1. 基础结构
本规范依赖于 Infra 标准。[INFRA]
2. 简介
2.1. 使用场景
2.1.1. 网页文本引用
文本片段的核心用例是允许 URL 作为跨网页的精确文本引用。例如,维基百科的引用可以链接到它们所引用页面上的确切文本。同样,搜索引擎可以提供 URL,将用户直接定位到页面中他们所寻找的答案,而不是链接到页面顶部。2.1.2. 用户分享
借助文本指令,浏览器可以实现“复制到此处 URL”的选项,当用户在文本选区上打开上下文菜单时,浏览器即可生成带有适当文本选区指定的 URL,URL 的接收者将方便地看到指定的文本被指示出来。如果没有文本片段,用户若想分享页面上一段文字,通常只是复制并粘贴该段文字,这样接收者就失去了页面的上下文。2.2. 链接生命周期
本规范力图最大化文本指令链接的有效期,例如,使用实际文本内容作为 URL 载荷,并允许使用元素 id 片段作为备用。然而,网页经常会更新和变更其内容。因此,此类链接可能会“失效”,即它们指向的文本内容在目标页面上不再存在。
尽管有这个问题,文本指令链接依然有用。在用户分享场景中,这类链接通常是临时的,仅用于发送后的短时间内。对于更长期的引用和网页链接等用例,文本指令依然有价值,因为它们能优雅降级为普通链接。此外,过期文本指令的存在也可以为用户展现有用的信息,以帮助用户理解原作者的用意,并提示页面内容自链接创建以来可能已发生更改。
关于如何创建健壮的文本指令链接,请参见§ 4 生成文本片段指令中的最佳实践。
3. 描述
3.1. 指示
本规范有意不定义用户代理如何“指示”文本匹配。有多种不同的体验和权衡,用户代理可以做出。可能的操作示例包括:
-
对文本段落进行视觉强调或高亮显示
-
在页面导航时自动滚动该段落至可见范围
-
在该段文字上激活用户代理的页面内查找功能
-
提供“点击以滚动至文本段落”的通知
-
当未在页面中找到文本段落时提供通知
3.2. 语法
文本指令在片段指令中指定(见§ 3.3 片段指令),格式如下:
#:~:text=[prefix-,]start[,end][,-suffix]
context |--match--| context
(方括号表示可选参数)
文本参数在匹配前会进行百分号解码。连字符(-)、和号(&)以及逗号(,)等字符在文本参数中会被百分号转义,以避免被解析为文本指令语法的一部分。
唯一必选的参数是start。如果只指定了start,则以该精确字符串首次出现处为目标文本。
如果还指定了end参数,则文本指令指向页面中的一段文本范围。目标文本范围是从首次出现的start开始,到其后首次出现的end为止。这等价于在start参数中指定完整的文本范围,但可避免因过长的文本指令导致URL膨胀。
3.2.1. 上下文术语
另外两个可选参数即为上下文术语。它们由连字符(-)连接在前缀和后缀处,以区别于start和end参数,可任意组合指定。
上下文术语用于消歧目标文本片段。上下文术语可分别指定文本片段之前(前缀)和之后(后缀)紧邻的文本内容,允许存在空白字符。
上下文术语不是目标文本片段的一部分,也不会被视觉指示。
#:~:text=this%20is-,an%20example,-text%20fragment 可匹配“this is an example text fragment”中的“an
example”,但不会匹配“here is an example text”中的“an example”。
3.2.2. 双向文本注意事项
由于 URL 字符串为 ASCII 编码,其本身不支持双向文本。但我们想要在页面上定位的内容可能是 LTR(从左到右)、RTL(从右到左)或双向文本。本节直观描述了规范中进一步章节隐含的行为。
文本片段中每个术语的字符都处于逻辑顺序,即母语读者阅读的顺序(也是内存中字符的存储顺序)。
同样,prefix与start表示另一个术语前的内容,suffix与end表示后续内容,均为逻辑顺序。
注意:用户代理可将 URL 以更符合本地读者习惯的方式呈现,比如显示为 Unicode。但 URL 的字符串表达始终是纯 ASCII 字符。
مِصر(埃及,阿拉伯语),前面是البحرين(巴林,阿拉伯语)。先对各个术语进行百分号编码:
مِصر 变为 "%D9%85%D8%B5%D8%B1"(注:UTF-8 字符 [0xD9,0x85] 为该阿拉伯词的第一个(最右)字符)。
البحرين 变为 "%D8%A7%D9%84%D8%A8%D8%AD%D8%B1%D9%8A%D9%86"
文本片段将如下:
:~:text=%D8%A7%D9%84%D8%A8%D8%AD%D8%B1%D9%8A%D9%86-,%D9%85%D8%B5%D8%B1
浏览器地址栏可按自然 RTL 方向渲染文本,呈现如下:
:~:text=البحرين-,مِصر
3.3. 片段指令
为避免与现有 URL 片段的使用发生兼容性问题,本规范引入了片段指令的概念。它是 URL 片段中位于片段指令分隔符之后的部分,也可能为 null(如果片段中未出现分隔符)。
片段指令分隔符为字符串 ":~:",即连续三个码点 U+003A (:)、U+007E (~)、U+003A (:)。
片段指令会被解析并处理为单个指令,即指示用户代理执行某项操作的指令。片段指令中可出现多个指令。
为防止影响页面运行,片段指令会从脚本可访问的 API 中剥离,防止与作者脚本交互。这也确保将来可安全添加更多指令,而不会有 web 兼容性风险。
3.3.1. 提取片段指令
本节描述了如何将片段指令从脚本中隐藏,以及它如何适配 HTML § 7.4 导航和会话历史。
-
会话历史条目现在包含一个新的“指令状态”属性
-
所有新条目创建时,指令状态初始为空值。如果新 URL 包含片段指令,该值将写入该状态(否则保持为 null)。
-
每当将可能包含片段指令的 URL 写入会话历史时,从 URL 中提取片段指令并存储到条目的指令状态属性。共有四处可能包含片段指令:
-
典型跨文档“navigate”步骤中
-
基于片段、同文档导航的“navigate to a fragment”步骤中
-
pushState/replaceState 等同步更新下的“URL 和历史更新步骤”中
-
重定向所得 URL 的“create navigation params by fetching”步骤中
-
-
仅更改片段的同文档导航,且新 URL 未指定指令时,新条目的指令状态指向前一个条目的指令状态。
在 HTML § 7.4.1 会话历史中,定义 指令状态:
猴补丁 HTML § 7.4.1 会话历史:
指令状态 保存会创建会话历史条目时的片段指令值,并用于每次遍历此条目时执行指令(如文本高亮)。其结构为:
同一 指令状态可被多个会话历史条目共享。
片段指令在 URL 设置到会话历史条目前会被移除,而存储于指令状态对象。这避免片段指令暴露给脚本 API,使其可独立指定、不干扰页面业务。
指令状态是对象而非原始字符串,因为多个连续历史条目可共用同一状态。仅当遍历导致指令状态从一条切换到另一条时,指令(如查找/高亮)才会被处理。
在 会话历史条目 的定义处补充:
增加一个帮助算法,可从URL中移除并返回片段指令字符串:
猴补丁 [HTML]:
TODO: 若 URL 片段以 ':~:' 结尾(即空指令),此时会返回 null,等同于未显式指定指令(且不会覆盖已有指令)。但或许此时应该返回空字符串?这样页面即可通过导航/pushState 到 '#:~:' 来显式清除指令/高亮。要从URL url中移除片段指令,执行:
下述四个猴补丁修改了会话历史条目的创建。当 URL 可能包含片段指令时,将其移除并存于指令状态。
在navigate定义中:
猴补丁 HTML § 7.4.2.2 开始导航:
导航 navigable 至 URL url...:
...
- 将 navigable 的 ongoing navigation 设为 navigationId。
若 url 的 scheme 为 "javascript",则...
并行执行以下步骤:
...
- 若 url 为 about:blank,则将 documentState 的 origin 设为 documentState 的 initiator origin。
否则,如 url 为 about:srcdoc,则 documentState 的 origin 设为 navigable 的父文档 origin。
Let historyEntry be a new session history entry, with its URL set to url and its document state set to documentState.- 令fragment directive为对url执行移除片段指令结果。
创建会话历史条目 historyEntry,URL 设为url,文档状态设为 documentState,指令状态设为directive state。
设 navigationParams 为 null。
...
导航至片段 navigable navigable,...:
令directive state为 navigable 当前活动会话历史条目的指令状态。
令fragment directive为执行移除片段指令于url的结果。
如fragment directive非空:
否则,仅片段变化且未指定指令则重用活动条目的指令状态,可防止片段变化后高亮丢失。创建会话历史条目 historyEntry:
URL url
文档状态为 navigable 当前活动会话历史条目的文档状态
滚动恢复模式为 navigable 当前活动会话历史条目的滚动恢复模式
指令状态为directive state
如 historyHandling 为"replace",则 entryToReplace 为 navigable 当前活动会话历史条目,否则为 null。
...
在URL 和 历史更新步骤定义中:
“URL 和历史更新步骤”,入参 Document document,...:
令navigable为document的 node navigable。
令activeEntry为navigable当前活动会话历史条目。
令fragment directive为对newUrl执行移除片段指令得到的结果。
新建会话历史条目historyEntry,其中
如 document 的 is initial about:blank 为 true,设 historyHandling 为"replace"。
如 historyHandling 为"push",则:
否则如fragment directive非空,将historyEntry的指令状态的值设为fragment directive。
如 serializedData 不为空,则恢复给定 document 和 newEntry 的历史对象状态。
在 create navigation params by fetching定义中:
“通过获取创建导航参数”,入参会话历史条目entry,...:
断言:此步骤在并行执行。
...
- 令 currentURL 为请求的当前 URL。
令 commitEarlyHints 为 null。
循环:
如请求的 reserved client 非空且 currentURL 的源与 reserved client 的创建 URL 源不同,则:
...
- 将 currentURL 设为 locationURL。
令fragment directive为对locationURL执行移除片段指令的结果。
将 entry 的 URL 设为 currentURL。将 entry 的 URL 设为 locationURL。
如 locationURL 的 scheme 不是 fetch scheme,则返回新的非 fetch scheme 导航参数,initiator origin 为请求的 current URL 源
...
由于文档由历史条目填充,其URL
并不包含片段指令。同理,window 的 Location
对象是URL的显示(当前活动文档),其所有 getter 都返回去除片段指令的版本。
同时,HashChangeEvent
在片段变化时
会触发,但如果导航或遍历仅更改了片段指令,则不会触发 hashchange。
下例用于说明各种边界情况。
window.location = "https://example.com#page1:~:hello"; console.log(window.location.href); // 'https://example.com#page1' console.log(window.location.hash); // '#page1'
首次导航创建了新的会话历史条目,该条目的 URL 已去除片段指令:"https://example.com#page1"。条目的指令状态值为 "hello"。由于文档由条目填充,web API 返回的 URL 不含片段指令。
location.hash = "page2"; console.log(location.href); // 'https://example.com#page2'
同文档导航仅更改片段。这会在 navigate to a fragment 步骤中新建一个历史条目。但因为只变更片段,新条目的指令状态仍引用首个条目的状态,值为 "bar"。
onhashchange = () => console.assert(false, "hashchange doesn’t fire."); location.hash = "page2:~:world"; console.log(location.href); // 'https://example.com#page2' onhashchange = null;
同文档导航仅更改片段但包含片段指令。此时新条目含有自己的指令状态,值为 "fizz"。
由于页面可见 fragment 未变,仅片段指令变化,因此不会触发 hashchange。原因在于 hashchange 比较会话历史条目的 URL,已移除片段指令。
history.pushState("", "", "page3");
console.log(location.href); // 'https://example.com/page3'
pushState 为同一文档创建了新历史条目。由于非片段 URL 改变,该条目指令状态值初值为 null。
对 URL 对象:
let url = new URL('https://example.com#foo:~:bar');
console.log(url.href); // 'https://example.com#foo:~:bar'
console.log(url.hash); // '#foo:~:bar'
document.url = url;
console.log(document.url.href); // 'https://example.com#foo:~:bar'
console.log(document.url.hash); // '#foo:~:bar'
<a> 或 <area> 元素:
<a id='anchor' href="https://example.com#foo:~:bar">Anchor</a> <script> console.log(anchor.href); // 'https://example.com#foo:~:bar' console.log(anchor.hash); // '#foo:~:bar' </script>
3.3.2. 将指令应用于文档
上节介绍了如何将片段指令从URL中分离出来,并存储在会话历史条目中。
本节定义了导航和遍历时,历史条目中的指令状态如何及何时被用来将会话历史条目关联的指令应用到文档上。
猴补丁 DOM § 4.5 文档接口:
在历史步骤应用时更新文档的定义中:
猴补丁 HTML § 7.4.6.2 更新文档:
3.3.3. 片段指令语法
注:本节为非规范性内容。
注:本语法仅供参考,解析的规则和步骤将在§ 3.4 文本指令节以命令方式给出。若实际行为与本语法描述有出入,应以那一节具体步骤为准。
FragmentDirective 可包含多个由 “&” 字符分隔的指令。目前允许页面存在多个文本指令以同时标示多段字符串,也为将来添加组合其它指令类型做扩展准备。为保持扩展性,遇到未知指令时不会导致整个解析失败。
若一个字符串匹配下述EBNF(扩展巴科斯范式)产生式,则为合法片段指令:
-
FragmentDirective::= -
(TextDirective | UnknownDirective) ("&" FragmentDirective)? -
TextDirective::= -
"text="CharacterString -
UnknownDirective::= -
CharacterString - TextDirective -
CharacterString::= -
(ExplicitChar | PercentEncodedByte)* -
ExplicitChar::= -
[a-zA-Z0-9] | "!" | "$" | "'" | "(" | ")" | "*" | "+" | "." | "/" | ":" | ";" | "=" | "?" | "@" | "_" | "~" | "," | "-"ExplicitChar 可为任何URL 码点,除了“&”。
若一个TextDirective匹配下述产生式,则为合法:
ValidTextDirective::="text=" TextDirectiveParametersTextDirectiveParameters::=-
(TextDirectivePrefix ",")? TextDirectiveString ("," TextDirectiveString)? ("," TextDirectiveSuffix)? TextDirectivePrefix::=TextDirectiveString"-"TextDirectiveSuffix::="-"TextDirectiveStringTextDirectiveString::=(TextDirectiveExplicitChar | PercentEncodedByte)+TextDirectiveExplicitChar::=-
[a-zA-Z0-9] | "!" | "$" | "'" | "(" | ")" | "*" | "+" | "." | "/" | ":" | ";" | "=" | "?" | "@" | "_" | "~"TextDirectiveExplicitChar 为任何未在FragmentDirective或ValidTextDirective语法中显式用到的 URL 码点,即“&”“-”“,”。文档中涉及“&”“-”“,”时需百分号编码。 PercentEncodedByte::="%" [a-zA-Z0-9][a-zA-Z0-9]
3.4. 文本指令
文本指令是一种指令,用于代表要向用户指示的文本范围。它是一个包含四个字符串的结构体:start、end、prefix、 suffix。start要求非null。其余三项可为null,表示未提供。空字符串在这四项中都是无效值。
各部分含义和用法见§ 3.2 语法。
-
如term为 null,则返回 null。
-
令decoded bytes为对term执行百分号解码的结果。
-
返回对decoded bytes执行不带 BOM 的 UTF-8 解码结果。
本算法以单一文本指令值字符串为输入(如 "prefix-,foo,bar"),尝试将其解析为指令组件(如 ("prefix", "foo", "bar", null))。各部分含义和用法见§ 3.2 语法。
若输入无效则返回 null,否则返回文本指令。
-
令prefix、suffix、start、end均为null。
-
如tokens长度小于1或大于4,则返回null。
-
如tokens首项结尾为U+002D(-):
-
设prefix为tokens[0]的从头截取长度=本身长度-1的子串。
-
移除tokens首项。
-
如prefix为空或包含U+002D(-),则返回null。
-
如tokens已空,则返回null。
-
-
如tokens末项起始为U+002D(-):
-
设suffix为tokens末项从第1位起至末尾的子串。
-
移除tokens末项。
-
如suffix为空或包含U+002D(-),则返回null。
-
如tokens已空,则返回null。
-
-
如tokens长度>2,则返回null。
-
设start为tokens首项。
-
移除tokens首项。
-
如start为空,或包含U+002D(-),则返回null。
-
如tokens非空:
-
设end为tokens首项。
-
如end为空或含U+002D(-),则返回null。
-
-
返回新文本指令:
3.4.1. 调用文本指令
本节描述如何处理和调用文档待处理文本指令,以指示相关的文本段落。
猴补丁 HTML § 7.4.6.3 滚动到片段:
对于HTML文档document,必须遵循如下处理模型,以确定其指示部分:
令text directives为文档的待处理文本指令。
如text directives非null:
如ranges非空:
令firstRange为ranges的首项。
以range方式,对ranges内每个范围进行实现自定义的视觉指示。该指示不得从作者脚本中观察到。见§ 3.7 指示文本匹配。
ranges中的第一个范围会滚动至可视区,但所有范围都应高亮指示给用户。将firstRange设为document的指示部分并返回。
令fragment为文档URL的片段。
如fragment为空字符串,则返回特殊值“文档顶端”。
令potentialIndicatedElement为给定文档和片段查找可能的指示元素结果。
...
在滚动到片段中,处理指示部分为范围的情形,并在启用强制顶部加载策略时阻止片段滚动。做如下修改:
猴补丁 HTML § 7.4.6.3 滚动到片段:
若document的指示部分为null,则将document的目标元素设为null。
否则,如document的指示部分为文档顶端,则:
将document的目标元素设为null。
将文档滚动至开头。
返回。
否则:
断言:document的指示部分为元素或范围。
令scrollTarget为document的指示部分。
令target为scrollTarget。
如target为范围:
断言:target为元素。
将document的目标元素设为target。
对target运行祖先详情揭示算法。
对target运行祖先hidden-until-found揭示算法。
如scrollTarget为范围,blockPosition设为"center",否则为"start"。
滚动到文本指令时,在区块方向居中显示。将target滚动到视图,行为设为"auto",block设为"start",inline设为"nearest"。- 滚动目标到视图, 参数target为scrollTarget,behavior为"auto",block为blockPosition,inline为"nearest"。
实现 MAY(可选)避免对由文本指令产生的目标滚动。
为target运行聚焦步骤,文档视口作为后备目标。
将顺序焦点导航起点移至target。
接下来两个猴补丁确保用户代理在片段查找完成时清理待处理文本指令。如因解析停止而结束文本指令查找,则再次尝试非文本片段。
在尝试滚动到片段定义中:
猴补丁 HTML § 7.4.6.3 滚动到片段:
要为文档document尝试滚动到片段,并行执行如下步骤:
等待一段实现自定义时间(用于优化用户体验和性能)。
在导航和遍历任务源上为document的相关全局对象排队全局任务,执行如下步骤:
在导航到片段定义中:
导航到片段,入参navigable navigable,...:
...
- 以navigable的活动文档、historyEntry、true、scriptHistoryIndex和scriptHistoryLength调用“历史步骤应用时更新文档”。
为navigable的活动文档滚动到片段。
- 将navigable的活动文档的待处理文本指令设为null。
令traversable为navigable的可遍历navigable。
...
滚动到指示部分只是“滚动到片段”中的众多操作之一。需重命名该及相关定义:
将HTML § 7.4.2.3.3 片段导航及相关步骤重命名为“指示片段”,以反映其更广泛的效果。
3.5. 安全与隐私
3.5.1. 动机
实现文本指令时必须确保无法被用于跨源窃取信息。脚本可以导航到带有文本指令的跨源URL。如果恶意行为者能判断导航导致目标页面上的文本片段被成功找到,则可推断出页面内容。
下述各子节给出的处理模型限制了该功能,缓解了已知的攻击向量。简而言之,文本指令限制如下:
-
仅适用于顶级可导航(即不用于iframe)。
-
这并非绝对,Chrome允许相同源发起的此用法。规范需进一步明确。[Issue #WICG/scroll-to-text-fragment#240]
-
-
由用户操作触发的导航
-
若导航为跨源发起,则目标页面要求 opener 隔离(即其它文档不可持有其全局对象引用)
3.5.2. 导航触发滚动
UA可以选择在匹配文本片段后自动滚动到可见区域。这对用户便捷,但也带来一些实现风险。
已知(或潜在未知)的方式可分辨导航触发滚动和用户自然滚动。
所有已知情景依赖于目标页的具体情况,因而并不普适。进一步对文本片段的调用条件加以限制,可进一步约束攻击者能力。但不同 UA 可根据自身判断风险是否可接受,确定是否在导航到文本片段时自动滚动。
符合规范的UA可选择导航时不自动滚动。此时可提供“点击滚动”等UI,或完全不滚动。此时 UA 应向用户提示有片段存在于页面下方。
上述例子展示在特殊情况下,攻击者可获取目标页面内容的1比特信息。但应防止可利用此途径持续攻击以获取任意内容。因此,基于用户激活与浏览上下文隔离的约束至关重要,必须严格实现。
但这同样确保恶意使用难以隐藏。一个组内唯一的浏览上下文将是顶级浏览上下文(即整个标签页/窗口)。
如UA选择自动滚动,必须确保文档在后台时(如处于非激活tab)不进行滚动,以防止攻击者在后台偷偷进行自动化搜索,确保恶意行为可见。
如UA选择不自动滚动,则必须无条件滚动后备元素id到可视区(如有),不论文本片段是否匹配。否则可用是否滚动该元素来判断文本片段是否成功匹配。
3.5.3. 查找时机
文本搜索算法的天真实现,可能因匹配与否导致运行时长差异,继而泄漏信息。攻击者如可同步导航到文本指令URL,即可通过导航耗时推断文本片段是否存在。
因此,实现必须确保§ 3.6 导航到文本片段步骤无论匹配与否运行时长无差异。
本规范不规定 UA 如何实现。可选做法如:即使已找到匹配,仍继续遍历树(见从文本指令查找范围);也可调度异步任务查找并设定文档的指示部分。
3.5.4. 限制文本片段
-
为 Document 和 Request 均添加布尔值
text directive user activation。当文档由用户激活的导航创建时设置该标志,并在因文本指令触发滚动时消费。若未被消费,可以在下一次出站导航请求时转移。这样实现了下方说明的 user-activation-through-redirects 行为。 -
定义一系列检查,针对文档、用户参与状态和导航的发起源,以确定是否应允许文本指令滚动。
-
在 "finalize a cross document navigation" 和 "navigate to a fragment steps" 计算滚动许可,并将其传递到 "scroll to the fragment" 步骤中,在此用于中止文本指令滚动。
补充请求和文档 的定义,加入新的布尔值text directive user activation字段:
猴补丁 [FETCH]:
一个请求关联一个布尔值text directive user activation, 初始为 false。
猴补丁 [HTML]:
每个文档有text directive user activation,为布尔型,初始为 false。
text directive user activation 提供了允许单次激活文本片段所需的用户手势信号。仅在导航因用户激活发生且跨客户端重定向时,于文档加载期间设为 true。若文档的text directive user activation未用于激活文本片段,则其用于将新导航请求的text directive user activation设为 true。因此,text directive user activation 可跨导航在文档间传递。
文档的text directive user activation和请求的text directive user activation在被使用时总归为 false,因此一次用户激活不能多次激活文本片段。
此机制允许文本片段通过许多主流网站常用的重定向方式激活。这些站点通过 200 状态码响应脚本,设置 window.location 以重定向用户到期望目标。
与真实 HTTP ( status 3xx ) 重定向不同,这些“客户端”
重定向无法传递导航属于用户手势。text directive user activation
机制可穿越此次特定范围内的导航。因此页面可编程导航至文本片段一次,效果等同拥有用户操作。但此后会重置
text fragment user activation,没人为操作则后续文本片段导航不会激活。
下图展示了这一标志如何支持通过客户端重定向服务激活文本片段:
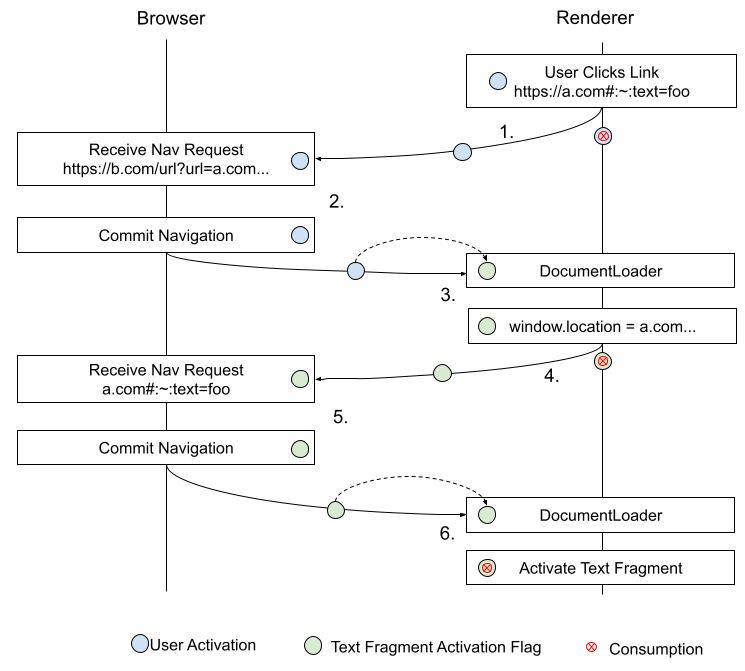
更详讨论见 redirects.md。
补充 create navigation params by fetching 步骤,将 活动文档 的 text directive user activation 赋值给 request 的 text directive user activation.
猴补丁 [HTML]:
断言:本步骤在并发执行。
令 documentResource 为 entry 的 document state 的 resource。
新建 request,其属性包括:
- url
- entry 的 URL
- ...
- ...
- referrer policy
- entry 的 document state 的 request referrer policy
- text directive user activation
- navigable 的 活动文档 的 text directive user activation
将 navigable 的 活动文档 的 text directive user activation 设为 false。
如 documentResource 为 POST 资源,则:
...
补充 navigation params,增加新字段:
猴补丁 [HTML]:
- user involvement
- 一个 用户导航介入 值。
所有创建 navigation params 的地方均初始化 user involvement 值。具体如 create navigation params by fetching 情况下初始化为 true:
猴补丁 [HTML]:
要 create navigation params by fetching,参数:session history entry entry,navigable,source snapshot params sourceSnapshotParams,target snapshot params targetSnapshotParams,string cspNavigationType,navigation ID-or-null navigationId,NavigationTimingType navTimingType,和 user navigation involvement user involvement,步骤如下。它们返回 navigation params、non-fetch scheme navigation params 或 null。
断言:本步骤并发执行。
...
- 令 resultPolicyContainer 为 determine navigation params policy container 结果,其参数为 response 的 URL、entry 的 document state 的 history policy container、sourceSnapshotParams 的 source policy container、null 和 responsePolicyContainer。
如 navigable 的 container 为 iframe,且 response 的 timing allow passed 标志置位,则将 container 的 pending resource-timing start time 设为 null。
返回新 navigation params,属性为:
- id
- navigationId
- ...
- ...
- about base URL
- entry 的 document state 的 about base URL
- user involvement
- user involvement
补充 create and initialize a Document object 步骤,计算并存储 text directive user activation 标志:
猴补丁 [HTML]:
调用 process link headers。
navigationParams 的 user involvement 是 "
activation";navigationParams 的 user involvement 是 "
browser UI";或navigationParams 的 request 属性中 text directive user activation 为 true。
text directive user activation 不可被复制,仅有一次用户激活的文本片段可被激活。返回 document。
一个text
directive allowing MIME type 是 MIME 类型,其本质
为 "text/html" 或 "text/plain"。
注:如滚动到片段所述, 片段处理由各 MIME 类型单独定义。因此滚动到片段中滚动文本指令只应应用于 text/html 类型的媒体。然而,实际上浏览器会对 text/plain 等其它类型应用 HTML 片段处理(如为 text/plain 文档加 id 后导航片段能滚动)。因此在 text/plain 文档启用文本指令有用。其余类型显式禁止,防止对敏感应用数据(如 text/css、application/json、application/javascript 等)发起 XS-Search 攻击。
-
如 document 的待处理文本指令为 null 或空,返回 false。
-
如 document 的text directive user activation 为 true,或 user involvement 为 "
activation" 或 "browser UI",则 is user involved 为 true,否则为 false。 -
将 document 的text directive user activation 设为 false。
-
如果document的content type非text directive allowing MIME type,返回 false。
-
如 user involvement 为 "
browser UI",返回 true。如导航始于浏览器UI,始终允许(因用户触发且页面/脚本未提供文本片段)。
本项意在区分由应用/页面控制URL还是由用户完全控制。如前者,则仅当目标加载于独立浏览上下文组,否则禁用文本片段滚动(防止同时控制片段且可观测副作用)。但如右键“新窗口中打开”属于灰色地带。
相关讨论见 sec-fetch-site 于 [FETCH-METADATA]。
-
如 is user involved 为 false,返回 false。
-
如 document 的node navigable 有父,返回 false。
-
如 initiator origin 非 null 且 document 的origin与initiator origin同源,返回true。
-
如 document 的browsing context 的group的browsing context set长度为1,返回true。
即仅在跨 origin 元素/脚本导航目标文档于 noopener 上下文(即新顶级浏览上下文组)时允许滚动,确保发起方无法脚本控制目标文档(可多进程)。 -
否则返回 false。
补充(已在§ 3.4.1 调用文本指令饱和修改)滚动到片段,新增布尔参数 allow text directive scroll:
猴补丁 HTML § 7.4.6.3 滚动到片段:
补充try to scroll to the fragment,新增布尔标志 allow text directive scroll,替换第2步任务内容:
猴补丁 [HTML]:
要为文档 document (及布尔变量 allow text directive scroll)尝试滚动到片段,并行执行如下步骤:
等待一段实现自定义时间。
在 navigation and traversal task source 上为 document 的关联全局对象排队全局任务,执行如下:
如 document 无解析器、解析器已停止、或 UA 认为用户已不关心滚动,则中止步骤。
按 document 和allow text directive scroll滚动到片段。
如 document 的指示部分依然为 null,再次用同参数 try to scroll to the fragment。
补充update document for history step application,新增布尔 allow text directive scroll,滚动时用之:
猴补丁 [HTML]:
To update document for history step application given a Document document, a session history entry entry, a boolean doNotReactivate, integers scriptHistoryLength and scriptHistoryIndex, an optional list of session history entries entriesForNavigationAPI, and a boolean allow text directive scroll:
Let documentIsNew be true if document’s latest entry is null; otherwise false.
...
- If documentsEntryChanged is true, then:
Let oldURL be document’s latest entry’s URL.
...
If documentIsNew is true, then:
Try to scroll to the fragment with document and allow text directive scroll.
补充apply the history step 算法,传递 allow text directive scroll 调用 update document for history step application :
猴补丁 [HTML]:
apply the history step,参数:step、traversable、checkForCancelation、sourceSnapshotParams、initiatorToCheck、userInvolvementForNavigateEvents,和 allow text directive scroll(默认 false),步骤如下,返回 "initiator-disallowed"、"canceled-by-beforeunload"、"canceled-by-navigate" 或 "applied"。
While completedChangeJobs does not equal totalChangeJobs:
...
- Queue a global task on navigation and traversal task source,入参:navigable 的 active window,执行如下步骤:
如 changingNavigableContinuation 的 update-only 为 false:
...
为 navigable 激活历史条目 targetEntry。
定义 updateDocument:执 targetEntry 的 document、targetEntry、changingNavigableContinuation 的 update-only、scriptHistoryLength、scriptHistoryIndex、entriesForNavigationAPI、allow text directive scroll
如 targetEntry 的 document 等于 displayedDocument,执 updateDocument。
Let totalNonchangingJobs be the size of nonchangingNavigablesThatStillNeedUpdates.
补充apply the push/replace history step,传递 allow text directive scrolling 至 apply the history step:
猴补丁 [HTML]:
apply the push/replace history step,参数:step、traversable,和布尔 allow text directive scroll(默认false):返回 apply the history step(stap, traversable, false, null, null, null, allow text directive scroll).
注:allow text directive scroll 在遍历和重载时故意不设置。这样可避免大量传递和发起源、用户参与、历史滚动状态等检查。此时文本指令仍可作为文档指示部分(高亮可恢复)。
补充 finalize a cross-document navigation,增加user involvement参数并计算及传递 allow text directive scrolling:
猴补丁 [HTML]:
finalize a cross-document navigation,参数:navigable、historyHandling、historyEntry、user navigation involvement user involvement(默认 "none"):
断言:执行于 navigable 的 traversable navigable 的会话历史遍历队列。
...
- 令allow text directive scroll为检查文本指令是否可被滚动的结果,参数为 historyEntry 的document、historyEntry 的document state 的initiator origin、user involvement
apply the push/replace history step,参数 targetStep、traversable,allow text directive scroll。
补充navigate算法,传递 user involvement 至 finalize a cross-document navigation:
猴补丁 [HTML]:
...
- . 并发执行如下步骤:
...
- . 努力用下述参数填充历史条目的文档:navigable、"navigate"、sourceSnapshotParams、targetSnapshotParams、navigationId、navigationParams、cspNavigationType,并在步骤完成后执行:
为 navigable 的 traversable 附加会话历史遍历步骤,调用 finalize a cross-document navigation,参数:navigable、historyHandling、historyEntry、userInvolvement。
补充navigate to a fragment 算法,添加 initiator origin 参数,且滚动时传递 allow text directive scroll:
猴补丁 [HTML]:
navigate to a fragment,参数:navigable、url、historyHandling、userInvolvement、navigationAPIState、navigationId,origin initiator origin:
令 navigation 为 navigable 的 active window 的 navigation API。
...
- 用 navigable 的 active document、historyEntry、true、scriptHistoryIndex、scriptHistoryLength 调用 update document for history step application。
用 navigation、historyEntry、historyHandling,更新 navigation API 的 same-document navigation 条目。
令allow text directive scroll为调用检查文本指令是否可被滚动,参数为navigable 的活动文档、initiator origin、userInvolvement。
用 navigable 的活动文档,allow text directive scroll,滚动到片段。
补充navigate算法,导航到片段时传递 initiator origin:
猴补丁 [HTML]:
如导航须替换,historyHandling 设为 "replace"。
如下列全为真:
documentResource 为 null;
response 为 null;
url 等于 navigable 活动会话历史条目(排除 fragment 版本);
url 的 fragment 非 null,
则:
使用参数 navigable、url、historyHandling、userInvolvement、navigationAPIState、navigationId、initiatorOriginSnapshot调用 navigate to a fragment。
令 navigation 为 navigable 的活动 window 的 navigation API。
3.5.5. 限制加载时滚动
本节定义如何使用 force-load-at-top 策略来阻止在加载新文档时发生所有类型的滚动,包括但不限于文本指令。
需要决定
force-load-at-top 与 Navigation API 的交互方式。[Issue
#WICG/scroll-to-text-fragment#242]
修订 restore persisted state 步骤,增加能抑制滚动恢复的新布尔参数:
猴补丁 [HTML]:
要 restore persisted state from a session history entry entry , and boolean suppressScrolling 执行:
如果 entry 的 scroll restoration mode 为 "auto",suppressScrolling 为 false,且 entry 的 document 的相关全局对象的导航 API 的 suppress normal scroll restoration during ongoing navigation 为 false,则根据 entry 恢复滚动位置信息。
...
修订 update document for history step
application 步骤,检查 force-load-at-top 策略,若被设置则避免在新文档中滚动。
猴补丁 [HTML]:
...
- 将 document 的历史对象长度设为 scriptHistoryLength。
令 scrollingBlockedInNewDocument 为对 document 获取 force-load-at-top 策略值的结果。
如果 documentsEntryChanged 为 true,则:
设 oldURL 为 document 的最新 entry 的 URL。
...
- 如果 documentIsNew 为 false,则:
为同文档导航用 navigation、entry 和 "traverse" 更新导航 API 条目。
派发名为 popstate 的事件...
用 entry 和 suppressScrolling 设为 false恢复持久化状态。
如果 oldURL 的 fragment 不等于...
否则,
断言:entriesForNavigationAPI 被传入。
用 entry 和 scrollingBlockedInNewDocument恢复持久化状态。
用 navigation、entriesForNavigationAPI 和 entry 初始化新文档的导航 API 条目。
如果 documentIsNew 为 true,则:
如 scrollingBlockedInNewDocument 为 false,为 document 尝试滚动到片段。
此时可为新建文档运行脚本。
否则,如果 documentsEntryChanged 为 false 且 doNotReactivate 为 false,则:
...
3.6. 导航到文本片段
-
令 commonAncestor 为 nodeA。
-
当 commonAncestor 非 null 且不是 包含 shadow 的包容祖先时,将 commonAncestor 设为 commonAncestor 的 包含 shadow 的父节点。
-
返回 commonAncestor。
-
如 node 是 shadow root,返回 node 的 host。
-
否则,返回 node 的 父节点。
3.6.1. 在文档中查找范围
高层来看,输入如:
text=prefix-,foo&unknown&text=bar,baz
我们拆分得到单独每条文本指令:
text=prefix-,foo text=bar,baz
依次对每条文本指令,在文档内查找首次匹配其所有限制条件的渲染文本。每一次查找互不影响:即无论其他指令数量与匹配结果如何,结果都一致。
若指令在文档中成功匹配某段文本,则返回一个 范围 指示该匹配。invoke text directives 步骤是本节提供的高阶 API。返回由单条指令匹配出的 范围 组成的 列表,顺序与片段指令字符串一致。
如某条指令未命中,则不会在返回列表中加入项。
end 可为 null。未指定时为“精确”查找,返回的 范围只包含和 start 完全相等的字符串。如 end 指定,则是“范围”查找,返回 范围从 start 开始,以 end 结束。下文统称以 start、end 匹配到的片段为"matching text"。
prefix 和 suffix 任一可为null。为null的方向无需额外上下文。例如 prefix 为null时,不要求被匹配文本前方内容。
-
令 searchRange 为范围 (document, 0) 到 (document, document 的 长度)
-
当 searchRange 未折叠时:
-
令 potentialMatch 为 null。
-
如 parsedValues 的 prefix 非null:
-
令 prefixMatch 为 find a string in range(参数:query = parsedValues 的prefix、searchRange、wordStartBounded = true、wordEndBounded = false)
-
如 prefixMatch 为 null,返回 null。
-
将 searchRange 的 start 指向 prefixMatch 的 边界点(即 prefixMatch 结尾后)。
-
如 matchRange 已折叠,返回 null。
如果 prefixMatch 的结尾或其后第一个非空白字符已在文档末尾,会发生此情况。 -
断言:matchRange 的 start node 必为
Text节点。matchRange 的起点现在就是 prefix 匹配后第一个非空白文本。 -
令 mustEndAtWordBoundary 为 true 当 parsedValues 的 end 非 null 或 parsedValues 的 suffix 为 null,否则为 false。
-
设 potentialMatch 为 find a string in range(参数:query = parsedValues 的 start,searchRange = matchRange,wordStartBounded = false,wordEndBounded = mustEndAtWordBoundary)。
-
如 potentialMatch 为 null,返回 null。
-
如 potentialMatch 的 start 不等于 matchRange 的 start,则 跳过本次 继续查找下一个 prefix 的实例。
此时虽找到前缀,但其后并非匹配文本,故继续查下次前缀。
-
-
否则:
-
令 mustEndAtWordBoundary 为 true 当 parsedValues 的 end 非 null 或 parsedValues 的 suffix 为 null,否则为 false。
-
设 potentialMatch 为 find a string in range(参数:query = parsedValues 的 start,searchRange,wordStartBounded = true,wordEndBounded = mustEndAtWordBoundary)。
-
如 potentialMatch 为 null,返回 null。
-
将 searchRange 的起点设为 potentialMatch 的 start 之后的第一个边界点。
-
-
令 rangeEndSearchRange 为范围,从 potentialMatch 的 end 到 searchRange 的 end。
-
当 rangeEndSearchRange 未折叠时:
-
如 parsedValues 的 end 非 null:
-
令 mustEndAtWordBoundary 为 true 当 parsedValues 的 suffix 为 null,否则为 false。
-
设 endMatch 为 find a string in range(参数:query = parsedValues 的 end,searchRange = rangeEndSearchRange,wordStartBounded = true,wordEndBounded = mustEndAtWordBoundary)。
-
如 endMatch 为 null 则返回 null。
-
-
如 parsedValues 的 suffix 为 null,返回 potentialMatch。
-
令 suffixRange 为 范围:起点等于 potentialMatch 的 end,终点等于 searchRange 的 end。
-
将 suffixRange 的起点推进到下一个非空白位置。
-
设 suffixMatch 为 find a string in range(参数:query = parsedValues 的 suffix,searchRange = suffixRange,wordStartBounded = false,wordEndBounded = true)。
-
如 suffixMatch 为 null,则返回 null。
如文档剩余文本中无 suffix,则无可能命中。 -
如 suffixMatch 的 start 等于 suffixRange 的 start,返回 potentialMatch。
-
如 parsedValues 的 end 为 null,则 中断;
对精确匹配如 suffix 不符,则跳出循环寻下个 start。对区间匹配则会继续尝试后续 rangeEnd。 -
将 rangeEndSearchRange 的起点设为 potentialMatch 的 end。
否则,表明 start 选对但 end 错,继续尝试下次 rangeEnd。
-
-
如 rangeEndSearchRange 已折叠,则:
-
-
返回 null
-
当 range 未折叠时:
-
令 node 为 range 的start node。
-
令 offset 为 range 的start offset。
-
如果 node 是不可搜索子树的一部分,或 node 不是可见文本节点,或 offset 等于 node 的长度,则:
-
将 range 的start node 设为下一个节点(按 包含shadow的树顺序)。
-
将 range 的start offset 设为 0。
-
-
如果 node 在 offset 处 6 个字符的子串数据为 " ",则:
-
range 的start offset加 6。
-
-
否则,若 node 在 offset 处 5 个字符的子串数据为 " ",则:
-
range 的start offset加 5。
-
-
否则:
-
令 cp 为 node 数据 码点中下标 offset 处的码点。
-
如 cp 未设有 White_Space 属性,则返回。
-
range 的start offset加 1。
-
-
此算法基本思路是在块内遍历所有可搜索文本节点,将其收集为列表。将该列表拼为单一字符串,在其中搜索命中,并用节点列表确定与 DOM 的边界点,用于返回 range。
一旦遇到块节点即终止收集,例如如下结构:
<div> a<em>b</em>c<div>d</div>e </div>
会先在 "abc" 上查找,再查 "d",再查 "e"。
因此,query 只会命中同一块级容器内,未被其他块元素打断的连续文本。
-
当 searchRange 未折叠时:
-
令 curNode 为 searchRange 的start node。
-
若 curNode 是不可搜索子树:
-
将 searchRange 的start node 设为下一个不是 包含shadow的后代 的节点(按包含shadow的树顺序)。
-
将 searchRange 的start offset 设为 0。
-
-
若 curNode 不是可见文本节点:
-
将 searchRange 的start node 设为下一个不是 doctype 的节点(按包含shadow的树顺序)。
-
将 searchRange 的start offset 设为 0。
-
-
令 blockAncestor 为 curNode 的最近块级祖先。
-
令 textNodeList 为 Text 节点列表, 初始为空。
-
当 curNode 是 blockAncestor 的包含shadow的后代且 (curNode, 0) 边界点不是 searchRange 的 end 之后时:
-
运行 find a range from a node list 步骤, 入参 query, searchRange, textNodeList, wordStartBounded, wordEndBounded。如果结果 range 非 null,则返回。
-
如 curNode 为 null,则 跳出。
-
将 searchRange 的 start 设为 (curNode, 0)。
-
-
返回 null。
如果一个节点是元素,属于HTML 命名空间,并且满足下列任一条件,则该节点为搜索不可见。
-
该节点序列化后为空元素。
-
类型为下列之一:
HTMLIFrameElement,HTMLImageElement,HTMLMeterElement,HTMLObjectElement,HTMLProgressElement,HTMLStyleElement,HTMLScriptElement,HTMLVideoElement,HTMLAudioElement
如果节点本身或其任一包含shadow的祖先 是搜索不可见,则为 不可搜索子树。
如果节点是 Text
节点,其父元素的样式计算值的 visibility 属性为 visible,且节点正在被渲染,则为 可见文本节点。
如果节点是 element,且其 样式计算值的 display 属性为下述任意值: block、table、flow-root、grid、flex、list-item,则有 块级显示。
-
如需起始词边界,则不会在 “color orange” 匹配。
-
如需结束词边界,则不会在 “forest ranger” 匹配。
见 § 3.6.2 词边界 了解详情与更多示例。
-
令 searchBuffer 为 拼接 nodes 内各节点的data。
data 不是所需的渲染文本。该算法需要针对渲染文本遍历(再映射回 DOM 范围)。[Issue #WICG/scroll-to-text-fragment#98]
-
令 searchStart = 0。
-
如 nodes 首项是 searchRange 的start node ,则 searchStart 设为 searchRange 的start offset。
-
令 start 和 end 均为边界点,初值为 null。
-
令 matchIndex 为 null。
-
当 matchIndex 为 null 时,循环:
-
从 searchStart 起,用基本字符对比(或 一级,见 [UTS10])在 searchBuffer 首次查找 queryString 的索引。
即大小写不敏感且忽略重音、变音等的查找。 -
如 matchIndex 为 null,返回 null。
-
令 endIx = matchIndex + queryString 的长度。
endIx 即命中最后一字符的下标+1。 -
设置 start 为 边界点,由 get boundary point at index(matchIndex, nodes, false)。
-
设置 end 为 边界点,由 get boundary point at index(endIx, nodes, true)。
-
如 wordStartBounded 为 true 且 matchIndex 在 searchBuffer 非 词边界(使用 start 的node 的 语言);或 wordEndBounded 为 true 且 matchIndex + queryString 的 长度 在 searchBuffer 非 词边界(用 end 的node 的 语言):
-
searchStart = matchIndex + 1。
-
matchIndex = null。
-
-
-
令 endInset = 0。
-
若 nodes 的最后一项为 searchRange 的end node,则 endInset = searchRange 的 end node 的 长度 − searchRange 的 end offset。
endInset 是最后一节点未被纳入范围的长度。 -
如 matchIndex + queryString 的长度 大于 searchBuffer 的长度 − endInset,则返回 null。
若匹配内容超出范围尾部则返回 null。
这是上文用到的小工具,用于推断拼接字符串中的下标属于哪个节点。
isEnd 用于区分起止边界。终止边界指向匹配结果后一字符,如命中刚好在节点边界,则终止偏移也留在本节点末尾而不是下个节点头。
3.6.2. 词边界
词边界 在 [UAX29] 的 Unicode 文本分割 § Word_Boundaries 中定义。Unicode 文本分割 § 默认词边界 定义了默认的词边界集合,但如规范所述,应根据区域设置使用更复杂的算法。
基于词典的词界定在没有单词分隔字符的语言区域设置中应特别注意。例如在英语中,单词由空格字符(' ')分隔;然而在日语中没有将单词彼此分隔的字符。在此类情况中,且当字母表字符少于 100 个时,词典中被视为有效的一字词不得超过字母表的 20%。
区域设置 是一个字符串,包含一个有效的 [BCP47] 语言标签,或为空字符串。空字符串表示主要语言未知。
在给定 区域设置 startLocale 和 endLocale 的情况下,子字符串在 字符串 text 中被称为 词界定,当且仅当其首字符的位置在给定 startLocale 下 处于词边界,并且其末字符之后的位置在给定 endLocale 下 处于词边界。
一个数字 position 在给定 区域设置 locale 的情况下,若在 字符串 text 中,按照 locale 的规则,要么在第 position 个代码单元之前立即存在一个 词边界,要么 text 的长度大于 0 且 position 等于 0 或等于 text 的长度,则称该 position 处于词边界。
对于有单词分隔符(例如空格)的语言,这(大多)是直接的;尽管还有诸如换行、连字符、引号等细节由上面的技术报告覆盖。
有些语言没有这样的分隔符(尤其是中/日/韩)。此类语言需要词典来确定给定区域设置中什么才是有效单词。
文本片段受限于匹配项在与其相邻的上下文项结合时为词界定。例如,在像 prefix,start,suffix
的精确搜索中,只有当整个结果为词界定时,"prefix+start+suffix" 才会匹配。然而,在类似 prefix,start,end,suffix
的范围搜索中,当且仅当 "prefix+start" 和 "end+suffix" 均为词界定时才会找到匹配。
目标是第三方必须已经知道它们正在匹配的完整 token。像 start,end 的范围匹配必须在两术语内部为词界定;否则第三方可以重复使用此方法试图揭示一个
token(例如在页面包含 "Balance: 123,456 $" 的情况下,第三方可以设置
prefix="Balance: "、end="$" 并通过改变 start 来逐位猜测数字 token)。
更多细节见 安全评审文档
3.7. 指示文本匹配
用户代理可以选择在 尝试滚动到片段 步骤中或通过其他机制将文本片段滚动到可见区域;但并不要求必须将匹配滚动到视图中。
用户代理应该以某种方式在视觉上指示被匹配的文本,使用户能够注意到该匹配,例如使用高对比度高亮。
用户代理应向用户提供某种取消匹配指示的方法,使得被匹配的文本不再以视觉方式被指示。
具体的指示外观和机制由用户代理定义。然而,用户代理不得使用任何作者脚本可观察的方式来指示匹配,例如使用文档的 selection。这样做可能允许内容外泄的攻击向量。
用户代理不得以任何方式对提供的上下文项进行可视指示。
由于指示器不是文档内容的一部分,用户代理应考虑将其与页面内容在用户感知上区分开来。
3.7.1. 用户代理功能中的 URL
用户代理为文档的 URL 提供了若干使用场景(不包括像 window.location 这样的程序化 API)。示例包括显示当前可见文档 URL
的地址栏,或当用户请求为当前页面创建书签时使用的 URL。
为避免用户困惑,用户代理在是否在这些 URL 中包含 片段指令 一事上应保持一致。本节为用户代理如何处理这些情况提供一组默认建议。
我们将这些作为一致行为的基线;然而,由于这些功能不影响跨用户代理互操作性,它们并非严格的一致性要求。
具体行为由实现的用户代理决定,用户代理可能有不同的约束或修改行为的理由。例如,用户代理可以允许用户配置默认值或在 UI 中提供选项,让用户选择是否希望在这些 URL 中包含片段指令。
也有利于允许用户代理试验以提供更好的体验。例如:也许当用户滚动并将文本片段移出视图时,用户代理显示的 URL 可以省略文本片段?
一般原则是:只有当视觉指示可见(即未被取消)时,URL 才应包含 片段指令。如果用户取消了指示,URL 应通过移除 片段指令 来反映该操作。
如果 URL 包含文本片段但在当前页面未找到匹配,用户代理可以选择在暴露的 URL 中省略它。
未在页面中找到的文本片段可以作为信息向用户展示,提示页面自链接创建以来已发生变化。
然而,对于书签来说,它通常并不太有用。
下面提供一些常见示例。
3.7.1.1. 地址栏
地址栏的 URL 在被视觉指示时应包含文本片段。当用户取消该指示时,片段指令应从地址栏 URL 中剥离。
建议即便在文档中未找到匹配,也在地址栏的 URL 中显示文本片段。
3.7.1.2. 书签
许多用户代理提供“书签”功能,允许用户在用户代理界面中存储指向当前页面的便捷链接。
新创建的书签默认应当在 URL 中包含 片段指令 当且仅当 已找到匹配并且视觉指示尚未取消。
从书签导航到 URL 应按典型导航的方式处理 片段指令。
3.7.1.3. 分享
一些用户代理提供将当前页面共享给他人的方法,通常是将 URL 提供给另一个应用或消息服务。
在这些情况下提供 URL 时,只有当已找到匹配并且视觉指示尚未取消时,才应包含 片段指令。
3.8. 文档策略集成
本规范在 Document Policy 中定义了名为
"force-load-at-top" 的配置点。其类型为 boolean,默认值 为
false。
https://example.com#:~:text=foo。example.com 服务器响应包含头:
Document-Policy: force-load-at-top
当页面加载时,包含 "foo" 的元素将被标记为指示部分并设为文档的目标元素。但是,"foo" 不会被滚动到可见区域。
该策略对基于片段的滚动阻止在对 滚动到片段 算法的修订中进行了规定,见本文件的 § 3.6 导航到文本片段 部分。
历史滚动恢复通过在 恢复持久化状态 步骤中插入新步骤(在步骤 2 之后)来被阻止:
3.9. 特性可检测性
为特性可检测性,我们建议添加一个新的 FragmentDirective 接口,当用户代理支持该特性时,通过 document.fragmentDirective 暴露。
[Exposed =Window ]interface { };FragmentDirective
我们将 Document
接口补充为包含一个 fragmentDirective 属性:
partial interface Document { [SameObject ]readonly attribute FragmentDirective ; };fragmentDirective
该对象未来可用于暴露有关文本片段或其他片段指令的更多信息。
4. 生成文本片段指令
本节包含建议,供用户代理自动生成带有 文本指令 的 URL 时参考。这些建议并非规范性,但用于确保生成的 URL 在稳定性和可用性上尽可能良好。
4.1. 优先精确匹配而非基于范围的匹配
匹配文本可以作为精确字符串 "text=foo%20bar%20baz" 提供,或作为范围 "text=foo,bar" 提供。
在可行情况下,优先指定整个字符串。这可以确保即使目标页面被删除或更改,预期的目标仍能从 URL 本身推断出来。
The first recorded idea of using digital electronics for computing was the 1931 paper "The Use of Thyratrons for High Speed Automatic Counting of Physical Phenomena" by C. E. Wynn-Williams.
我们可以创建一个基于范围的匹配,如下:
https://en.wikipedia.org/wiki/History_of_computing#:~:text=The%20first%20recorded,Williams
或者我们可以使用精确匹配对整句进行编码:
基于范围的匹配稳定性较差,意味着如果页面在更早处加入另一个 "The first recorded" 的实例,链接将定位到非预期的文本片段。
基于范围的匹配在语义上也不够有用。如果页面被更改以删除该句子,用户将不知道原本想指向什么。在精确匹配情况下,用户可以读取或用户代理可以显示所搜索但未找到的文本。
当引用文本过长且对整个字符串编码会产生难以处理的 URL 时,基于范围的匹配可能有帮助。
建议将短于 300 字符的文本片段使用精确匹配编码。超过该限值时,用户代理可以将字符串编码为基于范围的匹配。
4.2. 仅在必要时使用上下文
上下文项允许 文本指令 对页面上的文本片段进行消歧。然而,它们的使用在某些情况下会使 URL 更脆弱。通常,所需的字符串会在元素边界开始或结束。上下文因此可能存在于相邻元素中。页面结构的变化可能会使上下文与匹配文本不再相邻,从而使 文本指令 失效。
<div class="section">HEADER</div> <div class="content">Text to quote</div>
我们可以这样构造 文本指令:
text=HEADER-,Text%20to%20quote
但是,假设页面更改,在所有章节标题旁增加了一个 "[edit]" 链接。此时该 URL 将被破坏。
当文本片段足够长且唯一时,鼓励用户代理避免添加多余的上下文项。
仅在下列任一情况为真时使用上下文:
- 用户代理判断所引用文本存在歧义
- 所引用文本包含 3 个或更少的单词
4.3. 确定是否需要片段 id
当用户代理导航到包含 文本指令 的 URL 时,如果存在基于元素 id 的常规片段且未找到文本片段,将回退为滚动该元素 id 到视图中。
在文档中更改文本使 文本指令 失效的情况下,这可以作为一种有用的后备。
The earliest known tool for use in computation is the Sumerian abacus
通过指定文本出现的章节,我们确保如果文本被更改或删除,用户仍会被指向相关章节:
然而,用户代理应当确保回退的元素 id 片段是合适的:
By the late 1960s, computer systems could perform symbolic algebraic manipulations
尽管页面当前的 URL 为: https://en.wikipedia.org/wiki/History_of_computing#Early_computation,但使用 #Early_computation 作为回退并不合适。如果上面那句话被更改或删除,页面将加载到 #Early_computation 小节,可能会令用户感到困惑。
如果用户代理无法可靠地确定适当的回退片段,应该从 URL 中移除片段 id: