULL STOP 字符(.)的值 保留供未来扩展使用。禁止使用 ASCII 空白,因为否则 这些值会被解析为多个令牌。
当具有 itemprop
属性的元素向多个项目添加一个
属性时,上述关于令牌的要求分别适用于每个项目。
一个元素的属性名称是通过在 ASCII
空白处拆分该元素的 itemprop
属性值时发现该属性所包含的令牌;保留其顺序,但移除重复项
(每个名称仅保留第一次出现)。
在一个项目中,各属性相互之间 没有顺序,但名称相同的属性除外;这些属性按照定义项目属性的算法给出它们的顺序进行排序。
在以下示例中,“a”属性按该顺序具有值“1”和“2”, 但“a”属性是否位于“b”属性之前并不重要:
< div itemscope >
< p itemprop = "a" > 1</ p >
< p itemprop = "a" > 2</ p >
< p itemprop = "b" > 测试</ p >
</ div > 因此,以下代码与其等效:
< div itemscope >
< p itemprop = "b" > 测试</ p >
< p itemprop = "a" > 1</ p >
< p itemprop = "a" > 2</ p >
</ div > 以下代码也与其等效:
< div itemscope >
< p itemprop = "a" > 1</ p >
< p itemprop = "b" > 测试</ p >
< p itemprop = "a" > 2</ p >
</ div > 还有以下代码:
< div id = "x" >
< p itemprop = "a" > 1</ p >
</ div >
< div itemscope itemref = "x" >
< p itemprop = "b" > 测试</ p >
< p itemprop = "a" > 2</ p >
</ div > 由具有 itemprop
属性的元素添加的
名称—值对的属性值,由以下列表中第一个
匹配的情况确定:
itemscope
属性该值是由此元素创建的项目。
meta 元素
如果元素具有 content
属性,则该值是该属性的值;如果没有此属性,则为空字符串。
audio、embed、iframe、
img、source、track 或 video 元素
该值是在设置属性时,以元素的节点
文档为基准,给定元素的 src 属性值编码、解析并序列化 URL的结果;如果没有此
属性或结果为失败,则为空字符串。
a、area 或 link 元素该值是在设置属性时,以元素的节点
文档为基准,给定元素的 href 属性值编码、解析并序列化 URL的结果;如果没有此
属性或结果为失败,则为空字符串。
object
元素该值是在设置属性时,以元素的节点
文档为基准,给定元素的 data 属性值编码、解析并序列化 URL的结果;如果没有此
属性或结果为失败,则为空字符串。
data 元素
如果元素具有 value 属性,
则该值是此属性的值;否则为空字符串。
meter 元素
如果元素具有 value 属性,
则该值是此属性的值;否则为空字符串。
time 元素
该值是元素的日期时间值。
该值是元素的后代文本内容。
如果按照属性定义,某个属性的值是一个绝对 URL,则必须使用URL 属性元素指定该属性。
这些要求不会仅仅因为属性值恰好符合 URL 的语法而适用。只有在属性被明确地定义为接受此类 值时,它们才适用。
例如,一本关于首次登月的书可以
名为“mission:moon”。如果某个词汇表将“title”属性定义为字符串,
则不会期望在 a
元素中给出该标题,即使它看起来像一个
URL。另一方面,
如果存在一个(适用范围相当狭窄的)用于
“标题看起来像 URL 的图书”的词汇表,并将“title”属性定义为接受 URL,那么该
属性确实会要求在 a 元素(或其他
URL 属性元素之一)中给出标题,这是因为
上述要求。
要查找由元素 root 定义的项目的属性, 用户代理必须运行以下步骤。这些步骤还用于标记微数据错误。
令 results、memory 和 pending 为空的元素列表。
将元素 root 添加到 memory。
将 root 的子元素(如果有)添加到 pending。
如果 root 具有 itemref 属性,则在
ASCII 空白处拆分该 itemref 属性的值。对于每个所得的
令牌 ID,如果 root 的树中存在
ID 为 ID 的元素,则将第一个此类元素添加到
pending。
当 pending 不为空时:
按树顺序对 results 进行排序。
返回 results。
文档不得包含这样的项目: 用于查找项目 属性的算法发现了任何微数据 错误。
Document 中的所有 itemref 属性都必须满足以下
条件:将该 Document 中的每个项目表示为图中的节点,并将一个项目中值为另一个项目的每个
属性表示为
连接这两个项目的图中边时,所形成的图中不得存在环。
文档不得包含这样的元素:该元素具有 itemprop
属性,但如果确定该文档中所有项目的属性,该元素不会被发现是任何项目的属性。
在此示例中,通过表示作品的项目上的 itemref,将一条许可声明
应用于两个作品:
<!DOCTYPE HTML>
< html lang = "en" >
< head >
< title > 照片库</ title >
</ head >
< body >
< h1 > 我的照片</ h1 >
< figure itemscope itemtype = "http://n.whatwg.org/work" itemref = "licenses" >
< img itemprop = "work" src = "images/house.jpeg" alt = "森林中坐落着一座被木板封住的白色房屋。" >
< figcaption itemprop = "title" > 我发现的房屋。</ figcaption >
</ figure >
< figure itemscope itemtype = "http://n.whatwg.org/work" itemref = "licenses" >
< img itemprop = "work" src = "images/mailbox.jpeg" alt = "房屋外有一个邮箱。里面有一张传单。" >
< figcaption itemprop = "title" > 邮箱。</ figcaption >
</ figure >
< footer >
< p id = "licenses" > 所有图像均依据 < a itemprop = "license"
href = "http://www.opensource.org/licenses/mit-license.php" > MIT
许可证</ a > 进行许可。</ p >
</ footer >
</ body >
</ html > 上述代码会产生两个类型为“http://n.whatwg.org/work”的项目,
其中一个具有:
images/house.jpeg
http://www.opensource.org/licenses/mit-license.php
……另一个具有:
images/mailbox.jpeg
http://www.opensource.org/licenses/mit-license.php
目前,itemscope、itemprop
和其他微数据属性仅针对
HTML 元素定义。这意味着,
字面名称为“itemscope”、“itemprop”等的属性,不会使 SVG 等其他命名空间中的元素
发生微数据处理。
因此,在以下示例中只有一个项目,而不是 两个。
< p itemscope ></ p > <!-- 这是一个项目(没有属性和类型) -->
< svg itemscope ></ svg > <!-- 这不是项目,它只是一个具有无效未知属性的 SVG svg 元素 --> 本节中的词汇表主要用于演示如何指定词汇表,不过它们本身也可以使用。
具有项目类型 http://microformats.org/profile/hcard 的项目表示个人或
组织的联系信息。
此词汇表不支持项目的全局标识符。
以下是该类型的已定义属性 名称。它们基于《vCard 格式规范》 (vCard)及其扩展中定义的词汇表,有关如何解释这些值的更多信息可以 在其中找到。[RFC6350]
kind描述项目表示哪种联系人。
每个类型为 http://microformats.org/profile/hcard 的项目中,可以存在一个名为 kind 的属性。
fn给出与个人或组织名称对应的格式化文本。
值必须是文本。
每个类型为 http://microformats.org/profile/hcard 的项目中,必须恰好存在一个名为 fn 的属性。
n给出个人或组织的结构化名称。
值必须是一个项目,其中每种 family-name、given-name、additional-name、honorific-prefix 和
honorific-suffix
属性可以有零个或多个。
每个类型为 http://microformats.org/profile/hcard 的项目中,必须恰好存在一个名为 n 的属性。
family-name(位于 n 内)给出个人的姓氏,或组织的完整名称。
值必须是文本。
在构成类型为 http://microformats.org/profile/hcard 的项目的 n 属性的值的项目中,可以存在任意数量名为
family-name 的属性。
given-name(位于 n 内)给出个人的名字。
值必须是文本。
在构成类型为 http://microformats.org/profile/hcard 的项目的 n 属性的值的项目中,可以存在任意数量名为
given-name
的属性。
additional-name(位于 n 内)给出个人的任何附加名称。
值必须是文本。
在构成类型为 http://microformats.org/profile/hcard 的项目的 n 属性的值的项目中,可以存在任意数量名为
additional-name 的
属性。
honorific-prefix(位于 n 内)给出个人的敬称前缀。
值必须是文本。
在构成类型为 http://microformats.org/profile/hcard 的项目的 n 属性的值的项目中,可以存在任意数量名为 honorific-prefix
的属性。
honorific-suffix(位于 n 内)给出个人的敬称后缀。
值必须是文本。
在构成类型为 http://microformats.org/profile/hcard 的项目的 n 属性的值的项目中,可以存在任意数量名为 honorific-suffix
的属性。
nickname给出个人或组织的昵称。
昵称是代替或附加于个人、地点或事物自身名称而给出的描述性名称。
它还可用于指定由 fn 或 n 属性指定的专有名称的
熟悉形式。
值必须是文本。
每个类型为 http://microformats.org/profile/hcard 的项目中,可以存在任意数量名为 nickname 的属性。
photo给出个人或组织的照片。
每个类型为 http://microformats.org/profile/hcard 的项目中,可以存在任意数量名为 photo 的属性。
bday给出个人或组织的出生日期。
每个类型为 http://microformats.org/profile/hcard 的项目中,可以存在一个名为 bday 的属性。
anniversary给出个人或组织的出生日期。
每个类型为 http://microformats.org/profile/hcard 的项目中,可以存在一个名为 anniversary 的属性。
sex给出个人的生理性别。
值必须是以下值之一:
F,表示“女性”;
M,表示“男性”;
N,表示“无或不适用”;
O,表示“其他”;或者
U,表示“未知”。
每个类型为 http://microformats.org/profile/hcard 的项目中,可以存在一个名为 sex 的属性。
gender-identity给出个人的性别认同。
值必须是文本。
每个类型为 http://microformats.org/profile/hcard 的项目中,可以存在一个名为 gender-identity
的属性。
adr给出个人或组织的递送地址。
值必须是一个项目,其中可以有零个或多个 type、
post-office-box、
extended-address
和 street-address
属性,还可以有一个 locality 属性、一个
region 属性、一个
postal-code 属性
以及一个 country-name
属性。
如果在构成类型为 http://microformats.org/profile/hcard
的项目的 adr 属性的值的项目中不存在
type 属性,则隐含地址类型字符串 work。
每个类型为 http://microformats.org/profile/hcard 的项目中,可以存在任意数量名为 adr 的属性。
type(位于 adr 内)给出递送地址的类型。
在构成类型为 http://microformats.org/profile/hcard 的项目的 adr 属性的值的项目中,可以存在任意数量名为 type 的属性,但在每个此类 adr 属性项目中,每个不同的值只能有一个 type 属性。
post-office-box(位于 adr 内)给出个人或组织递送地址中的邮政信箱组成部分。
值必须是文本。
在构成类型为 http://microformats.org/profile/hcard 的项目的 adr 属性的值的项目中,可以存在任意数量名为 post-office-box
的属性。
vCard 建议作者不要使用此字段。
extended-address(位于 adr 内)给出个人或组织递送地址的附加组成部分。
值必须是文本。
在构成类型为 http://microformats.org/profile/hcard 的项目的 adr 属性的值的项目中,可以存在任意数量名为 extended-address
的属性。
vCard 建议作者不要使用此字段。
street-address(位于 adr 内)给出个人或组织递送地址中的街道地址组成部分。
值必须是文本。
在构成类型为 http://microformats.org/profile/hcard 的项目的 adr 属性的值的项目中,可以存在任意数量名为 street-address 的
属性。
locality(位于 adr 内)给出个人或组织递送地址中的地区组成部分(例如城市)。
值必须是文本。
在构成类型为 http://microformats.org/profile/hcard 的项目的 adr 属性的值的项目中,可以存在一个名为
locality 的属性。
region(位于 adr 内)给出个人或组织递送地址中的区域组成部分(例如州或省)。
值必须是文本。
在构成类型为 http://microformats.org/profile/hcard 的项目的 adr 属性的值的项目中,可以存在一个名为
region 的属性。
postal-code(位于 adr 内)给出个人或组织递送地址中的邮政编码组成部分。
值必须是文本。
在构成类型为 http://microformats.org/profile/hcard 的项目的 adr 属性的值的项目中,可以存在一个名为
postal-code 的属性。
country-name(位于 adr 内)给出个人或组织递送地址中的国家名称组成部分。
值必须是文本。
在构成类型为 http://microformats.org/profile/hcard 的项目的 adr 属性的值的项目中,可以存在一个名为
country-name
的属性。
tel给出个人或组织的电话号码。
值必须是可以
解释为 CCITT 规范 E.163 和 X.121 中所定义电话号码的文本,或者是一个项目,该项目具有零个或多个
type 属性和恰好一个 value 属性。[E163]
[X121]
如果在构成类型为 http://microformats.org/profile/hcard
的项目的 tel 属性的值的项目中不存在
type 属性,或者此类 tel 属性的值是文本,则隐含电话类型
字符串
voice。
每个类型为 http://microformats.org/profile/hcard 的项目中,可以存在任意数量名为 tel 的属性。
type(位于 tel 内)给出电话号码的类型。
在构成类型为 http://microformats.org/profile/hcard 的项目的 tel 属性的值的项目中,可以存在任意数量名为 type 的属性,但在每个此类 tel 属性项目中,每个不同的值只能有一个 type 属性。
value(位于 tel 内)给出个人或组织的实际电话号码。
值必须是可以 解释为 CCITT 规范 E.163 和 X.121 中所定义电话号码的文本。[E163] [X121]
在构成类型为 http://microformats.org/profile/hcard 的项目的 tel 属性的值的项目中,必须恰好存在一个名为 value 的属性。
email给出个人或组织的电子邮件地址。
值必须是文本。
每个类型为 http://microformats.org/profile/hcard 的项目中,可以存在任意数量名为 email 的属性。
impp给出一个用于与个人或组织进行即时消息和在线状态协议通信的 URL。
每个类型为 http://microformats.org/profile/hcard 的项目中,可以存在任意数量名为 impp 的属性。
lang给出个人或组织能够理解的语言。
每个类型为 http://microformats.org/profile/hcard 的项目中,可以存在任意数量名为 lang 的属性。
tz给出个人或组织的时区。
值必须是文本,并且必须 匹配以下语法:
每个类型为 http://microformats.org/profile/hcard 的项目中,可以存在任意数量名为 tz 的属性。
geo给出个人或组织的地理位置。
值必须是文本,并且必须 匹配以下语法:
应包含以星号(*)标记的可选组成部分,并且每个组成部分都应包含六位 数字。
该值按此顺序指定纬度和经度(即“LAT LON” 顺序),单位为十进制度。经度分别使用正实数或负实数表示本初 子午线以东和以西的位置。纬度分别使用正实数或负实数表示 赤道以北和以南的位置。
每个类型为 http://microformats.org/profile/hcard 的项目中,可以存在任意数量名为 geo 的属性。
title给出个人或组织的职称、职务职位或职能。
值必须是文本。
每个类型为 http://microformats.org/profile/hcard 的项目中,可以存在任意数量名为 title 的属性。
role给出个人或组织的角色、职业或业务类别。
值必须是文本。
每个类型为 http://microformats.org/profile/hcard 的项目中,可以存在任意数量名为 role 的属性。
logo给出个人或组织的徽标。
每个类型为 http://microformats.org/profile/hcard 的项目中,可以存在任意数量名为 logo 的属性。
agent给出将代表该个人或组织行事的另一个人的联系信息。
值必须是类型为 http://microformats.org/profile/hcard 的项目、一个绝对 URL或文本。
每个类型为 http://microformats.org/profile/hcard 的项目中,可以存在任意数量名为 agent 的属性。
org给出组织的名称和单位。
值必须是文本,或者是一个项目,该项目具有一个 organization-name
属性和零个或多个 organization-unit
属性。
每个类型为 http://microformats.org/profile/hcard 的项目中,可以存在任意数量名为 org 的属性。
organization-name(位于 org 内)给出组织的名称。
值必须是文本。
在构成类型为 http://microformats.org/profile/hcard 的项目的 org 属性的值的项目中,必须恰好存在一个名为 organization-name
的属性。
organization-unit(位于 org 内)给出组织单位的名称。
值必须是文本。
在构成类型为 http://microformats.org/profile/hcard 的项目的 org
属性的值的项目中,可以存在任意数量名为 organization-unit
的属性。
member给出表示群组成员的 URL。
如果类型为 http://microformats.org/profile/hcard 的每个项目还具有一个名为 kind 且值为“group”的属性,则该项目中可以存在任意数量名为 member 的属性。
related给出与另一个实体的关系。
值必须是一个项目,该项目具有一个 url
属性和一个 rel
属性。
每个类型为 http://microformats.org/profile/hcard 的项目中,可以存在任意数量名为 related 的属性。
url(位于 related 内)给出相关实体的 URL。
在构成类型为 http://microformats.org/profile/hcard 的项目的 related
属性的值的项目中,必须恰好存在一个名为 url 的属性。
rel(位于 related 内)给出该实体与相关实体之间的关系。
在构成类型为 http://microformats.org/profile/hcard 的项目的 related
属性的值的项目中,必须恰好存在一个名为 rel 的属性。
categories给出可用于对个人或组织进行分类的类别或标签的名称。
值必须是文本。
每个类型为 http://microformats.org/profile/hcard 的项目中,可以存在任意数量名为 categories
的属性。
note给出有关个人或组织的补充信息或评论。
值必须是文本。
每个类型为 http://microformats.org/profile/hcard 的项目中,可以存在任意数量名为 note 的属性。
rev给出联系信息的修订日期和时间。
值必须是一个有效 全局日期和时间字符串的文本。
该值用于将信息的当前修订版本与该信息的其他 呈现版本区分开来。
每个类型为 http://microformats.org/profile/hcard 的项目中,可以存在任意数量名为 rev 的属性。
sound给出与个人或组织相关的声音文件。
每个类型为 http://microformats.org/profile/hcard 的项目中,可以存在任意数量名为 sound 的属性。
uid给出与个人或组织相对应的全局唯一标识符。
值必须是文本。
每个类型为 http://microformats.org/profile/hcard 的项目中,可以存在一个名为 uid 的属性。
url给出与个人或组织相关的 URL。
每个类型为 http://microformats.org/profile/hcard 的项目中,可以存在任意数量名为 url 的属性。
种类字符串如下:
individual表示单个实体(例如一个人)。
group表示多个实体(例如邮件列表)。
org表示不是人的单个实体(例如公司)。
location表示地理场所(例如办公楼)。
地址类型字符串如下:
home表示住宅的递送地址。
work表示工作场所的递送地址。
电话类型字符串如下:
home表示住宅电话号码。
work表示工作场所的电话号码。
text表示该电话号码支持文本消息(SMS)。
voice表示语音电话号码。
fax表示传真电话号码。
cell表示移动电话号码。
video表示视频会议电话号码。
pager表示寻呼设备电话号码。
textphone表示供听力或言语有困难者使用的电信设备。
关系字符串如下:
emergency紧急联系人。
agent代表此实体行事的另一个实体。
具有 XFN 中定义的含义。[XFN]
给定 Document 中的节点列表
nodes,用户代理必须运行以下算法,以提取这些节点表示的任何
vCard 数据(仅返回第一个 vCard):
如果 nodes 中没有任何节点是具有项目类型 http://microformats.org/profile/hcard
的项目,则不存在 vCard。中止该
算法,并且不返回任何内容。
令 node 为 nodes 中第一个属于具有项目类型 http://microformats.org/profile/hcard
的项目的节点。
令 output 为空字符串。
向 output 添加一行
vCard,其类型为
“BEGIN”,值为
“VCARD”。
向 output 添加一行
vCard,其类型为
“PROFILE”,值为
“VCARD”。
向 output 添加一行
vCard,其类型为
“VERSION”,值为
“4.0”。
向 output 添加一行
vCard,其类型为
“SOURCE”,并以文档的 URL 作为
vCard 文本字符串进行转义所得的结果作为值。
如果title
元素不为 null,则向 output 添加一行 vCard,
其类型为“NAME”,并以从title 元素的后代
文本内容获得的 vCard 文本字符串进行转义所得的结果作为值。
令 sex 为空字符串。
令 gender-identity 为空字符串。
对于作为项目 node 的属性的每个元素 element:对于 element 的属性名称中的每个名称 name,运行以下子步骤:
令 parameters 为空的名称—值对集合。
从以下列表中运行适当的一组子步骤。这些步骤将设置变量 value,该变量会在下一步骤中使用。
n
令 value 为空字符串。
将在 subitem 中收集第一个
vCard 子属性名为 family-name
的结果追加到 value。
将在 subitem 中收集第一个 vCard
子属性名为 given-name
的结果追加到 value。
将在 subitem 中收集第一个 vCard
子属性名为 additional-name
的结果追加到
value。
将在 subitem 中收集第一个 vCard
子属性名为 honorific-prefix
的结果追加到 value。
将在 subitem 中收集第一个 vCard
子属性名为 honorific-suffix
的结果追加到 value。
adr
令 value 为空字符串。
将在 subitem 中收集
vCard 子属性名为 post-office-box
的结果追加到 value。
将在 subitem 中收集 vCard
子属性名为 extended-address
的结果追加到 value。
将在 subitem 中收集 vCard
子属性名为 street-address
的结果追加到 value。
将在 subitem 中收集第一个 vCard
子属性名为 locality
的结果追加到 value。
将在 subitem 中收集第一个 vCard
子属性名为 region
的
结果追加到 value。
将在 subitem 中收集第一个 vCard
子属性名为 postal-code
的结果追加到 value。
将在 subitem 中收集第一个 vCard
子属性名为 country-name
的结果追加到
value。
如果 subitem 中存在名为 type 的属性,
并且第一个此类属性的值不是项目,且其值仅由ASCII 字母数字字符组成,则向
parameters 添加一个名为“TYPE”的参数,其值为该属性的值。
org
令 value 为空字符串。
将在 subitem 中收集第一个 vCard
子属性名为 organization-name
的结果追加到 value。
对于 subitem 中每个名为 organization-unit
的属性,运行以下步骤:
http://microformats.org/profile/hcard
的项目 subitem,且
name 为 related
令 value 为在 subitem 中收集第一个 vCard
子属性名为 value 的结果。
如果 subitem 中存在名为 type 的属性,并且
第一个此类属性的值
不是项目,且其值
仅由ASCII 字母数字字符组成,则向
parameters 添加一个名为“TYPE”的参数,其值为该属性的值。
sex如果这是找到的第一个此类属性,则将 sex 设置为该属性的值。
gender-identity
如果这是找到的第一个此类属性,则将 gender-identity 设置为该属性的值。
令 value 为该属性的值。
如果 element 是URL 属性元素之一,则向
parameters 添加一个名称为“VALUE”、值为“URI”的
参数。
否则,如果 name 为 bday 或
anniversary,
且 value 是
一个有效日期字符串,则向
parameters 添加一个名称为“VALUE”、值为“DATE”的参数。
否则,如果 name 为 rev,且
value 是一个有效全局日期和时间
字符串,则向
parameters 添加一个名称为“VALUE”、值为“DATE-TIME”的
参数。
在 value 中的每个 U+005C REVERSE SOLIDUS 字符(\)前加上 另一个 U+005C REVERSE SOLIDUS 字符(\)。
在 value 中的每个 U+002C COMMA 字符(,)前加上一个 U+005C REVERSE SOLIDUS 字符(\)。
除非 name 为 geo,否则在
value 中的每个 U+003B SEMICOLON 字符(;)前加上一个 U+005C REVERSE
SOLIDUS 字符(\)。
将 value 中的每个 U+000D CARRIAGE RETURN U+000A LINE FEED 字符对(CRLF) 替换为一个 U+005C REVERSE SOLIDUS 字符(\),后跟一个 U+006E LATIN SMALL LETTER N 字符(n)。
将 value 中剩余的每个 U+000D CARRIAGE RETURN(CR)或 U+000A LINE FEED(LF) 字符替换为一个 U+005C REVERSE SOLIDUS 字符(\),后跟 一个 U+006E LATIN SMALL LETTER N 字符(n)。
向 output 添加一行 vCard,其类型为 name、参数为 parameters、值为 value。
如果 sex 或 gender-identity 中任意一个的值
不为空字符串,则向 output 添加一行
vCard,其类型为“GENDER”,
值由 sex、一个 U+003B SEMICOLON 字符(;)和
gender-identity 连接而成。
向 output 添加一行
vCard,其类型为
“END”,值为
“VCARD”。
当上述算法要求用户代理向字符串 output 添加一行 vCard, 该行由类型 type、可选的一些参数和值 value 组成时, 用户代理必须运行以下步骤:
令 line 为空字符串。
将 type 转换为 ASCII 大写形式,并追加到 line。
如果存在任何参数,则对于每个参数,按照添加这些参数的顺序运行 以下子步骤:
将一个 U+003B SEMICOLON 字符(;)追加到 line。
将参数名称追加到 line。
将一个 U+003D EQUALS SIGN 字符(=)追加到 line。
将参数值追加到 line。
将一个 U+003A COLON 字符(:)追加到 line。
将 value 追加到 line。
令 maximum length 为 75。
当 line 的码点 长度大于 maximum length 时:
将 line 的前 maximum length 个码点追加到 output。
从 line 中移除前 maximum length 个码点。
将一个 U+000D CARRIAGE RETURN 字符(CR)追加到 output。
将一个 U+000A LINE FEED 字符(LF)追加到 output。
将一个 U+0020 SPACE 字符追加到 output。
令 maximum length 为 74。
将 line(剩余的内容)追加到 output。
将一个 U+000D CARRIAGE RETURN 字符(CR)追加到 output。
将一个 U+000A LINE FEED 字符(LF)追加到 output。
当上述步骤要求用户代理获得在 subitem 中收集名为 subname 的 vCard 子属性的结果时,用户 代理必须运行以下步骤:
当上述步骤要求用户代理获得在 subitem 中收集第一个名为 subname 的 vCard 子属性的结果时,用户 代理必须运行以下步骤:
当上述算法要求用户代理转义 vCard 文本 字符串 value 时,用户代理必须使用 以下步骤:
在 value 中的每个 U+005C REVERSE SOLIDUS 字符(\)前加上 另一个 U+005C REVERSE SOLIDUS 字符(\)。
在 value 中的每个 U+002C COMMA 字符(,)前加上一个 U+005C REVERSE SOLIDUS 字符(\)。
在 value 中的每个 U+003B SEMICOLON 字符(;)前加上一个 U+005C REVERSE SOLIDUS 字符(\)。
将 value 中的每个 U+000D CARRIAGE RETURN U+000A LINE FEED 字符对(CRLF)替换为一个 U+005C REVERSE SOLIDUS 字符(\),后跟一个 U+006E LATIN SMALL LETTER N 字符(n)。
将 value 中剩余的每个 U+000D CARRIAGE RETURN(CR)或 U+000A LINE FEED(LF)字符 替换为一个 U+005C REVERSE SOLIDUS 字符(\),后跟一个 U+006E LATIN SMALL LETTER N 字符(n)。
返回修改后的 value。
如果输入不符合为 http://microformats.org/profile/hcard
项目类型和已定义属性
名称所述的规则,则此算法可能生成无效的 vCard 输出。
本节是非规范性的。
下面是一个名为“杰克·鲍尔”的虚构角色的较长 vCard 示例:
< section id = "jack" itemscope itemtype = "http://microformats.org/profile/hcard" >
< h1 itemprop = "fn" >
< span itemprop = "n" itemscope >
< span itemprop = "given-name" > 杰克</ span >
< span itemprop = "family-name" > 鲍尔</ span >
</ span >
</ h1 >
< img itemprop = "photo" alt = "" src = "jack-bauer.jpg" >
< p itemprop = "org" itemscope >
< span itemprop = "organization-name" > 反恐小组</ span >
(< span itemprop = "organization-unit" > 洛杉矶分部</ span > )
</ p >
< p >
< span itemprop = "adr" itemscope >
< span itemprop = "street-address" > 西皮科大道 10201 号</ span >< br >
< span itemprop = "locality" > 洛杉矶</ span > ,
< span itemprop = "region" > CA</ span >
< span itemprop = "postal-code" > 90064</ span >< br >
< span itemprop = "country-name" > 美国</ span >< br >
</ span >
< span itemprop = "geo" > 34.052339;-118.410623</ span >
</ p >
< h2 > 各种联系方式</ h2 >
< ul >
< li itemprop = "tel" itemscope >
< span itemprop = "value" > +1 (310) 597 3781</ span > < span itemprop = "type" > 工作</ span >
< meta itemprop = "type" content = "voice" >
</ li >
< li >< a itemprop = "url" href = "https://en.wikipedia.org/wiki/Jack_Bauer" > 我在维基百科上</ a >
,因此你可以在我的用户讨论页留言。</ li >
< li >< a itemprop = "url" href = "http://www.jackbauerfacts.com/" > 杰克·鲍尔事迹</ a ></ li >
< li itemprop = "email" >< a href = "mailto:j.bauer@la.ctu.gov.invalid" > j.bauer@la.ctu.gov.invalid</ a ></ li >
< li itemprop = "tel" itemscope >
< span itemprop = "value" > +1 (310) 555 3781</ span > < span >
< meta itemprop = "type" content = "cell" > 移动电话</ span >
</ li >
</ ul >
< ins datetime = "2008-07-20 21:00:00+01:00" >
< meta itemprop = "rev" content = "2008-07-20 21:00:00+01:00" >
< p itemprop = "tel" itemscope >< strong > 更新!</ strong >
我的新< span itemprop = "type" > 家庭</ span > 电话号码是
< span itemprop = "value" > 01632 960 123</ span > 。</ p >
</ ins >
</ section > 这种不规则的换行是必要的,因为换行符在微数据中具有意义:例如,转换为 vCard 格式时会保留换行符。
此示例显示了一个网站的联系信息(使用 address
元素),
其中包含具有两个街道地址组成部分的地址:
< address itemscope itemtype = "http://microformats.org/profile/hcard" >
< strong itemprop = "fn" >< span itemprop = "n" itemscope >< span itemprop = "given-name" > 阿尔弗雷德</ span >
< span itemprop = "family-name" > 珀森</ span ></ span ></ strong > < br >
< span itemprop = "adr" itemscope >
< span itemprop = "street-address" > 圆形剧场大道 1600 号</ span > < br >
< span itemprop = "street-address" > 43 号楼二层</ span > < br >
< span itemprop = "locality" > 山景城</ span > ,
< span itemprop = "region" > CA</ span > < span itemprop = "postal-code" > 94043</ span >
</ span >
</ address > vCard 词汇表也可以只用于标记人名:
< span itemscope itemtype = "http://microformats.org/profile/hcard"
>< span itemprop = fn >< span itemprop = "n" itemscope >< span itemprop = "given-name"
> 乔治</ span > < span itemprop = "family-name" > 华盛顿</ span ></ span
></ span ></ span > 这会创建一个具有两个名称—值对的项目,其中一个名称为“fn”,值为 “乔治·华盛顿”;另一个名称为“n”,其值为第二个项目。第二个 项目具有“given-name”和“family-name”两个名称—值对,其值分别为“乔治”和 “华盛顿”。这被定义为映射到以下 vCard:
BEGIN:VCARD PROFILE:VCARD VERSION:4.0 SOURCE:文档的地址 FN:George Washington N:Washington;George;;; END:VCARD
具有项目类型 http://microformats.org/profile/hcalendar#vevent 的项目表示
一个事件。
此词汇表不支持项目的全局标识符。
以下是该类型的已定义属性 名称。它们基于《互联网日历和 日程安排核心对象规范》(iCalendar)中定义的词汇表,有关 如何解释这些值的更多信息可以在其中找到。[RFC5545]
此处仅使用 iCalendar 词汇表中与事件有关的部分;此 词汇表无法表示完整的 iCalendar 实例。
attach给出与事件相关联的文档地址。
每个类型为 http://microformats.org/profile/hcalendar#vevent 的项目中,可以存在任意数量名为 attach 的属性。
categories给出可用于对事件进行分类的类别或标签名称。
值必须是文本。
每个类型为 http://microformats.org/profile/hcalendar#vevent 的项目中,可以存在任意数量名为 categories
的属性。
class给出有关事件信息的访问分类。
值必须是具有以下 值之一的文本:
publicprivateconfidential这仅供参考,不能视为保密 措施。
每个类型为 http://microformats.org/profile/hcalendar#vevent 的项目中,可以存在一个名为 class 的属性。
comment给出有关事件的评论。
值必须是文本。
每个类型为 http://microformats.org/profile/hcalendar#vevent 的项目中,可以存在任意数量名为 comment 的属性。
description给出事件的详细说明。
值必须是文本。
每个类型为 http://microformats.org/profile/hcalendar#vevent 的项目中,可以存在一个名为 description 的属性。
geo给出事件的地理位置。
值必须是文本,并且必须 匹配以下语法:
应包含以星号(*)标记的可选组成部分,并且每个组成部分都应包含六位 数字。
该值按此顺序指定纬度和经度(即“LAT LON” 顺序),单位为十进制度。经度分别使用正实数或负实数表示本初 子午线以东和以西的位置。纬度分别使用正实数或负实数表示 赤道以北和以南的位置。
每个类型为 http://microformats.org/profile/hcalendar#vevent 的项目中,可以存在一个名为 geo 的属性。
location给出事件的地点。
值必须是文本。
每个类型为 http://microformats.org/profile/hcalendar#vevent 的项目中,可以存在一个名为 location 的属性。
resources给出事件所需的资源。
值必须是文本。
每个类型为 http://microformats.org/profile/hcalendar#vevent 的项目中,可以存在任意数量名为 resources 的属性。
status给出事件的确认状态。
值必须是具有以下 值之一的文本:
tentativeconfirmedcanceled每个类型为 http://microformats.org/profile/hcalendar#vevent 的项目中,可以存在一个名为 status 的属性。
summary给出事件的简短摘要。
值必须是文本。
用户代理在使用值时,应将其中的 U+000A LINE FEED(LF)字符替换为 U+0020 SPACE 字符。
每个类型为 http://microformats.org/profile/hcalendar#vevent 的项目中,可以存在一个名为 summary 的属性。
dtend给出事件结束的日期和时间。
如果类型为 http://microformats.org/profile/hcalendar#vevent
的项目中存在名为 dtend 的属性,并且该项目
具有一个名为 dtstart、
其值为有效日期
字符串的属性,则名为 dtend 的属性的值也必须是一个有效日期
字符串的文本。否则,该属性的值必须是一个有效全局日期和时间字符串的文本。
无论哪种情况,该值在时间上都必须晚于同一项目的 dtstart 属性值。
dtend 属性给出的时间
不包含在事件内。因此,对于持续一整天的事件,dtend
属性的值将是事件
结束日期的次日。
每个类型为 http://microformats.org/profile/hcalendar#vevent 的项目中,可以存在一个名为 dtend 的属性,前提是该 http://microformats.org/profile/hcalendar#vevent
没有名为 duration 的属性。
dtstart给出事件开始的日期和时间。
值必须是一个 有效日期字符串或一个有效全局日期 和时间字符串的文本。
每个类型为 http://microformats.org/profile/hcalendar#vevent 的项目中,必须恰好存在一个名为 dtstart 的属性。
duration给出事件的持续时间。
值必须是一个有效 vEvent 持续时间字符串的文本。
所表示的持续时间是值中各整数表示的所有持续时间之和。
每个类型为 http://microformats.org/profile/hcalendar#vevent 的项目中,可以存在一个名为 duration 的属性,前提是该 http://microformats.org/profile/hcalendar#vevent
没有名为 dtend 的属性。
transp给出在进行忙闲时间查询时,是否应将该事件视为占用日历中的时间。
值必须是具有以下 值之一的文本:
opaquetransparent每个类型为 http://microformats.org/profile/hcalendar#vevent 的项目中,可以存在一个名为 transp 的属性。
contact给出事件的联系信息。
值必须是文本。
每个类型为 http://microformats.org/profile/hcalendar#vevent 的项目中,可以存在任意数量名为 contact 的属性。
url给出事件的 URL。
每个类型为 http://microformats.org/profile/hcalendar#vevent 的项目中,可以存在一个名为 url 的属性。
uid给出与事件相对应的全局唯一标识符。
值必须是文本。
每个类型为 http://microformats.org/profile/hcalendar#vevent 的项目中,可以存在一个名为 uid 的属性。
exdate给出尽管存在重复规则,事件仍不会发生的日期和时间。
值必须是一个 有效日期字符串或一个有效全局日期 和时间字符串的文本。
每个类型为 http://microformats.org/profile/hcalendar#vevent 的项目中,可以存在任意数量名为 exdate 的属性。
rdate给出事件重复发生的日期和时间。
值必须是以下 形式之一的文本:
每个类型为 http://microformats.org/profile/hcalendar#vevent 的项目中,可以存在任意数量名为 rdate 的属性。
rrule给出用于查找事件发生日期和时间的规则。
值必须是与 iCalendar 中定义的 RECUR 值类型匹配的文本。[RFC5545]
每个类型为 http://microformats.org/profile/hcalendar#vevent 的项目中,可以存在一个名为 rrule 的属性。
created给出事件信息首次在日历 系统中创建的日期和时间。
值必须是一个有效 全局日期和时间字符串的文本。
每个类型为 http://microformats.org/profile/hcalendar#vevent 的项目中,可以存在一个名为 created 的属性。
last-modified给出事件信息最后一次在日历 系统中修改的日期和时间。
值必须是一个有效 全局日期和时间字符串的文本。
每个类型为 http://microformats.org/profile/hcalendar#vevent 的项目中,可以存在一个名为 last-modified
的属性。
sequence给出事件信息的修订编号。
每个类型为 http://microformats.org/profile/hcalendar#vevent 的项目中,可以存在一个名为 sequence 的属性。
如果一个字符串与以下模式匹配,则它是一个有效 vEvent 持续时间字符串:
一个 U+0050 LATIN CAPITAL LETTER P 字符(P)。
以下情况之一:
给定 Document 中的节点列表
nodes,用户代理必须运行以下算法,以提取这些节点表示的任何
vEvent 数据:
如果 nodes 中没有任何节点是类型为 http://microformats.org/profile/hcalendar#vevent
的项目,则不存在
vEvent 数据。中止算法,并且不返回任何内容。
令 output 为空字符串。
向 output 添加一行
iCalendar,
其类型为“BEGIN”,
值为“VCALENDAR”。
向 output 添加一行 iCalendar,
其类型为“PRODID”,
值等于表示用户代理的用户代理特定字符串。
向 output 添加一行 iCalendar,
其类型为“VERSION”,
值为“2.0”。
对于 nodes 中每个属于类型为 http://microformats.org/profile/hcalendar#vevent
的项目的节点 node,运行以下
步骤:
向 output 添加一行 iCalendar,
其类型为“BEGIN”,
值为“VEVENT”。
向 output 添加一行 iCalendar,
其类型为“DTSTAMP”,值由表示当前日期和时间的 iCalendar DATE-TIME 字符串组成,
并带有注解“VALUE=DATE-TIME”。
[RFC5545]
对于作为项目 node 的属性的每个元素 element:对于 element 的属性名称中的每个名称 name,从以下列表中运行适当的一组子步骤:
跳过该属性。
dtend
dtstartexdaterdate
createdlast-modified
令 value 为从该属性的值中移除所有 U+002D HYPHEN-MINUS(-)和 U+003A COLON(:)字符所得的结果。
如果该属性的值是一个有效日期
字符串,则向 output 添加一行 iCalendar,
其类型为 name、值为 value,并带有注解
“VALUE=DATE”。
否则,如果该属性的值是一个
有效全局日期和时间
字符串,则向 output 添加一行 iCalendar,
其类型为 name、值为 value,并带有注解
“VALUE=DATE-TIME”。
否则,跳过该属性。
向 output 添加一行 iCalendar,其类型为 name,值为该属性的值。
向 output 添加一行 iCalendar,
其类型为“END”,
值为“VEVENT”。
向 output 添加一行 iCalendar,
其类型为“END”,值为
“VCALENDAR”。
当上述算法要求用户代理向字符串 output 添加一行 iCalendar, 该行由类型 type、值 value 和可选的 注解组成时,用户代理必须运行以下步骤:
令 line 为空字符串。
将 type 转换为 ASCII 大写形式,并追加到 line。
如果存在注解:
将一个 U+003B SEMICOLON 字符(;)追加到 line。
将注解追加到 line。
将一个 U+003A COLON 字符(:)追加到 line。
在 value 中的每个 U+005C REVERSE SOLIDUS 字符(\)前加上 另一个 U+005C REVERSE SOLIDUS 字符(\)。
在 value 中的每个 U+002C COMMA 字符(,)前加上一个 U+005C REVERSE SOLIDUS 字符(\)。
在 value 中的每个 U+003B SEMICOLON 字符(;)前加上一个 U+005C REVERSE SOLIDUS 字符(\)。
将 value 中的每个 U+000D CARRIAGE RETURN U+000A LINE FEED 字符对(CRLF)替换为一个 U+005C REVERSE SOLIDUS 字符(\),后跟一个 U+006E LATIN SMALL LETTER N 字符(n)。
将 value 中剩余的每个 U+000D CARRIAGE RETURN(CR)或 U+000A LINE FEED(LF)字符 替换为一个 U+005C REVERSE SOLIDUS 字符(\),后跟一个 U+006E LATIN SMALL LETTER N 字符(n)。
将 value 追加到 line。
令 maximum length 为 75。
当 line 的码点 长度大于 maximum length 时:
将 line 的前 maximum length 个码点追加到 output。
从 line 中移除前 maximum length 个码点。
将一个 U+000D CARRIAGE RETURN 字符(CR)追加到 output。
将一个 U+000A LINE FEED 字符(LF)追加到 output。
将一个 U+0020 SPACE 字符追加到 output。
令 maximum length 为 74。
将 line(剩余的内容)追加到 output。
将一个 U+000D CARRIAGE RETURN 字符(CR)追加到 output。
将一个 U+000A LINE FEED 字符(LF)追加到 output。
如果输入不符合为 http://microformats.org/profile/hcalendar#vevent
项目类型和已定义属性名称所述的规则,则此算法可能生成无效的
iCalendar 输出。
本节是非规范性的。
下面是一个使用 vEvent 词汇表标记事件的页面示例:
< body itemscope itemtype = "http://microformats.org/profile/hcalendar#vevent" >
...
< h1 itemprop = "summary" > 忧郁星期二:金钱之路</ h1 >
...
< time itemprop = "dtstart" datetime = "2009-05-05T19:00:00Z" > 5 月 5 日晚上 7 点</ time >
(至 < time itemprop = "dtend" datetime = "2009-05-05T21:00:00Z" > 晚上 9 点</ time > )
...
< a href = "http://livebrum.co.uk/2009/05/05/bluesday-tuesday-money-road"
rel = "bookmark" itemprop = "url" > 此页面的链接</ a >
...
< p > 地点:< span itemprop = "location" > The RoadHouse</ span ></ p >
...
< p >< input type = button value = "添加到日历"
onclick = "location = getCalendar(this)" ></ p >
...
< meta itemprop = "description" content = "来自 livebrum.co.uk" >
</ body > getCalendar() 函数留作读者的练习。
同一页面还可以提供如下标记, 供复制并粘贴到博客中:
< div itemscope itemtype = "http://microformats.org/profile/hcalendar#vevent" >
< p > 我要去参加
< strong itemprop = "summary" > 忧郁星期二:金钱之路</ strong > ,
< time itemprop = "dtstart" datetime = "2009-05-05T19:00:00Z" > 5 月 5 日晚上 7 点</ time >
至 < time itemprop = "dtend" datetime = "2009-05-05T21:00:00Z" > 晚上 9 点</ time > ,
地点是 < span itemprop = "location" > The RoadHouse</ span > !</ p >
< p >< a href = "http://livebrum.co.uk/2009/05/05/bluesday-tuesday-money-road"
itemprop = "url" > 在 livebrum.co.uk 上查看此事件</ a > 。</ p >
< meta itemprop = "description" content = "来自 livebrum.co.uk" >
</ div > 具有项目类型 http://n.whatwg.org/work 的项目表示一项作品(例如文章、
图像、视频、歌曲等)。此类型主要用于允许作者为作品包含
许可信息。
以下是该类型的已定义属性 名称。
work标识所描述的作品。
每个类型为 http://n.whatwg.org/work 的项目中,必须恰好存在一个名为 work 的属性。
title给出作品的名称。
每个类型为 http://n.whatwg.org/work 的项目中,可以存在一个名为 title 的属性。
author给出作品的一位作者或创作者的名称或联系信息。
值必须是类型为 http://microformats.org/profile/hcard
的项目或文本。
每个类型为 http://n.whatwg.org/work 的项目中,可以存在任意数量名为 author 的属性。
license标识可获得该作品所依据的一种许可。
每个类型为 http://n.whatwg.org/work 的项目中,可以存在任意数量名为 license 的属性。
本节是非规范性的。
此示例显示了一幅题为《我的池塘》的嵌入图像,该图像同时依据 知识共享署名—相同方式共享 4.0 国际许可协议和 MIT 许可证 进行许可。
< figure itemscope itemtype = "http://n.whatwg.org/work" >
< img itemprop = "work" src = "mypond.jpeg" >
< figcaption >
< p >< cite itemprop = "title" > 我的池塘</ cite ></ p >
< p >< small > 依据 < a itemprop = "license"
href = "https://creativecommons.org/licenses/by-sa/4.0/" > 知识共享
署名—相同方式共享 4.0 国际许可协议</ a >
和 < a itemprop = "license"
href = "http://www.opensource.org/licenses/mit-license.php" > MIT
许可证</ a > 进行许可。</ small >
</ figcaption >
</ figure > 给定 Document 中的节点列表
nodes,用户代理必须
运行以下算法,以将这些节点中的微数据提取为
JSON 形式:
此算法返回一个具有单个数组属性的对象,而不是 直接返回数组,以便将来在必要时可以扩展该算法。
当用户代理要为项目 item 获取对象时, 可以选择性地传入元素列表 memory,它必须运行以下 子步骤:
令 result 为空对象。
如果没有向算法传入 memory,则令 memory 为空列表。
将 item 添加到 memory。
如果 item 具有任何项目类型,则向
result 添加一个名为“type”的条目,其值是按
itemtype 属性中指定顺序列出
item 的项目类型的数组。
令 properties 为空对象。
对于每个具有一个或多个属性名称,并且是项目 item 的属性之一的元素 element,按照返回项目属性的算法给出这些元素的顺序,运行 以下子步骤:
向 result 添加一个名为“properties”的条目,其
值为对象 properties。
返回 result。
例如,考虑以下标记:
<!DOCTYPE HTML>
< html lang = "en" >
< title > 我的博客</ title >
< article itemscope itemtype = "http://schema.org/BlogPosting" >
< header >
< h1 itemprop = "headline" > 进展报告</ h1 >
< p >< time itemprop = "datePublished" datetime = "2013-08-29" > 今天</ time ></ p >
< link itemprop = "url" href = "?comments=0" >
</ header >
< p > 总的来说,他的游泳课进展不错。最大的问题是他不敢
把头浸入水中,不过我们已经解决了。</ p >
< section >
< h1 > 评论</ h1 >
< article itemprop = "comment" itemscope itemtype = "http://schema.org/UserComments" id = "c1" >
< link itemprop = "url" href = "#c1" >
< footer >
< p > 发布者:< span itemprop = "creator" itemscope itemtype = "http://schema.org/Person" >
< span itemprop = "name" > 格雷格</ span >
</ span ></ p >
< p >< time itemprop = "commentTime" datetime = "2013-08-29" > 15 分钟前</ time ></ p >
</ footer >
< p > 哈!</ p >
</ article >
< article itemprop = "comment" itemscope itemtype = "http://schema.org/UserComments" id = "c2" >
< link itemprop = "url" href = "#c2" >
< footer >
< p > 发布者:< span itemprop = "creator" itemscope itemtype = "http://schema.org/Person" >
< span itemprop = "name" > 夏洛特</ span >
</ span ></ p >
< p >< time itemprop = "commentTime" datetime = "2013-08-29" > 5 分钟前</ time ></ p >
</ footer >
< p > 你说“我们已经解决了”时……</ p >
</ article >
</ section >
</ article > 上述算法会将其转换为以下 JSON(假设该页面的
URL 为 https://blog.example.com/progress-report):
{
"items" : [
{
"type" : [ "http://schema.org/BlogPosting" ],
"properties" : {
"headline" : [ "Progress report" ],
"datePublished" : [ "2013-08-29" ],
"url" : [ "https://blog.example.com/progress-report?comments=0" ],
"comment" : [
{
"type" : [ "http://schema.org/UserComments" ],
"properties" : {
"url" : [ "https://blog.example.com/progress-report#c1" ],
"creator" : [
{
"type" : [ "http://schema.org/Person" ],
"properties" : {
"name" : [ "Greg" ]
}
}
],
"commentTime" : [ "2013-08-29" ]
}
},
{
"type" : [ "http://schema.org/UserComments" ],
"properties" : {
"url" : [ "https://blog.example.com/progress-report#c2" ],
"creator" : [
{
"type" : [ "http://schema.org/Person" ],
"properties" : {
"name" : [ "Charlotte" ]
}
}
],
"commentTime" : [ "2013-08-29" ]
}
}
]
}
}
]
} 仅一个引擎支持。
所有当前引擎均支持。
所有 都可以设置 hidden 内容
属性。 属性
是一个,具有
以下关键字和状态:
| 关键字 | 状态 | 简要说明 |
|---|---|---|
hidden
|
隐藏 | 不会被渲染。 |
until-found
|
找到之前隐藏 | 不会被渲染,但其内部的内容可供 和访问。 |
当元素的 属性处于 状态时,这表示该元素尚未与页面的当前状态直接相关,或已不再 与其直接相关,或者该元素用于声明要由页面其他部分重复使用的内容,而不是供用户直接访问。 用户代理不应渲染处于状态的元素。
要求用户代理不得渲染处于状态的元素,可以 通过样式层间接实现。例如,Web 浏览器可以使用“渲染”一节中 建议的规则实现这些要求。
当元素的 属性处于状态时,这表示该 元素像处于状态一样被隐藏,但 元素内部的内容可供和访问。当这些功能尝试滚动到 位于该元素子树中的目标时,用户代理将在滚动到内容之前移除 属性,以显示 内容,具体方法是对目标节点运行。
当 属性处于状态时,Web 浏览器将使用 'content-visibility: hidden' 而不是 'display: none', 如“渲染”一节所规定。
由于此属性通常使用 CSS 实现,因此也可以使用 CSS 覆盖它。 例如,对所有元素应用 'display: block' 的规则会抵消 状态的效果。因此,作者在编写样式表时 必须谨慎,以确保该属性仍按预期设置样式。此外,不支持状态的旧版用户代理将使用 'display: none' 而不是 'content-visibility: hidden',因此建议作者确保其样式 表不会更改元素的 'display' 或 'content-visibility' 属性。
由于 属性处于状态的元素使用 'content-visibility: hidden' 而不是 'display: none',因此状态有两个注意事项,使其 不同于 状态:
元素需要受影响,才能 通过页面内查找显示。这意味着,如果处于状态的元素的 'display' 值为 'none'、'contents' 或 'inline',则该元素不会通过页面内查找显示。
元素处于状态时仍会具有一个,这意味着 元素周围的边框、外边距和内边距仍会被渲染。
在以下框架示例中,该属性用于隐藏 Web 游戏的主屏幕, 直到用户登录:
< h1 > 示例游戏</ h1 >
< section id = "login" >
< h2 > 登录</ h2 >
< form >
...
<!-- 检查用户凭据后调用 login() -->
</ form >
< script >
function login() {
// 切换屏幕
document. getElementById( 'login' ). hidden = true ;
document. getElementById( 'game' ). hidden = false ;
}
</ script >
</ section >
< section id = "game" hidden >
...
</ section > 属性不得 用于隐藏可以合理地在另一种呈现中显示的内容。例如,使用 隐藏选项卡式 对话框中的面板是不正确的,因为选项卡式界面 只是一种溢出呈现方式——同样可以在一个带滚动条的大页面中显示所有表单 控件。同样,使用此属性只在一种呈现中隐藏 内容也是不正确的——如果某些内容被标记为 ,则它会在所有 呈现中隐藏,包括屏幕阅读器等。
自身未被设置为 的元素不得
到被设置为 的元素。自身未被
设置为 的
和 元素的
for 属性同样不得引用被设置为
的元素。在这两种
情况下,此类引用都会导致用户
困惑。
但是,元素和脚本可以在其他上下文中引用被设置为 的元素。
例如,使用 属性链接到用 属性标记的章节 是不正确的。如果该内容不适用或不相关,就没有理由链接到它。
但是,可以使用 ARIA 属性引用自身被设置为 的说明。虽然隐藏 这些说明意味着它们单独使用时没有用处,但可以采用某种方式编写它们,使其在 从其所描述的元素引用时的特定上下文中有用。
同样,具有 属性的 元素可以由脚本化图形引擎用作离屏缓冲区,而表单控件 可以使用其 属性引用隐藏的 元素。
位于由 属性隐藏的章节中的元素仍然 处于活动状态,例如,这些章节中的脚本和表单控件仍分别会执行和提交。 只有其向用户呈现的方式发生变化。
所有当前引擎均支持。
hidden 获取器
步骤
是:
如果 属性 处于状态,则返回“”。
如果设置了 属性, 则返回 true。
返回 false。
设置器步骤是:
如果给定值是一个字符串,并且与 “” 匹配, 则将 属性 设置为“”。
否则,如果给定值为 false,则移除 属性。
否则,如果给定值为空字符串,则移除 属性。
否则,如果给定值为 null,则移除 属性。
否则,如果给定值为 0,则移除 属性。
否则,如果给定值为 NaN,则移除 属性。
否则,将 属性设置为空 字符串。
祖先显示对是一个,由一个节点和一个字符串组成。
给定节点 target 的祖先显示算法如下:
令 ancestorsToReveal 为 « »。
令 ancestor 为 target。
当 ancestor 在中具有父节点时:
如果 ancestor 具有处于
状态的
属性,则将
(ancestor,
“until-found”)到
ancestorsToReveal。
如果 ancestor 被分配到一个没有 属性的
元素的第二个槽中,则将(ancestor 的父节点,“details”)到
ancestorsToReveal。
将 ancestor 设置为 ancestor 在 中的父节点。
对于 ancestorsToReveal 中的每个(ancestorToReveal, revealType):
如果 ancestorToReveal 未,则返回。
如果 revealType 为“until-found”:
如果 ancestorToReveal 的 属性 未处于状态,则 返回。
在 ancestorToReveal 上 名为 的事件, 并将 属性初始化为 true。
如果 ancestorToReveal 未,则 返回。
如果 ancestorToReveal 的 属性 未处于状态,则 返回。
从 ancestorToReveal 中移除 属性。
否则:
:revealType 为“details”。
如果 ancestorToReveal 具有 属性,则返回。
将 ancestorToReveal 的 属性设置为空字符串。
可遍历可导航对象的系统可见性状态, 包括其 创建时的初始值,由用户代理确定。它表示例如 浏览器窗口是否已最小化、浏览器选项卡当前是否位于后台,或者任务切换器等系统 元素是否遮挡了页面。
当用户代理确定可遍历可导航对象 traversable 的系统可见性状态已更改为 newState 时,它 必须运行以下步骤:
令 navigables 为 traversable 的活动文档的含自身后代可导航对象。
对于 navigables 中的每个 navigable 按什么顺序?:
令 document 为 navigable 的活动 文档。
给定 document 的相关全局对象,在用户交互 任务源上将一个全局任务加入队列,以使用 newState 更新 document 的可见性状态。
Document 具有一个可见性状态,其值
为“hidden”或“visible”,初始设置为
“hidden”。
所有当前引擎均支持。
所有当前引擎均支持。
要将 Document document 的
可见性状态更新为
visibilityState:
如果 document 的可见性 状态等于 visibilityState, 则返回。
将 document 的可见性 状态设置为 visibilityState。
将一个新的
VisibilityStateEntry
加入队列,其
可见性状态为
visibilityState,其时间戳为给定
document 的相关全局对象时的当前高分辨率时间。
使用 document 运行屏幕方向更改步骤。 [SCREENORIENTATION]
使用 document 运行视图过渡页面可见性更改 步骤。
使用可见性状态和 document,运行其他 规范中可能定义的任何页面可见性更改步骤。
如果规范作者提交拉取请求,直接从此处向其规范中添加调用, 而不是使用页面可见性更改 步骤钩子,会更好,这样可确保跨规范调用顺序得到明确定义。截至 编写本文时,已知以下规范具有页面可见性更改 步骤,这些步骤将以未指定的顺序运行:Device Posture API 和 Web NFC。[DEVICEPOSTURE] [WEBNFC]
在 document 上触发一个名为
visibilitychange
的事件,并将其 bubbles
属性
初始化为 true。
要将 Document document 的
初始可见性状态设置为
visibilityState:
VisibilityStateEntry
接口仅一个引擎支持。
VisibilityStateEntry
接口从文档变为活动状态的时刻起,
公开文档的可见性更改。
function wasHiddenBeforeFirstContentfulPaint() {
const fcpEntry = performance. getEntriesByName( "first-contentful-paint" )[ 0 ];
const visibilityStateEntries = performance. getEntriesByType( "visibility-state" );
return visibilityStateEntries. some( e =>
e. startTime < fcpEntry. startTime &&
e. name === "hidden" );
} 由于隐藏页面可能会导致渲染和其他用户代理 操作受到节流,因此通常将可见性更改用作已发生此类节流的指示。 但是,不同浏览器中的其他情况也可能导致节流,例如 长时间不活动。
[Exposed =(Window )]
interface VisibilityStateEntry : PerformanceEntry {
readonly attribute DOMString name ; // 遮蔽继承的 name
readonly attribute DOMString entryType ; // 遮蔽继承的 entryType
readonly attribute DOMHighResTimeStamp startTime ; // 遮蔽继承的 startTime
readonly attribute unsigned long duration ; // 遮蔽继承的 duration
};VisibilityStateEntry
具有一个关联的
DOMHighResTimeStamp
时间戳。
VisibilityStateEntry
具有一个关联的“visible”或
“hidden”可见性
状态。
entryType 获取器步骤是返回
“visibility-state”。
duration 获取器步骤是返回
零。
另请参阅 inert,
以了解对同名
属性的说明。
节点(尤其是元素和文本节点)可以是惰性的。当节点 为惰性时:
命中测试必须表现得如同 'pointer-events' CSS 属性被设置为 'none'。
文本选择功能必须表现得如同 'user-select' CSS 属性 被设置为 'none'。
如果节点是可编辑的,则该节点的行为如同其不可编辑。
用户代理应在页面内查找时忽略该节点。
惰性节点通常无法获得焦点,并且用户代理不会向无障碍 API 或辅助技术公开 惰性节点。作为命令的惰性节点将以上述方式变得不可供用户操作。
但是,用户代理可以允许用户覆盖页面内查找和 文本选择方面的限制。
默认情况下,节点不是惰性的。
如果 subject 是 Document
document 的顶层中最顶端的 dialog 元素,
则 document 被模态对话框阻塞
subject。当 document 以这种方式被阻塞时,所有
连接到 document 的节点,但
subject 元素及其扁平树后代除外,都必须变为
惰性。
subject 还可以通过 inert
属性变为惰性,但仅当该属性在 subject 自身上
指定时才会如此
(即 subject 可摆脱祖先的惰性);subject 的扁平
树后代可以用类似方式变为惰性。
dialog
元素的 showModal()
方法通过将 dialog 元素
添加到其
节点文档的顶层,触发此机制。
inert 属性所有当前引擎均支持。
inert 属性是
一个布尔属性,其
存在表示用户代理要使该元素及其所有未通过其他方式摆脱惰性的扁平树后代
(例如模态对话框)变为惰性。
惰性子树不应包含对于理解或使用页面中未处于惰性状态的部分而言至关重要的
任何内容或控件。惰性子树中的内容并非所有用户都能感知,也无法进行交互。
除非元素所表示的内容也以某种方式在视觉上被遮挡,否则作者不应将元素
指定为惰性。在大多数情况下,作者不应在单个表单控件上指定 inert 属性。在这些
情况下,disabled
属性可能更
合适。
以下示例展示了如何将部分加载、在视觉上被 “正在加载”消息遮挡的内容标记为惰性。
< section aria-labelledby = s1 >
< h3 id = s1 > 各城市人口</ h3 >
< div class = container >
< div class = loading >< p > 正在加载……</ p ></ div >
< div inert >
< form >
< fieldset >
< legend > 日期范围</ legend >
< div >
< label for = start > 开始</ label >
< input type = date id = start >
</ div >
< div >
< label for = end > 结束</ label >
< input type = date id = end >
</ div >
< div >
< button > 应用</ button >
</ div >
</ fieldset >
</ form >
< table >
< caption > 从 20-- 年到 20-- 年</ caption >
< thead >
< tr >
< th > 城市</ th >
< th > 州</ th >
< th > 20-- 年人口</ th >
< th > 20-- 年人口</ th >
< th > 百分比变化</ th >
</ tr >
</ thead >
< tbody >
<!-- ... -->
</ tbody >
</ table >
</ div >
</ div >
</ section > 
“正在加载”覆盖层遮挡了惰性内容,使人能从视觉上看出惰性
内容当前不可访问。请注意,标题和“正在加载”文本并不是具有 inert
属性的元素的后代。这将确保所有用户都能访问这些文本,
同时任何人都无法与惰性内容交互。
默认情况下,没有持久的视觉指示来表明元素或其子树处于
惰性状态。此类内容的适当视觉样式通常取决于上下文。例如,
位于屏幕外的惰性导航面板不需要默认样式,因为其屏幕外位置
已在视觉上遮挡了内容。同样,模态 dialog
元素的背景层
将
作为在视觉上遮挡网页惰性内容的方式,而不必专门为惰性内容设置样式。
但是,在许多其他情况下,强烈建议作者清楚标记文档的哪些部分 处于活动状态以及哪些部分处于惰性状态,以避免用户困惑。尤其值得记住的是, 并非所有用户都能同时看到页面的所有部分;例如,屏幕阅读器用户、 使用小型设备或放大镜的用户,甚至使用特别小的窗口的用户, 都可能看不到页面的活动部分;如果惰性章节未明显表现为惰性, 他们可能会感到沮丧。
为了防止滥用某些可能令用户厌烦的 API(例如打开弹出窗口或 使手机振动),用户代理仅在用户正在主动与网页交互或至少曾与页面交互过一次时, 才允许使用这些 API。这种“主动交互”状态通过本节定义的机制 进行维护。
为了跟踪用户激活,每个 Window W 都有两个
相关值:
一个上次激活时间戳,它可以是
DOMHighResTimeStamp、
正无穷大(表示 W 从未被
激活),或负无穷大(表示激活已被消耗)。初始值为正无穷大。
一个上次历史操作激活时间戳,它可以是
DOMHighResTimeStamp
或正无穷大,初始值为正无穷大。
用户代理还会定义一个瞬时激活持续时间,它是一个 常数,表示用户激活可供某些受用户 激活限制的 API(例如用于打开弹出窗口)使用多长时间。
瞬时激活持续时间预计最多只有几 秒,以便用户能够感知到与页面交互和 页面调用受激活限制的 API 之间的联系。
于是,W 具有以下布尔用户激活状态:
这是 W 的历史激活状态,表示用户是否曾经 在 W 中进行过交互。它初始为 false,当 W 收到第一次激活通知时变为 true(并且永远不会 再变回 false)。
这是 W 的当前激活状态,表示用户最近是否 在 W 中进行过交互。它初始为 false,并且在 W 每次收到激活通知后的一段有限时间内保持为 true。
当 W 的上次历史操作激活 时间戳不等于 W 的上次 激活时间戳时,称 W 具有 历史操作激活。
这是用户激活的一种特殊变体,用于允许访问某些会话历史记录 API;如果这些 API 使用得过于频繁,用户将更难使用浏览器 UI向后遍历。它初始为 false,并且每当 用户与 W 交互时变为 true,但会通过历史操作激活 消耗重置为 false。这可确保在两次调用之间没有用户激活的情况下, 这些 API 无法连续多次使用。但与 瞬时 激活不同,此类 API 的使用没有时间 限制。
上次激活时间戳和上次历史操作
激活时间戳即使在 Document 更改其
完全活动状态后仍会保留(例如,从
一个 Document 导航离开,
或导航到缓存的 Document)。这意味着只要同一个
Document 被重复使用,粘性激活状态
就会跨越多次导航。对于瞬时激活状态,原始过期时间
保持不变(即,该状态仍会在从原始触发激活的输入事件起算的瞬时激活
持续时间限制内过期)。在决定某些事项应基于粘性
激活还是瞬时
激活时,考虑这一点非常重要。
当用户交互导致在 Document
document 中触发触发激活的输入
事件时,用户代理必须在分派该事件之前执行以下激活通知步骤:
触发激活的输入事件是其 isTrusted
属性为 true,并且其 type
为以下值之一的任何事件:
“keydown”,
前提是该按键既不是
Esc 键,也不是用户代理保留的快捷键;
“mousedown”;
“pointerdown”,
前提是该事件的
pointerType
为“mouse”;
“pointerup”,
前提是该事件的
pointerType
不是“mouse”;或
“touchend”。
消耗历史操作
激活的
API可以在给定 Window
W 的情况下,通过执行以下步骤来消耗历史操作用户激活:
如果 W 的可导航对象为 null,则 返回。
令 navigables 为 top 的活动 文档的含自身后代可导航对象。
对于 windows 中的每个 window,将 window 的上次历史操作 激活时间戳设置为 window 的 上次 激活时间戳。
请注意,页面中受激活通知和激活
消耗影响的浏览
上下文集合是不对称的:激活消耗会将页面中所有浏览
上下文的瞬时激活状态更改为 false,
但激活通知只会将这些浏览
上下文的一个子集的状态更改为 true。此处消耗的彻底性是有意为之:它可以防止恶意网站
利用一次用户激活多次调用消耗激活的 API(可能通过利用由
iframe
构成的深层层次结构)。
依赖用户激活的 API 分为不同级别:
这些 API 要求粘性 激活状态为 true,因此在第一次用户激活之前,它们会被 阻止。
这些 API 要求瞬时激活状态为 true,但它们不会 消耗该状态,因此每次用户 激活后,在瞬时状态过期之前允许多次调用。
这些 API 要求历史操作激活状态为 true,并且每次调用都会 消耗历史操作用户 激活,以防止每次 用户激活期间进行多次调用。
UserActivation 接口每个 Window 都有一个关联的 UserActivation,它是一个
UserActivation
对象。创建 Window 对象时,其
关联的
UserActivation必须设置为一个在该 Window 对象的相关
Realm中创建的新
UserActivation
对象。
[Exposed =Window ]
interface UserActivation {
readonly attribute boolean hasBeenActive ;
readonly attribute boolean isActive ;
};
partial interface Navigator {
[SameObject ] readonly attribute UserActivation userActivation ;
};navigator.userActivation.hasBeenActive
返回窗口是否具有粘性激活。
navigator.userActivation.isActive
返回窗口是否具有瞬时激活。
userActivation 获取器步骤是返回
this 的相关全局对象的关联的
UserActivation。
出于用户代理自动化和应用程序测试的目的,本规范为 WebDriver 规范定义了以下扩展 命令。用户代理可以选择是否支持以下扩展 命令。 [WEBDRIVER]
| HTTP 方法 | URI 模板 |
|---|---|
`POST` |
/session/{session id}/window/consume-user-activation |
远程端 步骤如下:
如果 window 具有瞬时激活,则令 consume 为 true;否则为 false。
如果 consume 为 true,则消耗 window 的用户激活。
返回带有数据 consume 的成功结果。
HTML 中的某些元素具有激活行为,这意味着用户
可以激活它们。这始终由 click
事件引起。
用户代理应允许用户手动触发具有激活
行为的元素,例如使用键盘或语音输入,或通过鼠标点击。当
用户以点击之外的方式触发具有已定义激活行为的元素时,
交互事件的默认操作必须是在该元素上触发一个 click 事件。
element.click()
所有当前引擎均支持。
表现得如同该元素被点击。
每个元素都有一个关联的点击正在进行标志,该标志初始为 未设置。
click() 方法必须
运行
以下步骤:
ToggleEvent 接口所有当前引擎均支持。
所有当前引擎均支持。
[Exposed =Window ]
interface ToggleEvent : Event {
constructor (DOMString type , optional ToggleEventInit eventInitDict = {});
readonly attribute DOMString oldState ;
readonly attribute DOMString newState ;
readonly attribute Element ? source ;
};
dictionary ToggleEventInit : EventInit {
DOMString oldState = "";
DOMString newState = "";
Element ? source = null ;
};event.oldState
从关闭转换为打开时设置为“closed”,从打开转换为关闭时设置为
“open”。
event.newState
从关闭转换为打开时设置为“open”,从打开转换为关闭时设置为“closed”。
event.source设置为发起切换的元素,该元素可使用 popovertarget 和
commandfor
属性进行设置。如果没有源元素,
则设置为 null。
所有当前引擎均支持。
所有当前引擎均支持。
oldState 和 newState 属性必须返回它们
初始化时所用的值。
source
获取器步骤是返回将 source
针对 this 的 currentTarget
进行重新定向所得的结果。
DOM 标准问题 #1328 跟踪如何以一种对事件合理的方式更好地标准化关联的事件数据。 当前,初始化为某个值的事件属性不能同时具有获取器,因此需要一个内部 槽(或附加字段的映射)才能正确规定这一点。
切换任务跟踪器是一个结构体,它具有:
ToggleEvent 的任务。oldState
属性值的字符串。CommandEvent 接口[Exposed =Window ]
interface CommandEvent : Event {
constructor (DOMString type , optional CommandEventInit eventInitDict = {});
readonly attribute Element ? source ;
readonly attribute DOMString command ;
};
dictionary CommandEventInit : EventInit {
Element ? source = null ;
DOMString command = "";
};event.command
返回该元素能够执行的操作。
event.source
返回为了引发此事件而与之交互的 Element。
command 属性必须返回它
初始化时所用的值。
source
获取器步骤是
返回将 source
针对 this 的 currentTarget
进行重新定向所得的结果。
DOM 标准问题 #1328 跟踪如何以一种对事件合理的方式更好地标准化关联的事件数据。 当前,初始化为某个值的事件属性不能同时具有获取器,因此需要一个内部 槽(或附加字段的映射)才能正确规定这一点。
本节是非规范性的。
HTML 用户界面通常由多个交互式部件组成,例如表单 控件、可滚动区域、链接、对话框、浏览器选项卡等。这些部件构成 一个层次结构,其中一些部件(例如浏览器选项卡、对话框)包含其他部件(例如链接、表单 控件)。
使用键盘与界面交互时,按键输入会从系统 经由交互式部件的层次结构传送到一个活动部件,该部件称为 已聚焦。
考虑一个在图形环境中运行的浏览器选项卡内运行的 HTML 应用程序。 假设该应用程序有一个包含若干文本控件和链接的页面,并且当前显示着 一个模态对话框,该对话框本身又具有一个文本控件和一个按钮。
在这种情况下,可聚焦部件的层次结构将包括浏览器窗口, 其子项中会包含运行 HTML 应用程序的浏览器选项卡。该选项卡本身 的子项包括各种链接和文本控件,以及该对话框。该对话框 本身的子项包括文本控件和按钮。
如果此示例中具有焦点的部件是对话框中的文本 控件,则按键输入将从图形系统传送到 ① Web 浏览器,然后传送到 ② 选项卡,再传送到 ③ 对话框,最后传送到 ④ 文本 控件。
键盘事件始终以此已聚焦元素为目标。
当一个顶级可遍历对象的系统可见性状态为
“visible”,并且它具有系统焦点,或者与其直接相关的用户代理部件可以接收从操作系统传送的键盘
输入时,该对象具有用户注意力。
当浏览器窗口失去焦点时,用户注意力会丢失,而系统焦点 还可能转移到浏览器窗口中的其他系统部件,例如地址栏。
术语可聚焦区域用于指代可以进一步成为 此类键盘输入目标的界面区域。可聚焦区域可以是元素、元素的一部分或由 用户代理管理的其他区域。
每个可聚焦区域都有一个DOM
锚点,它是一个 Node
对象,
表示可聚焦区域在
DOM 中的位置。(当可聚焦
区域本身就是一个 Node
时,
它就是自己的DOM 锚点。)当没有其他 DOM 对象
可用于表示可聚焦区域时,某些 API 会使用DOM 锚点
代替可聚焦
区域。
下表描述了哪些对象可以是可聚焦 区域。左列中的单元格描述可以作为可聚焦区域的对象;右列中的单元格描述这些元素的DOM 锚点。(跨越两列的单元格是非规范性示例。)
| 可聚焦区域 | DOM 锚点 |
|---|---|
| 示例 | |
满足以下所有条件的元素:
|
元素本身。 |
|
|
|
与一个正在被渲染且不是惰性的
img 元素相关联的图像映射中,area 元素的形状。
|
img 元素。
|
|
在以下示例中, |
|
| 正在被渲染,并且并非 实际禁用或惰性的元素中,由用户代理提供的子部件。 | 其可聚焦区域是一个子部件的元素。 |
|
|
|
| 正在被 渲染且不是惰性的元素的可滚动区域。 | 为可滚动区域所滚动的框而创建的元素。 |
|
CSS 'overflow' 属性的 'scroll' 值通常会创建 一个可滚动区域。 |
|
具有非 null浏览上下文且不是惰性的 Document 的视口。
|
为其创建视口的 Document。
|
|
|
|
| 用户代理判定为可聚焦区域的任何其他元素或元素的一部分, 特别是为了帮助实现无障碍或更好地符合平台约定。 | 该元素。 |
|
用户代理可以使所有列表项项目符号都可顺序 聚焦,以便用户可以更轻松地浏览列表。 |
|
可导航容器(例如
iframe)是一个可聚焦区域,但路由到可导航
容器的按键事件会立即被路由到其内容
可导航对象的活动文档。同样,在
顺序焦点导航中,可导航容器实质上只是充当
其内容
可导航对象的活动文档的占位符。
每个 Document 中都有一个可聚焦区域被指定为文档的已聚焦
区域。根据本规范中的算法,被如此指定的控件会随时间而变化。
即使文档不是完全活动的且 未向用户显示,它仍可以具有文档的已聚焦区域。如果文档的完全 活动状态发生变化,其文档的已聚焦区域将保持不变。
traversable 这一顶级可遍历对象的当前已聚焦区域是由此算法 返回的可聚焦区域或 null:
当一个元素是某个可聚焦区域的DOM 锚点,并且该可聚焦区域成为 顶级可遍历对象的当前已聚焦区域时, 称该元素获得焦点。当一个元素是顶级可遍历对象的当前已聚焦区域的某个可聚焦区域的DOM 锚点时,该元素是已聚焦的。
可聚焦区域 subject 的焦点链是按如下方式构造的有序 列表:
令 output 为一个空列表。
令 currentObject 为 subject。
当 true 时:
将 currentObject 追加到 output。
如果 currentObject 是一个 area 元素的形状,则将该
area 元素追加到
output。
否则,如果 currentObject 的DOM 锚点是一个并非 currentObject 本身的元素,则将 currentObject 的DOM 锚点追加到 output。
如果 currentObject 是一个可聚焦 区域,则将 currentObject 设置为 currentObject 的DOM 锚点的节点 文档。
否则,如果 currentObject 是一个 Document,且其节点
可导航对象的父级非 null,则将
currentObject 设置为 currentObject 的节点可导航对象的父级。
否则,中断。
返回 output。
该链以 subject 开始,并且(如果 subject 是或可以成为
顶级可遍历对象的当前已聚焦区域)
沿焦点层次结构向上延伸,直至顶级可遍历对象的 Document。
所有作为可聚焦区域的元素都称为 可聚焦的。
可聚焦 区域有两种特殊的可聚焦性:
如果用户代理判定一个可聚焦区域可点击聚焦,则称其可点击聚焦。用户代理应将具有非 null tabindex 值的可聚焦区域视为可点击聚焦。
不是可聚焦的元素不是可聚焦区域,因此既不可顺序聚焦,也不可点击 聚焦。
“可聚焦”描述的是元素是否可以通过编程方式
获得焦点,例如通过 focus() 方法或
autofocus 属性。相比之下,
可顺序
聚焦和可点击聚焦控制用户代理如何响应用户
交互:分别响应顺序焦点导航以及作为
激活行为。
根据用户首选项,即使一个元素是可聚焦的,并且包含在其 Document 的顺序
焦点导航顺序中,用户代理仍可能判定该元素不可顺序聚焦。例如,macOS 用户可以设置
用户代理跳过非表单控件元素,或者仅使用 Tab 键(而不是同时使用
Option 和 Tab 键)进行顺序
焦点导航时跳过链接。
同样,即使元素是可聚焦的,用户代理仍可能判定该元素不可点击聚焦。 例如,在某些用户代理中,点击不可 编辑的表单控件不会使其获得焦点,即用户代理判定此类 控件不可点击聚焦。
因此,一个元素可以是可聚焦的,但既不可顺序 聚焦也不可点击聚焦。例如, 在某些用户代理中,具有负整数tabindex 值的 不可编辑表单控件不能通过用户交互获得焦点,只能通过编程 API 获得焦点。
请注意,聚焦并不是一种激活行为,即在元素上调用
click() 方法或在其上分派合成 click
事件不会使该元素获得焦点。
每个焦点导航作用域 所有者都有一个焦点导航作用域,它 是一个元素列表。其内容按如下方式确定:
每个元素 element 都有一个关联的焦点导航 所有者,它可以是 null 或一个焦点 导航作用域所有者。它由以下 算法确定:
然后,给定焦点导航作用域所有者 owner 的焦点导航作用域的内容,是所有其关联焦点导航 所有者为 owner 的元素。
焦点导航作用域内元素的顺序不会影响 本规范中的任何算法。顺序仅对下面定义的 按 tabindex 排序的焦点导航作用域和扁平化的按 tabindex 排序的焦点 导航作用域概念具有重要意义。
按 tabindex 排序的焦点导航作用域是一个由可聚焦区域和焦点导航 作用域所有者组成的列表。每个焦点导航作用域所有者 owner 都有一个按 tabindex 排序的焦点导航作用域,其 内容按如下方式 确定:
它包含 owner 的焦点导航作用域中 自身也是焦点 导航作用域所有者的所有元素, 但tabindex 值为负整数的元素除外。
它包含所有其DOM 锚点是 owner 的焦点导航作用域中的元素的可聚焦区域, 但tabindex 值 为负整数的可聚焦区域除外。
按 tabindex 排序的焦点导航作用域中的顺序 由每个 元素的tabindex 值决定,如下一节所述。
那里的规则没有给出精确顺序,因为它们主要由 “应当”语句和相对顺序组成。
扁平化的按 tabindex 排序的焦点导航 作用域是一个可聚焦区域列表。每个 焦点导航作用域 所有者 owner 都拥有一个不同的扁平化的按 tabindex 排序的焦点导航 作用域, 其内容由以下算法确定:
令 result 为 owner 的 按 tabindex 排序的焦点导航作用域的副本。
对于 result 中的每个 item:
如果 item 不是焦点导航作用域所有者,则 继续。
如果 item 不是可聚焦 区域,则使用 item 的扁平化的按 tabindex 排序的焦点 导航 作用域中的所有项替换 item。
否则,将 item 的扁平化的按 tabindex 排序的 焦点导航作用域的内容插入到 item 之后。
tabindex 属性所有当前引擎均支持。
tabindex
内容属性允许作者使一个元素以及以该元素作为其
DOM 锚点的区域成为可聚焦区域,允许或阻止
它们可顺序
聚焦,并确定它们在
顺序焦点
导航中的相对顺序。
“tab 索引”这一名称源自在可聚焦元素之间导航时通常使用 Tab 键。 “按 Tab 键切换”这一术语是指在可顺序 聚焦的可聚焦区域之间向前移动。
如果指定了 tabindex
属性,则其值必须
是一个有效整数。正数指定
元素的可聚焦区域在顺序
焦点
导航顺序中的相对位置,负数表示该控件不可
顺序聚焦。
开发者在为 tabindex 属性使用 0 或 −1
以外的值时应谨慎,因为正确使用这些值较为复杂。
以下是对
tabindex
属性可能取值的行为的非规范性摘要。下面的
处理模型给出了更精确的规则。
tabindex 属性值较大的元素
排在较后位置。
请注意,tabindex
属性不能用于使
元素变得不可聚焦。页面作者唯一能做到这一点的方法是禁用该元素,或使其
成为惰性。
元素的tabindex 值是其 tabindex 属性的值,使用
整数解析
规则进行解析。如果解析失败或未指定该属性,则tabindex
值为 null。
元素的tabindex 值必须按以下方式 解释:
用户代理应遵循平台约定来确定该元素是否应被视为 可聚焦区域;如果是,则确定 该元素以及以该元素作为 DOM 锚点的任何可聚焦 区域是否可顺序 聚焦;如果是,则确定它们在其 按 tabindex 排序的焦点导航 作用域中的相对位置。如果该元素 是焦点 导航作用域所有者,即使它不是可聚焦 区域,也必须将其包含在其 按 tabindex 排序的焦点导航 作用域中。
对于属于同一 焦点导航作用域 且tabindex 值为 null 的 元素和可聚焦区域, 它们在按 tabindex 排序的焦点导航 作用域中的相对顺序应遵循 包含 shadow 的树顺序。
用户代理必须将该元素视为可聚焦区域,但应从任何 按 tabindex 排序的焦点导航 作用域中省略该元素。
忽略“不允许作者通过顺序焦点导航引导至该元素”这一要求的一个合理原因,
是用户移动焦点的唯一机制就是顺序焦点导航。例如,仅使用键盘的用户无法
点击具有负 tabindex 的文本控件,
因此该用户的用户代理完全有理由允许用户通过按 Tab 键导航到该控件,
而不受此限制。
用户代理必须允许该元素被视为可聚焦区域,并且 应允许该元素以及以 该元素作为DOM 锚点的任何可聚焦区域可顺序 聚焦。
对于属于同一 焦点导航 作用域且tabindex 值 为零的元素和可聚焦区域, 它们在按 tabindex 排序的焦点导航 作用域中的相对顺序应遵循 包含 shadow 的树顺序。
用户代理必须允许该元素被视为可聚焦区域,并且 应允许该元素以及以 该元素作为DOM 锚点的任何可聚焦区域可顺序 聚焦,并且 应将该元素——下文称为 candidate——以及上述可聚焦区域放入 该元素所属的 按 tabindex 排序的焦点导航 作用域中,使它们相对于属于同一 焦点 导航作用域的其他元素和可聚焦 区域:
tabindex 属性已被
省略,或其值在解析时
返回错误,
tabindex 属性值
小于或等于零,
tabindex 属性值
大于零,但小于
candidate 上的 tabindex 属性值,
tabindex 属性值
等于 candidate 上的 tabindex 属性值,
但在包含 shadow 的树顺序中
位于 candidate 之前,
tabindex 属性值
等于 candidate 上的 tabindex 属性值,
但在包含 shadow 的树顺序中
位于 candidate 之后,并且
tabindex 属性值
大于 candidate 上的
tabindex 属性值。
所有当前引擎均支持。
tabIndex
获取器步骤如下:
根据元素类型而变化的默认值是历史遗留产物。
要为一个焦点目标获取可聚焦区域,该目标是一个
本身不是可聚焦区域的元素,
或者是一个可导航对象,并给定一个
可选字符串焦点触发器(默认为“other”),运行以下列表中第一个
匹配的步骤集:
area 元素,且其一个或
多个形状是
可聚焦区域
根据对扁平树进行的前序深度优先 遍历,返回该元素的第一个可滚动区域。[CSSSCOPING]
Document 的文档元素
令 focusedElement 为顶级可遍历对象的当前已聚焦 区域的DOM 锚点。
如果焦点目标是 focusedElement 的包含 shadow 的含自身祖先,则返回 focusedElement。
返回给定焦点触发器时 焦点目标的焦点委托。
对于顺序可聚焦性, 对shadow 宿主和委托焦点的处理, 是在构造顺序焦点导航顺序时完成的。也就是说, 在顺序焦点导航过程中,绝不会对这种shadow 宿主调用聚焦步骤。
返回 null。
给定可选字符串
focusTrigger(默认为“other”)时,focusTarget 的焦点委托由以下步骤给出:
如果 focusTarget 是一个shadow 宿主,并且 其shadow 根的委托焦点为 false, 则返回 null。
令 whereToLook 为 focusTarget。
如果 whereToLook 是一个shadow 宿主,则 将 whereToLook 设置为 whereToLook 的shadow 根。
令 autofocusDelegate 为给定 focusTrigger 时 whereToLook 的自动聚焦委托。
如果 autofocusDelegate 不为 null,则返回 autofocusDelegate。
对于 whereToLook 的后代中的每个 descendant,按树 顺序:
令 focusableArea 为 null。
如果 focusTarget 是一个 dialog 元素,
并且 descendant
可顺序
聚焦,则将 focusableArea 设置为
descendant。
否则,如果 focusTarget 不是 dialog,并且
descendant 是一个可聚焦区域,则将 focusableArea 设置为
descendant。
否则,将 focusableArea 设置为给定 focusTrigger 时,为 descendant 获取可聚焦区域所得的结果。
如果 focusableArea 不为 null,则返回 focusableArea。
这里重要的是,我们查看的不是包含 shadow 的后代,而只是 后代。Shadow 宿主则由上面提到的递归情况处理。
返回 null。
上述算法实质上返回第一个合适的可聚焦 区域,在该区域的DOM 锚点和 focusTarget 之间的路径上,任何 shadow 树边界都会委托焦点。
给定一个焦点触发器时,焦点目标的自动聚焦委托由以下步骤给出:
对象新焦点目标的聚焦步骤如下,该对象 可以是一个 可聚焦区域、一个本身 不是可聚焦区域的元素,或者一个 可导航对象。这些步骤可以选择在给定 一个后备 目标和一个字符串焦点触发器的情况下运行。
对象旧焦点目标的取消聚焦步骤如下,该对象 可以是可聚焦区域,或一个本身不是可聚焦区域的元素:
如果旧焦点目标是一个shadow 宿主,其 shadow 根的委托焦点为 true, 并且旧焦点目标的shadow 根 是顶级可遍历对象的当前已聚焦区域的DOM 锚点的包含 shadow 的含自身祖先, 则将旧焦点目标设置为 该顶级可遍历对象的当前已聚焦区域。
如果旧焦点目标是惰性的,则返回。
如果旧焦点目标是一个 area 元素,并且其
某个形状是
顶级可遍历对象的当前已聚焦区域,
或者,如果旧焦点目标是具有一个或多个可滚动区域的元素,并且其中一个区域是
顶级可遍历对象的当前已聚焦区域,
则令旧焦点目标为该顶级可遍历对象的当前已聚焦区域。
令旧链为旧焦点 目标所在顶级可遍历对象的当前焦点链。
如果旧焦点目标不是旧 链中的某一项,则返回。
如果旧焦点目标不是可聚焦区域,则返回。
令 topDocument 为旧链的最后一项。
如果 topDocument 的节点 可导航对象具有系统焦点,则为 topDocument 的视口运行聚焦步骤。
否则,应用任何相关的平台特定约定,从 topDocument 的节点可导航对象移除系统 焦点,并使用旧链、一个空列表和 null 运行焦点 更新步骤。
取消聚焦步骤并不总是会导致焦点发生变化,即使 将其应用于顶级可遍历对象的当前已聚焦区域。 例如,如果顶级可遍历对象的当前已聚焦区域是一个 视口,那么在使用聚焦步骤显式聚焦另一个 可聚焦区域之前,它通常会一直保持焦点。
分别给定一个旧链、一个新链 和一个新焦点目标时,焦点更新步骤如下:
如果旧链的最后一项和新链的最后一项相同,则从 旧链中弹出最后一项, 并从新链中弹出最后一项,然后重新执行此步骤。
对于旧链中的每个项 entry,按顺序运行 以下子步骤:
如果 entry 是一个 input 元素,
并且 change 事件适用于
该元素,并且该元素没有已定义的激活行为,并且
用户在控件获得焦点期间更改了该元素的值或其
已选文件列表,但未提交该更改
(因此它与控件最初获得焦点时的值不同):
如果 entry 是一个元素,则令模糊事件目标为 entry。
如果 entry 是一个 Document 对象,则令模糊
事件目标为
该 Document 对象的相关全局
对象。
否则,令模糊事件目标为 null。
如果 entry 是旧链的最后一项,并且
entry 是一个 Element,
并且新
链的最后一项也是一个 Element,
则令相关模糊目标
为新链的最后一项。否则,令相关模糊
目标为 null。
如果模糊事件目标不为 null,则在模糊
事件目标上触发一个焦点事件,
其名称为 blur,并将
相关模糊目标用作相关目标。
应用任何与聚焦新焦点目标相关的平台特定约定。 (例如,某些平台在文本控件获得焦点时会选择该控件的内容。)
对于新链中的每个项 entry,按相反 顺序运行以下子步骤:
如果 entry 是一个可聚焦区域,并且文档的已聚焦 区域不是 entry:
将 document 的相关全局对象的导航 API的正在进行导航期间焦点已更改 设置为 true。
将 entry 指定为文档的已聚焦区域。
如果 entry 是一个元素,则令焦点事件目标为 entry。
如果 entry 是一个 Document 对象,则令焦点
事件目标为
该 Document 对象的相关全局
对象。
否则,令焦点事件目标为 null。
如果 entry 是新链的最后一项,并且
entry 是一个 Element,
并且旧
链的最后一项也是一个 Element,
则令相关焦点目标
为旧链的最后一项。否则,令相关
焦点目标为 null。
如果焦点事件目标不为 null,则在焦点
事件目标上触发一个焦点事件,
其名称为 focus,并将
相关焦点目标用作相关目标。
要在元素 t 上使用给定相关目标 r触发一个焦点事件,其名称为 e,则在
t 上触发一个事件,
其名称为 e,使用 FocusEvent,
将 relatedTarget
属性初始化为 r,
将 view
属性初始化为 t 的
节点文档的相关全局对象,并设置composed
标志。
当要在一个顶级可遍历对象中路由按键事件时,用户代理必须 运行以下步骤:
给定一个 Document 对象 target
时,
具有焦点步骤如下:
每个 Document 都有一个顺序焦点导航顺序,它对
Document 中的部分或全部可聚焦区域进行相对排序。
其内容和顺序由该 Document 的
扁平化的按 tabindex 排序的
焦点导航作用域给出。
根据定义扁平化的按 tabindex 排序的
焦点导航
作用域的规则,该顺序不一定与
Document 的树顺序相关。
如果一个可聚焦区域被从其
Document 的顺序焦点导航
顺序中省略,则无法通过顺序焦点
导航到达该区域。
还可以有一个顺序焦点导航起始点。它最初 未设置。当用户指示应移动该起始点时,用户代理可以设置它。
例如,如果用户点击文档内容,用户代理可以将其设置为用户点击的位置。
在导航到片段时,用户代理必须将顺序焦点导航起始 点设置为目标元素。
顺序焦点方向是以下两个可能值之一:“forward”或“backward”。下面的算法使用它们
来描述顺序焦点应用户请求移动的方向。
选择机制是以下两个可能值之一:“DOM”或
“sequential”。它们用于
描述顺序导航搜索算法如何找到其返回的
可聚焦
区域。
当用户请求将焦点从顶级可遍历对象的当前已聚焦 区域移动到下一个或上一个可聚焦区域时(例如,作为按下 tab 键的默认操作),或者当用户最初请求将焦点按顺序移动到一个顶级可遍历对象时(例如,从 浏览器的位置栏移入),用户代理必须使用以下算法:
如果用户请求从顶级可遍历对象的当前已聚焦 区域按顺序移动焦点,则令 starting point 为该区域;否则,如果用户请求从 顶级可遍历对象之外移动焦点,则令 starting point 为该顶级 可遍历对象本身。
如果已定义一个顺序焦点导航 起始点,并且它位于 starting point 内部,则改为令 starting point 为该顺序 焦点导航起始点。
如果用户请求下一个控件,则令 direction 为“forward”;
如果用户请求上一个控件,则令其为“backward”。
通常,按下 tab 会请求下一个控件,而按下 shift + tab 会请求上一个控件。
循环:如果 starting point 是一个可导航对象,或者
starting point 位于其 Document 的顺序焦点导航顺序中,则令
selection mechanism 为“sequential”。
否则,starting point 不在其 Document 的顺序
焦点导航顺序中;令 selection mechanism 为“DOM”。
令 candidate 为使用 starting point、direction 和 selection mechanism 运行顺序导航搜索 算法所得的结果。
如果 candidate 不为 null,则为 candidate 运行聚焦步骤并返回。
否则,取消设置顺序焦点导航 起始点。
如果 starting point 是一个顶级可遍历对象,或是该顶级 可遍历对象中的一个可聚焦区域,则用户代理 应适当地将焦点转移到其自身的控件(如果有),并遵循 direction,然后返回。
例如,如果 direction 为向后,那么浏览器渲染区域之前的最后一个 可顺序 聚焦控件将成为要聚焦的控件。
如果用户代理没有可顺序聚焦的控件(例如自助终端模式 浏览器),则用户代理可以改为重新开始这些步骤,并将 starting point 设置为顶级可遍历对象本身。
否则,starting point 是一个子 可导航对象中的可聚焦区域。将 starting point 设置为该子可导航对象的父级,然后返回标有循环的步骤。
给定一个可聚焦区域 starting point、一个顺序焦点方向 direction 和 一个选择机制 selection mechanism 时,顺序导航搜索算法由以下步骤组成。 它们返回一个可聚焦 区域或 null。
从下表中选择适当的单元格,并遵循该单元格中的说明。
适当的单元格位于其表头描述 direction 的列中,并位于其表头描述 starting point 和 selection mechanism 的第一个行中。
direction 为“forward”
|
direction 为“backward”
|
|
|---|---|---|
| starting point 是一个可导航对象 | 如果存在,则令 candidate 为 starting point 的活动文档中的第一个合适的可顺序聚焦 区域;否则为 null。 | 如果存在,则令 candidate 为 starting point 的活动文档中的最后一个合适的可顺序 聚焦区域;否则为 null。 |
selection mechanism 为“DOM”
|
如果存在,则令 candidate 为在 starting point 的
在这种情况下,starting point 不一定属于其
|
如果存在,则令 candidate 为在 starting point 的
Document 中,按包含 shadow 的树顺序,出现在
starting point 之前且距离最近的合适的可顺序
聚焦区域;否则为 null。
|
selection mechanism 为“sequential”
|
如果存在,则令 candidate 为 starting point 的 Document 的
顺序焦点导航
顺序中位于 starting point 之后的第一个合适的可顺序
聚焦区域;否则为 null。
|
如果存在,则令 candidate 为 starting point 的 Document 的
顺序焦点导航
顺序中位于 starting point 之前的最后一个合适的可顺序
聚焦区域;否则为 null。
|
如果 candidate 是一个具有非 null内容 可导航对象的可导航容器:
令 recursive candidate 为使用 candidate 的内容可导航对象、
direction 和“sequential”
运行顺序
导航搜索算法所得的结果。
如果 recursive candidate 为 null,则返回使用 candidate、direction 和 selection mechanism 运行顺序导航搜索 算法所得的结果。
否则,将 candidate 设置为 recursive candidate。
返回 candidate。
dictionary FocusOptions {
boolean preventScroll = false ;
boolean focusVisible ;
};documentOrShadowRoot.activeElement
所有当前引擎均支持。
所有当前引擎均支持。
返回 documentOrShadowRoot 中按键事件正经由其路由或路由至其的最深层元素。 粗略地说,这就是文档中已聚焦的元素。
就此 API 而言,当一个子可导航对象获得焦点时,其容器在其父级的活动
文档中被视为已聚焦。例如,如果用户将焦点移动到
iframe 中的文本控件,
则在该 iframe 的节点文档中,activeElement
API 返回的元素是该 iframe。
同样,当已聚焦元素位于与 documentOrShadowRoot 不同的节点树中时,如果 documentOrShadowRoot 是已聚焦元素的包含 shadow 的含自身祖先,则返回的元素将是与 documentOrShadowRoot 位于同一节点 树中的宿主;否则返回 null。
document.hasFocus()
所有当前引擎均支持。
如果按键事件正经由 document 路由或路由至 document,则返回 true;否则 返回 false。粗略地说,这对应于 document 或嵌套在 document 内的文档已获得焦点。
window.focus()
所有当前引擎均支持。
如果存在,则将焦点移动到 window 的可导航对象。
element.focus()
所有当前引擎均支持。
element.focus({ preventScroll, focusVisible })
将焦点移动到 element。
如果 element 是一个可导航容器,则改为将焦点移动到其 内容可导航对象。
默认情况下,此方法还会将 element 滚动到视图中。提供 preventScroll
选项并将其设置为 true
可阻止此行为。
默认情况下,用户代理使用由实现定义的启发式方法来确定
是否通过焦点环指示焦点。
提供 focusVisible
选项并将其设置为 true 将确保焦点环始终可见。
element.blur()
所有当前引擎均支持。
将焦点移动到视口。不建议使用此方法;如果要聚焦
视口,请在
Document 的文档元素上调用 focus() 方法。
如果认为焦点环不美观,请勿使用此方法隐藏焦点环。相反,
请使用 :focus-visible
伪类覆盖 'outline'
属性,并提供另一种方式来显示哪个元素已获得焦点。请注意,如果未提供
替代聚焦样式,那么主要使用键盘浏览页面的用户,或依赖焦点
轮廓帮助浏览页面的视力较弱用户,将会发现页面的可用性显著降低。
例如,要隐藏 textarea 元素的轮廓,
并改用黄色背景指示焦点,可以使用:
textarea:focus-visible { outline : none; background : yellow; color : black; } DocumentOrShadowRoot
的 activeElement 获取器步骤如下:
Window 的 focus() 方法步骤如下:
所有当前引擎均支持。
Window 的 blur() 方法步骤是什么也不做。
从历史上看,focus()
和 blur() 方法实际上会影响
包含可导航对象的系统部件(例如选项卡或窗口)的系统级焦点,
但恶意网站普遍滥用此行为,损害了用户利益。
HTMLOrSVGOrMathMLElement
的
focus(options) 方法步骤如下:
HTMLOrSVGOrMathMLElement
的 blur()
方法步骤如下:
例如,如果不恰当地使用 blur()
方法来出于美观原因移除焦点环,则页面将无法供键盘用户使用。
因此,忽略对此方法的调用将允许键盘用户与页面交互。
给定一个 Document 对象
target 时,允许焦点步骤如下:
如果允许 target 使用“focus-without-user-activation”
特性,则返回 true。
返回 false。
autofocus 属性autofocus
内容属性允许作者指示元素应在页面加载后立即获得焦点,使用户无需手动
聚焦主要元素即可直接开始输入。
当在 dialog
元素内部的元素,或 popover 属性已设置的HTML 元素内部的元素上指定
autofocus
属性时,该元素将在对话框或
弹出框显示时获得焦点。
给定一个
Element
element 时,要查找最近的祖先自动聚焦作用域根元素:
不得存在两个具有同一个最近的祖先自动聚焦作用域
根
元素,并且都指定了 autofocus 属性的元素。
每个 Document 都有一个最初为空的
自动聚焦候选项列表。
每个 Document 都有一个
自动聚焦已处理标志布尔值,初始为
false。
在将元素存储到自动聚焦候选项列表之前,我们不会检查该元素是否为 可聚焦区域,因为即使它在 插入时不是可聚焦区域,到清空自动聚焦候选项处理它时,它也可能 已经变成可聚焦区域。
要为文档 topDocument 清空自动聚焦候选项,运行以下 步骤:
如果 topDocument 的自动聚焦已处理标志为 true,则 返回。
令 candidates 为 topDocument 的自动聚焦 候选项。
如果 candidates 为空,则 返回。
如果 topDocument 的已聚焦区域 不是 topDocument 本身,或者 topDocument 具有非 null 目标元素:
当 candidates 不为空时:
令 element 为 candidates[0]。
令 doc 为 element 的节点 文档。
如果 doc 的节点 可导航对象的顶级 可遍历对象与 topDocument 的节点可导航对象不同, 则从 candidates 中移除 element, 然后继续。
在这种情况下,element 是当前最佳候选项,但 doc 尚未准备好进行自动聚焦。下次调用清空 自动聚焦候选项时,我们会再次尝试。
从 candidates 中移除 element。
令 inclusiveAncestorDocuments 为一个列表,其中包含 doc 的含自身 祖先可导航对象的活动文档。
如果 inclusiveAncestorDocuments 中的任何 Document 具有非 null
目标元素,则继续。
令 target 为 element。
如果 target 不是一个可聚焦区域,则将 target 设置为 为 target 获取可聚焦区域所得的结果。
自动聚焦候选项可以包含并非可聚焦
区域的元素。除获取可聚焦
区域算法所处理的特殊情况外,还可能因为具有
autofocus
属性的非可聚焦区域元素被插入文档后始终未变为可聚焦,
或者该元素原本可聚焦,但在存储于自动聚焦
候选项期间其状态发生了变化。
如果 target 不为 null:
这会处理文档加载期间的自动聚焦。dialog
元素的 show() 和 showModal()
方法也会处理 autofocus 属性。
聚焦元素并不意味着用户代理在浏览器窗口已失去焦点时必须聚焦该窗口。
在以下代码片段中,文档加载时文本控件将获得焦点。
< input maxlength = "256" name = "q" value = "" autofocus >
< input type = "submit" value = "Search" > autofocus
属性适用于所有元素,而不仅仅适用于表单控件。这样便可以实现如下示例:
< div contenteditable autofocus > Edit < strong > me!</ strong >< div > 本节是非规范性的。
可以使用 accesskey 属性,
为每个可激活或可聚焦的元素分配一个用于激活它的单一组合键。
具体的快捷键由用户代理根据用户键盘的信息、平台上已有的键盘快捷键以及
页面上已指定的其他快捷键来确定,并将 accesskey 属性中
提供的信息用作指导。
为确保各种输入设备上都有可用的相关键盘快捷键,作者可以在 accesskey 属性中
提供多个替代项。
每个替代项都由单个字符组成,例如字母或数字。
用户代理可以向用户提供键盘快捷键列表,也鼓励作者这样做。accessKeyLabel IDL 属性
返回一个表示用户代理实际分配的组合键的字符串。
在此示例中,作者提供了一个可使用快捷键调用的按钮。为了 支持完整键盘,作者提供了“C”作为可能的按键。为了支持 仅配备数字键盘的设备,作者还提供了“1”作为另一个可能的按键。
< input type = button value = Collect onclick = "collect()"
accesskey = "C 1" id = c > 为了告诉用户快捷键是什么,作者在此选择显式地 将组合键添加到按钮的标签中:
function addShortcutKeyLabel( button) {
if ( button. accessKeyLabel != '' )
button. value += ' (' + button. accessKeyLabel + ')' ;
}
addShortcutKeyLabel( document. getElementById( 'c' )); 不同平台上的浏览器即使针对相同组合键,也会根据该平台上普遍使用的约定 显示不同的标签。例如,如果组合键由 Control 键、Shift 键和字母 C 组成, Windows 浏览器可能显示“Ctrl+Shift+C”,而 Mac 浏览器可能显示 “^⇧C”,Emacs 浏览器则可能只显示“C-C”。 同样,如果组合键由 Alt 键和 Escape 键组成,Windows 可能使用 “Alt+Esc”,Mac 可能使用“⌥⎋”,而 Emacs 浏览器可能使用 “M-ESC”或“ESC ESC”。
因此,一般而言,尝试解析 accessKeyLabel IDL 属性
返回的值是不明智的。
accesskey
属性所有当前引擎均支持。
所有HTML 元素都可以设置 accesskey
内容属性。用户代理将 accesskey
属性的值用作指导,
创建可激活或聚焦该元素的键盘快捷键。
如果指定了该属性,则其值必须是一个由空格分隔的唯一标记有序集, 其中没有任何标记与另一个标记相同,并且每个标记的长度必须恰好为一个 码点。
在以下示例中,为各种链接提供了访问键,以便熟悉该网站的键盘用户 可以更快地导航到相关页面:
< nav >
< p >
< a title = "Consortium Activities" accesskey = "A" href = "/Consortium/activities" > Activities</ a > |
< a title = "Technical Reports and Recommendations" accesskey = "T" href = "/TR/" > Technical Reports</ a > |
< a title = "Alphabetical Site Index" accesskey = "S" href = "/Consortium/siteindex" > Site Index</ a > |
< a title = "About This Site" accesskey = "B" href = "/Consortium/" > About Consortium</ a > |
< a title = "Contact Consortium" accesskey = "C" href = "/Consortium/contact" > Contact</ a >
</ p >
</ nav > 在以下示例中,为搜索字段提供了两个可能的访问键“s”和“0”(按此顺序)。 配有完整键盘的设备上的用户代理可能会选择 Ctrl + Alt + S 作为快捷键,而仅配有数字键盘的小型设备上的 用户代理可能只选择未经修饰的普通 0 键:
< form action = "/search" >
< label > Search: < input type = "search" name = "q" accesskey = "s 0" ></ label >
< input type = "submit" >
</ form > 在以下示例中,描述了按钮的可能访问键。随后脚本尝试 更新按钮的标签,以告知用户代理选择的组合键。
< input type = submit accesskey = "N @ 1" value = "Compose" >
...
< script >
function labelButton( button) {
if ( button. accessKeyLabel)
button. value += ' (' + button. accessKeyLabel + ')' ;
}
var inputs = document. getElementsByTagName( 'input' );
for ( var i = 0 ; i < inputs. length; i += 1 ) {
if ( inputs[ i]. type == "submit" )
labelButton( inputs[ i]);
}
</ script > 在一个用户代理中,按钮标签可能变为“Compose (⌘N)”。在 另一个用户代理中,它可能变为“Compose (Alt+⇧+1)”。如果用户代理未 分配按键,则它将只是“Compose”。确切的字符串取决于 已分配的访问键是什么,以及 用户代理如何表示该组合键。
元素的已分配访问键是从该元素的
accesskey
内容属性派生的组合键。最初,元素不得
具有已分配的访问
键。
每当元素的 accesskey
属性被设置、更改
或移除时,用户代理必须通过运行以下步骤来更新元素的已分配访问键:
如果元素没有 accesskey
属性,则跳到下面的后备步骤。
否则,在 ASCII 空白处拆分属性值,并令 keys 为所得的标记。
对于 keys 中的每个值,按照标记在属性值中出现的顺序, 依次运行以下子步骤:
如果该值不是长度恰好为一个码点的字符串,则跳过针对此值的其余步骤。
如果该值不对应系统键盘上的按键,则跳过针对此值的其余步骤。
![]() 如果用户代理可以找到零个或多个修饰键的某种组合,使其与属性中给定值对应的按键
结合后可用作访问键,则用户代理可以将该按键组合分配为元素的已分配访问键并
返回。
如果用户代理可以找到零个或多个修饰键的某种组合,使其与属性中给定值对应的按键
结合后可用作访问键,则用户代理可以将该按键组合分配为元素的已分配访问键并
返回。
后备:用户代理可以选择将其自行选定的组合键 分配为元素的已分配访问键,然后返回。
如果执行到此步骤,则元素没有已分配访问键。
一旦用户代理为元素选择并分配了访问键,除非 accesskey
内容属性发生更改,或该元素被移动到
另一个 Document,
否则用户代理不应更改元素的已分配访问键。
当用户按下与某个元素的已分配访问键 对应的组合键时,如果该元素定义了命令,该 命令的方面为 false(可见), 该命令的禁用状态方面也为 false (已启用),该元素位于具有非 null浏览 上下文的文档中,并且该元素及其任何祖先都未指定 属性, 则用户代理必须触发该命令的操作。
用户代理还可以公开具有
accesskey
属性的元素的其他访问方式,例如在响应特定组合键而显示的菜单中公开它们。
accessKeyLabel IDL 属性必须返回一个表示元素
的已分配访问键(如果有)的字符串。
如果元素没有已分配访问键,则该 IDL 属性必须返回空字符串。
contenteditable 内容
属性所有当前引擎均支持。
interface mixin ElementContentEditable {
[CEReactions ] attribute DOMString contentEditable ;
[CEReactions ] attribute DOMString enterKeyHint ;
readonly attribute boolean isContentEditable ;
[CEReactions ] attribute DOMString inputMode ;
};Global_attributes/contenteditable
所有当前引擎均支持。
contenteditable 内容属性是一个
枚举属性,具有
以下关键字和状态:
| 关键字 | 状态 | 简要说明 |
|---|---|---|
true
|
真 | 元素可编辑。 |
false
|
假 | 元素不可编辑。 |
plaintext-only
|
仅纯文本 | 只有元素的原始文本内容可编辑;富文本格式被禁用。 |
例如,考虑一个具有 form 和 textarea 的页面,
用于发布新文章,并期望用户使用 HTML 编写文章:
< form method = POST >
< fieldset >
< legend > New article</ legend >
< textarea name = article > < p>Hello world.< /p></ textarea >
</ fieldset >
< p >< button > Publish</ button ></ p >
</ form > 启用脚本后,可以使用 contenteditable
属性将 textarea 元素
替换为富文本控件:
< form method = POST >
< fieldset >
< legend > New article</ legend >
< textarea id = textarea name = article > < p>Hello world.< /p></ textarea >
< div id = div style = "white-space: pre-wrap" hidden >< p > Hello world.</ p ></ div >
< script >
let textarea = document. getElementById( "textarea" );
let div = document. getElementById( "div" );
textarea. hidden = true ;
div. hidden = false ;
div. contentEditable = "true" ;
div. oninput = ( e) => {
textarea. value = div. innerHTML;
};
</ script >
</ fieldset >
< p >< button > Publish</ button ></ p >
</ form > 可启用的功能(例如插入链接)可以使用 document.execCommand()
API 实现,也可以使用
Selection
API 和其他 DOM API 实现。[EXECCOMMAND] [SELECTION]
[DOM]
contenteditable
属性还可以发挥极大作用:
<!doctype html>
< html lang = en >
< title > Live CSS editing!</ title >
< style style = white-space:pre contenteditable >
html { margin : .2 em ; font-size : 2 em ; color : lime ; background : purple }
head , title , style { display : block }
body { display : none }
</ style > element.contentEditable [ = value ]
根据 contenteditable
属性的状态,返回“true”、“plaintext-only”、“false”或
“inherit”。
可以设置该值以更改该状态。
如果新值不是这些字符串之一,则抛出一个“SyntaxError” DOMException。
element.isContentEditable
所有当前引擎均支持。
如果元素可编辑,则返回 true;否则返回 false。
contentEditable IDL 属性在获取时,如果内容属性设置为真状态,则必须返回字符串
“true”;如果内容属性设置为仅纯文本状态,则返回
“plaintext-only”;如果内容属性设置为假状态,则返回“false”;
否则返回“inherit”。在设置时,如果新值与字符串“inherit”进行
ASCII
大小写不敏感匹配,则必须移除内容属性;如果新值与字符串“true”进行
ASCII 大小写不敏感匹配,则
必须将内容属性设置为字符串“true”;如果新值与字符串
“plaintext-only”进行
ASCII 大小写不敏感匹配,
则必须将内容属性设置为字符串“plaintext-only”;如果
新值与字符串“false”进行ASCII
大小写不敏感匹配,则必须将内容属性设置为字符串
“false”;否则,属性设置器必须抛出一个
“SyntaxError” DOMException。
designMode
获取器和设置器
document.designMode [ = value ]
所有当前引擎均支持。
如果文档可编辑,则返回“on”;如果不可编辑,则返回“off”。
可以设置该值以更改文档的当前状态。这会聚焦文档并重置该文档中的 选择。
Document
对象具有一个关联的设计模式已启用布尔值。
其初始值为 false。
designMode
设置器步骤如下:
鼓励作者将'white-space' 属性在编辑宿主以及 最初通过这些编辑机制创建的标记上设置为 'pre-wrap'。默认 HTML 空白处理不太适合所见即所得 编辑;如果'white-space' 保持其默认值,则在某些边缘情况下换行将无法正常工作。
作为改用默认 'normal' 值时会出现的问题示例,考虑用户输入 “yellow␣␣ball”的情况,其中两个单词之间有两个空格(此处 用“␣”表示)。使用'white-space' 默认值 ('normal')的编辑规则时,所得标记将由 “yellow ball”或“yellow ball”组成; 即除了常规空格外,两个单词之间还会有一个不换行空格。这是必要的,因为 'white-space' 的 'normal' 值 要求相邻的常规空格折叠在一起。
在前一种情况下,即使只有“yellow”可能适合放在行尾, “yellow⍽”也可能换到下一行(此处使用“⍽” 表示不换行空格);在后一种情况下,如果“⍽ball”换到 行首,则会因不换行空格而产生可见缩进。
但是,当'white-space' 设置为 'pre-wrap' 时,编辑规则将只在两个单词之间放置两个常规空格, 如果两个单词在行尾被分开,这些空格会从渲染中整齐地移除。
术语活动范围、……的编辑
宿主和可编辑的的定义,
作为编辑宿主或
可编辑元素的用户界面要求,以及
execCommand()、
queryCommandEnabled()、
queryCommandIndeterm()、
queryCommandState()、
queryCommandSupported()
和
queryCommandValue()
方法、文本选择以及删除
选择算法,均在 execCommand 中定义。[EXECCOMMAND]
用户代理可以支持检查可编辑文本的拼写和语法,无论是在表单控件中
(例如 textarea
元素的值),还是在编辑宿主中的元素中(例如使用 contenteditable)。
对于每个元素,用户代理必须通过默认值或用户表达的首选项建立一个默认 行为。每个元素有三种可能的默认行为:
spellcheck 属性
显式禁用拼写检查,则会检查该元素的拼写和语法。
spellcheck
属性
显式启用拼写检查,否则永远不会检查该元素的拼写和语法。
所有当前引擎均支持。
spellcheck
属性是一个枚举
属性,具有以下关键字和状态:
| 关键字 | 状态 | 简要说明 |
|---|---|---|
true
|
真 | 将检查拼写和语法。 |
false
|
假 | 不会检查拼写和语法。 |
该属性的缺失值默认值和无效值
默认值均为默认状态。默认状态表示
元素应按照默认行为行事,该行为可能基于父元素自身的
spellcheck 状态,
如下文所定义。该属性的空值默认值是真状态。
element.spellcheck [ = value ]
如果应检查元素的拼写和语法,则返回 true;否则返回 false。
可以设置该值,以覆盖默认值并设置 spellcheck 内容
属性。
spellcheck
IDL 属性在获取时,在以下任一情况下必须返回 true:元素的 spellcheck 内容
属性处于真状态;或者元素的 spellcheck 内容
属性处于默认状态,并且元素的默认
行为为默认为真;或者元素的
spellcheck
内容属性处于默认状态,元素的默认
行为为默认继承,并且元素父
元素的 spellcheck
IDL 属性将返回 true;
否则,如果这些条件均不适用,则该属性必须返回 false。
spellcheck IDL 属性
不受覆盖 spellcheck 内容
属性的用户首选项影响,因此可能无法反映实际的拼写检查状态。
在设置时,如果新值为 true,则必须将元素的 spellcheck 内容
属性设置为
“true”;否则必须将其设置为“false”。
就此功能而言,用户代理应仅将以下文本视为可检查文本:
input 元素的值,其
type
属性处于文本、搜索、
URL 或电子邮件状态,
并且该元素是可变的(即
未指定 readonly
属性,且未被禁用)。
readonly
属性且未被禁用的 textarea
元素的值。Text
节点中的文本。对于属于 Text
节点一部分的文本,与该文本关联的元素是单词、句子或其他文本片段的第一个字符的
直接父元素。对于属性中的文本,则是该属性所属的元素。对于
input
和 textarea
元素的值,则是元素本身。
要确定适用元素(如上文定义)中的单词、句子或其他文本片段是否应启用 拼写和语法检查,用户代理必须使用以下算法:
spellcheck 内容
属性,则:如果该属性处于
真
状态,则启用检查;否则,如果该属性处于假
状态,则禁用检查。
spellcheck 内容
属性且该属性不处于默认
状态的祖先元素,则:如果最近的此类祖先的 spellcheck
内容属性处于真状态,则
启用检查;否则禁用检查。如果对单词、句子或文本启用了检查,用户代理应指示该文本中的拼写
和语法错误。用户代理在建议拼写和语法更正时,应考虑文档中给出的其他语义。
用户代理可以使用元素的语言来确定要采用的拼写和语法规则,也可以使用用户首选的
语言设置。在可能的情况下,用户代理应使用 input 元素
的属性(例如 pattern)
来确保所得值有效。
如果禁用了检查,则用户代理不应指示该文本中的拼写或语法错误。
在以下示例中,ID 为“a”的元素将用于确定是否检查 单词“Hello”的拼写错误。在此示例中,不会进行检查。
< div contenteditable = "true" >
< span spellcheck = "false" id = "a" > Hell</ span >< em > o!</ em >
</ div > 在以下示例中,ID 为“b”的元素将启用检查(input 元素
属性值中的前导空格字符会导致该属性被忽略,因此无论默认值如何,都会改用祖先的值)。
< p spellcheck = "true" >
< label > Name: < input spellcheck = " false" id = "b" ></ label >
</ p > 本规范未定义拼写和语法检查器的用户界面。用户代理可以 提供按需检查,可以在启用检查时持续执行检查,也可以使用其他界面。
当用户在可编辑区域中输入时,用户代理会提供写作建议,这些区域可以是表单
控件(例如 textarea
元素),也可以是
编辑宿主中的元素。
writingsuggestions 内容属性是一个
枚举属性,具有
以下关键字和状态:
| 关键字 | 状态 | 简要说明 |
|---|---|---|
true
|
真 | 应在此元素上提供写作建议。 |
false
|
假 | 不应在此元素上提供写作建议。 |
该属性的缺失值
默认值是默认状态。默认状态表示
元素应按照默认行为行事,该行为可能基于父
元素自身的 writingsuggestions
状态,如下文所定义。
element.writingSuggestions [ = value ]
如果用户代理应在该元素的作用域内提供写作建议,则返回
“true”;否则返回“false”。
可以设置该值,以覆盖默认值并设置
writingsuggestions 内容属性。
给定 element 的计算出的写作建议值 通过运行以下步骤确定:
如果 element 的 writingsuggestions
内容属性处于假
状态,则返回“false”。
如果 element 的 writingsuggestions
内容属性处于默认状态,element 有
父元素,并且 element 父元素的计算出的写作建议值为
“false”,则返回
“false”。
返回“true”。
writingSuggestions
IDL
属性不受覆盖 writingsuggestions
内容属性的用户首选项影响,因此
可能无法反映实际的写作建议状态。
仅当给定 element 运行以下算法所得的结果为 true 时, 用户代理才应在元素的作用域内提供建议:
本规范未定义写作建议的用户界面。 用户代理可以提供按需建议、在用户输入时持续提供建议、内联 建议、弹出框中类似自动填充的建议,或者使用其他界面。
某些文本输入方法(例如移动设备上的虚拟键盘以及语音
输入)通常会通过自动将句子的首字母大写来辅助用户(当
使用具有这种约定的语言编写文本时)。实现自动大写功能的虚拟键盘
可能会在即将输入应自动大写的字母时,自动切换为显示大写字母
(但允许用户切换回小写)。其他类型的输入(例如语音输入)可能会以
不允许用户预先干预的方式执行自动大写。autocapitalize 属性
允许作者控制此类
行为。
autocapitalize
属性的典型实现
不会影响在物理键盘上输入时的行为。(出于这个原因,并且由于
用户在某些情况下可以覆盖自动大写行为,或在初次输入后编辑
文本,因此不得依赖该属性进行任何形式的输入
验证。)
autocapitalize
属性可用于编辑宿主,以控制
其承载的可编辑区域的自动大写行为;可用于 input
或 textarea 元素,
以控制向该元素
输入文本时的行为;或者可用于 form 元素,以控制
与该 form 元素关联的所有继承 autocapitalize 和 autocorrect 的
元素的默认
行为。
autocapitalize
属性绝不会为以下 input 元素启用
自动大写:其 type 属性处于 URL、电子邮件或密码状态之一。
(此行为包含在
下文的使用的
自动大写提示算法中。)
自动大写处理模型基于从五种 自动大写提示中进行选择,其定义如下:
用户代理和输入法应自行确定是否 启用自动大写。
不应应用自动大写(所有字母默认应为 小写)。
每个句子的首字母默认应为大写字母;所有其他字母 默认应为小写。
每个单词的首字母默认应为大写字母;所有其他字母 默认应为小写。
所有字母默认应为大写。
Global_attributes/autocapitalize
所有当前引擎均支持。
autocapitalize 属性是一个枚举
属性,其状态为可能的自动大写提示。由该
属性状态指定的自动大写提示
与其他考虑因素结合,形成使用的自动大写
提示,它会告知用户代理应采用的行为。该属性的关键字及其
状态映射如下:
| 关键字 | 状态 |
|---|---|
off
|
无 |
none
|
|
on
|
句子 |
sentences
|
|
words
|
单词 |
characters
|
字符 |
element.autocapitalize [ = value ]
返回元素当前的自动大写状态;如果尚未设置,则返回空字符串。请注意,对于
从 form
元素继承状态的 input 和 textarea 元素,
这将返回
form 元素的自动大写状态;
但对于可编辑区域中的
元素,这不会返回编辑宿主的自动大写状态(除非该元素实际上就是编辑
宿主)。
可以设置该值,以设置 autocapitalize 内容
属性(从而更改元素的自动大写行为)。
要计算元素 element 的自身自动大写提示,运行 以下步骤:
如果 element 上存在 autocapitalize
内容属性,并且其值不是空字符串,则返回该
属性的状态。
如果 element 是一个继承 autocapitalize 和 autocorrect 的 元素,并且具有非 null表单所有者, 则返回 element 的表单所有者的自身 自动大写提示。
返回默认。
autocapitalize 获取器步骤如下:
支持文本输入法的可自定义自动大写行为,并希望允许 Web 开发者 控制此功能的用户代理,应在向元素输入文本期间,计算该元素的 使用的自动大写提示。这将是一个 自动大写提示, 用于描述向该元素输入文本时建议采用的自动大写行为。
用户代理或输入法可以选择在某些情况下忽略或覆盖使用的自动大写 提示。
元素 element 的使用的 自动大写提示使用以下算法计算:
某些文本输入方法会在用户输入时自动更正拼写错误的单词,从而
为用户提供帮助,这一过程也称为自动更正。用户代理可以支持对可编辑
文本进行自动更正,这些文本可以位于表单控件中(例如 textarea 元素的值),也可以位于
编辑宿主中的元素中(例如使用 contenteditable)。
自动更正可能伴随用户
界面,用于指示文本即将被自动更正或已经被自动更正,并且通常会在
拼写错误的单词后插入标点符号、空格或新段落时执行。autocorrect
属性允许作者
控制此类行为。
autocorrect 属性可以
用于编辑宿主,
以控制其承载的可编辑区域的自动更正行为;可以用于 input 或
textarea 元素,以
控制向该元素插入文本时的行为;或者可以用于
form 元素,以控制
与该 form 元素关联的所有继承 autocapitalize 和 autocorrect 的
元素的默认行为。
autocorrect 属性绝不会
为以下 input 元素
启用自动更正:其 type
属性处于URL、电子邮件或密码状态之一。
(此行为包含在
下文的使用的自动更正
状态算法中。)
autocorrect
属性是一个枚举属性,具有
以下关键字和状态:
| 关键字 | 状态 | 简要说明 |
|---|---|---|
on
|
开 | 允许用户代理在用户输入时自动更正拼写错误。 是否在输入时自动更正拼写由用户代理决定, 并且可能取决于元素以及用户的首选项。 |
off
|
关 | 不允许用户代理在用户输入时自动更正拼写。 |
autocorrect
获取器步骤如下:如果元素的使用的自动更正状态为开,则返回 true;如果元素的
使用的自动更正
状态为关,则返回 false。
设置器步骤如下:如果
给定值为 true,则必须将元素的 autocorrect
属性设置为“on”;否则必须设置为“off”。
要计算元素 element 的使用的自动更正状态,运行以下 步骤:
如果 element 上存在 autocorrect
内容属性,则返回该属性的状态。
如果 element 是一个继承
autocapitalize 和 autocorrect 的
元素,并且具有非 null表单所有者,则
返回 element 的表单所有者的 autocorrect
属性的状态。
返回开。
autocorrect返回元素的自动更正行为。请注意,对于从 form
元素继承状态的继承 autocapitalize 和
autocorrect 的
元素,这将返回
form 元素的
自动更正行为;但对于可编辑
区域中的元素,这不会返回编辑宿主的自动更正行为(除非
该元素实际上就是编辑宿主)。
autocorrect
=
value
更新 autocorrect
内容属性(从而
更改元素的自动更正行为)。
以下示例中的 input 元素不允许自动更正,因为
它没有 autocorrect 内容属性,因此
从 form 元素继承,而后者的
属性值为“off”。
但是,textarea
元素将允许
自动更正,因为它具有值为“on”的 autocorrect 内容
属性。
< form autocorrect = "off" >
< input type = "search" >
< textarea autocorrect = "on" ></ textarea >
</ form > inputmode
属性用户代理可以在表单
控件(例如 textarea
元素的值)上支持 inputmode
属性,也可以在编辑
宿主中的元素(例如使用 contenteditable)上支持该属性。
所有当前引擎均支持。
inputmode
内容属性是一个枚举属性,用于指定哪种输入
机制对用户输入内容最有帮助。
| 关键字 | 说明 |
|---|---|
none
|
用户代理不应显示虚拟键盘。此关键字适用于 自行渲染键盘控件的内容。 |
text
|
用户代理应显示能够以用户区域设置进行文本输入的虚拟键盘。 |
tel
|
用户代理应显示能够输入电话号码的虚拟键盘。这 应包括数字 0 至 9、“#”字符和“*”字符对应的按键。在某些 区域设置中,还可以包括字母助记标签(例如在美国,标有 “2”的按键历来还标有字母 A、B 和 C)。 |
url
|
用户代理应显示能够以用户区域设置进行文本输入的虚拟键盘, 并包含有助于输入 URL 的按键,例如“/” 和“.”字符对应的按键,以及用于快速输入域名中常见字符串(例如 “www.”或“.com”)的按键。 |
email
|
用户代理应显示能够以用户区域设置进行文本输入的虚拟键盘, 并包含有助于输入电子邮件地址的按键,例如“@”字符 和“.”字符对应的按键。 |
numeric
|
用户代理应显示能够进行数字输入的虚拟键盘。此关键字 适用于输入 PIN。 |
decimal
|
用户代理应显示能够输入带小数部分数值的虚拟键盘。 应显示数字键和该区域设置使用的格式分隔符。 |
search
|
用户代理应显示针对搜索优化的虚拟键盘。 |
所有当前引擎均支持。
当未指定 inputmode
(或其处于用户代理不
支持的状态)时,用户代理应确定要显示的默认虚拟键盘。应使用输入的
type 或
pattern
属性等上下文信息,来确定应向用户呈现哪种
虚拟键盘。
enterkeyhint
属性用户代理可以在表单控件(例如 textarea
元素的值)上支持 enterkeyhint
属性,也可以在
编辑宿主中的元素(例如
使用 contenteditable)上支持该属性。
Global_attributes/enterkeyhint
所有当前引擎均支持。
enterkeyhint
内容属性是一个枚举
属性,用于指定在虚拟键盘的 Enter 键上显示什么操作标签(或图标)。
这使作者能够自定义 Enter 键的呈现方式,使其对用户更有帮助。
| 关键字 | 说明 |
|---|---|
enter
|
用户代理应显示“输入”操作的提示,通常表示 插入新行。 |
done
|
用户代理应显示“完成”操作的提示,通常 表示没有更多内容需要输入,并且输入法编辑器(IME) 将关闭。 |
go
|
用户代理应显示“前往”操作的提示,通常 表示将用户带到其输入文本所指向的目标。 |
next
|
用户代理应显示“下一个”操作的提示,通常 将用户带到下一个接受文本的字段。 |
previous
|
用户代理应显示“上一个”操作的提示,通常 将用户带到上一个接受文本的字段。 |
search
|
用户代理应显示“搜索”操作的提示,通常 将用户带到对其输入文本进行搜索所得的结果。 |
send
|
用户代理应显示“发送”操作的提示,通常 将文本传递到其目标。 |
所有当前引擎均支持。
enterKeyHint IDL 属性必须反映
enterkeyhint
内容属性,并仅限于
已知值。
当未指定 enterkeyhint
(或其处于用户代理不
支持的状态)时,用户代理应确定要显示的默认操作标签(或图标)。
应使用 inputmode、
type
或 pattern
属性等上下文信息,来确定应在虚拟
键盘上显示哪个操作标签(或图标)。
本节定义页面内查找——一种常见的用户代理机制,允许用户 在页面内容中搜索特定信息。
通过页面内查找 界面提供对页面内查找功能的访问。 这是由用户代理提供的用户界面,允许用户指定 输入和搜索参数。该界面可以因使用快捷键或 选择菜单项而出现。
页面内查找界面中的文本输入和设置组合表示 用户的查询。这通常包括用户希望 搜索的文本以及可选设置(例如将搜索限制为仅匹配完整 单词的功能)。
用户代理针对给定查询处理页面内容,并 识别零个或多个匹配项,它们是满足用户 查询的内容范围。
其中一个匹配项会作为活动匹配项呈现给用户。它会被突出显示并滚动到视图中。用户 可以使用页面内查找界面推进活动匹配项,从而在匹配项之间导航。
议题 #3539用于跟踪
如何标准化页面内查找作为当前尚未指定的
window.find() API 的基础。
当页面内查找开始搜索匹配项时,页面中所有未设置 属性的 元素,应使其第二个槽位的变得可访问, 而无需修改 属性,以便 页面内查找能够搜索这些内容。同样,所有具有处于 状态的 属性的 HTML 元素,应使其变得可访问,而无需修改 属性,以便页面内查找能够搜索 这些内容。页面内查找完成匹配项搜索后, 元素和 具有处于 状态的 属性的元素,应使其内容 再次被跳过。整个过程必须同步发生(因此用户或 作者代码无法观察到)。[CSSCONTAIN]
当页面内查找选择一个新的时,执行 以下步骤:
令 node 为中的第一个节点。
给定 node 的,在上,以在 node 上运行。
当页面内查找以这种方式自动展开 元素时,它将触发一个 事件。 与页面内查找触发的单独 事件一样,页面可能利用此事件 发现用户在页面内查找对话框中输入的内容。如果页面创建一个微小的 可滚动区域,其中包含当前搜索词和用户可能输入的每个下一个字符,并以 间隙分隔,然后观察浏览器滚动到哪一个字符,它就能将该字符添加到 搜索词中,并更新可滚动区域,从而逐步构建搜索词。通过将 每个可能的下一个匹配项包装在一个关闭的 元素中,页面可以监听 事件,而不是 事件。对于这两种事件,可以通过不对用户在页面内查找对话框中输入的 每个字符都采取操作,来应对此攻击。
页面内查找过程在文档上下文中调用,并且可能会影响 该文档的选择。具体而言,定义活动匹配项的范围可以 决定当前 选择。不过,这些选择更新可能在页面内查找过程中不同的时间发生 (例如,关闭页面内查找界面时,或活动匹配项范围发生变化时)。
用户可以以由实现定义(并且很可能因设备而异)的方式,向用户代理发送 关闭请求。这表示用户希望关闭 当前在屏幕上显示的某些内容,例如弹出框、菜单、对话框、选择器或 显示模式。
关闭请求的一些示例如下:
桌面平台上的 Esc 键。
Android 等某些移动平台上的返回按钮或手势。
任何辅助技术的关闭手势,例如 iOS VoiceOver 的双指擦除“z” 手势。
游戏控制器的标准“返回”按钮,例如 DualShock 游戏手柄上的圆形按钮。
每当用户代理收到以 Document
document 为目标的潜在关闭请求时,它必须给定 document 的相关全局对象,在用户
交互任务
源上将一个全局
任务加入队列,以执行以下关闭请求步骤:
如果 document 的全屏元素不为 null:
这不会触发任何相关事件,例如 keydown;
它只会导致最终触发 fullscreenchange。
可以选择跳到标有替代 处理的步骤。
例如,如果用户代理检测到用户因当前网页反复拦截关闭 请求而感到沮丧,则可以采用此路径。
根据 UI Events 或其他相关规范触发任何相关事件。 [UIEVENTS]
UI Events 模型中的一个相关事件示例,是
当用户按下键盘上的 Esc 键时,UI Events 建议触发的
keydown
事件。在大多数配有键盘的平台上,这会被视为一个关闭请求,因此会
触发这些关闭请求
步骤。
超出 UI Events 所给模型的相关事件示例,是当用户通过
关闭手势发送关闭请求时,辅助技术合成一个
Esc keydown
事件。
如果没有触发此类事件,则令 event 为 null;否则,令其为表示其中一个
已触发事件的 Event
对象。如果触发了多个事件,选择哪一个由实现定义。
如果 event 不为 null,并且设置了其已取消标志,则 返回。
如果 document 不是完全活动的,则 返回。
此步骤是必需的,因为如果 event 不为 null,则事件 监听器可能会导致 document 不再是完全活动的。
如果 closedSomething 为 true,则返回。
替代处理:否则,没有任何内容 在观察关闭请求。用户代理 可以改为将此交互解释为其他操作,而不是将其解释为关闭请求。
在按下 Esc 键会被解释为关闭
请求的平台上,用户代理必须将按键被按下解释为关闭
请求,而不是将按键被释放解释为关闭请求。因此,在上述算法中,触发的“相关事件”
必须是单个 keydown
事件。
在 Esc 是关闭请求的平台上,用户
代理会首先触发一个经过适当初始化的 keydown
事件。如果 Web 开发者通过调用 preventDefault()
取消该事件,则不会发生进一步操作。但是,如果
事件触发后未被取消,则用户代理继续处理关闭
观察器。
在返回按钮可能是关闭请求的平台上,不会 涉及任何事件,因此按下返回按钮时,用户代理会直接继续 处理关闭观察器。如果存在一个活动的关闭观察器,则会触发该观察器。 如果不存在,则用户代理可以用其他方式解释返回按钮的按下操作, 例如将其解释为按增量遍历历史记录 −1 的请求。
每个 Window 都有一个关闭观察器管理器,它是一个
结构,具有以下项:
关闭观察器管理器的大部分复杂性来自防滥用 保护,这些保护旨在防止开发者禁用用户的历史记录遍历能力,尤其是在 关闭请求的后备 操作是历史记录遍历主要机制的平台上。具体而言:
关闭观察器的分组设计为: 如果在没有历史记录操作激活的情况下创建 多个关闭观察器,它们会被归入同一组,因此用户触发的关闭请求将关闭该组中的所有关闭 观察器。这确保 Web 开发者无法通过创建关闭观察器来拦截无限数量的 关闭请求;相反,他们最多只能创建数量等于 1 加上 用户激活页面次数的关闭观察器。
下一次用户 交互允许新组 布尔值鼓励 Web 开发者以与单次用户激活绑定的方式创建关闭观察器。如果没有 该值,每次用户激活都会增加允许的组数, 即使 Web 开发者没有“使用”这些用户 激活来创建关闭观察器。概括如下:
允许:用户交互;创建一个单独成组的关闭观察器;用户交互; 在第二个独立组中创建一个关闭观察器。
不允许:用户交互;用户交互;创建一个单独成组的关闭观察器; 在第二个独立组中创建一个关闭观察器。
允许:用户交互;用户交互;创建一个单独成组的关闭观察器; 创建一个与前一个关闭观察器归为同组的关闭观察器。
此保护对于维持我们希望的“不超过 1 加上用户激活页面次数 个组”的不变量并不重要。决意滥用的人只会为每次用户交互创建一个关闭观察器, 将它们“储存”起来以备将来滥用。但此系统会使正常情况下的行为更可预测,并 鼓励非滥用开发者直接响应用户 交互来创建关闭观察器。
给定一个
Window window 时,要
通知关闭观察器管理器发生了用户
激活:
令 manager 为 window 的关闭观察器管理器。
如果 manager 的下一次用户交互 允许新组为 true,则递增 manager 的允许的 组数。
将 manager 的下一次用户交互 允许新组设置为 false。
一个window,即一个 Window。
一个取消操作,即一个接受 布尔参数并返回布尔值的算法。该参数指示取消 操作算法是否可以通过算法的返回值阻止关闭请求继续执行。 如果布尔参数为 true,则算法可以返回 true,以指示 调用者将继续执行关闭操作,也可以 返回 false,以指示调用者将中止。如果参数为 false,则返回值 始终为 false。此算法绝不会抛出异常。
一个关闭操作,即一个不接受 参数且不返回任何内容的算法。此算法绝不会抛出异常。
一个正在运行取消操作 布尔值。
一个获取启用状态,即一个 不接受参数并返回布尔值的算法。此算法绝不会抛出 异常。
给定一个 Window window、
一个步骤列表 cancelAction、
一个步骤列表 closeAction
和一个返回布尔值的算法 getEnabledState 时,要建立关闭观察器:
要使用布尔值 requireHistoryActionActivation 请求关闭一个关闭 观察器 closeWatcher:
如果 closeWatcher 不是活动的,则 返回 true。
如果运行 closeWatcher 的获取启用状态所得的结果为 false, 则返回 true。
如果 closeWatcher 的正在运行 取消操作为 true,则返回 true。
令 window 为 closeWatcher 的window。
如果 window 的关联的
Document不是完全活动的,则返回 true。
如果 requireHistoryActionActivation 为 false,或者 window 的关闭观察器管理器的组的大小 小于 window 的关闭观察器管理器的允许的 组数,并且 window 具有历史记录操作激活, 则令 canPreventClose 为 true;否则为 false。
将 closeWatcher 的正在运行 取消操作设置为 true。
令 shouldContinue 为给定 canPreventClose 运行 closeWatcher 的取消 操作所得的结果。
将 closeWatcher 的正在运行 取消操作设置为 false。
如果 shouldContinue 为 false:
断言:canPreventClose 为 true。
给定 window,消耗历史记录操作用户 激活。
返回 false。
请注意,由于这些子步骤会消耗历史记录操作用户 激活,因此在两次请求关闭一个 关闭观察器之间没有任何 用户激活时,第二次 canPreventClose 将为 false。
关闭 closeWatcher。
返回 true。
要关闭一个关闭观察器 closeWatcher:
要销毁一个关闭观察器 closeWatcher:
给定一个 Window window
时,要处理关闭观察器:
令 processedACloseWatcher 为 false。
返回 processedACloseWatcher。
CloseWatcher 接口[Exposed =Window ]
interface CloseWatcher : EventTarget {
constructor (optional CloseWatcherOptions options = {});
undefined requestClose ();
undefined close ();
undefined destroy ();
attribute EventHandler oncancel ;
attribute EventHandler onclose ;
};
dictionary CloseWatcherOptions {
AbortSignal signal ;
};watcher = new CloseWatcher()
watcher = new CloseWatcher({ signal })
创建一个新的 CloseWatcher 实例。
如果提供了 signal
选项,则可以通过中止给定的
AbortSignal
来销毁 watcher(如同调用 watcher.destroy())。
如果已有任何关闭观察器处于
活动状态,并且该 Window 不具有
历史操作激活,则生成的
CloseWatcher 将在响应任何
关闭请求时,与该已处于活动状态的关闭观察器一起关闭。(该已处于活动状态的
关闭观察器不一定必须是一个 CloseWatcher 对象;它
可以是一个模态
dialog
元素,或者是由具有 popover
属性的元素生成的弹出框。)
watcher.requestClose()
其行为如同向 watcher 发送了一个以其为目标的关闭请求:首先
触发一个 cancel 事件;
如果该事件未通过 preventDefault()
取消,则继续触发一个
close 事件,然后
停用该关闭观察器,如同调用了 watcher.destroy()。
这是一个辅助工具,可用于将取消和关闭逻辑集中到
cancel 和 close 事件
处理器中,方法是让所有非关闭请求触发的关闭方式调用此方法。
watcher.close()
立即触发 close 事件,然后
停用该关闭观察器,如同调用了 watcher.destroy()。
watcher.destroy()
停用 watcher,使其不再接收 close 事件,并使新的独立
CloseWatcher
实例能够被构造。
当相关 UI 元素通过关闭以外的其他方式被拆除时,应调用此方法。
每个 CloseWatcher 实例
都有一个内部关闭观察器,它是一个
关闭观察器。
new CloseWatcher(options)
构造函数步骤如下:
如果 this 的相关全局对象的关联的
Document不是完全活动的,则抛出一个“InvalidStateError”
DOMException。
令 closeWatcher 为给定 this 的相关全局 对象,并使用以下内容建立关闭观察器所得的结果:
cancelAction 给定
canPreventClose 时,返回在 this 上触发一个名为 cancel 的事件所得的结果,
并将 cancelable
属性初始化为
canPreventClose。
closeAction 为在
this 上触发一个名为
close
的事件。
getEnabledState 为返回 true。
以下是实现
CloseWatcher 接口的所有对象
必须作为事件
处理器 IDL 属性支持的事件处理器
(及其对应的事件处理器事件类型):
| 事件处理器 | 事件处理器 事件类型 |
|---|---|
oncancel |
cancel
|
onclose |
close
|
如果想要实现一个自定义选择器控件,使其在收到用户提供的
关闭请求时,以及在按下关闭
按钮时自行关闭,则以下代码展示了如何使用
CloseWatcher API
来处理关闭请求:
const watcher = new CloseWatcher();
const picker = setUpAndShowPickerDOMElement();
let chosenValue = null ;
watcher. onclose = () => {
chosenValue = picker. querySelector( 'input' ). value;
picker. remove();
};
picker. querySelector( '.close-button' ). onclick = () => watcher. requestClose(); 请注意,收集所选值的逻辑集中在
CloseWatcher
对象的 close 事件
处理器中,而关闭按钮的 click
事件处理器则通过调用 requestClose()
将处理委托给该逻辑。
CloseWatcher 对象上的
cancel 事件可以
用于阻止 close
事件触发,并阻止
CloseWatcher 被
销毁。一个典型用例如下:
watcher. oncancel = async ( e) => {
if ( hasUnsavedData && e. cancelable) {
e. preventDefault();
const userReallyWantsToClose = await askForConfirmation( "Are you sure you want to close?" );
if ( userReallyWantsToClose) {
hasUnsavedData = false ;
watcher. close();
}
}
}; 出于防止滥用的目的,只有当页面具有历史操作
激活时,此事件才是 cancelable
的,而该激活会在任何给定的关闭请求之后丢失。这确保
如果用户在没有任何用户激活介入的情况下连续发送两次关闭请求,
该请求必定成功;第二次请求会忽略任何 cancel
事件处理器
调用 preventDefault()
的尝试,并继续关闭
CloseWatcher。
结合以上两个示例,可以看出 requestClose()
和 close()
之间的区别。由于我们在关闭按钮的 click
事件处理器中使用了 requestClose(),
因此点击该按钮将
触发 CloseWatcher 的
cancel 事件,从而
在存在未保存数据时可能要求用户确认。如果我们使用的是 close(),
则会跳过此检查。有时这样做
是合适的,但对于由用户触发的关闭请求,通常 requestClose()
是更好的选择。
除了对 cancel 事件施加的用户激活限制之外,
CloseWatcher
的构造还受到一种更隐蔽的用户激活限制。如果在没有用户
激活的情况下创建多个
CloseWatcher,
则新创建的实例将与最近创建的关闭观察器归为一组,因此单个关闭
请求会同时关闭二者:
window. onload = () => {
// This will work as normal: it is the first close watcher created without user activation.
( new CloseWatcher()). onclose = () => { /* ... */ };
};
button1. onclick = () => {
// This will work as normal: the button click counts as user activation.
( new CloseWatcher()). onclose = () => { /* ... */ };
};
button2. onclick = () => {
// These will be grouped together, and both will close in response to a single close request.
( new CloseWatcher()). onclose = () => { /* ... */ };
( new CloseWatcher()). onclose = () => { /* ... */ };
}; 这意味着正确调用 destroy()、
close()
或 requestClose()
非常重要。这样做
是重新获得“免费”未分组关闭观察器槽位的唯一方式。此类在没有用户激活的情况下创建的关闭观察器
适用于会话非活动超时对话框或由服务器触发事件产生的紧急
通知等情形,因为它们并不是响应用户
激活而生成的。
所有当前引擎均支持。
本节定义一种基于事件的拖放机制。
本规范并未准确定义拖放操作究竟 是什么。
在配有指针设备的视觉媒体上,拖动操作可以是
一个 mousedown
事件的默认操作,随后发生一系列 mousemove
事件,而放置操作则可以由释放鼠标
触发。
使用指针设备以外的输入模态时,用户可能必须 明确表示其执行拖放操作的意图,分别说明希望 拖动什么以及希望将其放置到何处。
无论如何实现,拖放操作都必须有一个起点(例如点击 鼠标的位置,或为拖动而选择的选区或元素的起始位置),可以有 任意数量的中间步骤(拖动期间鼠标移过的元素,或 用户在循环浏览可能选项时选择作为潜在放置点的元素),并且必须 要么有一个终点(释放鼠标按钮时鼠标所在的元素,或最终 选定的元素),要么被取消。终点必须是放置发生前最后选定为 潜在放置点的元素(因此,如果操作未被取消,则中间步骤中必须至少 有一个元素)。
本节是非规范性的。
要使元素可拖动,请为该元素指定 draggable
属性,并为 dragstart 设置事件监听器,
以存储正在拖动的数据。
事件处理器通常需要检查正在拖动的内容不是文本选区,
然后需要将数据存储到 DataTransfer 对象中,并设置
允许的效果(复制、移动、链接或其某种组合)。
例如:
< p > What fruits do you like?</ p >
< ol ondragstart = "dragStartHandler(event)" >
< li draggable = "true" data-value = "fruit-apple" > Apples</ li >
< li draggable = "true" data-value = "fruit-orange" > Oranges</ li >
< li draggable = "true" data-value = "fruit-pear" > Pears</ li >
</ ol >
< script >
var internalDNDType = 'text/x-example' ; // set this to something specific to your site
function dragStartHandler( event) {
if ( event. target instanceof HTMLLIElement) {
// use the element's data-value="" attribute as the value to be moving:
event. dataTransfer. setData( internalDNDType, event. target. dataset. value);
event. dataTransfer. effectAllowed = 'move' ; // only allow moves
} else {
event. preventDefault(); // don't allow selection to be dragged
}
}
</ script > 要接受放置,放置目标必须监听以下事件:
dragenter 事件处理器
通过取消事件来报告
放置目标是否可能愿意接受放置。dragover 事件处理器
通过设置与该事件关联的
DataTransfer 的 dropEffect
属性,指定将向用户显示什么反馈。
此事件也需要被取消。
drop 事件处理器有最后一次
接受或拒绝放置的机会。如果接受放置,则事件处理器必须在
目标上执行放置操作。此事件需要被取消,以便
源能够使用 dropEffect
属性的值。否则,放置操作将被拒绝。例如:
< p > Drop your favorite fruits below:</ p >
< ol ondragenter = "dragEnterHandler(event)" ondragover = "dragOverHandler(event)"
ondrop = "dropHandler(event)" >
</ ol >
< script >
var internalDNDType = 'text/x-example' ; // set this to something specific to your site
function dragEnterHandler( event) {
var items = event. dataTransfer. items;
for ( var i = 0 ; i < items. length; ++ i) {
var item = items[ i];
if ( item. kind == 'string' && item. type == internalDNDType) {
event. preventDefault();
return ;
}
}
}
function dragOverHandler( event) {
event. dataTransfer. dropEffect = 'move' ;
event. preventDefault();
}
function dropHandler( event) {
var li = document. createElement( 'li' );
var data = event. dataTransfer. getData( internalDNDType);
if ( data == 'fruit-apple' ) {
li. textContent = 'Apples' ;
} else if ( data == 'fruit-orange' ) {
li. textContent = 'Oranges' ;
} else if ( data == 'fruit-pear' ) {
li. textContent = 'Pears' ;
} else {
li. textContent = 'Unknown Fruit' ;
}
event. target. appendChild( li);
}
</ script > 要从显示中移除原始元素(被拖动的元素),可以使用 dragend
事件。
对于此处的示例,这意味着要更新原始标记以处理该事件:
< p > What fruits do you like?</ p >
< ol ondragstart = "dragStartHandler(event)" ondragend = "dragEndHandler(event)" >
...as before...
</ ol >
< script >
function dragStartHandler( event) {
// ...as before...
}
function dragEndHandler( event) {
if ( event. dataTransfer. dropEffect == 'move' ) {
// remove the dragged element
event. target. parentNode. removeChild( event. target);
}
}
</ script > 拖放操作的底层数据称为拖动数据存储, 它由以下信息组成:
一个拖动数据存储项列表,它是一个表示 被拖动数据的项列表,每一项都由以下信息组成:
数据的种类:
文本。
带有文件名的二进制数据。
一个给出数据类型或格式的 Unicode 字符串,通常由 MIME 类型给出。由于历史原因,一些不是MIME 类型的值会被 特殊处理。该 API 不强制使用MIME 类型;也可以使用其他值。不过,在所有情况下,这些 值都会由 API 转换为 ASCII 小写形式。
每个项类型字符串最多只能有一个 文本项。
一个 Unicode 或二进制字符串,在某些情况下还带有文件名(文件名本身也是 Unicode 字符串), 具体取决于拖动数据 项种类。
拖动数据存储 项列表按照各项被添加到列表中的顺序排列;最近添加的项位于最后。
以下信息用于生成拖动期间的 UI 反馈:
一个拖动数据存储模式,它是以下模式之一:
一个拖动数据存储允许效果状态,它是一个 字符串。
创建一个拖动数据存储时,必须将其初始化为:
其拖动数据存储项列表为空;
不具有拖动数据
存储默认反馈;不具有拖动数据存储位图和
拖动
数据存储热点坐标;其拖动数据存储模式为受保护模式;其拖动数据存储允许效果
状态为字符串“uninitialized”。
DataTransfer 接口所有当前引擎均支持。
DataTransfer 对象用于
公开拖放操作底层的拖动数据存储。
[Exposed =Window ]
interface DataTransfer {
constructor ();
attribute DOMString dropEffect ;
attribute DOMString effectAllowed ;
[SameObject ] readonly attribute DataTransferItemList items ;
undefined setDragImage (Element image , long x , long y );
/* old interface */
readonly attribute FrozenArray <DOMString > types ;
DOMString getData (DOMString format );
undefined setData (DOMString format , DOMString data );
undefined clearData (optional DOMString format );
[SameObject ] readonly attribute FileList files ;
};dataTransfer = new DataTransfer()
所有当前引擎均支持。
创建一个新的 DataTransfer 对象,
其中包含一个空的拖动数据
存储。
dataTransfer.dropEffect [ = value ]
所有当前引擎均支持。
返回当前选择的操作种类。如果该操作种类不是
effectAllowed
属性所允许的种类之一,则该操作将
失败。
可以设置该值,以更改所选操作。
dataTransfer.effectAllowed [ = value ]
所有当前引擎均支持。
返回应允许的操作种类。
可以在 dragstart
事件期间设置该值,以更改
允许的操作。
可能的值为“none”、
“copy”、
“copyLink”、
“copyMove”、
“link”、
“linkMove”、
“move”、
“all”
和“uninitialized”。
dataTransfer.items
所有当前引擎均支持。
返回一个包含拖动数据的 DataTransferItemList
对象。
dataTransfer.setDragImage(element, x, y)
所有当前引擎均支持。
使用给定元素更新拖动反馈,并替换之前指定的任何 反馈。
dataTransfer.types
所有当前引擎均支持。
返回一个冻结数组,其中列出在
dragstart
事件中设置的格式。此外,如果正在
拖动任何文件,则其中一种类型将是字符串“Files”。
data = dataTransfer.getData(format)
所有当前引擎均支持。
返回指定数据。如果不存在此类数据,则返回空字符串。
dataTransfer.setData(format, data)
所有当前引擎均支持。
添加指定数据。
dataTransfer.clearData([ format ])
所有当前引擎均支持。
移除指定格式的数据。如果省略参数,则移除所有数据。
dataTransfer.files
所有当前引擎均支持。
如果存在正在拖动的文件,则返回这些文件的 FileList。
作为拖放事件的一部分创建的
DataTransfer 对象
仅在这些事件触发期间有效。
当 DataTransfer 对象
有效时,它会与一个拖动数据存储关联。
一个 DataTransfer 对象
有一个关联的类型数组,它是一个
FrozenArray<DOMString>,
初始为空。当
DataTransfer
对象的拖动数据
存储项列表的内容发生变化,或者
DataTransfer 对象
不再与拖动数据
存储关联时,运行以下步骤:
令 L 为一个空序列。
如果 DataTransfer
对象仍与拖动数据
存储关联:
对于 DataTransfer
对象的
拖动数据
存储项
列表中种类
为文本的每一项,向 L 添加一个由该项的类型字符串组成的条目。
如果 DataTransfer
对象的
拖动数据
存储
项列表中存在任何种类为文件的项,则
向 L 添加一个由字符串“Files”组成的条目。(此
值可与其他值区分,因为它不是小写形式。)
将 DataTransfer
对象的类型
数组设置为从 L 创建冻结数组所得的结果。
调用 DataTransfer() 构造函数时,必须返回一个
新创建的 DataTransfer 对象,
并按如下方式初始化:
将 dropEffect
和
effectAllowed
设置为“none”。
dropEffect 属性控制在拖放
操作期间提供给用户的拖放反馈。创建
DataTransfer 对象时,
dropEffect
属性会被设置为一个字符串值。在
获取时,它必须返回其当前值。在设置时,如果新值是“none”、“copy”、“link”或“move”之一,则必须将该属性的当前值
设置为新值。必须忽略其他值。
effectAllowed 属性用于
拖放处理模型,在 dragenter 和
dragover 事件期间
初始化 dropEffect
属性。
创建 DataTransfer
对象时,
effectAllowed
属性会被设置
为一个字符串值。在获取时,它必须返回其当前值。在设置时,如果拖动数据
存储的模式为读/写模式,并且新
值是“none”、“copy”、“copyLink”、“copyMove”、“link”、“linkMove”、“move”、“all”或“uninitialized”之一,则必须将该属性的
当前值设置为新值。否则,必须保持不变。
items
属性必须返回一个与
DataTransfer 对象
关联的 DataTransferItemList
对象。
setDragImage(image, x,
y) 方法必须运行以下步骤:
如果 DataTransfer
对象不再与拖动数据
存储关联,则返回。什么也不做。
如果 image 是一个 img 元素,则将
拖动数据存储
位图设置为该元素的图像(按其自然
大小);否则,将拖动数据存储位图设置为从
给定元素生成的图像(目前未指定执行此操作的确切机制)。
将拖动数据存储热点坐标 设置为给定的 x、 y 坐标。
types
属性必须返回此 DataTransfer
对象的类型数组。
getData(format) 方法必须运行
以下步骤:
如果 DataTransfer
对象不再与拖动数据
存储关联,则返回空字符串。
令 format 为第一个参数,并转换为 ASCII 小写形式。
令 convert-to-URL 为 false。
如果 format 等于“text”,则将其更改为“text/plain”。
如果 format 等于“url”,则将其更改为“text/uri-list”,并将
convert-to-URL 设置为 true。
令 result 为拖动数据存储项 列表中种类为纯 Unicode 字符串,且其类型字符串等于 format 的项的数据。
如果 convert-to-URL 为 true,则按照适用于
text/uri-list 数据的方式解析 result,然后将 result 设置为
列表中的第一个 URL(如果存在),否则设置为空字符串。[RFC2483]
返回 result。
setData(format, data) 方法
必须运行以下步骤:
clearData(format) 方法必须运行
以下步骤:
如果 DataTransfer
对象不再与拖动数据
存储关联,则返回。什么也不做。
如果调用该方法时未传入参数,则移除拖动数据存储 项列表中种类为纯 Unicode 字符串的每一项,然后返回。
将 format 设置为 format,并转换为 ASCII 小写形式。
如果 format 等于“text”,则将其更改为“text/plain”。
如果 format 等于“url”,则将其更改为“text/uri-list”。
clearData()
方法不会
影响拖动中是否包含任何文件,因此调用 clearData()
后,types
属性的列表可能仍不为空
(如果拖动中包含任何文件,则它仍会包含
“Files”字符串)。
files
属性必须返回一个实时 FileList
序列,其中包含表示通过以下步骤找到的文件的
File
对象。此外,对于给定的
FileList
对象和给定的底层文件,每次都必须使用同一个 File
对象。
此版本的 API 不会在拖动期间公开文件的类型。
DataTransferItemList
接口所有当前引擎均支持。
每个 DataTransfer
对象都与一个 DataTransferItemList
对象关联。
[Exposed =Window ]
interface DataTransferItemList {
readonly attribute unsigned long length ;
getter DataTransferItem (unsigned long index );
DataTransferItem ? add (DOMString data , DOMString type );
DataTransferItem ? add (File data );
undefined remove (unsigned long index );
undefined clear ();
};items.length
所有当前引擎均支持。
返回拖动数据存储中的项数。
items[index]返回表示拖动数据存储中第
index 个条目的 DataTransferItem
对象。
items.remove(index)
所有当前引擎均支持。
移除拖动数据存储中的第 index 个条目。
items.clear()
所有当前引擎均支持。
移除拖动数据存储中的所有条目。
items.add(data)
所有当前引擎均支持。
items.add(data, type)
向拖动数据存储添加给定数据的新条目。如果数据是纯 文本,则还必须提供 type 字符串。
当 DataTransferItemList
对象的 DataTransfer
对象与
一个拖动数据
存储关联时,DataTransferItemList
对象的
模式与拖动数据存储模式相同。当
DataTransferItemList
对象的 DataTransfer
对象
未与拖动数据
存储关联时,DataTransferItemList
对象的
模式为禁用模式。本节中引用的拖动数据存储(仅在
DataTransferItemList
对象未处于
禁用模式时使用)是与
DataTransferItemList
对象的 DataTransfer
对象
关联的拖动数据存储。
length 属性在对象处于
禁用模式时必须返回零;否则,它必须返回
拖动数据
存储项列表中的项数。
当 DataTransferItemList
对象未处于禁用模式时,其
支持的属性索引是索引,这些索引属于拖动数据存储
项列表。
要确定索引属性
i 的值,对于一个 DataTransferItemList
对象,用户代理必须返回一个
DataTransferItem
对象,该对象表示拖动数据存储中的第
i 个项。每次从此 DataTransferItemList
对象获取特定项时,都必须返回同一个对象。DataTransferItem
对象首次创建时,必须与
DataTransferItemList
对象所关联的同一个 DataTransfer 对象关联。
add() 方法必须运行以下步骤:
如果 DataTransferItemList
对象未处于读/写模式,则返回
null。
跳转到以下列表中适当的一组步骤:
如果拖动数据存储项列表中已存在一个
种类为文本,且其类型字符串等于该方法
第二个参数的值,并将其转换为
ASCII 小写形式的项,则抛出一个
“NotSupportedError” DOMException。
否则,向拖动数据存储项列表添加一个 种类为文本,其类型字符串等于该方法第二个 参数的值,并将其转换为 ASCII 小写形式,且其数据为该 方法第一个参数所给字符串的项。
File
向拖动数据存储项列表添加一个
种类为文件,其类型
字符串为该 File
的 type,
并将其转换为
ASCII 小写形式,且其数据与
该 File
的
数据相同的项。
确定与新添加项对应的索引属性的值,
并返回该值(一个新创建的
DataTransferItem
对象)。
remove(index) 方法必须运行
以下步骤:
如果 DataTransferItemList
对象未处于读/写模式,则抛出一个
“InvalidStateError” DOMException。
如果拖动数据 存储不包含第 index 个项,则 返回。
从拖动数据存储中移除第 index 个项。
如果 DataTransferItemList
对象处于读/写
模式,则 clear() 方法
必须从拖动数据存储中移除所有项。否则,它必须
什么也不做。
DataTransferItem
接口所有当前引擎均支持。
每个 DataTransferItem
对象都与一个 DataTransfer
对象关联。
[Exposed =Window ]
interface DataTransferItem {
readonly attribute DOMString kind ;
readonly attribute DOMString type ;
undefined getAsString (FunctionStringCallback ? _callback );
File ? getAsFile ();
};
callback FunctionStringCallback = undefined (DOMString data );item.kind
所有当前引擎均支持。
返回拖动 数据项种类,它是以下值之一:“string”、 “file”。
item.type
所有当前引擎均支持。
返回拖动数据项类型字符串。
item.getAsString(callback)
所有当前引擎均支持。
如果拖动数据项 种类为文本,则以字符串数据作为参数调用回调。
file = item.getAsFile()
所有当前引擎均支持。
当 DataTransferItem
对象的 DataTransfer
对象与一个拖动数据存储关联,并且该
拖动数据存储的拖动数据存储
项列表仍包含该 DataTransferItem
对象所表示的项时,DataTransferItem
对象的模式与拖动数据存储
模式相同。当 DataTransferItem
对象的 DataTransfer
对象
未与拖动数据存储关联,或者该
DataTransferItem
对象所表示的项已从相关拖动数据
存储项列表中移除时,DataTransferItem
对象的模式为禁用
模式。本节中引用的拖动数据
存储(仅在
DataTransferItem
对象未处于禁用模式时使用)是与
DataTransferItem
对象的 DataTransfer
对象关联的拖动数据
存储。
如果
DataTransferItem
对象处于禁用模式,则 kind 属性必须返回空字符串;否则,它必须返回
下表中第一列单元格包含该
DataTransferItem
对象所表示项的拖动数据项种类的行中,第二列单元格给出的字符串:
| 种类 | 字符串 |
|---|---|
| 文本 | “string”
|
| 文件 | “file”
|
如果
DataTransferItem
对象处于禁用模式,则 type 属性必须返回空字符串;否则,它必须返回
该 DataTransferItem
对象所表示项的拖动
数据项类型字符串。
getAsString(callback) 方法
必须运行以下步骤:
如果 callback 为 null,则返回。
如果 DataTransferItem
对象既未处于读/写模式,也未处于只读模式,
则返回。永远不会调用该回调。
如果拖动 数据项种类不是文本,则返回。 永远不会调用该回调。
否则,将一个任务加入队列以
调用 callback,并将该 DataTransferItem
对象所表示项的实际数据作为
参数传入。
getAsFile() 方法必须运行以下
步骤:
如果 DataTransferItem
对象既未处于读/写模式,也未处于只读模式,
则返回 null。
如果拖动 数据项种类不是文件,则返回 null。
返回一个新的 File
对象,该对象表示
DataTransferItem
对象所表示项的实际数据。
DragEvent 接口所有当前引擎均支持。
所有当前引擎均支持。
拖放处理模型涉及多个事件。它们都使用
DragEvent 接口。
[Exposed =Window ]
interface DragEvent : MouseEvent {
constructor (DOMString type , optional DragEventInit eventInitDict = {});
readonly attribute DataTransfer ? dataTransfer ;
};
dictionary DragEventInit : MouseEventInit {
DataTransfer ? dataTransfer = null ;
};event.dataTransfer
所有当前引擎均支持。
返回该事件的 DataTransfer
对象。
尽管为了与其他事件接口保持一致,DragEvent
接口具有构造函数,但它并不是特别有用。特别是,无法通过脚本
创建有用的 DataTransfer
对象,因为 DataTransfer 对象
具有由浏览器在拖放期间协调的处理和安全模型。
DragEvent 接口的
dataTransfer 属性必须返回
它被初始化为的值。它表示该事件的
上下文信息。
当要求用户代理在一个元素上使用特定的拖动数据存储触发名为 e 的 DND 事件, 并且可选地使用特定的 related target 时,用户代理必须运行以下步骤:
如果未提供特定的 related target,则将 related target 设置为 null。
如果 e 为 dragstart,则
将拖动数据存储模式设置为
读/写模式,
并将 dataDragStoreWasChanged 设置为 true。
令 dataTransfer 为一个新创建的 DataTransfer 对象,
它与给定的拖动数据
存储关联。
将 effectAllowed
属性设置为拖动数据
存储的拖动数据存储允许效果
状态。
如果 e 为 dragstart、
drag 或
dragleave,
则将 dropEffect
属性设置为“none”;
如果 e 为 drop
或 dragend,则将其设置为
与当前拖动
操作对应的值;否则(即 e 为 dragenter 或
dragover),
则按照下表,根据 effectAllowed
属性的值和
拖放源,将其设置为某个值:
effectAllowed
|
dropEffect
|
|---|---|
“none”
|
“none”
|
“copy”
|
“copy”
|
“copyLink”
|
“copy”,
或者在适当情况下为“link”
|
“copyMove”
|
“copy”,
或者在适当情况下为“move”
|
“all”
|
“copy”,
或者在适当情况下为“link”
或“move”
|
“link”
|
“link”
|
“linkMove”
|
“link”,
或者在适当情况下为“move”
|
“move”
|
“move”
|
当正在拖动的内容是文本控件中的选区时,为“uninitialized”
|
“move”,
或者在适当情况下为“copy”
或“link”
|
当正在拖动的内容是选区时,为“uninitialized”
|
“copy”,
或者在适当情况下为“link”
或“move”
|
当正在拖动的内容是具有 href
属性的 a 元素时,为“uninitialized”
|
“link”,
或者在适当情况下为“copy”
或“move”
|
| 任何其他情况 | “copy”,
或者在适当情况下为“link”
或“move”
|
如果上表提供了可能适用的 替代值,并且平台约定表明用户请求了这些替代效果,则用户代理可以改用列出的替代值。
例如,Windows 平台约定是在按住
“alt”键拖动时,表示用户更倾向于链接数据,而不是移动或复制
数据。因此,在 Windows 系统上,如果按下“alt”键时,根据
上表,“link”
是一个选项,则用户代理可以选择它,而不是
“copy”
或“move”。
将 event 的 type
属性初始化为
e,将其 bubbles
属性初始化为 true,将其 view
属性初始化为 window,将其 relatedTarget
属性初始化为 related
target,并将其 dataTransfer
属性初始化为
dataTransfer。
如果 e 既不是 dragleave,也不是
dragend,则
将 event 的 cancelable
属性初始化为 true。
根据输入设备的状态初始化 event 的鼠标和按键属性, 就像用户交互事件一样。
如果没有相关的指针设备,则将 event 的 screenX、
screenY、clientX、
clientY
和 button 属性初始化为 0。
在指定目标元素上分派 event。
将拖动数据存储允许效果
状态设置为
dataTransfer 的 effectAllowed
属性的当前值。(仅当 e 为 dragstart
时,其值才可能发生变化。)
解除 dataTransfer 与拖动数据 存储之间的关联。
当用户尝试开始拖动操作时,用户代理必须运行以下步骤。 即使拖动实际上始于另一个文档或应用程序,并且直到拖动 与用户代理管辖下的文档相交时,用户代理才意识到拖动正在发生, 用户代理也必须表现得如同运行了这些步骤。
按如下方式确定正在拖动什么:
如果拖动操作是在选区上调用的,则正在拖动的是该选区。
否则,如果拖动操作是在一个 Document
上调用的,则从用户尝试拖动的节点开始,
沿祖先链向上查找,其 IDL 属性 draggable 设置为 true
的第一个
元素就是正在拖动的内容。如果不存在此类
元素,则没有任何内容正在被拖动;返回,拖放操作永远不会
开始。
否则,拖动操作是在用户代理管辖范围之外调用的。正在 拖动的内容由拖动开始处的文档或应用程序定义。
创建一个 拖动数据存储。随后由本节步骤触发的所有 DND 事件 都必须使用此拖动数据存储。
按如下方式确定哪个 DOM 节点是源节点:
如果正在拖动的是选区,则源节点是用户开始拖动时所在的
Text
节点(通常是用户最初点击的 Text
节点)。如果用户未指定特定节点,例如
用户只是让用户代理开始拖动“选区”,则源
节点是包含选区一部分的第一个 Text
节点。
否则,如果正在拖动的是元素,则源节点是 正在被拖动的元素。
否则,源节点是另一个文档或应用程序的一部分。当本 规范要求在这种情况下向源节点分派事件时, 用户代理必须改为遵循与该情况相关的平台特定约定。
在拖放操作过程中,会在源节点上触发多个事件。
按如下方式确定被拖动节点列表:
如果正在拖动的是选区,则向拖动数据存储 项列表添加一个项,其属性设置如下:
text/plain”
否则,如果正在拖动任何文件,则向拖动数据 存储项列表中为每个文件添加一个项,其属性设置如下:
application/octet-stream”。
目前只能从可导航对象之外拖动文件, 例如从文件系统管理器应用程序中。
如果拖动在应用程序之外开始,则用户代理必须根据正在拖动的数据, 适当地向拖动数据 存储项列表添加项,并在适当情况下遵循平台约定;但是,如果平台约定不使用MIME 类型标记被拖动的数据,则用户代理必须尽最大努力 将这些类型映射为 MIME 类型,并且无论如何,所有拖动数据项类型字符串都必须 转换为 ASCII 小写形式。
用户代理还可以添加一个或多个以其他形式(例如 HTML)表示选区或被拖动元素的项。
如果被拖动 节点列表不为空,则将这些节点中的微数据提取为 JSON 形式,并向 拖动数据 存储项列表添加一个项,其属性设置如下:
application/microdata+json
运行以下子步骤:
令 urls 为 « »。
对于被拖动节点列表中的每个 node:
href
属性的 a 元素
href
内容属性的值,并相对于该元素的节点
文档对 URL 进行编码、解析和序列化
所得的结果。src
属性的 img
元素src 内容
属性的值,并相对于该元素的节点
文档对 URL 进行编码、解析和序列化
所得的结果。如果 urls 仍为空,则返回。
令 url string 为按添加顺序连接 urls 中的字符串所得的结果, 各字符串之间由 U+000D CARRIAGE RETURN U+000A LINE FEED 字符 对(CRLF)分隔。
向拖动数据存储项列表添加一个项,其 属性设置如下:
text/uri-list
根据用户代理的情况更新拖动数据存储默认反馈 (如果用户正在拖动选区,则该选区可能是此 反馈的基础;如果用户正在拖动元素,则会使用该元素的渲染结果;如果 拖动开始于用户代理之外,则应使用用于确定拖动 反馈的平台约定)。
在源节点上触发一个名为
dragstart
的 DND 事件。
如果事件被取消,则不应发生拖放操作;返回。
由于没有注册事件监听器的事件几乎按定义永远不会被 取消,因此如果作者没有明确阻止拖放,则用户始终可以进行拖放。
在源节点上触发一个名为 pointercancel
的指针事件,并按照
Pointer Events 的要求触发任何其他后续事件。[POINTEREVENTS]
以符合平台约定的方式,并按照下文的描述启动拖放 操作。
拖放反馈必须从以下可用来源中的第一个生成:
从用户代理要启动拖放 操作的时刻起, 直到拖放操作结束,都必须抑制设备输入事件(例如鼠标和键盘事件)。
在拖动操作期间,用户直接指定为放置目标的元素称为即时用户选择。(用户只能选择元素;其他 节点不得作为放置目标。)但是,即时用户 选择不一定是当前目标元素,后者是 当前为拖放操作的放置部分选择的元素。
当用户选择不同元素时,即时 用户选择会发生变化 (通过指针设备指向它们,或以其他方式选择它们)。当前目标 元素会在即时用户选择 发生变化时,根据文档中事件监听器的结果,按下文所述发生变化。
当前 目标元素和即时用户选择都可以 为 null,这意味着未选择目标元素。它们也都可以是其他 (基于 DOM 的)文档中的元素,或者完全位于其他(非 Web)程序中。(例如,用户可以将 文本拖动到文字处理器中。)当前目标元素初始为 null。
此外,还有一个当前拖动操作,它可以取
“none”、“copy”、“link”和“move”这些值。初始时,其值为
“none”。
用户代理按照以下步骤中的描述更新它。
用户代理必须在拖动操作一经启动后立即,并在此后拖动 操作持续期间每隔 350ms(±200ms),将一个任务加入队列,以 按顺序执行以下步骤:
如果下一次迭代到期时,用户代理仍在执行该序列的上一次迭代 (如果有),则此次迭代返回(实际上是“跳过 拖放操作中丢失的帧”)。
在源节点上触发一个名为
drag 的 DND 事件。
如果该事件被取消,则用户代理必须将当前
拖动操作设置为“none”
(无
拖动操作)。
如果 drag
事件未被取消,并且用户尚未
结束拖放操作,则按如下方式检查拖放操作的状态:
如果用户指示了与上一次迭代期间不同的即时用户选择 (或者这是第一次迭代),并且该即时用户 选择与当前目标元素不同,则按如下方式更新 当前 目标元素:
如果上一步导致当前目标元素发生变化,并且
先前的目标元素不为 null,也不是非 DOM 文档的一部分,则在先前的目标
元素上触发一个名为 dragleave
的 DND 事件,并将新的当前目标元素作为特定的
related
target。
如果当前目标元素是 DOM
元素,则在此当前
目标元素上触发一个
名为 dragover
的 DND 事件。
如果 dragover
事件未被取消,则运行
以下列表中的适当步骤:
textarea,
或者是一个 input
元素,其 type
属性处于文本
状态)、一个编辑宿主或
可编辑元素,并且拖动数据存储项列表中有一个
项,其拖动数据项类型
字符串为“text/plain”,
且其拖动
数据项种类为文本
否则(如果 dragover
事件已
被取消),则按照下表,根据
DragEvent 对象的
dataTransfer
对象的 effectAllowed
和 dropEffect
属性在事件分派
完成后的值,设置当前拖动操作:
effectAllowed
|
dropEffect
|
拖动操作 |
|---|---|---|
“uninitialized”、
“copy”、
“copyLink”、
“copyMove”
或“all”
|
“copy”
|
“copy”
|
“uninitialized”、
“link”、
“copyLink”、
“linkMove”
或“all”
|
“link”
|
“link”
|
“uninitialized”、
“move”、
“copyMove”、
“linkMove”
或“all”
|
“move”
|
“move”
|
| 任何其他情况 | “none”
|
|
否则,如果当前目标元素不是 DOM 元素,则使用 平台特定机制确定正在执行哪种拖动操作(无、复制、 链接或移动),并相应地设置当前拖动操作。
按如下方式更新拖动反馈(例如鼠标光标),以匹配当前拖动 操作:
| 拖动操作 | 反馈 |
|---|---|
“copy”
|
如果在此处放置,数据将被复制。 |
“link”
|
如果在此处放置,数据将被链接。 |
“move”
|
如果在此处放置,数据将被移动。 |
“none”
|
不允许任何操作,在此处放置将取消拖放操作。 |
否则,如果用户结束了拖放操作(例如在由鼠标驱动的拖放界面中释放鼠标按钮),
或者 drag
事件被取消,则这将是最后一次迭代。运行以下步骤,然后停止
拖放操作:
如果当前拖动操作为“none”
(无拖动操作),或者用户
通过取消拖放操作结束了该操作(例如按下 Escape 键),
或者当前目标元素为 null,则
拖动操作失败。运行
以下子步骤:
否则,拖动操作可能成功;运行以下子步骤:
令 dropped 为 true。
如果当前目标元素是 DOM
元素,则在其上触发一个名为
drop 的
DND 事件;
否则,使用
平台特定约定表示放置。
如果事件被取消,则将当前拖动操作设置为
DragEvent
对象的 dataTransfer
对象的 dropEffect
属性在事件分派
完成后的值。
否则,事件未被取消;执行该事件的默认操作,该操作取决于 确切的目标,如下所示:
textarea,
或者是一个 input
元素,其 type
属性处于文本
状态)、一个编辑
宿主或
可编辑元素,并且拖动数据存储项列表中有一个
项,其拖动数据项类型
字符串为“text/plain”,
且其拖动
数据项种类为文本
将拖动数据存储项
列表中第一个拖动数据项类型
字符串为“text/plain”,
且拖动
数据项种类为文本的项的实际数据,按照符合
平台特定约定的方式插入文本控件、
编辑宿主或可编辑元素中(例如,将其插入当前鼠标光标位置,或者
插入字段末尾)。
作为 dragend
事件的默认操作,运行以下列表中的适当步骤:
move”,
并且拖放操作的源是 DOM 中完全包含在
编辑宿主内的选区
删除选区。
move”,
并且拖放操作的源是文本控件中的选区用户代理应从相关文本控件中删除被拖动的选区。
none”
拖动已取消。如果平台约定规定应向 用户表示这一点(例如,通过将被拖动选区动画返回到拖放操作的 源位置),则应这样做。
该事件没有默认操作。
就此步骤而言,文本控件是一个 textarea
元素,或者
一个 input
元素,其 type
属性处于
文本、
搜索、
电话、
URL、
电子邮件、
密码或
数字
状态之一。
建议用户代理考虑如何响应可滚动区域边缘附近的拖动。 例如,如果用户将链接拖动到长页面视口的底部, 则滚动页面以便用户能将链接放置到页面更下方可能是合理的。
此模型与所涉及节点来自哪个 Document 对象无关;
无论操作涉及多少个文档,事件都按上述方式触发,处理模型的其余部分也都按上述方式运行。
本节为非规范性内容。
拖放模型涉及以下事件。
| 事件名称 | 目标 | 可取消? | 拖动数据存储模式 | dropEffect
|
默认操作 |
|---|---|---|---|---|---|
dragstart
Support in all current engines. Firefox9+Safari3.1+Chrome1+
Opera12+Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android12+ |
源节点 | ✓ 可取消 | 读/写模式 | "none"
|
启动拖放操作 |
drag
Support in all current engines. Firefox9+Safari3.1+Chrome1+
Opera12+Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android12+ |
源节点 | ✓ 可取消 | 受保护模式 | "none"
|
继续拖放操作 |
dragenter
Support in all current engines. Firefox9+Safari3.1+Chrome1+
Opera12+Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android12+ |
即时用户选择或 body 元素 | ✓ 可取消 | 受保护模式 | 基于 effectAllowed 值 |
拒绝将即时用户 选择作为潜在的目标 元素 |
dragleave
Support in all current engines. Firefox9+Safari3.1+Chrome1+
Opera12+Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android12+ |
先前的目标元素 | — | 受保护模式 | "none"
|
无 |
dragover
Support in all current engines. Firefox9+Safari3.1+Chrome1+
Opera12+Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android12+ |
当前目标元素 | ✓ 可取消 | 受保护模式 | 基于 effectAllowed 值 |
将当前拖动操作 重置为 "none" |
drop
Support in all current engines. Firefox9+Safari3.1+Chrome1+
Opera12+Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android12+ |
当前目标元素 | ✓ 可取消 | 只读模式 | 当前拖动操作 | 视情况而定 |
dragend
Support in all current engines. Firefox9+Safari3.1+Chrome1+
Opera12+Edge79+ Edge (Legacy)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android12+ |
源节点 | — | 受保护模式 | 当前拖动操作 | 视情况而定 |
所有这些事件都会冒泡、都是组合事件,并且 effectAllowed
属性始终具有它在
dragstart 事件之后所具有的值,
在 dragstart 事件中默认为
"uninitialized"。
draggable 属性Support in all current engines.
所有 HTML 元素都可以设置 draggable 内容
属性。draggable 属性是一个枚举属性,具有
以下关键字和状态:
| 关键字 | 状态 | 简要说明 |
|---|---|---|
true
|
真 | 该元素可拖动。 |
false
|
假 | 该元素不可拖动。 |
具有 draggable 属性的元素还应
具有一个
title 属性,该属性为
非视觉交互目的命名该元素。
element.draggable [ = value ]
如果元素可拖动,则返回 true;否则返回 false。
可以设置该值,以覆盖默认值并设置 draggable 内容
属性。
draggable IDL
属性的值以下文所述方式取决于内容属性,并控制
元素是否可拖动。通常只有文本选区可拖动,但
draggable IDL
属性为 true 的元素也会变得
可拖动。
如果元素的 draggable 内容属性
处于
真状态,则 draggable IDL 属性必须
返回 true。
否则,如果元素的 draggable 内容属性
处于假状态,则 draggable IDL 属性必须
返回 false。
否则,元素的 draggable 内容属性
处于
自动状态。如果
该元素是一个
img 元素、一个表示图像的 object 元素,或者
一个具有 href 内容
属性的 a 元素,则 draggable
IDL 属性必须返回 true;
否则,draggable
IDL 属性必须返回 false。
如果 draggable IDL
属性被设置为 false,
则 draggable 内容
属性必须被设置为字面
值 "false"。如果 draggable IDL
属性被设置为 true,则 draggable
内容
属性必须被设置为字面值 "true"。
在
dragstart
事件期间添加到 DataTransfer 对象
中的数据,在 drop
事件之前,
用户代理不得使其可供脚本访问,
因为否则,如果用户将敏感
信息从一个文档拖动到第二个文档,并在此
过程中经过恶意的第三个文档,该恶意文档就可能拦截数据。
出于同样的原因,只有当用户
明确结束拖动操作时,用户代理才必须认为放置成功——如果任何脚本结束拖动操作,则必须
将其视为不成功(已取消),并且不得
触发 drop
事件。
用户代理应注意不要响应脚本 操作而启动拖放操作。例如,在鼠标和窗口环境中,如果脚本在用户 按住鼠标按钮时移动窗口,用户代理不会认为这启动了拖动。这一点很重要, 因为否则用户代理可能在未经用户同意的情况下,使数据从敏感来源被拖动并放入 恶意文档。
用户代理应在潜在的活动(脚本化)内容(例如 HTML)被拖动 和放置时对其进行过滤,并使用已知安全特性的安全列表。同样,相对 URL 应被转换为绝对 URL,以避免引用以 意外方式发生变化。本规范未规定如何执行此操作。
考虑一个恶意页面提供某些内容,并诱使用户选择该内容,然后将其拖放
(或者复制并粘贴)到受害页面的 contenteditable
区域中。如果浏览器未确保
仅拖动安全内容,则选区中的脚本和事件处理器等潜在不安全内容
一旦被放置(或粘贴)到受害站点中,就会获得受害
站点的权限。这将使跨站脚本攻击成为可能。
popover 属性Support in all current engines.
所有 HTML 元素都可以设置 popover 内容
属性。指定该属性后,元素
在变为显示状态之前不会渲染;变为显示状态后,它将在其他页面
内容之上渲染。
popover 属性是一个
全局属性,它使
作者能够灵活地确保弹出框功能可以应用于具有最
相关语义的元素。
下面演示如何在网站的全局导航中 创建一个包含链接的弹出式子导航列表。
< ul >
< li >
< a href = ... > All Products</ a >
< button popovertarget = sub-nav >
< img src = down-arrow.png alt = "Product pages" >
</ button >
< ul popover id = sub-nav >
< li >< a href = ... > Shirts</ a >
< li >< a href = ... > Shoes</ a >
< li >< a href = ... > Hats etc.</ a >
</ ul >
</ li >
<!-- other list items and links here -->
</ ul > 在没有无障碍
语义的元素(例如 div 元素)上使用
popover 时,作者应使用
适当的 ARIA
属性,以确保弹出框可无障碍访问。
下面显示了创建自定义菜单弹出框的基准标记,其中由于使用了
autofocus 属性,当弹出框被调用时,第一个
菜单项将获得键盘焦点。使用箭头键在菜单项之间导航和
激活行为仍需要作者编写脚本。构建
自定义菜单部件的其他要求在 WAI-ARIA
规范中定义。
< button popovertarget = m > Actions</ button >
< div role = menu id = m popover >
< button role = menuitem tabindex = -1 autofocus > Edit</ button >
< button role = menuitem tabindex = -1 > Hide</ button >
< button role = menuitem tabindex = -1 > Delete</ button >
</ div > 弹出框可用于呈现状态消息,以确认用户执行的操作。
下面演示如何在 output
元素中显示弹出框。
< button id = submit > Submit</ button >
< p >< output >< span popover = manual ></ span ></ output ></ p >
< script >
const sBtn = document. getElementById( "submit" );
const outSpan = document. querySelector( "output [popover=manual]" );
let successMessage;
let errorMessage;
/* define logic for determining success of action
and determining the appropriate success or error
messages to use */
sBtn. addEventListener( "click" , ()=> {
if ( success ) {
outSpan. textContent = successMessage;
}
else {
outSpan. textContent = errorMessage;
}
outSpan. showPopover();
setTimeout( function () {
outSpan. hidePopover();
}, 10000 );
});
</ script > 将弹出框元素插入 output 元素通常
会使屏幕阅读器在内容变为可见时朗读它。根据内容的复杂程度
或出现频率,这对这些
辅助技术的用户而言可能有用,也可能令人厌烦。在使用 output 元素或其他
ARIA 实时区域时应牢记这一点,以确保最佳用户体验。
popover 属性是一个枚举
属性,具有以下关键字和状态:
| 关键字 | 状态 | 简要说明 |
|---|---|---|
auto
|
自动 | 打开时关闭其他弹出框;具有轻触 关闭,并响应关闭 请求。 |
manual
|
手动 | 不关闭其他弹出框;不会轻触 关闭,也不响应关闭 请求。 |
hint |
提示 | 打开时关闭其他提示弹出框,但不关闭其他自动弹出框;具有轻触关闭,并响应关闭请求。 |
Support in all current engines.
每个 HTML 元素都有一个弹出框可见性 状态,其初始值为, 并具有以下可能的 值:
隐藏
显示
每个 Document 都有一个弹出框 pointerdown 目标,它是一个HTML 元素或 null,初始为 null。
每个 HTML 元素都有一个弹出框触发器,它 是一个HTML 元素或 null,初始设置为 null。
每个 HTML 元素都有一个弹出框正在隐藏,它 是一个布尔值,初始设置为 false。
每个 HTML 元素都有一个弹出框切换任务跟踪器, 它是一个切换任务跟踪器或 null,初始为 null。
每个 HTML 元素都有一个弹出框关闭监视器, 它是一个关闭监视器或 null,初始 为 null。
每个 HTML 元素都有一个以弹出框
模式打开,其值为 "auto"、"hint" 或 null,
初始为 null。
每个 Document 都有一个隐藏弹出框嵌套计数,它是一个数字,
初始为 0。
每个 Document 都有一个正在显示弹出框,它是一个布尔值,初始
为 false。
每个 Document 都有一个提示栈父项,它是一个HTML
元素或 null,初始为 null。
提示栈父项会跟踪 正在显示的自动弹出框 列表中的哪一项是正在显示的提示弹出框列表中第一项的“父项”,或者 如果正在显示的提示弹出框列表中的第一项不是 正在显示的自动弹出框列表中某项的“子项”, 则为 null。
element.showPopover()popover 属性处于自动状态,则这
还会关闭所有其他自动弹出框,除非根据最顶层弹出框祖先算法,它们是
element 的祖先。
element.hidePopover()display: none 来隐藏它。
element.togglePopover()Support in all current engines.
showPopover(options) 方法的步骤如下:
要显示弹出框,给定一个HTML 元素 element、一个布尔值 throwExceptions,以及一个HTML 元素或 null source:
令 document 为 element 的节点文档。
如果 document 的正在显示 弹出框为 true,或者 document 的 隐藏弹出框 嵌套计数不为 0:
如果 throwExceptions 为 true,则抛出一个
"InvalidStateError" DOMException。
返回。
这会防止在显示或隐藏另一个弹出框期间显示弹出框。
令 validityResult 为运行检查弹出框有效性所得的结果, 给定 element、false 和 null。如果这抛出异常,则捕获它,并将 validityResult 设置为该异常。
如果 validityResult 不为 true:
如果 throwExceptions 为 true,并且 validityResult 是一个
DOMException,
则抛出 validityResult。
返回。
将 document 的正在显示 弹出框设置为 true。
令 cleanupShowingSteps 为以下步骤:
将 document 的正在显示 弹出框设置为 false。
如果在 element 上,使用 ToggleEvent,并将
cancelable
属性初始化为 true、将 oldState
属性初始化为 "closed"、将 newState
属性
初始化为 "open",并将 source
属性初始化为 source,触发一个名为
beforetoggle
的事件所得结果为 false,则运行 cleanupShowingSteps 并返回。
将 validityResult 设置为运行检查弹出框有效性所得的结果, 给定 element、false 和 document。如果这抛出异常,则捕获它, 并将 validityResult 设置为该异常。
之所以再次调用检查
弹出框有效性,是因为触发 beforetoggle 事件
可能已断开此元素的连接,或者
更改其 popover
属性。
如果 validityResult 不为 true:
运行 cleanupShowingSteps。
如果 throwExceptions 为 true,并且 validityResult 是一个
DOMException,
则抛出 validityResult。
返回。
令 shouldRestoreFocus 为 false。
令 originalType 为 element 的 popover 属性的当前状态。
令 effectiveType 为 originalType。
令 ancestor 为运行最顶层弹出框 祖先算法所得的结果,给定 element、source 和 true。
如果以下所有条件均为 true:
则将 effectiveType 设置为提示 状态。
提示弹出框的优先级低于 自动 弹出框,因此自动弹出框不能以提示弹出框作为 “父项”。为解决这种情况, effectiveType 会被“降级”为提示。
运行隐藏弹出框 栈直至,给定 document、 ancestor、提示、 shouldRestoreFocus 和 true。
如果 effectiveType 为自动 状态,则运行隐藏弹出框栈直至,给定 document、 ancestor、自动、 shouldRestoreFocus 和 true。
如果 originalType 不等于 element 的 popover 属性的值:
运行 cleanupShowingSteps。
如果 throwExceptions 为 true,则抛出一个
"InvalidStateError" DOMException。
返回。
将 validityResult 设置为运行检查弹出框有效性所得的结果, 给定 element、false 和 document。如果这抛出异常,则捕获 它,并将 validityResult 设置为该异常。
之所以再次调用检查
弹出框有效性,是因为运行上面的隐藏
弹出框栈直至可能已触发 beforetoggle
事件,而事件处理器可能已
断开此元素的连接或更改其 popover
属性。
如果 validityResult 不为 true:
运行 cleanupShowingSteps。
如果 throwExceptions 为 true,并且 validityResult 是一个
DOMException,
则抛出 validityResult。
返回。
如果在 document 上运行最顶层自动或提示弹出框所得的结果 为 null,则将 shouldRestoreFocus 设置为 true。
这确保仅对栈中的第一个弹出框, 将焦点返回到先前获得焦点的元素。
如果 effectiveType 为自动:
断言:document 的正在显示的自动弹出框列表不 包含 element。
将 element 的以弹出框模式打开设置为
"auto"。
否则:
断言:document 的正在显示的提示弹出框列表不 包含 element。
将 element 的以弹出框模式打开设置为
"hint"。
将 element 的弹出框关闭监视器设置为建立 关闭监视器所得的结果,给定 element 的相关全局对象,并使用:
cancelAction 为返回 true。
closeAction 为隐藏 弹出框,给定 element、true、true、 false 和 null。
getEnabledState 为返回 true。
将 element 的先前获得焦点的元素设置为 null。
给定 element,将元素添加到顶层。
如果 effectiveType 为提示,并且
ancestor 的以弹出框模式打开为 "auto",则
将 document 的提示
栈父项设置为 ancestor。
将 element 的弹出框 触发器设置为 source。
将 element 的隐式锚点元素设置为 source。
运行弹出框聚焦 步骤,给定 element。
如果 shouldRestoreFocus 为 true,并且 element 的 popover 属性不处于
无弹出框
状态,则将 element 的
先前
获得焦点的元素设置为 originallyFocusedElement。
运行 cleanupShowingSteps。
将弹出框切换事件任务加入队列,给定
element、"closed"、"open" 和 source。
要将弹出框切换事件任务加入队列,给定一个元素
element、一个字符串
oldState、一个字符串 newState,以及一个 Element
或 null
source:
如果 element 的弹出框切换任务跟踪器不为 null:
将 oldState 设置为 element 的弹出框切换任务 跟踪器的旧 状态。
从其任务队列中移除 element 的弹出框切换任务跟踪器的任务。
将 element 的弹出框切换任务跟踪器设置为 null。
将元素任务加入队列, 给定DOM 操作任务源和 element,以运行以下步骤:
在 element 上触发一个名为 toggle 的事件,
使用 ToggleEvent,并将
oldState
属性初始化为
oldState,将 newState
属性
初始化为 newState,并将 source
属性初始化为
source。
将 element 的弹出框切换任务跟踪器设置为 null。
将 element 的弹出框切换任务跟踪器设置为一个结构体,其中任务设置为刚刚加入队列的任务,而旧状态设置 为 oldState。
Support in all current engines.
要隐藏弹出框,给定一个HTML 元素 element、一个布尔值 focusPreviousElement、一个 布尔值 fireEvents、一个布尔值 throwExceptions,以及一个HTML 元素或 null source:
令 validityResult 为运行检查弹出框有效性所得的结果, 给定 element、true 和 null。如果这抛出异常,则捕获它,并令 validityResult 为该异常。
如果 validityResult 不为 true:
如果 throwExceptions 为 true,并且 validityResult 是一个
DOMException,
则抛出 validityResult。
返回。
令 document 为 element 的节点文档。
令 nestedHide 为 element 的弹出框正在隐藏。
将 element 的弹出框 正在隐藏设置为 true。
如果 nestedHide 为 true,则将 fireEvents 设置为 false。
递增 document 的隐藏弹出框嵌套计数。
令 cleanupSteps 为以下步骤:
如果 document 的 正在显示的自动弹出框列表包含 element,则令 autoPopoverListContainsElement 为 true;否则为 false。
如果 document 的 正在显示的提示 弹出框列表包含 element,则令 hintPopoverListContainsElement 为 true;否则为 false。
如果 element 的以弹出框模式打开为 "auto"
或 "hint":
如果 hintPopoverListContainsElement 为 true,则运行隐藏弹出框栈 直至,给定 document、element、提示、focusPreviousElement 和 fireEvents。
如果 element 是 document 的提示栈父项,则运行 隐藏弹出框 栈直至,给定 document、null、提示、focusPreviousElement 和 fireEvents。
如果 document 的提示栈父项正在被隐藏, 则会隐藏所有提示弹出框。
如果 autoPopoverListContainsElement 为 true,则运行隐藏弹出框栈 直至,给定 document、element、自动、focusPreviousElement 和 fireEvents。
将 validityResult 设置为运行检查弹出框有效性所得的结果, 给定 element、true 和 null。如果这抛出异常,则捕获它,并将 validityResult 设置为该异常。
之所以再次调用检查
弹出框有效性,是因为运行隐藏
弹出框栈直至可能已断开 element 的连接,或者更改其 popover 属性。
如果 validityResult 不为 true:
运行 cleanupSteps。
如果 throwExceptions 为 true,并且 validityResult 是一个
DOMException,
则抛出 validityResult。
返回。
如果 fireEvents 为 true:
在 element 上触发一个名为 beforetoggle
的事件,使用 ToggleEvent,并将
oldState
属性初始化为 "open",将 newState
属性初始化为 "closed",并将 source
属性设置为 source。
将 validityResult 设置为运行检查弹出框有效性所得的结果, 给定 element、true 和 null。如果这抛出异常,则捕获它,并将 validityResult 设置为该异常。
之所以再次调用检查
弹出框有效性,是因为触发 beforetoggle
事件可能已断开
element 的连接,或者更改其 popover 属性。
如果 validityResult 不为 true:
运行 cleanupSteps。
如果 throwExceptions 为 true,并且 validityResult 是一个
DOMException,
则抛出 validityResult。
返回。
给定 element,请求从顶层移除 元素。
将 element 的隐式锚点元素设置为 null。
否则,给定 element,立即从顶层移除元素。
将 element 的弹出框 触发器设置为 null。
将 element 的以弹出框模式打开设置为 null。
将 element 的弹出框可见性状态设置为。
如果 element 是 document 的提示栈父项,或者 document 的正在显示的提示弹出框列表为空,则将 document 的提示栈父项设置为 null。
如果 fireEvents 为 true,则将弹出框切换事件任务加入队列,
给定 element、"open"、"closed" 和
source。
令 previouslyFocusedElement 为 element 的先前获得焦点的 元素。
如果 previouslyFocusedElement 不为 null:
将 element 的先前获得焦点的元素设置为 null。
如果 focusPreviousElement 为 true,并且 document 的文档的已聚焦 区域的DOM 锚点是 element 的包含 shadow 的包含性 后代,则为 previouslyFocusedElement 运行聚焦步骤;执行此 步骤时不应滚动视口。
运行 cleanupSteps。
Support in all current engines.
togglePopover(options) 方法的步骤如下:
要隐藏弹出框直至,给定一个 Document document、一个
HTML 元素或 null endpoint、
一个布尔值
focusPreviousElement 和一个布尔值 fireEvents:
要隐藏弹出框栈直至,给定一个 Document document、一个
HTML 元素或 null endpoint、
一个自动或提示
stackType、一个布尔值 focusPreviousElement 和一个布尔值
fireEvents:
如果 stackType 为自动,则令 popoverList 为 document 的正在显示的自动弹出框列表;否则为 document 的正在显示的提示弹出框列表。
如果 popoverList 不包含 endpoint,则令 lastHideIndex 为 0;否则为 endpoint 在 popoverList 中的索引加 1。
对于 toHide 中的每个 popover:运行 隐藏弹出框 算法,给定 popover、 focusPreviousElement、fireEvents、false 和 null。
如果 stackType 为自动,则令 newPopoverList 为 document 的正在显示的自动弹出框 列表; 否则为 document 的正在显示的提示弹出框列表。
令 toCheck 为按逆序排列的 newPopoverList。
对于 toCheck 中的每个 popover:
如果 toRemain包含 popover, 则继续。
运行隐藏 弹出框算法,给定 popover、 focusPreviousElement、false、false 和 null。
如果在隐藏弹出框时又显示了弹出框,就会发生这种情况。例如,在
beforetoggle
事件中。这通常是开发者
错误,因此建议用户代理显示警告。在这个额外的隐藏阶段,
fireEvents 会被忽略,并改用 false。
隐藏 弹出框栈直至算法用于多种情况,以 隐藏在发生某些事情时不会保持打开的所有弹出框。例如,在弹出框的轻触关闭 期间,此算法确保仅关闭与用户所点击 节点无关的弹出框。
要查找最顶层弹出框祖先,给定一个 Node
newPopoverOrTopLayerElement、一个HTML
元素或
null source,以及一个布尔值 isPopover,执行以下步骤。它们
返回一个HTML 元素或 null。
最顶层弹出框 祖先算法会返回所提供弹出框或顶层元素的最顶层祖先弹出框。 弹出框可以通过多种方式彼此关联,从而创建弹出框树。一个弹出框(称为 “子”弹出框)可以通过两种路径具有最顶层祖先弹出框(称为“父” 弹出框):
弹出框在节点树中相互嵌套。在这种情况下,后代 弹出框是“子项”,其最顶层祖先弹出框是“父项”。
某个元素是弹出框的“源”(例如,一个 button,其 command 处于显示弹出框状态)。在这种情况下,
弹出框是“子项”,而触发元素所在的弹出框子树是“父项”。
触发元素必须位于某个弹出框中,并引用一个打开的弹出框。
在上述形成的每种关系中,父弹出框必须严格早于 子弹出框出现在正在显示的自动弹出框列表或 正在显示的提示弹出框 列表中,否则它不会形成有效的祖先关系。这排除了未显示的 弹出框和自引用(例如,弹出框包含一个指回 包含它的弹出框的调用元素),并允许从 (可能循环的)连接图中构建结构良好的树。只考虑自动 和提示弹出框。
如果所提供的元素是一个顶层元素,例如一个未作为弹出框
显示的 dialog,则最顶层弹出框祖先只会在节点
树中查找第一个弹出框。
如果 isPopover 为 true:
否则:
断言:source 为 null。
令 document 为 newPopoverOrTopLayerElement 的节点 文档。
令 combinedPopovers 为 document 的正在显示的自动弹出框 列表,并用 document 的正在显示的 提示弹出框列表对其进行扩展。
令 popoverAncestorIndex 为 combinedPopovers 中最后一个满足以下条件的项的索引: newPopoverOrTopLayerElement 是该项在扁平树中的后代;如果没有,则为 -1。
令 sourceAncestorIndex 为 -1。
如果 source 不为 null,则将 sourceAncestorIndex 设置为 combinedPopovers 中最后一个满足以下条件的项的索引: source 是该项在扁平树中的后代; 如果没有,则为 -1。
令 ancestorIndex 为 popoverAncestorIndex 和 sourceAncestorIndex 中的最大值。
如果 ancestorIndex 为 -1,则返回 null。
返回 combinedPopovers[ancestorIndex]。
要查找最顶层自动或提示弹出框,给定
一个 Document document,执行
以下步骤。它们返回一个HTML
元素或 null。
如果 document 的正在显示的提示弹出框列表不为空,则 返回 document 的正在显示的提示弹出框列表的最后一个元素。
如果 document 的正在显示的 自动弹出框列表不为空,则返回 document 的正在显示的 自动弹出框列表的最后一个元素。
返回 null。
要为一个HTML 元素 subject 执行弹出框聚焦步骤:
要为一个HTML 元素
element,给定一个布尔值 expectedToBeShowing 和一个 Document 或
null expectedDocument,检查弹出框有效性,执行以下步骤。它们会抛出异常或返回一个
布尔值。
如果 element 的 popover 属性处于无弹出框状态,
则抛出一个
"NotSupportedError" DOMException。
如果以下任一条件为 true:
expectedToBeShowing 为 false,并且 element 的弹出框 可见性状态不是,
则返回 false。
如果以下任一条件为 true:
返回 true。
要获取一个
Document document 的正在显示的自动弹出框列表:
要获取一个 Document
document 的正在显示的提示弹出框列表:
按钮可以具有以下 内容属性:
popovertarget
popovertargetaction
如果指定了 popovertarget
属性,则其值必须
是同一树中具有 popover 属性的元素的
ID,该树也包含具有 popovertarget
属性的按钮。
popovertargetaction
属性是一个
枚举属性,
具有以下关键字和状态:
| 关键字 | 状态 | 简要说明 |
|---|---|---|
toggle
|
切换 | 显示或隐藏目标弹出框元素。 |
show
|
显示 | 显示目标弹出框元素。 |
hide
|
隐藏 | 隐藏目标弹出框元素。 |
只要有可能,请确保弹出框元素在 DOM 中紧接其 触发元素之后放置。这样做将有助于确保弹出框按照符合逻辑的程序化 阅读顺序向屏幕阅读器等辅助技术的用户公开。
以下示例展示了如何结合使用 popovertarget
属性和 popovertargetaction
属性来显示和关闭弹出框:
< button popovertarget = "foo" popovertargetaction = "show" >
Show a popover
</ button >
< article popover = "auto" id = "foo" >
This is a popover article!
< button popovertarget = "foo" popovertargetaction = "hide" > Close</ button >
</ article > 如果未指定 popovertargetaction
属性,则默认操作将切换关联弹出框。以下示例展示了
只在调用按钮上指定 popovertarget
属性,如何在手动弹出框的打开和关闭状态之间进行切换。手动
弹出框不会响应轻触关闭或关闭请求:
< input type = "button" popovertarget = "foo" value = "Toggle the popover" >
< div popover = manual id = "foo" >
This is a popover!
</ div > HTMLButtonElement/popoverTargetElement
Support in all current engines.
HTMLInputElement/popoverTargetElement
Support in all current engines.
interface mixin PopoverTargetAttributes {
[CEReactions , Reflect ] attribute Element ? popoverTargetElement ;
[CEReactions ] attribute DOMString popoverTargetAction ;
};HTMLButtonElement/popoverTargetAction
Support in all current engines.
HTMLInputElement/popoverTargetAction
Support in all current engines.
popoverTargetAction IDL 属性必须
反映 popovertargetaction
属性,并仅限于已知值。
要运行弹出框目标属性激活
行为,给定一个 Node
node 和一个 Node
eventTarget:
令 popover 为 node 的弹出框目标元素。
如果 popover 为 null,则返回。
如果 eventTarget 是 popover 的包含 shadow 的包含性后代,并且 popover 是 node 的 包含 shadow 的后代, 则返回。
如果 node 的 popovertargetaction
属性处于显示状态,并且
popover 的弹出框可见性状态为显示,则
返回。
如果 node 的 popovertargetaction
属性处于隐藏状态,并且
popover 的弹出框可见性状态为,则
返回。
如果 popover 的弹出框可见性状态为显示,则 运行隐藏 弹出框算法,给定 popover、true、true、false 和 node。
否则:
“轻触关闭”是指,单击 popover
属性处于自动或提示
状态的弹出框之外的位置将关闭该弹出框。这是对此类弹出框响应关闭请求方式的补充。
要轻触关闭打开的弹出框,给定一个 PointerEvent
event:
令 target 为 event 的目标。
令 document 为 target 的节点文档。
如果给定 document 运行最顶层自动或提示弹出框所得的结果 为 null,则返回。
如果 event 的 type
为 "pointerdown":
将 document 的弹出框
pointerdown 目标设置为给定 target 运行最顶层被点击的弹出框所得的结果。
如果 event 的 type
为 "pointerup":
令 ancestor 为给定 target 运行最顶层被点击的弹出框 所得的结果。
如果 ancestor 是 document 的 弹出框 pointerdown 目标,则令 sameTarget 为 true。
将 document 的弹出框 pointerdown 目标设置为 null。
如果 sameTarget 为 false,则返回。
如果 document 的正在显示的提示 弹出框列表包含 ancestor,则令 endpointIsHint 为 true;否则为 false。
令 autoEndpoint 为 ancestor。
如果 endpointIsHint 为 true,则将 autoEndpoint 设置为 document 的提示栈 父项。
这意味着,如果单击了提示弹出框,则自动弹出框将被关闭,但 作为所单击提示弹出框父项的自动弹出框除外。
要查找最顶层被点击的弹出框,给定一个 Node
node:
令 clickedPopover 为给定 node 运行最近的包含性打开 弹出框所得的结果。
令 targetPopover 为给定 node 运行最近的包含性目标 弹出框所得的结果。
如果给定 clickedPopover获取弹出框栈 位置所得的结果大于给定 targetPopover获取 弹出框栈位置所得的结果,则返回 clickedPopover。
返回 targetPopover。
要获取弹出框栈位置,给定一个HTML 元素 popover:
令 hintList 为 popover 的节点 文档的正在显示的 提示弹出框列表。
令 autoList 为 popover 的节点 文档的正在显示的 自动弹出框列表。
如果 popover 位于 hintList 中,则返回 popover 在 hintList 中的索引 + autoList 的大小 + 1。
如果 popover 位于 autoList 中,则返回 popover 在 autoList 中的索引 + 1。
返回 0。
要查找最近的包含性目标弹出框,给定一个 Node
node:
要获取目标弹出框,给定一个 Node
node,执行
以下步骤。它们返回一个HTML
元素或 null。
如果 node 已禁用,则返回 null。
令 target 为运行 node 的获取与 commandfor 关联的
元素所得的结果。
如果 target 为 null,则返回 node 的弹出框目标 元素。
如果 node 具有表单所有者:
令 command 为 node 的 command 属性。
返回 target。
本节介绍最直接适用于 Web 浏览器的功能。尽管如此, 除非另有规定,否则本节中定义的要求确实适用于 所有用户代理,无论其是否为 Web 浏览器。
源是 Web 安全模型的基础单位。Web 平台中共享同一源的两个参与者被假定为相互信任,并具有相同的权限。 具有不同源的参与者被视为彼此可能具有敌意,并在不同程度上 相互隔离。
例如,如果托管在 bank.example.com 的示例银行网站尝试检查
托管在 charity.example.org 的示例慈善机构网站的
DOM,则会引发一个 "SecurityError"
DOMException。
一个源是以下之一:
源可以共享,例如由多个
Document 对象共享。此外,源通常是
不可变的。只有元组源的域可以更改,并且只能通过
document.domain API 更改。
一个源 origin 的有效域按以下方式计算:
源的序列化是通过对给定源 origin 应用以下算法而获得的字符串:
("https"、"xn--maraa-rta.example"、null、null) 的序列化为
"https://xn--maraa-rta.example"。
过去还存在 源的 Unicode 序列化。但是,它从未被广泛采用。
如果以下算法返回 true,则称两个源 A 和 B 同源:
如果以下算法返回 true,则称两个源 A 和 B 同源域:
| A | B | 同源 | 同源域 |
|---|---|---|---|
("https", "example.org", null, null)
|
("https", "example.org", null, null)
|
✅ | ✅ |
("https", "example.org", 314, null)
|
("https", "example.org", 420, null)
|
❌ | ❌ |
("https", "example.org", 314, "example.org")
|
("https", "example.org", 420, "example.org")
|
❌ | ✅ |
("https", "example.org", null, null)
|
("https", "example.org", null, "example.org")
|
✅ | ❌ |
("https", "example.org", null, "example.org")
|
("http", "example.org", null, "example.org")
|
❌ | ❌ |
方案和主机是由一个方案(一个ASCII 字符串)和一个主机(一个主机)组成的元组。
要获取站点,给定一个源 origin,运行以下步骤:
如果以下算法返回 true,则称两个站点 A 和 B同站点:
站点的序列化是通过对给定站点 site 应用以下 算法而获得的字符串:
必须能够从上下文中明确看出序列化后的值是站点而不是
源,因为二者之间不一定存在语法差异。例如,
源("https"、"shop.example"、null、null)和
站点("https"、"shop.example")具有相同的
序列化:"https://shop.example"。
如果以下算法返回 true,则称两个源 A 和 B 不考虑方案的同站点:
如果以下算法返回 true,则称两个源 A 和 B 同站点:
与同源和同源域概念不同, 对于不考虑方案的同站点和同站点,端口和域 组成部分将被忽略。
由于 URL 中 所述的原因,应尽可能避免使用 同站点和不考虑方案的同站点概念,而应优先使用同源检查。
假定 wildlife.museum、museum 和 com 是公共后缀,而 example.com 不是:
| A | B | 不考虑方案的同站点 | 同站点 |
|---|---|---|---|
("https", "example.com")
|
("https", "sub.example.com")
|
✅ | ✅ |
("https", "example.com")
|
("https", "sub.other.example.com")
|
✅ | ✅ |
("https", "example.com")
|
("http", "non-secure.example.com")
|
✅ | ❌ |
("https", "r.wildlife.museum")
|
("https", "sub.r.wildlife.museum")
|
✅ | ✅ |
("https", "r.wildlife.museum")
|
("https", "sub.other.r.wildlife.museum")
|
✅ | ✅ |
("https", "r.wildlife.museum")
|
("https", "other.wildlife.museum")
|
❌ | ❌ |
("https", "r.wildlife.museum")
|
("https", "wildlife.museum")
|
❌ | ❌ |
("https", "wildlife.museum")
|
("https", "wildlife.museum")
|
✅ | ✅ |
("https", "example.com")
|
("https", "example.com.")
|
❌ | ❌ |
document.domain [ = domain ]
返回当前用于安全检查的域。
可以设置为移除子域的值,以更改源的域,从而允许同一 域的其他子域上的页面(如果它们也执行相同操作)相互访问。这使域中不同主机上的页面 能够同步访问彼此的 DOM。
在沙盒化的 iframe、
具有不透明
源的 Document,以及没有浏览上下文的 Document 中,设置器将
抛出一个"SecurityError" 异常。当 crossOriginIsolated
或 originAgentCluster
返回 true 时,设置器将不执行任何操作。
请避免使用 document.domain
设置器。它会削弱同源策略提供的安全保护。使用共享托管时,这一点尤其严重;
例如,如果不受信任的第三方能够在同一个 IP 地址但不同端口上托管 HTTP
服务器,那么通常保护同一主机上两个不同站点的同源保护将失效,因为在使用
document.domain
设置器后,比较源时会忽略端口。
由于存在这些安全隐患,此功能正从 Web 平台中移除。(这是一个需要多年才能完成的漫长过程。)
应改用 postMessage()
或
MessageChannel
对象,以安全的方式在不同源之间通信。
domain
获取器步骤如下:
domain
设置器步骤如下:
如果this 的浏览上下文为
null,则抛出一个"SecurityError" DOMException。
如果this 的活动沙盒化标志集设置了
沙盒化
document.domain 浏览上下文标志,则
抛出一个"SecurityError" DOMException。
如果 effectiveDomain 为 null,则抛出一个
"SecurityError" DOMException。
如果给定值既不是
effectiveDomain 的可注册域后缀,也不等于它,则抛出
一个"SecurityError" DOMException。
要确定一个标量值 字符串 hostSuffixString是否为一个主机 originalHost 的可注册域后缀或与其相等:
| hostSuffixString | originalHost | 是 可注册域后缀或与其相等的结果 | 说明 |
|---|---|---|---|
"0.0.0.0" |
0.0.0.0 |
✅ | |
"0x10203" |
0.1.2.3 |
✅ | |
"[0::1]" |
::1 |
✅ | |
"example.com" |
example.com |
✅ | |
"example.com" |
example.com. |
❌ | 尾随点具有意义。 |
"example.com." |
example.com |
❌ | |
"example.com" |
www.example.com |
✅ | |
"com" |
example.com |
❌ | 在编写本文时,com 是一个公共后缀。 |
"example" |
example |
✅ | |
"compute.amazonaws.com" |
example.compute.amazonaws.com |
❌ | 在编写本文时,*.compute.amazonaws.com 是一个公共后缀。
|
"example.compute.amazonaws.com" |
www.example.compute.amazonaws.com |
❌ | |
"amazonaws.com" |
www.example.compute.amazonaws.com |
❌ | |
"amazonaws.com" |
test.amazonaws.com |
✅ | 在编写本文时,amazonaws.com 是一个可注册域。 |
Origin
接口Origin
接口表示一个
源,从而能够进行可靠的同源和同站点
比较。
[Exposed=*]
interface Origin {
constructor ();
static Origin from (any value );
readonly attribute boolean opaque ;
boolean isSameOrigin (Origin other );
boolean isSameSite (Origin other );
};平台对象具有一个提取源操作,除非另有规定,否则该操作返回 null。
静态 from(value) 方法的步骤如下:
通过安全上下文交付的
Document 可以使用
`Origin-Agent-Cluster` HTTP
响应标头,请求将其放入以源作为键的代理
集群中。此标头是一个结构化
标头,其值必须是一个布尔值。
[STRUCTURED-FIELDS]
根据创建并初始化新的
Document 对象中的处理模型,不是结构化标头布尔值
true(即 `?1`)的值将被忽略。
使用此标头的结果是,生成的
Document 的代理集群键将是其源,而不是对应的站点。从可观察效果来看,这意味着
尝试使用 document.domain
放宽同源
限制将不会执行任何操作,并且无法将 WebAssembly.Module
对象发送到跨源 Document(即使它们同站点)。在幕后,
这种隔离可以使用户代理更高效地分配与代理集群对应的实现特定资源,例如进程或线程。
请注意,在一个浏览上下文组中,
`Origin-Agent-Cluster`
标头永远不会导致同源 Document
对象最终位于不同的代理集群中,即使其中一个发送该标头而另一个未发送。这通过
历史代理集群键映射来防止。
这意味着,即使设置了标头,如果同一浏览上下文
组中先前加载的同源页面省略了该标头,originAgentCluster
获取器也可能返回 false。同样,即使未设置标头,它也可能返回 true。
具有不透明
源的 Document
可以被视为无条件地以源为键;对于它们,此标头不起作用,并且 originAgentCluster
获取器将始终返回 true。
同样,如果 Document 的代理集群的跨源隔离模式不是
"none",
则它们会自动以源为键。
`Origin-Agent-Cluster`
标头可能可以作为有关资源分配的额外提示,对实现有所帮助,因为用于实现跨源隔离的
`Cross-Origin-Opener-Policy`
和 `Cross-Origin-Embedder-Policy`
标头更侧重于确保同一地址空间中的所有内容都选择加入其中。但
添加该标头不会对作者代码产生任何额外的可观察效果。
打开者策略值允许导航到顶级浏览上下文中的文档强制创建一个新的 顶级 浏览上下文以及相应的组。可能的值如下:
unsafe-none"same-origin-allow-popups"same-origin"其行为与 "same-origin-allow-popups"
相同,但额外要求创建的任何辅助
浏览上下文都需要包含同源
且具有相同打开者策略的文档,否则在
打开者看来它将处于已关闭状态。
same-origin-plus-COEP"其行为与 "same-origin" 相同,
但额外将(新的)顶级浏览上下文的组的跨源隔离
模式设置为 "logical"
或 "concrete"。
无法通过 `Cross-Origin-Opener-Policy`
标头直接设置 "same-origin-plus-COEP",
它是同时设置
`Cross-Origin-Opener-Policy: same-origin`
和一个值与
跨源隔离兼容的
`Cross-Origin-Embedder-Policy`
标头的结果。
noopener-allow-popups"无论其前任如何,这都会强制为该文档创建新的顶级浏览上下文。
虽然包含 noopener-allow-popups
值会切断应用该值的文档与其打开者之间的打开者
关系,但不会在这些同源文档之间创建可靠的安全边界。
同源应用程序还存在以下风险:
获取文档内容的同源请求——可以通过 Fetch Metadata 过滤来缓解。[FETCHMETADATA]
同源框架嵌入——可以通过 X-Frame-Options
或 CSP
frame-ancestors
来缓解。
JavaScript 可访问的 cookie——可以通过确保所有 cookie 均为 httponly 来缓解。
localStorage
对敏感数据的访问。
安装服务工作者。
postMessage 或 BroadcastChannel
消息传递暴露敏感信息。
对于同源文档,自动填充可能不需要用户交互。
使用 noopener-allow-popups
的开发者需要确保其敏感应用程序不依赖其他同源文档可访问的客户端功能,
例如 localStorage
和其他客户端存储 API、
BroadcastChannel
及相关的同源通信机制。他们还需要确保其服务器端端点不会向非导航
请求返回敏感数据,因为同源文档可以访问这些响应内容。
打开者策略由以下内容组成:
一个值,它是一个打开者策略值,初始为 "unsafe-none"。
一个报告端点,它是字符串或 null,初始为 null。
一个仅报告值,它是一个打开者策略值,初始为 "unsafe-none"。
一个仅报告的报告端点, 它是字符串或 null,初始为 null。
要匹配打开者策略值,给定一个打开者策略 值 documentCOOP、一个源 documentOrigin、一个 打开者策略值 responseCOOP,以及一个源 responseOrigin:
如果 documentCOOP 为 "unsafe-none",
并且 responseCOOP 为 "unsafe-none",
则返回 true。
如果 documentCOOP 为 "unsafe-none",
或者 responseCOOP 为 "unsafe-none",
则返回 false。
如果 documentCOOP 是 responseCOOP,并且 documentOrigin 与 responseOrigin同源,则返回 true。
返回 false。
Headers/Cross-Origin-Opener-Policy
Support in all current engines.
Document 的跨源打开者
策略派生自 `Cross-Origin-Opener-Policy` 和 `Cross-Origin-Opener-Policy-Report-Only` HTTP 响应标头。
这些标头是结构化标头,其值必须
是一个令牌。[STRUCTURED-FIELDS]
有效的令牌
值为打开者策略值。令牌还可以附带参数;其中,"report-to" 参数可以具有一个有效 URL
字符串,用于标识适当的报告端点。[REPORTING]
根据下述处理模型,如果此标头包含无效值,用户代理将忽略它。同样,如果无法将该值解析为 令牌,用户代理也将忽略此标头。
要获取打开者策略,给定一个响应 response 和一个环境 reservedEnvironment:
令 policy 为一个新的打开者策略。
如果 reservedEnvironment 是一个非安全上下文,则返回 policy。
令 parsedItem 为从 response 的标头
列表中,给定 `Cross-Origin-Opener-Policy`
和 "item"获取结构化字段值所得的结果。
如果 parsedItem 不为 null:
如果 parsedItem[0] 为 "same-origin":
令 coep 为从 response 和 reservedEnvironment获取跨源嵌入者策略所得的结果。
如果 coep 的值与跨源
隔离兼容,则将 policy 的值设置为 "same-origin-plus-COEP"。
否则,将 policy 的值设置为
"same-origin"。
如果 parsedItem[0] 为 "same-origin-allow-popups",
则将
policy 的值设置为
"same-origin-allow-popups"。
如果 parsedItem[0] 为 "noopener-allow-popups",
则将
policy 的值设置为
"noopener-allow-popups"。
如果 parsedItem[1]["report-to"]存在并且它是字符串,则将 policy 的报告
端点设置为
parsedItem[1]["report-to"]。
将 parsedItem 设置为从 response 的标头
列表中,给定 `Cross-Origin-Opener-Policy-Report-Only`
和 "item"获取结构化字段值所得的结果。
如果 parsedItem 不为 null:
如果 parsedItem[0] 为 "same-origin":
令 coep 为从 response 和 reservedEnvironment获取跨源嵌入者策略所得的结果。
如果 coep 的值与跨源
隔离兼容,或者 coep 的仅报告值与
跨源隔离兼容,则将 policy 的仅报告值设置为 "same-origin-plus-COEP"。
仅报告 COOP 还会考虑仅报告 COEP,以分配特殊的
"same-origin-plus-COEP"
值。这让开发者可以更自由地安排 COOP 和 COEP 的部署顺序。
否则,将 policy 的仅报告值设置为 "same-origin"。
如果 parsedItem[0] 为 "same-origin-allow-popups",
则将
policy 的仅报告值设置为
"same-origin-allow-popups"。
如果 parsedItem[1]["report-to"]存在并且它是字符串,则将 policy 的仅报告的报告端点设置为
parsedItem[1]["report-to"]。
返回 policy。
要检查弹出窗口的 COOP 值是否要求切换浏览上下文组,给定两个源 responseOrigin 和 activeDocumentNavigationOrigin,以及两个打开者策略 值 responseCOOPValue 和 activeDocumentCOOPValue:
如果 responseCOOPValue 为 "noopener-allow-popups",
则返回 true。
如果以下所有条件均为 true:
activeDocumentCOOPValue 的值为
"same-origin-allow-popups"
或
"noopener-allow-popups";
并且
responseCOOPValue 为 "unsafe-none",
则返回 false。
如果使用 activeDocumentCOOPValue、activeDocumentNavigationOrigin、 responseCOOPValue 和 responseOrigin 进行匹配所得的结果为 true,则返回 false。
返回 true。
要检查 COOP 值是否要求 切换浏览上下文组,给定一个布尔值 isInitialAboutBlank、两个源 responseOrigin 和 activeDocumentNavigationOrigin,以及两个打开者策略 值 responseCOOPValue 和 activeDocumentCOOPValue:
如果 isInitialAboutBlank 为 true,则返回使用 responseOrigin、activeDocumentNavigationOrigin、 responseCOOPValue 和 activeDocumentCOOPValue检查 弹出窗口的 COOP 值是否要求切换浏览上下文组所得的结果。
此处处理的是非弹出窗口导航。
如果使用 activeDocumentCOOPValue、activeDocumentNavigationOrigin、 responseCOOPValue 和 responseOrigin 进行匹配所得的结果为 true,则返回 false。
返回 true。
要检查强制执行仅报告 COOP 是否会要求切换浏览上下文组,给定一个布尔值 isInitialAboutBlank、两个源 responseOrigin、activeDocumentNavigationOrigin,以及两个打开者 策略 responseCOOP 和 activeDocumentCOOP:
如果给定 isInitialAboutBlank、responseOrigin、 activeDocumentNavigationOrigin、responseCOOP 的仅报告 值和 activeDocumentCOOPReportOnly 的仅报告 值检查 COOP 值是否要求切换浏览上下文组所得的结果为 false,则返回 false。
匹配仅报告策略使网站可以在其所有页面上指定相同的仅报告 打开者策略,而不会收到有关这些页面之间导航的违规报告。
如果给定 isInitialAboutBlank、responseOrigin、 activeDocumentNavigationOrigin、responseCOOP 的值和 activeDocumentCOOPReportOnly 的仅报告 值检查 COOP 值是否要求切换浏览上下文组所得的结果为 true,则返回 true。
如果给定 isInitialAboutBlank、responseOrigin、 activeDocumentNavigationOrigin、responseCOOP 的仅报告 值和 activeDocumentCOOPReportOnly 的值检查 COOP 值是否要求切换浏览上下文组所得的结果为 true, 则返回 true。
返回 false。
一个布尔值需要切换浏览上下文组,初始为 false。
一个布尔值由于仅报告而需要切换浏览上下文组, 初始为 false。
一个URL url。
一个源 源。
一个打开者 策略 打开者策略。
一个布尔值当前上下文是导航源,初始为 false。
要执行响应的打开者策略,给定一个浏览 上下文 browsingContext、一个URL responseURL、一个 源 responseOrigin、一个打开者 策略 responseCOOP、一个打开者策略 执行 结果 currentCOOPEnforcementResult,以及一个引用者 referrer:
令 newCOOPEnforcementResult 为一个新的打开者 策略执行结果,其中
令 isInitialAboutBlank 为 browsingContext 的活动
文档的是初始
about:blank。
如果 isInitialAboutBlank 为 true,并且 browsingContext 的初始 URL为 null,则将 browsingContext 的初始 URL设置为 responseURL。
如果给定 isInitialAboutBlank、currentCOOPEnforcementResult 的打开者 策略的值、 currentCOOPEnforcementResult 的源、 responseCOOP 的值和 responseOrigin检查 COOP 值是否要求切换浏览上下文组所得的结果为 true:
将 newCOOPEnforcementResult 的需要 切换浏览上下文组设置为 true。
如果 browsingContext 的组的浏览 上下文集合的大小大于 1:
使用 responseCOOP、"enforce"、responseURL、
currentCOOPEnforcementResult 的url、
currentCOOPEnforcementResult 的源、
responseOrigin 和
referrer将
导航到 COOP 响应时因浏览上下文组切换而产生的违规报告加入队列。
使用 currentCOOPEnforcementResult 的打开者
策略、"enforce"、currentCOOPEnforcementResult 的
url、
responseURL、
currentCOOPEnforcementResult 的源、
responseOrigin 和
currentCOOPEnforcementResult 的当前
上下文是导航源将
离开 COOP 响应进行导航时因浏览上下文组切换而产生的违规报告加入队列。
如果给定 isInitialAboutBlank、responseOrigin、 currentCOOPEnforcementResult 的源、 responseCOOP 和 currentCOOPEnforcementResult 的打开者 策略检查 强制执行仅报告 COOP 是否会要求切换浏览上下文组所得的结果为 true:
将 newCOOPEnforcementResult 的由于 仅报告而需要切换浏览上下文组设置为 true。
如果 browsingContext 的组的浏览 上下文集合的大小大于 1:
使用 responseCOOP、"reporting"、responseURL、
currentCOOPEnforcementResult 的url、
currentCOOPEnforcementResult 的源、
responseOrigin 和
referrer将
导航到 COOP 响应时因浏览上下文组切换而产生的违规报告加入队列。
使用 currentCOOPEnforcementResult 的打开者
策略、"reporting"、
currentCOOPEnforcementResult 的url、
responseURL、currentCOOPEnforcementResult 的源、
responseOrigin 和
currentCOOPEnforcementResult 的当前
上下文是导航源将
离开 COOP 响应进行导航时因浏览上下文组切换而产生的违规报告加入队列。
返回 newCOOPEnforcementResult。
要获取用于导航响应的浏览上下文,给定导航参数 navigationParams:
如果 browsingContext 不是一个顶级 浏览上下文,则 返回 browsingContext。
令 coopEnforcementResult 为 navigationParams 的COOP 执行结果。
令 swapGroup 为 coopEnforcementResult 的需要 切换浏览上下文组。
令 destinationOrigin 为 navigationParams 的源。
如果 sourceOrigin 与 destinationOrigin 不同站点:
如果 sourceOrigin 或 destinationOrigin 中任一者具有一个不是HTTP(S) 方案的方案, 并且用户代理认为出于由实现定义的原因,有必要将 sourceOrigin 和 destinationOrigin 相互隔离,则可以选择将 swapGroup 设置为 true。
例如,如果用户从 about:settings 导航到
https://example.com,用户代理可以强制执行切换。
议题 #10842 跟踪在此确定可互操作行为,而不是让此行为可选。
如果 navigationParams 的
用户
参与为 "浏览器 UI",
则可以选择将
swapGroup 设置为 true。
议题 #6356 跟踪在此确定可互操作行为,而不是让此行为可选。
如果 browsingContext 的组的浏览 上下文集合的大小为 1,则可以选择将 swapGroup 设置为 true。
一些实现会出于性能原因在此切换浏览上下文组。
检查是否存在可以编写此上下文脚本的其他上下文,并不足以 防止可能影响网页的行为差异。即使当前没有其他上下文,目标页面也可以打开一个窗口, 然后如果用户向后导航,前一页面可能期望仍能为所打开的窗口编写脚本。在此执行切换会破坏 该用例。
如果 swapGroup 为 false:
如果 coopEnforcementResult 的由于 仅报告而需要切换浏览上下文组为 true,则将 browsingContext 的虚拟 浏览上下文组 ID设置为一个新的 唯一标识符。
返回 browsingContext。
令 newBrowsingContext 为创建 新的顶级浏览上下文和文档的第一个返回值。
在这种情况下,我们将执行浏览上下文组切换。
我们即将创建的
新 Document
将不会使用 browsingContext。如果其他
Document
也不使用它(例如后退/前进缓存中的文档),则用户代理此时可以
销毁它。
令 navigationCOOP 为 navigationParams 的跨源 打开者策略。
如果 navigationCOOP 的值为
"same-origin-plus-COEP",
则将
newBrowsingContext 的组的跨源
隔离模式设置为 "logical"
或 "concrete"。
具体选择哪一个是
由实现定义的。
在某些平台上,很难提供跨源
隔离能力所要求的安全属性。"concrete"
授予对该能力的访问权限,而 "logical"
不会。
如果 sandboxFlags 不为空:
断言:
navigationCOOP 的值为
"unsafe-none"。
断言: newBrowsingContext 的弹出窗口 沙盒化标志 集为空。
将 newBrowsingContext 的弹出窗口 沙盒化标志集设置为 sandboxFlags。
返回 newBrowsingContext。
访问者与被访问者关系是一个枚举,用于描述发生访问的两个 浏览上下文之间的 关系。它可以采用以下值:
要检查是否应报告两个浏览上下文之间的访问,给定两个浏览 上下文 accessor 和 accessed、一个 JavaScript 属性名称 P,以及一个环境设置 对象 environment:
如果 P 不是一个跨源可访问的窗口属性 名称,则返回。
令 accessorInclusiveAncestorOrigins 为以下列表:取得 accessor 的活动文档的包含性 祖先可导航对象中每一个的活动 文档的源。
令 accessedInclusiveAncestorOrigins 为以下列表:取得 accessed 的活动文档的包含性 祖先可导航对象中每一个的活动 文档的源。
如果 accessorInclusiveAncestorOrigins 中的任何源与 accessorTopDocument 的源不同源,或者 accessedInclusiveAncestorOrigins 中的任何源与 accessedTopDocument 的源不同源,则返回。
这可以避免向具有打开者策略报告的顶级框架泄露有关跨源 iframe 的信息。
如果 accessor 的顶级浏览上下文的虚拟 浏览上下文组 ID是 accessed 的顶级浏览上下文的虚拟 浏览上下文组 ID,则返回。
令 accessorAccessedRelationship 为一个新的访问者与被访问者 关系,其值为无。
如果 accessed 的顶级浏览上下文的打开者浏览上下文 是 accessor 或 accessor 的一个祖先,则将 accessorAccessedRelationship 设置为访问者是 打开者。
如果 accessor 的顶级浏览上下文的打开者浏览上下文 是 accessed 或 accessed 的一个祖先,则将 accessorAccessedRelationship 设置为访问者是 被打开者。
给定 accessorAccessedRelationship、accessorTopDocument 的打开者策略、accessedTopDocument 的打开者策略、 accessor 的活动 文档的URL、 accessed 的活动文档的URL、 accessor 的顶级浏览上下文的初始 URL、 accessed 的顶级浏览上下文的初始 URL、 accessor 的活动 文档的源、 accessed 的活动文档的源、 accessor 的顶级浏览上下文的创建时的打开者源、 accessed 的顶级浏览上下文的创建时的打开者源、 accessorTopDocument 的引用者、 accessedTopDocument 的引用者、 P 和 environment,将访问的违规报告加入队列。
要清理要在报告中发送的 URL,给定一个 URL url:
要将导航到 COOP 响应时因浏览上下文 组切换而产生的违规报告加入队列,给定一个打开者 策略 coop、一个字符串 disposition、一个URL coopURL、一个URL previousResponseURL、两个源 coopOrigin 和 previousResponseOrigin,以及一个 引用者 referrer:
如果 coop 的报告端点 为 null,则返回。
令 coopValue 为 coop 的值。
如果 disposition 为 "reporting",则将
coopValue 设置为 coop 的仅报告值。
令 serializedReferrer 为空字符串。
令 body 为包含以下属性的新对象:
| 键 | 值 |
|---|---|
| disposition | disposition |
| effectivePolicy | coopValue |
| previousResponseURL | 如果 coopOrigin 与 previousResponseOrigin同源,则此值为对 previousResponseURL 的清理结果;否则为 null。 |
| referrer | serializedReferrer |
| type | "navigation-to-response" |
要将离开 COOP 响应进行导航时因浏览上下文 组切换而产生的违规报告加入队列,给定一个打开者策略 coop、一个字符串 disposition、一个URL coopURL、一个URL nextResponseURL、两个源 coopOrigin 和 nextResponseOrigin,以及一个布尔值 isCOOPResponseNavigationSource:
如果 coop 的报告端点 为 null,则返回。
令 coopValue 为 coop 的值。
如果 disposition 为 "reporting",则将
coopValue 设置为 coop 的仅报告值。
令 body 为包含以下属性的新对象:
| 键 | 值 |
|---|---|
| disposition | disposition |
| effectivePolicy | coopValue |
| nextResponseURL | 如果 coopOrigin 与 nextResponseOrigin同源, 或 isCOOPResponseNavigationSource 为 true,则此值为对 nextResponseURL 的清理结果;否则为 null。 |
| type | "navigation-from-response" |
要将访问的违规报告加入队列,给定一个 访问者与被访问者 关系 accessorAccessedRelationship、两个打开者策略 accessorCOOP 和 accessedCOOP、 四个URL accessorURL、accessedURL、 accessorInitialURL、accessedInitialURL,四个源 accessorOrigin、accessedOrigin、 accessorCreatorOrigin 和 accessedCreatorOrigin,两个引用者 accessorReferrer 和 accessedReferrer、一个字符串 propertyName,以及一个环境设置 对象 environment:
如果 coop 的报告端点 为 null,则返回。
令 coopValue 为 coop 的值。
如果 disposition 为 "reporting",则将
coopValue 设置为 coop 的仅报告值。
如果 accessorAccessedRelationship 为访问者是打开者:
给定 accessorCOOP、accessorURL、 accessedURL、accessedInitialURL、 accessorOrigin、accessedOrigin、 accessedCreatorOrigin、propertyName 和 environment,将访问已打开窗口的违规报告 加入队列。
给定 accessedCOOP、accessedURL、 accessorURL、accessedOrigin、accessorOrigin、 propertyName 和 accessedReferrer,将来自打开者的访问违规报告加入队列。
否则,如果 accessorAccessedRelationship 为访问者是被打开者:
给定 accessorCOOP、accessorURL、 accessedURL、accessorOrigin、accessedOrigin、 propertyName、accessorReferrer 和 environment,将访问打开者的违规报告 加入队列。
给定 accessedCOOP、accessedURL、 accessorURL、accessorInitialURL、 accessedOrigin、accessorOrigin、 accessorCreatorOrigin 和 propertyName,将来自已打开窗口的访问违规报告 加入队列。
否则:
给定 accessorCOOP、accessorURL、 accessedURL、accessorOrigin、accessedOrigin、 propertyName 和 environment,将访问另一个窗口的违规报告 加入队列。
给定 accessedCOOP、accessedURL、 accessorURL、accessedOrigin、accessorOrigin 和 propertyName,将来自另一个窗口的访问违规报告 加入队列。
要将访问打开者的违规报告加入队列,给定一个打开者策略 coop、两个URL coopURL 和 openerURL、两个源 coopOrigin 和 openerOrigin、一个字符串 propertyName、一个引用者 referrer,以及一个环境设置对象 environment:
令 sourceFile、lineNumber 和 columnNumber 为 触发此报告的相关脚本 URL 和有问题的位置。
令 serializedReferrer 为空字符串。
令 body 为包含以下属性的新对象:
| 键 | 值 |
|---|---|
| disposition | "reporting" |
| effectivePolicy | coop 的仅报告 值 |
| property | propertyName |
| openerURL | 如果 coopOrigin 与 openerOrigin同源,则此值 为对 openerURL 的清理结果;否则为 null。 |
| referrer | serializedReferrer |
| sourceFile | sourceFile |
| lineNumber | lineNumber |
| columnNumber | columnNumber |
| type | "access-to-opener" |
要将访问已打开窗口的违规报告加入队列,给定一个打开者策略 coop、三个URL coopURL、openedWindowURL 和 initialWindowURL、三个源 coopOrigin、openedWindowOrigin 和 openerInitialOrigin、一个字符串 propertyName,以及一个环境设置对象 environment:
令 sourceFile、lineNumber 和 columnNumber 为 触发此报告的相关脚本 URL 和有问题的位置。
令 body 为包含以下属性的新对象:
| 键 | 值 |
|---|---|
| disposition | "reporting" |
| effectivePolicy | coop 的仅报告 值 |
| property | propertyName |
| openedWindowURL | 如果 coopOrigin 与 openedWindowOrigin同源,则此值 为对 openedWindowURL 的清理结果; 否则为 null。 |
| openedWindowInitialURL | 如果 coopOrigin 与 openerInitialOrigin同源, 则此值为对 initialWindowURL 的清理结果;否则为 null。 |
| sourceFile | sourceFile |
| lineNumber | lineNumber |
| columnNumber | columnNumber |
| type | "access-to-opener" |
要将访问另一个窗口的违规报告加入队列,给定一个打开者策略 coop、两个URL coopURL 和 otherURL、两个源 coopOrigin 和 otherOrigin、一个字符串 propertyName,以及一个环境设置对象 environment:
令 sourceFile、lineNumber 和 columnNumber 为 触发此报告的相关脚本 URL 和有问题的位置。
令 body 为包含以下属性的新对象:
| 键 | 值 |
|---|---|
| disposition | "reporting" |
| effectivePolicy | coop 的仅报告 值 |
| property | propertyName |
| otherURL | 如果 coopOrigin 与 otherOrigin同源,则此值 为对 otherURL 的清理结果;否则为 null。 |
| sourceFile | sourceFile |
| lineNumber | lineNumber |
| columnNumber | columnNumber |
| type | "access-to-opener" |
要将来自打开者的访问违规报告加入队列,给定一个打开者策略 coop、两个URL coopURL 和 openerURL、两个源 coopOrigin 和 openerOrigin、一个字符串 propertyName,以及一个引用者 referrer:
要将来自已打开窗口的访问违规报告加入队列,给定一个打开者策略 coop、三个URL coopURL、openedWindowURL 和 initialWindowURL、三个源 coopOrigin、openedWindowOrigin 和 openerInitialOrigin,以及一个字符串 propertyName:
如果 coop 的报告端点 为 null,则返回。
令 body 为包含以下属性的新对象:
| 键 | 值 |
|---|---|
| disposition | "reporting" |
| effectivePolicy | coopValue |
| property | coop 的仅报告 值 |
| openedWindowURL | 如果 coopOrigin 与 openedWindowOrigin同源,则此值 为对 openedWindowURL 的清理结果; 否则为 null。 |
| openedWindowInitialURL | 如果 coopOrigin 与 openerInitialOrigin同源, 则此值为对 initialWindowURL 的清理结果;否则为 null。 |
| type | "access-to-opener" |
要将来自另一个窗口的访问违规报告加入队列,给定一个打开者策略 coop、两个URL coopURL 和 otherURL、两个源 coopOrigin 和 otherOrigin,以及一个字符串 propertyName:
Headers/Cross-Origin-Embedder-Policy
Support in all current engines.
嵌入者策略值是三个字符串之一,用于控制 在未获得资源所有者明确许可的情况下获取跨源资源。
unsafe-none"
这是默认值。使用此值时,可以在未通过CORS 协议或
`Cross-Origin-Resource-Policy`
标头给予明确许可的情况下获取跨源资源。
require-corp"使用此值时,获取跨源资源需要服务器通过CORS 协议或
`Cross-Origin-Resource-Policy`
标头给予明确许可。
credentialless"使用此值时,获取跨源 no-CORS 资源将省略凭据。作为交换,不要求明确的
`Cross-Origin-Resource-Policy`
标头。其他携带凭据发送的请求需要服务器通过CORS
协议或 `Cross-Origin-Resource-Policy`
标头给予明确许可。
如果一个嵌入者策略值为 "credentialless" 或 "require-corp",则该值与跨源隔离兼容。
嵌入者策略由以下内容组成:
一个值,它是一个嵌入者策略值,初始为 "unsafe-none"。
一个报告 端点字符串,初始为空字符串。
一个仅报告
值,它是一个嵌入者策略
值,初始为
"unsafe-none"。
一个仅报告的报告端点 字符串,初始为空字符串。
"coep" 报告类型是一个报告类型,其值
为 "coep"。它对
ReportingObserver 可见。
`Cross-Origin-Embedder-Policy` 和
`Cross-Origin-Embedder-Policy-Report-Only` HTTP 响应
标头允许服务器为一个环境
设置对象声明一个嵌入者
策略。这些标头是结构化
标头,其值必须是令牌。
[STRUCTURED-FIELDS]
有效的令牌
值为嵌入者策略
值。令牌还可以附带参数;其中,"report-to" 参数可以具有一个有效 URL
字符串,用于标识适当的报告端点。[REPORTING]
如果存在无法解析为令牌的标头,处理模型将以开放方式失败(默认为
"unsafe-none")。
这包括合并给定响应中存在的多个
`Cross-Origin-Embedder-Policy`
标头实例而无意中创建的列表:
`Cross-Origin-Embedder-Policy`
|
最终嵌入者策略 值 |
|---|---|
| 未交付标头 | "unsafe-none" |
`require-corp` |
"require-corp" |
`unknown-value` |
"unsafe-none" |
`require-corp, unknown-value` |
"unsafe-none" |
`unknown-value, unknown-value` |
"unsafe-none" |
`unknown-value, require-corp` |
"unsafe-none" |
`require-corp, require-corp` |
"unsafe-none" |
(同样适用于 `Cross-Origin-Embedder-Policy-Report-Only`。)
要从一个响应 response 和一个环境 environment获取嵌入者策略:
令 policy 为一个新的嵌入者 策略。
如果 environment 是一个非安全上下文,则返回 policy。
令 parsedItem 为从 response 的标头
列表中,使用 `Cross-Origin-Embedder-Policy`
和 "item"获取结构化字段值所得的结果。
如果 parsedItem 不为 null,并且 parsedItem[0]与 跨源隔离兼容:
将 parsedItem 设置为从 response 的标头
列表中,使用 `Cross-Origin-Embedder-Policy-Report-Only`
和 "item"获取结构化字段值所得的结果。
如果 parsedItem 不为 null,并且 parsedItem[0]与 跨源隔离兼容:
返回 policy。
要检查导航响应是否遵守其 嵌入者策略,给定一个响应 response、一个可导航对象 navigable,以及一个嵌入者 策略 responsePolicy:
如果 navigable 不是一个子 可导航对象,则返回 true。
如果 parentPolicy 的仅报告
值与跨源
隔离兼容,而
responsePolicy 的值不兼容,则使用
response、"navigation"、parentPolicy 的仅报告的报告
端点、
"reporting",以及 navigable 的容器文档的相关设置
对象,将跨源
嵌入者策略继承违规加入队列。
如果 parentPolicy 的值不与跨源 隔离兼容,或者 responsePolicy 的值与跨源 隔离兼容,则返回 true。
使用 response、"navigation"、
parentPolicy 的报告端点、
"enforce",以及 navigable 的
容器
文档的相关设置
对象,将
跨源嵌入者策略继承违规加入队列。
返回 false。
要检查全局对象的嵌入者策略,给定一个 WorkerGlobalScope
workerGlobalScope、一个环境设置对象
owner,以及一个响应 response:
如果 workerGlobalScope 不是一个 DedicatedWorkerGlobalScope
对象,则返回 true。
令 policy 为 workerGlobalScope 的嵌入者策略。
如果 ownerPolicy 的仅报告
值与跨源
隔离兼容,而 policy 的
值不兼容,则使用
response、"worker
initialization"、ownerPolicy 的仅报告的报告
端点、
"reporting" 和 owner,将
跨源嵌入者策略继承违规加入队列。
使用 response、"worker initialization"、
ownerPolicy 的报告端点、
"enforce" 和 owner,将
跨源嵌入者策略继承违规加入队列。
返回 false。
要将跨源嵌入者策略 继承违规加入队列,给定一个响应 response、一个字符串 type、一个字符串 endpoint、一个字符串 disposition,以及一个环境设置 对象 settings:
令 serialized 为使用 response序列化用于报告的响应 URL所得的结果。
令 body 为包含以下属性的新对象:
| 键 | 值 |
|---|---|
| type | type |
| blockedURL | serialized |
| disposition | disposition |
在 settings 上,为 endpoint,将 body 作为
"coep" 报告类型加入队列。
沙盒化标志集是由以下零个或多个 标志组成的集合,这些标志 用于限制可能不受信任的资源所具有的能力:
此标志阻止内容导航除沙盒化浏览上下文本身 之外的浏览上下文(或进一步嵌套在其中的浏览上下文)、 辅助浏览上下文 (它们受接下来定义的沙盒化辅助导航浏览 上下文标志保护),以及 顶级浏览上下文 (它受下面定义的沙盒化 无用户激活的顶级 导航浏览上下文标志和沙盒化有用户激活的顶级 导航浏览上下文标志保护)。
如果未设置沙盒化辅助导航浏览 上下文标志,那么在 某些情况下,这些限制仍然允许打开弹出窗口(新的顶级浏览上下文)。这些浏览上下文始终具有一个获准的沙盒化导航者,它在 创建浏览上下文时设置,从而允许创建这些浏览上下文的浏览上下文实际导航它们。(否则,即使已打开它们,沙盒化导航浏览 上下文标志也会阻止对它们进行导航。)
此标志阻止内容创建新的辅助浏览
上下文,例如使用 target
属性或
window.open() 方法。
此标志阻止内容导航其顶级 浏览上下文,并阻止内容关闭其 顶级浏览上下文。仅当沙盒化浏览 上下文的活动窗口不具有瞬态激活时,才会检查此标志。
当未设置沙盒化 无用户激活的顶级导航浏览上下文 标志时,内容可以导航其顶级浏览 上下文,但其他浏览上下文 仍受沙盒化导航浏览上下文标志 以及可能存在的 沙盒化辅助导航浏览 上下文标志保护。
此标志阻止内容导航其顶级 浏览上下文,并阻止内容关闭其 顶级浏览上下文。仅当沙盒化浏览 上下文的活动窗口具有瞬态激活时,才会检查此标志。
与沙盒化 无用户激活的顶级导航浏览上下文 标志一样,此标志仅影响顶级浏览上下文;如果未 设置此标志,其他浏览上下文仍可能 受其他标志保护。
此标志强制内容使用不透明源,从而阻止 它访问来自同一源的其他内容。
此标志还会阻止脚本读取或写入
document.cookie IDL 属性,并阻止访问
localStorage。
此标志阻止表单提交。
此标志禁用指针锁定 API。[POINTERLOCK]
此标志阻止脚本执行。
document.domain
浏览上下文标志此标志阻止内容使用
document.domain 设置器。
此标志阻止内容使用以下任何功能生成模态 对话框:
此标志禁用锁定屏幕方向的能力。 [SCREENORIENTATION]
此标志禁用演示 API。[PRESENTATION]
当用户代理要解析沙盒化 指令时,给定一个字符串 input 和一个沙盒化标志集 output,它必须运行以下 步骤:
按 ASCII 空白拆分 input,以获得 tokens。
令 output 为空。
将以下标志添加到 output:
沙盒化辅助导航
浏览上下文标志,除非
tokens 包含 allow-popups 关键字。
沙盒化
无用户激活的顶级导航浏览上下文
标志,除非 tokens 包含 allow-top-navigation
关键字。
沙盒化
有用户激活的顶级导航浏览上下文标志,
除非 tokens 包含 allow-top-navigation-by-user-activation
关键字或 allow-top-navigation
关键字。
这意味着如果存在 allow-top-navigation,
则 allow-top-navigation-by-user-activation
关键字不会产生任何效果。因此,同时指定这两个关键字属于文档一致性错误。
沙盒化源浏览上下文标志,
除非 tokens
包含 allow-same-origin 关键字。
allow-same-origin
关键字
适用于两种情况。
第一,它可用于允许对来自同一站点的内容进行沙盒化以禁用 脚本,同时仍允许访问沙盒化内容的 DOM。
第二,它可用于嵌入来自第三方站点的内容,并对其进行沙盒化以阻止该 站点打开弹出窗口等,同时又不会阻止嵌入页面使用数据库 API 存储数据等方式与其源站点通信。
沙盒化表单浏览上下文标志,除非
tokens
包含 allow-forms 关键字。
沙盒化指针锁定浏览上下文
标志,除非 tokens
包含 allow-pointer-lock
关键字。
沙盒化脚本浏览上下文标志,
除非 tokens
包含 allow-scripts 关键字。
沙盒化自动功能浏览
上下文标志,除非
tokens 包含 allow-scripts
关键字(定义见上文)。
此标志由与脚本相同的关键字放宽,因为启用脚本时, 无论如何都可以轻易实现这些功能;如果强迫作者在沙盒化内容中使用 脚本来实现这些功能,而不是允许使用声明式功能,将会很不合理。
沙盒传播到辅助
浏览上下文标志,除非
tokens 包含 allow-popups-to-escape-sandbox
关键字。
沙盒化模态标志,
除非 tokens 包含 allow-modals
关键字。
沙盒化方向锁定浏览
上下文标志,除非
tokens 包含 allow-orientation-lock
关键字。
沙盒化演示浏览上下文
标志,除非 tokens
包含 allow-presentation
关键字。
沙盒化下载浏览上下文标志,
除非 tokens
包含 allow-downloads 关键字。
沙盒化自定义协议
导航浏览上下文标志,除非
tokens 包含 allow-top-navigation-to-custom-protocols
关键字、allow-popups
关键字或
allow-top-navigation
关键字。
每个顶级浏览 上下文都有一个弹出窗口沙盒化标志集,它 是一个沙盒化标志集。创建浏览上下文时,其 弹出窗口沙盒化标志集必须为 空。它由选择 可导航对象的规则和获取 用于导航响应的浏览上下文算法填充。
每个 iframe 元素都有一个iframe 沙盒化标志集,
它是一个沙盒化标志集。在任何特定时刻,iframe
沙盒化标志集中设置了哪些标志,由 iframe
元素的 sandbox 属性决定。
每个 Document 都有一个活动沙盒化标志集,
它是一个沙盒化标志集。创建
Document 时,其
活动沙盒化标志集
必须为空。它由导航算法填充。
要为一个浏览上下文 browsing context确定创建沙盒化 标志,给定 null 或一个元素 embedder,返回以下沙盒化标志集中存在的标志的并集:
如果 embedder 为 null,则为 browsing context 的 弹出窗口沙盒化标志 集中设置的标志。
如果 embedder 是一个元素,则为 embedder 的
iframe
沙盒化标志集中设置的标志。
iframe 元素
引用者策略要在给定元素或 null
embedder 的情况下确定
iframe 元素引用者策略:
如果 embedder 是一个 iframe
元素,则返回
embedder 的 referrerpolicy
属性状态所对应的关键字。
返回空字符串。
这用于允许在内部祖先源 对象列表 创建步骤中掩盖某些源。
策略容器是一个结构体,其中包含适用于
Document、WorkerGlobalScope 或 WorkletGlobalScope 的策略。
它具有以下项:
一个CSP 列表, 它是一个CSP 列表。它最初为空。
将其他策略移入策略容器。
要在给定一个策略容器 policyContainer 的情况下克隆策略容器:
要在给定一个响应 response 和一个 环境或 null environment 的情况下从获取响应创建策略 容器:
如果 response 的URL 的方案是 "blob",则返回
response 的URL 的blob URL
条目的环境的策略
容器的一个克隆。
令 result 为一个新的策略 容器。
将 result 的CSP 列表设置为给定 response解析响应的内容 安全策略所得的结果。
如果 environment 不为 null,则将 result 的嵌入者
策略设置为给定 response
和 environment获取嵌入者策略所得的结果。否则,将其设置为 "unsafe-none"。
将 result 的引用者
策略设置为给定 response解析
`Referrer-Policy` 标头所得的结果。
[REFERRERPOLICY]
使用 response 和 result解析 Integrity-Policy 标头。
返回 result。
要在给定一个URL responseURL 和四个策略容器或 null historyPolicyContainer、 initiatorPolicyContainer、parentPolicyContainer 和 responsePolicyContainer 的情况下确定导航参数 策略容器:
如果 historyPolicyContainer 不为 null:
断言:responseURL需要将策略 容器 存储在历史记录中。
返回 historyPolicyContainer 的一个克隆。
如果 responseURL 是 about:srcdoc:
如果 responseURL是本地的,并且 initiatorPolicyContainer 不为 null,则返回 initiatorPolicyContainer 的一个克隆。
如果 responsePolicyContainer 不为 null,则返回 responsePolicyContainer。
返回一个新的策略容器。
要在给定一个 WorkerGlobalScope
workerGlobalScope、一个响应 response
和一个环境
environment 的情况下初始化工作者全局作用域的策略
容器:
Window、
WindowProxy 和 Location 对象的安全基础设施
尽管通常不能跨源访问对象,但如果 Web 平台不存在一些 Web 所依赖的、对该规则的历史遗留例外,它也就不像 Web 平台了。
本节使用 JavaScript 规范中的术语和排版约定。[JAVASCRIPT]
当调用执行安全检查时,给定 platformObject、 identifier 和 type,运行以下步骤:
对于 CrossOriginProperties(platformObject) 的每个 e:
如果 SameValue(e.[[Property]], identifier) 为 true:
如果 type 为 "method",并且 e 既没有
[[NeedsGetter]] 也没有 [[NeedsSetter]],则返回。
否则,如果 type 为 "getter",并且
e.[[NeedsGetter]] 为 true,则返回。
否则,如果 type 为 "setter",并且
e.[[NeedsSetter]] 为 true,则返回。
如果 IsPlatformObjectSameOrigin(platformObject)
为 false,则
抛出一个"SecurityError" DOMException。
Window 和
Location
对象都具有一个
[[CrossOriginPropertyDescriptorMap]] 内部槽,其值最初是一个空
映射。
[[CrossOriginPropertyDescriptorMap]]
内部槽包含一个映射,
其中条目的键是(currentGlobal、objectGlobal、
propertyKey)元组,值是属性描述符;它用于记忆当
currentGlobal 检查来自 objectGlobal 的 Window 或
Location
对象时,脚本可见的内容。它由
CrossOriginGetOwnPropertyHelper
延迟填充,后者会在未来的查找中查询它。
当没有任何内容持有对值的任何部分的引用时,用户代理应允许映射中保存的值与其 对应键一起被垃圾回收。也就是说,只要 垃圾回收不可观察即可。
例如,对于 const href =
Object.getOwnPropertyDescriptor(crossOriginLocation, "href").set,映射中的值及其
对应键不能被垃圾回收,因为这将是可观察的。
用户代理可以进行一种优化,即在设置
document.domain
时从映射中移除键值对。这是不可观察的,因为 document.domain
无法恢复到之前的值。
例如,在 www.example.com 上将 document.domain
设置为 "example.com",意味着用户代理可以从映射中移除键的一部分为
www.example.com 的所有键值对,因为该值永远无法再次成为
源的一部分,因此对应的
值永远无法再从映射中检索。
如果 O 是一个 Location
对象,则返回 «
{ [[Property]]: "href", [[NeedsGetter]]: false, [[NeedsSetter]]: true },
{ [[Property]]: "replace" } »。
返回 «
{ [[Property]]: "window", [[NeedsGetter]]: true, [[NeedsSetter]]: false },
{ [[Property]]: "self", [[NeedsGetter]]: true, [[NeedsSetter]]: false },
{ [[Property]]: "location", [[NeedsGetter]]: true, [[NeedsSetter]]: true },
{ [[Property]]: "close" },
{ [[Property]]: "closed", [[NeedsGetter]]: true, [[NeedsSetter]]: false },
{ [[Property]]: "focus" },
{ [[Property]]: "blur" },
{ [[Property]]: "frames", [[NeedsGetter]]: true, [[NeedsSetter]]: false },
{ [[Property]]: "length", [[NeedsGetter]]: true, [[NeedsSetter]]: false },
{ [[Property]]: "top", [[NeedsGetter]]: true, [[NeedsSetter]]: false },
{ [[Property]]: "opener", [[NeedsGetter]]: true, [[NeedsSetter]]: false },
{ [[Property]]: "parent", [[NeedsGetter]]: true, [[NeedsSetter]]: false },
{ [[Property]]: "postMessage" } »。
此抽象操作不返回完成记录。
此算法不需要将索引属性列入安全列表,因为它们由 WindowProxy 对象直接处理。
如果一个 JavaScript 属性名称 P 是
"window"、"self"、"location"、"close"、
"closed"、
"focus"、"blur"、"frames"、
"length"、"top"、"opener"、
"parent"、"postMessage",或者是一个数组索引
属性名称,则它是一个跨源
可访问的窗口属性
名称。
如果 P 是 "then"、%Symbol.toStringTag%、
%Symbol.hasInstance% 或 %Symbol.isConcatSpreadable%,则
返回
PropertyDescriptor {
[[Value]]: undefined,
[[Writable]]: false,
[[Enumerable]]: false,
[[Configurable]]: true }。
此抽象操作不返回完成记录。
此处的当前设置对象大致对应于
“调用者”,
因为此检查发生在相关获取器、设置器或方法的执行
上下文进入JavaScript
执行上下文栈之前。例如,在代码 w.document 中,此
步骤在 document 获取器作为
WindowProxy
w 的 [[Get]] 算法的一部分被执行之前调用。
如果此抽象操作返回 undefined,且不存在自定义行为,则
调用者需要抛出一个"SecurityError" DOMException。
在
实践中,这由调用者调用CrossOriginPropertyFallback
来处理。
对于 CrossOriginProperties(O) 的每个 e:
如果 SameValue(e.[[Property]], P) 为 true:
如果 O 的 [[CrossOriginPropertyDescriptorMap]] 内部槽的值包含一个键为 crossOriginKey 的条目,则返回该 条目的值。
令 originalDesc 为 OrdinaryGetOwnProperty(O, P)。
令 crossOriginDesc 为 undefined。
如果 e.[[NeedsGetter]] 和 e.[[NeedsSetter]] 均不存在:
令 value 为 originalDesc.[[Value]]。
如果 IsCallable(value) 为 true,则将 value 设置为 一个在当前领域中创建的匿名内置函数, 该函数执行对象 O 上 IDL 操作 P 的相同 步骤。
将 crossOriginDesc 设置为 PropertyDescriptor { [[Value]]: value, [[Enumerable]]: false, [[Writable]]: false, [[Configurable]]: true }。
否则:
令 crossOriginGetter 为 undefined。
如果 e.[[NeedsGetter]] 为 true,则将 crossOriginGetter 设置为一个 在当前领域中创建的匿名内置函数, 该函数执行对象 O 上 IDL 属性 P 的获取器所执行的相同步骤。
令 crossOriginSetter 为 undefined。
如果 e.[[NeedsSetter]] 为 true,则将 crossOriginSetter 设置为一个 在当前领域中创建的匿名内置函数, 该函数执行对象 O 上 IDL 属性 P 的设置器所执行的相同步骤。
将 crossOriginDesc 设置为 PropertyDescriptor { [[Getter]]: crossOriginGetter, [[Setter]]: crossOriginSetter, [[Enumerable]]: false, [[Configurable]]: true }。
在 O 的 [[CrossOriginPropertyDescriptorMap]] 内部槽的值中创建一个条目,其键为 crossOriginKey,值为 crossOriginDesc。
返回 crossOriginDesc。
返回 undefined。
此抽象操作不返回完成记录。
此处生成的属性描述符可配置,是为了保留 JavaScript 规范要求的基本内部方法的不变量。 特别是,由于属性值可能因 导航而发生变化,因此要求该属性可配置。(不过,对于为了 与现有 Web 内容兼容而无法保留这些不变量的情况,请参阅tc39/ecma262 议题 #672以及本规范中 对它的其他引用。)[JAVASCRIPT]
尽管这与同源行为不匹配,但属性描述符不可枚举的原因 是为了与现有 Web 内容兼容。详情请参阅议题 #3183。
令 desc 为 ? O.[[GetOwnProperty]](P)。
断言:desc 不是 undefined。
如果 IsDataDescriptor(desc) 为 true,则返回 desc.[[Value]]。
断言:IsAccessorDescriptor(desc) 为 true。
令 getter 为 desc.[[Getter]]。
如果 getter 为 undefined,则抛出一个"SecurityError"
DOMException。
返回 ? Call(getter, Receiver)。
令 keys 为一个新的空列表。
对于 CrossOriginProperties(O) 的每个 e,将 e.[[Property]]追加到 keys。
返回 keys 与 « "then",
%Symbol.toStringTag%, %Symbol.hasInstance%, %Symbol.isConcatSpreadable%
» 的串联结果。
此抽象操作不返回完成记录。
Window 对象Support in all current engines.
[Global =Window ,
Exposed =Window ,
LegacyUnenumerableNamedProperties ]
interface Window : EventTarget {
// the current browsing context
[LegacyUnforgeable ] readonly attribute WindowProxy window ;
[Replaceable ] readonly attribute WindowProxy self ;
[LegacyUnforgeable ] readonly attribute Document document ;
attribute DOMString name ;
[PutForwards =href , LegacyUnforgeable ] readonly attribute Location location ;
readonly attribute History history ;
[Replaceable ] readonly attribute Navigation navigation ;
readonly attribute CustomElementRegistry customElements ;
[Replaceable ] readonly attribute BarProp locationbar ;
[Replaceable ] readonly attribute BarProp menubar ;
[Replaceable ] readonly attribute BarProp personalbar ;
[Replaceable ] readonly attribute BarProp scrollbars ;
[Replaceable ] readonly attribute BarProp statusbar ;
[Replaceable ] readonly attribute BarProp toolbar ;
attribute DOMString status ;
undefined close ();
readonly attribute boolean closed ;
undefined stop ();
undefined focus ();
undefined blur ();
// other browsing contexts
[Replaceable ] readonly attribute WindowProxy frames ;
[Replaceable ] readonly attribute unsigned long length ;
[LegacyUnforgeable ] readonly attribute WindowProxy ? top ;
attribute any opener ;
[Replaceable ] readonly attribute WindowProxy ? parent ;
readonly attribute Element ? frameElement ;
WindowProxy ? open (optional USVString url = "", optional DOMString target = "_blank", optional [LegacyNullToEmptyString ] DOMString features = "");
// Since this is the global object, the IDL named getter adds a NamedPropertiesObject exotic
// object on the prototype chain. Indeed, this does not make the global object an exotic object.
// Indexed access is taken care of by the WindowProxy exotic object.
getter object (DOMString name );
// the user agent
readonly attribute Navigator navigator ;
[Replaceable ] readonly attribute Navigator clientInformation ; // legacy alias of .navigator
readonly attribute boolean originAgentCluster ;
// user prompts
undefined alert ();
undefined alert (DOMString message );
boolean confirm (optional DOMString message = "");
DOMString ? prompt (optional DOMString message = "", optional DOMString default = "");
undefined print ();
undefined postMessage (any message , USVString targetOrigin , optional sequence <object > transfer = []);
undefined postMessage (any message , optional WindowPostMessageOptions options = {});
// also has obsolete members
};
Window includes GlobalEventHandlers ;
Window includes WindowEventHandlers ;
dictionary WindowPostMessageOptions : StructuredSerializeOptions {
USVString targetOrigin = "/";
};window.window
Support in all current engines.
window.frames
Support in all current engines.
window.self
Support in all current engines.
这些属性都返回 window。
window.document
Support in all current engines.
返回与
window 关联的 Document。
document.defaultView
Support in all current engines.
如果存在与
document 关联的 Window,则返回它;否则返回
null。
Window 对象具有一个关联的
Document,它是一个 Document
对象。它在
Window 对象创建时设置,并且仅在从初始
about:blank Document
进行导航期间才会更改。
Window 的浏览上下文是
其关联的
Document的浏览
上下文。它为 null 或一个
浏览上下文。
document 获取器
步骤
是返回 this
的关联的
Document。
与 Window 对象关联的
Document 对象只会在一种情况下
更改:当导航算法为
浏览上下文中加载的第一个页面创建新的
Document 对象时。
在这种特定情况下,会重用初始
about:blank 页面的
Window 对象,并为其设置一个新的 Document 对象。
defaultView 获取器步骤如下:
返回 this 的浏览上下文的
WindowProxy 对象。
Support in all current engines.
由于历史原因,Window 对象还必须
具有一个名为 HTMLDocument 的可写、可配置、
不可枚举属性,其值为
Document 接口对象。
window = window.open([ url [, target [, features ] ] ])
Support in all current engines.
打开一个窗口以显示 url(默认为 "about:blank"),
并返回
该窗口。target(默认为 "_blank")给出新
窗口的名称。如果已存在具有该名称的窗口,则会重用它。features
参数可以包含一个逗号分隔
标记集:
noopener"noreferrer"它们的行为等同于超链接上的 noopener
和 noreferrer
链接类型。
popup"鼓励用户代理为新
窗口提供最小化的 Web 浏览器用户界面。(也会影响所有
BarProp
对象上的 visible
获取器。)
globalThis. open( "https://email.example/message/CAOOOkFcWW97r8yg=SsWg7GgCmp4suVX9o85y8BvNRqMjuc5PXg" , undefined , "noopener,popup" ); window.name [ = value ]
Support in all current engines.
返回窗口的名称。
可以设置该值,以更改名称。
window.close()
Support in all current engines.
关闭窗口。
window.closed
Support in all current engines.
如果窗口已关闭,则返回 true;否则返回 false。
window.stop()
Support in all current engines.
取消文档加载。
要在给定一个 Document
sourceDocument、一个有序映射
tokenizedFeatures 和一个
URL 记录或 null
url 的情况下,获取窗口打开的 noopener,执行以下步骤。它们返回一个
布尔值。
如果 url 不为 null,并且 url 的blob URL 条目不为 null:
令 noopener 为 false。
如果 tokenizedFeatures["noopener"] 存在,则将 noopener 设置为将
tokenizedFeatures["noopener"] 解析为布尔特性所得的结果。
返回 noopener。
给定一个字符串 url、一个字符串 target 和一个字符串 features,窗口打开步骤如下:
令 sourceDocument 为入口全局
对象的关联的
Document。
令 urlRecord 为 null。
如果 url 不是空字符串:
将 urlRecord 设置为给定 url、相对于 sourceDocument对 URL 进行编码解析所得的结果。
如果 urlRecord 为失败,则抛出一个"SyntaxError"
DOMException。
如果 target 是空字符串,则将 target 设置为 "_blank"。
令 tokenizedFeatures 为对 features 进行标记化所得的结果。
令 noreferrer 为 false。
如果 tokenizedFeatures["noreferrer"] 存在,则将 noreferrer 设置为将
tokenizedFeatures["noreferrer"] 解析为布尔特性所得的结果。
令 noopener 为使用 sourceDocument、tokenizedFeatures 和 urlRecord获取 窗口打开的 noopener所得的结果。
从 tokenizedFeatures 中移除 ["noopener"] 和
tokenizedFeatures["noreferrer"]。
令 referrerPolicy 为空字符串。
如果 noreferrer 为 true,则将 noopener 设置为 true,并将
referrerPolicy 设置为 "no-referrer"。
令 targetNavigable 和 windowType 为给定 target、sourceDocument 的 节点 可导航对象和 noopener,应用选择 可导航对象的规则所得的结果。
假设某个用户代理支持按住 Control 键单击链接以在
新标签页中打开它,并且用户按住 Control 键单击一个元素,该元素的 onclick
处理程序使用 window.open()
API 在一个 iframe
元素中打开页面,
则用户代理可以覆盖目标浏览上下文的选择,改为以
新标签页为目标。
如果 targetNavigable 为 null,则返回 null。
如果 windowType 为 "new and unrestricted" 或 "new with no opener":
将 targetNavigable 的活动浏览上下文的 是否为弹出窗口 设置为给定 tokenizedFeatures检查是否请求了 弹出窗口所得的结果。
给定 tokenizedFeatures,为 targetNavigable 的活动浏览上下文设置浏览上下文特性。 [CSSOMVIEW]
如果 urlRecord 为 null,则将 urlRecord 设置为一个表示 about:blank
的URL
记录。
如果 urlRecord匹配
about:blank,则给定 targetNavigable 的活动文档和
urlRecord,执行
URL 和
历史记录更新步骤。
这在 url 类似于 about:blank?foo 时是必要的。如果
url 只是普通的 about:blank,则不会执行任何操作。
否则,使用 sourceDocument 将 targetNavigable导航 到 urlRecord,其中 referrerPolicy 设置为 referrerPolicy,并且 exceptionsEnabled 设置为 true。
否则:
如果 urlRecord 不为 null,则 使用 sourceDocument 将 targetNavigable导航 到 urlRecord,其中 referrerPolicy 设置 为 referrerPolicy,并且 exceptionsEnabled 设置为 true。
如果 noopener 为 false,则将 targetNavigable 的活动浏览上下文的 打开者浏览 上下文设置为 sourceDocument 的浏览 上下文。
如果 noopener 为 true,或 windowType 为 "new with no
opener",则返回 null。
返回 targetNavigable 的活动
WindowProxy。
open(url, target,
features) 方法步骤是使用
url、target 和 features 运行窗口打开步骤。
此方法提供了一种机制,用于导航现有的浏览上下文,或者打开 并导航一个辅助浏览 上下文。
要对 features 参数进行标记化:
令 tokenizedFeatures 为一个新的有序映射。
令 position 指向 features 的第一个码位。
当 position 未超过 features 末尾时循环:
令 name 为空字符串。
令 value 为空字符串。
给定 position,从 features 中收集一系列码位,这些码位不是 特性 分隔符。将 name 设置为收集到的字符,并转换为 ASCII 小写形式。
将 name 设置为对 name规范化 特性名称所得的结果。
当 position 未超过 features 末尾,并且 features 中 position 处的码位不是 U+003D (=) 时循环:
这会跳到第一个 U+003D (=),但不会越过 U+002C (,) 或 非分隔符。
如果 features 中 position 处的码位是一个特性 分隔符:
当 position 未超过 features 末尾,并且 features 中 position 处的码位是一个特性 分隔符时:
如果 features 中 position 处的码位是 U+002C (,),则 中断。
将 position 前进 1。
这会跳到第一个非分隔符,但不会越过 U+002C (,)。
给定 position,从 features 中收集一系列码位,这些码位 不是特性 分隔符码位。将 value 设置为收集到的码位,并转换为 ASCII 小写形式。
如果 name 不是空字符串,则将 tokenizedFeatures[name] 设置为 value。
返回 tokenizedFeatures。
要在给定 tokenizedFeatures、featureName 和 defaultValue 的情况下,检查窗口特性是否已设置:
如果 tokenizedFeatures[featureName] 存在,则返回将 tokenizedFeatures[featureName] 解析为布尔特性所得的结果。
返回 defaultValue。
要在给定 tokenizedFeatures 的情况下,检查是否请求了弹出窗口:
如果 tokenizedFeatures为空,则返回 false。
如果 tokenizedFeatures["popup"] 存在,则返回将
tokenizedFeatures["popup"] 解析为布尔
特性所得的结果。
令 location 为给定 tokenizedFeatures、"location" 和 false,检查
窗口特性是否已设置所得的结果。
令 toolbar 为给定 tokenizedFeatures、"toolbar" 和 false,检查
窗口特性是否已设置所得的结果。
如果 location 和 toolbar 均为 false,则返回 true。
令 menubar 为给定 tokenizedFeatures、"menubar" 和 false,检查
窗口特性是否已设置所得的结果。
如果 menubar 为 false,则返回 true。
令 resizable 为给定 tokenizedFeatures、"resizable" 和 true,检查
窗口特性是否已设置所得的结果。
如果 resizable 为 false,则返回 true。
令 scrollbars 为给定 tokenizedFeatures、"scrollbars" 和 false,检查
窗口特性是否已设置所得的结果。
如果 scrollbars 为 false,则返回 true。
令 status 为给定 tokenizedFeatures、"status" 和 false,检查
窗口特性是否已设置所得的结果。
如果 status 为 false,则返回 true。
返回 false。
如果一个码位是ASCII 空白、 U+003D (=) 或 U+002C (,),则它是一个特性分隔符。
由于历史原因,一些特性名称具有别名。要规范化特性名称 name,根据 name 进行切换:
screenx"
left"。
screeny"
top"。
innerwidth"
width"。
innerheight"
height"。
要在给定一个字符串 value 的情况下解析布尔特性:
如果 value 是空字符串,则返回 true。
如果 value是 "yes",则返回
true。
如果 value是 "true",则返回
true。
令 parsed 为将 value 解析为整数所得的结果。
如果 parsed 是错误,则将其设置为 0。
如果 parsed 为 0,则返回 false;否则返回 true。
name
设置器步骤如下:
将 this 的可导航对象的活动会话 历史记录条目的文档状态的可导航对象 目标名称设置为给定值。
close() 方法
步骤
如下:
如果一个可导航对象 是一个顶级 可遍历对象,并且以下任一条件为 true,则它是 可由脚本关闭的:
Window 对象的索引访问window.length
Support in all current engines.
返回文档树子可导航对象的数量。
window[index]返回与所指示的文档树子可导航对象相对应的 WindowProxy。
length 获取器步骤
是
返回 this 的关联的
Document的文档树子可导航对象的大小。
对文档树子可导航对象的索引访问
是通过
WindowProxy 对象的
[[GetOwnProperty]] 内部方法定义的。
Window 对象的命名访问window[name]返回所指示的元素或元素集合。
一般而言,依赖此功能会导致代码脆弱。例如,随着 Web 平台添加新功能,最终映射到
此 API 的 ID 可能会随时间变化。应改用
document.getElementById() 或 document.querySelector()。
Window 对象 window 的
文档树子
可导航对象目标名称属性集是运行以下步骤所得的
返回值:
这两次独立迭代意味着,在以下托管于 https://example.org/ 的示例中,
假设 https://elsewhere.example/
将 window.name 设置为
"spices",则在所有内容加载完成后求值
window.spices 将得到 undefined:
< iframe src = https://elsewhere.example.com/ ></ iframe >
< iframe name = spices ></ iframe > Window 对象支持命名
属性。Window 对象
window 在任何时刻的支持的属性名称由以下内容组成,按照贡献这些名称的元素的树顺序排列,
并忽略后续的重复项:
window 的文档树 子可导航对象目标名称属性 集;
所有具有非空 name 内容属性,并且位于以 window 的关联的
Document作为根的文档
树中的 embed、
form、
img 和
object
元素的
name 内容属性值;以及
所有具有非空 id 内容
属性,并且位于以 window 的关联的 Document作为
根的
文档
树中的所有HTML
元素的 id 内容
属性值。
要确定命名属性的值,即 Window
对象 window 中的 name,用户代理必须返回使用以下步骤获得的
值:
令 objects 为 window 中名称为 name 的命名 对象列表。
至少会存在一个这样的对象,否则该算法不会由 Web IDL 调用。
如果 objects 包含一个可导航对象:
令 container 为 window 的关联的
Document的后代中的第一个可导航对象容器,其内容
可导航对象位于 objects 中。
返回 container 的内容可导航对象的活动 WindowProxy。
否则,如果 objects 只有一个元素,则返回该元素。
否则,返回一个以 window 的关联的 Document为根的
HTMLCollection,其筛选器仅匹配
window 中名称为 name 的命名对象。
(根据定义,这些对象全都是元素。)
出于上述算法的目的,Window 对象
window 中名称为 name 的命名对象由以下内容
组成:
window 的关联的 Document中,
目标名称为 name 的文档树子可导航对象;
具有值为 name 的 name 内容属性,并且位于以
window 的关联的 Document作为
根的文档
树中的 embed、
form、
img 或
object
元素;以及
具有值为 name 的 id
内容属性,并且位于以 window 的
关联的
Document作为
根的文档
树中的HTML 元素。
由于 Window
接口具有 [Global]
扩展属性,因此其命名属性遵循
命名属性对象的规则,而不是旧式平台对象的规则。
window.top
Support in all current engines.
返回顶级可遍历对象的 WindowProxy。
window.opener [ = value ]
Support in all current engines.
返回打开者浏览上下文的 WindowProxy。
如果不存在打开者浏览上下文,或该属性已被设置为 null,则返回 null。
可以设置为 null。
window.parent
Support in all current engines.
返回父可导航对象的 WindowProxy。
window.frameElement
Support in all current engines.
返回可导航对象容器元素。
如果不存在该元素,或处于跨源情形,则返回 null。
opener 获取器步骤
如下:
如果 current 为 null,则返回 null。
如果 current 的打开者浏览上下文为 null,则返回 null。
返回 current 的打开者浏览上下文的
WindowProxy
对象。
opener
设置器步骤如下:
将 window.opener
设置为 null 会清除打开者
浏览上下文引用。实际上,这会阻止未来的脚本访问其打开者浏览上下文的
Window 对象。
默认情况下,脚本可以通过 window.opener
获取器访问其打开者浏览上下文的
Window 对象。
例如,脚本可以设置 window.opener.location,从而使打开者
浏览上下文进行导航。
parent 获取器步骤
如下:
如果 navigable 为 null,则返回 null。
返回 navigable 的活动
WindowProxy。
frameElement
获取器步骤如下:
以下是这些属性可以返回 null 的一个示例:
<!DOCTYPE html>
< iframe ></ iframe >
< script >
"use strict" ;
const element = document. querySelector( "iframe" );
const iframeWindow = element. contentWindow;
element. remove();
console. assert( iframeWindow. top === null );
console. assert( iframeWindow. parent === null );
console. assert( iframeWindow. frameElement === null );
</ script > 由于历史原因,Window
接口曾具有一些表示某些 Web 浏览器界面元素
可见性的属性。
出于隐私和互操作性原因,这些属性现在返回表示 Window 的浏览上下文的
是否为弹出窗口属性是 true 还是 false 的值。
每个界面元素均由一个 BarProp 对象表示:
Support in all current engines.
[Exposed =Window ]
interface BarProp {
readonly attribute boolean visible ;
};window.locationbar.visible
Support in all current engines.
window.menubar.visible
Support in all current engines.
window.personalbar.visible
Support in all current engines.
window.scrollbars.visible
Support in all current engines.
window.statusbar.visible
Support in all current engines.
window.toolbar.visible
Support in all current engines.
如果 Window 不是
弹出窗口,则返回 true;否则返回 false。
Support in all current engines.
visible
获取器
步骤如下:
每个 Window 对象都必须
存在以下 BarProp 对象:
BarProp 对象BarProp 对象BarProp 对象BarProp 对象BarProp 对象BarProp 对象locationbar
属性必须返回地址栏 BarProp
对象。
menubar
属性必须返回菜单栏
BarProp 对象。
personalbar
属性必须返回个人栏 BarProp
对象。
scrollbars
属性必须返回滚动条
BarProp 对象。
statusbar
属性必须返回状态栏
BarProp 对象。
toolbar
属性必须返回工具栏
BarProp 对象。
由于历史原因,Window 对象上的 status
属性在获取时必须返回最后一次设置给它的字符串,
在设置时必须将自身设置为新
值。当 Window 对象
创建时,该属性必须设置为空
字符串。它不执行任何其他操作。
Window 对象的脚本设置要设置窗口环境设置对象,给定一个URL creationURL、一个JavaScript 执行上下文 execution context、 null 或一个环境 reservedEnvironment、一个URL topLevelCreationURL,以及一个源 topLevelOrigin,运行以下 步骤:
令 realm 为 execution context 的 Realm 组件值。
令 window 为 realm 的全局 对象。
令 settings object 为一个新的环境设置对象,其 算法定义如下:
返回 execution context。
返回
window 的关联的
Document的模块映射。
返回 window 的
关联的
Document的当前
基础 URL。
返回 window 的
关联的
Document的源。
返回
window 的关联的
Document的策略容器。
如果以下两项均成立,则返回 true;否则返回 false:
window 的关联的
Document获准使用 "cross-origin-isolated"
特性。
返回 window 的关联的
Document的加载计时信息的导航
开始
时间。
如果 reservedEnvironment 不为 null:
否则,将 settings object 的id设置为一个新的唯一不透明字符串,将 settings object 的目标浏览 上下文设置为 null,并将 settings object 的活动服务 工作线程设置为 null。
将 settings object 的创建 URL设置为 creationURL,将 settings object 的顶级创建 URL设置为 topLevelCreationURL,并将 settings object 的顶级 源设置为 topLevelOrigin。
将 realm 的 [[HostDefined]] 字段设置为 settings object。
WindowProxy 奇异对象WindowProxy 是一个包装
Window 普通对象的奇异对象,它将
大多数操作间接传递给被包装的对象。
每个浏览上下文都有一个
关联的 WindowProxy
对象。当
浏览上下文被导航时,由该浏览
上下文的关联 WindowProxy
对象所包装的
Window
对象会发生变化。
除非下文另有明确规定,否则 WindowProxy
奇异
对象必须使用普通内部方法。
不存在 WindowProxy 接口对象。
每个 WindowProxy 对象
都具有一个表示被包装
Window 对象的 [[Window]] 内部槽。
尽管 WindowProxy 被称为
“代理”,但由于希望在 WindowProxy 和
Location 对象之间复用机制,
它不会像真正的代理那样对其目标的内部方法进行
多态分派。只要
Window 对象仍是普通
对象,这就是不可观察的,并且可以用
任一种方式实现。
令 W 为 this 的 [[Window]] 内部槽的值。
如果 IsPlatformObjectSameOrigin(W) 为 true,则返回 ! OrdinaryGetPrototypeOf(W)。
返回 null。
返回 ! SetImmutablePrototype(this, V)。
令 W 为 this 的 [[Window]] 内部槽的值。
如果 P 是一个数组索引属性名称:
令 index 为 ! ToUint32(P)。
令 children 为
W 的关联的
Document的文档树子可导航对象。
令 value 为 undefined。
如果 index 小于 children 的大小:
将 children按升序排序;如果
navigableA 的容器插入
W 的关联的 Document的时间
早于
navigableB 的容器,则认为
navigableA 小于 navigableB。
将 value 设置为 children[index] 的活动 WindowProxy。
如果 value 为 undefined:
如果 IsPlatformObjectSameOrigin(W) 为 true,则返回 undefined。
返回 PropertyDescriptor { [[Value]]: value, [[Writable]]: false, [[Enumerable]]: true, [[Configurable]]: true }。
如果 IsPlatformObjectSameOrigin(W) 为 true,则返回 ! OrdinaryGetOwnProperty(W, P)。
这是对 JavaScript 规范 基本内部 方法的不变量的有意违反,目的是保持与 现有 Web 内容的兼容性。有关更多信息,请参阅 tc39/ecma262 议题 #672。[JAVASCRIPT]
令 property 为 CrossOriginGetOwnPropertyHelper(W, P)。
如果 property 不是 undefined,则返回 property。
如果 property 为 undefined,并且 P 位于 W 的文档树 子可导航对象目标名称属性集中:
令 value 为 W 中名称为 P 的命名
对象的活动
WindowProxy。
返回 PropertyDescriptor { [[Value]]: value, [[Enumerable]]: false, [[Writable]]: false, [[Configurable]]: true }。
尽管这与同源行为不匹配,但属性描述符不可枚举的原因 是为了与现有 Web 内容兼容。详情请参阅议题 #3183。
返回 ? CrossOriginPropertyFallback(P)。
令 W 为 this 的 [[Window]] 内部槽的值。
如果 IsPlatformObjectSameOrigin(W) 为 true:
如果 P 是一个数组索引属性名称,则返回 false。
返回 ? OrdinaryDefineOwnProperty(W, P, Desc)。
这是对 JavaScript 规范 基本内部 方法的不变量的有意违反,目的是保持与 现有 Web 内容的兼容性。有关更多信息,请参阅 tc39/ecma262 议题 #672。[JAVASCRIPT]
令 W 为 this 的 [[Window]] 内部 槽的值。
给定当前全局对象的 浏览上下文、W 的浏览上下文、P 和当前设置 对象,检查是否应报告两个浏览上下文之间的 访问。
如果 IsPlatformObjectSameOrigin(W) 为 true, 则返回 ? OrdinaryGet(this, P, Receiver)。
返回 ? CrossOriginGet(this, P, Receiver)。
传递的是 this 而不是 W,因为 OrdinaryGet 和 CrossOriginGet 将调用 [[GetOwnProperty]] 内部方法。
令 W 为 this 的 [[Window]] 内部 槽的值。
给定当前全局对象的浏览 上下文、W 的浏览 上下文、P 和当前设置 对象,检查是否应报告两个浏览上下文之间的 访问。
如果 IsPlatformObjectSameOrigin(W) 为 true:
如果 P 是一个数组索引属性名称, 则返回 false。
返回 ? OrdinarySet(W, P, V, Receiver)。
返回 ? CrossOriginSet(this, P, V, Receiver)。
传递的是 this 而不是 W,因为 CrossOriginSet 将调用 [[GetOwnProperty]] 内部方法。
令 W 为 this 的 [[Window]] 内部槽的值。
如果 IsPlatformObjectSameOrigin(W) 为 true:
如果 P 是一个数组索引属性名称:
令 desc 为 ! this.[[GetOwnProperty]](P)。
如果 desc 为 undefined,则返回 true。
返回 false。
返回 ? OrdinaryDelete(W, P)。
令 W 为 this 的 [[Window]] 内部槽的值。
令 maxProperties 为 W 的关联的 Document的文档树
子可导航对象的大小。
令 keys 为从 0 到 maxProperties 的范围,不包括 maxProperties。
如果 IsPlatformObjectSameOrigin(W) 为 true,则返回 keys 与 OrdinaryOwnPropertyKeys(W) 的串联结果。
返回 keys 与 ! CrossOriginOwnPropertyKeys(W) 的串联结果。
Location 接口Support in all current engines.
Support in all current engines.
Support in all current engines.
每个 Window 对象都与一个
Location
对象的唯一实例关联,该实例在 Window 对象
创建时分配。
Location 奇异
对象是通过 IDL、
创建后调用 JavaScript 内部方法以及被覆盖的 JavaScript 内部
方法混合定义的。再加上其令人畏惧的安全策略,实现
这一赘生物时请格外小心。
要创建一个 Location 对象,运行
以下步骤:
令 valueOf 为 location 的相关 领域.[[Intrinsics]].[[%Object.prototype.valueOf%]]。
执行 ! location.[[DefineOwnProperty]]("valueOf", {
[[Value]]: valueOf,
[[Writable]]: false,
[[Enumerable]]: false,
[[Configurable]]: false })。
执行 ! location.[[DefineOwnProperty]](%Symbol.toPrimitive%, { [[Value]]: undefined, [[Writable]]: false, [[Enumerable]]: false, [[Configurable]]: false })。
将 location 的[[DefaultProperties]] 内部槽的值设置为 location.[[OwnPropertyKeys]]()。
返回 location。
添加 valueOf 和 %Symbol.toPrimitive% 自有
数据属性,以及 Location 的所有 IDL 属性均标记为
[LegacyUnforgeable] 这一事实,
是旧式代码所必需的;这些代码会查询
Location 接口或将其字符串化,
以确定文档 URL,然后
以安全敏感的方式使用它。
特别是,valueOf、%Symbol.toPrimitive% 和
[LegacyUnforgeable]
字符串化器缓解措施可确保诸如
foo[location] = bar 或 location + "" 之类的代码不会被
误导。
document.location [ = value ]
window.location [ = value ]
返回一个包含
当前页面位置的 Location 对象。
可以设置该值,以导航到另一个页面。
Location 对象提供其
关联的 Document 的URL 的表示形式,以及用于导航和重新加载
关联的可导航对象的方法。
[Exposed =Window ]
interface Location { // but see also additional creation steps and overridden internal methods
[LegacyUnforgeable ] stringifier attribute USVString href ;
[LegacyUnforgeable ] readonly attribute USVString origin ;
[LegacyUnforgeable ] attribute USVString protocol ;
[LegacyUnforgeable ] attribute USVString host ;
[LegacyUnforgeable ] attribute USVString hostname ;
[LegacyUnforgeable ] attribute USVString port ;
[LegacyUnforgeable ] attribute USVString pathname ;
[LegacyUnforgeable ] attribute USVString search ;
[LegacyUnforgeable ] attribute USVString hash ;
[LegacyUnforgeable ] undefined assign (USVString url );
[LegacyUnforgeable ] undefined replace (USVString url );
[LegacyUnforgeable ] undefined reload ();
[LegacyUnforgeable ] readonly attribute DOMStringList ancestorOrigins ;
};location.toString()location.href
Support in all current engines.
Support in all current engines.
返回 Location 对象的 URL。
可以设置该值,以导航到给定 URL。
location.origin
Support in all current engines.
返回 Location 对象的
URL 的源。
location.protocol
Support in all current engines.
返回 Location 对象的
URL 的方案。
可以设置该值,以导航到方案已更改的同一 URL。
location.host
Support in all current engines.
返回 Location 对象的
URL 的主机和端口(如果该端口不同于方案的默认
端口)。
可以设置该值,以导航到主机和端口已更改的同一 URL。
location.hostname
Support in all current engines.
返回 Location 对象的
URL 的主机。
可以设置该值,以导航到主机已更改的同一 URL。
location.port
Support in all current engines.
返回 Location 对象的
URL 的端口。
可以设置该值,以导航到端口已更改的同一 URL。
location.pathname
Support in all current engines.
返回 Location 对象的
URL 的路径。
可以设置该值,以导航到路径已更改的同一 URL。
location.search
Support in all current engines.
返回 Location 对象的
URL 的查询(如果非空,则包括开头的 "?")。
可以设置该值,以导航到查询已更改的同一 URL(忽略开头的 "?")。
location.hash
Support in all current engines.
返回 Location 对象的
URL 的片段(如果非空,则包括开头的 "#")。
可以设置该值,以导航到片段已更改的同一 URL(忽略开头的 "#")。
location.assign(url)
Support in all current engines.
导航到给定 URL。
location.replace(url)
Support in all current engines.
从会话历史记录中移除当前页面,并导航到给定 URL。
location.reload()
Support in all current engines.
重新加载当前页面。
location.ancestorOrigins
返回一个 DOMStringList
对象,其中列出祖先可导航对象的活动文档的源。
Location 对象具有一个关联的
相关 Document;
如果此 Location 对象的相关全局
对象的浏览上下文不为 null,则它是该对象的
相关
全局对象的浏览上下文的活动文档,否则为
null。
Location 对象具有一个关联的
URL;
如果此 Location 对象的相关
Document不为 null,则它是此 Location 对象的相关 Document的URL,否则为 about:blank。
要将一个 Location 对象
locationLocation 对象导航到一个URL
url,可以选择给定一个 NavigationHistoryBehavior
historyHandling
(默认为 "auto"):
令 sourceDocument 为现任
全局对象的关联的
Document。
如果 location 的相关
Document尚未完全加载,并且现任全局
对象不具有瞬态激活,则将
historyHandling 设置为 "replace"。
使用 sourceDocument 将 navigable导航到 url,其中 exceptionsEnabled 设置为 true,historyHandling 设置为 historyHandling。
href 获取器
步骤如下:
如果 this 的相关 Document不为 null,并且其源与
入口设置
对象的源不是同源域,则抛出一个
"SecurityError" DOMException。
href 设置器
步骤如下:
如果 this 的相关 Document为 null,则
返回。
令 url 为给定所提供的值、相对于入口设置对象对 URL 进行编码解析所得的结果。
如果 url 为失败,则抛出一个"SyntaxError"
DOMException。
将 thisLocation 对象导航到
url。
href
设置器有意不进行
安全检查。
origin
获取器步骤如下:
如果 this 的相关 Document不为 null,并且其源
与
入口设置
对象的源不是同源域,则抛出一个
"SecurityError" DOMException。
protocol
获取器步骤如下:
如果 this 的相关 Document不为 null,并且其源
与
入口设置
对象的源不是同源域,则抛出一个
"SecurityError" DOMException。
protocol
设置器
步骤如下:
如果 this 的相关 Document为 null,则
返回。
如果 this 的相关 Document的源
与
入口设置
对象的源不是同源域,则抛出一个
"SecurityError" DOMException。
令 possibleFailure 为基本 URL
解析给定值后跟 ":" 所得的结果,其中 copyURL
作为url,方案起始状态作为
状态覆盖。
由于 URL 解析器会忽略多个连续的冒号,因此提供值
"https:"(甚至 "https::::")与
提供值 "https" 相同。
如果 possibleFailure 为失败,则抛出一个
"SyntaxError" DOMException。
如果 copyURL 的方案不是 HTTP(S) 方案,则终止这些步骤。
将 thisLocation 对象导航到
copyURL。
host 获取器
步骤如下:
host 设置器
步骤如下:
如果 this 的相关 Document为 null,则
返回。
如果 this 的相关 Document的源
与
入口设置
对象的源不是同源域,则抛出一个
"SecurityError" DOMException。
如果 copyURL 具有不透明路径,则 返回。
将 thisLocation 对象导航到
copyURL。
hostname
获取器步骤如下:
如果 this 的相关 Document不为 null,并且其源
与
入口设置
对象的源不是同源域,则抛出一个
"SecurityError" DOMException。
hostname
设置器
步骤如下:
如果 this 的相关 Document为 null,则
返回。
如果 this 的相关 Document的源
与
入口设置
对象的源不是同源域,则抛出一个
"SecurityError" DOMException。
如果 copyURL 具有不透明路径,则 返回。
将 thisLocation 对象导航到
copyURL。
port 获取器
步骤如下:
如果 this 的相关 Document不为 null,并且其源
与
入口设置
对象的源不是同源域,则抛出一个
"SecurityError" DOMException。
port 设置器
步骤如下:
如果 this 的相关 Document为 null,则
返回。
如果 this 的相关 Document的源
与
入口设置
对象的源不是同源域,则抛出一个
"SecurityError" DOMException。
如果 copyURL不能具有用户名、密码或端口,则 返回。
如果给定值为空字符串,则将 copyURL 的端口设置为 null。
将 thisLocation 对象导航到
copyURL。
pathname
获取器步骤如下:
如果 this 的相关 Document不为 null,并且其源
与
入口设置
对象的源不是同源域,则抛出一个
"SecurityError" DOMException。
返回对此
Location 对象的URL进行URL 路径
序列化所得的结果。
pathname
设置器
步骤如下:
如果 this 的相关 Document为 null,则
返回。
如果 this 的相关 Document的源
与
入口设置
对象的源不是同源域,则抛出一个
"SecurityError" DOMException。
如果 copyURL 具有不透明路径,则 返回。
将 copyURL 的路径设置为空 列表。
将 thisLocation 对象导航到
copyURL。
search
获取器步骤如下:
如果 this 的相关 Document不为 null,并且其源
与
入口设置
对象的源不是同源域,则抛出一个
"SecurityError" DOMException。
search
设置器步骤如下:
如果 this 的相关 Document为 null,则
返回。
如果 this 的相关 Document的源
与
入口设置
对象的源不是同源域,则抛出一个
"SecurityError" DOMException。
如果给定值为空字符串,则将 copyURL 的查询设置为 null。
否则,运行以下子步骤:
将 thisLocation 对象导航到
copyURL。
hash 获取器
步骤如下:
如果 this 的相关 Document不为 null,并且其源
与
入口设置
对象的源不是同源域,则抛出一个
"SecurityError" DOMException。
hash 设置器
步骤如下:
如果 this 的相关 Document为 null,则
返回。
如果 this 的相关 Document的源
与
入口设置
对象的源不是同源域,则抛出一个
"SecurityError" DOMException。
如果 copyURL 的片段不为 null,则令 thisURLFragment 为该片段;否则为空 字符串。
令 input 为移除给定值开头的单个 "#"
后的结果(如果存在)。
将 copyURL 的片段设置为 空 字符串。
如果 copyURL 的片段为 thisURLFragment,则返回。
为了与已部署的内容兼容,此提前退出是必要的;这些内容会在滚动时重复设置
location.hash。它不适用于其他
片段导航机制,例如 location.href 设置器
或 location.assign()。
将 thisLocation 对象导航到
copyURL。
与 a 和 area 元素的等效 API 不同,
hash 设置器不会
对空字符串进行特殊处理,以
保持与已部署脚本的兼容性。
assign(url) 方法步骤如下:
如果 this 的相关 Document为 null,则
返回。
如果 this 的相关 Document的源
与
入口设置
对象的源不是同源域,则抛出一个
"SecurityError" DOMException。
令 urlRecord 为给定 url、相对于入口设置对象对 URL 进行编码解析所得的结果。
如果 urlRecord 为失败,则抛出一个"SyntaxError"
DOMException。
将 thisLocation 对象导航到
urlRecord。
replace(url) 方法步骤如下:
如果 this 的相关 Document为 null,则
返回。
令 urlRecord 为给定 url、相对于入口设置对象对 URL 进行编码解析所得的结果。
如果 urlRecord 为失败,则抛出一个"SyntaxError"
DOMException。
给定 "replace",将 thisLocation 对象导航到
urlRecord。
replace() 方法有意
不进行
安全检查。
reload()
方法
步骤如下:
令 document 为 this 的相关
Document。
如果 document 为 null,则返回。
如果 document 的源
与
入口设置
对象的源不是
同源域,则抛出一个
"SecurityError" DOMException。
Location 对象具有一个关联的
空
DOMStringList,它是一个
DOMStringList 对象,其
关联列表是一个空列表。
此对象无法跨导航携带状态,因为它仅在不存在相关
Document时返回;在这种情况下无法
导航,也无法返回到一个不为 null 的相关
Document。
ancestorOrigins 获取器步骤如下:
如果 this 的相关 Document为 null,则返回
this 的空
DOMStringList。
如果 this 的相关 Document的源
与
入口设置
对象的源不是同源域,则抛出一个
"SecurityError" DOMException。
断言:this 的相关 Document的祖先源列表不为
null。
否则,返回 this 的相关 Document的祖先源列表。
如前所述,Location 奇异对象
出于安全目的需要 IDL 之外的附加逻辑。除非下文另有明确规定,否则 Location 对象必须
使用普通内部方法。
此外,每个 Location 对象都有一个
[[DefaultProperties]] 内部槽,
表示其创建时的自有属性。
如果 IsPlatformObjectSameOrigin(this) 为 true,则返回 ! OrdinaryGetPrototypeOf(this)。
返回 null。
返回 ! SetImmutablePrototype(this, V)。
如果 IsPlatformObjectSameOrigin(this) 为 true:
令 desc 为 OrdinaryGetOwnProperty(this, P)。
如果 this 的 [[DefaultProperties]] 内部槽的值 包含 P,则将 desc.[[Configurable]] 设置为 true。
返回 desc。
令 property 为 CrossOriginGetOwnPropertyHelper(this, P)。
如果 property 不是 undefined,则返回 property。
返回 ? CrossOriginPropertyFallback(P)。
如果 IsPlatformObjectSameOrigin(this) 为 true:
如果 this 的 [[DefaultProperties]] 内部槽的值 包含 P,则返回 false。
返回 ? OrdinaryDefineOwnProperty(this, P, Desc)。
抛出一个 "SecurityError" DOMException。
如果 IsPlatformObjectSameOrigin(this) 为 true,则 返回 ? OrdinaryGet(this, P, Receiver)。
返回 ? CrossOriginGet(this, P, Receiver)。
如果 IsPlatformObjectSameOrigin(this) 为 true,则 返回 ? OrdinarySet(this, P, V, Receiver)。
返回 ? CrossOriginSet(this, P, V, Receiver)。
如果 IsPlatformObjectSameOrigin(this) 为 true, 则返回 ? OrdinaryDelete(this, P)。
抛出一个 "SecurityError" DOMException。
如果 IsPlatformObjectSameOrigin(this) 为 true,则返回 OrdinaryOwnPropertyKeys(this)。
返回 CrossOriginOwnPropertyKeys(this)。
History 接口Support in all current engines.
Support in all current engines.
enum ScrollRestoration { " auto " , " manual " };
[Exposed =Window ]
interface History {
readonly attribute unsigned long length ;
attribute ScrollRestoration scrollRestoration ;
readonly attribute any state ;
undefined go (optional long delta = 0);
undefined back ();
undefined forward ();
undefined pushState (any data , DOMString unused , optional USVString ? url = null );
undefined replaceState (any data , DOMString unused , optional USVString ? url = null );
};history.length
Support in all current engines.
history.scrollRestoration
Support in all current engines.
history.scrollRestoration = value
将活动会话历史记录 条目的滚动 恢复模式设置为 value。
history.state
Support in all current engines.
返回活动会话 历史记录条目的经典历史记录 API 状态,并将其反序列化 为 JavaScript 值。
history.go()
重新加载当前页面。
history.go(delta)
Support in all current engines.
在当前可遍历可导航对象的全部会话历史记录条目列表中,后退或前进指定的步数。
为零的增量会重新加载当前页面。
如果增量超出范围,则不执行任何操作。
history.back()
Support in all current engines.
在当前可遍历可导航对象的全部会话历史记录 条目列表中后退一步。
如果没有上一页,则不执行任何操作。
history.forward()
Support in all current engines.
在当前可遍历可导航对象的全部会话 历史记录条目列表中前进一步。
如果没有下一页,则不执行任何操作。
history.pushState(data, "")
Support in all current engines.
向会话历史记录中添加一个新条目,并将其经典历史记录 API 状态设置为 data 的序列化 结果。活动历史记录条目的 URL 将被复制并用作新条目的 URL。
(第二个参数出于历史原因而存在,并且不能省略;传统做法是传入 空字符串。)
history.pushState(data, "", url)
向会话历史记录中添加一个新条目,并将其经典历史记录 API 状态设置为 data 的序列化 结果,并将其 URL 设置为 url。
如果当前 Document 无法将其
URL 重写为 url,则会抛出一个 "SecurityError"
DOMException。
(第二个参数出于历史原因而存在,并且不能省略;传统做法是传入 空字符串。)
history.replaceState(data, "")
Support in all current engines.
将活动会话 历史记录条目的经典历史记录 API 状态更新为 data 的结构化 克隆。
(第二个参数出于历史原因而存在,并且不能省略;传统做法是传入 空字符串。)
history.replaceState(data, "", url)
将活动会话 历史记录条目的经典历史记录 API 状态更新为 data 的结构化 克隆,并将其 URL 更新为 url。
如果当前 Document 无法将其
URL 重写为 url,则会抛出一个 "SecurityError"
DOMException。
(第二个参数出于历史原因而存在,并且不能省略;传统做法是传入 空字符串。)
Document 具有一个历史记录对象,即一个
History 对象。
history 获取器步骤
是返回 this
的关联的
Document的历史记录对象。
每个 History 对象都有一个状态,
初始为 null。
每个 History 对象都有一个长度,它是一个
非负整数,初始为 0。
每个 History 对象都有一个索引,它是一个
非负整数,初始为 0。
虽然索引不会直接 暴露,但可以通过同步导航期间长度的变化推断出来。事实上,这正是 它的用途。
length
获取器
步骤如下:
如果 this 的相关全局对象的关联的
Document不是完全
活动的,则抛出一个 "SecurityError"
DOMException。
scrollRestoration 获取器步骤如下:
如果 this 的相关全局对象的关联的
Document不是完全
活动的,则抛出一个 "SecurityError"
DOMException。
返回 this 的相关全局对象的可导航对象的活动会话 历史记录 条目的滚动恢复 模式。
scrollRestoration
设置器步骤
如下:
如果 this 的相关全局对象的关联的
Document不是完全
活动的,则抛出一个 "SecurityError"
DOMException。
将 this 的相关全局对象的可导航对象的活动会话 历史记录 条目的滚动恢复模式设置为 给定值。
state 获取器
步骤如下:
如果 this 的相关全局对象的关联的
Document不是完全
活动的,则抛出一个 "SecurityError"
DOMException。
要给定整数
delta,对一个 History 对象
history
进行增量遍历:
令 document 为 history 的相关全局对象的
关联的
Document。
如果 document 不是完全
活动的,则抛出一个
"SecurityError" DOMException。
如果 history 的相关全局对象的可导航对象的获准执行导航 或历史记录更新 返回已阻止,则返回。
给定 document 的节点 可导航对象的可遍历 可导航对象、delta,并将 sourceDocument 设置为 document,按增量遍历历史记录。
pushState(data,
unused, url) 方法步骤是给定 this、data、url
和
"push",运行共享历史记录
推入/替换状态步骤。
replaceState(data, unused,
url) 方法步骤是给定 this、data、url 和
"replace",运行共享历史记录推入/替换状态
步骤。
给定一个
History
history、一个值 data、一个标量值
字符串或 null
url,以及一个历史记录处理行为 historyHandling,共享历史记录推入/替换状态步骤
如下:
令 document 为 history 的相关全局对象的
关联的
Document。
如果 document 不是完全
活动的,则抛出一个
"SecurityError" DOMException。
令 serializedData 为 StructuredSerializeForStorage(data)。 重新抛出任何异常。
令 newURL 为 document 的 URL。
如果 url 不是 null 或空字符串:
给定 url,相对于 history 的相关设置对象对 URL 进行编码解析,并将 newURL 设置为所得结果。
如果 newURL 为失败,则抛出一个 "SecurityError"
DOMException。
如果 document 无法将其 URL
重写为 newURL,则抛出一个 "SecurityError"
DOMException。
此处对空字符串的特殊处理是历史遗留行为,并且在比较诸如
location.href = ""
(它会对空字符串执行 URL 解析)与 history.pushState(null, "", "")(它会
绕过该解析)之类的代码时,会产生不同的结果 URL。
如果 history 的相关全局对象的可导航对象的获准执行 导航或历史记录更新 返回已阻止,则返回。
令 continue 为在
navigation 上触发推入/替换/重新加载
navigate 事件所得的结果,其中 navigationType 设置为
historyHandling,isSameDocument 设置
为 true,destinationURL 设置为
newURL,并且 classicHistoryAPIState 设置为
serializedData。
如果 continue 为 false,则返回。
给定 document 和 newURL,运行URL 和历史记录更新步骤,其中 serializedData 设置为 serializedData,并且 historyHandling 设置为 historyHandling。
用户代理可以限制每个页面添加到会话历史记录中的状态对象数量。如果某个
页面达到由实现定义的限制,则用户代理在添加新条目后,必须立即移除
会话历史记录中该 Document 对象的第一个条目之后的条目。
(因此,状态历史记录在逐出时充当 FIFO 缓冲区,但
在导航时充当 LIFO 缓冲区。)
如果以下算法返回 true,则一个 Document
document可以将其 URL 重写为一个
URL
targetURL:
| document 的 URL | targetURL | 可以重写其 URL |
|---|---|---|
https://example.com/home
|
https://example.com/home#about
|
✅ |
https://example.com/home
|
https://example.com/home?page=shop
|
✅ |
https://example.com/home
|
https://example.com/shop
|
✅ |
https://example.com/home
|
https://user:pass@example.com/home
|
❌ |
https://example.com/home
|
http://example.com/home
|
❌ |
file:///path/to/x
|
file:///path/to/x#hash
|
✅ |
file:///path/to/x
|
file:///path/to/x?search
|
✅ |
file:///path/to/x
|
file:///path/to/y
|
❌ |
about:blank
|
about:blank#hash
|
✅ |
about:blank
|
about:blank?search
|
❌ |
about:blank
|
about:srcdoc
|
❌ |
data:text/html,foo
|
data:text/html,foo#hash
|
✅ |
data:text/html,foo
|
data:text/html,foo?search
|
❌ |
data:text/html,foo
|
data:text/html,bar
|
❌ |
data:text/html,foo
|
data:bar
|
❌ |
blob:https://example.com/77becafe-657b-4fdc-8bd3-e83aaa5e8f43
|
blob:https://example.com/77becafe-657b-4fdc-8bd3-e83aaa5e8f43#hash
|
✅ |
blob:https://example.com/77becafe-657b-4fdc-8bd3-e83aaa5e8f43
|
blob:https://example.com/77becafe-657b-4fdc-8bd3-e83aaa5e8f43?search
|
❌ |
blob:https://example.com/77becafe-657b-4fdc-8bd3-e83aaa5e8f43
|
blob:https://example.com/anything
|
❌ |
blob:https://example.com/77becafe-657b-4fdc-8bd3-e83aaa5e8f43
|
blob:path
|
❌ |
请注意,只有 Document 的
URL
才重要,而其源并不重要。它们
在某些情况下可能不匹配,例如具有继承源的 about:blank
Document、沙盒化
iframe,或使用了
document.domain
设置器时。
设想一个游戏,用户可以沿着一条直线移动,使得用户始终位于某个 坐标,并且用户可以为与特定 坐标对应的页面添加书签,以便稍后返回。
在这种游戏中,实现 x=5 位置的静态页面可能如下所示:
<!DOCTYPE HTML>
<!-- this is https://example.com/line?x=5 -->
< html lang = "en" >
< title > Line Game - 5</ title >
< p > You are at coordinate 5 on the line.</ p >
< p >
< a href = "?x=6" > Advance to 6</ a > or
< a href = "?x=4" > retreat to 4</ a > ?
</ p > 这种系统的问题在于,每次用户单击时,整个页面都必须 重新加载。下面则是使用脚本实现此功能的另一种方式:
<!DOCTYPE HTML>
<!-- this starts off as https://example.com/line?x=5 -->
< html lang = "en" >
< title > Line Game - 5</ title >
< p > You are at coordinate < span id = "coord" > 5</ span > on the line.</ p >
< p >
< a href = "?x=6" onclick = "go(1); return false;" > Advance to 6</ a > or
< a href = "?x=4" onclick = "go(-1); return false;" > retreat to 4</ a > ?
</ p >
< script >
var currentPage = 5 ; // prefilled by server
function go( d) {
setupPage( currentPage + d);
history. pushState( currentPage, "" , '?x=' + currentPage);
}
onpopstate = function ( event) {
setupPage( event. state);
}
function setupPage( page) {
currentPage = page;
document. title = 'Line Game - ' + currentPage;
document. getElementById( 'coord' ). textContent = currentPage;
document. links[ 0 ]. href = '?x=' + ( currentPage+ 1 );
document. links[ 0 ]. textContent = 'Advance to ' + ( currentPage+ 1 );
document. links[ 1 ]. href = '?x=' + ( currentPage- 1 );
document. links[ 1 ]. textContent = 'retreat to ' + ( currentPage- 1 );
}
</ script > 在不支持脚本的系统中,它仍会像上一个示例一样工作。不过,确实 支持脚本的用户现在可以更快地导航,因为相同的体验不再需要网络访问。 此外,与仅使用简单脚本方式时用户所获得的体验不同,添加书签和遍历 会话历史记录仍然有效。
在上面的示例中,pushState()
方法的 data 参数与将发送到服务器的信息相同,
但采用了更方便的形式,因此脚本不必在用户每次导航时解析 URL。
大多数应用程序希望其所有历史记录条目都使用相同的滚动恢复模式值。为此,它们可以尽早设置 scrollRestoration
属性
(例如,在文档的 head
元素中的第一个 script 元素中),
以
确保添加到历史记录会话中的任何条目都获得所需的滚动恢复模式。
< head >
< script >
if ( 'scrollRestoration' in history)
history. scrollRestoration = 'manual' ;
</ script >
</ head >
本节为非规范性内容。
由全局 navigation
属性提供的导航 API,为管理导航和历史记录条目提供了一种现代化且面向 Web 应用程序的方式。它是经典
location
和 history API 的后继者。
该 API 提供的一项功能是检查会话历史记录条目。例如,以下代码将在有序列表中 显示这些条目的 URL:
const ol = document. createElement( "ol" );
ol. start = 0 ; // so that the list items' ordinal values match up with the entry indices
for ( const entry of navigation. entries()) {
const li = document. createElement( "li" );
if ( entry. index < navigation. currentEntry. index) {
li. className = "backward" ;
} else if ( entry. index > navigation. currentEntry. index) {
li. className = "forward" ;
} else {
li. className = "current" ;
}
li. textContent = entry. url;
ol. append( li);
} navigation.entries()
数组包含 NavigationHistoryEntry
实例,除了此处展示的 url
和 index
属性之外,这些实例还具有其他有用属性。请注意,该数组仅包含表示当前可导航对象的 NavigationHistoryEntry
对象,因此其内容不会受到 iframe 等可导航对象容器内部导航的影响,也不会受到在
iframe 内部使用导航
API 时父可导航对象导航的影响。此外,它
仅包含表示同源会话历史记录条目的 NavigationHistoryEntry
对象,这意味着,如果用户在当前源之前或之后访问过其他源,则不会存在相应的
NavigationHistoryEntry
对象。
导航 API 还可以用于导航、重新加载或遍历历史记录:
< button onclick = "navigation.reload()" > Reload</ button >
< input type = "url" id = "navigationURL" >
< button onclick = "navigation.navigate(navigationURL.value)" > Navigate</ button >
< button id = "backButton" onclick = "navigation.back()" > Back</ button >
< button id = "forwardButton" onclick = "navigation.forward()" > Forward</ button >
< select id = "traversalDestinations" ></ select >
< button id = "goButton" onclick = "navigation.traverseTo(traversalDestinations.value)" > Traverse To</ button >
< script >
backButton. disabled = ! navigation. canGoBack;
forwardButton. disabled = ! navigation. canGoForward;
for ( const entry of navigation. entries()) {
traversalDestinations. append( new Option( entry. url, entry. key));
}
</ script > 请注意,遍历同样仅限于同源目标,这意味着,例如,如果上一个会话历史记录条目属于另一个源的页面,则 navigation.canGoBack
将为 false。
导航 API 最强大的部分是 navigate
事件,每当当前可导航对象中发生几乎任何导航或遍历时,都会触发该事件:
navigation. onnavigate = event => {
console. log( event. navigationType); // "push", "replace", "reload", or "traverse"
console. log( event. destination. url);
console. log( event. userInitiated);
// ... and other useful properties
}; (当导航目标是新文档时,对于由地址栏发起的导航或从其他窗口发起的导航, 不会触发该事件。)
在大多数情况下,该事件的 cancelable
属性将为 true,这意味着可以使用 preventDefault()
取消该事件:
navigation. onnavigate = event => {
if ( event. cancelable && isDisallowedURL( event. destination. url)) {
alert( `Please don't go to ${ event. destination. url} !` );
event. preventDefault();
}
};
对于某些 "traverse"
导航,cancelable
属性将为 false,例如发生在子可导航对象内部的导航、跨越到新源的导航,或用户在之前调用 preventDefault()
阻止遍历后不久再次尝试遍历时。
NavigateEvent 的 intercept()
方法允许拦截导航并将其转换为同文档导航:
navigation. addEventListener( "navigate" , e => {
// Some navigations, e.g. cross-origin navigations, we cannot intercept.
// Let the browser handle those normally.
if ( ! e. canIntercept) {
return ;
}
// Similarly, don't intercept fragment navigations or downloads.
if ( e. hashChange || e. downloadRequest !== null ) {
return ;
}
const url = new URL( event. destination. url);
if ( url. pathname. startsWith( "/articles/" )) {
e. intercept({
async handler() {
// The URL has already changed, so show a placeholder while
// fetching the new content, such as a spinner or loading page.
renderArticlePagePlaceholder();
// Fetch the new content and display when ready.
const articleContent = await getArticleContent( url. pathname, { signal: e. signal });
renderArticlePage( articleContent);
}
});
}
}); 请注意,handler
函数可以返回一个 promise,以表示导航的异步进度以及成功或失败。
当该 promise 仍处于待定状态时,浏览器 UI 可以将导航视为仍在进行(例如,显示加载
指示器)。导航 API 的其他部分也会受到这些 promise 的影响,例如 navigation.navigate()
的返回值:
const { committed, finished } = await navigation. navigate( "/articles/the-navigation-api-is-cool" );
// The committed promise will fulfill once the URL has changed, which happens
// immediately (as long as the NavigateEvent wasn't canceled).
await committed;
// The finished promise will fulfill once the Promise returned by handler() has
// fulfilled, which happens once the article is downloaded and rendered. (Or,
// it will reject, if handler() fails along the way).
await finished; Navigation 接口[Exposed =Window ]
interface Navigation : EventTarget {
sequence <NavigationHistoryEntry > entries ();
readonly attribute NavigationHistoryEntry ? currentEntry ;
undefined updateCurrentEntry (NavigationUpdateCurrentEntryOptions options );
readonly attribute NavigationTransition ? transition ;
readonly attribute NavigationActivation ? activation ;
readonly attribute boolean canGoBack ;
readonly attribute boolean canGoForward ;
NavigationResult navigate (USVString url , optional NavigationNavigateOptions options = {});
NavigationResult reload (optional NavigationReloadOptions options = {});
NavigationResult traverseTo (DOMString key , optional NavigationOptions options = {});
NavigationResult back (optional NavigationOptions options = {});
NavigationResult forward (optional NavigationOptions options = {});
attribute EventHandler onnavigate ;
attribute EventHandler onnavigatesuccess ;
attribute EventHandler onnavigateerror ;
attribute EventHandler oncurrententrychange ;
};
dictionary NavigationUpdateCurrentEntryOptions {
required any state ;
};
dictionary NavigationOptions {
any info ;
};
dictionary NavigationNavigateOptions : NavigationOptions {
any state ;
NavigationHistoryBehavior history = "auto";
};
dictionary NavigationReloadOptions : NavigationOptions {
any state ;
};
dictionary NavigationResult {
Promise <NavigationHistoryEntry > committed ;
Promise <NavigationHistoryEntry > finished ;
};
enum NavigationHistoryBehavior {
" auto " ,
" push " ,
" replace "
};每个 Window 都有一个关联的导航
API,它是一个 Navigation
对象。创建 Window
对象时,其导航 API
必须设置为一个在该 Window 对象的相关领域中创建的
新 Navigation 对象。
以下是实现
Navigation 接口的所有对象必须以事件处理器 IDL
属性形式支持的事件处理器(以及
它们对应的事件
处理器事件类型):
| 事件处理器 | 事件处理器事件 类型 |
|---|---|
onnavigate
|
navigate
|
onnavigatesuccess
|
navigatesuccess
|
onnavigateerror
|
navigateerror
|
oncurrententrychange
|
currententrychange
|
每个 Navigation 都有一个关联的条目
列表,它是一个由 NavigationHistoryEntry
对象组成的列表,初始为空。
每个 Navigation 都有一个关联的当前条目索引,它是一个整数,初始为
−1。
一个 Navigation
navigation 的当前条目是运行以下步骤所得的结果:
如果以下步骤返回 true,则一个 Navigation
navigation禁用了条目和事件:
令 document 为 navigation 的相关全局对象的
关联的
Document。
如果 document 不是完全活动的, 则返回 true。
如果 document 的是
初始 about:blank为 true,则
返回 true。
返回 false。
要获取 Navigation
navigation 中一个会话历史记录
条目 she 的导航 API 条目
索引:
导航 API 中广泛使用的一个关键类型是 NavigationType
枚举:
enum NavigationType {
" push " ,
" replace " ,
" reload " ,
" traverse "
};它涵盖了 Web 开发者可见的主要“导航”类型,这些类型(如其他地方所述)并不完全对应于本标准唯一的 导航算法。每个值的含义 如下:
push"push",
或对应于
history.pushState()。
replace"replace",
或
对应于 history.replaceState()。
reload"traverse"NavigationType
枚举的值空间是
规范内部历史记录处理行为类型值空间的超集。本标准的多个
部分利用了这种重叠,将一个历史记录处理
行为传递给期望 NavigationType
的算法。
要给定一个
Navigation
navigation、一个由会话历史记录条目组成的列表 newSHEs,以及一个会话历史记录
条目 initialSHE,为新
文档初始化导航 API 条目:
如果 navigation禁用了条目和事件,则 返回。
对于 newSHEs 中的每个 newSHE:
令 newNHE 为在
navigation 的相关
领域中创建的一个新 NavigationHistoryEntry。
将 newNHE 的会话历史记录 条目设置为 newSHE。
newSHEs 最初将来自获取导航 API 的会话历史记录 条目,因此每个 newSHE 都将与 initialSHE 连续同源。
将 navigation 的当前条目 索引设置为在 navigation 中获取 initialSHE 的导航 API 条目索引所得的结果。
要给定一个
Navigation
navigation、一个由会话历史记录条目组成的列表 newSHEs,以及一个
会话历史记录
条目 reactivatedSHE,为
重新激活更新导航 API 条目:
如果 navigation禁用了条目和事件, 则 返回。
令 newNHEs 为一个新的空列表。
对于 newSHEs 中的每个 newSHE:
令 newNHE 为 null。
如果 oldNHEs包含一个
NavigationHistoryEntry
matchingOldNHE,其会话
历史记录条目是 newSHE:
将 newNHE 设置为 matchingOldNHE。
从 oldNHEs 中移除 matchingOldNHE。
否则:
将 newNHE 设置为在
navigation 的相关领域中创建的一个新 NavigationHistoryEntry。
将 newNHE 的会话 历史记录条目设置为 newSHE。
将 newNHE追加到 newNHEs。
newSHEs 最初将来自获取导航 API 的会话历史记录 条目,因此每个 newSHE 都将与 reactivatedSHE 连续同源。
在此循环结束时,仍留在
oldNHEs 中的所有 NavigationHistoryEntry
都表示在 Document 位于往返缓存期间被处置的会话历史记录条目。
将 navigation 的条目列表 设置为 newNHEs。
将 navigation 的当前条目 索引设置为在 navigation 中获取 reactivatedSHE 的导航 API 条目索引所得的结果。
给定 navigation 的相关全局对象,在导航和遍历任务 源上排入一个全局任务,以运行以下 步骤:
我们通过一个任务延迟这些步骤,以确保 dispose
事件将在 pageshow
事件之后触发。这
确保
pageshow
是页面在重新激活时收到的第一个事件。
(但是,此算法的其余部分在 pageshow 事件
触发之前运行。这确保在任何 pageshow 事件
处理器运行期间,navigation.entries()
和 navigation.currentEntry
都具有正确更新后的
值。)
要给定一个
Navigation
navigation、一个会话历史记录条目
destinationSHE,以及一个 NavigationType
navigationType,为同文档导航
更新导航 API 条目:
如果 navigation禁用了条目和事件, 则 返回。
令 oldCurrentNHE 为 navigation 的当前 条目。
令 disposedNHEs 为一个新的空列表。
如果 navigationType 是 "traverse":
将 navigation 的当前条目 索引设置为在 navigation 中获取 destinationSHE 的导航 API 条目索引所得的结果。
此算法仅对同文档遍历调用。跨文档 遍历将改为调用为新 文档初始化导航 API 条目或为重新激活更新导航 API 条目。
否则,如果 navigationType 是 "push":
否则,如果 navigationType 是 "replace":
将 oldCurrentNHE追加到 disposedNHEs。
如果 navigation 的进行中的 API 方法跟踪器非 null, 则给定 navigation 的进行中的 API 方法跟踪器和 navigation 的当前条目,通知已提交到的 条目。
在触发 dispose 或 currententrychange
事件之前执行此操作非常重要,因为事件处理器可能会
启动另一个导航,或以其他方式更改 navigation 的进行中的
API 方法跟踪器的值。
令 navigateEvent 为 navigation 的进行中的 navigate 事件。
令 apiMethodTracker 为 navigation 的进行中的 API 方法跟踪器。
给定 navigation 的相关设置 对象,准备运行 脚本。
请参阅有关其他导航 API 事件的讨论,以了解我们为何这样做。
在 navigation 上使用
NavigationCurrentEntryChangeEvent触发一个名为 currententrychange
的事件,并将其 navigationType
属性
初始化为 navigationType,将其 from
初始化为
oldCurrentNHE。
对于 disposedNHEs 中的每个 disposedNHE:
给定 navigation、navigateEvent 和 apiMethodTracker,运行导航事件拦截 提交处理器步骤。
在实现中,同文档导航可能会导致会话历史记录条目因从 会话历史记录条目列表的后端脱落而被处置。上述算法(或本标准的任何其他部分) 尚未处理这种情况。请参阅 issue #8620,以 跟踪定义此类情况下正确行为的进展。
NavigationHistoryEntry
接口[Exposed =Window ]
interface NavigationHistoryEntry : EventTarget {
readonly attribute USVString ? url ;
readonly attribute DOMString key ;
readonly attribute DOMString id ;
readonly attribute long long index ;
readonly attribute boolean sameDocument ;
any getState ();
attribute EventHandler ondispose ;
};entry.url
此导航历史记录条目的 URL。
如果该条目对应的 Document 与当前
Document 不同(即 sameDocument
为 false),并且该 Document
是使用
“no-referrer”或“origin”的来源策略获取的,则此值可以返回 null,因为这表明
所涉及的 Document
即使对其他同源页面也隐藏了其 URL。
entry.key
一个由用户代理生成的随机 UUID 字符串,表示此导航历史记录条目在
导航历史记录列表中的位置。由于 "replace"
导航而替换此实例的其他
NavigationHistoryEntry
实例将复用此值,并且此值将在重新加载和
会话恢复后保留。
这对于使用 navigation.traverseTo(key)
导航回导航历史记录列表中的此条目很有用。
entry.id
一个由用户代理生成的随机 UUID 字符串,表示此特定导航历史记录
条目。其他 NavigationHistoryEntry
实例将不会复用此值。此值将在重新加载和会话恢复后保留。
这对于使用其他存储 API 将数据与此导航历史记录条目关联起来很有用。
entry.index
此 NavigationHistoryEntry
在 navigation.entries()
中的索引;如果该条目不在
导航历史记录条目列表中,则为 −1。
entry.sameDocument
指示此导航历史记录条目是否属于与
当前条目相同的 Document。
例如,当该条目表示片段导航或单页应用导航时,此值将为 true。
entry.getState()
返回存储在此条目中的状态的反序列化结果,该状态是使用 navigation.navigate()
或 navigation.updateCurrentEntry()
添加到该条目中的。此状态
将在重新加载和会话恢复后保留。
请注意,通常情况下,除非状态值是原始值,否则 entry.getState() !== entry.getState(),因为每次都会
返回一个全新的反序列化结果。
此状态与经典历史记录 API 的 history.state
无关。
每个 NavigationHistoryEntry
都有一个关联的会话
历史记录条目,它是一个会话历史记录条目。
一个
NavigationHistoryEntry
nhe 的键由以下
算法的返回值给出:
如果 nhe 的相关全局对象的关联的
Document不是完全
活动的,则返回空字符串。
一个
NavigationHistoryEntry
nhe 的ID 由以下
算法的返回值给出:
如果 nhe 的相关全局对象的关联的
Document
不是完全
活动的,则返回空字符串。
一个
NavigationHistoryEntry
nhe 的索引由以下
算法的返回值给出:
如果 nhe 的相关全局对象的关联的
Document
不是完全
活动的,则返回 −1。
url 获取器步骤如下:
sameDocument 获取器步骤如下:
getState() 方法步骤如下:
如果 this 的相关全局对象的关联的
Document
不是完全
活动的,则返回 undefined。
返回 StructuredDeserialize(this 的会话 历史记录条目的导航 API 状态)。 重新抛出任何异常。
理论上这可能会抛出异常,例如在没有足够内存可用时尝试反序列化一个较大的
ArrayBuffer。
以下是实现
NavigationHistoryEntry
接口的所有对象必须以事件处理器 IDL 属性形式支持的事件
处理器(以及它们对应的事件处理器事件类型):
| 事件处理器 | 事件处理器事件类型 |
|---|---|
ondispose
|
dispose
|
entries = navigation.entries()
返回一个由 NavigationHistoryEntry
实例组成的数组,这些实例表示当前
导航历史记录条目列表,即此可导航对象的所有
与当前
会话历史记录条目同源且连续的会话历史
记录条目。
navigation.currentEntry
返回与当前会话历史记录条目对应的 NavigationHistoryEntry。
navigation.updateCurrentEntry({ state })
更新当前会话历史记录条目的导航
API 状态,而不执行像 navigation.reload()
那样的
导航。
此方法最适合用于捕获已经发生并且需要
反映到导航 API 状态中的页面更新。对于状态更新旨在
驱动页面更新的情况,请改用 navigation.navigate()
或 navigation.reload(),
它们将触发一个 navigate 事件。
navigation.canGoBack
如果当前当前会话
历史记录条目(即 currentEntry)
不是
导航历史记录条目列表中的第一个条目(即 entries()
中的第一个条目),则返回 true。
这意味着此可导航对象存在上一个
会话历史记录条目,
并且其文档状态的源与当前
Document 的源同源。
navigation.canGoForward
如果当前当前会话
历史记录条目(即 currentEntry)
不是
导航历史记录条目列表中的最后一个条目(即 entries()
中的最后一个条目),则返回 true。
这意味着此可导航对象存在下一个会话
历史记录条目,并且其
文档状态的源与当前
Document 的源同源。
entries()
方法步骤如下:
请记住,由于 Web IDL 的序列类型转换规则,每次调用都会
创建一个新的 JavaScript 数组对象。即
navigation.entries() !== navigation.entries()。
updateCurrentEntry(options)
方法步骤如下:
如果 current 为 null,则抛出一个 "InvalidStateError"
DOMException。
令 serializedState 为
StructuredSerializeForStorage(options["state"]),
并重新抛出任何
异常。
在 this 上使用
NavigationCurrentEntryChangeEvent触发一个名为 currententrychange
的事件,并将其 navigationType
属性
初始化为 null,将其 from
初始化为 current。
canGoBack 获取器步骤如下:
canGoForward 获取器步骤如下:
{ committed, finished } = navigation.navigate(url)
{ committed, finished } = navigation.navigate(url, options)
将当前页面导航到给定的 url。 options 可以包含以下值:
info 可以设置
为任何值;它
将填充对应 NavigateEvent
的 info
属性。
state
可以设置为任何
可序列化值;对于同文档导航,
导航完成后,它将填充由 navigation.currentEntry.getState()
获取的状态。(对于最终成为跨文档导航的导航,它将被忽略。)
默认情况下,这将执行完整导航(即跨文档导航,除非
给定 URL 与当前 URL 仅在片段上不同)。
navigateEvent.intercept()
方法可
用于将其转换为同文档导航。
返回的 promise 将按以下方式运行:
对于被中止的导航,两个 promise 都将以一个
"AbortError" DOMException
拒绝。
对于使用 navigateEvent.intercept()
方法创建的同文档导航,committed
将在导航
提交后兑现,而 finished
将根据传递给 intercept()
的处理器返回的任何 promise 兑现或
拒绝。
对于其他同文档导航(例如未被拦截的片段导航),两个 promise 都将 立即兑现。
对于跨文档导航,或服务器返回 204 或 205 状态或 `Content-Disposition: attachment`
标头字段的导航
(因此实际上不会导航),两个 promise 都永远不会敲定。
在所有情况下,当返回的 promise 兑现时,其兑现值将是
被导航到的 NavigationHistoryEntry。
{ committed, finished } = navigation.reload(options)
重新加载当前页面。
options 可以包含 info
和 state,
它们的行为如上所述。
执行当前页面的从网络或缓存重新加载这一默认行为,可以
通过使用 navigateEvent.intercept()
方法来覆盖。这样做意味着
此调用只会更新状态或传递适当的 info,
再加上执行 navigate 事件
处理器认为适合执行的任何操作。
返回的 promise 将按以下方式运行:
如果通过使用 navigateEvent.intercept()
方法拦截重新加载,则 committed
将在导航提交后兑现,而 finished
将根据传递给 intercept()
的处理器返回的任何 promise 兑现或
拒绝。
否则,两个 promise 都永远不会敲定。
{ committed, finished } = navigation.traverseTo(key)
{ committed, finished } = navigation.traverseTo(key, { info })
遍历到与具有给定
key 的 NavigationHistoryEntry
匹配的最近会话
历史记录条目。info
可以设置为任何值;
它将填充对应 NavigateEvent
的 info
属性。
如果到该会话历史记录条目的遍历已在
进行中,则此调用
将返回该原始遍历的 promise,并且 info
将被忽略。
返回的 promise 将按以下方式运行:
如果 navigation.entries()
中不存在其 key
与 key 匹配的 NavigationHistoryEntry,
则两个 promise 都将以一个 "InvalidStateError"
DOMException
拒绝。
对于由 navigateEvent.intercept()
方法拦截的同文档遍历,committed
将在遍历
得到处理并且 navigation.currentEntry
更新后立即兑现,而 finished
将根据传递给 intercept()
的处理器返回的任何 promise 兑现或
拒绝。
对于未被拦截的同文档遍历,两个 promise 都将在
遍历得到处理并且 navigation.currentEntry
更新后立即兑现。
对于跨文档遍历,包括最终导致服务器返回 204 或 205 状态或 `Content-Disposition: attachment`
标头字段的跨文档遍历尝试
(因此实际上不会遍历),两个 promise 都永远不会敲定。
{ committed, finished } = navigation.back(key)
{ committed, finished } = navigation.back(key, { info })
遍历到最近的上一个会话历史记录条目,该条目会使此
可导航对象发生遍历,即
对应于不同的
NavigationHistoryEntry,
因而将导致 navigation.currentEntry
发生变化。info
可以设置为任何值;它将填充对应
NavigateEvent
的 info
属性。
如果到该会话历史记录条目的遍历已在
进行中,则此调用
将返回该原始遍历的 promise,并且 info
将被忽略。
返回的 promise 的行为与 traverseTo()
返回的 promise 相同。
{ committed, finished } = navigation.forward(key)
{ committed, finished } = navigation.forward(key, { info })
遍历到最近的下一个会话历史记录条目,该条目会使此
可导航对象发生遍历,即
对应于不同的
NavigationHistoryEntry,
因而将导致 navigation.currentEntry
发生变化。info
可以设置为任何值;它将填充对应
NavigateEvent
的 info
属性。
如果到该会话历史记录条目的遍历已在
进行中,则此调用
将返回该原始遍历的 promise,并且 info
将被忽略。
返回的 promise 的行为与 traverseTo()
返回的 promise 相同。
navigate(url, options) 方法
步骤如下:
如果 urlRecord 为失败,则返回一个针对 "SyntaxError" DOMException
的早期错误结果。
如果 urlRecord 的方案是
"javascript",
则返回一个针对
"NotSupportedError" DOMException
的早期错误结果。
令 document 为 this 的相关
全局对象的关联的 Document。
如果 options["history"]
是 "push",
并且给定 urlRecord 和 document,该导航必须是
替换,则返回一个针对
"NotSupportedError" DOMException
的早期错误结果。
令 serializedState 为 StructuredSerializeForStorage(state)。 如果这抛出异常,则 返回一个针对该 异常的早期错误结果。
尽早执行此步骤很重要,因为序列化可以调用 Web 开发者代码,而该代码又可能更改我们在后续步骤中检查的各种内容。
如果 document 不是完全活动的,则返回一个针对
"InvalidStateError" DOMException
的早期错误结果。
如果 document 的卸载计数器大于 0,则返回
一个针对
"InvalidStateError" DOMException
的早期错误结果。
令 apiMethodTracker 为给定 info 和 serializedState,为 this设置 navigate/reload API 方法跟踪器所得的结果。
使用 document 将 document 的节点
可导航对象导航到
urlRecord,其中 historyHandling
设置为 options["history"],
navigationAPIState 设置为
serializedState,并且 apiMethodTracker
设置为 apiMethodTracker。
不同于 location.assign()
及类似方法,
它们可以跨源域边界公开,而
navigation.navigate()
只能由可直接同步访问 window.navigation
属性的代码访问。因此,我们避免了归属导航源文档的复杂问题,
也无需处理沙盒化允许导航
检查及其配套的 exceptionsEnabled 标志。我们只需
将所有导航视为来自与此
Navigation
对象本身对应的
Document
(即 document)。
返回一个针对 apiMethodTracker 的派生自导航 API 方法跟踪器的结果。
reload(options) 方法步骤如下:
令 document 为 this 的相关全局对象的关联的
Document。
令 serializedState 为 StructuredSerializeForStorage(undefined)。
如果 options["state"]存在,则将 serializedState 设置为
StructuredSerializeForStorage(options["state"])。
如果这抛出异常,则
返回一个针对该
异常的早期错误结果。
尽早执行此步骤很重要,因为序列化可以调用 Web 开发者代码,而该代码又可能更改我们在后续步骤中检查的各种内容。
否则:
如果 document 不是完全活动的,则返回一个针对
"InvalidStateError" DOMException
的早期错误结果。
如果 document 的卸载计数器大于 0,则
返回一个针对
"InvalidStateError" DOMException
的早期错误结果。
令 apiMethodTracker 为给定 info 和 serializedState,为 this设置 navigate/reload API 方法跟踪器所得的结果。
重新加载 document 的节点可导航对象,并将 navigationAPIState 设置为 serializedState,将 apiMethodTracker 设置为 apiMethodTracker。
返回一个针对 apiMethodTracker 的派生自导航 API 方法跟踪器的结果。
traverseTo(key, options)
方法步骤如下:
如果 this 的当前条目
索引为 −1,则返回一个针对
"InvalidStateError"
DOMException
的早期
错误结果。
如果 this 的条目列表不包含一个 NavigationHistoryEntry,
其会话历史记录条目的导航
API 键等于 key,则返回一个针对
"InvalidStateError" DOMException
的早期错误结果。
返回给定 this、key 和 options执行导航 API 遍历所得的结果。
back(options) 方法步骤如下:
如果 this 的当前条目
索引为 −1 或 0,则返回一个针对
"InvalidStateError" DOMException
的早期错误结果。
返回给定 this、key 和 options执行导航 API 遍历所得的结果。
forward(options) 方法步骤如下:
要给定一个 Navigation
navigation、一个字符串 key 和一个
NavigationOptions
options,执行导航 API 遍历:
令 document 为 navigation 的相关全局对象的
关联的
Document。
如果 document 不是完全活动的,则返回一个针对
"InvalidStateError" DOMException
的早期错误结果。
如果 document 的卸载计数器大于 0,则
返回一个针对
"InvalidStateError" DOMException
的早期错误结果。
令 current 为 navigation 的当前条目。
如果 key 等于 current 的会话历史
记录条目的导航 API 键,则返回 «[
"committed"
→ 一个以 current 兑现的promise,"finished"
→ 一个以 current 兑现的promise ]»。
如果 navigation 的即将进行的遍历 API 方法 跟踪器[key]存在,则返回 一个针对 navigation 的 即将进行的遍历 API 方法跟踪器[key] 的派生自导航 API 方法跟踪器的结果。
令 apiMethodTracker 为给定 key 和 info,为 navigation添加一个即将进行的 遍历 API 方法跟踪器所得的结果。
令 navigable 为 document 的节点可导航对象。
令 traversable 为 navigable 的可遍历可导航对象。
令 sourceSnapshotParams 为给定 document快照源快照 参数所得的结果。
将以下会话历史记录 遍历步骤追加到 traversable:
令 navigableSHEs 为给定 navigable获取会话历史记录 条目所得的结果。
令 targetSHE 为 navigableSHEs 中导航 API 键 为 key 的会话历史记录条目。 如果不存在此类条目:
给定 navigation 的相关全局对象,在导航和
遍历任务
源上排入一个
全局任务,以使用一个
"InvalidStateError" DOMException拒绝
apiMethodTracker 的 finished promise。
中止这些步骤。
当 navigation 的条目列表相较于 navigableSHEs 已过时时,会采用此路径;在所有相关线程和 进程因历史记录更改而同步期间,可能会短暂出现这种情况。
如果 targetSHE 是 navigable 的活动会话历史记录条目:
给定 navigation 的相关全局对象,在导航和
遍历任务
源上排入
一个全局任务,以使用一个
"InvalidStateError" DOMException拒绝
apiMethodTracker 的 finished promise。
中止这些步骤。
令 result 为给定
sourceSnapshotParams、navigable 和 "none",将由
targetSHE 的步骤给出的遍历历史记录步骤
应用于 traversable 所得的结果。
如果 result 是 "canceled-by-beforeunload",则给定
navigation 的相关全局对象,在导航和
遍历任务源上排入一个
全局任务,以使用一个在
navigation 的相关领域中创建的新
"AbortError" DOMException拒绝
apiMethodTracker 的 finished promise。
如果 result 是 "initiator-disallowed",则给定
navigation 的相关全局对象,在导航和
遍历任务源上排入一个
全局任务,以使用一个在
navigation 的相关领域中创建的新
"SecurityError" DOMException拒绝
apiMethodTracker 的 finished promise。
当 result 是 "canceled-by-beforeunload" 或
"initiator-disallowed" 时,navigate
事件从未触发,因此中止进行中的
导航并不正确;这会导致出现一个没有前置 navigate
事件的 navigateerror
事件。
在 "canceled-by-navigate" 情况下,navigate
事件会触发,但内部
navigate 事件触发算法将负责
中止进行中的
导航。
返回一个针对 apiMethodTracker 的派生自导航 API 方法跟踪器的结果。
异常
e 的早期错误结果是一个由 «[ "committed"
→ 一个以
e 拒绝的promise,"finished"
→ 一个以 e 拒绝的promise ]» 给出的 NavigationResult
字典实例。
要为一个导航 API 方法跟踪器或 null 的 apiMethodTracker 计算派生自导航 API 方法跟踪器的 结果:
如果 apiMethodTracker 是待定的,则返回一个
针对
"AbortError" DOMException
的早期错误结果。
返回一个由 «[ "committed"
→ apiMethodTracker 的committed promise,
"finished"
→ apiMethodTracker 的finished promise ]»
给出的 NavigationResult
字典实例。
在任何给定的导航期间(取该词的
广义含义),Navigation
对象都需要跟踪以下内容:
| 状态 | 持续时间 | 说明 |
|---|---|---|
NavigateEvent
|
在事件触发期间 | 以便在事件触发期间取消导航时,我们可以取消该事件 |
| 事件的中止控制器 | 直到传递给 intercept()
的处理器所返回的所有 promise 均已敲定
|
以便在导航被取消时,我们可以发出 中止信号 |
| 新元素是否已获得焦点 | 直到传递给 intercept()
的处理器所返回的所有 promise 均已敲定
|
以便在新元素已获得焦点的情况下,不会重置焦点 |
正在导航到的 NavigationHistoryEntry
|
从确定该条目时开始,直到传递给 intercept()
的处理器所返回的所有 promise 均已敲定
|
以便我们知道应使用什么值兑现任何 committed
和 finished
promise
|
返回的任何 finished
promise
|
直到传递给 intercept()
的处理器所返回的所有 promise 均已敲定
|
以便我们可以适当地兑现或拒绝它 |
| 状态 | 持续时间 | 说明 |
|---|---|---|
任何 state
|
在事件触发期间 | 以便在事件完成触发且未被取消时, 我们可以更新当前条目的导航 API 状态 |
| 状态 | 持续时间 | 说明 |
|---|---|---|
任何 info
|
直到用于触发 navigate
事件的任务
被排入队列
|
以便在经过会话历史遍历队列之后,
我们可以使用它触发 navigate。
|
返回的任何 committed
promise
|
直到会话历史被更新(在同一任务内) | 以便我们可以适当地兑现或拒绝它 |
是否调用了 intercept()
|
直到会话历史被更新(在同一任务内) | 以便我们可以抑制常规滚动恢复逻辑,改为采用 scroll
选项所给出的行为
|
由于 Web 开发者可能编写如下代码,因此我们也不能假定在任何给定时刻只请求了一个导航:
const p1 = navigation. navigate( url1). finished;
const p2 = navigation. navigate( url2). finished; 也就是说,在此场景中,我们需要确保导航到 url2 时仍然保留 promise
p1,以便我们可以拒绝它。我们不能在第二次调用
navigate()
时立即丢弃所有持续导航 promise。
我们最终通过将以下内容与每个
Navigation 相关联来实现
所有这些目标:
持续的 navigate 事件,为
NavigateEvent 或
null,初始为 null。
持续导航期间焦点已更改,为布尔值, 初始为 false。
在持续导航期间抑制常规滚动 恢复,为布尔值, 初始为 false。
持续的 API 方法跟踪器,为导航 API 方法跟踪器或 null,初始为 null。
即将进行的 traverse API 方法跟踪器,为一个从字符串 映射到导航 API 方法跟踪器的有序映射,初始为空。
此处未存储在导航 API 方法跟踪器中的状态,是即使对于 并非通过导航 API 方法发起的导航也需要跟踪的状态。
一个导航对象,为
Navigation
一个键,为字符串或 null
一个信息,为 JavaScript 值
一个序列化状态,为 序列化状态或 null
一个已提交到的条目,
为 NavigationHistoryEntry
或 null
一个已提交 promise,为 promise
一个已完成 promise,为 promise
一个待处理状态,为布尔值。
随后通过以下算法管理所有这些状态。
给定一个 Navigation
navigation、一个 JavaScript 值 info 和一个可为 null 的序列化
状态 serializedState,要设置 navigate/reload API
方法跟踪器:
令 committedPromise 和 finishedPromise 为在 navigation 的相关领域中创建的新 promise。
将 finishedPromise标记为已处理。
返回一个具有以下内容的新导航 API 方法跟踪器:
给定一个 Navigation
navigation、一个字符串 destinationKey 和一个 JavaScript 值
info,要添加即将进行的 traverse API
方法跟踪器:
令 committedPromise 和 finishedPromise 为在 navigation 的相关领域中创建的新 promise。
将 finishedPromise标记为已处理。
有关这样做的原因,请参阅前面的 讨论。
令 apiMethodTracker 为一个具有以下内容的新导航 API 方法跟踪器:
将 navigation 的即将进行的 traverse API 方法 跟踪器[destinationKey] 设置为 apiMethodTracker。
返回 apiMethodTracker。
要清理一个导航 API 方法跟踪器 apiMethodTracker:
令 navigation 为 apiMethodTracker 的导航对象。
如果 navigation 的持续的 API 方法跟踪器是 apiMethodTracker,则将 navigation 的持续的 API 方法 跟踪器设置为 null。
否则:
令 key 为 apiMethodTracker 的键。
断言:key 不为 null。
断言:navigation 的即将进行的 traverse API 方法 跟踪器[key] 存在。
从 navigation 的即将进行的 traverse API 方法跟踪器中移除[key]。
给定一个导航
API 方法
跟踪器 apiMethodTracker 和一个 NavigationHistoryEntry
nhe,要通知已提交到的条目:
将 apiMethodTracker 的已提交到的条目 设置为 nhe。
如果 apiMethodTracker 的序列化状态不为 null, 则将 nhe 的会话历史条目的导航 API 状态设置为 apiMethodTracker 的 序列化状态。
如果它为 null,则表示我们正在通过 navigation.traverseTo()
遍历到 nhe,而该方法不允许更改
状态。
此时,不再需要 apiMethodTracker 的序列化状态。 实现可能希望将其清除,以免在导航 API 方法跟踪器的整个生命周期内 一直保持其存活。
使用 nhe 兑现 apiMethodTracker 的已提交 promise。
此时,只有在 apiMethodTracker 的已提交 promise尚未返回给 作者代码的情况下,才仍需要它。实现可能希望将其清除,以免在导航 API 方法 跟踪器的整个生命周期内一直保持其存活。
要为一个导航 API 方法跟踪器 apiMethodTracker兑现已完成 promise:
使用其已提交到的条目 兑现 apiMethodTracker 的已完成 promise。
清理 apiMethodTracker。
要使用 JavaScript 值 exception 为一个导航 API 方法跟踪器 apiMethodTracker拒绝已完成 promise:
使用 exception 拒绝 apiMethodTracker 的已提交 promise。
如果 apiMethodTracker 的已提交 promise先前已通过 通知已提交到的 条目得到兑现,则此操作不会产生任何效果。
使用 exception 拒绝 apiMethodTracker 的已完成 promise。
清理 apiMethodTracker。
给定一个 Navigation
navigation 和一个可选的 DOMException
error,要中止持续导航:
令 event 为 navigation 的持续的 navigate 事件。
断言:event 不为 null。
将 navigation 的持续导航期间焦点已 更改设置为 false。
将 navigation 的在持续 导航期间抑制常规滚动恢复设置为 false。
如果未给出 error,则令 error 为一个新的
“AbortError” DOMException,它在
navigation 的相关领域中创建。
使用 error中止 event。
给定 reason,要中止
NavigateEvent event:
将 navigation 的持续的 navigate
事件设置为 null。
令 errorInfo 为从 reason 中提取错误 信息的结果。
例如,如果由于调用 window.stop()
而到达此算法,则这些属性最终很可能会根据调用 window.stop()
的脚本行进行初始化。但是,如果原因是用户单击了停止
按钮,则这些属性最终很可能会获得空字符串或
0 等默认值。
如果 navigation 的持续的 API 方法跟踪器不为 null, 则使用 reason 为 apiMethodTracker拒绝已完成 promise。
使用 ErrorEvent
在 navigation 上触发一个名为 navigateerror
的事件,其附加属性根据
errorInfo 进行初始化。
如果 navigation 的转换 为 null,则返回。
使用 reason 拒绝 navigation 的转换的已提交 promise。
使用 reason 拒绝 navigation 的转换的已完成 promise。
将 navigation 的转换 设置为 null。
要将中止导航通知导航 API,在一个可导航对象 navigable 中将中止导航通知导航 API:
如果此算法正在 navigable 的活动 窗口的相关代理的事件 循环上运行,则继续执行以下步骤。否则,给定 navigable 的活动窗口,在导航与遍历任务 源上将一个全局任务排入队列,以运行以下步骤。
当 navigation 的持续的 navigate 事件不为
null 时:
给定 navigation,中止持续导航。
如果存在持续的跨文档导航,这意味着导航 API 会收到该导航已中止的信号,例如通过触发 navigateerror
事件。这在一定程度上是准确的,因为 Document
接下来经历的导航将是此同文档导航,因此原本期望下一个完成的导航是跨文档导航的开发者,会收到一个有用的信号,
表明这种情况并未发生。不过,这在一定程度上也不准确,因为浏览器仍会继续处理持续的跨文档导航
(在此同文档导航同步完成后应用该跨文档导航)。
归根结底,当跨文档导航与同文档导航重叠时,导航 API 会变得有些复杂,因为持续导航跟踪机制和 API
被构建为仅公开一个持续导航。Web 开发者最好不要创建此类重叠情况,例如,在开始新的导航之前,
对 navigation.navigate()
返回的 promise 使用 await。
这里使用循环,是因为中止持续导航可以运行
JavaScript(例如通过 navigateerror
事件),而该 JavaScript
可能会启动新的导航。由于这种新启动的导航将被当前导航的完成所取代,因此导航 API 会收到该导航已中止的信号。
给定一个可导航对象 navigable,要将子可导航对象的销毁通知导航 API:
在 navigable 中将中止导航 通知导航 API。
令 traversalAPIMethodTrackers 为 navigation 的即将进行的 traverse API 方法 跟踪器的克隆。
对于 traversalAPIMethodTrackers 中的每个
apiMethodTracker:使用一个新的 “AbortError”
DOMException
为 apiMethodTracker拒绝已完成 promise;
该异常在 navigation 的相关领域中创建。
持续导航概念最直接地通过 navigation.transition
属性公开给 Web 开发者,该属性是
NavigationTransition
接口的实例:
[Exposed =Window ]
interface NavigationTransition {
readonly attribute NavigationType navigationType ;
readonly attribute NavigationHistoryEntry from ;
readonly attribute NavigationDestination to ;
readonly attribute Promise <undefined > committed ;
readonly attribute Promise <undefined > finished ;
};navigation.transition
一个 NavigationTransition,
表示尚未到达 navigatesuccess
或 navigateerror
阶段的任何持续导航(如果存在);如果没有正在进行的此类转换,则为 null。
由于 navigation.currentEntry
(以及 location.href
等其他属性)会在导航时立即更新,因此,根据传递给 navigateEvent.intercept()
的所有处理器,此 navigation.transition
属性可用于确定此类导航何时尚未完全敲定。
navigation.transition.navigationType
navigation.transition.from
此转换所来自的 NavigationHistoryEntry。
这可用于与 navigation.currentEntry
进行比较。
navigation.transition.to
此转换的 NavigationDestination。
这可以作为一种无需监听 navigate 事件,
即可反映当前导航目的地的 url
的方式。
navigation.transition.committed
一个在 navigation.currentEntry
和 URL
发生更改时兑现的 promise。此操作发生在其所有预提交处理器均已兑现之后。
如果一个或多个预提交处理器
被拒绝,则此 promise 也会被拒绝。
navigation.transition.finished
一个与 navigatesuccess
触发时同时兑现,或与 navigateerror
事件触发时同时被拒绝的 promise。
每个 Navigation 都有一个
转换,它为
NavigationTransition
或 null,初始为 null。
每个 NavigationTransition
都有关联的导航类型,它为
NavigationType。
每个 NavigationTransition
都有关联的来源条目,它为
NavigationHistoryEntry。
每个 NavigationTransition
都有关联的目的地,它为
NavigationDestination。
每个 NavigationTransition
都有关联的已提交 promise,它为一个 promise。
每个 NavigationTransition
都有关联的已完成 promise,它为一个 promise。
committed 获取器步骤为返回
this 的已提交
promise。
finished 获取器步骤为返回
this 的已完成
promise。
NavigationActivation
接口[Exposed =Window ]
interface NavigationActivation {
readonly attribute NavigationHistoryEntry ? from ;
readonly attribute NavigationHistoryEntry entry ;
readonly attribute NavigationType navigationType ;
};navigation.activation
一个 NavigationActivation,
其中包含有关最近一次跨文档导航的信息,即“激活”此 Document 的导航。
虽然 navigation.currentEntry
和
Document 的 URL
可能会因同文档导航而定期更新,但 navigation.activation
会保持不变,并且只有在该 Document
从历史记录中被重新激活时,
其属性才会更新。
navigation.activation.entry
一个 NavigationHistoryEntry,
等同于该 Document 被激活时
navigation.currentEntry
属性的值。
navigation.activation.from
一个 NavigationHistoryEntry,
表示紧接在当前 Document 之前处于活动状态的
Document。如果前一个
Document 与当前文档并非
同源,或者它是
初始
about:blank
Document,
则此值为 null。
在某些情况下,from
或 entry
NavigationHistoryEntry
对象可能不是 traverseTo()
方法的有效目标,因为它们可能未保留在历史记录中。例如,可以使用 location.replace()
激活该 Document,或者其初始
条目可能会被 history.replaceState()
替换。不过,仍然可以访问这些条目的 url
属性和 getState()
方法。
navigation.activation.navigationType
为“push”、
“replace”、
“reload”
或“traverse”
之一,指示激活此 Document 的导航类型。
每个 Navigation 都有一个
关联的激活,它为 null 或一个
NavigationActivation
对象,初始为 null。
每个 NavigationActivation
都具有:
旧条目,为 null 或一个
NavigationHistoryEntry。
新条目,为 null 或一个
NavigationHistoryEntry。
导航类型,为一个
NavigationType。
navigate 事件导航 API 的一项主要功能是 navigate
事件。此事件会在任何导航(取该词的广义含义)上触发,从而允许 Web 开发者监视此类传出导航。
在许多情况下,该事件是可取消的,因而可以阻止导航发生。
在其他情况下,可以使用 NavigateEvent 类的 intercept()
方法拦截导航,并将其替换为同文档导航。
NavigateEvent 接口[Exposed =Window ]
interface NavigateEvent : Event {
constructor (DOMString type , NavigateEventInit eventInitDict );
readonly attribute NavigationType navigationType ;
readonly attribute NavigationDestination destination ;
readonly attribute boolean canIntercept ;
readonly attribute boolean userInitiated ;
readonly attribute boolean hashChange ;
readonly attribute AbortSignal signal ;
readonly attribute FormData formData ;
readonly attribute DOMString ? downloadRequest ;
readonly attribute any info ;
readonly attribute boolean hasUAVisualTransition ;
readonly attribute Element ? sourceElement ;
undefined intercept (optional NavigationInterceptOptions options = {});
undefined scroll ();
};
dictionary NavigateEventInit : EventInit {
NavigationType navigationType = "push";
required NavigationDestination destination ;
boolean canIntercept = false ;
boolean userInitiated = false ;
boolean hashChange = false ;
required AbortSignal signal ;
FormData ? formData = null ;
DOMString ? downloadRequest = null ;
any info ;
boolean hasUAVisualTransition = false ;
Element ? sourceElement = null ;
};
dictionary NavigationInterceptOptions {
NavigationPrecommitHandler precommitHandler ;
NavigationInterceptHandler handler ;
NavigationFocusReset focusReset ;
NavigationScrollBehavior scroll ;
};
enum NavigationFocusReset {
" after-transition " ,
" manual "
};
enum NavigationScrollBehavior {
" after-transition " ,
" manual "
};
callback NavigationInterceptHandler = Promise <undefined > ();event.navigationType
event.destination
一个 NavigationDestination,
表示导航的目的地。
event.canIntercept
如果可以调用 intercept()
来拦截此导航,并将其转换为同文档导航以替换其常规行为,则为 true;否则为 false。
一般来说,只要当前 Document 的 URL
可以被重写为目的地 URL,此值就会为 true;但跨文档“traverse”
导航除外,在这种情况下它始终为 false。
event.userInitiated
如果此导航是由于用户单击 a 元素、
提交 form
元素,或使用浏览器 UI进行导航而产生的,则为 true;否则为 false。
event.hashChange
对于片段导航为 true; 否则为 false。
event.signal
一个 AbortSignal,如果导航被取消,
例如用户按下浏览器的“停止”按钮,或另一个导航中断了此导航,则该信号会变为已中止。
预期的模式是,开发者会将其传递给处理此导航时所执行的任何异步操作,例如
fetch()。
event.formData
如果此导航是表示 POST 表单提交的“push”
或“replace”
导航,则为表示为此导航提交的表单条目的 FormData;否则为 null。
(值得注意的是,即使是重新访问最初由表单提交创建的会话历史
条目的“reload”
或“traverse”
导航,此值也会为 null。)
event.downloadRequest
表示是否通过使用 a 或 area 元素的 download
属性,请求将此导航作为下载:
如果未请求下载,则此属性为 null。
如果请求了下载,则返回作为 download
属性值提供的文件名。(该值可以是空字符串。)
请注意,请求下载并不总是意味着下载会发生:例如,下载可能会被浏览器安全策略阻止,或因未指定的原因最终被视为“push”
导航。
同样,即使未请求将导航作为下载,导航最终也可能成为下载,这是因为目的地服务器使用
`Content-Disposition: attachment`
标头进行了响应。
最后,请注意,对于使用浏览器 UI 控件发起的下载,例如右键单击并选择保存链接目标所创建的下载,
navigate 事件根本不会
触发。
event.info通过发起此导航的某个导航 API 方法传递的任意 JavaScript 值;如果导航由用户或其他 API 发起,则为 undefined。
event.hasUAVisualTransition
如果用户代理在分派此事件之前为此导航执行了视觉转换,则返回 true。如果为 true, 则作者同步将 DOM 更新为导航后状态时,可提供最佳用户体验。
event.sourceElement
event.intercept({ precommitHandler, handler, focusReset, scroll })
拦截此导航,阻止其常规处理,转而将其转换为指向目的地 URL 的同类型同文档导航。
precommitHandler
选项可以是一个接受 NavigationPrecommitController
并返回 promise 的函数。预提交处理器函数将在 navigate 事件
完成触发之后,但在 navigation.currentEntry
属性更新之前运行。返回一个被拒绝的 promise 将中止导航及其效果,例如更新 URL
和会话历史。在所有预提交处理器均已兑现后,导航可以继续提交并调用其余处理器。只有在事件是可取消的情况下,才能传递 precommitHandler
选项:尝试向不可取消的 NavigateEvent 传递
precommitHandler
将抛出一个
“SecurityError” DOMException。
handler
选项可以是一个返回 promise 的函数。处理器函数将在 navigate 事件
完成触发,并且 navigation.currentEntry
属性已更新后运行。此返回的 promise 用于指示导航的持续时间以及成功或失败。
在其敲定后,浏览器会向用户发出导航已完成的信号(例如通过加载旋转图标 UI 或辅助技术)。
此外,它会根据情况触发 navigatesuccess
或 navigateerror
事件,Web 应用程序的其他部分可以响应这些事件。
默认情况下,使用此方法会在任何处理器返回的 promise 敲定时重置焦点。
焦点将被重置到第一个设置了 autofocus 属性的
元素;如果不存在该属性,则重置到body
元素。可以将 focusReset
选项设置为“manual”
以避免此行为。
默认情况下,对于“traverse”
或“reload”
导航,使用此方法会延迟浏览器的滚动恢复逻辑;对于“push”
或“replace”
导航,则会延迟其重置滚动位置或滚动到片段的逻辑,直到任何处理器返回的 promise 均已敲定。
可以将 scroll
选项设置为“manual”,
以完全关闭此导航中任何由浏览器驱动的滚动行为;也可以在 promise 敲定之前调用 scroll()
以提前触发此行为。
如果 canIntercept
为 false,或者 isTrusted
为 false,则此方法将抛出一个 “SecurityError” DOMException。
如果未在事件分派期间同步调用此方法,则将抛出一个
“InvalidStateError” DOMException。
event.scroll()
对于“traverse”
或“reload”
导航,使用浏览器常规的滚动恢复逻辑恢复滚动位置。
对于“push”
或“replace”
导航,将滚动位置重置到文档顶部;如果 destination.url
指定了片段,则滚动到该片段。
如果多次调用此方法,或者由于 scroll
选项保留为“after-transition”
而已发生自动转换后滚动处理之后调用此方法,或者在导航提交之前调用此方法,则此方法将抛出一个
“InvalidStateError” DOMException。
每个 NavigateEvent
都有一个拦截状态,它为“none”、
“intercepted”、“committed”、
“scrolled”或“finished”之一,初始为“none”。
每个 NavigateEvent
都有一个导航预提交处理器
列表,它是由 NavigationPrecommitHandler
回调组成的列表,初始为空。
每个 NavigateEvent
都有一个导航处理器列表,它是由
NavigationInterceptHandler
回调组成的列表,初始为空。
每个 NavigateEvent
都有一个焦点
重置行为,它为一个可为 null 的 NavigationFocusReset,
初始为 null。
每个 NavigateEvent
都有一个滚动
行为,它为一个可为 null 的 NavigationScrollBehavior,
初始为 null。
每个 NavigateEvent
都有一个中止控制器,它为一个可为 null 的
AbortController,初始为 null。
每个 NavigateEvent
都有一个经典历史记录 API 状态,它为一个
序列化状态或 null。
仅在某些事件的 navigationType
为“push”
或“replace”
的情况下才会使用它,并且会在事件被触发时进行适当设置。
navigationType、destination、canIntercept、userInitiated、
hashChange、signal、formData、downloadRequest、info、hasUAVisualTransition 和
sourceElement 属性
必须返回其初始化时所使用的值。
intercept(options) 方法的步骤
为:
如果 this 的 canIntercept
属性被初始化为 false,则抛出一个 “SecurityError”
DOMException。
如果 this 的分派标志未设置,
则抛出一个
“InvalidStateError” DOMException。
如果 options[“precommitHandler”]
存在:
如果 this 的 cancelable
属性被初始化为 false,则抛出一个 “InvalidStateError”
DOMException。
将 options[“precommitHandler”]
追加到
this 的导航
预提交处理器
列表。
如果 options[“focusReset”]
存在:
如果 this 的焦点重置
行为不为 null,并且它不等于 options[“focusReset”],
则用户代理可以向控制台报告警告,指出先前调用
intercept()
时使用的 focusReset
选项已被此新值覆盖,先前的值将被忽略。
将 this 的焦点重置
行为设置为 options[“focusReset”]。
scroll() 方法的步骤为:
如果 this 的拦截状态不是
“committed”,则抛出一个 “InvalidStateError”
DOMException。
要对一个 NavigateEvent
event执行共享检查:
如果 event 的相关全局对象的关联的
Document不是完全
活动的,则抛出一个 “InvalidStateError”
DOMException。
如果 event 的 isTrusted
属性被初始化为 false,则抛出一个 “SecurityError”
DOMException。
如果 event 的已取消标志已设置,则抛出一个
“InvalidStateError” DOMException。
NavigationPrecommitController
接口[Exposed =Window ]
interface NavigationPrecommitController {
undefined redirect (USVString url , optional NavigationNavigateOptions options = {});
undefined addHandler (NavigationInterceptHandler handler );
};
callback NavigationPrecommitHandler = Promise <undefined > (NavigationPrecommitController controller );precommitController.redirect(USVString url, NavigationNavigateOptions options)
对于“push”
或“replace”
导航,将 destination.url
设置为 url。
如果给定了 options,并且其中存在相应成员,则还会将 info
和产生的
NavigationHistoryEntry
的
状态分别设置为
options 的 info
和 state。
history
选项还可以在
“push”
和“replace”
导航类型之间切换。
对于“reload”
或“traverse”
导航,将抛出一个
“InvalidStateError”。
如果当前 Document 的
URL 不能被
重写为 url,则将抛出一个 “SecurityError”
DOMException。
precommitController.addHandler(NavigationInterceptHandler handler)
添加一个 NavigationInterceptHandler
回调,该回调会在导航提交后被调用,就像此方法作为 handler
传递给 navigateEvent.intercept()
方法一样。
每个 NavigationPrecommitController
都有一个 NavigateEvent
事件。
redirect(url,
options) 方法的步骤为:
如果 this 的事件的
拦截
状态不是“intercepted”,则抛出一个 “InvalidStateError”
DOMException。
如果 this 的事件的
navigationType
既不是“push”,
也不是“replace”,
则抛出一个
“InvalidStateError” DOMException。
令 document 为 this 的相关全局对象的关联的
Document。
令 destinationURL 为给定 document 对 url 进行解析的结果。
如果 destinationURL 为失败,则抛出一个
“SyntaxError” DOMException。
如果 document 的 URL 不能被
重写为 destinationURL,则抛出一个
“SecurityError” DOMException。
如果 options[“history”]
为“push”
或“replace”,
则将 this 的事件的
navigationType
设置为 options[“history”]。
令 serializedState 为调用
StructuredSerializeForStorage(options[“state”])
的结果。此操作可能抛出异常。
将 this 的事件的
destination的
状态设置为
serializedState。
将 this 的事件的 目标的持续的 API 方法 跟踪器的序列化 状态设置为 serializedState。
将 this 的事件的
destination的
URL设置为
destinationURL。
如果 options[“info”]
存在,则
将 this 的事件的
info
设置为 options[“info”]。
addHandler(handler,)
方法的步骤为:
NavigationDestination
接口[Exposed =Window ]
interface NavigationDestination {
readonly attribute USVString url ;
readonly attribute DOMString key ;
readonly attribute DOMString id ;
readonly attribute long long index ;
readonly attribute boolean sameDocument ;
any getState ();
};event.destination.url
正在导航到的 URL。
event.destination.key
如果这是“traverse”
导航,则为目的地 NavigationHistoryEntry
的 key
属性值;否则为空字符串。
event.destination.id
如果这是“traverse”
导航,则为目的地 NavigationHistoryEntry
的 id
属性值;否则为空字符串。
event.destination.index
如果这是“traverse”
导航,则为目的地 NavigationHistoryEntry
的 index
属性值;否则为 −1。
event.destination.sameDocument
指示此导航是否指向与当前 Document
相同的文档。
例如,对于片段导航或 history.pushState()
导航,此值为 true。
请注意,此属性指示导航的原始性质。如果使用 navigateEvent.intercept()
将跨文档导航转换为同文档导航,也不会改变此属性的值。
event.destination.getState()
对于“traverse”
导航,返回对目的地会话历史条目中存储的状态进行
反序列化所得的结果。
对于“push”
或“replace”
导航,如果导航由 navigation.navigate()
方法发起,则返回对传递给该方法的状态进行反序列化所得的结果;
如果不是,则返回 undefined。
对于“reload”
导航,如果重新加载由 navigation.reload()
方法发起,则返回对传递给该方法的状态进行反序列化所得的结果;
如果不是,则返回 undefined。
每个 NavigationDestination
都有一个 URL,它是一个 URL。
每个 NavigationDestination
都有一个条目,它为一个
NavigationHistoryEntry
或 null。
当且仅当该 NavigationDestination
对应于“traverse”
导航时,它才不为 null。
每个 NavigationDestination
都有一个状态,它是一个序列化
状态。
每个 NavigationDestination
都有一个是否为同一文档,它是一个
布尔值。
getState() 方法步骤为返回
StructuredDeserialize(this 的状态)。
标准的其他部分通过本节给出的一系列包装器算法触发 navigate 事件。
给定一个会话历史
条目 destinationSHE 和一个可选的
用户导航
参与 userInvolvement(默认为
“none”),要在一个
Navigation navigation
上触发 traverse navigate 事件:
令 event 为在 navigation 的相关领域中,给定
NavigateEvent
创建事件
所得的结果。
将 event 的经典历史记录 API 状态设置为 null。
令 destination 为在 navigation 的相关
领域中创建的一个新 NavigationDestination。
令 destinationNHE 为 navigation 的条目列表中,其会话历史条目为 destinationSHE 的 NavigationHistoryEntry;
如果不存在这样的 NavigationHistoryEntry,
则为 null。
如果 destinationNHE 不为 null:
否则:
将 destination 的条目设置为 null。
将 destination 的状态设置为 StructuredSerializeForStorage(null)。
如果 destinationSHE 的文档等于
navigation 的相关全局
对象的关联的
Document,
则将 destination 的是否为
同一文档设置为 true;否则设置为 false。
返回给定 navigation、“traverse”、
event、destination、userInvolvement、null、null 和
null 执行内部 navigate 事件触发
算法所得的结果。
给定一个 NavigationType
navigationType、一个 URL destinationURL、一个布尔值 isSameDocument、一个可选的用户
导航参与 userInvolvement(默认为
“none”)、一个可选且可为 null 的
Element
sourceElement(默认为 null)、一个
可选且可为 null 的条目列表 formDataEntryList(默认为 null)、一个
可选的序列化状态 navigationAPIState(默认为
StructuredSerializeForStorage(null))、一个可选且
可为 null 的序列化
状态 classicHistoryAPIState
(默认为 null),以及一个可选且可为 null 的导航 API 方法跟踪器 apiMethodTracker,要在一个
Navigation navigation
上触发 push/replace/reload navigate
事件:
令 document 为 navigation 的相关全局对象的关联的
Document。
在 document 的节点可导航对象中,通知导航 API 有关中止导航的信息。
如果 navigation 禁用了条目和事件,并且 apiMethodTracker 不为 null:
将 apiMethodTracker 的待处理设置为 false。
将 apiMethodTracker 设置为 null。
如果 navigation 禁用了条目和事件,那么
navigate()
和 reload()
调用将返回永远不会兑现的 promise。我们从不为这样的 Document 创建
NavigationHistoryEntry
对象,因此不存在可应用 serializedState 的 NavigationHistoryEntry,
也不存在可包含 info 的 navigate 事件。
因此,我们终究不需要跟踪此 API 方法调用。我们需要在中止先前的导航后进行此检查,以防
Document 因
navigateerror
事件而变为非完全活动状态。
如果 document 不是完全 活动的,则返回 false。
令 event 为在 navigation 的相关领域中,给定
NavigateEvent
创建事件所得的结果。
将 event 的经典历史记录 API 状态 设置为 classicHistoryAPIState。
令 destination 为在 navigation 的相关
领域中创建的一个新 NavigationDestination。
将 destination 的 URL 设置为 destinationURL。
将 destination 的条目设置为 null。
将 destination 的状态设置为 navigationAPIState。
将 destination 的是否为 同一文档设置为 isSameDocument。
返回给定 navigation、navigationType、event、
destination、userInvolvement、sourceElement、
formDataEntryList、null 和 apiMethodTracker 执行内部 navigate 事件触发
算法所得的结果。
给定一个 URL destinationURL、一个用户
导航参与 userInvolvement、一个可为 null 的
Element
sourceElement 和一个字符串
filename,要在一个
Navigation navigation
上触发下载请求 navigate 事件:
令 event 为在 navigation 的相关领域中,给定
NavigateEvent
创建事件所得的结果。
将 event 的经典历史记录 API 状态 设置为 null。
令 destination 为在 navigation 的相关
领域中创建的一个新 NavigationDestination。
将 destination 的 URL 设置为 destinationURL。
将 destination 的条目设置为 null。
将 destination 的状态设置为 StructuredSerializeForStorage(null)。
将 destination 的是否为 同一文档设置为 false。
返回给定 navigation、“push”、
event、destination、userInvolvement、
sourceElement、null 和 filename 执行内部 navigate 事件触发
算法所得的结果。
给定一个 Navigation
navigation、
一个 NavigationType
navigationType、一个 NavigateEvent
event、一个 NavigationDestination
destination、一个用户
导航参与 userInvolvement、一个可为 null 的 Element
sourceElement、一个可为 null 的条目列表
formDataEntryList、一个可为 null 的字符串 downloadRequestFilename,以及一个可选且
可为 null 的导航
API 方法
跟踪器 apiMethodTracker(默认为 null),内部
navigate 事件触发算法
由以下步骤组成:
如果 navigation 禁用了条目和事件:
断言:navigation 的持续的 API 方法跟踪器为 null。
断言:navigation 的即将进行的 traverse API 方法 跟踪器为空。
断言:apiMethodTracker 为 null。
返回 true。
这些断言成立,是因为当条目和事件被禁用时,traverseTo()、
back() 和
forward()
将立即失败(因为不存在可以遍历到的条目)。
断言:navigation 的持续的 API 方法跟踪器为 null。
如果 destination 的条目 不为 null:
断言:apiMethodTracker 为 null。
仅对于 navigate()
和 reload()
调用,apiMethodTracker 才会作为参数传递。
断言:destinationKey 不是空字符串。
如果 navigation 的即将进行的 traverse API 方法 跟踪器[destinationKey] 存在:
将 apiMethodTracker 设置为 navigation 的即将进行的 traverse API 方法跟踪器[destinationKey]。
从 navigation 的即将进行的 traverse API 方法跟踪器中移除[destinationKey]。
如果 apiMethodTracker 不为 null:
将 navigation 的持续的 API 方法跟踪器设置为 apiMethodTracker。
将 apiMethodTracker 的待处理设置为 false。
令 document 为 navigation 的相关全局对象的
关联的
Document。
如果 document 的 URL 可以被重写为
destination 的
URL,并且
destination 的是否为同一文档为 true,
或者 navigationType 不是“traverse”,
则将 event 的 canIntercept
初始化为 true。否则,将其初始化为 false。
如果满足以下任一条件:
navigationType 不是“traverse”;
或者
traverseCanBeCanceled 为 true,
则将 event 的 cancelable
初始化为 true。否则,将其初始化为 false。
将 event 的 navigationType
初始化为
navigationType。
将 event 的 destination
初始化为 destination。
将 event 的 downloadRequest
初始化为
downloadRequestFilename。
如果 apiMethodTracker 不为 null,则将 event 的 info
初始化为 apiMethodTracker 的信息。否则,将其初始化为
undefined。
此时不再需要 apiMethodTracker 的信息,可以将其置为 null,而不必在导航 API 方法 跟踪器的整个生命周期内使其保持活动。
如果用户代理执行了视觉转换,以显示 document 的最新
条目的缓存渲染状态,则将 event 的 hasUAVisualTransition
初始化为 true。否则,将其初始化为 false。
将 event 的 sourceElement
初始化为
sourceElement。
将 event 的中止
控制器设置为在 navigation 的相关领域中创建的一个新 AbortController。
令 currentURL 为 document 的 URL。
如果以下所有条件均为 true:
event 的经典历史记录 API 状态为 null;
destination 的是否为 同一文档为 true;
则将 event 的 hashChange
初始化为 true。否则,将其初始化为 false。
此处的第一个条件意味着,对于片段
导航,hashChange
将为 true;但对于 history.pushState(undefined, "", "#fragment") 之类的情况则为 false。
如果 userInvolvement 不是“none”,则
将 event 的 userInitiated
初始化为 true。否则,将其初始化为 false。
如果 formDataEntryList 不为 null,则将 event 的 formData
初始化为在 navigation 的相关领域中创建并与
formDataEntryList 关联的一个新 FormData。否则,将其初始化为 null。
断言:navigation 的持续的 navigate 事件为 null。
将 navigation 的持续的 navigate
事件设置为 event。
将 navigation 的持续导航期间焦点 已更改设置为 false。
将 navigation 的在持续导航期间抑制正常的 滚动恢复设置为 false。
令 dispatchResult 为在 navigation 上分派 event 所得的结果。
如果 dispatchResult 为 false:
如果 event 的拦截
状态不是“none”:
令 fromNHE 为 navigation 的当前 条目。
断言:fromNHE 不为 null。
将 navigation 的转换
设置为在 navigation 的相关领域中创建的一个新 NavigationTransition,
其具有:
destination
将 navigation 的转换的已完成 promise标记为已处理。
要了解为何这样做,请参阅有关其他已完成 promise 的讨论。
将 navigation 的转换的已提交 promise标记为已处理。
如果 event 的导航预提交 处理器列表为空,则给定 apiMethodTracker,提交 event。
否则:
令 precommitController 为在 navigation 的相关领域中创建的一个新 NavigationPrecommitController,
其事件为
event。
令 precommitPromisesList 为一个空列表。
对于 event 的导航 预提交处理器列表中的每个 handler:
等待 precommitPromisesList 中的所有 promise, 并执行以下成功步骤:给定 apiMethodTracker,提交 event;以及执行以下给定 reason 的失败步骤: 给定 event 和 reason,处理 navigate 事件处理器 失败。
如果 event 的拦截
状态为“none”,则返回 true。
返回 false。
给定一个 Navigation
navigation、一个 NavigateEvent 对象
event,以及一个导航
API 方法跟踪器 apiMethodTracker,navigate
事件拦截提交处理器步骤如下:
令 promisesList 为一个空列表。
如果 promisesList 的大小为 0,则将 promisesList 设置为 « 一个以 undefined 兑现的 promise »。
当给定零个 promise 和给定 ≥1 个 promise 时,等待全部调度其成功和失败步骤的方式存在细微的时序差异。
对于等待全部的大多数用途,这并不重要。但是,在此 API 中,
可能在大致相同时间触发的事件和 promise 处理器非常多,因此这种差异很容易观察到:
它可能导致事件和 promise 处理器的顺序发生变化。(涉及的一些事件和 promise 包括:
navigatesuccess
/ navigateerror、
currententrychange、
dispose、
apiMethodTracker 的 promise,以及 navigation.transition.finished
promise。)
等待 promisesList 中的所有 promise,并执行以下成功 步骤:
断言:event 等于 navigation 的持续的
navigate 事件。
将 navigation 的持续的 navigate
事件设置为 null。
给定 true,完成 event。
如果 apiMethodTracker 不为 null,则为 apiMethodTracker 兑现已完成 promise。
在 navigation 上触发一个名为 navigatesuccess
的事件。
如果 navigation 的转换不为 null,则以 undefined 兑现 navigation 的转换的已完成 promise。
将 navigation 的转换设置为 null。
并执行以下给定 reason 的失败步骤:给定 event 和 reason, 处理 navigate 事件处理器 失败。
给定一个 NavigateEvent 对象
event 和一个导航 API 方法跟踪器
apiMethodTracker,要提交 navigate 事件:
令 navigation 为 event 的目标。
如果 event 的相关全局对象的关联的
Document不是完全
活动的,则返回。
如果 event 的拦截状态不是
“none”,或者 event 的 destination的
是否为同一文档为 true,
则令 endResultIsSameDocument 为 true。
如果 event 的拦截
状态不是“none”:
将 event 的拦截状态设置为
“committed”。
根据 event 的 navigationType
切换:
push”
replace”
给定 event 的相关
全局对象的关联的
Document和 event 的 destination的
URL,运行URL
和历史记录更新步骤,并将
serializedData
设置为 event 的经典历史记录 API
状态,将
historyHandling 设置为 event 的 navigationType。
reload”
给定 navigation、navigable 的活动
会话历史条目和“reload”,
更新
同文档导航的导航 API 条目。
traverse”
将 navigation 的在持续 导航期间抑制正常的滚动恢复设置为 true。
如果 event 的滚动
行为被设置为“after-transition”,
则滚动恢复将在完成相关
NavigateEvent
的过程中发生。否则,不会进行滚动恢复。也就是说,被 intercept()
拦截的导航都不会经历常规滚动恢复过程;此类导航的滚动恢复要么由 Web 开发者手动完成,
要么在转换之后完成。
令 userInvolvement 为“none”。
如果 event 的 userInitiated
为 true,则将
userInvolvement 设置为“activation”。
在拦截后的此时,激活是否由浏览器 UI 产生并不重要。
向 navigable 的可遍历可导航对象追加以下会话 历史遍历步骤:
给定 event 的 destination的
条目的会话历史条目的步骤、
navigable 的可遍历可导航对象和
userInvolvement,继续应用
traverse 历史步骤。
如果 navigation 的转换 不为 null,则以 undefined 兑现 navigation 的转换的已提交 promise。
如果 endResultIsSameDocument 为 false 且 apiMethodTracker 不为 null, 则清理 apiMethodTracker。
给定 navigation 的相关 设置对象,运行脚本后进行清理。
根据前面的 注释,这会停止抑制任何可能的 promise 处理器微任务,使它们在此时或稍后运行。
给定一个 NavigateEvent 对象
event 和一个 reason,要处理 navigate
事件处理器失败:
通过调用 navigateEvent.intercept(),
Web
开发者可以抑制同文档导航的常规滚动和焦点行为,转而在稍后的时间调用类似跨文档导航的行为。本节中的算法会在
这些适当的稍后时间点被调用。
给定一个布尔值 didFulfill,要完成一个 NavigateEvent
event:
给定一个 NavigateEvent
event,要可能重置焦点:
令 focusChanged 为 navigation 的持续导航期间焦点 已更改。
将 navigation 的持续导航期间焦点 已更改设置为 false。
如果 focusChanged 为 true,则返回。
如果 event 的焦点重置
行为为“manual”,
则返回。
如果它保留为 null,则将其视为“after-transition”,
并继续执行。
令 document 为 event 的相关全局对象的关联的
Document。
令 focusTarget 为 document 的自动聚焦委托。
如果 focusTarget 为 null,则将 focusTarget 设置为 document 的body 元素。
如果 focusTarget 为 null,则将 focusTarget 设置为 document 的文档 元素。
将顺序焦点导航 起点移动到 focusTarget。
给定一个 NavigateEvent
event,要可能处理滚动行为:
给定一个 NavigateEvent
event,要处理滚动行为:
由于 NavigateEvent 接口较为复杂,
因此它有自己的
专门章节。
NavigationCurrentEntryChangeEvent
接口[Exposed =Window ]
interface NavigationCurrentEntryChangeEvent : Event {
constructor (DOMString type , NavigationCurrentEntryChangeEventInit eventInitDict );
readonly attribute NavigationType ? navigationType ;
readonly attribute NavigationHistoryEntry from ;
};
dictionary NavigationCurrentEntryChangeEventInit : EventInit {
NavigationType ? navigationType = null ;
required NavigationHistoryEntry from ;
};event.navigationType
返回导致当前条目发生更改的导航类型;如果更改是由 navigation.updateCurrentEntry()
引起的,则返回 null。
event.from
返回当前条目更改之前 navigation.currentEntry
的先前值。
如果 navigationType
为 null 或“reload”,
则此值将与 navigation.currentEntry
相同。在这种情况下,即使没有移动到新条目或替换当前条目,该事件也表示条目的内容发生了更改。
navigationType 和 from 属性必须返回其初始化时所使用的值。
PopStateEvent 接口所有当前引擎均支持。
所有当前引擎均支持。
[Exposed =Window ]
interface PopStateEvent : Event {
constructor (DOMString type , optional PopStateEventInit eventInitDict = {});
readonly attribute any state ;
readonly attribute boolean hasUAVisualTransition ;
};
dictionary PopStateEventInit : EventInit {
any state = null ;
boolean hasUAVisualTransition = false ;
};event.state
所有当前引擎均支持。
返回提供给 pushState()
或 replaceState()
的信息副本。
event.hasUAVisualTransition
如果用户代理在分派此事件之前为此导航执行了视觉转换,则返回 true。如果为 true, 作者同步将 DOM 更新为导航后状态时,可提供最佳用户体验。
state
属性必须返回其初始化时所使用的值。
它表示事件的上下文信息;如果所表示的状态是 Document
的初始状态,
则为 null。
hasUAVisualTransition 属性必须返回其初始化时所使用的值。
HashChangeEvent
接口HashChangeEvent/HashChangeEvent
所有当前引擎均支持。
所有当前引擎均支持。
[Exposed =Window ]
interface HashChangeEvent : Event {
constructor (DOMString type , optional HashChangeEventInit eventInitDict = {});
readonly attribute USVString oldURL ;
readonly attribute USVString newURL ;
};
dictionary HashChangeEventInit : EventInit {
USVString oldURL = "";
USVString newURL = "";
};event.oldURL
所有当前引擎均支持。
event.newURL
所有当前引擎均支持。
oldURL 属性必须返回其初始化时所使用的值。
它表示事件的上下文信息,具体而言,是所离开的会话历史
条目的 URL。
newURL 属性必须返回其初始化时所使用的值。
它表示事件的上下文信息,具体而言,是所到达的会话历史
条目的 URL。
PageSwapEvent 接口[Exposed =Window ]
interface PageSwapEvent : Event {
constructor (DOMString type , optional PageSwapEventInit eventInitDict = {});
readonly attribute NavigationActivation activation ;
readonly attribute ViewTransition viewTransition ;
};
dictionary PageSwapEventInit : EventInit {
NavigationActivation ? activation = null ;
ViewTransition viewTransition = null ;
};event.activation
一个 NavigationActivation
对象,表示跨文档导航的目的地和类型。对于跨源导航,此值为 null。
event.activation.entry
一个 NavigationHistoryEntry,
表示即将变为活动状态的 Document。
event.activation.from
一个 NavigationHistoryEntry,
等同于触发事件时 navigation.currentEntry
属性的值。
event.activation.navigationType
为“push”、
“replace”、
“reload”
或“traverse”
之一,指示即将导致页面交换的导航类型。
event.viewTransition
如果触发事件时出站跨文档视图转换处于活动状态,则返回表示该转换的 ViewTransition
对象。否则,返回 null。
activation 和 viewTransition 属性
必须返回其初始化时所使用的值。
PageRevealEvent
接口[Exposed =Window ]
interface PageRevealEvent : Event {
constructor (DOMString type , optional PageRevealEventInit eventInitDict = {});
readonly attribute ViewTransition viewTransition ;
};
dictionary PageRevealEventInit : EventInit {
ViewTransition viewTransition = null ;
};event.viewTransition
如果触发事件时入站跨文档视图转换处于活动状态,则返回表示该转换的 ViewTransition
对象。否则,返回 null。
viewTransition 属性必须返回其初始化时所使用的值。
PageTransitionEvent
接口PageTransitionEvent/PageTransitionEvent
所有当前引擎均支持。
所有当前引擎均支持。
[Exposed =Window ]
interface PageTransitionEvent : Event {
constructor (DOMString type , optional PageTransitionEventInit eventInitDict = {});
readonly attribute boolean persisted ;
};
dictionary PageTransitionEventInit : EventInit {
boolean persisted = false ;
};event.persisted
所有当前引擎均支持。
对于 pageshow
事件,
如果页面正在被全新加载(并且将触发 load
事件),
则返回 false。否则,返回 true。
对于 pagehide
事件,
如果页面将最后一次离开,则返回 false。否则,返回 true,这意味着如果用户导航回此页面,
该页面可能会被重用(前提是 Document 的可挽救状态保持为 true)。
可能导致页面不可挽救的情况包括:
persisted 属性必须返回其初始化时所使用的值。
它表示事件的上下文信息。
要在一个 Window
window 上,使用一个布尔值 persisted触发一个名为 eventName
的页面转换事件,
则使用 PageTransitionEvent,
在 window 上触发一个名为
eventName 的事件,并将 persisted
属性初始化为
persisted,将 cancelable
属性初始化为 true,将 bubbles
属性初始化为 true,并设置旧式目标覆盖标志。
cancelable
和 bubbles
的值没有任何实际意义,因为取消事件不会产生任何效果,并且事件不可能冒泡越过 Window 对象。
出于历史原因,它们被设置为 true。
BeforeUnloadEvent
接口所有当前引擎均支持。
[Exposed =Window ]
interface BeforeUnloadEvent : Event {
attribute DOMString returnValue ;
};不存在特定于 BeforeUnloadEvent
的初始化方法。
BeforeUnloadEvent
接口是一个旧式接口,它不仅允许通过取消事件控制检查
卸载是否已取消,还允许通过将 returnValue
属性设置为空字符串以外的值来进行控制。作者应该使用 preventDefault()
方法或其他取消事件的方式,而不应使用 returnValue。
returnValue 属性控制检查卸载是否已取消的过程。
创建事件时,该属性必须被设置为空字符串。获取时,它必须返回最后一次设置的值。
设置时,该属性必须被设置为新值。
此属性仅出于历史原因才是 DOMString。
空字符串以外的任何值都将被视为请求向用户询问确认。
NotRestoredReasons
接口[Exposed =Window ]
interface NotRestoredReasonDetails {
readonly attribute DOMString reason ;
[Default ] object toJSON ();
};
[Exposed =Window ]
interface NotRestoredReasons {
readonly attribute USVString ? src ;
readonly attribute DOMString ? id ;
readonly attribute DOMString ? name ;
readonly attribute USVString ? url ;
readonly attribute FrozenArray <NotRestoredReasonDetails >? reasons ;
readonly attribute FrozenArray <NotRestoredReasons >? children ;
[Default ] object toJSON ();
};notRestoredReasonDetails.reason
返回一个字符串,用于说明阻止文档从后退/前进缓存中提供的原因。 有关可能的字符串值,请参阅bfcache 阻塞详细信息的定义。
notRestoredReasons.src
如果文档的节点
可导航对象的容器是一个 iframe
元素,则返回其 src
属性。
如果未设置,或者该容器不是 iframe
元素,则此值可以为 null。
notRestoredReasons.id
如果文档的节点
可导航对象的容器是一个 iframe
元素,则返回其 id
属性。
如果未设置,或者该容器不是 iframe
元素,则此值可以为 null。
notRestoredReasons.name
如果文档的
节点可导航对象的容器是一个
iframe
元素,则返回其 name
属性。
如果未设置,或者该容器不是 iframe
元素,则此值可以为 null。
notRestoredReasons.url
返回文档的 URL;
如果文档位于跨源 iframe
中,则返回 null。除了 src
之外还会报告此值,因为 iframe
可能在设置原始 src
后进行了导航。
notRestoredReasons.reasons
返回文档的 NotRestoredReasonDetails
数组。如果文档位于跨源 iframe
中,则此值为 null。
notRestoredReasons.children
返回用于文档子项的 NotRestoredReasons
数组。如果文档位于跨源 iframe
中,则此值为 null。
一个 NotRestoredReasonDetails
对象具有一个支撑结构,它为一个未恢复原因
详细信息或 null,初始为 null。
给定一个未恢复原因详细信息
backingStruct 和一个领域
realm,要创建一个
NotRestoredReasonDetails 对象:
令 notRestoredReasonDetails 为在 realm 中创建的一个新 NotRestoredReasonDetails
对象。
将 notRestoredReasonDetails 的支撑 结构设置为 backingStruct。
返回 notRestoredReasonDetails。
原因,一个字符串,初始为空。
原因是一个字符串, 表示阻止页面从后退/前进缓存中恢复的原因。 该字符串为以下值之一:
fetch”Document
发起的 fetch 仍在进行并被取消,因此页面未处于可存储到后退/前进缓存中的状态。
navigation-failure”Document 的原始导航出错,
因此阻止了将产生的错误文档存储到后退/前进缓存中。parser-aborted”Document
从未完成其初始 HTML 解析,因此阻止了将未完成的文档存储到后退/前进缓存中。websocket”WebSocket
连接被关闭,因此页面未处于可存储到后退/前进缓存中的状态。
[WEBSOCKETS]
lock”masked”Document
具有位于跨源 iframe
中的子项,并且这些子项阻止了后退/前进缓存;或者,此 Document
由于用户代理特定的原因而无法被存储到后退/前进缓存中,并且用户代理选择不使用
用户代理特定阻塞原因列表中的
某个更具体的原因。
除上述列表外,用户代理还可以选择公开一个阻止页面从后退/前进缓存中恢复的 用户代理特定阻塞原因。它们为以下字符串之一:
audio-capture”Document
通过使用媒体捕获和流的 getUserMedia()
并指定音频,请求了音频捕获权限。[MEDIASTREAM]background-work”Document
通过调用 SyncManager 的
register()
方法、PeriodicSyncManager 的
register()
方法,或 BackgroundFetchManager 的
fetch()
方法,请求了后台工作。
broadcastchannel-message”BroadcastChannel
连接接收到消息,并触发了 message
事件。
idbversionchangeevent”Document
在卸载期间有一个待处理的
IDBVersionChangeEvent。
[INDEXEDDB]
idledetector”Document
在卸载期间有一个活动的
IdleDetector。
keyboardlock”Keyboard 的
lock()
方法,键盘锁仍处于活动状态。
mediastream”MediaStreamTrack
处于活动状态。[MEDIASTREAM]midi”Document
通过调用 navigator.requestMIDIAccess()
请求了 MIDI 权限。
modals”navigating”Document
未处于可存储到后退/前进缓存中的状态。
navigation-canceled”window.stop()
取消了导航请求,并且页面未处于可存储到后退/前进缓存中的状态。
non-trivial-browsing-context-group”Document 的浏览上下文组具有多个顶级浏览上下文。
otpcredential”Document
创建了一个 OTPCredential。
outstanding-network-request”
Document
有未完成的网络请求,并且未处于可存储到后退/前进缓存中的状态。
paymentrequest”Document
在卸载期间有一个活动的
PaymentRequest。
[PAYMENTREQUEST]
pictureinpicturewindow”Document
在卸载期间有一个活动的
PictureInPictureWindow。
[PICTUREINPICTURE]
plugins”Document
包含插件。request-method-not-get”Document
是根据一个 方法不是
`GET` 的 HTTP 请求创建的。
[FETCH]
response-auth-required”Document
是根据一个需要 HTTP 身份验证的 HTTP 响应创建的。response-cache-control-no-store”Document
是根据一个其 `Cache-Control`
标头包含“no-store”标记的 HTTP 响应创建的。[HTTP]response-cache-control-no-cache”Document
是根据一个其 `Cache-Control`
标头包含“no-cache”标记的 HTTP 响应创建的。[HTTP]response-keep-alive”Document
是根据一个包含 `Keep-Alive` 标头的 HTTP 响应创建的。response-scheme-not-http-or-https”Document
是根据一个其 URL的方案不是
HTTP(S) 方案的响应创建的。[FETCH]
response-status-not-ok”Document
是根据一个其状态不是成功状态的 HTTP 响应创建的。
[FETCH]
rtc”RTCPeerConnection
或
RTCDataChannel
被关闭,因此页面未处于可存储到后退/前进缓存中的状态。
[WEBRTC]
rtc-used-with-cache-control-no-store”
Document
是根据一个其
`Cache-Control`
标头包含“no-store”标记的 HTTP 响应创建的,并且它创建了一个可能用于接收敏感信息的
RTCPeerConnection
或
RTCDataChannel,
因此页面未处于可存储到后退/前进缓存中的状态。
[HTTP] [WEBRTC]
sensors”Document
请求了传感器访问权限。
serviceworker-added”Document 的service worker 客户端开始被一个
ServiceWorker
控制。[SW]
serviceworker-claimed”Document 的service worker 客户端的活动 service worker
被认领。[SW]serviceworker-postmessage”Document 的service worker 客户端的活动 service worker
接收到了一条消息。[SW]serviceworker-version-activated”Document 的service worker 客户端的活动 service worker的
版本被激活。
[SW]
serviceworker-unregistered”Document 的service worker 客户端的活动 service worker的service
worker 注册被取消注册。[SW]sharedworker”Document
位于一个 SharedWorkerGlobalScope
的所有者集合中。
对于使用共享 worker 的文档,如果用户代理支持后退/前进缓存,则可以使用更具体的原因,例如 “sharedworker-message”
或 “sharedworker-with-no-active-client”,
而不是使用这一通用原因,因为在这些原因所述情况之外,共享 worker 的使用本身是受支持的。
sharedworker-message”SharedWorkerGlobalScope
接收到了一条消息,该对象的所有者集合包含此 Document。
sharedworker-with-no-active-client”Document
位于一个并非活动所需的
SharedWorkerGlobalScope
的所有者集合中。
smartcardconnection”Document
在卸载期间有一个活动的
SmartCardConnection。
speechrecognition”Document
在卸载期间有一个活动的
SpeechRecognition。
storageaccess”Document
通过使用存储访问 API 请求了存储访问权限。unload-listener”Document
为 unload
事件注册了一个事件监听器。
video-capture”Document
通过使用媒体捕获和流的 getUserMedia()
并指定视频,请求了视频捕获权限。[MEDIASTREAM]webhid”Document
调用了 WebHID API 的 requestDevice()
方法。webshare”Document
使用了 Web Share API 的 navigator.share()
方法。websocket-used-with-cache-control-no-store”Document
是根据一个其
`Cache-Control`
标头包含“no-store”标记的 HTTP 响应创建的,并且它创建了一个可能用于接收敏感信息的
WebSocket
连接,因此页面未处于可存储到后退/前进缓存中的状态。
[HTTP] [WEBSOCKETS]
webtransport”WebTransport
连接被关闭,因此页面未处于可存储到后退/前进缓存中的状态。
[WEBTRANSPORT]
webtransport-used-with-cache-control-no-store”Document
是根据一个其
`Cache-Control`
标头包含“no-store”标记的 HTTP 响应创建的,并且它创建了一个可能用于接收敏感信息的
WebTransport
连接,因此页面未处于可存储到后退/前进缓存中的状态。
[HTTP] [WEBTRANSPORT]
webxrdevice”Document
创建了一个 XRSystem。
一个 NotRestoredReasons
对象具有一个支撑结构,
它为一个未恢复原因或 null,初始为 null。
一个 NotRestoredReasons
对象具有一个原因数组,它为一个
FrozenArray<
或 null,初始为 null。
NotRestoredReasonDetails>
一个 NotRestoredReasons
对象具有一个子项数组,它为一个
FrozenArray<NotRestoredReasons>
或 null,初始为 null。
给定一个未恢复原因
backingStruct 和一个领域
realm,要创建一个
NotRestoredReasons 对象:
src,一个标量值 字符串或 null,初始为 null。
id,一个字符串或 null,初始为 null。
name,一个字符串或 null,初始为 null。
url,一个 URL 或 null,初始为 null。
原因,null 或由未恢复原因 详细信息组成的列表,初始为 null。
本标准包含多个用于对文档序列进行分组的相关概念。以下是一个简短的非规范性摘要:
可导航对象是面向用户的
文档序列表示,也就是说,它们表示可在文档之间进行导航的事物。典型示例包括 Web 浏览器中的标签页或窗口、
iframe,
或 frame 中的
frameset。
可遍历可导航对象是一种特殊类型的 可导航对象,它控制自身及其后代可导航对象的会话历史。也就是说,除了表示其自身的文档序列之外, 它们还表示由更多文档序列组成的树,以及通过此树的扁平化视图线性向后和向前遍历的能力。
浏览
上下文是面向开发者的文档序列表示。它们与 WindowProxy
对象一一对应。每个可导航对象都可以呈现一系列浏览上下文,并且在某些明确定义的情况下,
这些浏览上下文之间会发生切换。
本标准的大部分内容都使用可导航对象的术语,但某些 API 会公开浏览上下文切换的存在, 因此标准的某些部分需要使用浏览上下文来表述。
一个可导航对象通过其活动会话历史条目向用户呈现一个
Document。每个可导航对象都具有:
一个 ID,它是一个新的唯一内部值。
一个父级,它是一个可导航对象或 null。
一个当前会话历史 条目,它是一个会话历史条目。
一个活动会话历史条目,它是一个 会话历史条目。
一个正在关闭布尔值,初始为 false。
此值只会为顶级可遍历对象设置为 true。
一个正在延迟 load
事件布尔值,初始为 false。
只有当可导航对象的父级不为 null 时,此值才会被设置为 true。
一个允许执行导航或历史记录 更新算法,它是由实现定义的,并返回允许或阻止。
例如,如果在特定时间段内调用次数过多,此算法可以返回阻止。
当前会话历史 条目与 活动会话历史条目通常相同, 但在以下情况下会不同步:
这可以在可导航对象的顶级可遍历对象的会话历史遍历队列中安全读取。
尽管一个可导航对象的活动历史条目可以同步更改,
但新条目始终具有相同的 Document。
一个可导航对象的活动
WindowProxy是其活动浏览上下文的关联 WindowProxy。
一个可导航对象的活动窗口
是其活动 WindowProxy的[[Window]]。
这将始终等于可导航对象的活动文档的相关全局对象;设为活动算法会使二者保持同步。
一个可遍历可导航对象是一个可导航对象,它还控制自身及其后代可导航对象的哪个 会话历史条目应成为当前会话历史条目和活动会话历史条目。
一个当前会话历史 步骤,它是一个数字,初始为 0。
一个会话历史遍历队列, 它是一个会话历史遍历并行 队列,为启动一个新的 会话历史遍历并行队列所得的结果。
一个正在运行嵌套的应用历史 步骤布尔值,初始为 false。
一个系统可见性状态,它为“hidden”或
“visible”。
有关此项的要求,请参阅页面可见性一节。
一个由 Web 内容创建布尔值,初始为 false。
要获取一个可导航对象 inputNavigable 的可遍历可导航对象:
一个顶级可遍历对象是一个父级为 null 的 可遍历可导航对象。
目前,所有可遍历可导航对象都是 顶级可遍历对象。 未来的提案设想引入非顶级可遍历对象。
用户代理持有一个顶级可遍历对象集合(由顶级可遍历对象组成的 集合)。这些对象通常以浏览器窗口或浏览器标签页的形式呈现给用户。
要获取一个可导航对象 inputNavigable 的顶级可遍历对象:
给定一个浏览上下文或 null opener、一个字符串 targetName,以及一个可选的可导航对象 openerNavigableForWebDriver,要创建一个新的顶级可遍历对象:
令 document 为 null。
如果 opener 为 null,则将 document 设置为创建一个新的顶级浏览 上下文和文档所得的第二个返回值。
否则,给定 opener,将 document 设置为创建一个新的 辅助浏览上下文和文档所得的第二个返回值。
令 documentState 为一个新的文档状态,其具有
令 traversable 为一个新的可遍历可导航对象。
给定 documentState,初始化可导航对象 traversable。
令 initialHistoryEntry 为 traversable 的活动会话历史条目。
将 initialHistoryEntry 的步骤设置为 0。
如果 opener 不为 null,则给定 opener 的顶级可遍历对象和 traversable,以旧式方式克隆可遍历对象的 存储棚。[STORAGE]
将 traversable追加到用户代理的 顶级 可遍历对象集合。
使用 traversable 和 openerNavigableForWebDriver 调用WebDriver BiDi 可导航对象已创建。
返回 traversable。
给定一个 URL initialNavigationURL 和一个可选的POST 资源或 null initialNavigationPostResource(默认为 null),要创建一个全新的顶级可遍历对象:
令 traversable 为给定 null 和空字符串创建一个新的顶级 可遍历对象所得的结果。
使用 traversable 的活动文档,将 traversable导航到 initialNavigationURL,并将 documentResource 设置为 initialNavigationPostResource。
我们将这些初始导航视为 traversable 导航其自身, 这将确保所有相关安全检查都能通过。
返回 traversable。
某些元素(例如 iframe 元素)
可以向用户呈现一个可导航对象。这些元素称为可导航对象容器。
每个可导航对象容器都具有一个内容可导航对象,它是一个可导航对象或 null。其初始为 null。
一个可导航对象 navigable 的容器文档是运行以下步骤所得的结果:
一个 Document
document 的容器文档是运行以下步骤所得的结果:
当一个可导航对象 navigable 的父级为另一个可导航对象 potentialParent 时,navigable 是 potentialParent 的一个 子可导航对象。我们也可以直接说一个可导航对象“是一个子可导航对象”, 这意味着其父级不为 null。
一个可导航对象 容器 container 的内容文档是运行以下步骤所得的结果:
一个可导航对象容器 container 的内容窗口是运行以下步骤所得的结果:
如果 container 的内容 可导航对象为 null,则返回 null。
返回 container 的内容
可导航对象的活动 WindowProxy的对象。
给定一个元素 element,要创建一个新的子可导航对象:
令 parentNavigable 为 element 的节点 可导航对象。
令 browsingContext 和 document 为给定 element 的节点文档、element 和 group创建一个新的 浏览上下文和文档所得的结果。
令 targetName 为 null。
如果 element 具有 name 内容属性,则将
targetName 设置为该属性的值。
令 documentState 为一个新的文档状态,其具有
令 navigable 为一个新的可导航对象。
给定 documentState 和 parentNavigable,初始化可导航对象 navigable。
将 element 的内容 可导航对象设置为 navigable。
令 historyEntry 为 navigable 的活动会话历史条目。
令 traversable 为 parentNavigable 的可遍历可导航对象。
向 traversable追加以下会话 历史遍历步骤:
使用 traversable 调用WebDriver BiDi 可导航对象已创建。
一种用于可视化文档序列,尤其是可导航对象及其会话 历史条目的实用方法,是Jake 图。一个典型的 Jake 图如下:
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
top |
/t-a | /t-a#foo | /t-b | ||
frames[0] |
/i-0-a | /i-0-b | |||
frames[1] |
/i-1-a | /i-1-b | |||
在这里,每个编号列表示可遍历对象的会话历史步骤的一个可能值。
每个带标签的行描述一个可导航对象,以及它在不同 URL 和文档之间的转换。
第一行标记为 top,表示顶级可遍历对象,其他行表示子可导航对象。
文档由每个单元格的背景颜色表示,新的背景颜色表示该可导航对象中的新文档。URL 由单元格的文本内容表示;
为简洁起见,通常使用相对 URL,
除非专门研究跨源情况。某个可导航对象在特定步骤中可能不存在,此时对应的单元格为空。
粗斜体步骤编号表示可遍历对象的当前会话历史步骤,
所有具有粗斜体 URL 的单元格都表示对应行可导航对象的当前会话历史条目。
因此,上面的 Jake 图描述了以下事件序列:
创建一个顶级可遍历对象,其起始 URL 为
/t-a,并具有两个子可导航对象,
它们分别从 /i-0-a 和 /i-1-a 开始。
将第一个子可导航对象导航到另一个文档,其 URL 为
/i-0-b。
将第二个子可导航对象导航到另一个文档,其 URL 为
/i-1-b。
将顶级可遍历对象导航到同一文档,并将其 URL 更新为
/t-a#foo。
将顶级可遍历对象导航到另一个文档,其 URL 为
/t-b。(请注意,该文档当然不会继承旧文档的子可导航对象。)
通过 −3 的增量遍历可遍历对象, 返回步骤 1。
Jake 图是一种可视化多个可导航对象、 导航和遍历之间交互的强大工具。它们无法表示所有可能的交互——例如,它们只能处理单层嵌套—— 但在本标准中,我们会多次使用它们来说明若干复杂情况。
Jake 图以其创造者、无与伦比的 Jake Archibald 命名。
在本标准的算法中,经常需要查看从给定 Document 开始的可导航对象集合。
本节包含一组经过整理的算法,用于收集这些可导航对象。
这些算法的返回值会经过排序,使父级出现在其子级之前。调用者依赖此顺序。
通常,从一个 Document 开始,
而不是从一个可导航对象开始会更好,因为这会使调用者意识到
它们是从一个完全活动的 Document
开始,还是从非完全活动的
Document 开始。
尽管非完全活动的 Document 确实具有祖先和后代可导航对象,但它们通常表现得如同没有一样
(例如在 window.parent 获取器中)。
一个 Document
document 的祖先可导航对象由以下步骤给出:
一个 Document
document 的包含自身的祖先可导航对象由以下步骤给出:
一个 Document
document 的后代可导航对象由以下步骤给出:
一个 Document
document 的包含自身的后代可导航对象由以下步骤给出:
这些收集后代的算法被描述为查看后代 Document 对象的 DOM 树。
实际上,这通常不可行,因为 DOM 树可能位于与算法调用者不同的进程中。相反,实现通常会在进程之间复制
相应的树。
一个 Document
document 的文档树子
可导航对象由以下步骤给出:
给定一个可导航对象容器 container,要销毁子可导航对象:
令 navigable 为 container 的内容 可导航对象。
如果 navigable 为 null,则返回。
将 container 的内容可导航对象设置为 null。
给定 navigable,向 导航 API 通知子可导航对象销毁。
向 traversable追加以下 会话历史遍历步骤:
给定 traversable,针对 可导航对象创建/销毁进行更新。
使用 navigable 调用WebDriver BiDi 可导航对象已销毁。
要销毁一个顶级 可遍历对象 traversable:
令 browsingContext 为 traversable 的活动浏览上下文。
移除 browsingContext。
从用户界面中移除 traversable(例如,在使用标签页的浏览器中关闭或隐藏其标签页)。
使用 traversable 调用WebDriver BiDi 可导航对象已销毁。
用户代理可以随时销毁顶级可遍历对象 (通常是响应用户请求)。
要确定关闭一个 顶级 可遍历对象 traversable:
令 toUnload 为 traversable 的活动 文档的包含自身的后代 可导航对象。
如果针对 toUnload检查卸载是否
已取消所得的结果不是
"continue",则返回。
向 traversable追加 以下会话历史遍历步骤:
关闭与确定关闭之间的
区分,使其他规范能够调用关闭;如果顶级可遍历对象
已经因 JavaScript 代码调用 window.close()
而正在关闭,则此调用不会执行任何操作。
可以为可导航对象指定目标
名称。目标名称是字符串,允许某些 API(例如 window.open() 或 a 元素的 target 属性)将
导航指向该可导航对象。
一个有效的可导航对象目标名称是任何 至少包含一个字符、不同时包含一个 ASCII 制表符或 换行符和一个 U+003C (<),并且不以 U+005F (_) 开头的字符串。(以 U+005F (_) 开头的名称保留 给特殊关键字使用。)
一个有效的可导航对象
目标名称或关键字是任何属于有效的可导航对象目标名称,或者与以下之一
ASCII
不区分大小写匹配的字符串:_blank、_self、_parent 或
_top。
根据页面是否处于沙盒中,这些值具有不同的含义,如以下(非规范性)表格所总结。在此表格中,
"当前"表示链接或脚本所在的可导航对象,"父级"表示链接或脚本所在的可导航对象的父级,
"顶级"表示链接或脚本所在的可导航对象的顶级可遍历对象,
"新建"表示一个父级为 null 的新可遍历可导航对象(根据各种用户偏好和用户代理策略,
它可能使用辅助浏览上下文),"无"表示不会发生任何事情,
而"可能新建"表示如果 sandbox
属性上还指定了
"allow-popups"
关键字(或者用户覆盖了
沙盒限制),则其含义与"新建"相同,否则与"无"相同。
| 关键字 | 通常效果 | 在具有以下设置的 iframe 中的效果……
|
|
|---|---|---|---|
sandbox=""
|
sandbox="allow-top-navigation"
|
||
| 对于链接和表单提交,未指定 | 当前 | 当前 | 当前 |
| 空字符串 | 当前 | 当前 | 当前 |
_blank
|
新建 | 可能新建 | 可能新建 |
_self
|
当前 | 当前 | 当前 |
没有父级时的 _parent
|
当前 | 当前 | 当前 |
父级也是顶级时的 _parent
|
父级/顶级 | 无 | 父级/顶级 |
存在父级且父级不是顶级时的 _parent
|
父级 | 无 | 无 |
顶级是当前对象时的 _top
|
当前 | 当前 | 当前 |
顶级不是当前对象时的 _top
|
顶级 | 无 | 顶级 |
| 不存在的名称 | 新建 | 可能新建 | 可能新建 |
| 存在且为后代的名称 | 指定的后代 | 指定的后代 | 指定的后代 |
| 存在且为当前对象的名称 | 当前 | 当前 | 当前 |
| 存在且为顶级祖先的名称 | 指定的祖先 | 无 | 指定的祖先/顶级 |
| 存在且为非顶级祖先的名称 | 指定的祖先 | 无 | 无 |
| 具有共同顶级对象的其他现有名称 | 指定的对象 | 无 | 无 |
| 具有不同顶级对象的现有名称,且二者相互熟悉并具有一个获准的沙盒导航器 | 指定的对象 | 指定的对象 | 指定的对象 |
| 具有不同顶级对象的现有名称,且二者相互熟悉,但没有一个获准的沙盒导航器 | 指定的对象 | 无 | 无 |
| 具有不同顶级对象的现有名称,且二者不相互熟悉 | 新建 | 可能新建 | 可能新建 |
对沙盒浏览上下文的大多数限制由其他算法应用,例如导航算法,而不是下面给出的选择可导航对象的 规则。
给定一个字符串 name 和一个可导航对象 currentNavigable,要按目标名称查找可导航对象:
令 currentDocument 为 currentNavigable 的活动文档。
令 sourceSnapshotParams 为给定 currentDocument生成源快照参数的快照所得的结果。
令 subtreesToSearch 为以下选项之一,其选择由实现定义:
« currentNavigable 的可遍历 可导航对象、currentNavigable »
currentDocument 的包含自身的祖先可导航对象
议题 #10848跟踪 确定这两种可能性之一的工作,以实现互操作性。
以相反顺序依次处理 subtreesToSearch 中的每个 subtreeToSearch:
令 currentTopLevelBrowsingContext 为 currentNavigable 的活动浏览上下文的顶级浏览 上下文。
令 group 为 currentTopLevelBrowsingContext 的组。
按照由实现定义的顺序(用户代理应选择一致的顺序,例如最近打开、 最近聚焦或关系更密切的顺序),依次处理 group 的浏览 上下文集合中的每个 topLevelBrowsingContext:
议题 #10850跟踪 选择特定顺序的工作,以实现互操作性。
如果 currentTopLevelBrowsingContext 为 topLevelBrowsingContext,则 继续。
令 documentToSearch 为 topLevelBrowsingContext 的活动 文档。
依次处理 documentToSearch 的包含自身的 后代可导航对象中的每个 navigable:
返回 null。
给定一个字符串 name、一个可导航对象 currentNavigable 和一个布尔值 noopener,选择 可导航对象的规则如下:
令 chosen 为 null。
令 windowType 为 "existing or none"。
如果 name 为空字符串,或者与 "_self"ASCII
不区分大小写匹配,则将 chosen 设置为
currentNavigable。
否则,如果 name 与 "_parent"ASCII
不区分大小写匹配,则在 currentNavigable 存在父级时,将 chosen 设置为该父级;
否则将其设置为 currentNavigable。
否则,如果 name 与 "_top"ASCII
不区分大小写匹配,则将 chosen 设置为 currentNavigable 的
可遍历可导航对象。
否则,如果 name 不与 "_blank"ASCII
不区分大小写匹配,并且 noopener 为 false,则将 chosen 设置为给定
name 和 currentNavigable按目标名称查找可导航对象所得的结果。
如果 chosen 为 null,则表示请求了一个新的顶级可遍历对象,接下来发生的事情取决于 用户代理的配置和能力——它由以下列表中第一个适用选项所给出的规则确定:
用户代理可以通知用户某个弹出窗口已被阻止。
用户代理可以向开发者控制台报告某个弹出窗口已被阻止。
将 windowType 设置为 "new and unrestricted"。
令 currentDocument 为 currentNavigable 的活动文档。
如果 currentDocument 的打开器
策略的值为
"same-origin" 或
"same-origin-plus-COEP",
并且
currentDocument 的源与
currentDocument 的相关设置
对象的顶级源不同源:
将 noopener 设置为 true。
将 name 设置为 "_blank"。
将 windowType 设置为 "new with no opener"。
存在打开器策略时,与其顶级浏览上下文的 活动文档跨源的嵌套文档始终会将 noopener 设置为 true。
令 targetName 为空字符串。
如果 name 不与 "_blank"ASCII 不区分大小写匹配,
则将 targetName 设置为 name。
如果 noopener 为 true,则将 chosen 设置为 给定 null、targetName 和 currentNavigable创建一个新的顶级 可遍历对象所得的结果。
否则:
将 chosen 设置为给定 currentNavigable 的活动 浏览上下文、targetName 和 currentNavigable创建一个新的顶级 可遍历对象所得的结果。
如果设置了 sandboxingFlagSet 的沙盒化导航 浏览上下文 标志,则将 chosen 的活动浏览 上下文的一个获准的沙盒 导航器设置为 currentNavigable 的活动 浏览上下文。
如果设置了 sandboxingFlagSet 的沙盒 传播至辅助浏览 上下文标志,则必须在 chosen 的活动 浏览上下文的弹出窗口 沙盒标志集合中设置 sandboxingFlagSet 中设置的所有标志。
将 chosen 的由 Web 内容创建设置为 true。
将 chosen 设置为 currentNavigable。
不执行任何操作。
鼓励用户代理提供一种方式,让用户可以将用户代理配置为始终选择 currentNavigable。
返回 chosen 和 windowType。
浏览上下文是文档序列的程序化表示,
一个可导航对象中可以存在多个浏览上下文。每个浏览
上下文都有一个对应的 WindowProxy
对象,以及以下各项:
一个打开器浏览上下文,它是一个浏览上下文或 null, 初始为 null。
一个创建时的打开器源,它是一个 源或 null,初始为 null。
一个是弹出窗口布尔值,初始为 false。
在本规范中,是
弹出窗口唯一强制性的影响是作用于相关
BarProp 对象的
visible 获取器。
不过,用户代理也可能将其用于用户界面方面的考量。
一个是辅助的布尔值,初始为 false。
一个初始 URL,它是一个URL或 null,初始为 null。
一个虚拟浏览上下文组 ID 整数,初始为 0。打开器策略 报告使用此项来跟踪在强制执行仅报告策略时本应发生的浏览上下文组切换。
一个浏览上下文的活动窗口是其
WindowProxy
对象的 [[Window]] 内部
槽值。一个
浏览上下文的活动文档是其活动
窗口的
关联的 Document。
目前尚不清楚是否需要单独的是辅助的 概念。在 议题 #5680中指出,我们也许可以 通过使用打开器浏览上下文是否为 null 来简化此概念。
现代规范在大多数情况下都应避免使用
浏览上下文概念,除非它们要处理
浏览上下文
组切换和代理集群分配的细微之处。
通常使用
Document 和可导航对象概念更为合适。
一个 Document 的浏览上下文是一个浏览上下文或 null,
初始为 null。
一个 Document 不一定具有
非 null 的浏览上下文。特别是,数据
挖掘工具很可能永远不会实例化浏览上下文。使用诸如 createDocument()
之类的 API 创建的 Document
永远不会具有非 null 的浏览上下文。
而最初为一个 iframe 元素
创建的 Document,如果该元素后来被从
文档中移除,则不会有关联的浏览上下文,因为该
浏览上下文已被置为 null。
通常,只要 Document 对象具有非 null 的浏览上下文,Window 对象与
Document 对象之间就是一一映射。
但有一个例外。一个
Window 可以被重用于在同一个浏览上下文中呈现第二个 Document,此时映射关系变为
一对二。当一个
浏览上下文从初始 about:blank Document导航到另一个文档时,就会出现这种情况,并且该导航将使用替换完成。
给定 null 或一个 Document
对象 creator、null 或一个元素 embedder,以及一个浏览上下文
组 group,要创建新的浏览上下文和文档:
令 browsingContext 为一个新的浏览上下文。
令 unsafeContextCreationTime 为 不安全的共享当前时间。
令 creatorOrigin 为 null。
令 creatorBaseURL 为 null。
如果 creator 不为 null:
将 creatorOrigin 设置为 creator 的源。
将 creatorBaseURL 设置为 creator 的文档基础 URL。
将 browsingContext 的虚拟浏览上下文组 ID 设置为 creator 的浏览上下文的顶级浏览上下文的虚拟浏览上下文组 ID。
令 sandboxFlags 为给定 browsingContext 和 embedder确定创建时 沙盒标志所得的结果。
令 origin 为给定 about:blank、
sandboxFlags 和
creatorOrigin确定
源所得的结果。
令 permissionsPolicy 为给定 embedder 和 origin创建权限策略所得的结果。 [PERMISSIONSPOLICY]
令 agent 为给定 origin、group 和 false获取相似源窗口 代理所得的结果。
令 realm execution context 为给定 agent 和以下自定义项创建新领域所得的结果:
对于全局对象,创建一个新的 Window 对象。
对于全局 this 绑定,使用 browsingContext 的
WindowProxy 对象。
如果 embedder 为 null,则令 topLevelCreationURL 为 about:blank;
否则为 embedder 的相关设置对象的顶级
创建 URL。
如果 embedder 为 null,则令 topLevelOrigin 为 origin; 否则为 embedder 的相关设置对象的顶级 源。
使用 about:blank、
realm execution context、null、topLevelCreationURL 和
topLevelOrigin设置窗口环境
设置对象。
令 loadTimingInfo 为一个新的文档加载计时信息,其 导航开始 时间设置为使用 unsafeContextCreationTime 和新环境设置对象的 跨源隔离 能力调用粗化时间所得的结果。
令 document 为一个新的 Document,其具有:
html"text/html"quirks"about:blankCustomElementRegistry
对象令 iframeReferrerPolicy 为给定 embedder确定
iframe 元素来源策略所得的结果。
将 document 的内部祖先 源对象 列表设置为给定 document 和 iframeReferrerPolicy运行内部祖先 源对象列表创建 步骤所得的结果。
将 document 的祖先 源列表设置为给定 document 运行祖先源列表创建 步骤所得的结果。
如果 creator 不为 null:
断言:document 的URL
和 document 的相关设置对象的创建
URL均为
about:blank。
将 document 标记为准备好执行加载后任务。
给定 document,填充
html/head/body。
将 document设为活动。
完全 完成加载 document。
返回 browsingContext 和 document。
要创建新的顶级浏览上下文和 文档:
令 group 和 document 为创建新的 浏览上下文组和文档所得的结果。
返回 group 的浏览上下文集合[0] 和 document。
给定一个浏览上下文 opener,要创建新的辅助浏览上下文和 文档:
令 group 为 openerTopLevelBrowsingContext 的组。
令 browsingContext 和 document 为使用 opener 的活动文档、null 和 group创建新的 浏览上下文和文档所得的结果。
将 browsingContext 的是 辅助的设置为 true。
将 browsingContext追加到 group。
将 browsingContext 的打开器浏览上下文设置为 opener。
将 browsingContext 的虚拟 浏览上下文组 ID设置为 openerTopLevelBrowsingContext 的虚拟浏览上下文组 ID。
返回 browsingContext 和 document。
给定一个 URL url、一个沙盒 标志集合 sandboxFlags,以及一个源或 null sourceOrigin,要确定源:
如果 sandboxFlags 设置了沙盒化源浏览 上下文标志,则返回一个新的不透明 源。
如果 url 为 null,则返回一个新的不透明 源。
如果 url 为 about:srcdoc:
断言:sourceOrigin 不为 null。
返回 sourceOrigin。
如果 url匹配
about:blank,并且
sourceOrigin 不为 null,则返回 sourceOrigin。
返回 url 的源。
返回 sourceOrigin 的情况会产生两个最终具有相同底层源的
Document,
这意味着 document.domain
会同时影响二者。
如果以下算法返回 true,则称一个浏览上下文 potentialDescendant 是浏览上下文 potentialAncestor 的祖先:
它不要求是一个顶级可遍历对象。
一个浏览上下文 start 的顶级浏览上下文是以下算法所得的结果:
一个顶级 浏览上下文具有关联的组(null 或一个浏览上下文 组)。其初始为 null。
用户代理持有一个浏览上下文组集合(由浏览上下文组组成的集合)。
一个浏览上下文组持有一个浏览 上下文集合(由顶级 浏览上下文组成的集合)。
当组被创建时,一个顶级浏览上下文会被添加到其中。 此后添加到该组中的所有顶级 浏览上下文都将是辅助 浏览上下文。
一个浏览上下文 组具有关联的代理集群映射(从代理集群 键到代理集群的弱映射)。当认为已经没有任何对象可以再访问代理集群时,用户代理负责 回收这些代理集群。
一个浏览上下文 组具有关联的历史代理集群键 映射,它是一个从源到代理集群键的映射。此映射通过记录给定源之前使用过哪些代理集群键, 来确保按源确定键的 代理集群功能的一致性。
历史代理集群键映射在 浏览上下文组的生命周期中只会增加条目。
一个浏览上下文
组具有一个跨源隔离模式,它是一个跨源
隔离模式。其初始为 "none"。
跨源隔离模式是以下三个可能值之一:"none"、"logical" 或 "concrete"。
"logical"
和 "concrete"
很相似。二者都用于满足以下条件的
浏览上下文
组:
每个顶级 Document
都具有
`Cross-Origin-Opener-Policy: same-origin`,
并且
每个 Document 都具有
`Cross-Origin-Embedder-Policy`
标头,其值与跨源
隔离兼容。
在某些平台上,很难提供安全访问由跨源
隔离
能力控制的 API 所需的安全属性。因此,只有 "concrete"
才能授予对该能力的访问权限。
"logical"
用于不支持
此能力的平台,在这些平台上,跨源隔离施加的各种限制仍将适用,但不会授予该能力。
要创建 新的浏览上下文组和文档:
令 group 为一个新的浏览上下文组。
令 browsingContext 和 document 为使用 null、null 和 group创建新的 浏览上下文和文档所得的结果。
将 browsingContext追加到 group。
返回 group 和 document。
要移除一个顶级浏览上下文 browsingContext:
追加和移除是帮助定义浏览
上下文组生命周期的基本操作。用于
Document 和浏览上下文的高级创建和销毁操作
会调用它们。
当不存在任何浏览上下文等于给定浏览
上下文的 Document 对象时(即所有此类 Document 均已被销毁),并且该浏览上下文的 WindowProxy
符合垃圾回收条件,那么该浏览上下文将永远不会再被访问。
如果它是一个顶级浏览上下文,那么此时用户代理必须
移除它。
当一个 Document
d 是一个可导航对象 navigable 的活动
文档,并且 navigable 是一个顶级
可遍历对象,或者 navigable 的容器
文档是完全活动的时,则称 d
完全
活动。
由于子
可导航对象与元素相关联,因此它们始终绑定到其父级可导航对象中的某个特定
Document,即其容器文档。用户代理不得允许
用户与其容器文档自身并非完全
活动的的子可导航对象交互。
以下示例说明了一个 Document 如何可以是其节点可导航对象的活动文档,但却不是
完全活动的。这里,
a.html 被加载到浏览器窗口中,
b-1.html 最初按如下所示加载到一个 iframe 中,而
b-2.html 和 c.html 被省略(它们可以只是
空文档)。
<!-- a.html -->
<!DOCTYPE html>
< html lang = "en" >
< title > Navigable A</ title >
< iframe src = "b-1.html" ></ iframe >
< button onclick = "frames[0].location.href = 'b-2.html'" > Click me</ button >
<!-- b-1.html -->
<!DOCTYPE html>
< html lang = "en" >
< title > Navigable B</ title >
< iframe src = "c.html" ></ iframe > 此时,由 a.html、b-1.html 和 c.html 给出的文档都是
各自节点可导航对象的活动文档。它们也都是完全活动的。
单击 button,从而将来自
b-2.html 的新 Document
加载到可导航对象 B 中后,
会得到以下结果:
欢迎来到龙口。导航、会话历史以及对该会话历史的遍历,是本标准中最复杂的部分之一。
其基本概念看起来可能并不那么困难:
稍后某个时刻,用户按下 浏览器的后退按钮,返回上一个会话历史 条目。
从这里已经可以窥见其中一些相互交织的复杂性:遍历如何引发导航(即对已存储 URL 的网络获取),以及导航如何必然需要与会话历史列表交互,以确保导航完成时用户 看到的是正确的内容。但真正的问题来自各种边缘情况以及相互作用的 Web 平台功能:
子可导航对象(例如,
包含在
iframe
中的对象)也可以导航和遍历,但这些导航需要被
线性化到单个会话历史列表中,
因为用户对于整个可遍历
可导航对象(例如浏览器标签页)只有一个后退/前进界面。
由于用户可以在会话历史中一次向后遍历多个步骤(例如按住后退按钮),当涉及子可导航对象时, 用户最终可能同时遍历多个可导航对象。这需要在所有涉及的可导航对象之间 同步,而这些对象可能涉及多个事件 循环,甚至多个代理集群。
在导航期间,服务器可以使用 204 或 205 状态码,或者使用 `Content-Disposition: attachment`
标头进行响应,这会导致
导航中止,并使可导航对象
停留在其原始活动
文档上。(如果这种情况发生在由遍历发起的导航期间,问题会严重得多!)
其他各种 HTTP 标头,例如 `Location`、
`Refresh`、`X-Frame-Options`,
以及内容安全策略相关标头,
会参与获取
过程或Document 创建
过程,或者同时参与二者。`Cross-Origin-Opener-Policy`
标头甚至还会参与浏览
上下文选择和创建过程!
某些导航(即片段导航和单页应用导航)是同步的,这意味着 JavaScript 代码期望立即观察到导航结果。然后,这些结果需要与树中所有其他可导航对象所看到的会话历史视图 同步;该过程可能受到竞态条件影响,并需要解决相互冲突的会话历史视图。
平台已经积累了各种令人兴奋的导航相关功能,需要对它们进行特殊处理,例如 javascript:
URL、具有 srcdoc 的
iframe,
以及 beforeunload
事件。
在下文中,我们尝试通过将这些复杂性适当地划分到带有标签的章节和算法中,并尽可能 给出适当的介绍性说明,引导读者理解它们。尽管如此,如果你希望真正理解导航 和会话历史,通常的建议将非常宝贵。
步骤,一个非负整数或 "pending",初始为
"pending"。
URL,一个 URL
文档状态,一个文档 状态。
经典历史 API 状态,它是序列化 状态,初始为 StructuredSerializeForStorage(null)。
导航 API 状态,它是一个 序列化状态,初始为 StructuredSerializeForStorage(undefined)。
导航 API 键,它是一个字符串, 初始设置为生成随机 UUID所得的结果。
导航 API ID,它是一个字符串,初始 设置为生成随机 UUID所得的结果。
持久化用户状态, 它由实现定义,初始为 null
例如,某些用户代理可能希望持久化表单控件的值。
鼓励持久化表单控件值的用户代理也持久化其方向性(元素的 dir
属性值)。当用户最初使用显式的非默认方向性输入值时,这可以防止在历史遍历之后
错误地显示这些值。
序列化状态是表示用户界面状态的对象通过 StructuredSerializeForStorage 得到的序列化结果。 我们有时会非正式地提及“状态对象”,即由作者提供的表示用户界面 状态的对象,或者通过 StructuredDeserialize 反序列化序列化状态所创建的对象。
页面可以向会话历史添加序列化状态。 当用户(或脚本)在历史中后退时,这些状态随后会被反序列化并返回给脚本,从而使作者即使在单页应用中也能使用 “导航”这一隐喻。
序列化状态主要用于
两个目的:第一,在 URL 中存储预解析的状态描述,
这样在简单情况下,作者就不必执行解析(不过,对于处理用户传递的URL,仍然需要解析,因此这只是一项小优化)。第二,使
作者可以存储不会放入 URL 中的状态,因为该状态仅适用于当前
Document 实例,并且如果打开一个新的
Document,就必须重建该状态。
后一种用途的示例是记录弹出式 div
开始动画时的精确坐标,
以便用户后退时,可以使其动画到相同位置。或者,也可以使用它保存指向
数据缓存的指针;这些数据原本会根据
URL 中的信息从服务器获取,这样在前进或后退时就不必再次获取这些信息。
滚动恢复模式指示用户代理在遍历到一个条目时,是否应恢复持久化的滚动位置 (如果存在)。滚动恢复模式是以下值之一:
auto"manual"文档状态在会话历史条目中保存有关如何呈现,以及在必要时如何重新创建
Document 的状态。它具有:
一个文档,即一个
Document 或 null,初始为 null。
一个历史策略容器,即一个策略容器或 null,初始为 null。
一个请求
引用来源,它是 "no-referrer"、"client",
或一个 URL,初始为
"client"。
一个发起者源, 它是一个源或 null,初始为 null。
一个源,它是一个 源或 null,初始为 null。
这是我们为使用 "about:" 方案的
Document 设置的源。我们将其存储
在这里,是因为在遍历期间恢复这些 Document 时也会使用它;
这些文档是在本地重建的,而不会访问网络。它还用于比较会话历史条目被重新填充前后的源。如果源发生变化,
则会清除可导航对象
目标名称。
一个about 基础 URL, 它是一个 URL 或 null,初始为 null。
此项只会为使用 "about:" 方案的
Document 填充,并将作为这些
Document 的后备基础 URL。它是发起者
Document 的文档
基础 URL的快照。
一个资源,即一个字符串、 POST 资源或 null,初始为 null。
字符串被视为 HTML。它用于存储iframe
srcdoc 文档的源。
一个重新加载待处理 布尔值,初始为 false。
一个曾被填充 布尔值,初始为 false。
一个可导航对象目标名称字符串,初始为空字符串。
一个未恢复 原因,即一个未恢复原因或 null,初始为 null。
只要 Document 不是完全活动的,用户代理就可以给定具有非 null
文档的文档
状态的文档,销毁文档及其后代。
除该限制之外,本标准未规定用户代理应在何时销毁文档 状态中存储的文档,以及何时应将其保留在缓存中。
一个POST 资源具有:
一个请求主体,即一个字节序列或失败。
此项只会被并行访问,因此 不需要存储在内存中。但是,它每次都必须返回相同的字节序列。如果由于磁盘上的资源发生变化而无法做到这一点, 或者资源已无法访问,则必须将此项设置为失败。
一个请求
内容类型,它是 `application/x-www-form-urlencoded`、
`multipart/form-data`,
或 `text/plain`。
一个嵌套历史记录具有:
此项以后将包含用于在重新加载之间识别子可导航对象的方法。
会话历史中的多个连续条目可以共享相同的文档状态。当初始条目通过普通导航到达,而后续条目通过 history.pushState()
添加时,就可能发生这种情况。也可能通过导航到片段发生这种情况。
所有共享相同文档 状态的条目(因此它们只是某个特定文档的不同状态)在构造上都是连续的。
一个 Document 具有一个最新
条目,它是一个会话历史
条目或
null。
这是最近由给定
Document 表示的条目。单个
Document 可以随时间推移表示多个会话历史条目,
因为如上所述,多个连续的会话历史
条目可以共享相同的文档
状态。
为了维护单一事实来源,对可遍历 可导航对象的会话历史条目所做的所有修改 都需要同步。由于会话历史会受到所有后代可导航对象的影响,进而受到多个事件 循环的影响,这一点尤为重要。为实现此目的,我们使用会话历史 遍历并行队列结构。
会话历史遍历 并行队列与并行队列非常相似。它具有一个算法集合,即一个有序集合。
一个会话历史 遍历并行 队列的算法 集合中的项是算法步骤,或者是同步导航 步骤;后者是一种特殊的算法步骤,涉及一个目标 可导航对象(一个可导航对象)。
给定算法步骤 steps,要向一个可遍历可导航对象 traversable追加会话历史同步 导航步骤,其中涉及一个可导航对象 targetNavigable,将 steps 作为以目标 可导航对象 targetNavigable 为目标的同步 导航 步骤追加到 traversable 的会话历史遍历 队列的算法 集合中。
要启动一个新的 会话历史遍历并行队列:
本节包含一组杂项操作,我们在整个标准中操作会话历史时都会执行这些操作。要了解这些操作 所做之事,最好的方法是查看它们的调用位置。
要获取一个 可导航对象 navigable 的会话历史条目:
给定一个整数 targetStep,要获取一个可导航对象 navigable 用于导航 API 的会话历史条目:
令 rawEntries 为针对 navigable获取会话历史 条目所得的结果。
令 entriesForNavigationAPI 为一个新的空列表。
令 startingIndex 为 rawEntries 中步骤小于或等于 targetStep,且步骤值最大的会话历史条目的索引。
请参阅此示例, 以了解为什么选择小于或等于 targetStep 的最大步骤。
将 rawEntries[startingIndex]追加到 entriesForNavigationAPI。
令 i 为 startingIndex − 1。
当 i > 0 时:
将 i 设置为 startingIndex + 1。
当 i < rawEntries 的大小时:
返回 entriesForNavigationAPI。
要清除一个可遍历 可导航对象 navigable 的前进会话历史:
要获取作为可遍历可导航对象 traversable 一部分的所有已使用历史步骤:
例如,跟随超链接、
表单提交,以及
window.open() 和 location.assign()
方法都可能引发导航。
在进入导航 算法本身之前,我们 需要先建立该算法使用的几个重要结构。
源快照参数结构用于捕获发起导航的
Document 中的数据。
它在导航开始时生成快照,并在导航的整个生命周期中使用。它具有以下项:
给定一个 Document 或 null
sourceDocument,要生成源快照参数的快照:
目标快照参数结构用于捕获正在被导航的 可导航对象中的数据。与源快照 参数一样,它在导航开始时生成快照,并在导航的整个生命周期中使用。它 具有以下项:
iframe 元素引用来源策略给定一个可导航对象 targetNavigable,要生成目标快照参数的快照, 返回一个新的目标快照 参数,其中:
iframe 元素
引用来源策略iframe 元素引用来源策略所得的结果
导航过程的大部分工作都与确定如何创建新的
Document 有关,
该过程最终发生在创建并初始化 Document
对象
算法中。该算法的参数通过导航参数结构进行跟踪,该结构具有以下项:
Document
创建后接受该对象的算法
Document 保留的环境Document 的一个源
Document 的一个策略容器Document 上的一个沙盒标志
集合iframe 元素
引用来源策略Document 的一个打开器
策略NavigationTimingType,
用于为新的 Document创建导航计时条目Document 的about 基础 URLDocument获取浏览上下文时使用
一旦创建了导航 参数结构,本标准便不会 修改其任何项。它们只会继续传递给其他 算法。
导航 ID是在导航期间生成的 UUID 字符串。它用于 与 WebDriver BiDi 规范交互,以及跟踪正在进行的 导航。[WEBDRIVERBIDI]
创建 Document 后,相关可遍历
可导航对象的会话历史会得到更新。
NavigationHistoryBehavior
枚举用于向导航算法指示所需的会话
历史更新类型。它是以下值之一:
push"replace"auto"push"
或 "replace"。
通常它会变为 "push",
但在某些情况下,它会改为 "replace"。
历史记录处理行为是一个 NavigationHistoryBehavior,
其值为
"push"
或 "replace",
即它已经从任何初始的
"auto"
值解析而来。
给定一个 URL url 和一个
Document
document,如果以下任一条件为 true,则导航必须是替换导航:
url 的方案为
"javascript";
或者
document 的是初始 about:blank为 true。
平台的各个部分会跟踪用户是否参与了导航。用户导航参与是以下值之一:
browser UI"activation"none"为了便于某些调用位置使用,一个 Event
event 的用户导航
参与定义如下:
要将一个可导航对象 navigable导航到一个
URL
url,使用一个可选的 Document 或 null
sourceDocument(默认为 null),并带有一个可选的POST
资源、字符串或 null documentResource(默认为 null)、一个可选的响应或 null response(默认为 null)、一个可选的布尔值 exceptionsEnabled(默认为 false)、一个可选的
NavigationHistoryBehavior
historyHandling(默认为 "auto")、
一个可选的序列化
状态或 null navigationAPIState(默认为 null)、一个可选的条目列表或
null formDataEntryList(默认为 null)、一个可选的引用来源策略
referrerPolicy(默认为空
字符串)、一个可选的用户导航参与
userInvolvement(默认为 "none")、一个可选的 Element
sourceElement(默认为 null)、一个可选的
布尔值 initialInsertion(默认为
false),以及一个
可选的导航 API
方法跟踪器或 null apiMethodTracker(默认为 null):
如果 formDataEntryList 不为 null,则令 cspNavigationType 为
"form-submission";否则为 "other"。
令 sourceSnapshotParams 为给定 sourceDocument生成源快照 参数的快照所得的结果。
令 initiatorOriginSnapshot 为一个新的不透明源。
令 initiatorBaseURLSnapshot 为 about:blank。
如果 sourceDocument 为 null:
断言:userInvolvement 为
"browser UI"。
如果 url 的方案为 "javascript",
则将 initiatorOriginSnapshot 设置为
navigable 的活动
文档的源。
否则:
断言:userInvolvement 不是 "browser UI"。
如果给定 sourceSnapshotParams,sourceDocument 的节点 可导航对象未被沙盒允许 导航 navigable:
如果 exceptionsEnabled 为 true,则抛出一个
"SecurityError" DOMException。
返回。
将 initiatorOriginSnapshot 设置为 sourceDocument 的源。
将 initiatorBaseURLSnapshot 设置为 sourceDocument 的文档 基础 URL。
令 navigationId 为生成随机 UUID所得的结果。 [WEBCRYPTO]
如果周围代理等于 navigable 的活动文档的相关代理,则继续执行这些 步骤。否则,给定 navigable 的活动 窗口,在导航和遍历任务 源上排入全局 任务,以继续执行这些步骤。
如果 navigable 的活动
文档的
卸载计数器大于 0,则使用
navigable 和一个WebDriver BiDi 导航状态调用WebDriver BiDi 导航
失败,其中
ID为
navigationId,状态为
"canceled",
并且 URL为
url,然后返回。
令 container 为 navigable 的容器。
如果 container 是一个 iframe 元素,并且给定
container 的是否将延迟加载元素步骤返回 true,则对
container停止
交叉观察延迟加载元素,并将
container 的延迟加载恢复步骤设置为 null。
如果 navigable 的允许执行导航
或历史记录更新
返回已阻止,则使用
navigable 和一个WebDriver BiDi 导航状态调用WebDriver BiDi 导航失败,其中ID为
navigationId,状态
为 "canceled",
并且 URL为
url,然后返回。
如果给定 url 和
navigable 的活动文档,导航
必须是替换导航,则将
historyHandling 设置为 "replace"。
如果 navigable 的父级不为 null,则将
navigable 的正在延迟 load 事件设置为
true。
令 targetSnapshotParams 为给定 navigable生成目标快照 参数的快照所得的结果。
使用 navigable 和一个新的
WebDriver BiDi 导航状态调用WebDriver BiDi 导航已开始,其中ID
为 navigationId,状态
为 "pending",
并且 URL为
url。
如果 navigable 的正在进行的
导航为 "traversal":
使用 navigable 和一个新的
WebDriver BiDi 导航状态调用WebDriver BiDi 导航失败,其中ID为
navigationId,状态为
"canceled",
并且 URL为
url。
返回。
将 navigable 的正在进行的 导航设置为 navigationId。
这将产生中止 navigable 的其他正在进行的导航的效果,因为在导航期间的 某些位置,对正在进行的 导航的更改会导致后续工作被放弃。
如果 url 的方案为 "javascript":
给定 navigable 的活动窗口,在导航和遍历任务
源上排入全局任务,以给定
navigable、
url、historyHandling、sourceSnapshotParams、
initiatorOriginSnapshot、userInvolvement、
cspNavigationType、initialInsertion 和
navigationId导航
到 javascript: URL。
返回。
如果以下所有条件均为 true:
userInvolvement 不是 "browser
UI";
navigable 的活动
文档的是
初始 about:blank为 false;并且
则:
如果 documentResource 是一个POST 资源,则令 entryListForFiring 为 formDataEntryList; 否则为 null。
如果 navigationAPIState 不为 null,则令 navigationAPIStateForFiring 为 navigationAPIState;否则为 StructuredSerializeForStorage(undefined)。
令 continue 为在 navigation 上触发 push/replace/reload
navigate
事件所得的结果,其中 navigationType 设置为
historyHandling,
isSameDocument 设置为 false,userInvolvement 设置为
userInvolvement,sourceElement 设置
为 sourceElement,formDataEntryList 设置为
entryListForFiring,destinationURL
设置为 url,navigationAPIState
设置为 navigationAPIStateForFiring,并且 apiMethodTracker 设置为
apiMethodTracker。
如果 continue 为 false,则返回。
userInvolvement 为 "browser UI"
的导航,或由一个跨源域的
sourceDocument 发起的导航,如果通过前面的导航到
片段路径,也可能触发 navigate
事件。
如果 sourceDocument 是 navigable 的容器文档,则给定 url 的源,为 navigable 的容器预留延迟获取 配额。
并行运行以下步骤:
令 unloadPromptCanceled 为针对 navigable 的活动 文档的包含自身的后代可导航对象检查卸载是否 已取消所得的结果。
如果 unloadPromptCanceled 不是 "continue",或者
navigable 的正在进行的导航不再是
navigationId:
使用 navigable 和一个
新的WebDriver BiDi 导航状态调用WebDriver BiDi 导航失败,其中ID为
navigationId,状态为 "canceled",
并且 URL为
url。
中止这些步骤。
给定 navigable 的活动窗口,在导航和遍历任务 源上排入全局任务,以给定 navigable 的活动 文档中止文档及其后代。
如果 url匹配
about:blank,或者
是 about:srcdoc:
将 documentState 的源设置为 initiatorOriginSnapshot。
将 documentState 的about 基础 URL设置为 initiatorBaseURLSnapshot。
令 historyEntry 为一个新的会话历史条目,其URL设置为 url,其文档状态设置为 documentState。
令 navigationParams 为 null。
如果 response 不为 null:
如果 sourceDocument 不为 null,则令 sourcePolicyContainer 为 sourceDocument 的策略容器的一个克隆;否则为 null。
令 policyContainer 为给定 response 的URL、 null、sourcePolicyContainer、navigable 的容器文档的策略容器和 null确定导航 参数策略容器所得的结果。
令 finalSandboxFlags 为 targetSnapshotParams 的沙盒 标志与 policyContainer 的CSP 列表的由 CSP 派生的沙盒标志的并集。
令 responseOrigin 为给定 response 的URL、 finalSandboxFlags 和 documentState 的发起者源确定源所得的结果。
令 coop 为一个新的打开器策略。
令 coopEnforcementResult 为一个新的打开器策略强制执行结果,其中
将 navigationParams 设置为一个新的导航参数,其中
iframe 元素
引用来源策略iframe
元素引用来源
策略navigate"
对于 historyEntry,给定 navigable、"navigate"、
sourceSnapshotParams、
targetSnapshotParams、userInvolvement、navigationId、
navigationParams、cspNavigationType,尝试填充
历史条目的文档,并将 allowPOST 设置为 true,将 completionSteps 设置为以下
步骤:
向 navigable 的可遍历对象追加会话历史 遍历步骤,以给定 navigable、historyHandling、 userInvolvement 和 historyEntry最终确定跨文档 导航。
虽然通常的跨文档导航情况会首先进入使用 Document 填充会话历史条目的过程,
但所有未被中止的导航最终都会调用
以下算法之一。
给定一个可导航对象 navigable、一个历史记录处理行为 historyHandling、一个 用户导航参与 userInvolvement 和一个会话历史 条目 historyEntry,要最终确定跨文档导航:
将 navigable 的正在延迟 load
事件设置为 false。
如果 historyEntry 的文档为 null,则 返回。
这意味着尝试填充 历史条目的文档最终没有创建 文档,例如由于导航被后续导航取消、收到 204 No Content 响应等。
如果以下所有条件均为 true:
如果 historyHandling 为 "replace",
则令 entryToReplace 为 navigable 的活动会话历史条目;
否则为 null。
令 traversable 为 navigable 的可遍历可导航对象。
令 targetStep 为 null。
令 targetEntries 为针对 navigable获取会话历史 条目所得的结果。
如果 entryToReplace 为 null:
将 targetStep 设置为 traversable 的当前会话历史 步骤 + 1。
将 historyEntry 的步骤设置为 targetStep。
将 historyEntry追加到 targetEntries。
否则:
给定 historyHandling 和 userInvolvement,向 traversable应用 push/replace 历史步骤 targetStep。
javascript: URL
特殊情况javascript:
URL 在议题跟踪器上有一个专用标签,
用于记录其规范中的各种问题。
给定一个可导航对象
targetNavigable、一个 URL url、一个历史记录
处理
行为 historyHandling、一个源快照参数
sourceSnapshotParams、一个源 initiatorOrigin、一个用户
导航参与 userInvolvement、一个字符串
cspNavigationType、一个布尔值 initialInsertion 和一个导航
ID navigationId,要导航到 javascript: URL:
如果 targetNavigable 的正在进行的导航不再是 navigationId,则返回。
将 targetNavigable 的正在进行的导航 设置为 null。
令 request 为一个新的请求,其URL为 url,其策略容器为 sourceSnapshotParams 的源 策略容器。
这是一个合成的请求,仅用于 传递给下一步骤。它永远不会访问网络。
如果给定 request 和 cspNavigationType,此类型的导航
请求是否应被内容安全
策略阻止?所得的结果为 "Blocked",则
返回。[CSP]
令 newDocument 为给定 targetNavigable、
url、initiatorOrigin 和 userInvolvement求值 javascript:
URL所得的结果。
如果 newDocument 为 null:
如果 initialInsertion 为 true,并且 targetNavigable 的活动文档的是初始
about:blank为 true,则给定 targetNavigable 的容器,运行iframe 加载事件步骤。
返回。
在这种情况下,执行了一些 JavaScript 代码,但没有创建新的
Document,因此
我们不会执行导航。
令 entryToReplace 为 targetNavigable 的活动会话历史条目。
令 oldDocState 为 entryToReplace 的文档状态。
令 documentState 为一个新的文档状态,其中
令 historyEntry 为一个新的会话历史条目,其中
对于 URL,我们不会使用
url,即调用导航算法时传入的实际 javascript:
URL。这意味着 javascript:
URL 永远不会存储在会话历史中,因此也永远无法
遍历到。
向 targetNavigable 的可遍历对象追加会话历史 遍历 步骤,以给定 targetNavigable、 historyHandling、userInvolvement 和 historyEntry最终确定跨文档 导航。
给定一个可导航对象
targetNavigable、一个 URL url、一个源
newDocumentOrigin 和一个用户导航参与
userInvolvement,要求值 javascript: URL:
令 urlString 为对 url 运行URL 序列化器所得的结果。
令 encodedScriptSource 为从
urlString 中移除开头的 "javascript:" 所得的结果。
令 scriptSource 为对 encodedScriptSource 进行百分号解码后,再进行UTF-8 解码所得的结果。
令 baseURL 为 settings 的API 基础 URL。
令 script 为给定 scriptSource、settings、baseURL 和默认脚本 获取选项创建经典脚本所得的结果。
令 evaluationStatus 为运行经典脚本 script 所得的结果。
令 result 为 null。
如果 evaluationStatus 是正常完成,并且 evaluationStatus.[[Value]] 是一个 String,则将 result 设置为 evaluationStatus.[[Value]]。
否则,返回 null。
令 response 为一个新的响应,其中
Content-Type`,
`text/html;charset=utf-8`) »编码为 UTF-8 意味着,在 HTML 解析器解码 响应主体后,未配对的代理项将无法往返保持不变。
令 finalSandboxFlags 为 policyContainer 的CSP 列表的由 CSP 派生的沙盒 标志。
令 coopEnforcementResult 为一个新的打开器 策略强制执行结果,其中
令 navigationParams 为一个新的导航参数,其中
Document
的引用来源为 null;这样正确吗?iframe 元素
引用来源策略iframe
元素引用来源
策略navigate"
返回给定 navigationParams加载 HTML 文档所得的结果。
给定一个可导航对象
navigable、一个 URL url、一个历史记录处理行为
historyHandling、一个用户导航参与
userInvolvement、一个 Element 或 null
sourceElement、一个序列化
状态或 null
navigationAPIState 和一个导航
ID navigationId,要导航到片段:
令 destinationNavigationAPIState 为 navigable 的活动会话历史条目的导航 API 状态。
如果 navigationAPIState 不为 null,则将 destinationNavigationAPIState 设置为 navigationAPIState。
令 continue 为在
navigation 上触发 push/replace/reload
navigate 事件所得的结果,其中 navigationType 设置为
historyHandling,isSameDocument 设置
为 true,userInvolvement 设置为
userInvolvement,sourceElement 设置
为 sourceElement,destinationURL
设置为 url,并且 navigationAPIState 设置为
destinationNavigationAPIState。
如果 continue 为 false:
如果 navigation 的正在进行的 navigate
事件不为 null,则将 navigable 的正在进行的导航设置为
navigationId。
这使得已拦截的哈希导航可以由浏览器 UI 或 window.stop()
取消。
返回。
令 historyEntry 为一个新的会话历史条目,其中
对于使用 navigation.navigate()
执行的导航,state
选项提供的值会用于新的导航 API
状态。(如果未为该选项提供值,
则会将其设置为 undefined 的序列化结果。)对于其他片段
导航,包括用户发起的导航,导航 API
状态会从上一个
条目中沿用。
经典 历史 API 状态永远不会 沿用。
如果 historyHandling 为 "replace",
则令 entryToReplace 为 navigable 的活动会话历史条目;
否则为 null。
令 scriptHistoryIndex 为 history 的索引。
令 scriptHistoryLength 为 history 的长度。
如果 historyHandling 为 "push":
将 history 的状态设置为 null。
递增 scriptHistoryIndex。
将 scriptHistoryLength 设置为 scriptHistoryIndex + 1。
将 navigable 的活动会话历史 条目设置为 historyEntry。
给定 navigable 的 活动文档、historyEntry、 true、 scriptHistoryIndex、scriptHistoryLength 和 historyHandling,针对历史步骤应用更新文档。
由于单次片段导航,此算法会被调用两次:第一次是同步调用,其中会设置
最佳猜测值 scriptHistoryIndex 和
scriptHistoryLength,将 history.state
置为 null,并触发各种事件;第二次是异步调用,其中会设置索引和长度的最终值,history.state 保持
不变,并且不会触发任何事件。
如果因为 Document 是新的,并且相关
ID 尚未被解析而导致滚动失败,则第二次
异步调用针对历史步骤应用更新
文档时将负责
滚动。
令 traversable 为 navigable 的可遍历可导航对象。
向 traversable追加以下涉及 navigable 的会话历史同步导航步骤:
给定 traversable、 navigable、historyEntry、entryToReplace、 historyHandling 和 userInvolvement,最终确定同文档导航。
使用 navigable 和一个
新的WebDriver BiDi 导航状态调用WebDriver BiDi 片段已导航,其中ID为
navigationId,URL为
url,并且状态为
"complete"。
给定一个可遍历可导航对象 traversable、一个可导航对象 targetNavigable、一个会话 历史条目 targetEntry、一个会话历史条目或 null entryToReplace、一个历史记录处理行为 historyHandling 和一个用户导航 参与 userInvolvement,要最终确定同文档导航:
此算法同时用于片段 导航和URL 和 历史记录更新步骤,二者是对会话历史仅有的同步更新。由于这些算法是同步的,因此它们在 顶级可遍历对象的会话 历史遍历队列之外执行。这会使它们与顶级 可遍历对象的当前会话历史 步骤不同步,因此使用此算法来解决竞态条件导致的冲突。
如果 targetNavigable 的活动会话 历史条目不是 targetEntry,则返回。
令 targetStep 为 null。
令 targetEntries 为针对 targetNavigable获取会话历史 条目所得的结果。
如果 entryToReplace 为 null:
将 targetStep 设置为 traversable 的当前会话历史步骤 + 1。
将 targetEntry 的步骤设置为 targetStep。
将 targetEntry追加到 targetEntries。
否则:
给定 historyHandling 和 userInvolvement,向 traversable应用 push/replace 历史步骤 targetStep。
即使对于 "replace"
导航也会执行此操作,因为它会解决多个同步导航之间的竞态
条件。
尝试创建非 获取方案文档的输入是非获取 方案导航参数结构。它是导航参数的轻量版本, 仅携带与非获取 方案导航情况相关的参数。它具有以下项:
一个源,可能用于面向用户的提示, 以确认是否调用外部软件包
这与文档 状态的发起者源略有不同,因为 非获取方案导航 参数的发起者源 会沿着重定向,一直跟踪到以非获取 方案 URL 结束的重定向链中最后一个获取方案 URL。
NavigationTimingType,
用于为新的 Document(如果创建了
一个)创建导航计时条目Document(如果创建了一个)获取浏览上下文时使用
如果要使用不影响 navigable 的机制处理 url,例如因为 url 的方案由外部处理:
给定 url、navigable、 navigationParams 的目标 快照沙盒标志、navigationParams 的源快照 具有瞬态 激活和 navigationParams 的发起者 源,移交给外部 软件。
返回 null。
通过显示某种内联内容来处理 url,例如由于指定的方案不是受支持的协议而显示错误消息, 或者显示内联提示,让用户可以为给定方案选择已注册的 处理器。返回给定 navigable、 navigationParams 的ID、 navigationParams 的导航 计时类型和 navigationParams 的用户参与显示内联内容所得的结果。
如果使用了已注册的处理器,则会使用新的 URL 调用导航。
给定一个 URL 或响应 resource、一个可导航对象 navigable、一个沙盒标志集合 sandboxFlags、一个布尔值 hasTransientActivation 和一个源 initiatorOrigin,用户代理应按以下步骤移交给外部软件:
如果以下所有条件均为 true:
navigable 不是一个顶级可遍历对象;
sandboxFlags 设置了沙盒化 自定义协议导航浏览 上下文标志;并且
sandboxFlags 设置了沙盒化 带用户激活的顶级导航浏览上下文标志,或者 hasTransientActivation 为 false,
则返回且不调用外部软件包。
iframe 内部朝向外部软件的导航可能会被用户视为一个
新弹出窗口或新的顶级导航。因此,在沙盒化的
iframe
中,只有指定了 allow-popups、
allow-top-navigation、
allow-top-navigation-by-user-activation
或 allow-top-navigation-to-custom-protocols
之一时,才允许这种导航。
适当地移交 resource,同时尝试降低这是一次针对目标软件的漏洞利用尝试的风险。 例如,用户代理可以提示用户确认是否允许 initiatorOrigin 调用相关外部 软件。特别是,如果 hasTransientActivation 为 false,则用户代理不应在未事先获得用户 确认的情况下调用外部软件包。
例如,目标软件的 URL 处理器中可能存在漏洞,恶意页面可能会试图通过诱骗用户单击链接来利用该漏洞。
有几种情况可以在导航过程的早期介入并使整个过程停止。当由于会话历史遍历而有多个可导航对象 同时进行导航时,这一点尤其令人兴奋。
在给定源快照参数 sourceSnapshotParams 的情况下,如果以下步骤 返回 true,则可导航对象 source 被沙盒化允许导航到另一个可导航对象 target:
如果 source 是 target,则返回 true。
如果 source 是 target 的祖先,则返回 true。
如果 target 是 source 的祖先:
如果 target 不是顶级可遍历对象,则返回 true。
如果 sourceSnapshotParams 的具有瞬态激活为 true,并且 sourceSnapshotParams 的沙盒化 标志中设置了具有用户激活的沙盒化 顶级导航浏览上下文 标志,则返回 false。
如果 sourceSnapshotParams 的具有瞬态激活为 false,并且 sourceSnapshotParams 的沙盒化 标志中设置了不具有用户激活的沙盒化 顶级导航浏览上下文 标志,则返回 false。
返回 true。
如果 target 是顶级可遍历对象:
如果 source 是 target 的唯一获准的沙盒化导航器,则返回 true。
如果 sourceSnapshotParams 的沙盒化标志中设置了沙盒化导航 浏览上下文标志,则返回 false。
返回 true。
如果 sourceSnapshotParams 的沙盒化标志中设置了沙盒化导航 浏览上下文标志,则返回 false。
返回 true。
要为一个由列表形式的可导航对象
navigablesThatNeedBeforeUnload,在给定可选的可遍历可导航对象
traversable、可选的整数
targetStep 以及可选的用户导航参与
userInvolvementForNavigateEvent 时,检查卸载是否已取消,运行以下步骤。它们返回
“canceled-by-beforeunload”、
“canceled-by-navigate”或
“continue”。
令 documentsToFireBeforeunload 为 navigablesThatNeedBeforeUnload 中每个项的活动 文档。
令 unloadPromptShown 为 false。
令 finalStatus 为“continue”。
如果给出了 traversable:
断言:已给出 targetStep 和 userInvolvementForNavigateEvent。
令 targetEntry 为在给定 traversable 和 targetStep 的情况下获取目标历史记录 条目的结果。
如果 targetEntry 不是 traversable 的当前会话历史条目,并且 targetEntry 的文档状态的源与 traversable 的当前会话历史 条目的文档 状态的源相同:
在这种情况下,我们将在此处为 traversable 触发 navigate 事件。
因为它在某些
情况下可能会被取消,所以我们需要将此操作与其他遍历
navigate
事件分开执行,后者会在稍后发生。
此外,因为我们希望 beforeunload
事件先于 navigate
事件触发,
这意味着我们需要在此处为 traversable
触发 beforeunload
(如果适用),而不是将其作为下方遍历
documentsToFireBeforeunload 的循环的一部分执行。
令 eventsFired 为 false。
如果 navigablesThatNeedBeforeUnload 包含 traversable,则令 needsBeforeunload 为 true;否则为 false。
如果 needsBeforeunload 为 true,则从 documentsToFireBeforeunload 中移除 traversable 的活动 文档。
在给定 traversable 的活动 窗口的情况下,在导航和遍历任务 源上排入一个全局任务,以执行 以下步骤:
如果 needsBeforeunload 为 true:
令(unloadPromptShownForThisDocument、
unloadPromptCanceledByThisDocument)为在给定
traversable 的活动文档和
false 的情况下,运行触发
beforeunload 的步骤所得的结果。
如果 unloadPromptShownForThisDocument 为 true,则将 unloadPromptShown 设置为 true。
如果 unloadPromptCanceledByThisDocument 为 true,则将
finalStatus 设置为“canceled-by-beforeunload”。
如果 finalStatus 为“canceled-by-beforeunload”,则
中止这些步骤。
令 navigateEventResult 为在 navigation 上,在给定
targetEntry 和
userInvolvementForNavigateEvent 的情况下,触发遍历
navigate
事件的结果。
如果 navigateEventResult 为 false,则将 finalStatus 设置为
“canceled-by-navigate”。
将 eventsFired 设置为 true。
等待,直到 eventsFired 为 true。
如果 finalStatus 不是“continue”,则返回
finalStatus。
令 totalTasks 为 documentsToFireBeforeunload 的大小。
令 completedTasks 为 0。
对于 documentsToFireBeforeunload 中的每个 document,在给定 document 的相关全局对象的情况下,在导航和遍历任务源上排入一个全局任务,以运行以下步骤:
令(unloadPromptShownForThisDocument、
unloadPromptCanceledByThisDocument)为在给定 document 和
unloadPromptShown 的情况下,运行触发
beforeunload 的步骤所得的结果。
如果 unloadPromptShownForThisDocument 为 true,则将 unloadPromptShown 设置为 true。
如果 unloadPromptCanceledByThisDocument 为 true,则将
finalStatus 设置为“canceled-by-beforeunload”。
将 completedTasks 递增。
等待 completedTasks 等于 totalTasks。
返回 finalStatus。
给定一个 Document
document 和一个布尔值 unloadPromptShown,触发
beforeunload 的步骤为:
令 unloadPromptCanceled 为 false。
将 document 的卸载 计数器增加 1。
令 eventFiringResult 为在 document 的相关全局对象上触发
名为 beforeunload
的事件所得的结果;使用 BeforeUnloadEvent,
并将 cancelable
属性初始化为
true。
如果以下各项均为 true:
unloadPromptShown 为 false;
eventFiringResult 为 false,或者 event 的 returnValue
属性不是空字符串;并且
显示卸载提示不太可能令人烦扰、具有欺骗性或毫无意义,
则:
将 unloadPromptShown 设置为 true。
令 userPromptHandler 为使用 document 的相关全局对象、
“beforeunload”和 "" 调用WebDriver BiDi 用户提示已打开所得的结果。
如果 userPromptHandler 为“dismiss”,则将
unloadPromptCanceled 设置为 true。
如果 userPromptHandler 为“none”:
询问用户以确认其是否希望卸载文档,并在等待用户响应期间暂停。
向用户显示的消息不可自定义,而是由用户代理确定。特别是,returnValue
属性的实际值会被忽略。
如果用户未确认页面导航,则将 unloadPromptCanceled 设置为 true。
使用 document 的
相关全局
对象、“beforeunload”,以及当
unloadPromptCanceled 为 false 时的 true,否则为 false,调用WebDriver BiDi 用户提示已关闭。
将 document 的卸载 计数器减少 1。
返回(unloadPromptShown、unloadPromptCanceled)。
要将可导航对象 navigable 的正在进行的导航设置为 newValue:
如果 navigable 的正在进行的 导航等于 newValue, 则返回。
在给定 navigable 的情况下,将导航中止通知给导航 API。
将 navigable 的正在进行的导航设置为 newValue。
要重新加载一个可导航对象
navigable,给定可选的
序列化状态或 null navigationAPIState(默认为 null)、一个可选的用户
导航参与 userInvolvement(默认为“none”),以及一个可选的导航 API
方法
跟踪器或 null apiMethodTracker
(默认为 null):
如果 userInvolvement 不是“browser UI”:
令 destinationNavigationAPIState 为 navigable 的活动会话 历史条目的导航 API 状态。
如果 navigationAPIState 不为 null,则将 destinationNavigationAPIState 设置为 navigationAPIState。
令 continue 为在 navigation 上触发 push/replace/reload
navigate
事件所得的结果,其中将 navigationType 设置为“reload”,
将 isSameDocument 设置为 false,将 userInvolvement 设置为
userInvolvement,将 destinationURL
设置为 navigable 的活动会话历史
条目的URL,将 navigationAPIState 设置为
destinationNavigationAPIState,并将 apiMethodTracker 设置为
apiMethodTracker。
如果 continue 为 false,则返回。
令 traversable 为 navigable 的可遍历可导航对象。
将以下会话 历史遍历步骤追加到 traversable:
在给定 userInvolvement 的情况下,将重新加载历史步骤应用于 traversable。
要在给定一个可遍历可导航对象
traversable、一个整数 delta 以及一个可选的 Document sourceDocument 时,按增量遍历历史记录:
令 sourceSnapshotParams 和 initiatorToCheck 为 null。
令 userInvolvement 为“browser
UI”。
如果给出了 sourceDocument:
将在给定 sourceDocument 的情况下创建源快照 参数的快照所得的结果设置为 sourceSnapshotParams。
将 initiatorToCheck 设置为 sourceDocument 的节点 可导航对象。
将 userInvolvement 设置为“none”。
将以下会话 历史遍历步骤追加到 traversable:
令 allSteps 为针对 traversable获取所有已使用的历史步骤所得的结果。
令 currentStepIndex 为 traversable 的当前会话历史步骤在 allSteps 中的索引。
令 targetStepIndex 为 currentStepIndex 加 delta。
如果 allSteps[targetStepIndex] 不存在,则中止这些步骤。
在给定 sourceSnapshotParams、initiatorToCheck 和 userInvolvement 的情况下,将遍历历史步骤应用 allSteps[targetStepIndex] 于 traversable。
除了导航算法之外,还可以通过另一种机制,即URL 和
历史记录更新步骤,推送或替换会话
历史条目。这些步骤最为人熟知的调用方是 history.replaceState()
和 history.pushState()
API,但标准的其他多个部分也需要更新活动
历史条目,并使用这些步骤完成更新。
给定一个 Document
document、一个URL newURL、一个可选的序列化
状态或 null serializedData(默认为
null),以及一个可选的历史记录处理行为 historyHandling(默认为“replace”),URL
和历史记录更新步骤为:
令 navigable 为 document 的节点可导航对象。
令 activeEntry 为 navigable 的活动会话历史条目。
令 newEntry 为一个新的会话历史条目,其具有
如果 document 的是初始
about:blank为 true,则将
historyHandling 设置为“replace”。
这意味着在一个初始
about:blank
Document 上调用 pushState()
的行为与调用 replaceState()
相同。
如果 historyHandling 为
“replace”,则令
entryToReplace 为 activeEntry,否则为 null。
如果 historyHandling 为“push”:
这些是用于立即同步访问的临时最佳猜测值。
如果 serializedData 不为 null,则在给定 document 和 newEntry 的情况下,恢复历史记录对象 状态。
在给定 document 的情况下,将 newURL设置为 URL。
因为这既不是一次导航,也不是一次历史遍历,所以它不会导致触发 hashchange 事件。
将 document 的最新条目 设置为 newEntry。
将 navigable 的活动会话历史 条目设置为 newEntry。
在给定 document 的相关全局对象的导航 API、 newEntry 和 historyHandling 的情况下,更新同文档导航的 导航 API 条目。
令 traversable 为 navigable 的可遍历可导航对象。
将以下涉及 navigable 的会话历史 同步导航步骤追加到 traversable:
在给定 traversable、
navigable、newEntry、entryToReplace、
historyHandling 和“none”的情况下,完成同文档导航。
使用 navigable 调用WebDriver BiDi 历史记录已更新。
尽管片段
导航和URL
和历史记录
更新步骤都会执行同步历史记录更新,但只有片段
导航会同步调用更新文档以应用历史步骤。而URL
和历史记录更新步骤仅在上述算法中执行少数选定的
更新,并省略其他更新。这多少是一个不幸的
历史遗留问题,并且通常会因这种不一致而导致Web 开发者
苦恼。例如,这意味着会为片段导航触发 popstate 事件,
但不会为 history.pushState()
调用触发该事件。
如概述中所述,导航和 遍历都涉及创建一个会话历史 条目,然后尝试填充其文档 成员,以便可以在可导航对象中呈现它。
这涉及以下方式之一:使用已经给定的
响应;使用存储在会话历史
条目中的srcdoc
资源;或者进行获取。该过程具有多种
失败模式,它们可能导致什么也不做(使可导航对象停留在其当前活动的 Document 上),也可能导致使用一个错误
文档填充
会话历史
条目。
要为一个会话历史
条目 entry 尝试填充历史条目的
文档,给定一个可导航对象
navigable、一个
NavigationTimingType
navTimingType、一个源快照参数
sourceSnapshotParams、一个目标快照参数
targetSnapshotParams、一个用户导航参与
userInvolvement、一个可选的导航
ID或 null navigationId
(默认为 null)、一个可选的导航参数或
null
navigationParams
(默认为 null)、一个可选字符串 cspNavigationType(默认为“other”)、一个可选的
布尔值 allowPOST(默认为 false),以及可选的
算法步骤 completionSteps(默认为空
算法):
断言:如果 navigationParams 不为 null,则 navigationParams 的响应不为 null。
如果 navigationParams 为 null:
如果 documentResource 是字符串,则将 navigationParams 设置为在给定 entry、navigable、 targetSnapshotParams、userInvolvement、navigationId 和 navTimingType 的情况下从 srcdoc 资源创建导航参数的结果。
否则,如果以下各项均为 true:
则将 navigationParams 设置为在给定 entry、 navigable、sourceSnapshotParams、targetSnapshotParams、 cspNavigationType、userInvolvement、navigationId 和 navTimingType 的情况下通过获取创建导航 参数的结果。
否则,如果 entry 的URL的方案不是获取方案,则将 navigationParams 设置为一个新的非获取方案导航 参数,其具有
要在给定一个会话历史
条目 entry、一个可导航对象
navigable、一个目标
快照参数 targetSnapshotParams、一个用户导航参与
userInvolvement、一个导航
ID或 null navigationId,以及一个
NavigationTimingType
navTimingType 时,从 srcdoc
资源创建导航参数:
令 response 为一个新的响应,其具有
about:srcdoc
Content-Type`,
`text/html`) »令 responseOrigin 为在给定 response 的URL、 targetSnapshotParams 的沙盒化 标志和 entry 的文档状态的 源的情况下,确定源的结果。
令 coop 为一个新的打开器策略。
令 coopEnforcementResult 为一个新的打开器 策略执行结果,其具有
令 policyContainer 为在给定 response 的URL、entry 的文档状态的历史记录策略 容器、null、 navigable 的容器文档的策略容器和 null 的情况下,确定 导航参数策略容器的结果。
返回一个新的导航参数,其具有
iframe
元素引用来源策略iframe
元素引用来源
策略此算法会改变 entry。
令 request 为一个新的请求,其具有
document” 当
navigable 具有容器时,会在下方更新目标。include”manual”navigate”如果 navigable 是顶级可遍历对象,则将 request 的顶级导航发起者源设置为 entry 的 文档 状态的发起者源。
如果 request 的客户端为 null:
这仅发生在由浏览器 UI 发起导航的情况下。
如果 documentResource 是POST 资源:
如果 sourceSnapshotParams 的具有 瞬态激活为 true,则将 request 的用户激活设置为 true。
如果 navigable 的容器不为 null:
令 response 为 null。
令 responseOrigin 为 null。
令 fetchController 为 null。
令 coopEnforcementResult 为一个新的打开器 策略执行结果,其具有
令 finalSandboxFlags 为空沙盒化标志集。
令 responsePolicyContainer 为 null。
令 responseCOOP 为一个新的打开器策略。
令 locationURL 为 null。
令 currentURL 为 request 的当前 URL。
令 commitEarlyHints 为 null。
当 true 时:
如果 request 的保留 客户端不为 null,并且 currentURL 的源与 request 的保留 客户端的创建 URL的源不相同:
如果 request 的保留 客户端为 null:
如果在给定 request 和 cspNavigationType 的情况下,指定类型的
导航请求是否应被内容安全
策略阻止?的结果为“Blocked”,则将
response 设置为网络
错误并中断。[CSP]
将 response 设置为 null。
如果 fetchController 为 null,则将 fetchController 设置为获取 request 的结果,其中将 processEarlyHintsResponse 设置为下方定义的 processEarlyHintsResponse,将 processResponse 设置为下方定义的 processResponse,并将 useParallelQueue 设置为 true。
令 processEarlyHintsResponse 为以下算法,给定一个响应 earlyResponse:
如果 commitEarlyHints 为 null,则将 commitEarlyHints 设置为在给定 earlyResponse 和 request 的保留客户端的情况下处理早期提示标头的结果。
令 processResponse 为以下算法,给定一个响应 fetchedResponse:
将 response 设置为 fetchedResponse。
否则,为 fetchController处理下一个手动重定向。
这会在我们第一次循环迭代期间调用上方提供的 processResponse, 从而设置 response。
导航会手动处理重定向,因为导航是 Web 平台中唯一需要关心重定向到 mailto:
URL
等情况的地方。
等待,直到 response 不为 null,或者 navigable 的正在进行的 导航发生变化,不再等于 navigationId。
如果发生后一种情况,则中止 fetchController,并返回。
否则,继续执行。
如果 request 的主体为 null,则将 entry 的文档状态的资源设置为 null。
获取会在某些特定重定向中清除主体。
将 responsePolicyContainer 设置为在给定 response 和 request 的保留客户端的情况下从获取响应创建 策略 容器的结果。
将 finalSandboxFlags 设置为 targetSnapshotParams 的沙盒化 标志与 responsePolicyContainer 的CSP 列表的CSP 派生沙盒化 标志的并集。
将 responseOrigin 设置为在给定 response 的URL、 finalSandboxFlags 和 entry 的文档状态的发起者源的情况下确定源的结果。
如果 response 是重定向,则 response 的URL将是导致重定向到 response 的位置 URL的 URL;它 不会是位置 URL本身。
如果 navigable 是顶级可遍历对象:
将 responseCOOP 设置为在给定 response 和 request 的保留客户端的情况下获取 打开器策略的结果。
将 coopEnforcementResult 设置为在给定 navigable 的活动 浏览上下文、 response 的URL、 responseOrigin、responseCOOP、coopEnforcementResult 和 request 的引用来源的情况下执行响应的打开器策略的结果。
如果 finalSandboxFlags 不为空,并且 responseCOOP 的值不是
“unsafe-none”,
则将 response 设置为适当的网络
错误并中断。
这会导致网络错误,因为无法同时使用打开器策略为响应提供一个干净的 环境并对导航到该响应的结果进行沙盒化。
如果 response 不是网络 错误,navigable 是一个 子可导航对象, 并且使用 navigable 的容器文档的源、navigable 的容器文档的相关设置 对象、request 的目标、response 和 true 执行跨源资源 策略检查的结果为 已阻止,则将 response 设置为网络 错误并中断。
此处我们针对父 可导航对象而不是 navigable 本身运行跨源资源策略检查。这是因为我们关心的是 嵌入内容相对于父上下文的同源性,而不是相对于导航源的同源性。
如果 locationURL 是失败或 null,则中断。
将 entry 的经典历史记录 API 状态设置为 StructuredSerializeForStorage(null)。
令 oldDocState 为 entry 的文档状态。
将 entry 的文档状态设置为一个新的 文档状态, 其具有
对于导航情况,只有 entry 引用了 oldDocState,该状态是在导航算法的早期 阶段创建的。因此,对于导航而言,这在功能上只是对 entry 的文档状态的更新。对于遍历 情况,相邻的会话历史 条目也可能引用 oldDocState,在这种情况下,即使我们更新了 entry 的文档 状态,它们仍将继续引用该状态。
oldDocState 的历史记录策略 容器只会在遍历情况下在此处不为 null,即在我们导航到一个要求 将策略容器存储在历史记录中的 URL 时填充它之后。
设置由以下Jake 图给出:
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
top |
/a | /a#foo | /a#bar | /b |
还假设步骤 0、1 和 2 中的条目共享的文档状态具有 null 文档,即bfcache 未参与其中。
现在考虑这样一种场景:我们向后遍历到步骤 2,但这一次在获取
/a 时,服务器响应了一个指向 /c 的
`Location` 标头。也就是说,locationURL 指向
/c,因此我们到达了此步骤,而不是中断循环。
在这种情况下,我们会替换占据步骤 2 的会话历史条目的文档状态,但我们不会替换 占据步骤 0 和 1 的条目的文档状态。生成的Jake 图如下所示:
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
top |
/a | /a#foo | /c#bar | /b |
请注意,即使我们最终通过重定向链返回到原始 URL,也会执行此替换。例如,如果
/c 本身具有一个指向
/a 的 `Location` 标头。此类情况最终会如下所示:
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
top |
/a | /a#foo | /a#bar | /b |
如果 locationURL 的方案不是 HTTP(S) 方案:
将 currentURL 设置为 locationURL。
将 entry 的URL设置为 currentURL。
如果 locationURL 是一个URL,其方案 不是获取方案,则返回一个新的 非获取方案导航 参数,其具有
此时,request 的当前 URL是重定向链中在重定向到非获取方案 URL之前,最后一个具有获取方案的URL。正是此URL的源 将被用作导航到非获取方案 URL的发起者源。
如果以下任一项为 true:
则返回 null。
令 resultPolicyContainer 为在给定 response 的URL、entry 的文档状态的历史记录策略 容器、 sourceSnapshotParams 的源 策略容器、null 和 responsePolicyContainer 的情况下,确定 导航参数 策略容器的结果。
如果 navigable 的容器是一个
iframe,
并且 response 的计时允许通过标志已设置,则将
navigable 的容器的待处理资源计时
开始时间设置为
null。
如果允许 iframe
向资源计时报告,
则不需要运行其后备步骤,因为正常报告将会发生。
返回一个新的导航参数,其具有
如果一个元素的 Document 的
节点可导航对象是顶级
可遍历对象,或者其
Document 的所有祖先可导航对象
都具有活动文档,并且这些活动文档的源与该元素的节点文档的源同源,则该元素具有浏览上下文作用域源。如果一个元素
具有浏览上下文作用域源,则
其值是该元素的节点文档的源。
此定义存在问题,需要调查其原本意图表达的内容:请参阅议题 #4703。
要在给定导航参数
navigationParams、源快照参数
sourceSnapshotParams
和源
initiatorOrigin 时加载文档,执行以下步骤。它们返回一个
Document 或 null。
如果用户代理已被配置为使用某种不同于在可导航对象中渲染内容的机制来处理给定 type 的资源,则跳过此步骤。否则,如果 type 是以下类型之一:
text/css”text/plain”
text/vtt”multipart/x-mixed-replace”
multipart/x-mixed-replace 文档的结果。
application/pdf”text/pdf”否则,继续执行。
明确支持的 XML MIME 类型是一个XML MIME 类型,
用户代理被配置为使用外部应用程序渲染该类型的内容,或者用户代理具有专用的处理规则。例如,具有内置 Atom
订阅源查看器的 Web 浏览器可以被认为明确支持 application/atom+xml
MIME
类型。
明确支持的 JSON MIME 类型是一个JSON MIME 类型, 用户代理被配置为使用外部应用程序渲染该类型的内容,或者用户代理具有专用的处理规则。
在这两种情况下,外部应用程序或用户代理会直接在 navigationParams 的可导航对象中内联显示内容,或者 将其移交给外部 软件。这两种情况都会在下方步骤中发生。
否则,文档的 type 表明该资源不会影响 navigationParams 的可导航对象,例如 因为该资源将被交给外部应用程序,或者因为它是将由作为下载处理所处理的未知类型。给定 navigationParams 的响应、 navigationParams 的可导航对象、 navigationParams 的最终沙盒化标志集、 sourceSnapshotParams 的具有瞬态 激活和 initiatorOrigin,移交给外部 软件。
返回 null。
对于导航和遍历,一旦我们明确了希望在会话历史记录中前往的位置,大部分工作就涉及将这一概念应用于可遍历
可导航对象以及相关的 Document。对于导航,此工作通常
发生在过程接近结束时;对于遍历,它则发生在开始时。
确保一个可遍历对象 最终到达正确的会话历史步骤尤其复杂,因为这可能涉及在该可遍历对象的多个可导航对象后代之间进行协调,并行填充它们,然后 重新同步,以确保所有各方对结果具有相同的视图。同步同文档导航与 跨文档导航混合在一起,以及网页逐渐形成了某些相对时序 预期,使这一过程更加复杂。
正在更改的可导航对象延续状态用于在 应用历史步骤 算法期间存储信息,从而允许算法的一些部分仅在 其他部分完成后继续执行。它是一个具有以下成员的结构体:
Document尽管对可遍历可导航对象的所有更新最终都会进入同一个应用 历史步骤算法,但每个可能的入口点都会附带一些细微的 自定义:
要在给定一个可遍历 可导航对象 traversable 时,针对可导航对象的创建/销毁进行更新:
要在给定一个历史记录处理 行为 historyHandling 和一个用户导航参与 userInvolvement 时,将一个非负整数 step 作为推送/替换历史步骤应用于一个可遍历 可导航对象 traversable:
返回在给定 false、null、null、 userInvolvement 和 historyHandling 的情况下,将历史 步骤 step 应用于 traversable 的结果。
应用推送/替换历史步骤绝不会将源 快照参数或发起者可导航对象 传递给应用历史 步骤。这是因为这些检查已经在导航算法的早期完成。
应用重新加载历史步骤绝不会将源快照
参数或发起者可导航对象传递给应用历史步骤。
这是因为重新加载始终被视为由可导航对象自身执行,
即使在 parent.location.reload() 之类的情况下也是如此。
要在给定源快照 参数 sourceSnapshotParams、可导航对象 initiatorToCheck 和用户 导航参与 userInvolvement 时,将一个非负整数 step 作为遍历历史步骤应用于一个 可遍历可导航对象 traversable:
要在给定一个非负整数
step、一个可遍历可导航对象
traversable 和用户
导航参与 userInvolvement 时,恢复应用遍历历史步骤,在给定
false、null、null、
userInvolvement 和“traverse”的情况下,将 step应用于
traversable。
恢复遍历时,我们已经完成了取消检查、发起者检查和 源快照检查,并且已经确定此次遍历是同文档 遍历。因此,我们可以为这些参数传递 false 和 null。
现在介绍算法本身。
要将一个非负整数 step
作为历史
步骤应用于一个可遍历可导航对象
traversable,并给定布尔值 checkForCancelation、源快照
参数或 null sourceSnapshotParams、可导航对象或 null
initiatorToCheck、用户导航参与
userInvolvement
和 NavigationType 或 null
navigationType,执行以下步骤。
它们返回“initiator-disallowed”、“canceled-by-beforeunload”、
“canceled-by-navigate”或
“applied”。
令 targetStep 为在给定 traversable 和 step 的情况下获取使用的步骤的结果。
如果 initiatorToCheck 不为 null:
断言:sourceSnapshotParams 不为 null。
对于获取
当前会话历史条目将发生更改或重新加载的所有
可导航对象中的每个 navigable:如果在给定
sourceSnapshotParams 的情况下,initiatorToCheck 未被沙盒化允许导航
navigable,则返回
“initiator-disallowed”。
令 navigablesCrossingDocuments 为在给定 traversable 和 targetStep 的情况下获取 所有可能经历跨文档遍历的可导航对象的结果。
如果 checkForCancelation 为 true,并且在给定
navigablesCrossingDocuments、traversable、
targetStep 和 userInvolvement 的情况下检查卸载
是否已取消的结果不是“continue”,
则返回该结果。
令 changingNavigables 为在给定 traversable 和 targetStep 的情况下获取 当前会话历史条目将发生更改或重新加载的所有可导航对象的结果。
令 nonchangingNavigablesThatStillNeedUpdates 为在给定 traversable 和 targetStep 的情况下获取 仅需要更新历史记录对象长度/索引的所有可导航对象的结果。
对于 changingNavigables 中的每个 navigable:
令 targetEntry 为在给定 navigable 和 targetStep 的情况下获取目标历史 条目的结果。
将 navigable 的当前会话 历史条目设置为 targetEntry。
在 navigable 的活动 窗口的导航和 遍历任务源上排入一个全局任务,以运行以下步骤:
将 navigation 的正在进行的 navigate 事件设置为
null。
将 navigation 的正在进行的 API 方法跟踪器设置为 null。
这可以防止因跨文档导航成功而触发 navigateerror
事件及相应的信号。
将 navigable 的正在进行的导航设置为
“traversal”。
令 totalChangeJobs 为 changingNavigables 的大小。
令 completedChangeJobs 为 0。
令 changingNavigableContinuations 为一个由正在更改的可导航对象延续 状态组成的空队列。
此队列用于将对 changingNavigables 的操作 拆分为两部分。具体而言,changingNavigableContinuations 保存第二部分所需的数据。
对于 changingNavigables 中的每个 navigable,在 navigable 的活动 窗口的导航和 遍历任务源上排入一个全局任务,以运行以下步骤:
这组步骤被拆分为两部分,以允许在文档卸载之前处理同步导航。 状态存储在 changingNavigableContinuations 中,供第二 部分使用。
令 displayedEntry 为 navigable 的活动会话历史条目。
令 targetEntry 为 navigable 的当前会话历史条目。
令 changingNavigableContinuation 为一个具有以下成员的正在更改的可导航对象延续 状态:
如果 displayedEntry 是 targetEntry,并且 targetEntry 的文档状态的重新加载 待处理为 false:
根据 navigationType 进行切换:
如果 targetEntry 的文档为 null,或者 targetEntry 的文档状态的重新加载待处理为 true:
如果 targetEntry 的文档为 null,则令
navTimingType 为“back_forward”;
否则为“reload”。
令 targetSnapshotParams 为在给定 navigable 的情况下创建目标 快照参数的快照的结果。
令 potentiallyTargetSpecificSourceSnapshotParams 为 sourceSnapshotParams。
如果 potentiallyTargetSpecificSourceSnapshotParams 为 null,则将其设置为在给定 navigable 的活动文档的情况下创建源快照 参数的快照的结果。
在这种情况下,遍历/重新加载没有明确的来源。我们将这种 情况视为 navigable 自行进行导航,但请注意, targetEntry 的原始发起者的一些属性仍保留在 targetEntry 的文档状态中, 例如发起者源和引用来源,它们会适当地影响 导航。
并行地,在给定 navigable、 potentiallyTargetSpecificSourceSnapshotParams、targetSnapshotParams、 userInvolvement 的情况下,为 targetEntry尝试填充 历史条目的文档,其中将 allowPOST 设置 为 allowPOST,并将completionSteps设置为: 在给定 navigable 的活动 窗口的情况下,在导航和遍历任务 源上排入一个全局 任务,以运行 afterDocumentPopulated。
否则,立即运行 afterDocumentPopulated。
在这两种情况下,令 afterDocumentPopulated 为以下步骤:
如果 targetEntry 的文档为 null,则 将 changingNavigableContinuation 的仅更新设置为 true。
这意味着我们尝试填充文档,但未能成功, 例如因为服务器返回了 204。
这些失败的导航或遍历不会通知给导航 API(例如通过任何
导航 API 方法跟踪器的 promise,
或通过 navigateerror
事件)。在跨源情况下,这样做会泄露有关其他源响应时序的信息,
而在跨源与同源情况下提供不同的结果被认为过于令人困惑。
但是,实现可以利用此机会清除
navigation.transition.finished
promise 的任何处理程序,因为此时可以保证它们永远不会运行。此外,如果导航 API
的任何部分发起了这些导航,实现可能希望向控制台报告警告,
以向 Web 开发者说明为什么其 promise 永远不会
敲定,事件也永远不会触发。
如果 targetEntry 的文档的源不是 oldOrigin,则将 targetEntry 的经典历史记录 API 状态设置为 StructuredSerializeForStorage(null)。
当源相对于 targetEntry 先前未发生重定向的加载发生变化时, 这会清除历史记录状态。这可能由于 CSP 沙盒标头发生变化而出现。
如果以下各项均为 true:
navigable 的父级 为 null;
将 changingNavigableContinuation入队到 changingNavigableContinuations。
此作业的其余部分会在此算法的稍后阶段运行。
令 navigablesThatMustWaitBeforeHandlingSyncNavigation 为空 集合。
当 completedChangeJobs 不等于 totalChangeJobs 时:
如果 traversable 的正在运行 嵌套的应用历史步骤为 false:
令 changingNavigableContinuation 为从 changingNavigableContinuations 中出队的结果。
如果 changingNavigableContinuation 不存在,则 继续。
令 displayedDocument 为 changingNavigableContinuation 的显示的文档。
令 targetEntry 为 changingNavigableContinuation 的目标条目。
令 navigable 为 changingNavigableContinuation 的可导航对象。
令(scriptHistoryLength、scriptHistoryIndex)为在给定 traversable 和 targetStep 的情况下获取历史记录对象 长度和索引的结果。
这些值自上次计算以来可能已经发生变化。
将 navigable追加到 navigablesThatMustWaitBeforeHandlingSyncNavigation。
一旦可导航对象在遍历中到达此处,额外排队的 同步导航步骤很可能预期在此次遍历之后而不是之前发生,因此它们不再插队。可在此处找到更多详细信息。
令 entriesForNavigationAPI 为在给定 navigable 和 targetStep 的情况下获取导航 API 的会话历史 条目的结果。
如果 changingNavigableContinuation 的仅更新为 true,或者 targetEntry 的文档 是 displayedDocument:
这是同文档导航:我们继续执行而不进行卸载。
将 navigable 的正在进行的导航 设置为 null。
这允许 navigable 开始新的导航,而在遍历期间这些导航会被阻止。
在给定 navigable 的活动窗口的情况下,在导航和遍历任务 源上排入一个全局 任务,以执行 afterPotentialUnloads。
否则:
在这两种情况下,令 afterPotentialUnloads 为以下步骤:
令 previousEntry 为 navigable 的活动会话历史条目。
如果 changingNavigableContinuation 的仅更新为 false,则为 navigable激活 历史条目 targetEntry。
令 updateDocument 为一个算法步骤,该步骤在给定 targetEntry 的文档、targetEntry、 changingNavigableContinuation 的仅更新、 scriptHistoryLength、scriptHistoryIndex、navigationType、 entriesForNavigationAPI 和 previousEntry 的情况下,执行更新 文档以应用历史步骤。
如果 targetEntry 的文档等于 displayedDocument,则执行 updateDocument。
否则,在给定 targetEntry 的文档的 相关 全局对象的情况下,在导航和遍历任务 源上排入一个 全局任务,以执行 updateDocument。
递增 completedChangeJobs。
令 totalNonchangingJobs 为 nonchangingNavigablesThatStillNeedUpdates 的大小。
从此步骤开始,会有意等待先前的所有操作 完成,因为其中包括处理同步 导航,而这些导航也会发布用于更新历史记录长度和索引的任务。
令 completedNonchangingJobs 为 0。
令(scriptHistoryLength、scriptHistoryIndex)为在给定 traversable 和 targetStep 的情况下获取历史记录对象 长度和索引的结果。
对于 nonchangingNavigablesThatStillNeedUpdates 中的每个 navigable,在给定 navigable 的活动窗口的情况下,在 导航和遍历任务 源上排入一个全局任务,以运行以下步骤:
等待 completedNonchangingJobs 等于 totalNonchangingJobs。
将 traversable 的当前 会话历史步骤设置为 targetStep。
返回“applied”。
要在给定一个
Document
displayedDocument、一个用户导航参与
userNavigationInvolvement、一个会话历史条目
targetEntry、一个 NavigationType
navigationType 和 afterPotentialUnloads 时,为跨文档
导航停用文档,其中 afterPotentialUnloads
是一个不接收任何参数的算法:
令 navigable 为 displayedDocument 的 节点可导航对象。
令 potentiallyTriggerViewTransition 为 false。
如果 userNavigationInvolvement 为“browser UI”,则令
isBrowserUINavigation 为 true;否则为
false。
将 potentiallyTriggerViewTransition 设置为在给定 displayedDocument、targetEntry 的文档、navigationType 和 isBrowserUINavigation 的情况下,调用导航能否触发 跨文档视图过渡?所得的结果。
如果 potentiallyTriggerViewTransition 为 false:
令 firePageSwapBeforeUnload 为以下步骤:
在给定
displayedDocument、targetEntry、navigationType 和
null 的情况下,触发
pageswap 事件。
将 navigable 的正在进行的导航 设置为 null。
这允许 navigable 开始新的导航, 而在遍历期间这些导航会被阻止。
在给定 displayedDocument、targetEntry 的文档、afterPotentialUnloads 和 firePageSwapBeforeUnload 的情况下,卸载文档及其 后代。
否则,在给定 navigable 的活动窗口的情况下,在 导航和遍历任务 源上排入一个全局 任务,以运行以下步骤:
令 proceedWithNavigationAfterViewTransitionCapture 为以下 步骤:
将以下会话 历史遍历步骤追加到 navigable 的可遍历可导航对象:
将 navigable 的正在进行的导航 设置为 null。
这允许 navigable 开始新的导航, 而在遍历期间这些导航会被阻止。
在给定 displayedDocument、targetEntry 的文档和 afterPotentialUnloads 的情况下,卸载文档及其 后代。
令 viewTransition 为在给定 displayedDocument、targetEntry 的文档、navigationType 和 proceedWithNavigationAfterViewTransitionCapture 的情况下,设置跨文档 视图过渡的结果。
在给定
displayedDocument、targetEntry、navigationType 和
viewTransition 的情况下,触发
pageswap 事件。
如果 viewTransition 为 null,则运行 proceedWithNavigationAfterViewTransitionCapture。
在视图过渡已开始的情况下,视图过渡 算法负责调用 proceedWithNavigationAfterViewTransitionCapture。
要在给定一个
Document
displayedDocument、一个会话历史条目
targetEntry、一个 NavigationType
navigationType 和一个
ViewTransition 或 null
viewTransition 时,触发 pageswap 事件:
令 activation 为 null。
如果以下各项均为 true:
targetEntry 的文档的 通过跨源 重定向创建为 false,或者 targetEntry 的 文档的最新条目不为 null,
则:
令 destinationEntry 根据 navigationType 按以下方式确定:
将 activation 设置为在
displayedDocument 的相关
领域中创建的一个新 NavigationActivation,其具有
这意味着导航期间的跨源重定向会导致旧文档的
PageSwapEvent 中的 activation
为 null,除非新文档正在从bfcache 中恢复。
在 displayedDocument 的
相关全局
对象上触发一个名为
pageswap 的事件,使用 PageSwapEvent,将其
activation
设置为 activation,
并将其 viewTransition
设置为
viewTransition。
要在给定一个可遍历 可导航对象 traversable 和一个非负整数 step 时,获取使用的步骤,执行 以下步骤。它们返回一个非负整数。
令 steps 为在 traversable 中获取所有已使用的历史步骤的结果。
返回 steps 中小于或等于 step 的最大项。
要在给定一个可遍历可导航对象 traversable 和一个非负整数 step 时,获取历史记录对象的长度和 索引,执行以下步骤。它们返回一个由两个 非负整数组成的元组。
令 steps 为在 traversable 中获取所有已使用的历史步骤的结果。
令 scriptHistoryLength 为 steps 的大小。
假定 step 已经通过获取使用的 步骤进行了调整。
令 scriptHistoryIndex 为 step 在 steps 中的索引。
返回(scriptHistoryLength、scriptHistoryIndex)。
要在给定一个可遍历 可导航对象 traversable 和一个非负整数 targetStep 时,获取当前会话历史条目将更改或重新加载的所有可导航对象, 执行以下步骤。它们返回一个由可导航对象组成的列表。
令 results 为空列表。
令 navigablesToCheck 为 « traversable »。
此列表会在下方循环中扩展。
对于 navigablesToCheck 中的每个 navigable:
令 targetEntry 为在给定 navigable 和 targetStep 的情况下获取目标历史 条目的结果。
如果 targetEntry 不是 navigable 的当前会话历史条目,或者 targetEntry 的文档状态的重新加载待处理为 true,则将 navigable追加到 results。
如果 targetEntry 的文档是 navigable 的文档,并且 targetEntry 的文档状态的重新加载待处理为 false,则使用 navigable 的子可导航对象扩展 navigablesToCheck。
将子 可导航对象添加到 navigablesToCheck,意味着这些可导航对象也会由此循环检查。只有在 navigable 的活动 文档不会在此次遍历中发生变化时,才会检查子可导航对象。
返回 results。
要在给定一个可遍历 可导航对象 traversable 和一个非负整数 targetStep 时,获取 仅需要更新历史记录对象长度/索引的所有可导航对象, 执行以下步骤。它们返回一个由可导航对象组成的列表。
其他可导航对象可能不会受到 遍历的影响。例如,如果响应为 204,当前活动文档将保持不变。 此外,在 204 之后“后退”会更改当前会话历史条目,但活动会话历史 条目已经是正确的。
要了解为什么获取目标历史条目会返回 其步骤小于或等于输入步骤且值最大的条目, 请考虑以下 Jake 图:
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
top |
/t | /t#foo | ||
frames[0] |
/i-0-a | /i-0-b | ||
对于输入步骤 1,top 可导航对象的目标历史条目
是 /t 条目,其步骤为 0,
而 frames[0] 可导航对象的目标历史条目是 /i-0-b 条目,其步骤为 1:
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
top |
/t | /t#foo | ||
frames[0] |
/i-0-a | /i-0-b | ||
类似地,给定输入步骤 3,我们会得到步骤为 3 的 top
条目,以及步骤为 1 的
frames[0] 条目:
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
top |
/t | /t#foo | ||
frames[0] |
/i-0-a | /i-0-b | ||
要在给定一个可遍历 可导航对象 traversable 和一个非负整数 targetStep 时,获取 所有可能经历跨文档遍历的可导航对象, 执行以下步骤。它们返回一个由可导航对象组成的列表。
从 traversable 的会话 历史遍历队列的角度来看,这些文档是在 targetStep 所描述的遍历期间 进行跨文档操作的候选项。如果其目标文档的状态码为 HTTP 204 No Content, 它们将不会经历跨文档遍历。
请注意,如果某个给定的可导航对象可能 经历跨文档遍历,则此算法会返回该可导航对象,但不会返回其 子 可导航对象。这些子可导航对象最终会被卸载,而不是 被遍历。
令 results 为空列表。
令 navigablesToCheck 为 « traversable »。
此列表会在下方循环中扩展。
对于 navigablesToCheck 中的每个 navigable:
令 targetEntry 为在给定 navigable 和 targetStep 的情况下获取目标历史 条目的结果。
如果 targetEntry 的文档不是 navigable 的文档,或者 targetEntry 的文档状态的重新加载待处理为 true,则将 navigable追加到 results。
尽管 navigable 的活动历史条目可以
同步更改,但新条目始终具有相同的 Document,因此访问
navigable 的文档
是可靠的。
否则,使用 navigable 的子 可导航对象扩展 navigablesToCheck。
将子 可导航对象添加到 navigablesToCheck,意味着这些可导航对象也会由此循环检查。只有在 navigable 的活动 文档不会在此次遍历中发生变化时,才会检查子可导航对象。
返回 results。
要在给定一个 Document
document、一个会话
历史条目 entry、一个布尔值
doNotReactivate、整数 scriptHistoryLength 和
scriptHistoryIndex、NavigationType 或 null
navigationType、一个可选的由会话历史条目组成的列表
entriesForNavigationAPI,以及一个可选的会话历史条目
previousEntryForActivation 时,更新文档以应用历史步骤:
如果 document 的最新条目 为 null,则令 documentIsNew 为 true;否则为 false。
如果 document 的最新 条目不是 entry,则令 documentsEntryChanged 为 true;否则为 false。
如果 documentsEntryChanged 为 true:
将 document 的最新 条目设置为 entry。
在给定 document 和 entry 的情况下,恢复历史记录对象状态。
如果 documentIsNew 为 false:
断言:navigationType 不为 null。
在给定 navigation、entry 和 navigationType 的情况下,更新 同文档导航的导航 API 条目。
在 document 的相关全局
对象上触发一个名为
popstate 的事件,
使用 PopStateEvent,将其
state
属性初始化为 document 的
历史记录对象的状态,并且如果
用户代理执行了用于显示最新
条目的缓存渲染状态的视觉过渡,则将 hasUAVisualTransition
初始化为
true。
在给定 entry 的情况下,恢复持久化状态。
如果 oldURL 的片段
不等于 entry 的URL的片段,则在给定
document 的相关全局
对象的情况下,在DOM
操作任务源上排入一个全局任务,以在
document 的相关全局
对象上触发一个名为
hashchange
的事件,
使用 HashChangeEvent,
将其 oldURL
属性初始化为 oldURL 的序列化,并将其 newURL
属性初始化为 entry 的URL的序列化。
否则:
断言:已给出 entriesForNavigationAPI。
在给定 entry 的情况下,恢复持久化状态。
在给定 navigation、entriesForNavigationAPI 和 entry 的情况下,初始化新文档的 导航 API 条目。
如果以下各项均为 true:
已给出 previousEntryForActivation;
navigationType 不为 null;并且
navigationType 为“reload”,
或者
previousEntryForActivation 的文档不是
document,
则:
如果 navigation 的激活为 null,则将
navigation 的
激活设置为在
navigation 的
相关领域中创建的一个新的
NavigationActivation
对象。
令 previousEntryIndex 为在 navigation 中获取 previousEntryForActivation 的导航 API 条目索引的结果。
如果 previousEntryIndex 为非负数,则将 activation 的 旧条目设置为 navigation 的条目列表[previousEntryIndex]。
否则,如果以下各项均为 true:
navigationType 为“replace”;
previousEntryForActivation 的文档的
是初始
about:blank为
false,
则将 activation 的旧条目
设置为在 navigation 的相关领域中的一个新的 NavigationHistoryEntry,
其会话历史条目为
previousEntryForActivation。
将 activation 的导航类型设置为 navigationType。
如果 documentIsNew 为 true:
断言:document 的用于 WebDriver BiDi 的加载期间导航 ID 不为 null。
使用 navigable 和一个新的WebDriver BiDi 导航状态调用WebDriver BiDi 导航已提交,该状态的id为
document 的用于 WebDriver
BiDi 的加载期间导航 ID,
状态为“committed”,
并且url为
document 的URL。
为 document尝试滚动到片段。
此时,脚本可以为新创建的文档 document 运行。
否则,如果 documentsEntryChanged 为 false,并且 doNotReactivate 为 false:
documentsEntryChanged 可能因以下两个原因之一而为 false:我们 正在从bfcache 恢复,或者正在异步完成一次 已经同步设置了 document 的最新 条目的同步导航。doNotReactivate 参数用于区分这两种 情况。
要在给定 Document
document 和会话历史条目 entry 时,恢复历史记录对象状态:
令 targetRealm 为 document 的相关领域。
令 state 为 StructuredDeserialize(entry 的经典 历史记录 API 状态,targetRealm)。 如果这抛出异常,则捕获该异常并令 state 为 null。
要使一个 Document document 成为活动状态:
令 window 为 document 的相关全局 对象。
将 document 的浏览上下文的
WindowProxy 的[[Window]]
内部槽值设置为 window。
要在给定一个会话历史条目
reactivatedEntry 和一个由会话历史条目组成的列表
entriesForNavigationAPI 时,重新激活一个
Document document:
此算法会在 document 离开bfcache 后,即再次成为完全活动 状态之后更新它。建议希望监视完全 活动状态这一变化的其他规范,将相应步骤添加到此算法中,从而明确 因此变化而发生的事件顺序。
要在给定一个 Document
document 和一个字符串 reason 时,使文档不可挽救:
将 details追加到 document 的 bfcache 阻止详细信息。
将 document 的可挽救 状态设置为 false。
要在给定 Document
document 时,构建文档状态的未恢复原因:
令 notRestoredReasonsForDocument 为一个新的未恢复原因。
如果 container 是一个 iframe 元素:
令 src 为空字符串。
如果 container 具有 src 属性:
令 src 为在给定 container 的 src 属性值,并以
container 的节点文档为相对基准时,编码、解析并序列化
URL的结果。
如果 src 为失败,则将 src 设置为 container 的 src 属性值。
将 notRestoredReasonsForDocument 的src设置为 src。
将 notRestoredReasonsForDocument 的id
设置为 container 的 id 属性值;
如果没有该属性,则设置为空字符串。
将 notRestoredReasonsForDocument 的name设置为
container 的 name 属性值;
如果没有该属性,则设置为空字符串。
将 notRestoredReasonsForDocument 的原因 设置为 document 的bfcache 阻止详细信息的克隆。
对于 document 的 文档树子可导航对象中的每个 navigable:
令 childDocument 为 navigable 的活动文档。
在给定 childDocument 的情况下,构建文档状态的未恢复原因。
将 childDocument 的未恢复原因追加到 notRestoredReasonsForDocument 的子项。
将 document 的节点 可导航对象的活动会话历史条目的文档状态的未恢复原因设置为 notRestoredReasonsForDocument。
要在给定顶级可遍历对象 topLevelTraversable 时,构建顶级可遍历对象及其后代的未恢复 原因:
一个 Document 具有布尔值 已被显示,初始值为 false。它用于
确保对于 Document 的每次激活,pagereveal 事件仅触发一次
(初始渲染时触发一次,并在每次
重新激活时触发一次)。
要显示一个 Document
document:
如果 document 的已被 显示为 true,则返回。
将 document 的已 被显示设置为 true。
令 transition 为针对 document 解析传入的跨文档 视图过渡的结果。
在 document 的
相关全局
对象上触发一个名为
pagereveal 的事件,使用 PageRevealEvent,并将其
viewTransition
设置为
transition。
如果 transition 不为 null:
激活 transition。
在给定 document 的 相关 设置对象的情况下,在运行脚本后进行 清理。
激活视图过渡可能会兑现或拒绝 promise,因此通过使用准备/清理步骤包装 激活过程,可以确保在下一次渲染步骤之前处理这些 promise。
尽管可以保证在首次显示页面最新版本的更新
渲染步骤期间触发 pagereveal,
但用户代理可以在触发该事件之前显示页面的缓存帧。这可以避免
因存在 pagereveal 处理程序而延迟
显示此类缓存帧。
要在给定一个
Document document 时,滚动到片段:
将 document 的目标 元素设置为 null。
为 document滚动到文档开头。 [CSSOMVIEW]
返回。
否则:
一个 Document 的指示部分是
其 URL 的片段所标识的部分;如果该片段未
标识任何内容,则为 null。如何将片段映射到节点,
其语义由定义 Document 所使用的MIME
类型的规范定义(例如,XML MIME
类型的片段处理由 RFC7303
负责)。[RFC7303]
每个 Document 还具有一个目标元素,它用于
定义 :target
伪类,并由上述算法更新。其初始值为 null。
要在给定一个 Document document
和一个
URL
url 时,选择指示部分:
令 fragment 为 url 的片段。
如果 fragment 为空字符串,则返回特殊值文档 顶部。
令 potentialIndicatedElement 为在给定 document 和 fragment 的情况下查找潜在指示元素的结果。
如果 potentialIndicatedElement 不为 null,则返回 potentialIndicatedElement。
令 fragmentBytes 为对 fragment 进行百分号解码的结果。
令 decodedFragment 为对 fragmentBytes 运行不带 BOM 的 UTF-8 解码所得的结果。
将 potentialIndicatedElement 设置为在给定 document 和 decodedFragment 的情况下查找潜在指示元素的结果。
如果 potentialIndicatedElement 不为 null,则返回 potentialIndicatedElement。
如果 decodedFragment 与字符串 top 以
ASCII 不区分大小写的方式匹配,则返回文档顶部。
返回 null。
要在给定一个 Document
document 和一个字符串 fragment 时,查找潜在指示元素,运行以下步骤:
要将持久化状态保存到一个会话历史条目 entry:
要从一个会话 历史条目 entry 中恢复持久化状态:
如果 entry 的滚动恢复
模式为“auto”,
并且 entry 的
文档的相关
全局对象的导航
API的在
正在进行的导航期间抑制正常滚动恢复为 false,则在给定
entry 的情况下恢复滚动位置数据。
用户代理不恢复滚动位置,并不意味着滚动 位置会保持为任何特定值(例如 (0,0))。实际滚动位置取决于 导航类型以及用户代理的具体缓存策略。因此,Web 应用程序 不能假定任何特定的滚动位置,而应将其设置为所需的 位置。
如果在
正在进行的导航期间抑制正常滚动恢复为
true,则恢复滚动位置数据
仍可能在稍后发生,作为完成相关
NavigateEvent 的一部分,或者
通过调用 navigateEvent.scroll()
方法来发生。
可选地,更新 entry 的文档及其渲染的其他方面,例如 用户代理先前记录在 entry 的持久化用户状态中的表单字段值。
这甚至可以包括更新 dir 属性,
该属性属于 textarea
元素,或其 type
属性
处于 文本、搜索、
电话、URL或电子邮件
状态的 input
元素,前提是持久化状态包含此类控件中用户输入的方向性。
在此过程中恢复表单控件的值不会触发任何
input
或 change 事件,但
可以触发表单关联自定义元素的
formStateRestoreCallback。
每个 Document 都具有布尔值
已由用户滚动,初始值为
false。如果用户滚动文档,则用户代理必须将该文档的已由
用户滚动设置为 true。
子可导航对象的
滚动恢复,作为这些可导航对象的 Document 所对应的会话历史条目状态
恢复的一部分进行处理。
要在给定一个会话历史 条目 entry 时,恢复滚动位置数据:
使用下方某个算法加载文档时,我们使用
以下步骤,在给定类型 type、内容类型 contentType 和
导航参数
navigationParams 的情况下,创建并初始化一个 Document
对象:
在创建新的浏览
上下文和文档时,也会创建 Document
对象;此类初始
about:blank Document 永远不会
由此算法创建。此外,还可以通过各种 API 创建不具有浏览
上下文的 Document 对象,例如 document.implementation.createHTMLDocument()。
令 browsingContext 为在给定 navigationParams 的情况下,获取用于 导航响应的浏览上下文的结果。
这可能导致浏览上下文
组切换,在这种情况下,browsingContext 将是一个新创建的浏览上下文,而
不是 navigationParams 的可导航对象的活动浏览
上下文。在这种情况下,所创建的 Window、Document 和
代理最终不会被使用;由于所创建的 Document 的
源是不透明的,我们最终会在此算法的稍后阶段创建一个新的
代理
和 Window,以与新的 Document 配合使用。
令 permissionsPolicy 为在给定 navigationParams 的可导航对象的容器、 navigationParams 的源和 navigationParams 的响应的情况下,从响应创建权限策略的结果。[PERMISSIONSPOLICY]
从响应创建权限策略算法会使用
所传递的源。如果已对
navigationParams 的可导航对象的容器文档使用 document.domain,则其
源无法与所传递的源同源域,因为这些步骤在
document 创建之前运行,因此它本身尚不可能使用 document.domain。请注意,
这意味着与改为执行同源检查相比,权限策略检查的许可性更低。
请参阅下方的一些实际示例。
如果 navigationParams 的请求 不为 null,则将 creationURL 设置为 navigationParams 的请求的当前 URL。
令 window 为 null。
如果 browsingContext 的活动文档的是初始
about:blank为 true,并且 browsingContext 的活动
文档的源与 navigationParams 的源同源域,则将
window 设置为
browsingContext 的活动窗口。
这意味着初始
about:blank Document,以及即将创建的新
Document,将共享同一个 Window 对象。
否则:
令 oacHeader 为从
navigationParams 的响应的
标头列表中,给定 `Origin-Agent-Cluster`
和“item”时获取结构化字段值的结果。
如果 oacHeader 不为 null,并且 oacHeader[0] 是布尔值 true,则令 requestsOAC 为 true;否则为 false。
如果 navigationParams 的保留 环境是一个非安全 上下文,则将 requestsOAC 设置为 false。
令 agent 为在给定 navigationParams 的源、 browsingContext 的组和 requestsOAC 的情况下,获取 相似源窗口代理的结果。
令 realmExecutionContext 为在给定 agent 和以下自定义项的情况下,创建新领域的结果:
对于全局对象,创建一个新的 Window 对象。
对于全局 this 绑定,使用 browsingContext 的
WindowProxy
对象。
将 window 设置为 realmExecutionContext 的 Realm 组件的全局 对象。
令 topLevelCreationURL 为 creationURL。
令 topLevelOrigin 为 navigationParams 的源。
如果 navigable 的容器不为 null:
使用 creationURL、 realmExecutionContext、navigationParams 的保留 环境、 topLevelCreationURL 和 topLevelOrigin,设置窗口 环境设置对象。
令 loadTimingInfo 为一个新的文档加载计时信息,其 导航 开始时间设置为 navigationParams 的响应的计时信息的开始时间。
令 document 为一个新的 Document,其具有
loading”CustomElementRegistry
对象将 window 的关联的
Document设置为 document。
将 document 的内部
祖先源对象
列表设置为在给定 document 和 navigationParams 的iframe
元素引用来源
策略的情况下,运行内部
祖先源对象列表创建
步骤的结果。
将 document 的祖先 源列表设置为在给定 document 的情况下,运行祖先源列表创建 步骤的结果。
在给定
document 的情况下,为
Document 运行 CSP 初始化。[CSP]
如果 navigationParams 的请求 不为 null:
如果 navigationParams 的获取 控制器不为 null:
令 redirectCount 为 0。
在给定 fullTimingInfo、redirectCount、navigationTimingType、 navigationParams 的响应的 服务工作线程计时信息 和 navigationParams 的响应的 主体信息的情况下,为 document创建导航计时条目。
使用 navigationParams 的响应的计时信息、redirectCount、 navigationParams 的导航计时 类型,以及 navigationParams 的响应的服务工作线程计时信息,为 document创建导航计时条目。
如果 navigationParams 的响应
具有一个 `Refresh`
标头:
令 value 为该标头值的同构解码。
使用 document 和 value 运行共享声明式刷新 步骤。
如果 navigationParams 的提交早期提示不为 null,则使用 document 调用 navigationParams 的提交早期 提示。
在给定 document、
navigationParams 的响应和
“pre-media”的情况下,处理
link 标头。
如果 navigationParams 的可导航对象
是顶级可遍历对象,则在给定
document 和 navigationParams 的响应的情况下,处理
`Speculation-Rules`
标头。
这是有条件的,因为只会为顶级可遍历对象考虑推测性 加载,否则获取这些规则将造成浪费。
为 document可能释放延迟获取配额。
返回 document。
在此示例中,子文档不允许使用 PaymentRequest,
尽管在子文档尝试使用它时两者已经同源
域。在初始化子文档时,只有父文档设置了 document.domain,
而子文档尚未设置。
<!-- https://foo.example.com/a.html -->
<!doctype html>
< script >
document. domain = 'example.com' ;
</ script >
< iframe src = b.html ></ iframe > <!-- https://bar.example.com/b.html -->
<!doctype html>
< script >
document. domain = 'example.com' ; // 这发生在文档初始化之后
new PaymentRequest( …); // 不允许使用
</ script > 在此示例中,子文档允许使用
PaymentRequest,
尽管在子文档尝试使用它时两者并不同源域。在初始化
子文档时,没有任何文档设置 document.domain,
因此同源
域会回退到普通的同源检查。
<!-- https://example.com/a.html -->
<!doctype html>
< iframe src = b.html ></ iframe >
<!-- 子文档现已初始化,发生在运行下方脚本之前。 -->
< script >
document. domain = 'example.com' ;
</ script > <!-- https://example.com/b.html -->
<!doctype html>
< script >
new PaymentRequest( …); // 允许使用
</ script > 要在给定一个
Document
document 时,使用
html/head/body 进行填充:
要加载 HTML 文档,给定导航 参数 navigationParams:
令 document 为给定“html”、“text/html”和
navigationParams 时,创建并初始化一个 Document
对象的结果。
如果 document 的URL 是
about:blank,则给定
document,使用
html/head/body 进行填充。
这种特殊情况中,即使是非初始
about:blank Document,
也会同步获得其元素
节点,这是为了与已部署的内容保持兼容所必需的。换言之,改为进入“否则”
分支,并将空字节序列馈送给
HTML 解析器以异步填充
document,是不兼容的。
否则,创建一个HTML 解析器,其允许声明式 影子 根为 true,并将其与 document 关联。
在获取运行期间,网络任务源 放入任务队列的每个任务,随后都必须 使用获取到的字节填充解析器的 输入字节流,并使HTML 解析器 对输入流执行适当处理。
在获取运行期间,网络任务
源放入任务队列的第一个任务,必须在该任务已由HTML
解析器处理之后,给定
document、navigationParams 的响应和“media”,处理 link
标头。
在任何脚本执行发生之前,用户代理必须等待 document 的脚本可以为 新创建的文档运行变为 true。
输入字节 流会将字节转换为供 分词器使用的字符。此过程部分依赖于 资源的实际Content-Type 元数据中发现的字符 编码信息;计算出的类型不用于此目的。
当不再有可用字节时,用户代理必须在给定
document 的相关
全局
对象的情况下,在网络任务源上排入一个全局任务,
使解析器处理隐含的 EOF 字符,这最终会导致触发
load 事件。
返回 document。
当需要内联显示 XML 文件时,给定导航参数
navigationParams 和字符串 type,用户代理必须遵循
XML、Namespaces in XML、XML Media
Types、DOM 以及其他相关规范中定义的要求,给定
“xml”、type 和
navigationParams,创建并初始化一个 Document 对象
document,并返回该 Document。
它们还必须创建一个相应的
XML 解析器。[XML] [XMLNS] [RFC7303]
[DOM]
在撰写本文时,XML 规范社区实际上尚未 规定 XML 与 DOM 如何交互。
在获取运行期间,网络任务源
放入任务队列的第一个任务,必须在该任务已由XML 解析器处理之后,给定
document、navigationParams 的响应和“media”,处理 link 标头。
根据上述规范中给出的规则确定字符编码时,必须使用实际的 HTTP 标头及其他元数据, 而不是由本规范中给出的算法修改或推断出的标头。一旦字符 编码确定,就必须将文档的字符编码设置为该 字符编码。
在任何脚本执行发生之前,用户代理必须等待新创建的 Document 的脚本可以为
新创建的文档运行变为 true。
解析完成后,用户代理必须将 document 的用于 WebDriver BiDi 的加载期间导航 ID设置为 null。
对于 HTML 文档,此项会在解析完成时、触发 load 事件之后重置。
解析过程中的错误消息(例如 XML 命名空间良构性错误)可以通过修改
Document 进行内联
报告。
要加载文本文档,给定导航 参数 navigationParams 和字符串 type:
令 document 为给定“html”、type 和
navigationParams 时,创建并初始化一个 Document
对象的结果。
将 document 的解析器无法更改模式标志设置为 true。
将 document 的模式
设置为“no-quirks”。
创建一个HTML 解析器,并将其与 document 关联。表现得如同分词器已发出一个标签名称为“pre”的开始标签词元, 后跟单个 U+000A LINE FEED (LF) 字符,并将HTML 解析器的分词器切换到 PLAINTEXT 状态。在获取运行期间, 网络任务源放入 任务队列的每个任务, 随后都必须使用获取到的字节填充解析器的输入字节 流,并使 HTML 解析器对输入流执行适当处理。
必须将 document 的编码 设置为解析期间用于解码文档的字符编码。
在获取运行期间,网络任务
源放入任务队列的第一个任务,必须在该任务已由HTML
解析器处理之后,给定
document、navigationParams 的响应和“media”,处理 link
标头。
在任何脚本执行发生之前,用户代理必须等待 document 的脚本可以为 新创建的文档运行变为 true。
当不再有可用字节时,用户代理必须在给定
document 的相关
全局
对象的情况下,在网络任务源上排入一个全局任务,
使解析器处理隐含的 EOF 字符,这最终会导致触发
load 事件。
用户代理可以向 document 的 head 元素添加内容,例如
链接样式表、提供脚本,或为文档提供一个 title。
特别是,如果用户代理支持 RFC 3676 的 Format=Flowed 功能,
则用户代理需要应用
额外样式,使文本正确换行并处理引用功能。例如,这可以
使用 CSS 扩展来实现。
返回 document。
如何将纯文本文档的字节转换为实际字符的规则,以及 如何实际向用户渲染文本的规则,由资源的 计算出的 MIME 类型(即 type)的规范定义。
multipart/x-mixed-replace
文档要加载
multipart/x-mixed-replace 文档,给定导航参数
navigationParams、源快照参数
sourceSnapshotParams
和源
initiatorOrigin:
令 firstPartNavigationParams 为 navigationParams 的副本。
将 firstPartNavigationParams 的响应设置为一个新的响应,表示 navigationParams 的响应的主体的多部分流中的第一部分。
令 document 为给定 firstPartNavigationParams、sourceSnapshotParams 和 initiatorOrigin 时,加载文档的结果。
对于从 navigationParams 的响应中获得的每个附加主体部分,
用户代理必须使用 document,将
document 的节点
可导航对象导航到
navigationParams 的请求的URL,其中将 response 设置为
navigationParams 的响应,并将 historyHandling 设置为
“replace”。
返回 document。
对于将这些主体部分视为完整独立资源进行处理的算法, 每当到达主体部分之后的边界时,用户代理必须表现得如同这些资源 不再有更多字节。
因此,每个加载的主体部分都会触发 load
事件(同样也会触发 unload 事件)。
要加载媒体文档,给定 navigationParams 和字符串 type:
令 document 为给定“html”、type 和
navigationParams 时,创建并初始化一个 Document
对象的结果。
将 document 的模式
设置为“no-quirks”。
给定
document,使用
html/head/body 进行填充。
将如下所述用于媒体的元素 host element 追加到
body 元素。
将元素 host element 的适当属性设置为图像、视频或音频资源的地址, 如下所述。
用户代理可以向 document 的 head 元素添加内容,
或向 host element 添加属性,例如链接样式表、提供脚本、
为文档提供一个 title,或使媒体自动播放。
给定
document、navigationParams 的响应和
“media”,处理 link 标头。
表现得如同用户代理已经为 document停止解析。
返回 document。
要为媒体创建的元素 host element,是在下表中首个单元格描述该媒体的行的 第二个单元格中给出的元素。要设置的适当属性,是同一行第三个单元格中给出的属性。
| 媒体类型 | 用于媒体的元素 | 适当属性 |
|---|---|---|
| 图像 | img
|
src
|
| 视频 | video
|
src
|
| 音频 | audio
|
src
|
在任何脚本执行发生之前,用户代理必须等待该 Document 的脚本可以为
新创建的文档运行变为 true。
当用户代理要创建一个文档,以内联显示用户
代理页面或 PDF 查看器时,给定一个可导航对象 navigable、一个导航 ID
navigationId、一个 NavigationTimingType
navTimingType,以及一个
用户导航
参与 userInvolvement,用户代理应:
令 origin 为一个新的不透明 源。
令 coop 为一个新的打开器策略。
令 coopEnforcementResult 为一个新的打开器 策略执行结果,其具有
令 navigationParams 为一个新的导航参数,其具有
令 document 为给定“html”、“text/html”和
navigationParams 时,创建并初始化一个 Document
对象的结果。
将 document 与不使用正常
Document 渲染规则渲染的自定义渲染相关联,
或修改 document,直到它
表示用户代理希望渲染的内容。
表现得如同用户代理已经为 document停止解析。
这样做是为了避免向父页面泄露有关导航是否
被 CSP 阻止,或者响应是否为网络
错误的信息。在
容器是 iframe 元素的情况下,停止
解析会导致iframe
load 事件步骤运行。
返回 document。
由于我们确保生成的 Document 的源是不透明的,并且生成的 Document 无法运行
能够访问 DOM 的脚本,因此 Web 开发者代码无法观察到此 Document
的存在及其属性。
这意味着上述大多数值,例如
text/html 类型,都无关紧要。
同样,navigationParams 中的大多数项也没有任何可观察的效果,
除了防止Document 创建
算法发生混乱,因此将它们设置为默认值。
一个 Document 具有一个完全加载时间(一个时间或 null),其
初始值为 null。
要完全完成加载一个 Document document:
将 document 的完全加载时间设置为当前 时间。
令 container 为 document 的节点可导航对象的容器。
当 document 是 frame 或 iframe 中的初始
about:blank Document 时,此值将为 null,
因为在调用此算法的浏览上下文创建时,
容器关系尚未建立。(这发生在创建新的
子可导航对象的后续步骤中。)
这样做的结果是,以下步骤不执行任何操作,即在此类
情况下,我们不会在容器元素上触发异步 load 事件。
相反,在处理
iframe 属性时,会在特殊的初始插入情况下触发一个同步 load 事件。
如果 container 是一个 iframe 元素,则在给定
container 的情况下,在DOM 操作任务源上排入一个元素
任务,以给定 container 运行
iframe load 事件
步骤。
否则,如果 container 不为 null,则在给定 container 的情况下,
在DOM
操作任务源上排入一个元素任务,
以在 container 上触发一个名为 load 的事件。
一个 Document 具有一个可挽救状态,其初始值必须为
true,以及一个页面正在显示布尔值,其初始值为 false。页面
正在显示布尔值用于确保脚本以一致的方式接收 pageshow 和 pagehide 事件
(例如,它们绝不会在中间没有 pageshow
的情况下连续接收两个
pagehide 事件,反之亦然)。
一个 Document 具有一个 DOMHighResTimeStamp
暂停时间,
初始值为 0。
一个 Document 具有一个由已暂停计时器句柄组成的列表,
初始为空。
事件循环具有一个终止嵌套级别 计数器,其初始值必须为 0。
Document 对象具有一个卸载
计数器,用于在下方算法运行时忽略某些操作。
该计数器最初必须设置为零。
要卸载一个 Document
oldDocument,给定一个可选的 Document
newDocument:
令 unloadTimingInfo 为一个新的文档卸载计时 信息。
如果未给出 newDocument,则将 unloadTimingInfo 设置为 null。
在这种情况下,不存在需要了解 oldDocument 卸载耗时的新文档。
否则,如果 newDocument 的事件 循环不是 oldDocument 的事件循环,则用户代理可能正在并行卸载 oldDocument。在 这种情况下,用户代理应将 unloadTimingInfo 设置为 null。
在这种情况下,newDocument 的加载不会受到卸载 oldDocument 所需时间的影响,因此传达该计时 信息没有意义。
如果用户代理打算使 oldDocument 在一个会话历史条目中保持存活, 以便稍后可以用于历史记录遍历,则令 intendToKeepInBfcache 为 true。
如果 oldDocument 不可挽救,或者存在任何用户代理不打算以同样方式保持存活的 oldDocument 后代,则此值必须为 false (包括由于这些后代缺乏可挽救性)。
将 eventLoop 的终止嵌套级别增加 1。
将 oldDocument 的卸载 计数器增加 1。
如果 intendToKeepInBfcache 为 false,则将 oldDocument 的可挽救状态设置为 false。
如果 oldDocument 的页面正在显示 为 true:
如果 unloadTimingInfo 不为 null,则将 unloadTimingInfo 的 卸载事件开始 时间设置为在给定 newDocument 的相关全局对象的情况下获得的当前高精度时间,并根据 oldDocument 的相关设置 对象的 跨源隔离 能力进行粗化。
如果 oldDocument 的可挽救
状态为 false,则在
oldDocument 的相关全局
对象上触发一个名为
unload 的事件,
并设置旧式目标覆盖标志。
如果 unloadTimingInfo 不为 null,则将 unloadTimingInfo 的 卸载事件结束时间设置为 在给定 newDocument 的相关全局对象的情况下获得的当前高精度时间,并根据 oldDocument 的相关设置 对象的 跨源隔离 能力进行粗化。
将 eventLoop 的终止嵌套级别减少 1。
将 oldDocument 的已由用户滚动设置为 false。
如果 oldDocument 的节点 可导航对象是一个顶级 可遍历对象,则给定 oldDocument 的节点可导航对象,构建 顶级可遍历对象及其 后代的未恢复原因。
将 oldDocument 的卸载 计数器减少 1。
如果已给出 newDocument,newDocument 的通过 跨源重定向创建为 false,并且 newDocument 的源与 oldDocument 的源相同,则将 newDocument 的前一文档卸载计时设置为 unloadTimingInfo。
要卸载文档及其后代,给定一个 Document
document、一个可选的 Document 或 null
newDocument(默认为
null)、一组可选步骤 afterAllUnloads,以及一组可选步骤
firePageSwapSteps:
令 childNavigables 为 document 的子可导航对象。
令 numberUnloaded 为 0。
对于 childNavigables 中的每个 childNavigable 按什么顺序?,在给定 childNavigable 的活动窗口的情况下,在导航和遍历任务源上排入一个 全局任务,以执行以下步骤:
等待直到 numberUnloaded 等于 childNavigable 的大小。
在给定 document 的相关全局对象的情况下,在 导航和遍历任务源上排入一个全局任务,以执行以下 步骤:
如果已给出 firePageSwapSteps,则运行 firePageSwapSteps。
卸载 document, 如果 newDocument 不为 null,则将其一并传递。
如果已给出 afterAllUnloads,则运行它。
本规范定义以下卸载
文档清理步骤。
其他规范可以定义更多步骤。给定一个 Document
document:
令 window 为 document 的相关全局 对象。
对于相关全局对象为 window 的每个 WebTransport
对象 transport,给定
transport,运行上下文清理步骤。
如果 document 的可挽救 状态为 false:
对于相关全局对象等于 window 的每个 EventSource 对象
eventSource,强制关闭
eventSource。
如果规范作者直接提交拉取请求,从这里向 其规范添加调用,而不是使用卸载文档清理 步骤钩子,会更好,因为这样可以确保跨规范调用顺序有明确定义。在撰写本文时, 已知以下规范具有卸载文档清理 步骤,这些步骤将以未指定的顺序运行:Fullscreen API、Web NFC、WebDriver BiDi、Compute Pressure、File API、 Media Capture and Streams、Picture-in-Picture、Screen Orientation、Service Workers、WebLocks API、WebAudio API、WebRTC。[FULLSCREEN] [WEBNFC] [WEBDRIVERBIDI] [COMPUTEPRESSURE] [FILEAPI] [MEDIASTREAM] [PICTUREINPICTURE] [SCREENORIENTATION] [SW] [WEBLOCKS] [WEBAUDIO] [WEBRTC]
议题 #8906跟踪 明确这些步骤顺序的工作。
要销毁一个
Document document:
中止 document。
将 document 的可挽救状态 设置为 false。
令 ports 为由以下 MessagePort 组成的列表:
其相关全局
对象的关联的
Document是
document。
对于 ports 中的每个 port,解除纠缠 port。
将 document 的浏览上下文设置为 null。
对于其集合包含 document 的每个 WorkerGlobalScope 对象,从其
所有者集合中移除 document。
对于 document 的工作线程全局 作用域中的每个 workletGlobalScope,终止 workletGlobalScope。
即使销毁之后,在我们销毁子可导航对象的情况下,脚本仍可能访问
Document 对象本身。
要销毁文档及其后代,给定一个 Document
document 和一组可选步骤 afterAllDestruction,并行执行
以下步骤:
如果 document 不是完全 活动:
令 reason 为用户代理特定阻止原因中的一个字符串。
如果没有适用的原因,则令 reason 为“masked”。
给定 document 和 reason,使 文档不可挽救。
如果 document 的节点 可导航对象是一个 顶级 可遍历对象, 则给定 document 的节点 可导航对象,构建 顶级可遍历对象及其后代的未恢复原因。
令 childNavigables 为 document 的子可导航对象。
令 numberDestroyed 为 0。
对于 childNavigables 中的每个 childNavigable 按什么顺序?,在给定 childNavigable 的活动窗口的情况下,在导航和遍历任务源上排入一个 全局任务,以执行 以下步骤:
等待直到 numberDestroyed 等于 childNavigable 的大小。
在给定 document 的相关全局对象的情况下,在 导航和遍历任务源上排入一个全局任务,以执行以下 步骤:
销毁 document。
如果已给出 afterAllDestruction,则运行它。
要中止一个 Document document:
取消 document 上下文中的所有获取算法实例,丢弃为它们排入的所有任务,
并丢弃之后从网络为它们接收的所有数据。如果这导致任何获取算法实例被取消,或任何已排入的任务或任何网络数据被
丢弃,则给定
document 和
“fetch”,使文档不可挽救。
如果 document 的用于 WebDriver BiDi 的加载期间 导航 ID不为 null:
使用 document 的
节点可导航对象和一个新的WebDriver BiDi 导航状态调用WebDriver BiDi 导航已中止,该状态的id为
document 的用于
WebDriver BiDi 的加载期间导航 ID,
状态为“canceled”,
并且url为
document 的URL。
将 document 的用于 WebDriver BiDi 的加载期间 导航 ID设置为 null。
如果 document 具有活动 解析器:
将 document 的活动解析器已中止设置为 true。
给定 document 和
“parser-aborted”,使
文档不可挽救。
要中止文档及其后代,给定一个 Document
document:
要停止加载一个 可导航对象 navigable:
通过其用户界面,用户代理还
允许停止遍历,即正在进行的导航为“traversal”的情况。
上述算法未考虑这一点。(另一方面,
用户代理不允许 window.stop() 停止
遍历,
因此上述算法对于该调用者是正确的。)请参阅议题
#6905。
推测性加载是在导航开始之前执行导航操作(例如预取)的做法。 这会使后续导航更快。
开发者可以使用推测规则发起推测性加载。用户代理也可能在某些 由实现定义的场景中执行推测性 加载,例如在地址栏中输入内容。
推测规则是 开发者向浏览器指示其认为有益的推测性加载操作的方式。它们 以 JSON 文档的形式通过以下任一方式提供:
从 `Speculation-Rules` HTTP
响应标头中指定的 URL 获取的资源。
以下 JSON 文档会被解析为一个推测规则集,其中指定了 多个期望条件,供用户代理启动由引用来源发起的导航 预取:
{
"prefetch" : [
{
"urls" : [ "/chapters/5" ]
},
{
"eagerness" : "moderate" ,
"where" : {
"and" : [
{ "href_matches" : "/*" },
{ "not" : { "selector_matches" : ".no-prefetch" } }
]
}
}
]
} 表示推测规则集的 JSON 文档必须满足以下 推测规则集编写要求:
它必须是有效的 JSON。[JSON]
该 JSON 必须表示一个 JSON 对象,并且最多只能包含三个键:“tag”、
“prefetch”和“prerender”。
在本标准中,“prerender”会在解析时可选地转换为
“prefetch”。某些实现可能会按照
Prerendering Revamped 中的规定,为预渲染实现不同的行为。[PRERENDERING-REVAMPED]
如果存在与“tag”键对应的值,则该值必须是一个
推测规则标签。
如果存在与“prefetch”和“prerender”键对应的值,则这些值必须是
由有效推测
规则组成的数组。
有效推测规则是满足以下要求的 JSON 对象:
它最多只能包含以下键:“source”、“urls”、“where”、
“relative_to”、
“eagerness”、“referrer_policy”、“tag”、“requires”、
“expects_no_vary_search”或“target_hint”。
在本标准中,“target_hint”
会被忽略。
如果存在与“source”键对应的值,则该值必须是
“list”或“document”。
如果与“source”键对应的值是“list”,则
必须存在“urls”键,并且
不得存在“where”键。
如果与“source”键对应的值是“document”,则
不得存在“urls”键。
“urls”和“where”键不得同时
存在。
如果与“source”键对应的值是“document”,或者
存在“where”键,则不得存在“relative_to”键。
如果存在与“urls”键对应的值,则该值必须是一个
由有效 URL 字符串组成的数组。
如果存在与“where”键对应的值,则该值必须是一个
有效文档
规则谓词。
如果存在与“relative_to”键对应的值,则该值必须
是“ruleset”或“document”。
如果存在与“eagerness”键对应的值,则该值必须是
一个推测规则
急切程度。
如果存在与“referrer_policy”键对应的值,
则该值必须是一个引用来源策略。
如果存在与“tag”键对应的值,则该值必须是一个
推测规则标签。
如果存在与“requires”键对应的值,则该值必须是
一个由推测规则
要求组成的数组。
如果存在与“expects_no_vary_search”键对应的值,
则该值必须是一个字符串,并且能够解析
为一个 `No-Vary-Search`
标头值。
有效文档规则谓词是满足以下 要求的 JSON 对象:
它必须恰好包含以下键之一:“and”、“or”、“not”、
“href_matches”或
“selector_matches”。
除了上述键或“relative_to”之外,它不得包含任何其他键。
如果它包含“relative_to”键,则还必须包含
“href_matches”键。
如果存在与“relative_to”键对应的值,则该值必须
是“ruleset”或“document”。
如果存在与“and”或“or”
键对应的值,则这些值必须是由有效文档
规则谓词组成的数组。
如果存在与“not”键对应的值,则该值必须是一个
有效文档
规则谓词。
如果存在与“href_matches”键对应的值,则该值必须
是一个有效 URL 模式
输入,或一个由有效 URL
模式输入组成的数组。
如果存在与“selector_matches”键对应的值,
则该值必须是一个匹配 <selector-list>
的字符串,或者一个由匹配 <selector-list>
的字符串组成的数组。
有效 URL 模式输入是以下任一项:
一个 JSON 对象,其键来自 URLPatternInit
字典的成员,且其值为标量值
字符串。
未来可能支持其他规则,例如预渲染规则。有关此类尚未被接受的扩展,请参阅 Prerendering Revamped。 [PRERENDERING-REVAMPED]
文档规则谓词是以下任一项:
一个文档 规则合取;
一个文档 规则析取;
一个文档规则 否定;
一个文档规则 URL 模式谓词; 或者
一个文档规则选择器谓词。
子句,一个文档规则谓词
推测规则急切程度是以下字符串之一:
immediate”开发者认为执行相关推测性加载很可能 值得,并且还可能预期该加载需要较长的提前时间才能完成。 用户代理通常应在实际可行时尽快实施该推测性加载候选项,但仍需 考虑用户偏好、设备状况和资源限制等因素。
eager”即使只有轻微迹象表明用户将来可能导航到该 URL, 用户代理也应实施该推测性加载候选项。例如,用户可能已将 光标移向某个链接或悬停在其上,即使只是短暂悬停;或者当该链接是 视口中较为醒目的链接之一时,用户暂停了滚动。作者希望尽可能多地捕获 导航,并且越早越好。
moderate”如果用户行为表明用户可能在不久的将来导航到
该 URL,用户代理就应实施该候选项。例如,用户可能已经将某个链接滚动到视口中,
并表现出可能点击它的迹象,例如将光标停留在该链接上一段时间。
开发者希望在“eager”和
“conservative”之间取得平衡。
conservative”只有当用户极有可能随时导航到 该 URL 时,用户代理才应实施该候选项。例如,用户可能已经开始与某个链接交互。 开发者希望以相对较小的资源代价,获得推测性加载的部分收益。
推测规则标签是一个ASCII 字符串,其码点均处于 U+0020 到 U+007E(含)范围内,或者为 null。
此码点范围限制可确保该值无需转义或修改即可在 HTTP 标头中发送。
推测规则要求是字符串
“anonymous-client-ip-when-cross-origin”。
未来可能会定义更多可能的要求。
由于推测性加载是一种渐进增强功能,本标准在解析行为方面相当保守。 特别是,未知键或无效值通常会导致解析失败, 因为什么也不做比可能错误解释推测规则更安全。
尽管如此,单个推测规则解析失败仍允许处理其他推测规则。 只有在顶层配置错误的情况下,整个推测规则集才会被丢弃。
要在给定一个字符串 input、
一个 Document document 和一个
URL baseURL 时,解析推测规则集字符串:
令 parsed 为在给定 input 的情况下,将 JSON 字符串解析为 Infra 值的结果。
令 result 为一个新的推测规则集。
令 tag 为 null。
如果 parsed[“tag”]存在:
令 typesToTreatAsPrefetch 为 « “prefetch” »。
用户代理可以将“prerender”追加
到 typesToTreatAsPrefetch。
由于本规范 只包含预取,这允许用户代理将预渲染请求视为 预取请求。按照 Prerendering Revamped 规范实现预渲染的用户代理,则会将这些请求解释为预渲染请求。 [PRERENDERING-REVAMPED]
对于 typesToTreatAsPrefetch 中的每个 type:
返回 result。
要在给定一个映射
input、一个推测规则标签
rulesetLevelTag、一个
Document document 和一个
URL baseURL 时,解析推测规则:
如果 input 不是一个映射:
用户代理可以向控制台报告警告,指明该规则 必须是一个 JSON 对象。
返回 null。
如果 input 具有除“source”、
“urls”、“where”、“relative_to”、“eagerness”、
“referrer_policy”、“tag”、“requires”、
“expects_no_vary_search”或“target_hint”之外的任何键:
用户代理可以向控制台报告警告,指明该规则 包含无法识别的键。
返回 null。
“target_hint”对
本标准中的处理模型没有影响。但是,
Prerendering Revamped 的实现可以将其用于预渲染规则,因此
要求用户代理对此类规则解析失败将适得其反。
[PRERENDERING-REVAMPED]。
令 source 为 null。
如果 input[“source”]存在,则将
source 设置为 input[“source”]。
否则,如果 input[“urls”]存在,且
input[“where”]不存在,则将
source 设置为“list”。
否则,如果 input[“where”]存在,且
input[“urls”]不存在,则将
source 设置为“document”。
如果 source 既不是“list”也不是“document”:
用户代理可以向控制台报告警告,指明无法推断 来源,或指定了无效来源。
返回 null。
令 urls 为空列表。
令 predicate 为 null。
如果 source 是“list”:
如果 source 是“document”:
如果 source 是“list”,则令 eagerness 为“immediate”;
否则为“conservative”。
如果 input[“eagerness”]存在:
令 referrerPolicy 为空字符串。
如果 input[“referrer_policy”]存在:
令 tags 为空有序集合。
如果 rulesetLevelTag 不为 null,则将 rulesetLevelTag追加到 tags。
如果 input[“tag”]存在:
令 requirements 为空有序集合。
如果 input[“requires”]存在:
令 noVarySearchHint 为默认 URL 搜索差异。
如果 input[“expects_no_vary_search”]存在:
如果 input[“expects_no_vary_search”]不是一个
字符串:
用户代理可以向控制台报告警告,指明
`No-Vary-Search`
提示无效。
返回 null。
将 noVarySearchHint 设置为在给定
input[“expects_no_vary_search”]的情况下,解析 URL 搜索差异的结果。
返回一个推测规则,其具有:
要在给定值
input、一个
Document document 和一个
URL baseURL 时,解析文档规则谓词:
如果 input 不是一个映射:
用户代理可以向控制台报告警告,指明 文档规则谓词无效。
返回 null。
如果 input 未恰好包含
“and”、“or”、“not”、“href_matches”或
“selector_matches”中的一个:
用户代理可以向控制台报告警告,指明 文档规则谓词为空或存在歧义。
返回 null。
令 predicateType 为上一步中找到的唯一键。
如果 predicateType 是“and”或“or”:
如果 predicateType 是“not”:
如果 predicateType 是“href_matches”:
如果 input 具有除
“href_matches”或“relative_to”之外的任何键:
用户代理可以向控制台报告警告,指明 文档规则谓词包含意外的额外选项。
返回 null。
如果 input[“relative_to”]存在:
令 rawPatterns 为 input[“href_matches”]。
如果 rawPatterns 不是一个列表,则将 rawPatterns 设置为 « rawPatterns »。
令 patterns 为空列表。
对于 rawPatterns 中的每个 rawPattern:
令 pattern 为在给定 rawPattern 和 baseURL 的情况下,从 Infra 值构建 URL 模式的结果。 如果此步骤抛出异常,则捕获该异常并将 pattern 设置为 null。
如果 pattern 为 null:
用户代理可以向控制台报告警告,指明 提供的 URL 模式无效。
返回 null。
将 pattern追加到 patterns。
返回一个文档规则 URL 模式 谓词,其模式为 patterns。
如果 predicateType 是“selector_matches”:
断言:永远不会到达此步骤,因为之前的某个分支已经 执行。
匿名化策略,一个 预取 IP 匿名化策略
预取 IP 匿名化策略是 null 或一个跨源预取 IP 匿名化策略。
跨源预取 IP 匿名化策略是一个 结构体,其 唯一的项是它的源,一个源。
如果以下步骤返回 true,则一个推测性加载候选项 candidateA 与另一个推测性加载 候选项 candidateB冗余:
如果 candidateA 的No-Vary-Search 提示 不等于 candidateB 的No-Vary-Search 提示,则返回 false。
如果给定 candidateA 的No-Vary-Search 提示,candidateA 的URL与 candidateB 的URL并非在忽略搜索差异时等价,则返回 false。
返回 true。
要求No-Vary-Search 提示 等价这一要求有些严格。这意味着某些理论上可以被视为 匹配的情况,并不会如此处理。因此,可能会发生冗余的推测性加载。
但是,允许更宽松的匹配会使该检查不再是等价关系,并且 生成此类匹配需要一种执行完整比较的实现策略, 而不是使用规范化 URL 键的更简单策略。这与 No Vary Search § 6 比较中针对服务器运营者的最佳实践和相关 HTTP 缓存实现说明一致。
在实践中,我们预计这不会导致冗余的推测性加载,因为服务器
运营者和相应编写推测规则的 Web 开发者会遵循最佳
实践,并使用静态的 `No-Vary-Search`
标头值/推测规则提示。
考虑三个推测性加载 候选项:
A 的URL为
https://example.com?a=1&b=1,并具有一个从
params=("a") 解析而来的No-Vary-Search 提示。
B 的URL为
https://example.com?a=2&b=1,并具有一个从
params=("b") 解析而来的No-Vary-Search 提示。
C 的URL为
https://example.com?a=2&b=2,并具有一个从
params=("a") 解析而来的No-Vary-Search 提示。
根据当前冗余的定义, 这些候选项彼此均不冗余。包含这三个候选项的推测规则 集可能会导致三次独立的推测性加载。
不要求No-Vary-Search 提示等价的定义, 可以认为 A 与 B 匹配(使用 A 的No-Vary-Search 提示),并且 B 与 C 匹配(使用 B 的No-Vary-Search 提示)。但它无法认为 A 与 C 匹配,因此它不具有传递性,也就不是 等价关系。
每个 Document 都具有推测规则集,一个由推测规则集组成的列表,初始
为空。
每个 Document 都具有一个
已排入考虑推测性加载微任务,
一个布尔值,初始为 false。
要为一个 Document
document考虑推测性加载:
如果 document 的节点可导航对象不是一个顶级 可遍历对象,则返回。
支持向子 可导航对象进行推测性加载存在一些复杂性,目前尚未定义。未来可能可以 对其进行定义。
如果 document 的已排入考虑推测性 加载微任务为 true, 则返回。
将 document 的已排入考虑推测性 加载微任务设置为 true。
给定 document,排入一个微任务以运行以下步骤:
将 document 的已排入 考虑推测性加载微任务设置为 false。
为 document 运行内部考虑 推测性加载步骤。
除了本标准中明确给出的调用位置之外:
当用户以用户代理用于实现 推测规则急切程度 启发式方法的某种由实现定义的方式,对超链接表示兴趣时,用户代理可以为该超链接的节点文档考虑 推测性加载。
例如,一个通过监视 pointerdown
事件来实现“conservative”
急切程度的用户代理,会希望在响应此类事件时考虑推测性
加载。
在本标准中,每次调用考虑推测性加载时,都只给出一个
Document,并且该
算法以无状态方式重新计算所有可能的候选项。
实际实现可能会缓存先前的计算,并从
调用位置传递信息,以提高更新效率。例如,如果一个 a 元素的 href
属性发生变化,则可以
传递该特定元素,以便仅更新相关的推测性加载候选项。
请注意,由于考虑推测性加载会排入一个 微任务,因此当内部考虑推测性 加载步骤运行时,多个更新(或取消)可能会一起处理。
一个 Document
document 的内部考虑推测性加载步骤是:
如果 document 不是完全活动,则返回。
令 prefetchCandidates 为空列表。
对于 document 的推测规则集中的每个 ruleSet:
令 anonymizationPolicy 为 null。
如果 rule 的要求包含
“anonymous-client-ip-when-cross-origin”,则将
anonymizationPolicy 设置为一个跨源
预取 IP 匿名化
策略,其源为
document 的源。
令 referrerPolicy 为给定 rule 和 null 时,计算 推测性加载引用来源策略的结果。
将一个新的预取候选项追加到 prefetchCandidates,其具有
如果 rule 的谓词不为 null:
令 prefetchCandidateGroups 为空列表。
对于 prefetchCandidates 中的每个 candidate:
令 group 为 « candidate »。
使用 prefetchCandidates 中除 candidate 本身之外的所有项扩展 group,这些项与 candidate冗余, 且其急切程度 相对于 candidate 的 急切程度至少同样急切。
将 group追加到 prefetchCandidateGroups。
{
"prefetch" : [
{
"tag" : "a" ,
"urls" : [ "next.html" ]
},
{
"tag" : "b" ,
"urls" : [ "next.html" ],
"referrer_policy" : "no-referrer"
}
]
} 此步骤将创建一个按给定顺序同时包含二者的组。(第二次
遍历不会创建一个组,因为其内容与第一个组相同,
只是顺序不同。)这意味着,如果用户代理选择执行下方“可以”步骤
来实施该组,它将实施第一个候选项,并忽略第二个。因此,
请求将使用默认引用来源策略,而不是使用“no-referrer”。
但是,从推测性加载候选项中
收集标签算法会
从该组中的两个候选项收集标签,因此 `Sec-Speculation-Tags`
标头值将为 `"a", "b"`。这向服务器运营者表明,
任一规则都可能导致该推测性加载。
对于 prefetchCandidateGroups 中的每个 group:
用户代理可以运行以下步骤:
令 prefetchCandidate 为 group[0]。
令 tagsToSend 为给定 group 时,从 推测性加载候选项中收集标签的结果。
令 prefetchRecord 为一个新的预取记录,其具有
speculation rules”给定 document 和 prefetchRecord,启动由引用来源发起的 导航预取。
在决定是否执行此“可以”步骤时,用户代理应考虑 prefetchCandidate 的急切程度,并 遵循用户当前行为和推测规则 急切程度的定义。
prefetchCandidate 的No-Vary-Search 提示也可用于实现为 推测规则急切程度 值定义的启发式方法。例如,用户悬停在某个链接上,而该链接的 URL 在给定 prefetchCandidate 的No-Vary-Search 提示的情况下,与 prefetchCandidate 的URL在忽略搜索 差异时等价,这可能向用户代理表明执行此步骤是有用的。
在决定是否执行此“可以”步骤时,用户代理应优先考虑用户 偏好(明确或隐含的,例如流量节省或电池节省模式),而不是 Web 开发者 提供的急切程度。
如果根据 predicate 的类型进行分支后,以下步骤返回 true,则一个文档
规则谓词 predicate匹配一个 a 或 area 元素
el:
推测规则功能使用推测规则任务源, 它是一个 任务源。
由于推测性加载通常不如为当前文档处理任务重要, 实现可能会为排入此处的任务赋予特别低的优先级。
目前,导航预取过程定义在 Prefetch 规范中。将其移入本标准的工作在议题 #11123中跟踪。[PREFETCH]
本标准引用其中定义的以下概念:
Speculation-Rules`
标头`Speculation-Rules` HTTP 响应
标头允许
开发者请求用户代理获取给定的推测规则集并将其应用
于当前 Document。它是一个结构化
标头,其值必须是一个由均为有效 URL 字符串的字符串组成的列表。
要在给定一个 Document
document 和一个响应
response 时,处理
`Speculation-Rules` 标头:
令 parsedList 为从
response 的标头列表中,给定
`Speculation-Rules`
和“list”时获取结构化字段值的结果。
如果 parsedList 为 null,则返回。
对于 parsedList 中的每个 item:
如果 url 为失败,则继续。
并行:
可选地,等待一段由实现定义的时间。
这允许实现在加载推测规则之前优先处理其他工作,
因为特别是在 Document 创建和
标头处理期间,通常会进行许多更重要的工作。
在给定 document 的相关全局对象的情况下,在推测规则任务源上排入一个全局 任务,以执行以下 步骤:
令 request 为一个新的请求,其
URL为 url,目标为
“speculationrules”,并且模式为
“cors”。
获取 request,并使用以下 processResponseConsumeBody 步骤,给定响应 response,以及 null、失败或一个 字节 序列 bodyBytes:
如果 bodyBytes 为 null 或失败,则中止这些步骤。
如果从 response 的标头列表中提取 MIME 类型的结果,
其本质不是
“application/speculationrules+json”,
则中止这些步骤。
令 bodyText 为对 bodyBytes 进行UTF-8 解码的结果。
令 ruleSet 为给定 bodyText、 document 和 response 的URL时,解析推测 规则集字符串的结果。如果这抛出异常,则中止 这些 步骤。
为 document考虑推测性加载。
Sec-Speculation-Tags`
标头`Sec-Speculation-Tags` HTTP
请求标头指定
与推测性导航请求相关联的、由 Web 开发者提供的标签。它还可以
用于区分推测性导航请求和推测性子资源请求,因为
`Sec-Purpose`
可以由这两类请求发送。
该标头是一个结构化
标头,其值必须
是一个列表。该列表可以包含词元或字符串值。字符串值表示
开发者提供的标签,而词元值表示预定义标签。目前,唯一的
预定义标签是 null,它表示一个没有开发者定义标签的
推测性导航请求。
Web 页面可以向跨站目标发起推测性加载。但是,由于 此类跨站推测性加载始终在不携带凭据的情况下执行,如 下文所述,因此环境权限仅限于 已经可以通过平台上的其他机制发出的请求。
`Speculation-Rules`
标头也可以用于发出针对 JSON
文档的请求,其主体将被解析为
推测规则集字符串。但是,它们使用“same-origin”
凭据模式、“cors”模式,
并且会忽略
未使用 application/speculationrules+json
MIME 类型
本质的响应,
因此它们无法用于发动攻击。
由于文档中的链接可以通过文档规则谓词被选择用于推测性加载,因此如果这些链接
可能包含用户生成的标记,开发者就需要谨慎。例如,如果一个链接的 href
可以由某个用户输入并显示给所有
其他用户,则恶意用户可能会选择类似“/logout”的值,从而导致
其他用户的浏览器在该链接被推测性加载时自动退出网站。
使用文档规则选择器谓词
排除此类潜在危险的链接,
或使用文档规则 URL 模式
谓词将已知安全的链接列入允许列表,是
这方面有用的技术。
与 script
元素的所有用法一样,开发者在
将用户提供的内容插入 <script type=speculationrules> 的
子文本
内容时需要谨慎。特别是,插入未经转义的结束 </script> 标签可能被用于
脱离 script
元素
上下文,并注入攻击者控制的标记。
<script type=speculationrules> 功能会响应
文档中发现的内容而引发活动,因此值得考虑能够注入
未转义 HTML 的攻击者可以利用哪些方式。此类攻击者本来就已经能够注入 JavaScript 或
iframe
元素。推测性加载通常不如任意脚本
执行危险。但是,使用文档规则
谓词可能被用于推测性加载文档中的链接,而这些加载的存在
可能成为泄露这些链接相关信息的途径。
内容安全策略提供了针对这种可能性的纵深防御。特别是,
script-src 指令可用于限制推测规则
script
元素的解析,而 default-src 指令适用于
由此类推测规则产生的导航预取请求。要求仅对可能可信的 URL执行推测性加载,
还提供了额外防御,因此路径上的攻击者只能
访问元数据并进行流量分析,而无法直接看到 URL。
[CSP]
通常不应将用户生成的内容作为任意响应
标头添加:如果可以这样做,服务器运营者本来就会遇到严重问题。
因此,`Speculation-Rules`
标头不太可能显著扩大
XSS 攻击面。出于这个原因,内容安全策略不适用于通过该标头
加载规则集。
本标准允许开发者请求使用用户代理提供的 IP 匿名化技术执行导航预取。该匿名化的细节未作 规定,但适用一些通用安全原则。
如果 IP 匿名化是使用代理服务实现的,则建议 尽量减少服务运营者及网络路径上其他实体可获得的信息。 这至少可能涉及对连接使用 TLS。
站点运营者需要注意,与虚拟专用网络(VPN)技术类似, HTTP 服务器看到的客户端 IP 地址可能无法精确对应用户实际的 网络提供商或位置,并且来自多个不同订阅者的流量可能源自 同一个客户端 IP 地址。这可能会影响站点运营者的安全和滥用防范 措施。IP 匿名化措施可能会尝试使用与用户具有 相似地理位置或位于同一司法管辖区的出口 IP 地址,但任何此类行为都 取决于用户代理,并不受保证。
考虑 推测性加载算法包含一个关键的“可以”步骤,该步骤 鼓励用户代理根据推测 规则急切程度和用户环境的其他特征组合,启动 由引用来源发起的导航预取。由于文档可以观察到 是否执行了推测性加载,因此用户代理在作出此类决定时必须谨慎保护 隐私,例如仅使用源已经可以获得的信息。如果这些启发式方法依赖 任何持久状态,则每当用户删除其他站点数据时,也必须删除该状态。 如果用户代理会不时自动清除其他站点数据,则必须同时删除此类持久状态。
此处有意使用源而不是站点。 尽管同站源通常可以按其意愿进行协调,但 Web 的安全 模型建立在阻止源访问其他源的数据之上,即使是同站 源也是如此。因此,用户代理需要确保不会无意中跨源泄露此类数据, 而不仅仅是防止跨站泄露。
文档已经知道的输入示例:
作者提供的急切程度
在文档中的出现顺序
链接是否位于视口中
光标是否靠近链接
链接的渲染尺寸
与源相关的持久数据示例(源本可以自行收集这些数据), 但必须根据用户意图将其删除:
用户是否在此文档或同一源上的其他文档中点击过该链接或类似链接
可能有助于决定推测性加载是否适当的设备信息示例, 但由于它们可能使用户在不同源之间更容易被识别,因此需要作为用户代理整体隐私 策略的一部分来考虑:
粗略的设备类别(CPU、内存)
粗略的电池电量
是否已知网络连接按流量计费
任何可由用户切换的设置,例如推测性加载开关、电池节省 开关或流量节省开关
启动由引用来源发起的导航 预取算法被设计为 确保其发出的 HTTP 请求与用户代理根据存储键对 凭据进行分区的方式保持一致。即使对于跨分区预取,也会如下维持此 属性。
如果未来使用预取响应的导航会在同一分区中加载文档, 则在预取时可以发送分区凭据,就像子资源 请求和脚本获取一样。如果此类未来导航会改为在 另一个分区中加载文档,那么为目标分区使用分区 凭据将与分区方案不一致(因为这会在没有顶级导航的情况下跨越分区边界), 而使用起始分区中的分区凭据也不一致 (因为这会导致用户看到一个状态与非预取导航不同的文档)。 相反,此类请求使用第三个、初始为空的分区。因此,这些请求 不会发送来自任一分区的凭据。但是,使用该初始为空的分区构造的 预取响应主体,只有在激活时目标分区不包含任何凭据的情况下才能 使用。
这与仅在提前已知目标分区不包含凭据时 才发送此类预取请求的行为有些相似。但是,为了避免此类 行为被用作探测凭据是否存在的方式,此类预取 请求始终会完成,而在存在冲突凭据的情况下,其结果不会 被使用。
这两类请求之间可能发生重定向。从同分区 URL 重定向到 跨分区 URL,可能包含源自起始分区中分区凭据的信息; 但是,这等同于起始文档自行获取 同分区 URL,然后再发出针对跨分区 URL 的请求。从 跨分区 URL 重定向到同源 URL,可能携带隔离分区中的凭据,但由于该 分区没有先前状态,因此不会基于用户在该站点上的先前浏览 活动启用跟踪,并且文档可以通过自行发出不携带凭据的 请求来构造相同状态。
推测性加载提供了一种机制,可在没有用户手势的情况下 为后续顶级导航发出 HTTP 请求。自然会产生一个问题:两个 协作站点是否可以关联用户身份。
由于不会发送目标站点的现有凭据
(如上一节所述),因此该站点在导航前识别用户的能力
与引用来源站点仅使用 fetch()
发出不携带凭据的请求时类似。导航发生后,这与普通导航类似
(例如点击一个未被推测性加载的链接)。
在用户代理尝试缓解普通获取和导航中的身份关联的范围内, 它们可以对推测性加载的导航应用类似的缓解措施。
X-Frame-Options` 标头所有当前引擎均支持。
`X-Frame-Options` HTTP 响应标头
是一种
控制是否以及如何允许一个 Document 在子
可导航对象中加载的方式。对于使用 CSP 的站点,frame-ancestors
指令可以对相同情形提供更细粒度的控制。
它最初定义于 HTTP Header Field X-Frame-Options,但
此处的定义和处理模型取代了该文档。
[CSP] [RFC7034]
特别是,HTTP Header Field X-Frame-Options 指定了该标头的
`ALLOW-FROM` 变体,但不得实现该变体。
根据下方处理模型,如果同一个响应中同时使用了
CSP frame-ancestors
指令和
`X-Frame-Options`
标头,则会忽略 `X-Frame-Options`。
对于 Web 开发者和一致性检查器,其值的ABNF 为:
X-Frame-Options = "DENY" / "SAMEORIGIN" 要在给定一个响应
response、一个可导航对象
navigable、一个CSP 列表
cspList 和
一个源
destinationOrigin 时,检查导航响应是否遵循
`X-Frame-Options`:
如果 navigable 不是一个子可导航对象,则返回 true。
对于 cspList 中的每个 policy:
如果 policy 的指令集
包含一个 frame-ancestors
指令,则返回 true。
令 rawXFrameOptions 为从 response 的标头列表中获取、解码并拆分
`X-Frame-Options`
的结果。
令 xFrameOptions 为一个新的集合。
对于 rawXFrameOptions 中的每个 value,将 value转换为 ASCII 小写,并追加到 xFrameOptions。
如果 xFrameOptions 的大小大于 1,并且
xFrameOptions包含
“deny”、“allowall”或“sameorigin”中的任意一个,则返回 false。
这里的意图是阻止任何试图应用
`X-Frame-Options`
的操作,这些操作原本试图执行有效操作,但看起来存在混淆。
这是旧式 `ALLOWALL` 值对处理模型的唯一影响。
如果 xFrameOptions 的大小大于 1,则 返回 true。
这意味着它包含多个无效值,我们会以与 完全省略该标头相同的方式进行处理。
如果 xFrameOptions[0] 是“deny”,则返回
false。
如果 xFrameOptions[0] 是“sameorigin”:
返回 true。
如果已经到达此处,则存在一个单独的无效值(可能
是旧式 `ALLOWALL` 或 `ALLOW-FROM` 形式之一)。这些值会被视为
完全省略该标头。
下表说明了该标头各种值的处理方式,其中包括 不符合要求的值:
`X-Frame-Options`
|
有效 | 结果 |
|---|---|---|
`DENY` |
✅ | 禁止嵌入 |
`SAMEORIGIN` |
✅ | 允许同源嵌入 |
`INVALID` |
❌ | 允许嵌入 |
`ALLOWALL` |
❌ | 允许嵌入 |
`ALLOW-FROM=https://example.com/` |
❌ | 允许嵌入(来自任何位置) |
下表说明了涉及多个值的各种不符合要求的情况如何 处理:
`X-Frame-Options`
|
结果 |
|---|---|
`SAMEORIGIN, SAMEORIGIN` |
允许同源嵌入 |
`SAMEORIGIN, DENY` |
禁止嵌入 |
`SAMEORIGIN,` |
禁止嵌入 |
`SAMEORIGIN, ALLOWALL` |
禁止嵌入 |
`SAMEORIGIN, INVALID` |
禁止嵌入 |
`ALLOWALL, INVALID` |
禁止嵌入 |
`ALLOWALL,` |
禁止嵌入 |
`INVALID, INVALID` |
允许嵌入 |
无论这些值是在单个以逗号分隔其值的标头中提供, 还是在多个标头中提供,都会得到相同结果。
Refresh` 标头`Refresh` HTTP 响应标头
在 HTTP 中等同于
一个 meta 元素,其
http-equiv
属性处于Refresh
状态。它采用相同的值,其工作方式也大致
相同。其处理模型在创建并初始化一个
Document
对象中详述。
浏览器用户代理应提供对其 顶级可遍历对象集合中的任何顶级可遍历对象执行导航、 重新加载和停止加载的能力。
例如,通过地址栏和重新加载/停止按钮用户界面。
浏览器用户代理应提供对其顶级 可遍历对象集合中的任何顶级可遍历对象按增量遍历的能力。
例如,通过后退和前进按钮,并可能包括长按 以更改增量的功能。
建议此类用户代理允许大于一的增量遍历,以避免
页面通过使用虚假条目填充会话历史记录而“困住”用户。(例如,
通过重复调用 history.pushState() 或
执行片段导航。)
某些用户代理具有将单次“后退”或“前进” 按钮按下转换为更大增量的启发式方法,专门用于克服此类滥用。我们正在考虑 在议题 #7832中规定这些启发式方法。
浏览器用户代理应允许用户在给定由用户提供或由用户代理确定的初始URL时,创建新的顶级 可遍历对象。
例如,通过“新建标签页”或“新建窗口”按钮。
浏览器用户代理应允许用户任意关闭其 顶级可遍历对象 集合中的任何顶级可遍历对象。
例如,通过点击“关闭标签页”按钮。
浏览器用户代理可以提供让用户显式使任何 可导航对象(而不仅仅是顶级可遍历对象)执行导航、重新加载或停止 加载的方式。
例如,通过上下文菜单。
浏览器用户代理可以允许用户销毁顶级 可遍历对象。
例如,通过强制关闭包含一个或多个此类顶级可遍历对象的窗口。
当用户请求重新加载一个可导航对象,且该对象的活动会话历史条目的文档状态的资源是一个POST 资源时,用户代理 应先提示用户确认该操作,因为否则可能会重复执行事务(例如 购买或数据库修改)。
当用户请求重新加载一个可导航对象时,用户代理可以提供 一种在重新加载时忽略所有缓存的机制。
由上述机制发起的所有导航调用,其 userInvolvement
参数必须设置为“browser UI”。
由上述机制发起的所有重新加载调用,其 userInvolvement
参数必须设置为“browser UI”。
由上述机制发起的所有按增量遍历历史记录调用, 都不得为 sourceDocument 参数传递值。
上述建议以及本规范中的数据结构,并不是为了 限制用户代理如何向用户表示会话历史记录。
例如,尽管一个顶级 可遍历对象的会话 历史条目以列表形式存储和维护,并且建议用户代理提供 一个用于按增量遍历该列表的界面,但新颖的用户代理 可以改为或额外呈现树状视图,其中每个页面都有多个可供用户 选择的“前进”页面。
类似地,尽管所有后代可导航对象的会话历史记录存储在其可遍历可导航对象中,但用户 代理可以向用户呈现更细致的、按可导航对象区分的会话 历史记录视图。
浏览器用户代理可以出于以下目的使用一个顶级浏览上下文的是否为 弹出窗口布尔值:
在这两种情况下,用户代理还可以考虑用户偏好,或让用户选择 是否采用弹出窗口方式。
建议为此类弹出窗口提供最小化用户界面的用户代理不要隐藏 浏览器的地址栏。
各种机制可能会导致作者提供的可执行代码在文档上下文中运行。 这些机制包括但可能不限于:
script
元素。javascript: URL。addEventListener() 注册、通过显式的事件处理程序
内容属性、通过
事件处理程序 IDL
属性注册,还是通过其他方式注册。
JavaScript 定义了代理的概念。本节给出该 语言层概念到 Web 平台的映射。
从概念上讲,代理概念是一个 与架构无关的理想化 “线程”,JavaScript 代码在其中运行。此类代码可能涉及多个能够 同步相互访问的全局对象/领域, 因此需要在单个执行线程中运行。
两个 Window 对象
拥有相同的代理,并不表示
它们可以直接访问彼此领域中创建的所有对象。它们必须
同源域;请参阅IsPlatformObjectSameOrigin。
Web 平台上存在以下类型的代理:
包含各种可能能够相互访问的 Window 对象,
它们可以直接访问,
或通过使用 document.domain
来访问。
如果所包含的代理集群的是否按源划分为
true,则
所有 Window
对象都将同源,能够直接相互访问,
并且 document.domain
将不执行任何操作。
包含单个 SharedWorkerGlobalScope。
包含单个 ServiceWorkerGlobalScope。
包含单个 WorkletGlobalScope
对象。
尽管给定工作单元可以具有多个领域,但每个此类领域都需要自己的 代理,因为每个领域都可以独立于其他领域并与其同时执行代码。
只有共享和专用工作线程代理允许使用
JavaScript Atomics
API 来
潜在地阻塞。
要在给定布尔值 canBlock 时创建代理:
JavaScript 还定义了代理集群的概念,本 标准通过在使用 获取 相似源窗口代理或 获取 工作线程/工作单元代理 算法创建代理时,适当地放置代理,将该概念映射 到 Web 平台。
代理集群概念
对于定义 JavaScript 内存模型至关重要,特别是定义在哪些代理之间可以共享
SharedArrayBuffer
对象的底层
数据。
从概念上讲,代理集群概念是一个 与架构无关的理想化“进程边界”,它将多个“线程” (代理)分组在一起。规范定义的代理 集群 通常比用户代理实际实现的进程边界更严格。通过在规范层面强制执行这些 理想化划分,我们可以确保即使面对不同且不断变化的用户代理进程模型, Web 开发者在共享内存方面也能看到可互操作的行为。
一个代理集群具有一个
关联的跨源隔离模式,它是一个
跨源隔离
模式。其初始值为“none”。
一个代理集群具有一个 关联的是否按源划分(布尔值),其 初始值为 false。
代理集群键是一个站点或元组源。如果 Web 开发者未采取行动来实现按源划分的代理集群,它将是一个 站点。
要在给定一个源 origin、一个浏览上下文组 group 和一个布尔值 requestsOAC 时,获取相似源窗口代理,运行以下步骤:
令 site 为使用 origin获取站点的结果。
令 key 为 site。
否则,如果 group 的历史 代理集群键 映射[origin]存在,则将 key 设置为 group 的历史 代理集群键映射[origin]。
否则:
如果 requestsOAC 为 true,则将 key 设置为 origin。
将 group 的历史 代理集群键映射[origin] 设置为 key。
这意味着每个浏览上下文代理集群中只有一个相似源窗口 代理。(但是,专用 工作线程和工作单元代理可能位于同一 集群中。)
以下内容定义了所有其他类型代理的代理 集群的分配。
要在给定一个环境设置 对象或 null outside settings、一个布尔值 isTopLevel 和一个布尔值 canBlock 时,获取工作线程/工作单元代理,运行以下步骤:
令 agentCluster 为 null。
如果 isTopLevel 为 true:
将 agentCluster 设置为一个新的代理集群。
将 agentCluster 的是否按源划分设置为 true。
这些工作线程可以被视为按源划分。但是,这不会
通过任何 API 暴露(不像 originAgentCluster
会暴露窗口是否按源划分)。
否则:
令 agent 为给定 canBlock 时创建 代理的结果。
将 agent 添加到 agentCluster。
返回 agent。
要在给定一个环境设置 对象 outside settings 和一个布尔值 isShared 时,获取专用/共享工作线程代理,返回给定 outside settings、 isShared 和 true 时获取 工作线程/工作单元代理的结果。
要在给定一个环境设置 对象 outside settings 时,获取工作单元代理,返回给定 outside settings、false 和 false 时获取 工作线程/工作单元代理的结果。
要获取服务工作线程代理,返回给定 null、true 和 false 时获取 工作线程/工作单元代理的结果。
JavaScript 规范引入了领域概念,它表示一个运行脚本的全局 环境。每个领域都带有一个由实现定义的 全局对象;本规范的大部分内容 都致力于定义该全局对象 及其属性。
对于 Web 规范,将值或算法与
领域/全局对象对相关联通常很有用。当这些值特定于某种领域类型时,它们会
直接与相关全局对象相关联,例如在
Window 或 WorkerGlobalScope
接口的定义中。当这些值可用于
多个领域时,我们使用环境设置对象概念。
最后,在某些情况下,甚至在 领域/全局对象/环境设置对象存在之前,就有必要跟踪相关值(例如,在 导航期间)。这些值在 环境概念中跟踪。
环境是一个标识当前或 潜在执行环境设置的对象(即导航 参数的保留环境 或请求的保留 客户端)。一个环境具有 以下字段:
唯一标识此环境的不透明字符串。
对于一个 Window 环境设置
对象,
此 URL 可能不同于其全局
对象的关联的
Document的URL,这是由于诸如
history.pushState()
等会修改
后者的机制所致。
一个目前由实现定义的值、null 或一个源。对于一个“顶级”潜在 执行环境,它为 null(即 尚无响应时);否则,它是“顶级”环境的源。对于专用工作线程或 worklet,它是 其创建者的顶级源。对于共享工作线程或 服务工作线程,它是一个 由实现定义的值。
一个指示环境设置是否完成的标志。它最初 未设置。
规范可以为环境定义环境丢弃步骤。这些 步骤接受一个环境作为输入。
环境 丢弃步骤只会为少数选定环境运行:即那些 永远不会进入执行就绪状态的环境,例如因为它们加载失败。
环境设置对象是一个环境,它 还为以下内容指定算法:
一个由使用此设置对象的所有 脚本共享的JavaScript 执行上下文,即给定 领域中的所有脚本。当我们运行经典脚本或运行模块 脚本时,此执行上下文会成为JavaScript 执行上下文 栈的顶部,并在其上压入另一个特定于相关脚本的执行上下文。 (此设置确保 源文本模块记录的 Evaluate 知道应使用哪个领域。)
一个在导入 JavaScript 模块时使用的模块映射。
一个用于安全检查的源。
一个用于安全检查的布尔值。
一个包含用于安全检查的策略的策略容器。
一个布尔值,表示使用此环境设置 对象的脚本是否允许使用需要跨源隔离的 API。
全局对象是一个作为 一个领域的 [[GlobalObject]] 字段的 JavaScript 对象。
在本规范中,所有领域都使用
全局
对象进行创建,这些对象是
Window、WorkerGlobalScope
或
WorkletGlobalScope
对象。
一个全局对象具有一个 处于错误报告模式 布尔值,其初始值为 false。
一个全局对象具有一个
未处理的已拒绝 promise 弱集合,它是一个由
Promise
对象组成的集合,初始为空。此集合
不得创建对其任何成员的强引用,实现可以通过由实现定义的方式限制
其大小,例如在添加新条目时移除其中的旧条目。
一个全局对象具有一个
即将通知的已拒绝 promise 列表,它是一个由
Promise
对象组成的列表,初始为空。
一个全局对象具有一个 导入映射, 其初始值为一个空导入 映射。
目前,只有 Window
全局
对象的导入映射会从
初始空映射被修改。导入映射仅
在解析根模块脚本时访问。
一个全局对象具有一个已解析模块集合,它是一个由说明符解析记录组成的集合, 初始 为空。
已解析模块集合确保模块
说明符解析在使用相同的(引用来源、说明符)对多次调用时
返回相同结果。它通过确保影响说明符在其
引用来源作用域中的导入
映射规则不能在其首次解析后定义来实现这一点。目前,只有 Window
全局对象的
模块集合数据结构会从初始空状态被修改。
要在一个代理 agent 中创建一个新 领域,并可选地提供创建 全局对象或全局 this 绑定(或两者)的指令,执行以下步骤:
使用为创建全局对象和全局 this 绑定所提供的自定义方式,执行InitializeHostDefinedRealm()。
令 realm execution context 为正在运行的 JavaScript 执行 上下文。
这是上一步中创建的JavaScript 执行上下文。
从JavaScript 执行上下文 栈中移除 realm execution context。
令 realm 为 realm execution context 的 Realm 分量。
如果 agent 的代理集群的跨源隔离
模式是“none”:
这样做是为了兼容 Web 内容,并且希望将来
可以将其移除。Web 开发者仍然可以通过
new WebAssembly.Memory({ shared:true, initial:0, maximum:0
}).buffer.constructor
获得该构造函数。
返回 realm execution context。
在本规范中定义算法步骤时,通常有必要指出 应使用哪个领域,或者等价地,应使用哪个全局对象或 环境设置对象。通常至少有四种 可能性:
请注意,入口、现任和当前概念可以直接使用而无需限定, 而相关概念必须应用于 特定的平台对象。
现任和入口 概念不应在新规范中使用, 因为它们极其复杂,使用起来也不直观。我们正在努力从平台中移除几乎 所有现有用法:关于现任,请参阅议题 #1430;关于入口,请参阅议题 #1431。
通常,Web 平台规范应使用应用于正在操作的对象
(通常是当前方法的 this 值)的相关概念。这与 JavaScript
规范不一致,后者通常将当前作为
默认值(例如,在确定应使用哪个领域的 Array
构造函数来构造 Array.prototype.map 中的结果时)。
但这种不一致在平台中根深蒂固,因此我们今后只能接受它。
考虑以下页面,其中 a.html 加载在浏览器
窗口中,b.html 如图所示加载在一个 iframe
中,而 c.html 和 d.html 被省略(它们可以只是空
文档):
<!-- a.html -->
<!DOCTYPE html>
< html lang = "en" >
< title > 入口页面</ title >
< iframe src = "b.html" ></ iframe >
< button onclick = "frames[0].hello()" > 你好</ button >
<!--b.html -->
<!DOCTYPE html>
< html lang = "en" >
< title > 现任页面</ title >
< iframe src = "c.html" id = "c" ></ iframe >
< iframe src = "d.html" id = "d" ></ iframe >
< script >
const c = document. querySelector( "#c" ). contentWindow;
const d = document. querySelector( "#d" ). contentWindow;
window. hello = () => {
c. print. call( d);
};
</ script > 每个页面都有自己的浏览上下文,因此也有自己的领域、 全局对象和环境设置对象。
当响应按下
a.html 中的按钮而调用 print()
方法时:
相关概念
通常比当前概念更适合作为默认选择的一个原因,
是它更适合
创建需要持久保存并多次返回的对象。例如,navigator.getBattery()
方法会在调用它的 Navigator 对象的
相关
领域中创建 promise。这会产生以下影响:[BATTERY]
<!-- outer.html -->
<!DOCTYPE html>
< html lang = "en" >
< title > 相关领域演示:外部页面</ title >
< script >
function doTest() {
const promise = navigator. getBattery. call( frames[ 0 ]. navigator);
console. log( promise instanceof Promise); // 输出 false
console. log( promise instanceof frames[ 0 ]. Promise); // 输出 true
frames[ 0 ]. hello();
}
</ script >
< iframe src = "inner.html" onload = "doTest()" ></ iframe >
<!-- inner.html -->
<!DOCTYPE html>
< html lang = "en" >
< title > 相关领域演示:内部页面</ title >
< script >
function hello() {
const promise = navigator. getBattery();
console. log( promise instanceof Promise); // 输出 true
console. log( promise instanceof parent. Promise); // 输出 false
}
</ script > 如果 getBattery()
方法的算法
改为使用当前领域,则所有结果都会反转。也就是说,
在 outer.html 中首次调用 getBattery()
后,inner.html 中的 Navigator 对象
将永久存储一个在 outer.html 的领域中创建的 Promise 对象,而在
hello() 函数内部的此类调用就会返回来自“错误”领域的 promise。由于
这是不可取的,因此该算法改用相关领域,从而得到
上述注释中所示的合理结果。
调用脚本的过程会将领域执行上下文压入或弹出JavaScript 执行上下文栈,并与其他执行上下文交错。
有了这些基础,我们将入口执行上下文定义为 JavaScript 执行上下文栈中最近 压入且属于领域执行上下文的项。入口 领域是入口执行 上下文的 Realm 分量。
所有JavaScript 执行上下文都必须 在其代码求值状态中包含一个确定现任时跳过 计数器值,其初始值为零。在准备运行回调和运行回调后清理的过程中,该值会递增和 递减。
每个事件循环都有一个关联的备用现任设置对象 栈,初始为空。粗略地说,当栈上没有作者代码,但作者代码以某种方式负责使 当前算法运行时,它用于确定现任 设置对象。准备运行回调和运行回调后清理的过程会操作此栈。 [WEBIDL]
当 Web IDL 用于调用作者 代码,或当HostEnqueuePromiseJob 调用 promise 作业时,它们使用以下 算法来跟踪用于确定现任设置对象的相关数据:
要使用一个环境设置对象 settings准备运行回调:
将 settings 压入备用现任设置对象 栈。
令 context 为最顶层含脚本执行 上下文。
如果 context 不为 null,则递增 context 的 确定现任时跳过计数器。
要使用一个环境设置 对象 settings在运行回调后清理:
令 context 为最顶层含脚本执行上下文。
这将与对应的准备运行 回调调用中的最顶层含脚本执行 上下文相同。
如果 context 不为 null,则递减 context 的 确定现任时跳过计数器。
断言: 备用现任设置对象 栈的最顶层条目是 settings。
从备用现任设置对象 栈中移除 settings。
这里,最顶层含脚本执行上下文是 JavaScript 执行上下文栈中具有非 null ScriptOrModule 分量的最顶层条目;如果JavaScript 执行上下文栈中没有此类条目,则为 null。
在具备以上所有机制后,现任设置对象按 以下方式确定:
令 context 为最顶层含脚本执行 上下文。
如果 context 为 null,或者 context 的 确定现任时跳过计数器 大于零:
返回 context 的 Realm 分量的设置对象。
以下一系列示例旨在说明所有不同 机制如何共同构成现任概念的定义:
考虑以下入门示例:
<!DOCTYPE html>
< iframe ></ iframe >
< script >
frames[ 0 ]. postMessage( "some data" , "*" );
</ script > 这里有两个值得关注的环境设置
对象:window 的环境设置对象和 frames[0] 的环境设置对象。我们关心的是:当
postMessage()
的算法执行时,现任设置对象是什么?
它应当是 window 的设置对象,以捕捉这样一种直观概念:负责使该算法发生的
作者脚本正在 window 中执行,而不是在
frames[0] 中执行。这是合理的:窗口
发送消息步骤使用现任设置对象来确定所产生的
MessageEvent 的 source 属性,在此情况下,
window 显然是消息
来源。
现在说明上述步骤如何为我们得出符合直觉的结果,即 window 的相关设置对象。
当窗口发送消息
步骤查找现任
设置对象时,最顶层含脚本执行上下文将是
对应于 script
元素的上下文:它在运行经典脚本
算法期间,作为ScriptEvaluation 的一部分被压入JavaScript
执行上下文栈。由于不涉及 Web IDL 回调调用,因此该上下文的
确定现任时跳过计数器为零,所以
会使用它来确定
现任设置对象;
结果是 window 的环境设置
对象。
(请注意,在调用 postMessage()
方法时,
frames[0] 的环境
设置对象是 this 的相关设置对象,因此参与
确定消息的目标。而现任对象用于确定
消息的来源。)
考虑以下更复杂的示例:
<!DOCTYPE html>
< iframe ></ iframe >
< script >
const bound = frames[ 0 ]. postMessage. bind( frames[ 0 ], "some data" , "*" );
window. setTimeout( bound);
</ script > 此示例与上一个非常相似,但额外通过
Function.prototype.bind 和 setTimeout()
进行了间接调用。不过答案应当
相同:异步调用
算法不应改变现任概念。
这一次,结果涉及更复杂的机制:
当 bound 被转换为
Web IDL 回调类型时,现任设置对象是与
window 对应的对象(与上述入门示例中的方式相同)。Web IDL 将其存储为
所产生回调值的回调
上下文。
当由 setTimeout() 发布的任务执行时,该任务的算法使用 Web IDL
调用存储的
回调值。Web IDL 随后调用上述准备
运行回调算法。这会将存储的
回调上下文压入备用
现任设置对象栈。此时(在计时器任务内部),栈上没有作者代码,因此最顶层
含脚本执行上下文为 null,也就没有任何对象的
确定现任时跳过计数器
被递增。
调用该回调随后会调用 bound,而它又会调用
frames[0] 的 postMessage()
方法。当 postMessage()
算法查找现任
设置对象时,栈上仍然没有作者代码,因为绑定函数只是直接调用内置方法。因此
最顶层含脚本执行上下文将为
null:JavaScript 执行
上下文栈只包含与 postMessage() 对应的执行上下文,
其下方没有
ScriptEvaluation 上下文或类似上下文。
此时我们会退回使用备用现任设置对象栈。如
上所述,其最顶层条目将包含
window 的相关设置对象。因此,在执行 postMessage()
算法时,它会被用作现任设置
对象。
考虑最后这个更加复杂曲折的示例:
<!-- a.html -->
<!DOCTYPE html>
< button > 点击我</ button >
< iframe ></ iframe >
< script >
const bound = frames[ 0 ]. location. assign. bind( frames[ 0 ]. location, "https://example.com/" );
document. querySelector( "button" ). addEventListener( "click" , bound);
</ script > <!-- b.html -->
<!DOCTYPE html>
< iframe src = "a.html" ></ iframe >
< script >
const iframe = document. querySelector( "iframe" );
iframe. onload = function onLoad() {
iframe. contentWindow. document. querySelector( "button" ). click();
};
</ script > 这里同样涉及两个值得关注的环境
设置对象:a.html 的设置对象和 b.html 的设置对象。当 location.assign()
方法触发Location 对象导航算法时,
现任设置
对象是什么?与之前一样,直观上它应当是 a.html 的设置对象:click
监听器最初由 a.html 调度,因此即使涉及 b.html 的某些操作导致该监听器触发,
负责的现任
仍是 a.html 的现任对象。
回调设置与上一个示例类似:当 bound 被
转换为 Web IDL 回调类型时,
现任设置对象是
与 a.html 对应的对象,
它被存储为回调的回调
上下文。
当在 b.html 内部调用 click() 方法时,它会在
a.html 内部的按钮上分派一个 click
事件。这一次,当准备运行回调算法
作为事件分派的一部分执行时,栈上确实存在作者代码;最顶层
含脚本执行上下文是 onLoad 函数的上下文,
其确定现任时跳过计数器会被
递增。此外,a.html 的环境设置对象(存储为
EventHandler 的回调上下文)会被压入
备用
现任设置对象栈。
现在,当Location
对象导航算法查找
现任设置对象时,
最顶层含脚本执行
上下文仍然是 onLoad 函数的上下文(因为我们
使用绑定函数作为回调)。但是,其确定现任时跳过
计数器值为一,因此我们会退回使用备用现任设置
对象栈。这会如预期那样得到 a.html 的环境设置对象。
请注意,这意味着即使进行导航的是 a.html 内部的 iframe,
被用作来源 Document 的仍然是
a.html 本身,它会确定包括请求客户端在内的事项。这可能是 Web 平台上现任概念唯一
合理的用法;在所有其他情况下,使用它产生的后果
只会令人困惑,我们希望有一天能将它们改为酌情使用当前或相关。
JavaScript 规范定义了当前领域,也称为“当前 Realm 记录”。[JAVASCRIPT]
一个平台 对象的相关领域是其 [[Realm]] 字段的值。
当以下所有 条件都为 true 时,脚本已启用于 一个环境设置对象 settings:
Window 对象,
或者 settings 的全局对象的
关联的
Document的活动
沙盒化标志集未设置其沙盒化脚本浏览
上下文标志。
如果以下任一条件为 true,则一个平台 对象 object 的脚本已禁用:
如果以下 算法返回 true,则一个环境 environment 是一个安全上下文:
如果 environment 是一个环境设置对象:
令 global 为 environment 的全局对象。
如果 global 是一个 WorkerGlobalScope:
如果 global 是一个 WorkletGlobalScope,
则返回 true。
worklet 只能在安全上下文中创建。
如果给定 environment 的顶级创建 URL时执行URL 是否可能可信?的结果是“Potentially
Trustworthy”,则返回 true。
返回 false。
脚本是两种可能的结构体 之一(即经典脚本或 模块脚本)。所有脚本都具有:
以下之一:
null,表示解析失败。
一个 JavaScript 值,仅当记录为 null 时才有意义,表示无法解析相应的脚本 源文本。
此值用于在创建脚本时,在内部跟踪立即发生的解析错误,不应直接使用。相反,在确定此脚本 “出了什么问题”时,应查看要重新抛出的错误。
一个表示将阻止求值成功的错误的 JavaScript 值。任何尝试运行该脚本的操作都会重新抛出此错误。
这可能是脚本的解析 错误,但对于模块脚本, 它也可能是其某个依赖项的解析错误,或来自解析 模块说明符的错误。
由于此异常值由 JavaScript 规范提供,因此我们知道 它永远不会为 null,所以使用 null 表示未发生错误。
Null 或一个用于解析模块说明符的基础URL。当不为 null 时,对于外部脚本,它将是 获取该脚本的 URL;对于内联脚本,它将是包含该脚本的文档的文档基础 URL。
一个布尔值,如果为 true,则表示不会为此脚本中的错误提供错误信息。 这用于静默跨源脚本的错误,因为这些错误可能泄露私密 信息。
模块脚本可以分为五种类型:
如果一个模块脚本的记录是一个合成模块记录,并且它 是通过创建 CSS 模块 脚本算法创建的,则它是一个CSS 模块脚本。CSS 模块脚本表示已解析的 CSS 样式表。
如果一个模块脚本的记录是一个合成模块记录,并且它 是通过创建 JSON 模块 脚本算法创建的,则它是一个JSON 模块脚本。JSON 模块脚本表示已解析的 JSON 文档。
如果一个模块脚本的 记录是一个WebAssembly 模块 记录,则它是一个WebAssembly 模块脚本。
由于 CSS 样式表、JSON 文档和文本不会导入依赖模块,也不会 在求值时抛出异常,因此CSS 模块脚本、JSON 模块 脚本和文本模块脚本的获取 选项和基础 URL 始终为 null。
活动脚本由以下算法确定:
令 record 为GetActiveScriptOrModule()。
如果 record 为 null,则返回 null。
返回 record.[[HostDefined]]。
活动脚本概念目前
仅由
import()
功能使用,以确定解析相对模块说明符时使用的基础
URL。
本节介绍若干用于获取脚本的算法,这些算法接受各种必要的 输入,并产生经典脚本或模块脚本。
用于初始获取和获取任何已导入模块的加密 nonce 元数据
用于初始获取的完整性元数据
用于初始获取和获取任何已导入模块的解析器 元数据
用于初始获取和获取任何已导入模块的引用来源策略
用于初始获取和获取任何已导入模块的阻塞渲染 布尔值。除非另有说明,其值为 false。
用于初始获取的优先级
回想一下,通过 import()
功能,经典脚本可以导入模块脚本。
默认脚本获取选项是一个脚本获取选项,其加密 nonce为空字符串,完整性元数据为空字符串,
解析器
元数据为“not-parser-inserted”,凭据模式为
“same-origin”,引用来源策略为空
字符串,并且获取优先级
为“auto”。
要在给定一个请求 request 和一个脚本获取选项 options 时,设置经典脚本请求, 将 request 的加密 nonce 元数据设置为 options 的加密 nonce,将其完整性元数据设置为 options 的 完整性元数据,将其解析器 元数据设置为 options 的解析器元数据,将其引用来源策略设置为 options 的引用来源策略,将其 阻塞渲染设置为 options 的 阻塞渲染,并将其 优先级设置为 options 的 获取优先级。
要在给定一个请求 request 和一个 脚本获取选项 options 时,设置模块脚本请求, 将 request 的加密 nonce 元数据设置为 options 的加密 nonce,将其完整性元数据设置为 options 的 完整性元数据,将其解析器 元数据设置为 options 的解析器元数据,将其凭据模式设置为 options 的凭据模式,将其引用来源策略设置为 options 的引用来源策略,将其 阻塞渲染设置为 options 的 阻塞渲染,并将其 优先级设置为 options 的 获取优先级。
要在给定一个脚本获取选项 originalOptions、一个URL url 和一个环境设置 对象 settingsObject 时,获取后代脚本获取选项:
令 newOptions 为 originalOptions 的副本。
令 integrity 为使用 url 和 settingsObject解析模块完整性 元数据的结果。
将 newOptions 的完整性元数据设置为 integrity。
将 newOptions 的获取优先级设置为
“auto”。
返回 newOptions。
下方若干算法可以使用执行获取
钩子算法进行自定义,该算法接受一个请求、一个布尔值 isTopLevel 和一个processCustomFetchResponse
算法。它使用一个响应和 null(失败时)或一个包含响应主体的字节
序列运行 processCustomFetchResponse。对于所有经典
脚本获取,以及在获取外部模块脚本图或获取模块工作线程脚本图时的初始获取,isTopLevel 将为
true;但对于
由图中遇到的 import 语句或
import() 表达式产生的获取,它为 false。
默认情况下,如果不提供执行获取 钩子,下方算法将直接获取 给定的请求,并对该请求应用特定于算法的自定义,并验证所得的响应。
要在这些特定于算法的自定义之上叠加自己的自定义,请提供一个执行获取 钩子,该钩子修改给定的 请求,获取它, 然后对所得的响应执行特定验证(如果 验证失败,则以网络错误完成)。
该钩子还可以用于执行更细微的自定义,例如保留一个 响应缓存,并完全避免执行获取。
Service Workers 是一个使用自己的钩子选项运行这些 算法的规范示例。[SW]
下面是这些算法本身。
要在给定一个URL url、一个 环境设置 对象 settingsObject、一个脚本获取 选项 options、一个CORS 设置 属性状态 corsSetting、一个编码 encoding 和 一个算法 onComplete 时,获取经典脚本,运行以下步骤。onComplete 必须是一个 接受 null(失败时)或一个经典 脚本(成功时)的算法。
令 request 为给定
url、“script”和 corsSetting 时创建潜在 CORS 请求的结果。
将 request 的客户端设置为 settingsObject。
将 request 的发起者
类型设置为“script”。
给定 request 和 options,设置 经典脚本请求。
使用以下 processResponseConsumeBody 步骤获取 request,这些步骤接受 响应 response 和 null、失败或一个 字节序列 bodyBytes:
response 可以是CORS 同源或 CORS 跨源。这只会影响 错误报告的方式。
将 response 设置为 response 的不安全响应。
如果以下任一条件为 true:
则给定 null 运行 onComplete,并中止这些步骤。
出于历史原因,与本节中的其他脚本获取算法不同, 此算法不包含 MIME 类型检查。
令 potentialMIMETypeForEncoding 为给定 response 的标头 列表时提取 MIME 类型的结果。
将 encoding 设置为给定 potentialMIMETypeForEncoding 和 encoding 时旧式 提取编码的结果。
这会有意忽略MIME 类型本质。
令 sourceText 为使用 encoding 作为后备编码,将 bodyBytes解码 为 Unicode 的结果。
如果文件包含 BOM,解码算法会覆盖 encoding。
如果 response 是 CORS 跨源,则令 mutedErrors 为 true;否则为 false。
令 script 为给定 sourceText、settingsObject、response 的URL、options、 mutedErrors 和 url 时创建经典脚本的结果。
要在给定一个URL url、一个 环境设置 对象 fetchClient、一个目标 destination、一个 环境设置 对象 settingsObject、一个算法 onComplete 和一个可选的执行 获取钩子 performFetch 时,获取经典工作线程脚本,运行以下步骤。onComplete 必须是一个接受 null(失败时)或一个经典脚本(成功时)的 算法。
令 request 为一个新的请求,其URL为 url,客户端为 fetchClient,目标为
destination,发起者类型为“other”,
模式为“same-origin”,凭据模式为“same-origin”,解析器
元数据为“not parser-inserted”,并且设置了其
使用 URL 凭据标志。
如果给出了 performFetch,则使用 request、 true 和下方定义的 processResponseConsumeBody 运行 performFetch。
否则,使用下方定义的 processResponseConsumeBody 作为 processResponseConsumeBody 来获取 request。
在这两种情况下,令给定响应 response 和 null、失败或一个字节 序列 bodyBytes 的 processResponseConsumeBody 为以下算法:
将 response 设置为 response 的不安全响应。
如果以下任一条件为 true:
则给定 null 运行 onComplete,并中止这些步骤。
如果以下所有条件均为 true:
response 的URL的方案是一个HTTP(S) 方案;并且
从 response 的标头列表中提取 MIME 类型的结果不是 JavaScript MIME 类型,
则给定 null 运行 onComplete,并中止这些步骤。
令 sourceText 为对 bodyBytes 进行UTF-8 解码的结果。
令 script 为使用 sourceText、settingsObject、response 的URL和默认脚本获取 选项创建经典脚本的结果。
给定 script 运行 onComplete。
要在给定一个URL url、一个环境设置对象 settingsObject 和一个 可选的执行 获取钩子 performFetch 时,获取经典工作线程导入脚本,运行以下步骤。该算法成功时返回一个经典脚本, 失败时抛出异常。
令 response 为 null。
令 bodyBytes 为 null。
令 request 为一个新的请求,其URL为 url,客户端为 settingsObject,目标为“script”,
发起者类型为“other”,解析器元数据
为“not parser-inserted”,并且设置了其使用 URL 凭据标志。
如果给出了 performFetch,则使用 request、 isTopLevel 和下方定义的 processResponseConsumeBody 运行 performFetch。
否则,使用下方定义的 processResponseConsumeBody 作为 processResponseConsumeBody 来获取 request。
在这两种情况下,令给定响应 res 和 null、失败或一个 字节序列 bb 的 processResponseConsumeBody 为以下算法:
将 bodyBytes 设置为 bb。
将 response 设置为 res。
暂停,直到 response 不为 null。
与本节中的其他算法不同,此处的获取过程是同步的。
将 response 设置为 response 的不安全响应。
如果以下任一条件为 true:
bodyBytes 为 null 或失败;
从 response 的标头列表中提取 MIME 类型的结果不是 JavaScript MIME 类型,
则抛出一个“NetworkError” DOMException。
令 sourceText 为对 bodyBytes 进行UTF-8 解码的结果。
如果 response 是 CORS 跨源,则令 mutedErrors 为 true;否则 为 false。
令 script 为给定 sourceText、settingsObject、response 的URL、默认脚本获取选项和 mutedErrors 时创建经典脚本的结果。
返回 script。
要在给定一个URL url、一个环境设置对象 settingsObject、一个脚本 获取选项 options 和一个 算法 onComplete 时,获取外部模块脚本图,运行以下步骤。onComplete 必须是一个 接受 null(失败时)或一个模块脚本 (成功时)的算法。
给定 url、settingsObject、
“script”、options、settingsObject、“client”、true,
并使用以下接受 result 的步骤,获取单个
模块脚本:
如果 result 为 null,则给定 null 运行 onComplete,并中止这些 步骤。
给定 settingsObject、“script”和
onComplete,获取
result 的后代并链接它。
要在给定一个URL url、 一个目标 destination、一个 环境设置 对象 settingsObject、一个脚本获取 选项 options 和一个算法 onComplete 时,获取 modulepreload 模块脚本图,运行以下步骤。 onComplete 必须是一个接受 null(失败时)或一个模块 脚本(成功时)的算法。
给定 url、settingsObject、
destination、options、settingsObject、“client”、true,
并使用以下接受 result 的步骤,获取单个
模块脚本:
给定 result 运行 onComplete。
如果 result 不为 null,则可选地给定 settingsObject、destination 和一个空算法,获取 result 的后代并链接它。
通常,执行此步骤有利于性能,因为它 允许预加载以后必然会通过诸如 获取外部 模块脚本图等获取整个图的算法请求的模块。但是,用户 代理在带宽受限的情况下,或相关获取已经进行中的情况下, 可能希望跳过它们。
要在给定一个字符串 sourceText、一个URL baseURL、一个环境设置 对象 settingsObject、一个脚本获取选项 options 和一个算法 onComplete 时,获取内联模块脚本图,运行以下步骤。onComplete 必须是一个 接受 null(失败时)或一个模块 脚本(成功时)的算法。
令 script 为使用 sourceText、settingsObject、 baseURL 和 options创建 JavaScript 模块脚本的结果。
给定 settingsObject、“script”和
onComplete,获取
script 的后代并链接它。
要在给定一个URL url、一个环境设置对象 fetchClient、一个目标 destination、一个凭据 模式 credentialsMode、一个环境设置对象 settingsObject 和一个算法 onComplete 时,获取模块工作线程脚本图,给定 url、fetchClient、destination、 credentialsMode、settingsObject 和 onComplete,获取 worklet/模块 工作线程脚本图。
要在给定一个URL url、一个 环境设置 对象 fetchClient、一个目标 destination、一个 凭据模式 credentialsMode、一个环境设置对象 settingsObject、一个模块响应 映射 moduleResponsesMap 和一个算法 onComplete 时,获取 worklet 脚本图,给定 url、fetchClient、 destination、credentialsMode、settingsObject、 onComplete 和以下给定 request 与 processCustomFetchResponse 的执行 获取钩子,获取 worklet/模块工作线程脚本图:
令 requestURL 为 request 的URL。
如果 moduleResponsesMap[requestURL]为“fetching”,则并行等待,直到该条目的值发生变化,然后
在网络任务源上排入一个任务,以继续运行
以下步骤。
如果 moduleResponsesMap[requestURL]存在:
令 cached 为 moduleResponsesMap[requestURL]。
使用 cached[0] 和 cached[1] 运行 processCustomFetchResponse。
返回。
将 moduleResponsesMap[requestURL]设置为
“fetching”。
获取 request,并将 processResponseConsumeBody 设置为以下步骤,这些步骤接受响应 response 和 null、失败或一个 字节序列 bodyBytes:
将 moduleResponsesMap[requestURL]设置为(response, bodyBytes)。
使用 response 和 bodyBytes 运行 processCustomFetchResponse。
以下算法仅供本规范在获取外部模块 脚本图或上述 其他类似概念的过程中内部使用,其他规范不应直接使用它们。
此图说明这些算法如何与上述算法以及彼此 关联:
要在给定一个 URL url、一个环境设置对象 fetchClient、一个 目标 destination、一个凭据模式 credentialsMode、一个环境设置对象 settingsObject、 一个算法 onComplete 和一个可选的执行获取钩子 performFetch 时,获取 worklet/模块工作线程脚本图,运行 以下步骤。onComplete 必须是一个接受 null(失败时)或一个 模块脚本(成功时)的算法。
令 options 为一个脚本获取选项,其加密 nonce为空字符串,完整性元数据为空字符串,
解析器元数据为
“not-parser-inserted”,凭据模式为
credentialsMode,引用来源
策略为空字符串,并且获取优先级为
“auto”。
给定 url、
fetchClient、destination、options、settingsObject、
“client”、true 和下方定义的 onSingleFetchComplete,获取单个
模块脚本。如果给出了
performFetch,也将其一并传递。
给定 result 的 onSingleFetchComplete 是以下算法:
如果 result 为 null,则给定 null 运行 onComplete,并中止这些 步骤。
给定 fetchClient、 destination 和 onComplete,获取 result 的后代并链接它。如果给出了 performFetch,也将 其一并传递。
要在给定一个模块脚本 moduleScript、一个环境 设置对象 fetchClient、一个目标 destination、一个算法 onComplete 和一个可选的执行 获取钩子 performFetch 时,获取其后代并 链接,运行以下步骤。onComplete 必须是一个 接受 null(失败时)或一个模块 脚本(成功时)的算法。
令 record 为 moduleScript 的记录。
如果 record 为 null:
令 state 为记录 { [[ErrorToRethrow]]: null, [[Destination]]: destination, [[PerformFetch]]: null, [[FetchClient]]: fetchClient }。
如果给出了 performFetch,则将 state.[[PerformFetch]] 设置为 performFetch。
令 loadingPromise 为 record.LoadRequestedModules(state)。
此步骤将递归加载所有模块的传递依赖项。
当 loadingPromise兑现时,运行以下 步骤:
当 loadingPromise拒绝时,运行 以下步骤:
如果 state.[[ErrorToRethrow]] 不为 null,则将 moduleScript 的要重新 抛出的错误设置为 state.[[ErrorToRethrow]],并给定 moduleScript 运行 onComplete。
否则,给定 null 运行 onComplete。
当 loadingPromise 因加载错误而 被拒绝时,state.[[ErrorToRethrow]] 为 null。
要获取单个模块脚本,给定一个 URL url、一个 环境设置 对象 fetchClient、一个目标 destination、一个脚本 获取选项 options、一个环境设置对象 settingsObject、一个引用来源 referrer、一个可选的ModuleRequest 记录 moduleRequest、一个 布尔值 isTopLevel、一个算法 onComplete,以及一个可选的执行 获取钩子 performFetch,运行以下步骤。onComplete 必须是一个 接受 null(失败时)或一个模块 脚本(成功时)的算法。
令 moduleType 为 "javascript-or-wasm"。
如果给出了 moduleRequest,则将 moduleType 设置为在给定 moduleRequest 的情况下,运行从模块请求获取模块类型步骤的结果。
断言:在给定 moduleType 和 settingsObject 的情况下,运行允许的模块类型步骤的结果为 true。否则,我们不会 到达此处,因为在 HostLoadImportedModule 或获取单个导入的模块脚本中检查 moduleRequest.[[Attributes]] 时,已经引发失败。
令 moduleMap 为 settingsObject 的模块映射。
如果 moduleMap[(url, moduleType)] 是一个 模块脚本或 null,则在给定 moduleMap[(url, moduleType)] 的情况下运行 onComplete,然后返回。
如果 moduleMap[(url, moduleType)] 是一个列表,则将 onComplete 追加到 moduleMap[(url, moduleType)],然后返回。
将 moduleMap[(url, moduleType)] 设置为 « onComplete »。
令 request 为一个新的请求,其
URL 为 url,模式为 "cors",引用来源为
referrer,且客户端为
fetchClient。
将 request 的目标设置为 在给定 destination 和 moduleType 的情况下,运行从模块类型获取获取目标步骤的结果。
如果 destination 为 "worker"、"sharedworker" 或
"serviceworker",并且
isTopLevel 为 true,则将 request 的模式设置为 "same-origin"。
将 request 的发起者
类型设置为 "script"。
在给定 request 和 options 的情况下,设置模块脚本请求。
如果给出了 performFetch,则使用 request、 isTopLevel,以及下文定义的 processResponseConsumeBody 运行 performFetch。
否则,获取 request,并将 processResponseConsumeBody 设置 为 下文定义的 processResponseConsumeBody。
在这两种情况下,令 processResponseConsumeBody 为以下算法,其给定一个响应 response,以及 null、失败或一个 字节序列 bodyBytes:
response 始终为 CORS 同源。
如果以下任一项为 true:
则:
令 mimeType 为从 response 的标头列表中提取 MIME 类型的结果。
令 moduleScript 为 null。
令 referrerPolicy 为在给定 response 的情况下,解析
`Referrer-Policy` 标头的结果。
[REFERRERPOLICY]
如果 referrerPolicy 不是空字符串,则将 options 的引用来源策略设置为 referrerPolicy。
如果 mimeType 的本质为
"application/wasm",
并且 moduleType 为 "javascript-or-wasm",则将
moduleScript 设置为在给定 bodyBytes、
settingsObject、response 的URL 和 options 的情况下,创建 WebAssembly 模块脚本的结果。
否则:
令 sourceText 为对 bodyBytes 进行UTF-8 解码的结果。
如果 moduleType 为 "text",则将
moduleScript 设置为在给定 sourceText 和
settingsObject 的情况下,创建文本模块脚本的结果。
如果 mimeType 是一个JavaScript MIME 类型,并且
moduleType 为 "javascript-or-wasm",则将
moduleScript 设置为在给定 sourceText、
settingsObject、response 的URL 和
options 的情况下,创建 JavaScript 模块脚本的结果。
如果 mimeType 的MIME
类型本质为 "text/css",
并且 moduleType 为 "css",则将 moduleScript 设置为
在给定 sourceText 和
settingsObject 的情况下,创建 CSS 模块脚本的结果。
如果 mimeType 是一个JSON MIME
类型,并且
moduleType 为 "json",则将 moduleScript 设置为
在给定 sourceText 和
settingsObject 的情况下,创建 JSON 模块脚本的结果。
令 callbacks 为 moduleMap[(url, moduleType)]。
如果 moduleScript 为 null,则从 moduleMap 中移除 [(url, moduleType);否则,将 moduleMap[(url, moduleType)] 设置为 moduleScript。
模块 映射有意使用请求 URL作为键, 而模块脚本的基准 URL 则设置为响应 URL。 前者用于 对获取操作进行去重,而后者用于 URL 解析。
对于 callbacks 中的每个 callback:在给定 moduleScript 的情况下运行 callback。
要在给定一个URL url、 一个环境 设置对象 fetchClient、一个目标 destination、一个脚本 获取选项 options、一个环境设置对象 settingsObject、一个引用来源 referrer、一个ModuleRequest 记录 moduleRequest、一个 算法 onComplete 和一个可选的执行获取钩子 performFetch 时,获取单个已导入模块脚本,运行 以下步骤。onComplete 必须是一个接受 null(失败时)或一个 模块脚本(成功时)的算法。
断言:moduleRequest.[[Attributes]] 不包含任何
记录 entry,使得 entry.[[Key]] 不是
“type”,因为我们在
HostGetSupportedImportAttributes 中仅请求了
“type”属性。
令 moduleType 为给定 moduleRequest 时运行从模块 请求获取模块类型步骤的结果。
如果给定 moduleType 和 settingsObject 时运行允许模块类型步骤的结果为 false,则给定 null 运行 onComplete,并返回。
给定 url、fetchClient、 destination、options、settingsObject、referrer、 moduleRequest、false 和 onComplete,获取单个 模块脚本。如果给出了 performFetch, 也将其一并传递。
本标准引用了其中定义的以下概念:
要创建经典脚本,给定一个 字符串 source、一个环境设置对象 settings、一个URL baseURL、一个脚本获取选项 options、一个可选布尔值 mutedErrors(默认为 false)、一个可选的 URL 或 null sourceURLForWindowScripts(默认为 null),以及一个可选 布尔值 bypassDisabledScripting(默认为 false):
bypassDisabledScripting 参数旨在用于 即使脚本已禁用也运行脚本。 某些自动化场景需要这样做,例如 WebDriver BiDi 命令"script.evaluate"。
bypassDisabledScripting 参数旨在用于 即使脚本已禁用也运行脚本。某些自动化场景需要这样做, 例如WebDriver BiDi 命令 "script.evaluate"。当脚本处理过程(例如,通过 WebDriver BiDi 命令执行脚本)在 bypassDisabledScripting 设置为 true 的情况下调用时,即使脚本已禁用,也允许事件循环 运行,以解析该脚本创建的 thenable(来自 promise)和 weakmap 终结操作。这是 确保测试脚本正常运行所必需的,因为测试脚本通常依赖异步 操作。
如果 mutedErrors 为 true,则将 baseURL 设置为
about:blank。
当 mutedErrors 为 true 时,baseURL 是脚本的 CORS 跨源响应的URL,该 URL 不应暴露给 JavaScript。因此, 此处会净化 baseURL。
如果对于 settings脚本已 禁用,并且 bypassDisabledScripting 为 false,则将 source 设置为空字符串。
令 script 为一个新的经典 脚本,此算法随后将对其进行初始化。
将 script 的设置 对象设置为 settings。
将 script 的基础 URL设置为 baseURL。
将 script 的获取 选项设置为 options。
将 script 的静默错误设置为 mutedErrors。
给定 script 和 sourceURLForWindowScripts,记录经典脚本创建时间。
令 result 为 ParseScript(source, settings 的领域, script)。
在此处将 script 作为最后一个参数传递可确保 result.[[HostDefined]] 为 script。
如果 result 是一个由错误组成的列表:
将 script 的记录设置为 result。
返回 script。
要创建 JavaScript 模块脚本, 给定一个字符串 source、一个环境设置 对象 settings、一个URL baseURL 和一个脚本获取 选项 options:
如果对于 settings脚本已 禁用,则将 source 设置为空字符串。
令 script 为一个新的模块脚本, 此算法随后将对其进行初始化。
将 script 的设置 对象设置为 settings。
将 script 的基础 URL设置为 baseURL。
将 script 的获取 选项设置为 options。
令 result 为 ParseModule(source, settings 的领域, script)。
在此处将 script 作为最后一个参数传递可确保 result.[[HostDefined]] 为 script。
如果 result 是一个由错误组成的列表:
将 script 的解析错误设置为 result[0]。
返回 script。
将 script 的记录设置为 result。
返回 script。
要创建 WebAssembly 模块脚本, 给定一个字节序列 bodyBytes、一个环境设置 对象 settings、一个URL baseURL 和一个脚本获取 选项 options:
如果对于 settings脚本已 禁用,则将 bodyBytes 设置为字节序列 0x00 0x61 0x73 0x6D 0x01 0x00 0x00 0x00。
此字节序列对应于一个仅提供魔数 字节和版本号的空 WebAssembly 模块。
令 script 为一个新的模块 脚本,此算法随后将对其进行初始化。
将 script 的设置 对象设置为 settings。
将 script 的基础 URL设置为 baseURL。
将 script 的获取 选项设置为 options。
令 result 为给定 bodyBytes、 settings 的领域和 script 时解析 WebAssembly 模块的结果。
在此处将 script 作为最后一个参数传递可确保 result.[[HostDefined]] 为 script。
如果上一步抛出了错误 error:
将 script 的解析错误设置为 error。
返回 script。
将 script 的记录设置为 result。
返回 script。
WebAssembly JavaScript 接口:ESM 集成规定了 WebAssembly 与 ECMA-262 模块加载集成所用的钩子。其中既包括 对直接依赖项导入的支持,也包括对源阶段导入的支持,后者支持虚拟化 和多重实例化。[WASMESM]
要创建 CSS 模块脚本,给定一个 字符串 source 和一个环境设置对象 settings:
令 script 为一个新的模块 脚本,此算法随后将对其进行初始化。
将 script 的设置 对象设置为 settings。
令 sheet 为使用空字典作为参数运行创建构造的
CSSStyleSheet步骤的结果。
给定 source,在 sheet 上运行同步替换
CSSStyleSheet 的规则的步骤。
如果这抛出异常,则捕获该异常,将 script 的解析错误设置为该异常,并返回 script。
如果 source 包含任何 @import 规则,同步替换
CSSStyleSheet 的规则的步骤将抛出异常。目前这是有意如此,因为对于
如何在 CSS 模块脚本中处理这些规则尚未达成
共识;因此,在达成共识之前会完全阻止这些规则。
将 script 的记录设置为 CreateDefaultExportSyntheticModule(sheet) 的结果。
返回 script。
要创建 JSON 模块脚本,给定一个 字符串 source 和一个环境设置对象 settings:
要创建文本模块脚本,给定一个 字符串 text 和一个环境设置对象 settings:
给定一个ModuleRequest 记录 moduleRequest,从模块请求获取模块类型的步骤如下:
令 moduleType 为 "javascript-or-wasm"。
如果 moduleRequest.[[Attributes]] 具有一个记录
entry,使得 entry.[[Key]] 为 "type":
如果 entry.[[Value]] 为 "javascript-or-wasm",则将
moduleType 设置为 null。
本规范在内部对JavaScript 模块脚本或
WebAssembly 模块
脚本使用 "javascript-or-wasm" 模块
类型,因此需要此步骤来防止使用
"javascript-or-wasm" 类型属性导入模块(null moduleType 将
导致允许模块类型
检查失败)。
否则,将 moduleType 设置为 entry.[[Value]]。
返回 moduleType。
给定一个字符串 moduleType 和一个环境 设置对象 settings,允许模块类型的步骤如下:
如果 moduleType 不是 "javascript-or-wasm"、"css"、"json"
或 "text",则
返回 false。
如果 moduleType 为 "css",并且
CSSStyleSheet
接口未在
settings 的领域中暴露,则
返回 false。
返回 true。
给定一个目标 defaultDestination 和一个 字符串 moduleType,从模块类型获取获取目标的步骤如下:
json",则返回 "json"。css",则返回 "style"。text",则返回 "text"。要运行经典脚本,给定一个经典脚本 script 和一个可选布尔值 rethrow errors(默认为 false):
令 settings 为 script 的设置 对象。
使用 settings检查能否运行 脚本。如果这返回 "do not run",则返回 NormalCompletion(empty)。
给定 script,记录经典脚本执行开始时间。
给定 settings,准备运行脚本。
令 evaluationStatus 为 null。
如果 script 的要重新 抛出的错误不为 null,则将 evaluationStatus 设置为 ThrowCompletion(script 的要重新 抛出的错误)。
否则,将 evaluationStatus 设置为ScriptEvaluation(script 的记录)。
如果由于用户代理中止了正在运行的脚本,导致ScriptEvaluation 未完成,则让 evaluationStatus 保持为 null。
如果 evaluationStatus 是一个突然 完成:
如果 rethrow errors 为 true,并且 script 的静默 错误为 false:
使用 settings在 运行脚本后清理。
重新抛出 evaluationStatus.[[Value]]。
如果 rethrow errors 为 true,并且 script 的静默 错误为 true:
使用 settings在运行脚本后 清理。
否则,rethrow errors 为 false。执行以下步骤:
对于 script 的设置 对象的全局 对象,报告由 evaluationStatus.[[Value]] 给出的异常。
使用 settings在运行脚本后 清理。
返回 evaluationStatus。
使用 settings在 运行脚本后清理。
如果 evaluationStatus 是正常完成,则返回 evaluationStatus。
如果已到达此处,则 evaluationStatus 保持为 null,是因为脚本在求值期间被过早
中止。
返回 ThrowCompletion(一个新的 QuotaExceededError)。
要运行模块脚本,给定一个模块脚本 script 和一个可选布尔值 preventErrorReporting(默认为 false):
令 settings 为 script 的设置 对象。
使用 settings检查能否运行 脚本。如果这返回 "do not run",则返回一个以 undefined 兑现的promise。
给定 script,记录模块脚本执行开始时间。
给定 settings,准备运行脚本。
令 evaluationPromise 为 null。
如果 script 的要重新 抛出的错误不为 null,则将 evaluationPromise 设置为一个以 script 的要重新 抛出的错误拒绝的promise。
否则:
令 record 为 script 的记录。
将 evaluationPromise 设置为 record.Evaluate()。
此步骤将递归求值模块的所有依赖项。
如果由于用户代理中止正在运行的
脚本而导致Evaluate 未能完成,则将
evaluationPromise 设置为一个以新的
QuotaExceededError
拒绝的promise。
如果 preventErrorReporting 为 false,则当 evaluationPromise 以 reason拒绝时,对于 script 的设置 对象的全局对象,报告由 reason 给出的异常。
使用 settings在 运行脚本后清理。
返回 evaluationPromise。
使用一个环境设置 对象 settings检查能否运行脚本的步骤如下。它们返回 "run" 或 "do not run"。
使用一个环境设置 对象 settings准备运行脚本的步骤如下:
将 settings 的领域执行上下文压入JavaScript 执行上下文栈;它现在是正在运行的 JavaScript 执行 上下文。
将 settings 添加到周围 代理的事件 循环的当前正在运行 任务的 脚本求值环境 设置对象集合。
使用一个 环境设置 对象 settings在运行脚本后清理的步骤如下:
断言:settings 的领域执行上下文是 正在运行的 JavaScript 执行上下文。
从 JavaScript 执行上下文栈中移除 settings 的领域执行上下文。
如果JavaScript 执行上下文栈现在为空,则执行 微任务检查点。(如果这会运行脚本,则会重入调用这些算法。)
这些算法不会由一个脚本直接调用另一个脚本而调用,但它们 可以以间接方式重入调用,例如,如果脚本分派了一个已注册 事件监听器的事件。
正在运行的脚本是正在运行的 JavaScript 执行 上下文的 ScriptOrModule 分量的 [[HostDefined]] 字段中的脚本。
虽然 JavaScript 规范没有考虑这种可能性,但有时
有必要中止正在
运行的脚本。这会使任何ScriptEvaluation
或源文本模块记录的Evaluate 调用
立即停止,并清空JavaScript 执行上下文栈,而不会
触发任何正常机制,例如 finally 块。
[JAVASCRIPT]
用户代理可以对脚本施加资源限制,例如 CPU 配额、内存限制、
总执行时间限制或带宽限制。当脚本超过限制时,用户
代理可以抛出一个 QuotaExceededError、
在不抛出异常的情况下中止脚本、提示用户,或限制脚本
执行速度。
例如,以下脚本永远不会终止。用户代理可以在等待 数秒后,提示用户终止脚本或让其继续运行。
< script >
while ( true ) { /* loop */ }
</ script > 鼓励用户代理在用户因脚本而收到提示时允许用户禁用脚本,
无论该提示是由脚本直接产生的(例如使用 window.alert() API),还是由于
脚本的行为产生的(例如因为脚本超过了时间限制)。
如果在脚本执行期间禁用了脚本,则应立即终止该 脚本。
用户代理可以允许用户专门禁用脚本,仅用于关闭 浏览上下文。
例如,上述示例中提到的提示还可以为
用户提供一种机制,直接完全关闭页面,而不运行任何 unload 事件处理器。
所有当前引擎均支持。
self.reportError(e)以与未处理异常相同的方式,针对给定值 e,在全局对象上
分派一个 error 事件。
要从 JavaScript 值 exception 中提取错误信息:
要为一个 特定全局对象 global 和可选布尔值 omitError(默认为 false),报告异常 exception,其中 exception 是一个 JavaScript 值:
令 notHandled 为 true。
令 errorInfo 为从 exception 中提取错误 信息的结果。
令 script 为以由实现定义的方式找到的一个脚本,或 null。通常这应当是 正在运行的 脚本(尤其是在运行经典脚本期间)。
对于在较少见情况下使用哪个脚本来确定是否静默错误, 各实现尚未就可互操作行为达成一致。
如果 script 是一个经典
脚本,并且 script 的静默
错误为 true,则将 errorInfo[error]设置为 null,
将 errorInfo[message]设置为
"Script error.",
将 errorInfo[filename]
设置为空
字符串,将 errorInfo[lineno]设置为 0,
并将
errorInfo[colno]设置为 0。
如果 omitError 为 true,则将 errorInfo[error]设置为 null。
如果 global 未处于错误报告模式:
如果 global 实现了 EventTarget,
则将 notHandled 设置为
在 global 上触发名为
error 的事件的结果,
使用 ErrorEvent,将
cancelable
属性初始化为 true,
并根据 errorInfo 初始化其他属性。
根据事件 处理器处理算法,在事件处理器中返回 true 会取消该事件。
将 global 的处于错误报告模式设置为 false。
如果 notHandled 为 true:
将 errorInfo[error]设置为
null。
如果 global 实现了 DedicatedWorkerGlobalScope,
则使用 global 的关联 Worker 的相关全局
对象,在DOM 操作任务源上排入一个
全局任务,以运行以下步骤:
令 workerObject 为与
global 关联的 Worker
对象。
将 notHandled 设置为在
workerObject 上触发
名为 error
的事件的结果,
使用 ErrorEvent,将
cancelable
属性初始化为 true,
并根据 errorInfo 初始化其他属性。
如果 notHandled 为 true,则为 workerObject 的相关全局对象报告 exception,并将omitError设置为 true。
实际的 exception 值在所有者 领域中不可用,但用户代理仍会传递足够的信息来设置消息、 文件名和其他属性,并可能报告到开发者控制台。
否则,用户代理可以将 exception 报告到开发者 控制台。
如果连接工作线程与其 Worker 对象的隐式端口已经
解缠(即父工作线程已终止),则用户代理必须像
Worker 对象没有 error 事件处理器,并且
该工作线程的 onerror
属性为
null 一样行事,但在其他方面必须按上述方式行事。
因此,错误报告会沿专用工作线程链向上传播,直至
原始 Document,即使该链中的某些
工作线程已经终止
并被垃圾回收。
本标准的先前修订版定义了一个报告该异常的算法。作为议题 #958的一部分,该算法已被报告 异常取代,后者行为不同,并接受不同的输入。议题 #10516跟踪规范 生态系统的更新。
尚不清楚静默是否 适用于此处。在 Chrome 和 Safari 中会静默,但在 Firefox 中不会。另请参阅议题 #958。
所有当前引擎均支持。
ErrorEvent 接口定义
如下:
[Exposed=*]
interface ErrorEvent : Event {
constructor (DOMString type , optional ErrorEventInit eventInitDict = {});
readonly attribute DOMString message ;
readonly attribute USVString filename ;
readonly attribute unsigned long lineno ;
readonly attribute unsigned long colno ;
readonly attribute any error ;
};
dictionary ErrorEventInit : EventInit {
DOMString message = "";
USVString filename = "";
unsigned long lineno = 0;
unsigned long colno = 0;
any error ;
};message
属性必须返回其初始化时的值。它表示错误消息。
filename
属性必须返回其
初始化时的值。它表示最初发生错误的脚本的URL。
lineno
属性必须返回其初始化时的值。它表示脚本中
发生错误的行号。
colno
属性必须返回其初始化时的值。它表示脚本中
发生错误的列号。
error
属性必须返回其初始化时的值。它最初必须初始化为
undefined。在适当情况下,它会被设置为表示错误的对象(例如,在未捕获异常的情况下为异常
对象)。
所有当前引擎均支持。
除了同步的运行时脚本错误之外,脚本
还可能遇到异步 promise 拒绝,这些拒绝通过 unhandledrejection
和 rejectionhandled
事件进行跟踪。对这些
拒绝的跟踪通过 HostPromiseRejectionTracker
抽象操作完成,但
对它们的报告在此处定义。
要在给定一个全局对象 global 时通知被拒绝的 promise:
令 list 为 global 的即将通知的被拒绝 promise 列表的一个克隆。
如果 list为空,则返回。
清空 global 的即将通知的 被拒绝 promise 列表。
给定 global,在DOM 操作任务源上排入一个全局任务, 以运行以下步骤:
对于 list 中的每个 promise p:
如果 p.[[PromiseIsHandled]] 为 true,则继续。
令 notCanceled 为在
global 上触发
名为 unhandledrejection
的事件的结果,
使用 PromiseRejectionEvent,
将 cancelable
属性初始化为 true,将 promise
属性初始化为
p,并将 reason
属性初始化为 p.[[PromiseResult]]。
如果 notCanceled 为 true,则用户代理可以将 p.[[PromiseResult]] 报告到开发者控制台。
如果 p.[[PromiseIsHandled]] 为 false,则将 p追加到 global 的未决的被拒绝 promise 弱集合。
所有当前引擎均支持。
PromiseRejectionEvent
接口定义
如下:
[Exposed=*]
interface PromiseRejectionEvent : Event {
constructor (DOMString type , PromiseRejectionEventInit eventInitDict );
readonly attribute object promise ;
readonly attribute any reason ;
};
dictionary PromiseRejectionEventInit : EventInit {
required object promise ;
any reason ;
};所有当前引擎均支持。
promise 属性必须返回其
初始化时的值。它表示此通知所涉及的 promise。
由于 Web IDL 对
Promise<T>
类型的转换规则始终会将输入包装到一个新的 promise 中,因此
promise
属性改为使用 object
类型,这更适合表示指向原始 promise 对象的不透明
句柄。
所有当前引擎均支持。
reason 属性必须返回其
初始化时的值。它表示 promise 的拒绝原因。
导入映射解析结果是一个结构,它类似于脚本,也可以存储在 script 元素的
结果中,但对于其他用途,
不计为脚本。它具有以下项:
要在给定一个 Window global 和一个
导入映射解析
结果 result 时注册导入映射:
如果 result 的要重新抛出的错误 不为 null,则为 global报告由 result 的要重新抛出的错误给出的异常,并 返回。
给定 global 和 result 的导入映射,合并现有导入映射和新导入 映射。
推测规则解析结果是一个结构,它类似于脚本,也可以存储在 script 元素的
结果中,但对于其他
用途,不计为脚本。
它具有以下项:
要在给定一个 Window global
和一个
推测规则解析结果
result 时注销推测规则:
如果 result 的要重新抛出的错误不为 null,则返回。
从 global 的关联
Document的推测规则集中移除 result 的推测规则集。
对于 global 的关联 Document,考虑推测性加载。
解析模块 说明符算法是将模块说明符字符串转换为 URL 的主要入口点。当不涉及导入映射时,它相对简单,并 可归结为解析类 URL 模块说明符。
当存在非空的导入映射时, 行为会更加复杂。它会检查所有适用模块说明符 映射中的候选条目,从最具体到最不具体的作用域(回退到顶层无作用域的imports),并从 最具体到最不具体的 前缀。对于每个候选项,解析 imports 匹配算法会给出以下结果之一:
最后,如果通过任何候选模块说明符映射都未找到成功的解析结果,则解析模块 说明符将抛出 异常。因此,结果始终是一个URL或抛出的异常。
要在给定一个script 或 null referringScript 和一个字符串 specifier 时解析模块说明符:
令 settingsObject 和 baseURL 为 null。
如果 referringScript 不为 null:
否则:
将 settingsObject 设置为当前设置对象。
将 baseURL 设置为 settingsObject 的API 基础 URL。
令 importMap 为一个空导入映射。
如果 settingsObject 的全局
对象实现了 Window,则
将 importMap 设置为
settingsObject 的全局对象的
导入映射。
令 serializedBaseURL 为序列化后的 baseURL。
令 asURL 为给定 specifier 和 baseURL 时解析类 URL 模块 说明符的结果。
如果 asURL 不为 null,则令 normalizedSpecifier 为 asURL 的序列化结果;否则为 specifier。
令 result 为一个URL 或 null,初始为 null。
对于 importMap 的scopes中的每个 scopePrefix → scopeImports:
如果 scopePrefix 是 serializedBaseURL,或者 scopePrefix 以 U+002F (/) 结尾并且 scopePrefix 是 serializedBaseURL 的码元 前缀:
令 scopeImportsMatch 为给定 normalizedSpecifier、asURL 和 scopeImports 时解析 imports 匹配的结果。
如果 scopeImportsMatch 不为 null,则将 result 设置为 scopeImportsMatch,并中断。
如果 result 为 null,则将 result 设置为给定 normalizedSpecifier、asURL 和 importMap 的imports 时解析 imports 匹配的结果。
如果 result 为 null,则将其设置为 asURL。
此时,如果 result 为 null,则 specifier 未被 importMap 重新映射到任何内容,但它可能能够转换为 URL。
如果 result 不为 null:
给定 settingsObject、 serializedBaseURL、normalizedSpecifier 和 asURL,将模块添加到已解析模块集合。
返回 result。
抛出一个 TypeError,
表明 specifier 是一个裸说明符,
但未被 importMap 重新映射到任何内容。
要在给定一个 字符串 normalizedSpecifier、一个URL 或 null asURL 和一个模块说明符 映射 specifierMap 时解析 imports 匹配:
对于 specifierMap 中的每个 specifierKey → resolutionResult:
如果 specifierKey 是 normalizedSpecifier:
如果以下所有条件均为 true:
specifierKey 以 U+002F (/) 结尾;
specifierKey 是 normalizedSpecifier 的码元 前缀;并且
asURL 为 null,或者 asURL是特殊的,
则:
如果 resolutionResult 为 null,则抛出一个 TypeError,
表明
specifierKey 的解析被 null 条目阻止。
这将终止整个解析模块说明符 算法,而不会进行任何进一步回退。
令 afterPrefix 为 normalizedSpecifier 中位于初始 specifierKey 前缀之后的部分。
令 url 为以 resolutionResult 作为基础对 afterPrefix 进行URL 解析的结果。
如果 url 为失败,则抛出一个 TypeError,
表明
normalizedSpecifier 的解析被阻止,因为 afterPrefix
部分无法相对于 specifierKey 前缀所映射到的
resolutionResult 进行 URL 解析。
这将终止整个解析模块说明符 算法,而不会进行任何进一步回退。
如果 resolutionResult 的序列化结果不是
url 的序列化结果的码元
前缀,则抛出一个
TypeError,
表明 normalizedSpecifier 的解析
因回退到其前缀 specifierKey 之上而被阻止。
这将终止整个解析模块说明符 算法,而不会进行任何进一步回退。
返回 url。
返回 null。
如果可能,解析模块说明符算法将
回退到
不那么具体的作用域,或回退到 "imports"。
要在给定一个字符串 specifier 和一个URL baseURL 时解析类 URL 模块 说明符:
如果 specifier以
"/"、"./" 或 "../" 开头:
令 url 为以 baseURL 作为基础对 specifier 进行URL 解析的结果。
如果 url 为失败,则返回 null。
一种可能的情况是 specifier 为 "../foo",而
baseURL 是一个 data:
URL。
返回 url。
这包括 specifier以
"//" 开头的情况,即相对于方案的 URL。因此,url 最终可能具有与
baseURL 不同的主机。
令 url 为对 specifier 进行URL 解析的结果 (不使用基础 URL)。
如果 url 为失败,则返回 null。
返回 url。
导入映射允许控制模块说明符解析。导入
映射通过内联 script
元素提供,这些元素的 type 属性
设置为 "importmap",并且
其子文本内容包含导入
映射的 JSON 表示。
一个 Document 可以处理多个导入映射,
这可以发生在任何模块导入之前或之后,例如通过 import()
表达式,或
script 元素,且其
type 属性设置
为 "module"。合并现有导入映射和新导入映射算法
确保新导入映射不能为已由过去的导入映射定义,或已经解析的模块
定义模块解析。
导入映射最简单的用途是全局重新映射裸模块说明符:
{
"imports" : {
"moment" : "/node_modules/moment/src/moment.js"
}
} 这使得类似 import moment from "moment";
的语句能够工作,并获取和求值位于 /node_modules/moment/src/moment.js URL 的 JavaScript 模块。
导入映射可以使用尾随 斜杠,将一类模块说明符重新映射到一类 URL,如下所示:
{
"imports" : {
"moment/" : "/node_modules/moment/src/"
}
} 这使得类似 import localeData from
"moment/locale/zh-cn.js"; 的语句能够工作,并获取和求值位于
/node_modules/moment/src/locale/zh-cn.js URL 的 JavaScript 模块。这种尾随斜杠
映射通常与裸说明符映射结合使用,例如
{
"imports" : {
"moment" : "/node_modules/moment/src/moment.js" ,
"moment/" : "/node_modules/moment/src/"
}
} 这样,由 "moment" 指定的“主模块”和
由类似 "moment/locale/zh-cn.js" 的路径指定的“子模块”都
可用。
裸说明符并不是导入映射可以重新映射的唯一模块说明符类型。
“类 URL”说明符,即可解析为绝对 URL,或者以
"/"、"./" 或 "../" 开头的说明符,也可以
被重新映射:
{
"imports" : {
"https://cdn.example.com/vue/dist/vue.runtime.esm.js" : "/node_modules/vue/dist/vue.runtime.esm.js" ,
"/js/app.mjs" : "/js/app-8e0d62a03.mjs" ,
"../helpers/" : "https://cdn.example/helpers/"
}
} 请注意,要重新映射的 URL 以及它所映射到的 URL,都可以指定为
绝对 URL,或以 "/"、"./" 或 "../" 开头的相对 URL。
(不能将它们指定为不带这些起始符号的相对
URL,因为这些符号有助于将它们与裸模块说明符区分开来。)还要
注意尾随斜杠映射在
此上下文中同样有效。
这种重新映射作用于规范化后的 URL,并不要求
导入映射键中提供的字面字符串与导入的模块说明符完全匹配。因此,
例如,如果此导入映射包含在 https://example.com/app.html 中,
那么不仅 import "/js/app.mjs" 会被重新映射,
import "./js/app.mjs" 和 import "./foo/../js/app.mjs" 也会被重新映射。
此前的所有示例都通过使用导入映射中的顶层 "imports" 键,
全局重新映射了模块说明符。顶层 "scopes"
键可用于提供局部重新映射,它们仅在引用模块
匹配特定 URL 前缀时适用。例如:
{
"scopes" : {
"/a/" : {
"moment" : "/node_modules/moment/src/moment.js"
},
"/b/" : {
"moment" : "https://cdn.example.com/moment/src/moment.js"
}
}
} 使用此导入映射时,语句 import "moment" 将根据包含该语句的引用脚本
而具有不同含义:
在位于 /a/ 下的脚本中,这将导入
/node_modules/moment/src/moment.js。
在位于 /b/ 下的脚本中,这将导入
https://cdn.example.com/moment/src/moment.js。
在位于 /c/ 下的脚本中,这将无法解析,
因而抛出异常。
作用域的一种典型用途是允许“同一”模块的多个版本存在于一个 Web 应用程序中,模块图的一些部分导入一个版本,而其他部分 导入另一个版本。
作用域可以相互重叠,也可以与全局 "imports"
说明符映射重叠。在解析时,会按照从最具体到最不具体的顺序查询作用域,
具体程度通过使用码元小于
操作对作用域排序来度量。因此,例如,"/scope2/scope3/" 被视为比
"/scope2/" 更具体,而后者又比顶层
(无作用域)映射更具体。
以下导入映射说明了这一点:
{
"imports" : {
"a" : "/a-1.mjs" ,
"b" : "/b-1.mjs" ,
"c" : "/c-1.mjs"
},
"scopes" : {
"/scope2/" : {
"a" : "/a-2.mjs"
},
"/scope2/scope3/" : {
"b" : "/b-3.mjs"
}
}
} 这会产生以下解析结果(为简洁起见使用相对 URL):
| 说明符 | ||||
|---|---|---|---|---|
"a"
|
"b"
|
"c"
|
||
| 引用方 | /scope1/r.mjs
|
/a-1.mjs
|
/b-1.mjs
|
/c-1.mjs
|
/scope2/r.mjs
|
/a-2.mjs
|
/b-1.mjs
|
/c-1.mjs
|
|
/scope2/scope3/r.mjs
|
/a-2.mjs
|
/b-3.mjs
|
/c-1.mjs
|
|
导入映射还可用于为模块提供完整性元数据,以用于 子资源完整性检查。[SRI]
以下导入映射说明了这一点:
{
"imports" : {
"a" : "/a-1.mjs" ,
"b" : "/b-1.mjs" ,
"c" : "/c-1.mjs"
},
"integrity" : {
"/a-1.mjs" : "sha384-Li9vy3DqF8tnTXuiaAJuML3ky+er10rcgNR/VqsVpcw+ThHmYcwiB1pbOxEbzJr7" ,
"/d-1.mjs" : "sha384-MBO5IDfYaE6c6Aao94oZrIOiC6CGiSN2n4QUbHNPhzk5Xhm0djZLQqTpL0HzTUxk"
}
} 上述示例提供了要对模块 /a-1.mjs 和
/d-1.mjs 强制执行的完整性元数据,即使后者未在映射中定义
为导入项。
表示导入映射的 script 元素的子文本内容必须符合以下导入映射编写
要求:
它必须是有效的 JSON。[JSON]
JSON 必须表示一个 JSON 对象,最多包含三个键 "imports"、
"scopes" 和 "integrity"。
如果存在,与 "imports"、"scopes" 和 "integrity"
键对应的值本身
必须是 JSON 对象。
如果存在,与 "imports" 键对应的值必须是
一个有效模块说明符
映射。
如果存在,与 "scopes" 键对应的值必须是一个
JSON 对象,其键为有效 URL 字符串,其
值为有效模块
说明符映射。
如果存在,与 "integrity" 键对应的值必须
是一个 JSON 对象,其键为有效 URL 字符串,其
值符合integrity
属性的要求。
有效模块说明符映射是一个满足以下 要求的 JSON 对象:
它的所有键都必须非空。
它的所有值都必须是字符串。
每个值必须是一个有效绝对 URL,或一个
有效 URL 字符串,并且该字符串以
"/"、"./" 或 "../" 开头。
如果给定键以 "/" 结尾,则对应的
值也必须如此。
模块说明符映射是一个有序映射,其键为字符串,其值为URL或 null。
模块完整性映射是一个有序映射,其键为URL,其值为将用作完整性元数据的字符串。
空导入映射是一个导入映射,其imports 和scopes都是空映射。
实现可以将 作为 URL 的说明符替换为一个布尔值, 用于指示说明符是裸说明符,还是特殊的类 URL 说明符。
要在给定一个环境设置 对象 settingsObject、一个字符串 serializedBaseURL、 一个字符串 normalizedSpecifier 和一个URL 或 null asURL 时将模块添加到已解析模块集合:
要在给定一个字符串 input 和一个 URL baseURL 时解析导入映射字符串:
令 parsed 为给定 input 时将 JSON 字符串解析为 Infra 值的结果。
令 sortedAndNormalizedImports 为一个空有序映射。
如果 parsed["imports"]存在:
如果 parsed["imports"] 不是一个有序
映射,则抛出一个 TypeError,
表明顶层 "imports" 键的值需要是一个 JSON 对象。
将 sortedAndNormalizedImports 设置为给定
parsed["imports"] 和
baseURL 时排序并
规范化模块说明符映射的结果。
令 sortedAndNormalizedScopes 为一个空有序映射。
如果 parsed["scopes"]存在:
如果 parsed["scopes"] 不是一个有序
映射,则抛出一个 TypeError,
表明顶层 "scopes" 键的值需要是一个 JSON 对象。
将 sortedAndNormalizedScopes 设置为给定
parsed["scopes"] 和
baseURL 时排序并规范化
作用域的结果。
令 normalizedIntegrity 为一个空有序映射。
如果 parsed["integrity"]存在:
如果 parsed["integrity"] 不是一个有序
映射,则抛出一个 TypeError,
表明顶层 "integrity" 键的值需要是一个 JSON 对象。
将 normalizedIntegrity 设置为给定
parsed["integrity"] 和
baseURL 时规范化模块
完整性映射的结果。
如果 parsed 的键包含除 "imports"、
"scopes" 或 "integrity" 以外的任何项,则用户代理应
向控制台报告警告,表明导入映射中
存在无效的顶层键。
这有助于检测拼写错误。这不是错误,因为将其视为错误会阻止任何 未来扩展以向后兼容的方式添加。
返回一个导入映射,其imports 为 sortedAndNormalizedImports, 其scopes为 sortedAndNormalizedScopes,其integrity为 normalizedIntegrity。
此解析算法产生的导入映射经过了高度规范化。
例如,给定基础 URL https://example.com/base/page.html,输入
{
"imports" : {
"/app/helper" : "node_modules/helper/index.mjs" ,
"lodash" : "/node_modules/lodash-es/lodash.js"
}
} «[
"https://example.com/app/helper" → https://example.com/base/node_modules/helper/index.mjs
"lodash" → https://example.com/node_modules/lodash-es/lodash.js
]»要在给定一个全局对象 global 和 一个导入映射 newImportMap 时合并现有导入映射和新导入映射:
令 newImportMapScopes 为 newImportMap 的scopes的深拷贝。
当这些副本被用于忽略作用域特定的规则时,我们会修改这些副本并从中移除项。 这不仅适用于 newImportMapScopes,也适用于下面的 newImportMapImports。
令 oldImportMap 为 global 的导入映射。
令 newImportMapImports 为 newImportMap 的imports的深拷贝。
对于 newImportMapScopes 中的每个 scopePrefix → scopeImports:
对于 global 的 已解析模块 集合中的每个 record:
如果 scopePrefix 是 record 的序列化基础 URL,或者 scopePrefix 以 U+002F (/) 结尾,并且 scopePrefix 是 record 的序列化基础 URL的码元 前缀:
鼓励实现者在处理已解析模块集合时实现更高效的匹配 算法。作为参考,大型应用程序中 已解析或已映射模块的数量可能达到数千个。
如果 scopePrefix 在 oldImportMap 的scopes中存在,则 将 oldImportMap 的scopes[scopePrefix]设置为 给定 scopeImports 和 oldImportMap 的scopes[scopePrefix]时 合并模块说明符映射的结果。
否则,将 oldImportMap 的scopes[scopePrefix]设置为 scopeImports。
将 oldImportMap 的imports设置为 给定 newImportMapImports 和 oldImportMap 的imports时合并模块说明符映射的结果。
上述算法会将新导入映射合并到给定环境设置 对象的全局对象的导入映射中。下面来看几个 示例:
当新导入映射影响一个已解析模块时,该规则会从 导入映射中丢弃。
因此,如果已解析模块
集合已包含 "/app/helper",则以下新导入映射:
{
"imports" : {
"/app/helper" : "./helper/index.mjs" ,
"lodash" : "/node_modules/lodash-es/lodash.js"
}
} 将等效于以下导入映射:
{
"imports" : {
"lodash" : "/node_modules/lodash-es/lodash.js"
}
} 对于影响特定作用域中定义的已解析模块的规则,情况也是如此。
如果我们已经从 "/app/main.mjs" 解析了 "/app/helper",则以下新导入映射:
{
"scopes" : {
"/app/" : {
"/app/helper" : "./helper/index.mjs"
}
},
"imports" : {
"lodash" : "/node_modules/lodash-es/lodash.js"
}
} 同样将等效于:
{
"imports" : {
"lodash" : "/node_modules/lodash-es/lodash.js"
}
} 还可能出现单个已解析模块说明符根据引用脚本的不同, 具有多个解析规则的情况。在这种情况下,只有相关规则 不会添加到映射中。
例如,如果我们已经从 "/app/vendor/main.mjs" 解析了 "/app/helper",则
以下新导入映射:
{
"scopes" : {
"/app/" : {
"/app/helper" : "./helper/index.mjs"
},
"/app/vendor/" : {
"/app/" : "./vendor_helper/"
},
"/vendor/" : {
"/app/helper" : "./helper/vendor_index.mjs"
}
},
"imports" : {
"lodash" : "/node_modules/lodash-es/lodash.js"
"/app/" : "./general_app_path/"
"/app/helper" : "./other_path/helper/index.mjs"
}
} 将等效于:
{
"scopes" : {
"/vendor/" : {
"/app/helper" : "./helper/vendor_index.mjs"
}
},
"imports" : {
"lodash" : "/node_modules/lodash-es/lodash.js"
}
} 这是通过合并算法跟踪已解析模块, 并在将新导入映射合并到现有映射之前,从新导入映射中移除影响这些模块的规则来实现的。
当新导入映射与现有导入映射具有冲突规则,但不存在受影响的 已解析模块时,现有导入映射规则会保留。
例如,以下现有导入映射和新导入映射:
{
"imports" : {
"/app/helper" : "./helper/index.mjs" ,
"lodash" : "/node_modules/lodash-es/lodash.js"
}
} {
"imports" : {
"/app/helper" : "./main/helper/index.mjs"
}
} 将等效于以下单个导入映射:
{
"imports" : {
"/app/helper" : "./helper/index.mjs" ,
"lodash" : "/node_modules/lodash-es/lodash.js" ,
}
} 要在给定一个有序映射 originalMap 和一个 URL baseURL 时排序并规范化模块 说明符映射:
令 normalized 为一个空有序映射。
对于 originalMap 中的每个 specifierKey → value:
令 normalizedSpecifierKey 为给定 specifierKey 和 baseURL 时规范化说明符 键的结果。
如果 normalizedSpecifierKey 为 null,则继续。
如果 value 不是一个字符串:
令 addressURL 为给定 value 和 baseURL 时解析类 URL 模块 说明符的结果。
如果 addressURL 为 null:
如果 specifierKey 以 U+002F (/) 结尾,而 addressURL 的序列化结果不以 U+002F (/) 结尾:
将 normalized[normalizedSpecifierKey]设置为 addressURL。
返回对 normalized 进行降序排序的结果,其中,如果 a 的键按码元 小于 b 的键,则条目 a 小于条目 b。
要在给定一个 有序映射 originalMap 和一个URL baseURL 时排序并规范化作用域:
令 normalized 为一个空有序映射。
对于 originalMap 中的每个 scopePrefix → potentialSpecifierMap:
如果 potentialSpecifierMap 不是一个有序映射,则抛出
一个
TypeError,
表明前缀为
scopePrefix 的作用域的值需要是一个 JSON 对象。
令 scopePrefixURL 为以 baseURL 作为基础对 scopePrefix 进行URL 解析的结果。
如果 scopePrefixURL 为失败:
令 normalizedScopePrefix 为 scopePrefixURL 的序列化结果。
将 normalized[normalizedScopePrefix]设置为 给定 potentialSpecifierMap 和 baseURL 时排序并 规范化模块说明符映射的结果。
返回对 normalized 进行降序 排序的结果,其中,如果条目 a 的键按码元 小于条目 b 的键,则 a 小于 b。
在上述两个算法中,按降序排列键和作用域会产生
将 "foo/bar/" 放在 "foo/" 之前的效果。这进而使
"foo/bar/" 在模块
说明符解析期间具有比 "foo/" 更高的优先级。
要在给定一个有序映射 originalMap 时规范化模块完整性映射:
令 normalized 为一个空有序映射。
对于 originalMap 中的每个 key → value:
令 resolvedURL 为给定 key 和 baseURL 时解析类 URL 模块 说明符的结果。
与 "imports" 不同,完整性映射的键被视为
URL,而不是模块说明符。不过,我们使用解析类 URL 模块
说明符算法来禁止类似 foo 的“裸”相对
URL,因为它们可能被误认为模块说明符。
如果 resolvedURL 为 null:
如果 value 不是一个字符串:
将 normalized[resolvedURL]设置为 value。
返回 normalized。
要在给定一个字符串 specifierKey 和一个URL baseURL 时规范化说明符键:
如果 specifierKey 是空字符串:
用户代理可以向控制台报告警告,指出 说明符键不得为空字符串。
返回 null。
令 url 为给定 specifierKey 和 baseURL 时解析类 URL 模块 说明符的结果。
如果 url 不为 null,则返回 url 的序列化结果。
返回 specifierKey。
JavaScript 规范包含许多由实现定义的抽象 操作,这些操作因宿主环境而异。本节为用户 代理宿主定义这些操作。
JavaScript 包含一个由实现定义的HostEnsureCanAddPrivateElement(O) 抽象操作。用户代理必须使用以下实现:[JAVASCRIPT]
如果 O 是一个 WindowProxy
对象,或者实现了
Location,
则返回 ThrowCompletion(一个
新的
TypeError)。
返回 NormalCompletion(unused)。
JavaScript 私有字段可以应用于任意对象。由于这可能会
显著增加特别奇异的宿主对象的实现复杂度,因此 JavaScript
语言规范提供了此钩子,以允许宿主拒绝向符合宿主定义条件的对象添加私有字段。在 HTML 中,WindowProxy
和
Location 具有
复杂的语义——尤其是在导航和
安全方面——这使得实现私有字段语义颇具挑战,因此我们的
实现直接拒绝这些对象。
JavaScript 包含一个由实现定义的HostEnsureCanCompileStrings 抽象操作, 该操作由动态代码品牌检查提案重新定义。用户代理必须使用 以下实现:[JAVASCRIPT] [JSDYNAMICCODEBRANDCHECKS]
执行 ? EnsureCSPDoesNotBlockStringCompilation(realm, parameterStrings, bodyString, codeString, compilationType, parameterArgs, bodyArg)。 [CSP]
动态代码品牌检查提案包含一个 由实现定义的HostGetCodeForEval(argument) 抽象操作。 用户代理必须使用以下实现:[JSDYNAMICCODEBRANDCHECKS]
如果 argument 是一个 TrustedScript
对象,
则返回 argument 的数据。
否则,返回 no-code。
JavaScript 包含一个由实现定义的HostPromiseRejectionTracker(promise, operation) 抽象操作。用户代理必须使用以下实现: [JAVASCRIPT]
令 script 为正在运行的脚本。
令 settingsObject 为当前设置对象。
如果 script 不为 null,则将 settingsObject 设置为 script 的设置 对象。
令 global 为 settingsObject 的全局对象。
如果 operation 为 "reject":
将 promise追加到 global 的 即将通知的 被拒绝 promise 列表。
如果 operation 为 "handle":
如果 global 的即将通知的 被拒绝 promise 列表包含 promise,则从该列表中移除 promise 并返回。
如果 global 的未决的 被拒绝 promise 弱集合不 包含 promise,则返回。
从 global 的未决的 被拒绝 promise 弱集合中移除 promise。
给定
global,在DOM 操作任务
源上排入一个全局任务,以在
global 上触发名为 rejectionhandled
的事件,使用
PromiseRejectionEvent,
将 promise
属性初始化为
promise,并将 reason
属性初始化为 promise.[[PromiseResult]]。
Temporal 提案包含一个由实现定义的HostSystemUTCEpochNanoseconds 抽象操作。 用户代理必须使用以下实现:[JSTEMPORAL]
令 settingsObject 为 global 的相关设置 对象。
令 time 为 settingsObject 的当前墙上 时间。
令 ns 为从Unix 纪元到 time 的纳秒数,舍入到最接近的整数。
返回将 ns限制在 nsMinInstant 和 nsMaxInstant 之间的结果。
Reference/Global_Objects/Promise#Incumbent_settings_object_tracking
仅一个引擎支持。
JavaScript 规范定义了由宿主调度并稍后运行的作业,以及
JobCallback 记录,后者封装了作为作业一部分
调用的 JavaScript 函数。JavaScript 规范包含许多
由实现定义的抽象操作,使宿主可以定义
如何调度作业以及如何处理 JobCallback。HTML 使用这些抽象操作,通过保存并
恢复 JobCallback 中活动脚本的
现任设置对象和一个JavaScript
执行
上下文,来跟踪 promise 和 FinalizationRegistry
回调中的现任设置
对象。本节为
用户代理宿主定义这些操作。
JavaScript 包含一个由实现定义的HostCallJobCallback(callback, V, argumentsList) 抽象操作,使宿主能够在从任务内部调用 JavaScript 回调时恢复状态。用户代理必须使用以下实现: [JAVASCRIPT]
令 incumbent settings 为 callback.[[HostDefined]].[[IncumbentSettings]]。
令 script execution context 为 callback.[[HostDefined]].[[ActiveScriptContext]]。
使用 incumbent settings准备运行 回调。
这会在回调运行期间影响现任 概念。
如果 script execution context 不为 null,则将 script execution context压入JavaScript 执行 上下文栈。
这会在回调运行期间影响活动 脚本。
令 result 为 Call(callback.[[Callback]], V, argumentsList)。
如果 script execution context 不为 null,则从JavaScript 执行上下文 栈中弹出 script execution context。
使用 incumbent settings在运行回调后 清理。
返回 result。
JavaScript 能够向 FinalizationRegistry
对象注册对象,
以便在发现这些对象已被垃圾回收时调度清理操作。JavaScript
规范包含一个由实现定义的HostEnqueueFinalizationRegistryCleanupJob(finalizationRegistry)
抽象操作,用于调度清理操作。
在 JavaScript 规范中,清理工作的时机和是否发生是由实现定义的。
用户代理在何时以及是否对对象进行垃圾回收方面可能有所不同,这既会影响 WeakRef.prototype.deref()
方法的返回值是否为 undefined,也会影响 FinalizationRegistry
清理回调是否发生。在流行的 Web 浏览器中,存在一些众所周知的情况:对象无法由 JavaScript 访问,但
仍被垃圾回收器无限期保留。HTML 会在执行微任务检查点
算法中清除保持存活的
WeakRef
对象。作者最好不要依赖垃圾回收实现的时序细节。
清理操作不会穿插在同步 JavaScript 执行过程中发生,而是 在已排队的任务中发生。用户代理必须使用 以下实现:[JAVASCRIPT]
JavaScript 包含一个由实现定义的HostEnqueueGenericJob(job, realm)
抽象操作,用于在特定领域中执行通用作业(例如,兑现由
Atomics.waitAsync
产生的 promise)。
用户代理必须使用以下实现:
[JAVASCRIPT]
令 global 为 realm 的全局 对象。
给定 global,在JavaScript 引擎任务源上排入一个全局任务,以执行 job()。
JavaScript 包含一个由实现定义的HostEnqueuePromiseJob(job, realm) 抽象操作,用于调度与 Promise 相关的操作。HTML 在 微任务队列中调度这些操作。用户代理必须使用以下实现:[JAVASCRIPT]
如果 realm 不为 null,则令 job settings 为 realm 的设置 对象。否则, 令 job settings 为 null。
如果 realm 不为 null,则它是将要
运行的作者代码的领域。当
job 由 NewPromiseReactionJob 返回时,它是
promise 处理器函数的领域。当 job 由
NewPromiseResolveThenableJob 返回时,它是
then
函数的领域。
如果 realm 为 null,则要么不会运行作者代码,要么保证作者代码会
抛出异常。对于前者,作者可能未传入要运行的代码,例如
promise.then(null, null)。对于后者,是因为传入了一个已撤销的 Proxy。
在这两种情况下,下面原本会使用 job settings 的所有步骤
都会被跳过。
NewPromiseResolveThenableJob 和 NewPromiseReactionJob 在代理已撤销的情况下似乎都会提供非 null 领域(当前领域记录)。 可以更新前面的文本以反映这一点。
排入一个微任务,以执行 以下步骤:
如果 job settings 不为 null,则使用 job settings准备运行脚本。
这会在作业运行期间影响入口概念。
令 result 为 job()。
job 是由
NewPromiseReactionJob 或 NewPromiseResolveThenableJob 返回的抽象
闭包。当 job 由 NewPromiseReactionJob 返回时的 promise
处理器函数,以及当 job 由
NewPromiseResolveThenableJob 返回时的
then 函数,都会封装在JobCallback
记录中。HTML 在
HostMakeJobCallback 中保存
现任
设置对象和
活动脚本的一个JavaScript 执行上下文,并在HostCallJobCallback 中恢复它们。
如果 job settings 不为 null,则使用 job settings在运行脚本后清理。
如果 result 是一个突然完成, 则 为 realm 的全局对象报告由 result.[[Value]] 给出的异常。
存在一个非常棘手的情况:HostEnqueuePromiseJob 在领域为 null 的情况下被调用(例如,因为使用 null 处理器调用了 Promise.prototype.then),但作业也 突然返回(因为 promise capability 的 resolve 或 reject 处理器抛出异常,可能是 因为这是 Promise 的一个子类,它接受所提供的函数,并在将它们传递给传入 Promise 超类 构造函数的函数之前,将其包装为会抛出异常的函数)。此时应使用哪个全局对象?考虑到通过使用另一个领域中的 Promise 构造函数或 Promise.prototype.then, 当前领域在每个步骤中都可能不同。请参阅议题 #10526。
JavaScript 包含一个由实现定义的HostEnqueueTimeoutJob(job, milliseconds) 抽象操作,用于调度在 超时后执行的操作。HTML 使用在超时后运行步骤来调度这些操作。用户代理 必须使用以下实现:[JAVASCRIPT]
令 global 为 realm 的全局 对象。
令 timeoutStep 为一个算法步骤,该步骤给定 global,在JavaScript 引擎任务源上排入一个全局任务,以执行 job()。
给定 global、"JavaScript"、milliseconds 和
timeoutStep,在超时后运行
步骤。
JavaScript 包含一个由实现定义的HostMakeJobCallback(callable) 抽象操作, 使宿主可以将状态附加到从任务内部调用的 JavaScript 回调。用户代理必须使用以下实现: [JAVASCRIPT]
令 incumbent settings 为现任设置对象。
令 active script 为活动 脚本。
令 script execution context 为 null。
如果 active script 不为 null,则将 script execution context 设置为一个新的 JavaScript 执行上下文,将其 Function 字段设置 为 null,将其 Realm 字段 设置为 active script 的设置 对象的领域,并将其 ScriptOrModule 设置为 active script 的 记录。
如下所示,这用于将当前活动 脚本传播到调用作业回调时。
active script 不为 null,并且以这种方式保存它很有用的一种情况是 如下:
Promise. resolve( 'import(`./example.mjs`)' ). then( eval); 如果没有此步骤(以及 HostCallJobCallback 中使用它的步骤),则在求值
import()
表达式时不会有活动脚本,
因为 eval()
是一个并非源自任何特定脚本的内置函数。
如果用户单击以下按钮,active script 可以为 null:
< button onclick = "Promise.resolve('import(`./example.mjs`)').then(eval)" > Click me</ button > 在这种情况下,事件 处理器的 JavaScript 函数将由获取事件处理器的当前 值算法创建,该算法会创建一个 [[ScriptOrModule]] 值为 null 的函数。因此,当 promise 机制调用 HostMakeJobCallback 时, 不会有可供传递的活动脚本。
因此,这意味着在求值 import()
表达式时,
仍然不会有活动脚本。
幸运的是,我们的
HostLoadImportedModule
实现会回退到使用
当前设置
对象的API 基础 URL,从而处理这种情况。
返回JobCallback 记录 { [[Callback]]: callable, [[HostDefined]]: { [[IncumbentSettings]]: incumbent settings, [[ActiveScriptContext]]: script execution context } }。
JavaScript 规范定义了模块语法,以及其处理模型中与宿主无关的一些部分。
本规范定义其处理模型的其余部分:如何通过 script
元素并将其 type
属性设置为 "module" 来引导
模块系统,以及如何获取、解析和执行模块。[JAVASCRIPT]
尽管 JavaScript 规范使用“脚本”与
“模块”来表述,但本规范通常使用经典
脚本与模块脚本来表述,因为二者都使用
script
元素。
modulePromise = import(specifier)
返回一个 promise,该 promise 对应由 specifier 标识的模块脚本的模块命名空间对象。
这允许在运行时动态导入模块脚本,而不是静态使用 import 语句形式。
说明符将相对于活动
脚本进行解析。
如果给定无效说明符,或者在获取或求值所得 模块图时遇到失败,则返回的 promise 将被拒绝。
url = import.meta.url
此语法只能在模块脚本中使用。
url = import.meta.resolve(specifier)
返回相对于活动脚本解析后的
specifier。也就是说,这会返回使用 import(specifier)
时将导入的 URL。
如果给定无效说明符,则抛出一个 TypeError
异常。
此语法只能在模块脚本中使用。
模块映射是一个映射,其键为由一个元组组成,该元组包含一个URL 记录和一个字符串。
该URL 记录是获取模块时所使用的请求
URL,而该字符串指示模块的类型
(例如 "javascript-or-wasm")。模块映射的值可以是一个模块
脚本、null(用于表示不匹配的MIME 类型),或一个
算法列表(这些算法正在等待获取完成)。模块映射用于确保导入的
模块脚本在每个 Document
或工作者中仅
获取、解析和求值一次。
由于模块映射以
(URL, 模块类型) 为键,因此以下代码将在模块映射中创建三个不同的条目,因为它
会产生三个不同的 (URL, 模块类型)元组(类型均为
"javascript-or-wasm"):
import "https://example.com/module.mjs" ;
import "https://example.com/module.mjs#map-buster" ;
import "https://example.com/module.mjs?debug=true" ; 也就是说,可以改变 URL 的查询和片段,以在 模块映射中创建不同条目; 它们不会被忽略。因此,将执行三次单独的获取和三次单独的 模块求值。
相比之下,以下代码只会在模块 映射中创建一个条目,因为在对这些输入应用URL 解析器后, 所得URL 记录相等:
import "https://example.com/module2.mjs" ;
import "https:example.com/module2.mjs" ;
import "https://///example.com\\module2.mjs" ;
import "https://example.com/foo/../module2.mjs" ; 因此,在第二个示例中,只会进行一次获取和一次模块求值。
由于模块类型也是模块映射键的一部分,以下代码将在模块映射中创建两个不同的条目(第一个的类型为
"javascript-or-wasm",第二个的类型为 "css"):
< script type = module >
import "https://example.com/module" ;
</ script >
< script type = module >
import "https://example.com/module" with { type: "css" };
</ script > 这可能导致执行两次单独的获取和两次单独的模块求值。
实际上,由于尚未规定的内存缓存(请参阅议题 #6110),在 WebKit 和基于 Blink 的浏览器中, 资源可能只会被获取一次。此外,只要所有模块类型都互斥,获取单个模块脚本中的模块类型检查 就会对至少一个导入失败,因此最多只会进行一次模块求值。
将类型包含在模块映射键中的目的,是使具有错误类型属性的导入 不会阻止对同一说明符但具有正确类型的另一导入成功。
从另一个 JavaScript 模块导入时,JavaScript 模块脚本是默认导入类型;
也就是说,当 import 语句缺少 type 导入属性时,所导入
模块脚本的类型将为 JavaScript。
尝试使用带有 type 导入属性的 import 语句导入 JavaScript 资源
将失败:
< script type = "module" >
// All of the following will fail, assuming that the imported .mjs files are served with a
// JavaScript MIME type. JavaScript module scripts are the default and cannot be imported with
// any import type attribute.
import foo from "./foo.mjs" with { type: "javascript" };
import foo2 from "./foo2.mjs" with { type: "js" };
import foo3 from "./foo3.mjs" with { type: "" };
await import ( "./foo4.mjs" , { with : { type: null } });
await import ( "./foo5.mjs" , { with : { type: undefined } });
</ script > Reference/Operators/import.meta/resolve
所有当前引擎均支持。
Reference/Operators/import.meta
所有当前引擎均支持。
JavaScript 包含一个由实现定义的HostGetImportMetaProperties 抽象操作。 用户代理必须使用以下实现:[JAVASCRIPT]
令 moduleScript 为 moduleRecord.[[HostDefined]]。
断言:moduleScript 的基础 URL不为 null,因为 moduleScript 是一个JavaScript 模块 脚本。
令 steps 为以下步骤,给定参数 specifier:
令 resolveFunction 为 ! CreateBuiltinFunction(steps,
1, "resolve", « »)。
返回 « 记录 {
[[Key]]: "url", [[Value]]: urlString },
记录 {
[[Key]]: "resolve",
[[Value]]: resolveFunction } »。
JavaScript 包含一个由实现定义的HostGetSupportedImportAttributes 抽象 操作。用户代理必须使用以下实现:[JAVASCRIPT]
返回 « "type" »。
JavaScript 包含一个由实现定义的HostLoadImportedModule 抽象操作。用户代理 必须使用以下实现:[JAVASCRIPT]
令 settingsObject 为当前设置对象。
如果 settingsObject 的全局
对象实现了 WorkletGlobalScope
或 ServiceWorkerGlobalScope,
并且 loadState 为 undefined:
当当前获取过程由动态 import()
调用启动时,无论是直接启动,还是在加载动态导入模块的
传递依赖项时启动,loadState 都为 undefined。
执行 FinishLoadingImportedModule(referrer,
moduleRequest, payload, ThrowCompletion(一个新的
TypeError))。
返回。
令 referencingScript 为 null。
令 originalFetchOptions 为默认脚本获取 选项。
令 fetchReferrer 为 "client"。
如果 referrer 是一个脚本记录或一个循环模块 记录:
将 referencingScript 设置为 referrer.[[HostDefined]]。
将 settingsObject 设置为 referencingScript 的设置对象。
将 fetchReferrer 设置为 referencingScript 的基础 URL。
将 originalFetchOptions 设置为 referencingScript 的获取选项。
referrer 通常是一个脚本记录或一个 循环模块 记录,但根据获取事件处理器的当前值 算法,对于事件处理器并非如此。例如,给定:
< button onclick = "import('./foo.mjs')" > Click me</ button > 如果发生 click
事件,则在
import()
表达式运行时,GetActiveScriptOrModule 将返回 null,
而此操作将接收当前领域作为后备
referrer。
如果 referrer 是一个循环 模块记录,并且 moduleRequest 等于 referrer.[[RequestedModules]] 的第一个元素:
对于 referrer.[[RequestedModules]] 中的每个ModuleRequest 记录 requested:
如果 requested.[[Attributes]] 包含一个记录 entry,
且 entry.[[Key]] 不是 "type":
令 error 为一个新的 SyntaxError
异常。
如果 loadState 不为 undefined,并且 loadState.[[ErrorToRethrow]] 为 null,则将 loadState.[[ErrorToRethrow]] 设置为 error。
执行 FinishLoadingImportedModule(referrer, moduleRequest, payload, ThrowCompletion(error))。
返回。
JavaScript 规范会再次执行此验证,但这里进行了重复, 以避免在验证失败时不必要地加载任何依赖项。
给定 referencingScript 和 requested.[[Specifier]],解析 模块说明符,并捕获任何异常。如果它们抛出异常,则令 resolutionError 为抛出的异常。
如果上一步抛出异常:
如果 loadState 不为 undefined,并且 loadState.[[ErrorToRethrow]] 为 null,则将 loadState.[[ErrorToRethrow]] 设置为 resolutionError。
执行 FinishLoadingImportedModule(referrer, moduleRequest, payload, ThrowCompletion(resolutionError))。
返回。
令 moduleType 为给定 requested 时运行从模块请求获取模块 类型步骤的结果。
如果给定 moduleType 和 settingsObject 时运行允许模块类型步骤的结果为 false:
令 error 为一个新的 TypeError
异常。
如果 loadState 不为 undefined,并且 loadState.[[ErrorToRethrow]] 为 null,则将 loadState.[[ErrorToRethrow]] 设置为 error。
执行 FinishLoadingImportedModule(referrer, moduleRequest, payload, ThrowCompletion(error))。
返回。
此步骤实质上是在首次针对静态模块依赖项列表调用 HostLoadImportedModule 时,验证所有请求的模块说明符和 类型属性,以便在任一依赖项存在静态错误时避免进一步的加载操作。 我们将具有无法解析的模块说明符或不受支持的类型属性的模块,视为与无法解析的模块相同; 在这两种情况下,语法问题都会使以后无法考虑链接该模块。
令 url 为给定 referencingScript 和 moduleRequest.[[Specifier]] 时解析 模块说明符的结果,并捕获任何异常。如果它们抛出异常,则令 resolutionError 为抛出的异常。
如果上一步抛出异常:
如果 loadState 不为 undefined,并且 loadState.[[ErrorToRethrow]] 为 null,则将 loadState.[[ErrorToRethrow]] 设置为 resolutionError。
执行 FinishLoadingImportedModule(referrer, moduleRequest, payload, ThrowCompletion(resolutionError))。
返回。
令 fetchOptions 为给定 originalFetchOptions、url 和 settingsObject 时获取后代脚本获取 选项的结果。
令 destination 为 "script"。
令 fetchClient 为 settingsObject。
如果 loadState 不为 undefined:
将 destination 设置为 loadState.[[Destination]]。
将 fetchClient 设置为 loadState.[[FetchClient]]。
给定 url、 fetchClient、destination、fetchOptions、 settingsObject、fetchReferrer、moduleRequest 和 下面定义的 onSingleFetchComplete,获取单个导入的模块脚本。如果 loadState 不为 undefined,并且 loadState.[[PerformFetch]] 不为 null,也将 loadState.[[PerformFetch]] 一并传入。
给定 moduleScript 的 onSingleFetchComplete 是以下 算法:
令 completion 为 null。
如果 moduleScript 为 null,则将 completion 设置为
ThrowCompletion(一个新的 TypeError)。
否则,如果 moduleScript 的解析 错误不为 null:
令 parseError 为 moduleScript 的解析错误。
将 completion 设置为 ThrowCompletion(parseError)。
如果 loadState 不为 undefined,并且 loadState.[[ErrorToRethrow]] 为 null,则将 loadState.[[ErrorToRethrow]] 设置为 parseError。
否则,将 completion 设置为 NormalCompletion(moduleScript 的记录)。
执行 FinishLoadingImportedModule(referrer, moduleRequest, payload, completion)。
为了协调事件、用户交互、脚本、渲染、网络等,用户 代理必须按照本节所述使用事件循环。每个代理都有一个关联的事件循环,该事件循环对该代理是唯一的。
事件循环不一定对应于实现 线程。例如,多个窗口事件 循环可以在单个线程中进行协作式调度。
但是,对于 [[CanBlock]] 设置为 true 的各种工作线程代理,JavaScript 规范确实对其向前进展提出了要求,这实际上相当于要求在这些情况下 为每个代理提供专用线程。
一个事件循环具有一个或多个任务 队列。一个 任务队列是一个由任务组成的集合。
任务队列是集合, 而不是队列, 因为事件 循环处理模型会从选定的队列中获取第一个可运行的任务, 而不是出队第一个任务。
任务封装了负责执行以下工作等的算法:
在特定
EventTarget
对象上分派一个 Event
对象通常由专用任务完成。
并非所有事件都使用任务 队列进行分派;许多事件会在其他任务期间分派。
HTML 解析器对一个或多个字节进行标记化,然后 处理任何所得标记,通常是一个任务。
调用回调通常由专用任务完成。
当算法获取资源时,如果获取 以非阻塞方式进行,那么一旦部分或全部资源 可用,就会由任务处理该资源。
某些元素具有响应 DOM 操作而触发的任务,例如当该 元素被插入文档时。
形式上,任务是一个 结构,它具有:
Document,或者对于不在
窗口事件循环中的任务为 null。
根据其源字段,每个任务都被定义为来自特定的任务 源。对于每个事件循环,每个任务源都必须与一个特定的任务队列关联。
本质上,标准使用任务源来分隔逻辑上不同类型的任务, 用户代理可能希望区分这些任务。用户代理使用任务队列, 将给定事件循环中的任务源合并起来。
例如,用户代理可以为鼠标和 键盘事件设置一个任务 队列(用户交互任务源与其关联),并为所有其他任务源设置另一个任务队列。然后,利用 事件循环 处理模型初始步骤所赋予的自由,它可以在四分之三的时间里优先处理键盘和鼠标事件, 从而保持界面响应,同时又不会使其他任务队列饥饿。 请注意,在这种设置中,处理模型仍会强制用户代理绝不会 乱序处理来自任何一个任务源的事件。
每个事件循环都有一个当前正在运行的任务,它是一个任务或 null。其初始值为 null。它用于处理 重入。
每个事件循环都有一个微任务 队列,它是一个由微任务组成的队列,初始为空。微任务是对通过 排入一个微任务算法创建的任务的通俗称呼。
每个事件循环都有一个正在执行微任务检查点布尔值, 其初始值为 false。它用于防止重入调用执行 微任务检查点算法。
每个窗口事件循环都有一个 DOMHighResTimeStamp
上次渲染机会时间,初始设置为零。
每个窗口事件循环都有一个 DOMHighResTimeStamp
上次空闲期开始时间,初始设置为零。
要在任务源 source 上排入一个任务,该任务执行一系列步骤 steps,其中 source 是一个任务源,并可选地给定事件循环 event loop 和文档 document:
在排入一个任务时不传递事件循环和文档,意味着 依赖含糊且规定不充分的隐含事件循环和隐含 文档概念。规范作者应当始终传递这些值,或者改用 包装算法排入一个全局任务或 排入一个元素任务。 建议使用包装算法。
要在任务源 source 上排入一个全局任务,并给定 一个全局对象 global 和一系列 步骤 steps,其中 source 是一个任务源:
如果 global 是一个 Window
对象,则令 document 为 global 的关联 Document;否则为 null。
给定 source、 event loop、document 和 steps,排入一个任务。
要在任务源 source 上排入一个元素任务, 并给定元素 element 和一系列步骤 steps,其中 source 是一个任务源:
要排入一个微任务,该微任务执行一系列步骤 steps, 并可选地给定文档 document:
如果一个微任务在初始执行期间自旋 事件循环,则它可能被移动到常规任务 队列。这是唯一会查阅微任务的源、文档 和脚本求值环境设置 对象集合的情况; 执行微任务检查点算法会忽略它们。
排入任务时的隐含事件循环是可以从 调用算法的上下文中推断出的事件循环。这通常没有歧义,因为大多数规范算法 只涉及单个代理(因此只有单个事件 循环)。例外情况是涉及或规定跨代理通信的算法(例如,在窗口 与工作线程之间);对于这些情况,不得依赖隐含 事件循环概念,并且规范在排入一个任务时必须显式提供一个事件 循环。
在事件循环 event loop 上排入任务时的隐含文档按以下方式确定,其中 event loop 是一个事件循环:
隐含事件循环和 隐含 文档都定义得很模糊,并具有大量远距离作用。我们希望移除 这些概念,尤其是隐含文档。请参阅议题 #4980。
只要一个事件循环存在,就必须持续运行 以下步骤:
令 oldestTask 和 taskStartTime 为 null。
令 taskQueue 为其中一个这样的任务队列,以由实现定义的方式选择。
请记住,微任务队列不是任务 队列,因此不会在此步骤中被选中。但是,与微任务任务源关联的任务队列可能会在此步骤中被 选中。在这种情况下,下一步选择的任务最初是 一个微任务,但它作为自旋事件 循环的一部分被移动了。
将 taskStartTime 设置为不安全的共享当前时间。
如果 oldestTask 的文档不为 null,则给定 taskStartTime 和 oldestTask 的文档,记录任务开始时间。
将该事件循环的当前正在运行的 任务设置为 oldestTask。
执行 oldestTask 的步骤。
将该事件循环的当前正在 运行的任务重新设置为 null。
令 taskEndTime 为不安全的共享当前时间。 [HRT]
如果 oldestTask 不为 null:
如果这是一个窗口事件 循环,并且该事件循环的任务队列中没有可运行的任务:
将该事件循环的上次 空闲期开始时间设置为 不安全的共享当前时间。
令 computeDeadline 为以下步骤:
令 deadline 为该事件循环的上次空闲期开始 时间加 50。
将未来时间上限设为 50ms,是为了确保在 人类感知阈值内响应新的用户输入。
令 hasPendingRenders 为 false。
如果 hasPendingRenders 为 true:
返回 deadline。
对于该事件 循环的同循环窗口中的每个 win, 使用以下步骤为 win 执行开始空闲期算法:返回调用 computeDeadline 的结果,并给定 win 的相关设置 对象的跨源 隔离能力对其进行粗化。[REQUESTIDLECALLBACK]
如果这是一个工作线程事件 循环:
如果该事件循环的代理的唯一领域的全局对象是一个受支持的
DedicatedWorkerGlobalScope,
并且用户代理认为此时更新其渲染会带来好处:
令 now 为给定该
DedicatedWorkerGlobalScope
时的当前高分辨率时间。
[HRT]
为该
DedicatedWorkerGlobalScope运行动画帧
回调,并传入 now 作为
时间戳。
更新该专用工作线程的渲染,以反映当前状态。
如果事件
循环的任务队列中没有任务,并且
WorkerGlobalScope
对象的closing 标志为 true,则销毁
该事件循环,中止这些步骤,
并恢复下面Web 工作线程一节中描述的运行工作线程步骤。
只要窗口事件循环 eventLoop 存在,它还必须并行运行以下步骤,其中 eventLoop 是一个窗口事件循环:
将 eventLoop 的上次渲染机会时间设置为不安全的 共享当前时间。
对于每个具有渲染机会的 navigable,给定 navigable 的活动窗口,在渲染任务源上排入一个 全局任务,以更新渲染:
这可能会导致重复调用更新渲染。但是, 根据不必要的渲染步骤,这些调用不会产生可观察的效果,因为 不需要进行渲染。实现可以引入进一步优化, 例如仅在该任务尚未排队时才将其排队。但是请注意,与任务 关联的文档可能在处理任务之前变为非活动状态。
令 frameTimestamp 为 eventLoop 的上次渲染机会 时间。
令 docs 为所有满足其相关代理的事件
循环为
eventLoop 的完全
活动的 Document
对象,并按任意顺序排序,但必须满足以下条件:
如果两个文档 A 和 B 具有相同的 非 null容器文档 C,则 A 和 B 在列表中的顺序必须与其各自的可导航 容器在 C 的节点树中的包括影子树的 树顺序一致。
在下面迭代 docs 的步骤中,每个 Document 都必须
按其在列表中出现的顺序处理。
过滤不可渲染的文档:从 docs 中移除满足以下任一条件的
Document 对象
doc:
不必要的渲染:从 docs 中移除满足以下所有条件的 Document 对象
doc:
从 docs 中移除所有用户代理
因其他原因认为最好跳过渲染更新的 Document
对象。
对于 docs 中的每个 doc,显露 doc。
对于 docs 中的每个 doc,为 doc运行调整大小步骤。[CSSOMVIEW]
对于 docs 中的每个 doc,为 doc运行滚动步骤。[CSSOMVIEW]
对于 docs 中的每个 doc,为 doc求值媒体查询并报告 更改。[CSSOMVIEW]
对于 docs 中的每个 doc,为 doc更新动画并发送 事件,并传入给定 frameTimestamp 和 doc 的相关全局对象时的相对高分辨率时间作为 时间戳。[WEBANIMATIONS]
对于 docs 中的每个 doc,为 doc运行全屏步骤。[FULLSCREEN]
对于 docs 中的每个 doc,如果用户代理检测到与
CanvasRenderingContext2D
或
OffscreenCanvasRenderingContext2D
context 关联的后备存储已丢失,则必须为每个此类 context 运行上下文丢失步骤:
如果 context 是一个
CanvasRenderingContext2D,
则令 canvas 为 context 的 canvas
属性的值;否则为 context 的关联
OffscreenCanvas
对象。
将 context 的上下文 已丢失设置为 true。
给定 context,将渲染 上下文重置为默认状态。
令 shouldRestore 为在 canvas 上触发名为
contextlost
的事件的结果,并将 cancelable
属性初始化为 true。
如果 shouldRestore 为 false,则中止这些步骤。
尝试通过使用 context 的属性创建后备存储并将其与 context 关联来恢复 context。如果失败, 则中止这些步骤。
将 context 的上下文 已丢失设置为 false。
在 canvas 上触发名为
contextrestored
的事件。
对于 docs 中的每个 doc,为 doc运行动画帧 回调,并传入给定 frameTimestamp 和 doc 的相关全局对象时的相对高分辨率时间作为 时间戳。
令 unsafeStyleAndLayoutStartTime 为不安全的共享当前 时间。
对于 docs 中的每个 doc:
令 resizeObserverDepth 为 0。
当 true 时:
重新计算 doc 的样式并更新布局。
令 hadInitialVisibleContentVisibilityDetermination 为 false。
对于每个 使用值为 'auto' 的 'content-visibility' 元素 element:
如果 hadInitialVisibleContentVisibilityDetermination 为 true,则 继续。
此步骤旨在使立即生效的初始视口接近程度 确定结果,反映在此循环前一步执行的样式和布局 计算中。初始确定以外的接近程度 确定会在下一个渲染 机会时生效。[CSSCONTAIN]
为 doc 在深度 resizeObserverDepth 处收集活动的调整大小观察。
如果 doc具有活动的调整大小观察:
将 resizeObserverDepth 设置为给定 doc 时广播活动的调整大小 观察所得的结果。
如果 doc具有已跳过的调整大小观察,则给定 doc传递 调整大小循环错误。
对于 docs 中的每个 doc,如果 doc 的聚焦区域不是一个可聚焦区域,则为 doc 的视口运行聚焦步骤,并将 doc 的相关全局对象的导航 API的正在进行的导航期间焦点已更改 设置为 false。
例如,这可能是因为元素添加了 属性,
导致它停止被渲染。也可能发生在 input 元素
被禁用时。
对于 docs 中的每个 doc,为 doc执行待处理的过渡 操作。[CSSVIEWTRANSITIONS]
对于 docs 中的每个 doc,为 doc运行更新交叉 观察步骤,并传入给定 now 和 doc 的相关全局对象时的相对高分辨率 时间作为时间戳。[INTERSECTIONOBSERVER]
对于 docs 中的每个 doc,给定 unsafeStyleAndLayoutStartTime,为 doc记录渲染时间。
对于 docs 中的每个 doc,为 doc标记 绘制时序。
对于 docs 中的每个 doc,更新 doc 及其节点 可导航对象的渲染或用户界面,以反映当前状态。
对于 docs 中的每个 doc,给定 doc处理顶层移除。
一个可导航对象的渲染机会
根据显示器刷新率等硬件限制以及页面性能等其他因素确定,还会考虑其活动
文档的
可见性状态是否为
"visible"。渲染机会
通常以固定间隔发生。
本规范不强制规定任何特定的渲染 机会选择模型。但是,例如,如果浏览器尝试达到 60Hz 刷新率,则 渲染机会最多每秒发生 60 次(约每 16.7ms 一次)。如果 浏览器发现某个可导航对象无法 维持此速率,它可能将该可导航对象降低到 更可持续的每秒 30 次渲染机会,而不是偶尔丢帧。同样,如果某个可导航对象不可见, 用户代理可能决定将该页面降至慢得多的每秒 4 次渲染机会, 甚至更少。
当用户代理要执行微任务 检查点时:
如果该事件循环的正在执行微任务检查点为 true, 则返回。
将该事件循环的正在执行微任务检查点 设置为 true。
将该事件循环的当前正在 运行的任务设置为 oldestMicrotask。
运行 oldestMicrotask。
这可能涉及调用脚本化回调,最终会调用在运行脚本后清理步骤, 后者会再次调用此执行微任务 检查点算法,因此我们使用正在执行微任务 检查点标志来避免重入。
将该事件循环的当前正在 运行的任务重新设置为 null。
对于每个其负责的事件 循环为此事件循环的环境设置对象 settingsObject,给定 settingsObject 的全局对象,通知被拒绝的 promise。
执行 ClearKeptObjects()。
当 WeakRef.prototype.deref()
返回一个对象时,该对象会保持存活,直到下一次调用ClearKeptObjects(),此后它会再次
成为垃圾回收的对象。
将该事件循环的正在执行微任务检查点 设置为 false。
当一个并行运行的算法要等待稳定状态时, 用户代理必须排入一个 微任务来运行以下步骤,然后必须停止 执行(当微任务运行时,算法会按照以下步骤所述恢复执行):
运行算法的同步部分。
如果适当,按照算法步骤中的说明并行恢复算法执行。
同步部分中的步骤 使用 ⌛ 标记。
如果算法步骤要求自旋事件循环,直到满足条件 goal,则等价于替换为以下算法步骤:
令 task 为该事件 循环的当前正在运行的 任务。
task 可以是一个微任务。
令 task source 为 task 的源。
令 old stack 为JavaScript 执行上下文 栈的一个副本。
如果 task 是一个微任务,则由于 正在执行微任务检查点 为 true,此步骤将不执行任何操作。
并行:
等待,直到满足条件 goal。
在 task source 上排入一个任务,以:
使用 old stack 替换JavaScript 执行上下文栈。
执行原始算法中此自旋事件循环实例之后出现的任何步骤。
这会恢复 task。
停止 task,允许调用它的任何算法恢复。
与本规范及其他规范中行为类似于编程语言函数调用的其他算法不同,自旋事件循环更像一个宏, 它通过展开为一系列步骤和操作,减少使用位置的键入量和缩进。
一个步骤如下的算法:
做某件事。
自旋事件 循环,直到奇妙的事情发生。
做另一件事。
是一种简写形式,在“宏展开”后会变为
做某件事。
令 old stack 为JavaScript 执行上下文 栈的一个副本。
并行:
等待,直到奇妙的事情发生。
在执行“做某件事”的任务源上排入一个任务,以:
使用 old stack 替换JavaScript 执行上下文栈。
做另一件事。
下面是一个更完整的替换示例,其中事件循环从一个 由并行工作排入的任务内部自旋。使用自旋事件循环的版本:
完全展开的版本:
并行:
执行并行事项 1。
令 old stack 为 null。
执行任务事项 1。
将 old stack 设置为JavaScript 执行上下文 栈的一个副本。
等待,直到奇妙的事情发生。
使用 old stack 替换JavaScript 执行上下文栈。
执行任务事项 2。
执行并行事项 2。
由于历史原因,本规范中的某些算法要求用户代理在运行任务时暂停,直到满足条件 goal。这意味着运行以下步骤:
暂停对用户体验极为不利, 尤其是在单个事件循环由多个文档共享的场景中。鼓励用户 代理尝试暂停的替代方案, 例如自旋事件 循环,甚至在可以保持与现有内容兼容的范围内, 完全不暂停执行而直接继续。如果发现一种与 Web 兼容且不那么激进的替代方案, 本规范将乐于作出更改。
在此期间,实现者应意识到,用户代理可能尝试的各种替代方案 会改变事件循环行为的细微方面,包括 任务和微任务的时序。实现应 继续进行试验,即使这样做会导致其违反 暂停操作所暗示的精确语义。
以下任务源由本规范及其他规范中许多 大多互不相关的功能使用。
此任务源用于响应用户交互的功能,例如 键盘或鼠标输入。
为响应用户输入而发送的事件(例如 click
事件)
必须使用通过用户交互任务源排入的任务来触发。[UIEVENTS]
此任务源用于响应网络 活动而触发的功能。
编写能与事件循环正确交互的规范可能很棘手。 本规范使用独立于并发模型的术语,这使问题更加复杂,因此我们会说“事件循环”和“并行”,而不是使用更 熟悉的特定模型术语,例如“主线程”或“在后台线程上”。
默认情况下,规范文本通常在事件循环上运行。这源于正式的事件循环处理模型,因为最终可以将大多数算法追溯到在那里排入的某个任务。
任何 JavaScript 方法的算法步骤都将由调用该方法的作者代码
调用。而作者代码只能通过已排入的任务运行,这些任务通常源自script 处理模型中的某处。
从这一出发点来看,首要准则是:规范需要执行的任何原本会阻塞事件 循环的工作,都必须改为与其并行执行。这包括但不限于:
执行大量计算;
显示面向用户的提示;
执行可能需要涉及外部系统的操作(即“跨进程”)。
下一个复杂之处在于,在并行的算法部分中,不得创建或操作与特定领域、全局对象或环境设置对象关联的对象。(用更 熟悉的术语来说,不得从后台线程直接访问主线程构件。) 这样做会产生 JavaScript 代码可观察到的数据竞争,因为毕竟,你的算法 步骤正在与 JavaScript 代码并行运行。
进一步而言,不能从并行运行的步骤中访问 Web IDL 的this 值,即使这些步骤由 确实可以访问this 值的算法激活。
但是,可以操作来自 Infra 的规范级数据结构和值,因为它们与领域无关。如果没有发生特定转换,它们绝不会直接公开给 JavaScript (通常通过 Web IDL)。 [INFRA] [WEBIDL]
因此,要影响可观察的 JavaScript 对象世界,必须排入一个全局 任务来执行任何此类操作。这可确保你的步骤相对于事件循环上发生的其他事情正确交错。此外,在排入一个全局 任务时,必须选择一个任务源;这会控制你的步骤相对于其他步骤的顺序。如果不确定应使用哪个 任务源,请选择一个听起来最适用的通用任务 源。最后,必须指明已排入任务与哪个全局 对象关联;这可确保该全局对象处于非活动状态时,任务不会运行。
排入一个全局任务所基于的基础原语是 排入一个任务算法。通常,排入一个全局任务更好, 因为它会自动选择正确的事件 循环,并在适当时选择文档。较旧的规范通常使用排入一个 任务,并结合隐含事件循环和隐含文档概念,但不建议这样做。
综合上述内容,可以为通常需要异步执行工作的算法提供以下模板:
以下算法在将传入的列表中的标量值字符串 input 解析为 URL 后,对其进行“加密”:
令 urls 为一个空列表。
对于 input 中的每个 string:
如果 parsed 为失败,则返回一个以
"SyntaxError" DOMException拒绝的 promise。
令 serialized 为对 parsed 应用URL 序列化器所得的结果。
将 serialized追加到 urls。
令 realm 为当前领域。
令 p 为一个新的 promise。
并行运行以下步骤:
返回 p。
关于此算法,有几点值得注意:
它在进入并行步骤之前,预先在事件循环上执行 URL 解析。这是 必要的,因为解析依赖于当前 设置对象,而进入并行状态后,它将不再是当前设置对象。
或者,它可以保存对当前设置 对象的API 基础 URL的引用,并在并行步骤中使用它; 这将是等效的。但是,我们建议像本示例一样,尽可能预先完成更多工作。尝试保存正确的值容易出错;例如,如果我们只保存了当前设置对象,而不是它的API 基础 URL,则可能发生竞争。
作为可观察的 JavaScript 对象,promise 从不会在并行步骤期间创建或操作。p 在进入这些步骤之前 创建,随后在专门为此目的排入的任务期间进行操作。
JavaScript 数组对象的创建也发生在已排入的任务期间,并且会谨慎地指明在哪个领域中创建数组,因为这已无法再从 上下文中明显得知。
(关于最后两点,另请参阅 whatwg/webidl 议题 #135 和 whatwg/webidl 议题 #371,我们仍在 考虑上述 promise 兑现模式的细微之处。)
另一点需要注意的是,如果此算法是从 Web IDL 规定的
接受 sequence<USVString>
的操作调用的,则会自动将作者作为输入提供的特定于领域的 JavaScript 对象转换为与领域无关的
sequence<USVString>
Web IDL 类型,随后我们将其视为由标量值字符串组成的列表。因此,根据规范的
结构方式,主事件循环上可能还会发生其他隐式步骤,它们在
让你准备进入并行状态的整个过程中发挥作用。
许多对象都可以指定事件处理器。 它们充当所指定对象的非捕获事件监听器。[DOM]
一个值,它是
null、回调对象或内部原始未编译处理器之一。EventHandler 回调
函数类型描述了其如何向脚本公开。最初,事件处理器的值
必须设置为 null。
一个监听器,它是 null 或负责运行事件 处理器处理算法的事件监听器。最初,事件处理器的监听器必须设置为 null。
事件处理器以两种方式公开。
第一种方式是作为事件处理器 IDL 属性,这适用于所有事件处理器。
第二种方式是作为事件处理器内容
属性。HTML
元素上的事件处理器以及
Window 对象上的部分事件处理器以这种方式公开。
对于这两种方式,事件
处理器都通过一个名称公开,该名称是一个始终以
"on" 开头,后跟处理器所针对事件名称的字符串。
大多数时候,公开事件处理器的对象
与添加相应事件监听器的对象相同。
但是,body 和
frameset 元素公开了多个事件
处理器,如果元素存在 Window
对象,则这些处理器作用于该对象。无论哪种
情况,我们都将事件
处理器所作用的对象称为该事件
处理器的目标。
要确定事件
处理器的目标,给定公开事件处理器的 EventTarget
对象 eventTarget,以及事件处理器名称
name,执行以下步骤:
如果 name 不是
WindowEventHandlers
接口混入的属性成员名称,并且反映
Window 的 body 元素事件处理器集合不包含
name,则返回 eventTarget。
如果 eventTarget 的节点文档 不是活动 文档,则返回 null。
例如,如果此对象是一个没有对应 Window
对象的 body 元素,
就可能发生这种情况。
此检查不一定会阻止并非其节点
文档的body 元素的 body 和
frameset 元素进入下一步。特别是,在活动文档中创建(可能使用 document.createElement())
但未连接的 body 元素,也会将其对应的
Window 对象作为通过它公开的多个事件处理器的目标。
每个指定了一个或多个事件
处理器的 EventTarget
对象,都有关联的事件处理器映射,
它是一个将表示事件处理器名称的字符串映射到事件处理器的映射。
事件处理器 映射中的条目顺序可以是任意的。任何操作该 映射的算法都无法观察到此顺序。
对于仅在某个对象上公开、但以其他对象为目标的事件 处理器,不会在该对象的事件处理器 映射中创建条目。
事件处理器 IDL 属性是用于特定事件 处理器的 IDL 属性。该 IDL 属性的名称与事件处理器的名称相同。
调用名称为 name 的事件处理器 IDL 属性的获取器时, 必须运行以下步骤:
令 eventTarget 为给定此对象和 name 时确定事件处理器目标的结果。
如果 eventTarget 为 null,则返回 null。
返回给定 eventTarget 和 name 时获取事件处理器当前值的结果。
调用名称为 name 的事件处理器 IDL 属性的设置器时, 必须运行以下步骤:
令 eventTarget 为给定此对象和 name 时确定事件 处理器目标的结果。
如果 eventTarget 为 null,则返回。
如果给定值为 null,则给定 eventTarget 和 name停用事件处理器。
否则:
某些事件处理器 IDL 属性具有额外要求,尤其是
MessagePort 对象的 onmessage
属性。
事件处理器内容属性 是用于特定事件处理器的内容属性。该内容 属性的名称与事件处理器的名称相同。
指定事件 处理器内容属性时,其必须包含有效的 JavaScript 代码,该代码在解析时,在自动插入分号后,应匹配 FunctionBody 产生式。
以下属性更改 步骤用于在事件处理器内容属性和 事件处理器之间进行同步:[DOM]
如果 namespace 不为 null,或者 localName 不是 element 上某个事件处理器内容属性的名称,则返回。
令 eventTarget 为给定 element 和 localName 时确定事件 处理器目标的结果。
如果 eventTarget 为 null,则返回。
如果 value 为 null,则给定 eventTarget 和 localName停用事件处理器。
否则:
如果对
element、"script attribute" 和 value 执行元素的内联行为是否应被内容安全
策略阻止?算法时返回 "Blocked",则
返回。[CSP]
令 handlerMap 为 eventTarget 的事件处理器 映射。
令 eventHandler 为 handlerMap[localName]。
令 location 为触发执行这些 步骤的脚本位置。
将 eventHandler 的值设置为 内部原始未编译处理器 value/location。
给定 eventTarget 和 localName激活 事件处理器。
根据 DOM 标准,即使 oldValue 和 value 相同(将属性设置为其当前值),也会运行这些步骤;但如果 oldValue 和 value 都为 null(移除当前不存在的属性),则不会运行。[DOM]
要停用事件处理器,给定 EventTarget
对象
eventTarget 和一个作为事件处理器名称的字符串 name,运行以下步骤:
要清除所有事件监听器和处理器,给定 EventTarget
对象
eventTarget,运行以下步骤:
此算法用于定义 document.open()。
要激活事件处理器,给定 EventTarget
对象
eventTarget 和一个作为事件处理器名称的字符串 name,运行以下步骤:
令 handlerMap 为 eventTarget 的事件处理器 映射。
令 eventHandler 为 handlerMap[name]。
如果 eventHandler 的监听器不为 null,则返回。
令 callback 为创建 Web IDL EventListener
实例所得的结果,该实例表示对一个单参数函数的引用,此函数给定
eventTarget、name 及其参数,执行事件处理器处理
算法的步骤。
EventListener
的
回调上下文可以
是任意的;它不会影响事件处理器处理
算法的步骤。[DOM]
回调明确不是事件处理器本身。每个事件处理器最终都 注册同一个回调,即下面定义的算法,该算法负责调用正确的代码,并 处理代码的返回值。
令 listener 为一个新的事件 监听器,其类型为与 eventHandler 对应的事件处理器事件类型,且回调为 callback。
为明确起见,事件
监听器与 EventListener
不同。
使用 eventTarget 和 listener添加事件监听器。
将 eventHandler 的监听器设置为 listener。
仅当事件 处理器的值被设置为非 null,并且 事件处理器尚未激活时,才会注册监听器。由于监听器 按注册顺序调用,假设没有发生停用,特定事件类型的事件 监听器顺序将始终为:
在事件处理器的值首次设置为
非 null 之前,使用 addEventListener()
注册的事件监听器
然后是当前设置的回调(如果有)
最后是在事件处理器的值首次设置为
非 null 之后,使用 addEventListener()
注册的事件监听器。
此示例演示事件监听器的调用顺序。如果用户单击此示例中的按钮, 页面将依次显示四个警告框,文本分别为 "ONE"、"TWO"、 "THREE" 和 "FOUR"。
< button id = "test" > Start Demo</ button >
< script >
var button = document. getElementById( 'test' );
button. addEventListener( 'click' , function () { alert( 'ONE' ) }, false );
button. setAttribute( 'onclick' , "alert('NOT CALLED')" ); // event handler listener is registered here
button. addEventListener( 'click' , function () { alert( 'THREE' ) }, false );
button. onclick = function () { alert( 'TWO' ); };
button. addEventListener( 'click' , function () { alert( 'FOUR' ) }, false );
</ script > 但是,在以下示例中,事件处理器在初次激活后被停用(其事件监听器也被移除), 随后又在稍后的时间重新激活。页面将依次显示五个警告框,内容分别为 "ONE"、"TWO"、 "THREE"、"FOUR" 和 "FIVE"。
< button id = "test" > Start Demo</ button >
< script >
var button = document. getElementById( 'test' );
button. addEventListener( 'click' , function () { alert( 'ONE' ) }, false );
button. setAttribute( 'onclick' , "alert('NOT CALLED')" ); // event handler is activated here
button. addEventListener( 'click' , function () { alert( 'TWO' ) }, false );
button. onclick = null ; // but deactivated here
button. addEventListener( 'click' , function () { alert( 'THREE' ) }, false );
button. onclick = function () { alert( 'FOUR' ); }; // and re-activated here
button. addEventListener( 'click' , function () { alert( 'FIVE' ) }, false );
</ script > 事件对象实现的接口不会影响事件处理器是否被触发。
对于 EventTarget
对象
eventTarget、表示事件处理器名称的字符串 name,以及
Event
对象 event,事件处理器处理算法如下:
如果 eventTarget 的脚本已禁用,则返回。
令 callback 为给定 eventTarget 和 name 时获取事件 处理器当前值的结果。
如果 callback 为 null,则返回。
如果 event 是一个
ErrorEvent 对象,
event 的 type
为
"error",并且
event 的 currentTarget
实现
WindowOrWorkerGlobalScope
混入,则令 special error event handling 为 true。否则,令 special error event
handling 为 false。
按以下方式处理 Event
对象 event:
令 return value 为使用 «
event 的 message、
event 的
filename、
event 的 lineno、
event 的 colno、
event 的 error »、
"rethrow"调用 callback 所得的结果,并将回调 this 值设置为
event 的 currentTarget。
令 return value 为使用 «
event » 和 "rethrow"调用 callback 所得的结果,并将回调 this 值设置为
event 的 currentTarget。
如果回调抛出异常,该异常将被重新抛出,从而结束这些 步骤。异常将传播到DOM 事件 分派逻辑,后者随后会报告该异常。
按以下方式处理 return value:
BeforeUnloadEvent
对象,并且 event 的 type
为 "beforeunload"
在这种情况下,事件处理器
IDL 属性的类型将为 OnBeforeUnloadEventHandler,
因此 return
value 已被强制转换为 null 或 DOMString。
如果 return value 不为 null:
设置 event 的已取消标志。
如果 event 的 returnValue
属性值为空
字符串,则将 event 的 returnValue
属性值设置为
return value。
如果 return value 为 true,则设置 event 的已取消 标志。
如果 return value 为 false,则设置 event 的已取消 标志。
如果进入此“否则”分支是因为 event 的 type
为 "beforeunload",
但 event不是
BeforeUnloadEvent
对象,则 return value 永远不会为 false,因为
在这种情况下,return value 已被强制转换为 null 或 DOMString。
EventHandler 回调
函数类型表示事件处理器所使用的回调。它在 Web IDL 中表示如下:
[LegacyTreatNonObjectAsNull ]
callback EventHandlerNonNull = any (Event event );
typedef EventHandlerNonNull ? EventHandler ;在 JavaScript 中,任何 Function
对象都实现此接口。
例如,以下文档片段:
< body onload = "alert(this)" onclick = "alert(this)" > ……会在文档加载时产生一个内容为 "[object Window]" 的警告框,并且每当
用户单击页面中的某处时,都会产生一个内容为 "[object HTMLBodyElement]" 的警告框。
函数的返回值会影响事件是否被取消:如上所述,如果返回值为 false,则事件会被取消。
由于历史原因,平台中存在两个例外:
全局对象上的 onerror
处理器,返回 true 会取消事件。
onbeforeunload
处理器,返回任何非 null 且非 undefined 的值都会取消事件。
由于历史原因,onerror 处理器具有不同的
参数:
[LegacyTreatNonObjectAsNull ]
callback OnErrorEventHandlerNonNull = any ((Event or DOMString ) event , optional DOMString source , optional unsigned long lineno , optional unsigned long colno , optional any error );
typedef OnErrorEventHandlerNonNull ? OnErrorEventHandler ;window. onerror = ( message, source, lineno, colno, error) => { … }; 类似地,onbeforeunload
处理器具有
不同的返回值:
[LegacyTreatNonObjectAsNull ]
callback OnBeforeUnloadEventHandlerNonNull = DOMString ? (Event event );
typedef OnBeforeUnloadEventHandlerNonNull ? OnBeforeUnloadEventHandler ;内部原始未编译处理器是一个包含以下 信息的元组:
未编译的脚本主体
脚本主体的来源位置,以便在需要时 报告错误
当用户代理要给定 EventTarget
对象
eventTarget 和一个作为事件处理器名称的字符串 name,获取事件处理器的
当前值时,必须运行以下步骤:
令 handlerMap 为 eventTarget 的事件处理器 映射。
令 eventHandler 为 handlerMap[name]。
如果 eventHandler 的值是一个 内部原始未编译处理器:
如果 eventTarget 是一个元素,则令 element 为
eventTarget,并令 document 为 element 的节点
文档。否则,eventTarget 是一个 Window 对象,令
element 为 null,并令 document 为 eventTarget 的关联
Document。
如果 document 的活动沙盒标志集合设置了 沙盒化脚本浏览上下文 标志,则返回 null。
令 body 为 eventHandler 的值中的未编译脚本主体。
令 location 为由 eventHandler 的值给出的脚本主体来源位置。
如果 element 不为 null,并且 element 有一个 表单所有者,则令 form owner 为该表单所有者。 否则,令 form owner 为 null。
令 settings object 为 document 的相关设置对象。
如果 body 无法解析为 FunctionBody, 或者解析检测到早期错误,则执行以下子步骤:
将 settings object 的领域执行上下文压入 JavaScript 执行上下文栈;它现在是 正在运行的 JavaScript 执行上下文。
这是必要的,以便随后调用OrdinaryFunctionCreate 时位于正确的 领域中。
令 function 为使用以下参数调用OrdinaryFunctionCreate所得的结果:
令 realm 为 settings object 的领域。
令 scope 为 realm.[[GlobalEnv]]。
如果 eventHandler 是元素的事件 处理器,则将 scope 设置为NewObjectEnvironment(document, true, scope)。
如果 form owner 不为 null,则将 scope 设置为NewObjectEnvironment(form owner, true, scope)。
如果 element 不为 null,则将 scope 设置为NewObjectEnvironment(element, true, scope)。
返回 scope。
从JavaScript 执行上下文栈中移除 settings object 的领域执行上下文。
将 function.[[ScriptOrModule]] 设置为 null。
这样做是因为,将所创建的函数与栈中最近的脚本关联的默认行为,可能导致 依赖路径的结果。例如,首次由用户 交互调用的事件处理器最终将具有 null [[ScriptOrModule]](因为此算法首次调用时活动 脚本为 null),而首次通过从脚本分派事件调用的处理器则会将其 [[ScriptOrModule]] 设置为该脚本。
相反,我们始终将 [[ScriptOrModule]] 设置为 null。无论如何,这样更直观;认为首次分派事件的脚本以某种方式 对事件处理器代码负责,是值得怀疑的。
实际上,这只会影响通过 import()
解析相对 URL 的过程,该过程会查阅关联
脚本的基础 URL。将
[[ScriptOrModule]] 设为 null 意味着HostLoadImportedModule 将
回退到当前设置对象的API 基础 URL。
将 eventHandler 的值设置为创建 Web IDL EventHandler 回调
函数对象所得的结果,该对象的对象
引用为 function,且其回调
上下文为 settings
object。
返回 eventHandler 的值。
Document
对象和 Window
对象上的事件处理器以下是所有HTML 元素都必须同时作为事件
处理器内容属性和事件处理器
IDL 属性支持的事件处理器(及其
对应的事件处理器事件
类型);所有 Document
和 Window
对象也必须将其作为事件处理器
IDL
属性支持:
| 事件处理器 | 事件 处理器事件类型 |
|---|---|
onabort
所有当前引擎均支持。 Firefox9+Safari3.1+Chrome3+
Opera12.1+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android?Samsung Internet?Opera Android12.1+ |
abort
|
onauxclick
Firefox53+Safari不支持Chrome55+
Opera?Edge79+ Edge(旧版)?Internet Explorer不支持 Firefox Android53+Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? |
auxclick
|
onbeforeinput |
beforeinput
|
onbeforematch |
beforematch
|
onbeforetoggle |
beforetoggle
|
oncancel
HTMLDialogElement/cancel_event 所有当前引擎均支持。 Firefox98+Safari15.4+Chrome37+
Opera?Edge79+ Edge(旧版)?Internet Explorer不支持 Firefox Android?Safari iOS?Chrome Android不支持WebView Android?Samsung Internet?Opera Android? |
cancel
|
oncanplay
HTMLMediaElement/canplay_event 所有当前引擎均支持。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
canplay
|
oncanplaythrough
HTMLMediaElement/canplaythrough_event 所有当前引擎均支持。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
canplaythrough
|
onchange
所有当前引擎均支持。 Firefox1+Safari3+Chrome1+
Opera9+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android10.1+ |
change
|
onclick
所有当前引擎均支持。 Firefox6+Safari3+Chrome1+
Opera11.6+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android6+Safari iOS1+Chrome Android?WebView Android?Samsung Internet?Opera Android12.1+ |
click
|
onclose |
close
|
oncommand |
command
|
oncontextlost |
contextlost
|
oncontextmenu |
contextmenu
|
oncontextrestored |
contextrestored
|
oncopy
所有当前引擎均支持。 Firefox22+Safari3+Chrome1+
Opera12.1+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android?Samsung Internet?Opera Android12.1+ |
copy
|
oncuechange
HTMLTrackElement/cuechange_event 所有当前引擎均支持。 Firefox68+Safari10+Chrome32+
Opera19+Edge79+ Edge(旧版)14+Internet Explorer不支持 Firefox Android?Safari iOS?Chrome Android?WebView Android4.4.3+Samsung Internet?Opera Android19+ |
cuechange
|
oncut
所有当前引擎均支持。 Firefox22+Safari3+Chrome1+
Opera12.1+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android?Samsung Internet?Opera Android12.1+ |
cut
|
ondblclick
所有当前引擎均支持。 Firefox6+Safari3+Chrome1+
Opera11.6+Edge79+ Edge(旧版)12+Internet Explorer8+ Firefox Android6+Safari iOS1+Chrome Android不支持WebView Android?Samsung Internet?Opera Android12.1+ |
dblclick
|
ondrag |
drag
|
ondragend |
dragend
|
ondragenter |
dragenter
|
ondragleave |
dragleave
|
ondragover |
dragover
|
ondragstart |
dragstart
|
ondrop |
drop
|
ondurationchange
HTMLMediaElement/durationchange_event 所有当前引擎均支持。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
durationchange
|
onemptied
HTMLMediaElement/emptied_event 所有当前引擎均支持。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
emptied
|
onended
所有当前引擎均支持。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
ended
|
onformdata |
formdata
|
oninput
所有当前引擎均支持。 Firefox6+Safari3.1+Chrome1+
Opera11.6+Edge79+ Edge(旧版)不支持Internet Explorer🔰 9+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android12+ |
input
|
oninvalid |
invalid
|
onkeydown
所有当前引擎均支持。 Firefox6+Safari1.2+Chrome1+
Opera12.1+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android12.1+ |
keydown
|
onkeypress |
keypress
|
onkeyup
所有当前引擎均支持。 Firefox6+Safari1.2+Chrome1+
Opera12.1+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android12.1+ |
keyup
|
onloadeddata
HTMLMediaElement/loadeddata_event 所有当前引擎均支持。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
loadeddata
|
onloadedmetadata
HTMLMediaElement/loadedmetadata_event 所有当前引擎均支持。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
loadedmetadata
|
onloadstart
HTMLMediaElement/loadstart_event 所有当前引擎均支持。 Firefox6+Safari4+Chrome3+
Opera12.1+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android?Samsung Internet?Opera Android12.1+ |
loadstart
|
onmousedown
所有当前引擎均支持。 Firefox6+Safari4+Chrome2+
Opera11.6+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android37+Samsung Internet?Opera Android12.1+ |
mousedown
|
onmouseenter
所有当前引擎均支持。 Firefox10+Safari7+Chrome30+
Opera?Edge79+ Edge(旧版)12+Internet Explorer5.5+ Firefox Android?Safari iOS?Chrome Android?WebView Android37+Samsung Internet?Opera Android? |
mouseenter
|
onmouseleave
所有当前引擎均支持。 Firefox10+Safari7+Chrome30+
Opera?Edge79+ Edge(旧版)12+Internet Explorer5.5+ Firefox Android?Safari iOS?Chrome Android?WebView Android37+Samsung Internet?Opera Android? |
mouseleave
|
onmousemove
所有当前引擎均支持。 Firefox6+Safari4+Chrome2+
Opera11.6+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android37+Samsung Internet?Opera Android12.1+ |
mousemove
|
onmouseout
所有当前引擎均支持。 Firefox6+Safari1+Chrome1+
Opera12.1+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android37+Samsung Internet?Opera Android12.1+ |
mouseout
|
onmouseover
所有当前引擎均支持。 Firefox6+Safari4+Chrome2+
Opera9.5+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android37+Samsung Internet?Opera Android10.1+ |
mouseover
|
onmouseup
所有当前引擎均支持。 Firefox6+Safari4+Chrome2+
Opera11.6+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android37+Samsung Internet?Opera Android12.1+ |
mouseup
|
onpaste
所有当前引擎均支持。 Firefox22+Safari3+Chrome1+
Opera12.1+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android12.1+ |
paste
|
onpause
所有当前引擎均支持。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
pause
|
onplay
所有当前引擎均支持。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
play
|
onplaying
HTMLMediaElement/playing_event 所有当前引擎均支持。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
playing
|
onprogress
HTMLMediaElement/progress_event 所有当前引擎均支持。 Firefox6+Safari3.1+Chrome3+
Opera12.1+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android?Samsung Internet?Opera Android12.1+ |
progress
|
onratechange
HTMLMediaElement/ratechange_event 所有当前引擎均支持。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
ratechange
|
onreset |
reset
|
onscrollend
Firefox109+Safari不支持Chrome114+
Opera?Edge114+ Edge(旧版)?Internet Explorer不支持 Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? Firefox109+Safari不支持Chrome114+
Opera?Edge114+ Edge(旧版)?Internet Explorer不支持 Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? |
scrollend
|
onsecuritypolicyviolation
Element/securitypolicyviolation_event 所有当前引擎均支持。 Firefox63+Safari10+Chrome41+
Opera?Edge79+ Edge(旧版)15+Internet Explorer不支持 Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? |
securitypolicyviolation
|
onseeked
所有当前引擎均支持。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
seeked
|
onseeking
HTMLMediaElement/seeking_event 所有当前引擎均支持。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
seeking
|
onselect
所有当前引擎均支持。 Firefox6+Safari1+Chrome1+
Opera12.1+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android12.1+ HTMLTextAreaElement/select_event 所有当前引擎均支持。 Firefox6+Safari1+Chrome1+
Opera12.1+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android12.1+ |
select
|
onslotchange
HTMLSlotElement/slotchange_event 所有当前引擎均支持。 Firefox63+Safari10.1+Chrome53+
Opera?Edge79+ Edge(旧版)?Internet Explorer不支持 Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? |
slotchange
|
onstalled
HTMLMediaElement/stalled_event 所有当前引擎均支持。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
stalled
|
onsubmit
所有当前引擎均支持。 Firefox1+Safari3+Chrome1+
Opera8+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS1+Chrome Android?WebView Android?Samsung Internet?Opera Android10.1+ |
submit
|
onsuspend
HTMLMediaElement/suspend_event 所有当前引擎均支持。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
suspend
|
ontimeupdate
HTMLMediaElement/timeupdate_event 所有当前引擎均支持。 Firefox3.5+Safari3.1+Chrome3+
Opera10.5+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
timeupdate
|
ontoggle |
toggle
|
onvolumechange
HTMLMediaElement/volumechange_event 所有当前引擎均支持。 Firefox6+Safari3.1+Chrome3+
Opera12.1+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android12.1+ |
volumechange
|
onwaiting
HTMLMediaElement/waiting_event 所有当前引擎均支持。 Firefox6+Safari3.1+Chrome3+
Opera12.1+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android12.1+ |
waiting
|
onwebkitanimationend |
webkitAnimationEnd
|
onwebkitanimationiteration |
webkitAnimationIteration
|
onwebkitanimationstart |
webkitAnimationStart
|
onwebkittransitionend |
webkitTransitionEnd
|
onwheel
所有当前引擎均支持。 Firefox17+Safari7+Chrome31+
Opera?Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS不支持Chrome Android?WebView Android?Samsung Internet?Opera Android? |
wheel
|
以下是除 body
和 frameset
元素之外的所有HTML 元素都必须同时作为事件
处理器内容属性和事件处理器
IDL
属性支持的事件处理器(及其
对应的事件处理器
事件类型);所有 Document
对象都必须将其作为事件处理器
IDL 属性支持;所有 Window
对象都必须将其作为 Window
对象自身上的事件处理器
IDL 属性支持,并且相应的事件
处理器内容
属性和事件处理器
IDL 属性必须公开在由该 Window
对象的关联
Document所拥有的所有 body
和 frameset
元素上:
| 事件处理器 | 事件 处理器事件类型 |
|---|---|
onblur
所有当前引擎均支持。 Firefox24+Safari3.1+Chrome1+
Opera11.6+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android12.1+ 所有当前引擎均支持。 Firefox6+Safari5.1+Chrome5+
Opera12.1+Edge79+ Edge(旧版)12+Internet Explorer11 Firefox Android?Safari iOS?Chrome Android?WebView Android37+Samsung Internet?Opera Android12.1+ |
blur
|
onerror
所有当前引擎均支持。 Firefox6+Safari5.1+Chrome10+
Opera?Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android37+Samsung Internet?Opera Android? |
error
|
onfocus
所有当前引擎均支持。 Firefox24+Safari3.1+Chrome1+
Opera11.6+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android12.1+ 所有当前引擎均支持。 Firefox6+Safari5.1+Chrome5+
Opera12.1+Edge79+ Edge(旧版)12+Internet Explorer11 Firefox Android?Safari iOS?Chrome Android?WebView Android37+Samsung Internet?Opera Android12.1+ |
focus
|
onload |
load
|
onresize |
resize
|
onscroll
所有当前引擎均支持。 Firefox6+Safari2+Chrome1+
Opera11.6+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android12+ 所有当前引擎均支持。 Firefox6+Safari1.3+Chrome1+
Opera12.1+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android12.1+ |
scroll
|
以下是 Window
对象必须作为 Window
对象自身上的事件处理器
IDL 属性支持的事件处理器(及其
对应的事件处理器
事件类型),并且相应的事件
处理器内容
属性和事件处理器
IDL 属性必须公开在由该 Window
对象的关联
Document所拥有的所有 body
和 frameset
元素上:
| 事件处理器 | 事件 处理器事件类型 |
|---|---|
onafterprint
所有当前引擎均支持。 Firefox6+Safari13+Chrome63+
Opera?Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? |
afterprint
|
onbeforeprint
所有当前引擎均支持。 Firefox6+Safari13+Chrome63+
Opera?Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? |
beforeprint
|
onbeforeunload
所有当前引擎均支持。 Firefox1+Safari3+Chrome1+
Opera12+Edge79+ Edge(旧版)12+Internet Explorer4+ Firefox Android?Safari iOS1+Chrome Android?WebView Android?Samsung Internet?Opera Android12+ |
beforeunload
|
onhashchange
所有当前引擎均支持。 Firefox3.6+Safari5+Chrome8+
Opera10.6+Edge79+ Edge(旧版)12+Internet Explorer8+ Firefox Android?Safari iOS5+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
hashchange
|
onlanguagechange
所有当前引擎均支持。 Firefox32+Safari10.1+Chrome37+
Opera?Edge79+ Edge(旧版)?Internet Explorer不支持 Firefox Android4+Safari iOS?Chrome Android?WebView Android?Samsung Internet4.0+Opera Android? |
languagechange
|
onmessage
所有当前引擎均支持。 Firefox9+Safari4+Chrome60+
Opera?Edge79+ Edge(旧版)12+Internet Explorer8+ Firefox Android?Safari iOS4+Chrome Android?WebView Android?Samsung Internet?Opera Android47+ |
message
|
onmessageerror
所有当前引擎均支持。 Firefox6+Safari3.1+Chrome3+
Opera11.6+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android?Samsung Internet?Opera Android12+ 所有当前引擎均支持。 Firefox57+Safari16.4+Chrome60+
Opera?Edge79+ Edge(旧版)18Internet Explorer不支持 Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android47+ |
messageerror
|
onoffline
所有当前引擎均支持。 Firefox9+Safari4+Chrome3+
Opera?Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android? |
offline
|
ononline
所有当前引擎均支持。 Firefox9+Safari4+Chrome3+
Opera?Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android? |
online
|
onpageswap |
pageswap
|
onpagehide |
pagehide
|
onpagereveal |
pagereveal
|
onpageshow |
pageshow
|
onpopstate
所有当前引擎均支持。 Firefox4+Safari5+Chrome5+
Opera11.5+Edge79+ Edge(旧版)12+Internet Explorer10+ Firefox Android?Safari iOS?Chrome Android?WebView Android37+Samsung Internet?Opera Android11.5+ |
popstate
|
onrejectionhandled
所有当前引擎均支持。 Firefox69+Safari11+Chrome49+
Opera?Edge79+ Edge(旧版)?Internet Explorer不支持 Firefox Android?Safari iOS11.3+Chrome Android?WebView Android?Samsung Internet?Opera Android? |
rejectionhandled
|
onstorage
所有当前引擎均支持。 Firefox45+Safari4+Chrome1+
Opera?Edge79+ Edge(旧版)15+Internet Explorer9+ Firefox Android?Safari iOS4+Chrome Android?WebView Android37+Samsung Internet?Opera Android? |
storage
|
onunhandledrejection
Window/unhandledrejection_event 所有当前引擎均支持。 Firefox69+Safari11+Chrome49+
Opera?Edge79+ Edge(旧版)?Internet Explorer不支持 Firefox Android?Safari iOS11.3+Chrome Android?WebView Android?Samsung Internet?Opera Android? |
unhandledrejection
|
onunload
所有当前引擎均支持。 Firefox1+Safari3+Chrome1+
Opera4+Edge79+ Edge(旧版)12+Internet Explorer4+ Firefox Android?Safari iOS1+Chrome Android?WebView Android?Samsung Internet?Opera Android10.1+ |
unload
|
此事件处理器列表通过
WindowEventHandlers
接口混入具体化为事件处理器
IDL
属性。
以下是 Document
对象必须作为事件
处理器 IDL 属性支持的事件处理器(及其
对应的事件处理器
事件类型):
| 事件处理器 | 事件 处理器事件类型 |
|---|---|
onreadystatechange |
readystatechange
|
onvisibilitychange
Document/visibilitychange_event 所有当前引擎均支持。 Firefox56+Safari14.1+Chrome62+
Opera49+Edge79+ Edge(旧版)18Internet Explorer🔰 10+ Firefox Android?Safari iOS?Chrome Android?WebView Android62+Samsung Internet?Opera Android46+ |
visibilitychange
|
interface mixin GlobalEventHandlers {
attribute EventHandler onabort ;
attribute EventHandler onauxclick ;
attribute EventHandler onbeforeinput ;
attribute EventHandler onbeforematch ;
attribute EventHandler onbeforetoggle ;
attribute EventHandler onblur ;
attribute EventHandler oncancel ;
attribute EventHandler oncanplay ;
attribute EventHandler oncanplaythrough ;
attribute EventHandler onchange ;
attribute EventHandler onclick ;
attribute EventHandler onclose ;
attribute EventHandler oncommand ;
attribute EventHandler oncontextlost ;
attribute EventHandler oncontextmenu ;
attribute EventHandler oncontextrestored ;
attribute EventHandler oncopy ;
attribute EventHandler oncuechange ;
attribute EventHandler oncut ;
attribute EventHandler ondblclick ;
attribute EventHandler ondrag ;
attribute EventHandler ondragend ;
attribute EventHandler ondragenter ;
attribute EventHandler ondragleave ;
attribute EventHandler ondragover ;
attribute EventHandler ondragstart ;
attribute EventHandler ondrop ;
attribute EventHandler ondurationchange ;
attribute EventHandler onemptied ;
attribute EventHandler onended ;
attribute OnErrorEventHandler onerror ;
attribute EventHandler onfocus ;
attribute EventHandler onformdata ;
attribute EventHandler oninput ;
attribute EventHandler oninvalid ;
attribute EventHandler onkeydown ;
attribute EventHandler onkeypress ;
attribute EventHandler onkeyup ;
attribute EventHandler onload ;
attribute EventHandler onloadeddata ;
attribute EventHandler onloadedmetadata ;
attribute EventHandler onloadstart ;
attribute EventHandler onmousedown ;
[LegacyLenientThis ] attribute EventHandler onmouseenter ;
[LegacyLenientThis ] attribute EventHandler onmouseleave ;
attribute EventHandler onmousemove ;
attribute EventHandler onmouseout ;
attribute EventHandler onmouseover ;
attribute EventHandler onmouseup ;
attribute EventHandler onpaste ;
attribute EventHandler onpause ;
attribute EventHandler onplay ;
attribute EventHandler onplaying ;
attribute EventHandler onprogress ;
attribute EventHandler onratechange ;
attribute EventHandler onreset ;
attribute EventHandler onresize ;
attribute EventHandler onscroll ;
attribute EventHandler onscrollend ;
attribute EventHandler onsecuritypolicyviolation ;
attribute EventHandler onseeked ;
attribute EventHandler onseeking ;
attribute EventHandler onselect ;
attribute EventHandler onslotchange ;
attribute EventHandler onstalled ;
attribute EventHandler onsubmit ;
attribute EventHandler onsuspend ;
attribute EventHandler ontimeupdate ;
attribute EventHandler ontoggle ;
attribute EventHandler onvolumechange ;
attribute EventHandler onwaiting ;
attribute EventHandler onwebkitanimationend ;
attribute EventHandler onwebkitanimationiteration ;
attribute EventHandler onwebkitanimationstart ;
attribute EventHandler onwebkittransitionend ;
attribute EventHandler onwheel ;
};
interface mixin WindowEventHandlers {
attribute EventHandler onafterprint ;
attribute EventHandler onbeforeprint ;
attribute OnBeforeUnloadEventHandler onbeforeunload ;
attribute EventHandler onhashchange ;
attribute EventHandler onlanguagechange ;
attribute EventHandler onmessage ;
attribute EventHandler onmessageerror ;
attribute EventHandler onoffline ;
attribute EventHandler ononline ;
attribute EventHandler onpagehide ;
attribute EventHandler onpagereveal ;
attribute EventHandler onpageshow ;
attribute EventHandler onpageswap ;
attribute EventHandler onpopstate ;
attribute EventHandler onrejectionhandled ;
attribute EventHandler onstorage ;
attribute EventHandler onunhandledrejection ;
attribute EventHandler onunload ;
};某些操作和方法被定义为在元素上触发事件。例如,click() 方法在 HTMLElement 接口上被定义为
在元素上触发 click
事件。[POINTEREVENTS]
在 target 上触发名为 e 的合成指针事件,并带有可选的 not trusted flag,意味着 运行以下步骤:
令 event 为使用
PointerEvent
创建事件的结果。
将 event 的 type
属性初始化为
e。
将 event 的 bubbles
和 cancelable
属性初始化为 true。
设置 event 的组合标志。
如果设置了 not trusted flag,则将 event 的 isTrusted
属性初始化为 false。
根据键输入设备的当前状态(如果有)初始化 event 的 ctrlKey、shiftKey、altKey 和
metaKey
属性(任何不可用的键均为 false)。
如果存在,将 event 的 view
属性初始化为
target 的节点
文档的 Window 对象,否则初始化为 null。
event 的 getModifierState() 方法应返回
适当描述键输入设备当前状态的值。
返回在 target 上分派 event 的结果。
在 target 上触发 click 事件
意味着在 target 上触发名为 click 的合成
指针事件。
WindowOrWorkerGlobalScope
混入接口WindowOrWorkerGlobalScope
混入接口供要在
Window 和 WorkerGlobalScope
对象上公开的 API 使用。
鼓励其他标准使用
partial
interface mixin WindowOrWorkerGlobalScope { … };
进一步扩展它,并附上
适当的引用。
typedef (DOMString or Function or TrustedScript ) TimerHandler ;
interface mixin WindowOrWorkerGlobalScope {
[Replaceable ] readonly attribute USVString origin ;
readonly attribute boolean isSecureContext ;
readonly attribute boolean crossOriginIsolated ;
undefined reportError (any e );
// base64 实用方法
DOMString btoa (DOMString data );
ByteString atob (DOMString data );
// 定时器
long setTimeout (TimerHandler handler , optional long timeout = 0, any ... arguments );
undefined clearTimeout (optional long id = 0);
long setInterval (TimerHandler handler , optional long timeout = 0, any ... arguments );
undefined clearInterval (optional long id = 0);
// 微任务排队
undefined queueMicrotask (VoidFunction callback );
// ImageBitmap
Promise <ImageBitmap > createImageBitmap (ImageBitmapSource image , optional ImageBitmapOptions options = {});
Promise <ImageBitmap > createImageBitmap (ImageBitmapSource image , long sx , long sy , long sw , long sh , optional ImageBitmapOptions options = {});
// 结构化克隆
any structuredClone (any value , optional StructuredSerializeOptions options = {});
};
Window includes WindowOrWorkerGlobalScope ;
WorkerGlobalScope includes WindowOrWorkerGlobalScope ;self.isSecureContext
所有当前引擎均支持。
返回此全局对象是否表示一个安全上下文。 [SECURE-CONTEXTS]
self.origin
所有当前引擎均支持。
返回全局对象的源,并将其序列化为字符串。
self.crossOriginIsolated
所有当前引擎均支持。
返回在此全局中运行的脚本是否允许使用需要
跨源隔离的 API。这取决于 `Cross-Origin-Opener-Policy`
和
`Cross-Origin-Embedder-Policy`
HTTP 响应标头以及“cross-origin-isolated”
特性。
强烈建议开发者使用 self.origin 而不是 location.origin。前者
返回环境的源,
后者返回环境 URL 的源。设想以下脚本在
https://stargate.example/ 上的文档中执行:
var frame = document. createElement( "iframe" )
frame. onload = function () {
var frameWin = frame. contentWindow
console. log( frameWin. location. origin) // "null"
console. log( frameWin. origin) // "https://stargate.example"
}
document. body. appendChild( frame) self.origin 是更可靠的安全指标。
实现 WindowOrWorkerGlobalScope
混入接口的元素具有以下
提取源步骤:
由于这些对象可能可以跨源访问(例如,通过
WindowProxy),因此在授予对源的访问权限之前,需要在此处进行
安全检查。
atob() 和 btoa() 方法
允许开发者在内容与 base64 编码之间进行转换。
在这些 API 中,为便于记忆,可以认为“b”代表 “binary”(二进制),“a”代表“ASCII”。但实际上,主要由于历史原因,这些函数的 输入和输出都是 Unicode 字符串。
result = self.btoa(data)
所有当前引擎均支持。
接受输入数据,该数据为仅包含 U+0000 到 U+00FF 范围内字符的 Unicode 字符串, 每个字符分别表示值为 0x00 到 0xFF 的二进制字节,并 将其转换为 base64 表示形式,然后返回该表示形式。
如果输入字符串包含任何超出范围的字符,则抛出 “InvalidCharacterError” DOMException。
result = self.atob(data)
所有当前引擎均支持。
接受输入数据,该数据为包含 base64 编码二进制数据的 Unicode 字符串, 对其进行解码,并返回由 U+0000 到 U+00FF 范围内的字符组成的字符串,每个字符 分别表示值为 0x00 到 0xFF 的二进制字节,与该二进制 数据相对应。
如果
输入字符串不是有效的 base64 数据,则抛出 “InvalidCharacterError” DOMException。
如果 data
包含任何码点大于 U+00FF 的字符,btoa(data) 方法必须抛出
“InvalidCharacterError” DOMException。
否则,用户代理必须
将 data 转换为一个字节序列,其中第 n 个字节是
data 第 n 个码点的八位表示,然后必须对该字节序列应用
宽容 base64 编码并返回
结果。
atob(data) 方法步骤是:
令 decodedData 为对 data 运行宽容 base64 解码的结果。
如果 decodedData 为失败,则抛出
“InvalidCharacterError” DOMException。
返回 decodedData。
用于将标记动态插入文档的 API 会与解析器交互, 因此其行为会根据它们是用于 HTML 文档(以及 HTML 解析器)还是 XML 文档(以及 XML 解析器)而有所不同。
Document 对象具有一个动态标记插入时抛出异常计数器,
它与为令牌创建元素算法结合使用,以防止自定义
元素构造函数在由解析器调用时
能够使用 document.open()、document.close() 和
document.write()。
最初,计数器必须设置为零。
document = document.open()
所有当前引擎均支持。
使 Document 被原地替换,
就好像它是一个新的
Document 对象,但会复用
先前的对象,随后返回该对象。
生成的 Document 与一个
HTML 解析器相关联,可以使用 document.write()
向其提供要解析的数据。
如果 Document 仍在解析,则该方法不起作用。
如果
Document 是一个 XML 文档,则抛出 “InvalidStateError” DOMException。
如果
解析器当前正在执行自定义元素构造函数,则抛出 “InvalidStateError” DOMException。
window = document.open(url, name, features)
工作方式与 window.open()
方法相同。
Document 对象具有一个活动解析器已中止布尔值,它
用于防止脚本在文档的活动解析器被
中止后(直接或间接)调用 document.open()
和 document.write()
方法。它最初为 false。
给定 document,文档打开步骤如下:
如果 document 是一个 XML 文档,则抛出
“InvalidStateError” DOMException。
如果 document 的动态标记插入时抛出异常
计数器大于
0,则抛出 “InvalidStateError”
DOMException。
令 entryDocument 为入口全局对象的关联
Document。
如果 document 的源
与 entryDocument 的
源不
同源,则抛出
“SecurityError” DOMException。
如果 document 具有一个活动 解析器,且其脚本 嵌套 层级大于 0,则返回 document。
这基本上会使 document.open()
在解析期间发现的内联脚本中被调用时遭到忽略,同时仍允许它
在由非解析器任务(例如定时器回调或事件处理器)调用时生效。
类似地,如果 document 的卸载计数器大于 0,则 返回 document。
这基本上会使 document.open()
在 beforeunload、
pagehide 或 unload 事件
处理器中被调用,而 Document
正在卸载时遭到忽略。
如果 document 的活动解析器已中止为 true,则返回 document。
特别是,这会使 document.open()
在导航开始后被调用时遭到忽略,但
仅限初始解析期间。有关更多背景信息,请参阅 议题
#4723。
如果 document 的节点 可导航对象非 null,并且 document 的节点 可导航对象的正在进行的 导航是一个 导航 ID,则停止加载 document 的节点 可导航对象。
对于 document 的每个影子树包含自身的后代 node,使用 node 清除所有事件监听器和 处理器。
如果 document 是 document 的相关全局对象的关联
Document,则使用 document 的相关
全局对象清除所有事件监听器和
处理器。
在 document 内用 null 替换 全部。
如果 document 完全 活动:
令 newURL 为 entryDocument 的 URL 的副本。
如果 entryDocument 不是 document,则将 newURL 的 片段 设置为 null。
使用 document 和 newURL 运行 URL 和历史记录更新步骤。
将 document 的是否为初始 about:blank设置为
false。
如果设置了 document 的iframe 加载正在进行标志,则设置 document 的静默 iframe 加载标志。
将 document 设置为无怪异 模式。
创建一个 HTML 解析器,其允许
声明式影子根为
document 的允许
声明式影子根,并将其与 document 关联。这是一个
脚本创建的解析器(意味着它可以由 document.open()
和 document.close()
方法关闭,并且分词器会等待
显式调用 document.close()
后再发出
文件结束令牌)。编码置信度
无关紧要。
将 document 的当前文档
就绪状态更新为“loading”。
这会触发 readystatechange
事件,但创作代码实际上无法观察到该事件,因为上一步
清除了所有可以观察该事件的事件监听器和
处理器。
返回 document。
文档打开
步骤不会影响 Document
是否已准备好执行加载后
任务或已完全加载。
open(unused1,
unused2) 方法必须返回使用 this 运行文档打开
步骤的结果。
unused1 和
unused2 参数会被忽略,但保留在 IDL 中,以便使用一个或两个参数调用该
函数的代码能够继续工作。由于 Web IDL
重载解析算法规则,它们是必需的;如果没有这些参数,此类调用会抛出
TypeError
异常。whatwg/webidl 议题 #581正在研究
更改算法以允许移除它们。[WEBIDL]
open(url,
name, features) 方法必须运行以下步骤:
如果 this 不完全活动,则抛出
“InvalidAccessError” DOMException。
返回使用 url、 name 和 features 运行窗口打开步骤的结果。
document.close()
所有当前引擎均支持。
关闭由 document.open()
方法打开的输入流。
如果
Document 是一个 XML 文档,则抛出 “InvalidStateError” DOMException。
如果
解析器当前正在执行自定义元素构造函数,则抛出 “InvalidStateError” DOMException。
close() 方法
必须运行以下
步骤:
如果 this 是一个 XML 文档,则抛出
“InvalidStateError” DOMException。
如果 this 的动态标记插入时抛出异常
计数器大于
零,则抛出 “InvalidStateError”
DOMException。
在解析器的输入 流末尾插入一个显式 “EOF”字符。
如果 this 的待处理的解析阻塞脚本不为 null,则 返回。
document.write()document.write(...text)
所有当前引擎均支持。
通常,将给定字符串添加到 Document 的输入流中。
此方法具有非常特殊的行为。在某些情况下,此方法可能会
在解析器运行时影响 HTML 解析器的状态,从而产生一个
与文档源代码不对应的 DOM
(例如,如果写入的字符串是
“<plaintext>”或“<!--”)。在其他情况下,
调用可能会先清除当前页面,就像调用了 document.open()
一样。在另一些情况下,该方法
会直接被忽略或抛出异常。用户代理被明确允许避免执行通过此方法插入的
script 元素。更糟糕的是,
此方法的确切行为在某些情况下可能取决于网络延迟,这可能导致非常难以调试的故障。
由于所有这些原因,强烈不建议
使用此方法。
在 XML 文档上
调用时,抛出 “InvalidStateError” DOMException。
如果
解析器当前正在执行自定义元素构造函数,则抛出 “InvalidStateError” DOMException。
此方法不会执行任何净化,以移除 script
或事件处理器
内容属性等具有潜在危险的元素和属性。
Document 对象具有一个忽略破坏性写入计数器,它
与 script 元素的处理结合使用,以防止
外部
脚本通过使用 document.write()
隐式调用 document.open() 来清除
文档。最初,计数器必须设置为零。
给定一个 Document 对象 document、
一个列表 text、一个布尔值 lineFeed 和一个字符串 sink,文档写入步骤如下:
令 string 为空字符串。
如果 text 包含一个字符串,则令 isTrusted 为 false;否则为 true。
对于 text 中的每个 value:
如果 value 是一个 TrustedHTML
对象,则
将 value 的关联数据追加到
string。
否则,将 value 追加到 string。
如果 isTrusted 为 false,则将 string 设置为使用
TrustedHTML、
this
的相关全局
对象、string、sink 和“script”调用
获取符合可信类型的
字符串算法的结果。
如果 lineFeed 为 true,则将 U+000A 换行符追加到 string。
如果 document 是一个 XML 文档,则抛出
“InvalidStateError” DOMException。
如果 document 的动态标记插入时抛出异常
计数器大于
0,则抛出 “InvalidStateError”
DOMException。
如果 document 的活动解析器已中止为 true,则 返回。
如果插入点未定义:
如果 document 的卸载 计数器大于 0,或 document 的忽略破坏性写入计数器大于 0,则 返回。
使用 document 运行文档打开步骤。
如果 document 的待处理的解析阻塞脚本为 null,则让
HTML 解析器逐个码点地处理
string,在生成的令牌被发出时对其进行处理,并在分词器到达插入
点时,或分词器的处理被树构建阶段中止时停止(如果分词器发出 script 结束标签令牌,
就可能发生这种情况)。
如果 document.write() 方法
是从内联执行的脚本中调用的(即因为解析器解析了一组
script 标签而执行),那么
这是一次对解析器的重入
调用。如果设置了解析器暂停
标志,则根据分词器的解析器暂停
标志检查,分词器会立即中止,并且不会解析任何 HTML。
document.writeln()document.writeln(...text)
所有当前引擎均支持。
将给定字符串添加到 Document 的输入流中,后跟一个换行
字符。如有必要,首先隐式调用 open()
方法。
此方法具有非常特殊的行为。出于与 document.write()
相同的原因,强烈不建议使用此方法。
在 XML 文档上
调用时,抛出 “InvalidStateError” DOMException。
如果
解析器当前正在执行自定义元素构造函数,则抛出 “InvalidStateError” DOMException。
此方法不会执行任何净化,以移除 script
或事件
处理器内容属性等具有潜在危险的元素和属性。
所有当前引擎均支持。
partial interface Element {
[CEReactions ] undefined setHTML (DOMString html , optional SetHTMLOptions options = {});
[CEReactions ] undefined setHTMLUnsafe ((TrustedHTML or DOMString ) html , optional SetHTMLUnsafeOptions options = {});
DOMString getHTML (optional GetHTMLOptions options = {});
[CEReactions ] attribute (TrustedHTML or [LegacyNullToEmptyString ] DOMString ) innerHTML ;
[CEReactions ] attribute (TrustedHTML or [LegacyNullToEmptyString ] DOMString ) outerHTML ;
[CEReactions ] undefined insertAdjacentHTML (DOMString position , (TrustedHTML or DOMString ) string );
};
partial interface ShadowRoot {
[CEReactions ] undefined setHTML (DOMString html , optional SetHTMLOptions options = {});
[CEReactions ] undefined setHTMLUnsafe ((TrustedHTML or DOMString ) html , optional SetHTMLUnsafeOptions options = {});
DOMString getHTML (optional GetHTMLOptions options = {});
[CEReactions ] attribute (TrustedHTML or [LegacyNullToEmptyString ] DOMString ) innerHTML ;
};
enum SanitizerPresets { " default " };
dictionary SetHTMLOptions {
(Sanitizer or SanitizerConfig or SanitizerPresets ) sanitizer = "default";
};
dictionary SetHTMLUnsafeOptions {
(Sanitizer or SanitizerConfig or SanitizerPresets ) sanitizer = {};
boolean runScripts = false ;
};
dictionary ParseHTMLUnsafeOptions {
(Sanitizer or SanitizerConfig or SanitizerPresets ) sanitizer = {};
};
dictionary GetHTMLOptions {
boolean serializableShadowRoots = false ;
sequence <ShadowRoot > shadowRoots = [];
};DOMParser 接口DOMParser 接口允许
作者通过将字符串解析为 HTML 或 XML 来创建新的 Document
对象。
parser = new DOMParser()
所有当前引擎均支持。
构造一个新的 DOMParser
对象。
document = parser.parseFromString(string, type)
所有当前引擎均支持。
根据 type,使用 HTML 或 XML 解析器解析 string,
并返回生成的 Document。
type 可以是“text/html”
(这将调用 HTML 解析器),也可以是“text/xml”、
“application/xml”、
“application/xhtml+xml”
或
“image/svg+xml”中的任意一个
(这将调用 XML 解析器)。
对于 XML 解析器,如果无法解析 string,则返回的
Document 将包含
描述所产生错误的元素。
请注意,script
元素不会在解析期间求值,并且生成的
文档的编码将始终为
UTF-8。文档的 URL 将
从 parser 的相关全局对象继承。
type 使用上述值以外的值将导致抛出 TypeError
异常。
DOMParser 被设计为一个需要先
构造,然后再调用其 parseFromString()
方法的类,这是一个令人遗憾的历史遗留问题。如果今天设计此功能,
它会是一个独立函数。对于 HTML 解析,现代替代方案是 Document.parseHTMLUnsafe()。
此方法不会执行任何净化,以移除 script 或事件
处理器内容属性等具有潜在危险的元素和属性。
[Exposed =Window ]
interface DOMParser {
constructor ();
[NewObject ] Document parseFromString ((TrustedHTML or DOMString ) string , DOMParserSupportedType type );
};
enum DOMParserSupportedType {
" text/html " ,
" text/xml " ,
" application/xml " ,
" application/xhtml+xml " ,
" image/svg+xml "
};new DOMParser() 构造函数
步骤不执行任何操作。
parseFromString(string,
type) 方法步骤是:
令 compliantString 为使用 TrustedHTML、
this 的相关全局
对象、string、“DOMParser parseFromString”和“script”
调用获取符合可信类型的
字符串算法的结果。
令 document 为一个新的 Document,其内容类型为 type,且 URL 为
this 的相关全局对象的关联
Document的 URL。
文档的编码将
保持其默认值 UTF-8。特别是,在解析
compliantString 时发现的任何 XML 声明或
meta 元素
都不会产生任何影响。
根据 type 进行分支:
text/html”给定 document 和 compliantString,从字符串解析 HTML。
创建一个与 document 关联且禁用了 XML 脚本支持的 XML 解析器 parser。
使用 parser 解析 compliantString。
如果上一步导致 XML 良构性错误或 XML 命名空间良构性 错误:
返回 document。
element.setHTML(html, options)
使用选项 options 通过 HTML 解析器解析 html,并用
结果替换 element 的子项。element 为
HTML 解析器提供上下文。解析出的片段根据
options 的“sanitizer”
成员进行净化,并且
移除不安全内容。
shadowRoot.setHTML(html, options)
使用选项 options 通过 HTML 解析器解析 html,并用
结果替换 shadowRoot 的子项。shadowRoot 的宿主为 HTML 解析器提供上下文。
解析出的片段根据 options 的
“sanitizer”
成员进行净化,并且移除不安全
内容。
element.setHTMLUnsafe(html, options)
使用选项 options 通过 HTML 解析器解析 html,并用
结果替换 element 的子项。element 为
HTML 解析器提供上下文。如果 options 字典包含“sanitizer”
成员,则使用它在将解析出的片段插入
element 之前对其进行净化。如果
options 字典的“runScripts”
成员为 true,则在更新节点树后,会立即执行
html 中包含的脚本。
shadowRoot.setHTMLUnsafe(html, options)
使用选项 options 通过 HTML 解析器解析 html,并用
结果替换 shadowRoot 的子项。shadowRoot 的宿主为 HTML 解析器提供上下文。如果
options 字典包含“sanitizer”
成员,则使用它在将解析出的片段插入
shadowRoot 之前对其进行净化。如果
options 字典的“runScripts”
成员为 true,则在更新节点树后,会立即执行
html 中包含的脚本。
doc = Document.parseHTML(html, options)
使用选项 options 通过 HTML 解析器解析 html,并返回
一个包含结果的新 Document。
生成的文档根据 options 的“sanitizer”
成员进行净化,并且移除不安全
内容。
doc = Document.parseHTMLUnsafe(html, options)
使用选项 options 通过 HTML 解析器解析 html,并返回
生成的 Document。
请注意,script
元素不会在解析期间求值,并且生成的
文档的编码将始终为
UTF-8。文档的 URL 将为
about:blank。如果
options 字典包含“sanitizer”
成员,则使用它
净化生成的 DOM。
带有 Unsafe 后缀的方法不会执行任何
净化,以移除 script 或
事件处理器
内容属性等具有潜在危险的元素和属性。
Element
的
setHTML(html, options) 方法
步骤是:
ShadowRoot
的
setHTML(html, options) 方法
步骤是:
给定 this、html、 options 和 true,设置并过滤 HTML。
Element
的
setHTMLUnsafe(html, options)
方法步骤是:
令 compliantHTML 为使用 TrustedHTML、
this 的相关全局
对象、html、“Element setHTMLUnsafe”和“script”
调用获取符合可信类型的
字符串算法的结果。
给定 target、compliantHTML、 options 和 false,设置并过滤 HTML。
ShadowRoot
的
setHTMLUnsafe(html,
options) 方法步骤是:
令 compliantHTML 为使用 TrustedHTML、
this 的相关全局
对象、html、“ShadowRoot setHTMLUnsafe”和“script”
调用获取符合可信类型的
字符串算法的结果。
给定 this、compliantHTML、 options 和 false,设置并过滤 HTML。
静态 parseHTML(html,
options) 方法步骤是:
将 document 的允许声明式影子根设置为 true。
给定 document 和 html,从字符串解析 HTML。
令 sanitizer 为使用 options 和 true 调用从选项获取净化器实例的结果。
使用 sanitizer 和 true 对 document 调用净化。
返回 document。
静态 parseHTMLUnsafe(html, options)
方法步骤是:
令 compliantHTML 为使用 TrustedHTML、
this 的相关全局
对象、html、“Document parseHTMLUnsafe”和“script”
调用获取符合可信类型的
字符串算法的结果。
将 document 的允许声明式影子根设置为 true。
给定 document 和 compliantHTML,从字符串解析 HTML。
令 sanitizer 为使用 options 和 false 调用从选项获取净化器实例的结果。
使用 sanitizer 和 false 对 document 调用净化。
返回 document。
html = element.getHTML({ serializableShadowRoots, shadowRoots })
返回将 element 序列化为 HTML 的结果。element 内的影子根根据所提供的选项进行序列化:
如果 serializableShadowRoots
为 true,则序列化所有标记为可序列化的影子根。
如果提供了 shadowRoots
数组,则序列化该数组中指定的所有影子根,无论
它们是否被标记为可序列化。
如果两个选项均未提供,则不会序列化任何影子根。
html = shadowRoot.getHTML({ serializableShadowRoots, shadowRoots })
使用其影子宿主作为上下文元素,返回将 shadowRoot 序列化为 HTML 的结果。shadowRoot 内的影子根根据所提供的选项按上述方式进行序列化。
Element
的
getHTML(options) 方法步骤是
返回使用
this、options[“serializableShadowRoots”]
和 options[“shadowRoots”]
运行 HTML 片段序列化算法的结果。
ShadowRoot
的
getHTML(options) 方法步骤是
返回使用
this、options[“serializableShadowRoots”]
和 options[“shadowRoots”]
运行 HTML 片段序列化
算法的结果。
innerHTML 属性innerHTML 属性
在 DOM 解析和序列化议题
跟踪器中还有许多未解决的议题,记录了其规范中的各种问题。
element.innerHTML
返回表示元素内容的 HTML 或 XML 片段。
对于 XML 文档,如果元素无法序列化为 XML,则抛出 “InvalidStateError”
DOMException。
element.innerHTML = value
使用从给定字符串解析出的节点替换元素的内容。
对于 XML 文档,如果给定字符串不是良构的,则抛出 “SyntaxError”
DOMException。
shadowRoot.innerHTML
返回表示影子根内容的 HTML 片段。
shadowRoot.innerHTML = value
使用从给定字符串解析出的节点替换影子根的内容。
这些属性的设置器不会执行任何净化,以移除
script 或事件
处理器
内容属性等具有潜在危险的元素和属性。
给定一个 Element、
Document 或 DocumentFragment
node 和一个布尔值 require
well-formed,片段序列化算法步骤是:
令 context document 为 node 的节点文档。
如果 context document 是一个 HTML 文档, 则返回使用 node、 false 和 « » 运行 HTML 片段序列化算法的结果。
返回给定 require well-formed 时 node 的 XML 序列化。
给定一个
Element
或
DocumentFragment
target、一个字符串 markup,以及一个可选的
解析器脚本模式
scriptingMode(默认为惰性),片段解析算法步骤是:
如果 target 的节点文档 是一个 XML 文档,则返回给定 target 和 markup 调用XML 片段解析 算法的结果。
返回给定 target、markup、false 和 scriptingMode 运行HTML 片段解析算法的结果。
ShadowRoot
的
innerHTML 获取器步骤是返回使用
this
和 true 运行片段序列化算法步骤的结果。
令 compliantString 为使用 TrustedHTML、
this 的相关全局
对象、给定值、“Element innerHTML”和“script”
调用获取符合可信类型的
字符串算法的结果。
令 target 为 this。
如果 target 是一个 template
元素,则将 target 设置为
template
元素的模板内容(一个
DocumentFragment)。
令 fragment 为使用 target 和 compliantString 调用片段解析算法 步骤的结果。
在 target 内用 fragment 替换 全部。
ShadowRoot
的
innerHTML
设置器
步骤是:
令 compliantString 为使用 TrustedHTML、
this 的相关全局
对象、给定值、“ShadowRoot innerHTML”和“script”
调用获取符合可信类型的
字符串算法的结果。
outerHTML 属性outerHTML 属性
在 DOM 解析和序列化议题
跟踪器中还有许多未解决的议题,记录了其规范中的各种问题。
element.outerHTML
返回表示元素及其内容的 HTML 或 XML 片段。
对于 XML 文档,如果元素无法序列化为 XML,则抛出 “InvalidStateError”
DOMException。
element.outerHTML = value
使用从给定字符串解析出的节点替换该元素。
对于 XML 文档,如果给定字符串不是良构的,则抛出 “SyntaxError”
DOMException。
如果
元素的父项是一个 Document,则抛出 “NoModificationAllowedError” DOMException。
此属性的设置器不会执行任何净化,以移除 script 或事件
处理器内容
属性等具有潜在危险的元素和属性。
令 compliantString 为使用 TrustedHTML、
this 的相关全局
对象、给定值、“Element outerHTML”和“script”
调用获取符合可信类型的
字符串算法的结果。
如果 parent 为 null,则返回。即使运行其余步骤,也无法获得对 所创建节点的引用。
如果 parent 是一个 Document,则抛出
“NoModificationAllowedError” DOMException。
如果 parent 是一个 DocumentFragment,
则将 parent 设置为给定 this 的
节点文档、“body”和 HTML
命名空间创建元素的结果。
令 fragment 为给定 parent 和 compliantString 调用片段解析算法 步骤的结果。
insertAdjacentHTML()
方法insertAdjacentHTML()
方法在 DOM 解析和序列化议题跟踪器中还有许多未解决的议题,记录了其规范中的
各种问题。
element.insertAdjacentHTML(position, string)
将 string 解析为 HTML 或 XML,并按照 position 参数指定的位置, 将生成的节点插入树中,如下所示:
beforebegin”afterbegin”beforeend”afterend”如果参数
具有无效值(例如,对于 XML
文档,给定字符串不是良构的),则抛出 “SyntaxError” DOMException。
如果给定位置不可行(例如,在
Document
的根元素之后插入元素),则抛出 “NoModificationAllowedError” DOMException。
此方法不会执行任何净化,以移除 script 或事件处理器内容属性等具有潜在危险的元素和属性。
Element
的
insertAdjacentHTML(position,
string) 方法步骤是:
令 compliantString 为使用 TrustedHTML、
this 的相关全局
对象、string、“Element insertAdjacentHTML”和“script”
调用获取符合
可信类型的字符串算法的结果。
令 context 为 null。
使用此列表中第一个匹配的项:
beforebegin”ASCII 不区分大小写地匹配afterend”ASCII 不区分大小写地匹配如果 context 为 null 或是一个 Document,则抛出
“NoModificationAllowedError” DOMException。
afterbegin”ASCII 不区分大小写地匹配beforeend”ASCII 不区分大小写地匹配如果 context 不是一个 Element,
或以下各项均为 true:
令 fragment 为使用 context 和 compliantString 调用片段解析算法 步骤的结果。
beforebegin”ASCII 不区分大小写地匹配afterbegin”ASCII 不区分大小写地匹配beforeend”ASCII 不区分大小写地匹配afterend”ASCII 不区分大小写地匹配与其他直接操作 Node
的 API 一样(但与 innerHTML
不同),insertAdjacentHTML()
不包含针对 template
元素的任何特殊处理。在大多数情况下,应使用
templateEl.content.insertAdjacentHTML(),
而不是直接操作 template
元素的子节点。
createContextualFragment()
方法createContextualFragment()
方法在 DOM 解析和序列化议题跟踪器中还有许多
未解决的议题,记录了其规范中的各种问题。
docFragment = range.createContextualFragment(string)
返回一个由标记字符串 string 创建的 DocumentFragment,
使用 range 的起始节点作为解析
fragment 的上下文。
此方法不会执行任何净化,以移除 script 或
事件处理器内容属性等具有潜在危险的元素和属性。
partial interface Range {
[CEReactions , NewObject ] DocumentFragment createContextualFragment ((TrustedHTML or DOMString ) string );
};Range
的
createContextualFragment(string)
方法步骤是:
令 compliantString 为使用 TrustedHTML、
this 的相关全局
对象、string、“Range createContextualFragment”和
“script”调用获取符合
可信类型的字符串算法的结果。
令 element 为 null。
如果 element 为 null,或以下各项均为 true:
XMLSerializer 接口XMLSerializer 接口在
DOM 解析和序列化议题跟踪器中还有许多未解决的议题,
记录了其规范中的各种问题。DOM 解析和序列化的其余部分将
逐步上游合并至此规范。
xmlSerializer = new XMLSerializer()
构造一个新的 XMLSerializer
对象。
string = xmlSerializer.serializeToString(root)
返回将 root 序列化为 XML 的结果。
如果
root 无法序列化为 XML,则抛出 “InvalidStateError” DOMException。
XMLSerializer 被设计为一个
需要先构造,然后再调用其 serializeToString()
方法的类,这是一个令人遗憾的历史遗留问题。如果今天设计此功能,
它会是一个独立函数。
[Exposed =Window ]
interface XMLSerializer {
constructor ();
DOMString serializeToString (Node root );
};new XMLSerializer()
构造函数步骤不执行任何操作。
serializeToString(root)
方法步骤是:
返回给定 false 时 root 的 XML 序列化。
本节为非规范性内容。
Web 应用通常需要处理不受信任的 HTML 字符串,例如在渲染 用户生成的内容或使用客户端模板时。要将这些字符串安全地插入 DOM, 需要进行仔细的净化,以防止基于 DOM 的跨站脚本(XSS)攻击。
HTML 净化提供了一种原生机制,用于安全地解析和净化 HTML 字符串。 通过使用用户代理自身的 HTML 解析器,它们可确保净化后的输出准确反映 浏览器渲染内容的方式,从而防止脚本执行,并缓解脚本 小工具等高级攻击。
这些 API 提供了将包含 HTML 的字符串解析为 DOM 树,并根据用户提供的配置 过滤生成的树的功能。这些方法主要分为 “安全”和“不安全”两类。
“安全”方法不会生成任何会执行脚本的标记。也就是说,它们 旨在防范 XSS。“不安全”方法会根据所提供的 配置进行解析和过滤,但默认情况下不具有相同的安全保证。
Sanitizer 接口[Exposed =Window ]
interface Sanitizer {
constructor (optional (SanitizerConfig or SanitizerPresets ) configuration = "default");
// 查询配置:
SanitizerConfig get ();
// 修改 Sanitizer 的列表和字段:
boolean allowElement (SanitizerElementWithAttributes element );
boolean removeElement (SanitizerElement element );
boolean replaceElementWithChildren (SanitizerElement element );
boolean allowProcessingInstruction (SanitizerPI pi );
boolean removeProcessingInstruction (SanitizerPI pi );
boolean allowAttribute (SanitizerAttribute attribute );
boolean removeAttribute (SanitizerAttribute attribute );
boolean setComments (boolean allow );
boolean setDataAttributes (boolean allow );
// 移除会执行脚本的标记。
boolean removeUnsafe ();
};config = sanitizer.get()
返回净化器配置的副本。
sanitizer.allowElement(element)
确保净化器配置允许指定元素。
sanitizer.removeElement(element)
确保净化器配置阻止指定元素。
sanitizer.replaceElementWithChildren(element)
配置净化器以移除指定元素,但保留其子 节点。
sanitizer.allowAttribute(attribute)
配置净化器以全局允许指定属性。
sanitizer.removeAttribute(attribute)
配置净化器以全局阻止指定属性。
sanitizer.allowProcessingInstruction(pi)
配置净化器以允许指定的处理指令。
sanitizer.removeProcessingInstruction(pi)
配置净化器以阻止指定的处理指令。
sanitizer.setComments(allow)
设置净化器是否保留注释。
sanitizer.setDataAttributes(allow)
设置净化器是否保留自定义数据属性(例如 data-*)。
sanitizer.removeUnsafe()
修改配置以自动移除被视为不安全的元素和属性。
Sanitizer 对象具有一个关联的
配置,
它是一个 SanitizerConfig。
new
Sanitizer(configuration) 构造函数步骤是:
给定一个字典 configuration 和一个布尔值
allowCommentsPIsAndDataAttributes,要配置一个
Sanitizer
sanitizer:
给定一个布尔值 allowCommentsPIsAndDataAttributes,要规范化配置 SanitizerConfig configuration:
如果 configuration[“elements”]
和 configuration[“removeElements”]
均不存在,则将 configuration[“removeElements”]
设置为空列表。
如果 configuration[“attributes”]
和 configuration[“removeAttributes”]
均不存在,则将 configuration[“removeAttributes”]
设置为空
列表。
如果 configuration[“processingInstructions”]
和
configuration[“removeProcessingInstructions”]
均不存在:
如果 allowCommentsPIsAndDataAttributes 为 true,则将
configuration[“removeProcessingInstructions”]
设置为空列表。
否则,将 configuration[“processingInstructions”]
设置为空
列表。
如果 configuration[“removeElements”]
存在,则将 configuration[“removeElements”]
设置为规范化
configuration[“removeElements”]的结果。
如果 configuration[“attributes”]
存在,则将 configuration[“attributes”]
设置为规范化
configuration[“attributes”]的结果。
如果 configuration[“removeAttributes”]
存在,则将 configuration[“removeAttributes”]
设置为规范化
configuration[“removeAttributes”]的结果。
如果 configuration[“replaceWithChildrenElements”]
存在,则将 configuration[“replaceWithChildrenElements”]
设置为
规范化
configuration[“replaceWithChildrenElements”]的结果。
如果 configuration[“processingInstructions”]
存在,则将 configuration[“processingInstructions”]
设置为规范化
configuration[“processingInstructions”]的结果。
如果 configuration[“removeProcessingInstructions”]
存在,则将 configuration[“removeProcessingInstructions”]
设置为规范化
configuration[“removeProcessingInstructions”]的结果。
如果 configuration[“comments”]
不存在,则将其设置为
allowCommentsPIsAndDataAttributes。
如果 configuration[“attributes”]
存在,并且 configuration[“dataAttributes”]
不存在,则将其设置为
allowCommentsPIsAndDataAttributes。
给定一个 SanitizerPI
pi,要规范化处理指令:
给定一个 DOMString
或字典 name,以及一个默认命名空间
defaultNamespace(默认为 null),要规范化净化器名称:
给定一个 SanitizerElement
element,要规范化净化器元素:
要查找列表 A 和 B 的规范化交集:
get() 方法步骤是:
在 get() 方法之外,
Sanitizer 的元素和
属性顺序不可观察。通过显式排序此方法的
结果,我们为实现提供了优化机会,例如在内部使用
无序集合。
对于 config[“elements”]
中的每个 element:
如果 element[“attributes”]
存在,则将 element[“attributes”]
设置为使用比较
净化器项排序
element[“attributes”]的
结果。
如果 element[“removeAttributes”]
存在,则将 element[“removeAttributes”]
设置为使用比较
净化器项排序
element[“removeAttributes”]的结果。
将 config[“elements”]
设置为使用比较
净化器
项排序
config[“elements”]的
结果。
否则:
将 config[“removeElements”]
设置为使用比较
净化器项排序
config[“removeElements”]的结果。
如果 config[“replaceWithChildrenElements”]
存在,则将 config[“replaceWithChildrenElements”]
设置为使用比较
净化器项排序 config[“replaceWithChildrenElements”]的结果。
如果 config[“processingInstructions”]
存在,则将 config[“processingInstructions”]
设置为排序 config[“processingInstructions”]的结果,
其中
piA[“target”]
按码元小于
piB[“target”]。
否则:
将 config[“removeProcessingInstructions”]
设置为排序
config[“removeProcessingInstructions”]的结果,
其中 piA[“target”]
按码元
小于 piB[“target”]。
如果 config[“attributes”]
存在,则将 config[“attributes”]
设置为给定比较
净化器
项排序 config[“attributes”]的结果。
否则:
将 config[“removeAttributes”]
设置为给定比较
净化器项排序
config[“removeAttributes”]的结果。
返回 config。
allowElement(element) 方法步骤
是:
将 element 设置为规范化 element 的结果。
如果 configuration[“elements”]
存在:
令 modified 为从 configuration[“replaceWithChildrenElements”]
中移除
element 的结果。
如果 configuration[“attributes”]
存在:
如果 element[“attributes”]
存在:
将 element[“attributes”]
设置为从
element[“attributes”]创建集合的结果。
将 element[“attributes”]
设置为
element[“attributes”]
与
configuration[“attributes”]的差集。
如果 configuration[“dataAttributes”]
为 true,则从 element[“attributes”]
中移除所有为自定义数据属性的项
item。
如果 element[“removeAttributes”]
存在:
将 element[“removeAttributes”]
设置为从
element[“removeAttributes”]创建集合的结果。
将 element[“removeAttributes”]
设置为
element[“removeAttributes”]
与 configuration[“attributes”]的交集。
否则:
如果 element[“attributes”]
存在:
将 element[“attributes”]
设置为从
element[“attributes”]创建集合的结果。
将 element[“attributes”]
设置为
element[“attributes”]
与
element[“removeAttributes”]
默认为 « »
时的
差集。
移除 element[“removeAttributes”]。
将 element[“attributes”]
设置为
element[“attributes”]
与
configuration[“removeAttributes”]的
差集。
如果 element[“removeAttributes”]
存在:
将 element[“removeAttributes”]
设置为从
element[“removeAttributes”]创建集合的结果。
将 element[“removeAttributes”]
设置为
element[“removeAttributes”]
与 configuration[“removeAttributes”]的差集。
令 currentElement 为 configuration[“elements”]
中符合以下条件的项:其 name
成员为 element 的 name
成员,且其 namespace
成员为
element 的 namespace
成员。
如果 element 等于 currentElement,则返回 modified。
返回 true。
否则:
如果 element[“attributes”]
存在,或者 element[“removeAttributes”]
默认为 « »
时不为空,则返回
false。
令 modified 为从 configuration[“replaceWithChildrenElements”]
中移除
element 的结果。
如果 configuration[“removeElements”]
不包含
element,则返回 modified。
从
configuration[“removeElements”]中移除 element。
返回 true。
replaceElementWithChildren(element)
方法步骤是:
将 element 设置为规范化 element 的结果。
如果内置不可替换元素 列表包含 element,则返回 false。
如果从
configuration[“removeElements”]
中移除 element
的结果为 true,则将
modified 设置为 true。
如果 configuration[“replaceWithChildrenElements”]
不包含 element:
将 element 追加到
configuration[“replaceWithChildrenElements”]。
返回 true。
返回 modified。
allowAttribute(attribute) 方法
步骤是:
将 attribute 设置为规范化 attribute 的结果。
如果 configuration[“attributes”]
存在:
如果 configuration[“dataAttributes”]
为 true,并且
attribute 是一个自定义数据属性,则返回 false。
如果 configuration[“attributes”]
包含 attribute,则返回 false。
如果 configuration[“elements”]
存在:
对于
configuration[“elements”]
中的每个 element:
如果 element[“attributes”]
默认为 « »
时包含
attribute,则从 element[“attributes”]中移除
attribute。
将 attribute 追加到
configuration[“attributes”]。
返回 true。
否则:
如果 configuration[“removeAttributes”]
不包含
attribute,则返回 false。
从
configuration[“removeAttributes”]中移除 attribute。
返回 true。
setComments(allow) 方法步骤
是:
setDataAttributes(allow) 方法
步骤是:
如果 configuration[“attributes”]
不存在,则返回 false。
如果 configuration[“dataAttributes”]
存在且等于 allow,则返回 false。
如果 allow 为 true:
如果 configuration[“elements”]
存在:
对于
configuration[“elements”]
中的每个 element:
如果 element[“attributes”]
存在,则从
element[“attributes”]
中移除所有为自定义数据属性的项
item。
从
configuration[“attributes”]
中移除所有为自定义数据属性的项 item。
将 configuration[“dataAttributes”]
设置为 allow。
返回 true。
allowProcessingInstruction(pi)
方法步骤是:
将 pi 设置为规范化 pi 的结果。
如果 configuration[“processingInstructions”]
存在:
如果 configuration[“processingInstructions”]
包含 pi,则返回 false。
将 pi 追加到
configuration[“processingInstructions”]。
返回 true。
否则:
如果 configuration[“removeProcessingInstructions”]
包含 pi:
从
configuration[“removeProcessingInstructions”]中移除 pi。
返回 true。
返回 false。
removeProcessingInstruction(pi)
方法步骤是:
将 pi 设置为规范化 pi 的结果。
如果 configuration[“processingInstructions”]
存在:
如果 configuration[“processingInstructions”]
包含 pi:
从
configuration[“processingInstructions”]中移除 pi。
返回 true。
返回 false。
否则:
如果 configuration[“removeProcessingInstructions”]
包含 pi,则返回 false。
将 pi 追加到
configuration[“removeProcessingInstructions”]。
返回 true。
dictionary SanitizerElementNamespace {
required DOMString name ;
DOMString ? _namespace = "http://www.w3.org/1999/xhtml";
};
// Used by "elements"
dictionary SanitizerElementNamespaceWithAttributes : SanitizerElementNamespace {
sequence <SanitizerAttribute > attributes ;
sequence <SanitizerAttribute > removeAttributes ;
};
dictionary SanitizerAttributeNamespace {
required DOMString name ;
DOMString ? _namespace = null ;
};
dictionary SanitizerProcessingInstruction {
required DOMString target ;
};
typedef (DOMString or SanitizerElementNamespace ) SanitizerElement ;
typedef (DOMString or SanitizerElementNamespaceWithAttributes ) SanitizerElementWithAttributes ;
typedef (DOMString or SanitizerProcessingInstruction ) SanitizerPI ;
typedef (DOMString or SanitizerAttributeNamespace ) SanitizerAttribute ;
dictionary SanitizerConfig {
sequence <SanitizerElementWithAttributes > elements ;
sequence <SanitizerElement > removeElements ;
sequence <SanitizerElement > replaceWithChildrenElements ;
sequence <SanitizerPI > processingInstructions ;
sequence <SanitizerPI > removeProcessingInstructions ;
sequence <SanitizerAttribute > attributes ;
sequence <SanitizerAttribute > removeAttributes ;
boolean comments ;
boolean dataAttributes ;
};当 SanitizerElementNamespace、
SanitizerAttributeNamespace、
SanitizerElementNamespaceWithAttributes
和
SanitizerProcessingInstruction
字典的所有成员都相等时,
这些字典被视为相等。
相等性应改为在 Infra 规范中定义。请参阅议题 #664。
本节是非规范性的。
开发者可以且应当修改配置,以使其符合自己的目的。可选方案包括:
从头编写一个新的 SanitizerConfig
字典;
使用修改器方法修改现有
Sanitizer 的配置;或者通过 get() 将现有 Sanitizer 的
配置作为字典获取并修改
该字典,然后使用它创建一个新的
Sanitizer。
空配置允许一切内容(使用诸如 setHTMLUnsafe()
这样的“不安全”方法调用时)。
配置“default”包含一个
内置安全默认配置。请注意,
“安全”和“不安全”的净化器方法
具有不同的默认值。
并非所有配置字典都有效。有效配置会避免冗余(例如 将同一个元素指定为允许两次)和矛盾(例如将一个元素指定为 既移除又允许)。
配置必须满足若干条件才有效:
混用全局允许列表和移除列表:
elements
或 removeElements
可以存在,但不能同时存在。如果
两者都不存在,则等同于 removeElements
是一个空列表。
attributes
或 removeAttributes
可以存在,但不能同时存在。
如果两者都不存在,则等同于 removeAttributes
是一个空
列表。
从概念上讲,dataAttributes
是 attributes
允许列表的扩展。
仅当使用 attributes
列表时,才允许使用 dataAttributes
成员。
不同全局列表之间的重复条目:
elements、
removeElements
或 replaceWithChildrenElements
之间不存在重复条目(即不存在相同元素)。
attributes
与 removeAttributes
之间不存在重复条目(即不存在相同属性)。
在同一个元素上混用局部允许列表和移除列表:
当存在 attributes
列表时,同一个元素上允许同时存在、仅存在其中任意一个或均不存在 attributes
和 removeAttributes
列表。
当存在 removeAttributes
列表时,
同一个元素上允许仅存在其中任意一个或均不存在 attributes
和 removeAttributes
列表,但不允许两者同时存在。
同一个元素上的重复条目:
同一个元素上的 attributes
与 removeAttributes
之间不存在重复条目。
内置不可替换元素
列表中的任何元素均不得出现在 replaceWithChildrenElements
中,
因为用这些元素的子节点替换它们可能导致重新解析问题或无效的
节点树。
elements
元素允许列表还可以
指定允许或移除给定元素的属性。这旨在反映本
标准的结构,该结构既包含全局属性,也包含适用于
特定元素的局部属性。全局属性和局部属性可以混用,但请注意,
若某个特定属性会被一个列表允许、却被另一个列表禁止,这类有歧义的配置
通常无效。
全局 attributes
|
全局 removeAttributes
|
|
|---|---|---|
局部 attributes
|
如果属性与任一列表匹配,则允许该属性。不允许重复。 | 仅当属性位于局部允许列表中时,才允许该属性。全局移除列表与 局部允许列表之间不允许存在重复条目。请注意,全局移除列表对这个 特定元素不起作用,但可以应用于没有 局部允许列表的其他元素。 |
局部 removeAttributes
|
如果属性位于全局允许列表中,但不在局部移除列表中,则允许该属性。 局部移除列表必须是全局允许列表的子集。 | 如果属性不在任一列表中,则允许该属性。全局移除列表与 局部移除列表之间不允许存在重复条目。 |
请注意这种不对称性:通常不允许全局列表与逐元素列表之间 存在重复项,但在全局允许列表与逐元素移除列表的组合中,后者必须 是前者的子集。以下是上表中仅关注重复项的 摘录:
全局 attributes
|
全局 removeAttributes
|
|
|---|---|---|
局部 attributes
|
不允许重复。 | 不允许重复。 |
局部 removeAttributes
|
局部移除列表必须是全局允许列表的子集。 | 不允许重复。 |
dataAttributes
设置允许
自定义数据属性。如果将 dataAttributes
视为允许列表,上述规则便可轻易扩展到
自定义数据属性:
设置了全局 attributes
和 dataAttributes
|
|
|---|---|
局部 attributes
|
允许所有自定义数据 属性。任何允许列表中都不能 列出自定义数据 属性,因为这会产生重复条目。 |
局部 removeAttributes
|
允许自定义数据 属性,除非它被列入 局部移除列表。全局允许列表中不能列出任何自定义数据 属性,因为这会产生重复 条目。 |
用文字表述这些规则:
全局列表和局部列表之间的重复项与交互:
如果存在全局 attributes
允许列表,
那么对于所有元素的局部列表:
如果存在局部 attributes
允许列表,
则这些列表之间不能存在重复条目。
如果存在局部 removeAttributes
移除列表,则其所有条目还必须列入全局 attributes
允许列表。
如果 dataAttributes
为 true,
则任何允许列表中都不能列出自定义
数据属性。
如果存在全局 removeAttributes
移除列表:
如果存在局部 attributes
允许列表,
则这些列表之间不能存在重复条目。
如果存在局部 removeAttributes
移除列表,则这些列表之间不能存在重复条目。
局部 attributes
允许列表
和局部 removeAttributes
移除列表不能同时存在。
dataAttributes
必须为
false。
要在给定 Element
或
DocumentFragment
target、字符串 html、
字典 options 和布尔值 safe 的情况下,设置并过滤 HTML:
断言:context 非空。
如果以下所有条件均为真:
则返回。
令 sanitizer 为在给定 safe 的情况下,通过 从 options 获取净化器所得的结果。
令 scriptingMode 为不活动。
如果 options["runScripts"]
为 true:
令 fragment 为使用 target、html、true 和 scriptingMode 调用 HTML 片段解析 算法所得的结果。
fragment 中的脚本只有在插入 target 后才会执行。
使用 sanitizer 和 safe 净化 fragment。
在 target 内,用 fragment 替换 全部。
要从具有布尔值 safe 的字典 options 中从选项获取净化器实例:
令 sanitizerSpec 为“default”。
如果 options["sanitizer"]
存在,则将 sanitizerSpec 设置为
options["sanitizer"]。
断言:sanitizerSpec 是 Sanitizer 实例、
SanitizerPresets 成员或
SanitizerConfig 字典。
如果 sanitizerSpec 是字符串:
如果 sanitizerSpec 是字典:
返回 sanitizerSpec。
要使用 Node
node、
SanitizerConfig
configuration 和布尔值
handleJavascriptNavigationUrls 执行内部净化步骤:
断言:child 是 Text、
Comment、
Element、
ProcessingInstruction
或 DocumentType
节点。
如果 child 是 DocumentType
或 Text
节点,则
继续。
如果 child 是 Comment
节点:
如果 child 是 ProcessingInstruction
节点:
令 piTarget 为 child 的目标。
如果 configuration["processingInstructions"]
存在:
如果 configuration["processingInstructions"]
不
包含
piTarget,则移除
child。
否则:
如果 configuration["removeProcessingInstructions"]
包含
piTarget,则移除
child。
否则:
令 elementName 为一个 SanitizerElementNamespace,其名称和命名空间分别为 child 的局部名称和命名空间。
如果 configuration["replaceWithChildrenElements"]
存在,并且 configuration["replaceWithChildrenElements"]
包含 elementName:
否则:
如果 configuration["removeElements"]
包含
elementName,则移除
child 并
继续。
如果 elementName["name"]
为“template”
并且
elementName["namespace"]
是 HTML
命名空间,则使用
child 的
模板内容、
configuration 和
handleJavascriptNavigationUrls 运行内部净化步骤。
如果 child 是影子 宿主,则使用 child 的影子 根、configuration 和 handleJavascriptNavigationUrls 运行内部净化 步骤。
令 elementWithLocalAttributes 为 «[ ]»。
如果 configuration["elements"]
存在,并且 configuration["elements"]
包含 elementName,则将
elementWithLocalAttributes 设置为 configuration["elements"][elementName]。
对于 child 的 属性列表中的每个 attribute:
令 attrName 为一个 SanitizerAttributeNamespace,其名称和命名空间分别为 attribute 的局部名称和 命名空间。
如果 elementWithLocalAttributes["removeAttributes"]
存在,并且 elementWithLocalAttributes["removeAttributes"]
包含
attrName,则移除 attribute。
否则,如果 configuration["attributes"]
存在:
如果 configuration["attributes"]
不包含
attrName,并且
elementWithLocalAttributes["attributes"]
默认值为
« » 时也不包含
attrName,且“data-”不是
attribute 的局部名称的代码单元前缀,或者 attribute 的命名空间不为空,或者
configuration["dataAttributes"]
不为 true,则
移除
attribute。
否则:
如果 elementWithLocalAttributes["attributes"]
存在,并且
elementWithLocalAttributes["attributes"]
不
包含
attrName,则移除 attribute。
否则,如果 configuration["removeAttributes"]
包含
attrName,则移除 attribute。
如果 handleJavascriptNavigationUrls 为 true:
如果二元组(elementName、attrName)与
内置导航 URL
属性列表中的条目匹配,并且 attribute
包含 javascript:
URL,则移除 attribute。
如果 child 的命名空间是
MathML 命名空间,attribute 的局部名称为“href”,
attribute 的命名空间
为空或是 XLink 命名空间,并且 attribute 包含
javascript: URL,则移除 attribute。
如果内置动画 URL
属性列表包含
二元组(elementName、attrName),并且
attribute 的值为“href”或
“xlink:href”,则移除 attribute。
使用 child、 configuration 和 handleJavascriptNavigationUrls 运行内部 净化步骤。
要确定属性 attribute 是否包含
javascript:
URL:
令 url 为对 attribute 的值运行基本 URL 解析器所得的结果。
如果 url 为失败,则返回 false。
如果 url 的方案为
“javascript”,则返回 true;否则返回 false。
要从 SanitizerConfig configuration 中移除元素 element:
将 element 设置为对 element 进行规范化所得的结果。
令 modified 为从 configuration["replaceWithChildrenElements"]
中移除
element 所得的结果。
否则:
如果 configuration["removeElements"]
包含 element,则返回 modified。
将 element 追加到
configuration["removeElements"]。
返回 true。
要从 SanitizerConfig configuration 中移除属性 attribute:
将 attribute 设置为对 attribute 进行规范化所得的结果。
如果 configuration["attributes"]
存在:
令 modified 为从 configuration["attributes"]
中移除
attribute 所得的结果。
如果 configuration["elements"]
存在:
对于
configuration["elements"]
中的每个 element:
如果 element["attributes"]
默认值为 «
» 时包含
attribute:
将 modified 设置为 true。
从
element["attributes"]
中移除
attribute。
如果 element["removeAttributes"]
默认值为 «
» 时包含
attribute:
断言:modified 为 true。
从
element["removeAttributes"]
中移除
attribute。
返回 modified。
否则:
如果 configuration["removeAttributes"]
包含 attribute,则返回 false。
如果 configuration["elements"]
存在:
对于
configuration["elements"]
中的每个 element:
如果 element["attributes"]
默认值为 «
» 时包含
attribute,则从 element["attributes"]
中移除
attribute。
如果 element["removeAttributes"]
默认值为 «
» 时包含
attribute,则从 element["removeAttributes"]
中移除
attribute。
将 attribute 追加到
configuration["removeAttributes"]。
返回 true。
要从 SanitizerConfig configuration 中移除不安全内容:
令 result 为 false。
对于内置安全
基线配置["removeElements"]
中的每个 element:
如果从 configuration 中移除 element 的结果为 true,则将 result 设置为 true。
对于内置安全
基线配置["removeAttributes"]
中的每个 attribute:
如果从 configuration 中移除 attribute 的结果为 true,则将 result 设置为 true。
对于每个事件 处理器内容属性 attribute:
如果从 configuration 中移除 attribute 的结果为 true,则将 result 设置为 true。
返回 result。
要比较净化器项目 itemA 和 itemB:
要规范化一个 SanitizerElementWithAttributes element:
令 result 为对 element 进行规范化所得的结果。
如果 element 是字典:
如果 element["attributes"]
存在,则将 result["attributes"]
设置为对
element["attributes"]
进行规范化所得的
结果。
如果 element["removeAttributes"]
存在,则将 result["removeAttributes"]
设置为对
element["removeAttributes"]
进行规范化所得的结果。
如果 result["attributes"]
和
result["removeAttributes"]
都不存在,则将 result["removeAttributes"]
设置为空列表。
返回 result。
要确定规范化的 SanitizerConfig config 是否有效:
预计传入的配置先前已经运行过 规范化配置步骤。我们将仅 断言该算法保证成立的 条件。
断言:config["elements"]
存在
或 config["removeElements"]
存在。
如果 config["elements"]
存在,并且 config["removeElements"]
存在,则返回 false。
断言:config["processingInstructions"]
存在,或者 config["removeProcessingInstructions"]
存在。
如果 config["processingInstructions"]
存在,并且 config["removeProcessingInstructions"]
存在,则返回 false。
断言:config["attributes"]
存在,或者 config["removeAttributes"]
存在。
如果 config["attributes"]
存在,并且 config["removeAttributes"]
存在,则返回 false。
断言:config 中的所有 SanitizerElementNamespaceWithAttributes、 SanitizerElementNamespace、SanitizerProcessingInstruction 和 SanitizerAttributeNamespace 项均已规范化,即它们 已视情况运行过规范化步骤。
否则:
如果 config["removeElements"]
存在
重复项,则返回 false。
如果 config["replaceWithChildrenElements"]
存在且存在
重复项,则返回 false。
如果 config["processingInstructions"]
存在:
如果 config["processingInstructions"]
存在
重复项,则返回 false。
否则:
如果 config["removeProcessingInstructions"]
存在
重复项,则返回 false。
如果 config["attributes"]
存在:
如果 config["attributes"]
存在
重复项,则返回 false。
否则:
如果 config["removeAttributes"]
存在
重复项,则返回 false。
如果 config["replaceWithChildrenElements"]
存在:
对于 config["replaceWithChildrenElements"]
中的每个 element:
如果内置不可替换 元素列表包含 element,则返回 false。
如果
config["elements"]
与
config["replaceWithChildrenElements"]
的交集
非空,则返回 false。
否则:
如果
config["removeElements"]
与 config["replaceWithChildrenElements"]
的交集
非空,则返回 false。
如果 config["attributes"]
存在:
断言:config["dataAttributes"]
存在。
对于
config["elements"]
中的每个 element:
如果 element["attributes"]
存在,并且 element["attributes"]
存在
重复项,则返回 false。
如果 element["removeAttributes"]
存在,并且 element["removeAttributes"]
存在
重复项,则返回 false。
如果
config["attributes"]
与
element["attributes"]
默认值为 «
» 时的交集非空,则返回 false。
如果 element["removeAttributes"]
默认值为 «
» 时不是
config["attributes"]
的子集,
则返回 false。
如果 config["dataAttributes"]
为 true,并且
element["attributes"]
包含自定义数据属性,则返回 false。
如果 config["dataAttributes"]
为 true,并且
config["attributes"]
包含
自定义数据
属性,则返回 false。
否则:
对于
config["elements"]
中的每个 element:
如果 element["attributes"]
存在,并且 element["removeAttributes"]
存在,则返回 false。
如果 element["attributes"]
存在,并且 element["attributes"]
存在
重复项,则返回 false。
如果 element["removeAttributes"]
存在,并且 element["removeAttributes"]
存在
重复项,则返回 false。
如果
config["removeAttributes"]
与
element["attributes"]
默认值为 «
» 时的交集非空,则返回 false。
如果
config["removeAttributes"]
与
element["removeAttributes"]
默认值为 «
» 时的交集非空,则返回
false。
如果 config["dataAttributes"]
存在,则返回 false。
返回 true。
元素的净化类别可以是以下类别之一:
SanitizerConfig 中。setHTMLUnsafe()
或 parseHTMLUnsafe()
保留,并由
setHTML()、parseHTML()
和 removeUnsafe()
移除。)
SanitizerConfig 中。
内置安全基线配置是一个 SanitizerConfig。其
removeElements
列表由各自定义中规范性标记为不安全的所有
HTML
元素、已废弃的 frame 元素,以及 SVG
script 和 SVG
use 元素组成;其 removeAttributes
列表为空。
在安全净化期间,移除
不安全内容算法会自动移除事件处理器内容属性,因此实际基线的行为就像这些属性
已包含在 removeAttributes
列表中一样。
内置安全默认配置是一个 SanitizerConfig,其 成员按如下方式初始化:
processingInstructions
attributes
dirlangtitlealignment-baseline
baseline-shift
clip-path
clip-rule
color
color-interpolation
cursor
direction
display
displaystyle
dominant-baseline
fill
fill-opacity
fill-rule
font-family
font-size
font-size-adjust
font-stretch
font-style
font-variant
font-weight
letter-spacing
marker-end
marker-mid
marker-start
mathbackground
mathcolor
mathsize
opacity
paint-order
pointer-events
scriptlevel
shape-rendering
stop-color
stop-opacity
stroke
stroke-dasharray
stroke-dashoffset
stroke-linecap
stroke-linejoin
stroke-miterlimit
stroke-opacity
stroke-width
text-anchor
text-decoration
text-overflow
text-rendering
transform
transform-origin
unicode-bidi
vector-effect
visibility
white-space
word-spacing
writing-mode
comments
dataAttributes
elements
attributes
列表中。下表列出在内置安全默认
配置中归类为默认的
MathML 和 SVG 元素,并表示为
SanitizerElementNamespaceWithAttributes
字典列表。对于表中的每一行,
“元素”列对应 name
成员,“命名空间”列对应 namespace
成员,而“允许的
属性”列对应 attributes
成员(其中
列出的每个属性在序列中均表示为 SanitizerAttribute):
内置导航 URL 属性列表对应于
在规范性定义中标有导航 URL 属性的所有 HTML 元素,以及
下表所表示的
元素—属性对。对于表中的每一行,元素对应一个
SanitizerElementNamespace,其 name
成员由“元素”列给出,
其 namespace
成员由“元素命名空间”列给出;属性则对应一个
SanitizerAttributeNamespace,其 name
成员由“属性”
列给出,其 namespace
成员
由“属性命名空间”列给出:
| 元素 | 元素命名空间 | 属性 | 属性命名空间 |
|---|---|---|---|
a
|
SVG | href
|
无命名空间 |
a
|
SVG | href
|
XLink |
内置动画 URL 属性列表是由
下表表示的元素—属性对
列表。对于表中的每一行,元素对应一个
SanitizerElementNamespace,其 name
成员由“元素”列给出,
其 namespace
成员由“元素命名空间”列给出;属性则对应一个
SanitizerAttributeNamespace,其 name
成员由“属性”
列给出,其 namespace
成员
为空:
| 元素 | 元素命名空间 | 属性 |
|---|---|---|
animate
|
SVG | attributeName
|
animateTransform
|
SVG | attributeName
|
set
|
SVG | attributeName
|
内置不可替换元素列表包含
不得用其子节点
替换的元素,因为这样做可能导致重新解析问题或无效的节点树。
它是下表所表示的 SanitizerElementNamespace 字典
列表。对于表中的每一行,“元素”列对应 name
成员,而“元素命名空间”列
对应 namespace
成员:
| 元素 | 元素命名空间 |
|---|---|
html
|
HTML |
svg
|
SVG |
math
|
MathML |
本节是非规范性的。
Sanitizer API 旨在通过遍历所提供的
HTML 内容并根据配置移除元素和属性,防止基于 DOM 的跨站脚本攻击。按照设计,
setHTML()
和 parseHTML()
方法无论提供何种配置,都会移除可执行脚本的标记;如果有任何配置能通过这些方法
保留此类标记,
那将是一个错误。
但是,Sanitizer API 无法防止某些安全问题。以下 各节将对其进行说明。
本节是非规范性的。
Sanitizer API 仅在 DOM 中运行,并提供遍历和过滤现有
DocumentFragment
的能力。Sanitizer API 不处理服务器端反射型
或存储型 XSS。
本节是非规范性的。
DOM 覆盖描述了一种攻击:恶意 HTML 通过使用
id 或
name 属性混淆应用程序,使诸如 HTML
元素的 children
属性之类的 DOM
属性被恶意内容遮蔽。
默认情况下,Sanitizer API 不防御 DOM 覆盖攻击,但可以
配置为移除 id 和
name
属性。
本节是非规范性的。
脚本小工具是一种攻击技术,攻击者利用流行 JavaScript 库中的现有应用程序代码使自己的代码得以执行。其通常通过注入 看似无害的代码或貌似不活动的 DOM 节点来实现;这些内容只会由某个 框架解析和解释,而该框架随后会根据这些输入执行 JavaScript。
Sanitizer API 无法防止这些攻击。相反,它要求创作者明确
允许一般意义上的未知元素,并另外明确允许常用于模板和框架特定代码的
属性、元素和标记,例如 data-* 和
slot 属性,以及
slot 和 template
等元素。
这些限制并非详尽无遗,
建议创作者检查其第三方库是否存在此类行为。
本节是非规范性的。
变异型 XSS(即 mXSS)描述了一种攻击:利用解析后的 DOM 结构 在序列化并重新解析后发生变化的情况,绕过序列化前执行的 净化。例如,可以依赖外部内容或错误嵌套标签的解析 行为发生变化来实施此类攻击。
Sanitizer API 仅提供将字符串转换为节点树的函数。所有净化器函数都隐式 提供上下文:setHTML() 使用当前元素;Document.parseHTML() 创建新文档。因此,Sanitizer API 不会直接受到变异型 XSS 的影响。
如果开发者将净化后的节点树作为字符串取回,例如通过 innerHTML,然后
再次解析它,就可能发生变异型 XSS。
强烈不建议采用这种做法。如果最终仍需要以字符串形式处理或传递 HTML,
则任何字符串都应被视为不可信,并在插入 DOM 时重新净化。
换言之,经过净化后又被序列化的 HTML 树不能再
被视为已净化。有关 mXSS 更完整的论述,请参阅 [MXSS]。
setTimeout() 和 setInterval() 方法允许创作者调度
基于定时器的
回调。
id = self.setTimeout(handler [, timeout [, ...arguments ] ])
所有当前引擎均支持。
调度一个定时器,在 timeout 毫秒后运行 handler。所有 arguments 都会直接传递给 handler。
id = self.setTimeout(code [, timeout ])
调度一个定时器,在 timeout 毫秒后编译并运行 code。
self.clearTimeout(id)
所有当前引擎均支持。
取消由 id 标识、通过 setTimeout() 或
setInterval() 设置的定时器。
id = self.setInterval(handler [, timeout [, ...arguments ] ])
所有当前引擎均支持。
调度一个定时器,每隔 timeout 毫秒运行一次 handler。所有 arguments 都会直接传递给 handler。
id = self.setInterval(code [, timeout ])
调度一个定时器,每隔 timeout 毫秒编译并运行一次 code。
self.clearInterval(id)
所有当前引擎均支持。
取消由 id 标识、通过 setInterval()
或 setTimeout() 设置的定时器。
定时器可以嵌套;但是,在五个这样的嵌套定时器之后,时间间隔会被 强制设置为至少四毫秒。
此 API 不保证定时器会严格按计划运行。由 CPU 负载、其他任务等造成的延迟是正常的。
实现 WindowOrWorkerGlobalScope
混入的对象具有一个
setTimeout 和
setInterval ID 映射,它是一个
初始为空的有序映射。此映射中的每个键
都是正整数,对应于一次 setTimeout() 或 setInterval() 调用的返回值。
每个值
都是一个唯一内部值,对应于
该对象的活动定时器映射中的一个键。
setTimeout(handler, timeout,
...arguments) 方法步骤是:使用
this、
handler、
timeout、arguments 和 false 运行定时器初始化步骤,并返回其结果。
setInterval(handler, timeout,
...arguments) 方法步骤是:使用
this、
handler、
timeout、arguments 和 true 运行定时器初始化步骤,并返回其结果。
clearTimeout(id) 和 clearInterval(id) 方法步骤
是移除 this 的 setTimeout 和
setInterval ID 映射[id]。
由于 clearTimeout() 和
clearInterval() 从同一个映射中清除条目,因此任一方法
都可以用于清除由 setTimeout() 或 setInterval() 创建的定时器。
要执行定时器初始化
步骤,给定一个 WindowOrWorkerGlobalScope
global、一个字符串或 Function
或 TrustedScript
handler、一个数值 timeout、一个列表 arguments、一个布尔值
repeat,以及可选的(且仅当 repeat 为 true 时)数值
previousId,执行以下步骤。这些步骤返回一个数值。
如果 global 是 WorkerGlobalScope
对象,则令 thisArg 为 global;否则令 thisArg 为与
global 对应的 WindowProxy。
如果给出了 previousId,则令 id 为 previousId; 否则,令 id 为一个大于零且尚未在 global 的 setTimeout 和 setInterval ID 映射中存在的由实现定义的整数。
如果周围代理的事件 循环的当前正在运行的任务 是由此算法创建的任务, 则令 nesting level 为该任务的定时器 嵌套层级。否则,令 nesting level 为 0。
任务的定时器嵌套
层级既用于对
setTimeout() 的嵌套调用,也用于由
setInterval() 创建的重复
定时器。(当然,也用于两者的任何
组合。)换言之,它表示此算法的嵌套调用,而不是某个特定
方法的嵌套调用。
如果 timeout 小于 0,则将 timeout 设置为 0。
如果 nesting level 大于 5,并且 timeout 小于 4, 则将 timeout 设置为 4。
令 realm 为 global 的相关 领域。
令 initiating script 为活动脚本。
令 uniqueHandle 为空。
令 task 为一个运行以下 子步骤的任务:
如果 id 在 global 的 setTimeout 和 setInterval ID 映射中不存在,则中止这些步骤。
如果 global 的 setTimeout 和 setInterval ID 映射[id] 不等于 uniqueHandle,则中止这些步骤。
这适用于 ID 已被一次 clearTimeout() 或 clearInterval() 调用清除,并被后续
setTimeout() 或 setInterval() 调用
重新使用的情况。
令 settings object 为 global 的相关设置 对象。
如果 settings object 的脚本已 禁用,则中止这些步骤。
使用 handler、 settings object 和 repeat 记录定时器处理器的计时信息。
如果 handler 是 Function,
则使用
arguments 和“report”调用
handler,并将回调 this 值设置为
thisArg。
否则:
如果未给出 previousId:
如果 global 是
Window 对象,则令 globalName
为“Window”;
否则为“WorkerGlobalScope”。
如果
repeat 为 true,则令 methodName
为“setInterval”;否则为“setTimeout”。
令 sink 为 globalName、U+0020 SPACE 和 methodName 的串联。
将 handler 设置为使用
TrustedScript、
global、
handler、sink 和“script”调用获取受信任类型
兼容字符串算法所得的结果。
断言:handler 是字符串。
执行 EnsureCSPDoesNotBlockStringCompilation(realm、 « »、handler、handler、timer、« »、handler)。如果这抛出 异常,则捕获该异常,为 global 报告该异常,并中止这些步骤。
令 fetch options 为默认脚本获取 选项。
令 base URL 为 settings object 的 API 基准 URL。
如果 initiating script 不为空:
将 fetch options 设置为一个脚本获取选项,其加密随机数是 initiating
script 的获取选项的
加密随机数,完整性元数据为空
字符串,解析器元数据为
“not-parser-inserted”,凭据模式为
initiating script 的获取
选项的凭据
模式,引用来源
策略为 initiating script 的获取选项的引用来源策略,并且获取优先级为
“auto”。
将 base URL 设置为 initiating script 的基准 URL。
这些步骤确保由 setTimeout() 和 setInterval() 执行的字符串编译
与由
eval()
执行的字符串编译具有等效行为。
也就是说,通过 import()
获取模块脚本时,在这两种上下文中的行为相同。
令 script 为使用 handler、settings object、base URL 和 fetch options 创建经典脚本所得的结果。
运行经典脚本 script。
如果 id 在 global 的 setTimeout 和 setInterval ID 映射中不存在,则中止这些步骤。
如果 global 的 setTimeout 和 setInterval ID 映射[id] 不等于 uniqueHandle,则中止这些步骤。
ID 可能已经由 handler 中调用
clearTimeout() 或
clearInterval() 的创作者代码移除。检查
uniqueHandle 是否不同,
可应对 ID 在被清除后又由后续 setTimeout() 或
setInterval() 调用重新使用的情况。
如果 repeat 为 true,则使用 global、handler、timeout、 arguments、true 和 id 再次执行定时器初始化 步骤。
否则,移除 global 的 setTimeout 和 setInterval ID 映射[id]。
将 nesting level 增加一。
将 task 的定时器嵌套层级设置为 nesting level。
令 completionStep 为一个算法步骤,该步骤使用 global 在定时器任务源上排入一个全局任务,以运行 task。
将 uniqueHandle 设置为使用 global、
“setTimeout/setInterval”、timeout 和
completionStep 在超时后运行步骤所得的结果。
将 global 的 setTimeout 和 setInterval ID 映射[id] 设置为 uniqueHandle。
返回 id。
Web IDL 所定义的参数转换(例如,对作为第一个参数传入的
对象调用 toString() 方法)发生在
Web IDL 定义的算法中,且发生在调用此算法之前。
例如,下面这段颇为愚蠢的代码会使日志包含
“ONE TWO ”:
var log = '' ;
function logger( s) { log += s + ' ' ; }
setTimeout({ toString: function () {
setTimeout( "logger('ONE')" , 100 );
return "logger('TWO')" ;
} }, 100 ); 要连续运行多个耗时数毫秒的任务而不产生任何延迟,同时仍将控制权交还给 浏览器以避免用户界面得不到处理(并避免浏览器因脚本 独占 CPU 而终止它),只需在执行工作之前将下一个定时器排入队列:
function doExpensiveWork() {
var done = false ;
// ...
// this part of the function takes up to five milliseconds
// set done to true if we're done
// ...
return done;
}
function rescheduleWork() {
var id = setTimeout( rescheduleWork, 0 ); // preschedule next iteration
if ( doExpensiveWork())
clearTimeout( id); // clear the timeout if we don't need it
}
function scheduleWork() {
setTimeout( rescheduleWork, 0 );
}
scheduleWork(); // queues a task to do lots of work 实现 WindowOrWorkerGlobalScope
混入的对象具有一个活动定时器
映射,它是一个初始为空的有序映射。
此映射中的每个键都是表示一个定时器的唯一内部
值,每个值都是一个
DOMHighResTimeStamp,
表示该定时器的到期时间。
要在超时后运行步骤,给定一个 WindowOrWorkerGlobalScope
global、一个字符串 orderingIdentifier、一个数值 milliseconds 和一组
步骤 completionSteps,执行以下步骤。这些步骤返回一个唯一
内部值。
令 timerKey 为一个新的唯一 内部值。
令 startTime 为给定 global 时的当前高精度时间。
并行运行以下步骤:
如果 global 是 Window 对象,则等待
global 的关联
Document 进一步处于完全
活动状态达 milliseconds 毫秒(不必
连续)。
否则,global 是 WorkerGlobalScope 对象;等待
工作线程未暂停的时间达到
milliseconds 毫秒(不必连续)。
等待所有满足以下条件的此算法调用完成:具有相同的 global 和 orderingIdentifier,在此次调用之前开始,且其 milliseconds 小于或等于此次调用的 milliseconds。
可以选择再等待一段由实现定义的时间。
这旨在允许用户代理根据需要延长超时时间,以优化 设备的功耗。例如,某些处理器具有一种低功耗模式,在该模式下 定时器的精度会降低;在此类平台上,用户代理可以减慢定时器以符合 此调度,而无需处理器使用更精确但 功耗更高的模式。
执行 completionSteps。
返回 timerKey。
在超时后运行
步骤旨在供其他规范使用,这些规范希望在开发者提供的超时之后执行开发者提供的代码,
其方式与 setTimeout() 类似。
(但是请注意,它
不具有 setTimeout() 的嵌套和钳制行为。)
此类规范可以选择一个 orderingIdentifier,以确保其规范的超时之间有序,
同时不限制其与其他规范的
超时之间的顺序。
所有当前引擎均支持。
queueMicrotask()
方法允许创作者在微任务队列上调度
回调。这使其代码能在
JavaScript 执行上下文栈下一次为空时运行,这发生在当前
正在执行的所有同步 JavaScript 均运行完毕之后。这样做不会像使用
setTimeout(f, 0)
时那样,将控制权交还给事件循环。
创作者应当意识到,调度大量微任务与运行大量同步代码具有相同的性能
缺点。两者都会阻止浏览器执行自己的
工作,例如渲染。在许多情况下,requestAnimationFrame()
或
requestIdleCallback()
是更好的选择。特别是,如果目标是在下一次渲染周期
之前运行代码,这正是 requestAnimationFrame()
的用途。
从以下示例可以看出,理解 queueMicrotask() 的最佳方式是将其视为一种
重新排列同步
代码的机制,它实际上会将排入队列的代码放在当前正在执行的同步
JavaScript 运行完毕之后。
使用 queueMicrotask()
最常见的原因是
创建一致的顺序,即使信息能够同步获得,
也不会引入不必要的延迟。
例如,假设某个自定义元素会触发 load 事件,同时还
维护一个包含先前已加载数据的内部缓存。一个简单的实现可能
如下所示:
MyElement. prototype. loadData = function ( url) {
if ( this . _cache[ url]) {
this . _setData( this . _cache[ url]);
this . dispatchEvent( new Event( "load" ));
} else {
fetch( url). then( res => res. arrayBuffer()). then( data => {
this . _cache[ url] = data;
this . _setData( data);
this . dispatchEvent( new Event( "load" ));
});
}
}; 然而,这种简单的实现存在问题,因为它会使用户 遇到不一致的行为。例如,以下代码
element. addEventListener( "load" , () => console. log( "loaded" ));
console. log( "1" );
element. loadData();
console. log( "2" ); 有时会记录“1, 2, loaded”(如果需要获取数据),有时则会记录“1,
loaded, 2”(如果数据已经缓存)。同样,在调用 loadData() 之后,
数据是否已设置到元素上也会
不一致。
为了获得一致的顺序,可以使用 queueMicrotask():
MyElement. prototype. loadData = function ( url) {
if ( this . _cache[ url]) {
queueMicrotask(() => {
this . _setData( this . _cache[ url]);
this . dispatchEvent( new Event( "load" ));
});
} else {
fetch( url). then( res => res. arrayBuffer()). then( data => {
this . _cache[ url] = data;
this . _setData( data);
this . dispatchEvent( new Event( "load" ));
});
}
}; 通过实质上重新排列排入队列的代码,使其位于 JavaScript 执行上下文 栈清空之后,这可确保元素状态的更新和执行顺序保持一致。
queueMicrotask()
的另一个有趣用途是
允许多个调用方以不协调的方式对工作进行“批处理”。例如,假设某个库
函数希望尽快将数据发送到某处,但如果很容易避免发送多次
网络请求,就不希望这样做。一种平衡方式如下:
const queuedToSend = [];
function sendData( data) {
queuedToSend. push( data);
if ( queuedToSend. length === 1 ) {
queueMicrotask(() => {
const stringToSend = JSON. stringify( queuedToSend);
queuedToSend. length = 0 ;
fetch( "/endpoint" , stringToSend);
});
}
} 采用这种架构,当前正在执行的同步 JavaScript 内对 sendData() 的多次后续调用
将被批处理为一次
fetch()
调用,同时不会有中间的事件循环任务抢占该获取操作(如果类似代码改用 setTimeout(),
则会发生这种情况)。
window.alert(message)
所有当前引擎均支持。
显示一个包含给定消息的模态警告,并等待用户将其 关闭。
result = window.confirm(message)
所有当前引擎均支持。
显示一个包含给定消息的模态“确定/取消”提示,等待用户关闭它; 如果用户单击“确定”,则返回 true,如果用户单击“取消”,则返回 false。
result = window.prompt(message [, default])
所有当前引擎均支持。
显示一个包含给定消息的模态文本控件提示,等待用户关闭 它,并返回用户输入的值。如果用户取消提示,则 改为返回 null。如果存在第二个参数,则使用给定值作为默认值。
调用这些方法时,依赖任务或微任务的逻辑(例如媒体元素 加载其媒体数据)会暂停。
alert() 和 alert(message) 方法
步骤
是:
如果调用该方法时没有参数,则令 message 为空 字符串;否则,令 message 为该方法的第一个 参数。
将 message 设置为给定 message 时规范化 换行符所得的结果。
将 message 设置为对 message 进行可选截断所得的结果。
令 userPromptHandler 为使用
this、“alert”和 message 执行WebDriver BiDi 用户提示已打开所得的结果。
如果 userPromptHandler 为“none”:
向用户显示 message,并将 U+000A LF 视为换行符。
可以选择在等待用户确认 消息时暂停。
使用 this、“alert”和 true 调用WebDriver BiDi 用户提示已关闭。
出于历史原因,此方法使用两个重载来定义,而不是使用
可选参数。其实际影响是:
alert(undefined) 被视为 alert("undefined"),但 alert() 被视为
alert("")。
confirm(message)
方法步骤是:
将 message 设置为给定 message 时规范化 换行符所得的结果。
将 message 设置为对 message 进行可选截断所得的结果。
向用户显示 message,将 U+000A LF 视为换行符,并要求用户 作出肯定或否定响应。
令 userPromptHandler 为使用
this、“confirm”和 message 执行WebDriver BiDi 用户提示已打开所得的结果。
令 accepted 为 false。
如果 userPromptHandler 为“none”:
暂停,直到用户作出肯定或 否定响应。
如果用户作出肯定响应,则将 accepted 设置为 true。
如果 userPromptHandler 为“accept”,则将
accepted 设置为 true。
使用 this、“confirm”和 accepted 调用WebDriver BiDi 用户提示已关闭。
返回 accepted。
prompt(message,
default) 方法步骤是:
将 message 设置为给定 message 时规范化 换行符所得的结果。
将 message 设置为对 message 进行可选截断所得的结果。
将 default 设置为对 default 进行可选截断所得的结果。
向用户显示 message,将 U+000A LF 视为换行符,并要求用户 使用字符串值响应或中止。响应必须以 default 给定的值作为默认值。
令 userPromptHandler 为使用
this、“prompt”和 message 执行WebDriver BiDi 用户提示已打开所得的结果。
令 result 为空。
如果 userPromptHandler 为“none”:
在等待用户响应时暂停。
如果用户没有中止,则将 result 设置为用户 响应的字符串。
否则,如果 userPromptHandler 为“accept”,则将
result 设置为空字符串。
使用 this、“prompt”、result 为空时的 false
或其他情况下的 true,以及 result 调用WebDriver BiDi 用户提示已关闭。
返回 result。
要可选地截断简单对话框字符串 s,返回 s 本身,或者从 s 派生出的某个更短字符串。用户代理不应 提供用于显示 s 被省略部分的 UI,因为这会使滥用者很容易 创建类似“重要安全警报!单击‘显示更多’以查看完整 详细信息!”的对话框。
例如,用户代理可能只想显示 消息的前 100 个字符。或者,用户代理可能用“…”替换字符串的中间部分。这类 修改有助于限制异常庞大且 看似可信的系统对话框所具有的滥用可能性。
当以下算法返回 true 时,我们无法显示简单对话框,
其中 Window 为 window:
所有当前引擎均支持。
window.print()提示用户打印页面。
print() 方法步骤
是:
令 document 为 this 的关联
Document。
如果 document 不是完全活动的,则 返回。
如果 document 的卸载计数器大于 0,则 返回。
如果 document 已准备好 执行加载后任务,则为 document 运行 打印步骤。
否则,设置 document 的加载后打印标志。
每当用户请求获得文档的实体形式(例如打印副本)或 实体形式的表示(例如 PDF 副本)时,用户代理也应当运行 打印步骤。
Document document 的打印步骤是:
用户代理可以向用户显示消息或返回(也可以两者都做)。
例如,信息亭浏览器可以静默忽略对
print() 方法的任何调用。
例如,移动设备上的浏览器可以检测到附近没有 打印机,并在继续提供“保存为 PDF”选项之前显示说明此情况的消息。
如果 document 的活动沙盒标志 集设置了沙盒化 模态标志,则返回。
如果打印对话框被 Document 的沙盒阻止,
则既不会触发 beforeprint 事件,也不会
触发 afterprint 事件。
用户代理必须在 document 的相关全局对象以及其中的所有子
可导航对象上触发一个名为 beforeprint 的事件。
此处仅在子对象中触发似乎并不正确,而且可能还需要将一些任务 排入队列。请参阅议题 #5096。
beforeprint
事件可用于
为打印副本添加注释,例如添加文档的打印时间。
用户代理应当为用户提供获得 document 的实体 形式(或实体形式的表示)的机会。用户代理可以 等待用户接受或拒绝后再返回;如果这样做,则用户代理在该方法等待期间必须 暂停。即使用户代理此时 不等待,它最终创建替代形式时,也必须使用相关文档在算法此处的状态。
用户代理必须在 document 的相关全局对象以及其中的所有子
可导航对象上触发一个名为 afterprint 的事件。
此处仅在子对象中触发似乎并不正确,而且可能还需要将一些任务 排入队列。请参阅议题 #5096。
afterprint
事件可用于
撤销先前事件中添加的注释,以及显示打印后 UI。例如,
如果某个页面正在引导用户完成申请住房贷款的各个步骤,则脚本
可以在打印表单或其他内容后自动前进到下一步。
Navigator 对象所有当前引擎均支持。
Navigator
的实例表示用户代理(客户端)的身份和状态。它也曾被用作放置各种 API 的通用全局对象,但这不应成为继续沿用的先例。应改用 WindowOrWorkerGlobalScope
混入或等效机制。
[Exposed =Window ]
interface Navigator {
// objects implementing this interface also implement the interfaces given below
};
Navigator includes NavigatorID ;
Navigator includes NavigatorLanguage ;
Navigator includes NavigatorOnLine ;
Navigator includes NavigatorContentUtils ;
Navigator includes NavigatorCookies ;
Navigator includes NavigatorPlugins ;
Navigator includes NavigatorConcurrentHardware ;这些接口混入是分别定义的,以便 WorkerNavigator 可以复用 Navigator 接口的部分内容。
每个 Window 都有一个关联的 Navigator,它是一个 Navigator
对象。创建 Window 对象时,必须将其关联的
Navigator
设置为一个在该 Window 对象的相关领域中创建的新
Navigator 对象。
所有当前引擎均支持。
navigator 和 clientInformation
的获取器步骤是返回
this 的关联
Navigator。
interface mixin NavigatorID {
readonly attribute DOMString appCodeName ; // constant "Mozilla"
readonly attribute DOMString appName ; // constant "Netscape"
readonly attribute DOMString appVersion ;
readonly attribute DOMString platform ;
readonly attribute DOMString product ; // constant "Gecko"
[Exposed =Window ] readonly attribute DOMString productSub ;
readonly attribute DOMString userAgent ;
[Exposed =Window ] readonly attribute DOMString vendor ;
[Exposed =Window ] readonly attribute DOMString vendorSub ; // constant ""
};在某些情况下,尽管整个行业都已尽最大努力,Web 浏览器仍存在错误和局限,迫使 Web 作者设法绕过它们。
本节定义了一组可由脚本用于确定当前所用用户代理种类的属性,以便绕过这些问题。
用户代理具有一个导航器兼容模式,其值为 Chrome、Gecko 或 WebKit。
导航器兼容模式会限制 NavigatorID
混入,使其只能采用已知与现有 Web 内容兼容的属性值组合,以及 taintEnabled()
和 oscpu 的存在情况。
客户端检测应始终仅限于检测已知的当前版本;对于未来版本和未知版本,应始终假定其完全符合规范。
self.navigator.appCodeName
返回字符串“Mozilla”。
self.navigator.appName
返回字符串“Netscape”。
self.navigator.appVersion
返回浏览器的版本。
self.navigator.platform
返回平台的名称。
self.navigator.product
返回字符串“Gecko”。
window.navigator.productSub
返回字符串“20030107”或字符串“20100101”。
self.navigator.userAgent
所有当前引擎均支持。
所有当前引擎均支持。
返回完整的 `User-Agent` 标头。
window.navigator.vendor
返回空字符串、字符串“Apple Computer, Inc.”
或字符串“Google Inc.”。
window.navigator.vendorSub
返回空字符串。
appCodeName 的获取器步骤是返回
“Mozilla”。
appName
的获取器步骤是返回“Netscape”。
appVersion 的获取器步骤如下:
令 userAgent 为 this 的相关设置对象的环境默认 `User-Agent` 值。
如果 userAgent 不以 `Mozilla/5.0 (` 开头,则返回空字符串。
令 trail 为 userAgent 中位于“Mozilla/”前缀之后的子字符串,并对其进行同构解码。
platform
的获取器步骤是返回一个表示浏览器正在其上执行的平台的字符串(例如“MacIntel”、“Win32”、
“Linux x86_64”、“Linux armv81”),或者出于隐私和兼容性考虑,返回一个通常由其他平台返回的字符串。
product
的获取器步骤是返回“Gecko”。
productSub
的获取器步骤是从以下列表中返回适当的字符串:
userAgent
的获取器步骤是返回 this 的相关设置对象的环境默认 `User-Agent` 值。
vendor
的获取器步骤是从以下列表中返回适当的字符串:
vendorSub
的获取器步骤是返回空字符串。
如果导航器兼容模式 为 Gecko,则用户代理还必须支持以下部分接口:
partial interface mixin NavigatorID {
[Exposed =Window ] boolean taintEnabled (); // constant false
[Exposed =Window ] readonly attribute DOMString oscpu ;
};taintEnabled() 方法必须返回 false。
oscpu
属性的获取器必须返回空字符串,或者一个表示浏览器正在其上执行的平台的字符串,例如“Windows NT 10.0; Win64; x64”、“Linux
x86_64”。
![]() 此 API 中任何因用户而异的信息都可用于对用户进行画像。事实上,如果能获取足够多的此类信息,甚至可以唯一识别某个用户。因此,强烈建议用户代理实现者在此 API 中包含尽可能少的信息。
此 API 中任何因用户而异的信息都可用于对用户进行画像。事实上,如果能获取足够多的此类信息,甚至可以唯一识别某个用户。因此,强烈建议用户代理实现者在此 API 中包含尽可能少的信息。
interface mixin NavigatorLanguage {
readonly attribute DOMString language ;
readonly attribute FrozenArray <DOMString > languages ;
};self.navigator.language
所有当前引擎均支持。
所有当前引擎均支持。
返回一个表示用户首选语言的语言标签。
self.navigator.languages
所有当前引擎均支持。
所有当前引擎均支持。
返回一个表示用户首选语言的语言标签数组,其中最优先的语言排在第一位。
最优先的语言就是 navigator.language
返回的语言。
当用户代理对用户首选语言的理解发生变化时,会在
Window 或 WorkerGlobalScope 对象上触发 languagechange 事件。
language 的获取器步骤如下:
languages 的获取器步骤如下:
在用户代理需要返回不同的值、采用不同的排列顺序或 emulatedLanguage 被更新之前,必须始终返回同一个对象。
每当用户代理需要让 navigator.languages
属性在 Window
或 WorkerGlobalScope
对象 global 上返回一组新的语言标签时,用户代理必须使用给定的 global,在 DOM 操作任务源上排入一个全局任务,以在 global 上触发一个名为 languagechange
的事件,并等到该任务开始执行后再实际返回新值。
为了确定一种合理的语言,用户代理应考虑以下几点:
en-US”;如果该服务的所有用户都使用相同的值,就能降低区分这些用户的可能性。
![]() 为避免引入更多指纹识别向量,用户代理应让本功能中定义的 API 与 HTTP `
为避免引入更多指纹识别向量,用户代理应让本功能中定义的 API 与 HTTP `Accept-Language`
标头使用相同的列表。
interface mixin NavigatorOnLine {
readonly attribute boolean onLine ;
};self.navigator.onLine
所有当前引擎均支持。
所有当前引擎均支持。
如果用户代理明确处于离线状态(与网络断开连接),则返回 false。 如果用户代理可能在线,则返回 true。
当 Window 或
WorkerGlobalScope
对象 global 的 navigator.onLine
属性将返回的值从 true 变为 false 时,用户代理必须使用给定的 global,在网络任务源上排入一个全局任务,以在 global 上触发一个名为 offline 的事件。
另一方面,当 Window 或
WorkerGlobalScope
对象 global 的 navigator.onLine
属性将返回的值从 false 变为 true 时,用户代理必须使用给定的 global,在网络任务源上排入一个全局任务,以在 Window 或 WorkerGlobalScope
对象上触发一个名为 online 的事件。
此属性本质上并不可靠。计算机可能已连接到网络,却无法访问互联网。
在此示例中,浏览器上线和离线时会更新一个指示器。
<!DOCTYPE HTML>
< html lang = "en" >
< head >
< title > Online status</ title >
< script >
function updateIndicator() {
document. getElementById( 'indicator' ). textContent = navigator. onLine ? 'online' : 'offline' ;
}
</ script >
</ head >
< body onload = "updateIndicator()" ononline = "updateIndicator()" onoffline = "updateIndicator()" >
< p > The network is: < span id = "indicator" > (state unknown)</ span >
</ body >
</ html > registerProtocolHandler()
方法Navigator/registerProtocolHandler
interface mixin NavigatorContentUtils {
[SecureContext ] undefined registerProtocolHandler (DOMString scheme , USVString url );
[SecureContext ] undefined unregisterProtocolHandler (DOMString scheme , USVString url );
};window.navigator.registerProtocolHandler(scheme, url)
在 url 注册一个用于处理 scheme 的处理程序。例如,在线电话消息服务可以将自身注册为 sms:
方案的处理程序,以便用户单击此类链接时,有机会使用该网站。[SMS]
url 中的字符串“%s”用作占位符,指示应在何处放置待处理内容的 URL。
如果用户代理阻止注册(例如,在尝试注册为“http”的处理程序时可能发生这种情况),则抛出 “SecurityError” DOMException。
如果 url 中缺少字符串“%s”,则抛出 “SyntaxError” DOMException。
window.navigator.unregisterProtocolHandler(scheme, url)
Navigator/unregisterProtocolHandler
仅一个引擎支持。
注销由参数指定的处理程序。
如果用户代理阻止注销(例如,当方案无效时可能发生这种情况),则抛出 “SecurityError” DOMException。
如果 url 中缺少字符串“%s”,则抛出 “SyntaxError” DOMException。
registerProtocolHandler(scheme,
url) 方法的步骤如下:
令(normalizedScheme、normalizedURLString)为使用 scheme、url 和 this 的相关设置对象运行规范化协议处理程序参数所得的结果。
并行地:为 normalizedScheme 和 normalizedURLString 注册协议处理程序。在所述约束范围内,用户代理可以自行决定如何处理。例如,用户代理可以提示用户,让用户选择将该网站添加到处理程序候选列表、将其设为默认处理程序或取消请求。用户代理也可以静默收集这些信息,仅在与用户相关时提供这些信息。
用户代理应记录哪些网站注册过处理程序(即使用户拒绝了这类注册),从而避免反复使用同一请求提示用户。
如果 this
的相关全局对象的关联 Document 的
registerProtocolHandler()
自动化模式不是“none”,则用户代理应先验证其处于自动化上下文中(参见 WebDriver 的安全注意事项)。然后,用户代理应跳过上述信息传达和用户同意收集过程,并根据
registerProtocolHandler()
自动化模式的值执行以下操作:
autoAccept”如同用户已查看注册详情并接受请求一样操作。
autoReject”如同用户已查看注册详情并拒绝请求一样操作。
当用户代理使用此处理程序处理 URL inputURL 时:
使用 inputURL 和空字符串设置用户名。
使用 inputURL 和空字符串设置密码。
令 inputURLString 为 inputURL 的序列化结果。
令 encodedURL 为使用组件百分号编码集对 inputURLString 运行 UTF-8 百分号编码所得的结果。
令 handlerURLString 为 normalizedURLString。
将 handlerURLString 中首次出现的“%s”替换为 encodedURL。
令 resultURL 为解析 handlerURLString 所得的结果。
如果用户访问了位于 https://example.com/ 的网站,并且该网站进行了以下调用:
navigator. registerProtocolHandler( 'web+soup' , 'soup?url=%s' ) ……而后在很久以后,用户访问 https://www.example.net/ 时单击了如下链接:
< a href = "web+soup:chicken-kïwi" > Download our Chicken Kïwi soup!</ a > ……那么用户代理可能会导航到以下 URL:
https://example.com/soup?url=web+soup:chicken-k%C3%AFwi
随后,该网站可以对汤执行它所要执行的任何操作(例如合成汤并将其寄给用户,诸如此类)。
这里没有定义何时使用处理程序。在一定程度上,跨文档导航的处理模型定义了一些与其相关的情况;但一般而言,用户代理可以在原本会考虑将方案交由原生插件或辅助应用程序处理的任何场合使用这些信息。
unregisterProtocolHandler(scheme,
url) 方法的步骤如下:
令(normalizedScheme、normalizedURLString)为使用 scheme、url 和 this 的相关设置对象运行规范化协议处理程序参数所得的结果。
并行地:注销由 normalizedScheme 和 normalizedURLString 描述的处理程序。
要规范化协议处理程序参数,给定字符串 scheme、字符串 url 和环境设置对象 environment,运行以下步骤:
将 scheme 设置为转换成 ASCII 小写形式后的 scheme。
如果 scheme 既不是安全列出的方案,也不是以“web+”开头、后跟一个或多个 ASCII
小写字母的字符串,则抛出 “SecurityError”
DOMException。
这意味着,在 scheme 中包含冒号(如“mailto:”)将导致抛出异常。
以下方案是安全列出的方案:
bitcoinftpftpsgeoimircircsmagnetmailtomatrixmmsnewsnntpopenpgp4fprsftpsipsmssmstosshtelurnwebcalwtaixmpp此列表可以更改。如果有应添加的方案,请发送反馈。
如果 url 不包含“%s”,则抛出
“SyntaxError” DOMException。
令 urlRecord 为以 environment 为基准、使用给定的 url编码并解析 URL 所得的结果。
如果 urlRecord 为失败,则抛出 “SyntaxError”
DOMException。
如果 %s 占位符位于 URL 的主机或端口中,则必然如此。
如果 urlRecord 的方案不是
HTTP(S) 方案,或者 urlRecord 的源与
environment 的源不同源,则抛出
“SecurityError” DOMException。
断言:使用给定的
urlRecord 运行URL
是否潜在可信?所得的结果为“Potentially Trustworthy”。
由于规范化协议处理程序参数是在安全上下文中运行的,因此同源条件已隐含保证了这一点。
返回(scheme、urlRecord)。
根据定义,urlRecord 的序列化结果不是有效 URL 字符串,因为其中包含字符串“%s”,而它不是 URL 中的有效组成部分。
自定义方案处理程序可能引发许多问题,尤其是隐私问题。
劫持所有 Web 使用行为。用户代理不应允许将对其正常运行至关重要的方案(例如 HTTP(S) 方案)重定向到第三方网站。这会导致用户的活动很容易被跟踪,并使用户信息(甚至安全连接中的用户信息)被收集。
劫持默认设置。强烈建议用户代理不要自动更改任何默认设置,因为这可能导致用户将数据发送给其未预料到的远程主机。新处理程序进行自我注册时,绝不应自动导致这些网站被使用。
注册垃圾信息。用户代理应考虑网站可能尝试注册大量处理程序的情况,这些处理程序可能来自多个域(例如,通过一系列页面进行重定向,每个页面位于不同的域,并且每个页面都为
web+spam: 注册处理程序——色情网站多年来一直采用类似做法滥用其他 Web 浏览器功能)。用户代理应妥善处理此类恶意尝试并保护用户。
恶意处理程序元数据。用户代理应防范针对嵌入其界面的字符串所实施的典型攻击,例如确保此类字符串中的标记或转义字符不会被执行、正确处理空字节、过长的字符串不会导致崩溃或缓冲区溢出等。
泄露私有数据。Web 页面作者可能使用被视为私有的 URL 数据引用自定义方案处理程序。他们这样做时可能预期用户选择的处理程序指向组织内部的页面,从而确保敏感数据不会泄露给第三方。但是,用户可能注册了一个指向外部网站的处理程序,导致数据泄露给该第三方。实现者可以考虑允许管理员在某些子域、内容类型或方案上禁用自定义处理程序。
干扰界面。用户代理应准备好处理有意传给这些方法的超长参数。例如,如果公开的用户界面由“接受”按钮和“拒绝”按钮组成,而“接受”绑定中包含处理程序的名称,就必须确保过长的名称不会将“拒绝”按钮挤出屏幕。
每个 Document 都有一个 registerProtocolHandler() 自动化模式。其默认值为“none”,但也可以是“autoAccept”
或“autoReject”。
为了实现用户代理自动化和网站测试,本标准定义了 设置 RPH 注册模式 WebDriver 扩展命令。它指示用户代理将一个 Document 置于自动模拟用户接受或拒绝注册确认提示对话框的模式。
| HTTP 方法 | URI 模板 |
|---|---|
`POST`
|
/session/{session id}/custom-handlers/set-mode
|
远端步骤如下:
如果 parameters 不是 JSON 对象,则返回一个 WebDriver 错误,其 WebDriver 错误码为 无效参数。
令 mode 为从 parameters 中获取名为“mode”的属性所得的结果。
如果 mode 不是“autoAccept”、
“autoReject”
或“none”,则返回一个
WebDriver 错误,其
WebDriver 错误码为 无效参数。
将 document 的 registerProtocolHandler()
自动化模式设置为 mode。
返回数据为 null 的成功。
interface mixin NavigatorCookies {
readonly attribute boolean cookieEnabled ;
};window.navigator.cookieEnabled
所有当前引擎均支持。
如果设置 Cookie 的操作会被忽略,则返回 false;否则返回 true。
如果用户代理尝试按照HTTP 状态管理机制处理 Cookie,则 cookieEnabled 属性必须返回 true;如果用户代理忽略
Cookie 更改请求,则返回 false。[COOKIES]
window.navigator.pdfViewerEnabled
如果用户代理在导航到 PDF 文件时支持内联查看,则返回 true;否则返回 false。在后一种情况下,PDF 文件将交由外部软件处理。
interface mixin NavigatorPlugins {
[SameObject ] readonly attribute PluginArray plugins ;
[SameObject ] readonly attribute MimeTypeArray mimeTypes ;
boolean javaEnabled ();
readonly attribute boolean pdfViewerEnabled ;
};
[Exposed =Window ,
LegacyUnenumerableNamedProperties ]
interface PluginArray {
undefined refresh ();
readonly attribute unsigned long length ;
getter Plugin ? item (unsigned long index );
getter Plugin ? namedItem (DOMString name );
};
[Exposed =Window ,
LegacyUnenumerableNamedProperties ]
interface MimeTypeArray {
readonly attribute unsigned long length ;
getter MimeType ? item (unsigned long index );
getter MimeType ? namedItem (DOMString name );
};
[Exposed =Window ,
LegacyUnenumerableNamedProperties ]
interface Plugin {
readonly attribute DOMString name ;
readonly attribute DOMString description ;
readonly attribute DOMString filename ;
readonly attribute unsigned long length ;
getter MimeType ? item (unsigned long index );
getter MimeType ? namedItem (DOMString name );
};
[Exposed =Window ]
interface MimeType {
readonly attribute DOMString type ;
readonly attribute DOMString description ;
readonly attribute DOMString suffixes ;
readonly attribute Plugin enabledPlugin ;
};虽然如今可以通过 navigator.pdfViewerEnabled
检测 PDF 查看器支持,但由于历史原因,仍存在许多复杂且相互关联、可提供相同功能的接口,旧版代码依赖于这些接口。本节同时规定简单的现代变体和复杂的历史变体。
![]() 每个用户代理都有一个 支持 PDF 查看器布尔值,其值由实现定义(并且可能根据用户偏好而变化)。
每个用户代理都有一个 支持 PDF 查看器布尔值,其值由实现定义(并且可能根据用户偏好而变化)。
此值还会影响导航处理模型。
每个 Window 对象都有一个 PDF 查看器插件对象列表。如果用户代理的支持 PDF 查看器为 false,则该列表为空。否则,该列表包含五个 Plugin 对象,其名称依次为:
PDF Viewer”Chrome PDF Viewer”Chromium PDF Viewer”Microsoft Edge PDF Viewer”WebKit built-in PDF”上述列表中的值构成 PDF 查看器插件名称列表。
这些名称是根据网站以往所搜索内容的证据选定的,因而也是用户代理为保持与现有内容的兼容性而必须公开的名称。它们按字母顺序排列。随后将“PDF Viewer”名称插入第 0
个位置,以便 enabledPlugin
获取器能够指向通用的插件名称。
每个 Window 对象都有一个 PDF 查看器 MIME 类型对象列表。如果用户代理的支持 PDF 查看器为 false,则该列表为空。否则,该列表包含两个 MimeType 对象,其类型依次为:
application/pdf”text/pdf”上述列表中的值构成 PDF 查看器 MIME 类型列表。
每个 NavigatorPlugins
对象都有一个插件数组,它是一个新的
PluginArray;还有一个 MIME 类型数组,它是一个新的
MimeTypeArray。
NavigatorPlugins
混入的 plugins 获取器步骤是返回 this 的插件数组。
NavigatorPlugins
混入的 mimeTypes 获取器步骤是返回
this 的MIME 类型数组。
NavigatorPlugins
混入的 javaEnabled() 方法步骤是返回 false。
所有当前引擎均支持。
NavigatorPlugins
混入的 pdfViewerEnabled 获取器步骤是返回用户代理的支持 PDF 查看器值。
PluginArray 接口支持具名属性。如果用户代理的支持 PDF 查看器为 true,则这些属性为 PDF 查看器插件名称。否则,它们为空列表。
PluginArray 接口的 namedItem(name) 方法步骤如下:
PluginArray 接口的 item(index) 方法步骤如下:
令 plugins 为 this 的相关全局对象的PDF 查看器插件对象。
如果 index < plugins 的大小,则返回 plugins[index]。
返回 null。
PluginArray 接口的 length
获取器步骤是返回 this 的相关全局对象的PDF 查看器插件对象的大小。
PluginArray 接口的 refresh()
方法步骤是什么也不做。
MimeTypeArray 接口支持具名属性。如果用户代理的支持 PDF 查看器为 true,则这些属性为 PDF 查看器 MIME 类型。否则,它们为空列表。
MimeTypeArray 接口的
namedItem(name) 方法步骤如下:
MimeTypeArray 接口的
item(index) 方法步骤如下:
令 mimeTypes 为 this 的相关全局对象的PDF 查看器 MIME 类型对象。
如果 index < mimeTypes 的大小,则返回 mimeTypes[index]。
返回 null。
MimeTypeArray 接口的
length 获取器步骤是返回
this
的相关全局对象的PDF 查看器 MIME
类型对象的大小。
每个 Plugin 对象都有一个名称,它在创建对象时设置。
Plugin 接口的 description
获取器步骤是返回“Portable Document Format”。
Plugin 接口的 filename
获取器步骤是返回“internal-pdf-viewer”。
Plugin 接口支持具名属性。如果用户代理的支持 PDF 查看器为 true,则这些属性为 PDF 查看器 MIME 类型。否则,它们为空列表。
Plugin 接口的 namedItem(name) 方法步骤如下:
Plugin 接口的 item(index)
方法步骤如下:
令 mimeTypes 为 this 的相关全局对象的PDF 查看器 MIME 类型对象。
如果 index < mimeTypes 的大小,则返回 mimeTypes[index]。
返回 null。
Plugin 接口的 length 获取器步骤是返回
this
的相关全局对象的PDF 查看器 MIME
类型对象的大小。
每个 MimeType 对象都有一个类型,它在创建对象时设置。
MimeType 接口的 description
获取器步骤是返回“Portable Document Format”。
MimeType 接口的 suffixes
获取器步骤是返回“pdf”。
MimeType 接口的 enabledPlugin 获取器步骤是返回
this
的相关全局对象的PDF
查看器插件对象[0](即通用的“PDF Viewer”对象)。
ImageData 接口所有当前引擎均支持。
typedef (Uint8ClampedArray or Float16Array ) ImageDataArray ;
enum ImageDataPixelFormat { " rgba-unorm8 " , " rgba-float16 " };
dictionary ImageDataSettings {
PredefinedColorSpace colorSpace ;
ImageDataPixelFormat pixelFormat = "rgba-unorm8";
};
[Exposed =(Window ,Worker ),
Serializable ]
interface ImageData {
constructor (unsigned long sw , unsigned long sh , optional ImageDataSettings settings = {});
constructor (ImageDataArray data , unsigned long sw , optional unsigned long sh , optional ImageDataSettings settings = {});
readonly attribute unsigned long width ;
readonly attribute unsigned long height ;
readonly attribute ImageDataArray data ;
readonly attribute ImageDataPixelFormat pixelFormat ;
readonly attribute PredefinedColorSpace colorSpace ;
};
ImageData 对象表示一个矩形位图,其宽度等于
width 属性,高度等于 height
属性。此位图的像素值存储在
data 属性中,按照从左到右、从上到下逐行排列,并从左上角像素的 0 开始;每个像素的颜色分量顺序和数值表示形式由 pixelFormat
属性确定。
位图像素值的颜色空间由 colorSpace
属性确定。
imageData = new ImageData(sw, sh [, settings])
所有当前引擎均支持。
返回一个具有给定尺寸和由 settings 指定的颜色空间的 ImageData 对象。返回对象中的所有像素都是透明黑色。
如果宽度或高度参数中的任意一个为零,则抛出 “IndexSizeError” DOMException。
imageData = new ImageData(data, sw [, sh [, settings ] ])
返回一个使用 ImageDataArray
参数中提供的数据,并按照给定尺寸和由 settings 指定的颜色空间进行解释的 ImageData 对象。
数据的字节长度必须是每像素字节数与给定宽度乘积的倍数。如果还提供了高度,则该长度必须恰好等于每像素字节数、宽度和高度三者的乘积。
如果无法以一致的方式解释给定的数据和尺寸,或者任一尺寸为零,则抛出 “IndexSizeError” DOMException。
imageData.width
所有当前引擎均支持。
imageData.height
所有当前引擎均支持。
返回 ImageData 对象中数据的实际尺寸,以像素为单位。
imageData.data
所有当前引擎均支持。
返回一个按 RGBA 顺序包含数据的一维数组,其整数值范围为 0 到 255。
imageData.colorSpace
返回像素的颜色空间。
new ImageData(sw,
sh, settings) 构造函数的步骤如下:
如果 sw 和 sh 中的一个或两个为零,则抛出
“IndexSizeError” DOMException。
new
ImageData(data, sw, sh, settings)
构造函数的步骤如下:
如果
settings[“pixelFormat”]
为“rgba-unorm8”,则令
bytesPerPixel 为 4;否则为 8。
令 length 为 data 的缓冲区源字节长度。
如果 length 不是 bytesPerPixel 的非零整数倍,则抛出
“InvalidStateError” DOMException。
令 length 为 length 除以 bytesPerPixel。
如果 length 不是 sw 的整数倍,则抛出
“IndexSizeError” DOMException。
在此步骤中,长度保证大于零(否则上述第二步已经中止这些步骤);因此,如果 sw 为零,此步骤将抛出异常并返回。
令 height 为 length 除以 sw。
如果提供了 sh,并且其值不等于 height,则抛出
“IndexSizeError” DOMException。
使用给定的 sw、sh、settings,以及设置为 data 的 source,初始化 this。
此步骤不会将 this 的数据设置为
data 的副本。
它会将数据设置为作为 data 传入的实际 ImageDataArray 对象。
要初始化 ImageData 对象
imageData,给定每行像素数的正整数 pixelsPerRow、行数的正整数
rows、一个 ImageDataSettings
settings、一个可选的
ImageDataArray source
和一个可选的 PredefinedColorSpace
defaultColorSpace:
如果提供了 source:
如果 settings[“pixelFormat”]
等于“rgba-unorm8”,并且
source 不是 Uint8ClampedArray,则抛出
“InvalidStateError” DOMException。
如果 settings[“pixelFormat”]
为“rgba-float16”,并且
source 不是 Float16Array,则抛出
“InvalidStateError” DOMException。
将 imageData 的 data 属性初始化为
source。
否则(未提供 source):
如果 settings[“pixelFormat”]
为“rgba-unorm8”,则将
imageData 的 data
属性初始化为新的 Uint8ClampedArray
对象。该 Uint8ClampedArray
对象必须使用新的
ArrayBuffer
作为其存储,并且其字节偏移量必须为零,字节长度必须等于其存储的字节长度。
用于存储的 ArrayBuffer
的长度必须为 4 × rows × pixelsPerRow 字节。
否则,如果 settings[“pixelFormat”]
为“rgba-float16”,则将
imageData 的 data
属性初始化为新的 Float16Array
对象。该 Float16Array
对象必须使用新的
ArrayBuffer
作为其存储,并且其字节偏移量必须为零,字节长度必须等于其存储的字节长度。
用于存储的 ArrayBuffer
的长度必须为 8 × rows × pixelsPerRow 字节。
如果无法分配用于存储的 ArrayBuffer,则重新抛出由
JavaScript 抛出的 RangeError,然后返回。
将 imageData 的 width 属性初始化为
pixelsPerRow。
将 imageData 的 height 属性初始化为
rows。
将
imageData 的 pixelFormat
属性初始化为
settings[“pixelFormat”]。
如果 settings[“colorSpace”]
存在,则将 imageData 的 colorSpace 属性初始化为
settings[“colorSpace”]。
否则,如果提供了 defaultColorSpace,则将 imageData 的 colorSpace
属性初始化为
defaultColorSpace。
否则,将 imageData 的 colorSpace
属性初始化为“srgb”。
ImageData 对象是可序列化对象。给定 value 和
serialized,它们的序列化步骤如下:
将 serialized.[[Width]] 设置为 value 的 width
属性值。
将 serialized.[[Height]] 设置为 value 的 height
属性值。
将 serialized.[[ColorSpace]] 设置为 value 的 colorSpace
属性值。
将 serialized.[[PixelFormat]] 设置为 value 的 pixelFormat
属性值。
给定 serialized、value 和 targetRealm,它们的反序列化步骤如下:
将 value 的 width 属性初始化为
serialized.[[Width]]。
将 value 的 height
属性初始化为 serialized.[[Height]]。
将 value 的 colorSpace
属性初始化为 serialized.[[ColorSpace]]。
将 value 的 pixelFormat
属性初始化为 serialized.[[PixelFormat]]。
ImageDataPixelFormat
枚举用于指定 ImageData
的 data
属性的类型,以及每个像素的颜色分量排列方式和数值表示形式。
“rgba-unorm8”值表示
ImageData 的
data 属性必须是 Uint8ClampedArray 类型。每个像素的颜色分量必须依次以红色、绿色、蓝色、Alpha
的顺序存储在四个连续元素中。每个元素表示该分量的 8 位无符号归一化值。
“rgba-float16”值表示
ImageData 的
data 属性必须是 Float16Array 类型。每个像素的颜色分量必须依次以红色、绿色、蓝色、Alpha 的顺序存储在四个连续元素中。每个元素表示该分量的值。
ImageBitmap 接口所有当前引擎均支持。
[Exposed =(Window ,Worker ), Serializable , Transferable ]
interface ImageBitmap {
readonly attribute unsigned long width ;
readonly attribute unsigned long height ;
undefined close ();
};
typedef (CanvasImageSource or
Blob or
ImageData ) ImageBitmapSource ;
enum ImageOrientation { " from-image " , " flipY " };
enum PremultiplyAlpha { " none " , " premultiply " , " default " };
enum ColorSpaceConversion { " none " , " default " };
enum ResizeQuality { " pixelated " , " low " , " medium " , " high " };
dictionary ImageBitmapOptions {
ImageOrientation imageOrientation = "from-image";
PremultiplyAlpha premultiplyAlpha = "default";
ColorSpaceConversion colorSpaceConversion = "default";
[EnforceRange ] unsigned long resizeWidth ;
[EnforceRange ] unsigned long resizeHeight ;
ResizeQuality resizeQuality = "low";
};ImageBitmap
对象表示一种能够在不会产生过度延迟的情况下绘制到画布上的位图图像。
何种程度的延迟属于过度延迟,由实现者自行准确判断;但一般而言,如果使用位图需要进行网络 I/O,甚至本地磁盘 I/O,那么延迟可能就是过度的;而如果只需要从 GPU 或系统 RAM 中进行阻塞式读取,那么该延迟可能是可以接受的。
promise = self.createImageBitmap(image [, options ])
所有当前引擎均支持。
promise = self.createImageBitmap(image, sx, sy, sw, sh [, options ])
接受 image,它可以是 img 元素、SVG
image 元素、video 元素、canvas 元素、
Blob
对象、ImageData 对象或另一个
ImageBitmap 对象,并返回一个将在创建新的
ImageBitmap 时兑现的 Promise。
如果无法构造 ImageBitmap
对象,例如提供的
image 数据实际上并不是图像,则会改为拒绝该 Promise。
如果提供了 sx、sy、sw 和 sh 参数,则源图像会被裁剪到给定像素,原图中缺失的任何像素均替换为透明黑色。这些坐标位于源图像的像素坐标空间中,而不是以 CSS 像素表示。
如果提供了 options,则会根据 options 修改 ImageBitmap 对象的位图数据。例如,如果将
premultiplyAlpha
选项设置为“premultiply”,则位图数据的非 Alpha 颜色分量会预乘 Alpha
分量。
如果源图像未处于有效状态(例如,img
元素未成功加载、ImageBitmap 对象的
[[Detached]] 内部槽值为 true、ImageData 对象的
data 属性值的
[[ViewedArrayBuffer]] 内部槽已分离,或者 Blob
的数据无法解释为位图图像),则使用 “InvalidStateError”
DOMException
拒绝该 Promise。
imageBitmap.close()
所有当前引擎均支持。
释放 imageBitmap 的底层位图数据。
imageBitmap.width
所有当前引擎均支持。
imageBitmap.height
所有当前引擎均支持。
[[Detached]] 内部槽值为 false 的 ImageBitmap 对象始终关联有包含宽度和高度的位图数据。但是,这些数据可能已损坏。如果 ImageBitmap
对象的媒体数据能够在不发生错误的情况下解码,则称其为完全可解码。
ImageBitmap 对象的位图具有源干净标志,用于指示该位图是否受到来自不同源的内容污染。该标志最初设置为 true,并且可能由 createImageBitmap()
的步骤更改为 false。
ImageBitmap 对象是可序列化对象和可传输对象。
给定 value 和 serialized,它们的序列化步骤如下:
如果未设置 value 的源干净标志,则抛出 “DataCloneError”
DOMException。
将 serialized.[[BitmapData]] 设置为 value 的位图数据的副本。
给定 value 和 dataHolder,它们的传输步骤如下:
如果未设置 value 的源干净标志,则抛出 “DataCloneError”
DOMException。
将 dataHolder.[[BitmapData]] 设置为 value 的位图数据。
取消设置 value 的位图数据。
createImageBitmap 方法使用位图任务源来敲定其返回的 Promise。
调用 createImageBitmap(image,
options) 和 createImageBitmap(image,
sx, sy, sw, sh, options) 方法时,必须运行以下步骤:
如果给出了 sw 或 sh,且其值为 0,则返回一个
因以下原因
被拒绝的 promise:一个 RangeError。
如果存在 options 的 resizeWidth 或
options 的
resizeHeight,并且其值为 0,则返回一个以 “InvalidStateError”
DOMException
拒绝的 Promise。
检查 image
参数的可用性。如果此操作抛出异常或返回不良,则返回一个以
“InvalidStateError” DOMException
拒绝的 Promise。
令 promise 为一个新的 Promise。
令 imageBitmap 为一个新的 ImageBitmap 对象。
根据 image 进行分支:
img
image
如果 image 的媒体数据没有自然尺寸(例如,它是未指定内容大小的矢量图形),并且 options 的 resizeWidth
或 options 的 resizeHeight
不存在,则返回一个以 “InvalidStateError”
DOMException
拒绝的 Promise。
如果 image 的媒体数据没有自然尺寸(例如,它是未指定内容大小的矢量图形),则应将其渲染为由 resizeWidth
和 resizeHeight
选项指定尺寸的位图。
将 imageBitmap 的位图数据设置为 image 的媒体数据的副本,并按照格式裁剪到源矩形。如果这是动画图像,则 imageBitmap 的位图数据必须仅取自动画的默认图像(即格式规定在不支持或禁用动画时使用的图像);如果没有此类图像,则取自动画的第一帧。
video
如果 image 的 networkState
属性为 NETWORK_EMPTY,则返回一个以 “InvalidStateError”
DOMException
拒绝的 Promise。
将 imageBitmap 的位图数据设置为当前播放位置处帧的副本,其尺寸为媒体资源的自然宽度和自然高度(即应用任何宽高比校正之后),并按照格式裁剪到源矩形。
canvas
Blob
并行运行以下步骤:
令 imageData 为读取 image 数据所得的结果。如果读取对象时发生错误,则使用位图任务源排入一个全局任务,以使用 “InvalidStateError” DOMException
拒绝 promise,并中止这些步骤。
应用图像嗅探规则来确定 imageData 的文件格式,其中以
image 的 MIME 类型(由 image 的 type
属性给出)作为官方类型。
如果 imageData 不是受支持的图像文件格式(例如,它根本不是图像),或者 imageData
以某种致命方式损坏,导致无法获得图像尺寸(例如,没有自然大小的矢量图形),则使用位图任务源排入一个全局任务,以使用 “InvalidStateError” DOMException
拒绝 promise,并中止这些步骤。
将 imageBitmap 的位图数据设置为 imageData,并按照格式裁剪到源矩形。如果这是动画图像,则 imageBitmap 的位图数据必须仅取自动画的默认图像(即格式规定在不支持或禁用动画时使用的图像);如果没有此类图像,则取自动画的第一帧。
ImageData
令 buffer 为 image 的 data
属性值的 [[ViewedArrayBuffer]] 内部槽。
如果 IsDetachedBuffer(buffer) 为 true,则返回一个以 “InvalidStateError”
DOMException
拒绝的 Promise。
将 imageBitmap 的位图数据设置为 image 的图像数据,并按照格式裁剪到源矩形。
ImageBitmap
VideoFrame
将 imageBitmap 的位图数据设置为 image 的可见像素数据的副本,并按照格式裁剪到源矩形。
返回 promise。
当上述步骤要求用户代理按照格式将位图数据裁剪到源矩形时,用户代理必须运行以下步骤:
令 input 为正在变换的位图数据。
如果指定了 sx、sy、sw 和 sh,则令 sourceRectangle 为一个矩形,其四个角点为(sx、 sy)、(sx+sw、sy)、(sx+sw、 sy+sh)和(sx、sy+sh)。否则,令 sourceRectangle 为一个矩形,其四个角点为(0、0)、(input 的宽度、0)、(input 的宽度、input 的高度)和(0、input 的高度)。
如果 sw 或 sh 为负数,则此矩形的左上角将位于(sx、sy)点的左侧或上方。
按以下方式确定 outputWidth:
resizeWidth
成员
resizeWidth
成员的值resizeWidth
成员,但指定了 resizeHeight
成员
resizeHeight
成员的值,再除以 sourceRectangle 的高度,并向上舍入到最接近的整数resizeWidth
也未指定 resizeHeight
按以下方式确定 outputHeight:
resizeHeight
成员
resizeHeight
成员的值resizeHeight
成员,但指定了 resizeWidth
成员
resizeWidth
成员的值,再除以 sourceRectangle 的宽度,并向上舍入到最接近的整数resizeWidth
也未指定 resizeHeight
将 input 放置在一个无限的透明黑色网格平面上,使其左上角位于平面的原点,x 坐标向右递增,y 坐标向下递增,并使 input 图像数据中的每个像素占据该平面网格上的一个单元格。
令 output 为平面上由 sourceRectangle 表示的矩形。
将 output 缩放到由 outputWidth 和
outputHeight 指定的尺寸。用户代理应使用 resizeQuality
选项的值来指导缩放算法的选择。
如果 options 的 imageOrientation 成员值为“flipY”,则必须垂直翻转
output,并忽略源中可能存在的任何图像方向元数据(例如 EXIF 元数据)。[EXIF]
如果值为“from-image”,则不需要额外步骤。
过去曾有一个“none”枚举值。它已重命名为“from-image”。将来,“none”
将以不同的含义重新添加。
如果 image 是 img 元素或
Blob
对象,则令
val 为 options 的 colorSpaceConversion 成员的值,然后运行以下子步骤:
如果 val 为“default”,则颜色空间转换行为由具体实现决定,并且应根据实现用于将图像绘制到画布上的默认颜色空间进行选择。
如果 val 为“none”,则必须在不执行任何颜色空间转换的情况下解码
output。这意味着图像解码算法必须忽略嵌入源数据中的颜色配置文件元数据以及显示设备的颜色配置文件。
令 val 为 options 的 premultiplyAlpha 成员的值,然后运行以下子步骤:
返回 output。
close()
方法的步骤如下:
将 this 的 [[Detached]] 内部槽值设置为 true。
width
获取器步骤如下:
如果 this 的 [[Detached]] 内部槽值为 true,则返回 0。
height
获取器步骤如下:
如果 this 的 [[Detached]] 内部槽值为 true,则返回 0。
ResizeQuality
枚举用于表示缩放图像时要使用的插值质量偏好。
“pixelated”值表示倾向于在缩放图像时尽可能保留原图的像素化效果,同时在目标尺寸不是原始尺寸的整倍数时,根据需要进行少量平滑处理,以避免图像失真。
要实现“pixelated”,应分别针对每个轴,首先确定其自然尺寸的一个大于零的整数倍,使其最接近目标尺寸。使用最近邻算法将其缩放到这一整数倍尺寸,然后使用双线性插值将其继续缩放到目标尺寸。
“low”
值表示倾向于使用低级别的图像插值质量。低质量图像插值在计算上可能比更高的设置更高效。
“medium”值表示倾向于使用中等级别的图像插值质量。
“high”值表示倾向于使用高级别的图像插值质量。高质量图像插值在计算上的开销可能高于较低的设置。
双线性缩放是一种相对快速、质量较低的图像平滑算法。双三次缩放或 Lanczos 缩放是能够生成较高质量输出的图像缩放算法示例。除上述“pixelated”外,本规范不强制要求使用特定的插值算法。
使用此 API,可以预先裁切和准备精灵图:
var sprites = {};
function loadMySprites() {
var image = new Image();
image. src = 'mysprites.png' ;
var resolver;
var promise = new Promise( function ( arg) { resolver = arg });
image. onload = function () {
resolver( Promise. all([
createImageBitmap( image, 0 , 0 , 40 , 40 ). then( function ( image) { sprites. person = image }),
createImageBitmap( image, 40 , 0 , 40 , 40 ). then( function ( image) { sprites. grass = image }),
createImageBitmap( image, 80 , 0 , 40 , 40 ). then( function ( image) { sprites. tree = image }),
createImageBitmap( image, 0 , 40 , 40 , 40 ). then( function ( image) { sprites. hut = image }),
createImageBitmap( image, 40 , 40 , 40 , 40 ). then( function ( image) { sprites. apple = image }),
createImageBitmap( image, 80 , 40 , 40 , 40 ). then( function ( image) { sprites. snake = image })
]));
};
return promise;
}
function runDemo() {
var canvas = document. querySelector( 'canvas#demo' );
var context = canvas. getContext( '2d' );
context. drawImage( sprites. tree, 30 , 10 );
context. drawImage( sprites. snake, 70 , 10 );
}
loadMySprites(). then( runDemo); 某些对象包含 AnimationFrameProvider
接口混入。
callback FrameRequestCallback = undefined (DOMHighResTimeStamp time );
interface mixin AnimationFrameProvider {
unsigned long requestAnimationFrame (FrameRequestCallback callback );
undefined cancelAnimationFrame (unsigned long handle );
};
Window includes AnimationFrameProvider ;
DedicatedWorkerGlobalScope includes AnimationFrameProvider ;每个 AnimationFrameProvider
对象还有一个用于存储提供者内部状态的目标对象。其定义如下:
每个目标对象都有一个动画帧回调映射,它是一个最初必须为空的有序映射;还有一个动画帧回调标识符,它是一个初始值必须为零的数字。
如果满足以下任一条件,则认为 AnimationFrameProvider
provider 是受支持的:
所有当前引擎均支持。
requestAnimationFrame(callback)
方法的步骤如下:
如果 this
不是受支持的,则抛出
“NotSupportedError” DOMException。
将 target 的动画帧回调标识符递增一,并令 handle 为所得结果。
令 callbacks 为 target 的动画帧回调映射。
将 callbacks[handle] 设置为 callback。
返回 handle。
所有当前引擎均支持。
cancelAnimationFrame(handle)
方法的步骤如下:
如果 this 不是受支持的,则抛出
“NotSupportedError” DOMException。
移除 callbacks[handle]。
要为带有时间戳 now 的目标对象 target 运行动画帧回调:
在 Worker 中,requestAnimationFrame()
可以与从 canvas
元素传输而来的 OffscreenCanvas
配合使用。首先,在文档中将控制权传输给 Worker:
const offscreenCanvas = document. getElementById( "c" ). transferControlToOffscreen();
worker. postMessage( offscreenCanvas, [ offscreenCanvas]); 然后,在 Worker 中,以下代码将绘制一个从左向右移动的矩形:
let ctx, pos = 0 ;
function draw( dt) {
ctx. clearRect( 0 , 0 , 100 , 100 );
ctx. fillRect( pos, 0 , 10 , 10 );
pos += 10 * dt;
requestAnimationFrame( draw);
}
self. onmessage = function ( ev) {
const transferredCanvas = ev. data;
ctx = transferredCanvas. getContext( "2d" );
draw();
}; WebSocket
接口过去在此定义。现在它定义于WebSockets中。[WEBSOCKETS]
MessageEvent 接口所有当前引擎均支持。
服务器发送事件、跨文档消息传递、通道消息传递、广播通道和
WebSockets 中的消息使用 MessageEvent 接口处理其 message
事件:[WEBSOCKETS]
[Exposed =(Window ,Worker ,AudioWorklet )]
interface MessageEvent : Event {
constructor (DOMString type , optional MessageEventInit eventInitDict = {});
readonly attribute any data ;
readonly attribute USVString origin ;
readonly attribute DOMString lastEventId ;
readonly attribute MessageEventSource ? source ;
readonly attribute FrozenArray <MessagePort > ports ;
undefined initMessageEvent (DOMString type , optional boolean bubbles = false , optional boolean cancelable = false , optional any data = null , optional USVString origin = "", optional DOMString lastEventId = "", optional MessageEventSource ? source = null , optional sequence <MessagePort > ports = []);
};
dictionary MessageEventInit : EventInit {
any data = null ;
USVString origin = "";
DOMString lastEventId = "";
MessageEventSource ? source = null ;
sequence <MessagePort > ports = [];
};
typedef (WindowProxy or MessagePort or ServiceWorker ) MessageEventSource ;每个 MessageEvent 都有一个来源(一个源、字符串或 null),其初始值为 null。
event.data
所有当前引擎均支持。
返回消息的数据。
event.origin
所有当前引擎均支持。
event.lastEventId
所有当前引擎均支持。
对于服务器发送事件,返回最后事件 ID 字符串。
event.source
所有当前引擎均支持。
对于跨文档消息传递,返回源窗口的 WindowProxy;对于在
SharedWorkerGlobalScope
对象上触发的 connect
事件,返回正在附加的 MessagePort。
event.ports
所有当前引擎均支持。
对于跨文档消息传递和通道消息传递,返回随消息发送的 MessagePort
数组。
data
属性必须返回其初始化时的值。它表示正在发送的消息。
在服务器发送事件和跨文档消息传递中,origin
属性表示发送消息的文档的源(通常是文档的方案、主机名和端口,但不包括其路径或片段)。
origin
获取器步骤如下:
当 origin
属性被“初始化”时(例如,在 MessageEvent 的构造函数执行期间),初始化值会被放入对象的来源中。
实现 MessageEvent 接口的对象的提取源步骤是:如果 this 的来源是一个源,则返回它;否则返回 null。
lastEventId 属性必须返回其初始化时的值。在服务器发送事件中,它表示事件源的最后事件 ID 字符串。
source
属性必须返回其初始化时的值。在跨文档消息传递中,它表示消息来源 Window 对象的浏览上下文的
WindowProxy;而在共享
Worker 所使用的 connect
事件中,它表示新连接的
MessagePort。
ports
属性必须返回其初始化时的值。在跨文档消息传递和通道消息传递中,它表示正在发送的 MessagePort 数组。
initMessageEvent(type, bubbles,
cancelable, data, origin, lastEventId,
source, ports) 方法必须以类似于同名 initEvent()
方法的方式初始化事件。
[DOM]
各种 API(例如 WebSocket、
EventSource)使用
MessageEvent 接口处理其 message 事件,而不使用 MessagePort
API。
所有当前引擎均支持。
本节为非规范性内容。
为了使服务器能够通过 HTTP 或专用的服务器推送协议将数据推送到网页,本规范引入了 EventSource 接口。
使用此 API 时,需要创建一个 EventSource
对象并注册事件
监听器。
var source = new EventSource( 'updates.cgi' );
source. onmessage = function ( event) {
alert( event. data);
}; 在服务器端,脚本(本例中为“updates.cgi”)使用 text/event-stream MIME
类型,按以下形式发送消息:
data: This is the first message. data: This is the second message, it data: has two lines. data: This is the third message.
作者可以使用不同的事件类型来区分事件。以下事件流包含“add”和“remove”两种事件 类型:
event: add data: 73857293 event: remove data: 2153 event: add data: 113411
处理这种事件流的脚本如下所示(其中 addHandler
和 removeHandler 是接受一个事件参数的函数):
var source = new EventSource( 'updates.cgi' );
source. addEventListener( 'add' , addHandler, false );
source. addEventListener( 'remove' , removeHandler, false ); 默认事件类型为“message”。
事件流始终以 UTF-8 解码,无法指定其他字符编码。
与普通 HTTP 请求一样,事件流请求可以使用 HTTP 301 和 307 重定向。如果连接关闭,客户端将重新连接; 可以使用 HTTP 204 No Content 响应状态码通知客户端停止重新连接。
使用此 API,而不是通过 XMLHttpRequest
或
iframe 模拟它,
可以在用户代理实现者与网络运营商能够预先协调的情况下,使用户代理更有效地利用网络资源。
除其他益处外,这可以显著节省便携式设备的电池电量。下文有关无连接
推送的章节对此进行了进一步讨论。
EventSource 接口所有当前引擎均支持。
[Exposed =(Window ,Worker )]
interface EventSource : EventTarget {
constructor (USVString url , optional EventSourceInit eventSourceInitDict = {});
readonly attribute USVString url ;
readonly attribute boolean withCredentials ;
// ready state
const unsigned short CONNECTING = 0;
const unsigned short OPEN = 1;
const unsigned short CLOSED = 2;
readonly attribute unsigned short readyState ;
// networking
attribute EventHandler onopen ;
attribute EventHandler onmessage ;
attribute EventHandler onerror ;
undefined close ();
};
dictionary EventSourceInit {
boolean withCredentials = false ;
};每个 EventSource 对象都关联有
以下内容:
一个 url(一个 URL 记录)。在构造期间设置。
一个 请求。其初始值必须为 null。
一个以毫秒为单位的 重新连接时间。其初始值必须是一个由实现定义的值,通常大约为 数秒。
一个 最后事件 ID 字符串。其初始值必须为 空字符串。
除 url 外,这些内容目前均未暴露在
EventSource 对象上。
source = new EventSource(
url [, { withCredentials:
true } ])
所有当前引擎均支持。
创建一个新的 EventSource
对象。
url 是一个字符串,用于给出提供事件流的 URL。
将 withCredentials
设置为 true,
会将向 url 发出的连接请求的凭据模式设置为
“include”。
source.close()
所有当前引擎均支持。
中止为此 EventSource
对象启动的所有 获取算法实例,
并将 readyState
属性设置为 CLOSED。
source.url
所有当前引擎均支持。
返回提供事件 流的 URL。
source.withCredentials
所有当前引擎均支持。
如果向提供事件流的
URL发出的连接请求的凭据模式
被设置为“include”,则返回 true;否则返回 false。
source.readyState
所有当前引擎均支持。
返回此 EventSource 对象的
连接状态。它可以具有下述值。
EventSource(url, eventSourceInitDict)
构造函数在调用时,必须运行以下步骤:
令 ev 为一个新的 EventSource 对象。
令 settings 为 ev 的相关设置对象。
令 urlRecord 为以 settings 为基准,给定 url,对 URL 进行编码解析的结果。
如果 urlRecord 为失败,则抛出一个 “SyntaxError”
DOMException。
将 ev 的 url 设置为 urlRecord。
令 corsAttributeState 为匿名。
如果 eventSourceInitDict 的 withCredentials
成员的值为 true,则将
corsAttributeState 设置为使用
凭据,并将 ev 的 withCredentials
属性设置为 true。
令 request 为给定 urlRecord、空字符串及 corsAttributeState,创建潜在 CORS 请求的结果。
将 request 的客户端设置为 settings。
用户代理可以在 request 的标头列表中设置
(`Accept`,
`text/event-stream`)。
将 request 的缓存
模式设置为
“no-store”。
将 request 的发起者
类型设置为“other”。
将 ev 的请求设置为 request。
令给定响应 res 的 processEventSourceEndOfBody 为以下步骤:如果 res 不是网络 错误,则重新建立 连接。
获取 request,将 processResponseEndOfBody 设置为 processEventSourceEndOfBody,并将 processResponse 设置为给定响应 res 的以下步骤:
返回 ev。
url
属性的获取器必须返回此 EventSource
对象的 url 的序列化结果。
withCredentials 属性必须返回其最后一次初始化时所用的值。
创建对象时,该属性必须初始化为 false。
readyState 属性表示连接的状态。
它可以具有以下值:
CONNECTING(数值 0)OPEN(数值
1)CLOSED
(数值 2)close()
方法。创建对象时,其 readyState
必须设置为 CONNECTING
(0)。下文给出的连接处理规则定义了该值何时发生变化。
close()
方法必须中止为此 EventSource
对象启动的所有 获取算法实例,
并且必须将 readyState
属性设置为 CLOSED。
所有实现 EventSource
接口的对象都必须将以下内容作为事件处理程序 IDL 属性予以支持:
下列事件处理程序
(以及相应的事件处理程序事件类型):
| 事件处理程序 | 事件处理程序 事件类型 |
|---|---|
onopen
所有当前引擎均支持。 Firefox6+Safari5+Chrome6+
Opera12+Edge79+ Edge(旧版)?Internet Explorer不支持 Firefox Android45+Safari iOS5+Chrome Android?WebView Android?Samsung Internet?Opera Android12+ |
open
|
onmessage
所有当前引擎均支持。 Firefox6+Safari5+Chrome6+
Opera12+Edge79+ Edge(旧版)?Internet Explorer不支持 Firefox Android45+Safari iOS5+Chrome Android?WebView Android?Samsung Internet?Opera Android12+ |
message
|
onerror
所有当前引擎均支持。 Firefox6+Safari5+Chrome6+
Opera12+Edge79+ Edge(旧版)?Internet Explorer不支持 Firefox Android45+Safari iOS5+Chrome Android?WebView Android?Samsung Internet?Opera Android12+ |
error
|
当用户代理要宣布连接时,用户代理必须排入一个
任务;如果 readyState
属性被
设置为除 CLOSED
之外的值,则将
readyState
属性设置为 OPEN
并在 EventSource
对象上触发名为 open 的
事件。
当用户代理要重新建立连接时,用户代理必须运行 以下步骤。这些步骤并行运行, 而不是作为任务的一部分运行。(当然,它所 排入队列的任务会像普通任务一样运行,这些任务本身并非并行运行。)
将一个任务加入队列,以运行以下步骤:
如果 readyState
属性被设置为
CLOSED,
则中止该任务。
将 readyState
属性设置为 CONNECTING。
在 EventSource 对象上触发名为 error 的事件。
等待一段等于事件源重新连接时间的延迟。
可以选择继续等待一段时间。特别是,如果上一次尝试失败,用户代理可以引入指数退避延迟, 以免使可能已经过载的服务器进一步过载。或者,如果操作系统报告当前没有网络连接, 用户代理可以在重试前等待操作系统通知网络连接已经恢复。
如果上述任务尚未运行,则等待该任务运行完毕。
将一个任务加入队列,以运行以下步骤:
如果 EventSource
对象的 readyState
属性未设置为 CONNECTING,
则返回。
令 request 为 EventSource 对象的请求。
如果 EventSource
对象的最后事件 ID 字符串不是空字符串:
令 lastEventIDValue 为 EventSource 对象的最后事件 ID 字符串,并将其编码为 UTF-8。
在 request 的标头列表中设置
(`Last-Event-ID`,
lastEventIDValue)。
获取 request,并按照本节前文所述处理以此方式获得的响应(如果有)。
当用户代理要使连接失败时,用户代理必须排入一个
任务;如果 readyState
属性被
设置为除 CLOSED
之外的值,则将
readyState
属性设置为 CLOSED,并在
EventSource 对象上触发名为 error 的
事件。
一旦用户代理已使连接失败,
它就不会尝试重新连接。
由 EventSource 对象排入队列的所有任务所使用的任务源是远程事件
任务源。
Last-Event-ID` 标头Last-Event-ID` HTTP 请求标头会在用户代理要重新建立连接时,向服务器报告
EventSource 对象的最后
事件 ID
字符串。
请参阅 whatwg/html issue #7363,以更好地定义值空间。它实际上可以是任何 UTF-8 编码的字符串,但不得 包含 U+0000 NULL、U+000A LF 或 U+000D CR。
此事件流格式的 MIME 类型是 text/event-stream。
事件流格式由以下 ABNF 中的 stream 产生式描述,其字符集为 Unicode。[ABNF]
stream = [ bom ] * event
event = * ( comment / field ) end-of-line
comment = colon * any-char end-of-line
field = 1* name-char [ colon [ space ] * any-char ] end-of-line
end-of-line = ( cr lf / cr / lf )
; characters
lf = %x000A ; U+000A LINE FEED (LF)
cr = %x000D ; U+000D CARRIAGE RETURN (CR)
space = %x0020 ; U+0020 SPACE
colon = %x003A ; U+003A COLON (:)
bom = %xFEFF ; U+FEFF BYTE ORDER MARK
name-char = %x0000-0009 / %x000B-000C / %x000E-0039 / %x003B-10FFFF
; a scalar value other than U+000A LINE FEED (LF), U+000D CARRIAGE RETURN (CR), or U+003A COLON (:)
any-char = %x0000-0009 / %x000B-000C / %x000E-10FFFF
; a scalar value other than U+000A LINE FEED (LF) or U+000D CARRIAGE RETURN (CR) 这种格式的事件流必须始终使用 UTF-8 编码。[ENCODING]
各行必须由以下任一种方式分隔:U+000D CARRIAGE RETURN U+000A LINE FEED (CRLF) 字符对、 单个 U+000A LINE FEED (LF) 字符,或者单个 U+000D CARRIAGE RETURN (CR) 字符。
由于为此类资源建立的远程服务器连接预期会长期存在,用户代理应确保采用适当的缓冲方式。 特别是,以单个 U+000A LINE FEED (LF) 字符作为行结束符的行缓冲是安全的, 而块缓冲或预期使用不同换行符的行缓冲可能导致事件分派延迟。
必须使用 UTF-8 解码算法对事件流进行解码。
UTF-8 解码算法会移除一个前导 UTF-8 字节顺序标记 (BOM)(如果存在)。
随后必须逐行读取所有内容来解析事件流。一行可以通过以下方式结束:U+000D CARRIAGE RETURN U+000A LINE FEED (CRLF) 字符对;前面没有 U+000D CARRIAGE RETURN (CR) 字符的单个 U+000A LINE FEED (LF) 字符;或者后面没有 U+000A LINE FEED (LF) 字符的单个 U+000D CARRIAGE RETURN (CR) 字符。
解析事件流时,必须为其关联一个 data 缓冲区、一个 event type 缓冲区和一个 last event ID 缓冲区。它们必须初始化为空字符串。
各行必须按照接收顺序,依照以下规则处理:
按照下文定义分派事件。
忽略该行。
收集该行中第一个 U+003A COLON 字符 (:) 之前的字符,并令 field 为该字符串。
收集该行中第一个 U+003A COLON 字符 (:) 之后的字符,并令 value 为该字符串。 如果 value 以 U+0020 SPACE 字符开头,则从 value 中移除该字符。
按照下文所述步骤处理字段,使用 field 作为字段名, 并使用 value 作为字段值。
按照下文所述步骤处理字段,使用整行作为字段名, 并使用空字符串作为字段值。
到达文件末尾后,必须丢弃所有待处理的数据。(如果文件在某个事件中间结束, 即最终空白行之前结束,则不会分派这个不完整的事件。)
给定字段名和字段值时,处理字段的步骤取决于字段名, 如下列列表所示。字段名必须按字面值比较,不得执行大小写折叠。
当要求用户代理分派 事件时,用户代理必须使用适合该用户代理的步骤处理 data 缓冲区、 event type 缓冲区和 last event ID 缓冲区。
对于 Web 浏览器,分派事件的适当步骤如下:
将事件源的最后事件 ID 字符串设置为 last event ID 缓冲区的值。该缓冲区不会重置,因此事件源的最后事件 ID 字符串将一直保持此值,直到服务器下一次设置它。
如果 data 缓冲区为空字符串,则将 data 缓冲区和 event type 缓冲区设置为空字符串,然后返回。
如果 data 缓冲区的最后一个字符是 U+000A LINE FEED (LF) 字符,则从 data 缓冲区中移除最后一个字符。
令 event 为在 EventSource 对象的相关领域中,
使用 MessageEvent
创建事件的结果。
将 event 的 type
属性初始化为
“message”,将其
data
属性初始化为 data,将其源初始化为事件流最终 URL
(即重定向后的 URL)的源,并将其 lastEventId
属性初始化为事件源的最后事件 ID 字符串。
如果 event type 缓冲区的值不是空字符串,则将新创建事件的类型更改为等于 event type 缓冲区的值。
将 data 缓冲区和 event type 缓冲区设置为 空字符串。
将一个任务加入队列。
如果 readyState
属性被设置为 CLOSED
以外的值,则该任务会在
EventSource 对象上分派新创建的事件。
如果某个事件没有“id”字段,但先前的事件设置过事件源的最后事件 ID 字符串,
则该事件的 lastEventId
字段将设置为最后一次看到的“id”字段的值。
对于其他用户代理,分派事件的适当步骤由实现定义, 但至少必须在返回前将 data 和 event type 缓冲区设置为空字符串。
以下事件流在后面跟随一个空白行时:
data: YHOO data: +2 data: 10
……会导致在 EventSource
对象上分派一个接口为
MessageEvent 的 message 事件。该事件的
data
属性将包含字符串“YHOO\n+2\n10”(其中“\n”表示换行符)。
其使用方式可以如下所示:
var stocks = new EventSource( "https://stocks.example.com/ticker.php" );
stocks. onmessage = function ( event) {
var data = event. data. split( '\n' );
updateStocks( data[ 0 ], data[ 1 ], data[ 2 ]);
}; ……其中 updateStocks() 是如下定义的函数:
function updateStocks( symbol, delta, value) { ... } ……或类似的形式。
以下事件流包含四个块。第一个块只有一条注释,不会触发任何事件。第二个块包含两个字段,
名称分别为“data”和“id”;该块会触发一个数据为“first event”的事件,
随后将最后事件 ID 设置为“1”。因此,如果连接在此块与下一块之间中断,服务器将收到一个值为
`1` 的 `Last-Event-ID` 标头。
第三个块会触发一个数据为“second event”的事件,并且也包含一个“id”字段,但这次该字段没有值,
因而将最后事件 ID 重置为空字符串(这意味着在尝试重新连接时,不再发送 `Last-Event-ID`
标头)。最后,最后一个块只会触发一个数据为“ third event”的事件(带有一个前导空格
字符)。请注意,最后一个块仍然必须以空白行结束;仅到达事件流末尾不足以触发最后一个事件的分派。
: test stream data: first event id: 1 data:second event id data: third event
以下事件流会触发两个事件:
data data data data:
第一个块触发的事件的数据被设置为空字符串;如果最后一个块后跟一个空白行,它也会如此。 中间的块会触发一个数据被设置为单个换行符的事件。最后一个块因为后面没有空白行而被丢弃。
以下事件流会触发两个相同的事件:
data:test data: test
这是因为如果冒号后存在空格,该空格会被忽略。
已知旧式代理服务器在某些情况下会在短暂超时后断开 HTTP 连接。 为防范此类代理服务器,作者可以大约每 15 秒包含一条注释行(以“:”字符开头的行)。
希望将事件源连接相互关联,或将其与此前提供的特定文档相关联的作者可能会发现,依赖 IP 地址并不可行, 因为单个客户端可能拥有多个 IP 地址(由于使用多个代理服务器),而单个 IP 地址也可能对应多个客户端 (由于共享代理服务器)。更好的做法是在提供文档时在其中加入唯一标识符,然后在建立连接时将该标识符 作为 URL 的一部分传递。
还要提醒作者,HTTP 分块可能会对本协议的可靠性产生意外的负面影响,尤其是在分块由不了解时序要求的 其他层执行时。如果这会造成问题,可以在提供事件流时禁用分块。
支持 HTTP 每服务器连接数限制的客户端,在从同一网站打开多个页面,而每个页面都具有一个连接到相同
域的 EventSource 时,可能会遇到问题。
作者可以使用较为复杂的机制,为每个连接使用唯一的域名;或者允许用户逐页启用或禁用 EventSource
功能;又或者使用共享工作线程共享一个 EventSource 对象,以避免此问题。
在受控环境中运行的用户代理(例如绑定到特定运营商的移动设备上的浏览器)可以将连接管理 卸载给网络中的代理。在这种情况下,为了符合性判断,用户代理被视为同时包括移动设备软件和 网络代理。
例如,移动设备上的浏览器在建立连接后,可能检测到自己位于支持此功能的网络中,并请求网络中的 代理服务器接管连接管理。这种情况下的时间线可能如下:
EventSource
构造函数中指定的资源。EventSource 构造函数中
指定的资源(可能包括一个 `Last-Event-ID` HTTP
标头等)。这可以减少总数据使用量,从而显著节省电量。
除了以本规范所定义的方式,以及以上述更分布式的方式实现现有 API 和 text/event-stream 线路格式外,
还可以支持由其他适用规范定义的事件分帧格式。本规范不定义
应当如何解析或处理这些格式。
当 EventSource 对象的 readyState 为
CONNECTING,
并且该对象为 open、message 或 error 事件注册了一个或多个事件
监听器时,从调用该 EventSource 对象构造函数的 Window 或 WorkerGlobalScope 对象,
到该 EventSource
对象本身之间,必须存在一个强引用。
当 EventSource 对象的 readyState
为 OPEN,并且该
对象为 message 或 error 事件注册了一个或多个事件
监听器时,从调用该 EventSource
对象构造函数的 Window 或 WorkerGlobalScope 对象,
到该 EventSource 对象本身之间,
必须存在一个强引用。
当 EventSource 对象在远程事件
任务源上排有任务时,从调用该 EventSource
对象构造函数的 Window 或
WorkerGlobalScope 对象,
到该 EventSource
对象之间,必须存在一个强引用。
如果用户代理要强制关闭一个
EventSource 对象(当 Document 对象永久消失时会发生这种情况),
用户代理必须中止为此 EventSource 对象启动的所有获取算法实例,并且必须将 readyState
属性设置为 CLOSED。
如果一个 EventSource 对象在
连接仍然打开时被垃圾回收,用户代理必须中止由此 EventSource
打开的所有获取算法实例。
本节为非规范性内容。
强烈建议用户代理在其开发者控制台中提供有关
EventSource 对象及其相关
网络连接的详细诊断信息,以帮助作者调试使用此 API 的代码。
例如,用户代理可以设置一个面板,显示页面所创建的所有 EventSource
对象;每个对象都列出构造函数的参数、是否发生过网络错误、连接的 CORS 状态,以及导致该状态的
客户端所发送和服务器所接收的标头、收到的消息及其解析方式等信息。
特别鼓励实现在每次触发 error 事件时,向开发者控制台
报告详细信息,因为事件本身几乎无法提供任何信息。
所有当前引擎均支持。
出于安全和隐私方面的原因,Web 浏览器会阻止不同域中的文档相互影响;也就是说,不允许跨站脚本。
尽管这是一项重要的安全功能,但即使来自不同域的页面并无恶意,它也会阻止这些页面进行通信。 本节引入一种消息传递系统,使文档无论其来源域为何都可以相互通信,同时其设计不会导致跨站脚本攻击。
![]()
postMessage() API
可被用作跟踪
向量。
本节为非规范性内容。
例如,如果文档 A 包含一个 iframe
元素,其中包含
文档 B,并且文档 A 中的脚本对文档 B 的 Window 对象调用 postMessage(),
则会在该对象上触发一个消息事件,并标明该事件源自文档 A 的 Window。文档 A
中的脚本可能如下所示:
var o = document. getElementsByTagName( 'iframe' )[ 0 ];
o. contentWindow. postMessage( 'Hello world' , 'https://b.example.org/' ); 为了为传入事件注册事件处理程序,脚本应使用 addEventListener()(或类似机制)。
例如,文档 B 中的脚本可能如下所示:
window. addEventListener( 'message' , receiver, false );
function receiver( e) {
if ( e. origin == 'https://example.com' ) {
if ( e. data == 'Hello world' ) {
e. source. postMessage( 'Hello' , e. origin);
} else {
alert( e. data);
}
}
} 此脚本首先检查域是否为预期的域,然后查看消息;它会将消息显示给用户,或者通过向最初发送该消息的 文档发回消息来作出响应。
使用此 API 时需要格外谨慎,以保护用户免受恶意实体为其自身目的滥用网站的侵害。
作者应检查 origin 属性,
以确保只接受来自预期域的消息。否则,作者的消息处理代码中的缺陷可能会被恶意网站利用。
此外,即使检查了 origin
属性,作者仍应检查相关数据是否采用预期格式。否则,如果事件源遭到利用跨站脚本漏洞实施的攻击,
对使用 postMessage() 方法发送的信息
继续进行未经检查的处理,可能会使攻击传播到接收方。
对于包含任何机密信息的消息,作者不应在 targetOrigin 参数中使用通配符关键字 (*),否则无法保证消息只被传递给预期接收方。
接受来自任意源的消息的作者应考虑拒绝服务攻击的风险。攻击者可能发送大量消息;如果接收页面针对每条 此类消息执行开销较大的计算或产生网络流量,攻击者的消息就可能被放大为拒绝服务攻击。建议作者采用 速率限制(每分钟只接受一定数量的消息),使此类攻击难以实施。
此 API 的完整性建立在以下前提之上:一个源中的脚本无法向其他源(即与其并非同源的源)中的对象发布任意事件(通过
dispatchEvent() 或其他方式)。
强烈建议实现者在实现此功能时格外谨慎。它允许作者将信息从一个域传输到另一个域, 而出于安全原因,这通常是不允许的。它还要求用户代理谨慎地允许访问某些属性,而禁止访问其他属性。
还建议用户代理考虑限制不同源之间的消息流量速率,以保护缺乏防范措施的网站免受拒绝服务 攻击。
window.postMessage(message [, options ])
所有当前引擎均支持。
向给定窗口发布消息。消息可以是结构化对象,例如嵌套对象和数组;可以包含 JavaScript 值
(字符串、数字、Date
对象等);还可以包含某些数据对象,例如 File
Blob、
FileList
和 ArrayBuffer
对象。
options 的 transfer
成员中列出的对象会被转移,而不仅仅是被克隆;这意味着它们在发送端不再可用。
可以使用 options 的 targetOrigin
成员指定目标源。如果未提供,则默认为“/”。此默认值将消息限制为只能发送给同源目标。
如果目标窗口的源与给定的目标源不匹配,则会丢弃消息,以避免信息泄露。若要不考虑源而将消息发送给
目标,请将目标源设置为“*”。
如果 transfer 数组包含重复对象,或者无法克隆 message,则抛出一个
“DataCloneError” DOMException。
window.postMessage(message, targetOrigin [, transfer ])
这是 postMessage()
的另一种形式,其中目标源作为参数指定。调用
window.postMessage(message, target, transfer) 等同于
window.postMessage(message, {targetOrigin,
transfer})。
向一个刚刚导航到新 Document 的浏览上下文的 Window 发布消息,很可能导致消息未被预期接收方收到:
目标浏览上下文中的脚本必须有时间
为消息设置监听器。因此,例如在要向新创建的子 iframe 的 Window 发送消息的情况下,建议作者让子 Document 向其父级发布一条消息,
宣告自己已准备好接收消息,并让父级等待收到该消息后再开始发布消息。
给定 targetWindow、message 和 options,窗口发布消息步骤如下:
令 targetRealm 为 targetWindow 的领域。
令 incumbentSettings 为 incumbent 设置对象。
令 targetOrigin 为 options["targetOrigin"]。
如果 targetOrigin 是单个 U+002F SOLIDUS 字符 (/),则将 targetOrigin 设置为 incumbentSettings 的源。
否则,如果 targetOrigin 不是单个 U+002A ASTERISK 字符 (*):
令 parsedURL 为对 targetOrigin 运行 URL 解析器的结果。
如果 parsedURL 为失败,则抛出一个 “SyntaxError”
DOMException。
将 targetOrigin 设置为 parsedURL 的源。
令 transfer 为 options["transfer"]。
令 serializeWithTransferResult 为 StructuredSerializeWithTransfer(message, transfer)。重新抛出 所有异常。
给定 targetWindow,在已发布消息任务源上将一个全局任务加入队列, 以运行以下步骤:
如果 targetOrigin 参数不是单个字面 U+002A ASTERISK 字符
(*),并且 targetWindow 的关联
Document 的源与
targetOrigin 并非同源,则返回。
令 origin 为 incumbentSettings 的源。
令 source 为与 incumbentSettings 的全局
对象(一个 Window 对象)
相对应的 WindowProxy 对象。
令 deserializeRecord 为 StructuredDeserializeWithTransfer(serializeWithTransferResult, targetRealm)。
如果此操作抛出异常,则捕获该异常,在
targetWindow 上触发名为 messageerror 的
事件,使用 MessageEvent,将其origin
初始化为 origin,并将
source
属性初始化为
source,然后返回。
令 messageClone 为 deserializeRecord.[[Deserialized]]。
令 newPorts 为一个新的冻结数组,它由
deserializeRecord.[[TransferredValues]] 中的所有 MessagePort 对象(如果有)组成,
并保持它们的相对顺序。
触发一个名为 message 的事件,其目标为
targetWindow,并使用
MessageEvent,将其origin
初始化为 origin,将 source
属性初始化为 source,将
data
属性初始化为
messageClone,并将 ports
属性
初始化为 newPorts。
Window 接口的 postMessage(message, targetOrigin,
transfer) 方法步骤是:给定此对象、message 和 «[ "targetOrigin"
→
targetOrigin, "transfer"
→ transfer ]»,运行窗口发布消息
步骤。
所有当前引擎均支持。
所有当前引擎均支持。
本节为非规范性内容。
为了使相互独立的代码(例如,在不同的浏览上下文中运行的代码)能够直接通信,作者可以使用通道 消息传递。
此机制中的通信通道被实现为双向管道,两端各有一个端口。在一个端口发送的消息会被传递到另一个端口, 反之亦然。消息以 DOM 事件的形式传递,不会中断或阻塞正在运行的任务。
要创建连接(两个“纠缠”的端口),需要调用 MessageChannel()
构造函数:
var channel = new MessageChannel(); 其中一个端口保留为本地端口,另一个端口则发送给远程代码,例如使用 postMessage():
otherWindow. postMessage( 'hello' , 'https://example.com' , [ channel. port2]); 要发送消息,需要使用端口上的 postMessage()
方法:
channel. port1. postMessage( 'hello' ); 要接收消息,需要监听 message 事件:
channel. port1. onmessage = handleMessage;
function handleMessage( event) {
// message is in event.data
// ...
} 在端口上发送的数据可以是结构化数据;例如,以下代码通过一个
MessagePort 传递字符串数组:
port1. postMessage([ 'hello' , 'world' ]); 本节为非规范性内容。
在此示例中,两个 JavaScript 库使用
MessagePort 相互连接。这样一来,
以后就可以在不同的框架或 Worker 对象中托管这些库,
而无需对 API 进行任何更改。
< script src = "contacts.js" ></ script > <!-- exposes a contacts object -->
< script src = "compose-mail.js" ></ script > <!-- exposes a composer object -->
< script >
var channel = new MessageChannel();
composer. addContactsProvider( channel. port1);
contacts. registerConsumer( channel. port2);
</ script > 以下是“addContactsProvider()”函数的一种可能实现:
function addContactsProvider( port) {
port. onmessage = function ( event) {
switch ( event. data. messageType) {
case 'search-result' : handleSearchResult( event. data. results); break ;
case 'search-done' : handleSearchDone(); break ;
case 'search-error' : handleSearchError( event. data. message); break ;
// ...
}
};
}; 或者,也可以按如下方式实现:
function addContactsProvider( port) {
port. addEventListener( 'message' , function ( event) {
if ( event. data. messageType == 'search-result' )
handleSearchResult( event. data. results);
});
port. addEventListener( 'message' , function ( event) {
if ( event. data. messageType == 'search-done' )
handleSearchDone();
});
port. addEventListener( 'message' , function ( event) {
if ( event. data. messageType == 'search-error' )
handleSearchError( event. data. message);
});
// ...
port. start();
}; 关键区别在于,使用 addEventListener()
时,还必须调用 start() 方法。使用
onmessage
时,则隐含调用了 start()。
start() 方法,
无论是显式调用,还是通过设置 onmessage
隐式调用,都会开始消息流:消息端口上发布的消息最初会暂停传递,从而避免脚本尚未来得及设置处理程序时
消息就被丢弃。
本节为非规范性内容。
可以将端口视为向系统中的其他参与者暴露有限能力(对象能力模型意义上的能力)的一种方式。 它既可以是一种弱能力系统,其中端口仅在某个特定源内被用作一种便利模型;也可以是一种强能力模型, 其中一个源 provider 提供端口,并将其作为另一个源 consumer 能够改变 provider 或从中获取信息的唯一机制。
例如,考虑这样一种情况:某个社交网站在一个 iframe
中嵌入用户的电子邮件联系人提供程序(来自第二个源的通讯录网站),并在第二个 iframe
中嵌入一个游戏(来自第三个源)。外层社交网站和第二个
iframe
中的游戏无法访问第一个 iframe
内的任何内容;它们合起来也只能:
将 iframe
导航到一个新的
URL,例如导航到相同的
URL,但使用不同的片段,从而使 iframe
中的 Window
接收到一个 hashchange
事件。
使用 window.postMessage()
API,向该 iframe
中的 Window
发送一个 message
事件。
联系人提供程序可以使用这些方法,尤其是第三种方法,提供一个可由其他源访问、用于操作用户通讯录的 API。
例如,它可以通过将指定人员和电子邮件地址添加到用户的通讯录中,来响应消息
“add-contact Guillaume Tell
<tell@pomme.example.net>”。
为了避免 Web 上的任意网站都能够操作用户的联系人,联系人提供程序可以只允许某些受信任的网站 (例如该社交网站)执行此操作。
现在假设游戏想要向用户的通讯录中添加联系人,并且社交网站愿意允许它代表自己这样做,这实际上是在 “共享”联系人提供程序对社交网站的信任。可以通过多种方式实现这一点;最简单的方式是由社交网站在游戏 网站和联系人网站之间代理消息。然而,这种解决方案存在许多困难:它要求社交网站要么完全信任游戏网站, 相信其不会滥用该权限;要么要求社交网站验证每个请求,以确保它不是社交网站不愿允许的请求 (例如添加多个联系人、读取联系人或删除联系人)。此外,如果多个游戏可能同时尝试与联系人提供程序 交互,还需要增加额外的复杂性。
然而,通过使用消息通道和 MessagePort
对象,所有这些问题都可以消除。当游戏通知社交网站它想要添加联系人时,社交网站可以向联系人提供程序
请求的不是让其添加联系人,而是添加单个联系人的能力。随后,联系人提供程序创建一对 MessagePort
对象,并将其中一个发回社交网站,由社交网站再将其转发给游戏。这样,游戏与联系人提供程序之间便有了
直接连接,并且联系人提供程序知道只应接受一个“添加联系人”请求,而不接受其他任何请求。换言之,
游戏获得了添加单个联系人的能力。
本节为非规范性内容。
继续上一节的示例,特别考虑其中的联系人提供程序。初始实现可能只是在服务的 iframe
中使用 XMLHttpRequest
对象,而在服务演进后,可能希望改为使用一个具有单个 WebSocket
连接的共享工作线程。
如果初始设计使用 MessagePort
对象授予能力,或者仅仅用于支持多个同时存在的独立会话,那么服务实现可以从
每个 iframe
使用 XMLHttpRequest
的模型切换到共享 WebSocket
的模型,而完全无需更改 API:服务提供程序一侧的所有端口都可以转发给共享工作线程,而丝毫不会影响
API 的使用者。
所有当前引擎均支持。
[Exposed =(Window ,Worker )]
interface MessageChannel {
constructor ();
readonly attribute MessagePort port1 ;
readonly attribute MessagePort port2 ;
};channel = new MessageChannel()
所有当前引擎均支持。
返回一个新的 MessageChannel
对象,其中包含两个新的 MessagePort 对象。
channel.port1
所有当前引擎均支持。
返回第一个 MessagePort 对象。
channel.port2
所有当前引擎均支持。
返回第二个 MessagePort 对象。
一个 MessageChannel 对象具有
一个关联的端口 1和一个关联的
端口 2,两者都是 MessagePort 对象。
new MessageChannel() 构造函数的步骤如下:
MessageEventTarget
混入
interface mixin MessageEventTarget {
attribute EventHandler onmessage ;
attribute EventHandler onmessageerror ;
};实现 MessageEventTarget
接口的对象必须将以下内容作为事件处理程序 IDL 属性予以支持:
下列事件处理程序
(以及相应的事件处理程序事件类型):
| 事件处理程序 | 事件 处理程序事件类型 |
|---|---|
onmessage
所有当前引擎均支持。 Firefox41+Safari5+Chrome2+
Opera10.6+Edge79+ Edge(旧版)12+Internet Explorer10+ Firefox Android?Safari iOS?Chrome Android?WebView Android37+Samsung Internet?Opera Android11.5+ DedicatedWorkerGlobalScope/message_event 所有当前引擎均支持。 Firefox3.5+Safari4+Chrome4+
Opera10.6+Edge79+ Edge(旧版)12+Internet Explorer10+ Firefox Android?Safari iOS5+Chrome Android?WebView Android37+Samsung Internet?Opera Android11.5+ |
message
|
onmessageerror
MessagePort/messageerror_event 所有当前引擎均支持。 Firefox57+Safari16.4+Chrome60+
Opera?Edge79+ Edge(旧版)18Internet Explorer不支持 Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android47+ DedicatedWorkerGlobalScope/messageerror_event 所有当前引擎均支持。 Firefox57+Safari16.4+Chrome60+
Opera?Edge79+ Edge(旧版)18Internet Explorer不支持 Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android47+ |
messageerror
|
所有当前引擎均支持。
每个通道都有两个消息端口。通过一个端口发送的数据由另一个端口接收,反之亦然。
[Exposed =(Window ,Worker ,AudioWorklet ), Transferable ]
interface MessagePort : EventTarget {
undefined postMessage (any message , sequence <object > transfer );
undefined postMessage (any message , optional StructuredSerializeOptions options = {});
undefined start ();
undefined close ();
// event handlers
attribute EventHandler onclose ;
};
MessagePort includes MessageEventTarget ;
dictionary StructuredSerializeOptions {
sequence <object > transfer = [];
};port.postMessage(message [, transfer])
所有当前引擎均支持。
port.postMessage(message [, { transfer }])
通过通道发布消息。transfer 中列出的对象会被转移,而不仅仅是被克隆; 这意味着它们在发送端不再可用。
如果 transfer 包含重复对象或 port,或者无法克隆
message,则抛出一个 “DataCloneError” DOMException。
port.start()
所有当前引擎均支持。
开始分派端口上接收到的消息。
port.close()
所有当前引擎均支持。
断开端口,使其不再处于活动状态。
每个 MessagePort 对象都有一个消息事件目标(一个
MessageEventTarget),
message 和 messageerror 事件会被分派到该目标。
除非另有说明,否则其默认为 MessagePort 对象本身。
每个 MessagePort 对象都可以与另一个
对象纠缠(这是一种对称关系)。每个 MessagePort
对象还具有一个名为端口消息队列的任务源,其初始为空。端口消息队列可以启用或禁用,其初始状态为禁用。端口一经启用便不能
再次禁用(不过,队列中的消息可以被移动到另一个队列或完全移除,这具有大致相同的效果)。MessagePort 还具有一个已被传送标志,其初始值必须为 false。
当端口的端口消息队列启用时,
事件循环必须将其用作自身的一个任务源。当端口的相关
全局对象是一个 Window 时,在其端口消息队列上排入队列的所有任务都必须与该端口的相关全局
对象的关联
Document相关联。
如果文档是完全活动的,但所有事件 监听器都是在并非完全活动的文档上下文中创建的,则在这些文档重新变为完全活动的之前,将无法接收到消息。
每个事件循环都有一个名为未传送端口消息队列的任务源。这是一个虚拟任务源:它必须如同包含每个 MessagePort 的每个端口消息队列中的任务一样运行;这些 MessagePort 的已被传送标志为 false,其端口消息队列已启用,并且其相关代理的事件循环就是该事件循环。这些任务按照其被添加到各自任务源的顺序排列。当一个任务本应从未传送端口消息
队列中移除时,必须改为从其端口消息队列中移除。
当 MessagePort 的已被传送标志为 false 时,为了事件循环的目的,必须忽略其端口消息队列。(改为使用未传送端口消息
队列。)
当一个端口、它的孪生端口或它所克隆自的对象正在或已经被转移时,已被传送标志会设置为 true。当 MessagePort 的已被传送标志为 true 时,其端口消息队列会作为一个一等任务源运行,不受任何未传送端口消息
队列影响。
当用户代理要纠缠两个 MessagePort 对象时,必须运行
以下步骤:
如果其中一个端口已被纠缠,则解除该端口与其所纠缠端口之间的纠缠。
如果此前纠缠的两个端口是某个
MessageChannel 对象的两个端口,
则该 MessageChannel 对象不再
表示实际的通道:该对象中的两个端口不再纠缠。
关联要纠缠的两个端口,使其构成一个新通道的两个部分。(不存在表示此通道的 MessageChannel 对象。)
完成此步骤的两个端口 A 和 B 现在被称为已纠缠;一个端口与另一个端口纠缠, 反之亦然。
尽管本规范将此过程描述为瞬时完成,实现更可能通过消息传递来实现它。与所有算法一样, 关键“仅仅”在于最终结果从黑盒角度看必须与规范描述无法区分。
给定发起解除纠缠的 MessagePort
initiatorPort,
解除纠缠步骤如下:
令 otherPort 为此前与 initiatorPort 纠缠的 MessagePort。
断言:otherPort 存在。
解除 initiatorPort 与 otherPort 的纠缠,使它们不再相互纠缠或关联。
MessagePort
对象是可转移
对象。给定 value 和 dataHolder,其转移步骤如下:
给定 dataHolder 和 value,其转移接收 步骤如下:
将 value 的已被传送标志设置为 true。
将 dataHolder.[[PortMessageQueue]] 中用于触发 message 事件的所有任务移动到 value 的端口消息队列(如果有)中,
使 value 的端口消息队列保持初始的禁用状态;并且,如果
value 的相关全局对象是一个 Window,则将移动的任务与 value 的相关全局对象的关联
Document相关联。
如果 dataHolder.[[RemotePort]] 不为 null,则纠缠 dataHolder.[[RemotePort]] 和 value。(这会解除 dataHolder.[[RemotePort]] 与被转移的原始端口之间的纠缠。)
给定 sourcePort、targetPort、message 和 options,消息端口发布消息步骤如下:
令 transfer 为 options["transfer"]。
如果 transfer 包含
sourcePort,则抛出一个 “DataCloneError”
DOMException。
令 doomed 为 false。
如果 targetPort 不为 null,并且 transfer 包含 targetPort,则将 doomed 设置为 true, 并可以选择向开发者控制台报告:目标端口被发布给其自身,导致通信通道丢失。
令 serializeWithTransferResult 为 StructuredSerializeWithTransfer(message, transfer)。重新抛出所有异常。
如果 targetPort 为 null,或者 doomed 为 true,则返回。
向 targetPort 的端口消息队列添加一个任务,以运行以下步骤:
令 finalTargetPort 为该任务当前所在端口消息队列所属的 MessagePort。
如果 targetPort 本身已被转移,因而它的所有任务也随之移动, 则该端口可能与 targetPort 不同。
令 messageEventTarget 为 finalTargetPort 的消息事件目标。
令 targetRealm 为 finalTargetPort 的相关领域。
令 deserializeRecord 为 StructuredDeserializeWithTransfer(serializeWithTransferResult, targetRealm)。
如果此操作抛出异常,则捕获该异常,在
messageEventTarget 上触发名为 messageerror 的
事件,使用 MessageEvent,然后返回。
令 messageClone 为 deserializeRecord.[[Deserialized]]。
令 newPorts 为一个新的冻结数组,它由
deserializeRecord.[[TransferredValues]] 中的所有 MessagePort 对象(如果有)组成,
并保持它们的相对顺序。
触发一个事件,名称为 message,目标为
messageEventTarget,使用
MessageEvent,并将 data 属性
初始化为 messageClone,将 ports 属性
初始化为
newPorts。
postMessage(message,
options) 方法的步骤如下:
令 targetPort 为与此对象纠缠的端口(如果有); 否则令其为 null。
以此对象、 targetPort、message 和 options 为参数,运行消息端口发布消息步骤。
postMessage(message,
transfer) 方法的步骤如下:
令 targetPort 为与此对象纠缠的端口(如果有); 否则令其为 null。
令 options 为 «[ "transfer"
→ transfer
]»。
以此对象、targetPort、message 和 options 为参数,运行消息端口发布消息步骤。
close()
方法的步骤如下:
将此对象的 [[Detached]] 内部槽值设置为 true。
所有实现 MessagePort 接口的对象,
都必须将以下内容作为事件处理程序 IDL
属性予以支持:
下列事件处理程序(以及相应的事件处理程序事件类型):
| 事件处理程序 | 事件处理程序事件类型 |
|---|---|
onclose |
close
|
第一次设置 MessagePort 对象的 onmessage IDL 属性时,必须启用该端口的端口消息队列,如同调用了 start() 方法一样。
当一个 MessagePort 对象 o 被垃圾回收时,如果 o
已纠缠,则用户代理必须解除
o 的纠缠。
当一个 MessagePort 对象 o 已纠缠,并且注册了 message 或 messageerror 事件监听器时,用户代理必须如同与 o
纠缠的 MessagePort 对象持有对 o 的强引用一样运行。
此外,当任务
队列中的某个任务引用了
一个将要在 MessagePort 对象上分派的事件时,或者该 MessagePort 对象的端口消息队列已启用且不为空时,
不得垃圾回收该 MessagePort 对象。
因此,可以接收一个消息端口,为其提供事件监听器,然后忘记它;只要该事件监听器仍可能接收消息, 通道就会得到维持。
当然,如果通道两侧都出现这种情况,则两个端口都可以被垃圾回收,因为尽管它们相互持有强引用, 但活动代码无法访问它们。不过,如果消息端口具有待处理消息,则不会对其进行垃圾回收。
强烈建议作者显式关闭 MessagePort
对象以解除其纠缠,从而可以回收其资源。创建大量
MessagePort 对象,
然后在不关闭它们的情况下将其丢弃,可能导致较高的瞬时内存占用,因为垃圾回收不一定会立即执行;
对于垃圾回收可能涉及跨进程协调的 MessagePort
尤其如此。
所有当前引擎均支持。
所有当前引擎均支持。
同一用户在同一用户代理中打开的、位于单个源上但处于不同且互不相关的浏览上下文中的页面, 有时需要相互发送通知,例如“嘿,用户在这里登录了,请重新检查你的凭据”。
对于复杂情况,例如管理共享状态的锁定、管理服务器与多个本地客户端之间的资源同步、与远程主机共享
WebSocket 连接等,共享工作线程是最合适的解决方案。
不过,对于使用共享工作线程会产生不合理开销的简单情况,作者可以使用本节所述的简单、基于通道的 广播机制。
[Exposed =(Window ,Worker )]
interface BroadcastChannel : EventTarget {
constructor (DOMString name );
readonly attribute DOMString name ;
undefined postMessage (any message );
undefined close ();
attribute EventHandler onmessage ;
attribute EventHandler onmessageerror ;
};broadcastChannel = new BroadcastChannel(name)
BroadcastChannel/BroadcastChannel
所有当前引擎均支持。
返回一个新的 BroadcastChannel 对象,可以通过该对象发送和接收给定通道名称的消息。
broadcastChannel.name
所有当前引擎均支持。
返回通道名称(即传递给构造函数的名称)。
broadcastChannel.postMessage(message)
所有当前引擎均支持。
将给定消息发送给为此通道设置的其他 BroadcastChannel 对象。消息可以是结构化对象,例如嵌套对象和数组。
broadcastChannel.close()
所有当前引擎均支持。
关闭 BroadcastChannel 对象,使其可以被垃圾回收。
一个 BroadcastChannel 对象具有一个通道名称和一个已关闭标志。
当一个 BroadcastChannel 对象的相关全局对象符合以下任一情况时,
称该对象符合消息传递条件:
一个 Window 对象,其关联
Document是完全活动的;或者
一个 WorkerGlobalScope 对象,其正在关闭标志为 false,
并且不是可挂起的。
postMessage(message) 方法的步骤如下:
如果此对象的已关闭标志
为 true,则抛出一个 “InvalidStateError”
DOMException。
令 serialized 为 StructuredSerialize(message)。 重新抛出所有异常。
令 sourceStorageKey 为使用此对象的相关设置 对象运行为非存储目的获取存储键的结果。
令 destinations 为符合以下条件的 BroadcastChannel 对象列表:
从 destinations 中移除 source。
对 destinations 进行排序,使相关代理相同的所有
BroadcastChannel 对象都按照创建顺序排列,最早创建的在前。
(这并未定义完整的顺序。在此约束范围内,用户代理可以采用任何由实现定义的方式对列表进行排序。)
对于 destinations 中的每个 destination,给定 destination 的相关全局对象,在DOM 操作任务源上将一个全局任务加入队列, 以执行以下步骤:
如果 destination 的已关闭标志 为 true,则中止这些步骤。
令 targetRealm 为 destination 的相关领域。
令 data 为 StructuredDeserialize(serialized, targetRealm)。
如果此操作抛出异常,则捕获该异常,触发一个
事件,其名称为 messageerror,
目标为
destination,使用 MessageEvent,
将其 origin 初始化为
sourceOrigin,然后
中止这些步骤。
触发一个事件,名为 message,
目标为 destination,使用
MessageEvent,
将 data
属性
初始化为 data,并将其 origin 初始化为
sourceOrigin。
当一个已关闭标志为 false 的
BroadcastChannel 对象注册了 message 或 messageerror 事件监听器时,从该 BroadcastChannel 对象的相关全局对象到该
BroadcastChannel 对象本身之间,必须存在一个强引用。
强烈建议作者在不再需要 BroadcastChannel 对象时显式关闭它们,以便对其进行垃圾回收。
创建大量 BroadcastChannel 对象,并在保留事件监听器且未将其关闭的情况下
丢弃它们,可能导致看似发生内存泄漏,因为只要这些对象仍具有事件监听器(或者直到其页面或工作线程关闭),
它们就会继续存活。
所有实现 BroadcastChannel 接口的对象,都必须将以下内容作为事件处理程序 IDL 属性予以支持:
下列事件处理程序(以及相应的事件处理程序事件类型):
| 事件处理程序 | 事件处理程序事件类型 |
|---|---|
onmessage
BroadcastChannel/message_event 所有当前引擎均支持。 Firefox38+Safari15.4+Chrome54+
Opera?Edge79+ Edge(旧版)?Internet Explorer不支持 Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? |
message
|
onmessageerror
BroadcastChannel/messageerror_event 所有当前引擎均支持。 Firefox57+Safari15.4+Chrome60+
Opera?Edge79+ Edge(旧版)?Internet Explorer不支持 Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android47+ |
messageerror
|
假设一个页面希望知道用户何时退出登录,即使用户是从同一网站的另一个标签页退出的:
var authChannel = new BroadcastChannel( 'auth' );
authChannel. onmessage = function ( event) {
if ( event. data == 'logout' )
showLogout();
}
function logoutRequested() {
// called when the user asks us to log them out
doLogout();
showLogout();
authChannel. postMessage( 'logout' );
}
function doLogout() {
// actually log the user out (e.g. clearing cookies)
// ...
}
function showLogout() {
// update the UI to indicate we're logged out
// ...
} 所有当前引擎均支持。
本节为非规范性内容。
本规范定义了一个 API,用于在后台运行脚本,而不依赖于任何 用户界面脚本。
这使长时间运行的脚本不会被响应点击或其他用户交互的脚本中断, 并允许在不通过让出执行权来保持页面响应的情况下执行长 任务。
Worker(本文对这些后台脚本的称呼)相对重量级,并且 不适合大量使用。例如,为四百万像素图像中的每个像素启动一个 worker 是不合适的。以下示例展示了 worker 的一些适当 用途。
通常,worker 应当长期存在,具有较高的启动性能成本,以及较高的 单实例内存成本。
本节为非规范性内容。
Worker 有多种用途。以下小节展示了这种用法的各种 示例。
本节为非规范性内容。
Worker 最简单的用途是在不中断用户界面的情况下执行计算 成本较高的任务。
在此示例中,主文档生成一个 worker,以(朴素方式)计算素数,并 逐步显示最近找到的素数。
主页面如下:
<!DOCTYPE HTML>
< html lang = "en" >
< head >
< meta charset = "utf-8" >
< title > Worker example: One-core computation</ title >
</ head >
< body >
< p > The highest prime number discovered so far is: < output id = "result" ></ output ></ p >
< script >
var worker = new Worker( 'worker.js' );
worker. onmessage = function ( event) {
document. getElementById( 'result' ). textContent = event. data;
};
</ script >
</ body >
</ html >
Worker()
构造函数调用会创建一个 worker,并返回一个表示该 worker 的
Worker 对象,该对象用于
与 worker 通信。
该对象的 onmessage
事件处理器
使代码能够接收来自 worker 的消息。
Worker 本身如下:
var n = 1 ;
search: while ( true ) {
n += 1 ;
for ( var i = 2 ; i <= Math. sqrt( n); i += 1 )
if ( n % i == 0 )
continue search;
// found a prime!
postMessage( n);
}
这段代码的主体只是一个未经优化的素数搜索。当找到素数时,使用 postMessage()
方法向页面发回
消息。
本节为非规范性内容。
目前为止的所有示例都展示了运行经典
脚本的 worker。也可以改用模块
脚本实例化 worker,它具有通常的优点:能够使用 JavaScript
import 语句导入其他模块;默认采用严格模式;以及
顶层声明不会污染 worker 的全局作用域。
由于可以使用 import 语句,因此 importScripts()
方法在模块 worker
内部会自动失败。
在此示例中,主文档使用 worker 在主线程之外处理图像。 它从另一个模块导入所使用的滤镜。
主页面如下:
<!DOCTYPE html>
< html lang = "en" >
< meta charset = "utf-8" >
< title > Worker example: image decoding</ title >
< p >
< label >
Type an image URL to decode
< input type = "url" id = "image-url" list = "image-list" >
< datalist id = "image-list" >
< option value = "https://html.spec.whatwg.org/images/drawImage.png" >
< option value = "https://html.spec.whatwg.org/images/robots.jpeg" >
< option value = "https://html.spec.whatwg.org/images/arcTo2.png" >
</ datalist >
</ label >
</ p >
< p >
< label >
Choose a filter to apply
< select id = "filter" >
< option value = "none" > none</ option >
< option value = "grayscale" > grayscale</ option >
< option value = "brighten" > brighten by 20%</ option >
</ select >
</ label >
</ p >
< div id = "output" ></ div >
< script type = "module" >
const worker = new Worker( "worker.js" , { type: "module" });
worker. onmessage = receiveFromWorker;
const url = document. querySelector( "#image-url" );
const filter = document. querySelector( "#filter" );
const output = document. querySelector( "#output" );
url. oninput = updateImage;
filter. oninput = sendToWorker;
let imageData, context;
function updateImage() {
const img = new Image();
img. src = url. value;
img. onload = () => {
const canvas = document. createElement( "canvas" );
canvas. width = img. width;
canvas. height = img. height;
context = canvas. getContext( "2d" );
context. drawImage( img, 0 , 0 );
imageData = context. getImageData( 0 , 0 , canvas. width, canvas. height);
sendToWorker();
output. replaceChildren( canvas);
};
}
function sendToWorker() {
worker. postMessage({ imageData, filter: filter. value });
}
function receiveFromWorker( e) {
context. putImageData( e. data, 0 , 0 );
}
</ script >
接下来的 worker 文件为:
import * as filters from "./filters.js" ;
self. onmessage = e => {
const { imageData, filter } = e. data;
filters[ filter]( imageData);
self. postMessage( imageData, [ imageData. data. buffer]);
};
它导入了文件 filters.js:
export function none() {}
export function grayscale({ data: d }) {
for ( let i = 0 ; i < d. length; i += 4 ) {
const [ r, g, b] = [ d[ i], d[ i + 1 ], d[ i + 2 ]];
// CIE luminance for the RGB
// The human eye is bad at seeing red and blue, so we de-emphasize them.
d[ i] = d[ i + 1 ] = d[ i + 2 ] = 0.2126 * r + 0.7152 * g + 0.0722 * b;
}
};
export function brighten({ data: d }) {
for ( let i = 0 ; i < d. length; ++ i)
d[ i] *= 1.2 ;
}
};
所有当前引擎均支持。
本节为非规范性内容。
本节使用 Hello World 示例介绍共享 worker。共享 worker 使用略有 不同的 API,因为每个 worker 可以有多个连接。
第一个示例展示了如何连接到 worker,以及 worker 在页面连接到它时如何向 页面发回消息。接收到的消息会显示在日志中。
HTML 页面如下:
<!DOCTYPE HTML>
< html lang = "en" >
< meta charset = "utf-8" >
< title > Shared workers: demo 1</ title >
< pre id = "log" > Log:</ pre >
< script >
var worker = new SharedWorker( 'test.js' );
var log = document. getElementById( 'log' );
worker. port. onmessage = function ( e) { // note: not worker.onmessage!
log. textContent += '\n' + e. data;
}
</ script >
JavaScript worker 如下:
onconnect = function ( e) {
var port = e. ports[ 0 ];
port. postMessage( 'Hello World!' );
}
第二个示例通过更改两点扩展了第一个示例:第一,消息使用
addEventListener() 接收,而不是使用事件处理器 IDL 属性;第二,向
worker 发送一条
消息,使 worker 再发回一条消息。接收到的消息同样
显示在日志中。
HTML 页面如下:
<!DOCTYPE HTML>
< html lang = "en" >
< meta charset = "utf-8" >
< title > Shared workers: demo 2</ title >
< pre id = "log" > Log:</ pre >
< script >
var worker = new SharedWorker( 'test.js' );
var log = document. getElementById( 'log' );
worker. port. addEventListener( 'message' , function ( e) {
log. textContent += '\n' + e. data;
}, false );
worker. port. start(); // note: need this when using addEventListener
worker. port. postMessage( 'ping' );
</ script >
JavaScript worker 如下:
onconnect = function ( e) {
var port = e. ports[ 0 ];
port. postMessage( 'Hello World!' );
port. onmessage = function ( e) {
port. postMessage( 'pong' ); // not e.ports[0].postMessage!
// e.target.postMessage('pong'); would work also
}
}
最后,该示例得到进一步扩展,以展示两个页面如何连接到同一个 worker;在此
情况下,第二个页面只是第一个页面中的一个 iframe,但同样的
原理也适用于位于单独顶级
可遍历对象中的完全独立页面。
外部 HTML 页面如下:
<!DOCTYPE HTML>
< html lang = "en" >
< meta charset = "utf-8" >
< title > Shared workers: demo 3</ title >
< pre id = "log" > Log:</ pre >
< script >
var worker = new SharedWorker( 'test.js' );
var log = document. getElementById( 'log' );
worker. port. addEventListener( 'message' , function ( e) {
log. textContent += '\n' + e. data;
}, false );
worker. port. start();
worker. port. postMessage( 'ping' );
</ script >
< iframe src = "inner.html" ></ iframe >
内部 HTML 页面如下:
<!DOCTYPE HTML>
< html lang = "en" >
< meta charset = "utf-8" >
< title > Shared workers: demo 3 inner frame</ title >
< pre id = log > Inner log:</ pre >
< script >
var worker = new SharedWorker( 'test.js' );
var log = document. getElementById( 'log' );
worker. port. onmessage = function ( e) {
log. textContent += '\n' + e. data;
}
</ script >
JavaScript worker 如下:
var count = 0 ;
onconnect = function ( e) {
count += 1 ;
var port = e. ports[ 0 ];
port. postMessage( 'Hello World! You are connection #' + count);
port. onmessage = function ( e) {
port. postMessage( 'pong' );
}
}
本节为非规范性内容。
在此示例中,可以打开多个窗口(查看器),它们都查看同一张地图。 所有窗口共享相同的地图信息,并由单个 worker 协调所有查看器。 每个查看器都可以独立移动,但如果它们在地图上设置了任何数据,所有查看器 都会更新。
主页面没有什么特别之处,它只是提供了一种打开查看器的方式:
<!DOCTYPE HTML>
< html lang = "en" >
< head >
< meta charset = "utf-8" >
< title > Workers example: Multiviewer</ title >
< script >
function openViewer() {
window. open( 'viewer.html' );
}
</ script >
</ head >
< body >
< p >< button type = button onclick = "openViewer()" > Open a new
viewer</ button ></ p >
< p > Each viewer opens in a new window. You can have as many viewers
as you like, they all view the same data.</ p >
</ body >
</ html >
查看器则要复杂一些:
<!DOCTYPE HTML>
< html lang = "en" >
< head >
< meta charset = "utf-8" >
< title > Workers example: Multiviewer viewer</ title >
< script >
var worker = new SharedWorker( 'worker.js' , 'core' );
// CONFIGURATION
function configure( event) {
if ( event. data. substr( 0 , 4 ) != 'cfg ' ) return ;
var name = event. data. substr( 4 ). split( ' ' , 1 )[ 0 ];
// update display to mention our name is name
document. getElementsByTagName( 'h1' )[ 0 ]. textContent += ' ' + name;
// no longer need this listener
worker. port. removeEventListener( 'message' , configure, false );
}
worker. port. addEventListener( 'message' , configure, false );
// MAP
function paintMap( event) {
if ( event. data. substr( 0 , 4 ) != 'map ' ) return ;
var data = event. data. substr( 4 ). split( ',' );
// display tiles data[0] .. data[8]
var canvas = document. getElementById( 'map' );
var context = canvas. getContext( '2d' );
for ( var y = 0 ; y < 3 ; y += 1 ) {
for ( var x = 0 ; x < 3 ; x += 1 ) {
var tile = data[ y * 3 + x];
if ( tile == '0' )
context. fillStyle = 'green' ;
else
context. fillStyle = 'maroon' ;
context. fillRect( x * 50 , y * 50 , 50 , 50 );
}
}
}
worker. port. addEventListener( 'message' , paintMap, false );
// PUBLIC CHAT
function updatePublicChat( event) {
if ( event. data. substr( 0 , 4 ) != 'txt ' ) return ;
var name = event. data. substr( 4 ). split( ' ' , 1 )[ 0 ];
var message = event. data. substr( 4 + name. length + 1 );
// display "<name> message" in public chat
var public = document. getElementById( 'public' );
var p = document. createElement( 'p' );
var n = document. createElement( 'button' );
n. textContent = '<' + name + '> ' ;
n. onclick = function () { worker. port. postMessage( 'msg ' + name); };
p. appendChild( n);
var m = document. createElement( 'span' );
m. textContent = message;
p. appendChild( m);
public. appendChild( p);
}
worker. port. addEventListener( 'message' , updatePublicChat, false );
// PRIVATE CHAT
function startPrivateChat( event) {
if ( event. data. substr( 0 , 4 ) != 'msg ' ) return ;
var name = event. data. substr( 4 ). split( ' ' , 1 )[ 0 ];
var port = event. ports[ 0 ];
// display a private chat UI
var ul = document. getElementById( 'private' );
var li = document. createElement( 'li' );
var h3 = document. createElement( 'h3' );
h3. textContent = 'Private chat with ' + name;
li. appendChild( h3);
var div = document. createElement( 'div' );
var addMessage = function ( name, message) {
var p = document. createElement( 'p' );
var n = document. createElement( 'strong' );
n. textContent = '<' + name + '> ' ;
p. appendChild( n);
var t = document. createElement( 'span' );
t. textContent = message;
p. appendChild( t);
div. appendChild( p);
};
port. onmessage = function ( event) {
addMessage( name, event. data);
};
li. appendChild( div);
var form = document. createElement( 'form' );
var p = document. createElement( 'p' );
var input = document. createElement( 'input' );
input. size = 50 ;
p. appendChild( input);
p. appendChild( document. createTextNode( ' ' ));
var button = document. createElement( 'button' );
button. textContent = 'Post' ;
p. appendChild( button);
form. onsubmit = function () {
port. postMessage( input. value);
addMessage( 'me' , input. value);
input. value = '' ;
return false ;
};
form. appendChild( p);
li. appendChild( form);
ul. appendChild( li);
}
worker. port. addEventListener( 'message' , startPrivateChat, false );
worker. port. start();
</ script >
</ head >
< body >
< h1 > Viewer</ h1 >
< h2 > Map</ h2 >
< p >< canvas id = "map" height = 150 width = 150 ></ canvas ></ p >
< p >
< button type = button onclick = "worker.port.postMessage('mov left')" > Left</ button >
< button type = button onclick = "worker.port.postMessage('mov up')" > Up</ button >
< button type = button onclick = "worker.port.postMessage('mov down')" > Down</ button >
< button type = button onclick = "worker.port.postMessage('mov right')" > Right</ button >
< button type = button onclick = "worker.port.postMessage('set 0')" > Set 0</ button >
< button type = button onclick = "worker.port.postMessage('set 1')" > Set 1</ button >
</ p >
< h2 > Public Chat</ h2 >
< div id = "public" ></ div >
< form onsubmit = "worker.port.postMessage('txt ' + message.value); message.value = ''; return false;" >
< p >
< input type = "text" name = "message" size = "50" >
< button > Post</ button >
</ p >
</ form >
< h2 > Private Chat</ h2 >
< ul id = "private" ></ ul >
</ body >
</ html >
关于查看器的编写方式,有几个值得注意的关键点。
多个监听器。这里的代码没有使用单个消息处理函数,而是 附加了多个事件监听器,每个监听器都会快速检查自己是否与该消息相关。 在此示例中,这并没有太大区别,但如果多位作者想要通过单个端口与 worker 通信来进行协作,这种方式就可以让代码彼此独立,而不必将所有更改都集中到 单个事件处理函数中。
以这种方式注册事件监听器,还可以在不再需要特定监听器时将其注销,
正如此示例中的 configure() 方法所做的那样。
最后是 worker:
var nextName = 0 ;
function getNextName() {
// this could use more friendly names
// but for now just return a number
return nextName++ ;
}
var map = [
[ 0 , 0 , 0 , 0 , 0 , 0 , 0 ],
[ 1 , 1 , 0 , 1 , 0 , 1 , 1 ],
[ 0 , 1 , 0 , 1 , 0 , 0 , 0 ],
[ 0 , 1 , 0 , 1 , 0 , 1 , 1 ],
[ 0 , 0 , 0 , 1 , 0 , 0 , 0 ],
[ 1 , 0 , 0 , 1 , 1 , 1 , 1 ],
[ 1 , 1 , 0 , 1 , 1 , 0 , 1 ],
];
function wrapX( x) {
if ( x < 0 ) return wrapX( x + map[ 0 ]. length);
if ( x >= map[ 0 ]. length) return wrapX( x - map[ 0 ]. length);
return x;
}
function wrapY( y) {
if ( y < 0 ) return wrapY( y + map. length);
if ( y >= map[ 0 ]. length) return wrapY( y - map. length);
return y;
}
function wrap( val, min, max) {
if ( val < min)
return val + ( max- min) + 1 ;
if ( val > max)
return val - ( max- min) - 1 ;
return val;
}
function sendMapData( viewer) {
var data = '' ;
for ( var y = viewer. y- 1 ; y <= viewer. y+ 1 ; y += 1 ) {
for ( var x = viewer. x- 1 ; x <= viewer. x+ 1 ; x += 1 ) {
if ( data != '' )
data += ',' ;
data += map[ wrap( y, 0 , map[ 0 ]. length- 1 )][ wrap( x, 0 , map. length- 1 )];
}
}
viewer. port. postMessage( 'map ' + data);
}
var viewers = {};
onconnect = function ( event) {
var name = getNextName();
event. ports[ 0 ]. _data = { port: event. ports[ 0 ], name: name, x: 0 , y: 0 , };
viewers[ name] = event. ports[ 0 ]. _data;
event. ports[ 0 ]. postMessage( 'cfg ' + name);
event. ports[ 0 ]. onmessage = getMessage;
sendMapData( event. ports[ 0 ]. _data);
};
function getMessage( event) {
switch ( event. data. substr( 0 , 4 )) {
case 'mov ' :
var direction = event. data. substr( 4 );
var dx = 0 ;
var dy = 0 ;
switch ( direction) {
case 'up' : dy = - 1 ; break ;
case 'down' : dy = 1 ; break ;
case 'left' : dx = - 1 ; break ;
case 'right' : dx = 1 ; break ;
}
event. target. _data. x = wrapX( event. target. _data. x + dx);
event. target. _data. y = wrapY( event. target. _data. y + dy);
sendMapData( event. target. _data);
break ;
case 'set ' :
var value = event. data. substr( 4 );
map[ event. target. _data. y][ event. target. _data. x] = value;
for ( var viewer in viewers)
sendMapData( viewers[ viewer]);
break ;
case 'txt ' :
var name = event. target. _data. name;
var message = event. data. substr( 4 );
for ( var viewer in viewers)
viewers[ viewer]. port. postMessage( 'txt ' + name + ' ' + message);
break ;
case 'msg ' :
var party1 = event. target. _data;
var party2 = viewers[ event. data. substr( 4 ). split( ' ' , 1 )[ 0 ]];
if ( party2) {
var channel = new MessageChannel();
party1. port. postMessage( 'msg ' + party2. name, [ channel. port1]);
party2. port. postMessage( 'msg ' + party1. name, [ channel. port2]);
}
break ;
}
}
连接到多个页面。该脚本使用 onconnect
事件监听器来监听
多个连接。
直接通道。当 worker 从一个查看器接收到一条指定另一个查看器名称的 “msg”消息时,它会在两者之间建立直接连接,使两个查看器可以直接 通信,而无需由 worker 代理所有消息。
本节为非规范性内容。
随着多核 CPU 日益普及,一种获得更高性能的方法是将计算 成本较高的任务拆分给多个 worker。在此示例中,需要对从 1 到 10,000,000 的每个数字执行的一项高计算成本任务,被分派给十个 子 worker。
主页面如下,它只负责报告结果:
<!DOCTYPE HTML>
< html lang = "en" >
< head >
< meta charset = "utf-8" >
< title > Worker example: Multicore computation</ title >
</ head >
< body >
< p > Result: < output id = "result" ></ output ></ p >
< script >
var worker = new Worker( 'worker.js' );
worker. onmessage = function ( event) {
document. getElementById( 'result' ). textContent = event. data;
};
</ script >
</ body >
</ html >
Worker 本身如下:
// settings
var num_workers = 10 ;
var items_per_worker = 1000000 ;
// start the workers
var result = 0 ;
var pending_workers = num_workers;
for ( var i = 0 ; i < num_workers; i += 1 ) {
var worker = new Worker( 'core.js' );
worker. postMessage( i * items_per_worker);
worker. postMessage(( i+ 1 ) * items_per_worker);
worker. onmessage = storeResult;
}
// handle the results
function storeResult( event) {
result += 1 * event. data;
pending_workers -= 1 ;
if ( pending_workers <= 0 )
postMessage( result); // finished!
}
它由一个用于启动子 worker 的循环以及一个等待所有子 worker 响应的处理器组成。
子 worker 的实现如下:
var start;
onmessage = getStart;
function getStart( event) {
start = 1 * event. data;
onmessage = getEnd;
}
var end;
function getEnd( event) {
end = 1 * event. data;
onmessage = null ;
work();
}
function work() {
var result = 0 ;
for ( var i = start; i < end; i += 1 ) {
// perform some complex calculation here
result += 1 ;
}
postMessage( result);
close();
}
它们通过两个事件接收两个数字,对由此指定的数字范围执行计算, 然后将结果报告给父 worker。
本节为非规范性内容。
假设有一个可用的密码学库,它提供以下三项任务:
该库本身如下:
function handleMessage( e) {
if ( e. data == "genkeys" )
genkeys( e. ports[ 0 ]);
else if ( e. data == "encrypt" )
encrypt( e. ports[ 0 ]);
else if ( e. data == "decrypt" )
decrypt( e. ports[ 0 ]);
}
function genkeys( p) {
var keys = _generateKeyPair();
p. postMessage( keys[ 0 ]);
p. postMessage( keys[ 1 ]);
}
function encrypt( p) {
var key, state = 0 ;
p. onmessage = function ( e) {
if ( state == 0 ) {
key = e. data;
state = 1 ;
} else {
p. postMessage( _encrypt( key, e. data));
}
};
}
function decrypt( p) {
var key, state = 0 ;
p. onmessage = function ( e) {
if ( state == 0 ) {
key = e. data;
state = 1 ;
} else {
p. postMessage( _decrypt( key, e. data));
}
};
}
// support being used as a shared worker as well as a dedicated worker
if ( 'onmessage' in this ) // dedicated worker
onmessage = handleMessage;
else // shared worker
onconnect = function ( e) { e. port. onmessage = handleMessage; }
// the "crypto" functions:
function _generateKeyPair() {
return [ Math. random(), Math. random()];
}
function _encrypt( k, s) {
return 'encrypted-' + k + ' ' + s;
}
function _decrypt( k, s) {
return s. substr( s. indexOf( ' ' ) + 1 );
}
请注意,此处的密码学函数只是存根,并不执行真正的密码学操作。
可以按如下方式使用此库:
<!DOCTYPE HTML>
< html lang = "en" >
< head >
< meta charset = "utf-8" >
< title > Worker example: Crypto library</ title >
< script >
const cryptoLib = new Worker( 'libcrypto-v1.js' ); // or could use 'libcrypto-v2.js'
function startConversation( source, message) {
const messageChannel = new MessageChannel();
source. postMessage( message, [ messageChannel. port2]);
return messageChannel. port1;
}
function getKeys() {
let state = 0 ;
startConversation( cryptoLib, "genkeys" ). onmessage = function ( e) {
if ( state === 0 )
document. getElementById( 'public' ). value = e. data;
else if ( state === 1 )
document. getElementById( 'private' ). value = e. data;
state += 1 ;
};
}
function enc() {
const port = startConversation( cryptoLib, "encrypt" );
port. postMessage( document. getElementById( 'public' ). value);
port. postMessage( document. getElementById( 'input' ). value);
port. onmessage = function ( e) {
document. getElementById( 'input' ). value = e. data;
port. close();
};
}
function dec() {
const port = startConversation( cryptoLib, "decrypt" );
port. postMessage( document. getElementById( 'private' ). value);
port. postMessage( document. getElementById( 'input' ). value);
port. onmessage = function ( e) {
document. getElementById( 'input' ). value = e. data;
port. close();
};
}
</ script >
< style >
textarea { display : block ; }
</ style >
</ head >
< body onload = "getKeys()" >
< fieldset >
< legend > Keys</ legend >
< p >< label > Public Key: < textarea id = "public" ></ textarea ></ label ></ p >
< p >< label > Private Key: < textarea id = "private" ></ textarea ></ label ></ p >
</ fieldset >
< p >< label > Input: < textarea id = "input" ></ textarea ></ label ></ p >
< p >< button onclick = "enc()" > Encrypt</ button > < button onclick = "dec()" > Decrypt</ button ></ p >
</ body >
</ html >
不过,API 的后续版本可能希望将所有密码学工作交给子 worker。 可以按如下方式实现:
function handleMessage( e) {
if ( e. data == "genkeys" )
genkeys( e. ports[ 0 ]);
else if ( e. data == "encrypt" )
encrypt( e. ports[ 0 ]);
else if ( e. data == "decrypt" )
decrypt( e. ports[ 0 ]);
}
function genkeys( p) {
var generator = new Worker( 'libcrypto-v2-generator.js' );
generator. postMessage( '' , [ p]);
}
function encrypt( p) {
p. onmessage = function ( e) {
var key = e. data;
var encryptor = new Worker( 'libcrypto-v2-encryptor.js' );
encryptor. postMessage( key, [ p]);
};
}
function encrypt( p) {
p. onmessage = function ( e) {
var key = e. data;
var decryptor = new Worker( 'libcrypto-v2-decryptor.js' );
decryptor. postMessage( key, [ p]);
};
}
// support being used as a shared worker as well as a dedicated worker
if ( 'onmessage' in this ) // dedicated worker
onmessage = handleMessage;
else // shared worker
onconnect = function ( e) { e. ports[ 0 ]. onmessage = handleMessage };
这些小型子 worker 如下所示。
用于生成密钥对:
onmessage = function ( e) {
var k = _generateKeyPair();
e. ports[ 0 ]. postMessage( k[ 0 ]);
e. ports[ 0 ]. postMessage( k[ 1 ]);
close();
}
function _generateKeyPair() {
return [ Math. random(), Math. random()];
}
用于加密:
onmessage = function ( e) {
var key = e. data;
e. ports[ 0 ]. onmessage = function ( e) {
var s = e. data;
postMessage( _encrypt( key, s));
}
}
function _encrypt( k, s) {
return 'encrypted-' + k + ' ' + s;
}
用于解密:
onmessage = function ( e) {
var key = e. data;
e. ports[ 0 ]. onmessage = function ( e) {
var s = e. data;
postMessage( _decrypt( key, s));
}
}
function _decrypt( k, s) {
return s. substr( s. indexOf( ' ' ) + 1 );
}
请注意,API 的用户甚至不必知道这一过程正在发生——API 并未发生变化;即使该库使用消息通道接收数据,它仍然可以在不更改其 API 的情况下 将工作委托给子 worker。
本节为非规范性内容。
创建 worker 需要一个指向 JavaScript 文件的 URL。调用 Worker() 构造函数时,将
该文件的 URL 作为其唯一
参数;随后会创建并返回一个 worker:
var worker = new Worker( 'helper.js' ); 如果希望将 worker 脚本解释为模块脚本,而不是 默认的经典脚本,则需要 使用稍有不同的签名:
var worker = new Worker( 'helper.mjs' , { type: "module" }); 本节为非规范性内容。
专用 worker 在底层使用 MessagePort 对象,
因此支持所有
相同的功能,例如发送结构化数据、传输二进制数据以及传输
其他端口。
要接收来自专用 worker 的消息,请使用 onmessage
事件处理器 IDL 属性,该属性位于
Worker 对象上:
worker. onmessage = function ( event) { ... }; 也可以使用 addEventListener()
方法。
专用 worker 所使用的隐式 MessagePort 在创建时,
其端口
消息队列会被隐式启用,因此
MessagePort
接口的 start()
方法在
Worker 接口上没有对应方法。
要向 worker 发送数据,请使用 postMessage()
方法。可以通过此
通信通道发送结构化数据。要高效发送 ArrayBuffer
对象
(通过传输而不是克隆它们),请在第二个
参数的数组中列出这些对象。
worker. postMessage({
operation: 'find-edges' ,
input: buffer, // an ArrayBuffer object
threshold: 0.6 ,
}, [ buffer]); 要在 worker 内部接收消息,需要使用 onmessage
事件处理器 IDL 属性。
onmessage = function ( event) { ... }; 同样也可以使用 addEventListener()
方法。
无论使用哪种方式,数据都由事件对象的 data
属性提供。
要发回消息,同样使用 postMessage()。
它以相同的
方式支持结构化数据。
postMessage( event. data. input, [ event. data. input]); // transfer the buffer back 所有当前引擎均支持。
本节为非规范性内容。
共享 worker 由用于创建它的脚本 URL 标识,也可以选择为其指定一个 显式名称。该名称允许启动某个特定共享 worker 的多个实例。
共享 worker 的作用域由源限定。两个不同 站点使用相同名称时 不会发生冲突。但是,如果一个页面尝试使用与同一站点上另一个页面相同的共享 worker 名称,但使用不同的脚本 URL,则会失败。
共享 worker 使用 SharedWorker()
构造函数创建。此构造函数将要使用的脚本 URL 作为第一个参数,并将
worker 的名称(如果有)作为第二个参数。
var worker = new SharedWorker( 'service.js' ); 与共享 worker 通信需要使用显式的 MessagePort 对象。由
SharedWorker() 构造函数返回的对象,在其
port 属性中保存着对端口的
引用。
worker. port. onmessage = function ( event) { ... };
worker. port. postMessage( 'some message' );
worker. port. postMessage({ foo: 'structured' , bar: [ 'data' , 'also' , 'possible' ]}); 在共享 worker 内部,会使用 connect
事件通知 worker 有新客户端。新客户端的端口
由事件对象的 source 属性提供。
onconnect = function ( event) {
var newPort = event. source;
// set up a listener
newPort. onmessage = function ( event) { ... };
// send a message back to the port
newPort. postMessage( 'ready!' ); // can also send structured data, of course
}; 本标准定义了两种 worker:专用 worker 和共享 worker。专用 worker 创建后会与其创建者关联,但可以使用消息端口从专用 worker 与多个其他浏览上下文或 worker 通信。另一方面,共享 worker 具有名称,创建后,在同一源中运行的任何脚本都可以 获取对该 worker 的引用并与其通信。Service Worker 定义了 第三种类型。[SW]
全局作用域是 worker 的“内部”。
WorkerGlobalScope 通用接口所有当前引擎均支持。
[Exposed =Worker ]
interface WorkerGlobalScope : EventTarget {
readonly attribute WorkerGlobalScope self ;
readonly attribute WorkerLocation location ;
readonly attribute WorkerNavigator navigator ;
undefined importScripts ((TrustedScriptURL or USVString )... urls );
attribute OnErrorEventHandler onerror ;
attribute EventHandler onlanguagechange ;
attribute EventHandler onoffline ;
attribute EventHandler ononline ;
attribute EventHandler onrejectionhandled ;
attribute EventHandler onunhandledrejection ;
};WorkerGlobalScope
作为特定类型 worker 全局
作用域对象的基类,包括 DedicatedWorkerGlobalScope、
SharedWorkerGlobalScope
和 ServiceWorkerGlobalScope。
一个 WorkerGlobalScope
对象具有关联的 所有者集合(一个由 Document 和 WorkerGlobalScope
对象组成的集合)。它
最初为空,并在创建或获取 worker 时填充。
它是一个集合,而不是单个所有者,以便
适应
SharedWorkerGlobalScope
对象。
一个 WorkerGlobalScope
对象具有关联的 类型(“classic”或“module”)。它在创建期间设置。
一个 WorkerGlobalScope
对象具有关联的 URL(null 或一个
URL)。它最初为
null。
一个 WorkerGlobalScope
对象具有关联的 名称(一个字符串)。它在创建期间设置。
名称对于 WorkerGlobalScope
的每个子类可以具有不同的
语义。对于
DedicatedWorkerGlobalScope
实例,它只是由开发者提供的名称,主要
用于调试。对于 SharedWorkerGlobalScope
实例,它允许
通过 SharedWorker()
构造函数获取对公共共享 worker 的引用。对于
ServiceWorkerGlobalScope
对象,它没有意义(因此根本不会通过
JavaScript API 暴露)。
一个 WorkerGlobalScope
对象具有关联的 策略容器(一个策略
容器)。它最初是一个新的策略容器。
一个 WorkerGlobalScope
对象具有关联的 嵌入器策略(一个嵌入器
策略)。
一个 WorkerGlobalScope
对象具有关联的 模块映射。它是一个模块映射,
最初为空。
一个 WorkerGlobalScope
对象具有关联的 跨源隔离
能力布尔值。它最初为 false。
workerGlobal.self
所有当前引擎均支持。
workerGlobal.location
所有当前引擎均支持。
WorkerLocation
对象。workerGlobal.navigator
所有当前引擎均支持。
WorkerNavigator
对象。workerGlobal.importScripts(...urls)
WorkerGlobalScope/importScripts
所有当前引擎均支持。
self 属性必须返回
WorkerGlobalScope
对象本身。
location 属性必须返回
WorkerLocation
对象,其关联的WorkerGlobalScope
对象是
该 WorkerGlobalScope
对象。
虽然 WorkerLocation
对象是在
WorkerGlobalScope
对象之后创建的,但这并不成问题,因为无法从
脚本中观察到这一点。
以下是实现
WorkerGlobalScope
接口的对象必须作为事件处理器 IDL 属性支持的事件
处理器(及其对应的事件处理器事件类型):
| 事件处理器 | 事件处理器事件类型 |
|---|---|
onerror
所有当前引擎均支持。 Firefox3.5+Safari4+Chrome4+
Opera11.5+Edge79+ Edge (Legacy)12+Internet Explorer10+ Firefox Android?Safari iOS5+Chrome Android?WebView Android?Samsung Internet?Opera Android? |
error
|
onlanguagechange
WorkerGlobalScope/languagechange_event 所有当前引擎均支持。 Firefox74+Safari4+Chrome4+
Opera11.5+Edge79+ Edge (Legacy)?Internet Explorer不支持 Firefox Android?Safari iOS5+Chrome Android?WebView Android37+Samsung Internet?Opera Android? |
languagechange
|
onoffline
WorkerGlobalScope/offline_event Firefox29+Safari8+Chrome不支持
Opera?Edge不支持 Edge (Legacy)?Internet Explorer不支持 Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? |
offline
|
ononline
WorkerGlobalScope/online_event Firefox29+Safari8+Chrome不支持
Opera?Edge不支持 Edge (Legacy)?Internet Explorer不支持 Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? |
online
|
onrejectionhandled |
rejectionhandled
|
onunhandledrejection |
unhandledrejection
|
DedicatedWorkerGlobalScope
接口所有当前引擎均支持。
[Global =(Worker ,DedicatedWorker ),Exposed =DedicatedWorker ]
interface DedicatedWorkerGlobalScope : WorkerGlobalScope {
[Replaceable ] readonly attribute DOMString name ;
undefined postMessage (any message , sequence <object > transfer );
undefined postMessage (any message , optional StructuredSerializeOptions options = {});
undefined close ();
};
DedicatedWorkerGlobalScope includes MessageEventTarget ;DedicatedWorkerGlobalScope
对象具有关联的 内部端口(一个
MessagePort)。
此端口是创建 worker 时所建立通道的一部分,
但不会被暴露。此对象绝不能先于
DedicatedWorkerGlobalScope
对象被垃圾回收。
dedicatedWorkerGlobal.name
DedicatedWorkerGlobalScope/name
所有当前引擎均支持。
dedicatedWorkerGlobal.postMessage(message [, transfer ])
DedicatedWorkerGlobalScope/postMessage
所有当前引擎均支持。
dedicatedWorkerGlobal.postMessage(message [, { transfer } ])
克隆 message,并将其传输到与
dedicatedWorkerGlobal 关联的 Worker
对象。可以将 transfer 作为对象列表传递,
这些对象将被传输而不是克隆。
dedicatedWorkerGlobal.close()
DedicatedWorkerGlobalScope/close
所有当前引擎均支持。
中止 dedicatedWorkerGlobal。
DedicatedWorkerGlobalScope
对象上的 postMessage(message,
transfer) 和 postMessage(message,
options) 方法的行为,
就如同它们在被调用时立即在端口上分别调用相应的 postMessage(message, transfer)
和 postMessage(message,
options),使用相同的参数,并返回相同的返回
值。
要在给定 workerGlobal 的情况下关闭 worker,请运行以下 步骤:
SharedWorkerGlobalScope
接口所有当前引擎均支持。
[Global =(Worker ,SharedWorker ),Exposed =SharedWorker ]
interface SharedWorkerGlobalScope : WorkerGlobalScope {
[Replaceable ] readonly attribute DOMString name ;
undefined close ();
attribute EventHandler onconnect ;
};对于每个连接,共享 worker 都会通过其 SharedWorkerGlobalScope
对象上的 connect
事件接收消息端口。
sharedWorkerGlobal.name
所有当前引擎均支持。
返回 sharedWorkerGlobal 的名称,即
传给
SharedWorker
构造函数的值。通过复用相同的
名称,多个 SharedWorker
对象可以对应于
同一个共享 worker(以及 SharedWorkerGlobalScope)。
sharedWorkerGlobal.close()
所有当前引擎均支持。
中止 sharedWorkerGlobal。
name 获取器步骤是返回
this 的名称。其
值
表示可以通过 SharedWorker
构造函数获取该 worker 引用时所使用的名称。
以下是实现
SharedWorkerGlobalScope
接口的对象必须作为事件处理器 IDL
属性支持的事件处理器(及其
对应的事件处理器事件
类型):
| 事件处理器 | 事件处理器事件 类型 |
|---|---|
onconnect
SharedWorkerGlobalScope/connect_event 所有当前引擎均支持。 Firefox29+Safari16+Chrome4+
Opera10.6+Edge79+ Edge (Legacy)?Internet Explorer不支持 Firefox Android?Safari iOS16+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
connect
|
worker 事件循环的任务队列仅将 事件、回调和网络活动作为任务。 这些worker 事件循环由 运行 worker算法创建。
每个 WorkerGlobalScope
对象都有一个 正在关闭
标志,该标志最初必须为
false,但可以由下方处理模型一节中的算法设置为 true。
一旦 WorkerGlobalScope 的正在关闭标志被
设置为 true,事件
循环的任务队列必须丢弃任何
后续会添加到其中的任务(队列中
已存在的任务不受影响,除非另有规定)。实际上,一旦正在关闭标志为
true,计时器就会停止触发,
所有待处理后台操作的通知都会被丢弃,等等。
Worker 通过消息通道及其 MessagePort
对象与其他 worker 以及 Window 通信。
每个 WorkerGlobalScope
对象 worker global scope 都有一个
worker 的端口列表,其中包含所有与另一个端口纠缠,且
恰好有一个端口由 worker
global scope 所有的 MessagePort 对象。
对于专用
worker,此列表包括隐式的 MessagePort。
在创建或获取 worker 时,给定一个环境设置
对象 o,要添加的相关所有者取决于
o 指定的全局
对象类型。如果 o 的全局对象是一个 WorkerGlobalScope
对象(即我们正在创建一个嵌套专用 worker),则相关所有者为该
全局对象。否则,o 的全局
对象是一个 Window 对象,而
相关所有者是该
Window 的关联
Document。
用户代理有一个由实现定义的值,即加载间共享 worker 超时,它是一小段时间。该值表示用户代理允许共享 worker 在页面加载期间存活多长时间,以防该页面将再次联系 共享 worker。将此值设置为大于零,可使用户代理避免在用户于 同一站点内从一个页面导航到另一个页面时,重新启动该站点所使用共享 worker 的 成本。
加载间共享 worker 超时的典型值可能是 5 秒。
用户代理有一个由实现定义的值,即延长生命周期的 共享 worker 超时,它是一段时间。该值表示用户代理允许 Web 开发者请求获得 延长生命周期的共享 worker,在其所有所有者都 消失后继续存活并执行工作的时长。用户代理应该选择一个等于 service worker 在没有任何客户端时所能存活的最长时长的值,并且 不得选择长于该时长的值。
延长生命周期的共享 worker 超时的典型值 可以 在 10 秒到 5 分钟之间,具体取决于实现对于某个源在没有用户可见表示的情况下 执行后台工作的具体策略。
如果以下算法返回 true,则 WorkerGlobalScope
global 处于延长生命周期中:
如果 global 不是 SharedWorkerGlobalScope,
则返回
false。
如果 global 的延长生命周期为 false, 则返回 false。
如果 global 的所有者集合为 空,但其为空的时长小于用户代理的延长生命周期的共享 worker 超时,则返回 true。
如果 owner 是一个 Document,并且
owner 处于非完全
活动状态的时长小于用户代理的
延长生命周期的共享 worker
超时,则返回 true。
如果 owner 是一个 WorkerGlobalScope,
且其处于
延长生命周期中,则返回 true。
返回 false。
如果以下算法返回 true,则 WorkerGlobalScope
global 是活动所需的:
如果 global 处于延长 生命周期中,则返回 true。
如果 owner 是一个 WorkerGlobalScope,
且其是活动
所需的,则返回 true。
返回 false。
如果以下算法返回 true,则 WorkerGlobalScope
global 是受保护的:
如果 global 不是活动所需的, 则返回 false。
如果 global 处于延长 生命周期中,则返回 true。
如果 global 是一个 SharedWorkerGlobalScope,
则返回 true。
如果 global 有未完成的计时器、数据库事务或网络 连接,则返回 true。
返回 false。
如果以下算法返回 true,则 WorkerGlobalScope
global 是允许存在的:
如果 global 处于延长 生命周期中,则返回 true。
如果以下所有条件均为 true:
global 是一个 SharedWorkerGlobalScope;
global 的所有者集合为空的时长不超过用户代理的加载间共享 worker 超时;并且
则返回 true。
返回 false。
这些术语之间存在以下关系:
每个处于
延长生命周期中的 WorkerGlobalScope
都是活动
所需、受保护且允许存在的。
每个活动
所需或受保护的 WorkerGlobalScope
都是允许存在的。
每个受保护的 WorkerGlobalScope
都是活动所需的。
但是,反过来并不总是成立:
一个 WorkerGlobalScope
可以是活动
所需但不受保护的;
例如,它是一个没有未完成异步工作的专用
worker,仍在代表一个完全活动的所有者执行计算,但其对应的 Worker
对象已被垃圾回收。由于垃圾回收,端口集合为空,因此
它不再受保护。
但是,其事件循环尚未让出执行权以清空其
所有者集合,因此它仍是
活动所需的。
一个 WorkerGlobalScope
可以是允许存在但不受保护,也不是活动所需的;
例如,其传递所有者集合中的所有 Document 都处于
往返缓存中,或者它是一个
SharedWorkerGlobalScope,
当前没有所有者,但在加载间共享 worker 超时期间仍被保持存活。
如果以下算法返回 true,则 WorkerGlobalScope
global 是可暂停的:
这些概念在本规范其他位置的规范性要求中按如下方式 使用:
Worker 会在不再受保护到不再允许存在之间的某个时刻,被作为孤立 worker 关闭。
已关闭但仍继续执行的 worker,一旦不再是活动 所需的,就可以由用户代理酌情终止。
当用户代理要为一个具有 Worker 或
SharedWorker 对象
worker、URL url、
环境
设置对象 outside settings、MessagePort
outside port 和 WorkerOptions 字典
options 的脚本运行 worker 时,必须
运行以下步骤:
如果 worker 是一个 SharedWorker
对象,则令 is shared 为 true;否则为 false。
令 owner 为给定 outside settings 时要添加的相关所有者。
令 unsafeWorkerCreationTime 为不安全的共享当前 时间。
令 agent 为在给定 outside settings 和 is shared 的情况下获取专用/共享 worker 代理的结果。在该代理中运行其余步骤。
令 realm execution context 为在给定 agent 和以下自定义项的情况下创建新 realm的结果:
对于全局对象,如果 is shared 为 true,则创建一个新的
SharedWorkerGlobalScope
对象。否则,创建一个新的
DedicatedWorkerGlobalScope
对象。
令 worker global scope 为 realm execution context 的 Realm 组件的全局 对象。
这是上一步创建的 DedicatedWorkerGlobalScope
或
SharedWorkerGlobalScope
对象。
使用 realm execution context、outside settings 和 unsafeWorkerCreationTime 设置 worker 环境 设置对象,并令结果为 inside settings。
如果 is shared 为 true:
将 worker global scope 的构造函数存储 键 设置为在给定 outside settings 的情况下,运行获取用于非存储 目的的存储键的结果。
将 worker global scope 的构造函数 URL设置为 url。
将 worker global scope 的凭据设置为
options["credentials"]。
将 worker global scope 的延长的生命周期设置为
options["extendedLifetime"]。
如果 is
shared 为 true,则令 destination 为“sharedworker”;否则为
“worker”。
根据 options["type"] 的值
获取 script:
classic"module"credentials
成员值、inside settings,以及下方定义的 onComplete 和
performFetch 的情况下,获取模块 worker 脚本图。
在两种情况下,令 performFetch 为以下执行获取钩子,给定 request、 isTopLevel 和 processCustomFetchResponse:
如果 isTopLevel 为 false,则使用设置为 processCustomFetchResponse 的 processResponseConsumeBody 获取 request,并中止这些步骤。
使用设置为以下步骤的 processResponseConsumeBody 获取 request; 给定响应 response,以及 null、failure 或一个字节序列 bodyBytes:
在给定 worker global scope、response 和 inside settings 的情况下,初始化 worker 全局作用域的 策略容器。
如果在 worker global scope 上执行为全局
对象运行 CSP 初始化算法时返回
“Blocked”,则将
response 设置为一个网络
错误。[CSP]
如果 worker global scope 的嵌入器策略的值与跨源
隔离兼容,且 is shared 为 true,则将 agent 的代理
集群的跨源隔离
模式设置为“logical”
或“concrete”。
所选择的值
由实现定义。
实际上应当在创建代理集群时设置这一项,而这需要 重新设计本节。
如果使用 worker global scope、outside settings 和 response 检查 全局对象的嵌入器策略所得结果为 false,则将 response 设置为一个 网络 错误。
如果 agent 的代理
集群的跨源隔离模式
为“concrete”,
则将 worker global scope 的跨源
隔离
能力设置为 true。
如果 is shared 为 false,并且 owner 的跨源 隔离 能力为 false,则将 worker global scope 的跨源 隔离 能力设置为 false。
如果 is shared 为 false,并且 response 的
URL的方案为
“data”,则将
worker global scope 的跨源
隔离
能力设置为 false。
在确定一般 worker,尤其是 data:
URL worker(它们与其所有者跨源),在权限策略上下文中将如何处理之前,
目前这是一个保守的默认值。更多详情请参阅
w3c/webappsec-permissions-policy
issue #207。
使用 response 和 bodyBytes 运行 processCustomFetchResponse。
在两种情况下,令给定 script 的 onComplete 为以下步骤:
如果 script 为 null,或者 script 的要重新抛出的错误非 null:
将 worker 与 worker global scope 关联。
令 inside port 为 inside settings 的realm中的一个新
MessagePort 对象。
如果 is shared 为 false:
纠缠 outside port 和 inside port。
创建一个新的 WorkerLocation 对象,
并将其与 worker global
scope 关联。
关闭孤立 worker:开始监视 worker global scope,使其在不再受保护之后不早于该时刻,并且在不再允许存在之前不晚于该时刻, 将 worker global scope 的正在关闭标志设置为 true。
暂停 worker:开始监视 worker global scope,使得每当 worker global scope 的正在关闭标志为 false,且其可暂停时,用户 代理就暂停 worker global scope 中脚本的执行,直到正在关闭标志变为 true,或 worker global scope 不再可暂停。
设置 inside settings 的执行就绪标志。
如果 script 是一个经典 脚本,则运行 经典脚本 script。否则,它是一个模块 脚本;运行 模块脚本 script。
启用 outside port 的端口消息队列。
如果 is shared 为 false,则启用 worker 隐式端口的端口消息队列。
如果 is shared 为 true,则在给定 worker global scope 的情况下,在DOM
操作任务源上排入一个全局任务,以使用
MessageEvent
在 worker global scope 上触发一个事件,其名称为
connect,
并将
data
属性
初始化为空字符串,将 ports
属性
初始化为一个包含 inside port 的新冻结
数组,并将 source
属性初始化为 inside
port。
启用
ServiceWorkerContainer
对象的客户端
消息队列,该对象关联的service worker 客户端是
worker global scope 的相关设置对象。
事件循环:运行由 inside settings 指定的负责的 事件循环,直到其被销毁。
由事件循环运行的任务对事件的处理或回调的执行,可能会被下方定义的终止 worker算法提前中止。
Worker 处理模型会停留在此步骤,直到事件循环 被销毁;按照事件循环处理模型中的描述,这发生在正在关闭 标志被设置为 true 之后。
解除worker 的端口列表中所有端口的纠缠。
当用户代理要终止 worker时,必须与 worker 的主循环 (上方定义的“运行 worker”处理 模型)并行运行以下步骤:
将 worker 的 WorkerGlobalScope
对象的正在关闭标志设置为 true。
如果
WorkerGlobalScope
对象的相关代理的事件循环的任务
队列中有任何已排队的任务,则丢弃它们而不进行处理。
中止 worker 中当前正在运行的 脚本。
如果 worker 的 WorkerGlobalScope
对象实际上是一个
DedicatedWorkerGlobalScope
对象(即 worker 是一个专用 worker),则
清空与 worker 隐式端口纠缠的端口的端口消息
队列。
当 worker 不再是活动所需的,并且 即使其正在关闭标志已设置为 true, 该 worker 仍继续执行时,用户代理可以调用终止 worker 算法。
每当 worker 的某个脚本中发生未捕获的运行时脚本错误时,如果该错误
并非在处理前一个脚本错误时发生,则用户代理将为 worker 的 WorkerGlobalScope 对象报告该错误。
AbstractWorker 混入
interface mixin AbstractWorker {
attribute EventHandler onerror ;
};以下是实现
AbstractWorker 接口的
对象必须作为事件处理器
IDL 属性支持的事件处理器
(及其对应的事件处理器事件类型):
| 事件处理器 | 事件处理器 事件类型 |
|---|---|
onerror
所有当前引擎均支持。 Firefox44+Safari11.1+Chrome40+
Opera?Edge79+ Edge (Legacy)17+Internet Explorer不支持 Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? 所有当前引擎均支持。 Firefox29+Safari16+Chrome5+
Opera10.6+Edge79+ Edge (Legacy)?Internet Explorer不支持 Firefox Android33+Safari iOS16+Chrome Android不支持WebView Android?Samsung Internet4.0–5.0Opera Android11–14 所有当前引擎均支持。 Firefox3.5+Safari4+Chrome4+
Opera10.6+Edge79+ Edge (Legacy)12+Internet Explorer10+ Firefox Android?Safari iOS5+Chrome Android?WebView Android?Samsung Internet?Opera Android11+ |
error
|
要在给定一个JavaScript 执行 上下文 execution context、一个环境设置对象 outside settings 和一个数值 unsafeWorkerCreationTime 的情况下,设置 worker 环境设置对象:
令 realm 为 execution context 的 Realm 组件值。
令 worker global scope 为 realm 的全局对象。
如果 worker global scope 的URL的方案为“data”,则令
origin 为一个唯一的不透明源;否则为
outside settings 的源。
令 settings object 为一个新的环境设置对象,其 算法定义如下:
将 settings object 的ID设置为一个新的 唯一不透明字符串,将创建 URL设置为 worker global scope 的 URL,将顶层创建 URL设置为 null, 将目标浏览上下文设置为 null,并将活动 service worker 设置为 null。
如果 worker global scope 是一个 DedicatedWorkerGlobalScope
对象,
则将 settings object 的顶层源设置为 outside
settings 的顶层源。
否则,将 settings object 的顶层源设置为一个 由实现定义的值。
有关正确定义此项的最新进展,请参阅客户端 存储分区。
将 realm 的 [[HostDefined]] 字段设置为 settings object。
返回 settings object。
Worker 接口
所有当前引擎均支持。
[Exposed =(Window ,DedicatedWorker ,SharedWorker )]
interface Worker : EventTarget {
constructor ((TrustedScriptURL or USVString ) scriptURL , optional WorkerOptions options = {});
undefined terminate ();
undefined postMessage (any message , sequence <object > transfer );
undefined postMessage (any message , optional StructuredSerializeOptions options = {});
};
dictionary WorkerOptions {
DOMString name = "";
WorkerType type = "classic";
RequestCredentials credentials = "same-origin"; // credentials is only used if type is "module"
};
enum WorkerType { "classic" , "module" };
Worker includes AbstractWorker ;
Worker includes MessageEventTarget ;worker = new Worker(scriptURL [, options ])
所有当前引擎均支持。
返回一个新的 Worker 对象。
scriptURL 将在后台获取并执行,
创建一个新的全局环境,而 worker 表示该全局环境的
通信通道。
options 可以包含以下值:
可以将 type
设置为值“module”,以将来自 scriptURL 的新
全局环境作为 JavaScript 模块加载。
credentials
可用于指定如何获取 scriptURL,但仅当 type
设置为“module”时才可以。
worker.terminate()
所有当前引擎均支持。
worker.postMessage(message [, transfer ])
所有当前引擎均支持。
worker.postMessage(message [, { transfer } ])
克隆 message,并将其传输到 worker 的全局环境。 可以将 transfer 作为要被传输而不是 克隆的对象列表传递。
每个 Worker 对象都有
一个关联的 外部端口(一个
MessagePort)。
此端口是创建 worker 时所建立通道的一部分,
但不会被暴露。此对象绝不能先于
Worker 对象被垃圾回收。
Worker 对象上的
postMessage(message, transfer)
和 postMessage(message,
options) 方法的行为,就如同它们在被调用时,
立即在 this 的外部端口上分别调用相应的 postMessage(message, transfer)
和 postMessage(message,
options),使用相同的
参数,并返回相同的返回值。
postMessage()
方法的第一个参数可以是结构化数据:
worker. postMessage({ opcode: 'activate' , device: 1938 , parameters: [ 23 , 102 ]}); new Worker(scriptURL,
options) 构造函数的步骤是:
令 compliantScriptURL 为使用 TrustedScriptURL、
this 的相关全局
对象、scriptURL、“Worker constructor”和“script”
调用获取符合可信类型要求的字符串算法所得的结果。
令 workerURL 为相对于 outsideSettings,在给定 compliantScriptURL 的情况下对 URL 进行编码解析所得的结果。
可以使用任何同源
URL(包括 blob:
URL)。也可以使用 data:
URL,但它们会创建一个具有不透明源的 worker。
如果 workerURL 为 failure,则抛出一个 “SyntaxError”
DOMException。
令 outsidePort 为
outsideSettings 的realm中的一个新 MessagePort。
令 worker 为 this。
并行运行此步骤:
在给定 worker、workerURL、 outsideSettings、outsidePort 和 options 的情况下,运行 worker。
SharedWorker 接口
所有当前引擎均支持。
[Exposed =Window ]
interface SharedWorker : EventTarget {
constructor ((TrustedScriptURL or USVString ) scriptURL , optional (DOMString or SharedWorkerOptions ) options = {});
readonly attribute MessagePort port ;
};
SharedWorker includes AbstractWorker ;
dictionary SharedWorkerOptions : WorkerOptions {
boolean extendedLifetime = false ;
};sharedWorker = new SharedWorker(scriptURL [, name ])
所有当前引擎均支持。
返回一个新的 SharedWorker
对象。scriptURL 将在后台获取并
执行,从而创建一个新的全局环境,而 sharedWorker
表示与该全局环境通信的通道。name 可用于定义该全局环境的名称。
sharedWorker = new SharedWorker(scriptURL [, options ])
返回一个新的 SharedWorker
对象。scriptURL 将在后台获取并
执行,从而创建一个新的全局环境,而 sharedWorker
表示与该全局环境通信的通道。
options 可以包含以下值:
可以将 type
设置为值
“module”,以将来自 scriptURL 的新全局
环境作为 JavaScript 模块加载。
credentials
可用于指定
如何获取 scriptURL,但仅当 type
设置为“module”时才可以。
可以设置 extendedLifetime,
以请求为新创建的全局环境提供额外时间,使其即使在所有所有者都
消失后仍能执行其操作。例如,这
可用于在页面卸载后执行异步工作。
请注意,如果尝试使用 options 构造共享 worker,
而其中的 type、
credentials
或 extendedLifetime
值与具有相同构造函数
URL 和名称的现有共享 worker
的相应值不匹配,则返回的
sharedWorker 将触发一个 error 事件,
并且不会连接
到现有共享 worker。
sharedWorker.port
所有当前引擎均支持。
返回 sharedWorker 的 MessagePort
对象,该对象可用于
与全局环境通信。
用户代理具有关联的共享 worker 管理器,它是启动新并行 队列的结果。
为简单起见,每个用户代理只有一个共享 worker 管理器。 实现也可以为每个源使用一个;这不会产生可观察到的 差异,并且 能够实现更多并发。
每个 SharedWorker
都有一个端口,它是一个
MessagePort,
在创建该对象时设置。
new
SharedWorker(scriptURL, options) 构造函数的步骤是:
令 compliantScriptURL 为使用 TrustedScriptURL、
this 的相关全局
对象、scriptURL、“SharedWorker constructor”和
“script”调用获取符合可信类型要求的字符串算法所得的结果。
如果 options 是一个 DOMString,
则将
options 设置为一个新的 WorkerOptions
字典,其 name
成员设置为 options 的值,
其他成员设置为各自的默认值。
令 urlRecord 为相对于 outsideSettings,在给定 compliantScriptURL 的情况下对 URL 进行编码解析所得的结果。
可以使用任何同源 URL(包括 blob:
URL)。也可以使用 data:
URL,但它们会创建一个具有不透明源的 worker。
如果 urlRecord 为 failure,则抛出一个 “SyntaxError”
DOMException。
令 outsidePort 为
outsideSettings 的realm中的一个新 MessagePort。
如果 outsideSettings 是一个安全 上下文,则令 callerIsSecureContext 为 true;否则为 false。
令 outsideStorageKey 为在给定 outsideSettings 的情况下运行为非存储用途获取 存储键所得的结果。
令 worker 为 this。
将以下步骤排入共享 worker 管理器:
令 workerGlobalScope 为 null。
对于所有
SharedWorkerGlobalScope
对象列表中的每个
scope:
如果以下所有条件均为 true:
name"],
则:
将 workerGlobalScope 设置为 scope。
中断。
data:
URL 会创建具有不透明源的工作者,如果使用该工作者自身的存储键,
就会导致这样的工作者
永远无法匹配。取而代之的是,会比较构造函数
存储
键(派生自创建环境)和构造函数
URL,
因此可以在一个存储
键内使用相同的 data:
URL 来获取同一个 SharedWorkerGlobalScope
对象,但不能使用它
来绕过存储键
限制。
如果 workerGlobalScope 非 null,但用户代理已被配置为 禁止由 workerGlobalScope 表示的 worker 与设置 对象为 outsideSettings 的脚本之间进行通信, 则将 workerGlobalScope 设置为 null。
例如,用户代理可以具有一种开发模式,将某个特定的顶级可遍历对象与 所有其他页面隔离,并且可以阻止该 开发模式中的脚本连接到在普通浏览器模式中运行的共享 worker。
如果 workerGlobalScope 非 null,并且以下任一条件为 true:
workerGlobalScope 的凭据
不等于
options["credentials"];
或者
workerGlobalScope 的延长
生命周期不
等于 options["extendedLifetime"],
则:
在给定 worker 的相关全局
对象的情况下,在DOM 操作
任务源上排入一个全局任务,
以在 worker 上触发一个事件,其名称为 error。
中止这些步骤。
如果 workerGlobalScope 非 null:
令 insideSettings 为 workerGlobalScope 的相关 设置对象。
如果 insideSettings 是一个安全 上下文,则令 workerIsSecureContext 为 true;否则为 false。
如果 workerIsSecureContext 不等于 callerIsSecureContext:
将 worker 与 workerGlobalScope 关联。
令 insidePort 为
insideSettings 的realm中的一个新 MessagePort。
纠缠 outsidePort 和 insidePort。
在给定 workerGlobalScope 的情况下,在DOM 操作
任务源上排入一个全局任务,
以使用 MessageEvent
在
workerGlobalScope 上触发一个事件,
其名称为 connect,
并将 data
属性初始化为空字符串,将
ports
属性初始化为一个仅包含 insidePort 的新冻结
数组,并将 source
属性初始化为
insidePort。
将给定 outsideSettings 时要添加的相关所有者追加到 workerGlobalScope 的所有者 集合。
否则,并行地,在给定 worker、 urlRecord、outsideSettings、outsidePort 和 options 的情况下运行 worker。
interface mixin NavigatorConcurrentHardware {
readonly attribute unsigned long long hardwareConcurrency ;
};self.navigator.hardwareConcurrency
返回用户代理可能可用的逻辑处理器数量。
![]()
navigator.hardwareConcurrency 属性的
获取器必须返回一个介于 1 与用户代理可能可用的逻辑处理器数量之间的数值。
如果无法确定,则获取器必须返回 1。
用户代理应该倾向于公开可用逻辑处理器的数量,仅在存在用户代理特定限制 (例如对可创建的 worker 数量的限制) 或用户代理希望限制指纹识别可能性时,才使用较低的 数值。
importScripts(...urls)
方法的步骤是:
令 urlStrings 为 « »。
对于 urls 中的每个 url:
使用 TrustedScriptURL、
this 的相关全局
对象、url、“WorkerGlobalScope importScripts”和
“script”调用获取
符合可信类型要求的字符串算法,并将结果追加到
urlStrings。
在给定 this 和 urlStrings 的情况下,将脚本导入 worker 全局作用域。
要在给定一个
WorkerGlobalScope
对象 worker global scope、一个由标量值
字符串 urls 组成的列表,以及一个可选的执行获取钩子
performFetch 的情况下,将脚本导入 worker 全局
作用域:
令 settings object 为当前设置对象。
如果 urls 为空,则返回。
令 urlRecords 为 « »。
对于 urls 中的每个 url:
令 urlRecord 为相对于 settings object,在给定 url 的情况下对 URL 进行编码解析所得的结果。
如果 urlRecord 为 failure,则抛出一个 “SyntaxError”
DOMException。
将 urlRecord 追加到 urlRecords。
对于 urlRecords 中的每个 urlRecord:
Service Worker 是一个使用其自身的执行获取 钩子运行此算法的规范示例。[SW]
WorkerNavigator 接口所有当前引擎均支持。
WorkerGlobalScope
接口的 navigator 属性必须返回一个
WorkerNavigator
接口实例,该实例表示用户代理
(客户端)的身份和状态:
[Exposed =Worker ]
interface WorkerNavigator {};
WorkerNavigator includes NavigatorID ;
WorkerNavigator includes NavigatorLanguage ;
WorkerNavigator includes NavigatorOnLine ;
WorkerNavigator includes NavigatorConcurrentHardware ;WorkerLocation 接口所有当前引擎均支持。
所有当前引擎均支持。
[Exposed =Worker ]
interface WorkerLocation {
stringifier readonly attribute USVString href ;
readonly attribute USVString origin ;
readonly attribute USVString protocol ;
readonly attribute USVString host ;
readonly attribute USVString hostname ;
readonly attribute USVString port ;
readonly attribute USVString pathname ;
readonly attribute USVString search ;
readonly attribute USVString hash ;
};一个 WorkerLocation 对象具有关联的
WorkerGlobalScope 对象(一个
WorkerGlobalScope 对象)。
所有当前引擎均支持。
href
获取器步骤是返回 this
的
WorkerGlobalScope
对象的URL的序列化结果。
所有当前引擎均支持。
origin 获取器步骤是返回 this 的WorkerGlobalScope 对象的
URL的源的序列化结果。
所有当前引擎均支持。
protocol 获取器步骤是返回
this 的WorkerGlobalScope 对象的
URL的方案,后跟“:”。
所有当前引擎均支持。
host
获取器步骤是:
所有当前引擎均支持。
hostname 获取器步骤是:
令 host 为 this 的WorkerGlobalScope 对象的
URL的主机。
如果 host 为 null,则返回空字符串。
返回 host 的序列化结果。
所有当前引擎均支持。
port
获取器步骤是:
令 port 为 this 的WorkerGlobalScope 对象的
URL的端口。
如果 port 为 null,则返回空字符串。
返回 port 的序列化结果。
所有当前引擎均支持。
pathname 获取器步骤是返回对 this 的WorkerGlobalScope 对象的
URL执行URL 路径序列化所得的结果。
所有当前引擎均支持。
search 获取器步骤是:
令 query 为 this 的WorkerGlobalScope 对象的
URL的查询。
如果 query 为 null 或空字符串,则返回空字符串。
返回“?”,后跟 query。
所有当前引擎均支持。
hash
获取器步骤是:
令 fragment 为 this 的WorkerGlobalScope 对象的
URL的片段。
如果 fragment 为 null 或空字符串,则返回空字符串。
返回“#”,后跟 fragment。
本节为非规范性内容。
Worklet 是一项规范基础设施,可用于独立于主 JavaScript 执行环境运行脚本, 同时不要求采用任何特定的实现模型。
Web 开发者无法直接使用此处规定的 worklet 基础设施。其他规范会 在其基础上创建可直接使用的 worklet 类型,这些类型专门用于 在浏览器实现管线的特定部分中运行。
本节为非规范性内容。
为渲染或实现管线中其他敏感部分(例如音频输出)提供扩展点
很困难。如果扩展点能够完全访问 Window 上可用的 API,引擎就必须
放弃先前对这些阶段中间可能发生之事所作的假设。例如,在布局阶段,渲染
引擎假定不会修改 DOM。
此外,在 Window 环境中定义扩展点,会限制
用户代理只能在与 Window 对象相同的线程中执行工作。(除非
实现添加复杂且开销较高的基础设施,以允许线程安全的 API,并
提供线程合并保证。)
Worklet 旨在允许扩展点,同时保留用户代理
当前所依赖的保证。这通过基于
WorkletGlobalScope
子类的新全局环境来实现。
Worklet 与 Web worker 类似。但是,它们:
与线程无关。也就是说,它们并非像每个 worker 那样,设计为在专用的独立线程中 运行。实现可以选择在任何位置运行 worklet(包括主 线程)。
可以为实现并行性而创建全局作用域的多个重复实例。
不使用基于事件的 API。相反,会在全局作用域上注册类,并由 用户代理调用其方法。
全局作用域上的 API 表面积更小。
由于 worklet 的开销相对较高,最好谨慎使用。因此,给定的
WorkletGlobalScope
预计会由多个独立脚本共享。(这
类似于单个 Window 由多个独立脚本共享的方式。)
Worklet 是一种服务于不同用例的通用技术。某些 worklet,例如 CSS Painting API 中定义的 worklet,提供用于无状态、 幂等且短时间运行的计算的扩展点,这些计算具有接下来几节中描述的特殊注意事项。 其他 worklet,例如 Web Audio API 中定义的 worklet,则用于 有状态且长时间运行的操作。[CSSPAINT] [WEBAUDIO]
某些使用 worklet 的规范旨在允许用户代理在多个线程之间并行执行工作, 或根据需要在线程之间移动工作。在这些规范中,用户 代理可能会以由实现定义的顺序调用 Web 开发者所提供类上的方法。
因此,为防止互操作性问题,在此类
WorkletGlobalScope
上注册类的作者,应该使其代码具有幂等性。也就是说,对于特定输入,类上的一个方法或一组
方法应该产生相同的输出。
本规范使用以下技术,鼓励作者以 幂等方式编写代码:
无法获得对全局对象的引用(即 WorkletGlobalScope
上没有与 self
对应的成员)。
尽管这是最初规定 worklet 时的意图,但
globalThis 的引入使其不再成立。更多讨论请参阅issue #6059。
代码作为模块脚本加载,
这会使代码以严格模式执行,并且不存在引用全局
代理的共享 this。
这些限制共同帮助防止两个不同的脚本通过 全局对象的属性共享状态。
此外,使用 worklet 并打算允许 由实现定义行为的规范,必须遵守以下要求:
它们必须要求用户代理始终为每个 Worklet 至少设置两个 WorkletGlobalScope
实例,并将类上的一个方法或一组方法随机分配给
某个特定的 WorkletGlobalScope
实例。这些规范可以在内存受限的情况下提供
退出机制。
这些规范必须允许用户代理随时创建和销毁其
WorkletGlobalScope
子类的实例。
某些使用 worklet 的规范可以根据用户代理的状态,调用 Web 开发者所提供类上的方法。为提高线程之间的并发性,用户代理可以 根据可能的未来状态推测性地调用方法。
在这些规范中,用户代理可以随时使用任何 参数调用此类方法,而不仅限于与用户代理当前状态相对应的参数。此类 推测性求值的结果不会立即显示,但可以缓存起来,以便在用户代理 状态与推测状态相符时使用。这可以提高用户代理与 worklet 线程之间的并发性。
因此,为防止用户代理之间的互操作性风险,在此类 WorkletGlobalScope
上注册类的作者应该使其代码无状态。也就是说,
调用方法的唯一效果应该是其结果,而不应产生更新可变状态等
副作用。
鼓励代码幂等性的相同技术也会 鼓励作者编写无状态代码。
本节为非规范性内容。
对于这些示例,我们将使用一个虚构的 worklet。Window 对象提供两个
Worklet 实例,每个实例都在其
自己的
FakeWorkletGlobalScope
集合中运行代码:
partial interface Window {
[SameObject , SecureContext ] readonly attribute Worklet fakeWorklet1 ;
[SameObject , SecureContext ] readonly attribute Worklet fakeWorklet2 ;
};每个 Window 都有两个 Worklet 实例,即 虚构
worklet 1 和 虚构 worklet 2。两者的worklet
全局作用域类型均设置为 FakeWorkletGlobalScope,
并且其worklet
目标类型设置为“fakeworklet”。用户代理应该为每个
worklet 至少创建两个 FakeWorkletGlobalScope
实例。
根据 Fetch,“fakeworklet”实际上不是有效的目标。
但这说明了真正的 worklet 通常如何具有其自身特定于 worklet 类型的目标。
[FETCH]
fakeWorklet1 获取器步骤是返回
this 的虚构 worklet 1。
fakeWorklet2 获取器步骤是返回
this 的
虚构 worklet 2。
[Global =(Worklet ,FakeWorklet ),
Exposed =FakeWorklet ,
SecureContext ]
interface FakeWorkletGlobalScope : WorkletGlobalScope {
undefined registerFake (DOMString type , Function classConstructor );
};每个 FakeWorkletGlobalScope
都有一个已注册类构造函数映射,
它是一个有序映射,最初为空。
registerFake(type, classConstructor) 方法的
步骤是,将 this 的已注册类构造函数
映射[type] 设置为 classConstructor。
本节为非规范性内容。
要将脚本加载到虚构 worklet 1 中, Web 开发者可以编写:
window. fakeWorklet1. addModule( 'script1.mjs' );
window. fakeWorklet1. addModule( 'script2.mjs' ); 请注意,哪个脚本先完成获取并先运行取决于网络时序:可能是
script1.mjs,也可能是 script2.mjs。如果为加载到 worklet 中而编写良好的脚本
遵循关于为推测性
求值做好准备的建议,这通常不会产生影响。
如果 Web 开发者希望仅在脚本成功运行并 加载到某些 worklet 中之后执行任务,可以编写:
Promise. all([
window. fakeWorklet1. addModule( 'script1.mjs' ),
window. fakeWorklet2. addModule( 'script2.mjs' )
]). then(() => {
// Do something which relies on those scripts being loaded.
}); 关于脚本加载的另一个要点是,已加载的脚本可以在每个
Worklet 的多个
WorkletGlobalScope
中运行,正如代码幂等性一节所讨论的那样。特别是,上方有关虚构 worklet 1 和虚构 worklet 2 的规范要求这样做。因此,
请考虑如下
场景:
// script.mjs
console. log( "Hello from a FakeWorkletGlobalScope!" ); // app.mjs
window. fakeWorklet1. addModule( "script.mjs" ); 这可能会使用户代理的控制台产生如下输出:
[fakeWorklet1#1] Hello from a FakeWorkletGlobalScope!
[fakeWorklet1#4] Hello from a FakeWorkletGlobalScope!
[fakeWorklet1#2] Hello from a FakeWorkletGlobalScope!
[fakeWorklet1#3] Hello from a FakeWorkletGlobalScope!如果用户代理在某个时刻决定终止并重新启动
FakeWorkletGlobalScope
的第三个实例,则发生此情况时,控制台将再次输出
[fakeWorklet1#3] Hello from a FakeWorkletGlobalScope!。
本节为非规范性内容。
假设 Web 开发者对虚构 worklet 的一个预期用途是允许 他们自定义高度复杂的布尔取反过程。他们可以按如下方式注册其 自定义项:
// script.mjs
registerFake( 'negation-processor' , class {
process( arg) {
return ! arg;
}
}); // app.mjs
window. fakeWorklet1. addModule( "script.mjs" ); 为了使用此类已注册的类,虚构 worklet 的规范可以定义一个求 true 的相反值算法,给定一个
Worklet
worklet:
可选地,为 worklet 创建 worklet 全局作用域。
令 classConstructor 为 workletGlobalScope 的已注册类
构造函数映射["negation-processor"]。
令 classInstance 为不带参数构造 classConstructor 所得的结果。
令 function 为 Get(classInstance,
"process")。重新抛出所有异常。
返回使用 « true » 和“rethrow”调用
callback,并将回调 this 值设置为
classInstance 所得的结果。
另一种可能更好的规范架构,是在注册时提取“process”
属性并将其转换为 Function,
将其作为 registerFake()
方法步骤的一部分。
WorkletGlobalScope 的子类用于
创建全局对象,加载到特定 Worklet 中的代码可以在其中
执行。
[Exposed =Worklet , SecureContext ]
interface WorkletGlobalScope {};其他规范旨在将 WorkletGlobalScope
子类化,添加用于注册类的 API,以及特定于其 worklet 类型的其他 API。
每个 WorkletGlobalScope
都具有关联的模块映射。它是一个模块映射,
最初为空。
本节为非规范性内容。
每个 WorkletGlobalScope
都包含在其自己的worklet
代理中,该代理具有对应的事件循环。但是在
实践中,这些代理和事件循环的实现预计会与大多数
其他代理和事件循环不同。
每个
WorkletGlobalScope
都有一个worklet 代理,因为从理论上讲,
实现可以为每个 WorkletGlobalScope
实例使用一个单独的线程,
而允许这种级别的并行性最好通过代理实现。但是,因为它们的
[[CanBlock]] 值为 false,所以并不要求代理与线程一一对应。这
允许实现自由地在任意线程上执行加载到 worklet 中的脚本,
包括运行来自其他 [[CanBlock]] 为 false 的代理的代码的线程,例如
相似源 window
代理的线程(“主
线程”)。这与专用 worker
代理形成对比,后者的
[[CanBlock]] 值为 true,
实际上要求它们获得一个专用的操作系统线程。
Worklet 事件循环也有些
特殊。它们仅用于与 addModule()
关联的任务、用户代理调用
作者定义方法的任务以及微任务。因此,
即使事件循环处理模型规定所有事件
循环持续运行,实现也可以使用一种更简单的策略获得可观察上等效的结果,
即仅调用作者提供的
方法,然后依靠该过程执行微任务检查点。
要为一个 Worklet
worklet 创建 worklet 全局作用域:
令 outsideSettings 为 worklet 的相关设置 对象。
令 agent 为在给定 outsideSettings 的情况下获取 worklet 代理所得的结果。在该 代理中运行其余步骤。
令 realmExecutionContext 为在给定 agent 和以下自定义项的情况下创建新 realm所得的结果:
对于全局对象,创建一个类型由 worklet 的worklet 全局作用域类型给出的新对象。
令 workletGlobalScope 为 realmExecutionContext 的 Realm 组件的全局 对象。
令 insideSettings 为在给定 realmExecutionContext 和 outsideSettings 的情况下设置 worklet 环境设置对象所得的结果。
令 runNextAddedModule 为以下步骤:
如果 pendingAddedModules 不为空:
令 moduleURL 为从 pendingAddedModules 中出队所得的结果。
在给定 moduleURL、 insideSettings、worklet 的worklet 目标类型、使用哪种凭据模式?、insideSettings、worklet 的 模块响应映射, 以及下面给定 script 的步骤的情况下,获取 worklet 脚本图:
这实际上不会执行网络请求,因为它只会复用 worklet 的模块响应映射中的响应。 此步骤的主要 目的是从该响应中创建一个新的、特定于 workletGlobalScope 的模块 脚本。
将 workletGlobalScope 追加到
outsideSettings 的全局
对象的关联
Document的worklet
全局作用域中。
运行由 insideSettings 指定的负责的事件循环。
运行 runNextAddedModule。
要在给定一个 WorkletGlobalScope
workletGlobalScope 的情况下终止 worklet
全局作用域:
等待 eventLoop 完成当前正在运行的 任务。
销毁 eventLoop。
从其全局作用域包含
workletGlobalScope 的 Worklet 的全局作用域中移除 workletGlobalScope。
从其worklet 全局
作用域包含 workletGlobalScope 的
Document 的worklet 全局作用域中移除 workletGlobalScope。
要在给定一个JavaScript 执行上下文 executionContext 和一个环境设置 对象 outsideSettings 的情况下,设置 worklet 环境设置对象:
令 origin 为一个唯一的不透明 源。
令 inheritedAPIBaseURL 为 outsideSettings 的API 基础 URL。
令 realm 为 executionContext 的 Realm 组件值。
令 workletGlobalScope 为 realm 的全局对象。
令 settingsObject 为一个新的环境设置对象,其 算法定义如下:
返回 executionContext。
返回 workletGlobalScope 的模块映射。
返回 inheritedAPIBaseURL。
与从单个资源派生的 worker 或其他全局对象不同,worklet
没有主要资源;相反,会通过 worklet.addModule()
将多个各自具有自己 URL 的脚本加载到
全局作用域中。因此,此API 基础 URL
与其他全局对象的 API 基础 URL 很不相同。但是到目前为止,这并不重要,因为
worklet 代码可用的 API 中没有任何 API 会使用API 基础 URL。
返回 origin。
返回 true。
返回 inheritedPolicyContainer。
返回 TODO。
将 settingsObject 的ID设置为一个新的 唯一不透明字符串,将创建 URL设置为 inheritedAPIBaseURL,将顶层创建 URL设置为 null,将顶层 源设置为 outsideSettings 的顶层源,将目标浏览上下文设置为 null,并将 活动 service worker设置为 null。
将 realm 的 [[HostDefined]] 字段设置为 settingsObject。
返回 settingsObject。
Worklet 类所有当前引擎均支持。
Worklet 类提供了将模块
脚本添加到其关联的
WorkletGlobalScope
中的能力。随后,用户
代理可以创建在
WorkletGlobalScope
上注册的类,并调用其方法。
[Exposed =Window , SecureContext ]
interface Worklet {
[NewObject ] Promise <undefined > addModule (USVString moduleURL , optional WorkletOptions options = {});
};
dictionary WorkletOptions {
RequestCredentials credentials = "same-origin";
};创建 Worklet 实例的规范
必须为给定实例指定以下内容:
其 worklet 全局作用域类型,该类型必须是一个
继承自 WorkletGlobalScope
的 Web IDL 类型;以及
其 worklet 目标类型,该类型必须是一个目标,并在获取 脚本时使用。
await worklet.addModule(moduleURL[, { credentials }])
所有当前引擎均支持。
将由 moduleURL 给出的模块脚本加载并执行到 worklet 的所有全局作用域中。根据 worklet 类型, 此过程还可以创建额外的全局作用域。一旦脚本已在所有全局 作用域中成功加载并运行,返回的 promise 就会兑现。
可以将 credentials
选项设置为一种凭据模式,以修改
脚本获取过程。其默认值为“same-origin”。
在获取脚本或其
依赖项时发生的任何失败,都会使返回的 promise 以一个
“AbortError” DOMException
拒绝。
解析脚本或其依赖项时发生的任何错误,都会使返回的 promise 以
解析期间生成的异常拒绝。
一个 Worklet 具有一个由
全局作用域组成的列表,其中包含
Worklet 的worklet 全局作用域类型的实例。
该列表最初
为空。
一个 Worklet 具有一个已添加模块
列表,它是一个由 URL 组成的列表,最初为空。
对此列表的访问应该是线程安全的。
一个 Worklet 具有一个模块
响应映射,它是一个从 URL 到
“fetching”或由一个响应以及 null、failure 或表示响应主体的一个字节
序列组成的元组的有序映射。此映射最初为空,并且对它的访问
应该是线程安全的。
已添加
模块列表和模块响应映射的存在,是为了确保
在不同时间创建的 WorkletGlobalScope
会基于相同的源文本在其中运行等效的模块
脚本。这使得创建额外的 WorkletGlobalScope
对作者而言是透明的。
在实践中,不期望用户代理使用线程安全的编程技术实现这些数据结构以及
查询这些数据结构的算法。相反,当调用 addModule() 时,
用户代理可以在主线程上获取模块
图,并将获取的源文本(即模块响应映射中包含的重要数据)发送到每个
具有 WorkletGlobalScope
的线程。
然后,当用户代理为给定的 Worklet
创建一个新的
WorkletGlobalScope 时,
它只需将已获取源文本的映射和入口点列表从主线程发送到包含
新 WorkletGlobalScope
的线程。
addModule(moduleURL,
options) 方法的步骤是:
令 moduleURLRecord 为相对于 outsideSettings,在给定 moduleURL 的情况下对 URL 进行编码解析所得的结果。
如果 moduleURLRecord 为 failure,则返回一个以
“SyntaxError” DOMException
拒绝的 promise。
令 promise 为一个新的 promise。
令 workletInstance 为 this。
并行运行以下步骤:
在给定 workletInstance 的情况下创建 worklet 全局作用域。
可选地,根据具体的 worklet 及其规范,在给定 workletInstance 的情况下创建额外的 全局作用域实例。
在继续之前,等待创建 过程的所有步骤——包括在worklet 代理中进行的步骤——完成。
令 addedSuccessfully 为 false。
对于 workletInstance 的全局
作用域中的每个 workletGlobalScope,在给定
workletGlobalScope 的情况下,在网络任务源上排入一个全局
任务,以在给定
moduleURLRecord、outsideSettings、workletInstance 的worklet 目标
类型、options["credentials"]、
workletGlobalScope 的
相关设置
对象、workletInstance 的模块响应映射,以及下面给定
script 的步骤的情况下,获取 worklet 脚本图:
这些获取中只有第一次会真正执行网络请求;
其他 WorkletGlobalScope
的获取会复用
workletInstance 的模块响应映射中的响应。
如果 script 为 null:
在给定 workletInstance 的相关全局对象的情况下,在网络任务源上排入一个全局 任务,以执行以下 步骤:
如果 pendingTasks 不为 −1:
将 pendingTasks 设置为 −1。
使用一个 “AbortError”
DOMException
拒绝 promise。
中止这些步骤。
如果 script 的要重新 抛出的错误非 null:
如果 addedSuccessfully 为 false:
在给定 script 的情况下运行模块脚本。
在给定 workletInstance 的相关全局对象的情况下,在网络任务 源上排入一个全局任务,以执行以下 步骤:
如果 pendingTasks 不为 −1:
将 pendingTasks 设置为 pendingTasks − 1。
如果 pendingTasks 为 0,则兑现 promise。
返回 promise。
Worklet 的生命周期没有特殊
注意事项;它与其所属的对象
绑定,例如 Window。
每个 Document 都有一个worklet
全局作用域,它是由 WorkletGlobalScope 组成的集合,最初
为空。
WorkletGlobalScope
的生命周期至少与
其worklet 全局
作用域包含它的
Document 绑定。特别是,销毁该
Document 将终止相应的
WorkletGlobalScope,并允许
对其进行垃圾回收。
此外,除非定义相应 worklet 类型的规范另有规定,否则用户代理可以随时终止给定的 WorkletGlobalScope。
例如,如果
worklet 代理的事件循环中没有排入任何
任务,或者用户代理没有任何计划使用该
worklet 的待处理操作,或者用户代理检测到无限循环或回调超过所施加时间限制等
异常操作,用户代理就可以终止它。
最后,特定 worklet 类型的规范可以更具体地说明何时为给定 worklet 类型创建 WorkletGlobalScope。
例如,它们可以在调用 worklet 代码的特定过程中创建这些对象,就像该示例中那样。
所有当前引擎均支持。
本节为非规范性内容。
本规范引入了两种相关机制,它们类似于 HTTP 会话 Cookie,用于 在客户端存储名称-值对。[COOKIES]
第一种机制适用于用户正在执行单个事务,但 同时可能在不同窗口中执行多个事务的场景。
Cookie 并不能很好地处理这种情况。例如,用户可能会 使用同一个站点在两个不同窗口中购买机票。如果站点使用 Cookie 跟踪用户正在购买哪张 机票,那么当用户在两个窗口中逐页点击时,当前正在购买的机票 就会从一个窗口“泄漏”到另一个窗口,这可能导致用户在没有注意到的情况下 为同一航班购买两张机票。
为了解决此问题,本规范引入了 sessionStorage 获取器。站点可以
将数据添加到会话
存储中,并且在该窗口中打开的同一站点的任何页面都可以访问这些数据。
例如,页面可以提供一个复选框,供用户勾选以 表示他们需要保险:
< label >
< input type = "checkbox" onchange = "sessionStorage.insurance = checked ? 'true' : ''" >
I want insurance on this trip.
</ label > 之后的页面可以通过脚本检查用户是否勾选了该复选框:
if ( sessionStorage. insurance) { ... } 如果用户在该站点上打开了多个窗口,每个窗口都会拥有其自身独立的 会话存储对象副本。
第二种存储机制用于跨越多个窗口、且持续时间 超过当前会话的存储。特别是,出于性能原因,Web 应用可能希望在客户端 存储数 MB 的用户数据,例如用户编写的完整文档或用户的邮箱。
同样,Cookie 也不能很好地处理这种情况,因为它们会随每个 请求一起传输。
localStorage 获取器用于
访问页面的本地
存储区域。
example.com 站点可以通过在页面底部 放置以下内容,显示用户加载该页面的次数:
< p >
You have viewed this page
< span id = "count" > an untold number of</ span >
time(s).
</ p >
< script >
if ( ! localStorage. pageLoadCount)
localStorage. pageLoadCount = 0 ;
localStorage. pageLoadCount = parseInt( localStorage. pageLoadCount) + 1 ;
document. getElementById( 'count' ). textContent = localStorage. pageLoadCount;
</ script > 每个站点都有其自身独立的存储区域。
localStorage
获取器提供对
共享状态的访问。本规范没有定义它与多进程用户代理中其他代理集群的
交互,并建议作者假定不存在任何锁定
机制。例如,站点可能尝试读取某个键的值、递增该值,然后
将其写回,并将新值用作会话的唯一标识符;如果站点
同时在两个不同的浏览器窗口中执行此操作,它最终可能为两个会话使用相同的
“唯一”标识符,从而可能产生灾难性后果。
所有当前引擎均支持。
Storage 接口[Exposed =Window ]
interface Storage {
readonly attribute unsigned long length ;
DOMString ? key (unsigned long index );
getter DOMString ? getItem (DOMString key );
setter undefined setItem (DOMString key , DOMString value );
deleter undefined removeItem (DOMString key );
undefined clear ();
};storage.length
所有当前引擎均支持。
返回键/值对的数量。
storage.key (n)
所有当前引擎均支持。
返回第 n 个键的名称;如果 n 大于或 等于键/值对的数量,则返回 null。
value = storage.getItem (key)
所有当前引擎均支持。
value = storage[key]返回与给定 key 关联的当前值;如果给定 key 不存在,则返回 null。
storage.setItem (key, value)
所有当前引擎均支持。
storage[key] = value将由 key 标识的键/值对的值设置为 value;如果此前 不存在对应于 key 的键/值对,则创建一个新的键/值对。
如果无法设置新值,则抛出 QuotaExceededError。
(例如,如果用户禁用了该站点的存储,或配额已
超出,则设置可能会失败。)
storage.removeItem (key)
所有当前引擎均支持。
delete
storage[key]
如果存在具有给定 key 的键/值对,则移除该键/值对。
storage.clear()
所有当前引擎均支持。
移除所有键/值对(如果存在)。
一个 Storage 对象具有关联的:
local”或“session”。
尽管很遗憾,但迭代顺序没有定义,并且会在大多数 变更后发生变化。
要在给定 key、oldValue 和 newValue 的情况下广播一个
Storage 对象
storage,请运行以下步骤:
令 thisDocument 为 storage 的相关全局对象的关联
Document。
令 remoteStorages 为除 storage 之外的所有 Storage 对象,且这些对象满足:
并且,如果类型为
“session”,则其相关
设置对象的关联
Document的节点
可导航对象的可遍历
可导航对象必须是 thisDocument 的节点
可导航对象的可遍历
可导航对象。
对于 remoteStorages 中的每个 remoteStorage:在给定
remoteStorage 的相关全局对象的情况下,在DOM 操作任务
源上排入
一个全局任务,以使用 StorageEvent
在
remoteStorage 的相关全局
对象上触发一个名为 storage 的事件,将 key 初始化为
key,将 oldValue
初始化为 oldValue,将 newValue
初始化为 newValue,将 url 初始化为
url,并将 storageArea
初始化为
remoteStorage。
与所得任务关联的 Document 对象不一定完全活动,但在此类对象上触发的事件会被事件循环忽略,直到该 Document
再次变为完全活动。
key(index)
方法的步骤是:
setItem(key,
value) 方法的步骤是:
removeItem(key) 方法的步骤是:
sessionStorage
获取器interface mixin WindowSessionStorage {
readonly attribute Storage sessionStorage ;
};
Window includes WindowSessionStorage ;window.sessionStorage
所有当前引擎均支持。
返回与该 window 的源的
会话存储区域关联的 Storage 对象。
如果
Document 的源
是一个不透明源,
或者请求违反了某项策略决定
(例如,用户代理被配置为不允许页面持久化数据),则抛出一个“SecurityError” DOMException。
一个 Document 对象具有关联的
会话存储持有者,它为
null 或一个 Storage 对象。
它最初为 null。
![]()
sessionStorage 获取器的步骤是:
如果 this 的关联
Document的会话存储持有者非 null,则返回
this 的关联
Document的会话存储持有者。
如果 map 为 failure,则抛出一个“SecurityError”
DOMException。
将 this 的关联
Document的会话存储持有者设置为
storage。
返回 storage。
在创建新的辅助浏览 上下文和文档后,会复制 会话存储。
localStorage 获取器interface mixin WindowLocalStorage {
readonly attribute Storage localStorage ;
};
Window includes WindowLocalStorage ;window.localStorage
所有当前引擎均支持。
返回与 window 的源的本地
存储区域关联的 Storage 对象。
如果
Document 的源
是一个不透明源,
或者请求违反了某项策略决定
(例如,用户代理被配置为不允许页面持久化数据),则抛出一个“SecurityError” DOMException。
一个 Document 对象具有关联的
本地存储持有者,它为 null
或一个 Storage 对象。它
最初为 null。
![]()
localStorage 获取器的步骤是:
如果 this 的关联
Document的本地存储持有者非 null,则返回
this 的关联
Document的本地存储持有者。
如果 map 为 failure,则抛出一个“SecurityError”
DOMException。
将 this 的关联
Document的本地存储持有者设置为 storage。
返回 storage。
StorageEvent 接口所有当前引擎均支持。
[Exposed =Window ]
interface StorageEvent : Event {
constructor (DOMString type , optional StorageEventInit eventInitDict = {});
readonly attribute DOMString ? key ;
readonly attribute DOMString ? oldValue ;
readonly attribute DOMString ? newValue ;
readonly attribute USVString url ;
readonly attribute Storage ? storageArea ;
undefined initStorageEvent (DOMString type , optional boolean bubbles = false , optional boolean cancelable = false , optional DOMString ? key = null , optional DOMString ? oldValue = null , optional DOMString ? newValue = null , optional USVString url = "", optional Storage ? storageArea = null );
};
dictionary StorageEventInit : EventInit {
DOMString ? key = null ;
DOMString ? oldValue = null ;
DOMString ? newValue = null ;
USVString url = "";
Storage ? storageArea = null ;
};event.key返回正在更改的存储项的键。
event.oldValue
返回其值正在更改的存储项键的 旧值。
event.newValue
返回其值正在更改的存储项键的 新值。
event.url返回其存储 项发生更改的文档的 URL。
event.storageArea
返回受影响的 Storage 对象。
key、
oldValue、
newValue、
url 和
storageArea
属性必须返回它们初始化时所使用的值。
initStorageEvent(type, bubbles,
cancelable, key, oldValue, newValue, url,
storageArea) 方法必须以类似于同名
initEvent()
方法的方式初始化事件。[DOM]
第三方广告商(或任何能够将内容分发到多个 站点的实体)可以使用存储在其本地存储区域中的唯一标识符,跨 多个会话跟踪用户,并建立用户兴趣的画像,从而投放高度定向的 广告。再结合知晓用户真实身份的站点(例如要求提供 身份验证凭据的电子商务站点),这可能使压迫性团体能够比在完全匿名使用 Web 的环境中 更准确地锁定个人。
有多种技术可以用于降低用户跟踪的风险:
用户代理可以将对 localStorage
对象的访问限制为源自顶级
可遍历对象的活动
文档所在域的脚本,例如拒绝在 iframe
中运行的其他域页面访问该
API。
用户代理可以自动删除存储了一段时间的 数据,并且可以允许用户配置此行为。
例如,用户代理可以被配置为将第三方本地存储区域视为 仅限会话的存储,并在用户关闭所有能够访问它的可导航对象后删除数据。
这可以限制站点跟踪用户的能力,因为站点此后只能在用户 向该站点本身进行身份验证时(例如进行购买或登录服务) 跨多个会话跟踪用户。
但是,这也会降低该 API 作为长期存储机制的实用性。如果用户没有充分理解数据 过期的影响,也可能使用户的数据面临风险。
如果用户试图通过清除 Cookie 来保护其隐私,却没有同时清除 本地存储区域中存储的数据,站点就可以将这两种功能互相用作 冗余备份,从而挫败这些尝试。用户代理应该以一种帮助用户理解这种可能性、 并允许他们同时删除所有持久存储功能中数据的方式,提供用于清除这些数据的界面。 [COOKIES]
用户代理可以允许站点以 不受限制的方式访问会话存储区域,但要求用户授权其访问 本地存储区域。
用户代理可以记录包含 导致数据被存储的第三方源内容的站点的源。
如果随后使用此信息展示当前持久存储中的数据, 用户就可以作出知情决定,选择要清理持久存储的哪些部分。结合阻止列表 (“删除这些数据,并阻止该域以后再存储数据”),用户可以将持久存储的使用 限制为其信任的站点。
用户代理可以允许用户共享其持久存储域阻止列表。
这将允许社区共同采取行动来保护隐私。
尽管这些建议可以防止简单地使用此 API 跟踪用户,但并不能完全阻止 用户跟踪。在单个域内,站点仍然可以在会话期间持续跟踪用户, 然后将所有这些信息连同该站点获得的任何身份识别信息 (姓名、信用卡号、地址)一起传给第三方。如果第三方与 多个站点合作来获取这些信息,仍然可以建立用户画像。
但是,即使用户代理完全不配合,也仍然可以在一定程度上跟踪用户, 例如在 URL 中使用会话标识符。这种技术已经普遍用于 无害目的,但很容易被重新用于跟踪用户(甚至可以追溯性地这样做)。随后可以将这些 信息与其他站点共享,使用访问者的 IP 地址和其他 用户特定数据(例如用户代理标头和配置设置),将各个独立 会话组合成连贯的用户画像。
用户代理应该将持久存储的数据视为可能具有敏感性;电子邮件、 日历约会、健康记录或其他机密文档完全可能存储在 此机制中。
为此,用户代理应该确保在删除数据时,及时将其从 底层存储中删除。
由于可能发生 DNS 欺骗攻击,因此无法保证声称 位于某个域中的主机确实来自该域。为缓解此问题,页面可以使用 TLS。使用 TLS 的页面可以确信,只有用户、代表用户运行的软件,以及其他使用 TLS 且其证书 表明它们来自同一域的页面,才能访问其存储区域。
共享同一主机名的不同作者,例如曾在现已关闭的
geocities.com 上托管内容的用户,会共享同一个本地存储对象。没有任何功能可以
按路径名限制访问。因此,强烈建议共享主机上的作者避免使用这些
功能,因为其他作者可以轻易读取并覆盖其中的数据。
即使提供了路径限制功能,通常的 DOM 脚本 安全模型也会使绕过此保护并从任意 路径访问数据变得轻而易举。
实现这些持久存储功能时的两个主要风险是:允许恶意 站点读取其他域的信息,以及允许恶意站点写入之后会被 其他域读取的信息。
允许第三方站点读取本不应从其域读取的数据会造成 信息泄露。例如,一个域中用户的购物愿望清单可能会被 另一个域用于定向广告;或者,由文字处理站点存储的用户尚未完成的机密文档 可能会被竞争公司的站点查看。
允许第三方站点向其他域的持久存储写入数据可能导致 信息欺骗,其危险程度相同。例如,恶意站点可以向 用户的愿望清单中添加项目;或者恶意站点可以将用户的会话标识符设置为一个已知 ID, 随后使用该 ID 跟踪用户在受害站点上的操作。
因此,严格遵循本规范中描述的源模型 对用户安全非常重要。
本节仅描述标记为 HTML MIME 类型的资源所适用的规则。XML 资源的规则在下方标题为“XML 语法”的一节中讨论。
本节仅适用于文档、创作工具和标记生成器。特别是, 它不适用于一致性检查器;一致性检查器必须使用下一节 (“解析 HTML 文档”)中给出的要求。
文档必须按给定 顺序由以下部分组成:
上文提到的各种内容类型将在接下来的几节中介绍。
此外,字符编码声明的序列化方式还存在一些限制,如 相关主题一节中所述。
文档解析时,html 元素之前、html 元素开头以及 head 元素之前的ASCII 空白会被丢弃;html 元素之后的ASCII 空白将被解析为好像位于 body 元素的末尾。因此,文档元素周围的ASCII
空白无法往返保持。
建议在 DOCTYPE 之后、文档元素之前的所有注释之后、html
元素的开始标签之后
(如果该标签未被省略),以及位于
html 元素内部但位于 head 元素之前的所有注释之后插入换行符。
HTML 语法中的许多字符串(例如元素及其属性的名称)不区分 大小写,但这仅适用于 ASCII 大写字母和 ASCII 小写字母。为方便起见,本节将其 简称为“不区分大小写”。
DOCTYPE 是 必需的前导部分。
由于历史原因,必须提供 DOCTYPE。如果省略,浏览器往往会使用一种 与某些规范不兼容的不同渲染模式。在文档中包含 DOCTYPE 可确保浏览器尽最大努力遵循相关 规范。
DOCTYPE 必须按以下顺序由以下组成部分构成:
<!DOCTYPE”进行ASCII
不区分大小写匹配的字符串。html”进行ASCII
不区分大小写匹配的字符串。换言之,即不区分大小写的 <!DOCTYPE html>。
对于无法输出短形式 DOCTYPE
“<!DOCTYPE html>”的 HTML 生成器,可以将一个DOCTYPE 旧式字符串插入
DOCTYPE 中(位于上文定义的位置)。此字符串必须由以下内容组成:
SYSTEM”进行ASCII
不区分大小写匹配的字符串。about:legacy-compat”。换言之,即 <!DOCTYPE html SYSTEM "about:legacy-compat"> 或
<!DOCTYPE html SYSTEM 'about:legacy-compat'>;除单引号或双引号中的
部分外,其余部分不区分大小写。
除非文档由无法输出较短字符串的系统生成,否则不应该使用DOCTYPE 旧式字符串。
元素有六种不同类型:空
元素、template
元素、原始文本
元素、可转义原始
文本元素、外来元素和
普通元素。
area, base, br, col, embed,
hr, img, input, link, meta,
source, track, wbr
template 元素templatescript, styletextarea, title标签用于在标记中界定元素的开始和结束位置。原始文本元素、可转义原始文本元素和普通元素都有 一个表示其开始位置的开始标签,以及一个表示其结束位置的结束标签。某些普通元素的开始标签和结束标签可以省略,如 下方可选标签一节所述。不能省略的标签 不得省略。空元素只有开始标签; 不得为空元素指定结束标签。外来元素必须 具有开始标签和结束标签,或者具有被标记为自闭合的开始标签;在后一种 情况下,它们不得具有结束标签。
元素的内容必须放置在 开始标签之后(在某些情况下,开始标签可能是隐含的)且结束标签之前 (同样,在某些情况下,结束标签可能是隐含的)的位置。每个元素具体允许的内容取决于 该元素的内容模型,如本规范前文所述。 元素不得包含其内容模型不允许的内容。不过,除了这些内容模型对内容施加的限制之外, 这五类元素还有额外的语法要求。
空元素不能包含任何内容 (因为没有结束标签,所以无法在开始标签和结束标签之间放置内容)。
template 元素可以具有
模板内容,但这些模板内容并不是
template 元素本身的子节点。
相反,它们存储在与另一个没有浏览上下文的 Document 关联的 DocumentFragment
中,以避免 template
的内容干扰主 Document。
template 元素的模板内容的标记放置在
template
元素的开始标签之后且 template
元素的结束标签之前(与其他元素相同),并且可以由任意文本、字符
引用、元素和注释组成,但
文本不得包含字符 U+003C LESS-THAN SIGN(<)或歧义与号。
可转义原始文本 元素可以包含文本和 字符引用,但文本不得包含 歧义与号。此外还存在下方所述的进一步限制。
开始标签标记为自闭合的外来元素不能包含任何内容 (同样,由于没有结束标签,无法在开始标签和结束标签之间放置内容)。 开始标签未标记为自闭合的外来元素可以 包含文本、字符 引用、CDATA 节、其他元素和注释,但 文本不得包含字符 U+003C LESS-THAN SIGN(<)或歧义与号。
HTML 语法不支持命名空间声明,即使在外来 元素中也是如此。
例如,请考虑以下 HTML 片段:
< p >
< svg >
< metadata >
<!-- this is invalid -->
< cdr:license xmlns:cdr = "https://www.example.com/cdr/metadata" name = "MIT" />
</ metadata >
</ svg >
</ p > 最内层的元素 cdr:license 实际上位于 SVG 命名空间中,因为
“xmlns:cdr”属性不起任何作用(与 XML 中不同)。事实上,正如
上述片段中的注释所述,该片段实际上不符合规范。这是因为
SVG 2 并未在 SVG 命名空间中定义任何名为
“cdr:license”的元素。
普通元素可以包含文本、字符 引用、其他元素和注释,但 文本不得包含字符 U+003C LESS-THAN SIGN(<)或歧义与号。某些普通元素 对其允许包含的内容还有更多限制,这些限制超出了内容模型和本 段所述的限制。这些限制将在下文介绍。
标签包含一个标签名称,用于给出元素名称。所有 HTML 元素的名称都只使用 ASCII 字母数字字符。在 HTML 语法中,标签名称(包括外来元素的标签名称) 可以使用任意大小写字母组合书写,只要全部转换为小写后 与元素的标签名称匹配;标签名称不区分大小写。
开始标签必须采用以下格式:
结束标签必须采用以下格式:
元素的属性写在 元素的开始标签内。
属性具有名称和值。属性名称 必须由一个或多个字符组成,但不得包含控制字符、 U+0020 SPACE、U+0022(")、U+0027(')、U+003E(>)、U+002F(/)、U+003D(=)和非字符。在 HTML 语法中,属性名称(包括 外来元素的属性名称)可以使用任意组合的 ASCII 小写字母和ASCII 大写字母书写。
属性值是文本和字符 引用的混合,但还有一项额外限制:文本不得包含歧义与号。
属性可以用四种不同方式指定:
仅写属性名称。其值隐式为 空字符串。
在以下示例中,disabled 属性
使用空属性语法指定:
< input disabled > 如果使用空属性语法的属性之后还有另一个属性,则两者之间 必须有ASCII 空白分隔。
属性名称,后跟零个或多个 ASCII 空白,后跟一个 U+003D EQUALS SIGN 字符, 再后跟零个或多个ASCII 空白,最后后跟属性值。除了上述属性值要求之外,该值还不得包含任何字面量ASCII 空白、任何 U+0022 QUOTATION MARK 字符(")、U+0027 APOSTROPHE 字符(')、U+003D EQUALS SIGN 字符(=)、U+003C LESS-THAN SIGN 字符(<)、U+003E GREATER-THAN SIGN 字符(>)或 U+0060 GRAVE ACCENT 字符(`),并且不得为空字符串。
在以下示例中,value 属性
使用不带引号的属性值语法指定:
< input value = yes > 如果使用不带引号属性语法的属性之后还有另一个属性,或者后跟上方开始标签语法第 6 步允许的可选 U+002F SOLIDUS 字符(/), 则两者之间必须有ASCII 空白分隔。
属性名称,后跟零个或多个 ASCII 空白,后跟一个 U+003D EQUALS SIGN 字符, 再后跟零个或多个ASCII 空白,再后跟一个 U+0027 APOSTROPHE 字符 ('),之后是属性 值。除了上述属性值要求之外,该值不得包含任何字面量 U+0027 APOSTROPHE 字符('),最后再后跟第二个 U+0027 APOSTROPHE 字符(')。
在以下示例中,type 属性
使用单引号属性值语法指定:
< input type = 'checkbox' > 如果使用单引号属性语法的属性之后还有另一个 属性,则两者之间必须有ASCII 空白分隔。
属性名称,后跟零个或多个 ASCII 空白,后跟一个 U+003D EQUALS SIGN 字符, 再后跟零个或多个ASCII 空白,再后跟一个 U+0022 QUOTATION MARK 字符 ("),之后是属性 值。除了上述属性值要求之外,该值不得包含任何字面量 U+0022 QUOTATION MARK 字符("),最后再后跟第二个 U+0022 QUOTATION MARK 字符(")。
在以下示例中,name
属性使用
双引号属性值语法指定:
< input name = "be evil" > 如果使用双引号属性语法的属性之后还有另一个 属性,则两者之间必须有ASCII 空白分隔。
同一个开始标签中绝不能存在两个或更多名称彼此进行ASCII 不区分大小写匹配的属性。
当外来元素具有以下表格某一行前两列给出的 本地名称和命名空间所对应的命名空间属性时,必须使用同一行第三列给出的名称书写。
| 本地名称 | 命名空间 | 属性名称 |
|---|---|---|
actuate |
XLink 命名空间 | xlink:actuate
|
arcrole |
XLink 命名空间 | xlink:arcrole
|
href |
XLink 命名空间 | xlink:href
|
role |
XLink 命名空间 | xlink:role
|
show |
XLink 命名空间 | xlink:show
|
title |
XLink 命名空间 | xlink:title
|
type |
XLink 命名空间 | xlink:type
|
lang |
XML 命名空间 | xml:lang
|
space |
XML 命名空间 | xml:space
|
xmlns |
XMLNS 命名空间 | xmlns
|
xlink |
XMLNS 命名空间 | xmlns:xlink
|
其他命名空间属性均无法在HTML 语法中表示。
上表中的属性是否符合规范由 其他规范(例如 SVG 2 和 MathML)定义;本节仅 描述使用 HTML 语法序列化这些属性时的语法规则。
某些标签可以被省略。
在下文所述情况下省略元素的开始标签,
并不意味着该元素不存在;它是隐含的,但仍然存在。例如,HTML 文档始终具有一个根
html 元素,即使
字符串 <html> 没有出现在标记中的任何位置。
如果 html 元素中的第一项不是注释,则可以省略该
html 元素的开始标签。
例如,在以下情况下,可以移除“<html>”
标签:
<!DOCTYPE HTML>
< html >
< head >
< title > Hello</ title >
</ head >
< body >
< p > Welcome to this example.</ p >
</ body >
</ html > 这样做后,文档将如下所示:
<!DOCTYPE HTML>
< head >
< title > Hello</ title >
</ head >
< body >
< p > Welcome to this example.</ p >
</ body >
</ html > 它具有完全相同的 DOM。特别要注意,文档 元素周围的空白会被解析器忽略。以下示例也会具有完全相同的 DOM:
<!DOCTYPE HTML> < head >
< title > Hello</ title >
</ head >
< body >
< p > Welcome to this example.</ p >
</ body >
</ html > 但是,在以下示例中,移除开始标签会将注释移动到
html 元素之前:
<!DOCTYPE HTML>
< html >
<!-- where is this comment in the DOM? -->
< head >
< title > Hello</ title >
</ head >
< body >
< p > Welcome to this example.</ p >
</ body >
</ html > 移除标签后,文档实际上会变得与以下内容相同:
<!DOCTYPE HTML>
<!-- where is this comment in the DOM? -->
< html >
< head >
< title > Hello</ title >
</ head >
< body >
< p > Welcome to this example.</ p >
</ body >
</ html > 这就是为什么只有在标签之后不是注释时才能移除该标签:当该位置存在注释时移除标签, 会改变文档最终得到的解析树。当然,如果 注释的位置并不重要,则可以省略该标签,就好像注释最初就已 移动到开始标签之前。
如果 html 元素之后
没有紧跟注释,则可以省略该
html 元素的结束标签。
如果 head 元素为空,
或者该 head 元素中的第一项是一个
元素,则可以省略其开始标签。
如果 head 元素之后
没有紧跟ASCII 空白或
注释,则可以省略该
head 元素的结束标签。
如果 body 元素为空,
或者该 body 元素中的第一项不是
ASCII 空白或注释,则可以省略其开始标签;但如果
body
元素中的第一项是 meta、noscript、
link、script、style 或 template 元素,则不能省略。
如果 body 元素之后没有紧跟
注释,则可以省略该
body 元素的结束标签。
请注意,在上面的示例中,head 元素的开始标签和结束标签,
以及
body 元素的开始标签均不能
省略,因为它们周围存在
空白:
<!DOCTYPE HTML>
< html >
< head >
< title > Hello</ title >
</ head >
< body >
< p > Welcome to this example.</ p >
</ body >
</ html > (body 和 html 元素的结束标签可以
顺利省略;这些标签之后的任何空格最终都会被解析到 body
元素中。)
不过,通常空白并不是问题。如果我们先移除不在意的 空白:
<!DOCTYPE HTML> < html >< head >< title > Hello</ title ></ head >< body >< p > Welcome to this example.</ p ></ body ></ html > 然后,我们就可以省略若干标签而不影响 DOM:
<!DOCTYPE HTML> < title > Hello</ title >< p > Welcome to this example.</ p > 此时,我们还可以重新添加一些空白:
<!DOCTYPE HTML>
< title > Hello</ title >
< p > Welcome to this example.</ p > 这等效于以下文档,其中省略的标签显示在
解析器隐含的位置;由此产生的唯一空白文本节点是
head 元素末尾的换行符:
<!DOCTYPE HTML>
< html >< head > < title > Hello</ title >
</ head >< body > < p > Welcome to this example.</ p > </ body ></ html > 如果 li 元素之后紧跟另一个
li 元素,或者父元素中
不再有其他内容,则可以省略该
li 元素的结束标签。
如果 dt 元素之后紧跟
另一个 dt 元素或
dd 元素,则可以省略该
dt 元素的结束标签。
如果 dd 元素之后紧跟
另一个 dd 元素或
dt 元素,或者父元素中不再有
其他内容,则可以省略该
dd 元素的结束标签。
如果 p 元素之后紧跟
address、article、
aside、blockquote、details、dialog、
div、dl、fieldset、figcaption、
figure、footer、form、h1、
h2、
h3、
h4、
h5、
h6、
header、
hgroup、hr、main、menu、nav、
ol、p、pre、search、section、
table 或 ul 元素,则可以省略该
p 元素的结束标签;或者,如果父元素中不再有其他内容,且父元素是一个
不属于 a、audio、del、ins、map、
noscript 或 video 元素,也不是自主自定义
元素的HTML 元素,也可以省略。
因此,我们可以进一步简化前面的示例:
<!DOCTYPE HTML> < title > Hello</ title >< p > Welcome to this example.如果 rt 元素之后紧跟
一个 rt 或 rp 元素,
或者父元素中不再有其他内容,则可以省略该
rt 元素的结束标签。
如果 rp 元素之后紧跟
一个 rt 或 rp 元素,
或者父元素中不再有其他内容,则可以省略该
rp 元素的结束标签。
如果 optgroup 元素之后
紧跟另一个 optgroup 元素,
或者紧跟一个
hr 元素,或者父元素中不再有
其他内容,则可以省略该
optgroup 元素的结束标签。
如果 option 元素之后
紧跟另一个 option 元素,
或者紧跟一个 optgroup 元素,
或者紧跟一个
hr 元素,或者父元素中不再有
其他内容,则可以省略该
option 元素的结束标签。
如果 colgroup 元素中的第一项是
col 元素,
并且该元素之前没有紧接另一个省略了结束标签的 colgroup 元素,
则可以省略该
colgroup 元素的开始标签。(如果该元素
为空,则不能省略。)
如果 colgroup 元素之后
没有紧跟ASCII 空白
或注释,则可以省略该
colgroup 元素的结束标签。
如果 caption 元素之后
没有紧跟ASCII 空白或
注释,则可以省略该
caption 元素的结束标签。
如果 thead 元素之后
紧跟一个 tbody 或
tfoot 元素,则可以省略该
thead 元素的结束标签。
如果 tbody 元素中的第一项是 tr 元素,并且该
元素之前没有紧接一个省略了结束标签的 tbody、thead 或
tfoot 元素,
则可以省略该
tbody 元素的开始标签。(如果该元素为空,
则不能省略。)
如果 tbody 元素之后
紧跟另一个 tbody 或
tfoot 元素,或者父元素中
不再有其他内容,则可以省略该
tbody 元素的结束标签。
如果父元素中不再有其他内容,则可以省略 tfoot
元素的结束标签。
如果 tr 元素之后紧跟
另一个 tr 元素,
或者父元素中不再有其他内容,则可以省略该
tr 元素的结束标签。
如果 td 元素之后紧跟
一个 td 或 th 元素,
或者父元素中不再有其他内容,则可以省略该
td 元素的结束标签。
如果 th 元素之后紧跟
一个 td 或 th 元素,
或者父元素中不再有其他内容,则可以省略该
th 元素的结束标签。
省略所有这些与表格相关的标签,可以使表格标记简洁得多。
请看此示例:
< table >
< caption > 37547 TEE Electric Powered Rail Car Train Functions (Abbreviated)</ caption >
< colgroup >< col >< col >< col ></ colgroup >
< thead >
< tr >
< th > Function</ th >
< th > Control Unit</ th >
< th > Central Station</ th >
</ tr >
</ thead >
< tbody >
< tr >
< td > Headlights</ td >
< td > ✔</ td >
< td > ✔</ td >
</ tr >
< tr >
< td > Interior Lights</ td >
< td > ✔</ td >
< td > ✔</ td >
</ tr >
< tr >
< td > Electric locomotive operating sounds</ td >
< td > ✔</ td >
< td > ✔</ td >
</ tr >
< tr >
< td > Engineer's cab lighting</ td >
< td ></ td >
< td > ✔</ td >
</ tr >
< tr >
< td > Station Announcements - Swiss</ td >
< td ></ td >
< td > ✔</ td >
</ tr >
</ tbody >
</ table > 除少量空白差异外,完全相同的表格可以用以下方式标记:
< table >
< caption > 37547 TEE Electric Powered Rail Car Train Functions (Abbreviated)
< colgroup >< col >< col >< col >
< thead >
< tr >
< th > Function
< th > Control Unit
< th > Central Station
< tbody >
< tr >
< td > Headlights
< td > ✔
< td > ✔
< tr >
< td > Interior Lights
< td > ✔
< td > ✔
< tr >
< td > Electric locomotive operating sounds
< td > ✔
< td > ✔
< tr >
< td > Engineer's cab lighting
< td >
< td > ✔
< tr >
< td > Station Announcements - Swiss
< td >
< td > ✔
</ table > 由于这些单元格以这种方式占用的空间少得多,还可以通过将每一 行放在一行中使其更加简洁:
< table >
< caption > 37547 TEE Electric Powered Rail Car Train Functions (Abbreviated)
< colgroup >< col >< col >< col >
< thead >
< tr > < th > Function < th > Control Unit < th > Central Station
< tbody >
< tr > < td > Headlights < td > ✔ < td > ✔
< tr > < td > Interior Lights < td > ✔ < td > ✔
< tr > < td > Electric locomotive operating sounds < td > ✔ < td > ✔
< tr > < td > Engineer's cab lighting < td > < td > ✔
< tr > < td > Station Announcements - Swiss < td > < td > ✔
</ table > 在 DOM 层面,这些表格之间唯一的差异是 (无论如何在语义上中立的)空白的精确位置。
但是,如果一个开始标签具有任何属性,则绝不能 省略。
回到之前移除所有空白、随后移除所有可选 标签的示例:
<!DOCTYPE HTML> < title > Hello</ title >< p > Welcome to this example.如果此示例中的 body 元素必须具有 class 属性,而 html 元素必须具有 lang 属性,则标记必须变为:
<!DOCTYPE HTML> < html lang = "en" >< title > Hello</ title >< body class = "demo" >< p > Welcome to this example.本节假定文档符合规范,特别是不存在内容模型违规情况。在不符合本规范所述内容模型的文档中,以本节所述方式省略标签, 很可能会导致意外的 DOM 差异(这在一定程度上正是内容模型旨在避免的情况)。
由于历史原因,某些元素除了其内容模型所规定的限制之外,还有额外限制。
table 元素不得
包含 tr 元素,即使根据
本规范所述的内容模型,这些
元素在技术上允许位于 table 元素内部。
(如果在标记中将一个 tr 元素放入
table 中,
实际上会在其之前隐含一个 tbody
开始标签。)
可以在 pre 和 textarea 元素的开始标签之后立即放置一个换行符。
这不会影响元素的处理。如果元素的内容本身以换行符开头,则原本可选的换行符必须包含在内(因为否则
内容开头的换行符会被视为该可选换行符并被忽略)。
原始文本和可转义原始文本
元素中的文本不得包含字符串“</”
(U+003C LESS-THAN SIGN、U+002F SOLIDUS)的任何实例,且其后跟有与
元素标签名称进行不区分大小写匹配的字符,再后跟 U+0009 CHARACTER TABULATION(制表符)、
U+000A LINE FEED(LF)、U+000C FORM FEED(FF)、U+000D CARRIAGE RETURN(CR)、
U+0020 SPACE、U+003E GREATER-THAN SIGN(>)或 U+002F SOLIDUS(/)之一。
文本允许出现在元素、属性值和注释内部。 根据文本要放置的位置,其他各节对文本中允许和不允许的内容施加了 额外限制。
HTML 中的换行符可以表示为 U+000D CARRIAGE RETURN(CR)字符、U+000A LINE FEED(LF)字符,或者按此顺序排列的一对 U+000D CARRIAGE RETURN(CR)、U+000A LINE FEED(LF)字符。
在允许使用字符引用的位置, U+000A LINE FEED(LF)字符的字符引用(但不包括 U+000D CARRIAGE RETURN(CR)字符) 也表示一个换行符。
在其他各节所述的某些情况下,文本可以 与字符引用混合使用。字符引用可用于转义 原本无法合法包含在文本中的字符。
字符引用必须以 U+0026 AMPERSAND 字符(&)开头。其后 可以是以下三种字符引用之一:
歧义与号是一个 U+0026 AMPERSAND 字符(&),其后跟随一个或多个ASCII 字母数字字符,再后跟一个 U+003B SEMICOLON 字符(;),但这些字符 与命名字符引用一节中给出的任何名称都不 匹配。
CDATA 节必须按以下顺序由以下组成部分构成:
<![CDATA[”。]]>”。]]>”。CDATA 节只能用于外来内容(MathML 或 SVG)。在此示例中,使用一个 CDATA
节转义一个 MathML
ms 元素的内容:
< p > You can add a string to a number, but this stringifies the number:</ p >
< math >
< ms > <![CDATA[x<y]]> </ ms >
< mo > +</ mo >
< mn > 3</ mn >
< mo > =</ mo >
< ms > <![CDATA[x<y3]]> </ ms >
</ math > 注释必须采用以下格式:
<!--”。>”开头,也不得以字符串
“->”开头,不得包含字符串“<!--”、
“-->”或
“--!>”,也不得以字符串“<!-”结尾。-->”。文本可以以字符串
“<!”结尾,例如 <!--My favorite operators are > and
<!-->。
处理指令标记文档中供进一步处理的位置。
处理指令必须采用以下格式:
目标由ASCII
字母数字字符、
U+002D(-)和 U+005F(_)码点组成。它必须以ASCII 字母或 U+005F
(_)开头,并且不得与“xml”
或“xml-stylesheet”进行ASCII
不区分大小写匹配。
数据是文本,另有一项 额外限制:文本不得包含 U+003E(>),也不得以 U+003F(?)结尾。
HTML 语法中的处理指令与XML 中的处理指令存在一些显著差异: [XML]
本节仅适用于用户代理、数据挖掘工具和一致性检查器。
将 XML 文档解析为 DOM 树的规则在下一 节“XML 语法”中介绍。
用户代理必须使用本节所述的解析规则,从
text/html 资源生成 DOM 树。这些规则共同定义了
所谓的
HTML 解析器。
尽管本规范所述的 HTML 语法与 SGML 和 XML 非常相似,但它是一种具有自身解析规则的独立语言。
HTML 的某些早期版本(尤其是 HTML2 至 HTML4)基于 SGML,并使用 SGML 解析规则。但是,几乎没有(如果有的话)Web 浏览器真正为 HTML 文档实现过 SGML 解析;历史上,严格将 HTML 作为 SGML 应用程序处理的唯一用户代理 一直是一致性检查器。由此产生的混乱——一致性检查器声称文档 具有一种表示形式,而广泛部署的 Web 浏览器却以可互操作方式实现了 另一种表示形式——浪费了数十年的生产力。因此,本版本 HTML 回归非 SGML 基础。
对于一致性检查器,如果资源被确定为使用HTML 语法,则它是一个HTML 文档。
如术语一节所述,
未明确指定命名空间的元素类型引用始终是指
HTML 命名空间中的元素。例如,如果规范
提到“一个 menu 元素”,则它是一个本地名称为
“menu”、命名空间为“http://www.w3.org/1999/xhtml”,并且
接口为 HTMLMenuElement 的元素。
在可能的情况下,对此类元素的引用
会链接到其定义。

HTML 解析过程的输入由一串码
点组成,该码点流先经过令牌化阶段,再经过树
构造阶段。输出是一个 Document 对象。
不支持脚本的实现不必
实际创建 DOM Document 对象,但在此类情况下,
DOM 树
仍被用作本规范其余部分的模型。
在常见情况下,令牌化阶段所处理的数据来自网络,但
也可以来自用户代理中运行的脚本,例如使用 document.write()
API。
令牌化阶段和树构造阶段都只有一组状态,但树构造阶段是可重入的, 这意味着在树构造阶段处理一个令牌时,令牌化器可能会恢复运行,从而在 第一个令牌处理完成之前发出并处理更多令牌。
在以下示例中,树构造阶段会在处理“script”结束标签令牌时 被调用来处理一个“p”开始标签令牌:
...
< script >
document. write( '<p>' );
</ script >
...为处理这些情况,解析器具有一个脚本嵌套层级, 其初始值必须设置为零,并具有一个解析器暂停标志, 其初始值必须设置为 false。
本规范定义了 HTML 文档的解析规则,无论其语法是否 正确。解析算法中的某些位置称为解析错误。解析错误的错误处理方式已有明确定义(即本规范各处所述的 处理规则),但用户代理在解析 HTML 文档时,可以在遇到第一个不希望应用本规范所述规则的解析 错误时中止解析器。
如果文档中存在一个或多个解析错误条件,一致性检查器必须向用户报告至少一个 解析错误条件;如果文档中不存在解析错误条件,则不得报告解析错误条件。 如果文档中存在多个解析错误条件,一致性检查器可以报告多个解析错误条件。
解析错误仅指 HTML 语法中的错误。除了 检查解析错误外,一致性检查器还会验证文档是否遵守本规范所述的所有 其他一致性要求。
某些解析错误具有下表所列的专用代码,一致性检查器在报告中应该使用这些代码。
下表中的错误描述为非规范性内容。
| 代码 | 描述 |
|---|---|
| abrupt-closing-of-empty-comment |
如果解析器遇到一个由 U+003E(>)码
点突然关闭的空注释(即
|
| abrupt-doctype-public-identifier |
如果解析器在 DOCTYPE 公共标识符中遇到 U+003E(>)码点(例如
|
| abrupt-doctype-system-identifier |
如果解析器在 DOCTYPE 系统标识符中遇到 U+003E(>)码点(例如
|
| absence-of-digits-in-numeric-character-reference |
如果解析器遇到一个不包含任何数字的数字字符引用(例如
|
| cdata-in-html-content |
如果解析器在外来内容(SVG 或 MathML)之外遇到CDATA
节,则会发生此错误。解析器会将此类 CDATA
节(包括开头的“ |
| character-reference-outside-unicode-range |
如果解析器遇到一个引用超出有效 Unicode 范围的码点的数字字符引用,则会发生此错误。 解析器会将此类字符引用解析为 U+FFFD REPLACEMENT CHARACTER。 |
| control-character-in-input-stream |
如果输入流包含一个既不是 ASCII 空白也不是 U+0000 NULL 的控制码点, 则会发生此错误。此类码点会按原样解析,并且通常在解析 规则未施加任何额外限制时进入 DOM。 |
| control-character-reference |
如果解析器遇到一个引用既不是ASCII 空白,或者是 U+000D CARRIAGE RETURN 的控制码点的数字字符引用,则会发生此错误。 解析器会按原样解析此类字符引用,但 C1 控制字符引用除外,后者会根据数字字符 引用结束状态进行替换。 |
| disallowed-processing-instruction-target |
如果解析器遇到一个与“ |
| duplicate-attribute |
如果解析器在一个已有同名属性的标签中遇到一个属性,则会发生此错误。解析器会忽略该属性的所有重复实例。 |
| end-tag-with-attributes | |
| end-tag-with-trailing-solidus |
如果解析器遇到一个在闭合 U+003E(>)
码点之前紧邻 U+002F(/)码点的结束
标签(例如 |
| eof-before-tag-name |
如果解析器在应出现标签名称的位置遇到输入流末尾,则会发生此错误。在这种情况下,
解析器会将开始标签的起始部分(即 |
| eof-in-cdata |
如果解析器在CDATA 节中遇到输入流末尾,则会发生此错误。解析器会将此类 CDATA 节视为在输入流末尾之前立即关闭。 |
| eof-in-comment | |
| eof-in-doctype |
如果解析器在 DOCTYPE 中遇到输入流末尾,则会发生此错误。
在这种情况下,如果 DOCTYPE 被正确放置为文档前导部分,解析器会将 |
| eof-in-processing-instruction |
如果解析器在处理
指令中遇到输入流末尾(例如 |
| eof-in-script-html-comment-like-text |
如果解析器在
|
| eof-in-tag | |
| incorrectly-closed-comment |
如果解析器遇到一个由“ |
| incorrectly-opened-comment |
如果解析器遇到一个“ 此错误的一种可能原因是在 HTML 中使用 XML 标记声明(例如
|
| invalid-character-sequence-after-doctype-name |
如果解析器在 DOCTYPE 名称之后遇到除
“ |
| invalid-first-character-of-processing-instruction-target |
如果解析器在应出现处理指令目标的第一个码点的位置,遇到一个既不是 ASCII 字母也不是 U+005F(_)的码点, 则会发生此错误。前面的 U+003F(?)以及其后直到 U+003E(>)(如果存在)或输入流末尾的所有内容都会被视为注释。 |
| invalid-first-character-of-tag-name |
如果解析器在应出现开始 标签名称或结束标签名称第一个码点的位置,遇到一个不是 ASCII 字母的码点, 则会发生此错误。如果预期的是开始标签,则该码点及其前面的 U+003C(<)会被视为文本 内容,而其后的所有内容会被视为标记。反之,如果预期的是结束标签,则该码点以及 其后直到 U+003E(>)码点(如果存在)或输入流末尾的所有内容都会被视为注释。 |
| invalid-processing-instruction-target |
如果解析器在应出现处理指令目标的位置,遇到一个既不是 ASCII 字母数字字符、U+002D(-)或 U+005F(_)的码点,则会发生此错误。前面的 U+003F(?)以及其后直到 U+003E(>)(如果存在)或 输入流末尾的所有内容都会被视为注释。 |
| missing-attribute-value |
如果解析器在应出现属性值的位置遇到 U+003E(>)码点(例如
|
| missing-doctype-name |
如果解析器遇到一个缺少名称的 DOCTYPE(例如
|
| missing-doctype-public-identifier |
如果解析器在应出现 DOCTYPE 公共标识符开头的位置遇到
U+003E(>)码点(例如
|
| missing-doctype-system-identifier |
如果解析器在应出现 DOCTYPE 系统标识符开头的位置遇到
U+003E(>)码点(例如
|
| missing-end-tag-name |
如果解析器在应出现结束标签名称的位置遇到 U+003E(>)码点,即
|
| missing-quote-before-doctype-public-identifier |
如果解析器遇到一个前面没有引号的 DOCTYPE 公共标识符(例如
|
| missing-quote-before-doctype-system-identifier |
如果解析器遇到一个前面没有引号的 DOCTYPE 系统标识符(例如
|
| missing-semicolon-after-character-reference |
如果解析器遇到一个未由 U+003B(;)码点终止的字符 引用,则会发生此错误。 解析器的行为与字符引用已由 U+003B (;)码点终止时相同。 大多数命名 字符引用都要求以 U+003B (;)码点终止。那些不需要终止分号的字符引用在某些歧义 场景中可能会被解析为更长的命名字符引用。 例如, |
| missing-whitespace-after-doctype-public-keyword |
如果解析器遇到一个“ |
| missing-whitespace-after-doctype-system-keyword |
如果解析器遇到一个“ |
| missing-whitespace-before-doctype-name |
如果解析器遇到一个“ |
| missing-whitespace-between-attributes |
如果解析器遇到没有由ASCII
空白分隔的属性(例如
|
| missing-whitespace-between-doctype-public-and-system-identifiers |
如果解析器遇到一个公共标识符与系统标识符之间没有由 ASCII 空白分隔的 DOCTYPE,则会发生此错误。在这种情况下,解析器的行为如同存在 ASCII 空白。 |
| nested-comment |
如果解析器遇到嵌套注释(例如
|
| noncharacter-character-reference | |
| noncharacter-in-input-stream |
如果输入流包含一个非字符,则会发生此错误。 此类码点会按原样解析,并且通常在解析 规则未施加任何额外限制时进入 DOM。 |
| non-void-html-element-start-tag-with-trailing-solidus |
如果解析器遇到一个元素的开始 标签,该元素不在空元素列表中,也不是外来内容的一部分 (即不是 SVG 或 MathML 元素),并且该标签在闭合 U+003E(>)码点之前紧邻 U+002F(/)码 点,则会发生此错误。解析器的行为如同 U+002F(/)不存在。 开始标签名称末尾的 U+002F(/)只能在外来 内容中用于指定自闭合标签。(HTML 中不存在自闭合标签。)空元素中也 允许使用该字符,但在这种情况下不起任何作用。 |
| null-character-reference |
如果解析器遇到一个引用 U+0000 NULL 码 点的数字字符引用,则会发生此错误。解析器会将此类字符引用解析为 U+FFFD REPLACEMENT CHARACTER。 |
| surrogate-character-reference |
如果解析器遇到一个引用代理项的数字字符引用,则会发生此错误。 解析器会将此类字符引用解析为 U+FFFD REPLACEMENT CHARACTER。 |
| surrogate-in-input-stream |
如果输入流包含一个代理项,则会发生此错误。此类码点会 按原样解析,并且通常在解析规则未施加任何额外限制时 进入 DOM。 代理项只能通过 |
| unexpected-character-after-doctype-system-identifier |
如果解析器在 DOCTYPE 系统标识符之后遇到除ASCII 空白或闭合 U+003E(>)之外的任何码 点,则会发生此错误。解析器会忽略这些码 点。 |
| unexpected-character-in-attribute-name |
如果解析器在属性名称中遇到 U+0022(")、U+0027(')或 U+003C(<)码点,则会发生此错误。 解析器会将此类码点包含在属性名称中。 触发此错误的码点通常是另一种语法 结构的一部分,可能表示属性名称附近存在拼写错误。 |
| unexpected-character-in-unquoted-attribute-value |
如果解析器在不带引号的属性值中遇到 U+0022(")、U+0027(')、U+003C(<)、 U+003D(=)或 U+0060(`)码点,则会发生此错误。解析器会将此类码点 包含在属性值中。 触发此错误的码点通常是另一种语法 结构的一部分,可能表示属性值附近存在拼写错误。 U+0060(`)之所以位于触发此错误的码点列表中,是因为 某些旧式用户代理会将其视为引号。 例如,请考虑以下标记: 由于 U+0027(')码点位置错误,解析器会将“ |
| unexpected-equals-sign-before-attribute-name |
如果解析器在属性名称之前遇到 U+003D(=)码点,则会发生此错误。在这种情况下,解析器会将 U+003D(=) 视为属性名称的第一个码点。 此错误的常见原因是忘记填写属性名称。 例如,请考虑以下标记: 由于忘记填写属性名称,解析器会将此标记视为一个 |
| unexpected-null-character |
如果解析器在输入流的某些位置遇到 U+0000 NULL 码点,则会发生此错误。通常, 此类码点会被忽略,或者出于安全原因被替换为 U+FFFD REPLACEMENT CHARACTER。 |
| unexpected-solidus-in-tag |
如果解析器在标签中遇到一个不属于带引号属性值的一部分,并且后面没有立即跟随
U+003E(>)码点的 U+002F(/)码点(例如 |
| unknown-named-character-reference |
构成令牌化阶段输入的码点流,最初会被用户代理视为 字节流(通常来自网络或本地文件系统)。这些字节根据特定的字符 编码对实际字符进行编码,用户代理使用该编码将字节解码为字符。
对于 XML 文档,用户代理确定字符编码时必须使用的算法由 XML 给出。本节不适用于 XML 文档。 [XML]
通常,使用下方定义的编码 嗅探算法确定字符编码。
开头的字节顺序标记(BOM)会使字符编码参数被 忽略,并且其自身也会被跳过。
原始字节流中不符合 Encoding 标准的字节或字节序列 (例如 UTF-8 输入字节流中的无效 UTF-8 字节序列)属于错误, 一致性检查器应当报告这些错误。[ENCODING]
解码器算法描述了如何处理无效输入;出于安全 原因,必须精确遵循这些规则。无效字节序列处理方式的差异可能导致 脚本注入漏洞(“XSS”)等问题。
HTML 解析器解码输入字节流时,会使用一个字符编码和一个置信度。置信度可以是暂定、 确定或无关。所使用的编码以及对该编码的置信度是 暂定还是确定,会在解析 期间使用,以确定是否更改编码。如果不需要编码, 例如解析器正在处理 Unicode 流,完全不必使用字符编码,则置信度为 无关。
某些算法通过直接向输入 流添加字符而不是向输入字节流添加字节,来向解析器提供输入。
当 HTML 解析器要处理具有已知 确定编码的输入字节流时,字符编码就是该编码,并且置信度为确定。
在某些情况下,在解析文档之前明确确定编码可能并不切实际。 因此,本规范提供了一种带有可选预扫描的两遍机制。如下所述,允许实现 在开始解析文档之前,对其当前可用的任何字节应用简化的解析 算法。然后使用从此次预解析和其他带外元数据中推导出的暂定编码启动 真正的解析器。如果用户代理在加载文档期间发现了与此信息冲突的字符 编码声明,则可以重新调用解析器,使用实际编码解析文档。
用户代理必须使用以下称为编码 嗅探算法的算法,确定第一遍解码文档时要使用的字符编码。 此算法将用户代理可用的任何带外元数据(例如文档的Content-Type 元数据)以及目前可用的所有 字节作为输入,并返回一个字符编码以及一个为暂定或 确定的置信度。
如果BOM 嗅探的结果是一个 编码,则返回该编码,并将置信度设为确定。
虽然解码算法本身会 根据是否存在字节顺序标记来更改所使用的编码,但此算法也会嗅探 BOM,以便 设置正确的文档字符编码和置信度。
如果用户明确指示用户代理使用特定编码覆盖文档的字符 编码,则可以返回该编码,并将置信度设为确定。
通常,用户代理会跨会话记住此类用户请求,并在某些
情况下也将其应用于 iframe
中的文档。
用户代理可以在此步骤或此算法之后的任何步骤中,等待资源的更多字节 可用。例如,用户代理可以等待 500 ms 或 1024 字节,以先达到者为准。通常,预解析源以查找编码可以提高 性能,因为它减少了在找到编码信息后丢弃解析时所用数据结构的需要。 但是,如果用户代理为获得确定编码所需的数据而延迟太久,则延迟成本 可能会超过预解析带来的任何性能提升。
字符编码声明的创作一致性要求将其限制为只能出现在前 1024 个字节中。因此,鼓励用户代理对前 1024 个字节使用下方的预扫描算法(由这些步骤调用),但不要等待超过该范围。
如果传输层指定了一个受支持的字符编码,则返回该 编码,并将置信度设为确定。
可选地,预扫描字节 流以确定其编码,其中结束 条件是用户代理认定继续扫描更多字节效率不高时。鼓励用户代理只预扫描前 1024 个字节。用户代理可以认定扫描任何字节都效率不高,在这种情况下, 完全跳过这些子步骤。
上述算法返回一个字符编码或 failure。如果它返回一个 字符编码,则返回相同的编码,并将置信度设为暂定。
否则,如果用户代理具有关于此页面可能使用的编码的信息,例如 基于上次访问该页面时的编码,则返回该编码,并将置信度设为暂定。
用户代理可以尝试通过对数据流应用频率 分析或其他算法来自动检测字符编码。此类算法可以使用资源内容之外的 信息,包括资源地址。如果自动检测成功确定了一个字符编码,并且该编码是受支持的 编码,则返回该编码,并将置信度设为暂定。 [UNIVCHARDET]
通常不鼓励用户代理尝试自动检测通过网络获得的资源的编码, 因为这样做涉及本质上不可互操作的启发式方法。尝试根据 HTML 文档的前导部分 检测编码尤其困难,因为 HTML 标记通常只使用 ASCII 字符,而 HTML 文档往往以 大量标记而不是文本内容开头。
UTF-8 编码具有非常容易检测的位模式。本地 文件系统中包含值大于 0x7F 且符合 UTF-8 模式的字节的文件 很可能使用 UTF-8,而包含不符合该模式的字节序列的文档很可能不是。 当用户代理可以检查整个文件而不只是前导部分时,专门检测 UTF-8 可能尤其有效。[PPUTF8] [UTF8DET]
否则,返回一个由实现定义或用户指定的默认字符 编码,并将置信度 设为暂定。
在受控环境或可以规定文档编码的环境中
(例如,专供新网络使用的用户代理),建议使用覆盖全面的
UTF-8 编码。
在其他环境中,默认编码通常取决于用户的区域设置(这是用户可能经常访问的 页面所使用语言,因而通常也是编码的近似值)。为与旧式内容兼容, 下表根据用户的区域设置给出了建议的默认值。区域设置使用 BCP 47 语言标签标识。 [BCP47] [ENCODING]
| 区域设置语言 | 建议的默认编码 | |
|---|---|---|
| ar | 阿拉伯语 | windows-1256 |
| az | 阿塞拜疆语 | windows-1254 |
| ba | 巴什基尔语 | windows-1251 |
| be | 白俄罗斯语 | windows-1251 |
| bg | 保加利亚语 | windows-1251 |
| cs | 捷克语 | windows-1250 |
| el | 希腊语 | ISO-8859-7 |
| et | 爱沙尼亚语 | windows-1257 |
| fa | 波斯语 | windows-1256 |
| he | 希伯来语 | windows-1255 |
| hr | 克罗地亚语 | windows-1250 |
| hu | 匈牙利语 | ISO-8859-2 |
| ja | 日语 | Shift_JIS |
| kk | 哈萨克语 | windows-1251 |
| ko | 韩语 | EUC-KR |
| ku | 库尔德语 | windows-1254 |
| ky | 吉尔吉斯语 | windows-1251 |
| lt | 立陶宛语 | windows-1257 |
| lv | 拉脱维亚语 | windows-1257 |
| mk | 马其顿语 | windows-1251 |
| pl | 波兰语 | ISO-8859-2 |
| ru | 俄语 | windows-1251 |
| sah | 雅库特语 | windows-1251 |
| sk | 斯洛伐克语 | windows-1250 |
| sl | 斯洛文尼亚语 | ISO-8859-2 |
| sr | 塞尔维亚语 | windows-1251 |
| tg | 塔吉克语 | windows-1251 |
| th | 泰语 | windows-874 |
| tr | 土耳其语 | windows-1254 |
| tt | 鞑靼语 | windows-1251 |
| uk | 乌克兰语 | windows-1251 |
| vi | 越南语 | windows-1258 |
| zh-Hans, zh-CN, zh-SG | 中文,简体 | GBK |
| zh-Hant, zh-HK, zh-MO, zh-TW | 中文,繁体 | Big5 |
| 所有其他区域设置 | windows-1252 | |
此表的内容取自 Windows、Chrome 和 Firefox 默认值的交集。
必须在用户代理使用返回值为输入字节流选择要使用的 解码器的同时,立即将文档字符编码设置为此算法返回的值。
当某个算法要求用户代理在给定某个已定义的结束条件的情况下, 预扫描字节流以确定其 编码时,必须运行以下 步骤。如果在这些步骤中的任何时刻(包括此算法调用的获取属性算法实例执行期间) 用户代理用完了字节(即下方第一步创建的 position 指针超出目前所获得字节流的末尾), 或者达到了其 end condition,则中止预扫描字节流 以确定其 编码算法,并返回对预扫描字节流 以确定其编码算法所应用的相同字节应用获取 XML 编码所得的结果。 否则,这些步骤将返回一个字符编码。
令 position 为指向输入字节流中某个字节的指针,最初 指向第一个字节。
预扫描 UTF-16 XML 声明:如果 position 指向:
返回 UTF-16LE。
返回 UTF-16BE。
由于历史原因,此前缀比 XML 的附录 F中长两个字节,并且 不检查编码名称。
循环:如果 position 指向:
<!--`)推进 position 指针,使其指向前面有两个 0x2D 字节的第一个 0x3E 字节(即 ASCII“-->”序列的末尾),并且该字节位于找到的 0x3C 字节之后。(这两个 0x2D 字节可以与“<!--”序列中的字节相同。)
推进 position 指针,使其指向下一个 0x09、 0x0A、0x0C、0x0D、0x20 或 0x2F 字节(即上方所匹配字符序列中的那个字节)。
令 attribute list 为空字符串列表。
令 got pragma 为 false。
令 need pragma 为 null。
令 charset 为 null 值(就此算法而言,此值不同于 无法识别的编码或空字符串)。
属性:获取一个 属性及其值。如果没有嗅探到属性,则跳转到下方的 处理步骤。
如果属性名称已在 attribute list 中,则返回标记为 属性的步骤。
将属性名称添加到 attribute list。
如果以下列表中的某个步骤适用,则运行相应步骤:
http-equiv”如果属性值为“content-type”,则将 got pragma 设置为 true。
content”应用从
meta 元素提取字符编码的
算法,将属性值作为要解析的字符串。如果返回了一个
字符编码,并且 charset 仍设置为 null,
则令 charset 为返回的编码,并将 need
pragma 设置为 true。
charset”令 charset 为从属性值获取编码所得的结果, 并将 need pragma 设置为 false。
返回标记为属性的步骤。
处理:如果 need pragma 为 null,则跳转到下方标记为 下一个字节的步骤。
如果 need pragma 为 true,但 got pragma 为 false,则跳转到下方标记为下一个字节的步骤。
如果 charset 为 failure,则跳转到下方标记为下一个 字节的步骤。
如果 charset 为 UTF-16BE/LE,则将 charset 设置为 UTF-8。
如果 charset 为 x-user-defined,则将 charset 设置为 windows-1252。
返回 charset。
推进 position 指针,使其指向下一个 0x09(HT)、 0x0A(LF)、0x0C(FF)、0x0D(CR)、0x20(SP)或 0x3E(>)字节。
反复获取属性, 直到找不到更多属性,然后跳转到下方标记为下一个 字节的步骤。
<!`)</`)<?`)推进 position 指针,使其指向找到的 0x3C 字节之后的第一个 0x3E 字节(>)。
不对该字节执行任何操作。
当预扫描字节流 以确定其编码算法要求获取 属性时,是指执行以下操作:
如果 position 处的字节是 0x09(HT)、0x0A(LF)、0x0C(FF)、0x0D(CR)、 0x20(SP)或 0x2F(/)之一,则将 position 推进到下一个字节,并重新执行此 步骤。
如果 position 处的字节为 0x3E(>),则中止获取属性 算法。不存在 属性。
否则,position 处的字节是属性名称的开头。 令 attribute name 和 attribute value 为空 字符串。
按以下方式处理 position 处的字节:
将 position 推进到下一个字节,并返回上一个 步骤。
空格:如果 position 处的字节是 0x09(HT)、0x0A(LF)、0x0C (FF)、0x0D(CR)或 0x20(SP)之一,则将 position 推进到下一个字节,然后重复 此步骤。
如果 position 处的字节不是 0x3D(=),则中止获取属性 算法。属性 名称是 attribute name 的值,属性值为空字符串。
将 position 推进到 0x3D(=)字节之后。
值:如果 position 处的字节是 0x09(HT)、0x0A(LF)、0x0C (FF)、0x0D(CR)或 0x20(SP)之一,则将 position 推进到下一个字节,然后重复 此步骤。
按以下方式处理 position 处的字节:
按以下方式处理 position 处的字节:
将 position 推进到下一个字节,并返回上一个 步骤。
当预扫描字节流 以确定其编码算法在未返回编码的情况下中止时,获取 XML 编码是指执行以下操作。
即使在 text/html 中,
也必须查找类似 XML 声明的语法,以便与现有内容兼容。
令 encodingPosition 为指向流开头的指针。
如果 encodingPosition 没有指向字节序列
0x3C、0x3F、0x78、0x6D、0x6C(`<?xml`)的开头,则返回 failure。
令 xmlDeclarationEnd 为指向输入字节流中下一个值为 0x3E(>)的字节的指针。如果不存在此类字节,则返回 failure。
将 encodingPosition 设置为当前 encodingPosition 处或其后
首次出现字节子序列 0x65、0x6E、0x63、0x6F、0x64、0x69、0x6E、0x67
(`encoding`)的位置。如果不存在此类序列,则返回
failure。
将 encodingPosition 推进到 0x67(g)字节之后。
当 encodingPosition 处的字节小于或等于 0x20 时(即它是 ASCII 空格或控制字符),将 encodingPosition 推进到下一个 字节。
如果 encodingPosition 处的字节不是 0x3D(=),则返回 failure。
将 encodingPosition 推进到下一个字节。
当 encodingPosition 处的字节小于或等于 0x20 时(即它是 ASCII 空格或控制字符),将 encodingPosition 推进到下一个 字节。
令 quoteMark 为 encodingPosition 处的字节。
如果 quoteMark 既不是 0x22(")也不是 0x27('),则返回 failure。
将 encodingPosition 推进到下一个字节。
令 encodingEndPosition 为 encodingPosition 处或其后 下一次出现 quoteMark 的位置。如果 quoteMark 没有 再次出现,则返回 failure。
令 potentialEncoding 为 encodingPosition(含)与 encodingEndPosition(不含)之间的字节序列。
如果 potentialEncoding 包含一个或多个字节值为 0x20 或 更低的字节,则返回 failure。
令 encoding 为在给定对 potentialEncoding 进行同构 解码所得结果的情况下获取 编码所得的结果。
如果 encoding 为 UTF-16BE/LE,则将其更改为 UTF-8。
返回 encoding。
为了实现互操作性,用户代理不应该使用返回结果与上述算法不同的预扫描 算法。(不过,如果确实这样做了,请至少告知我们,以便 改进此算法并使所有人受益……)
用户代理必须支持 Encoding 中定义的编码,包括但 不限于 UTF-8、 ISO-8859-2、 ISO-8859-7、 ISO-8859-8、 windows-874、 windows-1250、 windows-1251、 windows-1252、 windows-1254、 windows-1255、 windows-1256、 windows-1257、 windows-1258、 GBK、 Big5、 ISO-2022-JP、 Shift_JIS、 EUC-KR、 UTF-16BE、 UTF-16LE、 UTF-16BE/LE,以及 x-user-defined。 用户代理不得支持其他编码。
上述要求禁止支持例如 CESU-8、UTF-7、BOCU-1、SCSU、EBCDIC 和 UTF-32。本规范的算法不会尝试支持被禁止的编码; 因此,支持和使用被禁止的编码将导致意外行为。 [CESU8] [UTF7] [BOCU1] [SCSU]
当解析器要求用户代理更改编码时,必须运行 以下步骤。如果上文所述的编码嗅探算法 未能找到字符编码,或者它找到的字符编码不是文件的实际 编码,就可能发生这种情况。
如果已用于解释输入流的编码是 UTF-16BE/LE,则 将置信度设置为确定并 返回。忽略新 编码;如果它不是相同编码,则显然 不正确。
如果新编码是 UTF-16BE/LE,则 将其更改为 UTF-8。
如果新编码是 x-user-defined, 则将其更改为 windows-1252。
如果新编码与已用于解释输入流的编码相同或等效, 则将置信度设置为确定并 返回。 当文件中找到的编码信息与编码 嗅探算法确定的编码相匹配时,会发生这种情况;如果第一遍解析发现前一节所述的编码嗅探算法 未能找到正确编码,那么在解析器的第二遍处理中也会发生这种情况。
如果当前解码器已转换的最后一个字节之前的所有字节,在当前编码和新编码中都具有相同的 Unicode 解释,并且用户代理支持动态更改转换器,则用户代理可以动态切换到用于新 编码的转换器。将文档字符编码以及 用于转换输入流的编码设置为新编码,将置信度设置为确定,然后 返回。
否则,重新启动导航
算法,将 historyHandling 设置为“replace”,
并保持其他输入不变,但
这次跳过编码嗅探算法,改为直接将编码设置为
新编码,并将置信度设置为
确定。只要可能,就应该在不实际联系网络
层的情况下完成此操作(应从内存中重新解析字节),即使例如文档被标记为不可
缓存。如果无法做到这一点,并且联系网络层会涉及重复
使用非 `GET` 方法的请求,则改为将置信度设置为确定并
忽略新
编码。资源将被错误解释。用户代理可以通知用户此情况,
以帮助应用程序开发。
仅当在 meta
元素上发现声明的新编码时,才会调用此算法。
输入流由在输入字节 流被解码时推入其中的字符,或由直接操作输入流的各种 API 推入其中的字符组成。
任何代理项实例都是 surrogate-in-input-stream 解析错误。任何非字符实例都是 noncharacter-in-input-stream 解析错误;除ASCII 空白和 U+0000 NULL 字符之外的任何控制字符实例都是 control-character-in-input-stream 解析错误。
U+0000 NULL 字符的处理方式会根据发现字符的位置而有所不同, 并在解析的后续阶段进行处理。它们要么被忽略,要么出于安全 原因被替换为 U+FFFD REPLACEMENT CHARACTER。此处理方式必然分散在 令牌化阶段和树构造阶段中。
插入点是使用 document.write()
插入的内容实际被插入的位置(位于某个字符之前或输入流末尾之前)。
插入点相对于紧随其后的字符位置,而不是输入流中的绝对偏移量。
最初,插入点未定义。
下列表格中的“EOF”字符是一个表示输入流末尾的概念字符。如果解析器是一个由脚本创建的解析器,则当消费一个
显式“EOF”字符(由
document.close()
方法插入)时,即到达输入流末尾。否则,
“EOF”字符并不是流中的真实字符,而仅表示没有更多
字符。
插入模式是一个状态变量,用于控制树构造阶段的主要操作。
解析外来 内容中的令牌的规则并不是一种插入 模式。树 构造 分派器会独立于当前插入模式选择这些规则,在使用这些规则期间, 插入模式保持不变。
最初,插入模式为“初始”。在 解析过程中,它可以更改为“html 之前”、“head 之前”、“head 中”、“head noscript 中”、“head 之后”、 “body 中”、“文本”、“table 中”、“table 文本中”、“caption 中”、“列 组中”、“table 主体中”、“行中”、“单元格 中”、“template 中”、 “body 之后”、“frameset 中”、“frameset 之后”、“body 之后之后”,以及 “frameset 之后之后”,如树构造阶段所述。插入 模式会影响令牌的处理方式。
这些模式中的几个,即“head 中”、“body 中”和“table 中”,是特殊的,因为其他模式会在不同时间将处理交由它们完成。当下面的 算法指出用户代理要“使用 规则处理 m 插入模式”时,其中 m 是这些模式之一,用户代理必须使用 m 插入模式章节中所述的规则,但必须保持 插入模式不变,除非 m 中的规则本身将 插入模式切换为新值。
当插入模式切换为“文本”或 “table 文本中”时,还会设置原始插入 模式。树构造阶段将返回此插入模式。
类似地,为了解析嵌套的 template
元素,会使用一个template 插入
模式栈。它最初为空。当前 template
插入模式是最近添加到template 插入模式栈中的
插入模式。以下章节中的算法会将插入模式推入此栈,这意味着
将指定的插入模式添加到栈中;也会从栈中弹出插入模式,
这意味着必须从栈中移除最近添加的插入模式。
当下方步骤要求用户代理适当地重置插入模式时, 表示用户代理必须遵循以下步骤:
令 last 为 false。
令 node 为开放元素 栈中的最后一个节点。
循环:如果 node 是开放元素栈中的第一个节点,则将 last 设置为 true,并且,如果解析器是作为 HTML 片段 解析算法(片段情形)的一部分创建的, 则将 node 设置为传递给该算法的 上下文元素。
如果 node 是一个 td
或 th 元素,并且
last 为
false,则将插入模式
切换为“单元格
中”,然后返回。
如果 node 是一个 template 元素,
则将
插入模式切换为当前
template 插入模式,然后
返回。
如果 node 是一个 head 元素,并且
last 为
false,则将插入模式
切换为“head
中”,然后返回。
如果 node 是一个 frameset
元素,则将
插入模式切换为“frameset 中”,然后
返回。(片段情形)
如果 node 是一个 html 元素,则运行以下
子步骤:
现在令 node 为 开放元素栈中位于 node 之前的节点。
返回标记为循环的步骤。
最初,打开元素栈为空。栈向下增长; 栈中最上方的节点是最先添加到栈中的节点,而栈中最下方的节点是 最近添加到栈中的节点(尽管在处理错误嵌套的 标签时,会以随机访问方式操作栈)。
“在 html 之前”
插入模式会创建 html 文档元素,随后
将其添加到栈中。
在片段情况下,
打开元素栈
会被初始化为包含一个作为该算法的一部分创建的 html 元素。(片段情况会跳过
“在
html 之前”插入模式。)
无论 html 节点
是如何创建的,它都是栈中最上方的节点。只有当解析器完成时,它才会从栈中弹出。
当前节点是此打开 元素栈中最下方的节点。
打开 元素栈中的元素分为以下类别:
以下元素具有不同程度的特殊解析规则:HTML 的
address、
applet、area、article、
aside、base、basefont、bgsound、
blockquote、
body、br、button、
caption、
center、col、colgroup、
dd、details、dir、div、dl、
dt、embed、fieldset、
figcaption、
figure、footer、form、frame、
frameset、h1、
h2、
h3、
h4、
h5、
h6、
head、header、hgroup、
hr、html、iframe、
img、input、keygen、li、link、
listing、main、marquee、menu、
meta、nav、noembed、noframes、
noscript、
object、ol、p、
param、plaintext、pre、script、
search、section、select、source、
style、summary、table、tbody、
td、template、
textarea、
tfoot、
th、thead、title、tr、track、
ul、wbr、xmp;MathML
mi、
MathML mo、MathML mn、MathML
ms、MathML
mtext和 MathML
annotation-xml;以及 SVG foreignObject、SVG
desc和 SVG
title。
树构建器会处理 image 开始标签令牌,
但它不在此列表中,因为它不是元素;它会被转换为一个 img
元素。
以下 HTML 元素会进入活动格式化
元素列表:a、b、big、code、
em、font、i、nobr、s、
small、strike、strong、tt,以及
u。
解析 HTML 文档时发现的所有其他元素。
通常,特殊元素的
开始标签和结束标签令牌会被专门处理,而普通元素的令牌会落入“任何其他开始标签”
和“任何其他结束标签”分支;树构建器的某些部分还会检查打开
元素栈中的特定元素是否属于特殊类别。但是,某些
元素(例如 option 元素)的
开始标签或结束标签令牌会被专门处理,但它们仍不属于特殊
类别,因此在其他地方会接受普通处理。
当以下算法以匹配 状态终止时,称打开 元素栈在由元素类型列表 list 组成的特定作用域内具有元素 target node:
当打开 元素栈在由以下元素类型组成的特定作用域内具有 该元素时,称其在作用域内具有 特定元素:
当打开 元素栈在由以下元素类型组成的特定 作用域内具有该元素时,称其在列表项作用域内具有特定元素:
当打开 元素栈在由以下元素类型组成的特定 作用域内具有该元素时,称其在按钮作用域内具有特定元素:
当打开 元素栈在由以下元素类型组成的特定 作用域内具有该元素时,称其在表格作用域内具有特定元素:
如果在任何时候,打开元素栈中的任何元素
在 Document 树中
被移动到新位置或从中移除,则不会发生任何操作。特别是,
在这种情况下栈不会发生变化。这可能导致各种奇怪现象,例如内容
被追加到已不再位于 DOM 中的节点。
在某些情况下(即关闭错误嵌套的格式化 元素时),会以随机访问方式操作该栈。
最初,活动格式化元素列表为空。它 用于处理错误嵌套的格式化元素标签。
该列表包含格式化类别中的元素以及标记。当进入 applet、
object、
marquee、
template、
td、
th 和 caption
元素时,会插入标记,以防止格式化
“泄漏”到 applet、object、
marquee、
template、
td、th 和 caption
元素中。
此外,活动格式化 元素列表中的每个元素都与创建它时所使用的令牌关联,以便在 必要时可为该令牌创建更多元素。
当下方步骤要求用户代理将元素 element 压入活动格式化 元素列表时,用户代理必须执行以下 步骤:
如果活动格式化 元素列表中最后一个标记之后(如果有),或者在没有标记时列表中的任意位置, 已经存在三个与 element 具有相同标签名称、命名空间和属性的元素, 则从活动格式化 元素列表中移除最早的此类元素。为此, 必须按照解析器创建这些元素时的状态比较属性;如果两个元素的所有已解析属性 都可以配对,并且每一对中的两个属性都具有相同的名称、命名空间和值,则 两个元素具有相同属性(属性顺序无关紧要)。
这是诺亚方舟条款。不过每个家族允许三个,而不是两个。
将 element 添加到活动格式化 元素列表中。
当下方步骤要求用户代理重建活动格式化元素时, 用户代理必须执行以下步骤:
如果活动格式化 元素列表中没有条目,则无需重建任何内容;停止此算法。
如果活动格式化 元素列表中的最后一个(最近添加的)条目是一个标记,或者它是同时位于打开元素栈中的元素,则无需重建任何内容; 停止此算法。
令 entry 为活动格式化 元素列表中的最后一个(最近添加的)元素。
回退:如果活动格式化 元素列表中 entry 之前没有条目,则跳转到标记为创建的步骤。
令 entry 为活动格式化 元素列表中位于 entry 前一位的条目。
前进:令 entry 为活动格式化 元素列表中位于 entry 后一位的元素。
创建:为创建元素 entry 时所使用的令牌插入一个 HTML 元素,以获得 new element。
将列表中 entry 的条目替换为 new element 的条目。
如果活动格式化 元素列表中的 new element 条目不是列表中的最后一个条目,则返回标记为 前进的步骤。
其效果是重新打开当前 body、单元格或 caption(以最近者为准)中所有已打开但尚未被明确关闭的 格式化元素。
按照本规范的写法,活动格式化 元素列表始终按时间顺序包含元素,最早添加的元素位于最前, 最近添加的元素位于最后(当然,上述算法第 7 至第 10 步执行期间除外)。
当下方步骤要求用户代理清除活动格式化 元素列表直到最后一个标记时,用户代理必须执行以下步骤:
令 entry 为活动 格式化元素列表中的最后一个(最近添加的)条目。
从活动格式化 元素列表中移除 entry。
转到步骤 1。
最初,head 元素指针和form
元素指针都为 null。
一旦解析了一个 head 元素
(无论是隐式还是显式),
head 元素指针
就会被设置为指向该节点。
form 元素
指针指向最后一个已打开且尚未遇到结束标签的
form 元素。
出于历史原因,它用于在面对极其糟糕的标记时,使表单控件仍能与表单关联。
在 template
元素内部会忽略它。
根插入目标,它为 null 或一个 DocumentFragment
(最初为 null)。
一个布尔值允许声明式影子根(最初为 false)。
脚本模式,它是一个解析器脚本模式。
解析器脚本模式是以下模式之一:
async
和 defer
属性,并在遇到经典脚本时阻塞解析器。noscript 元素
可以表示后备
内容。async 和 defer
属性。此模式由 createContextualFragment()
使用。
创建解析器时,frameset-ok 标志被设置为“ok”。遇到某些令牌后, 它会被设置为“not ok”。
实现必须表现得如同使用以下状态机对 HTML 进行令牌化。该 状态机必须从数据状态开始。大多数状态 会消费一个字符, 这可能产生各种副作用,并且要么将状态机切换到新状态以 重新消费当前输入字符,要么切换到新状态以 消费下一个字符,要么保持在 同一状态以消费下一个字符。某些状态具有更复杂的行为,并且可以在切换到另一个状态之前消费多个 字符。在某些情况下,树构造阶段也会更改令牌化器状态。
当某个状态要求在指定状态中重新消费一个已匹配字符时, 表示切换到该状态,但当该状态尝试消费下一个输入字符时, 向其提供当前输入 字符。
某些状态的确切行为取决于插入模式和打开元素栈。某些 状态还会使用一个临时缓冲区跟踪进度,而字符引用 状态会使用一个返回状态返回到调用它的 状态。
令牌化步骤的输出是一系列零个或多个以下令牌: DOCTYPE、开始标签、结束标签、注释、字符、文件结束。DOCTYPE 令牌具有名称、公共 标识符、系统标识符和一个强制怪异标志。创建 DOCTYPE 令牌时,其名称、公共标识符和系统标识符必须被标记为缺失(这与 空字符串是不同的状态),并且强制怪异标志必须设置为 关闭(其另一状态为开启)。开始标签和结束标签令牌具有标签名称、 自闭合标志以及属性列表,每个属性都具有名称和值。 创建开始标签或结束标签令牌时,其自闭合标志必须未设置 (其另一状态为已设置),并且其属性列表必须为空。注释令牌和字符令牌具有数据。
发出令牌时,必须立即由树构造
阶段处理。树构造阶段可以影响令牌化阶段的状态,并可以向流中插入
额外字符。(例如,script 元素可能导致
脚本执行,并使用动态标记插入 API 将字符插入
正在令牌化的流中。)
创建令牌和发出令牌是不同的操作。令牌可能 已创建但被隐式放弃(永不发出),例如在将字符解析为开始标签令牌的过程中 文件意外结束时。
当发出一个已设置自闭合标志的开始标签令牌时,如果该标志在树 构造阶段处理它时未被确认,则这是一个 non-void-html-element-start-tag-with-trailing-solidus 解析错误。
当发出一个带属性的结束标签令牌时,这是一个end-tag-with-attributes 解析 错误。
当发出一个已设置自闭合标志的结束标签令牌时, 这是一个end-tag-with-trailing-solidus 解析错误。
适当的结束标签令牌是一个结束标签令牌,其标签名称与 此令牌化器最后发出的开始标签的标签名称相匹配(如果有)。如果此令牌化器尚未发出任何开始标签, 则没有任何结束标签令牌是适当的。
如果 返回状态是属性值(双引号)状态、 属性 值(单引号)状态或属性值(不带引号) 状态,则称一个字符引用被作为属性的一部分消费。
当某个状态要求刷新作为字符引用消费的码点时,表示 对 临时 缓冲区中的每个码点(按添加到缓冲区的顺序),如果字符引用是作为属性的一部分消费的,则用户代理必须将缓冲区中的码点追加到 当前属性的值中;否则,将该码点作为字符令牌发出。
在令牌化器执行每一步之前,用户代理必须先检查 解析器暂停标志。如果它为 true,则 令牌化器必须中止对令牌化器所有嵌套调用的处理,并将控制权交还给调用方。
令牌化器状态机由以下各小节中定义的状态组成。
消费下一个输入字符:
消费下一个输入字符:
消费下一个输入字符:
消费下一个输入字符:
消费下一个输入字符:
消费下一个输入字符:
消费下一个输入 字符:
消费下一个输入字符:
消费下一个输入 字符:
消费下一个输入 字符:
消费下一个输入 字符:
消费下一个输入 字符:
消费下一个输入 字符:
消费下一个输入 字符:
消费下一个输入 字符:
消费下一个输入 字符:
消费下一个输入 字符:
消费下一个输入 字符:
消费下一个 输入字符:
消费下一个输入 字符:
消费下一个输入 字符:
消费下一个 输入字符:
消费下一个输入字符:
消费下一个 输入字符:
消费下一个 输入字符:
消费下一个 输入字符:
script”,则切换到脚本数据双重已转义
状态。
否则,切换到脚本数据已转义状态。将
当前
输入
字符作为字符令牌发出。
消费下一个输入 字符:
消费下一个 输入字符:
消费下一个输入字符:
消费下一个输入字符:
消费下一个 输入字符:
script”,则切换到脚本数据已转义状态。否则,
切换到脚本数据双重已转义
状态。将当前输入
字符作为字符令牌发出。消费下一个输入 字符:
消费下一个输入 字符:
当用户代理离开属性名称状态时(并且在适当情况下,在发出标签令牌之前), 必须将完整的属性名称与同一 令牌上的其他属性进行比较;如果令牌上已存在名称完全相同的属性,则这是一个 duplicate-attribute 解析错误, 并且必须从令牌中移除新属性。
如果以这种方式从令牌中移除了属性,那么该属性及其之后 与之关联的值(如果有)都不会再被解析器使用,因此实际上会被 丢弃。不过,以这种方式移除属性不会改变其作为令牌化器所称“当前 属性”的状态。
消费下一个输入 字符:
消费下一个输入 字符:
消费下一个 输入字符:
消费下一个 输入字符:
消费下一个输入 字符:
消费下一个 输入字符:
消费下一个输入 字符:
消费下一个输入 字符:
如果接下来的若干字符是:
DOCTYPE”进行ASCII
不区分大小写匹配[CDATA[”[CDATA[”的注释令牌。切换到
伪注释
状态。
消费下一个输入 字符:
消费下一个输入 字符:
消费下一个输入字符:
消费下一个输入 字符:
消费下一个 输入字符:
消费下一个 输入字符:
消费下一个输入字符:
消费下一个输入 字符:
消费下一个输入字符:
消费下一个输入 字符:
消费下一个输入字符:
消费下一个输入 字符:
消费下一个输入 字符:
消费下一个输入 字符:
如果从当前输入字符开始的六个字符与
“PUBLIC”进行ASCII
不区分大小写匹配,则消费
这些字符并切换到DOCTYPE public 关键字之后状态。
否则,如果从当前输入字符开始的六个字符与
“SYSTEM”进行ASCII
不区分大小写匹配,则消费
这些字符并切换到DOCTYPE system 关键字之后状态。
否则,这是一个invalid-character-sequence-after-doctype-name 解析错误。将当前 DOCTYPE 令牌的强制怪异 标志设置为开启。在伪 DOCTYPE 状态中重新消费。
消费下一个 输入字符:
消费下一个 输入字符:
消费下一个输入字符:
消费下一个输入字符:
消费下一个 输入字符:
消费下一个输入字符:
消费下一个 输入字符:
消费下一个 输入字符:
消费下一个输入字符:
消费下一个输入字符:
消费下一个 输入字符:
消费下一个输入 字符:
消费下一个输入 字符:
U+0000 NULL 字符在树构造阶段处理,作为解析外来 内容中 的令牌的规则的一部分,这是唯一可以出现 CDATA 节的地方。
消费下一个输入 字符:
消费下一个输入 字符:
消费下一个 输入字符:
消费下一个 输入字符:
令 target 为 临时缓冲区中的码 点按照它们添加到缓冲区的顺序连接所得的结果。
如果 target 与“xml”或“xml-stylesheet”进行ASCII
不区分大小写匹配:
否则:
创建一个目标为 target、数据为空字符串的处理指令令牌。
消费下一个输入字符:
消费下一个 输入字符:
消费下一个输入字符:
将 临时 缓冲区设置为空字符串。将 一个 U+0026 AMPERSAND(&)字符追加到 临时 缓冲区中。消费下一个输入字符:
消费尽可能多的字符,其中所消费的字符是命名字符引用表第一列中的 标识符之一。消费每个字符时,将其追加到 临时 缓冲区中。
如果字符引用是作为属性的一部分 消费的,并且最后一个匹配的字符不是 U+003B SEMICOLON 字符(;),且 下一个输入 字符是 U+003D EQUALS SIGN 字符(=)或 ASCII 字母数字字符,则出于历史原因,刷新作为字符引用 消费的码点,并切换到 返回状态。
否则:
如果最后一个匹配的字符不是 U+003B SEMICOLON 字符(;),则这是一个 missing-semicolon-after-character-reference 解析错误。
将 临时缓冲区设置为空字符串。 将与字符引用名称对应的一个或两个字符(如命名字符引用表第二列所示) 追加到 临时缓冲区中。
如果标记中(不在属性中)包含字符串 I'm ¬it; I
tell you,则字符引用会被解析为“not”,即 I'm ¬it;
I tell you(并且这是一个解析错误)。但如果标记为 I'm
∉ I tell you,字符引用将被解析为“notin;”,结果为
I'm ∉ I tell you(并且没有解析错误)。
但是,如果标记在属性中包含字符串 I'm ¬it; I tell you,
则不会解析任何字符引用,字符串会保持不变(并且没有
解析错误)。
消费下一个输入 字符:
将字符引用代码设置为 零(0)。
消耗下一个 输入字符:
消费下一个输入字符:
消费下一个 输入字符:
消费下一个 输入字符:
检查 字符引用代码:
如果该数字为 0x00,则这是一个null-character-reference 解析 错误。将 字符引用代码设置为 0xFFFD。
如果该数字大于 0x10FFFF,则这是一个character-reference-outside-unicode-range 解析错误。将 字符引用 代码设置为 0xFFFD。
如果该数字是一个代理项,则这是 一个surrogate-character-reference 解析错误。将 字符引用 代码设置为 0xFFFD。
如果该数字是一个非字符, 则这是一个 noncharacter-character-reference 解析错误。
如果该数字为 0x0D,或者是一个不属于ASCII 空白的控制字符,则这是一个 control-character-reference 解析错误。如果 该数字是下表第一列中的某个数字,则找到第一列中包含该数字的行,并将 字符引用代码设置为该行第二 列中的数字。
| 数字 | 码点 | |
|---|---|---|
| 0x80 | 0x20AC | EURO SIGN(€) |
| 0x82 | 0x201A | SINGLE LOW-9 QUOTATION MARK(‚) |
| 0x83 | 0x0192 | LATIN SMALL LETTER F WITH HOOK(ƒ) |
| 0x84 | 0x201E | DOUBLE LOW-9 QUOTATION MARK(„) |
| 0x85 | 0x2026 | HORIZONTAL ELLIPSIS(…) |
| 0x86 | 0x2020 | DAGGER(†) |
| 0x87 | 0x2021 | DOUBLE DAGGER(‡) |
| 0x88 | 0x02C6 | MODIFIER LETTER CIRCUMFLEX ACCENT(ˆ) |
| 0x89 | 0x2030 | PER MILLE SIGN(‰) |
| 0x8A | 0x0160 | LATIN CAPITAL LETTER S WITH CARON(Š) |
| 0x8B | 0x2039 | SINGLE LEFT-POINTING ANGLE QUOTATION MARK(‹) |
| 0x8C | 0x0152 | LATIN CAPITAL LIGATURE OE(Œ) |
| 0x8E | 0x017D | LATIN CAPITAL LETTER Z WITH CARON(Ž) |
| 0x91 | 0x2018 | LEFT SINGLE QUOTATION MARK(‘) |
| 0x92 | 0x2019 | RIGHT SINGLE QUOTATION MARK(’) |
| 0x93 | 0x201C | LEFT DOUBLE QUOTATION MARK(“) |
| 0x94 | 0x201D | RIGHT DOUBLE QUOTATION MARK(”) |
| 0x95 | 0x2022 | BULLET(•) |
| 0x96 | 0x2013 | EN DASH(–) |
| 0x97 | 0x2014 | EM DASH(—) |
| 0x98 | 0x02DC | SMALL TILDE(˜) |
| 0x99 | 0x2122 | TRADE MARK SIGN(™) |
| 0x9A | 0x0161 | LATIN SMALL LETTER S WITH CARON(š) |
| 0x9B | 0x203A | SINGLE RIGHT-POINTING ANGLE QUOTATION MARK(›) |
| 0x9C | 0x0153 | LATIN SMALL LIGATURE OE(œ) |
| 0x9E | 0x017E | LATIN SMALL LETTER Z WITH CARON(ž) |
| 0x9F | 0x0178 | LATIN CAPITAL LETTER Y WITH DIAERESIS(Ÿ) |
将 临时 缓冲区设置为空字符串。将一个等于 字符引用代码的 码点追加到 临时 缓冲区中。刷新作为 字符引用消费的码点。切换到 返回状态。
树构造阶段的输入是来自
令牌化阶段的一系列令牌。创建解析器时,
树构造阶段会与一个 DOM
Document 对象关联。此阶段的
“输出”包括动态修改或扩展该文档的 DOM 树。
本规范没有定义交互式用户代理必须在何时渲染
Document,以使其可供用户使用,
或者必须在何时开始接受用户输入。
当令牌化器发出每个令牌时,用户代理必须遵循以下列表中的相应步骤, 该列表称为树构造分派器:
annotation-xml 元素,并且令牌是标签名称为“svg”的开始标签下一个令牌是即将由树 构造分派器处理的令牌(即使该令牌随后只是被忽略)。
如果一个节点是以下元素之一,则它是一个MathML 文本集成点:
mi 元素mo 元素mn 元素ms 元素mtext 元素如果一个节点是以下元素之一,则它是一个HTML 集成点:
annotation-xml 元素,其开始标签令牌具有一个名称为“encoding”的
属性,并且该属性的值与“text/html”进行ASCII
不区分大小写匹配annotation-xml 元素,其开始标签令牌具有一个名称为“encoding”的
属性,并且该属性的值与“application/xhtml+xml”进行ASCII
不区分大小写匹配foreignObject 元素desc 元素title 元素如果所讨论的节点是传递给HTML 片段 解析算法的 上下文元素,则该元素的开始标签令牌是由该HTML 片段解析算法创建的“伪造”令牌。
下方提到的标签名称并非全部都是本规范中符合规范的标签名称; 其中许多名称是为处理旧式内容而包含的。它们仍然构成实现必须实现以声称符合规范的 算法的一部分。
下方描述的算法不会限制所生成 DOM 树的深度,也不会限制
标签名称、属性名称、属性值、Text
节点等的长度。虽然鼓励实现者避免
任意限制,但实际问题很可能迫使用户代理施加嵌套深度
限制。
解析器处理令牌时,可以启用或禁用寄养。 这会影响以下算法。
插入节点的适当位置,可选地使用特定的 覆盖目标,是通过运行以下步骤返回的元素中的位置:
如果指定了覆盖目标,则令 target 为 覆盖目标。
否则,令 target 为当前节点。
使用以下列表中第一个匹配的步骤确定 调整后的插入位置:
table、tbody、tfoot、
thead 或
tr 元素
当内容在表格中错误嵌套时,会发生寄养。
运行以下子步骤:
如果存在 last template,并且不存在 last table,或者存在 last table,但 last template 在打开 元素栈中低于 (添加得更晚)last table,则令 调整后的插入位置位于 last template 的模板 内容内部、其最后一个子节点之后(如果有), 并中止这些步骤。
如果不存在 last table,则令 调整后的插入
位置位于打开元素栈中的第一个元素
(html
元素)内部、其最后一个子节点之后(如果有),并中止这些步骤。
(片段情况)
如果 last table 具有父节点,则令 调整后的插入位置位于 last table 的父 节点内部、紧邻 last table 之前,并中止这些步骤。
令 previous element 为打开 元素栈中紧邻 last table 上方的元素。
令 调整后的插入位置位于 previous element 内部、其最后一个子节点之后(如果有)。
这些步骤之所以存在,部分原因是元素,尤其是本例中的
table
元素,在由解析器插入后可能已被脚本在 DOM 中移动,
或者甚至被从 DOM 中完全移除。
令 调整后的插入位置位于 target 内部、 其最后一个子节点之后(如果有)。
如果 调整后的插入位置位于一个 template
元素内部,则改为令其位于该 template
元素的模板
内容内部、其最后一个子节点之后(如果有)。
返回 调整后的插入位置。
要在给定一个令牌 token、一个字符串 namespace 和一个 Node
对象
intendedParent 的情况下为令牌创建元素:
如果活动推测性 HTML 解析器非 null,则返回在给定 namespace、token 的标签名称和 token 的属性的情况下创建推测性模拟元素所得的结果。
否则,可选地在给定 namespace、token 的标签名称和 token 的属性的情况下创建推测性模拟元素。
不使用该结果。此步骤允许从非推测性解析中启动一次推测性获取。 此时该获取仍然是推测性的,因为例如在元素插入时, intendedParent 可能已经从文档中移除。
令 document 为 intendedParent 的节点文档。
令 localName 为 token 的标签名称。
如果 token 中存在“is”属性,则令
is 为该属性的值;否则为 null。
令 registry 为在给定 intendedParent 的情况下查找自定义元素注册表所得的结果。
令 definition 为在给定 registry、 namespace、localName 和 is 的情况下查找自定义元素 定义所得的结果。
如果 definition 非 null,并且解析器不是作为HTML 片段解析算法的一部分创建的, 则令 willExecuteScript 为 true;否则 为 false。
如果 willExecuteScript 为 true:
递增 document 的动态标记插入时抛出 计数器。
如果 JavaScript 执行上下文栈为空,则执行 微任务检查点。
令 element 为在给定 document、localName、 namespace、null、is、willExecuteScript 和 registry 的情况下创建 元素所得的结果。
如果 willExecuteScript 为 true,这将导致自定义元素 构造函数运行。但是,由于我们递增了动态标记插入时抛出 计数器,因此这不能导致向令牌化器插入新字符, 或者清空文档。
将给定令牌中的每个属性追加到 element。
这可能会为 attributeChangedCallback 排入自定义元素
回调反应,该反应可能立即运行(在下一
步中)。
即使 is 属性控制创建一个自定义内置元素,它在执行相关自定义元素构造函数期间并不存在;
它会在此步骤中与所有其他属性一起追加。
如果 willExecuteScript 为 true:
令 queue 为从 document 的相关 代理的自定义元素反应栈中弹出所得的结果。 (这将与上方压入的元素队列相同。)
调用 queue 中的自定义元素反应。
递减 document 的动态标记插入时抛出 计数器。
如果 element 具有一个位于XMLNS
命名空间中的 xmlns 属性,并且其值与元素的命名空间不完全相同,则这是一个
解析错误。类似地,如果
element 具有一个位于XMLNS 命名空间中的
xmlns:xlink 属性,并且其值不是
XLink 命名空间,则这是一个解析错误。
如果 element 是一个可重置元素,并且不是 表单关联的自定义元素,则调用其 重置算法。(这会根据元素的属性初始化 元素的值和选中状态。)
如果 element 是一个表单关联元素,且不是
表单关联的自定义元素,form
元素指针非 null,打开元素栈中没有
template
元素,element 要么不是列出元素,要么没有 form
属性,并且 intendedParent 与form 元素
指针所指向的元素位于同一个树中,则将 element 与form 元素
指针所指向的 form
元素关联,并设置
element 的解析器插入标志。
返回 element。
要在给定可选的插入位置 insertionLocation(默认为 null)的情况下计算调整后的插入位置:
如果 insertionLocation 为 null,则令 overrideTarget 为 null; 否则为 insertionLocation 所在的节点。
令 adjustedInsertionLocation 为在给定 overrideTarget 的情况下插入 节点的适当位置。
如果 adjustedInsertionLocation 所在的节点是打开元素栈中的第一个元素,并且解析器的根插入 目标非 null,则将 adjustedInsertionLocation 设置为解析器的 根插入 目标内部、其最后一个子节点之后(如果有)。
返回 adjustedInsertionLocation。
要使用元素 element 在调整后的插入 位置插入元素:
令 insertionLocation 为调整后的插入位置。
如果无法在 insertionLocation 处插入 element,则中止 这些步骤。
如果解析器不是作为HTML 片段解析 算法的一部分创建的,则将一个新的元素队列压入 element 的相关代理的自定义元素反应栈。
在 insertionLocation 处插入 element。
如果解析器不是作为HTML 片段解析 算法的一部分创建的,则从 element 的相关代理的自定义元素反应栈中弹出元素队列,并调用 该队列中的自定义元素反应。
如果调整后的插入位置无法接受更多元素,
例如它是一个已经具有元素子节点的 Document,则
element 会被丢弃。
要在给定一个令牌 token、一个字符串 namespace 和一个布尔值 onlyAddToElementStack 的情况下插入外来元素:
令 adjustedInsertionLocation 为插入 节点的适当位置。
令 element 为在给定 token、namespace 以及 adjustedInsertionLocation 所在元素的情况下为令牌创建元素所得的结果。
如果 onlyAddToElementStack 为 false,则使用 element 运行在调整后的 插入位置插入元素。
返回 element。
当下方步骤要求用户代理为令牌调整 MathML 属性时,
如果令牌具有一个名为 definitionurl 的属性,则将其名称更改为
definitionURL(注意大小写差异)。
当下方步骤要求用户代理为令牌调整 SVG 属性时, 对于令牌上属性名称是下表第一列中某个名称的每个属性,将该属性的名称更改为 第二列对应单元格中给出的名称。(这会修正并非全部为小写的 SVG 属性的大小写。)
| 令牌上的属性名称 | 元素上的属性名称 |
|---|---|
attributename |
attributeName
|
attributetype |
attributeType
|
basefrequency |
baseFrequency
|
baseprofile |
baseProfile
|
calcmode |
calcMode
|
clippathunits |
clipPathUnits
|
diffuseconstant |
diffuseConstant
|
edgemode |
edgeMode
|
filterunits |
filterUnits
|
glyphref |
glyphRef
|
gradienttransform |
gradientTransform
|
gradientunits |
gradientUnits
|
kernelmatrix |
kernelMatrix
|
kernelunitlength |
kernelUnitLength
|
keypoints |
keyPoints
|
keysplines |
keySplines
|
keytimes |
keyTimes
|
lengthadjust |
lengthAdjust
|
limitingconeangle |
limitingConeAngle
|
markerheight |
markerHeight
|
markerunits |
markerUnits
|
markerwidth |
markerWidth
|
maskcontentunits |
maskContentUnits
|
maskunits |
maskUnits
|
numoctaves |
numOctaves
|
pathlength |
pathLength
|
patterncontentunits |
patternContentUnits
|
patterntransform |
patternTransform
|
patternunits |
patternUnits
|
pointsatx |
pointsAtX
|
pointsaty |
pointsAtY
|
pointsatz |
pointsAtZ
|
preservealpha |
preserveAlpha
|
preserveaspectratio |
preserveAspectRatio
|
primitiveunits |
primitiveUnits
|
refx |
refX
|
refy |
refY
|
repeatcount |
repeatCount
|
repeatdur |
repeatDur
|
requiredextensions |
requiredExtensions
|
requiredfeatures |
requiredFeatures
|
specularconstant |
specularConstant
|
specularexponent |
specularExponent
|
spreadmethod |
spreadMethod
|
startoffset |
startOffset
|
stddeviation |
stdDeviation
|
stitchtiles |
stitchTiles
|
surfacescale |
surfaceScale
|
systemlanguage |
systemLanguage
|
tablevalues |
tableValues
|
targetx |
targetX
|
targety |
targetY
|
textlength |
textLength
|
viewbox |
viewBox
|
viewtarget |
viewTarget
|
xchannelselector |
xChannelSelector
|
ychannelselector |
yChannelSelector
|
zoomandpan |
zoomAndPan
|
当下方步骤要求用户代理为令牌调整外来
属性时,如果令牌上的任何属性与下表第一列中给出的字符串匹配,则令该属性成为
带命名空间的属性,其中前缀为第二列对应单元格中给出的字符串,本地名称为
第三列对应单元格中给出的字符串,命名空间为第四列对应单元格中给出的
命名空间。(这会修正命名空间属性的使用,尤其是XML
命名空间中的 lang 属性。)
| 属性名称 | 前缀 | 本地名称 | 命名空间 |
|---|---|---|---|
xlink:actuate |
xlink |
actuate |
XLink 命名空间 |
xlink:arcrole |
xlink |
arcrole |
XLink 命名空间 |
xlink:href |
xlink |
href |
XLink 命名空间 |
xlink:role |
xlink |
role |
XLink 命名空间 |
xlink:show |
xlink |
show |
XLink 命名空间 |
xlink:title |
xlink |
title |
XLink 命名空间 |
xlink:type |
xlink |
type |
XLink 命名空间 |
xml:lang |
xml |
lang |
XML 命名空间 |
xml:space |
xml |
space |
XML 命名空间 |
xmlns |
(无) | xmlns |
XMLNS 命名空间 |
xmlns:xlink |
xmlns |
xlink |
XMLNS 命名空间 |
当下方步骤要求用户代理在处理令牌时插入字符,用户代理必须运行以下步骤:
以下是一些提供给解析器的示例输入,以及它们生成的相应数量的 Text
节点,假设用户代理会执行脚本。
| 输入 | Text
节点数
|
|---|---|
|
文档中有一个 Text
节点,包含 "AB"。
|
|
有三个 Text
节点;脚本之前的 "A"、脚本内容,以及脚本之后的 "BC"(解析器追加到由脚本创建的
Text
节点)。
|
|
文档中有两个相邻的 Text
节点,分别包含 "A" 和 "BC"。
|
|
表格之前有一个 Text
节点,包含 "ABCD"。(这是由寄养引起的。)
|
|
表格之前有一个 Text
节点,包含 "A B C"(A-空格-B-空格-C)。(这是由寄养引起的。)
|
|
表格之前有一个 Text
节点,包含 "A BC"(A-空格-B-C),并且表格内部还有一个 Text
节点(作为一个 tbody
的子项),其中包含
一个空格字符。(被非字符令牌与非空格字符分隔的空格字符不受寄养影响,即使那些其他令牌随后被忽略。)
|
当下方步骤要求用户代理在处理注释令牌时插入注释,并给定一个可选的插入位置 insertionLocation(默认为 null)时,用户代理必须运行以下步骤:
当以下步骤要求用户代理在处理处理指令令牌时插入处理 指令,并带有可选的插入位置 insertionLocation(默认为 null)时,用户代理必须运行以下步骤:
通用原始文本元素解析算法和 通用 RCDATA 元素 解析算法由以下步骤组成。这些算法始终响应开始标签令牌而调用。
为该令牌插入一个 HTML 元素。
如果调用的算法是通用原始文本 元素解析 算法,则将令牌化器切换到RAWTEXT 状态;否则,调用的算法是通用 RCDATA 元素 解析算法,将令牌化器切换到 RCDATA 状态。
当下方步骤要求用户代理生成隐含结束标签时,只要
当前节点是一个 dd 元素、
一个 dt
元素、一个
li
元素、一个 optgroup
元素、一个 option
元素、一个
p
元素、一个 rb 元素、一个
rp
元素、一个 rt
元素或一个 rtc 元素,
用户代理就必须将当前节点从
打开
元素栈中弹出。
如果某个步骤要求用户代理生成隐含结束标签,但列出了一个要从该 过程中排除的元素,则用户代理必须执行上述步骤,如同该元素不在上述 列表中一样。
当下方步骤要求用户代理彻底生成所有隐含
结束标签时,只要当前
节点是一个 caption
元素、一个
colgroup
元素、一个 dd
元素、一个 dt
元素、一个
li
元素、一个 optgroup
元素、一个 option
元素、一个
p
元素、一个 rb 元素、一个
rp
元素、一个 rt
元素、一个 rtc 元素、一个
tbody
元素、一个 td 元素、
一个
tfoot
元素、一个 th 元素、
一个 thead
元素或一个
tr
元素,用户代理就必须将当前节点从
打开
元素栈中弹出。
一个 Document 对象具有关联的
解析器无法更改模式标志
(一个布尔值)。它最初为 false。
当用户代理要应用“初始”插入模式的规则时,用户代理必须按如下方式处理令牌:
忽略该令牌。
如果 DOCTYPE 令牌的名称不是 "html",或者令牌的公共
标识符并非缺失,或者令牌的系统标识符既非缺失也不是
"about:legacy-compat",
则存在一个解析错误。
令 doctype 为在给定 Document 节点、DOCTYPE
令牌中给出的名称(如果名称缺失,则为空
字符串)、DOCTYPE 令牌中给出的公共标识符(如果公共标识符缺失,则为空
字符串),以及 DOCTYPE 令牌中给出的系统标识符(如果系统标识符缺失,则为空字符串)的情况下,创建
文档类型的结果。然后将
doctype 追加到 Document 节点。
这还会确保 DocumentType
节点作为
doctype
属性的值返回,该属性属于
Document 对象。
然后,如果文档不是一个 iframe
srcdoc 文档,且解析器不能
更改模式标志为 false,并且 DOCTYPE 令牌匹配以下列表中的某一条件,则将 Document 设置为怪异模式:
html"。 -//W3O//DTD W3 HTML Strict 3.0//EN//" -/W3C/DTD HTML 4.0 Transitional/EN" HTML" http://www.ibm.com/data/dtd/v11/ibmxhtml1-transitional.dtd" +//Silmaril//dtd html Pro v0r11 19970101//" -//AS//DTD HTML 3.0 asWedit + extensions//" -//AdvaSoft Ltd//DTD HTML 3.0 asWedit + extensions//"
-//IETF//DTD HTML 2.0 Level 1//" -//IETF//DTD HTML 2.0 Level 2//" -//IETF//DTD HTML 2.0 Strict Level 1//" -//IETF//DTD HTML 2.0 Strict Level 2//" -//IETF//DTD HTML 2.0 Strict//" -//IETF//DTD HTML 2.0//" -//IETF//DTD HTML 2.1E//" -//IETF//DTD HTML 3.0//" -//IETF//DTD HTML 3.2 Final//" -//IETF//DTD HTML 3.2//" -//IETF//DTD HTML 3//" -//IETF//DTD HTML Level 0//" -//IETF//DTD HTML Level 1//" -//IETF//DTD HTML Level 2//" -//IETF//DTD HTML Level 3//" -//IETF//DTD HTML Strict Level 0//" -//IETF//DTD HTML Strict Level 1//" -//IETF//DTD HTML Strict Level 2//" -//IETF//DTD HTML Strict Level 3//" -//IETF//DTD HTML Strict//" -//IETF//DTD HTML//" -//Metrius//DTD Metrius Presentational//" -//Microsoft//DTD Internet Explorer 2.0 HTML Strict//"
-//Microsoft//DTD Internet Explorer 2.0 HTML//" -//Microsoft//DTD Internet Explorer 2.0 Tables//" -//Microsoft//DTD Internet Explorer 3.0 HTML Strict//"
-//Microsoft//DTD Internet Explorer 3.0 HTML//" -//Microsoft//DTD Internet Explorer 3.0 Tables//" -//Netscape Comm. Corp.//DTD HTML//" -//Netscape Comm. Corp.//DTD Strict HTML//" -//O'Reilly and Associates//DTD HTML 2.0//" -//O'Reilly and Associates//DTD HTML Extended 1.0//"
-//O'Reilly and Associates//DTD HTML Extended Relaxed 1.0//" -//SQ//DTD HTML 2.0 HoTMetaL + extensions//" -//SoftQuad Software//DTD HoTMetaL PRO 6.0::19990601::extensions to HTML 4.0//" -//SoftQuad//DTD HoTMetaL PRO 4.0::19971010::extensions to HTML 4.0//" -//Spyglass//DTD HTML 2.0 Extended//" -//Sun Microsystems Corp.//DTD HotJava HTML//" -//Sun Microsystems Corp.//DTD HotJava Strict HTML//"
-//W3C//DTD HTML 3 1995-03-24//" -//W3C//DTD HTML 3.2 Draft//" -//W3C//DTD HTML 3.2 Final//" -//W3C//DTD HTML 3.2//" -//W3C//DTD HTML 3.2S Draft//" -//W3C//DTD HTML 4.0 Frameset//" -//W3C//DTD HTML 4.0 Transitional//" -//W3C//DTD HTML Experimental 19960712//" -//W3C//DTD HTML Experimental 970421//" -//W3C//DTD W3 HTML//" -//W3O//DTD W3 HTML 3.0//" -//WebTechs//DTD Mozilla HTML 2.0//" -//WebTechs//DTD Mozilla HTML//" -//W3C//DTD HTML 4.01 Frameset//" -//W3C//DTD HTML 4.01 Transitional//" 否则,如果文档不是一个 iframe srcdoc
文档,且解析器不能更改
模式标志为 false,并且 DOCTYPE 令牌匹配以下列表中的某一条件,则将 Document 设置为有限怪异模式:
-//W3C//DTD XHTML 1.0 Frameset//" -//W3C//DTD XHTML 1.0 Transitional//" -//W3C//DTD HTML 4.01 Frameset//" -//W3C//DTD HTML 4.01 Transitional//" 系统标识符和公共标识符字符串必须以 ASCII 不区分大小写的方式,与以上列表中给出的值进行比较。对于以上条件, 值为空字符串的系统标识符不被视为缺失。
如果文档不是一个 iframe srcdoc
文档,则这是一个解析
错误;如果解析器不能更改模式标志
为 false,则将
Document 设置为怪异模式。
当用户代理要应用“在 html 之前”插入模式的规则时,用户代理必须按如下方式处理令牌:
解析错误。忽略该令牌。
忽略该令牌。
在HTML 命名空间中为令牌创建元素,
并将
Document 作为预期
父节点。将其追加到 Document 对象。将
此元素放入打开元素栈。
按照下方“其他任何情况”条目所述执行。
解析错误。忽略该令牌。
创建一个 html
元素,
其节点文档
为 Document 对象。将
其追加到 Document 对象。
将此元素放入打开
元素栈。
文档元素最终可能会从 Document
对象中被移除,例如由脚本移除;在这种情况下不会发生任何特殊操作,内容会继续按照下一节所述
追加到节点中。
当用户代理要应用“在 head 之前”插入模式的规则时,用户代理必须按如下方式处理令牌:
忽略该令牌。
插入注释。
解析错误。忽略该令牌。
为该令牌插入一个 HTML 元素。
按照下方“其他任何情况”条目所述执行。
解析错误。忽略该令牌。
为一个没有属性的“head”开始标签令牌插入一个 HTML 元素。
重新处理当前令牌。
当用户代理要应用“在 head 中”插入模式的规则时,用户代理必须按如下方式处理令牌:
插入注释。
解析错误。忽略该令牌。
为该令牌插入一个 HTML 元素。 立即将当前 节点从打开 元素栈中弹出。
如果令牌的自闭合 标志已设置,则确认该标志。
为该令牌插入一个 HTML 元素。立即将当前 节点从打开 元素栈中弹出。
如果令牌的自闭合 标志已设置,则确认该标志。
如果活动推测性 HTML 解析器为 null:
如果元素具有 charset 属性,
并且从其值获取编码得到一个编码,并且
置信度当前为暂定,
则将编码更改为所得编码。
否则,如果元素具有一个 http-equiv
属性,其值与“Content-Type”进行ASCII 不区分大小写匹配,并且元素具有一个 content 属性,
并且对该属性值应用从
meta 元素提取字符编码的算法返回一个编码,并且
置信度当前为暂定,
则将编码更改为提取出的编码。
推测性 HTML 解析器不会以推测方式应用字符 编码声明,以降低实现复杂度。
为该令牌插入一个 HTML 元素。
将插入模式切换为“在 head noscript 中”。
运行以下步骤:
令 adjustedInsertionLocation 为插入 节点的适当位置。
在HTML 命名空间中为令牌创建元素, 并将 adjustedInsertionLocation 所在的元素作为预期父节点。
如果脚本模式不是片段,则将元素的
解析器文档设置为 Document。
片段
脚本模式会将解析器插入的脚本视为不是由解析器插入,
从而允许例如在应用由
createContextualFragment()
创建的片段时执行脚本。
将元素的强制 async设置为 false。
这确保如果脚本是外部脚本,则脚本中的任何 document.write()
调用都会内联执行,而不是像大多数其他情况那样清空文档。它还会阻止
脚本在看到结束标签之前执行。
如果解析器是通过 document.write()
或 document.writeln()
方法调用的,则可以选择将
script
元素的已经启动设置为
true。(例如,用户代理可以使用此条款,防止在网络状况缓慢或页面已经加载了很长时间时,
执行通过 document.write()
插入的跨源
脚本。)
在给定 adjustedInsertionLocation 的情况下,将新创建的元素插入调整后的插入位置。
将令牌化器切换到脚本数据状态。
按照下方“其他任何情况”条目所述执行。
运行以下步骤:
令 templateStartTag 为该开始标签。
在活动 格式化元素列表的末尾插入一个标记。
将frameset-ok 标志设置为 “not ok”。
将插入模式切换为“在 template 中”。
将“在 template 中”压入 template 插入模式栈, 使其成为新的当前 template 插入模式。
令 adjustedInsertionLocation 为插入 节点的适当位置。
令 intendedParent 为 adjustedInsertionLocation 所在的元素。
令 document 为 intendedParent 的节点 文档。
如果以下任一项为 false:
shadowrootmode
不处于无状态;则为该令牌插入一个 HTML 元素。
否则:
令 declarativeShadowHostElement 为调整后的当前 节点。
令 template 为在给定 templateStartTag、HTML 命名空间和 true 的情况下插入外来元素所得的结果。
令 mode 为 templateStartTag 的 shadowrootmode
属性值。
令 slotAssignment 为“named”。
如果 templateStartTag 的 shadowrootslotassignment
属性处于
手动状态,则
将 slotAssignment 设置为“manual”。
如果 templateStartTag 具有 shadowrootclonable
属性,则令 clonable 为 true;否则
为 false。
如果 templateStartTag 具有 shadowrootserializable
属性,则令 serializable 为 true;
否则为 false。
如果 templateStartTag 具有 shadowrootdelegatesfocus
属性,则令 delegatesFocus 为 true;
否则为 false。
如果 declarativeShadowHostElement 是一个影子 宿主,则使用 template 在调整后的插入 位置插入元素。
否则:
如果 templateStartTag 具有 shadowrootcustomelementregistry
属性,则令 registry 为 null;否则为
declarativeShadowHostElement 的节点
文档的自定义元素注册表。
使用 declarativeShadowHostElement、mode、 clonable、serializable、delegatesFocus、 slotAssignment 和 registry 附加影子根。
如果抛出异常,则捕获它并:
使用 template 在调整后的 插入位置插入元素。
用户代理可以向开发者控制台报告错误。
返回。
令 shadow 为 declarativeShadowHostElement 的影子根。
将 shadow 的声明式设置为 true。
将 template 的模板内容设置为 shadow。
将 shadow 的可供元素内部使用设置为 true。
如果 templateStartTag 具有 shadowrootcustomelementregistry
属性,则将 shadow 的保持自定义元素注册表为 null设置为
true。
如果打开
元素栈中没有 template 元素,
则这是一个解析错误;忽略该令牌。
否则,运行以下步骤:
解析错误。忽略该令牌。
重新处理该令牌。
当用户代理要应用“在 head noscript 中”插入模式的规则时,用户代理必须按如下方式处理 令牌:
解析错误。忽略该令牌。
按照下方“其他任何情况”条目所述执行。
解析错误。忽略该令牌。
解析错误。
将当前节点(即
一个 noscript
元素)从
打开
元素栈中弹出;新的当前
节点将是一个
head 元素。
重新处理该令牌。
当用户代理要应用“在 head 之后”插入模式的规则时,用户代理必须按如下方式处理令牌:
插入注释。
解析错误。忽略该令牌。
为该令牌插入一个 HTML 元素。
将frameset-ok 标志 设置为“not ok”。
为该令牌插入一个 HTML 元素。
将插入模式 切换为“在 frameset 中”。
解析错误。
从打开
元素栈中移除head 元素指针
所指向的节点。(此时它可能不是当前节点。)
此时head 元素指针不可能为
null。
按照下方“其他任何情况”条目所述执行。
解析错误。忽略该令牌。
为一个没有属性的“body”开始标签令牌插入一个 HTML 元素。
重新处理当前令牌。
当用户代理要应用“在 body 中”插入模式的规则时,用户代理必须按如下方式处理令牌:
解析错误。忽略该令牌。
重建任何存在的活动格式化 元素。
重建任何存在的活动格式化 元素。
将frameset-ok 标志设置为“not ok”。
插入注释。
解析错误。忽略该令牌。
解析错误。
如果打开元素栈中存在一个 template 元素,
则忽略该令牌。
否则,对于令牌上的每个属性,检查该属性是否已存在于 打开元素栈顶部的元素上。如果不存在,则将该属性 及其对应的值添加到该元素。
解析错误。
如果打开元素栈中只有一个节点,或者
打开元素栈中的第二个元素不是一个 body 元素,或者
打开元素栈中存在一个
template
元素,则忽略该令牌。
(片段情况,或栈中存在一个 template 元素)
否则,将frameset-ok
标志设置为“not ok”;然后,对于令牌上的每个属性,检查该属性是否已存在于
打开元素栈中的 body 元素
(第二个元素)上,如果不存在,则将该属性
及其对应的值添加到该元素。
解析错误。
如果打开元素栈中只有一个节点,或者
打开元素栈中的第二个元素不是一个 body 元素,则忽略
该令牌。(片段情况,或
template
元素位于栈中)
如果frameset-ok 标志设置为 “not ok”,则忽略该令牌。
否则,运行以下步骤:
如果打开元素栈中的第二个元素具有父 节点,则从其父节点中移除该元素。
为该令牌插入一个 HTML 元素。
将插入模式切换为“在 frameset 中”。
如果template 插入模式栈不为空,则 使用“在 template 中”插入模式的规则处理该令牌。
否则,执行以下步骤:
如果打开元素栈中不在作用域内具有 body
元素,则这是一个解析错误;
忽略该令牌。
否则,如果打开元素栈中存在一个节点,且该节点既不是
dd 元素、dt 元素、li 元素、
optgroup
元素、option
元素、p 元素、
rb 元素、rp 元素、rt 元素、rtc 元素、tbody 元素、td 元素、tfoot 元素、th 元素、thead 元素、tr 元素、body 元素,也不是
html 元素,则
这是一个解析错误。
如果打开元素栈中不在作用域内具有 body
元素,则这是一个
解析错误;
忽略该令牌。
否则,如果打开元素栈中存在一个节点,且该节点既不是
dd 元素、dt 元素、li 元素、
optgroup
元素、option
元素、p 元素、
rb 元素、rp 元素、rt 元素、rtc 元素、tbody 元素、td 元素、tfoot 元素、th 元素、thead 元素、tr 元素、body 元素,也不是
html 元素,则
这是一个解析错误。
重新处理该令牌。
如果打开元素栈在按钮作用域内具有
p 元素,则关闭一个
p
元素。
为该令牌插入一个 HTML 元素。
如果打开元素栈在按钮作用域内具有
p 元素,则关闭一个
p
元素。
如果当前节点是一个标签名称为 “h1”、“h2”、“h3”、“h4”、“h5”或“h6”之一的HTML 元素,则这是一个解析 错误;将当前节点从 打开 元素栈中弹出。
为该令牌插入一个 HTML 元素。
如果打开元素栈在按钮作用域内具有
p 元素,则关闭一个
p
元素。
为该令牌插入一个 HTML 元素。
如果下一个令牌是一个 U+000A LINE FEED(LF)
字符令牌,则忽略该令牌并继续处理下一个令牌。(为了方便创作,会忽略 pre 块开头的换行符。)
将frameset-ok 标志设置为“not ok”。
如果form
元素指针非 null,并且打开
元素栈中没有 template
元素,则这是一个
解析错误;忽略该令牌。
否则:
为该令牌插入一个 HTML
元素,并且如果打开元素栈中没有 template
元素,则将form
元素指针设置为指向
所创建的元素。
运行以下步骤:
将frameset-ok 标志设置为 “not ok”。
将 node 初始化为当前 节点(栈中最下方的节点)。
循环:如果 node 是一个 li 元素,则运行以下
子步骤:
否则,将 node 设置为打开 元素栈中的前一个条目,并返回标记为循环的步骤。
完成:如果打开元素栈在按钮作用域内具有
p 元素,则关闭一个
p 元素。
最后,为该令牌插入一个 HTML 元素。
运行以下步骤:
将frameset-ok 标志设置为 “not ok”。
将 node 初始化为当前 节点(栈中最下方的节点)。
循环:如果 node 是一个 dd 元素,则运行以下
子步骤:
如果 node 是一个 dt 元素,则运行
以下子步骤:
否则,将 node 设置为打开 元素栈中的前一个条目,并返回标记为循环的步骤。
完成:如果打开元素栈在按钮作用域内具有
p 元素,则关闭一个
p 元素。
最后,为该令牌插入一个 HTML 元素。
如果打开元素栈在按钮作用域内具有
p 元素,则关闭一个
p
元素。
为该令牌插入一个 HTML 元素。
将令牌化器切换到PLAINTEXT 状态。
一旦遇到标签名称为“plaintext”的开始标签,所有剩余
令牌都将是字符令牌(以及最后的文件结束令牌),因为无法将
令牌化器从PLAINTEXT 状态切换出去。不过,由于树构建器
保持在其现有插入模式中,它在处理这些字符令牌时可能会重建活动格式化
元素。这意味着解析器可以将其他元素插入 plaintext
元素中。
如果打开元素栈在作用域内具有
button 元素,则运行以下子步骤:
重建任何存在的活动格式化 元素。
为该令牌插入一个 HTML 元素。
将frameset-ok 标志设置为 “not ok”。
如果打开元素栈中不在作用域内具有元素,该元素是一个与令牌具有相同 标签名称的HTML 元素,则这是一个解析 错误;忽略该令牌。
否则,运行以下步骤:
如果打开元素栈中不在按钮作用域内具有
p 元素,
则这是一个解析
错误;为一个没有属性的“p”开始标签令牌插入一个
HTML 元素。
如果打开元素栈中不在列表项作用域内具有 li
元素,则这是一个解析
错误;忽略该令牌。
否则,运行以下步骤:
如果打开元素栈中不在作用域内具有元素,该元素是一个与令牌具有相同 标签名称的HTML 元素,则这是一个解析 错误;忽略该令牌。
否则,运行以下步骤:
如果打开元素栈中不在作用域内具有元素,该元素是一个HTML 元素,且其标签名称为“h1”、“h2”、“h3”、“h4”、“h5”或“h6”之一,则这是 一个解析错误;忽略该令牌。
否则,运行以下步骤:
深吸一口气,然后按照下方“任何其他结束 标签”条目所述执行。
如果活动格式化元素列表在列表末尾与列表中最后一个标记之间(如果列表中没有标记,则为列表开头)包含一个 a 元素,则这是一个解析
错误;为该令牌运行收养代理算法,然后从活动格式化元素列表和打开元素栈中移除该元素,前提是收养代理算法尚未移除它
(如果该元素不在表格
作用域内,则算法可能没有移除它)。
在不符合规范的流
<a href="a">a<table><a href="b">b</table>x 中,
遇到第二个 a
元素时,第一个元素会被关闭,而字符“x”将位于指向“b”的链接内,而不是指向“a”的链接内。
尽管外层 a
元素不在表格作用域内,这仍然会发生(这意味着表格开头的普通 </a> 结束标签
不会关闭外层 a 元素)。结果是这两个
a 元素间接
嵌套在彼此内部——不符合规范的标记在解析时经常会产生不符合规范的 DOM。
重建任何存在的活动格式化 元素。
为该令牌插入一个 HTML 元素。将该元素压入活动 格式化元素列表。
重建任何存在的活动格式化 元素。
为该令牌插入一个 HTML 元素。将该元素压入活动 格式化元素列表。
重建任何存在的活动格式化 元素。
如果打开元素栈在作用域内具有
nobr 元素,则这是一个解析错误;为该令牌运行
收养代理
算法,然后再次重建任何存在的活动格式化
元素。
为该令牌插入一个 HTML 元素。将该元素压入活动 格式化元素列表。
为该令牌运行收养 代理算法。
重建任何存在的活动格式化 元素。
为该令牌插入一个 HTML 元素。
在活动 格式化元素列表末尾插入一个标记。
将frameset-ok 标志设置为“not ok”。
如果打开元素栈中不在作用域内具有元素,该元素是一个与令牌具有相同 标签名称的HTML 元素,则这是一个解析 错误;忽略该令牌。
否则,运行以下步骤:
如果 Document
没有设置为怪异模式,并且
打开元素栈在按钮作用域内具有
p 元素,则关闭一个
p
元素。
为该令牌插入一个 HTML 元素。
将frameset-ok 标志设置为“not ok”。
解析错误。从 令牌中移除属性,并按照下一个条目所述执行;也就是说,将其视为一个没有属性的“br”开始标签令牌, 而不是它实际所表示的结束标签令牌。
重建任何存在的活动格式化 元素。
为该令牌插入一个 HTML 元素。立即将当前 节点从打开元素栈中弹出。
如果令牌的自闭合 标志已设置,则确认该标志。
将frameset-ok 标志设置为“not ok”。
如果解析器是作为HTML 片段解析算法的一部分创建的
(片段情况),并且传递给该算法的上下文
元素是一个 select 元素:
解析错误。
忽略该令牌。
返回。
重建任何存在的活动格式化 元素。
为该令牌插入一个 HTML 元素。立即将当前 节点从打开元素栈中弹出。
如果令牌的自闭合 标志已设置,则确认该标志。
如果令牌没有名称为“type”的属性,或者有该属性,但属性值不与
“hidden”进行ASCII
不区分大小写匹配,则将frameset-ok
标志设置为“not ok”。
为该令牌插入一个 HTML 元素。立即将当前 节点从打开元素栈中弹出。
如果令牌的自闭合 标志已设置,则确认该标志。
如果打开元素栈在按钮作用域内具有
p 元素,则关闭一个
p
元素。
如果打开元素栈在作用域内具有
option 元素,或者在作用域内具有
optgroup 元素,则这是一个解析
错误。
为该令牌插入一个 HTML 元素。立即将当前 节点从打开元素栈中弹出。
如果令牌的自闭合 标志已设置,则确认该标志。
将frameset-ok 标志设置为“not ok”。
解析错误。将令牌的标签名称 更改为“img”并重新处理它。(别问。)
运行以下步骤:
为该令牌插入一个 HTML 元素。
如果下一个令牌是一个 U+000A LINE FEED
(LF)字符令牌,则忽略该令牌并继续处理下一个令牌。(为了方便创作,会忽略 textarea
元素开头的换行符。)
将令牌化器切换到RCDATA 状态。
将frameset-ok 标志设置为 “not ok”。
如果打开元素栈在按钮作用域内具有
p 元素,则关闭一个
p
元素。
重建任何存在的活动格式化 元素。
将frameset-ok 标志设置为“not ok”。
将frameset-ok 标志设置为“not ok”。
如果解析器是作为HTML 片段解析算法的一部分创建的
(片段情况),并且传递给该算法的上下文
元素是一个 select 元素:
解析错误。
忽略该令牌。
否则,如果打开
元素栈在作用域内具有
select 元素:
否则:
重建任何存在的活动格式化 元素。
为该令牌插入一个 HTML 元素。
将frameset-ok 标志设置为 “not ok”。
如果打开元素栈在作用域内具有
option 元素,则这是一个解析错误。
否则:
重建任何存在的活动格式化 元素。
为该令牌插入一个 HTML 元素。
如果打开元素栈在作用域内具有
option 元素,或者在作用域内具有
optgroup 元素,则这是一个解析
错误。
否则,如果当前节点是一个
option 元素,
则将
当前节点从打开
元素栈中弹出。
重建任何存在的活动格式化 元素。
为该令牌插入一个 HTML 元素。
如果打开元素栈在作用域内具有
ruby 元素,则生成隐含结束标签。如果
当前节点现在不是一个 ruby 元素,则这是一个
解析错误。
为该令牌插入一个 HTML 元素。
如果打开元素栈在作用域内具有
ruby 元素,则生成隐含结束标签,但排除
rtc 元素。如果当前节点现在既不是一个 rtc
元素,也不是一个 ruby
元素,则这是一个解析错误。
为该令牌插入一个 HTML 元素。
重建任何存在的活动格式化 元素。
为该令牌调整 MathML 属性。(这会修正并非全部为小写的 MathML 属性。)
为该令牌调整外来 属性。(这会修正命名空间属性的使用,尤其是 XLink。)
在给定MathML 命名空间和 false 的情况下,为该令牌插入外来 元素。
如果令牌已设置自闭合 标志,则将当前 节点从 打开 元素栈中弹出,并确认 令牌的自闭合标志。
重建任何存在的活动格式化 元素。
为该令牌调整 SVG 属性。 (这会修正并非全部为小写的 SVG 属性。)
为该令牌调整外来 属性。(这会修正命名空间属性的使用,尤其是 SVG 中的 XLink。)
在给定SVG 命名空间 和 false 的情况下,为该令牌插入外来 元素。
如果令牌已设置自闭合标志,则将当前节点从 打开 元素栈中弹出,并确认 令牌的自闭合标志。
解析错误。忽略该令牌。
重建任何存在的活动格式化 元素。
为该令牌插入一个 HTML 元素。
运行以下步骤:
当上述步骤要求用户代理关闭一个 p 元素时,
表示用户代理必须运行以下步骤:
收养代理算法仅接受一个参数, 即要为其运行算法的令牌 token,它由以下 步骤组成:
令 subject 为 token 的标签名称。
如果当前节点是一个标签名称为 subject 的HTML 元素, 并且当前节点不在 活动格式化元素列表中,则 将当前节点从 打开 元素栈中弹出并返回。
令 outerLoopCounter 为 0。
当 true 时:
如果 outerLoopCounter 大于或等于 8,则返回。
将 outerLoopCounter 递增 1。
令 formattingElement 为活动 格式化元素列表中最后一个满足以下条件的元素:
如果不存在这样的元素,则按照上方“任何其他结束标签”条目所述执行 并返回。
令 furthestBlock 为打开 元素栈中位于 formattingElement 下方的最上方节点,并且它是一个属于 特殊类别的元素。可能不存在这样的节点。
如果不存在 furthestBlock,则用户代理必须首先从 打开元素栈底部弹出所有节点,从当前节点开始,直到并包括 formattingElement;然后从 活动格式化元素列表中移除 formattingElement,最后返回。
令 commonAncestor 为打开元素栈中紧邻 formattingElement 上方的元素。
令一个书签记录 formattingElement 在活动 格式化元素列表中的位置,该位置相对于列表中其两侧的元素。
令 node 和 lastNode 均为 furthestBlock。
令 innerLoopCounter 为 0。
当 true 时:
将 innerLoopCounter 递增 1。
令 node 为打开 元素栈中紧邻 node 上方的元素;如果 node 已不再位于打开 元素栈中(例如因为它已被此算法移除),则为 node 被移除之前在 打开元素栈中紧邻 node 上方的元素。
如果 node 是 formattingElement,则中断。
如果 innerLoopCounter 大于 3,并且 node 位于 活动格式化 元素列表中,则从 活动格式化 元素列表中移除 node。
如果 node 不在活动 格式化元素列表中,则从打开 元素栈中移除 node 并继续。
在HTML 命名空间中,为创建元素 node 时所使用的令牌创建元素,并将 commonAncestor 作为预期 父节点;将活动格式化 元素列表中 node 的条目替换为新元素的条目,将 打开元素栈中 node 的条目替换为新元素的条目,并令 node 为新元素。
如果 lastNode 是 furthestBlock,则将上述 书签移动到活动 格式化元素列表中新 node 之后的紧邻位置。
将 lastNode 追加到 node。
将 lastNode 设置为 node。
令 insertionLocation 位于 commonAncestor 内部、其最后一个子节点之后 (如果有)。
将在上一步中最终得到的 lastNode 插入由 insertionLocation 给出的调整后的 插入位置。
在HTML 命名空间中,为创建 formattingElement 时所使用的令牌创建元素,并将 furthestBlock 作为预期父节点。
取出 furthestBlock 的所有子节点,并将它们追加到 上一步创建的元素中。
将该新元素追加到 furthestBlock。
从活动格式化 元素列表中移除 formattingElement,并将新元素插入 活动格式化 元素列表中上述书签所在的位置。
从打开 元素栈中移除 formattingElement,并将新元素插入打开元素栈中 furthestBlock 在该栈中所在位置的紧邻下方。
此算法的名称“收养代理算法”源于它会使元素 更换父节点,这与用于处理错误嵌套内容的其他可能算法形成对比。
当用户代理要应用“文本”插入模式的规则时,用户代理必须按如下方式处理 令牌:
这绝不可能是 U+0000 NULL 字符;令牌化器会将其转换为 U+FFFD REPLACEMENT CHARACTER 字符。
解析错误。
如果活动推测性 HTML 解析器为 null,并且 JavaScript 执行 上下文栈为空,则执行微任务检查点。
令 script 为当前
节点(即一个
script 元素)。
令旧插入点具有与当前插入点相同的值。令插入点位于下一个 输入字符之前。
将解析器的脚本 嵌套级别递增 1。
如果活动推测性 HTML 解析器为 null,则 准备 script 元素 script。这可能导致某些脚本执行,而脚本又可能导致 新字符被插入 令牌化器,并可能导致令牌化器输出更多令牌,从而产生解析器的重入 调用。
将解析器的脚本嵌套级别递减 1。如果解析器的脚本 嵌套级别为零,则将解析器暂停标志设置为 false。
令插入点具有 旧插入点的值。(换言之,将插入点恢复为之前的值。 此值可能是“undefined”。)
在此阶段,如果待处理的解析阻塞 脚本非 null:
将解析器暂停标志 设置为 true,并中止对令牌化器任何嵌套 调用的处理,将控制权交还给调用方。(当调用方返回到“外层”树构造阶段时, 令牌化将恢复。)
此特定解析器的树构造阶段正在被
重入调用,例如由对 document.write()
的调用引起。
当待处理的解析阻塞脚本非 null 时:
令 the script 为待处理的解析阻塞 脚本。
将待处理的解析阻塞脚本设置为 null。
为此 HTML 解析器实例启动推测性 HTML 解析器。
如果解析器的 Document 具有阻塞
脚本的样式表,或者 the script 的已准备好由解析器执行为 false,则
旋转事件循环,直到
解析器的 Document
没有阻塞脚本的
样式表,并且 the script 的已准备好由
解析器执行变为 true。
如果此解析器在此期间已中止,则 返回。
例如,在旋转事件循环
算法运行期间,Document 被销毁,或者在该 Document 上调用了 document.open()
方法,就可能发生这种情况。
为此 HTML 解析器实例停止推测性 HTML 解析器。
将解析器的脚本嵌套级别递增 1(在此步骤之前它应为零, 因此这会将其设置为 1)。
执行 script 元素 the script。
将解析器的脚本嵌套级别递减 1。如果解析器的 脚本嵌套 级别为零(此时它始终应为零),则将 解析器暂停标志 设置为 false。
再次将插入点设置为 undefined。
当用户代理要应用“在 table 中”插入模式的规则时,用户代理必须按如下方式处理令牌:
table、tbody、template、tfoot、thead 或 tr 元素
令待处理的 table 字符 令牌为空令牌列表。
将插入模式切换为“在 table 文本中”,并重新处理该令牌。
插入注释。
解析错误。忽略该令牌。
将栈清除回 table 上下文。(见下文。)
在活动 格式化元素列表末尾插入一个标记。
为该令牌插入一个 HTML 元素,然后将插入 模式切换为“在 caption 中”。
将栈清除回 table 上下文。(见下文。)
为该令牌插入一个 HTML 元素,然后将插入 模式切换为“在列 组中”。
将栈清除回 table 上下文。(见下文。)
为一个没有属性的“colgroup”开始标签令牌插入一个 HTML 元素,然后将插入模式切换为“在 列组中”。
重新处理当前令牌。
将栈清除回 table 上下文。(见下文。)
为该令牌插入一个 HTML 元素,然后将插入 模式切换为“在 table body 中”。
将栈清除回 table 上下文。(见下文。)
为一个没有属性的“tbody”开始标签令牌插入一个 HTML 元素,然后将插入模式切换为“在 table body 中”。
重新处理当前令牌。
解析错误。
如果打开元素栈不在表格作用域内具有
table 元素,则忽略该令牌。
否则:
如果打开元素栈不在表格作用域内具有
table 元素,则这是一个解析
错误;忽略该令牌。
否则:
解析错误。忽略该令牌。
如果令牌没有名称为“type”的属性,或者有该属性,但属性值不与
“hidden”进行ASCII
不区分大小写匹配,则按照下方“其他任何情况”条目所述执行。
否则:
解析错误。
为该令牌插入一个 HTML 元素。
如果令牌的自闭合 标志已设置,则确认该标志。
解析错误。
如果打开元素栈中存在一个 template 元素,
或者form 元素
指针非 null,则忽略该令牌。
否则:
为该令牌插入一个 HTML
元素,并将form 元素指针设置为指向
所创建的元素。
此元素列表与在表格作用域内具有元素步骤中使用的列表相同。
经过此过程后,当前节点为一个 html 元素,是一种片段情况。
当用户代理要应用“在 table 文本中”插入模式的规则时,用户代理必须按如下方式处理令牌:
解析错误。忽略该令牌。
将该字符令牌追加到 待处理的 table 字符令牌列表中。
如果 待处理的 table 字符令牌列表中的任何令牌是非ASCII 空白的字符令牌,则这是一个解析错误:使用“在 table 中”插入模式中“其他任何情况”条目给出的规则,重新处理 待处理的 table 字符令牌列表中的字符令牌。
否则,插入由 待处理的 table 字符令牌列表给出的字符。
当用户代理要应用“在 caption 中”插入模式的规则时,用户代理必须按如下方式处理令牌:
如果打开
元素栈不在表格作用域内具有
caption 元素,则这是一个解析
错误;忽略该令牌。(片段
情况)
否则:
如果打开
元素栈不在表格作用域内具有
caption 元素,则这是一个解析
错误;忽略该令牌。(片段
情况)
否则:
解析错误。忽略该令牌。
当用户代理要应用“在列组中”插入模式的规则时,用户代理必须按如下方式处理令牌:
插入注释。
解析错误。忽略该令牌。
为该令牌插入一个 HTML 元素。立即将当前 节点从打开元素栈中弹出。
如果令牌的自闭合 标志已设置,则确认该标志。
解析错误。忽略该令牌。
如果当前节点不是一个 colgroup
元素,则这是一个
解析错误;忽略该令牌。
重新处理该令牌。
当用户代理要应用“在 table body 中”插入模式的规则时,用户代理必须按如下方式处理令牌:
将栈清除回 table body 上下文。(见下文。)
为该令牌插入一个 HTML 元素,然后将插入 模式切换为“在行中”。
解析错误。
将栈清除回 table body 上下文。(见下文。)
为一个没有属性的“tr”开始标签令牌插入一个 HTML 元素,然后将插入模式切换为“在 行中”。
重新处理当前令牌。
如果打开 元素栈中不在表格作用域内具有元素,该元素是一个与令牌具有相同 标签名称的HTML 元素,则这是一个解析错误; 忽略该令牌。
否则:
将栈清除回 table body 上下文。(见下文。)
如果打开
元素栈不在表格作用域内具有 tbody、
thead 或
tfoot 元素,则这是一个解析错误;
忽略该令牌。
否则:
将栈清除回 table body 上下文。(见下文。)
重新处理该令牌。
解析错误。忽略该令牌。
当上述步骤要求用户代理将栈
清除回 table body 上下文时,
表示只要当前
节点不是 tbody、
tfoot、thead、template 或 html 元素,用户代理就必须从
打开元素栈中弹出
元素。
经过此过程后,当前节点为一个 html 元素,是一种片段情况。
当用户代理要应用“在 行中”插入模式的规则时,用户代理必须按如下方式处理令牌:
将栈清除回 table row 上下文。(见下文。)
为该令牌插入一个 HTML 元素,然后将插入 模式切换为“在 单元格中”。
在活动 格式化元素列表末尾插入一个标记。
如果打开
元素栈不在表格作用域内具有
tr 元素,则这是一个解析错误;
忽略该令牌。
否则:
将栈清除回 table row 上下文。(见下文。)
将当前节点(即一个
tr 元素)从
打开
元素栈中弹出。将插入模式切换为“在 table
body 中”。
如果打开
元素栈不在表格作用域内具有
tr 元素,则这是一个解析错误;
忽略该令牌。
否则:
将栈清除回 table row 上下文。(见下文。)
将当前节点(即一个
tr 元素)从
打开
元素栈中弹出。将插入模式切换为“在 table
body 中”。
重新处理该令牌。
如果打开 元素栈中不在表格作用域内具有元素,该元素是一个与令牌具有相同 标签名称的HTML 元素,则这是一个解析错误; 忽略该令牌。
如果打开
元素栈不在表格作用域内具有
tr 元素,则忽略该令牌。
否则:
将栈清除回 table row 上下文。(见下文。)
将当前节点(即一个
tr 元素)从
打开
元素栈中弹出。将插入模式切换为“在 table
body 中”。
重新处理该令牌。
解析错误。忽略该令牌。
经过此过程后,当前节点为一个 html 元素,是一种片段情况。
当用户代理要应用“在单元格中”插入模式的规则时,用户代理必须按如下方式处理令牌:
如果打开 元素栈中不在表格作用域内具有元素,该元素是一个与令牌具有相同 标签名称的HTML 元素,则这是一个解析 错误;忽略该令牌。
否则:
关闭单元格(见下文),并重新处理 该令牌。
解析错误。忽略该令牌。
如果打开 元素栈中不在表格作用域内具有元素,该元素是一个与令牌具有相同 标签名称的HTML 元素,则这是一个解析 错误;忽略该令牌。
否则,关闭单元格(见下文),并重新处理该令牌。
上述步骤中所述的关闭单元格,表示运行以下 算法:
打开
元素栈不可能同时在表格作用域内具有一个
td 元素和一个
th 元素,并且在调用关闭单元格算法时,也不可能两者都没有。
当用户代理要应用“在 template 中”插入模式的规则时,用户代理必须按如下方式处理令牌:
将当前 template 插入模式从template 插入模式栈中弹出。
将“在 table 中”压入 template 插入模式栈,使其成为新的当前 template 插入 模式。
将当前 template 插入模式从 template 插入模式栈中弹出。
将“在列 组中”压入 template 插入模式栈, 使其成为新的当前 template 插入模式。
将当前 template 插入模式从 template 插入模式栈中弹出。
将“在 table body 中” 压入template 插入模式栈,使其成为新的当前 template 插入 模式。
将插入模式切换为“在 table body 中”,并重新处理该令牌。
将当前 template 插入模式从 template 插入模式栈中弹出。
将“在行中”压入template 插入模式栈,使其成为新的当前 template 插入模式。
将当前 template 插入模式从 template 插入模式栈中弹出。
将“在 body 中”压入 template 插入模式栈,使其成为新的当前 template 插入模式。
解析错误。忽略该令牌。
如果打开
元素栈中没有 template
元素,则停止解析。(片段情况)
否则,这是一个解析错误。
从打开元素栈中弹出元素,直到一个
template
元素已从栈中弹出。
将当前 template 插入模式从 template 插入模式栈中弹出。
重新处理该令牌。
当用户代理要应用“在 body 之后”插入模式的规则时,用户代理必须按如下方式处理令牌:
解析错误。忽略该令牌。
如果解析器是作为HTML 片段解析算法的一部分创建的,则 这是一个解析错误;忽略该令牌。(片段情况)
否则,将插入 模式切换为“在 body 之后之后”。
停止解析。
当用户代理要应用“在 frameset 中”插入模式的规则时,用户代理必须按如下方式处理令牌:
插入注释。
解析错误。忽略该令牌。
为该令牌插入一个 HTML 元素。
如果当前节点是根 html 元素,则这是
一个
解析错误;忽略该令牌。(片段情况)
如果解析器不是作为HTML 片段解析算法的一部分创建的
(片段情况),并且当前节点不再是一个
frameset 元素,则将
插入模式切换为“在
frameset 之后”。
为该令牌插入一个 HTML 元素。立即将当前 节点从打开元素栈中弹出。
如果令牌的自闭合 标志已设置,则确认该标志。
如果当前节点不是根
html 元素,
则这是一个
解析错误。
停止解析。
解析错误。忽略该令牌。
当用户代理要应用“在 frameset 之后”插入模式的规则时,用户代理必须按如下方式处理令牌:
当用户代理要应用“在 body 之后之后”插入模式的规则时,用户代理必须按如下方式处理 令牌:
停止解析。
当用户代理要应用“在 frameset 之后之后” 插入模式的规则时,用户代理必须按如下方式处理 令牌:
当用户代理要应用解析外来内容中令牌的规则时,用户代理 必须按如下方式处理令牌:
将frameset-ok 标志设置为“not ok”。
插入注释。
解析错误。忽略该令牌。
解析错误。
只要当前节点既不是MathML 文本 集成点、HTML 集成 点,也不是HTML 命名空间中的元素,就从 打开 元素栈中弹出元素。
根据 HTML 内容中与当前插入模式对应的小节所给出的规则重新处理该令牌。
如果调整后的当前 节点是MathML 命名空间中的元素,则为该令牌调整 MathML 属性。(这会修正并非全部为小写的 MathML 属性。)
如果调整后的当前 节点是SVG 命名空间中的元素,并且 令牌的标签名称是下表第一列中的某个名称,则将标签 名称更改为第二列对应单元格中给出的名称。(这会修正 并非全部为小写的 SVG 元素名称。)
| 标签名称 | 元素名称 |
|---|---|
altglyph |
altGlyph
|
altglyphdef |
altGlyphDef
|
altglyphitem |
altGlyphItem
|
animatecolor |
animateColor
|
animatemotion |
animateMotion
|
animatetransform |
animateTransform
|
clippath |
clipPath
|
feblend |
feBlend
|
fecolormatrix |
feColorMatrix
|
fecomponenttransfer |
feComponentTransfer
|
fecomposite |
feComposite
|
feconvolvematrix |
feConvolveMatrix
|
fediffuselighting |
feDiffuseLighting
|
fedisplacementmap |
feDisplacementMap
|
fedistantlight |
feDistantLight
|
fedropshadow |
feDropShadow
|
feflood |
feFlood
|
fefunca |
feFuncA
|
fefuncb |
feFuncB
|
fefuncg |
feFuncG
|
fefuncr |
feFuncR
|
fegaussianblur |
feGaussianBlur
|
feimage |
feImage
|
femerge |
feMerge
|
femergenode |
feMergeNode
|
femorphology |
feMorphology
|
feoffset |
feOffset
|
fepointlight |
fePointLight
|
fespecularlighting |
feSpecularLighting
|
fespotlight |
feSpotLight
|
fetile |
feTile
|
feturbulence |
feTurbulence
|
foreignobject |
foreignObject
|
glyphref |
glyphRef
|
lineargradient |
linearGradient
|
radialgradient |
radialGradient
|
textpath |
textPath
|
如果调整后的当前 节点是SVG 命名空间中的元素,则 为该令牌调整 SVG 属性。 (这会修正并非全部为小写的 SVG 属性。)
为该令牌调整外来 属性。(这会修正命名空间属性的使用,尤其是 SVG 中的 XLink。)
使用调整后的当前 节点的命名空间和 false,为该令牌插入外来 元素。
如果令牌已设置自闭合标志,则运行下表中适用的步骤:
确认令牌的自闭合 标志,然后按照下方“script”结束标签的步骤执行。
将当前节点从打开 元素栈中弹出,并确认令牌的自闭合 标志。
script 元素令旧插入点具有与当前插入点相同的值。令插入点位于下一个 输入字符之前。
将解析器的脚本嵌套级别递增 1。将解析器暂停 标志设置为 true。
如果活动推测性
HTML 解析器为 null,并且
用户代理支持 SVG,则根据 SVG 规则处理
SVG script 元素。[SVG]
即使这导致新字符被 插入令牌化器,解析器也不会被重入执行,因为 解析器暂停标志为 true。
运行以下步骤:
将 node 初始化为当前节点(栈中最下方的 节点)。
如果将 node 的标签名称转换为 ASCII 小写后, 与令牌的标签名称不同,则这是一个解析错误。
如果将 node 的标签名称转换为 ASCII 小写后, 与令牌的标签名称相同,则从打开 元素栈中弹出元素,直到 node 已从栈中弹出,然后返回。
将 node 设置为打开 元素栈中的前一个条目。
如果 node 不是HTML 命名空间中的元素,则返回 标记为循环的步骤。
否则,根据 HTML 内容中与当前插入模式对应的小节所给出的规则处理该令牌。
Document/DOMContentLoaded_event
所有当前引擎均支持。
所有当前引擎均支持。
一旦用户代理停止解析文档,用户代理 必须运行以下步骤:
如果活动 推测性 HTML 解析器非 null,则停止 推测性 HTML 解析器并返回。
将插入点设置为 undefined。
将当前文档就绪状态更新为“interactive”。
从打开元素栈中弹出所有节点。
当文档完成解析时 将执行的脚本列表不为空时:
旋转事件循环,直到文档完成解析时
将执行的脚本列表中的第一个 script
的已准备好由解析器执行设置为
true,并且
解析器的 Document
没有阻塞
脚本的样式表。
执行 script
元素,即文档完成解析时
将执行的脚本列表中的第一个 script。
从文档完成解析时将
执行的脚本列表中移除第一个 script
元素(即移出列表中的第一个条目)。
在DOM 操作任务
源上,使用 Document 的相关全局对象排入全局任务,以运行以下子步骤:
将 Document 的加载计时信息的DOM 内容已加载
事件开始时间设置为在给定 Document 的相关全局对象的情况下取得的当前高精度时间。
在 Document
对象上触发名为 DOMContentLoaded
的事件,并将其 bubbles
属性初始化为 true。
将 Document 的加载计时信息的DOM 内容已加载
事件结束时间设置为在给定 Document 的相关全局对象的情况下取得的当前高精度时间。
启用 ServiceWorkerContainer
对象的客户端消息
队列,该对象关联的service worker 客户端是
Document 对象的相关设置对象。
使用 Document 的
浏览上下文,以及一个新的WebDriver BiDi
导航状态,调用WebDriver BiDi DOM 内容已加载;其中该状态的
id 为 Document 对象的WebDriver BiDi 加载期间导航
ID,status
为“pending”,
并且url 为 Document 对象的URL。
旋转事件循环,直到将尽快执行的脚本集合和将按顺序尽快 执行的脚本列表均为空。
在DOM 操作任务
源上,使用 Document 的相关全局对象排入全局任务,以运行以下步骤:
将当前文档就绪状态更新为
“complete”。
将 Document 的加载计时信息的load 事件开始
时间设置为在给定 window 的情况下取得的当前高精度时间。
使用 Document 的浏览上下文,以及一个新的WebDriver BiDi
导航状态,调用WebDriver BiDi 加载完成;其中该状态的id 为
Document 对象的WebDriver BiDi 加载期间
导航 ID,status
为“complete”,
并且url 为 Document 对象的URL。
将 Document 对象的WebDriver BiDi 加载期间
导航 ID设置为 null。
将 Document 的加载计时信息的load 事件结束
时间设置为在给定 window 的情况下取得的当前高精度时间。
Document 现在已准备好执行加载后任务。
当用户代理要中止解析器时,必须运行以下步骤:
丢弃输入流中任何待处理的内容,并丢弃以后 本应添加到其中的任何内容。
为此 HTML 解析器停止 推测性 HTML 解析器。
将当前文档就绪状态更新为“interactive”。
从打开元素栈中弹出所有节点。
将当前文档就绪状态更新为“complete”。
用户代理可以实现本节所述的优化,以便在 HTML 解析器等待待处理的 解析阻塞脚本被获取并执行时,或者在正常解析期间,当为令牌创建元素时, 推测性获取 HTML 标记中声明的资源。 尽管此优化没有被精确定义,但为了实现互操作性,仍有一些规则需要考虑。
每个HTML 解析器都可以具有一个活动推测性 HTML 解析器。它最初为 null。
推测性 HTML 解析器必须像普通 HTML 解析器一样工作(例如,树构建器规则仍适用),但有以下例外:
普通 HTML 解析器和文档本身的状态不得受到影响。
例如,普通 HTML 解析器的下一个输入字符或打开元素栈不会受到推测性 HTML 解析器的影响。
推入 HTML 解析器输入字节流的字节,也必须推入 推测性 HTML 解析器的输入字节流。从这些流中读取字节必须 相互独立。
推测性解析的结果主要是一系列推测性获取。要推测性获取哪些类型的资源 是由实现定义的,但用户代理不得推测性 获取在阻塞 HTML 解析器的脚本不执行任何操作的假设下,普通 HTML 解析器不会获取的资源。
同一段标记可能会先后被推测性 HTML 解析器和普通 HTML 解析器多次看到。预计缓存规则会防止 重复获取,但这些规则尚未被完整规定。
对于一个推测性模拟元素 element 的推测性获取, 必须遵循以下规则:
其中某些内容是否应该“真实地”应用到文档, 即使它们是通过推测发现的?
如果推测性 HTML 解析器遇到以下元素之一,则为了影响后续推测性 获取,应像该元素已被处理一样执行。
base
元素。meta 元素,
其 http-equiv
属性处于内容
安全策略状态。meta
元素,其 name
属性与“referrer”进行
ASCII 不区分大小写匹配。
meta
元素,其 name
属性与“viewport”进行
ASCII 不区分大小写匹配。
(这可能影响媒体查询列表是否匹配环境。)[CSSDEVICEADAPT]
令 url 为 element 在正常处理时将获取的URL。如果不存在这样的URL,或者它是空字符串,则不执行任何操作。否则,如果 url 已位于推测性获取 URL 列表中,则不执行任何操作。否则,像正常处理该元素时一样获取 url,并将 url 添加到推测性获取 URL 列表中。
每个 Document 都有一个推测性获取 URL 列表,它是一个
列表,包含
URL,最初为空。
要为 HTML 解析器实例 parser 启动推测性 HTML 解析器:
可选地,返回。
此步骤允许用户代理选择不使用推测性 HTML 解析。
如果 parser 的活动推测性 HTML 解析器非 null,则 为 parser 停止推测性 HTML 解析器。
当 document.write()
写入另一个解析器阻塞脚本时,可能发生这种情况。为简化起见,本规范总是重新启动
推测性解析,但用户代理可以实现更高效的策略,只要最终
结果等价即可。
令 speculativeParser 为一个新的推测性 HTML 解析器,其 状态与 parser 相同。
令 speculativeDoc 为 parser 的
Document 的一个新的同构表示,
其中所有元素都改为推测性模拟元素。令
speculativeParser 将内容解析到
speculativeDoc 中。
将 parser 的活动推测性 HTML 解析器设置为 speculativeParser。
要为 HTML 解析器实例 parser 停止推测性 HTML 解析器:
令 speculativeParser 为 parser 的活动推测性 HTML 解析器。
如果 speculativeParser 为 null,则返回。
丢弃 speculativeParser 的输入 流中任何待处理的内容,并丢弃以后本应添加到其中的任何内容。
将 parser 的活动推测性 HTML 解析器设置为 null。
推测性 HTML 解析器会创建推测性模拟元素,而不是普通元素。 树构建器通常在元素上执行的 DOM 操作,预期也能在推测性模拟元素上适当工作。
要在给定 namespace、 tagName 和 attributes 的情况下创建推测性模拟元素:
当树构建器要求将元素插入一个 template 元素的
模板内容时,如果该内容是一个
推测性模拟
元素,并且该
template
元素的模板内容不是一个
ShadowRoot
节点,则改为不执行任何操作。在非声明式影子根 template
元素内部推测性发现的 URL 可能本身也是模板的一部分,因此不得
被推测性获取。
当应用程序将HTML
解析器与 XML 管道结合使用时,构造出的 DOM 可能会以某些细微的方式与 XML 工具链
不兼容。例如,XML 工具链可能无法表示名称为 xmlns 的属性,
因为它们与 XML 命名空间语法冲突。HTML 解析器还会生成一些
不包含在 DOM 本身中的数据。本节规定了一些处理这些问题的规则。
如果所使用的 XML API 不支持 DOCTYPE,则工具可以完全丢弃 DOCTYPE。
如果 XML API 不支持名称为“xmlns”且不在任何命名空间中的属性、名称以
“xmlns:”开头的属性,或者位于XMLNS 命名空间中的属性,则
工具可以丢弃此类属性。
工具可以使用正常运行所需的任何命名空间声明来注释输出。
如果 XML API 限制元素和属性本地名称中允许使用的字符,则工具可以将该 API 不支持的所有元素和属性本地名称映射为一组受允许的名称,方法是将每个 不受支持的字符替换为大写字母 U,以及该字符码点以十六进制表示时的六位数字, 并按数值递增顺序使用数字 0-9 和大写字母 A-F 作为符号。
例如,元素名称 foo<bar 可以由
HTML 解析器输出,
尽管它既不是合法的 HTML 元素名称,也不是良构的 XML 元素名称,但它会被转换为
fooU00003Cbar,后者是一个良构的 XML 元素名称
(尽管它无论如何仍不是合法的 HTML 元素名称)。
再举一个例子,考虑属性 xlink:href。
当它用于 MathML 元素时,在经过调整后,会成为一个前缀为
“xlink”、本地名称为“href”的属性。但是,当它用于 HTML 元素时,
会成为一个没有前缀、本地名称为“xlink:href”的属性,该名称不是有效的 NCName,
因此可能不会被 XML API 接受。于是它可能会被转换,成为“xlinkU00003Ahref”。
此转换产生的名称不会与HTML 解析器生成的任何属性发生冲突,这一点很方便,因为这些属性要么全部为小写,要么是 调整外来属性算法的 表中列出的属性。
如果 XML API 限制注释中不得包含两个连续的 U+002D HYPHEN-MINUS 字符 (--),则工具可以在任何此类有问题的字符之间插入一个 U+0020 SPACE 字符。
如果 XML API 限制注释不得以 U+002D HYPHEN-MINUS 字符(-)结尾,则工具 可以在此类注释的末尾插入一个 U+0020 SPACE 字符。
如果 XML API 限制字符数据、属性值或注释中允许使用的字符, 则工具可以将任何 U+000C FORM FEED(FF)字符替换为 U+0020 SPACE 字符,并将 任何其他字面量非 XML 字符替换为 U+FFFD REPLACEMENT CHARACTER。
如果工具无法传递带外信息,则工具可以丢弃以下信息:
本节允许的变更应用于HTML
解析器的规则被应用之后。例如,一个 <a::> 开始标签
会由一个 </a::> 结束标签关闭,而绝不会由一个
</aU00003AU00003A> 结束标签关闭,即使用户代理使用上述规则,
随后在 DOM 中为该开始标签生成一个实际名称为 aU00003AU00003A 的元素。
本节是非规范性的。
本节检查一些错误标记,并讨论HTML 解析器 如何处理这些情况。
本节是非规范性的。
最常被讨论的错误标记示例如下:
< p > 1< b > 2< i > 3</ b > 4</ i > 5</ p > 对此标记的解析在“3”之前都很直接。此时,DOM 如下所示:
此时,打开元素栈中有五个元素:html、
body、p、b 和 i。活动
格式化元素列表中只有两个元素:b 和
i。插入
模式为“在 body 中”。
收到标签名称为“b”的结束标签令牌后,会调用“收养
代理算法”。这是一个简单情况,因为 formattingElement
是 b 元素,并且
不存在 furthest block。
因此,打开元素栈最终只剩下三个元素:html、
body 和 p,而活动格式化元素列表
中只剩下一个元素:i。此时 DOM
树没有发生改变。
下一个令牌是字符(“4”),它会触发重建活动格式化
元素,在本例中只有
i 元素。因此会为“4”
Text
节点创建一个新的 i 元素。随后还会接收到
“i”的结束标签令牌,并插入“5”
Text
节点,此时 DOM 如下所示:
本节是非规范性的。
与上一个示例类似的一种情况如下:
< b > 1< p > 2</ b > 3</ p > 在“2”之前,此处的解析都很直接:
有趣的部分发生在解析标签名称为“b”的结束标签令牌时。
在看到该令牌之前,打开元素栈中有四个元素:
html、body、b 和 p。活动
格式化元素列表中只有一个元素:b。插入模式为
“在 body 中”。
收到标签名称为“b”的结束标签令牌后,会像上一个示例一样调用“收养代理算法”。但是,在本例中存在一个
furthest block,即 p 元素。因此,这一次
不会跳过收养代理算法。
common ancestor 是 body 元素。一个概念上的
“书签”标记 b 在活动格式化
元素列表中的位置,但由于该列表中只有一个元素,因此书签不会产生太大
影响。
随着算法继续执行,node 最终被设置为格式化元素
(b),而
last node 最终被设置为 furthest
block(p)。
last node 会被追加(移动)到 common ancestor,从而使 DOM 如下所示:
会创建一个新的 b 元素,并将 p 元素的子节点
移动到其中:
最后,新创建的 b
元素会被追加到 p 元素中,从而使
DOM 如下所示:
b 元素会从
活动格式化元素列表
和打开
元素栈中移除,因此当解析“3”时,它会被追加到
p 元素:
本节是非规范性的。
由于历史原因,表格中的错误处理尤其奇怪。例如,考虑 以下标记:
< table > < b > < tr >< td > aaa</ td ></ tr > bbb</ table > ccc高亮显示的 b 元素
开始标签不允许像这样直接出现在表格内部,解析器会通过将该元素放在表格之前来处理这种情况。
(这称为寄养。)通过检查刚看到 table 元素开始
标签之后的 DOM 树,可以看到这一点:
……然后,在刚看到 b 元素开始标签后:
此时,打开元素栈中包含以下元素:
html、body、table 和 b(顺序如此,
尽管生成的 DOM 树并非如此);活动格式化元素列表中只有
b 元素;而
插入模式为“在 table 中”。
tr 开始标签会导致
b 元素从栈中弹出,
并隐含一个 tbody 开始标签;
随后会以相当直接的方式处理 tbody 和 tr 元素,
使解析器依次进入“在 table body
中”和“在行中”插入模式,
此后 DOM 如下所示:
此时,打开元素栈中包含以下元素:html、
body、table、tbody 和 tr;活动
格式化元素列表中仍有 b 元素;而
插入模式为“在行中”。
td 元素开始标签
令牌在将一个 td 元素放入
树中后,会在活动
格式化元素列表中放入一个标记(它还会切换到“在
单元格中”插入模式)。
该标记意味着,当看到“aaa”字符
令牌时,不会创建 b
元素来容纳生成的 Text
节点:
这些结束标签会以直接的方式处理;处理完后,打开
元素栈中包含以下元素:html、body、
table 和 tbody;活动格式化元素列表
中仍有 b 元素
(标记已由“td”结束标签令牌移除);而插入模式为“在 table body 中”。
于是会遇到“bbb”字符令牌。它们会触发使用“在 table 文本中”插入模式
(其中原始
插入模式设置为“在 table body
中”)。
字符令牌会被收集,并在看到下一个令牌(table 元素结束
标签)时作为一组处理。由于它们并非全是空格,因此会按照“在 table 中”
插入模式中的“其他任何情况”规则处理,该规则会转交给“在
body 中”
插入模式,但启用寄养。
当重建活动格式化
元素时,会创建一个 b
元素并对其进行寄养,随后将“bbb”
Text
节点追加到其中:
打开
元素栈中包含以下元素:html、
body、table、tbody 和新的
b(再次注意,
这与生成的树不匹配!);活动格式化元素列表
中包含新的 b 元素;而插入模式仍为
“在 table body 中”。
如果字符令牌不是“bbb”,而仅由ASCII 空白组成,那么该
ASCII 空白只会被追加到 tbody 元素。
最后,table 会由
“table”结束标签关闭。这会将打开
元素栈中的所有节点弹出,直到并包括 table 元素,
但它不会影响活动格式化元素列表,因此
表格之后的“ccc”字符令牌会导致创建另一个 b
元素,
这次位于表格之后:
本节是非规范性的。
考虑以下标记。在本例中,我们假设它是一个URL 为
https://example.com/inner 的文档,并作为另一个
URL 为
https://example.com/outer 的文档中一个 iframe
的内容渲染:
< div id = a >
< script >
var div = document. getElementById( 'a' );
parent. document. body. appendChild( div);
</ script >
< script >
alert( document. URL);
</ script >
</ div >
< script >
alert( document. URL);
</ script > 在第一个“script”结束标签之前,并且在脚本被解析之前,结果相对 直接:
但是,脚本被解析后,div
元素及其子
script
元素都消失了:
此时,它们位于前面提到的外层浏览
上下文的 Document 中。
但是,打开元素栈
中仍然包含
div
元素。
因此,当解析第二个 script
元素时,它会被插入外层
Document
对象中。
被解析到与创建解析器时所用文档不同的 Document
中的脚本不会执行,因此第一个警告框不会显示。
一旦解析了 div
元素的结束标签,div
元素就会从栈中弹出,因此下一个 script
元素位于内层
Document
中:
此脚本确实会执行,从而显示内容为“https://example.com/inner”的警告框。
本节是非规范性的。
在上一节示例的基础上,考虑第二个
script
元素是外部脚本的情况(即具有一个 src
属性)。由于该元素创建时不在解析器的
Document
中,因此该外部脚本甚至不会被下载。
在另一种情况下,一个具有 src
属性的 script
元素被正常解析到其解析器的 Document
中,但在下载外部
脚本期间,该元素被移动到另一个文档中,那么脚本会继续
下载,但不会执行。
通常,将 script
元素在不同 Document
之间移动被视为一种不良做法。
本节是非规范性的。
以下标记展示了嵌套的格式化元素(例如 b)如何被
收集,并且即使包含它们的元素已经关闭,它们仍会继续应用,但过多的重复项会被丢弃。
<!DOCTYPE html>
< p >< b class = x >< b class = x >< b >< b class = x >< b class = x >< b > X
< p > X
< p >< b >< b class = x >< b > X
< p ></ b ></ b ></ b ></ b ></ b ></ b > X生成的 DOM 树如下所示:
htmlhtml
请注意,标记中的第二个 p
元素没有任何显式的 b
元素,但在生成的 DOM 中,在该元素的“X”之前,每种格式化元素最多会重建三个
(在本例中是三个具有 class 属性的 b
元素,以及两个没有修饰的
b 元素)。
还要注意,这意味着在最后一个段落中,只需要六个 b 结束标签,
就能完全清除活动格式化元素列表,尽管到
此时已经看到了九个
b 开始标签。
以下步骤构成HTML 片段序列化算法。该算法接收一个称为
the node 的 DOM Element、
Document 或 DocumentFragment,
一个布尔值 serializableShadowRoots,以及一个
sequence<ShadowRoot> shadowRoots 作为输入,并返回一个字符串。
此算法序列化的是节点的子节点,而不是节点本身。
如果 the node 序列化为空,则返回空字符串。
令 s 为一个字符串,并将其初始化为空字符串。
如果 the node 是一个 template
元素,则改为令 the node 为该 template
元素的模板内容(一个 DocumentFragment
节点)。
如果 current node 是一个影子宿主:
令 shadow 为 current node 的 影子根。
如果以下条件之一为 true:
serializableShadowRoots 为 true,并且 shadow 的 可序列化为 true;或者
shadowRoots 包含 shadow,
则:
追加“<template shadowrootmode="”。
如果 shadow 的模式
为“open”,则追加“open”。
否则,追加“closed”。
追加 U+0022(")。
如果 shadow 的委托焦点已设置,则追加
“ shadowrootdelegatesfocus=""”。
如果 shadow 的可序列化已设置,则追加
“ shadowrootserializable=""”。
如果 shadow 的槽分配为“manual”,则追加
“ shadowrootslotassignment="manual"”。
如果 shadow 的可克隆已设置,则追加
“ shadowrootclonable=""”。
令 shouldAppendRegistryAttribute 为运行以下步骤所得的结果:
令 shadowRegistry 为 shadow 的自定义元素注册表。
如果 documentRegistry 为 null,并且 shadowRegistry 为 null,则 返回 false。
如果 documentRegistry 是全局自定义元素注册表,并且 shadowRegistry 是全局自定义元素注册表, 则返回 false。
返回 true。
如果 shouldAppendRegistryAttribute 为 true,则追加
“ shadowrootcustomelementregistry=""”。
追加 U+003E(>)。
追加使用 shadow、serializableShadowRoots 和 shadowRoots 运行HTML 片段序列化 算法所得的值(从而针对该元素递归调用此算法)。
追加“</template>”。
对于 the node 的每个子节点,按树顺序运行以下步骤:
令 current node 为正在处理的子节点。
将以下列表中的适当字符串追加到 s:
Element
如果 current node 是HTML 命名空间、MathML 命名空间或SVG 命名空间中的元素,则令 tagname 为 current node 的本地名称。 否则,令 tagname 为 current node 的限定名称。
追加 U+003C(<),后跟 tagname。
对于由HTML
解析器或 createElement()
创建的HTML
元素,tagname 将为小写。
如果 current node 的is 值非 null,并且该元素
的属性列表中没有 is
属性,则追加“ is="”,后跟 current
node 的is 值,该值按照下文所述在
属性模式下转义,
最后追加 U+0022(")。
对于元素具有的每个属性,追加 U+0020 SPACE、该属性的序列化名称(如下所述)、
“="”、该属性的值(按照下文所述在属性模式下转义),
以及 U+0022(")。
就上一段而言,属性的序列化名称 必须按如下方式确定:
属性的序列化名称为属性的本地名称。
对于由HTML
解析器或 setAttribute()
在HTML 元素上设置的属性,
本地名称将为小写。
属性的序列化名称为“xml:”后跟
属性的本地名称。
xmlns
属性的序列化名称为“xmlns”。
xmlns
属性的序列化名称为“xmlns:”后跟
属性的本地名称。
属性的序列化名称为“xlink:”后跟
属性的本地名称。
属性的序列化名称为属性的限定名称。
虽然属性的确切顺序是由实现定义的,并且可能 取决于原始标记中给出属性的顺序等因素,但排序顺序必须保持稳定, 以便连续调用此算法时,元素的属性总是按相同顺序序列化。
追加 U+003E(>)。
如果 current node 序列化为空,则此时继续处理下一个 子节点。
追加使用 current node、serializableShadowRoots 和
shadowRoots 运行HTML 片段序列化
算法所得的值(从而针对该节点递归调用此算法),后跟“</”、
tagname 和 U+003E(>)。
Text
节点如果 current node 的父节点是 style、
script、
xmp、iframe、
noembed、
noframes 或 plaintext 元素,或者
current node 的父节点是一个 noscript
元素,并且该节点的脚本已启用,则按字面值追加
current node 的数据。
Comment
追加“<!--”,后跟 current
node 的数据的值,以及
“-->”。
ProcessingInstruction
追加“<?”,后跟 current
node 的目标的值、
U+0020 SPACE、current node 的数据的值,以及
“?>”。
DocumentType
追加“<!DOCTYPE ”,后跟 current
node 的名称的值和 U+003E(>)。
返回 s。
如果此算法的输出由 HTML 解析器解析,则可能无法还原原始 树结构。无法通过序列化再重新解析步骤往返还原的树结构,也可能由 HTML 解析器本身生成,尽管此类 情况通常不符合规范。
例如,如果序列化一个已追加 Comment
节点的 textarea 元素,然后重新解析输出,
则注释最终会显示在文本控件中。类似地,如果由于 DOM 操作,某个元素
包含一个含有“-->”的注释,那么在解析该元素的序列化结果时,
注释会在该处被截断,其余注释会被解释为标记。更多示例包括使一个 script
元素包含一个文本字符串为“</script>”的 Text
节点,或者使一个 p 元素包含一个
ul 元素
(因为该 ul 元素的开始
标签会隐含 p 的结束标签)。
这可能导致跨站脚本攻击。一个示例是,某个页面允许用户输入一些字体系列名称,
然后通过 DOM 将它们插入 CSS style 块中,
随后使用 innerHTML
IDL 属性获取该 style
元素的
HTML 序列化:如果用户输入
“</style><script>attack</script>”作为字体系列名称,那么 innerHTML
将返回一段标记,如果在不同上下文中解析,该标记会包含一个 script 节点,
尽管原始 DOM 中并不存在任何 script 节点。
例如,考虑以下标记:
< form id = "outer" >< div ></ form >< form id = "inner" >< input > 它将被解析为:
input
元素将与内层 form 元素关联。
现在,如果序列化并重新解析此树结构,则 <form
id="inner"> 开始标签会被忽略,因此 input 元素将改为
与外层 form 元素关联。
< html >< head ></ head >< body >< form id = "outer" >< div > < form id = "inner" > < input ></ form ></ div ></ form ></ body ></ html > 再举一个例子,考虑以下标记:
< a >< table >< a > 它将被解析为:
也就是说,这些 a 元素
发生嵌套,因为第二个 a 元素被
寄养。经过一次序列化再重新解析往返后,
这些 a 元素和 table 元素将
全部成为兄弟节点,因为第二个 <a> 开始标签会隐式关闭第一个 a
元素。
< html >< head ></ head >< body >< a > < a > </ a >< table ></ table ></ a ></ body ></ html > 由于历史原因,此算法无法往返还原 pre、textarea 或
listing 元素开头的
U+000A(LF)字符,即使(在前两种情况下)被往返处理的标记可能是符合规范的。HTML
解析器
会在解析期间丢弃此类字符,但此算法不会额外序列化一个
U+000A(LF)字符。
例如,考虑以下标记:
< pre >
Hello.</ pre > 首次解析此文档时,pre 元素的子文本
内容以一个换行符开头。经过一次序列化再重新解析往返后,
pre 元素的子文本
内容只是“Hello.”。
由于 is 属性在指示创建
自定义
内置元素方面具有特殊作用,因为它提供了一种机制,使解析后的
HTML 可以设置元素的is
值,所以我们在序列化期间对其进行特殊处理。这确保元素的
is 值能够在
序列化再解析往返过程中保留。
通过解析器创建自定义内置元素时,开发者会直接使用
is 属性;在这种情况下,
序列化再解析往返
可以正常工作。
< script >
window. SuperP = class extends HTMLParagraphElement {};
customElements. define( "super-p" , SuperP, { extends : "p" });
</ script >
< div id = "container" >< p is = "super-p" > Superb!</ p ></ div >
< script >
console. log( container. innerHTML); // <p is="super-p">
container. innerHTML = container. innerHTML;
console. log( container. innerHTML); // <p is="super-p">
console. assert( container. firstChild instanceof SuperP);
</ script > 但是,通过构造函数或
createElement()
创建自定义内置元素时,不会添加 is
属性。相反,会直接设置is 值(这是自定义元素
机制所使用的值),而不通过属性作为中间步骤。
< script >
container. innerHTML = "" ;
const p = document. createElement( "p" , { is: "super-p" });
container. appendChild( p);
// The is attribute is not present in the DOM:
console. assert( ! p. hasAttribute( "is" ));
// But the element is still a super-p:
console. assert( p instanceof SuperP);
</ script > 为了确保序列化再解析往返仍然正常工作,序列化过程会明确地将元素的
is
值写出为一个 is 属性:
< script >
console. log( container. innerHTML); // <p is="super-p">
container. innerHTML = container. innerHTML;
console. log( container. innerHTML); // <p is="super-p">
console. assert( container. firstChild instanceof SuperP);
</ script > 转义字符串(就上述算法而言) 包括运行以下步骤:
将每次出现的“&”字符替换为“&”。
将每次出现的 U+00A0 NO-BREAK SPACE 字符替换为“ ”。
将每次出现的“<”字符替换为
“<”。
将每次出现的“>”字符替换为
“>”。
如果算法是在属性模式下调用的,则将每次出现的
“"”字符替换为“"”。
HTML 片段解析算法,给定一个 Element 或
DocumentFragment
target、一个字符串 input、一个可选布尔值
allowDeclarativeShadowRoots(默认为 false),以及一个可选的解析器脚本
模式 scriptingMode(默认为惰性),
由以下步骤组成。它们返回一个 DocumentFragment。
HTML 解析器一节的算法中标记为片段情况的部分,仅在解析器为此 算法创建时发生。算法中添加这些标记仅供参考; 此类标记不具有规范效力。如果某个被描述为片段情况的条件,即使解析器 并非为处理此算法而创建也可能发生,那么这是规范中的错误。
否则,如果 contextDocument 处于有限怪异模式,则将
document 的模式设置为
“limited-quirks”。
创建一个新的HTML 解析器,其允许 声明式影子根为 allowDeclarativeShadowRoots,并将其与 document 关联。
将解析器的脚本模式设置为 scriptingMode。
根据 context,按如下方式设置 HTML 解析器的令牌化阶段的状态:
titletextarea
stylexmpiframenoembednoframesscriptnoscript
plaintext出于性能原因,一个不报告错误并直接使用本规范所述实际状态机的 实现,可以在上述列表中提到 RAWTEXT 和脚本数据状态的位置使用 PLAINTEXT 状态。除有关解析错误的规则外,它们是等价的,因为在片段情况下不存在 适当的结束标签 令牌,而且 PLAINTEXT 状态涉及的状态转换少得多。
令 root 为在给定 document、“html”、HTML
命名空间、null、null、false,以及在给定 target 的情况下查找自定义元素注册表所得结果时,
创建元素所得的结果。
将 root 追加到 document。
将解析器的根 插入目标设置为 fragment。
如果 context 是一个 template
元素,则将“在
template 中”压入
template 插入模式栈,
使其成为新的当前 template
插入模式。
解析器会在该算法中引用 context 元素。
将HTML 解析器的form 元素
指针设置为最接近 context 的、属于
form 元素的节点(沿祖先链直接向上,
并且如果该元素本身是一个 form
元素,
则包括该元素本身)(如果存在)。
(如果不存在这样的 form
元素,则form
元素指针保持其初始值
null。)
启动HTML 解析器,并让它运行, 直到消费完刚刚插入输入流中的所有字符。
返回 fragment。
此表列出了 HTML 支持的字符 引用名称,以及它们所引用的码点。前面的 各节会引用此表。
出于旧式兼容性的考虑,许多码点有多个 字符引用名称,这是有意为之。例如,有些名称同时存在带结尾分号和不带结尾分号的形式, 或者具有不同的大小写形式。
| 名称 | 字符 | 字形 |
|---|---|---|
Aacute; |
U+000C1 | Á |
Aacute |
U+000C1 | Á |
aacute; |
U+000E1 | á |
aacute |
U+000E1 | á |
Abreve; |
U+00102 | Ă |
abreve; |
U+00103 | ă |
ac; |
U+0223E | ∾ |
acd; |
U+0223F | ∿ |
acE; |
U+0223E U+00333 | ∾̳ |
Acirc; |
U+000C2 | Â |
Acirc |
U+000C2 | Â |
acirc; |
U+000E2 | â |
acirc |
U+000E2 | â |
acute; |
U+000B4 | ´ |
acute |
U+000B4 | ´ |
Acy; |
U+00410 | А |
acy; |
U+00430 | а |
AElig; |
U+000C6 | Æ |
AElig |
U+000C6 | Æ |
aelig; |
U+000E6 | æ |
aelig |
U+000E6 | æ |
af; |
U+02061 | |
Afr; |
U+1D504 | 𝔄 |
afr; |
U+1D51E | 𝔞 |
Agrave; |
U+000C0 | À |
Agrave |
U+000C0 | À |
agrave; |
U+000E0 | à |
agrave |
U+000E0 | à |
alefsym; |
U+02135 | ℵ |
aleph; |
U+02135 | ℵ |
Alpha; |
U+00391 | Α |
alpha; |
U+003B1 | α |
Amacr; |
U+00100 | Ā |
amacr; |
U+00101 | ā |
amalg; |
U+02A3F | ⨿ |
AMP; |
U+00026 | & |
AMP |
U+00026 | & |
amp; |
U+00026 | & |
amp |
U+00026 | & |
And; |
U+02A53 | ⩓ |
and; |
U+02227 | ∧ |
andand; |
U+02A55 | ⩕ |
andd; |
U+02A5C | ⩜ |
andslope; |
U+02A58 | ⩘ |
andv; |
U+02A5A | ⩚ |
ang; |
U+02220 | ∠ |
ange; |
U+029A4 | ⦤ |
angle; |
U+02220 | ∠ |
angmsd; |
U+02221 | ∡ |
angmsdaa; |
U+029A8 | ⦨ |
angmsdab; |
U+029A9 | ⦩ |
angmsdac; |
U+029AA | ⦪ |
angmsdad; |
U+029AB | ⦫ |
angmsdae; |
U+029AC | ⦬ |
angmsdaf; |
U+029AD | ⦭ |
angmsdag; |
U+029AE | ⦮ |
angmsdah; |
U+029AF | ⦯ |
angrt; |
U+0221F | ∟ |
angrtvb; |
U+022BE | ⊾ |
angrtvbd; |
U+0299D | ⦝ |
angsph; |
U+02222 | ∢ |
angst; |
U+000C5 | Å |
angzarr; |
U+0237C | ⍼ |
Aogon; |
U+00104 | Ą |
aogon; |
U+00105 | ą |
Aopf; |
U+1D538 | 𝔸 |
aopf; |
U+1D552 | 𝕒 |
ap; |
U+02248 | ≈ |
apacir; |
U+02A6F | ⩯ |
apE; |
U+02A70 | ⩰ |
ape; |
U+0224A | ≊ |
apid; |
U+0224B | ≋ |
apos; |
U+00027 | ' |
ApplyFunction; |
U+02061 | |
approx; |
U+02248 | ≈ |
approxeq; |
U+0224A | ≊ |
Aring; |
U+000C5 | Å |
Aring |
U+000C5 | Å |
aring; |
U+000E5 | å |
aring |
U+000E5 | å |
Ascr; |
U+1D49C | 𝒜 |
ascr; |
U+1D4B6 | 𝒶 |
Assign; |
U+02254 | ≔ |
ast; |
U+0002A | * |
asymp; |
U+02248 | ≈ |
asympeq; |
U+0224D | ≍ |
Atilde; |
U+000C3 | Ã |
Atilde |
U+000C3 | Ã |
atilde; |
U+000E3 | ã |
atilde |
U+000E3 | ã |
Auml; |
U+000C4 | Ä |
Auml |
U+000C4 | Ä |
auml; |
U+000E4 | ä |
auml |
U+000E4 | ä |
awconint; |
U+02233 | ∳ |
awint; |
U+02A11 | ⨑ |
backcong; |
U+0224C | ≌ |
backepsilon; |
U+003F6 | ϶ |
backprime; |
U+02035 | ‵ |
backsim; |
U+0223D | ∽ |
backsimeq; |
U+022CD | ⋍ |
Backslash; |
U+02216 | ∖ |
Barv; |
U+02AE7 | ⫧ |
barvee; |
U+022BD | ⊽ |
Barwed; |
U+02306 | ⌆ |
barwed; |
U+02305 | ⌅ |
barwedge; |
U+02305 | ⌅ |
bbrk; |
U+023B5 | ⎵ |
bbrktbrk; |
U+023B6 | ⎶ |
bcong; |
U+0224C | ≌ |
Bcy; |
U+00411 | Б |
bcy; |
U+00431 | б |
bdquo; |
U+0201E | „ |
becaus; |
U+02235 | ∵ |
Because; |
U+02235 | ∵ |
because; |
U+02235 | ∵ |
bemptyv; |
U+029B0 | ⦰ |
bepsi; |
U+003F6 | ϶ |
bernou; |
U+0212C | ℬ |
Bernoullis; |
U+0212C | ℬ |
Beta; |
U+00392 | Β |
beta; |
U+003B2 | β |
beth; |
U+02136 | ℶ |
between; |
U+0226C | ≬ |
Bfr; |
U+1D505 | 𝔅 |
bfr; |
U+1D51F | 𝔟 |
bigcap; |
U+022C2 | ⋂ |
bigcirc; |
U+025EF | ◯ |
bigcup; |
U+022C3 | ⋃ |
bigodot; |
U+02A00 | ⨀ |
bigoplus; |
U+02A01 | ⨁ |
bigotimes; |
U+02A02 | ⨂ |
bigsqcup; |
U+02A06 | ⨆ |
bigstar; |
U+02605 | ★ |
bigtriangledown; |
U+025BD | ▽ |
bigtriangleup; |
U+025B3 | △ |
biguplus; |
U+02A04 | ⨄ |
bigvee; |
U+022C1 | ⋁ |
bigwedge; |
U+022C0 | ⋀ |
bkarow; |
U+0290D | ⤍ |
blacklozenge; |
U+029EB | ⧫ |
blacksquare; |
U+025AA | ▪ |
blacktriangle; |
U+025B4 | ▴ |
blacktriangledown; |
U+025BE | ▾ |
blacktriangleleft; |
U+025C2 | ◂ |
blacktriangleright; |
U+025B8 | ▸ |
blank; |
U+02423 | ␣ |
blk12; |
U+02592 | ▒ |
blk14; |
U+02591 | ░ |
blk34; |
U+02593 | ▓ |
block; |
U+02588 | █ |
bne; |
U+0003D U+020E5 | =⃥ |
bnequiv; |
U+02261 U+020E5 | ≡⃥ |
bNot; |
U+02AED | ⫭ |
bnot; |
U+02310 | ⌐ |
Bopf; |
U+1D539 | 𝔹 |
bopf; |
U+1D553 | 𝕓 |
bot; |
U+022A5 | ⊥ |
bottom; |
U+022A5 | ⊥ |
bowtie; |
U+022C8 | ⋈ |
boxbox; |
U+029C9 | ⧉ |
boxDL; |
U+02557 | ╗ |
boxDl; |
U+02556 | ╖ |
boxdL; |
U+02555 | ╕ |
boxdl; |
U+02510 | ┐ |
boxDR; |
U+02554 | ╔ |
boxDr; |
U+02553 | ╓ |
boxdR; |
U+02552 | ╒ |
boxdr; |
U+0250C | ┌ |
boxH; |
U+02550 | ═ |
boxh; |
U+02500 | ─ |
boxHD; |
U+02566 | ╦ |
boxHd; |
U+02564 | ╤ |
boxhD; |
U+02565 | ╥ |
boxhd; |
U+0252C | ┬ |
boxHU; |
U+02569 | ╩ |
boxHu; |
U+02567 | ╧ |
boxhU; |
U+02568 | ╨ |
boxhu; |
U+02534 | ┴ |
boxminus; |
U+0229F | ⊟ |
boxplus; |
U+0229E | ⊞ |
boxtimes; |
U+022A0 | ⊠ |
boxUL; |
U+0255D | ╝ |
boxUl; |
U+0255C | ╜ |
boxuL; |
U+0255B | ╛ |
boxul; |
U+02518 | ┘ |
boxUR; |
U+0255A | ╚ |
boxUr; |
U+02559 | ╙ |
boxuR; |
U+02558 | ╘ |
boxur; |
U+02514 | └ |
boxV; |
U+02551 | ║ |
boxv; |
U+02502 | │ |
boxVH; |
U+0256C | ╬ |
boxVh; |
U+0256B | ╫ |
boxvH; |
U+0256A | ╪ |
boxvh; |
U+0253C | ┼ |
boxVL; |
U+02563 | ╣ |
boxVl; |
U+02562 | ╢ |
boxvL; |
U+02561 | ╡ |
boxvl; |
U+02524 | ┤ |
boxVR; |
U+02560 | ╠ |
boxVr; |
U+0255F | ╟ |
boxvR; |
U+0255E | ╞ |
boxvr; |
U+0251C | ├ |
bprime; |
U+02035 | ‵ |
Breve; |
U+002D8 | ˘ |
breve; |
U+002D8 | ˘ |
brvbar; |
U+000A6 | ¦ |
brvbar |
U+000A6 | ¦ |
Bscr; |
U+0212C | ℬ |
bscr; |
U+1D4B7 | 𝒷 |
bsemi; |
U+0204F | ⁏ |
bsim; |
U+0223D | ∽ |
bsime; |
U+022CD | ⋍ |
bsol; |
U+0005C | \ |
bsolb; |
U+029C5 | ⧅ |
bsolhsub; |
U+027C8 | ⟈ |
bull; |
U+02022 | • |
bullet; |
U+02022 | • |
bump; |
U+0224E | ≎ |
bumpE; |
U+02AAE | ⪮ |
bumpe; |
U+0224F | ≏ |
Bumpeq; |
U+0224E | ≎ |
bumpeq; |
U+0224F | ≏ |
Cacute; |
U+00106 | Ć |
cacute; |
U+00107 | ć |
Cap; |
U+022D2 | ⋒ |
cap; |
U+02229 | ∩ |
capand; |
U+02A44 | ⩄ |
capbrcup; |
U+02A49 | ⩉ |
capcap; |
U+02A4B | ⩋ |
capcup; |
U+02A47 | ⩇ |
capdot; |
U+02A40 | ⩀ |
CapitalDifferentialD; |
U+02145 | ⅅ |
caps; |
U+02229 U+0FE00 | ∩︀ |
caret; |
U+02041 | ⁁ |
caron; |
U+002C7 | ˇ |
Cayleys; |
U+0212D | ℭ |
ccaps; |
U+02A4D | ⩍ |
Ccaron; |
U+0010C | Č |
ccaron; |
U+0010D | č |
Ccedil; |
U+000C7 | Ç |
Ccedil |
U+000C7 | Ç |
ccedil; |
U+000E7 | ç |
ccedil |
U+000E7 | ç |
Ccirc; |
U+00108 | Ĉ |
ccirc; |
U+00109 | ĉ |
Cconint; |
U+02230 | ∰ |
ccups; |
U+02A4C | ⩌ |
ccupssm; |
U+02A50 | ⩐ |
Cdot; |
U+0010A | Ċ |
cdot; |
U+0010B | ċ |
cedil; |
U+000B8 | ¸ |
cedil |
U+000B8 | ¸ |
Cedilla; |
U+000B8 | ¸ |
cemptyv; |
U+029B2 | ⦲ |
cent; |
U+000A2 | ¢ |
cent |
U+000A2 | ¢ |
CenterDot; |
U+000B7 | · |
centerdot; |
U+000B7 | · |
Cfr; |
U+0212D | ℭ |
cfr; |
U+1D520 | 𝔠 |
CHcy; |
U+00427 | Ч |
chcy; |
U+00447 | ч |
check; |
U+02713 | ✓ |
checkmark; |
U+02713 | ✓ |
Chi; |
U+003A7 | Χ |
chi; |
U+003C7 | χ |
cir; |
U+025CB | ○ |
circ; |
U+002C6 | ˆ |
circeq; |
U+02257 | ≗ |
circlearrowleft; |
U+021BA | ↺ |
circlearrowright; |
U+021BB | ↻ |
circledast; |
U+0229B | ⊛ |
circledcirc; |
U+0229A | ⊚ |
circleddash; |
U+0229D | ⊝ |
CircleDot; |
U+02299 | ⊙ |
circledR; |
U+000AE | ® |
circledS; |
U+024C8 | Ⓢ |
CircleMinus; |
U+02296 | ⊖ |
CirclePlus; |
U+02295 | ⊕ |
CircleTimes; |
U+02297 | ⊗ |
cirE; |
U+029C3 | ⧃ |
cire; |
U+02257 | ≗ |
cirfnint; |
U+02A10 | ⨐ |
cirmid; |
U+02AEF | ⫯ |
cirscir; |
U+029C2 | ⧂ |
ClockwiseContourIntegral; |
U+02232 | ∲ |
CloseCurlyDoubleQuote; |
U+0201D | ” |
CloseCurlyQuote; |
U+02019 | ’ |
clubs; |
U+02663 | ♣ |
clubsuit; |
U+02663 | ♣ |
Colon; |
U+02237 | ∷ |
colon; |
U+0003A | : |
Colone; |
U+02A74 | ⩴ |
colone; |
U+02254 | ≔ |
coloneq; |
U+02254 | ≔ |
comma; |
U+0002C | , |
commat; |
U+00040 | @ |
comp; |
U+02201 | ∁ |
compfn; |
U+02218 | ∘ |
complement; |
U+02201 | ∁ |
complexes; |
U+02102 | ℂ |
cong; |
U+02245 | ≅ |
congdot; |
U+02A6D | ⩭ |
Congruent; |
U+02261 | ≡ |
Conint; |
U+0222F | ∯ |
conint; |
U+0222E | ∮ |
ContourIntegral; |
U+0222E | ∮ |
Copf; |
U+02102 | ℂ |
copf; |
U+1D554 | 𝕔 |
coprod; |
U+02210 | ∐ |
Coproduct; |
U+02210 | ∐ |
COPY; |
U+000A9 | © |
COPY |
U+000A9 | © |
copy; |
U+000A9 | © |
copy |
U+000A9 | © |
copysr; |
U+02117 | ℗ |
CounterClockwiseContourIntegral; |
U+02233 | ∳ |
crarr; |
U+021B5 | ↵ |
Cross; |
U+02A2F | ⨯ |
cross; |
U+02717 | ✗ |
Cscr; |
U+1D49E | 𝒞 |
cscr; |
U+1D4B8 | 𝒸 |
csub; |
U+02ACF | ⫏ |
csube; |
U+02AD1 | ⫑ |
csup; |
U+02AD0 | ⫐ |
csupe; |
U+02AD2 | ⫒ |
ctdot; |
U+022EF | ⋯ |
cudarrl; |
U+02938 | ⤸ |
cudarrr; |
U+02935 | ⤵ |
cuepr; |
U+022DE | ⋞ |
cuesc; |
U+022DF | ⋟ |
cularr; |
U+021B6 | ↶ |
cularrp; |
U+0293D | ⤽ |
Cup; |
U+022D3 | ⋓ |
cup; |
U+0222A | ∪ |
cupbrcap; |
U+02A48 | ⩈ |
CupCap; |
U+0224D | ≍ |
cupcap; |
U+02A46 | ⩆ |
cupcup; |
U+02A4A | ⩊ |
cupdot; |
U+0228D | ⊍ |
cupor; |
U+02A45 | ⩅ |
cups; |
U+0222A U+0FE00 | ∪︀ |
curarr; |
U+021B7 | ↷ |
curarrm; |
U+0293C | ⤼ |
curlyeqprec; |
U+022DE | ⋞ |
curlyeqsucc; |
U+022DF | ⋟ |
curlyvee; |
U+022CE | ⋎ |
curlywedge; |
U+022CF | ⋏ |
curren; |
U+000A4 | ¤ |
curren |
U+000A4 | ¤ |
curvearrowleft; |
U+021B6 | ↶ |
curvearrowright; |
U+021B7 | ↷ |
cuvee; |
U+022CE | ⋎ |
cuwed; |
U+022CF | ⋏ |
cwconint; |
U+02232 | ∲ |
cwint; |
U+02231 | ∱ |
cylcty; |
U+0232D | ⌭ |
Dagger; |
U+02021 | ‡ |
dagger; |
U+02020 | † |
daleth; |
U+02138 | ℸ |
Darr; |
U+021A1 | ↡ |
dArr; |
U+021D3 | ⇓ |
darr; |
U+02193 | ↓ |
dash; |
U+02010 | ‐ |
Dashv; |
U+02AE4 | ⫤ |
dashv; |
U+022A3 | ⊣ |
dbkarow; |
U+0290F | ⤏ |
dblac; |
U+002DD | ˝ |
Dcaron; |
U+0010E | Ď |
dcaron; |
U+0010F | ď |
Dcy; |
U+00414 | Д |
dcy; |
U+00434 | д |
DD; |
U+02145 | ⅅ |
dd; |
U+02146 | ⅆ |
ddagger; |
U+02021 | ‡ |
ddarr; |
U+021CA | ⇊ |
DDotrahd; |
U+02911 | ⤑ |
ddotseq; |
U+02A77 | ⩷ |
deg; |
U+000B0 | ° |
deg |
U+000B0 | ° |
Del; |
U+02207 | ∇ |
Delta; |
U+00394 | Δ |
delta; |
U+003B4 | δ |
demptyv; |
U+029B1 | ⦱ |
dfisht; |
U+0297F | ⥿ |
Dfr; |
U+1D507 | 𝔇 |
dfr; |
U+1D521 | 𝔡 |
dHar; |
U+02965 | ⥥ |
dharl; |
U+021C3 | ⇃ |
dharr; |
U+021C2 | ⇂ |
DiacriticalAcute; |
U+000B4 | ´ |
DiacriticalDot; |
U+002D9 | ˙ |
DiacriticalDoubleAcute; |
U+002DD | ˝ |
DiacriticalGrave; |
U+00060 | ` |
DiacriticalTilde; |
U+002DC | ˜ |
diam; |
U+022C4 | ⋄ |
Diamond; |
U+022C4 | ⋄ |
diamond; |
U+022C4 | ⋄ |
diamondsuit; |
U+02666 | ♦ |
diams; |
U+02666 | ♦ |
die; |
U+000A8 | ¨ |
DifferentialD; |
U+02146 | ⅆ |
digamma; |
U+003DD | ϝ |
disin; |
U+022F2 | ⋲ |
div; |
U+000F7 | ÷ |
divide; |
U+000F7 | ÷ |
divide |
U+000F7 | ÷ |
divideontimes; |
U+022C7 | ⋇ |
divonx; |
U+022C7 | ⋇ |
DJcy; |
U+00402 | Ђ |
djcy; |
U+00452 | ђ |
dlcorn; |
U+0231E | ⌞ |
dlcrop; |
U+0230D | ⌍ |
dollar; |
U+00024 | $ |
Dopf; |
U+1D53B | 𝔻 |
dopf; |
U+1D555 | 𝕕 |
Dot; |
U+000A8 | ¨ |
dot; |
U+002D9 | ˙ |
DotDot; |
U+020DC | ◌⃜ |
doteq; |
U+02250 | ≐ |
doteqdot; |
U+02251 | ≑ |
DotEqual; |
U+02250 | ≐ |
dotminus; |
U+02238 | ∸ |
dotplus; |
U+02214 | ∔ |
dotsquare; |
U+022A1 | ⊡ |
doublebarwedge; |
U+02306 | ⌆ |
DoubleContourIntegral; |
U+0222F | ∯ |
DoubleDot; |
U+000A8 | ¨ |
DoubleDownArrow; |
U+021D3 | ⇓ |
DoubleLeftArrow; |
U+021D0 | ⇐ |
DoubleLeftRightArrow; |
U+021D4 | ⇔ |
DoubleLeftTee; |
U+02AE4 | ⫤ |
DoubleLongLeftArrow; |
U+027F8 | ⟸ |
DoubleLongLeftRightArrow; |
U+027FA | ⟺ |
DoubleLongRightArrow; |
U+027F9 | ⟹ |
DoubleRightArrow; |
U+021D2 | ⇒ |
DoubleRightTee; |
U+022A8 | ⊨ |
DoubleUpArrow; |
U+021D1 | ⇑ |
DoubleUpDownArrow; |
U+021D5 | ⇕ |
DoubleVerticalBar; |
U+02225 | ∥ |
DownArrow; |
U+02193 | ↓ |
Downarrow; |
U+021D3 | ⇓ |
downarrow; |
U+02193 | ↓ |
DownArrowBar; |
U+02913 | ⤓ |
DownArrowUpArrow; |
U+021F5 | ⇵ |
DownBreve; |
U+00311 | ◌̑ |
downdownarrows; |
U+021CA | ⇊ |
downharpoonleft; |
U+021C3 | ⇃ |
downharpoonright; |
U+021C2 | ⇂ |
DownLeftRightVector; |
U+02950 | ⥐ |
DownLeftTeeVector; |
U+0295E | ⥞ |
DownLeftVector; |
U+021BD | ↽ |
DownLeftVectorBar; |
U+02956 | ⥖ |
DownRightTeeVector; |
U+0295F | ⥟ |
DownRightVector; |
U+021C1 | ⇁ |
DownRightVectorBar; |
U+02957 | ⥗ |
DownTee; |
U+022A4 | ⊤ |
DownTeeArrow; |
U+021A7 | ↧ |
drbkarow; |
U+02910 | ⤐ |
drcorn; |
U+0231F | ⌟ |
drcrop; |
U+0230C | ⌌ |
Dscr; |
U+1D49F | 𝒟 |
dscr; |
U+1D4B9 | 𝒹 |
DScy; |
U+00405 | Ѕ |
dscy; |
U+00455 | ѕ |
dsol; |
U+029F6 | ⧶ |
Dstrok; |
U+00110 | Đ |
dstrok; |
U+00111 | đ |
dtdot; |
U+022F1 | ⋱ |
dtri; |
U+025BF | ▿ |
dtrif; |
U+025BE | ▾ |
duarr; |
U+021F5 | ⇵ |
duhar; |
U+0296F | ⥯ |
dwangle; |
U+029A6 | ⦦ |
DZcy; |
U+0040F | Џ |
dzcy; |
U+0045F | џ |
dzigrarr; |
U+027FF | ⟿ |
Eacute; |
U+000C9 | É |
Eacute |
U+000C9 | É |
eacute; |
U+000E9 | é |
eacute |
U+000E9 | é |
easter; |
U+02A6E | ⩮ |
Ecaron; |
U+0011A | Ě |
ecaron; |
U+0011B | ě |
ecir; |
U+02256 | ≖ |
Ecirc; |
U+000CA | Ê |
Ecirc |
U+000CA | Ê |
ecirc; |
U+000EA | ê |
ecirc |
U+000EA | ê |
ecolon; |
U+02255 | ≕ |
Ecy; |
U+0042D | Э |
ecy; |
U+0044D | э |
eDDot; |
U+02A77 | ⩷ |
Edot; |
U+00116 | Ė |
eDot; |
U+02251 | ≑ |
edot; |
U+00117 | ė |
ee; |
U+02147 | ⅇ |
efDot; |
U+02252 | ≒ |
Efr; |
U+1D508 | 𝔈 |
efr; |
U+1D522 | 𝔢 |
eg; |
U+02A9A | ⪚ |
Egrave; |
U+000C8 | È |
Egrave |
U+000C8 | È |
egrave; |
U+000E8 | è |
egrave |
U+000E8 | è |
egs; |
U+02A96 | ⪖ |
egsdot; |
U+02A98 | ⪘ |
el; |
U+02A99 | ⪙ |
Element; |
U+02208 | ∈ |
elinters; |
U+023E7 | ⏧ |
ell; |
U+02113 | ℓ |
els; |
U+02A95 | ⪕ |
elsdot; |
U+02A97 | ⪗ |
Emacr; |
U+00112 | Ē |
emacr; |
U+00113 | ē |
empty; |
U+02205 | ∅ |
emptyset; |
U+02205 | ∅ |
EmptySmallSquare; |
U+025FB | ◻ |
emptyv; |
U+02205 | ∅ |
EmptyVerySmallSquare; |
U+025AB | ▫ |
emsp; |
U+02003 | |
emsp13; |
U+02004 | |
emsp14; |
U+02005 | |
ENG; |
U+0014A | Ŋ |
eng; |
U+0014B | ŋ |
ensp; |
U+02002 | |
Eogon; |
U+00118 | Ę |
eogon; |
U+00119 | ę |
Eopf; |
U+1D53C | 𝔼 |
eopf; |
U+1D556 | 𝕖 |
epar; |
U+022D5 | ⋕ |
eparsl; |
U+029E3 | ⧣ |
eplus; |
U+02A71 | ⩱ |
epsi; |
U+003B5 | ε |
Epsilon; |
U+00395 | Ε |
epsilon; |
U+003B5 | ε |
epsiv; |
U+003F5 | ϵ |
eqcirc; |
U+02256 | ≖ |
eqcolon; |
U+02255 | ≕ |
eqsim; |
U+02242 | ≂ |
eqslantgtr; |
U+02A96 | ⪖ |
eqslantless; |
U+02A95 | ⪕ |
Equal; |
U+02A75 | ⩵ |
equals; |
U+0003D | = |
EqualTilde; |
U+02242 | ≂ |
equest; |
U+0225F | ≟ |
Equilibrium; |
U+021CC | ⇌ |
equiv; |
U+02261 | ≡ |
equivDD; |
U+02A78 | ⩸ |
eqvparsl; |
U+029E5 | ⧥ |
erarr; |
U+02971 | ⥱ |
erDot; |
U+02253 | ≓ |
Escr; |
U+02130 | ℰ |
escr; |
U+0212F | ℯ |
esdot; |
U+02250 | ≐ |
Esim; |
U+02A73 | ⩳ |
esim; |
U+02242 | ≂ |
Eta; |
U+00397 | Η |
eta; |
U+003B7 | η |
ETH; |
U+000D0 | Ð |
ETH |
U+000D0 | Ð |
eth; |
U+000F0 | ð |
eth |
U+000F0 | ð |
Euml; |
U+000CB | Ë |
Euml |
U+000CB | Ë |
euml; |
U+000EB | ë |
euml |
U+000EB | ë |
euro; |
U+020AC | € |
excl; |
U+00021 | ! |
exist; |
U+02203 | ∃ |
Exists; |
U+02203 | ∃ |
expectation; |
U+02130 | ℰ |
ExponentialE; |
U+02147 | ⅇ |
exponentiale; |
U+02147 | ⅇ |
fallingdotseq; |
U+02252 | ≒ |
Fcy; |
U+00424 | Ф |
fcy; |
U+00444 | ф |
female; |
U+02640 | ♀ |
ffilig; |
U+0FB03 | ffi |
fflig; |
U+0FB00 | ff |
ffllig; |
U+0FB04 | ffl |
Ffr; |
U+1D509 | 𝔉 |
ffr; |
U+1D523 | 𝔣 |
filig; |
U+0FB01 | fi |
FilledSmallSquare; |
U+025FC | ◼ |
FilledVerySmallSquare; |
U+025AA | ▪ |
fjlig; |
U+00066 U+0006A | fj |
flat; |
U+0266D | ♭ |
fllig; |
U+0FB02 | fl |
fltns; |
U+025B1 | ▱ |
fnof; |
U+00192 | ƒ |
Fopf; |
U+1D53D | 𝔽 |
fopf; |
U+1D557 | 𝕗 |
ForAll; |
U+02200 | ∀ |
forall; |
U+02200 | ∀ |
fork; |
U+022D4 | ⋔ |
forkv; |
U+02AD9 | ⫙ |
Fouriertrf; |
U+02131 | ℱ |
fpartint; |
U+02A0D | ⨍ |
frac12; |
U+000BD | ½ |
frac12 |
U+000BD | ½ |
frac13; |
U+02153 | ⅓ |
frac14; |
U+000BC | ¼ |
frac14 |
U+000BC | ¼ |
frac15; |
U+02155 | ⅕ |
frac16; |
U+02159 | ⅙ |
frac18; |
U+0215B | ⅛ |
frac23; |
U+02154 | ⅔ |
frac25; |
U+02156 | ⅖ |
frac34; |
U+000BE | ¾ |
frac34 |
U+000BE | ¾ |
frac35; |
U+02157 | ⅗ |
frac38; |
U+0215C | ⅜ |
frac45; |
U+02158 | ⅘ |
frac56; |
U+0215A | ⅚ |
frac58; |
U+0215D | ⅝ |
frac78; |
U+0215E | ⅞ |
frasl; |
U+02044 | ⁄ |
frown; |
U+02322 | ⌢ |
Fscr; |
U+02131 | ℱ |
fscr; |
U+1D4BB | 𝒻 |
gacute; |
U+001F5 | ǵ |
Gamma; |
U+00393 | Γ |
gamma; |
U+003B3 | γ |
Gammad; |
U+003DC | Ϝ |
gammad; |
U+003DD | ϝ |
gap; |
U+02A86 | ⪆ |
Gbreve; |
U+0011E | Ğ |
gbreve; |
U+0011F | ğ |
Gcedil; |
U+00122 | Ģ |
Gcirc; |
U+0011C | Ĝ |
gcirc; |
U+0011D | ĝ |
Gcy; |
U+00413 | Г |
gcy; |
U+00433 | г |
Gdot; |
U+00120 | Ġ |
gdot; |
U+00121 | ġ |
gE; |
U+02267 | ≧ |
ge; |
U+02265 | ≥ |
gEl; |
U+02A8C | ⪌ |
gel; |
U+022DB | ⋛ |
geq; |
U+02265 | ≥ |
geqq; |
U+02267 | ≧ |
geqslant; |
U+02A7E | ⩾ |
ges; |
U+02A7E | ⩾ |
gescc; |
U+02AA9 | ⪩ |
gesdot; |
U+02A80 | ⪀ |
gesdoto; |
U+02A82 | ⪂ |
gesdotol; |
U+02A84 | ⪄ |
gesl; |
U+022DB U+0FE00 | ⋛︀ |
gesles; |
U+02A94 | ⪔ |
Gfr; |
U+1D50A | 𝔊 |
gfr; |
U+1D524 | 𝔤 |
Gg; |
U+022D9 | ⋙ |
gg; |
U+0226B | ≫ |
ggg; |
U+022D9 | ⋙ |
gimel; |
U+02137 | ℷ |
GJcy; |
U+00403 | Ѓ |
gjcy; |
U+00453 | ѓ |
gl; |
U+02277 | ≷ |
gla; |
U+02AA5 | ⪥ |
glE; |
U+02A92 | ⪒ |
glj; |
U+02AA4 | ⪤ |
gnap; |
U+02A8A | ⪊ |
gnapprox; |
U+02A8A | ⪊ |
gnE; |
U+02269 | ≩ |
gne; |
U+02A88 | ⪈ |
gneq; |
U+02A88 | ⪈ |
gneqq; |
U+02269 | ≩ |
gnsim; |
U+022E7 | ⋧ |
Gopf; |
U+1D53E | 𝔾 |
gopf; |
U+1D558 | 𝕘 |
grave; |
U+00060 | ` |
GreaterEqual; |
U+02265 | ≥ |
GreaterEqualLess; |
U+022DB | ⋛ |
GreaterFullEqual; |
U+02267 | ≧ |
GreaterGreater; |
U+02AA2 | ⪢ |
GreaterLess; |
U+02277 | ≷ |
GreaterSlantEqual; |
U+02A7E | ⩾ |
GreaterTilde; |
U+02273 | ≳ |
Gscr; |
U+1D4A2 | 𝒢 |
gscr; |
U+0210A | ℊ |
gsim; |
U+02273 | ≳ |
gsime; |
U+02A8E | ⪎ |
gsiml; |
U+02A90 | ⪐ |
GT; |
U+0003E | > |
GT |
U+0003E | > |
Gt; |
U+0226B | ≫ |
gt; |
U+0003E | > |
gt |
U+0003E | > |
gtcc; |
U+02AA7 | ⪧ |
gtcir; |
U+02A7A | ⩺ |
gtdot; |
U+022D7 | ⋗ |
gtlPar; |
U+02995 | ⦕ |
gtquest; |
U+02A7C | ⩼ |
gtrapprox; |
U+02A86 | ⪆ |
gtrarr; |
U+02978 | ⥸ |
gtrdot; |
U+022D7 | ⋗ |
gtreqless; |
U+022DB | ⋛ |
gtreqqless; |
U+02A8C | ⪌ |
gtrless; |
U+02277 | ≷ |
gtrsim; |
U+02273 | ≳ |
gvertneqq; |
U+02269 U+0FE00 | ≩︀ |
gvnE; |
U+02269 U+0FE00 | ≩︀ |
Hacek; |
U+002C7 | ˇ |
hairsp; |
U+0200A | |
half; |
U+000BD | ½ |
hamilt; |
U+0210B | ℋ |
HARDcy; |
U+0042A | Ъ |
hardcy; |
U+0044A | ъ |
hArr; |
U+021D4 | ⇔ |
harr; |
U+02194 | ↔ |
harrcir; |
U+02948 | ⥈ |
harrw; |
U+021AD | ↭ |
Hat; |
U+0005E | ^ |
hbar; |
U+0210F | ℏ |
Hcirc; |
U+00124 | Ĥ |
hcirc; |
U+00125 | ĥ |
hearts; |
U+02665 | ♥ |
heartsuit; |
U+02665 | ♥ |
hellip; |
U+02026 | … |
hercon; |
U+022B9 | ⊹ |
Hfr; |
U+0210C | ℌ |
hfr; |
U+1D525 | 𝔥 |
HilbertSpace; |
U+0210B | ℋ |
hksearow; |
U+02925 | ⤥ |
hkswarow; |
U+02926 | ⤦ |
hoarr; |
U+021FF | ⇿ |
homtht; |
U+0223B | ∻ |
hookleftarrow; |
U+021A9 | ↩ |
hookrightarrow; |
U+021AA | ↪ |
Hopf; |
U+0210D | ℍ |
hopf; |
U+1D559 | 𝕙 |
horbar; |
U+02015 | ― |
HorizontalLine; |
U+02500 | ─ |
Hscr; |
U+0210B | ℋ |
hscr; |
U+1D4BD | 𝒽 |
hslash; |
U+0210F | ℏ |
Hstrok; |
U+00126 | Ħ |
hstrok; |
U+00127 | ħ |
HumpDownHump; |
U+0224E | ≎ |
HumpEqual; |
U+0224F | ≏ |
hybull; |
U+02043 | ⁃ |
hyphen; |
U+02010 | ‐ |
Iacute; |
U+000CD | Í |
Iacute |
U+000CD | Í |
iacute; |
U+000ED | í |
iacute |
U+000ED | í |
ic; |
U+02063 | |
Icirc; |
U+000CE | Î |
Icirc |
U+000CE | Î |
icirc; |
U+000EE | î |
icirc |
U+000EE | î |
Icy; |
U+00418 | И |
icy; |
U+00438 | и |
Idot; |
U+00130 | İ |
IEcy; |
U+00415 | Е |
iecy; |
U+00435 | е |
iexcl; |
U+000A1 | ¡ |
iexcl |
U+000A1 | ¡ |
iff; |
U+021D4 | ⇔ |
Ifr; |
U+02111 | ℑ |
ifr; |
U+1D526 | 𝔦 |
Igrave; |
U+000CC | Ì |
Igrave |
U+000CC | Ì |
igrave; |
U+000EC | ì |
igrave |
U+000EC | ì |
ii; |
U+02148 | ⅈ |
iiiint; |
U+02A0C | ⨌ |
iiint; |
U+0222D | ∭ |
iinfin; |
U+029DC | ⧜ |
iiota; |
U+02129 | ℩ |
IJlig; |
U+00132 | IJ |
ijlig; |
U+00133 | ij |
Im; |
U+02111 | ℑ |
Imacr; |
U+0012A | Ī |
imacr; |
U+0012B | ī |
image; |
U+02111 | ℑ |
ImaginaryI; |
U+02148 | ⅈ |
imagline; |
U+02110 | ℐ |
imagpart; |
U+02111 | ℑ |
imath; |
U+00131 | ı |
imof; |
U+022B7 | ⊷ |
imped; |
U+001B5 | Ƶ |
Implies; |
U+021D2 | ⇒ |
in; |
U+02208 | ∈ |
incare; |
U+02105 | ℅ |
infin; |
U+0221E | ∞ |
infintie; |
U+029DD | ⧝ |
inodot; |
U+00131 | ı |
Int; |
U+0222C | ∬ |
int; |
U+0222B | ∫ |
intcal; |
U+022BA | ⊺ |
integers; |
U+02124 | ℤ |
Integral; |
U+0222B | ∫ |
intercal; |
U+022BA | ⊺ |
Intersection; |
U+022C2 | ⋂ |
intlarhk; |
U+02A17 | ⨗ |
intprod; |
U+02A3C | ⨼ |
InvisibleComma; |
U+02063 | |
InvisibleTimes; |
U+02062 | |
IOcy; |
U+00401 | Ё |
iocy; |
U+00451 | ё |
Iogon; |
U+0012E | Į |
iogon; |
U+0012F | į |
Iopf; |
U+1D540 | 𝕀 |
iopf; |
U+1D55A | 𝕚 |
Iota; |
U+00399 | Ι |
iota; |
U+003B9 | ι |
iprod; |
U+02A3C | ⨼ |
iquest; |
U+000BF | ¿ |
iquest |
U+000BF | ¿ |
Iscr; |
U+02110 | ℐ |
iscr; |
U+1D4BE | 𝒾 |
isin; |
U+02208 | ∈ |
isindot; |
U+022F5 | ⋵ |
isinE; |
U+022F9 | ⋹ |
isins; |
U+022F4 | ⋴ |
isinsv; |
U+022F3 | ⋳ |
isinv; |
U+02208 | ∈ |
it; |
U+02062 | |
Itilde; |
U+00128 | Ĩ |
itilde; |
U+00129 | ĩ |
Iukcy; |
U+00406 | І |
iukcy; |
U+00456 | і |
Iuml; |
U+000CF | Ï |
Iuml |
U+000CF | Ï |
iuml; |
U+000EF | ï |
iuml |
U+000EF | ï |
Jcirc; |
U+00134 | Ĵ |
jcirc; |
U+00135 | ĵ |
Jcy; |
U+00419 | Й |
jcy; |
U+00439 | й |
Jfr; |
U+1D50D | 𝔍 |
jfr; |
U+1D527 | 𝔧 |
jmath; |
U+00237 | ȷ |
Jopf; |
U+1D541 | 𝕁 |
jopf; |
U+1D55B | 𝕛 |
Jscr; |
U+1D4A5 | 𝒥 |
jscr; |
U+1D4BF | 𝒿 |
Jsercy; |
U+00408 | Ј |
jsercy; |
U+00458 | ј |
Jukcy; |
U+00404 | Є |
jukcy; |
U+00454 | є |
Kappa; |
U+0039A | Κ |
kappa; |
U+003BA | κ |
kappav; |
U+003F0 | ϰ |
Kcedil; |
U+00136 | Ķ |
kcedil; |
U+00137 | ķ |
Kcy; |
U+0041A | К |
kcy; |
U+0043A | к |
Kfr; |
U+1D50E | 𝔎 |
kfr; |
U+1D528 | 𝔨 |
kgreen; |
U+00138 | ĸ |
KHcy; |
U+00425 | Х |
khcy; |
U+00445 | х |
KJcy; |
U+0040C | Ќ |
kjcy; |
U+0045C | ќ |
Kopf; |
U+1D542 | 𝕂 |
kopf; |
U+1D55C | 𝕜 |
Kscr; |
U+1D4A6 | 𝒦 |
kscr; |
U+1D4C0 | 𝓀 |
lAarr; |
U+021DA | ⇚ |
Lacute; |
U+00139 | Ĺ |
lacute; |
U+0013A | ĺ |
laemptyv; |
U+029B4 | ⦴ |
lagran; |
U+02112 | ℒ |
Lambda; |
U+0039B | Λ |
lambda; |
U+003BB | λ |
Lang; |
U+027EA | ⟪ |
lang; |
U+027E8 | ⟨ |
langd; |
U+02991 | ⦑ |
langle; |
U+027E8 | ⟨ |
lap; |
U+02A85 | ⪅ |
Laplacetrf; |
U+02112 | ℒ |
laquo; |
U+000AB | « |
laquo |
U+000AB | « |
Larr; |
U+0219E | ↞ |
lArr; |
U+021D0 | ⇐ |
larr; |
U+02190 | ← |
larrb; |
U+021E4 | ⇤ |
larrbfs; |
U+0291F | ⤟ |
larrfs; |
U+0291D | ⤝ |
larrhk; |
U+021A9 | ↩ |
larrlp; |
U+021AB | ↫ |
larrpl; |
U+02939 | ⤹ |
larrsim; |
U+02973 | ⥳ |
larrtl; |
U+021A2 | ↢ |
lat; |
U+02AAB | ⪫ |
lAtail; |
U+0291B | ⤛ |
latail; |
U+02919 | ⤙ |
late; |
U+02AAD | ⪭ |
lates; |
U+02AAD U+0FE00 | ⪭︀ |
lBarr; |
U+0290E | ⤎ |
lbarr; |
U+0290C | ⤌ |
lbbrk; |
U+02772 | ❲ |
lbrace; |
U+0007B | { |
lbrack; |
U+0005B | [ |
lbrke; |
U+0298B | ⦋ |
lbrksld; |
U+0298F | ⦏ |
lbrkslu; |
U+0298D | ⦍ |
Lcaron; |
U+0013D | Ľ |
lcaron; |
U+0013E | ľ |
Lcedil; |
U+0013B | Ļ |
lcedil; |
U+0013C | ļ |
lceil; |
U+02308 | ⌈ |
lcub; |
U+0007B | { |
Lcy; |
U+0041B | Л |
lcy; |
U+0043B | л |
ldca; |
U+02936 | ⤶ |
ldquo; |
U+0201C | “ |
ldquor; |
U+0201E | „ |
ldrdhar; |
U+02967 | ⥧ |
ldrushar; |
U+0294B | ⥋ |
ldsh; |
U+021B2 | ↲ |
lE; |
U+02266 | ≦ |
le; |
U+02264 | ≤ |
LeftAngleBracket; |
U+027E8 | ⟨ |
LeftArrow; |
U+02190 | ← |
Leftarrow; |
U+021D0 | ⇐ |
leftarrow; |
U+02190 | ← |
LeftArrowBar; |
U+021E4 | ⇤ |
LeftArrowRightArrow; |
U+021C6 | ⇆ |
leftarrowtail; |
U+021A2 | ↢ |
LeftCeiling; |
U+02308 | ⌈ |
LeftDoubleBracket; |
U+027E6 | ⟦ |
LeftDownTeeVector; |
U+02961 | ⥡ |
LeftDownVector; |
U+021C3 | ⇃ |
LeftDownVectorBar; |
U+02959 | ⥙ |
LeftFloor; |
U+0230A | ⌊ |
leftharpoondown; |
U+021BD | ↽ |
leftharpoonup; |
U+021BC | ↼ |
leftleftarrows; |
U+021C7 | ⇇ |
LeftRightArrow; |
U+02194 | ↔ |
Leftrightarrow; |
U+021D4 | ⇔ |
leftrightarrow; |
U+02194 | ↔ |
leftrightarrows; |
U+021C6 | ⇆ |
leftrightharpoons; |
U+021CB | ⇋ |
leftrightsquigarrow; |
U+021AD | ↭ |
LeftRightVector; |
U+0294E | ⥎ |
LeftTee; |
U+022A3 | ⊣ |
LeftTeeArrow; |
U+021A4 | ↤ |
LeftTeeVector; |
U+0295A | ⥚ |
leftthreetimes; |
U+022CB | ⋋ |
LeftTriangle; |
U+022B2 | ⊲ |
LeftTriangleBar; |
U+029CF | ⧏ |
LeftTriangleEqual; |
U+022B4 | ⊴ |
LeftUpDownVector; |
U+02951 | ⥑ |
LeftUpTeeVector; |
U+02960 | ⥠ |
LeftUpVector; |
U+021BF | ↿ |
LeftUpVectorBar; |
U+02958 | ⥘ |
LeftVector; |
U+021BC | ↼ |
LeftVectorBar; |
U+02952 | ⥒ |
lEg; |
U+02A8B | ⪋ |
leg; |
U+022DA | ⋚ |
leq; |
U+02264 | ≤ |
leqq; |
U+02266 | ≦ |
leqslant; |
U+02A7D | ⩽ |
les; |
U+02A7D | ⩽ |
lescc; |
U+02AA8 | ⪨ |
lesdot; |
U+02A7F | ⩿ |
lesdoto; |
U+02A81 | ⪁ |
lesdotor; |
U+02A83 | ⪃ |
lesg; |
U+022DA U+0FE00 | ⋚︀ |
lesges; |
U+02A93 | ⪓ |
lessapprox; |
U+02A85 | ⪅ |
lessdot; |
U+022D6 | ⋖ |
lesseqgtr; |
U+022DA | ⋚ |
lesseqqgtr; |
U+02A8B | ⪋ |
LessEqualGreater; |
U+022DA | ⋚ |
LessFullEqual; |
U+02266 | ≦ |
LessGreater; |
U+02276 | ≶ |
lessgtr; |
U+02276 | ≶ |
LessLess; |
U+02AA1 | ⪡ |
lesssim; |
U+02272 | ≲ |
LessSlantEqual; |
U+02A7D | ⩽ |
LessTilde; |
U+02272 | ≲ |
lfisht; |
U+0297C | ⥼ |
lfloor; |
U+0230A | ⌊ |
Lfr; |
U+1D50F | 𝔏 |
lfr; |
U+1D529 | 𝔩 |
lg; |
U+02276 | ≶ |
lgE; |
U+02A91 | ⪑ |
lHar; |
U+02962 | ⥢ |
lhard; |
U+021BD | ↽ |
lharu; |
U+021BC | ↼ |
lharul; |
U+0296A | ⥪ |
lhblk; |
U+02584 | ▄ |
LJcy; |
U+00409 | Љ |
ljcy; |
U+00459 | љ |
Ll; |
U+022D8 | ⋘ |
ll; |
U+0226A | ≪ |
llarr; |
U+021C7 | ⇇ |
llcorner; |
U+0231E | ⌞ |
Lleftarrow; |
U+021DA | ⇚ |
llhard; |
U+0296B | ⥫ |
lltri; |
U+025FA | ◺ |
Lmidot; |
U+0013F | Ŀ |
lmidot; |
U+00140 | ŀ |
lmoust; |
U+023B0 | ⎰ |
lmoustache; |
U+023B0 | ⎰ |
lnap; |
U+02A89 | ⪉ |
lnapprox; |
U+02A89 | ⪉ |
lnE; |
U+02268 | ≨ |
lne; |
U+02A87 | ⪇ |
lneq; |
U+02A87 | ⪇ |
lneqq; |
U+02268 | ≨ |
lnsim; |
U+022E6 | ⋦ |
loang; |
U+027EC | ⟬ |
loarr; |
U+021FD | ⇽ |
lobrk; |
U+027E6 | ⟦ |
LongLeftArrow; |
U+027F5 | ⟵ |
Longleftarrow; |
U+027F8 | ⟸ |
longleftarrow; |
U+027F5 | ⟵ |
LongLeftRightArrow; |
U+027F7 | ⟷ |
Longleftrightarrow; |
U+027FA | ⟺ |
longleftrightarrow; |
U+027F7 | ⟷ |
longmapsto; |
U+027FC | ⟼ |
LongRightArrow; |
U+027F6 | ⟶ |
Longrightarrow; |
U+027F9 | ⟹ |
longrightarrow; |
U+027F6 | ⟶ |
looparrowleft; |
U+021AB | ↫ |
looparrowright; |
U+021AC | ↬ |
lopar; |
U+02985 | ⦅ |
Lopf; |
U+1D543 | 𝕃 |
lopf; |
U+1D55D | 𝕝 |
loplus; |
U+02A2D | ⨭ |
lotimes; |
U+02A34 | ⨴ |
lowast; |
U+02217 | ∗ |
lowbar; |
U+0005F | _ |
LowerLeftArrow; |
U+02199 | ↙ |
LowerRightArrow; |
U+02198 | ↘ |
loz; |
U+025CA | ◊ |
lozenge; |
U+025CA | ◊ |
lozf; |
U+029EB | ⧫ |
lpar; |
U+00028 | ( |
lparlt; |
U+02993 | ⦓ |
lrarr; |
U+021C6 | ⇆ |
lrcorner; |
U+0231F | ⌟ |
lrhar; |
U+021CB | ⇋ |
lrhard; |
U+0296D | ⥭ |
lrm; |
U+0200E | |
lrtri; |
U+022BF | ⊿ |
lsaquo; |
U+02039 | ‹ |
Lscr; |
U+02112 | ℒ |
lscr; |
U+1D4C1 | 𝓁 |
Lsh; |
U+021B0 | ↰ |
lsh; |
U+021B0 | ↰ |
lsim; |
U+02272 | ≲ |
lsime; |
U+02A8D | ⪍ |
lsimg; |
U+02A8F | ⪏ |
lsqb; |
U+0005B | [ |
lsquo; |
U+02018 | ‘ |
lsquor; |
U+0201A | ‚ |
Lstrok; |
U+00141 | Ł |
lstrok; |
U+00142 | ł |
LT; |
U+0003C | < |
LT |
U+0003C | < |
Lt; |
U+0226A | ≪ |
lt; |
U+0003C | < |
lt |
U+0003C | < |
ltcc; |
U+02AA6 | ⪦ |
ltcir; |
U+02A79 | ⩹ |
ltdot; |
U+022D6 | ⋖ |
lthree; |
U+022CB | ⋋ |
ltimes; |
U+022C9 | ⋉ |
ltlarr; |
U+02976 | ⥶ |
ltquest; |
U+02A7B | ⩻ |
ltri; |
U+025C3 | ◃ |
ltrie; |
U+022B4 | ⊴ |
ltrif; |
U+025C2 | ◂ |
ltrPar; |
U+02996 | ⦖ |
lurdshar; |
U+0294A | ⥊ |
luruhar; |
U+02966 | ⥦ |
lvertneqq; |
U+02268 U+0FE00 | ≨︀ |
lvnE; |
U+02268 U+0FE00 | ≨︀ |
macr; |
U+000AF | ¯ |
macr |
U+000AF | ¯ |
male; |
U+02642 | ♂ |
malt; |
U+02720 | ✠ |
maltese; |
U+02720 | ✠ |
Map; |
U+02905 | ⤅ |
map; |
U+021A6 | ↦ |
mapsto; |
U+021A6 | ↦ |
mapstodown; |
U+021A7 | ↧ |
mapstoleft; |
U+021A4 | ↤ |
mapstoup; |
U+021A5 | ↥ |
marker; |
U+025AE | ▮ |
mcomma; |
U+02A29 | ⨩ |
Mcy; |
U+0041C | М |
mcy; |
U+0043C | м |
mdash; |
U+02014 | — |
mDDot; |
U+0223A | ∺ |
measuredangle; |
U+02221 | ∡ |
MediumSpace; |
U+0205F | |
Mellintrf; |
U+02133 | ℳ |
Mfr; |
U+1D510 | 𝔐 |
mfr; |
U+1D52A | 𝔪 |
mho; |
U+02127 | ℧ |
micro; |
U+000B5 | µ |
micro |
U+000B5 | µ |
mid; |
U+02223 | ∣ |
midast; |
U+0002A | * |
midcir; |
U+02AF0 | ⫰ |
middot; |
U+000B7 | · |
middot |
U+000B7 | · |
minus; |
U+02212 | − |
minusb; |
U+0229F | ⊟ |
minusd; |
U+02238 | ∸ |
minusdu; |
U+02A2A | ⨪ |
MinusPlus; |
U+02213 | ∓ |
mlcp; |
U+02ADB | ⫛ |
mldr; |
U+02026 | … |
mnplus; |
U+02213 | ∓ |
models; |
U+022A7 | ⊧ |
Mopf; |
U+1D544 | 𝕄 |
mopf; |
U+1D55E | 𝕞 |
mp; |
U+02213 | ∓ |
Mscr; |
U+02133 | ℳ |
mscr; |
U+1D4C2 | 𝓂 |
mstpos; |
U+0223E | ∾ |
Mu; |
U+0039C | Μ |
mu; |
U+003BC | μ |
multimap; |
U+022B8 | ⊸ |
mumap; |
U+022B8 | ⊸ |
nabla; |
U+02207 | ∇ |
Nacute; |
U+00143 | Ń |
nacute; |
U+00144 | ń |
nang; |
U+02220 U+020D2 | ∠⃒ |
nap; |
U+02249 | ≉ |
napE; |
U+02A70 U+00338 | ⩰̸ |
napid; |
U+0224B U+00338 | ≋̸ |
napos; |
U+00149 | ʼn |
napprox; |
U+02249 | ≉ |
natur; |
U+0266E | ♮ |
natural; |
U+0266E | ♮ |
naturals; |
U+02115 | ℕ |
nbsp; |
U+000A0 | |
nbsp |
U+000A0 | |
nbump; |
U+0224E U+00338 | ≎̸ |
nbumpe; |
U+0224F U+00338 | ≏̸ |
ncap; |
U+02A43 | ⩃ |
Ncaron; |
U+00147 | Ň |
ncaron; |
U+00148 | ň |
Ncedil; |
U+00145 | Ņ |
ncedil; |
U+00146 | ņ |
ncong; |
U+02247 | ≇ |
ncongdot; |
U+02A6D U+00338 | ⩭̸ |
ncup; |
U+02A42 | ⩂ |
Ncy; |
U+0041D | Н |
ncy; |
U+0043D | н |
ndash; |
U+02013 | – |
ne; |
U+02260 | ≠ |
nearhk; |
U+02924 | ⤤ |
neArr; |
U+021D7 | ⇗ |
nearr; |
U+02197 | ↗ |
nearrow; |
U+02197 | ↗ |
nedot; |
U+02250 U+00338 | ≐̸ |
NegativeMediumSpace; |
U+0200B | |
NegativeThickSpace; |
U+0200B | |
NegativeThinSpace; |
U+0200B | |
NegativeVeryThinSpace; |
U+0200B | |
nequiv; |
U+02262 | ≢ |
nesear; |
U+02928 | ⤨ |
nesim; |
U+02242 U+00338 | ≂̸ |
NestedGreaterGreater; |
U+0226B | ≫ |
NestedLessLess; |
U+0226A | ≪ |
NewLine; |
U+0000A | ␊ |
nexist; |
U+02204 | ∄ |
nexists; |
U+02204 | ∄ |
Nfr; |
U+1D511 | 𝔑 |
nfr; |
U+1D52B | 𝔫 |
ngE; |
U+02267 U+00338 | ≧̸ |
nge; |
U+02271 | ≱ |
ngeq; |
U+02271 | ≱ |
ngeqq; |
U+02267 U+00338 | ≧̸ |
ngeqslant; |
U+02A7E U+00338 | ⩾̸ |
nges; |
U+02A7E U+00338 | ⩾̸ |
nGg; |
U+022D9 U+00338 | ⋙̸ |
ngsim; |
U+02275 | ≵ |
nGt; |
U+0226B U+020D2 | ≫⃒ |
ngt; |
U+0226F | ≯ |
ngtr; |
U+0226F | ≯ |
nGtv; |
U+0226B U+00338 | ≫̸ |
nhArr; |
U+021CE | ⇎ |
nharr; |
U+021AE | ↮ |
nhpar; |
U+02AF2 | ⫲ |
ni; |
U+0220B | ∋ |
nis; |
U+022FC | ⋼ |
nisd; |
U+022FA | ⋺ |
niv; |
U+0220B | ∋ |
NJcy; |
U+0040A | Њ |
njcy; |
U+0045A | њ |
nlArr; |
U+021CD | ⇍ |
nlarr; |
U+0219A | ↚ |
nldr; |
U+02025 | ‥ |
nlE; |
U+02266 U+00338 | ≦̸ |
nle; |
U+02270 | ≰ |
nLeftarrow; |
U+021CD | ⇍ |
nleftarrow; |
U+0219A | ↚ |
nLeftrightarrow; |
U+021CE | ⇎ |
nleftrightarrow; |
U+021AE | ↮ |
nleq; |
U+02270 | ≰ |
nleqq; |
U+02266 U+00338 | ≦̸ |
nleqslant; |
U+02A7D U+00338 | ⩽̸ |
nles; |
U+02A7D U+00338 | ⩽̸ |
nless; |
U+0226E | ≮ |
nLl; |
U+022D8 U+00338 | ⋘̸ |
nlsim; |
U+02274 | ≴ |
nLt; |
U+0226A U+020D2 | ≪⃒ |
nlt; |
U+0226E | ≮ |
nltri; |
U+022EA | ⋪ |
nltrie; |
U+022EC | ⋬ |
nLtv; |
U+0226A U+00338 | ≪̸ |
nmid; |
U+02224 | ∤ |
NoBreak; |
U+02060 | |
NonBreakingSpace; |
U+000A0 | |
Nopf; |
U+02115 | ℕ |
nopf; |
U+1D55F | 𝕟 |
Not; |
U+02AEC | ⫬ |
not; |
U+000AC | ¬ |
not |
U+000AC | ¬ |
NotCongruent; |
U+02262 | ≢ |
NotCupCap; |
U+0226D | ≭ |
NotDoubleVerticalBar; |
U+02226 | ∦ |
NotElement; |
U+02209 | ∉ |
NotEqual; |
U+02260 | ≠ |
NotEqualTilde; |
U+02242 U+00338 | ≂̸ |
NotExists; |
U+02204 | ∄ |
NotGreater; |
U+0226F | ≯ |
NotGreaterEqual; |
U+02271 | ≱ |
NotGreaterFullEqual; |
U+02267 U+00338 | ≧̸ |
NotGreaterGreater; |
U+0226B U+00338 | ≫̸ |
NotGreaterLess; |
U+02279 | ≹ |
NotGreaterSlantEqual; |
U+02A7E U+00338 | ⩾̸ |
NotGreaterTilde; |
U+02275 | ≵ |
NotHumpDownHump; |
U+0224E U+00338 | ≎̸ |
NotHumpEqual; |
U+0224F U+00338 | ≏̸ |
notin; |
U+02209 | ∉ |
notindot; |
U+022F5 U+00338 | ⋵̸ |
notinE; |
U+022F9 U+00338 | ⋹̸ |
notinva; |
U+02209 | ∉ |
notinvb; |
U+022F7 | ⋷ |
notinvc; |
U+022F6 | ⋶ |
NotLeftTriangle; |
U+022EA | ⋪ |
NotLeftTriangleBar; |
U+029CF U+00338 | ⧏̸ |
NotLeftTriangleEqual; |
U+022EC | ⋬ |
NotLess; |
U+0226E | ≮ |
NotLessEqual; |
U+02270 | ≰ |
NotLessGreater; |
U+02278 | ≸ |
NotLessLess; |
U+0226A U+00338 | ≪̸ |
NotLessSlantEqual; |
U+02A7D U+00338 | ⩽̸ |
NotLessTilde; |
U+02274 | ≴ |
NotNestedGreaterGreater; |
U+02AA2 U+00338 | ⪢̸ |
NotNestedLessLess; |
U+02AA1 U+00338 | ⪡̸ |
notni; |
U+0220C | ∌ |
notniva; |
U+0220C | ∌ |
notnivb; |
U+022FE | ⋾ |
notnivc; |
U+022FD | ⋽ |
NotPrecedes; |
U+02280 | ⊀ |
NotPrecedesEqual; |
U+02AAF U+00338 | ⪯̸ |
NotPrecedesSlantEqual; |
U+022E0 | ⋠ |
NotReverseElement; |
U+0220C | ∌ |
NotRightTriangle; |
U+022EB | ⋫ |
NotRightTriangleBar; |
U+029D0 U+00338 | ⧐̸ |
NotRightTriangleEqual; |
U+022ED | ⋭ |
NotSquareSubset; |
U+0228F U+00338 | ⊏̸ |
NotSquareSubsetEqual; |
U+022E2 | ⋢ |
NotSquareSuperset; |
U+02290 U+00338 | ⊐̸ |
NotSquareSupersetEqual; |
U+022E3 | ⋣ |
NotSubset; |
U+02282 U+020D2 | ⊂⃒ |
NotSubsetEqual; |
U+02288 | ⊈ |
NotSucceeds; |
U+02281 | ⊁ |
NotSucceedsEqual; |
U+02AB0 U+00338 | ⪰̸ |
NotSucceedsSlantEqual; |
U+022E1 | ⋡ |
NotSucceedsTilde; |
U+0227F U+00338 | ≿̸ |
NotSuperset; |
U+02283 U+020D2 | ⊃⃒ |
NotSupersetEqual; |
U+02289 | ⊉ |
NotTilde; |
U+02241 | ≁ |
NotTildeEqual; |
U+02244 | ≄ |
NotTildeFullEqual; |
U+02247 | ≇ |
NotTildeTilde; |
U+02249 | ≉ |
NotVerticalBar; |
U+02224 | ∤ |
npar; |
U+02226 | ∦ |
nparallel; |
U+02226 | ∦ |
nparsl; |
U+02AFD U+020E5 | ⫽⃥ |
npart; |
U+02202 U+00338 | ∂̸ |
npolint; |
U+02A14 | ⨔ |
npr; |
U+02280 | ⊀ |
nprcue; |
U+022E0 | ⋠ |
npre; |
U+02AAF U+00338 | ⪯̸ |
nprec; |
U+02280 | ⊀ |
npreceq; |
U+02AAF U+00338 | ⪯̸ |
nrArr; |
U+021CF | ⇏ |
nrarr; |
U+0219B | ↛ |
nrarrc; |
U+02933 U+00338 | ⤳̸ |
nrarrw; |
U+0219D U+00338 | ↝̸ |
nRightarrow; |
U+021CF | ⇏ |
nrightarrow; |
U+0219B | ↛ |
nrtri; |
U+022EB | ⋫ |
nrtrie; |
U+022ED | ⋭ |
nsc; |
U+02281 | ⊁ |
nsccue; |
U+022E1 | ⋡ |
nsce; |
U+02AB0 U+00338 | ⪰̸ |
Nscr; |
U+1D4A9 | 𝒩 |
nscr; |
U+1D4C3 | 𝓃 |
nshortmid; |
U+02224 | ∤ |
nshortparallel; |
U+02226 | ∦ |
nsim; |
U+02241 | ≁ |
nsime; |
U+02244 | ≄ |
nsimeq; |
U+02244 | ≄ |
nsmid; |
U+02224 | ∤ |
nspar; |
U+02226 | ∦ |
nsqsube; |
U+022E2 | ⋢ |
nsqsupe; |
U+022E3 | ⋣ |
nsub; |
U+02284 | ⊄ |
nsubE; |
U+02AC5 U+00338 | ⫅̸ |
nsube; |
U+02288 | ⊈ |
nsubset; |
U+02282 U+020D2 | ⊂⃒ |
nsubseteq; |
U+02288 | ⊈ |
nsubseteqq; |
U+02AC5 U+00338 | ⫅̸ |
nsucc; |
U+02281 | ⊁ |
nsucceq; |
U+02AB0 U+00338 | ⪰̸ |
nsup; |
U+02285 | ⊅ |
nsupE; |
U+02AC6 U+00338 | ⫆̸ |
nsupe; |
U+02289 | ⊉ |
nsupset; |
U+02283 U+020D2 | ⊃⃒ |
nsupseteq; |
U+02289 | ⊉ |
nsupseteqq; |
U+02AC6 U+00338 | ⫆̸ |
ntgl; |
U+02279 | ≹ |
Ntilde; |
U+000D1 | Ñ |
Ntilde |
U+000D1 | Ñ |
ntilde; |
U+000F1 | ñ |
ntilde |
U+000F1 | ñ |
ntlg; |
U+02278 | ≸ |
ntriangleleft; |
U+022EA | ⋪ |
ntrianglelefteq; |
U+022EC | ⋬ |
ntriangleright; |
U+022EB | ⋫ |
ntrianglerighteq; |
U+022ED | ⋭ |
Nu; |
U+0039D | Ν |
nu; |
U+003BD | ν |
num; |
U+00023 | # |
numero; |
U+02116 | № |
numsp; |
U+02007 | |
nvap; |
U+0224D U+020D2 | ≍⃒ |
nVDash; |
U+022AF | ⊯ |
nVdash; |
U+022AE | ⊮ |
nvDash; |
U+022AD | ⊭ |
nvdash; |
U+022AC | ⊬ |
nvge; |
U+02265 U+020D2 | ≥⃒ |
nvgt; |
U+0003E U+020D2 | >⃒ |
nvHarr; |
U+02904 | ⤄ |
nvinfin; |
U+029DE | ⧞ |
nvlArr; |
U+02902 | ⤂ |
nvle; |
U+02264 U+020D2 | ≤⃒ |
nvlt; |
U+0003C U+020D2 | <⃒ |
nvltrie; |
U+022B4 U+020D2 | ⊴⃒ |
nvrArr; |
U+02903 | ⤃ |
nvrtrie; |
U+022B5 U+020D2 | ⊵⃒ |
nvsim; |
U+0223C U+020D2 | ∼⃒ |
nwarhk; |
U+02923 | ⤣ |
nwArr; |
U+021D6 | ⇖ |
nwarr; |
U+02196 | ↖ |
nwarrow; |
U+02196 | ↖ |
nwnear; |
U+02927 | ⤧ |
Oacute; |
U+000D3 | Ó |
Oacute |
U+000D3 | Ó |
oacute; |
U+000F3 | ó |
oacute |
U+000F3 | ó |
oast; |
U+0229B | ⊛ |
ocir; |
U+0229A | ⊚ |
Ocirc; |
U+000D4 | Ô |
Ocirc |
U+000D4 | Ô |
ocirc; |
U+000F4 | ô |
ocirc |
U+000F4 | ô |
Ocy; |
U+0041E | О |
ocy; |
U+0043E | о |
odash; |
U+0229D | ⊝ |
Odblac; |
U+00150 | Ő |
odblac; |
U+00151 | ő |
odiv; |
U+02A38 | ⨸ |
odot; |
U+02299 | ⊙ |
odsold; |
U+029BC | ⦼ |
OElig; |
U+00152 | Π|
oelig; |
U+00153 | œ |
ofcir; |
U+029BF | ⦿ |
Ofr; |
U+1D512 | 𝔒 |
ofr; |
U+1D52C | 𝔬 |
ogon; |
U+002DB | ˛ |
Ograve; |
U+000D2 | Ò |
Ograve |
U+000D2 | Ò |
ograve; |
U+000F2 | ò |
ograve |
U+000F2 | ò |
ogt; |
U+029C1 | ⧁ |
ohbar; |
U+029B5 | ⦵ |
ohm; |
U+003A9 | Ω |
oint; |
U+0222E | ∮ |
olarr; |
U+021BA | ↺ |
olcir; |
U+029BE | ⦾ |
olcross; |
U+029BB | ⦻ |
oline; |
U+0203E | ‾ |
olt; |
U+029C0 | ⧀ |
Omacr; |
U+0014C | Ō |
omacr; |
U+0014D | ō |
Omega; |
U+003A9 | Ω |
omega; |
U+003C9 | ω |
Omicron; |
U+0039F | Ο |
omicron; |
U+003BF | ο |
omid; |
U+029B6 | ⦶ |
ominus; |
U+02296 | ⊖ |
Oopf; |
U+1D546 | 𝕆 |
oopf; |
U+1D560 | 𝕠 |
opar; |
U+029B7 | ⦷ |
OpenCurlyDoubleQuote; |
U+0201C | “ |
OpenCurlyQuote; |
U+02018 | ‘ |
operp; |
U+029B9 | ⦹ |
oplus; |
U+02295 | ⊕ |
Or; |
U+02A54 | ⩔ |
or; |
U+02228 | ∨ |
orarr; |
U+021BB | ↻ |
ord; |
U+02A5D | ⩝ |
order; |
U+02134 | ℴ |
orderof; |
U+02134 | ℴ |
ordf; |
U+000AA | ª |
ordf |
U+000AA | ª |
ordm; |
U+000BA | º |
ordm |
U+000BA | º |
origof; |
U+022B6 | ⊶ |
oror; |
U+02A56 | ⩖ |
orslope; |
U+02A57 | ⩗ |
orv; |
U+02A5B | ⩛ |
oS; |
U+024C8 | Ⓢ |
Oscr; |
U+1D4AA | 𝒪 |
oscr; |
U+02134 | ℴ |
Oslash; |
U+000D8 | Ø |
Oslash |
U+000D8 | Ø |
oslash; |
U+000F8 | ø |
oslash |
U+000F8 | ø |
osol; |
U+02298 | ⊘ |
Otilde; |
U+000D5 | Õ |
Otilde |
U+000D5 | Õ |
otilde; |
U+000F5 | õ |
otilde |
U+000F5 | õ |
Otimes; |
U+02A37 | ⨷ |
otimes; |
U+02297 | ⊗ |
otimesas; |
U+02A36 | ⨶ |
Ouml; |
U+000D6 | Ö |
Ouml |
U+000D6 | Ö |
ouml; |
U+000F6 | ö |
ouml |
U+000F6 | ö |
ovbar; |
U+0233D | ⌽ |
OverBar; |
U+0203E | ‾ |
OverBrace; |
U+023DE | ⏞ |
OverBracket; |
U+023B4 | ⎴ |
OverParenthesis; |
U+023DC | ⏜ |
par; |
U+02225 | ∥ |
para; |
U+000B6 | ¶ |
para |
U+000B6 | ¶ |
parallel; |
U+02225 | ∥ |
parsim; |
U+02AF3 | ⫳ |
parsl; |
U+02AFD | ⫽ |
part; |
U+02202 | ∂ |
PartialD; |
U+02202 | ∂ |
Pcy; |
U+0041F | П |
pcy; |
U+0043F | п |
percnt; |
U+00025 | % |
period; |
U+0002E | . |
permil; |
U+02030 | ‰ |
perp; |
U+022A5 | ⊥ |
pertenk; |
U+02031 | ‱ |
Pfr; |
U+1D513 | 𝔓 |
pfr; |
U+1D52D | 𝔭 |
Phi; |
U+003A6 | Φ |
phi; |
U+003C6 | φ |
phiv; |
U+003D5 | ϕ |
phmmat; |
U+02133 | ℳ |
phone; |
U+0260E | ☎ |
Pi; |
U+003A0 | Π |
pi; |
U+003C0 | π |
pitchfork; |
U+022D4 | ⋔ |
piv; |
U+003D6 | ϖ |
planck; |
U+0210F | ℏ |
planckh; |
U+0210E | ℎ |
plankv; |
U+0210F | ℏ |
plus; |
U+0002B | + |
plusacir; |
U+02A23 | ⨣ |
plusb; |
U+0229E | ⊞ |
pluscir; |
U+02A22 | ⨢ |
plusdo; |
U+02214 | ∔ |
plusdu; |
U+02A25 | ⨥ |
pluse; |
U+02A72 | ⩲ |
PlusMinus; |
U+000B1 | ± |
plusmn; |
U+000B1 | ± |
plusmn |
U+000B1 | ± |
plussim; |
U+02A26 | ⨦ |
plustwo; |
U+02A27 | ⨧ |
pm; |
U+000B1 | ± |
Poincareplane; |
U+0210C | ℌ |
pointint; |
U+02A15 | ⨕ |
Popf; |
U+02119 | ℙ |
popf; |
U+1D561 | 𝕡 |
pound; |
U+000A3 | £ |
pound |
U+000A3 | £ |
Pr; |
U+02ABB | ⪻ |
pr; |
U+0227A | ≺ |
prap; |
U+02AB7 | ⪷ |
prcue; |
U+0227C | ≼ |
prE; |
U+02AB3 | ⪳ |
pre; |
U+02AAF | ⪯ |
prec; |
U+0227A | ≺ |
precapprox; |
U+02AB7 | ⪷ |
preccurlyeq; |
U+0227C | ≼ |
Precedes; |
U+0227A | ≺ |
PrecedesEqual; |
U+02AAF | ⪯ |
PrecedesSlantEqual; |
U+0227C | ≼ |
PrecedesTilde; |
U+0227E | ≾ |
preceq; |
U+02AAF | ⪯ |
precnapprox; |
U+02AB9 | ⪹ |
precneqq; |
U+02AB5 | ⪵ |
precnsim; |
U+022E8 | ⋨ |
precsim; |
U+0227E | ≾ |
Prime; |
U+02033 | ″ |
prime; |
U+02032 | ′ |
primes; |
U+02119 | ℙ |
prnap; |
U+02AB9 | ⪹ |
prnE; |
U+02AB5 | ⪵ |
prnsim; |
U+022E8 | ⋨ |
prod; |
U+0220F | ∏ |
Product; |
U+0220F | ∏ |
profalar; |
U+0232E | ⌮ |
profline; |
U+02312 | ⌒ |
profsurf; |
U+02313 | ⌓ |
prop; |
U+0221D | ∝ |
Proportion; |
U+02237 | ∷ |
Proportional; |
U+0221D | ∝ |
propto; |
U+0221D | ∝ |
prsim; |
U+0227E | ≾ |
prurel; |
U+022B0 | ⊰ |
Pscr; |
U+1D4AB | 𝒫 |
pscr; |
U+1D4C5 | 𝓅 |
Psi; |
U+003A8 | Ψ |
psi; |
U+003C8 | ψ |
puncsp; |
U+02008 | |
Qfr; |
U+1D514 | 𝔔 |
qfr; |
U+1D52E | 𝔮 |
qint; |
U+02A0C | ⨌ |
Qopf; |
U+0211A | ℚ |
qopf; |
U+1D562 | 𝕢 |
qprime; |
U+02057 | ⁗ |
Qscr; |
U+1D4AC | 𝒬 |
qscr; |
U+1D4C6 | 𝓆 |
quaternions; |
U+0210D | ℍ |
quatint; |
U+02A16 | ⨖ |
quest; |
U+0003F | ? |
questeq; |
U+0225F | ≟ |
QUOT; |
U+00022 | " |
QUOT |
U+00022 | " |
quot; |
U+00022 | " |
quot |
U+00022 | " |
rAarr; |
U+021DB | ⇛ |
race; |
U+0223D U+00331 | ∽̱ |
Racute; |
U+00154 | Ŕ |
racute; |
U+00155 | ŕ |
radic; |
U+0221A | √ |
raemptyv; |
U+029B3 | ⦳ |
Rang; |
U+027EB | ⟫ |
rang; |
U+027E9 | ⟩ |
rangd; |
U+02992 | ⦒ |
range; |
U+029A5 | ⦥ |
rangle; |
U+027E9 | ⟩ |
raquo; |
U+000BB | » |
raquo |
U+000BB | » |
Rarr; |
U+021A0 | ↠ |
rArr; |
U+021D2 | ⇒ |
rarr; |
U+02192 | → |
rarrap; |
U+02975 | ⥵ |
rarrb; |
U+021E5 | ⇥ |
rarrbfs; |
U+02920 | ⤠ |
rarrc; |
U+02933 | ⤳ |
rarrfs; |
U+0291E | ⤞ |
rarrhk; |
U+021AA | ↪ |
rarrlp; |
U+021AC | ↬ |
rarrpl; |
U+02945 | ⥅ |
rarrsim; |
U+02974 | ⥴ |
Rarrtl; |
U+02916 | ⤖ |
rarrtl; |
U+021A3 | ↣ |
rarrw; |
U+0219D | ↝ |
rAtail; |
U+0291C | ⤜ |
ratail; |
U+0291A | ⤚ |
ratio; |
U+02236 | ∶ |
rationals; |
U+0211A | ℚ |
RBarr; |
U+02910 | ⤐ |
rBarr; |
U+0290F | ⤏ |
rbarr; |
U+0290D | ⤍ |
rbbrk; |
U+02773 | ❳ |
rbrace; |
U+0007D | } |
rbrack; |
U+0005D | ] |
rbrke; |
U+0298C | ⦌ |
rbrksld; |
U+0298E | ⦎ |
rbrkslu; |
U+02990 | ⦐ |
Rcaron; |
U+00158 | Ř |
rcaron; |
U+00159 | ř |
Rcedil; |
U+00156 | Ŗ |
rcedil; |
U+00157 | ŗ |
rceil; |
U+02309 | ⌉ |
rcub; |
U+0007D | } |
Rcy; |
U+00420 | Р |
rcy; |
U+00440 | р |
rdca; |
U+02937 | ⤷ |
rdldhar; |
U+02969 | ⥩ |
rdquo; |
U+0201D | ” |
rdquor; |
U+0201D | ” |
rdsh; |
U+021B3 | ↳ |
Re; |
U+0211C | ℜ |
real; |
U+0211C | ℜ |
realine; |
U+0211B | ℛ |
realpart; |
U+0211C | ℜ |
reals; |
U+0211D | ℝ |
rect; |
U+025AD | ▭ |
REG; |
U+000AE | ® |
REG |
U+000AE | ® |
reg; |
U+000AE | ® |
reg |
U+000AE | ® |
ReverseElement; |
U+0220B | ∋ |
ReverseEquilibrium; |
U+021CB | ⇋ |
ReverseUpEquilibrium; |
U+0296F | ⥯ |
rfisht; |
U+0297D | ⥽ |
rfloor; |
U+0230B | ⌋ |
Rfr; |
U+0211C | ℜ |
rfr; |
U+1D52F | 𝔯 |
rHar; |
U+02964 | ⥤ |
rhard; |
U+021C1 | ⇁ |
rharu; |
U+021C0 | ⇀ |
rharul; |
U+0296C | ⥬ |
Rho; |
U+003A1 | Ρ |
rho; |
U+003C1 | ρ |
rhov; |
U+003F1 | ϱ |
RightAngleBracket; |
U+027E9 | ⟩ |
RightArrow; |
U+02192 | → |
Rightarrow; |
U+021D2 | ⇒ |
rightarrow; |
U+02192 | → |
RightArrowBar; |
U+021E5 | ⇥ |
RightArrowLeftArrow; |
U+021C4 | ⇄ |
rightarrowtail; |
U+021A3 | ↣ |
RightCeiling; |
U+02309 | ⌉ |
RightDoubleBracket; |
U+027E7 | ⟧ |
RightDownTeeVector; |
U+0295D | ⥝ |
RightDownVector; |
U+021C2 | ⇂ |
RightDownVectorBar; |
U+02955 | ⥕ |
RightFloor; |
U+0230B | ⌋ |
rightharpoondown; |
U+021C1 | ⇁ |
rightharpoonup; |
U+021C0 | ⇀ |
rightleftarrows; |
U+021C4 | ⇄ |
rightleftharpoons; |
U+021CC | ⇌ |
rightrightarrows; |
U+021C9 | ⇉ |
rightsquigarrow; |
U+0219D | ↝ |
RightTee; |
U+022A2 | ⊢ |
RightTeeArrow; |
U+021A6 | ↦ |
RightTeeVector; |
U+0295B | ⥛ |
rightthreetimes; |
U+022CC | ⋌ |
RightTriangle; |
U+022B3 | ⊳ |
RightTriangleBar; |
U+029D0 | ⧐ |
RightTriangleEqual; |
U+022B5 | ⊵ |
RightUpDownVector; |
U+0294F | ⥏ |
RightUpTeeVector; |
U+0295C | ⥜ |
RightUpVector; |
U+021BE | ↾ |
RightUpVectorBar; |
U+02954 | ⥔ |
RightVector; |
U+021C0 | ⇀ |
RightVectorBar; |
U+02953 | ⥓ |
ring; |
U+002DA | ˚ |
risingdotseq; |
U+02253 | ≓ |
rlarr; |
U+021C4 | ⇄ |
rlhar; |
U+021CC | ⇌ |
rlm; |
U+0200F | |
rmoust; |
U+023B1 | ⎱ |
rmoustache; |
U+023B1 | ⎱ |
rnmid; |
U+02AEE | ⫮ |
roang; |
U+027ED | ⟭ |
roarr; |
U+021FE | ⇾ |
robrk; |
U+027E7 | ⟧ |
ropar; |
U+02986 | ⦆ |
Ropf; |
U+0211D | ℝ |
ropf; |
U+1D563 | 𝕣 |
roplus; |
U+02A2E | ⨮ |
rotimes; |
U+02A35 | ⨵ |
RoundImplies; |
U+02970 | ⥰ |
rpar; |
U+00029 | ) |
rpargt; |
U+02994 | ⦔ |
rppolint; |
U+02A12 | ⨒ |
rrarr; |
U+021C9 | ⇉ |
Rrightarrow; |
U+021DB | ⇛ |
rsaquo; |
U+0203A | › |
Rscr; |
U+0211B | ℛ |
rscr; |
U+1D4C7 | 𝓇 |
Rsh; |
U+021B1 | ↱ |
rsh; |
U+021B1 | ↱ |
rsqb; |
U+0005D | ] |
rsquo; |
U+02019 | ’ |
rsquor; |
U+02019 | ’ |
rthree; |
U+022CC | ⋌ |
rtimes; |
U+022CA | ⋊ |
rtri; |
U+025B9 | ▹ |
rtrie; |
U+022B5 | ⊵ |
rtrif; |
U+025B8 | ▸ |
rtriltri; |
U+029CE | ⧎ |
RuleDelayed; |
U+029F4 | ⧴ |
ruluhar; |
U+02968 | ⥨ |
rx; |
U+0211E | ℞ |
Sacute; |
U+0015A | Ś |
sacute; |
U+0015B | ś |
sbquo; |
U+0201A | ‚ |
Sc; |
U+02ABC | ⪼ |
sc; |
U+0227B | ≻ |
scap; |
U+02AB8 | ⪸ |
Scaron; |
U+00160 | Š |
scaron; |
U+00161 | š |
sccue; |
U+0227D | ≽ |
scE; |
U+02AB4 | ⪴ |
sce; |
U+02AB0 | ⪰ |
Scedil; |
U+0015E | Ş |
scedil; |
U+0015F | ş |
Scirc; |
U+0015C | Ŝ |
scirc; |
U+0015D | ŝ |
scnap; |
U+02ABA | ⪺ |
scnE; |
U+02AB6 | ⪶ |
scnsim; |
U+022E9 | ⋩ |
scpolint; |
U+02A13 | ⨓ |
scsim; |
U+0227F | ≿ |
Scy; |
U+00421 | С |
scy; |
U+00441 | с |
sdot; |
U+022C5 | ⋅ |
sdotb; |
U+022A1 | ⊡ |
sdote; |
U+02A66 | ⩦ |
searhk; |
U+02925 | ⤥ |
seArr; |
U+021D8 | ⇘ |
searr; |
U+02198 | ↘ |
searrow; |
U+02198 | ↘ |
sect; |
U+000A7 | § |
sect |
U+000A7 | § |
semi; |
U+0003B | ; |
seswar; |
U+02929 | ⤩ |
setminus; |
U+02216 | ∖ |
setmn; |
U+02216 | ∖ |
sext; |
U+02736 | ✶ |
Sfr; |
U+1D516 | 𝔖 |
sfr; |
U+1D530 | 𝔰 |
sfrown; |
U+02322 | ⌢ |
sharp; |
U+0266F | ♯ |
SHCHcy; |
U+00429 | Щ |
shchcy; |
U+00449 | щ |
SHcy; |
U+00428 | Ш |
shcy; |
U+00448 | ш |
ShortDownArrow; |
U+02193 | ↓ |
ShortLeftArrow; |
U+02190 | ← |
shortmid; |
U+02223 | ∣ |
shortparallel; |
U+02225 | ∥ |
ShortRightArrow; |
U+02192 | → |
ShortUpArrow; |
U+02191 | ↑ |
shy; |
U+000AD | |
shy |
U+000AD | |
Sigma; |
U+003A3 | Σ |
sigma; |
U+003C3 | σ |
sigmaf; |
U+003C2 | ς |
sigmav; |
U+003C2 | ς |
sim; |
U+0223C | ∼ |
simdot; |
U+02A6A | ⩪ |
sime; |
U+02243 | ≃ |
simeq; |
U+02243 | ≃ |
simg; |
U+02A9E | ⪞ |
simgE; |
U+02AA0 | ⪠ |
siml; |
U+02A9D | ⪝ |
simlE; |
U+02A9F | ⪟ |
simne; |
U+02246 | ≆ |
simplus; |
U+02A24 | ⨤ |
simrarr; |
U+02972 | ⥲ |
slarr; |
U+02190 | ← |
SmallCircle; |
U+02218 | ∘ |
smallsetminus; |
U+02216 | ∖ |
smashp; |
U+02A33 | ⨳ |
smeparsl; |
U+029E4 | ⧤ |
smid; |
U+02223 | ∣ |
smile; |
U+02323 | ⌣ |
smt; |
U+02AAA | ⪪ |
smte; |
U+02AAC | ⪬ |
smtes; |
U+02AAC U+0FE00 | ⪬︀ |
SOFTcy; |
U+0042C | Ь |
softcy; |
U+0044C | ь |
sol; |
U+0002F | / |
solb; |
U+029C4 | ⧄ |
solbar; |
U+0233F | ⌿ |
Sopf; |
U+1D54A | 𝕊 |
sopf; |
U+1D564 | 𝕤 |
spades; |
U+02660 | ♠ |
spadesuit; |
U+02660 | ♠ |
spar; |
U+02225 | ∥ |
sqcap; |
U+02293 | ⊓ |
sqcaps; |
U+02293 U+0FE00 | ⊓︀ |
sqcup; |
U+02294 | ⊔ |
sqcups; |
U+02294 U+0FE00 | ⊔︀ |
Sqrt; |
U+0221A | √ |
sqsub; |
U+0228F | ⊏ |
sqsube; |
U+02291 | ⊑ |
sqsubset; |
U+0228F | ⊏ |
sqsubseteq; |
U+02291 | ⊑ |
sqsup; |
U+02290 | ⊐ |
sqsupe; |
U+02292 | ⊒ |
sqsupset; |
U+02290 | ⊐ |
sqsupseteq; |
U+02292 | ⊒ |
squ; |
U+025A1 | □ |
Square; |
U+025A1 | □ |
square; |
U+025A1 | □ |
SquareIntersection; |
U+02293 | ⊓ |
SquareSubset; |
U+0228F | ⊏ |
SquareSubsetEqual; |
U+02291 | ⊑ |
SquareSuperset; |
U+02290 | ⊐ |
SquareSupersetEqual; |
U+02292 | ⊒ |
SquareUnion; |
U+02294 | ⊔ |
squarf; |
U+025AA | ▪ |
squf; |
U+025AA | ▪ |
srarr; |
U+02192 | → |
Sscr; |
U+1D4AE | 𝒮 |
sscr; |
U+1D4C8 | 𝓈 |
ssetmn; |
U+02216 | ∖ |
ssmile; |
U+02323 | ⌣ |
sstarf; |
U+022C6 | ⋆ |
Star; |
U+022C6 | ⋆ |
star; |
U+02606 | ☆ |
starf; |
U+02605 | ★ |
straightepsilon; |
U+003F5 | ϵ |
straightphi; |
U+003D5 | ϕ |
strns; |
U+000AF | ¯ |
Sub; |
U+022D0 | ⋐ |
sub; |
U+02282 | ⊂ |
subdot; |
U+02ABD | ⪽ |
subE; |
U+02AC5 | ⫅ |
sube; |
U+02286 | ⊆ |
subedot; |
U+02AC3 | ⫃ |
submult; |
U+02AC1 | ⫁ |
subnE; |
U+02ACB | ⫋ |
subne; |
U+0228A | ⊊ |
subplus; |
U+02ABF | ⪿ |
subrarr; |
U+02979 | ⥹ |
Subset; |
U+022D0 | ⋐ |
subset; |
U+02282 | ⊂ |
subseteq; |
U+02286 | ⊆ |
subseteqq; |
U+02AC5 | ⫅ |
SubsetEqual; |
U+02286 | ⊆ |
subsetneq; |
U+0228A | ⊊ |
subsetneqq; |
U+02ACB | ⫋ |
subsim; |
U+02AC7 | ⫇ |
subsub; |
U+02AD5 | ⫕ |
subsup; |
U+02AD3 | ⫓ |
succ; |
U+0227B | ≻ |
succapprox; |
U+02AB8 | ⪸ |
succcurlyeq; |
U+0227D | ≽ |
Succeeds; |
U+0227B | ≻ |
SucceedsEqual; |
U+02AB0 | ⪰ |
SucceedsSlantEqual; |
U+0227D | ≽ |
SucceedsTilde; |
U+0227F | ≿ |
succeq; |
U+02AB0 | ⪰ |
succnapprox; |
U+02ABA | ⪺ |
succneqq; |
U+02AB6 | ⪶ |
succnsim; |
U+022E9 | ⋩ |
succsim; |
U+0227F | ≿ |
SuchThat; |
U+0220B | ∋ |
Sum; |
U+02211 | ∑ |
sum; |
U+02211 | ∑ |
sung; |
U+0266A | ♪ |
Sup; |
U+022D1 | ⋑ |
sup; |
U+02283 | ⊃ |
sup1; |
U+000B9 | ¹ |
sup1 |
U+000B9 | ¹ |
sup2; |
U+000B2 | ² |
sup2 |
U+000B2 | ² |
sup3; |
U+000B3 | ³ |
sup3 |
U+000B3 | ³ |
supdot; |
U+02ABE | ⪾ |
supdsub; |
U+02AD8 | ⫘ |
supE; |
U+02AC6 | ⫆ |
supe; |
U+02287 | ⊇ |
supedot; |
U+02AC4 | ⫄ |
Superset; |
U+02283 | ⊃ |
SupersetEqual; |
U+02287 | ⊇ |
suphsol; |
U+027C9 | ⟉ |
suphsub; |
U+02AD7 | ⫗ |
suplarr; |
U+0297B | ⥻ |
supmult; |
U+02AC2 | ⫂ |
supnE; |
U+02ACC | ⫌ |
supne; |
U+0228B | ⊋ |
supplus; |
U+02AC0 | ⫀ |
Supset; |
U+022D1 | ⋑ |
supset; |
U+02283 | ⊃ |
supseteq; |
U+02287 | ⊇ |
supseteqq; |
U+02AC6 | ⫆ |
supsetneq; |
U+0228B | ⊋ |
supsetneqq; |
U+02ACC | ⫌ |
supsim; |
U+02AC8 | ⫈ |
supsub; |
U+02AD4 | ⫔ |
supsup; |
U+02AD6 | ⫖ |
swarhk; |
U+02926 | ⤦ |
swArr; |
U+021D9 | ⇙ |
swarr; |
U+02199 | ↙ |
swarrow; |
U+02199 | ↙ |
swnwar; |
U+0292A | ⤪ |
szlig; |
U+000DF | ß |
szlig |
U+000DF | ß |
Tab; |
U+00009 | ␉ |
target; |
U+02316 | ⌖ |
Tau; |
U+003A4 | Τ |
tau; |
U+003C4 | τ |
tbrk; |
U+023B4 | ⎴ |
Tcaron; |
U+00164 | Ť |
tcaron; |
U+00165 | ť |
Tcedil; |
U+00162 | Ţ |
tcedil; |
U+00163 | ţ |
Tcy; |
U+00422 | Т |
tcy; |
U+00442 | т |
tdot; |
U+020DB | ◌⃛ |
telrec; |
U+02315 | ⌕ |
Tfr; |
U+1D517 | 𝔗 |
tfr; |
U+1D531 | 𝔱 |
there4; |
U+02234 | ∴ |
Therefore; |
U+02234 | ∴ |
therefore; |
U+02234 | ∴ |
Theta; |
U+00398 | Θ |
theta; |
U+003B8 | θ |
thetasym; |
U+003D1 | ϑ |
thetav; |
U+003D1 | ϑ |
thickapprox; |
U+02248 | ≈ |
thicksim; |
U+0223C | ∼ |
ThickSpace; |
U+0205F U+0200A | |
thinsp; |
U+02009 | |
ThinSpace; |
U+02009 | |
thkap; |
U+02248 | ≈ |
thksim; |
U+0223C | ∼ |
THORN; |
U+000DE | Þ |
THORN |
U+000DE | Þ |
thorn; |
U+000FE | þ |
thorn |
U+000FE | þ |
Tilde; |
U+0223C | ∼ |
tilde; |
U+002DC | ˜ |
TildeEqual; |
U+02243 | ≃ |
TildeFullEqual; |
U+02245 | ≅ |
TildeTilde; |
U+02248 | ≈ |
times; |
U+000D7 | × |
times |
U+000D7 | × |
timesb; |
U+022A0 | ⊠ |
timesbar; |
U+02A31 | ⨱ |
timesd; |
U+02A30 | ⨰ |
tint; |
U+0222D | ∭ |
toea; |
U+02928 | ⤨ |
top; |
U+022A4 | ⊤ |
topbot; |
U+02336 | ⌶ |
topcir; |
U+02AF1 | ⫱ |
Topf; |
U+1D54B | 𝕋 |
topf; |
U+1D565 | 𝕥 |
topfork; |
U+02ADA | ⫚ |
tosa; |
U+02929 | ⤩ |
tprime; |
U+02034 | ‴ |
TRADE; |
U+02122 | ™ |
trade; |
U+02122 | ™ |
triangle; |
U+025B5 | ▵ |
triangledown; |
U+025BF | ▿ |
triangleleft; |
U+025C3 | ◃ |
trianglelefteq; |
U+022B4 | ⊴ |
triangleq; |
U+0225C | ≜ |
triangleright; |
U+025B9 | ▹ |
trianglerighteq; |
U+022B5 | ⊵ |
tridot; |
U+025EC | ◬ |
trie; |
U+0225C | ≜ |
triminus; |
U+02A3A | ⨺ |
TripleDot; |
U+020DB | ◌⃛ |
triplus; |
U+02A39 | ⨹ |
trisb; |
U+029CD | ⧍ |
tritime; |
U+02A3B | ⨻ |
trpezium; |
U+023E2 | ⏢ |
Tscr; |
U+1D4AF | 𝒯 |
tscr; |
U+1D4C9 | 𝓉 |
TScy; |
U+00426 | Ц |
tscy; |
U+00446 | ц |
TSHcy; |
U+0040B | Ћ |
tshcy; |
U+0045B | ћ |
Tstrok; |
U+00166 | Ŧ |
tstrok; |
U+00167 | ŧ |
twixt; |
U+0226C | ≬ |
twoheadleftarrow; |
U+0219E | ↞ |
twoheadrightarrow; |
U+021A0 | ↠ |
Uacute; |
U+000DA | Ú |
Uacute |
U+000DA | Ú |
uacute; |
U+000FA | ú |
uacute |
U+000FA | ú |
Uarr; |
U+0219F | ↟ |
uArr; |
U+021D1 | ⇑ |
uarr; |
U+02191 | ↑ |
Uarrocir; |
U+02949 | ⥉ |
Ubrcy; |
U+0040E | Ў |
ubrcy; |
U+0045E | ў |
Ubreve; |
U+0016C | Ŭ |
ubreve; |
U+0016D | ŭ |
Ucirc; |
U+000DB | Û |
Ucirc |
U+000DB | Û |
ucirc; |
U+000FB | û |
ucirc |
U+000FB | û |
Ucy; |
U+00423 | У |
ucy; |
U+00443 | у |
udarr; |
U+021C5 | ⇅ |
Udblac; |
U+00170 | Ű |
udblac; |
U+00171 | ű |
udhar; |
U+0296E | ⥮ |
ufisht; |
U+0297E | ⥾ |
Ufr; |
U+1D518 | 𝔘 |
ufr; |
U+1D532 | 𝔲 |
Ugrave; |
U+000D9 | Ù |
Ugrave |
U+000D9 | Ù |
ugrave; |
U+000F9 | ù |
ugrave |
U+000F9 | ù |
uHar; |
U+02963 | ⥣ |
uharl; |
U+021BF | ↿ |
uharr; |
U+021BE | ↾ |
uhblk; |
U+02580 | ▀ |
ulcorn; |
U+0231C | ⌜ |
ulcorner; |
U+0231C | ⌜ |
ulcrop; |
U+0230F | ⌏ |
ultri; |
U+025F8 | ◸ |
Umacr; |
U+0016A | Ū |
umacr; |
U+0016B | ū |
uml; |
U+000A8 | ¨ |
uml |
U+000A8 | ¨ |
UnderBar; |
U+0005F | _ |
UnderBrace; |
U+023DF | ⏟ |
UnderBracket; |
U+023B5 | ⎵ |
UnderParenthesis; |
U+023DD | ⏝ |
Union; |
U+022C3 | ⋃ |
UnionPlus; |
U+0228E | ⊎ |
Uogon; |
U+00172 | Ų |
uogon; |
U+00173 | ų |
Uopf; |
U+1D54C | 𝕌 |
uopf; |
U+1D566 | 𝕦 |
UpArrow; |
U+02191 | ↑ |
Uparrow; |
U+021D1 | ⇑ |
uparrow; |
U+02191 | ↑ |
UpArrowBar; |
U+02912 | ⤒ |
UpArrowDownArrow; |
U+021C5 | ⇅ |
UpDownArrow; |
U+02195 | ↕ |
Updownarrow; |
U+021D5 | ⇕ |
updownarrow; |
U+02195 | ↕ |
UpEquilibrium; |
U+0296E | ⥮ |
upharpoonleft; |
U+021BF | ↿ |
upharpoonright; |
U+021BE | ↾ |
uplus; |
U+0228E | ⊎ |
UpperLeftArrow; |
U+02196 | ↖ |
UpperRightArrow; |
U+02197 | ↗ |
Upsi; |
U+003D2 | ϒ |
upsi; |
U+003C5 | υ |
upsih; |
U+003D2 | ϒ |
Upsilon; |
U+003A5 | Υ |
upsilon; |
U+003C5 | υ |
UpTee; |
U+022A5 | ⊥ |
UpTeeArrow; |
U+021A5 | ↥ |
upuparrows; |
U+021C8 | ⇈ |
urcorn; |
U+0231D | ⌝ |
urcorner; |
U+0231D | ⌝ |
urcrop; |
U+0230E | ⌎ |
Uring; |
U+0016E | Ů |
uring; |
U+0016F | ů |
urtri; |
U+025F9 | ◹ |
Uscr; |
U+1D4B0 | 𝒰 |
uscr; |
U+1D4CA | 𝓊 |
utdot; |
U+022F0 | ⋰ |
Utilde; |
U+00168 | Ũ |
utilde; |
U+00169 | ũ |
utri; |
U+025B5 | ▵ |
utrif; |
U+025B4 | ▴ |
uuarr; |
U+021C8 | ⇈ |
Uuml; |
U+000DC | Ü |
Uuml |
U+000DC | Ü |
uuml; |
U+000FC | ü |
uuml |
U+000FC | ü |
uwangle; |
U+029A7 | ⦧ |
vangrt; |
U+0299C | ⦜ |
varepsilon; |
U+003F5 | ϵ |
varkappa; |
U+003F0 | ϰ |
varnothing; |
U+02205 | ∅ |
varphi; |
U+003D5 | ϕ |
varpi; |
U+003D6 | ϖ |
varpropto; |
U+0221D | ∝ |
vArr; |
U+021D5 | ⇕ |
varr; |
U+02195 | ↕ |
varrho; |
U+003F1 | ϱ |
varsigma; |
U+003C2 | ς |
varsubsetneq; |
U+0228A U+0FE00 | ⊊︀ |
varsubsetneqq; |
U+02ACB U+0FE00 | ⫋︀ |
varsupsetneq; |
U+0228B U+0FE00 | ⊋︀ |
varsupsetneqq; |
U+02ACC U+0FE00 | ⫌︀ |
vartheta; |
U+003D1 | ϑ |
vartriangleleft; |
U+022B2 | ⊲ |
vartriangleright; |
U+022B3 | ⊳ |
Vbar; |
U+02AEB | ⫫ |
vBar; |
U+02AE8 | ⫨ |
vBarv; |
U+02AE9 | ⫩ |
Vcy; |
U+00412 | В |
vcy; |
U+00432 | в |
VDash; |
U+022AB | ⊫ |
Vdash; |
U+022A9 | ⊩ |
vDash; |
U+022A8 | ⊨ |
vdash; |
U+022A2 | ⊢ |
Vdashl; |
U+02AE6 | ⫦ |
Vee; |
U+022C1 | ⋁ |
vee; |
U+02228 | ∨ |
veebar; |
U+022BB | ⊻ |
veeeq; |
U+0225A | ≚ |
vellip; |
U+022EE | ⋮ |
Verbar; |
U+02016 | ‖ |
verbar; |
U+0007C | | |
Vert; |
U+02016 | ‖ |
vert; |
U+0007C | | |
VerticalBar; |
U+02223 | ∣ |
VerticalLine; |
U+0007C | | |
VerticalSeparator; |
U+02758 | ❘ |
VerticalTilde; |
U+02240 | ≀ |
VeryThinSpace; |
U+0200A | |
Vfr; |
U+1D519 | 𝔙 |
vfr; |
U+1D533 | 𝔳 |
vltri; |
U+022B2 | ⊲ |
vnsub; |
U+02282 U+020D2 | ⊂⃒ |
vnsup; |
U+02283 U+020D2 | ⊃⃒ |
Vopf; |
U+1D54D | 𝕍 |
vopf; |
U+1D567 | 𝕧 |
vprop; |
U+0221D | ∝ |
vrtri; |
U+022B3 | ⊳ |
Vscr; |
U+1D4B1 | 𝒱 |
vscr; |
U+1D4CB | 𝓋 |
vsubnE; |
U+02ACB U+0FE00 | ⫋︀ |
vsubne; |
U+0228A U+0FE00 | ⊊︀ |
vsupnE; |
U+02ACC U+0FE00 | ⫌︀ |
vsupne; |
U+0228B U+0FE00 | ⊋︀ |
Vvdash; |
U+022AA | ⊪ |
vzigzag; |
U+0299A | ⦚ |
Wcirc; |
U+00174 | Ŵ |
wcirc; |
U+00175 | ŵ |
wedbar; |
U+02A5F | ⩟ |
Wedge; |
U+022C0 | ⋀ |
wedge; |
U+02227 | ∧ |
wedgeq; |
U+02259 | ≙ |
weierp; |
U+02118 | ℘ |
Wfr; |
U+1D51A | 𝔚 |
wfr; |
U+1D534 | 𝔴 |
Wopf; |
U+1D54E | 𝕎 |
wopf; |
U+1D568 | 𝕨 |
wp; |
U+02118 | ℘ |
wr; |
U+02240 | ≀ |
wreath; |
U+02240 | ≀ |
Wscr; |
U+1D4B2 | 𝒲 |
wscr; |
U+1D4CC | 𝓌 |
xcap; |
U+022C2 | ⋂ |
xcirc; |
U+025EF | ◯ |
xcup; |
U+022C3 | ⋃ |
xdtri; |
U+025BD | ▽ |
Xfr; |
U+1D51B | 𝔛 |
xfr; |
U+1D535 | 𝔵 |
xhArr; |
U+027FA | ⟺ |
xharr; |
U+027F7 | ⟷ |
Xi; |
U+0039E | Ξ |
xi; |
U+003BE | ξ |
xlArr; |
U+027F8 | ⟸ |
xlarr; |
U+027F5 | ⟵ |
xmap; |
U+027FC | ⟼ |
xnis; |
U+022FB | ⋻ |
xodot; |
U+02A00 | ⨀ |
Xopf; |
U+1D54F | 𝕏 |
xopf; |
U+1D569 | 𝕩 |
xoplus; |
U+02A01 | ⨁ |
xotime; |
U+02A02 | ⨂ |
xrArr; |
U+027F9 | ⟹ |
xrarr; |
U+027F6 | ⟶ |
Xscr; |
U+1D4B3 | 𝒳 |
xscr; |
U+1D4CD | 𝓍 |
xsqcup; |
U+02A06 | ⨆ |
xuplus; |
U+02A04 | ⨄ |
xutri; |
U+025B3 | △ |
xvee; |
U+022C1 | ⋁ |
xwedge; |
U+022C0 | ⋀ |
Yacute; |
U+000DD | Ý |
Yacute |
U+000DD | Ý |
yacute; |
U+000FD | ý |
yacute |
U+000FD | ý |
YAcy; |
U+0042F | Я |
yacy; |
U+0044F | я |
Ycirc; |
U+00176 | Ŷ |
ycirc; |
U+00177 | ŷ |
Ycy; |
U+0042B | Ы |
ycy; |
U+0044B | ы |
yen; |
U+000A5 | ¥ |
yen |
U+000A5 | ¥ |
Yfr; |
U+1D51C | 𝔜 |
yfr; |
U+1D536 | 𝔶 |
YIcy; |
U+00407 | Ї |
yicy; |
U+00457 | ї |
Yopf; |
U+1D550 | 𝕐 |
yopf; |
U+1D56A | 𝕪 |
Yscr; |
U+1D4B4 | 𝒴 |
yscr; |
U+1D4CE | 𝓎 |
YUcy; |
U+0042E | Ю |
yucy; |
U+0044E | ю |
Yuml; |
U+00178 | Ÿ |
yuml; |
U+000FF | ÿ |
yuml |
U+000FF | ÿ |
Zacute; |
U+00179 | Ź |
zacute; |
U+0017A | ź |
Zcaron; |
U+0017D | Ž |
zcaron; |
U+0017E | ž |
Zcy; |
U+00417 | З |
zcy; |
U+00437 | з |
Zdot; |
U+0017B | Ż |
zdot; |
U+0017C | ż |
zeetrf; |
U+02128 | ℨ |
ZeroWidthSpace; |
U+0200B | |
Zeta; |
U+00396 | Ζ |
zeta; |
U+003B6 | ζ |
Zfr; |
U+02128 | ℨ |
zfr; |
U+1D537 | 𝔷 |
ZHcy; |
U+00416 | Ж |
zhcy; |
U+00436 | ж |
zigrarr; |
U+021DD | ⇝ |
Zopf; |
U+02124 | ℤ |
zopf; |
U+1D56B | 𝕫 |
Zscr; |
U+1D4B5 | 𝒵 |
zscr; |
U+1D4CF | 𝓏 |
zwj; |
U+0200D | |
zwnj; |
U+0200C | |
这些数据也可作为 JSON 文件获取。
上面显示的字形是非规范性的。有关上面所列字符的正式定义,请参阅 Unicode。
字符引用名称源自字符的 XML 实体定义,但只有上述内容被视为规范性内容。[XMLENTITY]
此列表是静态的,将来 不会扩充或更改。
所有当前引擎均支持。
本节仅描述 XML 资源的规则。text/html
资源的规则在上面题为“HTML
语法”的一节中讨论。
不建议使用 XML 语法,原因包括:没有任何规范定义
XML 解析器必须如何将字节或字符组成的字符串映射为一个 Document 对象;此外,
XML 语法基本上已无人维护——也就是说,预计以后不会再向 XML 语法添加任何
新功能(即使此类功能已经添加到HTML 语法中)。
HTML 的 XML 语法以前称为“XHTML”,但本规范不使用该术语 (其中一个原因是,MathML 和 SVG 的 HTML 语法并不使用此类术语)。
XML 的语法在 XML 和 XML 命名空间中定义。[XML] [XMLNS]
除 XML 本身定义的要求之外,本规范不定义任何语法层面的要求。
XML 文档可以根据需要包含 DOCTYPE,但符合本规范并不要求这样做。
本规范不定义公共标识符或系统标识符,也不提供正式的 DTD。
根据 XML,不能保证 XML 处理器会处理
DOCTYPE 中引用的外部 DTD 子集。这意味着,例如,如果 XML 文档中的字符实体引用定义在外部文件中,则使用它们并不安全
(<、>、&、
" 和 ' 除外)。
本节描述 XML 与 DOM 之间的关系,尤其强调它们与 HTML 的交互方式。
就本规范而言,XML 解析器是一种构造,
它遵循 XML 中给出的规则,将字节或字符组成的字符串映射为
一个 Document 对象。
在撰写本文时,实际上并不存在这样的规则。
XML 解析器在创建时要么与一个 Document 对象关联,
要么隐式创建一个这样的对象。
随后必须使用表示传递给解析器的输入树结构的 DOM 节点来填充此 Document,该树结构由
XML、XML
命名空间和 DOM 定义。创建表示元素的 DOM 节点时,
必须使用为令牌创建
元素算法,或某种在适当 XML 数据结构上运行的等效算法,以确保创建正确的元素接口,并正确设置自定义元素。
对于XML 解析器在 Document 的树上执行的操作,
用户代理必须表现得如同元素和属性分别被逐个追加和设置,从而触发本规范中关于元素插入文档或
设置其属性时会发生什么的规则;同时,DOM 关于变更观察器的要求意味着变更观察器确实会被触发。
[XML] [XMLNS] [DOM] [UIEVENTS]
从解析元素的开始标签起,到解析该元素的结束标签或解析器检测到良构性错误为止, 用户代理必须表现得如同该元素位于打开 元素栈中。
各种元素会使用此机制,使某些进程仅在它们从打开 元素栈中弹出后才启动。
本规范提供了以下额外信息,用户代理在检索外部实体时应使用这些信息: 下列列表中给出的公共标识符全部对应于 此链接所给出的 URL。(此 URL 是一个 DTD,其中包含实体 声明,这些声明对应于命名字符引用一节中列出的名称。)[XML]
-//W3C//DTD XHTML 1.0 Transitional//EN-//W3C//DTD XHTML 1.1//EN-//W3C//DTD XHTML 1.0 Strict//EN-//W3C//DTD XHTML 1.0 Frameset//EN-//W3C//DTD XHTML Basic 1.0//EN-//W3C//DTD XHTML 1.1 plus MathML 2.0//EN-//W3C//DTD XHTML 1.1 plus MathML 2.0 plus SVG 1.1//EN-//W3C//DTD MathML 2.0//EN-//WAPFORUM//DTD XHTML Mobile 1.0//EN-//WAPFORUM//DTD XHTML Mobile 1.1//EN-//WAPFORUM//DTD XHTML Mobile 1.2//EN此外,当使用上述公共标识符之一时,用户代理应尝试检索上述外部实体的内容, 并且不应尝试检索任何其他外部实体的内容。
严格来说,这并不违反 XML,但它确实违背了 XML 要求的精神。这样做是为了让所有 用户代理都能以互操作的方式处理实体,而无需通过网络访问来处理外部子集。[XML]
调用 XML 解析器时,可以启用 XML 脚本 支持或禁用 XML 脚本支持。 除非另有说明,否则调用 XML 解析器时会启用 XML 脚本支持。
当XML 解析器在启用 XML 脚本
支持的情况下创建一个 script 元素时,必须
设置其解析器
文档,并将其强制
async设置为 false。如果
解析器是作为XML
片段解析算法的一部分创建的,则必须将
元素的已经启动设置
为 true。随后解析该元素的结束标签时,用户代理必须执行微任务检查点,然后
准备该
script 元素。
如果这
导致出现一个待处理的解析阻塞脚本,则用户
代理必须运行
以下步骤:
旋转事件循环,直到
解析器的 Document 没有阻塞
脚本的样式表,并且待处理的解析阻塞
脚本的已准备好由解析器执行为 true。
执行由 script 元素,该元素由待处理的解析阻塞 脚本给出。
将待处理的解析阻塞脚本设置为 null。
由于 document.write() API
不可用于XML 文档,因此HTML
解析器中的大部分复杂性
在XML 解析器中并不需要。
当XML 解析器禁用 XML 脚本 支持时, 上述操作均不会发生。
当XML 解析器本应
将节点追加到
template 元素时,
它必须改为将该节点追加到 template 元素的
模板内容(一个 DocumentFragment
节点)中。
这是对 XML 的有意违反;
遗憾的是,
XML 无法以处理 template
所需的方式进行正式扩展。
[XML]
本规范中的某些算法会将字符逐个馈送给 解析器。在这种情况下,XML 解析器必须表现得 如同面对一个由所有这些字符连接而成的单个字符串。
就一致性检查器而言,如果确定某个资源采用XML 语法,则它是一个XML 文档。
对于一个 Document 或
Element
节点,XML 片段序列化
算法要么返回表示该节点的 XML 片段,要么抛出异常。
对于 Document,
如果下述错误情况均不适用,则算法必须返回一个具有文档实体形式的字符串。
对于 Element,
如果下述错误情况均不适用,则算法必须返回一个具有内部
通用已解析实体形式的字符串。
在这两种情况下,返回的字符串都必须是 XML 命名空间良构的,并且必须是该节点所有相关子节点按树顺序进行的同构
序列化。用户代理可以调整序列化中的前缀和命名空间声明(事实上,
在某些情况下,为了获得命名空间良构的 XML,可能必须这样做)。用户代理可以结合使用
普通文本和字符引用来表示 DOM 中的 Text
节点。
节点的相关子节点是根据以下规则适用的节点:
对于 Element,
如果序列化中的任何元素不在任何命名空间中,则必须将这些元素作用域内的
默认命名空间显式声明为空字符串。(这不适用于 Document
的情况。)[XML]
[XMLNS]
就本节而言,如果一个文档由一个没有命名空间声明的元素组成,并且其 内容是该内部通用已解析实体,而该文档本身是 XML 命名空间良构的,则该内部通用已解析实体 被认为是 XML 命名空间良构的。
如果在正在序列化的 DOM 子树中发现以下任何错误情况,则算法必须抛出一个
“InvalidStateError” DOMException,
而不是返回字符串:
Document 节点。DocumentType
节点,其外部子集公共标识符包含不匹配 XML PubidChar 产生式的
字符。[XML]DocumentType
节点,其外部子集系统标识符同时包含 U+0022 QUOTATION MARK(")和
U+0027 APOSTROPHE('),或者包含不匹配 XML Char 产生式的字符。[XML]Name
产生式的节点。[XML]xmlns”的 Attr
节点。[XMLNS]Element
节点。Attr
节点、Text
节点、Comment
节点或
ProcessingInstruction
节点,其数据包含不匹配 XML Char 产生式的字符。[XML]
Comment
节点,其数据包含两个相邻的 U+002D HYPHEN-MINUS 字符(-),或者以该字符结尾。ProcessingInstruction
节点,其目标名称与字符串“xml”进行ASCII
不区分大小写匹配。ProcessingInstruction
节点,其目标名称包含 U+003A COLON(:)。ProcessingInstruction
节点,其数据包含字符串“?>”。这些是使 DOM 无法序列化的唯一方式。DOM 会强制执行所有
其他 XML 约束;例如,尝试向一个 Document
节点追加两个元素
会抛出一个 “HierarchyRequestError” DOMException。
给定一个 Element
或
DocumentFragment
节点 target 和一个字符串 input,XML
片段解析算法运行以下步骤。它们返回一个 DocumentFragment。
创建一个新的XML 解析器。
向刚创建的解析器馈送与 context 的开始标签对应的字符串, 声明该元素在 DOM 中作用域内的所有命名空间前缀,以及该元素在 DOM 中作用域内的 默认命名空间(如果有)。
如果在该元素上调用 DOM lookupNamespaceURI() 方法时,会为某个前缀返回
非 null 值,则该命名空间前缀处于作用域内。
默认命名空间是对该元素调用 DOM isDefaultNamespace() 方法时会返回 true
的命名空间。
不会向解析器传递 DOCTYPE,因此不会引用
外部子集,也就不会识别任何实体。
向刚创建的解析器馈送字符串 input。
如果存在 XML 良构性错误或 XML 命名空间良构性错误,则抛出一个
“SyntaxError” DOMException。
如果所得 Document 的文档元素具有任何
兄弟节点,则抛出一个 “SyntaxError”
DOMException。
返回 fragment。
用户代理不需要以任何特定方式呈现 HTML 文档。但是,本节提供了一组 渲染 HTML 文档的建议,如果遵循这些建议,可能会带来与文档作者预期体验 非常接近的用户体验。为了避免对本节的规范性产生混淆,本节未使用“必须”。 相反,术语“预期”用于表示会带来此类体验的行为。对于被指定为支持建议的默认渲染的用户代理的一致性而言,本节中的 “预期”一词与“必须”具有相同的一致性含义。
本节中的建议通常以 CSS 术语表示。用户代理预期要么支持 CSS,要么将本节给出的 CSS 规则转换为适用于其他呈现机制的近似规则。
在没有相反的样式层规则(例如作者样式表)时,用户代理预期以一种能够向用户传达元素按照本规范描述所表示含义的方式渲染该元素。
本节中的建议通常假定视觉输出介质的分辨率为 96dpi 或更高,但 HTML 旨在适用于多种媒体(它是一种与媒体无关的语言)。鼓励用户代理实现者 根据其目标媒体调整本节中的建议。
如果一个元素具有任何关联的 CSS 布局框、SVG 布局框,或者在其他样式语言中具有 某种等效物,则该元素正在渲染。
仅仅位于屏幕外并不意味着该元素没有正在 渲染。存在 属性通常意味着该元素没有正在渲染,但样式表可能会覆盖这一点。
完全活动状态不会影响 元素是否正在渲染。即使文档不是 完全活动的,并且完全没有向 用户显示,其中的元素仍然可以符合“正在渲染”的条件。
与正在渲染状态类似,非完全活动文档中的元素仍然可以与视口相交。不同文档之间不共享视口, 并且视口可能并不总是向用户显示,因此非完全活动文档中的元素仍然可以与其文档关联的视口相交。
本规范未定义测试相交状态的确切时机,但建议其时机与 Intersection Observer API 保持一致。[INTERSECTIONOBSERVER]
如果一个元素没有正在渲染,但由于 CSS “display: contents”或其他样式语言中的某种等效机制,其子节点(如果有)可以被渲染, 则该元素将其渲染委托给其子节点。 [CSSDISPLAY]
即使用户代理不遵循作者级 CSS 样式表,也仍预期以符合本规范以及相关 CSS 和 Unicode 规范的方式,表现得如同应用了这些小节中给出的 CSS 规则。 [CSS] [UNICODE] [BIDI]
这对于涉及'display'、 'unicode-bidi' 和 'direction' 属性的问题尤其重要。
除非另有说明,这些小节中给出的 CSS 规则预期用作所有包含HTML 元素的文档中, 用户代理级样式表默认值的一部分。
有些规则旨在作为 CSS 层叠中作者级零优先级的表现提示部分; 这些规则会明确标记为表现提示。
当下文称元素 element 上的属性 attribute 映射到像素长度属性(或属性组) properties 时,这意味着如果 element 设置了属性 attribute,并且使用解析 非负整数的规则解析该属性的值不会产生错误,则用户代理预期将解析后的值 作为 properties 的表现 提示中的像素长度。
当下文称元素 element 上的属性 attribute 映射到尺寸属性(或属性组) properties 时,这意味着如果 element 设置了属性 attribute,并且使用解析尺寸值的 规则解析该属性的值不会产生错误,则用户代理预期将解析后的 尺寸作为 properties 的表现提示值; 如果该尺寸是长度,则以像素长度给出该值;如果该尺寸是百分比,则以百分比给出该值。
当下文称元素 element 上的属性 attribute 映射到尺寸属性 (忽略零)(或属性组) properties 时,这意味着如果 element 设置了属性 attribute,并且使用解析 非零尺寸值的规则解析该属性的值不会产生错误,则用户代理预期将解析后的 尺寸作为 properties 的表现 提示值;如果该尺寸是长度,则以像素长度给出该值;如果该尺寸是百分比,则以百分比给出该值。
当下文称元素 element 上的一对属性 w 和 h
映射到 aspect-ratio 属性时,这意味着如果
element 同时具有属性 w 和 h,并且使用解析
非负整数的规则解析这些属性的值时,两者均不会产生错误,则用户代理预期将解析后的
整数用作如下形式的
表现提示,
以设置
'aspect-ratio'
属性:auto w /
h。
当下文称元素 element 上的一对属性 w 和 h
映射到
aspect-ratio 属性(使用尺寸规则)时,这意味着如果 element 同时具有属性
w 和 h,并且使用解析
尺寸值的规则解析这些属性的值时,两者均不会产生错误或返回百分比,则用户代理预期
将解析后的尺寸用作如下形式的表现提示,
以设置 'aspect-ratio'
属性:auto w /
h。
当用户代理要对齐节点的后代时,用户代理预期仅对齐符合以下条件的后代:
其'margin-inline-start' 和 'margin-inline-end' 属性的计算值均不是
“auto”,处于过度约束状态,其中一个外边距的使用值被强制设为更大的值,并且其自身没有适用的
align 属性。当多个元素都要对齐某个特定
后代时,嵌套最深的此类元素预期覆盖其他元素。
对齐的元素预期通过相应设置其
行左侧和行右侧外边距的使用值来实现对齐。
[CSSLOGICAL] [CSSWM]
@namespace "http://www.w3.org/1999/xhtml" ;
area, base, basefont, datalist, head, link, meta, noembed,
noframes, param, rp, script, style, template, title {
display : none;
}
{
display : none;
}
[hidden=until-found i]:not(embed) {
content-visibility : hidden;
}
embed[hidden] { display : inline; height : 0 ; width : 0 ; }
input[type=hidden i] { display : none !important; }
@media (scripting) {
noscript { display: none !important; }
}@namespace "http://www.w3.org/1999/xhtml" ;
html, body { display : block; } 对于下表中的每个属性,给定一个 body 元素,
第一个存在的属性会在该 body 元素上映射到像素长度属性。如果
未找到某个属性对应的任何属性,或者找到的属性值无法成功解析,则该属性预期改用默认值 8px。
| 属性 | 来源 |
|---|---|
| 'margin-top'、'margin-bottom' | body 元素的 marginheight 属性
|
body 元素的 topmargin 属性
|
|
body 元素的容器框架元素的 marginheight
属性
|
|
| 'margin-left'、'margin-right' | body 元素的 marginwidth 属性
|
body 元素的 leftmargin 属性
|
|
body 元素的容器框架元素的
marginwidth
属性
|
如果 body 元素的节点文档的节点可导航对象是一个子可导航对象,并且该可导航对象的容器是一个 frame 或 iframe 元素,则
body 元素的容器框架元素就是该 frame 或
iframe 元素。否则,不存在
容器框架元素。
上述要求意味着,一个页面可以使用例如 iframe 更改另一个页面
(包括来自其他源的页面)的外边距。这可能构成安全风险,因为在某些情况下,
攻击者可能借此人为制造一种页面未按作者预期方式渲染的情形,可能用于网络钓鱼或
以其他方式误导用户。
如果一个 Document 的节点可导航对象是一个子可导航对象,则它预期被定位和调整大小,以适合该可导航对象的容器的内容
框内部。如果该容器没有正在渲染,则该可导航对象预期具有宽度和高度均为零的视口。
如果一个 Document 的节点可导航对象是一个子可导航对象,该可导航对象的容器是一个
frame 或 iframe 元素,
该元素具有 scrolling 属性,并且该属性的值与字符串
“off”、“noscroll”或“no”进行ASCII
不区分大小写匹配,则用户代理预期阻止为 Document 的节点可导航对象的视口显示任何滚动条,而不考虑应用于该视口的'overflow' 属性。
当一个 body 元素的 background
属性被设置为非空值时,新值预期相对于
该元素的节点文档进行编码解析并序列化;如果这不会返回失败,
则用户代理预期将该属性视为一个表现提示,把元素的'background-image' 属性设置为返回值。
当一个 body 元素设置了 bgcolor
属性时,新值预期使用解析旧式颜色值的规则进行解析;
如果这不会返回失败,则用户代理预期将该属性视为一个表现提示,把元素的'background-color' 属性设置为所得颜色。
当一个 body 元素具有 text 属性时,其
值预期使用解析旧式颜色值的
规则进行解析;如果这不会返回失败,则用户代理预期
将该属性视为一个表现
提示,把元素的'color' 属性设置为所得颜色。
当一个 body 元素具有 link 属性时,其
值预期使用解析旧式颜色值的
规则进行解析;如果这不会返回失败,则用户代理预期
将该属性视为一个表现
提示,把 Document 中匹配 :link 伪类的任何元素的'color' 属性设置为所得颜色。
当一个 body 元素具有 vlink 属性时,
其值预期使用解析旧式颜色值的
规则进行解析;如果这不会返回失败,则用户代理预期
将该属性视为一个表现
提示,把 Document 中匹配 :visited 伪类的任何元素的'color' 属性设置为所得颜色。
当一个 body 元素具有 alink 属性时,
其值预期使用解析旧式颜色值的
规则进行解析;如果这不会返回失败,则用户代理预期
将该属性视为一个表现
提示,把 Document 中同时匹配
:active 伪类,以及 :link 伪类或 :visited 伪类之一的任何元素的'color' 属性设置为所得颜色。
@namespace "http://www.w3.org/1999/xhtml" ;
address, blockquote, center, dialog, div, figure, figcaption, footer, form,
header, hr, legend, listing, main, p, plaintext, pre, search, xmp {
display : block;
}
blockquote, figure, listing, p, plaintext, pre, xmp {
margin-block : 1 em ;
}
blockquote, figure { margin-inline : 40 px ; }
address { font-style : italic; }
listing, plaintext, pre, xmp {
font-family : monospace; white-space : pre;
}
dialog:not([open]) { display : none; }
dialog {
position : absolute;
inset-inline-start : 0 ; inset-inline-end : 0 ;
width : fit-content;
height : fit-content;
margin : auto;
border : solid;
padding : 1 em ;
background-color : Canvas;
color : CanvasText;
}
dialog:modal {
position : fixed;
overflow : auto;
inset-block : 0 ;
max-width : calc ( 100 % - 6 px - 2 em );
max-height : calc ( 100 % - 6 px - 2 em );
}
dialog::backdrop {
background : rgba ( 0 , 0 , 0 , 0.1 );
}
[popover]:not(:popover-open):not(dialog[open]) {
display : none;
}
dialog:popover-open {
display : block;
}
[popover] {
position : fixed;
inset : 0 ;
width : fit-content;
height : fit-content;
margin : auto;
border : solid;
padding : 0.25 em ;
overflow : auto;
color : CanvasText;
background-color : Canvas;
}
:popover-open::backdrop {
position : fixed;
inset : 0 ;
pointer-events : none !important;
background-color: transparent;
}
slot {
display: contents;
}@namespace "http://www.w3.org/1999/xhtml" ;
pre[wrap] { white-space : pre-wrap; } @namespace "http://www.w3.org/1999/xhtml" ;
form { margin-block-end : 1 em ; } center 元素,以及具有 align 属性,且其值与字符串
“center”或字符串“middle”进行ASCII
不区分大小写匹配的 div 元素,
预期使其中的文本居中,如同在一个表现提示中将其'text-align'
属性设置为“center”,并将后代对齐到中央。
当 div 元素具有
align
属性,且其值与字符串“left”进行ASCII
不区分大小写匹配时,它预期使其中的文本左对齐,如同在一个表现提示中将其'text-align' 属性设置为“left”,并将后代对齐到左侧。
当 div 元素具有
align
属性,且其值与字符串“right”进行ASCII
不区分大小写匹配时,它预期使其中的文本右对齐,如同在一个表现提示中将其'text-align' 属性设置为“right”,并将后代对齐到右侧。
当 div 元素具有
align
属性,且其值与字符串“justify”进行ASCII
不区分大小写匹配时,它预期使其中的文本两端对齐,如同在一个表现提示中将其'text-align' 属性设置为“justify”,并将后代对齐到左侧。
@namespace "http://www.w3.org/1999/xhtml" ;
cite, dfn, em, i, var { font-style : italic; }
b, strong { font-weight : bolder; }
code, kbd, samp, tt { font-family : monospace; }
big { font-size : larger; }
small { font-size : smaller; }
sub { vertical-align : sub; }
sup { vertical-align : super; }
sub, sup { line-height : normal; font-size : smaller; }
ruby { display : ruby; }
rt { display : ruby-text; }
:link { color : #0000EE; }
:visited { color : #551A8B; }
:link:active, :visited:active { color : #FF0000; }
:link, :visited { text-decoration : underline; cursor : pointer; }
:focus-visible { outline : auto; }
mark { background : yellow; color : black; } /* 此颜色只是一项建议,可以根据实现反馈进行更改 */
abbr[title], acronym[title] { text-decoration : dotted underline; }
ins, u { text-decoration : underline; }
del, s, strike { text-decoration : line-through; }
q::before { content : open-quote; }
q::after { content : close-quote; }
br { display-outside : newline; } /* 这也会影响双向文本 */
nobr { white-space : nowrap; }
wbr { display-outside : break-opportunity; } /* 这也会影响双向文本 */
nobr wbr { white-space : normal; } @namespace "http://www.w3.org/1999/xhtml" ;
br[clear=left i] { clear : left; }
br[clear=right i] { clear : right; }
br[clear=all i], br[clear=both i] { clear : both; } 就 CSS ruby 模型而言,ruby 元素中不属于
rt 或 rp 元素的连续子节点,
预期被包装在匿名框中,这些匿名框的'display' 属性值为'ruby-base'。
[CSSRUBY]
当 ruby 的某个特定部分具有多个注音时,应将注音分布在基准文本的两侧, 以尽量减少注音在一侧的堆叠。
在能够做到时,上述要求会更新为使用 CSS ruby 表达。
(目前,CSS ruby 不处理嵌套的 ruby
元素或多个连续的 rt 元素,而这种语义正是
通过这些结构表达的。)
不支持正确 ruby 渲染的用户代理预期在没有 rp
元素时,在 rt 元素的文本周围渲染
圆括号。
用户代理预期按照 CSS
中关于此效果的非规范性注释所述,在行内元素上支持'clear' 属性
(以便渲染具有 clear 属性的 br 元素)。
'color' 属性的初始值预期为黑色。 'background-color' 属性的初始值预期为 “transparent”。画布的背景预期为白色。
当一个 font 元素具有 face
属性时,用户代理预期将该属性视为一个表现
提示,把元素的
'font-family' 属性设置为该属性的值。
当一个 font 元素具有 size
属性时,用户代理预期使用以下步骤(称为
解析旧式字体大小的规则),将该属性视为一个表现提示,以设置元素的
'font-size' 属性:
令 input 为该属性的值。
令 position 为指向 input 中的指针,最初指向 字符串的开头。
给定 position,在 input 中跳过 ASCII 空白。
如果 position 超出 input 的末尾,则不存在表现提示。返回。
如果 position 处的字符是 U+002B PLUS SIGN 字符(+),则令 mode 为相对加,并将 position 前进到下一个字符。 否则,如果 position 处的字符是 U+002D HYPHEN-MINUS 字符(-),则 令 mode 为相对减,并将 position 前进到下一个 字符。否则,令 mode 为绝对。
给定 position,从 input 中收集一串码点,这些码点均为ASCII 数字,并令 digits 为所得 序列。
如果 digits 是空字符串,则不存在表现提示。返回。
将 digits 解释为十进制整数。令 value 为所得 数字。
如果 mode 为相对加,则将 value 增加 3。如果 mode 为相对减,则令 value 为用 3 减去 value 所得的结果。
如果 value 大于 7,则将其设置为 7。
如果 value 小于 1,则将其设置为 1。
根据下表,将'font-size' 属性设置为与 value 的值对应的关键字:
| value | 'font-size' 关键字 |
|---|---|
| 1 | 'x-small' |
| 2 | 'small' |
| 3 | 'medium' |
| 4 | 'large' |
| 5 | 'x-large' |
| 6 | 'xx-large' |
| 7 | 'xxx-large' |
@namespace "http://www.w3.org/1999/xhtml" ;
[dir]:dir(ltr), bdi:dir(ltr), input[type=tel i]:dir(ltr) { direction : ltr; }
[dir]:dir(rtl), bdi:dir(rtl) { direction : rtl; }
address, blockquote, center, div, figure, figcaption, footer, form, header, hr,
legend, listing, main, p, plaintext, pre, summary, xmp, article, aside,
:heading, hgroup, nav, search, section, table, caption, colgroup, col, thead,
tbody, tfoot, tr, td, th, dir, dd, dl, dt, menu, ol, ul, li, bdi, output,
[dir=ltr i], [dir=rtl i], [dir=auto i] {
unicode-bidi : isolate;
}
bdo, bdo[dir] { unicode-bidi : isolate-override; }
input[dir=auto i]:is([type=search i], [type=tel i], [type=url i],
[type=email i]), textarea[dir=auto i], pre[dir=auto i] {
unicode-bidi : plaintext;
}
/* 有关 type 属性处于 Text 状态的 input 元素,请参阅正文 */
/* 在 br 和 wbr 元素上 设置 'content' 属性的规则 也会影响双向文本 */ 当一个 input 元素的
dir 属性处于
auto 状态,并且其 type
属性处于文本状态时,用户代理
预期表现得如同具有一条用户代理级样式表
规则,将'unicode-bidi' 属性设置为“plaintext”。
输入字段(即 textarea 元素,以及
input 元素,
当其 type 属性处于
文本、搜索、
电话、URL
或电子邮件状态时)预期提供一个编辑用户界面,
其方向性与元素的'direction' 属性相匹配。
当文档的字符编码为ISO-8859-8 时,在上述规则之后,以下规则也预期应用:[ENCODING]
@namespace "http://www.w3.org/1999/xhtml" ;
address, blockquote, center, div, figure, figcaption, footer, form, header, hr,
legend, listing, main, p, plaintext, pre, summary, xmp, article, aside,
:heading, hgroup, nav, search, section, table, caption, colgroup, col, thead,
tbody, tfoot, tr, td, th, dir, dd, dl, dt, menu, ol, ul, li, [dir=ltr i],
[dir=rtl i], [dir=auto i], *|* {
unicode-bidi : bidi-override;
}
input:not([type=submit i]):not([type=reset i]):not([type=button i]),
textarea {
unicode-bidi : normal;
} @namespace "http://www.w3.org/1999/xhtml" ;
article, aside, :heading, hgroup, nav, section {
display : block;
}
:heading { font-weight : bold; }
:heading(1) { margin-block : 0.67 em ; font-size : 2.00 em ; }
:heading(2) { margin-block : 0.83 em ; font-size : 1.50 em ; }
:heading(3) { margin-block : 1.00 em ; font-size : 1.17 em ; }
:heading(4) { margin-block : 1.33 em ; font-size : 1.00 em ; }
:heading(5) { margin-block : 1.67 em ; font-size : 0.83 em ; }
:heading(6, 7, 8, 9) {
font-size : 0.67 em ;
margin-block : 2.33 em ;
}
@namespace "http://www.w3.org/1999/xhtml" ;
dir, dd, dl, dt, menu, ol, ul { display : block; }
li { display : list-item; text-align : match-parent; }
dir, dl, menu, ol, ul { margin-block : 1 em ; }
:is(dir, dl, menu, ol, ul) :is(dir, dl, menu, ol, ul) {
margin-block : 0 ;
}
dd { margin-inline-start : 40 px ; }
dir, menu, ol, ul { padding-inline-start : 40 px ; }
ol, ul, menu { counter-reset : list-item; }
ol { list-style-type : decimal; }
dir, menu, ul {
list-style-type : disc;
}
:is(dir, menu, ol, ul) :is(dir, menu, ul) {
list-style-type : circle;
}
:is(dir, menu, ol, ul) :is(dir, menu, ol, ul) :is(dir, menu, ul) {
list-style-type : square;
} @namespace "http://www.w3.org/1999/xhtml" ;
ol[type="1"], li[type="1"] { list-style-type : decimal; }
ol[type=a s], li[type=a s] { list-style-type : lower-alpha; }
ol[type=A s], li[type=A s] { list-style-type : upper-alpha; }
ol[type=i s], li[type=i s] { list-style-type : lower-roman; }
ol[type=I s], li[type=I s] { list-style-type : upper-roman; }
ul[type=none i], li[type=none i] { list-style-type : none; }
ul[type=disc i], li[type=disc i] { list-style-type : disc; }
ul[type=circle i], li[type=circle i] { list-style-type : circle; }
ul[type=square i], li[type=square i] { list-style-type : square; } @namespace "http://www.w3.org/1999/xhtml" ;
li { list-style-position : inside; }
li :is(dir, menu, ol, ul) { list-style-position : outside; }
:is(dir, menu, ol, ul) :is(dir, menu, ol, ul, li) { list-style-position : unset; } 渲染 li 元素时,非 CSS 用户代理
预期使用 li 元素的序数值,在列表项标记中渲染计数器。
对于 CSS 用户代理,渲染列表项的某些方面由 CSS Lists 规范定义。 此外,以下属性映射预期应用: [CSSLISTS]
当一个 li 元素具有 value 属性,并且使用解析整数的规则解析该属性的值
不会产生错误时,用户代理预期使用解析后的值
value,作为如下形式的表现提示,以设置'counter-set' 属性:list-item value。
@namespace "http://www.w3.org/1999/xhtml" ;
table { display : table; }
caption { display : table-caption; }
colgroup, colgroup[hidden] { display : table-column-group; }
col, col[hidden] { display : table-column; }
thead, thead[hidden] { display : table-header-group; }
tbody, tbody[hidden] { display : table-row-group; }
tfoot, tfoot[hidden] { display : table-footer-group; }
tr, tr[hidden] { display : table-row; }
td, th { display : table-cell; }
colgroup[hidden], col[hidden], thead[hidden], tbody[hidden],
tfoot[hidden], tr[hidden] {
visibility : collapse;
}
table {
box-sizing : border-box;
border-spacing : 2 px ;
border-collapse : separate;
text-indent : initial;
}
td, th { padding : 1 px ; }
th { font-weight : bold; }
caption { text-align : center; }
thead, tbody, tfoot, table > tr { vertical-align : middle; }
tr, td, th { vertical-align : inherit; }
thead, tbody, tfoot, tr { border-color : inherit; }
table[rules=none i], table[rules=groups i], table[rules=rows i],
table[rules=cols i], table[rules=all i], table[frame=void i],
table[frame=above i], table[frame=below i], table[frame=hsides i],
table[frame=lhs i], table[frame=rhs i], table[frame=vsides i],
table[frame=box i], table[frame=border i],
table[rules=none i] > tr > td, table[rules=none i] > tr > th,
table[rules=groups i] > tr > td, table[rules=groups i] > tr > th,
table[rules=rows i] > tr > td, table[rules=rows i] > tr > th,
table[rules=cols i] > tr > td, table[rules=cols i] > tr > th,
table[rules=all i] > tr > td, table[rules=all i] > tr > th,
table[rules=none i] > thead > tr > td, table[rules=none i] > thead > tr > th,
table[rules=groups i] > thead > tr > td, table[rules=groups i] > thead > tr > th,
table[rules=rows i] > thead > tr > td, table[rules=rows i] > thead > tr > th,
table[rules=cols i] > thead > tr > td, table[rules=cols i] > thead > tr > th,
table[rules=all i] > thead > tr > td, table[rules=all i] > thead > tr > th,
table[rules=none i] > tbody > tr > td, table[rules=none i] > tbody > tr > th,
table[rules=groups i] > tbody > tr > td, table[rules=groups i] > tbody > tr > th,
table[rules=rows i] > tbody > tr > td, table[rules=rows i] > tbody > tr > th,
table[rules=cols i] > tbody > tr > td, table[rules=cols i] > tbody > tr > th,
table[rules=all i] > tbody > tr > td, table[rules=all i] > tbody > tr > th,
table[rules=none i] > tfoot > tr > td, table[rules=none i] > tfoot > tr > th,
table[rules=groups i] > tfoot > tr > td, table[rules=groups i] > tfoot > tr > th,
table[rules=rows i] > tfoot > tr > td, table[rules=rows i] > tfoot > tr > th,
table[rules=cols i] > tfoot > tr > td, table[rules=cols i] > tfoot > tr > th,
table[rules=all i] > tfoot > tr > td, table[rules=all i] > tfoot > tr > th {
border-color : black;
} @namespace "http://www.w3.org/1999/xhtml" ;
table[align=left i] { float : left; }
table[align=right i] { float : right; }
table[align=center i] { margin-inline : auto; }
thead[align=absmiddle i], tbody[align=absmiddle i], tfoot[align=absmiddle i],
tr[align=absmiddle i], td[align=absmiddle i], th[align=absmiddle i] {
text-align : center;
}
caption[align=bottom i] { caption-side : bottom; }
p[align=left i], h1[align=left i], h2[align=left i], h3[align=left i],
h4[align=left i], h5[align=left i], h6[align=left i] {
text-align : left;
}
p[align=right i], h1[align=right i], h2[align=right i], h3[align=right i],
h4[align=right i], h5[align=right i], h6[align=right i] {
text-align : right;
}
p[align=center i], h1[align=center i], h2[align=center i], h3[align=center i],
h4[align=center i], h5[align=center i], h6[align=center i] {
text-align : center;
}
p[align=justify i], h1[align=justify i], h2[align=justify i], h3[align=justify i],
h4[align=justify i], h5[align=justify i], h6[align=justify i] {
text-align : justify;
}
thead[valign=top i], tbody[valign=top i], tfoot[valign=top i],
tr[valign=top i], td[valign=top i], th[valign=top i] {
vertical-align : top;
}
thead[valign=middle i], tbody[valign=middle i], tfoot[valign=middle i],
tr[valign=middle i], td[valign=middle i], th[valign=middle i] {
vertical-align : middle;
}
thead[valign=bottom i], tbody[valign=bottom i], tfoot[valign=bottom i],
tr[valign=bottom i], td[valign=bottom i], th[valign=bottom i] {
vertical-align : bottom;
}
thead[valign=baseline i], tbody[valign=baseline i], tfoot[valign=baseline i],
tr[valign=baseline i], td[valign=baseline i], th[valign=baseline i] {
vertical-align : baseline;
}
td[nowrap], th[nowrap] { white-space : nowrap; }
table[rules=none i], table[rules=groups i], table[rules=rows i],
table[rules=cols i], table[rules=all i] {
border-style : hidden;
border-collapse : collapse;
}
table[border] { border-style : outset; } /* 仅当 border 不等价于零时 */
table[frame=void i] { border-style : hidden; }
table[frame=above i] { border-style : outset hidden hidden hidden; }
table[frame=below i] { border-style : hidden hidden outset hidden; }
table[frame=hsides i] { border-style : outset hidden outset hidden; }
table[frame=lhs i] { border-style : hidden hidden hidden outset; }
table[frame=rhs i] { border-style : hidden outset hidden hidden; }
table[frame=vsides i] { border-style : hidden outset; }
table[frame=box i], table[frame=border i] { border-style : outset; }
table[border] > tr > td, table[border] > tr > th,
table[border] > thead > tr > td, table[border] > thead > tr > th,
table[border] > tbody > tr > td, table[border] > tbody > tr > th,
table[border] > tfoot > tr > td, table[border] > tfoot > tr > th {
/* 仅当 border 不等价于零时 */
border-width : 1 px ;
border-style : inset;
}
table[rules=none i] > tr > td, table[rules=none i] > tr > th,
table[rules=none i] > thead > tr > td, table[rules=none i] > thead > tr > th,
table[rules=none i] > tbody > tr > td, table[rules=none i] > tbody > tr > th,
table[rules=none i] > tfoot > tr > td, table[rules=none i] > tfoot > tr > th,
table[rules=groups i] > tr > td, table[rules=groups i] > tr > th,
table[rules=groups i] > thead > tr > td, table[rules=groups i] > thead > tr > th,
table[rules=groups i] > tbody > tr > td, table[rules=groups i] > tbody > tr > th,
table[rules=groups i] > tfoot > tr > td, table[rules=groups i] > tfoot > tr > th,
table[rules=rows i] > tr > td, table[rules=rows i] > tr > th,
table[rules=rows i] > thead > tr > td, table[rules=rows i] > thead > tr > th,
table[rules=rows i] > tbody > tr > td, table[rules=rows i] > tbody > tr > th,
table[rules=rows i] > tfoot > tr > td, table[rules=rows i] > tfoot > tr > th {
border-width : 1 px ;
border-style : none;
}
table[rules=cols i] > tr > td, table[rules=cols i] > tr > th,
table[rules=cols i] > thead > tr > td, table[rules=cols i] > thead > tr > th,
table[rules=cols i] > tbody > tr > td, table[rules=cols i] > tbody > tr > th,
table[rules=cols i] > tfoot > tr > td, table[rules=cols i] > tfoot > tr > th {
border-width : 1 px ;
border-block-style : none;
border-inline-style : solid;
}
table[rules=all i] > tr > td, table[rules=all i] > tr > th,
table[rules=all i] > thead > tr > td, table[rules=all i] > thead > tr > th,
table[rules=all i] > tbody > tr > td, table[rules=all i] > tbody > tr > th,
table[rules=all i] > tfoot > tr > td, table[rules=all i] > tfoot > tr > th {
border-width : 1 px ;
border-style : solid;
}
table[rules=groups i] > colgroup {
border-inline-width : 1 px ;
border-inline-style : solid;
}
table[rules=groups i] > thead,
table[rules=groups i] > tbody,
table[rules=groups i] > tfoot {
border-block-width : 1 px ;
border-block-style : solid;
}
table[rules=rows i] > tr, table[rules=rows i] > thead > tr,
table[rules=rows i] > tbody > tr, table[rules=rows i] > tfoot > tr {
border-block-width : 1 px ;
border-block-style : solid;
} @namespace "http://www.w3.org/1999/xhtml" ;
table {
font-weight : initial;
font-style : initial;
font-variant : initial;
font-size : initial;
line-height : initial;
white-space : initial;
text-align : initial;
} 就 CSS 表格模型而言,col 元素预期
被视为出现了其 span
属性所指定的次数。
就 CSS 表格模型而言,如果 colgroup
元素不包含任何
col 元素,则预期将其视为具有与其 span 属性所指定数量相同的此类子元素。
就 CSS 表格模型而言,td 和 th 元素上的 colspan 和
rowspan 属性预期提供关于单元格跨行和跨列的
特殊信息。
@namespace "http://www.w3.org/1999/xhtml" ;
:is(table, thead, tbody, tfoot, tr) > form { display : none !important; }table 元素的 cellspacing
属性映射到该元素上的像素长度属性 'border-spacing'。
table 元素的 cellpadding
属性映射到像素长度属性 'padding-top'、'padding-right'、
'padding-bottom' 和 'padding-left',并应用于所有在与 table 元素对应的表格中具有对应单元格的 td 和
th 元素。
table 元素的 height 属性
映射到 table
元素上的尺寸属性 'height'。
table 元素的 width 属性
映射到尺寸属性(忽略零) 'width',并应用于
table 元素。
col 元素的 width 属性映射到 col
元素上的尺寸属性 'width'。
thead、tbody 和 tfoot 元素的 height 属性映射到元素上的尺寸属性
'height'。
tr 元素的 height 属性映射到 tr 元素上的尺寸属性 'height'。
td 和 th 元素的 height
属性映射到元素上的尺寸
属性(忽略零) 'height'。
td 和 th 元素的 width
属性映射到元素上的尺寸
属性(忽略零) 'width'。
当 thead、tbody、tfoot、tr、
td 和 th 元素具有
align
属性,且其值与字符串“center”或字符串“middle”进行ASCII
不区分大小写匹配时,它们预期
使其中的文本居中,如同在一个表现提示中将其'text-align'
属性设置为“center”,并将后代对齐到中央。
当 thead、tbody、tfoot、tr、
td 和 th 元素具有
align
属性,且其值与字符串“left”进行ASCII
不区分大小写匹配时,它们预期使其中的文本左对齐,如同
在一个表现提示中将其'text-align'
属性设置为“left”,并将后代对齐到左侧。
当 thead、tbody、tfoot、tr、
td 和 th 元素具有
align
属性,且其值与字符串“right”进行ASCII
不区分大小写匹配时,它们预期使其中的文本右对齐,如同
在一个表现提示中将其'text-align'
属性设置为“right”,并将后代对齐
到右侧。
当 thead、tbody、tfoot、tr、
td 和 th 元素具有
align
属性,且其值与字符串“justify”进行ASCII
不区分大小写匹配时,它们预期使其中的文本两端对齐,如同
在一个表现提示中将其'text-align'
属性设置为“justify”,并将后代对齐
到左侧。
用户代理预期在其用户代理样式表中具有一条规则,
该规则匹配其父节点的'text-align' 属性计算值为初始值的 th 元素,并且其声明块仅包含一条
将'text-align'
属性设置为“center”的声明。
当一个 table、thead、tbody、tfoot、
tr、td 或 th 元素的 background 属性设置为非空值时,新值
预期相对于该元素的节点文档进行编码解析并序列化;
如果这不会返回失败,则用户代理预期将该属性视为一个表现提示,把元素的'background-image' 属性设置为返回值。
当一个 table、thead、tbody、tfoot、
tr、td 或 th 元素设置了 bgcolor
属性时,新值预期使用解析旧式颜色值的规则进行解析;
如果这不会返回失败,则用户代理预期将该属性视为一个表现提示,把元素的'background-color' 属性
设置为所得颜色。
当一个 table 元素具有
bordercolor
属性时,其值预期使用解析旧式
颜色值的规则进行解析;如果这不会返回失败,则用户代理预期将该属性视为一个表现提示,把元素的
'border-top-color'、
'border-right-color'、'border-bottom-color' 和
'border-left-color' 属性设置为所得颜色。
table 元素的 border 属性映射到该元素上的像素长度属性
'border-top-width'、'border-right-width'、
'border-bottom-width' 和 'border-left-width'。如果该
属性存在,但使用解析
非负整数的规则解析其值时产生错误,则该属性预期改用默认值 1px。
上述 CSS 块中标记为“仅当 border 不等价于零时”的规则,
预期仅在规则选择器中提及的 border 属性不仅存在,
而且使用解析非负整数的规则进行解析时,
其值不为零或产生错误的情况下应用。
在怪异模式下,如果一个 td 元素或一个 th 元素具有
nowrap 属性,同时还具有
width 属性,并且使用解析
非零尺寸值的规则解析该属性值时,所得结果为长度(不是错误,也不是被归类为百分比的数字),
则该元素预期具有一个表现提示,将元素的'white-space'
属性设置为
“normal”,覆盖上述 CSS 块中将其设置为“nowrap”的规则。
如果一个节点是一个并非元素间空白的文本节点, 或者是一个元素节点,则该节点是实质性节点。
如果一个节点是一个不包含任何实质性节点的元素, 则该节点是空白节点。
具有默认外边距的元素
是以下元素:blockquote、
dir、dl、
h1、
h2、
h3、
h4、
h5、
h6、
listing、menu、ol、
p、plaintext、pre、ul、xmp。
在怪异模式下,任何作为 body、td 或 th 元素的子节点,并且没有任何实质性前置兄弟节点的具有默认外边距的元素,
预期具有一条用户代理级样式表规则,
将其'margin-block-start' 属性设置为零。
在怪异模式下,任何作为 body、td 或 th 元素的子节点,没有任何实质性前置兄弟节点,并且是空白节点的具有默认外边距的元素,
预期还具有一条用户代理
级样式表规则,将其'margin-block-end' 属性设置为零。
在怪异模式下,任何作为 td 或 th 元素的子节点,没有任何实质性后置兄弟节点,并且是空白节点的具有默认外边距的元素,
预期具有一条用户代理
级样式表规则,将其'margin-block-start' 属性设置为零。
@namespace "http://www.w3.org/1999/xhtml" ;
input, button, textarea {
letter-spacing : initial;
word-spacing : initial;
line-height : initial;
}
input, select, button, textarea {
text-transform : initial;
text-indent : initial;
text-shadow : initial;
appearance : auto;
}
input:not([type=range i], [type=checkbox i], [type=radio i]) {
overflow : clip !important;
overflow-clip-margin: 0 !important;
}
input[type=image i] {
overflow-clip-margin: content-box !important;
}
input, select, textarea {
text-align: initial;
}
:autofill {
field-sizing: fixed !important;
}
input:is([type=reset i], [type=button i], [type=submit i]), button {
text-align: center;
}
input, button {
display: inline-block;
}
input[type=hidden i], input[type=file i], input[type=image i] {
appearance: none;
}
input:is([type=radio i], [type=checkbox i], [type=reset i], [type=button i],
[type=submit i], [type=color i], [type=search i]), select, button {
box-sizing: border-box;
}
textarea { white-space: pre-wrap; }@namespace "http://www.w3.org/1999/xhtml" ;
input:not([type=image i]), textarea { box-sizing : border-box; } 每种表单控件也在控件一节中进行了描述,该节描述控件的 外观和体验。
对于 input 元素,
当其 type 属性
既不处于状态,也不处于图像
按钮状态,并且该元素正在渲染时,预期按以下方式运行:
内部显示类型始终为“flow-root”。
hr 元素@namespace "http://www.w3.org/1999/xhtml" ;
hr {
color : gray;
border-style : inset;
border-width : 1 px ;
margin-block : 0.5 em ;
margin-inline : auto;
overflow : hidden;
} @namespace "http://www.w3.org/1999/xhtml" ;
hr[align=left i] { margin-left : 0 ; margin-right : auto; }
hr[align=right i] { margin-left : auto; margin-right : 0 ; }
hr[align=center i] { margin-left : auto; margin-right : auto; }
hr[color], hr[noshade] { border-style : solid; } 如果一个 hr 元素具有
color 属性
或 noshade 属性,并且
还具有 size 属性,
且使用解析非负整数的规则
解析该属性的值不会产生错误,则用户代理预期使用解析后的值除以二所得的结果,作为该元素上
表现提示中的像素长度,
以设置属性 'border-top-width'、
'border-right-width'、'border-bottom-width' 和
'border-left-width'。
否则,如果一个 hr 元素
既没有 color
属性,也没有 noshade
属性,但具有 size
属性,并且使用解析非负整数的规则
解析该属性的值不会产生错误,则:如果解析后的值为一,用户代理预期将该属性作为一个表现提示,把元素的
'border-bottom-width' 设置为 0;否则,如果解析后的值
大于一,则用户代理预期使用解析后的值减去二所得的结果,作为
表现提示中的像素长度,以设置该元素的'height' 属性。
hr 元素上的
width 属性映射到元素上的尺寸属性 'width'。
当一个 hr 元素具有
color 属性时,其
值预期使用解析旧式颜色
值的规则进行解析;如果这不会返回失败,则用户代理预期
将该属性视为一个表现
提示,把元素的'color' 属性设置为所得颜色。
fieldset 和
legend
元素
@namespace "http://www.w3.org/1999/xhtml" ;
fieldset {
display : block;
margin-inline : 2 px ;
border : groove 2 px ThreeDFace;
padding-block : 0.35 em 0.625 em ;
padding-inline : 0.75 em ;
min-inline-size : min-content;
}
legend {
padding-inline : 2 px ;
}
legend[align=left i] {
justify-self : left;
}
legend[align=center i] {
justify-self : center;
}
legend[align=right i] {
justify-self : right;
} 当 fieldset
元素生成一个CSS 框时,
预期按以下方式运行:
这不会改变计算值。
如果该元素的框具有一个满足下列条件的子框,则第一个此类子框就是 “fieldset”元素的已渲染图例:
legend
元素。在块起始侧为元素边框分配的空间,预期为元素的'border-block-start-width',或
已渲染图例的外边距框在 fieldset
块流方向上的尺寸,两者取较大者。
为了计算使用的 'block-size',如果计算后的 'block-size' 不是“auto”,则为已渲染 图例超出边框的外边距框部分所分配的空间(如果有)预期 从 'block-size' 中减去。如果内容框的块尺寸会变为 负数,则改为令内容框的块尺寸为 0。
匿名 fieldset 内容框
预期出现在已渲染图例之后,并且预期包含 fieldset
元素的内容(包括“::before”和“::after”伪元素),但不包括
已渲染图例(如果存在)。
'padding-top'、'padding-right'、 'padding-bottom' 和 'padding-left' 属性的使用值预期为零。
为了计算最小内容行内尺寸,使用已渲染图例的最小内容行内尺寸与 匿名 fieldset 内容框的 最小内容行内尺寸两者中的较大者。
为了计算最大内容行内尺寸,使用已渲染图例的最大内容行内尺寸与 匿名 fieldset 内容框的 最大内容行内尺寸两者中的较大者。
fieldset
元素的已渲染图例(如果有)
预期按以下方式运行:
这不会改变计算值。
如果 'inline-size' 的计算值为“auto”,则其使用值为适合内容的行内尺寸。
该元素预期按块的正常方式 在行内方向上定位(例如,考虑外边距和'justify-self' 属性)。
该元素的框预期在行内方向上受到 fieldset
的行内内容尺寸约束,如同它使用了其计算后的行内
内边距。
例如,如果 fieldset
指定了 50px 的内边距,则已渲染图例会定位在距离 fieldset
边框 50px 的位置。该内边距还会应用于匿名 fieldset 内容框,
而不是应用于 fieldset
元素本身。
fieldset
元素的匿名 fieldset 内容框
预期按以下方式运行:
'block-size' 属性预期设置为 “100%”。
为了计算百分比内边距,表现得如同该内边距是为 fieldset
元素计算的。
以下元素可以是替换
元素:audio、canvas、embed、iframe、
img、input、object 和 video。
embed、
iframe 和
video 元素
预期被视为替换
元素。
一个表示嵌入
内容的 canvas
元素预期被视为一个替换
元素;此类元素的内容是该元素的位图(如果有),否则是一个与该元素具有相同自然
尺寸的透明
黑色位图。其他 canvas
元素预期在渲染模型中被视为普通元素。
一个表示图像、插件或其内容可导航对象的
object
元素预期被视为一个替换
元素。其他 object
元素预期在渲染模型中被视为普通元素。
当 audio
元素正在向用户公开用户界面时,
预期将其视为一个约一行高、
宽度足以显示用户代理用户界面功能的替换
元素。当一个 audio 元素
没有向用户公开用户界面时,
用户代理预期强制其'display' 属性计算为“none”,而不考虑 CSS 规则。
一个 video 元素
是否正在向用户公开用户界面,
预期不会影响渲染尺寸;
控件预期叠加在页面内容之上,
而不会引起任何布局变化,并且预期在用户不需要时消失。
当一个 video
元素
表示海报帧或视频帧时,该海报帧或视频帧预期以在保持其宽高比的同时,
不高于也不宽于 video
元素本身的最大尺寸进行渲染,并且预期在
video
元素中居中。
任何字幕或说明文字预期按照相关渲染规则的定义,
直接叠加在其 video
元素之上;对于 WebVTT,这些规则是更新 WebVTT 文本轨道显示的
规则。[WEBVTT]
当用户代理开始为一个 video 元素
向用户公开用户
界面时,用户代理应对该 video
元素的文本轨道列表中,每个处于显示状态,
且其文本轨道种类为
subtitles
或 captions
之一的文本
轨道,运行更新文本轨道
渲染的规则(例如,对于基于 WebVTT 的文本
轨道,运行更新 WebVTT 文本
轨道显示的规则)。[WEBVTT]
调整 video 和
canvas
元素的大小不会中断视频播放或清除画布。
以下 CSS 规则预期应用:
@namespace "http://www.w3.org/1999/xhtml" ;
iframe { border : 2 px inset; }
video { object-fit : contain; } 用户代理预期根据以下列表中第一个适用的规则,
渲染 img 元素,以及
input 元素中其 type 属性处于
图像按钮状态的元素:
input 元素,该元素预期呈现为按钮状,以表明该元素是一个按钮。
img 元素
img 元素
input 元素
上述图标预期相对较小,以免干扰大多数文本, 但应易于点击。例如,在视觉环境中,图标可以是 16×16 像素的正方形;如果图像可缩放, 则可以是 1em×1em。在音频环境中,图标可以是一声短促的提示音。这些图标旨在向用户表明, 可以通过它们访问用户代理为图像提供的任何选项,并且在适当情况下,预期提供对上下文菜单的访问, 就像用户与实际图像交互时会出现的菜单一样。
具有相同绝对 URL和相同图像数据的所有动画图像, 预期作为一组同步渲染到同一时间线, 该时间线从该组中最早加入的图像加入时开始。
换言之,当具有相同绝对 URL和动画图像数据的第二幅图像插入文档时, 它会跳到第一幅图像当前显示的动画周期位置。
以下 CSS 规则预期应用:
@namespace "http://www.w3.org/1999/xhtml" ;
img:is([sizes="auto" i], [sizes^="auto," i]) {
contain : size !important;
contain-intrinsic-size: 300px 150px;
}当 Document
处于怪异模式时,以下 CSS 规则预期应用:
@namespace "http://www.w3.org/1999/xhtml" ;
img[align=left i] { margin-right : 3 px ; }
img[align=right i] { margin-left : 3 px ; } @namespace "http://www.w3.org/1999/xhtml" ;
embed[align=left i], iframe[align=left i], img[align=left i],
input[type=image i][align=left i], object[align=left i] {
float : left;
}
embed[align=right i], iframe[align=right i], img[align=right i],
input[type=image i][align=right i], object[align=right i] {
float : right;
}
embed[align=top i], iframe[align=top i], img[align=top i],
input[type=image i][align=top i], object[align=top i] {
vertical-align : top;
}
embed[align=baseline i], iframe[align=baseline i], img[align=baseline i],
input[type=image i][align=baseline i], object[align=baseline i] {
vertical-align : baseline;
}
embed[align=texttop i], iframe[align=texttop i], img[align=texttop i],
input[type=image i][align=texttop i], object[align=texttop i] {
vertical-align : text-top;
}
embed[align=absmiddle i], iframe[align=absmiddle i], img[align=absmiddle i],
input[type=image i][align=absmiddle i], object[align=absmiddle i],
embed[align=abscenter i], iframe[align=abscenter i], img[align=abscenter i],
input[type=image i][align=abscenter i], object[align=abscenter i] {
vertical-align : middle;
}
embed[align=bottom i], iframe[align=bottom i], img[align=bottom i],
input[type=image i][align=bottom i], object[align=bottom i] {
vertical-align : bottom;
} 当一个 embed、
iframe、
img 或
object
元素,或者一个其 type
属性处于图像按钮状态的
input
元素,具有 align 属性,并且其值与字符串“center”或字符串
“middle”进行ASCII
不区分大小写匹配时,用户代理预期表现得如同元素的'vertical-align' 属性被设置为一个值,
该值会使元素的垂直中点与父元素的基线对齐。
embed、
img
或 object
元素,以及其 type
属性处于图像
按钮状态的 input
元素的 hspace 属性,映射到元素上的尺寸
属性 'margin-left' 和
'margin-right'。
embed、
img
或 object
元素,以及其 type
属性处于图像
按钮状态的 input
元素的 vspace 属性,映射到元素上的尺寸
属性 'margin-top' 和 'margin-bottom'。
当一个 iframe
元素具有 frameborder
属性,并且使用解析整数的规则解析其值时,
所得结果为零或错误,则用户代理预期具有表现
提示,将元素的
'border-top-width'、'border-right-width'、
'border-bottom-width' 和 'border-left-width' 属性设置为零。
当一个 img
元素、object
元素,或者一个其 type
属性处于图像按钮状态的
input
元素,具有 border 属性,并且使用解析
非负整数的规则解析其值时,所得结果为大于零的数字,则用户代理预期将解析后的值用于
八个表现提示:
其中四个将解析后的值作为像素长度,设置元素的'border-top-width'、
'border-right-width'、'border-bottom-width' 和
'border-left-width' 属性;
另外四个将元素的
'border-top-style'、'border-right-style'、
'border-bottom-style' 和 'border-left-style' 属性设置为“solid”。
width 和
height
属性在 img
元素的尺寸属性
来源上,分别映射到尺寸
属性
'width' 和 'height',这些属性位于 img
元素上。它们还会以类似方式映射到
aspect-ratio 属性(使用尺寸规则),该属性属于
img
元素。
embed、
iframe、
object 和 video
元素,以及其 type
属性处于图像按钮状态,
且表示图像或用户预计最终将表示图像的 input
元素上的 width 和
height
属性,分别映射到元素上的尺寸
属性
'width' 和 'height'。
width 和
height
属性在
img
和 video
元素,以及其 type
属性处于图像
按钮状态的 input
元素上,映射到
aspect-ratio 属性(使用尺寸规则)。
width
和 height
属性映射到
canvas
元素上的 aspect-ratio 属性。
就 CSS 层叠而言,图像映射上的形状预期表现为独立于原始 area 元素的元素,
它们恰好匹配相同的样式规则,但继承自 img 或 object
元素。
因此,例如,如果一个 area
元素具有 style 属性,将'cursor' 属性设置为“help”,
那么当用户指向该形状时,光标会变为帮助光标。
类似地,如果一个 area
元素具有一条 CSS 规则,
将其'cursor' 属性设置为“inherit”(或者根本没有任何设置'cursor'
属性的规则匹配该元素),则该形状的光标会继承自图像映射的
img 或 object 元素,
而不是继承自 area 元素的父元素。
CSS Basic User Interface 规范将可以具有原生外观的元素称为控件,并根据'appearance' 属性定义是否使用该原生 外观。反过来,该逻辑取决于每个元素是被归类为可退化 控件,还是不可退化 控件。本节定义哪些 HTML 元素匹配这些概念、它们的原生 外观是什么,以及其退化状态或基础 外观的任何特殊之处。 [CSSUI]
就 CSS 'appearance' 属性而言,以下元素可以具有原生 外观。
若干控件的渲染由 'writing-mode' CSS 属性控制。就这些控件而言,使用以下定义。
如果解析控件的 'writing-mode' 属性得到的计算值为“horizontal-tb”,则为水平书写模式。
如果解析控件的 'writing-mode' 属性 得到的计算值为“vertical-rl”、“vertical-lr”、“sideways-rl”或“sideways-lr”之一, 则为垂直书写模式。
按钮布局如下:
如果该元素是绝对定位的,则就 CSS 视觉格式化模型而言, 表现得如同该元素是一个替换 元素。[CSS]
如果 'inline-size' 的计算值为“auto”,则其 使用值为适合内容的行内尺寸。
就 'align-self' 属性的“normal”关键字而言, 表现得如同该元素是一个替换元素。
如果该元素是一个 input
元素,或者它是一个 button 元素,
并且其 'display' 计算值不是
“inline-grid”、“grid”、“inline-flex”或“flex”,则该元素的框具有一个匿名按钮内容
框子框,并具有以下行为:
否则,不存在匿名按钮内容框。
需要定义基础 外观。
button 元素当 button 元素
生成一个CSS 框时,
预期描绘一个按钮,并使用按钮布局;其匿名按钮
内容框的内容(如果存在匿名按钮
内容框)是该元素的框原本会具有的子框。
details 和
summary
元素
@namespace "http://www.w3.org/1999/xhtml" ;
details, summary {
display : block;
}
details > summary:first-of-type {
display : list-item;
counter-increment : list-item 0 ;
list-style : disclosure-closed inside;
}
details[open] > summary:first-of-type {
list-style-type : disclosure-open;
} details
元素预期具有一个包含三个子元素的内部影子
树:
第一个子元素是一个 slot,
预期接收
details
元素的第一个 summary
元素子节点(如果有)。该元素具有单个 summary
子元素,称为默认摘要,其文本内容是由实现定义的(并且可能因语言区域而异)。
第二个子元素是一个 slot,
预期接收
details
元素的其余后代(如果有)。该元素没有内容。
该元素预期匹配 '::details-content' 伪元素。
当 details
元素没有 open
属性时,该元素的 style
属性预期设置为
“display: block; content-visibility: hidden;”。当它具有 open
属性时,style 属性
预期设置为
“display: block;”。
由于这些槽隐藏在影子树内部,因此作者代码无法直接看到此 style 属性。
但是,它的影响是可见的。尤其是,选择 content-visibility: hidden
而不是例如 display: none,会影响各种查询布局信息的 API 的结果。
第三个子元素是一个 link 或
style
元素,其中包含以下用于默认摘要的样式:
:host summary {
display : list-item;
counter-increment : list-item 0 ;
list-style : disclosure-closed inside;
}
:host([open]) summary {
list-style-type : disclosure-open;
} 无法观察到该子元素相对于另外两个子元素的位置。 这意味着实现可以使其相对于兄弟节点处于不同顺序。实现甚至可以使用并非元素的机制, 将该样式与影子树关联。
通过 details
元素的子节点和 '::details-content' 伪元素
对 CSS 样式的响应方式,可以观察到该影子树的结构。
input
元素
一个 input
元素,如果其 type
属性处于搜索
状态,则是一个可退化控件。其原生
外观预期渲染为一个描绘单行文本控件的
'inline-block'
框。如果该元素的 'appearance'
属性的计算
值不是 'textfield',
则它可以具有表明其为搜索字段的独特样式。
对于其 type
属性处于上述状态之一的 input
元素,'line-height'
属性的使用值必须是一个长度值,
并且不得小于“line-height: normal”对应的使用值。
该使用值不会是实际的“normal”关键字。此外,此 规则不会影响计算值。
如果这些文本控件提供文本选择,那么当用户更改当前选择时,用户代理预期在给定
input
元素的情况下,在用户交互任务源上排入元素任务,以在该元素上触发名为
select
的事件,并将其 bubbles
属性初始化为 true。
一个 input
元素,如果其 type
属性处于上述状态之一,则是一个具有默认首选尺寸的元素,
并且用户代理预期将
'field-sizing' CSS
属性应用于该元素。用户代理预期使用以下步骤确定其固有尺寸的行内尺寸:
如果该元素上的 'field-sizing'
属性的计算
值为“content”,则行内尺寸
由该元素显示的文本确定。该文本要么是一个值,要么是由
placeholder
属性指定的短提示。用户代理可以在行内
尺寸中考虑文本插入符的尺寸。
如果该元素具有 size
属性,并且使用解析
非负整数的规则解析该属性值不会产生错误,则返回将该属性值应用于将字符宽度
转换为像素算法所得的值。
否则,返回将数字 20 应用于将字符宽度 转换为像素算法所得的值。
将字符宽度转换为像素算法返回 (size-1)×avg + max, 其中 size 是要转换的字符宽度,avg 是运行该算法的元素所使用的 主字体的平均字符宽度(以像素为单位),而 max 是同一字体的最大字符宽度, 同样以像素为单位。(元素的 'letter-spacing' 属性不会影响结果。)
这些文本控件预期是滚动 容器,并支持在行内轴上滚动,但不支持在块 轴上滚动。
input
元素
一个 input
元素,如果其 type
属性处于数字状态,
则是一个具有默认首选尺寸的元素,并且用户代理
预期
将 'field-sizing' CSS
属性应用于该元素。其固有尺寸的块尺寸
约为一行高。如果该元素上的 'field-sizing'
属性的计算值为
“content”,则其固有尺寸的行内尺寸
预期约为显示当前
值所需的宽度。
否则,其固有尺寸的行内尺寸
预期约为显示
可能出现的最宽值所需的宽度。
input 元素当此控件具有水平书写模式时,该控件 预期为水平滑块。 如果'direction' 属性的计算值为“rtl”,则最低值位于右侧;否则位于左侧。 当此控件具有垂直书写模式时,它 预期为垂直滑块。 如果'direction' 属性的计算值为“rtl”,则最低值位于底部;否则位于顶部。
预定义的建议值(由 list
属性提供)预期显示为滑块上的
刻度标记,滑块可以吸附到这些标记。
需要详细说明基础 外观。
input 元素一个 input
元素,如果其 type 属性处于
颜色
状态,则预期描绘一个颜色井;
激活该颜色井时,会向用户提供一个颜色选择器(例如色轮或调色板),以便更改颜色。当该元素生成一个CSS
框时,预期使用按钮布局,其中匿名按钮内容框没有任何子框。该匿名按钮内容框
预期具有一个表现提示,
将 'background-color' 属性设置为元素的值。
预定义的建议值(由 list
属性提供)预期显示在颜色选择器界面中,
而不是显示在颜色井本身上。
input
元素input
元素
一个 input
元素,如果其 type
属性处于文件上传状态,
则当它生成一个CSS
框时,预期渲染为一个
'inline-block'
框,其中包含一段显示已选文件文件名
(如果有)的文本,后跟一个按钮;激活该按钮时,会向用户提供文件选择器,以便更改选择。
该按钮预期使用按钮布局,并匹配
'::file-selector-button' 伪元素。其匿名按钮
内容框的内容预期为由实现定义的文本(并且可能因语言区域而异),
例如“选择文件”。
用户代理可以将一个其
type
属性处于文件上传状态的
input
元素,作为一个具有默认首选尺寸的元素进行处理,并且用户代理可以
将 'field-sizing' CSS
属性应用于该元素。如果该元素上的 'field-sizing'
属性的计算值为
“content”,则该元素的固有尺寸
预期取决于其内容,
例如 '::file-selector-button' 伪元素和已选文件名。
input 元素一个 input
元素,如果其 type
属性处于
提交按钮、重置
按钮或按钮状态,则当它生成一个CSS 框时,
预期描绘一个按钮并使用按钮布局,且匿名按钮内容框的内容预期为元素的 value
属性的文本(如果有);如果没有,则为以由实现定义的方式(并且可能因语言区域而异),
从元素的 type
属性派生的文本。
marquee 元素@namespace "http://www.w3.org/1999/xhtml" ;
marquee {
display : inline-block;
text-align : initial;
overflow : hidden !important;
}当 marquee
元素处于开启状态时,
预期根据其属性按以下方式进行动画渲染:
behavior
属性处于
scroll 状态
按照下文定义的 direction
属性所描述的方向滑动元素的内容,使其从 marquee
的起始侧之外开始,并在内侧结束边与其齐平时结束。
例如,如果 direction
属性为left(默认值),则内容开始时,
其左边缘位于 marquee 的内容区域右边缘之外,随后内容会一直滑动,
直到其左边缘与 marquee 的内容区域左侧内边缘齐平。
动画结束后,用户代理预期递增 marquee 当前循环索引。如果此后该元素仍处于开启状态,则用户代理 预期重新启动动画。
behavior
属性处于
slide 状态
按照下文定义的 direction
属性所描述的方向滑动元素的内容,使其从 marquee
的起始侧之外开始,并在 marquee
的结束侧之外结束。
例如,如果 direction
属性为left(默认值),则内容开始时,
其左边缘位于 marquee 的内容区域右边缘之外,随后内容会一直滑动,
直到内容的右边缘与 marquee 的内容区域左侧内边缘齐平。
动画结束后,用户代理预期递增 marquee 当前循环索引。如果此后该元素仍处于开启状态,则用户代理 预期重新启动动画。
behavior
属性处于
alternate 状态
当marquee
当前循环索引为偶数(或零)时,按照下文定义的 direction
属性所描述的方向滑动元素的内容,使其开始时与
marquee
的起始侧齐平,并在结束时与 marquee
的结束侧齐平。
当marquee
当前循环索引为奇数时,
按照与下文定义的 direction
属性所描述方向相反的方向滑动元素的内容,使其开始时与
marquee
的结束侧齐平,并在结束时与
marquee
的起始侧齐平。
例如,如果 direction
属性为left(默认值),则内容开始时,
其右边缘与 marquee 的内容区域右侧内边缘齐平,随后内容会一直滑动,
直到内容的左边缘与 marquee 的内容区域左侧内边缘齐平。
动画结束后,用户代理预期递增 marquee 当前循环索引。如果此后该元素仍处于开启状态,则用户代理 预期继续动画。
direction
属性具有下表所述的含义:
direction
属性状态
|
动画方向 | 起始边 | 结束边 | 相反方向 |
|---|---|---|---|---|
| left | ← 从右向左 | 右侧 | 左侧 | → 从左向右 |
| right | → 从左向右 | 左侧 | 右侧 | ← 从右向左 |
| up | ↑ 向上(从下到上) | 底部 | 顶部 | ↓ 向下(从上到下) |
| down | ↓ 向下(从上到下) | 顶部 | 底部 | ↑ 向上(从下到上) |
无论如何,动画应按以下方式进行:每帧之间应有由marquee 滚动间隔给出的延迟,并且内容在每一帧中移动的距离最多为marquee 滚动 距离给出的距离。
当一个 marquee
元素设置了 bgcolor
属性时,其值预期使用解析旧式颜色值的
规则进行解析;如果这不会返回失败,则用户代理
预期将该属性视为一个表现提示,把元素的
'background-color' 属性
设置为所得颜色。
marquee 元素上的
width 和 height 属性分别映射到元素上的
尺寸属性
'width' 和 'height'。
marquee 元素的
vspace 属性映射到元素上的
尺寸属性 'margin-top' 和 'margin-bottom'。marquee
元素的 hspace 属性映射到元素上的
尺寸属性
'margin-left' 和 'margin-right'。
meter 元素@namespace "http://www.w3.org/1999/xhtml" ;
meter { appearance : auto; } meter 元素是一个
可退化控件。其原生
外观预期渲染为一个
'inline-block' 框,其
'block-size' 为“1em”,'inline-size' 为“5em”,
'vertical-align' 为“-0.2em”,并且其内容描绘一个计量表。
当此元素具有水平书写模式时,其描绘 预期为水平计量表。如果 'direction' 属性的计算值为 “rtl”,则最小值位于右侧;否则位于左侧。当此元素具有垂直书写模式时,它 预期描绘一个垂直计量表。如果 'direction' 属性的计算值为 “rtl”,则最小值位于底部;否则位于顶部。
用户代理预期使用与平台计量表惯例一致的表现形式 (如果存在此类惯例)。
计量表中必须描绘哪些内容的要求,包含在 meter 元素的定义中。
需要详细说明基础外观。
progress 元素@namespace "http://www.w3.org/1999/xhtml" ;
progress { appearance : auto; } progress
元素是一个可退化控件。其
原生外观预期渲染为一个
'inline-block' 框,其'block-size'
为“1em”,
'inline-size' 为“10em”,并且'vertical-align' 为“-0.2em”。
 当此
元素具有水平
书写模式时,该元素预期被描绘为
水平进度条。如果该元素上的 'direction' 属性的计算值为“rtl”,则起点位于右侧,终点位于左侧;
否则起点位于左侧,终点位于右侧。当此元素具有
垂直书写模式时,它
预期被描绘为垂直
进度条。如果该元素上的
'direction' 属性的计算值为“rtl”,则起点位于底部,终点位于顶部;
否则起点位于顶部,终点位于底部。
当此
元素具有水平
书写模式时,该元素预期被描绘为
水平进度条。如果该元素上的 'direction' 属性的计算值为“rtl”,则起点位于右侧,终点位于左侧;
否则起点位于左侧,终点位于右侧。当此元素具有
垂直书写模式时,它
预期被描绘为垂直
进度条。如果该元素上的
'direction' 属性的计算值为“rtl”,则起点位于底部,终点位于顶部;
否则起点位于顶部,终点位于底部。
用户代理预期使用与平台进度条惯例一致的表现形式。 特别是,用户代理预期对确定型和不确定型进度条使用 不同的表现形式。用户代理还 预期根据元素的尺寸改变表现形式。
如何确定进度条是确定型还是不确定型,以及确定型进度条应显示何种进度的要求,
包含在 progress 元素的
定义中。
需要详细说明基础外观。
select 元素select 元素是一个
具有默认首选尺寸的元素,并且
用户代理预期将 'field-sizing' CSS 属性应用于
select 元素。
根据其属性,一个 select 元素
要么是一个列表框,要么是一个下拉框。
一个具有 multiple
属性的 select
元素,如果其显示尺寸大于 1,
则预期渲染为多选列表
框。如果 select 元素具有
multiple 属性,
且显示尺寸为 1,
则如果平台支持,它可以渲染为多选下拉框;否则渲染为多选
列表框。
一个没有 multiple
属性的 select
元素,如果其显示尺寸为
1,则预期渲染为单选下拉
框;如果其显示尺寸
大于 1,则渲染为单选列表框。
当该元素渲染为列表框时,它是一个可退化控件,
预期渲染为一个'inline-block'
框。其固有尺寸的行内
尺寸为select 标签的
宽度加上滚动条的宽度。其固有尺寸的块尺寸由以下步骤确定:
如果该元素上的 'field-sizing' 属性的计算值 为“content”,则返回容纳所有项目行所需的高度。
如果 size 属性
不存在或没有有效值,则返回容纳四行所需的高度。
否则,返回容纳由元素的显示尺寸给出的项目行数所需的高度。
一个正在渲染为下拉框的 select 元素
预期渲染为一个'inline-block'
框。其固有尺寸的行内尺寸为select
标签的
宽度。如果该元素上的 'field-sizing' 属性的计算
值为“content”,则固有尺寸的行内尺寸
取决于所显示的文本。所显示的文本通常是一个选中性设置为 true 的 option 的标签。
当该元素渲染为下拉
框时,它是一个可退化
控件。它在退化状态下的外观,以及当元素的 'appearance'
属性的计算值为
'menulist-button' 时的
外观,都是下拉框的外观,包括一个“下拉按钮”,但不一定使用宿主操作系统的原生控件进行渲染。
在这种状态下,不应忽略 'color'、'background-color' 和“border”等 CSS 属性
(按元素的原生外观渲染元素时,通常允许忽略这些属性)。
无论是哪种情况(列表框或下拉框),元素的项目
预期为元素的选项
列表,并在适用时由元素的 optgroup 元素子节点为选项组提供标题。
渲染为下拉框的 select 元素,
除了原生外观和基础外观之外,还支持基准
外观。
渲染为不具有 multiple
属性的
下拉框,或者渲染为
列表框的 select 元素,
除了原生外观和基础
外观之外,还支持基准外观。
select 元素的
select 弹出框支持基础
外观和原生
外观。仅当关联的 select
正以
基础外观渲染时,select 弹出框才能
以基础外观
渲染。
当一个 select
以具有基准
外观的下拉框形式渲染时,
预期使用一个包含以下元素的影子树进行渲染:
一个select 按钮槽,它是一个 slot 元素。
它作为第一个子节点追加到
select 的影子根。如果
select 的第一个
子元素是一个 button,
则该槽预期接收该第一个子元素。
一个select 后备按钮文本,它是一个 div 元素。
它被追加到select 按钮
槽。
一个select 弹出框,它是一个 div 元素。
它作为第二个子节点,在select 按钮
槽之后追加到
select 的影子根。如果提供的参数为 select,
则 select 元素的
'::picker' 伪元素就是该select 弹出框。
一个select 弹出框槽,它是一个 slot 元素。
它被追加到select 弹出框。
它预期接收
select 的所有子节点,
但由select 按钮槽接收的第一个
button 子节点除外。
由于基准外观是通过计算样式确定的,因此在切换外观时
无法交换此 DOM 结构。实现可以在 select 渲染为
下拉框时,始终包含用于基准外观的 DOM 结构,
然后选择将其包含在布局树中或从布局树中排除,以控制是否渲染它。
只有当select 弹出框独立于
select 元素选择使用基准
外观时,才会渲染该弹出框。否则,使用原生选择器。
当一个 select
以具有基准
外观的列表框形式渲染时,预期使用一个包含
select 列表框槽的影子树进行渲染,该槽是一个 slot 元素。该select 列表框
槽作为第一个子节点追加到 select 的影子根。
该select 列表框槽预期接收
select
元素的所有子节点。
select 弹出框的隐式锚定元素是与其关联的
select 元素。
当一个 select
元素使用原生
外观或基础外观进行渲染,或者 select 元素渲染为
列表框时,'::picker' 伪元素和
'::picker-icon' 伪元素不适用。
当 '::picker' 伪元素具有原生 外观或基础 外观时,不会渲染该伪元素。
'::checkmark' 伪元素仅适用于使用基准外观进行渲染的 option 元素。
一个 optgroup
元素具有一个内部影子树,其中至少包含一个
slot 元素。
如果一个 optgroup
元素具有一个最近的祖先
select,并且该 select 的内容正在使用基准外观
进行渲染,则该元素使用基准
外观进行渲染。
如果一个 optgroup
元素没有使用基准外观进行渲染,则
预期通过显示该元素的标签和子节点来渲染它。
如果一个 optgroup
元素正在使用基准外观进行渲染,则
预期使用一个包含以下元素的影子
树进行渲染:
一个optgroup 图例槽,它是一个 slot 元素。
它作为第一个子节点追加到
optgroup 的影子根。如果
optgroup 的第一个
子元素是一个 legend 元素,
则该槽预期接收该第一个子元素。
一个optgroup 标签元素,它是一个 div 元素。
它被追加到optgroup 图例槽。
它预期包含一个 Text
节点,其数据为
optgroup 的
label 属性的值;
如果该属性不存在,则为空字符串。
一个optgroup 内容槽,它是一个 slot 元素。
它在optgroup 图例
槽之后追加到
optgroup 的影子根。它
预期接收
optgroup
元素的所有剩余子节点。
要确定给定 select 元素
select 的select
的内容是否正在使用基准外观
进行渲染:
一个 option 元素具有
一个内部影子树,其中包含一个
slot 元素。
如果一个 option 元素
具有一个最近的祖先
select,并且该 select 的内容正在使用基准
外观进行渲染,则该元素使用基准
外观进行渲染。
如果一个 option
没有最近的祖先 select,
则预期渲染其子节点。
否则,如果一个 option 元素没有
使用基准外观进行渲染,则
预期通过显示在给定
option 和
true 的情况下运行收集选项文本所得的结果来渲染。
一个option 内容槽,它是一个 slot 元素。
它作为第一个子节点追加到
option 的影子根。
如果 option
元素具有值不为空字符串的 label
属性,则option 内容槽
预期不接收任何节点。否则,它
预期接收
option 元素的所有
子节点。
当option 内容槽不接收任何元素时,option 标签元素作为后备内容进行渲染。
一个option 标签元素,它是一个 span 元素。
它被追加到option 内容
槽。它预期包含一个
Text
节点,其数据为
option 的 label 属性的值。
由一个或多个作为兄弟节点的 hr 子元素组成的每个序列,
可以渲染为单个分隔线。
select 标签的宽度是渲染最宽的
optgroup 所需的
宽度,与渲染元素的选项
列表中最宽的 option
元素
(包括其缩进,如果有)所需的宽度两者中的较大者。如果 select 具有
multiple 属性,
并且正在渲染为下拉框,则该宽度还应足以容纳
select 中任意组合的
option 被选中时
所渲染的文本。
select 标签的宽度需要考虑
multiple,
因为某些实现会使用特殊文本来表示选择了多个选项,例如“已选择 2 项”。在这种情况下,select 除了要能够
渲染各个 option 之外,
还需要足够宽以渲染“已选择 2 项”。
如果一个 select 元素
包含一个占位标签
选项,则用户代理预期以一种能够传达该
option 是标签而不是控件有效选项的方式
渲染它。这可以包括阻止用户显式选择该占位标签
选项。当占位标签
选项的选中性为
true 时,控件
预期以表明当前未选择任何有效选项的方式显示。
用户代理预期以如下方式渲染
select 中的标签:
无论标签作为页面的一部分显示,还是在菜单控件中显示,任何对齐方式都保持一致。
@namespace "http://www.w3.org/1999/xhtml" ;
option {
display : block;
}
optgroup {
display : block;
font-weight : bolder;
} 当 select 元素
使用原生
外观或基础
外观进行渲染时,以下样式预期应用于这些元素:
@namespace "http://www.w3.org/1999/xhtml" ;
select {
letter-spacing : initial;
word-spacing : initial;
line-height : initial;
} 当 select 元素
以具有原生外观或
基础外观的下拉框形式渲染时,
以下样式预期应用于这些元素:
@namespace "http://www.w3.org/1999/xhtml" ;
select {
display : inline-block;
} 当 select 元素
使用基准外观进行渲染时,
以下样式预期应用于这些元素:
@namespace "http://www.w3.org/1999/xhtml" ;
select {
background-color : transparent;
border : 1 px solid currentColor;
user-select : none;
box-sizing : border-box;
}
select option:enabled:hover {
background-color : color-mix ( currentColor 10 % , transparent);
}
select option:enabled:active {
background-color : color-mix ( currentColor 20 % , transparent);
}
select option:disabled {
color : color-mix ( currentColor 50 % , transparent);
}
select option {
min-inline-size : 24 px ;
min-block-size : max ( 24 px , 1 lh );
padding-inline : 0.5 em ;
padding-block-end : 0 ;
display : flex;
align-items : center;
gap : 0.5 em ;
white-space : nowrap;
}
select option::checkmark {
content : '\2713' / '' ;
}
select option:not(:checked)::checkmark {
visibility : hidden;
}
select optgroup {
display : block;
font-weight : bolder;
}
select optgroup option {
font-weight : normal;
}
select optgroup legend {
padding-inline : 0.5 em ;
min-block-size : 1 lh ;
} 当 select 元素
以具有基准外观的下拉框形式渲染时,
以下样式预期应用于这些元素:
@namespace "http://www.w3.org/1999/xhtml" ;
select {
border-radius : 0.5 em ;
padding-block : 0.25 em ;
padding-inline : 0.5 em ;
min-block-size : calc-size ( auto, max ( size, 24 px , 1 lh ));
min-inline-size : calc-size ( auto, max ( size, 24 px ));
display : inline-flex;
gap : 0.5 em ;
border-radius : 0.5 em ;
field-sizing : content !important;
}
select > button:first-child {
all: unset;
display: contents;
}
select:enabled:hover {
background-color: color-mix(currentColor 10%, transparent);
}
select:enabled:active {
background-color: color-mix(currentColor 20%, transparent);
}
select:disabled {
color: color-mix(currentColor 50%, transparent);
}
::picker(select) {
box-sizing: border-box;
border: 1px solid;
padding: 0;
color: CanvasText;
background-color: Canvas;
margin: 0;
inset: auto;
min-inline-size: anchor-size(self-inline);
max-block-size: stretch;
overflow: auto;
position-area: self-block-end span-self-inline-end;
position-try-order: most-block-size;
position-try-fallbacks:
self-block-start span-self-inline-end,
self-block-end span-self-inline-start,
self-block-start span-self-inline-start;
}
select::picker-icon {
content: counter(fake-counter-name, disclosure-open);
display: block;
margin-inline-start: auto;
}当 select 元素
以具有基准外观的列表框形式渲染时,
以下样式预期应用于这些元素:
@namespace "http://www.w3.org/1999/xhtml" ;
select {
overflow : auto;
display : inline-block;
block-size : calc ( max ( 24 px , 1 lh ) * attr(size type(<integer>), 4));
}以下样式预期应用于optgroup 标签 元素:
padding-inline: 0.5em
min-block-size: 1lh
textarea 元素textarea
元素是一个可退化控件,预期
渲染为一个描绘多行文本控件的'inline-block'
框。如果此多行文本控件提供文本选择,那么当用户更改当前选择时,
用户代理预期在给定 textarea 元素的情况下,
在用户
交互任务源上排入元素任务,以在该元素上触发名为 select
的事件,并将其 bubbles
属性初始化为 true。
textarea
元素是一个具有默认首选尺寸的元素,并且
用户代理预期将 'field-sizing' CSS 属性应用于
textarea
元素。
如果该元素上的 'field-sizing' 属性的计算值
为“content”,则固有尺寸
根据元素显示的文本确定。该文本要么是一个原始值,要么是由
placeholder
属性指定的短提示。用户代理可以在固有尺寸中考虑文本插入符的尺寸。
否则,其固有尺寸根据textarea 有效宽度和
textarea 有效
高度(定义如下)计算。
textarea 元素的
textarea 有效宽度为
size×avg + sbw,其中
size 是元素的字符宽度,
avg 是元素主字体的平均字符宽度,以CSS
像素为单位,sbw 是滚动条的宽度,也以CSS 像素为单位。(元素的'letter-spacing' 属性不会影响结果。)
用户代理预期将 'white-space'
CSS 属性应用于
textarea
元素。出于历史原因,如果该元素具有 wrap
属性,
并且其值与字符串“off”进行ASCII
不区分大小写匹配,则用户代理预期将该属性视为一个
表现提示,把元素的
'white-space' 属性设置为“pre”。
用户代理预期将 frameset 元素渲染为一个
高度和宽度均与视口相同的框,其表面按照以下布局算法渲染:
cols 和 rows 变量是由零个或多个“数字与单位”对组成的列表, 其中单位为百分比、相对和绝对之一。
如果元素具有 cols 属性,则使用解析尺寸列表的规则
解析该属性的值。
令 cols 为所得结果;如果不存在该属性,则令其为空列表。
如果元素具有 rows 属性,则使用解析尺寸
列表的规则解析该属性的值。
令 rows 为所得结果;如果不存在该属性,则令其为空列表。
对于 cols 或 rows 中数字为零且单位为相对的任何条目, 将该条目的数字更改为一。
如果 cols 没有任何条目,则向 cols 添加一个由值 1 和 相对单位组成的条目。
如果 rows 没有任何条目,则向 rows 添加一个由值 1 和 相对单位组成的条目。
调用下文定义的将尺寸列表转换为像素
值列表算法,将 cols 用作输入列表,并将用于渲染
frameset 的表面宽度
(以CSS
像素为单位)用作输入尺寸。令 sized cols 为所得列表。
调用下文定义的将尺寸列表转换为像素
值列表算法,将 rows 用作输入列表,并将用于渲染
frameset 的表面高度
(以CSS
像素为单位)用作输入尺寸。令 sized rows 为所得列表。
将表面划分为由 w×h 个矩形组成的网格,其中 w 是 sized cols 中的条目数, h 是 sized rows 中的条目数。
调整各列的大小,使网格中的每一列宽度都与 sized cols 列表中对应条目所给出的 CSS 像素数相同。
调整各行的大小,使网格中的每一行高度都与 sized rows 列表中对应条目所给出的 CSS 像素 数相同。
令 children 为作为调用此算法的 frameset 元素的子节点的
frame 和 frameset 元素列表。
对于上一步创建的矩形网格中的每一行,按从上到下的顺序运行以下子步骤:
如果 frameset 元素具有边框,则使用元素的框架边框颜色,
在这些矩形周围绘制一组外边框。
对于每个矩形,如果有元素被分配给该矩形,并且该元素具有边框,则使用 该元素的框架边框 颜色,在该矩形周围绘制一组内边框。
对于每条(可见)边框,如果它不与一个分配了具有 noresize
属性的 frame 元素的矩形相邻
(包括进一步嵌套的 frameset 元素中的矩形),
则用户代理预期允许用户移动该边框,
调整其中矩形的大小,同时保持任何嵌套 frameset 网格的比例。
如果以下算法返回 true,则一个 frameset 或 frame 元素具有边框:
如果该元素具有 frameborder 属性,其值不为空字符串,并且其第一个字符是
U+0031 DIGIT ONE(1)、U+0079 LATIN SMALL LETTER Y(y)或
U+0059 LATIN CAPITAL LETTER Y(Y)之一,则返回 true。
否则,如果该元素具有 frameborder 属性,则返回 false。
否则,如果该元素具有一个作为 frameset
元素的父元素,
则如果该元素具有边框,返回 true;
如果没有,则返回 false。
否则,返回 true。
一个 frameset 或 frame 元素的
框架边框颜色是通过以下算法获得的颜色:
如果该元素具有 bordercolor 属性,并且对该属性的值应用
解析旧式颜色值的
规则不会返回失败,则返回所得颜色。
否则,返回灰色。
将尺寸列表转换为像素值 列表的算法由以下步骤组成:
令 input list 为传递给该算法的数字和单位列表。
令 output list 为一个与 input list 长度相同、 所有值均为零的数字列表。
output list 中的条目与 input list 中处于相同位置的条目相对应。
令 input dimension 为传递给该算法的尺寸。
令 total percentage 为 input list 中单位为百分比的 所有数字之和。
令 total relative 为 input list 中单位为相对的 所有数字之和。
令 total absolute 为 input list 中单位为绝对的 所有数字之和。
令 remaining space 为 input dimension 的值。
如果 total absolute 大于 remaining space,则对于 input list 中单位为绝对的每个条目,将 output list 中对应的值 设置为 input list 中该条目的数字乘以 remaining space,再除以 total absolute。然后,将 remaining space 设置为零。
否则,对于 input list 中单位为绝对的每个条目,将 output list 中对应的值设置为 input list 中该条目的数字。 然后,将 remaining space 减去 total absolute。
如果 total percentage 乘以 input dimension 再除以 100 所得的值大于 remaining space,则对于 input list 中单位为百分比的每个条目,将 output list 中对应的值设置为 input list 中该条目的数字乘以 remaining space,再除以 total percentage。然后,将 remaining space 设置为零。
否则,对于 input list 中单位为百分比的每个条目,将 output list 中对应的值设置为 input list 中该条目的数字乘以 input dimension,再除以 100。然后,将 remaining space 减去 total percentage 乘以 input dimension 再除以 100 所得的值。
对于 input list 中单位为相对的每个条目,将 output list 中对应的值设置为 input list 中该条目的数字乘以 remaining space,再除以 total relative。
返回 output list。
使用整数值表示框架宽度的用户代理(与能够以子像素精度布局框架的用户代理相对) 预期按以下顺序分配余数: 首先分配给单位为相对的最后一个条目,然后平均(而非按比例)分配给每个单位为 百分比的条目,再平均(而非按比例)分配给每个单位为绝对的条目, 最后,如果以上均不适用,则分配给最后一个条目。
一个没有 frameset 父元素的
frame 元素的内容
预期渲染为透明黑色;在这种情况下,用户代理
预期不渲染其内容可导航对象,并且其
内容可导航对象预期具有一个宽度和高度均为零的视口。
用户代理预期允许用户控制 超链接激活和表单提交的各个方面,例如后续 导航要使用哪个可导航对象。
用户代理预期允许用户在触发 超链接和表单的导航之前发现其目标。
用户代理预期告知用户某个超链接是否包含超链接审计, 并且至少让用户知道作为此类审计的一部分会联系哪些域。
用户代理可以允许用户将可导航对象导航到 q、
blockquote、
ins 和 del 元素的
cite 属性所指示的 URL。
如前文所述,
用户代理可以在其用户界面中显示由 link
元素创建的超链接。
title 属性用户代理预期在用户请求时公开元素的提示信息, 并让用户知道存在此类信息。
在用户可以使用指针设备的交互式图形系统上,这可以采用工具提示的形式。当用户无法使用 指针设备时,用户代理预期以其他方式提供该内容,例如使该 元素成为一个可聚焦区域,并始终显示当前已聚焦元素的提示 信息,或者当用户在触摸设备上平移屏幕时,显示用户手指下方元素的提示 信息。
U+000A LINE FEED(LF)字符预期会在工具提示中产生换行;U+0009 CHARACTER TABULATION (制表符)字符预期渲染为非零的水平位移,使下一个字形与下一个制表位对齐, 制表位位于 U+0020 SPACE 字符宽度的 8 倍的整数倍位置。
例如,视觉用户代理可以使具有 title 属性的元素可聚焦,并且可以让任何具有 title 属性的已聚焦元素在获得焦点时,
在该元素下方显示其工具提示。这将允许用户通过 Tab 键在文档中移动,以查找所有提示文本。
再举一个例子,屏幕阅读器可以在读取具有工具提示的元素时提供音频提示, 并提供一个关联按键,用于读取最近一次播放提示音的工具提示。
当前文本编辑插入符(即活动范围,如果它为空并且位于编辑宿主中)(如果有),就 CSS 渲染模型而言,预期表现得像一个行内替换元素,具有插入符的垂直尺寸且宽度为零。
这意味着,即使是空块也可以在其中放置插入符,并且当插入符位于此类元素中时, 它会阻止外边距穿过该元素折叠。
用户代理预期遵循用户界面中所公开文本的 Unicode 语义,例如支持对话框、标题栏、弹出菜单和工具提示中所显示文本的双向算法。从元素内容获得的文本 预期以遵循获取该文本的元素之方向性的方式渲染。 从属性获得的文本预期以遵循该属性方向性的方式渲染。
考虑以下标记,其中包含询问编程语言的希伯来语文本;由于某些语言名称中包含标点, 保持这些语言名称文本从左到右的方向非常重要:
< p dir = "rtl" lang = "he" >
< label >
בחר שפת תכנות:
< select >
< option dir = "ltr" > C++</ option >
< option dir = "ltr" > C#</ option >
< option dir = "ltr" > FreePascal</ option >
< option dir = "ltr" > F#</ option >
</ select >
</ label >
</ p > 如果 select
元素渲染为下拉框,则正确的渲染会确保标点在下拉列表中和显示当前选择的框中保持一致。

属性的方向性取决于属性以及元素的 dir
属性,
如以下示例所示。考虑此标记:
< table >
< tr >
< th abbr = "(א" dir = ltr > A
< th abbr = "(א" dir = rtl > A
< th abbr = "(א" dir = auto > A
</ table > 如果渲染 abbr
属性,例如在工具提示或其他用户界面中,则第一个会显示左括号(因为方向为“ltr”),
第二个会显示右括号(因为方向为“rtl”),第三个会显示右括号
(因为根据属性值确定其方向为“rtl”)。
但是,如果该属性不是支持方向性的属性, 则结果会有所不同:
< table >
< tr >
< th data-abbr = "(א" dir = ltr > A
< th data-abbr = "(א" dir = rtl > A
< th data-abbr = "(א" dir = auto > A
</ table > 在这种情况下,如果用户代理要在用户界面中公开 data-abbr 属性
(例如在调试环境中),则最后一种情况会使用左括号渲染,
因为方向会根据元素的内容确定。
脚本提供的字符串(例如传递给 window.alert()
的参数)在显示时预期被视为由一个或多个独立的双向算法段落
组成,如双向算法所定义,例如包括支持 U+000A LINE FEED(LF)字符的段落分隔行为。
就在双向算法中确定此类文本的段落级别而言,本规范不提供对规则 P2 和 P3 的高层覆盖。
[BIDI]
必要时,作者可以通过在给定段落开头添加 Unicode U+200E LEFT-TO-RIGHT MARK 或 U+200F RIGHT-TO-LEFT MARK 字符,强制指定该段落的方向。
因此,以下脚本:
alert( '\u05DC\u05DE\u05D3 HTML \u05D4\u05D9\u05D5\u05DD!' ) ……总是会生成一条内容为 “למד LMTH היום!” 的消息(而不是“דמל HTML םויה!”), 而不考虑用户代理界面的语言、页面方向或其任何元素的方向。
作为一个更复杂的示例,考虑以下脚本:
/* 警告:此脚本无法正确处理从右到左的文字 */
var s;
if ( s = prompt( 'What is your name?' )) {
alert( s + '! Ok, Fred, ' + s + ', and Wilma will get the car.' );
} 当用户输入“Kitty”时,用户代理会发出警告: “Kitty! Ok, Fred, Kitty, and Wilma will get the car.”。 但是,如果用户输入“لا أفهم”,则双向算法会确定该段落的方向为从右到左, 因而输出会成为以下非预期的混乱内容:“لا أفهم! derF ,kO, لا أفهم, rac eht teg lliw amliW dna.”
要强制以用户提供的文本(或其他方向未知的文本)开头的警告从左到右渲染, 可以在字符串前添加一个 U+200E LEFT-TO-RIGHT MARK 字符:
var s;
if ( s = prompt( 'What is your name?' )) {
alert( ' \u200E ' + s + '! Ok, Fred, ' + s + ', and Wilma will get the car.' );
} 用户代理预期允许用户请求获得一个 Document 的物理形式(或物理形式的表示)。例如,选择打印页面或将其转换为 PDF
格式的选项。[PDF]
当用户实际获得物理形式(或物理形式的表示)的 Document 时,用户代理
预期为打印媒体创建该 Document 的新渲染。
在某些情况下,HTML 用户代理可能需要渲染使用其没有任何内置知识的词汇表的非 HTML 文档。 本节提供了一种让用户代理以某种有用方式处理此类文档的方法。
当一个 Document 是一个无样式文档时,用户代理
预期渲染无样式文档视图。
当一个 Document 满足以下条件时,
它是一个无样式文档:
Document 没有作者样式表
(无论该样式表是由 HTTP 标头、处理指令、诸如 link 之类的元素、
诸如 style
之类的内联元素,还是任何其他机制引用)。
Document 中没有任何元素具有任何表现提示。
Document 中没有任何元素具有任何style 属性。
Document 中没有任何元素位于以下任何
命名空间中:HTML 命名空间、SVG 命名空间、MathML 命名空间。
Document 除视口之外,没有任何可聚焦区域(例如来自 XLink)。
Document 没有任何超链接(例如来自 XLink)。
Document 作为其关联
Document 的 Window 对象。
Document 中没有任何元素注册了事件
监听器。
无样式文档视图是指不按照 CSS 渲染 DOM
(在此上下文中,由于没有适用的样式,这只会产生一整块文本),而是以对开发者有用的方式进行渲染。
这可以只是显示 Document 对象的源代码,
可能带有语法高亮;也可以只显示 DOM 树;或者仅显示一条说明该页面不是样式化文档的消息。
如果一个 Document 不再是无样式文档,
则上述条件不再适用,因此遵循这些要求的用户代理会切换为使用常规 CSS 渲染。
本节列出的功能会在一致性检查器中触发警告。
作者不应在 img 元素上指定
border 属性。
如果该属性存在,其值必须为字符串“0”。应改用 CSS。
作者不应在 script
元素上指定 charset
属性。如果该属性存在,其值必须与“utf-8”进行ASCII
不区分大小写匹配。(在符合本标准其他部分要求、
采用 UTF-8 编码的文档中,这没有任何影响。)
作者不应在 script
元素上指定 language
属性。如果该属性存在,其值必须与字符串“JavaScript”进行ASCII
不区分大小写匹配,并且要么省略
type 属性,
要么其值必须与字符串“text/javascript”进行ASCII
不区分大小写匹配。
应改为完全省略该属性(当值为“JavaScript”时,它没有任何作用),或者改用 type 属性。
作者不应在 script
元素上为 type
属性指定空字符串,或指定与JavaScript MIME 类型本质匹配的值。
相反,应省略该属性,其效果相同。
作者不应在 style
元素上
指定 type 属性。
如果该属性存在,其值必须与“text/css”进行ASCII
不区分大小写匹配。
作者不应在 a 元素上指定 name 属性。
如果该属性存在,其值不得为空字符串;不得等于该元素的树中任何ID 的值,但该元素自身的ID(如果有)除外;也不得等于该元素的树中其他 a 元素的任何
name
属性值。如果存在此属性,并且该元素具有ID,则属性值必须等于元素的ID。在该语言的早期版本中,此属性旨在用于指定
URL 中片段的可能目标。应改用
id 属性。
作者不应这样做,但即使本规范其他地方有相反要求,仍可以在其 type 属性处于
数字状态的
input 元素上,
指定 maxlength
和 size
属性。无论如何仍使用这些属性的一个合理原因,是帮助不支持
type="number" 的旧式用户代理,仍能以有用的宽度渲染文本控件。
为了便于从 HTML4 Transitional 文档过渡到本规范定义的语言,并阻止使用仅在极少数 情况下允许的某些功能,当文档中使用以下功能时,一致性检查器必须向用户发出警告。 这些通常是没有任何作用的旧式过时功能,仅允许使用它们,是为了区分可能的错误 (常规一致性错误)与仅仅残留的标记或不寻常且不鼓励的做法(这些警告)。
以下功能必须按上述方式分类:
当 script
元素上的 charset
属性值与“utf-8”进行ASCII
不区分大小写匹配时,该属性的存在。
当 script
元素上的 language
属性值与字符串“JavaScript”进行ASCII
不区分大小写匹配,并且不存在 type
属性,或者存在该属性且其值与字符串“text/javascript”进行ASCII
不区分大小写匹配时,该属性的存在。
当 script
元素上的 type
属性值与JavaScript MIME 类型本质
匹配时,该属性的存在。
当 style
元素上的 type
属性值与“text/css”进行ASCII
不区分大小写匹配时,该属性的存在。
一致性检查器必须区分没有一致性错误且没有这些过时功能的页面,与没有一致性错误但确实具有 某些此类过时功能的页面。
例如,验证器可以将某些页面报告为“有效 HTML”,而将其他页面报告为 “有效 HTML,但有警告”。
以下列表中的元素已完全过时,作者不得使用:
appletacronym改用 abbr。
bgsound改用 audio。
dir改用 ul。
frameframesetnoframes改用 iframe 和 CSS,
或者使用服务器端包含功能,生成已合并各个不变部分的完整页面。
isindexkeygen对于企业设备管理用例,请使用设备上的原生管理功能。
对于证书注册用例,请使用 Web Cryptography API 为证书生成密钥对,然后导出证书和密钥, 以允许用户手动安装它们。[WEBCRYPTO]
listingmenuitem要实现自定义上下文菜单,请使用脚本处理 contextmenu
事件。
nextid改用 GUID。
noembedparamplaintext改用“text/plain”
MIME 类型。
rbrtcstrikexmpbasefontbigblinkcenterfontmarqueemulticolnobrspacertt改用适当的元素或 CSS。
如果原本使用 tt 元素标记键盘输入,
请考虑使用 kbd 元素;
对于变量,请考虑使用 var 元素;
对于计算机代码,请考虑使用 code
元素;
对于计算机输出,请考虑使用
samp 元素。
类似地,如果使用 big 元素表示标题,
请考虑使用 h1
元素;如果用于标记重要段落,请考虑使用
strong
元素;如果用于突出显示供参考的文本,请考虑使用 mark 元素。
另请参阅文本级语义用法摘要,其中包含更多带示例的建议。
以下属性已过时(尽管这些元素仍是该语言的一部分),作者不得使用:
a 元素上的 charsetlink 元素上的 charset改为在所链接的资源上使用 HTTP `Content-Type` 标头。
script
元素上的 charset
(上一节所述情况除外)
a 元素上的 coordsa 元素上的 shapea 元素上的 methodslink 元素上的 methods改用 HTTP OPTIONS 功能。
a 元素上的 name
(上一节所述情况除外)embed 元素上的 nameimg 元素上的 nameoption 元素上的 name改用 id 属性。
a 元素上的 revlink 元素上的 rev改用 rel
属性,并使用相反的术语。(例如,使用 rel="author" 代替
rev="made"。)
a 元素上的 urnlink 元素上的 urn改用 href
属性指定首选的持久标识符。
form 元素上的 acceptarea 元素上的
hreflang
area 元素上的 type这些属性没有任何有用作用,并且由于历史原因,area 元素上
没有对应的 IDL 属性。请将其完全省略。
area 元素上的 nohrefhead 元素上的 profile没有必要。请将其完全省略。
html 元素上的
manifest
改用 Service Worker。[SW]
html 元素上的 version没有必要。请将其完全省略。
input 元素上的
ismap
没有必要。请将其完全省略。所有其 type
属性处于图像
按钮状态的 input
元素,
都会作为服务器端图像映射处理。
input 元素上的
usemap
object 元素上的
usemap
对于图像映射,请使用 img 元素。
iframe 元素上的
longdesc
img 元素上的 longdescimg 元素上的 lowsrc请使用渐进式 JPEG 图像(在 src 属性中给出),
而不是使用两个单独的图像。
link 元素上的
target
没有必要。请将其完全省略。
menu 元素上的 type要实现自定义上下文菜单,请使用脚本处理 contextmenu
事件。对于工具栏菜单,请省略该属性。
menu 元素上的 labelcontextmenuonshow要实现自定义上下文菜单,请使用脚本处理 contextmenu
事件。
meta 元素上的 scheme每个字段只使用一种方案,或者使方案声明成为值的一部分。
object 元素上的
archive
object 元素上的
classid
object 元素上的
code
object 元素上的
codebase
object 元素上的
codetype
object 元素上的
declare
每次要重新使用资源时,完整重复 object
元素。
object 元素上的
standby
优化所链接的资源,使其能够快速加载,或者至少能够增量加载。
object 元素上的
typemustmatch
避免将 object
元素用于不受信任的资源。
script 元素上的
language
(上一节所述情况除外)
script 元素上的
event
script 元素上的
for
使用 DOM 事件机制注册事件监听器。[DOM]
style 元素上的
type
(上一节所述情况除外)
table 元素上的 datapagesize
没有必要。请将其完全省略。
table 元素上的
summary
td 元素上的 abbr使用以明确而简洁的方式开头的文本,并将任何更详细的文本放在其后。title 属性也可以用于
包含更详细的文本,从而使单元格内容保持简洁。如果这是一个标题,请使用
th(它具有
abbr 属性)。
td 和 th 元素上的
axis
td 元素上的 scope标题单元格请使用 th 元素。
a、button、div、frame、iframe、img、input、label、legend、marquee、object、option、select、span、table 和 textarea
元素上的 datasrc
a、button、div、fieldset、frame、iframe、img、input、label、legend、marquee、object、select、span 和 textarea
元素上的 datafld
button、div、input、label、legend、marquee、object、option、select、span 和 table 元素上的
dataformatas
使用脚本和诸如 XMLHttpRequest
之类的机制动态填充页面。[XHR]
dropzonebody 元素上的 alinkbody 元素上的 bgcolorbody 元素上的 bottommargin
body 元素上的 leftmargin
body 元素上的 linkbody 元素上的 marginheight
body 元素上的 marginwidthbody 元素上的 rightmarginbody 元素上的 textbody 元素上的 topmargin
body 元素上的 vlinkbr 元素上的 clearcaption 元素上的
align
col 元素上的 aligncol 元素上的 charcol 元素上的 charoffcol 元素上的 valigncol 元素上的 widthdiv 元素上的 aligndl 元素上的 compactembed 元素上的
align
embed 元素上的
hspace
embed 元素上的
vspace
hr 元素上的 alignhr 元素上的 colorhr 元素上的 noshadehr 元素上的 sizehr 元素上的 widthh1—h6
元素上的 aligniframe 元素上的
align
iframe 元素上的
allowtransparency
iframe 元素上的
frameborder
iframe 元素上的
framespacing
iframe 元素上的
hspace
iframe 元素上的
marginheight
iframe 元素上的
marginwidth
iframe 元素上的
scrolling
iframe 元素上的
vspace
input 元素上的
align
input 元素上的
border
input 元素上的
hspace
input 元素上的
vspace
img 元素上的 alignimg 元素上的 border
(上一节所述情况除外)img 元素上的 hspaceimg 元素上的 vspacelegend 元素上的
align
li 元素上的 typemenu 元素上的 compactobject 元素上的
align
object 元素上的
border
object 元素上的
hspace
object 元素上的
vspace
ol 元素上的 compactp 元素上的 alignpre 元素上的 widthtable 元素上的
align
table 元素上的
bgcolor
table 元素上的
border
table 元素上的
bordercolor
table 元素上的
cellpadding
table 元素上的
cellspacing
table 元素上的
frame
table 元素上的
height
table 元素上的
rules
table 元素上的
width
tbody、thead 和 tfoot 元素上的
align
tbody、thead 和 tfoot 元素上的
char
tbody、thead 和 tfoot 元素上的
charoff
thead、tbody 和 tfoot 元素上的
height
tbody、thead 和 tfoot 元素上的
valign
td 和 th 元素上的
align
td 和 th 元素上的
bgcolor
td 和 th 元素上的
char
td 和 th 元素上的
charoff
td 和 th 元素上的
height
td 和 th 元素上的
nowrap
td 和 th 元素上的
valign
td 和 th 元素上的
width
tr 元素上的 aligntr 元素上的 bgcolortr 元素上的 chartr 元素上的 charofftr 元素上的 heighttr 元素上的 valignul 元素上的 compactul 元素上的 typebody、table、thead、tbody、tfoot、tr、td 和 th 元素上的
background
改用 CSS。
marquee
元素
marquee 元素是一个
为内容添加动画的表现性元素。CSS 过渡和动画是更合适的机制。
[CSSANIMATIONS] [CSSTRANSITIONS]
marquee 元素
必须实现 HTMLMarqueeElement
接口。
[Exposed =Window ]
interface HTMLMarqueeElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect ] attribute DOMString behavior ;
[CEReactions , Reflect ] attribute DOMString bgColor ;
[CEReactions , Reflect ] attribute DOMString direction ;
[CEReactions , Reflect ] attribute DOMString height ;
[CEReactions , Reflect ] attribute unsigned long hspace ;
[CEReactions ] attribute long loop ;
[CEReactions , Reflect , ReflectDefault=6] attribute unsigned long scrollAmount ;
[CEReactions , Reflect , ReflectDefault=85] attribute unsigned long scrollDelay ;
[CEReactions , Reflect ] attribute boolean trueSpeed ;
[CEReactions , Reflect ] attribute unsigned long vspace ;
[CEReactions , Reflect ] attribute DOMString width ;
undefined start ();
undefined stop ();
};marquee 元素
可以处于开启或关闭状态。
创建时,它处于开启状态。
marquee 元素上的
behavior
内容属性是一个枚举属性,具有以下关键字和状态
(全部不符合规范):
| 关键字 | 状态 |
|---|---|
scroll
|
scroll |
slide
|
slide |
alternate
|
alternate |
marquee
元素上的 direction 内容属性是一个枚举
属性,具有以下关键字和状态(全部不符合规范):
| 关键字 | 状态 |
|---|---|
left
|
left |
right
|
right |
up
|
up |
down
|
down |
marquee
元素上的 truespeed 内容属性是一个布尔属性。
一个 marquee 元素具有一个
marquee 滚动间隔,其获取方式如下:
如果该元素具有 scrolldelay 属性,并且使用解析非负整数的规则
解析其值时不会返回错误,则令 delay 为解析后的值。否则,令
delay 为 85。
如果该元素没有 truespeed
属性,并且 delay 值小于 60,则改为令 delay 为 60。
marquee 滚动 间隔为 delay,以毫秒解释。
一个 marquee 元素具有一个
marquee 滚动距离。如果该元素具有
scrollamount 属性,并且使用解析非负整数的规则
解析其值时不会返回错误,则该距离为解析后的值,并以CSS 像素解释;
否则为 6 CSS
像素。
loop
IDL 属性在获取时,必须返回元素的
marquee 循环次数;在设置时,如果新值与元素的
marquee 循环次数不同,并且该值大于零或等于 −1,
则必须将元素的 loop 内容属性
(必要时添加)设置为表示新值的有效整数。
(其他值会被忽略。)
一个 marquee 元素
还具有一个marquee 当前循环索引,
该索引在元素创建时为零。
渲染层有时会递增 marquee 当前循环索引,这必须导致运行以下步骤:
如果marquee 循环次数为 −1,则返回。
将marquee 当前循环索引增加一。
如果marquee
当前循环索引现在大于或等于元素的marquee
循环次数,则关闭
marquee 元素。
frameset 元素在使用框架的文档中充当body 元素。
frameset 元素必须实现 HTMLFrameSetElement
接口。
[Exposed =Window ]
interface HTMLFrameSetElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect ] attribute DOMString cols ;
[CEReactions , Reflect ] attribute DOMString rows ;
};
HTMLFrameSetElement includes WindowEventHandlers ;frameset 元素将 Window 对象的若干事件处理器公开为事件处理器内容
属性。它还镜像这些处理器的事件处理器 IDL
属性。
由Window-反映 body 元素事件
处理器集命名,并公开在 frameset 元素上的 Window 对象事件处理器,会替换通常由HTML
元素支持的同名通用事件处理器。
frame 元素具有一个与 iframe 元素类似的内容可导航对象,但它渲染在 frameset 元素内。
给定 insertedNode,frame 的HTML 元素插入步骤为:
如果 insertedNode 不在文档树中,则返回。
为 insertedNode 创建新的子可导航对象。
为 insertedNode 处理
frame 属性,并将
initialInsertion 设置为 true。
给定 removedNode,frame 的HTML 元素移除步骤,
是在给定 removedNode 的情况下销毁子可导航对象。
每当具有非 null 内容可导航对象的 frame 元素的
src 属性被设置、更改或移除时,用户代理必须处理
frame 属性。
要为元素 element 处理
frame 属性,并可选地给定布尔值 initialInsertion:
令 url 为在给定 element 和
initialInsertion 的情况下,运行iframe 和
frame 元素的共享属性处理步骤所得的结果。
如果 url 为 null,则返回。
如果 url 匹配
about:blank,并且
initialInsertion 为 true:
给定 element、url、空字符串和
initialInsertion,导航
iframe 或
frame。
frame 元素必须实现 HTMLFrameElement 接口。
[Exposed =Window ]
interface HTMLFrameElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect ] attribute DOMString name ;
[CEReactions , Reflect ] attribute DOMString scrolling ;
[CEReactions , ReflectURL ] attribute USVString src ;
[CEReactions , Reflect ] attribute DOMString frameBorder ;
[CEReactions , ReflectURL ] attribute USVString longDesc ;
[CEReactions , Reflect ] attribute boolean noResize ;
readonly attribute Document ? contentDocument ;
readonly attribute WindowProxy ? contentWindow ;
[CEReactions , Reflect ] attribute [LegacyNullToEmptyString ] DOMString marginHeight ;
[CEReactions , Reflect ] attribute [LegacyNullToEmptyString ] DOMString marginWidth ;
};就语义和渲染而言,用户代理必须以等同于 abbr
元素的方式处理 acronym 元素。
partial interface HTMLAnchorElement {
[CEReactions , Reflect ] attribute DOMString coords ;
[CEReactions , Reflect ] attribute DOMString charset ;
[CEReactions , Reflect ] attribute DOMString name ;
[CEReactions , Reflect ] attribute DOMString rev ;
[CEReactions , Reflect ] attribute DOMString shape ;
};partial interface HTMLAreaElement {
[CEReactions , Reflect ] attribute boolean noHref ;
};partial interface HTMLBodyElement {
[CEReactions , Reflect ] attribute [LegacyNullToEmptyString ] DOMString text ;
[CEReactions , Reflect ] attribute [LegacyNullToEmptyString ] DOMString link ;
[CEReactions , Reflect ] attribute [LegacyNullToEmptyString ] DOMString vLink ;
[CEReactions , Reflect ] attribute [LegacyNullToEmptyString ] DOMString aLink ;
[CEReactions , Reflect ] attribute [LegacyNullToEmptyString ] DOMString bgColor ;
[CEReactions , Reflect ] attribute DOMString background ;
};由于历史原因,background
IDL 属性不使用 ReflectURL 或
USVString。
partial interface HTMLBRElement {
[CEReactions , Reflect ] attribute DOMString clear ;
};partial interface HTMLTableCaptionElement {
[CEReactions , Reflect ] attribute DOMString align ;
};partial interface HTMLTableColElement {
[CEReactions , Reflect ] attribute DOMString align ;
[CEReactions , Reflect="char"] attribute DOMString ch ;
[CEReactions , Reflect="charoff"] attribute DOMString chOff ;
[CEReactions , Reflect ] attribute DOMString vAlign ;
[CEReactions , Reflect ] attribute DOMString width ;
};就语义和渲染而言,用户代理必须以等同于 ul
元素的方式处理 dir 元素。
dir 元素必须实现
HTMLDirectoryElement
接口。
[Exposed =Window ]
interface HTMLDirectoryElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect ] attribute boolean compact ;
};partial interface HTMLDivElement {
[CEReactions , Reflect ] attribute DOMString align ;
};partial interface HTMLDListElement {
[CEReactions , Reflect ] attribute boolean compact ;
};partial interface HTMLEmbedElement {
[CEReactions , Reflect ] attribute DOMString align ;
[CEReactions , Reflect ] attribute DOMString name ;
};font 元素必须实现
HTMLFontElement
接口。
[Exposed =Window ]
interface HTMLFontElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect ] attribute [LegacyNullToEmptyString ] DOMString color ;
[CEReactions , Reflect ] attribute DOMString face ;
[CEReactions , Reflect ] attribute DOMString size ;
};partial interface HTMLHeadingElement {
[CEReactions , Reflect ] attribute DOMString align ;
};有意省略了 head 元素
(具有 HTMLHeadElement
接口)上的 profile
IDL 属性。除非其他适用规范要求,
否则实现将不支持此属性。(这里提及它,是因为它曾在早期版本的 DOM 中定义。)
partial interface HTMLHRElement {
[CEReactions , Reflect ] attribute DOMString align ;
[CEReactions , Reflect ] attribute DOMString color ;
[CEReactions , Reflect ] attribute boolean noShade ;
[CEReactions , Reflect ] attribute DOMString size ;
[CEReactions , Reflect ] attribute DOMString width ;
};partial interface HTMLHtmlElement {
[CEReactions , Reflect ] attribute DOMString version ;
};partial interface HTMLIFrameElement {
[CEReactions , Reflect ] attribute DOMString align ;
[CEReactions , Reflect ] attribute DOMString scrolling ;
[CEReactions , Reflect ] attribute DOMString frameBorder ;
[CEReactions , ReflectURL ] attribute USVString longDesc ;
[CEReactions , Reflect ] attribute [LegacyNullToEmptyString ] DOMString marginHeight ;
[CEReactions , Reflect ] attribute [LegacyNullToEmptyString ] DOMString marginWidth ;
};partial interface HTMLImageElement {
[CEReactions , Reflect ] attribute DOMString name ;
[CEReactions , ReflectURL ] attribute USVString lowsrc ;
[CEReactions , Reflect ] attribute DOMString align ;
[CEReactions , Reflect ] attribute unsigned long hspace ;
[CEReactions , Reflect ] attribute unsigned long vspace ;
[CEReactions , ReflectURL ] attribute USVString longDesc ;
[CEReactions , Reflect ] attribute [LegacyNullToEmptyString ] DOMString border ;
};partial interface HTMLInputElement {
[CEReactions , Reflect ] attribute DOMString align ;
[CEReactions , Reflect ] attribute DOMString useMap ;
};partial interface HTMLLegendElement {
[CEReactions , Reflect ] attribute DOMString align ;
};partial interface HTMLLIElement {
[CEReactions , Reflect ] attribute DOMString type ;
};partial interface HTMLLinkElement {
[CEReactions , Reflect ] attribute DOMString charset ;
[CEReactions , Reflect ] attribute DOMString rev ;
[CEReactions , Reflect ] attribute DOMString target ;
};就语义和渲染而言,用户代理必须以等同于 pre
元素的方式处理 listing 元素。
partial interface HTMLMenuElement {
[CEReactions , Reflect ] attribute boolean compact ;
};partial interface HTMLMetaElement {
[CEReactions , Reflect ] attribute DOMString scheme ;
};当处理一个具有 name
属性,并且其值被用户代理识别为支持 scheme
属性的 meta
元素时,用户代理可以将 meta 元素上的
scheme 内容属性视为元素的 name
内容属性的扩展。
鼓励用户代理忽略 scheme
属性,而是针对 scheme
属性的每个预期值,处理提供给元数据名称的值,就像该值已分别指定一样。
例如,如果用户代理会处理 name
属性值为“eGMS.subject.keyword”的 meta
元素,并且知道 scheme
属性与此元数据名称一起使用,那么它可以考虑 scheme
属性,将其视为 name
属性的扩展。因此,以下两个 meta
元素可以被视为为两个不同的元数据名称提供值:一个由“eGMS.subject.keyword”和
“LGCL”组合而成,另一个由“eGMS.subject.keyword”和“ORLY”组合而成:
<!-- 此标记无效 -->
< meta name = "eGMS.subject.keyword" scheme = "LGCL" content = "Abandoned vehicles" >
< meta name = "eGMS.subject.keyword" scheme = "ORLY" content = "Mah car: kthxbye" > 但是,建议对此标记所作的处理等同于以下内容:
< meta name = "eGMS.subject.keyword" content = "Abandoned vehicles" >
< meta name = "eGMS.subject.keyword" content = "Mah car: kthxbye" > 所有当前引擎均支持。
partial interface HTMLObjectElement {
[CEReactions , Reflect ] attribute DOMString align ;
[CEReactions , Reflect ] attribute DOMString archive ;
[CEReactions , Reflect ] attribute DOMString code ;
[CEReactions , Reflect ] attribute boolean declare ;
[CEReactions , Reflect ] attribute unsigned long hspace ;
[CEReactions , Reflect ] attribute DOMString standby ;
[CEReactions , Reflect ] attribute unsigned long vspace ;
[CEReactions , ReflectURL ] attribute DOMString codeBase ;
[CEReactions , Reflect ] attribute DOMString codeType ;
[CEReactions , Reflect ] attribute DOMString useMap ;
[CEReactions , Reflect ] attribute [LegacyNullToEmptyString ] DOMString border ;
};partial interface HTMLOListElement {
[CEReactions , Reflect ] attribute boolean compact ;
};partial interface HTMLParagraphElement {
[CEReactions , Reflect ] attribute DOMString align ;
};param 元素必须实现
HTMLParamElement
接口。
[Exposed =Window ]
interface HTMLParamElement : HTMLElement {
[HTMLConstructor ] constructor ();
[CEReactions , Reflect ] attribute DOMString name ;
[CEReactions , Reflect ] attribute DOMString value ;
[CEReactions , Reflect ] attribute DOMString type ;
[CEReactions , Reflect ] attribute DOMString valueType ;
};就语义和渲染而言,用户代理必须以等同于
pre
元素的方式处理 plaintext 元素。
(不过,解析器对此元素具有特殊行为。)
partial interface HTMLPreElement {
[CEReactions , Reflect ] attribute long width ;
};partial interface HTMLStyleElement {
[CEReactions , Reflect ] attribute DOMString type ;
};partial interface HTMLScriptElement {
[CEReactions , Reflect ] attribute DOMString charset ;
[CEReactions , Reflect ] attribute DOMString event ;
[CEReactions , Reflect="for"] attribute DOMString htmlFor ;
};partial interface HTMLTableElement {
[CEReactions , Reflect ] attribute DOMString align ;
[CEReactions , Reflect ] attribute DOMString border ;
[CEReactions , Reflect ] attribute DOMString frame ;
[CEReactions , Reflect ] attribute DOMString rules ;
[CEReactions , Reflect ] attribute DOMString summary ;
[CEReactions , Reflect ] attribute DOMString width ;
[CEReactions , Reflect ] attribute [LegacyNullToEmptyString ] DOMString bgColor ;
[CEReactions , Reflect ] attribute [LegacyNullToEmptyString ] DOMString cellPadding ;
[CEReactions , Reflect ] attribute [LegacyNullToEmptyString ] DOMString cellSpacing ;
};partial interface HTMLTableSectionElement {
[CEReactions , Reflect ] attribute DOMString align ;
[CEReactions , Reflect="char"] attribute DOMString ch ;
[CEReactions , Reflect="charoff"] attribute DOMString chOff ;
[CEReactions , Reflect ] attribute DOMString vAlign ;
};partial interface HTMLTableCellElement {
[CEReactions , Reflect ] attribute DOMString align ;
[CEReactions , Reflect ] attribute DOMString axis ;
[CEReactions , Reflect ] attribute DOMString height ;
[CEReactions , Reflect ] attribute DOMString width ;
[CEReactions , Reflect="char"] attribute DOMString ch ;
[CEReactions , Reflect="charoff"] attribute DOMString chOff ;
[CEReactions , Reflect ] attribute boolean noWrap ;
[CEReactions , Reflect ] attribute DOMString vAlign ;
[CEReactions , Reflect ] attribute [LegacyNullToEmptyString ] DOMString bgColor ;
};partial interface HTMLTableRowElement {
[CEReactions , Reflect ] attribute DOMString align ;
[CEReactions , Reflect="char"] attribute DOMString ch ;
[CEReactions , Reflect="charoff"] attribute DOMString chOff ;
[CEReactions , Reflect ] attribute DOMString vAlign ;
[CEReactions , Reflect ] attribute [LegacyNullToEmptyString ] DOMString bgColor ;
};partial interface HTMLUListElement {
[CEReactions , Reflect ] attribute boolean compact ;
[CEReactions , Reflect ] attribute DOMString type ;
};就语义和渲染而言,用户代理必须以等同于 pre
元素的方式处理 xmp 元素。
(不过,解析器对此元素具有特殊行为。)
partial interface Document {
[CEReactions ] attribute [LegacyNullToEmptyString ] DOMString fgColor ;
[CEReactions ] attribute [LegacyNullToEmptyString ] DOMString linkColor ;
[CEReactions ] attribute [LegacyNullToEmptyString ] DOMString vlinkColor ;
[CEReactions ] attribute [LegacyNullToEmptyString ] DOMString alinkColor ;
[CEReactions ] attribute [LegacyNullToEmptyString ] DOMString bgColor ;
[SameObject ] readonly attribute HTMLCollection anchors ;
[SameObject ] readonly attribute HTMLCollection applets ;
undefined clear ();
undefined captureEvents ();
undefined releaseEvents ();
[SameObject ] readonly attribute HTMLAllCollection all ;
};如果body 元素是一个
body
元素(而不是 frameset 元素),
则下表第一列列出的 Document 对象属性,
必须反映body 元素上,
同一行第二列对应单元格中给定名称的内容属性。
当不存在body 元素,或者它是一个
frameset
元素时,这些属性在获取时必须改为返回空字符串,并且在设置时不执行任何操作。
| IDL 属性 | 内容属性 |
|---|---|
fgColor
|
text
|
linkColor
|
link
|
vlinkColor
|
vlink
|
alinkColor
|
alink
|
bgColor
|
bgcolor
|
anchors
属性必须返回一个以 Document 节点为根的
HTMLCollection,
其过滤器仅匹配具有 name
属性的 a 元素。
applets
属性必须返回一个以 Document 节点为根的
HTMLCollection,
其过滤器不匹配任何内容。(它因历史原因而存在。)
clear()、
captureEvents() 和
releaseEvents() 方法必须不执行任何操作。
all 属性必须返回一个以
Document 节点为根、
且其过滤器匹配所有元素的 HTMLAllCollection。
partial interface Window {
undefined captureEvents ();
undefined releaseEvents ();
[Replaceable , SameObject ] readonly attribute External external ;
};captureEvents() 和 releaseEvents() 方法必须不执行任何操作。
[Exposed =Window ]
interface External {
undefined AddSearchProvider ();
undefined IsSearchProviderInstalled ();
};AddSearchProvider() 和 IsSearchProviderInstalled() 方法
必须不执行任何操作。
text/html此注册供社区审阅,并将提交给 IESG 进行审查、批准并在 IANA 注册。
charset可以提供 charset 参数来指定文档的字符编码,覆盖文档中除字节顺序标记
(BOM)之外的任何字符编码声明。该参数的值必须与字符串
“utf-8”进行ASCII 不区分大小写匹配。
[ENCODING]
关于适用于 HTML 文档的安全注意事项,整本书都可以写出来。本文档列出了其中许多内容, 读者可参阅本文档以获取更多详细信息。不过,这里值得提及一些一般性问题:
HTML 是一种可编写脚本的语言,并且具有大量 API(其中一些在本文档中描述)。 脚本可能使用户面临信息泄露、凭据泄露、跨站脚本攻击、跨站请求伪造以及许多其他问题。 虽然本规范中的设计在正确实现时旨在保证安全,但完整实现是一项庞大的工程,并且与任何软件一样, 用户代理很可能存在安全漏洞。
即使没有脚本,HTML 中也存在一些特定功能;由于历史原因,为了与旧式内容保持广泛兼容,
必须支持这些功能,但它们会使用户面临不良的安全问题。尤其是,img
元素可以与其他某些功能结合,
从用户在互联网中的位置执行端口扫描。这可能暴露攻击者原本无法确定的本地网络拓扑。
HTML 依赖一种有时称为同源策略的隔离方案。在大多数情况下,一个源由使用相同协议、相同端口、 从相同主机提供的所有页面组成。
因此,必须确保构成站点一部分的任何不受信任内容,都托管在与该站点上任何敏感内容不同的源上。不受信任的内容可以轻易伪装同源中的 任何其他页面、读取该源的数据、使该源中的脚本执行、向该源提交表单或从该源提交表单, 即使这些表单通过唯一令牌防范了跨站请求伪造攻击,也可以利用向该源公开的任何第三方资源, 或授予该源的任何权限。
html”和“htm”通常用作 HTML 文档的扩展名,
但绝非仅限于此。TEXT与 text/html 资源一起使用的片段,要么指向对应 Document 的所指示部分,
要么为页面内脚本提供状态信息。
multipart/x-mixed-replace此注册供社区审阅,并将提交给 IESG 进行审查、批准并在 IANA 注册。
boundary(在 RFC2046 中定义)[RFC2046]
multipart/x-mixed-replace
资源的子资源可以是任何类型,包括具有重大安全影响的类型,例如 text/html。
multipart/mixed
相同。[RFC2046]
multipart/x-mixed-replace
资源。与 multipart/x-mixed-replace
资源一起使用的片段,按照各正文部分所使用的类型定义,
应用于每个正文部分。
application/xhtml+xml此注册供社区审阅,并将提交给 IESG 进行审查、批准并在 IANA 注册。
application/xml 相同
[RFC7303]
application/xml 相同
[RFC7303]
application/xml 相同
[RFC7303]
application/xml 相同
[RFC7303]
application/xml 相同
[RFC7303]
application/xhtml+xml
类型标记资源,表示该资源是一个 XML 文档,并且很可能具有一个来自HTML 命名空间的文档元素。因此,相关规范是 XML、
XML 命名空间和本规范。[XML]
[XMLNS]
application/xml 相同
[RFC7303]
application/xml
相同
[RFC7303]
xhtml”和“xht”有时用作具有来自HTML 命名空间的文档元素的 XML 资源扩展名。TEXT与 application/xhtml+xml
资源一起使用的片段,与任何XML MIME 类型中的语义相同。
[RFC7303]
text/ping此注册供社区审阅,并将提交给 IESG 进行审查、批准并在 IANA 注册。
charset可以提供 charset 参数。该参数的值必须为
“utf-8”。此参数没有任何用途;仅为与旧式服务器兼容而允许。
如果仅以超链接审计上下文中所述的方式使用, 此类型不会引入新的安全问题。
text/ping 资源始终由四个字节
0x50 0x49 0x4E 0x47(`PING`)组成。ping 属性时生成的 HTTP POST 请求。片段对于 text/ping 资源没有任何意义。
application/microdata+json
此注册供社区审阅,并将提交给 IESG 进行审查、批准并在 IANA 注册。
application/json
相同
[JSON]
application/json
相同 [JSON]application/json
相同 [JSON]application/json
相同 [JSON]application/microdata+json
类型标记资源,表示该资源是一个 JSON 文本,其中包含一个仅有一个名为“items”
的条目的对象,该条目的值是一个条目数组;每个条目都是一个对象,其中包含一个名为
“id”且值为字符串的条目、一个名为“type”且值为另一个字符串的条目,
以及一个名为“properties”且值为对象的条目;该对象中的每个条目,
其值都由对象或字符串组成的数组构成,其中对象的形式与上述“items”条目中的对象相同。
因此,相关规范是 JSON 和本规范。[JSON]
传输旨在与 HTML 微数据功能一起使用的数据的应用程序,尤其是在拖放上下文中, 是此类型的主要应用类别。
application/json
相同 [JSON]
application/json
相同 [JSON]
application/json
相同 [JSON]
与 application/microdata+json
资源一起使用的片段,与用于
application/json
时具有相同语义(即在撰写本文时完全没有语义)。
[JSON]
application/speculationrules+json
此注册供社区审阅,并将提交给 IESG 进行审查、批准并在 IANA 注册。
application/json
相同 [JSON]
application/json
相同 [JSON]
application/json
相同 [JSON]
application/json
相同 [JSON]
application/microdata+json
类型标记资源,表示该资源是一个遵循推测规则集创作
要求的 JSON 文本。因此,相关规范是 JSON 和本规范。
[JSON]
Web 浏览器。
application/json
相同 [JSON]
application/json
相同 [JSON]
application/json
相同 [JSON]
与 application/speculationrules+json
资源一起使用的片段,与用于
application/json
时具有相同语义(即在撰写本文时完全没有语义)。
[JSON]
text/event-stream此注册供社区审阅,并将提交给 IESG 进行审查、批准并在 IANA 注册。
charset可以提供 charset 参数。该参数的值必须为
“utf-8”。此参数没有任何用途;仅为与旧式服务器兼容而允许。
来自与使用事件流的内容不同源的事件流可能导致信息泄露。为避免这种情况, 用户代理必须应用 CORS 语义。[FETCH]
事件流可能压垮用户代理;用户代理预期应用适当限制,以避免事件流中的 过量信息耗尽本地资源。
如果服务器导致客户端快速重新连接,服务器可能会不堪重负。服务器应使用 5xx 状态码表示容量问题,因为这会阻止符合规范的客户端自动重新连接。
片段对于
text/event-stream 资源
没有任何意义。
web+ 方案前缀本节描述了一种与 IANA URI 方案注册表配合使用的约定。它本身不注册特定方案。 [RFC7595]
web+”开头,后跟一个或多个处于
a-z 范围内字母的方案。
web+”方案都应在相关情况下使用 UTF-8 编码。web+”方案注册处理器。因此,这些方案不得用于
旨在成为核心平台功能的功能(例如 HTTP)。同样,此类方案不得在其 URL 中存储
机密信息,例如用户名、密码、个人信息或机密项目名称。
以下各节仅涵盖符合规范的元素和功能。
本节是非规范性的。
单元格中的星号(*)表示实际规则比上表中所示的更复杂。
†“父元素”列中的类别指的是其内容模型列出给定类别的父元素,
而不是自身处于这些类别中的元素。例如,a 元素的“父元素”列写着
“短语内容”,因此任何内容模型包含“短语内容”类别的元素,都可以成为
a 元素的父元素。
由于“流内容”类别包含所有“短语内容”元素,这意味着 th 元素可以作为
a 元素的父元素。
本节是非规范性的。
本节是非规范性的。
| 属性 | 元素 | 描述 | 值 |
|---|---|---|---|
abbr
|
th
|
在其他上下文中引用标题单元格时使用的替代标签 | 文本* |
accept
|
input
|
文件上传控件中预期文件类型的提示 | 由不带参数的有效 MIME 类型字符串
或 audio/*、video/* 或 image/* 组成的逗号分隔
标记集*
|
accept-charset
|
form
|
表单提交所使用的字符编码 | 与“UTF-8”进行ASCII
不区分大小写匹配
|
accesskey
|
HTML 元素 | 用于激活元素或使元素获得焦点的键盘快捷键 | 有序且唯一的空格分隔 标记集,其中没有任何标记与其他标记相同, 且每个标记的长度均为一个码点 |
action
|
form
|
用于表单提交的URL | 可能由空格包围的有效非空 URL |
allow
|
iframe
|
要应用于 iframe 内容的权限
策略
|
序列化权限策略 |
allowfullscreen
|
iframe
|
是否允许 iframe 的内容使用
requestFullscreen()
|
布尔属性 |
alpha
|
input
|
允许设置颜色的 alpha 分量 | 布尔属性 |
alt
|
area;
img;
input
|
图像不可用时使用的替代文本 | 文本* |
as
|
link
|
预加载请求的目标(用于 rel="preload" 和 rel="modulepreload")
|
对于 rel="preload",为预加载目标;对于 rel="modulepreload",
为模块预加载
目标
|
async
|
script
|
脚本可用时执行脚本,并且在获取期间不阻塞 | 布尔属性 |
autocapitalize
|
HTML 元素 | 建议的自动大写行为(用于受支持的输入法) | “on”;
“off”;
“none”;
“sentences”;
“words”;
“characters”
|
autocomplete
|
form
|
表单中控件的自动填充功能默认设置 | “on”;“off”
|
autocomplete
|
input;
select;
textarea
|
表单自动填充功能的提示 | 自动填充字段名称和相关标记* |
autocorrect
|
HTML 元素 | 建议的自动更正行为(用于受支持的输入法) | “on”;
“off”;
空字符串
|
autofocus
|
HTML 元素 | 页面加载时自动使元素获得焦点 | 布尔属性 |
autoplay
|
audio;
video
|
提示页面加载时可以自动开始播放媒体资源 | 布尔属性 |
blocking
|
link;
script;
style
|
元素是否可能阻塞渲染 | 无序且唯一的空格分隔 标记集* |
charset
|
meta
|
字符编码声明 | “utf-8”
|
checked
|
input
|
控件是否已选中 | 布尔属性 |
cite
|
blockquote;
del;
ins;
q
|
指向引用来源或有关编辑内容的更多信息的链接 | 可能由空格包围的有效 URL |
class
|
HTML 元素 | 元素所属的类 | 空格分隔标记集 |
closedby
|
dialog
|
哪些用户操作会关闭对话框 | “any”;
“closerequest”;
“none”;
|
color
|
link
|
自定义站点图标时使用的颜色(用于 rel="mask-icon")
|
CSS <color> |
colorspace
|
input
|
序列化颜色的色彩空间 | “limited-srgb”;
“display-p3”
|
cols
|
textarea
|
每行的最大字符数 | 大于零的有效非负整数 |
colspan
|
td;
th
|
单元格要跨越的列数 | 大于零的有效非负整数 |
command
|
button
|
向目标元素指示要执行的操作。 | “toggle-popover”;
“show-popover”;
“hide-popover”;
“close”;
“request-close”;
“show-modal”;
一个自定义命令
关键字
|
commandfor
|
button
|
指定要调用的另一个目标元素。 | ID* |
content
|
meta
|
元素的值 | 文本* |
contenteditable
|
HTML 元素 | 元素是否可编辑 | “true”;
“false”;
“plaintext-only”;
空字符串
|
controls
|
audio;
video
img;
|
显示用户代理控件 | 布尔属性 |
coords
|
area
|
在图像映射中要创建的形状坐标 | 有效浮点数列表* |
crossorigin
|
audio;
img;
link;
script;
video
|
元素处理跨源请求的方式 | “anonymous”;
“use-credentials”;
空字符串
|
data
|
object
|
资源地址 | 可能由空格包围的有效非空 URL |
datetime
|
del;
ins
|
更改的日期和可选时间 | 带可选时间的有效日期字符串 |
datetime
|
time
|
机器可读值 | 有效月份字符串、 有效日期字符串、 有效无年份日期 字符串、 有效时间字符串、 有效本地 日期和时间字符串、 有效时区 偏移字符串、 有效全局 日期和时间字符串、 有效周字符串、 有效非负 整数,或 有效时长字符串 |
decoding
|
img
|
处理此图像以进行呈现时使用的解码提示 | “sync”;
“async”;
“auto”
|
default
|
track
|
如果没有其他更合适的文本轨道,则启用该轨道 | 布尔属性 |
defer
|
script
|
延迟脚本执行 | 布尔属性 |
dir
|
HTML 元素 | 元素的文本方向性 | “ltr”;“rtl”;“auto”
|
dir
|
bdo
|
元素的文本方向性 | “ltr”;“rtl”
|
dirname
|
input;
textarea
|
在表单提交中用于发送元素方向性的表单控件名称 | 文本* |
disabled
|
button;
input;
optgroup;
option;
select;
textarea;
表单关联自定义元素
|
表单控件是否已禁用 | 布尔属性 |
disabled
|
fieldset
|
除 legend 内部的控件外,
后代表单控件是否已禁用
|
布尔属性 |
disabled
|
link
|
链接是否已禁用 | 布尔属性 |
download
|
a;
area
|
是否下载资源而不是导航到该资源,以及下载时所使用的文件名 | 文本 |
draggable
|
HTML 元素 | 元素是否可拖动 | “true”;“false”
|
enctype
|
form
|
表单提交所使用的条目列表编码类型 | “application/x-www-form-urlencoded”;
“multipart/form-data”;
“text/plain”
|
enterkeyhint
|
HTML 元素 | 用于选择回车键操作的提示 | “enter”;
“done”;
“go”;
“next”;
“previous”;
“search”;
“send”
|
fetchpriority
|
img;
link;
script
|
设置元素发起的获取的优先级 | “auto”;
“high”;
“low”
|
for
|
label
|
将标签与表单控件关联 | ID* |
for
|
output
|
指定用于计算输出的控件 | 由 ID 组成的无序且唯一的空格分隔 标记集* |
form
|
button;
fieldset;
input;
object;
output;
select;
textarea;
表单关联自定义元素
|
将元素与 form 元素关联
|
ID* |
formaction
|
button;
input
|
用于表单提交的URL | 可能由空格包围的有效非空 URL |
formenctype
|
button;
input
|
表单提交所使用的条目列表编码类型 | “application/x-www-form-urlencoded”;
“multipart/form-data”;
“text/plain”
|
formmethod
|
button;
input
|
表单提交所使用的变体 | “get”;
“post”;
“dialog”
|
formnovalidate
|
button;
input
|
表单提交时绕过表单控件验证 | 布尔属性 |
formtarget
|
button;
input
|
用于表单提交的可导航对象 | 有效可导航目标名称或关键字 |
headers
|
td;
th
|
此单元格的标题单元格 | 由 ID 组成的无序且唯一的空格分隔 标记集* |
headingoffset
|
HTML 元素 | 偏移后代的标题级别 | 0 到 8 之间的有效非负整数 |
headingreset
|
HTML 元素 | 阻止标题偏移计算越过具有该属性的元素进行遍历 | 布尔属性 |
height
|
canvas;
embed;
iframe;
img;
input;
object;
source(位于 picture 中);
video
|
垂直尺寸 | 有效非负整数 |
hidden
|
元素是否相关 | “”; “”; 空字符串 | |
high
|
meter
|
高值范围的下限 | 有效浮点数* |
href
|
a;
area
|
超链接的地址 | 可能由空格包围的有效 URL |
href
|
link
|
超链接的地址 | 可能由空格包围的有效非空 URL |
href
|
base
|
文档基准 URL | 可能由空格包围的有效 URL |
hreflang
|
a;
link
|
所链接资源的语言 | 有效的 BCP 47 语言标记 |
http-equiv
|
meta
|
Pragma 指令 | “content-type”;
“default-style”;
“refresh”;
“x-ua-compatible”;
“content-security-policy”
|
id
|
HTML 元素 | 元素的 ID | 文本* |
imagesizes
|
link
|
不同页面布局下的图像尺寸(用于 rel="preload")
|
有效源尺寸列表 |
imagesrcset
|
link
|
用于不同情况的图像,例如高分辨率显示器、小型显示器等(用于 rel="preload")
|
由图像候选字符串组成的逗号分隔列表 |
inert
|
HTML 元素 | 元素是否惰性。 | 布尔属性 |
inputmode
|
HTML 元素 | 用于选择输入方式的提示 | “none”;
“text”;
“tel”;
“email”;
“url”;
“numeric”;
“decimal”;
“search”
|
integrity
|
link;
script
|
在子资源完整性检查中使用的完整性元数据 [SRI] | 文本 |
is
|
HTML 元素 | 创建一个自定义内置元素 | 已定义自定义内置元素的有效自定义元素名称 |
ismap
|
img
|
图像是否为服务器端图像映射 | 布尔属性 |
itemid
|
HTML 元素 | 微数据项的全局标识符 | 可能由空格包围的有效 URL |
itemprop
|
HTML 元素 | 微数据项的属性名称 | 由有效绝对 URL、已定义属性名称或文本组成的无序且唯一的空格分隔 标记集* |
itemref
|
HTML 元素 | 被引用的元素 | 由 ID 组成的无序且唯一的空格分隔 标记集* |
itemscope
|
HTML 元素 | 引入一个微数据项 | 布尔属性 |
itemtype
|
HTML 元素 | 微数据项的项类型 | 由有效绝对 URL组成的无序且唯一的空格分隔 标记集* |
kind
|
track
|
文本轨道的类型 | “subtitles”;
“captions”;
“descriptions”;
“chapters”;
“metadata”
|
label
|
optgroup;
option;
track
|
用户可见的标签 | 文本 |
lang
|
HTML 元素 | 元素的语言 | 有效的 BCP 47 语言标记或空字符串 |
list
|
input
|
自动完成选项列表 | ID* |
loading
|
iframe;
img;
audio;
video
|
在确定是否延迟加载时使用 | “lazy”;
“eager”
|
loop
|
audio;
video
|
是否循环播放媒体资源 | 布尔属性 |
low
|
meter
|
低值范围的上限 | 有效浮点数* |
max
|
input
|
最大值 | 视情况而定* |
max
|
meter;
progress
|
范围上限 | 有效浮点数* |
maxlength
|
input;
textarea
|
值的最大长度 | 有效非负整数 |
media
|
link;
meta;
source;
style
|
适用媒体 | 有效媒体查询列表 |
method
|
form
|
表单提交所使用的变体 | “get”;
“post”;
“dialog”
|
min
|
input
|
最小值 | 视情况而定* |
min
|
meter
|
范围下限 | 有效浮点数* |
minlength
|
input;
textarea
|
值的最小长度 | 有效非负整数 |
multiple
|
input;
select
|
是否允许多个值 | 布尔属性 |
muted
|
audio;
video
|
默认情况下是否使媒体资源静音 | 布尔属性 |
name
|
button;
fieldset;
input;
output;
select;
textarea;
表单关联自定义元素
|
用于表单提交和 form.elements API 的元素名称
|
文本* |
name
|
details
|
一组互斥 details 元素的名称
|
文本* |
name
|
form
|
在 document.forms API
中使用的表单名称
|
文本* |
name
|
iframe;
object
|
内容可导航对象的名称 | 有效可导航目标名称或关键字 |
name
|
map
|
供 usemap 属性引用的图像映射名称
|
文本* |
name
|
meta
|
元数据名称 | 文本* |
name
|
slot
|
影子树槽的名称 | 文本 |
nomodule
|
script
|
阻止在支持模块脚本的用户代理中执行 | 布尔属性 |
nonce
|
HTML 元素 | 在内容安全策略检查中使用的加密 nonce [CSP] | 文本 |
novalidate
|
form
|
表单提交时绕过表单控件验证 | 布尔属性 |
open
|
details
|
详细信息是否可见 | 布尔属性 |
open
|
dialog
|
对话框是否正在显示 | 布尔属性 |
optimum
|
meter
|
计量表中的最佳值 | 有效浮点数* |
pattern
|
input
|
表单控件的值要匹配的模式 | 与 JavaScript Pattern 产生式匹配的正则表达式 |
ping
|
a;
area
|
要 ping 的 URL | 由有效非空 URL组成的空格分隔标记集 |
placeholder
|
input;
textarea
|
放置在表单控件内部的用户可见标签 | 文本* |
playsinline
|
video
|
鼓励用户代理在元素的播放区域内显示视频内容 | 布尔属性 |
popover
|
HTML 元素 | 使元素成为弹出框元素 | “auto”;
“manual”;
“hint”;
空字符串
|
popovertarget
|
button;
input
|
指定要切换、显示或隐藏的弹出框元素 | ID* |
popovertargetaction
|
button;
input
|
指示要切换、显示还是隐藏目标弹出框元素 | “toggle”;
“show”;
“hide”
|
poster
|
video
|
视频播放前显示的海报帧 | 可能由空格包围的有效非空 URL |
preload
|
audio;
video
|
提示媒体资源可能需要缓冲多少内容 | “none”;
“metadata”;
“auto”;
空字符串
|
readonly
|
input;
textarea
|
是否允许用户编辑值 | 布尔属性 |
readonly
|
表单关联自定义元素 | 影响 willValidate,
以及自定义元素作者添加的任何行为
|
布尔属性 |
referrerpolicy
|
a;
area;
iframe;
img;
link;
script
|
元素发起的获取所使用的引用来源策略 | 引用来源策略 |
rel
|
a;
area
|
文档中包含超链接的位置与目标资源之间的关系 | 无序且唯一的空格分隔 标记集* |
rel
|
link
|
包含超链接的文档与目标资源之间的关系 | 无序且唯一的空格分隔 标记集* |
required
|
input;
select;
textarea
|
表单提交是否要求该控件 | 布尔属性 |
reversed
|
ol
|
对列表进行反向编号 | 布尔属性 |
rows
|
textarea
|
要显示的行数 | 大于零的有效非负整数 |
rowspan
|
td;
th
|
单元格要跨越的行数 | 有效非负整数 |
sandbox
|
iframe
|
嵌套内容的安全规则 | 由以下内容组成的、ASCII
不区分大小写的无序且唯一的空格分隔
标记集:
|
scope
|
th
|
指定标题单元格适用于哪些单元格 | “row”;
“col”;
“rowgroup”;
“colgroup”
|
selected
|
option
|
选项默认是否选中 | 布尔属性 |
shadowrootclonable
|
template
|
在声明式影子根上设置可克隆 | 布尔属性 |
shadowrootcustomelementregistry
|
template
|
使声明式影子根能够指示其将使用自定义元素注册表 | 布尔属性 |
shadowrootdelegatesfocus
|
template
|
在声明式影子根上设置委托焦点 | 布尔属性 |
shadowrootmode
|
template
|
启用流式声明式影子根 | “open”;
“closed”
|
shadowrootserializable
|
template
|
在声明式影子根上设置可序列化 | 布尔属性 |
shadowrootslotassignment
|
template
|
在声明式影子根上设置槽分配 | “named”;
“manual”
|
shape
|
area
|
在图像映射中要创建的形状种类 | “circle”;
“default”;
“poly”;
“rect”
|
size
|
input;
select
|
控件的尺寸 | 大于零的有效非负整数 |
sizes
|
link
|
图标的尺寸(用于 rel="icon")
|
由尺寸组成的、ASCII 不区分大小写的无序且唯一的空格分隔 标记集* |
sizes
|
img;
source
|
不同页面布局下的图像尺寸 | 有效源尺寸列表 |
slot
|
HTML 元素 | 元素所需的槽 | 文本 |
span
|
col;
colgroup
|
元素所跨越的列数 | 大于零的有效非负整数 |
spellcheck
|
HTML 元素 | 是否检查元素的拼写和语法 | “true”;
“false”;
空字符串
|
src
|
audio;
embed;
iframe;
img;
input;
script;
source(位于 video 或 audio 中);
track;
video
|
资源地址 | 可能由空格包围的有效非空 URL |
srcdoc
|
iframe
|
要在 iframe 中渲染的文档
|
iframe
srcdoc 文档的源*
|
srclang
|
track
|
文本轨道的语言 | 有效的 BCP 47 语言标记 |
srcset
|
img;
source
|
用于不同情况的图像,例如高分辨率显示器、小型显示器等。 | 由图像候选字符串组成的逗号分隔列表 |
start
|
ol
|
列表的起始值 | 有效整数 |
step
|
input
|
表单控件的值要匹配的粒度 | 大于零的有效浮点数,或“any”
|
style
|
HTML 元素 | 呈现和格式化指令 | CSS 声明* |
tabindex
|
HTML 元素 | 元素是否可聚焦并可按顺序聚焦, 以及元素在顺序焦点导航中的相对顺序 | 有效整数 |
target
|
a;
area
|
用于超链接导航的可导航对象 | 有效可导航目标名称或关键字 |
target
|
base
|
用于超链接导航和表单提交的默认可导航对象 | 有效可导航目标名称或关键字 |
target
|
form
|
用于表单提交的可导航对象 | 有效可导航目标名称或关键字 |
title
|
HTML 元素 | 元素的提示信息 | 文本 |
title
|
abbr;
dfn
|
完整术语或缩写的展开形式 | 文本 |
title
|
input
|
模式的描述(与 pattern
属性一起使用时)
|
文本 |
title
|
link
|
链接的标题 | 文本 |
title
|
link;
style
|
CSS 样式表集名称 | 文本 |
translate
|
HTML 元素 | 页面本地化时是否翻译该元素 | “yes”;“no”;空字符串
|
type
|
a;
link
|
被引用资源类型的提示 | 有效 MIME 类型字符串 |
type
|
button
|
按钮类型 | “submit”;
“reset”;
“button”
|
type
|
embed;
object;
source
|
嵌入资源的类型 | 有效 MIME 类型字符串 |
type
|
input
|
表单控件的类型 | input 类型关键字
|
type
|
ol
|
列表标记的种类 | “1”;
“a”;
“A”;
“i”;
“I”
|
type
|
script
|
脚本类型 | “module”;“importmap”;“speculationrules”;
一个不是JavaScript MIME 类型本质匹配的有效 MIME 类型字符串
|
usemap
|
img
|
要使用的图像映射名称 | 有效哈希名称引用* |
value
|
button;
option
|
用于表单提交的值 | 文本 |
value
|
data
|
机器可读值 | 文本* |
value
|
input
|
表单控件的值 | 视情况而定* |
value
|
li
|
列表项的序数值 | 有效整数 |
value
|
meter;
progress
|
元素的当前值 | 有效浮点数 |
width
|
canvas;
embed;
iframe;
img;
input;
object;
source(位于 picture 中);
video
|
水平尺寸 | 有效非负整数 |
wrap
|
textarea
|
表单提交时如何换行表单控件的值 | “soft”;
“hard”
|
writingsuggestions
|
HTML 元素 | 元素是否可以提供写作建议。 | “true”;
“false”;
空字符串
|
单元格中的星号(*)表示实际规则比上表中所示的更复杂。
所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
所有当前引擎均支持。
本节是非规范性的。
本节是非规范性的。
AudioTrackAudioTrackListBarPropBeforeUnloadEventBroadcastChannelCanvasGradientCanvasPatternCanvasRenderingContext2D
CloseWatcherCommandEventCustomElementRegistryCustomStateSetDOMParserDOMStringListDOMStringMapDataTransferDataTransferItemDataTransferItemList
DedicatedWorkerGlobalScope
Document,部分接口 1 2DragEventElement,
部分接口
ElementInternalsErrorEventEventSourceExternalFormDataEventHTMLAllCollectionHTMLAnchorElement,部分接口HTMLAreaElement,部分接口HTMLAudioElementHTMLBRElement,部分接口HTMLBaseElementHTMLBodyElement,部分接口HTMLButtonElementHTMLCanvasElementHTMLDListElement,部分接口HTMLDataElementHTMLDataListElementHTMLDetailsElementHTMLDialogElementHTMLDirectoryElement
HTMLDivElement,部分接口HTMLElementHTMLEmbedElement,部分接口HTMLFieldSetElementHTMLFontElementHTMLFormControlsCollection
HTMLFormElementHTMLFrameElementHTMLFrameSetElementHTMLHRElement,部分接口HTMLHeadElementHTMLHeadingElement,部分接口HTMLHtmlElement,部分接口HTMLIFrameElement,部分接口HTMLImageElement,部分接口HTMLInputElement,部分接口HTMLLIElement,部分接口HTMLLabelElementHTMLLegendElement,部分接口HTMLLinkElement,部分接口HTMLMapElementHTMLMarqueeElementHTMLMediaElementHTMLMenuElement,部分接口HTMLMetaElement,部分接口HTMLMeterElementHTMLModElementHTMLOListElement,部分接口HTMLObjectElement,部分接口HTMLOptGroupElementHTMLOptionElementHTMLOptionsCollectionHTMLOutputElementHTMLParagraphElement,
部分接口
HTMLParamElementHTMLPictureElementHTMLPreElement,部分接口HTMLProgressElementHTMLQuoteElementHTMLScriptElement,部分接口HTMLSelectElementHTMLSelectedContentElement
HTMLSlotElementHTMLSourceElementHTMLSpanElementHTMLStyleElement,部分接口HTMLTableCaptionElement,
部分接口
HTMLTableCellElement,
部分接口
HTMLTableColElement,部分接口HTMLTableElement,部分接口HTMLTableRowElement,部分接口HTMLTableSectionElement,
部分接口
HTMLTemplateElementHTMLTextAreaElementHTMLTimeElementHTMLTitleElementHTMLTrackElementHTMLUListElement,部分接口HTMLUnknownElementHTMLVideoElementHashChangeEventHistoryImageBitmapImageBitmapRenderingContext
ImageDataLocationMediaErrorMessageChannelMessageEventMessagePortMimeTypeMimeTypeArrayNavigateEventNavigationNavigationActivation
NavigationCurrentEntryChangeEvent
NavigationDestinationNavigationHistoryEntry
NavigationPrecommitController
NavigationTransition
Navigator,部分接口NotRestoredReasonDetails
NotRestoredReasonsOffscreenCanvasOffscreenCanvasRenderingContext2D
OriginPageRevealEventPageSwapEventPageTransitionEventPath2DPluginPluginArrayPopStateEventPromiseRejectionEventRadioNodeListRange,
部分接口
SanitizerShadowRoot,
部分接口
SharedWorkerSharedWorkerGlobalScope
StorageStorageEventSubmitEventTextMetricsTextTrackTextTrackCueTextTrackCueListTextTrackListTimeRangesToggleEventTrackEventUserActivationValidityStateVideoTrackVideoTrackListVisibilityStateEntry
Window,部分接口WorkerWorkerGlobalScopeWorkerLocationWorkerNavigatorWorkletWorkletGlobalScopeXMLSerializer本节是非规范性的。
下表列出了本规范触发的事件,但不包括已在媒体元素事件和 拖放事件中定义的事件。
| 事件 | 接口 | 相关目标 | 描述 |
|---|---|---|---|
DOMContentLoaded
所有当前引擎均支持。 Firefox1+Safari3.1+Chrome1+
Opera9+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android37+Samsung Internet?Opera Android10.1+ |
Event
|
Document
|
解析器完成后,在 Document 上触发
|
afterprint
所有当前引擎均支持。 Firefox6+Safari13+Chrome63+
Opera?Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? |
Event
|
Window
|
打印后在 Window 上触发
|
beforeprint
所有当前引擎均支持。 Firefox6+Safari13+Chrome63+
Opera?Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? |
Event
|
Window
|
打印前在 Window 上触发
|
beforematch
仅一个引擎支持。 Firefox否Safari否Chrome102+
Opera否Edge102+ Edge(旧版)?Internet Explorer否 Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? |
Event
|
元素 | 在具有 属性的元素显示之前,于这些元素上触发。 |
beforetoggle
HTMLElement/beforetoggle_event 所有当前引擎均支持。 Firefox🔰
114+Safari预览版+Chrome114+
Opera?Edge114+ Edge(旧版)?Internet Explorer否 Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? |
ToggleEvent
|
元素 | 当具有 popover
属性的元素在显示状态与隐藏状态之间转换时,于该元素上触发
|
beforeunload
所有当前引擎均支持。 Firefox1+Safari3+Chrome1+
Opera12+Edge79+ Edge(旧版)12+Internet Explorer4+ Firefox Android?Safari iOS1+Chrome Android?WebView Android?Samsung Internet?Opera Android12+ |
BeforeUnloadEvent
|
Window
|
当页面即将卸载时,在 Window 上触发,
以便页面在需要时显示警告提示
|
blur
|
Event
|
Window、元素
|
当节点不再获得焦点时,在节点上触发 |
cancel
HTMLDialogElement/cancel_event 所有当前引擎均支持。 Firefox98+Safari15.4+Chrome37+
Opera?Edge79+ Edge(旧版)?Internet Explorer否 Firefox Android?Safari iOS?Chrome Android否WebView Android?Samsung Internet?Opera Android? |
Event
|
CloseWatcher、dialog 元素、input 元素
|
当 CloseWatcher 对象或
dialog 元素收到
关闭请求时,或者当其 type 属性处于文件状态的 input 元素中用户未更改其选择时触发
|
change
所有当前引擎均支持。 Firefox1+Safari3+Chrome1+
Opera9+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android10.1+ |
Event
|
表单控件 | 当用户确认值更改时,在控件上触发(另请参阅 input
事件)
|
click
|
PointerEvent
|
元素 | 通常是鼠标事件;当通过非指针输入设备(例如键盘)激活元素时,也会在运行元素的激活行为之前,于该元素上以合成方式触发 |
close
所有当前引擎均支持。 Firefox98+Safari15.4+Chrome37+
Opera?Edge79+ Edge(旧版)?Internet Explorer否 Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? |
Event
|
CloseWatcher、dialog 元素、MessagePort
|
当 CloseWatcher 对象或
dialog 元素通过
关闭请求或 Web 开发者代码关闭时触发,
或者当 MessagePort 对象被解除纠缠时触发
|
command
|
CommandEvent
|
元素 | 当元素通过 commandfor
属性处理用户调用时,
在该元素上触发。
|
connect
SharedWorkerGlobalScope/connect_event 所有当前引擎均支持。 Firefox29+Safari16+Chrome4+
Opera10.6+Edge79+ Edge(旧版)?Internet Explorer否 Firefox Android?Safari iOS16+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
MessageEvent
|
SharedWorkerGlobalScope
|
当新客户端连接时,在共享工作者的全局作用域上触发 |
contextlost
HTMLCanvasElement/webglcontextlost_event 仅一个引擎支持。 Firefox否Safari否Chrome98+
Opera?Edge98+ Edge(旧版)?Internet Explorer否 Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? |
Event
|
canvas 元素、OffscreenCanvas 对象
|
当对应的 CanvasRenderingContext2D
或 OffscreenCanvasRenderingContext2D
丢失时触发
|
contextrestored
HTMLCanvasElement/contextrestored_event 仅一个引擎支持。 Firefox否Safari否Chrome98+
Opera?Edge98+ Edge(旧版)?Internet Explorer否 Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? |
Event
|
canvas 元素、OffscreenCanvas 对象
|
当对应的 CanvasRenderingContext2D
或 OffscreenCanvasRenderingContext2D
在丢失后恢复时触发
|
currententrychange
|
NavigationCurrentEntryChangeEvent
|
Navigation
|
当 navigation.currentEntry
发生更改时触发
|
dispose
|
Event
|
NavigationHistoryEntry
|
当与 NavigationHistoryEntry
对应的会话历史记录条目
被永久从会话历史记录中移除,且无法再遍历到该条目时触发
|
error
所有当前引擎均支持。 Firefox6+Safari5+Chrome6+
Opera12+Edge79+ Edge(旧版)?Internet Explorer否 Firefox Android45+Safari iOS5+Chrome Android?WebView Android?Samsung Internet?Opera Android12+ 所有当前引擎均支持。 Firefox6+Safari5.1+Chrome10+
Opera?Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android37+Samsung Internet?Opera Android? |
Event
或 ErrorEvent
|
全局作用域对象、Worker 对象、元素、
与网络相关的对象
|
发生意外错误时触发(例如网络错误、脚本错误、解码错误) |
focus
|
Event
|
Window、元素
|
当节点获得焦点时,在节点上触发 |
formdata
HTMLFormElement/formdata_event 所有当前引擎均支持。 Firefox72+Safari15+Chrome77+
Opera?Edge79+ Edge(旧版)?Internet Explorer否 Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? |
FormDataEvent
|
form 元素
|
当 form 元素
构造条目列表时,
在该元素上触发
|
hashchange
所有当前引擎均支持。 Firefox3.6+Safari5+Chrome8+
Opera10.6+Edge79+ Edge(旧版)12+Internet Explorer8+ Firefox Android?Safari iOS5+Chrome Android?WebView Android37+Samsung Internet?Opera Android11+ |
HashChangeEvent
|
Window
|
当文档 URL 的片段部分发生更改时,在 Window 上触发
|
input
|
Event
|
元素 | 当用户更改 contenteditable
元素的内容,
或更改表单控件的值时触发。对于表单控件,另请参阅 change 事件。
|
invalid
HTMLInputElement/invalid_event 所有当前引擎均支持。 Firefox4+Safari5+Chrome10+
Opera10+Edge79+ Edge(旧版)12+Internet Explorer10+ Firefox Android64+Safari iOS5+Chrome Android?WebView Android4+Samsung Internet4.0+Opera Android12+ |
Event
|
表单控件 | 在表单验证期间,如果控件不满足其约束条件,则在该控件上触发 |
languagechange
所有当前引擎均支持。 Firefox32+Safari10.1+Chrome37+
Opera?Edge79+ Edge(旧版)?Internet Explorer否 Firefox Android4+Safari iOS?Chrome Android?WebView Android?Samsung Internet4.0+Opera Android? WorkerGlobalScope/languagechange_event 所有当前引擎均支持。 Firefox74+Safari4+Chrome4+
Opera11.5+Edge79+ Edge(旧版)?Internet Explorer否 Firefox Android?Safari iOS5+Chrome Android?WebView Android37+Samsung Internet?Opera Android? |
Event
|
全局作用域对象 | 当用户的首选语言发生更改时,在全局作用域对象上触发 |
load
|
Event
|
Window、元素
|
当文档完成加载时,在 Window 上触发;
当包含资源的元素(例如 img、embed)中的资源完成加载时,
在该元素上触发
|
message
BroadcastChannel/message_event 所有当前引擎均支持。 Firefox38+Safari15.4+Chrome54+
Opera?Edge79+ Edge(旧版)?Internet Explorer否 Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? DedicatedWorkerGlobalScope/message_event 所有当前引擎均支持。 Firefox3.5+Safari4+Chrome4+
Opera10.6+Edge79+ Edge(旧版)12+Internet Explorer10+ Firefox Android?Safari iOS5+Chrome Android?WebView Android37+Samsung Internet?Opera Android11.5+ 所有当前引擎均支持。 Firefox6+Safari5+Chrome6+
Opera12+Edge79+ Edge(旧版)?Internet Explorer否 Firefox Android45+Safari iOS5+Chrome Android?WebView Android?Samsung Internet?Opera Android12+ 所有当前引擎均支持。 Firefox41+Safari5+Chrome2+
Opera10.6+Edge79+ Edge(旧版)12+Internet Explorer10+ Firefox Android?Safari iOS?Chrome Android?WebView Android37+Samsung Internet?Opera Android11.5+ 所有当前引擎均支持。 Firefox9+Safari4+Chrome60+
Opera?Edge79+ Edge(旧版)12+Internet Explorer8+ Firefox Android?Safari iOS4+Chrome Android?WebView Android?Samsung Internet?Opera Android47+ 所有当前引擎均支持。 Firefox3.5+Safari4+Chrome4+
Opera10.6+Edge79+ Edge(旧版)12+Internet Explorer10+ Firefox Android?Safari iOS5+Chrome Android?WebView Android?Samsung Internet?Opera Android11.5+ |
MessageEvent
|
Window、EventSource、MessagePort、BroadcastChannel、DedicatedWorkerGlobalScope、
Worker、ServiceWorkerContainer
|
当对象接收到消息时,在该对象上触发 |
messageerror
BroadcastChannel/messageerror_event 所有当前引擎均支持。 Firefox57+Safari15.4+Chrome60+
Opera?Edge79+ Edge(旧版)?Internet Explorer否 Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android47+ DedicatedWorkerGlobalScope/messageerror_event 所有当前引擎均支持。 Firefox57+Safari16.4+Chrome60+
Opera?Edge79+ Edge(旧版)18Internet Explorer否 Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android47+ MessagePort/messageerror_event 所有当前引擎均支持。 Firefox57+Safari16.4+Chrome60+
Opera?Edge79+ Edge(旧版)18Internet Explorer否 Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android47+ 所有当前引擎均支持。 Firefox57+Safari16.4+Chrome60+
Opera?Edge79+ Edge(旧版)18Internet Explorer否 Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android47+ 所有当前引擎均支持。 Firefox57+Safari16.4+Chrome60+
Opera?Edge79+ Edge(旧版)18Internet Explorer否 Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android47+ |
MessageEvent
|
Window、MessagePort、BroadcastChannel、DedicatedWorkerGlobalScope、
Worker、ServiceWorkerContainer
|
当对象接收到无法反序列化的消息时,在该对象上触发 |
navigate
|
NavigateEvent
|
Navigation
|
在可导航对象导航、重新加载、遍历或以其他方式更改其 URL 之前触发 |
navigateerror
|
ErrorEvent
|
Navigation
|
当导航未成功完成时触发 |
navigatesuccess
|
Event
|
Navigation
|
当导航成功完成时触发 |
offline
所有当前引擎均支持。 Firefox9+Safari4+Chrome3+
Opera?Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android? |
Event
|
全局作用域对象 | 当网络连接失败时,在全局作用域对象上触发 |
online
所有当前引擎均支持。 Firefox9+Safari4+Chrome3+
Opera?Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS3+Chrome Android?WebView Android37+Samsung Internet?Opera Android? |
Event
|
全局作用域对象 | 当网络连接恢复时,在全局作用域对象上触发 |
open
所有当前引擎均支持。 Firefox6+Safari5+Chrome6+
Opera12+Edge79+ Edge(旧版)?Internet Explorer否 Firefox Android45+Safari iOS5+Chrome Android?WebView Android?Samsung Internet?Opera Android12+ |
Event
|
EventSource
|
建立连接时,在 EventSource
对象上触发
|
pageswap
|
PageSwapEvent
|
Window
|
因导航导致文档即将卸载之前,在 Window 上触发。
|
pagehide
所有当前引擎均支持。 Firefox6+Safari5+Chrome3+
Opera?Edge79+ Edge(旧版)12+Internet Explorer11 Firefox Android?Safari iOS?Chrome Android?WebView Android37+Samsung Internet?Opera Android? |
PageTransitionEvent
|
Window
|
当页面的会话历史记录条目不再是活动条目时,在 Window 上触发
|
pagereveal
|
PageRevealEvent
|
Window
|
当页面在初始化或重新激活后首次开始渲染时,在 Window 上触发
|
pageshow
所有当前引擎均支持。 Firefox6+Safari5+Chrome3+
Opera?Edge79+ Edge(旧版)12+Internet Explorer11 Firefox Android?Safari iOS?Chrome Android?WebView Android37+Samsung Internet?Opera Android? |
PageTransitionEvent
|
Window
|
当页面的会话历史记录条目
成为活动条目时,在
Window 上触发
|
pointercancel
|
PointerEvent
|
元素和 Text
节点
|
当用户尝试启动拖放操作时,在源节点上触发 |
popstate
所有当前引擎均支持。 Firefox4+Safari5+Chrome5+
Opera11.5+Edge79+ Edge(旧版)12+Internet Explorer10+ Firefox Android?Safari iOS?Chrome Android?WebView Android37+Samsung Internet?Opera Android11.5+ |
PopStateEvent
|
Window
|
在某些会话历史记录遍历
情况下,于 Window 上触发
|
readystatechange
Document/readystatechange_event 所有当前引擎均支持。 Firefox4+Safari5.1+Chrome9+
Opera12.1+Edge79+ Edge(旧版)12+Internet Explorer4+ Firefox Android?Safari iOS?Chrome Android?WebView Android37+Samsung Internet?Opera Android12.1+ |
Event
|
Document
|
当 Document 完成解析时触发,
并在其所有子资源完成加载时再次触发
|
rejectionhandled
|
PromiseRejectionEvent
|
全局作用域对象 | 当先前未处理的 promise 拒绝变为已处理时,在全局作用域对象上触发 |
reset
所有当前引擎均支持。 Firefox6+Safari3+Chrome1+
Opera12.1+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS1+Chrome Android?WebView Android37+Samsung Internet?Opera Android12.1+ |
Event
|
form 元素
|
当 form 元素被重置时,在该元素上触发
|
select
所有当前引擎均支持。 Firefox6+Safari1+Chrome1+
Opera12.1+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android12.1+ HTMLTextAreaElement/select_event 所有当前引擎均支持。 Firefox6+Safari1+Chrome1+
Opera12.1+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android12.1+ |
Event
|
表单控件 | 当表单控件的文本选区被调整时(无论是通过 API 还是由用户调整),在该控件上触发 |
storage
所有当前引擎均支持。 Firefox45+Safari4+Chrome1+
Opera?Edge79+ Edge(旧版)15+Internet Explorer9+ Firefox Android?Safari iOS4+Chrome Android?WebView Android37+Samsung Internet?Opera Android? |
StorageEvent
|
Window
|
当对应的 localStorage 或 sessionStorage 存储区域发生更改时,
在 Window 上触发
|
submit
所有当前引擎均支持。 Firefox1+Safari3+Chrome1+
Opera8+Edge79+ Edge(旧版)12+Internet Explorer9+ Firefox Android?Safari iOS1+Chrome Android?WebView Android?Samsung Internet?Opera Android10.1+ |
SubmitEvent
|
form 元素
|
当 form 元素被提交时,在该元素上触发
|
toggle
HTMLDetailsElement/toggle_event 所有当前引擎均支持。 Firefox49+Safari10.1+Chrome36+
Opera?Edge79+ Edge(旧版)?Internet Explorer否 Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? 所有当前引擎均支持。 Firefox🔰
114+Safari预览版+Chrome114+
Opera?Edge114+ Edge(旧版)?Internet Explorer否 Firefox Android?Safari iOS?Chrome Android?WebView Android?Samsung Internet?Opera Android? |
ToggleEvent
|
details 和弹出框元素
|
当 details
元素打开或关闭时,在该元素上触发;当具有
popover 属性的元素
在显示状态与隐藏状态之间转换时,在该元素上触发
|
unhandledrejection
Window/unhandledrejection_event 所有当前引擎均支持。 Firefox69+Safari11+Chrome49+
Opera?Edge79+ Edge(旧版)?Internet Explorer否 Firefox Android?Safari iOS11.3+Chrome Android?WebView Android?Samsung Internet?Opera Android? |
PromiseRejectionEvent
|
全局作用域对象 | 当 promise 拒绝未被处理时,在全局作用域对象上触发 |
unload
所有当前引擎均支持。 Firefox1+Safari3+Chrome1+
Opera4+Edge79+ Edge(旧版)12+Internet Explorer4+ Firefox Android?Safari iOS1+Chrome Android?WebView Android?Samsung Internet?Opera Android10.1+ |
Event
|
Window
|
当页面即将离开时,在 Window
对象上触发
|
visibilitychange
Document/visibilitychange_event 所有当前引擎均支持。 Firefox56+Safari14.1+Chrome62+
Opera49+Edge79+ Edge(旧版)18Internet Explorer🔰 10+ Firefox Android?Safari iOS?Chrome Android?WebView Android62+Samsung Internet?Opera Android46+ |
Event
|
Document
|
当页面对用户变为可见或隐藏时,在 Document 对象上触发
|
本节是非规范性的。
本规范定义了以下 HTTP 请求标头:
Last-Event-ID`Ping-From`Ping-To`本规范定义了以下 HTTP 响应标头:
Cross-Origin-Embedder-Policy`
Cross-Origin-Embedder-Policy-Report-Only`
Cross-Origin-Opener-Policy`
Cross-Origin-Opener-Policy-Report-Only`
Origin-Agent-Cluster`
Refresh`X-Frame-Options`本节是非规范性的。
本规范提到了以下 MIME 类型:
application/atom+xmlapplication/jsonapplication/octet-stream
application/microdata+json
application/rss+xmlapplication/wasmapplication/x-www-form-urlencoded
application/xhtml+xml
application/xmlimage/gifimage/jpegimage/pngimage/svg+xmlmultipart/form-datamultipart/mixedmultipart/x-mixed-replace
text/csstext/event-streamtext/javascripttext/jsontext/plaintext/htmltext/pingtext/uri-listtext/vcardtext/vtttext/xmlvideo/mp4
video/mpeg除非标记为“非规范性”,否则所有参考文献均为规范性的。
XMLHttpRequest,A. van Kesteren。WHATWG。
感谢 Tim Berners-Lee 发明 HTML;没有 HTML,这一切都不会存在。
感谢 Aankhen, Aaqa Ishtyaq, Aaron Boodman, Aaron Leventhal, Aaron Krajeski, Abhishek Ghaskata, Abhishek Gupta, Adam Barth, Alexandra Borovova, Adam de Boor, Adam Hepton, Adam Klein, Adam Rice, Adam Roben, Addison Phillips, Adele Peterson, Adrian Bateman, Adrian Roselli, Adrian Sutton, Agustín Fernández, Aharon (Vladimir) Lanin, Ajai Tirumali, Ajay Poshak, Akash Balenalli, Akatsuki Kitamura, Alan Jeffrey, Alan Plum, Alastair Campbell, Alejandro G. Castro, Alex Bishop, Alex Nicolaou, Alex Nozdriukhin, Alex Rousskov, Alex Soncodi, Alexander Farkas, Alexander J. Vincent, Alexander Kalenik, Alexandre Dieulot, Alexandre Morgaut, Alexey Feldgendler, Алексей Проскуряков (Alexey Proskuryakov), Alexey Shvayka, Alexis Deveria, Alfred Agrell, Ali Juma, Alice Boxhall, Alice Wonder, Allan Clements, Allen Wirfs-Brock, Alex Komoroske, Alex Russell, Alphan Chen, Aman Ansari, Ami Fischman, Amos Jeffries, Amos Lim, Anders Carlsson, André Bargull, André E. Veltstra, Andrea Rendine, Andreas, Andreas Deuschlinger, Andreas Farre, Andreas Kling, Andrei Popescu, Andres Gomez, Andres Rios, Andreu Botella, Andrew Barfield, Andrew Clover, Andrew Gove, Andrew Grieve, Andrew Kaster, Andrew Macpherson, Andrew Oakley, Andrew Paseltiner, Andrew Simons, Andrew Smith, Andrew W. Hagen, Andrew Williams, Andrey V. Lukyanov, Andry Rendy, Andy Davies, Andy Earnshaw, Andy Heydon, Andy Paicu, Andy Palay, Anjana Vakil, Ankur Kaushal, Anna Belle Leiserson, Anna Sidwell, Anthony Boyd, Anthony Bryan, Anthony Hickson, Anthony Ramine, Anthony Ricaud, Anton Vayvod, Antonio Sartori, Antti Koivisto, Arfat Salman, Arkadiusz Michalski, Arne Thomassen, Aron Spohr, Arphen Lin, Arthur Hemery, Arthur Sonzogni, Arthur Stolyar, Arun Patole, Aryeh Gregor, Asanka Herath, Asbjørn Ulsberg, Ashley Gullen, Ashley Sheridan, Asumu Takikawa, Atsushi Takayama, Attila Haraszti, Aurelien Levy, Ave Wrigley, Avi Drissman, Axel Dahmen, 방성범 (Bang Seongbeom), Barry Pollard, Ben Boyle, Ben Godfrey, Ben Golightly, Ben Kelly, Ben Lerner, Ben Leslie, Ben Meadowcroft, Ben Millard, Benjamin Carl Wiley Sittler, Benjamin Hawkes-Lewis, Benjamin VanderSloot, Benji Bilheimer, Benoit Ren, Bert Bos, Bijan Parsia, Bil Corry, Bill Mason, Bill McCoy, Billy Wong, Billy Woods, Bjartur Thorlacius, Björn Höhrmann, Blake Frantz, Bob Lund, Bob Owen, Bobby Holley, Boris Zbarsky, Brad Fults, Brad Neuberg, Brad Spencer, Bradley Meck, Brady Eidson, Brandon Jones, Brendan Eich, Brenton Simpson, Brett Wilson, Brett Zamir, Brian Birtles, Brian Blakely, Brian Campbell, Brian Korver, Brian Kuhn, Brian M. Dube, Brian Ryner, Brian Smith, Brian Wilson, Bryan Sullivan, Bruce Bailey, Bruce D'Arcus, Bruce Lawson, Bruce Miller, Bugs Nash, C. Scott Ananian, C. Williams, Cameron McCormack, Cameron Zemek, Cao Yipeng, Carlos Amengual, Carlos Gabriel Cardona, Carlos Ibarra López, Carlos Perelló Marín, Carolyn MacLeod, Casey Leask, Cătălin Badea, Cătălin Mariș, Cem Turesoy, ceving, Chao Cai, 윤석찬 (Channy Yun), Charl van Niekerk, Charlene Wright, Charles Iliya Krempeaux, Charles McCathie Nevile, Charlie Reis, 白丞祐 (Cheng-You Bai), Chris Apers, Chris Cressman, Chris Dumez, Chris Evans, Chris Harrelson, Chris Markiewicz, Chris Morgan, Chris Morris, Chris Nardi, Chris Needham, Chris Pearce, Chris Peterson, Chris Rebert, Chris Weber, Chris Wilson, Christian Biesinger, Christian Johansen, Christian Schmidt, Christoph Päper, Christophe Dumez, Christopher Aillon, Christopher Cameron, Christopher Ferris, Chriswa, Clark Buehler, Cole Robison, Colin Fine, Collin Jackson, Conrad Crawford, Corey Farwell, Corprew Reed, Craig Cockburn, Csaba Gabor, Csaba Marton, Cynthia Shelly, Cyrille Tuzi, Daksh Shah, Dan Callahan, Dan Yoder, Dane Foster, Daniel Barclay, Daniel Bratell, Daniel Brooks, Daniel Brumbaugh Keeney, Daniel Buchner, Daniel Cheng, Daniel Clark, Daniel Davis, Daniel Ehrenberg, Daniel Ethridge, Daniel Glazman, Daniel Holbert, Daniel Peng, Daniel Schattenkirchner, Daniel Spång, Daniel Steinberg, Daniel Tan, Daniel Trebbien, Daniel Vogelheim, Danny Sullivan, Daphne Preston-Kendal, Darien Maillet Valentine, Darin Adler, Darin Fisher, Darxus, Dave Camp, Dave Cramer, Dave Hodder, Dave Lampton, Dave Singer, Dave Tapuska, Dave Townsend, David Baron, David Bloom, David Bokan, David Bruant, David Carlisle, David E. Cleary, David Egan Evans, David Fink, David Flanagan, David Gerard, David Grogan, David Hale, David Håsäther, David Hyatt, David I. Lehn, David John Burrowes, David Matja, David Remahl, David Resseguie, David Smith, David Storey, David Vest, David Woolley, David Zbarsky, Dave Methvin, DeWitt Clinton, Dean Edridge, Dean Edwards, Dean Jackson, Debanjana Sarkar, Debi Orton, Delan Azabani, Derek Featherstone, Derek Guenther, Devarshi Pant, Devdatta, Devin Mullins, Devin Rousso, Di Zhang, Diego Ferreiro Val, Diego González Zúñiga, Diego Ponce de León, Dimitri Glazkov, Dimitry Golubovsky, Dirk Pranke, Dirk Schulze, Dirkjan Ochtman, Divya Manian, Dmitry Lazutkin, Dmitry Titov, dolphinling, Dominic Cooney, Dominique Hazaël-Massieux, Don Brutzman, Donovan Glover, Doron Rosenberg, Doug Kramer, Doug Simpkinson, Drew Wilson, Edgar Chen, Edmund Lai, Eduard Pascual, Eduardo Vela, Edward Welbourne, Edward Z. Yang, Eemeli Aro, Ehsan Akhgari, Ehsan Karamad, Eira Monstad, Eitan Adler, Eli Friedman, Eli Grey, Eliot Graff, Elisabeth Robson, Elizabeth Castro, Elliott Sprehn, Elliotte Harold, Emilio Cobos Álvarez, Emily Stark, Eric Carlson, Eric Casler, Eric Lawrence, Eric Portis, Eric Rescorla, Eric Semling, Eric Shepherd, Eric Willigers, Erik Arvidsson, Erik Charlebois, Erik Rose, 栗本 英理子 (Eriko Kurimoto), espretto, Evan Jacobs, Evan Martin, Evan Prodromou, Evan Stade, Evert, Evgeny Kapun, ExE-Boss, Ezequiel Garzón, fantasai, Félix Sanz, Felix Sasaki, Fernando Altomare Serboncini, Forbes Lindesay, Francesco Schwarz, Francis Brosnan Blazquez, Franck 'Shift' Quélain, François Marier, Frank Barchard, Frank Liberato, Franklin Shirley, Frederik Braun, Fredrik Söderquist, 鵜飼文敏 (Fumitoshi Ukai), Futomi Hatano, Gavin Carothers, Gavin Kistner, Gareth Rees, Garrett Smith, Gary Blackwood, Gary Kacmarcik, Gary Katsevman, Geoff Richards, Geoffrey Garen, Georg Neis, George Lund, Gianmarco Armellin, Giovanni Campagna, Giuseppe Pascale, Glenn Adams, Glenn Maynard, Graham Klyne, Greg Botten, Greg Houston, Greg Wilkins, Gregg Tavares, Gregory J. Rosmaita, Gregory Terzian, Grey, guest271314, Guilherme Johansson Tramontina, Guy Bedford, Gytis Jakutonis, Håkon Wium Lie, Habib Virji, Hajime Morrita, Hallvord Reiar Michaelsen Steen, Hanna Laakso, Hans S. Tømmerhalt, Hans Stimer, Harald Alvestrand, Hayato Ito, 何志翔 (HE Zhixiang), Henri Sivonen, Henrik Lied, Henrik Lievonen, Henry Lewis, Henry Mason, Henry Story, Hermann Donfack Zeufack, 中川博貴 (Hiroki Nakagawa), Hiroshige Hayashizaki, Hiroyuki USHITO, Hitoshi Yoshida, Hongchan Choi, 王华 (Hua Wang), Hugh Bellamy, Hugh Guiney, Hugh Winkler, Ian Bicking, Ian Clelland, Ian Davis, Ian Fette, Ian Henderson, Ian Kilpatrick, Ibrahim Ahmed, Ido Green, Ignacio Javier, Igor Oliveira, 安次嶺 一功 (Ikko Ashimine), Ilya Grigorik, Ingvar Stepanyan, isonmad, Iurii Kucherov, Ivan Enderlin, Ivan Nikulin, Ivan Panchenko, Ivo Emanuel Gonçalves, J. King, J.C. Jones, Jackson Ray Hamilton, Jacob Davies, Jacques Distler, Jake Archibald, Jake Verbaten, Jakub Vrána, Jakub Łopuszański, Jakub Wilk, James Browning, James Craig, James Graham, James Greene, James Justin Harrell, James Kozianski, James M Snell, James Perrett, James Robinson, Jamie Liu, Jamie Lokier, Jamie Mansfield, Jan Kühle, Jan Miksovsky, Janice Shiu, Janusz Majnert, Jan-Ivar Bruaroey, Jan-Klaas Kollhof, Jared Jacobs, Jason Duell, Jason Kersey, Jason Lustig, Jason Orendorff, Jason White, Jasper Bryant-Greene, Jasper St. Pierre, Jatinder Mann, Jay Henry Kao, Jayson Chen, Jean-Yves Avenard, Jed Hartman, Jeff Balogh, Jeff Cutsinger, Jeff Gilbert, Jeff "=JeffH" Hodges, Jeff Schiller, Jeff Walden, Jeffrey Yasskin, Jeffrey Zeldman, 胡慧鋒 (Jennifer Braithwaite), Jellybean Stonerfish, Jennifer Apacible, Jens Bannmann, Jens Fendler, Jens Oliver Meiert, Jens Widell, Jer Noble, Jeremey Hustman, Jeremy Keith, Jeremy Orlow, Jeremy Roman, Jeroen van der Meer, Jerry Smith, Jesse Renée Beach, Jessica Jong, jfkthame, Jian Li, Jihye Hong, Jim Jewett, Jim Ley, Jim Meehan, Jim Michaels, Jin Dongxun (金东勋, 金東勳, 김동훈), Jinho Bang, Jinjiang (勾三股四), Jirka Kosek, Jjgod Jiang, Joaquim Medeiros, João Eiras, Jochen Eisinger, Joe Clark, Joe Gregorio, Joel Spolsky, Joel Verhagen, Joey Arhar, Johan Herland, Johanna Herman, John Boyer, John Bussjaeger, John Carpenter, John Daggett, John Fallows, John Foliot, John Harding, John Keiser, John Law, John Musgrave, John Snyders, John Stockton, John-Mark Bell, Johnny Stenback, Jon Coppeard, Jon Ferraiolo, Jon Gibbins, Jon Jensen, Jon Perlow, Jonas Sicking, Jonathan Cook, Jonathan Kew, Jonathan Neal, Jonathan Oddy, Jonathan Rees, Jonathan Watt, Jonathan Worent, Jonny Axelsson, Joram Schrijver, Jordan Tucker, Jorgen Horstink, Joris van der Wel, Jorunn Danielsen Newth, Joseph Kesselman, Joseph Mansfield, Joseph Pecoraro, Josh Aas, Josh Hart, Josh Juran, Josh Levenberg, Josh Matthews, Joshua Bell, Joshua Chen, Joshua Randall, Juan Olvera, Juanmi Huertas, Jukka K. Korpela, Jules Clément-Ripoche, Julian Reschke, Julio Lopez, 小勝 純 (Jun Kokatsu), Jun Yang (harttle), Jungkee Song, Jürgen Jeka, Justin Lebar, Justin Novosad, Justin Rogers, Justin Schuh, Justin Sinclair, Juuso Lapinlampi, Ka-Sing Chou, Kagami Sascha Rosylight, Kai Hendry, Kamishetty Sreeja, 呂康豪 (KangHao Lu), Karl Dubost, Karl Tomlinson, Kartik Arora, Kartikaya Gupta, Kathy Walton, 河童エクマ(Kawarabe Ecma) Keith Cirkel, Keith Rollin, Keith Yeung, Kelly Ford, Kelly Norton, Ken Russell, Kenji Baheux, Kevin Babbitt, Kevin Benson, Kevin Cole, Kevin Gadd, Kevin McNee, Kevin Venkiteswaran, Khushal Sagar, Kinuko Yasuda, Koji Ishii, Kornél Pál, Kornel Lesinski, 上野 康平 (UENO, Kouhei), Kris Northfield, Kristian Spangsege, Kristof Zelechovski, Krzysztof Maczyński, 黒澤剛志 (Kurosawa Takeshi), Kurt Catti-Schmidt, Kyle Barnhart, Kyle Hofmann, Kyle Huey, Léonard Bouchet, Léonie Watson, Lachlan Hunt, Larry Masinter, Larry Page, Lars Gunther, Lars Solberg, Laura Carlson, Laura Granka, Laura L. Carlson, Laura Wisewell, Laurens Holst, Lawrence Forooghian, Lee Kowalkowski, Leif Halvard Silli, Leif Kornstaedt, Lenny Domnitser, Leonard Rosenthol, Leons Petrazickis, Liviu Tinta, Lobotom Dysmon, Logan, Logan Moore, Lorenz Ackermann, Loune, Luca Casonato, Lucas Gadani, Łukasz Pilorz, Luke Kenneth Casson Leighton, Luke Warlow, Luke Wilde, Maciej Stachowiak, Magne Andersson, Magnus Kristiansen, Maik Merten, Majid Valipour, Maksim Sadym, Malcolm Rowe, Manish Goregaokar, Manish Tripathi, Manuel Martinez-Almeida, Manuel Rego Casasnovas, Marc Hoyois, Marc-André Choquette, Marc-André Lafortune, Marco Zehe, Marcus Bointon, Marcus Otterström, Marijn Kruisselbrink, Mark Amery, Mark Birbeck, Mark Davis, Mark Green, Mark Miller, Mark Nottingham, Mark Pilgrim, Mark Rogers, Mark Rowe, Mark Schenk, Mark Vickers, Mark Wilton-Jones, Markus Cadonau, Markus Stange, Martijn van der Ven, Martijn Wargers, Martin Atkins, Martin Chaov, Martin Dürst, Martin Honnen, Martin Janecke, Martin Kutschker, Martin Nilsson, Martin Robinson, Martin Thomson, Masataka Yakura, Masatoshi Kimura, Mason Freed, Mason Mize, Mathias Bynens, Mathieu Henri, Matias Larsson, Matt Brubeck, Matt Di Pasquale, Matt Falkenhagen, Matt Giuca, Matt Harding, Matt Schmidt, Matt Wright, Matthew Gaudet, Matthew Gregan, Matthew Mastracci, Matthew Noorenberghe, Matthew Raymond, Matthew Thomas, Matthew Tylee Atkinson, Mattias Waldau, Max Romantschuk, Maxim Tsoy, Mayeul Cantan, Menachem Salomon, Menno van Slooten, Micah Dubinko, Micah Nerren, Michael 'Ratt' Iannarelli, Michael A. Nachbaur, Michael A. Puls II, Michael Carter, Michael Daskalov, Michael Day, Michael Dyck, Michael Enright, Michael Ficarra, Michael Gratton, Michael Kohler, Michael McKelvey, Michael Nordman, Michael Powers, Michael Rakowski, Michael(tm) Smith, Michael Walmsley, Michal Zalewski, Michel Buffa, Michel Fortin, Michelangelo De Simone, Michiel van der Blonk, Miguel Casas-Sanchez, Mihai Şucan, Mihai Parparita, Mike Brown, Mike Dierken, Mike Dixon, Mike Hearn, Mike Pennisi, Mike Schinkel, Mike Shaver, Mikko Rantalainen, Mingye Wang, Mirko Brodesser, Mohamed Zergaoui, Mohammad Al Houssami, Mohammad Reza Zakerinasab, Momdo Nakamura, Morten Stenshorne, Mounir Lamouri, Ms2ger, mtrootyy, 邱慕安 (Mu-An Chiou), Mukilan Thiyagarajan, Mustaq Ahmed, Myles Borins, Nadia Heninger, Nate Chapin, NARUSE Yui, Navid Zolghadr, Neil Deakin, Neil Rashbrook, Neil Soiffer, Nereida Rondon, networkException, Nicholas Shanks, Nicholas Stimpson, Nicholas Zakas, Nickolay Ponomarev, Nicolas Gallagher, Nicolas Pena Moreno, Nicolò Ribaudo, Nidhi Jaju, Nigel Megitt, Nikki Bee, Niklas Gögge, Nina Satragno, Noah Mendelsohn, Noah Slater, Noam Rosenthal, Noel Gordon, Nolan Waite, NoozNooz42, Norbert Lindenberg, Oisín Nolan, Ojan Vafai, Olaf Hoffmann, Olav Junker Kjær, Oldřich Vetešník, Oli Studholme, Oliver Hunt, Oliver Rigby, Olivia (Xiaoni) Lai, Olivier Gendrin, Olli Pettay, Ondřej Žára, Ori Avtalion, Oriol Brufau, oSand, Pablo Flouret, Patrick Dark, Patrick Garies, Patrick H. Lauke, Patrik Persson, Paul Adenot, Paul Lewis, Paul Norman, Per-Erik Brodin, 一丝 (percyley), Perry Smith, Peter Beverloo, Peter Karlsson, Peter Kasting, Peter Moulder, Peter Occil, Peter Stark, Peter Van der Beken, Peter van der Zee, Peter-Paul Koch, Phil Pickering, Philip Ahlberg, Philip Brembeck, Philip Taylor, Philip TAYLOR, Philippe De Ryck, Pierre-Arnaud Allumé, Pierre-Marie Dartus, Pierre-Yves Gérardy, Piers Wombwell, Pooja Sanklecha, Prashant Hiremath, Prashanth Chandra, Prateek Rungta, Pravir Gupta, Prayag Verma, Psychpsyo, 李普君 (Pujun Li), Rachid Finge, Rafael Weinstein, Rafał Miłecki, Rahim Abdi, Rahul Purohit, Raj Doshi, Rajas Moonka, Rakina Zata Amni, Ralf Stoltze, Ralph Giles, Rebecca Star, Remci Mizkur, Remco, Remy Sharp, Rene Saarsoo, Rene Stach, Ric Hardacre, Rich Clark, Rich Doughty, Richa Rupela, Richard Gibson, Richard Ishida, Richard Torres, Ricky Mondello, Rigo Wenning, Rikkert Koppes, Rimantas Liubertas, Riona Macnamara, River Champeimont, Rob Buis, Rob Ennals, Rob Jellinghaus, Rob S, Rob Smith, Robert Blaut, Robert Collins, Robert Hogan, Robert Kieffer, Robert Linder, Robert Millan, Robert O'Callahan, Robert Sayre, Robin Berjon, Robin Schaufler, Rodger Combs, Roland Steiner, Roma Matusevich, Romain Deltour, Roman Ivanov, Roy Fielding, Rune Lillesveen, Russell Bicknell, Ruud Steltenpool, Ryan King, Ryan Landay, Ryan Sleevi, Ryo Kajiwara, Ryo Kato, Ryosuke Niwa, S. Mike Dierken, Salvatore Loreto, Sam Atkins, Sam Dutton, Sam Kuper, Sam Ruby, Sam Sneddon, Sam Weinig, Samikshya Chand, Samuel Bronson, Samy Kamkar, Sander van Lambalgen, Sanjoy Pal, Sanket Joshi, Sarah Gebauer, Sarven Capadisli, Satrujit Behera, Sayan Sivakumaran, Schalk Neethling, Scott Beardsley, Scott González, Scott Hess, Scott Jehl, Scott Miles, Scott O'Hara, Sean B. Palmer, Sean Feng, Sean Fraser, Sean Hayes, Sean Hogan, Sean Knapp, Sebastian Markbåge, Sebastian Schnitzenbaumer, Sendil Kumar N, Seth Call, Seth Dillingham, Shannon Booth, Shannon Moeller, Shanti Rao, Shaun Inman, Shiino Yuki, 贺师俊 (HE Shi-Jun), Shiki Okasaka, Shivani Sharma, shreyateeza, Shubheksha Jalan, Sidak Singh Aulakh, Sierk Bornemann, Sigbjørn Finne, Sigbjørn Vik, Silver Ghost, Silvia Pfeiffer, Šime Vidas, Simon Fraser, Simon Montagu, Simon Sapin, Yu Han, Simon Spiegel, Simon Wülker, Siye Liu, skeww, Smylers, Srirama Chandra Sekhar Mogali, Stanton McCandlish, stasoid, Stefan Håkansson, Stefan Haustein, Stefan Santesson, Stefan Schumacher, Ştefan Vargyas, Stefan Weiss, Steffen Meschkat, Stephen Chenney, Stephen Ma, Stephen Stewart, Stephen White, Steve Comstock, Steve Faulkner, Steve Fink, Steve Orvell, Steve Runyon, Steven Bennett, Steven Bingler, Steven Garrity, Steven Tate, Stewart Brodie, Stuart Ballard, Stuart Langridge, Stuart Parmenter, Subramanian Peruvemba, Sudhanshu Jaiswal, sudokus999, Sunava Dutta, Surma, Susan Borgrink, Susan Lesch, Sylvain Pasche, T.J. Crowder, Tab Atkins-Bittner, Taiju Tsuiki, Takashi Toyoshima, Takayoshi Kochi, Takeshi Yoshino, Tantek Çelik, 田村健人 (Kent TAMURA), Tawanda Moyo, Taylor Hunt, Ted Mielczarek, Terence Eden, Terrence Wood, Tetsuharu OHZEKI, Theresa O'Connor, Thijs van der Vossen, Thomas Broyer, Thomas Koetter, Thomas O'Connor, Tim Altman, Tim Dresser, Tim Flynn, Tim Johansson, Tim Nguyen, Tim Perry, Tim van der Lippe, TJ VanToll, Tobias Schneider, Tobie Langel, Toby Inkster, Todd Moody, Tom Baker, Tom Pike, Tom Schuster, Tom ten Thij, Tomasz Jakut, Tomek Wytrębowicz, Tommy Thorsen, Tony Ross, Tooru Fujisawa, Toru Kobayashi, Traian Captan, Travis Leithead, Trevor Rowbotham, Trevor Saunders, Trey Eckels, triple-underscore, Tristan Fraipont, Tristan Parisot, 保呂 毅 (Tsuyoshi Horo), Tyler Close, Valentin Gosu, Vardhan Gupta, Vas Sudanagunta, Veli Şenol, Victor Carbune, Victor Costan, Vipul Snehadeep Chawathe, Vitya Muhachev, Vlad Levin, Vladimir Katardjiev, Vladimir Vukićević, Vyacheslav Aristov, voracity, Walter Steiner, Wakaba, Wayne Carr, Wayne Pollock, Wellington Fernando de Macedo, Wenson Hsieh, Weston Ruter, Wilhelm Joys Andersen, Will Levine, Will Ray, William Chen, William Swanson, Willy Martin Aguirre Rodriguez, Wladimir Palant, Wojciech Mach, Wolfram Kriesing, Xan Gregg, xenotheme, XhmikosR, Xida Chen, Xidorn Quan, Xue Fuqiao, Yang Chen, Yao Xiao, Yash Handa, Yay295, Ye-Kui Wang, Yehuda Katz, Yi Xu, Yi-An Huang, Yngve Nysaeter Pettersen, Yoav Weiss, Yoel Hawa, Yonathan Randolph, Yu Huojiang, Yuki Okushi, Yury Delendik, 平野裕 (Yutaka Hirano), Yuzo Fujishima, 西條柚 (Yuzu Saijo), Zhenbin Xu, 张智强 (Zhiqiang Zhang), Zoltan Herczeg, Zyachel, 以及 Øistein E. Andersen, 感谢他们多年来提出的各种有益意见,无论大小,这些意见都促使本规范发生了改进。
还要感谢所有曾在博客、公共邮件列表或论坛中讨论 HTML 的人,包括 各个 W3C HTML WG 列表和 各个 WHATWG 列表的所有贡献者。
特别感谢 Richard Williamson 在 Safari 中创建了
canvas
的首个实现,canvas 功能正是在此基础上设计的。
还要特别感谢 Microsoft 员工,他们首次实现了基于事件的拖放机制、contenteditable,
以及其他最早由 Windows Internet Explorer 浏览器广泛部署的功能。
特别感谢 David Hyatt,并奖励其 10,000 美元;他提出了一个有缺陷的收养代理算法实现,编辑在将其用于解析章节之前, 不得不对其进行逆向工程并加以修复。
感谢微数据可用性研究的参与者允许我们将他们的错误用作设计微数据功能的指导。
感谢为规范中的示例提供灵感的众多来源。
还要感谢 Microsoft 博客社区提供的一些想法,感谢 W3C Web 应用程序和复合文档研讨会的 与会者提供的灵感,感谢 #mrt 团队、#mrt.no 团队和 #whatwg 团队,以及 Pillar 和 Hedral 提供的想法和支持。
感谢 Igor Zhbanov 生成本规范的 PDF 版本。
特别感谢 RICG 开发
picture
元素及相关功能;尤其感谢 Adrian Bateman、
Bruce Lawson、David Newton、Ilya Grigorik、John Schoenick、Leon de Rijke、Mat Marquis、Marcos
Cáceres、Tab Atkins、Theresa O'Connor 和 Yoav Weiss 的贡献。
特别感谢 WPWG 孵化 自定义元素功能。尤其感谢 David Hyatt 和 Ian Hickson 通过 XBL 规范产生的影响,感谢 Dimitri Glazkov 编写自定义元素规范的第一份 草案,并感谢 Alex Komoroske, Alex Russell, Andres Rios, Boris Zbarsky, Brian Kardell, Daniel Buchner, Dominic Cooney, Erik Arvidsson, Elliott Sprehn, Hajime Morrita, Hayato Ito, Jan Miksovsky, Jonas Sicking, Olli Pettay, Rafael Weinstein, Roland Steiner, Ryosuke Niwa, Scott Miles, Steve Faulkner, Steve Orvell, Tab Atkins, Theresa O'Connor, Tim Perry, 以及 William Chen 的贡献。
特别感谢 CSSWG 开发 worklet。尤其感谢 Ian Kilpatrick 担任原始 worklet 规范编辑所做的工作。
特别感谢 WICG 孵化推测性加载功能。尤其感谢 Jeremy Roman 担任原始推测规则和预取规范编辑所做的工作。
特别感谢 WICG 孵化 Sanitizer API。尤其感谢 Frederik Braun、Mario Heiderich、Daniel Vogelheim 和 Tom Schuster 担任原始 Sanitizer API 规范编辑所做的工作。
从 2003 年开始的大约十年间,本标准几乎完全由 Ian Hickson (Google,ian@hixie.ch)编写。
从 2015 年开始,编辑团队有所扩展。目前由 Anne van Kesteren(Apple,annevk@annevk.nl)、 Domenic Denicola(Google,d@domenic.me) Dominic Farolino(Google,domfarolino@gmail.com)、 Philip Jägenstedt(Google,philip@foolip.org),以及 Simon Pieters(Mozilla,zcorpan@gmail.com)维护。
The image in the introduction is based on a photo by Wonderlane. (CC BY 2.0)
The image of the wolf in the embedded content introduction is based on a photo by Barry O'Neill. (Public domain)
The image of the kettlebell swing in the embedded content introduction is based on a photo by kokkarina. (CC0 1.0)
The Blue Robot Player sprite used in the canvas demo is based on a work by JohnColburn. (CC BY-SA 3.0)
The photograph of robot 148 climbing the tower at the FIRST Robotics Competition 2013 Silicon Valley Regional is based on a work by Lenore Edman. (CC BY 2.0)
The diagram showing how async and defer impact script loading is based on a
similar diagram from a
blog post by Peter Beverloo.
(CC0 1.0)
The image decoding demo used to demonstrate module-based workers draws on some example code from a tutorial by Ilmari Heikkinen. (CC BY 3.0)
The <flag-icon> example was inspired by a custom element by Steven
Skelton. (MIT)
Part of the revision history of the
picture element and related features
can be found in the ResponsiveImagesCG/picture-element
repository, which is available under the W3C Software and
Document License.
Part of the revision history of the theme-color metadata name can be found in the whatwg/meta-theme-color
repository, which is available under CC0.
Part of the revision history of the custom elements feature can be found in the w3c/webcomponents repository, which
is available under the W3C Software and
Document License.
Part of the revision history of the innerText getter and setter can be found in the rocallahan/innerText-spec
repository, which is available under CC0.
Part of the revision history of the worklets feature can be found in the w3c/css-houdini-drafts
repository, which is available under the W3C Software and
Document License.
Part of the revision history of the import
maps feature can be found in the WICG/import-maps
repository, which is available under the W3C Software and
Document License.
Part of the revision history of the navigation API feature can be found in the WICG/navigation-api
repository, which is available under the W3C Software and
Document License.
Part of the revision history of the Close requests and close watchers section can be
found in the WICG/close-watcher
repository, which is available under the W3C Software and
Document License.
Part of the revision history of the Speculative loading section can be
found in the WICG/nav-speculation
repository, which is available under the W3C Software and
Document License.
Copyright © WHATWG (Apple, Google, Mozilla, Microsoft). This work is licensed under a Creative Commons Attribution 4.0 International License. To the extent portions of it are incorporated into source code, such portions in the source code are licensed under the BSD 3-Clause License instead.
This is the Living Standard. Those interested in the patent-review version should view the Living Standard Review Draft.
{kind=link}