摘要 注释通常用于传达关于某个资源的信息,或用于资源之间的关联。
简单的例子包括在单个网页或图片上的评论或标签,或是一篇关于新闻文章的博客帖子。
《网页注释数据模型》规范描述了一种结构化的模型和格式,使注释能够在不同硬件和软件平台之间共享和复用。常见的用例可以用简单便捷的方式进行建模,同时也支持更复杂的需求,例如将任意内容与特定数据点或定时多媒体资源的片段关联起来。
该规范基于符合这些用例的概念模型,提供了便于创建和消费注释的专门 JSON 格式,以及用于表达模型的术语词汇。
目录
1. 引言
1.1
模型目标1.2
模型序列化1.3
一致性
1.3.1 与选择器相关的一致性要求
1.4
术语
2.
网页注释原则3.
网页注释框架
3.1
注释3.2
主体与目标
3.2.1 外部网络资源3.2.2
类3.2.3 外部资源片段3.2.4 内嵌文本主体3.2.5
字符串主体3.2.6 主体和目标的基数3.2.7 多主体选择
3.3
其他属性
3.3.1 生命周期信息3.3.2
代理3.3.3
目标受众3.3.4 内容可访问性3.3.5 动机与目的3.3.6
权利信息3.3.7
其他标识
4. 特定资源
4.1 外部网络资源用途4.2
选择器
4.2.1
片段选择器4.2.2
CSS 选择器4.2.3
XPath 选择器4.2.4
文本引用选择器4.2.5 文本位置选择器4.2.6 数据位置选择器4.2.7
SVG 选择器4.2.8
范围选择器4.2.9 选区细化
4.3 状态
4.3.1
时间状态4.3.2 请求头状态4.3.3
状态细化化
4.4 样式4.5
渲染软件4.6
资源范围
5. 集合
5.1
注释集合5.2
注释页
A. 媒体类型与选择器的对应
A.1 其他媒体类型/选择器组合
B. 完整示例C. JSON 键索引D.
主体与目标集合E.
致谢F.
候选推荐阶段退出标准G.
版本变更记录
G.1 2017-01-17 版推荐提案变更G.2 2016-11-22 版候选推荐变更G.3 2016-09-06 版候选推荐变更G.4 2016-07-05 版候选推荐变更G.5 2016-03-31 工作草案变更G.6 开放注释草案变更
H. 参考文献
H.1
规范性引用H.2
补充性引用
2. 网页注释原则
Web注释数据模型定义时遵循如下基本原则:
注释是一个有根有向图,表达资源之间的关系。
此关系的两个基本参与资源类型为主体和目标。
注释可以有0个或多个主体。
注释有1个或多个目标。
主体资源内容与目标资源内容相关,且通常是“关于”目标内容的。
注释、主体和目标可以拥有自己的属性和关系,通常包括创建和描述信息。
创建注释或者包含特定主体或目标背后的动机是非常重要的属性,由动机资源表示。
以下原则进一步说明目标和主体的具体区别:
目标或主体资源可以比其IRI 单独标识的实体更具体。
具体来说,
目标或主体资源可以是资源的特定片段。
目标或主体资源可以被特定样式化。
目标或主体资源可以为资源的特定状态。
目标或主体资源可以因为特定角色而被包含在注释中。
目标或主体资源可以是上述多重组合。
带有这些约束的资源是独立于注释、主体或目标的,称为 SpecificResource。
SpecificResource 指向源资源及其使之更具体的约束。
SpecificResource 的标识独立于有关约束的描述。
主体资源可以在多个资源之间做出选择。
注释文档中包含的外部资源(如主体和目标)的属性仅作为客户端的提示,不应视为权威信息。这包括诸如创建时间、创建者、修改时间、权利声明、格式、语言或外部资源文本方向等属性。
3. 网页注释框架
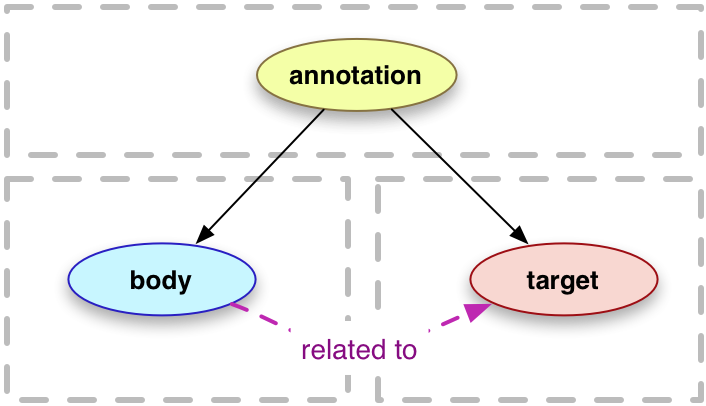
3.1 注释
注释是一个网络资源。通常情况下,一个注释包含一个主体(通常是评论或其它描述性资源),以及一个该主体“关于”的目标。注释通常还包含其他描述性属性。
用例示例: Alice 写了一篇评论特定网页的帖子。她的客户端创建了一个注释,将该帖子作为主体资源,网页作为目标资源。
模型
术语
类型
说明
@context
属性
决定该 JSON 作为注释含义的上下文。
必须 包含一个或多个@context值,并且http://www.w3.org/ns/anno.jsonld
必须 为其中之一。如果只有一个值,则必须 以字符串形式给出。
id
属性
注释的唯一标识。
必须 有且仅有一个标识它的IRI 。
type
关系
注释的类型。
必须 有一个或多个类型,并且Annotation类必须 为其一。
Annotation
类
网络注释的类。
Annotation类必须 通过type与注释关联。
body
关系
注释与其主体的关系。
应当 有一个或多个body关系与注释关联,但可以 为0个。
target
关系
注释与其目标的关系。
必须 有一个或多个target关系与注释关联。
示例
示例 1 :基本注释模型
{
"@context" : "http://www.w3.org/ns/anno.jsonld" ,
"id" : "http://example.org/anno1" ,
"type" : "Annotation" ,
"body" : "http://example.org/post1" ,
"target" : "http://example.com/page1"
}
3.2 主体与目标
3.2.1 外部网络资源网络资源以IRI
进行标识,并具有各种属性,通常包括资源内容的格式或语言。即使资源的表现需从网络获取,这些信息也可以作为注释的一部分被记录。
用例示例: Beatrice 对一项专利撰写了长篇分析,并以 mp3 音频形式发布在她的网站上。然后她创建了一个注释,将 mp3 作为主体,将专利的 PDF 作为目标。
模型
术语
类型
说明
id
属性
标识 Body 或 Target 资源的IRI 。
必须 有且只有一个
id,其值为资源的IRI 。
format
属性
网络资源内容的格式。
应当 有且仅有一个 format 属性,但可以 有0个或多个。该属性值应当 使用 [rfc6838
language
属性
网络资源内容的语言。
应当 有且仅有一个 language 属性,但可以 有0个或多个,例如无法识别语言或资源包含多种语言。该属性值应当 为 [bcp47
processingLanguage
属性
用于文本处理算法(如断行、断字、字体选择等)的语言。
可以 有且只有一个
processingLanguage。该属性值应当 为
[bcp47 应当 将其用于处理需求。
textDirection
关系
资源文本的整体基础方向。
可以 有且仅有一个 textDirection 属性。其值必须 为下文定义的方向之一(ltr、rtl或auto)。
ltr
实例
表示资源内容为显式方向隔离的从左到右文本。
rtl
实例
表示资源内容为显式方向隔离的从右到左文本。
auto
实例
表示资源内容为显式方向隔离文本,由程序通过值自动判断方向。
注
[
iana-media-types ]
文档提供了可以用于
format属性的官方媒体类型注册表。[
w3c-language-tags ]
文章对实现者在
language属性中可能遇到的取值做了很好的总结。文本方向以及
auto、
ltr、
rtl 的定义直接引用自 HTML5 [
html5 ] 的
dir
属性。还需注意,如果外部资源提供的信息与注释中的信息有冲突,则以外部资源为准,注释中的信息应舍弃。
示例
示例 2 :外部网络资源
{
"@context" : "http://www.w3.org/ns/anno.jsonld" ,
"id" : "http://example.org/anno2" ,
"type" : "Annotation" ,
"body" : {
"id" : "http://example.org/analysis1.mp3" ,
"format" : "audio/mpeg" ,
"language" : "fr"
},
"target" : {
"id" : "http://example.gov/patent1.pdf" ,
"format" : "application/pdf" ,
"language" : ["en" , "ar" ],
"textDirection" : "ltr" ,
"processingLanguage" : "en"
}
}
3.2.2 类让客户端预先了解一个网络资源的大致类型是有用的。如果客户端无法渲染视频,那么提前知道主体是视频,可以避免无谓下载可能很大的内容流。对于没有明显媒体类型的资源(如许多数据格式),让客户端了解诸如
text/csv 格式的资源不应仅作为纯文本渲染也是有用的(尽管其媒体类型的首部分为 text),而 application/pdf 虽然主类型是
'application',但用户代理可能可以直接渲染。
用例示例: Corina 用手机录制了她对某网站的评论视频并上传。她通过注释将视频与网站关联,她的客户端将类型信息添加为消费系统的提示。
模型
术语
类型
说明
type
关系
Body 或 Target 资源的类型。
可以 有一个或多个
type,如有,其值应当 选自下方类列表,也可以 采用其他词汇表中的值。
Dataset
类
封装结构化数据的资源所用的类。
Image
类
主要用于视觉展示的图片资源的类。
Video
类
有无音频的,供观看的视频资源的类。
Sound
类
主要供听觉感知的资源所用类。
Text
类
主要供阅读的资源所用类。
示例
示例 3 :主体和目标的类型
{
"@context" : "http://www.w3.org/ns/anno.jsonld" ,
"id" : "http://example.org/anno3" ,
"type" : "Annotation" ,
"body" : {
"id" : "http://example.org/video1" ,
"type" : "Video"
},
"target" : {
"id" : "http://example.org/website1" ,
"type" : "Text"
}
}
3.2.3 外部资源片段许多注释只涉及外部网络资源的一部分而非整体。在 Web [webarch IRI
标识,这既描述了如何从资源中提取感兴趣片段,也标识了被提取内容。对于简单注释,能够将带片段组件的 IRI 当作主体或目标的标识符非常有用。
用例示例: Dawn 希望描述图片的某一特定区域。她在客户端高亮该区域并输入描述。客户端随后构造出带有片段组件的 IRI 作为目标。
模型
术语
类型
说明
id
属性
标识 Body 或 Target 资源的 IRI。
必须 有且只有一个id,其值为资源的
IRI,也可以 带有片段组件。
注
资源的其他属性如
type、
format 和
language 及下方
其他属性 章节所述内容,都可以像应用于完整资源一样,应用于片段。
需意识到带片段组件 IRI 的使用后果,以及对实现的约束。
片段是针对于特定媒体类型定义的。例如,HTML 明确规定 IRI 片段部分的语义。
并非每种媒体类型都有片段规范。例如,Office 文档可能有媒体类型,也可发布在网络,但未必有片段部分对应的语义。
即使某媒体类型定义了片段,常常也不能精准描述感兴趣的片段。例如,HTML 的片段不能用来描述任意文本区间。
在未明确知晓媒体类型前,无法确定片段所指对象,因为同样的片段字符串在不同规范下可能意义不同。例如,某片段既可能指向图片中的一个矩形区域,也可能指向 HTML 文档中特定命名的区段。
带有片段组件的 IRI 不适用于其它更具体片段表述方式。例如,无法通过该 IRI 描述如何获取正确的表现、添加样式信息或关联角色。这类需求的描述方法见片段选择器 及特定资源 章节。
IRI 视为不透明字符串时,注释系统在以不含片段的 IRI 搜索时,可能无法发现含片段注释。例如目标为
http://example.com/image.jpg#xywh=1,1,1,1 的注释,在简单搜索
http://example.com/image.jpg 时不会被搜出,尽管其为后者一部分。
有关带片段组件 IRI 的使用细节,参见最佳实践 [fragid-best-practices
示例
示例 4 :带片段
IRI
{
"@context" : "http://www.w3.org/ns/anno.jsonld" ,
"id" : "http://example.org/anno4" ,
"type" : "Annotation" ,
"body" : "http://example.org/description1" ,
"target" : {
"id" : "http://example.com/image1#xywh=100,100,300,300" ,
"type" : "Image" ,
"format" : "image/jpeg"
}
}
3.2.4 内嵌文本主体许多情况下,注释的主体将采用文本格式,并在创建注释时同步生成而没有单独的
IRI。在这些情况下,可以将主体文本直接包含在注释中,无需与多个系统交互。主体也可以拥有“外部网络资源”属性,尤其是文本的语言和格式等。
用例示例: Emily 发表了一条自己喜欢图片的评论(在图片分享网站),客户端在注释中直接内嵌这条评论,并声明评论为法语且使用 HTML 格式。
模型
纯文本主体的基本特征如下:
术语
类型
说明
id
属性
标识该文本主体的 IRI。
可以 有一个唯一标识自身的 IRI。
type
关系
文本主体资源的类型。
应当 有TextualBody类,也可以 有其他类。
TextualBody
类
赋予主体,用于在注释中内嵌文本资源的类。
应当 有TextualBody类。
value
属性
文本主体内容的字符序列。必须 有且只有一个value属性与
TextualBody 关联。
系统应当 假定纯文本主体具有上方 类 部分描述的
Text 类,即使其在type属性中未明确声明。
“外部网络资源”属性如 language 和 format 同样适用于内嵌文本主体资源。
示例
示例 5 :文本主体
{
"@context" : "http://www.w3.org/ns/anno.jsonld" ,
"id" : "http://example.org/anno5" ,
"type" : "Annotation" ,
"body" : {
"type" : "TextualBody" ,
"value" : "<p>j'adore !</p>" ,
"format" : "text/html" ,
"language" : "fr"
},
"target" : "http://example.org/photo1"
}
3.2.5 字符串主体
最简单的主体类型是纯文本字符串,不带其他信息或属性。这种主体只适用于极其简单的注释。不建议用于主体需要在注释外被引用 的场景。
用例示例 Franceska 希望通过简单命令行客户端快速创建注释。她在文本文件中创建 JSON 串,并发送到注释服务器保存。
模型
术语
类型
说明
bodyValue
属性
注释主体的字符串值。
可以 有且只有一个bodyValue,其值必须 符合以下要求。如果有 bodyValue
属性,则body 关系 不能 出现。
关于该形式的使用时机和解释有几个限制:
必须 是单个 xsd:string,且不得 在串行化中声明数据类型。
不得 有绑定语言属性。必须 视为 TextualBody 的 value 属性值。
必须 视为 TextualBody 有 format 属性,值为
text/plain。
不得 将注释资源上的其它类似属性推断为 TextualBody 的属性值。
如上述解释不适用,则必须 使用TextualBody结构
注
系统
可以 将注释重写为
TextualBody结构,而不是保留
bodyValue形式。
TextualBody结构更优,因为语言和格式信息对客户端处理注释很重要。
示例
示例 6 :字符串主体
{
"@context" : "http://www.w3.org/ns/anno.jsonld" ,
"id" : "http://example.org/anno6" ,
"type" : "Annotation" ,
"bodyValue" : "Comment text" ,
"target" : "http://example.org/target1"
}
等价于:
示例 7 :等价文本主体
{
"@context" : "http://www.w3.org/ns/anno.jsonld" ,
"id" : "http://example.org/anno7" ,
"type" : "Annotation" ,
"body" : {
"type" : "TextualBody" ,
"value" : "Comment text" ,
"format" : "text/plain"
},
"target" : "http://example.org/target1"
}
3.2.6 主体和目标的基数有些注释可能根本没有主体,比如仅做高亮或书签,不带任何文本说明。一个注释也可以拥有多个主体和/或目标。在这种情况下,每个主体都被认为与每一个目标单独关联,而不是与所有目标集合关联。
用例示例: Gretchen 在她的电子书中用绿色高亮一段区域,因为她知道这种高亮代表什么,所以没有添加评论。她的客户端将样式表和注释关联,根本没有创建主体。
用例示例: Hannah 用单个注释将一个标签和一个描述与两张图片关联。
模型
当注释没有主体时,省略 body 关系。
注释的 body 和/或 target 关系可以是数组而不仅仅是单个对象。值可以是包含资源 IRI 的字符串,也可以是对象。
示例
示例 8 :无主体的注释
{
"@context" : "http://www.w3.org/ns/anno.jsonld" ,
"id" : "http://example.org/anno8" ,
"type" : "Annotation" ,
"target" : "http://example.org/ebook1"
}
示例 9 :多个主体或目标
{
"@context" : "http://www.w3.org/ns/anno.jsonld" ,
"id" : "http://example.org/anno9" ,
"type" : "Annotation" ,
"body" : [
"http://example.org/description1" ,
{
"type" : "TextualBody" ,
"value" : "tag1"
}
],
"target" : [
"http://example.org/image1" ,
"http://example.org/image2"
]
}
3.2.7 多主体选择选择结构拥有一个有序的资源列表,应用程序应从中只选一个进行处理或展示。顺序依照注释创建者或发布者的偏好,从最优先到最不优先。
用例示例: Irina 用法语和英语写了同一网站的讨论。两条评论是等价的,无需同时展示,而是希望法语读者看到法语评论,其余看到英语版本。她的客户端创建一个选择结构,将英文评论放在首位。
模型
术语
类型
说明
id
属性
标识该选择结构的 IRI。
可以 只有一个 IRI 标识。
type
关系
资源的类型。
必须 有且只有一个 type,且必须 为 CHOICE 类。
Choice
类
告知消费应用只应选择列表中一个资源而非全部渲染的结构。
items
关系
待选资源列表,默认选项排在首位。
注
客户端可以 用任意算法确定选择哪个资源,应当 自动利用已有信息判断,也可以 让用户手动选择。
示例
示例 10 :选择结构
{
"@context" : "http://www.w3.org/ns/anno.jsonld" ,
"id" : "http://example.org/anno10" ,
"type" : "Annotation" ,
"body" : {
"type" : "Choice" ,
"items" : [
{
"id" : "http://example.org/note1" ,
"language" : "en"
},
{
"id" : "http://example.org/note2" ,
"language" : "fr"
}
]
},
"target" : "http://example.org/website1"
}
3.3 其他属性
资源何时被创建、修改或生成
谁创建、修改或生成了注释或其他资源的序列化形式,以及这些资源面向谁
为何该资源被包含在注释中,或为何创建了该注释
资源还拥有哪些其它标识
根据其权利和许可,资源如何被使用
注
除本节描述的特性外,注释或模型中任何资源还
可以 添加其他属性。有关如何执行此操作的更多信息,请参阅注释词汇 [
annotation-vocab ] 的 Extension 部分。
3.3.2 代理
通常需要比仅提供标识它们的 IRI 更多的关于参与创建注释的代理的信息。这包括它们是个人、群体还是软件,以及诸如真实姓名、账户昵称和电子邮件地址等属性。
用例示例: Kelly 想将注释提交到一个不管理其身份的系统,并希望显示一个别名。她的客户端将此信息添加到要发送到该服务的注释中。
模型
Term
Type
Description
id
Property
标识代理的 IRI。
应当 有且只有1个用于标识它的 IRI,且不得 有超过1个。
type
Relationship
代理的类型。
应当 有1个或多个类,优先从下列列出的类中选择。
Person
Class
表示人为代理的类。
Organization
Class
表示组织(而非个人)的类。
Software
Class
表示软件代理的类,例如用户的客户端或创建注释的机器学习系统。
name
Property
代理的名称。
应当 有且只有1个 name 属性,且可以 为0个或多个。
nickname
Property
代理的昵称。
应当 有且只有1个 nickname 属性,且可以 为0个。
email
Relationship
与代理关联的电子邮件地址,使用 mailto: IRI 方案 [rfc6086 可以 有1个或多个 email 地址。
email_sha1
Property
对代理的 email IRI(包括 'mailto:' 前缀且无空白)应用 sha1
算法后得到的文本表示。这样可以在不公开电子邮件地址的情况下,将其用作标识符。可以 在
email_sha1 属性中有1个或多个值。
homepage
Relationship
代理的主页。可以 有1个或多个主页。
示例
Example 12 :
Agents
{
"@context" : "http://www.w3.org/ns/anno.jsonld" ,
"id" : "http://example.org/anno12" ,
"type" : "Annotation" ,
"creator" : {
"id" : "http://example.org/user1" ,
"type" : "Person" ,
"name" : "My Pseudonym" ,
"nickname" : "pseudo" ,
"email_sha1" : "58bad08927902ff9307b621c54716dcc5083e339"
},
"generator" : {
"id" : "http://example.org/client1" ,
"type" : "Software" ,
"name" : "Code v2.1" ,
"homepage" : "http://example.org/client1/homepage1"
},
"body" : "http://example.net/review1" ,
"target" : "http://example.com/restaurant1"
}
3.3.3 目标受众除与注释和其他资源的创建及管理相关的代理外,了解该资源面向的受众或消费代理类别也很有价值。这允许记录受众的角色(例如教师与学生)或该类别的属性(例如建议的年龄范围)。
用例示例: Lynda 为使用某教科书授课添加了一些笔记。她将注释的目标受众标注为教师(使用该教科书的人),以区别于可能面向学生的注释(学生也使用该教科书,但用于学习)。
模型
Term
Type
Description
id
Property
标识受众的 IRI。
提供 且只有1个用于标识受众的 IRI。
type
Relationship
受众的类型,来自 schema.org 的类结构。应当 有1个或多个
type,且这些类型应当 来自 schema.org 的类结构。
audience
Relationship
注释与其目标受众之间的关系。
可以 有0个或多个受众。
描述受众的其他属性来自 schema.org 的 Audience 类。属性和类名必须 在 JSON 中使用 schema: 前缀,以确保它们与任何其他属性或类唯一区分。
使用 audience 并不意味着或启用任何访问限制来阻止注释被查看。系统应当 基于其对用户的了解,使用该信息来过滤注释的显示,而不要假定注释或其他资源需要身份验证和授权。
示例
Example 13 :
Audience
{
"@context" : "http://www.w3.org/ns/anno.jsonld" ,
"id" : "http://example.org/anno13" ,
"type" : "Annotation" ,
"audience" : {
"id" : "http://example.edu/roles/teacher" ,
"type" : "schema:EducationalAudience" ,
"schema:educationalRole" : "teacher"
},
"body" : "http://example.net/classnotes1" ,
"target" : "http://example.com/textbook1"
}
3.3.4 内容可访问性联合国承认获取信息为一项基本人权。Web
能够消除各种身体障碍带来的交流与互动障碍,从而促进社会包容,同时也扩大了信息的潜在受众。对于被用作注释的主体或目标的资源,记录该资源所具备的便于不同能力范围用户访问的特性是有价值的。
用例示例: Megan 的听力很有限,偏好在与视频交互时阅读字幕。她使用注释客户端对这样的视频发表评论,并为了帮助处于类似情况的用户,客户端在注释中包含该视频具备此可访问性特性的信息。
模型
Term
Type
Description
accessibility
Property
来自一个枚举值列表的一个或多个字符串,每个字符串描述资源所具有的一项可访问性特征。
可以 列出0个或多个可访问性特征。
示例
Example 14 :
Accessibility
{
"@context" : "http://www.w3.org/ns/anno.jsonld" ,
"id" : "http://example.org/anno14" ,
"type" : "Annotation" ,
"motivation" : "commenting" ,
"body" : "http://example.net/comment1" ,
"target" : {
"id" : "http://example.com/video1" ,
"type" : "Video" ,
"accessibility" : "captions"
}
}
3.3.5 动机与目的在许多情况下,理解创建注释或在注释中包含文本主体的原因(即“为什么”)比仅知道参与的时间和代理(即“谁”与“何时”)更重要。这些原因通过声明创建注释的动机或在注释中包含文本主体的目的来提供;它们回答的是“为什么”而非前述部分描述的“谁”和“何时”。
用例示例: Noelle 出于将来引用的目的对某资源做了注释,并提供了描述和标签以便更易查找。她的客户端将适当的动机添加到注释和文本主体资源中以捕捉该信息。
模型
Term
Type
Description
motivation
Relationship
注释与动机之间的关系。
应当 有且只有1个 motivation,但也可以 为0个或多个。
purpose
Relationship
文本主体被包含在注释中的原因。
TextualBody 可以 有0个或多个
purpose 关联。
Motivation
Class
注释的动机是创建注释的原因,可能包括回复另一个注释、对资源发表评论或链接到相关资源等。
动机示例
assessing
Instance
当用户打算以某种方式评估目标资源(而不仅仅是评论)时使用的动机。比如撰写书评、评估数据集质量或评估学生作业的质量等。
bookmarking
Instance
当用户打算为目标或其某一部分创建书签时使用的动机。例如将读者阅读结束处作为书签的注释。
classifying
Instance
当用户打算将目标分类为某种类型时使用的动机。例如将一张图片分类为肖像。
commenting
Instance
当用户打算对目标发表评论时使用的动机。例如就某个 PDF 文档提供评论。
describing
Instance
当用户打算描述目标(而非例如对其准确性进行评论)时使用的动机。例如描述上述 PDF 的内容,而不是评论其准确性。
editing
Instance
当用户打算请求对目标资源进行更改或编辑时使用的动机。例如请求纠正一个错别字的注释。
highlighting
Instance
当用户打算突出目标资源或其中片段时使用的动机。例如为强调注释者不同意的选中文本而突出显示。
identifying
Instance
当用户打算为目标分配一个身份时使用的动机。例如将标识城市的 IRI 与网页中对该城市的提及关联起来。
linking
Instance
当用户打算链接到与目标相关的资源时使用的动机。
moderating
Instance
当用户打算为目标分配某种值或质量时使用的动机。例如在信任网络或线程讨论中对注释进行上调以进行审核。
questioning
Instance
当用户打算就目标提出问题时使用的动机。例如就特定文本段落寻求帮助或质疑其真实性。
replying
Instance
当用户打算回复先前的陈述(注释或其他资源)时使用的动机。例如提供上文中请求的帮助。
tagging
Instance
当用户打算将标签与目标关联时使用的动机。
示例
Example 15 :
Motivation and Purpose
{
"@context" : "http://www.w3.org/ns/anno.jsonld" ,
"id" : "http://example.org/anno15" ,
"type" : "Annotation" ,
"motivation" : "bookmarking" ,
"body" : [
{
"type" : "TextualBody" ,
"value" : "readme" ,
"purpose" : "tagging"
},
{
"type" : "TextualBody" ,
"value" : "A good description of the topic that bears further investigation" ,
"purpose" : "describing"
}
],
"target" : "http://example.com/page1"
}
3.3.7 其他标识在像 Web 这样高度分布式的系统中,信息常被复制。为了追踪注释及其他相关资源的来源,可记录还标识该资源的附加 IRI。这些可能是可解引用的“永久链接”、由客户端离线分配且不知晓 Web
的标识,或仅仅是当前抓取系统发现该资源的位置。
用例示例: Petra 创建了一个注释并将其发送给多个维护系统,一个个人的、一个公共的。她希望能够对齐这些副本,因此将 UUID 设置为规范 IRI,允许服务为其分配一个 HTTP
IRI。之后某个系统抓取了公共副本,保留了发现时的规范 UUID,然后将原始的 HTTP IRI 移至 via,并用其控制下的 IRI 代替之。
模型
Term
Type
Description
canonical
Relationship
注释、主体或目标与用于跟踪其身份的 IRI 之间的关系,该 IRI应当 被用于跟踪其身份,无论该资源在何处可访问。如果设置了此属性,则系统不得 更改或删除它。系统不应 在没有事先约定的情况下为资源分配规范 IRI,因为该注释在其他地方可能已有规范 IRI。
可以 有且只有1个 canonical IRI。
via
Relationship
注释、主体或目标与该系统获取该资源时所在位置的 IRI 之间的关系。
via 中可以 提供0个或多个 IRI。
示例
Example 17 : Other
Identities
{
"@context" : "http://www.w3.org/ns/anno.jsonld" ,
"id" : "http://example.org/anno17" ,
"type" : "Annotation" ,
"canonical" : "urn:uuid:dbfb1861-0ecf-41ad-be94-a584e5c4f1df" ,
"via" : "http://other.example.org/anno1" ,
"body" : {
"id" : "http://example.net/review1" ,
"rights" : "http://creativecommons.org/licenses/by/4.0/"
},
"target" : "http://example.com/product1"
}
4. 特定资源
仅通过前述结构,使用带有片段组件的 IRI 创建引用资源某部分的注释是可行的,但在许多场景下还不够用。例如,图片中的简单圆形区域或对角线都无法仅用片段实现;在 HTML
页面中选取任意文本区间(或许是最常见的注释概念)也无法通过片段支持。此外,还有一些非片段用例,如客户端需检索资源的特定状态或表现、以特定方式为其设定样式、将特定于注释用途的角色与资源关联,或者只有在资源被用在特定上下文中时注释才适用等。
网页注释数据模型引入了一种新资源类型来捕捉这些注释专用需求:SpecificResource。SpecificResource
作为注释和主体或目标之间的过渡,用于记录该资源在注释中的具体使用方式。其描述通常以独立实体从 SpecificResource 引用,可以为不同类型,以适应不同需求。例如,如果注释的目标是图片中的一个圆形区域,则
SpecificResource 即为该圆形区域,由 Selector 描述,同时与源图片资源关联。
SpecificResource 和说明器可以 是带有自身 IRI 的外部网络资源,如Selector 结构示例。但建议 将其包含在注释表现内,以避免处理注释时为获取所有所需信息而产生不必要的网络交互。
本文档定义的进一步细化类型有:
用途: 描述将源资源包含于注释中的目的选择器: 描述注释所需的源资源片段状态: 描述注释所需的源资源表现样式: 描述注释所需的源资源展现样式渲染: 描述创建注释时客户端用于渲染该资源的系统范围: 描述注释中源资源适用的范围
模型
术语
类型
说明
id
属性
特定资源的唯一标识。
可以 只有1个唯一标识它的 IRI。
type
关系
特定资源的类。
应当 声明 SpecificResource
类。
SpecificResource
类
特定资源的类。
SpecificResource 类应当 与特定资源关联,明确其作为其他资源某更具体区域或状态的角色。
source
关系
特定资源与其所细化表述的资源之间的关系。
必须 与1个source关系关联。源资源可以 如前所述被详细描述,也可仅为资源 IRI。
同一组 Specific Resource 和说明器类既用于 Target,也用于 Body。本节示例只演示其一,但模型适用于两者。
4.1 外部网络资源用途类似文本主体,外部网络资源也可以分配动机说明其为何被包含在注释内。这可通过 Specific Resource 模式实现,其用途与 Selector 描述片段、State
描述表现一样,说明资源在注释上下文中的使用方式。
用例示例: Qitara 想给一张照片打上城市标记,而不是直接输入城市名(后者可能有歧义)。她的客户端通过检索获得该城市的知名 IRI,并创建 Specific Resource 来管理用途分配。
模型
术语
类型
说明
purpose
关系
将网络资源包含于注释中的原因。
没有 或有多个用purpose关联的动机。
示例
示例 18 :带用途的资源
{
"@context" : "http://www.w3.org/ns/anno.jsonld" ,
"id" : "http://example.org/anno18" ,
"type" : "Annotation" ,
"body" : {
"type" : "SpecificResource" ,
"purpose" : "tagging" ,
"source" : "http://example.org/city1"
},
"target" : {
"id" : "http://example.org/photo1" ,
"type" : "Image"
}
}
4.2 选择器很多注释的 Target 并不是引用整个资源,而只是其中一部分。这部分资源称为片段。选择器用于描述如何从 Source
资源中确定该片段。选择器的类型取决于资源类型,因为为不同媒体类型描述片段的方法不同。可以通过多种方式为同一片段定义多个选择器,以尽可能提高后续发现的机会,并保证消费方至少能用其中一种选择器。
用例示例: Ramona 想将网页上选中的一段文本与数据集中的一段关联。她用客户端选中两者,并为 Body 和 Target 各创建带有选择器的 SpecificResource 注释。
模型
术语
类型
说明
selector
关系
特定资源与选择器之间的关系。
没有 或有多个selector关系。多个选择器应当 选取同一内容,但不同选择器精度未必一致。消费方必须 在内容不同时选用其中一个片段。
示例
示例 19 :选择器
{
"@context" : "http://www.w3.org/ns/anno.jsonld" ,
"id" : "http://example.org/anno19" ,
"type" : "Annotation" ,
"body" : {
"source" : "http://example.org/page1" ,
"selector" : "http://example.org/paraselector1"
},
"target" : {
"source" : "http://example.com/dataset1" ,
"selector" : "http://example.org/dataselector1"
}
}
4.2.1 片段选择器最常见的片段选取机制是用 IRI 片段,这受资源媒体类型定义。因此允许通过选择器进行片段描述,可让现有和未来的片段规范都能一致地用于特定资源。为明确使用了哪类片段类型,选择器可指明其规范。
用例示例: Sally 想将视频中某一时段作为图像描述。她选中视频的时间段并点击描述目标。客户端用 FragmentSelector 和describing动机构造
SpecificResource 注释。
模型
术语
类型
说明
type
关系
选择器的类。必须 有且只有1个type,值须为FragmentSelector。
FragmentSelector
类
通过 IRI 片段描述片段的资源。
value
属性
描述该片段的 IRI 片段内容。FragmentSelector 必须 有且只有1个value属性。
conformsTo
关系
FragmentSelector 与定义 value 片段语法的规范之间的关系。
应当 有且只有1个conformsTo指向规范,且不得 超过1个。
建议 用 FragmentSelector 作为描述 SpecificResource
的主流方式,而不是直接用带片段的 IRI。消费应用应当 同时支持两种方式。
下列 IRI 是定义片段语义的一些规范,因此可配合 conformsTo 使用。也可用其它 IRI。
名称
片段规范
说明
HTML
http://tools.ietf.org/rfc/rfc3236
[rfc3236 namedSection
PDF
http://tools.ietf.org/rfc/rfc3778
[rfc3778 page=10&viewrect=50,50,640,480
纯文本
http://tools.ietf.org/rfc/rfc5147
[rfc5147 char=0,10
XML
http://tools.ietf.org/rfc/rfc3023
[rfc3023 xpointer(/a/b/c)
RDF/XML
http://tools.ietf.org/rfc/rfc3870
[rfc3870 namedResource
CSV
http://tools.ietf.org/rfc/rfc7111
[rfc7111 row=5-7
多媒体
http://www.w3.org/TR/media-frags/
[media-frags xywh=50,50,640,480
SVG
http://www.w3.org/TR/SVG/
[SVG11 svgView(viewBox(50,50,640,480))
EPUB3
http://www.idpf.org/epub/linking/cfi/epub-cfi.html
[cfi epubcfi(/6/4[chap01ref]!/4[body01]/10[para05]/3:10)
注
IRI 片段可以通过拼接 source、#和value 得到。例如,下方示例中的 IRI 就是
http://example.org/video1#t=30,60。
示例
示例 20 :片段选择器
{
"@context" : "http://www.w3.org/ns/anno.jsonld" ,
"id" : "http://example.org/anno20" ,
"type" : "Annotation" ,
"body" : {
"source" : "http://example.org/video1" ,
"purpose" : "describing" ,
"selector" : {
"type" : "FragmentSelector" ,
"conformsTo" : "http://www.w3.org/TR/media-frags/" ,
"value" : "t=30,60"
}
},
"target" : "http://example.org/image1"
}
4.2.2 CSS 选择器在 HTML 文档对象模型中选取元素最常见的方法之一是使用 CSS 选择器 [CSS3-selectors
请注意 CSS 也可用于为注释中的资源设定样式 。该类主要用于复用 CSS 选择器机制,选择符合 DOM 的资源片段。
用例示例: Teynika 在网页中选中一个段落,想要对此写评论。她的客户端计算出一个能准确定位该元素的 CSS 路径,并将其添加到注释。
模型
术语
类型
说明
type
关系
选择器的类。必须 只有一个
type,其值必须 为 CssSelector。
CssSelector
类
CSS 选择器资源的类型。
必须 关联该类。
value
属性
到片段的 CSS 选择路径。
必须 恰有一个 value。
注
实现者应当 仅使用 CSS 中直接用于元素或内容选取、被广泛支持的功能,而非样式和变换,以最大化系统间的互操作性。
示例
示例 21 :CSS
选择器
{
"@context" : "http://www.w3.org/ns/anno.jsonld" ,
"id" : "http://example.org/anno21" ,
"type" : "Annotation" ,
"body" : "http://example.org/note1" ,
"target" : {
"source" : "http://example.org/page1.html" ,
"selector" : {
"type" : "CssSelector" ,
"value" : "#elemid > .elemclass + p"
}
}
}
4.2.3 XPath 选择器另一种在支持 DOM 的资源(如 XML 或 HTML 文档)中选取元素和内容的常见方法是使用 XPath 选择 [DOM-Level-3-XPath
注
实现者需注意
HTML5 规范 允许解析器在 DOM
中添加缺失元素。XPath
应当 基于这些元素构造,而非基于文档源结构。
用例示例: Ulrika 在 HTML 页的表格中选中 span 元素并对内容做评论。为了明确指代该元素,客户端仔细构造了 XPath 以标识其注释目标。
模型
术语
类型
说明
type
关系
选择器的类。必须 恰有一个type,其值必须 为XPathSelector。
XPathSelector
类
XPath 选择器资源的类型。
必须 关联该类。
value
属性
所选片段的 xpath 路径。
必须 恰有一个 value。
注
实现者应当 仅使用 XPath 中直接作用于元素或内容选取的广泛支持特性,以最大化系统间互操作性。
示例
示例 22 :XPath
选择器
{
"@context" : "http://www.w3.org/ns/anno.jsonld" ,
"id" : "http://example.org/anno22" ,
"type" : "Annotation" ,
"body" : "http://example.org/note1" ,
"target" : {
"source" : "http://example.org/page1.html" ,
"selector" : {
"type" : "XPathSelector" ,
"value" : "/html/body/p[2]/table/tr[2]/td[3]/span"
}
}
}
4.2.4 文本引用选择器该选择器通过复制文本中的一段,并附上其前后部分(前缀和后缀)来描述选区,以区分同样字符序列的多处出现。
例如,如果文档内容为 "abcdefghijklmnopqrstuvwxyz",可以通过前缀 "abcd",匹配 "efg" 及后缀 "hijk" 来选中 "efg"。
用例示例: Valeria 在网页中选择了拼写错误('anotation'),并添加评论说明应该改为正确拼写('annotation')。
模型
术语
类型
说明
type
关系
选择器的类。必须 恰有一个
type,其值必须 为
TextQuoteSelector。
TextQuoteSelector
类
通过引用内容以及前后文进行文本片段选取的选择器类型。
必须 关联该类。
exact
属性
被选中文本的副本(经过规范化)。
必须 恰有一个 exact
属性。
prefix
属性
被选文本前紧邻的一段文本。
应当 恰有一个
prefix,且不得 多于一个。
suffix
属性
被选文本后紧邻的一段文本。
应当 恰有一个
suffix,且不得 多于一个。
文本选择必须 基于 unicode 码位(“字符编号”)而非代码单元数量(某种数据类型下的数字)。选区不应 从字符组合体中间开始或结束。选择必须 基于文本逻辑顺序 ,不应以视觉顺序计算,特别是双向文本。Web
文本字符模型信息见 [charmod
被记录在注释中的文本必须 先做规范化。所以 HTML/XML 标签应当 去除,字符实体应当 替换为其编码的字符。注意这不会影响被注释文档内容,只影响注释文本的记录方式。
如基于 prefix、exact 和 suffix 匹配后,客户端发现多个匹配文本序列,则此选择应当 视为匹配所有这些。
注
如内容受版权或其它权利保护,则该选取方式可能存在风险。用户可能选中全文作为注释,这不应被复制到注释中再分享。对具限制的静态文本,更推荐使用文本位置选择器。
示例
示例 23 :文本引用选择器
{
"@context" : "http://www.w3.org/ns/anno.jsonld" ,
"id" : "http://example.org/anno23" ,
"type" : "Annotation" ,
"body" : "http://example.org/comment1" ,
"target" : {
"source" : "http://example.org/page1" ,
"selector" : {
"type" : "TextQuoteSelector" ,
"exact" : "anotation" ,
"prefix" : "this is an " ,
"suffix" : " that has some"
}
}
}
4.2.5 文本位置选择器
该选择器通过记录在内容流中的起止位置,选取一段文本。位置 0 表示首字符前,位置 1 表示第二个字符前,以此类推。起始字符包含在选区内,但结束字符不包含。
例如,如果文档为 "abcdefghijklmnopqrstuvwxyz",起始 4,结束 7,则选区为 "efg"。
用例示例: Wendy 对不允许提取内容的电子书写了评论。她的客户端用内容的起止位置描述选区。
模型
术语
类型
说明
type
关系
选择器的类。必须 恰有一个 type,其值必须 为 TextPositionSelector。
TextPositionSelector
类
通过起止位置描述文本区间的选择器类型。
必须 关联该类。
start
属性
文本区间起点,全文首字符位置为 0,且该字符包含在选区中。
必须 恰有一个 start
属性,且值必须 为非负整数。
end
属性
文本区间终点,该字符不包含在选区内。
必须 恰有一个 end
属性,且值必须 为非负整数。
需与文本引用选择器以相同方式,对被选取文本进行选区和规范化,然后计数以确认起止位置。
注
与文本引用选择器不同,使用该选择器无需将文本从源文档复制到注释图谱;但它对资源内容的变动极为敏感,任何编辑或动态内容挂载都可能改变选区,因此
建议 结合
状态 一起使用以辅助定位正确表现。
示例
示例 24 :文本位置选择器
{
"@context" : "http://www.w3.org/ns/anno.jsonld" ,
"id" : "http://example.org/anno24" ,
"type" : "Annotation" ,
"body" : "http://example.org/review1" ,
"target" : {
"source" : "http://example.org/ebook1" ,
"selector" : {
"type" : "TextPositionSelector" ,
"start" : 412 ,
"end" : 795
}
}
}
4.2.6 数据位置选择器
与文本位置选择器类似,数据位置选择器使用相同的属性,但是在比特流的字节级别工作,而不是在文本的字符级别。
用例示例: Xena 针对网络磁盘镜像的特定区域撰写法医用途的评论,并描述仿真要求。她的客户端根据二进制流生成起始和结束位置,而不是她正在使用的人类可读显示。
模型
术语
类型
说明
type
关系
选择器的类。必须 有且只有一个
type,并且其值必须 为
DataPositionSelector。
DataPositionSelector
类
描述数据流中基于起始和结束字节的范围的选择器类型。
必须 关联该类。
start
属性
数据分段的起始位置。第一个字节的字符位置为 0。
必须 恰有一个 start 属性。
end
属性
数据分段的结束位置。最后一个字符不包含在分段中。
必须 恰有一个 end 属性。
示例
示例 25 :数据位置选择器
{
"@context" : "http://www.w3.org/ns/anno.jsonld" ,
"id" : "http://example.org/anno25" ,
"type" : "Annotation" ,
"body" : "http://example.org/note1" ,
"target" : {
"source" : "http://example.org/diskimg1" ,
"selector" : {
"type" : "DataPositionSelector" ,
"start" : 4096 ,
"end" : 4104
}
}
}
4.2.7 SVG 选择器SvgSelector 通过 Scalable Vector Graphics [SVG11
请注意 SvgSelector 用于用 SVG 选中资源的区域。对于 SVG 表现的片段,也可以用选择器选取,包括 FragmentSelector 或 SvgSelector 本身。
用例示例: Yadira 在线给一张旧地图为一条历史公路标注对角线区域。她的客户端创建 SVG 多边形,相对于图像内容描述该区域。
模型
术语
类型
说明
type
关系
选择器的类。必须
有且只有一个 type ,其值必须 包含
SvgSelector。
SvgSelector
类
使用 SVG 标准定义所选区域形状的选择器类型。
必须 关联该类。
value
属性
SVG 内容的字符序列。可以 有且只有一个 value
属性,如果有,其值必须 是格式良好的 SVG XML。
SVG 形状或画布的尺寸必须 以源资源的尺寸为基准,以保证将形状缩放到图片全尺寸时能准确描述目标区域。
注
实现者应当 只用 SVG 中直接用于区域描述、广泛支持的功能,而不是样式或变换,以最大化系统间互操作性。不推荐 在 SVG
元素中包含样式信息、Javascript、动画、文本或其它非形状信息。客户端应当 忽略此类内容。
示例
示例 26 :SVG
选择器
{
"@context" : "http://www.w3.org/ns/anno.jsonld" ,
"id" : "http://example.org/anno26" ,
"type" : "Annotation" ,
"body" : "http://example.org/road1" ,
"target" : {
"source" : "http://example.org/map1" ,
"selector" : {
"id" : "http://example.org/svg1" ,
"type" : "SvgSelector"
}
}
}
示例 27 :SVG
选择器(内嵌)
{
"@context" : "http://www.w3.org/ns/anno.jsonld" ,
"id" : "http://example.org/anno27" ,
"type" : "Annotation" ,
"body" : "http://example.org/road1" ,
"target" : {
"source" : "http://example.org/map1" ,
"selector" : {
"type" : "SvgSelector" ,
"value" : "<svg:svg> ... </svg:svg>"
}
}
}
4.2.8 范围选择器用户的选区操作可能跨越表现内部边界,或非常广泛,此时很难用单一选择器稳健描述目标内容。范围选择器可通过引用其它选择器分别识别选区的起点与终点。这样可用最合适的机制分别精确定位两个点,再将它们组合成选区。选区包含从起始选择器位置开始,到结束选择器位置开始为止(不包含结束选择器起始)的全部内容。
用例示例: Zara 想对网页表格中相邻两单元格评论。她选中这两格,客户端为首格和第二格紧邻的下一个单元格分别构造 XPath,并创建范围选择器用首 XPath
选择器作为起点,后者作为终点。
模型
术语
类型
说明
type
关系
选择器的类。必须
有且只有一个 type ,其值必须 为
RangeSelector。
RangeSelector
类
范围选择器资源类型。
必须 关联该类。
startSelector
关系
描述范围起点(包含)的选择器。
必须 恰有一个 startSelector 关联。
endSelector
关系
描述范围终点(不包含)的选择器。
必须 恰有一个 endSelector
关联。startSelector 和 endSelector 应 同属一个类别。
示例
示例 28 :范围选择器
{
"@context" : "http://www.w3.org/ns/anno.jsonld" ,
"id" : "http://example.org/anno28" ,
"type" : "Annotation" ,
"body" : "http://example.org/comment1" ,
"target" : {
"source" : "http://example.org/page1.html" ,
"selector" : {
"type" : "RangeSelector" ,
"startSelector" : {
"type" : "XPathSelector" ,
"value" : "//table[1]/tr[1]/td[2]"
},
"endSelector" : {
"type" : "XPathSelector" ,
"value" : "//table[1]/tr[1]/td[4]"
}
}
}
}
4.2.9 选区细化有时更便捷、可靠或精确的方法是基于已有选区再次选区,而不是直接从完整资源选区。特别是对于包含其他资源的复杂内容(如各种打包格式),当组件没有唯一标识符时,也可分解选择机制以实现精确定位。这是通过串联多个选择器——每个细化上一个选择器结果——来完成的。
用例示例: Alexandra 先选中一个段落,然后在其中再选一短语进行评论。她的客户端记录一个 TextQuoteSelector(文本引用选择器)用于进一步细化用于定位该短语所属段落的
FragmentSelector(片段选择器)。
模型
术语
类型
说明
refinedBy
关系
宽泛选择器和更具体选择器之间的关系,更具体选择器应当 对前者结果进一步限定。
可以 被一个或多个 refinedBy
引用。若有多个,则视作均可达成相同选区的备选方案。
示例
示例 29 :选区细化
{
"@context" : "http://www.w3.org/ns/anno.jsonld" ,
"id" : "http://example.org/anno29" ,
"type" : "Annotation" ,
"body" : "http://example.org/comment1" ,
"target" : {
"source" : "http://example.org/page1" ,
"selector" : {
"type" : "FragmentSelector" ,
"value" : "para5" ,
"refinedBy" : {
"type" : "TextQuoteSelector" ,
"exact" : "Selected Text" ,
"prefix" : "text before the " ,
"suffix" : " and text after it"
}
}
}
}
4.3 状态状态描述了某个资源与该注释相关时应有的状态,从而为获取该资源的正确表现提供所需信息。Web 资源会随时间变化,状态可用于描述如何恢复到原定的历史版本。Web
资源也可能有多种格式,状态同样可以用来描述如何获取特定格式。可以提供多个状态来描述同一表现,以尽量增大被消费方取回对应表现的几率。
用例示例: Britney 评论了一个变化频繁的网页。她的客户端记录了信息,便于其他客户端尽量重现该注释的原目标。
模型
术语
类型
说明
state
关系
SpecificResource 与状态之间的关系。
可以 有 0 个或多个 state
关系。多个状态应当 描述同一表现,但有些状态的精确度可能不同。消费方必须 在实际不同时选择其一。
状态必须 在处理选择器或样式信息之前进行处理。
示例
示例 30 :状态
{
"@context" : "http://www.w3.org/ns/anno.jsonld" ,
"id" : "http://example.org/anno30" ,
"type" : "Annotation" ,
"body" : "http://example.org/note1" ,
"target" : {
"source" : "http://example.org/page1" ,
"state" : {
"id" : "http://example.org/state1"
}
}
}
4.3.1 时间状态时间状态资源记录了在注释中,资源适用的时间,通常为注释创建时的时间点和/或指向当前版本持久副本的链接。资源时间戳可采用 RFC 7089 [rfc7089
用例示例: Carla 针对新闻网站首页的当前状态作注,并标明该页面经常变化。她的客户端为注释页面的这一版本加入包含当前时间的状态。
模型
术语
类型
说明
type
关系
状态的类。必须 只有一个 type,其值必须 为
TimeState。
TimeState
类
描述如何获取时间上适用于该注释的 Source 资源表现。
必须 关联该类。
sourceDate
属性
注释应当在该时刻解释 Source 资源。
可以 有 0 个或多个 sourceDate
属性。如有多个,分别表示 Source 可被解释的不同时刻。时间戳必须 为
xsd:dateTime 格式,并且必须 带有 "Z" 的 UTC
时区。如果有 sourceDate,则不可有 sourceDateStart 和
sourceDateEnd。
sourceDateStart
属性
Source 资源解释有效时间区间的起点。
可以 有且只有1个sourceDateStart属性,且时间戳必须 为xsd:dateTime格式并带 UTC 时区“Z”。若设置
sourceDateStart,则sourceDateEnd 必须 同时提供。
sourceDateEnd
属性
Source 资源解释有效时间区间的终点。
可以 有且只有1个sourceDateEnd属性,且时间戳必须 为xsd:dateTime格式并带 UTC 时区“Z”。若设置
sourceDateEnd,则sourceDateStart 必须 同时提供。
cached
关系
指向适用于该注释的 Source 资源表现副本的链接。
可以 有 0 个或多个 cached
关系。如有多个,分别表示表现的备选副本。
示例
示例 31 :时间状态
{
"@context" : "http://www.w3.org/ns/anno.jsonld" ,
"id" : "http://example.org/anno31" ,
"type" : "Annotation" ,
"body" : "http://example.org/note1" ,
"target" : {
"source" : "http://example.org/page1" ,
"state" : {
"type" : "TimeState" ,
"cached" : "http://archive.example.org/copy1" ,
"sourceDate" : "2015-07-20T13:30:00Z"
}
}
}
4.3.3 状态细化类似选区细化 ,可将合适的资源状态拆解为一组原子状态层级进行描述,这样或许更容易、更可靠或更精确。特别适用于同时涉及内部转换状态和外部请求状态结合的场景。这种分解通过多级串联状态实现,方式同选择器一样。
此外,鉴于状态通常最终决定某一表现,还可能用具体选择器描述该表现的片段。为此,状态也可以通过选择器进一步细化。
用例示例: Erin 针对某旅游电子书的不同版本和格式发表评论,并希望特别针对某具体版本格式评论。客户端同时添加了时间状态捕获时间、请求头状态捕获格式,然后结合适用于该格式的片段选择器。
模型
术语
类型
说明
refinedBy
关系
广义状态与更具体状态或选择器之间的关系,后者应当 对前者结果进一步限定。
可以 被一个或多个其它状态或选择器 refinedBy
进一步限制。如果有多个,则视为同等可选方案,都能达成同一结果。
示例
示例 33 :状态细化
{
"@context" : "http://www.w3.org/ns/anno.jsonld" ,
"id" : "http://example.org/anno33" ,
"type" : "Annotation" ,
"body" : "http://example.org/comment1" ,
"target" : {
"source" : "http://example.org/ebook1" ,
"state" : {
"type" : "TimeState" ,
"sourceDate" : "2016-02-01T12:05:23Z" ,
"refinedBy" : {
"type" : "HttpRequestState" ,
"value" : "Accept: application/pdf" ,
"refinedBy" : {
"type" : "FragmentSelector" ,
"value" : "page=10" ,
"conformsTo" : "http://tools.ietf.org/rfc/rfc3778"
}
}
}
}
}
4.4 样式特定注释或注释主体的解释,可能依赖于在不同实现中注释渲染风格的一致性。对于图片或视频等二进制内容的注释,目标的背景色可能无法被注释客户端获取,而默认配色可能难以分辨,例如在夜空图片上高亮目标区域为黑色。渲染信息采用
CSS 样式表及其定义的 class 引用进行记录。
用例示例: Felicity 在文档中高亮了两个段落,并在客户端中选择其中一个标红显示,另一个标黄。她评论称黄色部分与红色部分矛盾。她的客户端记录下了她选择红色和黄色作为目标着色的行为。
模型
术语
类型
说明
type
关系
样式的类。可以 有 type,如有则其值必须 为
CssStylesheet。
CssStylesheet
类
用 CSS 描述参与注释的资源样式的资源。
可以 与样式表资源关联。
stylesheet
关系
注释 与样式的关系。
可以 有 0 或 1 个 stylesheet 关系。
styleClass
属性
应当应用于 Specific Resource 的 CSS class 名称。可以 有 0 个或多个 styleClass 属性。
CSS 样式表与注释实体关联,提供关于注释组成资源的渲染提示。它可以 有自己的可解引用
IRI,也可直接嵌入在注释中。这样可以避免每个资源都单独引用不同单行样式表,而允许引用单一 IRI 统一管理一组样式。
发布系统不得 假定样式一定会被应用;这些信息只是渲染提示,而非强制要求。
渲染 Specific Resource 时,消费应用应当 检测是否有 styleClass
属性。如果有,则应当 尝试在 CSS 文档中找到对应选择器,并应用该样式规则。如果 Specific Resource 有
styleClass 值,但注释未附带该 class 的 stylesheet,则该 styleClass必须 被忽略。
示例
示例 34 :CSS 样式
{
"@context" : "http://www.w3.org/ns/anno.jsonld" ,
"id" : "http://example.org/anno34" ,
"type" : "Annotation" ,
"stylesheet" : "http://example.org/style1" ,
"body" : "http://example.org/comment1" ,
"target" : {
"source" : "http://example.org/document1" ,
"styleClass" : "red"
}
}
示例 35 :嵌入式 CSS
样式
{
"@context" : "http://www.w3.org/ns/anno.jsonld" ,
"id" : "http://example.org/anno35" ,
"type" : "Annotation" ,
"stylesheet" : {
"type" : "CssStylesheet" ,
"value" : ".red { color: red }"
},
"body" : "http://example.org/body1" ,
"target" : {
"source" : "http://example.org/target1" ,
"styleClass" : "red"
}
}
4.5 渲染软件了解创建注释时处理或渲染目标资源所用的软件,有时是有价值的。后续系统可利用这些信息重建环境,从而更易、更准确地将注释与目标资源的相关部分重新关联。该生命周期信息与 Specific Resource
关联,因为同一目标的不同注释很可能用到不同软件,不能直接与目标资源关联。
用例示例: Gabrielle 通过基于浏览器的客户端渲染一篇学术论文的 PDF。她的浏览器使用某个库将 PDF 渲染为 HTML。她在所见 HTML
渲染视图中给段落添加注释,客户端记录下参与渲染的库,以及她的评论和目标 PDF。
模型
术语
类型
说明
renderedVia
关系
表示注释中目标 Specific Resource 与用于渲染目标的系统或软件之间的关系(注释创建时)。
可以 有关联 0 个或多个
renderedVia。
注
可以为渲染系统关联其他属性,如 schema:softwareVersion、辅助功能、标签、代码引用等。这些扩展超出本规范范围,详见 [
annotation-vocab ] 的扩展部分。
示例
示例 36 :渲染软件
{
"@context" : "http://www.w3.org/ns/anno.jsonld" ,
"id" : "http://example.org/anno36" ,
"type" : "Annotation" ,
"body" : "http://example.org/comment1" ,
"target" : {
"source" : "http://example.edu/article.pdf" ,
"selector" : "http://example.org/selectors/html-selector1" ,
"renderedVia" : {
"id" : "http://example.com/pdf-to-html-library" ,
"type" : "Software" ,
"schema:softwareVersion" : "2.5"
}
}
}
4.6 资源范围注释有时需要捕获其创建时的上下文,也就是注释者当时所浏览或所用的资源。这并不代表注释仅在该页面或范围有效,只是记录当时页面确实被查看。
用例示例: Heather 针对某页面中的图片评论它不是正确组织的 logo。客户端记录图片被渲染时所属页面,但注释实际与图片资源本身关联。
模型
术语
类型
说明
scope
关系
Specific Resource 与为其提供上下文或范围的资源之间的关系。
可以 有关联 0 个或多个
scope。
示例
示例 37 :范围
{
"@context" : "http://www.w3.org/ns/anno.jsonld" ,
"id" : "http://example.org/anno37" ,
"type" : "Annotation" ,
"body" : "http://example.org/note1" ,
"target" : {
"source" : "http://example.org/image1" ,
"scope" : "http://example.org/page1"
}
}
5. 集合将多个注释收集到一起组成一个有序列表——称为注释集合(Annotation Collection)——往往非常有用。该列表始终有序,用于引用其所包含的注释,并维护与集合本身相关的各种信息。
集合模型分为两部分:Annotation Collection,用于管理列表的身份和描述;以及 Annotation Page,列出集合中成员注释的页面。
用例示例: Ingeborg 在出版公司工作,将作者关于蒸汽朋克小说的评论整理为一组注释用于销售。公司希望这些注释作为已购客户的附加内容,也希望与新书打包销售。
5.1 注释集合由于注释集合可能非常庞大,模型把集合本身与其组成页(页面序列)区分开。集合维护自身信息,包括创建和描述等,帮助发现和理解集合,同时也维护对至少第一页注释的引用。从第一页的首个注释开始,依次遍历到最后一页的最后一个注释,就可以找到集合中的全部注释。
单个注释可以 属于多个集合,集合可以 由不同于注释创建者/维护者的代理创建或维护。
模型
术语
类型
说明
@context
属性
决定 JSON 作为注释集合含义的上下文。
必须 包含一个或多个
@context且http://www.w3.org/ns/anno.jsonld 必须 包含其中之一。
id
属性
集合的唯一标识。必须
恰好有一个标识对应的 IRI。
type
属性
集合的类型。必须
有一个或多个类型,且AnnotationCollection类必须 包含其中之一。
AnnotationCollection
类
注释有序集合的类。必须 通过type和集合关联。
label
属性
作为集合名称的人类可读标签。应当 有一个或多个label,值必须 为字符串。
total
属性
集合中注释总数。应当 恰有一个total,如有则必须 为xsd:nonNegativeInteger。
first
关系
集合内包含注释的第一页。必须
有唯一的first注释页。第一页可以 内嵌于集合的表现,也可以 作为 IRI 给出。
last
关系
集合内包含注释的最后一页。应当 有一个 IRI
引用last注释页。
集合可以 添加其它属性用于描述集合的用途、知识产权、来源等其它有用特性。这些属性应当 优先使用本规范描述的词汇,也可以 使用其它合适的词汇表。
示例
示例 38 :注释集合
{
"@context" : "http://www.w3.org/ns/anno.jsonld" ,
"id" : "http://example.org/collection1" ,
"type" : "AnnotationCollection" ,
"label" : "Steampunk Annotations" ,
"creator" : "http://example.com/publisher" ,
"total" : 42023 ,
"first" : "http://example.org/page1" ,
"last" : "http://example.org/page42"
}
5.2 注释页注释页是注释集合的一部分,包含集合中部分或全部注释的有序列表。每个集合可以有多个页面,通过页面间的next和prev链接进行遍历。
模型
术语
类型
说明
@context
属性
决定 JSON 作为注释集合页含义的上下文。
必须 有一个或多个@context值,且http://www.w3.org/ns/anno.jsonld
必须 包含其一。若为内嵌,则不应 有@context属性。
id
属性
页面的唯一标识。必须
恰好有一个 IRI 标识自己。
type
属性
页面的类型。必须
有一个或多个类型,且AnnotationPage类必须 为其一。
AnnotationPage
类
注释页的类。必须 通过type和页面关联。
partOf
关系
页面与其所属注释集合的关系。应当 有唯一的partOf关系,值可以为集合
IRI,或带有集合部分或全部属性(至少含id)的对象。
items
关系
页面中的注释列表。必须 有一个含一个或多个注释的数组作为items值。
next
关系
集合中下一个页面的引用。必须 有指向后续页面 IRI 的引用。
prev
关系
集合中前一页面的引用。应当 有指向前一页面 IRI 的引用。
startIndex
属性
本页items列表中第一个注释在注释集合中的相对位置。第一页的首条为0。应当 恰有一个startIndex,不得 有多个。值必须 为xsd:nonNegativeInteger。
示例
示例 39 :注释页
{
"@context" : "http://www.w3.org/ns/anno.jsonld" ,
"id" : "http://example.org/page1" ,
"type" : "AnnotationPage" ,
"partOf" : {
"id" : "http://example.org/collection1" ,
"label" : "Steampunk Annotations" ,
"total" : 42023
},
"next" : "http://example.org/page2" ,
"startIndex" : 0 ,
"items" : [
{
"id" : "http://example.org/anno1" ,
"type" : "Annotation" ,
"body" : "http://example.net/comment1" ,
"target" : "http://example.com/book/chapter1"
},
{
"id" : "http://example.org/anno2" ,
"type" : "Annotation" ,
"body" : "http://example.net/comment2" ,
"target" : "http://example.com/book/chapter2"
}
]
}
示例 40 :带内嵌页的注释集合
{
"@context" : "http://www.w3.org/ns/anno.jsonld" ,
"id" : "http://example.org/collection1" ,
"type" : "AnnotationCollection" ,
"label" : "Two Annotations" ,
"total" : 2 ,
"first" : {
"id" : "http://example.org/page1" ,
"type" : "AnnotationPage" ,
"startIndex" : 0 ,
"items" : [
{
"id" : "http://example.org/anno1" ,
"type" : "Annotation" ,
"body" : "http://example.net/comment1" ,
"target" : "http://example.com/book/chapter1"
},
{
"id" : "http://example.org/anno2" ,
"type" : "Annotation" ,
"body" : "http://example.net/comment2" ,
"target" : "http://example.com/book/chapter2"
}
]
}
}
E. 致谢本节为非规范性内容。
Web Annotation 工作组感谢 Open Annotation Community
Group 的贡献。该小组的 成果 对当前数据模型具有基础性作用。特别感谢 Los
Alamos 国家实验室的 Herbert Van de Sompel,在整个社区小组流程中为编辑工作做出的贡献。
以下人员在本规范的创作过程中,为思路、反馈、评审、内容、意见和建议提供了重要帮助:
Vladimir Alexiev, Art Barstow, Tim Berners-Lee, Chris Birk, Dan Brickley, Sarven Capadisli, Paolo Ciccarese,
Tim Cole, Ray Denenberg, TB Dinesh, Sergiu Gordea, Benjamin Goering, Amy Guy, Ivan Herman, Frederick Hirsch,
Antoine Isaac, Jacob Jett, Takeshi Kanai, Gregg Kellogg, Andreas Kuckartz, Randall Leeds, Hugo Manguinhas,
Shane McCarron, Ben De Meester, Luc Moreau, Addison Phillips, Davis Salisbury, Robert Sanderson, Felix
Sasaki, Doug Schepers, Tzviya Siegman, Stian Soiland-Reyes, Manu Sporny, Nick Stenning, Jon Stroop, Lutz
Suhrbier, Kyrce Swenson, Raphaël Troncy, Simeon Warner, Erik Wilde, Dan Whaley, Benjamin Young
↑