简介
到目前为止,网页上的音频一直相当原始,直到最近才需要通过 Flash 和 QuickTime 等插件来传递音频。HTML5 中引入的
audio
元素非常重要,允许进行基本的流音频播放。但是,它还不足以处理更复杂的音频应用程序。对于复杂的基于网页的游戏或交互式应用程序,需要另一种解决方案。本规范的目标是包含现代游戏音频引擎中的功能,以及现代桌面音频制作应用中用于混音、处理和过滤的任务。
API 的设计考虑了多种使用案例 [webaudio-usecases]。理想情况下,它应该能够支持任何可以合理地用优化的 C++ 引擎通过脚本在浏览器中运行的使用案例。话虽如此,现代桌面音频软件可能具有非常高级的功能,其中一些功能使用此系统构建起来非常困难甚至不可能。例如,Apple 的 Logic Audio 支持外部 MIDI 控制器、任意插件音频效果和合成器、高度优化的直接磁盘音频文件读写、紧密集成的时间拉伸等功能。然而,拟议的系统将完全能够支持大量相当复杂的游戏和交互式应用程序,包括音乐类应用程序。此外,它可以很好地补充 WebGL 提供的更高级的图形功能。API 的设计也允许以后添加更高级的功能。
特性
API 支持以下主要特性:
-
模块化路由,用于简单或复杂的混合/效果架构。
-
高动态范围,使用 32 位浮点数进行内部处理。
-
采样精确的声音播放调度,具有低 延迟,适用于对节奏精度要求很高的音乐应用,例如鼓机和音序器。这还包括动态创建效果的可能性。
-
自动化音频参数,用于包络、渐入/渐出、粒子效果、滤波扫频、LFO 等。
-
灵活处理音频流中的通道,允许拆分和合并它们。
-
使用
MediaStream从getUserMedia()获取的实时音频输入进行处理。 -
与 WebRTC 集成
-
使用
MediaStreamTrackAudioSourceNode处理从远程对等方接收的音频,并参考 [webrtc]。 -
使用
MediaStreamAudioDestinationNode发送生成或处理过的音频流到远程对等方,并参考 [webrtc]。
-
-
使用 脚本直接合成和处理音频流。
-
空间化音频,支持广泛的 3D 游戏和沉浸式环境:
-
声像模型:equalpower、HRTF、直通
-
距离衰减
-
声锥
-
遮挡 / 阻塞
-
基于源 / 监听者
-
-
用于广泛线性效果的卷积引擎,特别是非常高质量的房间效果。以下是一些可能的效果示例:
-
小 / 大房间
-
大教堂
-
音乐厅
-
洞穴
-
隧道
-
走廊
-
森林
-
圆形剧场
-
从门口听到的远处房间的声音
-
极端滤波器
-
奇怪的反向效果
-
极端梳状滤波效果
-
-
动态压缩以整体控制和优化混音效果
-
高效的 实时时域和频域分析 / 音乐可视化支持。
-
高效的双二阶滤波器,用于低通、高通和其他常见滤波器。
-
用于失真和其他非线性效果的波形整形效果
-
振荡器
模块化路由
模块化路由允许不同的 AudioNode
对象之间进行任意连接。每个节点可以有 输入 和/或 输出。
一个 源节点 没有输入且只有一个输出。
一个 目标节点
有一个输入且没有输出。其他节点如滤波器可以放置在源节点和目标节点之间。当两个对象连接在一起时,开发者不必担心底层的流格式细节;正确的事情会自动发生。
例如,如果一个单声道音频流连接到一个立体声输入,它会适当地混合到左右声道合适的位置。
在最简单的情况下,单个源可以直接路由到输出。所有路由都在一个包含单个 AudioContext
和 AudioDestinationNode
的上下文中进行:
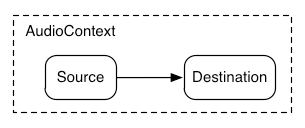
为了说明这个简单的路由,这里是一个简单的播放单个声音的示例:
const context= new AudioContext(); function playSound() { const source= context. createBufferSource(); source. buffer= dogBarkingBuffer; source. connect( context. destination); source. start( 0 ); }
这里是一个更复杂的例子,有三个音源和一个卷积混响发送,最终输出阶段有一个动态压缩器:
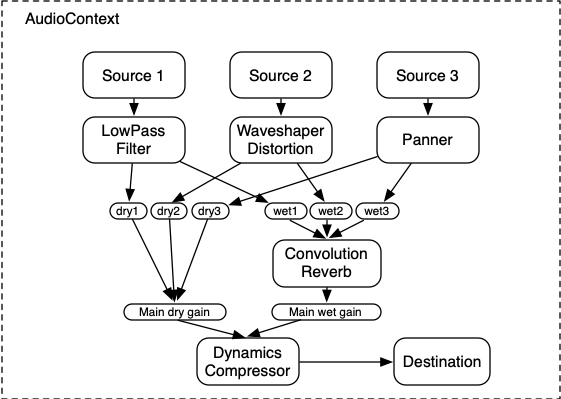
...
模块化路由还允许 AudioNode
的输出被路由到 AudioParam
参数,从而控制其他 AudioNode
的行为。在这种情况下,节点的输出可以充当调制信号,而不是输入信号。
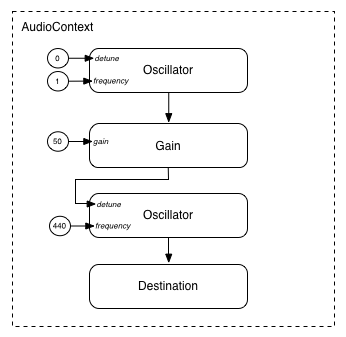
function setupRoutingGraph() { const context= new AudioContext(); // Create the low frequency oscillator that supplies the modulation signal const lfo= context. createOscillator(); lfo. frequency. value= 1.0 ; // Create the high frequency oscillator to be modulated const hfo= context. createOscillator(); hfo. frequency. value= 440.0 ; // Create a gain node whose gain determines the amplitude of the modulation signal const modulationGain= context. createGain(); modulationGain. gain. value= 50 ; // Configure the graph and start the oscillators lfo. connect( modulationGain); modulationGain. connect( hfo. detune); hfo. connect( context. destination); hfo. start( 0 ); lfo. start( 0 ); }
API 概述
定义的接口包括:
-
一个 AudioContext 接口,包含表示
AudioNode之间连接的音频信号图。 -
一个
AudioNode接口,代表音频源、音频输出和中间处理模块。AudioNode可以以 模块化的方式 动态连接在一起。AudioNode存在于AudioContext中。 -
一个
AnalyserNode接口, 是一个AudioNode, 用于音乐可视化工具或其他可视化应用程序。 -
一个
AudioBuffer接口,用于处理内存中的音频资产。 这些音频资产可以表示一次性播放的声音,或者较长的音频片段。 -
一个
AudioBufferSourceNode接口, 是一个AudioNode,用于从 AudioBuffer 生成音频。 -
一个
AudioDestinationNode接口, 是一个AudioNode子类, 代表所有渲染音频的最终目标。 -
一个
AudioParam接口, 用于控制AudioNode的某个具体方面的功能,例如音量。 -
一个
AudioListener接口, 与PannerNode一起用于空间化处理。 -
一个
AudioWorklet接口, 代表一个用于创建自定义节点的工厂,这些节点可以直接使用脚本处理音频。 -
一个
AudioWorkletGlobalScope接口, 代表 AudioWorkletProcessor 处理脚本运行的上下文。 -
一个
AudioWorkletNode接口, 是一个AudioNode,代表在 AudioWorkletProcessor 中处理的节点。 -
一个
AudioWorkletProcessor接口, 代表音频工作者中的单个节点实例。 -
一个
BiquadFilterNode接口, 是一个AudioNode,用于常见的低阶滤波器,例如:-
低通滤波器(Low Pass)
-
高通滤波器(High Pass)
-
带通滤波器(Band Pass)
-
低架滤波器(Low Shelf)
-
高架滤波器(High Shelf)
-
峰值滤波器(Peaking)
-
陷波滤波器(Notch)
-
全通滤波器(Allpass)
-
-
一个
ChannelMergerNode接口, 是一个AudioNode,用于将多个音频流的通道合并为一个音频流。 -
一个
ChannelSplitterNode接口, 是一个AudioNode,用于在路由图中访问音频流的各个通道。 -
一个
ConstantSourceNode接口, 是一个AudioNode,用于生成名义上恒定的输出值, 并使用AudioParam来自动化控制该值。 -
一个
ConvolverNode接口, 是一个AudioNode,用于应用实时线性效果(例如音乐厅的声音)。 -
一个
DynamicsCompressorNode接口, 是一个AudioNode,用于动态压缩。 -
一个
IIRFilterNode接口, 是一个AudioNode,用于通用 IIR 滤波。 -
一个
MediaElementAudioSourceNode接口, 是一个AudioNode,用于从audio、video或其他媒体元素中生成音频。 -
一个
MediaStreamAudioSourceNode接口, 是一个AudioNode, 用于从MediaStream中获取音频源, 如实时音频输入或来自远程对等体的音频。 -
一个
MediaStreamTrackAudioSourceNode接口, 是一个AudioNode, 用于从MediaStreamTrack获取音频源。 -
一个
MediaStreamAudioDestinationNode接口, 是一个AudioNode, 用于作为MediaStream的音频目标,发送给远程对等体。 -
一个
PannerNode接口, 是一个AudioNode, 用于在 3D 空间中对音频进行空间化 / 定位。 -
一个
PeriodicWave接口, 用于为OscillatorNode指定自定义的周期波形。 -
一个
OscillatorNode接口, 是一个AudioNode, 用于生成周期波形。 -
一个
StereoPannerNode接口, 是一个AudioNode, 用于在立体声流中等功率定位音频输入。 -
一个
WaveShaperNode接口, 是一个AudioNode, 用于应用非线性波形整形效果,用于失真和其他更微妙的增暖效果。
Web Audio API 还有几个功能已被弃用,但尚未删除,等待替代方案的实现经验:
-
一个
ScriptProcessorNode接口, 是一个AudioNode, 用于直接使用脚本生成或处理音频。 -
一个
AudioProcessingEvent接口, 是与ScriptProcessorNode对象一起使用的事件类型。
1. 音频 API
1.1.
BaseAudioContext
接口
此接口表示一组 AudioNode
对象及其连接。它允许将信号任意路由到 AudioDestinationNode。节点是从上下文中创建的,然后相互
连接。
BaseAudioContext
不能直接实例化,而是通过具体接口 AudioContext(用于实时渲染)和
OfflineAudioContext
(用于离线渲染)来扩展。
BaseAudioContext
创建时带有一个内部槽 [[pending promises]],它是一个初始为空的有序承诺列表。
每个 BaseAudioContext
都有一个唯一的 媒体元素事件任务源。
此外,BaseAudioContext
具有几个私有槽 [[rendering thread state]] 和
[[control thread state]],
它们的值取自 AudioContextState,
且都最初设置为 "suspended",并有一个私有槽 [[render quantum size]],它是一个无符号整数。
enum {AudioContextState "suspended" ,"running" ,"closed" };
| 枚举值 | 描述 |
|---|---|
"suspended"
| 该上下文当前被挂起(上下文时间不继续,音频硬件可能已关闭/释放)。 |
"running"
| 正在处理音频。 |
"closed"
| 该上下文已被释放,不能再用于处理音频。所有系统音频资源均已释放。 |
enum {AudioContextRenderSizeCategory "default" ,"hardware" };
| 枚举说明 | |
|---|---|
"default"
| AudioContext 的渲染量子大小为默认值 128 帧。 |
"hardware"
| User-Agent 选择一个适合当前配置的渲染量子大小。
注意: 这会暴露有关主机的信息,并可能用于指纹识别。 |
callback DecodeErrorCallback =undefined (DOMException );error callback DecodeSuccessCallback =undefined (AudioBuffer ); [decodedData Exposed =Window ]interface BaseAudioContext :EventTarget {readonly attribute AudioDestinationNode destination ;readonly attribute float sampleRate ;readonly attribute double currentTime ;readonly attribute AudioListener listener ;readonly attribute AudioContextState state ;readonly attribute unsigned long renderQuantumSize ; [SameObject ,SecureContext ]readonly attribute AudioWorklet audioWorklet ;attribute EventHandler onstatechange ;AnalyserNode createAnalyser ();BiquadFilterNode createBiquadFilter ();AudioBuffer createBuffer (unsigned long ,numberOfChannels unsigned long ,length float );sampleRate AudioBufferSourceNode createBufferSource ();ChannelMergerNode createChannelMerger (optional unsigned long numberOfInputs = 6);ChannelSplitterNode createChannelSplitter (optional unsigned long numberOfOutputs = 6);ConstantSourceNode createConstantSource ();ConvolverNode createConvolver ();DelayNode createDelay (optional double maxDelayTime = 1.0);DynamicsCompressorNode createDynamicsCompressor ();GainNode createGain ();IIRFilterNode createIIRFilter (sequence <double >,feedforward sequence <double >);feedback OscillatorNode createOscillator ();PannerNode createPanner ();PeriodicWave createPeriodicWave (sequence <float >,real sequence <float >,imag optional PeriodicWaveConstraints = {});constraints ScriptProcessorNode createScriptProcessor (optional unsigned long bufferSize = 0,optional unsigned long numberOfInputChannels = 2,optional unsigned long numberOfOutputChannels = 2);StereoPannerNode createStereoPanner ();WaveShaperNode createWaveShaper ();Promise <AudioBuffer >decodeAudioData (ArrayBuffer ,audioData optional DecodeSuccessCallback ?,successCallback optional DecodeErrorCallback ?); };errorCallback
1.1.1. 属性
audioWorklet, 类型 AudioWorklet, 只读-
允许访问
Worklet对象,可以通过 [HTML] 和AudioWorklet中定义的算法导入包含AudioWorkletProcessor类定义的脚本。 currentTime, 类型 double, 只读-
这是由上下文的渲染图最近处理的音频块中紧跟在最后一个样本帧之后的样本帧的时间(以秒为单位)。如果上下文的渲染图尚未处理任何音频块,则
currentTime的值为零。在
currentTime的时间坐标系统中,值为零对应于图中处理的第一个块中的第一个样本帧。此系统中的经过时间对应于由BaseAudioContext生成的音频流中的经过时间,这可能不同步于系统中的其他时钟。(对于OfflineAudioContext,因为流并未被任何设备主动播放,所以没有接近真实时间的概念。)Web Audio API 中的所有计划时间都是相对于
currentTime的值。当
BaseAudioContext处于“running”状态时,此属性的值会单调递增,并由渲染线程以均匀的增量更新,对应于一个 渲染量子。因此,对于正在运行的上下文,currentTime随系统处理音频块而稳步增加,并始终表示将要处理的下一个音频块的起始时间。同时,它也是当前状态下计划中的任何更改可能生效的最早时间。currentTime必须在控制线程上 原子性 读取后再返回。 destination, 类型 AudioDestinationNode, 只读-
一个
AudioDestinationNode,具有一个输入,表示所有音频的最终目标。通常,它表示实际的音频硬件。所有正在积极渲染音频的AudioNode都将直接或间接连接到destination。 listener, 类型 AudioListener, 只读-
一个
AudioListener,用于 3D 空间化。 onstatechange, 类型 EventHandler-
用于设置 事件处理程序 的属性,当 AudioContext 的状态发生变化时(即,当相应的承诺将被解决时),会向
BaseAudioContext派发一个事件。此事件处理程序的事件类型为statechange。使用Event接口的事件将被派发给事件处理程序,事件处理程序可以直接查询 AudioContext 的状态。新创建的 AudioContext 将始终以suspended状态开始,并且每当状态更改为不同状态时,都会触发状态更改事件。此事件会在complete事件之前触发。 sampleRate, 类型 float, 只读-
BaseAudioContext处理音频的采样率(每秒采样帧数)。假设上下文中的所有AudioNode都以该速率运行。在做出这个假设的前提下,实时处理不支持采样率转换器或“变速”处理器。奈奎斯特频率是这个采样率值的一半。 state, 类型 AudioContextState, 只读-
描述
BaseAudioContext的当前状态。获取此属性会返回[[control thread state]]槽的内容。 renderQuantumSize, 类型 unsigned long, 只读-
获取此属性会返回
[[render quantum size]]槽的值。
1.1.2. 方法
createAnalyser()-
工厂方法 用于创建一个
AnalyserNode。无参数。返回类型:AnalyserNode createBiquadFilter()-
工厂方法 用于创建一个
BiquadFilterNode,它表示一个二阶滤波器,可以配置为几种常见的滤波器类型之一。无参数。返回类型:BiquadFilterNode createBuffer(numberOfChannels, length, sampleRate)-
创建给定大小的 AudioBuffer。缓冲区中的音频数据将被初始化为零(静音)。如果任何参数为负、零或超出其正常范围,必须抛出一个
NotSupportedError异常。BaseAudioContext.createBuffer() 方法的参数。 参数 类型 可空 可选 描述 numberOfChannelsunsigned long✘ ✘ 决定缓冲区将有多少个通道。实现必须至少支持 32 个通道。 lengthunsigned long✘ ✘ 确定缓冲区的大小(以采样帧为单位)。此值必须至少为 1。 sampleRatefloat✘ ✘ 描述缓冲区中线性 PCM 音频数据的采样率,以每秒采样帧数表示。实现必须至少支持 8000 到 96000 之间的采样率。 返回类型:AudioBuffer createBufferSource()-
工厂方法 用于创建一个
AudioBufferSourceNode。无参数。返回类型:AudioBufferSourceNode createChannelMerger(numberOfInputs)-
工厂方法 用于创建一个
ChannelMergerNode,用于表示一个通道合并器。如果numberOfInputs小于 1 或大于支持的通道数,则必须抛出一个IndexSizeError异常。BaseAudioContext.createChannelMerger(numberOfInputs) 方法的参数。 参数 类型 可空 可选 描述 numberOfInputsunsigned long✘ ✔ 决定输入的数量。必须支持最多 32 个通道。如果未指定,则使用 6。返回类型:ChannelMergerNode createChannelSplitter(numberOfOutputs)-
工厂方法 用于创建一个
ChannelSplitterNode,用于表示一个通道分离器。如果numberOfOutputs小于 1 或大于支持的通道数,则必须抛出一个IndexSizeError异常。BaseAudioContext.createChannelSplitter(numberOfOutputs) 方法的参数。 参数 类型 可空 可选 描述 numberOfOutputsunsigned long✘ ✔ 输出的数量。必须支持最多 32 个输出。如果未指定,则使用 6。返回类型:ChannelSplitterNode createConstantSource()-
工厂方法 用于创建一个
ConstantSourceNode。无参数。返回类型:ConstantSourceNode createConvolver()-
工厂方法 用于创建一个
ConvolverNode。无参数。返回类型:ConvolverNode createDelay(maxDelayTime)-
工厂方法 用于创建一个
DelayNode。初始默认的延迟时间为 0 秒。BaseAudioContext.createDelay(maxDelayTime) 方法的参数。 参数 类型 可空 可选 描述 maxDelayTimedouble✘ ✔ 指定延迟线允许的最大延迟时间(单位:秒)。如果指定了该值,它必须大于零且小于三分钟,否则必须抛出 NotSupportedError异常。如果未指定,则使用1。返回类型:DelayNode createDynamicsCompressor()-
工厂方法 用于创建一个
DynamicsCompressorNode。无参数。返回类型:DynamicsCompressorNode createGain()-
无参数。返回类型:
GainNode createIIRFilter(feedforward, feedback)-
BaseAudioContext.createIIRFilter() 方法的参数。 参数 类型 可空 可选 描述 feedforwardsequence<double>✘ ✘ 传递函数的前馈(分子)系数数组。该数组的最大长度为 20。如果所有值均为零,必须抛出 InvalidStateError。 如果数组长度为 0 或大于 20,必须抛出NotSupportedError。feedbacksequence<double>✘ ✘ 传递函数的反馈(分母)系数数组。该数组的最大长度为 20。如果数组的第一个元素为 0,必须抛出 InvalidStateError。 如果数组长度为 0 或大于 20,必须抛出NotSupportedError。返回类型:IIRFilterNode createOscillator()-
工厂方法 用于创建一个
OscillatorNode。无参数。返回类型:OscillatorNode createPanner()-
工厂方法 用于创建一个
PannerNode。无参数。返回类型:PannerNode createPeriodicWave(real, imag, constraints)-
工厂方法 用于创建一个
PeriodicWave。调用此方法时,请执行以下步骤:-
如果
real和imag长度不相等,则必须抛出一个IndexSizeError。 -
创建一个新的类型为
PeriodicWaveOptions的对象 o。 -
将 o 的
disableNormalization属性设置为传递给工厂方法的constraints属性中的disableNormalization属性的值。 -
构建一个新的
PeriodicWavep,传递给工厂方法所调用的BaseAudioContext作为第一个参数,以及 o。 -
返回 p。
BaseAudioContext.createPeriodicWave() 方法的参数。 参数 类型 可空 可选 描述 realsequence<float>✘ ✘ 余弦参数的序列。有关详细描述,请参阅其构造函数参数 real。imagsequence<float>✘ ✘ 正弦参数的序列。有关详细描述,请参阅其构造函数参数 imag。constraintsPeriodicWaveConstraints✘ ✔ 如果未给出,波形将被规范化。否则,将根据 constraints给定的值进行规范化。返回类型:PeriodicWave -
createScriptProcessor(bufferSize, numberOfInputChannels, numberOfOutputChannels)-
工厂方法 用于创建一个
ScriptProcessorNode。 此方法已弃用,因为它将由AudioWorkletNode替代。 该方法用于通过脚本直接处理音频,生成一个ScriptProcessorNode。 如果参数bufferSize、numberOfInputChannels或numberOfOutputChannels超出有效范围,则必须抛出IndexSizeError异常。参数
numberOfInputChannels和numberOfOutputChannels不允许同时为零。在这种情况下,必须抛出IndexSizeError。BaseAudioContext.createScriptProcessor(bufferSize, numberOfInputChannels, numberOfOutputChannels) 方法的参数。 参数 类型 可空 可选 描述 bufferSizeunsigned long✘ ✔ bufferSize参数决定了缓冲区大小,以样本帧为单位。如果未传递该参数或值为0,则由实现选择最佳缓冲区大小,且该大小在节点的整个生命周期内始终为2的幂次方。 否则,如果作者明确指定了 bufferSize,其值必须为以下之一:256、512、1024、2048、4096、8192、16384。 该值控制audioprocess事件的调度频率,以及每次调用需要处理的样本帧数量。 较小的 bufferSize 值会导致较低的(更好的)延迟,而较大的值则可能需要避免音频中断和音频问题。 建议作者不要指定此 bufferSize,允许实现选择合适的大小,以平衡延迟和音频质量。 如果该参数的值不是上述允许的2的幂次方之一,必须抛出IndexSizeError。numberOfInputChannelsunsigned long✘ ✔ 该参数决定了此节点输入的通道数。默认值为2,支持多达32个通道。 如果通道数不受支持,必须抛出 NotSupportedError。numberOfOutputChannelsunsigned long✘ ✔ 该参数决定了此节点输出的通道数。默认值为2,支持多达32个通道。 如果通道数不受支持,必须抛出 NotSupportedError。返回类型:ScriptProcessorNode createStereoPanner()-
工厂方法 用于创建一个
StereoPannerNode。无参数。返回类型:StereoPannerNode createWaveShaper()-
工厂方法 用于创建一个
WaveShaperNode, 用于表示非线性失真。无参数。返回类型:WaveShaperNode decodeAudioData(audioData, successCallback, errorCallback)-
异步解码包含在
ArrayBuffer中的音频文件数据。 例如,可以通过将XMLHttpRequest的responseType设置为"arraybuffer"后, 从response属性加载ArrayBuffer。 音频文件数据可以是任何由audio元素支持的格式。传递给decodeAudioData()的缓冲区 通过嗅探来确定其内容类型,如 [mimesniff] 所述。虽然主要通过返回的 Promise 来与此函数交互,但提供了回调参数以便于向后兼容。
建议在文件损坏时提醒作者,因为无法抛出错误,这样做会导致不兼容的变更。
注意:如果压缩的音频数据字节流已损坏,但仍然可以继续解码,建议实现通过开发工具等方式提醒作者。当调用decodeAudioData时,必须在控制线程上执行以下步骤:-
如果 this 的 相关全局对象 的 关联文档 不是 完全活跃,则返回 一个被拒绝的 Promise,其错误为 "
InvalidStateError"DOMException。 -
定义 promise 作为一个新的 Promise。
-
-
将 promise 添加到
[[pending promises]]。 -
分离
audioDataArrayBuffer。 如果此操作抛出异常,跳转到步骤3。 -
队列一个在其他线程上执行的解码操作。
-
-
否则,执行以下错误步骤:
-
定义 error 作为一个
DataCloneError。 -
用 error 拒绝 promise,并从
[[pending promises]]中移除。 -
队列一个媒体元素任务 来调用
errorCallback及 error。
-
-
返回 promise。
当将解码操作排队以在其他线程上执行时,必须在非 控制线程 和 渲染线程 上执行以下步骤, 称为解码线程。注意:多个
解码线程可以并行运行,以处理对decodeAudioData的多个调用。-
定义 can decode 作为一个布尔标志,初始值为 true。
-
尝试使用 MIME Sniffing § 6.2 匹配音频或视频类型模式 确定
audioData的 MIME 类型。如果音频或视频类型模式匹配算法返回undefined, 则将 can decode 设置为 false。 -
如果 can decode 为 true,则尝试将编码的
audioData解码为 线性 PCM。 在失败的情况下,将 can decode 设置为 false。如果媒体字节流包含多个音轨,则只解码第一个音轨为 线性 PCM。
注意:需要更多控制解码过程的作者可以使用 [WEBCODECS]。
-
如果 can decode 为
false,则 队列一个媒体元素任务 以执行以下步骤:-
定义 error 作为
DOMException,其名称为EncodingError。-
用 error 拒绝 promise,并从
[[pending promises]]中移除。
-
-
如果
errorCallback不为空,则使用 error 调用errorCallback。
-
-
否则:
-
将解码结果表示为解码的 线性 PCM 音频数据, 如果其采样率与
BaseAudioContext的采样率不同,则重新采样。 -
队列一个媒体元素任务以执行以下步骤:
-
定义 buffer 为包含最终结果的
AudioBuffer(可能经过采样率转换)。 -
用 buffer 解析 promise。
-
如果
successCallback不为空,则使用 buffer 调用successCallback。
-
-
参数表:BaseAudioContext.decodeAudioData() 方法。 参数名称 类型 可为空 可选 描述 audioDataArrayBuffer✘ ✘ 包含压缩音频数据的 ArrayBuffer。 successCallbackDecodeSuccessCallback?✔ ✔ 在解码完成时被调用的回调函数。该回调函数的唯一参数是一个代表解码后的 PCM 音频数据的 AudioBuffer。 errorCallbackDecodeErrorCallback?✔ ✔ 在解码音频文件出错时被调用的回调函数。 返回类型:Promise<AudioBuffer> -
1.1.3. 回调 DecodeSuccessCallback()
参数
decodedData, 类型为AudioBuffer-
包含解码音频数据的 AudioBuffer。
1.1.4. 回调 DecodeErrorCallback()
参数
error, 类型为DOMException-
解码时发生的错误。
1.1.5. 生命周期
一旦创建,一个 AudioContext
将持续播放声音,直到没有更多的声音可播放,或者页面被关闭。
1.1.6. 缺少自省或序列化原语
Web Audio API 采用一种 一次触发 的音频源调度方式。也就是说,在 AudioContext
的生命周期内,每个音符会创建 源节点,并且从不会显式地从图中移除。这种方式与序列化 API 不兼容,因为没有稳定的节点集可以被序列化。
此外,拥有自省 API 可能会使内容脚本观察垃圾回收行为。
1.1.7. 与 BaseAudioContext
子类相关的系统资源
子类 AudioContext
和 OfflineAudioContext
应被视为昂贵的对象。创建这些对象可能涉及创建一个高优先级线程,或使用低延迟的系统音频流,这两者都会影响能耗。在一个文档中通常不需要创建多个 AudioContext。
构造或恢复一个 BaseAudioContext
子类会涉及为该上下文 获取系统资源。对于 AudioContext,这还需要创建一个系统音频流。这些操作将在上下文开始从其关联的音频图生成输出时返回。
此外,用户代理可以具有一个实现定义的最大 AudioContext
数量,超过该数量后,任何创建新 AudioContext
的尝试都将失败,抛出 NotSupportedError。
suspend
和 close
允许作者 释放系统资源,包括线程、进程和音频流。暂停一个
BaseAudioContext
允许实现释放其部分资源,并通过调用 resume
使其以后继续运行。关闭一个 AudioContext
允许实现释放所有资源,此后它不能再被使用或恢复。
注意:例如,这可能涉及等待音频回调定期触发,或等待硬件准备好进行处理。
1.2. AudioContext
接口
此接口表示一个音频图,其 AudioDestinationNode
被路由到一个实时输出设备,该设备产生指向用户的信号。在大多数用例中,每个文档只使用一个 AudioContext。
enum {AudioContextLatencyCategory "balanced" ,"interactive" ,"playback" };
| 枚举值 | 描述 |
|---|---|
"balanced"
| 平衡音频输出延迟和能耗。 |
"interactive"
| 在不产生音频失真的情况下,提供最低的音频输出延迟。这是默认值。 |
"playback"
| 优先持续播放而不中断,而不是音频输出延迟。最低能耗。 |
enum {AudioSinkType "none" };
| 枚举值 | 描述 |
|---|---|
"none"
| 音频图将被处理但不会通过音频输出设备播放。 |
[Exposed =Window ]interface AudioContext :BaseAudioContext {constructor (optional AudioContextOptions contextOptions = {});readonly attribute double baseLatency ;readonly attribute double outputLatency ; [SecureContext ]readonly attribute (DOMString or AudioSinkInfo )sinkId ; [SecureContext ]readonly attribute AudioRenderCapacity renderCapacity ;attribute EventHandler onsinkchange ;attribute EventHandler onerror ;AudioTimestamp getOutputTimestamp ();Promise <undefined >resume ();Promise <undefined >suspend ();Promise <undefined >close (); [SecureContext ]Promise <undefined >((setSinkId DOMString or AudioSinkOptions ));sinkId MediaElementAudioSourceNode createMediaElementSource (HTMLMediaElement );mediaElement MediaStreamAudioSourceNode createMediaStreamSource (MediaStream );mediaStream MediaStreamTrackAudioSourceNode createMediaStreamTrackSource (MediaStreamTrack );mediaStreamTrack MediaStreamAudioDestinationNode createMediaStreamDestination (); };
当用户代理允许上下文状态从 "suspended"
过渡到 "running"
时,AudioContext
被称为 允许启动。用户代理可以拒绝这种初始转换,只有当 AudioContext
的 相关全局对象具有 粘性激活 时,才允许这种转换。
AudioContext
具有以下内部槽:
[[suspended by user]]-
一个布尔标志,表示上下文是否被用户代码挂起。初始值为
false。 [[sink ID]]-
一个
DOMString或AudioSinkInfo,分别表示当前音频输出设备的标识符或信息。初始值为"",表示默认的音频输出设备。 [[pending resume promises]]
1.2.1. 构造函数
AudioContext(contextOptions)-
如果 当前设置对象的相关全局对象的关联的文档不是完全激活,则抛出“
创建InvalidStateError”并中止这些步骤。AudioContext时,执行以下步骤:-
令 context 为一个新的
AudioContext对象。 -
在 context 上将
[[控制线程状态]]设置为suspended。 -
在 context 上将
[[渲染线程状态]]设置为suspended。 -
令 messageChannel 为一个新的
MessageChannel。 -
令 controlSidePort 为 messageChannel 的
port1属性的值。 -
令 renderingSidePort 为 messageChannel 的
port2属性的值。 -
令 serializedRenderingSidePort 为 StructuredSerializeWithTransfer(renderingSidePort, « renderingSidePort ») 的结果。
-
将此
audioWorklet的port设置为 controlSidePort。 -
排队控制消息以在 AudioContextGlobalScope 上设置 MessagePort,使用 serializedRenderingSidePort。
-
如果提供了
contextOptions,执行以下子步骤:-
如果指定了
sinkId,则令 sinkId 为contextOptions.的值,并运行以下子步骤:sinkId-
如果 sinkId 和
[[sink ID]]均为DOMString类型,且相等,则中止这些子步骤。 -
如果 sinkId 是
AudioSinkOptions类型,且[[sink ID]]是AudioSinkInfo类型,且type在 sinkId 中与type在[[sink ID]]中相等,则中止这些子步骤。 -
令 validationResult 为 sink 标识符验证 sinkId 的返回值。
-
如果 validationResult 是
DOMException类型,抛出一个包含 validationResult 的异常并中止这些子步骤。 -
如果 sinkId 是
DOMString类型,将[[sink ID]]设置为 sinkId 并中止这些子步骤。 -
如果 sinkId 是
AudioSinkOptions类型,将[[sink ID]]设置为由type的值创建的新AudioSinkInfo实例。
-
-
根据
contextOptions.设置 context 的内部延迟,如latencyHintlatencyHint所述。 -
如果指定了
contextOptions.,则将 context 的sampleRatesampleRate设置为此值。否则,执行以下子步骤:-
如果 sinkId 是空字符串或
AudioSinkOptions类型,则使用默认输出设备的采样率。中止这些子步骤。 -
如果 sinkId 是
DOMString,则使用由 sinkId 标识的输出设备的采样率。中止这些子步骤。
如果
contextOptions.与输出设备的采样率不同,则用户代理必须将音频输出重新采样以匹配输出设备的采样率。sampleRate注意:如果需要重新采样,context 的延迟可能会受到影响,可能会有较大的影响。
-
-
-
返回 context。
发送一个 控制消息 以开始处理意味着执行以下步骤:-
尝试获取系统资源以使用以下音频输出设备进行渲染,基于
[[sink ID]]:-
空字符串表示默认音频输出设备。
-
由
[[sink ID]]标识的音频输出设备。
-
如果资源获取失败,执行以下步骤:
-
如果 document 不允许使用标识为
"speaker-selection"的功能,则中止这些子步骤。 -
排队媒体元素任务以触发一个事件,事件名为
error,目标是AudioContext,然后中止后续步骤。
-
-
-
将 this 的
[[渲染线程状态]]设置为running,用于AudioContext。 -
排队媒体元素任务以执行以下步骤:
-
将
state属性设置为running,目标是AudioContext。 -
触发一个事件,事件名为
statechange,目标是AudioContext。
-
注意: 在没有参数的情况下构造
AudioContext并且资源获取失败的情况下,用户代理将尝试通过模拟音频输出设备的机制静默渲染音频图。发送一个 控制消息 以在MessagePort上设置AudioWorkletGlobalScope的含义是执行以下步骤,在 渲染线程 上,使用传递给AudioWorkletGlobalScope的 serializedRenderingSidePort:AudioContext.constructor(contextOptions) 方法的参数。 参数 类型 可为空 可选 描述 contextOptionsAudioContextOptions✘ ✔ 用户指定的控制如何构造 AudioContext的选项。 -
1.2.2. 属性
baseLatency, 类型 double, 只读-
表示
AudioContext将音频从AudioDestinationNode传递到音频子系统时产生的处理延迟(以秒为单位)。它不包括由AudioDestinationNode输出到音频硬件之间的其他处理可能导致的额外延迟,也不包括音频图本身产生的延迟。例如,如果音频上下文以 44.1 kHz 的速率运行,并具有默认的渲染量子大小,并且
AudioDestinationNode在内部实现了双缓冲,并且每个 渲染量子 都能处理和输出音频,那么处理延迟大约为 \((2\cdot128)/44100 = 5.805 \mathrm{ ms}\)。 outputLatency, 类型 double, 只读-
音频输出延迟的估计值(以秒为单位),即用户代理请求主机系统播放缓冲区的时间与缓冲区中第一个样本实际被音频输出设备处理的时间之间的间隔。对于诸如扬声器或耳机之类的设备,这后一时间指的是样本声音被产生的时间。
outputLatency属性值依赖于平台和连接的音频输出设备硬件。outputLatency属性值可能会在上下文运行期间或相关音频输出设备更改时发生变化。为了实现准确的同步,频繁查询该值是有用的。 renderCapacity, 类型 AudioRenderCapacity, 只读-
返回与
AudioContext相关联的AudioRenderCapacity实例。 sinkId, 类型(DOMString 或 AudioSinkInfo), 只读-
返回内部插槽
[[sink ID]]的值。该属性在更新后会被缓存,并返回相同的对象。 onsinkchange, 类型 EventHandler-
用于
setSinkId()的 事件处理器。该事件处理器的事件类型是sinkchange。当输出设备更改完成时,将调度此事件。注意: 这不会为
AudioContext构造中的初始设备选择而调度。statechange事件可用于检查初始输出设备的准备状态。 onerror, 类型 EventHandler-
用于从
AudioContext派发的 事件处理器。该处理器的事件类型是error,用户代理在以下情况下可调度此事件:-
在初始化和激活选定音频设备时遇到故障。
-
当关联音频输出设备的
AudioContext在上下文运行时断开连接。 -
当操作系统报告音频设备故障时。
-
1.2.3. 方法
close()-
关闭
AudioContext,释放所使用的系统资源。这不会自动释放所有由AudioContext创建的对象,但会暂停AudioContext的currentTime的推进,并停止处理音频数据。调用 close 方法时,执行以下步骤:-
如果 this 的 相关全局对象 的 关联的文档不是 完全活动的,则返回 一个被拒绝的 Promise,带有 "
InvalidStateError"DOMException。 -
让 promise 成为一个新的 Promise。
-
如果
[[control thread state]]标志在AudioContext上为closed,则拒绝该 promise,带有InvalidStateError,中止这些步骤,返回 promise。 -
将
[[control thread state]]标志在AudioContext上设置为closed。 -
排队控制消息以关闭
AudioContext。 -
返回 promise。
运行关闭AudioContext的 控制消息,即在 渲染线程上运行以下步骤:-
尝试释放系统资源。
-
将
[[rendering thread state]]设置为suspended。这将停止渲染。 -
如果此 控制消息 是响应文档被卸载而运行的,则中止此算法。
在这种情况下,没有必要通知控制线程。 -
排队媒体元素任务以执行以下步骤:
-
解决 promise。
-
如果
state属性在AudioContext上还不是 "closed":-
将
state属性在AudioContext上设置为 "closed"。 -
排队媒体元素任务以 触发事件,名为
statechange,在AudioContext上。
-
-
当
AudioContext被关闭时,任何连接到AudioContext的MediaStream和HTMLMediaElement将不再输出。这意味着这些元素将不再对扬声器或其他输出设备产生任何输出。为了获得更灵活的行为,请考虑使用HTMLMediaElement.captureStream()。注意: 当
AudioContext被关闭时,实施可以选择比暂停时更积极地释放更多资源。无参数。 -
createMediaElementSource(mediaElement)-
给定一个
MediaElementAudioSourceNode,创建一个HTMLMediaElement。调用此方法后,来自HTMLMediaElement的音频将被重新路由到AudioContext的处理图中。AudioContext.createMediaElementSource() 方法的参数。 参数 类型 可空 可选 描述 mediaElementHTMLMediaElement✘ ✘ 将被重新路由的媒体元素。 createMediaStreamDestination()-
创建一个
MediaStreamAudioDestinationNode无参数。 createMediaStreamSource(mediaStream)-
创建一个
MediaStreamAudioSourceNode。AudioContext.createMediaStreamSource() 方法的参数。 参数 类型 可空 可选 描述 mediaStreamMediaStream✘ ✘ 将作为源的媒体流。 createMediaStreamTrackSource(mediaStreamTrack)-
创建一个
MediaStreamTrackAudioSourceNode。AudioContext.createMediaStreamTrackSource() 方法的参数。 参数 类型 可空 可选 描述 mediaStreamTrackMediaStreamTrack✘ ✘ 将作为源的 MediaStreamTrack。其kind属性的值必须等于"audio",否则必须抛出InvalidStateError异常。 getOutputTimestamp()-
返回一个新的
AudioTimestamp实例,其中包含上下文的两个相关的音频流位置值:contextTime成员包含由音频输出设备当前正在渲染的采样帧的时间(即输出音频流位置),其单位和起点与上下文的currentTime相同;performanceTime成员包含估算的时刻,即存储的contextTime值对应的采样帧被音频输出设备渲染的时间,其单位和起点与performance.now()(详见 [hr-time-3])相同。如果上下文的渲染图尚未处理音频块,则
getOutputTimestamp调用返回一个AudioTimestamp实例,两个成员均为零。在上下文的渲染图开始处理音频块后,其
currentTime属性值总是大于从getOutputTimestamp方法调用获得的contextTime值。通过getOutputTimestamp方法返回的值可以用于获取稍后上下文时间值的性能时间估算:function outputPerformanceTime( contextTime) { const timestamp= context. getOutputTimestamp(); const elapsedTime= contextTime- timestamp. contextTime; return timestamp. performanceTime+ elapsedTime* 1000 ; } 在上面的例子中,估算的准确性取决于参数值与当前输出音频流位置的接近程度:给定的
contextTime越接近timestamp.contextTime,所获得的估算的准确性就越高。注意: 上下文的
currentTime值和从getOutputTimestamp方法调用获得的contextTime之间的差异不能被视为可靠的输出延迟估算,因为currentTime可能在不均匀的时间间隔中递增,因此应该使用outputLatency属性。无参数。返回类型:AudioTimestamp resume()-
在
AudioContext已经暂停时,恢复其currentTime的进程。调用 resume 时,执行以下步骤:-
如果 this 的 相关全局对象 的 关联文档 不是 完全活跃,则返回 一个拒绝的 Promise,带有 "
InvalidStateError"DOMException。 -
设 promise 为一个新的 Promise。
-
如果
[[控制线程状态]]在AudioContext中为关闭,则拒绝该 Promise,带有InvalidStateError,中止这些步骤,并返回 promise。 -
将
[[被用户暂停]]设为false。 -
如果上下文不 允许启动,将 promise 添加到
[[待处理的 Promise]]和[[待恢复的 Promise]],并中止这些步骤,返回 promise。 -
将
[[控制线程状态]]在AudioContext中设为运行中。 -
排队一个控制消息,以恢复
AudioContext。 -
返回 promise。
运行一个 控制消息 以恢复AudioContext,意味着在 渲染线程 上执行这些步骤:-
尝试 获取系统资源。
-
将
[[渲染线程状态]]在AudioContext中设为运行中。 -
开始 渲染音频图。
-
如果失败,排队一个媒体元素任务来执行以下步骤:
-
按顺序拒绝所有
[[待恢复的 Promise]],然后清除[[待恢复的 Promise]]。 -
此外,从
[[待处理的 Promise]]中移除这些 Promise。
-
-
排队一个媒体元素任务来执行以下步骤:
-
按顺序解析所有
[[待恢复的 Promise]]。 -
清除
[[待恢复的 Promise]],此外,从[[待处理的 Promise]]中移除这些 Promise。 -
解析 promise。
-
如果
state属性在AudioContext中不为 "运行中":-
将
state属性在AudioContext中设为 "运行中"。 -
排队一个媒体元素任务以 触发一个事件,名为
statechange,在AudioContext中。
-
-
无参数。 -
suspend()-
暂停
AudioContext的currentTime的进程, 允许所有当前已处理的上下文块播放到目标设备,然后允许系统释放对音频硬件的控制。 当应用程序知道它在一段时间内不需要AudioContext时,这通常非常有用,并希望暂时释放与AudioContext相关的系统资源。 当帧缓冲区为空(已交给硬件)时,或者如果上下文已经处于suspended状态,则 Promise 将立即解析(没有其他效果)。 如果上下文已关闭,则 Promise 将被拒绝。调用 suspend 时,执行以下步骤:-
如果 this 的 相关全局对象 的 关联文档 不是 完全活跃,则返回 一个拒绝的 Promise,带有 "
InvalidStateError"DOMException。 -
设 promise 为一个新的 Promise。
-
如果
[[控制线程状态]]在AudioContext中为关闭,则拒绝该 Promise,带有InvalidStateError,中止这些步骤,并返回 promise。 -
将 promise 添加到
[[待处理的 Promise]]中。 -
将
[[被用户暂停]]设为true。 -
将
[[控制线程状态]]在AudioContext中设为suspended。 -
排队一个控制消息,以暂停
AudioContext。 -
返回 promise。
运行一个 控制消息 以暂停AudioContext,意味着在 渲染线程 上执行这些步骤:-
尝试 释放系统资源。
-
将
[[渲染线程状态]]在AudioContext中设为suspended。 -
排队一个媒体元素任务来执行以下步骤:
-
解析 promise。
-
如果
state属性在AudioContext中不为 "suspended":-
将
state属性在AudioContext中设为 "suspended"。 -
排队一个媒体元素任务以 触发一个事件,名为
statechange,在AudioContext中。
-
-
当
AudioContext被暂停时,MediaStream的输出将被忽略;即,数据将因媒体流的实时性而丢失。HTMLMediaElement的输出也将被忽略,直到系统恢复。AudioWorkletNode和ScriptProcessorNode在暂停时将不再调用其处理程序,但在上下文恢复时将继续调用。对于AnalyserNode窗口函数来说,数据被视为连续流——也就是说,resume()和suspend()不会导致在AnalyserNode的数据流中出现静音。特别地,当AudioContext被暂停时,反复调用AnalyserNode函数应返回相同的数据。无参数。 -
setSinkId((DOMString or AudioSinkOptions) sinkId)-
设置输出设备的标识符。当调用此方法时,用户代理必须执行以下步骤:
-
设 sinkId 为该方法的第一个参数。
-
如果 sinkId 等于
[[sink ID]],立即返回一个 Promise,解析它并中止这些步骤。 -
设 validationResult 为对 sinkId 进行 sink identifier validation 返回的值。
-
如果 validationResult 不为
null,则返回一个被 validationResult 拒绝的 Promise,中止这些步骤。 -
设 p 为一个新的 Promise。
-
发送一个带有 p 和 sinkId 的 控制消息 以开始处理。
-
返回 p。
在setSinkId()方法中,发送一个控制消息以开始处理意味着执行以下步骤:-
设 p 为传入此算法的 Promise。
-
设 sinkId 为传入此算法的接收器标识符。
-
如果 sinkId 和
[[sink ID]]都是DOMString类型,并且它们相等,排队一个媒体元素任务以解析 p,并中止这些步骤。 -
如果 sinkId 是
AudioSinkOptions类型,并且[[sink ID]]是AudioSinkInfo类型,并且type在 sinkId 中和type在[[sink ID]]中相等,排队一个媒体元素任务以解析 p,并中止这些步骤。 -
设 wasRunning 为 true。
-
如果
[[渲染线程状态]]在AudioContext中为"suspended",则将 wasRunning 设为 false。 -
在当前渲染量处理后暂停渲染器。
-
尝试 释放系统资源。
-
如果 wasRunning 为 true:
-
将
[[渲染线程状态]]在AudioContext中设为"suspended"。 -
排队一个媒体元素任务以执行以下步骤:
-
如果
state属性在AudioContext中不为 "suspended":-
将
state属性在AudioContext中设为 "suspended"。 -
触发一个事件,名为
statechange,在相关的AudioContext中。
-
-
-
-
尝试 获取系统资源以使用基于
[[sink ID]]的以下音频输出设备进行渲染:-
空字符串对应的默认音频输出设备。
-
由
[[sink ID]]标识的音频输出设备。
如果获取失败,则使用 "
InvalidAccessError" 拒绝 p,并中止以下步骤。 -
-
排队一个媒体元素任务以执行以下步骤:
-
如果 sinkId 是
DOMString类型,将[[sink ID]]设为 sinkId。中止这些步骤。 -
如果 sinkId 是
AudioSinkOptions类型,并且[[sink ID]]是DOMString类型,则将[[sink ID]]设为使用 sinkId 中的type值创建的新AudioSinkInfo实例。 -
如果 sinkId 是
AudioSinkOptions类型,并且[[sink ID]]是AudioSinkInfo类型,则将type设为 sinkId 中的type值。 -
解析 p。
-
触发一个事件,名为
sinkchange,在相关的AudioContext中。
-
-
如果 wasRunning 为 true:
-
将
[[渲染线程状态]]在AudioContext中设为"running"。 -
排队一个媒体元素任务以执行以下步骤:
-
如果
state属性在AudioContext中不为 "running":-
将
state属性在AudioContext中设为 "running"。 -
触发一个事件,名为
statechange,在相关的AudioContext中。
-
-
-
-
1.2.4.
验证 sinkId
此算法用于验证修改 sinkId
提供的信息:
-
让 document 成为当前设置对象的 关联文档。
-
让 sinkIdArg 成为传递给此算法的值。
-
如果 document 不被允许使用标识为
"speaker-selection"的功能,则返回一个新的DOMException,其名称为 "NotAllowedError"。 -
如果 sinkIdArg 是
DOMString类型,但它不是空字符串,或者它不匹配enumerateDevices()提供的任何音频输出设备,则返回一个新的DOMException,其名称为 "NotFoundError"。 -
返回
null。
1.2.5. AudioContextOptions
AudioContextOptions
字典用于为 AudioContext
指定用户指定的选项。
dictionary AudioContextOptions { (AudioContextLatencyCategory or double )latencyHint = "interactive";float sampleRate ; (DOMString or AudioSinkOptions )sinkId ; (AudioContextRenderSizeCategory or unsigned long )renderSizeHint = "default"; };
1.2.5.1. 字典 AudioContextOptions
成员
latencyHint, 类型为(AudioContextLatencyCategory 或 double),默认为"interactive"-
标识播放类型,这影响音频输出延迟和功耗之间的权衡。
latencyHint的首选值是来自AudioContextLatencyCategory的值。然而,也可以指定一个 double 值,表示延迟的秒数,以便更精细地控制延迟和功耗之间的平衡。浏览器可以自行决定如何适当解释该数值。实际使用的延迟由 AudioContext 的baseLatency属性给出。 sampleRate, 类型为 float-
为要创建的
AudioContext设置sampleRate。支持的值与AudioBuffer的采样率相同。如果指定的采样率不受支持,必须抛出NotSupportedError异常。如果未指定
sampleRate,则使用此AudioContext输出设备的首选采样率。 sinkId, 类型为(DOMString 或 AudioSinkOptions)-
音频输出设备的标识符或相关信息。有关更多详细信息,请参阅
sinkId。 renderSizeHint, 类型为(AudioContextRenderSizeCategory 或 unsigned long),默认为"default"-
这允许用户在传递整数时请求特定的 渲染量子大小,如果未指定或传递
"default",则使用默认的 128 帧;如果指定"hardware",则请求用户代理选择一个合适的 渲染量子大小。这只是一个可能不会被尊重的提示。
1.2.6. AudioSinkOptions
AudioSinkOptions
字典用于指定 sinkId
的选项。
dictionary AudioSinkOptions {required AudioSinkType type ; };
1.2.6.1. 字典 AudioSinkOptions
成员
type, 类型为 AudioSinkType-
值为
AudioSinkType,用于指定设备的类型。
1.2.7. AudioSinkInfo
AudioSinkInfo
接口用于通过 sinkId
获取当前音频输出设备的信息。
[Exposed =Window ]interface AudioSinkInfo {readonly attribute AudioSinkType type ; };
1.2.7.1. 属性
type, 类型为 AudioSinkType,只读-
表示设备类型的
AudioSinkType值。
1.2.8. AudioTimestamp
dictionary AudioTimestamp {double contextTime ;DOMHighResTimeStamp performanceTime ; };
1.2.8.1. 字典 AudioTimestamp
成员
contextTime, 类型为 double-
表示 BaseAudioContext 的
currentTime时间坐标系中的一个点。 performanceTime, 类型为 DOMHighResTimeStamp-
表示
Performance接口实现的时间坐标系中的一个点(描述于 [hr-time-3])。
1.2.9. AudioRenderCapacity
[Exposed =Window ]interface :AudioRenderCapacity EventTarget {undefined start (optional AudioRenderCapacityOptions = {});options undefined stop ();attribute EventHandler onupdate ; };
此接口提供 AudioContext
的渲染性能指标。为了计算这些指标,渲染器会在每次 系统级音频回调 中收集一个 负载值。
1.2.9.1. 属性
onupdate, 类型为 EventHandler-
此事件处理程序的事件类型是
update。派发到事件处理程序的事件将使用AudioRenderCapacityEvent接口。
1.2.9.2. 方法
start(options)-
开始收集和分析指标。这将会反复地触发一个事件,其名称为
update,并在AudioRenderCapacity上触发,使用AudioRenderCapacityEvent,其更新间隔由AudioRenderCapacityOptions指定。 stop()-
停止收集和分析指标。同时停止派发
update事件。
1.2.10.
AudioRenderCapacityOptions
AudioRenderCapacityOptions
词典用于为 AudioRenderCapacity
提供用户选项。
dictionary {AudioRenderCapacityOptions double updateInterval = 1; };
1.2.10.1. 词典 AudioRenderCapacityOptions
成员
updateInterval, 类型为 double,默认值为1-
用于调度
AudioRenderCapacityEvent的更新间隔(以秒为单位)。每个系统级音频回调都会计算一个 负载值,并且在指定的间隔期内会收集多个负载值。例如,如果渲染器的采样率为 48Khz,系统级音频回调的缓冲区大小为 192 帧,那么在 1 秒间隔内将会收集 250 个负载值。如果给定的值小于 系统级音频回调的持续时间,则会抛出
NotSupportedError。
1.2.11. AudioRenderCapacityEvent
[Exposed =Window ]interface :AudioRenderCapacityEvent Event {(constructor DOMString ,type optional AudioRenderCapacityEventInit = {});eventInitDict readonly attribute double timestamp ;readonly attribute double averageLoad ;readonly attribute double peakLoad ;readonly attribute double underrunRatio ; };dictionary :AudioRenderCapacityEventInit EventInit {double = 0;timestamp double = 0;averageLoad double = 0;peakLoad double = 0; };underrunRatio
1.2.11.1. 属性
timestamp, 类型为 double,只读-
数据收集周期的开始时间,基于关联的
AudioContext的currentTime。 averageLoad, 类型为 double,只读-
在给定的更新间隔中收集的负载值的平均值。精度限制为 1/100。
peakLoad, 类型为 double,只读-
在给定的更新间隔中收集的负载值的最大值。精度同样限制为 1/100。
underrunRatio, 类型为 double,只读-
在给定的更新间隔中,缓冲区欠载次数(当负载值大于 1.0 时)与系统级音频回调总数之间的比率。
设 \(u\) 为缓冲区欠载次数,\(N\) 为给定更新间隔中的系统级音频回调数,则缓冲区欠载比率为:
-
如果 \(u\) = 0,则比率为 0.0。
-
否则,计算 \(u/N\),并取最接近的 1/100 的向上取整值。
-
1.3. 接口 OfflineAudioContext
OfflineAudioContext
是 BaseAudioContext
的一种特殊类型,用于以比实时更快的速度进行渲染/混合。它不会直接渲染到音频硬件,而是尽可能快地渲染,并以 AudioBuffer
的形式返回渲染结果。
[Exposed =Window ]interface OfflineAudioContext :BaseAudioContext {constructor (OfflineAudioContextOptions contextOptions );constructor (unsigned long numberOfChannels ,unsigned long length ,float sampleRate );Promise <AudioBuffer >startRendering ();Promise <undefined >resume ();Promise <undefined >suspend (double );suspendTime readonly attribute unsigned long length ;attribute EventHandler oncomplete ; };
1.3.1. 构造函数
OfflineAudioContext(contextOptions)-
如果 当前设置对象的相关全局对象的关联文档不是完全活跃, 则抛出一个
令 c 为一个新的InvalidStateError并终止这些步骤。OfflineAudioContext对象。 初始化 c 如下:-
设置 c 的
[[控制线程状态]]为"suspended"。 -
设置 c 的
[[渲染线程状态]]为"suspended"。 -
根据
renderSizeHint的值确定此OfflineAudioContext的[[渲染量子大小]]:-
如果其值为默认值
"default"或"hardware", 则将[[渲染量子大小]]私有槽设置为 128。 -
否则,如果传入的是整数,用户代理可以选择是否尊重该值,并将其设置为
[[渲染量子大小]]私有槽。
-
-
构造一个
AudioDestinationNode, 其channelCount设置为contextOptions.numberOfChannels。 -
令 messageChannel 为一个新的
MessageChannel。 -
令 controlSidePort 为 messageChannel 的
port1属性的值。 -
令 renderingSidePort 为 messageChannel 的
port2属性的值。 -
令 serializedRenderingSidePort 为结构化序列化和传输(renderingSidePort, « renderingSidePort »)的结果。
-
将此
audioWorklet的port设置为 controlSidePort。 -
排队控制消息, 使用 serializedRenderingSidePort 设置 AudioContextGlobalScope 上的 MessagePort。
参数用于 OfflineAudioContext.constructor(contextOptions) 方法。 参数 类型 可为空 可选 描述 contextOptions构造此上下文所需的初始参数。 -
OfflineAudioContext(numberOfChannels, length, sampleRate)-
OfflineAudioContext可以使用与 AudioContext.createBuffer 相同的参数进行构造。如果任何参数为负数、零或超出其标称范围,则必须抛出NotSupportedError异常。OfflineAudioContext 的构造方式如下
new OfflineAudioContext({ numberOfChannels: numberOfChannels, length: length, sampleRate: sampleRate}) 相当于调用上述代码。
用于 OfflineAudioContext.constructor(numberOfChannels, length, sampleRate) 方法的参数。 参数 类型 可为空 可选 描述 numberOfChannelsunsigned long✘ ✘ 确定缓冲区将拥有的通道数。请参见 createBuffer()以了解支持的通道数。lengthunsigned long✘ ✘ 确定缓冲区的大小,以采样帧数计算。 sampleRatefloat✘ ✘ 描述缓冲区中线性 PCM 音频数据的采样率,以每秒采样帧数计算。请参见 createBuffer()以获取有效的采样率。
1.3.2. 属性
length, 类型为 unsigned long,只读-
缓冲区的大小,以采样帧数计算。这与构造函数的
length参数相同。 oncomplete, 类型为 EventHandler-
此事件处理程序的事件类型为
complete。分派到事件处理程序的事件将使用OfflineAudioCompletionEvent接口。它是OfflineAudioContext上触发的最后一个事件。
1.3.3. 方法
startRendering()-
根据当前的连接和计划的更改,开始渲染音频。
虽然获取渲染的音频数据的主要方式是通过其返回的 promise,但实例也会因为兼容原因触发一个名为
complete的事件。让[[rendering started]]成为这个OfflineAudioContext的一个内部槽。 初始化这个槽为 false。当调用
startRendering时,以下步骤必须在 控制线程 上执行:- 如果 this 的 相关全局对象 的 关联文档不是 完全激活,则返回 一个被拒绝的 promise,值为 "
InvalidStateError"DOMException。 - 如果
[[rendering started]]槽上的OfflineAudioContext为 true,返回一个被拒绝的 promise,值为InvalidStateError, 并中止这些步骤。 - 将
[[rendering started]]槽设置为 true。 - 创建一个新的 promise,赋值给 promise。
- 创建一个新的
AudioBuffer, 其通道数、长度和采样率分别等于传递给此实例构造函数的contextOptions参数中的numberOfChannels、length和sampleRate的值。 将此缓冲区分配给OfflineAudioContext的一个内部槽[[rendered buffer]]。 - 如果在调用上述
AudioBuffer构造函数期间抛出异常,使用该异常拒绝 promise。 - 否则,如果缓冲区成功构建,开始离线渲染。
- 将 promise 添加到
[[pending promises]]。 - 返回 promise。
要 开始离线渲染,必须在为此创建的 渲染线程 上执行以下步骤:- 根据当前的连接和计划的更改,开始将
length个采样帧的音频渲染到[[rendered buffer]]中。 - 对于每个 渲染量子,检查并
暂停渲染(如有必要)。 - 如果已暂停的上下文被恢复,则继续渲染缓冲区。
- 渲染完成后,队列媒体元素任务以执行以下步骤:
- 使用
[[rendered buffer]]来解决由startRendering()创建的 promise。 - 队列媒体元素任务 以 触发一个名为
complete的事件, 在OfflineAudioContext上, 使用OfflineAudioCompletionEvent, 其renderedBuffer属性设置为[[rendered buffer]]。
- 使用
无参数。返回类型:Promise<AudioBuffer> - 如果 this 的 相关全局对象 的 关联文档不是 完全激活,则返回 一个被拒绝的 promise,值为 "
resume()-
恢复
OfflineAudioContext的currentTime的进度,当其已被暂停时。当调用 resume 时,执行以下步骤:-
如果 this 的 相关全局对象 的 关联文档 不是 完全激活,则返回 一个被拒绝的 promise,值为 "
InvalidStateError"DOMException。 -
创建一个新的 Promise,赋值给 promise。
-
如果以下任意条件为真,则中止这些步骤并使用
InvalidStateError拒绝 promise:-
[[control thread state]]在OfflineAudioContext上的值为closed。 -
[[rendering started]]槽在OfflineAudioContext上的值为 false。
-
-
将
[[control thread state]]标志设置为running,针对OfflineAudioContext。 -
返回 promise。
运行一个 控制消息 来恢复OfflineAudioContext表示在为此创建的 渲染线程 上执行这些步骤:-
将
[[rendering thread state]]在OfflineAudioContext上设置为running。 -
开始 渲染音频图。
-
如果失败,队列媒体元素任务 以拒绝 promise 并中止剩余的步骤。
-
队列媒体元素任务 以执行以下步骤:
-
解决 promise。
-
如果
state属性在OfflineAudioContext中还不是 "running":-
将
state属性在OfflineAudioContext设置为 "running"。 -
队列媒体元素任务 以 触发一个名为
statechange的事件,在OfflineAudioContext。
-
-
无参数。 -
suspend(suspendTime)-
在指定的时间安排音频上下文的时间进度暂停,并返回一个 promise。这通常用于在
OfflineAudioContext上同步操作音频图时使用。注意,暂停的最大精度为 渲染量子 的大小, 并且指定的暂停时间将向上舍入到最近的 渲染量子 边界。 因此,不允许在同一个量化帧安排多个暂停。此外,应在上下文未运行时进行安排,以确保精确的暂停。
OfflineAudioContext.suspend() 方法的参数OfflineAudioContext.suspend()。 参数 类型 可为空 可选 描述 suspendTimedouble✘ ✘ 在指定的时间安排渲染的暂停,该时间被量化并向上舍入到 渲染量子 大小。如果量化后的帧号 - 为负或
- 小于或等于当前时间或
- 大于或等于总渲染持续时间或
- 由另一个暂停安排在相同的时间,
InvalidStateError拒绝。
1.3.4. OfflineAudioContextOptions
此选项用于构建 OfflineAudioContext
时指定使用的选项。
dictionary OfflineAudioContextOptions {unsigned long numberOfChannels = 1;required unsigned long length ;required float sampleRate ; (AudioContextRenderSizeCategory or unsigned long )renderSizeHint = "default"; };
1.3.4.1. Dictionary OfflineAudioContextOptions
成员
length, 类型为 unsigned long-
渲染的
AudioBuffer的长度,以采样帧(sample-frames)为单位。 numberOfChannels, 类型为 unsigned long,默认值为1-
此
OfflineAudioContext的声道数量。 sampleRate, 类型为 float-
此
OfflineAudioContext的采样率。 renderSizeHint, 类型为(AudioContextRenderSizeCategory 或 unsigned long),默认值为"default"-
此
OfflineAudioContext的 渲染量子大小 的提示。
1.3.5.
The OfflineAudioCompletionEvent
接口
这是一个 Event
对象,由于兼容性原因被派发给 OfflineAudioContext。
[Exposed =Window ]interface OfflineAudioCompletionEvent :Event {(constructor DOMString ,type OfflineAudioCompletionEventInit );eventInitDict readonly attribute AudioBuffer renderedBuffer ; };
1.3.5.1. 属性
renderedBuffer, 类型为 AudioBuffer, 只读-
包含已渲染音频数据的
AudioBuffer。
1.3.5.2.
OfflineAudioCompletionEventInit
dictionary OfflineAudioCompletionEventInit :EventInit {required AudioBuffer renderedBuffer ; };
1.3.5.2.1. 字典 OfflineAudioCompletionEventInit
成员
renderedBuffer, 类型为 AudioBuffer-
要分配给事件的
renderedBuffer属性的值。
1.4. The AudioBuffer
接口
此接口表示一个存储在内存中的音频资源。它可以包含一个或多个声道,每个声道的内容为 32 位浮点线性 PCM值,标称范围为 \([-1,1]\),但数值并不局限于此范围。通常,PCM
数据的长度预期较短(通常小于一分钟)。对于更长的声音,如音乐原声,应当使用
audio
元素和 MediaElementAudioSourceNode
进行流式传输。
一个 AudioBuffer
可以被一个或多个 AudioContext
使用,并且可以在 OfflineAudioContext
和 AudioContext
之间共享。
AudioBuffer
有四个内部槽位:
[[number of channels]]-
此
AudioBuffer的音频声道数量,是一个无符号长整数。 [[length]]-
此
AudioBuffer每个声道的长度,是一个无符号长整数。 [[sample rate]]-
此
AudioBuffer的采样率,以 Hz 为单位,是一个浮点数。 [[internal data]]-
一个包含音频样本数据的 数据块。
[Exposed =Window ]interface AudioBuffer {constructor (AudioBufferOptions );options readonly attribute float sampleRate ;readonly attribute unsigned long length ;readonly attribute double duration ;readonly attribute unsigned long numberOfChannels ;Float32Array getChannelData (unsigned long );channel undefined copyFromChannel (Float32Array ,destination unsigned long ,channelNumber optional unsigned long = 0);bufferOffset undefined copyToChannel (Float32Array ,source unsigned long ,channelNumber optional unsigned long = 0); };bufferOffset
1.4.1. 构造函数
AudioBuffer(options)-
-
如果
options中的任何值超出其标称范围,则抛出NotSupportedError异常,并中止以下步骤。 -
让 b 成为一个新的
AudioBuffer对象。 -
分别将构造函数中传入的
AudioBufferOptions的属性numberOfChannels、length、sampleRate的值分别分配给内部槽位[[number of channels]]、[[length]]、[[sample rate]]。 -
将此
AudioBuffer的内部槽位[[internal data]]设置为调用CreateByteDataBlock的结果(。[[length]]*[[number of channels]])注意:这将把底层存储初始化为零。
-
返回 b。
参数列表 AudioBuffer.constructor() 方法。 参数 类型 可为 null 可选 描述 optionsAudioBufferOptions✘ ✘ 一个 AudioBufferOptions,用于确定此AudioBuffer的属性。 -
1.4.2. 属性
duration, 类型为 double,只读-
PCM 音频数据的时长,单位为秒。
该值通过
[[sample rate]]和[[length]]计算得出,计算方法是将[[length]]除以[[sample rate]]。 length, 类型为 unsigned long,只读-
PCM 音频数据的长度,单位为采样帧。这必须返回
[[length]]的值。 numberOfChannels, 类型为 unsigned long,只读-
离散音频通道的数量。这必须返回
[[number of channels]]的值。 sampleRate, 类型为 float,只读-
PCM 音频数据的采样率,单位为每秒采样数。这必须返回
[[sample rate]]的值。
1.4.3. 方法
copyFromChannel(destination, channelNumber, bufferOffset)-
copyFromChannel()方法从AudioBuffer指定通道中复制样本到destination数组。设
buffer为AudioBuffer,具有 \(N_b\) 帧,设 \(N_f\) 为destination数组的元素个数,\(k\) 为bufferOffset的值。然后从buffer复制到destination的帧数为 \(\max(0, \min(N_b - k, N_f))\)。如果此值小于 \(N_f\),则剩余的destination元素将不会被修改。参数 AudioBuffer.copyFromChannel() 方法。 参数 类型 可为空 可选 描述 destinationFloat32Array✘ ✘ 要复制通道数据的数组。 channelNumberunsigned long✘ ✘ 要从中复制数据的通道索引。如果 channelNumber大于等于AudioBuffer的通道数量,必须抛出IndexSizeError。bufferOffsetunsigned long✘ ✔ 可选的偏移量,默认为 0。从此偏移量开始从 AudioBuffer中复制数据到destination。返回类型:undefined copyToChannel(source, channelNumber, bufferOffset)-
copyToChannel()方法从source数组中复制样本到AudioBuffer指定通道。如果
source无法复制到缓冲区,可能抛出UnknownError。设
buffer为AudioBuffer,具有 \(N_b\) 帧,设 \(N_f\) 为source数组的元素个数,\(k\) 为bufferOffset的值。然后从source复制到buffer的帧数为 \(\max(0, \min(N_b - k, N_f))\)。如果此值小于 \(N_f\),则buffer中的剩余元素将不会被修改。参数 AudioBuffer.copyToChannel() 方法。 参数 类型 可为空 可选 描述 sourceFloat32Array✘ ✘ 从中复制通道数据的数组。 channelNumberunsigned long✘ ✘ 要复制数据的通道索引。如果 channelNumber大于等于AudioBuffer的通道数量,必须抛出IndexSizeError。bufferOffsetunsigned long✘ ✔ 可选的偏移量,默认为 0。从此偏移量开始将 source数据复制到AudioBuffer。返回类型:undefined getChannelData(channel)-
根据 获取内容 的规则,允许要么对
[[internal data]]进行写入,要么获取存储在该内部数据块中的字节副本,并创建一个新的Float32Array。如果
[[internal data]]或新创建的Float32Array无法被创建,可能抛出UnknownError。参数 AudioBuffer.getChannelData() 方法。 参数 类型 可为空 可选 描述 channelunsigned long✘ ✘ 表示要获取数据的特定通道的索引。索引值为 0 表示第一个通道。此索引值必须小于 [[number of channels]],否则必须抛出IndexSizeError异常。返回类型:Float32Array
注意: 方法 copyToChannel()
和 copyFromChannel()
可以通过传入 Float32Array
作为较大数组的视图,来填充数组的一部分。当从 AudioBuffer
的通道读取数据并以块形式处理数据时,应优先使用 copyFromChannel(),而不是调用
getChannelData()
并访问结果数组,因为这样可以避免不必要的内存分配和复制。
当某些 API 实现需要使用 AudioBuffer
的内容时,会调用内部操作 获取 AudioBuffer
的内容。该操作会向调用方返回不可变的通道数据。
AudioBuffer
进行 获取内容 操作时,执行以下步骤:
-
如果
AudioBuffer的任何ArrayBuffer被 分离,返回true,中止这些步骤,并向调用方返回一个零长度的通道数据缓冲区。 -
分离 由此
AudioBuffer上的getChannelData()方法之前返回的所有ArrayBuffer。注意:由于
AudioBuffer只能通过createBuffer()或AudioBuffer构造函数创建,因此这不会抛出异常。 -
保留这些
ArrayBuffer的[[internal data]]底层数据,并将它们的引用返回给调用方。 -
将包含数据副本的
ArrayBuffer附加到AudioBuffer,以便在下次调用getChannelData()时返回。
在以下情况下会调用 获取 AudioBuffer 内容 操作:
-
当调用
AudioBufferSourceNode.start时,会 获取节点的buffer的内容。如果操作失败,则不会播放任何内容。 -
当
buffer被设置给一个AudioBufferSourceNode且之前已经调用了AudioBufferSourceNode.start,则设置器会 获取AudioBuffer的内容。如果操作失败,则不会播放任何内容。 -
当
ConvolverNode的buffer设置为AudioBuffer时,它会 获取AudioBuffer的内容。 -
当
AudioProcessingEvent的分派完成时,它会 获取 其outputBuffer的内容。
注意: 这意味着 copyToChannel()
不能用于更改目前被 AudioNode 使用的
AudioBuffer
的内容,因为该 AudioNode 已经
获取了该 AudioBuffer
的内容,并将继续使用之前获取的数据。
1.4.4.
AudioBufferOptions
此部分指定用于构造 AudioBuffer
的选项。
length
和
sampleRate
成员是必需的。
dictionary AudioBufferOptions {unsigned long numberOfChannels = 1;required unsigned long length ;required float sampleRate ; };
1.4.4.1.
Dictionary
AudioBufferOptions
Members
该字典成员的允许值是有约束的。请参见
createBuffer()
。
-
length, 类型为 unsigned long -
缓冲区的采样帧长度。请参见
length了解约束。 -
numberOfChannels, 类型为 unsigned long ,默认值为1 -
缓冲区的通道数。请参见
numberOfChannels了解约束。 -
sampleRate, 类型为 float -
缓冲区的采样率,单位为 Hz。请参见
sampleRate了解约束。
1.5. The AudioNode
Interface
AudioNode 是
AudioContext
的构建模块。
该接口表示音频源、音频目标和中间处理模块。这些模块可以相互连接以形成用于将音频渲染到音频硬件的 处理图。
每个节点可以有 输入 和/或 输出。一个 源节点 没有输入且只有一个输出。
大多数处理节点,如滤波器,将有一个输入和一个输出。每种类型的 AudioNode 在其处理或合成音频的细节上有所不同。
但通常情况下,一个 AudioNode
会处理其输入(如果有)并为其输出(如果有)生成音频。
每个输出有一个或多个通道。确切的通道数取决于具体的 AudioNode 的详细信息。
一个输出可以连接到一个或多个 AudioNode 的输入,从而支持 扇出。一个输入最初没有连接,但可以从一个或多个 AudioNode
的输出连接,从而支持 扇入。
当调用 connect() 方法将一个 AudioNode 的输出连接到另一个 AudioNode 的输入时,我们称之为对该输入的
连接。
每个 AudioNode
的 输入 在任何给定时间都有特定数量的通道。
这个数量可能会根据对该输入进行的 连接 而发生变化。
如果该输入没有连接,则它有一个静音的通道。
对于每个 输入,一个 AudioNode 对所有连接到该输入的连接执行混合操作。
请参见 § 4 通道上混和下混 获取规范要求和详细信息。
输入的处理和 AudioNode
的内部操作在
AudioContext
时间上持续进行,
无论节点是否有连接的输出,也无论这些输出是否最终到达 AudioContext 的 AudioDestinationNode。
[Exposed =Window ]interface AudioNode :EventTarget {AudioNode connect (AudioNode destinationNode ,optional unsigned long output = 0,optional unsigned long input = 0);undefined connect (AudioParam destinationParam ,optional unsigned long output = 0);undefined disconnect ();undefined disconnect (unsigned long output );undefined disconnect (AudioNode destinationNode );undefined disconnect (AudioNode destinationNode ,unsigned long output );undefined disconnect (AudioNode destinationNode ,unsigned long output ,unsigned long input );undefined disconnect (AudioParam destinationParam );undefined disconnect (AudioParam destinationParam ,unsigned long output );readonly attribute BaseAudioContext context ;readonly attribute unsigned long numberOfInputs ;readonly attribute unsigned long numberOfOutputs ;attribute unsigned long channelCount ;attribute ChannelCountMode channelCountMode ;attribute ChannelInterpretation channelInterpretation ; };
1.5.1. AudioNode 创建
AudioNode
可以通过两种方式创建:一种是使用该特定接口的构造函数,另一种是使用
BaseAudioContext
或
AudioContext
上的
工厂方法。
作为 AudioNode
构造函数第一个参数传递的
BaseAudioContext,
被称为要创建的 AudioNode 的
关联的 BaseAudioContext。
类似地,当使用工厂方法时,关联的
BaseAudioContext 是调用该工厂方法的
BaseAudioContext。
BaseAudioContext c 上创建一个特定类型 n 的新
AudioNode,执行以下步骤:
-
让 node 成为一个新对象,类型为 n。
-
让 option 成为与该工厂方法关联的接口 关联的字典类型。
-
对于传递给工厂方法的每个参数,将 option 中同名的字典成员设置为该参数的值。
-
使用 c 和 option 作为参数在 node 上调用 n 的构造函数。
-
返回 node
AudioNode
的对象 o,
意味着执行以下步骤,给定传递给此接口构造函数的参数 context 和 dict。
-
将 o 的关联
BaseAudioContext设置为 context。 -
将其值为
numberOfInputs,numberOfOutputs,channelCount,channelCountMode,channelInterpretation设置为此特定接口在每个AudioNode部分中概述的默认值。 -
对于传入的 dict 的每个成员,执行以下步骤,k 为成员的键,v 为其值。 如果在执行这些步骤时抛出任何异常,终止迭代并将异常传播给算法(构造函数或工厂方法)的调用者。
-
如果 k 是此接口上
AudioParam的名称, 则将此AudioParam的value属性设置为 v。 -
否则,如果 k 是此接口上的属性名称,则将与此属性关联的对象设置为 v。
-
工厂方法的关联接口是从此方法返回的对象的接口。 接口的关联选项对象是可以传递给该接口构造函数的选项对象。
AudioNode 是
EventTarget,
如 [DOM] 所述。这意味着可以向
AudioNode
派发事件,
就像其他 EventTarget
接受事件一样。
enum {ChannelCountMode "max" ,"clamped-max" ,"explicit" };
ChannelCountMode,
与节点的 channelCount
和 channelInterpretation
值结合使用,
用于确定控制如何混合输入到节点的计算出的通道数。
计算出的通道数如下所示。
有关混音的更多信息,请参阅§ 4 通道上混合和下混合。
| 枚举值 | 描述 |
|---|---|
"max" |
计算出的通道数是输入的所有连接通道数中的最大值。在这种模式下,
channelCount
被忽略。
|
"clamped-max" |
计算出的通道数的确定方式与
"max"
相同,然后将其限制为给定的最大值
channelCount。
|
"explicit" |
计算出的通道数是
channelCount
指定的确切值。
|
enum {ChannelInterpretation "speakers" ,"discrete" };
| 枚举值 | 描述 |
|---|---|
"speakers" |
使用 上混合公式 或 下混合公式。当通道数量不匹配任何这些基本扬声器布局时,恢复为
"discrete"。
|
"discrete" |
通过填充通道直到用完来上混合,然后将剩余的通道置为零。通过填充尽可能多的通道来下混合,然后丢弃剩余的通道。 |
1.5.2. AudioNode 尾时间
一个 AudioNode
可以具有尾时间。
这意味着即使 AudioNode
输入为静音,其输出也可能是非静音的。
AudioNode
如果具有内部处理状态,
即过去的输入会影响未来的输出,则具有非零的尾时间。即使输入从非静音过渡到静音,这些 AudioNode
也可能在计算的尾时间内继续产生非静音的输出。
1.5.3. AudioNode 生命周期
一个 AudioNode
在 渲染量子期间可能是主动处理的,如果以下条件中的任何一个成立。
-
如果且仅当
AudioScheduledSourceNode在当前渲染量子的某部分时间内播放时,它是主动处理的。 -
如果且仅当
MediaElementAudioSourceNode的mediaElement在当前渲染量子的某部分时间内正在播放,它是主动处理的。 -
当与
MediaStreamTrack关联的MediaStreamAudioSourceNode或MediaStreamTrackAudioSourceNode的readyState属性等于"live",muted属性等于false且enabled属性等于true时,它们是主动处理的。 -
当
DelayNode在一个循环中时, 只有当当前 渲染量子 中的任何输出样本的绝对值大于或等于 \( 2^{-126} \) 时,它是主动处理的。 -
当
ScriptProcessorNode的输入或输出已连接时,它是主动处理的。 -
当
AudioWorkletNode的AudioWorkletProcessor的[[callable process]]返回true,且它的 活动源标志为true或连接到其输入之一的任何AudioNode是主动处理的。 -
其他所有
AudioNode在连接到其输入之一的任何AudioNode是主动处理时开始主动处理, 当接收来自其他主动处理AudioNode的输入不再影响输出时,停止主动处理。
1.5.4. 属性
channelCount,类型为 无符号长整型-
channelCount是用于上混和下混连接到节点的任何输入的通道数量。默认值是2,除了一些特定节点的值是特别确定的。对于没有输入的节点,此属性没有效果。如果此值设置为零或超过实现的最大通道数量,实施必须抛出NotSupportedError异常。此外,一些节点对通道数量的可能值具有额外的channelCount 约束:
AudioDestinationNode-
行为取决于目标节点是否是
AudioContext或OfflineAudioContext的目标:AudioContext-
通道数量必须在 1 到
maxChannelCount之间。任何试图将通道数量设置在此范围之外的操作必须抛出IndexSizeError异常。 OfflineAudioContext-
通道数量不能更改。任何试图更改此值的操作必须抛出
InvalidStateError异常。
AudioWorkletNodeChannelMergerNode-
通道数量不可更改,任何试图更改此值的操作必须抛出
InvalidStateError异常。 ChannelSplitterNode-
通道数量不可更改,任何试图更改此值的操作必须抛出
InvalidStateError异常。 ConvolverNode-
通道数量不能大于 2,任何试图将其更改为大于 2 的值的操作必须抛出
NotSupportedError异常。 DynamicsCompressorNode-
通道数量不能大于 2,任何试图将其更改为大于 2 的值的操作必须抛出
NotSupportedError异常。 PannerNode-
通道数量不能大于 2,任何试图将其更改为大于 2 的值的操作必须抛出
NotSupportedError异常。 ScriptProcessorNode-
通道数量不可更改,任何试图更改此值的操作必须抛出
NotSupportedError异常。 StereoPannerNode-
通道数量不能大于 2,任何试图将其更改为大于 2 的值的操作必须抛出
NotSupportedError异常。
有关此属性的更多信息,请参阅 § 4 通道上混和下混。
channelCountMode,类型为 ChannelCountMode-
channelCountMode决定在上混和下混连接到节点的任何输入时如何计算通道数量。默认值为 "max"。 对于没有输入的节点,此属性没有效果。此外,一些节点对通道数量模式的可能值具有额外的 channelCountMode 约束:
AudioDestinationNode-
如果
AudioDestinationNode是目标节点的OfflineAudioContext, 则通道数量模式不能更改。任何试图更改此值的操作必须抛出InvalidStateError异常。 ChannelMergerNode-
通道数量模式不能从 "
explicit" 更改,任何试图更改此值的操作必须抛出InvalidStateError异常。 ChannelSplitterNode-
通道数量模式不能从 "
explicit" 更改,任何试图更改此值的操作必须抛出InvalidStateError异常。 ConvolverNode-
通道数量模式不能设置为 "
max", 任何试图将其设置为 "max" 的操作必须抛出NotSupportedError异常。 DynamicsCompressorNode-
通道数量模式不能设置为 "
max", 任何试图将其设置为 "max" 的操作必须抛出NotSupportedError异常。 PannerNode-
通道数量模式不能设置为 "
max", 任何试图将其设置为 "max" 的操作必须抛出NotSupportedError异常。 ScriptProcessorNode-
通道数量模式不能从 "
explicit" 更改,任何试图更改此值的操作必须抛出NotSupportedError异常。 StereoPannerNode-
通道数量模式不能设置为 "
max", 任何试图将其设置为 "max" 的操作必须抛出NotSupportedError异常。
有关此属性的更多信息,请参阅 § 4 通道上混和下混部分。
channelInterpretation,类型为 ChannelInterpretation-
channelInterpretation决定在将连接上混或下混到节点的输入时如何处理各个通道。默认值为 "speakers"。 对于没有输入的节点,此属性没有效果。此外,一些节点对通道解释的可能值有额外的 channelInterpretation 约束:
ChannelSplitterNode-
通道解释不能从 "
discrete" 更改,任何试图更改此值的操作必须抛出InvalidStateError异常。
有关此属性的更多信息,请参阅 § 4 通道上混和下混。
context,类型为 BaseAudioContext,只读-
拥有此
AudioNode的BaseAudioContext。 numberOfInputs,类型为 无符号长整型,只读-
传入
AudioNode的输入数量。对于 源节点,此值为 0。对于许多AudioNode类型,此属性是预定的,但对于某些AudioNode, 如ChannelMergerNode和AudioWorkletNode, 输入数量是可变的。 numberOfOutputs,类型为 无符号长整型,只读-
从
AudioNode输出的数量。对于某些AudioNode类型,此属性是预定的,但对于某些节点类型,如ChannelSplitterNode和AudioWorkletNode, 输出数量是可变的。
1.5.5. 方法
connect(destinationNode, output, input)-
在特定节点的给定输出和另一个特定节点的给定输入之间只能有一个连接。具有相同终点的多个连接将被忽略。
此方法返回
destinationAudioNode对象。AudioNode.connect(destinationNode, output, input) 方法的参数。 参数 类型 可为 null 可选 描述 destinationNodedestination参数是要连接的AudioNode。如果destination参数是一个来自另一个AudioNode,并且该AudioContext已被创建,那么必须抛出一个InvalidAccessError。 也就是说,AudioNodes 不能在多个AudioContexts 之间共享。多个AudioNodes 可以连接到同一个AudioNode, 这在 频道上行混合和下行混合 部分有描述。output无符号长整型✘ ✔ output参数是一个索引,用于描述要从中连接的AudioNode的哪个输出。如果该参数超出边界,必须抛出IndexSizeError异常。 可以通过多次调用 connect() 将一个AudioNode输出连接到多个输入,从而支持“扇出”。inputinput参数是一个索引,用于描述要连接到的目标AudioNode的哪个输入。如果该参数超出边界,必须抛出IndexSizeError异常。 可以将一个AudioNode连接到另一个AudioNode的输入或AudioParam, 从而形成循环。返回类型:AudioNode connect(destinationParam, output)-
将
AudioNode连接到AudioParam, 通过 a-rate 信号控制参数值。可以通过多次调用 connect() 将
AudioNode输出连接到多个AudioParam, 从而支持“扇出”。可以通过多次调用 connect() 将多个
AudioNode输出连接到一个AudioParam, 从而支持“扇入”。AudioParam将从连接到它的任何AudioNode输出中获取渲染的音频数据,并将其 转换为单声道,如果它不是单声道,则通过下混合,然后与其他这些输出混合在一起,最后与固有参数值(即在没有任何音频连接的情况下,AudioParam通常具有的value值)一起混合,包括为该参数安排的任何时间线更改。将音频数据下混为单声道的过程等效于
AudioNode的下混,前提是channelCount= 1,channelCountMode= "explicit", 并且channelInterpretation= "speakers"。在特定节点的给定输出和特定的
AudioParam之间只能有一个连接。具有相同终点的多个连接将被忽略。AudioNode.connect(destinationParam, output) 方法的参数。 参数 类型 可为 null 可选 描述 destinationParamAudioParam✘ ✘ destination参数是要连接的AudioParam。 此方法不返回destinationAudioParam对象。如果destinationParam属于一个AudioNode, 而该BaseAudioContext与创建此方法调用的BaseAudioContext不同,则必须抛出InvalidAccessError异常。output无符号长整型✘ ✔ output参数是一个索引,用于描述要从中连接的AudioNode的哪个输出。如果parameter参数超出边界,则必须抛出IndexSizeError异常。返回类型:undefined disconnect()-
断开来自
AudioNode的所有输出连接。无参数。返回类型:undefined disconnect(output)-
断开
AudioNode的单个输出与任何其他AudioNode或AudioParam对象的连接。AudioNode.disconnect(output) 方法的参数。 参数 类型 可为 null 可选 描述 output无符号长整型✘ ✘ 此参数是一个索引,用于描述要断开的 AudioNode的哪个输出。它将断开给定输出的所有连接。如果此参数超出边界,则必须抛出IndexSizeError异常。返回类型:undefined disconnect(destinationNode)-
断开
AudioNode的所有输出与指定目标AudioNode的连接。AudioNode.disconnect(destinationNode) 方法的参数。 参数 类型 可为 null 可选 描述 destinationNodedestinationNode参数是要断开的AudioNode。 它将断开到给定destinationNode的所有输出连接。如果没有到destinationNode的连接,则必须抛出InvalidAccessError异常。返回类型:undefined disconnect(destinationNode, output)-
断开
AudioNode的特定输出与某个目标AudioNode的所有输入的连接。AudioNode.disconnect(destinationNode, output) 方法的参数。 参数 类型 可为 null 可选 描述 destinationNodedestinationNode参数是要断开的AudioNode。 如果给定输出没有连接到destinationNode,则必须抛出InvalidAccessError异常。output无符号长整型✘ ✘ output参数是一个索引,用于描述要断开的AudioNode的哪个输出。如果此参数超出边界,则必须抛出IndexSizeError异常。返回类型:undefined disconnect(destinationNode, output, input)-
断开
AudioNode的特定输出与某个目标AudioNode的特定输入的连接。AudioNode.disconnect(destinationNode, output, input) 方法的参数。 参数 类型 可为 null 可选 描述 destinationNodedestinationNode参数是要断开的AudioNode。 如果给定输出到给定输入没有连接到destinationNode,则必须抛出InvalidAccessError异常。output无符号长整型✘ ✘ output参数是一个索引,用于描述要断开的AudioNode的哪个输出。如果此参数超出边界,则必须抛出IndexSizeError异常。inputinput参数是一个索引,用于描述目标AudioNode的哪个输入要断开。如果此参数超出边界,则必须抛出IndexSizeError异常。返回类型:undefined disconnect(destinationParam)-
断开
AudioNode的所有输出与特定目标AudioParam的连接。当此操作生效时,该AudioNode对计算出的参数值的贡献变为 0。本征参数值不受此操作的影响。AudioNode.disconnect(destinationParam) 方法的参数。 参数 类型 可为 null 可选 描述 destinationParamAudioParam✘ ✘ destinationParam参数是要断开的AudioParam。 如果没有到destinationParam的连接,则必须抛出InvalidAccessError异常。返回类型:undefined disconnect(destinationParam, output)-
断开
AudioNode的特定输出与某个目标AudioParam的连接。当此操作生效时,该AudioNode对计算出的参数值的贡献变为 0。本征参数值不受此操作的影响。AudioNode.disconnect(destinationParam, output) 方法的参数。 参数 类型 可为 null 可选 描述 destinationParamAudioParam✘ ✘ destinationParam参数是要断开的AudioParam。 如果没有到destinationParam的连接,则必须抛出InvalidAccessError异常。output无符号长整型✘ ✘ output参数是一个索引,用于描述要断开的AudioNode的哪个输出。如果该参数超出边界,则必须抛出IndexSizeError异常。返回类型:undefined
1.5.6.
AudioNodeOptions
此项指定了构建所有 AudioNode
的选项。所有成员都是可选的。然而,实际节点使用的具体值取决于每个节点的实际情况。
dictionary AudioNodeOptions {unsigned long channelCount ;ChannelCountMode channelCountMode ;ChannelInterpretation channelInterpretation ; };
1.5.6.1. 字典 AudioNodeOptions
成员
channelCount, 类型为 unsigned long-
所需的
channelCount属性的通道数量。 channelCountMode, 类型为 ChannelCountMode-
所需的
channelCountMode属性的模式。 channelInterpretation, 类型为 ChannelInterpretation-
所需的
channelInterpretation属性的模式。
1.6. AudioParam
接口
AudioParam
控制单个 AudioNode 功能的
方面,如音量。可以使用 value 属性立即将参数设置为特定值。或者,可以安排值的更改,
这些更改将在非常精确的时间发生(在 AudioContext
的 currentTime
属性的坐标系统中),用于包络、音量渐变、低频振荡器(LFO)、滤波器扫描、粒子窗等。通过这种方式,
可以在任何 AudioParam
上设置
任意的基于时间轴的自动化曲线。此外,来自 AudioNode
输出的音频信号
可以连接到 AudioParam,
与 固有 参数值相加。
一些合成和处理的 AudioNode
具有作为属性的 AudioParam,
其值必须考虑每个音频样本。对于其他 AudioParam,
样本精度不重要,可以更粗略地采样值的变化。每个单独的 AudioParam
会指定它是一个 a-rate 参数,这意味着它的值
必须在每个音频样本的基础上考虑,或者它是一个 k-rate 参数。
实现必须使用块处理,每个 AudioNode
处理一个 渲染量子。
对于每个 渲染量子,k-rate
参数的值必须在第一个样本帧的时间进行采样,并且该值必须用于整个块。a-rate 参数必须为该块的每个样本帧进行采样。
根据 AudioParam,
可以通过设置 automationRate
属性为 "a-rate"
或 "k-rate"
来控制其速率。
详细信息请参阅每个 AudioParam
的描述。
每个 AudioParam
包含 minValue
和 maxValue
属性,这两个属性共同形成参数的 简单名义范围。
实际上,参数的值被限制在 \([\mathrm{minValue}, \mathrm{maxValue}]\) 范围内。详细信息请参见 § 1.6.3
值的计算。
对于许多 AudioParam,
minValue
和 maxValue
应设置为最大可能范围。在这种情况下,maxValue
应设置为 最正单精度浮动
值,即 3.4028235e38。(然而,在仅支持 IEEE-754 双精度浮动值的 JavaScript 中,必须写成 3.4028234663852886e38。)
同样,minValue
应设置为 最负单精度浮动 值,
即最正单精度浮动值的负数:-3.4028235e38。(在 JavaScript 中,这应写成 -3.4028234663852886e38。)
一个 AudioParam
保持一个零个或多个 自动化事件
的列表。每个自动化事件
指定在特定时间范围内对参数值的变化,基于其 自动化事件时间,
在 AudioContext
的
currentTime
属性的时间坐标系统中。自动化事件的列表按自动化事件时间的升序排列。
给定自动化事件的行为是 AudioContext
当前时间的函数,
以及该事件和列表中相邻事件的自动化事件时间。以下 自动化方法
通过向事件列表中添加一个新的事件来改变事件列表,该事件的类型特定于该方法:
-
setValueAtTime()-设置值 -
linearRampToValueAtTime()-线性渐变到值 -
exponentialRampToValueAtTime()-指数渐变到值 -
setTargetAtTime()-设置目标 -
setValueCurveAtTime()-设置值曲线
调用这些方法时将适用以下规则:
-
自动化事件时间 不会根据当前的采样率进行量化。计算曲线和渐变的公式会应用于调度事件时给定的精确数值时间。
-
如果在已经有一个或多个事件的时间点添加了这些事件,它将被放置在它们之后,但在事件时间点之后的事件之前。
-
如果在时间 \(T\) 和持续时间 \(D\) 调用 setValueCurveAtTime(),并且有任何事件的时间严格大于 \(T\), 但严格小于 \(T + D\),则必须抛出
NotSupportedError异常。 换句话说,在包含其他事件的时间段内调度值曲线是不允许的,但可以在其他事件的时间点精确调度值曲线。 -
类似地,如果在时间区间 \([T, T+D)\) 内的任何时间调用了任何 自动化方法,其中 \(T\) 是曲线的时间,\(D\) 是其持续时间,则必须抛出
NotSupportedError异常。
注意: AudioParam
属性是只读的,除了 value
属性外。
可以通过设置 automationRate
属性来选择 AudioParam
的自动化速率,
该属性可以有以下值。然而,一些 AudioParam
有一些关于是否可以更改自动化速率的限制。
enum {AutomationRate "a-rate" ,"k-rate" };
| 枚举值 | 描述 |
|---|---|
"a-rate"
| 该 AudioParam
被设置为 a-rate
处理。
|
"k-rate"
| 该 AudioParam
被设置为 k-rate
处理。
|
每个 AudioParam
都有一个内部槽 [[current value]],
初始设置为该 AudioParam 的
defaultValue。
[Exposed =Window ]interface AudioParam {attribute float value ;attribute AutomationRate automationRate ;readonly attribute float defaultValue ;readonly attribute float minValue ;readonly attribute float maxValue ;AudioParam setValueAtTime (float ,value double );startTime AudioParam linearRampToValueAtTime (float ,value double );endTime AudioParam exponentialRampToValueAtTime (float ,value double );endTime AudioParam setTargetAtTime (float ,target double ,startTime float );timeConstant AudioParam setValueCurveAtTime (sequence <float >,values double ,startTime double );duration AudioParam cancelScheduledValues (double );cancelTime AudioParam cancelAndHoldAtTime (double ); };cancelTime
1.6.1. 属性
automationRate, 类型为 AutomationRate-
该
AudioParam的自动化速率。 默认值取决于实际的AudioParam; 有关每个单独AudioParam的默认值,请参见其描述。一些节点有附加的 自动化速率约束,如下所示:
AudioBufferSourceNode-
该
AudioParam的playbackRate和detune必须是 "k-rate"。 如果速率被更改为 "a-rate",必须抛出InvalidStateError异常。 DynamicsCompressorNode-
该
AudioParam的threshold,knee,ratio,attack, 和release必须是 "k-rate"。 如果速率被更改为 "a-rate",必须抛出InvalidStateError异常。 PannerNode-
如果
panningModel是 "HRTF", 则automationRate的设置对于任何AudioParam都被忽略。 同样地,设置automationRate对于任何AudioParam的AudioListener也会被忽略。在这种情况下,AudioParam的行为就像automationRate被设置为 "k-rate" 一样。
defaultValue, 类型为 float,只读-
该
value属性的初始值。 maxValue, 类型为 float,只读-
该参数可以接受的最大名义值。与
minValue一起,定义了该参数的 名义范围。 minValue, 类型为 float,只读-
该参数可以接受的最小名义值。与
maxValue一起,定义了该参数的 名义范围。 value, 类型为 float-
该参数的浮动值。此属性的初始值为
defaultValue。获取此属性时,返回
[[current value]]插槽的内容。请参阅 § 1.6.3 计算值,了解返回值的算法。设置此属性等效于将请求的值分配给
[[current value]]插槽,并调用 setValueAtTime() 方法,传递当前AudioContext的currentTime和[[current value]]。 如果setValueAtTime()抛出任何异常,则设置该属性时也会抛出相同的异常。
1.6.2. 方法
cancelAndHoldAtTime(cancelTime)-
这与
cancelScheduledValues()类似,都会取消所有调度的参数变化,取消的时间为大于或等于cancelTime。 然而,除此之外,发生在cancelTime时的自动化 值将被延续,直到引入其他自动化事件为止。在调用
cancelAndHoldAtTime()后,自动化运行时引入事件的时间点非常复杂。cancelAndHoldAtTime()方法的行为因此被以下算法指定。设 \(t_c\) 为cancelTime的值。 然后-
设 \(E_1\) 为时间 \(t_1\) 的事件(如果存在),其中 \(t_1\) 是满足 \(t_1 \le t_c\) 的最大值。
-
设 \(E_2\) 为时间 \(t_2\) 的事件(如果存在),其中 \(t_2\) 是满足 \(t_c \lt t_2\) 的最小值。
-
如果 \(E_2\) 存在:
-
如果 \(E_2\) 是线性或指数变化,
-
将 \(E_2\) 实质性地重写为相同类型的变化,结束时间为 \(t_c\),结束值为原始变化在时间 \(t_c\) 时的值。

-
转到第5步。
-
-
否则,转到第4步。
-
-
如果 \(E_1\) 存在:
-
如果 \(E_1\) 是
setTarget事件,-
在时间 \(t_c\) 隐式插入一个
setValueAtTime事件,其值为setTarget在时间 \(t_c\) 时的值。
-
转到第5步。
-
-
如果 \(E_1\) 是
setValueCurve事件,起始时间为 \(t_3\),持续时间为 \(d\)-
如果 \(t_c > t_3 + d\),转到第5步。
-
否则,
-
实质性地替换该事件为一个新的
setValueCurve事件,起始时间为 \(t_3\),持续时间为 \(t_c - t_3\)。 但这不是一个真正的替换;这个自动化必须确保生成与原始相同的输出,而不是使用不同持续时间计算的输出。(否则会导致值曲线采样略有不同,产生不同的结果。)
-
转到第5步。
-
-
-
-
删除所有时间大于 \(t_c\) 的事件。
如果没有添加事件,那么
cancelAndHoldAtTime()调用后的自动化值将是原始时间轴在时间 \(t_c\) 时的常数值。AudioParam.cancelAndHoldAtTime() 方法的参数。 参数 类型 可空 可选 描述 cancelTimedouble✘ ✘ 取消所有先前调度的参数变化的时间。它与 AudioContext的currentTime属性使用相同的时间坐标系统。如果RangeError异常被抛出,则cancelTime不得为负数。如果cancelTime小于currentTime, 它会被限制为currentTime。返回类型:AudioParam -
cancelScheduledValues(cancelTime)-
取消所有计划的参数变化,取消时间大于或等于
cancelTime。 取消计划的参数变化意味着从事件列表中移除该计划事件。任何活跃的自动化,其 自动化事件时间 小于cancelTime的自动化也会被取消,这种取消可能会导致不连续,因为原始值(在自动化之前的值)会立即恢复。如果在cancelAndHoldAtTime()方法中调度的保持值在cancelTime之后,保持值也会被移除。对于
setValueCurveAtTime(), 设 \(T_0\) 和 \(T_D\) 分别为该事件的startTime和duration。 如果cancelTime在 \([T_0, T_0 + T_D]\) 范围内,则该事件将从时间轴中移除。参数列表:AudioParam.cancelScheduledValues() 方法。 参数 类型 可空 可选 描述 cancelTimedouble✘ ✘ 取消所有先前调度的参数变化的时间。它与 AudioContext的currentTime属性使用相同的时间坐标系统。如果RangeError异常被抛出,则cancelTime不得为负数。 如果cancelTime小于currentTime, 它会被限制为currentTime。返回类型:AudioParam exponentialRampToValueAtTime(value, endTime)-
调度一个指数连续的参数值变化,从上一个调度的参数值到给定的值。表示滤波器频率和播放速率的参数最好以指数方式变化,因为人类感知声音的方式是如此。
在时间间隔 \(T_0 \leq t < T_1\) (其中 \(T_0\) 是前一个事件的时间,\(T_1\) 是传入此方法的
endTime参数的时间),值将按以下公式计算:$$ v(t) = V_0 \left(\frac{V_1}{V_0}\right)^\frac{t - T_0}{T_1 - T_0} $$其中 \(V_0\) 是在时间 \(T_0\) 时的值,\(V_1\) 是传入此方法的
value参数的值。 如果 \(V_0\) 和 \(V_1\) 具有相反符号,或者 \(V_0\) 为零,则 \(v(t) = V_0\) 对于 \(T_0 \le t < T_1\)。这也意味着,指数变化到 0 是不可能的。可以使用
setTargetAtTime()方法来获得一个合适的时间常数,从而获得一个不错的近似。如果在此 ExponentialRampToValue 事件之后没有更多的事件,那么对于 \(t \geq T_1\),\(v(t) = V_1\)。
如果没有前置事件,则指数变化会像调用
setValueAtTime(value, currentTime)方法一样,其中value是当前属性值,currentTime是currentTime属性的上下文时间。如果前置事件是一个
SetTarget事件,那么 \(T_0\) 和 \(V_0\) 将从当前时间和SetTarget自动化的当前值中选择。即,如果SetTarget事件尚未开始,那么 \(T_0\) 是事件的开始时间,\(V_0\) 是事件开始前的值。在这种情况下,ExponentialRampToValue事件实际上替代了SetTarget事件。如果SetTarget事件已经开始,那么 \(T_0\) 是当前的上下文时间,\(V_0\) 是当前SetTarget自动化值的时间 \(T_0\)。在这两种情况下,自动化曲线是连续的。参数列表:AudioParam.exponentialRampToValueAtTime() 方法。 参数 类型 可空 可选 描述 valuefloat✘ ✘ 参数将在给定时间内指数变化到的值。如果此值为 0,必须抛出 RangeError异常。endTimedouble✘ ✘ 指数变化结束的时间,使用与 AudioContext的currentTime属性相同的时间坐标系统。如果endTime为负数或不是一个有限的数字,必须抛出RangeError异常。 如果 endTime 小于currentTime, 它会被限制为currentTime。返回类型:AudioParam linearRampToValueAtTime(value, endTime)-
安排参数值从之前计划的值线性连续变化到给定值。
在时间区间 \(T_0 \leq t < T_1\)(其中 \(T_0\) 是前一个事件的时间,\(T_1\) 是此方法传递的
endTime参数),值将计算为:$$ v(t) = V_0 + (V_1 - V_0) \frac{t - T_0}{T_1 - T_0} $$其中 \(V_0\) 是 \(T_0\) 时的值,\(V_1\) 是此方法传递的
value参数。如果此 LinearRampToValue 事件之后没有更多事件,那么对于 \(t \geq T_1\),\(v(t) = V_1\)。
如果没有前置事件,则线性坡道行为就像调用
setValueAtTime(value, currentTime)方法一样,其中value是当前属性值,currentTime是上下文的currentTime时间。如果前置事件是
SetTarget事件,那么 \(T_0\) 和 \(V_0\) 将从当前时间和SetTarget自动化的当前值中选择。也就是说,如果SetTarget事件尚未开始,\(T_0\) 是事件的开始时间,\(V_0\) 是事件开始前的值。在这种情况下,LinearRampToValue事件实际上替代了SetTarget事件。如果SetTarget事件已经开始,那么 \(T_0\) 是当前的上下文时间,\(V_0\) 是当前SetTarget自动化值的时间 \(T_0\)。在这两种情况下,自动化曲线是连续的。参数列表:AudioParam.linearRampToValueAtTime() 方法。 参数 类型 可空 可选 描述 valuefloat✘ ✘ 参数将在给定时间内线性变化到的值。 endTimedouble✘ ✘ 指数变化结束的时间,使用与 AudioContext的currentTime属性相同的时间坐标系统。如果endTime为负数或不是一个有限的数字,必须抛出RangeError异常。 如果 endTime 小于currentTime, 它会被限制为currentTime。返回类型:AudioParam setTargetAtTime(target, startTime, timeConstant)-
开始以给定的时间常数的速率指数接近目标值。在实现 ADSR 包络的“衰减”和“释放”部分时尤其有用。请注意,参数值在给定时间不会立即变化到目标值,而是逐渐变化。
在时间区间:\(T_0 \leq t\),其中 \(T_0\) 是
startTime参数:$$ v(t) = V_1 + (V_0 - V_1)\, e^{-\left(\frac{t - T_0}{\tau}\right)} $$其中 \(V_0\) 是初始值(
[[current value]]属性)在 \(T_0\)(startTime参数)时的值,\(V_1\) 等于target参数,\(\tau\) 是timeConstant参数。如果在此事件之后有
LinearRampToValue或ExponentialRampToValue事件,则行为如linearRampToValueAtTime()或exponentialRampToValueAtTime()中所描述。如果是其他事件,则SetTarget事件将在下一个事件发生时结束。参数列表:AudioParam.setTargetAtTime() 方法。 参数 类型 可空 可选 描述 targetfloat✘ ✘ 参数将在给定时间开始变化到的目标值。 startTimedouble✘ ✘ 指数接近将在给定时间开始,该时间使用与 AudioContext的currentTime属性相同的时间坐标系统。如果start为负数或不是一个有限的数字,必须抛出RangeError异常。 如果 startTime 小于currentTime, 它会被限制为currentTime。timeConstantfloat✘ ✘ 首次到达目标值的时间常数。这个值越大,过渡的时间就越慢。该值必须是非负的,否则必须抛出 RangeError异常。如果timeConstant为零,输出值会立即跳跃到最终值。更准确地说,timeConstant 是一个线性时间不变系统在响应阶跃输入时(从0到1的变化),需要达到 \(1 - 1/e\)(大约63.2%)所需的时间。返回类型:AudioParam setValueAtTime(value, startTime)-
在给定的时间调度一个参数值的变化。
如果在此
SetValue事件之后没有更多的事件, 那么对于 \(t \geq T_0\),\(v(t) = V\),其中 \(T_0\) 是startTime参数,\(V\) 是value参数。换句话说,值将保持不变。如果此
SetValue事件之后的下一个事件(时间为 \(T_1\))不是LinearRampToValue或ExponentialRampToValue类型, 那么对于 \(T_0 \leq t < T_1\):$$ v(t) = V $$换句话说,在此时间间隔内,值将保持不变,从而允许创建“阶跃”函数。
如果此
SetValue事件之后的下一个事件是LinearRampToValue或ExponentialRampToValue类型, 请参见linearRampToValueAtTime()或exponentialRampToValueAtTime(),分别。AudioParam.setValueAtTime() 方法的参数。 参数 类型 可空 可选 描述 valuefloat✘ ✘ 参数将在给定时间变为的值。 startTimedouble✘ ✘ 参数值将在给定时间变更的时刻,这个时间使用与 BaseAudioContext的currentTime属性相同的时间坐标系统。如果startTime为负数或不是有限数字,则必须抛出RangeError异常。如果 startTime 小于currentTime, 它会被限制为currentTime。返回类型:AudioParam setValueCurveAtTime(values, startTime, duration)-
在给定的时间和持续时间内设置一组任意的参数值。值的数量将被缩放以适应所需的持续时间。
令 \(T_0\) 为
startTime, \(T_D\) 为duration, \(V\) 为values数组, 和 \(N\) 为values数组的长度。那么,在时间间隔 \(T_0 \le t < T_0 + T_D\) 内,令:$$ \begin{align*} k &= \left\lfloor \frac{N - 1}{T_D}(t-T_0) \right\rfloor \\ \end{align*} $$然后通过线性插值计算 \(v(t)\),它介于 \(V[k]\) 和 \(V[k+1]\) 之间。
在曲线时间间隔结束后 (\(t \ge T_0 + T_D\)),值将保持在最终曲线值,直到出现下一个自动化事件(如果有的话)。
在时间 \(T_0 + T_D\) 隐式调用
setValueAtTime()方法,值为 \(V[N-1]\),以便后续的自动化从setValueCurveAtTime()事件的结束处开始。AudioParam.setValueCurveAtTime() 方法的参数。 参数 类型 可空 可选 描述 valuessequence<float>✘ ✘ 表示参数值曲线的 float 值序列。这些值将在给定的时间开始应用并持续指定的时间。调用此方法时,将为自动化目的创建曲线的内部副本。随后修改传入数组的内容不会影响 AudioParam。如果该属性是长度小于 2 的sequence<float>对象,必须抛出InvalidStateError异常。startTimedouble✘ ✘ 值曲线将应用的开始时间,与 AudioContext的currentTime属性的时间坐标系统相同。如果startTime为负数或不是有限数字,必须抛出RangeError异常。如果 startTime 小于currentTime, 它会被限制为currentTime。durationdouble✘ ✘ 值将根据 values参数计算的时间长度(以秒为单位)。如果duration不是严格正数或不是有限数字,必须抛出RangeError异常。返回类型:AudioParam
1.6.3. 值的计算
有两种不同类型的 AudioParam,
简单参数 和 复合参数。简单参数(默认)用于单独计算 AudioNode
的最终音频输出。
复合参数 是与其他 AudioParam
一起使用的
AudioParam,
用于计算一个值,该值随后用于计算 AudioNode
的输出。
computedValue 是最终控制音频 DSP 的值,并且在每个渲染时间量子期间由音频渲染线程计算。
AudioParam
值的过程分为两部分:
-
由音频渲染线程在每个 渲染量子 期间计算的最终值 paramComputedValue,控制音频 DSP。
这些值必须按如下方式计算:
-
paramIntrinsicValue 会在每个时间点进行计算,这个时间点的值要么是直接设置到
value属性的值,要么是如果此时有任何自动化事件(其时间在当前时间之前或等于当前时间),则根据这些事件计算的值。如果自动化事件在给定的时间范围内被移除,则 paramIntrinsicValue 的值将保持不变,并继续保留在其之前的值,直到直接设置value属性,或者在该时间范围内添加新的自动化事件。 -
在此 渲染量子 开始时,将
[[current value]]设置为 paramIntrinsicValue 的值。 -
paramComputedValue 是 paramIntrinsicValue 的值与 输入 AudioParam 缓冲区 的值之和。如果和为
NaN,则将其替换为defaultValue。 -
如果此
AudioParam是一个 复合参数,则与其他AudioParam一起计算其最终值。 -
将 computedValue 设置为 paramComputedValue。
名义范围 是一个 computedValue
的低值和高值,这个参数可以有效地具有这些值。对于 简单参数,computedValue 被夹紧到此参数的 简单名义范围 内。复合参数 在由它们所组成的不同 AudioParam
值计算之后,其最终值会被夹紧到它们的 名义范围。
当使用自动化方法时,夹紧仍然会被应用。 然而,自动化会像没有夹紧一样运行。 只有当自动化值应用于输出时,才会按上述方式进行夹紧。
N. p. setValueAtTime( 0 , 0 ); N. p. linearRampToValueAtTime( 4 , 1 ); N. p. linearRampToValueAtTime( 0 , 2 );
曲线的初始斜率为 4,直到它达到最大值 1,此时输出保持不变。最后,在接近时间 2 时,曲线的斜率为 -4。下图展示了音频参数自动化的夹紧效果,虚线表示如果没有夹紧会发生的情况,实线表示由于夹紧到名义范围后音频参数的实际行为。
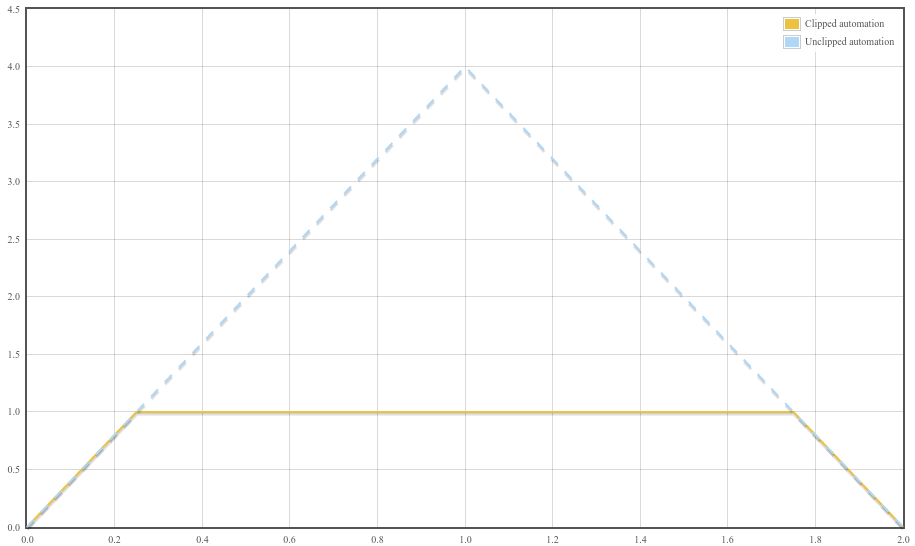
1.6.4. AudioParam
自动化示例
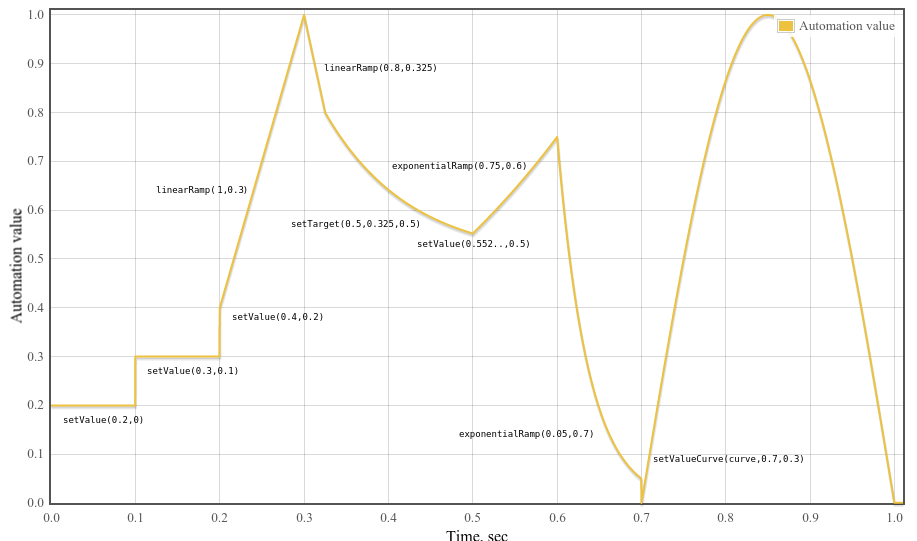
const curveLength= 44100 ; const curve= new Float32Array( curveLength); for ( const i= 0 ; i< curveLength; ++ i) curve[ i] = Math. sin( Math. PI* i/ curveLength); const t0= 0 ; const t1= 0.1 ; const t2= 0.2 ; const t3= 0.3 ; const t4= 0.325 ; const t5= 0.5 ; const t6= 0.6 ; const t7= 0.7 ; const t8= 1.0 ; const timeConstant= 0.1 ; param. setValueAtTime( 0.2 , t0); param. setValueAtTime( 0.3 , t1); param. setValueAtTime( 0.4 , t2); param. linearRampToValueAtTime( 1 , t3); param. linearRampToValueAtTime( 0.8 , t4); param. setTargetAtTime( .5 , t4, timeConstant); // Compute where the setTargetAtTime will be at time t5 so we can make // the following exponential start at the right point so there’s no // jump discontinuity. From the spec, we have // v(t) = 0.5 + (0.8 - 0.5)*exp(-(t-t4)/timeConstant) // Thus v(t5) = 0.5 + (0.8 - 0.5)*exp(-(t5-t4)/timeConstant) param. setValueAtTime( 0.5 + ( 0.8 - 0.5 ) * Math. exp( - ( t5- t4) / timeConstant), t5); param. exponentialRampToValueAtTime( 0.75 , t6); param. exponentialRampToValueAtTime( 0.05 , t7); param. setValueCurveAtTime( curve, t7, t8- t7);
1.7. AudioScheduledSourceNode
接口
该接口表示源节点的公共特性,例如 AudioBufferSourceNode、ConstantSourceNode
和 OscillatorNode。
在源节点开始之前(通过调用 start()),源节点必须输出静音(0)。在源节点停止之后(通过调用
stop()),源节点也必须输出静音(0)。
AudioScheduledSourceNode
不能直接实例化,而是由源节点的具体接口扩展。
一个 AudioScheduledSourceNode
被称为 正在播放,
当它关联的 BaseAudioContext
的
currentTime
大于或等于 AudioScheduledSourceNode
设置开始的时间,
且小于它设置停止的时间。
AudioScheduledSourceNode
通过内部布尔值槽 [[source started]]
创建,初始
值设置为 false。
[Exposed =Window ]interface AudioScheduledSourceNode :AudioNode {attribute EventHandler onended ;undefined start (optional double when = 0);undefined stop (optional double when = 0); };
1.7.1. 属性
onended, 类型为 EventHandler-
此属性用于为
ended事件类型设置一个 事件处理程序,该事件将在AudioScheduledSourceNode节点类型上触发。当源节点停止播放时(由具体节点确定),将触发一个使用Event接口的事件,并分发到事件处理程序。对于所有
AudioScheduledSourceNode, 当由stop()确定的停止时间达到时,ended事件被触发。 对于AudioBufferSourceNode, 该事件也会被触发,因为duration已经达到,或者整个buffer已经播放完成。
1.7.2. 方法
start(when)-
安排声音在准确的时间播放。
当调用此方法时,执行以下步骤:-
如果此
AudioScheduledSourceNode内部槽[[source started]]为真,则必须抛出InvalidStateError异常。 -
检查是否有由于下面描述的参数约束条件必须抛出的错误。如果在此步骤中抛出任何异常,则中止这些步骤。
-
将此
AudioScheduledSourceNode的内部槽[[source started]]设置为true。 -
队列一个控制消息 以启动
AudioScheduledSourceNode, 包括消息中的参数值。 -
仅当满足以下所有条件时,向相关联的
AudioContext发送一个 控制消息,以启动渲染线程:-
上下文的
[[control thread state]]为 "suspended"。 -
上下文被 允许启动。
-
[[suspended by user]]标志为false。
注意: 这可以允许
start()启动一个当前为 允许启动 的AudioContext, 但以前曾被阻止启动。 -
AudioScheduledSourceNode.start(when) 方法的参数。 参数 类型 可为空 可选 描述 whendouble✘ ✔ when参数描述了声音应该在何时(以秒为单位)开始播放。它与AudioContext的currentTime属性使用相同的时间坐标系统。当由AudioScheduledSourceNode发出的信号依赖于声音的开始时间时,when的确切值始终被使用,而不四舍五入到最近的采样帧。如果传递的值为 0 或小于currentTime,则声音将立即开始播放。如果when为负数,则必须抛出RangeError异常。返回类型:undefined -
stop(when)-
安排声音在准确的时间停止播放。如果在已调用
stop后再次调用,它会覆盖之前的调用,只有最后一次调用才会生效;除非缓冲区已经停止,否则之前设置的停止时间将不再生效。如果缓冲区已经停止,则后续调用stop将没有效果。如果停止时间在计划开始时间之前达到,则声音将不会播放。当调用此方法时,执行以下步骤:-
如果此
AudioScheduledSourceNode内部槽[[source started]]不是true,则必须抛出InvalidStateError异常。 -
检查是否有由于下面描述的参数约束条件必须抛出的错误。
-
队列一个控制消息 以停止
AudioScheduledSourceNode, 包括消息中的参数值。
AudioScheduledSourceNode.stop(when) 方法的参数。 参数 类型 可为空 可选 描述 whendouble✘ ✔ when参数描述了源应停止播放的时间(以秒为单位)。它与AudioContext的currentTime属性使用相同的时间坐标系统。如果此值为 0 或小于currentTime, 则声音将立即停止播放。如果when为负数,则必须抛出RangeError异常。返回类型:undefined -
1.8. AnalyserNode
接口
此接口表示一个能够提供实时频率和时域分析信息的节点。音频流将从输入传递到输出,未经处理。
| 属性 | 值 | 备注 |
|---|---|---|
numberOfInputs
| 1 | |
numberOfOutputs
| 1 | 此输出可以不连接。 |
channelCount
| 2 | |
channelCountMode
| "max"
| |
channelInterpretation
| "speakers"
| |
| tail-time | 没有 |
[Exposed =Window ]interface AnalyserNode :AudioNode {constructor (BaseAudioContext ,context optional AnalyserOptions = {});options undefined getFloatFrequencyData (Float32Array );array undefined getByteFrequencyData (Uint8Array );array undefined getFloatTimeDomainData (Float32Array );array undefined getByteTimeDomainData (Uint8Array );array attribute unsigned long fftSize ;readonly attribute unsigned long frequencyBinCount ;attribute double minDecibels ;attribute double maxDecibels ;attribute double smoothingTimeConstant ; };
1.8.1. 构造函数
AnalyserNode(context, options)-
当构造函数使用
BaseAudioContextc 和一个选项对象 option 被调用时,用户代理必须 初始化 AudioNode this,并将 context 和 options 作为参数。Arguments for the AnalyserNode.constructor() 方法。 参数 类型 可空 可选 描述 contextBaseAudioContext✘ ✘ 新的 AnalyserNode将会与该BaseAudioContext关联。optionsAnalyserOptions✘ ✔ 此 AnalyserNode的可选初始参数值。
1.8.2. 属性
fftSize, 类型为 unsigned long-
用于频域分析的FFT大小(以样本帧为单位)。此值必须是2的幂,范围为32到32768,否则必须抛出
IndexSizeError异常。默认值为2048。请注意,较大的FFT大小可能需要耗费更多的计算资源。如果
fftSize更改为不同的值, 那么与频率数据平滑相关的所有状态(如getByteFrequencyData()和getFloatFrequencyData()) 将被重置。也就是说,用于 前一个块,\(\hat{X}_{-1}[k]\), 用于 时间平滑的值将被设为0,适用于所有\(k\)。请注意,增大
fftSize意味着 当前时域数据 必须扩展,以包括之前没有的过去帧。 这意味着AnalyserNode必须保留最后的32768个样本帧,并且 当前时域数据 是这些帧中最近期的fftSize个样本帧。 frequencyBinCount, 类型为 unsigned long,只读-
FFT大小的一半。
maxDecibels, 类型为 double-
maxDecibels是用于将FFT分析数据转换为无符号字节值的缩放范围中的最大功率值。默认值为-30。如果 此属性的值被设置为小于或等于minDecibels, 必须抛出IndexSizeError异常。 minDecibels, 类型为 double-
minDecibels是用于将FFT分析数据转换为无符号字节值的缩放范围中的最小功率值。默认值为-100。如果 此属性的值被设置为大于或等于maxDecibels, 必须抛出IndexSizeError异常。 smoothingTimeConstant, 类型为 double-
一个介于0到1之间的值,其中0表示没有与最后一个分析帧进行时间平均。默认值为0.8。如果此属性的值被设置为小于0或大于1的值,必须抛出
IndexSizeError异常。
1.8.3. 方法
getByteFrequencyData(array)-
写入 当前的 频率数据 到 array。如果 array 的 字节长度 小于
frequencyBinCount, 超出的元素会被丢弃。如果 array 的 字节长度 大于frequencyBinCount, 超出的元素将被忽略。计算频率数据时使用最新的fftSize帧。如果在同一个 渲染量子 内再次调用
getByteFrequencyData()或getFloatFrequencyData()时,当前的频率数据不会使用相同的数据进行更新。相反,返回之前计算的数据。存储在无符号字节数组中的值是通过以下方式计算的。设 \(Y[k]\) 为 当前频率数据,如 FFT 窗口化和平滑处理 所描述。然后字节值 \(b[k]\) 为
$$ b[k] = \left\lfloor \frac{255}{\mbox{dB}_{max} - \mbox{dB}_{min}} \left(Y[k] - \mbox{dB}_{min}\right) \right\rfloor $$其中 \(\mbox{dB}_{min}\) 是
minDecibels且 \(\mbox{dB}_{max}\) 是maxDecibels参数列表:AnalyserNode.getByteFrequencyData() 方法。 参数 类型 可为空 可选 描述 arrayUint8Array✘ ✘ 此参数是频率域分析数据将被复制到的地方。 返回类型:undefined getByteTimeDomainData(array)-
写入 当前的 时域数据(波形数据) 到 array。如果 array 的 字节长度 小于
fftSize, 超出的元素会被丢弃。如果 array 的 字节长度 大于fftSize, 超出的元素将被忽略。计算字节数据时使用最新的fftSize帧。存储在无符号字节数组中的值是通过以下方式计算的。设 \(x[k]\) 为时域数据。然后字节值 \(b[k]\) 为
$$ b[k] = \left\lfloor 128(1 + x[k]) \right\rfloor. $$如果 \(b[k]\) 超出 0 到 255 的范围,\(b[k]\) 将被裁剪到该范围内。
参数列表:AnalyserNode.getByteTimeDomainData() 方法。 参数 类型 可为空 可选 描述 arrayUint8Array✘ ✘ 此参数是时域数据将被复制到的地方。 返回类型:undefined getFloatFrequencyData(array)-
写入 当前的 频率数据 到 array。如果 array 的元素少于
frequencyBinCount, 多余的元素将被丢弃。如果 array 的元素多于frequencyBinCount, 多余的元素将被忽略。计算频率数据时使用最新的fftSize帧。如果在同一个 渲染量子 内再次调用
getFloatFrequencyData()或getByteFrequencyData()时,当前的频率数据不会更新为相同的数据。相反,返回之前计算的数据。频率数据是以 dB 单位表示的。
参数列表:AnalyserNode.getFloatFrequencyData() 方法。 参数 类型 可为空 可选 描述 arrayFloat32Array✘ ✘ 此参数是频率域分析数据将被复制到的地方。 返回类型:undefined getFloatTimeDomainData(array)-
写入 当前的 时域数据(波形数据) 到 array。如果 array 的元素少于
fftSize, 多余的元素将被丢弃。如果 array 的元素多于fftSize, 多余的元素将被忽略。写入最新的fftSize帧数据(经过下混处理)。参数列表:AnalyserNode.getFloatTimeDomainData() 方法。 参数 类型 可为空 可选 描述 arrayFloat32Array✘ ✘ 此参数是时域数据将被复制到的地方。 返回类型:undefined
1.8.4.
AnalyserOptions
此选项指定在构造 AnalyserNode
时要使用的选项。
所有成员都是可选的;如果未指定,则使用默认值构造该节点。
dictionary AnalyserOptions :AudioNodeOptions {unsigned long fftSize = 2048;double maxDecibels = -30;double minDecibels = -100;double smoothingTimeConstant = 0.8; };
1.8.4.1. 字典 AnalyserOptions
成员
fftSize, 类型为 unsigned long,默认为2048-
用于频域分析的期望初始FFT大小。
maxDecibels, 类型为 double,默认为-30-
FFT分析的期望初始最大功率(以dB为单位)。
minDecibels, 类型为 double,默认为-100-
FFT分析的期望初始最小功率(以dB为单位)。
smoothingTimeConstant, 类型为 double,默认为0.8-
FFT分析的期望初始平滑常数。
1.8.5. 时域下混合
当计算当前时域数据时,输入信号必须被下混合为单声道,假设 channelCount
为 1,channelCountMode
为 "max"
且 channelInterpretation
为 "speakers"。
这与AnalyserNode
本身的设置无关。最近的fftSize
帧将用于下混合操作。
1.8.6. FFT 窗口化和时间平滑
当计算当前频率数据时,需要执行以下操作:
-
计算当前时域数据。
-
应用布莱克曼窗口到时域输入数据。
-
对窗口化的时域输入数据应用傅里叶变换,以获取实部和虚部频率数据。
以下内容中,令 \(N\) 为此fftSize
属性的值,属于该AnalyserNode。
$$
\begin{align*}
\alpha &= \mbox{0.16} \\ a_0 &= \frac{1-\alpha}{2} \\
a_1 &= \frac{1}{2} \\
a_2 &= \frac{\alpha}{2} \\
w[n] &= a_0 - a_1 \cos\frac{2\pi n}{N} + a_2 \cos\frac{4\pi n}{N}, \mbox{ for } n = 0, \ldots, N - 1
\end{align*}
$$
窗口化的信号 \(\hat{x}[n]\) 为
$$
\hat{x}[n] = x[n] w[n], \mbox{ for } n = 0, \ldots, N - 1
$$
$$
X[k] = \frac{1}{N} \sum_{n = 0}^{N - 1} \hat{x}[n]\, W^{-kn}_{N}
$$
对于 \(k = 0, \dots, N/2-1\),其中 \(W_N = e^{2\pi i/N}\)。
-
令 \(\hat{X}_{-1}[k]\) 为此操作在前一块上的结果。前一块定义为 前一次时间平滑操作计算得到的缓冲区,或者如果这是第一次进行时间平滑操作,则为一个包含 \(N\) 个零的数组。
-
令 \(\tau\) 为该
smoothingTimeConstant属性的值。 -
令 \(X[k]\) 为当前块应用傅里叶变换的结果。
然后,平滑后的值 \(\hat{X}[k]\) 通过以下公式计算:
$$
\hat{X}[k] = \tau\, \hat{X}_{-1}[k] + (1 - \tau)\, \left|X[k]\right|
$$
-
如果 \(\hat{X}[k]\) 为
NaN,正无穷大或负无穷大,则设置 \(\hat{X}[k]\) = 0。
对于 \(k = 0, \ldots, N - 1\)。
$$
Y[k] = 20\log_{10}\hat{X}[k]
$$
对于 \(k = 0, \ldots, N-1\)。
这个数组 \(Y[k]\) 被复制到getFloatFrequencyData()的输出数组中。
对于getByteFrequencyData(),
\(Y[k]\) 被限制在minDecibels
和maxDecibelsminDecibels
由值 0
表示,maxDecibels
1.9. AudioBufferSourceNode
接口
该接口表示来自内存中音频资源的音频源,存储在一个 AudioBuffer
中。
它适用于播放需要高调度灵活性和准确性的音频资源。如果需要精确到采样的播放(例如网络或磁盘上的资源),
实现者应该使用 AudioWorkletNode
来实现播放。
使用 start()
方法来安排何时开始播放音频。start()
方法不能多次调用。当缓冲区的音频数据播放完成时(如果 loop
属性为 false),或者调用 stop()
方法且指定的时间已到时,播放将自动停止。更多详细信息请参见 start()
和 stop()
方法的描述。
| 属性 | 值 | 备注 |
|---|---|---|
numberOfInputs
| 0 | |
numberOfOutputs
| 1 | |
channelCount
| 2 | |
channelCountMode
| "max"
| |
channelInterpretation
| "speakers"
| |
| 尾时 | 无 |
输出的通道数等于分配给 buffer
属性的 AudioBuffer 的通道数,或者如果 buffer
为 null,则为一个静音通道。
此外,如果缓冲区有多个通道,那么在下一个渲染量子开始时,AudioBufferSourceNode
的输出必须变为一个静音的单通道,前提是以下任一条件成立:
对于一个 AudioBufferSourceNode
来说,播放头位置
被定义为一个时间偏移量(以秒为单位),相对于缓冲区中第一个采样帧的时间坐标。这些值应独立于节点的 playbackRate
和 detune
参数来考虑。
一般来说,播放头位置可以达到子采样精度,并且不需要精确指向特定的采样帧位置。其有效值范围应为 0 到缓冲区的时长。
playbackRate
和 detune
属性形成一个 复合参数。它们共同用于计算
计算的播放速率 值:
computedPlaybackRate(t) = playbackRate(t) * pow(2, detune(t) / 1200)
该 复合参数 的 名义范围 为 \((-\infty, \infty)\)。
AudioBufferSourceNode
是通过一个内部布尔值槽 [[buffer set]] 创建的,初始值为
false。
[Exposed =Window ]interface AudioBufferSourceNode :AudioScheduledSourceNode {constructor (BaseAudioContext ,context optional AudioBufferSourceOptions = {});options attribute AudioBuffer ?buffer ;readonly attribute AudioParam playbackRate ;readonly attribute AudioParam detune ;attribute boolean loop ;attribute double loopStart ;attribute double loopEnd ;undefined start (optional double when = 0,optional double offset ,optional double duration ); };
1.9.1. 构造函数
AudioBufferSourceNode(context, options)-
当构造函数以
BaseAudioContextc 和一个选项对象 option 被调用时,用户代理必须 初始化 AudioNode this,使用 context 和 options 作为参数。参数列表:AudioBufferSourceNode.constructor() 方法。 参数 类型 可为空 可选 描述 contextBaseAudioContext✘ ✘ 这个新的 AudioBufferSourceNode将与BaseAudioContext关联。optionsAudioBufferSourceOptions✘ ✔ 这个 AudioBufferSourceNode的可选初始参数值。
1.9.2. 属性
buffer, 类型为 AudioBuffer, 可为空-
表示要播放的音频资源。
设置buffer属性,请执行以下步骤:-
让 new buffer 为要分配给
AudioBuffer或null的值。 -
如果 new buffer 不是
null且[[buffer set]]为真,则抛出一个InvalidStateError错误并中止这些步骤。 -
如果 new buffer 不是
null,将[[buffer set]]设置为 true。 -
将 new buffer 分配给
buffer属性。
-
detune, 类型为 AudioParam, 只读-
用于调节音频流渲染速度的附加参数,以分为单位。这个参数是一个 复合参数,与
playbackRate一起形成一个 计算的播放速率。参数 值 说明 defaultValue0 minValue最小的负单精度浮点数 大约为 -3.4028235e38 maxValue最大的正单精度浮点数 大约为 3.4028235e38 automationRate" k-rate"具有 自动化速率约束 loop, 类型为 booleanloopEnd, 类型为 double-
如果
loop属性为 true,则循环应结束的可选 播放头位置。 其值不包括循环的内容。默认值为 0,可以设置为任何介于 0 和缓冲区持续时间之间的值。如果loopEnd小于或等于 0,或者大于缓冲区的持续时间, 则循环将在缓冲区的末尾结束。 loopStart, 类型为 double-
如果
loop属性为 true,则循环应开始的可选 播放头位置。其默认值为 0,可以设置为任何介于 0 和缓冲区持续时间之间的值。如果loopStart小于 0,则循环将在 0 开始。如果loopStart大于缓冲区持续时间,则循环将在缓冲区的末尾开始。 playbackRate, 类型为 AudioParam, 只读-
渲染音频流的速度。它是一个 复合参数,与
detune一起形成一个 计算的播放速率。参数 值 说明 defaultValue1 minValue最小的负单精度浮点数 大约为 -3.4028235e38 maxValue最大的正单精度浮点数 大约为 3.4028235e38 automationRate" k-rate"具有 自动化速率约束
1.9.3. 方法
start(when, offset, duration)-
计划在准确的时间播放声音。
当调用此方法时,执行以下步骤:-
如果此
AudioBufferSourceNode的内部槽[[source started]]为true,则必须抛出InvalidStateError异常。 -
检查是否有任何必须抛出的错误,基于下文描述的参数约束。如果在此步骤中抛出异常,则中止后续步骤。
-
将此
AudioBufferSourceNode的内部槽[[source started]]设置为true。 -
排队一个控制消息 来启动
AudioBufferSourceNode,并在消息中包含参数值。 -
向相关的
AudioContext发送一个 控制消息 来 开始运行其渲染线程,仅当以下所有条件都满足时:-
上下文的
[[control thread state]]为suspended。 -
上下文被 允许开始。
-
[[suspended by user]]标志为false。
注意:这可以允许
start()启动一个当前为 允许开始 的AudioContext,但先前已被阻止启动。 -
参数列表:AudioBufferSourceNode.start(when, offset, duration) 方法。 参数 类型 可空 可选 描述 whendouble✘ ✔ when参数描述了声音应开始播放的时间(秒)。它与AudioContext的currentTime属性使用相同的时间坐标系统。如果为此值传递 0 或小于 currentTime 的值,则声音将立即开始播放。如果when为负值,则必须抛出RangeError异常。offsetdouble✘ ✔ offset参数指定了播放开始的位置。如果传入 0,则播放将从缓冲区的开头开始播放。如果offset为负值,则必须抛出RangeError异常。 如果offset大于loopEnd,并且playbackRate为正值或零,并且loop为true,则播放将从loopEnd开始。offset被默认为 [0,duration] 进行限制。durationdouble✘ ✔ duration参数描述了播放的声音持续时间,以秒为单位,涵盖了任何完整或部分的循环迭代。如果duration为负值,则必须抛出RangeError异常。返回类型:undefined -
1.9.4. AudioBufferSourceOptions
这指定了构造 AudioBufferSourceNode
的选项。
所有成员都是可选的;如果未指定,则在构造节点时使用默认值。
dictionary AudioBufferSourceOptions {AudioBuffer ?buffer ;float detune = 0;boolean loop =false ;double loopEnd = 0;double loopStart = 0;float playbackRate = 1; };
1.9.4.1. Dictionary AudioBufferSourceOptions
成员
buffer, 类型为 AudioBuffer, 可为空-
要播放的音频资源。这相当于将
buffer分配给buffer属性的AudioBufferSourceNode。 detune, 类型为 float,默认为0-
用于设置
detune的初始值,属于 AudioParam。 loop, 类型为 boolean,默认为false-
用于设置
loop属性的初始值。 loopEnd, 类型为 double,默认为0-
用于设置
loopEnd属性的初始值。 loopStart, 类型为 double,默认为0-
用于设置
loopStart属性的初始值。 playbackRate, 类型为 float,默认为1-
用于设置
playbackRate的初始值,属于 AudioParam。
1.9.5. 循环
本节为非规范性内容。有关规范性要求,请参见播放算法。
将 loop
属性设置为 true 会使得缓冲区中由 loopStart
和 loopEnd
定义的区域循环播放,直到该区域的任意部分被播放完毕。只要 loop
仍为 true,循环播放将继续,直到发生以下情况之一:
-
stop()被调用, -
到达预定的停止时间,
-
如果调用
start()时指定了duration值,则超过了duration。
循环的主体被认为占据了从 loopStart
到(但不包括) loopEnd
的区域。播放方向受节点播放速率符号的影响。对于正播放速率,循环发生在从 loopStart
到 loopEnd;
对于负播放速率,循环发生在从 loopEnd
到 loopStart。
循环不会影响 offset 参数的解释,后者来自 start()。
播放总是从请求的偏移量开始,循环仅在播放过程中遇到循环区域时才开始。
有效的循环起始点和结束点必须位于零和缓冲区持续时间的范围内,具体要求请参见下文算法。
loopEnd
还进一步限制为必须位于或在 loopStart
之后。
如果这些约束条件被违反,循环将被认为包含整个缓冲区的内容。
循环端点具有子采样精度。当端点未落在精确的采样帧偏移量上,或者播放速率不等于 1 时,循环的播放将进行插值,以将循环的开始和结束拼接在一起,就像循环的音频发生在缓冲区的顺序、非循环区域中一样。
与循环相关的属性可以在播放过程中进行更改,通常会在下一个渲染量子中生效。具体结果由下面的规范性播放算法定义。
loopStart
和 loopEnd
属性的默认值均为 0。由于 loopEnd
的默认值为零,相当于缓冲区的长度,因此默认的循环端点会导致整个缓冲区包含在循环中。
请注意,循环端点的值是以缓冲区的采样率为单位的时间偏移量表示的,这意味着这些值独立于节点的 playbackRate
参数,该参数可以在播放过程中动态变化。
1.9.6. AudioBuffer 内容的播放
本规范性章节指定了缓冲区内容的播放,考虑到播放受到以下因素的综合影响:
-
一个起始偏移量,可以用子采样精度表示。
-
循环点,可以用子采样精度表示,并且可以在播放过程中动态变化。
-
播放速率和音调偏移参数,它们结合产生一个单一的 computedPlaybackRate,该值可以为正或负的有限值。
为了从 AudioBufferSourceNode
生成输出,内部遵循以下原则:
-
用户代理(UA)可以在任何所需的点对缓冲区进行重新采样,以提高输出的效率或质量。
-
子采样起始偏移量或循环点可能需要在采样帧之间进行额外的插值。
-
循环缓冲区的播放应该与不循环的缓冲区相同,后者包含连续的循环音频内容,排除插值的影响。
算法的描述如下:
let buffer; // AudioBuffer employed by this node let context; // AudioContext employed by this node // The following variables capture attribute and AudioParam values for the node. // They are updated on a k-rate basis, prior to each invocation of process(). let loop; let detune; let loopStart; let loopEnd; let playbackRate; // Variables for the node's playback parameters let start= 0 , offset= 0 , duration= Infinity ; // Set by start() let stop= Infinity ; // Set by stop() // Variables for tracking node's playback state let bufferTime= 0 , started= false , enteredLoop= false ; let bufferTimeElapsed= 0 ; let dt= 1 / context. sampleRate; // Handle invocation of start method call function handleStart( when, pos, dur) { if ( arguments. length>= 1 ) { start= when; } offset= pos; if ( arguments. length>= 3 ) { duration= dur; } } // Handle invocation of stop method call function handleStop( when) { if ( arguments. length>= 1 ) { stop= when; } else { stop= context. currentTime; } } // Interpolate a multi-channel signal value for some sample frame. // Returns an array of signal values. function playbackSignal( position) { /* This function provides the playback signal function for buffer, which is a function that maps from a playhead position to a set of output signal values, one for each output channel. If |position| corresponds to the location of an exact sample frame in the buffer, this function returns that frame. Otherwise, its return value is determined by a UA-supplied algorithm that interpolates sample frames in the neighborhood of |position|. If |position| is greater than or equal to |loopEnd| and there is no subsequent sample frame in buffer, then interpolation should be based on the sequence of subsequent frames beginning at |loopStart|. */ ... } // Generate a single render quantum of audio to be placed // in the channel arrays defined by output. Returns an array // of |numberOfFrames| sample frames to be output. function process( numberOfFrames) { let currentTime= context. currentTime; // context time of next rendered frame const output= []; // accumulates rendered sample frames // Combine the two k-rate parameters affecting playback rate const computedPlaybackRate= playbackRate* Math. pow( 2 , detune/ 1200 ); // Determine loop endpoints as applicable let actualLoopStart, actualLoopEnd; if ( loop&& buffer!= null ) { if ( loopStart>= 0 && loopEnd> 0 && loopStart< loopEnd) { actualLoopStart= loopStart; actualLoopEnd= Math. min( loopEnd, buffer. duration); } else { actualLoopStart= 0 ; actualLoopEnd= buffer. duration; } } else { // If the loop flag is false, remove any record of the loop having been entered enteredLoop= false ; } // Handle null buffer case if ( buffer== null ) { stop= currentTime; // force zero output for all time } // Render each sample frame in the quantum for ( let index= 0 ; index< numberOfFrames; index++ ) { // Check that currentTime and bufferTimeElapsed are // within allowable range for playback if ( currentTime< start|| currentTime>= stop|| bufferTimeElapsed>= duration) { output. push( 0 ); // this sample frame is silent currentTime+= dt; continue ; } if ( ! started) { // Take note that buffer has started playing and get initial // playhead position. if ( loop&& computedPlaybackRate>= 0 && offset>= actualLoopEnd) { offset= actualLoopEnd; } if ( computedPlaybackRate< 0 && loop&& offset< actualLoopStart) { offset= actualLoopStart; } bufferTime= offset; started= true ; } // Handle loop-related calculations if ( loop) { // Determine if looped portion has been entered for the first time if ( ! enteredLoop) { if ( offset< actualLoopEnd&& bufferTime>= actualLoopStart) { // playback began before or within loop, and playhead is // now past loop start enteredLoop= true ; } if ( offset>= actualLoopEnd&& bufferTime< actualLoopEnd) { // playback began after loop, and playhead is now prior // to the loop end enteredLoop= true ; } } // Wrap loop iterations as needed. Note that enteredLoop // may become true inside the preceding conditional. if ( enteredLoop) { while ( bufferTime>= actualLoopEnd) { bufferTime-= actualLoopEnd- actualLoopStart; } while ( bufferTime< actualLoopStart) { bufferTime+= actualLoopEnd- actualLoopStart; } } } if ( bufferTime>= 0 && bufferTime< buffer. duration) { output. push( playbackSignal( bufferTime)); } else { output. push( 0 ); // past end of buffer, so output silent frame } bufferTime+= dt* computedPlaybackRate; bufferTimeElapsed+= dt* computedPlaybackRate; currentTime+= dt; } // End of render quantum loop if ( currentTime>= stop) { // End playback state of this node. No further invocations of process() // will occur. Schedule a change to set the number of output channels to 1. } return output; }
以下非规范性图示说明了算法在各种关键场景下的行为。未考虑缓冲区的动态重采样,但只要循环位置的时间不发生变化,这不会实质性地影响结果播放。在所有图示中,适用以下约定:
-
上下文采样率为 1000 Hz
-
AudioBuffer内容从 x 原点开始,显示第一个采样帧。 -
输出信号以时间
start的采样帧显示在 x 原点。 -
整个过程均使用线性插值表示,尽管用户代理(UA)可能会使用其他插值技术。
-
图示中标注的
duration值指的是buffer,而不是start()的参数。
此图示说明了缓冲区的基本播放,采用一个简单的循环,循环在缓冲区的最后一个采样帧后结束:
AudioBufferSourceNode
基本播放 此图示说明了 playbackRate 插值,展示了缓冲区内容的半速播放,其中每隔一个输出采样帧就会插值。特别需要注意的是循环输出中的最后一个采样帧,它是使用循环起始点进行插值的:
AudioBufferSourceNode
playbackRate 插值 此图示说明了采样率插值,展示了一个采样率为上下文采样率 50% 的缓冲区的播放,从而导致计算出的播放速率为 0.5,这样就可以修正缓冲区与上下文之间的采样率差异。结果输出与前面的示例相同,但原因不同。
AudioBufferSourceNode
采样率插值 此图示说明了子采样偏移播放,其中缓冲区中的偏移量从精确的半个采样帧开始。因此,每个输出帧都会插值:
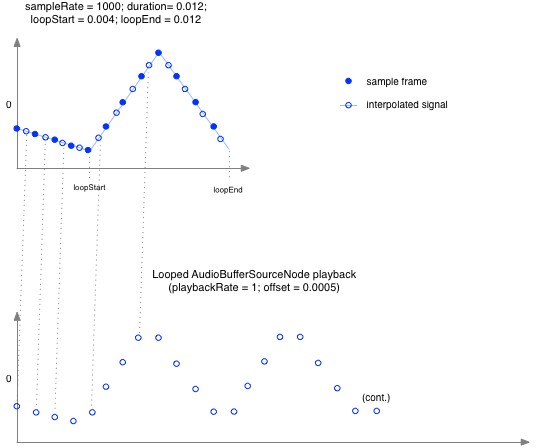
AudioBufferSourceNode
子采样偏移播放 此图示说明了子采样循环播放,展示了循环端点中的分数帧偏移如何映射到缓冲区中的插值数据点,并且这些数据点遵循这些偏移,就像它们是指向精确采样帧的引用一样:
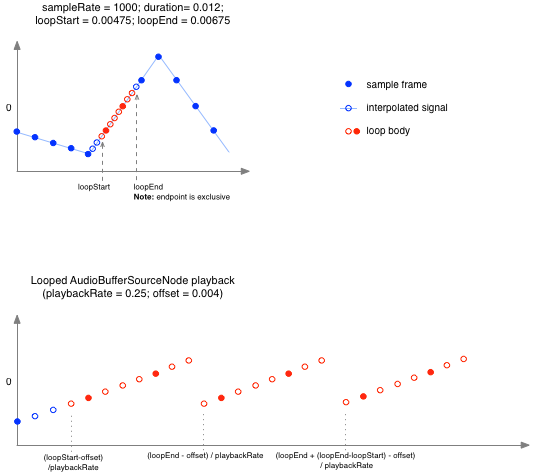
AudioBufferSourceNode
子采样循环播放 1.10. AudioDestinationNode
接口
这是一个 AudioNode
,表示最终的音频目的地,用户最终将听到的声音。它通常被认为是一个音频输出设备,连接到扬声器。所有将被听到的渲染音频将被路由到此节点,这是 AudioContext
路由图中的“终端”节点。每个 AudioContext
只有一个 AudioDestinationNode,
该节点通过 destination 属性提供,位于 AudioContext
中。
AudioDestinationNode
的输出是通过 汇总其输入 产生的,
这允许将 AudioContext
的输出捕获到,例如 MediaStreamAudioDestinationNode,
或者 MediaRecorder(在 [mediastream-recording] 中描述)。
AudioDestinationNode
可以是 AudioContext
或 OfflineAudioContext
的目标,
并且其通道属性取决于上下文。
对于一个 AudioContext,
默认值为:
| 属性 | 值 | 备注 |
|---|---|---|
numberOfInputs
| 1 | |
numberOfOutputs
| 1 | |
channelCount
| 2 | |
channelCountMode
| "explicit"
| |
channelInterpretation
| "speakers"
| |
| tail-time | 无 |
channelCount
可以设置为小于或等于 maxChannelCount
的任何值。
如果此值不在有效范围内,必须抛出一个 IndexSizeError
异常。
举个例子,如果音频硬件支持 8 通道输出,那么我们可以将 channelCount
设置为 8,并渲染 8 通道的输出。
对于一个 OfflineAudioContext,
默认值为:
| 属性 | 值 | 备注 |
|---|---|---|
numberOfInputs
| 1 | |
numberOfOutputs
| 1 | |
channelCount
| numberOfChannels | |
channelCountMode
| "explicit"
| |
channelInterpretation
| "speakers"
| |
| tail-time | 无 |
其中 numberOfChannels 是在构建 OfflineAudioContext
时指定的通道数。
这个值是不能改变的; 如果尝试更改 channelCount
为不同的值,则必须抛出 NotSupportedError
异常。
[Exposed =Window ]interface AudioDestinationNode :AudioNode {readonly attribute unsigned long maxChannelCount ; };
1.10.1. 属性
maxChannelCount, 类型为 unsigned long,只读-
可以设置的最大通道数,即
channelCount属性的最大值。表示音频硬件端点的AudioDestinationNode(通常情况下)如果音频硬件是多通道的,可能输出超过 2 个通道的音频。maxChannelCount是该硬件支持的最大通道数。
1.11. AudioListener
接口
此接口表示听音人(音频场景的听者)的位置信息和朝向。所有的 PannerNode
对象根据 BaseAudioContext
的
listener
进行空间化处理。有关空间化的更多信息,请参阅 § 6 空间化/平移。
positionX,
positionY,
和 positionZ
参数表示听音人在 3D 笛卡尔坐标空间中的位置。PannerNode
对象使用此位置来进行音频源的空间化处理。
forwardX,
forwardY,
和 forwardZ
参数表示 3D 空间中的方向向量。forward 向量和 up 向量用于确定听音人的朝向。简单来说,forward
向量表示听音人鼻子指向的方向,而 up 向量则表示听音人头顶朝向的方向。这两个向量应该是线性独立的。关于这些值的解释规范要求,请参阅 § 6 空间化/平移 部分。
[Exposed =Window ]interface AudioListener {readonly attribute AudioParam positionX ;readonly attribute AudioParam positionY ;readonly attribute AudioParam positionZ ;readonly attribute AudioParam forwardX ;readonly attribute AudioParam forwardY ;readonly attribute AudioParam forwardZ ;readonly attribute AudioParam upX ;readonly attribute AudioParam upY ;readonly attribute AudioParam upZ ;undefined setPosition (float ,x float ,y float );z undefined setOrientation (float ,x float ,y float ,z float ,xUp float ,yUp float ); };zUp
1.11.1. 属性
forwardX, 类型为 AudioParam, 只读-
设置监听器在 3D 笛卡尔坐标空间中指向的前向方向的 x 坐标分量。
参数 值 备注 defaultValue0 minValue最小负单精度浮点数 大约 -3.4028235e38 maxValue最大正单精度浮点数 大约 3.4028235e38 automationRate" a-rate" forwardY, 类型为 AudioParam, 只读-
设置监听器在 3D 笛卡尔坐标空间中指向的前向方向的 y 坐标分量。
参数 值 备注 defaultValue0 minValue最小负单精度浮点数 大约 -3.4028235e38 maxValue最大正单精度浮点数 大约 3.4028235e38 automationRate" a-rate" forwardZ, 类型为 AudioParam, 只读-
设置监听器在 3D 笛卡尔坐标空间中指向的前向方向的 z 坐标分量。
参数 值 备注 defaultValue-1 minValue最小负单精度浮点数 大约 -3.4028235e38 maxValue最大正单精度浮点数 大约 3.4028235e38 automationRate" a-rate" positionX, 类型为 AudioParam, 只读-
设置音频监听器在 3D 笛卡尔坐标空间中的 x 坐标位置。
参数 值 备注 defaultValue0 minValue最小负单精度浮点数 大约 -3.4028235e38 maxValue最大正单精度浮点数 大约 3.4028235e38 automationRate" a-rate" positionY, 类型为 AudioParam, 只读-
设置音频监听器在 3D 笛卡尔坐标空间中的 y 坐标位置。
参数 值 备注 defaultValue0 minValue最小负单精度浮点数 大约 -3.4028235e38 maxValue最大正单精度浮点数 大约 3.4028235e38 automationRate" a-rate" positionZ, 类型为 AudioParam, 只读-
设置音频监听器在 3D 笛卡尔坐标空间中的 z 坐标位置。
参数 值 备注 defaultValue0 minValue最小负单精度浮点数 大约 -3.4028235e38 maxValue最大正单精度浮点数 大约 3.4028235e38 automationRate" a-rate" upX, 类型为 AudioParam, 只读-
设置监听器在 3D 笛卡尔坐标空间中指向的上方方向的 x 坐标分量。
参数 值 备注 defaultValue0 minValue最小负单精度浮点数 大约 -3.4028235e38 maxValue最大正单精度浮点数 大约 3.4028235e38 automationRate" a-rate" upY, 类型为 AudioParam, 只读-
设置监听器在 3D 笛卡尔坐标空间中指向的上方方向的 y 坐标分量。
参数 值 备注 defaultValue1 minValue最小负单精度浮点数 大约 -3.4028235e38 maxValue最大正单精度浮点数 大约 3.4028235e38 automationRate" a-rate" upZ, 类型为 AudioParam, 只读-
设置监听器在 3D 笛卡尔坐标空间中指向的上方方向的 z 坐标分量。
参数 值 备注 defaultValue0 minValue最小负单精度浮点数 大约 -3.4028235e38 maxValue最大正单精度浮点数 大约 3.4028235e38 automationRate" a-rate"
1.11.2. 方法
setOrientation(x, y, z, xUp, yUp, zUp)-
此方法已弃用。它相当于设置
forwardX.value,forwardY.value,forwardZ.value,upX.value,upY.value, 和upZ.value直接与给定的x,y,z,xUp,yUp, 和zUp值相等。因此,如果任何
forwardX,forwardY,forwardZ,upX,upY和upZAudioParam已通过setValueCurveAtTime()设置了自动化曲线,并且在调用此方法时,将抛出NotSupportedError错误。setOrientation()描述了听众在3D笛卡尔坐标空间中的朝向方向。提供了一个 前向 向量和一个 上向 向量。从简单的人类角度来看,前向 向量表示人的鼻子指向的方向,上向 向量表示人头顶的方向。这两个向量预期是线性独立的。有关如何解释这些值的规范要求,请参见 § 6 空间化/平移。参数
x,y, 和z表示3D空间中的 前向 方向向量,默认值为 (0,0,-1)。参数
xUp,yUp, 和zUp表示3D空间中的 上向 方向向量,默认值为 (0,1,0)。Arguments for the AudioListener.setOrientation() 方法。 参数 类型 是否可为空 是否可选 描述 xfloat✘ ✘ 前向 x 方向的 AudioListeneryfloat✘ ✘ 前向 y 方向的 AudioListenerzfloat✘ ✘ 前向 z 方向的 AudioListenerxUpfloat✘ ✘ 向上 x 方向的 AudioListeneryUpfloat✘ ✘ 向上 y 方向的 AudioListenerzUpfloat✘ ✘ 向上 z 方向的 AudioListener返回类型:undefined setPosition(x, y, z)-
此方法已弃用。它等同于设置
positionX.value,positionY.value, 和positionZ.value直接与给定的x、y和z值对应。因此,如果这些
positionX,positionY, 和positionZAudioParams 对于此AudioListener设置了自动化曲线,使用setValueCurveAtTime()方法在调用此方法时,必须抛出一个NotSupportedError错误。setPosition()设置监听器在三维笛卡尔坐标系中的位置。PannerNode对象使用该位置 相对于各个音频源进行空间化处理。默认值为 (0,0,0)。
Arguments for the AudioListener.setPosition() 方法。 参数 类型 是否可为空 是否可选 描述 xfloat✘ ✘ x 坐标,表示 AudioListener的位置yfloat✘ ✘ y 坐标,表示 AudioListener的位置zfloat✘ ✘ z 坐标,表示 AudioListener的位置
1.11.3. 处理
因为 AudioListener
的
参数可以与 AudioNode 连接
并且它们也可以影响同一图形中 PannerNode
的输出,
所以节点排序算法应该在计算处理顺序时考虑 AudioListener。
因此,图形中的所有 PannerNode 都
有 AudioListener
作为输入。
1.12. AudioProcessingEvent
接口 - 已弃用
这是一个 事件
对象,分派到 ScriptProcessorNode
节点。当 ScriptProcessorNode 被移除时,它也会被移除,因为替代的 AudioWorkletNode
使用了不同的方法。
事件处理程序通过访问 inputBuffer 属性中的音频数据处理输入音频(如果有)。
处理结果的音频数据(或没有输入时合成的数据)然后被放入 outputBuffer。
[Exposed =Window ]interface AudioProcessingEvent :Event {(constructor DOMString ,type AudioProcessingEventInit );eventInitDict readonly attribute double playbackTime ;readonly attribute AudioBuffer inputBuffer ;readonly attribute AudioBuffer outputBuffer ; };
1.12.1. 属性
inputBuffer, 类型为 AudioBuffer,只读-
包含输入音频数据的 AudioBuffer。它的通道数量与
createScriptProcessor()方法的numberOfInputChannels参数相等。 这个 AudioBuffer 只在audioprocess事件处理程序函数的作用范围内有效。其值在此作用范围外将毫无意义。 outputBuffer, 类型为 AudioBuffer,只读-
一个 AudioBuffer,必须写入输出音频数据。它的通道数量与
createScriptProcessor()方法的numberOfOutputChannels参数相等。脚本 代码应当在audioprocess事件处理程序函数的作用范围内修改这个 AudioBuffer 中代表每个通道数据的Float32Array数组。 在此范围外对这个 AudioBuffer 的任何脚本修改将不会产生可听的效果。 playbackTime, 类型为 double,只读-
音频将要播放的时间,使用与
AudioContext的currentTime相同的时间坐标系。
1.12.2. AudioProcessingEventInit
dictionary AudioProcessingEventInit :EventInit {required double playbackTime ;required AudioBuffer inputBuffer ;required AudioBuffer outputBuffer ; };
1.12.2.1. 字典 AudioProcessingEventInit
成员
inputBuffer, 类型为 AudioBuffer-
要分配给事件的
inputBuffer属性的值。 outputBuffer, 类型为 AudioBuffer-
要分配给事件的
outputBuffer属性的值。 playbackTime, 类型为 double-
要分配给事件的
playbackTime属性的值。
1.13.
BiquadFilterNode
接口
BiquadFilterNode
是一个 AudioNode
处理器,实现在非常常见的低阶滤波器。
低阶滤波器是基本音调控制(低音、中音、高音)、图形均衡器和更高级滤波器的构建模块。
可以组合多个 BiquadFilterNode
滤波器来形成更复杂的滤波器。滤波器的参数,如 frequency
可以随着时间的推移进行改变,以实现滤波器的扫频等效果。每个 BiquadFilterNode
可以配置为多种常见的滤波器类型,如下所示。默认滤波器类型为 "lowpass"。
频率和 detune
形成一个 复合参数
并且它们都是 a-rate。它们一起用于确定 计算频率 值:
computedFrequency(t) = frequency(t) * pow(2, detune(t) / 1200)
| 属性 | 值 | 备注 |
|---|---|---|
numberOfInputs
| 1 | |
numberOfOutputs
| 1 | |
channelCount
| 2 | |
channelCountMode
| "max"
| |
channelInterpretation
| "speakers"
| |
| 尾时 | 是 | 即使没有输入,仍会继续输出非静音音频。由于这是一个IIR滤波器,滤波器将永远产生非零输入,但实际上,这可以在一段有限时间后限制,输出足够接近零。实际时间取决于滤波器系数。 |
输出的频道数始终等于输入的频道数。
enum {BiquadFilterType "lowpass" ,"highpass" ,"bandpass" ,"lowshelf" ,"highshelf" ,"peaking" ,"notch" ,"allpass" };
| 枚举值 | 描述 |
|---|---|
"lowpass"
|
一个 低通滤波器
允许低于截止频率的频率通过,并衰减高于截止频率的频率。它实现了一个标准的二阶共振低通滤波器,具有 12dB/八度的衰减。
|
"highpass"
|
一个 高通滤波器
是低通滤波器的反向操作。它允许高于截止频率的频率通过,但衰减低于截止频率的频率。它实现了一个标准的二阶共振高通滤波器,具有 12dB/八度的衰减。
|
"bandpass"
|
一个 带通滤波器
允许一定范围内的频率通过,并衰减低于和高于该范围的频率。它实现了一个二阶带通滤波器。
|
"lowshelf"
|
低棚滤波器允许所有频率通过,但对低频部分增加增益(或衰减)。它实现了一个二阶低棚滤波器。
|
"highshelf"
|
高棚滤波器是低棚滤波器的反向操作,允许所有频率通过,但对高频部分增加增益。它实现了一个二阶高棚滤波器。
|
"peaking"
|
峰值滤波器允许所有频率通过,但对一范围内的频率增加增益(或衰减)。
|
"notch"
|
击穿滤波器(也称为 带阻或带拒绝滤波器)是带通滤波器的反向操作。它允许所有频率通过,除了某些频率。
|
"allpass"
| 一个 全通滤波器 允许所有频率通过,但改变频率之间的相位关系。它实现了一个二阶全通滤波器。 |
所有 BiquadFilterNode
的属性都是 a-rate AudioParams。
[Exposed =Window ]interface BiquadFilterNode :AudioNode {(constructor BaseAudioContext ,context optional BiquadFilterOptions = {});options attribute BiquadFilterType type ;readonly attribute AudioParam frequency ;readonly attribute AudioParam detune ;readonly attribute AudioParam Q ;readonly attribute AudioParam gain ;undefined getFrequencyResponse (Float32Array ,frequencyHz Float32Array ,magResponse Float32Array ); };phaseResponse
1.13.1. 构造函数
BiquadFilterNode(context, options)-
当构造函数被调用时,传入一个
BaseAudioContextc 和 一个选项对象 option,用户代理必须 初始化 AudioNode this,以 context 和 options 作为参数。对于 BiquadFilterNode.constructor() 方法的参数。 参数 类型 可空 可选 描述 contextBaseAudioContext✘ ✘ 新的 BaseAudioContext与此BiquadFilterNode将会 关联。optionsBiquadFilterOptions✘ ✔ 该参数为此 BiquadFilterNode的可选初始参数值。
1.13.2. 属性
Q, 类型为 AudioParam, 只读-
过滤器的 Q 因子。
对于
低通和高通滤波器,Q值被解释为 dB。对于这些滤波器,标称范围为 \([-Q_{lim}, Q_{lim}]\),其中 \(Q_{lim}\) 是使得 \(10^{Q/20}\) 不溢出的最大值。大约为 \(770.63678\)。对于
带通,陷波,全通, 和峰值滤波器,值为线性值。该值与滤波器的带宽相关,因此应为正值。 标称范围为 \([0, 3.4028235e38]\),上限为 最大单精度浮点数。参数 值 备注 defaultValue1 minValue最小单精度浮点数 大约是 -3.4028235e38,但请参见上述不同滤波器的实际限制 maxValue最大单精度浮点数 大约是 3.4028235e38,但请参见上述不同滤波器的实际限制 automationRate" a-rate" detune, 类型为 AudioParam, 只读-
用于频率的调谐值,以分为单位。它与
frequency形成一个 复合参数, 以形成 computedFrequency。参数 值 备注 defaultValue0 minValue\(\approx -153600\) maxValue\(\approx 153600\) 此值大约为 \(1200\ \log_2 \mathrm{FLT\_MAX}\),其中 FLT_MAX 是最大的 float值。automationRate" a-rate" frequency, 类型为 AudioParam, 只读-
该
BiquadFilterNode将在该频率下(以Hz为单位)工作。它与 复合参数 形成,与detune一起形成 computedFrequency。参数 值 备注 defaultValue350 minValue0 maxValueNyquist frequency automationRate" a-rate" gain, 类型为 AudioParam, 只读-
滤波器的增益。其值以dB为单位。增益仅在
lowshelf,highshelf, 和peaking滤波器中使用。参数 值 备注 defaultValue0 minValue最小单精度浮点数 约为 -3.4028235e38 maxValue\(\approx 1541\) 此值约为 \(40\ \log_{10} \mathrm{FLT\_MAX}\),其中 FLT_MAX 是最大的 float值。automationRate" a-rate" type, 类型为 BiquadFilterType-
此
BiquadFilterNode的类型。 默认值为 "lowpass"。 其他参数的确切含义取决于type属性的值。
1.13.3. 方法
getFrequencyResponse(frequencyHz, magResponse, phaseResponse)-
给定每个滤波器参数的
[[current value]],同步计算指定频率的频率响应。三个参数必须是长度相同的Float32Array, 否则必须抛出InvalidAccessError。返回的频率响应必须使用为当前处理块采样的
AudioParam进行计算。BiquadFilterNode.getFrequencyResponse() 方法的参数。 参数 类型 可空 可选 描述 frequencyHzFloat32Array✘ ✘ 该参数指定一个频率数组(以Hz为单位),将在这些频率上计算响应值。 magResponseFloat32Array✘ ✘ 该参数指定一个输出数组,用于接收线性幅度响应值。如果 frequencyHz参数中的值不在 [0, sampleRate/2] 范围内, 其中sampleRate是sampleRate属性的值,magResponse数组中对应索引的值必须是NaN。phaseResponseFloat32Array✘ ✘ 该参数指定一个输出数组,用于接收相位响应值(以弧度为单位)。如果 frequencyHz参数中的值不在 [0; sampleRate/2] 范围内, 其中sampleRate是sampleRate属性的值,phaseResponse数组中对应索引的值必须是NaN。返回类型:undefined
1.13.4. BiquadFilterOptions
这指定了构造 BiquadFilterNode
时使用的选项。
所有成员都是可选的;如果未指定,将使用默认值来构造该节点。
dictionary BiquadFilterOptions :AudioNodeOptions {BiquadFilterType type = "lowpass";float Q = 1;float detune = 0;float frequency = 350;float gain = 0; };
1.13.4.1. 字典 BiquadFilterOptions
成员
Q, 类型为 float,默认值为1-
指定
Q的期望初始值。 detune, 类型为 float,默认值为0-
指定
detune的期望初始值。 frequency, 类型为 float,默认值为350-
指定
frequency的期望初始值。 gain, 类型为 float,默认值为0-
指定
gain的期望初始值。 type, 类型为 BiquadFilterType,默认值为"lowpass"-
指定滤波器的期望初始类型。
1.13.5. 滤波器特性
有多种实现方式可以实现 BiquadFilterNode
提供的滤波器类型,每种方式具有非常不同的特性。本节中的公式描述了 符合标准的实现 必须实现的滤波器,因为它们决定了不同
滤波器类型的特性。这些公式受到 Audio EQ
Cookbook 中公式的启发。
BiquadFilterNode
处理音频时,其传递函数为:
$$
H(z) = \frac{\frac{b_0}{a_0} + \frac{b_1}{a_0}z^{-1} + \frac{b_2}{a_0}z^{-2}}
{1+\frac{a_1}{a_0}z^{-1}+\frac{a_2}{a_0}z^{-2}}
$$
这相当于以下的时域方程:
$$
a_0 y(n) + a_1 y(n-1) + a_2 y(n-2) =
b_0 x(n) + b_1 x(n-1) + b_2 x(n-2)
$$
初始滤波器状态为 0。
注意:虽然固定滤波器是稳定的,但使用 AudioParam
自动化,可能会创建不稳定的二阶滤波器。开发者有责任管理此问题。
注意:用户代理(UA)可能会发出警告,通知用户滤波器状态中出现了 NaN 值。这通常表示滤波器不稳定。
上述传递函数中的系数对于每种节点类型都是不同的。计算它们时需要以下中间变量,这些变量基于 computedValue,即 AudioParam
的值
计算的结果。
-
令 \(F_s\) 为此
sampleRate属性的值,适用于此AudioContext。 -
令 \(f_0\) 为 computedFrequency 的值。
-
令 \(G\) 为
gainAudioParam的值。 -
令 \(Q\) 为
QAudioParam的值。 -
最后令:
$$ \begin{align*} A &= 10^{\frac{G}{40}} \\ \omega_0 &= 2\pi\frac{f_0}{F_s} \\ \alpha_Q &= \frac{\sin\omega_0}{2Q} \\ \alpha_{Q_{dB}} &= \frac{\sin\omega_0}{2 \cdot 10^{Q/20}} \\ S &= 1 \\ \alpha_S &= \frac{\sin\omega_0}{2}\sqrt{\left(A+\frac{1}{A}\right)\left(\frac{1}{S}-1\right)+2} \end{align*} $$
每种滤波器类型的六个系数(\(b_0, b_1, b_2, a_0, a_1, a_2\))如下:
- "
lowpass" -
$$ \begin{align*} b_0 &= \frac{1 - \cos\omega_0}{2} \\ b_1 &= 1 - \cos\omega_0 \\ b_2 &= \frac{1 - \cos\omega_0}{2} \\ a_0 &= 1 + \alpha_{Q_{dB}} \\ a_1 &= -2 \cos\omega_0 \\ a_2 &= 1 - \alpha_{Q_{dB}} \end{align*} $$ - "
highpass" -
$$ \begin{align*} b_0 &= \frac{1 + \cos\omega_0}{2} \\ b_1 &= -(1 + \cos\omega_0) \\ b_2 &= \frac{1 + \cos\omega_0}{2} \\ a_0 &= 1 + \alpha_{Q_{dB}} \\ a_1 &= -2 \cos\omega_0 \\ a_2 &= 1 - \alpha_{Q_{dB}} \end{align*} $$ - "
bandpass" -
$$ \begin{align*} b_0 &= \alpha_Q \\ b_1 &= 0 \\ b_2 &= -\alpha_Q \\ a_0 &= 1 + \alpha_Q \\ a_1 &= -2 \cos\omega_0 \\ a_2 &= 1 - \alpha_Q \end{align*} $$ - "
notch" -
$$ \begin{align*} b_0 &= 1 \\ b_1 &= -2\cos\omega_0 \\ b_2 &= 1 \\ a_0 &= 1 + \alpha_Q \\ a_1 &= -2 \cos\omega_0 \\ a_2 &= 1 - \alpha_Q \end{align*} $$ - "
allpass" -
$$ \begin{align*} b_0 &= 1 - \alpha_Q \\ b_1 &= -2\cos\omega_0 \\ b_2 &= 1 + \alpha_Q \\ a_0 &= 1 + \alpha_Q \\ a_1 &= -2 \cos\omega_0 \\ a_2 &= 1 - \alpha_Q \end{align*} $$ - "
peaking" -
$$ \begin{align*} b_0 &= 1 + \alpha_Q\, A \\ b_1 &= -2\cos\omega_0 \\ b_2 &= 1 - \alpha_Q\,A \\ a_0 &= 1 + \frac{\alpha_Q}{A} \\ a_1 &= -2 \cos\omega_0 \\ a_2 &= 1 - \frac{\alpha_Q}{A} \end{align*} $$ - "
lowshelf" -
$$ \begin{align*} b_0 &= A \left[ (A+1) - (A-1) \cos\omega_0 + 2 \alpha_S \sqrt{A})\right] \\ b_1 &= 2 A \left[ (A-1) - (A+1) \cos\omega_0 )\right] \\ b_2 &= A \left[ (A+1) - (A-1) \cos\omega_0 - 2 \alpha_S \sqrt{A}) \right] \\ a_0 &= (A+1) + (A-1) \cos\omega_0 + 2 \alpha_S \sqrt{A} \\ a_1 &= -2 \left[ (A-1) + (A+1) \cos\omega_0\right] \\ a_2 &= (A+1) + (A-1) \cos\omega_0 - 2 \alpha_S \sqrt{A}) \end{align*} $$ - "
highshelf" -
$$ \begin{align*} b_0 &= A\left[ (A+1) + (A-1)\cos\omega_0 + 2\alpha_S\sqrt{A} )\right] \\ b_1 &= -2A\left[ (A-1) + (A+1)\cos\omega_0 )\right] \\ b_2 &= A\left[ (A+1) + (A-1)\cos\omega_0 - 2\alpha_S\sqrt{A} )\right] \\ a_0 &= (A+1) - (A-1)\cos\omega_0 + 2\alpha_S\sqrt{A} \\ a_1 &= 2\left[ (A-1) - (A+1)\cos\omega_0\right] \\ a_2 &= (A+1) - (A-1)\cos\omega_0 - 2\alpha_S\sqrt{A} \end{align*} $$
1.14.
ChannelMergerNode
接口
ChannelMergerNode
用于更高级的应用,通常与 ChannelSplitterNode
一起使用。
| 属性 | 值 | 备注 |
|---|---|---|
numberOfInputs
| 见备注 | 默认为 6,但由 ChannelMergerOptions、numberOfInputs
或 createChannelMerger
指定的值确定。
|
numberOfOutputs
| 1 | |
channelCount
| 1 | 具有 channelCount 约束 |
channelCountMode
| "explicit"
| 具有 channelCountMode 约束 |
channelInterpretation
| "speakers"
| |
| 尾部时间 | 无 |
此接口表示一个 AudioNode
用于将多个音频流的频道合并为一个单一音频流。它具有可变数量的输入(默认为 6),但并非所有输入都需要连接。只有一个输出,其音频流在任何输入 正在处理 时,其频道数等于输入的数量。如果没有输入处于 正在处理
状态,则输出为单声道静音。
为了将多个输入合并成一个流,每个输入都会根据指定的混合规则混合为一个单声道。未连接的输入仍然在输出中计为一个静音频道。更改输入流不会影响输出频道的顺序。
ChannelMergerNode
具有两个连接的立体声输入,第一个和第二个输入将分别被混合为单声道,然后合并。输出将是一个 6 频道的流,其中前两个频道将被填充为前两个(混合过的)输入,其余的频道将为静音。
此外,ChannelMergerNode
还可以用来为多通道扬声器阵列(例如 5.1 环绕声系统)排列多个音频流。合并器不会解释频道身份(如左、右等),而是简单地按照输入的顺序合并频道。

[Exposed =Window ]interface ChannelMergerNode :AudioNode {constructor (BaseAudioContext ,context optional ChannelMergerOptions = {}); };options
1.14.1. 构造函数
ChannelMergerNode(context, options)-
当构造函数使用
BaseAudioContextc 和一个选项对象 option 被调用时,用户代理必须 初始化 AudioNode this,并使用 context 和 options 作为参数。参数列表:ChannelMergerNode.constructor() 方法。 参数 类型 是否可空 是否可选 描述 contextBaseAudioContext✘ ✘ 新建的 ChannelMergerNode将会与BaseAudioContextcontext 关联。optionsChannelMergerOptions✘ ✔ 此 ChannelMergerNode的可选初始参数值。
1.14.2. ChannelMergerOptions
dictionary ChannelMergerOptions :AudioNodeOptions {unsigned long numberOfInputs = 6; };
1.14.2.1. 字典 ChannelMergerOptions
成员
numberOfInputs, 类型为 unsigned long,默认为6-
指定
ChannelMergerNode的输入数量。 查看createChannelMerger()以了解此值的约束条件。
1.15. ChannelSplitterNode
接口
ChannelSplitterNode
用于更高级的应用,通常与 ChannelMergerNode
一起使用。
| 属性 | 值 | 备注 |
|---|---|---|
numberOfInputs
| 1 | |
numberOfOutputs
| 见备注 | 默认为6,但由 ChannelSplitterOptions.numberOfOutputs
或者通过 createChannelSplitter
或 ChannelSplitterOptions
字典中的 constructor
来决定。
|
channelCount
| numberOfOutputs
| 具有 channelCount 限制 |
channelCountMode
| "explicit"
| 具有 channelCountMode 限制 |
channelInterpretation
| "discrete"
| 具有 channelInterpretation 限制 |
| 尾时间 | 无 |
该接口表示一个 AudioNode,用于
访问音频流中的各个通道,通常在路由图中使用。它有一个输入,以及多个“活动”输出,这些输出
等于输入音频流中的通道数。例如,如果将立体声输入连接到 ChannelSplitterNode
,则活动输出的数量将是两个(一个来自左通道,一个来自右通道)。输出的总数始终为 N(由
numberOfOutputs 参数决定,参见 AudioContext
中的 createChannelSplitter()
方法),
如果未提供此值,默认值为 6。任何非“活动”输出将输出静音,通常不会连接到其他地方。
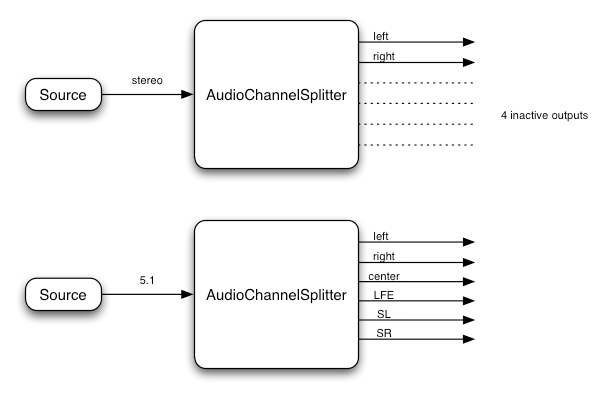
一个应用案例是使用 ChannelSplitterNode
进行“矩阵混音”,其中需要对每个通道进行独立的增益控制。
[Exposed =Window ]interface ChannelSplitterNode :AudioNode {constructor (BaseAudioContext ,context optional ChannelSplitterOptions = {}); };options
1.15.1. 构造函数
ChannelSplitterNode(context, options)-
当构造函数使用
BaseAudioContextc 和 一个选项对象 option 被调用时,用户代理必须 初始化 AudioNode this,将 context 和 options 作为参数传递。ChannelSplitterNode.constructor() 方法的参数。 参数 类型 可空 可选 描述 contextBaseAudioContext✘ ✘ 新的 BaseAudioContext会与此新建的ChannelSplitterNode关联。optionsChannelSplitterOptions✘ ✔ 此 ChannelSplitterNode的可选初始化参数值。
1.15.2. ChannelSplitterOptions
dictionary ChannelSplitterOptions :AudioNodeOptions {unsigned long numberOfOutputs = 6; };
1.15.2.1. 字典 ChannelSplitterOptions
成员
numberOfOutputs, 类型为 unsigned long,默认值为6-
用于
ChannelSplitterNode的输出数量。 请参阅createChannelSplitter()以获取该值的限制。
1.16.
ConstantSourceNode
接口
该接口表示一个常量音频源,其输出 nominally 为常量值。它在一般情况下作为常量源节点非常有用,并且可以像构造出的 AudioParam
一样通过自动化其 offset
或连接其他节点来使用。
此节点的单一输出由一个通道(单声道)组成。
| 属性 | 值 | 备注 |
|---|---|---|
numberOfInputs
| 0 | |
numberOfOutputs
| 1 | |
channelCount
| 2 | |
channelCountMode
| "max"
| |
channelInterpretation
| "speakers"
| |
| tail-time | 无 |
[Exposed =Window ]interface ConstantSourceNode :AudioScheduledSourceNode {constructor (BaseAudioContext ,context optional ConstantSourceOptions = {});options readonly attribute AudioParam offset ; };
1.16.1. 构造函数
ConstantSourceNode(context, options)-
当构造函数被调用时,传入一个
BaseAudioContextc 和 一个选项对象 option,用户代理必须 初始化 AudioNode this,并使用 context 和 options 作为参数。参数用于 ConstantSourceNode.constructor() 方法。 参数 类型 可空 可选 描述 contextBaseAudioContext✘ ✘ 新的 ConstantSourceNode将与此BaseAudioContext关联。optionsConstantSourceOptions✘ ✔ 此 ConstantSourceNode的可选初始参数值。
1.16.2. 属性
offset, 类型为 AudioParam, 只读-
源的常量值。
参数 值 备注 defaultValue1 minValue最小负单精度浮点数 约为 -3.4028235e38 maxValue最大正单精度浮点数 约为 3.4028235e38 automationRate" a-rate"
1.16.3. ConstantSourceOptions
此选项用于构造 ConstantSourceNode。
所有成员都是可选的;如果没有指定,则会使用构造节点的默认值。
dictionary ConstantSourceOptions {float offset = 1; };
1.16.3.1. 字典 ConstantSourceOptions
成员
offset, 类型为 float,默认为1-
此节点的
offsetAudioParam 的初始值。
1.17. ConvolverNode
接口
此接口表示一个处理节点,它根据脉冲响应应用线性卷积效果。
| 属性 | 值 | 备注 |
|---|---|---|
numberOfInputs
| 1 | |
numberOfOutputs
| 1 | |
channelCount
| 2 | 具有 channelCount 约束 |
channelCountMode
| "clamped-max"
| 具有 channelCountMode 约束 |
channelInterpretation
| "speakers"
| |
| tail-time | 是 | 在 buffer
长度内继续输出非静音音频,即使没有输入。
|
此节点的输入可以是单声道(1 通道)或立体声(2 通道),并且不能增加更多通道。来自更多通道的节点连接将被 适当下混。
此节点有 channelCount 约束 和 channelCountMode 约束。这些约束确保节点的输入为单声道或立体声。
[Exposed =Window ]interface ConvolverNode :AudioNode {constructor (BaseAudioContext ,context optional ConvolverOptions = {});options attribute AudioBuffer ?buffer ;attribute boolean normalize ; };
1.17.1. 构造函数
ConvolverNode(context, options)-
当构造函数被调用时,传入
BaseAudioContextcontext 和一个选项对象 options,执行以下步骤:-
将属性
normalize设置为disableNormalization的反值。 -
如果
buffer存在,将buffer属性设置为其值。注意: 这意味着 buffer 将根据
normalize属性的值进行标准化。 -
令 o 为新的
AudioNodeOptions字典。 -
如果
channelCount存在于 options 中,则将channelCount设置为 o 上的相同值。 -
如果
channelCountMode存在于 options 中,则将channelCountMode设置为 o 上的相同值。 -
如果
channelInterpretation存在于 options 中,则将channelInterpretation设置为 o 上的相同值。 -
初始化 AudioNode this,使用 c 和 o 作为参数。
参数用于 ConvolverNode.constructor() 方法。 参数 类型 可空 可选 描述 contextBaseAudioContext✘ ✘ 这个新的 ConvolverNode将与BaseAudioContext关联。optionsConvolverOptions✘ ✔ 此 ConvolverNode的可选初始参数值。 -
1.17.2. 属性
buffer, 类型为 AudioBuffer, 可为空-
当设置此属性时,
buffer和normalize属性的状态将用于配置ConvolverNode,使用此脉冲响应并应用给定的归一化。此属性的初始值为 null。设置buffer attribute时,执行以下 同步 步骤:-
如果缓冲区的
通道数不是 1、2 或 4,或者缓冲区的采样率与其BaseAudioContext的采样率不相同,则必须抛出NotSupportedError错误。 -
获取内容 来自
AudioBuffer。
注意:如果将
buffer设置为新缓冲区,可能会发生音频闪烁。如果不希望发生此情况,建议创建一个新的ConvolverNode来替换旧的,并可能在两个节点之间进行交叉渐变。注意:当
ConvolverNode只有在输入通道数为 1 且缓冲区为单通道时,才会输出单声道。在所有其他情况下,输出为立体声。特别地,当buffer具有四个通道且有两个输入通道时,ConvolverNode将执行矩阵“真正”的立体声卷积。有关规范信息,请参见 通道配置图。 -
normalize, 类型为 boolean-
控制在设置
buffer属性时,脉冲响应是否会通过均衡功率归一化进行缩放。其默认值为true,以便在加载不同脉冲响应时实现更加均匀的输出级别。如果normalize设置为false,则卷积将不进行脉冲响应的预处理/缩放。对该值的更改直到下次设置buffer属性时才会生效。如果在设置
buffer属性时,normalize属性为 false,则ConvolverNode将执行线性卷积,使用buffer中包含的精确脉冲响应。否则,如果在设置
buffer属性时,normalize属性为 true,则ConvolverNode将首先对缓冲区中的音频数据执行缩放 RMS 功率分析,以计算一个 normalizationScale,并使用以下算法:function calculateNormalizationScale( buffer) { const GainCalibration= 0.00125 ; const GainCalibrationSampleRate= 44100 ; const MinPower= 0.000125 ; // Normalize by RMS power. const numberOfChannels= buffer. numberOfChannels; const length= buffer. length; let power= 0 ; for ( let i= 0 ; i< numberOfChannels; i++ ) { let channelPower= 0 ; const channelData= buffer. getChannelData( i); for ( let j= 0 ; j< length; j++ ) { const sample= channelData[ j]; channelPower+= sample* sample; } power+= channelPower; } power= Math. sqrt( power/ ( numberOfChannels* length)); // Protect against accidental overload. if ( ! isFinite( power) || isNaN( power) || power< MinPower) power= MinPower; let scale= 1 / power; // Calibrate to make perceived volume same as unprocessed. scale*= GainCalibration; // Scale depends on sample-rate. if ( buffer. sampleRate) scale*= GainCalibrationSampleRate/ buffer. sampleRate; // True-stereo compensation. if ( numberOfChannels== 4 ) scale*= 0.5 ; return scale; } 在处理过程中,ConvolverNode 将使用计算出的 normalizationScale 值,并将其与输入信号与冲激响应(由
buffer表示) 进行线性卷积的结果相乘,以产生最终输出。或者可以使用任何数学上等效的操作,例如将输入信号预乘以 normalizationScale,或将冲激响应的版本预乘以 normalizationScale。
1.17.3.
ConvolverOptions
指定用于构建 ConvolverNode
的选项。
所有成员都是可选的;如果未指定,则节点将使用正常的默认值进行构建。
dictionary ConvolverOptions :AudioNodeOptions {AudioBuffer ?buffer ;boolean disableNormalization =false ; };
1.17.3.1. Dictionary ConvolverOptions
成员
buffer, 类型为 AudioBuffer,可为 null-
为
ConvolverNode指定的缓冲区。 该缓冲区将根据disableNormalization的值进行归一化处理。 disableNormalization, 类型为 boolean,默认为false-
与
normalize属性的初始值相反的值,属于ConvolverNode。
1.17.4. 输入、脉冲响应和输出的通道配置
实现必须支持以下允许的脉冲响应通道配置,以在 ConvolverNode
中实现各种混响效果,输入为 1 或 2 个通道。
如下面的图表所示,单通道卷积操作使用单声道音频输入,采用单声道脉冲响应,并生成单声道输出。剩余的图像展示了对于单声道和立体声播放的支持情况,其中输入的通道数为 1 或 2,而 buffer
的通道数为 1、2 或 4。
开发人员如果需要更复杂或任意的矩阵化操作,可以使用 ChannelSplitterNode,
多个单通道的 ConvolverNode,
和一个 ChannelMergerNode。
如果该节点没有 正在处理,则输出为一个通道的静音。
注意: 以下图表展示了在 正在处理 时的输出。
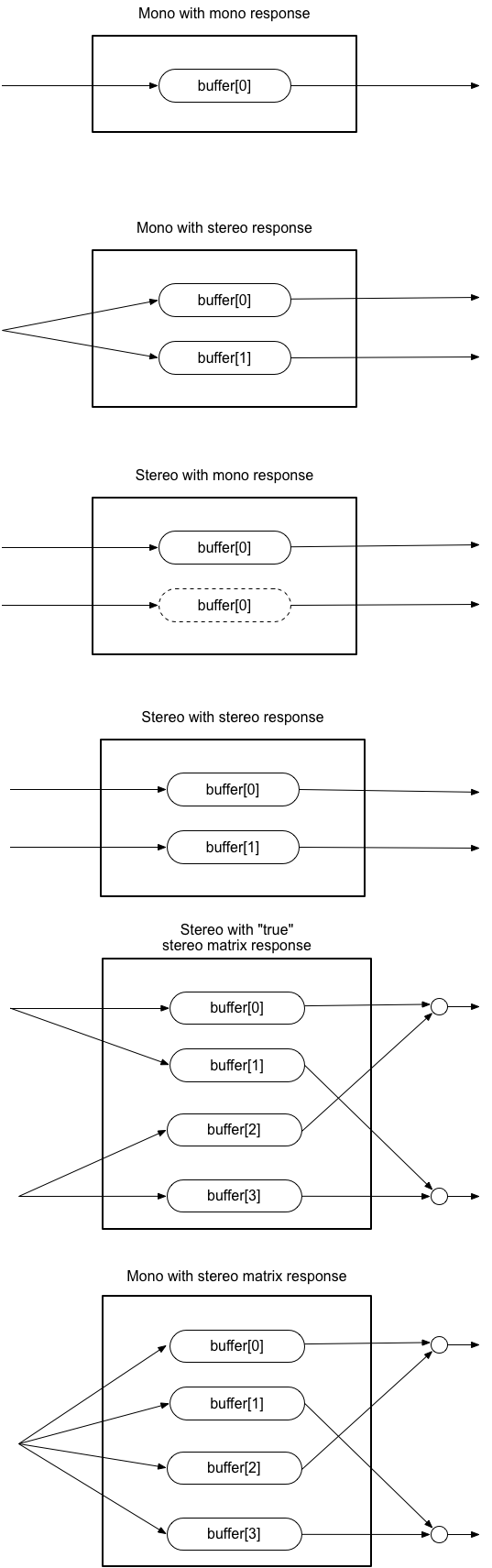
ConvolverNode
时支持的输入和输出通道数的图示。
1.18. DelayNode
接口
延迟线是音频应用中的一个基本构建块。
这个接口是一个 AudioNode
,具有一个输入和一个输出。
| 属性 | 值 | 备注 |
|---|---|---|
numberOfInputs
| 1 | |
numberOfOutputs
| 1 | |
channelCount
| 2 | |
channelCountMode
| "max"
| |
channelInterpretation
| "speakers"
| |
| tail-time | 是 | 当输入为零时,继续输出非静音音频,直到节点的 maxDelayTime。
|
输出的通道数始终等于输入的通道数。
它通过一定的时间延迟输入的音频信号。
具体来说,在每个时刻 t,输入信号 input(t)、延迟时间 delayTime(t) 和
输出信号 output(t),输出将是 output(t) = input(t - delayTime(t))。默认的 delayTime 为 0 秒
(无延迟)。
当 DelayNode 的
输入通道数发生变化时(因此输出通道数也发生变化),可能会有一些延迟的音频样本尚未被节点输出,并且是其内部状态的一部分。如果这些样本之前是以不同的通道数接收的,它们必须在与新接收到的输入混合之前进行上混或下混,以便所有内部延迟线混音操作都使用单一的通道布局。
注意: 根据定义,DelayNode
引入一个音频处理
延迟,等于延迟的时间。
[Exposed =Window ]interface DelayNode :AudioNode {constructor (BaseAudioContext ,context optional DelayOptions = {});options readonly attribute AudioParam delayTime ; };
1.18.1. 构造函数
DelayNode(context, options)-
当构造函数使用
BaseAudioContextc 和 一个选项对象 option 被调用时,用户代理必须 初始化 AudioNode this,并将 context 和 options 作为参数传入。参数列表:DelayNode.constructor() 方法。 参数 类型 可为空 可选 描述 contextBaseAudioContext✘ ✘ 此新 DelayNode将与BaseAudioContext关联。optionsDelayOptions✘ ✔ 此 DelayNode的可选初始参数值。
1.18.2. 属性
delayTime, 类型为 AudioParam, 只读-
一个
AudioParam对象,表示要应用的延迟量(以秒为单位)。其默认value为 0(无延迟)。最小值为 0, 最大值由maxDelayTime参数指定,该参数来自AudioContext方法createDelay()或maxDelayTime属性,位于DelayOptions字典中,作为构造函数的参数。如果
DelayNode是循环的一部分(循环), 则delayTime属性的值将被限制为最小值为一个 渲染量。参数 值 备注 defaultValue0 minValue0 maxValuemaxDelayTimeautomationRate" a-rate"
1.18.3. DelayOptions
此选项用于构造 DelayNode。所有成员都是可选的;如果未提供,则节点将使用默认值构造。
dictionary DelayOptions :AudioNodeOptions {double maxDelayTime = 1;double delayTime = 0; };
1.18.3.1. 字典 DelayOptions
成员
delayTime, 类型为 double,默认值为0-
节点的初始延迟时间。
maxDelayTime, 类型为 double,默认值为1-
节点的最大延迟时间。请参见
createDelay(maxDelayTime)获取约束。
1.18.4. 处理
DelayNode
有一个内部缓冲区,保存 delayTime
秒的音频数据。
DelayNode
的处理分为两部分:写入延迟线和从延迟线读取。这是通过两个内部 AudioNode(这些节点不可供作者使用,存在仅为便于描述节点的内部工作原理)来完成的。两个节点都是从
DelayNode
创建的。
为 DelayNode
创建一个 DelayWriter 意味着创建一个与
AudioNode
拥有相同接口的对象,并且该对象将输入音频写入 DelayNode
的内部缓冲区。它具有与它所创建的 DelayNode
相同的输入连接。
为 DelayNode
创建一个 DelayReader 意味着创建一个与
AudioNode
拥有相同接口的对象,并且该对象可以从 DelayNode
的内部缓冲区读取音频数据。它与 AudioNode
有相同的连接。DelayReader 是一个 源节点。
处理输入缓冲区时,DelayWriter 必须将音频写入 DelayNode
的内部缓冲区。
生成输出缓冲区时,DelayReader 必须产生正好为延迟时间之前由相应的 DelayWriter 写入的音频数据。
注意: 这意味着通道计数的变化会在延迟时间过后反映出来。
1.19. DynamicsCompressorNode
接口
DynamicsCompressorNode
是一个实现动态压缩效果的 AudioNode
处理器。
动态压缩在音乐制作和游戏音频中非常常见。它降低信号中最响亮部分的音量,并提高最柔和部分的音量。总体上,可以实现更响亮、更丰富、更饱满的声音。它在游戏和音乐应用中尤其重要,因为这些应用中同时播放大量独立的声音,以控制整体信号水平并帮助避免音频输出到扬声器时产生削波(失真)。
| 属性 | 值 | 备注 |
|---|---|---|
numberOfInputs
| 1 | |
numberOfOutputs
| 1 | |
channelCount
| 2 | 具有 channelCount 约束 |
channelCountMode
| "clamped-max"
| 具有 channelCountMode 约束 |
channelInterpretation
| "speakers"
| |
| tail-time | 是 | 此节点具有一个 尾时长,使得即使没有输入信号,该节点也会继续输出非静音音频,这是由于前瞻延迟造成的。 |
[Exposed =Window ]interface DynamicsCompressorNode :AudioNode {constructor (BaseAudioContext ,context optional DynamicsCompressorOptions = {});options readonly attribute AudioParam threshold ;readonly attribute AudioParam knee ;readonly attribute AudioParam ratio ;readonly attribute float reduction ;readonly attribute AudioParam attack ;readonly attribute AudioParam release ; };
1.19.1. 构造函数
DynamicsCompressorNode(context, options)-
当构造函数被调用时,传入一个
BaseAudioContextc 和 一个选项对象 option,用户代理必须 初始化 AudioNode this,并将 context 和 options 作为参数传入。让
[[internal reduction]]成为 this 上的一个私有槽位,用于保存一个浮动点数值,单位为分贝。将[[internal reduction]]设置为 0.0。DynamicsCompressorNode.constructor() 方法的参数。 参数 类型 可空 可选 描述 contextBaseAudioContext✘ ✘ 此新的 DynamicsCompressorNode将会与BaseAudioContext关联。optionsDynamicsCompressorOptions✘ ✔ 此 DynamicsCompressorNode的可选初始参数值。
1.19.2. 属性
attack, 类型为 AudioParam, 只读-
降低增益 10dB 所需的时间(以秒为单位)。
参数 值 备注 defaultValue.003 minValue0 maxValue1 automationRate" k-rate"具有 自动化速率约束 knee, 类型为 AudioParam,只读-
表示阈值以上的分贝值,在该范围内,曲线平滑过渡到 "比率" 部分。
参数 值 备注 defaultValue30 minValue0 maxValue40 automationRate" k-rate"具有 自动化速率约束 ratio, 类型为 AudioParam, 只读-
输入信号变化 1 dB 时,输出信号变化的 dB 数量。
参数 值 备注 defaultValue12 minValue1 maxValue20 automationRate" k-rate"具有 自动化速率约束 reduction, 类型为 float,只读-
一个只读的分贝值,用于测量目的,表示压缩器当前对信号施加的增益减少量。如果没有信号输入,值将为 0(没有增益减少)。当读取此属性时,返回私有槽位
[[internal reduction]]的值。 release, 类型为 AudioParam, 只读-
增加增益 10dB 所需的时间(以秒为单位)。
参数 值 备注 defaultValue.25 minValue0 maxValue1 automationRate" k-rate"具有 自动化速率约束 threshold, 类型为 AudioParam, 只读-
压缩开始生效的分贝值。
参数 值 备注 defaultValue-24 minValue-100 maxValue0 automationRate" k-rate"具有 自动化速率约束
1.19.3. DynamicsCompressorOptions
这指定了在构造 DynamicsCompressorNode
时使用的选项。所有成员都是可选的;如果未指定,则在构造节点时使用默认值。
dictionary DynamicsCompressorOptions :AudioNodeOptions {float attack = 0.003;float knee = 30;float ratio = 12;float release = 0.25;float threshold = -24; };
1.19.3.1. 字典 DynamicsCompressorOptions
成员
attack, 类型为 float,默认为0.003-
初始化值,用于
attackAudioParam。 knee, 类型为 float,默认为30-
初始化值,用于
kneeAudioParam。 ratio, 类型为 float,默认为12-
初始化值,用于
ratioAudioParam。 release, 类型为 float,默认为0.25-
初始化值,用于
releaseAudioParam。 threshold, 类型为 float,默认为-24-
初始化值,用于
thresholdAudioParam。
1.19.4. 处理
动态压缩可以通过多种方式实现。DynamicsCompressorNode
实现了一个具有以下特征的动态处理器:
-
固定前瞻(这意味着
DynamicsCompressorNode在信号链中添加了固定的延迟)。 -
可配置的攻击速度、释放速度、阈值、膝部硬度和比率。
-
不支持侧链处理。
-
通过
reduction属性在DynamicsCompressorNode上报告增益压缩。 -
压缩曲线有三部分:
-
第一部分是恒等函数:\(f(x) = x\)。
-
第二部分是软膝部分,必须是单调递增的函数。
-
第三部分是线性函数:\(f(x) = \frac{1}{ratio} \cdot x \)。
此曲线必须是连续的,并且分段可微,表示基于输入水平的目标输出水平。
-
从图形上看,这样的曲线大致如下所示:

在内部,DynamicsCompressorNode
是通过其他AudioNodes的组合以及一种特殊的算法来计算增益压缩值。
下面是内部使用的AudioNode图,其中input和output分别是输入和输出的AudioNode,context是此BaseAudioContext
关联的DynamicsCompressorNode,以及一个新类EnvelopeFollower,它实例化一个类似AudioNode的特殊对象,如下所示:
const delay = new DelayNode(context, {delayTime: 0.006});
const gain = new GainNode(context);
const compression = new EnvelopeFollower();
input.connect(delay).connect(gain).connect(output);
input.connect(compression).connect(gain.gain);

AudioNode图。
注意: 这实现了预延迟和应用增益压缩。
下面的算法描述了DynamicsCompressorNode
对输入信号应用EnvelopeFollower对象的处理过程,以生成增益压缩值。一个EnvelopeFollower对象有两个槽,保存浮动的浮点值。这些值在算法调用过程中持续存在。
-
让
[[detector average]]为一个浮动的浮点数,初始化为0.0。 -
让
[[compressor gain]]为一个浮动的浮点数,初始化为1.0。
-
让attack和release分别为
attack和release的值,分别在处理时取样(它们是k-rate参数),乘以与此BaseAudioContext关联的样本率。 -
让detector average为槽
[[detector average]]的值。 -
让compressor gain为槽
[[compressor gain]]的值。 -
对于渲染量的每个输入input样本,执行以下步骤:
-
如果 input 的绝对值小于 0.0001,则让 attenuation 为 1.0。否则,令 shaped input 为应用 压缩曲线 到 input 的绝对值的结果。令 attenuation 为 shaped input 除以 input 的绝对值。
-
令releasing为
true,如果attenuation大于compressor gain,否则为false。 -
令 detector rate 为将 检测器曲线 应用到 attenuation 的结果。
-
从attenuation中减去detector average,并将结果乘以detector rate。将此新结果加到detector average。
-
将detector average限制为最大值1.0。
-
令envelope rate为根据attack和release的值计算的包络速率。
-
如果releasing为
true,将compressor gain设置为compressor gain与envelope rate的乘积,且限制最大值为1.0。 -
否则,如果releasing为
false,令gain increment为detector average减去compressor gain。将gain increment乘以envelope rate,并将结果加到compressor gain。 -
计算 metering gain 为 reduction gain,转换为分贝。
-
-
将
[[compressor gain]]设置为compressor gain。 -
将
[[detector average]]设置为detector average。 -
原子性地 设置内部槽
[[internal reduction]]为 metering gain 的值。注意: 此步骤使得 metering gain 在每个块结束时更新, 在块处理的末尾。
补偿增益是一个固定的增益阶段,仅依赖于压缩器的比例、膝部和阈值参数,而不依赖于输入信号。其目的是增加压缩器的输出水平,以使其与输入水平可比。
-
让full range gain为应用压缩曲线到值1.0时返回的值。
-
让full range makeup gain为full range gain的倒数。
-
返回full range makeup gain的0.6次方的结果。
-
包络速率必须是从compressor gain与detector average的比值计算得出的。
注意: 在攻击时,此值小于或等于1,而在释放时,此值严格大于1。
-
攻击曲线必须是一个在范围\([0, 1]\)内连续、单调递增的函数。此曲线的形状可以通过
attack来控制。 -
释放曲线必须是一个连续的、单调递减的函数,并且始终大于1。此曲线的形状可以通过
release来控制。
此操作返回通过将此函数应用于compressor gain与detector average的比值计算得出的值。
应用检测曲线到攻击或释放时的变化速率,允许实现自适应释放。它是一个必须遵守以下约束的函数:
-
函数的输出必须在\([0, 1]\)范围内。
-
该函数必须是单调递增的,且连续的。
注意: 例如,可以有一个执行自适应释放的压缩器,即压缩越强,释放越快,或者攻击和释放的曲线形状不同。
-
让threshold和knee分别为
阈值和膝部的值,分别转换为线性单位,并在此块的处理时进行采样(作为k-rate参数)。 -
让knee end threshold为此和转换为线性单位后的值。
-
此函数是恒等函数,直到线性threshold的值(即,\(f(x) = x\))。
-
从threshold到knee end threshold,用户代理可以选择曲线形状。整个函数必须是单调递增且连续的。
注意: 如果knee为0,则
DynamicsCompressorNode称为硬膝压缩器。 -
此函数在线性部分是基于ratio的,即\(f(x) = \frac{1}{ratio} \cdot x\)。
-
如果\(v\)等于零,返回-1000。
-
否则,返回\( 20 \, \log_{10}{v} \)。
1.20. GainNode
接口
改变音频信号的增益是音频应用中的一个基本操作。此接口是一个具有单个输入和单个输出的AudioNode:
| 属性 | 值 | 备注 |
|---|---|---|
numberOfInputs
| 1 | |
numberOfOutputs
| 1 | |
channelCount
| 2 | |
channelCountMode
| "max"
| |
channelInterpretation
| "speakers"
| |
| 尾时间 | 无 |
每个通道的每个样本,GainNode 的输入数据
必须乘以 computedValue,该值来自 gain
AudioParam。
[Exposed =Window ]interface GainNode :AudioNode {constructor (BaseAudioContext ,context optional GainOptions = {});options readonly attribute AudioParam gain ; };
1.20.1. 构造函数
GainNode(context, options)-
当构造函数被调用时,传入
BaseAudioContextc 和选项对象 option,用户代理必须初始化 AudioNode this,并将context和options作为参数传递。GainNode.constructor() 方法的参数。 参数 类型 可为空 可选 描述 contextBaseAudioContext✘ ✘ 此新 GainNode将与BaseAudioContextcontext关联。optionsGainOptions✘ ✔ 此 GainNode的可选初始参数值。
1.20.2. 属性
gain, 类型为 AudioParam,只读-
表示要应用的增益量。
参数 值 备注 defaultValue1 minValue最小负单精度浮点数 大约 -3.4028235e38 maxValue最大正单精度浮点数 大约 3.4028235e38 automationRate" a-rate"
1.20.3. GainOptions
这指定了构造GainNode时使用的选项。所有成员都是可选的;如果未指定,则在构造节点时将使用默认值。
dictionary GainOptions :AudioNodeOptions {float gain = 1.0; };
1.20.3.1. 字典 GainOptions
成员
gain, 类型为 float,默认值为1.0-
初始增益值,用于
gainAudioParam。
1.21. IIRFilterNode
接口
IIRFilterNode
是一个AudioNode
处理器,实现了通用的IIR滤波器。一般来说,最好使用BiquadFilterNode来实现更高阶的滤波器,原因如下:
-
通常对数值问题不太敏感
-
滤波器参数可以自动化
-
可以用于创建所有偶数阶IIR滤波器
然而,无法创建奇数阶滤波器,因此,如果需要奇数阶滤波器或者不需要自动化,IIR滤波器可能更合适。
一旦创建,IIR滤波器的系数不能更改。
| 属性 | 值 | 备注 |
|---|---|---|
numberOfInputs
| 1 | |
numberOfOutputs
| 1 | |
channelCount
| 2 | |
channelCountMode
| "max"
| |
channelInterpretation
| "speakers"
| |
| tail-time | 是 | 即使没有输入,IIR滤波器也会继续输出非静音音频。由于这是IIR滤波器,滤波器会永远产生非零输入,但实际上,这可以在一段有限的时间后被限制,在该时间段内输出接近零。实际时间取决于滤波器系数。 |
输出的通道数总是等于输入的通道数。
[Exposed =Window ]interface IIRFilterNode :AudioNode {constructor (BaseAudioContext ,context IIRFilterOptions );options undefined getFrequencyResponse (Float32Array ,frequencyHz Float32Array ,magResponse Float32Array ); };phaseResponse
1.21.1. 构造函数
IIRFilterNode(context, options)-
当构造函数使用
BaseAudioContextc 和选项对象option调用时,用户代理必须初始化 AudioNode this,使用context 和 options作为参数。IIRFilterNode.constructor() 方法的参数。 参数 类型 可为空 可选 描述 contextBaseAudioContext✘ ✘ 此新 IIRFilterNode将与BaseAudioContext相关联。optionsIIRFilterOptions✘ ✘ 此 IIRFilterNode的初始参数值。
1.21.2. 方法
getFrequencyResponse(frequencyHz, magResponse, phaseResponse)-
根据当前的滤波器参数设置,异步计算指定频率的频率响应。三个参数必须是长度相同的
Float32Array,否则必须抛出InvalidAccessError。IIRFilterNode.getFrequencyResponse()方法的参数。 参数 类型 可为空 可选 描述 frequencyHzFloat32Array✘ ✘ 此参数指定计算响应值的频率数组,单位为Hz。 magResponseFloat32Array✘ ✘ 此参数指定一个输出数组,用于接收线性幅度响应值。如果 frequencyHz参数中的某个值不在[0, sampleRate/2]范围内,其中sampleRate是sampleRate属性的值,magResponse数组中相同索引位置的值必须为NaN。phaseResponseFloat32Array✘ ✘ 此参数指定一个输出数组,用于接收以弧度表示的相位响应值。如果 frequencyHz参数中的某个值不在[0, sampleRate/2]范围内,其中sampleRate是sampleRate属性的值,phaseResponse数组中相同索引位置的值必须为NaN。返回类型:undefined
1.21.3.
IIRFilterOptions
IIRFilterOptions 字典用于指定 IIRFilterNode
的滤波器系数。
dictionary IIRFilterOptions :AudioNodeOptions {required sequence <double >feedforward ;required sequence <double >feedback ; };
1.21.3.1. 字典 IIRFilterOptions
成员
feedforward, 类型为 sequence<double>-
用于
IIRFilterNode的前馈系数。 该成员是必需的。请参阅feedforward参数,在createIIRFilter()方法中有其他约束。 feedback, 类型为 sequence<double>-
用于
IIRFilterNode的反馈系数。 该成员是必需的。请参阅feedback参数,在createIIRFilter()方法中有其他约束。
1.21.4. 滤波器定义
令 \(b_m\) 为 feedforward 系数,\(a_n\) 为 feedback 系数,且由 createIIRFilter()
或 IIRFilterOptions
字典指定给 构造函数。
然后,通用IIR滤波器的传递函数为:
$$
H(z) = \frac{\sum_{m=0}^{M} b_m z^{-m}}{\sum_{n=0}^{N} a_n z^{-n}}
$$
其中 \(M + 1\) 为 \(b\) 数组的长度,\(N + 1\) 为 \(a\) 数组的长度。系数 \(a_0\) 必须不为0(参见 反馈参数
对应于 createIIRFilter())。
至少有一个 \(b_m\) 必须非零(参见 前馈参数
对应于 createIIRFilter())。
等价地,时域方程为:
$$
\sum_{k=0}^{N} a_k y(n-k) = \sum_{k=0}^{M} b_k x(n-k)
$$
初始滤波器状态为全零状态。
注意:用户代理可能会生成警告,通知用户滤波器状态中出现了NaN值。这通常表示滤波器不稳定。
1.22.
MediaElementAudioSourceNode
接口
| 属性 | 值 | 备注 |
|---|---|---|
numberOfInputs
| 0 | |
numberOfOutputs
| 1 | |
| 尾时间 引用 | 否 |
输出的通道数与 HTMLMediaElement
所引用的媒体通道数一致。因此,对媒体元素的 src 属性的更改会改变此节点输出的通道数。
如果 HTMLMediaElement
的采样率与关联的 AudioContext
的采样率不同,那么 HTMLMediaElement
的输出必须重新采样以匹配上下文的 采样率。
使用 HTMLMediaElement
创建一个 MediaElementAudioSourceNode,
使用 AudioContext
的 createMediaElementSource()
方法,
或者使用 MediaElementAudioSourceOptions
字典中的 mediaElement
成员,
通过 构造函数。
单个输出的通道数等于作为参数传递给 HTMLMediaElement
的音频的通道数,或者如果 HTMLMediaElement
没有音频,则为 1。
HTMLMediaElement
必须在创建 MediaElementAudioSourceNode
后表现一致,除了渲染的音频不再直接听到,而是通过路由图中 MediaElementAudioSourceNode
连接后才会听到。因此,暂停、跳跃、音量、src 属性的变化以及 HTMLMediaElement
的其他方面必须表现得像平时那样,如果不与 MediaElementAudioSourceNode
一起使用的话。
const mediaElement= document. getElementById( 'mediaElementID' ); const sourceNode= context. createMediaElementSource( mediaElement); sourceNode. connect( filterNode);
[Exposed =Window ]interface MediaElementAudioSourceNode :AudioNode {constructor (AudioContext ,context MediaElementAudioSourceOptions ); [options SameObject ]readonly attribute HTMLMediaElement mediaElement ; };
1.22.1. 构造函数
MediaElementAudioSourceNode(context, options)-
-
初始化 AudioNode this,使用 context 和 options 作为参数。
参数用于 MediaElementAudioSourceNode.constructor() 方法。 参数 类型 可空 可选 描述 contextAudioContext✘ ✘ 此新创建的 MediaElementAudioSourceNode将与AudioContext关联。optionsMediaElementAudioSourceOptions✘ ✘ 此 MediaElementAudioSourceNode的初始参数值。 -
1.22.2. 属性
mediaElement, 类型为 HTMLMediaElement,只读
1.22.3.
MediaElementAudioSourceOptions
用于构建 MediaElementAudioSourceNode
的选项。
dictionary MediaElementAudioSourceOptions {required HTMLMediaElement mediaElement ; };
1.22.3.1. 字典 MediaElementAudioSourceOptions
成员
mediaElement, 类型为 HTMLMediaElement-
将被重新路由的媒体元素。必须指定。
1.22.4. MediaElementAudioSourceNode 与跨域资源的安全性
HTMLMediaElement
允许播放跨域资源。因为 Web Audio 允许检查资源的内容(例如使用 MediaElementAudioSourceNode、
以及 AudioWorkletNode
或 ScriptProcessorNode
读取样本),如果来自一个 来源
的脚本检查另一个来源的资源内容,可能会导致信息泄漏。
为防止这种情况,如果使用 HTMLMediaElement
创建的资源被 fetch
算法 标记为 [FETCH] 的 CORS-跨域 资源,则 MediaElementAudioSourceNode
必须输出 静音 而不是 HTMLMediaElement
的正常输出。
1.23.
MediaStreamAudioDestinationNode
接口
该接口是表示 MediaStream
的音频目的地,
其中包含一个 MediaStreamTrack,
其 kind 为 "audio"。该 MediaStream
会在节点创建时生成,并可通过 stream
属性访问。此流可与通过 MediaStream
获取的流类似使用,例如,可以通过 RTCPeerConnection(详见 [webrtc])
addStream() 方法发送到远程对等方。
| 属性 | 值 | 备注 |
|---|---|---|
numberOfInputs
| 1 | |
numberOfOutputs
| 0 | |
channelCount
| 2 | |
channelCountMode
| "explicit"
| |
channelInterpretation
| "speakers"
| |
| 尾时间(tail-time) | 否 |
输入的通道数量默认是 2(立体声)。
[Exposed =Window ]interface MediaStreamAudioDestinationNode :AudioNode {constructor (AudioContext ,context optional AudioNodeOptions = {});options readonly attribute MediaStream stream ; };
1.23.1. 构造函数
MediaStreamAudioDestinationNode(context, options)-
-
初始化 AudioNode this,使用 context 和 options 作为参数。
MediaStreamAudioDestinationNode.constructor() 方法的参数。 参数 类型 可为空 可选 描述 contextAudioContext✘ ✘ 这个新 BaseAudioContext将与MediaStreamAudioDestinationNode关联。optionsAudioNodeOptions✘ ✔ 此 MediaStreamAudioDestinationNode的可选初始参数值。 -
1.23.2. 属性
stream, 类型为 MediaStream,只读-
包含与该节点相同数量的通道的单个
MediaStreamTrack的MediaStream,并且其kind属性的值为"audio"。
1.24. MediaStreamAudioSourceNode
接口
该接口表示来自 MediaStream
的音频源。
| 属性 | 值 | 备注 |
|---|---|---|
numberOfInputs
| 0 | |
numberOfOutputs
| 1 | |
| 尾时间 参考 | 否 |
输出的通道数量与 MediaStreamTrack
的通道数量相对应。
当 MediaStreamTrack
结束时,此 AudioNode
输出一通道的静音。
如果 MediaStreamTrack
的采样率与关联的 AudioContext
的采样率不同,
则 MediaStreamTrack
的输出会被重采样以匹配上下文的 采样率。
[Exposed =Window ]interface MediaStreamAudioSourceNode :AudioNode {constructor (AudioContext ,context MediaStreamAudioSourceOptions ); [options SameObject ]readonly attribute MediaStream mediaStream ; };
1.24.1. 构造函数
MediaStreamAudioSourceNode(context, options)-
-
如果
mediaStream成员在options中未引用至少一个MediaStreamTrack其kind属性值为"audio",则抛出InvalidStateError并中止这些步骤。否则,将该流设为 inputStream。 -
令 tracks 为所有 inputStream 中
MediaStreamTrack列表,这些 track 的kind为"audio"。 -
根据
id属性对 tracks 的元素进行排序,使用对 代码单元值的排序。 -
初始化 AudioNode this,以 context 和 options 作为参数。
-
在此
MediaStreamAudioSourceNode上设置内部插槽[[input track]]为 tracks 的第一个元素。这是此MediaStreamAudioSourceNode用作输入音频的 track。
构造完成后,任何传递给构造函数的
MediaStream的更改都不会影响此AudioNode的底层输出。插槽
[[input track]]仅用于保持对MediaStreamTrack的引用。注意:这意味着从
MediaStreamAudioSourceNode的构造函数中选择的 track 从传递到此构造函数的MediaStream中移除后,MediaStreamAudioSourceNode仍将从相同的 track 中获取输入。注意:为了向后兼容,选择用于输出的 track 的行为是任意的。 可以使用
MediaStreamTrackAudioSourceNode来明确使用哪个 track 作为输入。MediaStreamAudioSourceNode.constructor() 方法的参数。 参数 类型 可为空 可选 描述 contextAudioContext✘ ✘ 新 AudioContext将与此MediaStreamAudioSourceNode关联。optionsMediaStreamAudioSourceOptions✘ ✘ 用于此 MediaStreamAudioSourceNode的初始参数值。 -
1.24.2. 属性
mediaStream, 类型为 MediaStream,只读-
在构造此
MediaStreamAudioSourceNode时使用的MediaStream。
1.24.3.
MediaStreamAudioSourceOptions
此选项用于构造 MediaStreamAudioSourceNode。
dictionary MediaStreamAudioSourceOptions {required MediaStream mediaStream ; };
1.24.3.1. 字典 MediaStreamAudioSourceOptions
成员
mediaStream, 类型为 MediaStream-
将作为源的媒体流。此项必须指定。
1.25.
MediaStreamTrackAudioSourceNode
接口
此接口表示来自 MediaStreamTrack
的音频源。
| 属性 | 值 | 备注 |
|---|---|---|
numberOfInputs
| 0 | |
numberOfOutputs
| 1 | |
| 尾时长 引用 | 无 |
输出的通道数与 mediaStreamTrack
的通道数对应。
如果 MediaStreamTrack
的采样率与关联的 AudioContext
的采样率不同,
那么 mediaStreamTrack
的输出将被重新采样以匹配上下文的 采样率。
[Exposed =Window ]interface MediaStreamTrackAudioSourceNode :AudioNode {constructor (AudioContext ,context MediaStreamTrackAudioSourceOptions ); };options
1.25.1. 构造函数
MediaStreamTrackAudioSourceNode(context, options)-
-
如果
mediaStreamTrack的kind属性不是"audio",则抛出InvalidStateError并中止这些步骤。 -
初始化 AudioNode this,以 context 和 options 作为参数。
用于 MediaStreamTrackAudioSourceNode.constructor() 方法的参数。 参数 类型 可为 null 可选 描述 contextAudioContext✘ ✘ 此新的 MediaStreamTrackAudioSourceNode将与AudioContext相关联。optionsMediaStreamTrackAudioSourceOptions✘ ✘ 此 MediaStreamTrackAudioSourceNode的初始参数值。 -
1.25.2. MediaStreamTrackAudioSourceOptions
这指定了构造 MediaStreamTrackAudioSourceNode
的选项。
这是必需的。
dictionary MediaStreamTrackAudioSourceOptions {required MediaStreamTrack mediaStreamTrack ; };
1.25.2.1. Dictionary MediaStreamTrackAudioSourceOptions
成员
mediaStreamTrack, 类型为 MediaStreamTrack-
将作为源的媒体流轨道。如果此
MediaStreamTrackkind属性不是"audio",则必须抛出InvalidStateError。
1.26. OscillatorNode
接口
OscillatorNode
代表一个生成周期波形的音频源。它可以设置为几种常用的波形。此外,还可以通过使用 PeriodicWave
对象设置为任意周期波形。
振荡器是音频合成中的常见基础构建块。OscillatorNode 会在 start()
方法指定的时间开始发出声音。
从数学角度讲,连续时间的周期波形在频域中可能具有非常高(或无限高)的频率信息。当这个波形以特定采样率作为离散时间的数字音频信号进行采样时,必须小心地丢弃(滤除)高于 奈奎斯特频率 的高频信息,然后再将波形转换为数字形式。如果不这样做,那么高频(大于 奈奎斯特频率)会折叠回频率低于 奈奎斯特频率 的镜像频率。在许多情况下,这会导致听起来令人不悦的伪影。这是音频数字信号处理(DSP)中的一个基本且被广泛理解的原理。
为了避免这种混叠,实施方案有几种实际的做法。无论采用哪种方式,理想化的离散时间数字音频信号在数学上是明确定义的。实现的权衡问题在于实现成本(CPU 使用量)与理想音频信号的忠实度之间的平衡。
预计实施方案在实现这一理想时会有所注意,但在较低端硬件上,考虑采用质量较低且成本较低的方法是合理的。
属性 frequency
和 detune
是 a-rate 参数,构成一个 复合参数。它们一起用来确定 computedOscFrequency 值:
computedOscFrequency(t) = frequency(t) * pow(2, detune(t) / 1200)
OscillatorNode 在每个时间点的瞬时相位是 computedOscFrequency 的定积分,假设节点的精确启动时间的相位角为零。其 标称范围 是 [-奈奎斯特频率,奈奎斯特频率]。
该节点的单个输出由一个通道(单声道)组成。
| 属性 | 值 | 备注 |
|---|---|---|
numberOfInputs
| 0 | |
numberOfOutputs
| 1 | |
channelCount
| 2 | |
channelCountMode
| "max"
| |
channelInterpretation
| "speakers"
| |
| tail-time | 无 |
enum {OscillatorType "sine" ,"square" ,"sawtooth" ,"triangle" ,"custom" };
| 枚举值 | 描述 |
|---|---|
"sine"
| 正弦波 |
"square"
| 占空比为 0.5 的方波 |
"sawtooth"
| 锯齿波 |
"triangle"
| 三角波 |
"custom"
| 自定义周期波形 |
[Exposed =Window ]interface OscillatorNode :AudioScheduledSourceNode {constructor (BaseAudioContext ,context optional OscillatorOptions = {});options attribute OscillatorType type ;readonly attribute AudioParam frequency ;readonly attribute AudioParam detune ;undefined setPeriodicWave (PeriodicWave ); };periodicWave
1.26.1. 构造函数
OscillatorNode(context, options)-
当构造函数使用
BaseAudioContextc 和一个选项对象 option 调用时,用户代理必须使用 context 和 options 作为参数,初始化 AudioNode this。构造方法 OscillatorNode.constructor() 的参数。 参数 类型 可为空 可选 描述 contextBaseAudioContext✘ ✘ 这个新的 OscillatorNode将会 与BaseAudioContext相关联。optionsOscillatorOptions✘ ✔ 该 OscillatorNode的可选初始参数值。
1.26.2. 属性
detune, 类型为 AudioParam, 只读-
一个偏移值(单位为 cents),该值将会 将
频率偏移指定的量。默认value为 0。此参数是 a-rate。它与频率组成一个 复合参数,形成 computedOscFrequency。下面列出的名义范围允许此参数在整个频率范围内偏移频率。参数 值 备注 defaultValue0 minValue\(\approx -153600\) maxValue\(\approx 153600\) 该值大约为 \(1200\ \log_2 \mathrm{FLT\_MAX}\),其中 FLT_MAX 是最大的 float值。automationRate" a-rate" frequency, 类型为 AudioParam, 只读-
周期波形的频率(单位为赫兹)。默认
value为 440。此参数是 a-rate。它 与 复合参数detune共同组成 computedOscFrequency。其 名义范围 是 [-奈奎斯特频率, 奈奎斯特 频率].参数 值 备注 defaultValue440 minValue-奈奎斯特频率 maxValue奈奎斯特频率 automationRate" a-rate" type, 类型为 OscillatorType-
周期波形的形状。可以直接设置为任何类型常量值,除了 "
custom"。 如果这样做,必须抛出一个InvalidStateError异常。 可以使用setPeriodicWave()方法设置自定义波形,这将导致此属性设置为 "custom"。 默认值是 "sine"。 设置此属性时,必须保持振荡器的相位。
1.26.3. 方法
setPeriodicWave(periodicWave)-
给定一个
PeriodicWave,设置任意自定义周期波形。OscillatorNode.setPeriodicWave() 方法的参数。 参数 类型 可为空 可选 描述 periodicWavePeriodicWave✘ ✘ 振荡器使用的自定义波形 返回类型:undefined
1.26.4.
OscillatorOptions
此处指定了用于构造 OscillatorNode
的选项。
所有成员都是可选的;如果未指定,则使用默认值来构造振荡器。
dictionary OscillatorOptions :AudioNodeOptions {OscillatorType type = "sine";float frequency = 440;float detune = 0;PeriodicWave periodicWave ; };
1.26.4.1. 字典 OscillatorOptions
成员
detune, 类型为 float,默认值为0-
OscillatorNode的初始微调值。 frequency, 类型为 float,默认值为440-
OscillatorNode的初始频率。 periodicWave, 类型为 PeriodicWave-
用于
OscillatorNode的PeriodicWave。 如果指定了此选项,则任何有效的type值都将被忽略; 它将被视为指定了 "custom"。 type, 类型为 OscillatorType,默认值为"sine"-
要构造的振荡器类型。如果设置为 "custom" 而未指定
periodicWave, 则必须抛出InvalidStateError异常。如果指定了periodicWave, 则任何有效的type值都将被忽略; 它将被视为设置为 "custom"。
1.26.5. 基本波形相位
各种振荡器类型的理想数学波形在下面定义。总的来说,所有波形在数学上都被定义为一个在时间 0 具有正斜率的奇函数。 振荡器产生的实际波形可能有所不同,以防止混叠效应。
振荡器必须产生与使用适当的傅里叶级数创建 PeriodicWave
并将 disableNormalization
设置为 false 所得到的结果相同,以生成这些基本波形。
- "
sine" -
正弦振荡器的波形为:
$$ x(t) = \sin t $$ - "
square" -
方波振荡器的波形为:
$$ x(t) = \begin{cases} 1 & \mbox{for } 0≤ t < \pi \\ -1 & \mbox{for } -\pi < t < 0. \end{cases} $$通过利用波形是一个周期为 \(2\pi\) 的奇函数的事实,可以将其扩展到所有 \(t\) 上。
- "
sawtooth" -
锯齿振荡器的波形为斜坡:
$$ x(t) = \frac{t}{\pi} \mbox{ for } -\pi < t ≤ \pi; $$通过利用波形是一个周期为 \(2\pi\) 的奇函数的事实,可以将其扩展到所有 \(t\) 上。
- "
triangle" -
三角波振荡器的波形为:
$$ x(t) = \begin{cases} \frac{2}{\pi} t & \mbox{for } 0 ≤ t ≤ \frac{\pi}{2} \\ 1-\frac{2}{\pi} \left(t-\frac{\pi}{2}\right) & \mbox{for } \frac{\pi}{2} < t ≤ \pi. \end{cases} $$通过利用波形是一个周期为 \(2\pi\) 的奇函数的事实,可以将其扩展到所有 \(t\) 上。
1.27. PannerNode
接口
该接口表示一个处理节点,用于在三维空间中定位/空间化输入的音频流。空间化是相对于 BaseAudioContext
的
AudioListener
(listener
属性)来实现的。
| 属性 | 值 | 备注 |
|---|---|---|
numberOfInputs
| 1 | |
numberOfOutputs
| 1 | |
channelCount
| 2 | 具有 channelCount 限制 |
channelCountMode
| "clamped-max"
| 具有 channelCountMode 限制 |
channelInterpretation
| "speakers"
| |
| 尾部时间 | 可能 | 如果 panningModel
被设置为 "HRTF",
则由于头部响应的固有处理,该节点将为静音输入产生非静音输出。否则,尾部时间为零。
|
此节点的输入可以是单声道(1 声道)或立体声(2 声道),但不能增加。来自具有较少或较多声道的节点的连接将适当地进行上混音或下混音。
如果该节点正在进行处理,则此节点的输出硬编码为立体声(2 声道),不能配置。如果节点未正在进行处理,则输出为单声道的静音。
PanningModelType
枚举决定了将在 3D 空间中定位音频所使用的空间化算法。默认值为 "equalpower"。
enum {PanningModelType "equalpower" ,"HRTF" };
| 枚举值 | 描述 |
|---|---|
"equalpower"
|
使用等功率平移的简单且高效的空间化算法。
注意:当使用此平移模型时,所有用于计算该节点输出的 |
"HRTF"
|
使用与人类受试者测量的脉冲响应卷积的高质量空间化算法。此平移方法会渲染立体声输出。
注意:当使用此平移模型时,所有用于计算该节点输出的 |
一个 AudioParam
在 PannerNode
中的 有效自动化速率 由
panningModel
和 automationRate
决定。如果 panningModel
是 "HRTF",则
有效自动化速率
为 "k-rate",与
automationRate
的设置无关。
否则,有效自动化速率 为 automationRate
的值。
DistanceModelType
枚举决定了当音频源远离监听者时将使用哪种算法来减少音量。默认值为 "inverse"。
在下面每个距离模型的描述中,设 \(d\) 为监听者与平移器之间的距离;\(d_{ref}\) 为 refDistance
属性的值;\(d_{max}\) 为 maxDistance
属性的值;\(f\) 为 rolloffFactor
属性的值。
enum {DistanceModelType "linear" ,"inverse" ,"exponential" };
| 枚举值 | 描述 |
|---|---|
"linear"
|
线性距离模型,按以下公式计算distanceGain:
$$
1 - f\ \frac{\max\left[\min\left(d, d’_{max}\right), d’_{ref}\right] - d’_{ref}}{d’_{max} - d’_{ref}}
$$
其中 \(d’_{ref} = \min\left(d_{ref}, d_{max}\right)\),\(d’_{max} = \max\left(d_{ref}, d_{max}\right)\)。当 \(d’_{ref} = d’_{max}\) 时,线性模型的值为 \(1-f\)。 注意 \(d\) 被限制在 \(\left[d’_{ref},\, d’_{max}\right]\) 区间内。 |
"inverse"
|
反比例距离模型,按以下公式计算distanceGain:
$$
\frac{d_{ref}}{d_{ref} + f\ \left[\max\left(d, d_{ref}\right) - d_{ref}\right]}
$$
也就是说,\(d\) 被限制在 \(\left[d_{ref},\, \infty\right)\) 区间内。如果 \(d_{ref} = 0\),则反比例模型的值为 0,与 \(d\) 和 \(f\) 的值无关。 |
"exponential"
|
指数距离模型,按以下公式计算distanceGain:
$$
\left[\frac{\max\left(d, d_{ref}\right)}{d_{ref}}\right]^{-f}
$$
也就是说,\(d\) 被限制在 \(\left[d_{ref},\, \infty\right)\) 区间内。如果 \(d_{ref} = 0\),则指数模型的值为 0,与 \(d\) 和 \(f\) 的值无关。 |
[Exposed =Window ]interface PannerNode :AudioNode {constructor (BaseAudioContext ,context optional PannerOptions = {});options attribute PanningModelType panningModel ;readonly attribute AudioParam positionX ;readonly attribute AudioParam positionY ;readonly attribute AudioParam positionZ ;readonly attribute AudioParam orientationX ;readonly attribute AudioParam orientationY ;readonly attribute AudioParam orientationZ ;attribute DistanceModelType distanceModel ;attribute double refDistance ;attribute double maxDistance ;attribute double rolloffFactor ;attribute double coneInnerAngle ;attribute double coneOuterAngle ;attribute double coneOuterGain ;undefined setPosition (float ,x float ,y float );z undefined setOrientation (float ,x float ,y float ); };z
1.27.1. 构造函数
PannerNode(context, options)-
当使用
BaseAudioContextc 和选项对象 option 调用构造函数时,用户代理必须使用 context 和 options 作为参数 初始化 AudioNode this。PannerNode.constructor() 方法的参数。 参数 类型 可为 null 可选 描述 contextBaseAudioContext✘ ✘ 该 BaseAudioContext新的PannerNode将被关联。optionsPannerOptions✘ ✔ 该 PannerNode的可选初始参数值。
1.27.2. 属性
coneInnerAngle, 类型为 double-
用于定向音频源的参数,以度为单位的角度,在该角度内不会有音量衰减。 默认值为 360。如果角度超出区间 [0, 360],行为是未定义的。
coneOuterAngle, 类型为 double-
用于定向音频源的参数,以度为单位的角度,超过该角度后音量将减小到
coneOuterGain。 默认值为 360。如果角度超出区间 [0, 360],行为是未定义的。 coneOuterGain, 类型为 double-
用于定向音频源的参数,表示在
coneOuterAngle之外的增益。默认值为 0。它是范围为 [0, 1] 的线性值(非 dB)。如果参数超出该范围,必须抛出InvalidStateError异常。 distanceModel, 类型为 DistanceModelType-
指定该
PannerNode使用的距离模型。 默认值为 "inverse"。 maxDistance, 类型为 double-
源和监听器之间的最大距离,超过此距离后音量将不再进一步减小。默认值为 10000。 如果设置为非正值,必须抛出
RangeError异常。 orientationX, 类型为 AudioParam,只读-
描述音频源在三维笛卡尔坐标空间中指向的方向向量的 \(x\)-分量。
参数 值 备注 defaultValue1 minValuemost-negative-single-float 大约为 -3.4028235e38 maxValuemost-positive-single-float 大约为 3.4028235e38 automationRate" a-rate"具有 自动化率约束 orientationY, 类型为 AudioParam, 只读-
描述音频源在三维笛卡尔坐标空间中指向的方向向量的 \(y\)-分量。
参数 值 备注 defaultValue0 minValue最小负单精度浮点数 大约为 -3.4028235e38 maxValue最大正单精度浮点数 大约为 3.4028235e38 automationRate" a-rate"具有 自动化率约束 orientationZ, 类型为 AudioParam, 只读-
描述音频源在三维笛卡尔坐标空间中指向的方向向量的 \(z\)-分量。
参数 值 备注 defaultValue0 minValue最小负单精度浮点数 大约为 -3.4028235e38 maxValue最大正单精度浮点数 大约为 3.4028235e38 automationRate" a-rate"具有 自动化率约束 panningModel, 类型为 PanningModelType-
指定此
PannerNode使用的平移模型。默认值为 "equalpower"。 positionX, 类型为 AudioParam, 只读-
设置音频源在三维笛卡尔坐标系中的 \(x\)-坐标位置。
参数 值 备注 defaultValue0 minValue最小负单精度浮点数 大约为 -3.4028235e38 maxValue最大正单精度浮点数 大约为 3.4028235e38 automationRate" a-rate"具有 自动化率约束 positionY, 类型为 AudioParam, 只读-
设置音频源在三维笛卡尔坐标系中的 \(y\)-坐标位置。
参数 值 备注 defaultValue0 minValue最小负单精度浮点数 大约为 -3.4028235e38 maxValue最大正单精度浮点数 大约为 3.4028235e38 automationRate" a-rate"具有 自动化率约束 positionZ, 类型为 AudioParam, 只读-
设置音频源在三维笛卡尔坐标系中的 \(z\)-坐标位置。
参数 值 备注 defaultValue0 minValue最小负单精度浮点数 大约为 -3.4028235e38 maxValue最大正单精度浮点数 大约为 3.4028235e38 automationRate" a-rate"具有 自动化率约束 refDistance, 类型为 double-
参考距离,用于在音源远离听众时减小音量。对于小于此距离的情况,音量不减少。默认值为 1。 如果将该值设置为负值,则必须抛出
RangeError异常。 rolloffFactor, 类型为 double-
描述音源远离听众时音量减少的速度。默认值为 1。如果将该值设置为负值,则必须抛出
RangeError异常。rolloffFactor的名义范围 指定了rolloffFactor可具有的最小值和最大值。超出此范围的值将被限制在该范围内。名义范围取决于distanceModel,如下所示:- "
linear" -
名义范围是 \([0, 1]\)。
- "
inverse" -
名义范围是 \([0, \infty)\)。
- "
exponential" -
名义范围是 \([0, \infty)\)。
请注意,限制操作是在距离计算的处理过程中进行的。该属性反映的是已设置的值,而不会被修改。
- "
1.27.3. 方法
setOrientation(x, y, z)-
此方法已弃用。它等同于直接设置
orientationX.value,orientationY.value,和orientationZ.value属性,分别使用x、y和z参数。因此,如果在调用此方法时,任何
orientationX、orientationY和orientationZAudioParam已设置自动化曲线,并使用setValueCurveAtTime()方法, 则必须抛出NotSupportedError异常。此方法描述了音频源在三维笛卡尔坐标空间中指向的方向。根据声音的指向性(由 cone 属性控制),远离听者的声音可以非常安静或完全静音。
x,y和z参数表示三维空间中的方向向量。默认值为 (1, 0, 0)。
参数列表:PannerNode.setOrientation() 方法。 参数 类型 可空 可选 描述 xfloat✘ ✘ yfloat✘ ✘ zfloat✘ ✘ 返回类型:undefined setPosition(x, y, z)-
此方法已弃用。它等同于直接设置
positionX.value,positionY.value,和positionZ.value属性,分别使用x、y和z参数。因此,如果在调用此方法时,任何
positionX、positionY和positionZAudioParam已设置自动化曲线,并使用setValueCurveAtTime()方法, 则必须抛出NotSupportedError异常。此方法设置音频源相对于
监听器的位置。使用三维笛卡尔坐标系统。x、y和z参数表示三维空间中的坐标。默认值为 (0, 0, 0)。
参数列表:PannerNode.setPosition() 方法。 参数 类型 可空 可选 描述 xfloat✘ ✘ yfloat✘ ✘ zfloat✘ ✘ 返回类型:undefined
1.27.4. PannerOptions
此项指定了构造 PannerNode
的选项。
所有成员都是可选的;如果未指定,则在构造节点时将使用默认值。
dictionary PannerOptions :AudioNodeOptions {PanningModelType panningModel = "equalpower";DistanceModelType distanceModel = "inverse";float positionX = 0;float positionY = 0;float positionZ = 0;float orientationX = 1;float orientationY = 0;float orientationZ = 0;double refDistance = 1;double maxDistance = 10000;double rolloffFactor = 1;double coneInnerAngle = 360;double coneOuterAngle = 360;double coneOuterGain = 0; };
1.27.4.1. 字典 PannerOptions
成员
coneInnerAngle, 类型为 double,默认为360-
节点的
coneInnerAngle属性的初始值。 coneOuterAngle, 类型为 double,默认为360-
节点的
coneOuterAngle属性的初始值。 coneOuterGain, 类型为 double,默认为0-
节点的
coneOuterGain属性的初始值。 distanceModel, 类型为 DistanceModelType,默认为"inverse"-
节点使用的距离模型。
maxDistance, 类型为 double,默认为10000-
节点的
maxDistance属性的初始值。 orientationX, 类型为 float,默认为1-
节点的
orientationXAudioParam 的初始 \(x\)-分量值。 orientationY, 类型为 float,默认为0-
节点的
orientationYAudioParam 的初始 \(y\)-分量值。 orientationZ, 类型为 float,默认为0-
节点的
orientationZAudioParam 的初始 \(z\)-分量值。 panningModel, 类型为 PanningModelType,默认为"equalpower"-
节点使用的声道平移模型。
positionX, 类型为 float,默认为0-
节点的
positionXAudioParam 的初始 \(x\)-坐标值。 positionY, 类型为 float,默认为0-
节点的
positionYAudioParam 的初始 \(y\)-坐标值。 positionZ, 类型为 float,默认为0-
节点的
positionZAudioParam 的初始 \(z\)-坐标值。 refDistance, 类型为 double,默认为1-
节点的
refDistance属性的初始值。 rolloffFactor, 类型为 double,默认为1-
节点的
rolloffFactor属性的初始值。
1.27.5. 通道限制
StereoPannerNode
的 通道限制 集也适用于 PannerNode。
1.28. PeriodicWave
接口
PeriodicWave
表示一个用于 OscillatorNode
的任意周期波形。
一个 符合实现的系统必须支持 PeriodicWave
至少包含 8192 个元素。
[Exposed =Window ]interface PeriodicWave {constructor (BaseAudioContext ,context optional PeriodicWaveOptions = {}); };options
1.28.1. 构造函数
PeriodicWave(context, options)-
-
令 p 为一个新的
PeriodicWave对象。令[[real]]和[[imag]]为类型为Float32Array的两个内部槽,并令[[normalize]]为一个内部槽。 -
根据以下情况之一处理
options:-
如果
options.real和options.imag都存在-
如果
options.real和options.imag的长度不同或长度小于 2,则抛出IndexSizeError并中止此算法。 -
将
[[real]]和[[imag]]设置为具有与options.real相同长度的新数组。 -
将
options.real的所有元素复制到[[real]],并将options.imag复制到[[imag]]。
-
-
如果仅
options.real存在-
如果
options.real的长度小于 2,则抛出IndexSizeError并中止此算法。 -
将
[[real]]和[[imag]]设置为与options.real具有相同长度的数组。 -
将
options.real复制到[[real]],并将[[imag]]设置为全 0。
-
-
如果仅
options.imag存在-
如果
options.imag的长度小于 2,则抛出IndexSizeError并中止此算法。 -
将
[[real]]和[[imag]]设置为与options.imag具有相同长度的数组。 -
将
options.imag复制到[[imag]],并将[[real]]设置为全 0。
-
-
否则
注意: 当将这个
PeriodicWave设置为OscillatorNode时,这相当于使用内建类型 "sine"。
-
-
将
[[normalize]]初始化为disableNormalization属性的反值,该属性属于PeriodicWaveConstraints上的PeriodicWaveOptions。 -
返回 p。
PeriodicWave.constructor() 方法的参数。 参数 类型 可为空 可选 描述 contextBaseAudioContext✘ ✘ 此新的 BaseAudioContext关联的PeriodicWave。与AudioBuffer不同,PeriodicWave不能跨AudioContext或OfflineAudioContext共享。它与特定的BaseAudioContext相关联。optionsPeriodicWaveOptions✘ ✔ 此新的 PeriodicWave的可选初始参数值。 -
1.28.2. PeriodicWaveConstraints
PeriodicWaveConstraints
字典用于指定如何对波形进行标准化。
dictionary PeriodicWaveConstraints {boolean disableNormalization =false ; };
1.28.2.1. 字典 PeriodicWaveConstraints
成员
disableNormalization, 类型为 boolean,默认为false-
控制周期波形是否标准化。如果为
true,则波形不会标准化;否则,波形将被标准化。
1.28.3. PeriodicWaveOptions
PeriodicWaveOptions
字典用于指定如何构建波形。如果仅指定了 real
或 imag,则将另一个视为具有相同长度的全
0 数组,如下文在字典成员的描述中所指定。如果两者都未给出,则创建的 PeriodicWave
必须等同于 OscillatorNode,其
type
为 "sine"。如果两者都给出,则序列必须具有相同的长度;否则会抛出
类型为 NotSupportedError
的错误。
dictionary PeriodicWaveOptions :PeriodicWaveConstraints {sequence <float >real ;sequence <float >imag ; };
1.28.3.1. 字典 PeriodicWaveOptions
成员
imag, 类型为 sequence<float>-
imag参数表示sine项的数组。第一个元素(索引 0)在傅立叶级数中不存在。第二个元素(索引 1)表示基频。第三个表示第一个谐波,依此类推。 real, 类型为 sequence<float>-
real参数表示cosine项的数组。第一个元素(索引 0)是周期波形的 DC 偏移。第二个元素(索引 1)表示基频。第三个表示第一个谐波,依此类推。
1.28.4. 波形生成
createPeriodicWave()
方法采用两个数组来指定 PeriodicWave
的傅立叶系数。令 \(a\) 和 \(b\) 分别表示 [[real]]
和 [[imag]]
数组,长度为 \(L\)。则基本时域波形 \(x(t)\) 可通过以下方式计算:
$$
x(t) = \sum_{k=1}^{L-1} \left[a[k]\cos2\pi k t + b[k]\sin2\pi k t\right]
$$
这是基本的(未标准化的)波形。
1.28.5. 波形标准化
如果此 PeriodicWave
的内部槽 [[normalize]]
为 true(默认值),则会对上一节中定义的波形进行标准化,使最大值为 1。标准化过程如下。
令
$$
\tilde{x}(n) = \sum_{k=1}^{L-1} \left(a[k]\cos\frac{2\pi k n}{N} + b[k]\sin\frac{2\pi k n}{N}\right)
$$
其中 \(N\) 是 2 的幂次方。(注意:\(\tilde{x}(n)\) 可以方便地通过逆 FFT 计算得出。)固定的标准化因子 \(f\) 计算如下。
$$
f = \max_{n = 0, \ldots, N - 1} |\tilde{x}(n)|
$$
因此,实际的标准化波形 \(\hat{x}(n)\) 为:
$$
\hat{x}(n) = \frac{\tilde{x}(n)}{f}
$$
这个固定的标准化因子必须应用于所有生成的波形。
1.28.6. 振荡器系数
内置振荡器类型是使用 PeriodicWave
对象创建的。为了完整性,这里提供了每个内置振荡器类型的 PeriodicWave
的系数。如果需要内置类型但不需要默认的标准化,这将非常有用。
在以下描述中,令 \(a\) 为实系数数组,\(b\) 为 createPeriodicWave()
的虚系数数组。在所有情况下,对于所有 \(n\),\(a[n] = 0\),因为波形是奇函数。此外,在所有情况下 \(b[0] = 0\)。因此,下面仅指定 \(b[n]\) 的情况,其中 \(n \ge 1\)。
- "
sine" -
$$ b[n] = \begin{cases} 1 & \mbox{for } n = 1 \\ 0 & \mbox{otherwise} \end{cases} $$ - "
square" -
$$ b[n] = \frac{2}{n\pi}\left[1 - (-1)^n\right] $$ - "
sawtooth" -
$$ b[n] = (-1)^{n+1} \dfrac{2}{n\pi} $$ - "
triangle" -
$$ b[n] = \frac{8\sin\dfrac{n\pi}{2}}{(\pi n)^2} $$
1.29. 接口 ScriptProcessorNode
- 已弃用
此接口是 AudioNode,可以直接使用脚本生成、处理或分析音频。此节点类型已弃用,将由
AudioWorkletNode
取代;此文本仅用于提供信息,直到实现移除此节点类型。
| 属性 | 值 | 说明 |
|---|---|---|
numberOfInputs
| 1 | |
numberOfOutputs
| 1 | |
channelCount
| numberOfInputChannels
| 这是构造此节点时指定的通道数量。存在channelCount 限制。 |
channelCountMode
| "explicit"
| 具有channelCountMode 限制 |
channelInterpretation
| "speakers"
| |
| 尾时间 | 否 |
ScriptProcessorNode
是通过 bufferSize
构造的,值必须是以下之一:256、512、1024、2048、4096、8192、16384。此值控制 audioprocess
事件的调度频率以及每次调用需要处理的采样帧数。仅当 ScriptProcessorNode
至少有一个输入或一个输出连接时,才会调度 audioprocess
事件。较低的 bufferSize
数值会导致较低(更好)的延迟。为了避免音频中断和失真,需要更高的数值。如果未传入或设置为 0,则由实现选择
createScriptProcessor()
的 bufferSize 参数。
numberOfInputChannels
和 numberOfOutputChannels
确定输入和输出通道数。两个 numberOfInputChannels
和 numberOfOutputChannels
都为零是无效的。
[Exposed =Window ]interface ScriptProcessorNode :AudioNode {attribute EventHandler onaudioprocess ;readonly attribute long bufferSize ; };
1.29.1. 属性
bufferSize, 类型为 long,只读-
每次触发
audioprocess时需要处理的缓冲区大小(以采样帧为单位)。合法值为(256、512、1024、2048、4096、8192、16384)。 onaudioprocess, 类型为 EventHandler-
用于设置 事件处理器的属性,用于调度到
ScriptProcessorNode节点类型的audioprocess事件类型。调度到事件处理器的事件使用AudioProcessingEvent接口。
1.30. 接口
StereoPannerNode
此接口表示一个处理节点,该节点使用 低成本声道定位算法将传入的音频流定位在立体声图像中。此声道定位效果在将音频组件定位于立体声流中非常常见。
| 属性 | 值 | 说明 |
|---|---|---|
numberOfInputs
| 1 | |
numberOfOutputs
| 1 | |
channelCount
| 2 | 存在 channelCount 限制 |
channelCountMode
| "clamped-max"
| 存在 channelCountMode 限制 |
channelInterpretation
| "speakers"
| |
| 尾时间 | 否 |
此节点的输入为立体声(2 个通道),无法增加。与通道数更少或更多的节点连接时,将进行上混音或下混音。
此节点的输出硬编码为立体声(2 个通道),无法配置。
[Exposed =Window ]interface StereoPannerNode :AudioNode {constructor (BaseAudioContext ,context optional StereoPannerOptions = {});options readonly attribute AudioParam pan ; };
1.30.1. 构造函数
StereoPannerNode(context, options)-
当使用
BaseAudioContextc 和一个选项对象 option 调用构造函数时,用户代理必须使用 context 和 options 作为参数 初始化 AudioNode this。StereoPannerNode.constructor() 方法的参数。 参数 类型 可空 可选 描述 contextBaseAudioContext✘ ✘ 此新 StereoPannerNode将关联的BaseAudioContext。optionsStereoPannerOptions✘ ✔ 此 StereoPannerNode的可选初始参数值。
1.30.2. 属性
pan, 类型为 AudioParam,只读-
输入在输出立体声图像中的位置。-1 表示完全左侧,+1 表示完全右侧。
参数 值 说明 defaultValue0 minValue-1 maxValue1 automationRate" a-rate"
1.30.3. StereoPannerOptions
这指定了用于构造 StereoPannerNode
的选项。所有成员都是可选的;如果未指定,则在构造节点时使用默认值。
dictionary StereoPannerOptions :AudioNodeOptions {float pan = 0; };
1.30.3.1. 字典 StereoPannerOptions
成员
pan, 类型为 float,默认值为0-
初始值用于
panAudioParam。
1.30.4. 通道限制
由于其处理受到上述定义的限制,StereoPannerNode
限制为最多混合 2 个音频通道,并生成精确的 2 个通道。可以使用 ChannelSplitterNode、
由 GainNode
或其他节点组成的子图进行中间处理,
并通过 ChannelMergerNode
重新组合,以实现任意的声道定位和混音方法。
1.31. 接口
WaveShaperNode
WaveShaperNode
是一个 AudioNode
处理器,能够实现非线性失真效果。
非线性波形整形失真常用于微妙的非线性暖音或更明显的失真效果。可以指定任意的非线性整形曲线。
| 属性 | 值 | 说明 |
|---|---|---|
numberOfInputs
| 1 | |
numberOfOutputs
| 1 | |
channelCount
| 2 | |
channelCountMode
| "max"
| |
channelInterpretation
| "speakers"
| |
| 尾时间 | 可能有 | 只有在 oversample
属性设置为 "2x"
或 "4x"
时才有尾时间。
该 尾时间 的实际持续时间取决于实现。
|
输出的通道数始终等于输入的通道数。
enum {OverSampleType "none" ,"2x" ,"4x" };
| 枚举值 | 描述 |
|---|---|
"none"
| 不进行过采样 |
"2x"
| 过采样两倍 |
"4x"
| 过采样四倍 |
[Exposed =Window ]interface WaveShaperNode :AudioNode {constructor (BaseAudioContext ,context optional WaveShaperOptions = {});options attribute Float32Array ?curve ;attribute OverSampleType oversample ; };
1.31.1. 构造函数
WaveShaperNode(context, options)-
当构造函数以
BaseAudioContextc 和选项对象 option 被调用时,用户代理必须使用 context 和 options 作为参数 初始化 AudioNode this。另外,让
[[curve set]]成为该WaveShaperNode的一个内部槽。将该槽初始化为false。如果给定options并指定了curve, 则将[[curve set]]设置为true。参数列表 WaveShaperNode.constructor() 方法。 参数 类型 可为空 可选 描述 contextBaseAudioContext✘ ✘ 新创建的 WaveShaperNode将与该BaseAudioContext关联。optionsWaveShaperOptions✘ ✔ 此 WaveShaperNode的可选初始参数值。
1.31.2. 属性
curve, 类型为 Float32Array,可为空-
用于波形塑形效果的塑形曲线。输入信号名义上在范围 [-1, 1] 内。范围内的每个输入样本将索引到塑形曲线中, 如果曲线数组中有奇数个条目,则信号级别为零对应于曲线数组的中心值;如果数组中有偶数个条目,则在两个最中心值之间进行插值。 任何小于 -1 的样本值将对应于曲线数组的第一个值。任何大于 +1 的样本值将对应于曲线数组的最后一个值。
实现必须对曲线中的相邻点进行线性插值。初始时,曲线属性为 null,这意味着 WaveShaperNode 将 其输入直接传递给输出,不进行任何修改。
曲线的值在 [-1; 1] 范围内均匀分布。这意味着具有偶数个值的
curve没有表示信号为零的值,而具有奇数个值的curve有一个表示信号为零的值。输出由以下算法确定。-
令 \(x\) 为输入样本,\(y\) 为节点的对应输出,\(c_k\) 为
curve的第 \(k\) 个元素,\(N\) 为curve的长度。 -
令
$$ \begin{align*} v &= \frac{N-1}{2}(x + 1) \\ k &= \lfloor v \rfloor \\ f &= v - k \end{align*} $$ -
那么
$$ \begin{align*} y &= \begin{cases} c_0 & v \lt 0 \\ c_{N-1} & v \ge N - 1 \\ (1-f)\,c_k + fc_{k+1} & \mathrm{otherwise} \end{cases} \end{align*} $$
如果将此属性设置为长度小于 2 的
Float32Array, 则必须抛出InvalidStateError。设置该属性时,
WaveShaperNode会创建该曲线的内部副本。因此,随后修改用于设置该属性的数组的内容不会产生任何影响。要设置curve属性,请执行以下步骤:-
令 new curve 为要分配给
Float32Array或null的新曲线。 。 -
如果 new curve 不是
null且[[curve set]]为 true,则抛出InvalidStateError并中止这些步骤。 -
如果 new curve 不是
null,将[[curve set]]设置为 true。 -
将 new curve 分配给
curve属性。
注意: 使用对于零输入值生成非零输出值的曲线将导致该节点生成直流信号,即使没有输入连接到该节点。 这种情况将持续到该节点与下游节点断开连接。
-
oversample, 类型为 OverSampleType-
指定在应用塑形曲线时应使用的过采样类型(如果有)。默认值为 "
none", 这意味着曲线将直接应用于输入样本。值 "2x" 或 "4x" 可以通过避免一些混叠来提高处理的质量,其中 "4x" 值提供最高的质量。对于某些应用,最好不使用过采样以获得非常精确的塑形曲线。值 "2x" 或 "4x" 表示必须执行以下步骤:-
将输入样本上采样到
AudioContext的采样率的 2 倍或 4 倍。因此,对于每个 渲染量子,生成两倍(对于 2x)或四倍(对于 4x)样本。 -
应用塑形曲线。
-
将结果下采样回
AudioContext的采样率。因此,取先前处理的样本,生成一个渲染量子值作为最终结果。
上采样和下采样滤波器的具体实现未指定,可根据声音质量(低混叠等)、低延迟或性能进行调整。
注意: 使用过采样会引入一定程度的音频处理延迟, 这是由于上采样和下采样滤波器造成的。此延迟的数量可能因实现而异。
-
1.31.3.
WaveShaperOptions
这指定了用于构造 WaveShaperNode
的选项。所有成员都是可选的;如果未指定,则在构造节点时使用默认值。
dictionary WaveShaperOptions :AudioNodeOptions {sequence <float >curve ;OverSampleType oversample = "none"; };
1.31.3.1. 字典 WaveShaperOptions
成员
curve, 类型为 sequence<float>-
用于波形塑形效果的塑形曲线。
oversample, 类型为 OverSampleType,默认值为"none"-
用于塑形曲线的过采样类型。
1.32. AudioWorklet
接口
[Exposed =Window ,SecureContext ]interface AudioWorklet :Worklet {readonly attribute MessagePort port ; };
1.32.1. 属性
port, 类型为 MessagePort,只读-
连接到
AudioWorkletGlobalScope上端口的MessagePort。注意: 在此
port的"message"事件上注册事件侦听器的作者应在close在AudioWorklet或AudioWorkletGlobalScope端的任一端调用 以允许资源被收集。
1.32.2. 概念
AudioWorklet
对象允许开发人员提供脚本(如 JavaScript 或 WebAssembly 代码)在渲染线程上处理音频,支持自定义 AudioNode。
这种处理机制确保脚本代码与音频图中的其他内置 AudioNode
同步执行。
必须定义一对关联的对象才能实现这一机制:AudioWorkletNode
和 AudioWorkletProcessor。
前者表示主全局范围内的接口,类似于其他 AudioNode
对象,而后者在一个名为 AudioWorkletGlobalScope
的特殊范围内实现内部音频处理。

AudioWorkletNode
和 AudioWorkletProcessor
每个 BaseAudioContext
拥有一个 AudioWorklet。
AudioWorklet
的 worklet 全局范围类型 为 AudioWorkletGlobalScope。
AudioWorklet
的 worklet 目标类型 为 "audioworklet"。
通过 addModule(moduleUrl)
方法导入脚本会在 AudioWorkletGlobalScope
下注册 AudioWorkletProcessor
的类定义。对于导入的类构造函数和由该构造函数创建的活动实例,存在两个内部存储区域。
AudioWorklet
有一个内部槽:
-
节点名称到参数描述符映射,这是一个映射,包含与 节点名称到处理器构造函数映射相同的一组字符串键,并与匹配的 parameterDescriptors 值相关联。此内部存储是在
registerProcessor()方法在 渲染线程中调用的结果而填充的。在addModule()在上下文的audioWorklet上返回的 promise 解析之前,填充操作已完成。
// bypass-processor.js 脚本文件,在 AudioWorkletGlobalScope 上运行 class BypassProcessorextends AudioWorkletProcessor{ process( inputs, outputs) { // 单个输入,单个通道。 const input= inputs[ 0 ]; const output= outputs[ 0 ]; output[ 0 ]. set( input[ 0 ]); // 仅在有活动输入时进行处理。 return false ; } }; registerProcessor( 'bypass-processor' , BypassProcessor);
// 主全局范围 const context= new AudioContext(); context. audioWorklet. addModule( 'bypass-processor.js' ). then(() => { const bypassNode= new AudioWorkletNode( context, 'bypass-processor' ); });
在主全局范围内实例化 AudioWorkletNode
时,相应的 AudioWorkletProcessor
也将在 AudioWorkletGlobalScope
中创建。这两个对象通过 § 2 处理模型中描述的异步消息传递进行通信。
1.32.3. AudioWorkletGlobalScope
接口
这个特殊的执行上下文旨在使脚本能够直接在音频 渲染线程 中生成、处理和分析音频数据。用户提供的脚本代码在此范围内评估,以定义一个或多个 AudioWorkletProcessor
子类,这些子类又用于在主范围内与 AudioWorkletNode
1:1 关联的方式实例化 AudioWorkletProcessor。
每个包含一个或多个 AudioWorkletNode
的 AudioContext
恰好有一个 AudioWorkletGlobalScope。
导入脚本的运行由 UA 按照 [HTML] 中定义执行。覆盖 [HTML]
中的默认规定,AudioWorkletGlobalScope
不得被用户代理任意
终止。
AudioWorkletGlobalScope
具有以下内部槽:
-
节点名称到处理器构造函数映射,它是一个存储键值对的映射,形式为 处理器名称 →
AudioWorkletProcessorConstructor实例。 最初此映射为空,并在调用registerProcessor()方法时填充。 -
挂起的处理器构造数据 存储由
AudioWorkletNode构造函数生成的用于实例化相应AudioWorkletProcessor的临时数据。挂起的处理器构造数据 包含以下项目:-
节点引用,最初为空。 此存储用于从
AudioWorkletNode构造函数传递过来的AudioWorkletNode引用。 -
传递的端口,最初为空。 此存储用于从
MessagePort反序列化后传递过来的AudioWorkletNode构造函数。
-
注意: AudioWorkletGlobalScope
还可能包含由这些实例共享的任何其他数据和代码。例如,多个处理器可能共享一个定义波表或脉冲响应的 ArrayBuffer。
注意: AudioWorkletGlobalScope
与单个 BaseAudioContext
相关联,
并与该上下文的单个音频渲染线程相关联。这可以防止全局范围代码在并发线程中运行时发生数据竞争。
callback =AudioWorkletProcessorConstructor AudioWorkletProcessor (object ); [options Global =(Worklet ,AudioWorklet ),Exposed =AudioWorklet ]interface AudioWorkletGlobalScope :WorkletGlobalScope {undefined registerProcessor (DOMString name ,AudioWorkletProcessorConstructor processorCtor );readonly attribute unsigned long long currentFrame ;readonly attribute double currentTime ;readonly attribute float sampleRate ;readonly attribute unsigned long renderQuantumSize ;readonly attribute MessagePort port ; };
1.32.3.1. 属性
currentFrame, 类型为 unsigned long long,只读-
正在处理的音频块的当前帧。该值必须等于
[[current frame]]的内部槽值,该槽属于BaseAudioContext。 currentTime, 类型为 double,只读-
正在处理的音频块的上下文时间。根据定义,该值将等于最近在 控制线程 中可观察到的
BaseAudioContext的currentTime属性的值。 sampleRate, 类型为 float,只读-
与其关联的
BaseAudioContext的采样率。 renderQuantumSize, 类型为 unsigned long,只读-
与其关联的
BaseAudioContext的私有槽 [[render quantum size]] 的值。 port, 类型为 MessagePort,只读-
一个
MessagePort, 连接到AudioWorklet的端口。注意: 在这个
"message"事件的port上注册事件监听器的作者 应在close的任一端调用, 在MessageChannel中(无论是在AudioWorklet还是在AudioWorkletGlobalScope端), 以允许资源被 回收。
1.32.3.2. 方法
registerProcessor(name, processorCtor)-
注册从
AudioWorkletProcessor派生的类构造函数。当调用registerProcessor(name, processorCtor)方法时,执行以下步骤。 如果在任何步骤中抛出异常,则中止剩余步骤。-
如果 name 是一个空字符串,抛出
NotSupportedError。 -
如果 name 已作为键存在于 节点名称到处理器构造函数映射 中,抛出
NotSupportedError。 -
如果
IsConstructor(argument=processorCtor)的结果为false,抛出TypeError。 -
令
prototype为Get(O=processorCtor, P="prototype")的结果。 -
令 parameterDescriptorsValue 为
Get(O=processorCtor, P="parameterDescriptors")的结果。 -
如果 parameterDescriptorsValue 不是
undefined, 执行以下步骤:-
令 parameterDescriptorSequence 为 转换 的结果, 从 parameterDescriptorsValue 到类型为
sequence<AudioParamDescriptor>的 IDL 值。 -
令 paramNames 为一个空数组。
-
对 parameterDescriptorSequence 中的每个 descriptor:
-
令 paramName 为 descriptor 中成员
name的值。 如果 paramNames 已包含 paramName 值,则抛出NotSupportedError。 -
将 paramName 添加到 paramNames 数组中。
-
令 defaultValue 为 descriptor 中成员
defaultValue的值。 -
令 minValue 为 descriptor 中成员
minValue的值。 -
令 maxValue 为 descriptor 中成员
maxValue的值。 -
如果表达式 minValue <= defaultValue <= maxValue 的结果为假, 抛出
InvalidStateError。
-
-
-
将键值对 name → processorCtor 添加到 相关的 节点名称到处理器构造函数映射 的
AudioWorkletGlobalScope中。 -
排队媒体元素任务,将键值对 name → parameterDescriptorSequence 添加到 相关的 节点名称到参数描述符映射 的
BaseAudioContext中。
注意: 类构造函数应只查找一次,因此在注册后无法动态更改。
参数 AudioWorkletGlobalScope.registerProcessor(name, processorCtor) 方法。 参数 类型 可为 null 可选 描述 nameDOMString✘ ✘ 表示要注册的类构造函数的字符串键。此键用于在构建 AudioWorkletNode时查找AudioWorkletProcessor的构造函数。processorCtorAudioWorkletProcessorConstructor✘ ✘ 从 AudioWorkletProcessor扩展的类构造函数。返回类型:undefined -
1.32.3.3. 实例化 AudioWorkletProcessor
在 AudioWorkletNode
构造结束时,
将为跨线程传输准备一个名为
处理器构造数据 的
结构体。
此 结构体 包含以下 项:
-
name 是一个
DOMString, 用于在 节点名称到处理器构造函数映射 中查找。 -
node 是对已创建的
AudioWorkletNode的引用。 -
options 是传递给
AudioWorkletNode的构造函数的序列化AudioWorkletNodeOptions。 -
port 是一个与
AudioWorkletNode的port配对的序列化MessagePort。
在 AudioWorkletGlobalScope
上接收到传输数据后,
渲染线程 将调用以下算法:
-
令 processorName、nodeReference 和 serializedPort 分别为 constructionData 的 name、node 和 port。
-
令 serializedOptions 为 constructionData 的 options。
-
令 deserializedPort 为 StructuredDeserialize(serializedPort, 当前 Realm) 的结果。
-
令 deserializedOptions 为 StructuredDeserialize(serializedOptions, 当前 Realm) 的结果。
-
令 processorCtor 为在
AudioWorkletGlobalScope的 节点名称到处理器构造函数映射 中查找 processorName 的结果。 -
将 nodeReference 和 deserializedPort 分别存储到此
AudioWorkletGlobalScope的 挂起的处理器构造数据 中的 节点引用 和 传输端口。 -
从 processorCtor 构造一个具有 deserializedOptions 参数的 回调函数。 如果在回调中抛出任何异常,排队一个任务到 控制线程,以使用
ErrorEvent在 nodeReference 上 触发一个名为processorerror的事件。 -
清空 挂起的处理器构造数据 槽。
1.32.4.
AudioWorkletNode
接口
该接口表示一个用户定义的 AudioNode,
它位于 控制线程 中。
用户可以从 BaseAudioContext
创建
AudioWorkletNode,
这样的节点可以与其他内置的 AudioNode 连接
以形成音频图。
| 属性 | 值 | 说明 |
|---|---|---|
numberOfInputs
| 1 | |
numberOfOutputs
| 1 | |
channelCount
| 2 | |
channelCountMode
| "max"
| |
channelInterpretation
| "speakers"
| |
| tail-time | 见说明 | 任何 tail-time 都由节点本身处理 |
每个 AudioWorkletProcessor
都有一个相关的 活动源 标志,初始值为
true。
该标志导致节点在没有任何连接输入的情况下保留在内存中并执行音频处理。
从 AudioWorkletNode
发布的所有任务都将发布到其关联的 BaseAudioContext
的任务队列中。
[Exposed =Window ]interface {AudioParamMap readonly maplike <DOMString ,AudioParam >; };
该接口通过 readonly maplike 提供 "entries"、"forEach"、"get"、"has"、"keys"、"values"、@@iterator 方法和一个
"size" 获取器。
[Exposed =Window ,SecureContext ]interface AudioWorkletNode :AudioNode {constructor (BaseAudioContext ,context DOMString ,name optional AudioWorkletNodeOptions = {});options readonly attribute AudioParamMap parameters ;readonly attribute MessagePort port ;attribute EventHandler onprocessorerror ; };
1.32.4.1. 构造函数
AudioWorkletNode(context, name, options)-
AudioWorkletNode.constructor() 方法的参数。 参数 类型 可为空 可选 描述 contextBaseAudioContext✘ ✘ 新建的 AudioWorkletNode所关联的BaseAudioContext。nameDOMString✘ ✘ 用于查找 BaseAudioContext的 节点名称到参数描述符映射 的字符串键。optionsAudioWorkletNodeOptions✘ ✔ 此 AudioWorkletNode的可选初始参数值。调用构造函数时,用户代理必须在控制线程上执行以下步骤:
当AudioWorkletNode构造函数被调用并传递 context、nodeName、options 时:-
如果 nodeName 不存在于
BaseAudioContext的 节点名称到参数描述符映射 中,抛出InvalidStateError异常并中止这些步骤。 -
令 node 为 this 值。
-
初始化 AudioNode node,参数为 context 和 options。
-
配置 node 的输入、输出和输出通道,参数为 options。 如果引发任何异常,则中止剩余的步骤。
-
令 messageChannel 为新的
MessageChannel。 -
令 nodePort 为 messageChannel 的
port1属性的值。 -
令 processorPortOnThisSide 为 messageChannel 的
port2属性的值。 -
令 serializedProcessorPort 为 结构化序列化(processorPortOnThisSide, « processorPortOnThisSide ») 的结果。
-
将 options 字典转换为 optionsObject。
-
令 serializedOptions 为 结构化序列化(optionsObject) 的结果。
-
设置 node 的
port为 nodePort。 -
从 节点名称到参数描述符映射 中检索 nodeName 的结果,设为 parameterDescriptors:
-
令 audioParamMap 为新的
AudioParamMap对象。 -
对于 parameterDescriptors 中的每个 descriptor:
-
令 paramName 为 descriptor 中
name成员的值。 -
令 audioParam 为新的
AudioParam实例,使用automationRate、defaultValue、minValue和maxValue这些成员值均等于 descriptor 中对应的成员值。 -
将键值对 paramName → audioParam 添加到 audioParamMap 的条目中。
-
-
如果
parameterData存在于 options 上,执行以下步骤:-
令 parameterData 为 options 中
parameterData的值。 -
对于 parameterData 中的每个 paramName → paramValue:
-
如果 audioParamMap 中存在键为 paramName 的映射条目, 令 audioParamInMap 为该条目。
-
将 audioParamInMap 的
value属性设置为 paramValue。
-
-
-
设置 node 的
parameters为 audioParamMap。
-
-
排队控制消息 以 调用 相应的
构造函数, 传递 处理器构造数据,包含: nodeName、node、serializedOptions 和 serializedProcessorPort。
-
1.32.4.2. 属性
onprocessorerror, 类型为 EventHandler-
当处理器的
constructor、process方法或任何用户定义的类方法中抛出未处理的异常时,处理器将 排队一个媒体元素任务 以 触发一个事件,名为processorerror,在相关联的AudioWorkletNode上使用ErrorEvent。ErrorEvent在控制线程上被创建并正确初始化,其message、filename、lineno、colno属性被设置。请注意,一旦抛出未处理的异常,处理器将在其整个生命周期内输出静音。
parameters, 类型为 AudioParamMap,只读-
parameters属性是AudioParam对象与其关联名称的集合。该类似映射的对象是在实例化时由AudioWorkletProcessor类构造函数中的AudioParamDescriptor列表填充的。 port, 类型为 MessagePort,只读-
每个
AudioWorkletNode都有一个关联的port,即MessagePort。 它连接到对应的AudioWorkletProcessor对象上的端口,从而允许AudioWorkletNode与其AudioWorkletProcessor之间进行双向通信。注意: 注册了此
port的"message"事件监听器的作者应调用close, 以关闭MessageChannel的任一端(无论是在AudioWorkletProcessor端还是AudioWorkletNode端),以允许资源被 回收。
1.32.4.3. AudioWorkletNodeOptions
AudioWorkletNodeOptions
字典可用于初始化 AudioWorkletNode
实例中的属性。
dictionary AudioWorkletNodeOptions :AudioNodeOptions {unsigned long numberOfInputs = 1;unsigned long numberOfOutputs = 1;sequence <unsigned long >outputChannelCount ;record <DOMString ,double >parameterData ;object processorOptions ; };
1.32.4.3.1. 字典 AudioWorkletNodeOptions
成员
numberOfInputs, 类型为 unsigned long,默认值为1-
用于初始化
AudioNode的numberOfInputs属性的值。 numberOfOutputs, 类型为 unsigned long,默认值为1-
用于初始化
AudioNode的numberOfOutputs属性的值。 outputChannelCount, 类型为sequence<unsigned long>-
该数组用于配置每个输出中的通道数量。
parameterData, 类型为 record<DOMString, double>-
这是一个用户定义的键值对列表,用于设置与
AudioWorkletNode中匹配名称的AudioParam的初始value。 processorOptions, 类型为 object-
包含用于初始化与
AudioWorkletNode相关联的AudioWorkletProcessor实例中自定义属性的用户定义数据。
1.32.4.3.2. 使用 AudioWorkletNodeOptions
配置通道
以下算法描述了如何使用 AudioWorkletNodeOptions
来配置各种通道配置。
-
设 node 为一个
AudioWorkletNode实例,该实例被传递给此算法。 -
如果
numberOfInputs和numberOfOutputs都为零, 则抛出NotSupportedError并中止剩余步骤。 -
如果
outputChannelCount存在,-
如果
outputChannelCount中的任何值为零 或大于实现的最大通道数,则抛出NotSupportedError并中止剩余步骤。 -
如果
outputChannelCount的长度不等于numberOfOutputs, 则抛出IndexSizeError并中止剩余步骤。 -
如果
numberOfInputs和numberOfOutputs都为 1, 则将 node 输出的通道数设置为outputChannelCount中的一个值。 -
否则,将 node 的第 k 个输出的通道数设置为
outputChannelCount序列中的第 k 个元素,并返回。
-
-
如果
outputChannelCount不存在,-
如果
numberOfInputs和numberOfOutputs都为 1, 则将 node 输出的初始通道数设置为 1 并返回。注意: 对于这种情况,输出通道数将在运行时根据输入和
channelCountMode动态更改为 computedNumberOfChannels。 -
否则,将 node 的每个输出的通道数设置为 1 并返回。
-
1.32.5. AudioWorkletProcessor
接口
该接口表示在音频 渲染线程
上运行的音频处理代码。它存在于 AudioWorkletGlobalScope
中,类的定义体现了实际的音频处理。请注意,AudioWorkletProcessor
的构造只能在 AudioWorkletNode
的构造之后发生。
[Exposed =AudioWorklet ]interface AudioWorkletProcessor {constructor ();readonly attribute MessagePort port ; };callback AudioWorkletProcessCallback =boolean (FrozenArray <FrozenArray <Float32Array >>,inputs FrozenArray <FrozenArray <Float32Array >>,outputs object );parameters
AudioWorkletProcessor
有两个内部槽:
[[node reference]]-
一个对关联的
AudioWorkletNode的引用。 [[callable process]]-
一个布尔标志,表示 process() 是否是可以调用的有效函数。
1.32.5.1. 构造函数
AudioWorkletProcessor()-
当
AudioWorkletProcessor的构造函数被调用时,以下步骤将在 渲染线程 上执行。-
让 nodeReference 为 在当前
AudioWorkletGlobalScope的 待处理构造数据节点引用 上查找的结果。如果插槽为空,则抛出TypeError异常。 -
设 processor 为 this 值。
-
将 processor 的
[[node reference]]设置为 nodeReference。 -
将 processor 的
[[callable process]]设置为true。 -
让 deserializedPort 为 在 已传输端口 中查找的结果。
-
将 processor 的
port设置为 deserializedPort。 -
清空 待处理构造数据 插槽。
-
1.32.5.2. 属性
port, 类型为 MessagePort, 只读-
每个
AudioWorkletProcessor都有一个关联的port,这是一个MessagePort。 它连接到对应的AudioWorkletNode对象上的端口, 允许AudioWorkletNode与其AudioWorkletProcessor之间进行双向通信。注意: 如果开发者在此
"message"事件上注册了事件监听器, 应该调用close来关闭MessageChannel的任一端(无论是在AudioWorkletProcessor端还是AudioWorkletNode端),以便释放资源。
1.32.5.3. 回调 AudioWorkletProcessCallback
用户可以通过扩展 AudioWorkletProcessor
来定义自定义音频处理器。子类必须定义一个名为
process() 的
AudioWorkletProcessCallback,
实现音频处理算法,并且可以具有一个名为
parameterDescriptors
的静态属性,
该属性是 AudioParamDescriptor
的可迭代集合。
process() 回调函数在 渲染图形 时按指定方式处理。
AudioWorkletProcessor
的关联 AudioWorkletNode
的生命周期。
这种生命周期策略可以支持内置节点中的多种方法,包括以下几种:
-
转换其输入的节点,并且仅在存在连接的输入和/或脚本引用时处于活动状态。此类节点应在 process() 中返回
false, 这样可以根据连接输入的有无来确定AudioWorkletNode是否处于 活动处理中。 -
转换其输入的节点,但在其输入断开后仍保持活动状态一段时间。在这种情况下, process() 在
inputs被发现不包含任何通道后的一段时间内应该返回true。 可以从全局作用域的currentTime中获取当前时间来测量尾时间间隔的开始和结束,或者根据处理器的内部状态动态计算该间隔。 -
作为输出源的节点,通常具有生命周期。此类节点应在 process() 中返回
true, 直到它们不再产生输出为止。
请注意,前述定义意味着当 process() 的实现未提供返回值时,
其效果与返回 false 是相同的(因为有效返回值是虚假的值 undefined)。
对于任何只有在有活动输入时才处于活动状态的 AudioWorkletProcessor,
这都是合理的行为。
下面的示例展示了如何在 AudioWorkletProcessor
中定义和使用 AudioParam。
class MyProcessorextends AudioWorkletProcessor{ static get parameterDescriptors() { return [{ name: 'myParam' , defaultValue: 0.5 , minValue: 0 , maxValue: 1 , automationRate: "k-rate" }]; } process( inputs, outputs, parameters) { // 获取第一个输入和输出。 const input= inputs[ 0 ]; const output= outputs[ 0 ]; const myParam= parameters. myParam; // 一个用于单一输入和输出的简单放大器。请注意, // automationRate 为 "k-rate",因此每个渲染量子将具有索引 [0] 处的单一值。 for ( let channel= 0 ; channel< output. length; ++ channel) { for ( let i= 0 ; i< output[ channel]. length; ++ i) { output[ channel][ i] = input[ channel][ i] * myParam[ 0 ]; } } } }
1.32.5.3.1.
回调 AudioWorkletProcessCallback
参数
以下描述了 AudioWorkletProcessCallback
函数的参数。
通常,inputs
和 outputs
数组将在调用之间重用,因此不会进行内存分配。然而,如果拓扑结构发生变化,例如输入或输出中的通道数量发生变化,则会重新分配新的数组。如果 inputs
或 outputs
数组的任何部分被传输,也会重新分配新数组。
inputs, 类型为FrozenArray<FrozenArray<Float32Array>>-
由用户代理提供的来自输入连接的音频缓冲区。
inputs[n][m]是第 \(n\) 个输入的第 \(m\) 个通道的音频采样的Float32Array。 虽然输入的数量在构造时是固定的,但通道的数量可以根据 computedNumberOfChannels 动态更改。如果当前渲染量子中
AudioWorkletNode的第 \(n\) 个输入没有连接任何正在活动处理的AudioNode, 则inputs[n]的内容为空数组,表示没有可用的输入通道。这是inputs[n]的元素数量为零的唯一情况。 outputs, 类型为FrozenArray<FrozenArray<Float32Array>>-
用户代理要使用的输出音频缓冲区。
outputs[n][m]是第 \(n\) 个输出的第 \(m\) 个通道的音频采样的Float32Array对象。每个Float32Array都用零填充。当节点只有一个输出时,输出的通道数量将与 computedNumberOfChannels 匹配。 parameters, 类型为object-
一个 有序映射,由 name → parameterValues 组成。
parameters["name"]返回 parameterValues,这是一个FrozenArray<Float32Array>, 其中包含 name 的AudioParam的自动化值。对于每个数组,该数组包含参数在整个 渲染量子 中的 计算值。然而,如果在此渲染量子中没有安排自动化,则该数组可以具有长度为 1 的单个值,该数组元素为
AudioParam在此 渲染量子 中的常量值。该对象根据以下步骤被冻结
-
令 parameter 为 有序映射, 包含名称和参数值。
-
SetIntegrityLevel(parameter, frozen)
在算法中计算的这个冻结的 有序映射 被传递到
parameters参数中。注意: 这意味着对象不能被修改, 因此可以在连续调用中使用相同的对象, 除非数组的长度发生变化。
-
1.32.5.4. AudioParamDescriptor
AudioParamDescriptor
字典用于为在 AudioWorkletNode
中使用的 AudioParam
对象指定属性。
dictionary AudioParamDescriptor {required DOMString name ;float defaultValue = 0;float minValue = -3.4028235e38;float maxValue = 3.4028235e38;AutomationRate automationRate = "a-rate"; };
1.32.5.4.1. 字典 AudioParamDescriptor
成员
这些成员的值有约束条件。有关约束,请参阅处理 AudioParamDescriptor 的算法。
automationRate, 类型为 AutomationRate,默认为"a-rate"-
表示默认的自动化速率。
defaultValue, 类型为 float,默认为0-
表示参数的默认值。
maxValue, 类型为 float,默认为3.4028235e38-
表示最大值。
minValue, 类型为 float,默认为-3.4028235e38-
表示最小值。
name, 类型为 DOMString-
表示参数的名称。
1.32.6. AudioWorklet 事件序列
下图说明了相对于 AudioWorklet
发生的一组理想化事件序列:
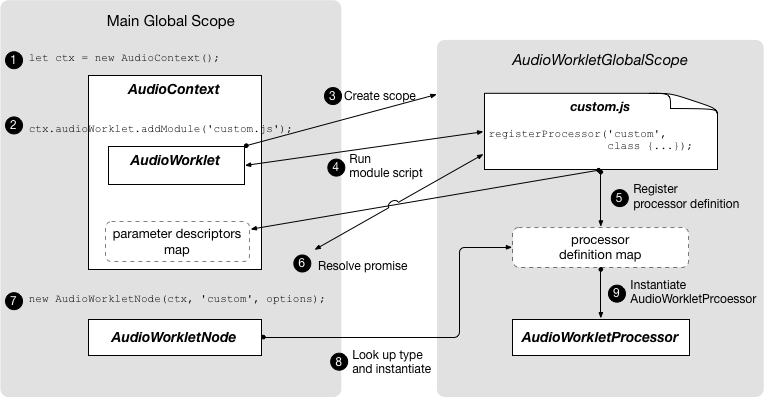
AudioWorklet
序列 图中所示的步骤是涉及创建 AudioContext
及其
关联的 AudioWorkletGlobalScope
的
一种可能的事件序列,然后创建一个 AudioWorkletNode
及其关联的 AudioWorkletProcessor。
-
创建一个
AudioContext。 -
在主作用域中,请求
context.audioWorklet添加脚本模块。 -
由于还不存在,因此在与上下文关联的情况下创建一个新的
AudioWorkletGlobalScope。 这是将评估AudioWorkletProcessor类定义的全局作用域。(在后续调用中,将使用先前创建的作用域。) -
导入的脚本在新创建的全局作用域中运行。
-
作为运行导入脚本的一部分,
AudioWorkletProcessor以一个键(例如上图中的"custom")注册到AudioWorkletGlobalScope中。 这会填充全局作用域和AudioContext中的映射。 -
addModule()调用的 promise 被解析。 -
在主作用域中,使用用户指定的键和选项字典创建一个
AudioWorkletNode。 -
作为节点创建的一部分,使用该键查找要实例化的正确的
AudioWorkletProcessor子类。 -
使用选项字典的结构化克隆实例化
AudioWorkletProcessor子类的一个实例。 此实例与先前创建的AudioWorkletNode进行配对。
1.32.7. AudioWorklet 示例
1.32.7.1. 比特压缩器节点
比特压缩是一种通过量化样本值(模拟较低的比特深度)和量化时间分辨率(模拟较低的采样率)来降低音频流质量的机制。本例展示了如何在 AudioParam(此处作为
a-rate)内部使用,嵌套在 AudioWorkletProcessor
中。
const context= new AudioContext(); context. audioWorklet. addModule( 'bitcrusher.js' ). then(() => { const osc= new OscillatorNode( context); const amp= new GainNode( context); // Create a worklet node. 'BitCrusher' identifies the // AudioWorkletProcessor previously registered when // bitcrusher.js was imported. The options automatically // initialize the correspondingly named AudioParams. const bitcrusher= new AudioWorkletNode( context, 'bitcrusher' , { parameterData: { bitDepth: 8 } }); osc. connect( bitcrusher). connect( amp). connect( context. destination); osc. start(); });
class Bitcrusherextends AudioWorkletProcessor{ static get parameterDescriptors() { return [{ name: 'bitDepth' , defaultValue: 12 , minValue: 1 , maxValue: 16 }, { name: 'frequencyReduction' , defaultValue: 0.5 , minValue: 0 , maxValue: 1 }]; } constructor () { super (); this . _phase= 0 ; this . _lastSampleValue= 0 ; } process( inputs, outputs, parameters) { const input= inputs[ 0 ]; const output= outputs[ 0 ]; const bitDepth= parameters. bitDepth; const frequencyReduction= parameters. frequencyReduction; if ( bitDepth. length> 1 ) { for ( let channel= 0 ; channel< output. length; ++ channel) { for ( let i= 0 ; i< output[ channel]. length; ++ i) { let step= Math. pow( 0.5 , bitDepth[ i]); // Use modulo for indexing to handle the case where // the length of the frequencyReduction array is 1. this . _phase+= frequencyReduction[ i% frequencyReduction. length]; if ( this . _phase>= 1.0 ) { this . _phase-= 1.0 ; this . _lastSampleValue= step* Math. floor( input[ channel][ i] / step+ 0.5 ); } output[ channel][ i] = this . _lastSampleValue; } } } else { // Because we know bitDepth is constant for this call, // we can lift the computation of step outside the loop, // saving many operations. const step= Math. pow( 0.5 , bitDepth[ 0 ]); for ( let channel= 0 ; channel< output. length; ++ channel) { for ( let i= 0 ; i< output[ channel]. length; ++ i) { this . _phase+= frequencyReduction[ i% frequencyReduction. length]; if ( this . _phase>= 1.0 ) { this . _phase-= 1.0 ; this . _lastSampleValue= step* Math. floor( input[ channel][ i] / step+ 0.5 ); } output[ channel][ i] = this . _lastSampleValue; } } } // No need to return a value; this node's lifetime is dependent only on its // input connections. } }; registerProcessor( 'bitcrusher' , Bitcrusher);
注意: 在 AudioWorkletProcessor
类的定义中,如果作者提供的构造函数有显式的返回值,并且该返回值不是 this 或者没有正确调用 super(),将抛出 InvalidStateError。
1.32.7.2. VU 表节点
这个简单的声音电平表示例进一步说明了如何创建一个 AudioWorkletNode
子类,该子类像原生的 AudioNode
一样,接受构造函数选项,并封装了 AudioWorkletNode
和 AudioWorkletProcessor
之间的线程间通信(异步)。这个节点不使用任何输出。
/* vumeter-node.js: Main global scope */ export default class VUMeterNodeextends AudioWorkletNode{ constructor ( context, updateIntervalInMS) { super ( context, 'vumeter' , { numberOfInputs: 1 , numberOfOutputs: 0 , channelCount: 1 , processorOptions: { updateIntervalInMS: updateIntervalInMS|| 16.67 } }); // States in AudioWorkletNode this . _updateIntervalInMS= updateIntervalInMS; this . _volume= 0 ; // Handles updated values from AudioWorkletProcessor this . port. onmessage= event=> { if ( event. data. volume) this . _volume= event. data. volume; } this . port. start(); } get updateInterval() { return this . _updateIntervalInMS; } set updateInterval( updateIntervalInMS) { this . _updateIntervalInMS= updateIntervalInMS; this . port. postMessage({ updateIntervalInMS: updateIntervalInMS}); } draw() { // Draws the VU meter based on the volume value // every |this._updateIntervalInMS| milliseconds. } };
/* vumeter-processor.js: AudioWorkletGlobalScope */ const SMOOTHING_FACTOR= 0.9 ; const MINIMUM_VALUE= 0.00001 ; registerProcessor( 'vumeter' , class extends AudioWorkletProcessor{ constructor ( options) { super (); this . _volume= 0 ; this . _updateIntervalInMS= options. processorOptions. updateIntervalInMS; this . _nextUpdateFrame= this . _updateIntervalInMS; this . port. onmessage= event=> { if ( event. data. updateIntervalInMS) this . _updateIntervalInMS= event. data. updateIntervalInMS; } } get intervalInFrames() { return this . _updateIntervalInMS/ 1000 * sampleRate; } process( inputs, outputs, parameters) { const input= inputs[ 0 ]; // Note that the input will be down-mixed to mono; however, if no inputs are // connected then zero channels will be passed in. if ( input. length> 0 ) { const samples= input[ 0 ]; let sum= 0 ; let rms= 0 ; // Calculated the squared-sum. for ( let i= 0 ; i< samples. length; ++ i) sum+= samples[ i] * samples[ i]; // Calculate the RMS level and update the volume. rms= Math. sqrt( sum/ samples. length); this . _volume= Math. max( rms, this . _volume* SMOOTHING_FACTOR); // Update and sync the volume property with the main thread. this . _nextUpdateFrame-= samples. length; if ( this . _nextUpdateFrame< 0 ) { this . _nextUpdateFrame+= this . intervalInFrames; this . port. postMessage({ volume: this . _volume}); } } // Keep on processing if the volume is above a threshold, so that // disconnecting inputs does not immediately cause the meter to stop // computing its smoothed value. return this . _volume>= MINIMUM_VALUE; } });
/* index.js: Main global scope, entry point */ import VUMeterNodefrom './vumeter-node.js' ; const context= new AudioContext(); context. audioWorklet. addModule( 'vumeter-processor.js' ). then(() => { const oscillator= new OscillatorNode( context); const vuMeterNode= new VUMeterNode( context, 25 ); oscillator. connect( vuMeterNode); oscillator. start(); function drawMeter() { vuMeterNode. draw(); requestAnimationFrame( drawMeter); } drawMeter(); });
2. 处理模型
2.1. 背景
本节是非规范性的。
需要低延迟的实时音频系统通常使用 回调函数 实现,其中操作系统在需要计算更多音频以使播放保持不中断时回调程序。理想情况下,这种回调是在高优先级线程(通常是系统中最高优先级)上调用的。这意味着处理音频的程序仅在这个回调中执行代码。跨线程边界或在渲染线程和回调之间添加一些缓冲自然会增加延迟,或使系统更容易出现故障。
因此,在 Web 平台上执行异步操作的传统方式(事件循环)在这里不起作用,因为线程不是 持续执行 的。此外,传统执行上下文(窗口和 Worker)中存在许多不必要且可能阻塞的操作,这并不是实现可接受的性能水平所期望的。
此外,Worker 模型使得为脚本执行上下文创建专用线程成为必要,而所有 AudioNode
通常共享相同的执行上下文。
注意: 本节指定了最终结果应该如何呈现,而不是应该如何实现。特别地,代替使用消息队列,实施者可以使用在线程之间共享的内存,只要这些内存操作没有被重新排序。
2.2. 控制线程和渲染线程
Web Audio API 必须使用 控制线程 和 渲染线程 来实现。
控制线程 是实例化 AudioContext
的线程,并且是开发者操作音频图的线程,也就是说,操作 BaseAudioContext
的操作都是在该线程中调用的。而 渲染线程
是实际音频输出计算所在的线程,响应来自 控制线程
的调用。如果计算 AudioContext
的音频,它可以是基于实时回调的音频线程;如果计算 OfflineAudioContext
的音频,则可以是普通线程。
从 控制线程 到 渲染线程 的通信是通过 控制消息 传递来完成的。相反方向的通信则是通过常规的事件循环任务来完成的。
每个 AudioContext
都有一个 控制消息队列,它是一个包含在 渲染线程 上运行的操作的 控制消息 列表。
排队一个控制消息
是指将消息添加到 BaseAudioContext
的 控制消息队列 的末尾。
注意: 例如,成功调用 start() 方法来启动 AudioBufferSourceNode
source,就会将 控制消息 添加到关联的 BaseAudioContext
的 控制消息队列 中。
控制消息 在 控制消息队列 中按插入时间排序。因此,最旧的消息 就位于 控制消息队列 的前面。
2.3. 异步操作
对 AudioNode
的方法调用实际上是异步的,必须分为两个阶段:同步部分和异步部分。对于每个方法,一些操作在 控制线程 上执行(例如,在参数无效时抛出异常),而另一些操作则在 渲染线程 上执行(例如,更改 AudioParam
的值)。
在描述对 AudioNode 和
BaseAudioContext
的每次操作时,同步部分用 ⌛ 标记。所有其他操作都按照 并行 的方式执行,详见 [HTML]。
同步部分在 控制线程 上执行,立即发生。如果失败,方法执行将中止,并可能抛出异常。如果成功,则会将编码要在 渲染线程 上执行的操作的 控制消息 排队到该 渲染线程 的 控制消息队列 中。
同步和异步部分相对于其他事件的顺序必须保持一致:对于两个操作 A 和 B,其各自的同步和异步部分为 ASync 和 AAsync,以及 BSync 和 BAsync,如果 A 发生在 B 之前,那么 ASync 发生在 BSync 之前,AAsync 发生在 BAsync 之前。换句话说,同步和异步部分不能重新排序。
2.4. 渲染音频图
音频图的渲染以样本帧块为单位进行,每个块的大小在 BaseAudioContext
的整个生命周期内保持不变。块中样本帧的数量称为 渲染量子大小,该块本身称为 渲染量子。其默认值为 128,可以通过设置 renderSizeHint
来配置。
在给定线程上以 原子性 执行的操作只能在没有其他 原子 操作在另一个线程上运行时执行。
从 BaseAudioContext
G 中渲染一个音频块并使用 控制消息队列
Q 的算法包括多个步骤,并在 渲染图 算法中有更详细的解释。
AudioContext
的 渲染线程 由一个 系统级音频回调
驱动,该回调在定期的时间间隔内周期性调用。每次调用都有一个 系统级音频回调缓冲区大小,它是一个需要在下次 系统级音频回调 到来之前按时计算的样本帧数。
每个 系统级音频回调 计算一个 负载值,通过将其执行持续时间除以 系统级音频回调缓冲区大小 除以 sampleRate
来计算。
理想情况下,负载值 应低于 1.0,这意味着渲染音频的时间少于播放它的时间。当 负载值 大于 1.0 时,会发生 音频缓冲区欠载:系统无法及时渲染出实时音频。
请注意,系统级音频回调 和 负载值 的概念不适用于 OfflineAudioContext。
音频回调也作为任务排队到 控制消息队列
中。用户代理必须执行以下算法,通过填充请求的缓冲区大小来处理渲染量子以完成此任务。除了 控制消息队列,每个 AudioContext
还有一个常规的 任务队列,称为其 关联任务队列,用于从控制线程向渲染线程发布的任务。在处理渲染量子之后,将执行一个额外的微任务检查点,以运行在执行
process 方法期间排队的任何微任务,这些方法属于 AudioWorkletProcessor。
所有从 AudioWorkletNode
发布的任务都会发布到其关联的 BaseAudioContext
的 关联任务队列 中。
-
将
BaseAudioContext的内部槽[[current frame]]设置为 0。同时将currentTime设置为 0。
渲染一个量化块时必须执行以下步骤。
-
设 render result 为
false。 -
处理 控制消息队列。
-
处理
BaseAudioContext的关联任务队列。-
设 task queue 为
BaseAudioContext的关联任务队列。 -
设 task count 为 task queue 中的任务数量。
-
当 task count 不等于 0 时,执行以下步骤:
-
设 oldest task 为 task queue 中第一个可运行的任务,并从 task queue 中移除它。
-
将渲染循环的当前运行任务设置为 oldest task。
-
执行 oldest task 的步骤。
-
将渲染循环的当前运行任务设置回
null。 -
递减 task count。
-
执行一个微任务检查点。
-
-
-
处理一个渲染量化块。
-
如果
[[渲染线程状态]]的BaseAudioContext不是running,则返回 false。 -
对
AudioNode进行排序,以便处理BaseAudioContext。-
令 ordered node list 为一个空的
AudioNode和AudioListener的列表。最终会包含AudioNode和AudioListener的有序列表。 -
令 nodes 为由此
BaseAudioContext创建且仍然存活的所有节点。 -
将
AudioListener添加到 nodes。 -
对于 nodes 中的每个
AudioNodenode:-
如果 node 是一个属于循环的
DelayNode,将其添加到 cycle breakers,并从 nodes 中移除。
-
-
对于 cycle breakers 中的每个
DelayNodedelay:-
令 delayWriter 和 delayReader 分别为 DelayWriter 和 DelayReader,用于 delay。将 delayWriter 和 delayReader 添加到 nodes 中。将 delay 从其所有输入和输出中断开。
注意:这会打破循环:如果
DelayNode在一个循环中,其两端可以被视为独立部分,因为循环中的延迟线不能小于一个渲染量化。
-
-
将 nodes 中的所有元素视为未标记状态。当 nodes 中还有未标记的元素时:
-
选择 nodes 中的一个元素 node。
-
访问 node。
-
-
反转 ordered node list 的顺序。
-
-
计算值的
AudioListener的AudioParams 对于此块。 -
对于 ordered node list 中的每个
AudioNode:-
对于此
AudioNode的每个AudioParam,执行以下步骤:-
如果此
AudioParam有任何连接到它的AudioNode,求和 所有连接到此AudioParam的AudioNode缓冲区 可用于读取的缓冲区,下混合 结果缓冲区至单声道, 并将此缓冲区称为 输入 AudioParam 缓冲区。 -
计算值的此
AudioParam对于此块。 -
排队控制消息以设置此
[[current value]]槽 的AudioParam,按照§ 1.6.3 计算值。
-
-
如果此
AudioNode有任何连接到其输入的AudioNode, 求和所有连接到此AudioNode的AudioNode提供的缓冲区, 并将结果缓冲区称为 输入缓冲区。 上混合或下混合它以匹配此AudioNode的输入通道数。 -
如果此
AudioNode是一个AudioWorkletNode, 执行以下子步骤:-
令 processor 为与此
AudioWorkletNode相关联的AudioWorkletProcessor实例。 -
令 O 为对应于 processor 的 ECMAScript 对象。
-
令 processCallback 为一个未初始化的变量。
-
令 completion 为一个未初始化的变量。
-
令 getResult 为 获取(O, "process")。
-
如果 getResult 是 突然中止, 则将 completion 设置为 getResult 并跳转到标记为 返回 的步骤。
-
将 processCallback 设置为 getResult.[[Value]]。
-
如果 IsCallable(processCallback) 为
false,则: -
将
[[callable process]]设置为true。 -
执行以下子步骤:
-
令 args 为一个 Web IDL 参数列表,包含
inputs,outputs,以及parameters。 -
令 esArgs 为 将 args 转换为 ECMAScript 参数列表 的结果。
-
令 callResult 为 调用(processCallback, O, esArgs)。 此操作 计算音频块,传递 esArgs。 在成功调用函数时,一个包含由
Float32Array传递的outputs元素的缓冲区会被提供读取。 此调用内解析的任何Promise将排队到AudioWorkletGlobalScope的微任务队列中。 -
如果 callResult 是 突然中止,则将 completion 设置为 callResult,并跳转到标记为 返回 的步骤。
-
-
返回:此时,completion 将被设置为 ECMAScript 完成记录 值。
-
如果 completion 是 突然中止:
-
将
[[callable process]]设置为false。 -
将 processor 的 激活源 标志设置为
false。 -
排队一个任务到 控制线程, 触发一个事件, 事件名为
processorerror, 在相关联的AudioWorkletNode上, 使用ErrorEvent。
-
-
-
否则,处理 输入缓冲区,并 使生成的缓冲区可供读取。
-
-
以原子方式执行以下步骤:
-
将
[[current frame]]增加 渲染量子大小。 -
将
currentTime设置为[[current frame]]除以sampleRate。
-
-
将 render result 设置为
true。
-
-
返回 render result。
静音一个 AudioNode
意味着其输出在渲染此音频块时必须是静音的。
使缓冲区可供读取 从一个
AudioNode
意味着将其置于一个状态,
使得连接到此 AudioNode 的其他
AudioNode
可以安全地从中读取。
注意: 例如,实现可以选择分配一个新的缓冲区,或者使用更复杂的机制,重复使用当前未被使用的缓冲区。
记录输入 一个
AudioNode
意味着将此 AudioNode
的输入数据复制以供将来使用。
计算音频块 意味着
运行此 AudioNode
的算法,
以生成 [[render quantum size]]
采样帧。
处理输入缓冲区 意味着
运行一个 AudioNode
的算法,
使用 输入缓冲区 和此
AudioParam(s)
的值作为该算法的输入。
2.5. 处理系统音频资源在
AudioContext
上的错误
AudioContext
audioContext 在发生音频系统资源错误时在 渲染线程 上执行以下步骤。
-
如果 audioContext 的
[[rendering thread state]]为running:-
尝试 释放系统资源。
-
将 audioContext 的
[[rendering thread state]]设置为suspended。 -
排队媒体元素任务 以执行以下步骤:
-
将 audioContext 的
[[suspended by user]]设置为false。 -
将 audioContext 的
[[control thread state]]设置为suspended。 -
触发事件,事件名称为
statechange,目标为 audioContext。
-
中止这些步骤。
-
-
如果 audioContext 的
[[rendering thread state]]为suspended:
注意: 系统音频资源错误的一个例子是,当外部或无线音频设备在
AudioContext
正在进行活动渲染时断开连接。
2.6. 卸载文档
为使用 BaseAudioContext
的文档定义了额外的卸载文档清理步骤:
-
对于关联全局对象与文档的 Window 相同的每个
AudioContext和OfflineAudioContext, 使用InvalidStateError拒绝所有[[pending promises]]的承诺。 -
停止所有
解码线程。 -
排队控制消息到
close()以关闭AudioContext或OfflineAudioContext。
3. 动态生命周期
3.1. 背景
注意:AudioContext
和
AudioNode
的生命周期特性规范描述由
AudioContext 生命周期和 AudioNode
生命周期描述。
本节为非规范性内容。
除了允许创建静态路由配置之外,还应该能够对动态分配的具有有限生命周期的语音进行自定义效果路由。为了讨论的目的,我们将这些短命的语音称为“音符”。许多音频应用程序结合了音符的概念,例子包括鼓机、音序器和有许多一次性声音根据游戏玩法触发的3D游戏。
在传统的软件合成器中,音符是从可用资源池中动态分配和释放的。当接收到 MIDI note-on 消息时分配音符。当音符由于到达样本数据的末尾(如果非循环)、其包络的保持阶段为零或由于 MIDI note-off 消息将其置于包络的释放阶段时,音符就会结束播放并被释放。在 MIDI note-off 的情况下,音符不会立即释放,而是当释放包络阶段结束时才释放。在任何给定时间,可能会有大量的音符在播放,但音符集会随着新音符被添加到路由图中而不断变化,旧的音符会被释放。
音频系统会自动处理单个“音符”事件的路由图部分的拆除。“音符”由 AudioBufferSourceNode
表示,可以直接连接到其他处理节点。当音符播放完成时,上下文会自动释放对 AudioBufferSourceNode
的引用,从而释放对它连接的任何节点的引用,依此类推。当节点没有更多引用时,它们会自动从图中断开并被删除。图中的长寿命和共享的节点可以显式管理。尽管听起来很复杂,但这些操作都是自动发生的,不需要额外的处理。
3.2. 示例
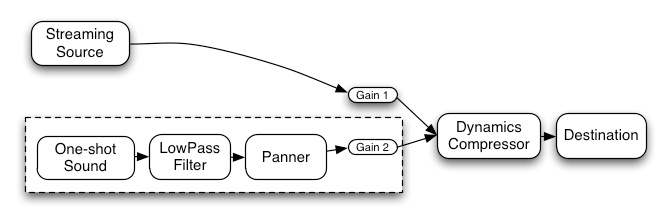
低通滤波器、声相器和第二个增益节点是从一次性声音直接连接的。因此,当它播放完毕时,上下文将自动释放它们(虚线内的所有内容)。如果不再有一次性声音和连接节点的引用,它们将立即从图中移除并删除。流源具有全局引用,将保持连接状态,直到显式断开。以下是它可能在 JavaScript 中的实现:
let context= 0 ; let compressor= 0 ; let gainNode1= 0 ; let streamingAudioSource= 0 ; // 初始设置“长寿命”路由图部分 function setupAudioContext() { context= new AudioContext(); compressor= context. createDynamicsCompressor(); gainNode1= context. createGain(); // 创建一个流式音频源。 const audioElement= document. getElementById( 'audioTagID' ); streamingAudioSource= context. createMediaElementSource( audioElement); streamingAudioSource. connect( gainNode1); gainNode1. connect( compressor); compressor. connect( context. destination); } // 稍后响应一些用户操作(通常是鼠标或按键事件) // 可以播放一次性声音。 function playSound() { const oneShotSound= context. createBufferSource(); oneShotSound. buffer= dogBarkingBuffer; // 创建滤波器、声相器和增益节点。 const lowpass= context. createBiquadFilter(); const panner= context. createPanner(); const gainNode2= context. createGain(); // 建立连接 oneShotSound. connect( lowpass); lowpass. connect( panner); panner. connect( gainNode2); gainNode2. connect( compressor); // 从现在开始 0.75 秒后播放(要立即播放则传入 0) oneShotSound. start( context. currentTime+ 0.75 ); }
4. 通道上混和下混
本节为规范性内容。
AudioNode 输入有用于组合所有连接到它的通道的混合规则。
例如,如果一个输入连接自一个单声道输出和一个立体声输出,则单声道连接通常会被上混为立体声并与立体声连接求和。但是,当然有必要为每个 AudioNode
的每个输入定义确切的
混合规则。所有输入的默认混合规则已选择,使得在不需过多担心细节的情况下,事情能够“正常工作”,尤其是在非常常见的单声道和立体声流的情况下。当然,规则可以为高级用例(尤其是多通道)进行更改。
为了定义一些术语,上混是指将具有较少通道数的流转换为具有更多通道数的流的过程。下混是指将具有较多通道数的流转换为具有较少通道数的流的过程。
一个 AudioNode
的输入需要混合连接到该输入的所有输出。作为此过程的一部分,它会计算一个内部值
computedNumberOfChannels,
代表在任何给定时间输入的实际通道数。
AudioNode
的每个输入,实现必须:
-
对于连接到输入的每个连接:
-
根据节点的
ChannelInterpretation属性给出的channelInterpretation值, 上混或 下混该连接到 computedNumberOfChannels。
-
4.1. 扬声器通道布局
当 channelInterpretation
为
"speakers"
时,
上混和 下混 是针对特定通道布局定义的。
必须支持单声道(一通道)、立体声(两通道)、四声道(四通道)和 5.1 声道(六通道)。其他通道布局可能在本规范的未来版本中支持。
4.2. 通道排序
通道排序由下表定义。单个多声道格式可能不支持所有中间通道。实现必须按下方定义的顺序呈现提供的通道,跳过不存在的通道。
| 顺序 | 标签 | 单声道 | 立体声 | 四声道 | 5.1 声道 |
|---|---|---|---|---|---|
| 0 | SPEAKER_FRONT_LEFT | 0 | 0 | 0 | 0 |
| 1 | SPEAKER_FRONT_RIGHT | 1 | 1 | 1 | |
| 2 | SPEAKER_FRONT_CENTER | 2 | |||
| 3 | SPEAKER_LOW_FREQUENCY | 3 | |||
| 4 | SPEAKER_BACK_LEFT | 2 | 4 | ||
| 5 | SPEAKER_BACK_RIGHT | 3 | 5 | ||
| 6 | SPEAKER_FRONT_LEFT_OF_CENTER | ||||
| 7 | SPEAKER_FRONT_RIGHT_OF_CENTER | ||||
| 8 | SPEAKER_BACK_CENTER | ||||
| 9 | SPEAKER_SIDE_LEFT | ||||
| 10 | SPEAKER_SIDE_RIGHT | ||||
| 11 | SPEAKER_TOP_CENTER | ||||
| 12 | SPEAKER_TOP_FRONT_LEFT | ||||
| 13 | SPEAKER_TOP_FRONT_CENTER | ||||
| 14 | SPEAKER_TOP_FRONT_RIGHT | ||||
| 15 | SPEAKER_TOP_BACK_LEFT | ||||
| 16 | SPEAKER_TOP_BACK_CENTER | ||||
| 17 | SPEAKER_TOP_BACK_RIGHT |
4.3. 尾时间对输入和输出通道数的影响
当一个 AudioNode
具有非零的 尾时间,且输出通道数取决于输入通道数时,当输入通道数发生变化时,必须考虑到 AudioNode 的
尾时间。
当输入通道数减少时,输出通道数的变化必须在之前接收到的较多通道的输入不再影响输出时发生。
当输入通道数增加时,行为取决于 AudioNode 类型:
-
对于
DelayNode或DynamicsCompressorNode,当之前接收到的较多通道的输入开始影响输出时,输出通道数必须增加。 -
对于其他具有 尾时间 的
AudioNode,输出通道数必须立即增加。注意: 对于
ConvolverNode,这仅适用于脉冲响应为单声道的情况。否则,ConvolverNode始终输出立体声音频信号,无论其输入通道数如何。
注意: 直观上,这样可以避免在处理过程中丢失立体声信息:当多个具有不同通道数的输入渲染量对一个输出渲染量做出贡献时,输出渲染量的通道数是输入渲染量的输入通道数的超集。
4.4. 上混音扬声器布局
Mono 上混音:
1 -> 2 : 从单声道上混到立体声
output.L = input;
output.R = input;
1 -> 4 : 从单声道上混到四声道
output.L = input;
output.R = input;
output.SL = 0;
output.SR = 0;
1 -> 5.1 : 从单声道上混到 5.1 声道
output.L = 0;
output.R = 0;
output.C = input; // 放在中心声道
output.LFE = 0;
output.SL = 0;
output.SR = 0;
立体声上混音:
2 -> 4 : 从立体声上混到四声道
output.L = input.L;
output.R = input.R;
output.SL = 0;
output.SR = 0;
2 -> 5.1 : 从立体声上混到 5.1 声道
output.L = input.L;
output.R = input.R;
output.C = 0;
output.LFE = 0;
output.SL = 0;
output.SR = 0;
四声道上混音:
4 -> 5.1 : 从四声道上混到 5.1 声道
output.L = input.L;
output.R = input.R;
output.C = 0;
output.LFE = 0;
output.SL = input.SL;
output.SR = input.SR;
4.5. 下混音扬声器布局
例如,如果处理 5.1 源材料,但回放为立体声,则需要下混音。
单声道下混音:
2 -> 1 : 立体声到单声道
output = 0.5 * (input.L + input.R);
4 -> 1 : 四声道到单声道
output = 0.25 * (input.L + input.R + input.SL + input.SR);
5.1 -> 1 : 5.1 到单声道
output = sqrt(0.5) * (input.L + input.R) + input.C + 0.5 * (input.SL + input.SR)
立体声下混音:
4 -> 2 : 四声道到立体声
output.L = 0.5 * (input.L + input.SL);
output.R = 0.5 * (input.R + input.SR);
5.1 -> 2 : 5.1 到立体声
output.L = L + sqrt(0.5) * (input.C + input.SL)
output.R = R + sqrt(0.5) * (input.C + input.SR)
四声道下混音:
5.1 -> 4 : 5.1 到四声道
output.L = L + sqrt(0.5) * input.C
output.R = R + sqrt(0.5) * input.C
output.SL = input.SL
output.SR = input.SR
4.6. 通道规则示例
// 将增益节点设置为明确的 2 通道(立体声)。 gain. channelCount= 2 ; gain. channelCountMode= "explicit" ; gain. channelInterpretation= "speakers" ; // 为 DJ 应用设置“硬件输出”为 4 通道,具有两个立体声输出总线。 context. destination. channelCount= 4 ; context. destination. channelCountMode= "explicit" ; context. destination. channelInterpretation= "discrete" ; // 设置“硬件输出”为 8 通道,用于具有自定义矩阵混音的自定义多通道扬声器阵列。 context. destination. channelCount= 8 ; context. destination. channelCountMode= "explicit" ; context. destination. channelInterpretation= "discrete" ; // 设置“硬件输出”为 5.1 通道以播放 HTMLAudioElement。 context. destination. channelCount= 6 ; context. destination. channelCountMode= "explicit" ; context. destination. channelInterpretation= "speakers" ; // 明确将通道下混到单声道。 gain. channelCount= 1 ; gain. channelCountMode= "explicit" ; gain. channelInterpretation= "speakers" ;
5. 音频信号值
5.1. 音频采样格式
线性脉冲 编码调制(线性PCM)描述了一种音频值在规律间隔下采样的格式,其中两个连续值之间的量化级别是线性均匀的。
当本规范中公开信号值时,它们采用线性32位浮点脉冲编码调制格式(线性32位浮点PCM),通常以Float32Array
对象的形式表示。
5.2. 渲染
任何音频图的目标节点上所有音频信号的范围名义上为[-1, 1]。本规范未定义该范围之外的信号值或NaN、正无穷大或负无穷大的音频渲染。
6. 空间化/平移
6.1. 背景
现代3D游戏的一个常见功能需求是能够动态地将多个音频源空间化并在3D空间中移动。 例如,OpenAL具备这一能力。
使用 PannerNode,可以将音频流空间化或相对于
AudioListener
定位。一个 BaseAudioContext
将包含一个 AudioListener。Panner
和 Listener 都在三维空间中有一个位置,使用的是右手笛卡尔坐标系。坐标系统中使用的单位没有定义,并且不需要定义,因为使用这些坐标计算的效果与任何特定单位(如米或英尺)无关/不受其影响。PannerNode
对象(表示音源流)具有一个 方向 向量,表示声音投射的方向。此外,它们还有一个
声音锥,表示声音的指向性。例如,声音可以是全向的,在这种情况下,无论其方向如何都可以被听到,或者它可以更具方向性,只有当它面向听者时才会被听到。AudioListener
对象(表示人的耳朵)具有 前向 和 向上 向量,表示人面向的方向。
空间化的坐标系如下面的图所示,显示了默认值。为了更好地查看,我们将AudioListener
和PannerNode
的位置从默认位置移动了。

在渲染过程中,PannerNode
计算一个方位角和仰角。这些值由实现内部使用,以渲染空间化效果。有关如何使用这些值的详细信息,请参见平移算法部分。
6.2. 方位角和仰角
必须使用以下算法来计算方位角和仰角。实现必须适当地考虑以下各个AudioParam是否为"a-rate"
或"k-rate"。
// Let |context| be a BaseAudioContext and let |panner| be a // PannerNode created in |context|. // Calculate the source-listener vector. const listener= context. listener; const sourcePosition= new Vec3( panner. positionX. value, panner. positionY. value, panner. positionZ. value); const listenerPosition= new Vec3( listener. positionX. value, listener. positionY. value, listener. positionZ. value); const sourceListener= sourcePosition. diff( listenerPosition). normalize(); if ( sourceListener. magnitude== 0 ) { // Handle degenerate case if source and listener are at the same point. azimuth= 0 ; elevation= 0 ; return ; } // Align axes. const listenerForward= new Vec3( listener. forwardX. value, listener. forwardY. value, listener. forwardZ. value); const listenerUp= new Vec3( listener. upX. value, listener. upY. value, listener. upZ. value); const listenerRight= listenerForward. cross( listenerUp); if ( listenerRight. magnitude== 0 ) { // Handle the case where listener's 'up' and 'forward' vectors are linearly // dependent, in which case 'right' cannot be determined azimuth= 0 ; elevation= 0 ; return ; } // Determine a unit vector orthogonal to listener's right, forward const listenerRightNorm= listenerRight. normalize(); const listenerForwardNorm= listenerForward. normalize(); const up= listenerRightNorm. cross( listenerForwardNorm); const upProjection= sourceListener. dot( up); const projectedSource= sourceListener. diff( up. scale( upProjection)). normalize(); azimuth= 180 * Math. acos( projectedSource. dot( listenerRightNorm)) / Math. PI; // Source in front or behind the listener. const frontBack= projectedSource. dot( listenerForwardNorm); if ( frontBack< 0 ) azimuth= 360 - azimuth; // Make azimuth relative to "forward" and not "right" listener vector. if (( azimuth>= 0 ) && ( azimuth<= 270 )) azimuth= 90 - azimuth; else azimuth= 450 - azimuth; elevation= 90 - 180 * Math. acos( sourceListener. dot( up)) / Math. PI; if ( elevation> 90 ) elevation= 180 - elevation; else if ( elevation< - 90 ) elevation= - 180 - elevation;
6.3. 平移算法
单声道到立体声和立体声到立体声平移必须被支持。当输入的所有连接都是单声道时,使用单声道到立体声处理。否则,使用立体声到立体声处理。
6.3.1. PannerNode "等功率" 平移
这是一个简单且相对经济的算法,提供了基本但合理的结果。当PannerNode的panningModel
属性设置为"equalpower"时,将使用此算法,此时忽略仰角值。
此算法必须根据automationRate所指定的适当速率来实现。
如果PannerNode的任何AudioParam或AudioListener的AudioParam为"a-rate",
则必须使用a-rate处理。
-
对于由此
AudioNode计算的每个样本:-
让azimuth是方位角和仰角部分中计算的值。
-
azimuth值首先被限制在[-90, 90]的范围内,方法如下:
// 首先,将方位角限制在[-180, 180]的范围内。 azimuth= max( - 180 , azimuth); azimuth= min( 180 , azimuth); // 然后将其调整到[-90, 90]的范围内。 if ( azimuth< - 90 ) azimuth= - 180 - azimuth; else if ( azimuth> 90 ) azimuth= 180 - azimuth; -
对于单声道输入,从azimuth计算一个归一化值x:
x
= ( azimuth+ 90 ) / 180 ; 对于立体声输入:
if ( azimuth<= 0 ) { // -90 -> 0 // 将方位角值从[-90, 0]度变换到[-90, 90]的范围内。 x= ( azimuth+ 90 ) / 90 ; } else { // 0 -> 90 // 将方位角值从[0, 90]度变换到[-90, 90]的范围内。 x= azimuth/ 90 ; } -
左右增益值计算如下:
gainL
= cos( x* Math. PI/ 2 ); gainR= sin( x* Math. PI/ 2 ); -
对于单声道输入,立体声输出计算如下:
outputL
= input* gainL; outputR= input* gainR; 对于立体声输入,输出计算如下:
if ( azimuth<= 0 ) { outputL= inputL+ inputR* gainL; outputR= inputR* gainR; } else { outputL= inputL* gainL; outputR= inputR+ inputL* gainR; } -
应用距离增益和锥体增益,其中距离的计算描述在距离效果中,锥体增益描述在声音锥体中:
let distance= distance(); let distanceGain= distanceModel( distance); let totalGain= coneGain() * distanceGain(); outputL= totalGain* outputL; outputR= totalGain* outputR;
-
6.3.2. PannerNode "HRTF" 平移(仅限立体声)
这需要一组HRTF(与头部相关的传递函数)脉冲响应,记录在各种方位角和仰角下。实现需要一个高度优化的卷积函数。它比“等功率”稍微昂贵,但提供了更具感知性的空间化声音。
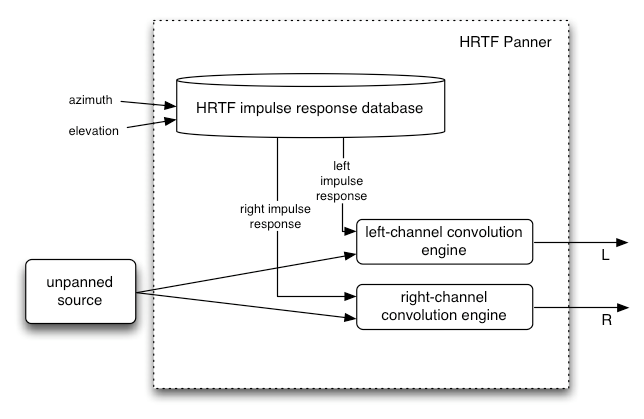
6.3.3. StereoPannerNode 平移
StereoPannerNode,必须实现以下算法。
-
对于由此
AudioNode计算的每个样本:-
让pan为该
StereoPannerNode的panAudioParam的计算值。 -
将pan限制在[-1, 1]范围内。
pan
= max( - 1 , pan); pan= min( 1 , pan); -
通过将pan值归一化到[0, 1],计算x。对于单声道输入:
x
= ( pan+ 1 ) / 2 ; 对于立体声输入:
if ( pan<= 0 ) x= pan+ 1 ; else x= pan; -
左右增益值计算如下:
gainL
= cos( x* Math. PI/ 2 ); gainR= sin( x* Math. PI/ 2 ); -
对于单声道输入,立体声输出计算如下:
outputL
= input* gainL; outputR= input* gainR; 对于立体声输入,输出计算如下:
if ( pan<= 0 ) { outputL= inputL+ inputR* gainL; outputR= inputR* gainR; } else { outputL= inputL* gainL; outputR= inputR+ inputL* gainR; }
-
6.4. 距离效果
距离较近的声音会更响,而距离较远的声音会更安静。声音音量如何根据与听者的距离变化取决于distanceModel属性。
在音频渲染期间,将根据平移器和听者的位置计算距离值:
function distance( panner) { const pannerPosition= new Vec3( panner. positionX. value, panner. positionY. value, panner. positionZ. value); const listener= context. listener; const listenerPosition= new Vec3( listener. positionX. value, listener. positionY. value, listener. positionZ. value); return pannerPosition. diff( listenerPosition). magnitude; }
距离将用于计算取决于distanceModel属性的距离增益。请参阅DistanceModelType部分,了解每种距离模型如何计算。
作为其处理的一部分,PannerNode会将输入音频信号乘以距离增益,以使远处的声音变得更安静,近处的声音更响。
6.5. 声锥
听者和每个声源都有一个描述它们朝向的方向向量。每个声源的声投射特性由描述声源/听者与声源方向向量的角度的内外“锥体”来描述。因此,直接对准听者的声源会比偏离轴线的声源更响。声源也可以是全向的。
下图说明了声源的锥体与听者的关系。在图中,coneInnerAngle
=
50coneOuterAngle
= 120

必须使用以下算法来计算由于锥体效果引起的增益贡献,给定声源(即PannerNode)和听者:
function coneGain() { const sourceOrientation= new Vec3( source. orientationX, source. orientationY, source. orientationZ); if ( sourceOrientation. magnitude== 0 || (( source. coneInnerAngle== 360 ) && ( source. coneOuterAngle== 360 ))) return 1 ; // 没有指定锥体 - 增益为 1 // 标准化的声源-听者向量 const sourcePosition= new Vec3( panner. positionX. value, panner. positionY. value, panner. positionZ. value); const listenerPosition= new Vec3( listener. positionX. value, listener. positionY. value, listener. positionZ. value); const sourceToListener= sourcePosition. diff( listenerPosition). normalize(); const normalizedSourceOrientation= sourceOrientation. normalize(); // 声源方向向量与声源-听者向量之间的角度 const angle= 180 * Math. acos( sourceToListener. dot( normalizedSourceOrientation)) / Math. PI; const absAngle= Math. abs( angle); // 由于API是完整角度(而不是半角),在这里除以2 const absInnerAngle= Math. abs( source. coneInnerAngle) / 2 ; const absOuterAngle= Math. abs( source. coneOuterAngle) / 2 ; let gain= 1 ; if ( absAngle<= absInnerAngle) { // 无衰减 gain= 1 ; } else if ( absAngle>= absOuterAngle) { // 最大衰减 gain= source. coneOuterGain; } else { // 介于内锥和外锥之间 // 内 -> 外,x 从 0 -> 1 const x= ( absAngle- absInnerAngle) / ( absOuterAngle- absInnerAngle); gain= ( 1 - x) + source. coneOuterGain* x; } return gain; }
7. 性能考虑
7.1. 延迟
对于 Web 应用程序,鼠标和键盘事件(keydown, mousedown 等)与声音被听到之间的时间延迟是很重要的。
这个时间延迟被称为延迟,它是由多个因素引起的(输入设备延迟、内部缓冲延迟、数字信号处理延迟、输出设备延迟、用户耳朵与扬声器之间的距离等),并且是累积的。延迟越大,用户的体验就越不令人满意。在极端情况下,它可能使音乐制作或游戏玩法变得不可能。在适中的水平上,它会影响时机并给人一种声音滞后或游戏响应迟缓的印象。对于音乐应用程序,时机问题影响节奏。对于游戏,时机问题影响游戏的精准度。对于互动应用程序,它通常会降低用户体验,类似于非常低的动画帧率所带来的效果。根据应用程序,合理的延迟范围可能是从 3-6 毫秒到 25-50 毫秒。
实现通常会寻求最小化整体延迟。
除了最小化整体延迟之外,实现通常还会寻求最小化 AudioContext
的
currentTime 与 AudioProcessingEvent
的
playbackTime 之间的差异。
随着 ScriptProcessorNode
的弃用,
这一考虑将随着时间的推移变得不那么重要。
此外,某些 AudioNode
会在某些音频路径上添加延迟,
特别是:
-
AudioWorkletNode可以运行一个脚本,该脚本内部缓冲,导致信号路径延迟。 -
DelayNode, 其作用是添加受控的延迟时间。 -
BiquadFilterNode和IIRFilterNode过滤器设计可能会延迟传入的样本,这是因果滤波过程的自然结果。 -
ConvolverNode根据冲激响应,可能会延迟传入的样本,这是卷积操作的自然结果。 -
DynamicsCompressorNode具有前瞻算法,会导致信号路径中的延迟。 -
MediaStreamAudioSourceNode,MediaStreamTrackAudioSourceNode和MediaStreamAudioDestinationNode, 视实现而定,可能会内部添加缓冲区,从而增加延迟。 -
ScriptProcessorNode可能在控制线程和渲染线程之间有缓冲。 -
WaveShaperNode, 在超采样时,取决于超采样技术,可能会给信号路径添加延迟。
7.2. 音频缓冲区复制
当对一个 获取内容 操作在一个 AudioBuffer
上执行时,
整个操作通常可以在不复制通道数据的情况下实现。特别是,最后一步应当在下一个 getChannelData()
调用时延迟执行。
这意味着,如果没有中断的 getChannelData()
调用(例如多个 AudioBufferSourceNode
播放相同的 AudioBuffer),
可以在没有分配或复制的情况下实现。
实现可以执行额外的优化:如果在一个 getChannelData()
被调用时,新的 ArrayBuffer
尚未分配,
但是所有之前的 获取内容 操作的调用者都已经停止使用该 AudioBuffer
的数据,
那么原始数据缓冲区可以被回收并用于新的 AudioBuffer,
从而避免重新分配或复制通道数据。
7.3. AudioParam 过渡
当直接设置一个 value
属性时,不会进行自动平滑,但对于某些参数,平滑过渡比直接设置值更为合适。
使用 setTargetAtTime()
方法,并使用较低的 timeConstant,可以让作者实现平滑过渡。
7.4. 音频故障
音频故障是由正常连续音频流的中断引起的,导致出现 loud click 和 pop 声音。它被认为是多媒体系统的灾难性故障,必须避免。它可能是由于负责将音频流传递到硬件的线程出现问题,例如线程优先级和时间约束不正确导致的调度延迟。它还可能是由于音频 DSP 尝试在给定 CPU 速度的实时限制下做更多的工作而引起的。
8. 安全性和隐私考虑
根据 自审问卷:安全性和隐私 § 问题:
-
此规范是否涉及个人身份信息?
可以使用 Web 音频 API 执行听力测试,从而揭示一个人能听到的频率范围(这随年龄增长而下降)。很难在没有用户意识和同意的情况下做到这一点,因为它需要用户的积极参与。
-
此规范是否涉及高价值数据?
没有。Web 音频不会使用信用卡信息等。虽然可以使用 Web 音频来处理或分析语音数据,这可能涉及隐私问题,但访问用户麦克风是基于权限的,通过
getUserMedia()。 -
此规范是否引入在浏览会话之间持久化的状态?
没有。AudioWorklet 不会在浏览会话之间持久化。
-
此规范是否向 Web 暴露跨源持久状态?
是的,支持的音频采样率和输出设备通道数量被暴露。请参见
AudioContext。 -
此规范是否向一个源暴露它当前没有访问的数据?
是的。通过提供有关可用的
AudioNode的信息,Web 音频 API 可能 暴露有关客户端特征的信息(例如音频硬件采样率)给任何使用AudioNode接口的页面。此外,通过AnalyserNode或ScriptProcessorNode接口可以收集时间信息。该信息 可能随后被用来创建客户端的指纹。普林斯顿 CITP 的 Web 透明度 和责任项目的研究表明,
DynamicsCompressorNode和OscillatorNode可以 用来从客户端收集熵以进行设备指纹识别。 这是由于不同实现之间的 DSP 架构、重采样策略和舍入权衡的微小、通常是不可闻的差异。精确的编译器标志以及 CPU 架构(ARM 与 x86)也对这一熵做出贡献。然而,实际上,这仅仅允许推测通过更简单的方式(用户代理字符串)已经可以获取的信息,如“这是浏览器 X 在平台 Y 上运行”。然而,为了减少额外指纹识别的可能性,我们要求浏览器采取措施减轻可能从任何节点输出中产生的指纹识别问题。
基于时钟偏移的指纹识别 已由 Steven J Murdoch 和 Sebastian Zander 描述。可能通过
getOutputTimestamp来确定这一点。 基于偏移的指纹识别也已在 Nakibly 等人的 HTML 研究中演示。高分辨率时间 § 10. 隐私考虑 部分应参考进一步的时钟分辨率和漂移信息。通过延迟进行指纹识别也是可能的;可能通过
baseLatency和outputLatency来推断。 缓解策略包括添加抖动(抖动)和量化,以便错误地报告精确的偏移。然而,请注意,大多数音频系统旨在 低延迟, 以便将 WebAudio 生成的音频与其他 音频或视频源或视觉提示(例如游戏中的音频或音频录制或音乐制作环境)同步。过高的延迟会降低可用性,可能成为一个无障碍问题。通过
AudioContext的采样率进行指纹识别也是可能的。我们建议采取以下步骤来尽量减少这种情况:-
允许 44.1 kHz 和 48 kHz 作为默认采样率;系统会根据最佳适用性选择其中之一。(显然,如果音频设备本身是 44.1 kHz,则选择 44.1;如果系统本身是 96 kHz,则可能选择 48 kHz,而不是 44.1 kHz。)
-
系统应为本地支持不同采样率的设备重新采样为这两种率之一,尽管这可能会因为重采样音频而增加额外的电池消耗。(同样,系统将选择最兼容的速率——例如,如果本地系统是 16 kHz,预计会选择 48 kHz。)
-
预计(但不是强制的),浏览器将提供一个用户选项来强制使用本地采样率——例如通过设置设备上的浏览器标志。此设置不会通过 API 暴露。
-
还预期的行为是,可以在构造函数中显式请求不同的采样率
AudioContext(这已经在规范中;它通常导致音频渲染以请求的采样率进行,然后再进行上或下采样到设备输出),如果该速率本地支持,则可以直接通过渲染。这将使应用程序能够在没有用户干预的情况下渲染到更高的速率——例如,如果MediaDevices功能被读取(需要用户干预)并指示支持更高的速率。
通过
AudioContext的输出通道数量进行指纹识别也是可能的。我们建议将maxChannelCount设置为 2 (立体声)。立体声是最常见的通道数量。 -
-
此规范是否启用新的脚本执行/加载机制?
没有。它使用的是 [HTML] 脚本执行方法,在该规范中定义。
-
此规范是否允许一个源访问用户的位置?
没有。
-
此规范是否允许一个源访问用户设备上的传感器?
不直接。目前,音频输入没有在本文档中指定,但它将涉及访问客户端机器的音频输入或麦克风。这将要求以适当的方式请求用户许可,可能通过
getUserMedia()API。此外,应注意 媒体捕获和流 规范中的安全性和隐私考虑。特别是,分析环境音频或播放独特音频可能使得 用户位置的识别精度达到房间级别,甚至能够识别多个用户或设备同时占用同一房间。访问音频输出和音频输入还可能 使得在浏览器中的不同上下文之间进行通信。
-
此规范是否允许一个源访问用户本地计算环境的某些方面?
不直接;所有请求的采样率都得到支持,必要时进行上采样。 通过 MediaTrackSupportedConstraints 使用 Media Capture 和 Streams 可以探测支持的音频采样率。此操作需要明确的用户同意。 它提供了一小部分指纹识别信息。然而,在实际应用中,大多数消费者和专业设备使用两种标准采样率:44.1kHz(最初用于 CD)和 48kHz(最初用于 DAT)。高度受限的设备可能支持语音质量的 11kHz 采样率,高端设备通常支持 88.2kHz、96kHz,甚至 audiophile 192kHz 率。
要求所有实现都将其上采样到一个统一的、常见支持的速率(例如 48kHz)将增加 CPU 成本,但不会带来任何实际好处,而要求高端设备使用较低的速率则可能导致 Web 音频被标记为不适用于专业使用。
-
此规范是否允许一个源访问其他设备?
通常不允许访问其他联网设备(在高端录音室中可能有一个例外,例如 Dante 网络设备,尽管这些通常使用单独的专用网络)。 它的确允许访问用户的音频输出设备或设备,这些设备有时是独立于计算机的。
对于语音或声音驱动设备,Web 音频 API 可能 用来控制其他设备。此外,如果声音驱动设备对近超声频率敏感,则该控制可能是不可听的。 这种可能性在 HTML 中也存在,通过 <audio> 或 <video> 元素。
在常见的音频采样率下,人类听力的极限通常认为是 20kHz。对于 44.1kHz 采样率,奈奎斯特限制为 22.05kHz。由于无法物理实现真正的砖墙滤波器,因此在 20kHz 到 22.05kHz 之间的空间用于快速滚降滤波器,以强烈衰减所有高于奈奎斯特频率的信号。
在 48kHz 采样率下,20kHz 到 24kHz 的频带仍然会迅速衰减(但在通带中避免了相位波动误差)。
-
此规范是否允许源对用户代理的本地 UI 进行某些控制?
如果 UI 具有音频组件,例如语音助手或屏幕阅读器,Web 音频 API 可能被用来模拟本地 UI 的某些方面,使攻击看起来更像是本地系统事件。
-
此规范是否向 Web 暴露临时标识符?
没有。
-
此规范是否区分第一方和第三方上下文中的行为?
没有。
-
在用户代理的“隐身”模式下,如何应对此规范?
没有区别。
-
此规范是否会将数据持久化到用户的本地设备?
没有。
-
此规范是否有“安全性考虑”和“隐私考虑”部分?
有(您正在阅读它)。
-
此规范是否允许降级默认的安全特性?
没有。
9. 需求和用例
请参阅 [webaudio-usecases]。
10. 规范代码的常见定义
本节描述了本规范中使用的 JavaScript 代码中的常见函数和类。
// 三维向量类。 class Vec3{ // 从 3 个坐标构造。 constructor ( x, y, z) { this . x= x; this . y= y; this . z= z; } // 与另一个向量的点积。 dot( v) { return ( this . x* v. x) + ( this . y* v. y) + ( this . z* v. z); } // 与另一个向量的叉积。 cross( v) { return new Vec3(( this . y* v. z) - ( this . z* v. y), ( this . z* v. x) - ( this . x* v. z), ( this . x* v. y) - ( this . y* v. x)); } // 与另一个向量的差。 diff( v) { return new Vec3( this . x- v. x, this . y- v. y, this . z- v. z); } // 获取此向量的大小。 get magnitude() { return Math. sqrt( dot( this )); } // 获取此向量乘以标量后的副本。 scale( s) { return new Vec3( this . x* s, this . y* s, this . z* s); } // 获取此向量的归一化副本。 normalize() { const m= magnitude; if ( m== 0 ) { return new Vec3( 0 , 0 , 0 ); } return scale( 1 / m); } }
11. 变更日志
12. 致谢
本规范是 W3C 音频工作组的集体成果。
工作组成员和曾为该规范做出贡献的人员包括(按字母顺序排列):
Adenot, Paul (Mozilla Foundation) - 规范联合编辑;
Akhgari, Ehsan (Mozilla Foundation);
Becker, Steven (Microsoft Corporation);
Berkovitz, Joe (邀请专家,隶属于 Noteflight/Hal Leonard) - 2013年9月到2017年12月工作组联合主席);
Bossart, Pierre (Intel Corporation);
Borins, Myles (Google, Inc);
Buffa, Michel (NSAU);
Caceres, Marcos (邀请专家);
Cardoso, Gabriel (INRIA);
Carlson, Eric (Apple, Inc);
Chen, Bin (Baidu, Inc);
Choi, Hongchan (Google, Inc) - 规范联合编辑;
Collichio, Lisa (Qualcomm);
Geelnard, Marcus (Opera Software);
Gehring, Todd (Dolby Laboratories);
Goode, Adam (Google, Inc);
Gregan, Matthew (Mozilla Foundation);
Hikawa, Kazuo (AMEI);
Hofmann, Bill (Dolby Laboratories);
Jägenstedt, Philip (Google, Inc);
Jeong, Paul Changjin (HTML5融合技术论坛);
Kalliokoski, Jussi (邀请专家);
Lee, WonSuk (电子与电信研究所);
Kakishita, Masahiro (AMEI);
Kawai, Ryoya (AMEI);
Kostiainen, Anssi (Intel Corporation);
Lilley, Chris (W3C工作人员);
Lowis, Chris (邀请专家) - 2012年12月至2013年9月工作组联合主席,隶属于英国广播公司;
MacDonald, Alistair (W3C邀请专家) — 2011年3月到2012年7月工作组联合主席;
Mandyam, Giridhar (Qualcomm Innovation Center, Inc);
Michel, Thierry (W3C/ERCIM);
Nair, Varun (Facebook);
Needham, Chris (英国广播公司);
Noble, Jer (Apple, Inc);
O’Callahan, Robert(Mozilla Foundation);
Onumonu, Anthony (英国广播公司);
Paradis, Matthew (英国广播公司) - 2013年9月至今工作组联合主席;
Pozdnyakov, Mikhail (Intel Corporation);
Raman, T.V. (Google, Inc);
Rogers, Chris (Google, Inc);
Schepers, Doug (W3C/MIT);
Schmitz, Alexander (JS Foundation);
Shires, Glen (Google, Inc);
Smith, Jerry (Microsoft Corporation);
Smith, Michael (W3C/Keio);
Thereaux, Olivier (英国广播公司);
Toy, Raymond (Google, Inc.) - 2017年12月至今工作组联合主席;
Toyoshima, Takashi (Google, Inc);
Troncy, Raphael (Institut Telecom);
Verdie, Jean-Charles (MStar Semiconductor, Inc.);
Wei, James (Intel Corporation);
Weitnauer, Michael (IRT);
Wilson, Chris (Google, Inc);
Zergaoui, Mohamed (INNOVIMAX)